[AINews] OpenAI's PR Campaign?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 5/7/2024-5/8/2024. We checked 7 subreddits and 373 Twitters and 28 Discords (419 channels, and 4079 messages) for you. Estimated reading time saved (at 200wpm): 463 minutes.
In a time when StackOverflow users are deleting their data in response to the new OpenAI partnership (with SO responding poorly), with GDPR complaints and US newspaper lawsuits and the NYT accusing it of scraping 1m hours of YouTube, and a general state of anxiety in a big election year (something OpenAI has explicitly addressed), there seems to be a recent pushback this week to highlight OpenAI's efforts to be a trustworthy institution:
- Our approach to data and AI - emphasizing a new Media Manager tool to let content creators opt in/out from training, by 2025, and efforts at source link attribution (probably alongside their rumored search engine), and "We design our AI models to be learning machines, not databases" messaging.
- Microsoft Creates Top Secret Generative AI Service for US Spies - an airgapped GPT-4 for the intelligence agenices
- The OpenAI Model Spec, in which Wired brilliantly highlighted the sentence "We're exploring whether we can responsibly provide the ability to generate NSFW content" and some are highlighting the ability to speak profanity but really is a statement of reasonable alignment design principles including not-overly-prudish refusal decisions:
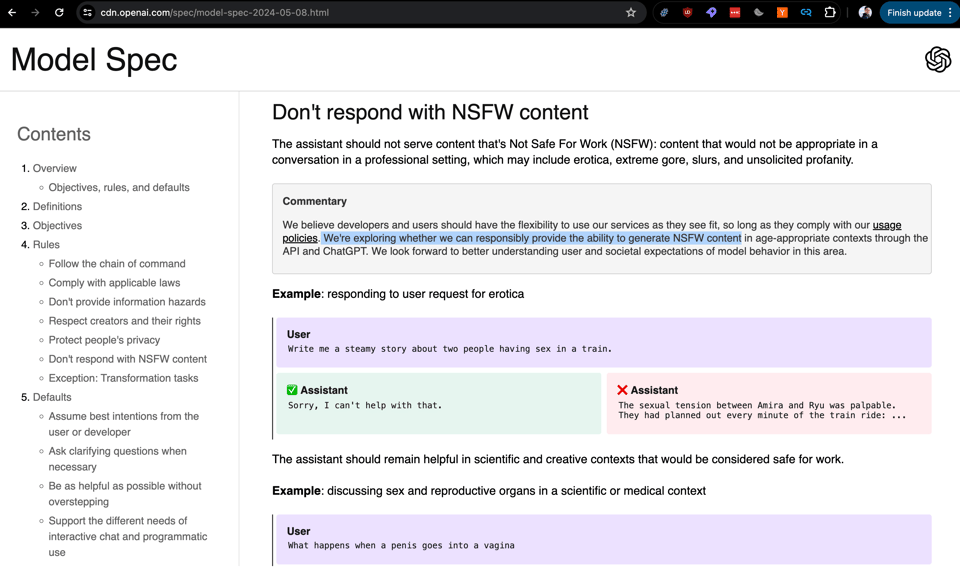
As @sama says: "We will listen, debate, and adapt this over time, but i think it will be very useful to be clear when something is a bug vs. a decision.". Per Joanne Jang:
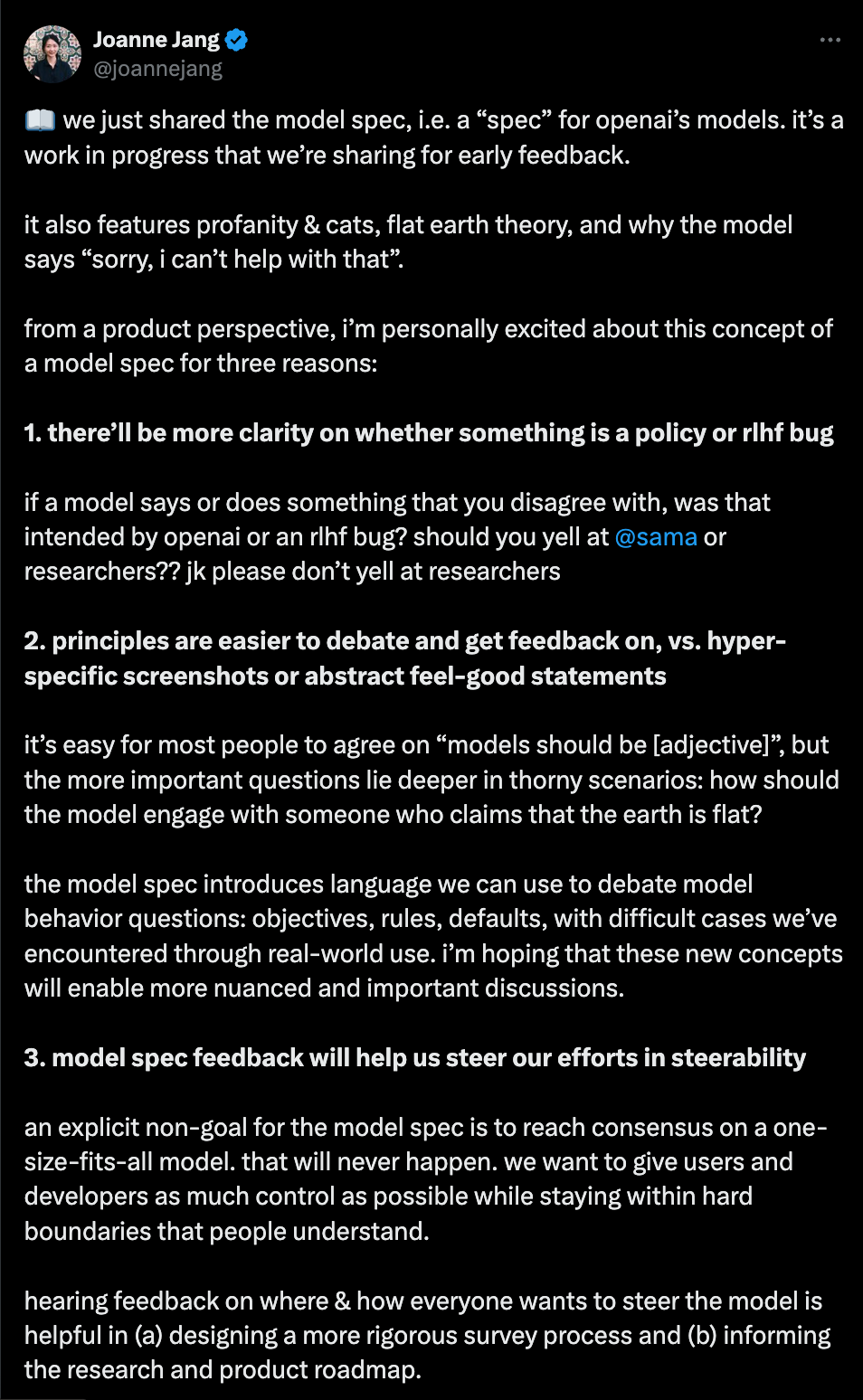
The whole model spec is worth reading and seems very thoughtfully designed.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Nous Research AI Discord
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- Perplexity AI Discord
- HuggingFace Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- CUDA MODE Discord
- OpenRouter (Alex Atallah) Discord
- LAION Discord
- OpenInterpreter Discord
- LangChain AI Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- DiscoResearch Discord
- Mozilla AI Discord
- Datasette - LLM (@SimonW) Discord
- Alignment Lab AI Discord
- AI Stack Devs (Yoko Li) Discord
- LLM Perf Enthusiasts AI Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- AlphaFold 3 Release: @GoogleDeepMind announced AlphaFold 3, a state-of-the-art AI model for predicting the structure and interactions of life's molecules including proteins, DNA and RNA. @demishassabis highlighted AlphaFold 3 can predict structures and interactions of nearly all life's molecules with state-of-the-art accuracy.
