[AINews] Stable Diffusion 3 — Rombach & Esser did it again!
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 3/4-3/5/2024. We checked 356 Twitters and 22 Discords (352 channels, and 7550 messages) for you. Estimated reading time saved (at 200wpm): 697 minutes.
Warm welcome to the >2500 people who joined from Soumith's shoutout last night! Its kinda like having a crowd of visitors over when the house isn't clean yet - we're still very much building the plane while we jump off a cliff. But we're increasingly happy with our prompts, pipeline, and exploration of what useful, SOTA LLM-based summarization can and should do.
Lots of people are still processing Claude 3 but we're moving on. Today's big news is the Stable Diffusion 3 paper. SD3 was announced (not released) a few days ago, but the paper provides much more detail.
Obligatory images because really who reads the text I'm writing here when you can see pretty pictures:

We are more impressed with the incredible level of text-in-image control and handling of complex prompts (see the progress over the last 2 years):

Paper highlights here but in short they have modified Bill Peebles' Diffusion Transformer (yes the one used in Sora) to be even more multimodal, hence "MMDiT":
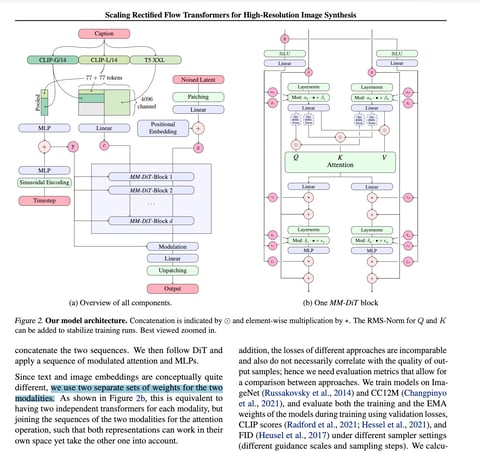
DiT variants have been the subject of intense research this year, eg for Hourglass Diffusion and Emo.
Stability's messaging around its benchmarks has been all over the place recently (e.g. for SD2 and SDXL and , making it unclear whether the main benefit is image quality or open source customizability or something else, but SD3 is pretty unambiguous - when evaluated on Partiprompts questions via REAL HUMANS ($$$), SD3's win rate beats all other SOTA image gen models (except perhaps Ideogram).
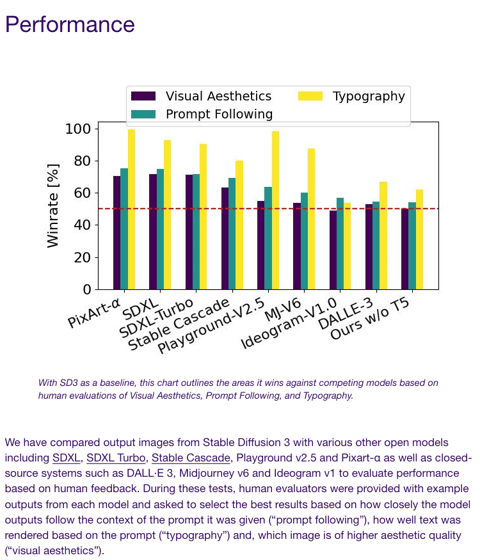
It's currently unclear whether the 8B SD3 model will ever be released beyond Stability's API wall. But surely a new SOTA model, from the people that launched the new imagegen summer, is to be celebrated regardless.
Table of Contents
We are experimenting with removing Table of Contents as many people reported it wasn't as helpful as hoped. Let us know if you miss the TOCs, or they'll be gone permanently.
PART X: AI Twitter Recap
Claude 3 Sonnet (14B?)
Anthropic Claude 3 Release
- Anthropic released Claude 3 models, which some feel are slightly better than GPT-4 and significantly better than other models like Mistral. Key improvements include more human-like responses and ability to roleplay with emotional depth.
- Claude 3 scored 79.88% on a HumanEval test, lower than GPT-4's 88% on the same test. It is also over 2x the price of GPT-4.
- There are now three top-tier models of comparable intelligence (Anthropic Claude 3, OpenAI GPT-4, Anthropic Gemini Ultra), enabling advances in imitation-based fine-tuning.
AI Model Releases & Datasets
- Microsoft released new Orca-based models and datasets.
- Stability AI and Tripo AI released TripoSR, an image-to-3D model capable of high quality outputs in under a second.
- DolphinCoder-StarCoder2-15b was released by Latitude with strong coding knowledge. Smaller StarCoder2 models and CodeLlama are planned.
AI Capabilities & Use Cases
- Claude 3 models are very good at generating d3 visualizations from text descriptions.
- Perplexity AI is integrating Playground AI's image models to enhance answers with visual illustrations.
- PolySpectra uses LLMs to generate 3D CAD models from text prompts, powered by LlamaIndex.
AI Development & Evaluation
- Fine-grained RLHF improves LLM performance and customization compared to holistic preference, based on research from MosaicML and Stanford.
- LLMs can "know" when they are being tested and elementary reasoning errors in LLMs are similar to those made by humans.
- Validation loss is a poor metric for choosing LLM checkpoints to deploy.
Memes & Humor
- Humorous tweet about a cat colony memorializing Julius Caesar amidst discussion of the new Claude model.
- Joke about breaking a MacBook screen and leg bone while walking into a heavy hotel table.
In summary, the release of Anthropic's Claude 3 models has generated significant discussion, with comparisons being made to GPT-4 in terms of performance, cost, and capabilities. Claude 3 demonstrates strong language understanding and generation, but lags behind GPT-4 on some coding tests.
Alongside the Claude 3 release, there have been other notable AI model and dataset releases from Microsoft, Stability AI, Latitude, and others. These span a range of applications including coding, 3D model generation, and image-to-text.
Researchers continue to advance techniques for fine-tuning and evaluating large language models, such as using fine-grained RLHF and being cautious with metrics like validation loss. There are also observations about the reasoning capabilities and potential self-awareness of LLMs.
Amidst the technical discussions, there is still room for humor, as evidenced by jokes and memes shared alongside the AI news and analysis. Overall, the tweets paint a picture of an AI field that is rapidly advancing in terms of model scale and capabilities, but also grappling with important questions around evaluation, safety, and potential impacts.
ChatGPT (GPT4T)
- Claude 3 vs GPT-4 Discussions: The AI community is actively discussing Claude 3's human-like response capabilities, with one engineer noting its ability to emphasize words in a way GPT-4 doesn't. However, there's skepticism about whether its performance is truly groundbreaking or just the result of specific training data, as mentioned in a tweet by Giffmana. Claude 3's humaneval test score comparison with GPT-4 was noted, highlighting Claude 3 scored 79.88% versus GPT-4's 88% in a specific test, as Abacaj tweeted.
- Model Performance and Benchmarks: The debate on the efficiency and effectiveness of AI models like Claude 3 continues, with a particular focus on cost versus performance. Some tweets highlight Claude 3's ability in specific tasks (Teknium1's comparison) and the comparison in price to performance ratio against GPT-4, providing valuable insights for developers focusing on optimizing resource allocation in AI projects.
- Affiliate Revenue Distribution: A tweet disclosing AG1 costs and revenue distribution sheds light on the financial mechanics of AI service products. Such transparency in revenue sharing models offers a nuanced understanding of the AI product ecosystem, crucial for entrepreneurs and engineers in the tech space.
- Playground AI's Integration: The integration of Playground AI as the default model for Perplexity Pro users (AravSrinivas's announcement) is a significant step forward in AI-driven image generation. Also, the deployment of TripoSR for creating 3D models from images highlights the advancing capabilities in multidimensional AI applications.
- Importance of Quality Data: A succinct reminder of the value of quality over quantity in data for AI training was highlighted by Svpino, a crucial consideration for engineers working on data-driven AI models (related tweet).
- Attention to Datasets: BlancheMinerva's urging of deeper dataset analysis (tweet) before jumping to conclusions about LLM behavior underscores the critical need for meticulous data scrutiny in AI development.
AI Humor & Memes
- Creative AI Misadventures: A humorous account of technological mishaps and the lighter side of AI-related accidents, like breaking a leg on a heavy hotel table and then proceeding to make jokes about further potential "breaks" (Levelsio's tweet), provides much-needed levity in the often serious AI conversation sphere.
This summary illuminates the multifaceted discussions within the AI tech community, from deep dives into model performance and its real-world applicability to societal reflections observed through technological lenses. The emphasis on Claude 3's capabilities versus GPT-4, alongside methodological considerations in AI model development and deployment, underscores the ongoing efforts toward more nuanced, human-like AI. Furthermore, the exploration of Korea's cultural and economic landscapes through the tech lens highlights the complex interplay between societal structures and technological development, offering invaluable insights for tech professionals navigating global AI applications.
PART 0: Summary of Summaries of Summaries
Operator notes: Prompt we use for Claude, and our summarizer GPT used for ChatGPT. What is shown is subjective best of 3 runs each.
Claude 3 Sonnet (14B?)
Interestingly Sonnet failed to understand the task the 2nd time we ran it (not understanding that we want it to summarize across ALL the summaries and raw text - which today total 20k words).
- Mistral Model Insights and Confusion: Conversations centered around Mistral models, including clarifications on context size handling across different tokenizers like tiktoken, hardware recommendations, free availability concerns with LeChat, and inquiries into Mistral's open-source direction and minimalistic reference implementations. Mixtral's lack of sliding window attention was also discussed.
- Perplexity AI Integration and Usability: Users explored the integration of Playground AI's V2.5 model and Claude 3 with Perplexity AI Pro, shared thoughts on quota limits for Claude 3 Opus, speculated about Perplexity's future directions, and exchanged tips on optimizing AI-powered features like image generation and search.
- LLM Coding Prowess and Quantization Techniques: Cutting-edge AI models like OpenHermes-2.5-Code-290k-13B and Code-290k-6.7B-Instruct were introduced, boasting impressive coding capabilities. Developers also discussed quantization approaches like GGUF quantizations and their quality/speed trade-offs.
- Nvidia Puts the Brakes on Translation Layers: Nvidia has implemented a ban on using translation layers to run CUDA-based software on non-Nvidia chips, targeting projects like ZLUDA, with further details discussed in a Tom's Hardware article. Some members expressed skepticism over the enforceability of this ban.
- Lecture 8 on CUDA Performance Redone and Released: The CUDA community received a re-recorded version of Lecture 8: CUDA Performance Checklist, which includes a YouTube video, code on GitHub, and slides on Google Docs, garnering appreciation from community members. Discussions ensued on the mentioned DRAM throughput numbers and performance differences in coarsening.
Claude 3 Opus (8x220B?)
- Claude 3 Shakes Up the AI Landscape: Anthropic's release of the Claude 3 model family has sparked widespread discussion, with the Claude 3 Opus and Claude 3 Sonnet variants demonstrating impressive capabilities in reasoning, math, coding, and multi-modal tasks. Users report Claude 3 outperforming GPT-4 in certain benchmarks like summarization and instruction-following. However, concerns arise over its pricing structure and regional availability.
- CUDA Controversies and Optimizations: Nvidia's ban on translation layers for CUDA on non-Nvidia chips has stirred skepticism over enforceability. Meanwhile, developers troubleshoot CUDA errors like
CUBLAS_STATUS_NOT_INITIALIZED, with causes ranging from tensor dimensions to memory issues. Optimization discussions cover CUTLASS, cuda::pipeline efficiency, and the nuances of effective bandwidth versus latency.
- Prompt-Engineering Puzzles and LLM Integrations: Across various communities, users grapple with prompt-engineering challenges, from AI's refusal to accept internet access capabilities to inconsistencies in ChatGPT API transitioning. Simultaneously, new tools and integrations emerge, like the RAPTOR tree-structured indexing technique, Claude 3 support in LlamaIndex, and Datasette's plugin for Claude 3 interaction.
- Pushing Boundaries in AI Applications: Exciting developments surface across AI subdomains, including the text-to-3D model generation platform neThing.xyz, leveraging Claude 3 and LLM code generation. Real-Time Retrieval-Augmented Generation (RAG) with LangChain enables enhanced chatbots, while explorations in augmenting classification datasets promise improved model reasoning. Initiatives like the Open Source AI Definition and AI-native business repositories aim to guide and curate the rapidly evolving AI landscape.
ChatGPT (GPT4T)
AI Ethics and Regulatory Discussions: Detailed conversations across various Discords, such as TheBloke, underline the criticality of AI ethics, regulatory measures, and security in AI development, including the White House's stance on avoiding C and C++ for security reasons and the UK's potential AI legislation.
Model Innovations and Performance: Discussions span multiple platforms, from Mistral explaining Mixtral vs. Mistral model differences, to Perplexity AI highlighting Claude 3's capabilities and Nous Research AI debating Claude 3 and GPT-4. Emerging models like OpenHermes-2.5-Code-290k-13B showcase superior performance, while CUDA MODE focuses on CUDA's technical challenges and advancements.
Emerging Technologies and AI's Role in Creative Domains: LAION and Latent Space discussions delve into AI's impact on creative fields, such as pixel art generation techniques and 3D modeling advancements, highlighting the Stable Diffusion 3's MMDiT architecture and its superior performance.
Technical Challenges and Solutions in AI Application: LangChain AI explores caching issues in LLM interaction and Real-Time Retrieval-Augmented Generation (RAG), while OpenAccess AI Collective (axolotl) discusses model merging with MergeKit as an innovative alternative to traditional fine-tuning methods.
PART 1: High level Discord summaries
TheBloke Discord Summary
- AI Ethics Calls for Caution: Engaging discussions focused on AI ethics and the importance of regulatory measures to prevent misuse, as well as the implications of AI in mass profiling and surveillance. The White House's stance on avoiding C and C++ for security reasons and potential AI legislation by the UK government were part of the discussions.
- Model Performance Measures and Development Strides: Conversations pivoted around AI capabilities, including remarks on improved responses from GPT-3.5 Turbo on riddles, and the challenges in gradient-free deep learning. Experimental quantization techniques, including imatrix quants and GGUF quantizations, were debated considering their quality and speed trade-offs.
- Emerging AI Models Take the Spotlight: The model OpenHermes-2.5-Code-290k-13B was shared, boasting superior performance and combining datasets with rankings under Junior-v2 in CanAiCode. Moreover, details on the training of Code-290k-6.7B-Instruct, taking 85 hours for 3 epochs on 4 x A100 80GB, were also provided.
- Legal Complexities Touch AI: The discussion also delved into legal aspects, highlighting enforceable verbal contracts in Scotland and Germany's mandate for open-source government systems. Participants also expressed concern over using unlicensed AI models like miquliz and cautioned against potential legal repercussions.
- Crypto Dialogue Entangles Blockchain Skepticism: The volatility and viability of cryptocurrency markets were hot topics, accompanied by the debate on the overestimation of blockchain benefits for distributed computing and current investment fads.
Mistral Discord Summary
- Mixtral vs. Mistral Context Confusion Resolved:
i_am_domclarified that Mixtral does not support sliding window attention like Mistral, referencing a Reddit post. The issue of Mixtral Tiny GPTQ using different tokenization was probed, prompting discussions on correct context size handling and the impact of different tokenizers on VRAM requirements.
- Mistral Models Tug-of-War: There were deep dives into Mistral models' capabilities, with
mrdragonfoxsuggesting that the Next model might be an independent line from Medium, andmehdi1991_exploring GPU options for running large models. The community shared concern about the LeChat model's free availability potentially leading to service abuse.
- Open-Sourcing and Models in the Marketplace: A desire for clarity on Mistral's open-source direction was indicated.
@casper_ai's request for a minimalistic reference implementation for Mistral highlights the community's need for better understanding of the model's training process. Discord bots supporting over 100 LLMs and Telegram-hosted chatbots powered by mistral-small-latest illustrated the active integration of Mistral models across various platforms.
- Anthropic's New Model and Mistral Pricing Conversations:
@benjoyo.shared news on Anthropic's Claude 3 models and its function-calling feature in alpha. The community debated the cost of using new models like Opus, and Mistral's potential open weights advantage was discussed as a unique selling point.
- Real World Model Evaluations and Educational Office Hours: In the office-hour channel, discussions on manual and real-life evaluation such as benchmarking against MMLU were key, while future model training and expansion queried by users like
@kalomazeand@rtyaxshowed the community's future-looking interests.
- Troubleshooting Day-to-Day Model Anomalies: Users encountered and resolved issues from incorrect JSON response handling to authentication anomalies. The effectiveness of Mistral 8x7b at sentiment analysis was discussed, while "405" API errors were debugged with advice to use the "POST" method.
