[AINews] RouteLLM: RIP Martian? (Plus: AINews Structured Summaries update)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
LLM Preference data is all you need.
AI News for 6/28/2024-7/1/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (419 channels, and 6896 messages) for you. Estimated reading time saved (at 200wpm): 746 minutes. You can now tag @smol_ai for AINews discussions!
Remember the Mistral Convex Hull of April, and then the DeepSeekV2 win of May?. The cost-vs-performance efficient frontier is being pushed out again, but not at the single-model or MoE level, rather across all models:
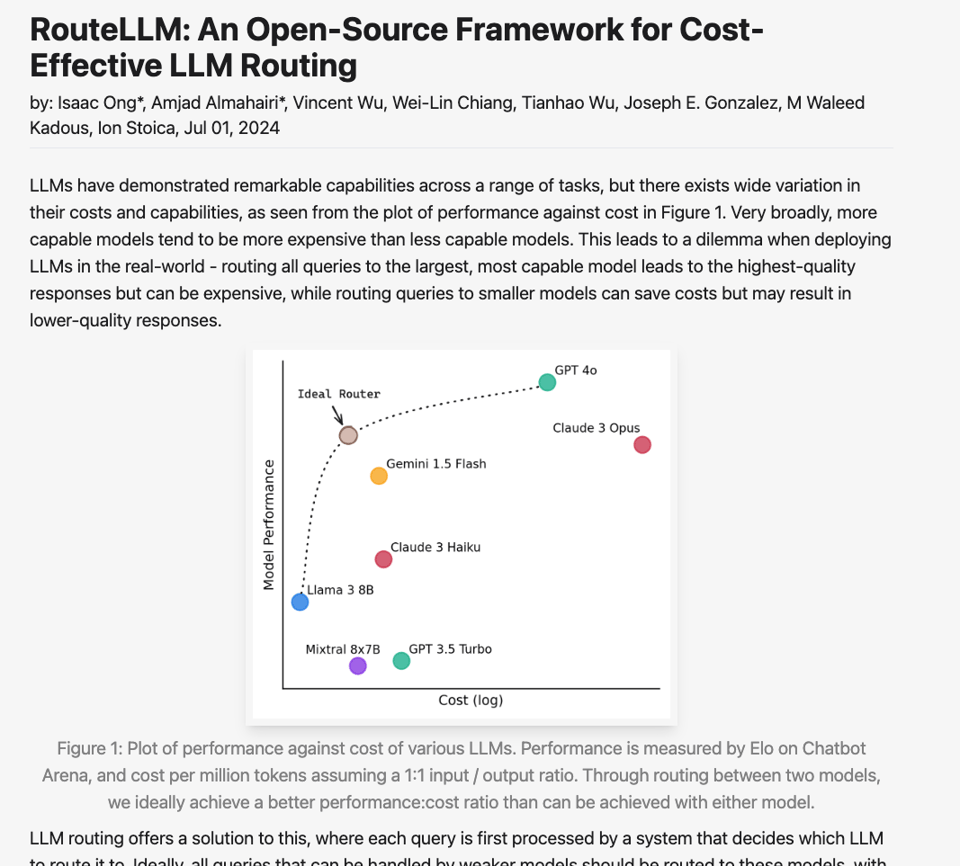
The headline feature to note is this sentence: We trained four different routers using public data from Chatbot Arena and demonstrate that they can significantly reduce costs without compromising quality, with cost reductions of over 85% on MT Bench, 45% on MMLU, and 35% on GSM8K as compared to using only GPT-4, while still achieving 95% of GPT-4’s performance.
The idea of LLM routing isn't new; model-router was a featured project at the "Woodstock of AI" meetup in early 2023, and subsequently raised a sizable $9m seed round off that concept. However these routing solutions were based off of task-specific routing, the concept that different models are better at different tasks, which stands in direct contrast with syntax-based MoE routing.
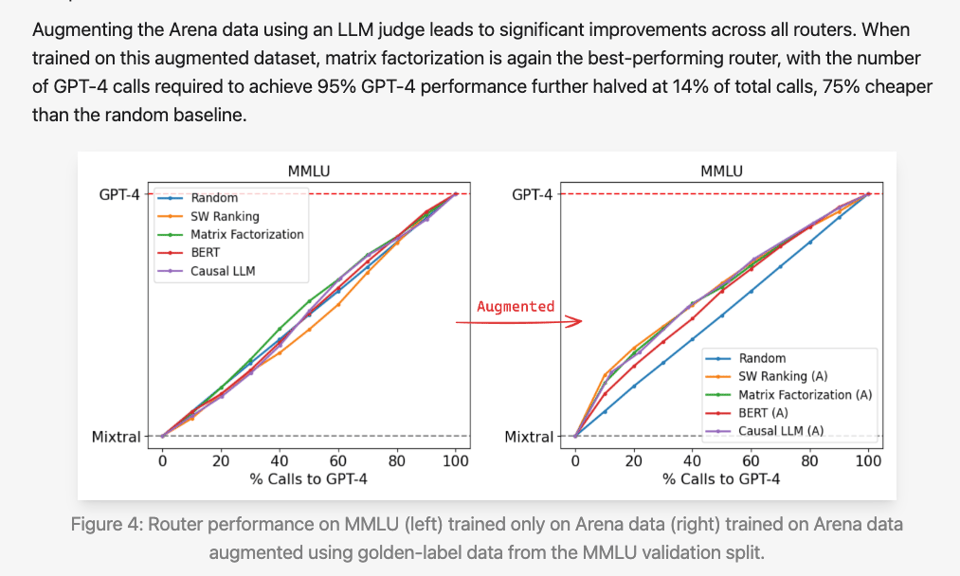
LMSys' new open source router framework, RouteLLM, innovates by using preference data from The Arena for training their routers, based on predicting the best model a user prefers conditional upon a prompt. They also use data augmentation of the Arena data to further improve their routing benefits:
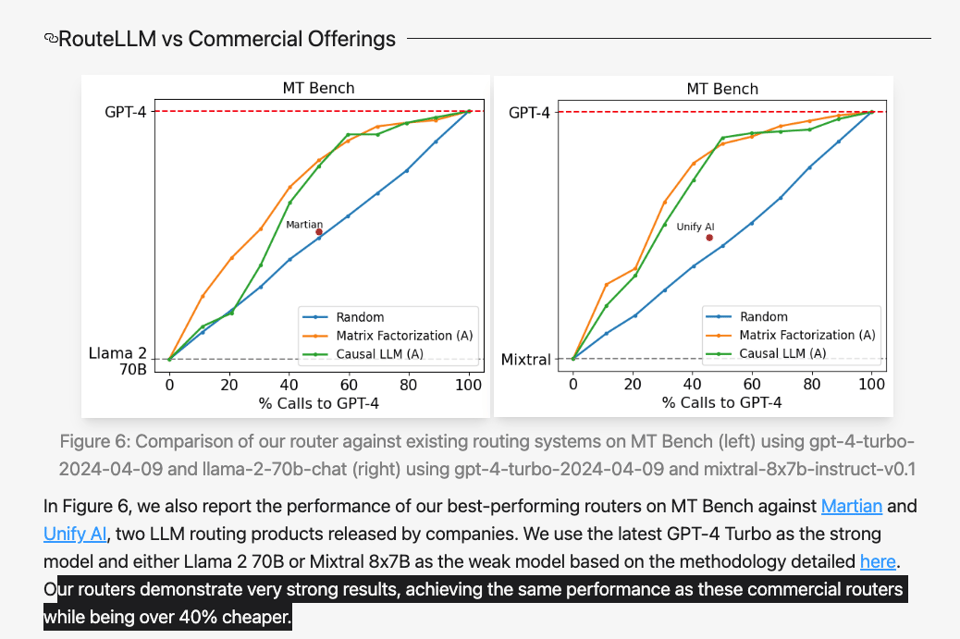
Perhaps most brutally, LMSys claim to beat existing commercial solutions by 40% for the same performance.
