AI week Feb 5: AI translation's last mile problem
Hi! This week's newsletter is a little bit different. I'm going to deep-dive on machine translation: how it works, how it doesn't, and its impacts on translation quality and on human translators. I spent about six hours writing this article, and it should take about 10-15 minutes to read. (Human translation is like that, too.)
In this newsletter:
- Last Mile problems
- Introduction: What's up with this translation?
- A brief history of machine translation
- Challenges for NMT ("AI translation")
- Literary translation: the last mile?
- Longreads
But first, a unicorn.
 Source: https://garymarcus.substack.com/p/one-genai-image-ten-errors
Source: https://garymarcus.substack.com/p/one-genai-image-ten-errors
The Last Mile problem in AI
Transportation planning has a problem known as the last mile problem: it's easy to get people or packages most of the way, but hard to get everyone and everything right to their door.
The last mile often requires a completely different solution than the first 90% of the journey. For example, a train can take people from downtown to a suburb, but the train isn't going to deliver everyone to their door; to get people the last mile, public transit systems turn to feeder buses, bike infrastructure, incentivized car pools, etc.
AI is experiencing its own Last Mile problem right now. The stabby unicorn above is an good example. Generative AI can make a picture of a unicorn and an old man, but it doesn't know that the unicorn shouldn't go through the old man, or vice versa.
An even better example is AI translation, which we're going to deep-dive on this issue. Automated, AI-boosted translation has gotten to a place where it can translate most of a text correctly, but like the old man and the unicorn, sometimes the result makes no sense.
I'm calling this a last mile problem because, like the transportation problem, I think that solving it is going to require a completely different approach than the first 90% of the journey.
Introduction: What's up with this translation?
Let's begin with this small mystery:
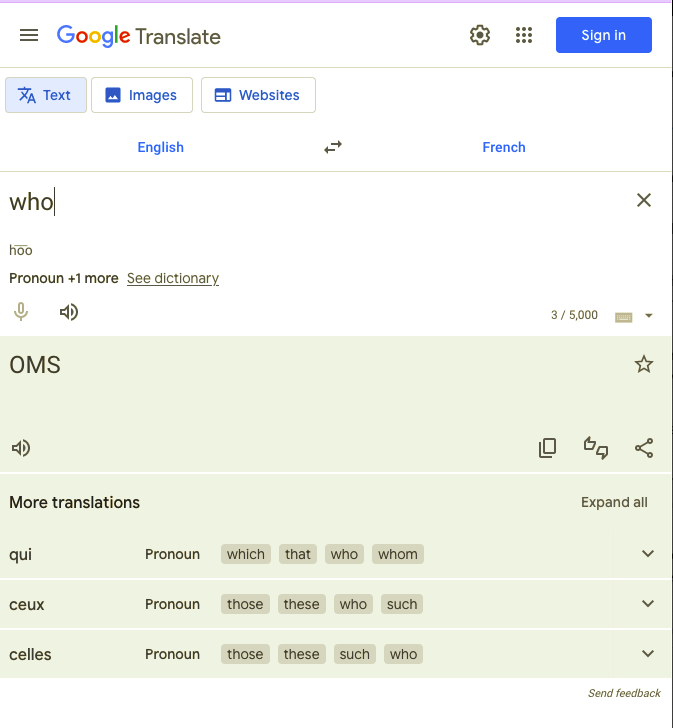 Google Translate showing "who" translated as "OMS"
Google Translate showing "who" translated as "OMS"
Google Translate thinks "who" in French is "OMS": Organisation Mondiale de la Santé, the World Health Organization. Even if you speak zero French, you can tell that's not what you want from a translation tool. (The expected result is "qui".)
Google Translate makes the same mistake in other languages: it renders "who" in Spanish as "OMS" instead of "quién", and in Ukrainian as "ВООЗ" (WHO), not "коли" (who).
The English pane even says that "who" is a pronoun, but the translation is... not the pronoun. The pronoun is there, under "More translations," and "qui" has to be a more common translation for "who" than "OMS". So why is "OMS" the result?
