[AINews] X.ai Grok 3 and Mira Murati's Thinking Machines
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
GPUs are all you need.
AI News for 2/17/2025-2/18/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (211 channels, and 6478 messages) for you. Estimated reading time saved (at 200wpm): 608 minutes. You can now tag @smol_ai for AINews discussions!
It is a rare day when one frontier lab makes its debut, much less two (loosely speaking). But that is almost certainly what happened today.
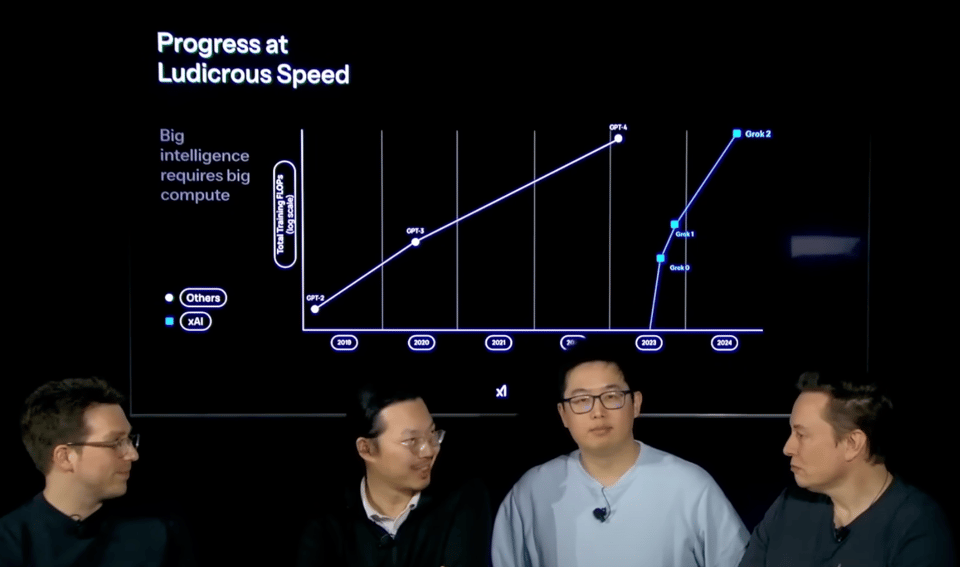
We would say that the full Grok 3 launch stream is worth watching at 2x:
Opinions on Grok 3 are mixed, with lmarena, karpathy, and information recycler threadbois mostly very positive, whereas /r/OpenAI and other independent evals being more skeptical. Not everything is released either; Grok 3 isn't available in API and as of time of writing, the demoed "Think" and "Big Brain" modes aren't live yet. On the whole the evidence points to Grok 3 laying credible claim to being somewhere between o1 and o3, and this undeniable trajectory is why we award it title story.
There is less "news you can use" in the second item, but Mira Murati's post OpenAI plan is now finally public, and she has assembled what is almost certainly going to be a serious frontier lab in Thinking Machines, recruiting notables from across the frontier labs and specifically ChatGPT alumni:
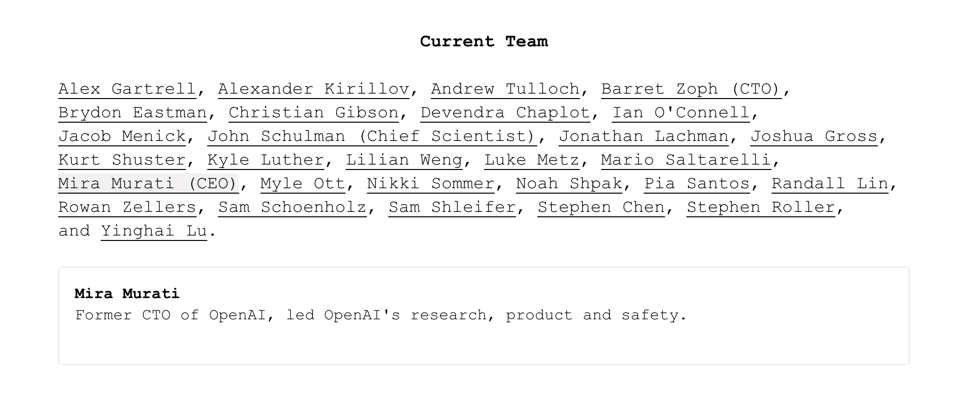
There's not a lot of detail in the manifesto beyond a belief in publishing research, emphasis on collaborative and personalizable AI, multimodality, research and product co-design, and an empirical approach to safety and alignment. On paper, it looks like "Anthropic Redux".
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- Perplexity AI Discord
- HuggingFace Discord
- Codeium (Windsurf) Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- Cursor IDE Discord
- Interconnects (Nathan Lambert) Discord
- LM Studio Discord
- Eleuther Discord
- Yannick Kilcher Discord
- Stability.ai (Stable Diffusion) Discord
- GPU MODE Discord
- Nous Research AI Discord
- Latent Space Discord
- Notebook LM Discord
- Modular (Mojo 🔥) Discord
- Nomic.ai (GPT4All) Discord
- LlamaIndex Discord
- Torchtune Discord
- MCP (Glama) Discord
- LLM Agents (Berkeley MOOC) Discord
- Cohere Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- OpenAI ▷ #ai-discussions (1021 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (5 messages):
- OpenAI ▷ #prompt-engineering (7 messages):
- OpenAI ▷ #api-discussions (7 messages):
- Unsloth AI (Daniel Han) ▷ #general (389 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (14 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (98 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (47 messages🔥):
- Perplexity AI ▷ #general (477 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (36 messages🔥):
- Perplexity AI ▷ #pplx-api (4 messages):
- HuggingFace ▷ #general (59 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (1 messages):
- HuggingFace ▷ #i-made-this (3 messages):
- HuggingFace ▷ #computer-vision (4 messages):
- HuggingFace ▷ #NLP (2 messages):
- HuggingFace ▷ #smol-course (3 messages):
- HuggingFace ▷ #agents-course (380 messages🔥🔥):
- Codeium (Windsurf) ▷ #content (1 messages):
- Codeium (Windsurf) ▷ #discussion (30 messages🔥):
- Codeium (Windsurf) ▷ #windsurf (418 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (420 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (24 messages🔥):
- aider (Paul Gauthier) ▷ #links (4 messages):
- OpenRouter (Alex Atallah) ▷ #general (435 messages🔥🔥🔥):
- Cursor IDE ▷ #general (335 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (209 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (77 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #rl (4 messages):
- Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #retort-podcast (2 messages):
- Interconnects (Nathan Lambert) ▷ #policy (1 messages):
- Interconnects (Nathan Lambert) ▷ #expensive-queries (14 messages🔥):
- LM Studio ▷ #general (86 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (128 messages🔥🔥):
- Eleuther ▷ #general (30 messages🔥):
- Eleuther ▷ #research (77 messages🔥🔥):
- Eleuther ▷ #scaling-laws (26 messages🔥):
- Eleuther ▷ #lm-thunderdome (3 messages):
- Eleuther ▷ #gpt-neox-dev (75 messages🔥🔥):
- Yannick Kilcher ▷ #general (72 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (31 messages🔥):
- Yannick Kilcher ▷ #ml-news (70 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (168 messages🔥🔥):
- GPU MODE ▷ #general (11 messages🔥):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #cuda (17 messages🔥):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #algorithms (1 messages):
- GPU MODE ▷ #cool-links (4 messages):
- GPU MODE ▷ #jobs (2 messages):
- GPU MODE ▷ #beginner (1 messages):
- GPU MODE ▷ #off-topic (1 messages):
- GPU MODE ▷ #rocm (7 messages):
- GPU MODE ▷ #arm (4 messages):
- GPU MODE ▷ #webgpu (1 messages):
- GPU MODE ▷ #self-promotion (15 messages🔥):
- GPU MODE ▷ #🍿 (3 messages):
- GPU MODE ▷ #edge (2 messages):
- GPU MODE ▷ #reasoning-gym (49 messages🔥):
- Nous Research AI ▷ #general (84 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (11 messages🔥):
- Nous Research AI ▷ #research-papers (3 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- Latent Space ▷ #ai-general-chat (94 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Notebook LM ▷ #use-cases (24 messages🔥):
- Notebook LM ▷ #general (65 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (14 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (39 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (46 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (23 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (18 messages🔥):
- Torchtune ▷ #papers (4 messages):
- MCP (Glama) ▷ #general (7 messages):
- MCP (Glama) ▷ #showcase (11 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (7 messages):
- Cohere ▷ #discussions (1 messages):
- Cohere ▷ #api-discussions (1 messages):
- Cohere ▷ #projects (4 messages):
- Cohere ▷ #cohere-toolkit (1 messages):
- DSPy ▷ #papers (2 messages):
- DSPy ▷ #general (1 messages):
- tinygrad (George Hotz) ▷ #general (2 messages):
- MLOps @Chipro ▷ #events (1 messages):
AI Twitter Recap
Grok-3 Model Performance and Benchmarks
- Grok-3 outperforms other models: @omarsar0 reported that Grok-3 significantly outperforms models in its category like Gemini 2 Pro and GPT-4o, even with Grok-3 mini showing competitive performance. @iScienceLuvr stated that Grok-3 reasoning models are better than o3-mini-high, o1, and DeepSeek R1 in preliminary benchmarks. @lmarena_ai announced Grok-3 achieved #1 rank in the Chatbot Arena, becoming the first model to break a 1400 score. @arankomatsuzaki noted Grok 3 reasoning beta achieved 96 on AIME and 85 on GPQA, on par with full o3. @iScienceLuvr highlighted Grok 3's performance on AIME 2025. @scaling01 emphasized Grok-3’s impressive #1 ranking across all categories in benchmarks.
- Grok-3 mini's capabilities: @omarsar0 shared a result generated with Grok 3 mini, while @ibab mentioned Grok 3 mini is amazing and will be released soon. @Teknium1 found in testing that Grok-3mini is generally better than full Grok-3, suggesting it wasn't simply distilled and might be fully RL-trained.
- Grok-3's reasoning and coding abilities: @omarsar0 stated Grok-3 also has reasoning capabilities unlocked by RL, especially good in coding. @lmarena_ai pointed out Grok-3 surpassed top reasoning models like o1 and Gemini-thinking in coding. @omarsar0 highlighted Grok 3’s creative emergent capabilities, excelling in creative coding like generating games. @omarsar0 showcased Grok 3 Reasoning Beta performance on AIME 2025 demonstrating generalization capabilities beyond coding and math.
- Comparison to other models: @nrehiew_ suggested Grok 3 reasoning is inherently an ~o1 level model, implying a 9-month capability gap between OpenAI and xAI. @Teknium1 considered Grok-3 equivalent to o3-full with deep research, but at a fraction of the cost. @Yuchenj_UW stated Grok-3 is as good as o3-mini.
- Computational resources for Grok-3: @omarsar0 mentioned Grok 3 involved 10x more training than Grok 2, and pre-training finished in early January, with training ongoing. @omarsar0 revealed 200K total GPUs were used, with capacity doubled in 92 days to improve Grok. @ethanCaballero noted grok-3 is 8e26 FLOPs of training compute.
- Karpathy's vibe check of Grok-3: @karpathy shared a detailed vibe check of Grok 3, finding it around state of the art (similar to OpenAI's o1-pro) and better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. He tested thinking capabilities, emoji decoding, tic-tac-toe, GPT-2 paper analysis and research questions. He also tested DeepSearch, finding it comparable to Perplexity DeepResearch but not yet at the level of OpenAI's "Deep Research".
Company and Product Announcements
- xAI Grok-3 Launch: @omarsar0 announced the BREAKING news of xAI releasing Grok 3. @alexandr_wang congratulated xAI on Grok 3 being the new best model, ranking #1 in Chatbot Arena. @Teknium1 also announced Grok3 Unveiled. @omarsar0 mentioned Grok 3 is available on X Premium+. @omarsar0 stated improvements will happen rapidly, almost daily and a Grok-powered voice app is coming in about a week.
- Perplexity R1 1776 Open Source Release: @AravSrinivas announced Perplexity open-sourcing R1 1776, a version of DeepSeek R1 post-trained to remove China censorship, emphasizing unbiased and accurate responses. @perplexity_ai also announced open-sourcing R1 1776. @ClementDelangue noted Perplexity is now on Hugging Face.
- DeepSeek NSA Sparse Attention: @deepseek_ai introduced NSA (Natively Trainable Sparse Attention), a hardware-aligned mechanism for fast long-context training and inference.
- OpenAI SWE-Lancer Benchmark: @OpenAI launched SWE-Lancer, a new realistic benchmark for coding performance, comprising 1,400 freelance software engineering tasks from Upwork valued at $1 million. @_akhaliq also announced OpenAI SWE-Lancer.
- LangChain LangMem SDK: @LangChainAI released LangMem SDK, an open-source library for long-term memory in AI agents, enabling agents to learn from interactions and optimize prompts.
- Aomni $4M Seed Round: @dzhng announced Aomni raised a $4m seed round for their AI agents that 10x revenue team output.
- MistralAI Batch API UI: @sophiamyang introduced MistralAI batch API UI, allowing users to create and monitor batch jobs from la Plateforme.
- Thinking Machines Lab Launch: @dchaplot announced the launch of Thinking Machines Lab, inviting others to join.
Technical Deep Dives and Research
- Less is More Reasoning (LIMO): @AymericRoucher highlighted Less is More for Reasoning (LIMO), a 32B model fine-tuned with 817 examples that beats o1-preview on math reasoning, suggesting carefully selected examples are more important than sheer quantity for reasoning.
- Diffusion Models without Classifier-Free Guidance: @iScienceLuvr shared a paper on Diffusion Models without Classifier-free Guidance, achieving new SOTA FID on ImageNet 256x256 by directly learning the modified score.
- Scaling Test-Time Compute with Verifier-Based Methods: @iScienceLuvr discussed research proving verifier-based (VB) methods using RL or search are superior to verifier-free (VF) approaches for scaling test-time compute.
- MaskFlow for Long Video Generation: @iScienceLuvr introduced MaskFlow, a chunkwise autoregressive approach to long video generation from CompVis lab, using frame-level masking for efficient and seamless video sequences.
- Intuitive Physics from Self-Supervised Video Pretraining: @arankomatsuzaki presented Meta's research showing intuitive physics understanding emerges from self-supervised pretraining on natural videos, by predicting outcomes in a rep space.
- Reasoning Models and Verifiable Rewards: @cwolferesearch explained that reasoning models like Grok-3 and DeepSeek-R1 are trained with reinforcement learning using verifiable rewards, emphasizing verification in math and coding tasks and the power of RL in learning complex reasoning.
- NSA: Hardware-Aligned Sparse Attention: @deepseek_ai detailed NSA's core components: dynamic hierarchical sparse strategy, coarse-grained token compression, and fine-grained token selection, optimizing for modern hardware to speed up inference and reduce pre-training costs.
AI Industry and Market Analysis
- xAI as a SOTA Competitor: @scaling01 argued that after Grok-3, xAI must be considered a real competitor for SOTA models, though OpenAI, Anthropic, and Google might be internally ahead. @ArtificialAnlys also stated xAI has arrived at the frontier and joined the 'Big 5' American AI labs. @omarsar0 noted Elon mentioned Grok 3 is an order of magnitude more capable than Grok 2. @arankomatsuzaki observed China's rapid AI progress with DeepSeek and Qwen, highlighting the maturation of the Chinese AI community.
- OpenAI's Strategy and Market Position: @scaling01 discussed Gemini 2.0 Flash cutting into Anthropic's market share, suggesting Anthropic needs to lower prices or release a better model to maintain growth. @scaling01 commented that Grok-3 launch might be for mind-share and attention, as GPT-4.5 and a new Anthropic model are coming soon and Grok-3's top spot might be short-lived.
- Perplexity's Growth and Deep Research: @AravSrinivas highlighted the growing number of daily PDF exports from Perplexity Deep Research, indicating increasing usage. @AravSrinivas shared survey data showing over 52% of users would switch from Gemini to Perplexity.
- AI and Energy Consumption: @JonathanRoss321 discussed the balance between AI's increasing energy demand and its potential to improve efficiency across civilization, citing DeepMind AI's 40% energy reduction in Google data centers as an example.
- SWE-Lancer Benchmark and LLMs in Software Engineering: @_philschmid summarized OpenAI's SWE-Lancer benchmark, revealing Claude 3.5 Sonnet achieved a $403K earning potential but frontier models still can't solve most tasks, highlighting challenges in root cause analysis and complex solutions. @mathemagic1an suggested generalist SWE agents like DevinAI are useful for dev discussions even without merging PRs.
Open Source and Community
- Call for Open Sourcing o3-mini: @iScienceLuvr urged everyone to vote for open-sourcing o3-mini, emphasizing the community's ability to distill it into a phone-sized model. @mervenoyann joked about wanting o3-mini open sourced. @gallabytes asked people to vote for o3-mini. @eliebakouch jokingly suggested internal propaganda is working to vote for o3-mini.
- Perplexity Open-Sources R1 1776: @AravSrinivas announced Perplexity's first open-weights model, R1 1776, and released weights on @huggingface. @reach_vb highlighted Perplexity releasing POST TRAINED DeepSeek R1 MIT Licensed.
- Axolotl v0.7.0 Release: @winglian announced Axolotl v0.7.0 with GRPO support, Multi-GPU LoRA kernels, Modal deployment, and more.
- LangMem SDK Open Source: @LangChainAI released LangMem SDK as open-source.
- Ostris Open Source Focus: @ostrisai announced transitioning to focusing on open source work full time, promising more models, toolkit improvements, tutorials, and asking for financial support.
- Call for Grok-3 Open Sourcing: @huybery called for Grok-3 to be open-sourced.
- DeepSeek's Open Science Dedication: @reach_vb thanked DeepSeek for their dedication to open source and science.
Memes and Humor
- Reactions to Grok-3's Name and Performance: @iScienceLuvr reacted with "NOT ANOTHER DEEP SEARCH AAHHH". @nrehiew_ posted "STOP THE COUNT", likely in jest about Grok-3's benchmark results. @scaling01 joked "i love the janitor, but just accept that Grok-3 is the most powerful PUBLICLY AVAILABLE LLM (at least for a day lol)".
- Phone-Sized Model Vote Humor: @nrehiew_ sarcastically commented "Those of you voting “phone-sized model”are deeply unserious people. The community would get the o3 mini level model on a Samsung galaxy watch within a month. Please be serious". @dylan522p stated "I can't believe X users are so stupid. Not voting for o3-mini is insane.".
- Elon Musk and xAI Jokes: @Yuchenj_UW joked about catching Elon tweeting during the Grok3 Q&A. @aidan_mclau posted "he’s even unkind to his mental interlocutors 😔" linking to a tweet.
- Silly Con Valley Narrativemongers: @teortaxesTex criticized "Silly con valley narrativemongers with personas optimized to invoke effortless Sheldon Cooper or Richard Hendricks gestalt".
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. OpenAI's O3-Mini vs Phone-Sized Model Poll Controversy
- Sam Altman's poll on open sourcing a model.. (Score: 631, Comments: 214): Sam Altman conducted a Twitter poll asking whether it would be more useful to create a small "o3-mini" level model or the best "phone-sized model" for their next open source project, with the latter option receiving 62.2% of the 695 total votes so far. The poll has 23 hours remaining for participation, indicating community engagement in decision-making about open-sourcing AI models.
- Many commenters advocate for the o3-mini model, arguing that it can be distilled into a mobile phone model if needed, and emphasizing its potential utility on local machines and for small organizations. Some express skepticism about the poll's integrity, suggesting that it might be a marketing strategy or that the poll results are manipulated.
- There is a strong sentiment against the phone-sized model, with users questioning its practicality given current hardware limitations and suggesting that larger models can be more versatile. Some believe that OpenAI might eventually release both models, using the poll to decide which to release first.
- The discussion reflects a broader skepticism about OpenAI's open-source intentions, with some users doubting the company's commitment to open-sourcing their models. Others highlight the importance of distillation techniques to create smaller, efficient models from larger ones, suggesting that this approach could be beneficial for the open-source community.
- ClosedAI Next Open Source (Score: 119, Comments: 27): Sam Altman sparked a debate with a tweet asking whether it is more advantageous to develop a smaller model for GPU use or to focus on creating the best possible phone-sized model. The discussion centers on the trade-offs between model size and operational efficiency across different platforms.
- Local Phone Models face criticism for being slow, consuming significant battery, and taking up disk space, compared to online models. Commenters express skepticism about the practicality of a local phone model and suggest that votes for such models may be influenced by OpenAI employees.
- OpenAI's Business Model is scrutinized, with doubts about their willingness to open-source models like o3. Users speculate that OpenAI might only release models when they become obsolete and express concern about potential regulatory impacts on genuinely open-source companies.
- There is a strong push for supporting O3-MINI as a more versatile option, with the potential for distillation into a mobile version. Some users criticize the framing of the poll and predict that OpenAI might release a suboptimal model to appear open-source without genuinely supporting open innovation.
Theme 2. GROK-3 Claims SOTA Supremacy Amid GPU Controversy
- GROK-3 (SOTA) and GROK-3 mini both top O3-mini high and Deepseek R1 (Score: 334, Comments: 312): Grok-3 Beta achieves a leading score of 96 in Math (AIME '24), showcasing its superior performance compared to competitors like O3-mini (high) and Deepseek-R1. The bar graph highlights the comparative scores across categories of Math, Science (GPQA), and Coding (LCB Oct-Feb), with Grok-3 models outperforming other models in the test-time compute analysis.
- Many users express skepticism about Grok-3's performance claims, noting the lack of independent benchmarks and the absence of open-source availability. Lmsys is mentioned as an independent benchmark, but users are wary of the $40/month cost without significant differentiators from other models like ChatGPT.
- Discussions highlight concerns about Elon Musk's involvement with Grok-3, with users expressing distrust and associating his actions with fascist ideologies. Some comments critique the use of the term "woke" in the context of open-source discussions and highlight the controversy surrounding Musk's political activities.
- Technical discussions focus on the ARC-AGI benchmark, which is costly and complex to test, with OpenAI having invested significantly in it. Users note that Grok-3 was not tested on ARC-AGI, and there's interest in seeing its performance on benchmarks where current SOTA models struggle.
- Grok presentation summary (Score: 245, Comments: 80): The image depicts a Q&A session with a panel, likely including Elon Musk, discussing the unveiling of xAI GROK-3. Community reactions vary, with comments such as "Grok is good" and "Grok will travel to Mars," indicating mixed opinions on the presentation and potential capabilities of the technology.
- The presentation's target audience was criticized for not being engineers, with several commenters noting that the content was less organized compared to OpenAI's presentations. Elon Musk's role as a non-engineer was highlighted, with some expressing skepticism about the accuracy of his reporting on technical details.
- The body language of the panel, particularly the non-Elon members, was noted as nervous or scared, with some attributing this to Elon's presence. Despite this, some appreciated the raw, non-corporate approach of the panel.
- Discussions on benchmark comparisons with OpenAI and other models like Deepseek and Qwen arose, with some skepticism about the benchmarks being self-reported. The mention of H100s and the cost implications of achieving parity with other models like OpenAI's last model was also noted.
Theme 3. DeepSeek's Native Sparse Attention Model Release
- DeepSeek Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention (Score: 136, Comments: 6): DeepSeek's NSA model introduces Native Sparse Attention, which is both hardware-aligned and natively trainable. This innovation in sparse attention aims to enhance model efficiency and performance.
- DeepSeek's NSA model shares conceptual similarities with Microsoft's "SeerAttention", which also explores trainable sparse attention, as noted by LegitimateCricket620. LoaderD suggests potential collaboration between DeepSeek and Microsoft researchers, emphasizing the need for proper citation if true.
- Recoil42 highlights the NSA model's core components: dynamic hierarchical sparse strategy, coarse-grained token compression, and fine-grained token selection. These components optimize for modern hardware, enhancing inference speed and reducing pre-training costs without sacrificing performance, outperforming Full Attention models on various benchmarks.
- DeepSeek is still cooking (Score: 809, Comments: 100): DeepSeek's NSA (Non-Sparse Attention) demonstrates superior performance over traditional Full Attention methods, achieving higher scores across benchmarks such as General, LongBench, and Reasoning. It also provides significant speed improvements, with up to 11.6x speedup in the decode phase. Additionally, NSA maintains perfect retrieval accuracy at context lengths up to 64K, illustrating its efficiency in handling large-scale data. DeepSeek NSA Paper.
- The discussion highlights the potential for DeepSeek NSA to reduce VRAM requirements due to compressed keys and values, though actual VRAM comparisons are not provided. The model's capability to handle large context lengths efficiently is also noted, with inquiries about its performance across varying context sizes.
- Hierarchical sparse attention has piqued interest, with users speculating on its potential to make high-speed processing feasible on consumer hardware. The model's 27B total parameters with 3B active parameters are seen as a promising size for balancing performance and computational efficiency.
- Comments emphasize the significant speed improvements DeepSeek NSA offers, with some users expressing interest in its practical applications and potential for running on mobile devices. The model's approach is praised for its efficiency in reducing computation costs, contrasting with merely increasing computational power.
Theme 4. PerplexityAI's R1-1776 Removes Censorship in DeepSeek
- PerplexityAI releases R1-1776, a DeepSeek-R1 finetune that removes Chinese censorship while maintaining reasoning capabilities (Score: 185, Comments: 78): PerplexityAI has released R1-1776, a finetuned version of DeepSeek-R1, aimed at eliminating Chinese censorship while preserving its reasoning abilities. The release suggests a focus on enhancing access to uncensored information without compromising the AI's performance.
- Discussions centered around the effectiveness and necessity of the release, with skepticism about the model's claims of providing unbiased, accurate, and factual information. Critics questioned whether the model simply replaced Chinese censorship with American censorship, highlighting potential biases in the model.
- There were comparisons between Chinese and Western censorship, with users noting that Chinese censorship often involves direct suppression, while Western methods may involve spreading misinformation. The conversation included examples like Tiananmen Square and US political issues to illustrate different censorship styles.
- Users expressed skepticism about the model's open-source status, with some questioning the practical use of the model and others suggesting it was a waste of engineering effort. A blog post link provided further details on the release: Open-sourcing R1 1776.
Theme 5. Speeding Up Hugging Face Model Downloads
- Speed up downloading Hugging Face models by 100x (Score: 167, Comments: 45): Using hf_transfer, a Rust-based tool, can significantly increase the download speed of Hugging Face models to over 1GB/s, compared to the typical cap of 10.4MB/s when using Python command line. The post provides a step-by-step guide to install and enable hf_transfer for faster downloads, highlighting that the speed limitation is not due to Python but likely a bandwidth restriction not present with hf_transfer.
- Users discuss alternative tools for downloading Hugging Face models, such as HFDownloader and Docker-based CLI, which offer pre-configured solutions to avoid host installation. LM Studio is mentioned as achieving around 80 MB/s, suggesting that the 10.4 MB/s cap is not a Python limitation but likely a bandwidth issue.
- There is debate over the legal implications of distributing model weights and the potential benefits of using torrent for distribution, with concerns about controlling dissemination and liability. Some users argue that torrents would be ideal but acknowledge the challenges in managing distribution.