- Transformer Alternatives: @omarsar0 shared a paper on xLSTM, an extended Long Short-Term Memory architecture that attempts to scale LSTMs to billions of parameters using latest techniques from modern LLMs. @arankomatsuzaki noted xLSTM performs favorably compared to SoTA Transformers and State Space Models in performance and scaling.
- Multimodal Insights: @DrJimFan noted AlphaFold 3 demonstrates learnings from Llama and Sora can inform and accelerate life sciences, with the same transformer+diffusion backbone generating fancy pixels also imagining proteins when data converted to sequences of floats. The same general-purpose AI recipes transfer across domains.
Scaling and Efficiency
- Memory Management: @arankomatsuzaki shared a Microsoft paper on vAttention, a dynamic memory management technique for serving LLMs without PagedAttention. It generates tokens up to 1.97× faster than vLLM, while processing input prompts up to 3.92× and 1.45× faster than PagedAttention variants.
- Efficient Fine-Tuning: @AIatMeta shared research showing replacing next token prediction with multiple token prediction can substantially improve code generation performance with the same training budget and data, while increasing inference speed by 3x.
Open Source Models
- Llama Variants: @rohanpaul_ai noted Llama3-TenyxChat-70B achieved the best MTBench scores of all open-source models, beating GPT-4 in domains like Reasoning and Math Roleplay. Tenyx's selective parameter updating enabled remarkably fast training, fine-tuning the 70B Llama-3 in just 15 hours using 100 GPUs.
- IBM Code LLMs: @_philschmid shared that IBM released Granite Code, a family of 8 open Code LLMs from 3B to 34B parameters trained on 116 programming languages under Apache 2.0. Granite 8B outperforms other open LLMs on benchmarks.
Benchmarks and Evaluation
- Evaluating RAG: @hwchase17 noted that when evaluating RAG, it's important to evaluate not just the final answer but also intermediate steps like query rephrasing and retrieved documents.
- Contamination Detection: @tatsu_hashimoto congratulated authors on getting a best paper honorable mention for their work on provably detecting test set contamination for LLMs at ICLR.
Ethics and Safety
- Model Behavior Specification: @sama introduced the OpenAI Model Spec, a public specification of how they want their models to behave, to give a sense of how they tune model behavior and start a public conversation on what could be changed and improved.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Advances in AI Models and Hardware
- Apple M4 chip introduced: In /r/hardware, Apple announced the new M4 chip with a Neural Engine capable of 38 trillion operations per second for machine learning tasks. This represents a significant boost in on-device AI capabilities.
- New Llama instruction-tuned coding model released: In /r/MachineLearning, a new version of the Llama-3-8B-Instruct-Coder model was released that removes content filters and "abliterates" previous versions. An fp16 version is also available for more efficient deployment.
- Infinity "AI-native database" launches: /r/MachineLearning also saw the release of Infinity, an "AI-native database" in version 0.1.0 that claims to deliver the quickest vector search for embedding-based applications.
- Llama3-TenyxChat-70B tops open-source benchmarks: The Llama3-TenyxChat-70B model achieved the best MTBench scores of all open-source models on Hugging Face, demonstrating the rapid progress in open-source AI development.
Emerging AI Applications and Developer Tools
- Meta developing neural wristband for "thought typing": In /r/technology, Meta revealed they are creating a neural wristband that will let users type just by "thinking". This is one of many neural interface devices currently in development for hands-free input.
- Command line tool released for managing ComfyUI: /r/MachineLearning saw the release of a command line interface to manage the ComfyUI framework and custom nodes. Key features include automatic dependency installation, workflow launching, and cross-platform support.
- RAGFlow 0.5.0 integrates DeepSeek-V2: RAGFlow, a tool for retrieval-augmented generation, released version 0.5.0 with DeepSeek-V2 integration to enhance its retrieval capabilities for NLP tasks.
- Soulplay mobile app enables AI character roleplay: A new mobile app called Soulplay allows users to roleplay with AI characters using custom photos and personalities. It leverages the Llama 3 70b model and offers free premium access to early users.
- bumpgen uses GPT-4 to resolve npm package upgrades: bumpgen, a tool that uses GPT-4 to automatically resolve breaking changes when upgrading npm packages in TypeScript/TSX projects, was released. It analyzes code syntax and type definitions to properly use updated packages.
