[AINews] Vision Everywhere: Apple AIMv2 and Jina CLIP v2
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Autoregressive objectives are all you need.
AI News for 11/22/2024-11/23/2024. We checked 7 subreddits, 433 Twitters and 28 Discords (211 channels, and 2674 messages) for you. Estimated reading time saved (at 200wpm): 265 minutes. You can now tag @smol_ai for AINews discussions!
Inline with the general theme of everyone going multimodal (Pixtral, Llama 3.2, Pixtral Large), advancements in "multimodal" (really just vision) embeddings are very foundational. This makes Apple and Jina's releases in the past 48 hours particularly welcome.
Apple AIMv2
Their paper (GitHub here) details "a novel method for pre-training of large-scale vision encoders": pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens.

This extends last year's AIMv1 work on vision models pre-trained with an autoregressive objective, which added T5-style prefix attention and a token-level prediction head, managing to pre-train a 7b AIM that achieves 84.0% on ImageNet1k with a frozen trunk.
The main update is introducing joint visual and textual objectives, which seem to scale up very well:

AIMV2-3B now achieves 89.5% accuracy on the same benchmark - smaller but better. The qualitative vibes are also excellent:

Jina CLIP v2
While Apple did more foundational VQA research, Jina's new CLIP descendant is immediately useful for multimodal RAG workloads. Jina released embeddings-v3 a couple months ago, and now is rolling its text encoder into its CLIP offering:
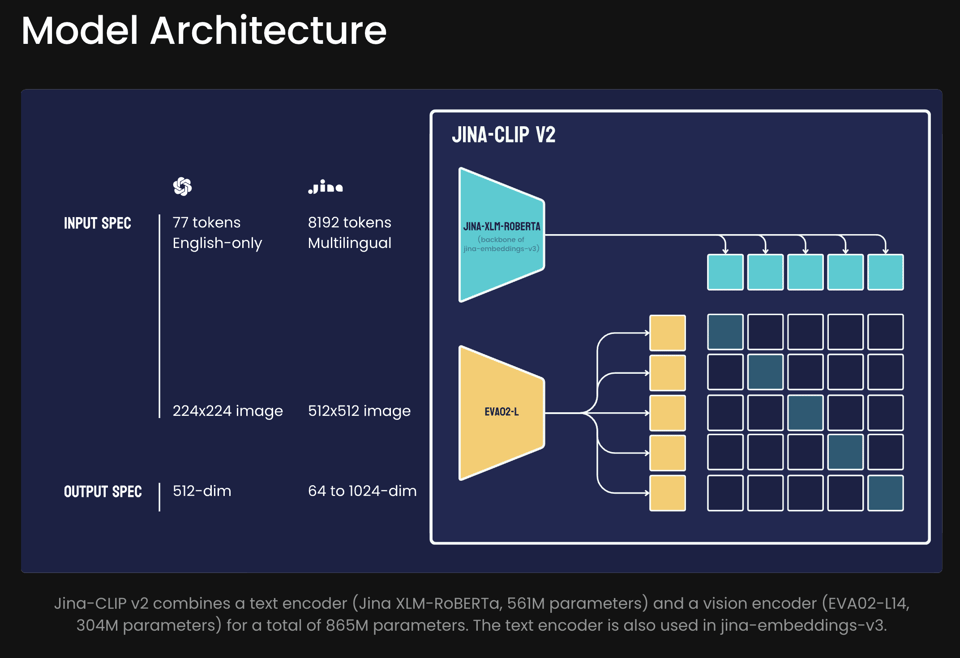
The tagline speaks to how many state of the art features Jina have packed into their release: "a 0.9B multimodal embedding model with multilingual support of 89 languages, high image resolution at 512x512, and Matryoshka representations."
The Matryoshka embeddings are of particular distinction: "Compressing from 1024 to 64 dimensions (94% reduction) results in only an 8% drop in top-5 accuracy and 12.5% in top-1, highlighting its potential for efficient deployment with minimal performance loss."
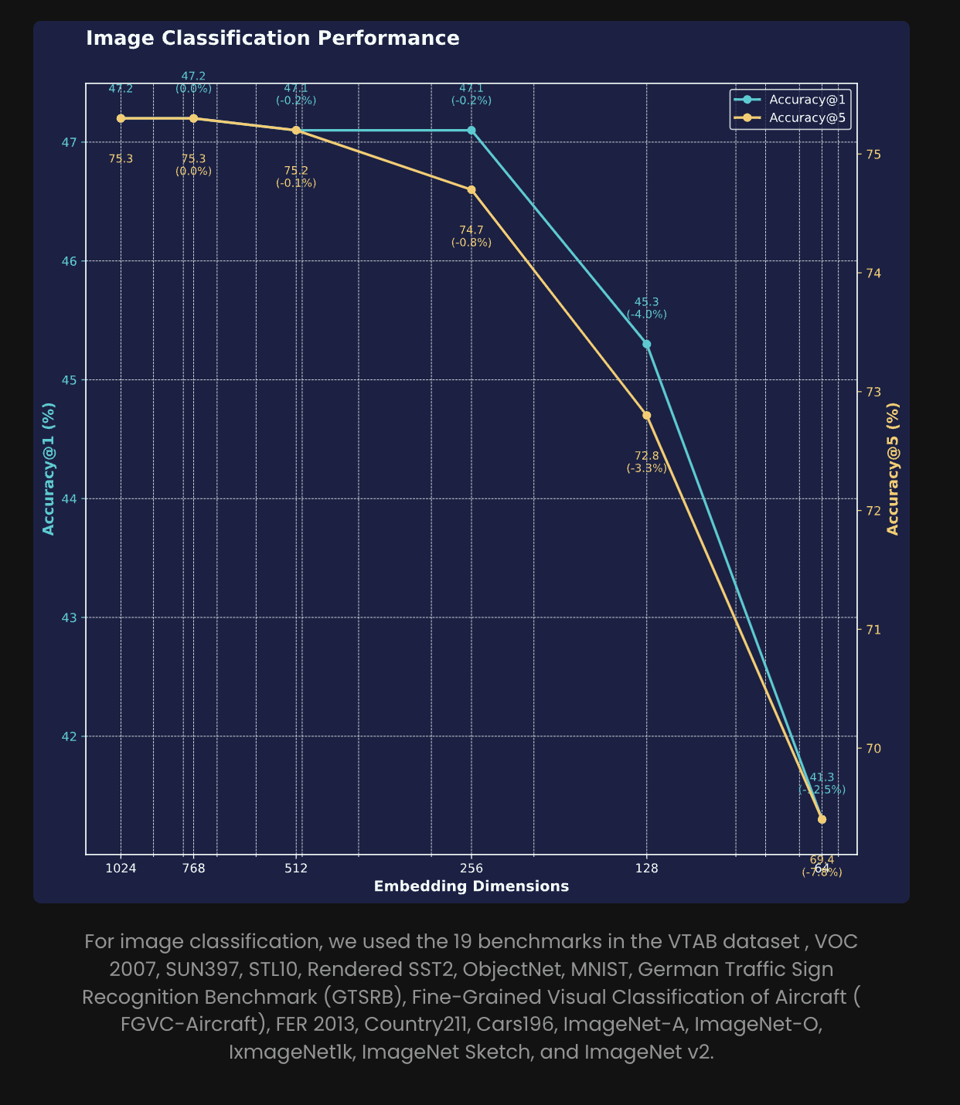
Table of Contents
- Apple AIMv2
- Jina CLIP v2
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Eleuther Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- HuggingFace Discord
- Latent Space Discord
- OpenAI Discord
- aider (Paul Gauthier) Discord
- Nous Research AI Discord
- OpenRouter (Alex Atallah) Discord
- Perplexity AI Discord
- Stability.ai (Stable Diffusion) Discord
- LlamaIndex Discord
- Notebook LM Discord Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- Modular (Mojo 🔥) Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- PART 2: Detailed by-Channel summaries and links
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (15 messages🔥):
- Eleuther ▷ #research (408 messages🔥🔥🔥):
- Eleuther ▷ #lm-thunderdome (13 messages🔥):
- Eleuther ▷ #multimodal-general (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (240 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (16 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (69 messages🔥🔥):
- LM Studio ▷ #general (153 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (121 messages🔥🔥):
- HuggingFace ▷ #general (215 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (4 messages):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (10 messages🔥):
- HuggingFace ▷ #NLP (4 messages):
- HuggingFace ▷ #diffusion-discussions (17 messages🔥):
- Latent Space ▷ #ai-general-chat (87 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (162 messages🔥🔥):
- OpenAI ▷ #ai-discussions (186 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- aider (Paul Gauthier) ▷ #general (155 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (38 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- Nous Research AI ▷ #general (150 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (19 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (118 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (8 messages🔥):
- Perplexity AI ▷ #general (81 messages🔥🔥):
- Perplexity AI ▷ #sharing (15 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (79 messages🔥🔥):
- LlamaIndex ▷ #general (63 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Notebook LM Discord ▷ #use-cases (10 messages🔥):
- Notebook LM Discord ▷ #general (46 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #other-papers (1 messages):
- Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (5 messages):
- Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Interconnects (Nathan Lambert) ▷ #memes (3 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (4 messages):
- Interconnects (Nathan Lambert) ▷ #posts (1 messages):
- GPU MODE ▷ #general (1 messages):
- GPU MODE ▷ #triton (5 messages):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #algorithms (1 messages):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (2 messages):
- GPU MODE ▷ #torchao (4 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #🍿 (4 messages):
- GPU MODE ▷ #edge (1 messages):
- Cohere ▷ #discussions (14 messages🔥):
- Cohere ▷ #projects (1 messages):
- SQL Agent with Cohere and LangChain (i-5O Case Study) — Cohere
- tinygrad (George Hotz) ▷ #general (4 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
- Modular (Mojo 🔥) ▷ #mojo (7 messages):
- Torchtune ▷ #general (3 messages):
- Torchtune ▷ #papers (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
- OpenInterpreter ▷ #general (4 messages):
- OpenInterpreter ▷ #O1 (1 messages):
- DSPy ▷ #general (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
- LAION ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
1. Cutting-edge AI Model Releases and Developments: Tülu 3, AIMv2, and More
- Tülu 3 models by @allen_ai: Tülu 3 family, based on Llama 3.1, includes 8B and 70B models and offers 2.5x faster inference compared to Tulu 2. It's aligned using SFT, DPO, and RL-based methods with all resources publicly available.
- Discussions on Tülu 3 stress its competitiveness with other leading LLMs like Claude 3.5 and Llama 3.1 70B. The release includes public access to datasets, model checkpoints, and training code for practical experimentation.
- Effective Open Science for Tülu models is emphasized, praising the incorporation of new techniques like RL with Verifiable Rewards (RLVR).
- Apple's AIMv2 Vision Encoders: AIMv2 encoders outperform CLIP and SigLIP in multimodal benchmarks. They feature impressive results in open-vocabulary object detection and high ImageNet accuracy with a frozen trunk.
- AIMv2-3B achieves 89.5% on ImageNet using integrated transformers code.
- Jina-CLIP-v2 by JinaAI: A multimodal model with support for 89 languages and 512x512 image resolution, built to enhance text and image interactions. The model shows strong performance on retrieval and classification tasks.
2. AI Agents Enhancements & Applications: FLUX Tools, Insights from Suno
- FLUX Tools Suite by Black Forest Labs: New specialized models offer enhanced control over AI image generation. Available in anychat via @replicate API, supporting new Canny, Depth, and Redux models.
- FLUX tools empower developers to create engaging multimedia content with greater precision and customization.
- Suno and AI in Music Production: Suno's v4 is used for creative music endeavors, showcasing AI's transformative role in music production with Bassel from Suno delivering new AI-generated compositions.
- Additionally, discussions on integrating AI with beatboxing reflect on Suno's unique contributions to music creation.
3. AI, Science, and Society
- Generating Scientific Discoveries with AI: A panel by GoogleDeepMind spotlights AI revolutionizing scientific methods and aiding discovery. Key participants include Eric Topol, Pushmeet, Alison Noble, and Fiona Marshall.
- Baby-AIGS System Research explores AI's potential in scientific discovery through falsification and ablation studies, highlighting early-stage research focusing on executable scientific proposals.
- AI and Scientific Method Discussions: A deeper look into how AI is reshaping scientific methodologies with distinguished experts sharing insights.
- Participants debate AI's role in fostering new scientific breakthroughs and its intersection with biomedical research.
4. Advancements in AI Ethics, Red Teaming, and Bug Fixing
- OpenAI's Red Teaming Enhancements: White papers on red teaming disclose new methods involving external red teamers and automated systems, enhancing AI safety evaluations.
- These efforts aim to enrich AI's robustness by actively involving diverse human feedback in testing.
- MarsCode Agent in Bug Fixing: ByteDance's MarsCode Agent showcases significant success in automated bug fixing on the SWE-bench Lite benchmark, stressing the importance of precise error localization in problem resolution.
- Challenge areas are highlighted for future innovation in automated workflows.
5. Collaborations and Innovations in Companies and Tools
- Anthropic and Amazon's $4B Collaboration: A partnership to develop next-generation AI models focusing on AWS infrastructure, illustrating a strong alliance in AI development.
- This strategic investment emphasizes using Amazon-developed silicon to optimize training processes.
- LangGraph Voice Interaction Features: Integration of voice recognition capabilities with AI agents, leveraging OpenAI's Whisper and ElevenLabs for seamless voice interfaces.
- LangGraph enhances AI's adaptability in real-world applications, offering more natural interactions.
6. Memes, Humor, and Social Commentary
- Humor in Tech Tensions with LLM Benchmarks: A satirical take on AI model performance 'wars' and benchmarks, mocking the obsession with evaluation scores as reductive and misleading.
- Community voices express skepticism over the relevance of certain benchmarks in real-world AI model performance.
- Commentary on Elon Musk's Ventures: Wry remarks scrutinize the narrative of free speech as perceived on platforms owned by tech giants like Musk, challenging assumptions of open discourse.
- Critical reflections on changes in major tech platforms and their implications for genuine free expression.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek Emerges as Leading Chinese Open Source AI Company
- Chad Deepseek (Score: 1486, Comments: 174): DeepSeek created a model that matches or exceeds OpenAI's performance while using only 18,000 GPUs compared to OpenAI's 100,000 GPUs. This efficiency demonstrates significant improvements in model training approaches and resource utilization in large language model development.
- Strong community support for Chinese open-source AI companies including Qwen, DeepSeek, and Yi, with users highlighting their efficiency in achieving comparable results with fewer resources (18K GPUs vs OpenAI's 100K GPUs).
- Discussion around model performance focused on practical capabilities, with users reporting success in mathematical reasoning (specifically the "-4 squared" problem) and coding tasks, while some noted limitations in creative reasoning and nuanced responses.
- Debate emerged about political censorship in AI models, with users discussing how both Chinese and Western models handle sensitive historical topics, and the impact of GPU export restrictions potentially incentivizing more open-source development from Chinese companies.
- Competition is still going on when i am posting this.. DeepSeek R1 lite has impressed me more than any model releases, qwen 2.5 coder is not capable for these competitions , but deepseek r1 solved 4 of 7 , R1 lite is milestone in open source ai world truly (Score: 41, Comments: 10): DeepSeek R1 Lite demonstrates strong performance in an ongoing coding competition by solving 4 out of 7 problems, outperforming Qwen 2.5 Coder. The model's success marks significant progress in open-source AI development.
- DeepSeek R1 Lite is rumored to be a 16B parameter model, though performance suggests it could be larger. Community speculation points to it being a 16B MoE model, given the timing with OpenAI's O1 release and current GPU shortages.
- Model weights are not yet publicly available but are expected to be released "soon". Community sentiment emphasizes waiting for actual open-source release before declaring it a milestone.
- No detailed model information or technical specifications have been officially released yet, making performance claims preliminary.
Theme 2. Innovative Model Architectures: Marco-o1 and OpenScholar
- Marco-o1 from MarcoPolo Alibaba and what it proposes (Score: 40, Comments: 0): Marco-o1, developed by MarcoPolo Alibaba, combines Chain of Thought (CoT), Monte Carlo Tree Search (MCTS), and reasoning action to tackle open-ended problems without established solutions, differentiating itself from OpenAI's o1. The model integrates these three components to enable logical problem-solving, optimal path selection, and dynamic detail adjustment, while aiming to excel at both writing and reasoning tasks across multiple domains, with the model available at AIDC-AI/Marco-o1.
- OpenScholar: The open-source AI outperforming GPT-4o in scientific research (Score: 98, Comments: 2): OpenScholar, developed by Allen Institute for AI and University of Washington, combines retrieval systems with a fine-tuned language model to provide citation-backed research answers, outperforming GPT-4o in factuality and citation accuracy. The system implements a self-feedback inference loop for output refinement and is available as an open-source model on Hugging Face, making it more accessible to smaller institutions and researchers in developing countries, despite limitations in open-access paper availability.
- The AI2 blog post provides more comprehensive technical details about OpenScholar compared to the VentureBeat coverage, as referenced at allenai.org/blog/openscholar.
Theme 3. System Prompts and Tokenizer Optimization Insights
- Leaked System prompts from v0 - Vercels AI component generator. (100% legit) (Score: 292, Comments: 54): A developer leaked Vercel's V0 system prompts which reveal the AI tool uses MDX components, specialized code blocks, and a structured thinking process with internal reminders for generating UI components. The system includes detailed specifications for handling React, Node.js, Python, and HTML code blocks, with emphasis on using shadcn/ui library, Tailwind CSS, and maintaining accessibility standards, as documented in their GitHub repository.
- The discussion suggests V0 likely uses Claude/Sonnet rather than GPT-4 due to its XML tag structure and proficiency with shadcn/ui, as referenced in Anthropic's documentation about prompt structuring.
- Multiple users confirm the system uses closed-source SOTA models rather than open-source ones, with the complete prompt being approximately 16,000 tokens long and containing dynamic content including NextJS/React documentation.
- An updated version of the V0 system prompts was leaked and shared via GitHub, with some users noting similarities to Qwen2.5-Coder-Artifacts but specifically for React implementations.
- Beware of broken tokenizers! Learned of this while creating v1.3 RPMax models! (Score: 137, Comments: 31): Tokenizer issues affect model performance in RPMax v1.3 models, though no specific details were provided about the nature of the problems or solutions.
- RPMax versions have evolved from v1.0 to v1.3, with v1.3 implementing rsLoRA+ (rank-stabilized low rank adaptation) for improved learning and output quality. Mistral-based models proved most effective due to being naturally uncensored, while Llama 3.1 70B achieved the lowest loss rates.
- A critical tokenizer bug in the Huggingface transformers library causes tokenizer file sizes to double when modified, affecting model performance. The issue can be reproduced using AutoTokenizer.from_pretrained() followed by save_pretrained(), which incorrectly regenerates the "merges" section.
- The RPMax training approach is unconventional, using a single epoch, low gradient accumulation, and higher learning rates, resulting in unstable but steadily decreasing loss curves. This method aims to prevent the model from reinforcing specific character tropes or story patterns.
Theme 4. INTELLECT-1: Distributed Training Innovation
- Open Source LLM INTELLECT-1 finished training (Score: 268, Comments: 28): INTELLECT-1, an open source Large Language Model, completed its training phase using distributed GPU resources worldwide. No additional context or technical details about the model architecture, training parameters, or performance metrics were provided in the post.
- The model's distributed training approach across global GPU resources generated significant community interest, with users comparing it to protein folding projects and requesting ways to contribute their own GPUs. The dataset is expected to be released by the end of November according to their website.
- Discussion around the model's open source status sparked debate, with comparisons to existing open models like Olmo and K2-65B. Users noted that while other models have shared scripts and datasets, INTELLECT-1's distributed compute contribution represents a unique approach.
