[AINews] Ways to use Anthropic's Tool Use GA
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Tools are all AIs need.
AI News for 5/30/2024-5/31/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (393 channels, and 2911 messages) for you. Estimated reading time saved (at 200wpm): 337 minutes.
Together with Anthropic's GA of tool use/function calling today on Anthropic/Amazon/Google, with support for streaming, forced use, and vision...
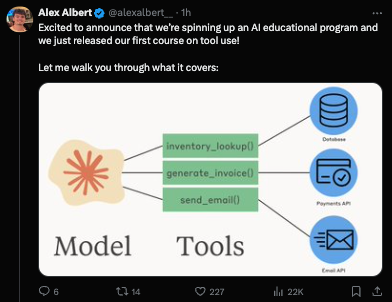
Alex Albert shared 5 architectures for using them in an agentic context:
- Delegation: Use cheaper, faster models for cost and speed gains.
- For example, Opus can delegate to Haiku to read a book and return relevant passages. This works well if the task description & result are more compact than the full context.
- Parallelization: Cut latency (but not cost) by running agents in parallel.
- e.g. 100 sub-agents each read a different chapter of a book, then return key passages.
- Debate: Multiple agents with different roles engage in discussion to reach better decisions.
- For example, a software engineer proposes code, a security engineer reviews it, a product manager gives a user's view, then a final agent synthesizes and decides.
- Specialization: A generalist agent orchestrates, while specialists execute tasks.
- For example, the main agent uses a specifically prompted (or fine-tuned) medical model for health queries or a legal model for legal questions.
- Tool Suite Experts: When using 100s or 1000s of tools, specialize agents in tool subsets.
- Each specialist (the same model, but with different tools) handles a specific toolset. The orchestrator then maps tasks to the right specialist (keeps the orchestrator prompt short).
Nothing particularly groundbreaking here but a very handy list to think about for patterns. Anthropic also launched a self guided course on tool use:
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Research and Development
- Open Science and Research Funding: @ylecun expressed a clear ethical rule for research: "Do not get research funding from entities that restrict your ability to publish." He emphasized that making new knowledge available to the world is intrinsically good, regardless of the funding source. @ylecun noted that this ethical rule has made him a strong advocate of open science and open source.
- Emergence of Superintelligence: @ylecun believes the emergence of superintelligence will be a gradual process, not a sudden event. He envisions starting with an architecture at the intelligence level of a rat or squirrel and progressively ramping up its intelligence while designing proper guardrails and safety mechanisms. The goal is to design an objective-driven AI that fulfills goals specified by humans.
- Convolutional Networks for Image and Video Processing: @ylecun recommends using convolutions with stride or pooling at low levels and self-attention circuits at higher levels for real-time image and video processing. He believes @sainingxie's work on ConvNext has shown that convolutional networks can be just as good as vision transformers if done right. @ylecun argues that self-attention is equivariant to permutations, which is nonsensical for low-level image/video processing, and that global attention is not scalable since correlations are highly local in images and video.
- AI Researchers in Industry vs. Academia: @ylecun noted that if a graph showed absolute numbers instead of percentages, it would reveal that the numbers of AI researchers in industry, academia, and government have all grown, with industry growing earlier and faster than the rest.
AI Tools and Applications
- Suno AI: @suno_ai_ announced the release of Suno v3.5, which allows users to make 4-minute songs in a single generation, create 2-minute song extensions, and experience improved song structure and vocal flow. They are also paying $1 million to the top Suno creators in 2024. @karpathy expressed his love for Suno and shared some of his favorite songs created using the tool.
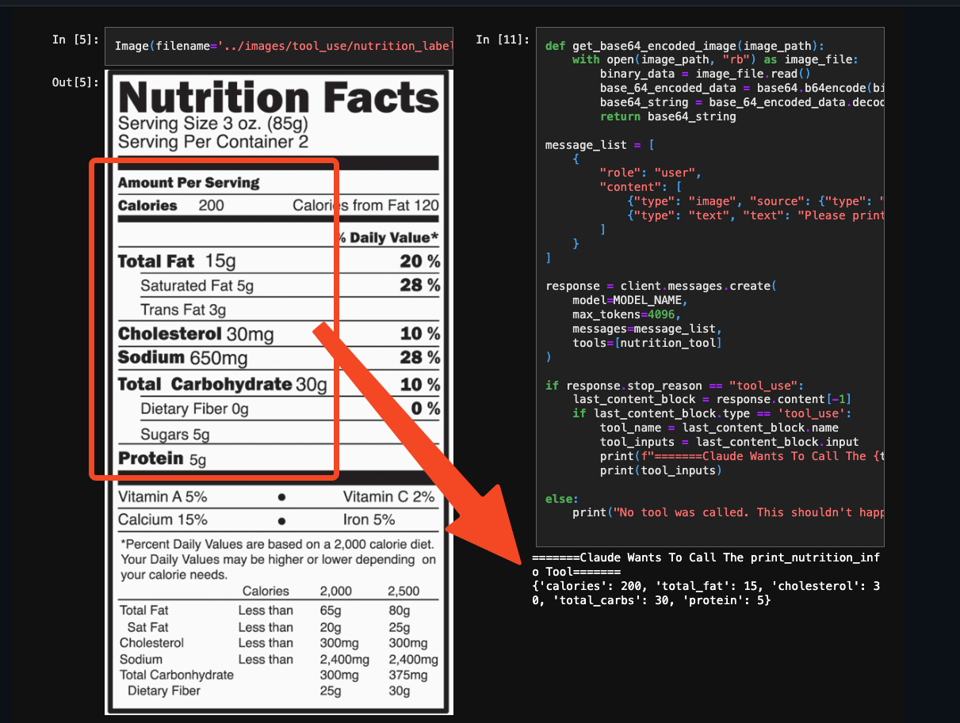
- Claude by Anthropic: @AnthropicAI announced that tool use for Claude is now generally available in their API, Amazon Bedrock, and Google Vertex AI. With tool use, Claude can intelligently select and orchestrate tools to solve complex tasks end-to-end. Early customers use Claude with tool use to build bespoke experiences, such as @StudyFetch using Claude to power Spark.E, a personalized AI tutor. @HebbiaAI uses Claude to power complex, multi-step customer workflows for their AI knowledge worker.
