[AINews] Hybrid SSM/Transformers > Pure SSMs/Pure Transformers
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
7% Transformers are all you need.
AI News for 6/12/2024-6/13/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (414 channels, and 3646 messages) for you. Estimated reading time saved (at 200wpm): 404 minutes. You can now tag @smol_ai for AINews discussions!
Lots of fun image-to-video and canvas-to-math demos flying around today, but not much technical detail, so we turn elsewhere, to Bryan Catanzaro of NVIDIA calling attention to their new paper studying Mamba models:
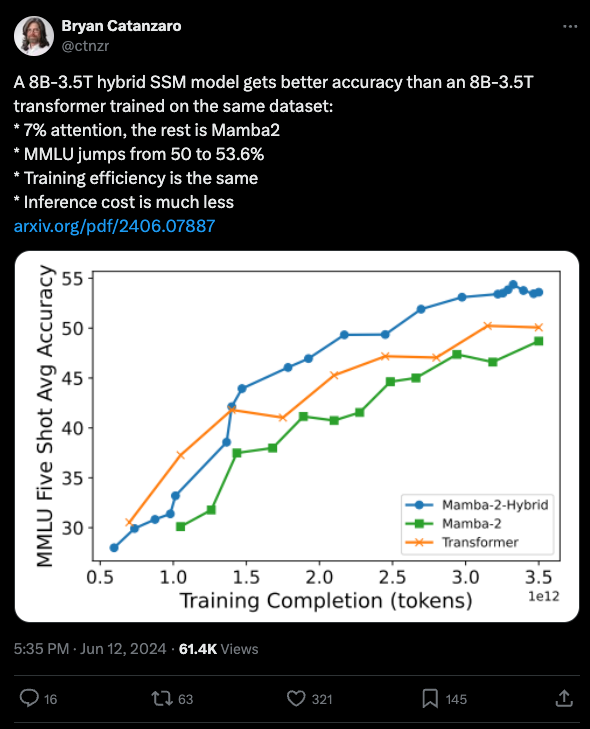
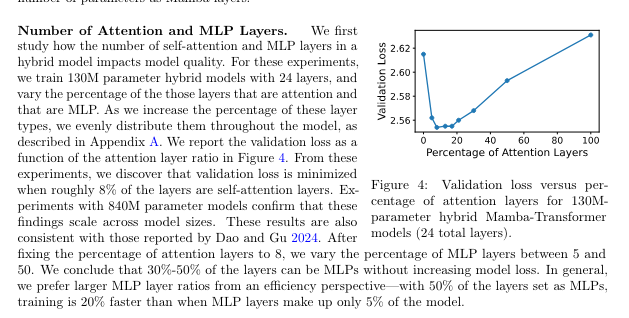
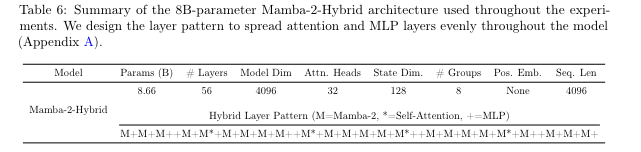
As Eugene Cheah remarked in the Latent Space Discord, this is the third team (after Jamba and Zamba that has independently found the result that mixing Mamba and Transformer blocks does better than either can alone. And the paper does conclude empirically that the optimal amount of Attention is <20%, being FAR from all you need.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
LLM Capabilities and Evaluation
- Mixture-of-Agents Enhances LLM Performance: @bindureddy noted that Mixture-of-Agents (MoA) uses multiple LLMs in a layered architecture to iteratively enhance generation quality, with the MoA setup using open-source LLMs scoring 65.1% on AlpacaEval 2.0 compared to GPT-4 Omni's 57.5%.
- LiveBench AI Benchmark: @bindureddy and @ylecun announced LiveBench AI, a new LLM benchmark with challenges that can't be memorized. It evaluates LLMs on reasoning, coding, writing, and data analysis, aiming to provide an independent, objective ranking.
- Mamba-2-Hybrid Outperforms Transformer: @ctnzr shared that an 8B-3.5T hybrid SSM model using 7% attention gets better accuracy than an 8B-3.5T Transformer on the same dataset, with MMLU jumping from 50 to 53.6% while having the same training efficiency and lower inference cost.
- GPT-4 Outperforms at Temperature=1: @corbtt found that GPT-4 is "smarter" at temperature=1 than temperature=0, even on deterministic tasks, based on their evaluations.
- Qwen 72B Leads Open-Source Models: @bindureddy noted that Qwen 72B is the best performing open-source model on LiveBench AI.
LLM Training and Fine-Tuning
- Memory Tuning for 95%+ Accuracy: @realSharonZhou announced @LaminiAI Memory Tuning, which uses multiple LLMs as a Mixture-of-Experts to iteratively enhance a base LLM. A Fortune 500 customer case study showed 95% accuracy on a SQL agent task, up from 50% with instruction fine-tuning alone.
