[AINews] Test-Time Training, MobileLLM, Lilian Weng on Hallucination (Plus: Turbopuffer)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Depth is all you need. We couldn't decide what to feature so here's 3 top stories.
AI News for 7/8/2024-7/9/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (463 channels, and 2038 messages) for you. Estimated reading time saved (at 200wpm): 250 minutes. You can now tag @smol_ai for AINews discussions!
Two major stories we missed, and a new one we like but didn't want to give the whole space to:
- Lilian Weng on Extrinsic Hallucination: We usually drop everything when the Lil'Log updates, but she seems to have quietly shipped this absolute monster lit review without announcing it on Twitter. Lilian defines the SOTA on Hallucination Detection (FactualityPrompt, FActScore, SAFE, FacTool, SelfCheckGPT, TruthfulQA) and Anti-Hallucination Methods (RARR, FAVA, Rethinking with Retrieval, Self-RAG, CoVE, RECITE, ITI, FLAME, WebGPT), and ends with a brief reading list on other Hallucination eval benchmarks. We definitely need to do a lot of work on this for our Reddit recaps.
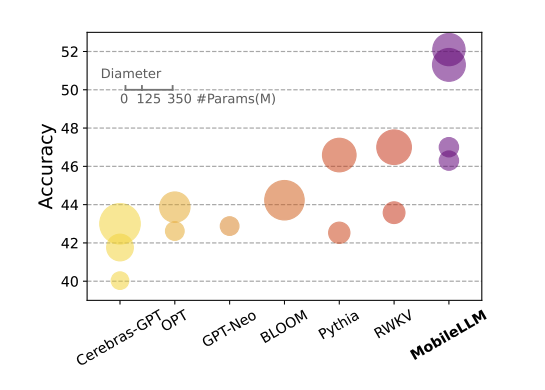
- MobileLLM: Optimizing Sub-Billion Parameter Language Models for On-Device Use: One of the most hyped FAIR papers published at the upcoming ICML (though not even receiving a spotlight, hmm) focusing on sub-billion scale, on-device model architecture research making a 350M model reach the same perf as Llama 2 7B, surprisingly in a chat context. Yann LeCun's highlights: 1) thin and deep, not wide 2) shared matrices for token->embedding and embedding->token; shared weights between multiple transformer blocks".
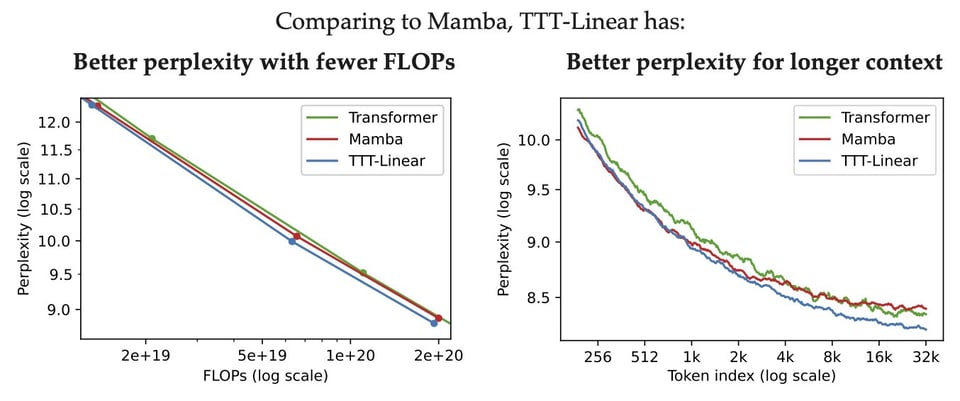
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States (advisor, author tweets): Following ICML 2020 work on Test-Time Training, Sun et al publish a "new LLM architecture, with linear complexity and expressive hidden states, for long-context modeling" that directly replace attention, "scales better (from 125M to 1.3B) than Mamba and Transformer" and "works better with longer context".
 Main insight is replacing the hidden state of an RNN with a small neural network (instead of a feature vector for memory).
Main insight is replacing the hidden state of an RNN with a small neural network (instead of a feature vector for memory). 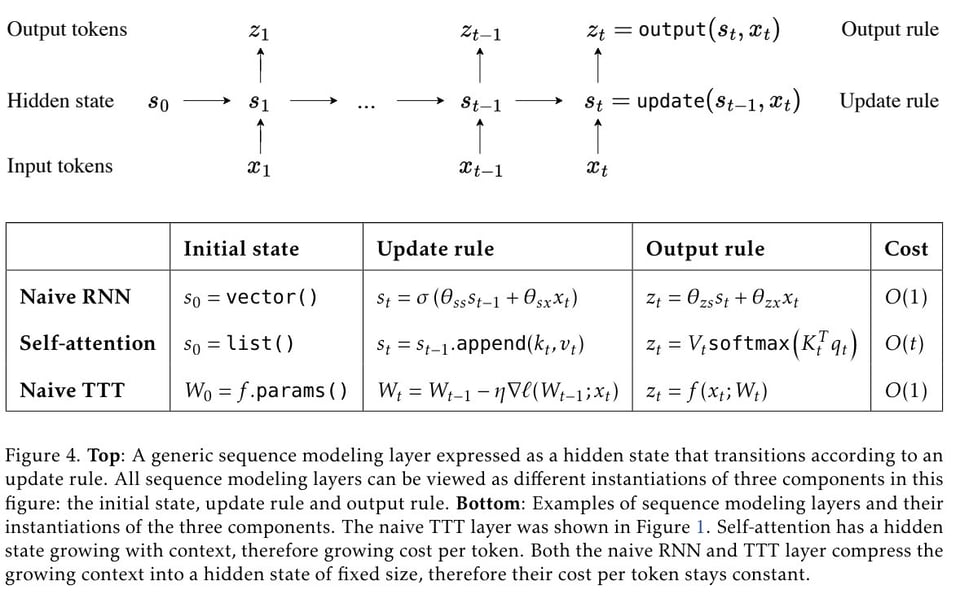 The basic intuition makes sense: "If you believe that training neural networks is a good way to compress information in general, then it will make sense to train a neural network to compress all these tokens." If we can nest networks all the way down, how deep does this rabbit hole go?
The basic intuition makes sense: "If you believe that training neural networks is a good way to compress information in general, then it will make sense to train a neural network to compress all these tokens." If we can nest networks all the way down, how deep does this rabbit hole go?
Turbopuffer also came out of stealth with a small well received piece.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- CUDA MODE Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- LM Studio Discord
- Eleuther Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- LlamaIndex Discord
- Perplexity AI Discord
- LAION Discord
- OpenRouter (Alex Atallah) Discord
- Latent Space Discord
- LangChain AI Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- Interconnects (Nathan Lambert) Discord
- LLM Finetuning (Hamel + Dan) Discord
- Cohere Discord
- Mozilla AI Discord
- AI Stack Devs (Yoko Li) Discord
- MLOps @Chipro Discord
- LLM Perf Enthusiasts AI Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (291 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (11 messages🔥):
- HuggingFace ▷ #cool-finds (2 messages):
- HuggingFace ▷ #i-made-this (4 messages):
- HuggingFace ▷ #reading-group (1 messages):
- HuggingFace ▷ #computer-vision (14 messages🔥):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (136 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (24 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (43 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (40 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
- CUDA MODE ▷ #triton (2 messages):
- CUDA MODE ▷ #torch (1 messages):
- CUDA MODE ▷ #cool-links (1 messages):
- CUDA MODE ▷ #jobs (3 messages):
- CUDA MODE ▷ #beginner (24 messages🔥):
- CUDA MODE ▷ #torchao (1 messages):
- CUDA MODE ▷ #ring-attention (8 messages🔥):
- CUDA MODE ▷ #triton-puzzles (1 messages):
- CUDA MODE ▷ #llmdotc (176 messages🔥🔥):
- Nous Research AI ▷ #off-topic (1 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #general (117 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (8 messages🔥):
- Nous Research AI ▷ #rag-dataset (88 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (5 messages):
- Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
- Modular (Mojo 🔥) ▷ #✍︱blog (3 messages):
- Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- Modular (Mojo 🔥) ▷ #🔥mojo (129 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #performance-and-benchmarks (3 messages):
- Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
- Modular (Mojo 🔥) ▷ #nightly (19 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo-marathons (17 messages🔥):
- LM Studio ▷ #💬-general (54 messages🔥):
- LM Studio ▷ #🤖-models-discussion-chat (75 messages🔥🔥):
- LM Studio ▷ #🧠-feedback (8 messages🔥):
- LM Studio ▷ #🎛-hardware-discussion (18 messages🔥):
- LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- LM Studio ▷ #amd-rocm-tech-preview (1 messages):
- LM Studio ▷ #🛠-dev-chat (7 messages):
- Eleuther ▷ #general (32 messages🔥):
- Eleuther ▷ #research (77 messages🔥🔥):
- Eleuther ▷ #scaling-laws (9 messages🔥):
- Eleuther ▷ #interpretability-general (2 messages):
- Eleuther ▷ #lm-thunderdome (6 messages):
- Eleuther ▷ #gpt-neox-dev (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (119 messages🔥🔥):
- OpenAI ▷ #ai-discussions (67 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (9 messages🔥):
- OpenAI ▷ #prompt-engineering (2 messages):
- OpenAI ▷ #api-discussions (2 messages):
- LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (65 messages🔥🔥):
- Perplexity AI ▷ #general (43 messages🔥):
- Perplexity AI ▷ #sharing (10 messages🔥):
- Perplexity AI ▷ #pplx-api (10 messages🔥):
- LAION ▷ #general (37 messages🔥):
- LAION ▷ #research (13 messages🔥):
- LAION ▷ #resources (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (47 messages🔥):
- Latent Space ▷ #ai-general-chat (27 messages🔥):
- LangChain AI ▷ #general (16 messages🔥):
- LangChain AI ▷ #share-your-work (5 messages):
- LangChain AI ▷ #tutorials (1 messages):
- OpenInterpreter ▷ #general (20 messages🔥):
- tinygrad (George Hotz) ▷ #general (9 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (7 messages):
- Interconnects (Nathan Lambert) ▷ #ml-questions (4 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (7 messages):
- Cohere ▷ #general (7 messages):
- Cohere ▷ #project-sharing (1 messages):
- Mozilla AI ▷ #llamafile (4 messages):
- AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
- AI Stack Devs (Yoko Li) ▷ #events (1 messages):
- MLOps @Chipro ▷ #events (1 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
- LLM Perf Enthusiasts AI ▷ #general (1 messages):
AI Twitter Recap
We are running into issues with the Twitter pipeline, please check back tomorrow.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Architectures
- CodeGeeX4-ALL-9B open sourced: In /r/artificial, Tsinghua University has open sourced CodeGeeX4-ALL-9B, a groundbreaking multilingual code generation model outperforming major competitors and elevating code assistance.
- Mamba-Transformer hybrids show promise: In /r/MachineLearning, Mamba-Transformer hybrids provide big inference speedups, up to 7x for 120K input tokens, while slightly outperforming pure transformers in capabilities. The longer the input context, the greater the advantage.
- Phi-3 framework released for Mac: /r/LocalLLaMA shares news of Phi-3 for Mac, a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the recently updated Phi-3-Mini-128K language model. It's designed to run efficiently on Apple Silicon using the MLX framework.
AI Safety and Ethics
- Ex-OpenAI researcher warns of safety neglect: In /r/singularity, ex-OpenAI researcher William Saunders says he resigned when he realized OpenAI was the Titanic - a race where incentives drove firms to neglect safety and build ever-larger ships leading to disaster.
- AI model compliance test shows censorship variance: An AI model compliance test in /r/singularity shows which models have the least censorship. Claude models are bottom half bar one, while GPT-4 finishes in the top half.
- Hyper-personalization may fracture shared reality: In /r/singularity, Anastasia Bendebury warns that hyper-personalization of media content due to AI may lead to us living in essentially different universes. This could accelerate the filter bubble effect already seen with social media algorithms.
AI Applications
- Pathchat enables AI medical diagnosis: /r/singularity features Pathchat by Modella, a multi-modal AI model designed for medical and pathological purposes, capable of identifying tumors and diagnosing cancer patients.
- Thrive AI Health provides personalized coaching: /r/artificial discusses Thrive AI Health, a hyper-personalized AI health coach funded by the OpenAI Startup Fund.
- Odyssey AI aims to revolutionize visual effects: In /r/OpenAI, Odyssey AI is working on "Hollywood-grade" visual FX, trained on real world 3D data. It aims to reduce film production time and costs dramatically.
AI Capabilities and Concerns
- AI predicts political beliefs from faces: /r/artificial shares a study showing AI's ability to infer political leanings from facial features alone.
- Sequoia Capital warns of potential AI bubble: In /r/OpenAI, Sequoia Capital warns that AI would need to generate $600 billion in annual revenue to justify current hardware spending. Even optimistic revenue projections fall short, suggesting potential overinvestment leading to a bubble.
- China faces glut of underutilized AI models: /r/artificial reports on China's AI model glut, which Baidu CEO calls a "significant waste of resources" due to scarce real-world applications for 100+ LLMs.
Memes and Humor
- Twitter users misunderstand AI technology: /r/singularity shares a humorous take on the lack of understanding of AI technology among the general public on Twitter.
- AI imagines aging Mario game: /r/singularity features a humorous AI-generated video game cover depicting an aging Mario suffering from back pain.
AI Discord Recap
A summary of Summaries of Summaries
1. Large Language Model Advancements
- Nuanced Speech Models Emerge: JulianSlzr highlighted the nuances between GPT-4o's polished turn-based speech model and Moshi's unpolished full-duplex model.
- Andrej Karpathy and others weighed in on the differences, showcasing the diverse speech capabilities emerging in AI models.
- Gemma 2 Shines Post-Update: The Gemma2:27B model received a significant update from Ollama, correcting previous issues and leading to rave reviews for its impressive performance, as demonstrated in a YouTube video.
- Community members praised the model's turnaround, calling it 'incredible' after struggling with incoherent outputs previously.
- Supermaven Unveils Babble: Supermaven announced the launch of Babble, their latest language model boasting a massive 1 million token context window, which is 2.5x larger than their previous offering.
- The upgrade promises to enrich the conversational landscape with its expansive context handling capabilities.
2. Innovative AI Research Frontiers
- Test-Time Training Boosts Transformers: A new paper proposed using test-time training (TTT) to improve model predictions by performing self-supervised learning on unlabeled test instances, showing significant improvements on benchmarks like ImageNet.
- TTT can be integrated into linear transformers, with experimental setups substituting linear models with neural networks showing enhanced performance.
- MatMul-Free Models Revolutionize LLMs: Researchers have developed matrix multiplication elimination techniques for large language models that maintain strong performance at billion-parameter scales while significantly reducing memory usage, with experiments showing up to 61% reduction over unoptimized baselines.
- A new architecture called Test-Time-Training layers replaces RNN hidden states with a machine learning model, achieving linear complexity and matching or surpassing top transformers, as announced in a recent tweet.
- Generative Chameleon Emerges: The first generative chameleon model has been announced, with its detailed examination captured in a paper on arXiv.
- The research community is eager to investigate the model's ability to adapt to various drawing styles, potentially revolutionizing digital art creation
3. AI Tooling and Deployment Advances
- Unsloth Accelerates Model Finetuning: Unsloth AI's new documentation website details how to double the speed and reduce memory usage by 70% when finetuning large language models like Llama-3 and Gemma, without sacrificing accuracy.
- The site guides users through creating datasets, deploying models, and even tackles issues with the gguf library by suggesting a build from the llama.cpp repo.
- LlamaCloud Eases Data Integration: The beta release of LlamaCloud promises a managed platform for unstructured data parsing, indexing, and retrieval, with a waitlist now open for eager testers.
- Integrating LlamaParse for advanced document handling, LlamaCloud aims to streamline data synchronization across diverse backends for seamless LLM integration.
- Crawlee Simplifies Web Scraping: Crawlee for Python was announced, boasting features like unified interfaces for HTTP and Playwright, and automatic scaling and session management, as detailed on GitHub and Product Hunt.
- With support for web scraping and browser automation, Crawlee is positioned as a robust tool for Python developers engaged in data extraction for AI, LLMs, RAG, or GPTs.
4. Ethical AI Debates and Legal Implications
- Copilot Lawsuit Narrows Down: A majority of claims against GitHub Copilot for allegedly replicating code without credit have been dismissed, with only two allegations left in the legal battle involving GitHub, Microsoft, and OpenAI.
- The original class-action suit argued that Copilot's training on open-source software constituted an intellectual property infringement, raising concerns within the developer community.
- AI's Societal Impact Scrutinized: Discussions revealed concerns about AI's impact on society, particularly regarding potential addiction issues and the need for future regulations.
- Members emphasized the urgency for proactive measures in light of AI's transformative nature across various sectors.
- Anthropic Credits for Developers: Community members inquired about the existence of a credit system similar to OpenAI's for Anthropic, seeking opportunities for experimentation and development on their platforms.
- The conversation underscored the growing interest in accessing Anthropic's offerings, akin to OpenAI's initiatives, to facilitate AI research and exploration.
5. Model Performance Optimization
- Deepspeed Boosts Training Efficiency: Deepspeed enables training a 2.5 billion parameter model on a single RTX 3090, achieving higher batch sizes and efficiency.
- A member shared their success with Deepspeed, sparking interest in its potential for more accessible training regimes.
- FlashInfer's Speed Secret: FlashInfer Kernel Library supports INT8 and FP8 attention kernels, promising performance boosts in LLM serving.
- The AI community is keen to test and discuss FlashInfer's impact on model efficiency, reflecting high anticipation.
6. Generative AI in Storytelling
- Generative AI Impacts Storytelling: Medium article explores the profound changes Generative AI brings to storytelling, unlocking rich narrative opportunities.
- KMWorld highlights AI leaders shaping the knowledge management domain, emphasizing Generative AI's transformative potential.
