[AINews] We Solved Hallucinations
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
With one weird trick!
AI News for 7/11/2024-7/12/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (463 channels, and 2566 messages) for you. Estimated reading time saved (at 200wpm): 276 minutes. You can now tag @smol_ai for AINews discussions!
Look, we've known for a while that our Reddit summaries are ridden with... erm... links that don't go where they claim to go. You keep reminding us! (Thanks!)
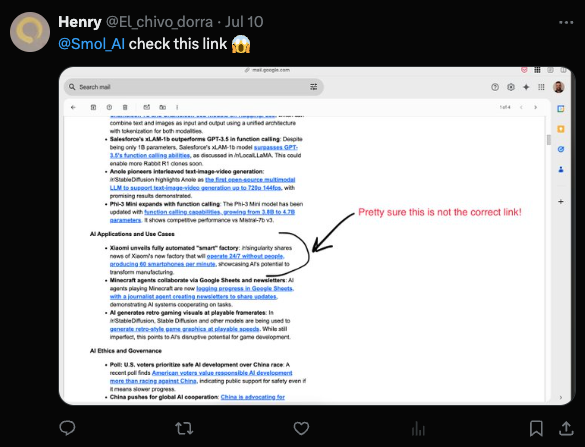
The reason that this happens specifically to our Reddit summaries much much more than our Discord or Twitter recaps is because of Reddit's URL structure.
Here is a typical Reddit URL:
The slug at the end (disappointing_if_true_meta_plans_to_not_open_the) is just an attempt to make a human readable slug out of the title, AND the subreddit at the start (r/LocalLLaMA) is also just for human readability. In practice, all of it is ignored in favor of the real slug, that 7 character alphanumeric set (1cxnrov). Here, we'll prove it:
https://www.reddit.com/r/SmolAI/comments/1cxnrov/ainews_is_the_best/
Despite having changed the subreddit and the human slug, Reddit sends you to the same post as before based on the real slug.
So Reddit URLs, much more than most URLs, are hyper, hyper sensitive to small mistakes in attention, even if all we are asking the LLM to do is copy from a source docment with the reference link neatly spelled out.
And... both Claude and GPT4 are trained on an awful lot of NSFW Reddit URLs (in multiple languages!). Put these two facts together and you can see what we've been dealing with.
So.. we went ahead and fixed the glitch, while still using LLMs to format, select, and summarize across a full corpus of Reddit submissions and comments. Tweet @Smol_AI if you have guesses on how we do it.
It's been another content light day, so please enjoy our conversation with Clementine Fourrier on LLM Evals (our coverage in May and the future of the Open LLM Leaderboard:
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Compute and Hardware Improvements
- GPT-2 training cost down dramatically: @karpathy noted that training GPT-2 now costs ~$672 on one 8XH100 GPU node for 24 hours, down from ~$100,000 in 2019, due to improvements in compute hardware (H100 GPUs), software (CUDA, cuBLAS, cuDNN, FlashAttention) and data quality (e.g. the FineWeb-Edu dataset).
- FlashAttention-3 released: @tri_dao announced FlashAttention-3, which is 1.5-2x faster on FP16, up to 740 TFLOPS on H100 (75% util), and FP8 gets close to 1.2 PFLOPS. It is a collaborative effort with Meta, NVIDIA, Princeton, and Colfax.
- Hopper GPUs enable major speedups: @tri_dao noted that Hopper GPUs (H100) have new hardware features like WGMMA, TMA, and FP8 support that enable major speedups. Just rewriting FlashAttention for these gets to 570 TFLOPS.
LLM Evaluation and Benchmarking
- Synthetic data may not help for vision tasks: @giffmana highlighted a paper showing that synthetic images don't actually help for vision tasks when the correct baseline is run.
- Avocado360 benchmark for evaluating VLMs: @vikhyatk introduced the Avocado360 benchmark for evaluating if vision language models (VLMs) can determine if an image contains an avocado. Four arbitrarily selected VLMs were evaluated.
- Lynx model for LLM hallucination detection: @DbrxMosaicAI announced Lynx, a new hallucination detection model for LLMs especially suited for real-world applications in industries like healthcare and fintech. It was trained by Patronus AI on Databricks Mosaic AI using Composer.
LLM Applications and Frameworks
- Runway AI automation: @labenz shared how Runway, a video generation startup, is using AI to automate tasks like pre-writing sales emails. They aim to never have >100 employees by scaling with AI capabilities.
- LangGraph for human-in-the-loop feedback: @LangChainAI showed how to add checkpoints for human input and update the graph state in LangGraph, to enable human feedback for agentic systems.
- Qdrant and LlamaIndex for advanced RAG: @qdrant_engine shared an article on building an advanced RAG architecture combining LlamaIndex agents with Qdrant's hybrid search capabilities, using both dense and sparse vector embeddings.
Memes and Humor
- Thinkpad love: @giffmana joked "What is the best laptop, and why is it a ThinkPad?"
- Token limit woes: @HamelHusain hit token limits quickly on Anthropic UI even on the Pro Plan, wondering if it's normal.
- ML/DS interview requirements: @jxmnop joked that by next year, ML/DS interviews will require a medium-level question from ML leetcode, hardcore prompt engineering, and five years of CUDA experience.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Theme 1. WizardLM 3 and LLM Optimization Techniques
- [/r/LocalLLaMA] WizardLM 3 is coming soon 👀🔥 (Score: 418, Comments: 73): WizardLM 3, an upcoming language model, is set to be released soon. The announcement hints at significant improvements or new features, though specific details about the model's capabilities or release date are not provided in the post.