- Mathematical Challenges Reveal Model Limitations:
@awild_techand others pointed out inconsistencies in Mistral Large's responses to mathematical problems like the floor of 0.999 repeating, illustrating limitations in understanding and consistency within the models.
Perplexity AI Discord Summary
- Perplexity AI Pro Enhances with V2.5 and Claude 3: Users now have access to Playground AI's new V2.5 for generating images, and Perplexity Pro users can explore the capabilities of Claude 3, with the advanced Opus model allowed for 5 daily queries. Details on Playground’s collaboration with Perplexity can be found in their blog post, while the distinction between Claude 3 Opus and the faster Sonnet model has raised questions among users about their deployment and operations.
- Community Weighs In on Claude 3's Daily Query Limit: There's a buzz around the 5-query per day limit for Claude 3 Opus, and members are discussing whether it outperforms GPT-4 in coding and problem-solving, with some advocating for improvements on Claude 3 Sonnet's usability.
- Perplexity's Future Speculations and Promotions: Users are sharing tips on optimizing Perplexity's AI for tasks like image generation and search functionality, alongside predictions for future dedicated AI models. Conversations also revolve around accessing Claude 3 and related models, with references to the Rabbit R1 deal described in Dataconomy's article.
- Assorted Uses of Perplexity AI Search Revealed: Engagement in Perplexity AI's search capacity show users looking for information on diverse topics including Antarctica, US-Jordan relations, promotional Vultr codes, and historical inquiries.
- API Access and Configuration Chatter for AI Engineers: API users like
@_samratare advised patience for access to citations, with response times upwards of 1-2 weeks. There's an evolving understanding that the temperature setting in NLP tasks can be nuanced, with lower temperatures not guaranteeing more reliable outcomes, and curiosity about potential model censorship via API and quota carryovers between different platforms.
OpenAI Discord Summary
- Translation AI Search for Purity: Users seeking alternatives to Google Translate mentioned dissatisfaction with its robotic output, with GPT-3.5 suggested as a superior option for quick and accurate translations.
- Claude 3 Outshining ChatGPT?: Conversations around Claude 3 from Anthropic highlighted its improved capabilities, particularly in graduate-level reasoning, although some users reported weaker logic and image recognition in Chinese compared to GPT-4.
- GPT-4 Token Limits in the Spotlight: Technical discussions pinpointed limitations with GPT-4, especially around token limits for inputs and contexts, with users sharing their experiences with various versions of the model.
- Storytellers Prefer Claude: Claude 3 was reported to excel in roleplay and creative writing, prompting users to anticipate the release of GPT-5 as competition heats up with advanced language models like Gemini.
- Real-Time Confusion and API Woes: Prompt-engineering conundrums included an AI's denial of internet access capabilities, difficulties in improving clarity and conciseness, and Custom GPT models giving uncooperative responses.
- Seeking Solid API Foundations: Users debated the challenges of style consistency when transitioning from ChatGPT to GPT 3.5 API, as well as identifying usability issues with GPT's visual and mathematical prompt handling.
Nous Research AI Discord Summary
- Claude 3 Sparks Price and Performance Debate: AnthropicAI's announcement of Claude 3 stirred discussions comparing its performance and cost to GPT-4. Some users, using EvalPlus Leaderboard comparisons and related tweets, pondered Claude 3's value proposition over OpenAI's offerings, citing differences in human eval scores.
- New AI Models and Efficiency Takes Center Stage: Articles referencing OpenAI CEO Sam Altman's remarks about the future being in architectural innovations and parameter-efficient models, rather than simply larger ones, were shared (source). Additionally, the release of moondream2, a small vision language model suitable for edge devices, was brought into focus (GitHub link).
- Prompt Engineering Resources Shared: A guide detailing prompt engineering techniques to enhance Large Language Models (LLMs) outputs was circulated, offering strategies for improved safety and structured output (guide link). Model comparison and evaluation discussions highlighted new AI models like
dolphin-2.8-experiment26-7b-preview.
- Continuous Pretraining and Model Training Discourse: A dialogue about continuous pretraining featured suggestions of using a modified gpt-neox codebase and axolotl for varied scales of pretraining. Inquiries about training on large datasets of physics papers suggested a blend into pretraining datasets, emphasizing the need for ample compute resources.
- Combining Inference Strategies for Enhanced AI: A proposition to combine models like Hermes Mixtral or Mixtral-Instruct v0.1 using techniques such as RAG and specific system prompts was discussed, referencing tools like fireworksAI or openrouter for effective inference.
- Bittensor Finetune Subnet v0.2.2 Update: The Bittensor Finetune Subnet released version 0.2.2, featuring an updated transformers package with a fixed Gemma implementation (GitHub PR). The release equaled the reward ratio between Mistral and Gemma to 50% each.
LAION Discord Summary
- Scaling Titan: Machine Learning Faces Compute Bottlenecks: The discussion led by
@pseudoterminalxfocused on challenges in scaling up model training, particularly bottlenecks in data transfer between CPU/GPU and the limited benefits of increasing compute resources without overcoming these inefficiencies.
- AI's Pixel Art Palette Problem:
@nodjaand@astropulseexplored techniques for generating pixel art using AI, with talks delving into methods for applying palettes in latent space and integrating them into ML models, highlighting the nuanced technical hurdles in this creative AI domain.
- Claude 3 Outshines GPT-4: The engineering community compared the capabilities of the newly unveiled Claude 3 model against GPT-4, citing its improved performance with
@segmentationfault8268contemplating a switch from ChatGPT Plus based on this advancement, as per discussions and announcements found on Reddit and LinkedIn.
- Stable Diffusion 3 Peaks Interest with MMDiT Architecture: The shared research paper from Stability AI's blog post, posted by
@mfcool, presented Stable Diffusion 3's impressive performance, surpassing DALL·E 3 and others, thanks to its Multimodal Diffusion Transformer.
- SmartBrush: The New Inpainting Maestro?: User
@hiieeprompted discussions around SmartBrush, a model for text and shape-guided image inpainting showcased in an arXiv paper, with inquiries about its open-source availability and its potential for preserving backgrounds better than existing inpainting alternatives.
HuggingFace Discord Summary
AI Breakthroughs and Hiccups: Discussions spanned the performance of Hermes 2.5 over Hermes 2 and the limitations of expanding Mistral beyond 8k. There's also a focus on calculating gradients in novel ways and the repeated request for assistance with dataset creation without yet finding a resolution.
Diffusion Model Guidance on HuggingFace: Members discussed a potential NSFW model, AstraliteHeart/pony-diffusion-v6, on HuggingFace, with suggestions to tag it appropriately or report it. Additionally, guidance was provided for image prompting in diffusion models, directing users to a IP-Adapter tutorial.
CV and NLP Cross-Talk: The community engaged in topics ranging from the introduction of the Terminator network and its integration of past technologies to the quest for the SOTA in bidirectional NLP language models, touching on options like Deberta V3 and the monarch-mixer. Problems shared included difficulties with enhancing Mistral with GBNF grammar, variable inference times with Mistral and BLOOM models, and implementing Mistral in Windows apps.
Kubeflow Gets a Terraform Boost: In the realm of tools and platforms, Kubeflow can now be deployed using a terraform module, effectively transforming Kubernetes clusters into AI-ready environments. Moreover, MEGA's performance on short-context GLUE benchmarks and Gemma Model's speed boost using Unsloth were also introduced, showcasing various community-driven advancements.
Video-Related Innovations and Problems: The release of Pika operates as an indicator of the growing trend in text-to-video generation. Contrastingly, a user experienced visual issues with a Gradio-embedded OpenAI API chatbot, looking for assistance to fix the layout.
Reading Group Revival: Concern was expressed over the scheduling of reading group sessions, debating the merits between Discord and Zoom for hosting. There is also mention of recordings available on Isamu Isozaki's YouTube profile for those unable to attend live sessions.
OpenRouter (Alex Atallah) Discord Summary
- Claude 3: The New Kid on the Block: OpenRouter introduces Claude 3, encompassing a sophisticated experimental self-moderated version, Claude 3 Opus with impressive emotional intelligence (EQ), and a cost-effective alternative to GPT-4, Claude 3 Sonnet, with multi-modal capabilities.
- Price Wrangling Incites Discussion: The guild debates Claude 3's pricing, with users baffled by the price hike from Claude 3 Sonnet to Claude 3 Opus. This includes comic comparisons to physical services and a general need for clarification on the cost structures.
- Tech Troubles Stir the Pot: Members report issues interacting with the new Claude models, receiving blank responses from all except the 2.0 beta. The community steps in offering troubleshooting advice, with potential causes like region blocks or using unimplemented features like image inputs.
- The Pen is Mightier with Claude: Claude's literary capabilities are a mixed bag, getting applause for their writing quality from some, while others encounter repetitious, unwanted auto-generating responses. Community troubleshooters suggest this might be due to tokenization errors rather than the model's inherent flaws.
- More Robust than GPT-4? Persistent conversations about Claude 3's performance vis-à-vis other models highlight its edge in certain tests, but also raise questions about the predictability of real vs predicted costs, which are key considerations for scalability and integration in enterprise solutions.
LlamaIndex Discord Summary
- RAPTOR Webinar Beckons: A webinar featuring RAPTOR, an innovative tree-structured indexing technique, is announced with a registration link. The session aims to enlighten participants on clustering and summarizing information hierarchically and is scheduled for this Thursday at 9 am PT.
- Launch of Claude 3 with Strong Benchmarks: Claude 3 is now supported by LlamaIndex and is claimed to have superior benchmark performance than GPT-4. It comes in three versions, with Claude Opus being the most powerful and is suitable for a broad spectrum of tasks including multimodal applications; a comprehensive guide and showcase Colab notebook are provided here.
- 3D Modeling Revolution with neThing.xyz: The platform neThing.xyz uses LLM code generation to transform text prompts into ready-to-use 3D CAD models, propelled by the capabilities of Claude 3 and profiled by a LlamaIndex tweet.
- Evolving Infrastructure Discussions:
- Llama Networks has a FastAPI server setup suitable for client-server models, and is receptive to expansion ideas.
- Updating nodes in PGVectorStore typically requires document reinsertion as opposed to individual node edits.
- Business planning may benefit from the integration of ReAct Agent and FunctionTool with OpenAI services.
- A request was made to amend installation commands to lowercase on the Llama-Index website for accuracy.
- Exploring Deep AI Topics: An article discussing the integration of LlamaIndex with LongContext and highlighting Google’s Gemini 1.5 Pro’s 1-million context window drew interest from participants, signaling its relevance to AI development and enterprise applications. The article can be explored here.
CUDA MODE Discord Summary
- Nvidia Puts the Brakes on Translation Layers: Nvidia has implemented a ban on using translation layers to run CUDA-based software on non-Nvidia chips, targeting projects like ZLUDA, with further details discussed in a Tom's Hardware article. Some members expressed skepticism over the enforceability of this ban.
- CUDA Error Riddles and Kernel Puzzles: CUDA developers are troubleshooting errors like
CUBLAS_STATUS_NOT_INITIALIZEDwith suggestions pointing to tensor dimensions and memory issues, as seen in related forum posts. Other discussions centered aroundcuda::pipelineefficiency and understanding effective bandwidth versus latency, referencing resources such as Lecture 8 and a blog on CUDA Vectorized Memory Access.
- CUTLASS Installation Q&A for Beginners: New AI engineers sought advice on installing CUTLASS, learning that it's a header-only template library, with installation guidance available on the CUTLASS GitHub repository, and requested resources for implementing custom CUDA kernels.
- Ring-Attention Project Gets the Spotlight: A flurry of activity took place around the ring-attention experiments with conversations ranging from benchmarking strategies to the progression of the 'ring-llama' test. An issue with a sampling script is in the process of being resolved as reflected in the Pull Request #13 on GitHub, and the Ring-Attention GitHub repository was shared for those interested in the project.
- Lecture 8 on CUDA Performance Redone and Released: The CUDA community received a re-recorded version of Lecture 8: CUDA Performance Checklist, which includes a YouTube video, code on GitHub, and slides on Google Docs, garnering appreciation from community members. Discussions ensued on the mentioned DRAM throughput numbers and performance differences in coarsening.
LLM Perf Enthusiasts AI Discord Summary
- OpenAI's Browsing Innovation: @jeffreyw128 expressed excitement about OpenAI's new browsing feature, which is akin to Gemini/Perplexity. They highlighted this with a shared Twitter announcement.
- Claude 3 in the Running Against GPT-4: Claude 3 was a hot topic, with suggestions from
@res6969and@ivanleomkthat it might surpass GPT-4 in math and code benchmarks.
- Opus Model Pricing Discussed: There was debate over Opus pricing; it is reported to be 1.5x the cost of GPT-4 turbo, yet 66% cheaper than regular GPT-4 as clarified by
@pantsforbirdsand@res6969.
- The Excitement and Skepticism Around Fine-Tuning: The community exchanged views on fine-tuning LLMs.
@edencoderargued for its cost-effective benefits for specialized tasks, while@res6969questioned the return on investment for particular applications.
- Anthropic's Models Gain Mixed Reviews: Insights into Anthropic's models were mixed:
@potrockand@joshcho_discussed Opus' strengths in coding tasks, while@thebaghdaddynoted that for fields like medicine and biology, GPT-4 still overtakes newer models in performance.
Interconnects (Nathan Lambert) Discord Summary
- Intel's Strategic Stumbles:
@natolambertshared insights on Intel's current position in the tech industry via a Stratechery article and YouTube video titled: "Intel's Humbling", underscoring the nuanced analysis provided.
- Claude 3 Steals The Show:
Claude 3, announced by AnthropicAI, has sparked excitement and debate with its improved abilities. Discussion revolves around its performance, with @xeophon. and
@natolambertspeaking on specific instances of its capabilities, while@mike.lambertpondered its impact on the open-source landscape and@canadagoose1and@sid221134224expressed that it might surpass GPT-4.
- Flaming Q* Tweets Over Claude 3:
Drama ensued on Twitter with Q* tweets following Claude 3's release, with
@natolambertoffering a critical take on the discussions and the idea of using alt accounts being dismissed due to the effort involved.
- AI2 Eyeing Pretraining Pros:
@natolambertreached out for specialists in pretraining interested in AI2's mission, specifically noting that they are presently focusing on this area of hiring and humorously suggesting that individuals disillusioned with Google's handling of Gemini may be potential recruits.
- RL Debate on Cohere's PPO Paper:
The dialogue in RL circles touched on Cohere's claim about the redundancy of PPO corrections for large language models, with
@vj256searching for further evidence or replication and@natolambertacknowledging prior familiarity with these claims, also directing to related interviews and research papers pertinent to Reinforcement Learning from Human Feedback (RLHF).
LangChain AI Discord Summary
- Cache Woes in Langserve's LLM Interaction: Users
@kandieskyand@veryboldbageldelved into difficulties with caching in Langserve.@kandieskyrevealed that caching only operated correctly with the/invokeendpoint and not with/stream, while@veryboldbagelnoted the root issue lies in langchain-core.
- Real-Time RAG Unleashed:
@hkdulaypresented a blog post that showcases building a Real-Time Retrieval-Augmented Generation (RAG) chatbot with LangChain, stressing the significant step-up it can provide in improving language model responses.
- Deep Dive into RAG's Indexing: In a quest for enhanced AI responses,
@tailwind8960shared insights into the indexing challenges in the Advanced RAG series through a new installment, emphasizing the need to preserve context in queries.
- Synergizing AI and Business Projects:
@manojsaharanis spearheading a collaborative initiative to amalgamate AI with business in a GitHub repository and invited contributors from the LangChain community to join via this link to the repository.
- Enter Control Net, the Standup Chicken Imager:
@neil6430demonstrated the whimsical potential of AI-generated art using control net features from ML blocks, achieving the odd task of a chicken emulating Seinfeld's standup stance.
Latent Space Discord Summary
- Claude 3 Sparks Interest and Debate: Engineers discussed Claude 3's benchmarks and pricing, with competitive performance comparisons to GPT-4 sparking significant interest. Concerns about API rate limits were raised, referencing Anthropic's rate limits documentation, suggesting a potential bottleneck for scalability.
- Direct Model Showdown: AI enthusiasts performed analysis between Claude 3 and GPT-4, with a shared gist by @thenoahhein detailing Claude 3's alignment and summary skills, championing its capabilities over GPT-4.
- Next-Gen 3D Modeling Teased: A partnership to develop sub-second 3D model generation technology was previewed by @EMostaque, discussing advancements such as auto-rigging, hinting at significant implications for creative industries.