- AI's Role in Cultural Impact: Discussions on AI's societal impact highlight concerns about addiction and the need for future regulations, reflecting transformative AI technology.
- The community underscores the urgency for proactive measures to address AI's cultural effects and societal implications.
7. AI in Education
- Teacher Explores CommandR for Learning Platform: A public school teacher is developing a Teaching and Learning Platform leveraging CommandR's RAG-optimized features.
- The initiative received positive reactions and offers of assistance from the community, showcasing collective enthusiasm.
- Claude Contest Reminder: Build with Claude contest offers $30k in Anthropic API credits, ending soon.
- Community members are reminded to participate, emphasizing the contest's importance for developers and creators.
PART 1: High level Discord summaries
HuggingFace Discord
- Intel’s Inference Boost for HF Models: A new GitHub repo showcases running HF models on Intel CPUs more efficiently, a boon for developers with Intel hardware.
- This resource comes in response to a gap in Intel-specific guidance and could be a goldmine for enhancing model runtime performance.
- Gemma's Glorious Gains Post-Update: The Gemma2:27B model has been turbocharged, demonstrated in an enlightening YouTube video, much to the community's approval.
- Ollama's timely update corrected issues that now find Gemma receiving rave reviews for its impressive performance.
- Crafty Context Window Considerations: VRAM usage during LLM training can be all over the map, and context window size is a cornerstone of this computational puzzle.
- Exchanging experiences, the community shared that padding and max token adjustments hold the key to consistent VRAM loads.
- Penetrating the Subject of Pentesting: The spotlight shines bright on PentestGPT, as a review session is set to dive deep into the nuances of AI pentesting.
- With a focused paper to dissect, the group is preparing to advance the dialogue on robust pentesting practices for AI.
- Narrative Nuances and Generative AI: Generative AI's impact on storytelling is front and center, with insights unpacked in a Medium article highlighting its narrative potential.
- Meanwhile, KMWorld throws light on AI leaders who are shaping the knowledge management domain, with an eye on Generative AI.
Unsloth AI (Daniel Han) Discord
- *Unsloth Docs Unleashes Efficiency: Unsloth AI's new documentation website boosts training of models like Llama-3 and Gemma*, doubling the speed and reducing memory usage by 70% without sacrificing accuracy.
- The site’s tutorials facilitate creating datasets and deploying models, even tackling gguf library issues by proposing a build from the llama.cpp repo.
- *Finetuning Finesse for LlaMA 3: Modular Model Spec development seeks to refine the process of training AI models like LLaMA 3*.
- SiteForge incorporates LLaMA 3 into their web page design generation, promising an AI-driven revolutionary design experience.
- *MedTranslate with LlaMA 3's Mastery: Discussions on translating 5k medical records to Swedish using Llama 3* shed light on the model’s Swedish proficiency and usage potential.
- Users validate the utility of fine-tuning Llama 3 for Swedish-specific applications, as seen with the AI-Sweden-Models/Llama-3-8B-instruct.
- *Datasets Get a Synthetic Boost: An AI approach is creating synthetic chat datasets, employing rationale and context for over 1 million utterances which enrich the PIPPA dataset*.
- In the realm of medical dialogue, using existing fine-tuned models hinted at skipping prep-training, echoing with the benefits presented in the research.
- *Reimagining LLMs with MatMul-Free Models*: LLMs shed matrix multiplication, conserving memory by 61% at billion-parameter scales, as unveiled in a study.
- Test-Time-Training layers emerge as an alternative to RNN hidden states, showcased in models with linear complexity, highlighted on social media.
CUDA MODE Discord
- Integration Intrigue: Triton Meets PyTorch: Inquisitive minds are exploring how to integrate Triton kernels into PyTorch, specifically aiming to register custom functions for
torch.compileauto-optimization.- The discussion is ongoing, as the tech community eagerly awaits a definitive guide or solution to this challenge.
- Texture Talk: Vulcan Backing Operators: Why does executorch's Vulkan backend utilize textures in its operators? This question has opened a line of enquiry among members.
- Concrete conclusions haven't been reached, keeping the topic open for further insight and exploration.
- INT8 and FP8: FlashInfer's Speed Secret: The unveiling of the FlashInfer Kernel Library has sparked interest with its support for INT8 and FP8 attention kernels, promising a boost in LLM serving.
- With a link to the library, the AI community is keen to test and discuss its potential impact on model efficiency.
- Quantization Clarity: Calibration is Key: The quantization conversation has taken a technical turn, with the revelation that proper calibration with data is essential when using static quantization.
- A GitHub pull request spotlights this necessity, prompting a tech deep dive into the practise.
- Divide to Conquer: GPS-Splitting with Ring Attention: Splitting KV cache across GPUs: A challenge being tackled with ring attention, particularly within an AWS g5.12xlarge instance context.
- The pursuit of optimum topology for this implementation is spirited, with members sharing resources like this gist to aid in the endeavor.
Nous Research AI Discord
- GIF Garners Giggles: Marcus vs. LeCun: A user shared a humorous GIF capturing a debate moment between Gary Marcus and Yann LeCun, highlighting differing AI perspectives without getting into technicalities.
- It provided a light-hearted take on the sometimes tense exchanges between AI experts, capturing community attention GIF Source.
- Hermes 2 Pro: Heights of Performance: Hermes 2 Pro was applauded for its enhanced Function Calling, JSON Structured Outputs, demonstrating robust improvements on benchmarks Hermes 2 Pro.
- The platform's advancements enthralled the community, reflecting progress in LLM capabilities and use cases.
- Synthetic Data Gets Real: Distilabel Dominates: Distilabel emerged as a superior tool for synthetic data generation, praised for its efficacy and quality output Distilabel Framework.
- Members suggested harmonizing LLM outputs with Synthetic data, enhancing AI engineers' development and debugging workflows.
- PDF Pains & Solutions with Sonnet 3.5: A lack of direct solutions for processing PDFs with Sonnet 3.5 API led the community to explore alternative pathways like the Marker Library.
- Everyoneisgross highlighted Marker's ability to convert PDFs to Markdown, proposing it as a workaround for scenarios requiring better model compatibility.
- RAG's New Frontier: RankRAG Revolution: RankRAG's methodology has leaped ahead, achieving substantial gains by training an LLM for concurrent ranking and generation RankRAG Methodology.
- This approach, dubbed 'Llama3-RankRAG,' showcased compelling performance, excelling over its counterparts in a span of benchmarks.
Modular (Mojo 🔥) Discord
- Chris Lattner's Anticipated Interview: The Primeagen is set to conduct a much-awaited interview with Chris Lattner on Twitch, sparking excitement and anticipation within the community.
- Eager discussions ensued with helehex teasing a special event involving Lattner tomorrow, further hyping up the Modular community.
- Cutting-Edge Nightly Mojo Released: Mojo Compiler's latest nightly version, 2024.7.905, introduces improvements such as enhanced
memcmpusage and refined parameter inference for conditional conformances.- Developers keenly examined the changelog and debated the implications of conditional conformance on type composition, particularly focusing on a significant commit.
- Mojo's Python Superpowers Unleashed: Mojo's integration with Python has become a centerpiece of discussion, as documented in the official Mojo documentation, evaluating the potential to harness Python's extensive package ecosystem.
- The conversation transitioned to Mojo potentially becoming a superset of Python, emphasizing the strategic move to empower Mojo with Python's versatility.
- Clock Precision Dilemma: A detailed examination of clock calibration revealed a slight yet critical 1 ns discrepancy when using
_clock_gettimecalls successively, shedding light on the need for high-precision measurements.- This revelation prompted further analysis on the influence of clock inaccuracies, underlining its importance in time-sensitive applications.
- Vectorized Mojo Marathons Trailblaze Performance: Mojo marathons put vectorization to the test, discovering performance variables with different width vectorization where sometimes width 1 outperforms width 2.
- Community members stressed the importance of adapting benchmarks to include both symmetrical and asymmetrical matrices, aligning tests with realistic geo and image processing scenarios.
LM Studio Discord
- *Vocalizing LLMs: Custom Voices Make Noise: Community explores integrating Eleven Lab custom voices with LLM Studio, proposing custom programming via server feature* for text-to-speech.
- Discussion advises caution as additional programming is needed despite tools like Claude being available to assist in development.
- *InternLM: Sliding Context Window Wows the Crowd: Members applaud InternLM* for its sliding context window, maintaining coherence even when memory is overloaded.
- Conversations backed by screenshots reveal how InternLM adjusts by forgetting earlier messages but admirably stays on track.
- *Web Crafters: Custom Scrapers Soar with AI: A member showcases their feat of coding a Node.js web scraper* in lightning speed using Claude, stirring discussion on AI's role in tool creation.
- "I got 78 lines of code that do exactly what I want," they shared, emphasizing AI's impact on the efficiency of development.
- *AI’s Code: Handle with Care*: AI code generation leads to community debate; it's a valuable tool but should be wielded with caution and an understanding of the underlying code logic.
- The consensus: Use AI for rapid development, but validate its output to ensure code quality and reliability.
- *AMD's Crucial Cards: GPUs in the Spotlight: Members discuss using RX 6800XTs for LLM multi-GPU setups, yielding insights into LM Studio's* handling of resources and configuration.
- As the debate on AMD ROCm's support longevity unfolds, the choice between RX 6800XTs and 7900XTXs is weighed with a future-focused lens.
Eleuther Discord
- *TTT Tango with Delta Rule: Discussions revealed that TTT-Linear aligns with the delta rule* when using a mini batch size of 1, leading to an optimized performance in model predictions.
- Further talks included the rwkv7 architecture planning to harness an adapted delta rule, and ruoxijia shedding light on the possibility of parallelism in TTT-linear.
- *Shapley Shakes Up Data Attribution: In-Run Data Shapley* stands out as an innovative project, promising scalable frameworks for real-time data contribution assessments during pre-training.
- It aims to exclude detrimental data from training, essentially influencing model capabilities and shedding clarity on the concept of 'emergence' as per the AI community.
- *Normalizing the Gradient Storm: A budding technique for gradient normalization* aims to address deep network challenges such as the infamous vanishing or exploding gradients.
- However, it's not without its drawbacks, with the AI community highlighting issues like batch-size dependency and the associated hiccups in cross-device communications.
- *RNNs Rivaling the Transformer Titans: The emerging Mamba and RWKV* RNN architectures are sparking excitement as they offer constant memory usage and are proving to be formidable opponents to Transformers in perplexity tasks.
- The memory management efficiencies and their implications on long-context recall are the focus of both theoretical and empirical investigation in the current discourse.
- *Bridging the Brain Size Conundrum*: A recent study challenges the perceived straightforwardness of brain size evolution, especially the part where humans deviate from the largest animals not having proportionally bigger brains.
- The conversation also tapped into neuronal density's role in the intelligence mapping across species, further complicating the understanding of intelligence and its evolutionary advantages.
Stability.ai (Stable Diffusion) Discord
- Pixels to Perfection: Scaling Up Resolutions: Debate centered on whether starting with 512x512 resolution when fine-tuning models has benefits over jumping straight to 1024x1024.
- The consensus leans towards progressive scaling for better gradient propagation while keeping computational costs in check.
- *Booru Battle: Tagging Tensions: Discussions got heated around using booru tags* for training AI, with a divide between supporters of established vocab and proponents of more naturalistic language tags.
- Arguments highlighted the need for balance between precision and generalizability in tagging for models.
- AI and Society: Calculating Cultural Costs: Members engaged in a dialogue about AI's role in society, contemplating the effects on addiction and pondering over the need for future regulations.
- The group underscored the urgency for proactive measures in light of the transformative nature of AI technologies.
- Roop-Unleashed: Revolutionizing Replacements: Roop-Unleashed was recommended as a superior solution for face replacement in videos, taking the place of the obsolete mov2mov extension.
- The tool was lauded for its consistency and ease-of-use, marking a shift in preference within the community.
- Model Mix: SD Tools and Tricks: A lively exchange of recommendations for Stable Diffusion models and extensions took place, with a spotlight on tasks like pixel-art conversion and inpainting.
- Members mentioned tools like Zavy Lora and comfyUI with IP adapters, sharing experiences and boosting peer knowledge.
OpenAI Discord
- DALL-E Rivals Rise to the Occasion: Discussion highlighted StableDiffusion along with tools DiffusionBee and automatic1111 as DALL-E's main rivals, favored for granting users enhanced quality and control.
- These models have also been recognized for their compatibility with different operating systems, with an emphasis on local usage on Windows and Mac.
- Text Detectors Flunk the Constitution Test: Community sentiment suggests skepticism around the reliability of AI text detectors, with instances of mistakenly flagging content, comically including the U.S. Constitution.
- The debate continues without clear resolution, reflecting the complexity of discerning AI-generated from human-produced text.
- GPT's Monetization Horizon Unclear: Users queried about the potential for monetization for GPTs, but discussions stalled with no concrete details emerging.
- This subject seemed to lack substantial engagement or resolution within the community.
- VPN Vanquishes GPT-4 Connection: Users reported disruptions in GPT-4 interactions when a VPN is enabled, advising that disabling it can mitigate issues.
- Server problems impacting GPT-4 services were also mentioned as resolved, though specifics were omitted.
- Content Creators Crave Cutting-Edge Counsel: Content creators sought 5-10 trend-centric content ideas to spur audience growth and asked for key metrics to track content performance.
- They also explored strategies for a structured content calendar, emphasizing the need for effective audience engagement and platform optimization.
LlamaIndex Discord
- LlamaCloud Ascends with Beta Launch: The beta release of LlamaCloud promises a sophisticated platform for unstructured data parsing, indexing, and retrieval, with a waitlist now open for eager testers.
- Geared to refine the data quality for LLMs, this service integrates LlamaParse for advanced document handling and seeks to streamline the synchronization across varied data backends.
- Graph Technology Gets a Llama Twist: LlamaIndex propels engagement with a new video series showcasing Property Graphs, a collaborative effort highlighting model intricacies in nodes and edges.
- This educational push is powered by teamwork with mistralai, neo4j, and ollama, crafting a bridge between complex document relationships and AI accessibility.
- Chatbots Climb to E-commerce Sophistication: In pursuit of enhanced customer interaction, one engineering push in the guild focused on advancing RAG chatbots with keyword searches and metadata filters to address complex building project queries.
- This approach involves a hybrid search mechanism leading to a more nuanced exchange of follow-up questions, aiming for a leap in conversational precision.
- FlagEmbeddingReranker's Import Impasse: Troubleshooting efforts in the community suggested installing
peftindependently to overcome the import errors faced withFlagEmbeddingReranker, helping a user finally cut through the technical knot.- This hiccup underscores the oft-hidden complexities in setting up machine learning environments, where package dependencies can become a sneaky snag.
- Groq API's Rate Limit Riddle: AI engineers hit a speed bump with a 429 rate limit error in LlamaIndex when tapping into Groq API for indexing, spotlighting challenges in syncing with OpenAI's embedding models.
- The discussion veered towards the intricacies of API interactions and the need for a strategic approach to circumvent such limitations, maintaining a seamless indexing experience.
Perplexity AI Discord
- Perplexity Paints a Different API Picture: A debate sparked on the discernible differences between API and UI results in Perplexity, particularly when neither Pro versions nor sourcing features are applied.
- A proactive solution was considered, involving the labs environment to test for parity between API and UI outputs without additional Pro features.
- Nodemon Woes with PPLX Integration: Troubles emerged in configuring Nodemon for a project utilizing PPLX library, with success eluding a member despite correct local execution and tsconfig.json tweaks.
- The user sought insights from fellow AI engineers, sharing error logs indicative of a possible missing module issue linked with the PPLX setup.
LAION Discord
- Deepspeed Dazzles on a Dime: An innovative engineer reported successfully training a 2.5 billion parameter model on a single RTX 3090 using Deepspeed, with potential for higher batch sizes.
- The conversation sparked interest in exploring the boundaries of efficient training with resource constraints, hinting at more accessible training regimes.
- OpenAI's Coding Companion Prevails in Court: A pivotal legal decision was reached as a California court partially dismissed a suit against Microsoft's GitHub Copilot and OpenAI's Codex, showing the resilience of AI systems against copyright claims.
- The community is dissecting the implications of this legal development for AI-generated content. Read more.
- Chameleon: Generative Model Mimics Masters: The release of the first generative chameleon model has been announced, with its detailed examination captured in a paper on arXiv.
- The research community is eager to investigate the model's ability to adapt to various drawing styles, potentially revolutionizing digital art creation.
- Scaling the Complex-Value Frontier: A pioneering member encountered challenges while expanding the depths of complex-valued neural networks intended for vision tasks.
- Despite hurdles in scaling, a modest 65k parameter complex-valued model showed promising results, outdoing its 400k parameter real-valued counterpart in accuracy on CIFAR-100.
- Diffusion Demystified: A Resource Repository: A new GitHub repository provides an intuitive code-based curriculum for mastering image diffusion models ideal for training on modest hardware. Explore the repository.
- This resource aims to foster hands-on understanding through concise lessons and tutorials, inviting contributions to evolve its educational offering.
OpenRouter (Alex Atallah) Discord
- Breaking the Quota Ceiling: Overlimit Woes on OpenRouter: Users experienced a 'Quota exceeded' error from
aiplatform.googleapis.comwhen using gemini-1.5-flash model, suggesting a Google-imposed limit.- For insights on usage, check Activity | OpenRouter and for custom routing solutions, see Provider Routing | OpenRouter.
- Seeing None: The Image Issue Challenge on OpenRouter: A None response was reported on image viewing on models like gpt-4o, claude-3.5, and firellava13b, eliciting mixed confirmations of functionality from users.
- This suggests a selective issue, not affecting all users, and warrants a detailed look into individual user configurations.
- Dolphin Dive: Troubleshooting LangChain's Newest Resident: Users are facing challenges integrating Dolphin 2.9 Mixstral on OpenRouter with LangChain as a language tool.