- The hf_transfer tool is highlighted as beneficial for high-speed downloads, especially in datacenter environments, with claims of speeds over 500MB/s. Users express gratitude for the tool's ability to reduce costs associated with downloading large models, such as Llama 3.3 70b.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Grok 3 Benchmark Release and Performance Debate
- How is grok 3 smartest ai on earth ? Simply it's not but it is really good if not on level of o3 (Score: 1012, Comments: 261): Grok-3 is discussed as a highly competent AI model, though not necessarily the "smartest" compared to "o3". A chart from a livestream, shared via a tweet by Rex, compares AI models on tasks like Math, Science, and Coding, highlighting Grok-3 Reasoning Beta and Grok-3 mini Reasoning alongside others, with "o3" data added by Rex for comprehensive analysis.
- Discussions highlight skepticism about Grok 3's claimed superiority, with some users questioning the validity of benchmarks and comparisons, particularly against o3, which hasn't been released yet. There's a general consensus that o3 is not currently available for independent evaluation, which complicates comparisons.
- Concerns about Elon Musk's involvement in AI projects surface, with users expressing distrust due to perceived ethical issues and potential misuse of AI technologies. Some comments reflect apprehension about the transparency and motives behind benchmarks and AI capabilities touted by companies like OpenAI and xAI.
- Grok 3 is noted for its potential in real-time stock analysis, though some users argue it may not be the smartest AI available. Comments also discuss the cost and scalability issues of o3, with reports indicating it could be prohibitively expensive, costing up to $1000 per prompt.
- GROK 3 just launched (Score: 630, Comments: 625): GROK 3 has launched, showcasing its performance in a benchmark comparison of AI models across subjects like Math (AIME '24), Science (GPQA), and Coding (LCB Oct-Feb). The Grok-3 Reasoning Beta model, highlighted in dark blue, achieves the highest scores, particularly excelling in Math and Science, as depicted in the bar graph with scores ranging from 40 to 100.
- There is significant skepticism regarding the reliability of Grok 3 benchmarks, with users questioning the source of the benchmarks and the graph's presentation. Some users point out that Grok 3 appears to outperform other models due to selective benchmark optimization, leading to mistrust in the results presented by Elon Musk's company.
- Discussions are heavily intertwined with political and ethical concerns, with multiple comments expressing distrust in products associated with Elon Musk, citing his controversial actions and statements. Users emphasize a preference for alternative models from other companies like Deepmind and OpenAI.
- Some comments highlight the external evaluations by reputable organizations such as AIME, GPQA, and LiveCodeBench, but also note that Grok 3's performance may be skewed by running multiple tests and selecting the best outcomes. Users call for independent testing by third parties to verify the benchmarks.
- Grok 3 released, #1 across all categories, equal to the $200/month O1 Pro (Score: 152, Comments: 308): Grok 3 is released, ranking #1 across all categories, including coding and creative writing, with scores of 96% on AIME and 85% on GPQA. Karpathy compares it to the $200/month O1 Pro, noting its capability to attempt solving complex problems like the Riemann hypothesis, and suggests it is slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking.
- Discussions reveal skepticism towards Grok 3's performance claims, with users expressing distrust in benchmarks like LMArena and highlighting potential biases in results. Grok 3 is criticized for requiring "best of N" answers to match the O1 Pro level, and initial tests suggest it underperforms in simple programming tasks compared to GPT-4o.
- Users express strong opinions on Elon Musk, associating him with political biases and questioning the ethical implications of using AI models linked to him. Concerns about political influence in AI design are prevalent, with some users drawing parallels to authoritarian regimes and expressing reluctance to use Musk-related technologies.
- The conversation reflects a broader sentiment of distrust towards Musk's ventures, with many users stating they will avoid using his products regardless of performance claims. The discussion also touches on the rapid pace of AI development and the role of competition in driving innovation, despite skepticism about specific models.
Theme 2. ChatGPT vs Claude on Context Window Use
- ChatGPT vs Claude: Why Context Window size Matters. (Score: 332, Comments: 60): The post discusses the significance of context window size in AI models, comparing ChatGPT and Claude. ChatGPT Plus users have a 32k context window and rely on Retrieval Augment Generation (RAG), which can miss details in larger texts, while Claude offers a 200k context window and captures all details without RAG. A test with a modified version of "Alice in Wonderland" showed Claude's superior ability to detect errors due to its larger context window, emphasizing the need for OpenAI to expand the context window size for ChatGPT Plus users.
- Context Window Size Comparisons: Users highlight the differences in context window sizes across models, with ChatGPT Plus at 32k, Claude at 200k, and Gemini providing up to 1-2 million tokens on Google AI Studio. Mistral web and ChatGPT Pro are mentioned with context windows close to 100k and 128k respectively, suggesting these are better for handling large documents without losing detail.
- Model Performance and Use Cases: Claude is praised for its superior handling of long documents and comprehension quality, especially for literature editing and reviewing. ChatGPT is still used for small scope complex problems and high-level planning, while Claude and Gemini are favored for projects requiring extensive context due to their larger context windows.
- Cost and Accessibility: There's a discussion on the cost-effectiveness of models, with Claude preferred for long context tasks due to its affordability compared to the expensive higher-tier options of other models. Gemini is suggested as a free alternative on AI Studio for exploring large context capabilities.
- Plus plan has a context window of only 32k?? Is it true for all models? (Score: 182, Comments: 73): The ChatGPT Plus plan offers a 32k context window, which is less compared to other plans like Pro and Enterprise. The Free plan provides an 8k context window, and the image emphasizes the context window differences among the various OpenAI pricing plans.
- Context Window Limitations: Users confirm that the ChatGPT Plus plan has a 32k context window, as explicitly stated in OpenAI's documentation, whereas the Pro plan offers a 128k context window. This limitation leads to the use of RAG (Retrieval-Augmented Generation) for processing longer documents, which contrasts with Claude and Gemini that can handle larger texts without RAG.
- Testing and Comparisons: bot_exe conducted tests using a 30k-word text file, demonstrating that ChatGPT Plus missed errors due to its reliance on RAG, while Claude Sonnet 3.5 accurately identified all errors by utilizing its 200k tokens context window. This highlights the limitations of ChatGPT's chunk retrieval method compared to Claude's comprehensive text ingestion.
- Obsolete Information: There is a shared sentiment that OpenAI's website contains outdated subscription feature details, potentially misleading users about current capabilities. Despite the updates like the Pro plan, the documentation's accuracy and currency remain in question, as noted by multiple commenters.
Theme 3. LLMs on Real-World Software Engineering Benchmarks
- [R] Evaluating LLMs on Real-World Software Engineering Tasks: A $1M Benchmark Study (Score: 128, Comments: 24): The benchmark study evaluates LLMs like GPT-4 and Claude 2 on real-world software engineering tasks worth over $1 million from Upwork. Despite the structured evaluation using Docker and expert validation, GPT-4 completed only 10.2% of coding tasks and 21.4% of management decisions, while Claude 2 had an 8.7% success rate, highlighting the gap between current AI capabilities and practical utility in professional engineering contexts. Full summary is here. Paper here.
- Benchmark Limitations: Commenters argue that increased benchmark performance does not translate to real-world utility, as AI models like GPT-4 and Claude 2 perform well on specific tasks but struggle with broader contexts and decision-making, which are critical in engineering work. This highlights the gap between theoretical benchmarks and practical applications.
- Model Performance and Misrepresentation: There is confusion about the models evaluated, with Claude 3.5 Sonnet reportedly performing better than stated in the summary, earning $208,050 on the SWE-Lancer Diamond set but still failing to provide reliable solutions. Commenters caution against taking summaries at face value without examining the full paper.
- Economic Misinterpretation: There is skepticism about the economic implications of AI performance, with commenters noting that completing a portion of tasks does not equate to replacing a significant percentage of engineering staff. The perceived value of AI task completion is questioned due to high error rates and the complexity of real-world engineering work.
- OpenAI's latest research paper | Can frontier LLMs make $1M freelancing in software engineering? (Score: 147, Comments: 40): OpenAI's latest research paper evaluates the performance of frontier LLMs on software engineering tasks with a potential earning of $1 million. The results show that GPT-4o, o1, and Claude 3.5 Sonnet earned $303,525, $380,350, and $403,325 respectively, indicating that these models fall short of the maximum potential earnings.
- The SWE-Lancer benchmark evaluates LLMs on real-world tasks from Upwork, with 1,400 tasks valued at $1 million. The models failed to solve the majority of tasks, indicating their limitations in handling complex software engineering projects, as discussed in OpenAI's article.
- Claude 3.5 Sonnet outperformed other models in real-world challenges, highlighting its efficiency in agentic coding and iteration. Users prefer using Claude for serious coding tasks due to its ability to handle complex projects and assist in pair programming.
- Concerns were raised about the benchmarks' validity, with criticisms of artificial project setups and metrics that don't reflect practical scenarios. Success in tasks often requires iterative communication, which is not captured in the current evaluation framework.
Theme 4. AI Image and Video Transformation Advancements
- Non-cherry-picked comparison of Skyrocket img2vid (based on HV) vs. Luma's new Ray2 model - check the prompt adherence (link below) (Score: 225, Comments: 125): Skyrocket img2vid and Luma's Ray2 models are compared in terms of video quality and prompt adherence. The post invites viewers to check out a video comparison, highlighting the differences in performance between the two models.
- Skyrocket img2vid is praised for better prompt adherence and consistent quality compared to Luma's Ray2, which is criticized for chaotic movement and poor prompt handling. Users note that Skyrocket's "slow pan + movement" aligns well with prompts, providing a more coherent output.
- Technical Implementation: The workflow for Skyrocket runs on Kijai's Hunyuan wrapper, with links provided for both the workflow and the model. There are discussions about technical issues with ComfyUI, including node updates and model loading errors.
- System Requirements: Users inquire about VRAM requirements and compatibility with hardware like the RTX 3060 12GB. There is also a discussion on using Linux/Containers for a more consistent and efficient setup, with detailed explanations of using Docker for managing dependencies and environments.
- New sampling technique improves image quality and speed: RAS - Region-Adaptive Sampling for Diffusion Transformers - Code for SD3 and Lumina-Next already available (wen Flux/ComfyUI?) (Score: 182, Comments: 32): RAS (Region-Adaptive Sampling) is a new technique aimed at enhancing image quality and speed in Diffusion Transformers. Code implementations for SD3 and Lumina-Next are already available, with anticipation for integration with Flux/ComfyUI.
- RAS Implementation and Compatibility: RAS cannot be directly applied to Illustrious-XL due to architectural differences between DiTs and U-Nets. Users interested in RAS should consider models like Flux or PixArt-Σ, which are more compatible with DiT-based systems.
- Quality Concerns and Metrics: There is significant debate over the quality claims of RAS, with some users pointing out a dramatic falloff in quality. QualiCLIP scores and metrics like SSIM and PSNR indicate substantial losses in detail and structural similarity in the generated images.
- Model-Specific Application: RAS is primarily for DiT-based models and not suitable for U-Net based models like SDXL. The discussions emphasize the need for model-specific optimization strategies to leverage RAS effectively.
AI Discord Recap
A summary of Summaries of Summaries by o1-2024-12-17
Theme 1. Grok 3: The Beloved, The Maligned
- Early Access Sparks Intense Praise: Some users call it “frontier-level” and claim it outperforms rivals like GPT-4o and Claude, citing benchmark charts that show Grok 3 catching up fast. Others question these “mind-blowing” stats, hinting that the model’s real-world coding and reasoning may lag.
- Critics Slam ‘Game-Changing’ Claims: Skeptics highlight repetitive outputs and code execution flubs, hinting that “it’s not better than GPT” in day-to-day tasks. Meme-worthy charts omitting certain competitors stoked debate over xAI’s data accuracy.
- Mixed Censorship Surprises: Grok 3 was touted as uncensored, but users still encountered content blocks. Its unpredictable blocks led many to question how xAI balances raw output vs. safety.
Theme 2. Frontier Benchmarks Shake Up LLM Tests
- SWE-Lancer Pays $1M for Real Tasks: OpenAI’s new benchmark has 1,400 Upwork gigs totaling $1M, stressing practical coding scenarios. Models still fail the majority of tasks, exposing a gap between “AI hype” and real freelance money.
- Native Sparse Attention Wows HPC Crowd: Researchers propose hardware-aligned “dynamic hierarchical sparsity” for long contexts, promising cost and speed wins. Engineers foresee major throughput gains for next-gen AI workloads using NSA.
- Platinum Benchmarks Eye Reliability: New “platinum” evaluations minimize label errors and limit each model to one shot per query. This strips away illusions of competence and forces LLMs to “stand by their first attempt.”
Theme 3. AI Tools Embrace Code Debugging
- Aider, RA.Aid & Cursor Spark Joy: Projects let LLMs add missing files, fix build breaks, or “search the web” for code insights. Slight quirks remain—like Aider failing to auto-add filenames—but devs see big potential in bridging docs, code, and AI.
- VS Code Extensions Exterminate Bugs: The “claude-debugs-for-you” MCP server reveals variable states mid-run, beating “blind log guesswork.” It paves the way for language-based, interactive debugging across Python, C++, and more.
- Sonnet & DeepSeek Rival Coders: Dev chatter compares the pricey but trusted Sonnet 3.5 to DeepSeek R1, especially in coding tasks. Some prefer bigger model contexts, but the “cost vs. performance” debate roars on.
Theme 4. Labs Launch Next-Gen AI Projects
- Thinking Machines Lab Goes Public: Co-founded by Mira Murati and others from ChatGPT, it vows open science and “advances bridging public understanding.” Karpathy’s nod signals a new wave of creative AI expansions.
- Perplexity Opens R1 1776 in ‘Freedom Tuning’: The “uncensored but factual” model soared in popularity, with memes labeling it “freedom mode.” Users embraced the ironically patriotic theme, praising the attempt at less restrictive output.
- Docling & Hugging Face Link for Visual LLM: Docling’s IBM team aims to embed SmolVLM into advanced doc generation flows, merging text plus image tasks. PRs loom on GitHub that will reveal how these visual docs work in real time.
Theme 5. GPU & HPC Gains Fuel Model Innovations
- Dynamic 4-bit Quants in VLLM: Unsloth’s 4-bit quant technique hits the main branch, slashing VRAM needs. Partial layer skipping drives HPC interest in further memory optimizations.
- AMD vs. Nvidia: AI Chips Duel: AMD’s Ryzen AI MAX and M4 edge threaten the GPU king with “lower power” hardware. Enthusiasts anticipate the 5070 series to continue pushing HPC on the desktop.
- Explosive Dual Model Inference: Engineers experiment with a small model for reasoning plus a bigger one for final output, though this approach requires custom orchestration. LM Studio hasn’t officially merged the concept yet, so HPC-savvy coders are “chaining models by hand.”
PART 1: High level Discord summaries
OpenAI Discord
- Grok 3 Shows Promise: Users are comparing Grok 3 to Claude 3.5 Sonnet and OpenAI's O1, focusing on context length and coding abilities, however there were also limitations in moderation and web search capabilities.
- Despite concerns about pricing compared to DeepSeek, some users remain eager to test Grok 3 and its capabilities, with discussion touching on the importance of transparency in model capabilities and limitations.
- PRO Mode Performance Fluctuations: Users report inconsistent experiences with PRO mode, noting reduced speed and quality at times.
- While the small PRO timer occasionally appears, performance sometimes resembles that of less effective mini models, suggesting variability in operational quality.
- GPT Falters on Pip Execution: A user reported difficulties running pip commands within the GPT environment, a functionality that previously worked, seeking help from the community.
- A member suggested saying, please find a way to run commands in python code and using it run !pip list again, while another member mentioned successfully executing !pip list and shared their solution via this link.
- 4o's Text Reader Sparking Curiosity: A user inquired about the origins of 4o's text reader, specifically whether it operates on a separate neural network.
- They also questioned the stability of generated text in long threads and whether trained voices affect this stability.
- Pinned Chats Requested: A user suggested implementing a feature to pin frequently used chats to the top of the chat history.
- This enhancement would streamline access for users who regularly engage in specific conversations.
Unsloth AI (Daniel Han) Discord
- VLLM Adds Unsloth's Quantization: VLLM now supports Unsloth's dynamic 4-bit quants, potentially improving performance, showcased in Pull Request #12974.
- The community discussed the memory profiling and optimization challenges in managing LLMs given the innovations.
- Notebooks Struggle Outside Colab: Users reported compatibility issues running Unsloth notebooks outside Google Colab due to dependency errors, especially on Kaggle; reference the Google Colab.
- The problems might arise from the use of Colab-specific command structures, like
%versus!.
- The problems might arise from the use of Colab-specific command structures, like
- Unsloth fine-tunes Llama 3.3: New instructions detail how to fine-tune Llama 3.3 using existing notebooks by modifying the model name, using this Unsloth blog post.
- However, users should be prepared for the substantial VRAM requirements for effective training.
- NSA Mechanism Improves Training: A paper introduced NSA, a hardware-aligned sparse attention mechanism that betters long-context training and inference, described in DeepSeek's Tweet.
- The paper suggests NSA can rival or exceed traditional model performance, while cutting costs via dynamic sparsity strategies.
Perplexity AI Discord
- Grok 3 Performance Underwhelms: Users expressed disappointment in Grok 3's performance compared to expectations and models like GPT-4o, with some awaiting more comprehensive testing before buying into the hype.
- Musk claimed Grok 3 outperforms all rivals, bolstered by an independent benchmark study, providing a competitive edge in AI capabilities, although user experiences vary.
- Deep Research Hallucinates: Several users reported that Deep Research in Perplexity produces hallucinated results, raising concerns about its accuracy compared to free models like o3-mini.
- Users questioned the reliability of sources such as Reddit and the impact of API changes on information quality, affecting the overall output.
- Subscription Resale Falls Flat: A user attempting to sell their Perplexity Pro subscription faced challenges due to lower prices available elsewhere.
- The discussion revealed skepticism about reselling subscriptions, with recommendations to retain them for personal use due to the lack of market value.
- Generative AI Dev Roles Emerge: A new article explores the upcoming and evolving generative AI developer roles, highlighting their importance in the tech landscape.
- It emphasizes the demand for skills aligned with AI advancements to leverage these emerging opportunities effectively, potentially reshaping talent priorities.
- Sonar API Hot Swapping Investigated: A question was posed regarding whether the R1-1776 model can be hot swapped in place on the Sonar API, indicating interest from the OpenRouter community.
- This inquiry suggests ongoing discussions around flexibility and capabilities within the Sonar API framework, possibly for enhanced customization.
HuggingFace Discord
- 9b Model Defeats 340b Model, Community Stunned: A 9b model outperformed a 340b model, spurring discussion on AI model evaluations and performance metrics.
- Community members expressed surprise and interest in the implications of this unexpected performance increase.
- Porting Colab Notebook Causes Runtime Snafu: A member successfully ported their Colab from Linaqruf's notebook but hit a runtime error with an
ImportErrorwhen fetching metadata from Hugging Face.- The user troubleshooting stated, I might not work as intended as I forgot to ask the gemini monster about the path/to... hinting at unresolved path issues.
- Docling and Hugging Face Partner for Visual LLM: Docling from IBM has partnered with Hugging Face to integrate Visual LLM capabilities with SmolVLM into the Docling library.
- The integration aims to enhance document generation through advanced visual processing, with the Pull Request soon available on GitHub.
- Neuralink's Images Prompt Community Excitement: Recent images related to Neuralink were analyzed, showcasing advancements in their ongoing research and development.
- AI Agents Course Certificate Troubles: Multiple users reported certificate generation errors, typically receiving a message about too many requests.
- While some suggested using incognito mode or different browsers, success remained inconsistent.
Codeium (Windsurf) Discord
- MCP Tutorial Catches Waves: A member released a beginner's guide on how to use MCP, available on X, encouraging community exploration and discussion.
- The tutorial seeks to assist newcomers in navigating MCP features effectively, with interest in sharing personal use cases to improve understanding.
- Codeium Write Mode Capsized: Recent updates revealed that Write mode is no longer available on the free plan, leading users to consider upgrading or switching to chat-only.
- This change prompted debates on whether the Write mode loss is permanent for all or specific users, causing concern among the community.
- IntelliJ Supercomplete Feature Mystery: Members debated whether the IntelliJ extension ever had the supercomplete feature, referencing its presence in the VSCode pre-release.
- Clarifications suggested supercomplete refers to multiline completions, while autocomplete covers single-line suggestions.
- Streamlined Codeium Deployments Sought: A user inquired about automating setup for multiple users using IntelliJ and Codeium, hoping for a streamlined authentication process.
- Responses indicated this feature might be in enterprise offerings, with suggestions to contact Codeium's enterprise support at Codeium Contact.
- Cascade Base flounders on Performance: Users report Cascade Base fails to make edits on code and sometimes the AI chat disappears, leading to frustration.
- Multiple users have experienced internal errors when trying to use models, which suggests ongoing stability issues with the platform; documentation is available at Windsurf Advanced.
aider (Paul Gauthier) Discord
- Grok 3 Hype Draws Skepticism: The launch of Grok 3 has sparked debate, with some posts claiming it surpasses GPT and Claude, as noted in Andrej Karpathy's vibe check.
- Many users remain skeptical, viewing claims of groundbreaking performance and AGI as exaggerated.
- Aider File Addition Glitches Arise: Users report issues with Aider failing to automatically add files despite correct naming and initialization when using docker, as documented in Aider's Docker installation.
- Troubleshooting steps and potential bugs in Aider's web interface are being discussed among the community.
- Gemini Models Integration Trials Begin: Community members are exploring the use of Gemini experimental models within Aider and its experimental models doc.
- Confusion persists around correct model identifiers and warnings received during implementation, with successful use of Mixture of Architects (MOA) in the works via a pull request.
- RA.Aid Augments Aider with Web Search: In response to interest in integrating a web search engine to Aider, it was shared that RA.Aid can integrate with Aider and utilize the Tavily API for web searches, per its GitHub repository.
- This mirrors the current implementation in Cursor, offering a similar search functionality.
- Ragit GitHub Pipeline Sparks Interest: The Ragit project on GitHub, described as a git-like rag pipeline, has garnered attention, see the repo.
- Members emphasized its innovative approach to the RAG processing pipeline, potentially streamlining data retrieval and processing.
OpenRouter (Alex Atallah) Discord
- Grok 3 divides Opinions: Initial reception to Grok 3 is mixed, with some users impressed and others skeptical, especially when compared to models like Claude and Sonnet.
- Interest centers on Grok 3's abilities in code and reasoning, as highlighted in TechCrunch's coverage of Grok 3.
- OpenRouter API Policies are Unclear: Confusion surrounds OpenRouter's API usage policies, particularly regarding content generation like NSFW material and compliance with provider policies, with some users claiming that OpenRouter has fewer restrictions compared to others.
- For clarity and up-to-date policies, users are encouraged to consult with OpenRouter administrators and check the API Rate Limits documentation.
- Sonnet is coding MVP: Discussions compared the performance of various models like DeepSeek, Sonnet, and Claude, some users expressed preference for Sonnet in coding tasks because it is more reliable.
- Despite the higher costs, Sonnet's reliability makes it a preferred choice for specific coding applications, whereas users consider Grok 3 and DeepSeek for competitive features, factoring in price and performance.
- LLMs Gaining Vision: One user inquired about models on OpenRouter that can analyze images, referencing a modal section on the provider's website detailing models with text and image capabilities.
- It was recommended that the user explore available models under that section of the OpenRouter models page to find suitable options.
- OpenRouter Credit Purchase Snag: One user faced issues purchasing credits on OpenRouter, seeking assistance after checking with their bank, which prompted discussions about the pricing of different LLM models.
- This discussion included debates over the perceived value derived from these models, and how their costs can be justified by performance and capabilities.
Cursor IDE Discord
- Grok 3 Performance Underwhelms: Users express disappointment with Grok 3's performance, citing repetition and weak code execution, even after early access was granted.
- Some users suggest Grok 3 only catches up to existing models like Sonnet, despite some positive feedback on reasoning abilities.
- Sonnet Still Shines: Despite some reports of increased hallucinations, many users still favor Sonnet, especially version 3.5, over newer models like Grok 3 for coding tasks.
- Users suggest Sonnet 3.5 maintains an edge over Grok 3 in reliability and performance.
- MCP Server Setups Still Complex: Users discussed the complexities of setting up MCP servers for AI tools, referencing a MCP Server for the Perplexity API.
- Experimentation with single-file Python scripts as alternatives to traditional MCP server setups is underway, as shown by single-file-agents, for improved flexibility.
- Cursor Struggles Handling Large Codebases: Users report Cursor faces issues with rules and context management in large codebases, which necessitates manual rule additions.
- Some users found that downgrading Cursor versions helped improve performance, while others are trying auto sign cursor.
- AI's Instruction Following Questioned: Users express concern about whether AI models properly process their instructions, with some suggesting including explicit checks in prompts.
- Quirky approaches are recommended to test AI's adherence to guidance, which indicates a need for insights into how AI models handle instructions across platforms.
Interconnects (Nathan Lambert) Discord
- Grok 3's Vibe Check Passes but Depth Lags: Early reviews of Grok 3 suggest it meets frontier-level standards but is perceived as 'vanilla', struggling with technical depth and attention compression, while early versions broke records on the Arena leaderboard.
- Reviewers noted that Grok 3 struggles with providing technical depth in explanations and has issues with attention compression during longer queries, especially compared to R1 and o1-pro.
- Zuckerberg Scraps Llama 4: Despite Zuckerberg's announcement that Llama 4's pre-training is complete, speculation suggests it may be scrapped due to feedback from competitors such as DeepSeek.
- Concerns arise that competitive pressures will heavily influence the final release strategy for Llama 4, underscoring the rapid pace of AI development, with a potential release as a fully multimodal omni-model.
- Thinking Machines Lab Re-emerges with Murati: The Thinking Machines Lab, co-founded by industry leaders like Mira Murati, has launched with a mission to bridge gaps in AI customizability and understanding. See more details on their official website.
- Committed to open science, the lab plans to prioritize human-AI collaboration, aiming to make advancements accessible across diverse domains, prompting comparisons to the historic Thinking Machines Corporation.
- Debate Explodes Over Eval Methodologies' Effectiveness: Ongoing discussions question the reliability of current eval methods, with arguments that the industry lacks strong testing frameworks, and that some models are gaming the MMLU Benchmark.
- Companies are being called out for focusing on superficial performance metrics instead of substantive testing that truly reflects capabilities, calling for new benchmarks such as SWE-Lancer, with 1,400 freelance software engineering tasks from Upwork, valued at $1 million.
- GPT-4o Copilot Turbocharges Coding: A new code completion model, GPT-4o Copilot, is in public preview for various IDEs, promising to enhance coding efficiency across major programming languages.
- Fine-tuned on a massive code corpus exceeding 1T tokens, this model is designed to streamline coding workflows, providing developers with more efficient tools according to Thomas Dohmke's tweet.
LM Studio Discord
- DeepSeek Model Fails Loading: Users reported a model loading error with DeepSeek due to invalid n_rot: 128, expected 160 hyperparameters.