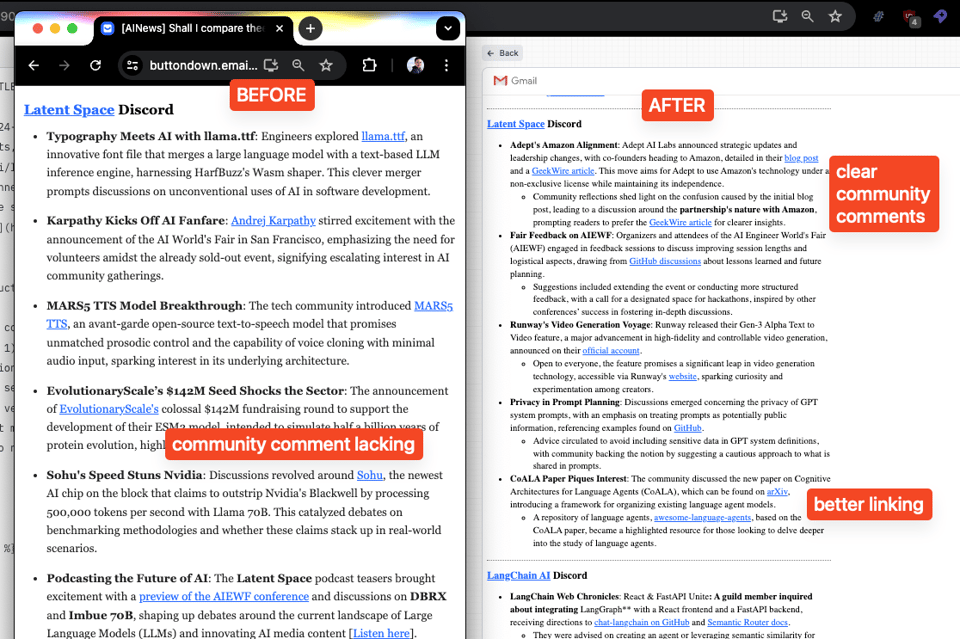
SPECIAL AINEWS UPDATE: Structured Summaries
We have revised our core summary code to use structured output, focusing on achieving 1) better topic selection, 2) separation between fact and opinion/reation, and 3) better linking and highlighting. You can see the results accordingly. We do see that they have become more verbose, with this update, but we hope that the structure makes it more scannable, our upcoming web version will also be easier to navigate.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- Gemma 2 model family: @armandjoulin noted Gemma 2 27B is now the best open model while being 2.5x smaller than alternatives, validating the team's work. @bindureddy said Gemma 2 27B approaches Llama 3 70B performance, and Gemma 2 9B is beyond that Pareto front with excellent post-training.
- Block Transformer architecture: @rohanpaul_ai shared a paper showing up to 20x improvement in inference throughput with Block Transformer compared to vanilla transformers with equivalent perplexity, by reducing KV cache IO overhead from quadratic to linear. It isolates expensive global modeling to lower layers and applies fast local modeling in upper layers.
- Fully Software 2.0 computer vision: @karpathy proposed a 100% fully Software 2.0 computer with a single neural net and no classical software. Device inputs directly feed into the neural net, whose outputs display as audio/video.
AI Agents and Reasoning
- Limitations of video generation models: @ylecun argued video generation models do not understand basic physics or the human body. @giffmana was annoyed to see AI leaders use a clunky gymnastics AI video to claim human body physics is complicated, like showing a DALL-E mini generation to say current image generation is doomed.
- Q* for multi-step reasoning: @rohanpaul_ai shared a paper on Q, which guides LLM decoding through deliberative planning to improve multi-step reasoning without task-specific fine-tuning. It formalizes reasoning as an MDP and uses fitted Q-iteration and A search.
- HippoRAG for long-term memory: @LangChainAI shared HippoRAG, a neurobiologically inspired long-term memory framework for LLMs to continuously integrate knowledge. It enriches documents with metadata using Unstructured API.
AI Applications
- AI for legal workflows: @scottastevenson noted agents are coming for legal workflows, tagging @SpellbookLegal.
- AI doctor from Eureka Health: @adcock_brett shared that Eureka Health introduced Eureka, the "first AI doctor" offering personalized care 90x faster than most US care according to early tests.
- AI-generated Olympic recaps: @adcock_brett reported NBC will launch 10-minute AI-generated recaps for the 2024 Olympics, cloning Al Michaels' voice to narrate highlights on Peacock. The demo is hardly distinguishable from human-made content.
Memes and Humor
- @nearcyan joked "im going to become the joker what is wrong with you all" in response to AI sparkle icons.
- @francoisfleuret humorously suggested if you cannot generate 6-7 birds, you are socially dead, as 4-5 are validated but 0-5 and 2-5 are too hard while 5-5 is too easy.
- @kylebrussell shared an image joking "you deserve to have opponents who make you feel this way".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Humor/Memes
- AI-generated humorous videos: In /r/StableDiffusion, users shared AI-generated videos with humorous content, such as a man opening a box of chocolates that explodes in his face. Comments noted the dream-like quality and uncanny movement in AI videos, drawing parallels to human brain processing.
- AI combining memes: Another AI-generated video combined various memes, which users found entertaining and a good use case for AI.
- Superintelligent AI memes: Image macro memes were shared depicting the relationship between humans and superintelligent AI, and a person trying to control an advanced AI with a remote. Another meme showed relief at an AI saying it won't kill humans.
AI Art
- Vietnam War with demons: In /r/StableDiffusion, AI-generated images depicted a fictional Vietnam War scenario with marines battling demons, inspired by the horror art styles of Beksinski, Szukalski and Giger. Users shared the detailed prompts used to create the images.
- Blåhaj through time: A series of images showed the IKEA stuffed shark toy Blåhaj in various historical and futuristic settings.
- 1800s kids playing video games: An AI-generated video from Luma Dream machine depicted children in the 1800s anachronistically playing video games.
AI Scaling and Capabilities
- Kurzweil's intelligence expansion prediction: In a Guardian article, AI scientist Ray Kurzweil predicted that AI will expand intelligence a millionfold by 2045.
- Scaling limits of AI: A YouTube video explored how far AI can be scaled.
- Model size vs data quality: A post in /r/LocalLLaMA suggested that sometimes a smaller 9B model with high-quality data can outperform a 2T model on reasoning tasks, sparking discussion on the relative importance of model size and data quality. However, commenters noted this is more of an exception.
- Processor performance plateau: An image of a processor performance graph with a logarithmic y-axis was shared, suggesting performance is not actually exponential and will plateau.
AI Models and Benchmarks
- Gemma 2 9B model: In /r/LocalLLaMA, a user made an appreciation post for the Gemma 2 9B model, finding it better than Llama 3 8B for their use case.
- Llama 400B release timing: Another post discussed the potential impact of Llama 400B, suggesting it needs to be released soon to be impactful. Commenters noted a 400B model is less practical than ~70B models for most users.
