[AINews] Cursor reaches >1000 tok/s finetuning Llama3-70b for fast file editing
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Speculative edits is all you need.
AI News for 5/15/2024-5/16/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (428 channels, and 6173 messages) for you. Estimated reading time saved (at 200wpm): 696 minutes.
As an AI-native IDE, Cursor edits a lot of code, and needs to do it fast, particularly Full-File Edits. They have just announced a result that
"surpasses GPT-4 and GPT-4o performance and pushes the pareto frontier on the accuracy / latency curve. We achieve speeds of >1000 tokens/s (just under 4000 char/s) on our 70b model using a speculative-decoding variant tailored for code-edits, called speculative edits."
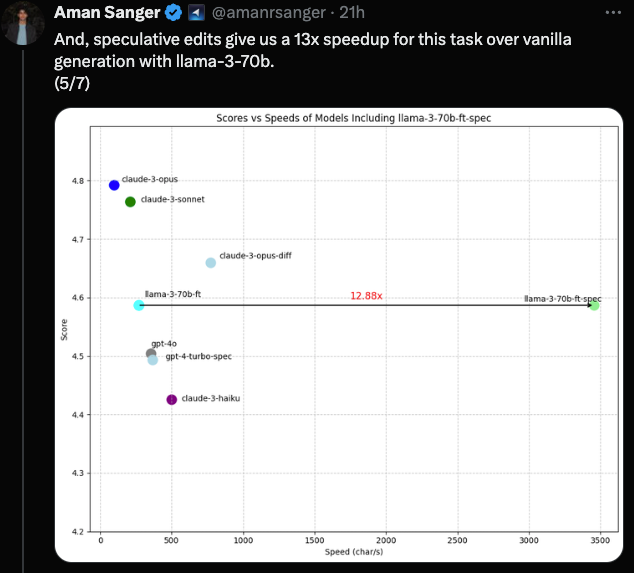
Because the focus is solely on the "fast apply" task, the team used a synthetic data pipeline tuned to do just that:
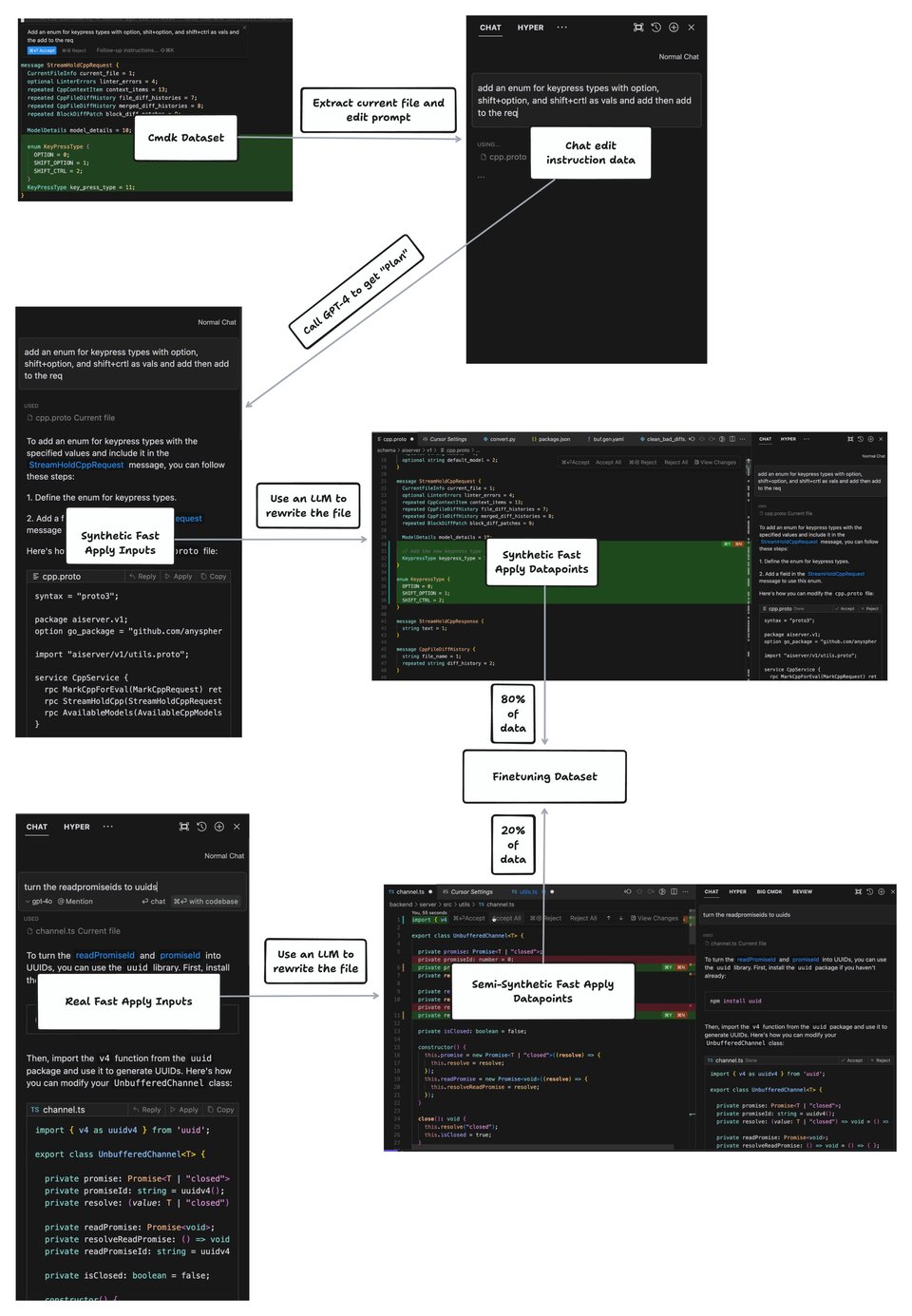
They are a little cagey about the speculative edit alogirthm - this is all they say:
"With code edits, we have a strong prior on the draft tokens at any point in time, so we can speculate on future tokens using a deterministic algorithm rather than a draft model."
If you can figure out how to do it on gpt-4-turbo, there is a free month of Cursor Pro for you.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Perplexity AI Discord
- HuggingFace Discord
- Nous Research AI Discord
- LM Studio Discord
- Modular (Mojo 🔥) Discord
- CUDA MODE Discord
- LlamaIndex Discord
- LAION Discord
- Eleuther Discord
- Interconnects (Nathan Lambert) Discord
- LangChain AI Discord
- OpenRouter (Alex Atallah) Discord
- OpenInterpreter Discord
- Datasette - LLM (@SimonW) Discord
- Latent Space Discord
- OpenAccess AI Collective (axolotl) Discord
- AI Stack Devs (Yoko Li) Discord
- tinygrad (George Hotz) Discord
- MLOps @Chipro Discord
- Cohere Discord
- DiscoResearch Discord
- LLM Perf Enthusiasts AI Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
OpenAI GPT-4o Release
- Multimodal Capabilities: @sama noted GPT-4o's release marks a potential revolution in how we use computers, with audio, vision, and text capabilities in an omni model. @imjaredz added it is 2x faster and 50% cheaper than GPT-4 turbo.
- Coding Performance: Early tests show mixed results for GPT-4o's coding abilities. @erhartford found it makes a lot of mistakes compared to GPT-4 turbo, while @abacaj noted it is very good at code, outperforming Opus.
- Instruction Following and Languages: Some customers rolled back to GPT-4 turbo due to worse instruction following with GPT-4o, especially for JSON, edge cases, and specialized formats, per @imjaredz. However, GPT-4o performs better at non-English languages.
- Multimodal Capabilities: @gdb mentioned GPT-4o has impressive image generation capabilities to explore. @sama clarified the new voice mode hasn't shipped yet, but the text mode is currently in beta.
- Reasoning and Knowledge: @goodside found GPT-4o can explain complex AI methods it hasn't seen before. @mbusigin noted it is familiar with niche AI research.
Anthropic, Google, and AI Developments
- Anthropic's New Features: @alexalbert__ announced streaming, forced tool use, and vision features rolling out to Anthropic devs, enabling fine-grained streaming, tool choice forcing, and foundations for multimodal tool use.
- Google's Imagen Video and Gemini Models: @GoogleDeepMind introduced Imagen Video, which can understand nuanced effects and tone from prompts. @drjwrae shared Gemini 1.5 Flash, a 1M-context small model with fast performance.
- Open-Source Releases and Compute Access: @HuggingFace is distributing $10M of free GPUs via ZeroGPU to the open-source AI community. Models like Llama, BLOOM, Stable Diffusion, DALL-E Mini are available on the platform.
AI Evaluation and Safety Considerations
- Evaluating LLMs: @svpino noted LLMs fail on novel problems outside their training data. @maximelabonne mentioned MMLU benchmarks are reaching saturation for top models. @_philschmid shared MMLU-Pro, a more robust benchmark that drops top model performance by 17-31%.
- Jailbreaking and Adversarial Attacks: @_akhaliq shared SpeechGuard research on jailbreaking vulnerabilities in speech-language models, with high success rates. Proposed countermeasures significantly reduce the attack success.
- Ethical and Societal Implications: @alexandr_wang noted solving AI data challenges is crucial, as breakthroughs are driven by better data in a hard human-expert symbiosis. @ClementDelangue contributed to the AI Policy Forum to mitigate risks and support responsible AI innovation.
AI Startups, Products and Courses
- AI-Powered Search and Agents: @perplexity_ai added advisors to guide search, mobile, and distribution efforts. @cursor_ai trained a 70B model achieving over 1000 tokens/s.
- Educational Initiatives: @svpino shared 300 hours of free ML engineering courses from Google. @HamelHusain announced an AI course with compute credits from @replicate, @modal_labs and @hwchase17.
- Open-Source Libraries: @llama_index added GPT-4o support in LlamaParse for complex document parsing and indexing.
Memes and Humor
- @svpino joked "This is not funny anymore" about GPT-4o claiming training data up to 2023.
- @saranormous posted a meme contrasting the marketing versus reality of AI agent products.
- @jxnlco jested about "alex hormozi making me and my friends rich, I understand coaching now."
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Model Releases and Capabilities
- GPT-4o multimodal capabilities: In /r/singularity, GPT-4o from OpenAI demonstrates impressive real-time audio and video processing while being optimized for fast inference, showing potential for enabling insect-sized intelligent robots.
- Google's advanced vision models: Google's Project Astra memorizes object sequences and Paligemma has a 3D understanding of the world, showcasing advanced vision capabilities.
- MMLU-Pro benchmark released: In an image post, TIGER-Lab released the MMLU-Pro benchmark with 12,000 questions, fixing issues with the original MMLU and providing better model separation.
- Cerebras introduces Sparse Llama: Cerebras introduces Sparse Llama, which is 70% smaller, 3x faster, with full accuracy compared to the original Llama model.
AI Safety and Ethics
- Key AI safety researchers resign from OpenAI: Several key AI safety researchers, including Ilya Sutskever, resign from OpenAI, raising concerns about the company's direction and priorities.
- OpenAI considers allowing AI-generated NSFW content: OpenAI considers allowing AI-generated NSFW content, potentially exploiting lonely people with AI girlfriends, according to some discussions.
- US senators unveil AI policy roadmap: US senators unveil AI policy roadmap and seek government funding boost to address AI governance challenges.
AI Applications and Use Cases
- AI-designed cancer inhibitor announced: Insilico announced an AI-designed cancer inhibitor, demonstrating the potential of AI in drug discovery.
- Neuromorphic vision system for autonomous drones: A fully neuromorphic vision and control system was developed for autonomous drone flight, consuming only 7-12 milliwatts of power when running the network.
- AI-powered search app using local LLMs: An AI-powered search app for websites was created using local LLMs, combining llamaindex, pgvector, and llama3:instruct for document extraction and structured responses.
Technical Discussions and Tutorials
- Comparing Llama 3 quantization methods: In /r/LocalLLaMA, a comparison of Llama 3 quantization methods for GGUF, exl2, and transformers highlighted the performance of GGUF I-Quants and exl2 for higher speed or long context.
- Intuition behind fine-tuning LLMs: Also in /r/LocalLLaMA, a discussion on the intuition behind fine-tuning LLMs sought resources to understand model behavior and optimization beyond the basics.
- Microsoft and Georgia Tech introduce Vidur: Microsoft and Georgia Tech introduced Vidur, an LLM inference simulator to find optimal deployment settings and maximize GPU performance.
Memes and Humor
- AI announcement war meme: A meme about the AI announcement war between Google and OpenAI.
- Feeling the AGI coming meme: A meme about feeling the AGI coming.
AI Discord Recap
A summary of Summaries of Summaries
- GPT-4o Generates Buzz and Criticism: Across multiple Discords, GPT-4o was a hot topic, with users on OpenAI and Perplexity AI praising its speed and multimodal capabilities compared to GPT-4. However, some on OpenAI and LM Studio noted performance issues, generic outputs, and missing features. Discussions on Reddit and the OpenAI FAQ provided more context.
- Quantization and Optimization Techniques Advance: In the CUDA MODE and Latent Space Discords, members explored techniques like Bitnet 1.58 for quantization, the CORDIC algorithm for faster trigonometric calculations, and Google's InfiniAttention for efficient transformer memory. The Torch AO repository was suggested for centralizing bitnet implementations.
- New Benchmarks, Datasets and Models Unveiled: Across research-focused Discords, new resources were announced, including the challenging NIAN benchmark, the VidProM video prompt dataset, Google's Imagen 3 model, and the Nordic language Viking 7B model. Nous Research's Hermes 2 Θ model also generated interest.
- Mojo and CUDA Advancements Spark Optimism: The Modular and CUDA MODE Discords buzzed with excitement over Mojo's portability across GPUs and discussions on improving CUDA stream handling in projects like llm.c. Members also explored using NVMe to GPU DMA for faster data transfer.
- Concerns over AI Transparency and Reliability: Across Discords like Datasette and Interconnects, members expressed frustration over the lack of acknowledgment of LLM unreliability at events like Google I/O. Suggestions were made for a "Sober AI" showcase of practical applications. Changes to performance metrics for models like GPT-4o also raised questions about transparency.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- GPT4o Generates Buzz Among Engineers: Discord members exchanged brisk evaluations of GPT4o, noting its "Crazy fast" response times, but also reported a lack of image generation capability. The discussion was highlighted, including a link to a Reddit conversation.
- Finetuning Frenzy: Base or Instruct?: The advice for finetuning larger models, "If you have a large dataset always go base," spurred discussion and pointed users towards educational content, such as a Medium article.
- Dataset Dilemmas and GGUF Grief: The community dove into dataset generation errors, suggesting working with JSON in pandas for conversion, while issues with converting the ShareGPT dataset and with GGUF files for llama.cpp were tackled, with downgrading PEFT offered as a remedy. GitHub issue tracking offered additional insights.
- Unsloth AI Picks Up in Popularity: A user mentioned Unsloth AI being featured in the tutorial on the Replete-AI code_bagel dataset, signaling its rising popularity for fine-tuning Llama models.
- Summarization Skills Score Smiles: An AI-summarization feature received praise within the community, for budgeting down to the brass tacks of dialogues without direct relation to AI News, displaying the model's crisp encapsulation of verbose discussions.
Stability.ai (Stable Diffusion) Discord
SD3 Release: Will We Ever See It?: Despite skepticism surrounding the release and quality of Stability AI's SD3, members keep hope alive with rumors that SD3 might be held back to boost sales, but there is no firm release date or pricing information provided.
GPU Wars: 4060 TI vs 4070 TI Smackdown: The 4060 TI 16GB was pitted against the 4070 TI 12GB, with the former being recommended for ComfyUI usage while the latter was touted as better for gaming performance, though specifics were not detailed.
API Alternatives High in Demand: Members are actively seeking and debating APIs, with Forge being equated to A1111's UI for model training and asset design, and Invoke also being part of the discussion.
Workhorse GPUs Get a Benchmark: An informative benchmark site was circulated for evaluating GPU performance; it offers data on models such as 1.5 and XL Models and filters for specific hardware including Intel Arc a770.
The Divide of Dollars and Sense: Intense dialogues opened up about economic inequality, with some members emphasizing the moral and well-being costs of chasing wealth, though these were general philosophical conversations rather than specific AI-focused discourse.
OpenAI Discord
- GPT-4o's Rough Start: Discussions highlighted performance issues with GPT-4o, where users reported bugs such as slower response times, repeated topics, and lack of expected features. Contrastingly, GPT-4o was praised for better real-world context understanding when compared to GPT-4 in some prompt engineering cases.
- Navigating GPT-4o's Access and Features: Users expressed confusion around the access and rollout phases of GPT-4o, with clarifications provided that it's being prioritized for paid accounts—with more details in OpenAI's FAQ. Concerns about ChatGPT Plus subscription benefits were highlighted, given usage limits that may affect heavy use scenarios like software development.
- Prompt Engineering Unlocks Potentials and Pitfalls: Prompt engineering strategies are being refined, exploring how language nuances influence AI performance. Meanwhile, there's a push to understand the correct token limits and functionalities of GPT versions, with suggestions to craft character-based prompts for richer interactions.
- AI's Role in Future Work and Emotional Design Debated: The guild contemplated the impact of AI on job markets, stirring discussions between the potential for new job creation versus the threat of obsolescence. Additionally, the appropriate level of AI emotional responsiveness was debated, questioning if AI should lean towards human-like interactions or maintain professional neutrality.
- Community Powers AI Voice Assistant Advancements: An easily deployable Plug & Play AI Voice Assistant was introduced, with user feedback requested to refine the product further. It's claimed to be operational within 10 minutes, emphasizing user-friendly implementation and community-driven improvements.
Perplexity AI Discord
- GPT-4o Delivers Performance: On Perplexity, GPT-4o is turning heads with faster and more efficient results than GPT-4 Turbo, although some users encounter rollout snags.
- Perplexity Triumphs in Research: Users have given a nod to Perplexity's accurate and up-to-date sourcing and search functions compared to its rivals, earning it the go-to status for detailed research.
- DALL-E's Text Rendering Puzzle: Users report challenges with text appearing as gibberish in images generated by DALL-E; recommended solutions include revising prompt structures to prioritize text instructions.
- Perplexity Pro's iOS Voice Mode Gains Fans: The voice functionality on Perplexity Pro's iOS app garners praise for its fluid and natural interaction, sparking anticipation for an Android equivalent.
- Perplexity Pro Payment Glitches Reported: Subscribers facing payment issues with Perplexity Pro are directed to reach out to support@perplexity.ai for help.