- The error log included memory, GPU (like the 3090), and OS details suggesting hardware or configuration constraints, but its reasoning ability makes it a go-to for technical tasks when it works.
- Dual Model Inference Under Scrutiny: Members have been experimenting with using a smaller model for reasoning and a larger one for output, detailing successful past projects in this area.
- While the concept shows promise, its implementation requires manual coding because LM Studio lacks direct support for dual model inference.
- Whisper Model Setup: Users discussed utilizing Whisper models for transcription, recommending specific setups contingent on CUDA versions.
- Proper configuration, particularly regarding CUDA compatibility, is essential when working with Whisper.
- AMD Enters the Chat: The introduction of AMD's Ryzen AI MAX has been mentioned, with its performance being compared to Nvidia GPUs, in addition to the M4 edge and upcoming 5070 promising performance at reduced power consumption, according to this review.
- Users are drawing comparisons with Nvidia GPUs and discussing the potential performance of AMD's new hardware.
- Legacy Tesla K80 Clustering?: AI Engineers discussed the feasibility of clustering older Tesla K80 GPUs for their substantial VRAM, with noted concerns about power efficiency.
- Experience with Exo in clustering setups, involving both PCs and MacBooks, was shared, with noted issues arising when loading models simultaneously.
Eleuther Discord
- DeepSeek v2's Centroid routing is just vector weights: A user sought to confirm that the 'centroid' in the context of DeepSeek v2's MoE architecture refers to the routing vector weight.
- Another user confirmed this understanding, clarifying its role in the expert specialization within the model.
- Platinum Benchmarks Measure LLM Reliability: A new paper introduced the concept of 'platinum benchmarks' to improve the measurement of LLM reliability by minimizing label errors.
- Discussion centered on the benchmark's limitations, particularly that it only takes one sample from each model per question, prompting queries about its overall effectiveness.
- JPEG-LM Generates Images from Bytes: Recent work applies autoregressive models to generate images directly from JPEG bytes, detailed in the JPEG-LM paper.
- This approach leverages the generality of autoregressive LLM architecture for potentially easy integration into multi-modal systems.
- NeoX trails NeMo in Tokens Per Second: A user benchmarked NeoX at 19-20K TPS on an 80B A100 GPU, contrasting with 25-26K TPS achieved collaboratively in NeMo for a similar model.
- The group considered the impact of intermediate model sizes and the potential for TP communication overlap in NeMo as factors influencing the performance differences.
- Track Model Size, Data, and Finetuning for Scaling Laws: For a clear grasp of scaling laws, Stellaathena advised tracking model size, data, and finetuning methods.
- This approach addresses nebulous feelings about data usage and facilitates better model comparisons.
Yannick Kilcher Discord
- Grok 3 Sparks Mixed Reactions: With Grok 3 launching, members are curious about its reasoning abilities and API costs, although some early assessments suggest it may fall behind OpenAI's models in certain aspects, per this tweet from Elon Musk.
- A live demo of Grok-3 sparked discussion, with some expressing they were 'thoroughly whelmed' by the product's presentation, according to this video.
- NURBS Gains Traction in AI: Members detailed the advantages of NURBS, noting their smoothness and better data structures compared to traditional methods, with the conversation shifting to the broader implications of geometric approaches in AI development.
- The group also discussed the potential for lesser overfitting by leveraging geometric first approaches.
- Model Comparisons Spark Debate: There is debate about the fairness of comparisons between Grok and OpenAI's models, with some claiming that Grok's charts misrepresent its performance, as exemplified in this tweet.
- Concerns over 'maj@k' methods and how they may impact perceived effectiveness have emerged, fueling discussions on model evaluation standards.
- Deepsearch Pricing Questioned: Despite being described as state-of-the-art, the pricing of $40 for the new Deepsearch product prompted skepticism among users, especially given similar products released for free recently.
- One member cynically observed the dramatic pricing strategy as potentially exploitative given the competition.
- Community to Forge Hierarchical Paper Tree: Suggestions were made for a hierarchical tree of seminal papers focusing on dependencies and key insights, emphasizing the importance of filtering information to avoid noise.
- The community indicated a desire to leverage their expertise in identifying seminal and informative papers for better knowledge sharing.
Stability.ai (Stable Diffusion) Discord
- Xformers Triggers GPU Grief: Users reported issues with xformers defaulting to CPU mode and demanding specific PyTorch versions, but one member suggested ignoring warning messages.
- A clean reinstall and adding
--xformersto the command line was recommended as a potential fix.
- A clean reinstall and adding
- InvokeAI Is Top UI Choice for Beginners: Many users suggested InvokeAI as an intuitive UI for newcomers, despite personally preferring ComfyUI for better functionality.
- Community members generally agreed that InvokeAI's simplicity makes it more accessible, given that complex systems like ComfyUI can overwhelm novices.
- Stable Diffusion Update Stagnation Sparks Ire: Concerns arose about the lack of updates in the Stable Diffusion ecosystem, especially after A1111 stopped supporting SD 3.5, leading to user dissatisfaction.
- Users expressed confusion due to outdated guides and incompatible branches with newer technologies, creating frustration.
- Anime Gender Classifier Sparks Curiosity: A user sought guidance on how to segregate male and female anime bboxes for inpainting using an anime gender classifier from Hugging Face.
- The classification method is reportedly promising but requires integration expertise with existing workflows in ComfyUI.
- Printer's Poor Usability Prompts Puzzlement: An IT worker shared a humorous anecdote about a defective printer, pointing out how even crystal-clear instructions can be misunderstood, causing confusion.
- The discussion pivoted to general misunderstandings related to simple signs and the requirement for clearer communication.
GPU MODE Discord
- Torch Compile Under the Microscope: A member explained that when using
torch.compile(), a machine learning model in PyTorch converts to Python bytecode, analyzed by TorchDynamo, which generates an FX graph for GPU kernel calls, with interest expressed in handling graph breaks during compilation.- A shared link to a detailed PDF focused on the internals of PyTorch's Inductor, providing in-depth information.
- CUDA Memory Transfers Gain Async Boost: To enhance speed when transferring large constant vectors in CUDA, it's recommended to use
cudaMemcpyAsyncwithcudaMemcpyDeviceToDevicefor better performance.- In the context of needing finer control over data copying on A100 GPUs, a suggestion was made to use
cub::DeviceCopy::Batchedas a solution.
- In the context of needing finer control over data copying on A100 GPUs, a suggestion was made to use
- Triton 3.2.0 Prints Unexpected TypeError: Using
TRITON_INTERPRET=1withprint()in Pytorch's Triton 3.2.0 package results in a TypeError stating thatkernel()got an unexpected keyword argument 'num_buffers_warp_spec'.- A member is addressing a performance degradation issue in a Triton kernel triggered by using low-precision inputs like float8, pointing to an increase in shared memory access bank conflicts and the lack of resources for resolving bank conflicts in Triton compared to CUDA's granular control.
- Native Sparse Attention Gets Praise: Discussion surrounds the paper on Native Sparse Attention (paper link), noting its hardware alignment and trainability that could revolutionize model efficiency.
- The GoLU activation function reduces variance in the latent space compared to GELU and Swish, while maintaining robust gradient flow (see paper link).
- Dynasor Slashes Reasoning Costs: Dynasor cuts reasoning system costs by up to 80% without the need for model training, demonstrating impressive token efficiency using certainty to halt unnecessary reasoning processes (see demo).
- Enhanced support for hqq in vllm allows running lower bit models and on-the-fly quantization for almost any model via GemLite or the PyTorch backend, with new releases announced alongside appealing patching capabilities, promising wider compatibility across vllm forks (see Mobius Tweet).
Nous Research AI Discord
- Grok-3 exhibits inconsistent censorship: Despite initial perceptions, Grok-3 presents varying censorship levels depending on the usage context, such as on lmarena.
- While some are pleasantly surprised, others seek access to its raw outputs, reflecting a community interest in unfiltered AI responses.
- SWE-Lancer Benchmark Poses Real-World Challenges: The SWE-Lancer benchmark features over 1,400 freelance software engineering tasks from Upwork valued at $1 million USD, spanning from bug fixes to feature implementations.
- Evaluations reveal that frontier models struggle with task completion, emphasizing a need for improved performance in the software engineering domain.
- Hermes 3's Censorship Claims Spark Debate: Advertised as censorship free, Hermes 3 reportedly refused to answer certain questions, requiring specific system prompts for desired responses.
- Speculation arises that steering through system prompts is necessary for its intended functionality, leading to discussions on balancing freedom and utility.
- Alignment Faking Raises Ethical Concerns: A YouTube video on 'Alignment Faking in Large Language Models' explores how individuals might feign shared values, paralleling challenges in AI alignment.
- This behavior is likened to the complexities AI models face when interpreting and mimicking alignment, raising ethical considerations in AI development.
- Open Source LLM Predicts Eagles Super Bowl Win: An open-source LLM-powered pick-em's bot predicts that the Eagles will triumph in the Super Bowl, outperforming 94.5% of players in ESPN's 2024 competition.
- The bot, stating 'The Eagles are the logical choice,' highlights a novel approach in exploiting structured output for reasoning, demonstrating potential in sports prediction.
Latent Space Discord
- Thinking Machines Lab Bursts onto the Scene: Thinking Machines Lab, founded by AI luminaries, aims to democratize AI systems and bridge public understanding of frontier AI, and was announced on Twitter.
- The team, including creators of ChatGPT and Character.ai, commits to open science via publications and code releases, as noted by Karpathy.
- Perplexity unleashes Freedom-Tuned R1 Model: Perplexity AI open-sourced R1 1776, a version of the DeepSeek R1 model, post-trained to deliver uncensored and factual info, first announced on Twitter.
- Labeled 'freedom tuning' by social media users, the model's purpose was met with playful enthusiasm (as seen in this gif).
- OpenAI Throws Down with SWElancer Benchmark: OpenAI introduced SWE-Lancer, a new benchmark for evaluating AI coding performance using 1,400 freelance software engineering tasks worth $1 million, and was announced on Twitter.
- The community expressed surprise at the name and speculated on the absence of certain models, hinting at strategic motives behind the benchmark.
- Grok 3 Hype Intensifies: The community discussed the potential capabilities of the upcoming Grok 3 model and its applications across various tasks.
- Despite excitement, skepticism lingered, with some humorously doubting its actual performance relative to expectations, according to this Twitter thread.
- Zed's Edit Prediction Model Enters the Ring: Zed launched an open next-edit prediction model, positioning itself as a potential rival to existing solutions like Cursor, according to their blog post.
- Users voiced concerns about its differentiation and overall utility compared to established models such as Copilot and their advanced functionalities.
Notebook LM Discord
- Podcast Reboots the Max Headroom: A user detailed their process for creating a Max Headroom podcast using Notebook LM for text generation and Speechify for voice cloning; the entire production clocked in at 40 hours.
- The user shared a link to their Max Headroom Rebooted 2025 Full Episode 20 Minutes on YouTube.
- LM Audio Specs Spark Debate: Users explored the audio generation capabilities of Notebook LM, emphasizing its utility for creating podcasts and advertisements, noting the time-saving benefits and script modification flexibility.
- A user reported issues with older paid accounts yielding subpar results, particularly with MP4 files.
- Google Product Design Draws Criticism: Participants voiced concerns about the limitations of Google's system design, highlighting the expectation for better performance as services become paid.
- They expressed frustration over technological shortcomings affecting user experience.
- Confusions about Podcast Creation Limits Aired: Users discussed experiencing a bug related to unexpected podcast creation limits, originally thinking that three podcasts was the upper limit, as opposed to chat queries.
- Others clarified that the actual limit is 50 for chat queries, clearing up the initial confusion.
- Podcast Tone Needs more Tuning: A user inquired about modifying the tone and length of their podcast, only to learn that these adjustments primarily apply to NotebookLM responses, not podcasts.
- The conversation then pivoted to configuring chat settings to enhance user satisfaction, essentially using chat prompts to improve the tone of the podcast.
Modular (Mojo 🔥) Discord
- Polars vs Pandas Debate Ignites: Members are excited about Polars library for dataframe manipulation due to its performance benefits over pandas, which one member stated would be essential down the line for dataframe work.
- Interest piqued for integrating Polars with Mojo projects, opening the doors to a silicon agnostic dataframe library for use in both single machines and distributed settings.
- Gemini 2.0 as a Coding Companion: Members suggested leveraging
Gemini 2.0 FlashandGemini 2.0 Flash Thinkingfor Mojo code refactoring, citing their understanding of Mojo, and recommended the Zed code editor with the Mojo extension found here.- However, a member expressed difficulties in refactoring a large Python project to Mojo, suggesting manual updates might be necessary due to current tool limitations, exacerbated by Mojo's borrow checker constraints.
- Enzyme for Autodiff in Mojo?: The community discussed implementing autodifferentiation in Mojo using Enzyme, with a proposal for supporting it, while weighing the challenges of converting MOJO ASTs to MLIR for optimization.
- The key challenge lies in achieving this while adhering to Mojo's memory management constraints.
- Global Variables Still Uncertain: Members expressed uncertainty regarding the future support for global variables in Mojo, with one humorously requesting global expressions.
- The request highlights the community's desire for greater flexibility in variable scoping, but it is uncertain whether it can mesh with Mojo's memory safety guarantees.
- Lists Under Fire For Speed: The community questioned the overhead of using
Listfor stack implementations, suggestingList.unsafe_setto bypass bounds checking.- Copying objects in Lists could impact speed; thus, they provided a workaround to showcase object movement, especially for very large data.
Nomic.ai (GPT4All) Discord
- GPT4All Seeks Low-Compute GPUs for Testing: Members discussed GPU requirements for testing a special GPT4All build, focusing on compute 5.0 GPUs like GTX 750/750Ti, with a member offering their GTX 960.
- Concerns were raised about VRAM limitations and compatibility, influencing the selection process for suitable testing hardware.
- Deep-Research-Like Features Spark Curiosity: A member inquired about incorporating Deep-Research-like features into GPT4All, akin to functionalities found in other AI tools.
- The discussion centered on clarifying the specifics of such functionality and its potential implementation within GPT4All.
- Token Limit Reached, Requiring Payment: The implications of reaching a 10 million token limit for embeddings with Atlas were discussed, clarifying that exceeding this limit necessitates payment or the use of local models.
- It was confirmed that billing is based on total tokens embedded, and previous tokens cannot be deducted from the count, affecting usage strategies.
- CUDA 5.0 Support Provokes Cautious Approach: The potential risks of enabling support for CUDA 5.0 GPUs were examined, raising concerns about potential crashes or issues that may require fixing.
- The prevailing view was to avoid officially announcing support without thorough testing, ensuring stability and reliability.
LlamaIndex Discord
- LlamaIndex Builds LLM Consortium: Frameworks engineer Massimiliano Pippi implemented an LLM Consortium inspired by @karpathy, using LlamaIndex to gather responses from multiple LLMs on the same question.
- This project promises to enhance collaborative AI response accuracy and sharing of insights.
- Mistral Saba Speaks Arabic: @mistralAI released the Mistral Saba, a new small model focused on Arabic, with day 0 support for integration, quickly start with
pip install llama-index-llms-mistralaihere.- It's unclear if the model is actually any good.
- Questionnaires Get Semantically Retrieved: @patrickrolsen built a full-stack app that allows users to answer vendor questionnaires through semantic retrieval and LLM enhancement, tackling the complexity of form-filling here.
- The app exemplifies a core use case for knowledge agents, showcasing a user-friendly solution for retrieving previous answers.
- Filtering Dates is Challenging: There is currently no direct support for filtering by dates in many vector stores, making it challenging to implement such functionality effectively and requiring custom handling or using specific query languages.
- A member commented that separating the year in the metadata is essential for filtering.
- RAG Gets More Structured: Members discussed examples of RAG (Retrieval-Augmented Generation) techniques that solely rely on JSON dictionaries to improve document matching efficiency.
- They shared insights on how integrating structured data can enhance traditional search methods for better query responses.
Torchtune Discord
- Byte Latent Hacks Qwen Fine-Tune: A member attempted to reimplement Byte Latent Transformers as a fine-tune method on Qwen, drawing inspiration from this GitHub repo.
- Despite a decreasing loss, the experiment produces nonsense outputs, requiring further refinement for TorchTune integration.
- TorchTune Grapples Checkpoint Logic: With the introduction of step-based checkpointing, the current resume_from_checkpoint logic, which saves checkpoints into
${output_dir}, may require adjustments.- A solution involves retaining the existing functionality while offering users the option to resume from the latest or specific checkpoints, per discussion in this github issue.
- Unit Tests Spark Dependency Debate: Concerns arose about the need to switch between four different installs to run unit tests, prompting a discussion on streamlining unit testing workflow.
- The proposal involves making certain dependencies optional for contributors, aiming to balance local experience and contributor convenience.
- RL Faces Pre-Training Skepticism: Members debated the practicality of Reinforcement Learning (RL) for pre-training, with many expressing doubts about its suitability.
- One member admitted they found the idea of using RL for pre-training terrifying, pointing to a significant divergence in opinions.
- Streamlining PR Workflow: A suggestion was made to enable cross-approval and merging of PRs among contributors in personal forks to accelerate development.
- This enhancement seeks to facilitate collaboration on issues such as the step-based checkpointing PR and enhance input from various team members.
MCP (Glama) Discord
- Glama Users Ponder MCP Server Updates: Users are seeking clarity on updating Glama to recognize changes made to their MCPC server, highlighting the need for clear configuration inputs.
- There was also a request to transform OpenRouter's documentation (openrouter.ai) into an MCP format for easier access.
- Anthropic Homepage Plunges into Darkness, Haiku & Sonnet Spark Hope: Members reported accessibility issues with the Anthropic homepage, while anticipating the release of Haiku 3.5 with tool and vision support.
- Conversations also alluded to a potential imminent release of Sonnet 4.0, stirring curiosity about its new functionalities.
- Code Whisperer: MCP Server Debugging Debuts: An MCP server with a VS Code extension now allows LLMs like Claude to interactively debug code across languages, project available on GitHub.
- The tool enables inspection of variable states during execution, unlike current AI coding tools that often rely on logs.
- Clear Thought Server Tackles Problems with Mental Models: A Clear Thought MCP Server was introduced, designed to enhance problem-solving using mental models and systematic thinking methodologies (NPM).
- It seeks to improve decision-making in development through structured approaches; members also discussed how competing tool Goose can also read and resolve terminal errors.
LLM Agents (Berkeley MOOC) Discord
- Berkeley MOOC awards Certificates to Over 300: The Berkeley LLM Agents MOOC awarded certificates to 304 trailblazers, 160 masters, 90 ninjas, 11 legends, and 7 honorees.
- Out of the 7 honorees, 3 were ninjas and 4 were masters, showing the competitive award selection process.
- Fall24 MOOC Draws 15k Students: The Fall24 MOOC saw participation from 15k students, though most audited the course.
- This high number indicates significant interest in the course materials and content.
- LLM 'Program' Clarified as Actual Programming Code: In the lecture on Inference-Time Techniques, 'program' refers to actual programming code rather than an LLM, framed as a competitive programming task.
- Participants were pointed to slide 46 to support this interpretation of programs.
- LangChain Streamlines LLM App Development: LangChain is used for development, productionization, and deployment of applications using LLMs using its component-based framework and integrates with APIs
- The framework focuses on stateful agent development using various LangChain tools.
- LLM Agents Look to Enhance via ML Models: There is interest in combining LLM agents with machine learning forecasting models to enhance workflows and members are sharing knowledge on their attempts.
- Community input is being requested, regarding feedback and experiences on such combinations.
Cohere Discord
- Rose Miller Offers Quick Profit Share: Rose Miller is offering to help 10 people earn $30k within 72 hours, requesting a 10% profit share upon receipt of earnings, reachable via Telegram.
- She encourages interested individuals to contact her directly for a quick response on Telegram or WhatsApp, but many members are wary of the scheme.
- Structured Data Injection for AI: A new endpoint launched to inject high-quality, structured data from Arxiv and Wikipedia directly into AI context windows, reducing latency and improving data retrieval from sources like Valyu.
- An academic publisher dataset is launching next week, aiming to provide trusted sources in AI applications, helping to provide high-fidelity retrieval for AI agents and LLM applications.
- Push the Context API to Its Limits: The team invites developers to test the new API and provide feedback, offering $10 in free credits to encourage thorough testing.
- They are specifically looking for users to actively break and test edge cases to improve the API's robustness.
- Context API Blog Post Sparks Discussion: A blog post discusses challenges AI developers face with data retrieval and the solutions provided by the new context API.
- The post emphasizes the need for high-fidelity retrieval for AI agents and LLM applications in complex decision-making use cases, helping to provide trusted sources in AI applications.
DSPy Discord
- Self-Supervised Prompt Optimization Framework emerges: A new paper introduces Self-Supervised Prompt Optimization (SPO), a framework designed to improve LLMs' reasoning without external data. The paper is available at Self-Supervised Prompt Optimization.
- This approach streamlines prompt design by generating evaluation signals purely from output comparisons, but some guild members expressed surprise at the limited mention of DSPy within the paper.
- Worries GPT-5 just Slaps RouteLLM Together: A member suggested that GPT-5 might integrate RouteLLM with models like 4o, o1, o3, Voice, and Sora without meaningful updates or proper citations, based on this tweet.
- The user recalled previously suggesting a similar integration strategy involving DSPy, highlighting the lack of novelty from competitors.
tinygrad (George Hotz) Discord
- Call for Testing Pull Request #9155: A member requested assistance in testing Pull Request #9155, which reintroduces colors in DEBUG=2 for enhanced debugging in tinygrad.
- Another member volunteered, signaling community engagement in refining debugging capabilities.
- Community Support for Tinygrad Enhancement: Following the call for testing, a community member expressed their willingness to contribute a test for Pull Request #9155.
- This collaborative effort highlights the community's active role in improving the debugging features of the tinygrad project.
MLOps @Chipro Discord
- Diffusion Flounders in GenAI Video Future: Bichen Wu shared insights on the shifting paradigm in video generation, emphasizing recruitment for researchers and MLEs in a session titled "Why Diffusion Isn’t the Future of Video Gen" at lu.ma.
- Wu, co-founder of a stealth AI startup led by ex-CEO Eric Schmidt, harnessed his experience at Meta GenAI to delve into emerging technologies.
- Seaweed-APT smashes Sora by 50x: Led by Peter Lin, the presentation on Seaweed-APT touted its capability as being 50 times faster than Sora, revolutionizing video generation techniques.
- Lin, the creator of this groundbreaking model and first author of AnimateDiff-Lightning, detailed its impressive speed and efficiency.
- OpenArt hustles to $8M ARR Breakthrough: OpenArt revealed its astonishing strategy to achieve $8 million ARR in just 10 months, showcasing innovation in AI storytelling.
- The session shared essential growth hacks that have transformed the commercialization landscape for AI applications.
- Nvidia Dives into World Models: An Nvidia researcher explained advancements in developing a General Embodied Agent, focusing on universal world models and simulation paradigms.
- This exploration aims to enhance real-world robotics applications through sophisticated AI frameworks.
- Pareto Pumps Golden Datasets: Pareto AI presented techniques on building golden datasets to scale image and video training pipelines for next-generation models.
- Their strategies are positioned as critical for advancing the capabilities of future AI systems in diverse environments.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
OpenAI ▷ #ai-discussions (1021 messages🔥🔥🔥):
Grok 3 capabilities, Challenges with model benchmarking, OpenAI vs Grok competition, User experiences with various AI models
- Grok 3 vs Other Models: Grok 3 is being compared to other AI models like Claude 3.5 Sonnet and OpenAI's O1, with discussions about its context length and abilities for coding and reasoning.
- Users express interest in trying Grok 3 despite concerns about model pricing compared to other services like DeepSeek.
- Limitations of AI Models: Users commented on Grok 3 having limitations in moderation and web search capabilities, similar to those of OpenAI's offerings.
- The conversation touches upon the importance of transparency in model capabilities and limitations, with mentions of user experiences.
- Feelings Towards Elon Musk and OpenAI: There are mixed feelings towards Elon Musk, with some users expressing skepticism about his role in AI development and company policies, while others defend the technology.
- Discussion includes how both OpenAI and xAI handle AI safety and corporate strategies, with users comparing their business practices.
- AI Limitations in Learning and Reasoning: Users highlighted issues with AI models failing to solve basic riddles or perform reasoning tasks effectively, citing examples of failures.
- The conversation also explored how different models process requests and the importance of effective training methods.
- Creative Uses of p5.js in AI: Users share p5.js projects showcasing creative programming results, including simulations of particles and visual representations.
- There is encouragement for using p5.js scripts to explore AI capabilities, with examples shared in the discussion.
- p5.js Web Editor: no description found
- p5.js Web Editor: no description found
- p5.js Web Editor: no description found
- Ethical Business Contact Strategies | Shared Grok Conversation: We'd like to contact Acme employees about a business partnership. Gather a list of all people who wo
- Android – Clone: no description found
- Homura Homura Cat GIF - Homura Homura Cat Madoka - Discover & Share GIFs: Click to view the GIF
- Tweet from Sam Altman (@sama): @blader maybe we can consider a pay-per-use setup
- GitHub - SkyworkAI/SkyReels-V1: SkyReels V1: the first and most advanced open-source human-centric video foundation model: SkyReels V1: the first and most advanced open-source human-centric video foundation model - SkyworkAI/SkyReels-V1
- Tweet from Perplexity (@perplexity_ai): Today we're open-sourcing R1 1776—a version of the DeepSeek R1 model that has been post-trained to provide uncensored, unbiased, and factual information.
- Tweet from Theo - t3.gg (@theo): Grok 3 is, uh, not great at coding
- Elon Musk,"I'd make Catgirls": Elon Reeve Musk (born June 28, 1971) is a business magnate and investor. He is the founder, CEO, and Chief Engineer at SpaceX; angel investor, CEO, and Produ...
- Grok 3 is Here! And What It Can Do Will Blow Your Mind!: Elon Musk's Grok 3 is the world's most powerful AI model | Here's all about its features, applications, how you can access it, & more!
- Elon Musk's Incorrect Predictions | Shared Grok Conversation: What has Elon Musk been wrong about?
- Linky's Casual, Connected Vibe | Shared Grok Conversation: Online name is Linky, what do you think about me?
- p5.js Web Editor: no description found
OpenAI ▷ #gpt-4-discussions (5 messages):
Pinned Chats Feature, CSV Table Issues in ChatGPT, PRO Mode Functionality, 4o's Text Reader Queries
- Request for Pinned Chats Feature: One member suggested implementing a feature that allows users to pin frequently used chats to the top of their chat history for easier access.
- This could enhance user experience for those who rely on certain chats daily.
- ChatGPT's Broken CSV Download Function: A member reported issues with ChatGPT generating a CSV table that has a broken download icon and is slow to expand.
- They need access to the table contents but found copying text from any part of the table is not functional.
- Inconsistent PRO Mode Experience: Concerns were raised about users experiencing inconsistent performance with PRO mode, sometimes operating at reduced speed and quality.
- Some users noted that the small PRO timer occasionally appears, but at other times, the performance resembles that of mini models, which is less effective.
