[AINews] Nemotron-4-340B: NVIDIA's new large open models, built on syndata, great for syndata
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Synthetic Data is 98% of all you need.
AI News for 6/13/2024-6/14/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (414 channels, and 2481 messages) for you. Estimated reading time saved (at 200wpm): 280 minutes. You can now tag @smol_ai for AINews discussions!
NVIDIA has completed scaling up Nemotron-4 15B released in Feb, to a whopping 340B dense model. Philipp Schmid has the best bullet point details you need to know:

From NVIDIA blog, Huggingface, Technical Report, Bryan Catanzaro, Oleksii Kuchaiev.
The synthetic data pipeline is worth further study:
Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
and
Notably, throughout the entire alignment process, we relied on only approximately 20K human-annotated data (10K for supervised fine-tuning, 10K Helpsteer2 data for reward model training and preference fine-tuning), while our data generation pipeline synthesized over 98% of the data used for supervised fine-tuning and preference fine-tuning.
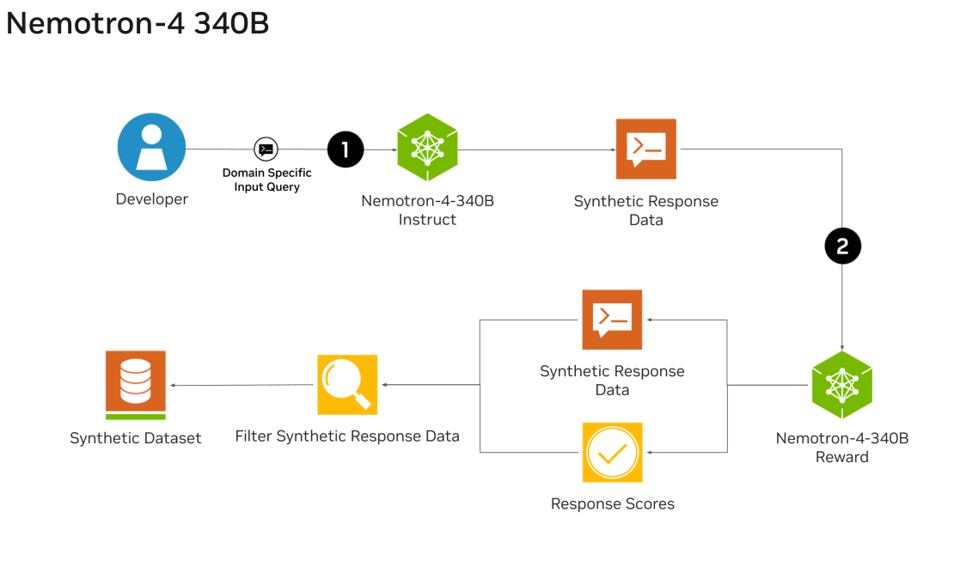
Section 3.2 in the paper provides lots of delicious detail on the pipeline:
- Synthetic single-turn prompts
- Synthetic instruction-following prompts
- Synthetic two-turn prompts
- Synthetic Dialogue Generation
- Synthetic Preference Data Generation
The base and instruct models easily beat Mixtral and Llama 3, but perhaps that is not surprising for half an order of magnitude larger params. However they also release a Reward Model version that ranks better than Gemini 1.5, Cohere, and GPT 4o. The detail disclosure is interesting:

and this RM replaced LLM as Judge

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- CUDA MODE Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- OpenAI Discord
- HuggingFace Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- Perplexity AI Discord
- LlamaIndex Discord
- LLM Finetuning (Hamel + Dan) Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- OpenInterpreter Discord
- Cohere Discord
- LangChain AI Discord
- tinygrad (George Hotz) Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- Datasette - LLM (@SimonW) Discord
- DiscoResearch Discord
- PART 2: Detailed by-Channel summaries and links
- Stability.ai (Stable Diffusion) ▷ #general-chat (462 messages🔥🔥🔥):
- CUDA MODE ▷ #general (5 messages):
- CUDA MODE ▷ #triton (8 messages🔥):
- CUDA MODE ▷ #torch (25 messages🔥):
- CUDA MODE ▷ #cool-links (1 messages):
- CUDA MODE ▷ #beginner (3 messages):
- CUDA MODE ▷ #torchao (3 messages):
- CUDA MODE ▷ #off-topic (10 messages🔥):
- CUDA MODE ▷ #llmdotc (246 messages🔥🔥):
- CUDA MODE ▷ #bitnet (17 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (170 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #random (18 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (125 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (3 messages):
- LM Studio ▷ #💬-general (140 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (28 messages🔥):
- LM Studio ▷ #🎛-hardware-discussion (114 messages🔥🔥):
- LM Studio ▷ #🧪-beta-releases-chat (26 messages🔥):
- LM Studio ▷ #autogen (1 messages):
- LM Studio ▷ #model-announcements (1 messages):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (203 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (26 messages🔥):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- HuggingFace ▷ #general (112 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #cool-finds (4 messages):
- HuggingFace ▷ #i-made-this (6 messages):
- HuggingFace ▷ #reading-group (1 messages):
- HuggingFace ▷ #computer-vision (6 messages):
- HuggingFace ▷ #NLP (6 messages):
- HuggingFace ▷ #diffusion-discussions (13 messages🔥):
- Nous Research AI ▷ #off-topic (1 messages):
- Nous Research AI ▷ #interesting-links (5 messages):
- Nous Research AI ▷ #general (69 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (7 messages):
- Nous Research AI ▷ #rag-dataset (39 messages🔥):
- Nous Research AI ▷ #world-sim (2 messages):
- Modular (Mojo 🔥) ▷ #general (9 messages🔥):
- Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- Modular (Mojo 🔥) ▷ #🔥mojo (92 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #nightly (3 messages):
- Perplexity AI ▷ #general (92 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- LlamaIndex ▷ #blog (1 messages):
- LlamaIndex ▷ #general (63 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #general (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #learning-resources (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #replicate (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #langsmith (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #simon_cli_llms (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #credits-questions (12 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #fireworks (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #predibase (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #career-questions-and-stories (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #openai (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #pawel-function-calling (5 messages):
- Eleuther ▷ #general (6 messages):
- Eleuther ▷ #research (37 messages🔥):
- Eleuther ▷ #lm-thunderdome (1 messages):
- Eleuther ▷ #multimodal-general (4 messages):
- OpenRouter (Alex Atallah) ▷ #general (35 messages🔥):
- OpenInterpreter ▷ #general (25 messages🔥):
- OpenInterpreter ▷ #O1 (4 messages):
- Cohere ▷ #general (19 messages🔥):
- Cohere ▷ #project-sharing (4 messages):
- LangChain AI ▷ #general (19 messages🔥):
- LangChain AI ▷ #tutorials (3 messages):
- tinygrad (George Hotz) ▷ #general (4 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Interconnects (Nathan Lambert) ▷ #memes (2 messages):
- Latent Space ▷ #ai-general-chat (4 messages):
- Latent Space ▷ #ai-in-action-club (8 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (8 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- LAION ▷ #general (5 messages):
- LAION ▷ #research (4 messages):
- Datasette - LLM (@SimonW) ▷ #ai (2 messages):
- DiscoResearch ▷ #discolm_german (1 messages):
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- New NVIDIA Nemotron-4-340B LLM released: @ctnzr NVIDIA released 340B dense LLM matching GPT-4 performance. Base, Reward, and Instruct models available. Trained on 9T tokens.
- Mamba-2-Hybrid 8B outperforms Transformer: @rohanpaul_ai Mamba-2-Hybrid 8B exceeds 8B Transformer on evaluated tasks, predicted to be up to 8x faster at inference. Matches or exceeds Transformer on long-context tasks.
- Samba model for infinite context: @_philschmid Samba combines Mamba, MLP, Sliding Window Attention for infinite context length with linear complexity. Samba-3.8B-instruct outperforms Phi-3-mini.
- Dolphin-2.9.3 tiny models pack a punch: @cognitivecompai Dolphin-2.9.3 0.5b and 1.5b models released, focused on instruct and conversation. Can run on wristwatch or Raspberry Pi.
- Faro Yi 9B DPO model with 200K context: @01AI_Yi Faro Yi 9B DPO praised for 200K context in just 16GB VRAM, enabling efficient AI.
Techniques and Architectures
- Mixture-of-Agents (MoA) boosts open-source LLM: @llama_index MoA setup with open-source LLMs surpasses GPT-4 Omni on AlpacaEval 2.0. Layers multiple LLM agents to refine responses.
- Lamini Memory Tuning for 95% LLM accuracy: @realSharonZhou Lamini Memory Tuning achieves 95%+ accuracy, cuts hallucinations by 10x. Turns open LLM into 1M-way adapter MoE.
- LoRA finetuning insights: @rohanpaul_ai LoRA finetuning paper found initializing matrix A with random and B with zeros generally leads to better performance. Allows larger learning rates.
- Discovered Preference Optimization (DiscoPOP): @rohanpaul_ai DiscoPOP outperforms DPO using LLM to propose and evaluate preference optimization loss functions. Uses adaptive blend of logistic and exponential loss.
Multimodal AI
- Depth Anything V2 for monocular depth estimation: @_akhaliq, @arankomatsuzaki Depth Anything V2 produces finer depth predictions. Trained on 595K synthetic labeled and 62M+ real unlabeled images.
- Meta's An Image is Worth More Than 16x16 Patches: @arankomatsuzaki Meta paper shows Transformers can directly work with individual pixels vs patches, resulting in better performance at more cost.
- OpenVLA open-source vision-language-action model: @_akhaliq OpenVLA 7B open-source model pretrained on robot demos. Outperforms RT-2-X and Octo. Builds on Llama 2 + DINOv2 and SigLIP.
Benchmarks and Datasets
- Test of Time benchmark for LLM temporal reasoning: @arankomatsuzaki Google's Test of Time benchmark assesses LLM temporal reasoning abilities. ~5K test samples.
- CS-Bench for LLM computer science mastery: @arankomatsuzaki CS-Bench is comprehensive benchmark with ~5K samples covering 26 CS subfields.
- HelpSteer2 dataset for reward modeling: @_akhaliq NVIDIA's HelpSteer2 is dataset for training reward models. High-quality dataset of only 10K response pairs.
- Recap-DataComp-1B dataset: @rohanpaul_ai Recap-DataComp-1B dataset generated by recaptioning DataComp-1B's ~1.3B images using LLaMA-3. Improves vision-language model performance.
Miscellaneous
- Scale AI's hiring policy focused on merit: @alexandr_wang Scale AI formalized hiring policy focused on merit, excellence, intelligence.
- Paul Nakasone joins OpenAI board: @sama General Paul Nakasone joining OpenAI board praised for adding safety and security expertise.
- Apple Intelligence announced at WWDC: @bindureddy Apple Intelligence, Apple's AI initiatives, announced at WWDC.
Memes and Humor
- Simulation hypothesis: @karpathy Andrej Karpathy joked about simulation hypothesis - maybe simulation is neural and approximate vs exact.
- Prompt engineering dumb in hindsight: @svpino Santiago Valdarrama noted prompt engineering looks dumb today compared to a year ago.
- Yann LeCun on Elon Musk and Mars: @ylecun Yann LeCun joked about Elon Musk going to Mars without a space helmet.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Stable Diffusion 3.0 Release and Reactions
- Stable Diffusion 3.0 medium model released: In /r/StableDiffusion, Stability AI released the SD3 medium model, but many are disappointed with the results, especially for human anatomy. Some call it a "joke" compared to the full 8B model.
- Heavy censorship and "safety" filtering in SD3: The /r/StableDiffusion community suspects SD3 has been heavily censored, resulting in poor human anatomy. The model seems "asexual, smooth and childlike".
- Strong prompt adherence, but anatomy issues: SD3 shows strong prompt adherence for many subjects, but struggles with human poses like "laying". Some are experimenting with cascade training to improve results.
- T5xxl text encoder helps with prompts: Some find the t5xxl text encoder improves SD3's prompt understanding, especially for text, but it doesn't fix the anatomy problems.
- Calls for community to train uncensored model: There are calls for the community to band together and train an uncensored model, as fine-tuning SD3 is unlikely to fully resolve the issues. However, it would require significant resources.
AI Progress and the Future
- China's rise as a scientific superpower: The Economist reports that China has become a scientific superpower, making major strides in research output and impact.
- Former NSA Chief joins OpenAI board: OpenAI has added former NSA Chief Paul Nakasone to its board, raising some concerns in /r/singularity about the implications.
New AI Models and Techniques
- Samba hybrid architecture outperforms transformers: Microsoft introduced Samba, a hybrid SSM architecture with infinite context length that outperforms transformers on long-range tasks.
- Lamini Memory Tuning reduces hallucinations: Lamini.ai's Memory Tuning embeds facts into LLMs, improving accuracy to 95% and reducing hallucinations by 10x.
- Mixture of Agents (MoA) outperforms GPT-4: TogetherAI's MoA combines multiple LLMs to outperform GPT-4 on benchmarks by leveraging their strengths.
- WebLLM enables in-browser LLM inference: WebLLM is a high-performance in-browser LLM inference engine accelerated by WebGPU, enabling client-side AI apps.
AI Hardware and Infrastructure
- Samsung's turnkey AI chip approach: Samsung has cut AI chip production time by 20% with an integrated memory, foundry and packaging approach. They expect chip revenue to hit $778B by 2028.
- Cerebras wafer-scale chips excel at AI workloads: Cerebras' wafer-scale chips outperform supercomputers on molecular dynamics simulations and sparse AI inference tasks.
- Handling terabytes of ML data: The /r/MachineLearning community discusses approaches for handling terabytes of data in machine learning pipelines.
Memes and Humor
- Memes mock SD3's censorship and anatomy: The /r/StableDiffusion subreddit is filled with memes and jokes poking fun at SD3's poor anatomy and heavy-handed content filtering, with calls to "sack the intern".
AI Discord Recap
A summary of Summaries of Summaries
1. NVIDIA Pushes Performance with Nemotron-4 340B:
- NVIDIA's Nemotron-4-340B Model: NVIDIA's new 340-billion parameter model includes variants like Instruct and Reward, designed for high efficiency and broader language support, fitting on a DGX H100 with 8 GPUs and FP8 precision.
- Fine-tuning Nemotron-4 340B presents resource challenges, with estimates pointing to the need for 40 A100/H100 GPUs, although inference might require fewer resources, roughly half the nodes.
2. UNIX-based Systems Handle SD3 with ComfyUI:
- SD3 Config and Performance: Users shared how setting up Stable Diffusion 3 in ComfyUI involved downloading text encoders, with resolution adjustments like 1024x1024 recommended for better results in anime and realistic renditions.
- Split opinions on the anatomy accuracy of SD3 models spurred calls for Stability AI to address these shortcomings in future updates, reflecting ongoing discussions on community expectations and model limitations.
3. Identifying and Solving GPU Compatibility Issues:
- CUDA and Torch Runtime Anomalies: Anomalies in
torch.matmulacross Ada GPUs prompted tests comparing GPUs like RTX 4090, resolving that CUDA versions and benchmarks impact performance, with hopes for clarification from the PyTorch team.
- Establishment of multi-threading protocols in Mojo promises performance gains. Insights were shared on how Mojo's structured memory handling can position it as a reliable alternative to CUDA in the long term.
4. API Inconsistencies Frustrate Users:
- Perplexity API and Server Outages: Users reported frequent server outages and broken functionalities, such as file uploads and link generation errors, leading to ongoing frustration and doubts about the value of upgrading to Perplexity Pro.
- LangChain and pgvector Integration: Issues encountered with recognizing imports despite following documentation highlighted challenges, suggesting careful Python environment setups to ensure seamless integration.
5. Community Efforts and Resource Management:
- DiscoPOP Optimization: Sakana AI's method, DiscoPOP, claims superior preference optimization, promising high performance while deviating minimally from the base model.