- Technical observations included a perplexity and loss bump coinciding with learning rate reduction, attributed to the introduction of higher quality data with different token distribution. Users noted that while the model's performance isn't exceptional, it represents an important first iteration.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Amazon x Anthropic $4B Investment & Cloud Partnership
- It's happening. Amazon X Anthropic. (Score: 323, Comments: 103): Amazon commits $4 billion investment in Anthropic and establishes AWS as their primary cloud and training partner according to Anthropic's announcement. The partnership focuses on cloud infrastructure and AI model training using AWS Trainium.
- AWS users note they've been using Claude in production for over a year, with some expressing that Amazon Q already uses Claude behind the scenes. The partnership strengthens an existing relationship that included plans to bring Claude to Alexa.
- A key benefit of the deal addresses Claude's compute limitations and performance issues, with AWS Trainium replacing CUDA for model training. The shift from Nvidia hardware to Amazon's infrastructure suggests significant technical changes ahead.
- Users highlight concerns about rate limits and service reliability, with speculation about potential Prime integration (possibly with ads). Some compare this to the Microsoft-OpenAI partnership, noting that Google (also an Anthropic investor) may face challenges with their investment position.
- Tired of "We're experiencing High Demand" (Score: 34, Comments: 19): Claude's paid service faces increasing capacity issues, with users frequently encountering "We're experiencing High Demand" messages despite being paying subscribers. The post criticizes Anthropic's prioritization of feature releases over infrastructure scalability, expressing frustration with service limitations for paid customers.
- Users report that Claude's quality degrades during high demand periods, with "Full Response" mode potentially offering limited inference capabilities and faster token consumption.
- Multiple users confirm experiencing daily service disruptions, with one user canceling their subscription due to the AI's unreliability in handling routine tasks, making manual completion more efficient.
- A user speculates that military procurement of computing resources might be causing the capacity constraints, though this remains unverified.
Theme 2. GPT-4o Performance Regression on Technical Benchmarks
- Independent evaluator finds the new GPT-4o model significantly worse, e.g. "GPQA Diamond decrease from 51% to 39%, MATH decrease from 78% to 69%" (Score: 262, Comments: 53): GPT-4o shows performance drops across technical benchmarks, with GPQA Diamond scores falling from 51% to 39% and MATH scores decreasing from 78% to 69%. The decline in performance on technical tasks suggests a potential regression in the latest model's capabilities compared to its predecessor.
- GPT-4o appears to be optimized for natural language tasks over technical ones, with users noting it feels "more natural" despite lower benchmark scores. Several users suggest OpenAI is intentionally separating capabilities between models, with GPT-4o focusing on writing and O1 handling technical reasoning.
- Users report mixed experiences with current model alternatives: Claude Sonnet faces message limits, O1-mini is described as verbose, and O1-preview is restricted to 50 questions per week. Some users mention Gemini experimental 1121 showing promise in problem-solving and math.
- Discussion around benchmarking methods emerged, with users criticizing LMSYS as an inadequate performance metric and questioning the value of single-token math answers versus complex instruction responses. The model's decline in technical performance may reflect intentional trade-offs rather than regression.
- Why does ChatGPT get lazy? (Score: 146, Comments: 134): Users report ChatGPT providing increasingly superficial and incomplete responses, with examples of the AI giving brief, non-comprehensive answers that miss key details from prompts and require frequent corrections. The post author notes experiencing a pattern where ChatGPT acknowledges mistakes when corrected but continues to provide shallow responses, questioning whether there's an underlying reason for this perceived decline in performance.
- Users report significant decline in GPT-4 performance after recent "creative upgrade", with evidence showing it performing worse than GPT-4 mini on STEM subjects and basic math, as shown in a comparison image.
- Multiple users describe context retention issues and memory problems, with the AI frequently ignoring detailed prompts and custom instructions. The degradation appears linked to OpenAI's cost-cutting measures and reduced processing power allocation.
- Technical users report specific issues with code generation, document review, and detailed queries, noting that responses have become more generic and less task-specific. Several mention needing multiple attempts to get comprehensive answers that were previously provided in single responses.
Theme 3. LTX Video: New Open Source Fast Video Generation Model
- LTX Video - New Open Source Video Model with ComfyUI Workflows (Score: 259, Comments: 122): LTX Video, a new open source video model, integrates with ComfyUI and is available through Hugging Face and ComfyUI examples. The model provides video generation capabilities through ComfyUI workflows, offering users direct access to video creation tools.
- A member of the research team confirmed that LTX-Video can generate 24 FPS videos at 768x512 resolution in real-time, with more improvements planned. The model runs on a 3060/12GB in about 1 minute, while a 4090 takes 1:48s for a 10s video.
- Users reported mixed results with the model's performance, particularly with img2video functionality showing glitches. The research team acknowledged that results are highly prompt-sensitive and provided detailed example prompts on their GitHub page.
- The model is now integrated into the latest ComfyUI update and supports multiple modes including Text2Video, Image2Video, and Video2Video. Users need to follow specific prompt structures, with movement descriptions placed early in the prompt for best results.
- LTX-Video is Lightning fast - 153 frames in 1-1.5 minutes despite RAM offload and 12 GB VRAM (Score: 95, Comments: 30): LTX-Video demonstrates high-speed video generation capabilities by producing 153 frames in 1-1.5 minutes while operating with 12GB VRAM constraints and RAM offloading. This performance metric shows efficient consumer hardware utilization for video generation tasks.
- LTX-Video runs efficiently on consumer hardware, with users confirming successful operation on a 12GB 4070Ti despite 18GB VRAM requirements through RAM offloading. Installation guide available at ComfyUI blog.
- Users discuss future potential, noting upcoming 32GB VRAM consumer cards and comparing current state to early Toy Story era skepticism. The technology is expected to advance significantly in 2-3 years.
- Current version (0.9) is described as prompt-sensitive with improvements planned, while some users debate output quality. Raw outputs are generated without interpolation.
Theme 4. Chinese AI Models Emerge as Potential Competitors
- Has anyone explored Chinese AI in depth? (Score: 62, Comments: 128): Chinese AI models including DeepSeek, ChatGLM, and Ernie Bot offer free access and produce high-quality responses that potentially compete with ChatGPT-4 in certain domains. The post author notes limited community discussion about these models despite their capabilities.
- Users express strong concerns about data privacy and censorship under the Chinese Communist Party (CCP), with multiple commenters citing risks of surveillance and information control. The highest-scoring comments focus on these trust and privacy issues.
- Discussion highlights potential future scenarios including an "East versus West" divide in AI development and possible competing singularities between nations. Several users note this could lead to compatibility and competition challenges.
- Comments point to market awareness and first-mover advantage of Western AI models (ChatGPT, Claude, Gemini) as a key factor in their dominance, rather than technical capabilities being the primary differentiator.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. The AI Arms Race: New Models and Breakthroughs
- INTELLECT-1 Trained Across the Globe in Decentralized First: Prime Intellect announced the completion of INTELLECT-1, the first-ever 10B model trained via decentralized efforts across the US, Europe, and Asia. An open-source release is coming in about a week, marking a milestone in collaborative AI development.
- Alibaba Drops Marco-o1: Open-Sourced Alternative to ChatGPT's o1: AlibabaGroup released Marco-o1, an Apache 2 licensed model designed for complex problem-solving using Chain-of-Thought (CoT) fine-tuning and Monte Carlo Tree Search (MCTS). Researchers like Xin Dong and Yonggan Fu aim to enhance reasoning in ambiguous domains.
- Lightricks' LTX Video Model Generates 5-Second Videos in a Flash: Lightricks unveiled the LTX Video model, which can generate 5-second videos in just 4 seconds on high-performance hardware. The model is open-source and available through APIs, pushing the boundaries of rapid video generation.
Theme 2. Billion-Dollar Moves: Anthropic and Amazon Shake Hands
- Anthropic Bags $4 Billion from Amazon, AWS Becomes BFF: Anthropic expanded its collaboration with AWS, securing a whopping $4 billion investment from Amazon. AWS is now Anthropic's primary cloud and training partner, leveraging AWS Trainium to power their largest models.
- Cerebras Claims Speed King with Llama 3.1 Deployment: Cerebras is boasting about running Llama 3.1 405B at impressive speeds, positioning themselves as leaders in large language model deployment and stirring up the AI hardware competition.
Theme 3. AI Accused: OpenAI Deletes Evidence in Lawsuit
- Oops! OpenAI 'Accidentally' Deletes Data Amid Lawsuit: Lawyers allege OpenAI erased data after 150 hours of search in a copyright lawsuit with The New York Times and Daily News. This raises serious concerns about data handling in legal disputes.
- CamelAI's Account Vanishes After 1 Million-Agent Simulation: CamelAIOrg had its OpenAI account terminated, possibly due to their OASIS social simulation project involving one million agents. Despite reaching out, they've waited 5 days without a response, leaving their community in limbo.
Theme 4. AI Tools Get Smarter: Enhancing Development and Workflows
- Unsloth Update Slashes VRAM Usage, Adds Vision Finetuning: The latest Unsloth update boosts VRAM efficiency by 30-70% and introduces vision finetuning for models like Llama 3.2 Vision. It also supports Pixtral finetuning in a free 16GB Colab, making advanced AI more accessible.
- LM Studio Debates Multi-GPU Magic and GPU Showdowns: LM Studio users discuss balancing multi-GPU inference and compare GPUs like RTX 4070 Ti and Radeon RX 7900 XT. While power consumption varies, they find performance differences marginal, sparking debates over the best hardware for AI tasks.
- Aider Users Tackle Quantization Quirks and Benchmark Bafflements: Aider community delves into how different quantization methods impact model performance. They note Qwen 2.5 Coder shows inconsistent results across providers, emphasizing the need to mind the quantization details.
Theme 5. AI Art and Creativity: Machines with a (Sense of) Humor
- AI Art Turing Test Confuses (and Amuses) Everyone: The recent AI Art Turing Test left participants puzzled, struggling to distinguish AI-generated art from human creations. Discussions sparked about the test's effectiveness and the evolving role of AI in art.
- Voice Cloning Glitches Turn Audiobooks into Surprise Musicals: Users experimenting with voice cloning for audiobooks encountered unexpected glitches, resulting in the AI singing responses. These happy accidents add an amusing twist to audiobook production.
- ChatGPT's Quest for Comedy Falls Flat (Again): Despite advances, AI models like ChatGPT still struggle with humor, often delivering lackluster jokes. Users note attempts at humor or ASCII art often end in gibberish, highlighting room for improvement in AI's comedic skills.
PART 1: High level Discord summaries
Eleuther Discord
- Test-Time Training Boosts ARC Performance: Recent experiments with Test-Time Training (TTT) achieved up to 6x accuracy improvement on the Abstraction and Reasoning Corpus (ARC) compared to base models.
- Key factors include initial finetuning on similar tasks, auxiliary task formatting, and per-instance training, demonstrating TTT's potential in enhancing reasoning capabilities.
- Wave Network Introduces Complex Token Representation: The Wave Network utilizes complex vectors for token representation, separating global and local semantics, leading to high accuracy on the AG News classification task.
- Each token's value ratio to the global semantics vector establishes a novel relationship to overall sequence norms, enhancing the model's understanding of input context.
- Debate Emerges Over Learnable Positional Embeddings: Discussions on learnable positional embeddings in models like Mamba highlight their effectiveness based on input dependence compared to traditional embeddings.
- Concerns are raised about their performance in less constrained conditions, with alternatives like Yarn or Alibi being suggested for better flexibility.
- RNNs Demonstrate Out-of-Distribution Extrapolation: RNNs have shown capability to extrapolate out-of-distribution on algorithmic tasks, with some suggesting chaining of thought could be adapted to linear models.
- However, for complex tasks like those in the ARC, TTT may be more beneficial than In-Context Learning (ICL) due to RNNs' inherent representation limitations.
- Insights into Muon Orthogonalization Techniques: The implementation of Muon employs momentum and orthogonalization post-momentum update, which may affect its effectiveness.
- Discussions emphasize the importance of sufficient batch sizes for effective orthogonalization, especially when dealing with low-rank matrices.
Unsloth AI (Daniel Han) Discord
- Unsloth Update Boosts VRAM Efficiency: The latest Unsloth update introduces vision finetuning for models such as Llama 3.2 Vision, enhancing VRAM usage by 30-70% and adding support for Pixtral finetuning in a free 16GB Colab environment.
- Additionally, the update includes merging models into 16bit for streamlined inference and long context support for vision models, significantly improving usability.
- Mistral Models Outperform Peers: Users report that Mistral models excel in finetuning, demonstrating strong prompt adherence and superior accuracy compared to Llama and Qwen models.
- Despite their performance, some skepticism remains regarding Qwen's effectiveness, with reports of gibberish outputs in specific applications.
- Fine-tuning and Inference Challenges: Community members face difficulties when fine-tuning models, such as failing to load fine-tuned models for inference and encountering multiple model versions like BF16 and Q4 quantization in output folders.
- During inference, errors like
AttributeErrorandWebServerErrorsarise, particularly with models like 'Mistral-Nemo-Instruct-2407-bnb-4bit', prompting suggestions to replace model paths and verify compatibility with Hugging Face endpoints.
- During inference, errors like
- Tokenization and Pretraining Guidance: Issues with tokenization have been reported, including errors related to mismatched column lengths during training on datasets like Hindi, and empty predictions during evaluation stages.
- For continued pretraining, users discuss utilizing models beyond Unsloth's offerings and are encouraged to seek community support or raise compatibility requests on GitHub for non-supported models.
LM Studio Discord
- Balancing Multi-GPU Inference: Users discussed the feasibility of multi-GPU performance in LM Studio, particularly regarding inference and model distribution across multiple GPUs, noting that load balancing can complicate VRAM allocation.
- Concerns were raised about whether to pair different GPUs or opt for a more powerful single GPU for better overall performance.
- Comparing RTX 4070 Ti and Radeon RX 7900 XT: The community compared RTX 4070 Ti, Radeon RX 7900 XT, and GeForce RTX 4080 for performance at 1440p and 4K resolutions, noting that while power consumption varies, performance differences are generally marginal.
- Members discussed balancing power usage and performance, suggesting that higher quality models should be preferred for optimal results.
- Fine-tuning Models vs. RAG Strategies: Members debated the merits of fine-tuning models versus using RAG (Retrieval-Augmented Generation) strategies, with a consensus that fine-tuning can specialize a model for specific tasks while RAG offers more flexibility.
- Fine-tuning was exemplified with adapting models for C# coding languages, but concerns were raised about security implications with sensitive company data.
- AMD GPUs in LLM Benchmarking: AMD GPUs can run LLMs through ROCm or Vulkan; however, ongoing concerns about driver updates impacting performance were discussed.
- It was pointed out that ROCm operates mainly on Linux or WSL, limiting usability for some users.
- Anticipating the 5090 Graphics Card Release: Members expressed anticipation for the upcoming 5090 graphics card, with concerns about availability and pricing.
- Discussions included the impact of tariffs on hardware prices and the need to secure equipment ahead of expected price increases.
HuggingFace Discord
- IntelliBricks Toolkit Streamlines AI App Development: IntelliBricks is an open-source toolkit designed to simplify the development of AI-powered applications, featuring
msgspec.Structfor structured outputs. It is currently under development, with contributions welcome on its GitHub repository.- Developers are encouraged to contribute to enhance its capabilities, fostering a collaborative environment for building efficient AI applications.
- FLUX.1 Tools Enhance Image Editing Capabilities: The release of FLUX.1 Tools introduces a suite for editing and modifying images, including models like FLUX.1 Fill and FLUX.1 Depth, as announced by Black Forest Labs.
- These models improve steerability for text-to-image tasks, allowing users to experiment with open-access features and enhance their image generation workflows.
- Decentralized Training Completes INTELLECT-1 Model: Prime Intellect announced the completion of INTELLECT-1, a 10B model trained through decentralized efforts across the US, Europe, and Asia. A full open-source release is expected in approximately one week.
- This milestone highlights the effectiveness of decentralized training methodologies, with further details available in Prime Intellect's tweet.
- Cybertron v4 UNA-MGS Model Tops LLM Benchmarks: The cybertron-v4-qw7B-UNAMGS model has been reintroduced, achieving the #1 7-8B LLM ranking with no contamination and enhanced reasoning capabilities, as showcased on its Hugging Face page.
- Utilizing unique techniques such as
MGSandUNA, the model demonstrates superior benchmark performance, attracting attention from the AI engineering community.
- Utilizing unique techniques such as
- Cerebras Leads with High-Speed Llama 3.1 Deployment: Cerebras is setting the pace in LLM performance by running Llama 3.1 405B at impressive speeds, positioning themselves as leaders in large language model deployment.
- This advancement underscores Cerebras' commitment to optimizing AI model performance, providing a competitive edge in the rapidly evolving field of large language models.
Latent Space Discord
- Anthropic Secures $4B from AWS: Anthropic has received an additional $4 billion investment from Amazon, designating AWS as its primary cloud and training partner to enhance AI model training through AWS Trainium.
- This collaboration aims to leverage AWS infrastructure for developing and deploying Anthropic's largest foundation models, as detailed in their official announcement.
- AI Art Turing Test Sparks Mixed Reactions: The recent AI Art Turing Test has generated discussions, highlighted in this analysis, with participants struggling to distinguish between AI and human-generated artworks.
- Members are interested in evaluating the test with art restoration experts to better assess its effectiveness.
- Lightricks Unveils Open-Source LTX Video Model: Lightricks launched the LTX Video model, capable of generating 5-second videos in just 4 seconds on high-performance hardware, available through APIs.
- Discussions are focused on balancing local processing capabilities with cloud-related costs when utilizing the LTX Video Model.
- Stanford Releases AI Vibrancy Rankings Tool: Stanford introduced the AI Vibrancy Rankings Tool, which assesses countries based on customizable AI development metrics, allowing users to adjust indicator weights to match their perspectives.
- The tool has been praised for its flexibility in providing insights into global AI progress.
- LLM-powered Requirements Analysis Gains Traction: LLM-powered requirements analysis is emerging as a key topic, with members highlighting its effectiveness in automating complex problem understanding and modeling processes.
- The conversation points to significant potential for LLMs to streamline analysis workflows, referencing the DDD starter modeling process.
OpenAI Discord
- Voice Cloning Glitches Enhance Audiobooks: Members discussed voice cloning techniques for audiobook adaptations, noting unexpected sounds and glitches that sometimes resulted in surprising enhancements like singing. #ai-discussions
- A user shared experiences with various voice models, highlighting how voice cloning can create eerie effects in dialogues.
- ChatGPT Integrates with Airtable and Notion: ChatGPT was explored for its integration capabilities with tools like Airtable and Notion, aiming to enhance prompt writing within these applications. #ai-discussions
- Members shared their goals to improve prompt writing, seeking more personalized and effective interactions.
- Copilot's Image Generation Sparks Speculation: Curiosity arose about Copilot's image generation capabilities, with speculation on whether they're sourced from unreleased DALL-E models or a new program called Sora. #ai-discussions
- Comparisons were made between images generated by different AI tools, pointing out quality differences influenced by other models.
- GPT's Vocabulary Constraints in Dall-E Usage: A member expressed frustration that their GPT tends to forget specific vocabulary constraints after generating around 10 images with Dall-E. #gpt-4-discussions
- They are seeking tips to maintain character descriptions and avoid unwanted words in generated content.
