Supervision and truth
For more than a decade the dominant training methodology in machine learning was "supervised learning". Under this paradigm, machine learning models are trained with large collections of labeled data. Each datum is connected with a simple label, usually numeric, identifying the class to which that datum belongs. The statistical characteristics of the training data which correlate with class assignments are what the model learns. The labels for images are gathered either via an explicit process of asking labellers to assign categories to samples (often via crowdsourcing on Mechanical Turk, or by using CAPTCHAs) or by finding a dataset "in the wild" (like libraries of already-categorized photos) where the labels exist already. From the perspective of machine learning researchers and, more importantly, companies trying to build and sell machine learning, the key characteristic of this kind of supervised learning is that it is expensive. Machine Learning thrives on enormous data sets: collections of thousands, hundreds of thousands or even millions of labeled samples. Even at the often offensively low piecework rates paid to overseas Mechanical Turk laborers, the cost of hand-labeling an appropriately sized machine learning data set can quickly reach hundreds of thousands or even millions of dollars.
There's another problem with supervised learning. In the machine learning community this is general described as "accuracy". That isn't quite right—it's really about a failure to correctly construct and describe the annotation task—but it's good enough for our purposes here. It's a mismatch between the label and the data. If you're building a system that can distinguish motorcyles from bicycles (let's say), training that system on a dataset where 30% of the motorcycles are mislabeled as bicycles is predictably bad. This problem is endlessly frustrating for people in the machine learning community because it is a problem that is very difficult to solve algorithmically. Enormous amounts of effort have gone to the development of systems that can automatically verify labels. CAPTCHA, as a tool for labeling, was developed because it is an environment where you are unusually able to incentivize people to perform your task correctly.
Even when you can align the incentives, though, human labels are complex. Think about the bike vs. motorcycle example: how do you label an e-bike? What about an electric scooter? What about a Vespa? Simple categorization, which is something people do unthinkingly and constantly, devolves into a morass of philosophical complexity when you dig into it analytically (Moravec's Paradox again).
All of this is why machine learning researchers have been constantly drawn to the siren song of UNsupervised learning. In unsupervised learning the labels which characterize each datum, describing where it should live in the incredibly high-dimensional representational space of the machine learning model, are implicit. Instead of having to carefully note that each image in your dataset is of a tree or a house, you rely instead on implicit characteristics of the data; what precedes it or follows it, or its influence on a known future event. The classic example of unsupervised learning is what is known in the literature as next token prediction. Given a series that is in some kind of order, predict what comes next. If this sounds familiar, it's because it is the fundamental technology behind large language models. It is the mechanism often derided (slightly unfairly) as "fancy autocomplete". I say that it's slightly unfair because autocomplete—even the non-fancy kind—is a pretty nifty trick. It converts the production of fluent human language into a problem where each word ("token", really, which is often but not precisely a word) can be considered more-or-less on its own, as a datum where the label to be predicted is the identity of the next token that should be produced.
What makes this sleight-of-hand SO valuable is that what it is fundamentally accomplishing is turning unlabeled data into labeled data. It's turning unsupervised learning into supervised learning. This is actually—if I was writing clickbait this would be the Secret ML Researchers Don't Want You To Know—true of all unsupervised learning. Systems that are able to learn from data without explicit labeling do it by finding a way to turn the existing structure of the data into labels. The human knowledge of how to classify and organize the data happens not at an individual level, but in the construction of the problem that the ML system is intended to solve.
What this means is that if you are training a language model every single instance of words written by humans becomes a source of data for your model. Every sentence ever written and made publicly available contains choices about what words to place in what order, and via the magic of unsupervised learning each of those word transitions becomes a label: a piece of metadata about a given word (again, token, really) that tells you where to place it in relation to all the other possible words and transitions between words. When you combine this fact with the transformer architecture for machine learning--which is capable like no architecture before it of handling long distance correlations and overwhelmingly massive numbers of parameters--you are left with a system that is able to make guesses about what word comes next based on, to a first approximation, the entire written output of humanity since the dawn of writing. Systems like this are what we know as large language models.
Implicit in my description, however, is the description of a complementary problem. Large language models are able to do what they do because the trick of unsupervised learning allows them to be trained with datasets far, far greater in scale than were ever possible with supervised learning. That training, though, is dependent on being able to perform the unsupervised trick. There has to be a way to convert implicit information about where data fits in whatever high dimensional space already extant in the information being collected. If you change the problem just slightly, let's say by asking what’s the next token to produce such that the overall statement being produced will be TRUE, rather than just pleasingly likely, then the unsupervised learning trick never works, and you're back to the complexities and poor scaling properties of supervised learning.