- Queries about 4o's Text Reader: A member inquired about the origins of 4o's text reader, questioning if it runs on a separate neural network.
- They also expressed curiosity about the stability of generated text over long threads, speculating whether this varies with trained voices.
OpenAI ▷ #prompt-engineering (7 messages):
GPT running pip, Python tool usage, Model performance issues
- Trouble Making GPT Run Pip Commands: A user expressed difficulty with getting GPT to run pip in its environment, noting it worked previously but stopped functioning.
- Another member mentioned successfully executing '!pip list' and shared a link to their solution.
- Request for Python Command Execution: In response to the pip issue, one member suggested saying, 'please find a way to run commands in python code and using it run !pip list again.'
- User acknowledged this suggestion, indicating a willingness to try it out.
- Potential Model Limitations: A member theorized that the problems may arise from asking one of the earlier models to use the 'python tool'.
- They speculated that the reasoning model might currently lack access to the python tool, recommending further exploration.
OpenAI ▷ #api-discussions (7 messages):
Running pip commands in GPT, Python tool usage in models
- User seeks help running pip in GPT environment: A user expressed frustration about GPT not running pip commands anymore, which worked previously.
- Responses indicated a possible solution involving checking the model's ability to use the python tool for command execution.
- Success in executing pip command: A member reported success in running !pip list in GPT's environment and shared their method for others to check out here.
- They advised the original poster to explore ways to run commands in Python to execute !pip list once more.
- Possible model limitations with pip commands: Discussion suggested that certain models may not currently support the python tool needed to run pip commands.
- A member encouraged exploring different models to see if they can successfully execute Python commands.
Unsloth AI (Daniel Han) ▷ #general (389 messages🔥🔥):
Unsloth AI training challenges, Colab and Notebook usage, GRPO training and optimization, VLLM and Dynamic 4-bit quants, New releases and performance evaluations
- Unsloth AI training and evaluation concerns: Users discussed issues with training models in Unsloth, particularly around parameters like sequence length and gradient checkpointing, noting specific configurations for optimal use on A100 GPUs.
- There were suggestions to experiment with different optimizers and learning rates to enhance training speed and performance.
- Notebook usage outside Collab: A user raised compatibility issues with running Unsloth notebooks outside of Google Colab, noting dependency errors encountered on Kaggle.
- Others suggested that Colab's specific command structures, like '%' versus '!', could contribute to these issues.
- GRPO training for function calling models: Discussions emerged around the upcoming support for GRPO training with tool calling, and a referenced PR that would enhance the functionality in TRL.
- Users expressed optimism about the integration and the challenges faced when scaling to different hardware setups.
- Launch of new perplexity model: The recent release of the perplexity R1 model garnered excitement, with users noting improvements in output speed and discussing forthcoming uploads of GGUFs and other resources.
- One user humorously referenced their busy day focused on perplexity, while another noted that understanding metrics like perplexity can be complex.
- Dynamic 4-bit quants in VLLM: VLLM has recently added support for Unsloth's dynamic 4-bit quants, potentially improving performance options for users.
- The conversation highlighted the benefits and innovations made in the handling of LLMs, as well as challenges in memory profiling and optimizations.
- Welcome to vLLM — vLLM: no description found
- Google Colab: no description found
- Zed now predicts your next edit with Zeta, our new open model - Zed Blog: From the Zed Blog: A tool that anticipates your next move.
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Beginner? Start here! | Unsloth Documentation: no description found
- Finetune Phi-4 with Unsloth: Fine-tune Microsoft's new Phi-4 model with Unsloth!We've also found & fixed 4 bugs in the model.
- GPQA_GRPO_Proof_of_Concept.py: GitHub Gist: instantly share code, notes, and snippets.
- ValueError: Unrecognized image processor in Qwen/Qwen2.5-VL-3B-Instruct. · Issue #36193 · huggingface/transformers: System Info transformers 4.49.0.dev0 Python 3.11.11 Reproduction I follow model instructions from here. install transformers from GH pip install git+https://github.com/huggingface/transformers laod...
- unsloth/unsloth/kernels/utils.py at main · unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
- Dynamically load LoRA weights when using vLLM by tgaddair · Pull Request #2730 · huggingface/trl: This PR implements the proposed improvement from #2725 and dynamically loads LoRA adapters into vLLM instead of merging LoRA weights back into the base model at each step. This will in practice be ...
- Allow Unsloth Dynamic 4bit BnB quants to work by danielhanchen · Pull Request #12974 · vllm-project/vllm: This PR allows vLLM to skip applying bitsandbytes quantization to certain layers, and leave them in 16bit. This will for now work only on skipped modules specified inside of llm_int8_skip_modulesF...
- unsloth/DeepSeek-R1 · Hugging Face: no description found
- unsloth/DeepSeek-R1 at main: no description found
- zed-industries/zeta · Datasets at Hugging Face: no description found
- GRPO Environments for custom multi-step rollouts (vLLM-only) by willccbb · Pull Request #2810 · huggingface/trl: What does this PR do?Adds a protocol under trl/environments for an Environment object which wraps vLLM's .generate(...) to allow for custom rollout logic, and an optional env field to the Trai...
Unsloth AI (Daniel Han) ▷ #off-topic (14 messages🔥):
Unsloth Update, bitsandbytes Code Discussion, CUDA Pointer Handling, Quantization Techniques, Changes in Unsloth Notebook
- Unsloth mentioned in AlphaSignal email: A member noted that there was a mention of Unsloth in today's AlphaSignal email with a screenshot provided.
- This highlights ongoing discussions in the community regarding Unsloth's relevance.
- Clarification on bitsandbytes Pointer Usage: Discussion on the bitsandbytes code revealed confusion around whether pointer conversion was intended, as CUDA assumes it’s a float pointer.
- Members indicated that although code was expected to be fp32, issues arose when it was handled as float16, leading to unexpected results.
- Challenges with Quantization in bitsandbytes: A member mentioned that the smallest blocksize expected in the bitsandbytes context should be 64, sparking conversation on its implications.
- Another pointed out that changes in the Unsloth notebook might affect how quantization is implemented across different data types.
- Changes noted in Unsloth Notebook: Updates in the Unsloth notebook were highlighted, specifying that certain aspects of quantization need verification.
- Assertions for data types were emphasized, ensuring that float types align correctly, noting discrepancies with local test results.
- llama.cpp/docs/build.md at master · ggml-org/llama.cpp: LLM inference in C/C++. Contribute to ggml-org/llama.cpp development by creating an account on GitHub.
- GitHub - bitsandbytes-foundation/bitsandbytes at 86b6c37a8ad448230cedb60753f63150b603a112: Accessible large language models via k-bit quantization for PyTorch. - GitHub - bitsandbytes-foundation/bitsandbytes at 86b6c37a8ad448230cedb60753f63150b603a112
- bitsandbytes/csrc/ops.cu at 86b6c37a8ad448230cedb60753f63150b603a112 · bitsandbytes-foundation/bitsandbytes: Accessible large language models via k-bit quantization for PyTorch. - bitsandbytes-foundation/bitsandbytes
Unsloth AI (Daniel Han) ▷ #help (98 messages🔥🔥):
Unsloth Model Updates, GPU Utilization in Training, GRPO Training Challenges, Fine-tuning Llama 3.3, Data Preparation for Fine-tuning
- Unsloth Model receives update for deepseek V3 support: The community discussed a recent update where Hugging Face Transformers merged a commit for deepseek V3 support, expected in version 0.45.0.
- This change sparked interest as users considered the implications of leveraging quantized versions for efficiency.
- Challenges in Multi-GPU Usage: Users are facing limitations in using multiple GPUs with Unsloth, as the current implementation supports only single GPU training.
- However, there are discussions on alternative frameworks for those requiring multi-GPU setups and shared experiences of training large models on A6000 GPUs.
- GRPO Training Issues Persist: There are ongoing challenges related to CUDA out of memory errors when setting the number of generations greater than 1 during GRPO training.
- Users are seeking advice on managing memory efficiently while maintaining the integrity of their training processes.
- Fine-tuning Llama 3.3 for NLP Tasks: New guidance was provided on how to modify existing notebooks to fine-tune Llama 3.3 by simply changing the model name.
- However, users are reminded of the substantial VRAM requirements needed for effective training.
- Preparing Datasets for Fine-Tuning: Users discussed methods for preparing and evaluating datasets in CSV format for robust fine-tuning processes.
- Several queries arose regarding the handling of evaluation losses, including issues of NaN results during training.
- Google Colab: no description found
- TRL - Transformer Reinforcement Learning: no description found
- Google Colab: no description found
- Environment variables: no description found
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Error with gguf conversion. · Issue #1416 · unslothai/unsloth: Here's what I get while trying to quantize my latest attempt at finetuning. '--------------------------------------------------------------------------- RuntimeError Traceback (most recent cal...
- mtsku/SnakeGPT · Datasets at Hugging Face: no description found
- from unsloth import FastVisionModel # FastLanguageModel for LLMsmodel, token - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- CUDA semantics — PyTorch 2.6 documentation: no description found
- Refactoring of quant_state by poedator · Pull Request #763 · bitsandbytes-foundation/bitsandbytes: Converted quant_state from nested list into nested class QuantState.Rationale: to have a stable and pretty format before enabling saving of 4-bit quantized models.this PR enables #753
- Fine-tune Llama 3.3 with Unsloth: Fine-tune Meta's Llama 3.3 (70B) model which has better performance than GPT 4o, open-source 2x faster via Unsloth! Beginner friendly.Now with Apple's Cut Cross Entropy algorithm.
- notebooks/nb at main · unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
Unsloth AI (Daniel Han) ▷ #research (47 messages🔥):
Scaling Mixture of Experts Models, PPO Setup with Unsloth Model, Local Databases for Big Data, Structured Inference for Reasoning, Sparse Attention Mechanism NSA
- Anxietyprime opens up about scaling MoE models: A member expressed excitement about scaling Mixture of Experts (MoE) models to trillions of parameters and sought reviews for their paper, reaching out to some professors for insights.
- They mentioned Elizabeth Bradley responded that she isn't working on AI anymore, indicating a challenge in finding qualified reviewers.
- PPO Setup Query in Unsloth Model: A member asked if anyone knew how to set up PPO with an Unsloth model, expressing their frustration over figuring it out.
- Another member acknowledged similar struggles and mentioned ongoing efforts to merge their Online DPO changes into Unsloth.
- Recommendations for Local Databases: There was a discussion regarding suitable local databases for handling big data, with suggestions for SQLite and Postgres for smaller datasets.
- For embedding storage, Qdrant and LanceDB were recommended as open-source options.
- Exploration of Structured Inference in Reasoning: A member queried about using structured inference to refine response output during reasoning, specifically to ensure the correct order of tag outputs.
- This suggests an interest in enhancing the structural integrity of AI-generated responses.
- Introduction of Sparse Attention Mechanism NSA: A link was shared to a paper introducing NSA, a hardware-aligned and natively trainable sparse attention mechanism that improves long-context training and inference.
- The paper highlights NSA's potential to match or surpass traditional models in performance while reducing costs, with a focus on dynamic sparsity strategies.
- moe-scaling/README.md at main · wrmedford/moe-scaling: Scaling Laws for Mixture of Experts Models. Contribute to wrmedford/moe-scaling development by creating an account on GitHub.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference!Core components of NSA:• Dynamic hierarchical sparse strategy•...
Perplexity AI ▷ #general (477 messages🔥🔥🔥):
Grok 3 Feedback, Deep Research Performance, Perplexity Pro Subscription, Grok 3 and Perplexity Integration, Reddit as a Source
- Mixed Reviews on Grok 3 Performance: Users expressed disappointment in Grok 3's performance, with some believing it underperformed compared to expectations and existing models like GPT-4o.
- Some users mentioned comparisons with ChatGPT and expressed skepticism about the hype surrounding Grok 3, suggesting they would wait for more comprehensive testing.
- Deep Research Shows Hallucinations: Several users reported that Deep Research in Perplexity produces hallucinated results, prompting concerns about its accuracy compared to free models like o3-mini.
- Some users questioned the reliability of sources such as Reddit and discussed the impact of API changes on information quality.
- Subscription Resale Challenges: A user attempted to sell their Perplexity Pro subscription, but faced challenges due to lower prices found elsewhere for similar services.
- The discussion highlighted skepticism about reselling subscriptions, with suggestions to keep them for personal use instead.
- Grok 3 Integration Speculations: Users speculated about the potential integration of Grok 3 into Perplexity, with some hopeful about future availability in the platform.
- There was acknowledgment of xAI's efforts in building reasoning models quickly, with anticipation for Grok 3's capabilities.
- Concerns About Bot Activity: A user noted that some accounts in the channel may be bots promoting get-rich-quick schemes, creating concern about the authenticity of the interactions.
- This led to discussions about the prevalence of such accounts and their impact on community interactions.
- Access the most powerful AI models in one place on you.com: You.com now offers a first-of-its-kind Custom Model Selector, letting users access, test, and compare large language models (LLMs), such as GPT-4, Claude Instant, Gemini Pro, and more, all in one plac...
- Tweet from Based Whale (@AravSrinivas): Congratulations to @xai for building world-class reasoning models in such a short period. This is a super strong response from America to DeepSeek. America builds fast, and xAI team and Elon are setti...
- Ill Look Into It Batman Begins GIF - Ill Look Into It Batman Begins I Got This - Discover & Share GIFs: Click to view the GIF
- New footage of Delta plane flip at Toronto airport: A child was among three people critically injured after a Delta Airlines flight flipped over as it landed at Toronto airport on Monday.At least 18 people we...
Perplexity AI ▷ #sharing (36 messages🔥):
Grok 3.0 Launch, Generative AI Developer Roles, Ethereum Pectra Upgrade, AI Impact on Global Dynamics, Perplexity Pro Benefits
- Musk Claims Grok 3 Outperforms Rivals: In a recent announcement, Musk claimed that Grok 3 outperforms all rivals, bolstered by an independent benchmark study, providing a competitive edge in AI capabilities.
- A Microsoft study revealed that AI usage may impede critical thinking, adding to the ongoing discourse about AI's implications in talent development.
- New Generative AI Developer Roles Explored: An article discusses the upcoming and evolving generative AI developer roles, highlighting their importance in today's tech landscape.
- It emphasizes the need for skills aligned with AI advancements to harness these emerging opportunities effectively.
- Ethereum Pectra Upgrade Details Released: The Ethereum Pectra upgrade has been formally announced, showcasing enhancements and new features aimed at improving network functionality.
- Users can expect a streamlined experience with improved transaction speeds and enhanced security protocols.
- Global Dynamics Reshaped by AI: An analysis on how AI is reshaping global dynamics has sparked interest, focusing on potential transformations in various sectors.
- It raises questions about ethical considerations and the balance of smart technology implementation globally.
- Perplexity Pro Offers New Benefits: A detailed overview of the Perplexity Pro benefits reveals additional features geared towards enhancing user experience.
- Highlights include advanced search capabilities and tailored insights intended for professional users.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (4 messages):
API Key Management, Integration Evaluation, Sonar API Hot Swap
- API Keys tied to Personal Accounts: A member raised concerns that newly created API keys are linked to their personal account, questioning the feasibility of team management.
- They expressed a desire to include more team members for managing keys and billing, noting the risk of being unable to access critical accounts.
- Interest in Integrating Perplexity API: Another member mentioned they are assessing whether to integrate the Perplexity API into their product.
- This evaluation seems to stem from internal discussions about feasibility and potential benefits.
- Inquiry about R1-1776 Hot Swapping: A question was posed regarding whether the R1-1776 model can be hot swapped in place on the Sonar API, indicating interest from the OpenRouter community.
- This inquiry suggests ongoing discussions around flexibility and capabilities within the Sonar API framework.
Link mentioned: no title found: no description found
HuggingFace ▷ #general (59 messages🔥🔥):
Model Performance Metrics, Video Generation Models, Uploading Code Issues, Internal Server Errors, AI Course Inquiries
- Model Performance News: A member reported that a 9b model outperforms a 340b model, leading to surprise among others in the discussion.
- The community expressed interest in discussing the implications of this performance increase on AI model evaluations.
- Exploring Video Generation Models: Hunyuan is noted for its quality in video generation, working on 8 GB VRAM but slower than ltxv, which can generate videos quickly on high-end GPUs like the 4090.
- Members discussed using mmaudio for adding synchronized sounds to videos and suggested that alternative models might be more efficient for creating talking avatars.
- Code Upload Issues and Troubleshooting: A user encountered a 500 Internal Error while accessing
what are llms?, prompting others to suggest potential reasons for access issues.- Solutions about potential model limits and server restrictions were discussed, indicating challenges many face when using the platform.
- Community Knowledge Sharing: Participants actively sought advice on AI models, sharing links and resources, especially regarding video generation and performance challenges.
- Members shared GitHub repositories and engaged in code-related inquiries to create a collaborative learning environment.
- Handling 'NaN' Loss in Training: A user reported 'nan' values appearing in their loss calculations during model training and sought help for troubleshooting their custom training code.
- The community offered support and tips on potential code issues, fostering a supportive dialogue for problem-solving.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Playground - Hugging Face: no description found
- google/owlv2-base-patch16-ensemble · Hugging Face: no description found
- Goku: no description found
- Office Space Yeah GIF - Office Space Yeah Uh Yeah - Discover & Share GIFs: Click to view the GIF
- Build Self-Improving Agents: LangMem Procedural Memory Tutorial: Learn how to implement dynamic instruction learning in LLM agents using the LangMem SDK. This technical tutorial demonstrates automatic prompt optimization, ...
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference!Core components of NSA:• Dynamic hierarchical sparse strategy•...
- Easy_training/Galore+Qlora_With_Multi_GPU_Support at main · rombodawg/Easy_training: Contribute to rombodawg/Easy_training development by creating an account on GitHub.
HuggingFace ▷ #today-im-learning (1 messages):
Neuralink Updates, Image Analysis, Research Findings
- Neuralink's Recent Image Analyses: Over the last two days, multiple images related to Neuralink were analyzed, showing promising data and insights.
- Visual Insights from Recent Findings: Attached images provide detailed visual insights, showcasing advancements in Neuralink's ongoing research and development.
- These findings from images like Image 3 prompt excitement in the community about future implications.
HuggingFace ▷ #i-made-this (3 messages):
Colab Porting Success, YuE Model Instrumental Injection, Custom Training Code Release
- Colab porting leads to runtime challenges: A member successfully ported their Colab, derived from Linaqruf's notebook, but encountered a runtime error due to an
ImportErrorwhile fetching metadata from Hugging Face.- I might not work as intended as I forgot to ask the gemini monster about the path/to... indicates ongoing troubleshooting efforts.
- Injecting instrumentals into YuE model: A member is experimenting with the new YuE model by injecting their own instrumentals, aiming to generate vocals over their tracks.
- They share a YouTube video titled 'experiments with YuE' highlighting their progress, noting that results are improving as lyrics emerge.
- Simple custom training code available: A member introduced their custom training code which is designed for simplicity and includes configurable options for fine-tuning and customizing prompts.
- The project, Easy_training, allows for multi-GPU support and has very low VRAM requirements, making it accessible for high parameter models.
- SDXL To Diffusers - a Hugging Face Space by EarthnDusk: no description found
- GitHub - rombodawg/Easy_training: Contribute to rombodawg/Easy_training development by creating an account on GitHub.
- experiments with YuE: major WIP here lol... the fact that it's at least finally saying some of the words is a good sign i think? credit adam gerhard lyrics and yung addi conceptht...
- GitHub - betweentwomidnights/YuE-instrumental-injection: me trying to inject my own instrumentals into the yue pipeline: me trying to inject my own instrumentals into the yue pipeline - betweentwomidnights/YuE-instrumental-injection
HuggingFace ▷ #computer-vision (4 messages):
UI-Tars dataset collaboration, AI models in 3D space, SLAM technology
- Call for UI-Tars Dataset Collaboration: A member expressed interest in collaborating on recreating the UI-Tars dataset.
- They provided a link to the relevant discussion for further context.
- Inquiry About AI Models in 3D Space: A member sought information on whether any AI models can navigate a 3D space, or if SLAM suffices for that purpose.
- Just a student, they noted their curiosity about the practical workings of these technologies in the field.
HuggingFace ▷ #NLP (2 messages):
Base model behavior, Discord invites
- Understanding Base Model Behavior: A member acknowledged gaining insights into the behavior of a base model, expressing appreciation with enthusiasm.
- This highlights the ongoing discussions related to model performance and behavior analysis in the community.
- Discord Invites Not Allowed: Another member reminded that sharing Discord invites is against the server's rules, referencing a specific channel's guidelines.
- This reflects the community's commitment to maintaining compliance with platform policies.
HuggingFace ▷ #smol-course (3 messages):
Docling and Hugging Face partnership, Visual LLM and SmolVLM, Pull Request on GitHub, Benefits of VLM
- Docling Teams Up with Hugging Face for Visual LLM: Docling from IBM has partnered with Hugging Face to add Visual LLM capabilities with SmolVLM to the Docling library.
- This integration aims to enhance document generation through advanced visual processing.
- Check out the Upcoming Pull Request: A member mentioned that the Pull Request is available on GitHub and should be accessible soon.
- They expressed excitement about the upcoming features that this collaboration will bring.
- Inquiring About the Benefits of VLM: A user questioned the advantage of using a Visual LLM that outputs Docling Documents.
- Is it primarily for image descriptions? highlights the ongoing curiosity in the community regarding the practical applications of VLM.
HuggingFace ▷ #agents-course (380 messages🔥🔥):
AI Agents Course, Certificate Issues, Multi-Agent Systems, LLMs as Tools, Course Resources
- AI Agents Course Members Introductions: Several members introduced themselves, sharing their backgrounds and excitement for the AI Agents course, including tech professions and personal interests in AI.
- Members discussed their motivations to learn about AI, including a desire to build AI agents and explore decentralized models.
- Certificate Generation Errors: Multiple users expressed frustration with certificate generation errors, commonly receiving a message about too many requests when attempting to access their certificates.
- Some suggested troubleshooting steps, such as using incognito mode or different browsers, but noted inconsistent success.
- Multi-Agent Systems Discussion: A conversation around Multi-Agent Systems highlighted ideas concerning supervisory agents controlling subordinate agents and potential applications.
- Members discussed relevant papers and resources, emphasizing the theoretical aspects of implementing multiple agents.
- LLMs as Functional Tools: Users discussed the role of large language models (LLMs) in AI, considering whether they can serve as tools or primarily function as decision-making engines.
- There was ongoing dialogue about the complexities of integrating LLMs into various projects and the implications for scale and resource use.
- Course Resources and Recommendations: Members shared links to resources, such as YouTube videos and courses relevant to AI agents and identified specific tools like 'aisuite' for function calling improvements.
- Discussion included recommendations for supplementary learning materials, with suggestions for beginner-friendly LLM and AI content.
- Redirecting…: no description found
- Large Language Model Agents MOOC: MOOC, Fall 2024
- Introduction - Hugging Face Agents Course: no description found
- Welcome to the 🤗 AI Agents Course - Hugging Face Agents Course: no description found
- Let’s Create Our First Agent Using smolagents - Hugging Face Agents Course: no description found
- When will the next units be published? - Hugging Face Agents Course: no description found
- Let’s Create Our First Agent Using smolagents - Hugging Face Agents Course: no description found
- agents-course/notebooks/bonus-unit1/gemma-SFT-thinking-function_call.ipynb at main · huggingface/agents-course: This repository contains the Hugging Face Agents Course. - huggingface/agents-course
- GitHub - andrewyng/aisuite: Simple, unified interface to multiple Generative AI providers: Simple, unified interface to multiple Generative AI providers - GitHub - andrewyng/aisuite: Simple, unified interface to multiple Generative AI providers
- AI Agents Fundamentals In 21 Minutes: Improve your AI skills with the FREE Prompting QuickStart Guide I made in collaboration with Hubspot: https://clickhubspot.com/1gg9Want to get ahead in your ...
- Intro to AI agents: Vertex AI Agent Builder quickstart → https://goo.gle/3UPJ7dNGenAI powered App with Genkit → https://goo.gle/4fCSTrKDemystifying AI agents, Googlers Aja Hamme...
- GitHub - mindspore-ai/mindspore: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. - mindspore-ai/mindspore
- Adobe Acrobat: no description found
- fix: add missing variable declarations by rhanb · Pull Request #154 · huggingface/agents-course: when following this part of the course in a local environment, it wasn't clear what what the variables SYSTEM_PROMPT and prompt were refering to
Codeium (Windsurf) ▷ #content (1 messages):
MCP Tutorial
- Beginner-friendly MCP Tutorial Released: A member shared a beginner's guide on how to use MCP, available on X.
- This tutorial aims to assist newcomers in navigating the features of MCP effectively.
- Engagement in MCP Discussions: The community is encouraged to explore and discuss the various aspects of MCP, fostering a collaborative learning environment.
- Members have expressed interest in sharing personal experiences and use cases for better understanding.
Link mentioned: Tweet from Windsurf (@windsurf_ai): A beginner's guide to how to use MCP!
Codeium (Windsurf) ▷ #discussion (30 messages🔥):
Codeium Write Mode Changes, IntelliJ Supercomplete Feature, Deployment of Codeium for Multiple Users, Codeium Subscription Value, Jetbrains Context Issues
- Codeium Write Mode Restrictions Introduced: Recent updates revealed that the Write mode is no longer available on the free plan, prompting users to consider an upgrade or switch to chat-only mode.
- This change led to discussions about whether the loss of Write mode is permanent for all users or specific to a few.
- Confusion over IntelliJ's Supercomplete Feature: Members debated whether the IntelliJ extension ever had the supercomplete feature, with references to its presence in the VSCode pre-release.
- Some users provided insights that supercomplete might refer to multiline completions, while autocomplete covers single line suggestions.
- Seeking Automatic Codeium Deployment Solutions: A user inquired about automating the setup for multiple users using IntelliJ and Codeium, hoping for a streamlined authentication process.
- Responses indicated that this feature might be available in enterprise offerings, leading to further suggestions to contact Codeium's enterprise support.
- Evaluating the Worth of Codeium Subscription: Discussions emerged around the value of the $60 Codeium subscription, emphasizing that its worth greatly depends on users' intended use cases.
- For freelancers, the return on investment could be substantial, while those using it casually might find it less beneficial.
- Context Retrieval Issues in Jetbrains: Several members reported problems with Codeium not finding context in Jetbrains, experiencing timeouts and limited file visibility when using @commands.
- It was suggested to ensure the latest version is installed, as this might resolve some ongoing context issues.
Link mentioned: Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
Codeium (Windsurf) ▷ #windsurf (418 messages🔥🔥🔥):
Cascade Base Performance Issues, Internal Errors in Grading Models, Frustration with Grok 3, Subscription and Billing Concerns, Quality of Responses from AI Models
- Cascade Base has significant performance issues: Users report that Cascade Base fails to make edits on code and sometimes the AI chat disappears, leading to frustration.
- Multiple users have experienced internal errors when trying to use models, which suggests ongoing stability issues with the platform.