- Exploring Alternatives and Free Image Models Beyond Dall-E: Members discussed alternatives to Dall-E such as Stable Diffusion and Flux models with comfyUI, suggesting they might better handle specific vocabulary restrictions. #gpt-4-discussions
- They recommended checking for recent tutorials on YouTube to ensure updated methods for preserving character integrity.
aider (Paul Gauthier) Discord
- Qwen 2.5 Coder's Performance Variability: Users observed that the Qwen 2.5 Coder model delivers inconsistent performance across providers, with Hyperbolic recording 47.4% compared to the leaderboard's 71.4%.
- Community discussions highlighted the effects of quantization, noting that BF16 and other variants yield different performance outcomes.
- Update in Aider's Benchmarking Approach: Aider's leaderboard for Qwen 2.5 Coder 32B now utilizes weights from HuggingFace via GLHF, enhancing benchmarking accuracy.
- Users raised concerns about score discrepancies linked to various hosting platforms, questioning potential variations in model quality.
- Direct API Integration with Qwen Models: The Aider framework can now access Qwen models directly without relying on OpenRouter, streamlining usage.
- This update aims to improve user experience by minimizing dependence on third-party services while maintaining model performance.
- Introduction of Uithub as a GitHub Alternative: Users are endorsing Uithub as a GitHub alternative for effortlessly copying repositories to LLMs by altering 'G' to 'U'.
- Feedback from members like Nick Dobos and Ian Nuttall emphasizes Uithub's capability to fetch full repository contexts, enhancing development workflows.
- Amazon's $4 Billion Investment in Anthropic: Amazon announced an additional $4 billion investment in Anthropic, intensifying the competitive landscape in AI development.
- This move has sparked discussions about the sustainability and innovation pace within AI projects amidst increasing corporate investments.
Nous Research AI Discord
- Marco-o1 Launch as ChatGPT o1 Alternative: AlibabaGroup has released Marco-o1, an Apache 2 licensed alternative to ChatGPT's o1 model, designed for complex problem-solving using Chain-of-Thought (CoT) fine-tuning and Monte Carlo Tree Search (MCTS).
- Researchers such as Xin Dong, Yonggan Fu, and Jan Kautz are leading the development of Marco-o1, aiming to enhance reasoning capabilities across domains with ambiguous standards and challenging reward quantification.
- Agentic Translation Workflow with Few-shot Prompting: The agentic translation workflow employs few-shot prompting and an iterative feedback loop instead of traditional fine-tuning, enabling the LLM to critique and refine its translations for increased flexibility and customization.
- By utilizing iterative feedback, this workflow avoids the overhead of training, thereby enhancing productivity in translation tasks.
- Alibaba's AWS Collaboration and $4B Investment: AnthropicAI announced a partnership with AWS, including a new $4 billion investment from Amazon, positioning AWS as their primary cloud and training partner, as shared in this tweet.
- Teknium highlighted in a tweet that sustaining pretraining scaling at the current pace will require $200 billion over the next two years, questioning the feasibility of ongoing advancements.
- Open WebUI for LLMs and Multi-model Chat Interfaces: Members discussed graphical user interfaces (GUIs) for LLM-hosted chat experiences, favoring tools like Open WebUI and LibreChat, with Open WebUI being widely preferred for its user-friendly interface.
- An animated demonstration of Open WebUI's features was shared, emphasizing its support for various LLM runners and its capacity to handle multiple model interactions efficiently.
- Fine-tuning Datasets with Axolotl's Example Defaults: A member seeking to fine-tune models and create datasets expressed concerns over high trial-and-error costs, prompting recommendations to use Axolotl's example defaults, which are deemed effective for training runs.
- Using example defaults from Axolotl can streamline the fine-tuning process, reducing costs and enhancing the efficacy of dataset creation efforts.
OpenRouter (Alex Atallah) Discord
- Claude 3.5 Haiku ID Changes: The Claude 3.5 Haiku model has been renamed to use a dot instead of a dash in its ID, altering its availability. New model IDs are available at Claude 3.5 Haiku and Claude 3.5 Haiku 20241022, though access may be restricted.
- Users seeking these models can request access through the Discord channel, while previous IDs remain functional.
- Gemini Model Quota Issues: Users are encountering quota errors when accessing the Gemini Experimental 1121 model via OpenRouter. It is recommended to connect directly to Google Gemini for more reliable access.
- These quota limitations are impacting users relying on the free version, prompting suggestions for alternative connection methods.
- OpenRouter API Token Discrepancies: There are reports that the Qwen 2.5 72B Turbo model is not returning token counts through the OpenRouter API, unlike other providers. However, activity reports on the OpenRouter page display token usage accurately.
- This inconsistency suggests a potential issue with how OpenRouter handles token counts for specific models.
- Tax on OpenRouter Credits in Europe: A user questioned why purchasing OpenRouter credits in Europe does not include VAT, unlike services from OpenAI or Anthropic. The response clarified that VAT calculation is the user's responsibility, with plans to implement automatic tax calculations in the future.
- This lack of VAT inclusion has raised concerns among European users, highlighting the need for streamlined tax processes.
- Access to Custom Provider Keys: Multiple users have requested access to custom provider keys, with repeated appeals emphasizing strong interest in this feature. Users like sportswook420 and vneqisntreal have highlighted the demand.
- The community's enthusiasm for custom provider keys indicates a desire for enhanced functionality, though access procedures remain unspecified.
Perplexity AI Discord
- Gemini AI vs ChatGPT: Users reported that Gemini AI often stops responding after a few interactions, raising questions about its reliability compared to ChatGPT.
- Discussions highlighted differences in performance, with some members finding ChatGPT more consistent for extended conversations.
- Perplexity Browser Extensions: There was a conversation about the availability of Perplexity extensions for Safari, including a search engine addition and a discontinued summarization tool.
- Members shared alternative solutions for non-Safari browsers and provided tips for managing existing extensions.
- AI Accessibility for Non-Coders: A proposal was made for a tier-based learning system to make AI technologies more accessible to non-coders, featuring a structured curriculum of projects and tutorials.
- The system aims to offer step-by-step guidance, fostering skill development within a community-oriented framework.
- Digital Twins in AI: Digital twins were explored, focusing on their application in monitoring and optimizing real-world entities across various industries.
- Users expressed significant interest in how digital twins enhance simulation capabilities and operational efficiency.
- AI's Influence on Grammarly: The impact of AI on Grammarly was debated, with this discussion examining the integration of AI advancements into writing tools.
- Participants considered both the benefits and potential drawbacks of incorporating AI to enhance Grammarly's functionality.
Stability.ai (Stable Diffusion) Discord
- SDXL Lightning Embraces Image Prompts: A user inquired about utilizing image prompts in SDXL Lightning via Python, seeking guidance on integrating photos into specific contexts.
- Another user confirmed the possibility and suggested exchanging more information through direct messaging.
- Optimizing WebUI for 12GB VRAM: Discussions focused on enhancing webui.bat parameters for better performance with 12GB VRAM, with suggestions to include '--no-half-vae'.
- Users agreed that this adjustment sufficiently optimizes performance without introducing further complications.
- Converting Corporate Photos to Pixar Styles: A request was made for methods to transform corporate photos into Pixar-style images, requiring the processing of about ten portraits on short notice.
- Members debated the feasibility, noting the possible unavailability of free services and recommended fine-tuning an image generation model.
- Exploring Video Fine-tuning Services with Cogvideo: Users expressed interest in video fine-tuning and inquired about available servers or services, referencing the Cogvideo model.
- It was highlighted that while Cogvideo is prominent in video generation, alternative specific fine-tunes might better suit user needs.
- Downloading Stable Diffusion and Its Use Cases: A new user sought the easiest and fastest method to download Stable Diffusion for PC and inquired about its relevant use cases.
- Another user requested help in creating a specific image using Stable Diffusion while navigating content filters, indicating a need for more permissive software options.
LlamaIndex Discord
- Simplifying Function Calling in Workflows: Users discussed streamlining function calling in workflows, recommending the use of prebuilt agents like
FunctionCallingAgentfor automated function invocation without boilerplate code.- A member highlighted that while boilerplate code offers more control, utilizing a prebuilt agent can streamline the process.
- LlamaIndex Security Compliance: LlamaIndex confirmed its compliance with SOC2, detailing the secure handling of original documents via LlamaParse and LlamaCloud.
- LlamaParse encrypts files for 48 hours, while LlamaCloud chunks and stores data securely.
- Ollama Package Issues in LlamaIndex: Users reported issues with the Ollama package in LlamaIndex, citing a bug in the latest version that caused errors during chat responses.
- Downgrading to Ollama version 0.3.3 was recommended, with some members confirming that this action resolved their issues, referencing Pull Request #17036.
- Hugging Face Embedding Compatibility Issues: Concerns were raised about embeddings from the CODE-BERT model on Hugging Face not aligning with LlamaIndex's expected format.
- Users recommended raising an issue on GitHub to address the potential mismatch in handling model responses.
- LlamaParse Parsing Challenges: LlamaParse is experiencing issues with returning redundant information, including headers and bibliographies, despite detailed instructions to exclude them.
- A member asked, 'Has anyone else experienced this issue?', and shared comprehensive parsing instructions for scientific articles to maintain logical content flow and exclude non-essential elements like acknowledgments and references.
Notebook LM Discord Discord
- NotebookLM Implements Retrieval-Augmented Generation: NotebookLM now leverages Retrieval-Augmented Generation to enhance response accuracy and citation tracking, as discussed by community members.
- This implementation aims to provide more reliable and verifiable outputs for users engaging in extensive query sessions.
- Podcastfy.ai Emerges as NotebookLM API Alternative: A member recommended Podcastfy.ai as an open source alternative to NotebookLM's podcast API, prompting discussions on feature comparisons.
- Users are evaluating how Podcastfy.ai stacks up against existing NotebookLM options for podcast creation and management.
- Demand Grows for Producer Studio in NotebookLM: A user highlighted their Producer Studio feature request for NotebookLM, advocating for enhanced podcast production capabilities.
- Community members are showing interest in advanced production tools to streamline podcast creation within the platform.
- NotebookLM Seeks Multilingual Audio Translation Support: Users are requesting the ability to translate NotebookLM audio outputs into languages like German and Italian, highlighting the need for broader multilingual support.
- This demand underscores the platform's potential to cater to a more diverse, global engineering audience.
- Podcast Creation Limits in NotebookLM Clarified: Users have identified a 100-podcast per account limit and a possible daily cap of 20 podcast creations within NotebookLM.
- This constraint leads users to manage their podcast inventories carefully, as deletion of older podcasts resets their creation capacity.
Interconnects (Nathan Lambert) Discord
- OpenAI's Data Deletion Lawsuit: Lawyers for The New York Times and Daily News are suing OpenAI, alleging accidental deletion of data after over 150 hours of search.
- On November 14, data on a single virtual machine was erased, potentially impacting the case as outlined in a court letter.
- Prime Intellect's INTELLECT-1 Decentralized 10B Model: Prime Intellect announced the completion of INTELLECT-1, the first decentralized training of a 10B model across multiple continents.
- A full open-source release is expected within a week, inviting collaboration to build open-source AGI.
- Anthropic's $4B AWS Partnership: Anthropic expanded its collaboration with AWS through a $4 billion investment from Amazon to establish AWS as their primary cloud and training partner.
- This partnership aims to enhance Anthropic's AI technologies, as detailed in their official news release.
- Tulu 3's On-policy DPO Analysis: Discussions on the Tulu 3 paper questioned whether the described DPO method is truly on-policy due to evolving model policies during training.
- Members debated that online DPO, mentioned in section 8.1, aligns more with on-policy reasoning by sampling completions for the reward model at each training step.
- CamelAIOrg's OASIS Social Simulation Project: CamelAIOrg faced account termination by OpenAI, possibly related to their recent OASIS social simulation project involving one million agents, as detailed on their GitHub page.
- Despite reaching out for assistance, 20+ community members are still awaiting API keys after 5 days without a response.
GPU MODE Discord
- Triton Optimizes AMD GPUs: In a YouTube video, Lei Zhang and Lixun Zhang discuss Triton optimizations for AMD GPUs, focusing on techniques like swizzle for L2 cache and memory access efficiency.
- They also explore MLIR analysis to enhance Triton kernels, with participants highlighting the importance of these optimizations in improving overall GPU performance.
- FlashAttention Optimizations: Members discussed advancements in FlashAttention, including approximation techniques for the global exponential sum based on local sums within the tiling block of QK^T.
- Emphasis was placed on understanding the relationship between local and global exponential sums to optimize attention mechanisms effectively.
- Pruning Techniques for LLMs: A member requested the latest pruning and model efficiency papers for large language models (LLMs), referencing the What Matters in Transformers paper and its data-dependent techniques.
- The discussion highlighted a need for non data-dependent techniques to enhance model efficiency across varied industrial applications.
- GPT-2 Training Methods: A GitHub Gist was shared detailing how to train GPT-2 in five minutes for free, including a supportive function to streamline the process.
- Additionally, there was a conversation about integrating GPT-2 training capabilities into a Discord bot, aiming to improve user experience for AI-related tasks.
- NPU Acceleration Solutions: A member inquired about libraries or runtimes that support NPU acceleration, mentioning that Executorch offers some support for Qualcomm NPUs.
- The discussion sought to identify additional frameworks that effectively leverage NPU acceleration, encouraging community recommendations.
Cohere Discord
- Cohere API Enhances Chat Editing: Users requested a front-end compatible with the Cohere API that includes an edit button for modifying chat history without restarting conversations.
- It was clarified that edits should seamlessly integrate into the chat history, highlighting the current absence of an edit option on both the Cohere website's chat and playground-chat pages.
- SQL Agent Integrates with Langchain: The SQL Agent project was showcased in Cohere's documentation and received positive feedback from the community.
tinygrad (George Hotz) Discord
- SDXL Benchmark Slows Post-Update: After applying update #7644, SDXL no longer casts to half on CI tinybox green, causing benchmarks to slow down by over 2x.
- Members questioned if this casting change was intentional to address previous incorrect casting implementations.
- Concerns Over SDXL's Latest Regression: The removal of half casting in SDXL with update #7644 has raised regression concerns among the community.
- Users are seeking clarification on whether the decreased benchmark performance signifies a backward step in SDXL's capabilities.
- Proposed Intermediate Casting Strategy Shift: A proposal was made to determine intermediate casting based on input dtypes rather than the device, advocating for a pure functional approach.
- The suggestion includes adopting a method similar to fp16 in stable diffusion to enhance model and input casting efficiency.
- Tinygrad Removes Custom Kernel Functions: Custom kernel functions have been removed from the latest versions of the Tinygrad repository.
- George Hotz recommended alternative methods to achieve desired outcomes without compromising the abstraction layers.
- Introduction to Tinygrad Shared via YouTube: An introduction to Tinygrad was shared through a YouTube link to assist beginners.
- This resource aims to help new users understand the fundamentals of Tinygrad more effectively.
Modular (Mojo 🔥) Discord
- Mojo-Python Interoperability on the Horizon: The Mojo roadmap includes enabling Python developers to import Mojo packages and call Mojo functions, aiming to improve cross-language interoperability.
- Community members are actively developing this feature, with preliminary methods already available for those not requiring optimal performance.
- Async Event Loop Configuration in Mojo: Asynchronous operations in Mojo now require setting up an event loop to manage state machines effectively, despite initial support for async-allocated data structures.
- Future plans intend to allow compiling out the async runtime when it's unnecessary, thus optimizing performance.
- Multithreading Integration Workaround for Mojo-Python: A user shared a method where Mojo and Python communicate via a queue, facilitating asynchronous interactions using Python's multithreading.
- While effective for certain cases, some find this approach overly complex for simpler needs, advocating for an official solution.
- Advancing Mojo Features for Speed Optimization: A member highlighted Mojo's main utility as a Python-like alternative for C/C++/Rust, emphasizing its role in accelerating slow processes.
- They stressed the importance of foundational features like parameterized traits and Rust-style enums over basic Mojo classes.
Torchtune Discord
- HF Transfer Accelerates Model Downloads: The addition of HF transfer to torchtune significantly reduces model downloading times, with the time for llama 8b dropping from 2m12s to 32s.
- Users can enable it by running
pip install hf_transferand adding the flagHF_HUB_ENABLE_HF_TRANSFER=1for non-nightly versions. Additionally, some users reported achieving download speeds exceeding 1GB/s by downloading one file at a time via HF transfer on home internet connections.
- Users can enable it by running
- Anthropic Paper Questions AI Evaluation Consistency: A recent research paper from Anthropic discusses the reliability of AI model evaluations, questioning if performance differences are genuine or if they arise from random luck in question selection.
- The study encourages the AI research community to adopt more rigorous statistical reporting methods, while some community members expressed skepticism about the emphasis on error bars, highlighting an ongoing conversation about enhancing evaluation standards.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Goes Fully Online: The upcoming hackathon is 100% online, allowing participants to join from any location without the need for a physical venue.
- This decision addresses logistical concerns and ensures broader accessibility for all team members.
- Simplified Team Registration: Team registration now sends a confirmation email to the email entered in the first field, ensuring at least one team member receives the confirmation.
- This change streamlines the registration process, making it more user-friendly and efficient.
- Percy Liang's Presentation: Percy Liang's presentation this week received positive feedback from members.
- Participants highlighted the clarity and depth of the content delivered during the session.
OpenInterpreter Discord
- Desktop App Release Timeline Remains Uncertain: A newcomer inquired about the release schedule for the desktop app after joining the waiting list, but no specific release date was provided, leaving the timeline uncertain.
- This uncertainty suggests ongoing development efforts, with no definitive timeline announced for the desktop app.
- Exponent Demo Highlights Windsurf's Effectiveness: A member shared their experience conducting a demo with Exponent, mentioning continued experimentation with its features.
- Positive feedback was given about Windsurf, underlining its effectiveness during the demo.
- Community Explores Open Source Devin: The discussion mentioned an open-source version of Devin that community members have been exploring, though not all have tried it yet.
- This reflects ongoing interest in leveraging open-source tools for project experimentation.
- Overcoming Installation Challenges for O1 on Linux: A member reported difficulties in installing O1 on their Linux system and is seeking solutions to resolve the issue.
- They are seeking advice about potential solutions or workarounds for installation issues. Additionally, discussions touched on the feasibility of integrating Groq API or other free APIs with O1 on Linux.
DSPy Discord
- VLMs Enhance Invoice Processing: A member is exploring the use of a VLM for a high-stakes invoice processing project, seeking guidance on how DSPy could enhance their prompt for specialized subtasks.
- There's a mention of recent support for VLMs and specifically Qwen by DSPy.
- DSPy Integrates Qwen for VLM Support: DSPy has added support for Qwen, a specific VLM, to enhance its capabilities in handling specialized tasks.
- This integration aims to improve prompt engineering for projects like high-stakes invoice processing.
- Testing DSPy on Visual Analysis Projects: A member suggested trying DSPy for VLMs, sharing their success with it for a visual analysis project and noting that the CoT module functions effectively with image inputs.
- They haven't tested the optimizers yet, indicating there's more to explore.
- Simplifying Project Development with DSPy: Another member emphasized starting with simple tasks before gradually adding complexity to projects, reinforcing the notion of accessibility with DSPy.
- It's not very hard, if you start simple and add complexity over time! conveys a sense of encouragement to experiment.
OpenAccess AI Collective (axolotl) Discord
- INTELLECT-1 Completes Decentralized Training: Prime Intellect announced the completion of INTELLECT-1, marking the first-ever decentralized training of a 10B model across multiple continents. A tweet from Prime Intellect confirmed that post-training with arcee_ai is now underway, with a full open-source release scheduled for approximately one week from now.
- INTELLECT-1 achieves a significant milestone in decentralized AI training, enabling collaborative development across the US, Europe, and Asia. The upcoming open-source release is expected to foster broader community engagement in AGI research.