- Perplexity AI: @AravSrinivas introduced Perplexity Pages, described as "AI Wikipedia," which allows users to analyze sources and synthesize a readable page with a simple "one-click convert." Pages are available for all Pro users and rolling out more widely to everyone. Users can create a page as a separate entity or convert their Perplexity chat sessions into the page format. @perplexity_ai noted that Pages lets users share in-depth knowledge on any topic with formatted images and sections.
- Gemini by DeepMind: @GoogleDeepMind announced that developers can now start building with Gemini 1.5 Flash and Pro models using their API pay-as-you-go service. Flash is designed to be fast and efficient to serve, with an increased rate limit of 1000 requests per minute.
Memes and Humor
- @huybery introduced im-a-good-qwen2, a chatbot that interacts in the comments.
- @karpathy shared his opinion on 1-on-1 meetings, stating that he had around 30 direct reports at Tesla and didn't do 1-on-1s, which he believes was great. He finds 4-8 person meetings and large meetings for broadcast more useful.
- @ReamBraden shared a meme about the challenges of being a startup founder.
- @cto_junior shared a meme about Tencent AI developers working to replace underpaid anime artists.
- @nearcyan made a humorous comment about people who believe we should not talk to animals, build houses, or power plants, and instead "rot in caves and fight over scraps as god intended."
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Image & Video Generation
- Photorealistic avatars: In /r/singularity, impressive photorealistic avatars were showcased from the Neural Parametric Gaussian Avatars (NPGA) research at the University of Munich, Germany (example 1, example 2). These high-quality avatars demonstrate the rapid advancements in AI-generated human-like representations.
- Cartoon generation and interpolation: The ToonCrafter model was introduced for generating and interpolating cartoon-style images, with experiments showcasing its capabilities. This highlights the expanding range of AI-generated content beyond photorealistic imagery.
- AI-powered game development: An open-source game engine was presented that leverages AI models like Stable Diffusion, AnimateDiff, and ControlNet to generate game assets and animations. The engine's source code and techniques for rendering animated sprites are fully available.
- AI animation APIs: The Animate Anyone API, with code available on GitHub, enables the animation of people in images. However, comments suggest that alternatives like MusePose may offer better results.
AI Ethics & Societal Impact
- AI partnerships and competition: Microsoft CEO Satya Nadella expressed concerns over a potential OpenAI-Apple deal, highlighting the strategic importance of AI partnerships and the competitive landscape.
- Deepfake concerns: The growing potential for misuse of deepfake technology was emphasized, underscoring the need for safeguards and responsible AI practices.
- AI in the film industry: Sony's plans to use AI for reducing film production costs raised questions about the impact on the creative industry and potential job displacement.
- AI-generated content and realism: An AI-generated image titled "All Eyes On Rafah" faced criticism for lacking realism and potentially misrepresenting a sensitive situation, highlighting the challenges of AI-generated content.
- AI and influence campaigns: OpenAI reported that Russia and China used its AI tools for covert influence campaigns, emphasizing the need for proactive measures against AI misuse, as detailed in their efforts to combat deceptive AI use.
AI Capabilities & Advancements
- Bioprocessors and brain organoids: A groundbreaking bioprocessor utilizing human brain organoids was developed, offering highly efficient computation compared to digital chips.
- AI in healthcare: New AI technology was shown to predict cardiac events related to coronary inflammation up to 10 years in advance, based on a landmark study published in The Lancet.
- Quantum computing breakthrough: Chinese researchers, led by a US-returned physicist, claimed to have built the world's most powerful ion-based quantum computer.
OpenAI News & Developments
- Leadership clarification: Paul Graham clarified that Y Combinator did not fire Sam Altman, contrary to circulating rumors.
- Robotics research revival: OpenAI is rebooting its robotics team, signaling a renewed focus on the intersection of AI and robotics.
- Addressing concerns: OpenAI board members responded to warnings raised by former members regarding the company's direction and practices.
- AI for nonprofits: OpenAI launched an initiative to make its tools more accessible to nonprofit organizations, promoting beneficial AI applications.
- Partnership with Reddit: The announcement of a partnership between OpenAI and Reddit raised questions about the potential implications for both platforms.
AI Humor & Memes
- Robots then and now: A humorous comparison of the "I, Robot" movie's portrayal of robots in the past versus the present day was shared.
AI Discord Recap
A summary of Summaries of Summaries
1. Model Performance Optimization and Benchmarking
- K2 Triumphs Over Llama 2: The K2 model from LLM360 surpasses Llama 2 70B in performance while using 35% less compute, fully open-sourced under Apache 2.0 license.