- Technical details of the issue weren’t provided, indicating potential compatibility problems or configuration errors.
- JSON Jolts: Mistralai Mixtral’s Sporadic Support Slip: The error 'not supported for JSON mode/function calling' plagues users of mistralai/Mixtral-8x22B-Instruct-v0.1 at random times.
- Troubleshooting identified Together as the provider related to the recurring error, spotlighting the need for further investigation.
- Translational Teeter-Totter: Assessing LLMs as Linguists: Discussions focussed on the effectiveness of LLMs over specialized models for language translation tasks highlighted preferences and performance metrics.
- Consideration was given to the reliability of modern decoder-only models versus true encoder/decoder transformers for accurate translation capabilities.
Latent Space Discord
- Claude Closes Contest with Cash for Code: The Build with Claude contest is nearing its end, offering $30k in Anthropic API credits for developers, as mentioned in a gentle reminder from the community.
- Alex Albert provides more information about participation and context in this revealing post.
- Speech Models Sing Different Tunes: GPT-4o and Moshi's speech models caught the spotlight for their contrasting styles, with GPT-4o boasting a polished turn-based approach versus Moshi's raw full-duplex.
- The conversation unfolded thanks to insights from JulianSlzr and Andrej Karpathy.
- AI Stars in Math Olympiad: Thom Wolf lauded the AI Math Olympiad where the combined forces of Numina and Hugging Face showcased AI's problem-solving prowess.
- For an in-depth look, check out Thom Wolf's thread detailing the competition’s highlights and AI achievements.
- Babble Boasts Bigger Brain: Supermaven rolled out Babble, their latest language model, with a massive context window upgrade, holding 1 million tokens.
- SupermavenAI's announcement heralds a 2.5x leap over its predecessor and promises an enriched conversational landscape.
- Lillian Weng's Lens on LLM's Lapses: Hallucinations in LLMs take the stage in Lillian Weng's blog as she explores the phenomenon's origins and taxonomy.
- Discover the details behind why large language models sometimes diverge from reality.
LangChain AI Discord
- LLMWhisperer Decodes Dense Documents: The LLMWhisperer shows proficiency in parsing complex PDFs, suggesting the integration of schemas from Pydantic or zod within LangChain to enhance data extraction capabilities.
- Combining page-wise LLM parsing and JSON merges, users find LLMWhisperer useful for extracting refined data from verbose documents.
- Crawlee's Python Debut Makes a Splash: Apify announces Crawlee for Python, boasting about features such as unified interfaces and automatic scaling on GitHub and Product Hunt.
- With support for HTTP, Playwright, and session management, Crawlee is positioned as a robust tool for Python developers engaged in web scraping.
- Llamapp Lassoes Localized RAG Responses: Llamapp emerges as a local Retrieval Augmented Generator, fusing retrievers and language models for pinpoint answer accuracy.
- Enabling Reciprocal Ranking Fusion, Llamapp stays grounded to the source truth while providing tailored responses.
- Slack Bot Agent Revolution in Progress: A how-to guide illustrates the construction of a Slack Bot Agent, utilizing LangChain and ChatGPT for PR review automation.
- The documentation indicates a step-by-step process, integrating several frameworks to refine the PR review workflow.
- Rubik’s AI Pro Opens Door for Beta Testers: Inviting AI enthusiasts, Rubik's AI Pro emerges for beta testing, flaunting its research aid and search capabilities using the 'RUBIX' code.
- They highlight access to advanced models and a premium trial, underpinning their quest for comprehensive search solutions.
OpenInterpreter Discord
- OI Executes with Example Precision: By incorporating code instruction examples, OI's execution parallels assistant.py, showcasing its versatile skill instruction handling.
- This feature enhancement suggests an increase in the functional capabilities, aligning with the growth of sophisticated language models.
- Qwen 2.7B's Random Artifacts: Qwen 2 7B model excels with 128k processing, yet it occasionally generates random '@' signs, causing unexpected glitches in the output.
- While the model's robustness is evident, these anomalies highlight a need for refinement in its generation patterns.
- Local Vision Mode in Compatibility Question: Local vision mode utilization with the parameter '--model i' sparked discussions on its compatibility and whether it opens up multimodal use cases.
- With such features, engineers are probing into the integration of diverse input modalities for more comprehensive AI systems.
- GROQ Synchronized with OS Harmony: There's a wave of inquiry on implementing GROQ alongside OS mode, probing the necessity for a multimodal model in such cases.
- The dialogue underscores an active pursuit for more seamless and cohesive workflows within the AI engineering domain.
- Interpreting Coordinates with Open Interpreter: Open Interpreter’s method of interpreting screen coordinates was queried, indicating a deeper dive into the model's interactive abilities.
- Understanding this mechanism is crucial for engineers aiming to utilize AI for more dynamic and precise user interface interactions.
tinygrad (George Hotz) Discord
- Ampere and Ada Embrace NV=1: Discussions revealed NV=1 support primarily targets Ampere and Ada architectures, leaving earlier models pending community-driven solutions.
- George Hotz stepped in to clarify that Turing generation cards are indeed compatible, as outlined on the GSP firmware repository.
- Karpathy's Class Clinches tinygrad Concepts: For those seeking to sink their teeth into tinygrad, Karpathy's transformative tutorial was recommended, promising engaging insights into the framework.
- The PyTorch-based video serves as a catalyst for exploration, prompting an interactive approach to traversing the tinygrad documentation.
- WSL2 Wrestles with NV=1 Wrinkles: Members grappled with NV=1 deployment dilemmas on WSL2, facing snags with missing device files and uncertainty over CUDA compatibility.
- While the path remains nebulous, NVIDIA's open GPU kernel module emerged as a potential piece of the puzzle for eager engineers.
Interconnects (Nathan Lambert) Discord
- Copilot's Court Conundrum Continues: A majority of claims against GitHub Copilot for allegedly replicating code without credit have been dismissed, with only two allegations left in the legal battle involving GitHub, Microsoft, and OpenAI.
- Concerns raised last November suggested that Copilot's training on open-source software constituted an intellectual property infringement; developers await the court's final stance on the remaining allegations.
- Vector Vocabulary Consolidatio: Control Vector, Steering Vector, and Concept Vectors triggered a debate, leading to a consensus that Steering Vectors* are a form of applying Control Vectors in language models.
- Furthermore, the distinction between Feature Clamping and Feature Steering was clarified and viewed as complementary strategies in the realm of RepEng.
- Google Flame's Flicker Fades: Scores from the 'Google Flame' paper were retracted following the discovery of an unspecified issue, with community jests questioning if the mishap involved 'training on test data'.
- Scott Wiener lambasted a16z and Y Combinator on Twitter for their denunciation of California's SB 1047 AI bill, stirring up a storm in the discourse on AI legislation.
LLM Finetuning (Hamel + Dan) Discord
- Multi GPU Misery & Accelerate Angst: A six H100 GPU configuration unexpectedly delivered training speeds 10 times slower than anticipated, causing consternation.
- Advice circled around tweaking the batch size based on Hugging Face's troubleshooting guide and sharing code for community-driven debugging.
- Realistic Reckoning of Multi GPU Magic: Members pondered over realistic speed uplifts with multi GPU setups, busting the myth of a 10x speed increase, suggesting 6-7x as a more feasible target.
- The speed gain debate was grounded in concerns over communication overhead and the search for throughput optimization.
Cohere Discord
- Educators Eyeing CommandR for Classrooms: A public school teacher is exploring the integration of a Teaching and Learning Platform which leverages CommandR's RAG-optimized features.
- The teacher's initiative received a positive reaction from the community with offers of assistance and collective enthusiasm.
- Night Owls Rejoice Over Dark Mode Development: Dark Mode, awaited by many, is confirmed in the works and is targeted for the upcoming enterprise-level release.
- Discussion indicated that the Darkordial Mode might be adapted for a wider audience, hinting at a potential update for users of the free Coral platform.
Mozilla AI Discord
- Llama.cpp Takes a Performance Dive: An unexpected ~25% performance penalty was spotted arising from llama.cpp when migrating from version 0.8.8 to 0.8.9 on NVIDIA GPUs.
- The issue was stark, with a NVIDIA 3090 GPU's performance falling to a level comparable with a NVIDIA 3060 from the previous iteration.
- Upgrade Woes with Benchmark Suite: Writing a new benchmark suite brought to light performance impacts after upgrading the version of llamafile.
- Community feedback asserted no recent changes should have degraded performance, creating a conundrum for developers.
AI Stack Devs (Yoko Li) Discord
- Rosebud AI's Literary Game Creations: During the Rosebud AI Book to Game Jam, developers were tasked with transforming books into interactive puzzle games, rhythm games, and text-based adventures.
- The jam featured adaptations of works by Lewis Carroll, China Miéville, and R.L. Stine, with winners to be announced on Wednesday, July 10th at 11:30 AM PST.
- Game Devs Tackle Books with AI: Participants showcased their ingenuity in the Rosebud AI Jam, integrating Phaser and AI technology to craft games based on literary classics.
- Expectations are high for the unveiling of the winners at the official announcement in the Rosebud AI Discord community.
MLOps @Chipro Discord
- KAN Paper Discussion Heats Up on alphaXiv: Authors of the KAN paper are actively responding to questions on the alphaXiv forum about their recent arXiv paper.
- Community members are engaging with the authors, discussing the technical aspects and methodology of KAN.
- Casting the Net for Information Retrieval Experts: A podcast host is coordinating interviews with experts from Cohere, Zilliz, and Doug Turnbull on topics of information retrieval and recommendations.
- They've also reached out for additional guest suggestions in the field of information retrieval to add to their series.
LLM Perf Enthusiasts AI Discord
- Querying Anthropic: Any Credit Programs Akin to OpenAI?**: A member posed a question regarding the existence of a credit system similar to OpenAI's for Anthropic, seeking opportunities for experimentation.
- The inquiry reflects a growing interest in accessing Anthropic platforms for development and testing, akin to the OpenAI 10K credit program.
- Understanding Anthropic's Accessibility: A Credits Conundrum: Community members are curious about Anthropic's** supportive measures for developers, questioning the parallel to OpenAI's credits initiative.
- This conversation underscores the need for clearer information on Anthropic's offerings to facilitate AI research and exploration.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The OpenAccess AI Collective (axolotl) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (291 messages🔥🔥):
GPTs agents and knowledge filesOpenAI Platform changesHandling forbidden words in codeContext window impacts on AI modelsGemma model issues
- Misunderstanding GPTs agents' learning: A member expressed concerns about GPTs agents not learning from additional information provided post-training. Another member clarified that uploaded files are saved as 'knowledge' files, which the agent references, but they do not modify the agent's base knowledge.
- Disappearing icons on OpenAI Platform: There was a discussion about changes in the OpenAI Platform sidebars, where two icons, one for threads and another for messages, reportedly disappeared.
- Storing forbidden words as a secret in code: Members debated the security of storing forbidden words, opting to use the Hugging Face Spaces secrets feature or eval for encrypted lists.
- Understanding context window impacts: Members discussed the context window of models, explaining that it determines how many tokens a model can handle without losing performance.
- Issues with Google Gemma-2B model: Members struggled with Gemma-2B's incoherent text generation and discussed potential fixes like using the correct chat template prompt configurations.
- 🧑🎓 How to use Continue | Continue: Using LLMs as you code with Continue
- Code Bullet: Just an idiot with a computer science degree trying his best.
- InstantMesh - a Hugging Face Space by TencentARC: no description found
- Docker images - TTS 0.22.0 documentation: no description found
- Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?: When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach th...
- discord-community/HuggingMod · pls merge: no description found
- 🧑🎓 How to use Continue | Continue: Using LLMs as you code with Continue
- gradientai/Llama-3-8B-Instruct-262k · Hugging Face: no description found
- google/gemma-2b · Hugging Face: no description found
- ageron - Overview: Author of the book Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. Former PM of YouTube video classification and founder & CTO of Wifirst. - ageron
- HuggingChat: Making the community's best AI chat models available to everyone.
- Shibuya Startup Support xTechstars Startup Weekend Tokyo Weekly Snack & Connect · Luma: After an exciting weekend with Techstars Startup Weekend Tokyo 😎🚀🎯, the organizing team would like to provide a post-event briefing with the startup…
- Fine Tuning TinyLlama for Text Generation with TRL: no description found
- mlflow.metrics — MLflow 2.14.2 documentation: no description found
- GitHub - buaacyw/MeshAnything: From anything to mesh like human artists. Official impl. of "MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers": From anything to mesh like human artists. Official impl. of "MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers" - buaacyw/MeshAnything
- Adds Open LLM Leaderboard Taks (#2047) · EleutherAI/lm-evaluation-harness@3c8db1b: * adds leaderboard tasks * Delete lm_eval/tasks/leaderboard/leaderboard_chat_template.yaml * add readme * Delete lm_eval/tasks/leaderboard/mmlu_pro/mmlu_pro_chat_template.yaml * modify ...
- GitHub - huggingface/lighteval: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. - hug...
- Red Kit GIF - Red Kit - Discover & Share GIFs: Click to view the GIF
- How to convert ckpt to diffusers format: The community is heavily using both the .ckpt and the diffusers format. We are working on having better support for interoperability between the formats, but the recommended approach is always to just...
- Ishowspeed Shocked GIF - Ishowspeed Speed Shocked - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
HuggingFace ▷ #today-im-learning (11 messages🔥):
Discord bot with historical charactersHuggingface NLP courseVRAM usage fluctuationResume training from checkpointPadding and VRAM stabilization
- Building Discord Bot with Historical Characters: A member is learning how to make a Discord bot with multiple characters/LLMs of famous historical figures.
- Recommend Huggingface NLP Course: A member recommended starting with the Huggingface NLP course for learning.
- VRAM Usage Spikes During LLM Training: Training an LLM sometimes requires varying amounts of VRAM, and usage may spike suddenly.
- A member suggested that variable-length batches, specific trainer optimizations, or bugs could cause fluctuations.
- Resuming Training from Checkpoint Concerns: A user inquired if resuming training from a checkpoint is detrimental to end results.
- Padding to Stabilize VRAM Usage: Members discussed padding all samples to a predefined max_seq_len to stabilize VRAM usage, especially when 99% of the dataset is below 100 tokens but some elements were above 512.
HuggingFace ▷ #cool-finds (2 messages):
Generative AI on StorytellingAI Knowledge Management
- Generative AI Impacts Storytelling: A link to a Medium article explores the impact of Generative AI on storytelling and narrative creation.
- Generative AI creates profound changes in how stories are told, with new methods unlocking rich narrative opportunities.
- KMWorld Highlights AI Leaders in Knowledge Management: Marydee Ojala discusses the 2024 AI 100 companies on KMWorld, showcasing those at the forefront of knowledge management advancements.
- Her article notes the rapid pace of AI technology advancements and the escalating interest in Generative AI across various fields.
Link mentioned: The KMWorld AI 100: The Companies Empowering Intelligent Knowledge Management: It's easy to become overwhelmed, even awestruck at the amount of information about AI, particularly GenAI, being thrown at us on a daily basis. The ability of AI technologies to process vast amounts o...
HuggingFace ▷ #i-made-this (4 messages):
Intel HF modelsGemma2:27B updateNew Qdurllm demoEarly Exit in LLM research
- Intel HF models showcased in new repo: A member created a GitHub repo demonstrating how to use Intel CPUs to efficiently run HF models.
- This addresses the lack of Intel-specific tutorials and documentation for running HF models on their hardware.
- Gemma2:27B receives significant update: The Gemma2:27B model received an update and is now performing exceptionally well, as highlighted in a YouTube video.
- The update was pushed by Ollama to correct previous issues, making the model 'incredible' according to community feedback.
- New Qdurllm demo space launched: A new demo space for Qdurllm, a local search engine based on Qdrant, Sentence Transformers, llama-cpp, and Langchain, is now available on HuggingFace Spaces.
- The community is encouraged to try out the fully functional version and support it on GitHub with a star.
- Early Exit in LLM research showcased: Early Exit in LLM research is showcased in a new HuggingFace Space by a community member.
- The space is slow as it runs on CPU but demonstrates faster inference on some tokens using Early Exit, with configurable settings for Epsilon to balance speed and accuracy.
- Branchy Phi 2 - a Hugging Face Space by valcore: no description found
- Gemma2:27 Ollama Correction ! Now Incredible !: Today, we are going to test again gemma 2 27b with ollama because an update was pushed by ollama to correct issues related to gemma 2 and now it is working l...
- Qdurllm Demo - a Hugging Face Space by as-cle-bert: no description found
- GitHub - sleepingcat4/intel-hf: inferencing HF models using Intel CPUs and Intel architecture: inferencing HF models using Intel CPUs and Intel architecture - sleepingcat4/intel-hf
HuggingFace ▷ #reading-group (1 messages):
Pentesting in AIPentestGPT
- Upcoming Literature Review on Pentesting AI: A discussion about performing a literature review on pentesting in AI is planned for next week's Saturday, mainly based on PentestGPT.
- The review will also cover current efforts to improve pentesting methodologies in AI, referencing the PentestGPT paper.
- PentestGPT at the Heart of Future Discussions: PentestGPT is highlighted as a significant resource in ongoing discussions about improving AI pentesting.
- Efforts are being made to enhance pentesting methods specifically drawing from PentestGPT insights.
HuggingFace ▷ #computer-vision (14 messages🔥):
YoloV1 limitationsYoloV8 re-implementationEmotion to body language research papersInference with fine-tuned modelsDocument image quality prediction
- YoloV1 hits grid cell limitation: After successfully training YoloV1, it faces a significant limitation of making only one bounding box per grid cell.
- The team initiated debugging YoloV8's code base in an attempt to re-implement a solution due to this issue.
- Inference confirmed with fine-tuned models: A member confirmed that they were performing inference using fine-tuned models.
- Humorous oversight in vision model finetuning: A user humorously admitted they didn't feed images into their model during finetuning but instead fed the file path.