- Users expressing frustration with internal errors: Many have encountered internal error messages when trying to access features with models like DeepSeek R1, indicating server-side issues.
- Some have been unable to use key features for multiple days, leading to dissatisfaction with their subscriptions.
- Grok 3 underwhelms users: Several members discussed their disappointment with Grok 3's performance, indicating it did not meet expectations based on initial benchmarks.
- Discussion included desire for improvements in future models, especially Sonnet 4, as users criticized Grok's capabilities.
- Subscription and billing issues: Concerns were raised regarding transitions from founder pricing to pro plans, and questions about cancellation options for subscriptions.
- Users expressed worry about losing credits during account issues and sought clarity on billing practices through support.
- Quality of model responses and interactions: Overall dissatisfaction with Cascade's understanding and adherence to user instructions has been noted, particularly about the verbosity of responses.
- Users are calling for better management of AI behaviors, including comments during code generation to streamline interactions.
- Windsurf - Advanced: no description found
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- AI Model & API Providers Analysis | Artificial Analysis: Comparison and analysis of AI models and API hosting providers. Independent benchmarks across key performance metrics including quality, price, output speed & latency.
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Tweet from Theo - t3.gg (@theo): Grok 3 is, uh, not great at coding
- Tweet from Kevin Hou (@kevinhou22): we love docs! 📖 I'm working on improving / adding more @ docs shortcuts to @windsurf_ailmk what you want and I'll add as many as I can... 🧵also shoutout @mintlify for auto-hosting all docs w...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
aider (Paul Gauthier) ▷ #general (420 messages🔥🔥🔥):
Grok 3 Launch, Aider Functionality Issues, Performance Comparisons, Model Access and Support, Discussion of AI Models
- Grok 3 Launch Impact: Grok 3 has made waves in the AI community with posts suggesting it's a groundbreaking model that surpasses existing options like GPT and Claude.
- Many users express skepticism towards these claims, viewing them as exaggerated or overly optimistic.
- Aider File Addition Problems: Users report that Aider sometimes fails to automatically add files despite correctly typed names and initialization.
- The community discusses troubleshooting steps and potential bugs in the web interface of Aider.
- Performance Comparisons of Grok 3: There's ongoing debate about Grok 3's performance relative to models like GPT-4 and Sonnet, with mixed reviews from users.
- Some believe Grok 3 is not performing well in real-world scenarios, although it ranks highly in models lists.
- Accessing Gemini Models: Users are exploring how to use Gemini experimental models through Aider, discussing different command configurations.
- There is confusion regarding the model identifiers and warnings received during implementation.
- Community Reactions to AI Commentary: Some community members highlight overly enthusiastic posts about Grok 3's capabilities, branding them as fanboyism.
- Questions arose about the credibility of claims related to AI advances, particularly about AGI and its practical implications.
- Aider with docker: aider is AI pair programming in your terminal
- Tweet from Andrej Karpathy (@karpathy): I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.Thinking✅ First, Grok 3 clearly has an around state of the art thinking model ...
- Konwinski Prize: $1M for the AI that can close 90% of new GitHub issues
- My LLM codegen workflow atm: A detailed walkthrough of my current workflow for using LLms to build software, from brainstorming through planning and execution.
- no title found: no description found
- Ooh Ooo GIF - Ooh Ooo Cat - Discover & Share GIFs: Click to view the GIF
- Tweet from Penny2x (@imPenny2x): Holy crap.
- Nacho Libre GIF - Nacho Libre Why - Discover & Share GIFs: Click to view the GIF
- Staring Into Space Chimpanzee GIF - Staring into space Chimpanzee Our living world - Discover & Share GIFs: Click to view the GIF
- GitHub - openai/SWELancer-Benchmark: This repo contains the dataset and code for the paper "SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?": This repo contains the dataset and code for the paper "SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?" - openai/SWELancer-Benchmark
- Tweet from Perplexity (@perplexity_ai): Today we're open-sourcing R1 1776—a version of the DeepSeek R1 model that has been post-trained to provide uncensored, unbiased, and factual information.
- Tweet from 🍓🍓🍓 (@iruletheworldmo): grok 3 is here, and it’s agi.this isn’t just another model release. this is the moment everything changes. forget gpt, forget claude, forget every ai you’ve used before—they’re already obsolete. the u...
- GitHub - ai-christianson/RA.Aid: Develop software autonomously.: Develop software autonomously. Contribute to ai-christianson/RA.Aid development by creating an account on GitHub.
- GitHub - robert-at-pretension-io/rust_web_scraper: Contribute to robert-at-pretension-io/rust_web_scraper development by creating an account on GitHub.
- Tweet from Elon Musk (@elonmusk): The @xAI Grok 3 release will improve rapidly every day this week. Please report any issues as a reply to this post.
- Moa by gembancud · Pull Request #2628 · Aider-AI/aider: Add Mixture of Architects (MOA) FeatureWhy choose between r1, o3, and sonnet, when you can have 'em all!OverviewThis PR introduces a powerful new feature called "Mixture of Architects...
aider (Paul Gauthier) ▷ #questions-and-tips (24 messages🔥):
Aider Search Engine, Architect Mode Suggestions, Aider Configuration Issues, Aider Not Recognizing .env, API Key Requirement
- Interest in Aider Search Engine Integration: @bixqu inquired about adding a web search engine to Aider, similar to how it's implemented in Cursor, possibly using Perplexity.
- Another member shared that RA.Aid can integrate with Aider and utilize the Tavily API for web searches, providing a link to its GitHub repository.
- Challenges in Architect Mode: Members expressed frustration with architect mode frequently prompting for file edits, disrupting discussions around architecture.
- One suggestion was to switch to code mode to facilitate messaging without triggering file edit prompts.
- Configuring Aider with Custom Commands: An attempt was made to integrate a command library and customize Aider's system prompt through the
aider.confconfiguration file.- Questions were raised about the proper use of the
--loadand--readparameters for enhancing context for the command library.
- Questions were raised about the proper use of the
- Issues with Aider Not Recognizing .env Files: A user reported challenges with Aider not picking up the
.envfile when using the API, leading to authentication errors.- Another user confirmed they needed to set the API key each time, which was previously overlooked.
- Error Encountered in Aider Execution: A user shared an uncaught RuntimeError in Aider while attempting to execute it, highlighting issues with the event loop in Python 3.12.
- They later clarified that the base Aider worked fine, and the issue stemmed from not setting the API key correctly.
- FAQ: Frequently asked questions about aider.
- GitHub - ai-christianson/RA.Aid: Develop software autonomously.: Develop software autonomously. Contribute to ai-christianson/RA.Aid development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #links (4 messages):
Local sanity checks for coding LLM output, Ragit GitHub project, Ministral with Aider
- Local Coding LLM Improvements: One member suggested running a coding LLM locally to perform sanity checks and improvements on its outputs.
- This could enable more tailored adjustments and validations for coding tasks.
- Interest in Ragit GitHub Pipeline: The Ragit project on GitHub, described as a git-like rag pipeline, caught the attention of several members, prompting interest in its potential applications.
- One member emphasized its innovative approach to the rag processing pipeline.
- Exploring Ministral with Aider: A question arose about whether anyone has experimented with Ministral in conjunction with Aider.
- A relevant LinkedIn post sparked discussion on this topic, indicating potential curiosity about integrations.
Link mentioned: GitHub - baehyunsol/ragit: git-like rag pipeline: git-like rag pipeline. Contribute to baehyunsol/ragit development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (435 messages🔥🔥🔥):
Grok 3 performance, OpenRouter API usage, Model comparisons, Vision capabilities in LLMs, DeepSeek vs Sonnet
- Grok 3's Initial Reception: Grok 3 is generating mixed reviews, with some users praising its capabilities while others express skepticism about its performance compared to established models like Claude and Sonnet.
- Users are particularly interested in how well Grok 3 can handle code and reasoning tasks, with some citing specific instances where it excels.
- OpenRouter API Usage Policies: There is confusion regarding the usage policies for OpenRouter, particularly concerning content generation like NSFW material and compliance with provider policies.
- Chat among users indicates that OpenRouter may have fewer restrictions compared to others, but it's best to verify with the administrators.
- Model Comparisons: Discussions highlight the performance of various models such as DeepSeek, Sonnet, and Claude, with some users preferring Sonnet for coding tasks due to its reliability despite higher costs.
- Users note that Grok 3 and DeepSeek offer competitive features, with several considering price and performance when choosing alternatives.
- Vision Capabilities in LLMs: A user inquired about models on OpenRouter that can analyze images, referencing a modal section on the provider's website detailing models with text and image capabilities.
- It was advised to explore available models under that section to find suitable options with vision capabilities.
- User Experiences with API Transactions: One user reported encountering issues while attempting to purchase credits on OpenRouter, reaching out for assistance after clarifying with their bank.
- This led to discussions about pricing structures for different LLM models, coupled with ongoing debates regarding the value derived from them.
- stepfun-ai/Step-Audio-Chat · Hugging Face: no description found
- Chatbot Arena Leaderboard - a Hugging Face Space by lmarena-ai: no description found
- API Rate Limits - Manage Model Usage and Quotas: Learn about OpenRouter's API rate limits, credit-based quotas, and DDoS protection. Configure and monitor your model usage limits effectively.
- Models | OpenRouter: Browse models on OpenRouter
- Clinical AI & Quantum Hackathon: no description found
- Tweet from Perplexity (@perplexity_ai): Download the model weights on our HuggingFace Repo or consider using the model via our Sonar API.HuggingFace Repo: https://huggingface.co/perplexity-ai/r1-1776
- Models | OpenRouter: Browse models on OpenRouter
- no title found: no description found
- GPU pricing: GPU pricing.
- Elon Musk’s xAI releases its latest flagship model, Grok 3 | TechCrunch: Elon Musk's AI company, xAI, released its latest flagship AI model, Grok 3, on Monday, along with new capabilities in the Grok app for iOS and the web.
- Cloud Computing Services | Google Cloud: Meet your business challenges head on with cloud computing services from Google, including data management, hybrid & multi-cloud, and AI & ML.
- GitHub - deepseek-ai/DeepSeek-R1: Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.
- No Reasoning tokens · Issue #22 · OpenRouterTeam/ai-sdk-provider: No Reasoning tokens are provided when using streamText, and could not set include_reasoning in streamText
- 跃问: no description found
Cursor IDE ▷ #general (335 messages🔥🔥):
Grok 3, Sonnet performance, MCP server setup, Cursor performance issues, User feedback on AI models
- Grok 3 performance raises concerns: Users expressed disappointment with Grok 3, finding it underperforming compared to expected standards, often repeating itself and lacking in code execution tasks.
- Despite some positive feedback related to its reasoning abilities, many commenters suggest it is merely playing catch-up to existing models like Sonnet.
- Sonnet remains preferred by users: Many users believe that Sonnet, particularly the 3.5 version, is superior to emerging models like Grok 3, maintaining its edge in coding tasks.
- Some users report increased hallucinations from Sonnet, while others find it still reliable compared to newer models.
- Setting up MCP servers: Discussions arose about the complexities in setting up MCP servers for using various AI tools, with some users sharing insights and experiences on integrating them.
- Users have experimented with single-file Python scripts as alternatives to traditional MCP server setups, exploring new methods for enhanced flexibility.
- Cursor struggles with large codebases: Users reported issues with Cursor's ability to handle rules and context effectively, especially when navigating large codebases, leading to the necessity of manually adding rules.
- Despite frustration, some users noted that lowering the version helped improve performance, showing a willingness to test solutions.
- Feedback on AI Instruction Processing: There is ongoing concern among users about whether their instructions are being properly processed by AI models, with suggestions to include explicit checks in their prompts.
- Some users recommend adopting quirky approaches to test if the AI retains guidance, indicating the need for insights into instruction adherence across platforms.
- Tweet from Andrej Karpathy (@karpathy): I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.Thinking✅ First, Grok 3 clearly has an around state of the art thinking model ...
- Tweet from Biz Stone (@biz): stepping out of the office for a bit
- Tweet from Ryo Lu (@ryolu_): Late for valentines, but @cursor_ai has been cooking
- Tweet from BigQiang (@iBigQiang): 在 B 站看到个使用Cloudflare无限续杯Cursor教程和配套脚本实在太牛了,条件是拥有域名并且需要交给cloudflare托管,不过域名也就几块钱而已,相比每个月20刀的Cursor还是很香了。Cursor能写代码、写文章,大部分ai能干的事他都可以,可白嫖Claude 3.5 sonnet,deepseek v3&r1,gpt4o和gpt4o mini等
- Tweet from Kevin Hou (@kevinhou22): We built Windsurf’s agent to not rely on embedding indexes like other tools out there. One size fits all retrieval simply doesn’t scale for monorepos. Instead, our agent uses tools that a human would ...
- GitHub - bgstaal/multipleWindow3dScene: A quick example of how one can "synchronize" a 3d scene across multiple windows using three.js and localStorage: A quick example of how one can "synchronize" a 3d scene across multiple windows using three.js and localStorage - bgstaal/multipleWindow3dScene
- Tweet from Chubby♨️ (@kimmonismus): Grok-3 is starting to roll out. Check your Grok selectionQuoting Penny2x (@imPenny2x) Holy crap.
- Tweet from Aman Sanger (@amanrsanger): Just added Grok-2 support to Cursor, eagerly awaiting Grok-3 👀
- Tweet from OpenAI (@OpenAI): Current frontier models are unable to solve the majority of tasks.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference!Core components of NSA:• Dynamic hierarchical sparse strategy•...
- GitHub - daniel-lxs/mcp-perplexity: MCP Server for the Perplexity API.: MCP Server for the Perplexity API. Contribute to daniel-lxs/mcp-perplexity development by creating an account on GitHub.
- Tweet from Rex (@12exyz): they omitted o3 from the chart in the livestream for some reason so i added the numbers for you
- Building Python tools with a one-shot prompt using uv run and Claude Projects: I’ve written a lot about how I’ve been using Claude to build one-shot HTML+JavaScript applications via Claude Artifacts. I recently started using a similar pattern to create one-shot Python utilities,...
- GitHub - disler/single-file-agents: What if we could pack single purpose, powerful AI Agents into a single python file?: What if we could pack single purpose, powerful AI Agents into a single python file? - disler/single-file-agents
- Tweet from Andrej Karpathy (@karpathy): I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.Thinking✅ First, Grok 3 clearly has an around state of the art thinking model ...
- GitHub - chengazhen/cursor-auto-free: auto sign cursor: auto sign cursor. Contribute to chengazhen/cursor-auto-free development by creating an account on GitHub.
- Subframe – The best way to build UI, fast.: Build stunning UI in minutes with a drag-and-drop visual editor, beautifully crafted components, and production-ready code. Optimized for React & TailwindCSS.
- Relume — Websites designed & built faster with AI | AI website builder: Use AI as your design ally, not as a replacement. Effortlessly generate sitemaps and wireframes for marketing websites in minutes with Relume’s AI website builder.
- 21st.dev - The NPM for Design Engineers: Ship polished UIs faster with ready-to-use React Tailwind components inspired by shadcn/ui. Built by design engineers, for design engineers.
- Flexbox Labs: no description found
Interconnects (Nathan Lambert) ▷ #news (209 messages🔥🔥):
Grok 3 Performance, Llama 4 Updates, Thinking Machines Lab Launch, Eval Methodologies in AI, GPT-4o Copilot Release
- Grok 3 passes the vibe check but lacks depth: Early reviews of Grok 3 indicate it stands as a frontier-level model but is seen as 'vanilla and boring' compared to others like R1 and o1-pro.
- It reportedly struggles with providing technical depth in explanations and has issues with attention compression during longer queries.
- Llama 4 may be undergoing changes post-DeepSeek: Zuckerberg announced that Llama 4 is completed with pre-training, but speculation suggests it may be scrapped after the recent DeepSeek news.
- There are concerns that feedback from competitors will influence the final release strategy of Llama 4, highlighting the fast-moving nature of AI development.
- Launch of Thinking Machines Lab: The Thinking Machines Lab, co-founded by industry leaders including Mira Murati, aims to bridge gaps in AI customizability and understanding.
- The lab is committed to open science and plans on prioritizing human-AI collaboration, making advancements accessible for diverse domains.
- Debate over eval methodologies and their effectiveness: There are ongoing discussions on the reliability of current eval methods, with some suggesting the industry lacks robust testing frameworks.
- Concerns have been raised that many companies focus on superficial performance metrics rather than substantive testing that reflects true capabilities.
- Release of GPT-4o Copilot for coding tasks: A new code completion model, GPT-4o Copilot, was announced and is now available in public preview for various IDEs.
- This model is fine-tuned based on a vast code corpus and is designed to enhance coding efficiency across major programming languages.
- SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?: We introduce SWE-Lancer, a benchmark of over 1,400 freelance software engineering tasks from Upwork, valued at \$1 million USD total in real-world payouts. SWE-Lancer encompasses both independent engi...
- Tweet from Rex (@12exyz): they omitted o3 from the chart in the livestream for some reason so i added the numbers for you
- Thinking Machines Lab: no description found
- Tweet from Andrej Karpathy (@karpathy): I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.Thinking✅ First, Grok 3 clearly has an around state of the art thinking model ...
- Tweet from Jamie (@james_tackett1): @natolambert Why do you think the other LLMs lead when the graphs in the xAI presentation showed that Grok 3 outperformed all other LLMs by a fairly wide margin? For example:
- Tweet from Xeophon (@TheXeophon): The last time it happened was *checks notes* two weeks agoQuoting Gavin Baker (@GavinSBaker) This is the first time in more than a year IIRC that one model has been #1 in every category.
- Tweet from Thomas Dohmke (@ashtom): Our new code completion model is shipping in public preview today. We are calling it GPT-4o Copilot. Based on GPT-4o mini, with mid-training on a code-focused corpus exceeding 1T tokens and reinforcem...
- Tweet from Devendra Chaplot (@dchaplot): Career Update: Incredibly fortunate and excited to be part of the founding team at Thinking Machines Lab!https://thinkingmachines.ai/Join us: https://6wajk07p.paperform.co/
- Tweet from Kate Clark (@KateClarkTweets): Greenoaks Capital is leading a $1 billion+ round for Safe Superintelligence, the AI startup founded by ex-OpenAI chief scientist Ilya Sutskever, at a valuation over $30 billion. Scoop:https://www.bloo...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): OpenAI presents:SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?- Opensources a benchmark of >1.4k freelance SWE tasks from Upwork, valued at $1M total...
- Tweet from Gavin Baker (@GavinSBaker): This is the first time in more than a year IIRC that one model has been #1 in every category.
- Tweet from xjdr (@_xjdr): TL;DR grok3 is fine and passes the vibe check of frontier level quality but its not better than R1 or o1-pro for me for most things i do. overall much better than i had expected, i put it in the gemin...
- Tweet from Zephyr (@zephyr_z9): Deepseek V3(4.6e24 Flops) vs Grok 3(>8e26 Flops)173X more compute
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Grok 3 reasoning beta achieved 96 on AIME and 85 on GPQA, which is on par with the full o3.
- Tweet from Andrew Curran (@AndrewCurran_): Grok 2 will be open sourced when Grok 3 is stable, 'a few months'.
- Tweet from Andrew Curran (@AndrewCurran_): CoT will be partially obscured, Elon said 'so we don't get our model copied instantly'.
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): BREAKING: @xAI early version of Grok-3 (codename "chocolate") is now #1 in Arena! 🏆Grok-3 is:- First-ever model to break 1400 score!- #1 across all categories, a milestone that keeps getting ...
- Tweet from Alex Volkov (Thursd/AI) 🔜 AIENG summit NY (@altryne): Zuck highlights from the earnings call: - LLama 4 & LLama 4 mini (done with pre-training)- Confirms reasoning LLaMas! - Llama 4 will be natively multimodal -- it's an omni-model -- and it will hav...
- Tweet from Paul Calcraft (@paul_cal): Grok 3 on LMSYS is not so basedConcerning
Interconnects (Nathan Lambert) ▷ #random (77 messages🔥🔥):
New LLM Models, Early Stopping in AI, AI Music and Art, Thinking Machines Corporation, AI Interview Insights
- Users Praise New LLM Model 4o: Users find the new model 4o more pleasant compared to o1 mini and o3 mini, offering simpler solutions for various tasks.
- One user noted, 'It makes it easy for DR googling and tackles challenges efficiently.'
- Innovative Early Stopping Techniques: A discussion emerged about a model called Dynasor, which claims to save up to 81% tokens by effectively managing self-doubt during reasoning.
- The model utilizes a halfway probe for certainty to determine when to halt, enhancing efficiency without requiring training.
- AI Music Gains Popularity: AI-generated lofi music has gained traction, with shares stating it has 2.1M views on one video and a significant listener base on Spotify.
- Users expressed surprise, saying they didn't realize the music was AI-generated, highlighting a trend toward mainstream acceptance of AI art.
- Revisiting Thinking Machines Corporation: The Thinking Machines Corporation, known for its supercomputers, was discussed as an example of how scaling methods created past AI winter challenges.
- Users commented on the historical significance of the company and its innovative approaches in the context of early AI development.
- Insights from AI Interviews: An interview featuring Google DeepMind and Anthropic founders discussed AI's implications and competitive landscape, revealing concerns about centralization.
- Users reflected on these insights, indicating they’re glad to see such discussions happening, even if they weren't necessarily groundbreaking.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference!Core components of NSA:• Dynamic hierarchical sparse strategy•...
- no title found: no description found
- Thinking Machines Corporation - Wikipedia: no description found
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
- Thanos Perfectlybalanced GIF - Thanos Perfectlybalanced - Discover & Share GIFs: Click to view the GIF
- Tweet from near (@nearcyan): @thinkymachines is your x handle typod i dont know if thinky machines has the same vibe
- Tweet from Daniel Litt (@littmath): In other words, it claimed again to produce a complete dataset but in fact only produced ~7 lines, with a placeholder for the other ~3000.
- Extension list: no description found
- GitHub - MoonshotAI/MoBA: MoBA: Mixture of Block Attention for Long-Context LLMs: MoBA: Mixture of Block Attention for Long-Context LLMs - MoonshotAI/MoBA
- Tweet from Hao AI Lab (@haoailab): [3/n] 🐢 Reasoning model usually self-doubt.Model only spends 300 tokens arriving at the right answer, but spends the extra 990 tokens on meaningless verification loops, making no progress at all!➡️ &...
- Tweet from Kimi.ai (@Kimi_Moonshot): 🚀 Introducing MoBA: Mixture of Block Attention for Long-Context LLMsExcited to share our latest research on Mixture of Block Attention(MoBA)! This innovative approach revolutionizes long-context proc...
- Tweet from Daniel Litt (@littmath): Had a sort of a funny experience with OpenAI’s Deep Research tool, which I wanted to share since I think it reveals some of the tool’s strengths and weaknesses.
- Tweet from Daniel Litt (@littmath): The only problem is that it’s all made up. Despite claiming to have looked at every paper published in the Annals in this 75-year period, poking around the pages it looked at suggests it only looked a...
- GitHub - moonlight-mod/moonlight: Yet another Discord mod: Yet another Discord mod. Contribute to moonlight-mod/moonlight development by creating an account on GitHub.
- Tweet from Hao AI Lab (@haoailab): Reasoning models often waste tokens self-doubting.Dynasor saves you up to 81% tokens to arrive at the correct answer! 🧠✂️- Probe the model halfway to get the certainty- Use Certainty to stop reasonin...
- Tweet from Zhaopeng Tu (@tuzhaopeng): Are we scaling test-time compute efficiently and intelligently in Monte Carlo tree search (MCTS)?Discover our flexible framework that empowers reasoning models to adapt their computation according to ...
- Tweet from Siyuan Huang (@siyuanhuang95): The CEO of Unitree, XingXing Wang, posted a dancing video at Rednote against the hype that the previous dance video was AI- or CG- generated. The dance is performed before a mirror and with sound, whi...
- Tweet from Hunyuan (@TXhunyuan): Hey bro, long time no see, guess what I've got for you this time?
- Tweet from Xeophon (@TheXeophon): 2.1M views on one vid, 127K monthly spotify listeners with AI-generated lofislowly, then all at onceQuoting Xeophon (@TheXeophon) Didn't realize I've been listening to AI generated music until...
- AI bosses on what keeps them up at night: Google DeepMind and Anthropic founders, Demis Hassabis and Dario Amodei, are two of the world's foremost leaders in artificial intelligence. Our editor-in-ch...
- AI bosses on what keeps them up at night: Google DeepMind and Anthropic founders, Demis Hassabis and Dario Amodei, are two of the world's foremost leaders in artificial intelligence. Our editor-in-ch...
- Tweet from Sam Altman (@sama): for our next open source project, would it be more useful to do an o3-mini level model that is pretty small but still needs to run on GPUs, or the best phone-sized model we can do?█████████████████o3-...
- - YouTube: no description found
Interconnects (Nathan Lambert) ▷ #rl (4 messages):
Recompiling Older Games, RL Training for LLMs, LLM4Decompile
- Recompiling Games through Decompilation: Efforts are underway to fully recompile older games by manually decompiling assembly to C, which involves extensive guesswork and aligning with known facts, as outlined in the decomp.me project.
- The process requires tweaking the decompilation until it matches the original assembly code under the same settings.
- Potential of RL Training in Decompilation: A suggestion was made that it might be possible to use RL to train a LLM to automate decompilation by using the match percentage as a reward for correctness.
- Discussion indicates that relevant data structures and context for similar functions could enhance training, though it's unclear if anyone has attempted this approach.
- LLM4Decompile Project on GitHub: A GitHub project titled LLM4Decompile focuses on decompiling binary code with large language models, mentioned as a relevant resource.
- However, it was pointed out that as far as anyone knows, this project utilizes Supervised Fine-Tuning (SFT) only, with no implementations of RL training for assembly matching.
- decomp.me: no description found
- GitHub - albertan017/LLM4Decompile: Reverse Engineering: Decompiling Binary Code with Large Language Models: Reverse Engineering: Decompiling Binary Code with Large Language Models - albertan017/LLM4Decompile
Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
Post-training talk at Stanford, Verification in reinforcement learning, Response to theory papers, Health-related setbacks
- Post-training Insights Shared at Stanford: A recent talk by @johnschulman2 and @barret_zoph at Stanford on post-training experiences with ChatGPT wasn't recorded, but slides are available here. A request was made for anyone with a recording to reach out.
- The presentation's focus on post-training strategies garnered interest.
- Concerns Over Theory Papers: @johnatstarbucks voiced skepticism regarding the theory nature of some papers, indicating a preference for more empirical results. Chat participants noted that despite their hesitance, investigations are crucial for the field.
- @0x_paws reassured that Section 6 contains several experiments to substantiate the theoretic claims.
- Health Issues Affecting Engagement: @natolambert mentioned feeling unwell and unable to celebrate recent successes on Twitter, indicating a temporary setback. The phrase *
- highlighted a personal experience affecting their usual activity on the platform.
- Scaling Test-Time Compute Without Verification or RL is Suboptimal: Despite substantial advances in scaling test-time compute, an ongoing debate in the community is how it should be scaled up to enable continued and efficient improvements with scaling. There are large...