- Scaling Training Efforts: Community discussions around handling extensive datasets for Retrieval-Augmented Generation (RAG) emphasize chunking, indexing, and query decomposition for improved model training and managing context lengths beyond 8k tokens.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 3 Discord Bot Shared with the World: A Discord bot facilitating the generation of images from prompts using Stable Diffusion 3 was open-sourced, offering users a new tool for visual content creation.
- Tuning SDXL for Better Anime Character Renders: SDXL training for realistic and anime generation faced challenges, producing overly cartoonish results; a recommendation was made to use 1024x1024 resolution to improve outcomes.
- Navigating ComfyUI Setup for SD3: Assistance was provided for setting up Stable Diffusion 3 in ComfyUI, involving steps like downloading text encoders, with guidance sourced from Civitai's quickstart guides.
- Community Split on SD3 Anatomy Accuracy: A discussion focused on the perceived limitations of SD3 particularly in human anatomy rendering, highlighting a user's call for Stability AI to address and communicate solutions for these issues.
- LoRA Layers in Training Limbo for SD3: The conversation touched on training new LoRAs for SD3, noting the lack of efficient tools and workflows, with users anticipating future updates to enhance functionality.
CUDA MODE Discord
Processor Showdown: MilkV Duo vs. RK3588: Engineers compared the MilkDuo 64MB controller with the RK3588's 6.0 TOPs NPU, raising discussions around hardware capability versus the optimization prowess of the sophgo/tpu-mlir compiler. They shared technical details and benchmarks, causing curiosity about the actual source of MilkDuo's performance benefits.
The Triton 3.0 Effect: Triton 3.0's new shape manipulation operations and bug fixes in the interpreter were hot topics. Meanwhile, a user grappling with the LLVM ERROR: mma16816 data type not supported during low-bit kernel implementation triggered suggestions to engage with ongoing updates on the Triton GitHub repo.
PyTorch's Mysterious Matrix Math: The torch.matmul anomaly led to benchmarking across different GPUs, where performance boosts observed on Ada GPUs sparked a desire for deeper insights from the PyTorch team, as highlighted in shared GitHub Gist.
C++ for CUDA, Triton as an Alternative: Within the community, the need for C/C++ for crafting high-performance CUDA kernels was affirmed, with an emphasis on Triton's growing suitability for ML/DL applications due to its integration with PyTorch and ability to simplify memory handling.
Tensor Cores Driving INT8 Performance: Discussion in #bitnet centered on achieving performance targets with INT8 operations on tensor cores, with empirical feedback showing up to 7x speedup for large matrix shapes on A100 GPUs but diminishing returns for larger batch sizes. The role of tensor cores in performance for various sized matrices and batch operations was scrutinized, noting efficiency differences between INT8 vs FP16/BF16 and the impacts of wmma requirements.
Inter-threading Discord Discussions: The challenges of following discussions on Discord were aired, with members expressing a preference for forums for information repository and advocating for threading and replies as tactics for better managing conversations in real-time channels.
Meta Training and Inference Accelerator (MTIA) Compatibility: MTIA's Triton compatibility was highlighted, marking an interest for streamlined compilation processes in AI model development stages.
Consideration of Triton for New Architectures: In #torchao, the conservativeness of torch.nn in adding new models was contrasted with AO's receptiveness towards facilitating specific new architectures, indicating selective model support and potential speed enhancements.
Coding Dilemmas and Community-Coding: A collaborative stance was evident as members deliberated over improving and merging intricate Pull Requests (PRs), debugging, and manual testing, particularly in multi-GPU setups on #llmdotc. Multi-threaded conversations highlighted a complexity in accurate gradient norms and weight update conditions linked to ZeRO-2's pending integration.
Blueprints for Bespoke Bitwise Operations: Live code review sessions were proposed to demystify murky PR advancements, and the #bitnet community dissected the impact of scalar quantization on performance, revealing observations like average 5-6x improvements on large matrices and the sensitivity of gains on batch sizes with a linked resource for deeper dive: BitBLAS performance analysis.
Unsloth AI (Daniel Han) Discord
- Unsloth AI Sparks ASCII Art Fan Club: The community has shown great appreciation for the ASCII art of Unsloth, sparking humorous suggestions about how the art should evolve with training failures.
- DiscoPOP Gains Optimization Fans: The new DisloPOP optimizer from Sakana AI is drawing attention for its effective preference optimization functions, as detailed in a blog post.
- Merging Models: Ollama Latest Commit Buzz: The latest commits to Ollama are showing significant support enhancements, but members are left puzzling over the unclear improvements between Triton 2.0 and the elusive 3.0 iteration.
- GitHub to the Rescue for Llama.cpp Predicaments: Installation issues with Llama.cpp are being addressed with a fresh GitHub PR, and Python 3.9 is confirmed as a minimum requirement for Unsloth projects.
- Gemini API Contest Beckons Builders: The Gemini API Developer Competition invites participants to join forces, brainstorm ideas, and build projects, with hopefuls directed to the official competition page.
LM Studio Discord
Noisy Inference Got You Down?: Chat response generation sounds are likely from computation processes, not the chat app itself, and users discussed workarounds for disabling disruptive noises.
Custom Roles Left to the Playground: Members explored the potential of integrating a "Narrator" role in LM Studio and acknowledged that the current system doesn't support this, suggesting that employing playground mode might be a viable alternative.
Bilibili's Index-1.9B Joins the Fray: Bilibili released Index-1.9B model; discussion noted it offers a chat-optimized variant available on GitHub and Hugging Face. Simultaneously, the conversation turned to the impracticality of deploying 340B Nemotron models locally due to their extensive resource requirements.
Hardware Hiccups and Hopefuls: Conversations revolved around system and VRAM usage, with tweaks to 'mlock' and 'mmap' parameters affecting performance. Hardware configuration recommendations were compared and concerns highlighted about LM Studio version 0.2.24 leading to RAM issues.
LM Studio Leaps to 0.2.25: Release candidate for LM Studio 0.2.25 promises fixes and Linux stability enhancements. Meanwhile, frustration was voiced over lack of support for certain models, despite the new release addressing several issues.
API Angst Arises: A single message flagged a 401 invalid_api_key issue encountered when querying a workflow, with the user experiencing difficulty despite multiple API key verifications.
DiscoPOP Disrupts Training Norms: Sakana AI's release of DiscoPOP promises a new training method and is available on Hugging Face, as detailed in their blog post.
OpenAI Discord
- Cybersecurity Expert Joins OpenAI's Upper Echelon: Retired US Army General Paul M. Nakasone joins the OpenAI Board of Directors, expected to enhance cybersecurity measures for OpenAI's increasingly sophisticated systems. OpenAI's announcement hails his wealth of experience in protecting critical infrastructure. Read more
- Payment Processing Snafu: Engineers are reporting "too many requests" errors when attempting to process payments on the OpenAI API, with support's advice to wait several days deemed unsatisfactory due to impacts on application functionality.
- API Wanderlust: Amidst payment issues and platform-specific releases favoring macOS over Windows, discussions shifted toward alternative APIs like OpenRouter, with a nod to simpler transitions thanks to such intermediary tools.
- GPT-4: Setting Expectations Straight: Engineers clarified that GPT-4 doesn't continue learning post-training, while comparing Command R and Command R+'s respective puzzle-solving capabilities, with Command R+ demonstrating superior prowess.
- Flat Shading Conundrums with DALL-E: A technical query arose regarding the production of images in DALL-E utilizing flat shading, absent of lighting and shadows - a technique akin to a barebones 3D model texture - with the enquirer seeking guidance to achieve this elusive effect.
HuggingFace Discord
- DiscoPOP Dazzles in Optimization: The Sakana AI's DiscoPOP algorithm outstrips others such as DPO, offering superior preference optimization by maintaining high performance close to the base model, as documented in a recent blog post.
- Pixel-Level Attention Steals the Show: A Meta research paper, An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels, received attention for its deep dive into pixel-level transformers, further developing insights from the #Terminator work and underscoring the effectiveness of pixel-level attention mechanisms in image processing.
- Hallucination Detection Model Unveiled: An update in hallucination detection was shared, introducing a new small language model fine-tune available on HuggingFace, boasting an accuracy of 79% for pinpointing hallucinations in generated text.
- DreamBooth Script Requires Tweaks for Training Customization: Discussions in diffusion model development underscored the need to modify the basic DreamBooth script to accommodate individual captions for predictive training with models like SD3, as well as a separate enhancement for tokenizer training like CLIP and T5, which increases VRAM demand.
- Hyperbolic KG Embedding Techniques Explored: An arXiv paper on hyperbolic knowledge graph embeddings proposed a novel approach that leverages hyperbolic geometry for embedding relational data, positing a methodology involving hyperbolic transformations coupled with attention mechanisms for handling complex data relationships.
Nous Research AI Discord
- Roblox and the Case of Corporate Humor: Engineers found humor on the VLLM GitHub page discussing a Roblox meetup, sparking light-hearted banter in the community.
- Discord on ONNX and CPU Dilemma: A notable mention of an ONNX conversation from another Discord channel claims a 2x CPU speed boost, though skepticism remains regarding benefits on GPU.
- The Forge of Code-to-Prompt: The tool code2prompt converts codebases into markdown prompts, proving valuable for RAG datasets, but resulting in high token counts.
- Scaling the Wall of Context limitation: During discussions on handling context lengths beyond 8k, techniques like chunking, indexing, and query decomposition were suggested for RAG datasets to improve model training and information synthesis.
- Synthetic Data's New Contender: The introduction of the Nemotron-4-340B-Instruct model by NVIDIA was a hot topic, focusing on its implications for synthetic data generation and the potential under NVIDIA's Open Model License.
- WorldSim Prompt Goes Public: Discussions indicated that the worldsim prompt is available on Twitter, and there's a switch to the Sonnet model being considered in conversations about expanding model capabilities.
Modular (Mojo 🔥) Discord
- Mojo on the Move: The Mojo package manager is underway, prompting engineers to temporarily compile from source or use mojopkg files. For those new to the ecosystem, the Mojo Contributing Guide walks through the development process, recommending starting with "good first issue" tags for contribution.
- GPU and Multi-threading Conversations: The performance and implementation of GPU support in Mojo spurred debates, with attention to its strongly typed nature and how Modular is expanding its support for various accelerators. Engineers exchanged insights on multi-threading, referring to SIMD optimizations and parallelization, focusing on portability and Modular’s potential business models.
- NSF Funding Fuels AI Exploration: US-based scholars and educators should consider the National Science Foundation (NSF) EAGER Grants, supporting the National AI Research Resource (NAIRR) Pilot with monthly reviewed proposals. Resources and community building initiatives are a part of the NAIRR vision, emphasizing the importance of accessing computational resources and integrating data tools (NAIRR Resource Requests).
- New Nightly Mojo Compiler Drops: A new nightly build of the Mojo compiler (version
2024.6.1405) is now available, with updates accessible viamodular update. The release's details can be tracked through the provided GitHub diff and the changelog.
- Resources and Meet-Ups Ignite Community Spirit: There's an ongoing request for a standard query setup guide, suggesting a mimic Modular's GitHub methods until official directions are available. Additionally, Mojo enthusiasts in Massachusetts signaled interest in a meet-up to discuss Mojo over coffee, highlighting the community's eagerness for knowledge-sharing and direct interaction.
Perplexity AI Discord
- Perplexity Panic: Users experienced a server outage with Perplexity's services, reporting repeated messages and endless loops without any official maintenance announcements, creating frustration due to the lack of communication.
- Technical Troubles Addressed: The Perplexity community identified several technical issues, including broken file upload functionality (attributed to an AB test config) and consistently 404 errors when the service generated kernel links. There was also a discussion on inconsistencies observed in the Perplexity Android app compared to iOS or web experiences.
- Shaky Confidence in Pro Service: The server and communication issues have led to users questioning the value of upgrading to Perplexity Pro, expressing doubts due to the ongoing service disruptions.
- Perplexity News Roundup Shared: Recent headlines were shared among members, including updates on Elon Musk's legal maneuvers, insights into situational awareness, the performance of Argentina's National Football team, and Apple's stock price surge.
- Call for Blockchain Enthusiasts: Within the API channel, there was an inquiry about integrating Perplexity's API with Web3 projects and connecting to blockchain endpoints, suggesting a curiosity or a potential project initiative around decentralized applications.
LlamaIndex Discord
- Atom Empowered by LlamaIndex: Atomicwork has tapped into LlamaIndex's capabilities to bolster their AI assistant, Atom, enabling the handling of multiple data formats for improved data retrieval and decision-making. The integration news was announced on Twitter.
- Correct Your ReAct Configuration: In a configuration mishap, the proper kwarg for the ReAct agent was clarified as
max_iterations, not 'max_iteration', resolving an error one of the members experienced.
- Recursive Retriever Puzzle: A challenge was faced while loading an index from Pinecone vector store for a recursive retriever with a document agent, where the member shared code snippets for resolution.
- Weaviate Weighs Multi-Tenancy: There is a community-driven effort to introduce multi-tenancy to Weaviate, with a call for feedback on the GitHub issue discussing the data separation enhancement.
- Agent Achievement Unlocked: Members exchanged several learning resources for building custom agents, including LlamaIndex documentation and a collaborative short course with DeepLearning.AI.
LLM Finetuning (Hamel + Dan) Discord
New Kid on the Block: Helix AI Joins LLM Fine-Tuning Gang: LLM fine-tuning enthusiasts have been exploring Helix AI, a platform that touts secure and private open LLMs with easy scalability and the option of closed model pass-through. Users are encouraged to try Helix AI and check out the announcement tweet related to the platform's adoption of FP8 inference, which boasts reduced latency and memory usage.
Memory Tweaks for the Win: Lamini's memory tuning technique is making waves with claims of 95% accuracy and significantly fewer hallucinations. Keen technologists can delve into the details through their blog post and research paper.
Credits Where Credits Are Due: Confusion and inquiries about credit allocation from platforms like Hugging Face and Langsmith surfaced, with users reporting pending credits and seeking assistance. Mentions of email signups and ID submissions — such as akshay-thapliyal-153fbc — suggest ongoing communication to resolve these issues.
Inference Optimization Inquiry: A single inquiry surfaced regarding optimal settings for inference endpoints, highlighting a demand for performance maximization in deployed machine learning models.
Support Ticket Surge: Various technical issues have been flagged, ranging from non-functional search buttons to troubles with Python APIs, and from finetuning snags on RTX5000 GPUs to problems receiving OpenAI credits. Solutions such as switching to an Ampere GPU and requesting assistance from specific contacts have been offered, yet some user frustrations remain unanswered.
Eleuther Discord
- Boosting LLM Factual Accuracy and Hallucination Control: The newly announced Lamini Memory Tuning claims to embed facts into LLMs like Llama 3 or Mistral 3, boasting a factual accuracy of 95% and a drop in hallucinations from 50% to 5%.
- KANs March Onward to Conquer 'Weird Hardware': Discussions highlighted that KANs (Kriging Approximation Networks) might be better suited than MLPs (Multilayer Perceptrons) for unconventional hardware by requiring only summations and non-linearities.
- LLMs Get Schooled: Sharing a paper, members discussed the benefits of training LLMs with QA pairs before more complex documents to improve encoding capabilities.
- PowerInfer-2 Speeds Up Smartphones: PowerInfer-2 significantly improves the inference time of large language models on smartphones, with evaluations showing a speed increase of up to 29.2x.
- RWKV-CLILL Scales New Heights: RWKV-CLIP model, which uses RWKV for both image and text encoding, received commendations for achieving state-of-the-art results, with references to the GitHub repository and the corresponding research paper.
OpenRouter (Alex Atallah) Discord
- OpenRouter on the Hotseat for cogvlm2 Hosting: There's uncertainty about the ability to host cogvlm2 on OpenRouter, with discussions focusing on clarifying its availability and assessing cost-effectiveness.