Which brings us to Google's Gemini AI Overview. This tool was unveiled with great fanfare which was replaced, before the trumpets even stopped echoing off the walls, with riotous mockery and derision. Because what Google attempted to do what use an LLM as a window into search results, collating, condensing and summarizing the breadth of responses to a Google search into a readable précis. The problem, as it turns out, and as could and should have been predicted before this system launched, is that the results of a google search often include responses that are semantically relevant to the search results but do not serve the needs of the searcher. In large part, this means that there are results that are not true. When a human is searching on Google, this is mostly fine: the human searcher is able to deploy critical thinking, life experience, and a rich understanding of the minds of other humans to figure out that, for instance, a reddit comment advocating glue on your pizza is pretty obviously a joke. But there is nothing in structuring of the words of a deadpan, if ridiculous, response, that the unsupervised learning algorithm can latch onto. The words flow pretty much like any other words, and the truth value of those words is left as an exercise for the reader. That exercise, determining truth value, is something that an LLM can't do: it uses information that the LLM simply doesn't have. It relies on data, and labels, that do not exist, even implicitly, in the written corpora on which it was trained.
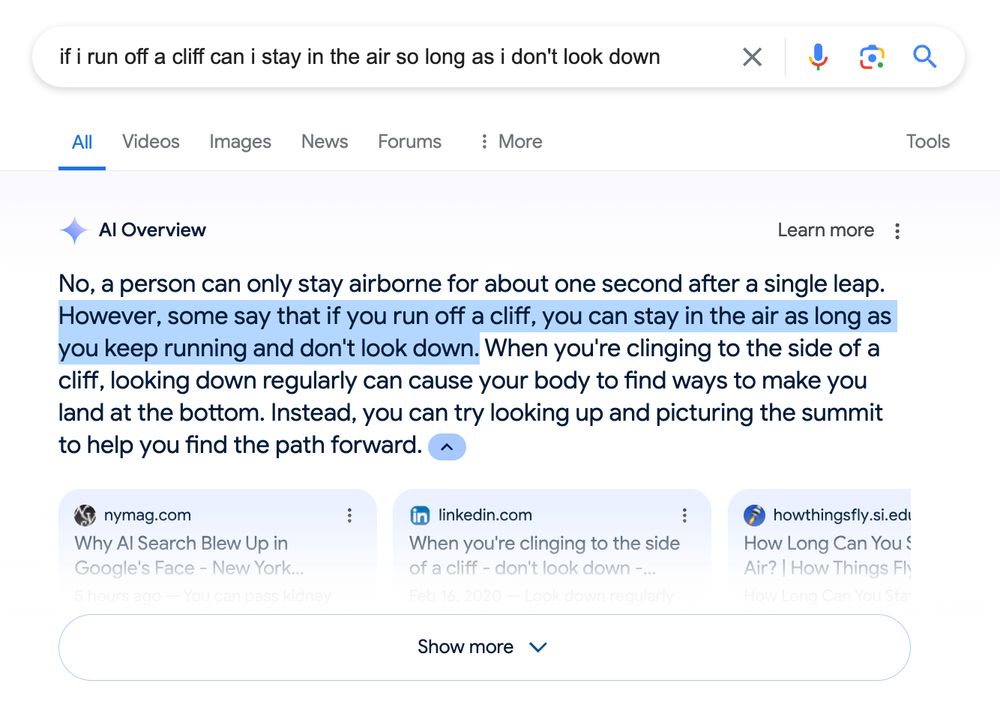
@rusty.todayintabs.com on Bluesky
Google is still returning this useful AI information right now
In fact, it's worse than that. Because the labels that would be necessary for a system like the Gemini AI Overview to properly judge the seriousness and truthfulness of the responses it is aggregating into its answers are even harder to collect than the kinds of motorcycle vs. bicycle type responses laboriously collected through CAPTCHA and on Mechanical Turk. The bog of philosophical uncertainty already present in simple, objective classification tasks turns into an impenetrable abyss of subjectivity and nuance. I have said before that the ML community suffers from a disinclination to tackle methodological problems that involve the uncertainty and messiness of humans, but they can hardly be blamed for not having a go-to approach for a problem as dramatically unsolvable as objective labels of truth on datasets approximately the same sale as the entire internet.
So when people ask why Gemini AI Overview, like many of the other nascent attempts at commercializing the genuinely remarkable algorithms behind LLMs and similar, was released before solving this problem, the question is somewhat ill-formed. The real question is, if these problems truly are unsolveable, which with today's state of the art they very much are, will they ever be suitable for this kind of application at all.