- Sakana's Evolutionary LLM Optimization: @andrew_n_carr highlighted Sakana AI Lab's work using evolutionary strategies to discover new loss functions for preference optimization, outperforming DPO.
Multimodal and Video Models
- Luma Labs Dream Machine: @karpathy and others noted the impressive text-to-video capabilities of Luma Labs' new Dream Machine model, which can extend images into videos.
- MMWorld Benchmark: @_akhaliq introduced MMWorld, a benchmark for evaluating multimodal language models on multi-discipline, multi-faceted video understanding tasks.
- Table-LLaVa for Multimodal Tables: @omarsar0 shared the Table-LLaVa 7B model for multimodal table understanding, which is competitive with GPT-4V and outperforms existing MLLMs on multiple benchmarks.
Open-Source Models and Datasets
- LLaMA-3 for Image Captioning: @_akhaliq and @arankomatsuzaki highlighted a paper that fine-tunes LLaVA-1.5 to recaption 1.3B images from the DataComp-1B dataset using LLaMA-3, showing benefits for training vision-language models.
- Stable Diffusion 3 Release: @ClementDelangue and others noted the release of Stable Diffusion 3 by Stability AI, which quickly became the #1 trending model on Hugging Face.
- Hugging Face Acquires Argilla: @_philschmid and @osanseviero announced that Argilla, a leading company in dataset creation and open-source contributions, is joining Hugging Face to enhance dataset creation and iteration.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Stable Diffusion 3 Medium Release
- Resource-efficient model: In /r/StableDiffusion, Stable Diffusion 3 Medium weights were released, a 2B parameter model that is resource-efficient and capable of running on consumer GPUs.
- Improvements over previous models: SD3 Medium overcomes common artifacts in hands and faces, understands complex prompts, and achieves high quality text rendering.
- New licensing terms: In /r/OpenAI, Stability AI announced new licensing terms for SD3: free for non-commercial use, $20/month Creator License for limited commercial use, and custom pricing for full commercial use.
- Mixed initial feedback: First testers are reporting mixed experiences, with some facing issues replicating results and others giving positive feedback on prompt adherence, detail richness, and lighting/colors.
Issues and Limitations of SD3 Medium
- Struggles with human anatomy: In /r/StableDiffusion, users report that SD3 Medium struggles with human anatomy, especially when generating images of people lying down or in certain poses. This issue is further discussed with nuanced thoughts on the model's limitations.
- Heavy censorship: The model appears to have been heavily censored, resulting in poor performance when generating nude or suggestive content.
- Difficulty with artistic styles: SD3 Medium has difficulty adhering to artistic styles and concepts, often producing photorealistic images instead.
Comparisons with Other Models
- Varying strengths and weaknesses: Comparisons between SD3 Medium, SDXL, and other models like Stable Cascade and PixArt Sigma show varying strengths and weaknesses across different types of images (photorealism, paintings, landscapes, comic art). Additional comparison sets further highlight these differences.
- Outperforms in specific areas: SD3 Medium outperforms other models in certain areas, such as generating images of clouds or text, but falls short in others like human anatomy.
Community Reactions and Speculation
- Disappointment with release: Many users in /r/StableDiffusion express disappointment with the SD3 Medium release, citing issues with anatomy, censorship, and lack of artistic style. Some even call it a "joke".
- Speculation on causes: Some users speculate that the poor performance may be due to bugs in adopting the weights or the model architecture.
- Reliance on fine-tuning: Others suggest that the community will need to rely on fine-tuning and custom datasets to improve SD3's capabilities, as was done with previous models.
Memes and Humor
- Poking fun at shortcomings: Users share memes and humorous images poking fun at SD3's shortcomings, particularly its inability to generate anatomically correct humans. Some even sarcastically claim "huge success" with the model.
AI Discord Recap
A summary of Summaries of Summaries
-
Stable Diffusion 3 Faces Scrutiny but Offers Alternatives:
- SD3 Faces Criticism for Model Quality: Users conveyed dissatisfaction with SD3—highlighting anatomical inaccuracies and prompt issues—while medium models can be downloaded on Huggingface.
- Preferred Interfaces & Tools Discussed: ComfyUI emerged as the favored interface, with suggested samplers like uni_pc and ddim_uniform for optimal performance. Alternatives like Juggernaut Reborn and Playground are highlighted for their specific capabilities.
-
Boosting AI Performance and Infrastructure Insights:
- LLM Performance Boosted by Higher Model Rank: Shifting from rank 16 to 128 resolved Qwen2-1.5b's gibberish output, aligning it with llama-3 caliber outputs.
- Perplexity AI's Efficient LLM Use: Quick results are achieved by leveraging NVIDIA A100 GPUs, AWS p4d instances, and TensorRT-LLM optimizations.
-
Innovations in Fine-Tuning and Quantization:
- Fine-Tuning LLMs with New Models: The discussion covered the legal aspects of using GPT-generated data, referencing OpenAI's business terms. Experimentations with ToolkenGPT show creative approaches to synthetic data for fine-tuning.