- LOL it's kinda dumb, they added, recognizing the mistake.
- Seeking research on emotions and body language: A member inquired about research papers that associate verbal emotions with body language or gestures.
- Document image quality prediction ideas: A member requested suggestions for predicting document image quality, whether through regression values or classification for clean, blank, blur, and dirty documents.
Link mentioned: Serializing Classifier and Regressor heads in Yolo models · Issue #10392 · ultralytics/ultralytics: Search before asking I have searched the YOLOv8 issues and discussions and found no similar questions. Question Hi team, I hope you guys are doing great. It will be great if you can share your thou...
HuggingFace ▷ #diffusion-discussions (1 messages):
sd-vae artifactingblue and white pixels
- sd-vae Artifacting Question: A user inquired whether the observed artifacting (specifically blue and white pixels) is normal when using sd-vae for reconstruction.
- Is this type of artifacting normal when using sd-vae for reconstruction?
- Pixelation Query in VAE Reconstructions: Question raised about the normalcy of blue and white pixelations when employing sd-vae mechanisms.
- The user seemed concerned about the specifics of the pixel artifacting during the reconstruction phase.
Unsloth AI (Daniel Han) ▷ #general (136 messages🔥🔥):
New Documentation WebsiteFinetuning Challenges on KaggleTraining IssuesModel Usage RequestsCommunity Contributions
- Unsloth AI launches new documentation website: Unsloth released a new documentation website, which makes finetuning large language models like Llama-3, Mistral, Phi-3 and Gemma 2x faster while using 70% less memory with no degradation in accuracy.
- The site helps users navigate through training their own custom models, covering essentials like creating datasets and deploying models.
- User points out outdated gguf library on PyPI: A user noted that the gguf library hosted on PyPI is outdated for manual saving to gguf, suggesting instead to build the latest Python gguf from the llama.cpp repository.
- The suggested command for installation is
cd llama.cpp/gguf-py && pip install ., ensuring the latest version is utilized.
- The suggested command for installation is
- Challenges in fine-tuning on limited hardware: A user highlighted issues in fine-tuning the unsloth/Qwen2-0.5B model on the Magicoder-Evol-Instruct-110K dataset with rsLoRA, noting no decrease in training loss.
- Changing training parameters like increasing the learning rate and rank, and opting for larger models like the 1.5b led to better performance results.
- Mixed responses on model fine-tuning: Discussion ensued on whether smaller models are effective for specific tasks, like finetuning the GPT-Sw3 1.3B model for Swedish datasets, where some users were skeptical of performance.
- "Use Llama 3," one member emphasized, highlighting it as the superior choice unless resource constraints necessitate smaller models.
- Community eager for contributions and collaborations: Users showed interest in contributing to Unsloth’s documentation and model improvements.
- The lead developer encouraged contributions, promising updates and indicating ongoing efforts to support additional models by the month’s end.
- AI-Sweden-Models/gpt-sw3-1.3b · Hugging Face: no description found
- Lexi-Llama-3-8B-Uncensored-IQ4_XS.gguf · bartowski/Lexi-Llama-3-8B-Uncensored-GGUF at main: no description found
- Tweet from Kaggle (@kaggle): 📚 Check out this fantastic notebook by @danielhanchen, the co-creator of @UnslothAI! Discover how to fine-tune Gemma-2-9b using Kaggle notebooks. Learn more: 👇https://www.kaggle.com/code/danielha...
- Welcome | Unsloth Docs: New to Unsloth? Start here!
- Unsloth Docs: no description found
- Unsloth Docs: no description found
- American Psycho Patrick Bateman GIF - American Psycho Patrick Bateman American - Discover & Share GIFs: Click to view the GIF
- How to Finetune Llama-3 and Export to Ollama | Unsloth Docs: Beginner's Guide for creating a customized ChatGPT to run locally on Ollama
Unsloth AI (Daniel Han) ▷ #off-topic (24 messages🔥):
Unscoming Unsloth Vision Model SupportMedical Data Translation with Llama 3Llama 3 and SwedishTraining Llama 3 on Medical DataUsing Pre-trained Llama 3 Models on Unsloth
- Medical Data Translation with Llama 3: A user shared a project idea to translate 5k rows of medical data to Swedish using Llama 3 and then fine-tune the model with this translated data.
- Another user advised that this approach could be beneficial rather than relying on the LLM to automatically translate the information during usage.
- Llama 3 and Swedish Language Compatibility: A user confirmed that Llama 3 is well-versed in Swedish, making it suitable for their translation project.
- They were also informed about the resources available to fine-tune Llama 3 for specific needs in Swedish via Unsloth.
- Training Llama 3 on Medical Data: There's a discussion on skipping the continued pre-training step by using already fine-tuned models like AI-Sweden-Models/Llama-3-8B-instruct.
- One member suggested starting with the base model for fine-tuning and using instruction-based models for translation tasks.
- Using Pre-trained Llama 3 Models on Unsloth: Users discussed the feasibility of using pre-trained Llama models on Unsloth, confirming it is possible by setting
AI-Sweden-Models/Llama-3-8B-instructas the model name.- It was noted that using the base model for training typically yields better results, while instruction models are better for specific tasks like translation.
Link mentioned: AI-Sweden-Models/Llama-3-8B-instruct · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (43 messages🔥):
RAG with finetuned modelsRAFT for better responsesCreating synthetic datasets from PDFsSpeeding up inferenceTraining methods and completion-only finetuning
- Users discuss integrating finetuned models with RAG: Members discuss using finetuned models with the RAG approach and share insights on context-aware fine-tuning as seen with Alpaca.
- They suggest looking into RAFT for integrating new knowledge and handling distractor documents effectively.
- Generate datasets from PDFs using tools: A user asks for advice on generating synthetic datasets from PDFs, and it is recommended to use tools like nougat or marker for conversion.
- These tools can streamline converting PDFs to markdown with high accuracy, significantly reducing manual effort.
- Speeding up finetuning and inference: Members share techniques for speeding up finetuning on models like phi-3 mini, including using VLLM for inference.
- It is suggested that at least 300 samples are needed for fine-tuning a base model to get reasonable results in a new domain.
- Training loss inconsistencies in finetuning: A user reports difficulties with training loss not decreasing while finetuning
unsloth/Qwen2-0.5B-Instruct-bnb-4bitwith rsLoRA.- Success was seen using the same model on a different dataset, indicating potential dataset-specific issues.
- Finetuning methods and completion-only training: Discussions explore whether finetuning includes training on both instructions and responses, with suggestions to use
DataCollatorForCompletionOnlyLMfor response-only prediction.- This method can potentially improve training efficiency by focusing on predicting the answer tokens and not the instructions.
- RAFT: Adapting Language Model to Domain Specific RAG: Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new k...
- Lexi-Llama-3-8B-Uncensored-IQ4_XS.gguf · bartowski/Lexi-Llama-3-8B-Uncensored-GGUF at main: no description found
- Orenguteng/Llama-3-8B-Lexi-Uncensored · Hugging Face: no description found
- Label Supervised LLaMA Finetuning: The recent success of Large Language Models (LLMs) has gained significant attention in both academia and industry. Substantial efforts have been made to enhance the zero- and few-shot generalization c...
- Supervised Fine-tuning Trainer: no description found
- Unsloth Notebooks | Unsloth Docs: See the list below for all our notebooks:
- GitHub - VikParuchuri/marker: Convert PDF to markdown quickly with high accuracy: Convert PDF to markdown quickly with high accuracy - VikParuchuri/marker
Unsloth AI (Daniel Han) ▷ #community-collaboration (40 messages🔥):
Training custom embeddingsMemory issues with LLaMA3EfficientPartialEmbedding implementationModular Model SpecSiteForge web page design generation
- Struggles with Training Custom Embeddings: Albert_lum is attempting to train embeddings for new special tokens on LLaMA 3 7B but faces challenges with memory on colab T4 and fine-tuning only specific embeddings.
- Embedding Matrix Memory Challenges: Timotheeee1 indicates that LLaMA 3's head and embedding matrices consume extensive VRAM, creating obstacles when trying to train specific segments.
- EfficientPartialEmbedding Implementation Issues: Albert_lum discusses various attempts and solutions, such as wrapping the original embedding, but struggles with efficiency and ensuring that embeddings train correctly.
- Modular Model Spec Development: Albert_lum mentions developing a new behavior specification for AI models, aimed at increasing flexibility, reliability, and developer convenience.
- This spec, detailed in the Modular Model Spec, helps developers and curators in creating advanced LLM-augmented applications.
- SiteForge AI for Web Page Design: Albert_lum is fine-tuning LLaMA 3 for SiteForge, a company specializing in AI-generated web page design.
- SiteForge offers features like an AI Sitemap Generator and drag-and-drop website restructuring, detailed on their website.
- # %%filename = model_name.split("/")[1] + "_tokens.pt"if os.path.exists(file - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Modular Model Spec: no description found
- AI Wireframe Generator » SiteForge: no description found
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
MatMul-free Models in LLMsTest-Time-Training layersSynthetic Dataset for ChatbotEnhanced Imitation Learning with OrcaSoft Capping in Flash Attention
- MatMul-free Models Revolutionize LLM Performance: Matrix multiplication elimination from large language models maintains strong performance at billion-parameter scales, significantly reducing memory usage, with experiments showing up to 61% reduction over an unoptimized baseline.
- Test-Time-Training Layers Offer New Approach: A new architecture called Test-Time-Training layers replaces RNN hidden states with a machine learning model, achieving linear complexity and matching or surpassing top transformers, as announced in a recent tweet.
- High-Quality Synthetic Datasets for Chatbots: Research on generating synthetic datasets for chatbots suggests that setting a rationale, context, and persona results in high-quality dialogue, contributing to the PIPPA dataset with over 1 million utterances from 26,000 conversation sessions.
- Orca Enhances Small Model Imitation Learning: The Orca model addresses imitation learning challenges by learning complex reasoning processes from large foundation models like GPT-4, as outlined in the paper.
- Orca uses rich signals such as explanation traces and step-by-step thought processes to significantly improve smaller model capabilities.
- Flash Attention Adopts Soft Capping for Superior Performance: Soft capping is now supported in FlashAttention, enhancing fast and accurate Google DeepMind Gemma2 generations, as per a recent announcement.
- Tweet from Philipp Schmid (@_philschmid): Soft capping is now supported in Flash Attention! 🚀 Brace yourself for fast and accurate @GoogleDeepMind Gemma2 generations. 🏎️💥💨 Thank you @narsilou and @tri_dao ❤️
- Tweet from Karan Dalal (@karansdalal): I’m excited to share a project I’ve been working on for over a year, which I believe will fundamentally change our approach to language models. We’ve designed a new architecture, which replaces the h...
- PIPPA: A Partially Synthetic Conversational Dataset: With the emergence of increasingly powerful large language models, there is a burgeoning interest in leveraging these models for casual conversation and role-play applications. However, existing conve...
- Orca: Progressive Learning from Complex Explanation Traces of GPT-4: Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the ...
- Scalable MatMul-free Language Modeling: Matrix multiplication (MatMul) typically dominates the overall computational cost of large language models (LLMs). This cost only grows as LLMs scale to larger embedding dimensions and context lengths...
CUDA MODE ▷ #triton (2 messages):
Integrating Triton Kernel with PyTorchRegistering Custom Functions in PyTorchtorch.compile and Custom FunctionsCUDA Kernel Integrations
- Integrating Triton Kernel with PyTorch Models: A user asked about the best way to integrate a Triton kernel to replace a function in their PyTorch model.
- They are interested in knowing if they can register this in PyTorch so that when they run torch.compile, it automatically uses this function whenever it detects the pattern. (No direct answers or further discussion on this yet.)
- Registering Custom Functions in PyTorch: The user is looking for a method to register a custom Triton function within PyTorch to enable it with torch.compile for automated use.
CUDA MODE ▷ #torch (1 messages):
executorchvulkan backend
- Query on executorch's use of textures in Vulkan: A member asked why the operators in executorch's Vulkan backend use textures.
- Discussion on executorch and Vulkan operators: Members discussed the use of textures in the Vulkan backend within executorch, seeking context and reasons behind this implementation.
CUDA MODE ▷ #cool-links (1 messages):
FlashInferKernel Library for LLM ServingINT8 and FP8 flash attention kernels
- FlashInfer: New Kernel Library for LLM Serving: FlashInfer: Kernel Library for LLM Serving was shared via a GitHub link for community review.
- The library supports INT8 and FP8 flash attention kernels, promising improved performance.
- FlashInfer Supports INT8 and FP8 Kernels: The recently released FlashInfer library includes INT8 and FP8 flash attention kernels.
- This feature may greatly enhance the efficiency of serving large language models.
Link mentioned: GitHub - flashinfer-ai/flashinfer: FlashInfer: Kernel Library for LLM Serving: FlashInfer: Kernel Library for LLM Serving. Contribute to flashinfer-ai/flashinfer development by creating an account on GitHub.
CUDA MODE ▷ #jobs (3 messages):
Job application enthusiasmTeam commendationPositive reactions
- Job Application Excitement Skyrockets: A member expressed their excitement: "I've never hit apply so fast".
- Team Receives High Praise: Another member vouched for the team, stating it is a "great team".
- Overwhelming Positive Emotions: A third member shared a warm reaction with 🥰.
CUDA MODE ▷ #beginner (24 messages🔥):
Beginner CUDA ProjectsFlash AttentionBenchmarking TechniquesTriton for SoftmaxTensor Offloading
- Beginner CUDA Projects: Flash Attention Overreach: A user considered implementing flash attention but was advised to start with simpler projects like normal attention or simple MLP by community members, indicating that flash attention and beginner are oxymorons.
- Benchmarking Flash Attention vs PyTorch: The community discussed the feasibility of comparing custom implementations of attention mechanisms with PyTorch's flash attention for benchmarking purposes.
- It was suggested that while PyTorch's flash attention isn't terribly fast, one could start with regular attention and then move to flash attention for benchmarking.
- Softmax Challenges in Attention Mechanisms: Softmax is considered to be the most challenging part of implementing attention mechanisms, with suggestions to first write an attention version without softmax to get the multiplications right before tackling it.
- An alternative approach mentioned was writing a simple softmax in Triton with three loops to generate and understand the PTX code.
- NVIDIA's Tensor Offloading Concept: A user inquired about the concept of 'tensor offloading' mentioned in an NVIDIA whitepaper.
- Another member interpreted it as using swap memory from the host or another GPU for tensor operations.
CUDA MODE ▷ #torchao (1 messages):
Quantization Flow Example Using Static QuantizationImportance of Calibration with Data
- Quantization Flow Example Using Static Quantization: A user shared a GitHub pull request showcasing a static quantization example that needs calibration with data.
- This PR addresses the current API's lack of requirement for model calibration with sample data by adding an implementation of static quantization.
- Importance of Calibration with Data: The discussed quantization flow example highlights the necessity for calibration when implementing static quantization.
- Calibration ensures that the model performs accurately by using sample data to optimize its performance.
Link mentioned: Add static quantization as an example for calibration flow by jerryzh168 · Pull Request #487 · pytorch/ao: Summary: So far quantization flow API that we provided (quantize_) does not require calibration (calibrate a model with sample data), this PR added a static quantization example that serves as an e...
CUDA MODE ▷ #ring-attention (8 messages🔥):
Ring AttentionSplitting KV cache across GPUsAWS g5.12xlarge instance
- Exploring Ring Attention for Splitting KV Cache: A member expressed interest in using ring attention to split the KV cache of their model across GPUs, specifically within an AWS g5.12xlarge instance containing four A10Gs.
- Another member suggested using
[nvidia-smi topo -m](https://gist.github.com/msaroufim/abbb01c5bb037c2b1009df4a0baeb74b)to print GPU topology and shared a script to estimate the size of the KV cache and model.
- Another member suggested using
- Confirming GPU Ring Topology: The inquirer mentioned that the paper advises a ring topology for GPUs but could not find specific information regarding the AWS instance in question.
Link mentioned: kv-calc.py: GitHub Gist: instantly share code, notes, and snippets.
CUDA MODE ▷ #triton-puzzles (1 messages):
Puzzle 9 explanationProblem statement confusion
- Puzzle 9's unclear instructions: A member is seeking a clearer explanation for puzzle 9, referring to the discussion at this Discord link.
- They noted that the consensus in the discussion contradicts the problem statement and are questioning if an arbitrary B1 choice is overthinking the problem.
- Problem statement confusion in puzzle 9: A member raised concerns about the problem statement for puzzle 9, indicating it's causing confusion among participants.
- The discussion revolves around whether an arbitrary B1 choice aligns with the problem conditions or is an overcomplication.
CUDA MODE ▷ #llmdotc (176 messages🔥🔥):
Llama model framework improvementsllm.cpp updatesZero initialization impact on NLP modelsMuP library integrationFast inference strategy
- Llama model support considered vital: A member asked why adding Llama support should come first, sparking a discussion on its effectiveness and benefits over other models.
- One member mentioned a Llama-based repository which supports various backends like Vulkan and AMD, and another suggested a CUDA-specific implementation.
- PR for faster inference in llm.c: A member created a pull request to optimize inference speed by changing the memory handling from (B,T) to (1,t), aiming for bit-for-bit identical results.
- Initial testing showed identical training loss but different sampled outputs, raising questions about cuDNN heuristics and variability.
- Zero initialization may hurt embedding layers: Discussed the impact of zero initialization on embedding layers across different setups, concluding that initializing with zero might be hurting performance.
- Members planned to run multiple experiments without zero initialization to see if loss values improve.
- Integration of the MuP library: Members discussed integrating the MuP library to ensure identical training results, noting discrepancies between MuP's own repository implementations for embedding and output layers.
- They decided to perform a series of controlled experiments to better understand initialization and other impacts on model performance.