- Gemma2-27B LMSYS performance: Discussion around Gemma2-27B outperforming larger Qwe2-72B and Llama3-70B models on the LMSYS benchmark, questioning if this reflects real capabilities or LMSYS-specific factors.
- Llama 400B speculation: Speculation that Meta may have internally released Llama 400B and made it available on WhatsApp based on an alleged screenshot.
- Llama 3 405B release implications: An image suggesting the release of Llama 3 405B could spur other big tech companies to release powerful open-source models.
- Gemma-2-9B AlpacaEval2.0 performance: The UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3 model achieved a 53.27% win rate on the AlpacaEval2.0 benchmark according to its Hugging Face page.
AI Discord Recap
A summary of Summaries of Summaries
-
Model Training, Quantization, and Optimization:
- Adam-mini Optimizer: Saves VRAM by 45-50%. Achieves performance akin to AdamW without the excessive memory overhead, useful for models like llama 70b and GPT-4.
- Hugging Face's new low-precision inference boosts transformer pipeline performance. Aimed at models like SD3 and PixArt-Sigma, it improves computational efficiency.
- CAME Optimizer: Memory-efficient optimization. Shows better or comparable performance with reduced memory need, beneficial for stable diffusion training.
-
New AI Models and Benchmarking:
- Gemma 2 demonstrates mixed performance but shows potential against models like Phi3 and Mistral, pending further optimization.
- Claude 3.5 faces contextual retention issues despite high initial expectations; alternative models like Claude Opus perform reliably.
- Persona Hub leverages diverse data applications to skyrocket MATH benchmark scores, proving synthetic data's efficacy in broader AI applications.
-
Open-Source AI Tools and Community Engagement:
- Rig Library: Integrates fully with Cohere models, aimed at Rust developers with $100 feedback rewards for insights.
- LlamaIndex introduces its best Jina reranker yet and provides a comprehensive tutorial for hybrid retrieval setups, promising advancements in retrieval pipelines.
- Jina Reranker: A new hybrid retriever tutorial details combining methods for better performance, allowing integration with tools like Langchain and Postgres.
-
Technical Challenges and Troubleshooting:
- BPE Tokenizer Visualizer helps understand tokenizer mechanics in LLMs, inviting community feedback to refine the tool.
- Database Queue Issues plague Eleuther and Hugging Face models' benchmarking efforts, urging users to look at alternatives like vllm for better efficiency.
- Training GPT Models across multiple systems: Discussions emphasized handling GPU constraints and optimizing scales for effective resource usage.
-
AI in Real-World Applications:
- Featherless.ai launches to provide serverless access to LLMs at a flat rate, facilitating easy AI persona application development without GPU setups.
- Deepseek Code V2 highly praised for its performance in solving complex calculus and coding tasks efficiently.
- Computer Vision in Healthcare: Exploring agentic hospitals using CV, emphasizing compute resources integration to enhance patient care and reduce administrative workloads.
PART 1: High level Discord summaries
HuggingFace Discord
- Protein Prediction Precision: New Frontiers with ESM3-SM-open-v1: Evolutionary Scale unleashes ESM3-SM-open-v1**, a transformative model for predicting protein sequences, underpinned by a sophisticated understanding of biological properties. Its utility is amped by the GitHub repository and an interactive Hugging Face space, a synergy poised to further biological research.
- Momentum gathers as practitioners are beckoned to leverage the model, crafting research pathways over at Hugging Face, with the community already branding it as a refreshing leap in biological AI applications.
- Aesthetic Essence Extracted: Unveiling Datasets for Enhanced Model Refinement: Terminusresearch** curates a trove of visual data, their photo-aesthetics dataset with 33.1k images, for honing the aesthetic discernment of AI. This dataset, brimming with real photographs, sets the stage for nuanced model training.
- Additional sets capturing images of architectures and people engaged with objects complement the principal dataset, as this fledgling endeavor shows promise in advancing models' abilities to navigate and interpret the visual domain with an aesthetically attuned eye.
- Tokenization Tamed: BPE Depictions Emerge for LLM Clarity**: The BPE Tokenizer, a cornerstone in LLM workings, gains greater transparency with a novel visualizer crafted by a vigilant community contributor. This deployable utility is set to clarify tokenizer mechanics, augmenting developer fluency with LLM intricacies.
- Crowdsourced improvement efforts are in flight, as calls echo for feedback to rectify issues and finesse the visualizer—an initiative slated to enrich LLM accessibility.
- Visionary Venues for Healing: Charting Agentic Hospitals with CV: A clarion call resounds for computer vision to pioneer agentic hospitals—a blend envisioned by a Sydney and Hyderabad doctor, aiming to curb administrative hefty loads. Fisheye cameras** are slated to serve as the linchpin in orchestrating smooth operations and patient-centric care enhancements.
- The pursuit of computational gifts surges as a plea is extended for compute resources, heralding a potential revolution where AI could transform healthcare dynamics, fostering tech-powered medical ecosystems.
- Inference Ingenuity: Embracing Low-Precision Aim in Transformers: Exploration into low-precision inference within transformer pipelines like SD3 and PixArt-Sigma** signals a shift towards computational economy. A GitHub discourse unveils the technique's promise of boosting the alacrity of model performance.
- While ripe with the potential to optimize, this emerging approach beams with challenges that need judicious solving to unlock its full spectrum of benefits.
Unsloth AI (Daniel Han) Discord
- RAM-tough Configs: Unsloth Sails on WSL2**: Engineers recommended optimizations for running Unsloth AI on WSL2 to utilize full system resources. Configurations such as setting memory limits in
.wslconfigand using specific install commands were exchanged for performance gains on various hardware setups.- Troubleshooting tips to address installation obstacles were shared, with consensus forming around memory allocation tweaks and fresh command lines as keys to unleashing Unsloth's efficiency on both Intel and AMD architectures.
- DRM's Dual Role: Multi-GPU Support Meets Licensing in Unsloth**: Unsloth's inclusion of a DRM system for multi-GPU training outlined strict NDA-covered tests that ensure GPU ID pinning and persistent IDs, revealing a behind-the-scenes effort to marry licensing control with functional flexibility.
- Community chatter lit up discussing the configurations and boundaries of multi-GPU setups, with updates on the DRM's stability being pivotal to scaling AI training capacities.
- Fine-Precise Feats: Navigating Fine-Tuning Mechanisms with Unsloth**: AI enthusiasts dissected the mazes of fine-tuning Lexi and Gemma models noting specific quirks such as system tokens, troubleshooting endless generation outputs post-fine-tuning, and emphasizing bold markdown syntax for clarity.
- Shared techniques for finessing the fine-tuning process included multi-language dataset translation, careful curation to avert critical forgetting, and using tokenizer functions fittingly to line up with custom training data.
- Synthetic Personas Shaping Data: Billion-Dollar Boost in MATH**: The Persona Hub's billion-persona-strong methodology for generating synthetic data has been a hot topic, presenting a quantum leap in mathematical reasoning scores that stoked buzz about the ease-of-use presented in its abstract.
- Amid a volley of perspectives on the project, some stressed the weight of the assembled data over the creation code itself, sparking debate on the critical elements of large-scale synthetic data applications.
LM Studio Discord
- Gemma's GPU Gambits: While Gemma 2 GPU offloads to Cuda and Metal, updates beyond 0.2.23 are crucial to squash issues plaguing this AI models' performance, according to community feedback. Deep exploration revealed Gemma 2 struggles with lengthy model loads on specific setups; the AI gurus implored continuous patch works.