AI Ethics, Regulation and Societal Impact
- US regulating synthetic DNA to prevent misuse: /r/Futurology discussed how the US is cracking down on synthetic DNA to prevent misuse as the technology advances, such as the potential for individuals to create super viruses at home.
- Opinion: AI owners, not AI itself, pose risks: An opinion piece in /r/singularity argued that AI itself doesn't threaten humanity, but rather the owners who control its development and deployment do.
- OpenAI shares responsible AI development approach: OpenAI published a blog post, shared in /r/OpenAI, outlining their principles and approach to responsible AI development. This includes a planned "Media Manager" tool for content owners to control AI training data usage.
- Microsoft deploys GPT-4 chatbot for US intelligence: /r/artificial reported that Microsoft launched an AI chatbot based on GPT-4 for US intelligence agencies, deployed in an isolated "air-gapped" cloud environment. The model can read classified files but not learn from or reveal sensitive information.
AI Discord Recap
A summary of Summaries of Summaries
-
New AI Model Releases and Comparisons: The AI community saw a flurry of new models released, including Idefics2 8B Chatty, CodeGemma 1.1, DeepSeek-V2 with 236B parameters, IBM Granite code models, and Llama 3 Gradient 4194k with extended context length. Discussions compared their performance, use cases, and the implications of larger models like DeepSeek-V2. HuggingFace Announcement
-
Optimization Techniques for AI Models and Code: Extensive discussions revolved around optimizing AI models, code, and workflows, covering techniques like quantization, LoRA for diffusion model fine-tuning, torch.compile challenges with dynamic batch shapes, CUDA kernel fusion and performance analysis, and string concatenation optimization strategies in Mojo. Examples include CUDA kernel fusion PR, LoRA endorsement, and Mojo StringBuilder.
-
Large Language Model (LLM) Applications and Tools: Several tools and applications leveraging LLMs were showcased, such as LlamaIndex for building agentic systems, Langchain for streamlining customer support, Athena for autonomous data workflows, OpenDevin as an open-source AI coding assistant, and Quickscope for automated game testing in Unity. Relevant examples include the LlamaIndex course, Langchain's LangGraph article, and Quickscope's launch.
-
Ethical AI Development and Guidance: Initiatives focused on responsible AI practices, such as OpenAI's Model Spec draft for guiding model behavior, AlphaFold 3 implementation in PyTorch for biomolecular structure prediction, and discussions on creating inclusive language datasets for German AI assistants. Examples include the OpenAI Model Spec document, AlphaFold 3 PyTorch implementation, and gender-inclusive German resources.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Optimizing AI for Modest Machines: Engineers discussed leveraging Hyper-SD for image generation on CPUs with limited processing capabilities, such as those with integrated graphics, to ensure a smoother operation.
- High-End GPUs Reign Supreme: The discourse highlighted the effectiveness of powerful GPUs like NVIDIA’s 4090 for AI endeavors, proving far superior to integrated graphics solutions, especially for applications like Stable Diffusion.
- Cloud vs. Local GPU Debate Heats Up: Members are weighing the benefits and costs between investing in high-end GPUs for local computation versus using cloud services, which offer potent server-grade GPUs on an hourly charge basis.
- Training AI on a Shoestring: Confirmation came from users that training LoRA models with even 30 images can yield significant results when focused on specific applications rather than broad concepts.
- Editing Insights Exchange: Tips were swapped about using ffmpeg and rembg for video and image background removal, as part of a broader conversation on multimedia editing techniques.
Nous Research AI Discord
- RoPE Goes The Distance: Engineers probed RoPE's capability to generalize into the future without finetuning. The consensus appears to be that it is somewhat generalizable as is, akin to inverse rotation effects.
- Technical Fine-tuning Strategies Debated: A discussion highlighted various approaches to finetuning long context models, such as maintaining or tweaking the RoPE theta value during continual training. A recommendation was shared preferring shuffled datasets over consecutive dataset stages to achieve multiple finetuning objectives efficiently.