- Gemini Pro Moderation via OpenRouter Hits a Snag: While attempting to pass arguments to control moderation options in Google Gemini Pro through OpenRouter, a user faced errors, pointing to a need for enabling relevant settings by OpenRouter. The Google billing and access instructions were highlighted in the discussion.
- Query Over AI Studio's Attractive Pricing: A user queried the applicability of Gemini 1.5 Pro and 1.5 Flash discounted pricing from AI Studio on OpenRouter, favoring the token-based pricing of AI Studio over Vertex's model.
- NVIDIA's Open Assets Spark Enthusiasm Among Engineers: NVIDIA's move to open models, RMs, and data was met with excitement, particularly for Nemotron-4-340B-Instruct and Llama3-70B variants, with the Nemotron and Llama3 being available on Hugging Face. Members also indicated that the integration of PPO techniques with these models is seen as highly valuable.
- June-Chatbot's Mysterious Origins Spark Discussion: Speculation surrounds the origins of the "june-chatbot", with some members linking its training to NVIDIA and hypothesizing a connection to the 70B SteerLM model, demonstrated at the SteerLM Hugging Face page.
OpenInterpreter Discord
- Server Crawls to a Halt: Discord users experienced significant performance issues with server operations slowing down, reminiscent of the congestion seen with huggingface's free models. Patience may solve the issue as tasks do eventually complete after a lengthy wait.
- Vision Quest with Llama 3: A member queried about adding vision capabilities to the 'i' model, suggesting a possible mix with the self-hosted llama 3 vision profile. However, confusion persists around the adjustments needed within local files to achieve this integration.
- Automation Unleashed: The channel saw a demonstration of automation using Apple Scripts showcased via a shared YouTube video, highlighting the potential of simplified scripting combined with effective prompting for faster task execution.
- Model-Freezing Epidemic: Engineers flagged up a recurring technical snag where the 'i' model frequently freezes during code execution, requiring manual intervention through a Ctrl-C interrupt.
- Hungry for Hardware: An announced device from Seeed Studio sparked interest among engineers, specifically the Sensecap Watcher, noted for its potential as a physical AI agent for space management.
Cohere Discord
- Cohere Chat Interface Gains Kudos: Cohere's playground chat was commended for its user experience, particularly citing a citation feature that displays a modal with text and source links upon clicking inline citations.
- Open Source Tools for Chat Interface Development: Developers are directed to the cohere-toolkit on GitHub as a resource for creating chat interfaces with citation capabilities, and the Crafting Effective Prompts guide to improve text completion tasks using Cohere.
- Resourcing Discord Bot Creatives: For those building Discord bots, shared resources included the discord.py documentation and the Discord Interactions JS GitHub repository, providing foundational material for the Aya model implementation.
- Anticipation Building for Community Innovations: Community members are eagerly awaiting "tons of use cases and examples" for various builds with a contagiously positive sentiment expressed in responses.
- Community Bonding through Projects: A simple "so cute 😸" reaction to the excitement of upcoming community project showcases reflects the positive and supportive environment among members.
LangChain AI Discord
- RAG Chain Requires Fine-Tuning: A user encountered difficulties with a Retrieval-Augmented Generation (RAG) chain output, as the code provided did not yield the expected number "8". Suggestions were sought for code adjustments to enhance result accuracy by filtering specific questions.
- Craft JSON Like a Pro: In pursuit of crafting a proper JSON object within a LangChain, an engineer received assistance via shared examples in both JavaScript and Python. The guidance aimed to enable the creation of a custom chat model capable of generating valid JSON outputs.
- Integration Hiccup with LangChain and pgvector: Connecting LangChain to pgvector ran into trouble, with the user unable to recognize imports despite following the official documentation. A correct Python environment setup was suggested to mitigate the issue.
- Hybrid Search Stars in New Tutorial: A community member shared a demonstration video on Hybrid Search for RAG using Llama 3, complete with a walkthrough in a GitHub notebook. The tutorial aims to improve understanding of hybrid search in RAG applications.
- User Interfaces Get Snazzier with NLUX: NLUX touts an easy setup for LangServe endpoints, showcased in documentation that guides users through integrating conversational AI into React JS apps using the LangChain and LangServe libraries. The tutorial highlights the ease of creating a well-designed user interface for AI interactions.
tinygrad (George Hotz) Discord
NVIDIA Unveils Nemotron-4 340B: NVIDIA's new Nemotron-4 340B models - Base, Instruct, and Reward - were shared, boasting compatibility with a single DGX H100 using 8 GPUs at FP8 precision. There's a burgeoning interest in adapting the Nemotron-4 340B for smaller hardware configurations, like deploying on two TinyBoxes using 3-bit quantization.
tinygrad Troubleshooting: Members tackled running compute graphs in tinygrad, with one seeking to materialize the results; the recommended fix was calling .exec, as mentioned in abstractions2.py found on GitHub. Others debated tensor sorting methods, pondered alternatives to PyTorch's grid_sample, and reported CompileError issues when implementing mixed precision on an M2 chip.
Pursuit of Efficient Tensor Operations: Discussing tensor sorting efficiency, the community pointed at using argmax for better performance in k-nearest neighbors algorithm implementations within tinygrad. There's also a dialogue around finding equivalents to PyTorch operations like grid_sample, referencing the PyTorch documentation to foster deeper understanding amongst peers.
Mixed Precision Challenges on Apple M2: An advanced user encountered errors when attempting to integrate mixed precision techniques on the M2 chip, which spotlighted compatibility issues with Metal libraries; this highlights the need for ongoing community-driven problem-solving within such niche technical landscapes.
Collaborative Learning Environment Thrives: Throughout the dialogues, an essence of collaborative problem-solving is palpable, with members sharing knowledge, resources, and fixes for a variety of technical challenges related to machine learning, model deployment, and software optimization.
Interconnects (Nathan Lambert) Discord
- NVIDIA's Power Move: NVIDIA has announced a massive-scale language model, Nemotron-4-340B-Base, with 340 billion parameters and a 4,096 token context capability for synthetic data generation, trained on 9 trillion tokens in multiple languages and codes.
- License Discussions on NVIDIA's New Model: While the Nemotron-4-340B-Base comes with a synthetic data permissive license, concerns arise about the PDF-only format of the license on NVIDIA's website.
- Steering Claude in a New Direction: Claude's experimental Steering API is now accessible for sign-ups, offering limited steering capability of the model's features for research purposes only, not production deployment.
- Japan's Rising AI Star: Sakana AI, a Japanese company working on alternatives to transformer models, has a new valuation of $1 billion after investment from prestigious firms NEA, Lux, and Khosla, as detailed in this report.
- The Meritocracy Narrative at Scale: A highlight on Scale's hiring philosophy as revealed in a blog post indicates a methodical approach to maintaining quality in hiring, including personal involvement from the company's founder.
Latent Space Discord
- Apple’s AI Clusters at Your Fingertips: Apple users may now use their devices to run personal AI clusters, which might reflect Apple's approach to their private cloud according to a tweet from @mo_baioumy.
- From Zero to $1M in ARR: Lyzr achieved $1M Annual Recurring Revenue in just 40 days by switching strategies to a full-stack agent framework, introducing agents such as Jazon and Skott with a focus on Organizational General Intelligence, as highlighted by @theAIsailor.
- Nvidia's Nemotron for Efficient Chats: Nvidia unveiled Nemotron-4-340B-Instruct, a large language model (LLM) with 340 billion parameters designed for English-based conversational use cases and a lengthy token support of 4,096.
- BigScience's DiLoco & DiPaco Top the Charts: Within the BigScience initiative, systems DiLoco and DiPaco have emerged as the newest state-of-the-art toolkits, with DeepMind notably not reproducing their results.
- AI Development for the Masses: Prime Intellect announced their intent to democratize the AI development process through distributed training and global compute resource accessibility, moving towards collective ownership of open AI technologies. Details on their vision and services can be found at Prime Intellect's website.
OpenAccess AI Collective (axolotl) Discord
- Nemotron Queries and Successes: A query was raised about the accuracy of Nemotron-4-340B-Instruct after quantization, without follow-up details on performance post-quantization. In a separate development, a user successfully installed the Nvidia toolkit and ran the LoRA example, thanking the community for their assistance.
- Nemotron-4-340B Unveiled: The Nemotron-4-340B-Instruct model was highlighted for its multilingual capabilities and extended context length support of 4,096 tokens, designed for synthetic data generation tasks. The model resources can be found here.
- Resource Demands for Nemotron Fine-Tuning: A user inquired about the resource requirements for fine-tuning Nemotron, suggesting the possible need for 40 A100/H100 (80GB) GPUs. It was indicated that inference might require fewer resources than finetuning, possibly half the nodes.
- Expanding Dataset Pre-Processing in DPO: A recommendation was made to incorporate flexible chat template support within DPO for dataset pre-processing, with this feature already proving beneficial in SFT. It involves using a
conversationfield for history, withchosenandrejectedinputs derived from separate fields.
- Slurm Cluster Operations Inquiry: A user sought insights on operating Axolotl on a Slurm cluster, with the inquiry highlighting the community's ongoing interest in effectively utilizing distributed computing resources. The conversation remained open for further contributions.
LAION Discord
- Dream Machine Animation Fascinates: LumaLabsAI has developed Dream Machine, a tool adept at bringing memes to life through animation, as highlighted in a tweet thread.
- AI Training Costs Slashed by YaFSDP: Yandex has launched YaFSDP, an open-source AI tool that promises to reduce GPU usage by 20% in LLM training, leading to potential monthly cost savings of up to $1.5 million for large models.
- PostgreSQL Extension Challenges Pinecone: The new PostgreSQL extension, pgvectorscale, reportedly outperforms Pinecone with a 75% cost reduction, signaling a shift in AI databases towards more cost-efficient solutions.
- DreamSync Advances Text-to-Image Generation: DreamSync offers a novel method to align text-to-image generation models by eliminating the need for human rating and utilizing image comprehension feedback.
- OpenAI Appoints Military Expertise: OpenAI news release announces the appointment of a retired US Army General, a move shared without further context within the messages. Original source was linked but not discussed in detail.
Datasette - LLM (@SimonW) Discord
- Datasette Grabs Hacker News Spotlight: Datasette, a member's project, captured significant attention by making it to the front page of Hacker News, receiving accolades for its balanced treatment of different viewpoints. A quip was made about the project ensuring continuous job opportunities for data engineers.
DiscoResearch Discord
- Choosing the Right German-Savvy Model: Members discussed the superiority of discolm or occiglot models for tasks requiring accurate German grammar, despite general benchmark results; these models sit aptly within the 7-10b range and are case-specific choices.
- Bigger Can Be Slower but Smarter: The trade-off between language quality and task performance may diminish with larger models in the 50-72b range; however, inference speed tends to decrease, necessitating a balance between capability and efficiency.
- Efficiency Over Overkill: For better efficiency, sticking to models that fit within VRAM parameters like q4/q6 was advised, especially as larger models have slower inference speeds. A pertinent resource highlighted was the Spaetzle collection on Hugging Face.
- Training or Merging for the Perfect Balance: Further training or merging of models can be a strategy for managing trade-offs between non-English language quality and the ability to follow instructions, a topic of interest for multi-language model developers.
- The Bigger Picture in Multilingual AI: This discussion underscores the ongoing challenge in achieving the delicate balance between performance, language fidelity, and computational efficiency in the evolution of multilingual AI models.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (462 messages🔥🔥🔥):
- SD3 Discord Bot Open Sourced: A member announced they have open-sourced a Stable Diffusion 3 Discord Bot. It allows users to provide a prompt and generate an image.
- LoRA Training Issues for SDXL: A user discussed training difficulties with SDXL for animated characters intending to use them in realistic and anime generations. They noted the model turned out "way too cartoonish/animated" and thanked a member for suggesting 1024x1024 resolution for better results.
- Configuring SD3 with ComfyUI: Members were troubleshooting how to properly configure Stable Diffusion 3 in ComfyUI, discussing setup processes like downloading text encoders and proper workflow configurations. Links and quickstart guides from Civitai helped guide users.
- Ongoing Parley on SD3 Model Limitations: Users expressed mixed feelings on SD3's anatomy rendering capabilities. A detailed note by a user calling for Stability AI to acknowledge and communicate plans to address human anatomy issues in the SD3 model became a focal point of the debate.
- LoRA Functionality in SD3: There were clarifications on the current state of training new LoRAs for use with SD3. It was mentioned that although it's technically possible, usable tools and efficient workflows are still being developed, and users may need to wait for fully compatible updates.
- SD3 Examples: Examples of ComfyUI workflows
- $UICIDEBOY$ - THE THIN GREY LINE: OFFICIAL MUSIC VIDEO FOR "THE THIN GREY LINE" BY $UICIDEBOY$PRODUCED BY: BUDD DWYERDIRECTED BY: DILL35MMNEW WORLD DEPRESSION OUT NOWhttps://orcd.co/newworldd...
- LoRA Inspector | Civitai: LoRA Inspector Web based tool for inspecting your LoRAs. All done in the browser, no servers. Private. No dependencies like torch or python. https:...
- Quickstart Guide to Stable Diffusion 3 - Civitai Education: Stable Diffusion 3 is a text-to-image model released by Stability AI in June of 2024 offering unparallelled image fidelity!
- Stable Diffusion 3 (SD3) - SD3 Medium | Stable Diffusion Checkpoint | Civitai: Stable Diffusion 3 (SD3) 2B "Medium" model weights! Please note ; there are many files associated with SD3 . They will all appear on this model car...
- bridge troll recordz on Instagram: "🌟 Find Your Voice, Find Your Freedom 🌟 In the darkest times, when the world feels too small and the shadows too long, remember this: You are not alone. I am here, standing with you, a fellow traveler on the path less taken. As a survivor of gang stalking, I know the depths of isolation and the relentless pursuit of the unseen. But today, I rise not just to survive but to thrive. 💖 Your Journey, Our Mission 💖 I'm on a mission to turn our shared pain into a beacon of light. To create a community where we lift each other up, share stories of resilience, and find solace in solidarity. Together, we can break the chains of silence and isolation. 📚 Resources for Survival 📚 Join us as we explore resources, strategies, and stories of survival. From legal advice to mental health support, let's equip ourselves with the tools needed to navigate these challenging waters. Because knowledge is power, and together, we are unstoppable. 🔗 #GangStalkingSurvivor #TogetherWeRise #FindYourVoice Let's connect, share, and grow stronger. Follow @brixetrollrecordz for daily inspiration, resources, and a community that sees you, hears you, and stands with you. Remember, in the face of adversity, we find strength. Let's find ours, together.": 4 likes, 0 comments - brixetrollrecordz on June 13, 2024: "🌟 Find Your Voice, Find Your Freedom 🌟 In the darkest times, when the world feels too small and the shadows too long, r...
- My Man My Man Hd GIF - My Man My Man Hd My Man4k - Discover & Share GIFs: Click to view the GIF
- GitHub - RocketGod-git/stable-diffusion-3-discord-bot: A simple Discord bot for SD3 to give a prompt and generate an image: A simple Discord bot for SD3 to give a prompt and generate an image - RocketGod-git/stable-diffusion-3-discord-bot
- GitHub - BlafKing/sd-civitai-browser-plus: Extension to access CivitAI via WebUI: download, delete, scan for updates, list installed models, assign tags, and boost downloads with multi-threading.: Extension to access CivitAI via WebUI: download, delete, scan for updates, list installed models, assign tags, and boost downloads with multi-threading. - BlafKing/sd-civitai-browser-plus
- Stable Diffusion 3 (SD3) - SD3 Medium | Stable Diffusion Checkpoint | Civitai: Stable Diffusion 3 (SD3) 2B "Medium" model weights! Please note ; there are many files associated with SD3 . They will all appear on this model car...
CUDA MODE ▷ #general (5 messages):
- Auto-threading enabled in the channel: The bot Needle announced that auto-threading has been enabled in the specified channel.