First, is this even an AI or ML (machine learning) issue? Yes: Google Translate has been AI since 2016.
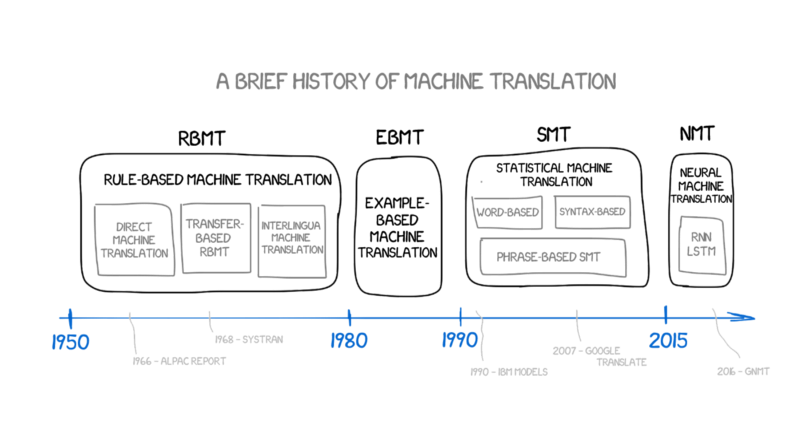
A brief history of machine translation
To get at this mystery, we need to take a quick tour through the history of machine translation.
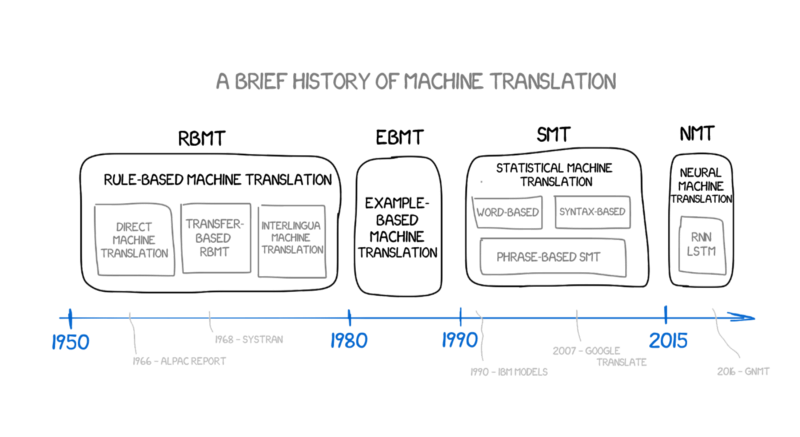 Image source: Ilya Pestov on FreeCodeCamp
Image source: Ilya Pestov on FreeCodeCamp
Stage 1: Rules-based machine translation
One of the first machine translation systems was the 1954 Georgetown-IBM experiment, which used hand-coded rules and a dictionary to successfully translate a few sentences from Russian to English. This proof-of-concept, coming in the midst of the Cold War, unlocked a great deal of funding for machine translation.

The Georgetown-IBM Experiment: MT's First Major Debut
The Georgetown-IBM experiment led the way for machine translation resulting in the services we have today.
At the time, some experts apparently predicted that they'd have translation licked in five years or so. It turned out to be much harder than they'd expected. Why is it hard? For starters, it may seem obvious to us now, but it took until the end of the 1950s for American scientists to realize that the fact that one word can have several meanings is an issue for machine translation.
Consider the verb "put" in "put out the lights" and "put out the cat". If you haven't run across these phrases, "put out the cat" means "make the cat go outside," and "put out the light" means "turn off the light." (I apologize on behalf of the English language.) Both phrases use the same word, but the light doesn't need to go outside and the cat doesn't need extinguishing.