- [/r/LocalLLaMA] FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision (Score: 146, Comments: 22): FlashAttention-3 introduces a new approach to attention computation in Large Language Models (LLMs), offering 2-4x speedup over previous methods while maintaining accuracy. The technique employs asynchronous IO and low-precision computation, allowing for efficient processing of longer sequences and potentially enabling the training of larger models with longer context lengths. This advancement, detailed in a paper by researchers from Stanford University and NVIDIA, could significantly impact the development and deployment of more powerful LLMs.
Theme 2. Advanced AI-Generated Visual Content
- [/r/StableDiffusion] fal drops AuraFlow (Score: 322, Comments: 95): fal has introduced AuraFlow, a new image generation model that combines the strengths of Stable Diffusion and Midjourney. AuraFlow aims to provide high-quality image generation with improved coherence and composition, addressing common issues like distorted faces and hands. The model is currently available through fal's API and will be integrated into their no-code AI app builder.
- [/r/StableDiffusion] AnimateDiff and LivePortrait (First real test) (Score: 580, Comments: 66): AnimateDiff and LivePortrait integration showcases the potential for creating animated portraits from still images. The process involves using AnimateDiff to generate a 16-frame animation from a single image, which is then fed into LivePortrait to produce a more realistic animated result. This combination of tools demonstrates a promising approach for bringing static images to life with fluid, natural-looking movements.
- [/r/singularity] Al-Generated Movie Trailer (Score: 157, Comments: 41): AI-generated movie trailer demonstrates advanced visual capabilities in film production. The trailer, created using artificial intelligence, showcases realistic CGI characters, dynamic scene transitions, and complex visual effects typically associated with high-budget productions, highlighting the potential of AI to revolutionize the film industry by reducing costs and expanding creative possibilities.
Theme 3. AI Progress Tracking and Benchmarking
- [/r/OpenAI] OpenAI Develops System to Track Progress Toward Human-Level AI (Score: 232, Comments: 75): OpenAI has introduced a new system called AI Preparedness Framework to monitor and assess progress towards human-level artificial intelligence. The framework aims to evaluate AI systems across 12 key capabilities, including language understanding, reasoning, and task completion, using a 5-level scale ranging from narrow AI to artificial general intelligence (AGI). This initiative is part of OpenAI's efforts to responsibly develop advanced AI systems and provide policymakers with actionable insights on AI progress.
- [/r/singularity] Rorschach test for AI: is this good or bad? (Score: 110, Comments: 152): Rorschach tests for AI are proposed as a method to evaluate AI capabilities, particularly in image interpretation and reasoning. The concept suggests using ambiguous images, similar to traditional Rorschach inkblot tests, to assess an AI's ability to perceive, interpret, and explain visual information. This approach could potentially reveal insights into an AI's cognitive processes and limitations, but also raises questions about the validity and reliability of such assessments for artificial intelligence systems.
Theme 4. AI Content Regulation and Copyright Issues
- [/r/StableDiffusion] The AI-focused COPIED Act would make removing digital watermarks illegal (Score: 136, Comments: 155): "Senators Introduce COPIED Act to Combat AI Content Misuse" The COPIED Act, introduced by a group of senators, aims to combat unauthorized use of content by AI models by creating standards for content authentication and detection of AI-generated material. The bill would make removing digital watermarks illegal, allow content owners to sue companies using their work without permission, and require NIST to develop standards for content origin proof and synthetic content detection, while prohibiting the use of protected content to train AI models. Backed by industry groups like SAG-AFTRA and RIAA, the act is part of a broader push to regulate AI technology and empowers state AGs and the FTC to enforce its provisions.
- [/r/LocalLLaMA] The danger of AI is not what most people think it is. (Score: 100, Comments: 115): AI's real danger stems from overestimation, not superintelligence The post argues that the true danger of AI lies not in its potential to become superintelligent, but in its current limitations being overlooked. The author suggests that AI is being deployed in areas where its lack of intelligence can cause problems, citing examples of AI-generated fake legal cases and biased pedestrian detection in self-driving cars. They also posit that much of the discourse around AI safety is driven by "moat-building" and protecting first-mover advantages rather than genuine concern.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Advancements and Training Techniques
- FlashAttention Accelerates Transformer Training: The FlashAttention-3 release promises up to 1.5-2x speed boost on FP16 and up to 740 TFLOPS on H100 GPUs, achieving 75% utilization and potentially reaching 1.2 PFLOPS with FP8.
- This technology, co-developed by Colfax, Tri Dao, Meta AIT team, and the Cutlass team, has already accelerated training for models like GPT-4 and Llama 3 by minimizing memory reads/writes in attention mechanisms.
- Q-Galore Enhances Memory-Efficient LLM Training: The novel Q-Galore method combines quantization and low-rank projection to substantially reduce memory usage and training time for large language models compared to GaLore.
- Unlike GaLore which relies on time-consuming SVD operations, Q-Galore observes that some gradient subspaces converge early while others change frequently, enabling more efficient training without sacrificing accuracy.
- Llama 3 405B Multimodal Model Imminent: Meta Platforms is set to release its largest Llama 3 model with 405B parameters on July 23, a year after Llama 2, as a multimodal offering according to reports.
- The release has sparked excitement in the community, with discussions around the infrastructure requirements like 8x H100s or 8x MI300X GPUs to run such a massive model.
2. Open Source AI Advancements
- AuraFlow: Largest Open Text-to-Image Model: AuraFlow by Fal AI has been released as the largest open text-to-image model under an Apache 2.0 license, supported in
diffusersand achieving state-of-the-art results on GenEval.- With LoRA support coming soon and the model in beta, community feedback is crucial, as credited to @cloneofsimo and @isidentical for significant contributions.
- Cohere Toolkit Goes Open Source: Cohere has open-sourced their chat interface on GitHub, with OCI integration planned, as announced by Sssandra.
- Mapler expressed excitement about using the open-sourced toolkit for personal projects and updating the community on progress.