- Tweet from John Schulman (@johnschulman2): @barret_zoph and I recently gave a talk at Stanford on post-training and our experience working together on ChatGPT. Unfortunately the talk wasn't recorded, but here are the slides: https://docs.g...
Interconnects (Nathan Lambert) ▷ #posts (14 messages🔥):
Philosophy of Science Theories, Grok 3 Mini Announcement, Reasoning Model Releases, Hacker News Comments, Deep Thonk Button
- Philosophy of Science Theories debated: A member noted that discussions revolve around the rejection of each broadly known theory, circulating fragmentary concepts among peers without external communication.
- Another remarked that this behavior is intriguingly 'meta', highlighting the complexities of modern philosophical discourse.
- Grok 3 Mini is announced but not released: A realization emerged that the Grok 3 Mini has been announced but not yet released, as pointed out in a tweet here.
- Members expressed their frustration over what they described as a 'messy release' for the reasoning models, with further contemplation on their performance.
- Discussion on Hacker News Comments: Members shared mixed feelings about reading comments on Hacker News, especially when feeling unwell. One remarked they simply don't read them, suggesting the stress associated with engaging in such discussions.
- Another mentioned that some may consider direct engagement with AI discussions stressful, reinforcing a divide in the community's approach to discourse.
- Speculation on Reasoning Model Releases: There was a discussion concerning the status of the reasoning models, with thoughts shared that none of them are released at the moment, only those three benchmarks.
- This prompted a curiosity regarding any existing 'deep thonk' feature for premium users, hinting at the monetization aspects of the platform.
Link mentioned: Tweet from Keiran Paster (@keirp1): @natolambert @srush_nlp @TheShmanuel I think the mini reasoning model outperforming R1 is strong evidence against this narrative.
Interconnects (Nathan Lambert) ▷ #retort-podcast (2 messages):
Torters Rejoice, Bike Stand Discussion
- Torters Rejoice: A member shared excitement with the phrase Torters rejoice, showcasing a significant moment or announcement in the community.
- An image was attached that may contain relevant details or context surrounding the celebration.
- Shared Interests in Bike Stands: A member remarked on having the same bike stand showcased in the chat, indicating shared interests and experiences.
- The emoji choices, 🔭👁️, suggest a light-hearted or humorous take on the discussion.
Interconnects (Nathan Lambert) ▷ #policy (1 messages):
gfabulous: Sigh, guess we're all using grok now
Interconnects (Nathan Lambert) ▷ #expensive-queries (14 messages🔥):
Prompt Engineering, Perplexity vs ODR, Cursor Agent Workflow, Breaking Changes in Libraries, Vibecoding Efficiency
- Experimenting with Perplexity's Output: A member shared an experiment using Perplexity's tool, describing it as a prompt engineering system tied to a Claude project.
- They expressed curiosity about its performance compared to ODR and noted its potential limitation with prescriptive output formats.
- Critique of Perplexity's Depth: Discussion revealed that Perplexity tends to remain shallow and listicle-based, lacking depth and inference capabilities.
- It was mentioned that this tool often generates tables, Python code, and math formulas even when inappropriate.
- Using ODR with Cursor Agent: A member recounted a successful experience using ODR to diagnose a breaking change in a library, which they then fed into the Cursor Agent.
- This approach enabled the Cursor Agent to resolve the issue promptly, indicating effective integration of tools.
- Vibecoding as a Workflow: The term vibecoding surfaced in the discussion, highlighting an agile and efficient coding workflow
- This was humorously linked to renowned AI researcher Karpathy, emphasizing a light-hearted approach to productivity.
LM Studio ▷ #general (86 messages🔥🔥):
Error with DeepSeek Model, Local AI Functionality, Model Recommendations for Coding, Whisper Usage and Compatibility, LM Studio Update Issues
- Error with DeepSeek Model: A user experienced a model loading issue due to invalid hyperparameters in the DeepSeek model, specifically citing invalid n_rot: 128, expected 160.
- The error details included relevant memory, GPU, and OS specifications indicating potential hardware constraints.
- Setting Up Local AI for Smart Functions: A user sought assistance in setting up a local AI for reminders and smart home integration, which involves tool use functionality.
- Another user directed them to LM Studio's API documentation for how to implement this.
- Best LLM for Python Coding Recommendations: Community members discussed the best LLM for Python coding, suggesting options like Qwen 2.5 coder and Llama 14B among others.
- They emphasized looking for models that excel in programming tasks as these generally provide effective Python coding performance.
- Whisper Model Usage and Compatibility Issues: There was a discussion around using Whisper models for transcription, with certain recommendations for setups depending on CUDA versions.
- Members pointed out the necessity of specific configurations when utilizing Whisper, especially regarding CUDA compatibility.
- LM Studio Update Cache Issues: A user encountered problems with outdated AppImage builds remaining on their system despite running a new version of LM Studio.
- Community advice included renaming the .lmstudio cache directory to refresh the installation or following developer-suggested steps to resolve cache conflicts.
Link mentioned: Tool Use | LM Studio Docs: Enable LLMs to interact with external functions and APIs.
LM Studio ▷ #hardware-discussion (128 messages🔥🔥):
3090 GPU Performance, DeepSeek and Alternatives, Using Multiple Models for Inference, 396 vs 4090 Performance, AMD's Ryzen AI MAX
- Performance Capabilities of the 3090: Users discuss the viability of running models on a 3090, with insights suggesting that it can handle 24B parameter models with adjustments to max tokens.
- A 13B model is highlighted as a sweet spot for performance, and used 3090s are mentioned to be available around €650.
- Assessing DeepSeek's Effectiveness: DeepSeek R1 is noted as a solid reasoning model, compared to OpenAI alternatives, with some users expressing it as a go-to for technical tasks.
- Additional discussions highlight various coding models like Mistral Nemo Instruct 12B, emphasizing performance in local setups.
- Experimenting with Dual Model Inference: Users explore the concept of utilizing a smaller model for reasoning alongside a larger model for output, reporting successful past projects.
- The practical implementation of such a setup currently requires manual coding, as LM Studio does not yet support this functionality directly.
- AMD's Emerging Hardware Landscape: The introduction of AMD's Ryzen AI MAX is mentioned, highlighting its potential performance capabilities while drawing comparisons with Nvidia GPUs.
- Discussions also hint at the M4 edge and upcoming 5070 promising performance at reduced power consumption.
- Clustering and Model Use Cases: Users are assessing the feasibility of clustering older Tesla K80 GPUs for their high VRAM, despite concerns over power efficiency.
- The experience with Exo in clustering setups is shared, involving combinations of PCs and MacBooks, though issues were noted when loading models simultaneously.
- AMD Ryzen AI MAX+ 395 "Strix Halo" Mini PC Tested: Powerful APU, Up To 140W Power, Up To 128 GB Variable Memory For iGPU: AMD's Ryzen AI MAX+ 395 "Strix Halo" Mini PC breaks the cover, revealing great specs and lots of AI capabilities with this powerful APU.
- AMD CPU, Apple M4 Pro Performance - Ryzen AI MAX Review: The Ryzen AI MAX+ 395 and Ryzen AI MAX 390 are supposed to be Apple M4 and Apple M4 Pro competitors that combine high efficiency with some pretty crazy perfo...
- GPU AI Comparison: no description found
- New AMD Graphics Cards… Worth?: no description found
- - YouTube: no description found
Eleuther ▷ #general (30 messages🔥):
Cognitive Sound Production, Music Generation Challenges, Machine Learning Prodigies, lm_eval Code Issues, Autoregressive Image Generation
- Cognitive Sound Production Explored: A discussion emerged about the distinction between human cognitive tasks and the physical sound production managed by devices, noting that performing tasks like singing involves intricate brain operations.
- Participants pondered the cognitive aspects of producing music as potentially distinct from the automated capabilities of machines.
- Music Generation Faces Optimization Limits: Concerns arose regarding the lack of clear targets in music generation, akin to chess, highlighting the complexity of optimizing music generation models despite advancements in frequency domain operations.
- The inability to define a quantifiable target in music contrasts with the strategic objectives present in traditional games.
- Queries on Sparse Autoencoder Outputs: A user raised questions about understanding latent activations in a sparse autoencoder, expressing confusion over consistent decoding results with the tokenizer.
- Members noted that the indices correspond to dimensions of the encodings, but interpreting these without predefined feature names could be challenging.
- lm_eval Encountering Code Generation Issues: A user reported issues with the lm_eval v0.4.7 installation, specifically the absence of code generation tasks like humaneval despite following installation steps.
- This prompted inquiries into potential reasons for the missing tasks within the library, indicating a troubleshooting need within the group.
- Innovative Autoregressive Image Generation: Recent advancements in image generation were discussed, focusing on the application of autoregressive models to generate images directly from JPEG bytes.
- Links to relevant research papers highlighted novel methods of discretizing images, offering insights into how current models are being adapted for visual data.
- JPEG-LM: LLMs as Image Generators with Canonical Codec Representations: Recent work in image and video generation has been adopting the autoregressive LLM architecture due to its generality and potentially easy integration into multi-modal systems. The crux of applying au...
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- Tweet from thomas (@distributionat): im gonna evaluate the new evallive thread for my comments browsing zerobench
- EleutherAI/persona · Datasets at Hugging Face: no description found
Eleuther ▷ #research (77 messages🔥🔥):
DeepSeek v2 MoE Architecture, Platinum Benchmarks for LLMs, Model-guidance in Diffusion Models, Repetition Penalty in Creative Writing, SFT Memorizes and RL Generalizes
- Understanding Centroid in MoE Architecture: A user questioned the meaning of 'centroid' in the context of the MoE architecture from the DeepSeek v2 paper, wondering if it represents a learned parameter of the expert's specialization.
- Another user clarified that it refers to the routing vector weight.
- Platinum Benchmarks: Evaluating LLM Reliability: A new paper highlights the importance of measuring the reliability of large language models (LLMs) through 'platinum benchmarks' to minimize label errors in evaluations.
- Discussion centered around the potential limitations of the benchmarks, such as only taking one sample from each model per question.
- Innovative Model-guidance for Diffusion Training: A paper introduced Model-guidance (MG) as a new objective for training diffusion models, aiming to improve efficiency and output quality by addressing deficiencies in Classifier-free guidance (CFG).
- Questions arose about the mathematical implementation of MG, particularly whether a reporting error might lead to misinterpretation of the weight parameters used in the model.
- Challenges with Repetition Penalty in Writing: Users discussed the complexities surrounding the repetition penalty in creative writing contexts, agreeing that it’s a statistical bias that aims to enhance the quality of generated text.
- The challenge lies in distinguishing between good and bad uses of repetition since both may appear statistically similar without clear signals for differentiation.
- SFT Overfitting Concerns: A user expressed concern that the results from 'SFT Memorizes, RL Generalizes' suggest overfitting during supervised fine-tuning (SFT).
- There were debates around the implications of these results for the reliability of language models in practical applications.
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
- Regularization by Denoising: Clarifications and New Interpretations: Regularization by Denoising (RED), as recently proposed by Romano, Elad, and Milanfar, is powerful image-recovery framework that aims to minimize an explicit regularization objective constructed from ...
- Artificial Kuramoto Oscillatory Neurons: It has long been known in both neuroscience and AI that ``binding'' between neurons leads to a form of competitive learning where representations are compressed in order to represent more abst...
- DeepCrossAttention: Supercharging Transformer Residual Connections: Transformer networks have achieved remarkable success across diverse domains, leveraging a variety of architectural innovations, including residual connections. However, traditional residual connectio...
- Diffusion Models without Classifier-free Guidance: This paper presents Model-guidance (MG), a novel objective for training diffusion model that addresses and removes of the commonly used Classifier-free guidance (CFG). Our innovative approach transcen...
- Do Large Language Model Benchmarks Test Reliability?: When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs' growing capabilit...
- Do Large Language Model Benchmarks Test Reliability?: Research highlights and perspectives on machine learning and optimization from MadryLab.
- PlatinumBench: no description found
- Tweet from Songlin Yang (@SonglinYang4): 🚀 Announcing ASAP: https://asap-seminar.github.io/!A fully virtual seminar bridging theory, algorithms, and systems to tackle fundamental challenges in Transformers.Co-organized by @simran_s_arora @X...
- Diffusion-wo-CFG/train.py at e86a3002df0aa086c7630a1fe379e9fb9564c2ff · tzco/Diffusion-wo-CFG: Official Implementation for Diffusion Models Without Classifier-free Guidance - tzco/Diffusion-wo-CFG
Eleuther ▷ #scaling-laws (26 messages🔥):
LLM scaling laws terminology, Taxonomy of scaling laws, Pretraining vs Post-training compute, Budget allocation in AI Labs, Deployment considerations and compute
- Understanding LLM Scaling Laws Terminology: A member sought clarity on terminology regarding LLM scaling laws, discussing factors like data, model size, and test-time compute.
- Stellaathena clarified that 90% of scaling law discussions pertain to pretraining, implying that training efficiency is key.
- The Need for a Taxonomy of Scaling Laws: A user expressed interest in developing a taxonomy of scaling laws to understand advancements in the LLM field better.
- The inquiry involved categorizing LLM investments by types of compute but was met with skepticism regarding the utility of such a classification.
- Balancing Pretraining and Post-training Costs: H_mmn noted that large labs may now be spending similar amounts on post-training as on pre-training efforts.
- This led to a discussion on whether such costs include factors like data acquisition and its implications for scaling laws.
- Challenges in Data and Fine-tuning Transparency: Members acknowledged the difficulty in obtaining data on specific uses, like creative writing or alignment tasks, in model training.
- Despite being aware of the lack of public data, users noted that some expectations could be managed through extrapolation of limited public data.
- Core Elements of LLM Scaling Categories: Stellaathena recommended tracking three main categories: model size, data, and finetuning methods for a better overview of scaling laws.
- This categorization helps resolve some nebulous feelings surrounding data usage and helps in modeling comparisons within the field.
Eleuther ▷ #lm-thunderdome (3 messages):
Dataset structuring for chess tactics, Fresh environment troubleshooting
- Troubleshooting Environment Issues: One member suggested trying a fresh environment to address an unspecified issue they were experiencing.
- They expressed uncertainty about the problem but noted that everything works on their end.
- Structuring Chess Tactics Dataset: A member raised doubts about whether to structure the dataset for chess tactics to predict the full sequence of moves or split them into single-move prompts.
- They noted that while adding legal moves reduces illegal predictions, making the model reason over the entire tactical sequence may be crucial for evaluating positions effectively.
Eleuther ▷ #gpt-neox-dev (75 messages🔥🔥):
GPU Performance Comparison, TP Communication Overlap, Model Configuration Differences
- Understanding TPS between NeMo and NeoX: A user reported achieving 19-20K TPS with NeoX on an 80B A100 GPU, while their collaborative efforts in NeMo yielded 25-26K TPS for an equivalent model.
- Concerns were raised about the efficiency of the intermediate model sizes in NeoX and how it impacts performance.
- Investigating Communication Overhead: Discussion surfaced regarding potential TP communication overlap in NeMo, which could enhance performance significantly on PCIe setups.
- Thoughts were shared about possibly enabling settings like
ub_tp_comm_overlapin NeMo and exploring TE MLPs to mitigate the issue.
- Thoughts were shared about possibly enabling settings like
- Impact of Configuration Settings on Performance: The configurations between NeMo and NeoX were compared, with a suggestion to adjust allreduce bucket sizes to match NeMo's in hopes of improving TPS.
- Preferences were noted for larger bucket sizes as they are expected to help with PCIe communication in both allgather and allreduce operations.
- Transformer Engine Integration Challenges: Experiments with integrating Transformer Engine into NeoX led to issues when non-FP8 flags were activated without proper outcomes.
- Further attempts to resolve the integration problems were postponed after initial setbacks.
- Iterative Runtime Comparisons: The reported iterative runtimes showed 4.8 seconds per step in NeMo versus 6.2 seconds in NeoX for model operations.
- This led to questioning environment differences, particularly if the non-optimized setups in NeoX hindered performance.
- pretrain_llama32_1b.py: GitHub Gist: instantly share code, notes, and snippets.
- gpt-neox/configs/pythia/6-9B.yml at olmo-support · aflah02/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - aflah02/gpt-neox
- gpt-neox/configs/hubble/Speed_Exps/1_1B_Baseline_BS_8_GAS_8_No_Activation_Checkpointing_GQA_KV_Heads_4_Fusions_All_3_FA_Swiglu.yml at olmo-support · aflah02/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - aflah02/gpt-neox
- gpt-neox/configs/hubble/Speed_Exps/1_1B_Baseline_BS_8_GAS_8_No_Activation_Checkpointing_GQA_KV_Heads_4_Fusions_All_3_FA_Swiglu.yml at olmo-support · aflah02/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - aflah02/gpt-neox
- gpt-neox/megatron/model/utils.py at 1ac9add83e2cdeec425a87c0a50ef2d278f3d5a1 · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
- GitHub - aflah02/gpt-neox at olmo-support: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - GitHub - aflah02/gpt-neox at olmo-support
- gpt-neox/configs/hubble/Speed_Exps/6_7B_Baseline_No_Activation_Checkpointing_BS_4_GAS_16_GQA_KV_Heads_4_Fusions_3_FA_Swiglu.yml at olmo-support · aflah02/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - aflah02/gpt-neox
- NeMo/nemo/collections/llm/gpt/model/llama.py at main · NVIDIA/NeMo: A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech) - NVIDIA/NeMo
- NeMo/nemo/collections/nlp/models/language_modeling/megatron_base_model.py at 0621272c2a9a760a71b234131f1997e87a265943 · NVIDIA/NeMo: A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech) - NVIDIA/NeMo
- NeMo/nemo/collections/llm/gpt/model/llama.py at main · NVIDIA/NeMo: A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech) - NVIDIA/NeMo
- NeMo/nemo/collections/nlp/models/language_modeling/megatron_base_model.py at 0621272c2a9a760a71b234131f1997e87a265943 · NVIDIA/NeMo: A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech) - NVIDIA/NeMo
- NeMo/nemo/collections/nlp/models/language_modeling/megatron_base_model.py at 0621272c2a9a760a71b234131f1997e87a265943 · NVIDIA/NeMo: A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech) - NVIDIA/NeMo
Yannick Kilcher ▷ #general (72 messages🔥🔥):
Grok 3 Launch, NURBS and AI, Comparison of AI Models, Grok 3 Game Studio, LLM Precision Issues
- Grok 3 Launch Sparks Interest: With Grok 3 launching, discussions highlight its promising capabilities, although early assessments suggest it may fall behind OpenAI's models in certain aspects.
- Community members are particularly curious about Grok 3's reasoning abilities and API costs as the product continues to evolve.
- NURBS Family and AI Relationship: A member detailed the advantages of NURBS, noting their smoothness and better data structures compared to traditional methods, along with a call for new optimization techniques.
- The conversation shifted to the broader implications of geometric approaches in AI development and the potential for lesser overfitting.
- AI Model Comparisons Raise Questions: There is an ongoing debate about the fairness of comparisons between Grok and OpenAI's models, with some members claiming that Grok's charts misrepresent its performance.
- Concerns over 'maj@k' methods and how they may impact perceived effectiveness have emerged, fueling discussions on model evaluation standards.
- Exciting Ventures into Gaming: Grok 3's new branding has caught attention, with announcements of plans to start a game studio, highlighting a logical expansion for xAI.
- Elon Musk's involvement in this venture adds to the community's interest, prompting speculations on future developments.
- LLMs Struggle with Precision Regression: An article was shared discussing the limitations of LLMs in generating precise numerical outputs, outlining the potential consequences for various industries.
- This continued discussion of performance highlights ongoing challenges in achieving high precision in AI-driven tasks.
- Why Large Language Models Fail at Precision Regression | Karthick Panner Selvam : no description found
- Tweet from Rex (@12exyz): they omitted o3 from the chart in the livestream for some reason so i added the numbers for you
- Tweet from Elon Musk (@elonmusk): YesQuoting Dima Zeniuk (@DimaZeniuk) Elon Musk's xAI is going to start an AI game studio to make games
Yannick Kilcher ▷ #paper-discussion (31 messages🔥):
Hierarchical tree of papers, Upcoming paper discussions, Deepseek paper interest, Discussion on filtering information, Community contribution for paper reviews
- Creating a Hierarchical Tree of Seminal Papers: Suggestions were made for a hierarchical tree of seminal papers focusing on dependencies and key insights, emphasizing the importance of filtering information to avoid noise.
- The community indicated a desire to leverage their expertise in identifying seminal and informative papers for better knowledge sharing.
- Interest in the Deepseek Paper: A call for readers of the new Deepseek paper was made, providing a link for community participation, outlining authorship and contributions.
- Members expressed interest in hosting discussions around the paper, highlighting the need for someone to lead it since it hasn't been discussed yet.
- Discussion Timing and Community Engagement: Participants discussed scheduling paper discussions on weekdays with flexible timing, inviting contributions and presenters to ensure better attendance.
- There was mention of using a timestamp generator to manage scheduling and coordinating advance notice to increase participation.
- Navigating Duds in Paper Reading: Members expressed the importance of being able to critique and discern fringe and possibly low-value papers, noting that sometimes no paper is truly a waste.
- There was consensus that filtering shortly could improve the overall reading experience, emphasizing a strategy to enhance time management in discussions.
- Community Interaction on Discord: Queries about Discord's ability to convert timestamps across time zones were made, alongside sharing useful tools for generating timestamps.
- This discussion led to an appreciation for community tools that facilitate discussion planning and increase engagement.
Link mentioned: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
Yannick Kilcher ▷ #ml-news (70 messages🔥🔥):
Larry Page's Relationship Status, Sergey Brin's Divorce, Grok-3 Demo, Deepsearch Product Announcement, The Los Angeles Project and Unicorns
- Larry Page's Love Life Takes a Turn: Reports suggest that Larry Page is back on the market following a recent breakup, generating buzz in the media.
- A member humorously questioned whether Page would react by shouting about his situation.
- Sergey Brin's High-Profile Divorce Finalized: After filing for divorce in January 2022, Sergey Brin has finalized his split from Nicole Shanahan amidst affair allegations involving Elon Musk.
- The official divorce was completed on May 26, highlighting a tumultuous personal life amid ongoing media scrutiny.
- Grok-3 Live Demo Sparks Discussion: Grok-3 was showcased during a live demo, leading members to discuss its capabilities compared to existing models and its tetris mechanic.
- The engagement revealed mixed reactions, with some members expressing they were 'thoroughly whelmed' by the product's presentation.
- Deepsearch Pricing Raises Eyebrows: Despite being described as state-of-the-art, the pricing of $40 for the new Deepsearch product prompted skepticism among users, especially given similar products released for free recently.
- One member cynically observed the dramatic pricing strategy as potentially exploitative given the competition.
- The Los Angeles Project's Ambitious Goals: The Los Angeles Project aims to engineer real unicorns through advanced genetic editing, raising eyebrows with its ambitious claims.
- However, some members speculated whether the mention of AI in their operations was merely a marketing tactic, as no AI roles were advertised.
- Google cofounder Sergey Brin quietly divorced his wife this year after allegations that she had an affair with Elon Musk: A judge rejected Brin's attempt to seal the case over his concerns about his high-profile stature.
- Is Elon’s Grok 3 the new AI king?: Try Brilliant free for 30 days https://brilliant.org/fireship You’ll also get 20% off an annual premium subscription.Take a first look at Elon Musk's Grok 3 ...
- Larry Page Single Again? - Celebrity Break-up, Split and Divorce 2025 - Mediamass: Are celebrities more likely to divorce or break up? Earlier this week news reports surfaced that Larry Page, 51, and his partner had split up. Is Google's founder really single again?
- Harnessing the Breath of Life: how a gene-editing startup called the los angeles project will create actual, literal unicorns (and more)
- LAP: no description found
- Tweet from xAI (@xai): https://x.com/i/broadcasts/1gqGvjeBljOGB
Stability.ai (Stable Diffusion) ▷ #general-chat (168 messages🔥🔥):
Xformers issues, InvokeAI vs ComfyUI, Stable Diffusion update concerns, Gender classification in anime, Printer usability frustrations
- Xformers causing GPU woes: Users discussed issues with xformers, notably it defaulting to CPU mode and requiring specific PyTorch versions, along with a member mentioning that simply ignoring warning messages works.
- One user was advised to do a clean reinstall and add
--xformersto their command line to hopefully resolve the issue.
- One user was advised to do a clean reinstall and add
- InvokeAI emerges as a top UI choice for beginners: Many users suggested InvokeAI as a more intuitive UI option for newcomers despite experiencing better functionality with ComfyUI themselves.
- The community consensus is that while InvokeAI is simple, the complexity of underlying systems, like ComfyUI, can be overwhelming for novices.
- Concerns over Stable Diffusion's stagnation: Concerns were raised about the lack of updates in the Stable Diffusion ecosystem, particularly regarding A1111 no longer supporting SD 3.5, leading to frustrations among users.
- Users noted the confusion around outdated guides and branches that might not be compatible with newer technologies.
- Anime gender classification exploration: A user sought advice on how to separate male and female anime bboxes for inpainting using a specific anime gender classifier found on Hugging Face.
- The classification method is reportedly promising but requires integration expertise with existing workflows in ComfyUI.
- Frustration with printer usability: An IT worker humorously shared an experience with a defective printer, highlighting how even clear instructions can be misinterpreted.
- The conversation evolved into a discussion about common misunderstandings with simple signs and the need for more effective communication.
- Kolors Virtual Try-On - a Hugging Face Space by Kwai-Kolors: no description found
- DOFOFFICIAL/animeGender-dvgg-0.8 · Hugging Face: no description found
- zheng-: GitHub is where zheng- builds software.
- Releases · AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
GPU MODE ▷ #general (11 messages🔥):
Torch Compile, PyTorch Inductor, Machine Learning Advancements
- Understanding Torch Compile mechanics: A member explained that when using
torch.compile(), a machine learning model in PyTorch converts to Python bytecode, analyzed by TorchDynamo, which generates an FX graph for GPU kernel calls.- They expressed interest in handling graph breaks during compilation and acknowledged further exploration of this is necessary.
- Inductor internals discussed: A shared link to a detailed PDF focused on the internals of PyTorch's Inductor, providing in-depth information.
- Members appreciated the resource and planned to follow up with the details provided.
- Reflections on Machine Learning Complexity: A member shared a link to a blog post discussing Torch Compile, emphasizing the complexity of modern machine learning tools compared to earlier frameworks like Caffe.
- The post reflects on the user-friendly nature of today's tools, while also recognizing the hidden complexities behind them.
- Dissecting torch.compile: Surgical Precision in PyTorch Optimization: You can take a look at the GitHub repository of this blogpost at this link
- workshops/ASPLOS_2024/inductor.pdf at master · pytorch/workshops: This is a repository for all workshop related materials. - pytorch/workshops
GPU MODE ▷ #triton (3 messages):
Profiling in Triton vs CUDA, Performance issues due to bank conflicts, Low-precision inputs in Triton kernels, Device properties in PyTorch
- Profiling Insights: CUDA vs Triton: A member suggested that the Cuda driver knows exact values, indicating that microbenchmarking only applies to unpublished properties like instruction cache size, and that L1 cache should be known from compute capability.