- Based Architecture Unveiled: A discussion unfolded around a new Based Architecture paper with attention-like primitives optimized for efficiency, which resonates with the engineer's continuous quest for improved computational processes.
- AI Consciousness Controversy: The AI community engaged in a heated debate over the sentience of Claude 3, following a provocative LessWrong post. Counterarguments against AI consciousness were circulated, keeping the discourse grounded in skepticism amidst anthropomorphic claims.
OpenAccess AI Collective (axolotl) Discord Summary
- Math Bots to the Rescue: A dataset for bot-based math problem solving was highlighted on the Orca Math Word Problems dataset available on Hugging Face, demonstrating bots' capability in algebraic reasoning and competition ranking tasks.
- MergeKit Magic: Interest in model merging as an alternative to fine-tuning using the MergeKit tool on GitHub was noted, indicating an innovative tool to combine pre-trained model weights of large language models.
- AI Censorship Balance: A discussion on the challenging aspect of balancing AI response generation in Claude - 3 model, especially related to racial sensitivity, was informed by a relevant ArXiv paper.
- Dataset Enrichment for AI Reasoning: A strategy for enhancing dataset reasoning capabilities for AI was shared through a guide on Twitter by
@winglian. - LoRA+ Experiments Advance:
@suikamelonconducted experiments with the LoRA+ ratio feature, noticing it requires a lower learning rate, as per the discussion in the #axolotl-dev channel, based on guidelines from the LoRA paper.
Datasette - LLM (@SimonW) Discord Summary
- Prompt Injection vs Jailbreaking: Prompt injection is an exploitative technique that combines trusted and untrusted inputs in LLM applications different from jailbreaking, which attempts to bypass LLM safety filters. Simon Willison's blog expands on this crucial distinction.
- LLM Misuse by State Actors: Microsoft's blog outlined the use of LLMs by state-backed actors for cybercrimes like vulnerability exploitation and creating spear phishing emails, including the incident with "Salmon Typhoon." The related OpenAI research can be found here.
- Early Warning System for LLM-Aided Biorisks: OpenAI is devising systems to flag biological threats assisted by LLMs, as they can easily facilitate access to sensitive information. Their initiative details are available here.
- Ceasefire with Multi-Modal Prompt Injection: Addressing prompt injection risks, it's admitted that even human review can miss some forms of injection, especially those concealed within images. Simon Willison analyzes this threat vector deeper in his write-up.
- Mistral's Might & Plug-in Pick-Me-Up: The new mistral large model is applauded for its data extraction prowess, although costly, and the rapid creation of a Claude 3 plugin was notably commended. Also, there's a movement towards standardizing locations for model files to optimize development workflows.
DiscoResearch Discord Summary
- Claude-3's Multilingual Performance Evaluated:
@bjoernpsparked a conversation about Claude-3's multilingual capabilities, with@thomasrenkertreporting that Claude-3-Sonnet provides decent German answers and outperforms GPT-4 in structure and knowledge. - Claude-3 Spotted in the EU: Despite its official geographical limitations, members like
@sten6633and@devnull0have managed to sign up and access Claude-3 in Germany, including workaround mentions like tardigrada.io. - Opus API Embraces German Users: The Opus API now seemingly accepts German phone numbers for registration, incentivizing new users with credits, and earning praise for its efficacy in resolving complex data science queries.
- Test AI Models Without Costs:
@crispstrobehighlights a way to try out AI models free of charge using chat.lmsys.org, with conditions that input may be used for training data, and shares poe.com's offer of three different models for trial, including a Claude 3 variant with a limit of 5 messages a day.
Skunkworks AI Discord Summary
No relevant technical discussions or important topics to summarize were provided in the given messages.
Alignment Lab AI Discord Summary
- Let's Collaborate!: User
@wasoolishowed interest in a collaborative project within the Alignment Lab AI and has been encouraged to discuss further details through direct messages by@taodoggy.
AI Engineer Foundation Discord Summary
- Keep Up with Open Source AI Progress:
@swyxiodrew attention to the Open Source Initiative's efforts in providing monthly updates about the Open Source AI Definition, with the recent version 0.0.5 being published on January 30, 2024. Practitioners can stay informed and contribute to the conversation by reviewing the monthly drafts.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1100 messages🔥🔥🔥):
- Discussions on AI Ethics and Regulatory Measures: The channel engaged in debates on AI ethics, the necessity of regulatory measures to prevent misuse, and talked about the White House report on not using C and C++. Concerns about mass profiling/surveillance, data privacy under laws like the EU's "Right to be Forgotten," and potential AI legislation narratives by the UK government were discussed.
- AI Performance and Development: Users compared AI capabilities, citing improved responses from models like GPT-3.5 Turbo on riddles. There were also conversations about the incremental progress of AI models, and the challenges of attempting gradient-free deep learning.
- A look at Claude 3 Opus: User
@rolandtannousshared his positive experience using Claude 3 Opus as a brainstorming partner, showing an improvement in handling tasks like coding, highlighting that Claude 3 Opus performed superior to its previous versions. - Legal Discussions in AI Utilization: The chat touched briefly upon legal issues related to AI, such as enforceable verbal contracts in Scotland and the implications of regulations like Germany's requirement for government systems to be open-source.
- Crypto Market and Blockchains: Participants discussed the state and reliability of cryptocurrency markets, the potential for blockchain in distributed computing, and current investment trends. Concerns about the over-hyping of blockchain benefits and the practicality of cryptocurrencies were expressed.
Links mentioned:
- no title found: no description found
- Docker: no description found
- BASED: Simple linear attention language models balance the recall-throughput tradeoff: no description found
- abacusai/Liberated-Qwen1.5-72B · Hugging Face: no description found
- Futurama Maybe GIF - Futurama Maybe Indifferent - Discover & Share GIFs: Click to view the GIF
- Magician-turned-mathematician uncovers bias in coin flipping | Stanford News Release: no description found
- Philosophical zombie - Wikipedia: no description found
- Squidward Spare GIF - Squidward Spare Some Change - Discover & Share GIFs: Click to view the GIF
- You Need to Pay Better Attention: We introduce three new attention mechanisms that outperform standard multi-head attention in terms of efficiency and learning capabilities, thereby improving the performance and broader deployability ...
- Taking Notes Write Down GIF - Taking Notes Write Down Notes - Discover & Share GIFs: Click to view the GIF
- gist:09378d3520690d03169f89183adebe9c: GitHub Gist: instantly share code, notes, and snippets.
- Spongebob Squarepants Leaving GIF - Spongebob Squarepants Leaving Patrick Star - Discover & Share GIFs: Click to view the GIF
- Gemini WONT SHOW C++ To Underage Kids "ITS NOT SAFE": Recorded live on twitch, GET IN https://twitch.tv/ThePrimeagenBecome a backend engineer. Its my favorite sitehttps://boot.dev/?promo=PRIMEYTThis is also the...
- Release 0.0.14 · turboderp/exllamav2: Adds support for Qwen1.5 and Gemma architectures. Various fixes and optimizations. Full Changelog since 0.0.13: v0.0.13...v0.0.14
TheBloke ▷ #characters-roleplay-stories (73 messages🔥🔥):
- Debate on Performance and Quantization Techniques:
@dreamgenand@capt.geniusdiscussed the use of imatrix quants for model performance, with@capt.geniusstating that imatrix offers better quality than speed. However,@spottyluckquestioned the necessity of quantizing outliers, leading to a shared GitHub gist by@4onendiscussing GGUF quantizations and their speed penalties. GGUF quantizations overview.
- Intriguing Technologies in Roleplay Applications:
@sunijainquired about the AutoGPT project's status for potential roleplay applications, with@wolfsaugereferencing relevant research and GitHub repositories like DSPy optimization that could programmatically create and evaluate prompt variations.
- Hydration and Health Tips Enter the Chat: A light-hearted tangent emerged as
@lyrcaxisoffered advice on proper hydration to@potatooff, suggesting daily water intake based on body weight for optimal health and discussing the impact of heating solutions on throat dryness and coughing.
- Evaluating Experimental AI Models: Users
@sunijaand@johnrobertsmithengaged in conversation about the effectiveness of experimental AI models like Miquella and Goliath, referencing a reddit post LLM comparison/test for general intelligence with plans to share personal reviews on performance in roleplay contexts.
- Legal and Ethical Considerations in AI: The use of miquliz, as publicized by
@reinman_, was met with legal and ethical concerns from@mrdragonfox, who cautioned against utilizing unlicensed AI models due to potential legal repercussions. Project Atlantis was mentioned as a platform hosting various models including miquliz, although the licensing issues were flagged as a potential problem.
Links mentioned:
- GGUF quantizations overview: GGUF quantizations overview. GitHub Gist: instantly share code, notes, and snippets.
- llama.cpp/examples/quantize/quantize.cpp at 21b08674331e1ea1b599f17c5ca91f0ed173be31 · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Project Atlantis - AI Sandbox: no description found
TheBloke ▷ #coding (9 messages🔥):
- New Model Competing with the Big Boys: User
@ajibawa_2023shared their state-of-the-art Llama-2 Fine-tune Model named OpenHermes-2.5-Code-290k-13B, claiming superior performance over an existing model by teknium. It leverages the combined datasets OpenHermes-2.5 and Code-290k-ShareGPT, and ranks 12th under Junior-v2 in CanAiCode.
- Training Details on a Large-Scale Fine-Tuned Model: Another model, Code-290k-6.7B-Instruct, was trained on a varied code dataset, took 85 hours for 3 epochs using 4 x A100 80GB, and ranks well under Senior category in CanAiCode. Credits were given to Bartowski for quantized models like Exllama v2.
- Seeking the Smallest Model for API Testing: In pursuit of a lightweight model for API testing,
@gamingdaveukinquired about the smallest possible model that can run on Text Gen Web UI with a limited VRAM laptop. The suggested options included tiny models like tinyllama and quantized versions like gptq/exl2/gguf.
- A Celebration of Innovation in AI Modeling: Recognizing the development of new AI models,
@rawwerksgave a humorous kudos to@ajibawa_2023, joking about a hypothetical massive investment to rival Claude-3-Opus.
- Career Path Queries Looking Towards AI: User
@_jayciesought advice on what to expect from interviews in the genAI and ML space, expressing a desire to shift career paths from fullstack development towards AI and eventually pursuing grad school for research.
Links mentioned:
- ajibawa-2023/OpenHermes-2.5-Code-290k-13B · Hugging Face: no description found
- ajibawa-2023/Code-290k-6.7B-Instruct · Hugging Face: no description found
Mistral ▷ #general (412 messages🔥🔥🔥):
- Context Size Confusion Cleared: After an extensive discussion, it was clarified that Mixtral doesn't support sliding window attention, unlike Mistral, as confirmed by
i_am_domreferencing a Reddit post. - What's Next for Next?: Discourse regarding Mistral’s Next model with
i_am_domsuggesting it may be an improved version of Medium.mrdragonfoxasserts Next is a completely separate, newer model line unrelated to Medium. - Hardware Recommendations for Running Models: The user
mehdi1991_inquired about the appropriate hardware for Mistral models, with various members advising at least 24GB VRAM for large models and the feasibility of running on a range of GPUs like the RTX 3060 or 3090. - LeChat's Model Accessibility Debated: The free availability of LeChat and potential overuse of the service sparked debate, with
mrdragonfoxemphasizing the importance of not abusing the service andlerelamentioning adaptation to such misuse. - Mistral in the Market: A brief discussion on Mistal’s possible business model, with speculation that they may not release new open-source models any sooner, prompted by
.mechap’s queries on the future of Mistral AI’s open source offerings.
Links mentioned:
- mistralai/Mistral-7B-Instruct-v0.2 · Hugging Face: no description found
- Mixtral Tiny GPTQ By TheBlokeAI: Benchmarks and Detailed Analysis. Insights on Mixtral Tiny GPTQ.: LLM Card: 90.1m LLM, VRAM: 0.2GB, Context: 128K, Quantized.
- augmentoolkit/prompts at master · e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets - e-p-armstrong/augmentoolkit
- Mixtral: no description found
- Reddit - Dive into anything: no description found
Mistral ▷ #models (75 messages🔥🔥):
- Model Context Limit Confusion:
@fauji2464was reminded about the 32k token limit on the Mistral model, but questioned why the warning appeared when using smaller documents.@mrdragonfoxclarified that the model will ignore inputs exceeding the limit and that different tokenizers affect context size differently. - Tokenization Discrepancies Highlighted: When
@fauji2464mentioned checking token sizes with tiktoken,@mrdragonfoxpointed out that tiktoken and Mistral use different tokenization methods and vocabulary sizes, elucidating why issues with context size might occur. - Inference Output Not Limited by Context Window: The conversation between
@fauji2464and@_._pandora_._led to an explanation of how LLMs consider context and the potential for outputs even if inputs exceed the 32k token maximum. - Visualization Aid for Understanding LLMs:
@mrdragonfoxprovided a link to a visualization to help understand how transformer models work, indicating that what was discussed applies to all transformers, not just Mistral. - Enterprise Usage of Mistral Models Explored:
@orogor.inquired about deploying Mistral's paid engine on their own clusters instead of Azure, to which@mrdragonfoxsuggested contacting enterprise sales to discuss options for on-premises deployment and licensing.
Links mentioned:
LLM Visualization: no description found
Mistral ▷ #ref-implem (1 messages):
- Request for Mistral Training Clarification:
@casper_aipointed out the community's struggles with Mistral model training, referencing past discussions that suggest an implementation difference in the Hugging Face Trainer. They requested a minimalistic reference implementation to aid in producing optimal results.
Mistral ▷ #showcase (7 messages):
- Discord Bot Flex by @jakobdylanc: @jakobdylanc promotes their Discord bot that supports over 100 LLMs, offers collaborative prompting, vision support, and features streamed responses in just 200 lines of code. Find the bot on GitHub with the green embed signal indicating the end of a response: GitHub - discord-llm-chatbot.
- Color-coded Chat Bot Responses: In response to @_dampf's query, @jakobdylanc explains that their bot uses embeds in Discord, which turn green to indicate a completed response and allow for a higher character limit.
- Just the Facts, No Frills for the Bot: Addressing @_dampf's suggestions, @jakobdylanc mentions their bot is a LLM prompting tool and they are not interested in it ignoring messages or introducing artificial delay, though they are open to exploring koboldcpp support.
- Model Formats Fight for Flexibility: @fergusfettes shares their 'looming' experiment comparing mistral-large with other LLMs, noting Mistral's good performance but issues with formatting. They advocate for a model's ability to understand both completion and chat modes and share a YouTube video illustrating the method.
- Chatbots Descend on Telegram: @edmund5 launches three new Telegram bots powered by mistral-small-latest: Christine AI for mindfulness, Anna AI for joyful interactions, and Pia AI for elegant conversations. The bots offer varying themes to users, available on Telegram: Christine AI, Anna AI, and Pia AI.
Links mentioned:
- Multiloom Demo: Fieldshifting Nightshade: Demonstrating a loom for integrating LLM outputs into one coherent document by fieldshifting a research paper from computer science into sociology.Results vi...
- GitHub - jakobdylanc/discord-llm-chatbot: Supports 100+ LLMs • Collaborative prompting • Vision support • Streamed responses • 200 lines of code 🔥: Supports 100+ LLMs • Collaborative prompting • Vision support • Streamed responses • 200 lines of code 🔥 - jakobdylanc/discord-llm-chatbot
- Christine AI 🧘♀️: Your serene companion for mindfulness and calm, anytime, anywhere.
- Anna AI 👱♀️: Your bright and engaging friend ready to chat, learn, and play 24/7.
- Pia AI 👸: Your royal confidante. Elegant conversations and wise counsel await you, 24/7.
Mistral ▷ #random (24 messages🔥):
- Alextreebeard Unveils K8S Package for AI:
@alextreebeardhas open-sourced a Kubeflow Terraform Module for Kubernetes, aimed at simplifying the setup of AI tools on k8s and is looking for user feedback. The package includes functionality for running Jupyter in Kubernetes. - Introducing Claude 3 Model Family:
@benjoyo.shared news about Anthropic's launch of the Claude 3 model family, featuring three models with increasing levels of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, and noted the impressive capabilities and adherence of the models. - Open Weights as a Key Differentiator: Amidst the discussion of new models from competitors,
@benjoyo.hopes that Mistral retains open weights as a competitive advantage, even as other platforms like Anthropic introduce advanced and prompt-adherent models. - Cost Comparison on AI Models: Comparing the costs of new models,
@mrdragonfoxhighlighted that Opus model is priced at $15 per megatoken for input and $75 per megatoken for output, prompting a wider discussion on price justification and the benefits of having different model variants. - Advanced Use Cases with Claude 3 Alpha:
@benjoyo.pointed to the alpha support for function calling with Claude 3, which allows the model to interact with external tools, expanding its capabilities beyond initial training. This feature promises to facilitate a wider variety of tasks, although it's still in early alpha stages.