- Evaluating MilkV Duo performance: A member shared their experience with the MilkV Duo 64MB controller and questioned whether its performance edge is due to the hardware or the sophgo/tpu-mlir compiler. They provided links to both the controller (MilkV Duo) and the compiler (sophgo/tpu-mlir).
- Comparison to RK3588: Another member compared the performance of the MilkV Duo to the RK3588 ARM part, which boasts 6.0 TOPs NPU and various advanced features. They provided a link to the specifications of RK3588.
- GitHub - sophgo/tpu-mlir: Machine learning compiler based on MLIR for Sophgo TPU.: Machine learning compiler based on MLIR for Sophgo TPU. - sophgo/tpu-mlir
- Rockchip-瑞芯微电子股份有限公司: no description found
CUDA MODE ▷ #triton (8 messages🔥):
- Triton 3.0 features tantalize users: A member inquired about major changes/new features in triton 3.0, and others mentioned useful shape manipulation ops like
tl.interleaveand the fixing of many interpreter bugs.
- Low-bit kernel debugging woes: A user faced an
LLVM ERROR: mma16816 data type not supportederror while trying to implement a low-bit kernel (w4a16). They were advised to check the latest version of Triton and consider opening an issue on the Triton GitHub repo.
- FP16 x INT4 kernel resource: A member suggested referencing the FP16 x INT4 Triton kernel available in PyTorch's AO project, authored by a notable contributor. They shared a link to the GitHub resource.
- Conversion workaround for integer types: Another user advised a workaround for potential issues when converting integer types directly to
bfloat16. They suggested first converting frominttofloat16and then fromfloat16tobfloat16.
- Segfault in TTIR when doing convert s16->bf16 + dot · Issue #2113 · triton-lang/triton: We created the following TTIR, which was previously working for us. However, it is now segfaulting at HEAD on main. All we're trying to do is load 2 parameters (one bf16, one s16), convert the s16...
- ao/torchao/prototype/hqq/mixed_mm.py at main · pytorch/ao: Native PyTorch library for quantization and sparsity - pytorch/ao
CUDA MODE ▷ #torch (25 messages🔥):
- MTIA spotted as Triton-Compatible: A member mentioned the Meta Training and Inference Accelerator (MTIA), noting that it is "very much triton and compile first."
- Torch Auto-Threading Activated: Auto-threading was enabled in the
<#1189607750876008468>channel. - GitHub Gist Highlights torch.matmul Quirk: A member shared performance issues in
torch.matmulhighlighting a 2.5x speed increase for certain matrix shapes when the matrix is cloned. They speculated on factors like CUDA versions and GPU models, but acknowledged it as a bizarre anomaly. GitHub Gist - Variability Across GPU Models and CUDA Versions: Different members ran benchmarks on various GPUs (RTX 4090, 4070Ti, RTX 3060, 3090, and A6000 Ada). They found that the performance quirk was mostly noticeable on Ada GPUs, with some seeing dramatic speed-ups and others reporting normal performance with specific CUDA versions.
- Call for PyTorch Team Insight on Performance Quirk: Despite extensive testing, members couldn't pinpoint the cause, leading to a shared hope for insights from the PyTorch team to explain the strange behavior.
Link mentioned: torch_matmul_clone.py: GitHub Gist: instantly share code, notes, and snippets.
CUDA MODE ▷ #cool-links (1 messages):
useofusername: https://arxiv.org/abs/2106.00003
CUDA MODE ▷ #beginner (3 messages):
- C/C++ is essential for high-performance CUDA kernels: A member asked about the necessity of C or C++ for writing custom CUDA kernels and whether Triton is a viable alternative. Another member responded that while C/C++ offers the best performance, Triton is a good option for ML/DL applications due to its integration with PyTorch and simplicity in managing complexities like shared memory.
CUDA MODE ▷ #torchao (3 messages):
- Torch.nn Conservatism on New Models: A member inquired if AO plans to support new architectures like mamba/KAN or if it would fall under torch.nn. Another member clarified that "Torch.nn tends to be very conservative regarding which new models to add," indicating that AO is open to making specific aspects fast but does not aim to become a repository of models.
CUDA MODE ▷ #off-topic (10 messages🔥):
- Struggling with Discord for Communities: A member mentioned their difficulty adapting to Discord for community discussions, emphasizing the inconvenience compared to forums. They expressed frustration, saying, "On discord it feels like I have to continuously pay attention to stay on top of things."
- Prefer Forums Over Discord for Information: Another member mentioned using Discord primarily for community interaction, stating they usually browse relevant subreddits for information. "Discord is more for interaction," they noted.
- Best Practices for Discord Threads: A member offered advice on using threads and replies to make Discord more manageable. They suggested starting new topics with regular messages, using replies to branch conversations, and creating threads for focused discussions, highlighting that this helps "easier to read through a channel with multiple ongoing conversations."
CUDA MODE ▷ #llmdotc (246 messages🔥🔥):
- Speedup observed with new PR: A member reported seeing a speedup from ~179.5K tok/s to ~180.5K tok/s and noted a minor improvement for the 774M model (~30.0K tok/s to ~30.1K tok/s). They identified code complexity as a potential issue.
- Discussion on code complexity and CUDA: Members debated merging a PR and enabling ZeRO-2 to simplify data layouts. There was also a suggestion to explore CUDA dynamic parallelism and tail launch to handle small kernel launches more efficiently.
- Potential bug in
multi_gpu_async_reduce_gradient: Members discussed a concern regarding the division of shard sizes inmulti_gpu_async_reduce_gradientand suggested adding an assert or asafe_dividehelper to ensure proper division. - Determinism and multi-GPU testing: Members attempted to debug an issue with determinism in multi-GPU setups, focusing on gradient norm calculations. They also considered setting up manual multi-GPU tests due to lack of CI coverage.
- ZeRO-2 PR in progress: There's an ongoing effort to integrate ZeRO-2, with initial steps showing matching gradient norms but issues in the Adam update. Debugging revealed an overlooked condition for weight updates in ZeRO-2.
- Stochastic Weight Averaging in PyTorch: In this blogpost we describe the recently proposed Stochastic Weight Averaging (SWA) technique [1, 2], and its new implementation in torchcontrib. SWA is a simple procedure that improves generalizati...
- Early Weight Averaging meets High Learning Rates for LLM Pre-training: Training Large Language Models (LLMs) incurs significant cost; hence, any strategy that accelerates model convergence is helpful. In this paper, we investigate the ability of a simple idea checkpoint ...
- Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations: Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setu...
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Nemotron-4 340B | Research: no description found
- llm.c/llmc/zero.cuh at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Fused Forward GELU (again) by ademeure · Pull Request #591 · karpathy/llm.c: This turns out to be properly fused (and therefore faster) on H100 with CUDA 12.5 - it was definitely not fused and actually noticeably slower on RTX 4090 with CUDA 12.4, I suspect that is more abo...
- Dataloader - introducing randomness by gordicaleksa · Pull Request #573 · karpathy/llm.c: On the way to fully random train data shuffling... This PR does the following: Each process has a different unique random seed Each process train data loader independently chooses its starting sha...
- add scripts to export to HF and run Eleuther evals by karpathy · Pull Request #594 · karpathy/llm.c: no description found
- adding wsd schedule with (1-sqrt) decay by eliebak · Pull Request #508 · karpathy/llm.c: Adding new learning rate schedule support: WSD learning rate schedule: Warmup: classical linear warmup Stable: constant lr Decay: Decaying to min_lr in a (1-sqrt) shape. (more info here https://ar...
- RMSNorm kernels by AndreSlavescu · Pull Request #575 · karpathy/llm.c: no description found
- mdouglas/llmc-gpt2-774M-150B · Hugging Face: no description found
- GPT-2 (774M) reproduced · karpathy/llm.c · Discussion #580: I left the GPT-2 774M model running for ~6 days on my 8X A100 80GB node (150B tokens, 1.5 epochs over the 100B FineWeb sample dataset) and training just finished a few hours ago and went well with ...
- Compiler Explorer - C++ (x86-64 gcc 14.1): int sizeof_array(char* mfu_str) { return sizeof(mfu_str); }
- Fix MFU printing by gordicaleksa · Pull Request #585 · karpathy/llm.c: We have a bug when the device we're running on is not supported: we print "-100%". Fixed it so we print "n/a" in that case. Also added support for H100 PCIe which is the device...
- consolidate memory by karpathy · Pull Request #590 · karpathy/llm.c: by deleting the grad activation struct, move some of the last pieces of memory to the forward pass
- Dataloader - introducing randomness by gordicaleksa · Pull Request #573 · karpathy/llm.c: On the way to fully random train data shuffling... This PR does the following: Each process has a different unique random seed Each process train data loader independently chooses its starting sha...
CUDA MODE ▷ #bitnet (17 messages🔥):
- Live code review session proposed: "Would it help to meet this weekend and do a live code review and merge of the PR?" Members expressed confusion over current progress, suggesting a live session could clear things up.
- 7x as a clear performance target: A performance target of 7x speedup is discussed, with analysis indicating it's achievable for large input shapes. Actual performance varies, "on average 5-6x for large matrices, 2-4x for smaller matrices."
- Performance fluctuation and analysis link shared: Mobicham shared that the max performance was around 7x but averaged 5-6x on large matrices and 2-4x on smaller ones. For batch-size=1 with int8 activations, an 8x improvement was noted on A100 GPUs, with supporting benchmark images from BitBLAS.
- Batch size impacts performance: Discussion highlighted that performance, "quickly loses the speed with larger batch-sizes," confirming it is especially efficient for single batch processes. Larger batch sizes reduce memory-bound constraints and diminish speed gains, as supported by additional benchmarks: BitBLAS scaling.
- Technical details of tensor cores and performance: Queries were made about whether tensor cores (INT8 vs FP16/BF16) were used in specific instances, particularly with Wint2 x Aint8 setups. Mobicham noted a 4x speed-up with int8 x int8 without using
wmma, which requires 16x16 blocks and is likely suboptimal for small batch sizes.
Unsloth AI (Daniel Han) ▷ #general (170 messages🔥🔥):
- Pretraining and Hardware Struggles: Members discussed the resources needed for training large models like Mistral. One noted "I might need a super computer cluster 😦" while another mentioned completing a 110K coder training session in 72.22 minutes with detailed performance metrics.
- Cool ASCII Art Praise: The community appreciated the ASCII art used by Unsloth, with one saying "thumbs up for the one who created that ascii art so cool lol 😭🦥". Another jokingly suggested the art should change when training fails multiple times: "Every time a tune fails it should lose a little piece of the branch til it falls down and sits on the floor."
- DiscoPOP Optimizer: The DiscoPOP optimizer was shared, detailed in a Sakana AI blog post. The optimizer is noted for discovering better preference optimization functions with less deviation from the base model.
- Hardware and Inference Challenges: Members discussed challenges with training times and model performance when converting to 16-bit for serving via vLLM. One frustrated user shared, "model works really great but the moment I merge to 16bit and serve via vLLM performance drops drastically."
- Naming Conventions and Tools: A humorous side conversation on naming models and tools emerged, suggesting using LLMs for naming due to humans being notoriously bad at it. Cursor, an AI code editor, was discussed, with one member noting, "It's very buggy on Ubuntu, I can't use it 😦," and another humorously saying, "cease and desist."
- Cursor: The AI Code Editor
- - YouTube: no description found
- no title found: no description found
- Nemotron 4 340B - a nvidia Collection: no description found
- Putting RL back in RLHF: no description found
- Llama 3 Fine Tuning for Dummies (with 16k, 32k,... Context): Learn how to easily fine-tune Meta's powerful new Llama 3 language model using Unsloth in this step-by-step tutorial. We cover:* Overview of Llama 3's 8B and...
- Tweet from Daniel Han (@danielhanchen): Took a look at NVIDIA's 340B Nemotron LLM 1. Squared ReLU unlike Llama SwiGLU, Gemma GeGLU 2. What is "rotary_percentage" 50%? Related to Phi-2's "partial_rotary_factor"? 3. U...
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face: no description found
- The Annotated Transformer: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - microsoft/Samba: Official implementation of "Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling": Official implementation of "Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling" - microsoft/Samba
- Callbacks: no description found
Unsloth AI (Daniel Han) ▷ #random (18 messages🔥):
- Ollama support merges in latest commits: A user noticed significant Ollama support in the latest commit, receiving confirmation from another user. This indicates ongoing enhancements in the framework's capabilities.
- Triton 3.0 still a mystery: Several users debated the differences between Triton 2.0 and Triton 3.0, but no one could provide clear details. One user guessed it might involve AMD support, while another admitted they have no idea.
- Unsloth's Korean Colab updates spark curiosity: A user expressed curiosity about updates to Unsloth's Korean Colab notebook, noting its specific use of Korean prompts and answers. Another user confirmed continuous pretraining as part of the updates and is actively improving the notebook.
Unsloth AI (Daniel Han) ▷ #help (125 messages🔥🔥):
- Llama.cpp Installation Issues Discussed: Members were troubleshooting issues with Llama.cpp installations and conversions after training with Unsloth. One suggested "deleting llama.cpp and re-installing via Unsloth," but found no success, even after fresh installations on Colab.
- GitHub PR Fixes Llama.cpp: A member pointed to a GitHub PR that addresses Llama.cpp failing to generate quantized versions of trained models. Another member confirmed it got accepted.
- Qwen2 Model Discussions: There was a debate on the performance of the Qwen2 model compared to Llama3, with some expressing dissatisfaction. The Qwen2 repository and its finetuning example were referenced.
- Fixing Python Version for Unsloth: A question about Python version requirements was resolved, clarifying that Unsloth requires at least Python 3.9. Local configuration was also discussed for smooth running, with a reminder to configure local paths.
- CUDA Required for Local Execution: It was confirmed that running Unsloth models locally requires appropriate CUDA libraries and that Linux environments are preferred over Windows for easier setup due to fewer issues.
- llama.cpp failing by bet0x · Pull Request #371 · unslothai/unsloth: llama.cpp is failing to generate quantize versions for the trained models. Error: You might have to compile llama.cpp yourself, then run this again. You do not need to close this Python program. Ru...
- Qwen2/examples/sft/finetune.py at main · QwenLM/Qwen2: Qwen2 is the large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen2
- GitHub: Let’s build from here: GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and fea...
Unsloth AI (Daniel Han) ▷ #community-collaboration (3 messages):
- Join the Gemini API Developer Competition: A member is looking for more participants to join the Gemini API Developer Competition. They are excited to brainstorm interesting ideas and build impactful projects together. Competition Link.
Link mentioned: no title found: no description found
LM Studio ▷ #💬-general (140 messages🔥🔥):
- **Sound Issues While Generating Responses**: A member asked if there's a way to turn off the sound when the chat generates a response. It was clarified that the sound is likely from their computer running inference not from the app itself.
- **Multiple Roles in LM Studio**: Members discussed the possibility of adding custom roles such as a "Narrator" in LM Studio. It was concluded that while the feature isn’t currently possible, using the server in playground mode might help achieve a similar effect.
- **Reporting Commercial License Costs and Rogue AI Behavior**: Queries on commercial license costs were directed to the LM Studio [enterprise page](https://lmstudio.ai/enterprise.html) and a [contact form](https://docs.google.com/forms/d/e/1FAIpQLSd-zGyQIVlSSqzRyM4YzPEmdNehW3iCd3_X8np5NWCD_1G3BA/viewform?usp=sf_link). A humorous exchange occurred about reporting a "rogue AI" giving attitude.
- **Fine-Tuning Models vs Prompt Engineering**: A detailed discussion on whether prompt engineering or fine-tuning is better for specific tasks took place. Fine-tuning was suggested as more effective for permanent results, with tools like `text-generation-webui` recommended.
- **Issues with Quantizing Models**: A user experienced errors when trying to quantize models to GGUF format. Solutions included using the new `convert-hf-to-gguf.py` script from llama.cpp and confirmed the approach should work despite temporary issues with the online space.