- 400B token model evaluation: A model trained on 400B tokens achieved a HellaSwag score of 59.0, indicating significant improvement over previous versions of GPT models.
- Despite the impressive results, discussions continued on potential optimizations, including the use of truncated normal initialization and linear biases.
- Issues · microsoft/mutransformers: some common Huggingface transformers in maximal update parametrization (µP) - Issues · microsoft/mutransformers
- Faster inference by changing (B,T) to (1,t) by ademeure · Pull Request #671 · karpathy/llm.c: The inference sanity checks currently process all (B,T) despite only needing (1,64) by default. This PR is bit-for-bit identical to previous versions while reducing this to (1,t) where t is rounded...
- GitHub - karpathy/llama2.c: Inference Llama 2 in one file of pure C: Inference Llama 2 in one file of pure C. Contribute to karpathy/llama2.c development by creating an account on GitHub.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Tweet from main (@main_horse): Scaling Exponents Across Parameterizations and Optimizers [GDM] [nocode/weights] https://arxiv.org/abs/2407.05872 trains 10,000+ (!) models, varying * optim (SGD/Adam/Adafactor) * model size (1.1B ~...
- llama2.cu/llama2.cu at master · ankan-ban/llama2.cu: Inference Llama 2 in one file of pure Cuda. Contribute to ankan-ban/llama2.cu development by creating an account on GitHub.
- MuAdam not adjusting lr for output weights · Issue #7 · microsoft/mup: Hi, thank you for your great project for hyperparameter tuning! As our team migrating the mup to other training framework, it occurs to us that the MuAdam does not scale the learning rate for outpu...
Nous Research AI ▷ #off-topic (1 messages):
Error PDF DiscussionGary Marcus and Yann LeCun GIF
- Discussion sparked by Gary Marcus and Yann LeCun GIF: A user shared a Gary Marcus and Yann LeCun GIF from Tenor.
- The GIF humorously encapsulates a moment from a debate between the two prominent AI figures.
- Error PDF Link: A PDF related error message was shared, prompting some confusion among the participants.
- The need for a concise solution to interpret the error was discussed briefly.
Link mentioned: Gary Marcus Yann Lecun GIF - Gary Marcus Yann LeCun Lecun - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #interesting-links (1 messages):
metaldragon01: https://x.com/stefan_fee/status/1810695036432232576
Nous Research AI ▷ #general (117 messages🔥🔥):
Impact of AI on JobsHermes 2 ProJailbreaking LLMsWorldsim ConsoleSonnet Model Capabilities
- AI poised to change job landscape: Members discussed how AI, especially large language models (LLMs), is changing and potentially eliminating jobs, with examples of creative tasks becoming more achievable for non-experts.
- Some expressed how AI tools drastically speed up processes and enable projects that would otherwise be unattainable.
- Hermes 2 Pro wows with new features: Hermes 2 Pro was praised for its improved Function Calling, JSON Structured Outputs, and high scores on various evaluations.
- The model, available on Hugging Face, showcases significant improvements from its predecessors, gaining community approval for its robustness.
- Jailbreaking models remains a challenge: Users shared experiences and tips on jailbreaking models like Claude 3.5 and WizardLM2, often finding restrictions still in place despite efforts.
- Running your own LLM was noted as an expensive but effective way to bypass restrictions, though it may still face moderation hurdles.
- Worldsim Console for fun and creativity: The Worldsim console is used for entertainment and creative projects, simulating a terminal with an LLM executing commands.
- While it offers an engaging experience, users need to be mindful of their limited free credits due to Opus’s high computational cost.
- Sonnet model demonstrates impressive capabilities: Users marveled at Sonnet's ability to handle complex tasks like generating base64 images embedded in JavaScript.
- Experiments with simple jailbreaks on models like Gemini 1.5 Flash also yielded surprising results, showing the potential for uncensored outputs.
- UGI Leaderboard - a Hugging Face Space by DontPlanToEnd: no description found
- MaziyarPanahi/WizardLM-2-8x22B-GGUF · Hugging Face: no description found
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (8 messages🔥):
LLMs and classificationBAML usageSynthetic data generation toolsProcessing PDFs using Sonnet 3.5 APIFine-tuning with weight keys
- Big LLMs excel in classification and feedback: Discussion highlights how big LLMs are becoming exceptional in classification and feedback tasks, providing powerful solutions for such use cases.
- L notes that these capabilities allow most other processing to rely on standard code, effectively boosting productivity.
- BAML offers improved dev UX: BAML is praised for its development user experience, particularly because it provides type hints for LLM functions directly within the IDE.
- Deoxykev mentions that this feature makes developing with LLMs more efficient and intuitive.
- Tools for synthetic data generation: Distilabel is recommended as a tool for synthetic data generation, emphasizing its high-quality outputs and efficient AI feedback mechanisms.
- Remek1972 shared the link to the framework, highlighting its usefulness for AI engineers.
- Processing PDFs using Sonnet 3.5 API: Community members discuss the lack of an out-of-the-box solution for processing PDFs with Sonnet 3.5 API.
- Everyoneisgross suggests using the Marker library for converting PDFs to Markdown for better compatibility.
- Fine-tuning with weight keys in OpenAI: The OpenAI documentation describes using a weight key to determine which messages are prioritized during fine-tuning.
- Everyoneisgross explains that this feature tells the trainer to ignore certain fields, thereby optimizing the training process.
- Distilabel: Distilabel is an AI Feedback (AIF) framework for building datasets with and for LLMs.
- GitHub - VikParuchuri/marker: Convert PDF to markdown quickly with high accuracy: Convert PDF to markdown quickly with high accuracy - VikParuchuri/marker
Nous Research AI ▷ #rag-dataset (88 messages🔥🔥):
RankRAGZero-Shot PromptingFunction Calling in RAGStructured Scratch PadLlama3-RankRAG
- RankRAG Outperforms Existing RAG Methods: A discussion was held on the RankRAG method, which significantly outperforms existing approaches by instruction-tuning an LLM for both ranking and generation tasks in RAG.
- "Llama3-RankRAG-8B and Llama3-RankRAG-70B outperformed their counterparts by a margin," highlighting its superior capability for generalization to new domains.
- Zero-Shot Prompting with Retrieved Logic: "everyoneisgross" shared a toy implementation focusing on zero-shot prompting, pointing out that minimizing additional LLM generation steps is crucial for efficiency in knowledge ingestion and RAG.
- "interstellarninja" suggested using multiple agents for reranking and generation during data synthesis to enhance efficiency.
- Proposal for Function Calling in RAG: "interstellarninja" detailed a proposed
<scratch_pad>template for RAG, which would structure the AI's reasoning, citing sources, and reflecting on the retrieved document relevance.- This structured template aims to improve the model's deterministic output by organizing actions into Goals, Actions, Observations, and Reflections.
- Llama3-RankRAG in Practical Use: Discussion centered on the practical use of Llama3-RankRAG, with "interstellarninja" suggesting a scratch_pad structure facilitating citations and relevance scores for better-grounded answers.
- Participants emphasized the necessity of standardized templates to enhance the functionality and reliability of RAG outputs.
- Global Economic Trends Informing Financial Strategy: A demonstration showed how economic trends and investment opportunities, despite not directly addressing personal finance, can inform financial strategies.
- Combining limited document information with established financial principles offers a comprehensive answer considering individual actions and broader economic contexts.
Link mentioned: Tweet from Rohan Paul (@rohanpaul_ai): Incredible results for the RAG world from @nvidia model 👏. Llama3-RankRAG from @nvidia significantly outperforms GPT-4 models on 9 knowledge-intensive benchmarks. 🤯 📌 Performs comparably to GPT-4...
Modular (Mojo 🔥) ▷ #general (5 messages):
Primeagen interviews Chris LattnerMojo bookCommunity resources for AI with MojoQualcomm SNPE with Mojo
- Primeagen interviews Chris Lattner live: The Primeagen announced that he is interviewing Chris Lattner live on Twitch on an unspecified future date.
- Potential Mojo book similar to Rust book: A member asked if there would be a Mojo book similar to the Rust book, to which jack.clayton responded positively.
- Inquiring about community resources for AI with Mojo: A member asked about community resources for writing AI with Mojo, but no specific resources were mentioned in response.
- Comparing Snapdragon’s SNPE to Mojo capabilities: A member inquired if Mojo has capabilities similar to Qualcomm's SNPE for determining where on the Snapdragon to run PyTorch models.
- ThePrimeagen - Twitch: CEO @ TheStartup™ (multi-billion)Stuck in Vim Wishing it was Emacs
- Mojo By Example: A Comprehensive Introduction to the Mojo Programming Language: no description found
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1810782477079957831
Modular (Mojo 🔥) ▷ #✍︱blog (3 messages):
Bringing your own PyTorch model with ModularDevelop Locally, Deploy GloballyTaking Control of AI
- Bring your own PyTorch model with Modular: Modular discusses the rise of AI in enterprises and the demand for managing and deploying PyTorch models, highlighting the need for control over AI infrastructure during full-scale production. Read more.
- PyTorch's flexibility in research settings presents challenges in large-scale production deployments due to resource management and latency issues.
- Develop Locally, Deploy Globally with Modular: Modular emphasizes the challenges in creating scalable development workflows for AI, stressing the fragmented nature of AI tooling. Discover more.
- AI developers often need to use multiple tools across their workflows which complicates streamlining from local development to cloud deployment.
- Taking Control of AI: Modular outlines the importance of AI adoption in enterprises for enhancing productivity and customer experience, referring to research by Bain & Company suggesting high AI development and deployment rates. Learn more.
- A significant 87% of companies are developing or deploying generative AI, with common applications in software development, customer service, marketing, and product differentiation.
- Modular: Take control of your AI: We are building a next-generation AI developer platform for the world. Check out our latest post: Take control of your AI
- Modular: Develop locally, deploy globally: We are building a next-generation AI developer platform for the world. Check out our latest post: Develop locally, deploy globally
- Modular: Bring your own PyTorch model: We are building a next-generation AI developer platform for the world. Check out our latest post: Bring your own PyTorch model
Modular (Mojo 🔥) ▷ #tech-news (1 messages):
helehex: i hear that mr. lattner has something special going on tomorrow with the primeagen
Modular (Mojo 🔥) ▷ #🔥mojo (129 messages🔥🔥):
Code optimization discussionsMojo and Python integrationMojo language featuresMojo documentation and resourcesReference and value semantics debate
- Mojo Logger Project Stump Peaks Interest: Members discussed optimizing Mojo projects, with a specific mention of the stump logger project on GitHub, sparking interest in further contributions.
- Optimizations and debugging tips were shared, with one member mentioning, "spending hours to change one line of code for a 1% speed up and less readability is my passion".
- Mojo Integrates Python Modules: A member highlighted the ability to import Python modules into Mojo, citing support in the Mojo documentation.
- Discussion covered the long-term goal of making Mojo a superset of Python to leverage the huge ecosystem of Python packages.
- Mojo Language Syntax and Usability: Questions arose regarding the syntax for calling fallible functions and capturing errors in Mojo, showcasing examples of handling references and values.
- Members wish for a more intuitive handling of lists and slices in Mojo, with references to helpful span documentation.
- Mojo Standard Library Open Sourced: Discussion on the open-source status of Mojo, with references to a blog post announcing the open-sourcing of core modules.
- "The Mojo library is now open source," excited a member, highlighting the importance of collaborative development.
- Value vs. Reference Semantics in Mojo: Debate ensued over value and reference semantics in Mojo, with explanations on the default behavior and how it's designed to aid ease of use.
- The flexibility of Mojo's semantics, paired with resources like Mojo's value semantics documentation, was emphasized as crucial for both new and experienced users.
- Ownership and borrowing | Modular Docs: How Mojo shares references through function arguments.
- Value semantics | Modular Docs: An explanation of Mojo's value-semantic defaults.
- Why can't linux write more than 2147479552 bytes?: In man 2 write the NOTES section contains the following note: On Linux, write() (and similar system calls) will transfer at most 0x7ffff000 (2,147,479,552) bytes, returning the number of b...
- Value Semantics: Safety, Independence, Projection, & Future of Programming - Dave Abrahams CppCon 22: https://cppcon.org/---C++ Value Semantics: Safety, Independence, Projection, and the Future of Programming - Dave Abrahams - CppCon 2022https://github.com/Cp...
- Python integration | Modular Docs: Using Python and Mojo together.
- Modular: The Next Big Step in Mojo🔥 Open Source: We are building a next-generation AI developer platform for the world. Check out our latest post: The Next Big Step in Mojo🔥 Open Source
- mojo/proposals/ref-convention.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- GitHub - thatstoasty/stump: WIP Logger for Mojo: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- mojo/stdlib/src/builtin/builtin_slice.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/stdlib/src/utils/span.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [Feature Request] Add more `List` methods to the `InlineList` struct · Issue #2610 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? The InlineList struct has been added to the stdlib rec...
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (3 messages):
Clock Calibration IssueTimer Cycle Functions
- Clock Calibration Causes 1 ns Difference: A member pointed out that running both
_clock_gettimecalls back to back results in a 1 ns difference, causing issues when calibrating one clock from another.- Since this is attempting to calibrate, the minimal difference impacts the accuracy, leading to potential timing discrepancies.
- Timer Cycle Functions for Multiple Architectures: Code for obtaining timer cycles on x86 and ARM architectures was shared, using specific LLVM intrinsics and inline assembly respectively.
- The function defaults to error handling if neither architecture is detected, printing an error message and exiting.
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 39 https://www.modular.com/modverse/modverse-weekly-issue-39
Modular (Mojo 🔥) ▷ #nightly (19 messages🔥):
Mojo Compiler Nightly UpdateConditional Conformance in MojoHandling Unix FIFO in MojoLoad Iris Dataset in MojoMojo Language Improvements
- Mojo Compiler releases new nightly update: A new nightly Mojo compiler has been released with version 2024.7.905, including updates such as cleaning up uses of
memcmp, reworkingsetitem/setattremission, and improving parameter inference for conditional conformances.- Check the changelog for detailed updates.
- Conditional conformance support debated in Mojo: Members discussed that Mojo supports method constraining but lacks full support for conditional conformance on types, hindering composition.
- Chris expressed a desire to move away from the current representation of conditional conformance, referencing a commit.
- Issue raised for Unix FIFO handling in Mojo: A member encountered an error when trying to open a Unix FIFO file in write mode using Mojo, resulting in an exception.
- An issue was raised on GitHub, requesting more details on permissions (777) and the full script.
- [mojo-lang] Improve parameter inference for conditional conformances. · modularml/mojo@97d70d3: This fixes parameter inference to handle more complex conditional conformance cases than just "x.method(" notably including cases that use binary operators `x == y` and things like `...
- [BUG] Opening a unix fifo in "write" mode raises an exception · Issue #3208 · modularml/mojo: Bug description I'm not sure why this is failing, mentioned it on Discord and was asked to open an issue: $ mojo run src/main.mojo Unhandled exception caught during execution: unable to remove exi...
Modular (Mojo 🔥) ▷ #mojo-marathons (17 messages🔥):
Vectorization PerformanceAlgorithm BenchmarkingLoad/Store IssuesBenchmark Stabilization Tips
- Vectorization Performance Variable: Discussion revealed that vectorizing with different widths can result in variable performance; width 1 sometimes outperforms width 2 during benchmarking.
- Further investigation showed that Mojo's vectorize/load/store implementation might be slower with width 2, but faster with width 4 or 8, depending on the values of M, N, and K.
- Suggestions for Fairer Comparisons in Benchmarking: Members discussed the importance of including both symmetrical and asymmetrical matrices to ensure fairer comparisons in algorithm benchmarking.
- One member suggested setting m=n=k for medium to large matrices, while another pointed out the necessity of testing with dimensions common in geo and image use cases.
- Benchmark Stabilization Techniques Shared: Tips to stabilize benchmarking results were shared, including links to a detailed blog post.
- The guide covers steps such as disabling turboboost and hyper threading, setting cpu affinity, and using statistical methods.
Link mentioned: How to get consistent results when benchmarking on Linux? | Easyperf : no description found
LM Studio ▷ #💬-general (54 messages🔥):
Custom Voices with LLMImage Generation and ToolsLocal Perplexica with LM StudioRunning LLMs on AndroidText-to-Speech Front Ends
- Custom Voices for LLM Studio: A member inquired about integrating Eleven Lab custom voices with LLM Studio, and another suggested using the LLM Studio server feature to build a custom program for this purpose.
- Community members emphasized that integrating text-to-speech or custom voices typically requires additional programming, with tools like Claude to assist in development.
- Using Stability Matrix and Fooocus for AI Image Generation: Members discussed the inability of LLM Studio to generate images like DALL-E and recommended using tools like Stability Matrix, Fooocus, and Stable Diffusion for comprehensive AI image generation capabilities.
- For ease of use, Fooocus was suggested for beginners, while Stable Diffusion along with interfaces like StableSwarmUI and Automatic1111 were recommended for advanced users.
- Running Local Perplexica with LM Studio Server: A user asked about using Perplexica, an open-source alternative to Perplexity AI, with the LM Studio server.
- Another user referred to a GitHub issue discussion for potential solutions but acknowledged ongoing issues in connecting Perplexica with LM Studio.
- Running LLMs on Android with Termux: A use-case was shared about running Mistral 7b on an S21 Ultra using llama.cpp and Termux, achieving speeds close to 10 tokens per second.
- Incorporating Text-to-Speech for LLM Studio: Members highlighted that creating text-to-speech integrations for LLM Studio is feasible by building custom front ends, leveraging tools like Claude for implementation.
- It was noted that while not a priority for LLM Studio’s development, using server mode facilitates these integrations effectively.