- CUDA Quantization Project discussions: Projects like the BiLLM showcase rapid quantization of large models, essential for efficient AI deployments.
-
Model Management and Deployment Techniques:
- Strategies for Handling Large Embeddings: Queries about 170,000 embedding indexes led to recommendations on using Qdrant or FAISS for faster retrieval. Specific fixes for erroneous queries were shared here.
- Docker and GPU Configuration Troubleshooting: Users dealing with Docker GPU detection on WSL found solutions by consulting the official NVIDIA toolkit guide.
-
AI Community Trends and Updates:
- OpenAI's Revenue Milestone and Focus Shift: OpenAI's revenue doubled, reflecting sales direct from ChatGPT and other services, not primarily facilitated by Microsoft (source).
- Partnerships and Conferences Engage Community: Aleph Alpha and Silo AI joined forces to advance European AI (read more), and Qwak's free virtual conference promises deep dives into AI mechanisms and networking opportunities.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
SD3's Rocky Release: Users have expressed dissatisfaction with Stable Diffusion 3 (SD3), citing issues such as anatomical inaccuracies and non-compliance with prompts compared to SDXL and SD1.5. Despite the critiques, the medium model of SD3 is now downloadable on Huggingface, requiring form completion for access.
Preferred Interfaces and Samplers: ComfyUI is currently the go-to interface for running SD3, and users are advising against Euler samplers. The favored samplers for peak performace with SD3 are uni_pc and ddim_uniform.
Exploring Alternatives: Participants in the channel have highlighted alternative models and tools like Juggernaut Reborn and Divinie Animemix to achieve more realism or anime style, respectively. Other resources include Playground and StableSwarm for managing and deploying models.
Keep Discussions Relevant: Moderators have had to direct conversations back on topic after detours into global politics and personal anecdotes sidetracked from the technical AI discussions.
Big Models, Bigger Needs: The 10GB model of SD3 was mentioned as a very sought-after option among the community, showing the desire for larger, more powerful models despite the mixed reception of the SD3 release.
Unsloth AI (Daniel Han) Discord
- Boosting Model Performance with Higher Rank: Increasing the model rank from 16 to 128 resolved issues with Qwen2-1.5b producing gibberish during training, aligning the output quality with results from llama-3 training.
- scGPT's Limited Practical Applications: Despite interesting prompting and tokenizer implementation, scGPT, a custom transformer written in PyTorch, is deemed impractical for use outside of an academic setting.
- Embracing Unsloth for Efficient Inference: Implementing Unsloth has significantly reduced memory usage during both training and inference activities, offering a more memory-efficient solution for artificial intelligence models.
- Mixture of Agents (MoA) Disappoints: The MoA approach by Together AI, meant to layer language model agents, has been criticized for being overly complex and seemingly more of a showpiece than a practical tool.
- Advancing Docker Integration for LLMs: AI engineers are recommending the creation of command-line interface (CLI) tools for facilitating workflows and better integrating notebooks with frameworks like ZenML for substantial outcomes in real-world applications.
HuggingFace Discord
SD3 Revolutionizes Stable Diffusion: Stable Diffusion 3 (SD3) has dropped with a plethora of enhancements - now sporting three formidable text encoders (CLIP L/14, OpenCLIP bigG/14, T5-v1.1-XXl), a Multimodal Diffusion Transformer, and a 16 channel AutoEncoder. Details of SD3's implementation can be found on the Hugging Face blog.
Navigating SD3 Challenges: Users encountered difficulties with SD3 on different platforms, with recommendations such as applying pipe.enable_model_cpu_offload() for faster inference and ensuring dependencies like sentencepiece are installed. GPU setup tips include using RTX 4090, employing fp16 precision, and making sure paths are correctly formulated.
Hugging Face Extends Family With Argilla: In an exciting turn of events, Hugging Face welcomes Argilla into its fold, a move celebrated by the community for the potential to advance open-source AI initiatives and new collaborations.
Community and Support in Action: From universities, such as the newly created University of Glasgow organization on Hugging Face, to individual contributions like Google Colab tutorials for LLM, members have been contributing resources and sourcing support for their various AI undertakings.
Enriched Learning Through Shared Resources: Members are actively exchanging knowledge, with highlighted assets including a tutorial for LLM setup on Google Colab, a proposed reading group discussion on the MaPO technique for text-to-image models, and an Academic paper on NLP elucidating PCFGs.
OpenAI Discord
- Path to AI Expertise: Aspiring AI engineers were directed towards resources by Andrej Karpathy and a YouTube series by sentdex on creating deep learning chatbots. The discussions revolved around the necessary knowledge and skillsets for AI engineering careers.
- GPT-4.5 Turbo Speculations Ignite Debate: A debated topic was a leaked mention of GPT-4.5 Turbo, speculated to have a 256k context window and a knowledge cutoff in June 2024. It stirred speculation on its potential continuous pretraining feature.