- One cogent point raised was Gemma 2's current fencing in by Cuda and Metal, with suggested future broadening of horizons. Community dialogues surfaced detailing the technical challenges and positing potential updates to bolster model robustness and compatibility.
- AutoUpdater's Agile Advancements: LM Studio's AutoUpdater sleekly slides in, vaulting users ahead to v0.2.26 with simmering anticipation for v0.3. A public post conveys enhancements aimed squarely at the LLama 3 8B model, curing it of its troublesome ignoring of stop sequences - a much-welcome modification.
- The conversation surrounding recent feature releases revolved around their capacity to straighten out past sore spots, such as a refusal to heed stop sequences. Users exchanged active voice approval of updates that promise a harmonious human-model interaction.
- Deepseek's CPU Chronicles: Deepseek v2 flaunts its prowess, flexing only 21B of its 200B+ parameters on powerful CPUs, clocking 3-4 tokens/sec on meaty Threadripper systems. Caseloads of user-generated performative data sink into community dialogues, grounding claims about CPU feasibility.
- Shared User Testing meandered through a maze of metrics from RAM usage to loading speeds, encapsulating experiences with Deepseek v2's muscular but curiously well-managed performance on top-tier CPUs. The robust evaluations aim to steer the ship for future development and utility in practical settings.
- Trials of Quantization Quests: Quantization queries dominated discussion, with a particularly piquant focus on 'GGUF quants' known for dancing deftly between performance and efficiency. Experimental tangoes with q5_k_l sparked analytic anecdotes aiming for a blend of briskness and lightness in resource consumption.
- With a bevy of benchmarked brainchildren like q5_k_l and GGUF quants, the conclave of AI crafters probed for precision in performance while pressing for preservation of prowess. Documented discussions dial in on data and user feedback, pursuing the pinnacle of practice for these pioneering performance enhancers.
- Smooth Sailing with Sliding Window: The freshest chapter in Gemma 2's saga stars the Sliding Window Attention, freshly fused into the latest llama.cpp. This savvy update sanctions the AI to skillfully sift through past tokens, dexterously deepening its contextual comprehension. Users await with baited breath for fixes to lingering quality quandaries.
- As the bold Sliding Window Attention feature debuts in the Gemma 2 scene, bringing with it the promise of enhanced performance by adeptly managing token history, eclectic anecdotal evidence of its success emerges from the virtual corridors. Yet, spattered within this hope, voices of caution remain tenacious, precariously positioning expectations for comprehensive future felicitations.
Stability.ai (Stable Diffusion) Discord
- Loras In Limbo with SD3: A spirited discussion centered on the challenges in training Loras for Stable Diffusion 3, focusing on the need for robust support. Enthusiasm is building for the potential ease of SD 8b.
- While some are eager to start, a cautionary tone prevailed urging patience for better training tools and data, to prevent substandard creations of Loras or checkpoints.
- GPU Gurus Guide Newcomers: Debate flourished regarding the hardware requirements for running Stable Diffusion, with the common consensus leaning towards Nvidia GPUs with a minimum of 12GB VRAM.
- Notably, existing RTX 3090 cards were commended, while the latest RTX 4080 and 4090 were highlighted for their future-proofing attributes despite their hefty price tags.
- Installation Inception: Users banded together to tackle installation issues with Stable Diffusion, sharing knowledge about various interfaces like Automatic1111 and ComfyUI, along with key setup commands.
- Helpful resources and guides were traded, including specific configuration advice such as incorporating 'xformers' and 'medvram-sdxl' to enhance performance of complex workflows.
- High-Res Hacking for Sharper Art: The community dove into the use of high-resolution fix settings in SDXL to achieve crisper images, underscoring the importance of exact parameter settings, like '10 hires steps'.
- Participants amplified the benefits of plugins such as adetailer, highlighting its ability to refine critical aspects of imagery, particularly faces and eyes in anime-style graphics.
- Model Mining and Loras Lore: Conversations unearthed sources for finding models and Loras, naming platforms like Civitai for their extensive collections and user contributions.
- Insight was shared on the validity of using prompt examples as a guide to accurately exploit these assets, accentuating the collective effort in model training and distribution.
CUDA MODE Discord
- Synchronizing Watches: Time-Zone Tools Tackle Scheduling Tangles: Two tools, Discord Timestamps and When2meet, were shared to streamline meeting coordination across time-zones.
- Both Discord Timestamps and When2meet ease scheduling woes by converting times and pooling availability, fostering effortless collective scheduling.
- Stable Footing on Log Scale's Numerical Grounds: Discussion on the log exp function's role in numeric stability was stimulated by a blog post, emphasizing its use to prevent underflow in calculations.
- Debate ensued over frequency of necessity, with questions raised on the indispensability of log scales in modelling and ML, accentuating the divide in practices.
- Tensor Tales: Metadata Woes in the PyTorch Workshop: Challenge to retain metadata in
torch.Tensorthrough operations posted, with suggestions like subclassing posited, yet no definitive solution surfaced.- Compiled quandaries surfaced with
torch.compilegiven constraints in supporting dynamic input shapes, layering complexity on HuggingFace transformers usage, with proposed yet unused solutions.
- Compiled quandaries surfaced with
- Flashing Insight: AI Engineers Laud Notable Speaker Series: Endorsements filled the chat for the enlightening **
- Stephen Jones' delivery earns accolades for consistently insightful content, reinforcing his reputation in AI engineering circles.
- Performance Peaks and Valleys: Traversing Kernel Landscapes with FP16: Kernel performance became a hot topic with FP16 showing a single launch efficiency versus bfloat's multiple, sparking strategies for optimizing big tensor operations.
- Bitpacking optimization shows promise on smaller tensors but wanes with bulkier ones, prompting further exploration in kernel performance enhancement.
Perplexity AI Discord
- Gemma's Glorious Launch: Gemma 2 Models Hit Perplexity Labs: The Gemma 2 models** have landed on Perplexity Labs, aiming to spur community engagement through user feedback on their performance.
- Enthusiastic participants can now test-drive the new models and contribute insights, as the announcement encourages interactive community experience.
- Chatty Androids: Push-to-Talk vs Hands-Free Modes: Perplexity AI's Android app is now boasting a voice-to-voice feature**, enhancing user accessibility with hands-free and push-to-talk modes, as detailed in their latest update.
- The hands-free mode initiates immediate listening upon screen activation, contrasting with push-to-talk which awaits user command, aiming to enrich user interaction.
- Claude's Context Clumsiness: Users Decry Forgetfulness: Reports surge of Claude 3.5** failing to cling to context, diverging into generalized replies despite the chatter on specific topics, challenging engineers with unexpected twists in conversations.
- Switches to the Opus model have shown improvements for some, hinting at potential bugs in Claude 3.5 affecting engagement, with community calls for smarter Pro search to preserve context.
- API Vexations: Discrepancies Emerge in Perplexity's API**: Perplexity API users grapple with inconsistencies, spotting that date-specific filters like
after:2024-05-28may lure the API into crafting forward-dated content, sparking a debate on its predictive prowess.- Feedback bubbles as a user's interaction with the Perplexity Labs Playground hits a snag due to Apple ID recognition issues, sparking dialogues on user inclusivity and experience refinement.
- Gaming the System: Minecraft Mechanics Misinform Minors?**: A fiery thread unfolds critiquing Minecraft's Repair Mechanics, suggesting the in-game logic might twist youngsters' grasp on real-world tool restoration.