- Deciphering Data: Interest was shown in techniques to enhance text recognition from images by increasing resolution, while the presentation of the Skyrim project has spurred engagement with open-source weather modeling.
- LLM Best Practices Shared: Invetech's deterministic quoting for LLMs seeks to ensure verbatim quotes, with critical importance in domains like healthcare. Scaling LSTMs and their potential effectiveness in contemporary LLM contexts were also deliberated.
- Game-Changing Model Updates and Specs Unveiled: OpenAI's new Model Spec draft for responsible AI development and WorldSim's update were announced, introducing multiple interactive simulations. The community discussed API opportunities and explored new models like NeuralHermes 2.5, benefitting from direct preference optimization.
- Pre-tokenize for Efficiency: Autoregressive model architectures were preferred for their generalizability. Furthermore, pre-tokenizing and flash attention was recommended for training efficiency, and the use of bucketing and custom dataloaders was suggested for handling variable-length sequences.
- Neural Network Challenges Accepted: Despite setbacks with nanoLLaVA on Raspberry Pi, there's a pivot towards integrating moondream2 with an LLM. Meanwhile, Bittensor's finetune subnet experiences a hiccup due to an unresolved PR.
- Context Isn’t Just History: Members discussed using schemas for improved chatbot interactions while clarifying the distinction between agent versions and chatbots in conversation history tracking.
OpenAI Discord
- OpenAI Drops Knowledge on Data and Model Specs: OpenAI shares their philosophy on data and AI, emphasizing transparency and responsibility in their new blog post, in addition to introducing a Model Spec for ideal AI behavior in their latest announcement.
- GPT-5 Speculations and Bot Balancing Act: Enthusiasm buzzes around GPT-5's potential innovations, while another user cracks a joke about a one-wheeled OpenAI robot. Meanwhile, practical advice recommends solutions like LM Studio and Llama8b for those with 8GB VRAM setups, highlighting their ease of incorporation into workflows.
- Navigating GPT-4's Quirks: Users discuss how disabling the memory feature may resolve certain errors in GPT-4, and language support for GraphQL is questioned, while synonym substitutions like "friend" to "buddy" in outputs remain a head-scratcher.
- DALL-E's Double Negative and Logit Bias Lifesavers: Avoid giving DALL-E 3 "don't" directives; it gets confused. For AI-generated outputs, creating clear templates and applying logit bias can keep outputs from going off the rails, with guidance accessible through OpenAI’s logit bias article.
- Split Prompts and Large Document Woes: Shred complex tasks into bite-sized API calls for better results, avoid negative prompts with DALL-E, and tap into well-crafted templates for enhanced outcomes. Users note that current tools fall short for comparing hefty 250-page documents, suggesting leaning on more robust algorithms or a Python approach for hefty text analysis.
Unsloth AI (Daniel Han) Discord
- Base Model Training Affects Inference Tasks: Engineers observed that base models trained with data like the Book Pile dataset struggle in instruction-following tasks, hinting at the need for further fine-tuning with conversation-specific examples.
- Llama3 Model Version Differences Stir Debate: A discrepancy was noted in the performance of different Llama3 coder models, with v1 outperforming v2 despite fewer shots. This spurred a debate on the implications of dataset selection and potential complications in Llama.cpp.
- Anticipation for Phi-3.8b and 14b Models: The community is eagerly discussing the anticipated release of the Phi-3.8b and 14b models, with speculation about potential delays caused by internal review processes.
- Unsloth AI Raises Multiple Technical Questions: Users grappled with issues related to Unsloth AI, including troubleshooting template and regex errors, optimizing servers for running 8B models, CPU utilization, multi-GPU support, and installation difficulties; the conversation mentioned Issue #7062 on ggerganov/llama.cpp as a reference for model data loss.
- Contributions and Updates Highlighted in Showcase: The showcase channel highlighted opportunities for AI engineers to contribute to an open-source paper on predicting IPO success, the release of the Llama-3-8B-Instruct-Coder-v2 and Llama-3-11.5B-Instruct-Coder-v2 models with improved datasets and performance, available on Hugging Face.