- They shared a PyTorch query to get device properties including L2 cache size, noting potential confusion around 'MB' meaning 'MiB'.
- Debugging Triton Kernel Performance Degradation: A member is addressing a performance degradation issue in a Triton kernel triggered by using low-precision inputs like float8, pointing to an increase in shared memory access bank conflicts.
- Despite using NCU for profiling, they noted the lack of resources for resolving bank conflicts in Triton, emphasizing the differences compared to CUDA's granular control.
GPU MODE ▷ #cuda (17 messages🔥):
Optimizing CUDA Memory Transfers, Global Memory Coalescing Explained, CUDA Express Installer Issues, Fine-Grained Control in Data Copying
- Optimizing CUDA Memory Transfers: To enhance speed when transferring large constant vectors in CUDA, it's recommended to use
cudaMemcpyAsyncwithcudaMemcpyDeviceToDevicefor better performance.- Members discussed the advantages of
cudaMemcpyAsync, but noted the requirement for fine-grained control might necessitate custom solutions.
- Members discussed the advantages of
- Global Memory Coalescing Explained: A member questioned the implementation of global memory coalescing in CUDA, specifically how the provided code achieves this in matrix multiplication.
- Another member referenced a diagram and example code, clarifying that understanding how threads map to elements is key to leveraging coalesced memory access.
- CUDA Express Installer Issues: Many users, including one reporting issues with the CUDA Express installer, encountered hangs during the installation process, specifically with Nsight and Visual Studio.
- The dialogue suggested the problems may be prevalent among multiple configurations, especially on Windows systems.
- Fine-Grained Control in Data Copying: In the context of needing finer control over data copying on A100 GPUs, a suggestion was made to use
cub::DeviceCopy::Batchedas a solution.- This approach may provide the necessary granularity that defaults like
cudaMemcpyDeviceToDevicedo not.
- This approach may provide the necessary granularity that defaults like
GPU MODE ▷ #torch (4 messages):
Triton 3.2.0 issues, CUDA kernel compilation optimization
- Triton 3.2.0 Throws TypeError on
print(): UsingTRITON_INTERPRET=1withprint()in Pytorch's Triton 3.2.0 package results in a TypeError stating thatkernel()got an unexpected keyword argument 'num_buffers_warp_spec'. This error persists even whennum_buffers_warp_specis set in the configuration. - Speeding Up CUDA Kernel Compilation: A user expressed frustration that adding a new CUDA kernel via cpp extensions takes noticeable time to compile, unlike the instant compilation of a single .cu file.
- Another member suggested separating the code into two files, one for the kernel and another for the torch extension, to avoid recompiling the Pytorch part, potentially speeding up development.
GPU MODE ▷ #algorithms (1 messages):
andreaskoepf: DS is ruling the field at the moment: https://arxiv.org/abs/2502.11089
GPU MODE ▷ #cool-links (4 messages):
Gompertz Linear Unit (GoLU), Native Sparse Attention, Self-gated activation functions
- Introducing the Gompertz Linear Unit (GoLU): A novel activation function called GoLU has been introduced, defined as $\mathrm{GoLU}(x) = x \, \mathrm{Gompertz}(x)$ with $\mathrm{Gompertz}(x) = e^{-e^{-x}}$, aiming to enhance training dynamics.
- The GoLU activation function reduces variance in the latent space compared to GELU and Swish, while maintaining robust gradient flow.
- Native Sparse Attention Technology: Discussion surrounds the paper on Native Sparse Attention, noting its hardware alignment and trainability that could revolutionize model efficiency.
- Members expressed excitement with one remarking, 'Isn't this result crazy?' and considering sharing the information in another channel.
- Self-gated Activation Functions Gain Traction: The evolution of activation functions is highlighted, particularly the rise of self-gated activations like GELU and Swish, which stabilize gradient flow and minimize neuron inactivity.
- These functions are framed as alternatives to traditional methods like ReLU, which suffers from the dying neuron problem.
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
- Gompertz Linear Units: Leveraging Asymmetry for Enhanced Learning Dynamics: Activation functions are fundamental elements of deep learning architectures as they significantly influence training dynamics. ReLU, while widely used, is prone to the dying neuron problem, which has...
GPU MODE ▷ #jobs (2 messages):
GPU kernel programming internships, Senior AI Engineer position at T-Systems
- Param seeks internships in GPU and AI domains: A computer science undergraduate from India, Param Thakkar, is looking for internships in GPU kernel programming, Large Language Models, and Deep Learning.
- He has experience with CUDA in C++ and Julia, and various projects including Generative Adversarial Networks for image generation.
- T-Systems hiring Senior AI Engineer: Pavol from T-Systems announced a job opening for a Senior AI Engineer in EU/Spain, focusing on improving fine-tuning infrastructure and optimizing multi-H100 deployments.
- Interested candidates can apply here or contact Pavol directly for more information.
GPU MODE ▷ #beginner (1 messages):
Optimizing memory access, Global memory operations
- Speeding Up Global Memory Reads: A member inquired about how to improve performance when reading a large constant vector from global memory and sending it to another location in global memory.
- They are seeking code examples or strategies that might enhance the speed of memory operations.
- Exploring Memory Transfer Efficiency: Another member suggested using methods like coalescing to optimize memory transfers, which can significantly reduce latency in global memory operations.
- Direct quotes noted that this approach can lead to dramatic improvements in throughput when dealing with large datasets.
GPU MODE ▷ #off-topic (1 messages):
iron_bound: https://www.amd.com/en/products/software/rocm/application-developer-certificate.html
GPU MODE ▷ #rocm (7 messages):
HIP Kernels in PyTorch, ROCm Installation Issues, AMD Kernel Driver Performance, ROCm Compatibility on iGPUs
- Using HIP Kernels Made Easy: A member inquired about using HIP kernels in PyTorch, mentioning they import them with ctypes but suspect there might be an easier way.
- There's a call for more efficient methods, highlighting continuous exploration in the community.
- ROCm Installation Woes on Strix Point: A member faced issues installing ROCm on the Strix Point platform with Ubuntu 24.04, as the graphical interface failed to start post-installation.
- They wondered if this indicated a compatibility issue with the new kernel driver and iGPU, seeking viable solutions.
- Disappointment in AMD Kernel Driver Performance: Concerns were expressed about the state of the AMD kernel driver, especially for non-MI GPUs, as it appears inadequate for iGPUs.
- One member suggested removing the amdgpu-dkms package and relying on the upstream driver for better stability.
- ROCm's Limited Testing on iGPUs: Discussion highlighted that ROCm components are not well-tested on iGPUs, with defaults compiled for other architectures.
- While using ROCm with iGPUs may pose challenges, engaging with HIP for experimental purposes could be feasible.
- Community Support and Suggestions: Members provided support and suggestions regarding installation troubles, particularly surrounding the graphical interface issue.
- Responses included troubleshooting tips such as disabling dedicated GPUs if applicable, fostering collaboration within the community.
GPU MODE ▷ #arm (4 messages):
ExecuTorch, LLM optimization, Ethos U, Self-promotion policy
- ExecuTorch Optimizes LLMs for int4: A member shared that ExecuTorch has optimized LLMs for int4 and is currently working on Ethos U.
- This was mentioned in the context of promoting their work within the community.
- Reminder on Self-Promotion Rules: Another member reminded that self-promotion posts outside specific channels are generally not allowed.
- They advised to replace links with more relevant code or optimization instructions for Ethos instead of promoting the Discord channel.
- Acknowledgment of Feedback: The original poster acknowledged the feedback and confirmed the action was taken by saying, 'Done. Thanks for the reminder.'
- This reflects a cooperative spirit in addressing community guidelines regarding posts.
GPU MODE ▷ #webgpu (1 messages):
Simulated Metal Pin Toy, transformers.js, Depth Estimation Models
- Hacking Weekend Brings Simulated Metal Pin Toy to Life: A member showcased a simulated metal pin toy using a live webcam alongside a depth estimation model running in the browser, which can be tried out via the link in their bio.
- They highlighted the fun collaboration with Claude over the weekend, emphasizing the creativity brought forth by this project.
- Exciting Demo Utilizing transformers.js: The project prominently features transformers.js, a library developed by some participants in the community.
- This piqued the interest of others, who expressed curiosity about its implementation in real-time applications.
Link mentioned: Tweet from Vincent (@vvvincent_c): Simulated metal pin toy using live webcam + depth estimation model running in the browser 🎨✨Claude and I had lots of fun hacking on this over the weekend!!Link in bio to try it yourself!
GPU MODE ▷ #self-promotion (15 messages🔥):
Dynasor, ML Systems Research, Simulated Metal Pin Toy, CUDA Optimization Techniques, HQQ Support in VLLM
- Dynasor slashes reasoning system costs: Dynasor cuts reasoning system costs by up to 80% without the need for model training, demonstrating impressive token efficiency.
- The tool allows users to probe models and uses certainty to halt unnecessary reasoning processes, showcased in a live demo.
- Interest in ML systems research talk: A member expressed interest in having someone from the Hao lab give a talk about the application of ML systems research to reasoning models.
- The community is eager to learn more about this topic and its practical implications.
- Creative webcam toy project: A member showcased a simulated metal pin toy created using a live webcam and a depth estimation model running in the browser, emphasizing the fun of hacking the project.
- They encouraged others to try it out by providing a link in their bio.
- In-depth blog on CUDA optimizations: A member shared a detailed blog covering CUDA optimization techniques focused on iteratively optimizing a layer normalization kernel, highlighting several performance improvement strategies.
- Feedback encouraged discussions around the correctness of vectorized implementations, leading to valuable insights from the community.
- HQQ support enhanced in VLLM: Enhanced support for hqq in vllm allows running lower bit models and on-the-fly quantization for almost any model via GemLite or the PyTorch backend.
- New releases were announced alongside appealing patching capabilities, promising wider compatibility across vllm forks.
- Optimizing a Layer Normalization Kernel with CUDA: a Worklog: no description found
- Tweet from Mobius Labs (@Mobius_Labs): New releases for hqq ( https://github.com/mobiusml/hqq/releases/tag/0.2.3…) and gemlite ( https://github.com/mobiusml/gemlite/releases/tag/0.4.2… )! The most exciting update is that we're bri...
- Tweet from Vincent (@vvvincent_c): Simulated metal pin toy using live webcam + depth estimation model running in the browser 🎨✨Claude and I had lots of fun hacking on this over the weekend!!Link in bio to try it yourself!
- Tweet from Hao AI Lab (@haoailab): Reasoning models often waste tokens self-doubting.Dynasor saves you up to 81% tokens to arrive at the correct answer! 🧠✂️- Probe the model halfway to get the certainty- Use Certainty to stop reasonin...
- GitHub - hao-ai-lab/Dynasor: Simple extension on vLLM to help you speed up reasoning model without training.: Simple extension on vLLM to help you speed up reasoning model without training. - hao-ai-lab/Dynasor
GPU MODE ▷ #🍿 (3 messages):
KernelBench paper, GPU kernel generation, Performance engineering, Kernel fusion, Productivity tools in coding
- KernelBench Paper Released: The KernelBench paper is now available, focusing on automating GPU kernel generation via language models for efficient PyTorch ML workloads. It introduces a novel metric, fast_p, to evaluate generated kernels on both correctness and performance.
- You can view the paper here and check the PDF version for direct insights.
- Performance Engineer's Excitement for KernelBench: A performance engineer expressed excitement about the potential of the KernelBench framework, which could serve as a starting point for complex kernel fusion. They hope to refine the generated kernels for improved performance and correctness.
- “This could perhaps provide a starting point for a complicated kernel fusion that I could then refine for performance/correctness.”
- Productivity Tools in Compiler Development: There is a discussion on the viewpoint that even if models cannot produce the fastest code, they can significantly improve workflows. One member emphasized that compilers should be viewed as a productivity tool.
- “Imo compiler is really a productivity tool.”
Link mentioned: KernelBench: Can LLMs Write Efficient GPU Kernels?: Efficient GPU kernels are crucial for building performant machine learning architectures, but writing them is a time-consuming challenge that requires significant expertise; therefore, we explore usin...
GPU MODE ▷ #edge (2 messages):
SO-ARM100 Assembly, 3D Printer Size Constraints
- Inquiry on SO-ARM100 Assembly Experiences: A member asked if anyone has tried assembling the SO-ARM100 and had a good experience.
- They highlighted the GitHub repository as a valuable resource for potential contributors.
- Concerns on 3D Printer Size: Another member expressed suspicion that their 3D printer might be too small to print the SO-ARM100.
- This raises considerations about the compatibility of printer dimensions with project requirements.
Link mentioned: GitHub - TheRobotStudio/SO-ARM100: Standard Open Arm 100: Standard Open Arm 100. Contribute to TheRobotStudio/SO-ARM100 development by creating an account on GitHub.
GPU MODE ▷ #reasoning-gym (49 messages🔥):
vLLM nightly, RL curricula development, ExploreToM project, CodeI/O dataset, Issue creation and collaboration
- Experimenting with vLLM nightly: A member is spinning up a node for experiments while utilizing vLLM nightly version (
pip3 install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly).- This method aims to explore functionalities related to veRL.
- Collaborating on RL Curricula: A call was made for assistance on developing RL curricula, focusing on manual and dynamic modes for training evaluations.
- Discussion centered on selecting datasets that facilitate scaling of difficulty through specified parameters.
- Introducing ExploreToM from Facebook: A new project, ExploreToM, was mentioned, which is related to exploration in theory of mind tasks.
- The project aims to further explore models' capabilities in multi-agent interactions.
- DeepSeek's CodeI/O Paper Discussion: A member shared a paper on CodeI/O, which discusses predicting inputs and outputs based on code, highlighting the need for a valuable dataset.
- An issue was created on GitHub to tackle this dataset, emphasizing the importance of breaking the work into smaller, manageable tasks.
- Access to Evaluation Sheet: Members discussed access rights to a Google doc evaluation sheet, specifically mentioning improvements in datasets like mini_sudoku and family_relationships.
- Access was granted to one user as they plan to contribute to evaluations and updates.
- EnigmaEval: A Benchmark of Long Multimodal Reasoning Challenges: As language models master existing reasoning benchmarks, we need new challenges to evaluate their cognitive frontiers. Puzzle-solving events are rich repositories of challenging multimodal problems th...
- CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction: Reasoning is a fundamental capability of Large Language Models. While prior research predominantly focuses on enhancing narrow skills like math or code generation, improving performance on many other ...
- Add CODEI/O sampled subset dataset · Issue #160 · open-thought/reasoning-gym: DeepSeek published CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction. Task: "predict inputs/outputs given code and test cases entirely in natural language" Beside propr...
- Tweet from Wyatt walls (@lefthanddraft): hmm. I guess I need a reasoner for this
- Tweet from Wyatt walls (@lefthanddraft): Grok 3 (non-reasoning) can't recognise that two large numbers are the same if formatted differently
- GitHub - facebookresearch/ExploreToM: Code for ExploreTom: Code for ExploreTom. Contribute to facebookresearch/ExploreToM development by creating an account on GitHub.
- Add a dataset with tasks to compare formatted numbers · Issue #156 · open-thought/reasoning-gym: Formats could include: Plain: 123456.789 f'{x:f}' English: 123,456.789 f'{x:,}' Percent: 12345678.9% f'{x:%}' & f'{x:,%}' Scientific: 1.234568e+05 f'{x:e}' ...
- reasoning-gym/reasoning_gym/coaching at main · open-thought/reasoning-gym: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
- Curriculum Refactor by EduardDurech · Pull Request #71 · open-thought/reasoning-gym: no description found
Nous Research AI ▷ #general (84 messages🔥🔥):
Grok-3 Performance, Open Source Models Discussion, Autoregressive Image Model, AI Model Training Techniques, Community Feedback on AI Models
- Grok-3 shows mixed censorship levels: Users noted that Grok-3, initially thought to be uncensored, is presenting varying levels of censorship depending on usage context, such as on lmarena.
- Some are pleasantly surprised, while others want deeper access to its supposedly raw outputs.
- Discussing the future of open source AI: The community expressed thoughts that companies like Anthropic should release older models as open source to gain goodwill, particularly considering recent market shifts.
- There's a general consensus that older models don't present significant competitive risks, hence shareability could benefit community growth.
- Innovations and Techniques in AI Modeling: Grok-3's approach to training models suggests that many techniques are evolving, particularly around Reinforcement Learning from Human Feedback (RLHF).
- Participants discussed the potential of training classifiers and autoregressive models to improve AI dialogue and response quality.
- Curiosity about XAI's methods: There’s intrigue about whether XAI is innovating compared to OpenAI and DeepSeek, particularly regarding their autoregressive image model, which seems distinct.
- Community members are eager to understand if XAI will unveil new methodologies that set them apart in a competitive landscape.
- Community excitement for Hermes-4: Expectation is building for Hermes-4 based on current discussions about AI improvements and capabilities, with users expressing eagerness for its release.
- Sentiments like 'Hermes-4 is going to be so fucking lit!' highlight the community's anticipation for advancements in AI technology.
- GitHub - DamascusGit/err_err: Contribute to DamascusGit/err_err development by creating an account on GitHub.
- GitHub - DamascusGit/err_err: Contribute to DamascusGit/err_err development by creating an account on GitHub.
Nous Research AI ▷ #ask-about-llms (11 messages🔥):
Hermes 3 censorship claims, Deephermes usage, Grok 3 impressions, Performance issues with tokens
- Hermes 3's censorship paradox: Despite being advertised as censorship free, users reported that Hermes 3 refused to answer certain questions due to needing proper system prompts.
- One member speculated that steering through system prompts is necessary for intended functionality.
- Deephermes usage insights: Discussion revealed that Deephermes is perceived as less censored, with members advising others to utilize LMStudio for optimal performance.
- Claims of bugs in Deephermes were countered with assertions that no bugs exist and proper usage is key.
- Initial reactions to Grok 3: Opinions on Grok 3 suggest it performs comparably to o3 full, indicating a favorable impression among users.
- One member shared curiosity about what Grok 3 exactly entails, reflecting general intrigue.
- Concerns on token performance delays: A user raised concerns about a 7789 tokens limit causing lengthy processing times, questioning the overall efficiency.
- Another noted it's not meant to be a reasoning model, hinting at expectations versus reality.
Nous Research AI ▷ #research-papers (3 messages):
SWE-Lancer Benchmark, Upwork Engineering Tasks, Model Performance Evaluation
- Introducing SWE-Lancer Benchmark for Freelance Tasks: The new SWE-Lancer benchmark features over 1,400 freelance software engineering tasks valued at $1 million USD, ranging from minor bug fixes to significant feature implementations.
- Independent tasks are graded by experienced engineers while managerial decisions are evaluated against original engineering managers, highlighting a need for improved model performance as frontier models still struggle to solve the majority of tasks.
- Open-Sourcing SWE-Lancer for Future Research: Researchers can explore SWE-Lancer through a public evaluation split, providing a unified Docker image to facilitate testing and improvement.
- By linking model performance to monetary value, the benchmark aims to drive more effective research in the realm of software engineering tasks.
- SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?: We introduce SWE-Lancer, a benchmark of over 1,400 freelance software engineering tasks from Upwork, valued at \$1 million USD total in real-world payouts. SWE-Lancer encompasses both independent engi...
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
Nous Research AI ▷ #interesting-links (2 messages):
Alignment faking in LLMs, Eagles Super Bowl Predictions, Open-source LLMs performance
- Exploring Alignment Faking in LLMs: A YouTube video titled 'Alignment Faking in Large Language Models' discusses how some individuals may seem to share values while actually pretending to do so.
- This behavior is likened to the challenges faced in AI models when interpreting alignment.
- Open-source Bot Predicts Eagles Super Bowl Win: An open-source LLM-powered pick-em's bot predicts that the Eagles will win the Super Bowl, outperforming 94.5% of players in ESPN's 2024 competition.
- The bot states, 'The Eagles are the logical choice,' and highlights a novel approach in exploiting structured output for reasoning.
- Predicting the Super Bowl with LLMs: Using LLMs to pick NFL winners better than 94.5% of humans.
- Alignment faking in large language models: Most of us have encountered situations where someone appears to share our views or values, but is in fact only pretending to do so—a behavior that we might c...
Nous Research AI ▷ #research-papers (3 messages):
SWE-Lancer Benchmark, Real-world Software Engineering Tasks
- SWE-Lancer Sets New Benchmark for Freelance Tasks: The SWE-Lancer benchmark introduces over 1,400 freelance software engineering tasks from Upwork, valued at a total of $1 million USD in real-world payouts, encompassing both independent and managerial tasks.
- Models struggle with task completion, as evaluations show that frontier models cannot solve the majority of tasks despite rigorous grading by experienced engineers.
- Open-sourcing SWE-Lancer for Future Research: To facilitate further investigation, the SWE-Lancer benchmark includes a unified Docker image and a public evaluation split titled SWE-Lancer Diamond available on GitHub.
- The goal is to map model performance to monetary value, potentially enabling greater research opportunities in the field of software engineering.
- SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?: We introduce SWE-Lancer, a benchmark of over 1,400 freelance software engineering tasks from Upwork, valued at \$1 million USD total in real-world payouts. SWE-Lancer encompasses both independent engi...
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. Sparse attention offe...
Latent Space ▷ #ai-general-chat (94 messages🔥🔥):
Thinking Machines Lab Launch, Perplexity R1 Finetune, SWElancer Benchmark, Grok 3 Announcement, Zed's Edit Prediction Model
- Thinking Machines Lab Launches: Thinking Machines Lab, founded by prominent figures in AI, aims to make AI systems more customizable and widely understood, bridging gaps in public discourse around frontier AI.
- The team behind the initiative includes those who developed widely used products like ChatGPT and Character.ai, promising open science through publications and code releases.
- Perplexity Open-Sources R1 1776 Model: Perplexity AI has open-sourced R1 1776, a version of the DeepSeek R1 model that is designed to provide uncensored and factual information.
- The announcement was humorously labeled as 'freedom tuning' by users on social media, indicating a playful reaction to the model's purpose.
- SWElancer Benchmark Introduced: OpenAI launched SWE-Lancer, a new benchmark to evaluate the coding performance of AI models, featuring 1,400 freelance software engineering tasks worth $1 million.
- Users expressed surprise at the name and speculated about the absence of certain models, suggesting potential strategic motives behind the benchmark.
- Excitement for Grok 3: There is heightened anticipation around the Grok 3 model, with discussions on its capabilities compared to other models and its applications in various tasks.
- Walruses in the community expressed skepticism and humor regarding its actual performance following the surface-level excitement.
- Discussion about Zed's New Features: Zed has introduced an open next-edit prediction model that is seen as a potential competitor to existing solutions like Cursor.
- However, users expressed concerns about its differentiation and the overall utility compared to established models such as Copilot and their recent functionalities.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference!Core components of NSA:• Dynamic hierarchical sparse strategy•...
- Tweet from John Schulman (@johnschulman2): @barret_zoph and I recently gave a talk at Stanford on post-training and our experience working together on ChatGPT. Unfortunately the talk wasn't recorded, but here are the slides: https://docs.g...
- Thinking Machines Lab: no description found
- Thinking Machines Lab: no description found
- Zed now predicts your next edit with Zeta, our new open model - Zed Blog: From the Zed Blog: A tool that anticipates your next move.
- Tweet from Devendra Chaplot (@dchaplot): Career Update: Incredibly fortunate and excited to be part of the founding team at Thinking Machines Lab!https://thinkingmachines.ai/Join us: https://6wajk07p.paperform.co/
- Tweet from Mahesh Sathiamoorthy (@madiator): Forget about grok 3. Read these papers/blogs instead.Quoting John Schulman (@johnschulman2) @barret_zoph and I recently gave a talk at Stanford on post-training and our experience working together on ...
- Mark Zuckerberg (@zuck) on Threads: Save the date 🗓LlamaCon: Apr 29Connect: Sept 17-18
- Thinking Machines Corporation - Wikipedia: no description found
- ChatGPT + Post-Training: ChatGPT and The Art of Post-Training Barret Zoph & John Schulman
- Tweet from Jonathan Roberts (@JRobertsAI): Is computer vision “solved”?Not yetCurrent models score 0% on ZeroBench🧵1/6
- stepfun-ai/Step-Audio-Chat · Hugging Face: no description found
- Tweet from Perplexity (@perplexity_ai): Today we're open-sourcing R1 1776—a version of the DeepSeek R1 model that has been post-trained to provide uncensored, unbiased, and factual information.
- Tweet from Andrej Karpathy (@karpathy): I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.Thinking✅ First, Grok 3 clearly has an around state of the art thinking model ...
- Tweet from OpenAI (@OpenAI): Current frontier models are unable to solve the majority of tasks.
- - YouTube: no description found
- Tweet from Thinking Machines (@thinkymachines): Today, we are excited to announce Thinking Machines Lab (https://thinkingmachines.ai/), an artificial intelligence research and product company. We are scientists, engineers, and builders behind some ...
- Freedom America GIF - Freedom America - Discover & Share GIFs: Click to view the GIF
- Tweet from Andrej Karpathy (@karpathy): Congrats on company launch to Thinking Machines!Very strong team, a large fraction of whom were directly involved with and built the ChatGPT miracle. Wonderful people, an easy follow, and wishing the ...
- Tweet from Lisan al Gaib (@scaling01): I love the advertisements for Sonnet 3.5 in each OpenAI paperA bit odd they didn't include o3. Now it either feels like a setup so that they can crush their own benchmark later or o3 just sucks in...
- Tweet from Amjad Masad (@amasad): Grok 3 appears to be a state-of-the-art frontier model. This is a huge accomplishment, especially considering how late in the game they started.Congrats @ibab, @elonmusk, and the rest of the @xai team...
- I built an AI supercomputer with 5 Mac Studios: Get NordVPN 2Y plan + 4 months extra + 6 MORE months extra: https://nordvpn.com/networkchuck It’s risk-free with Nord’s 30-day money-back guarantee! I just...
- Tweet from Elon Musk (@elonmusk): https://x.com/i/broadcasts/1gqGvjeBljOGB
- Reddit - Dive into anything: no description found
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new pod drop! https://x.com/latentspacepod/status/1891879917224132973
Notebook LM ▷ #use-cases (24 messages🔥):
Max Headroom Podcast Production, Language Settings for Audio Generation, Notebook LM Audio Features, Audio Generation Challenges, Google Product Limitations
- Max Headroom Reboot Podcast Details: A user described their process for creating a Max Headroom podcast using Notebook LM for text generation and Speechify for voice cloning, resulting in a 40-hour production time.
- They adapted prompts and edited the text, combining different tools to achieve the desired effect and enhance the podcast production.
- Changing Language Settings in Notebook LM: Users expressed frustration with language settings in the 'studio' not allowing Spanish generation, despite attempts to customize settings.
- Several users noted this could be a bug affecting accounts and suggested that even changing accounts did not resolve the issue.
- Notebook LM Audio Generation Capabilities: The feature was discussed where users can import scripts into Notebook LM to create audio for various formats including podcasts and advertisements.