- NeurIPS Hosts Model Merging Competition: A competition with an $8,000 prize invites contenders to blend optimal AI models, details available on the NeurIPS Model Merging Website.
- Tailored Positional Embeddings Boost Transformer Arithmetic: Researchers achieved 99% accuracy on 100-digit sums using specific embeddings, detailed in their paper.
2. Fine-Tuning and Prompt Engineering
- Tackling Dataset Merging and Training Tips: Axolotl users discussed effective merging datasets during fine-tuning to avoid issues like catastrophic forgetting. Recommended tools include Hugging Face Accelerate.
- Fine-Tuning Techniques for Legal Draft Systems and Chatbots: Users fine-tuning LLMs for applications like legal drafts and financial document summarization swapped strategies, with resources like Fine-Tune PaliGemma.
- Resolving Training Issues for Text Classification Models: Issues with training Spanish entity categorization models involved fine-tuning recommendations, exploring frameworks like RoBERTa.
3. Open-Source AI Developments and Collaborations
- Milvus Lite for Efficient Vector Storage: Introducing Milvus Lite, a lightweight solution for Python-focused vector storage, detailed in the Milvus documentation.
- MixMyAI Integrates Multiple AI Models on a Single Platform: The mixmyai.com platform consolidates open and closed-source models, emphasizing privacy and avoiding server storage of chat data.
- LlamaIndex Offers Flexible Retrieval Systems: New Django-based web app templates facilitate Retrieval Augmented Generation (RAG) applications, utilizing data management and user access controls, as detailed here.
4. AI Community Innovations and Knowledge Sharing
- Using Axolotl for Consistent Prompt Formats: Adjustments in Axolotl were made to ensure prompt format consistency, guiding users to settings like Axolotl prompters.py.
- Challenges with Language Support in Ghost XB Beta: Unsloth AI discussed multilingual support in models like Ghost XB Beta aiming for 9+ languages during training phases, highlighting Ghost XB details.
- Incorporating OpenAI and LangChain Tools: Resources like LangChain Intro, and real-time features announced for GPT-4 Alpha, were discussed for creating advanced AI applications.
5. Hardware Advancements and Compatibility Challenges
- NVIDIA's New 4nm Research Chip Impresses: Achieving 96 int4 TOPs/Watt efficiency, significantly outpacing Blackwell's capabilities, with discussion on impacts shared here.
- ROCm Support Challenges on AMD GPUs: Frustrations over ROCm's lack of support for GPUs like RX 6700 and RX580 led to discussions on potential alternatives and performance impacts.
- Implementing Efficient Data Handling in CUDA: Discussions on optimizing CUDA operations, using techniques like fusing element-wise operations for better performance, with source code insights available here.
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
- Transformer Trainings and Troubleshooting: Interactive sessions on Transformer architecture were requested for better understanding of complex topics like RoPE and RMS Normalization. In the meantime, Google Gemini Flash will allow free fine-tuning come June 17th, while careful calculation of costs for production using RAG LLMs remains imperative, prioritizing GPU time and third-party services considerations. The GGUF format is being advocated for to maintain compatibility with ecosystem tools, easing the fine-tuning process. (Fine-tune PaliGemma for image to JSON use cases)
- Braving BM25 and Retrieval Woes: A hunt for a reliable BM25 implementation was launched, with the Python package
rank_bm25in the crosshairs due to its limited functionality. The conversation focused on enhancing vector retrieval; meanwhile, Modal users are directed to documentation for next steps after deploying v1 finetuned models, and a Modal credits initiative clarified expiration concerns.
- Data Dominates Dialogue: The parsing of structured information from document AI required techniques like OCR and LiLT models. In parallel, data processing for 5K scraped LinkedIn profiles was considered with OpenPipe and GPT-4, while multi-modal approaches and document understanding stayed hot topics. Emphasis on precise matching of training data file formats to prevent
KeyError: 'Input'surfaced as a troubleshooting tip.
- Learning LLM Legwork and LangChain Link-Up: Resources from Humble Bundle and Sebastian Raschka offered insights into prompt engineering and LLM finetuning, though skepticism was raised about the quality of some materials. Reflecting the community's thirst for knowledge, O'Reilly released Part II of their series on building with LLMs, targeting operational challenges in LLM applications.
- Curating Conversational Context: The distinction between instruct-LLM and chat-LLM models was dissected with the former following clear instructions, and the latter mastering conversational context. Projects discussed ranged from an Alexa-like music player to a legal draft system and a chatbot for financial document summaries, indicating the range of possible implementations for fine-tuned LLMs.
- Modal Moves and Market Reach: Mediums like blogs played a vital role in spreading knowledge, with John Whitaker's blog becoming a go-to place for learning about things like Basement Hydroponics and LLM performance. More when practitioners shared gradient optimization tricks such as gradient checkpointing and agreed that sometimes, the simplest explanations, like those from Johno's sessions, resonate best.
- Space for Spaces: Queries on how to change prompt styles for the alpaca format in Axolotl and Qwen tokenizer usage issues were discussed, with references pointing to specific GitHub configs. Meanwhile, deploying a Gradio-based RAG app sparked interest in using HF Spaces due to its ease of use.