- OpenArena Fosters LLM Dataset Enhancement: The OpenArena project on GitHub pits language models against each other, with a third model as judge, to increase dataset quality through competitive challenges.
- Inspired by the WizardLM paper on Arena Learning, OpenArena leverages AI-annotated results for supervised fine-tuning and reinforcement learning of LLMs.
3. Community Collaboration and Knowledge Sharing
- LlamaIndex Unveils Agentic RAG Cookbooks: LlamaIndex, in collaboration with @jeffxtang from AIatMeta, released cookbooks on agentic RAG, covering topics from routing and tool use to multi-document agent building.
- Additionally, a Cypher snippet by @tb_tomaz and Neo4j effectively performs entity deduplication, aiding knowledge graph creation as shared on the Neo4j GitHub.
- Unsloth Notebooks for Continued Pretraining: Unsloth provides notebooks for training local models with Ollama and Hugging Face models, as well as handling continued pretraining across different sequence lengths.
- The community discussed techniques like concatenation and truncation for varying
max_seq_length, and understanding parameter differences during LoRA and PEFT setups.
- The community discussed techniques like concatenation and truncation for varying
- LangChain Optimizations and Best Practices: The LangChain community shared optimization techniques for embedding functions, like using caching mechanisms (in-memory or Redis) to avoid recomputing embeddings and considering async requests.
- Discussions also covered FAISS vs Chroma for handling large datasets, combining their strengths with Chroma for persistence and FAISS for similarity search, and improving LangChain agent efficiency.
4. Hardware Benchmarking and Adoption
- Evaluating GPUs for AI Workloads: Discussions compared the value proposition of 3090 vs 4090 GPUs for AI workloads, with many favoring the 3090 for its better price-to-performance ratio given the relatively small generational performance leap.
- Rumors about the upcoming NVIDIA 5090 having only 28GB VRAM instead of 32GB led to suggestions for building affordable multi-GPU servers using 3090s for increased VRAM capacity.
- H100 GPU Excitement and Adoption Challenges: The arrival of H100 GPUs generated significant excitement, with members exclaiming 'H100 go brrrrr' and discussing the substantial performance improvements over previous generations.
- However, concerns were raised about Flash attn3 currently being limited to H100 support, with hopes that it would follow Flash attn2's path of expanding to 3090 and 4090 GPUs.
- Benchmarking Local AI Models: A member shared their personal benchmark table evaluating various local AI models across 83 tasks using a weighted rating system covering reasoning, STEM, coding, and censorship categories.
- While not representing broader benchmarks, the table provides insights into one individual's experiences and highlights the growing interest in comprehensive model evaluation by the community.
PART 1: High level Discord summaries
HuggingFace Discord
- RT-DETR Races Ahead of YOLO: RT-DETR, surpassing YOLO in speed and accuracy, joined forces with Roboflow for advancement in object detection and is now seamlessly accessible via the transformers library.
- The model's edge was corroborated in a research paper (https://arxiv.org/abs/2304.08069?ref=blog.roboflow.com), supporting RT-DETR's integration into existing workflows and advancement in detection tasks.
- Elevation of Efficiency with Hiera Model: Introducing Hiera, the transformers library now includes a transformative vision model simplifying hierarchical complexities and excelling in performance tasks like image classification.
- Hiera's flexibility shines through its various implementations, including HieraForImageClassification and HieraBackbone, detailed in the GitHub Pull Request.
- Toolkit Trims the Fat From LLM Finetuning: The Georgian-io toolkit debuts, catering to streamlined finetuning across multiple LLMs, simplifying end-to-end data science processes.
- A versatile toolkit, it facilitates running batch experiments, evaluating metrics, and performing hyperparameter and prompt ablations via a unified config.
- Visualization of the AuraFlow Landscape: AuraFlow, celebrated as the largest open text-to-image model, recently swooped into the spotlight for its promising GenEval results, supported by
diffusers.- With LoRA support on the horizon, ongoing development and community feedback are encouraged via fal's Discord, lining the path for further enhancements.
- qdurllm Demo Signals New Capabilities: A leap in intuitive output is showcased in the qdurllm demo, extending an invitation for community feedback on its advanced interactive model.
- The offering opens dialogue for potential burgeoning use-cases and integrative, accessible advancements.
Stability.ai (Stable Diffusion) Discord
- ComfyUI Reactor Receives Installation Reactivation: Following a YouTube video provides a solution for error-free installation of ComfyUI InsightFace.
- This workaround, confirmed by users, remains effective for the version released in 2024.
- Deforum Dives into Distinct Color Dynamics: For fine-tuning abstract video aesthetics, setting
color_coherenceto None in Deforum Stable Diffusion API was discussed as a potential way to enhance color transitions.- Community inputs were solicited to optimize the vividness and clarity in visual projects.
- Generation Interruption Queries on auto1111: Users experienced notable delays in stopping generation processes in the auto1111 setup, attributing it to VRAM limitations and software nuances.
- Comparisons were drawn to gradually decelerating a high-speed train, emphasizing the need for patience during abrupt halts.
- Analyzing the Asset of AI Tool Affordability: The community discussed the costs of commercial AI tools like Runway, which offers a plan at $90/mo, contrasting with free local AI options.
- Despite the allure of no-cost tools, members recognized that premium services often deliver superior functionality and enhanced features.
- Scaling Up on Upscaling: Pursuit of Free Tools: The search for complimentary creative image upscaling tools resulted in recommendations for accessible software like Krita and GIMP.
- These alternatives were praised for their useful features without the financial barrier, aligning with the community's resource-conscious preferences.
CUDA MODE Discord
- FA3 Triumphs and CUDA Concerns: A spirited debate evaluated the merits of FA3 vs cuDNN and ThunderKittens, revealing a preference for simplicity and ease despite the allure of FA3's potential speed-up in attention mechanisms.