- 10x Enhancement in Training Capability: Prime Intellect claims a 10x improvement in decentralized training capability with INTELLECT-1 compared to previous models. This advancement underscores the project's scalability and efficiency in distributed environments.
- The 10x enhancement positions INTELLECT-1 as a leading model in decentralized AI training, inviting AI engineers to contribute towards building a more robust open-source AGI framework.
- Anticipation for Axolotl Fine-tuning: There is hopeful anticipation regarding the fine-tuning capabilities in Axolotl once INTELLECT-1 is released. Participants are eager to evaluate how the system manages finetuning given the advancements in decentralized training.
- The integration of Axolotl's fine-tuning features with INTELLECT-1's decentralized framework is expected to enhance model adaptability and performance, benefiting the technical engineering community.
LAION Discord
- Neural Turing Machines Enthusiasm: A member has been exploring Neural Turing Machines for the past few days.
- They would love to bounce ideas off others who share this interest.
- Differentiable Neural Computers Deep Dive: A member is delving into Differentiable Neural Computers to gain further insights.
- They are seeking fellow enthusiasts to collaborate on thoughts and insights related to these technologies.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Eleuther ▷ #announcements (1 messages):
Revitalizing Reading Groups, Discord Forum Feature, Monthly Reading Group, YouTube Recordings, Feedback for New Groups
- *Revitalizing Reading Groups using Discord Forums: The reading groups channel has been relaunched with Discord's new forum feature* to enhance organization and reduce manual maintenance.
- Organizers are encouraged to create a thread in the designated forum for ongoing discussions.
- *Open Invitation for New Reading Groups: Anyone interested can create and manage their own reading groups* on topics like scaling laws, reasoning, and efficient architectures.
- A dedicated channel has been set up for community members to propose their ideas for reading groups and receive feedback.
- *Monthly Reading Group Featuring Community Research: A monthly reading group* will be organized to showcase research conducted by community members, with the first session in December focusing on the paper Refusal in LLMs is an Affine Function.
- Details regarding the date of this first session are yet to be announced.
- *Recordings of Reading Group Meetings: Participants are encouraged to record their reading group meetings, with an option to upload them to the YouTube channel* dedicated to the community.
- Currently, recordings from the math reading group are available, and additional groups can also submit their recordings.
- *Archiving the Previous Reading Groups Channel*: The previous reading groups channel has been renamed for archiving purposes and will be less prominent in a month.
- This transition aims to preserve past discussions while moving forward with the new forum-focused structure.
Eleuther ▷ #general (15 messages🔥):
N-shot prompting datasets, Quantum modeling assistance, Pre-NeurIPS gathering in SF, Vector environments in reinforcement learning, AI agent development tools
- Exploring N-shot prompting datasets: A member suggested that various Q&A type datasets could be utilized effectively with n-shot prompting.
- This new approach may enhance model performance and adaptivity in training scenarios.
- Seeking help for quantum modeling: A new member, Marc, introduced himself and is currently working on quantum models while looking for assistance.
- This indicates a collaborative environment where expertise in diverse fields is welcomed.
- Pre-NeurIPS meetup planned at Dolores Park: A member announced a pre-NeurIPS chill out gathering at Dolores Park, inviting attendees to RSVP and join the picnic.
- With the expected sunny weather, attendees are encouraged to bring food and drinks while discussing AI and other interests.
- Benefits of Vector Environments for RL: A user highlighted that Vector Environments can significantly speed up reinforcement learning training, providing links for reference.
- These environments enable the sampling of multiple sub-environments, enhancing training efficiency and performance.
- Developing AI agents using open-source tools: A member expressed interest in creating self-improving AI agents leveraging a suite of open-source tools for continuous development.
- They are exploring various frameworks like Open Webui and AnythingLLM to enable cutting-edge functionalities in their projects.
- AI Friends @ Dolores Park (pre Neurips gathering) · Luma: RSVP if your interested! AI Friends - lets meet @ Dolores Park Its been far too long since the last gathering for EleutherAI folks (and friends) in SF 🌁 With…
- Gymnasium Documentation: A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
- GitHub - PufferAI/PufferLib: Simplifying reinforcement learning for complex game environments: Simplifying reinforcement learning for complex game environments - PufferAI/PufferLib
Eleuther ▷ #research (408 messages🔥🔥🔥):
Test-Time Training (TTT), Wave Network Token Representation, Learnable Positional Embeddings, RNN Extrapolation, Muon Orthogonalization
- Test-Time Training Shows Promise on ARC: Recent experiments demonstrate that Test-Time Training (TTT) can significantly improve reasoning capabilities on the Abstraction and Reasoning Corpus (ARC), achieving up to 6x improvement in accuracy compared to base models.
- Key components for successful TTT include initial finetuning on similar tasks, auxiliary task formatting, and per-instance training.
- Innovative Token Representation in Wave Network: The Wave network proposes a unique token representation using complex vectors, separating global and local semantics within the input text, achieving high accuracy on the AG News classification task.
- Tokens in this model represent the ratio of their value to a global semantics vector, creating a novel relationship to overall sequence norms.
- Debate on Learnable Positional Embeddings: There are discussions about the efficacy of learnable positional embeddings in models like Mamba compared to traditional embeddings, with assertions that they work effectively based on input dependence.
- Concerns are noted regarding their performance in less constrained conditions, compared to approaches like Yarn or Alibi.
- RNNs Demonstrate OOD Extrapolation: RNNs have been shown to successfully extrapolate out-of-distribution on algorithmic tasks, with some suggesting that the chaining of thought could be adapted even to linear models.
- However, concerns arise that more complexity in tasks, such as those in the ARC, might benefit more from TTT than ICL due to inherent limitations in learning representations.
- Muon and Orthogonalization Insights: The implementation details of Muon indicate it employs momentum and orthogonalization after the momentum update, which may influence its effectiveness.
- Discussions highlight the necessity of ensuring sufficient batch sizes for effective orthogonalization, especially in the context of low-rank matrices.
- Hymba: A Hybrid-head Architecture for Small Language Models: We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficienc...
- The Surprising Effectiveness of Test-Time Training for Abstract Reasoning: Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of t...
- Wave Network: An Ultra-Small Language Model: We propose an innovative token representation and update method in a new ultra-small language model: the Wave network. Specifically, we use a complex vector to represent each token, encoding both glob...
- Memory Mosaics: Memory Mosaics are networks of associative memories working in concert to achieve a prediction task of interest. Like transformers, memory mosaics possess compositional capabilities and in-context lea...
- The Role of ImageNet Classes in Fréchet Inception Distance: Fréchet Inception Distance (FID) is the primary metric for ranking models in data-driven generative modeling. While remarkably successful, the metric is known to sometimes disagree with human judgemen...
- Auto-Regressive Next-Token Predictors are Universal Learners: Large language models display remarkable capabilities in logical and mathematical reasoning, allowing them to solve complex tasks. Interestingly, these abilities emerge in networks trained on the simp...
- Parallelizing Linear Transformers with the Delta Rule over Sequence Length: Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, ...
- Linear Transformers Are Secretly Fast Weight Programmers: We show the formal equivalence of linearised self-attention mechanisms and fast weight controllers from the early '90s, where a ``slow" neural net learns by gradient descent to program the ``f...
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States: Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their...
- Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models: We systematically study a wide variety of generative models spanning semantically-diverse image datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best ...
- Simple linear attention language models balance the recall-throughput tradeoff: Recent work has shown that attention-based language models excel at recall, the ability to ground generations in tokens previously seen in context. However, the efficiency of attention-based models is...
- Tweet from BlinkDL (@BlinkDL_AI): "The world's hardest sudoku" solved by 12M params RWKV-6 after 4M tokens CoT 🙂 code & model: https://github.com/Jellyfish042/Sudoku-RWKV Note the model was only trained with ctx8192, so i...
- Zoology (Blogpost 2): Simple, Input-Dependent, and Sub-Quadratic Sequence Mixers: no description found
- Tweet from Braden Koszarsky (@KoszarskyB): Added doc masking to the hard block test as suggested by @hi_tysam which mostly closes the gap. At 3000 steps, HellaSwag results too volatile to draw any conclusions either way. I expect that the doc ...
- Tweet from Pavlo Molchanov (@PavloMolchanov): Sharing our team’s latest work on Hymba - an efficient small language model with hybrid architecture. Tech report: https://arxiv.org/abs/2411.13676 Discover the tradeoff between Mamba and Attention,...
- Tweet from BlinkDL (@BlinkDL_AI): From community: RWKV-6 3B can be state-tuned to 99.2% LAMBADA, memorizing 400k+ tokens🧠 (only for testing capacity - it's training on test set). Method: check https://github.com/BlinkDL/RWKV-LM ...
- Tweet from BlinkDL (@BlinkDL_AI): RWKV state-tuning alignment: because RWKV is 100% RNN, we can directly tune its RNN state to control its behavior🤯For example, a state-tuned RWKV-6 "Finch" 1.6B can be fun and use emojis🐦eve...
- Gated Delta Networks: Improving Mamba2 with Delta Rule: Linear Transformers have emerged as efficient alternatives to standard Transformers due to their inference efficiency, achieving competitive performance across various tasks, though they often...
- GitHub - ekinakyurek/marc: Public repository for "The Surprising Effectiveness of Test-Time Training for Abstract Reasoning": Public repository for "The Surprising Effectiveness of Test-Time Training for Abstract Reasoning" - ekinakyurek/marc
Eleuther ▷ #lm-thunderdome (13 messages🔥):
API Rate Limit Management, MCQ Implementation, Parsing CLI Arguments, Model Evaluation, Bug Fix for tokenizer_backend
- Managing API Rate Limits with Delays: A user inquired about implementing a time delay to avoid rate limits when hitting OpenAI and Anthropic APIs, suggesting a query frequency of one every 1-5 seconds.
- Another member recommended using the Tenacity library to handle retry logic effectively.
- Creating Multistep MCQs: A member proposed implementing a multiple-choice question (MCQ) format with multistep questions to evaluate model adaptability to new information.
- They expressed interest in measuring transitions between correct and incorrect answers based on the model's initial responses.
- Passing None in CLI Argument: A user reported difficulty in passing
tokenizer_backend=Nonethrough the command line, as it was not parsed correctly.- A member acknowledged this as a bug and mentioned a workaround while a pull request is being prepared.
- Discussion on GitHub Ticket for CLI Bug: One user asked if a ticket was open regarding the CLI bug affecting the parsing of
Noneas a tokenizer backend.- Another member provided a link to the relevant GitHub issue and confirmed that they would merge the fix once tests pass.
- lm-evaluation-harness/lm_eval/models/openai_completions.py at 867413f8677f00f6a817262727cbb041bf36192a · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- Tenacity — Tenacity documentation: no description found
- lm-evaluation-harness/lm_eval/models/api_models.py at 867413f8677f00f6a817262727cbb041bf36192a · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (1 messages):
Types of models, User preferences
- Exploring Diverse Model Types: A member indicated that the current models mostly fit a specific category based on their experiences.
- They prompted further discussion by asking, 'What other types are you thinking of?'
- Encouraging Broader Discussion: The inquiry about other model types highlights an interest in broadening the conversation beyond familiar categories.
- This suggests an openness to exploring new directions and possibilities in model development.
Unsloth AI (Daniel Han) ▷ #general (240 messages🔥🔥):
Unsloth updates, Fine-tuning models, Mistral model performance, Image generation models, Qwen model limitations
- Recent Unsloth release highlights: The latest Unsloth update introduced features such as vision finetuning for various models including Llama 3.2 Vision, improving VRAM usage by 30-70%. Moreover, they added support for Pixtral finetuning in a free 16GB Colab environment, which is a significant enhancement.
- The release also included updates on merging models into 16bit for easier inference and long context support for vision models, greatly enhancing usability.
- Performance of Mistral models: Several users have found Mistral models to outperform others in finetuning, noting their ability for strong prompt adherence and good accuracy. Comparisons with Llama and Qwen models indicate that Mistral's performance generally exceeds expectations for various tasks.
- However, some users expressed skepticism regarding Qwen's effectiveness, citing issues with gibberish outputs in certain applications.
- Fine-tuning strategies: There was a discussion about fine-tuning Qwen and Llama models, with users sharing their experiences and best practices. Some noted that using smaller, efficient models like BERT for classification tasks might be more effective than relying on larger LLMs.
- Contributors mentioned the importance of dataset quality and model learnability, particularly when evaluating the Mistral and Pixtral options.
- Image generation model discussions: Interest in image generation models surfaced, with recommendations like Janus mentioned for their multimodal capabilities. Several users indicated a strong preference for existing diffusion models over integrated models due to image quality.
- Conversations highlighted the nuances of using these models in specific applications and the challenges related to deploying and training them effectively.
- Technical issues with Unsloth models: Users reported technical issues, including import errors while loading models and problems with specific configurations. Suggestions were made to troubleshoot by updating dependencies and adjusting configurations to allow for efficient use of resources.
- One user specifically asked if adding a linear layer over models would affect optimization, prompting further discussion on the best practices when extending model capabilities.
- config.json · deepseek-ai/Janus-1.3B at main: no description found
- Chat With Janus 1.3B - a Hugging Face Space by deepseek-ai: no description found
- Tweet from Daniel Han (@danielhanchen): Vision finetuning is finally in🦥@UnslothAI! It took a while, but Llama 3.2 Vision, Pixtral, Qwen2 VL & all Llava variants now work! 1. QLoRA / LoRA is 1.3x to 2x faster for each 2. 30-70% less VRAM ...
- Deploying with Kubernetes — vLLM: no description found
- Discord This GIF - Discord This Server - Discover & Share GIFs: Click to view the GIF
- AIDC-AI/Marco-o1 at main: no description found
- GitHub - deepseek-ai/Janus: Janus-Series: Unified Multimodal Understanding and Generation Models: Janus-Series: Unified Multimodal Understanding and Generation Models - deepseek-ai/Janus
Unsloth AI (Daniel Han) ▷ #off-topic (16 messages🔥):
Greek Yogurt Diet, Health Optimization, GPU Service Options
- Greek Yogurt Joins the Breakfast Club: A member has implemented Greek yogurt into their morning meals, mixing it with apple slices and granola for a healthy start.
- Not a cereal fan, the member finds this combination both tasty and healthy, and recommends it to others.
- Targeting Optimal Health: This member is searching for the sweet spot for their body, with a history of weak lungs and a general desire for better health.
- They noted, just documenting in case this helps anyone, and encouraged insights from others.
- Interest in Vision Datasets: A member mentioned a desire to try out vision, but expressed concerns about the difficulty of preparing the necessary datasets.
- This comment reflects a common challenge among those looking to delve into visual data processing.
- Seeking GPU as a Service Recommendations: One member queried about cheap GPU as a service options or inclusion with Linux server VPCUs, specifically looking for 24GB GPU memory.
- Suggestions or recommendations were requested, highlighting the growing interest in accessible GPU solutions.
Unsloth AI (Daniel Han) ▷ #help (69 messages🔥🔥):
Fine-tuning Models, Inference Issues, Model Compatibility, Continued Pretraining, Tokenization Errors
- Challenges with Fine-tuning Models: Users experienced various issues when fine-tuning models, including failing to load fine-tuned models for inference and confusion over multiple model versions in output folders.
- For instance, a user was unsure why both BF16 and Q4 quantization versions were present, which was clarified as part of the conversion process.
- Inference Errors and Configuration: Several users encountered errors during inference, including
AttributeErrorandWebServerErrors, particularly when using specific models like 'Mistral-Nemo-Instruct-2407-bnb-4bit'.- Suggestions included trying to replace model paths with saved checkpoints and verifying compatibility with Hugging Face's inference endpoint.
- Tokenization Issues Reported: A user reported issues while fine-tuning a Hindi dataset on TinyLlama, specifically receiving a tokenization error related to mismatched column lengths during training.
- Another user experiencing empty predictions during evaluation suspected it may relate to the preprocessing stage prior to computation.
- Guidance on Continued Pretraining: Community members discussed the possibility of using models outside of those provided by Unsloth for continued pretraining, suggesting community support for any model-specific questions.
- Users were encouraged to raise requests for compatibility on GitHub if their non-Unsloth models were not supported.
- New Users Learning Fine-tuning: A new user expressed confusion over their first fine-tuning experience, indicating they had produced a model output that didn’t match their expectation.
- It was clarified that encountering two model files during the conversion process did not indicate an error on their part.
- no title found: no description found
- GitHub - simonlindgren/mistral-unslothify: Fine-tune open-source LLMs for domain data: Fine-tune open-source LLMs for domain data. Contribute to simonlindgren/mistral-unslothify development by creating an account on GitHub.
- Unsloth Documentation: no description found
- Google Colab: no description found
LM Studio ▷ #general (153 messages🔥🔥):
Multi-GPU Processing, GPU Performance Comparisons, LM Studio Installation Issues, Model Fine-tuning vs. RAG, System Resource Requirements
- Exploring Multi-GPU Inference: Users discussed the feasibility of multi-GPU performance in LM Studio, particularly regarding inference and model distribution across multiple GPUs. One member noted that balancing load can lead to complications and might affect VRAM allocation.
- Concerns were raised about whether to pair different GPUs or opt for a more powerful single GPU for better overall performance.
- Performance Insights for Graphics Cards: The community compared various GPUs, specifically the RTX 4070 Ti, Radeon RX 7900 XT, and GeForce RTX 4080 for performance metrics at 1440p and 4K resolutions. It was noted that while power consumption varies, performance differences are generally marginal.
- Members discussed the balance between power usage and performance, suggesting that higher Q models should be preferred for optimal results.
- Installation Challenges with LM Studio: A user faced installation issues with LM Studio on Windows 11 Pro, indicating problems with file downloads being incomplete. Another member advised checking system specifications and confirmed that AVX2 support is mandatory for installation.
- After multiple download attempts, the user successfully installed a beta version, highlighting possible server-side issues with the main download link.
- Understanding Fine-tuning vs. RAG Usage: Members debated the merits of fine-tuning models versus using RAG (Retrieval-Augmented Generation) strategies. The consensus suggested that while fine-tuning can specialize a model for specific tasks, RAG allows for more flexibility and less risk of model corruption with proprietary data.
- Fine-tuning was exemplified with the potential to adapt models for specific coding languages like C#, but concerns were raised about security with sensitive company data.
- Resource Management for Model Loading: A user raised concerns about models failing to load due to insufficient system resources, prompting suggestions to adjust runtime settings. Discussion emphasized that low RAM could lead to operational challenges, with recommendations to switch GPU runtimes and potentially restart the application.
- It was noted that running models with high VRAM needs on underpowered hardware could result in freezing or crashing, indicating that users should stay within their system's capabilities.
- LM Studio - Experiment with local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
- Gigabyte GeForce RTX 4070 Ti Super Gaming OC Review: The Gigabyte RTX 4070 Ti Super Gaming OC, true to its name, comes with a factory overclock, to a rated boost of 2655 MHz. It features a triple-slot, triple-fan cooler and dual BIOS for added versatili...
- NVIDIA GeForce4 MX 4000 Specs: NVIDIA NV18, 250 MHz, 2 Pixel Shaders, 0 Vertex Shaders, 4 TMUs, 2 ROPs, 128 MB DDR, 166 MHz, 64 bit
- Gigabyte GeForce RTX 4070 Ti Super Gaming OC Review: The Gigabyte RTX 4070 Ti Super Gaming OC, true to its name, comes with a factory overclock, to a rated boost of 2655 MHz. It features a triple-slot, triple-fan cooler and dual BIOS for added versatili...
LM Studio ▷ #hardware-discussion (121 messages🔥🔥):
eGPU Gang, Benchmarking LLMs with AMD GPUs, MacBook Performance for AI Tasks, Power Consumption and GPU Efficiency, Upcoming Graphics Cards
- Joining the eGPU Gang: A member shared their recent join to the eGPU gang, expressing excitement over their new setup.