- Credit Craze and Communal Connects: Moments of panic and clarification underscored the urgency of filling out credit forms, as emphasized in urgent announcements. Social gatherings and discussions ranged from SF eval meetups to Modal Labs hosting office hours in NYC, indicating robust community connections and knowledge-sharing events.
- Europe Engagement and Predibase Prospects: Check-ins from across Europe, such as Nuremberg, Germany and Milan, Italy, manifested the group's geographical span. Elsewhere, the mention of a 30-day free trial of Predibase offering $25 in credits reflected ongoing efforts to provide accessible finetuning and deployment platforms.
- Career Crossroads: From academia to industry, members shared experiences and encouraged one another in career transitions. The discussion showcased contracting as a viable pathway, with mentorship and perseverance identified as crucial for navigating the tech landscape where GitHub portfolios can serve as vital stepping stones.
These summaries encapsulate the detailed, often granular discussions among AI Engineers in the Discord guild, highlighting the collective endeavor to optimize LLM fine-tuning and deployment amidst pursuit of career growth and community building.
HuggingFace Discord
K2 Triumphs Over Llama 2: LLM360's K2 model outpaces Llama 2 70B, achieving better performance with 35% less computational effort; it's touted as fully-reproducible and is accessible under the Apache 2.0 license.
Numbers Are No Match for Positional Embeddings: Researchers cracked the nut on transformers' arithmetic abilities; with tailored positional embeddings, transformers reach a 99% accuracy on 100-digit sums, a monumental feat outlined in their paper.
NeurIPS Throws Down the Merging Gauntlet: With an $8,000 purse, the NeurIPS Model Merging Competition invites contenders to blend optimal AI models. Hugging Face, among others, sponsors this competition, more info in the announcement and competition website.
Data Dive: From 150K Datasets to Clothing Sales: A treasure trove of 150k+ datasets is now at engineers' fingertips for exploration with DuckDB, explained in a blog post, while a novel clothing sales dataset propelled the development of an image regression model which was then detailed in this article.
Learning Resources and Courses Amplify Skills: In the perpetually advancing field of AI, engineers can bolster their expertise through Hugging Face courses in Reinforcement Learning and Computer Vision, with more information accessible at Hugging Face - Learn.
Unsloth AI (Daniel Han) Discord
Quantization Quandaries and High-Efficiency Hardware: Unsloth AI guild members highlight challenges with the quantized Phi3 finetune results, noting performance issues without quantization tricks. NVIDIA's new 4nm research chip is generating buzz with its 96 int4 tera operations per second per watt (TOPs/Watt) efficiency, overshadowing Blackwell's 20T/W and reflecting industry-wide advancements in power efficiency, numerical representation, Tensor Cores' efficiency, and sparsity techniques.
Model Fine-Tuning and Upscaling Discussions: AI engineers share insights on fine-tuning strategies, including dataset merging, with one member unveiling an 11.5B upscale model of Llama-3 using upscaling techniques. An emerging fine-tuning method, MoRA, suggests a promising avenue for parameter-efficient updates.
Troubleshooting Tools and Techniques: Engineers confront various hurdles, from GPU selection in Unsloth (os.environ["CUDA_VISIBLE_DEVICES"]="0") and troubleshooting fine-tuning errors to handling dual-model dependencies and addressing VRAM spikes during training. Workarounds for issues like Kaggle installation challenges underscore the need for meticulous problem-solving.
AI in Multiple Tongues: Ghost XB Beta garners attention for its capability to support 9+ languages fluently and is currently navigating through its training stages. This progress reaffirms the guild’s commitment to developing accessible, cost-efficient AI tools for the community, especially emphasizing startup support.
Communal Cooperative Efforts and Enhancements: Guild discussions reveal a collective push for self-deployment and community backing, with members sharing updates and seeking assistance across a spectrum of AI-related endeavors such as the Open Empathic project and Unsloth AI model improvements.
Perplexity AI Discord
- Tako Widgets Limited Geographic Scope?: Discussion around the Tako finance data widget raised questions about its geographic limitations, with some users unsure if it's exclusive to the United States.
- Perplexity Pro Trials End: Users talked about the discontinuation of Perplexity Pro trials, including the yearly 7-day option, spurring conversations around potential referral strategies and self-funded trials.
- Perplexity's Page-Section Editing Quirks: Some confusion arose around editing sections on Perplexity pages, where users can alter section details but not the text itself – a limitation confirmed by multiple members.
- Search Performance Trade-offs Noted: There's been observance of a slowdown in Perplexity Pro search, attributed to a new strategy that sequentially breaks down queries, which, despite lower speeds, offers more detailed responses.
- Exploring Perplexity's New Features: Excitement was apparent as users shared links to newly introduced Perplexity Pages and discussions about Codestral de Mistral, hinting at enhancements or services within the Perplexity AI platform.
CUDA MODE Discord
- NVIDIA and Meta's Chip Innovations Generate Buzz: The community was abuzz with NVIDIA's revelation of a 4nm inference chip achieving 96 int4 TOPs/Watt, outperforming the previous 20T/W benchmark, and Meta unveiling a next-generation AI accelerator clocking in at 354 TFLOPS/s (INT8) with only 90W power consumption, signaling a leap forward in AI acceleration capabilities.
- Deep Dive into CUDA and GPU Programming: Enthusiasm surrounded the announcement of a FreeCodeCamp CUDA C/C++ course aimed at simplifying the steep learning curve of GPU programming. Course content requests emphasized the importance of covering GEMM for rectangular matrices and broadcasting rules pertinent to image-based convolution applications.