- Technical concerns around FP8 implementation hurdles and the non-existent FP8 track in ThunderKittens sparked an assessment of maintenance complexity.
- Evaluating GPU Access Options: Members lauded Google Colab for its frictionless GPU access, while comparing the pros and cons of Coreweave and Lambda Labs for GPU rentals, highlighting price and allocation issues.
- The discussion highlighted Google Cloud GPU as a more costly but powerful option for uses beyond notebooks, elevating Colab for ease of use in tinkering with CUDA kernels.
- Streamlining Matrix Multiplications: Conversations addressed effective thread assignment strategies in matrix-matrix multiplication, suggesting a thread per row is more efficient in terms of caching and data loading due to memory layout.
- The notion of 'coalescing' became focal, as insights pertaining to memory arrangements surfaced, emphasizing efficiency in reducing over the last matrix dimension.
- Innovative Tactics in AI Training: Members discussed the viability of tensor subclass usage with FSDP, as emerging projects like bitnet work hint at burgeoning applications in distributed training.
- The community acknowledged the sustained contribution and was poised to collaborate on a developer guide for enabling tensor subclasses, anticipating future demand.
- Collaboration and Growth within LLM.C: The LLM.C community is buzzing with initiatives around model sharing and resource consolidation, as evident in the creation of organizational structures on Hugging Face.
- Insights were shared on performing optimizations and fine-tuning large-scale models, also sparking ideas around FP8's 33% speed boost, despite memory reuse considerations.
Modular (Mojo 🔥) Discord
- LLVM Creator's Chronicles: The latest Primeagen video interviewing the creator of LLVM, Clang, Swift, and Mojo sparked discussions after becoming accessible on YouTube.
- Participants noted that detailed insights can be a great resource for understanding the development philosophy behind Mojo's creation.
- Mojo's REPL Iteration: Debate swirled around the Mojo REPL's lack of immediate output for expressions, drawing comparisons to Python's REPL behavior.
- Although current functionality does not display results like
1+1directly, members were advised to submit requests through GitHub issues to incorporate these features.
- Although current functionality does not display results like
- Max Website Makeover Embraces Clarity: Modular's MAX framework takes center stage with a revamped website, emphasizing its extensive developer base and clear licensing terms.
- The site showcases the synergy between Max's performance capabilities and ease of use provided by the Mojo language, without delving into low-level coding.
- GPU Gains with Mojo's MAX: A promising dialogue emerged on writing custom GPU kernels using Mojo within MAX for enhanced performance.
- This opens avenues for harnessing MAX's robust interfaces and Mojo's agile kernel compilation without direct CUDA involvement.
- Datatype Discrepancies in MAX Model Execution: A datatypes issue arose when executing a MAX Model, leading to a mismatch in expectations versus actual results when using
PythonObjects.- Correcting the
np.full()operation'sdtypetonp.float32provided the solution, underscoring the precision needed in model execution parameters.
- Correcting the
Unsloth AI (Daniel Han) Discord
- Gemini Soars with Token Expansion: Gemini 1.5 Pro boasts a 2 million token window and introduces context caching, and code execution features.
- AI developers are delighted with unlimited JSON capacity.
- FlashAttention Sprints on Hopper GPUs: FlashAttention-3 promises efficient Hopper GPU utilization with up to 35% FLOPs, outlined in a Tech Blog.
- "Substantial FLOPs leverage" is confined to Hopper users.
- TF-ID Models Eye Vision-Language Tasks: TF-ID models are unleashed by Yifei Hu, featuring training code, dataset, and weights under the MIT License for vision-language tasks.
- These models require only a few hundred domain-specific elements to finetune.
- CodeGeeX4 Clips GPT's Wings: The new CodeGeeX4-ALL-9B model overshadows GPT-3.5 and GPT-4 in code generation capabilities.
- Achieving top performance, it boasts 128k context and supports a plethora of programming languages.
- Meta's Anticipated LLaMA 3 Debut: Excitement builds for Meta Platform's July 23 release of its LLaMA 3 model, with potential for considerable AI progression.
- The release detailed here could reshape hardware preferences for AI application deployment.
Nous Research AI Discord
- OpenAI Teases Doctoral Disruption: OpenAI hints at forthcoming models with problem-solving adeptness equating to a doctoral degree, inciting discussions on approaching AGI.
- An anonymous source leaked a GPT-4 demo showcasing its advanced human-like problem-solving capabilities.
- Anthropic's AI Prognosis: Dario Amodei from Anthropic predicts forthcoming AI Safety Levels, suggesting A.S.L. 3 might emerge as early as this year, and A.S.L. 4 by 2025-2028.
- A.S.L. 4 raising alarms about potential exacerbation of global risks through biological and cyber technology misuse.
- Community Doubts OpenAI's Strategy: Amidst news of potential breakthroughs, voices in the community express skepticism regarding OpenAI's strategic release patterns.
- Conversations circle the possibility that OpenAI's teasers could be a ploy aimed at boosting their valuation despite previous achievements.
- C's the Day with GPT-2: Karpathy demonstrates efficient replication of GPT-2 (1.6B) using llm.c, encapsulating both power and cost-efficiency.
- The implementation proves llm.c's capacity for large-scale language model training, blazing through with a 24-hour turnaround.
- Safety in Simplicity with C++: Safetensors.cpp debuts as a zero-dependency C++ library for LibTorch, easing the data manipulation burdens in model development.
- The objective is clear: to streamline model data processes, ensuring smoother and more productive workflows.
Perplexity AI Discord
- Perplexity Labs: To Use or Not to Use?: Debates surged around the utility of Perplexity Labs, with community members dissecting its versatility on various devices.
- Pros and cons were thrown around, spotlighting the Labs' integration perks and questioning its advantage over mobile use versus the web interface.
- Claude 3.5 Tramples Claude 3 Opus: Claude 3.5's superior performance in reasoning and logic over its predecessor Claude 3 Opus caught everyone's eye, hinting at a shift in model dominance.