 Source: Asurobson on istockphoto
Source: Asurobson on istockphoto
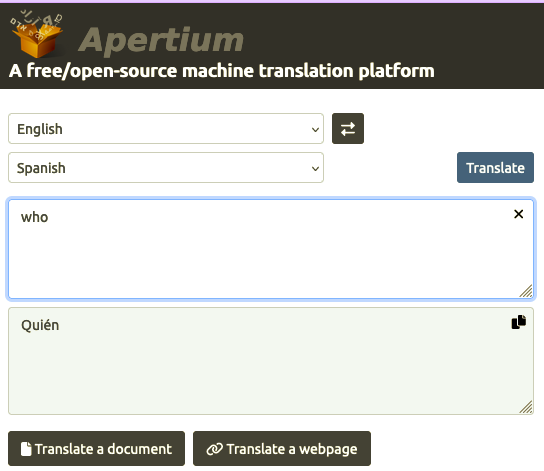
Several rule-based systems were developed in the 70s. Rule-based systems require a great deal of detailed linguistic analysis to tease out every single linguistic rule in both the source and target languages. Some rule-based translation systems are still in use today. Here's one, Apertium, outdoing Google Translate on "who":
Stage 2: Example-based machine translation
In the 80s, Japanese researchers developed a new kind of machine translation system, example-based machine translation (EBMT for short). This takes a corpus (Latin for "body", as in "of knowledge"; plural "corpora") that consists of a large number of texts in the source language and their translations into the target language. In EMBT, the corpus is sort of used as a translation dictionary for sentence chunks instead of words.
| As an example, the translation of "He buys a book on international politics" would draw from translated texts in the corpus containing "He buys a notebook/Kare wa noto o kau" and "I read a book on international politics/Watashi wa kokusai seiji nitsuite kakareta hon o yomu" to produce the translation "Kare wa kokusai seiji nitsuite kakareta hon o kau." |
Stage 3: Statistical machine translation
Rules-based machine translation works, but building a rules-based system requires an enormous amount of effort, and the results often sound stilted. Another approach, statistical translation, started to take off in the 90s.
Like EBMT, statistical translation requires a large corpus of a large number of texts in the source language and their translations into the target language. Instead of using or building a dictionary, statistical translation uses the corpus to calculate the probability that the translation of X is Y. The corpus has to be big: a minimum of 2 million words.
Instead of going word-by-word, statistical translation systems often translate phrases. As a rough example, given a bunch of texts where the phrase "put out the cat" appears in the source language (English), statistical analysis of its translations into French would give "faire sortir le chat" (make the cat exit) as a much more common translation than "éteindre le chat" (extinguish the cat).
 SVP, éteindre le chat! (Credit: Flame Beast by christoskarapanos)
SVP, éteindre le chat! (Credit: Flame Beast by christoskarapanos)
Altavista BabelFish, a free online translator in the early days of the web, used statistical machine translation. (If you don't remember using BabelFish, it managed to be both miraculous and fairly useless at once.) Google Translate was a statistical translation system until 2016, when they introduced the Google Neural Machine Translation system (GNMT).
Statistical machine translation produces texts that sound more fluent than rules-based machine translation, but it depends heavily on having a lot of translated texts to draw from: It doesn't do well at translating phrases that aren't in its reference texts.
Stage 3: Deep Learning
Neural Machine Translation (NMT), or Deep Learning, is what we mean by "AI translation." NMT requires the same giant corpus of translated texts as statistical machine translation, but instead of statistical analysis, a neural network is trained to encode source-language sentences into state vectors, then decode them into the target language.