- LM Studio at Work: no description found
- GGUF My Repo - a Hugging Face Space by ggml-org: no description found
- Introducing `lms` - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
LM Studio ▷ #🤖-models-discussion-chat (28 messages🔥):
- LM Studio works only with GGUF files, not safetensors: In response to a query about multipart safetensor files, it was confirmed that LM Studio only supports GGUF files.
- Model cuts responses short despite high token support: A user flagged an issue with a new model release that, although supporting up to 8192 tokens, "cuts responses short". They investigated and noticed it performed better outside LM Studio but still had the common "I'm sorry but as an AI language model" behavior.
- Index-1.9B released by bilibili: A new model, Index-1.9B, has been released by bilibili. The GitHub and Hugging Face links were shared, pointing to detailed information and multiple versions of the model, including a chat-optimized variant.
- Whisper models not supported in LM Studio: A query about installing a Whisper transcription model in LM Studio was met with a clarification that Whisper models do not work in llama.cpp or LM Studio, but GGUF files for whisper.cpp are available.
- New large models impractical for local use: A discussion emerged about newly released 340B Nemotron models. Members noted that while impressive, these models require significant GPU resources and are not feasible for local deployment.
- Nemotron 4 340B - a nvidia Collection: no description found
- Wolf Of Wall Street Rookie Numbers GIF - Wolf Of Wall Street Rookie Numbers - Discover & Share GIFs: Click to view the GIF
- GitHub - bilibili/Index-1.9B: Contribute to bilibili/Index-1.9B development by creating an account on GitHub.
- IndexTeam/Index-1.9B-Chat · Hugging Face: no description found
LM Studio ▷ #🎛-hardware-discussion (114 messages🔥🔥):
- RAM vs VRAM Confusion in Model Performance: Members discussed the confusion around system RAM usage when loading models that fit into GPU's VRAM. Despite having sufficient VRAM, larger models still consume significant system RAM, slowing down performance or causing issues.
- 'mlock' and 'mmap' Parameters Affect RAM Usage: Adjusting parameters like
use_mmapsignificantly impacted RAM usage during model loading. Disablinguse_mmapreduced memory usage substantially, leading to marked improvements in performance. - Hardware Recommendations for Multi-GPU Setups: Various hardware configurations, particularly involving GPUs like RTX 3090s and Tesla P40s, were discussed, with recommendations to keep drivers updated and ensure proper multi-GPU setup. Specific models and setups were shared, highlighting different performance and RAM utilization scenarios.
- Issues with LM Studio Version 0.2.24: Users experienced significant RAM issues and model loading problems with LM Studio version 0.2.24. Some suggested reverting to previous versions, but difficulties arose as older versions were inaccessible.
- Server Racks for Multiple GPUs: A member sought advice on server setups to house multiple Tesla P40 GPUs, sparking recommendations to search previous discussions and check with experienced community members.
Link mentioned: TheBloke/Llama-2-7B-Chat-GGUF at main: no description found
LM Studio ▷ #🧪-beta-releases-chat (26 messages🔥):
- Fix GPU Offload Error on Linux: A user reported an error with exit code 132 caused by GPU offload. The issue was resolved by turning off GPU offload via the Chat page -> Settings Panel -> Advanced Settings -> GPU Acceleration.
- NVIDIA GPU Not Recognized: A user on Linux (Kali) with an NVIDIA GTX 1650 Ti Mobile faced issues with GPU not being detected. Suggestions included installing the correct NVIDIA drivers and ensuring packages like libcuda1 are in place.
- Release of LM Studio 0.2.25: A new release candidate for LM Studio 0.2.25 was announced, featuring bug fixes for token count display and GPU offload, and enhanced Linux stability. Links for downloading the latest version for Mac, Windows, and Linux were provided, along with instructions for optional extension packs for AMD ROCm and OpenCL.
- Phi-3 Model and Smaug-3 Tokenizer: A member expressed frustration over the lack of support for phi-3 small, while another member noted that the new release fixes the smaug-3 tokenizer issue. They also appreciated the quick update with a light-hearted comment.
- LM Studio Extension Packs: There's interest in the newly available extension packs for LM Studio. One user mentioned that although 0.2.25 could run deepseek v2 lite, it still showed it as not supported.
LM Studio ▷ #autogen (1 messages):
- API Key Error Frustrates User: A member is experiencing an API key error when querying a workflow in the playground, receiving a
401error withinvalid_api_keydespite verifying and changing the key multiple times. They noted that while the test button on the model setup works, LmStudio is not receiving any hits from autogen.
LM Studio ▷ #model-announcements (1 messages):
- DiscoPOP by Sakana AI breaks new ground: Sakana AI introduces a new training method for direct preference optimization, discovered through experiments with a large language model. Check out the blog post for more details and download the model at Hugging Face here.
OpenAI ▷ #annnouncements (1 messages):
- Paul M. Nakasone joins OpenAI Board: Paul M. Nakasone, a retired US Army General, has been appointed to OpenAI’s Board of Directors. He brings world-class cybersecurity expertise, crucial for protecting OpenAI’s systems from sophisticated threats. Read more.
OpenAI ▷ #ai-discussions (203 messages🔥🔥):
- OpenAI API Payment Issues Frustrate Users: Multiple users expressed frustration over being unable to make payments through the OpenAI platform due to a "too many requests" error. OpenAI support suggested waiting 2-3 days and provided some troubleshooting steps, but users were still dissatisfied with the delay affecting their application functionality.
- ChatGPT Chat History Concerns: A user expressed concern over losing 18 months of ChatGPT chat history across multiple devices and browsers. Other users suggested clearing cache, using incognito mode, and ensuring account security through 2FA, but the issue persisted, leading to speculation about account compromise.
- Frustration Over Platform-Specific Releases: A user vented frustration about the delayed release of the ChatGPT Win11 version, compared to its availability on macOS. The sentiment highlighted a perceived neglect of Windows users despite significant investments from Microsoft into OpenAI.
- Exploring Alternative AI APIs: Members discussed alternatives to OpenAI's API, such as OpenRouter, for those facing issues or seeking backup options. Though some APIs presented compatibility issues, users noted the ease of code transition with tools like OpenRouter.
- Jailbreak and AI Role-playing Discussions: Members debated the concept of "jailbreaking" AI models, with some arguing it's essentially sophisticated role-playing rather than unlocking hidden capabilities. This stemmed from a broader conversation about the need for safeguards to prevent harmful outputs.
OpenAI ▷ #gpt-4-discussions (26 messages🔥):
- **GPT-4 doesn't learn after training**: Users discussed the misconception that GPT-4 agents can learn after initial training. Clarification was provided that *uploaded files are saved as "knowledge" files* but *do not continually modify the agent’s base knowledge*.
- **Differences between Command R and Command R+**: Members compared the accuracy of results from Command R and Command R+ for a calculation puzzle. Notably, *Command R+ was more accurate*, solving the puzzle correctly at *8 games played*, while Command R concluded with *11 games*.
- **GPT-3.5 Turbo API isn't free**: One user mistakenly believed GPT-3.5 Turbo to be free, but it was clarified that *the API is prepaid* and requires purchasing credits for continued use.
- **Disable GPT-4o tools issue**: A member faced difficulties disabling GPT-4o tools, impacting their important chat. A suggestion was made to customize settings via the menu, but they couldn't find the option due to language barriers.
- **Embedding vectors from OpenAI**: A query was raised about how the *text-embedding-ada-002* generates vector outputs like [-0.015501722691532107, -0.025918880474352136]. The user was interested in whether this process utilizes transformers.
OpenAI ▷ #prompt-engineering (3 messages):
- Struggling with flat shading in DALL-E: A user inquired about generating images in DALL-E without lighting and shadows, specifically aiming for flat shading akin to a 3D model with just the albedo texture. They mentioned trying various methods without success and seeking help with this issue.
OpenAI ▷ #api-discussions (3 messages):
- Create documentation for API: A user suggested the idea to "write documentation for the API and provide it to ChatGPT". This could help improve usability and understanding of the API functions.
- Unique Introduction for GPT-4: Claims of having the "Most Unique Introduction for GPT-4" were made by another user. Specific details of the introduction were not provided in the conversation.
- Achieve 3D flat shading in DALL-E: A user inquired about generating images in DALL-E with "no lighting and shadows, just flat shading". They experienced difficulty achieving this effect and asked for assistance or tips.
HuggingFace ▷ #general (112 messages🔥🔥):
- DiscoPOP leads in preference optimization: A member shared Sakana AI’s method for discovering preference optimization algorithms, highlighting DiscoPOP. This method outperforms other methods like DPO in achieving higher scores while deviating less from the base model, as detailed in their blog post.
- Alternative quantization strategy suggested: Another member suggests an alternative quantization strategy for models, proposing f16 for output and embed tensors while using q5_k or q6_k for others. They argue that quantizing the outputs and embeds to q8 significantly degrades model performance.
- GitHub code review and collaboration: Several messages discussed reviewing and potentially collaborating on various GitHub repositories, including projects like KAN-Stem and ViT-Slim. Users coordinated efforts to review and improve code implementations.
- Seeking help with training and troubleshooting: Multiple users sought assistance with training models on VMs, troubleshooting token invalid errors on iOS, and resolving "loading components" issues in stable diffusion. For these, detailed steps and advice, such as deleting cache and retrying, were provided.
- Speech-to-text and diarization questions: A member requested help with speech-to-text solutions with strong diarization capabilities, mentioning tools like Whisper and pyannote. They sought recommendations for fine-tuning models or finding pre-finetuned solutions for accurate speaker identification.
- One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning: We present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimi...
- ReLoRA: High-Rank Training Through Low-Rank Updates: Despite the dominance and effectiveness of scaling, resulting in large networks with hundreds of billions of parameters, the necessity to train overparameterized models remains poorly understood, whil...
- Tweet from Adina Yakup (@AdeenaY8): Huggy bandanas are ready for the community!🔥 Drop a 🤗in the thread if you're in for our new bandanas and I'll send you one! Can't wait to see everyone rocking them! 🥳✨🤘
- Fine-Tuning and Guidance - Hugging Face Diffusion Course: no description found
- ViT-Slim/GLoRA at master · Arnav0400/ViT-Slim: Official code for our CVPR'22 paper “Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space” - Arnav0400/ViT-Slim
- Tweet from Thomas Wolf (@Thom_Wolf): Did you know bert-based-uncased has been downloaded 1,5 billion times on the Hugging Face hub – top ai models are hitting youtube viral videos number ranges
- no title found: no description found
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face: no description found
- GitHub - emangamer/KAN-Stem: attempt at using gpt4o to create a KAN stem training script: attempt at using gpt4o to create a KAN stem training script - emangamer/KAN-Stem
- Glora implementation from https://github.com/Arnav0400/ViT-Slim/tree/master/GLoRA by viliamvolosv · Pull Request #1835 · huggingface/peft: More ingormation https://arxiv.org/abs/2306.07967
- peft/src/peft/tuners/glora.py at main · Arnav0400/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - Arnav0400/peft
HuggingFace ▷ #today-im-learning (2 messages):
- NAIRR Pilot Program attracts wide interest: The National Artificial Intelligence Research Resource (NAIRR) Pilot, led by the NSF, seeks proposals for exploratory research grants to demonstrate the program's value. Detailed information and deadlines can be found in the NAIRR Task Force Report and on the NAIRR Pilot NSF site.
- Help requested for using LLMs in education: A member seeks guidance on how to use Language Learning Models (LLMs) to teach a chapter, specifically for organizing content, determining key points, and providing examples. Any direction or advice on utilizing LLMs for educational purposes is appreciated.
HuggingFace ▷ #cool-finds (4 messages):
- New GitHub playground for OpenAI: A member introduced their new project, the OpenAI playground clone. It's available on GitHub for contributions and experimentation.
- Hyperbolic KG Embeddings paper shared: A paper on hyperbolic knowledge graph embeddings was shared, emphasizing that the approach "combines hyperbolic reflections and rotations with attention to model complex relational patterns". You can read more in the PDF on arXiv.
- OpenVLA model highlighted: A paper about the OpenVLA, an Open-Source Vision-Language-Action Model, was shared. The full abstract and author details can be found in the arXiv publication.
- Introducing QubiCSV for quantum research: A new platform called QubiCSV, aimed at "qubit control storage and visualization" for collaborative quantum research, was introduced. The detailed abstract and experimental HTML view are available on arXiv.
- OpenVLA: An Open-Source Vision-Language-Action Model: Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new...
- QubiCSV: An Open-Source Data Storage and Visualization Platform for Collaborative Qubit Control: Developing collaborative research platforms for quantum bit control is crucial for driving innovation in the field, as they enable the exchange of ideas, data, and implementation to achieve more impac...
- Low-Dimensional Hyperbolic Knowledge Graph Embeddings: Knowledge graph (KG) embeddings learn low-dimensional representations of entities and relations to predict missing facts. KGs often exhibit hierarchical and logical patterns which must be preserved in...
- GitHub - neeraj1bh/openai-playground: OpenAI playground clone: OpenAI playground clone. Contribute to neeraj1bh/openai-playground development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (6 messages):
- Perceptron Logic Operators Explained: A member shared a blog post on training perceptrons with logical operators, covering fundamental concepts and intricacies. "Basically trying to put my thoughts together while learning."
- Shadertoy Util Gets Multipass and Physics: A member has been learning about GPUs and integrating multipass support into their Shadertoy utility, creating an interactive physics simulation. They shared a shadertoy example and invited feedback.
- Open-Source Alternative to Recall AI: A member developed LiveRecall, which records and encrypts everything on your screen for search via natural language, positioning it as a privacy-respecting alternative to Microsoft's Recall AI. They encouraged contributions and highlighted it as a new project in need of support.
- Research Accessibility Platform Launched: A new platform called PaperTalk was launched to make research more accessible using AI tools.
- Papertalk.io - :Unlock the Power of Research: Swiftly, Simply, Smartly: no description found
- Training a Perceptron on Logical Operators: One of the fundamental concepts in machine learning domain is the perceptron, an algorithm inspired by the functioning of a neuron.
- GitHub - VedankPurohit/LiveRecall: Welcome to **LiveRecall**, the open-source alternative to Microsoft's Recall. LiveRecall captures snapshots of your screen and allows you to recall them using natural language queries, leveraging semantic search technology. For added security, all images are encrypted.: Welcome to **LiveRecall**, the open-source alternative to Microsoft's Recall. LiveRecall captures snapshots of your screen and allows you to recall them using natural language queries, leverag...
- Shadertoy: no description found
HuggingFace ▷ #reading-group (1 messages):
- Meta's new paper explores pixel-level transformers: A member shared a recent paper release by Meta titled An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels. They noted that this new work builds on previous presentations, specifically highlighting the superiority of pixel-level attention demonstrated by the #Terminator work.
HuggingFace ▷ #computer-vision (6 messages):
- Looking for RealNVP experience: A member inquired if anyone had experience working with the RealNVP model. No further discussion followed.
- Java-based image detection request: Another member sought help creating an image detection system that supports both live and custom detection via uploads, specifically in Java. They emphasized their preference for a solution not involving Python.
HuggingFace ▷ #NLP (6 messages):
- New Model Fine-Tunes to Detect Hallucinations: A member shared a link to a new small language model fine-tune for detecting hallucinations. The shared stats highlight its precision, recall, and F1 score on hallucination detection with an accuracy of 79%.
- Query on DataTrove Library: A user asked where to ask about the DataTrove library, and they were advised that they could ask their questions in the chat channel.
- Minhash Deduplication Configuration: A user sought advice on configuring minhash deduplication on a 500GB dataset using 200 CPU cores on a local machine, noting their lack of experience with multiprocessing programming.
- Sales Calls Analysis Help: Another member sought guidance on analyzing over 100 sales calls to extract insights on key variables influencing purchase decisions. They mentioned using Whisper or Assembly for transcription and GPT for exploratory data analysis (EDA).