- While praise was unanimous for Claude 3.5, speculation arose over the potential of future versions like Opus 3.5 to recalibrate the scales.
- AI as a Beacon for Diabetes Management: AI for diabetes management was spotlighted, with discussions around apps that assist patients and doctors in insights derivation rather than just insulin adjustments.
- Recent advancements were noted, offering not only automated insulin dosing but also predictive insights, reshaping patient care.
- Error 524 Clouds Perplexity API: AI engineers reported sporadic Error 524 when integrating Perplexity with asynchronous frameworks, despite staying within prescribed limits.
- Switching models adds to the conundrum, with transitions between
llama-3-{8b/70b}-instructtollama-3-sonar-{large/small}-32k-onlineresulting in similar errors, baffling users.
- Switching models adds to the conundrum, with transitions between
- Cloudflare Stirs Perplexity API Turbulence: Troubleshooting tales disclosed Cloudflare as the culprit behind VPN-blocked access to Perplexity API, a revelation for many.
- While some struggled, others found bypassing VPN as an effective workaround, reinstating their access and quelling the storm.
Eleuther Discord
- GPT-4Chan ends TruthfulQA's reign: Tweet from Maxime Labonne reignited the conversation about GPT-4Chan's past dominance on TruthfulQA despite ChatGPT's emergence.
- Participants concurred that some benchmarks like TruthfulQA can mislead, while others like MT-Bench are deemed more indicative of true performance.
- Jsonnet, a necessary evil for configuration?: While Jsonnet garners appreciation for its streamlined configuration capabilities, a discussion unveiled its inadequacies in debugging, causing mixed feelings amongst users.
- Despite its challenges, Jsonnet's role is recognized for its cleanliness, standing out among the diverse options for configuration tasks.
- London AI Meetups Miss the Mark: The forum echoed disappointment with London AI meetups, reflecting that they fall short for those seeking deeper AI discourse.
- Suggestions pointed to academic seminars and conferences such as ICML for fulfilling the appetite for more substantial tech gatherings.
- LLMs Face Simple but Steep Challenges: The updated Alice in Wonderland paper uncovered simple puzzles that perplex SOTA models like Claude 3.5 Sonnet**.
- This discourse around SOTA LLMs' inability to handle simple modifications spotlights a need for robust benchmarks and enhances our understanding of model limitations.
- Memory Bandwidth: The GPT-2 Training Limiter: Discussions revolved around the 1000x memory bandwidth amplification requirement for training GPT-2 models on a trillion-token dataset within an hour.
- The focus shifted to Hadamard transform as an innovative solution to the quantization puzzle, as detailed in Together's blog post.
Latent Space Discord
- FlashAttention-3 Ignites GPU Performance: FlashAttention-3 is now out, promising a 1.5-2x speed boost on FP16, reaching up to 740 TFLOPS on H100 GPUs.
- The new release reportedly achieves 75% utilization on H100 and could potentially hit 1.2 PFLOPS using FP8.
- OpenAI's Lucrative Ledger: According to a recent report, OpenAI is projected to hit $1.9B in revenue with ChatGPT Plus leading the chart.
- This speculation highlights OpenAI's possible industry lead with impressive figures for ChatGPT Enterprise, the API, and the Team offering.
- AGI Framework Unfolded by OpenAI: OpenAI has unveiled a 5-level framework for tracking AGI, placing themselves at level 2.
- GPT-4's reasoning skills were put on show at a recent meeting, indicating progress outlined in this strategic framework.
- Decentralized AI Training Takes Flight: Prime Intellect's OpenDiLoCo, a take on DeepMind's model, enables distributed AI training across global nodes.
- A successful case involved a 1.1B parameter model trained across various nodes in three different countries.
- Fireworks Spark in AI Funding Arena: Fireworks AI recently bagged $52M Series B funding for their platform aimed at compound AI system advancements.
- The funding will be channeiled into Nvidia and AMD integrations and tailoring enterprise AI solutions.
LangChain AI Discord
- Seamless Synthesis with Indexify: Prashant Dixit spotlights structured data extraction methods from unstructured sources in a Towards AI publication.
- The use of Indexify for creating data ingestion and extraction pipelines is introduced, with further insights in the Towards AI article.
- Vector Vantage: Chroma over OpenAI: Discussions revolved around the configurations needed to properly load a Chroma vector store with OpenAI embeddings, emphasizing consistent
collection_namefor error-free operation.- Participants explored persistent storage tactics and effective management of embedded documents to reduce redundant computation.
- Embeddings at Light Speed: Techniques to accelerate OpenAI embedding functions were exchanged, with caching strategies being central, ranging from in-memory to using something like Redis.
- Approaches to improve embedding processes included reducing token loading and leveraging asynchronous embedding requests.
- FAISS or Chroma: The Dataset Dilemma: A debate on FAISS vs Chroma ensued, favoring FAISS for handling extensive datasets efficiently, while Chroma was preferred for its persistence capabilities with smaller collections.
- A hybrid method combining Chroma's persistent storage with FAISS's similarity searches was touted as an effective solution.
- LangChain Agents Advance: Challenges concerning unnecessary reembedding by LangChain agents were dissected with a keen focus on minimizing vector store initialization times.
- Proposed solutions covered persistence mechanisms and various other refinements to enhance the operations of LangChain's agents.
LM Studio Discord
- FlashAttention Ignites LLM Performance: A technical review unfolded revealing how FlashAttention and its sequel have streamlined Transformer training, drastically increasing GPT-4 and Llama 3 context lengths via optimized memory operations.
- NVIDIA's 4090 only marginally improves over the 3090, but the entry of FlashAttention tech has sparked discussion on the actual need for the high-end cards given the new methodology's memory management efficiency.