- The digital debate digs into the educational impact, urging a reality check on how virtual environments like Minecraft could seed misunderstandings, prompting programmers to ponder the implications.
Nous Research AI Discord
- Billion Persona Breakthrough: Skyrocketing Math Benchmarks: Aran Komatsuzaki's tweet highlighted the successful creation of a billion persona dataset, pushing MATH benchmark scores from 49.6 to 64.9. The method behind it, including the diverse data applications, is detailed in the Persona Hub GitHub and the corresponding arXiv paper.
- The new dataset enabled synthetic generation of high-quality mathematical problems and NPC scenarios for gaming. This innovation demonstrates significant performance gains with synthetic data, providing numerous use cases for academic and entertainment AI applications.
- Dream Data Duality: The Android & Human Dataset: The dataset contrasts 10,000 legitimate dreams with 10,000 synthesized by the Oneirogen model, showcased on Hugging Face. Oneirogen's variants, 0.5B, 1.5B, and 7B, offer a new standard for dream narrative assessment.
- The corpus is available for discerning the differences between authentic and generated dream content, paving the way for advanced classification tasks and psychological AI studies.
- Tech Giants' Mega Ventures: Microsoft & OpenAI's Data Center: Microsoft revealed collaboration with OpenAI on the Stargate project, potentially infusing over $100 billion into the venture as reported by The Information. The companies aim to address the growing demands for AI with significant processing power needs.
- This initiative could shape the energy sector significantly, considering Microsoft's nuclear power strategies to sustain such extensive computational requirements.
- Speculative Speed: SpecExec's LLM Decoding Innovation: SpecExec offers a brand new method for LLM inference, providing speed increases of up to 18.7 times by using 4-bit quantization on consumer GPUs. This breakthrough facilitates quicker LLM operations, potentially streamlining AI integration into broader applications.
- The model speculatively decodes sequences, verified speedily by the core algorithm, stoking discussions on compatibility with different LLM families and integration into existing platforms.
- Charting the Phylogeny of LLMs with PhyloLM: PhyloLM's novel approach introduces phylogenetic principles to assess the lineage and performance of LLMs, as seen in the arXiv report. The method crafts dendrograms based on LLM output resemblance, evaluating 111 open-source and 45 closed-source models.
- This method teases out performance characteristics and relationships between LLMs without full transparency of training data, offering a cost-effective benchmarking technique.
Modular (Mojo 🔥) Discord
- Errors as Values Spark Design Discussion: Discourse in Mojo uncovered nuances between handling errors as values versus traditional exceptions. The discussion revealed a preference for Variant[T, Error], and the need for better match statements.
- Contributors differentiated the use of try/except in Mojo as merely sugar coating, suggesting deeper considerations in language design for elegant error resolution.
- Ubuntu Users Unite for Mojo Mastery: A collaborative effort emerged as users grappled with setting up Mojo on Ubuntu. Success stories from installations on Ubuntu 24.04 on a Raspberry Pi 5 showcased the communal nature of troubleshooting.
- Dialogues featured the significance of community support in surmounting setup struggles, particularly for newcomers navigating different Ubuntu versions.
- Marathon Mojo: Coding Challenges Commence: Monthly coding challenges have been initiated, providing a dynamic platform for showcasing and honing skills within the Mojo community.
- The initiative, driven by @Benny-Nottonson, focuses on practical problems like optimized matrix multiplication, with detailed participation instructions on the GitHub repository.
- AI Aspirations: Cody Codes with Mojo: The intersection of Cody and Mojo sparked interest, with discussions on using Cody to predict language features. The Python-like syntax paves the way for streamlined integration.
- With aspirations to explore advanced Mojo-specific features such as SIMD, the community is poised to push the boundaries of what helper bots like Cody can achieve.
- Asynchronous I/O and Systemic Mojo Strengths: Engagement soared with conversations on the I/O module's current constraints. Members advocated for async APIs like
io_uring, aiming for enhanced network performance.- Darkmatter__ and Lukashermann.com debated the trade-off between powerful but complex APIs versus user-friendly abstractions, emphasizing the need for maintainability.
OpenRouter (Alex Atallah) Discord
- OpenRouter's Oopsie: Analytics on OpenRouter went offline due to a database operation mistake, as stated in the announcements. Customer data remains secure and unaffected by the mishap.
- The team promptly assured users with a message of regret, clarifying that customer credits were not compromised and are addressing the data fix actively.
- DeepSeek Code Charms Calculus: Praise was given to DeepSeek Code V2 via OpenRouter API for its impressive accuracy in tackling calculus problems, shared through the general channel. Economical and effective attributes were highlighted.
- It was confirmed that the model in use was the full 263B one, suggesting considerable power and versatility for various tasks. Details available on DeepSeek-Coder-V2's page.
- Mistral API Mix-Up: A report surfaced of a Mistral API error while using Sonnet 3.5 on Aider chat, causing confusion among users who were not employing Mistral at the time.
- Users were directed to contact Aider's support for specific troubleshooting, hinting at an automatic fallback to Mistral during an outage. Details discussed in the general channel.
Latent Space Discord
- Adept's Amazon Alignment: Adept AI Labs announced strategic updates and leadership changes, with co-founders heading to Amazon, detailed in their blog post and a GeekWire article. This move aims for Adept to use Amazon's technology under a non-exclusive license while maintaining its independence.
- Community reflections shed light on the confusion caused by the initial blog post, leading to a discussion around the partnership's nature with Amazon, prompting readers to prefer the GeekWire article for clearer insights.
- Fair Feedback on AIEWF: Organizers and attendees of the AI Engineer World's Fair (AIEWF) engaged in feedback sessions to discuss improving session lengths and logistical aspects, drawing from GitHub discussions about lessons learned and future planning.
- Suggestions included extending the event or conducting more structured feedback, with a call for a designated space for hackathons, inspired by other conferences’ success in fostering in-depth discussions.
- Runway's Video Generation Voyage: Runway released their Gen-3 Alpha Text to Video feature, a major advancement in high-fidelity and controllable video generation, announced on their official account.
- Open to everyone, the feature promises a significant leap in video generation technology, accessible via Runway's website, sparking curiosity and experimentation among creators.
- Privacy in Prompt Planning: Discussions emerged concerning the privacy of GPT system prompts, with an emphasis on treating prompts as potentially public information, referencing examples found on GitHub.
- Advice circulated to avoid including sensitive data in GPT system definitions, with community backing the notion by suggesting a cautious approach to what is shared in prompts.
- CoALA Paper Piques Interest: The community discussed the new paper on Cognitive Architectures for Language Agents (CoALA), which can be found on arXiv, introducing a framework for organizing existing language agent models.
- A repository of language agents, awesome-language-agents, based on the CoALA paper, became a highlighted resource for those looking to delve deeper into the study of language agents.
LangChain AI Discord
- LangChain Web Chronicles: React & FastAPI Unite: A guild member inquired about integrating LangGraph** with a React frontend and a FastAPI backend, receiving directions to chat-langchain on GitHub and Semantic Router docs.
- They were advised on creating an agent or leveraging semantic similarity for routing, using outlined methods for a solid foundation in tool implementation.
- Embeddings Nesting Games: Speeding Through with Matryoshka: Prashant Dixit showcased a solution for boosting retrieval speeds using Matryoshka RAG and llama_index**, detailed in a Twitter post and a comprehensive Colab tutorial.
- The technique employs varied embedding dimensions (768 to 64), promising enhanced performance and memory efficiency.