- Demystifying ChatGPT's Storage Strategy: It was suggested that better memory management within ChatGPT could involve techniques for collective memory summary and cleanup to resolve current limitations.
- Teamwork Makes the Dream Work: Key points about ChatGPT Team accounts were shared, emphasizing the double prompt limit and the financial commitment for multiple team seats when not billed annually.
- Breaking Down Big Data: There was advice on managing substantial text data, like 300MB files, by chunking and trimming them down for practicality. Useful tools and guides were linked, including a forum post with practical tips for large documents and a notebook on handling lengthy texts through embeddings.
LLM Finetuning (Hamel + Dan) Discord
- Fine-Tuning LLMs: Adding New Knowledge: AI enthusiasts discussed fine-tuning large language models (LLMs) like "Nous Hermes" to introduce new knowledge, despite costs. A legal debate ensued concerning the use of GPT-generated data, with users consulting OpenAI's business terms; a separate mention was made of generating synthetic data referenced in the ToolkenGPT paper.
- Technical Glitches and Advice: In the realm of LLMs, users reported preprocessing errors with models like llama-3-8b and mistral-7b. On the practical side, members traded tips on maintaining SSH connections via
nohup, with recommendations found on this SuperUser thread.
- Innovative Model Frameworks on Spotlight: Model frameworks gained attention, with LangChain and LangGraph sparking diverse opinions. The introduction of the glaive-function-calling-v1 prompted talk about function execution capabilities in models.
- Deployments and Showcases in Hugging Face Spaces: Several users announced their RAG-based applications, such as the RizzCon-Answering-Machine, built with Gradio and hosted on Hugging Face Spaces, though some noted the need for speed improvements.
- Credits and Resources Quest Continues: Queries arose about missing credits and who to contact for platforms like OpenPipe. Users who haven't received credits shared their usernames (e.g., anopska-552142, as-ankursingh3-1-817d86), and a mention of a second round of credits expected on the 14th was made.
Nous Research AI Discord
- LLM Objective Discovery Without Human Experts: A paper on arXiv details a method for discovering optimization algorithms for large language models (LLMs) driven by the models themselves, which could streamline the optimization of LLM preferences without needing expert human input. The approach employs iterative prompting of an LLM to enhance performance according to specified metrics.
- MoA Surpasses GPT-4 Omni: A Mixture-of-Agents (MoA) architecture, as highlighted in a Hugging Face paper, shows that combining multiple LLMs elevates performance, surpassing GPT-4 Omni with a 65.1% score on AlpacaEval 2.0. For AI enthusiasts wanting to contribute or delve deeper, the MoA model's implementation is available on GitHub.
- Stable Diffusion 3: A Mixed Bag of Early Impressions: While Stable Diffusion 3 garners both applause and criticism in its initial release, discussions around GPT-4's counterintuitive better performance with higher temperature settings fuel the debate on model configuration. Conversely, a community member circulates an uncensored version of the OpenHermes-2.5 dataset, and a paper on eliminating MatMul operations promises remarkable memory savings.
- In Search of the Lost Paper: Engagement is seen around the task of locating a forgotten paper on interleaving pretraining with instructions, suggesting active interest in cutting-edge research sharing within community channels.
- RAG Dataset Development Continues: The dataset schema for RAG is still a work in progress, with further optimization needed for Marker's document conversion tool, where setting min_length could boost processing speeds. Simultaneously, Pandoc and make4ht emerge as possible conversion solutions for varied document types.
- World-sim Project Status Quo: There's no change yet in the closed-source status of the World-sim project, despite discussions and potential for future reconsideration. Additionally, calls for making the world-sim AI bolder and adapting it for mobile platforms reflect the community's forward-looking thoughts.
Perplexity AI Discord
- Enthusiasm for Perplexity's Search Update: Members showed great excitement for the recently introduced search feature in Perplexity AI, with immediate interest expressed for an iOS version.
- Musk and OpenAI Legal Battle Closes: Elon Musk has withdrawn his lawsuit against OpenAI, alleging a shift from mission-driven to profit-orientation, a day prior to the court hearing. The lawsuit included claims of prioritizing investor interests such as those from Microsoft (CNBC).
- Perplexity AI Speed with Large Language Models: Perplexity.ai is achieving fast results despite using large language models by utilizing NVIDIA A100 GPUs, AWS p4d instances, and software optimizations like TensorRT-LLM (Perplexity API Introductions).
- Custom GPT Woes on Perplexity: Engineers are experiencing connectivity issues with Custom GPTs; problems seem confined to the web version of the platform as no issues are reported on desktop applications, suggesting potential API or platform-specific complications.
- Email's Environmental Footprint: An average email emits about 4 grams of CO2; the carbon impact can be mitigated by preferential use of file share links over attachments (Mailjet's Guide to Email Carbon Footprint).