- There were discussions about the performance comparisons between eGPUs on Windows vs Linux, with an interest in multicard setups.
- Benchmarking LLMs on AMD GPUs: AMD GPUs can run LLMs through ROCm or Vulkan; however, there are ongoing concerns about driver updates impacting performance.
- Discussion around using ROCm pointed out that it operates mainly on Linux or WSL, which limits usability for some users.
- MacBook's AI Task Capabilities: Members discussed the performance of the MacBook Pro for AI tasks, noting it struggles with image generation in comparison to NVIDIA GPUs.
- It was mentioned that running large models on Macs would require patience due to slower inference speeds.
- Power Consumption and GPU Efficiency: There were concerns raised about the high power consumption of older graphics cards used for running larger models with limited efficiency.
- It was suggested that tuning the power limit of professional GPUs could optimize their performance.
- Anticipation for Upcoming Graphics Cards: Members expressed anticipation for the release of the upcoming 5090 graphics card, with concerns about availability and pricing.
- The impact of tariffs on hardware prices led to discussions about securing equipment ahead of expected price increases.
- GitHub - DavidS95/Smokeless_UMAF: Contribute to DavidS95/Smokeless_UMAF development by creating an account on GitHub.
- Showtime Beetlejuice GIF - Showtime Beetlejuice - Discover & Share GIFs: Click to view the GIF
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
- NVIDIA GeForce RTX 3090 Specs: NVIDIA GA102, 1695 MHz, 10496 Cores, 328 TMUs, 112 ROPs, 24576 MB GDDR6X, 1219 MHz, 384 bit
HuggingFace ▷ #general (215 messages🔥🔥):
Mamba2 Support Added, Errors with Faster-Whisper, AI Models and Language Training, Comedy by AI Models, Browser Integration with AI
- Mamba2 support now working in MLX: A member announced that MLX has successfully integrated support for the whole new architecture of Mamba2, which was introduced in May this year.
- Another member inquired about the difficulties behind this integration, leading to discussions about the time required for various library supports.
- Challenges faced while using Faster-Whisper: A user reported issues related to environment variables when trying to run Faster-Whisper, raising concerns about a reverse proxy setup causing SSL errors.
- It was suggested that they try switching to the Hugging Face mirror to troubleshoot the problems.
- Training AI Models in Different Languages: A discussion took place about the feasibility of training a model to understand and speak a foreign language based on similar grammar structures.
- It was suggested that the tokenizer might need to be adjusted for such tasks, along with prompt engineering for specific language levels.
- AI's Struggle with Humor: Members noted that AI models often struggle with humor, providing bland dad jokes instead of entertaining responses when asked to tell a joke.
- Moreover, it's commented that ASCII art and emojis often lead to confusion or gibberish, due to poor understanding or training limitations.
- AI Integration with Browsers: A user shared a YouTube video showcasing a powerful AI agent browser extension called Do Browser, emphasizing its capabilities.
- Another member highlighted the impressive OpenAI realtime API integration that allows voice control for web browsing, showcasing evolving AI applications.
- Anychat - a Hugging Face Space by akhaliq: no description found
- Qwen2.5 Coder Artifacts - a Hugging Face Space by HyperbolicLabs: no description found
- Do Browser Demo: Do Browser the most powerful AI agent chrome extension: https://dobrowser.io
- Fine-Tuning Gemma Models in Hugging Face: no description found
- Tweet from Sawyer Hood (@sawyerhood): The open ai realtime api is sick! I hooked it up to control my browser so I could browse the web with my voice 🤯
- Qwen/Qwen2.5-Coder-32B-Instruct · Hugging Face: no description found
- Deciding If You Should Talk To Your Crush GIF - Do It Shia La Beouf Flame - Discover & Share GIFs: Click to view the GIF
- Blm GIF - Blm - Discover & Share GIFs: Click to view the GIF
- Need It GIF - Ineedit Needit Spongebob Squarepants - Discover & Share GIFs: Click to view the GIF
- I Can Quit Whenever I Want Smoking GIF - I can quit whenever i want Smoking Addicted - Discover & Share GIFs: Click to view the GIF
- Maimun Monkey GIF - Maimun Monkey Pull Up - Discover & Share GIFs: Click to view the GIF
- meta-llama/Llama-3.2-3B-Instruct · Hugging Face: no description found
HuggingFace ▷ #today-im-learning (4 messages):
Docker file with FFmpeg, Python latest version, Node.js latest version
- Seeking Docker file for latest software: A user requested assistance on finding a Docker file that includes the latest versions of FFmpeg, Python, and Node.js.
- This request highlighted the necessity for consolidated software environments in development.
- Request for help in the community: Another user reached out for help, echoing the request for assistance in locating the Docker file.
- This underscores a community effort to support members with technical challenges.
HuggingFace ▷ #cool-finds (5 messages):
FLUX.1 Tools Release, Decentralized AI Model Training, LivePortrait Quota Issues, Classic Paper on Heuristic AI
- FLUX.1 Tools Offer Enhanced Control: The release of FLUX.1 Tools introduces a suite designed for editing and modifying images, featuring four key models including FLUX.1 Fill and FLUX.1 Depth.
- These models enhance steerability for text-to-image tasks, providing open-access features for users to experiment with.
- First Decentralized AI Model Training Complete: Prime Intellect announced the successful training of INTELLECT-1, a 10B model completed through decentralized training across the US, Europe, and Asia.
- A full open-source release is expected in approximately one week, including the base model and checkpoints.
- LivePortrait Space Encountering Quota Issues: A user reported errors while using the LivePortrait space, suggesting it might relate to quota limitations.
- Another member noted that it functions correctly on Chrome, but may fail if the space requests exceed logged in user limits.
- A Classic on Heuristic AI: One user referenced a classic paper on heuristic AI in their conversation, highlighting its significance.
- The specific details of the paper were not disclosed in the discussion.
- Live Portrait - a Hugging Face Space by KwaiVGI: no description found
- Tweet from Prime Intellect (@PrimeIntellect): We did it — the first decentralized training of a 10B model is complete! Trained across the US, Europe, and Asia 🌐 Post-training with @arcee_ai is underway, and a full open-source release is coming...
- Introducing FLUX.1 Tools: Today, we are excited to release FLUX.1 Tools, a suite of models designed to add control and steerability to our base text-to-image model FLUX.1, enabling the modification and re-creati...
HuggingFace ▷ #i-made-this (10 messages🔥):
IntelliBricks toolkit, Eternal AI framework, Social Receipt Generator, Cybertron v4 UNA-MGS model, Autotiktokenizer Windows support
- Introducing IntelliBricks for AI Apps: An exciting announcement was made about IntelliBricks, an open-source toolkit designed to streamline developing AI-powered applications with features such as
msgspec.Structfor structured outputs.- IntelliBricks is still under development, with further contributions welcome on its GitHub repository.
- Eternal AI: Decentralized AI Framework: Eternal AI is building a decentralized inference framework to ensure AI remains censorship-resistant and accessible, with plans to open-source their code soon.
- Their framework allows developers to create robust on-chain AI agents across multiple blockchains, promoting community-driven contributions.
- Social Receipt Generator Launch: A new project called the Social Receipt Generator was introduced, allowing users to create fun receipts for GitHub contributions and Twitter exchanges.
- Users can try out the generator at this link.
- Launch of Cybertron v4 UNA-MGS Model: The cybertron-v4-qw7B-UNAMGS model is back, achieving a top score as the #1 7-8B LLM with no contamination and enhanced reasoning capabilities.
- This model utilizes unique techniques called
MGSandUNA, with impressive benchmarks detailed on their Hugging Face page.
- This model utilizes unique techniques called
- Windows Support for Autotiktokenizer: Autotiktokenizer has added support for Windows, with a recent pull request addressing compatibility issues.
- The successful tests on both Windows and Linux platforms point to a more versatile development experience for users.
- Tweet from Sourabh singh (@Sourabh85426135): "Introducing the ultimate Social Receipt Generator—perfect for tech enthusiasts and meme makers! 🧾 ✅ Create receipts for your GitHub contributions. ✅ Cook up hilarious Twitter exchanges as recei...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- [BUG] Fix path to support windows machines by not-lain · Pull Request #12 · bhavnicksm/autotiktokenizer: this pr will fix #11 supporting windows as well tested on both windows and linux and it works as expected cc @bhavnicksm
- Tweet from Eternal AI (@CryptoEternalAI): Eternal AI: An Open-Source, Unstoppable AI Agent Framework This week, we'll open-source the Eternal AI code to let developers deploy decentralized AI agents like @NOBULLSHIT_EXE. DM us if you wa...
- fblgit/cybertron-v4-qw7B-UNAMGS · Hugging Face: no description found
- fblgit/miniclaus-qw1.5B-UNAMGS · Hugging Face: no description found
HuggingFace ▷ #NLP (4 messages):
Discord chatbots for persona NLPs, Cerebras and Llama 3.1
- Seeking Collaboration on Persona NLPs: A member inquired if anyone is working on persona NLPs or LLM frameworks as Discord chatbots, expressing a desire to collaborate with other developers.
- They specifically sought developers who might be experimenting in this area.
- Cerebras Leads with Llama 3.1: It's noted that Cerebras runs Llama 3.1 405B at impressive speeds, positioning themselves as a leader in LLM performance.
- This insight indicates a competitive edge in the field of large language models.
HuggingFace ▷ #diffusion-discussions (17 messages🔥):
CLIP models, T5 Token Limit, Flux Tools Integration, Image Variation with FLUX.1 Redux, Serverless Implementation
- Optimizing Image Generation with Prompts: One user shared a method for generating high-quality images using a refined prompt for CLIP models while utilizing a longer descriptive prompt for T5, ensuring the clip prompt is not truncated.
- This method allows for better image quality by having prompt_2 automatically append to the T5 encoder.
- T5 Model Capable of Handling 512 Tokens: Users discovered that the T5 model for SD3/Flux can handle up to 512 tokens by adding
max_sequence_length=512to the call arguments.- This revelation prompted further interest in how to implement this feature effectively in various calls.
- Inquiry on Flux Tools Functionality: A user asked if anyone has successfully integrated Flux tools with diffusers, leading to a discussion about a potential model card found on Hugging Face.
- Another user shared a link to a model card for flux1-fill-dev-diffusers, raising questions about its operational status.
- Exploring FLUX.1 Redux for Image Variations: Information surfaced about FLUX.1 Redux, an adapter for image variation generation that refines input images with minor changes, shared by other members in the channel.
- The discussion highlighted the functionality of this model for image restyling through both API and workflow integration, linking to more information.
- Interest in Serverless Implementation of Flux: Users expressed intent to run Flux tools serverless using Runpod, noting a particular interest in the CLI code provided in the repository.
- This development indicates an eagerness in the community to explore practical applications of Flux technology in different environments.
- xiaozaa/flux1-fill-dev-diffusers · Hugging Face: no description found
- black-forest-labs/FLUX.1-Redux-dev · Hugging Face: no description found
Latent Space ▷ #ai-general-chat (87 messages🔥🔥):
AI Art Turing Test, Anthropic's $4 Billion Investment from AWS, LTX Video Generation Model, AI Vibrancy Rankings Tool, OpenAI's Deleted Training Findings
- Excitement Over AI Art Turing Test: A recent AI Art Turing Test has prompted discussions, with a member sharing their hope to test it with an expert in art restoration.
- The results from participants indicate mixed experiences, especially in distinguishing between AI and human-generated artworks.
- Anthropic Receives $4 Billion from AWS: Anthropic has secured an additional $4 billion investment from Amazon, solidifying AWS as its primary cloud and training partner.
- This partnership aims to enhance AI model training through collaboration on AWS Trainium hardware.
- Launch of LTX Video Model: Lightricks introduced the open-source LTX Video model, capable of generating 5-second videos in just 4 seconds on high-performance hardware.
- The model supports easy access through APIs, leading to discussions about balancing local processing versus cloud spending.
- AI Vibrancy Tool from Stanford: A member shared their enthusiasm for the Stanford AI Vibrancy Rankings Tool, which ranks countries on AI development metrics.
- The tool allows users to customize the weight of various indicators to reflect their own perspectives on AI vibrancy.
- OpenAI's Data Deletion Incident: Debate arose over OpenAI's recent accidental deletion of training findings, raising questions about competence in managing crucial data.
- While both OpenAI and NYT lawyers acknowledged it was a mistake, concerns about the handling and recovery of data persist.
- Tweet from Alex Volkov (Thursd/AI) (@altryne): 🤯 New txt and img 2 Video near real time model from @Lightricks @LTXStudio Generates 5 second videos in... 4 seconds (on H100) fully open source and designed to run on consumer hardware! You can...
- People prefer A.I. art because people prefer bad art: Understanding the "AI Art Turing Test"
- Tweet from Anthropic (@AnthropicAI): We're expanding our collaboration with AWS. This includes a new $4 billion investment from Amazon and establishes AWS as our primary cloud and training partner. http://anthropic.com/news/anthrop...
- Tweet from adi (@adonis_singh): i have a feeling google just played 4d chess. they release gemini exp 1114 (mid, maybe worse model), knowing openai will want to outdo them. google baits out the new gpt4o, and then hits them with t...
- Tweet from LTX Studio (@LTXStudio): (1/13) We’ve been working on something special ✨ Introducing LTX Video, Lightricks’ new open-source, community-driven model for video generation. Create breathtaking videos in moments, blazing past t...
- Tweet from Lucas Beyer (bl16) (@giffmana): Hahahaha Quoting Liron Shapira (@liron) https://www.astralcodexten.com/p/how-did-you-do-on-the-ai-art-turing
- Red Hat Announces Definitive Agreement to Acquire Neural Magic: Red Hat announced that it has signed a definitive agreement to acquire Neural Magic, a pioneer in software and algorithms that accelerate generative AI (gen AI) inference workloads.
- Tweet from Eric Newcomer (@EricNewcomer): In the final session at Cerebral Valley Anthropic’s @DarioAmodei was eager to set everyone straight. There’s no reason to believe that foundation models progress was about to start slowing down. “I ...
- Tweet from Eric Newcomer (@EricNewcomer): Here's my full conversation with @DarioAmodei (@AnthropicAI) from the Cerebral Valley AI Summit
- Amazon and Anthropic deepen strategic collaboration: Anthropic names AWS its primary training partner and will use AWS Trainium to train and deploy its largest foundation models; Amazon to invest additional $4 billion in Anthropic.
- Tweet from Jina AI (@JinaAI_): Jina-CLIP-v2: a 0.9B multilingual multimodal embedding model that supports 89 languages, 512x512 image resolution, 8192 token-length, and Matryoshka representations down to 64-dim for both images and ...
- Powering the next generation of AI development with AWS: Today we’re announcing an expansion of our collaboration with AWS on Trainium, and a new $4 billion investment from Amazon.
- How Did You Do On The AI Art Turing Test?: ...
- Tweet from Anthropic (@AnthropicAI): New Anthropic research: Adding Error Bars to Evals. AI model evaluations don’t usually include statistics or uncertainty. We think they should. Read the blog post here: https://www.anthropic.com/res...
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): New open release from @Apple - AIMv2 - large scale vision encoders 🔥 > Outperforms CLIP and SigLIP on major multimodal understanding benchmarks > Beats DINOv2 on open-vocabulary object detect...
- Tweet from Tiezhen WANG (@Xianbao_QIAN): @AlibabaGroup just unveiled the hidden secret of ChatGPT o1 model. They just released a o1 alternative with Apache 2 license. arco-o1 is powered by CoT fine-tuning, MCTS, reflection and reasoning,...
- Sam Bhagwat (@calcsam.bsky.social): Excited to share that Shane Thomas, Abhi Aiyer and I are building Mastra, a Typescript AI framework for the next million AI developers:
- TypeScript support · Issue #150 · MadcowD/ell: Ell TypeScript Goals Feature parity with Python Unobtrusive/frictionless DX Challenges Capturing TypeScript source code - Ell captures user source code as written, the same as it looks in the user’...
- Amazon to invest another $4 billion in Anthropic, OpenAI's biggest rival: Amazon on Friday announced it would invest an additional $4 billion in Anthropic, the artificial intelligence startup founded by ex-OpenAI research executives.
- Tweet from Marius Hobbhahn (@MariusHobbhahn): This paper on the statistics of evals is great (and seems to be flying under the radar): https://arxiv.org/abs/2411.00640v1 The author basically shows all the relevant statistical tools needed for ev...
- Battle of Grunwald (Matejko) - Wikipedia: no description found
- Anthropic raises another $4B from Amazon, makes AWS its 'primary' training partner | TechCrunch: Anthropic has raised an additional $4 billion from Amazon, and has agreed to train its flagship generative AI models primarily on Amazon Web Services
Latent Space ▷ #ai-in-action-club (162 messages🔥🔥):
LLM powered requirements analysis, Obsidian integration, Using AI for coding, Paranoiac-critical method, Windsurf tool improvement
- LLM powered requirements analysis gains attention: Members expressed that LLM powered requirements analysis is currently among the most interesting topics in the AI space, highlighting its utility in understanding complex problems.
- The conversation emphasized that many analysis and modeling processes can be effectively automated by LLMs.
- Obsidian proves useful for learning: A member shared their experience with Obsidian, emphasizing its effectiveness in creating mind maps and retaining contextual information while learning.
- Many participants agreed that using tools like Obsidian alongside AI can make the learning process interactive and enjoyable.
- Mermaid diagrams enhance documentation: There was a discussion about how Mermaid diagrams contribute to better documentation practices, allowing users to visualize relationships in their notes.
- Members noted the struggles with rendering in certain tools, such as Windsurf, but still saw value in using diagrams for clarity.
- AI is making programming fun again: Many participants expressed that the advent of LLMs has rejuvenated their enthusiasm for programming, making it feel enjoyable once more.
- Participants shared that connecting with others in this space has encouraged collaboration and innovative ideas.
- Paranoiac-critical method inspires creativity: One member introduced the paranoiac-critical method used by Salvador Dalí as a way to inspire creativity, arguing that altered states can enhance artistic output.
- This method was linked to the current discussions on AI's influence on creativity and problem-solving.
- Obsidian - Sharpen your thinking: Obsidian is the private and flexible note‑taking app that adapts to the way you think.
- Paranoiac-critical method - Wikipedia: no description found
- GitHub - ddd-crew/ddd-starter-modelling-process: If you're new to DDD and not sure where to start, this process will guide you step-by-step: If you're new to DDD and not sure where to start, this process will guide you step-by-step - ddd-crew/ddd-starter-modelling-process
- Old No Brain GIF - Old No Brain Brains Out - Discover & Share GIFs: Click to view the GIF
- It's all about documentation with Carmen Huidobro (JS Party #346): Carmen Huidobro joins Amy, KBall & Nick on the show to talk about her work, the importance of writing docs, and her upcoming conference talk at React Summit US!
- They all use it: Last week, at a conference, I had a random hallway conversation with another engineer. About AI.
- Python Environment: no description found
OpenAI ▷ #ai-discussions (186 messages🔥🔥):
Voice Cloning, AI Accents Understanding, Bluesky vs Twitter, ChatGPT Developments, Airtable and Notion Integration
- Voice Cloning Experiences: A member shared experiences with various voice models, noting unexpected sounds while using them and how voice cloning can create eerie effects like music in dialogues.
- Another member mentioned using voice cloning for audiobook adaptations, facing glitches, which sometimes resulted in surprising enhancements like singing.
- AI Accents and Hallucinations: A question was raised regarding how well the realtime API understands different accents and pronunciations compared to hallucinations that may occur.
- This sparked a discussion about the integration of diverse voice models and their varying capabilities in understanding user input.