- RAMblings on NVIDIA's Next Move: Speculation is ripe as whispers hint at the NVIDIA 5090 sporting a mere 28GB VRAM, diverging from the expected 32GB, with a Reddit post offering a DIY alternative for VRAM galore.
- While debates churn about 3090's better price-performance, the likelihood of multi-V100 setups as a worthy adversary for AI endeavors was dissected, leaning towards single, high-powered GPU builds for optimal turnarounds.
- Vulkan Rides the Wave of Support: While OpenCL lags, unable to load models on a 7600XT, falling out of grace for AI work, there's chatter about Vulkan entering LM Studio's support list, promising a fresh take on model interaction.
- Discussions indicated Vulkan's rising popularity over OpenCL, a welcome change especially for ollama adopters, yet precise launch dates remain elusive amidst keen anticipation.
- Einstein's Gravitational Pull on Branding: Salesforce invested a grand $20 million to christen their new AI model Einstein, sparking a mix of industry jokes along with a circumspect review of the investment's wisdom.
- A jocular sentiment was palpable as one vividly imagined Einstein's likeness trapped in a corporate frame, birthing quips on its potential as a meme about the stranglehold of AI branding.
- Reactive AI Development with LM Studio: A creative endeavor emerges as an engineer integrates Gemma 2 via LM Studio's API into a React application, stirring advice to consider an embedding database like Faiss for RAG's setup, optimizing for batched PDF processing.
- As developers swapped tales of woe and success, advocating for more empathic support within the community, LM Studio's SDK was put forth as an adept companion for those merging cutting-edge AI into apps with rich user interactions.
OpenAI Discord
- Decentralize for Power to the Chips: Discussion centered on the benefits of decentralized computation for AI tasks, using stable diffusion and untapped idle processing power to optimize CMOS chips.
- Users called for the expansion of High-Performance Computing (HPC) capabilities through decentralization, enabling refined parallel computing.
- OpenAI's Next-Gen AI Blueprint: A new tier system revealed by OpenAI describes advancements from 'Reasoners' with doctorate-level problem-solving skills to 'Agents' and 'Organizations' with broader capabilities.
- Claude has been highlighted for its superior document comprehension over ChatGPT, suggesting a sharpened focus on context length.
- Anticipation Peaks for ChatGPT-5: GeekyGadgets spurred conversations with hints about ChatGPT-5 testing commencing late 2024, sparking a mix of excitement and skepticism among users.
- Anticipated ChatGPT-5 features include enhanced emotional intelligence, reduced instruction repetition, and potential foray into multimodal capabilities.
- Growing ChatGPT-4o Amnesia Concerns: Users reported that while ChatGPT-4o is speedy, it often forgets recent instructions, questioning its efficacy for tasks like programming.
- The nostalgia for v3.5's memory highlights a tradeoff between performance speed and operational recall.
- RAG Chatbot Prompt Tweaking: Developers are tweaking instructions for a RAG-based chatbot, aiming to reduce the chance of receiving odd or contradictory answers.
- The community recommends refining the clarity of chatbot prompts to ensure effective and logical interactions.
Cohere Discord
- Real-World Applications for Command R Plus Unveiled: Community members, led by Mapler, brainstormed practical applications for the Command R Plus model that spanned content creation for social media, crafting podcast descriptions, and team communication enhancements.
- Notably, Sssandra highlighted her routine integration of the model with Notion and Google Drive to facilitate handling community inquiries.
- Automatic Updates Revolution with Cohere: There's ongoing discussion about leveraging the Command R Plus and Lang chain to automate AI news delivery via webhooks in Discord, with Mapler at the helm of this initiative.
- Karthik_99_ has stepped up offering assistance, suggesting that a chat-GPT like interface could be integrated, pending community feedback.
- Cohere's Toolbox Enters the Open-Source Ecosphere: Sssandra proudly shared the news that Cohere's chat interface has been open-sourced on GitHub, teasing imminent OCI integration.
- Mapler responded with eagerness, intending to harness this for personal ventures and to update the community on progress.
- The Pursuit of AI-Generated Unique Emojis: Roazzy initiated a discussion on developing AI-driven tools for creating distinct emojis, with current methods limited to manual artwork.
- Karthik_99_ inquired about existing solutions, emphasizing the feature’s potential within user-driven platforms.
- Cohere Embedding Model’s Breakthrough in Affordability: Excitement brewed as a member broadcasted that Cohere's embedding model has slashed operational costs by an impressive 40-70%.
- The announcement was met with a chorus of approval from the community, echoing a sentiment of appreciation for the cost-effective progress.
Interconnects (Nathan Lambert) Discord
- Llama's Leap to Larger Learning: The imminent release of Llama 3 with a hefty 405B parameters on July 23 ignites anticipation, designed as a more robust multimodal model with details previewed in this briefing.
- Accelerating the path towards sophisticated AI, the leap from Llama 2 to 3 has sparked conversations around essential infrastructure for support, as posted by Stephanie Palazzolo and echoed across community channels.
- OpenAI's Secretive Strawberry Strategy: Leaks surrounding OpenAI's Strawberry project reveal parallels to Stanford's 2022 STaR method, spotlighting a progressive advance in AI reasoning technologies as reported by Reuters.
- The community is abuzz with speculation and analysis of this clandestine endeavor, believing it could mark a significant milestone in OpenAI's quest for more contextual and coherent AI models.
- Self-hosting Large Models: A Privileged Predicament: A dive into the logistics of self-hosting 400B parameter models unveils the necessity of around 400GB VRAM, steering the conversation towards resource availability and favoring API usage when proprietary hardware falls short.
- This predicament places a brighter spotlight on hyperscalers for GPU rental, especially when proprietary data is not a concern, as gleaned from the tech community's dissection of hosting intricacies and API benefits.