The decoding process goes word-by-word, but as the decoder works on each encoding, it pays attention to the preceding and following bits of the sentence encoding to find the right word. This GIF is from Google:
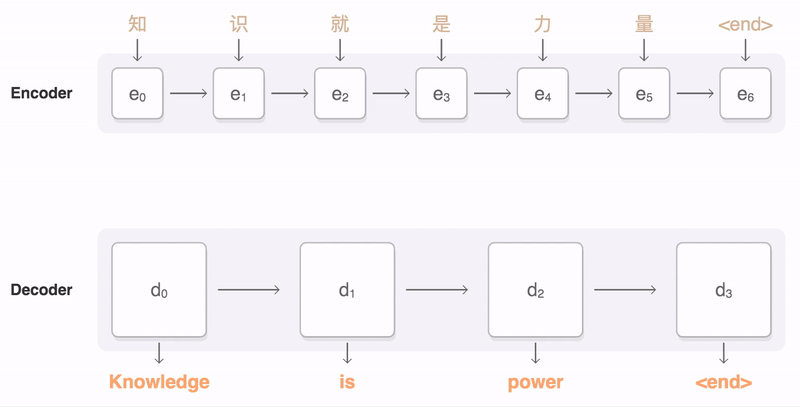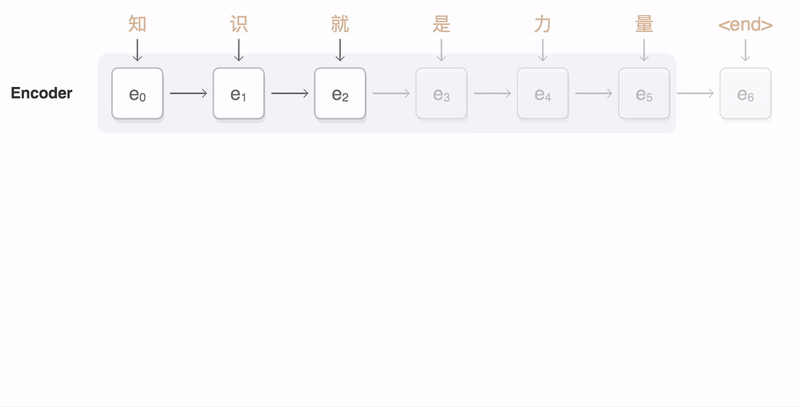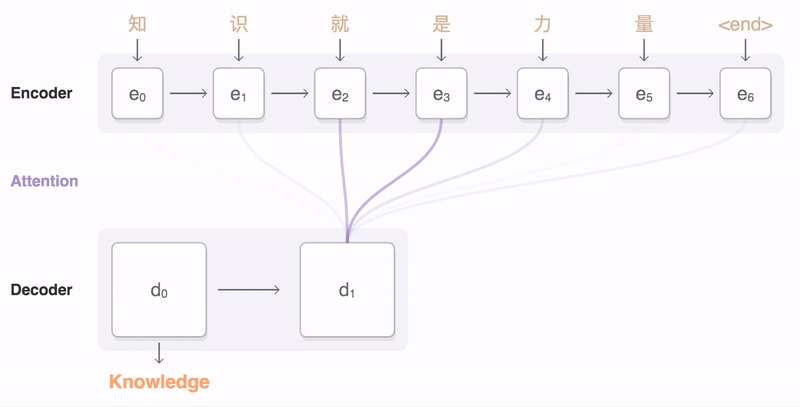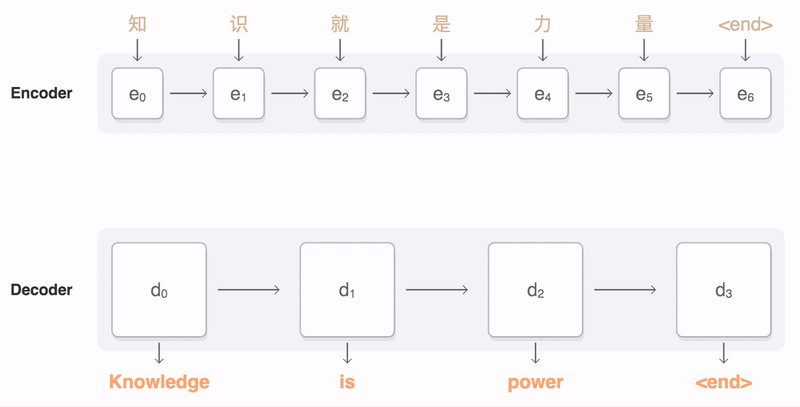 Source: Google
Source: Google
(If you really want to get into the nuts and bolts of NMT, this deep dive looks good.)
Compared to statistical translation, NMT is more accurate, and its translations sound more fluent. But it's not as good as a human translator, and here are some of the reasons why.
Challenges for NMT
NMT uses sentence-level context, but when translating a larger document, it's not always capable of holding context across several sentences, let alone across long paragraphs. For example, NMT can lose track of "his" and "hers" in translating from a language that uses these pronouns differently.