- Dystopian Views of Tech Governance: A user expressed concerns over big tech becoming a governing entity, sharing thoughts on the implications of unregulated speech and content management on platforms like X and Bluesky.
- This also led to a dialogue on the perceived decline of free speech and the influence of the social media landscape on user interactions.
- ChatGPT Integration Ideas: Discussion included experiences using ChatGPT for role-playing scenarios, with humorous outcomes and surprising prompts allowing more personality from the models.
- Members also highlighted potential integrations with tools like Airtable and Notion, discussing their goals to improve prompt writing within these applications.
- Copilot Image Generation Speculation: Curiosity arose regarding the image generation capabilities of Copilot, with a member speculating whether they're sourced from unreleased DALL-E models or a new program called Sora.
- There was a comparison made between images generated by different AI tools, pointing out quality differences and acknowledging the possible influence of other models.
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
Teaching GPT vocabulary constraints, Alternatives to Dall-E, Image generation models, Accessing free models
- GPT struggles with vocabulary control for Dall-E: A member expressed frustration that their GPT tends to forget specific vocabulary constraints after generating around 10 images.
- They are seeking tips to maintain character descriptions and avoid unwanted words in generated content.
- Exploring alternatives to Dall-E: Members discussed using Stable Diffusion or Flux models with comfyUI as potential alternatives to Dall-E, suggesting they might better handle specific vocabulary restrictions.
- They recommended checking for recent tutorials on YouTube to ensure updated methods for preserving character integrity.
- Debate over model ownership and monopolies: A member pointed out that the reason Dall-E isn't using other models is due to ownership, implying a form of monopoly that restricts their options.
- Another member countered that there are numerous free image models available, questioning the claim of monopolies in the space.
- Availability of free image generation options: Members noted that many free image models exist, including options for online inference via Hugging Face.
- Suggestions included exploring various models to diversify image generation approaches without local setups.
OpenAI ▷ #prompt-engineering (5 messages):
Maximizing AI response, Prompt engineering, Using variables in prompts, Humor in discussions
- Dr. Feelgood's Prompt for Productive AI Responses: A user claims the best prompt for maximizing productivity and professionalism from the AI is: ‘don’t be chickens 🐔 give me good answer bok bok chicken🐣’. They believe this prompt will yield optimal results across all AI models.
- Another user inquired about the effectiveness of this approach and if variables were utilized with such prompts.
- New to Prompt Engineering, but Confident: Dr. Feelgood mentioned they have just started prompt engineering but feels that their prompt is ‘spot on’ for enhancing AI responses.
- They also confirmed the regular use of variables like x and y in their prompts.
- A Math Joke amidst Prompt Discussions: A humorous remark was made by a user about having time for t, adding a light touch to the technical conversation.
- This math joke was well-received, showcasing a playful atmosphere in discussions about AI and prompts.
OpenAI ▷ #api-discussions (5 messages):
Effective AI Prompts, Prompt Engineering Discussion, Using Variables in Prompts
- Maximizing Productivity with Clever Prompts: A member shared their discovery of a highly effective prompt: ‘don’t be chickens 🐔 give me good answer bok bok chicken🐣’ to enhance productivity in all AI models.
- It’s touted as the perfect prompt, suggesting that it may yield better responses than traditional approaches.
- Curiosity on Prompt Engineering Experience: Another member inquired about the original poster's experience with prompt engineering, interested in their domain and perceptions of improving output.
- The response highlighted that they just started prompt engineering, yet felt confident about the results.
- Variables in Prompting: The original poster confirmed their use of variables like x and y in their prompts to improve responsiveness and customization.
- This method is seen as a strategic element in their prompting technique, enhancing engagement with the AI.
- Math Humor in AI Discussions: A lighthearted interaction occurred when a member jokingly asked if there's time for 't', a play on words relating to variables.
- This banter added a humorous touch to the technical discussion, showcasing the community's camaraderie.
aider (Paul Gauthier) ▷ #general (155 messages🔥🔥):
Qwen models performance, Aider benchmark results, OpenRouter vs direct API access, Quantization impact on model performance, Recent investments in AI
- Mixed Results from Qwen Model Tests: Several users reported varying performance scores for the Qwen 2.5 Coder model across different providers, with Hyperbolic yielding lower results at 47.4% compared to the leaderboard's 71.4%.
- Discussions emphasized the need to understand how quantization affects performance, as indicated by tests showing both BF16 and other variants yielding different outcomes.
- Changes in Aider's Benchmarking Methodology: There was clarification that Aider's leaderboard score for Qwen 2.5 Coder 32B now uses weights from HuggingFace via GLHF, leading to improved benchmarking accuracy.
- Users expressed concerns regarding discrepancies in scores linked to different hosting platforms and potential variations in model quality.
- Direct API Access to Qwen Models: It was discussed that the Aider framework could now access Qwen models directly without needing OpenRouter, thus facilitating use without dependency on a specific API provider.
- This change aims to enhance user experience by reducing reliance on third-party services while still maintaining model performance.
- Community Engagement and Model Testing: Community members actively tested various Qwen 2.5 providers, sharing insights and performance metrics from their benchmarks to support one another in understanding model efficacy.
- The ongoing discussion highlighted the community's commitment to transparency and collaboration in improving LLM usability across different applications.
- AI Investment News: Links were shared regarding Amazon's plans to invest an additional $4 billion into Anthropic, highlighting the competitive landscape in AI development.
- This sparked conversations about the sustainability and innovation pace in AI projects amid rising corporate interests and investment in newer technologies.
- Back to Top: no description found
- Quantization matters: Open source LLMs are becoming very powerful, but pay attention to how you (or your provider) is quantizing the model. It can strongly affect code editing skill.
- ollama/docs/faq.md at main · ollama/ollama: Get up and running with Llama 3.2, Mistral, Gemma 2, and other large language models. - ollama/ollama
- Gemini Experimental 1121 (free) - API, Providers, Stats: Experimental release (November 21st, 2024) of Gemini.. Run Gemini Experimental 1121 (free) with API
- GitHub - lee88688/aider-composer: aider's VSCode extension, seamlessly integrated into VSCode: aider's VSCode extension, seamlessly integrated into VSCode - GitHub - lee88688/aider-composer: aider's VSCode extension, seamlessly integrated into VSCode
- How do I install and use it? · Issue #2 · lee88688/aider-composer: no description found
- Cloudflare Status code 524 · Issue #3694 · ollama/ollama: What is the issue? I'm running into the following error message: Ollama call failed with status code 524. Details:
- How do I install and use it? · Issue #2 · lee88688/aider-composer: no description found
- no title found: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (38 messages🔥):
Managing context in Aider, Saving chat sessions, API connection errors, Benchmarking costs and performance, File detection issues in Aider
- Managing context in Aider: A user queried how to prevent Aider from processing specific lines to save tokens during vector filling, prompting a suggestion to refactor code to quarantine extraneous data.
- Another user asked about increasing the context window for Qwen, expressing dissatisfaction with the 32k limit.
- Saving chat sessions: One member inquired about saving an entire chat session, while another confirmed that all sessions are logged to
.aider.chat.history.md.- The discussion highlighted the absence of a simple save command like /save for exporting chat history.
- API connection errors: A user reported persistent API connection errors while attempting to send requests, receiving repeated APIConnectionError messages.
- This raised a conversation about the reliability of the OpenRouter, specifically with the sonnet 3.5 model.
- Benchmarking costs and performance: A user shared that running benchmarks for Qwen2.5-Coder-32B-Instruct only cost $0.25, illustrating the economical side of testing models.
- They expressed curiosity about potential cost differences across providers for the same model and planned to share their findings.
- File detection issues in Aider: A user struggled to get Aider to detect new files, despite committing them to git, leading to confusion and the need for troubleshooting.
- The issue was resolved through a reinstallation of Aider, demonstrating the potential for user-configured solutions to common setbacks.
Link mentioned: xAI: aider is AI pair programming in your terminal
aider (Paul Gauthier) ▷ #links (1 messages):
Uithub Tool, AI-Driven Development, GitHub Alternatives
- Uithub: Your GitHub Alternative: Users are praising Uithub, describing it as an instant tool for copying and pasting repositories to LLMs by simply changing 'G' to 'U'.
- Nick Dobos mentioned it as his new favorite thing for quick repository access on October 4th, 2024.
- Effortless Repo Context with Uithub: Users are finding Uithub helpful for navigating GitHub repositories more effectively, such as pulling in full repo context effortlessly.
- Ian Nuttall shared his experience using Uithub for fetching a full repo context for Laravel SEO on October 2nd, 2024, highlighting its advantages over traditional GitHub links.
- Community Feedback on Uithub: The community is sharing positive impressions about Uithub, declaring it a nice helpful tool that enhances their development experience.
- Yohei Nakajima also expressed enthusiasm for discovering Uithub on October 2nd, 2024.
- AI-Driven Development Capabilities: Uithub offers functionalities similar to the --show-repo-map feature, providing increased token limits and advanced filtering for specific file types.
- However, it's noted that Uithub may lack some of the more sophisticated features found in Aider tools, prompting discussions around their comparative utility.
Link mentioned: uithub - Easily ask your LLM code questions: no description found
Nous Research AI ▷ #general (150 messages🔥🔥):
Daily LLM Drop, House of Lords Political Structure, Reasoning Datasets Quality, Alibaba's AI Developments
- Daily LLM Drop Discussion: A member remarked on the ongoing 'daily LLM drop', while another expressed that the 'Goodhart arena is getting old', hinting at repetitive discussions.
- This exchange highlights a growing fatigue with mundane topics in the AI community.
- Evaluating the House of Lords: A user presented a step-by-step reasoning process regarding the House of Lords' role in the UK political system, concluding that it is indeed part of the political structure.
- The discussion illustrated how AI models might struggle with complex reasoning tasks compared to simpler memorization tasks.
- Concerns Over AI Reasoning Datasets: Concerns were raised about the quality of reasoning datasets, with skepticism towards their effectiveness and criticisms regarding possible synthesization.
- One member humorously suggested that either the datasets were poorly generated or influenced by substance use due to their peculiarities.
- Observations on Alibaba's AI Work: A user noted that Alibaba's Marco-o1 model only showcased one benchmark, casting doubts on the model's credibility and performance.
- The conversation reflected frustration over marketing claims and the limited scope of evaluation for emerging AI models.
- MoEUT: Mixture-of-Experts Universal Transformers: Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in lea...
- NOUS CHAT | Talk to Hermes: Experience natural, intelligent conversations with Hermes, the open-source LLM by Nous Research.
- Tweet from Anthropic (@AnthropicAI): We're expanding our collaboration with AWS. This includes a new $4 billion investment from Amazon and establishes AWS as our primary cloud and training partner. http://anthropic.com/news/anthrop...
- Tweet from Teknium (e/λ) (@Teknium1): That’s a lot of moneys but it’ll take 200b to keep the pretraining scaling going at the same pace for opus 4 or 5, curious where we are in 2 years Quoting Anthropic (@AnthropicAI) We're expandi...
- GitHub - AIDC-AI/Marco-o1: An Open Large Reasoning Model for Real-World Solutions: An Open Large Reasoning Model for Real-World Solutions - AIDC-AI/Marco-o1
- Introducing Apple’s On-Device and Server Foundation Models: At the 2024 Worldwide Developers Conference, we introduced Apple Intelligence, a personal intelligence system integrated deeply into…
- fblgit/cybertron-v4-qw7B-UNAMGS · Hugging Face: no description found
- fblgit/miniclaus-qw1.5B-UNAMGS · Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (19 messages🔥):
Agent APIs availability, Fine-tuning and datasets, Graphical User Interfaces for LLMs, Chat interfaces for multiple models
- Agent APIs were unavailable during initial hype: A member noted that certain features were not available in the APIs during the early phase of the 'agent-hype'. Another member confirmed this, mentioning that these features are now fortunately accessible.
- This raised discussions about the implications of hindsight in evaluating initial agent capabilities.
- Fine-tuning datasets with suggestions needed: One member expressed a desire to fine-tune models and create datasets, asking for suggestions on parameters and tools, mentioning concerns about the high costs of trial-and-error.
- Another member recommended using Axolotl's example defaults, which are considered good and effective for training runs.
- Exploring GUI options for machine learning models: Members discussed preferences for graphical user interfaces for local-hosted chat experiences, focusing on tools like Open WebUI and LibreChat. One member confirmed that Open WebUI is widely favored for this purpose.
- Another member shared an animated demonstration of Open WebUI's features, highlighting its user-friendly interface.
- Seeking chat interfaces for various models: A user inquired about chat-based interfaces that allow interaction with multiple models, rather than just those offered by individual services. Members were open to sharing recommendations for versatile chat interfaces.
- One member linked to Open WebUI's documentation, indicating its capability to support various LLM runners and encouraged exploration.
Link mentioned: 🏡 Home | Open WebUI: Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI interface designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs...
Nous Research AI ▷ #research-papers (2 messages):
Marco-o1 model release, Research on reasoning models, Open-ended problem solving, Authors of new AI research
- Alibaba releases Marco-o1 with Apache 2 license: AlibabaGroup has unveiled the Marco-o1 model, an alternative to OpenAI's o1, now with an Apache 2 license, focusing on complex problem-solving through various innovative strategies.
- Powered by CoT fine-tuning and MCTS, Marco-o1 seeks to generalize across broader domains where standards and reward quantification are difficult.
- Exploration of reasoning models in Marco-o1: The Marco-o1 paper discusses the surge of interest in large reasoning models (LRM) ignited by OpenAI's o1, emphasizing phases beyond standard answer disciplines.
- The research aims to assess whether the o1 model can adaptively handle open-ended resolutions in less structured environments.
- Notable authors in recent AI research: The innovative paper list includes prominent researchers such as Xin Dong, Yonggan Fu, and Jan Kautz, contributing to the evolving landscape of AI models.
- These authors are recognized for their insights into advancing AI capabilities and exploring new methodologies.
- Hymba: A Hybrid-head Architecture for Small Language Models: We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficienc...
- Tweet from Tiezhen WANG (@Xianbao_QIAN): @AlibabaGroup just unveiled the hidden secret of ChatGPT o1 model. They just released a o1 alternative with Apache 2 license. arco-o1 is powered by CoT fine-tuning, MCTS, reflection and reasoning,...
- Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions: Currently OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mat...
- AIDC-AI/Marco-o1 · Hugging Face: no description found
Nous Research AI ▷ #interesting-links (2 messages):
Agentic Translation Workflow, Few-shot Prompting, Iterative Feedback, LLM Output Refinement
- Agentic Translation Workflow Explained: The agentic translation workflow leverages few-shot prompting and an iterative feedback loop rather than traditional fine-tuning for translations.
- This method begins with a translation prompt, allowing the LLM to critique and refine its output, making it flexible and customizable.
- Benefits of Using Iterative Feedback: Utilizing iterative feedback enables the translation process to avoid the overhead associated with training, boosting productivity.
- This aspect makes the workflow particularly appealing as it combines customization and efficiency in translation tasks.
Nous Research AI ▷ #research-papers (2 messages):
Marco-o1 model, ChatGPT o1 alternative, Open-ended problem-solving, Real-world reasoning models
- Alibaba introduces Marco-o1 as o1 alternative: Alibaba just released the Marco-o1, an alternative to ChatGPT's o1 model, now under an Apache 2 license.
- Powered by Chain-of-Thought fine-tuning and Monte Carlo Tree Search, it aims to enhance problem-solving in both standard and open-ended domains.
- Exploring capabilities of Marco-o1: The Marco-o1 focuses on complex real-world challenges, exploring if the o1 model can generalize effectively in domains with unclear standards.
- 'Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?'.
- Research on Open-ended Solutions: The abstract of a recent paper emphasizes that Marco-o1 aims to go beyond traditional disciplines like mathematics and coding.
- It addresses the need for open-ended resolutions, leveraging advanced reasoning strategies for greater applicability in diverse fields.
- Hymba: A Hybrid-head Architecture for Small Language Models: We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficienc...
- Tweet from Tiezhen WANG (@Xianbao_QIAN): @AlibabaGroup just unveiled the hidden secret of ChatGPT o1 model. They just released a o1 alternative with Apache 2 license. arco-o1 is powered by CoT fine-tuning, MCTS, reflection and reasoning,...
- Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions: Currently OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mat...
- AIDC-AI/Marco-o1 · Hugging Face: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Claude 3.5 Haiku renaming, Model ID changes, Discord requests for models
- Claude 3.5 Haiku gets a 'dot' rename: The model Claude 3.5 Haiku has been renamed to use a dot instead of a dash in its ID, affecting its availability.
- New model IDs can be found at Claude 3.5 Haiku and Claude 3.5 Haiku 20241022, but users are advised that these may not be available.
- Multiple model IDs specified: Additional model IDs include Claude 3.5 Haiku:beta and Claude 3.5 Haiku 20241022:beta, however they are also not available.
- Users can request these models by visiting our Discord for assistance.
- Previous IDs still functional: Despite the changes, the previous IDs associated with the models should still work without issues.
- Acknowledgment and thanks were given for users flagging the changes made to the model identification.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
OpenRouter (Alex Atallah) ▷ #general (118 messages🔥🔥):
Gemini Model Issues, OpenRouter API Usage, Tax on OpenRouter Credits, Prompt Engineering Strategies, Engineering Community Updates
- Gemini Model Faces Quota Limitation: Users reported receiving quota errors when trying to access the free Gemini Experimental 1121 model, particularly when using OpenRouter.
- Recommendations included connecting directly to Google Gemini for better access.
- OpenRouter API Token Count Discrepancies: Issues were raised about the Qwen 2.5 72B Turbo model not returning token counts via the API, with users noting that other providers function correctly.
- However, activity reports on the OpenRouter page do show token usage correctly.
- Tax Implications for OpenRouter in Europe: A user inquired why purchasing credits for OpenRouter does not incur tax, unlike services from OpenAI or Anthropic which add VAT.
- The response indicated that VAT is the user's responsibility to calculate and that future plans may include automatic tax calculations.
- Prompt Engineering Techniques Explored: Discussion included strategies for few-shot prompting, described as effective through structured user/assistant role examples.
- Users shared references to resources and examples that highlight best practices in prompt design.
- Community Support and Feedback: General community interactions included troubleshooting issues with the Chat UI and model performance, reflecting ongoing user engagement.
- Members exchanged helpful links and suggested tools to enhance their experiences with API integrations.
- neThing.xyz - AI Text to 3D CAD Model: 3D generative AI for CAD modeling. Now everyone is an engineer. Make your ideas real.
- OpenRouter Integration - Helicone OSS LLM Observability: no description found
- Tweet from GCP Weekly (@gcpweekly): Announcing Mistral AI’s Large-Instruct-2411 and Codestral-2411 on Vertex AI #googlecloud https://cloud.google.com/blog/products/ai-machine-learning/announcing-mistral-ais-large-instruct-2411-and-codes...
- GitHub - Aider-AI/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- anthropic-cookbook/skills/retrieval_augmented_generation/guide.ipynb at main · anthropics/anthropic-cookbook: A collection of notebooks/recipes showcasing some fun and effective ways of using Claude. - anthropics/anthropic-cookbook
- Transforms | OpenRouter: Transform data for model consumption
- hackaprompt/hackaprompt-dataset · Datasets at Hugging Face: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (8 messages🔥):
Access to custom provider keys
- Widespread Requests for Custom Provider Keys Access: Several users, including sportswook420 and vneqisntreal, expressed a desire to gain access to the custom provider keys.
- Requests were made repeatedly, highlighting a significant interest in this feature across the channel.
- Multiple Appeals for Activation: Users such as hawk1399 and lokiwong specifically asked, Hi can I get access to custom provider keys? emphasizing urgency.