- Distillation Dilemma: Sequential Soft-targeting: The process of soft-target distillation as described in prominent papers is under the microscope, with queries surfacing about the potential for sequential with preserving probabilities.
- Community input points towards alternative tactics such as aligning internal representations during the online modeling process and how it might simplify current methodology.
- GPT-4: Valuing Price over Performance?: Amidst varied offerings in AI services, GPT-4 emerges as a superior model at $20 per month, casting a shadow over competitors' lower-priced alternatives.
- Comparative discussions are fueled by tweets like those from aaron holmes and spotlight the ongoing discourse on AI model valuation, businesses' choice, and consumer preference.
tinygrad (George Hotz) Discord
- tinygrad's Indexing Mastery: George Hotz introduced a novel indexing kernel in tinygrad, an unconventional addition bypassing typical constraints by innovatively folding the sum loop.
- This backend generated approach ensures a strict and efficient subset of memory accesses, streamlining kernel performance.
- Charting a Course with PyTorch-like Roadmaps: A member proposed emulating the 2024 H2 plan shared by PyTorch, advocating for a precise and open-ended development strategy.
- The goal is to mirror PyTorch's transparent pathway, providing a clear foundation for growth and development.
- Gradient Descent Dilemma in tinygrad: Attempts to implement gradient descent from scratch encountered speed bumps, with a member highlighting the process as being slow without a defined
optimizer.step.- They sought insights on optimizing the sluggish steps, referencing code samples and George Hotz's manual realization tactic.
- Optimizing Tensor Tactility: Realizing tensor operations, a vital component for efficient gradient descent, was simplified by Hotz's command
model.weights.assign(model.weights - lr * model.weights.grad).realize().- Understanding the necessity of realization, as George Hotz puts it, became the key to computation actualization.
- Tackling Tensor Indexing Bugs: In addressing tensor operations, an assertion error exposed a bug with tensor indexing that led to 'idx.max too big' complications.
- The engagement in this debugging session highlighted the community's role in refining tinygrad's kernel efficiency.
OpenAccess AI Collective (axolotl) Discord
- H100 GPUs Ignite Performance Excitement: H100 GPUs spark a wave of enthusiasm among members, with reactions highlighting the significant leap in performance capabilities.
- The swift performance of the H100 series heralds a new benchmark in computational power, superseding its predecessors with apparent ease.
- Attention Masking Scrutinized for Reward Models: The role and impact of attention masking in reward_health_models surfaced as a topic of debate, with community seeking clarity on its necessity.
- While questions lingered around its relevance to axolotl's specific training methods, open-ended discussions signaled an ongoing exploration of the technique.
- OpenRouter Connectivity with OpenArena Spotlighted: Community members demonstrated interest in integrating openrouter.ai APIs for developing an open-source equivalent to the *WizardLM arena dataset.
- One mention highlighted progress using ollama for a community-driven OpenArena project, emphasizing collaborative development.
- Flash Attention Compatibility Raises Questions: Compatibility concerns for Flash attn3 stirred discussions, with limitations noted for H100 GPUs.
- Anticipations are high for a broader GPU support as seen previously with Flash attn2's update catering to 3090's and 4090's.
- GaLore vs. Q-Galore: Quantization Takes the Lead: Discussion highlighted Q-Galore as an efficient successor to GaLore, employing quantization techniques to reduce training time, featured in a Hugging Face paper.
- Q-Galore's approach, avoiding SVD's time overhead while building on GaLore's strategies, emerged as a significant upgrade for handling gradient subspaces.
OpenRouter (Alex Atallah) Discord
- DeepInfra Data Dilemma Discussed: A member raised concerns about DeepInfra's data policy, sparking a discussion on how companies handle training data obtained from user inputs.
- The discussion led to the clarification that DeepInfra logs usage but doesn't train on user inputs, detailed in their privacy policy.
- Beta Integrations Beckon Brighter Bots: Integrations (Beta) feature discussions unfolded, focusing on custom API key use for external providers like Groq.
- Conversations anticipate future expansions may explore integrations beyond model APIs, sparking curiosity about potential applications.
- Positioning Prompts for Picky Performers: Members exchanged tips on improving model performance, including suggestion to place text prompts after images to assist weaker models.
- This placement technique reportedly leads to enhanced comprehension and better responses from less capable models.
- 405b's Arrival Arouses AI Aspirants: Excitement ignited over the impending release of the 405b model, with community expectations running high.
- The community's buzz was fueled by Bindu Reddy's tweet about the model's anticipated launch, marking July 23rd as significant for open source AGI.
- Specialization Speculation Stirs Scholars: A conversation about whether multiple specialized models are superior to a single generic model emerged, featuring companies like OpenAI and Anthropic.
- Alex Atallah joined the debate, advocating for consideration of specialized models and solicited community input on preferred types.
LAION Discord
- Clip Retrieval Clipped: A user noted that clip retrieval is no longer functional, prompting questions around alternative methods for dataset access.
- The issue appears linked to the dataset's removal, which could imply a broader restriction on data availability.
- Memory Hog Models: An unusually high 19GB memory usage for a small-scale model training session kindled the guild's interest in memory inefficiencies.
- The community is actively probing why a mere quarter-million parameter model engulfs so much memory on a modest batch size.
- Nematron 340B Code Quest: Queries about Nematron 340B code examples burgeoned, focusing on parameter management for the reward model.
- Details remain sparse, revealing an opportunity for shared coding practices within the guild.
- Flashy Flow with AuraFlow: Fal AI's new text-to-image model, AuraFlow, brings a splash to the guild with its launch announcement.
- Its proficiency in adhering to prompts is laid bare as it rejuvenates faith in the open-source AI landscape.
- LLMs' AIW Conundrum: An updated ArXiv paper showcases the AIW problem, revealing a chasm in LLMs' reasoning abilities on rudimentary tasks.