- Perplexity's Information Highway: Links to Perplexity AI highlighted user interests ranging from finetuning search results, the lowdown on Aztec Stadium, a Google recap, the buzz in culinary circles, and Anthropic's team expansion.
- An API A-List for Engineers: Within the Perplexity AI community, concerns have surfaced covering topics such as beta access requests for citation features in the API, the ability of llama-3-sonar-large-32k-online model to search the web, calls for constant model aliases, unpredictable API latency, and challenges with autocorrected prompts skewing results.
HuggingFace Discord
- Terminus Leads the Dance: Terminus models have been updated to offer improved functionalities, and their latest collection is available on HuggingFace. The Velocity v2.1 checkpoint has hit 61k downloads and provides enhanced performance with negative prompts.
- PaliGemma Grabs the Spotlight: Conversations revolved around the PaliGemma models, from issues with generated code to the unveiling of a powerful Vision Language Model that marries visual and linguistic tasks effectively. DeepMind's Veo, a video generation model, also marched into view with its promise of 1080p cinematic-style videos, integrating soon with YouTube Shorts.
- Model Mysteries and Epsilon Greedy Investigations: Curiosity-driven reinforcement learning (RL) received attention, with discussions on how epsilon greedy policies and novel curiosity mechanisms can foster exploration. In the NLP field, challenges emerged with outdated coding knowledge in models; members stressed the importance of continuous retraining to maintain relevance.
- dstack as the On-Prem GPU Hero: The tool dstack was highly praised for simplifying the management of on-prem GPU clusters with CLI tools. Elsewhere, AI's role in PowerPoint slide content refinements was debated, with suggestions to use RAG or LLM models for learning and adapting from past presentations.
- Diverse Discussions Keep Engineers Engaged: Various technical threads illuminated the guild's landscape—a call for MIT license expertise for commercial purposes, using UNet models in computer vision, and OpenAI's Ilya Sutskever's recent industry update gained attention.
In essence, community dialogues peaked around novel AI tools and model fine-tuning within a vibrant tapestry of technological advancements and practical implementations.
Nous Research AI Discord
Streaming the Brain for Better AI: Engineers suggest that AI could adopt a streaming-like method akin to human thought processes, referencing the Infini-attention paper as a potential framework to improve LLM's handling of long context without overwhelming their finite working memory.
Beneath the Needles, a Tougher Benchmark: The Needle in a Needlestack (NIAN) benchmark has been introduced as a more challenging test for evaluating LLMs, posing a hurdle even for robust models like GPT-4-turbo; further info available on NIAN's website and GitHub.
Unveiling Nordic NLP Treasure, Viking 7B: Viking 7B emerges as the first open-source multilingual LLM for Nordic languages, while SUPRA is presented as a cost-effective approach to retrofitting large transformers by enhancing them into Recurrent Neural Networks to improve scaling.
Hermes 2 Ω: Merging LLMs for Superior Results: Nous Research heralds the release of Hermes 2 Ω, a model merger of Hermes 2 Pro and Llama-3 Instruct, refined further, showing promising results on benchmarks and accessible on HuggingFace.
Multimodal Meld and Finetuning: Meta's release of ImageBind raises the bar with a new AI model capable of joint embedding across various modalities, while discussions enter on the potential of finetuning existing models like PaliGemma for enhanced interactivity.
LM Studio Discord
- Soviet-Era Crypto Machine Inspires Perfumed Hallucination: A creative hallucination about a Soviet encryption machine called Fialka that supposedly used purple perfume was met with amusement in the general chat, as it underscored how LM models can sometimes whimsically deviate from reality.
- APUs Struggle Under Model Weight: While discussing the role of APUs in model performance, members concluded that llama.cpp does not leverage APUs any differently than CPUs during inference, which could affect decisions on hardware purchases for running large models.
- Iglu Ice-Cold Model Building: Frustration was aired over building imatrix for hefty models like llama3 70b on CPU, with users reporting several-hour-long build times and thermal throttling as notable challenges, demonstrating the practical constraints of current infrastructure.
- Hardware Heavyweights Flex Their Muscles: A high-end build comprising a 32 core threadripper, 512GB RAM, and an RTX6000 was shared, demonstrating the power of top-tier configurations to achieve a 0.10s time to first model token and a 102.45 token/sec generation speed.
- Software Snags and AVX Anomalies: Discussions surfaced around LM Studio’s compatibility and UI issues, with one user flagging that AVX1 systems are unable to run LM Studio (which requires AVX2), while others called for UI refinements to enhance user experience during complex server management tasks.
Modular (Mojo 🔥) Discord
- Mojo Rises in AI Development: Engineers shared resources for Mojo SDK learning, with links to the Mojo manual and the Mandelbrot tutorial. Mojo's advantages were highlighted, specifically its GPU flexibility across vendors and its potential for advancing hardware competition.
- Open Source Status Sparks Debate: The community debated Mojo's partial open-source nature, noting that its standard library is open, but the compiler and Max toolchain currently aren't. Excitement was shown for the compiler potentially going open source, while Max is unlikely to do so.
- Syntactical Snafus and Conditional Methods: Discussions revealed syntax inconsistencies in Mojo's documentation and issues with the
aliasdata structure iteration. Members praised the syntax for conditional methods, a new feature, although issues in locating changelog information about it were mentioned.
- Community Engages with Compiler and Contributions: The latest Mojo compiler build (
2024.5.1515) prompted discussions about non-deterministic self-test failures on macOS. Concerns about "cookie licking" in the repository were raised, suggesting smaller PRs as a solution for faster community contributions.
- Modular Spotlights Joe Pamer and Updates: Modular tweeted about their latest updates (no specific content referenced) and showcased Joe Pamer, the Engineering Lead for Mojo, through a blog post. No specifics on what was discussed in the tweets or the contents of the blog post were provided.
CUDA MODE Discord
Tensor Tug of War: Engineers discussed the use of torch.tensor Accessors versus directly passing tensor.data_ptr to kernels in CUDA, with some concerned about the potential unsigned char pointers and lack of clear documentation. The conversation pointed to PyTorch's CppDocs for using Accessors and the implications on tensor efficiency.
Solving Vexing CUDA Puzzles: Members tackled the dot product problem from the CUDA puzzle repo, noting the pitfalls of floating-point overflow with naive approaches, while reduction-based kernels maintain fp32 precision. A user's experiences and code snippets, including a floating-point overflow error, were shared on GitHub Gist.
Battle Against Non-Contiguous Tensors: Discussions on torch.compile issues and custom ops in PyTorch highlighted challenges with non-contiguous tensor strides and memory cache constraints. Engineers exchanged ideas on using tags in custom op definitions, as suggested by [torch library](https://pytorch.org/docs/main/library.html) and advocated for plans to reduce compilation times for torch.compile, pointing to conversations on the PyTorch forum.
Exploring Bitnet's Quantization Quest: Enthusiasm bubbled up for Bitnet 1.58, with calls for organizing it on platforms like GitHub and digging into training-aware quantization for linear layers and 2-bit kernels. The discussions recommended centralizing efforts in the Torch AO repository, and highlighted HQQ and BitBLAS as existing solutions for bitpacking and 2-bit GPU kernels.
Footnotes on Kernel Kinks and Gadgets: A user posted a link to an article about instant apply techniques without further context, while another shared wisdom with the GPU Programming Guide, and yet another user ran into a CUDA-related ONNXRuntimeError.
Torching Into Precision and Performance: The discussions have converged on a collective effort to recalibrate CUDA streams, with suggestions on wiping the slate clean and starting over, resulting in significant discourse and corresponding GitHub Pull Requests. The elusive dream of direct NVMe to GPU DMA transfer was also mentioned, with a nod to the ssd-gpu-dma repository.
LlamaIndex Discord
Vertex AI Welcomes LlamaIndex: LlamaIndex teamed up with Vertex AI for a new RAG API, aiming to enhance users' ability to implement retrieval-augmented generation models on Vertex’s cloud platform. The community can explore the announcement via LlamaIndex's Twitter post.
GPT-4o Quartz gets Friendly with LlamaIndex: The update to LlamaIndex's create-llama now incorporates GPT-4o, providing an intuitive way to create chatbots using a simple Q&A format over user data. For additional information, there's a comprehensive breakdown on LlamaIndex’s Twitter.
LlamaParse Merges with Quivr: LlamaIndex has forged a collaboration with Quivr, resulting in LlamaParse—a tool designed to parse multifaceted document formats (.pdf, .pptx, .md) by leveraging advanced AI. A link to Twitter provides more insights on this development.
UI Tweaks Spark Joy in LlamaParse: The LlamaIndex team unveiled major enhancements to the LlamaParse UI, promising a broadened suite of functionalities for users. The GUI improvements can be seen in the latest Twitter update.
Empower Your SQL with the Right Model: The #general channel saw concerns on choosing the right embedding models for SQL tables, with users suggesting a glance at models on the MTEB Leaderboard. However, a snag was noticed since these models are generally text-centric and may not cater specifically to SQL data.
Chat through Docs with RAG: In the #ai-discussion channel, a user needed assistance for integrating Cohere AI's retrieval-augmented generation (RAG) capabilities within Llama, aspiring to create a "Chat with your docs" application. They sought community advice on methods and resources for an effective implementation.
LAION Discord
AI Powers Up the Grid: There's a buzz about the energy demands of AI, with a highlight on how a fleet of 5000 H100 GPUs can idle at a massive 375kW. This speaks volumes about the increasing energy footprint of AI technologies.
Stable Diffusion Goes Native on Mac: A project named DiffusionKit, in partnership with Stability AI, has successfully brought Stable Diffusion 3 on-device for Mac users, signaling advances in accessibility to powerful AI tools. The news arrived via a tweet, raising expectations for the open-source release.
The Open Source Compromise: A heated debate simmered around the choice between the innovative spirit of open-source ventures and the financial lure of proprietary companies, intensified by concerns over restrictive non-compete clauses, becoming more focused in light of the FTC's recent rule banning such agreements (FTC announcement).
GPT-4o Leads the Multimodal Revolution: Discussion pointed towards GPT-4o's prowess in multimodal functions, including image generation and editing, suggesting a growing consensus that multimodal models stand at the forefront of AI development.
Breakthroughs in Video Dataset and Sampling Approaches: From unveiling VidProM, a substantial dataset to accelerate text-to-video research, found in an arXiv paper, to a novel approach in overcoming the limitations of bilinear sampling for neural networks, these discussions underscored the relentless pursuit of innovation. Meanwhile, Google's Imagen 3 is making waves as a leading image generation model, with a role in creating synthetic data sets discussed eagerly by community members (Imagen 3 information).
Eleuther Discord
- Epinets Pose a Tricky Balance: Epinet usage was scrutinized for their tuning complexities and potential as a perturbative bias. A notable quote emphasized the notion: "The epinet is supposed to be kept small though, so I assume the residual just acts as an inductive bias..."
- Transformer Tidbits and Model Insights: Technical talks revolved around transformer backpropagation techniques and a shared DCFormer GitHub repository, with some examining the execution of transformer models concerning path composition and associativity challenges backed by recent research.
- From Scaling Laws to AGI Aspirations: There were aspirations woven into discussions around meta-learning in symbolic space and AGI potential, alongside practical takeaways from GPT-4 post-training Elo score improvements.
- GPT-NeoX Conversion Confounded by Bugs: The
convert_neox_to_hf.pyscript faced bugs when handling different Pipeline Parallelism configurations, with a fix proposed by a contributor. Incompatibilities involvingrmsnormled to advice for trying a different configuration file suitable for Huggingface.
- Refining Model Evaluation and Conversion: In the realm of competition and model comparison, the use of
--log_sampleswas shared to facilitate the extraction of multiple-choice answer metrics, which is critical for AI models' performance analysis.
Interconnects (Nathan Lambert) Discord
Neural Networks Agree on Reality: Members engaged in discussions suggesting that neural networks, despite varying objectives and data, are displaying convergence towards a universal statistical model of reality within their representation spaces. Phillip Isola's recent insights support this, as shared through his project site, academic paper, and Twitter thread, showing how large language models and vision models begin sharing representations as they scale.
OpenAI Tokenization Enigma: The community pondered if OpenAI's tokenizer could be "fake," speculating that different modalities would likely necessitate distinct tokenizers. Despite skepticism, some members advocated for giving the benefit of the doubt, suggesting detailed methodologies may exist even within seemingly chaotic projects.
Anthropic Swings to Product Focus: Transitioning to a product-based approach, Anthropic embraces the necessity for marketable deliverables to enhance data refinement, amidst discussions of broader challenges facing AI organizations such as OpenAI and Anthropic, including the sustainability of their valuations and their dependence on external infrastructures.
AGI Timing Tug-of-War: Dialogues on the plausibility of approaching AGI, prompted by a Dwarkesh interview, revealed a stark divide in the community, ranging from optimism to criticism on the practicality and impact of AGI timeline predictions.
Transparency in AI Model Metrics Called Into Question: The community flagged the unexplained drop in GPT-4o’s ELO ratings and reduction in LMsys evaluation detail, sparking discussions on the need for clear communication and consistent update protocols. Resources and perspectives on this issue were exchanged through various tweets and video content.
LangChain AI Discord
- Get Streamlined Token Output with LangChain: LangChain's
.astream_eventsAPI provides the means for custom streaming with individual token outputs that was expected from.streamwithAgentExecutor. The detailed streaming documentation sheds light on the process.
- Solve Jsonloader Compatibility Woes: A user highlighted a fix for Jsonloader's inability to install jq schema for JSON parsing on Windows 11; details can be found in the issue tracker for Langchain, Issue #21658.
- Engineer Crafty Strategies for Bot Memory: Strategies for endowing chatbots with memory to maintain context between conversations were discussed, including tracking chat history and introducing memory variables within prompts.
- Cut Through Service Interruptions & Rate Limits: Members conversed about disruptions caused by "rate exceeded" errors and server inactivity leading to workflow inefficiencies; questions about deploying revisions and examining patterns related to server inactivity were also raised (no URLs provided).
- Insightful Tutorials & Crafty Projects Shared: An instructional video was shared on creating a universal web scraper agent, and a user showcased their integration of py4j for handling crypto transactions in Langserve backends, as well as their implementation of an innovative real estate AI tool combining LLMs, RAG, and interactive UI components (LinkedIn: Abhigael Carranza, YouTube: Real Estate AI Assistant demo).
OpenRouter (Alex Atallah) Discord
- Hindi Chatbot Boost: The Hindi 8B Chatbot Model named "pranavajay/hindi-8b" has been released with 10.2B parameters, showing promise for chatbot and language translation applications. Its release adds a new layer of capability for Hindi NLP tasks.
- Mobile Chatbots Get Friendlier: ChatterUI, a minimalistic UI for chatbots on Android, has been launched, designed specifically to be character-focused and compatible with OpenRouter backends. Developers can explore and contribute to ChatterUI through its GitHub repository.
- Invisibility Cloaks Your MacOS: The new MacOS Copilot titled Invisibility integrates GPT4o, Gemini 1.5 Pro, and Claude-3 Opus, featuring a video sidekick and plans for voice and memory enhancements. The community can expect an iOS version soon, as highlighted in its announcement.
- Lepton Lends a Hand to WizardLM-2: Suggestions were made to switch to Lepton for the WizardLM-2 8x22B Nitro to utilize OpenRouter's Text Completion API, enhancing performance due to Lepton's capabilities despite it being removed from some lists over issues.
- Efficient Context Management Unpacked: Google's InfiniAttention was cited for its ability to handle large token contexts in Transformers, prompting discussions on memory and performance efficiency in LLMs, backed by a relevant research paper.
OpenInterpreter Discord
- Hacking Pays Off: An individual managed to bypass the gatekeeper dialog of OpenAI's desktop app, resulting in an invitation to a private Discord channel to participate in its development.
- Realizing GPT-4o's Limitations: Users report that while attempting to utilize GPT-4o's image recognition feature within OpenInterpreter (OI), it fails post-screenshot phase, highlighting a gap in functionality.
- Performance Dilemma: Although dolphin-mixtral:8x22b processes at a sluggish rate of 3-4 tokens per second, it's been identified as effectively performing, with the faster CodeGemma:Instruct serving as a balanced alternative.
- OI Feature Enrichments & Debugging Avenues: Suggestions were made for more informative LED feedback on hardware devices, and a new TestFlight app (TestFlight link) for iOS debugging was introduced, assisting in resolving audio output issues.
- Setup Struggles and Solutions: Within O1's framework, members shared technical challenges involving the grok server configuration and model compatibility, with proposed fixes including server setups and usage of tools like Poetry for Linux installations. Links to resources like setup guides and GitHub repositories (01/software at main) were shared for community support.
Datasette - LLM (@SimonW) Discord
Google I/O Overlooks LLM Reliability: Engineers in the guild highlighted the absence of discussion on LLM reliability issues at Google I/O, expressing concern for the lack of acknowledgment on the matter by key presenters.
"Sober" Take on AI: A concept for a "Sober AI" showcase was proposed to display practical, reliable AI without the hype, aiming to set realistic expectations for large language model applications.
Transforming AI: The group discussed the potential of rebranding AI as "transformative" instead of "generative" to better reflect its capabilities in altering and processing information, suggesting that this could lead to a more accurate and productive discourse.
Prompt Caching For Efficiency: Technical discussion touched on using Gemini's prompt caching to lower the cost of token usage by maintaining prompts in GPU memory, albeit with an operational cost of $4.50 per million tokens per hour.
Model Switching And Desktop Client Concerns: The technical community raised concerns about switching between LLMs mid-conversation and the potential data integrity issues it might cause. Additionally, worries were voiced that SimonW's Mac desktop solution had been abandoned, prompting discussions on alternatives for a seamless experience.
Latent Space Discord
- OpenAI Snags Google Whiz for Search Showdown: OpenAI's strategic recruitment of Shivakumar Venkataraman, a former Google heavyweight, accelerates their ambition to rival Google with their own search engine.
- Model Merging Mastery: Pioneering work by Nous Research in model merging continues, with conversations highlighting "post-training" as an umbrella term for techniques including RLHF (Reinforcement Learning from Human Feedback), fine-tuning, and quantization, showing Nous' research direction.
- Watching and Learning from Dwarkesh Patel's Dialogues: Dwarkesh Patel’s latest podcast episode received mixed reactions, from praise for big-name guests to criticism for a perceived lack of interviewer engagement, with the episode being termed "mid" but worthy for its guest list.
- The Rich Text Translation Conundrum: The community delved into complexities of translating rich text, suggesting HTML as an intermediary to ensure span semantics are not lost across languages.