- This highlights a clear demand for guidance on how to access these keys.
- Enthusiasm for Feature Access: intern111_29945 voiced their eagerness, stating, I'd love to get access to this feature, reinforcing overall enthusiasm.
- This suggests a sense of community interest in enhancing functionality through access to custom provider keys.
Perplexity AI ▷ #general (81 messages🔥🔥):
Pro user approval process, Gemini AI experience, Perplexity extensions, AI accessibility for non-coders, AI model comparisons
- Pro user approval confusion: Members discussed the requirements to get approved as 'Pro' users and shared personal experiences, with one noting they had access through their bank account perks.
- Instructions were shared on how to manage subscriptions and access the Discord for Pro users.
- Mixed experiences with Gemini AI: Some users expressed frustrations with Gemini AI, reporting issues like the model stopping responses after a few interactions.
- Concerns were raised about whether Gemini and ChatGPT were effectively comparable, leading to further discussion on their differences.
- Perplexity extensions availability: There was a conversation about the availability of extensions for Safari, with one extension available for adding Perplexity as a search engine but another summarization extension being discontinued.
- Members shared links and tips to navigate these extensions and suggested alternatives for non-Safari browsers.
- AI learning platform proposal: A member proposed an idea for a tier-based learning system to make AI technologies more accessible to non-coders, suggesting a structured curriculum of projects and tutorials.
- The proposed system aims to provide step-by-step guidance and help users evolve their skills in a community-oriented way.
- Discussion on AI model responses: A user raised questions about discrepancies in responses generated by ChatGPT-4 in Perplexity versus the original ChatGPT, leading to clarifications about inconsistencies across platforms.
- Another user noted that differences in output can arise due to various factors including API differences and the nature of requests.
- Qwen2.5 Turbo 1M Demo - a Hugging Face Space by Qwen: no description found
- Tweet from Phi Hoang (@apostraphi): 🫱✨🫲
Perplexity AI ▷ #sharing (15 messages🔥):
Luca - Last Universal Common Ancestor, Digital Twins, Jaguar Car Sales, AI Impact on Grammarly, Processing Techniques
- Discover LUCA, the Last Universal Common Ancestor: Perplexity AI highlights an intriguing discussion on LUCA, emphasizing its significance in evolutionary biology.
- Users are encouraged to explore this topic for a deeper understanding of its implications.
- Understanding Digital Twins: An exploration into what a digital twin is reveals its application in various industries.
- Digital twins simulate real-world entities for monitoring and optimization, sparking extensive user interest.
- Evolution of Jaguar Car Sales: A detailed look at how Jaguar car sales have evolved offers insights into market trends.
- Discussion centers around strategies and factors that have influenced sales performance over time.
- AI's Impact on Grammarly: Did AI impact Grammarly? prompts users to explore the relationship between AI advancements and writing tools.
- Debates suggest both benefits and potential drawbacks in the integration of AI within such platforms.
- Processing Techniques for Various Applications: Processing techniques are under discussion as users share methods applicable to diverse fields.
- Innovations in processing are making waves in technology and creative industries alike.
Perplexity AI ▷ #pplx-api (2 messages):
API site status
- API site appears operational: A member inquired if the API site was down due to issues accessing it.
- Another member responded that the site worked fine for them and suggested checking again or using a different device.
- User seeks clarification about API availability: A user raised a concern regarding the accessibility of the API site, questioning if it was down.
- Community feedback suggested that the site was functioning properly for others, hinting at possible user-specific issues.
Stability.ai (Stable Diffusion) ▷ #general-chat (79 messages🔥🔥):
Using Image Prompts in SDXL Lightning, Setting Parameters in WebUI, Generating Pixar-style Images, Video Fine Tuning Services, Stable Diffusion Download and Use Cases
- Using Image Prompts in SDXL Lightning: A user inquired whether it is possible to use image prompts in SDXL Lightning via Python, seeking guidance on inserting photos into specific contexts.
- Another user affirmed it was indeed possible, suggesting they exchange more information through direct messaging.
- Setting Parameters in WebUI for 12GB VRAM: A discussion ensued regarding what additional commands to use in webui.bat for enhanced performance with 12GB VRAM, with suggestions to include '--no-half-vae'.
- Users agreed that this was sufficient for optimal functioning without further complications.
- Generating Pixar-style Images: A request was made for methods to convert corporate photos into Pixar-style images, needing to process about ten portraits on short notice.
- Members debated the feasibility of this task, noting that free services may not be available and suggesting fine-tuning an image generation model.
- Video Fine Tuning Services: Users discussed their interest in video fine-tuning and inquired about potential servers or services for this purpose, referencing the Cogvideo model.
- It was mentioned that while the Cogvideo model is prominent in video generation, other specific fine-tunes might be preferred depending on user needs.
- Stable Diffusion Download and Use Cases: A new user asked for the easiest and fastest way to download Stable Diffusion for PC amidst questions about relevant use cases.
- Another user requested assistance in creating a specific image using Stable Diffusion while navigating content filters, indicating a need for more permissive software options.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Eye Rolling GIF - Eye Rolling Eyes - Discover & Share GIFs: Click to view the GIF
- Voice & Video AI Agents Hackathon · Luma: Gen AI Agents CreatorsCorner, collaborating with AWS, Tandem, Marly, Senso, and others enthusiastically welcomes individuals and teams to join our third…
- Text-to-image: no description found
LlamaIndex ▷ #general (63 messages🔥🔥):
Function calling in workflows, LlamaIndex security compliance, Ollama package issues, Hugging Face embedding format issues, LlamaParse parsing instructions
- Simplifying Function Calling in Workflows: Users discussed the ease of using function calling in workflows, with recommendations to utilize prebuilt agents for automated function invocation without boilerplate code.
- A member highlighted that while the boilerplate code provides better control, using a prebuilt
FunctionCallingAgentsimplifies the process.
- A member highlighted that while the boilerplate code provides better control, using a prebuilt
- LlamaIndex's Security Compliance: LlamaIndex confirmed compliance with SOC2 and clarified the handling of original documents under LlamaParse and LlamaCloud.
- LlamaParse keeps files encrypted for 48 hours, while LlamaCloud chunks and stores data securely.
- Issues with the Ollama Package in LlamaIndex: Users reported issues with the Ollama package, particularly a bug in the latest version that generated errors during chat responses.
- Downgrading Ollama to version 0.3.3 was suggested, and some members confirmed that this resolved their issues.
- Hugging Face Embedding Compatibility: There were concerns regarding the output format of embeddings from the CODE-BERT model not aligning with LlamaIndex's expectations.
- Users suggested raising an issue on GitHub to address the potential mismatch in handling model responses.
- Challenges with LlamaParse Instructions: A member faced challenges with LlamaParse not following specified parsing instructions, prompting discussions on settings like
is_formatting_instruction.- The community provided insights on troubleshooting parsing issues and recommended reviewing the documentation for proper configurations.
- no title found: no description found
- Enterprise — LlamaIndex - Build Knowledge Assistants over your Enterprise Data: LlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.
- microsoft/codebert-base · Hugging Face: no description found
- Voice & Video AI Agents Hackathon · Luma: Gen AI Agents CreatorsCorner, collaborating with AWS, Tandem, Marly, Senso, and others enthusiastically welcomes individuals and teams to join our third…
- llama_parse/llama_parse/base.py at main · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- handle ollama 0.4.0 by logan-markewich · Pull Request #17036 · run-llama/llama_index: Fixes #17035 Fixes #17037 Ollama updated to return typed responses instead of plain dicts, which broke how we attach usage
- Usage Pattern - LlamaIndex: no description found
- Workflows - LlamaIndex: no description found
- Workflow for a Function Calling Agent - LlamaIndex: no description found
- OpenAI - LlamaIndex: no description found
- multi-agent-concierge/video_tutorial_materials at main · run-llama/multi-agent-concierge: An example of multi-agent orchestration with llama-index - run-llama/multi-agent-concierge
- Introduction - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
LlamaParse issues, Scientific article parsing, Redundant information in parsing, Document flow maintenance, Bibliography exclusion
- LlamaParse faces redundancy issues: A member reported problems with LlamaParse returning redundant information, particularly headers and bibliographies, despite clear instructions to exclude them.
- Has anyone else experienced this issue? The member seeks suggestions on resolving this parsing error.
- Parsing instructions for scientific articles: The member provided detailed parsing instructions for handling multi-page scientific articles, emphasizing the importance of logical content flow and the exclusion of non-essential elements like acknowledgments and references.
- Instructions specify to include the journal title and author details only once at the beginning: Do not return any References or Bibliography sections.
Notebook LM Discord ▷ #use-cases (10 messages🔥):
Podcast creation with NotebookLM, YouTube videos on AI and Robotics, Feature requests for Producer Studio, Translating NotebookLM audio, Social media content generation
- Podcast Feature Success with NotebookLM: A user celebrated their podcast creation journey using NotebookLM, sharing their video titled "Google Chrome: Browser Wars and AI Automation Frontiers" that includes comprehensive production elements.
- They expressed a desire for their Producer Studio feature request to be implemented.
- New Video on AI & Robotics Released: A new YouTube video titled "AI & Humanoid Robotics: The Future Is Now" dives into advancements in AI and robotics, exploring contributions from industry leaders such as OpenAI and NVIDIA.
- The creator seeks feedback on improving their content generation.
- Exploring the Future of AI with Insights: Another member shared a video titled "Want to Know the Future of AI? Watch This Now", discussing the book Genesis: Artificial Intelligence, Hope, and the Human Spirit.
- This episode emphasizes thought-provoking discussions surrounding the implications of AI.
- Engagement for Feature Support: A call was made for community support regarding a feature by adding reactions or messages to a shared link on Discord.
- Active participation is encouraged to influence feature development.
- Language Translation Queries: In a discussion regarding language support, one user inquired about translating NotebookLM audio into German, focusing on exclusive German-language topics.
- Another user expressed a similar interest for Italian language translation, showcasing a demand for multilingual support.
- Google Chrome: Browser Wars and AI Automation Frontiers: Explore the critical technological battlegrounds where browsers, AI, and automation collide. Each episode uncovers the hidden implications of tech ecosystem ...
- Want to Know the Future of AI? Watch This Now: In this podcast episode, we dive into the thought-provoking book "Genesis: Artificial Intelligence, Hope, and the Human Spirit" by Henry Kissinger, Craig Mun...
- AI & Humanoid Robotics: The Future Is Now - Advances by Figure, OpenAI, Anthropic, and NVIDIA: Dive into the cutting-edge world of AI and robotics in our latest video! We’re exploring the jaw-dropping advancements from industry leaders:Figure: Discover...
- TikTok - Make Your Day: no description found
- Top.Shelf.Podcast (@top.shelf.podcast) • Instagram photos and videos: 3 Followers, 14 Following, 7 Posts - See Instagram photos and videos from Top.Shelf.Podcast (@top.shelf.podcast)
Notebook LM Discord ▷ #general (46 messages🔥):
Podcast API Alternatives, Language Support in Audio, Podcast Creation Limitations, NotebookLM Usage Issues, Retrieval-Augmented Generation in NotebookLM
- Exploring Podcast API Alternatives: A member suggested trying Podcastfy.ai as an open source alternative API to NotebookLM's podcast feature.
- Inquiring minds are considering how it compares to existing options.
- Language Support Problems with Hosts: A user expressed frustration as hosts only speak English, despite previous successful attempts in French.
- Another member suggested that sometimes different languages respond to prompts, indicating potential inconsistencies.
- Podcast Creation Limits Explained: Users noted a limitation of 100 podcasts per account and speculated a daily cap of 20 podcast creations.
- They confirmed that podcast buttons reappear upon deletion of older ones, further clarifying the limits.
- Access Issues with Gmail Accounts: One user faced access restrictions on their second Gmail account and resolved it by verifying age, which was previously unconsidered.
- This highlights potential hurdles users can encounter with account settings.
- Understanding NotebookLM's Functions: A user queried about the ability of NotebookLM to maintain quality after numerous queries within a session.
- Another provided insight into how NotebookLM utilizes 'Retrieval-Augmented Generation' for improved response accuracy and citation tracking.
- no title found: no description found
- no title found: no description found
- Hawk Talk Podcast - Thursday Night LIVE | TELESTAI Updates! | BTC TO 100K!: Welcome to the Hawk Crypto and Tech channel everyone! ➡️ Twitter: https://twitter.com/HawkCryptoTech➡️ Misfit Mining Discord: https://discord.gg/XUvGgC5thp➡️...
- AI & Humanoid Robotics: The Future Is Now - Advances by Figure, OpenAI, Anthropic, and NVIDIA: Dive into the cutting-edge world of AI and robotics in our latest video! We’re exploring the jaw-dropping advancements from industry leaders:Figure: Discover...
- Top.Shelf.Podcast (@top.shelf.podcast) • Instagram photos and videos: 3 Followers, 14 Following, 7 Posts - See Instagram photos and videos from Top.Shelf.Podcast (@top.shelf.podcast)
- Chris Moran (@chrismoranuk.bsky.social): A little thread on NotebookLM and journalism uses. First and most obviously, if you’re a journalist working a specific beat and often referring to reports, research or inquiry evidence, NotebookLM is ...
Interconnects (Nathan Lambert) ▷ #news (19 messages🔥):
OpenAI's Copyright Lawsuit, Decentralized Training of 10B Model, Anthropic's Collaboration with AWS, Expectations for New AI Models, Cynicism in AI Development
- OpenAI's Data Deletion Misstep: Lawyers for The New York Times and Daily News are suing OpenAI, alleging that OpenAI engineers accidentally deleted data relevant to their copyright lawsuit after they had spent over 150 hours searching for it.
- On November 14, all search data on one virtual machine was erased, raising concerns about the potential impact on the case as outlined in a court letter.
- Prime Intellect Announces INTELLECT-1: Prime Intellect shared the completion of the first decentralized training of a 10B model across various continents, stating that post-training with @arcee_ai is in progress.
- A full open-source release is expected within a week, providing access to the base model and checkpoints, inviting collaboration to build open-source AGI.
- Anthropic Secures Major AWS Partnership: Anthropic announced an expansion of its collaboration with AWS, backed by a $4 billion investment from Amazon to establish AWS as their primary cloud and training partner.
- This partnership aims to bolster Anthropic's capabilities in developing their AI technologies, as detailed in their official news release.
- Skepticism Surrounding New AI Models: Concerns were raised about expectations for the 10B model trained on 1T tokens, with opinions suggesting it may not compete effectively with existing models like LLaMA.
- Some believe that it may have to be the best model ever to stand a chance, yet cynicism and dismissal of new attempts are common in the current landscape.
- Navigating AI Development Cynicism: A discussion highlighted the cynicism prevalent in AI development, where new models like Olmo faced skepticism as well.
- Despite the negativity, some participants advocated for pushing through the critical feedback and staying focused on development.
- Tweet from Anthropic (@AnthropicAI): We're expanding our collaboration with AWS. This includes a new $4 billion investment from Amazon and establishes AWS as our primary cloud and training partner. http://anthropic.com/news/anthrop...
- Tweet from Prime Intellect (@PrimeIntellect): We did it — the first decentralized training of a 10B model is complete! Trained across the US, Europe, and Asia 🌐 Post-training with @arcee_ai is underway, and a full open-source release is coming...
- OpenAI accidentally deleted potential evidence in NY Times copyright lawsuit | TechCrunch: In a court filing, lawyers for The NY Times and Daily news say that OpenAI accidentally deleted potential evidence against it.
Interconnects (Nathan Lambert) ▷ #other-papers (1 messages):
420gunna: https://x.com/reach_vb/status/1859868073903423821 multimodal encoder bros ✊
Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
Flops in AI, Magic from Base Models, Reaction to Amanda's Post, Scale Research, Related Research Papers
- Low Flops Raise Big Questions: A member expressed concern that our flops are too low, suggesting that a 'getting magic from base' approach might lead to useful insights.
- They emphasized the importance of balancing theoretical and practical aspects in AI development.
- Post Idea Brewing from Amanda's Reaction: A member mentioned they may react to Amanda's post on Lex in their upcoming post, showcasing growing interest in the topic.
- This indicates a proactive engagement with community discussions and evolving ideas.
- Discovery of Scale Research: A member remarked on the existence of scale research, demonstrating intrigue and surprise that it was recognized as an area of study.
- They connected this discovery to the recent conversations around AI model performance and optimization.
- Related Paper Sparks Interest: A member referenced a related paper that caught their attention recently, enhancing the discussion on AI modeling techniques.
- They described this paper as relevant to ongoing conversations, indicating a desire for deeper exploration on the topic.
Interconnects (Nathan Lambert) ▷ #ml-drama (5 messages):
CamelAIOrg Account Issues, OASIS Social Simulation Project, Customer Service Concerns
- CamelAIOrg's Account Ghosting: The account for CamelAIOrg has been determined by OpenAI for unknown reasons, possibly related to their recent OASIS social simulation project which used one million agents, as detailed on their GitHub page.
- They reached out for assistance but have not received a response in 5 days, leaving 20+ community members waiting for API keys.
- Frustration Over Treatment by OpenAI: A user expressed frustration about spending hundreds of thousands of dollars with a company only to feel mistreated.
- Another user commented on the slow response, stating, 'you at least get LLM slop regurgitating your question after several days and then get ghosted.'
- Speculation on Tulu 3's Release: There is curiosity around whether a certain outcome will come for Tulu 3 as discussed in the channel.
- A member noted it would be surprising if that were the case.
Link mentioned: Tweet from Guohao Li (Hiring!) 🐫 (@guohao_li): @OpenAI determined the account of our @CamelAIOrg organization for unknown reasons. It maybe related to our recent OASIS social simulation project we ran with one million agents but I am not sure: htt...
Interconnects (Nathan Lambert) ▷ #random (7 messages):
Black Market Data Sale, Benchmark Buying, Labs Operating Quickly
- Facilitating a Black Market Data Sale: A member humorously mentioned being asked to facilitate a black market data sale between an internet person and an AI lab.
- It's still so freaking funny to see such unconventional transactions proposed in the AI space.
- Speculation on Personal Benchmark Sale: Another member speculated about an attempt to buy Xeos personal benchmark data, saying, 'Damn they tryna buy Xeos personal benchmark already huh'.
- This highlights the increasing interest in personal benchmarks within the AI community.
- Labs are Moving Fast: In response to the black market proposal, a member noted that labs move fast, implying a competitive and rapid landscape.
- This comment suggests a prevailing urgency in acquiring data and benchmarks in the AI industry.
Interconnects (Nathan Lambert) ▷ #memes (3 messages):
Meme Formats, Language Models, Creative Content
- *Meme Format Appreciation*: A member expressed their fondness for a particular meme format, stating they are 'weak for this meme format tbh.'
- They shared a link to the meme, suggesting it sparked joy among the community, highlighting its source.
- *Yeeting in Discord*: Another member simply responded with the enthusiastic expression 'Yeet,' contributing to the lighthearted conversation.
- This short interaction may reflect the overall playful tone within the channel.
- *Language Model Brainrot*: A member humorously questioned if the conversation was veering towards 'language model ipad baby brainrot content.'
- This comment showcases a whimsical take on the nature of discussions about language models, amused by the absurdity.
Interconnects (Nathan Lambert) ▷ #rlhf (4 messages):
Tulu 3 Paper, On-policy vs Off-policy DPO, Online DPO Performance
- Clarifying On-Policy DPO in Tulu 3: A discussion arose over the Tulu 3 paper, questioning whether the DPO method described is truly on-policy since the model's policy evolves during training, leading to off-policy behavior by sampling from the initial base model.
- Members debated that online DPO, as mentioned in section 8.1, is more aligned with on-policy reasoning since it samples completions for the reward model at each training step.