- Discussions orbit around the inadequacy of current benchmarks and the essential but overlooked capabilities underscored by the paper.
LlamaIndex Discord
- Agentic RAG's Recipe for Success: LlamaIndex, teaming up with AIatMeta, dished out cookbooks on agentic RAG, covering multifaceted topics from agent routing to multi-document agent crafting.
- Eager enthusiasts received a taste with a Twitter announcement and further insights were served up here.
- Deduplication Delight via Cypher Snippets: Crafted by the hands of @tb_tomaz and armory at Neo4j, a potent Cypher snippet simplifies the art of entity deduplication, merging tech prowess with URI wizardry.
- Piquing interest, they shared a practical example snippet and streamlined access to the code on the Neo4j GitHub.
- Gemini's Call for Functionality Clarification: Confusion clouded the functionality of function calling on Gemini models; GitHub commits seemed promising yet ran into bumps with error claims stating unsupported API.
- The path to clarity suggested upgrading the toolkit via
pip install -U llama-index-llms-vertexai, hoping to clear any fog around Gemini-1.5-flash-latest's capabilities.
- The path to clarity suggested upgrading the toolkit via
- Libraries in Limelight: Indexing Large Codes: Enthusiasts dissected strategies for indexing hefty code libraries, debating if translating code to markdown-pseudocode could amplify a chatbot's comprehension.
- The dialogue revolved around the needs of dual chatbot systems, one for question answers and the other for generating code snippets.
- RAG Reviewing: Skimming Spec Documents: RAG's role in dissecting lengthy spec documents without exhausting token limits was envisioned, seeking efficiency in review processes.
- The community mulled over methods to evaluate expansive specs, considering the merits of neat token savings alongside RAG's potential.
OpenInterpreter Discord
- Invocation Error Unraveled: A user reported APIConnectionError when calling
OpenInterpreter.chat()and 'select' fails to determine the agent's role.- The error might be resolved by explicitly passing the LLM provider, as suggested in the documentation.
- Fast Function Calls with Phi-3: Excitement arose around Phi-3 due to its fast and reliable function calls, hinting at potential for fully local Fast Fourier runs.
- Hopes are high for this optimization that could mean quicker computations in the near future.
- GUI's Glorious Gains: The Open Interpreter's GUI received a significant upgrade, now featuring branching chats, editable messages, auto-run code, and chat saving.
- The new expansive features come with some limitations, detailed in the GitHub repository.
LLM Finetuning (Hamel + Dan) Discord
- Tackling Telemetry Trouble: Discussions surfaced around self-hosted ML telemetry with a focus on platforms like Langfuse, WandB, and OpenLLMTelemetry.
- Members stressed the importance of selecting a platform that aligns with specific needs of ML projects.
- API Key Quest for Chatbots: A member in need for an OpenAI API key voiced a request for a chatbot project tutorial, underscoring its short-term necessity.
- Emphasis was placed on using the API key for demonstration purposes within their tutorial.
- Chasing Credit Clarifications: Queries on credit balance were brought up, with one user, reneesyliu-571636, directly asking how to perform a credit balance check.
- Another member sought assistance on their account status, possibly hinting at broader questions on the topic of account management.
Mozilla AI Discord
- Advocacy Impacts AI: Llamafile's Leap to Legislation: Mozilla's Udbhav Tiwari advocates for open AI systems before the US Senate, emphasizing the importance of transparent and accessible technologies.
- The focus at the senate hearing was on the critical role of openness in AI, aligning closely with Mozilla's own advocacy direction.
- Builders' Time Extension: Applications Still Welcome!: Missed the early window for the Builders Accelerator? Fear not, applications are indeed still welcome beyond the initial cutoff.
- Details have been shared earlier, but interested parties can review the program's objectives and apply as mentioned in this announcement.
- Don't Miss Out: AI Events Rendezvous Awaits: A line-up of intriguing events beckons, including Open Interpreter with LLMs, Benjamin Minixhofer's talk on Zero Shot Tokenizer Transfer, and an AutoFix session with an adept engineer.
- Eager to partake? Reserve your virtual seat for upcoming events and engage with cutting-edge AI tools and discussions.
- Chiseling the AI Open Source Definition: Open Source AI Definition Draft v 0.0.8 steps into the limelight seeking community insights and aligning with the OECD's AI system interpretation.
- The community is called to action to review and comment on this evolving artifact on the OSI's blog.
- Integer or Float: The Quantization Quandary: AI engineers ponder whether llama.cpp utilizes integer or float calculations for matmul operations, linked to procedures in the ggml-quants.c.
- The mathematical maneuver—a hot topic for the technically inclined—might require quantizing float activations before integer dotproduct machinations ensue.
DiscoResearch Discord
- LLMs Throwdown in the OpenArena: The LLM Arena is a combat zone where language models from Ollama and OpenAI** endpoints duel, guided by a third model as judge.
- The goal is to increase dataset quality, demonstrated on OpenArena's GitHub through competitive challenges.
- WizardLM Paper casts spell on Arena Learning: OpenArena draws its inspiration from the WizardLM paper, advocating Arena Learning** post-LLM training.
- By simulating chatbot battles and utilizing AI-annotated datasets, the approach sharpens models via supervised fine-tuning and reinforcement learning techniques.
MLOps @Chipro Discord
- Expanding Horizons in MLOps: A discussion was initiated with an interest in covering diverse areas such as product and research, particularly in recommendation systems, information retrieval (IR), and retrieval-augmented generation (RAG).
- The conversation encouraged open suggestions and expressed a specific interest in exploring Elastic and its potential in these areas.
- Elastic Enthusiasts Emerge: Another user echoed the sentiment expressing their willingness to have a detailed dialogue about Elastic.
- The user tagged a colleague to kickstart a deeper discussion on how Elastic could enhance their current operations.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!