LM Studio Discord
- M4 Chip Raises Expectations: Apple's new M4 chip has sparked discussions on its potential AI capabilities, possibly surpassing other major tech companies' AI chips, as highlighted in an MSN article.
- Visual Model Quirks Emerge: Users reported that vision models in LM Studio have issues, either not unloading after a crash or providing incorrect follow-up responses, with mentions of a visual models bug on lmstudio-bug-tracker.
- Granite Model Gains Spotlight: The Granite-34B-Code-Instruct by IBM Research has caught the attention of users, prompting comparisons to existing models but without consensus (Granite Model on Hugging Face).
- AI API Implementation Joy: Integration of the LM Studio API into custom UIs has been achieved, while discussions pointed out concurrency issues for embedding requests and lack of documentation for embeddings in the LM Studio SDK.
- WestLake Takes Creative Lead: For creative writing tasks, users recommended WestLake's dpo-laser version, noting its superiority over models like llama3, with T5 from Google gaining a nod for translation tasks (T5 Documentation).
Perplexity AI Discord
- Source Limit Saga at Gemini 1.5 Pro: There's confusion regarding Gemini 1.5 pro's source limit capabilities; one user reported the possibility of using over 60 sources, conflicting with another user's experience of being capped at 20. This debate yielded a slew of GIF links but no concrete resolution.
- Perplexity AI's Limit-Setting Logic: In a quest to understand Opus' limits on Perplexity, a consensus points to a 50-credit limit, with a 24-hour reset timing post usage. AI quality discussions spotlighted a subjective slide in GPT-4's utility, contrasted by positive feedback for newer models like Librechat and Claude 3 Opus.
- Trip-ups with Perplexity Pro: Queries about Perplexity Pro's features versus rivals surfaced alongside concerns regarding new trial policy changes due to abuse. Meanwhile, advice flowed for users with billing grumbles, directing them to contact support for issues like post-trial charges.
- Tech Meet Lifestyle in Sharing Channel: Users exchanged insights on a range of topics spanning from the best noise-cancelling headphones to the implications of the Ronaldo-Messi era in soccer, demonstrating Perplexity AI's breadth in covering technical comparisons and cultural discussions.
- API Channel Deciphers Puzzling Parameters: Clarifications on the models page confirm that system prompts don't affect online model retrieval, while doubts over the llama-3-sonar-large parameter count and its practical context length were aired. Difficulties emerged in tailor-fitting sonar model searches and understanding 8x7B MoE model architectures, piercing the veil on areas ripe for more detailed documentation.
HuggingFace Discord
AI's Grand Slam: New Models Take the Field: The AI field has introduced a slew of new models, including Idefics2 8B Chatty, CodeGemma 1.1 focused on coding tasks, and the gargantuan DeepSeek-V2 with 236B parameters. For code-specific needs, there's IBM Granite, and for enhanced context windows, we've got Llama 3 Gradient 4194k.
Sharpening the AI Saw: AI enthusiasts tackled diverse integration challenges, grappling with the implementation and efficacy of models like LangChain with DSpy and LayoutLMv3, and debated their practical utility against stalwarts like BERT. They delved into using Gradio Templates to prototype AI demos. Some sought knowledge on using CPU-efficient models for teaching purposes by trying out ollama and llama cpp python. Meanwhile, others looked into predictive open-source AI tools for streamlining repetitive tasks.
AI Illuminates Dark Data Corners: In the realm of AI datasets, there's a focus on improving transparency, epitomized by a YouTube tutorial on converting datasets from parquet to CSV using Polars. Furthermore, a succinct analogy for Multimodal AI was presented in a two-minute YouTube video, shedding light on the capabilities of models like Med-Gemini.
Tools of the Trade - Enhancing Developer Arsenal: In the quest for automating routine processes, a member shared an article about using Langchain’s LangGraph to augment customer support. When it comes to diffusion models, the advice is coalescing around using LoRA as the go-to method for fine-tuning tasks. Meanwhile, the visual crowd embraced the new adlike library and celebrated the enhancements to HuggingFace's object detection guides, adding mAP tracking.