CUDA MODE Discord
Compute Intensity Discussion Left Hanging: A member inquired whether the compute intensity calculation should consider only floating-point operations on data from Global Memory. The topic remained open for discussion without a conclusive answer.
Streamlined Triton 3.0 Setup: Two practical installation methods for Triton 3.0 surfaced; one guide details installing from source, while another involves using make triton with a specific version from the PyTorch repository.
Optimizing Optimizers in PyTorch: A robust conversation on creating a fast 8-bit optimizer using pure PyTorch and torch.compile, as well as making a drop-in replacement for 32-bit with comparable accuracy was had, drawing inspiration from the bitsandbytes implementation.
Breakthroughs in Quantization and Training Dynamics: The BiLLM project boasts rapid quantization of large language models, while torchao members debate the trade-offs in speed and accuracy across various numeric representations during matrix multiplication, from INT8 to FP8 and even INT6.
Hardware Showdown and Quantization Innovations: AMD's MI300X showcases higher throughput for LLM inference than NVIDIA's H100, and Bitnet sees progress with refactoring and nightly build strategies, but a lingering build issue remains due to an unrelated mx format test.
LM Studio Discord
Gemini 1.5 JSON Woes: Engineers report that Gemini 1.5 flash struggles with JSON mode, causing intermittent issues with output. Users are invited to share insights or solutions to this challenge.
Tess Takes the Stage: The Tess 2.5 72b q3 and q4 quant models are now live on Hugging Face, offering new tools for experimentation.
AVX2 Instruction Essential: Users facing direct AVX2 errors should verify their CPU's support for AVX2 instructions to ensure compatibility with application requirements.
LM Studio Limitations and Solutions: LM Studio cannot be run on headless web servers or support safetensor files, but it succesfully employs GGUF format and Flash Attention can be enabled via alternatives like llama.cpp.
Hardware Market Fluctuations: There's a spike in the price of electronically scrapped P40 GPUs with current prices over $200, as well as a humorous note on sanctions possibly affecting Russian P40 stocks. A community member shares specs for an efficient home server build: R3700X, 128GB RAM, RTX 4090, and multiple storage options.
Eleuther Discord
- LLAMA3 70B Shows Diverse Talents: LLAMA3 70B displays a wide-ranging output capability, producing 60% AI2 arc format, 20% wiki text, and 20% code when prompted from an empty document, suggesting a tuning for specific formats. In a separate query, there's guidance on finetuning BERT for longer texts with a sliding window technique, pointing to resources such as a NeurIPS paper and its implementation.
- Samba Dances Over Phi3-mini: Microsoft's Samba model, trained on 3.2 trillion tokens, notably outperforms Phi3-mini in benchmarks while maintaining linear complexity and achieving exceptional long-context retrieval capabilities. A different conversation delves into Samba's passkey retrieval for 256k sequences, discussing Mamba layers and SWA effectiveness.
- Magpie Spreads Its Wings: The newly introduced method Magpie prompts aligned Large Language Models (LLMs) to auto-generate high-quality instruction data, circumventing manual data creation. Along this innovative edge, another discussion highlights the controversial practice of tying embedding and unembedding layers, sharing insights from a LessWrong post.
- Debating Normalization Standards: Within the community, the metrics for evaluating models spurred debate, particularly whether to normalize accuracy by tokens or by bytes for models with identical tokenizers. A related log from a test on Qwen1.5-7B-Chat was shared, discussing solutions for troubleshooting empty responses in
truthfulqa_gentasks.
- Open Flamingo Spreads Its Wings: A brief message pointed members to LAION's blog post about Open Flamingo, a likely reference to their multimodal model work.
LlamaIndex Discord
TiDB AI Experimentation on GitHub: PingCap demonstrates a RAG application using their TiDB database with LlamaIndex's knowledge graph, all available as open-source code with a demo and the source code on GitHub.
Paris AI Infrastructure Meetup Beckons: Engineers can join an AI Infrastructure Meetup at Station F in Paris featuring speakers from LlamaIndex, Gokoyeb, and Neon; details and sign-up are available here.
Vector Database Solutions for Quick Queries: For indexes containing 170,000 embeddings, use of Qdrant or FAISS Index is recommended; discussion includes fixing an AssertionError related to FAISS queries and direct node retrieval from a VectorStoreIndex with Chroma.
Adjacent Node Retrieval from Qdrant: A user inquiring about fetching adjacent nodes for law texts in a Qdrant vector store is advised to leverage node relationships and the latest API features for directional node retrieval.
Pushing LLM-Index Capabilities with PDF Embedding: An AI Engineer discusses embedding PDFs and documents into Weaviate using LLM-Index, demonstrating interest in expanding the ingestion of complex data types into vector databases.
Cohere Discord
- Command-R Takes the Stage: Coral has been rebranded as Command-R, yet both Command-R and the original Coral remain operational facilitating model-related tasks.