- Automate Wise, Analyze Wise: EDA-GPT Revolution: Shaunak announced EDA-GPT, a GitHub project for automated data analysis with LLMs, deployable via Streamlit**, and aided by a video tutorial for setup found in the project's README.
- This innovation streamlines the data analysis process, simplifying workflows for engineers.
- Postgres Meets LangChain: A Match Made for Persistence: Andy Singal's Medium post highlights the merging of LangChain and Postgres** to optimize persistence, bringing the reliability of Postgres into LangChain projects.
- The synergistic pair aims to bolster state management with Postgres' sturdiness in storage.
- Casting MoA Magic with LangChain: A YouTube tutorial titled "Mixture of Agents (MoA) using langchain" walked viewers through the process of creating a multi-agent system within LangChain, aiming to amplify task performance.
- The video provided an entry point to MoA, with specific code examples for engineering audiences interested in applying combined agent strengths.
Interconnects (Nathan Lambert) Discord
- Adept in Amazon's Ambit: Adept shifts strategy and integrates with Amazon; co-founders join Amazon, as detailed in their blog post. The company, post-departure, operates with about 20 remaining employees.
- This strategic move by Adept resembles Microsoft's strategy with Inflection AI, sparking speculations on Adept's direction and organizational culture changes, as discussed in this tweet.
- AI Mastery or Mystery?: Debate ensues on whether AI agent development is lagging, paralleling early-stage self-driving cars. Projects like Multion are criticized for minimal advancements in capabilities beyond basic web scraping.
- Community conjectures that innovative data collection methods are the game changer for AI agents, with a pivot to generating high-quality, model-specific data as a crucial piece to surmount current limitations.
- Cohere's Clever Crack at AI Clarity: Cohere's CEO, Aidan Gomez, shares insights on combating AI hallucinations and boosting reasoning power in a YouTube discussion, hinting at the potential of synthetic data generation.
- The community compares these efforts to Generative Active Learning and the practice of hard negative/positive mining for LLMs, echoing the significance at 5:30 and 15:00 marks in the video.
- Model Value Conundrum: The $1B valuation of user-rich Character.ai, contrasted with Cognition AI's non-operational $2B valuation, incites discussions around pitching strength and fundraising finesse.
- Cognition AI waves the flag of its founders' IMO accolades, targeting developer demographics and facing scrutiny over their merit amidst fierce competition from big tech AI entities.
- Layperson's RL Leap: An AI aficionado wraps up Silver's RL intro and Abeel's Deep RL, aiming next at Sutton & Barto, scouting for any unconventional advice with an eye towards LM alignment.
- The RL rookies get tipped to skim Spinning Up in Deep RL and dabble in real code bases, performing hands-on CPU-powered tasks for a grounded understanding, as guided possibly by the HF Deep RL course.
OpenInterpreter Discord
- Cross-OS Setup Sagas: Members report friction setting up
01on macOS and Windows, despite following the foreseen steps with hurdles like API key dependency and terminal command confusions. @killian and others have floated potential solutions, amidst general consensus on setup snags.- Consistent calls for clarity in documentation echo across trials, as highlighted by a thread discussing desktop app redundancy. A GitHub pull request may be the beacon of hope with promising leads on simplified Windows procedures laid out by dheavy.
- Amnesic Assistants? Addressing AI Forgetfulness: An inquiry into imbuing Open Interpreter with improved long-term memory has surfaced, pinpointing pain points in Sonnet model's ability to learn from past interactions.
- Discourse on memory enhancements signifies a collective trial with the OI memory constraints, yet remains without a definitive advanced strategy despite suggestions for specific command usage and esoteric pre-training ventures.
- Vector Search Pioneers Wanted: A hands-on tutorial on vector search integration into public datasets has been showcased in a Colab notebook by a proactive member, setting the stage for a cutting-edge presentation at the Fed.
- The collaborator extends an olive branch for further vector search enhancement ventures, heralding a potential new chapter for community innovation and applied AI research.
- Multimodal Model Hunt Heats Up: Queries on selecting top-notch open-source multimodal models for censored and uncensored projects bubbled up, prompting suggestions like Moondream for visual finesse paired with robust LLMs.
- The conversation led to fragmented views on model adequacy, reflecting a panorama of perspectives on multimodal implementation strategies without a unified winner in sight.
- Windows Woes and Installation Wobbles: Discontent bubbles over typer installation troubles on Windows for OpenInterpreter, with members finessing the pyproject.toml file and manipulating
poetry installmaneuvers for success.- A narrative of documentation woes weaves through the guild, amplifying the outcry for transparent, up-to-date guidelines, and inviting scrutiny over the practicality of their 01 Light setups. @Shadowdoggie spotlights the dichotomy between macOS ease and Windows woe.
LlamaIndex Discord
- Reranker Revolution: Excitement builds with the Jina reranker's new release, claimed to be their most effective yet, detailed here. The community praises its impact on retrieval strategies and results combinatorics.
- The guide to build a custom hybrid retriever is welcomed for its thorough approach in combining retrieval methods, shared by @kingzzm and available here. Feedback reveals its far-reaching potential for advanced retrieval pipelines.
- LlamaIndex's Toolkit Expansion: Integration uncertainties arise as users ponder over the compatibility of Langchain Tools with LlamaIndex, an inquiry sparked by a community member's question.
- Discussion thrives around using Langchain Tools alongside LlamaIndex agents, with a keen interest on how to merge their functionalities for refined efficiency.
- Query Quandaries Quelled: Users grapple with query pipeline configuration in LlamaIndex, with insightful suggestions like utilizing kwargs to manage the
source_keyfor improved input separation and retrieval setup.- Embedding performance concerns with large CSV files lead to a proposal to upscale
embed_batch_size, broadening pathways to incorporate more substantial LLMs for better code evaluation.
- Embedding performance concerns with large CSV files lead to a proposal to upscale
- Sub-Agent Specialization: The curiosity around sub-agents manifests as users seek guidance to customize them using prompts and inputs to enhance task-specific actions.
- CodeSplitter tool gains attention for its potential in optimizing metadata extraction, hinting at a shift towards more efficient node manipulation within the LlamaIndex.
- Kubernetes & Multi-Agent Synergy: The launch of a new multi-agent systems deployment starter kit by @nerdai paves the way for moving local agent services to Kubernetes with ease, found here.
- The kit enables transitioning to k8s deployment without friction, marking a significant stride in scaling service capabilities.
OpenAccess AI Collective (axolotl) Discord
- Llamas Leap with Less: Community members are astounded by the llama3 70b model achieving high performance on a mere 27 billion parameters, triggering a discussion on the plausibility of such a feat. While some remain dedicated to Mixtral for its well-rounded performance and favorable licensing for consumer hardware.
- Debate unfolds on Hugging Face regarding the Hermes 2 Theta and Pro iterations – one a novel experiment and the other a polished finetune – while users ponder the merits of structured JSON Outputs exclusive to the Pro version.
- Formatting Flair and Frustrations: Issues with Axolotl's custom ORPO formatter stirred discussions due to improper tokenization and how system roles are managed in ChatML.
- Suggestions for using alternative roles to navigate the challenges were met with concerns about conflict, showcasing the need for more seamless customization solutions.
- Synthetic Slowdown Sparks Speculation: The Nvidia synthetic model under the microscope for its sluggish data generation, moving at a snail's pace compared to faster models like llama 70b or GPT-4.
- This prompted queries on the advantages smaller models might hold, especially in terms of efficiency and practical application.