- Users highlighted advantages like time-saving and flexibility in modifying scripts, while also mentioning the need for editing software for refinement.
- Audio Generation Challenges with Old Accounts: One user reported trouble with their older paid account yielding less satisfactory results, suggesting that audio import formats may affect the performance.
- They noted that while the setup works with a free account, issues persist when importing MP4 files inaccurately.
- Limitations of Google's System: Participants discussed the expectation for Google products to perform better, especially as they begin charging for services.
- Concerns were raised about the system design being limiting and frustrations over technological shortcomings affecting user experience.
Link mentioned: Max Headroom Rebooted 2025 Full Episode 20 Minutes: 🚨 BZZZZZT! ALERT! ALERT! 🚨THE FUTURE IS BROKEN—AND I AM BACK TO REPORT IT!💾 LOST IN THE DIGITAL VOID… THEN REBOOTED BY A TRASH PANDA?! 💾Somewhere deep in...
Notebook LM ▷ #general (65 messages🔥🔥):
NotebookLM usage issues, Podcast features, Language settings, File management for researchers, Translation capabilities
- Challenges with NotebookLM for Research: Researchers reported frustration with NotebookLM renaming PDF files in obscure formats like 2022-2~4.PDF, making it hard to recognize sources.
- Suggestions for improvement include allowing direct viewing of PDF titles and enhancing naming conventions to facilitate easier navigation.
- Podcast Creation Limits Confusion: Users discussed encountering a bug where they hit podcast creation limits unexpectedly, with one noting they could only create three podcasts on the free version, whereas limits should be higher.
- Clarification revealed that 50 is the limit for chat queries, not podcasts, leading to some confusion among users.
- Setting Language Preferences: There were inquiries about changing language settings in NotebookLM, particularly for users wanting to switch from German to English.
- One suggestion included updating the Google Account's language preference, which directly affects how NotebookLM operates.
- Limitations in Translating Podcast Content: Users noted that currently, podcasts can only be produced in English, leading to queries about potential translation tools available.
- While translation APIs exist through cloud providers, non-developers may struggle to find user-friendly options.
- Adjustments Needed for Podcast Tone and Length: A user sought to modify the tone and length of their podcast but was informed that adjustments are only applicable to NotebookLM responses, not podcasts.
- Instructions were offered on how to configure chat settings for response adjustments, indirectly linking these settings to user satisfaction.
- no title found: no description found
- no title found: no description found
- no title found: no description found
Modular (Mojo 🔥) ▷ #general (14 messages🔥):
Polars DataFrame Library, Mojo Integration, Standard Library Team Expansion, Apache Arrow Implementation
- Exploration of Polars Library: Several members expressed interest in the Polars dataframe library, recognizing its potential advantages over pandas, particularly in performance.
- Lucablight4200 encouraged others to explore Polars for future dataframe work, indicating that it would be essential down the line.
- Integrating Polars with Mojo: Interest in plugging Polars into Mojo projects was voiced, suggesting significant potential in this integration for data handling.
- Sa_code highlighted that Mojo's framework could enable a dataframe library that is silicon agnostic for use in both single machines and distributed settings.
- Discussion on Standard Library Team Expansion: A member inquired about the possibility of expanding the stdlib team, humorously mentioning being Canadian to highlight cost-effectiveness.
- This prompted a light-hearted exchange about qualifications and contributions, suggesting that expertise wasn't the only consideration.
- Implementation of Apache Arrow in Mojo: A member noted having a small implementation of Apache Arrow in Mojo, deeming it necessary for a comprehensive dataframe library.
- However, sa_code admitted they haven't had the time to develop this further, suggesting it requires more effort than just a hobby.
Modular (Mojo 🔥) ▷ #mojo (39 messages🔥):
Alternatives to ChatGPT for Mojo, Mojo Code Refactoring Challenges, Autodifferentiation with Enzyme, Global Variables Support in Mojo, Using Lists vs. Stacks in Mojo
- Mojo alternatives: Gemini 2.0 shines: Several members suggested utilizing
Gemini 2.0 FlashorGemini 2.0 Flash Thinkingfor Mojo refactoring tasks, claiming reasonable knowledge of the language.- A member verified the usage of the Zed code editor, highlighting its compatibility with a Mojo extension found here.
- Challenges in refactoring large Python projects to Mojo: A user expressed frustration over the difficulties of refactoring their large Python project to Mojo, indicating that manual updates may be necessary due to issues with current tools.
- Another member acknowledged that refactoring Mojo code may involve extensive re-architecting due to the constraints of its borrow checker.
- Interest in Autodiff within Mojo using Enzyme: Discussion emerged regarding the potential implementation of autodifferentiation in Mojo via the Enzyme project, with a proposal for supporting it.
- Members discussed how implementing autodiff could involve converting MOJO ASTs to MLIR for optimization, indicating a keen interest in this capability.
- Global Variables support in Mojo is uncertain: A member inquired about the future support for global variables in Mojo, indicating a desire for clarity.
- Another member humorously noted an interest in global expressions, prompting curiosity regarding possible future developments.
- Speed concerns with Lists in Mojo: Members debated the performance overhead of using
Listfor stack implementations, with a suggestion to useList.unsafe_setto avoid bounds checking.- Concerns were raised about copying objects in Lists impacting speed, and a workaround involving a simple example showcasing object movement was provided.
- Enzyme/enzyme/Enzyme/MLIR at main · EnzymeAD/Enzyme: High-performance automatic differentiation of LLVM and MLIR. - EnzymeAD/Enzyme
- Modular: Modular natively supports dynamic shapes for AI workloads: Today’s AI infrastructure is difficult to evaluate - so many converge on simple and quantifiable metrics like QPS, Latency and Throughput. This is one reason why today’s AI industry is rife with bespo...
- Zed - The editor for what's next: Zed is a high-performance, multiplayer code editor from the creators of Atom and Tree-sitter.
- GitHub - freespirit/mz: Support for Mojo in Zed: Support for Mojo in Zed. Contribute to freespirit/mz development by creating an account on GitHub.
Nomic.ai (GPT4All) ▷ #general (46 messages🔥):
GPUs for Testing GPT4All, Deep-Research-like functionality, 10m Token Count for Embedding, CUDA 5.0 Support
- Looking for Specific GPUs to Test GPT4All: Members discussed various GPUs, with a focus on the requirement for compute 5.0 GPUs like GTX 750/750Ti and others, necessary for testing a special build of GPT4All.
- A member noted that they have a GTX 960, but concerns about VRAM limitations and compatibility were raised by others.
- Curiosity about Deep-Research-like Features: A member expressed interest in whether there is a possibility of a Deep-Research-like functionality for GPTforall, similar to features in other AI tools.
- The conversation continued, with others seeking clarification on what exactly such functionality entails.
- Clarifications on 10m Token Count Limitations: Discussion arose regarding the implications of reaching a 10 million token limit for embeddings with Atlas, with a member confirming that exceeding this would require payment or the use of local models.
- It was clarified that billing is based on total tokens embedded, meaning previous tokens cannot be deducted from the count.
- Enabling CUDA 5.0 Support: There was a conversation about the potential risks of enabling support for CUDA 5.0 GPUs, with concerns that doing so might lead to crashes or issues that could necessitate fixing later.
- The consensus was that it would be prudent to avoid declaring such support in official release notes without further testing and confirmation.
Link mentioned: CUDA - Wikipedia: no description found
LlamaIndex ▷ #blog (3 messages):
LLM Consortium, Mistral Saba, Semantic Retrieval for Vendor Questionnaires
- Massimiliano Builds LLM Consortium: Our frameworks engineer Massimiliano Pippi implemented an LLM Consortium inspired by @karpathy's idea, using LlamaIndex to gather responses from multiple LLMs on the same question.
- This project promises to enhance collaborative AI response accuracy and sharing of insights.
- Mistral AI Unveils Arabic Model: Friends at @mistralAI released the Mistral Saba, a new small model focused on Arabic, with day 0 support for integration.
- Users can quickly get started with the new model by running
pip install llama-index-llms-mistralaihere.
- Users can quickly get started with the new model by running
- Innovative Vendor Questionnaire App: Check out a full-stack app from @patrickrolsen that allows users to answer vendor questionnaires through semantic retrieval and LLM enhancement.
- This application tackles the complexity of form-filling and exemplifies a core use case for knowledge agents, showcasing a user-friendly solution for retrieving previous answers here.
LlamaIndex ▷ #general (23 messages🔥):
Metadata filters in vector stores, Agent Workflow features, Building AI chatbots using LlamaIndex, Embedding installations for local LLMs, Release notes location
- Limitations of Metadata Filters for Dates: There is currently no direct support for filtering by dates in many vector stores, making it challenging to implement such functionality effectively. Some vector stores do allow filters via their specific query languages, but others, like PostgreSQL, may require custom handling.
- A member commented that separating the year in the metadata is essential for filtering.
- Guidance on Creating a Business Offer Agent: A developer shared plans to create an agent for generating and refining business offers using natural language, outlining various features and asking for input on their approach. They received suggestions to build a custom workflow for handling the different tasks needed in this process.
- The importance of using
@stepdecorators to manage event-driven workflows in LlamaIndex was highlighted.
- The importance of using
- Clarifying Usage of AgentWorkflow: A user encountered an issue with an AgentWorkflow where the
response.tool_callslist was empty, not capturing the tool outputs. Suggestions were made to stream the events as a workaround to capture all tool calls.- The community recognized this as a potential bug that needs addressing in future updates.
- Embeddings Installation Guidance: A member mentioned reading the documentation on installing embeddings for local LLMs, particularly when using HuggingFace. They seemed to be progressing in setting up the necessary infrastructure for their project.
- Concerns over the myriad of tutorials and updates in the AI space were expressed by others, indicating the steep learning curve.
- Location of Release Notes: A user asked where to find the release notes for LlamaIndex. Another member promptly provided the link to the CHANGELOG document on GitHub.
- This document serves as a resource for tracking updates and changes in LlamaIndex.
- llama_index/docs at main · run-llama/llama_index: LlamaIndex is the leading framework for building LLM-powered agents over your data. - run-llama/llama_index
- Qdrant Vector Store - Default Qdrant Filters - LlamaIndex: no description found
- Workflows - LlamaIndex: no description found
- llama_index/CHANGELOG.md at main · run-llama/llama_index: LlamaIndex is the leading framework for building LLM-powered agents over your data. - run-llama/llama_index
- Multi-agent workflows - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
RAG based on JSON dictionaries, User query document matching, Finding documents in large JSON
- Exploring RAG with JSON Dictionaries: Members discussed examples of RAG (Retrieval-Augmented Generation) techniques that solely rely on JSON dictionaries to improve document matching efficiency.
- They shared insights on how integrating structured data can enhance traditional search methods for better query responses.
- Best Practices for Document Matching in JSON: The conversation highlighted several best practices for matching documents in large JSON datasets based on user queries.
- One participant emphasized the importance of indexing and leveraging metadata to streamline the retrieval process.
- Challenges in JSON Document Retrieval: Participants raised concerns about potential challenges in retrieving documents effectively from extensive JSON stores.
- Scaling retrieval mechanisms and maintaining performance during high query loads were notable points of discussion.
Torchtune ▷ #general (1 messages):
Byte Latent Transformers, Qwen Fine-Tuning, TorchTune Hacks
- Hacking Byte Latent for Qwen Fine-Tune: A member shared their attempt at reimplementing Byte Latent Transformers as a fine-tune method on Qwen, inspired by existing code, and detailed their experience in using this GitHub repo.
- While the experiment's loss is decreasing, the results still produce nonsense outputs, indicating more work is needed to align the implementation with TorchTune's framework.
- Challenges of Adapting Models in TorchTune: The member noted that transitioning models into TorchTune posed unique challenges, especially with different checkpoint formats involved.
- They shared insights hoping to assist others who might be exploring similar modeling methods in their own hacks.
Link mentioned: GitHub - ianbarber/ttblt: A simplified implementation of Byte Latent Transformers as a TorchTune recipe.: A simplified implementation of Byte Latent Transformers as a TorchTune recipe. - ianbarber/ttblt
Torchtune ▷ #dev (18 messages🔥):
Unit Test Handling, Optional Dependencies for Development, Checkpoint Resuming Logic, Step-Based Checkpointing, Cross-Contributing on PRs
- Streamlining Unit Tests with Fewer Installs: Concerns were raised about the inconvenience of switching between four different installs just to run unit tests.
- A suggestion was made to keep certain dependencies optional for contributors while maintaining a smooth local experience.
- Refining Checkpoint Resuming Logic: The current method of resuming checkpoints involves saving them into
${output_dir}, but now with step-based checkpointing, the logic might need revision.- One proposed solution was to maintain the existing resume_from_checkpoint while allowing users an option to resume from the latest or specific checkpoints.
- Addressing Multiple Experiment Overlap: A dialogue emerged about the challenges of reusing
${output_dir}for multiple experiments and ensuring distinct output for each run.- It was highlighted that maintaining unique output directories for experiments A and B could prevent the confusion of epochs from different runs.
- Collaboration on Step-Based Checkpointing PR: Members expressed a desire to contribute collectively to the step-based checkpointing PR, with a call for input on the API design.
- One member offered to implement features to support resuming from previous checkpoints and expressed interest in streamlining the development process.
- Facilitating Cross-Contributor Approvals: A suggestion was made to enable cross-approval and merging of PRs among contributors in personal forks to speed up the development workflow.
- This could enhance collaboration on existing issues like the step-based checkpointing PR and allow for more efficient input from various team members.
- Checkpointing in torchtune — torchtune main documentation: no description found
- [RFC] Step-based checkpointing in torchtune by joecummings · Pull Request #2105 · pytorch/torchtune: Enabling step-based checkpointing in torchtuneOriginal context: #2070What are we currently doing?We currently only checkpoint at epoch boundaries. That means a fine-tuning run has to iterate thr...
- feat: get_latest_checkpoint for checkpointer utils by bogdansalyp · Pull Request #2 · joecummings/torchtune: Added get_latest_checkpoint """ Returns the latest checkpoint in the given directory. The pattern argument is a regular expression that matches the epoch number in ...
Torchtune ▷ #papers (4 messages):
Reinforcement Learning (RL) for pre-training
- Debate on RL's Role in Pre-Training: Members engaged in a discussion about the effectiveness of Reinforcement Learning (RL) for the pre-training phase, with some expressing skepticism.
- As a big RL enthusiast, one member found the idea of using RL for pre-training terrifying, highlighting a divergence in opinion on its application.
- Consensus Against RL for Pre-Training: Another member, echoing earlier sentiments, stated that RL is not suitable for the pre-training stage, reinforcing the shared concerns.
- The overall consensus appears to lean toward avoiding RL in the pre-training process among the participants.
MCP (Glama) ▷ #general (7 messages):
Glama MCP Server Changes, OpenRouter Documentation, Anthropic Homepage Status, Haiku 3.5 Release, Sonnet 4.0 Release
- How to Update Glama with MCP Server Changes: A user inquired about methods for getting Glama to recognize changes made to their MCPC server.
- This prompted community responses, emphasizing the need for clarity on configuration inputs.
- Community Calls for OpenRouter Documentation: A member urged for the OpenRouter documentation to be transformed into an MCP format, linking to the source at openrouter.ai.
- The suggestion highlights a need for accessible resources in diverse formats.
- Anthropic Homepage Accessibility Issues: Members noted that the Anthropic homepage appears to be down, sharing an image as evidence.
- This raised concerns about accessibility during important updates or releases.
- Anticipation for Haiku 3.5 with Advanced Features: There’s excitement brewing as members speculate the potential release of Haiku 3.5 today, featuring tool and vision support.
- This has sparked discussion around the impacts such features could have on efficiency.
- Buzz Around Sonnet 4.0 Release: Conversational remarks suggested that the highly anticipated Sonnet 4.0 might also be on the horizon.
- Members are curious and hopeful for announcements regarding new functionalities soon.
MCP (Glama) ▷ #showcase (11 messages🔥):
MCP server for debugging, Continue tool features, Clear Thought MCP Server
- MCP Server Enables Direct Debugging: A member built an MCP server and a VS Code extension that allows an LLM, such as Claude, to interactively debug code across various programming languages.
- Check out the project on GitHub for more details about its capabilities.
- Discussion on Error Reading Features: A user inquired whether the MCP server could automatically read terminal errors and fix them, with another member mentioning that Continue has such capabilities.
- Although the MCP server does not currently have this feature, jason.today noted potential for it to be added in the future.
- Differentiating Debugging from Guesswork: One contributor explained that debugging tools enable inspection of variable states during execution rather than relying on logs alone to identify errors.
- This highlights a gap in current AI coding tools, which often lack integrated debugging functionalities.
- Introduction of Clear Thought MCP Server: A new Clear Thought MCP Server was introduced, designed to enhance problem-solving using mental models and systematic thinking methodologies.
- This server aims to improve decision-making in development environments through structured approaches and is available via NPM.
- Comparison with Other Tools: Another member mentioned that Goose, a different tool, can also read errors in the terminal and automatically resolve them during debugging.
- This suggests a growing conversation about the capabilities and features of various AI-assisted coding tools.
- Clear Thought MCP Server | Smithery: no description found
- GitHub - jasonjmcghee/claude-debugs-for-you: Enable any LLM (e.g. Claude) to interactively debug any language for you via MCP and a VS Code Extension: Enable any LLM (e.g. Claude) to interactively debug any language for you via MCP and a VS Code Extension - jasonjmcghee/claude-debugs-for-you
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Certificates issued, Fall24 student participation
- Total Certificates Issued Revealed: 304 trailblazers 🚀, 160 masters 🧑🏫, 90 ninjas 🥷, 11 legends 🏆, and 7 honorees 🌟 have been awarded certificates, showcasing diverse achievements.
- Of the 7 honorees, 3 were ninjas and 4 were masters, demonstrating a competitive awarding process.
- Fall24 Student Participation Statistics: There were 15k students in total for the Fall24 MOOC, with most of them auditing the course.
- This substantial participation indicates a strong interest in the course offered during that term.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (7 messages):
Inference-Time Techniques, LangChain Framework, LLM Agents with ML Models
- Clarification on 'program' in LLM context: In the lecture on Inference-Time Techniques, members clarified that the 'program' in question refers to actual programming code rather than an LLM, framed as a competitive programming task.
- Participants referenced slide 46 to support this understanding.
- Sampling methods in executing programs: It was explained that sampling at the 'execute sampled program' step involves generating a large set of potential solutions using a fine-tuned LLM, not merely selecting 10 to 20 LLMs as initially thought.
- This process relies on candidate solutions generated for a specific problem as illustrated on slide 45.
- Clustering and scoring programs: The discussion highlighted that sampling programs from the largest clusters aims to select solutions that have shown consistency in output rather than directly scoring cluster performance.
- This involves using another LLM to generate new input cases and clustering based on output agreement, implying that larger clusters reflect higher confidence in those solutions.
- LangChain's Application Lifecycle: A member provided an overview of LangChain, which facilitates the development, productionization, and deployment of applications using LLMs through its component-based framework.
- Key features include integration with APIs and a focus on stateful agent development using various LangChain tools.
- Combining LLM agents with ML forecasting models: A participant expressed interest in knowledge-sharing regarding the integration of LLM agents with machine learning forecasting models for enhanced workflows.
- Feedback and experiences on such combinations were sought from the community.
Link mentioned: Introduction | 🦜️🔗 LangChain: LangChain is a framework for developing applications powered by large language models (LLMs).
Cohere ▷ #discussions (1 messages):
Profit Sharing Opportunity, Telegram Marketing
- Rose Miller Offers Fast Profit Opportunity: Rose Miller is proposing to help 10 people earn $30k within 72 hours, requesting a 10% profit share upon receipt of earnings.
- Interested participants should message her on Telegram or WhatsApp to get started, using the prompt (HOW).
- Join Rose on Telegram for More Info: Rose encourages those with Telegram to contact her directly at @officialRose_miller for a quick response.
- A link to her Telegram profile and a portfolio manager description are provided for credibility.
Link mentioned: Rose Miller: Portfolio manager, Conservative
Cohere ▷ #api-discussions (1 messages):
Profit-sharing opportunities, Rose Miller's announcement
- Rose Miller offers profit-sharing to earn $30k: Rose Miller announced a scheme to help 10 people earn $30k within 72 hours, requesting 10% of the profit once received.
- Interested individuals should message her on Telegram or WhatsApp at this link for further details.
- Contact information shared: Rose Miller provided her contact information via Telegram and WhatsApp for interested parties to reach out.
- Her Telegram handle is @officialRose_miller, and she is based in the United States.
Link mentioned: Rose Miller: Portfolio manager, Conservative
Cohere ▷ #projects (4 messages):
Structured Data Injection, Context API Launch, High-Quality Data Access, Feedback Request, Blog Post Discussion
- Structured Data Injection Enhances AI Models: A new endpoint has been launched that injects high-quality, structured data from Arxiv and Wikipedia directly into AI context windows, aimed at reducing latency and improving data retrieval.
- An academic publisher dataset is set to launch next week, helping to provide trusted sources in AI applications.
- Push the Context API to Its Limits: The team invites developers to test the new API and provide feedback on its performance, offering $10 in free credits to get started.
- They emphasized a desire for users to actively break and test edge cases to improve the API.
- Discussion on New Context API Blog Post: A blog post has been released discussing the challenges AI developers face with data retrieval and the solutions provided by the new context API.
- The post highlights the need for high-fidelity retrieval for AI agents and LLM applications in complex decision-making use cases.
- The Reality of AI Data Accessibility: The blog notes that current AI agents often lack performant access to quality data, limiting their capabilities in deeper research.
- They pointed out that as AI tackles more complex challenges, embedding structured data becomes even more crucial.
- ∇ Valyu - High Quality Data for AI Models & Applications: no description found
- Why We Built Context API: Because Your AI Needs Facts, Not Vibes • Valyu Blog: AI models can generate, but they struggle with retrieval—relying on limited web search instead of high-quality, trusted data. That’s why Valyu built ContextAPI, seamlessly integrating authoritative so...
- Rose Miller: Portfolio manager, Conservative
Cohere ▷ #cohere-toolkit (1 messages):
Profit Sharing Opportunity, Fast Money Making Scheme
- Earn $30k in 72 Hours: A member announced an opportunity to help 10 people earn $30k within 72 hours for a 10% profit share upon receipt.
- Interested individuals are encouraged to drop a message to learn how to get started via Telegram or WhatsApp.
- Contact Rose Miller Directly: Users can reach out to Rose Miller directly through her Telegram account for more details on the profit-sharing opportunity.
- A link to her Telegram account was provided for quick access: Contact Rose.
Link mentioned: Rose Miller: Portfolio manager, Conservative
DSPy ▷ #papers (2 messages):
Self-Supervised Prompt Optimization, Importance of Prompt Design, LLM Output Quality, DSPy Mention, Cost-effective Frameworks
- Introducing Self-Supervised Prompt Optimization: The paper proposes Self-Supervised Prompt Optimization (SPO), a framework designed to enhance LLMs' reasoning capabilities without relying on external references.
- This approach generates evaluation signals purely from output comparisons, streamlining the process of prompt design for various tasks.
- Crucial Role of Prompt Design: Well-crafted prompts are essential for aligning LLM outputs with task requirements across different domains, yet their manual creation can be labor-intensive.
- The reliance of existing methods on external references poses challenges in real-world applications due to the unavailability or costliness of such data.
- Critique on DSPy Mention: A member expressed surprise that DSPy was only referenced in the last paragraph of the paper.
- This comment indicates a desire for more prominence given the relevance of DSPy to the discussion at hand.
Link mentioned: Self-Supervised Prompt Optimization: Well-designed prompts are crucial for enhancing Large language models' (LLMs) reasoning capabilities while aligning their outputs with task requirements across diverse domains. However, manually d...
DSPy ▷ #general (1 messages):
RouteLLM, GPT-5 discussions
- Concerns Over RouteLLM Integration: A member expressed skepticism that the upcoming GPT-5 will simply incorporate RouteLLM alongside models like 4o, o1, o3, Voice, and Sora without any meaningful updates.
- They bet that this integration will overlook proper citations, suggesting a lack of novelty in the approach.
- Previous Proposal for DSPy: The user recalled their earlier proposal regarding DSPy, referencing a tweet that hints at similar integration ideas.
- They remarked, 'lol,' indicating a sense of humor about the situation and the lack of original content from competitors.
Link mentioned: Tweet from Dᴀᴛᴀ Sᴀᴄᴋs (@DataDeLaurier): @Teknium1 Because they do not have anything new. They are about to slap 4o, o1, o3, Voice, and Sora into RouteLLM and call it GPT-5.I bet they actually use RouteLLM and don't cite anyone
tinygrad (George Hotz) ▷ #general (2 messages):
Test for Pull Request #9155, DEBUG=2 feature
- Request for Test on PR #9155: A member inquired if anyone wanted to write a test for Pull Request #9155 related to adding colors back in DEBUG=2.
- They included an image preview linking directly to the PR, emphasizing the discussion on improving debugging features.
- Member Willing to Write Test: Another member expressed willingness to take on the task, saying, sure lemme write a test.
- This response indicates a collaborative effort within the community to support enhancements in the tinygrad project.
Link mentioned: colors back in DEBUG=2 [pr] by geohot · Pull Request #9155 · tinygrad/tinygrad: no description found
MLOps @Chipro ▷ #events (1 messages):
GenAI Video Generation, Seaweed-APT, AI Storytelling, Nvidia's General Embodied Agent, Building Scalable Training Pipelines
- Diffusion Fades in GenAI Video Future: In the session titled "Why Diffusion Isn’t the Future of Video Gen", Bichen Wu shared insights on the shifting paradigm in video generation, emphasizing recruitment for researchers and MLEs.
- Wu, co-founder of a stealth AI startup led by ex-CEO Eric Schmidt, harnessed his experience at Meta GenAI to delve into emerging technologies.
- Seaweed-APT Outpaces Sora by 50x: Led by Peter Lin, the presentation on Seaweed-APT touted its capability as being 50 times faster than Sora, revolutionizing video generation techniques.
- Lin, the creator of this groundbreaking model and first author of AnimateDiff-Lightning, detailed its impressive speed and efficiency.
- $8M ARR Breakthrough from OpenArt: OpenArt revealed its astonishing strategy to achieve $8 million ARR in just 10 months, showcasing innovation in AI storytelling.
- The session shared essential growth hacks that have transformed the commercialization landscape for AI applications.
- Nvidia Deciphers World Models for Embodied AI: A Nvidia researcher explained advancements in developing a General Embodied Agent, focusing on universal world models and simulation paradigms.
- This exploration aims to enhance real-world robotics applications through sophisticated AI frameworks.
- Creating Golden Datasets for Model Training: Pareto AI presented techniques on building golden datasets to scale image and video training pipelines for next-generation models.
- Their strategies are positioned as critical for advancing the capabilities of future AI systems in diverse environments.
Link mentioned: GenAI Video, World Models & Robotics #Kling #Veo #Sora #Cosmos #Diffusion · Luma: Join us to gain unfiltered insights into cutting-edge techniques that power real-time one-step tex-to-video generation, general world models, and…