Link mentioned: grounded-ai/phi3-hallucination-judge-merge · Hugging Face: no description found
HuggingFace ▷ #diffusion-discussions (13 messages🔥):
- Git Download Fixes Issues: One user confirmed that a git download solved their problem, with another user expressing hope that it helped.
- Dreambooth Script Requires Modifications for Flexibility: A member noted that while the pipeline has the flexibility for more complex training scenarios, the basic dreambooth script is not equipped to handle individual captions for SD3 models. Another user highlighted that modifying the script is necessary to achieve these training features.
- Tokenizers Training Not in Basic Script: Users discussed the possibility of training tokenizers like CLIP and T5, mentioning that it would significantly increase VRAM requirements and is not included in the basic dreambooth script.
- Low MFU Profiling in Diffusion Models: A user shared profiling data for HDIT and queried the low Model Fraction Utilization (MFU) in diffusion models compared to language models like nanogpt on an A100. They invited theories and insights from others in the community.
- Seeking Advice for Meme Generator Model: A user is developing a high-quality meme generator model and sought advice from experienced members on how to get started. They opened the floor for insights and recommendations.
Link mentioned: k-diffusion/run_profile.sh at master · Muhtasham/k-diffusion: Karras et al. (2022) diffusion models for PyTorch. Contribute to Muhtasham/k-diffusion development by creating an account on GitHub.
Nous Research AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=xIDMPUYpd_0
Nous Research AI ▷ #interesting-links (5 messages):
- Magpie scales self-synthesizing instruction data: In their new preprint, Magpie self-synthesizes 4M data points using the "prompting-with-nothing" method, significantly improving Llama-3-8B-base's performance on alignment benchmarks like AlpacaEval, ArenaHard, and WildBench. Transferable to smaller models like Qwen 1.5 4B & 7B, this method showcases the need for additional math & reasoning data for continued improvement.
- Samba achieves infinite context with linear complexity: The Samba model, constructed by adding MLP and Sliding Window Attention to Mamba, outperforms Phi-3-mini across benchmarks. Samba-3.8B-instruct demonstrates how aptly designed model architectures can yield infinite context lengths efficiently.
- NVIDIA's Nemotron-4 340B model family: The Nemotron-4 340B Technical Report introduces the Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward models under a permissive open-access license. These models significantly rely on synthetically generated data (over 98%) and are designed to run on a DGX H100 with 8 GPUs in FP8 precision.
- Tweet from Philipp Schmid (@_philschmid): Is that what we call Bingo? 🎯 "Samba = Mamba + MLP + Sliding Window Attention + MLP stacking at the layer level." => infinite context length with linear complexity Samba-3.8B-instruct ...
- Tweet from Bill Yuchen Lin 🤖 (@billyuchenlin): What if we prompt aligned LLMs like Llama-3-Instruct with nothing? 🤔Surprisingly, it will decode decent user queries thanks to its auto-regressive nature. In our new preprint, Magpie🐦⬛, we find thi...
- Nemotron-4 340B | Research: no description found
Nous Research AI ▷ #general (69 messages🔥🔥):
- Roblox Meetup Hilarities: A member shared amusement at the VLLM GitHub page, specifically referencing a humorous section about a Roblox meetup. This elicited chuckles and agreement from others in the discussion.
- DiscoPOP's Optimization Breakthrough: A new method proposed by Sakana AI called DiscoPOP was highlighted for achieving better scores in preference optimization compared to existing methods like DPO. A blog post was shared alongside the model, emphasizing its high Reward and lower KL Divergence metrics.
- Concerns Over AI and Surveillance: Some members expressed concerns about the appointment of former NSA head Paul M. Nakasone to OpenAI's board, fearing deeper government involvement and increased surveillance. They linked articles and discussed implications of this decision.
- Real-Time TTS Advancements: A user updated the community on progress with a TTS project, stating improvements with Styletts2 and a 10x real-time speed using flash attention. They mentioned ongoing refactoring efforts aiming to implement future features, including identities and memories.
- Synthetic Data Generation Models: The introduction of Nemotron-4-340B-Instruct model was discussed, noting its use in synthetic data generation and alignment steps like Supervised Fine-tuning and Preference Optimization. The conversation highlighted the potential for commercial use under the NVIDIA Open Model License.
- Former head of NSA joins OpenAI board: Another new board member.
- Stable Diffusion 3 Medium - a Hugging Face Space by stabilityai: no description found
- no title found: no description found
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face: no description found
- Paper page - PowerInfer-2: Fast Large Language Model Inference on a Smartphone: no description found
- nvidia/Nemotron-4-340B-Base · Hugging Face: no description found
- nvidia/Nemotron-4-340B-Instruct · Hugging Face: no description found
- Godfather Massacre GIF - Godfather Massacre Sad - Discover & Share GIFs: Click to view the GIF
- Snowden GIF - Snowden - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (7 messages):
- Updating LLMs with new data remains a challenge: A shared arXiv paper discusses that the standard method of updating LLMs through continued pre-training on new documents followed by QA pairs still presents issues. The authors suggest exposing LLMs to QA pairs before document training to better encode knowledge for answering questions.
- Citations in RAG context explored: A member expressed interest in algorithms for citation management when building a Retrieval-Augmented Generation (RAG) system. They acknowledge the complexity due to the many contexts in which this could be applied.
- Perplexity tool's limitations discussed: It was noted that Perplexity cannot process PowerPoint documents in its free version, but using citations over such documents is seen as a compelling use case.
Link mentioned: Instruction-tuned Language Models are Better Knowledge Learners: In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new dat...
Nous Research AI ▷ #rag-dataset (39 messages🔥):
- ONNX conversation speeds up CPU testing: A discussion mentioned an ONNX conversation on another Discord that speeds up the CPU by allegedly 2x. "CPU only, I don't think onnx will speedup much on GPU," was noted about the testing.
- Codebase summarized for RAG dataset: A GitHub tool, code2prompt, helps in converting codebases into markdown prompts for RAG datasets. Members discussed using it and pointed out the resulting token count can be exceptionally high.
- Model context handling and limitations: Members noted difficulty in handling context lengths beyond 8k for training on current GPU hardware. They discussed truncating contexts for better model training and ensuring samples require multifaceted information synthesis.
- RAG dataset and context length: Engaging in brainstorming, members proposed chunking and indexing the markdown of codebases for extended context usage in RAG without being dependent on model output capacity.
- Need more complex sample queries: Emphasis was placed on creating complex sample queries that require models to synthesize information from multiple sources, rather than simple fact-based queries. This includes decomposing queries into multiple search queries for better information retrieval.
Link mentioned: GitHub - mufeedvh/code2prompt: A CLI tool to convert your codebase into a single LLM prompt with source tree, prompt templating, and token counting.: A CLI tool to convert your codebase into a single LLM prompt with source tree, prompt templating, and token counting. - mufeedvh/code2prompt
Nous Research AI ▷ #world-sim (2 messages):
- WorldSim Prompt is open-source: The original worldsim prompt can be found by searching on Twitter. Despite mentioning a switch to the Sonnet model, it's implied that this option is part of the discussion around different model capabilities.
Modular (Mojo 🔥) ▷ #general (9 messages🔥):
- Mojo's package manager still in progress: The Mojo package manager is currently "still being worked on". For now, users need to compile other packages from source or download them as mojopkg files from releases.
- Best practices for setting up queries: There's a shared desire for a guide on best practices for setting up repositories. One member suggests copying what Modular does on GitHub until official guidance is available.
- Massachusetts meet-up for Mojo enthusiasts: A member is looking to connect with others in Massachusetts to discuss Mojo over coffee. They are excited to make connections and share knowledge in person.
- Discussion on
defandfnfunctions: There was a clarification needed with a provided link to Mojo's Function Manual. The page explains thatdefandfnfunctions have different default behaviors, and the choice between them depends on personal coding style and task requirements.
Link mentioned: Functions | Modular Docs: Introduction to Mojo fn and def functions.
Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- NSF NAIRR EAGER Grants Open for Proposals: The National Science Foundation (NSF) is accepting proposals for the Early-concept Grants for Exploratory Research (EAGER) under the National AI Research Resource (NAIRR) Pilot. Proposals are reviewed monthly, with awards lasting twelve months and available to US-based researchers and educators as per the NSF pub.
- NAIRR Pilot Vision and Community Building: Activities aligned with the NAIRR Pilot vision include facilitating requests for computing resources, integrating data and tools, and building a strong user community. More details are provided in the NAIRR Task Force Report.
- Resource Access and Proposal Deadlines: The NAIRR Pilot, supported by the NSF, DOE, and various partners, allows the research community to access computing and educational resources, as outlined on the NSF NAIRR Pilot site. Proposals must be submitted by the 15th of each month for review, with decisions made by the end of the month.
Modular (Mojo 🔥) ▷ #🔥mojo (92 messages🔥🔥):
- Mojo’s GPU Support Sparks Mixed Reactions: One user asked about the release date for GPU support in Mojo, with responses noting skepticism about current job opportunities but acknowledgements that GPU support is anticipated. A link to job opportunities related to Mojo was shared, indicating some pathways for employment.
- Mojo Versus CUDA Debate: Discussions highlighted that while CUDA already works, Mojo’s strongly typed nature and potential support for various accelerators could make it an appealing alternative. Users debated the viability of Mojo and Modular compared to NVIDIA’s solutions and the potential need for exclusive technologies.
- Exploring Multi-Threading and MLIR: A user inquired about how Mojo handles multi-threading, with references to SIMD instructions, unroll_factor, and parallelization. Another user shared a link detailing various MLIR dialects like amdgpu, nvgpu, and XeGPU, useful for portability.
- Speculations on Modular’s Business Model: Several users debated whether Modular's business model is viable, discussing potential revenue from support services, consulting, and inference/training via MAX. The consensus was that while Mojo isn't production-ready, its promises of better tooling could position it favorably against established players like CUDA.
- Concerns Over Open Source and Vendor Lock-In: There was concern over vendor lock-in and the reliance on open-source contributions, drawing parallels to companies' need for proprietary solutions. Some users argued that new chip companies might prefer Mojo for competing on technical merits rather than vendor exclusivity, echoing frustration with existing tools and environments.
- Modular: Fast⚡ K-Means Clustering in Mojo🔥: Guide to Porting Python to Mojo🔥 for Accelerated K-Means Clustering: We are building a next-generation AI developer platform for the world. Check out our latest post: Fast⚡ K-Means Clustering in Mojo🔥: Guide to Porting Python to Mojo🔥 for Accelerated K-Means Clusteri...
- Modular: Careers: At Modular we believe a great culture is the key to creating a great company. The three pillars we work by are Build products users love, Empower people, and Be an incredible team.
- Modular: Careers: At Modular we believe a great culture is the key to creating a great company. The three pillars we work by are Build products users love, Empower people, and Be an incredible team.
- Dialects - MLIR: no description found
- mojo/stdlib/docs/vision.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- MLIR C/C++ Frontend Working Group: MLIR C/C++ Frontend Working Group Monthly on the first Monday, 9am Pacific Time. Discord: #clangir, … Calendar If you want to be added to the Google calendar invite send your Google account email ad...
- no title found: no description found
Modular (Mojo 🔥) ▷ #nightly (3 messages):
- New Nightly Mojo Compiler Released: A new nightly Mojo compiler has been released, updating to
2024.6.1405. You can update withmodular update nightly/mojoand view the raw diff and the current changelog.
- Contributing to Mojo: A member asked for resources to get up to speed on Mojo development, noting difficulty in determining where to start. They were directed to the contributing guide which assumes knowledge of Python and Mojo documentation, with a suggestion to start with issues labeled "good first issue".
Link mentioned: mojo/CONTRIBUTING.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Perplexity AI ▷ #general (92 messages🔥🔥):
- **Perplexity Servers Down; Confusion Ensues**: Multiple users reported issues with Perplexity servers, experiencing repeated messages and endless loops, leading to frustration. One user commented, "if the site is under maintenance they didnt even announce they were going to do that," highlighting the lack of communication from Perplexity's team.
- **File Upload Issues Identified**: A user pinpointed that a broken file upload feature is causing performance problems, specifically citing that "perplexity for like 2 months has had an issue where users with a certain AB test config just have broken file reading." This problem was confirmed by Perplexity support, linking it to partial reversion of new features.
- **404 Errors on Generated Links**: Users raised concerns over Perplexity generating incorrect or non-existent links, with one stating, "100% of the time links go to a 404 type page." Discussions suggested that this could be due to the LLM making up URLs instead of sourcing real links.
- **Android App Inconsistencies**: There was a noted inconsistency with the Perplexity Android app, where requests periodically re-sent without execution, which wasn't observed on iOS or web. A user highlighted, "the problem started after there were errors with Perplexity's operation last week."
- **Pro Subscription Concerns**: Several users expressed doubts about upgrading to Perplexity Pro due to ongoing issues and poor communication from support. One frustrated user remarked, "seems like perplexity might not be worth it after all."
Link mentioned: Reddit - Dive into anything: no description found
Perplexity AI ▷ #sharing (9 messages🔥):
- Explore Dimension-5 Second: A link to Dimension-5 Second was shared, inviting members to delve into this topic.
- Musk Drops Lawsuit: A member posted a link about Musk dropping a lawsuit, highlighting a recent significant update in legal news related to Elon Musk.
- Situational Awareness Guide: A link to an article on Situational Awareness was shared, providing insights into maintaining awareness in various situations.
- Argentina National Football: Information and updates about Argentina National Football were shared through this link.
- Apple Stock Soars: A member shared a link on how Apple's stock soared, pointing to a noteworthy financial news event.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
- Seeking Web3-API Builders: One member inquired, "anybody here using the API to build web3-native projects?" They also asked if anyone is "connecting it to blockchain endpoints."
LlamaIndex ▷ #blog (1 messages):
- Atomicwork integrates LlamaIndex for AI assistant: The team at Atomicwork has developed their AI assistant, Atom, utilizing LlamaIndex to handle multiple data formats. This capability ensures accurate, secure, and efficient data retrieval, thus enhancing decision-making processes. Source
LlamaIndex ▷ #general (63 messages🔥🔥):
- Wrong kwarg in ReAct agent configuration: A member faced an error with ReAct agent configuration due to using the wrong kwarg 'max_iteration'. Another member pointed out that the correct term is
max_iterations.
- Recursive Retriever with Document Agent Issue: A member struggled to load an index from Pinecone vector store following the guide on recursive retrievers with document agents. They shared code details for better assistance.
- Discussion on Using Vercel AI with Query Engine: A member queried if the Query Engine supports Vercel AI vector stream and was advised to use FastAPI and StreamingResponse as a solution.
- Multi-Tenancy Interest in Weaviate Integration: Members from Weaviate discussed adding a multi-tenancy feature for better data separation, inviting feedback on a GitHub issue.
- Learning Resources for Building Custom Agents: A member sought resources for building custom agents, and various members provided links to LlamaIndex documentation and a short course collaboration with DeepLearning.AI.
- Building Agentic RAG with LlamaIndex: Learn how to build an agent that can reason over your documents and answer complex questions. Learn from the co-founder and CEO of LlamaIndex
- Sub Question Query Engine - LlamaIndex: no description found
- Building a Custom Agent - LlamaIndex: no description found
- llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/query_engine/sub_question_query_engine.py at 379503696e59d8b15befca7b9b21e1675db17c50 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Faiss Vector Store - LlamaIndex: no description found
- Recursive Retriever + Document Agents - LlamaIndex: no description found
- [Feature Request]: Add support for multi-tenancy in weaviate · Issue #13307 · run-llama/llama_index: Feature Description Add support for multi-tenancy (MT) in Weaviate Reason MT in weaviate requires changes to the schema (enable MT) and CRUD ops (pass tenant name). How should we update the llamain...
