Weekly API Evangelist Governance (Guidance) For April 29th, 2026
In an effort to drive my work at Naftiko, I am finding renewed energy for API Evangelist, and profiling of APIs, as we all collide with the AI delusions of the market. I’ve turned back on my API crawler, and spent some cycles this week refining how I profile APIs. Looking through APIs always inspires me to write on API Evangelist, while allowing me to stay in tune with what API producers are up to beneath all of the hype. Paying attention to what APIs are up to reminds me of why API Evangelist exists, and why it is important to be showcasing the interesting things happening with APIs behind the applications most people are tuned into.

API Governance From Practitioners
I showcased an ebook on API governance from Supreet Nagi this week. I had Supreet on the Naftiko Capabilities a while back, but I wanted to showcase his writing on API governance because there isn’t a lot of material on how to do APIs from enterprise organizations. Most of what we encounter is from API service providers, and a) I want to support API practitioners and their storytelling, but b) the storytelling is closer to reality on the ground floor than what us vendors and analysts are pushing. Supreet’s approach focuses on guardrails and not gates, which reflects my guidance-driven approach to governing APIs. I’d like to encourage more practitioners to tell their story, sharing the reality of how they approach API operations and governance, and let me know when you publish and I’ll make sure to get the word out.

The Status of GitHub
When profiling APIs I define what their properties are using APIs.json. One of common properties of leading APIs for over a decade is a status page. I published a story this week about GitHub sharing a story about their approach to their status page. I am always a fan of API providers sharing the story behind the properties of their operations, and I also like trying to understand the technology of these properties, but also the business and politics. I suspect there is more to the way GitHub is splitting hairs about the availability of their services, APIs, and LLMs, but I can’t quite put my finger on it quite yet. There is always a motivation behind why an API providers pulls back the curtains on the properties of their API operations. Writing about these properties is how I get my brain spinning about what these reasons might be—something I think in how AI models are driving a shift in performance.

Front Door for Agents
I am a big fan of Cloudflare. I use them for DNS, and increasingly for Cloudflare Workers. Cloudflare provides dead simple ways to deploy APIs and Claude is very good at managing them. Cloudflare’s APIs are top notch and I enjoy using their services.
Cloudflare had an interesting piece on their Radar AI Insights, which provides a breakdown into all the signals Cloudflare customers send when they are supporting. Cloudflare has incorporated robots.txt, Sitemap, AI rules in robots.txt, Link headers, OAuth discovery, Markdown negotiation, Universal Commerce Protocol (UCP), Content signals, OAuth Protected Resource, Agent Skills, Web Bot Auth, MCP Server Card, API catalog, A2A Agent Card, WebMCP, x402 Payment, and AP2 (Agent Payments Protocol) into their Radar AI insights report.
The list of protocols provides a pretty nice list of the front door for agents. It is a real patchwork of standards and specifications, but also reflect how websites and applications are responding (or not) to this AI moment. I wrote about them so I could begin getting my head around the standards. I am very familiar with robots.txt, sitemap.xml, and some of the others, but there is plenty in this stack that I know nothing about. These are all interfaces. These interfaces aren’t just for artificial intelligence. For me, it provides a very street view of the evolution of the web, automation, and how AI is pushing forward some existing patterns, but turning them into more of a priority.