- To Tune or Not to Tune: In the pursuit of optimal model performance, debate flourished with some engineers emphasizing prompt engineering over parameter tuning, while others exchanged note-worthy configurations.
- Navigating Cohere's Acceptable Use: A collective effort was noted to decode the nuances of the Cohere Acceptable Use Policy, with a focus on delineating private versus commercial usage nuances in the context of personal projects.
- Trials and Tribulations with Trial Keys: The community exchanged frustrations regarding trial keys encountering permission issues and limitations, contrasting these experiences with the smoother sailing reported by production key users.
- Hats Off to Fluent API Support: A quick nod was given in the conversations to the preference for Fluent API and appreciation for its inclusion by Cohere, evidenced by a congratulatory tone for a recent project release featuring Cohere support.
LAION Discord
- Gender Imbalance Troubles in Stable Diffusion: The community discussed that Stable Diffusion has problems generating images of women, clothed or otherwise, due to censorship, suggesting the use of custom checkpoints and img2img techniques with SD1.5 as workarounds. Here's the discussion thread.
- Dream Machine Debuts: Luma AI's Dream Machine, a text-to-video model, has been released and is generating excitement for its potential, though users note its performance is inconsistent with complex prompts. Check out the model here.
- AI Landscape Survey: Comparisons across models such as SD3 Large, SD3 Medium, Pixart Sigma, DALL E 3, and Midjourney were discussed, alongside the reopening of the /r/StableDiffusion subreddit and Reddit's API changes. The community is keeping an eye on these models and these issues, and the Reddit post offers a comparison.
- Model Instability Exposed: A study revealed that models like GPT-4o breakdown dramatically when presented with the Alice in Wonderland scenario involving minor changes to input—highlighting a significant issue in reasoning capabilities. Details can be found in the paper.
- Recaptioning the Web: Enhancements in AI-generated captions for noisy web images are on the horizon, with DataComp-1B aiming to improve model training by better aligning textual descriptions. For further insights, review the overview and the scientific paper.
LangChain AI Discord
- Chasing the Best Speech-to-Text Solution: Engineers discussed speech-to-text solutions, seeking datasets with MP3s and diarization, beyond tools like AWS Transcribe, OpenAI Whisper, and Deepgram Nova-2. The need for robust processing that could handle simple responses without tools and manage streaming responses without losing context was also highlighted.
- LangChain Links Chains and States: In LangChain AI, integration of user and thread IDs in state management was explicitedly discussed, and tips to leverage LangGraph for maintaining state succinctly across various interactions were shared. For message similarity checks within LangChain, both string and embedding distance metrics were suggested with practical use cases.
- Simplifying LLMs for All: A GitHub project called tiny-ai-client was presented to streamline LLM interactions, and a YouTube tutorial showed how to set up local executions of LLMs with Docker and Ollama. Meanwhile, another member shared a GitHub tutorial to set up LLM on Google Colab utilizing the 15GB Tesla T4 GPU.
- Code Examples and Conversations to Streamline Development: Throughout the discussions, various code examples and issues were referenced to aid in troubleshooting and streamlining LLM development processes, with links like the Chat Bot Feedback Template and methodologies for evaluating off-the-shelf evaluators and maintaining Q&A chat history in LangChain.
- Community Knowledge Sharing: Members actively shared their own works, methods, and problem-solving strategies, creating a community knowledge base that included how-tos and responses to non-trivial LangChain scenarios, affirming the collaborative ethos of the engineering community.
Modular (Mojo 🔥) Discord
- Windows Woes and Workarounds: Engineers discussed Windows support for Modular (Mojo 🔥), with a predicted release in the Fall and a livestream update anticipated. Meanwhile, some have turned to WSL as a temporary solution for Mojo development.
- Mojo Gets Truthy with Strings: It was noted that non-empty strings in Mojo are considered truthy, potentially causing unexpected results in code logic. Meanwhile, Mojo LSP can be set up in Neovim with configurations available on GitHub.
- Optimizing Matrix Math: Benchmarks revealed that Mojo has superior performance to Python in small, fixed-size matrix multiplications, attributing the speed to the high overhead of Python's numpy for such tasks.
- Loop Logic and Input Handling: The peculiar behavior of
forloops in Mojo led to a suggestion to usewhileloops for iterations requiring variable reassignment. Additionally, the current lack ofstdinsupport in Mojo was confirmed.
- Nightly Updates and Compiler Quips: Mojo compiler release
2024.6.1305was announced, sparking conversations about update procedures with advice to usemodular update nightly/maxand consider aliases for simplification. Discussions also addressed compiler limitations and the potential benefits of the ExplicitlyCopyable trait for avoiding implicit copies in the language.
Interconnects (Nathan Lambert) Discord
- OpenAI's Indirect Profit Path: OpenAI's revenue surges without Microsoft's aid, nearly doubling in the last six months primarily due to direct sales of products like ChatGPT rather than relying on Microsoft's channels, contradicting industry expectations. Read more.