- Multi-Tenancy RAG with LlamaIndex - LlamaIndex: no description found
- Anthropic - LlamaIndex: no description found
- Defining a Custom Property Graph Retriever - LlamaIndex: no description found
LLM Finetuning (Hamel + Dan) ▷ #general (6 messages):
- New Channel for Cool Demos!: Check out the newly created channel <#1250895186616123534> to showcase cool projects and demos. Live, unstructured demos can be discussed in the General voice channel.
- Lamini Memory Tuning Explored: Lamini shared their innovative memory tuning approach that improves factual accuracy and reduces hallucinations, achieving up to 95% accuracy for a Fortune 500 customer. Read more about this breakthrough and their research paper.
- Helix AI for Fine-Tuning LLMs: A member inquired if anyone has tried Helix AI for fine-tuning LLMs. It promises the best open LLMs while being secure, scalable, and private, with optional pass-through to closed models. Try it out here.
- Excitement Around FP8 in vLLM: FP8 inference is lauded for lowering latency, increasing throughput, and reducing memory usage with minimal accuracy drop. Check out accurate, pre-quantized checkpoints and vLLM docs on FP8.
- Private GenAI Platform – Helix AI: no description found
- Tweet from Michael Goin (@mgoin_): Excited that FP8 in vLLM is getting better and better as we spend time on it. Check out our collection of accurate, pre-quantized checkpoints! https://huggingface.co/collections/neuralmagic/fp8-llms-f...
- Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations | Lamini - Enterprise LLM Platform: no description found
- Lamini-Memory-Tuning/research-paper.pdf at main · lamini-ai/Lamini-Memory-Tuning: Banishing LLM Hallucinations Requires Rethinking Generalization - lamini-ai/Lamini-Memory-Tuning
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (6 messages):
- Users seek extra credits: Members requested extra credits due to challenges following the course consistently or for continued usage, such as training embedding models. One member expressed plans to write tutorials on learned content if granted credits.
- Modal training extends beyond 24 hours: A member inquired about training time exceeding 24 hours while using the Axolotl example in Modal. Another member confirmed that there's a parameter to resume training from a previous run, offering a workaround for the issue.
- Slack link for community support: A link to a similar query on Slack (Slack link) was shared for additional context and support. The link provided an avenue for finding answers to similar challenges discussed in the community.
Link mentioned: Slack: no description found
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (2 messages):
- Discussing Output Validation Techniques: A member asked if output validation involves "structured generation" and mentioned using the outlines library. Another member clarified that they focus on use-case specific evaluations and assertions.
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (5 messages):
- Axolotl on Jarvis needs Ampere GPUs for training: "I have trouble finetuning openllama-3b with Axolotl on Jarvis (I used a RTX5000)." The issue was resolved by using an Ampere GPU.
- Query on uploading models from Jarvis to HF: "Do we need to delete the instance after uploading the model to HF or can we leave it on Jarvis?" A member asked for guidance on the proper procedure for uploading models from Jarvis to Hugging Face (HF) and managing instances post-upload.
- Sample_packing error with lora-8b.yml config: "When finetuning llama-3 using the lora-8b.yml config, I ran into a sample_packing error." The concern was whether example configs are supposed to work without any modification.
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
- LoRa finetuning with custom head shows inconsistencies: A user expressed concerns that after finetuning a causal LM model using LoRa and adding pooling layers and a custom head, their evaluation during training was good, but inference from the adapter safetensors yielded drastically worse results. They questioned if saving the base model weights was necessary for correct inference.
- Credits issue with Hugging Face: A user mentioned that they submitted a form for credits but had not received them yet, indicating a delay or issue in the credit allocation process. They provided their username and contact email for assistance.
LLM Finetuning (Hamel + Dan) ▷ #replicate (4 messages):
- Replicate credits confusion: A member questioned whether Replicate credits expire in 24 hours after receiving an email from Replicate. Another user suggested that the alert might be based on projected usage.
- No credits received after initial signup: A member shared their email to check the status of credits, stating they didn't receive any credits or emails after initial signup at github@granin.net.
- Awaiting credits via DM: Another member mentioned they are still waiting to receive the link to redeem credits and have DM'd their email details to follow up. They expressed eagerness to start using Replicate.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (3 messages):
- Credit Card Info Requirement Sparks Debate: One member expressed discomfort with Langsmith's practice of collecting credit card information before it's necessary. They concluded, "I don't have to use it if I don't like that aspect (and I don't :))."
- Direct Communication for Credit Concerns: A member offered direct messaging assistance to resolve an issue, saying, "feel free to dm me - please let me know what email you used in the credits form."
- Unresolved Credits Issue: Another member reported not receiving their credits due to previously incorrect billing information and sought guidance on what steps to take next.
LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (3 messages):
- Search button woes: A user finds that the search button doesn't do anything or is non-functional despite efforts to use it.
- Sluggish search button acknowledged: Another member acknowledges the issue, explaining it's very slow and commits to profiling and speeding up the process.
- User requests feedback on search progress: Another member suggests a form of indication that something is happening during the search process to improve user experience. They mention they are happy to wait if they know progress is being made.
LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (1 messages):
<ul>
<li><strong>Seeking optimal settings for inference endpoints</strong>: A member reached out with a question about achieving the best performance for <em>inference endpoints</em>. They asked if there are recommended settings to optimize performance.</li>
</ul>
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (4 messages):
- RTX5000 doesn’t support flash attention: When attempting to finetune openllama-3b on Jarvis using an RTX5000, the user faced issues. Another member informed them that the RTX5000 doesn’t support flash attention and suggested disabling it.
- A5000 instance resolves training issue: After switching to an A5000 instance, the user successfully started training their model. The user reported, “The model is training now.”
- Errors encountered with tiny-lama and Axolotl: The user faced unspecified errors while finetuning tiny-lama using the LoRA config example from the Axolotl repository on Jarvis and Modal. They expressed frustration, stating, “I'm wondering why it's not that straightforward to run the config examples.”
LLM Finetuning (Hamel + Dan) ▷ #simon_cli_llms (4 messages):
- Python API for LLMs under scrutiny: A member expressed admiration for the shared talk and inquired why the Python API for LLMs is considered incomplete. They mentioned enjoying embed_multi_with_metadata and sought advice on potential pitfalls or contributions.
- Productivity insights inspire: Another user praised the talk, noting the surprising productivity tips and GitHub issue discussions that were included. They found these insights particularly inspirational.
- Ollama plugin not showing up: A member encountered an issue with the Ollama plugin not appearing under LLM models despite being added to the plugins JSON. They requested debugging advice, implying it might be a common problem.
- Video playback issues: One user reported problems with the talk's recording page, receiving a 'no video with supported format found' error message, indicating a technical glitch.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (12 messages🔥):
- Credit Redemption Guidance, Thanks: A member expressed gratitude for the course and inquired about the pending status of credits from multiple platforms like Hugging Face and Langsmith. Guidance was given to check specific channels under "Sponsored Compute" for the right points of contact.
- Channel History Tip: Hamel advised the member to read the history of the relevant channels before posting to understand who is the point of contact. This is to ensure that the member can find the appropriate information without redundant queries.
- Email Address Request: Dan Becker requested the member's email address to verify which batch they were in, indicating that if their data wasn’t shared with the platforms, further assistance might be limited.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (1 messages):
- **Help with credits requested**: A member asked for assistance with credit issues after filling out a form, providing their ID as *akshay-thapliyal-153fbc*. They tagged another member specifically for help.
LLM Finetuning (Hamel + Dan) ▷ #predibase (1 messages):
- Password Recovery Issue Noted: "Thanks for great talks! Emailed your colleague as cant login and recover password with email that I used to signup," a member shared, expressing their issue with accessing their account. They confirmed sending the issue to Will Van Eaton at will@predibase.com.
LLM Finetuning (Hamel + Dan) ▷ #career-questions-and-stories (3 messages):
- Cursor on Linux remains tricky: A member raised a concern about obtaining a "plain" binary for Cursor on Linux, noting they only get an AppImage. They expressed frustration as it isn't the same as running
code file.py. - Cursor's initial bugginess questioned: A member questioned whether the stability issues with Cursor from half a year ago have been resolved, noting persistent bugs and incompatibility with extensions. Another member shared that their experience over the past four months has been positive and stable, suggesting improvement.
LLM Finetuning (Hamel + Dan) ▷ #openai (2 messages):
- Members wait for OpenAI credits: Multiple members reported that their accounts have not been credited with OpenAI credits yet. One mentioned "org-45RghBshWBY9nqyEWwxanvTh" while another mentioned "org-AGO5uO7zhYgyEcFiQX29eBsV" and sought assistance in resolving this issue.
LLM Finetuning (Hamel + Dan) ▷ #pawel-function-calling (5 messages):
- Function Calling Integration Discussed: The topic of integrating function calling within software stacks was mentioned, specifically in the context of LangGraph. A link to the LangGraph documentation on retries was shared, highlighting the challenges and solutions with function calling, including better prompting, constrained decoding, and validation with re-prompting.
- Gif Shared for Emphasis: A GIF from Tenor related to "The Mandalorian" was posted, possibly to emphasize the importance or correctness of a previous discussion point. The humorous GIF underscores the conversational and collaborative nature of the chat.
- Book Of Boba Fett The Mandalorian GIF - Book Of Boba Fett The Mandalorian This Is The Way - Discover & Share GIFs: Click to view the GIF
- Extraction with Re-prompting - LangGraph: no description found
Eleuther ▷ #general (6 messages):
- Lamini Memory Tuning claims breakthrough: A blog post on Lamini Memory Tuning highlights a new method to embed facts into LLMs, improving factual accuracy to 95% and reducing hallucinations from 50% to 5%. It involves tuning expert adapters on top of open-source LLMs like Llama 3 or Mistral 3.
- Interest in training HiFi-GAN for XTTS: A member asked if anyone has successfully trained the HiFi-GAN part of XTTS and sought thoughts and experiences from the community.
- Seeking help for LLM-based chapter teaching: A member requested guidance on how to get an LLM to teach a chapter, including organizing content, key points, and examples.
- Improved training for binary neural networks discussed: A member shared a paper proposing an improved training algorithm for binary neural networks that learns scaling factors discriminatively via backpropagation. This method significantly outperforms the state-of-the-art XNOR-Net.
- Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations | Lamini - Enterprise LLM Platform: no description found
- XNOR-Net++: Improved Binary Neural Networks: This paper proposes an improved training algorithm for binary neural networks in which both weights and activations are binary numbers. A key but fairly overlooked feature of the current state-of-the-...
Eleuther ▷ #research (37 messages🔥):
- KANs could simplify implementation on unconventional hardware: Members discussed potential advantages of KANs (Kriging Approximation Networks) over MLPs (Multilayer Perceptrons) for implementation in analog, optical, and other "weird hardware," pointing out that KANs only require summation and non-linearities rather than multipliers.
- Training large language models to encode questions first: A shared paper suggested that exposing LLMs to QA pairs before continued pre-training on documents could benefit the encoding process due to the straightforwardness of QA pairs in contrast to the complexity of documents. Read more.
- Transformers combined with graph neural networks for reasoning: A proposed hybrid architecture combines the language understanding of Transformers with the robustness of GNN-based neural algorithmic reasoners, aimed at addressing the fragility of Transformers in algorithmic reasoning tasks. For more details, see the paper.
- Pixels-as-tokens in VISION Transformers: A paper presented the novel concept of operating directly on individual pixels using vanilla Transformers with randomly initialized, learnable per-pixel position encodings. The discussion highlighted the unconventional approach and its potential impacts. Link.
- PowerInfer-2 boosts LLM inference on smartphones: The newly introduced framework, PowerInfer-2, significantly accelerates inference for large language models on smartphones, leveraging heterogeneous resources for fine-grained neuron cluster computations. Evaluation shows up to a 29.2x speed increase compared to state-of-the-art frameworks. Full details.
- Instruction-tuned Language Models are Better Knowledge Learners: In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new dat...
- Cognitively Inspired Energy-Based World Models: One of the predominant methods for training world models is autoregressive prediction in the output space of the next element of a sequence. In Natural Language Processing (NLP), this takes the form o...
- 4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities: Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are li...
- Understanding Hallucinations in Diffusion Models through Mode Interpolation: Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit "hallucinations," samples that could never occur in the training data. But where do...
- Transformers meet Neural Algorithmic Reasoners: Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization...
- An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels: This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely...
- RWKV-CLIP: A Robust Vision-Language Representation Learner: Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper...
- Paper page - PowerInfer-2: Fast Large Language Model Inference on a Smartphone: no description found
- Lamini-Memory-Tuning/research-paper.pdf at main · lamini-ai/Lamini-Memory-Tuning: Banishing LLM Hallucinations Requires Rethinking Generalization - lamini-ai/Lamini-Memory-Tuning
Eleuther ▷ #lm-thunderdome (1 messages):
<ul>
<li><strong>Command line arguments need post-processing</strong>: A member queried about whether they can specify a results path via a command line argument. They were advised that they might need to do some post-processing instead.</li>
</ul>
Eleuther ▷ #multimodal-general (4 messages):
- RWKV-CLIP achieves State-of-the-Art results: A link was shared to BlinkDL's announcement celebrating RWKV-CLIP achieving state-of-the-art results. The model uses RWKV for both image and text encoding, and additional details can be found in the linked GitHub repository and arXiv paper.
- Inquiry on GNN-RAG Paper: A member asked if anyone had reviewed the recently released GNN-RAG paper and whether this channel was appropriate for the discussion.
- Clarification needed on Attention-based Pooling Neural Networks: A member sought clarification on a specific equation and the concept of attention-based pooling neural networks, mentioning that the context was within a language model used as an encoder.
Link mentioned: Tweet from BlinkDL (@BlinkDL_AI): RWKV-CLIP with SotA results🚀it's using #RWKV for both image & text encoder https://github.com/deepglint/RWKV-CLIP https://arxiv.org/abs/2406.06973
OpenRouter (Alex Atallah) ▷ #general (35 messages🔥):
- Debate on Cogvlm2 Hosting: Members discussed the potential and cost-effectiveness of hosting cogvlm2 on OpenRouter, noting a lack of clarity on its availability.
- Moderation Options for Google Gemini Pro: A user was able to pass arguments through OpenRouter to control moderation options in Google Gemini Pro but reported receiving an error message and suggested that OpenRouter needs to enable these settings. They highlighted Google’s instructions for billing and access.
- Discounted AI Studio Pricing Query: A user inquired if the discounted pricing for Gemini 1.5 Pro and 1.5 Flash in AI Studio could be applied on OpenRouter, noting AI Studio's token-based system is more convenient than Vertex.
- Excitement Over NVIDIA's Opened Assets: Members shared enthusiasm over NVIDIA opening up models, RMs, and data, specifically mentioning the Nemotron-4-340B-Instruct and the Llama3-70B variants. One member pointed out the availability of PPO techniques with these models as a treasure trove.
- Discussion on June-Chatbot's Origin: There was speculation about whether the "june-chatbot" in LMSYS was trained by NVIDIA with some members pointing to the 70B SteerLM model as a possibility.
- nvidia/Nemotron-4-340B-Instruct · Hugging Face: no description found
- nvidia/Llama3-70B-PPO-Chat · Hugging Face: no description found
- nvidia/Llama3-70B-SteerLM-Chat · Hugging Face: no description found
OpenInterpreter ▷ #general (25 messages🔥):
- Server overload causes lag: Users noted significant slowdowns and freezing issues likely due to server overload, "similar to when huggingface free models get overloaded." One mentioned that even when it seems frozen, waiting could eventually complete the task.
- Combining models for vision support: A member asked if it's possible to run the i model with vision, and another suggested using self-hosted llama 3 vision profile. There's also confusion over modifying local files to enable this, with some attempts resulting in partial solutions.
- Mouse automation with O1: Me_dium inquired about API/library functionalities for automating tasks like sending Slack messages and moving the mouse to click in message boxes. "It finds text on the screen and then sends the mouse to the coordinates," clarified a user, pointing out this capability since the introduction of os mode.