Outline of an API Evangelist Repo
I setup a single repository in the API Evangelist GitHub organization for each company I profile. The profiling of each company begins with an APIs.json, providing name, description, and some of the common properties of an API. If they have a developer portal and documentation I spider those looking for OpenAPI, AsyncAPI, JSON Schema, Postman and Bruno collections. If I don’t find these artifacts I generate them from the documentation. Each repo ends up with potentially APIs.json, OpenAPI, AsyncAPI, JSON Schema, and Postman or Bruno collections, but I’ve also begun adding JSON Structure, XSDs, JSON-LD, and Naftiko Capabilities now. Next, I will be doing a diff of these standards and specifications Cloudflare is showcasing with what I populate each repo with—this will include the technology, but also the business side, as I work to understand the economics of this shift that is happening and the automation being pushed on us by artificial intelligence.
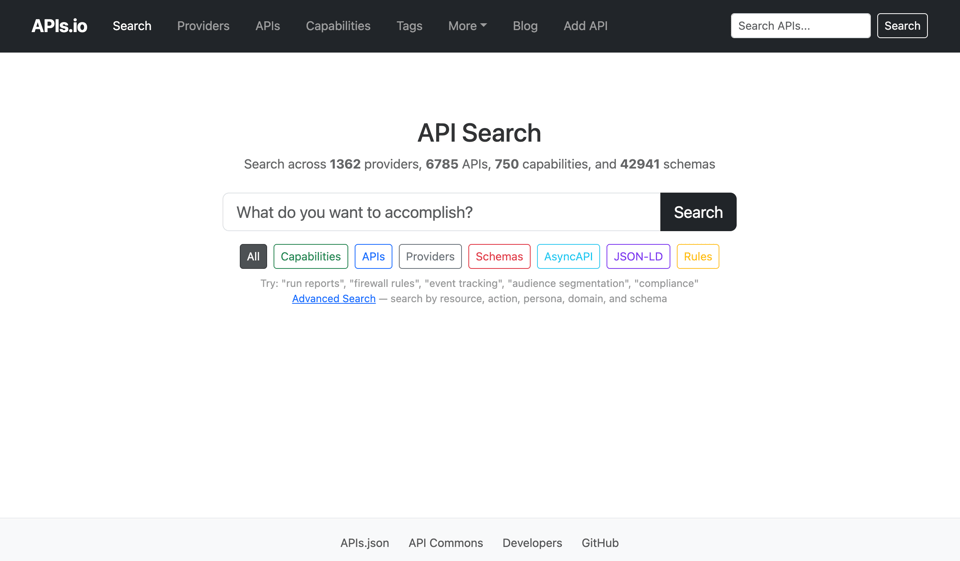
MOAR Specs on APIs.io
API Evangelist profiling powers the APIs.io index. So along with the addition of new specs and different aspects of profiling, APIs.io got a refresh regarding what it offers. You can find 1302 providers, 6494 APIs, 746 capabilities, 42884 schemas, 6451, tags, and other artifacts on APIs.io—with the count growing everyday as it is fed by my API Evangelist crawler. I have over 5K providers in the API Evangelist GitHub organization, which I estimate will put APIs.io at around 50K APIs when everything is profiled again. Then I will turn on the web crawler again to discover new APIs. Right now I am just looking to profile all of the APIs I currently have in the API Evangelist index, and get everything profiled according to my current standards.
I have ran the sync between API Evangelist and APIs.io three times this week, and as I do, I find myself thinking deeply about what API discovery means today. Even as I refine the search for APIs.io, I find myself questioning that everything we know about discovery is wrong, and something that is currently being pushed for by agents, and not always in a good way. Regardless of whether it is good or bad, I want to be understanding it, and no better place to learn than via API Evangelist and APis.io.

Agent Front Door for APIs.io
This week I evolved APIs.io into an agent-ready API directory by layering on the standards I learned about from Cloudflare across the multiple subdomains that powers Apis.io. First, I shipped a robots.txt on every part of site that explicitly permits search indexing, AI inference, and AI training via Cloudflare Content Signals and the IETF AIPREF draft, plus a per-site sitemap.xml so crawlers and agents can enumerate the full catalog effectively.
Next I published an RFC 9727 api-catalog linkset at apis.apis.io/.well-known/api-catalog listing 5,026 APIs with machine-readable OpenAPI, AsyncAPI, and other artifacts, and a parallel catalog at providers.apis.io/.well-known/api-catalog covering 1,088 providers — a single fetch gets an agent the entire surface area of the network in RFC 9264 JSON linkset format. To make those resources discoverable from any entry point, I deployed a Cloudflare Worker fronting *.apis.io that adds RFC 8288 Link headers (rel=api-catalog, rel=sitemap, rel=agent-skills, rel=alternate type=text/markdown) to every HTML response, fixes the Content-Type on the api-catalog files —most importantly — performs HTTP content negotiation: hit any API or provider URL with Accept: text/markdown and the Worker synthesizes a clean structured markdown response from the catalog, eliminating the HTML-scraping tax that agents normally pay. I didn’t stop there. I scaffolded Web Bot Auth (draft-meunier-web-bot-auth-architecture, RFC 9421) detection so signed agent traffic is surfaced in x-bot-auth response headers, ready to wire into real signature verification once we see it in the wild.
Finally, I published filesystem-style Agent Skills (per agentskills.io) at apis.io/skills/ — three SKILL.md files plus a JSON manifest — that teach an agent how to navigate the catalogs, search for APIs, and pull specifications without trial and error. Why it matters: as agents become the dominant consumers of API metadata, the networks that publish their content in machine-first formats (linksets, content negotiation, signed identity, executable skills) get used; the ones that only publish HTML get scraped poorly and ranked accordingly. apis.io now speaks every protocol an agent might use to discover, evaluate, and integrate APIs — and it does so on top of a static GitHub Pages stack with a single Cloudflare Worker, proving the agent-readiness bar is reachable without rebuilding the entire site.
AI Choosing Our Services and Tools
I was setting up a Cloudflare Worker to handle the registration for a new website I setup to tell the story of what I see in Central Park each day. I needed a simple set of APIs to support the registration, sending of email, and validating of new signup accounts. When I setup new Cloudflare Workers I use Claude to help me develop, configure, and deploy my APIs, and when I was requesting the setup of the emailing portion of the workflow, Claude responded with, “I’ll write the Worker for Resend (simplest API, free tier, just an API key). If you'd rather use AWS SES, Mailgun, or Postmark, say so.” This was super interesting. Claude making service recommendations.
It leaves you wondering how does Claude prioritize Resend over AWS SES, Mailgun, or Postmark? It foretells a pretty interesting way of discovering and onboarding users to APIs, which continues to push forward my thoughts about API discovery.