- AI Research Goes Full Circle: Sakana AI's DiscoPOP, a state-of-the-art preference optimization algorithm, boasts its origins in AI-driven discovery, suggesting a new era where LLMs can autonomously improve AI research methods. Explore the findings in their paper and contribute via the GitHub repo.
- Hardware Hype and Research Revelations: Anticipation builds around Nvidia's potentially forthcoming Nemotron as teased in a tweet, while groundbreaking advancements are discussed with the release of a paper exploring speech modeling by researchers like Jupinder Parmar and Shrimai Prabhumoye.
- SSMs Still in the Game: The community holds its breath with a 50/50 split on the continuation of Structured State Machines (SSMs), despite a leaning interest towards hybrid SSM/transformer architectures as attention layers may not be needed at each step.
- Benchmarks Blasted by New Architecture: Introducing Samba 3.8B, an architecture merging Mamba and Sliding Window Attention, showcasing it can significantly outclass models like Phi3-mini in major benchmarks, offering infinite context length with linear complexity. Details of Samba's prowess are found in this paper.
Latent Space Discord
- Haize Labs Takes on AI Guardrails: Haize Labs launched a manifesto on identifying and fixing AI failure modes, demonstrating breaches in leading AI safety systems by successfully jailbreaking their protection mechanisms.
- tldraw Replicates iPad Calculator with Open Source Flair: The team behind tldraw has reconstructed Apple's iPad calculator as an open-source project, showcasing their commitment to sharing innovative work.
- Amazon's Conversational AI Missteps Analyzed: An examination of Amazon's conversational AI progress, or lack thereof, pointed to a culture and operational process that prioritizes products over long-term AI development, according to insights from former employees in an article shared by cakecrusher.
- OpenAI's Surging Fiscal Performance: OpenAI has achieved an annualized revenue run rate of nearly \$3.4 billion, igniting dialogue about the implications of such earnings, including sustainability and spending rates.
- Argilla Merges with Hugging Face for Better Datasets: Argilla has merged with Hugging Face, setting the stage for improved collaborations to drive forward improvements in AI dataset and content generation.
OpenInterpreter Discord
- Open Interpreter Empowers LLMs: Open Interpreter is being discussed as a means to transform natural language into direct computer control, offering a bridge to future integrations with tailored LLMs and enhanced sensory models.
- Vision Meets Code in Practical Applications: The community shared experiences and troubleshooting tips on running code alongside vision models using Open Interpreter, particularly focusing on the
llama3-vision.pyprofile, and strategies for managing server load during complex tasks.
- Browser Control Scores a Goal: A real-world application saw Open Interpreter successfully navigating a browser to check live sports scores, showcasing the simplicity of user prompts and the implications on server demand.
- DIY Approach to Whisper STT: While seeking a suitable Whisper Speech-To-Text (STT) library, a guild member ended up crafting a unique solution themselves, reflecting the community's problem-solving ethos.
- Tweaking for Peak Performance: Discussions on fine-tuning Open Interpreter, such as altering core.py, highlighted the ongoing efforts to address performance and server load challenges to meet the particular needs of users.
OpenAccess AI Collective (axolotl) Discord
- Apple's 3 Billion Parameter Breakthrough: Apple has unveiled a 3 billion parameter on-device language model at WWDC, achieving the same accuracy as uncompressed models through a strategy that mixes 2-bit and 4-bit configurations, averaging 3.5 bits-per-weight. The approach optimizes memory, power, and performance; more details are available in their research article.
- Dockerized AI Hits GPU Roadblock: An engineer encountered issues when Docker Desktop failed to recognize a GPU on an Ubuntu virtual machine over Windows 11 despite commands like
docker run --gpus all --rm -it winglian/axolotl:main-latest. Suggested diagnostic steps include checking GPU status withnvidia-smiand confirming the installation of the CUDA toolkit.
- CUDA Confusions and WSL 2 Workarounds: The conversation shifted towards whether the CUDA toolkit should be set up on Windows or Ubuntu, with a consensus forming around installation within WSL 2 for Ubuntu. A user has expressed intent to configure CUDA on Ubuntu WSL, armed with the official NVIDIA toolkit installation guide.
OpenRouter (Alex Atallah) Discord
Param Clamping in OpenRouter: Alex Atallah specified that parameters exceeding support, like Temp > 1, are clamped at 1 for OpenRouter, and parameters like Min P aren't passed through the UI, despite UI presentation suggesting otherwise.
Mistral 7B's Lag Time Mystery: Users noticed increased response times for Mistral 7B variants, attributing it to context length changes and potential rerouting, supported by data from an API watcher and a model uptime tracker.
Blockchain Developer on the Market: A senior full-stack & blockchain developer is on the lookout for new opportunities, showcasing experience in the field and eagerness to engage.