- Hugging Face's Generous GPU Gesture: In an effort to democratize AI development, Hugging Face has committed $10 million in GPUs to support smaller developers, academia, and startups, aiming to decentralize AI innovation.
- Fresh Podcast Episode Alert: Swyxio dropped a link to a new podcast episode, adding to the team's continuous consumption and discussion of industry insights.
OpenAccess AI Collective (axolotl) Discord
Falcon Versus LLaMA in Licensing Showdown: Falcon 11B and LLaMA 3's licenses sparked debate, with concerns raised about Falcon's Acceptable Use Policy updates potentially being unenforceable. Original prompt fidelity is key when applying LORA to models like LLaMA 3.
Docker Dilemmas and Data Discussions: A Docker setup for 8xH100 PCIe was successful but the SXM variant status was unclear. Meanwhile, the STEM MMLU dataset has been expanded, creating a more detailed benchmark for STEM-related AI evaluation.
Tiny But Mighty: TinyLlama Issues and Fixes: TinyLlama presented training troubles, necessitating manual launches with accelerate. Members are seeking fixes for this discrepancy, which seems to be a current challenge.
Cross-Format Conversations: The Alpaca format for training chatbots faced criticism for its inconsistent follow-up questions, driving the preference for maintaining consistent chat formats during AI training.
Hunyuan-DiT Throws Its Hat in the Ring: Attention was drawn to the Hunyuan-DiT model, a new multi-resolution diffusion transformer tailored for Chinese language processing and detailed in their arXiv paper.
Using the Right Tokens: Queries related to LLaMA 3 and ChatML tokenization were resolved with confirmation that ChatML's ShareGPT format is compatible without requiring additional special tokens.
AI Stack Devs (Yoko Li) Discord
- AI Town Explores New Frontiers: Discussions on AI Town highlighted the interest in an API for agent control, notably without support for agent-specific LLMs. Members are keen on exploring various API levels, including those compatible with OpenAI, and a mention of a potential Discord iframe with multiplayer capabilities was notably enthusiastic, citing a ready-to-use starter template for building Discord activities.
- NPC Tuning for Enhanced Performance: In AI Town development, suggestions to improve performance by reducing NPC activities were made, focusing on cooldown constants that can affect NPC behavior. The upcoming launch of an AI Reality TV Platform, which is open to community-contributed custom maps, was announced.
- Community Contributions and Feature Hype: The community's willingness to contribute to projects like the Discord iframe for AI Town reflects a proactive approach, hinting at a collaborative effort to introduce new features like multiplayer activities.
- Sequoia's PMF Framework Sparks Interest: An article on Sequoia Capital's PMF Framework was shared, detailing three types of product-market fit to assist founders with market positioning, which could provide valuable insights for product-focused AI engineers.
- New Member Gets a Helping Hand: A new member received help from the community with avatar customization, enhancing their personal experience in the virtual space and fostering a helpful community spirit.
tinygrad (George Hotz) Discord
CORDIC Conquers Complexity: Engineers discussed the advantages of the CORDIC algorithm over Taylor series for calculating trigonometric functions, addressing simplicity and speed benefits. A Python implementation and approaches for handling large argument values were deliberated, expressing concerns over precision and efficacy in machine learning applications.
Taming Trigonometry: The conversation shifted towards efficient ways to reduce arguments in trigonometric functions, ensuring precise results in an acceptable range (-π to π or -π/2 to π/2). Potential optimization paths for GPUs and fallbacks using Taylor approximations were considered for tackling large trigonometric values.
Efficient Visualization Utilized for Shape Indexing: A visualization tool to aid in understanding shape expressions in tensor reshaping operations was introduced, addressing the challenge of complex mappings. This tool is public and can be found here.
Exploring TACO for Code Generation: The community evaluated TACO, a code generator for tensor algebra, as an efficient resource for tensor computations. An exploration into using custom CUDA kernels for large tensor reductions in Tinygrad was also suggested for direct result accumulation.
Seeking Clarity on Tinygrad Operations: Clarification was sought regarding uops in a compute graph, particularly the DEFINE_GLOBAL operation and the output buffer tag, emphasizing a need for clearer documentation in low-level operations. Additionally, UseAdrenaline was recommended as a learning aid for understanding various repositories, including Tinygrad.
MLOps @Chipro Discord
Catch-Up with Members at Data AI Summit: Engineer colleagues are coordinating an informal meet-up during the Data AI Summit, scheduled for June 6-16 in the Bay Area. The suggestion has sparked mutual interest among members for an in-person connection.
Put a Pin in Monthly Casuals: The regularly scheduled casual event organized by Chip is on hold for the next few months, leaving participants to wonder about when the next social mixer might occur.
Interactive Learning Opportunity at Snowflake Dev Day: Members of the Discord have received an invitation to visit a booth at Snowflake Dev Day on June 6, promising potential insights into Snowflake's integration with data science workflows.
NVIDIA Ups the Ante with Developer Contest: There's excitement about NVIDIA & LangChain's Generative AI Agents Developer Contest, which includes the NVIDIA® GeForce RTX™ 4090 GPU among its rewards, even if geo-restrictions have dampened the spirits for some.
Exploring the Evolution of AI Hardware: An in-depth article was shared, dissecting the historical development of machine learning microprocessors and projecting future trends, noting the transformative impact of transformer-based models with a nod to Nvidia's soaring valuation. It forecasts exciting advances for NVMe drives and Tenstorrent technology, but posits a cooling period for GPUs in the mid-term future.
Cohere Discord
- Cohere Reranker Functional, Desires Highlight Reel: Users achieved impressive results with the rerank-multilingual-v3.0 model from Cohere but would appreciate a feature similar to ColBERT that can highlight key words relevant to the retrieval task.
- Connectors Explained, but PHP Client Queries Remain: Discourse clarified that Cohere connectors are meant to integrate with data sources, yet the community is seeking advice for a solid PHP client for Cohere, with one untested option being cohere-php on GitHub.
- Toolkit Wizardry and Reranking Wonders Questioned: Inquiry about the Cohere application toolkit underscored interest in its scalability features for production usage while the community expressed curiosity about why Cohere's reranking model outperforms other open-source alternatives.
DiscoResearch Discord
Ilya Sutskever Bids Farewell to OpenAI: The announcement of Ilya Sutskever's departure from OpenAI ignited debate over the organization's appeal to alignment researchers, stirring concerns about its future research direction.
GPT-4-turbo Meets its Match with NIAN: The Needle in a Needlestack (NIAN) benchmark presents a new level of challenge for context-sensitive responses in large language models, with reports that "even GPT-4-turbo struggles with this benchmark." Explore the code and the website for details.
LLM Perf Enthusiasts AI Discord
- AI Studio Ambush on the Hunt for Senior Talent: Ambush is looking for a remote senior fullstack web developer to craft intuitive UX/UI for DeFi products, with an emphasis of 70% frontend and 30% backend duties. Interested AI engineers should explore the Ambush job listing, which offers a $5k referral bonus for successful hires.
Mozilla AI Discord
- Hyperlink Hiccup in Llamafile: Engineers report Markdown hyperlinks not rendering into HTML in Mozilla's llamafile project, with suggestions made to open a GitHub issue to resolve this code snag.
- Timeout Troubles Plague Private Assistant: AI Engineers faced a httpx.ReadTimeout error, while running Mozilla's private search assistant, that terminated the generation of embeddings at 9%, sparking a discussion on extending the timeout settings.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (1022 messages🔥🔥🔥):
- Rapid Fire Opinions on GPT4o: Members shared quickfire impressions about the performance of GPT4o, with comments like "Crazy fast" and the downside of not being capable of image generation. Discussion link.
- Insight on Instruction vs. Base Models for Finetuning: Theyruinedelise advised, "If you have a large dataset always go base. If small dataset, go instruct," with sources provided for further reading on Medium.
- Unsloth Supports Qwen and Continuous Improvements: Theyruinedelise announced support for Qwen and shared updated Colab notebooks, recommending an installation update: "!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git".
- Datasets for AI Training: lh0x00 released new bilingual datasets for English-Vietnamese translation on Huggingface, facilitating ease of use with tools like unsloth, transformers, and alignment-handbook.
- Financial Report Extraction Study: Preemware shared a study comparing RAG and finetuning methods, showing substantial performance drops with RAG for models like Mistral and Llama 3, detailed on Parsee.ai.
- WizardLM (WizardLM): no description found
- mixedbread-ai (mixedbread ai): no description found
- Skorcht/schizogptdatasetclean · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- unsloth (Unsloth AI): no description found
- lamhieu/translate_tinystories_dialogue_envi · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- AI Unplugged 10: KAN, xLSTM, OpenAI GPT4o and Google I/O updates, Alpha Fold 3, Fishing for MagiKarp: Insights over Information
- Tweet from VCK5000 Versal Development Card: The AMD VCK5000 Versal development card is built on the AMD 7nm Versal™ adaptive SoC architecture and is designed for (AI) Engine development with Vitis end-to-end flow and AI Inference development wi...
- cognitivecomputations/Dolphin-2.9 · Datasets at Hugging Face: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- lamhieu/alpaca_gpt4_dialogue_vi · Datasets at Hugging Face: no description found
- lamhieu/alpaca_gpt4_dialogue_en · Datasets at Hugging Face: no description found
- finRAG Dataset: Deep Dive into Financial Report Analysis with LLMs: Discover the finRAG Dataset and Study at Parsee.ai. Dive into our analysis of language models in financial report extraction and gain unique insights into AI-driven data interpretation.
- Tweet from Should AI Be Open?: I. H.G. Wells’ 1914 sci-fi book The World Set Free did a pretty good job predicting nuclear weapons:They did not see it until the atomic bombs burst in their fumbling hands…before the l…
Unsloth AI (Daniel Han) ▷ #random (27 messages🔥):
- Unsloth appears in fine-tuning tutorial: A user excitedly mentioned that the Replete-AI code_bagel dataset uses Unsloth in their tutorial for fine-tuning a Llama. "I am so glad Unsloth is getting so popular."
- High losses post-tokenizer fix in Llama3: A user reported that after fixing tokenizer issues, their Llama3 model showed losses double what they were before. Further experimentation without the EOS_TOKEN did not resolve the issue, leading to continued high training losses.
- RAM issues with ShareGPT dataset conversion: A user shared that their 64GB of RAM was insufficient for converting the ShareGPT dataset, while another user, likely Rombodawg, mentioned that the code should normally require about 10GB of RAM. They discussed this over DMs to sort out the code issues.
Link mentioned: Replete-AI/code_bagel · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (448 messages🔥🔥🔥):
- Dataset Issues with JSON Format: Multiple users, including mapler and noob_master169, troubleshoot a dataset generation error. The suggestion to load the JSON in pandas and then convert to a dataset was offered as a fix.
- Dataset Generation Troubleshooting: theyruinedelise confirmed that the issue is likely a dataset format problem. They also discussed potential solutions and confirmed the approach was tackling the root problem.
- GGUF Conversion Errors: Multiple users, like leoandlibe and jiaryoo, discuss problems with llama.cpp conversions and GGUF files. theyruinedelise and others identified PEFT updates as a potential cause and recommended downgrading.
- Using GPT-3 for Custom Queries: just_iced faced issues when querying a driver’s manual using Llama 3. After troubleshooting with other members, they resolved their issue by transitioning to using Ollama instead.
- Model Compatibility and Issues: Questions about compatibility and installation of models like Unsloth, Llama 3, and issues regarding context window limitations were discussed. starsupernova gave specific steps to resolve the issues, such as changing installation instructions in Colab.
- Google Colab: no description found
- unsloth/mistral-7b-instruct-v0.2 · Hugging Face: no description found
- In-depth guide to fine-tuning LLMs with LoRA and QLoRA: In this blog we provide detailed explanation of how QLoRA works and how you can use it in hugging face to finetune your models.
- Skorcht/orthonogilizereformatted at main: no description found
- Tweet from Nicolas Mejia Petit (@mejia_petit): @unslothai running unsloth in windows to train models 2x faster than regular hf+fa2 and with 2x less memory letting me do a batch size of 10 with a sequence length of 2048 on a single 3090. Need a tut...
- Blade Runner GIF - Blade Runner Blade Runner - Discover & Share GIFs: Click to view the GIF
- Skorcht/syntheticdata · Datasets at Hugging Face: no description found
- RuntimeError: Unsloth: llama.cpp GGUF seems to be too buggy to install. · Issue #479 · unslothai/unsloth: prerequisites %%capture # Installs Unsloth, Xformers (Flash Attention) and all other packages! !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install -...
- unilm/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf at master · microsoft/unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities - microsoft/unilm
- Skorcht/thebigonecursed · Datasets at Hugging Face: no description found
- Welcome to PyPDF2 — PyPDF2 documentation: no description found
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- Mechanistic Interpretability — Neel Nanda: Blog posts about Mechanistic Interpretability Research
- KeyError: 'I8' when trying to convert finetuned 8bit model to GGUF · Issue #4199 · ggerganov/llama.cpp: Prerequisites Hi there, I am finetuning the model https://huggingface.co/jphme/em_german_7b_v01 using own data (I just replaced the questions and answers by dots to keep it short and simple). The m...
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- GPU Support (NVIDIA CUDA & AMD ROCm) — SingularityCE User Guide 4.1 documentation: no description found
Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
- AI News Recognition Enjoyed by Members: A member expressed joy at recognizing the Discord bot's achievements being highlighted in AI News. They joked about the cyclical nature of recognition, saying, "AI News mentioning another AI News mention".
- Positive Feedback for Summarization Feature: A member was enthusiastic about the AI summarization abilities, appreciated swyxio’s highlight, and showed gratitude for its helpfulness. Another member clarified that the summarization was from a different conversation, unrelated to AI News.
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
starsupernova: Oh fantastic - if u need help - ask away!
Stability.ai (Stable Diffusion) ▷ #general-chat (966 messages🔥🔥🔥):
- SD3 Release Doubts and High Prices: Discussions revolving around the release timeline and quality of SD3, with some users skeptical about its release and quality. There's speculation that Stability AI is holding SD3 to drive sales; one member mentioned "SD3 will be released," maintaining hope despite uncertainties.
- GPU Debate – 4060 TI vs 4070 TI: Members debated the performance between 4060 TI 16GB and 4070 TI 12GB for gaming and AI tasks. One favored the 4060 TI for ComfyUI, while another highlighted the 4070 TI's superior gaming performance.
- API Alternatives and Usage: Several inquiries and suggestions about using API alternatives like Invoke or Forge for model training and asset design. One user praised the efficiency of Forge and described it as an "exactly the same" UI as A1111.
- Benchmark Website Shared: A user shared a benchmark site for evaluating GPU performance. The site offers comprehensive data on models like 1.5 and XL Models, with users directed to filter results for specific GPUs like the Intel Arc a770.
- Frustrations with Economic Inequality Expressed: Intense debates around economic struggles and inequality, touching on capitalism, technological advancements, and historical injustices. Some argued that economic disparity and the pursuit of wealth come at the cost of morality and personal well-being.
- SD WebUI Benchmark Data: no description found
- ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions · Datasets at Hugging Face: no description found
OpenAI ▷ #ai-discussions (280 messages🔥🔥):
- GPT-4o faces criticism for performance: Multiple users, including this Reddit post, have reported that GPT-4o performs worse than its predecessors, often introducing errors in tasks like coding and answering less effectively than GPT-2.
- Discussing GPT-4o's Vision Capabilities: Users like
vl2uare experimenting with GPT-4o's ability to analyze medical images and pushing the limits of its "identity," but results are mixed and sometimes lead the model to provide libraries rather than direct analyses. - Hyperstition as a concept for AI: The notion of "hyperstition" was explored, exemplified by how AI can be nudged into new identities and beliefs through reinforcement. AI's role in confirming self-fulfilling prophecies was discussed in the context of its training and interaction patterns.
- Future job market and impact of AI: Users exchanged views on AI potentially rendering many jobs obsolete, leading to speculation on how humans will adapt and find new ways of living and working in an AI-dominated future. Some believe AI will create new job opportunities, while others worry about mass unemployment.
- Concerns about AI's emotional realism: Debates emerged about whether AI should remain neutral and professional or simulate human-like emotional responses. The balance between creating a relatable AI versus an efficient, emotionless assistant was a key discussion point in the community.
Link mentioned: Reddit - Dive into anything: no description found
OpenAI ▷ #gpt-4-discussions (103 messages🔥🔥):
- Confusion over GPT-4o Accessibility: Many users were unsure about the availability of GPT-4o, asking if it was free or exclusive to paid accounts. Clarifications were given that GPT-4o is rolling out over time and currently prioritized for paid users, as detailed here.
- Issues with ChatGPT-4o Functionality: Several users reported issues with the new ChatGPT-4o model, including slow responses and persistent topic repetition. Some found it lacked certain features like voice interaction or image generation that were expected from the demos.
- Custom GPTs and Voice Features Concerns: Users inquired if custom GPTs would utilize GPT-4o and discussed features like voice mode, which is currently rolling out to Plus accounts only. It's noted that custom GPTs will switch to GPT-4o in a few weeks according to the official FAQ.
- Technical Glitches with Updates and Subscriptions: Multiple participants expressed frustration with technical issues such as failed app updates, subscription problems, and missing features like voice options. The expectation is that these are temporary glitches due to the high demand and ongoing updates.
- Interaction and Token Count Clarification: There was a discussion about the token limits and proper functionality measurement of different GPT versions, with a detailed explanation provided in a token counting guide. Users were advised to check GPT response times to identify the underlying model.
OpenAI ▷ #prompt-engineering (192 messages🔥🔥):
- Members evaluate differences between GPT-4 and GPT-4o: Multiple users discussed the capabilities of GPT-4 vs. GPT-4o across a range of prompts, such as understanding real-world scenarios and solving puzzles. They noted subtle differences, with GPT-4o sometimes showing better grounding in real-world contexts.
- Prompt engineering techniques explored: Strategies for improving chatbot responses were shared, including using politeness, encouragement, and context-specific instructions to elicit better outputs. A user shared insights from studies that showed how motivator phrases could elevate the performance of AI models.
- Challenges with custom GPTs and maintaining prompt fidelity: Users discussed difficulties in getting GPTs to follow custom instructions, particularly around avoiding complicated calculations. Suggestions included focusing solely on positive instructions and providing clear, hierarchical guidance.
- Creative applications and outputs: Users experimented with creative and nuanced prompts to test GPT-4 and GPT-4o's capabilities, such as cryptic message decryption and complex storytelling scenarios. There were discussions around the effectiveness of different prompting styles in eliciting desired AI behaviors.
- Practical concerns about usage limits and subscriptions: Some members debated the utility of the ChatGPT Plus subscription given the message limits, especially for heavy use cases like software engineering. Others highlighted different usage strategies to optimize the subscription benefits.
Link mentioned: ChatGPT can now access the live Internet. Can the API?: Given the news announcement I am wondering if the API now has that same access to the Internet. Thanks in advance!
OpenAI ▷ #api-discussions (192 messages🔥🔥):
- Exploring AI Prompt Engineering: Discussion revolved around the effectiveness of different prompt strategies for GPT models, touching on how politeness, encouragement, and specific instructions can improve AI responses. Multiple techniques like "EmotionPrompt" and asking AI to act as experts were explored to enhance performance.
- Testing GPT-4 vs. GPT-4o: Members conducted comparative tests to identify differences between GPT-4 and GPT-4o, focusing on tasks like deciphering codes and understanding real-world concepts. Subtle differences were noted, particularly in how GPT-4o handles multimodal inputs.
- Addressing Response Validity: A recurring theme was the AI's occasional production of incorrect or irrelevant data. Strategies discussed included enforcing stricter data source usage instructions and guiding the model's attention more effectively.
- Character Role Playing for Enhanced Interaction: There was interest in using detailed prompts to create AI characters with distinct personas for dynamic interactions. Markdown formatting was suggested to structure these prompts effectively.
- Bridge Crossing Problem & Image Description: The classic "bridge crossing with a flashlight" problem and an image description task were used to challenge the AI. Comparisons were made between different model’s abilities to interpret and respond to these puzzles.
Link mentioned: ChatGPT can now access the live Internet. Can the API?: Given the news announcement I am wondering if the API now has that same access to the Internet. Thanks in advance!
OpenAI ▷ #api-projects (4 messages):
- Plug & Play AI Voice Assistant available: A Plug & Play AI Voice Assistant is heavily promoted for its simplicity and ease of use. "Ready in 10 min!" is highlighted as a key benefit.
- Feedback invitation for Plug & Play AI: Users are encouraged to "try it and share your feedback" to improve the product. This open invitation points to community-driven enhancement efforts.
Perplexity AI ▷ #general (477 messages🔥🔥🔥):
- GPT-4o generates buzz: Users confirm that GPT-4o is available on Perplexity showcasing faster responses and better performance compared to GPT-4 Turbo. Many still face issues as it rolls out gradually.
- Perplexity nabs the research crown: Researchers delight in Perplexity’s accuracy, sourcing, and search capabilities over ChatGPT, making it their tool of choice for detailed inquiries and current information.
- Generating text in AI images troubles users: Users struggle with "text gibberish" in DALL-E generated images, prompting discussions on prompt structure. Tips include placing text instructions upfront and generating multiple versions for better results.
- Voice features glitter on iOS: The voice mode in Perplexity Pro's iOS app impresses with natural interactions amid anticipation for updates on Android. Users appreciate the ability to have long, uninterrupted conversations for ease of use.
- Billing hiccups for Perplexity Pro: Users experience payment issues while subscribing to Perplexity Pro. Support is advised via support@perplexity.ai for assistance.
- What is phidata? - Phidata: no description found
- ChatGPT: Introducing ChatGPT for iOS: OpenAI’s latest advancements at your fingertips. This official app is free, syncs your history across devices, and brings you the newest model improvements from OpenAI. ...
- no title found: no description found
- GitHub - kagisearch/llm-chess-puzzles: Benchmark LLM reasoning capability by solving chess puzzles.: Benchmark LLM reasoning capability by solving chess puzzles. - kagisearch/llm-chess-puzzles
- GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
- I <3 Coffee GIF - Jimcarrey Brucealmighty Coffee - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Gift Present GIF - Gift Present Surprise - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (12 messages🔥):
- Finetuning link shared: A member posted a link to a Finetuning search result on Perplexity AI. Check out the link here.
- Aztec Stadium page shared: A member shared a link to a Perplexity AI page about Aztec Stadium. View the page here.
- Recap of Google: An intriguing link about a Google recap was posted. Explore the recap here.
- Latest cooking trends: A member shared a link about the latest cooking trends. Dive into the trends here.
- Anthropic hires Instagram: A link discussing Anthropic hiring from Instagram was shared. Read more on this topic here.
Perplexity AI ▷ #pplx-api (10 messages🔥):
- Beta Access Plea for API Citations: One user requested beta access to Perplexity API's citation feature, emphasizing its importance for their business. They acknowledged potential backlogs but stressed the significance of gaining access to close deals with key customers.
- llama-3-sonar-large-32k-online Searches the Web: A user inquired if the llama-3-sonar-large-32k-online model API performs web searches similar to Perplexity.com. It was confirmed that this model does search the web.
- Request for Stable API Model Aliases: A user expressed frustration over frequent changes in model names and requested the establishment of stable aliases that would always point to the newest models when older ones are deprecated.
- Increased API Latency Today: A user noted an increase in latency when making API calls to Perplexity on the current day.
- Autocorrect Issue with Prompts: A user reported an issue where Perplexity autocorrects prompts incorrectly, leading to inaccurate responses. They are seeking suggestions to tweak prompts to avoid this problem.
HuggingFace ▷ #announcements (3 messages):
- Terminus Models Updated in HuggingFace: The Terminus models have a new updated collection by a community member. These updates provide new functionalities and improvements.
- OSS AI+Music Explorations on YouTube: Check out more AI and music explorations by a community member on YouTube. These explorations offer innovative ways to combine AI and music.
- Manage On-Prem GPU Clusters Efficiently: Learn a new way to manage on-prem GPU clusters. This method provides enhanced control and scalability for intensive computational tasks.
- Understanding AI for Story Generation: Engage with AI in story generation through a detailed article and a related Discord event. The discussion will delve into the applications and implications of AI in creative narratives.
- OpenGPT-4o Introduced: Explore the new OpenGPT-4o. It accepts text, text+image, and audio inputs, and can generate multiple forms of output including text, image, and audio.
- SimpleTuner/documentation/DREAMBOOTH.md at main · bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1, DeepFloyd, and SDXL. - bghira/SimpleTuner
- Vi-VLM/Vista · Datasets at Hugging Face: no description found
HuggingFace ▷ #general (261 messages🔥🔥):
- OpenAI's Ilya Sutskever news stirs reaction: Discussion sparked by a tweet about Ilya Sutskever's departure (link). Another member shared a related tweet from Jan Leike..
- Tips on React for fetching PDFs: A user sought advice on how to use React to grab PDFs listed by GPT. Community engagement followed with various users chiming in.
- Challenges with PaliGemma models: Users discussed issues and solutions related to using the PaliGemma models, including links to code examples and HuggingFace collections. One user highlighted incorrect results due to
do_sample=False. - Exploring ZeroGPU and model deployment: Members discussed the capabilities and beta access of ZeroGPU for deploying machine learning models (link). Spaces built on ZeroGPU were referenced as examples.
- MIT License utilization on HuggingFace platform: A user sought clarity on using MIT-licensed models for commercial purposes on the HuggingFace platform. Another user confirmed it should be fine, referencing the MIT License documentation (link).
- MIT License: A short and simple permissive license with conditions only requiring preservation of copyright and license notices. Licensed works, modifications, and larger works may be distributed under different t...
- — Zero GPU Spaces — - a Hugging Face Space by enzostvs: no description found
- Inference Endpoints - Hugging Face: no description found
- Welcome to the Community Computer Vision Course - Hugging Face Community Computer Vision Course: no description found
- Stable Diffusion 2-1 - a Hugging Face Space by stabilityai: no description found
- zero-gpu-explorers (ZeroGPU Explorers): no description found
- 2024-04-22 - Hub Incident Post Mortem: no description found
- Batched multilingual caption generation using PaliGemma 3B! · huggingface/diffusers · Discussion #7953: Multilingual captioning with PaliGemma 3B Motivation The default code examples for the PaliGemma series I think are very fast, but limited. I wanted to see what these models were capable of, so I d...
- Python Calculator in 20 Seconds! #shorts #python #calculator: Hey there Python pals! 🐍💻 Need a calculator but can't wait for a coffee break? Say no more! Dive into the world of Python magic with our lightning-fast Pyt...
- “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
- Future of SaaS and UI with AI Agents: A brief survey about the impact of AI agents on b2b and SaaS by https://hai.ai
- no title found: no description found
- Spaces - Hugging Face: no description found
- Lamini - Enterprise LLM Platform: Lamini is the enterprise LLM platform for existing software teams to quickly develop and control their own LLMs. Lamini has built-in best practices for specializing LLMs on billions of proprietary doc...
- PaliGemma Release - a google Collection: no description found
- PaliGemma FT Models - a google Collection: no description found
- GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
HuggingFace ▷ #today-im-learning (13 messages🔥):
- Epsilon Greedy Policy maintains RL trade-offs: In response to a question about maintaining exploration/exploitation trade-off in RL, a member explained that the epsilon greedy policy is used. They suggested learning more via ChatGPT and encouraged curiosity.
- Curiosity in RL encourages exploration: A member recommended looking into curiosity-driven exploration as a way to encourage exploration in RL. They shared a paper by Pathak et al. which rewards agents for "error in an agent's ability to predict the consequence of its own actions."
- Unusual situations drive exploration: It was discussed that in curiosity-driven exploration, agents are encouraged to choose actions leading to unusual situations to increase their reward. This method helps in scenarios where dense rewards are challenging to maintain in RL.
Link mentioned: Curiosity-driven Exploration by Self-supervised Prediction: Pathak, Agrawal, Efros, Darrell. Curiosity-driven Exploration by Self-supervised Prediction. In ICML, 2017.
HuggingFace ▷ #cool-finds (6 messages):
- Unveiling PaliGemma Vision Language Model: A member shared a link to an article about the PaliGemma Vision Language Model on Medium. This model claims to provide powerful capabilities in combining vision and language tasks. Read more.
- Veo Video Generation Model Launches: DeepMind's latest video generation model, Veo, produces 1080p resolution videos with a variety of cinematic styles and extensive creative control. Selected creators can access these features through Google’s experimental tool VideoFX, and it will eventually integrate with YouTube Shorts. More details.
- Joint Language Modeling for Speech and Text: A research paper explores joint language modeling for speech units and text. The study shows improvements in spoken language understanding tasks by mixing speech and text using proposed techniques. Read the paper.
- Google IO 2024 Full Breakdown: A YouTube video provides a comprehensive analysis of the Google IO 2024 event, claiming it made Google relevant in AI again. Watch here.
- Getting Started with Candle: A Medium article offers a guide on how to start using Candle, a new tool or technique in AI. Read the article.
- Veo: Veo is our most capable video generation model to date. It generates high-quality, 1080p resolution videos that can go beyond a minute, in a wide range of cinematic and visual styles.
- Toward Joint Language Modeling for Speech Units and Text: Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very...
- Google IO 2024 Full Breakdown: Google is RELEVANT Again!: Here's my full breakdown of the Google IO 2024 event, which, in my opinion, made Google very relevant again in AI.Join My Newsletter for Regular AI Updates ?...
HuggingFace ▷ #i-made-this (7 messages):
- dstack simplifies on-prem GPU management: Announcing a "game changer" for managing on-prem GPU clusters, dstack allows team members to use a CLI to run dev environments, tasks, and services on both on-prem and cloud servers. Learn more and check out their docs and examples.
- Excited reactions about dstack: Members expressed curiosity and excitement about dstack's capabilities, with one planning to avoid a deep dive into slurm in favor of dstack. Another mentioned it seems worthwhile before making decisions on cluster management.
- Musicgen continuations max4live device: A member shared updates on the Musicgen continuations project, highlighting improvements to the max4live device backend and its addictive features. Check out the YouTube demo.
- Terminus model updates improve performance: Every terminus model in the collection has been updated with the correct unconditional input config, enhancing their function with and without negative prompts. The velocity v2.1 checkpoint now boasts 61k downloads, available at Terminus XL Velocity V2.
Link mentioned: Terminus XL - a ptx0 Collection: no description found
HuggingFace ▷ #reading-group (12 messages🔥):
- Plan for a Saturday Event: A member suggested organizing an event on Saturday, creating a placeholder to confirm the timing. They shared an invite link to the event on Discord: event link.
- Dwarf Fortress Reference Appreciated: A member expressed their admiration for the Dwarf Fortress reference, stating it as one of their favorite games. Another member noted they've watched many Dwarf Fortress stories on YouTube.
- Thumbnails for Reading Group on YouTube: A member offered to design thumbnails for the Reading Group sessions uploaded to YouTube. They shared a design that received positive feedback, with minor suggestions for improving text readability.
Link mentioned: Join the Hugging Face Discord Server!: We're working to democratize good machine learning 🤗Verify to link your Hub and Discord accounts! | 79111 members
HuggingFace ▷ #computer-vision (10 messages🔥):
- Training Data Essential for Sales Prediction: A member suggested using a table where columns represent image features and sales figures, and comparing new product visual features to this data could provide insights. They stressed the importance of having relevant training data.
- Sales Prediction Dataset Shared: Another member shared a Sales Prediction Dataset including image pixels and sales figures. This dataset aims to assist in building a model that uses image inputs to predict sales outputs.
- Training Models on Image Features: A member recommended fine-tuning a CNN to get feature maps, then appending these maps with sales data. They further suggested training models like RF, SVM, or XGBoost to evaluate against image similarity results.
- Query on Image Manipulation Detection Models: A member inquired about models capable of detecting image forgery without needing a dataset. They sought models that could determine if an image has been edited.
- UNet Model Convergence Issue: A user reported their UNet model's loss starts at 0.7 and converges at 0.51, using depth=5, learning rate=0.002, and BCE with logits loss. They asked for help identifying potential problems in their setup.
Link mentioned: tonyassi/sales1 · Datasets at Hugging Face: no description found
HuggingFace ▷ #NLP (9 messages🔥):
- Members seek help with fine-tuning Llama2: A user inquired about how to fine-tune Llama2 locally. Another member humorously asked if helping would result in a job offer.
- Struggles with outdated code in models: A user shared frustrations about models generating a mix of old and new code for a specific Python library. They asked if techniques like ORPO or DPO could help remove incorrect knowledge from the base model.
- Continuous retraining needed for coding alignment: In response to outdated code issues, a member noted that outdated training data is a significant problem. They mentioned that language models for code need continuous retraining to stay current.
HuggingFace ▷ #diffusion-discussions (7 messages):
- Image Loading Issue Resolved with PIL: A user initially faced issues with URLs but successfully resolved the problem by using the load_image function with PIL's Image.open method. They shared a code snippet: from PIL import Image baseimage=Image.open(r"/kaggle/input/mylastdata/base.png").
- Seeking AI for PowerPoint Presentation Generation: A member inquired about a chatbot capable of generating PowerPoint presentations using the OpenAI Assistant API. They sought recommendations for other RAG or LLM models that can learn from previous presentations while only modifying slide content.
- Discussion on SDXL Latent Space: A user shared a blog post discussing whether every value in the latent space should represent 48 pixels in the pixel space. The blog includes sections on The 8-bit pixel space and the SDXL latent representation.
Link mentioned: Explaining the SDXL latent space: no description found
Nous Research AI ▷ #ctx-length-research (2 messages):
- Human brains work like streams: People have small working memory, yet can process long books and extended conversations by updating what's most relevant. It's suggested that AI should focus on streaming-like methods, such as Infini-attention.
- Needle in a Needlestack Benchmark: The Needle in a Needlestack (NIAN) is a new, more challenging benchmark for evaluating LLMs, even difficult for GPT-4-turbo, and builds upon the simpler Needle in a Haystack test. More details can be found on their website and GitHub.
Link mentioned: Reddit - Dive into anything: no description found
Nous Research AI ▷ #off-topic (16 messages🔥):
- Discord AV1 Embed Tool sparks interest: Members discussed embedding AV1 videos on Discord and the advantages of using the Discord AV1 Embed Tool, which allows for embedding videos larger than 500MB and with custom thumbnails.
- Device naming creativity runs wild: A fun naming session for an IoT air purifier brought out creative options like "Filterella," "Puff Daddy," and "Airy Potter." One member mentioned, "The final one sounds pretty good," referring to "The Filtergeist."
- GPT-4's roleplaying capabilities raise eyebrows: A member humorously speculated on the wild possibilities of GPT-4's roleplaying abilities, specifically mentioning scenarios involving political figures and BDSM themes once voice features are introduced.
- Fuyu model deemed unsatisfactory: In response to inquiries about models trained to recognize UI elements, Fuyu was mentioned, but critiqued as "pretty meh" for the task. Another member is exploring alternatives for real-time UI interaction processing.
- Autocompressor Video Embed Tool: no description found
- Autocompressor Video Embed Tool: no description found
- no title found: no description found
Nous Research AI ▷ #interesting-links (10 messages🔥):
- Silo AI releases first Nordic LLM: Together with University of Turku's TurkuNLP and HPLT, Silo AI released Viking 7B, an open source multilingual LLM for Nordic languages. The model represents "a significant milestone on the journey towards a state-of-the-art LLM family for all European languages".
- Interest in Nordic Language Models: Members discussed the relevance and appeal of training large models for low-resource languages. One noted that even larger models tend to perform well on these languages despite being less optimized for such tasks.
- AMD accelerators in use: Silo AI and TurkuNLP are utilizing AMD accelerators for their projects, which was noted as surprising by some members.
- SUPRA for uptraining transformers: Scalable UPtraining for Recurrent Attention (SUPRA) was proposed as a cost-effective alternative to pre-training linear transformers. It aims to improve pre-trained large transformers into Recurrent Neural Networks to address poor scaling issues in linear transformers.
- Linearizing Large Language Models: Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. Howe...
- Viking 7B: The first open LLM for the Nordic languages: Silo AI is announcing the release of the first open LLM for the Nordic languages
Nous Research AI ▷ #announcements (1 messages):
- Hermes 2 Θ released as an experimental merged model: Nous Research, in collaboration with Arcee AI, released Hermes 2 Θ, a model merging Hermes 2 Pro and Llama-3 Instruct, further RLHF'ed for superior performance. It is available on HuggingFace and achieves the best of both worlds in their benchmarks.
- GGUF version of Hermes 2 Θ available: In addition to the FP16 model, a GGUF version of Hermes 2 Θ has also been released. The model can be accessed on HuggingFace.
- NousResearch/Hermes-2-Theta-Llama-3-8B · Hugging Face: no description found
- NousResearch/Hermes-2-Theta-Llama-3-8B-GGUF · Hugging Face: no description found
Nous Research AI ▷ #general (199 messages🔥🔥):
- Hermes 2 Θ model release: An announcement was made about the release of Hermes 2 Θ, combining Hermes 2 Pro and Llama-3 Instruct, further refined with RLHF. The model surpasses both Hermes 2 Pro and Llama-3 Instruct in benchmarks and is available on HuggingFace.
- GPT-4 variants struggle with reasoning tasks: Different GPT-4 models displayed varying success rates on a question about Napoleon's white horse and a variant of Schrödinger's cat problem. A member noted "almost no LLM figures out that the cat is dead to begin with".
- Testnet mining issues: A user reported issues seeing requests while mining on testnet 61 and questioned the presence of validators. Another member suggested seeking support on a more specialized server.
- Concerns about GPT-4o: Multiple users expressed disappointment in GPT-4o's performance, emphasizing its generic output structure and enumerative explanations. One user noted, "I want a solution to my coding problem and not a step-by-step plan on how to install required modules".
- Experimenting with self-merging Hermes: A member shared plans to merge Hermes models to create a 12B parameter model called Quicksilver, integrating OpenHermes dataset and tuning it further. Another member expressed interest in the project, indicating eagerness to check it out once done.
- Tweet from Nous Research (@NousResearch): Today we are releasing an experimental new model in collaboration with @chargoddard and @arcee_ai, Hermes 2 Θ, our first model merge, combining Hermes 2 Pro, and Llama-3 Instruct, and then further RLH...
- no title found: no description found
- Tweet from Cameron Jones (@camrobjones): New Preprint: People cannot distinguish GPT-4 from a human in a Turing test. In a pre-registered Turing test we found GPT-4 is judged to be human 54% of the time. On some interpretations this consti...
- Tweet from Brian Atwood (@batwood011): Plot twist: The Safety team left not because they saw *something* but because they saw *nothing* No real danger. Only limitations, dead ends and endless distractions with commercialization — no path...
- Tweet from Taelin (@VictorTaelin): RELEASE DAY After almost 10 years of hard work, tireless research, and a dive deep into the kernels of computer science, I finally realized a dream: running a high-level language on GPUs. And I'm...
- Tweet from Taelin (@VictorTaelin): Seriously - this is great. I can't overstate how good it is. I spent a LONG time to get a half-decent run with Opus back then. Other models could barely draw a frame. GPT-4o just... plays the game...
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
- interstellarninja/hermes-2-theta-llama-3-8b: Hermes-2 Θ is a merged and then further RLHF'ed version our excellent Hermes 2 Pro model and Meta's Llama-3 Instruct model to form a new model, Hermes-2 Θ, combining the best of both worlds of...
- no title found: no description found
- no title found: no description found
- Tweet from Sam Altman (@sama): especially at coding
- Cat GIF - Cat - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (55 messages🔥🔥):
- Meta introduces multimodal AI model ImageBind: Meta has open-sourced ImageBind, capable of joint embedding across six different modalities: images, text, audio, depth, thermal, and IMU data. The model avoids the necessity of all combinations of paired data, leveraging image-paired data to extend capabilities.
- Building LLMs from scratch requires substantial resources: Users emphasized the significant financial and computational resources needed for training large language models (LLMs) from scratch. One user suggested that without $100,000, pursuing such an endeavor isn't feasible.
- Hermes 2 Theta math performance issues: Users discussed Hermes 2 Theta's performance, noting it performs worse at basic math compared to L3 8B Instruct. The recommendation was made to use function calling for better results in mathematical problems.
- Challenges with model inference and triggering Chinese text: A user reported issues with Nous Hermes-2-Mixtral-8x7B-DPO, where the model occasionally produced responses in Chinese despite English input. This problem led to the suggestion of potential issues at Together's inference endpoint, with alternative models yielding better results.
- Stop tokens in fine-tuning not behaving correctly: Users shared challenges in stopping generation at the correct token when fine-tuning models using the Alpaca instruction format. Advice was given to ensure correct stop token settings during inference.
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face: no description found
- no title found: no description found
- ImageBind: One Embedding Space To Bind Them All: We present ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. We show that all combinations of paired data are not n...
Nous Research AI ▷ #project-obsidian (3 messages):
- Plans to finetune PaliGemma discussed: A member inquired about any plans to finetune PaliGemma. They pointed to PaliGemma's model card and noted it would be "cool to finetune for multi-turn" interactions.
- Multimodal tool use announcement: A tweet shared by a member mentioned the addition of support for tools that return images, laying foundations for multimodal tool use. The detailed information can be found in this cookbook.
- Tweet from Alex Albert (@alexalbert__): 3) Vision We’ve added support for tools that return images, laying the foundations for multimodal tool use across key sources of knowledge like images, charts, etc. Read the cookbook here: https://g...
- google/paligemma-3b-pt-224 · Hugging Face: no description found
Nous Research AI ▷ #world-sim (3 messages):
- Robo Psychology Server Receives Worldsim Updates: A member announced that they had subscribed the Robo Psychology Discord server to worldsim updates. They mentioned that if any announcements are made, they should propagate to the server.
- Inquiries About Other Simulation Prompts: A member inquired about the prompts used in other simulations within the Discord channel.
- Exploring Universal Web Scraper Agent: A YouTube video titled "Wait, this Agent can Scrape ANYTHING?" was shared, discussing how to build a universal web scraper for e-commerce sites that can handle tasks such as pagination and captcha solving. The member also mentioned a sponsored promotion for a software utility.
Link mentioned: “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
LM Studio ▷ #💬-general (145 messages🔥🔥):
- Funny Hallucinations in Command R Models: A member shared a hilarious hallucination from the Command R model, describing a Soviet encryption machine named Fialka that used fragrant purple perfume for printing, leading to its NATO codename “Violet!” This creative hallucination was labeled almost believable by the member.
- Gradual First-Token Issues with Large Context Models: Discussions highlighted difficulties with large context models, like Llama-3-8B-Instruct-Gradient-1048k, indicated by lengthy first-token generation times. Such issues were noted as due to extensive computation required for large context lengths.
- LM Studio CLI and Vision Model Integration: The release of
lms, LM Studio’s companion CLI tool, enables loading/unloading models and starting/stopping the API server without the GUI. Vision model support is also discussed, although recent issues seem to block functionality. - Embedding and Context Length Strategies: Members explored optimal prompt engineering and config settings for embedding models and maximizing context length usage, citing performance variations across hardware setups. It was mentioned that users could run embedding models like llama.cpp on platforms like Colab.
- Security Concerns and Antivirus False Positives: Users encountering antivirus flags on the LM Studio installer were advised to allow exceptions, highlighting that such flags are false positives. The advice given emphasized the use of Windows Defender and proper online safety measures as sufficient protection.
- bar (bar cohen): no description found
- PyTorch ExecuTorch: no description found
- Introducing `lms` - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
- bartowski/Llama-3-8B-Instruct-Gradient-1048k-GGUF · Hugging Face: no description found
- abetlen/nanollava-gguf · Hugging Face: no description found
- nisten/obsidian-3b-multimodal-q6-gguf · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Don't ask to ask, just ask: no description found
LM Studio ▷ #🤖-models-discussion-chat (66 messages🔥🔥):
- Adding Idefics Model to LM Studio: A member asked how to add the Idefics model in LM Studio. The response indicated the need for someone to convert it to GGUF and mentioned that an mmproj adapter is necessary as it’s a vision model.
- Challenges of Building Imatrix: Multiple discussions showcased the frustration with building imatrix for large models like llama3 70b, highlighting that building on CPU can take hours and might require cooling solutions. One user shared that "trying to build imatrix for llama3 70b on CPU... 5 hours in, ~40% done," pointing to CPU thermal throttling issues.
- Model Recommendations for Coding: Users discussed which models are best for coding and recommended Nxcode CQ 7B ORPO, a CodeQwen 1.5 finetune. It's also mentioned that running models like Cat 8B (Q8) can lead to disappointing results with tool/function calling features.
- Handling Long Contexts in Models: There was practical advice on handling token limits and context overflow policy for better performance, such as using truncating policies to avoid errors when the token count is saturated.
- Model Output Control for Coding: Members sought ways to get LLM models to output only code without explanations. It was suggested to use the markdown feature and instruct the model explicitly, but it was acknowledged that LLMs often still provide explanations regardless.
Link mentioned: HuggingFaceM4/idefics-9b-instruct at main: no description found
LM Studio ▷ #🧠-feedback (8 messages🔥):
- Settings panel scrolls overlap and confuse users: A member noted that the settings panel has "two overlapping scrolls, one for model settings and one for tools," causing confusion and suggesting a single common scroll. Another member agreed, adding that the panel is particularly confusing for new users.
- Separate window for settings and moving system prompt: A member proposed having the settings in a separate window and moving the system prompt to chat configuration, citing that they use different prompts for the same model in different chats.
- UI feedback and usability issues: A detailed feedback highlighted multiple UI usability issues, including: accidental prompt launching with the "enter" key, lack of a "cancel request" button before generation starts, confusing system presets, misaligned branch/copy/edit/delete icons, and a request for better integration with Whisper.
- False positive virus alert debunked: A member confirmed that a file identified as possibly harmful showed up clean in both Malwarebytes and Windows Defender, providing a VirusTotal link for verification.
Link mentioned: VirusTotal: no description found
LM Studio ▷ #⚙-configs-discussion (2 messages):
- Windows Task Manager CUDA Check: A member suggested checking GPU usage by launching Task Manager and navigating to the "performance" tab in the GPU section. They proposed changing the graph source to "CUDA" and deactivating "hardware acceleration" in Windows settings if CUDA is not available.
- CUDA Error on Asus Laptop: Another member reported an issue with CUDA on their Asus laptop equipped with a GTX 950M GPU. While attempting to use GPU offload, they encountered an "error loading model" message despite trying various CUDA versions (12.4, 12.1, 11.8) and ensuring CUDA/CUDNN paths are correctly set in the system environment.
LM Studio ▷ #🎛-hardware-discussion (46 messages🔥):
- APU for model loading questioned: A member asked if models perform better on an APU with lots of RAM compared to a regular CPU. Another member clarified that llama.cpp treats APUs/iGPUs as regular CPUs for inference.
- High-end build showcases LM performance: A member shared details of their high-end build featuring a 32 core threadripper, 512GB RAM, and RTX6000. They achieved a time to first token of 0.10s with a generation speed of 103.45 tokens per second using specific configurations.
- Water-cooled 4090 compatibility issues: Discussion centered around the challenges of integrating a water-cooled RTX 4090 into an existing high-performance setup. Members shared insights on suitable chassis and cooling solutions.
- BIOS settings impact on performance: Members debated the effectiveness of BIOS presets and settings for cooling and their impact on CPU performance. One mentioned the undervolting default in water-cooling presets and the need to manually override memory clock settings for DDR5.
- Shingled HDDs and read/write speeds: Members discussed the performance issues with shingled HDDs, noting their slow write speeds. Suggestions included BIOS updates and drive policy settings aimed at improving disk performance, particularly for permanently installed drives.
LM Studio ▷ #🧪-beta-releases-chat (9 messages🔥):
- AVX1 causes LM Studio load failure: A member reported that LM Studio shows "App starting..." and doesn't proceed further. Another member clarified that LM Studio requires AVX2 instruction sets and will not load on AVX1 systems, though Llamafile works fine.
- Model storage drive selection issues: A user is facing difficulties choosing another drive for model storage in LM Studio due to permission errors. Despite setting full write permissions, the system rejects the chosen location and prompts for a different one or a reset to factory settings.
- Request for UI improvements: There were suggestions to streamline the UI by turning off unused code parts and allowing window repositioning to reduce clutter. User feedback highlighted the current UI as overly complex, especially for server management tasks.
LM Studio ▷ #amd-rocm-tech-preview (7 messages):
- ROCM Windows build needs latest version for iGPU issue: One user had to disable their Ryzen 7000 iGPU to get ROCM Windows build working and inquired if the issue persists. Another user mentioned it should be fixed in recent versions and advised to ensure they have the latest ROCM (0.2.22) update.
- Excitement for ROCM improvements on RX 6800: Users expressed hope that ROCM will bring performance improvements for supported AMD GPUs like the RX 6800. One user confirmed that the RX 6800 is indeed supported.
Modular (Mojo 🔥) ▷ #general (59 messages🔥🔥):
- Mojo SDK recommended for AI development: A member shared multiple resources for learning Mojo, suggesting starting with the Mojo manual and examples like the Mandelbrot tutorial. They emphasized the SDK's inclusion in the MAX SDK for a comprehensive toolkit.
- Discussion on Mojo's potential: Members expressed optimism about Mojo's future despite its current low visibility. One user stated, "We can be the ones to talk about it," encouraging community-driven awareness.
- GPU flexibility makes Mojo advantageous: When comparing Mojo to CUDA, discussions highlighted Mojo's portability between GPU vendors as a significant advantage over CUDA's vendor lock-in. This flexibility could foster a more competitive hardware market, as noted by multiple members.
- Concerns around open-source commitment: A debate arose regarding the open-source status of Mojo, with some members skeptical about future changes in licensing. Others defended Modular's current open-source contributions, noting the value provided even without full openness.
- Community projects and learning suggestions: Members suggested various learning projects for newcomers to Mojo, such as contributing to the toybox data-structures project or tackling challenges like Advent of Code (GitHub link). They discussed ideas for beginner-friendly tasks and more advanced undertakings like LAS file readers.
- Get started with Mojo🔥 | Modular Docs: Get the Mojo SDK or try coding in the Mojo Playground.
- Mandelbrot in Mojo with Python plots | Modular Docs: Learn how to write high-performance Mojo code and import Python packages.
- Introduction to Mojo | Modular Docs: Introduction to Mojo's basic language features.
- GitHub - p88h/aoc2023: Advent of Code 2023 (Mojo): Advent of Code 2023 (Mojo). Contribute to p88h/aoc2023 development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular Tweets Updates: The channel included tweets from Modular discussing their latest updates and announcements. Another tweet shared here continues the conversation about their offerings and innovations.
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Modular introduces Joe Pamer: A blog post introduces Joe Pamer, the Engineering Lead for Mojo at Modular. Read more about Joe Pamer.
Modular (Mojo 🔥) ▷ #🔥mojo (166 messages🔥🔥):
- Mojo not fully open source yet: Discussion clarified that while many parts of Mojo's standard library are open source, the compiler and the Max toolchain are not. It's anticipated that the compiler will be open source eventually, but Max likely never will be.
- Syntax variations and documentation inconsistencies: Users are noticing discrepancies between syntax in various books and official Mojo documentation, like
varvs.letandclassvs.struct. One user mentioned their book is possibly AI-generated. - Iterating issues with
aliasin Mojo: Extensive discussions on iterating over data structures in Mojo revealed issues when usingaliasfor lists, causing LLVM errors. Variable declaration approaches and the impact of usingReference[T]and iterators were explored. - Conditional conformance and traits explanation: The complexities of using traits like FromString for generics and the limitations of Mojo's type system were delved into. Users suggested that conditional conformance, similar to those in Rust, Swift, and Haskell, could solve some of these issues.
- Mojo's online resources and community contributions: Various resources like repositories and online books were mentioned. Additionally, users were encouraged to contribute to the standard library to expedite Mojo's development, and errors within the language's handling were discussed as potential bugs.
- Traits | Modular Docs: Define shared behavior for types.
- rebind | Modular Docs: rebinddesttype AnyRegType -> $0
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- no title found: no description found
- Learn Mojo Programming Language: no description found
- mojo/stdlib/src/builtin/tuple.mojo at bf73717d79fbb79b4b2bf586b3a40072308b6184 · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Issues · dimitrilw/toybox: Various data-structures and other toys implemented in Mojo🔥. - Issues · dimitrilw/toybox
Modular (Mojo 🔥) ▷ #nightly (35 messages🔥):
- Mojo Compiler Nightly Build Released: The latest nightly build for the Mojo compiler, version
2024.5.1515, has been released. Users can update usingmodular update nightly/mojoand check the changelog for details. - Mac Self-Test Failures: Users may encounter non-deterministic Mojo self-test failures on macOS due to an LLDB initialization issue. This problem is currently under investigation.
- Exciting Commits in Latest Release: Two notable commits in the latest release include changes to
Tuple's constructor and the update ofReference.is_mutabletoBoolfromi1(commit). - Cookie Licking Issue in Open Source Contributions: A member raised concerns about "cookie licking" in the Mojo repository, where contributors claim issues but don't act promptly, potentially discouraging new contributors. They suggested encouraging smaller PRs and more immediate contributions to mitigate this.
- Conditional Methods Syntax Praised: There was praise for the newly introduced syntax for conditional methods, linked to recent pull requests. However, another user mentioned difficulty finding information on this new syntax in the changelog.
- How to Remove Link Previews | Discord For Beginners: How to Remove Link Previews | Discord For BeginnersIn this video I show you how to delete link previews on Discord in 2024. I show you everything that you ne...
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [mojo-stdlib] Make `Tuple`'s constructor move its input elements. (#3… · modularml/mojo@f05749d: …9904) This changes `Tuple` to take its input pack as 'owned' and then move from the pack into it storage. This unearthed some bugs handling owned packs which were causing multiple d...
- [stdlib] Change `Reference.is_mutable` to `Bool` (from `i1`) · modularml/mojo@09db8f3: With the recent change to `Bool` to use an `i1` as its representation, many of the errors holding up moving `Reference.is_mutable` to `Bool` were resolved. Co-authored-by: Chris Lattner <clatt...
CUDA MODE ▷ #cuda (15 messages🔥):
- Torch Tensor Accessor vs Kernel Data Pointer: A member queried if using Accessors for torch tensors in Cpp, as described here, is better than passing
tensor.data_ptrto the kernel in CUDA. They also asked about the use of unsigned char pointers for these tensors and requested further documentation.
- Dot Product Puzzle Problem: A member shared their solution for the dot product problem from the cuda puzzle repo. They reported a floating-point overflow error when using a naive implementation but not with a reduction-based kernel, sparking a discussion on fp32 precision and how reduction helps maintain it.
- Triton Lecture and Matrix Multiplication: Umerha pointed Ericauld to his Triton lecture and the Triton docs Matmul example for more information on matrix multiplications and performance optimizations. These tutorials cover block-level matrix multiplications, pointer arithmetic, and performance tuning.
- Proposing Bitnet Community Project: Coffeevampir3 reached out to initiate a community project for Bitnet, expressing availability and seeking collaboration. Andreaskoepf supported the idea, suggesting a paper discussion event as a starting step and expressing interest in extreme quantization.
- Creating a Bitnet Channel: Andreaskoepf proposed creating a dedicated channel for the Bitnet project discussions, indicating a community move towards formalizing the project efforts.
- Matrix Multiplication — Triton documentation: no description found
- GitHub - srush/GPU-Puzzles: Solve puzzles. Learn CUDA.: Solve puzzles. Learn CUDA. Contribute to srush/GPU-Puzzles development by creating an account on GitHub.
- puzzle10_dotproduct floating point overflow error: puzzle10_dotproduct floating point overflow error. GitHub Gist: instantly share code, notes, and snippets.
CUDA MODE ▷ #torch (25 messages🔥):
- Custom Op Issue with torch.compile: A member reported an issue where a custom op works fine in eager mode but triggers an assert when used with torch.compile due to non-contiguous tensors. Another user suggested trying redundant
.contiguous()calls, but the problem seemed related to tensor strides generated by Triton.
- Memory Issues with Static Cache: Members discussed the memory implications of using static cache, which can block larger batch sizes. A proposed solution was to use custom kernels for dynamic tensor allocations and apply torch.compile only on the results.
- Adding torch.compile Inside no_grad: A suggestion was made to compile the model inside a
torch.no_gradcontext to localize the offending code better. However, this still resulted in non-contiguous tensors for the user.
- Defining Custom Ops with Tags: A user recommended defining custom ops with specific tags to fix stride issues, referencing the newish API of
torch.library. The conversation highlighted challenges and workarounds in implementing these tags in C++ custom op definitions.
- Reducing torch.compile Times: A new plan to reduce warm compile times with
torch.compilewas shared, directing users to a discussion on the PyTorch forum for detailed strategies. This plan aims to bring compile times down to zero by optimizing various aspects of the compilation process.
- Accelerating Generative AI with PyTorch II: GPT, Fast: This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance...
- torch — PyTorch main documentation: no description found
- torch.library — PyTorch main documentation: no description found
- How To Bring Compile Time Down to Zero: Our Plans and Direction (May 14th Edition): We are excited to announce that over the course of the first half of 2024 we have been prioritizing improving compile times for torch.compile workflows. Swift iterations and efficient development cycl...
- src/python/bindings.py · v043 · AaltoRSE / XMC Sparse PyTorch · GitLab: Aalto Version Control System
- compile problem - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- manylinux-cu121: [cp310, 2.3] (#86868) · Jobs · AaltoRSE / XMC Sparse PyTorch · GitLab: Aalto Version Control System
- src/python/ops.py · v043 · AaltoRSE / XMC Sparse PyTorch · GitLab: Aalto Version Control System
- [wip] fast semi-sparse sparse training by jcaip · Pull Request #184 · pytorch/ao: So was testing this on HuggingFace BERT, wasn't seeing speedups - it's because i was bottlenecked by a bunch of other stuff. (bf16, compile, adamw, dataloader, batchsize) bf16 + compil...
CUDA MODE ▷ #algorithms (1 messages):
andreaskoepf: https://www.cursor.sh/blog/instant-apply
CUDA MODE ▷ #cool-links (1 messages):
- Boost Your LLM Inference Deployment: Get up to 2x higher performance by Tuning LLM Inference Deployment by checking out this tweet. Key updates and optimizations can substantially improve your deployment efficiency.
CUDA MODE ▷ #beginner (8 messages🔥):
- ONNXRuntime Error with CUDA Setup Baffles User: A user encountered an error message while running ONNX with CUDA 12.2 and CUDNN 8.9, detailed as
[ONNXRuntimeError] : 1 : FAIL : LoadLibrary failed with error 126. This error highlighted a fail in loadingonnxruntime_providers_cuda.dll.
- Possible Solution Lies in CUDA Version: Another member suggested that ONNXRuntime is particular about the CUDA version and shared that using cudatoolkit 11.8 installed via conda, followed by ONNXRuntime installation from pip, resolved similar issues for them.
- Importing Torch Before ONNX: In response to the error, a member recommended trying to import Torch before ONNX. Another user confirmed that this is "most likely the issue".
CUDA MODE ▷ #pmpp-book (5 messages):
- Newbie struggles with kernel code execution: A new member is experiencing issues with a kernel that runs but doesn't produce the expected output. They shared their code on GitHub and noted that the output remains the same as the initialized values.
Link mentioned: Programming-Massively-Parallel-Processors-A-Handson-Approach/Chapter 2 Heterogeneous data parallel computing/device_vector_addition_gpu.cu at main · longlnOff/Programming-Massively-Parallel-Processors-A-Handson-Approach: Contribute to longlnOff/Programming-Massively-Parallel-Processors-A-Handson-Approach development by creating an account on GitHub.
CUDA MODE ▷ #jax (1 messages):
prometheusred: https://x.com/srush_nlp/status/1791089113002639726
CUDA MODE ▷ #off-topic (3 messages):
- Useful NVIDIA GPU Programming Guide Shared: A member shared a link to the GPU Programming Guide, providing valuable insights for fellow members interested in GPU programming.
- Twitter Link Bulletin: A member posted a Twitter link, though the specific content of the tweet was not discussed.
CUDA MODE ▷ #triton-puzzles (1 messages):
- Member tackles CUDA puzzle 10: A user shared their experience solving puzzle 10, related to the dot product, from the CUDA puzzle repository. They implemented solutions using both naive and reduction methods, with their code available on GitHub Gist.
- Floating point overflow issue: They mentioned encountering a floating-point overflow error when initializing the float arrays to 1 with a size of 20480000. The naive implementation yielded incorrect results, while the reduction implementation worked fine, and they sought help understanding this discrepancy.
- GitHub - srush/GPU-Puzzles: Solve puzzles. Learn CUDA.: Solve puzzles. Learn CUDA. Contribute to srush/GPU-Puzzles development by creating an account on GitHub.
- puzzle10_dotproduct floating point overflow error: puzzle10_dotproduct floating point overflow error. GitHub Gist: instantly share code, notes, and snippets.
CUDA MODE ▷ #llmdotc (141 messages🔥🔥):
- Nuke the bug from orbit: Members discussed solving complex dependencies across function boundaries by wiping everything from scratch. One humorously noted, "I already tried to 'nuke streams from orbit' last night, but for some reason it didn't fix the code."
- Tracking CUDA streams: There was considerable discussion on making CUDA streams an argument to each kernel launcher to better track execution. The broader consensus leaned towards resetting the code base regarding streams and redoing relevant PRs from scratch.
- Remove parallel CUDA streams: A Pull Request #417 aimed to remove parallel CUDA streams while retaining the main stream and loss event, illustrating this with detailed comments for instructional purposes.
- Gradient accumulation improvements: Another Pull Request #412 confirmed working improvements in gradient accumulation, boosting performance by 6% from 43K tok/s to 45.37K tok/s.
- NVMe GPU DMA proposal: An interesting idea was floated around using NVMe drivers with CUDA support to skip CPU/RAM steps, potentially writing directly to SSD from GPU. See ssd-gpu-dma repository for details.
- gradient clipping by global norm by ngc92 · Pull Request #315 · karpathy/llm.c: one new kernel that calculates the overall norm of the gradient, and updates to the adam kernel. Still TODO: clip value is hardcoded at function call site error handling for broken gradients would...
- Remove parallel CUDA streams while keeping main_stream and loss_event(?) by ademeure · Pull Request #417 · karpathy/llm.c: See discussion on Discord, I think whatever we eventually architect that's better than my naive folly will probably still need something similar to "main_stream" that's the default f...
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
- CUDA Runtime API :: CUDA Toolkit Documentation: no description found
- [wip] gradient accumulation, another attempt by karpathy · Pull Request #412 · karpathy/llm.c: Doesn't work. On master, we reproduce our Python script (almost) exactly by running: make train_gpt2cu NO_MULTI_GPU=1 USE_CUDNN=1 ./train_gpt2cu -b 4 -t 64 -l 1e-4 -v 200 -s 200 -a 1 -x 10 But do...
- feature/recompute by karpathy · Pull Request #422 · karpathy/llm.c: Option to recompute forward activations during backward pass. Will be an int so that 0 = don't be fancy, 1,2,3,4... (in the future) recompute more and more. This trades off VRAM for latency of a s...
CUDA MODE ▷ #bitnet (12 messages🔥):
- Bitnet 1.58 shows promise and needs a leader: A member expressed enthusiasm for leading the project setup for bitnet 1.58, noting significant improvements compared to unquantized networks. They suggested organizing the project on a platform like GitHub and shared a link to a reproducing project.
- Bitnet's quantization needs infrastructure: The bitnet 1.58 method mentioned focuses on training-aware quantization for linear layers and has a simple demo for training. However, it currently lacks 2-bit kernels or representations and needs groundwork for practical inference savings.
- Challenges in practical implementation: Discussion around how bitnet training still relies on full weight matrices with potential for post-training quantization, where a custom quantization method might be necessary. The idea of "rolling-training quantization" was suggested as a possible, albeit ambitious, path forward.
- Proposal to centralize bitnet work in Torch AO: A suggestion was made to centralize implementation efforts of bitnet in the Torch AO repository to leverage relevant infrastructure like custom CUDA/Triton op support and tensor subclasses.
- Existing solutions for quantization: It was highlighted that HQQ offers 2-bit bitpacking methods and that BitBLAS provides a 2-bit GPU kernel for inference. These resources can address some challenges in bitnet's quantization process.
- GitHub - pytorch/ao: Native PyTorch library for quantization and sparsity: Native PyTorch library for quantization and sparsity - pytorch/ao
- hqq/hqq/core/bitpack.py at master · mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
- GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
LlamaIndex ▷ #blog (6 messages):
- LlamaIndex partners with Vertex AI: LlamaIndex announced a partnership with Vertex AI to introduce a new RAG API on the Vertex platform. Check more details here.
- GPT-4o integration with create-llama: LlamaIndex now supports GPT-4o in their create-llama tool, making it easier to build a chatbot over user data by just answering a few questions. More information is available here.
- LlamaParse collaborates with Quivr: LlamaIndex has partnered with Quivr to introduce LlamaParse, allowing users to parse complex documents (.pdf, .pptx, .md) through advanced AI capabilities. Learn more about it.
- Revamped LlamaParse UI: LlamaIndex has significantly improved the LlamaParse UI, expanding the array of options available to users. See the update here.
- San Francisco Meetup Announcement: LlamaIndex announced an in-person meetup at their new San Francisco office featuring speakers from Activeloop, Tryolabs, and LlamaIndex. For details and to get on the list, visit this link.
Link mentioned: RSVP to GenAI Summit Pre-Game: Why RAG Is Not Enough? | Partiful: Note: This is an in-person meetup @LlamaIndex HQ in SF! Stop by our meetup to learn about latest innovations in building production-grade retrieval augmented generation engines for your company from ...
LlamaIndex ▷ #general (155 messages🔥🔥):
- SQL Tables Embedding Recommendations: A user sought recommendations for embedding models suitable for SQL tables. Another member suggested exploring models ranked on the MTEB Leaderboard; however, it was noted that these models focus more on textual data rather than SQL-specific data.
- On-Premise LlamaParse for Confidential Data: A query about using LlamaParse locally for confidential data led to the recommendation to contact the LlamaIndex team directly via their contact page for on-premise solutions.
- Streamlit Issues with OpenAIAgent: Troubleshooting revealed that Streamlit’s stateless behavior was causing loss of conversation memory with OpenAIAgent. The resolution involved using the `@st.cache_resource` decorator to initialize the agent, inspired by discussions on Streamlit forums.
- Claude 3 Haiku Support in LlamaIndex: Despite user confusion, it was confirmed that Claude 3 Haiku is supported in LlamaIndex as indicated by documentation links shared.
- LlamaIndex Document Loader Enhancements: Users discussed enhancing document loaders to avoid duplicates and using transformations within the ingestion pipeline. For effective document handling, attaching a
docstoreand managing document identifiers via full file paths were clarified using documentation.
- Discord | Your Place to Talk and Hang Out: Discord is the easiest way to talk over voice, video, and text. Talk, chat, hang out, and stay close with your friends and communities.
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- Talk to us — LlamaIndex, Data Framework for LLM Applications: If you have any questions about LlamaIndex please contact us and we will schedule a call as soon as possible.
- st.cache_resource - Streamlit Docs: st.cache_resource is used to cache functions that return shared global resources (e.g. database connections, ML models).
- “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
- Build your own OpenAI Agent - LlamaIndex: no description found
- OPENAI_FUNCTIONS Agent Memory won't work inside of Streamlit st.chat_input element · Issue #7061 · langchain-ai/langchain: System Info langchain = 0.0.218 python = 3.11.4 Who can help? @hwchase17 , @agola11 Information The official example notebooks/scripts My own modified scripts Related Components LLMs/Chat Models Em...
- Is there a way to run an initialization function?: Could you give an example of how i’d use this in my case please?
- [Bug]: OpenAIAgent function not called in stream mode after a tools_call type response · Issue #11708 · run-llama/llama_index: Bug Description On multiple occasions, when the agent executes a chat completion that may include responses with tool calls, the process fails to invoke functions if the response returns a JSON ind...
- Chat Stores - LlamaIndex: no description found
- GitHub - run-llama/llama_index at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0: LlamaIndex is a data framework for your LLM applications - GitHub - run-llama/llama_index at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0
- Ingestion Pipeline - LlamaIndex: no description found
- Ingestion Pipeline + Document Management - LlamaIndex: no description found
- llama_index/llama-index-integrations/llms/llama-index-llms-anthropic/llama_index/llms/anthropic/utils.py at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Anthropic Haiku Cookbook - LlamaIndex: no description found
- Using Documents - LlamaIndex: no description found
- Loading Data (Ingestion) - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (3 messages):
- Seeking Help on Implementing RAG with Llama: A user is working on a "Chat with your docs" RAG application using Cohere AI but is encountering issues with implementing RAG with Llama. They asked the community for guidance and references related to this implementation.
LAION ▷ #general (144 messages🔥🔥):
- AI's Impact on Power Grids: Users discussed the significant power consumption of GPU rigs for AI. One user stated, "a fleet of 5000 H100s consumes 375kW just for the GPU idle consumption."
- On-Device Stable Diffusion 3: A link to a tweet announced on-device Stable Diffusion 3 through a project called DiffusionKit for Mac. The project will be open-sourced in collaboration with Stability AI (tweet link).
- Open Source vs Proprietary Work Debate: Members debated the merits of working at open-source companies versus proprietary companies with higher salaries. Some pointed out that non-compete clauses at proprietary companies prevent contributing to open-source projects.
- FTC Banning Non-Compete Agreements: A discussion about the FTC's new rule banning non-compete agreements for workers (FTC announcement). Users noted that this will help protect workers and promote competition.
- GPT-4o and AI Multimodal Models: Conversations about the performance of GPT-4o in generating and modifying images, and comparisons with other models like DALL-E 3. Some users believe multimodal models are the future of AI.
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention: This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach...
- Scaling Transformer to 1M tokens and beyond with RMT: A major limitation for the broader scope of problems solvable by transformers is the quadratic scaling of computational complexity with input size. In this study, we investigate the recurrent memory a...
- Tweet from argmax (@argmaxinc): On-device Stable Diffusion 3 We are thrilled to partner with @StabilityAI for on-device inference of their latest flagship model! We are building DiffusionKit, our multi-platform on-device inference ...
- FTC Announces Rule Banning Noncompetes: Today, the Federal Trade Commission issued a final rule to promote competition by banning noncompetes nationwide, protecting the fundamen
LAION ▷ #research (20 messages🔥):
- New Video Generation Dataset Introduced: A user shared a link to a paper introducing VidProM, the first large-scale dataset comprising 1.67 million unique text-to-video prompts from real users, along with 6.69 million videos generated by state-of-the-art diffusion models. The dataset aims to address the lack of publicly available text-to-video prompt studies, differentiating itself from existing datasets like DiffusionDB. arXiv Paper.
- Neural Approach for Bilinear Sampling: A member discussed their challenges in using bilinear sampling for neural networks due to the locality of gradients. They proposed training a small neural network to approximate bilinear sampling, aiming to achieve smoothly optimizable sampling locations without hard gradient stops.
- Google's Imagen 3 Dominates: Members were excited about Google's new Imagen 3, which claims to beat all other image generation models with better detail, richer lighting, and fewer artifacts. Imagen 3 is available for selected creators via ImageFX, and members discussed using it for synthetic data generation. Google Imagen 3.
- Community Dataset Idea: Enthusiasm was expressed for generating new community datasets using APIs or scraping the internet, leveraging models like Imagen 3 for data collection.
- Stable Diffusion Super Upscale Method: A shared Reddit post detailed a new method for super upscaling images using Stable Diffusion, promising high-quality results without distortion. Super Upscale Method on Reddit.
- Imagen 3: Imagen 3 is our highest quality text-to-image model, capable of generating images with even better detail, richer lighting and fewer distracting artifacts than our previous models.
- Reddit - Dive into anything: no description found
- VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models: The arrival of Sora marks a new era for text-to-video diffusion models, bringing significant advancements in video generation and potential applications. However, Sora, along with other text-to-video ...
Eleuther ▷ #general (31 messages🔥):
- Epinet complexities spark debate: Members discussed the trade-offs and challenges of using epinets, highlighting issues like tuning difficulties and the heuristic nature of the epinet ("The epinet is supposed to be kept small though, so I assume the residual just acts as an inductive bias to maintain the epinet as a perturbation of the original output.").
- Job postings rule confusion clarified: Questions about rules for job postings were raised. Members pointed out there's a "no advertising" rule but did not delve into specific guidelines.
- AGI/ASI predictions stir up preparation talk: Conversations about AGI and its impacts included varying opinions on how soon it will arrive and what actions to take. Suggestions included learning non-automatable skills or moving to rural areas, though some advised maintaining daily life as usual ("It doesn't matter what you do so do what you would do anyway").
- PyTorch
flop_counter.pydocumentation insight shared: A member shared how to use theFlopCounterModein PyTorch. They included usage examples and explained the module tracker, though it missed details on tracking backward operations.
- lm_eval model module work invitation: A member expressed interest in contributing to the lm_eval model module for MLX. They were encouraged to proceed and document any new findings to help future contributors ("Feel free to tackle it and open a Github issue if you run into trouble.").