- Making Sense of Scan Algorithms and Parallel Computing: The community engaged in eager anticipation of the second part of a scan algorithm series. At the same time, questions were raised regarding practical challenges with parallel scan algorithms highlighted in the
Single-pass Parallel Prefix Scan with Decoupled Look-backpaper, as well as requests for clarification of CUDA kernel naming in Triton for improved traceability in kernel profiling.
- Strategies for Model Training and Data Optimization Shared: The conversation included a sharing of strategies on efficient homogeneous model parameter sharing to avoid inefficient replication during batching in PyTorch, and issues like loss spikes during model training which could potentially be diagnosed through gradient norm plotting. The idea of hosting datasets on Hugging Face was floated to facilitate access, with compression methods suggested to expedite downloads.
- Cross-Platform Compatibility and Community Wins Celebrated: Progress and challenges in extending CUDA and machine learning library compatibility to Windows were discussed, with acknowledgment of Triton's intricacies. Meanwhile, the community celebrated reaching 20,000 stars for a repository and shared updates on structuring and merging directories to enhance organization, strengthening the ongoing collaboration within the community.
Stability.ai (Stable Diffusion) Discord
- Online Content Privacy Calls for Education: A participant emphasized the importance of not publishing content as a privacy measure and stressed the need to educate people about the risks of providing content to companies.
- Striving for Consistent AI Tool Results: Users noted inconsistencies when using ComfyUI compared to Forge, suggesting that different settings and features such as XFormers might influence results, despite identical initial settings.
- Strategies for Merging AI Models Discussed: Conversations revolved around the potential of combining models like SDXL and SD15 to enhance output quality, though ensuring consistent control nets across model phases remains crucial.
- Custom AI Model Training Insights Shared: Enthusiasts exchanged tips on training bespoke models, mentioning resources like OneTrainer and kohya_ss for Lora model training, and sharing helpful YouTube tutorials.
- Beginner Resources for AI Exploration Recommended: For AI newbies, starting with simple tools like Craiyon was recommended to get a feel for image generation AI, before progressing to more sophisticated platforms.
LM Studio Discord
GPU Blues with ROCm? Not Music to Our Ears: Engineers discussed GPU performance with ROCm, lamenting the lack of support for RX 6700 and old AMD GPUs like RX580, influencing token generation speeds and overall performance. Users seeking performance benchmarks on multi-GPU systems with models such as LLAMA 3 8B Q8 reported a 91% efficiency with two GPUs compared to one.
VRAM Envy: The release of LM Studio models ignited debates on VRAM adequacy, where the 4070's 12GB was compared unfavorably to the 1070's 20GB, especially concerning suitability for large models like "codestral."
CPU Constraints Cramp Styles: CPU requirements for running LM Studio became a focal point, where AVX2 instructions proved mandatory, leading users with older CPUs to use a prior version (0.2.10) for AVX instead.
Routing to the Right Template: AI engineers shared solutions and suggestions for model templates, such as using Deepseek coder prompt template for certain models, and advised checking tokenizer configurations for optimal formatting with models like TheBloke/llama2_7b_chat_uncensored-GGUF.
New Kids on the Block - InternLM Models: Several InternLM models designed for Math and Coding, ranging from 7B to a mixtral 8x22B, were announced. Models such as AlchemistCoder-DS-6.7B-GGUF and internlm2-math-plus-mixtral8x22b-GGUF were highlighted among the latest tools available for AI engineers.
OpenRouter (Alex Atallah) Discord
- Speed Boost to Global API Requests: OpenRouter has achieved a global reduction in latency, lowering request times by ~200ms, especially benefiting users from Africa, Asia, Australia, and South America by optimizing edge data delivery.
- MixMyAI Launches Unified Pay-as-You-Go AI Platform: A new service called mixmyai.com has been launched, consolidating open and closed-source models in a user-friendly interface that emphasizes user privacy and avoiding the storage of chats on servers.
- MPT-7B Redefines AI Context Length: The Latent Space podcast showcased MosaicML's MPT-7B model and its breakthrough in exceeding the context length limitations of GPT-3 as detailed in an in-depth interview.
- Ruby Developers Rejoice with New AI Library: A new OpenRouter Ruby client library has been released, along with updates to Ruby AI eXtensions for Rails, essential tools for Ruby developers integrating AI into their applications.
- Server Stability and Health Checks Called Into Question: OpenRouter users confronted sporadic 504 errors across global regions, with interim solutions provided and discussions leaning towards the need for a dedicated health check API for more reliable status monitoring.
OpenAI Discord
Pro Privileges Propel Chat Productivity: Pro users of OpenAI now enjoy enhanced capabilities such as higher rate limits, and exclusive GPT creation, along with access to DALL-E and real-time communication features. The alluring proposition maintains its charm despite the $20 monthly cost, marking a clear divide from the limited toolkit available to non-paying users.
AI Framework Favorites Facilitate Functional Flexibility: The Chat API is recommended over the Assistant API for those developing AI personas with idiosyncratic traits, as it offers superior command execution without surplus functionalities such as file searching.
Bias Brouhaha Besieges ChatGPT: A suspension due to calling out perceived racism in ChatGPT's outputs opened up a forum of contention around inherent model biases, spotlighting the relentless pursuit of attenuating such biases amidst the ingrained nuances of training data.