Vision for Vision Models: A request surfaced for the inclusion of more advanced vision models such as cogvlm2 in OpenRouter to enhance dataset captioning capabilities.
tinygrad (George Hotz) Discord
- Bounty for RDNA3 Assembly in tinygrad: George Hotz sparked interest with a bounty for RDNA3 assembly support in tinygrad, inviting collaborators to work on this enhancement.
- Call for Qualcomm Kernel Driver Development: An opportunity has arisen for developing a "Qualcomm Kernel level GPU driver with HCQ graph support," targeting engineers with expertise in Qualcomm devices and Linux systems.
- tinygrad's Mobile Capabilities Confirmed: Confirmation was given that tinygrad is functional within the Termux app, showcasing its adaptability to mobile environments.
- In Discussion: Mimicking Mixed Precision in tinygrad: A discourse on implementing mixed precision through casting between bfloat16 and float32 during matrix multiplication revealed potential speed benefits, especially when aligned with tensor core data types.
- Tensor Indexing and UOp Graph Execution Queries: Efficient tensor indexing techniques are being explored, referencing boolean indexing and UOp graph execution with
MetalDeviceandMetalCompiler, with an emphasis on streamlined kernel execution usingcompiledRunner.
Datasette - LLM (@SimonW) Discord
- A Dose of Reality in AI Hype: A blog from dbreunig suggests that the AI industry is predominantly filled with grounded, practical work, comparing the current stage of LLM work to the situation of data science circa 2019. His article hit Hacker News' front page, signaling a high interest in the pragmatic approach to AI beyond the sensationalist outlook.
- CPU Yesteryear, GPU Today: The search for computing resources has shifted from RAM and Spark capacity to GPU cores and VRAM, illustrating the changing technical needs as AI development progresses.
- Token Economics in LLM Deployment: Databricks’ client data shows a 9:1 input-to-output ratio for Large Language Models (LLMs), highlighting that input token cost can be more critical than output, which has economic implications for those operating LLMs.
- Spotlight on Practical AI Application: The recognition of dbreunig's observations at a Databricks Summit by Hacker News underscores community interest in discussions about the evolution and realistic implementation of AI technologies.
DiscoResearch Discord
- European AI Synergy: A strategic partnership has been formed between Aleph Alpha and Silo AI to push the frontiers of open-source AI and tailor enterprise-grade solutions for Europe. This collaboration leverages Aleph Alpha’s advanced tech stack and Silo AI’s robust 300+ AI expert team, with an eye to accelerate AI deployment in European industrial sectors. Read about the partnership.
Torchtune Discord
- Participate in the Poll, Folks: A user has requested the community's participation in a poll regarding how they serve their finetuned models, with an undercurrent of gratitude for their engagement.
- Tokenizers Are Getting a Makeover: An RFC for a comprehensive tokenizer overhaul has been proposed, promoting a more feature-rich, composable, and accessible framework for model tokenization, as found in a pull request on GitHub.
MLOps @Chipro Discord
- Free Virtual Conference for AI Buffs: Infer: Summer '24, a free virtual conference happening on June 26, will bring together AI and ML professionals to discuss the latest in the field, including recommender systems and AI application in sports.
- Industry Experts Assemble: Esteemed professionals such as Hudson Buzby, Solutions Architect at Qwak, and Russ Wilcox, Data Scientist at ArtifexAI, will be sharing their insights at the conference, representing companies like Lightricks, LSports, and Lili Banking.
- Live Expert Interactions: Attendees at the conference will have the chance for real-time engagement with industry leaders, providing a platform to exchange practical knowledge and innovative solutions within ML and AI.
- Hands-On Learning Opportunity: Scheduled talks promise insights into the pragmatic aspects of AI systems, such as architecture and user engagement strategies, with a focus on building robust, predictive technologies.
- Networking with AI Professionals: Participants are encouraged to network and learn from top ML and AI professionals by registering for free access to the event. The organizers emphasize the event as a key opportunity to broaden AI understanding and industry connections.
Mozilla AI Discord
- Don't Miss the Future of AI Development: An event discussing how AI software development systems can amplify developers is on the horizon. Further info and RSVP can be found here.
- Catch Up on Top ML Papers: The newest Machine Learning Paper Picks has been curated for your reading pleasure, available here.
- Engage with CambAI Team's Latest Ventures: Join the upcoming event with CambAI Team to stay ahead in the field. RSVP here to be part of the conversation.
- Claim Your AMA Perks: Attendees of the AMA, remember to claim your 0din role to get updates about swag like T-shirts by following the customized link provided in the announcement.
- Contribute to Curated Conversations with New Tag: The new
member-requestedtag is now live for contributions to a specially curated discussion channel, reflecting community-driven content curation.
- Funding and Support for Innovators: The Builders Program is calling for members seeking support and funding for their AI projects, with more details available through the linked announcement.
YAIG (a16z Infra) Discord
- GitHub Codespaces Roll Call: A survey was launched in #tech-discussion to determine the usage of GitHub Codespaces among teams, using ✅ for yes and ❌ for no as response options.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!