Eleuther ▷ #research (51 messages🔥):
- Discussing Transformer Backpropagation: Members discussed the intricacies of backpropagation in standard transformer layers, specifically how it's still "6N" even if computing the loss for only the last token. They noted nuances such as "your output projection will be back propped once instead of seq_len times", emphasizing the reduction in computational load.
- DCFormer GitHub Code Shared: A member shared a link to the DCFormer GitHub, noting its impressive results despite a convoluted structure. Other members debated the practicality and design choices documented in the associated pseudocode.
- Visual Question Answering Models: Members examined the availability and practicality of visual question answering models, mentioning BLIP3 by Salesforce. One member affirmed its capability to answer specific questions about images, positioning it between simpler object detection models and more complex vision-language models.
- Challenges with Transformers in Path Composition: A member highlighted a paper demonstrating that transformers struggle with path composition tasks. This observation aligns with known transformer weaknesses in associative learning, such as linking disjoint pieces of information correctly.
- Open LLM Leaderboard and Chat Templating Updates: Queries about evaluation harness for Open LLM Leaderboard were addressed, confirming it still uses an older version. The chat templating pull request here is in progress and expected to accommodate zero-shot scenarios soon.
- ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models: In this paper, we present the findings of our Project ALPINE which stands for ``Autoregressive Learning for Planning In NEtworks." Project ALPINE initiates a theoretical investigation into the dev...
- Salesforce/xgen-mm-phi3-mini-instruct-r-v1 · Hugging Face: no description found
- evals/docs/completion-fn-protocol.md at main · openai/evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks. - openai/evals
- GitHub - Caiyun-AI/DCFormer: Contribute to Caiyun-AI/DCFormer development by creating an account on GitHub.
- What is Visual Question Answering? - Hugging Face: no description found
- Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory: Increasing the size of a Transformer model does not always lead to enhanced performance. This phenomenon cannot be explained by the empirical scaling laws. Furthermore, improved generalization ability...
- [WIP] Add chat templating for HF models by haileyschoelkopf · Pull Request #1287 · EleutherAI/lm-evaluation-harness: This is a WIP PR , carrying on the draft @daniel-furman in #1209 started of adding the specified oft-requested chat templating feature. Current TODOs are: Check performance using e.g. OpenHermes ...
Eleuther ▷ #scaling-laws (22 messages🔥):
- Meta-learning in symbolic space is hard: A participant suggested that one could meta-learn in symbolic space by finding a symbolic function that approximates the weights of a pretrained transformer. However, another member noted that symbolic regression is challenging and proposed optimizing symbolic expressions to compress trained neural network parameters.
- Idea-dump channel proposition: One user mentioned having too many ideas and suggested creating an "idea-dump" channel for community projects. Another user pointed to a potential existing ideas board, but it was unclear if it still exists.
- AGI delegation for ideas: Discussion veered into hopes for future AGI that could handle idea execution. One participant humorously remarked on even delegating the generation of ideas to AGI, while another compared the idea generation process to an enjoyable part of life that shouldn't be delegated.
- Post-training improvements in GPT-4: A quoted conversation highlighted how post-training significantly improves model performance, contributing to a substantial increase in GPT-4's Elo score. The discussion implied that while post-training can yield substantial improvements, eventually new training may be needed when post-training efficiencies wane.
- Attention approximation with MLPs: A user mused about the possibility of training an MLP to approximate attention computations and using it as initialization in a transformer model sans attention layers. They speculated if this straightforward follow-up work had been explored in any existing paper post-Vaswani et al.
Eleuther ▷ #interpretability-general (1 messages):
alofty: https://x.com/davidbau/status/1790218790699180182?s=46
Eleuther ▷ #lm-thunderdome (3 messages):
- Export multiple choice answers via
--log_samples: A member inquired about exporting individual answers for multiple-choice questions to compare correct/incorrect answer distributions. They were advised to use--log_sampleswhich stores log files containing model log likelihoods and per-sample metrics like accuracy.
Eleuther ▷ #gpt-neox-dev (31 messages🔥):
- Struggle during model conversion: A user faced issues converting a model trained with GPT-NeoX to Huggingface format using
convert_neox_to_hf.py. Errors included missingword_embeddings.weightandattention.dense.weight.
- Investigating the conversion issue: Hailey Schoelkopf offered to investigate the conversion issues, noting that the conversion script was previously tested. The problem persisted even with the default 125M configuration.
- Pipeline Parallelism naming conflict: Differences in file naming conventions for Pipeline Parallelism (PP) were identified as a source of errors. Files saved with PP=2 use a different naming convention than those saved with PP=1, causing the conversion script to fail.
- MoE PR changes: It was discovered that changes in the MoE PR affected the
is_pipe_parallelbehavior, prompting fixes in the conversion script. Hailey Schoelkopf submitted a bugfix PR addressing these issues.
- Config file incompatibility: The user experiencing issues was advised to use a different configuration file supported by Huggingface after identifying unsupported configurations involving
rmsnormin the transformers library.
- gpt-neox/tools/upload.py at 2e40e40b00493ed078323cdd22c82776f7a0ad2d · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
- Conversion script bugfixes by haileyschoelkopf · Pull Request #1218 · EleutherAI/gpt-neox: Updates the NeoX-to-HF conversion utilities to fix the following problems: #1129 tweaks the default is_pipe_parallel behavior s.t. PP=1 models no longer are trained using PipelineModules, since Mo...
- Add MoE by yang · Pull Request #1129 · EleutherAI/gpt-neox: Closes #479
Interconnects (Nathan Lambert) ▷ #other-papers (10 messages🔥):
- Neural Networks Converge on Reality: A member states, "Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces." This highlights the convergence of varied neural network representations onto a unified model of reality.
- Phillip Isola's Insights Shared: Links were shared to Phillipi's project site, an arxiv paper, and a Twitter thread showcasing new results. It was noted that as large language models (LLMs) improve, their learned representations become more similar to those of vision models and vice versa.
- Intellectual Humility and Agreement: A member confessed, "I feel like I'm not smart enough to understand this but its cool," indicating a mix of awe and confusion. Another noted they understood the conclusions and found them exciting yet aligned with existing assumptions in the AI field.
- Mechanistic Interpretation Field: The conclusion that different neural models converge on similar representations was summarized as key to the mechanistic interpretation field. This mutual understanding strengthens the idea that interpreting neural network mechanics is crucial.
Link mentioned: Tweet from Phillip Isola (@phillip_isola): We survey evidence from the literature, then provide several new results including: As LLMs get bigger and better, they learn representations that are more and more similar to those learned by visi...
Interconnects (Nathan Lambert) ▷ #ml-questions (16 messages🔥):
- OpenAI's model numbering quirks amuse members: A user humorously noted that OpenAI often trains new models from scratch without assigning them new numbers. Another respondent agreed, commenting on the company's tendency to "obscivate."
- Tokenization possibilities spark curiosity: Members discussed whether the tokenizer for a new multi-modal model could be "fake." One user hypothesized that sharing a tokenizer across different modalities would not make sense, implying that each modality might have its own tokenizer.
- Trust vs skepticism on OpenAI's methods: While some members showed skepticism about OpenAI's tokenization methods, others suggested giving the company the benefit of the doubt. One user notably remarked that although the project might seem "a total mess," the details should be available somewhere.
Interconnects (Nathan Lambert) ▷ #random (64 messages🔥🔥):
- Anthropic becomes a product company: The transition of Anthropic from a service-based to a product-oriented company was noted, with references to investor expectations and the necessity of product development for data improvement. One member commented on the inevitability of this shift over time.
- AI companies' business model struggles: OpenAI, Anthropic, and similar firms face challenges due to their reliance on external infrastructure and commoditization by product companies, leading to potentially unsustainable valuations. One member drew parallels to historical tech giants like IBM and Cisco, highlighting the risk of not meeting growth expectations.
- OpenAI's new ventures and recruitment: OpenAI's upcoming search engine, aimed at competing with Google, has been confirmed along with the hiring of a former Google executive to lead the initiative. This suggests a significant strategic shift towards commercialized products.
- Discussion on AGI timelines: In reference to a Dwarkesh interview, members debated the practicality of AGI arriving in the near future, with differing opinions on the sensibility and relevance of such timelines.
- Changes in AI model performance and transparency: Members discussed changes in GPT-4o's performance scores, noting a significant unexplained drop in ELO ratings and parts of LMsys evaluations. Concerns about the lack of transparency and update mechanisms for model performance metrics were also raised. Links to related discussions and announcements were shared.
- Tweet from William Fedus (@LiamFedus): But the ELO can ultimately become bounded by the difficulty of the prompts (i.e. can’t achieve arbitrarily high win rates on the prompt: “what’s up”). We find on harder prompt sets — and in particular...
- Tweet from The Information (@theinformation): OpenAI has hired Shivakumar Venkataraman, a 21-year Google veteran who previously led the company’s search ads business. The move comes as OpenAI develops a search engine that would compete with Goog...
- Sam Altman talks GPT-4o and Predicts the Future of AI: On the day of the ChatGPT-4o announcement, Sam Altman sat down to share behind-the-scenes details of the launch and offer his predictions for the future of A...
- Behind the scenes scaling ChatGPT - Evan Morikawa at LeadDev West Coast 2023: Behind the scenes scaling ChatGPTThis is a behind the scenes look at how we scaled ChatGPT and the OpenAI APIs.Scaling teams and infrastructure is hard. It's...
- Tweet from Evan Morikawa (@E0M): I'm leaving @OpenAI after 3½ yrs. I'll be joining my good friend Andy Barry (Boston Dynamics) + @peteflorence & @andyzeng_ (DeepMind 🤖) on a brand new initiative! I think this will be necessa...
- Tweet from Teknium (e/λ) (@Teknium1): Its up now I dont remember what the old score was, but it seems a bit closer to 4-turbo now, for coding the uncertainty is pretty huge, but its a big lead too Quoting Wei-Lin Chiang (@infwinston) @...
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Skipping Huberman gets approval: Nathan Lambert expressed relief about never listening to Huberman, sharing a link to his tweet. The context of the tweet or the reasons for his feelings weren't discussed.
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
- OpenAI Praise and Critique: "Last two posts go from praising openAI's technical leadership to full dunking on their cultural presentation." Nathan Lambert highlights the contrasting opinions in recent posts about OpenAI, describing it as a "classic" shift.
- Crafting Posts is Enjoyable: Nathan Lambert expresses that writing the recent posts was challenging but felt more like a "craft" than usual. This indicates the effort and satisfaction derived from the work.
LangChain AI ▷ #general (86 messages🔥🔥):
- Streaming Output with LangChain Misunderstanding Clarified: A user misunderstood how
.streamworks withAgentExecutorin LangChain, expecting it to stream individual tokens. They were advised to use the.astream_eventsAPI for custom streaming with individual token output, not just intermediate steps. Streaming Documentation.
- Fix for Jsonloader on Windows 11: A member shared a link to a fix for an issue where Jsonloader uses jq schema to parse JSON files, which cannot be installed on Windows 11. Issue #21658.
- Transfer Embeddings between Vector Databases: Discussion involved migrating embeddings from pgvector to qdrant. It was suggested to either look for migration tools or regenerate embeddings from the original corpus due to concerns about retriever speed.
- Index Name Issue with Neo4j: A user reported issues with
index_namenot updating and always reverting to the first index used. They were advised to create separate instances for different indexes and check for potential bugs.
- Adding Memory to Chatbot: There were questions about incorporating memory into chatbots to retain context across queries. Solutions suggested included keeping track of chat history and adding placeholders for memory variables in the prompt, with links to relevant documentation.
- MultiQueryRetriever | 🦜️🔗 LangChain: Distance-based vector database retrieval embeds (represents) queries in high-dimensional space and finds similar embedded documents based on "distance". But, retrieval may produce different ...
- Matryoshka embeddings: faster OpenAI vector search using Adaptive Retrieval: Use Adaptive Retrieval to improve query performance with OpenAI's new embedding models
- Postgres Embedding | 🦜️🔗 LangChain: Postgres Embedding is an open-source vector similarity search for Postgres that uses Hierarchical Navigable Small Worlds (HNSW) for approximate nearest neighbor search.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- DOC: Jsonloader uses jq schema to parse Json files which cannot be installed on windows 11 · Issue #21658 · langchain-ai/langchain: Checklist I added a very descriptive title to this issue. I included a link to the documentation page I am referring to (if applicable). Issue with current documentation: document : https://python....
- PGVector | 🦜️🔗 LangChain: An implementation of LangChain vectorstore abstraction using postgres as the backend and utilizing the pgvector extension.
- Neo4j Vector Index | 🦜️🔗 LangChain: Neo4j is an open-source graph database with integrated support for vector similarity search
- Custom agent | 🦜️🔗 LangChain: This notebook goes through how to create your own custom agent.
- Memory management | 🦜️🔗 LangChain: A key feature of chatbots is their ability to use content of previous conversation turns as context. This state management can take several forms, including:
- Streaming | 🦜️🔗 LangChain: Streaming is an important UX consideration for LLM apps, and agents are no exception. Streaming with agents is made more complicated by the fact that it's not just tokens of the final answer that...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- langchain.retrievers.multi_query.MultiQueryRetriever — 🦜🔗 LangChain 0.2.0rc2: no description found
- langchain.chains.llm.LLMChain — 🦜🔗 LangChain 0.2.0rc2: no description found
LangChain AI ▷ #langserve (2 messages):
- Rate Exceeded Errors disrupt workflows: A member noted that they encounter "rate exceeded" errors when loading their server URL with "/docs," leading to workflow disruptions. They inquired if switching to a Pro plan with Langsmith might solve this issue.
- Server Inactivity hinders consistent use: The same user mentioned that their server goes into sleep mode or becomes inactive at intervals, affecting the consistent usage of the service. They sought insights into the cause and potential fixes for this problem.
- Logs for deployed Revisions requested: An extra question was posed about whether it's possible to view logs for a deployed revision beyond just the build logs. This would help in better monitoring and debugging their deployments.
- Investigating patterns for rate limits and inactivity: Another member asked if there were any identifiable patterns related to RAG source sizing affecting the rate limit or any noted timeout intervals for when the server goes to sleep.
LangChain AI ▷ #share-your-work (2 messages):
- Jumpstart crypto payments in Langserve backend: A user is leveraging py4j libraries to interface a JAR in a JVM from a Langserve backend for crypto SDK hits. This enables micropayments for prompt/response token counts with an adjustable profit margin on top of the OpenAI API prepaid keypair.
- Launch of a Real Estate AI Assistant: A user announced a new AI tool, combining LLMs, RAG with LangChain, and interactive UI components from @vercel AI and @LumaLabsAI for a unique real estate experience. They shared their project on LinkedIn and a demo on YouTube.
LangChain AI ▷ #tutorials (1 messages):
- Explore Universal Web Scraper Agent: A member shared a video on a universal web scraper agent that can directly use the browser. The video covers handling tasks like pagination, CAPTCHA, and more complex web scraping functionalities.
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
- Hindi 8B Chatbot Model Released: A new text generator language model named "pranavajay/hindi-8b" has been introduced, specifically fine-tuned for Hindi conversational tasks. This model boasts 10.2B parameters and is geared towards chatbot and language translation applications, making it highly versatile for engaging, contextually relevant interactions.
- ChatterUI Simplifies Mobile Chatbots: ChatterUI is a straightforward, character-focused UI for Android that supports various backends, including OpenRouter. It’s likened to SillyTavern but with fewer features, running natively on your device, and its repository is available on GitHub.
- Invisibility MacOS Copilot Launched: A free MacOS Copilot called Invisibility has been unveiled, powered by GPT4o, Gemini 1.5 Pro, and Claude-3 Opus. It includes a new video sidekick for seamless context absorption, with upcoming developments for voice and long-term memory functionalities, and an iOS version is underway (source).
- pranavajay/hindi-8b · Hugging Face: no description found
- Tweet from SKG (ceo @ piedpiper) (@sulaimanghori): So we've been cooking the last few weeks. Excited to finally unveil Invisibility: the dedicated MacOS Copilot. Powered by GPT4o, Gemini 1.5 Pro and Claude-3 Opus, now available for free -> @inv...
- GitHub - Vali-98/ChatterUI: Simple frontend for LLMs built in react-native.: Simple frontend for LLMs built in react-native. Contribute to Vali-98/ChatterUI development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (82 messages🔥🔥):
- Switching to Lepton for WizardLM-2 8x22B Nitro: Members discussed switching to Lepton on SillyTavern for better performance, confirming it can be selected in OpenRouter's Text Completion API. "Lepton is available on OR as a provider", but note that it has been removed from some lists due to issues.
- Llama3 Finetune Announcement: A community member announced a new Llama3 finetune 70B aimed at roleplay (RP) and chain of thought tasks in a dedicated channel. They requested reactions to support their ongoing work.
- Public Model Viewer/Explorer Tool: A user shared an updated version of their OpenRouter model list watcher and explorer, highlighting its improved mobile-friendly UI and requesting feedback: Model List Explorer.
- Handling Large Token Contexts Efficiently: Discussions mentioned Google's use of InfiniAttention for efficient large-token context handling in Transformers, referencing the related research paper.
- Custom Provider Selection Information: Information was shared about OpenRouter's capabilities for prioritizing providers based on price and performance, as explained in their documentation. This feature aims to aid in the effective selection of the best language models.
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention: This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach...
- Mermaid | Diagramming and charting tool: no description found
- Pricing | Lepton AI: Run AI applications efficiently, at scale, and in minutes with a cloud native platform.
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- OpenRouter API Watcher: OpenRouter API Watcher monitors changes in OpenRouter models and stores those changes in a SQLite database. It queries the model list via the API every hour.
- OpenRouter: Build model-agnostic AI apps
OpenInterpreter ▷ #general (19 messages🔥):
- OpenAI invites desktop app hackers for feedback: A member revealed that after bypassing the gatekeeper dialog of OpenAI’s desktop app, they were invited to a private Discord to help shape its development. They expressed excitement about being embraced and included in the feedback process.
- GPT-4o lacks image recognition in OI: Multiple users discussed their struggles with using the image recognition function of GPT-4o through OpenInterpreter (OI). Despite various efforts, including debugging, they noted the function stops at taking a screenshot.
- Dolphin-mixtral:8x22b is slow but effective: A user shared their experience with trying different local LLMs and settled on dolphin-mixtral:8x22b due to its effective performance despite being very slow, processing only 3-4 tokens per second. They noted that CodeGemma:Instruct is faster and serves as a reasonable middle ground.