- Cutting-Edge Compaction in Optimization: AI enthusiasts probed into innovative memory-efficient optimizers like CAME and Adam-mini with the promise of reduced memory usage without compromising performance.
- Technical aficionados were directed to CAME's paper and Adam-mini's research to dive into the details and potential application in areas like stable diffusion training.
Eleuther Discord
- Benchmarks Caught in Queue Quagmire: Hot topics included the computation resource bottleneck affecting leaderboard benchmark queue times, speculated to stem from HF's infrastructure. Stellaathena implied that control over the queues was not possible, indicating a need for alternative solutions.
- @dimfeld suggested vllm as an alternative, pointing to a helpful wiki for technical guidance on model memory optimization.
- Im-Eval Ponders 'HumanEval' Abilities: Questions arose over im-eval's capability to handle
HumanEvalandHumanEvalPlus, with Johnl5945 sparking a discussion on configuring evaluation temperatures for the evaluation tool.- The conversation concluded without a firm resolution, highlighting a potential area for follow-up research or clarification on im-eval's functionality and temperature control.
- Adam-mini: The Lightweight Optimizer: The Adam-mini optimizer was a notable subject, offering significant memory savings by using block-wise single learning rates, promising comparable performance to AdamW.
- Members evaluated its efficacy, recognizing the potential to scale down optimizer memory usage without impacting model outcomes, which could usher in more memory-efficient practices in ML workflows.
- Gemma 2's Metrics Mystify Users: Discrepancies in replicating Gemma 2 metrics led to confusion, despite diligent use of recommended practices, such as setting
dtypetobfloat16. Concerns arose over a substantial difference in reported accuracies across benchmarks like piqa and hellaswag.- Further probing into potential issues has been urged after the proper debugging commands seemed to return correct but inconsistent results, as reported in an informative tweet by @LysandreJik.
- Token Representation 'Erasure Effect' Uncovered: A recent study unveiled an 'erasure effect' in token representations within LLMs, particularly notable in multi-token named entities, stirring a vibrant discourse around its implications.
- The academic exchange focused on how such an effect influences the interpretation of semantically complex token groups and the potential for enhanced model designs to address this representation challenge.
tinygrad (George Hotz) Discord
- Codebase Cleanup Crusade: George Hotz issued a call to action for streamlining tinygrad by moving RMSNorm from LLaMA into
nn/__init__.py, complete with tests and documentation.- Community response involved, suggesting enhancements to the organization and potentially unifying code standards across the project.
- Mondays with tinygrad: During the latest meeting, participants discussed various recent advancements including a sharding update and a single pass graph rewrite, touching on tensor cores and new bounties.
- The detailed exchange covered lowerer continuation, the Qualcomm runtime, and identified the next steps for further improvements in the tinygrad development process.
- Standalone tinygrad Showdown: Queries emerged on the potential for compiling tinygrad programs into standalone C for devices like Raspberry Pi, with a shared interest in targeting low-power hardware.
- Members shared resources like tinygrad for ESP32 to inspire pursuit of applications beyond traditional environments.
- Bounty Hunting Brilliance: A robust discussion clarified the requirements for the llama 70b lora bounty, including adherence to the MLPerf reference with flexibility in the computational approach.
- The community explored the possibility of employing qlora and shared insights on implementing the bounty across different hardware configurations.
- Graph Rewrite Revelation: The exchange on graph rewrite included interest in adopting new algorithms into the process, with a focus on optimizing the scheduler.
- ChenYuy's breakdown of the meeting noted while specific graph algorithms have yet to be chosen, there's momentum behind migrating more functions into the graph rewrite framework.
LAION Discord
- 27 Billion Big Doubts, Little Triumphs: Amidst mixed opinions, the 27B model faced skepticism yet received some recognition for potential, eclipsing Command R+ in even its less promising scenarios. One member bolstered the conversation by noting Gemma 2 9B's unexpectedly superior performance.
- Enthusiasm tinged with doubt flowed as "True but even in the worst case(-15) it's better than command r+" was a shared sentiment indicating a lean towards the 27B's superior potential over its counterparts.
- ChatGPT's Slippery Slope to Second-Rate: Troubles were aired regarding the ChatGPT 4 and 4o models losing their grip on nuanced programming tasks, with comparisons drawn favorably towards the 3.5 iteration. Several users felt the latest models were over-zealous, taking prompts too literally.
- Frustration bubbled as a member's comment "Sometimes the paid 4 and 4o models feel absolutely useless when programming" captured the communal drift towards more reliable free alternatives.
- Gemini's Rising, ChatGPT's Falling: Gemini 1.5 Pro took the spotlight with commendations fir its responsive interaction, while ChatGPT faced complaints of growing inefficiency, especially in programming tasks. Users are applauding Gemini's can-do attitude in contrast to ChatGPT's waning enthusiasm.
- Comparisons made by users like "Gemini 1.5 pro does a super excellent job compared to chatgpt's increasing laziness" highlight a shift towards alternative models that maintain their zest and engagement over time.
- Claude Crafts Artifact Appeal: Claude's artifact feature won over users, providing a more immersive and efficient experience that challenges the status quo established by ChatGPT. This particular feature has attracted a growing audience ready to switch allegiances.
- Community consensus is reflected in statements like "The artifacts feature is a much better experience", signaling a rising trend for enthusiast tools that resonate more closely with the user-experience expectations.
- The Language Labyrinth & LLMs: The discussion shifted toward a global audience as non-English speakers sought LLMs skilled in diverse languages, prioritizing conversational capabilities in their native tongues over niche task efficiency. This global tilt continues despite the varying effectiveness of the models in specific tasks.
- The narrative "It's already up there not because it can answer difficult platform, but due its multilingual capabilities" showcases a surging demand for models that democratize language inclusivity and support localized user interactions.
LLM Finetuning (Hamel + Dan) Discord
- JSONL Jugglers Gather: Efforts to simplify JSONL editing result in shared expertise, with a simple JSONL editor for quick edits and a scripting method maintained for diverse JSON-structured file manipulations.
- Community exchange recommends direct editing and prompt engineering for extracting summaries from structured patient data in JSON format, avoiding new package implementations and minimizing the incidence of hallucinations in LLM evaluations.
- Kv-Caching to Enlighten Vision-LLMs: LLM users explore kv-caching enhancements for vision-centric models, finding valuable improvements in prediction probabilities.
- The guide provides actionable optimization advice for vision models on constrained GPU setups, drawing practical interest and implementation feedback.
- Navigating LLM Inference on Kubernetes: Skepticism appears over ML inference implementations on Kubernetes, with a light-hearted tweet inciting in-depth discussions on cloud infrastructure alternatives for ML workloads.
- Despite some shared difficulties with tool scaling on Modal, confidence is expressed in Modal over Kubernetes for specific distributed systems.
- Hugging Face Credits: A Relief to Users: Clarifications emerged on Hugging Face credits, confirming a 2-year validity period, easing users' concerns of any immediate credit expiration.
- Discussions point to a community need for improved communication channels about credit status and management on Hugging Face.
- In Pursuit of Optimal IDEs: Zed IDE wins over a Sublime Text veteran with impressive features and AI integrations, yet curiosity about Cursor's offerings remains peaked.
- Community feedback sought on user experiences with Cursor, suggesting a broader exploration of AI integration in development environments.
Cohere Discord
- Cohere Cultivates Interns: A community member keen on Cohere's internship mentioned their AAAI conference paper and past co-op, probing for Cohere's API advancements and novel LLM feature tasks.
- Conversations evolved around resources for blending LLMs with reinforcement learning, enriching Cohere's technical landscape.