This is a real problem for machine translation, especially literary translation. Last year, I Google Translated several literary stories from Ukrainian into English. Without speaking the source language (Ukrainian), I could still tell the machine translation had literally lost the plot more often than not.
Another issue is that NMT needs a large corpus, and the smaller the corpus, the worse the translations. NMT translations into or out of languages that don't have a big Internet presence aren't very good.
What's going on with the WHO?
NMT can also be unexpectedly bad at translating short phrases, since it uses the context of the sentence to pick the correct decoding. If I had to guess, I'd say that's what's happening with the translation of "who" as "WHO": there is no context.
One way to get around this is to have the translation software use statistical translation for single words and short phrases, but NMT for sentences. Here's an example of Yandex doing this in 2017:
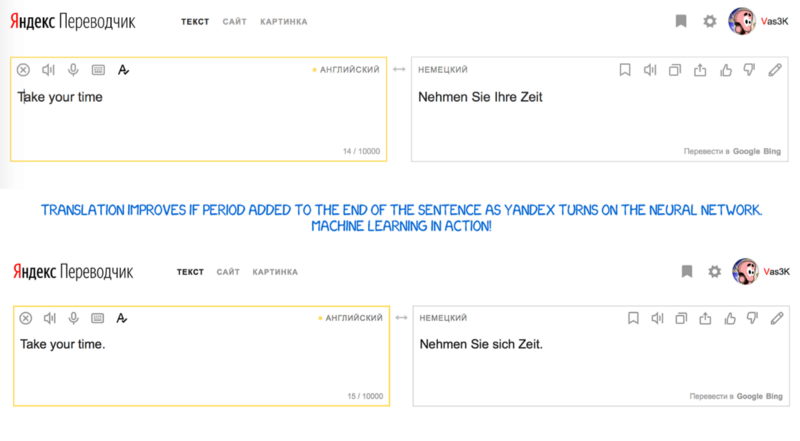
I have to wonder whether Google Translate used to use statistical translation for single words, and recently turned it off. Interestingly, DeepL translate, which is also NMT-based, doesn't have the WHO problem.
Future Stage 4: Self-poisoning translations?
The larger the corpus of translated texts NMT has to draw from, the better its translations. But there's a potential problem with any corpus-based approach: if the corpus of translations draws from the Internet, and the Internet is filling up with low-quality machine translations (as Vice noted last month), translation quality will plummet.
Literary translation: The last mile
Last month, an article in The Atlantic (non-paywalled on MSN) proposed literary translation as "The Last Frontier of Machine Translation". They didn't get into context, which is definitely a problem for literary translation, but creativity and style.
| "Literary translation," as I'm using it here, means "a translation for which the quality of the text really matters." As a writer, I think that text quality always matters, but many companies have judged that it isn't important to pay authors or translators for high-quality text: for example, in technical manuals (which need to be human-comprehensible but don't need to be beautiful), or SEO-oriented blog posts (which don't even need to be human-comprehensible). |
This is where Mr. Stabby Unicorn comes in. Literary translation may be a last-mile problem for machine translation.
Why literary translation is hard
I've done a little literary translation. Non-translators often don't realize that a literary translator is essentially rewriting the story in another language. Idiom doesn't translate across languages, for one thing. A literal translation isn't going to capture tone and nuance, for another.
I think the best way to get this is by considering how many different ways there are to write the same sentence in English. Let's write a sentence about this kid:

Here are a few alternatives:
- He drank warm water from a glass.
- He gulped room-temperature water from a tumbler.
- He sipped tepid water from a glass.
As a monolingual English author, when would I pick "tepid" over "warm"? When would I pick "tumbler" over "glass"?
It all depends on the context. If the subject is a cowboy who staggered into a bar, he's going to gulp from a tumbler. If it's a small child, he might sip from a glass. If the action takes place outside, as in this picture, I wouldn't use "room-temperature". Literary translation involves this kind of decision with every sentence.