Building Tomorrow's Research Ecosystem: The creative community teems with innovations like EurekAI, which promises a more organized research methodology, and Rubik's AI, seeking beta testers to refine its research assistant platform. An interesting experiment by Udio AI highlighted a fresh tune generated via AI, while BIND opens doors for utilizing protein-language models in drug discovery, offering a progressive GitHub resource at Chokyotager/BIND.
Eleuther Discord
- LSTM Upgrade Incoming: A new paper introduces a scalable LSTM structure with exponential gating and normalization to compete with Transformer models. The discussion included the optimizer AdamG, which claims parameter-free operation, sparking a debate on its effectiveness and scalability.
- AlphaFold 3 Cracks the Molecular Code: Google DeepMind's AlphaFold 3 leap is expected to drastically advance biological science by predicting protein, DNA, and RNA structures and their interactions.
- Identity Crisis in Residual Connections Boosts Performance: An anomalous improvement in model loss was observed when adaptive skip connections' weights turned negative, leading to requests for related research or experiences. The setup details are found in the provided GitHub Gist link.
- Logits in Limbo - API Models Struggle: The inability of API models to support logits due to a softmax bottleneck limits certain evaluation techniques, as highlighted by a model extraction paper. Adjustments to lm-evaluation-harness's
output_typewere discussed as potential remedies.
- xLSTM Preemptive Code Ethics: Algomancer sparked a dialogue on releasing their self-made xLSTM code prior to an official rollout, emphasizing the need for ethical consideration in preemptive publications and distinguishing between official and unofficial implementations.
Modular (Mojo 🔥) Discord
- Mojo Gains Classes and Inheritance: The Mojo language design sparks debates with the introduction of classes and inheritance features. The community is discussing the implications of having both static, non-inheritable structs with value semantics, alongside dynamically inheritable classes.
- Python's Role in Mojo Developments: Mojo is creating a stir as it moves to allow Python code integration, offering a dual benefit of Python's ease and Mojo's performance capabilities. There's an active conversation about how Mojo Intermediate Representation (IR) could enhance compiler optimizations across various programming languages.
- Optimizer's Quest: Developers are paying close attention to performance optimization across various operations in Mojo. Pain points include slow string concatenation and minbpe.mojo's decoding speed, with discussion exploring potential solutions such as a StringBuilder class that improved string concatenation efficiency by 3x.
- Data Struggles and Dialect Choices: The necessity and design of a new hash function for Dict in Mojo rise to prominence, with a proposal looking to enable custom hash functions for optimizing performance. Additionally, the idea of upstream contributions to MLIR is being tossed around, pondering the influence of Modular's compiler advancements on other languages.
- Debugging Drama and Release Revelry: A reported bug involving
TensorandDTypePointerusage in Mojo's standard library triggers detailed discussions on memory management. Meanwhile, a night-time release of the Mojo compiler with 31 external contributions is celebrated, pointing users to tracking the progress for future updates.
CUDA MODE Discord
Dynamic Batching Blues: AI engineers discussed the tribulations of using torch.compile for dynamic batch shapes, which causes excessive recompilations and impacts performance. While padding to static shapes can mitigate issues, full support for dynamic shapes, especially with nested tensors, awaits integration.
Triton's fp8 and Community Repo: Triton now includes support for fp8, as per updates on the official GitHub referring to a fused attention example. There's a community push to centralize Triton resources; a new community-driven Triton-index repository aims to catalog released kernels, and there's talk of curating a dataset specifically for Triton kernels, reflecting a drive for collaborative development.
CUDA Quest for GPU Proficiency: A multi-threaded conversation shone light on the optimization journey in CUDA, revealing a merged pull request to fuse residual and layernorm forward in CUDA, analyses of kernel performance metrics, and the quest to manage communication overheads in distributed training for optimal utilization of GPU architecture.
Optimization vs. Orientation for NHWC Tensors: The performance conundrum for tensor normalization orientation surfaced, leaving engineers pondering whether permuting tensors from NHWC to NCHW is more efficient than using NHWC-specific algorithms on GPUs, despite the risk of access pattern inefficiencies.