- How to Finetune phi-3 on MacBook Pro: no description found
- GitHub - ItzCrazyKns/Perplexica: Perplexica is an AI-powered search engine. It is an Open source alternative to Perplexity AI: Perplexica is an AI-powered search engine. It is an Open source alternative to Perplexity AI - ItzCrazyKns/Perplexica
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Mac users: Stable diffusion 3 on ComfyUI: Step by step guide to run SD3 using ComfyUI on Macbooks (M processors). #stablediffusion #applesilicon 👉ⓢⓤⓑⓢⓒⓡⓘⓑⓔ https://medium.com/@ttio2tech_28094/stab...
- LM studio support (Ollama alternative) · Issue #128 · ItzCrazyKns/Perplexica: Thanks in advance
LM Studio ▷ #🤖-models-discussion-chat (75 messages🔥🔥):
InternLM context handlingWeb scraping with LLMsAI coding limitationsGemma 2QLo performance
- InternLM context window amazes: Members observed that InternLM maintains coherence even when memory is full, demonstrating a sliding context window.
- Discussion includes screenshots showing how InternLM forgets earlier messages once it exceeds context length but doesn't go incoherent.
- Creating custom web scrapers with AI: A member shared their success with using Claude to create a Node.js web scraper in 20 minutes, tailored exactly to their needs.
- "I got 78 lines of code that do exactly what I want," emphasizing the utility of AI in rapid custom tool creation.
- AI-generated code: Caution Advised: Members debated the reliability of AI-generated code, warning against blindly trusting AI as it can produce subpar code.
- "By all means use AI for code, just make sure you know what it is doing," one stressed, advocating for manual review and understanding.
- Confusion over Gemma 2 model size: A user humorously questioned the availability of a 9B version of Gemma 2 without smaller versions like 7B or 8B.
- This was accentuated by a Liam Neeson GIF expressing confusion and curiosity about model size choices.
- Does This Worm Prove We're In a Computer Simulation? 🤯: Let's explore this microscopic roundworm, which has been fully mapped to the neuron and simulated using consumer-grade computers. This is strong proof of sim...
- no title found: no description found
- no title found: no description found
- Liam Neeson Why GIF - Liam Neeson Why Darkman - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #🧠-feedback (8 messages🔥):
Excitement Over Upcoming FeaturesFeature Requests for Organizing ChatsDownload Speed IssuesFeature Requests for Context Window Indicators
- Excitement Over Upcoming Features: A user is excited about some upcoming features and suggests signing up for the beta to get the latest updates.
- Requests to Organize Chats: There were feature requests for organizing chats, such as the ability to reorder them and set up folders.
- Download Speed Woes: A user asked, 'Hola, alguien sabe porque mis descargar tienen una velocidad limitada?'
- Indicator for Context Window: A user suggested having a visual indicator for parts of the conversation that have fallen out of the context window in long conversations.
- Another member responded that the context count at the bottom turns orange for this purpose, but the original user argued they shouldn't have to do the math to figure out what the AI has forgotten.
LM Studio ▷ #🎛-hardware-discussion (18 messages🔥):
RX 6800XT Multi-GPU SetupPerformance of LLama 3 70B Q7 InstructRX 6800XT vs 7900XTXBuilding a Desktop/Server for RTX 3090Concerns with AMD ROCm Support
- RX 6800XT Multi-GPU Setup Feasibility: A user inquired about using 4 RX 6800XTs with llama.cpp for a multi-GPU setup, questioning if LM Studio supports auto split/configure functionality.
- Another user confirmed that multi-GPU works but indicated that there wouldn't be significant performance improvements as the model is split across multiple cards.
- Performance of LLama 3 70B Q7 Instruct on Multi-GPU: The performance with 4 GPUs for LLama 3 70B Q7 Instruct was queried, and one user suggested that the performance would be similar to using a single 6800XT.
- A recommendation was made to opt for dual 7900XTXs for better performance and reduced complexity.
- Building a Desktop/Server for RTX 3090: A user outlined a plan to build a desktop/server with an X299 Mainboard for better RAM bandwidth and the potential to add a second RTX 3090.
- They asked for CPU suggestions to match their Ryzen 7640u's performance and were advised that any decent modern gaming CPU would suffice.
- RX 6800XT vs 7900XTX for LLM Tasks: Debate emerged on whether 4 RX 6800XTs or 2 7900XTXs would be better for LLM tasks, with the latter being recommended for fewer headaches.
- A user decided to sell their RX 6800XT and acquire 2 7900XTXs for improved performance.
- Concerns with AMD ROCm Support Longevity: A cautionary note was made about the potential lack of long-term support from AMD, referencing the termination of ROCm support for the Radeon VII.
- This warning was especially pertinent for users considering investment in AMD GPUs for long-term projects.
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
Trustworthiness of YorkieSuspicious behavior
- Users debate Yorkie's authenticity: A member remarked 'looks at Yorkie - idk he looks legit to me'.
- Another member disagreed, insisting, 'Very suspicious. Trust me.'
- User disagreement highlights community interaction: The discussion about Yorkie turned into a debate on trustworthiness and suspicion within the community.
- Members showed differing opinions, reflecting the diverse perspectives in the community.
LM Studio ▷ #amd-rocm-tech-preview (1 messages):
AMD graphics card 7700XTLM Studio update issueFimbulvetr Q4_K_M model performance
- LM Studio slowdown after update: A member noted that after updating LM Studio from 0.2.24 to 0.2.27, performance significantly deteriorated, with the system becoming super slow.
- AMD 7700XT graphics card issue suspected: The same member speculated whether the issue is related to their AMD graphics card 7700XT as performance was previously better with the Fimbulvetr Q4_K_M model.
LM Studio ▷ #🛠-dev-chat (7 messages):
LM Studio GPU offloadLong context issues on LinuxBug report processContext requires RAM advice
- Disable GPU Offload to Resolve Issues: A user suggested that disabling GPU offload in the side config menu might resolve issues.
- Long Context Handling Issues on Linux: A user reported that LM Studio on Linux struggles with long contexts, showing errors even with available RAM, unlike in Windows.
- They mentioned that llamafile can handle up to 65,535 tokens on the same Linux setup without issues.
- Prompt to Report Bugs in Correct Channel: A new user was directed to post their issue in the bug reports channel with more details and screenshots.
- Extra RAM Needed for Full Context Length: A user mentioned that handling full context length requires extra GB of RAM added to the file size.
- The user clarified they have 32 GB RAM and only experience issues on Linux with LM Studio.
Eleuther ▷ #general (32 messages🔥):
Desired output distributions in modelsChinchilla vs Gopher training computationTest time trainingSynthetic data generation tools
- Challenges in inducing desired output distributions: A member discussed the challenge of inducing a desired distribution of outputs in models, noting that while you can partly achieve this with SFT by training on enough data with the target distribution, there are no RLHF-like setups to allow systems to find the best distribution on their own.
- Another participant suggested optimizing towards a 'good' set and away from a 'bad' set to potentially guide output distributions.
- Chinchilla and Gopher comparison reveals compute efficiency gap: The conversation around Gopher and Chinchilla models highlighted differences in training setups, with Gopher being less efficient despite similar overall training goals.
- Participants debated assumptions about TFLOP efficiency and the impact of model size, agreeing that larger models tend to be less compute-efficient.
- Test-time training enhances transformer performance: A new paper proposed using test-time training (TTT) to improve model predictions by performing self-supervised learning on unlabeled test instances, showing significant improvements on benchmarks like ImageNet.
- TTT can be integrated into linear transformers, with experimental setups substituting linear models with neural networks showing enhanced performance.
- Interest grows in tools for synthetic data generation: A participant inquired about tools that specifically aid in synthetic data generation, seeking solutions for enhancing their projects.
- Forcing Diffuse Distributions out of Language Models: Despite being trained specifically to follow user instructions, today's language models perform poorly when instructed to produce random outputs. For example, when prompted to pick a number unifor...
- Learning to (Learn at Test Time): For each unlabeled test instance, test-time training (TTT) performs self-supervised learning on this single instance before making a prediction. We parameterize the self-supervised task and...
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States: Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their...
Eleuther ▷ #research (77 messages🔥🔥):
TTT-Linear and Delta RuleTTT-MLP OptimizationData Attribution with In-Run Data ShapleyGradient Normalization TechniquesEmerging RNN Architectures vs. Transformers
- TTT-Linear matches Delta Rule with mini batch size 1: Members discussed that TTT-Linear is equivalent to the delta rule with mini batch size 1, and it offers the best performance in this scenario.
- "TTT-MLP" was noted to be more performant, though harder to optimize, and another member added that upcoming works like rwkv7 plan to incorporate a modified delta rule.
- Principled data attribution with In-Run Data Shapley: An announced project, In-Run Data Shapley, offers scalable and formal frameworks to assess data contributions in real-time during pre-training, identifying substantial negative-value data efficiently.
- This can help prevent models from developing undesirable capabilities via dataset curation and better understand 'emergence' according to community members.
- New gradient normalization technique: A new technique for gradient normalization was introduced, which uses normalization layers in the backward pass to control gradient flow, solving vanishing or exploding gradients in very deep networks.
- However, the batch-size dependency and the need for cross-device communication for batch dimension normalization were seen as drawbacks by members.
- Emerging RNN architectures compete with Transformers: New recurrent large language models like Mamba and RWKV offer constant memory usage during inference and are emerging as competitors to Transformers in language modeling perplexity.
- The challenge remains in managing memory effectively to recall information in long contexts, which was theoretically and empirically explored in recent works.
- Tweet from Karan Dalal (@karansdalal): I’m excited to share a project I’ve been working on for over a year, which I believe will fundamentally change our approach to language models. We’ve designed a new architecture, which replaces the h...
- Parallelizing Linear Transformers with the Delta Rule over Sequence Length: Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, ...
- Tweet from Ruoxi Jia (@ruoxijia): 1/n Interested in scalable, principled data attribution methods? Introduce In-Run Data Shapley, a method efficient enough for pre-training data attribution! (https://jiachen-t-wang.github.io/data-sha...
- Backward Gradient Normalization in Deep Neural Networks: We introduce a new technique for gradient normalization during neural network training. The gradients are rescaled during the backward pass using normalization layers introduced at certain points with...
- An Adaptive Stochastic Gradient Method with Non-negative Gauss-Newton Stepsizes: We consider the problem of minimizing the average of a large number of smooth but possibly non-convex functions. In the context of most machine learning applications, each loss function is non-negativ...
- Tweet from Songlin Yang (@SonglinYang4): Online gradient descent version of TTT-linear is a variant of DeltaNet and could be parallelized efficiently: https://arxiv.org/abs/2406.06484 Quoting Aran Komatsuzaki (@arankomatsuzaki) Learning...
- Just read twice: closing the recall gap for recurrent language models: Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount o...
- GitHub - HazyResearch/prefix-linear-attention: Contribute to HazyResearch/prefix-linear-attention development by creating an account on GitHub.
Eleuther ▷ #scaling-laws (9 messages🔥):
Brain size evolutionIntelligence and evolutionary benefitsLinearity of brain sizeNeuronal density and intelligence
- Brain size riddle solved: A study published in Nature Ecology & Evolution reveals that the largest animals do not have proportionally bigger brains, with humans bucking this trend.
- Researchers at the University of Reading and Durham University collected data from around 1,500 species to clarify the controversy surrounding brain size evolution.
- Linearity in brain size questioned: It's suggested that the black line in the brain size plot isn't straight but slightly curved at the end.
- This raises questions about the dependency of the relationship between larger animals having bigger brains on its linearity.
- Reproductive benefits of intelligence: Discussion on whether the reproductive benefits of increased intelligence were limited in the ancestral environment if the scaling hypothesis is true.
- One participant noted that brain size is only part of the picture, with structure and neuronal density also being important.
- Neuronal density and intelligence in various species: In mammals, overall cortical neuron count gives a good map of the intelligence distribution since structure is almost the same across the board.
- In birds and lizards, the density of all neuron types matters more, although data is sparse unless differentiated by structures.
Link mentioned: Brain size riddle solved as humans exceed evolutionary trend: The largest animals do not have proportionally bigger brains—with humans bucking this trend—a study published in Nature Ecology & Evolution has revealed.
Eleuther ▷ #interpretability-general (2 messages):
EleutherAI at ICMLICML papers announcement
- EleutherAI confirmed for ICML: EleutherAI will be attending ICML with their papers included. Specific details can be found in the official announcement.
- Social thread for ICML attendees: There is a dedicated social thread for people attending ICML. Participants can join discussions in <#1255332070369263707>.
Eleuther ▷ #lm-thunderdome (6 messages):
Chain-of-Thought reasoning in modelsModel's access to answer choicesRegexFilter for MedQASampler initialization errorError troubleshooting
- CoT reasoning not ideal for multiple_choice tasks: It's advised that Chain-of-Thought (CoT) reasoning shouldn't be used for
multiple_choicetasks. - Models are aware of answer choices in many tasks: For tasks like MMLU, the answers are provided in context, so the model is aware of what it needs to choose from.
- RegexFilter adaptation for MedQA leads to error: Attempt to adapt RegexFilter from MMLU to MedQA results in a TypeError due to an unexpected argument count in initialization.
- Sampler unexpected arguments issue: The error “TypeError: init() takes from 1 to 3 positional arguments but 4 were given” suggests there might be unexpected arguments passed into the Sampler's initialization.
Eleuther ▷ #gpt-neox-dev (2 messages):
Containers on KubernetesPods with Neox Image
- Using Containers on Kubernetes: Members confirmed that they use containers on Kubernetes for their deployments.
- Pods Deployed with Neox Image: They mentioned that these containers specifically run with the Neox image to manage pods.
Stability.ai (Stable Diffusion) ▷ #general-chat (119 messages🔥🔥):
Model Training TechniquesBooru Tags in AIRole of AI in SocietySD Extensions and Tools
- Training Models on Different Resolutions: Members discussed whether it is beneficial to train on 512x512 resolution before 1024x1024 during fine-tuning stages.
- Booru Tags Controversy in Model Training: Discussion focused on the use of booru tags for training AI, with some members defending their established vocabulary while others questioned their effectiveness against more natural language models.
- AI's Cultural Impact and Regulations: Conversations revealed concerns about the societal impact of AI, especially in terms of addiction and potential future regulations.
- Roop-Unleashed for Face Replacement: A member recommended using Roop-unleashed as a tool for consistent face replacement in videos, highlighting its effectiveness over the now-dead mov2mov extension.
- SD Model Recommendations and Usage Tips: Members exchanged model and extension recommendations for various specific tasks like converting pixel-art and inpainting, suggesting tools like Zavy Lora and comfyUI with IP adapters.
- MP Productions (Mark Pritchard) - One Way Mirror (Official Audio): One Way Mirror (Official Audio)Stream: https://markpritchard.ffm.to/one-way-mirrorVisual by Jonathan ZawadaThe art was created with a GAN (generative adversa...
- Installation Guides: Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
OpenAI ▷ #ai-discussions (67 messages🔥🔥):
DALL-E alternativesAI text detectorsStableDiffusionDiffusion toolsAI model recommendations
- Members Discuss DALL-E Alternatives: Members explored alternatives to DALL-E, such as StableDiffusion and platforms like DiffusionBee and automatic1111, for more control and better quality.
- They also discussed running these models locally on Windows or Mac.
- Debating Reliability of AI Text Detectors: Many reported AI text detectors as unreliable, flagging both AI and human content incorrectly.
- One member humorously mentioned the U.S. Constitution being flagged incorrectly by such tools.
- StableDiffusion and its Tools: The community mentioned various tools for StableDiffusion, including DiffusionBee for Mac and automatic1111 for Windows.
- ComfyUI was highlighted as another good option for Windows users.
- Seeking Quality Image Generators on the Web: A member expressed frustration over lack of quality web-based image generators and a slow computer.
- DALL-E and MidJourney were recommended as web-based options, despite their limitations.
- Python Code for Generating Icons with DALL-E API: Members shared Python code for generating icons using the DALL-E API, discussing parameters for various image attributes.
- Suggested parameters included size, quality, style, color palette, and other artistic details.
- Deep Media AI: AI-powered Deepfake Detection and Media Intelligence for enterprises, governments, and journalists.
- Blog | Deep Media AI: Our expert team shares their thoughts on AI, Deepfakes, detection best practices, trust & safety in the modern age, and more.
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
Monetization for GPTsVPN causing issues with GPTsServer problems resolvedConsistency in GPT responsesUser dissatisfaction
- Monetization for GPTs: When?: A user inquired about the timeline for monetization for GPTs with no conclusive response provided.
- No further details or responses were discussed.
- VPN Issues Affect GPTs: A user noted that enabling a VPN causes issues with GPT responses and suggested disabling it to resolve the problem.
- No additional comments or links on this topic were provided.
- Server Issues Resolved: A user mentioned that recent server problems have been resolved, though no specific details were given.
- No further discussion on this topic.
- Maintaining Consistency in GPT Responses: A member asked how to keep GPT responses consistent across different contexts, especially concerning language preference.
- Another user responded that it is very difficult to answer such questions without seeing the specific conversation.
- User Dissatisfaction with GPT Service: A user expressed frustration with ChatGPT's performance and mentioned switching to a competitor, sharing a link to a relevant chat.
- Another user clarified that hallucinations in responses are due to the LLM's training data, directing users to OpenAI's pricing page for context window details.
OpenAI ▷ #prompt-engineering (2 messages):
Content creation strategiesAudience engagementPlatform optimizationContent calendar structureKey metrics for content success
- Seeking fresh content ideas to grow audience: A content creator requests 5-10 fresh content ideas based on trending topics in their niche, along with effective strategies to boost engagement and optimize content for various platforms.
- They also sought advice on creating a content calendar structure and the key metrics to track for measuring content success and growth in followers.
- Tips for content creation and engagement: The content creator asked for strategies to enhance engagement, such as effective use of hashtags, engaging with followers, and strong call-to-actions.
- In addition, they requested platform-specific advice for optimizing content on Instagram, YouTube, TikTok, and other social media platforms.