Virtual Video Ventures Verified: Sora and Veo stand as subjects of a speculative spree as the guild contemplates the curated claims and practical potency of the pioneering video generation models, juxtaposed against the realities of AI-assisted video crafting.
API Agitations and Advancements Announced: Persistent problems presented by memory leaks causing lag and browser breakdowns mar the ChatGPT experience, triggering talks on tactical chat session limits and total recall of past interactions to dodge the dreariness of repetition. Meanwhile, the anticipated arrival of real-time voice and visual features in GPT-4 has been slated to debut in an Alpha state for a select circle, broadening over subsequent months as per OpenAI's update.
Nous Research AI Discord
NeurIPS Competition: Merge Models for Glory and Cash: NeurIPS will host a Model Merging competition with an $8K prize, sponsored by Hugging Face and Sakana AI Labs—seeking innovations in model selection and merging. Registration and more info can be found at llm-merging.github.io as announced on Twitter.
AI's Quest to Converse with Critters: A striking $500K Coller Prize is up for grabs for those who can demystify communication with animals using AI, sparking excitement for potential breakthroughs (info). This initiative echoes Aza Raskin's Earth Species Project, aiming to untangle interspecies dialogue (YouTube video).
Puzzling Over Preference Learning Paradox: The community is abuzz after a tweet highlighted unexpected limitations in RLHF/DPO methods—preference learning algorithms are not consistently yielding better ranking of preferred responses, challenging conventional wisdom and suggesting a potential for overfitting.
LLMs Reigning Over Real-Time Web Content: A revelation for web users: LLMs are often churning out web pages in real-time, rendering what you see as it loads. This routine faces hiccups with lengthy or substantial pages due to context constraints, an area ripe for strategic improvements.
Google Enhances AI-Driven Search: Google has upgraded its AI Overviews for US search users, improving both satisfaction and webpage click quality. Despite some glitches, they're iterating with a feedback loop, detailed in their blog post – AI Overviews: About last week.
LlamaIndex Discord
- Milvus Lite Elevates Python Vector Databases: The introduction of Milvus Lite offers a lightweight, efficient vector storage solution for Python, compatible with AI development stacks like LangChain and LlamaIndex. Users are encouraged to integrate Milvus Lite into their AI applications for resource-constrained environments, with instructions available here.
- Crafting Web Apps with Omakase: A new Django-based web app template facilitates the building of scalable Retrieval Augmented Generation (RAG) applications, complete with RAG API, data source management, and user access control. The step-by-step guide can be found here.
- Navigating Data Transfer for Retrieval Systems: For those prototyping retrieval systems, the community suggests creating an "IngestionPipeline" to efficiently handle data upserts and transfers between SimpleStore classes and RedisStores.
- Complexities in Vector Store Queries Assessed: The functionalities of different vector store query types like
DEFAULT,SPARSE,HYBRID, andTEXT_SEARCHin PostgreSQL were clarified, with the consensus that bothtextandsparsequeries utilizetsvector.
- Troubleshooting OpenAI Certificate Woes: Addressing SSL certificate verification issues in a Dockerized OpenAI setup, it was recommended to explore alternative base Docker images to potentially resolve the problem.
Eleuther Discord
- Luxia Language Model Contamination Alert: Luxia 21.4b v1.2 has been reported to show a 29% increase in contamination on GSM8k tests over v1.0, as detailed in a discussion on Hugging Face, raising concerns about benchmark reliability.
- Ready, Set, Merge!: NeurIPS Model Merging Showdown: A prize of $8K is up for grabs in the NeurIPS 2023 Model Merging Competition, enticing AI engineers to carve new paths in model selection and merging.
- Cutting-Edge CLIP Text Encoder and PDE Solver Paradigm Shifts: Recognition is given for advancements in the CLIP text encoder methodology through pretraining, as well as the deployment of Poseidon, a new model for PDEs with sample-efficient and accurate results, highlighting papers on Jina CLIP and Poseidon.
- Softmax Attention's Tenure in Transformers: A debate has crystallized around the necessity of softmax weighted routing in transformers, with some engineers suggesting longstanding use trumps the advent of nascent mechanisms like "function attention" that retain similarities to existing methodologies.
- A Reproducibility Conundrum with Gemma-2b-it: Discrepancies emerged in attempts to replicate Gemma-2b-it's 17.7% success rate, with engineers turning to a Hugging Face forum and a Colab notebook for potential solutions, while results for Phi3-mini via lm_eval have proven more aligned with expected outcomes.
Modular (Mojo 🔥) Discord
- Mojo Rising: Package Management and Compiler Conundrums: The Mojo community is awaiting updates on a proposed package manager, as per Discussion #413 and Discussion #1785. The recent nightly Mojo compiler version
2024.5.3112brought fixes and feature changes, outlined in the raw diff and current changelog.
- Ready for Takeoff: Community Meetings and Growth: The Mojo community looks forward to the next meeting featuring interesting talks on various topics with details available in the community doc and participation through the Zoom link.
- The Proof is in the Pudding: Mojo Speeds and Fixes: A YouTube video demonstrates a significant speedup by porting K-Means clustering to Mojo, detailed here. The discovery of a bug in
reversed(Dict.items())which caused flaky tests was rectified with a PR found here.
- STEMming the Learning Curve: Educational Resources for Compilers: For learning about compilers, an extensive syllabus has been recommended, available here.