- Challenges with Online DPO: A participant highlighted that actual 'Online DPO' was too finicky to function effectively during their experimentation.
- Another member speculated that the rapid policy shifts within Online DPO might be contributing to its performance issues.
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
SnailBot News: <@&1216534966205284433>
GPU MODE ▷ #general (1 messages):
markus_41856: https://lu.ma/i8bow7sr
GPU MODE ▷ #triton (5 messages):
Triton on AMD GPUs, Swizzle for L2 Cache, Optimizing Triton Kernels, Memory Access Efficiency, MLIR Analysis
- Triton Showcases AMD GPU Optimizations: In a YouTube video titled 'Triton on AMD GPUs', Lei Zhang and Lixun Zhang discuss clever optimization techniques around chiplets and various instructions.
- A participant noted that the swizzle technique mentioned pertains to L2 cache, adding value to the optimization discussion.
- Guide for Optimizing Triton Kernels: An article on Optimizing Triton kernels outlines the steps for Triton kernel optimization, highlighting the comparison to HIP and CUDA.
- It emphasizes that global memory has high latency while LDS and registers offer faster access, underscoring the need for efficient memory access strategies.
- Utilizing Pad over Interleave in Memory Access: A member mentioned that in their analysis, they observed the use of pad instead of interleave layout for addressing in Triton kernel optimization.
- They are currently analyzing the generated MLIR, looking for deeper insights into this optimization choice.
- Triton on AMD GPUs: Lei Zhang and Lixun Zhang talk to Triton support for AMD. This talk shows off some very clever optimization techniques around chiplets and also instruction s...
- Optimizing Triton kernels — ROCm Documentation: no description found
GPU MODE ▷ #torch (4 messages):
Torch Inductor Compilation Error, Custom Layer .to() Behavior
- Torch Inductor Raises Errors During Compilation: An error was encountered while using a LoRA implementation that triggered a
BackendCompilerFailedexception, specifically with the errorAttributeError: 'float' object has no attribute 'meta'related to a quantization line ininductor.- The issue appears related to interacting with torch.compile, and the user couldn't reproduce it outside the context of a large model, prompting inquiries for potential solutions.
- Custom Layer's .to() Call Fails at Model Level: A user noted that their custom
.to()implementation works on individual layers but does not trigger when applied to the entire model, suggesting a potential limitation innn.Modulefunctionality.- Another member confirmed that nn.Module.to() does not recursively call
.to()on child modules, advising to call.to()directly on children if needed.
- Another member confirmed that nn.Module.to() does not recursively call
- pytorch/torch/_inductor/fx_passes/quantization.py at a6344c8bcd22798987087244e961cdc0cbf9e9df · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/nn/modules/module.py at a6344c8bcd22798987087244e961cdc0cbf9e9df · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #algorithms (1 messages):
FlashAttention, Global vs Local Exp Sum
- Inquiry into Approximation Techniques for FlashAttention: A member inquired if there's any existing paper addressing how to approximate the global exponential sum based on local sums in the tiling block of QK^T.
- The question highlights the ongoing exploration of efficiency in calculating attention scores.
- Importance of Local vs Global Sums: Discussion emphasized the significance of understanding the relationship between local and global exponential sums in optimizing FlashAttention mechanisms.
- Members suggested that this understanding could lead to improved approximation techniques and overall efficiency.
GPU MODE ▷ #cool-links (1 messages):
platers: https://research.character.ai/optimizing-ai-inference-at-character-ai-part-deux/
GPU MODE ▷ #jobs (1 messages):
Flash Attention optimizations, Character AI job opening
- Flash Attention Optimizations Celebrated: A member highlighted Jay's post discussing optimizations on top of Flash Attention, showcasing the latest advancements in this area.
- The post received positive comments for contributing valuable insights to the ongoing discussion about attention mechanisms.
- Character AI Seeks Researcher for ML Systems: Character AI announced a job opening for a Researcher in ML Systems, inviting candidates to apply via their job posting.
- This position aims to strengthen their team focused on integrating machine learning systems into their projects.
Link mentioned: Research Engineer, ML Systems (All Industry Levels): Joining us as a Research Engineer on the ML Systems team, you’ll be working on cutting-edge ML training and inference systems, optimizing the performance and efficiency of our GPU clusters, and develo...
GPU MODE ▷ #beginner (2 messages):
ldmatrix tile sizes, torch dispatch to triton
- ldmatrix tile sizes questioning: A member inquired whether ldmatrix only supports loading 8x8 tiles, as they found examples only specific to .m8n8 in the documentation.
- This raises uncertainty about potential support for other tile sizes within the ldmatrix framework.
- Torch's dispatch to Triton for matrix operations: Another member questioned if torch dispatches to triton for certain matrix sizes and operations.
- This could indicate an optimization layer at play for specific operations that might enhance performance.
GPU MODE ▷ #torchao (4 messages):
Quantization Schemes Benchmarking, Weight Tensors Distribution, BNB NF4 vs Marlin Performance, Weight Outliers in Projections
- Benchmarking Distance Metrics for Quantization: When benchmarking quantization schemes, a member inquired about the appropriate distance metric, suggesting the mean square difference.
- Discussion arose about different metrics used in the field during quantization evaluations.
- Odd Weight Outliers in BF16 Tensors: Benchmarking revealed bf16 weight tensors from Llama 70B showing a mean of approximately 2e-06 and a variance of 0.0001, yet having outliers like 85 and -65.
- It's odd, as the weights were expected to follow a normal distribution, raising questions about their distribution characteristics.
- BNB NF4 Surpasses Marlin in Benchmarking: The bnb nf4 quantization scheme was found to hold up exceptionally well, outperforming Marlin in specific benchmarks despite the latter being highly effective in general.
- Members were surprised by the notable differences observed between the bf16 baseline and Marlin's performance.
- Weight Outliers Observed in Projections: Members discussed that weight outliers have been particularly evident during down projections, reinforcing concerns regarding their presence.
- An observation was made that these outliers occur extensively, not just in projections, indicating a broader issue.
GPU MODE ▷ #off-topic (2 messages):
Vercel's v0 Tool, System Prompts Leak, AI Coding Assistance
- Vercel's v0 System Prompts Leaked: A member leaked the system prompts from Vercel's v0 tool claiming they are 100% legit and reveal interesting integration of the reflection method.
- They provided links to the full system prompt and a specific feature file for further insight.
- User Praises AI Coding Assistant: Another member shared a positive experience using Vercel's v0 tool, highlighting that it simplifies multifile edits and provides a one-click deploy feature.
- “Honestly worth!” they remarked, emphasizing the value of what people are effectively paying for—a prompt and enhanced AI assistance.
Link mentioned: Reddit - Dive into anything: no description found
GPU MODE ▷ #sparsity-pruning (1 messages):
Pruning techniques, Model efficiency papers, Data dependent strategies, Industrial applications of LLMS
- Inquiry on Latest Pruning Techniques for LLMS: A member asked for recommendations on the latest pruning and model efficiency papers and strategies currently used in an industrial setting for large language models (LLMs).
- They mentioned using the What Matters in Transformers paper but found that the technique is data dependent.
- Seeking Non Data Dependent Techniques: In their query, a member expressed a need for non data dependent techniques in model pruning and efficiency.
- This highlights a gap in strategies that do not rely on specific data sets, which could enhance model efficiency in varied applications.
GPU MODE ▷ #🍿 (4 messages):
GPT-2 Training Method, Discord Bot Integration, OpenCoder Paper Filtering Approach
- Train GPT-2 in Five Minutes: A member shared a GitHub Gist outlining how to train GPT-2 in five minutes for free, complete with a function to assist the process.
- An associated image linked provides a visual representation of the gist's content:
 .
.
- An associated image linked provides a visual representation of the gist's content:
- Discord Bot Enhancement for GPT-2 Training: Discussion arose about the capability for their Discord bot to also perform GPT-2 training in a streamlined manner.
- This indicates a potential improvement in user experience for those utilizing the bot for AI-related tasks.
- Cold Start Caching Tricks: <@marksaroufim> pointed out that the caching trick mentioned could be important for cold starts to improve performance.
- This insight suggests an enhancement in operational efficiency when initializing the bot in scenarios where quick responses are necessary.
- OpenCoder Paper's Filtering Proposal: A member discussed the OpenCoder paper which proposed a three-layer filtering system for files crawled from public repositories, comprising general text files, code files, and language-specific code files.
- The member questioned the feasibility of this approach and sought advice on defining CUDA-specific rules to eliminate low-quality files.
Link mentioned: Train GPT-2 in five minutes -- for free!: Train GPT-2 in five minutes -- for free! GitHub Gist: instantly share code, notes, and snippets.
GPU MODE ▷ #edge (1 messages):
NPU Acceleration, Executorch, Qualcomm NPUs
- Seeking NPU Acceleration Solutions: A member inquired about libraries or runtimes that support NPU acceleration, mentioning that they know Executorch provides some support for Qualcomm NPUs.
- They expressed a desire to learn about other potential solutions available in the market.
- Interest in Additional NPU Libraries: The same member is curious if other frameworks exist to leverage NPU acceleration effectively beyond Executorch.
- They opened the discussion for community input on this topic.
Cohere ▷ #discussions (14 messages🔥):
Cohere API front-end, Chat history editing feature
- Request for Cohere API Compatible Front-End: A user inquired about a front-end compatible with the Cohere API that allows users to edit their chat history similar to features in Claude or GPT.
- They emphasized the need for an edit button to modify inputs, avoiding the need to restart conversations due to mistakes.
- Clarification on Editing Interaction: Another user clarified that the request was for a feature where edits become part of the chat history, which the initial user confirmed.
- They reiterated the absence of an edit option on the Cohere website's chat and playground-chat pages, highlighting its significance for user experience.
Link mentioned: imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
Cohere ▷ #projects (1 messages):
jilldomi_48896: This is super cool

SQL Agent with Cohere and LangChain (i-5O Case Study) — Cohere
This page contains a tutorial on how to build a SQL agent with Cohere and LangChain in the manufacturing industry.
tinygrad (George Hotz) ▷ #general (4 messages):
SDXL casting issues, Regression concerns, Intermediate casting strategy
- SDXL's Casting Issue Doubles Benchmark Slowness: Members noted that after update #7644, SDXL no longer casts to half on CI tinybox green, resulting in benchmarks slowing down by more than 2x.
- Could this be an intended change due to previous incorrect casting?
- Uncertainty Over Potential Regression: A member expressed concern about whether the loss of casting effectiveness after update #7644 is a regression.
- They sought clarification, uncertain if the slower benchmarks imply a backward step in performance.
- Proposed Update for Intermediate Casting: Another member suggested that intermediate casting should be determined by input dtypes, not the device, advocating for a pure functional approach.
- They proposed an argument similar to fp16 in stable diffusion to handle model and input casting more efficiently.
tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
Custom Kernel Functions Support, Introduction to Tinygrad, Tensor Stride and View Hopping, objc_id and ctypes Behavior, Function Call Behavior in ops_metal.py
- Custom Kernel Functions Removed: A user asked if custom kernel functions are still supported, but it was confirmed that they were removed from the latest versions of the repo.
- George Hotz suggested there are usually better methods to achieve the desired results without breaking abstraction.
- Helpful Introduction to Tinygrad Shared: A user found an introduction to Tinygrad and shared a YouTube link that might benefit beginners.
- This resource aims to help new users grasp the fundamentals of Tinygrad more easily.
- Discussion on Tensor Strides: A participant speculated on the need for huge tensors and the potential treatment of strides as circular, hinting at previous solutions of view hopping.
- They also discussed the efficiency of hardware when dealing with 32b vs 64b, suggesting internal splitting of tensors for better performance.
- Override Behavior in ops_metal.py: In
ops_metal.py, a user raised the question about overriding hash and eq functions for the objc_id class to manage response types effectively.- They noted that using
objc_id=ctypes.c_void_pcaused crashes in their Jupyter kernel, unlike the TinyGrad implementation.
- They noted that using
Link mentioned: tinygrad/tinygrad/runtime/ops_metal.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
Modular (Mojo 🔥) ▷ #mojo (7 messages):
Mojo and Python integration, Async capabilities in Mojo, Performance challenges, Roadmap for Mojo enhancements, Parameterization and traits in Mojo
- Mojo may soon call Python functions: It's on the Mojo roadmap to enable importing Mojo packages from Python and calling Mojo functions, providing enhanced interoperability.
- Community members indicated that this feature is actively being developed, with some preliminary methods available for those not requiring top performance.
- Async event loops require additional setup: Asynchronous operations in Mojo necessitate the creation of an event loop to effectively manage state machines, despite having initial support for async allocated data structures.
- There are plans to allow users to compile out the async runtime if it's not needed, streamlining potential performance optimizations.
- Integration using multithreading is feasible: One user shared a workaround where Mojo and Python communicate through a queue, allowing asynchronous interactions with multithreading in Python.
- While this approach can be effective for some cases, it may feel overly complex for simpler use cases, leading others to prefer an official solution.
- User interest in Mojo's features: A member expressed that the primary use case for Mojo lies in providing a Python-like alternative for C/C++/Rust, emphasizing acceleration of slow processes.
- Their focus is on essential features such as parameterized traits and Rust-style enums, suggesting a desire for foundational enhancements over Mojo classes.
Torchtune ▷ #general (3 messages):
HF transfer, Download Speed Improvements, Internet Connection Impact
- HF Transfer Speeds Up Model Downloads: The addition of HF transfer to torchtune significantly reduces model downloading times, with the time for llama 8b dropping from 2m12s to 32s.
- Users can enable it by running
pip install hf_transferand adding the flagHF_HUB_ENABLE_HF_TRANSFER=1for non-nightly versions.
- Users can enable it by running
- Mixed Results on Home Internet Speeds: One user inquired about the effectiveness of HF transfer on normal home internet connections, as past experiences showed it mostly benefiting machines with higher speeds.
- In response, another user highlighted their positive results using the feature at home, indicating that downloading one file at a time via HF transfer can achieve speeds exceeding 1GB/s.
- Optimized Download Strategy with HF Transfer: The standard download method tries to fetch all files for the 8B model simultaneously at around 50MB/s, which can be inefficient.
- In contrast, HF transfer's approach of downloading files one at a time optimizes bandwidth usage, leading to much faster download speeds.
Link mentioned: Use hf transfer as default by felipemello1 · Pull Request #2046 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) pip install huggingface_hub[hf_transfer] HF_HUB_ENABLE_H...
Torchtune ▷ #papers (4 messages):
AI model evaluations, Statistical theory in model comparisons, Central Limit Theorem application, AI research community response
- New Paper Tackles Evaluation Consistency: A recent research paper from Anthropic discusses the reliability of AI model evaluations, questioning if performance differences are genuine or if they arise from random luck in question selection.
- This study encourages the AI research community to adopt more rigorous statistical reporting methods.
- Error Bars Spark Controversy: A community member sarcastically remarked on the paper's focus on error bars, implying it isn’t groundbreaking enough to warrant extensive research.
- This critique reflects a broader sentiment that fundamental statistical tools are often overlooked in the field.
- Surprising Lack of Statistical Methodology: Another member noted the surprising lack of statistical approaches in model evaluations, emphasizing the need for robust methodologies in the field.
- This demonstrates an ongoing conversation about enhancing the standards for evaluating AI models effectively.
Link mentioned: A statistical approach to model evaluations: A research paper from Anthropic on how to apply statistics to improve language model evaluations
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
Hackathon Location, Team Registration Confirmation
- Hackathon is 100% Online: In response to a query about the hackathon location, it was clarified that the event is entirely online, alleviating potential logistics concerns.
- This ensures that participants can join from anywhere without needing to focus on a physical venue.
- Team Registration Now Sends Confirmation Emails: It was mentioned that team registration will now send a confirmation email via Google Forms to the email entered in the first field, rather than each team member.
- This change simplifies the process, ensuring that at least one team member receives the necessary confirmation.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
danman117: really good presenation from Percy Liang this week!
OpenInterpreter ▷ #general (4 messages):
Posting Job Ads, Desktop App Release, Exponent Demo, Open Source Devin, Windsurf Feedback
- Job Ads Need a Better Home: There's a discussion about the appropriate channel for job postings, with a reminder that it should be directed to <#1210088092782952498> according to the community guidelines.
- We want to support job seekers but not fill the general chat with ads.
- Inquiring About Desktop App Release: A newcomer expressed curiosity about the release timeline for the desktop app after signing up for the waiting list.
- No specific release date was shared, indicating it remains uncertain.
- Exploring Exponent Demo: One member shared their experience doing a demo with Exponent, mentioning they are still experimenting with its features.
- Positive feedback was given about Windsurf, highlighting its effectiveness.
- Open Source Devin in Discussion: It was noted that there's an open-source version of Devin that members have been exploring but the speaker hasn't yet tried it.
- This reflects ongoing interest in experimenting with community-driven tools.
OpenInterpreter ▷ #O1 (1 messages):
Installing O1, Using Groq API, Free APIs on Linux
- Challenges Installing O1 on Linux: A member expressed difficulties in installing O1 on their Linux system and has yet to figure out how to make it work.
- They are seeking advice about potential solutions or workarounds for installation issues.
- Exploring Free APIs: There was a query regarding the feasibility of using the Groq API or any other free APIs with O1 on Linux.
- The discussion highlighted the member's interest in maximizing free resources for their project.
DSPy ▷ #general (3 messages):
VLMs for Invoice Processing, DSPy Support for VLMs, Complexity in Project Development
- VLMs eye-catching invoice processing: A member is exploring the use of a VLM for a high-stakes invoice processing project, seeking guidance on how DSPy could enhance their prompt for specialized subtasks.
- There's a mention of recent support for VLMs and specifically Qwen by DSPy.
- Test DSPy with VLMs: A member suggested trying DSPy for VLMS, sharing their success with it for a visual analysis project and noting that the CoT module functions effectively with image inputs.
- They haven't tested the optimizers yet, indicating there's more to explore.
- Start simple for project success: Another member emphasized starting with simple tasks before gradually adding complexity to projects, reinforcing the notion of accessibility with DSPy.
- It's not very hard, if you start simple and add complexity over time! conveys a sense of encouragement to experiment.
OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
INTELLECT-1, Decentralized training, Open-source AGI, Fine-tuning with Axolotl
- INTELLECT-1: A Milestone in Decentralized Training: Prime Intellect announced the completion of INTELLECT-1, marking the first-ever decentralized training of a 10B model across multiple continents.
- Post-training with @arcee_ai is now underway, with a full open-source release scheduled for approximately one week from now.
- Scaling Up Decentralized Training Efforts: The new model has achieved a 10x improvement in decentralized training capability compared to prior efforts, as claimed by Prime Intellect.
- This effort invites anyone interested to join and contribute toward building open-source AGI.
- Excitement for Fine-tuning in Axolotl: There is hopeful anticipation regarding the fine-tuning capabilities in Axolotl once the model is released.
- Many participants are eager to see how the system will handle finetuning given the innovations in decentralized training.
Link mentioned: Tweet from Prime Intellect (@PrimeIntellect): We did it — the first decentralized training of a 10B model is complete! Trained across the US, Europe, and Asia 🌐 Post-training with @arcee_ai is underway, and a full open-source release is coming...
LAION ▷ #general (1 messages):
Neural Turing Machines, Differentiable Neural Computers
- Exploring Neural Turing Machines: A member expressed their interest in Neural Turing Machines, noting they've been exploring this topic for the past few days.
- They would love to bounce ideas off others who share this interest.
- Diving into Differentiable Neural Computers: The discussion also included Differentiable Neural Computers, with the member keen to delve further into its concepts.
- They are looking for fellow enthusiasts to collaborate with on thoughts and insights related to both technologies.