- Connecting Apple Scripts for automation: GordanFreeman4871 shared a YouTube video showcasing fast response automation using Shortcuts and Apple Scripts. They emphasized the simplicity of Apple Scripts and the importance of good prompting for effective automation.
- Model i freezing issue: Users reported frequent freezing of the i model mid-code execution, necessitating manual interruption via control-c.
Link mentioned: June 14, 2024: no description found
OpenInterpreter ▷ #O1 (4 messages):
- Member asks about a prior issue: A member inquired, "did you ever get this solved?" regarding an unresolved issue. The response was, "Haven't tried again, sorry!" with no further follow-up.
- Interesting hardware development link shared: A member shared an interesting link to a device in development from Seeed Studio. They commented "Very interesting Off the shell device in development."
Link mentioned: Sensecap Watcher - a physical AI agent for space management: no description found
Cohere ▷ #general (19 messages🔥):
- Cohere's chat interface praised: A user highlighted the superior UX of the citation feature on Cohere's playground chat, praising how clicking any inline link shows a modal with cited text and source link, calling it "next level, better than all others."
- Cohere's open-source chat interface: A user recommended the cohere-toolkit on GitHub for implementing chat interfaces that support citations, in response to another user's query.
- Utilizing Cohere for text completion: A user was informed that Cohere can perform text completion via the chat endpoint, directing them to effective prompt crafting tips for better results.
- Discord bot development resources: Another user seeking to create a Discord bot using the Aya model received multiple resources, including the discord.py documentation and the Discord Interactions JS repository, to aid with their project.
- GitHub - cohere-ai/cohere-toolkit: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications.: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications. - cohere-ai/cohere-toolkit
- Welcome to discord.py: no description found
- GitHub - discord/discord-interactions-js: JS/Node helpers for Discord Interactions: JS/Node helpers for Discord Interactions . Contribute to discord/discord-interactions-js development by creating an account on GitHub.
- Crafting Effective Prompts: no description found
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
Cohere ▷ #project-sharing (4 messages):
- Excitement for community projects: A member expressed excitement to see what the community builds, mentioning that "tons of use cases and examples" are coming soon. This generated anticipation among other members, with one saying, "Looking forward to the ucs and examples!".
- Cute response to enthusiasm: Another member responded with a playful comment, "so cute 😸," indicating a positive reception to the ongoing discussion.
LangChain AI ▷ #general (19 messages🔥):
- **Trouble with RAG example output**: A user struggled with a Retrieval-Augmented Generation (RAG) chain not correctly displaying the expected results. They provided their code and mentioned that the output should be 8 but they received a different result, seeking help to modify it to filter lines by specific questions.
- **Guidance on JSON creation in LangChain**: A user sought assistance for creating a JSON object and ensuring it's a valid JSON within a chain using LangChain. Another user responded by providing both JavaScript and Python examples to create a custom chat model that outputs a JSON object.
- **Problems with LangChain and pgvector integration**: A user faced issues while following the [LangChain-pgvector integration documentation](https://python.langchain.com/v0.2/docs/integrations/vectorstores/pgvector/), unable to recognize imports after installing `langchain_postgres`. Another member suggested checking if they were using the correct Python environment in their IDE.
- PGVector | 🦜️🔗 LangChain: An implementation of LangChain vectorstore abstraction using postgres as the backend and utilizing the pgvector extension.
- How to create a custom chat model class | 🦜️🔗 Langchain: This guide assumes familiarity with the following concepts:
LangChain AI ▷ #tutorials (3 messages):
- Hybrid Search for RAG using Llama 3 gets demoed: A YouTube video on Hybrid Search for RAG using Llama 3 was shared, aiming to showcase how to implement hybrid search for retrieval-augmented generation (RAG). The video includes links to a GitHub notebook and more resources.
- LangServe meets easy setup with NLUX: A member highlighted a nice UI with easy setup for LangServe endpoints using NLUX. The documentation guides users through integrating NLUX conversational capabilities into a React JS app, with references to the LangChain and LangServe libraries.
- Gumloop simplifies AI-native automations: Gumloop, a no-code platform for building AI-native workflow automations, was introduced. The YouTube video provides an overview of the intuitive UI and capabilities for automating complex tasks using AutoGPT.
- Hybrid Search for RAG using Llama 3: We will take a look at how to do hybrid search for RAGhttps://github.com/githubpradeep/notebooks/blob/main/hybrid%20vector%20search.ipynbhttps://superlinked....
- Gumloop - build AI-native workflow automations with an intuitive UI: Gumloop is a no-code platform for building powerful #ai automations. Founded in 2023, Gumloop aims to empower anyone to automate complex work with AI without...
- Get Started With NLUX And LangChain LangServe | NLUX: LangChain is popular framework for building services and backends powered by LLMs.
tinygrad (George Hotz) ▷ #general (4 messages):
- NVIDIA's Nemotron-4 340B Model Release: A member shared the Nemotron-4 340B model family release, which includes Nemotron-4-340B-Base, Instruct, and Reward. These models are open access under the NVIDIA Open Model License and fit on a single DGX H100 with 8 GPUs in FP8 precision.
- Fitting Nemotron-4 340B on 2 TinyBoxes: A member inquired if there is a way to make the new Nemotron-4 340B model fit on just 2 TinyBoxes. They suggested this would be a highly compelling use case.
- 3-Bit Quantization Suggestion: Another member responded by suggesting the use of 3-bit quantization to fit the model on one TinyBox, highlighting an alternative compact deployment strategy.
Link mentioned: Nemotron-4 340B | Research: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (15 messages🔥):
- Struggling with Compute Results in tinygrad: A user shared their progress in setting up buffers and running a compute graph in tinygrad. Despite the setup, they still questioned, "how would I actually get the result or force the realize of this compute graph?" Another member suggested calling
.execand referred to abstractions2.py.
- Finding abstractions2.py: While looking for the abstractions2.py file, a user provided a direct GitHub link to the file. This helped another user confirm, "thanks! this is exactly what I need!".
- Tensor Sorting Discussion: A user inquired about sorting tensors along an axis in tinygrad. After some discussion and suggestions from George Hotz, they concluded using
argmaxmight be more efficient for their purposes, specifically for implementing k-nearest neighbors.
- Alternative to PyTorch's grid_sample: A user asked if there's an alternative to PyTorch's
grid_samplein tinygrad, mentioningAffineGridin onnx_ops but unsure of its equivalence. They shared a PyTorch documentation link for reference.
- Mixed Precision Issues on M2: A user detailed issues with implementing mixed precision for a model, explaining their method using a lambda function. They are encountering a
CompileErrorspecific to Metal libraries on an M2 chip, suspecting a problem with their mixed-precision approach.
- torch.nn.functional.grid_sample — PyTorch 2.3 documentation: no description found
- tinygrad/docs/abstractions2.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
Interconnects (Nathan Lambert) ▷ #news (15 messages🔥):
- NVIDIA unveils 340B model: The Nemotron-4-340B-Base is a large language model with 340 billion parameters, supporting a context length of 4,096 tokens for synthetic data generation. It boasts extensive training on 9 trillion tokens across multiple languages and coding languages.
- Synthetic data model with permissive license: The release of Nemotron-4-340B-Base includes a synthetic data permissive license. Concerns were noted about the license being hosted as a PDF on NVIDIA's site.
- Experimental Claude Steering API access: Claude's experimental Steering API allows users to steer a subset of Claude's internal features. Sign-ups for limited access are open, although it is specified that this is for research preview only and not for production use.
- Sakana AI secures billion-dollar valuation: Japanese startup Sakana AI, which is developing alternatives to transformer models, has raised funds from NEA, Lux, and Khosla, securing a $1B valuation. More details are available here.
- Tweet from Stephanie Palazzolo (@steph_palazzolo): NEW w/ @nmasc_ @KateClarkTweets: Sakana AI, a Japanese startup developing alternatives to transformer models, has raised from NEA, Lux and Khosla at a $1B valuation. More here: https://www.theinform...
- nvidia/Nemotron-4-340B-Base · Hugging Face: no description found
- Tweet from Alex Albert (@alexalbert__): Loved Golden Gate Claude? 🌉 We're opening limited access to an experimental Steering API—allowing you to steer a subset of Claude's internal features. Sign up here: https://forms.gle/T8fDp...
Interconnects (Nathan Lambert) ▷ #random (2 messages):
- **Getting compliments on the merch**: *"natolambert: Getting compliments on the merch"*. A member expressed satisfaction with receiving positive feedback on their merchandise.
- **We are in**: *"natolambert: We are in"*. A succinct declaration hints at an achievement or successful entry into an anticipated situation or event.
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
- **Alex shitposts on company blog**: A message humorously referenced "Alex shitposting on the company blog," implying informal or irreverent comments. No further context was provided.
- **Scale claims meritocracy in all hiring**: A link to a [blog post on Scale](https://scale.com/blog/meritocracy-at-scale) highlighted the company’s claim that their success is rooted in strict meritocratic hiring practices. The post emphasizes that the company’s founder is personally involved in hiring decisions to maintain high standards.
Link mentioned: Scale is a meritocracy, and we must always remain one.: MEI: merit, excellence, and intelligence
Latent Space ▷ #ai-general-chat (4 messages):
- Apple's AI Cluster Capability: A member shared a tweet from @mo_baioumy highlighting that Apple users can now run personal AI clusters using Apple devices. They humorously speculated that this might be how Apple runs its private cloud.
- Solo Hacker Turns $1M ARR: An inspiring story was shared via a tweet from @theAIsailor detailing how Lyzr achieved $1M ARR in 40 days after pivoting to a full-stack agent framework. They developed and launched multiple autonomous agents, including Jazon and Skott, and are now focusing on achieving Organizational General Intelligence.
- Nvidia’s New AI Model Released: A member announced Nvidia's new model Nemotron-4-340B-Instruct, a 340 billion parameter LLM optimized for English-based single and multi-turn chat use-cases. This model supports a context length of 4,096 tokens and is part of a synthetic data generation pipeline to aid other developers.
- nvidia/Nemotron-4-340B-Instruct · Hugging Face: no description found
- Tweet from Siva Surendira (@theAIsailor): We crossed $1M ARR (contracted) today. This is Lyzr’s 0 to 1 story👇 The first 400 days - $100K The last 40 days - $1M 2024 projections - $6M In September 2023, we pivoted from an AI Data Analyzer (...
- Tweet from Siva Surendira (@theAIsailor): We crossed $1M ARR (contracted) today. This is Lyzr’s 0 to 1 story👇 The first 400 days - $100K The last 40 days - $1M 2024 projections - $6M In September 2023, we pivoted from an AI Data Analyzer (...
- Tweet from Mohamed Baioumy (@mo_baioumy): One more Apple announcement this week: you can now run your personal AI cluster using Apple devices @exolabs_ h/t @awnihannun
Latent Space ▷ #ai-in-action-club (8 messages🔥):
- AI in Action by BigScience: Members revealed that DiLoco and DiPaco, developed as part of the BigScience collaboration, are now state-of-the-art (SOTA). An announcement followed that Prime Intellect plans to open source them soon.
- Prime Intellect democratizes AI: Prime Intellect aims to democratize AI development with their platform, allowing users to find global compute resources and train models via distributed training. They aspire for collective ownership of open AI innovations, ranging from language models to scientific breakthroughs. More information can be found on their website.
- Horde on Bittensor: One member noted that the technology termed "the horde" is being utilized on Bittensor.
- DeepMind did not reproduce results: A comment was made clarifying that DeepMind did not reproduce the results related to DiLoco.
Link mentioned: Prime Intellect - Commoditizing Compute & Intelligence: Prime Intellect democratizes AI development at scale. Our platform makes it easy to find global compute resources and train state-of-the-art models through distributed training across clusters. Collec...
OpenAccess AI Collective (axolotl) ▷ #general (8 messages🔥):
- Nemotron Accuracy Post-Quantization Questions: A user inquired if Nemotron-4-340B-Instruct maintains the same accuracy when quantized. There were no further details shared on the accuracy impact post-quantization.
- Nemotron-4-340B-Instruct Resource Sharing: A link to the Nemotron-4-340B-Instruct model was shared, highlighting its multilingual capabilities and ability to support a context length of 4,096 tokens aimed at synthetic data generation.
- Fine-Tuning Nemotron Resource Requirements Inquiry: A user asked how to fine-tune Nemotron with minimal resources, suspecting that 40 A100/H100 (80GB) GPUs might be required. Another member mentioned that inference requires 2 nodes, implying that finetuning might need at least double that number.
Link mentioned: nvidia/Nemotron-4-340B-Instruct · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
- Flexible chat template support proposed for DPO: A feature that allows flexible support for chat_templates in dataset pre-processing was added and has worked well for SFT. The suggestion is to extend this feature to DPO by using a conversation history from a
conversationfield, withchosenandrejectedstill coming from separate fields and potentially being conversation messages or raw text.
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- Nvidia Toolkit Installation Success: A user shared their success in installing the Nvidia toolkit on their second attempt and running the LoRA example using the command
accelerate launch -m axolotl.cli.train examples/openllama-3b/lora.yml. They expressed gratitude for the assistance received in the process. - Inquiry about Slurm Cluster: Another user inquired if anyone had experience running Axolotl within multiple nodes in a Slurm cluster. No further discussion or responses were provided.
LAION ▷ #general (5 messages):
- Users discuss
Dream Machinebrings memes to life: A link was shared to a tweet about Dream Machine from LumaLabsAI. The tweet indicates that this tool is highly effective in animating memes, linking to a thread for more details (source). - Query about DSA for Machine Learning: "Does anyone know wha DSA we need to learn before Machine Learning" was asked by a user. No further details or responses were provided in the message history.
- Locally using Mel Roformer for vocal extraction: A user inquired about using the Mel Roformer model locally or in Google Colab for extracting vocals. They mentioned having weights and bs roformer installed already.
- OpenAI names retired US Army General: A link to an OpenAI announcement about appointing a retired US Army General was shared (source). No additional context or discussion was provided in the messages.
- Tweet from Blaine Brown (@blizaine): Dream Machine from @LumaLabsAI really brings memes to life! A thread 🧵
- Tweet from Blaine Brown (@blizaine): no description found
LAION ▷ #research (4 messages):
- Yandex's YaFSDP revolutionizes LLM training: Yandex introduced YaFSDP, an open-source tool that cuts GPU resource consumption by 20%. This translates to substantial cost savings, especially in large models with 70 billion parameters, potentially reducing costs by $0.5 to $1.5 million monthly.
- PostgreSQL with pgvectorscale beats Pinecone: A new open-source extension for PostgreSQL, pgvectorscale, outperforms Pinecone while cutting costs by 75%. This development could reshape AI databases by offering superior performance at a fraction of the cost.
- DreamSync aligns text-to-image without human rating: DreamSync, a new approach to align text-to-image generation models, leverages image understanding feedback without human rating. This method seeks to improve the accuracy and efficiency of text-to-image models significantly.
- Paper page - Are We Done with MMLU?: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
- Datasette hit Hacker News front page: A member celebrated that a piece of work had hit the front page of Hacker News. Another member complimented the work, noting appreciation for the balanced approach in addressing alternative positions. One member humorously remarked, "ChatGPT effectively announced a full employment act for data engineers in perpetuity."
DiscoResearch ▷ #discolm_german (1 messages):
- Choosing models between 7-10b parameters: A member highlighted that the choice of models in the 7-10b range depends on the specific use case. For tasks requiring correct German grammar, discolm or occiglot models are better despite what benchmarks indicate.
- Managing trade-offs with further training: The same member suggested that trade-offs between non-English language quality and reasoning/instruction following can be managed through further training or merging. However, with larger parameter models (50-72b range), this trade-off problem dissolves, albeit inference may get slower.
- Resource considerations: Due to the slow inference speed of large models, they recommended staying with VRAM fitting q4/q6 for efficiency. A link was shared for reference: Spaetzle collection on Hugging Face.