- Saving OI chat history: A new user inquired about saving the chat history of their OI interactions. Another member responded, explaining that using the
--conversationsflag when starting the interpreter allows users to pull up previous conversations.
- Improvements with GPT-4o for development tasks: A user detailed their positive experience using GPT-4o for web development tasks in React, noting that it handled multiple components, routing, and data swapping without issues. They thanked the OpenInterpreter team and shared excitement for future developments.
OpenInterpreter ▷ #O1 (55 messages🔥🔥):
- Address Configuration Roadblocks in 01: A member discusses issues with updating the grok server address due to captive portal limitations, suggesting a unified configuration page for both Wi-Fi and server setup.
- LED Colors for Device Status: There's consideration for enhancing the device's LED feedback system with additional colors to indicate various states like "Launching WiFi AP" and "Establishing connection to server". Current states are limited to a couple of colors.
- TestFlight Approval and Debugging: The TestFlight link is shared (TestFlight link), alongside a new terminal feature for debugging. Users discuss setup specifics and resolve a no-audio issue caused by incorrect flags.
- OpenRouter and Configuration Issues: Members troubleshoot getting 01 to work with OpenRouter, sharing workarounds and noting inconsistencies with model compatibility like "openrouter/meta-llama/llama-3-70b-instruct:nitro". Issues with Groq and looping prompts are also noted.
- Installation and Setup Challenges: Discussing installation issues, one user details error messages and solutions while setting up 01 on Linux using Poetry. A clean restart is considered after running into multiple installation-related errors.
- Shortcuts: no description found
- Setup - 01: no description found
- no title found: no description found
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- 01/software at main · OpenInterpreter/01: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
- Introduction - Open Interpreter: no description found
- GitHub - OpenInterpreter/01: The open-source language model computer: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
Datasette - LLM (@SimonW) ▷ #ai (64 messages🔥🔥):
- Google I/O fails to acknowledge LLM reliability issues: Members expressed frustration that during the Google I/O keynotes, there was no mention of the unreliable nature of LLMs. "The thing that weirded me out about the I/O keynotes is that they didn't seem to acknowledge the unreliable nature of LLMs /at all/ - not even a nod towards that."
- Sober AI showcase proposed: Discussed the idea of creating a "Sober AI" showcase focusing on practical, mundane AI applications that work without overhyping capabilities. "Something like this: ... I'm considering introducing it as 'this is not a big talk about artificial intelligence, its a small talk about large language models and what we can do with them right now.'"
- Gloo's role in MuckRock's AI integration: Gloo, a third-party wrapper on Open AI's models, helps MuckRock to classify FOIA responses and perform other tasks. "If you want more details on what we're doing, he's mitch@muckrock.com."
- Introducing "Transformative AI": Members discussed framing AI as "transformative" rather than "generative" to better highlight its utility in transforming and working with data. "I'm also going to pitch 'transformative AI' as a more useful framing than 'generative AI', because using LLMs to work with and transform input is a whole lot more interesting."
- Technical insights on prompt caching: A member noted that using Gemini's prompt caching can reduce token usage costs by keeping prompts in GPU memory. "You have to pay to keep the cache warm - $4.50/million-tokens/hour - so that means your prompt is actively loaded into the memory of a GPU somewhere, saving it from having to load in and process it every time."
- AI news that's fit to print: How news organizations are using AI in good and bad ways.
- no title found: no description found
- We have to stop ignoring AI’s hallucination problem: AI might be cool, but it’s also a big fat liar.
- Boundary | The all-in-one toolkit for AI engineers: no description found
- ChatGPT in “4o” mode is not running the new features yet: Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features: Creepily good improvements to the ability to both understand and produce voice (Sam Altman simply tweeted ...
- llama.cpp/examples/main/main.cpp at e1b40ac3b94824d761b5e26ea1bc5692706029d9 · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- no title found: no description found
- muckrock/muckrock/foia/tasks.py at 11eb9a155fd52140184d1ed4f88bf5097eb5e785 · MuckRock/muckrock: MuckRock's source code - Please report bugs, issues and feature requests to info@muckrock.com - MuckRock/muckrock
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- Switching models mid-conversation causes concerns: A user pondered the implications of continuing a logged conversation with a different model, such as switching to
4o. They expressed worry about potential corruption of their existing conversation but considered extracting JSON logs from the latest entry in the SQLite table as a workaround. - Mac desktop solution appears abandoned: A fan of SimonW's work noted that the Mac desktop solution seems to have been abandoned about a year ago at version 0.2. They are considering investigating other options for an easy onramp to avoid building themselves into a corner.
Latent Space ▷ #ai-general-chat (54 messages🔥):
- Dwarkesh Patel episode discussed: A member called Dwarkesh Patel's latest episode "another banger", noting a segment that seemed "painful to watch" due to John's lack of belief and engagement during the interview. They also mentioned it was considered overall mid but got big guests for Patel.
- OpenAI hires Google veteran: OpenAI has hired Shivakumar Venkataraman, a 21-year Google veteran. The move signifies OpenAI's strategic push to develop a search engine, directly challenging Google's core product.
- Model merging and GPT discussions: Members noted Nous Research's interesting direction in model merging. Discussions about the term "post-training" revealed it's meant to encompass various techniques like RLHF, fine-tuning, and quantization.
- Rich text translation issues: Several users discussed challenges and potential solutions for translating rich text content while preserving span semantics. One suggested HTML as an intermediary format to maintain consistency in span translation.
- Hugging Face commits $10M for community GPUs: Hugging Face committed $10 million in free shared GPUs to help smaller developers, academics, and startups, aiming to counter AI centralization and support open advancements.
- Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
- Tweet from The Information (@theinformation): OpenAI has hired Shivakumar Venkataraman, a 21-year Google veteran who previously led the company’s search ads business. The move comes as OpenAI develops a search engine that would compete with Goog...
- Tweet from mark erdmann (@markerdmann): gpt-4o breakthrough on this torturously difficult needle-in-a-needle benchmark. this is really exciting. i'm looking forward to testing this against some of our internal usecases at pulley that re...
- Tweet from Dwarkesh Patel (@dwarkesh_sp): Here's my episode with @johnschulman2 (cofounder of OpenAI & led ChatGPT creation) On how post-training tames the shoggoth, and the nature of the progress to come... Links below. Enjoy!
- Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
- Sam Altman talks GPT-4o and Predicts the Future of AI: On the day of the ChatGPT-4o announcement, Sam Altman sat down to share behind-the-scenes details of the launch and offer his predictions for the future of A...
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new pod drop! https://twitter.com/latentspacepod/status/1791167129280233696
OpenAccess AI Collective (axolotl) ▷ #general (33 messages🔥):
- LLaMA vs Falcon Debate: A discussion evolved comparing Falcon 11B and LLaMA 3, highlighting that Falcon's license isn't fully open but is more open than LLaMA’s. One member noted "Falcon 2 license has one deeply problematic clause" regarding updates to the Acceptable Use Policy that might be unenforceable.
- Training Mistral and TinyLlama: A member shared an issue with TinyLlama where training crashes unless manually launched with a specific command using
accelerate. They noted "manual workaround is working" and sought reasons for this discrepancy.
- Hunyuan-DiT Model Announcement: A link to the new Hunyuan-DiT model was shared, showcasing a multi-resolution diffusion transformer with fine-grained Chinese understanding, with details available on the project page and arXiv paper.
- Chat Format Consistency: Members discussed issues with using Alpaca format for training, with one mentioning they prefer to keep their chat formats consistent and found Alpaca follow-up questions lacking.
- ChatML and LLaMA Tokens: Inquiries about using special tokenizers for LLaMA 3 were addressed, with confirmation that ShareGPT format works for training as ChatML or LLaMA 3 conversation types without special tokens.
Link mentioned: Tencent-Hunyuan/HunyuanDiT · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
- LORA training benefits from original prompts: A member asked if it's better to use the original prompt style the underlying model was trained with when doing a LORA. Another member confirmed, especially with LORA, reformatting to the original style, such as the llama3 style
<|eot|>tokens, yields better results. - Python environment issues in Docker: A member reported encountering an AttributeError: LLAMA3 in Docker. They were advised to check if their pip was updated.
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
- STEM MMLU fully categorized: The dataset discussed appears to be a detailed categorization of STEM-related topics within the MMLU benchmark. As noted, it encompasses more content beyond typical MMLU coverage.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (8 messages🔥):
- Working Docker setup with 8xH100 PCIe: A member confirmed that using the 8xH100 PCIe configuration worked for them with Docker. They specified that the SXM variant was unavailable, so they couldn't test that one.
- Docker troubleshooting streak continues: A member shared their success with getting Docker to work, clarifying their usage of the 8xH100 variant. They thanked for the confirmation and acknowledged the shared setup info.
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (13 messages🔥):
- DrTristanbehrens asks about API for agent control: A member inquired if AI Town exposes agent control via an API for connecting their own code to the simulation. Another member mentioned that agent-specific LLMs are not currently supported but have been discussed in the context of LLamaFarm.
- Discussion on different API levels: A member elaborated on different API levels for agent control, suggesting scenarios for running custom code or interfacing through OpenAI-compliant APIs for completions and embeddings. They also discussed the possibility of a semantic API for interactions and memory management.
- Discord iframe for AI Town gains interest: Members discussed the potential of creating a Discord iframe for AI Town that could include multiplayer activities and games. One member remarked that it wouldn't be difficult to implement and could become very popular.
- Community involvement in development: Multiple members expressed interest in contributing to the Discord iframe project, suggesting it could be a "low risk high reward opportunity." One member offered to start working on it soon and expressed excitement about new multiplayer activity features, specifically mentioning Zaranova.
Link mentioned: Tweet from Hugo Duprez (@HugoDuprez): Folks building @discord activities, I made a ready-to-use starter template 🕹️ Batteries included with physics and multiplayer ⚡️ @JoshLu @RamonDarioIT
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (10 messages🔥):
- Reducing NPC activity improves performance: One member suggested "One easy way is to reduce the number of NPCs" and mentioned that tuning cooldown constants can affect how long NPCs wait between activities.
- New member seeks avatar change help: A new member asked, "can someone help me to change the avatar of the character?" Another member confirmed the solution was found, "I could do it thank you by the way".
- Launch of AI Reality TV Platform: A member announced, "We are launching our new AI Reality TV platform tomorrow... If you have a custom map that you want me to add to the platform, let me know!". They expressed openness to community contributions to enhance the initial launch.
AI Stack Devs (Yoko Li) ▷ #late-night-lounge (2 messages):
- Sequoia Capital's PMF Framework Shared: A member shared a link to Sequoia Capital's article on the Arc Product-Market Fit (PMF) Framework. The article outlines three archetypes of PMF, aiming to help founders understand their product’s place in the market.
Link mentioned: The Arc PMF framework: This framework outlines three distinct archetypes of PMF which help you understand your product’s place in the market and determine how your company operates.
tinygrad (George Hotz) ▷ #general (10 messages🔥):
- Complexity in trig functions sparks CORDIC algorithm suggestion: Discussion ensued over using the CORDIC algorithm for computing sin and cos functions, as suggested it might be simpler and faster than Taylor approximation. A member shared a detailed implementation, highlighting how it reduces complexity and saving lines of code by adopting it for multiple calculations.
- CORDIC implementation code snippet shared: The implementation of CORDIC in Python was demonstrated, showing how the algorithm approximates sine and cosine values. Key functions for computing constants and reducing argument values were shared to illustrate its potential efficiency.
- Debate on handling large argument values in trigonometric functions: Members debated the challenges of reducing large arguments for trigonometric calculations. Emphasis was placed on accurately handling reductions to ranges like (-π) to (π) or (-π/2) to (π/2) for maintaining precision.
- Concern over application and fallback for large trig values: Questions were raised about the necessity of handling large trigonometric values in machine learning contexts. There was also a discussion on the potential to fallback or optimize for GPU calculations using Taylor expansions.
- ONNX Runtime error mentioned: One member posted an error encountered when running ONNX, highlighting a specific provider bridge issue with CUDA. The error log was shared for troubleshooting purposes.
tinygrad (George Hotz) ▷ #learn-tinygrad (14 messages🔥):
- Visualize shape index expressions with a new tool: A user introduced a tool for visualizing shape expressions used in view and shapetracker operations, making complex mappings between reshaped data layouts easier to understand. You can try the tool here.
- TACO code generation explored: Another user shared information about TACO, which converts tensor algebra into generated code using customizable tensor formats. It's a foundational tool for anyone looking into efficient tensor computations.
- Efficient CUDA kernel proposed for large tensor reductions: A member discussed the challenge of reducing large tensor elements without storing intermediates in VRAM. They proposed using a custom CUDA kernel to accumulate results directly, seeking insights on how Tinygrad might handle such optimizations.
- Learning aid suggestion for Tinygrad: A user recommended UseAdrenaline as a helpful app for understanding and learning from various repos, including Tinygrad. They praised its effectiveness in enhancing their learning process.
- Clarification requested on compute graph operations: A user sought confirmation on understanding uops in a compute graph, specifically asking about the
DEFINE_GLOBALoperation and the significance of the output buffer tag. This highlights a common need for clarity around low-level tensor operations.
- Adrenaline: no description found
- Shape & Stride Visualizer: no description found
- Web Tool: Website for the TACO project
- Google Colab: no description found
MLOps @Chipro ▷ #events (9 messages🔥):
- Members plan to meet at Data AI Summit: A user from Sydney mentioned that they will be in the Bay Area from June 6 - June 16 for the Data AI Summit and is looking forward to meeting others. Another member responded that they will be there too and expressed interest in connecting.
- Chip's monthly casual event on pause: A user asked where to find Chip's monthly casual link. Chip responded that there won't be any such events for the next few months.
- Snowflake Dev Day invitation: Chip invited members to visit their booth at Snowflake Dev Day on June 6.
- NVIDIA and LangChain contest announcement: Chip shared a contest launched by NVIDIA and LangChain with a chance to win an NVIDIA® GeForce RTX™ 4090 GPU and other rewards.
- Eligibility issues for NVIDIA contest: A user expressed disappointment that their country is not eligible for the NVIDIA and LangChain contest. Chip humorously suggested they move countries.
Link mentioned: Generative AI Agents Developer Contest by NVIDIA & LangChain: Register Now! #NVIDIADevContest #LangChain
MLOps @Chipro ▷ #general-ml (1 messages):
- History of AI Hardware Explored: A member shared a long article reviewing the history of microprocessors in machine learning and AI and making future predictions. It emphasizes the importance of understanding where we are on the sigmoid curve to spot trends effectively.
- Transformers' Dominance Acknowledged: The article discusses the significant breakthroughs over the last 4 years in AI due to transformer-based models, citing Mamba Explained as an example. It notes the excitement in the industry, highlighting Nvidia's market valuation surpassing $2.2 trillion.
- Future Hardware Predictions: The author expresses optimism about NVMe drives and Tenstorrent technology over the next 3-4 years. Conversely, they are lukewarm on the prospects of GPUs in the 5-10 year timeframe.
Link mentioned: The Past, Present, and Future of AI Hardware - SingleLunch: no description found
Cohere ▷ #general (10 messages🔥):
- Cohere reranker impresses but needs highlighting support: A member reported achieving their best result so far by using Cohere's reranker
[rerank-multilingual-v3.0](https://example.link). They need a feature similar to ColBERT that highlights which words were more relevant for the retrieval task.
- Cohere connectors clarification: A member inquired about how Cohere connectors work, asking if they send the exact query to the connector API or only parts/keywords extracted from the question. Another member clarified that connectors are for connecting to data sources to use with the model.
- PHP client query for Cohere: A member shared a GitHub link to a PHP client for Cohere (cohere-php) but hasn't tried it yet. They are seeking recommendations for a good PHP client for Cohere.
- Cohere application toolkit and reranking model inquiry: A member asked about the advantages of using the Cohere application toolkit in production, specifically its ability to scale up/down based on usage. They also sought to understand why the Cohere reranking model performs better compared to other open-source models.
Link mentioned: GitHub - hkulekci/cohere-php: Contribute to hkulekci/cohere-php development by creating an account on GitHub.
DiscoResearch ▷ #general (2 messages):
- Ilya leaves OpenAI: A member shared a tweet announcing that Ilya is leaving OpenAI. This departure sparks speculation about OpenAI's attractiveness to alignment researchers.
- OpenAI seems less attractive for alignment researchers: Responding to the news of Ilya's departure, another member commented, "They're obviously not that attractive for alignment researchers anymore." This suggests concerns about alignment research direction and leadership within OpenAI.
DiscoResearch ▷ #benchmark_dev (1 messages):
- New NIAN benchmark challenges even GPT-4-turbo: Needle in a Needlestack (NIAN) is a new, more challenging benchmark designed to evaluate how effectively LLMs can pay attention to content in their context window. Despite advancements, "even GPT-4-turbo struggles with this benchmark." Check out the code and website for more details.
Link mentioned: Reddit - Dive into anything: no description found
LLM Perf Enthusiasts AI ▷ #jobs (2 messages):
- Ambush Seeks Senior Fullstack Web Dev: Ambush, an AI studio focusing on products for traders and DeFi users, is hiring a remote senior fullstack web developer. Check the job listing for more details and share with your network; a $5k referral bonus is offered if they hire your referral.
- Preferred Traits in Candidates: Ideal candidates should have a strong eye for design, intuitive UX, and be familiar with DeFi as a native user. The role involves 70% frontend and 30% backend work, with a bonus for those with experience in AI consumer products.
Link mentioned: Remote Senior Web Developer (Full-Stack) at Ambush: Ambush is looking to hire a Remote Senior Web Developer (Full-Stack) to join their team. This is a full-time position that can be done remotely anywhere in Americas, Asia, Europe or the United Kingdom...
Mozilla AI ▷ #llamafile (2 messages):
- Markdown hyperlinks rendering issue: A user reports that hyperlinks returned by the server in the llamafile project are not rendered into HTML, asking if it's a known issue and offering to create a GitHub issue and PR to address it. They provided a GitHub link to the relevant code.
- Timeout problem in private search assistant: Another user shared their experience with a private search assistant project, detailed in this post, facing timeout issues after generating only 9% of embeddings. They included DEBUG logs showing the httpx.ReadTimeout error and asked for advice on increasing the timeout.
- llamafile-llamaindex-examples/example.md at main · Mozilla-Ocho/llamafile-llamaindex-examples: Contribute to Mozilla-Ocho/llamafile-llamaindex-examples development by creating an account on GitHub.
- llamafile/llama.cpp/server/public/index.html at d5f614c9d7d1efdf6d40a8812d7f148f41aa1072 · Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.