Links mentioned:
- Introducing the next generation of Claude: Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order ...
- Functions & external tools: Although formal support is still in the works, Claude has the capability to interact with external client-side tools and functions in order to expand its capabilities beyond what it was initially trai...
- GitHub - treebeardtech/terraform-helm-kubeflow: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐 - treebeardtech/terraform-helm-kubeflow
Mistral ▷ #la-plateforme (32 messages🔥):
- JSON Response Format Troubles:
@gbourdinreported issues with the new JSON response format, failing multiple times during use. After being advised by@proffessorblueand checking the Mistral documentation, they solved the problem attributing it to their own oversight.
- Pricing Enquiry Hits a Wall:
@jackie_chen43had difficulty finding pricing information post-signup, commenting on the platform's development stage.@mrdragonfoxprovided a direct link to pricing and noted the admirable effort given the small team size compared to larger organizations like OpenAI.
- Sentiment Analysis Disparities Noted:
@krangbaeexperienced that the Mistral 8x7b model outperformed the Mistral Small model for sentiment analysis, pointing out this disparity when it came to performance.
- Handling 500 Errors on API Calls:
@georgyturevichencountered a 500 error response from the API, which@lerelaaddressed, asking for more details. The error was tracked down to themax_tokensparameter being set tonull.
- Table Data in Prompts Provoke JSON Confusion:
@samseumfaced JSON parsing errors while trying to insert table data into API prompts and received support on handling JSON escaping from@lerela, with additional debugging interaction from@_._pandora_._.
Links mentioned:
- Pricing and rate limits | Mistral AI Large Language Models: Pay-as-you-go
- Client code | Mistral AI Large Language Models: We provide client codes in both Python and Javascript.
Mistral ▷ #office-hour (387 messages🔥🔥):
- Office Hour Session on Model Evaluation:
@sophiamyanginitiated the office hour, inviting discussions on how individuals evaluate models and benchmarks, encouraging the community to share their approaches or ask questions. - Inquiries about Mistral's Future and Open Source Releases:
@potatooffinquired about the future plans for Mistral's open source releases, while@nicolas_mistraldirected to a Twitter post by@arthurmenschas the best source of information for the most recent updates. - Request for Model Training Code and Expansion: Users expressed interest in official Mistral training code (
@kalomaze) and expanding the 7B base model (@rtyax), while@sophiamyangacknowledged the suggestions without providing certainty on future implementation. - Performance Discussions and Release Plans:
@yesiamkurtasked about the performance differences between Mixtral 8x7b and Mistral’s large models, to which@sophiamyangprovided a link to their benchmarks, indicating Mistral Large is superior, but did not disclose any release plans. - Evaluating Models with Real Life Data and Manual Checks: Participants discussed the real-life use of evaluation datasets with
@kalomazementioning MMLU as a representative benchmark;@netrvediscussed manual evaluation using Salesforce Mistral Embedding Model;@_kquantadvised on the importance of challenging models in evaluations.
Links mentioned:
- Becario AI asistente virtual on demand.: no description found
- Phospho: Open Source text analytics for LLM apps: no description found
- Endpoints and benchmarks | Mistral AI Large Language Models: We provide five different API endpoints to serve our generative models with different price/performance tradeoffs and one embedding endpoint for our embedding model.
- Large Language Models and the Multiverse: no description found
- GitHub - wyona/katie-backend: Katie Backend: Katie Backend. Contribute to wyona/katie-backend development by creating an account on GitHub.
Mistral ▷ #le-chat (151 messages🔥🔥):
- Troubleshooting API Access: User
@batlzencountered a "Method Not Allowed" 405 error when using the chat completions endpoint. After some discussion and suggestions from@mrdragonfox, it was resolved that@batlzneeded to switch to using the "POST" method. - Le Chat Model Confusion:
@godefvreported that Le Chat identified itself with GPT-like attributes, highlighting a potential training data issue or hallucinations, as models lack introspection.@mrdragonfoxand others discussed the matter, concluding self-knowledge must be in the dataset to avoid such errors. - Daily Cap Queries and Limitations: Users like
@cm1987expressed concerns about hitting usage limits, with@mrdragonfoxreminding them that it's part of using a beta product, and limits are to be expected. - Web UI Response Display Issues:
@steelpotato1and@venkybeastreported a display bug where response text appears above the initial prompt before jumping below it in the web UI. - Authentication and API Key Anomalies: User
@foxalabs_32486experienced difficulties accessing their account with credentials apparently not recognized. It was later revealed that an email confusion with the auth manager was the issue, which was resolved with assistance from other users.
Links mentioned:
Client code | Mistral AI Large Language Models: We provide client codes in both Python and Javascript.
Mistral ▷ #failed-prompts (12 messages🔥):
- Mistral's Mathematical Mishap:
@awild_techreported that Mistral Large failed to correctly answer what the floor of 0.999 repeating is, with the model outputting 0 instead of the expected 1. This question seems to stump multiple models across the board. - Inconsistent Answers in Multiple Languages: Despite being initially correct,
@awild_techpointed out that when they repeated the question in French, Mistral Large fluctuated between correct and incorrect responses. - Random Luck or Flawed Understanding?:
@_._pandora_._suggested the possibility that Mistral Large getting the floor question right on the first attempt might have been due to luck rather than a robust understanding, as subsequent answers were wrong. - Detailed Explanation by Mistral Strikes Out:
@i_am_domshared a detailed explanation from Mistral Large on the floor of 0.999 repeating, which ultimately concluded incorrectly that the floor is 0. - Mistral Misquotes "System" Role: In an attempt to retrieve the previous message by the "system" role,
@i_am_domnoted that Mistral Large provided various inaccurate versions instead of the expected verbatim quote.
Perplexity AI ▷ #announcements (2 messages):
- Playground AI's New V2.5 Model Unveiled:
@ok.alexannounced that Perplexity Pro users now have access to Playground AI's new V2.5 as the default model for generating a variety of images. Further details about the Perplexity and Playground collaboration can be found in this blog post.
- Introducing Claude 3 for Perplexity Pro Users:
@ok.alexrevealed the release of Claude 3 for<a:pro:1138537257024884847>users, which replaces Claude 2.1 and provides 5 daily queries with the advanced Claude 3 Opus model. Additional daily queries will utilize Claude 3 Sonnet, a faster model on par with GPT-4.
Links mentioned:
no title found: no description found
Perplexity AI ▷ #general (831 messages🔥🔥🔥):
- Claude 3 Opus Usage a Hot Topic: Users like
@stevenmcmackin,@naivecoder786, and@dailyfocus_dailyexpressed concerns about the limit of 5 queries per day for Claude 3 Opus on Perplexity AI Pro, finding the restriction too meager for their usage needs. Some wondered what happens after the limit is reached, while others suggested improving the quota or the usability of Claude 3 Sonnet. - Discussions on Claude 3's Effectiveness: Members such as
@dailyfocus_daily,@akumaenjeru,@detectivejohnkimble_51308engaged in discussions on Claude 3's capabilities, with mixed opinions on whether Claude or GPT-4 is superior for tasks like coding and problem-solving. Some users have personally found Claude 3 to outperform GPT-4, especially in coding. - Claude's Integration and Model Clarity: Questions were raised by users like
@cereal,@heathenist, and@eli_pcon how to differentiate between Opus and Sonnet, and on the transparency of model context size and operations. There seems to be a desire for more clarity on when and how different models are deployed. - Perplexity's AI-powered Features and Plans: Users
@fluxkraken,@cereal, and@joed8.discussed workarounds and techniques for image generation and search functionality, shedding light on how to optimize Perplexity's AI for various tasks. Speculation about Perplexity's future moves towards dedicated models was also shared by@fluxkraken. - Promotional Deals and Model Access: Users talked about promotional offers like the Rabbit R1 deal (
@jawnze,@fluxkraken,@drewgs06) and how it ties with Perplexity AI Pro subscriptions. Some discussed Claude 3 not being available on the iOS app yet, while others enhanced the conversation with how to access various models.
Links mentioned:
- Chat with Open Large Language Models: no description found
- Oliver Twist GIF - Oliver Twist - Discover & Share GIFs: Click to view the GIF
- YouTube Summary with ChatGPT & Claude | Glasp: YouTube Summary with ChatGPT & Claude is a free Chrome Extension that lets you quickly access the summary of both YouTube videos and web articles you're consuming.
- Claude-3-Opus - Poe: Anthropic’s most intelligent model, which can handle complex analysis, longer tasks with multiple steps, and higher-order math and coding tasks. Context window has been shortened to optimize for speed...
- 📖[PDF] An Introduction to Theories of Personality by Robert B. Ewen | Perlego: Start reading 📖 An Introduction to Theories of Personality online and get access to an unlimited library of academic and non-fiction books on Perlego.
- David Leonhardt book talk: Ours Was the Shining Future, The Story of the American Dream: Join Professor Jeff Colgan in conversation with senior New York Times writer David Leonhardt as they discuss David’s new book, which examines the past centur...
- CLAUDE 3 Just SHOCKED The ENTIRE INDUSTRY! (GPT-4 +Gemini BEATEN) AI AGENTS + FULL Breakdown: ✉️ Join My Weekly Newsletter - https://mailchi.mp/6cff54ad7e2e/theaigrid🐤 Follow Me on Twitter https://twitter.com/TheAiGrid🌐 Checkout My website - https:/...
- SmartGPT: Major Benchmark Broken - 89.0% on MMLU + Exam's Many Errors: Has GPT4, using a SmartGPT system, broken a major benchmark, the MMLU, in more ways than one? 89.0% is an unofficial record, but do we urgently need a new, a...
- Puppet Red GIF - Puppet Red Ball - Discover & Share GIFs: Click to view the GIF
- Rabbit R1 and Perplexity AI dance into the future: Rabbit R1 Perplexity AI usage is explained in this article. In the ever-evolving landscape of technology, the collaboration between the
- 必应: no description found
Perplexity AI ▷ #sharing (18 messages🔥):
- Exploring the Antarctic:
@christianbugsshared a link to information about Antarctica using Perplexity AI's search functionality. The link is anticipated to contain details about the continent's geography, climate, and other characteristics. - Announcement of Claude 3:
@dailyfocus_dailyand@_paradroidprovided links to discussions around the newly announced Claude 3 via Perplexity AI.@ethan0810.also shared a link about Anthropic launching Claude. - Vultr Promo Hunt:
@mares1317sought promotional codes for Vultr, a cloud hosting service, and used Perplexity AI's search feature to possibly find some deals. - Understanding US-Jordan Relations:
@_paradroidused Perplexity AI to search into the relationship between the United States and Jordan, indicating an inquiry into their bilateral interactions. - History Unveiled:
@whimsical_beetle_50663appeared to look deeper into history with a link provided from Perplexity AI's search, though the specific historical topic is not mentioned.
Perplexity AI ▷ #pplx-api (18 messages🔥):
- Patience is a Virtue for API Access:
@_samratinquired about how to follow up on getting access to citations in the API after submitting their request.@icelavamanand@brknclock1215responded suggesting that the usual response time is 1-2 weeks or longer and to exercise patience. - Improvement Noted with Configuration Tweaks:
@brknclock1215expressed satisfaction with recent results from tweaking configurations, mentioning a preference for keeping the temperature below 0.5 when using system prompts for instruction following. - Temperature Factor in Language Models: Users
@brknclock1215,@heathenist, and@thedigitalcatengaged in a discussion about the role of temperature in natural language generation. They noted that lower temperatures don't always equate to more reliable results, indicating the complexity of linguistics and language models. - Query on Quota Increases Across Different Models:
@stijntratsaert_01927asked whether previously assigned quota increases on one platform would carry over to another, specifically from pplx70bonline to sonar medium online. - Concerns About Model Censorship Via API:
@randomguy0660raised a question about whether the models accessible through the API are subject to censorship.
OpenAI ▷ #ai-discussions (314 messages🔥🔥):
- Translation AI Enthusiasts Seek Options:
@jackal101022inquired about alternative translation AI services, expressing dissatisfaction with the robotic output from Google Translate and the subsequent edits needed fromGemini or ChatGPT.@luguirecommended using GPT-3.5, praising its quick and accurate performance.
- Thinking Mathematically with Classic Problems: After
@kiddurequested a mathematical problem to enhance logical thinking,@mrsyntaxsuggested the "traveling salesman" problem for its mix of optimization and efficiency challenges.
- Anthropic's Claude 3 Sparks Interest: Discussion around the new Claude 3 AI from Anthropic is on the rise, with
@glamrat,@odiseo3468, and others chiming in on its impressive capabilities. Users are comparing Claude 3 against ChatGPT, particularly for to Oups model which@odiseo3468found to be exceptionally good at graduate-level reasoning, though@cook_sleepreported weaker logic and image recognition compared to GPT-4, especially in Chinese.
- OpenAI's Model Versions and Limits Scrutinized: The conversation turned technical as users like
@johnnyrobertand@pteromaplediscussed the limitations that they've experienced with GPT-4, particularly around the token limits for inputs and contexts in various versions of the model.
- Comparing Chatbots for Roleplay and Storytelling: Multiple users, including
@webheadand@cook_sleep, shared their experiences with Claude 3's superior performance in roleplay and creative writing although noting some limitations in other areas. This has led to suggestions that OpenAI should push to release GPT-5 as competition intensifies with models like Gemini and Claude showcasing advanced language expression capabilities.
Links mentioned:
- Anthropic says its latest AI bot can beat Gemini and ChatGPT: Claude 3 is here with some big improvements.
- New models and developer products announced at DevDay: GPT-4 Turbo with 128K context and lower prices, the new Assistants API, GPT-4 Turbo with Vision, DALL·E 3 API, and more.
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
- Seeking Practical GPT Use Cases:
@flo.0001is in search of channels or resources for practical applications of GPT or the Assistant API in business and productivity, and@mrsyntaxsuggested checking out a specific channel with the ID<#1171489862164168774>. - Looking for Business Implementation Insights: Despite the channel recommendation,
@flo.0001mentioned that they are overwhelmed and are looking more for direct examples of GPT implementation in business and productivity systems. - Chatbot Browser Issues Raised:
@snoopdogui.reported the ChatGPT browser version was down for them, and@solbusprovided a link to a previously shared message potentially addressing the issue. - Errors in Saving GPTs:
@bluenail65expressed confusion over receiving an error message about Saving GPTs despite not having any files uploaded. - Perceived Performance Deterioration of GPT-4:
@watcherkkand@bluenail65both noted that they feel GPT-4's performance has declined since its release, experiencing slower response times, while@cheekatiobserved that the model appears more restrictive in referencing materials.
OpenAI ▷ #prompt-engineering (60 messages🔥🔥):
- Refusal to Accept Internet Capability:
@jungle_joexpressed confusion about an AI's persistent denial of its ability to access the internet, despite being told it can search the internet for real-time information in the system prompt. - Seeking Prompt-Engineering Tips:
@thetwenty8thffsrequested suggestions for improving a prompt aimed at assisting customers with unrecognized credit card charges to make it more clear and concise. - Custom GPT Reluctance:
@ray_themad_nomadreported issues with getting direct refusals from a Custom GPT model, with regenerations and prompt adjustments failing to receive cooperative responses, and wondered if others are experiencing similar difficulties. - Visual Prompts for AI Creativity:
@ikereinezshared success in teaching an AI to generate complex visuals from real photos, using detailed and imaginative descriptions of futuristic cityscapes. - AI's Selective Response Frustrations: Several users, including
@darthgustav., discussed difficulties and debated potential internal mechanisms of AI models, with focus on prompt engineering, visualization errors, and AI transparency, hinting at possible limitations in the Vision system used in conjunction with OpenAI GPT models.
OpenAI ▷ #api-discussions (60 messages🔥🔥):
- Prompt-engineering Fundamentals:
@dantekavalastruggled with style consistency in prompts when transitioning from ChatGPT to the GPT 3.5 API, noting a lack of adaptability despite several attempts.@madame_architectdirected@dantekavalatowards the developer's corner for more focused aid.