- Stringing Performance Together: A more efficient string builder is proposed to avoid memory overhead and the conversation inclines toward zero-copy optimizations along with using
iovecandwritevfor better memory management.
LangChain AI Discord
- Public Access for LangChainAPI: A request was made for a method to expose LangChainAPI endpoints publicly for LangGraph use cases, with an interest in utilizing LangServe but awaiting an invite.
- LangGraph Performance Tuning: Discussions around optimizing LangGraph configurations focused on reducing load times and increasing the start-up speed of agents, indicating a preference for more efficient processes.
- Memory and Prompt Engineering in Chat Applications: Participants sought advice on integrating summaries from "memory" into
ChatPromptTemplateand combiningConversationSummaryMemorywithRunnableWithMessageHistory. They shared tactics for summarizing chat history to manage the token count effectively, alongside relevant GitHub resources and LangChain documentation.
- LangServe Website Glitch Reported: An error on the LangServe website was reported, together with sharing a link to the site for further details.
- Prompt Crafting with Multiple Variables: Queries were made on how to structure prompts with several variables from the LangGraph state, providing a formulated prompt example and inquiries about variable insertion timing.
- Community Projects and Tool Showcases: In the community work sphere, two projects were highlighted: a YouTube tutorial on creating custom tools for agents (Crew AI Custom Tools Basics), and an AI tool named AIQuire for document insights, which is available for feedback at aiquire.app.
LAION Discord
- Fineweb Fires Up Image-Text Grounding: A promising approach called Fineweb utilizes Puppeteer to scrape web content, extracting images with text for VLM input—offering novel means for grounding visual language models. See the Fineweb discussion here.
- StabilityAI's Selective Release Stirs Debate: StabilityAI's decision to only release a 512px model, leaving the full suite of SD3 checkpoints unpublished, incites discussion among members on how this could influence future model improvements and resource allocation.
- Positional Precision: There's technical chatter regarding how positional embeddings in DiT models may lead to mode collapse when tackling higher resolution images, despite their current standard uses.
- Open-Source Jubilation: The open-source project tooncrafter excites the community with its potential, although minor issues are being addressed, showcasing a communal drive towards incremental advancement.
- Yudkowsky's Strategy Stirs Controversy: Eliezer Yudkowsky's institute published a "2024 Communication Strategy" advocating for a halt in AI development, sparking diverse reactions amongst tech aficionados. Delve into the strategy.
- Merging Models at NeurIPS: NeurIPS is hosting a Model Merging competition with an $8K prize to spur innovation in LLMs. Interested participants should visit the official Discord and registration page.
- RB-Modulation for Aesthetic AI Artistry: The RB-Modulation method presents a novel way to stylize and compose images without additional training, and members can access the project page, paper, and soon-to-be-released code.
OpenAccess AI Collective (axolotl) Discord
- Yuan2 Model Sparks Community Interest: Members shared insights on the Yuan2 model on Huggingface, highlighting a keen interest in examining its training aspects.
- Training Techniques Face-Off: Detailed discussions compared various preference training methodologies, spotlighting the ORPO method, which was suggested to supersede SFT followed by DPO, due to its "stronger effect". Supporting literature was referenced through an ORPO paper.
- Challenging Model Fine-Tuning: Concerns emerged over struggles in fine-tuning models like llama3 and mistral for Spanish entity categorization. One instance detailed issues with model inference after successful training.
- Members Seek and Offer Tech Aid: From installation queries about Axolotl and CUDA to configuring an early stopping mechanism using Hugging Face Accelerate library for overfitting issues, the guild members actively sought and rendered technical assistance. Shared resources included the axolotl documentation and the early stopping configuration guide.
- Axolotl Configuration Clarifications: There was an advisory exchange regarding the proper configuration of the
chat_templatein Axolotl, recommending automatic handling by Axolotl to manage Alpaca formatting with LLama3.
DiscoResearch Discord
- DiscoLeo Caught in Infinite Loop: The incorporation of ChatML into DiscoLeo has resulted in an End Of Sentence (EOS) token issue, causing a 20% chance of the model entering an endless loop. Retraining DiscoLeo with ChatML data is proposed for resolution.
- ChatML Favored for Llama-3 Template: German finetuning has shown a preference for using ChatML over the Llama-3 instruct template, especially when directed towards models like Hermes Theta that are already ChatML-based.
- IBM’s “Granite” Models Spark Curiosity: Engineers are exploring IBM's Granite models, including Lab version, Starcode-based variants, and Medusa speculative decoding, with resources listed on IBM’s documentation and InstructLab Medium article.
- Merlinite 7B Pit Against Granite: The Merlinite 7B model has garnered attention for its proficiency in German, vying for comparison with the IBM Granite models tracked under the Lab method.
- Quality Concerns Over AI-Generated Data: The community indicated dissatisfaction with the quality of AI-generated data, illustrated by sub-par results in benchmarks like EQ Bench on q4km gguf quants, and showed interest in new strategies to enhance models without catastrophic forgetting.
Interconnects (Nathan Lambert) Discord
- Google's Expansion Raises Eyebrows: A tweet has hinted at Google bolstering its compute resources, sparking speculation over its implications for AI model training capacities.
- OpenAI Puts Robotics Back on Table: OpenAI reboots its robotics efforts, now hiring research engineers, as reported via Twitter and in a Forbes article, marking a significant re-entry into robotics since 2020.