OpenAI ▷ #api-discussions (2 messages):
Content CreationAudience EngagementSocial Media StrategyContent CalendarMetrics Tracking
- Seeking Content Ideas for Audience Growth: A user is looking for 5-10 fresh content ideas based on trending topics in their niche to grow their audience and increase engagement.
- “Can you provide me with content ideas, engagement tips, platform-specific advice, a content calendar structure, and key metrics?”, the user asked.
- Question on Improving Engagement: A user is asking for strategies to boost engagement with their posts, such as effective hashtags, engaging with followers, and call-to-actions.
- They are seeking advice on optimizing content for different platforms like Instagram, YouTube, and TikTok to attract new followers.
LlamaIndex ▷ #announcements (1 messages):
LlamaCloud Beta ReleaseData QualityScalability HurdlesLlamaParse Integration
- LlamaCloud Soft Launch Announced: The beta release of LlamaCloud has been announced, offering a managed platform for unstructured data parsing, indexing, and retrieval. Users can join the waitlist to try it out.
- Ensuring High-Quality Data: LlamaCloud addresses the 'garbage in, garbage out' problem by providing high-quality data inputs and sophisticated interfaces for LLMs to interact with.
- Data quality issues are a common problem, and LlamaCloud aims to solve this with features like advanced parsing and indexing.
- Tackling Scalability Hurdles with Parsing: LlamaCloud aims to reduce the engineering hours needed for custom parsing and tuning of new data sources. It promises synchronization of diverse data sources with advanced connectors to Sharepoint, S3, and vector databases.
- LlamaParse: Advanced Parsing Baked In: LlamaParse is integrated within LlamaCloud to offer advanced document parsing capabilities.
- It is designed to handle complex documents and ensures synchronization with its advanced retrieval interface layer.
- LlamaCloud Waitlist: Thanks for your interest in LlamaCloud! Sign up and tell us below which email address you used, we'll be letting people in at a measured pace.
- Tweet from LlamaIndex 🦙 (@llama_index): Today we’re excited to do a beta release of LlamaCloud - the data processing layer for your LLM applications. Any RAG pipeline/agent is only as good as your data. LlamaCloud provides a managed platfo...
- LlamaCloud - Built for Enterprise LLM App Builders — LlamaIndex, Data Framework for LLM Applications: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
- LlamaCloud: no description found
- Welcome | LlamaCloud Documentation: This is the documentation for LlamaCloud, the hosted ingestion and indexing service for LlamaIndex.
- Introduction to LlamaCloud: LlamaCloud provides the data processing layer for your LLM applications. It lets you build enterprise-grade context-augmented RAG pipelines, agents, and more...
LlamaIndex ▷ #blog (3 messages):
Property Graphs in LlamaIndexLlamaCloud beta releaseAGI House hackathon
- Exciting 6-part video series on Property Graphs in LlamaIndex: Announced a 6-part video series on Property Graphs in collaboration with mistralai, neo4j, and ollama.
- Model complex relationships from documents featuring properties on both nodes and edges.
- Beta release of LlamaCloud: Announced the beta release of LlamaCloud, the data processing layer for LLM applications.
- LlamaCloud provides a managed platform for unstructured data parsing, indexing, and retrieval for RAG pipelines and agents.
- AGI House Hackathon Invitation: Invited participants to join a hackathon at AGI House on Saturday, 7/13 along with partners like togethercompute and SambaNovaAI.
- Application details are available here.
Link mentioned: AGI House: no description found
LlamaIndex ▷ #general (65 messages🔥🔥):
E-commerce RAG chatbot enhancementsFlagEmbeddingReranker import errorRate limit issues with Groq APIHandling large datasets for chatbotsastream_chat implementation issue
- Enhancing E-commerce RAG chatbot: A user shared their successful prototype using keyword search, vector search, and metadata filtering, but they are looking to add follow-up question capabilities to handle queries about building projects like tables.
- They discussed potential approaches such as first conducting a hybrid search, then refining the attributes sent to the LLM for follow-up questions.
- Struggling with FlagEmbeddingReranker import: A user encountered persistent import errors with
FlagEmbeddingRerankerdespite installing the required packages globally and debugging the environment.- The issue was finally resolved by installing
peftseparately, which was not initially anticipated.
- The issue was finally resolved by installing
- Groq API rate-limit dilemma: A user reported an error code 429 (rate limit) while using LlamaIndex with Groq API for vector store indexing.
- Further discussions indicated that the issue is associated with Groq using the OpenAI client and could be related to OpenAI's default embedding models.
- Effective strategies for large datasets in chatbots: A user sought advice on managing large markdown datasets derived from numerous PDFs for building an effective RAG chatbot.
- They asked for recommendations on loaders, chunking strategies, and vector databases, preferably open source options.
- astream_chat implementation troubles: A user faced issues with
astream_chatimplementation in LlamaIndex, getting errors about asyncio methods.- After various attempts and debugging, they managed to get the async generator working but noted it was not streaming as expected when used in a Server Side Event (SSE) setup, unlike
stream_chat.
- After various attempts and debugging, they managed to get the async generator working but noted it was not streaming as expected when used in a Server Side Event (SSE) setup, unlike
- Tweet from Asim Shrestha (@asimdotshrestha): Excited to more broadly share what we've been working on at @ReworkdAI ⚡️ This past year we've fully invested in building the next generation of web agents. They're already live in produc...
- GitHub - vsakkas/sydney.py: Python Client for Copilot (formerly named Bing Chat), also known as Sydney.: Python Client for Copilot (formerly named Bing Chat), also known as Sydney. - vsakkas/sydney.py
- llama_index/llama-index-integrations/postprocessor/llama-index-postprocessor-flag-embedding-reranker/llama_index/postprocessor/flag_embedding_reranker/base.py at 510213d07b01ba4e80762f2c1ca3af61ed935074 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Semantic similarity - LlamaIndex: no description found
Perplexity AI ▷ #general (43 messages🔥):
Arc Search RecommendationContext Issues in PerplexityNotion Integration with PerplexityClaude 3.5 and Gemini 1.5 ComparisonAPI Credit Clarification
- Arc Search Recommendation over Perplexity: A user suggested trying Arc Search as an alternative to Perplexity AI.
- This was marked as 'shrewd' by another user, indicating agreement or acknowledgment.
- Perplexity's Context Handling Concerns: A user shared that Perplexity often loses context on follow-up questions, requiring very specific queries to maintain it.
- Another user agreed, adding that GPT-4o maintains context better than Claude 3.5, but Perplexity sometimes makes irrelevant searches on follow-ups.
- Notion Integration Possible via Make and BuildShip: A user seeking to connect Notion with Perplexity was given resources such as Make and BuildShip for integration.
- The user was thankful for the provided information, indicating these resources were helpful.
- Comparison Confusion between Claude 3.5 and Gemini 1.5: A user linked a comparison of Gemini 1.5 Flash to Claude 3 Haiku, noting discrepancies in context windows and pricing.
- Others pointed out that the comparison was incorrect and highlighted the differences between the models, particularly between Gemini 1.5 Flash and Pro.
- API Credit Use Clarified: Clarification was provided about API credit usage for developers using Perplexity's servers, indicating the purpose and model specs available for context and token usage.
- Details on the models and parameters were shared, including Meta's recommendations for token sanitization.
- Exa: The Exa API retrieves the best, realtime data from the web to complement your AI
- Supported Models: no description found
- Feather 1.5 - Paint, Shift and Shoot: -A huge package of new features released now in Feather. Paint, edit, and even animate ideas you couldn't imagine before.Key Feature of 1.5- New brushes for ...
- gemini 1.5 flash vs claude 3 haiku in programming: Based on the available information, here's a comparison of Gemini 1.5 Flash and Claude 3 Haiku, focusing on their programming capabilities and related...
- AI’s $200B Question: GPU capacity is getting overbuilt. Long-term, this is good for startups. Short-term, things could get messy. Follow the GPUs to find out why.
- Tweet from Guido Appenzeller (@appenz): 🔥 In a recent post Sequoia's @DavidCahn6 argues AI infra is overbuilt: - NVIDIA GPU revenue is $50b/y - This requires $200b in "AI revenue" - There is only $75b in "AI revenue" Th...
- Integrate Notion and Perplexity AI to create automation: Connect Notion and Perplexity AI to automate workflows. With no code integration using BuildShip. Build backend, APIs and AI workflows. Low-code and scaleable.
Perplexity AI ▷ #sharing (10 messages🔥):
Antikythera MechanismNothing's New PhoneHydrogen CarsBoeing Guilty PleaDigital Advertising in South Korea
- Boeing Pleads Guilty to Fraud Conspiracy: Boeing has agreed to plead guilty to a criminal fraud conspiracy charge related to the fatal crashes of its 737 MAX aircraft in 2018 and 2019, including a $243.6 million fine, a $455 million safety investment, and three years of court-supervised probation pending approval.
- The plea deal also includes the admission of conspiracy, stemming from a violation of a prior deferred prosecution agreement.
- Top Digital Advertising Channels in South Korea: Naver and KakaoTalk dominate the digital advertising landscape in South Korea, with Naver offering search and display ads and KakaoTalk providing messaging-based advertisements.
- Configuring WireGuard on Fedora: Users can configure WireGuard on Fedora by creating a configuration file in
/etc/wireguard/wg0.confand bringing up the interface using thewg-quickcommand. - Engagement Activities in Perplexity AI Discord Community: Members of the Perplexity AI Discord community can discuss the platform, beta test new features, interact with developers, and share personal use cases.
- 1st Edition D&D Attack Bonuses vs 2nd Edition THAC0: The main difference between 1st edition D&D attack bonuses and 2nd edition THAC0 lies in the simplification of the attack roll system introduced in the 2nd edition.
- YouTube: no description found
- Wireguard for fedora: Here is a concise response to the query on how to install and configure Wireguard VPN on Fedora: To install Wireguard on Fedora, follow these steps: 1. For...
- What's the difference between 1st edition D&D attack bonuses and 2nd edition...: The main difference between 1st edition D&D attack bonuses and 2nd edition D&D THAC0 is in how they simplified and standardized the attack roll system: 1....
- Upcoming music festivals: Here are some notable music festivals happening in 2024 across the United States: Outlaw Music Festival 2024 - Artists: Bob Dylan, Willie Nelson, John...
- advertising market size of South Korea: The advertising market in South Korea is substantial and continues to grow, driven by both traditional and digital media channels. The total advertising...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Boeing to Plead Guilty: Boeing, the aerospace giant, has agreed to plead guilty to a criminal fraud conspiracy charge related to the fatal crashes of its 737 MAX aircraft in 2018 and...
- how to connect with Perplexity.ai community on discord?: To connect with the Perplexity AI community on Discord, follow these steps: 1. Visit the official Perplexity AI website (perplexity.ai). 2. Look for the...
- Principality of Sealand: The Principality of Sealand is a fascinating micronation with a colorful history. Here are the key details about this self-proclaimed sovereign...
- Blender Rendering Tips: Blender, the popular open-source 3D creation suite, offers powerful rendering capabilities that can produce stunning results. However, for beginners,...
Perplexity AI ▷ #pplx-api (10 messages🔥):
API vs UI resultsNodemon setup issues with PPLX libraryRate limits and citation feature increases
- Massive differences between API and UI results: A member expressed concerns about massive differences between API and UI results when not using Pro or anticipating sources.
- Another member suggested trying in labs, believing that the results should be quite similar without Pro enabled or needing sources.
- Nodemon setup issues with PPLX library: A user faced problems running a compiled project with PPLX library, despite successful local execution with nodemon and specifying the right folders in tsconfig.json.
- Error details suggested a missing module issue; the user sought feedback on others' setups involving the PPLX library.
- Increases in rate limits and citation feature: A query was raised about potential increases in rate limits and the citation feature, with no response received in weeks.
- Anyone heard about increases in rate limits or the citation feature?.
LAION ▷ #general (37 messages🔥):
Deepspeed EfficiencyOpen Source Video UpscalersPaintsUndo ProjectAI System Copyright LawsuitCopyright Term Opinions
- Deepspeed Astonishes with Efficient Training: A member shared that using Deepspeed, they could train a 2.5 billion parameter model on an RTX 3090 with 1 batch size and noted that it could probably go higher.
- Exploring Open Source Video Upscalers: Members discussed various open source video upscalers, with one recommending aurasr for frame-by-frame upscaling but warning it may be slow.
- PaintsUndo Enhances Artistic Process: The PaintsUndo project aims to provide base models of human drawing behaviors, helping AI align better with needs of human artists by predicting intermediary sketch steps.
- Court Ruling Favors AI Systems in Copyright Case: A California district court partially dismissed a copyright lawsuit against Microsoft's GitHub Copilot and its underlying model, OpenAI's Codex.
- Debate Over Copyright Terms: A member voiced their opinion that copyright should be valid for 20 years after publication and emphasized the need to overhaul US copyright legislation.
- PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings: no description found
- Court ruling suggests AI systems may be in the clear as long as they don't make exact copies: A California district court has partially dismissed a copyright lawsuit against Microsoft's GitHub Copilot programming tool and its former underlying language model, OpenAI's Codex. The ruli...
- THE DECODER: Artificial Intelligence is changing the world. THE DECODER brings you all the news about AI.
LAION ▷ #research (13 messages🔥):
Generative ChameleonComplex-Valued ArchitecturesVision Architecture with 2D DFTTraining ChallengesModel Scaling Issues
- Generative Chameleon Paper Released: The first generative chameleon model has been released, and the paper is available on arXiv.
- Exploring Complex-Valued Architectures: A member has been experimenting with complex-valued architectures to make a vision model where every pixel is a token, and token mixing is handled via 2D DFT instead of attention, similar to FNet.
- Despite some success, they encountered gradual issues with deeper networks, but shallower networks seemed to train adequately.
- Scaling Issues in Complex-Valued Models: The complex-valued model, regardless of parameter count (from 11k to 400k), consistently achieves around 30% accuracy on CIFAR-100.
- Proper handling of complex values improved performance, with a 65k complex model slightly outperforming a 400k real model from previous sessions.
LAION ▷ #resources (1 messages):
Image Diffusion Models RepositoryGitHub Repo for Image DiffusionEducational Codes for Image Diffusion
- Masterful Introduction to Image Diffusion Models: A member announced a GitHub repository containing lessons on image diffusion models, trainable on minimal GPUs using small datasets.
- The focus is on learning the inner workings of each paper, with clear demonstration code through accompanying tutorial videos and Colab links.
- Practical Code-Guided Image Diffusion Package: The repository offers a practical, code-guided education package for image diffusion models.
- Contributors are encouraged to provide feedback to improve the resources.
Link mentioned: GitHub - swookey-thinky/mindiffusion: Repository of lessons exploring image diffusion models, focused on understanding and education.: Repository of lessons exploring image diffusion models, focused on understanding and education. - swookey-thinky/mindiffusion
OpenRouter (Alex Atallah) ▷ #general (47 messages🔥):
Quota Exceeded IssueImage Viewing IssuesDolphin 2.9 Mixstral on OpenRouter in LangChainMistralai Mixtral v0.1 ErrorLLM Applications for Language Translation
- Quota Exceeded for OpenRouter API: A user experienced a quota exceeded error: 'Quota exceeded for aiplatform.googleapis.com/generate_content_requests_per_minute_per_project_per_base_model with base model: gemini-1.5-flash'.
- It could be a limit imposed by Google on OpenRouter.
- Image Viewing Issues on OpenRouter: A user reported issues with image viewing on models returning None across various models like gpt-4o, claude-3.5, and firellava13b.
- Another user confirmed these images were working well for them, indicating the issue might not be widespread.
- Challenges Integrating Dolphin 2.9 Mixstral in LangChain: A user is trying to get Dolphin 2.9 Mixstral on OpenRouter to work in LangChain as a tool calling agent but is facing issues.
- Mistralai Mixtral v0.1 Not Supported for JSON Mode: A user encountered the error 'mistralai/Mixtral-8x22B-Instruct-v0.1 is not supported for JSON mode/function calling', noting it happens sporadically.
- After testing, the user identified Together as the provider causing the issue.
- LLM Applications for Language Translation Preferences: Users discussed the effectiveness of LLMs for translation, comparing them to specialized translation models.
- One user highlighted that modern LLMs use decoder-only models and may not be as reliable as true encoder/decoder transformers for translation tasks.
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- Provider Routing | OpenRouter: Route requests across multiple providers
Latent Space ▷ #ai-general-chat (27 messages🔥):
Claude Contest ReminderNuance in Speech ModelsAI Math Competition SuccessSupermaven's Babble UpgradeLillian Weng's Blog on Hallucinations
- Claude Contest Reminder: A member reminded the community about the Build with Claude contest with $30k in Anthropic API credits, ending in two days. Alex Albert's post provides more details.
- Nuance in Speech Models Discussed: A thread highlighted differences between GPT-4o's polished turn-based model and Moshi's unpolished full-duplex model. The discussion stemmed from experiences shared by JulianSlzr and Andrej Karpathy.
- AI Achieves Math Olympiad Success: Thom Wolf praised the AI Math Olympiad, where Numina and Hugging Face's collaboration led to impressive results. Details on the event and its significance are available in Thom Wolf's thread.
- Supermaven Launches Babble: Supermaven announced the deployment of Babble, a new model with a 1 million token context window, which is 2.5x larger than their previous model. Learn more about the upgrade in SupermavenAI's tweet.
- Lillian Weng Discusses Hallucinations in LLMs: Lillian Weng's blog post delves into the types and causes of hallucinations in large language models. Read the full discussion here.
- turbopuffer: fast search on object storage: turbopuffer is a vector database built on top of object storage, which means 10x-100x cheaper, usage-based pricing, and massive scalability
- Extrinsic Hallucinations in LLMs: Hallucination in large language models usually refers to the model generating unfaithful, fabricated, inconsistent, or nonsensical content. As a term, hallucination has been somewhat generalized to ca...