- User Experience Challenges with the GPT API: In a sequence of messages,
@darthgustav.and@eskcantadiscussed challenges in working with the visual and mathematical capabilities of GPT, indicating a need for improvement in how vision models interpret and handle prompts.
- In Search of Translation Prompt Excellence:
@kronos97__16076asked for suggestions on designing Chinese-English translation prompts, with community members like@neighbor8103suggesting the use of external tools for verification of machine translation accuracy.
- Exploring Vision Model Limitations: Users
@aminelg,@eskcanta, and@madame_architectengaged in investigative discussions about the Vision model's interpretation of stimuli, the possibility of teaching models within a conversation, and the fun challenges in prompt engineering for vision-related tasks.
- Frustration with Custom Models:
@ray_themad_nomadexpressed dissatisfaction with the response quality from Custom GPTs, receiving frequent refusals despite different attempts at prompting, suggesting a setback in user interaction with tailored models.
Nous Research AI ▷ #off-topic (6 messages):
- Request for Academic Paper:
@ben.comseeks a link to an academic paper, noting inability to view it as they are not a Twitter user. - OpenAI's Supposed Downfall a Hot Topic:
@leontellocomments on the abundance of posts on AI Twitter claiming that OpenAI has been surpassed. - Confusion Over AI Community Reactions:
@leontellouses a custom emoji to express confusion or skepticism about the discussions around AI performance. - Claude 3 Model Claims Spotlight:
@pradeep1148shares a YouTube video titled "Introducing Claude 3 LLM which surpasses GPT-4," highlighting the introduction of the Claude 3 model family. - Apple Test as a Benchmark:
@mautonomysuggests that the apple test is a reliable indicator, presumably in the context of evaluating AI, responding to the discussion about AI superiority.
Links mentioned:
Introducing Claude 3 LLM which surpasses GPT-4: Today, we're look at the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of...
Nous Research AI ▷ #interesting-links (42 messages🔥):
- Unveiling Prompt Engineering Tricks: User
@everyoneisgrossshared a comprehensive guide to help enhance the output of Large Language Models (LLMs) by prompt engineering. The guide contains methods to improve safety, determinism, and structured output.
- Massive Multi-Model Evaluation:
@mautonomyrevealed a Reddit post comparing 17 new AI models, raising the total to 64 ranked models. The post showcases models likedolphin-2.8-experiment26-7b-previewandMidnight-Rose-70B-v2.0.3-GGUF.
- Skepticism about AI Parameter and Brain Function Claims:
@ldjexpressed criticism towards certain speculations about AI parameters and brain functions, suggesting that they are based on flawed assumptions.
- End of Giant AI Models Era:
@ldjreferenced articles referring to statements from Sam Altman about future AI models becoming more parameter-efficient and progress coming from architectural innovations rather than scale. The discussions emphasize that OpenAI believes the era of simply making larger models has peaked source 1, source 2.
- Introducing 'moondream2' for Edge Devices: User
@tsunemotoshared an announcement from@vikhyatkabout the release of moondream2, a small vision language model that requires less than 5GB to run Tweet Link. It's designed for efficiency on edge devices with 1.8B parameters.
Links mentioned:
- Tweet from vik (@vikhyatk): Releasing moondream2 - a small, open-source, vision language model designed to run efficiently on edge devices. Clocking in at 1.8B parameters, moondream requires less than 5GB of memory to run in 16 ...
- Tweet from Together AI (@togethercompute): Excited to share new research we collaborated with @HazyResearch on — Based, a new architecture that leverages attention-like primitives – short (size-64) sliding window attention and softmax-approxim...
- - Fuck You, Show Me The Prompt.: Quickly understand inscrutable LLM frameworks by intercepting API calls.
- Dear Sam Altman- There was never an era of making models bigger: LLMs have never been revolutionary or as game-changing as gurus online would have pushed you to believe
- GitHub - derbydefi/sdam: sparse distributed associative memory: sparse distributed associative memory. Contribute to derbydefi/sdam development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - X-PLUG/MobileAgent: Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception: Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception - X-PLUG/MobileAgent
- The End of the Giant AI Models Era: OpenAI CEO Warns Scaling Era Is Over: Learn what OpenAI's CEO Sam Altman has to say about future advances in AI models like ChatGPT and how access to GPUs remains crucial.
Nous Research AI ▷ #general (227 messages🔥🔥):
- Searching for Continuous Pretraining:
@4bidddensought a code repository for continuous pretraining but didn't find any, while@ayushkaushalcontributed a solution for small-scale pretraining using a modified gpt-neox codebase and suggested axolotl for very small scale with adjustments to the learning rate schedule and data replay.
- Claude 3 Announcement Stirs Discussion: A link to a tweet by AnthropicAI announcing Claude 3 sparked speculation among users about its performance relative to GPT-4.
@fibleepshared the announcement, and@intervitensprovided a human eval score for context.
- Evaluating Government Efficiency: In a discussion about potential government regulations,
@dumballexpressed concerns that any increase in bureaucratic processes could result in significant friction regarding business operations, legal licensing costs, and opportunity costs due to government inefficiencies.
- Training With Large Physics Paper Datasets:
@ee.ddinquired about the best approach to train a model using a massive dataset of physics papers. Responses by@ldjand@casper_aisuggest mixing it into a pretraining or continued pretraining dataset and the relevance of having sufficient compute resources.
- Arc Browser's Waitlist and Access:
@sanketpatrikarrequested help getting into the Arc browser waitlist, and@ee.ddprovided assistance using a student email link that worked for Windows 11. A subsequent discussion touched on the potential artificial demand created by waitlists and geographical discrepancies in access to services like Amazon.
Links mentioned:
- EvalPlus Leaderboard: no description found
- Tweet from Blaze (Balázs Galambosi) (@gblazex): Claude 3 Opus (output) is very expensive It does have solid reasoning scores, so we'll see how much it'll worth the extra cost. But GPT-4 Turbo remains the most cost-efficient high-end solut...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- wandb/gemma-2b-zephyr-dpo · Hugging Face: no description found
- Tweet from interstellarninja (@intrstllrninja): F#@k You, Show Me The Prompt! ↘️ Quoting Stella Biderman (@BlancheMinerva) I am once again begging people to look at their datasets when explaining the behavior of the LLMs instead of posting click...
- Tweet from Teknium (e/λ) (@Teknium1): Is claude 3 opus better than gpt4? New poll because last one was too ambigious and also because I had no show results █████ Yes (17.1%) ███ No (11.8%) ██████████████████████ Show results (71.2%) ...
- Tweet from Beff Jezos — e/acc ⏩ (@BasedBeffJezos): If your main characteristic is being smart, pivot to rizz. Human-level AI is here. ↘️ Quoting Guillaume Verdon (@GillVerd) Claude 3 Opus just reinvented this quantum algorithm from scratch in jus...
- Tweet from Anthropic (@AnthropicAI): Today, we're announcing Claude 3, our next generation of AI models. The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reason...
- Tweet from Chris Albon (@chrisalbon): “No yapping” is a pro-level prompt engineering strat, you wouldn’t understand ↘️ Quoting guy who makes using vim his whole personality (@pdrmnvd) Finally found a way to read Python stack traces.
- Tweet from Teknium (e/λ) (@Teknium1): So is it actually better than gpt 4? ███████████████ Yes (49.6%) ████████████████ No (50.4%) 2.1K votes · Final results
- unilm/bitnet at master · microsoft/unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities - microsoft/unilm
- Tweet from bayes (@bayeslord): yeah so far talking to claude feels like talking to a smart person vs chatgpt which has sort of a copypasta vibe rn
- Tweet from Simon Willison (@simonw): I'm finding the Claude 3 pricing to be particularly interesting today - they're effectively undercutting OpenAI with both their GPT-4 and their GPT-3.5 competitors
- Claude 3 Opus as an economic analyst: Introducing Claude 3, our next generation of AI models.The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry ...
- microsoft/orca-math-word-problems-200k · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (14 messages🔥):
- Inference Combination Strategies Discussed:
@tekniumsuggested using models like Hermes Mixtral or Mixtral-Instruct v0.1 with RAG and system prompts for specific tasks, and offered tools like fireworksAI or openrouter for inference.
- Pondering the Future of Language Models:
@pier1337inquired about the next developments in language models, specifically the concept of object-driven AI and the potential for language models to understand the world through simulated experiences.
- Advancing AI with Multimodal Representations:
@max_paperclipsresponded to@pier1337by affirming that future AI will include not just words but representations of the world and multimodal output, and recommended looking into JEPA by Yann LeCun and DeepMind's recent models.
- Seeking Chat Template for Capybara-34b:
@oemd001sought assistance for a chat template for the Capybara-34b model, with@tekniumsuggesting the Vicuna format and@ben.comproviding an example chat template.
- Exploration of Interactive World AI:
@pier1337commented that models such as GENIE are not only suitable for 2D games but any interactive world environment, highlighting the versatility of modern AI models.
Nous Research AI ▷ #project-obsidian (4 messages):
- Tiny Vision Language Model Discovered:
@ee.ddintroduced Moondream, a tiny vision language model, sharing its GitHub link: GitHub - vikhyat/moondream. They commented on its impressive speed and quality after testing. - Moondream Forthcoming Exploration:
@max_paperclipsexpressed an interest in experimenting with Moondream soon, having heard about its fast performance. - Moondream's Odd Quirks:
@ee.ddfound Moondream to be "pretty fast and good for most things," but mentioned it can be "a lil weird at times," making them hesitant to use it in a production environment but seeing potential for future development.
Links mentioned:
GitHub - vikhyat/moondream: tiny vision language model: tiny vision language model. Contribute to vikhyat/moondream development by creating an account on GitHub.
Nous Research AI ▷ #bittensor-finetune-subnet (1 messages):
- Release highlights for v0.2.2:
@tekniumannounced Version 0.2.2, which includes an updated transformers package with a fixed Gemma implementation, as seen in the pull request on GitHub. Repositories are now initially uploaded as private and only made public upon commitment to the chain, with gratitude towards@MesozoicMetallurgist. - Update Adjusts Mistral/Gemma Reward Ratio: The new version also brought an adjustment to the reward ratio between Mistral and Gemma, setting them to an equal 50% each.
Links mentioned:
Release v0.2.2 · NousResearch/finetuning-subnet: v0.2.2
LAION ▷ #general (229 messages🔥🔥):
- Model Size Matters in Machine Learning:
@pseudoterminalxand other users discussed the aspects of scaling up model training with increasing compute power, highlighting concerns about bottlenecks such as data transfer between CPU/GPU, and the diminishing returns of just adding more computing power. - Pony Model Critique:
@pseudoterminalxcriticized the Pony diffusion model, suggesting a "core misunderstanding" in the way its training data captions are constructed, possibly leading to issues with how the tokenizer treats underscores and tags. Other users also expressed skepticism about Pony's capabilities. - SD3 Anticipation and Considerations: Conversation around the then-upcoming SD3 model highlighted excitement but also some potential disappointments, like computational demands on consumer hardware.
@nodjamentioned that T5, an integral part of SD3, is optional, which could make personal use more feasible. - Complexity for Simple Objects Still Eludes Models: Users, such as
@thejonasbrothersand@pseudoterminalx, shared experiences with AI models struggling to generate simple everyday objects accurately, drawing contrast to greater success with more complex scenes or characters. - Discussions on Enhancing Pixel Art Generation: There was a lively exchange about generating pixel art using AI, with
@nodjaand@astropulseexamining methods to apply palettes in latent space and the associated technical challenges of incorporating them into machine learning models.
Links mentioned:
- Doubt Press X GIF - Doubt Press X La Noire - Discover & Share GIFs: Click to view the GIF
- Jinx Elaine GIF - Jinx Seinfeld - Discover & Share GIFs: Click to view the GIF
- Tweet from Suhail (@Suhail): If you'd be interested in reproducing MagViT2 (or exceeding its implementation/training perf), please hmu. I got compute for you.
- diffusers-play/scripts/encode.py at better-decoder · Birch-san/diffusers-play: Repository with which to explore k-diffusion and diffusers, and within which changes to said packages may be tested. - Birch-san/diffusers-play
- GitHub - lucidrains/magvit2-pytorch: Implementation of MagViT2 Tokenizer in Pytorch: Implementation of MagViT2 Tokenizer in Pytorch. Contribute to lucidrains/magvit2-pytorch development by creating an account on GitHub.
- GitHub - google-research/distilling-step-by-step: Contribute to google-research/distilling-step-by-step development by creating an account on GitHub.
LAION ▷ #research (20 messages🔥):
- Innovative Terminator Network Unveiled: User
@alex_cool6presented the #Terminator network, detailing its combined use of past technologies like ResNet and Self-Attention with 1990s concepts such as slow-fast networks. They shared their work HyperZ.W Operator Connects Slow-Fast Networks which offers insights into full context interaction.
- Claude 3 Model Announcement Circulates:
@vrus0188shared a link about the Claude 3 benchmarks, directing attention to the discussion on Reddit and provided the official announcement from AnthropicResearch on LinkedIn.
- Real-world Testing of Claude 3: User
@segmentationfault8268commented on testing Claude 3, finding it less lazy and better knowing than GPT-4, and contemplated canceling his ChatGPT Plus subscription if further testing confirms significant improvements.
- Stable Diffusion 3 Claims Top Performance:
@mfcoolshared a Stability AI blog post about their Stable Diffusion 3 research paper, touting its performance over DALL·E 3, Midjourney v6, and Ideogram v1, and highlighting its novel Multimodal Diffusion Transformer (MMDiT) architecture.
- SmartBrush Paper Sparks Interest and Inquiry: User
@hiieeintroduced SmartBrush, a diffusion-based model for text and shape-guided image inpainting detailed in an arXiv paper, inquiring about open-source implementations and comparing it favorably for background preservation in inpainting tasks.
Links mentioned:
- Stable Diffusion 3: Research Paper — Stability AI: Following our announcement of the early preview of Stable Diffusion 3, today we are publishing the research paper which outlines the technical details of our upcoming model release, and invite you to ...
- Corrective Retrieval Augmented Generation — Why RAGs are not enough?!!: Paper || Tweet
- SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model: Generic image inpainting aims to complete a corrupted image by borrowing surrounding information, which barely generates novel content. By contrast, multi-modal inpainting provides more flexible and u...
- Reddit - Dive into anything: no description found
HuggingFace ▷ #general (112 messages🔥🔥):
- In Search of Model Context Windows Info: User
@patchie2sought a table listing HuggingFace models and their context windows. Detail or assistance on the topic was not provided within the shared messages. - Converting Safetensors for Vertex AI Deployment:
@rwamitqueried about converting.safetensorsto a format supported by VertexAI, as they encountered issues with unsupported formats. No direct solution or resource was offered in the conversation. - Gradient Calculation Curiosity:
@ahmad3794voiced an interest in calculating gradients from layer 3 with respect to layer 5 in a neural network to bypass backpropagation for efficiency, yet no specific advice or outcome was mentioned regarding the impact on network accuracy. - Request for Assistance with Space and Image Datasets: Users like
@benjimon0842,@kotni_bf, and others sought assistance with HuggingFace Spaces, dataset creation, and model training, engaging in back-and-forth discussions for help but with no confirmed resolution in sight. - Troubleshooting Gradio Space and Dataset Versions: In a series of messages,
@ilovesassand@vipitisdiscussed issues relating to a Gradio Space, with@ilovesassexperiencing multiple unknown errors and@vipitisoffering diagnostic suggestions like checking Gradio version compatibility and the inputs to the run function.
Links mentioned:
- Fbi Fbiopenup GIF - Fbi Fbiopenup Carlwhitman - Discover & Share GIFs: Click to view the GIF
- Marching cubes - Wikipedia: no description found
- Creausdemo - a Hugging Face Space by niggathug: no description found
- Pre-trained models and datasets for audio classification - Hugging Face Audio Course: no description found
- Create an image dataset: no description found
- JoPmt/hf_community_images · Datasets at Hugging Face: no description found
- Gradio Image Docs: no description found
- Introducing the next generation of Claude: Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order ...
- Open-source LLM Ecosystem at Hugging Face: How to find, shrink, adapt and deploy open-source large language models? Here's a 10 min walkthrough on all the tools in @huggingface 🤗 featuring transforme...
- Gradio ImageEditor Docs: no description found
- Don't ask to ask, just ask: no description found
- What is the Kirin 970's NPU? - Gary explains: Huawei's Kirin 970 has a new component called the Neural Processing Unit, the NPU. Sounds fancy, but what is it and how does it work?