Plus, the direct translation is sometimes the wrong word. A great example are Québecois-French swears: "Communion wafer!" carries the same heft as "Fuck!", and "fucké" (lit. fucked, as in over or up) is barely even a swear.
Cultural context comes into it, too. If the glass or the water is culturally significant in the source culture, should I communicate that to the readers in the destination language? If the water's from a hose, North American readers would understand what "hose water" means (warm, fusty), but Parisian readers might not: so as a translator, mindful of my audience, I'd translate "warm, fusty water from the hose" instead of the source phrase "hose water".
| Some literary translation difficulties for AI: |
|---|
| Good translation takes into account tone, setting, and character. |
| Idioms usually don't translate directly. |
| Picking the right idiom requires an understanding of the tone, nuances, and social register of both source and destination idioms. |
| Translation is also cross-cultural. |
Literary translations are specific to the source text and destination culture/language. They require an understanding of idiom and culture, and an understanding of the text's tone, setting and characters.
The main way to improve the quality of NMT, enlarging the corpus, is unlikely to help NMT get better at any of these tasks.
Compounding this, literary translators generally hold the copyright to their translations, meaning that (at least in theory) trainers of NMT need permission to add literary translations to their corpora.
Like the last mile in transportation, getting machine translation to match human translators will require a completely different approach.
 Image source: Alliance Solutions Group
Image source: Alliance Solutions Group
How AI is affecting literary translation
Unfortunately, translators are almost always hired by non-translators, who almost always want to pay less for translation. I've seen three approaches:
- Machine translation is good enough; we're laying off translators.
- Machine translation needs checking: we're paying target-language people to read over the text to make sure it doesn't have any really embarrassing mistakes.
- Machine translation isn't good enough, but I still want to pay less for translation. So I'll hire a translator to "check" the machine's work for me, and pay them substantially less since they're just reviewing it (so-called "post-editing").
The first and second approaches are more common outside literary translation. Unfortunately, both mean worse translations, that can even diverge from the source text due to "hallucinations". The third approach is more common in literary translation, but it also means worse translations, that can actually be harder for the translator than just translating from scratch.
Picture something you know how to do really well, whether it's building furniture, painting, cooking a meal, whatever. Now imagine the effort to make something from scratch, vs. the effort needed to fix an amateur's botched work. It's going to take at least as long to redo the botched work, and it probably won't come out as well as if you'd just done it yourself from the start, right? It's the same with translation. It's harder to make a mediocre translation good than it is to make a good translation.
Translators are fighting back with organizations like "Collectif En Chair et En Os," a polyglot alliance of translators and creators with the tagline "Say No to Soulless Translations." You can sign their petition below.

Pétition · Littérature, cinéma, presse, jeux vidéo : non à des traductions sans âme · Change.org
Littérature, cinéma, presse, jeux vidéo : non à des traductions sans âme
Longreads
1. Translation Slam
The Emerging Translator's Network recently ran a 3-part series on AI and literary translation, starting with a real-time translation slam: human vs. Google Translate. Parts 2 and 3 cover the impacts of AI translation on literary translators and copyright.

(Wo)man Versus Machine – Part One – ETN
By Amanda Oliver The Goethe-Institut London recently put on a brilliant event: hosted in gameshow format with a live audience, literary translators Christophe Fricker of the University of Bristol, …
2. A more detailed history of machine translation
A history of machine translation from the Cold War to deep learning
by Ilya Pestov A history of machine translation from the Cold War to deep learning Photo by Ant Rozetsky [https://unsplash.com/photos/H9m6mfeeakU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText] on Unsplash [https://unsplash.com/search/photos/russia?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText] I open Google Translate twice as often as Facebook, and the instant translation of the price tags is not a cyberpunk for me anymore. That’s what
NEXT WEEK: Does ChatGPT understand what it's saying?
It's pretty clear that image-generating AI doesn't "understand" the images it makes, or we wouldn't get images like Mr. Stabby Unicorn up there. But do LLMs like ChatGPT "understand" what they're saying? I'm planning to focus next week's newsletter on the argument over whether or not LLMs like ChatGPT understand their output, for any value of the word "understand."
Add a comment: