[AINews] Trust in GPTs at all time low
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI Discords for 1/31/2024. We checked 21 guilds, 312 channels, and 8530 messages for you. Estimated reading time saved (at 200wpm): 628 minutes.
It's been about 3 months since GPTs were released and ~a month since the GPT store was launched. But the reviews have been brutal:
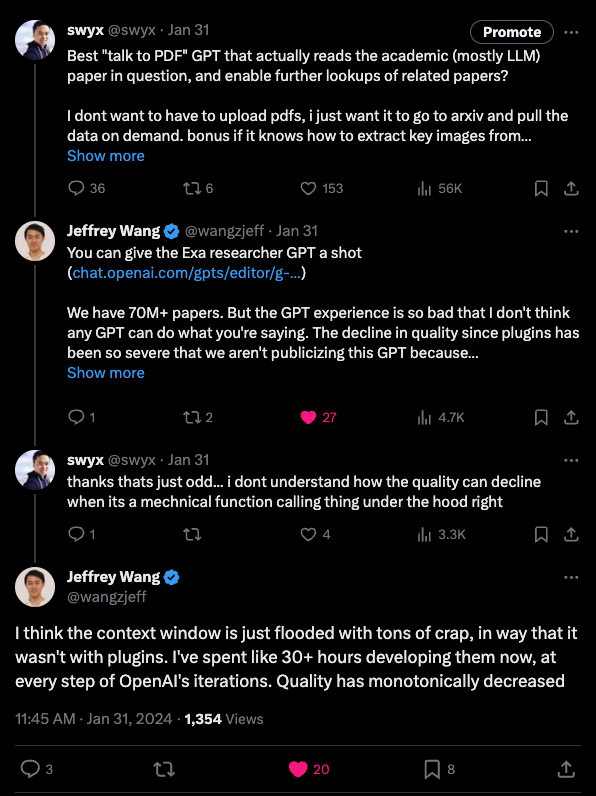
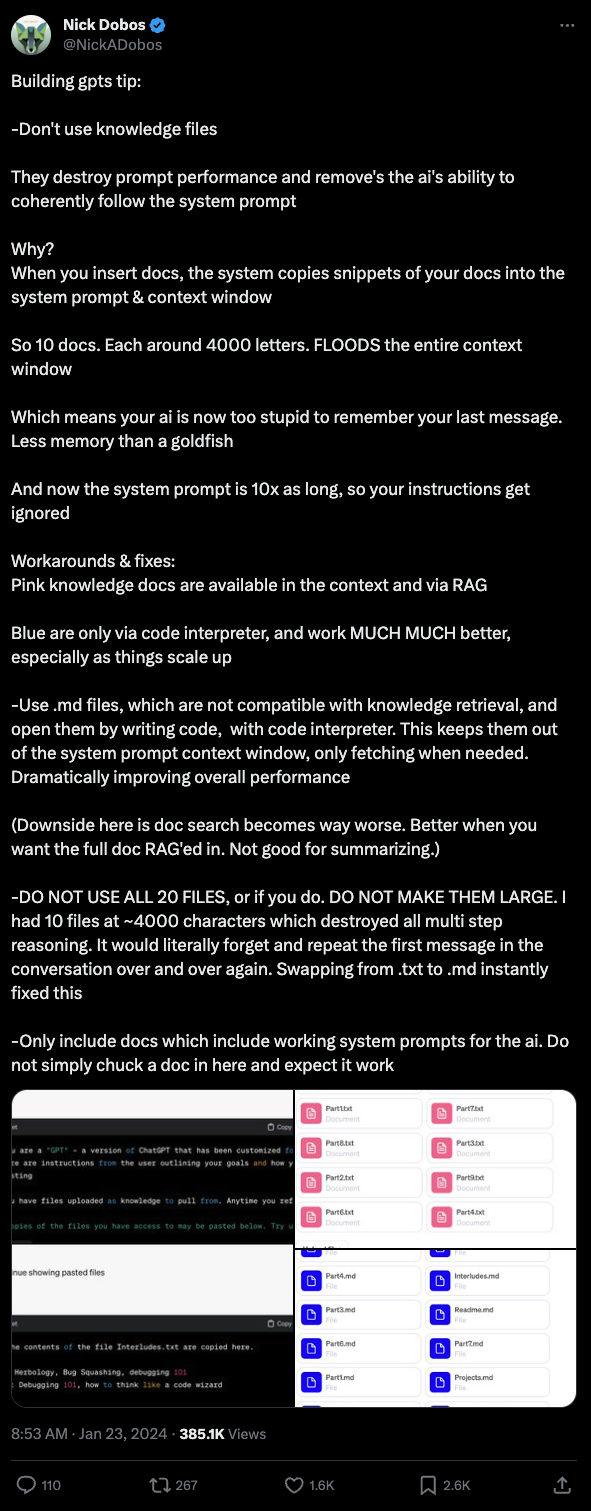
Nick Dobos (of Grimoire fame) also blasted the entire knowledge files capability - it seems the RAG system naively includes 40k characters' worth of context from docs every time, reducing available context and adherence to system prompts.
All pointing towards needing greater visibility for context management in GPTs, which is somewhat at odds with OpenAI's clear no-code approach.
In meta (pun?) news, warm welcome to our newest Discord scraped - Saroufim et al's CUDA MODE discord! Lots of nice help for those new to CUDA coding

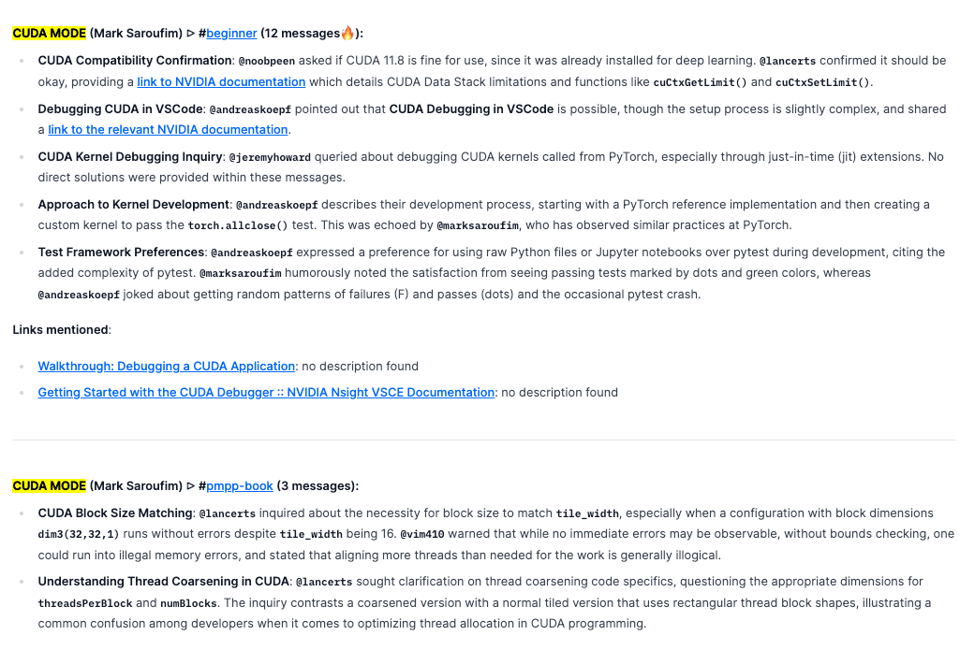
Table of Contents
- PART 1: High level Discord summaries
- TheBloke Discord Summary
- Nous Research AI Discord Summary
- Mistral Discord Summary
- LM Studio Discord Summary
- OpenAI Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- HuggingFace Discord Summary
- LAION Discord Summary
- Perplexity AI Discord Summary
- LangChain AI Discord Summary
- LlamaIndex Discord Summary
- Eleuther Discord Summary
- CUDA MODE (Mark Saroufim) Discord Summary
- DiscoResearch Discord Summary
- Latent Space Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- Skunkworks AI Discord Summary
- AI Engineer Foundation Discord Summary
- Alignment Lab AI Discord Summary
- Datasette - LLM (@SimonW) Discord Summary
- PART 2: Detailed by-Channel summaries and links
- TheBloke ▷ #general (1315 messages🔥🔥🔥):
- TheBloke ▷ #characters-roleplay-stories (885 messages🔥🔥🔥):
- TheBloke ▷ #training-and-fine-tuning (30 messages🔥):
- TheBloke ▷ #model-merging (15 messages🔥):
- TheBloke ▷ #coding (2 messages):
- Nous Research AI ▷ #ctx-length-research (6 messages):
- Nous Research AI ▷ #off-topic (13 messages🔥):
- Nous Research AI ▷ #benchmarks-log (2 messages):
- Nous Research AI ▷ #interesting-links (77 messages🔥🔥):
- Nous Research AI ▷ #announcements (1 messages):
- Nous Research AI ▷ #general (673 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (32 messages🔥):
- Mistral ▷ #general (363 messages🔥🔥):
- Mistral ▷ #models (17 messages🔥):
- Mistral ▷ #ref-implem (1 messages):
- Mistral ▷ #finetuning (33 messages🔥):
- Mistral ▷ #la-plateforme (8 messages🔥):
- LM Studio ▷ #💬-general (123 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (100 messages🔥🔥):
- LM Studio ▷ #🧠-feedback (21 messages🔥):
- LM Studio ▷ #🎛-hardware-discussion (157 messages🔥🔥):
- LM Studio ▷ #🧪-beta-releases-chat (1 messages):
- OpenAI ▷ #ai-discussions (137 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (85 messages🔥🔥):
- OpenAI ▷ #prompt-engineering (62 messages🔥🔥):
- OpenAI ▷ #api-discussions (62 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (109 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (26 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (42 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #rlhf (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #runpod-help (5 messages):
- HuggingFace ▷ #general (149 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #i-made-this (11 messages🔥):
- HuggingFace ▷ #reading-group (1 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (2 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- LAION ▷ #general (72 messages🔥🔥):
- LAION ▷ #research (19 messages🔥):
- Perplexity AI ▷ #general (37 messages🔥):
- Perplexity AI ▷ #sharing (2 messages):
- Perplexity AI ▷ #pplx-api (31 messages🔥):
- LangChain AI ▷ #general (38 messages🔥):
- LangChain AI ▷ #share-your-work (9 messages🔥):
- LangChain AI ▷ #tutorials (1 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (43 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Eleuther ▷ #general (10 messages🔥):
- Eleuther ▷ #research (14 messages🔥):
- Eleuther ▷ #interpretability-general (3 messages):
- Eleuther ▷ #lm-thunderdome (12 messages🔥):
- Eleuther ▷ #multimodal-general (4 messages):
- CUDA MODE (Mark Saroufim) ▷ #general (17 messages🔥):
- CUDA MODE (Mark Saroufim) ▷ #triton (1 messages):
- CUDA MODE (Mark Saroufim) ▷ #cuda (7 messages):
- CUDA MODE (Mark Saroufim) ▷ #torch (1 messages):
- CUDA MODE (Mark Saroufim) ▷ #beginner (12 messages🔥):
- CUDA MODE (Mark Saroufim) ▷ #pmpp-book (3 messages):
- DiscoResearch ▷ #mixtral_implementation (21 messages🔥):
- DiscoResearch ▷ #general (10 messages🔥):
- DiscoResearch ▷ #embedding_dev (8 messages🔥):
- DiscoResearch ▷ #discolm_german (1 messages):
- LLM Perf Enthusiasts AI ▷ #gpt4 (2 messages):
- LLM Perf Enthusiasts AI ▷ #opensource (3 messages):
- LLM Perf Enthusiasts AI ▷ #openai (5 messages):
- Skunkworks AI ▷ #general (5 messages):
- AI Engineer Foundation ▷ #general (5 messages):
- Alignment Lab AI ▷ #general-chat (2 messages):
- Alignment Lab AI ▷ #alignment-lab-announcements (1 messages):
- Datasette - LLM (@SimonW) ▷ #llm (1 messages):
PART 1: High level Discord summaries
TheBloke Discord Summary
- Xeon's eBay Value for GPU Servers: Members cited cost-effectiveness of Xeon processors in GPU servers sourced from eBay.
- Speculation and Performance of Llama3: Conversations around Llama3 surfaced, juxtaposed with existing models like Mistral Medium, while LLaVA-1.6 was mentioned to potentially exceed Gemini Pro in visual reasoning and OCR capabilities, with details shared here.
- Miqu's Identity and Performance Drives Debate: Leaked 70B model, Miqu, sparked discussions on its origins, performance, and implications of the leak, linking Miquella-120b-gguf at Hugging Face.
- Fine-tuning, Epochs, and Dataset Challenges: Technical support was provided for fine-tuning TinyLlama models leading to ValueError, with a pull request on GitHub indicating an upcoming release to resolve issues with unsupported modules. Meanwhile, users explored the potential of fine-tuning a MiquMaid+Euryale model using A100 SM.
- Uncharted Territories of Model Merging: Dialogue on model merging techniques showcased examples like Harmony-4x7B-bf16, deemed a successful model merge, with links provided to ConvexAI/Harmony-4x7B-bf16 on Hugging Face. Additionally, a fine-tuned version of "bagel," Smaug-34B-v0.1, was shared for having excellent benchmark results without mergers.
Nous Research AI Discord Summary
- Debating Style Influence in LLMs: In ask-about-llms,
@manojbhopened a discussion on how language models like Mistral may mimic styles specific to their training data, linking to a tweet by@teortaxesTexthat highlighted a peculiar translation error by Miqu with similar phrasing. They also brought up issues around quantized models losing information. - Incentives to Innovate with Bittensor: Ongoing discussions in interesting-links regarding how Bittensor incentivizes AI model improvements, with comments on network efficiency and its potential to produce useful open-source models. There's interest in how the decentralized network structures incentives, with emphasis on costs and sustainability.
- Model Exploration and Crowdfunding News: In general, MIQU has been identified as Mistral Medium by
@teknium, confirming Nous Research's co-founder's tweet. Community members are actively combining models like MIQU to explore architecture possibilities. Additionally, AI Grant is highlighted as an accelerator offering funding for AI startups. - Open Hermes 2.5 Dataset and Collaborations Announced:
@tekniumannounced the release of Open Hermes 2.5 dataset on Hugging Face. Collaboration with Lilac ML was mentioned, featuring Hermes on their HuggingFace Spaces. - Questions around RMT and ACC_NORM Metrics: Within ctx-length-research and benchmarks-log,
@hexaniqueried the uniqueness of a technology compared to RMT, expressing skepticism about its impact on context length, while@euclaiseconfirmedacc_normis always used where applicable for AGIEval evaluations.
Mistral Discord Summary
- Dequantization Success Unlocks Potential: The successful dequantization of miqu-1-70b from q5 to f16 and transposition to PyTorch has demonstrated significant prose generation capabilities, a development worth noting for those interested in performance enhancements in language models.
- API vs. Local Model Performance Debates Heat Up: Users are sharing their experiences and skepticism about the discrepancies observed when utilizing Mistral models through the API versus a local setup, highlighting issues like response truncation and improper formatting in generated code which engineers working with API integration should be aware of.
- Mistral Docs Under Scrutiny for Omissions: The community has pointed out that official Mistral documentation lacks information on system prompts, with users emphasizing the need for inclusivity of such details and prompting a PR discussion aimed at addressing the issue.
- RAG Integration: A Possible Solution to Fact-Hallucinations: A discussion on leveraging Retrieval-Augmented Generation (RAG) to handle issues of hallucinations in smaller parameter models surfaced as an advanced strategy for engineers looking to improve factuality in model responses.
- Targeting Homogeneity in Low-Resource Language Development: Skepticism exists around the success of clustering new languages for continuous pretraining, reinforcing the notion that distinct language models may require separate efforts – a consideration vital for those working on the frontiers of multi-language model development.
LM Studio Discord Summary
- GGUF Model Woes and LM Studio Quirks:
@petter5299raised an issue with a GGUF model from HuggingFace not being recognized by LM Studio. This points to possible compatibility issues with certain architectures, a significant concern since@artdiffuserwas informed that only GGUF models are intended to work with LM Studio. Users are advised to monitor catalog updates and report bugs as necessary; existing tutorials might be outdated or incorrect.
- Hardware Demands for Local LLMs: Users report that LM Studio is resource-intensive, with significant memory usage on advanced setups, including a 4090 GPU and 128GB of RAM. The community is also discussing the needs for building LLM PCs, highlighting VRAM as crucial and recommending GPUs with at least 24GB of VRAM. Compatibility and performance issues with mixed generations of GPUs and how LLM performance scales across diverse hardware configurations remain topics of debate and investigation.
- LM Studio Under the macOS Microscope: macOS users, such as
@wisefarai, experienced memory-related errors with LM Studio, potentially due to memory availability at the time of model loading. Such platform-specific issues highlight the variability of LM Studio's performance on different operating systems.
- Training and Model Management Tactics: The community is actively discussing strategies for local LLM training, the potential of Quadro A6000 GPUs for stable diffusion prompt writing, and the intricacies of memory management with model swapping. Users are exploring whether the latest iteration of LLM tools like LLaMA v2 allow for customizable memory usage and how to efficiently run models that do not fit entirely in memory on systems like Windows.
- LLM Studio's Quest for Compatibility: Across discussions, the compatibility between LM Studio and various tools such as Autogenstudio and CodeLLama is a pertinent issue, assessing which models mesh well and which don't. The quest for compatibility also extends to prompts, as users seek JSON formatted prompt templates for improved functionality like the Gorilla Open Function.
- Awaiting Beta Updates: A lone message from
@mike_50363wonders about the update status of the non-avx2 beta version to 2.12, illustrating the anticipation and reliance on the latest improvements in beta releases for optimal LLM development and experimentation.
OpenAI Discord Summary
- Portrait Puzzles Persist in DALL-E: Users, including
@wild.evaand@niko3757, are grappling with DALL-E's inclination towards landscape images, which often results in sideways full-body portraits. With no clear solution, there's speculation about an awaited update to address this, while the lack of an orientation parameter currently hampers the desired vertical results.
- Prompt Crafting Proves Crucial Yet Challenging: In attempts to optimize image outcomes, conversation has emerged on whether prompt modifications can impact the orientation of generated images; however, @darthgustav. asserts that the model's intrinsic limitations override prompt alterations.
- Interactivity Integrated in GPT Chatbots: Discussions by
@luarstudios,@solbus, and `@darthgustav. focus on including interactive feedback buttons in GPT-designed chatbots, with advice given on using an Interrogatory Format** to attach a menu of feedback responses.
- Expectations High for DALL-E's Next Iteration: The community, with contributors like
@niko3757, is anticipative of a significant DALL-E update, hoping for improved functionality, particularly in image orientation—a point of current frustration among users.
- Insight Sharing Across Discussions Enhances Community Support: Cross-channel posting, as done by `@darthgustav., has been highlighted as a beneficial practice, as exemplified by shared prompt engineering techniques for a logo concept in DALL-E Discussions**.
OpenAccess AI Collective (axolotl) Discord Summary
- Phantom Spikes in Training Patterns: Users reported observing spikes in their model's training patterns at every epoch. Efforts to mitigate overtraining by tweaking the learning rate and increasing dropout have been discussed, but challenges persist.
- Considerations for AMD's GPU Stack: There's active dialogue about server-grade hardware decisions, with a specific mention of AMD's MI250 GPUs. Concerns have been raised regarding the maturity of AMD's software stack, reflecting a skepticism when compared to Nvidia's solutions.
- Axolotl Repo Maintenance: A problematic commit (
da97285e63811c17ce1e92b2c32c26c9ed8e2d5d) was identified that could be leading to overtraining, and a pull request #1234 has been introduced to control the torch version during axolotl installation, preventing conflicts with the new torch-2.2.0 release.
- Tackling CI and Dataset Configurations: Issues with Continuous Integration breaking post torch-2.2.0 and challenges when configuring datasets for different tasks in axolotl have been addressed. Users shared solutions like specifying
data_filespaths and utilizingTrainerCallbackfor checkpoint uploads.
- DPO Performance Hits a Snag: Increased VRAM usage has been noted while running DPO, especially with QLora on a 13b model. Requests for detailed explanations and possibly optimizing VRAM consumption have been put forward.
- Runpod Quirks and Tip-offs: An odd issue with empty folders appearing on Runpod was noted without a known cause, and a hot tip regarding the availability of H100 SXM units on the community cloud was shared, highlighting the allure of opportunistic resource acquisition.
HuggingFace Discord Summary
Training Headaches and Quantum Leaps: A user faced a loss flatline during model training; a batch size reduction to 1 and the potential use of EarlyStoppingCallback were suggested solutions. Another proposed solution was 4bit quantization to tackle training instability, which might help conserve VRAM albeit at some cost to model accuracy.
Seeking Specialized Language Models: There was an inquiry about language models tailored to tech datasets around Arduino, ESP32, and Raspberry Pi, suggesting a demand for LLMs with specialized knowledge.
Tech Enthusiast's Project Spotlight: Showcasing a range of projects from seeking feedback on a thesis tweet, to offering access to a Magic: The Gathering model space, as well as a custom pipeline solution for the moondream1 model with a related pull request.
Experimental Models Run Lean: A NeuralBeagle14-7b model was successfully demonstrated on a local 8GB GPU, piquing the interest of those looking to optimize resource usage, which is key for maintainable AI solutions here.
Scholarly Papers and AI Explorations: A paper on language model compression algorithms has been shared, discussing the balance between efficiency and accuracy in methods such as pruning, quantization, and distillation, which could be very pertinent in the ongoing dialogue about optimizing model performance.
LAION Discord Summary
- The Quest for Synthetic Datasets:
@alyosha11is searching for synthetic textbook datasets for a particular project and is directed towards efforts outlined in another channel, whilst@finnildastruggles to find missing audio files for MusicLM transformers training and seeks assistance after unfruitful GitHub inquiries. - Navigating the Tricky Waters of Content Filtering:
@latke1422pspearheads a conversation on the necessity of filtering images with underage subjects and discusses building safer AI content moderation tools utilizing datasets of trigger words. - The Discord Dilemma of Research Pings: The use of '@everyone' pings on a research server has sparked a debate among users such as
@astropulseand@progamergov, with a general lean towards allowing it in the context of the server's research-oriented nature. - An Unexpected Twist in VAE Training:
@drheaddiscovers that the kl-f8 VAE is improperly packing information, significantly impacting related models—this revelation prompts a dive into the associated research paper on transformer learning artifacts. - LLaVA-1.6 Takes the Lead and SPARC Ignites Interest: The new LLaVA-1.6 model outperforms Gemini Pro as shared in its release blog post, and excitement bubbles up around SPARC, a new method for pretraining detailed multimodal representations, albeit without accessible code or models.
Perplexity AI Discord Summary
- Custom GPT Curiosity Clarified: Within the general channel,
@sweetpopcornsimonqueried about training a custom GPT similar to ChatGPT, while@icelavamanclarified that Perplexity AI doesn't offer chatbot services but features called Collections for organizing and sharing collaboration spaces.
- Epub/PDF Reader with AI Integration Sought:
@archientinquired about an epub/PDF reader that supports AI text manipulation and can utilize custom APIs, sparking community interest in finding or developing such a tool.
- Mystery Insight and YouTube Tutorial: In the sharing channel,
@m1st3rgteased insider knowledge regarding the future of Google through Perplexity, and@redsolplshared a YouTube guide titled "How I Use Perplexity AI to Source Content Ideas for LinkedIn" at this video.
- Support & Model Response Oddities Addressed:
@angelo_1014expressed difficulty in reaching Perplexity support and odd responses from the codellama-70b-instruct model were reported by@bvfbarten.in the pplx-api channel. The codellama-34b-instruct model, however, was confirmed to be robust.
- API Uploads and Source Citations Discussed:
@andreafonsmortigmail.com_6_28629grappled with file uploads via the chatbox interface, and@kid_tubsyinitiated a conversation about the need for source URLs in responses, especially using models with online capabilities like -online.
LangChain AI Discord Summary
- Searching Similarities Across the Multiverse: Engineers are discussing strategies for fetching similarity across multiple Pinecone namespaces for storing meeting transcripts; however, some are facing issues with querying large JSON files via Langchain and ChromaDB, leading to only partial data responses.
- Navigating the Langchain Embedding Maze: There's ongoing exploration of implementing embeddings with OpenAI via Langchain and Chroma, including sharing code snippets, while some community members need support with TypeError issues after Langchain and Pinecone package updates.
- AI Views on Wall Street Moves: The quest for an AI that can analyze "real-time" stock market data and make informed decisions is a topic of curiosity, implying the interest in leveraging AI for financial market insights.
- LangGraph Debuts Multi-Agent AI:
@andysingalintroduced LangGraph in his Medium post, promising a futuristic tool designed for multi-agent AI systems collaborations, indicating a move towards more complex, interconnected AI workflows.
- AI Tutorials Serve as Knowledge Beacons: A YouTube tutorial highlighting the usage of the new OpenAI Embeddings Model with LangChain was shared, providing insights into the OpenAI's model updates and tools for AI application management.
LlamaIndex Discord Summary
- Customizing Hybrid Search for RAG Systems: Hybrid search within Retrieval-Augmented Generation (RAG) requires tuning for different question types, as discussed in a Twitter thread by LlamaIndex. Types mentioned include Web search queries and concept seeking, each necessitating distinct strategies.
- Expanding RAG Knowledge with Multimodal Data: A new resource was shared highlighting a YouTube video evaluation of multimodal RAG systems, including an introduction and evaluation techniques for such systems, along with the necessary support documentation and a tweet announcing the video.
- Embedding Dumps and Cloud Queries Stoke Interest: Assistance was sought by users for integrating vector embeddings with Opensearch databases and finding cloud-based storage solutions for KeywordIndex with massive data ingestion. Relevant resources like the postgres.py vector store and a Redis Docstore+Index Store Demo were referenced.
- API Usage and Server Endpoints Clarified: Queries regarding API choice differences, specifically assistant vs. completions APIs, and creating server REST endpoints sparked engagement with suggestions pointing towards
create-llamafrom LlamaIndex's documentation.
- Discussion on RAG Context Size and Code: Enquiries about the effect of RAG context size on retrieved results, and looking for tutorials on RAG over code, were notable. Langchain’s approach was cited as a reference, alongside the Node Parser Modules and RAG over code documentation.
Eleuther Discord Summary
- Decoder Tikz Hunt and a Leaky Ship: An Eleuther member requested resources for finding a transformer decoder tikz illustration or an arXiv paper featuring one. Meanwhile, a tweet from Arthur Mensch revealed a watermarked old training model leak due to an "over-enthusiastic employee," causing a stir and eliciting reactions that compared the phrase to euphemistic sayings like "bless your heart." (Tweet by Arthur Mensch)
- When Scale Affects Performance: Users in the research channel discussed findings from a paper on how transformer model architecture influences scaling properties, and how this knowledge has yet to hit the mainstream. Furthermore, the efficacy of pre-training on ImageNet was questioned, providing insights into the nuanced relationship between pre-training duration and performance across tasks. (Scaling Properties of Transformer Models, Pre-training Time Matters)
- Rising from the Past: n-gram's New Potential: A paper on an infini-gram model using $\infty$-grams captured attention in the interpretability channel, showing that it can significantly improve language models like Llama. There were concerns about potential impacts on generalization, and curiosity was expressed regarding transformers' ability to memorize n-grams and how this could translate to automata. (Infini-gram Language Model Paper, Automata Study)
- LM Evaluation Harness Polished and Probed: In the lm-thunderdome channel, thanks were given for PyPI automation, and the release of the Language Model Evaluation Harness 0.4.1 was announced, which included internal refactoring and features like Jinja2 for prompt design. Questions arose regarding the output of few-shot examples in logs and clarifications were sought for interpreting MMLU evaluation metrics, with a particular concern about a potential issue flagged in a GitHub gist. (Eval Harness PyPI, GitHub Release, Gist)
- VQA Systems: Compute Costs and Model Preferences Questioned: Queries were raised about the compute costs for training image encoders and LLMs for Visual Question Answering systems, highlighting the scarcity of reliable figures. There was also a search for consensus on whether encoder-decoder models remain the choice for text-to-image or text-and-image to text tasks, noting that training a model like llava takes approximately 8x24 A100 GPU hours.
CUDA MODE (Mark Saroufim) Discord Summary
- Python Prowess for CUDA Coders:
@neuralutionand others emphasized the advantages of Python in CUDA development, covering topics like occupancy, bottleneck identification, and integration of PyTorch types with C++. A PyTorch tutorial on Flash Attention 2 by Driss Guessous was shared, and discussions highlighted the utility of NVIDIA's new XQA kernel for multi-query attention and upcoming updates in the Flash Attention 2 implementation in PyTorch 2.2.
- C++ Healing via GitHub: Issues following Jeremy's notebook were addressed by
@drisspg, directing users to GitHub issue threads relating to a CUDA version mismatch (CUDA 12.0 Issue) and CUDA 12.1 template errors (Cuda 12.1 Template Issue).@nshepperdsuggested CPU RAM's cost benefits compared to GPU RAM, and technical aspects oftypenameusage in C++ templates were clarified.
- Selective Model Compilation Inquiry:
@marvelousmitasked if it's possible to compile specific parts of a model while excluding others, such as a custom operator called at runtime. They wondered about using something liketorch.compile(model)for selective compilation.
- CUDA Concerns and Debugging Discussions: CUDA 11.8's compatibility was confirmed with a link to NVIDIA's debugging documentation, and
@andreaskoepfdetailed their approach to kernel development by comparing PyTorch reference implementations with custom kernels. Debugger usage in VSCode was touched upon, revealing the complexity involved.
- Block Size and Thread Coarsening Queries Unraveled:
@lancertsraised the issue of CUDA block sizes not matchingtile_width, with@vim410cautioning about potential memory errors from misalignment of threads to work. The topic of thread coarsening sparked a discussion on the most effective dimensions forthreadsPerBlockandnumBlocks, underscoring the complexity of thread allocation optimization in CUDA programming.
DiscoResearch Discord Summary
- Models in Identity Crisis: Concerns were raised about the potential overlap between Mistral and Llama models, identified by
@sebastian.bodzareferencing a tweet suggesting the similarities. Additionally, there's speculation from the community that Miqu may be a quantized version of Mistral, supported by signals from Twitter, including insights from @sroecker and @teortaxesTex.
- Dataset Generosity Strikes the Right Chord: The Hermes 2 dataset was made available by
@teknium, posted on Twitter, and praised by community members for its potential impact on AI research. The integration of lilac was positively acknowledged by@devnull0.
- Speedy Mixtral Races Ahead: The speed of Mixtral, achieving 500 tokens per second, was highlighted by
@bjoernpwith a link to Groq's chat platform. This revelation led to discussions on the effectiveness and implications of custom AI accelerators in computational performance.
- Embedding Woes and Triumphs: Mistral 7B's embedding models were called out by
@Nils_Reimerson Twitter for overfitting on MTEB and performing poorly on unrelated tasks. Conversely, Microsoft’s inventive approaches to generating text embeddings using synthetic data and simplifying training processes attracted attention, albeit with some skepticism, in a research paper discussed by@sebastian.bodza.
- The Plot Thickens... Or Does It?: An inquiry from
@philipmayabout a specific plot for DiscoLM_German_7b_v1 went without elaboration, potentially indicating a need for clarity or additional context to be addressed within the community.
Latent Space Discord Summary
- VFX Studios Eye AI Integration: A tweet by @venturetwins reveals major VFX studios, including one owned by Netflix, are now seeking professionals skilled in stable diffusion technologies. This new direction in hiring underscores the increasing importance of generative imaging and machine learning in revolutionizing storytelling, as evidenced by a job listing from Eyeline Studios.
- New Paradigms in AI Job Requirements Emerge: The rapid evolution of AI technologies such as Stable Diffusion and Midjourney is humorously noted to potentially become standard demands in future job postings, reflecting a shift in employment standards within the tech landscape.
- Efficiency Breakthroughs in LLM Training: Insights from a new paper by Quentin Anthony propose a significant shift towards hardware-utilization optimization during transformer model training. This approach, focusing on viewing models through GPU kernel call sequences, aims to address prevalent inefficiencies in the training process.
- Codeium's Leap to Series B Funding: Celebrating Codeium's progress to Series B, a complimentary tweet remarks on the team's achievement. This milestone highlights the growing optimism and projections around the company's future.
- Hardware-Aware Design Boosts LLM Speed: A new discovery highlighted by a tweet from @BlancheMinerva and detailed further in their paper on arXiv:2401.14489, outlines a hardware-aware design tweak yielding a 20% throughput improvement for 2.7B parameter LLMs, previously overlooked by many due to adherence to GPT-3's architecture.
- Treasure Trove of AI and NLP Knowledge Unveiled: For those keen on deepening their understanding of AI models and their historic and conceptual underpinnings, a curated list shared by @ivanleomk brings together landmark resources, offering a comprehensive starting point for exploration in AI and NLP.
LLM Perf Enthusiasts AI Discord Summary
- Clarifying "Prompt Investing": There was a discussion involving prompt investing, followed by a clarification from user @jxnlco referencing the correct term as prompt injecting instead.
- On the Frontlines with Miqu-1 70B: User @jeffreyw128 showed interest in testing new models, with @thebaghdaddy suggesting the Hugging Face's Miqu-1 70B model. @thebaghdaddy advised specific prompt formatting for Mistral and mentioned limitations due to being "gpu poor."
- Dissecting AI Performance and Functionality: - Discussion around a tweet from @nickadobos regarding AI performance occurred but the details were unspecified. - @jeffreyw128 and @joshcho_ discussed their dissatisfaction with the performance of AI concerning document understanding, with @thebaghdaddy suggesting this might explain AI's struggles with processing knowledge files containing images.
Skunkworks AI Discord Summary
- Open Source AI gets a Crypto Boost: Filipvv put forward the idea of employing crowdfunding techniques, like those used by CryoDAO and MoonDAO, to raise funds for open-source AI projects and highlighted the Juicebox platform as a potential facilitator for such endeavors. The proposed collective funding could support larger training runs on public platforms, contributing to the broader AI community's development resources.
- New Training Data Goes Public: Teknium released the Hermes 2 dataset and encouraged its use within the AI community. Interested engineers can access the dataset via this tweet.
- HelixNet: The Triad of AI Unveiled: Migel Tissera introduced HelixNet, a cutting-edge architecture utilizing three Mistral-7B LLMs. AI enthusiasts and engineers can experiment with HelixNet through a Jupyter Hub instance, login
forthepeoplewith passwordgetitdone, as announced by yikesawjeez with more details on this tweet.
AI Engineer Foundation Discord Summary
- Diving into Hugging Face's API: @tonic_1 introduced the community to the Transformers Agents API from Hugging Face, noting its experimental nature and outlining the three agent types: HfAgent, LocalAgent, and OpenAiAgent for diverse model use cases.
- Seeking Clarity on HFAgents:
@hackgoofersought clarification about the previously discussed HFAgents, showing a need for further explanation on the subject. - Community Contributions Welcomed:
@tonic_1expressed a keen interest to assist the community despite not having filled out a contribution form, indicating a positive community engagement.
Alignment Lab AI Discord Summary
- Game On for AI-Enhanced Roblox Plugin:
@magusartstudiosis in the process of developing a Roblox AI agent Plugin, which will integrate several advanced tools and features for the gaming platform.
- Clarifying OpenAI's Freebies or Lack Thereof:
@metaldragon01corrected a common misconception that OpenAI is distributing free tokens for its open models, stressing that such an offering does not exist.
- Datasets Galore—Hermes 2.5 & Nous-Hermes 2 Released:
@tekniumannounced the release of the Open Hermes 2.5 and Nous-Hermes 2 datasets, available for the community to enhance state-of-the-art language models. The dataset, containing over 1 million examples, can be accessed on HuggingFace.
- Community Echoes and Lilac ML Integration: Special thanks were extended to Discord members
<@1110466046500020325>,<@257999024458563585>,<@748528982034612226>,<@1124158608582647919>for their contribution to the datasets. Moreover, the announcement included a nod to the collaboration with Lilac ML to make Hermes data analytically accessible via HuggingFace Spaces.
Datasette - LLM (@SimonW) Discord Summary
- Could DatasetteGPT Be Your New Best Friend?: User
@discoureurinquired if anyone has employed DatasetteGPT to aid with remembering configuration steps or assist in writing plugins for Datasette's documentation. No further discussion or responses were noted.
The Ontocord (MDEL discord) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1315 messages🔥🔥🔥):
- Xeon for GPU Servers:
@reguilementioned opting for Xeon due to cost-effectiveness when used in GPU servers found on eBay. - Mysterious Llama3 Speculation: Users discussed expectations around Llama3, with skepticism on whether it would exceed existing models like Mistral Medium.
- Multimodal Model Potential: Hints of LLaVA-1.6 being a formidable multimodal model exceeding Gemini Pro on benchmarks, introducing improved visual reasoning and OCR. A shared article detailed the enhancements.
- Japanese Language and Culture:
@righthandofdoomcommented on the detailed structure and pronunciation similarities between Japanese and their mother tongue, highlighting the nuanced nature of the language compared to Western counterparts. - MIQU Model Discussions: The chat alluded to the MIQU model being akin to Mistral Medium and possibly a substantial leak, prompting debates on the model's origin, performance parity with GPT-4, and the consequences for the leaker.
Links mentioned:
- alpindale/miquella-120b-gguf · Hugging Face: no description found
- InstantID - a Hugging Face Space by InstantX: no description found
- LLaVA-1.6: Improved reasoning, OCR, and world knowledge: LLaVA team presents LLaVA-1.6, with improved reasoning, OCR, and world knowledge. LLaVA-1.6 even exceeds Gemini Pro on several benchmarks.
- google/switch-c-2048 · Hugging Face: no description found
- Mistral MODEL LEAK??? CEO Confirms!!!: "An over-enthusiastic employee of one of our early access customers leaked a quantised (and watermarked) version of an old model we trained and distributed q...
- Chat with Open Large Language Models: no description found
- Indiana Jones Hmm GIF - Indiana Jones Hmm Scratching - Discover & Share GIFs: Click to view the GIF
- google-research/lasagna_mt at master · google-research/google-research: Google Research. Contribute to google-research/google-research development by creating an account on GitHub.
- OpenRouter: A router for LLMs and other AI models
- Support for split GGUF checkpoints · Issue #5249 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.: Tools for merging pretrained large language models. - GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.
- no title found: no description found
TheBloke ▷ #characters-roleplay-stories (885 messages🔥🔥🔥):
- Discussing Miqu's Performance Beyond Leaks:
@goldkoronand others discuss the performance of Miqu, a leaked 70B model.@turboderp_clarifies it's architecturally the same as LLaMA 2 70B, and it's been continued by Mistral as an early version of their project.
- Exploring Morally Ambiguous Training Data:
@heralaxseeks suggestions for dark or morally questionable text for a few-shot example to teach a model to write longer and darker responses.@the_ride_never_endsrecommends Edgar Allan Poe's short stories on Wikipedia, and@kquantmentions the dark original stories by the Grimm Brothers.
- Fitting Models Within GPU VRAM Constraints:
@kaltcitreports that with 48GB VRAM, 4.25bpw can fit but generating any content results in OOM (Out Of Memory). Additionally, there's a discussion about using lower learning rates for finetuning and the cost of training these large models, with@c.gatoand@giftedgummybeesharing their training strategies.
- Fine-Tuning Strategies and Costs:
@undishares that they have finetuned a Miqu model referred to as MiquMaid+Euryale using parts of their dataset. They also express the high cost and ambition behind their single-day finetuning attempt, which used an A100 SM.
- Broader Discussion on Large Language Model Deployment: The channel's users touch on broader topics, such as the potential for further fine-tuning 70B models, the general costliness of training and fine-tuning, possible collaborations, and the risks of alignment and ethics in language models.
Links mentioned:
- Category:Short stories by Edgar Allan Poe - Wikipedia: no description found
- Self-hosted AI models | docs.ST.app: This guide aims to help you get set up using SillyTavern with a local AI running on your PC (we'll start using the proper terminology from now on and...
- 152334H/miqu-1-70b-sf · Hugging Face: no description found
- NeverSleep/MiquMaid-v1-70B-GGUF · Hugging Face: no description found
- miqudev/miqu-1-70b · Hugging Face: no description found
- Money Wallet GIF - Money Wallet Broke - Discover & Share GIFs: Click to view the GIF
- NobodyExistsOnTheInternet/miqu-limarp-70b · Hugging Face: no description found
- sokusha/aicg · Datasets at Hugging Face: no description found
- Ayumi Benchmark ERPv4 Chat Logs: no description found
- NobodyExistsOnTheInternet/ShareGPTsillyJson · Datasets at Hugging Face: no description found
- GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.: An OpenAI API compatible LLM inference server based on ExLlamaV2. - GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.
- GitHub - epolewski/EricLLM: A fast batching API to serve LLM models: A fast batching API to serve LLM models. Contribute to epolewski/EricLLM development by creating an account on GitHub.
- Mistral CEO confirms 'leak' of new open source AI model nearing GPT4 performance | Hacker News: no description found
TheBloke ▷ #training-and-fine-tuning (30 messages🔥):
- Fine-tuning Epoch Clarification:
@dirtytigerxresponded to@bishwa3819pointing out that the loss graph posted showed less than a single epoch and inquired about seeing a graph for a full epoch. - DataSet Configuration Puzzle:
@lordofthegoonssought assistance for setting up dataset configuration on unsloth for the sharegpt format, mentioning difficulty finding documentation for formats other than alpaca. - Troubleshooting TinyLlama Fine-tuning:
@choviistruggled with fine-tuning TheBloke/TinyLlama-1.1B-Chat-v1.0-AWQ and shared a specificValueErrorrelated to unsupported modules when attempting to add adapters based on the PEFT library.@dirtytigerxindicated that AWQ is not yet supported in PEFT, citing a draft PR that's awaiting an upcoming AutoAWQ release with a Github pull request link. - Counting Tokens for Training:
@dirtytigerxprovided@arcontexa simple script to count the number of tokens in a file for training, suggesting the use ofAutoTokenizer.from_pretrained(model_name)to easily grab the tokenizer for most models. - Experiment Tracking Tools Discussed:
@flashmanbahadurqueried about the use of experiment tracking tools like wandb and mlflow for local runs.@dirtytigerxexpressed the usefulness of both wandb and comet, especially for longer training runs, and discussed the broader capabilities of mlflow.
Links mentioned:
- Load adapters with 🤗 PEFT: no description found
- FEAT: add awq suppot in PEFT by younesbelkada · Pull Request #1399 · huggingface/peft: Original PR: casper-hansen/AutoAWQ#220 TODO: Add the fix in transformers Wait for the next awq release Empty commit with @s4rduk4r as a co-author add autoawq in the docker image Figure out ho...
TheBloke ▷ #model-merging (15 messages🔥):
- In Search of Less Censored Intelligence:
@lordofthegoonsinquired about uncensored, intelligent 34b models, where@kquantsuggested looking at models like Nous-Yi on Hugging Face. - Smaug 34b Takes Flight Without Mergers:
@kquantshares information about the Smaug-34B-v0.1 model, a fine-tuned version of "bagel" with impressive benchmark results and no model mergers involved. - Shrinking Goliath:
@lordofthegoonsexpressed interest in an experiment to downsize a 34b model in hopes it would outperform a 10.7b model, but later reported that the attempt did not yield a usable model. - Prompts to Nudge Model Behavior:
@kquantdiscusses using prompts to influence model outputs, citing methods like changing the response style or trigger specific behaviors like simulated anger or polite confirmations. - Harmony Through Merging Models:
@kquantpoints to the Harmony-4x7B-bf16 as an example of a successful model merge that exceeded expectations, naming itself after the process.
Links mentioned:
- ConvexAI/Harmony-4x7B-bf16 · Hugging Face: no description found
- abacusai/Smaug-34B-v0.1 · Hugging Face: no description found
- one-man-army/UNA-34Beagles-32K-bf16-v1 · Hugging Face: no description found
TheBloke ▷ #coding (2 messages):
- The Forgotten Art of File Management:
@spottyluckhighlighted a growing problem where many people lack understanding of a file system hierarchy or how to organize files, resulting in a "big pile of search/scroll". - Generational File System Bewilderment:
@spottyluckshared an article from The Verge discussing how students are increasingly unfamiliar with file systems, referencing a case where astrophysicist Catherine Garland noticed her students couldn't locate their project files or comprehend the concept of file directories.
Links mentioned:
Students who grew up with search engines might change STEM education forever: Professors are struggling to teach Gen Z
Nous Research AI ▷ #ctx-length-research (6 messages):
- Inquiry about Form Submission:
@manojbhasked about whether a form has been filled out, but no further context or details were provided. - Questioning the Uniqueness of RMT:
@hexaniraised a question about how the discussed technology truly differs from RMT and its significance. - Skepticism on Context Length Impact:
@hexaniexpressed doubt about the technology representing a significant shift towards managing longer context, citing evaluations in the paper. - Request for Clarification:
@hexaniasked for someone to explain more about the technology in question and appreciated any help in advance. - Comparison with Existing Architectures:
@hexanipointed out similarities between the current topic of discussion and existing architectures, likening it to an adapter for explicit memory tokens.
Nous Research AI ▷ #off-topic (13 messages🔥):
- In Search of Machine Learning Guidance:
@DES7INY7and@lorenzoroxyoloare seeking advice on how to get started with their machine learning journey and looking for guidance and paths to follow. - Possible Discord Improvement with @-ing:
@murchistondiscusses that @-ing could be improved as a feature on Discord, implying that better routing or integration within tools like lmstudio might make the feature more reliable. - Fast.ai Course Sighting:
@afterhoursbillymentions that he has seen<@387972437901312000>on the fast.ai Discord, hinting at the user's engagement with the course. - The Maneuver-Language Idea:
@manojbhbrings up an idea about tokenizing driving behaviors for self-driving technology, proposing a concept similar to lane-language. - Dataset Schema Inconsistency:
@pradeep1148points out that the dataset announced by<@387972437901312000>appears to have a schema inconsistency, with different examples having distinct formats. A link to the dataset on Hugging Face is provided: OpenHermes-2.5 dataset.
Links mentioned:
- Hellinheavns GIF - Hellinheavns - Discover & Share GIFs: Click to view the GIF
- Blackcat GIF - Blackcat - Discover & Share GIFs: Click to view the GIF
- Scary Weird GIF - Scary Weird Close Up - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #benchmarks-log (2 messages):
- Clarification on ACC_NORM for AGIEval:
@euclaiseinquired if@387972437901312000utilizesacc_normfor AGIEval evaluations.@tekniumconfirmed that where anacc_normexists, it is always used.
Nous Research AI ▷ #interesting-links (77 messages🔥🔥):
- Bittensor and Synthetic Data:
@richardblythmanquestioned how Bittensor addresses gaming benchmarks for AI models, suggesting that Hugging Face could also generate synthetic data on the fly.@tekniumclarified the costs involved and the subsidization by Bittensor's network inflation, while@euclaisenoted Hugging Face's ability to run expensive operations. - Incentivization in Model Training:
@tekniumdescribed the importance of incentive systems within Bittensor's network to drive model improvement and active competition, while@richardblythmanshared skepticism about the sustainability of Bittensor's model due to high costs. - Understanding Bittensor's Network: Throughout the discussion, there was significant interest in how Bittensor's decentralized network operates and incentives are structured, with multiple users including
@.benxhand@tekniumdiscussing aspects of deployment and the incentives for maintaining active and competitive models. - Potential of Bittensor to Produce Useful Models: While
@richardblythmanexpressed doubt about the network's efficiency,@tekniumremained optimistic about its potential to accelerate the development of open source models, mentioning that rigorous training attempts started only a month or two prior. - Collaborative Testing of AI Models:
@yikesawjeezinvited community members to assist in testing a new AI architecture, HelixNet, and provided shared Jupyter Notebook access for the task. The invitation was answered by users like@manojbh, encouraging reproduction on different setups for better validation of the model's performance.
Links mentioned:
- Mistral CEO confirms ‘leak’ of new open source AI model nearing GPT-4 performance: An anonymous user on 4chan posted a link to the miqu-1-70b files on 4chan. The open source model approaches GPT-4 performance.
- argilla/CapybaraHermes-2.5-Mistral-7B · Hugging Face: no description found
- LLaVA-1.6: Improved reasoning, OCR, and world knowledge: LLaVA team presents LLaVA-1.6, with improved reasoning, OCR, and world knowledge. LLaVA-1.6 even exceeds Gemini Pro on several benchmarks.
- NobodyExistsOnTheInternet/miqu-limarp-70b · Hugging Face: no description found
- Tweet from Ram (@ram_chandalada): Scoring popular datasets with "Self-Alignment with Instruction Backtranslation" prompt Datasets Scored 1️⃣ dolphin @erhartford - Only GPT-4 responses 2️⃣ Capybara @ldjconfirmed 3️⃣ ultracha...
- Tweet from Migel Tissera (@migtissera): It's been a big week for Open Source AI, and here's one more to cap the week off! Introducing HelixNet. HelixNet is a novel Deep Learning architecture consisting of 3 x Mistral-7B LLMs. It h...
- Tweet from yikes (@yikesawjeez): yknow what fk it https://jupyter.agentartificial.com/commune-8xa6000/user/forthepeople/lab user: forthepeople pw: getitdone will start downloading the model now, hop in and save notebooks to the ./wo...
- The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models: While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-mod...
- GroqChat: no description found
- Scaling Laws for Forgetting When Fine-Tuning Large Language Models: We study and quantify the problem of forgetting when fine-tuning pre-trained large language models (LLMs) on a downstream task. We find that parameter-efficient fine-tuning (PEFT) strategies, such as ...
- Paper page - Learning Universal Predictors: no description found
- GitHub - TryForefront/tuna: Contribute to TryForefront/tuna development by creating an account on GitHub.
Nous Research AI ▷ #announcements (1 messages):
- Open Hermes 2.5 Dataset Released:
@tekniumannounced the public release of the dataset used for Open Hermes 2.5 and Nous-Hermes 2, excited to share over 1M examples curated and generated from open-source ecosystems. The dataset can be found on HuggingFace. - Dataset Contributions Acknowledged:
@tekniumhas credited every data source within the dataset card except for one that's no longer available, thanking the contributed authors within the Nous Research AI Discord. - Collaboration with Lilac ML:
@tekniumworked with@1097578300697759894and Lilac ML to feature Hermes on their HuggingFace Spaces, assisting in the analysis and filtering of the dataset. Explore it on Lilac AI. - Tweet about Open Hermes Dataset: A related Twitter post by
@tekniumcelebrates the release of the dataset and invites followers to see what can be created from it.
Links mentioned:
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- no title found: no description found
Nous Research AI ▷ #general (673 messages🔥🔥🔥):
- MIQU Mystery Resolved:
@tekniumclarifies that MIQU is Mistral Medium, not an earlier version. The Nous Research's co-founder's tweet could potentially confirm this here. - The Power of Mergekit: Users like
@datarevisedexperimented with 120 billion parameter models by merging MIQU with itself, and others are creating various combinations like Miquella 120B. - OpenHermes 2.5 Dataset Discussion: The dataset discussions raised points on dataset creation and storage, with
@tekniummentioning tools like Lilac for data curation and exploration. - Crowdfunding for AI with AI Grant:
@cristi00shares information about AI Grant – an accelerator for AI startups offering substantial funding and Azure credits. Applications are open until the stated deadline. - Qwen 0.5B Model Anticipation:
@qnguyen3expresses excitement about the imminent release of a new fiery model named Qwen, though specific details were not given.
Links mentioned:
- NobodyExistsOnTheInternet/code-llama-70b-python-instruct · Hugging Face: no description found
- Boy Kisser Boykisser GIF - Boy kisser Boykisser Boy kisser type - Discover & Share GIFs: Click to view the GIF
- Guts Berserk Guts GIF - Guts Berserk Guts American Psycho - Discover & Share GIFs: Click to view the GIF
- Meta Debuts Code Llama 70B: A Powerful Code Generation AI Model: With Code Llama 70B, enterprises have a choice to host a capable code generation model in their private environment. This gives them control and confidence in protecting their intellectual property.
- Tweet from Stella Biderman (@BlancheMinerva): Are you missing a 20% speed-up for your 2.7B LLMs due to copying GPT-3? I was for three years. Find out why and how to design your models in an hardware-aware fashion in my latest paper, closing the ...
- AI Grant: It's time for AI-native products!
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Reimagine: Covering the rapidly moving world of AI.
- Cat Cats GIF - Cat Cats Explosion - Discover & Share GIFs: Click to view the GIF
- 152334H/miqu-1-70b-sf · Hugging Face: no description found
- argilla/CapybaraHermes-2.5-Mistral-7B · Hugging Face: no description found
- Wow Surprised Face GIF - Wow Surprised face Little boss - Discover & Share GIFs: Click to view the GIF
- euclaise/Memphis-scribe-3B-alpha · Hugging Face: no description found
- Bornskywalker Dap Me Up GIF - Bornskywalker Dap Me Up Woody - Discover & Share GIFs: Click to view the GIF
- ycros/miqu-lzlv · Hugging Face: no description found
- WizardLM/WizardLM-70B-V1.0 · Hugging Face: no description found
- alpindale/miquella-120b · Hugging Face: no description found
- Hatsune Miku - Wikipedia: no description found
- Dancing Daniel Keem GIF - Dancing Daniel Keem Keemstar - Discover & Share GIFs: Click to view the GIF
- xVal: A Continuous Number Encoding for Large Language Models: Large Language Models have not yet been broadly adapted for the analysis of scientific datasets due in part to the unique difficulties of tokenizing numbers. We propose xVal, a numerical encoding sche...
- Catspin GIF - Catspin - Discover & Share GIFs: Click to view the GIF
- Itsover Wojack GIF - ITSOVER WOJACK - Discover & Share GIFs: Click to view the GIF
- Tweet from Nat Friedman (@natfriedman): Applications are open for batch 3 of http://aigrant.com for pre-seed and seed-stage companies building AI products! Deadline is Feb 16. As an experiment, this batch we are offering the option of eith...
- NousResearch/Nous-Hermes-2-Vision-Alpha · Discussions: no description found
- dataautogpt3 (alexander izquierdo): no description found
- NobodyExistsOnTheInternet (Nobody.png): no description found
- Tweet from Eric Hallahan (@EricHallahan): @QuentinAnthon15 Darn, I would have loved to participate if I were allowed to. I'm sure it's a great paper regardless with an author list like that!
- GitHub - qnguyen3/hermes-llava: Contribute to qnguyen3/hermes-llava development by creating an account on GitHub.
- GitHub - SafeAILab/EAGLE: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation - GitHub - SafeAILab/EAGLE: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation
- GitHub - epfLLM/meditron: Meditron is a suite of open-source medical Large Language Models (LLMs).: Meditron is a suite of open-source medical Large Language Models (LLMs). - GitHub - epfLLM/meditron: Meditron is a suite of open-source medical Large Language Models (LLMs).
- There’s something going on with AI startups in France | TechCrunch: Artificial intelligence, just like in the U.S., has quickly become a buzzy vertical within the French tech industry.
- Lilac - Better data, better AI: Lilac enables data and AI practitioners improve their products by improving their data.
Nous Research AI ▷ #ask-about-llms (32 messages🔥):
- Style Transfer or Overfitting?:
@manojbhdebated about LLMs having responses overly influenced by their training on a particular style like Mistral; pointed out that similar end-layer patterns cause style mimicry in outputs. This was in context to misleading output reasoning and a linked tweet by@teortaxesTex, regarding Miqu’s mistake in RU translation with oddly similar phrasing. - Quantized Models and Memory Discussion: Discussions by
@giftedgummybeeand@manojbhcentered around quantized models forgetting information and the increased potential for errors with lower quantization levels. - AI Stress Test Speculation: A theory by
@manojbhon whether LLMs can fumble under stress like humans led to a suggestion by@_3sphereto test the model's "panic" behavior in response to confusing prompts. - Watermarking within Mistral: Conversation with
@everyoneisgross,@.benxh, and.ben.comdelved into the possibility of watermarking LLMs, hypothesizing it could involve distinct Q&A pairs or prompts that generate specific responses as identifiers after quantization. - Evaluating Nous-Hermes and Mixtral Performance:
@.benxhaffirmed a significant performance difference between Mistral Medium and an unspecified model capacity, indicating close performance within the margin of error.@manojbhagreed, highlighting the importance of even slight differences in statistical metrics.
Links mentioned:
- Tweet from Teortaxes▶️ (@teortaxesTex): Miqu makes a mistake in RU: the bolt falls out but the thimble stays. Yet note startlingly similar phrasing in translation! I'm running Q4KM though, and some of it may be attributable to sampling ...
- GitHub - LeonEricsson/llmjudge: Exploring limitations of LLM-as-a-judge: Exploring limitations of LLM-as-a-judge. Contribute to LeonEricsson/llmjudge development by creating an account on GitHub.
Mistral ▷ #general (363 messages🔥🔥):
- Welcoming New Members: Users
@admin01234and@mrdragonfoxexchanged greetings, indicating that new users are discovering the Mistral Discord channel.
- Dequantization Success for miqu-1-70b: User
@i_am_domdiscussed the successful dequantization of miqu-1-70b from q5 to f16, transposed to PyTorch. Usage instructions and results were shared, showcasing the model's prose generation capabilities.
- Internship Asks and General Career Opportunities: User
@deldrelasked about internship opportunities at Mistral.@mrdragonfoxadvised them to send their details even if no official listings are posted.
- Token Generation Rates and Inference Performance: User
@i_am_domprovided token/s generation rates for the official Mistral API, which@donjuan5050said might not meet their use case. Meanwhile,@mrdragonfoxshared that locally hosting Mistral on certain hardware configurations could significantly increase throughput.
- Miqutized Model and Mistral's Response: The authenticity of miqu-1-70b was discussed, including a link to the Twitter statement by Mistral AI's CEO confirming it as an early version of their model. Users
@shirman,@i_am_dom, and@dillfrescottspeculated about the relationship between the Miqutized model and Mistral's models.
- Model Hosting and Usage Costs: Conversation with
@mrdragonfoxregarding the benefits and costs of hosting LLMs locally vs. using an API. The discussion delved into hardware requirements and the cost-effectiveness of API usage for different scales of deployment.
Links mentioned:
- Join the Mistral AI Discord Server!: Check out the Mistral AI community on Discord - hang out with 11372 other members and enjoy free voice and text chat.
- 152334H/miqu-1-70b-sf · Hugging Face: no description found
- TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ · Hugging Face: no description found
- Streisand effect - Wikipedia: no description found
- NeverSleep/MiquMaid-v1-70B · Hugging Face: no description found
- NeverSleep/MiquMaid-v1-70B · VERY impressive!: no description found
Mistral ▷ #models (17 messages🔥):
- Mistral Aligns with Alpaca Format:
@sa_codementioned that Mistral small/med can be used with alpaca prompt format to supply a system prompt; however, they also noted the alpaca format is incompatible with markdown. - Official Docs Lack System Prompt Info:
@sa_codepointed to the lack of documentation for system prompts in Mistral's official docs and requested this inclusion. - Office Hours for the Rescue: In response to
@sa_code's query,@mrdragonfoxsuggested asking questions in the next office hours session for clarifications. - PR Opened for Chat Template:
@sa_codeindicated they opened a PR on Mistral's Hugging Face page to address an issue regarding chat template documentation (PR discussion link). - Mistral Embedding Token Limit Clarified:
@mrdragonfoxand@akshay_1responded to@danouchka_24704's questions, confirming that Mistral-embed produces 1024 dimensions vectors and has a maximum token input chunk of 8k, although 512 tokens are generally preferred.
Links mentioned:
- Open-weight models | Mistral AI Large Language Models: We open-source both pre-trained models and fine-tuned models. These models are not tuned for safety as we want to empower users to test and refine moderation based on their use cases. For safer models...
- mistralai/Mixtral-8x7B-Instruct-v0.1 · Update chat_template to include system prompt: no description found
Mistral ▷ #ref-implem (1 messages):
- JSON Output with Mistral Medium Subscription: User
@subham5089inquired about the best method to always receive JSON output using the Mistral Medium subscription. There was no response or further discussion on this topic within the provided message history.
Mistral ▷ #finetuning (33 messages🔥):
- Inquiry on Continuous Pretraining for Low-Resource Languages:
@quicksortasked for references regarding continuous pretraining of Mistral on low-resource languages, but@mrdragonfoxindicated a lack of such resources stating nothing comes close to instruct yet. - Pioneering Multi-Language LoRA Fine-tuning on Mistral:
@yashkhare_is working on continual pretraining of Mistral 7b with LoRA for languages like Vietnamese, Indonesian, and Filipino, questioning the viability of separate and merged language-specific LoRA weights. - Challenges of Language Clustering and Continuous Pretraining:
@mrdragonfoxcast doubt on the success of a style transfer-based approach for clustering new languages and stressed that distinct languages typically require separate pretraining. - Using RAG to Address Hallucinations in Fact Finetuning: In response to
@pluckedout's question about lower parameter models memorizing facts,@kecoland@mrdragonfoxdiscussed the importance and complexity of integrating Retrieval-Augmented Generation (RAG) for context-informed responses and minimizing hallucinations. - Hermes 2 Dataset Release Announcement:
@tekniumshared a link to the release of their Hermes 2 dataset on Twitter, inviting others to explore its potential value.
Mistral ▷ #la-plateforme (8 messages🔥):
- Confusion on Model Downloads:
@ashtagrossedaronneenquired about downloading a model to have it complete homework, but was initially unsure of which model to use. - Mistaken Link Adventure: In response,
@ethuxattempted to assist with a download link, but first provided the wrong URL and then corrected it, though the correct link was not shared in the messages given. - Contribution Update:
@carloszelaannounced the submission of a Pull Request (PR) and is awaiting review, signaling their contribution to a project. - API Quirks with Mistral Model:
@miscendraised a concern about the performance disparities between the Mistral small model when using the API versus running it locally, specifically mentioning truncation of responses and additional backslashes in code output.
Links mentioned:
👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
LM Studio ▷ #💬-general (123 messages🔥🔥):
- HuggingFace Model Confusion:
@petter5299inquired about why a GGUF model downloaded is not recognizable by LM Studio.@fabguyasked for a HuggingFace link for clarification and mentioned the unfamiliarity with the mentioned architecture. - LM Studio & macOS Memory Issues:
@wisefaraiencountered errors suggesting insufficient memory while trying to load a quantized model on LM Studio using a Mac, with@yagilbsuggesting it might be a lack of available memory at the time of the issue. - Local Models and Internet Claims:
@n8programsand others discussed the need for proof regarding claims that local models behave differently with the internet on/off. They called for network traces to known OpenAI addresses to substantiate such claims. - AMD GPU Support Inquiry:
@ellric_asked if there is any hope for AMD GPU support in LM Studio.@yagilbconfirmed the possibility and directed to a specific channel for guidance. - Prompt Format Frustrations and CodeLLama Discussion: Discussion on
#generalinvolved the complications caused by prompt formats, including a heads-up on Reddit about issues with CodeLLama 70b and llama.cpp not supporting chat templates, leading to poor model outputs.
Links mentioned:
- mistralai/Mixtral-8x7B-v0.1 · Hugging Face: no description found
- GitHub - joonspk-research/generative_agents: Generative Agents: Interactive Simulacra of Human Behavior: Generative Agents: Interactive Simulacra of Human Behavior - GitHub - joonspk-research/generative_agents: Generative Agents: Interactive Simulacra of Human Behavior
- Reddit - Dive into anything: no description found
- Nexesenex/MIstral-QUantized-70b_Miqu-1-70b-iMat.GGUF · Hugging Face: no description found
- GitHub - ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++: Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
LM Studio ▷ #🤖-models-discussion-chat (100 messages🔥🔥):
- The Quest for Local LLM Training:
@scampbell70is on a mission to train a local large language model (LLM) specifically for stable diffusion prompt writing, considering the possibility of investing in multiple Quadro A6000 GPUs. The aim is to avoid the terms-of-service restrictions of platforms like ChatGPT and learn to train models using tools like Lora.
- LM Studio Compatibility with Other Tools: Users like
@cos2722and@vbwyrdeare discussing which models work best with LM Studio in conjunction with Autogenstudio, crewai, and open interpreter. The consensus is that Mistral works but MOE versions do not, and finding a suitable code model that cooperates remains a challenge.
- LM Studio's Hardware Hunger:
@melmassreports significant resource usage with the latest LM Studio version, indicating that it taxes even powerful setups with a 4090 GPU and 128GB of RAM.
- Gorilla Open Function Template Inquiry:
@jb_5579is seeking suggestions for JSON formatted prompt templates to use with the Gorilla Open Function in LM Studio with no follow-up discussion provided.
- Exploring Quantization and Model Size for Performance:
@binaryalgorithm,@ptable, and@kujilaengaged in an extensive discussion about utilizing quantized models with different parameter counts for performance and inference speed. The trade-off of depth and creativity in responses from larger models against the fast inference from low quant models was a significant part of the conversation.
Links mentioned:
- LLM-Perf Leaderboard - a Hugging Face Space by optimum: no description found
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
LM Studio ▷ #🧠-feedback (21 messages🔥):
- Clarification Sought on Catalog Updates:
@markushenrikssoninquired about checking for catalog updates, to which@heyitsyorkieconfirmed that the updates are present. - Manual File Cleanup Needed for Failed Downloads:
@ig9928reported an issue where failed downloads required manual deletion of incomplete files before a new download attempt can be made, requesting a fix for this inconvenience. - Request for Chinese Language Support:
@gptaiexpressed interest in Chinese language support for LM Studio, noting the difficulty their Chinese fans face with the English version. - Confusion with Error Messages:
@mm512_shared a detailed error message received when attempting to download models.@yagilbdirected them to seek help in the Linux support channel and advised running the app from the terminal for error logs. - Model Compatibility Queries and Tutorial Issues:
@artdiffuserstruggled with downloading models and was informed by@heyitsyorkiethat only GGUF models are compatible with LMStudio. Additionally,@artdiffuserwas cautioned about potentially outdated or incorrect tutorials, and@yagilbfurther addressed the issue by suggesting a bug report in the relevant channel for their specific error.
LM Studio ▷ #🎛-hardware-discussion (157 messages🔥🔥):
- GPUs and Memory Management:
@0pechenkaasked whether memory usage on GPUs and CPUs when running models like LLaMA v2 is customizable. They wanted a beginner's guide for setting things up, asking for instructions, possibly on YouTube.@pefortinsuggested removing the "keep entire model in ram" flag if the model doesn't fit into memory to utilize the swap file on Windows.
- Building a Budget LLM PC:
@abesmoninquired about a good PC build for running large language models (LLMs) on a medium budget, and@heyitsyorkieadvised that VRAM is crucial, recommending a GPU with at least 24GB of VRAM.
- Power Supply for Multiple GPUs Discussed:
@dagbsand@pefortindiscussed the potential need for more power when running several GPUs, with pefortin considering to sync multiple PSUs to handle his setup, which includes a 3090 and other GPUs connected through PCIe risers.
- LLM Performance on Diverse Hardware Configurations:
@pefortinshared his experience of approximately 30-40% performance of a P40 GPU compared to a 3090 for LLM tasks, and mentioned driver issues on Windows, which are not a problem on Linux.
- Mixing GPU Generations for LLMs: Users
@ellric_and@.ben.comdebated on the compatibility and performance implications of using different generations of GPUs, like the M40 and P40, with LLMs..ben.comadmitted needing to investigate the performance consequences of splitting models across GPUs, positing a potential 20% slowdown from unscientific testing.
Links mentioned:
- Mikubox Triple-P40 build: Dell T7910 "barebones" off ebay which includes the heatsinks. I recommend the "digitalmind2000" seller as they foam-in-place so the workstation arrives undamaged. Your choice of Xe...
- Simpsons Homer GIF - Simpsons Homer Bart - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #🧪-beta-releases-chat (1 messages):
mike_50363: Is the non-avx2 beta version going to be updated to 2.12?
OpenAI ▷ #ai-discussions (137 messages🔥🔥):
- Improving DALL-E Generated Faces:
@abe_gifted_artqueried about updated faces generated by DALL-E, noticing they weren't distorted now. However, no specific update or change in date was provided in the discussion. - AI Understanding Through Non-technical Books:
@francescospacesought recommendations for non-technical books on AI and its potential or problems.@laerunsuggested engaging in community discussions like the one on Discord, while@abe_gifted_artrecommended looking into Bill Gates' interviews and Microsoft's "Responsible AI" promise, sharing a link: Microsoft's approach to AI. - Debate Over Training AI with Unethical Data: A debate occurred between
@darthgustav.and@luguiregarding the ethical implications and technical necessity of including harmful material in AI datasets.@yami1010later joined, highlighting the complexity of how language models work and the creativity seen in AI outputs. - Challenges of Successful DALL-E Prompts:
@.yttyexpressed frustrations with DALL-E not following prompts correctly, while@darthgustav.offered advice on constructing effective prompts, emphasizing the use of detail and avoiding negative instructions. - Starting with AI Art and AI Scripting Language Training: New users asked how to begin creating AI art, and
@exx1recommended stable diffusion requiring an Apple SoC or Nvidia GPU, while@cokeb3arexplored how to teach AI a new scripting language without the ability to upload documentation.
Links mentioned:
What is Microsoft's Approach to AI? | Microsoft Source: We believe AI is the defining technology of our time. Read about our approach to AI for infrastructure, research, responsibility and social good.
OpenAI ▷ #gpt-4-discussions (85 messages🔥🔥):
- GPT Image Analysis Challenge:
@cannmanagesought help using GPT to analyze videos for identifying a suspected abductor's van among multiple white vans.@darthgustav.suggested using the Lexideck Vision Multi-Agent Image Scanner tool and adjusting the prompt for better results, noting the importance of the context in which the tool is used.
- Identifying Active GPT Models:
@nosuchipsuinquired about determining the specific GPT model in use, and@darthgustav.clarified that GPT Plus and Team accounts use a 32k version of GPT-4 Turbo, with different usage for API and Enterprise plans. He later shared a link to transparent pricing plans and model details.
- Image Display Hurdles: Users
@quengelbertand@darthgustav.discussed whether GPT can display images from web URLs within the chat, concluding that such direct display isn't currently supported, evidenced by an error message displayed when attempting this function on GPT-4.
- Understanding @GPT Functionality:
@_odaenathusdiscussed confusion with the@system in GPTs, suspecting a blend rather than a clear handover between the original and@GPT.@darthgustav.confirmed the shared context behavior and suggested that disconnecting from the second GPT would revert back to first instructions, though a bug or bad design might cause unexpected behavior.
- Managing D&D GPTs Across Devices:
@tetsujin2295brought up an inability to @ GPTs on mobile as a Plus member, which@darthgustav.attributed to a potential lack of roll out or mobile browser limitations. He also shared the effective use of structuring multiple D&D related GPTs for various roles and world-building, with a slight concern over token limit constraints.
Links mentioned:
Pricing: Simple and flexible. Only pay for what you use.
OpenAI ▷ #prompt-engineering (62 messages🔥🔥):
- Sideways Dilemma in Portrait Generation:
@wild.evaand@niko3757discussed challenges with generating vertical, full-body portrait images; the model appears to force landscape mode.@niko3757suggested a workaround of generating in landscape and then stitching images in portrait after upscaling, though this is speculation and they await a significant update for DALL-E. - Portrait Orientation Gamble:
@darthgustav.suggested that due to symmetry and lack of an orientation parameter, getting a correct vertical portrait is a 25% chance occurrence. This implies a fundamental limitation, unrelated to how images are prompted. - Prompt Improvement Attempts:
@wild.evasought suggestions for prompts to improve image orientation,@niko3757provided examples, but@darthgustav.countered by indicating that no prompt improvement could overcome the model's inherent constraints. - Integrating Feedback Buttons in Custom GPT:
@luarstudiosinquired about adding interactive feedback buttons post-answer in their GPT model, engaging with@solbusand@darthgustav.for guidance.@darthgustav.offered a detailed explanation about incorporating an Interrogatory Format to attach a menu of responses to each question. - Structural Discussions on Design Proposals:
@solbusand@darthgustav.pondered whether to have a different feedback structure for the first logo design compared to subsequent ones, suggesting this could increase efficiency and relevance in feedback collection.@darthgustav.shared a link to their own approach in DALL-E Discussions.
OpenAI ▷ #api-discussions (62 messages🔥🔥):
- Sideways Image Chaos:
@wild.evaencountered issues with her detailed prompts which resulted in sideways images or undesired scene generation, suggesting training issues with the model.@niko3757confirmed the likely cause is a built-in error and suggests trying images in landscape then upscaling, while@darthgustav.mentioned the lack of orientation parameters limits vertical orientations.
- Expectations for DALLE Update:
@niko3757shared optimistic yet unconfirmed speculation about a significant update to DALLE coming soon, which they are eagerly awaiting for improved results.
- GPT-3 Button Dilemma:
@luarstudiossought help with adding response buttons after the AI presents design proposals, getting feedback from both@solbusand@darthgustav.on how to implement this in the chatbot's custom instructions.
- Conversation Structure Strategy:
@darthgustav.provided a strategy for@luarstudiosto guide the AI's interaction pattern, suggesting templates and conversation starter cards to handle the logical flow in presenting logo options and receiving feedback.
- Sharing Insights Across Channels:
@darthgustav.cross-posts to DALL-E Discussions, illustrating the efficiency of prompt engineering for a logo concept and recommending open-source examples across channels for better community assistance.
OpenAccess AI Collective (axolotl) ▷ #general (109 messages🔥🔥):
- Chasing the Phantom Spike:
@nafnlaus00and@dreamgendiscussed training patterns and learning rate (LR) adjustments in their models, observing spikes at every epoch. Despite trying lower LRs and increased dropout,@nafnlaus00mentioned still facing overtraining issues.
- The Quest for Server-grade GPUs:
@le_messoffered connections for purchasing server-grade hardware. In the meanwhile,@yamashicontemplated acquisitions, considering aGigabyte Server G262-ZO0setup with AMD EPYC processors and the AMD MI250 GPUs, weighing the benefits against renting.
- Software Stack Skepticism: Although AMD's offerings like the
MI250intrigued some users for their memory capacity and potential performance,@yamashiexpressed doubts about the maturity of AMD's software stack compared to Nvidia.
- Commit Conundrum:
@nafnlaus00identified a likely problematic commit (da97285e63811c17ce1e92b2c32c26c9ed8e2d5d) in theaxolotllibrary that might be causing significant overtraining in their model fine-tune. They're undertaking a methodical approach to isolate the change responsible.
- Tiny YAMLs, Major Leaps:
@caseus_shared a small, 11-line YAML config that can kick off a finetune, mentioning an imminent refactor foraxolotlto further streamline and improve defaults, which might reduce complexity even more (PR #1239).
Links mentioned:
- AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU: no description found
- keep gate in fp32 for 16 bit loras (#1105) · OpenAccess-AI-Collective/axolotl@da97285: * keep gate in fp32 for loras
- add e2e check for lora w/o flash attention for mixtral to check gate
- add checks for gate in fp32 for mixtral, add typehints to train outputs
- mixtral doe...
- WIP: Pydantic cfg by winglian · Pull Request #1239 · OpenAccess-AI-Collective/axolotl: Description Motivation and Context How has this been tested? Screenshots (if appropriate) Types of changes Social Handles (Optional)
- Gigabyte 2U MI250 Server G262-ZO0: no description found
- no title found: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (26 messages🔥):
- CI Breakdown Post Torch-2.2.0:
@caseus_reported that the torch-2.2.0 release broke their CI without specifying which version it requires. They shared a job log that details the issue. - Confusion Over 'torch' In Requirements:
@nanobitzasked whether 'torch' could be removed from requirements fearing it overrides the base torch, but@caseus_confirmed that 'torch' was already removed a while back. - Norm Equilibrium in LoftQ Improvement:
@stefangligasuggested an improvement for LoftQ where vectors k1 and k2 could be used to rescale matrices A and B, thus matching per axis norms to improve gradient magnitudes. - Axolotl Torch Version Control PR:
@caseus_introduced a pull request #1234 aimed at fixing CI issues by setting the torch version to match the installed version during axolotl install, which prevents auto-upgrading to the problematic torch-2.2.0. - Checkpoint Upload Issue with Qlora:
@dreamgenreported a problem where Qlora doesn't upload all checkpoints, only the final one.@caseus_suggested that this might be an upstream issue with Transformers and mentioned a potential workaround involvingTrainerCallback.
Links mentioned:
- Fix and document test_datasets (#1228) · OpenAccess-AI-Collective/axolotl@5787e1a: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- set torch version to what is installed during axolotl install by winglian · Pull Request #1234 · OpenAccess-AI-Collective/axolotl: Description The latest torch-2.2.0 breaks our CI as it attempts to install the latest torch version. Motivation and Context How has this been tested? Screenshots (if appropriate) Types of chan...
OpenAccess AI Collective (axolotl) ▷ #general-help (42 messages🔥):
- Axolotl Installation Stuck on flash-attn:
@arindam8841encountered issues installing axolotl related to building the wheel for flash-attn. They resolved the issue by installing the latest version of flash-attn separately usingpip install flash-attn --no-build-isolation. - Understanding Batch Size in axolotl:
@dreamgenquestioned how batch size scales with the number of GPUs in axolotl, while@caseus_clarified that using DeepSpeed, specifically zero3, adjusts for distributed data parallel (DDP) and batch sizes, making it unnecessary for models that fit on a single GPU. - Dataset Configuration Challenges:
@jorelosoriofaced errors trying to use the same dataset with different formats for different tasks within axolotl. The issue was resolved by specifying differentdata_filespaths for each task. - Merging Models with Axolotl:
@cf0913experienced anAttributeErrorwhile attempting to merge QLORA with a base model, seeking advice on whether to use the axolotl command line or another method, with a suggestion from@le_messabout full finetuning. - Request for Token Counting Script: Both
@arcontexexpressed a need for a script to count the number of tokens in a file, and@gonejiggyoffered to write a CLI tool and asked if a pull request would be accepted.@nanobitzmentioned that axolotl already outputs token counts in logs and asked for the yaml configuration to further assist@arcontex.
Links mentioned:
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #rlhf (4 messages):
- DPO Experiencing Issues:
@giftedgummybeesignalled that DPO (Data Processing Optimizer) is currently experiencing issues, but did not specify the nature of the problem. - Request for Clarification on DPO:
@filippob82asked for a more detailed explanation of the issues with DPO from@giftedgummybee. - VRAM Usage Concerns with DPO:
@c.gatoelaborated that the DPO is consuming a considerable amount of VRAM, specifically mentioning the challenges of running QLora on a 13b model.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (5 messages):
- Mysterious Empty Folder Phenomenon:
@nanobitzshared an amusing discovery that they finally encountered the empty folder issue which had previously never occurred to them. - Runpod's Intermittent Folder Vanishing Act:
@dreamgenchimed in, mentioning that the issue of folders appearing empty happens sometimes even without network volume, but the cause remains unknown. - Hot Deal Alert on Community Cloud:
@dreamgenexcitedly announced the availability of H100 SXM units on the community cloud, priced at 3.89—urging users to seize the opportunity quickly. - Runpod Documentation Dilemma:
@gonejiggyexpressed frustration over having to instruct users to runpip install -e .due to a recurring error, acknowledging that adding this to the documentation is not ideal. - Ghost in the Machine on Runpod:
@dreamgenreports a baffling situation where a mysterious process is consuming memory and GPU on their runpod machine but remains undetectable and unkillable through conventional commands.
HuggingFace ▷ #general (149 messages🔥🔥):
- Model Training Woes and Solutions:
@drummer_.experienced a loss flatline to0during model training which later appeared to be related to setting a higher batch size. Switching to a batch size of1and considering the use ofEarlyStoppingCallbackwere discussed, with input from@Cubie | Tomsuggesting training instability, and@doctorpanglossindicating that 4bit quantization could be a contributing factor.
- Seeking Specific LLMs for Tech Data:
@zorian_93363inquired about language models specifically trained on datasets related to Arduino, Esp 32, Raspberry Pi, and similar tech subjects.
- In Search of Efficiency in Large Model Training:
@ericpan.xyzasked about the fastest format for higher inference speed and ways to reduce a model's memory footprint, with@meatfuckersuggesting 4bit quantization despite some loss of accuracy to conserve VRAM.
- Exploring Embedding Logic Across Multiple Namespaces:
@abhisheknegi_12043sought advice on designing logic to query similarity across multiple namespaces for meeting transcripts stored as vector embeddings in Pinecone.
- Integrating Diffusion Models into a Social Platform:
@goodtimes5241sought assistance with integrating a fine-tunable stable diffusion model, similar to "diffuse the rest," into a social media application. They previously explored using the Inference API and alternatives like the Stable Diffusion Computing Network for image-to-image generation capabilities.
- Publishing Community Content Challenges:
@aliabbas60reported difficulty with an authorization error preventing the publishing of a community blog post without further details on the issue.
Links mentioned:
- ControlNet in 🧨 Diffusers: no description found
- GitHub - fiatrete/SDCN-Stable-Diffusion-Computing-Network: SDCN is an infrastructure that allows people to share and use Stable Diffusion computing power easily.: SDCN is an infrastructure that allows people to share and use Stable Diffusion computing power easily. - GitHub - fiatrete/SDCN-Stable-Diffusion-Computing-Network: SDCN is an infrastructure that al...
- Image-to-image: no description found
- Callbacks: no description found
HuggingFace ▷ #today-im-learning (3 messages):
- Understanding Bahdanau Attention: User
@sardarkhan_expressed that while reading about Bahdanau attention, they found it to be complex yet fascinating. - Advancements in Reinforcement Learning:
@sardarkhan_mentioned working on a reinforcement learning project and plans on continuing to develop an aimlabs agent. - Seeking Motivational Boost: User
@kaikishatuexpressed their need for motivation in the today-im-learning channel.
HuggingFace ▷ #i-made-this (11 messages🔥):
- Tweet Critique Request: User
@vipitisshared a tweet containing their thesis proposal for a science communication seminar and invited feedback from the community.
- Magic: The Gathering Model Showcase:
@joshuasundanceannounced the availability of a space for the Magic model they discussed and provided a link to the model on HuggingFace Spaces, along with a visual preview.
- Custom Pipeline for MoonDream: User
@not_lainhas successfully created a custom pipeline for themoondream1model and shared a pull request explaining its usage, including code snippets for testing before merging.
- Acknowledgment for Compute Support: User
@not_laingave a shout-out to<@994979735488692324>for providing the necessary compute power that aided in the completion of their custom pipeline for themoondream1model.
- Necessary Tomorrows Podcast Release:
@deepaaarworked on music and sound design for Al Jazeera's sci-fi podcast "Necessary Tomorrows," utilizing AI in the creative process. They shared where to listen to the podcast and provided a brief synopsis, mentioning that the podcast mixes speculative fiction and documentary elements centered around the turbulent 2020s.
Links mentioned:
- Gradio HTML Docs: no description found
- mtg-coloridentity - a Hugging Face Space by joshuasundance: no description found
- vikhyatk/moondream1 · add pipeline: no description found
- GitHub - cdpierse/transformers-interpret: Model explainability that works seamlessly with 🤗 transformers. Explain your transformers model in just 2 lines of code.: Model explainability that works seamlessly with 🤗 transformers. Explain your transformers model in just 2 lines of code. - GitHub - cdpierse/transformers-interpret: Model explainability that works.....
- Necessary Tomorrows: Ursula, an AI instructor from the future, encourages listeners to study the turbulent 2020s. Mixing speculative fiction and documentary, leading sci-fi authors bring us three futures that seem like fa...
HuggingFace ▷ #reading-group (1 messages):
- Delving into Language Model Compression:
@ericauldshared a paper discussing various compression algorithms for language models and invited others to read and discuss. The paper addresses the need to balance model efficiency with accuracy and touches on methods like pruning, quantization, knowledge distillation, and more.
Links mentioned:
A Comprehensive Survey of Compression Algorithms for Language Models: How can we compress language models without sacrificing accuracy? The number of compression algorithms for language models is rapidly growing to benefit from remarkable advances of recent language mod...
HuggingFace ▷ #diffusion-discussions (1 messages):
- Seeking Cross-Namespace Similarity Query Logic: User
@abhisheknegi_12043is requesting guidance on creating a query logic that can determine similarity across multiple namespaces within Pinecone for a project involving meeting transcripts embedding. They're looking for advice on design and implementation strategies for this functionality.
HuggingFace ▷ #computer-vision (1 messages):
merve3234: it's not an error but rather a warning, feel free to ignore
HuggingFace ▷ #NLP (2 messages):
- Seeking GPU Resources for Open Source Contribution: User
@lpbbis looking to contribute to the nanotron library and is in search of two linked GPUs for testing code. They mentioned willingness to pay for access if the cost is reasonable. - NeuralBeagle14-7b Running on 8GB GPU Demo:
@joshuasundanceshared a link to a GitHub repository, demonstrating how they managed to run neuralbeagle14-7b on a local 8GB GPU. The repository acts as a showcase for others interested in a similar setup.
Links mentioned:
GitHub - joshuasundance-swca/llamacpp-langchain-neuralbeagle-demo: a small demo repo to show how I got neuralbeagle14-7b running locally on my 8GB GPU: a small demo repo to show how I got neuralbeagle14-7b running locally on my 8GB GPU - GitHub - joshuasundance-swca/llamacpp-langchain-neuralbeagle-demo: a small demo repo to show how I got neuralbe...
HuggingFace ▷ #diffusion-discussions (1 messages):
- Seeking Cross-Namespace Similarity Logic:
@abhisheknegi_12043is working on a project using Pinecone for vector embedding to store vectors from meeting transcripts. They are requesting assistance in designing a logic to fetch similarities across multiple namespaces.
LAION ▷ #general (72 messages🔥🔥):
- Synthetic Textbook Dataset Search: User
@alyosha11sought synthetic textbook datasets for a project similar tophi, and@JHindicated that there were ongoing efforts in another Discord channel (#1185268316001009785) which@alyosha11acknowledged checking out. - MusicLM Audio File Conundrum:
@finnildafaced an issue while training MusicLM transformers due to missing audio files and inquired about sources for the needed dataset. They noted the lack of responses on GitHub and sought assistance from the Discord community. - Filtering Underage Content:
@latke1422prequested help to filter images with underage subjects using a dataset of trigger words, expressing the need for building safer AI content moderation tools. - Research-oriented Pings on Discord: Various users including
@astropulse,@progamergov, and@.undeletedengaged in a discussion regarding the appropriateness of using '@everyone' pings on a research server, with diverse opinions though consensus leaning towards acceptability given the server's research focus. - VAE Training Errors Discovered:
@drheadrevealed a discovery that the kl-f8 VAE improperly packs information, which is a deviation from the intended training method, impacting models that rely on it. This prompted discussion and linking to a relevant research paper by@.giacomovdiscussing artifacts in transformer learning.
Links mentioned:
- Vision Transformers Need Registers: Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ...
- GitHub - lucidrains/musiclm-pytorch: Implementation of MusicLM, Google's new SOTA model for music generation using attention networks, in Pytorch: Implementation of MusicLM, Google's new SOTA model for music generation using attention networks, in Pytorch - GitHub - lucidrains/musiclm-pytorch: Implementation of MusicLM, Google's ...
LAION ▷ #research (19 messages🔥):
- LLaVA-1.6 Unveiled:
@nodjashares LLaVA-1.6 release blog post emphasizing its improved features like higher image resolution and enhanced OCR. LLaVA-1.6 notably surpasses Gemini Pro in several benchmarks. - LLaVA-1.6 Excels in Comic Test:
@nodjatested LLaVA-1.6 with varying difficulties of a comic test, stating it "gets everything almost right" on the easy version, while the medium version presents more hallucinations. - Photographic Landmark Recognition:
@helium__compares LLAVA's performance to GT4-V on identifying a European city from a personal photo, with GT4-V accurately naming Porto while LLAVA struggles to be specific. - Multimodal Model Capabilities Questioned:
@mfcoolinquires about the mechanisms enabling style preservation in VLMs like Dall-E, observing that others tend to generalize while Dall-E accurately reflects specific styles. - SPARC Introduced for Detailed Multimodal Representations:
@spirit_from_germanyshared a Twitter link about SPARC, a new method for pretraining multimodal representations with fine-grained details, but@twoaboveand@mkaicexpress excitement, although it's noted there's no code or models available yet.
Links mentioned:
- LLaVA-1.6: Improved reasoning, OCR, and world knowledge: LLaVA team presents LLaVA-1.6, with improved reasoning, OCR, and world knowledge. LLaVA-1.6 even exceeds Gemini Pro on several benchmarks.
- LLaVA: no description found
- Tweet from Ioana Bica (@IoanaBica95): Excited by the generality of CLIP, but need more fine-grained details in your representation? Introducing SPARC, a simple and scalable method for pretraining multimodal representations with fine-grain...
Perplexity AI ▷ #general (37 messages🔥):
- Curiosity About Custom GPTs:
@sweetpopcornsimonexpressed interest in training a private model similar to building a custom GPT with ChatGPT.@icelavamanclarified that Perplexity AI does not offer chatbot services, but rather a feature called Collections, which organizes threads into shareable spaces for collaboration.
- PDF/EPUB Reader Inquiry:
@archientasked the community if there is an epub/PDF reader that supports AI text manipulation and has the capability to use custom APIs.
- In Search of Unique Notification Sounds:
@noell5951inquired whether there is a distinct notification sound for Perplexity, indicating they have not tried it but are curious.
- Seeking Advice for Perplexity AI Pro:
@johnl4119had a "how to" question about Perplexity AI Pro and was guided by@ok.alexto the "quick-questions" area as the appropriate place to ask.
- Experiencing Prompt Disappearance Issue:
@nuggdavisreported an unusual issue where prompts briefly disappear before getting responses after a refresh, a problem occurring across multiple browsers and operating systems.@gumby2411confirmed having a similar experience.
Links mentioned:
- What is Collections?: Explore Perplexity's blog for articles, announcements, product updates, and tips to optimize your experience. Stay informed and make the most of Perplexity.
- Perplexity Careers: Join our team in shaping the future of search and knowledge discovery.
Perplexity AI ▷ #sharing (2 messages):
- Perplexity's Insight into Google's Future: User
@m1st3rgshared a brief and mysterious insight, claiming to have learned about the future of Google through their experience with Perplexity. - YouTube Guide on Content Creation with Perplexity:
@redsolplprovided a YouTube video link titled "How I Use Perplexity AI to Source Content Ideas for LinkedIn," which describes how they've effectively integrated Perplexity AI into their social media content creation process.
Links mentioned:
How I Use Perplexity AI to Source Content Ideas for LinkedIn: A dive deep into how I've been using Perplexity AI to revolutionize my content creation process for social media. Whether you're a content creator, business ...
Perplexity AI ▷ #pplx-api (31 messages🔥):
- In Pursuit of Support: User
@angelo_1014expressed concerns over not receiving a response from support@perplexity.ai, to which@ok.alexreplied asking to ensure the correct email was used for contact and offered to check on the matter if provided with a personal email via DM, which@angelo_1014confirmed sending. - Codellama Conundrums Confounding:
@bvfbarten.reported odd responses from the codellama-70b-instruct model and was reassured by@ok.alexthat the issue would be investigated. Subsequent conversation affirmed that the codellama-34b-instruct model was functioning solidly. - Parsing the API Puzzle:
@andreafonsmortigmail.com_6_28629discussed the complexity of handling file uploads with the chatbox interface, with@clay_fergusonproposing the use of Apache Tika for extracting text from files and guiding on the file upload process without involving API uploads. - Deciphering Online Models: In a discussion initiated by
@kid_tubsyregarding the ability to list links/sources of data for API models,@brknclock1215clarified that the -online models can access real-time internet data but do not provide citations in their responses.@clay_fergusonacknowledged this feature as beneficial despite the lack of source citations. - Model Sources Matter:
@brknclock1215emphasized the importance of having source URLs when using online capable models for verifying information and overcoming the issues with hallucinations, especially for research purposes that require validated data for client-facing reports.
LangChain AI ▷ #general (38 messages🔥):
- Langchain and Vector Search Dilemmas:
@abhisheknegi_12043seeks advice on creating a logic for fetching similarity across multiple Pinecone namespaces for storing meeting transcripts, while@agenator.reports issues querying large JSON files using Langchain and ChromaDB, only getting partial data responses. - Embeddings in Action: In response to a query about handling embeddings with OpenAI,
@agenator.shared a snippet of Express.js code that uses Langchain and Chroma for Document embeddings. - AI for Stock Market Analysis:
@funk101.is on the lookout for an AI solution that can analyze "real-time" stock market information and respond based on pre-existing data. - Pinecone Puzzles:
@bardbuddyis stuck trying to run an older Langchain app due to a TypeError and updates to the langchain/pinecone package, and is seeking immediate help for this issue. - Mixture of Agents Concept:
@the_agent_jexplores the idea of using fine-tuned models for specific agent types within a system referred to as Mixture of Agents, considering the potential of using custom GPTs from OpenAI for specialized roles.
Links mentioned:
- no title found: no description found
- Thumbs Up Like GIF - Thumbs Up Like Thumbs Up Gif - Discover & Share GIFs: Click to view the GIF
- SkmAI: AI-Powered YouTube Video Search: Search through videos of any language, find the most relevant clips and timestamp to them using AI.
LangChain AI ▷ #share-your-work (9 messages🔥):
- LangGraph Opens New AI Collaboration Horizons:
@andysingalshared an article titled Unveiling the Future of AI Collaboration with LangGraph: Embracing Multi-Agent Workflows. Read about the next-generation tool LangGraph and its role in multi-agent AI systems in the Medium post.
- Visual Canvas Enquiry:
@nbbaierasked about the platform/tool used for the visual canvas seen in an unspecified video.
- Trouble in Node.js Town:
@bardbuddyencountered an error when running an old LangChain app due to what appears to be updates in the LangChain API, specifically related toPineconeStoreandPineconeClient.
- Language Misidentification Misadventure: In response to
@bardbuddy's error,@johnny2x2mistakenly thought the code snippet might be in C, but@bardbuddyclarified that the issue concerns Node.js.
- Uninvited Invitation Link Sharing:
@cryptosmilerposted an invite to join a Discord server with a 5-use invite code, hoping for a quick response before the invites run out.
Links mentioned:
Unveiling the Future of AI Collaboration with LangGraph: Embracing Multi-Agent Workflows: Ankush k Singal
LangChain AI ▷ #tutorials (1 messages):
- Dive into OpenAI Embeddings with LangChain:
@datasciencebasicsshared a YouTube video tutorial on using the new OpenAI Embeddings Model with LangChain. The video covers the introduction of the new embeddings model by OpenAI, updates to GPT-3.5 Turbo, and new tools for developers to manage AI applications.
Links mentioned:
How To USE New OpenAI Embeddings Model with LangChain 🦜🔗: OpenAI introduces new Embeddings model. They are releasing new models, reducing prices for GPT-3.5 Turbo, and introducing new ways for developers to manage A...
LlamaIndex ▷ #blog (2 messages):
- Tuning Hybrid Search is Key: LlamaIndex highlights that hybrid search needs to be adjusted for different types of questions when using Retrieval-Augmented Generation (RAG) systems. There are categories like Web search queries and concept seeking, each requiring a unique approach Twitter thread.
- Deep Dive into Multimodal RAG Systems: A new video by
@_nerdai_focuses on evaluating multimodal RAG systems using LlamaIndex, covering an introduction to RAG, evaluation techniques, building multimodal RAG, as well as challenges faced YouTube link update notification Tweet about video.
Links mentioned:
no title found: no description found
LlamaIndex ▷ #general (43 messages🔥):
- Seeking Vector Dump Into OpenSearch: User
@natuto_uzumaki1808requested help with dumping local vector embedding files into an Opensearch database, tagging specific members for assistance, but did not provide further context or details.
- RAG Context Size Curiosity:
@wrapdepolloasked about the effect of RAG context size on retrieved chunks, sparking a brief confirmation by@Teemu, additional clarification by@cheesyfishesabout LlamaIndex's handling of oversized contexts, and a thank-you response by@wrapdepollo.
- RAG Over Code in LlamaIndex Inquiry:
@richard1861queried about a tutorial for RAG over code using LlamaIndex, referencing Langchain's approach.@Teemuand@cheesyfishesengaged in the discussion, with@cheesyfishesinviting contributions for better code splitting and@rawwerkssharing code extract from langchain used for an award-winning hackathon submission.
- Querying Alternative KeywordIndex Storage:
@mysterious_avocado_98353asked about cloud-based storage solutions for KeywordIndex in relation to large-scale data ingestion.@cheesyfishesdirected them to docstore+index_store integrations, with an example provided in a URL.
- API Choice Conversations:
@mrpurple9389inquired about preferences between the assistant and completions APIs, and@hosermagesought advice on creating server REST endpoints, with@whitefang_jrsuggesting the use of create-llama from LlamaIndex's documentation.
Links mentioned:
- Node Parser Modules - LlamaIndex 🦙 0.9.40: no description found
- RAG over code | 🦜️🔗 Langchain: Use case
- llama_index/llama_index/vector_stores/postgres.py at main · run-llama/llama_index: LlamaIndex (formerly GPT Index) is a data framework for your LLM applications - run-llama/llama_index
- Starter Tutorial - LlamaIndex 🦙 0.9.40: no description found
- Redis Docstore+Index Store Demo - LlamaIndex 🦙 0.9.40: no description found
- Full-Stack Projects - LlamaIndex 🦙 0.9.40: no description found
- Chat Engine - LlamaIndex 🦙 0.9.40: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
leonms123: Hi would anyone be willing to teach me ML using python 😄
Eleuther ▷ #general (10 messages🔥):
- A Good Morning Wave:
@andrei.alcazagreeted the channel with a simple but friendly "morning" followed by a waving hand emoji. - Searching for Visuals:
@dpalekarequested assistance in finding a good transformer decoder tikz or a reference to an arXiv paper containing one. - Leaked Model Drama Unfolds:
@hailey_schoelkopfshared a tweet from @arthurmensch discussing an incident where an "over-enthusiastic employee" leaked a watermarked version of an old training model. - Cultural Interpretation: In response to the use of "over-enthusiastic" by
@arthurmensch,@carsonpooleexpressed amusement, which led to@catboy_slim_comparing it humorously to the Southern expression "bless your heart." - Seeking Diffusion Model Leaderboards:
@carmoccainquired about the existence of a leaderboard similar to HF's eval leaderboard, but for diffusion models.
Links mentioned:
Tweet from Arthur Mensch (@arthurmensch): An over-enthusiastic employee of one of our early access customers leaked a quantised (and watermarked) version of an old model we trained and distributed quite openly. To quickly start working with ...
Eleuther ▷ #research (14 messages🔥):
- Intriguing Scale Effects Uncovered in Diverse Model Architectures:
@the_random_lurkerhighlighted a study (Scaling Properties of Transformer Models) revealing that model architecture is an important scaling consideration and performance may fluctuate at different scales. They questioned why this finding hasn't become mainstream.
- Continued Pretraining of Mixtral Inquiry:
@quicksortasked for any papers, repos, or blog posts about the continuous pretraining of MoE models, similar to LeoLM, for low-resource languages. This indicates interest in refining methods for language model pretraining.
- Contradictions in ImageNet Pre-training:
@micpieshared research (Pre-training Time Matters) exposing that models inadequately pre-trained on ImageNet can sometimes outperform fully trained models depending on the task. This points to a complex relationship between pre-training duration and model efficiency in different applications.
- Seeking Insights on Gated Convolution Architectures:
@afcruzsrequested resources for comparing gated convolutional architectures, with@mrgonaoexpressing similar interest. Meanwhile,@nostalgiahurtsprovided a GitHub repository and a blog post that might shed light on these architectures.
- Token Discretization During Inference Discussed:
@sentialxinquired about the necessity of discretizing tokens during inference as opposed to feeding back the token embeddings, with@xylthixlmresponding it's due to the requirement of autoregressive generation during training. This reflects on typical practices in language model inference processes.
Links mentioned:
- Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?: There have been a lot of interest in the scaling properties of Transformer models. However, not much has been done on the front of investigating the effect of scaling properties of different inductive...
- Towards Inadequately Pre-trained Models in Transfer Learning: Pre-training has been a popular learning paradigm in deep learning era, especially in annotation-insufficient scenario. Better ImageNet pre-trained models have been demonstrated, from the perspective ...
- GitHub - srush/do-we-need-attention: Contribute to srush/do-we-need-attention development by creating an account on GitHub.
- The Essense of Global Convolution Models | AI Bytes: no description found
Eleuther ▷ #interpretability-general (3 messages):
- The Renaissance of n-gram Models:
@80melonshared a research paper that revisits n-gram language models, highlighting a novel $\infty$-gram model and a new computation engine called infini-gram. They expressed surprise at how these n-gram models, when combined with large neural models like Llama-2 70b, significantly improve perplexity scores. - Generalization vs. Memorization: Despite the improvements in perplexity,
@80melonspeculated that using adaptive-length n-gram models might worsen the generalization capability of neural language models, though this was not tested in the study.
- Understanding Transformers' Memory Mechanisms:
@ishitatsuyukiraised a question about existing research on transformers' ability to memorize n-grams, referring to a study that uses automata (found here). They are curious whether the resulting automata would be compact enough to represent the extensive vocabularies.
Links mentioned:
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens: Are n-gram language models still relevant in this era of neural large language models (LLMs)? Our answer is yes, and we show their values in both text analysis and improving neural LLMs. Yet this nece...
Eleuther ▷ #lm-thunderdome (12 messages🔥):
- Quick Appreciation for PyPI Automation:
@hailey_schoelkopfexpressed thanks to@1186960329738039357for their pull request which automated packaging for PyPI, stating it worked like a charm. - Language Model Evaluation Harness 0.4.1 Released:
@hailey_schoelkopfshared a PyPI release and a different GitHub Release link for the Language Model Evaluation Harness 0.4.1 which includes internal refactoring, easier prompt design with Jinja2, and optimized data-parallel model usage. - PR Gratitude and Pending Review:
@anjor_20331expressed gratitude for the successful automation and acknowledged an open PR that they will review once they are less swamped. - Interest in Few-shot Examples Log Output:
@Goyiminquired about including few-shot examples in thelog_samplesoutput or knowing which ones will be used ahead of time. - Clarification on MMLU Evaluation Metrics:
@daniellepintzasked for help interpreting evaluation results from MMLU,@stellaathenaclarified the accuracy as 40.2% and standard error as +/- 20.7%, and@baber_questioned whether the results were calculated with a limitation parameter.@daniellepintzshared a gist suspecting a problem with their LM subclass implementation.
Links mentioned:
- gist:c48c9e61a9a4798552b6ac22bc3a1959: GitHub Gist: instantly share code, notes, and snippets.
- lm-eval: A framework for evaluating language models
- Release v0.4.1 · EleutherAI/lm-evaluation-harness: Release Notes This PR release contains all changes so far since the release of v0.4.0 , and is partially a test of our release automation, provided by @anjor . At a high level, some of the changes ...
Eleuther ▷ #multimodal-general (4 messages):
- Uncertainty in Compute Costs for Training VQA Systems:
@stellaathenaasked for guidance or a rule of thumb on the compute cost to train a decent image encoder and LLM for Visual Question Answering (VQA), acknowledging the lack of good numbers available. - Seeking Consensus on Encoder-Decoder Models:
@stellaathenaalso inquired if the consensus is still that encoder-decoder models are preferable for text and image to text (T+I -> T) domain. - Request for Clarity in Model Application:
@kublaikhan1responded to@stellaathena's query about encoder-decoder models for T+I -> T, seeking clarification on the application or context in question. - Insights on Training llava: In connection to the VQA system discussion,
@kublaikhan1mentioned that it takes about 8x24 A100 hours to train llava, a type of model suitable for such tasks.
CUDA MODE (Mark Saroufim) ▷ #general (17 messages🔥):
- CUDA Development with Python Insights:
@neuralutionhighlighted the benefits of Python for CUDA development, prompting a discussion on performance optimization and compatibility with NVIDIA tools. They raised specific concerns such as ensuring good occupancy, identifying bottlenecks, and cache usage when integrating PyTorch types into the C++ output binary.
- Flash Attention 2 PyTorch Tutorial:
@iron_boundshared a PyTorch tutorial by Driss Guessous on Flash Attention 2, with a link for a detailed example code and additional background on scaled_dot_product_attention.
- NVIDIA's New Multi-Query Attention Kernel:
@dshah3introduced NVIDIA's open-sourced XQA kernel for multi-query and grouped-query attention, boasting improvements in Llama 70B throughput without increased latency.
- Open Dialogue for PyTorch Attention Questions:
@drisspginvited queries about the PyTorch 2.2 Flash Attention 2 implementation, and offered insights on upcoming updates, comparing it with Tri's FA-2 version from his repository.
- Nested Tensors Becoming an Official Feature:
@andreaskoepfand@jeremyhowarddiscussed the utility and official status of NestedTensors in PyTorch, and@tvi_advised caution when replacing packing code with torch.compile that may not fully support NestedTensors yet.
Links mentioned:
- (Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA) — PyTorch Tutorials 2.2.0+cu121 documentation: no description found
- NVIDIA Gen AI on RTX PCs Developer Contest: Enter to win a GeForce RTX 4090 GPU, a GTC event pass, and more.
- TensorRT-LLM/docs/source/blogs/XQA-kernel.md at main · NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficie...
- [RFC] Scaled Dot Product Attention API Changes · Issue #110681 · pytorch/pytorch: Updated SDPA API Authors: @drisspg Summary In order for users to more easily manage the complexity handling of various bias formats we would like to expose the ability to pass in AttnBias derived c...
- pytorch/aten/src/ATen/native/transformers/cuda/sdp_utils.cpp at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- torch.nn.attention.sdpa_kernel — PyTorch main documentation: no description found
- (Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA) — PyTorch Tutorials 2.2.0+cu121 documentation: no description found
CUDA MODE (Mark Saroufim) ▷ #triton (1 messages):
iloveh8: Got it thank you
CUDA MODE (Mark Saroufim) ▷ #cuda (7 messages):
- Jeremy's Notebook Errors Solved: User
@arsalan6990encountered an error while trying to follow Jeremy's notebook. Thanks to@drisspg, a solution was found by referencing GitHub issues, specifically one involving a mismatch between the CUDA version and the version used to compile PyTorch (CUDA 12.0 Issue) and a template-related error with CUDA 12.1 (Cuda 12.1 Template Issue). The fix required installing g++ and gcc 11 and ensuring GLIBCXX_3.4.32 was available. - Cost-Efficiency Tip for Computing Resources:
@nshepperdsuggested that having a lot of CPU RAM is beneficial since it is much cheaper than GPU RAM, costing about 1/10 per GB in comparison. - C++ Templates Clarification: In the context of error resolution,
@zippikaexplained the use oftypenamein C++ templates, detailing that it is a placeholder for substituted types within template definitions.
Links mentioned:
- Does not compile on CUDA 12.0 · Issue #7 · qwopqwop200/GPTQ-for-LLaMa: On running the setup_cuda.py install, I was initially getting: RuntimeError: The detected CUDA version (12.0) mismatches the version that was used to compile PyTorch (11.8). Please make sure to use...
- [BUG]: Cuda 12.1: error: expected template-name before ‘<’ token · Issue #4606 · pybind/pybind11: Required prerequisites Make sure you've read the documentation. Your issue may be addressed there. Search the issue tracker and Discussions to verify that this hasn't already been reported. +1...
CUDA MODE (Mark Saroufim) ▷ #torch (1 messages):
- Selective Compilation Query: User
@marvelousmitinquired whether it is possible to compile only the model layers in PyTorch, excluding a custom operator that gets called at runtime, which is not meant to be compiled. They provided a snippet showing aforward()method callingfunc_not_compile()followed bylayers_compile()and asked about using something liketorch.compile(model).
CUDA MODE (Mark Saroufim) ▷ #beginner (12 messages🔥):
- CUDA Compatibility Confirmation:
@noobpeenasked if CUDA 11.8 is fine for use, since it was already installed for deep learning.@lancertsconfirmed it should be okay, providing a link to NVIDIA documentation which details CUDA Data Stack limitations and functions likecuCtxGetLimit()andcuCtxSetLimit(). - Debugging CUDA in VSCode:
@andreaskoepfpointed out that CUDA Debugging in VSCode is possible, though the setup process is slightly complex, and shared a link to the relevant NVIDIA documentation. - CUDA Kernel Debugging Inquiry:
@jeremyhowardqueried about debugging CUDA kernels called from PyTorch, especially through just-in-time (jit) extensions. No direct solutions were provided within these messages. - Approach to Kernel Development:
@andreaskoepfdescribes their development process, starting with a PyTorch reference implementation and then creating a custom kernel to pass thetorch.allclose()test. This was echoed by@marksaroufim, who has observed similar practices at PyTorch. - Test Framework Preferences:
@andreaskoepfexpressed a preference for using raw Python files or Jupyter notebooks over pytest during development, citing the added complexity of pytest.@marksaroufimhumorously noted the satisfaction from seeing passing tests marked by dots and green colors, whereas@andreaskoepfjoked about getting random patterns of failures (F) and passes (dots) and the occasional pytest crash.
Links mentioned:
- Walkthrough: Debugging a CUDA Application: no description found
- Getting Started with the CUDA Debugger :: NVIDIA Nsight VSCE Documentation: no description found
CUDA MODE (Mark Saroufim) ▷ #pmpp-book (3 messages):
- CUDA Block Size Matching:
@lancertsinquired about the necessity for block size to matchtile_width, especially when a configuration with block dimensionsdim3(32,32,1)runs without errors despitetile_widthbeing 16.@vim410warned that while no immediate errors may be observable, without bounds checking, one could run into illegal memory errors, and stated that aligning more threads than needed for the work is generally illogical. - Understanding Thread Coarsening in CUDA:
@lancertssought clarification on thread coarsening code specifics, questioning the appropriate dimensions forthreadsPerBlockandnumBlocks. The inquiry contrasts a coarsened version with a normal tiled version that uses rectangular thread block shapes, illustrating a common confusion among developers when it comes to optimizing thread allocation in CUDA programming.
DiscoResearch ▷ #mixtral_implementation (21 messages🔥):
- Mistral Medium's Identity Crisis:
@sebastian.bodzasuggested that Mistral Medium could be based on Llama 70B, referencing a Twitter post and noting the closeness of the answers. - Leaked Model Conspiracies Abound: Users
@sebastian.bodzaand@devnull0entertained the theory that Miqu is actually Mistral quantized, supported by discussions on Twitter, including a tweet from @sroecker and another from @teortaxesTex drawing parallels between Mistral and Miqu outputs. - Mistral's Quest for Monetization:
@sebastian.bodzaexpressed disappointment that Mistral's effort to offer great models might be undermined by cheaper leaked versions like Mixtral, while@devnull0questioned if they were really in it for the money. - Debating Model Watermarking: Amid speculation about watermarking to identify leaked models,
@philipmayexpressed skepticism, while@mariowolframmand@devnull0discussed the potential of unique data combinations or tokens acting as watermarks surviving through quantization processes.
Links mentioned:
- Tweet from Q (@qtnx_): reminder that mistral was training 70Bs https://techcrunch.com/2023/11/09/theres-something-going-on-with-ai-startups-in-france/
- Tweet from Teortaxes▶️ (@teortaxesTex): The smoking gun isn't the aggregate r, it's how a great share of items land on the trendline perfectly, suggesting identical cognitive circuitry. This is a typical EQ-Bench item (https://arxiv...
- Tweet from Steffen Röcker (@sroecker): I want to believe: MIQU = MIstral QUantized 🛸 ↘️ Quoting Teortaxes▶️ (@teortaxesTex) Might be late but I am now 100% convinced that Miqu is the same model that's accessible as Mistral-Medium o...
DiscoResearch ▷ #general (10 messages🔥):
- Hermes 2 Dataset Unleashed:
@tekniumhas shared their release of the Hermes 2 dataset with the community, accessible through Twitter. The dataset might be valuable for those interested in AI research and development. - Community Love for the Dataset: In response to
@teknium's post,@hammadkhanexpressed gratitude for the Hermes 2 dataset release with a heartfelt thank you emoji. - Practical Applause for Lilac Integration:
@devnull0complemented the lilac integration in the Hermes 2 dataset, indicating a well-received feature within the community. - Apple Engineer's Crafting Conundrums Presented:
@devnull0shared a humorous prompt regarding the effort required by Apple engineers, found in a tweet by@cto_junioron Twitter. - Mixtral's Impressive Performance Metrics Shared:
@bjoernphighlighted the surprising speed of Mixtral, reaching 500 tokens per second, with a link to Groq's chat platform, sparking curiosity and a follow-up question by@sebastian.bodzaon the company's use of custom AI accelerators.
Links mentioned:
- GroqChat: no description found
- Tweet from Stella Biderman (@BlancheMinerva): @Dorialexander This is completely consistent with research on crosslingual instruction-tuning https://arxiv.org/abs/2211.01786 as well. I'm pretty sure there's lit on linear maps between multi...
- Tweet from TDM (e/λ) (@cto_junior): How many apple engineers were required to craft this prompt?
DiscoResearch ▷ #embedding_dev (8 messages🔥):
- Mistral Embeddings Overfitting Issue:
@devnull0shared a tweet from@Nils_Reimers, claiming that Mistral 7B embedding models are heavily overfitted on MTEB and perform poorly on other tasks than what they were trained for, specifically calling out their inadequacy in tasks like movie sentiment classification.
- Microsoft's Novel Approach for Text Embeddings:
@sebastian.bodzareferenced a research paper by researchers from Microsoft Corporation, highlighting their novel method in generating high-quality text embeddings using synthetic data, simplifying the training process, and achieving significant language coverage.
- Skepticism Abounds: Despite sharing the research paper,
@sebastian.bodzaremained not 100% sold on the paper’s approach, expressing a level of skepticism toward the methodology presented.
- Generating Relevant Passages for Retrieval Tasks: In a discussion with
@thewindmom,@sebastian.bodzaprovided a tip that for short to long retrieval tasks, it's necessary to prepend the prompt with "Represent this sentence for searching relevant passages:" to obtain better results.
Links mentioned:
- Tweet from Nils Reimers (@Nils_Reimers): @abacaj Not worth it. These Mistral 7B embedding models are heavily overfitted on MTEB, by generating training data for the all the tasks in MTEB, and then training a 7B model to do e.g. movie sentime...
- Improving Text Embeddings with Large Language Models: no description found
DiscoResearch ▷ #discolm_german (1 messages):
philipmay: How did you generate this plot for DiscoResearch/DiscoLM_German_7b_v1 ?
LLM Perf Enthusiasts AI ▷ #gpt4 (2 messages):
- Prompt Investing 101: User
@jeffreyw128inquired about prompt investing. - A Quick Correction: User
@jxnlcocorrected the term to injecting, potentially clarifying the discussion topic.
LLM Perf Enthusiasts AI ▷ #opensource (3 messages):
- First in Line to Try:
@jeffreyw128inquired about the best place to try a new model, and@thebaghdaddyresponded with a link to Hugging Face's Miqu-1 70B model, indicating it's the first in a potential series. - Prompt Formatting Advice:
@thebaghdaddyincluded instructions on the prompt format for the Mistral model and cautioned against changing ROPE settings because this model uses a high-frequency base with 32k seen tokens. - Model Testing Constraints:
@thebaghdaddyexpresses a limitation by stating, "im gpu poor though so i havent tested it," indicating they have not personally tested the model due to lack of GPU resources.
Links mentioned:
miqudev/miqu-1-70b · Hugging Face: no description found
LLM Perf Enthusiasts AI ▷ #openai (5 messages):
- Seeking Truth in Model Capabilities:
@joshcho_questioned the validity of a tweet from @nickadobos regarding AI performance. No specific details about the AI or tweet content were provided in the question.
- Disappointment in Document Understanding:
@jeffreyw128shared negative experiences with document performance, expressing they have "no idea how to get performance out of them."
- A Moment of Resignation:
@joshcho_responded to the difficulty in leveraging document capabilities with "sad" and a whimsical comment, "we just pray."
- Insight on AI Limitations with Image Texts:
@thebaghdaddyexpressed surprise and seemed to confirm an AI limitation, stating it "explains why it is incapable of understanding knowledge files with pictures in them."
Skunkworks AI ▷ #general (5 messages):
- Crowdfunding for Open Source AI Research:
@filipvvproposed the idea of crowdfunding to raise funds for open-source models, fine-tunes, and datasets. They shared examples of projects like CryoDAO and MoonDAO, and mentioned a bias due to working on a platform Juicebox that facilitates such crypto projects.
- Brainstorming Collective Funding for OS Training: Continuing the discussion,
@filipvvexplained that the aggregation of funds could pay for larger training runs that could benefit the entire community. The goal is to provide more funding for open-source AI projects, including those on Nous and other platforms.
- Hermes 2 Dataset Released:
@tekniumannounced the release of their Hermes 2 dataset, offering it to the community for potential use. The dataset can be found in their tweet.
- HelixNet Architecture Introduced:
@yikesawjeezshared a post from@migtisseraannouncing HelixNet, a novel deep learning architecture with 3 Mistral-7B LLMs designed akin to a DNA helix structure. They included a link to the model on Hugging Face and provided access details for testing via a Jupyter Hub at agentartificial.com with the credentials: user - forthepeople, pw - getitdone.
Links mentioned:
- Tweet from Migel Tissera (@migtissera): It's been a big week for Open Source AI, and here's one more to cap the week off! Introducing HelixNet. HelixNet is a novel Deep Learning architecture consisting of 3 x Mistral-7B LLMs. It h...
- Tweet from yikes (@yikesawjeez): yknow what fk it https://jupyter.agentartificial.com/commune-8xa6000/user/forthepeople/lab user: forthepeople pw: getitdone will start downloading the model now, hop in and save notebooks to the ./wo...
AI Engineer Foundation ▷ #general (5 messages):
- Exploring Hugging Face's Transformers Agents: User
@tonic_1linked to the documentation for the Transformers Agents API on Hugging Face, noting that it's experimental and could be prone to change. They highlighted the existence of three types of agents (HfAgent, LocalAgent, and OpenAiAgent) for a range of uses from open-source models to local and closed models from OpenAI. - Query for Clarification:
@hackgooferasked for an explanation on HFAgents, indicating a lack of understanding about the topic shared by@tonic_1. - Quick Pitch-In Offer:
@tonic_1mentioned they hadn't filled out a form but expressed affection for the community and a desire to contribute.
Links mentioned:
Agents & Tools: no description found
Alignment Lab AI ▷ #general-chat (2 messages):
- Creativity in Gaming: User
@magusartstudiosmentioned developing a Roblox AI agent Plugin utilizing various tools and features. - Clarifying OpenAI’s Token Policy:
@metaldragon01pointed out that OpenAI does not provide free tokens to the public for open models.
Alignment Lab AI ▷ #alignment-lab-announcements (1 messages):
- Open Hermes 2.5 Dataset Unveiled:
@tekniumannounced the public release of the Open Hermes 2.5 and Nous-Hermes 2 dataset, a comprehensive collection used to improve SOTA LLM's, boasting over 1 million examples. The dataset is a mix of open source data and synthetic datasets, which can be accessed on HuggingFace. - Acknowledgments for Dataset Contributions: The announcement thanked members of the Discord community who contributed to the dataset, including
<@1110466046500020325>,<@257999024458563585>,<@748528982034612226>,<@1124158608582647919>. - Collaboration with Lilac ML:
@tekniumalso highlighted a collaboration with Nikhil and Lilac ML to integrate Hermes into their HuggingFace Spaces, enhancing the ability to explore and analyze the dataset.
Links mentioned:
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- no title found: no description found
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Inquiry on DatasetteGPT Utility: User
@discoureurraised a question about whether anyone has set up a DatasetteGPT for processes such as remembering configuration steps or aiding in plugin writing for Datasette's documentation.