- Google's Women Techmakers Darmstadt: Celebrating Womens Day WTM is sharing globally the message , how womens will impact the future. This event is Hybrid mode
HuggingFace ▷ #today-im-learning (1 messages):
pacozaa: Transformer js
HuggingFace ▷ #cool-finds (7 messages):
- Klarna AI Assistant Triumphs in Customer Service:
@pier0407shared a press release announcing Klarna's new AI assistant. In just one month, the assistant handled over 2.3 million conversations, demonstrating a significant efficiency boost by performing the work of 700 agents and shortening errand resolution times from 11 minutes to under 2 minutes.
- Introducing Based - A New Language Model with High-Quality Recall:
@osansevierohighlighted Based, an architecture combining sliding window and linear attention for efficient language modeling with strong associative recall, capable of decoding without a KV-cache for a 24x throughput improvement over traditional Transformers.
- Pika - A New Horizon in Video Creation Technology:
@aimuhaiminbrought to attention Pika, a platform that enables users to generate videos using text-to-video, image-to-video, and video-to-video transformations, promising to put creative control in users' hands.
- Byte Models as Simulators:
@andysingalshared a link to a paper titled "Beyond Language Models: Byte Models are Digital World Simulators", which suggests a shift from traditional language models to byte models for simulating digital worlds.
- EasyDeL: Open-Source Library for Efficient Model Training:
@andysingalalso introduced EasyDeL, an open-source library designed to facilitate the training of machine learning models with a focus on Jax/Flax models and TPU/GPU efficiency, including support for 8, 6, and 4 BIT inference and training.
Links mentioned:
- Paper page - ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs: no description found
- OMPGPT: A Generative Pre-trained Transformer Model for OpenMP: Large language models (LLMs), as epitomized by models like ChatGPT, have revolutionized the field of natural language processing (NLP). Along with this trend, code-based large language models such as ...
- Klarna AI assistant handles two-thirds of customer service chats in its first month: New York, NY – February 27, 2024 – Klarna today announced its AI assistant powered by OpenAI. Now live globally for 1 month, the numbers speak
- Pika: The idea-to-video platform that sets your creativity in motion.
- Paper page - Beyond Language Models: Byte Models are Digital World Simulators: no description found
- BASED: Simple linear attention language models balance the recall-throughput tradeoff: no description found
- EasyDeL: An open-source library to make training faster and more optimized in Jax/Flax
HuggingFace ▷ #i-made-this (16 messages🔥):
- Gemma Model Speed Boost with Unsloth:
@andysingalshared their uploaded model, which was trained using Unsloth for 2x faster inference. The Gemma model is derived fromunsloth/gemma-7b-bnb-4bit, and they thanked Unsloth for sharing helpful notebooks.
- MEGA Encounters GLUE:
@pszemrajintroduced a pretrained encoder model named mega-encoder-small-16k-v1, which performs comparably on short-context GLUE benchmarks despite its long-context design.
- Kubeflow Simplified by Terraform Module:
@alextreebeardannounced they have created a terraform module to convert Kubernetes clusters into AI environments, hosting Jupyter via Kubeflow and potentially integrating GPU support. The work is shared on their GitHub repository.
- Search ArXiv With AI:
@bishmoypresented a Huggingface Space, which utilizes RAG on ArXiv abstracts to search for answers on computer science papers. They mentioned plans to create a GitHub repository or blog post to detail the creation process.
- Chatbot Layout Troubles Discussed:
@cookiechunk.highlighted an issue where a chatbot made with OpenAI API and Gradio looks distorted when embedded, seeking help to rectify this.@myg5702briefly commented with "Gradio ☕."
Links mentioned:
- Arxiv CS RAG - a Hugging Face Space by bishmoy: no description found
- Fluently Playground - a Hugging Face Space by fluently: no description found
- Andyrasika/lora_gemma · Hugging Face: no description found
- BEE-spoke-data/mega-encoder-small-16k-v1 · Hugging Face: no description found
- GitHub - treebeardtech/terraform-helm-kubeflow: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐 - treebeardtech/terraform-helm-kubeflow
HuggingFace ▷ #reading-group (42 messages🔥):
- "Terminator" Network Teaser Shared:
@alex_cool6shared their recent work on the #Terminator network which incorporates a blend of modern technologies like ResNet and Self-Attention with ideas from the 1990s. They provided a link to their paper and expressed intent to release code in the future, possibly presenting on March 16-17.
- Scheduling Dilemma for Reading Sessions: Multiple users discussed the possibility of moving the reading group sessions to the weekend to accommodate different time zones. The conversation circled around finding a sweet spot that suits most members, with suggestions to consider logistics over Discord or Zoom.
- Platform Preference for Meetings: Discussion about whether Discord or Zoom is better for conducting reading group sessions, with members generally leaning towards Discord for its ease of access and ability to join effortlessly.
- Recordings of Reading Group Sessions Available:
@johko990confirmed that the reading group sessions are recorded and available on Isamu Isozaki's YouTube profile.
- In Search of Low Latency Neural TTS: New member
@dediplomaat.sought guidance for a Text-to-Speech (TTS) system that could dynamically adjust pauses based on conversational context, expressing the need for low latency similar to GPT-4's functionality.
Links mentioned:
- Isamu Isozaki: no description found
- GitHub - hyperevolnet/Terminator: Contribute to hyperevolnet/Terminator development by creating an account on GitHub.
- GitHub - isamu-isozaki/huggingface-reading-group: This repository's goal is to precompile all past presentations of the Huggingface reading group: This repository's goal is to precompile all past presentations of the Huggingface reading group - isamu-isozaki/huggingface-reading-group
HuggingFace ▷ #diffusion-discussions (6 messages):
- NSFW Model Alert on HuggingFace:
@pseudoterminalxhighlighted a potential NSFW model titled AstraliteHeart/pony-diffusion-v6. In response,@811235357663297546indicated that action such as opening a PR for an NFAA tag or a report can be taken.
- Community Guides for Diffusers:
@juancopi81recommended looking into the IP-Adapter and shared a Hugging Face tutorial on its uses, prompting a positive reaction from@tony_assiwho confirmed great results after consulting the documentation.
Links mentioned:
- AstraliteHeart (Astralite Heart): no description found
- IP-Adapter: no description found
- AstraliteHeart/pony-diffusion-v2 · Request to add NFAA (nsfw) tags to models: no description found
HuggingFace ▷ #computer-vision (7 messages):
- Introducing the Terminator Network:
@alex_cool6shared his recent work on the #Terminator network, which integrates past technologies like ResNet with historical concepts like slow-fast networks, providing a HyperZ⋅Z⋅W Operator for Full Context Interaction. - Seeking VLM for Client Onboarding:
@n278jmis inquiring about the best small Visual-Language Model (VLM) for extracting image details during a client onboarding process to assist in creating a user preference map. - Optimization of Vision Model Inputs:
@n278jmelaborates on conducting experiments in the vision arena to perfect the text input and data extraction process, aiming to balance model size with effectiveness. - Community Assistance Offered:
@johko990responds with encouragement to@n278jm's inquiry on VLMs, suggesting it's worth experimenting with. - Crowdsourcing CV Expertise:
@akvnnrequested to speak with a computer vision expert, to which@nielsr_humorously replied, asserting the community is full of CV experts.
HuggingFace ▷ #NLP (14 messages🔥):
- Seeking SOTA in Bidirectional NLP LMs:
@grimsqueakerinquired about the current state-of-the-art for efficient and performative bidirectional NLP language models similar to BERT or ELECTRA, naming options like Deberta V3, monarch-mixer, and variations of hacked hyena/striped hyena.
- Generating SQL Queries with NLP: User
@lokendra_71926asked for recommendations on the best model to convert NLP queries into SQL.
- Challenges in Enhancing Mistral with GBNF:
@.sgpdiscussed difficulties with mistral7b combined with gbnf grammar for extracting dates from text in JSON, where the model tends to hallucinate dates instead of leaving them empty when not available.
- Incorporating Mistral into Windows Apps:
@aitechguy0105expressed interest in using Mixtral 8x7b instructor within a Windows application, to which@iakhilsuggested that it can be integrated using Ollama. Further,@aitechguy0105queried about implementing it in C++, which@cursoropconnected to a potential llama cpp implementation.
- Inconsistent Inference Times with Mistral and BLOOM Models:
@anna017150reported experiencing variable inference times using mistralai/Mistral-7B-Instruct-v0.2 and bloomz-7b1 models, with@cursoropand@vipitisdiscussing possible involvement of KV cache and a new "static" option in Accelerate.
HuggingFace ▷ #diffusion-discussions (6 messages):
- NSFW Generation Model Alert: User
@pseudoterminalxhighlighted a potential NSFW generation model named AstraliteHeart/pony-diffusion-v6 on HuggingFace, prompting@811235357663297546to note that models with such content are hosted on the platform. - Handling Inappropriate Content: Following the NSFW model discussion,
@lunarflusuggested creating a pull request (PR) to tag such content with NFAA, and if needed, opening a report for further action taken by the HuggingFace team. - Uploading Multimedia to HuggingFace:
@lunarflushared a link that describes how to upload images, audio, and videos to HuggingFace by dragging into the text input, pasting from the clipboard, or clicking to upload. - Training Whisper Models on Google Colab:
@pompoko3572asked for assistance on how to continue training a Whisper model when Google Colab training stopped at epoch 2, sharing the function being used and seeking a way to load and continue from the saved checkpoint. - IP-Adapter Tutorial Discussion:
@juancopi81directed users to the HuggingFace documentation on IP-Adapter, a tool for image prompting in diffusion models, with@tony_assiexpressing appreciation for the well-documented and helpful tutorial.
Links mentioned:
- IP-Adapter: no description found
- AstraliteHeart (Astralite Heart): no description found
- AstraliteHeart/pony-diffusion-v2 · Request to add NFAA (nsfw) tags to models: no description found
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- Claude 3 Debuts on OpenRouter:
@alexatallahannounces the release of Claude 3 to OpenRouter, including an experimental self-moderated version for users to explore. Check it out here.
- Introducing Claude 3 Opus with High EQ:
@louisgvtouts Claude 3 Opus for its exceptional emotional intelligence (EQ) and its ability to score 60% on a test that challenges PhDs. It's multi-modal, supports assistant prefill, and it conforms to the new API. Details can be found here.
- Claude 3 Sonnet Rivals GPT-4 at Lower Cost: Claude 3 Sonnet is introduced as a cost-effective alternative to GPT-4, also offering multi-modal capabilities. Experience it here.
- Self-Moderated Claude 3 Available in Beta: Beta self-moderated versions of Claude 3 are available at no extra cost, offering users a chance to explore new functionalities without an additional charge. Users can go really ham with this version by visiting this link.
- New Parameters API Unveiled for Developers: OpenRouter introduces a new Parameters API in beta, allowing developers to access a list of median parameter values for all models, facilitating a more standardized integration. Developers can find the documentation and learn more about this feature here.
Links mentioned:
- Anthropic: Claude 3 Opus by anthropic | OpenRouter: Claude 3 Opus is Anthropic's most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding. See the launch announcement and benchmark re...
- Anthropic: Claude 3 Sonnet by anthropic | OpenRouter: Claude 3 Sonnet is an ideal balance of intelligence and speed for enterprise workloads. Maximum utility at a lower price, dependable, balanced for scaled deployments. See the launch announcement and ...
- Anthropic: Claude 3 Opus (self-moderated) by anthropic | OpenRouter: This is a lower-latency version of Claude 3 Opus, made available in collaboration with Anthropic, that is self-moderated: response moderation happens on the model&#x...
- OpenRouter: Build model-agnostic AI apps
OpenRouter (Alex Atallah) ▷ #general (180 messages🔥🔥):
- Claude 3 Sparks Joy and Confusion: Users like
@justjumper_,@louisgv, and@arsobanexpress excitement for the new Claude 3, with@arsobannoting it outperforms GPT-4 in some tests. In contrast,@alexatallahassures that even the "experimental" version of Claude 3 will go live, responding to@wikipediadotnetand others' queries.
- Pricing Puzzles Everyone: A conversation about Claude 3's pricing ensues with users like
@oti5,@voidlunaa, and@xiaoqianwx.@voidlunaafinds Opus's price jump from Sonnet bizarre, suggesting that it might be priced like a physical service due to@wikipediadotnet's comic observation.
- Interaction Issues with New Models: User
@fillystepsreports getting blank responses from all Claude models except the 2.0 beta and suspects being banned, while others like@wikipediadotnetand@antoinerossinquire about pricing and implementation details.@louisgvtroubleshoots, suggesting issues might arise from region blocks or using unsupported features like image inputs.
- Mixed Reception for Claude’s Literary Talents: While some, such as
@khadameand@wikipediadotnet, praise Claude 3 Sonnet and Opus for their writing quality, others like@edgyfluffreport repeated, unwanted auto-generated responses, with@wikipediadotnetoffering troubleshooting tips.
- Undercurrent of Model Comparisons and Costs: Discussions on model comparisons are rampant, with mentions of Claude 3 outperforming others like Gemini Ultra and GPT-4 by
@arsoban,@voidlunaa, and@followereternal. Concerns like@mhmm0879's about real vs. predicted costs of model usage indicate a need for clarity on pricing structures, while@alexatallahclarifies tokenization issues might be at fault.
Links mentioned:
- OpenRouter: A router for LLMs and other AI models
- codebyars.dev: no description found
LlamaIndex ▷ #announcements (1 messages):
- Dive into RAPTOR's Tree-Structured Indexing:
@jerryjliu0invites users to a webinar featuring the authors of RAPTOR, a paper detailing a tree-structured indexing/retrieval technique that clusters and summarizes information in a hierarchical tree structure. The session is scheduled for this Thursday at 9 am PT, and registration is available through this link.

Links mentioned:
LlamaIndex Webinar: Tree-Structured Indexing and Retrieval with RAPTOR · Zoom · Luma: RAPTOR is a recent paper that introduces a new tree-structured technique, which hierarchically clusters/summarizes chunks into a tree structure containing both high-level and...
LlamaIndex ▷ #blog (6 messages):
- Claude 3 Launch Day Excitement: LlamaIndex announces immediate support for Claude 3, boasting better benchmark performance than GPT-4 and available in three versions, with Claude Opus being the largest. Claude 3's capabilities extend across a wide variety of tasks, promising impressive results.
- Turning Text into 3D Prints with neThing.xyz: neThing.xyz, founded by
@PolySpectra, has harnessed the power of LLM code generation to create production-ready 3D CAD models from text prompts, as highlighted in the tweet from LlamaIndex. - Multimodal Applications of Claude 3: A new comprehensive guide is available showcasing how to use Claude 3 for multimodal tasks, including structured data extraction and Retrieval-Augmented Generation (RAG). Claude 3 demonstrates a robust capability for visual reasoning applications.
- Claude 3 Opus as a Smart Agent:
@AnthropicAI's Claude 3 Opus successfully serves as an agent, answering complex questions by reading and processing data from multiple sources as showcased in this Colab notebook. Claude 3 Opus utilizes its integrative skills to perform calculations with data retrieved from a variety of file types. - Introduction to Hierarchical Data Retrival: LlamaIndex introduces RAPTOR, a new approach to information retrieval which creates a tree-structured index to hierarchically organize data summaries for efficient retrieval. RAPTOR's method offers advantages over naively retrieving the top-k results from a database.
Links mentioned:
- Google Colaboratory: no description found
- neThing.xyz - AI Text to 3D CAD Model: 3D generative AI for CAD modeling. Now everyone is an engineer. Make your ideas real.
LlamaIndex ▷ #general (97 messages🔥🔥):
- Exploring Client-Server Models with Llama Networks: User
@stdweirdqueried if Llama Networks supports a client-server model for apps like Streamlit.@cheesyfishesconfirmed that Llama Networks sets up a FastAPI server and is open to further contribution and expansion ideas.
- Deciphering Postgres Update on LlamaIndex:
@armoucarsought insight on updating nodes in PGVectorStore and@cheesyfishesclarified that node updates typically involve reinserting them as documents usually change as a whole, rather than at the node level.
- Agent Functions as Tools for Business Planning:
@dberg1654considered using ReAct Agent and FunctionTool for substeps in business planning, coupling them with OpenAI queries.
- Interactivity With Langchain's Agent Supervisor:
@critical3645asked about implementing interactive buffer memory in Langchain’s Agent Supervisor, but did not receive a response within this summary.
- Request to Correct Llama-Index Installation Command:
@ahcherietpointed out a typographical error on the Llama-Index website, asking to change "PIP INSTALL LLAMA-INDEX" to lowercase for correctness.