- Confusion Clouds GPT-3.5's API: Community members expressed frustration with the confusing documentation and availability narrative around GPT-3.5; some pointed out discrepancies in timelines and the inconvenience caused by deleted technical documentation.
- Sergey's Call to Arms for Physical Intelligence: Nathan Lambert relayed Sergey's recruitment for a project in physical intelligence, signaling opportunities for those with interest in Reinforcement Learning (RL) to contribute to practical robot utilization.
- 'Murky Waters in AI Policy' Session Served Hot: The latest episode of the Murky Waters in AI Policy podcast dishes out discussions on California's controversial 1047 bill and a rapid-fire roundup of recent OpenAI and Google mishaps. Nathan Lambert missed the open house for the bill, details of attendance or reasons were not provided.
Cohere Discord
- Cohere Pioneering AI Sustainability: Cohere was noted for prioritizing long-term sustainability over immediate grand challenges, with a focus on concrete tasks like information extraction from invoices.
- AGI Still Room to Grow: Within the community, it's agreed that the journey to AGI is just starting, and there's a continuous effort to understand what lies beyond the current "CPU" stage of AI development.
- Enhanced Server Experience with Cohere: The server is undergoing a makeover to simplify channels, add new roles and rewards, replace server levels with "cohere regulars," and introduce Coral the AI chatbot to enhance interactions.
- Express Yourself with Custom Emojis: For a touch of fun and to improve interactions, the server will incorporate new emojis, with customization options available through moderator contact.
- Feedback Wanted on No-Code AI Workflows: A startup is looking for insights on their no-code workflow builder for AI models, offering a $10 survey incentive—they're curious why users might not return after the first use.
Latent Space Discord
Adapter Layers Bridge the Gap: Engineers are exploring embedding adapters as a means to improve retrieval performance in AI models, with evidence showcased in a Chroma research report. The effectiveness of these can be likened to Froze Embeddings, which the Vespa team employs to eliminate frequent updates in dynamic systems (Vespa's blog insights).
ChatGPT Goes Corporate with PwC: The acquisition of ChatGPT Enterprise licenses by PwC for roughly 100,000 employees sparked debates around the estimated value of $30M/year, with member guesses on the cost per user ranging from $8 to $65 per month.
Google's Twin Stars: Gemini 1.5 Flash & Pro: Release updates for Google Gemini 1.5 Flash and Pro have been pushed to general availability, introducing enhancements such as increased RPM limits and JSON Schema mode (Google developers blog post).
TLBrowse Joins the Open Source Universe: TLBrowse, melding Websim with TLDraw, was open-sourced, allowing users to conjure up infinite imagined websites on @tldraw canvas, with access to a free hosted version.
AI Stack Devs (Yoko Li) Discord
- Literary Worlds in Your Browser: Rosebud AI gears up for their "Book to Game" game jam, inviting participants to build games from literary works with Phaser JS. The event offers a $500 prize and runs until July 1st, details available through their Twitter and Discord.
- Navigating the Digital Terrain: A new guild member expressed difficulties in using the platform on Android, describing the experience as "glitchy and buggy". They also sought help with changing their username to feel more at home within the virtual space.
OpenInterpreter Discord
- Check the Pins for Manufacturing Updates: It's crucial to stay on top of the manufacturing updates in the OpenInterpreter community; make sure to check the pinned messages in the #general channel for the latest information.
- Codestral Model Sparks Curiosity: Engineers have shown interest in the Codestral model with queries about its efficiency appearing in multiple channels; however, user experiences have yet to be shared. Additionally, it's noted that Codestral is restricted to non-commercial use.
- Combating Integration Challenges: There's a shared challenge in integrating HuggingFace models with OpenInterpreter, with limited success using the
interpreter -ycommand. Engineers facing these issues are advised to seek advice in the technical support channel. - Scam Alert Issued: Vigilance is essential as a "red alert" was issued about a potential scam within the community. No further details about the scam were provided.
- Android Functionality Discussions Ongoing: Members are engaged in discussions regarding O1 Android capability, specifically around installation in Termux, although no conclusive responses have been observed yet.
Mozilla AI Discord
- Llamafile Joins Forces with AutoGPT: AutoGPT member announced a collaboration to weave Llamafile into their system, expanding the tool's reach and capabilities.
- Inquiry into Content Blocks: Queries were made about whether Llamafile can handle content blocks within messages, seeking parity with an OpenAI-like feature; similar clarity was sought for llama.cpp's capabilities in this domain.
MLOps @Chipro Discord
- Netflix PRS Event Gathering AI Enthusiasts: AI professionals are buzzing about the PRS event at Netflix, with multiple members of the community confirming attendance for networking and discussions.
Datasette - LLM (@SimonW) Discord
- Mistral 45GB Model Composition Speculations: Interest is brewing around the Mistral 45GB model's language distribution, with a hypothesis suggesting a strong bias towards English and a smaller presence of programming languages.
- Codestral Compliance Conundrum: The community is engaging with the intricacies of the Mistral AI Non-Production License (MNPL), finding its restrictions on sharing derivative or hosted works underwhelming and limiting for Codestral development.
tinygrad (George Hotz) Discord
- TensorFlow vs. PyTorch Debate Continues: A user named helplesness asked why TensorFlow might be considered better than PyTorch, sparking a comparison within the community. The discussion did not provide an answer but is indicative of the ongoing preference debates among frameworks in the AI engineering world.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!