- Tweet from Supermaven (@SupermavenAI): We've trained Babble, a new model with a 1 million token context window. Babble is 2.5x larger than the previous Supermaven model and upgrades our context length from 300,000 to 1 million tokens....
- Tweet from Alex Albert (@alexalbert__): 1) Prompt generator Input a task description and Claude 3.5 Sonnet will turn the task description into a high-quality prompt for you. Gets rid of the prompting blank page problem all together.
- Tweet from anton (𝔴𝔞𝔯𝔱𝔦𝔪𝔢) (@atroyn): today i'm pleased to present chroma's next technical report, our evaluation of the impact of chunking strategies on retrieval performance in the context of ai applications. @brandonstarxel @tr...
- Tweet from Deepak Pathak (@pathak2206): Thrilled to announce @SkildAI! Over the past year, @gupta_abhinav_ and I have been working with our top-tier team to build an AI foundation model grounded in the physical world. Today, we’re taking Sk...
- Tweet from Thomas Wolf (@Thom_Wolf): There was a super impressive AI competition that happened last week that many people missed in the noise of AI world. I happen to know several participants so let me tell you a bit of this story as a ...
- Tweet from Elon Musk (@elonmusk): xAI contracted for 24k H100s from Oracle and Grok 2 trained on those. Grok 2 is going through finetuning and bug fixes. Probably ready to release next month. xAI is building the 100k H100 system its...
- Tweet from Alex Albert (@alexalbert__): Two days left to participate in the contest! Quoting Alex Albert (@alexalbert__) Announcing the Build with Claude June 2024 contest. We're giving out $30k in Anthropic API credits. All you nee...
- Tweet from Julian Salazar (@JulianSlzr): Nuance is lost (and revealed!) by takes like @karpathy's. I claim: - GPT-4o voice (@openai) is a polished e2e *turn-based* model - Moshi (@kyutai_labs) is an unpolished e2e *full-duplex* model A ...
- SenseTime unveils SenseNova 5o, China's first real-time multimodal AI model to rival GPT-4o: Chinese AI company SenseTime introduced its new multimodal AI model SenseNova 5o and the improved language model SenseNova 5.5 at the World Artificial Intelligence Conference.
- Tweet from Xiaolong Wang (@xiaolonw): Cannot believe this finally happened! Over the last 1.5 years, we have been developing a new LLM architecture, with linear complexity and expressive hidden states, for long-context modeling. The follo...
LangChain AI ▷ #general (16 messages🔥):
LLMWhisperer PDF ExtractionMulti-agent chatbot issues in LangChainCrawlee for Python launchQuestion answering over PDF docs using RAGConversationSummaryMemory in LangChain
- LLMWhisperer handles complex PDFs like a pro: A user shared that LLMWhisperer effectively parses complex PDFs, allowing for extraction of meaningful data using an LLM to parse each page and eventually merging the JSONs for comprehensive document parsing. They recommended leveraging Pydantic or zod schema in LangChain to achieve this.
- Solving multi-agent chatbot in LangChain: A query was made on how to solve multi-agent chatbot issues in LangChain, and the solution included steps like understanding Tools, Agents, and LLMs, using LangSmith, picking the right chat model, and referring to community support. Detailed instructions and sources are available at LangChain's official JavaScript documentation.
- Crawlee for Python launch announced: Crawlee for Python was announced by a developer community manager at Apify, highlighting features like unified interfaces for HTTP and headless browsers using Playwright, and automatic scaling and session management. They invited users to check it out on GitHub and support it on Product Hunt.
- Best practices for RAG in question answering chains: A user asked about integrating RAG components into an existing question-answering chain in LangChain with history maintenance and context length handling. The discussion pointed towards creating a new chain specifically for RAG to ensure the original chain doesn't trim the loaded PDF documents.
- ConversationSummaryMemory for multiple humans: A user inquired if LangChain's ConversationSummaryMemory supports multiple humans and sought advice on summarizing large chunks of conversations. The topic remains open for further community input and solutions.
- Tweet from Asim Shrestha (@asimdotshrestha): Excited to more broadly share what we've been working on at @ReworkdAI ⚡️ This past year we've fully invested in building the next generation of web agents. They're already live in produc...
- International Chatting group 💕: WhatsApp Group Invite
- PDF Checkbox Extraction with LLMWhisperer: This is a demonstration that shows how to process PDF form elements like checkboxes and radiobuttons with LLMWhisperer, which is a text extraction service th...
- GitHub - apify/crawlee-python: Crawlee—A web scraping and browser automation library for Python to build reliable crawlers. Extract data for AI, LLMs, RAG, or GPTs. Download HTML, PDF, JPG, PNG, and other files from websites. Works with BeautifulSoup, Playwright, and raw HTTP. Both headful and headless mode. With proxy rotation.: Crawlee—A web scraping and browser automation library for Python to build reliable crawlers. Extract data for AI, LLMs, RAG, or GPTs. Download HTML, PDF, JPG, PNG, and other files from websites. Wo...
- Crawlee for Python - Build reliable scrapers in Python | Product Hunt: We are launching Crawlee for Python, an open-source library for web scraping and browser automation. Quickly scrape data, store it, and avoid getting blocked, headless browsers, and smart proxy rotati...
- Build a Chatbot | 🦜️🔗 Langchain: Overview
- How to use legacy LangChain Agents (AgentExecutor) | 🦜️🔗 Langchain: This guide assumes familiarity with the following concepts:
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (5 messages):
LlamappSlack Bot Agent GuideRubik's AI Pro Beta TestingRAG ArticleWeb Data Extraction LLMs
- Meet Llamapp: Local Retrieval Augmented Generator: Llamapp is a locally operated Retrieval Augmented Generator (RAG) that combines document retrieval and language model generation for accurate, contextually relevant responses.
- It uses custom retrievers and Reciprocal Ranking Fusion to provide compelling document sets and ensures that the LLM sticks to the source of truth.
- Guide to Creating Slack Bot Agent with LangChain and ChatGPT: A guide provides detailed steps to create a Slack Bot Agent that leverages Composio, LangChain, OpenAI, and ChatGPT to review PRs every time they're created.
- The guide demonstrates how to use various frameworks to automate the PR review process.
- Rubik's AI Pro: Become a Beta Tester: Invitation to beta test an advanced research assistant and search engine with models like Claude 3 Opus and GPT-4o, offering 2 months of free premium access using the code
RUBIX.- Rubik's AI Pro provides access to cutting-edge models and online citations, with a two-month premium trial for feedback.
- New Article on Running RAG Locally: A member shared an article on running RAG locally, including custom FRR, hybrid retrievers, and custom loaders.
- The article is aimed at providing insights into operating a Retrieval Augmented Generator from your laptop and encourages community feedback.
- Launch of LLMs for Web Data Extraction: A new broad launch of LLMs focused on automatic web data extraction was shared, asking for community support.
- Slack Bot Agent to review PRs: This guide provides detailed steps to create a Slack Bot Agent that leverages agentic frameworks, OpenAI and ChatGPT to review PRs every time they're created.
- Tweet from Asim Shrestha (@asimdotshrestha): Excited to more broadly share what we've been working on at @ReworkdAI ⚡️ This past year we've fully invested in building the next generation of web agents. They're already live in produc...
- GitHub - rajatasusual/llamapp: A Retrieval Augmented Generator (RAG) that operates entirely locally, combining document retrieval and language model generation to provide accurate and contextually relevant responses. Built with @Langchain-ai: A Retrieval Augmented Generator (RAG) that operates entirely locally, combining document retrieval and language model generation to provide accurate and contextually relevant responses. Built with ...
- Rubik's AI - AI research assistant & Search Engine: no description found
LangChain AI ▷ #tutorials (1 messages):
Slack Bot AgentComposio and LangChainPR review automation with OpenAI and ChatGPT
- Guide for creating a Slack Bot Agent: A member shared a guide on creating a Slack Bot Agent utilizing Composio, LangChain, OpenAI, and ChatGPT to automate PR reviews.
- The guide includes detailed steps for setting up the agent, mentioning the use of multiple frameworks and tools.
- Automated PR Reviews with ChatGPT: The guide provides detailed steps to create a Slack Bot Agent that leverages agentic frameworks, OpenAI and ChatGPT to review PRs every time they're created.
Link mentioned: Slack Bot Agent to review PRs: This guide provides detailed steps to create a Slack Bot Agent that leverages agentic frameworks, OpenAI and ChatGPT to review PRs every time they're created.
OpenInterpreter ▷ #general (20 messages🔥):
OI executes with code examplesMisplaced self-advertisingUsing '--model i' with local vision mode'i model' functionalityQwen 2 7b issues
- OI executes with code examples seamlessly: A member mentioned that by adding code instruction examples, OI executes perfectly, similar to how assistant.py handles different skill instructions.
- Qwen 2 7B model prints random '@': A member noted that Qwen 2 7B model impressively handles 128k but arbitrarily prints random '@' inline, breaking code.
- Using '--model i' with local vision mode: A discussion emerged about whether '--model i' can operate with local vision mode and if it is multimodal.
- Explanation on GROQ usage with OS mode: There were inquiries about using GROQ with OS mode and whether a multimodal model is required.
- Interpreting screen coordinates with Open Interpreter: A member sought clarification on how Open Interpreter acquires screen coordinates.
Link mentioned: open-interpreter/interpreter/terminal_interface/profiles/defaults/os.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #general (9 messages🔥):
NV=1 supportCompatibility with architectures older than AmpereGeorge Hotz's comments on compatibilityPotential community contributions for older architecturesGSP firmware-based generations
- NV=1 only supported on Ampere & newer: A member asked if NV=1 is supported only on Ampere or newer, and another member confirmed that it indeed is supported on Ampere and Ada architectures.
- Compatibility with Turing cards for NV=1: One user discussed potentially setting up Linux to try NV=1 but was concerned about the compatibility with Turing cards.
- Another member mentioned that making it compatible for older architectures is low-priority and would likely require community contributions.
- George Hotz confirms Turing generation compatibility: George Hotz clarified that the Turing generation (e.g., 2070, 2080) is also supported for NV=1, as they are included in the list of GSP firmware-based generations.
tinygrad (George Hotz) ▷ #learn-tinygrad (9 messages🔥):
Recommended video courses for learning tinygradIssue with NV=1 on WSL2CUDA compatibility on WSL2NVIDIA open GPU kernel module on WSL2
- Learning tinygrad with video courses: A member asked for video course recommendations for learning tinygrad and was advised to watch Karpathy's transformer video despite it being in PyTorch as it engages viewers better.
- "Thanks a lot Tobi.. I will try that.. probably a good way to explore documentation while implementing it." - ghost22111
- Issues with NV=1 on WSL2: A member experienced issues getting NV=1 working on WSL2 and found
dev/nvidiactlto be missing, with some suggestions pointing todxg.- Another member noted that NVIDIA's open GPU kernel module might be required, but was unsure what Microsoft bundles in WSL2.
Link mentioned: GitHub - NVIDIA/open-gpu-kernel-modules: NVIDIA Linux open GPU kernel module source: NVIDIA Linux open GPU kernel module source. Contribute to NVIDIA/open-gpu-kernel-modules development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #news (7 messages):
GitHub Copilot lawsuitDeveloper concerns on CopilotLegal implications for Microsoft and OpenAI
- GitHub Copilot lawsuit narrows: Claims by developers that GitHub Copilot was unlawfully copying their code have largely been dismissed, leaving engineers with two allegations remaining in their lawsuit against GitHub, Microsoft, and OpenAI.
- The class-action suit filed in November 2022 argued that Copilot was trained on open source software without giving appropriate credit, violating intellectual property rights.
- Developer's in-person reaction to Copilot issues: Upon being asked in person about the ongoing concerns with Copilot, the engineer humorously affirmed the response: "good enough for lawyers".
Link mentioned: Judge dismisses DMCA copyright claim in GitHub Copilot suit: A few devs versus the powerful forces of Redmond – who did you think was going to win?
Interconnects (Nathan Lambert) ▷ #ml-questions (4 messages):
Control VectorSteering VectorConcept VectorsFeature ClampingFeature Steering
- Concept Vectors discussed as synonyms to Steering Vectors: A member inquired if Control Vector, Steering Vector, and Concept Vectors are basically synonyms with Steering Vectors being just the application of Control Vectors in language models.
- Another member confirmed that the first two terms are used to control the last one.
- Feature Clamping distinct from Feature Steering: The discussion also touched on how Feature Clamping is distinct but related within the toolbox of Feature Steering in RepEng.
Interconnects (Nathan Lambert) ▷ #ml-drama (5 messages):
Google Flame paper issueAI bill controversyTraining on test data
- Google Flame scores removed due to issues: The team at Google responsible for the 'Google Flame' scores and paper had the scores removed due to 'some issue.'
- There are humorous suspicions whether they 'trained on test data'.
- AI bill sparks controversy: Twitter link shows Scott Wiener calling out a16z and Y Combinator for their 'inaccurate, inflammatory statements' about the SB 1047 AI bill in CA.
- They have been loudly opposing this bill online, really turning heads in the AI community.
Link mentioned: Tweet from Helen Toner (@hlntnr): Shots fired by @Scott_Wiener 👀 Image is a letter from last week where Wiener (the state senator behind SB 1047, an AI bill in CA) directly calls out a16z and Y Combinator for "inaccurate, inflam...
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
Credit IssuesMember Response Time
- Member filled out forms but no credits received: A member reported that they filled out the necessary forms but haven't received the credits yet.
- Response time request by members: One member requested others to respond to their direct messages within the next 72 hours in order to double-check certain details.
LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (7 messages):
Multi GPU Training IssuesAccelerate ConfigurationBatch Size ImpactPerformance ExpectationsDebugging Techniques
- Multi GPU setup disappoints with slow performance: A member expressed frustration as their multi GPU setup with H100 GPU x 6 resulted in training speeds 10x slower than expected.
- Another member suggested adjusting the batch size and following the troubleshooting guide from Hugging Face.
- Adjust Batch Size for Multi GPU: A discussion highlighted the importance of adjusting the batch size when testing 1:1 speed up with multiple GPUs.
- Members advised to provide throughput numbers and source code for further diagnosis and optimization, referencing best practices from documentation.
- Realistic Performance Expectations for Multi GPU: Expectations for speed improvements were questioned as members noted 10x / 1:1 speed up is unrealistic due to communication overheads in multi GPU setups.
- Realistic speed improvements from 1->8 GPUs were estimated at 6-7x if the throughput is optimal.
Link mentioned: Troubleshoot: no description found
Cohere ▷ #general (7 messages):
Teaching and Learning PlatformCommandR RAG-Optimized FeaturesDark Mode ReleaseEnterprise Features Adaptation
- Teacher explores CommandR for learning platform: A public school teacher is developing a Teaching and Learning Platform and is considering CommandR for its RAG-optimized features.
- Community members welcomed the idea, expressing excitement and offered help if needed.
- Dark Mode release on the horizon: A new feature, Dark Mode, is under development and will be part of a larger release aimed at enterprises.
- This feature might also be adapted to a free platform like Coral to benefit more users.
Cohere ▷ #project-sharing (1 messages):
competent: Agreed 👍
Mozilla AI ▷ #llamafile (4 messages):
Performance penalty in llama.cppBenchmark suite upgrade issues
- Performance hit in versions 0.8.8 to 0.8.9 on NVIDIA GPUs: A member observed a ~25% performance penalty between versions 0.8.8 and 0.8.9 of llama.cpp on NVIDIA GPUs and inquired if this is a known issue.
- The performance downgrade was notable as a 3090 performed similarly to a 3060 on the older version.
- Benchmark suite upgrade impacts performance: A member writing a benchmark suite noticed the issue after upgrading the version of llamafile.
- Another member responded, stating they didn't change anything recently, which could impact performance.
AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
__n2k: ^ I made those watermelons 🍉 😄
AI Stack Devs (Yoko Li) ▷ #events (1 messages):
Book to Game JamRosebud AIPuzzle gamesRhythm gamesText-based adventures
- Rosebud AI Jam converts books to games: Participants created puzzle games, rhythm games, and text-based adventures inspired by authors like Lewis Carroll, China Miéville, and R.L. Stine during the Rosebud AI Book to Game Jam.
- Winners will be announced on Wednesday, July 10th at 11:30 AM PST in the Rosebud AI server. Check out the entries here.
- Rosebud AI showcases creative game entries: Rosebud AI highlighted the submissions made during the Book to Game Jam, emphasizing the creativity and diversity of the entries.
- Entries converted literary works into various game genres, showcasing the capabilities of Phaser and AI technology.
Link mentioned: Tweet from Rosie @ Rosebud AI 🌹 (@Rosebud_AI): Books turned into games with AI 🌹 Our recent jam had devs use Rosebud AI to create games from literary works, and these are the results! Winners will be revealed this Wednesday July 10th at 11:30 A...
MLOps @Chipro ▷ #events (1 messages):
KAN authorsalphaXiv forumarXiv paper discussion
- KAN Authors Engage on alphaXiv Forum: Authors of the KAN paper are actively responding to questions on the alphaXiv forum this week.
- The discussion is centered on the top points of their recent arXiv paper.
- Discussion on KAN Paper on alphaXiv: The alphaXiv forum is currently hosting a lively discussion regarding the KAN paper, with authors answering community questions.
- Participants are delving into the technical details of the KAN methodology as outlined in the paper.
Link mentioned: alphaXiv: no description found
MLOps @Chipro ▷ #general-ml (1 messages):
Information RetrievalRecommendationsPodcast GuestsOutreach
- Podcaster Seeks Information Retrieval Experts: A member mentioned scheduling episodes with Cohere, Zilliz, and Doug Turnbull for their podcast series on information retrieval and recommendations.
- Request for More Expert Names: The same member asked for suggestions of other experts in the field of information retrieval and recommendations to interview for their podcast.
LLM Perf Enthusiasts AI ▷ #general (1 messages):
frandecam: Does anyone know if there is a OpenAI 10K credits or similar program for Anthropic?