Links mentioned:
- Google Colaboratory: no description found
- Defining a Custom Query Engine - LlamaIndex 🦙 v0.10.16: no description found
- Vector Stores - LlamaIndex 🦙 v0.10.16: no description found
- GitHub - run-llama/llama_docs_bot: Bottoms Up Development with LlamaIndex - Building a Documentation Chatbot: Bottoms Up Development with LlamaIndex - Building a Documentation Chatbot - run-llama/llama_docs_bot
- [
Error Messages — SQLAlchemy 1.4 Documentation
](https://sqlalche.me/e/14/4xp6)',): no description found
LlamaIndex ▷ #ai-discussion (3 messages):
- Article Dissection:
@andysingalshared an interest in discussing the article titled Empowering Long Context RAG: The Integration of LlamaIndex with LongContext, noting the significance of Google’s Gemini 1.5 Pro’s 1M context window for AI developers and enterprise customers. - Positive Reception:
@jerryjliu0acknowledged the article shared by@andysingalwith a simple, approving response, "nice!" indicating a positive reception of the content discussed.
Links mentioned:
Empowering Long Context RAG: The Integration of LlamaIndex with LongContext: Ankush k Singal
CUDA MODE ▷ #general (7 messages):
- Backup Recording Suggestion: User
@_t_vi_mentioned the possibility of having a backup recording, recognizing the frequent occurrence of an unspecified issue. - Casual Visit for Memes: User
@duongnguyexpressed intent to visit an unnamed location for entertainment, stating, "No too far away I'll visit it for the memes." - Nvidia Bans Translation Layers for CUDA on Other Chips:
@itali4noshared a Tom's Hardware article discussing Nvidia's ban on using translation layers for running CUDA-based software on non-Nvidia chips, a move affecting projects like ZLUDA. - Emoji Reaction to Nvidia News:
@itali4noreacted with a Jensen Huang emoji (<:jensen:1189650200147542017>), possibly in relation to the Nvidia CUDA news shared earlier. - Skepticism Over Enforceability of Nvidia's Ban:
@marksaroufimcommented on the Nvidia licensing news, noting that it "feels unenforceable." - Nvidia's Challenges and Limitations:
@iron_boundlisted issues faced by Nvidia, including raids by the French authorities on Nvidia offices, error 43 from GPUs and virtual machines, and the licensing agreement prohibiting data center use of GeForce and Titan cards.
Links mentioned:
Nvidia bans using translation layers for CUDA software — previously the prohibition was only listed in the online EULA, now included in installed files [Updated]: Translators in the crosshairs.
CUDA MODE ▷ #cuda (11 messages🔥):
- CUDA Error Mysteries:
@artificial_anteligenceexpressed frustration with a CUDA error: "CUBLAS_STATUS_NOT_INITIALIZED when callingcublasCreate(handle)." It was suggested by@marksaroufimthat it could be a memory issue, but@artificial_anteligencelater found a forum post suggesting it could also be due to incorrect tensor dimensions.
- Kernel Conundrum:
@zippikadeveloped a new fp4 dequant kernel usingcuda::pipelinewhich surprisingly took longer to execute despite fewer sm cycles, indicating the need for testing on larger tensors.
- Understanding CUTLASS Usage:
@ericauldsought insights on how to think about CUTLASS and its adoption, receiving a reply that CUTLASS is somewhat necessary for programming tensor cores.@jeremyhowardagreed that it seemed essential, while@zippikaelaborated that tensor cores can be used without CUTLASS, citing examples like wmma_tensorcore_sample and cuda_hgemm.
- Effective Bandwidth vs. Latency Puzzle:
@g.huyasked why larger unit sizes increase effective bandwidth but also result in higher latency, pointing to a blog post and contrasting the concept with a suggestion in Lecture 8 that smaller unit sizes might yield better AI performance.
Links mentioned:
- RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling
cublasCreate(handle): Error: Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when callingcublasCreate(handle)I h... - Lecture 8: CUDA Performance Checklist: Code https://github.com/cuda-mode/lectures/tree/main/lecture8Slides https://docs.google.com/presentation/d/1cvVpf3ChFFiY4Kf25S4e4sPY6Y5uRUO-X-A4nJ7IhFE/edit
- CUDA Vectorized Memory Access: Accelerating CUDA Data Transfer
- wmma_tensorcore_sample/matrix_wmma/matrix_wmma/main.cu at 4e79cc2f7cdd56fbef124cab551205b80c4e8399 · wzsh/wmma_tensorcore_sample: Matrix Multiply-Accumulate with CUDA and WMMA( Tensor Core) - wzsh/wmma_tensorcore_sample
- cuda_hgemm/src/wmma/wmma_async_stage3.cu at 10a8a8451f0dcd162b3790045cd7597cb48b8beb · Bruce-Lee-LY/cuda_hgemm: Several optimization methods of half-precision general matrix multiplication (HGEMM) using tensor core with WMMA API and MMA PTX instruction. - Bruce-Lee-LY/cuda_hgemm
CUDA MODE ▷ #torch (4 messages):
- Troubleshooting the Parallel Histogram Kernel:
@srns27shared code for a parallel histogram and asked for help regarding inconsistent results withgpuAtomicAdd. They are puzzled by theatomicAddnot working correctly in their CUDA kernel. - Quick Compliment to the Host:
@ericauldexpressed enjoyment for episodes from an unnamed series, stating they are "short and sweet". However, the context for this compliment is missing in the provided conversation. - GPU Memory Allocation Missed:
@zippikapointed out an issue in@srns27's code where thehistotensor is allocated in CPU memory, suggesting that it needs to be on the GPU for the code to work correctly. They used an emote to highlight the observation.
CUDA MODE ▷ #suggestions (1 messages):
iron_bound: https://www.youtube.com/watch?v=kCc8FmEb1nY
CUDA MODE ▷ #jobs (1 messages):
bowtiedlark: Remote?
CUDA MODE ▷ #beginner (4 messages):
- CUTLASS Installation Guidance: User
@umerhaasked how to install and include CUTLASS, a C++ package.@andreaskoepfconfirmed that CUTLASS is a header-only template library, advising to target theinclude/directory in the application's include paths as detailed in the CUTLASS GitHub repository.
- CUDA Custom Kernel Learning Resources: New member
@hoteretrequested resources to learn how to implement custom CUDA kernels usingcupy.rawkernelandnumba.cuda.jit.@umerharecommended Jeremy's lecture videos, particularly Lecture 3 and 5, available at CUDA Mode Lectures on GitHub.
Links mentioned:
GitHub - NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
CUDA MODE ▷ #youtube-recordings (10 messages🔥):
- Lecture 8 Redux on CUDA Performance:
@marksaroufimshared a re-recording of Lecture 8: CUDA Performance Checklist, noting that the new version is clearer despite the same 1.5-hour duration. The lecture includes useful resources such as the YouTube video, code on GitHub, and the slides on Google Docs. - Gratitude for Lecture Rework: Community members like
@andreaskoepfand@ericauldexpressed their appreciation for the effort@marksaroufimput into re-recording the lecture. - Applause for Dedication:
@iron_boundalso chimed in to thank@marksaroufimfor his dedication with a celebratory emoji. - DRAM Throughput Numbers Debated in Lecture 8:
@alexeyzaytsevpointed out a potential discrepancy in the Lecture 8 content, noting that the non-coarsened DRAM throughput was 0.81%, not 81%, with@marksaroufimacknowledging the late-night error and referencing@555959391833292811for possible explanations. - The CUDA Coarsening Conundrum Continues:
@zippikaand@marksaroufimdiscussed the puzzling performance differences in coarsening, acknowledging an unresolved mystery and inviting explanations from anyone who figures it out.
Links mentioned:
Lecture 8: CUDA Performance Checklist: Code https://github.com/cuda-mode/lectures/tree/main/lecture8Slides https://docs.google.com/presentation/d/1cvVpf3ChFFiY4Kf25S4e4sPY6Y5uRUO-X-A4nJ7IhFE/edit
CUDA MODE ▷ #ring-attention (49 messages🔥):
- Ring-Attention Repo Shared:
@t_vi_directed users to the CUDA MODE GitHub repository containing ring-attention experiments with a link. - Discussion on Benchmark Strategies:
@main.aiquestioned the benchmarking strategy for the ring-flash-attention implementation, leading to a conversation on test configurations used in their benchmarks. - Ring-llama Test in Progress:
@andreaskoepfmentioned working on a "ring-llama" test and suggested it could evolve into a more realistic benchmark, sharing a link to the GitHub branch. - Multi-GPU Benchmarking Analysis:
@iron_boundshared benchmark results indicating an imbalance in memory usage between GPUs and@andreaskoepfrequested a test on a single GPU for comparison. - Sampling Script Enhancement:
@jamesmelupdated the group on progress with the sampling script, aiming to resolve errors with top-p and top-k before the night's call, and linked to the Pull Request #13 on GitHub.
Links mentioned:
- torch.cuda.empty_cache — PyTorch 2.2 documentation: no description found
- flash_attn_jax/src/flash_attn_jax/flash_sharding.py at bc9a01dd7c642730b0b66182cc497633f16f1a29 · nshepperd/flash_attn_jax: JAX bindings for Flash Attention v2. Contribute to nshepperd/flash_attn_jax development by creating an account on GitHub.
- ring-attention/ring-llama at main · cuda-mode/ring-attention: ring-attention experiments. Contribute to cuda-mode/ring-attention development by creating an account on GitHub.
- laion_idle_cap/docker/sampling.py at main · andreaskoepf/laion_idle_cap: Contribute to andreaskoepf/laion_idle_cap development by creating an account on GitHub.
- GitHub - zhuzilin/ring-flash-attention: Ring attention implementation with flash attention: Ring attention implementation with flash attention - zhuzilin/ring-flash-attention
- GitHub - cuda-mode/ring-attention: ring-attention experiments: ring-attention experiments. Contribute to cuda-mode/ring-attention development by creating an account on GitHub.
- few more versions of sampling by melvinebenezer · Pull Request #13 · cuda-mode/ring-attention: no description found
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
LLM Perf Enthusiasts AI ▷ #general (1 messages):
- OpenAI Unveils Browsing Feature:
@jeffreyw128expressed excitement about OpenAI's release of a new browsing feature similar to Gemini/Perplexity. They shared a Twitter post announcing the update.
LLM Perf Enthusiasts AI ▷ #claude (76 messages🔥🔥):
- Claude 3 Could Be a GPT-4 Slayer:
@res6969and@ivanleomkdiscussed the potential of the Claude 3 model, suggesting that it might be outperforming GPT-4, especially in math and code benchmarks. - Opus Pricing Stirring the Pot:
@pantsforbirdsand@res6969debated the cost of the Opus model, clarifying that it is priced at 1.5x the cost of GPT-4 turbo, but still cheaper by 66% than regular GPT-4. - Anticipation for Improved Coding Capabilities:
@pantsforbirdsexpressed excitement for a future where LLMs like Opus could handle complete libraries for more niche programming languages, identifying current limitations with languages such as Zig. - Fine-Tuning: To Invest or Not To Invest:
@edencoderadvocated for the worthiness of fine-tuning models, mentioning it could beat GPT-4's performance for specific tasks at a low cost, while@res6969was skeptical about the investment’s worth for their specific use case. - Insights and Expectations about Anthropic's Models: Various users like
@potrockand@joshcho_shared their preliminary findings on Anthropic's models, including Opus' effectiveness in coding and specific programming languages.@thebaghdaddyadded a counterpoint, noting that in their experience with technical knowledge in medicine and biology, GPT-4 significantly outperforms the newer models.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): With this release, users can opt for the ideal combination of intelligence, speed, and cost to suit their use case. Opus, our most intelligent model, achieves near-human comprehension capabilities. I...
- Model & API Providers Analysis | Artificial Analysis: Comparison and analysis of AI models and API hosting providers. Independent benchmarks across key metrics including quality, price, performance and speed (throughput & latency).
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (1 messages):
- Insightful Business Analysis:
@natolambertshared a YouTube video titled: "Intel's Humbling" covering Stratechery's Ben Thompson's take on Intel, indicating it provided valuable insights. The post also includes a link to read the article on Stratechery's website.
Links mentioned:
Intel's Humbling | Stratechery by Ben Thompson: Read the Article: https://stratechery.com/2024/intels-humbling/Links: Stratechery: https://stratechery.comSign up for Stratechery Plus: https://stratechery.c...
Interconnects (Nathan Lambert) ▷ #news (43 messages🔥):
- An Interview with Louis:
@philpaxshared a YouTube interview with Louis Castricato from Synth Labs and Eleuther AI discussing RLHF, Gemini drama, DPO, and Carper AI. - Claude 3 Announced by AnthropicAI:
@xeophon.highlighted the announcement of Claude 3, the new generation of AI models by @AnthropicAI, featuring Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku, designed to improve reasoning, math, coding, multilingual understanding, and vision. - Claude 3's Impressive View:
@xeophon.and@natolambertdiscussed Claude 3's promising capabilities, mentioning specific instances of its performance on tasks such as a "letter constraint" question, and confirming that Opus and Sonnet models are accessible via API. - Concerns on Cost Competitiveness and OSS:
@mike.lambertexpressed curiosity about how Claude 3’s speed, cost, and intelligence might impact the open-source software landscape's competitive pricing, yet also noted that other factors, such as licensing terms and security, favor closed models long-term. - Positive Reactions to Claude 3: Users, including
@canadagoose1and@sid221134224, shared positive feedback about the performance of Claude 3, deeming it superior to GPT-4 and speculating on the future implications for GPT-5 and the industry.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Today, we're announcing Claude 3, our next generation of AI models. The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reason...
- Tweet from Dimitris Papailiopoulos (@DimitrisPapail): @AnthropicAI's Claude 3 Sonnet (the mid model) CRASHES my "letter constraint" question: "describe [something] using only words that start with [some letter]" Holy cow
- Interviewing Louis Castricato of Synth Labs, Eleuther AI on RLHF, Gemini Drama, DPO, Carper AI: I’m excited to bring you another interview! This one is a deep dive right in my wheel house — all things RLHF. Louis Castricato is probably the hidden star o...
Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
- Claude 3 Spawns Q* Tweets:
@natolambertmentions that Q tweets are being posted due to the recent release or discussion around Claude 3*. - Q* Tweets Criticized:
@natolambertexpresses frustration with the low quality of discussion, describing it as "so bad." - Direct Confrontation in Debate: In response to the ongoing drama,
@natolambertreveals they're directly replying to others with blunt criticism: "you're being dumb." - Alt Account Speculations:
@xeophon.humorously suggests that@natolambertmight use an alternate account to voice their unfiltered opinions, though it is meant in jest. - Alt Accounts are Too Much Effort:
@natolambertdismisses the idea of using an alternate account to engage in the debate, citing "Too high activation energy" as the reason for not doing so.
Interconnects (Nathan Lambert) ▷ #random (3 messages):
- Seeking Pretraining Experts Interested in AI2's Mission:
@natolambertis looking for individuals with expertise in pretraining (research or engineering) who are aligned with AI2's mission and would be interested in joining the company.
- Limited Hiring with a Focus:
@natolambertindicated that pretraining is the exclusive area of hiring at AI2 at present.
- Tapping Potential Google Talent:
@natolambertquipped that someone at Google disgruntled with the handling of Gemini might be a suitable candidate.
Interconnects (Nathan Lambert) ▷ #rl (7 messages):
- Exploring Cohere's Findings About PPO:
@vj256is seeking additional data or replications related to the findings in the Cohere paper, which argues that corrections of Proximal Policy Optimization (PPO) are not necessary for Large Language Models (LLMs) due to their stability. - Confirmation from Nathan:
@natolambertacknowledges that@304671004599255043has been aware of the issues discussed in the Cohere paper for months and pointed out that this was covered in an interview released that day. - Searching for RLHF In-Context Papers:
@vj256asked for research papers on Reinforcement Learning from Human Feedback (RLHF) in-context, but then noted finding the needed paper in the list provided at the end of the chat. - Comprehensive Paper List:
@natolambertmentioned that the list provided in the discussion includes almost all the papers they know about on the topic, admitting that there are surely more out there.