- Coral's Cribs: The Rate Limit Riddle: Frustrations sparked around Coral's API rate limits, with users chafing at a sparse 5 calls/minute constraint.
- Insights were exchanged via a practical guide, casting production keys in a hero's light with a lavish 10,000 calls/minute.
- Mixed Messages Over Aya-23 Models: The guild navigated a fog of versions for Aya-23 models, spotlighting the 8B and 35B models found on Hugging Face, while chasing phantom rumors of a 9B variant.
- A consensus clarified no current application of these model versions for running inferences, reaffirming their adequacy.
- Cohere's Climb to Clearer Cognition: Members buzzed about Cohere's plans to curb AI hallucinations, following Aidan Gomez's enlightenment on enhancing AI reasoning.
- The CEO's roadmap refrained from external partnerships, instead spotlighting self-reliant development.
- Rig Wrangles Cohere Compatibility: Rust enthusiasts rejoiced as the Rig library announced full integration with Cohere models, encouraging feedback through a rewarding review program.
- Contributors can clinch a $100 honorarium by providing insights to refine Rig, making it a linchpin for LLM-powered projects.
Torchtune Discord
- Diving into DPO with Data-driven Precision: Debate ensued on the benefits of DPO training for datasets with robust data, with some considering immediate use of DPO/PPO while others expressed hesitation. It was suggested to utilize PreferenceDataset for these applications.
- The discussions highlighted that Socket experts should guide such decisions, referencing past successes of straight DPO/PPO training on llama2 and Pythia 1B-7B.
- WandB to the Rescue for Phi Mini Fine-tuning: An AI enthusiast successfully fine-tuned a Phi Mini (LoRA) model and looked for guidance on evaluating logs. The consensus was to adopt WandBLogger for sophisticated log management and visualization.
- Warnings were voiced about yaml configuration pitfalls and the importance of a well-set WandBLogger to prevent errors and gain enhanced training oversight was emphasized.
- Fine-tuning Fineries: Logs & Gradient Governance: Technical talk touched on the appropriateness of gradient size with suggestions tabled to tailor it to dataset specifics. Shared logs spurred scrutiny for signs of overfitting and discussion about extending training epochs.
- Logs revealed irregularities in loss and learning rate metrics, especially within smaller datasets, underscoring the utility of tools like WandB for clarity in the fine-tuning foray.
AI Stack Devs (Yoko Li) Discord
- Featherless Flies with Flat Fees: The recent launch of Featherless.ai offers a subscription-based access to all LLM models available on Hugging Face, starting at $10/month without the need for local GPU setups as shown here. The platform has seen an uptick in use for local AI persona applications like Sillytaven, along with needs such as language tuning and exploiting SQL models.
- Text-to-Speech (TTS) Temptation emerges as Featherless.ai considers integrating TTS systems like Piper based on growing user requests to enhance NPC voice diversity in online gaming, maintaining a focus on popular models unrunnable on local CPU setups.
- Windows Wisdom with WSL README: New member Niashamina brings Windows wisdom to the guild by creating a README for using WSL to get AI Town operational on Windows, mentioning the possibility of Docker integration in the near future.
- While the integration into Docker is still underway and the README's draft awaits its GitHub debut, Niashamina quips about its eventual usefulness, hinting at the hands-on Windows progress they're pioneering.
- Hexagen.World’s New Geographic Gems: A brief but notable announcement unveils fresh locations available at Hexagen.World, expanding the domain's virtual landscape offerings.
- The reveal doesn't dive into details but plants seeds of curiosity for those inclined to explore the newly added virtual terrains, opening windows to new localizations.
Mozilla AI Discord
- Facebook Crafts Compiler Capabilities: LLM Compiler Model: Facebook released its LLM Compiler model** with the prowess to compile C, optimize assembly, and LLVM IR, now conveniently packaged by Mozilla into llamafiles for various operating systems.
- The llamafile, supporting both AMD64 and ARM64 architectures, has been uploaded by Mozilla to Hugging Face to enhance accessibility for its users.
- Llamafile Leaps to Official: Integration Saga on Huggingface**: Aiming for the official status of llamafile on Huggingface, contributors are poised to create pull requests to update the model libraries and corresponding code snippets files.
- This integration will ease the user experience by adding a button on repositories using llamafile, and autofill code to load the model seamlessly.
- Tech Specs Uncorked: llamafile's Hardware Haunt: Community discussions surfaced about the feasibility of running llamafile on varied devices; however, it requires a 64-bit system**, sidelining the Raspberry Pi Zero from the action.
- While llamafile server v2.0 impresses with its minimal memory footprint, using only 23mb for hosting embeddings to HTTP clients with all-MiniLM-L6-v2.Q6_K.gguf, iPhone 13 support remains unconfirmed.
- llamafile v0.8.9 Ascends Android: Gemma2 Gets a Grip: llamafile v0.8.9** strikes with its official Android compatibility and refined support for the Google Gemma2 architecture, alongside Windows GPU extraction fixes.
- The newly spun v0.8.9 release also highlights advancements in server mode operations while underpinning Google Gemma v2 enhancements.
MLOps @Chipro Discord
- Zooming into AI Engineering Confusion: An anticipated 'From ML Engineering to AI(cntEngr)' event's recording turned into a digital goose chase, with members encountering invalid Zoom links and access code issues.
- Despite the effort, the community couldn't retrieve the recording, highlighting the gaps in event-sharing infrastructure within the AI engineering space.
- Pipeline Wizardry Workshop Wonders: Data Talks Club's upcoming Zoomcamp promises hands-on journey for AI engineers with focus on building open-source data pipelines using dlt and LanceDB scheduled for July 8.
- With guidance by Akela Drissner from dltHub, participants will dive deep into REST APIs, data vectorizing, and orchestration tools, aiming to deploy pipelines across varying environments including Python notebooks and Airflow.
Datasette - LLM (@SimonW) Discord
- Pack Pulls Ahead in Database Dominance: On the topic of database progression, dbreunig highlighted a noticeable trend starting from May 19th, showing competitors closing in on the lead in database technologies.
- The commentary suggests a shift in the AI database landscape with multiple players improving and vying for the top position.
- Catch-Up Clause in Computation: In a recent insight by dbreunig, data since May 19th indicates a tightening race among leading database contenders.
- This observation pinpoints a critical period where competing technologies began to show significant gains, catching up with industry leaders.
DiscoResearch Discord
- Coders in a Memory Jam: An engineer's attempt at training a BPE tokenizer for the Panjabi language on a hefty 50 GB corpus hits a snag with an OOM issue on a 1TB RAM machine. They've shed light on the ordeal by sharing comparable GitHub issues.
- Despite reaching beyond the Pre-processing sequences steps continue beyond len(ds), memory consumption keeps soaring, hinting at a possible misfire in the
train_from_iteratorfunction, detailed in this related issue. Technical insights or alternative training methodologies are in high demand for this perplexing issue.
- Despite reaching beyond the Pre-processing sequences steps continue beyond len(ds), memory consumption keeps soaring, hinting at a possible misfire in the
- Debugging Dilemma: Delving into the Rusty Depths: The quest to crack the OOM mystery during BPE tokenizer training leads one intrepid coder to a wall, as the
train_from_iteratorfunction intokenization_utils_fast.pybecomes an impenetrable fortress.- Speculations arise that the issue may stem from executable/binary Rust code, a theory supported by other community encounters, leaving our engineer scratching their head and seeking expert aid.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!