Shifting How I Use RSS
Like everything else in my world, I have been refactoring how I consume information. One of the things I profile when looking at API providers and API service providers is whether or not they have an RSS feed. Historically I plug these into my RSS reader to stay up to date on what is going on. The problem is that I don’t always spend time in my RSS reader like I use to, but when doing work in different areas I still need to know what is going on. So I have begun injecting RSS feeds for different groups of API service providers into my agentic workflows and available at my fingertips in Claude.
Of course I am using a Naftiko Capability to consume the RSS feeds of the different providers offering API documentation, and then I expose these as an HTTP API or MCP server that I use in agentic workflows and Claude copilot. Capabilities allow me to translate all of this information I am supposed to be consuming into my regular workflows, allowing me to ask questions of the documentation slice of the API ecosystem. Something that is replicated across each dimension of the space I track on.

More Love for FHIR in Healthcare
I have also been using Naftiko to help rekindle my research and storytelling around the Fast Healthcare Interoperability Requirements, or FHIR. I am exploring how you can translate from X12 278 to FHIR, and how healthcare providers can use a the Capability Spec to close the Prior Authorization Gap. Like with RSS, I can use Naftiko Capabilities to be the change I need in any existing interface, without having to write code. In this case, I need legacy healthcare formats to be available as standardized FHIR. I will be doing one or two of these types of stories a week, because I feel that delivering on the promise of standardization is one of the strengths of what we are building at Naftiko, and one of the most important things we can do to have an impact on mainstream businesses when it comes to Apis.

With API Knowledge Comes Great Power
I am always trying to find the most impactful way of convincing people that they should care about APIs. The reasons why people should care will vary from industry to industry and role to role, but one way I can convince people is by sharing with them that it will help them be more successful in their career. I have numerous examples of how knowledge about APIs within an industry or a company will benefit what you are looking to accomplish. It is one constant of my API career that hasn’t shifted the whole time. If you know where the APIs are, you have more control over your workplace, business, and career. They are the plumbing to our digital world, and APIs are where power accumulates, especially in an AI-driven market.
SDKs, Clients, and Copilots
I recently did a podcast with Redmonk about SDKs. It was an interesting conversation about not just SDKs, but clients, and what is happening with copilots as part of development. Watching the world respond to AI is interesting, but I think the SDK, CLI, client, and copilot intersection reflects the ongoing tussle that occurs at the API consumer level. I think the only thing that is new, is just the intensity of API consuming as introduced by AI and agents. I don’t think any of the traditional approaches are going away, but our behavior when it comes to consumption is definitely shifting, and our discussions reflected where I think we are headed.

Come See Me At APIDays NYC
I am getting ready for API Days NYC in May. I will be giving a talk, and have begun lining up discussions with people I want to hang out with. I love events on my home turf. Nothing like being able to sleep in your own bed and then hang out with API folks by day. If you are going to be there, make sure you email me or ping me on LinkedIn. I’m in full startup GTM and sales mode, so looking to chat with API practitioners within enterprise, but I am also looking to develop partnerships with API service providers. I’ll be my usual API Evangelist self, but driven by my Naftiko GTM and sales appetite. I am looking for design partners to help us build out the Naftiko Framework powers by capabilities, and governed as a Naftiko “Navy” fleet.
Our 1950s Future
I will end with this image of the future from in the 19th century. The future was the 1950s. I love all the power lines strung up everywhere because they had yet to move into the era of regulation by municipalities—so that wasn’t even in their projections of the future. Which pretty much sums up where I think we are when it comes to APIs today.