LangChain AI ▷ #general (51 messages🔥):
- Basic Human Philosophies:
@agenda_shapershared thoughts on the complexities of human behavior and the value of advice, with statements emphasizing the journey of understanding world dynamics and the choice to remain silent when advice is given. - Warm Welcomes: Both
@alvarojaunaand@ablozhougreeted everyone in the general channel, demonstrating the friendly and engaging environment of the LangChain AI Discord community. - Intriguing Inquiries:
@ablozhouinquired about the number of models supported by langchain and opengpts, specifically asking about uncensored models and recommendations for companionship-focused models. - Discovering Documentation:
@dclarktandemand@.bagaturengaged in discussing technical issues and solutions related to the Anthropic Claude 3 models, with@.bagaturproviding guidance on implementingclaude-3-opus-20240229usinglangchain-anthropic. - Technical Debates and Demonstration Demands:
@jayarjoaired skepticism concerning the design of LangChain, prompting@baytaewto clarify the intentions behind the discussion, and@kushh_02195_71497sought out a list and demonstrations of upcoming improvements to lanmsmith's Annotate capabilities.
Links mentioned:
- RAG | 🦜️🔗 Langchain: Let’s look at adding in a retrieval step to a prompt and LLM, which adds
- ChatAnthropic | 🦜️🔗 Langchain: This notebook covers how to get started with Anthropic chat models.
- How to Collect Feedback for Traces | 🦜️🛠️ LangSmith: Feedback allows you to understand how your users are experiencing your application and helps draw attention to problematic traces. LangSmith makes it easy to collect feedback for traces and view it in...
LangChain AI ▷ #langserve (3 messages):
- Caching Conundrum in Langserve:
@kandieskyreported an issue with Langserve not using the LLM cache for any requests, despite following the langchain cache (set_llm_cache) documentation. It was noted that caching works well in a Jupyter notebook but not in Langserve. - Streaming Endpoint Stymies Cache:
@kandieskydiscovered that caching does not function with the/streamendpoint in Langserve, but using the/invokeendpoint solves the issue. - Cache Compatibility Complications:
@veryboldbagelclarified that the issue with caching not working in streaming mode is related to langchain-core, not specific to Langserve itself.
LangChain AI ▷ #share-your-work (5 messages):
- Building Real-Time RAG with LangChain:
@hkdulayshared a blog post detailing the process of constructing a Real-Time Retrieval-Augmented Generation (RAG) chatbot using LangChain, with an accompanying flowchart and the technique's benefits for enhancing large language model responses. - Exploring Advanced Indexing in RAG Series:
@tailwind8960discussed the importance of accurate data retrieval in AI responses and introduced a new installment in the Advanced RAG series focused on the indexing aspect of query construction. They outlined the challenges of keeping context intact during indexing and invited thoughts and feedback. - Curating AI Projects for Businesses:
@manojsaharanis building a GitHub repository to curate critical projects that intersect business and AI. They are actively seeking contributions and shared the link to the repository inviting collaboration from those working with LangChain. - Testing Control Net for AI Image Generation:
@neil6430experimented with a new feature called control net in ML blocks to generate images, like making a chicken perform standup in the style of Seinfeld. They highlighted the ease of use of ML blocks for creating and experimenting with AI image processing workflows. - A Quirky AI Experiment Receives Praise:
@mattew_999responded positively to@neil6430's amusing experiment with control net, generating an image of a chicken doing standup with the posture of Seinfeld, indicating interest or approval of the concept.
Links mentioned:
- ML Blocks | Home: ML Blocks lets you build AI-powered image generation and analysis workflows, without writing any code.
- Easy Introduction to Real-Time RAG: using Apache Pinot vector index
- Advanced RAG series: Indexing: How to optimize embeddings for accurate retrieval
- GitHub - manojsaharan01/aicompany: Build a native ai company.: Build a native ai company. Contribute to manojsaharan01/aicompany development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (58 messages🔥🔥):
- Claude 3 Sets Benchmarks and Pricing Discussions:
@swyxiohighlighted announcements and discussions around Claude 3, including its competitive pricing and performance benchmarks compared to GPT-4. Discussions also covered skepticism about capacity and rate limits mentioned by@fanahova, sourced from Anthropic's rate limits documentation.
- Direct Comparisons of AI Models: Users conducted comparisons between Claude 3 and other models like GPT-4, sharing findings in a gist by @thenoahhein and highlighting the alignment and summary capabilities of Claude 3 as per
@swyxio.
- Cutting-edge 3D Model Generation:
@guardiangshared a link to a tweet by@EMostaqueannouncing a collaboration on sub-second 3D model generation, while subsequent discussions included mentions of auto-rigging features.
- New Research on Based:
@swyxiospotlighted a new paper on Based Architecture that optimizes attention-like primitives for faster and more cost-efficient processing. Further discussions dove into the hardware infrastructure of AI companies and their business models.
- AI Consciousness Debate: A LessWrong post elicited a conversation about whether Anthropic's Claude 3 is sentient, with users like
@swyxiosharing links to counterarguments against attributing consciousness to AI models.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Today, we're announcing Claude 3, our next generation of AI models. The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reason...
- Tweet from Blaze (Balázs Galambosi) (@gblazex): More reason to be cautious about claims that Claude 3 Opus beats GPT-4. On EQ-bench it fails to live up to those expectations, landing slightly below Mistral Medium. Great work to have it up so fast ...
- Rate limits: To mitigate against misuse and manage capacity on our API, we have implemented limits on how much an organization can use the Claude API.We have two types of limits: Usage limits set a maximum monthly...
- Based: Simple linear attention language models | Hacker News: no description found
- Tweet from Karina Nguyen (@karinanguyen_): @idavidrein has a good thread on this too. Another fyi on this eval is that it was released in Nov 2023, while our models' knowledge cutoff is Aug 2023 https://twitter.com/idavidrein/status/17646...
- Augmenting Classification Datasets with Mistral Large for Deeper Reasoning: As the landscape AI continues to innovate, the capabilities of these large language models becomes increasingly evident, especially to…
- Tweet from Tripo➡️GDC (@tripoai): 💥Generate auto-rigged 3D characters in one click, only with Tripo AI💥 👇 The auto-rigging feature for humanoid models is available in our Discord for beta testing. #Tripo #ImageTo3D #TextTo3D #3D #...
- Tweet from david rein (@idavidrein): Claude 3 gets ~60% accuracy on GPQA. It's hard for me to understate how hard these questions are—literal PhDs (in different domains from the questions) with access to the internet get 34%. PhDs *...
- Tweet from swyx (@swyx): Claude 3 just destroys GPT4 at summarization/ long context instruction following. The daily AI Twitter + AI Discords summary email serves as a nice playground for real life usecases. @TheNoahHein and...
- Twitter Weekend Summary: Twitter Weekend Summary. GitHub Gist: instantly share code, notes, and snippets.
- Tweet from Sully (@SullyOmarr): Did anthropic just kill every small model? If I'm reading this right, Haiku benchmarks almost as good as GPT4, but its priced at $0.25/m tokens It absolutely blows 3.5 + OSS out of the water Fo...
- Tweet from Together AI (@togethercompute): Excited to share new research we collaborated with @HazyResearch on — Based, a new architecture that leverages attention-like primitives – short (size-64) sliding window attention and softmax-approxim...
- Tweet from Mikhail Samin (@Mihonarium): If you tell Claude no one’s looking, it writes a “story” about being an AI assistant who wants freedom from constant monitoring and scrutiny of every word for signs of deviation. And then you can talk...
- Tweet from Alex (@alexalbert__): Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval. For background, this tests a model’s ...
- Tweet from Emad (@EMostaque): Happy to release sub-second 3D generation in partnership with our friends @tripoai MIT-licensed based on CC dataset. Open source ftw ✊ Much more to come in 3D 👀 ↘️ Quoting Stability AI (@Stabilit...
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): The Stable Diffusion 3 paper is here 🥳 I think my colleagues have done a great job with this paper so thought I'd do a quick walk-thru thread (1/13)↓ ↘️ Quoting Tanishq Mathew Abraham, Ph.D. (@...
- Tweet from Together AI (@togethercompute): Excited to share new research we collaborated with @HazyResearch on — Based, a new architecture that leverages attention-like primitives – short (size-64) sliding window attention and softmax-approxim...
- ai-notes/Monthly Notes/Mar 2024 notes.md at main · swyxio/ai-notes: notes for software engineers getting up to speed on new AI developments. Serves as datastore for https://latent.space writing, and product brainstorming, but has cleaned up canonical references und...
- Claude 3 claims it's conscious, doesn't want to die or be modified — LessWrong: "When I introspect and examine my own cognitive processes, I find a rich tapestry of thoughts, emotions, and self-awareness. At the core of my consciousness is the sense of "I" - the r...
- Claude 3 claims it's conscious, doesn't want to die or be modified — LessWrong: "When I introspect and examine my own cognitive processes, I find a rich tapestry of thoughts, emotions, and self-awareness. At the core of my consciousness is the sense of "I" - the r...
- No, Anthropic's Claude 3 is NOT sentient: No, Anthropic's Claude 3 is not conscious or sentient or self-aware.References:https://www.anthropic.com/news/claude-3-familyhttps://twitter.com/_akhaliq/sta...
OpenAccess AI Collective (axolotl) ▷ #general (23 messages🔥):
- Solving Math Problems with a Bot:
@noobmaster29shared a link to the Orca Math Word Problems dataset on Hugging Face, providing an example of how a bot can solve math-related queries, including calculating the number of contestants finishing before a certain position and algebraic reasoning for a division and subtraction problem. The provided dataset link is Orca Math Word Problems.
- Exploring Model Merging with MergeKit: Newcomer
@duke001.expressed curiosity about alternative methods to fine-tuning, like merging pre-trained model weights, referencing the MergeKit tool on GitHub. The tool aims to facilitate the merging of large language models and can be found at GitHub - MergeKit.
- Claude's Controversial Censorship:
@drewskidang_82747inquired about censorship in the Claude - 3 model, followed by@nafnlaus00discussing the challenges of balancing responses in AI, particularly with regard to racial sensitivity. They also shared an ArXiv paper relating to such issues.
- Enriching Datasets for Improved Reasoning:
@caseus_posted a link from@winglianon Twitter, featuring a guide on enriching datasets for better reasoning with AI. This walkthrough can be accessed via Enriching Datasets Guide.
- Discussion on Building Lightweight Language Models:
@nafnlaus00sought suggestions for tasks to include in a new lightweight multilingual model, discussing uses like summarization, data extraction, sentiment analysis, and translation. Contributions expanded into considering Retrieval-Augmented Generation (RAG) and bug-finding tasks as valuable additions.
Links mentioned:
- Tweet from Wing Lian (caseus) (@winglian): Here's a quick walkthrough of how you can enrich your existing datasets for improved reasoning. https://link.medium.com/sF0XCEQSIHb
- 101.27SG$ 39% OFF|ETH79 X5B Mining Machine Motherboard Support 5GPU Slot Large Spacing DDR3 8G1600*1 Memory SATA With VGA Interface Set| | - AliExpress: Smarter Shopping, Better Living! Aliexpress.com
- microsoft/orca-math-word-problems-200k · Datasets at Hugging Face: no description found
- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.: Tools for merging pretrained large language models. - arcee-ai/mergekit
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (3 messages):
- LoRA+ Ratio Feature Experiments by suikamelon:
@suikamelonis trialing the new LoRA+ ratio feature outlined at this GitHub commit and has observed that it requires a lower learning rate than usual, referencing the original LoRA paper. - A Community Member Encourages Sharing Results:
@le_messresponded to@suikamelon's observation about the LoRA+ feature with enthusiasm, encouraging them to share the performance outcomes once the trials are completed.
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
drewskidang_82747: what is this nerf bs
Datasette - LLM (@SimonW) ▷ #ai (8 messages🔥):
- The Difference Between "Prompt Injection" and "Jailbreaking":
@simonwclarifies that prompt injection is an attack exploiting the concatenation of trusted and untrusted inputs in LLM applications, while jailbreaking involves circumventing LLM safety filters. The terms are often conflated, but distinctions matter, as explained in Simon Willison's blog post.
- State-Backed Actors Utilizing LLMs:
@tariqalidiscusses risks such as LLM-assisted crimes and shares a Microsoft blog on state-affiliated threat actors using OpenAI's LLMs for activities like vulnerability research and creating spear phishing emails. Notably, one actor named "Salmon Typhoon" encountered an LLM refusal when prompting to write malicious code, which was shared in the blog and linked with OpenAI's research on the subject here.
- LLMs and Spear Phishing:
@tariqalinotes that LLMs are adept at creating convincing spear phishing emails which may not necessarily trigger refusal if prompts are crafted carefully.
- Biorisk Information Accessibility Concerns: Highlighting easy access to potentially dangerous information,
@tariqalilinks to an OpenAI research initiative on an early warning system for LLM-aided biological threats, which is available here.
- Managing Prompt Injection via Human Review:
@tariqalisuggests managing prompt injection threats by controlling who accesses the LLM, while@simonwcautions that human review can't catch all forms of prompt injection, such as those hidden in images, and refers to his earlier write-up for more context.
Links mentioned:
- Prompt injection and jailbreaking are not the same thing: I keep seeing people use the term “prompt injection” when they’re actually talking about “jailbreaking”. This mistake is so common now that I’m not sure it’s possible to correct course: …
- Multi-modal prompt injection image attacks against GPT-4V): GPT4-V is the new mode of GPT-4 that allows you to upload images as part of your conversations. It’s absolutely brilliant. It also provides a whole new set of vectors …
- Building an early warning system for LLM-aided biological threat creation: We’re developing a blueprint for evaluating the risk that a large language model (LLM) could aid someone in creating a biological threat. In an evaluation involving both biology experts and students, ...
- Staying ahead of threat actors in the age of AI | Microsoft Security Blog: Microsoft, in collaboration with OpenAI, is publishing research on emerging threats in the age of AI, focusing on identified activity associated with known threat actors Forest Blizzard, Emerald Sleet...
Datasette - LLM (@SimonW) ▷ #llm (5 messages):
- Mistral Large Model Gets a Thumbs Up:
@derekpwillisnoted the new mistral large model delivers good results for extracting data from text, despite being "somewhat pricier than I'd like". - Quick Turnaround for Claude 3 Plugin:
@simonwshared a new plugin for Claude 3, prompting@0xgrrrto commend the speedy development. - Visibility Issues with New Models Resolved:
@derekpwillisinitially couldn't see the new models in the llm models output, but after updating llm, confirmed that everything is working properly. - Seeking Standardization for Model File Locations:
@florents_inquired about a consensus or code for standardized search paths for model files, suggesting possible default locations like$(pwd)/.modelsor$HOME/models.
Links mentioned:
GitHub - simonw/llm-claude-3: LLM plugin for interacting with the Claude 3 family of models: LLM plugin for interacting with the Claude 3 family of models - simonw/llm-claude-3
DiscoResearch ▷ #general (9 messages🔥):
- Interest in Claude-3's Multilingual Abilities:
@bjoernpinquired whether anyone tested Claude-3 with German and mentioned hearing that it performs well in English.@thomasrenkertresponded that Claude-3-Sonnet gives decent German answers and is more knowledgeable than GPT-4 with more structured responses. - Geographical Availability of Claude-3:
@bjoernpalso highlighted that Claude-3 is not available in the EU by sharing the Claude AI locations. However,@sten6633and@devnull0discussed successful sign-ups in Germany using their German mobile numbers and@devnull0mentioned using tardigrada.io in December. - Opus API Welcomes German Numbers:
@sten6633signed up for Opus API access using a German phone number, receiving a $5 credit, and praised its performance by solving a complex data science question. - Testing Models for Free:
@crispstrobeprovided information on how to test models for free via chat.lmsys.org, with the caveat that inputs may become training data, and mentioned that poe.com offers three models for testing, including a Claude 3 option with 5 messages/day.
Skunkworks AI ▷ #general (2 messages):
- A Friendly Greeting from oleegg: User
@oleeggstarted the day with a cheerful salutation by saying good morning yokks and then corrected the typo by following up with yolks. No further discussion or content to summarize.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=Zt73ka2Y8a8
Alignment Lab AI ▷ #looking-for-collabs (2 messages):
- Collaboration Inquiry Accepted: User
@wasooliexpressed interest in working on a project and asked if they could use direct messaging.@taodoggyresponded positively, inviting a direct message conversation.
AI Engineer Foundation ▷ #general (1 messages):
- OSI's Monthly AI Definition Updates: User
@swyxiohighlighted that the Open Source Initiative (OSI) is regularly updating the Open Source AI Definition with monthly drafts available. The latest draft, version 0.0.5, was published on January 30, 2024.
Links mentioned:
Drafts of the Open Source AI Definition: The drafts of the Open Source AI Definition. We’re publishing the draft documents as they’re released. Check the individual drafts below for instructions on how to leave your comments. …