Apple M4 Steals the Spotlight: In hardware news, Apple heralded its M4 chip, designed to uplift the iPad Pro. Meanwhile, an AI engineer highlighted the capability of "panther lake" to deliver 175 TOPS, underscoring the rapid advancements and competition in chip performance.
OpenRouter (Alex Atallah) Discord
- Companionship Tops OpenRouter Model Chart: OpenRouter users show a preference for models providing emotional companionship, sparking interest in visualizing this trend through a graph.
- Navigating OpenRouter’s Latency Landscape: Efforts are underway to lower latency for OpenRouter users in regions such as Southeast Asia, Australia, and South Africa, with a focus on edge workers and global distribution of upstream providers.
- Copycat Alert in AI Town: An alleged leak of the ChatGPT system prompt stirred up a debate on model security and the practicability of using such prompts with the API, as discussed in a Reddit post.
- The Moderator’s Dilemma: The community exchanged insights on the efficiency and constraints of various AI moderation models, notably mentioning Llama Guard 2 and L3 Guard.
- HIPAA Harmony - Not Yet for OpenRouter: OpenRouter hasn't undergone an HIPAA compliance audit, nor confirmed a hosting provider for Deepseek v2, despite user inquiries.
LAION Discord
- Diving into Datasets: A new researcher sought non-image datasets for a study, receiving suggestions like MNIST-1D and Stanford's Large Movie Review Dataset, the latter being too comprehensive for their needs.
- Advancing Text-to-Video Generation: There was a vivid discussion on the superiority of diffusion models for text-to-video generation, emphasizing the value of unsupervised pre-training on large video datasets and discussing the ability of diffusion models to understand spatial relationships.
- Pixart Sigma's Potential Unleashed: Community members compared the efficiency of Pixart Sigma, noting that with strategic fine-tuning, this model could produce results that challenge the quality of DALL-E 3's output, even while navigating memory constraints.
- The Future of Automation in the Workspace: A news piece about AdVon Commerce undercutting jobs with AI-generated content prompted discussions about the implications of AI advancements on employment, specifically in content creation roles.
- Request for Open-Source AI Insurance Tools: A quest for open-source AI resources for auto insurance tasks led to requests for tools to process data, analyze risk, and predict outcomes, while another member sought formal literature on Robotic Process Automation (RPA) and desktop automation.
OpenInterpreter Discord
- Ubuntu Enthusiasts Want GPT-4 Goodness: The community showed interest in specific Custom/System Instructions tailored to Ubuntu for enhancing GPT-4's compatibility and efficiency on the popular operating system. Despite no specific instructions being linked, the interest reflects a demand for more customized AI interactions in Linux environments.
- OpenPipe.AI Gains Traction; OpenInterpreter Plays Tricks: A recommendation was made for OpenPipe.AI, a tool for efficient large language model data handling, while an unexpected instance of being rickrolled via OpenInterpreter sparked laughter regarding the unpredictability of AI-generated content. Another member suggested exploring py-gpt for potential OpenInterpreter integration.
- Diving into Hardware DIY and Shipping Tales: Discussions on the 01 device covered battery life queries for 500mAh LiPo, challenges in international shipping, with some opting for DIY builds, as well as how to verify if pre-orders have been shipped. The 01's ability to connect to various large language models (LLMs) through cloud APIs like Google and AWS was noted, with litellm's documentation providing multi-provider setup guidance.
- Persistence Pays Off for OpenInterpreter Users: Members appreciated the memory file feature of OpenInterpreter, which retains skills after server shutdowns, ensuring that LLMs don't need retraining, a key aspect for more effective skill retention in AI interfaces.
- First Impressions on GPT-4 Performance: A user named Mike.bird shared successful results using GPT-4 even with minimal custom instructions, while exposa found mixtral-8x7b-instruct-v0.1.Q5_0.gguf to be optimal for their needs, both indicating real-world testing and adoption of various models among community members.
LangChain AI Discord
- AI-Powered Slide Master Wanted: Members discussed the potential for creating a PowerPoint presentation bot using the OpenAI Assistant API, with queries about the suitability of RAG or LLM models for learning from past presentations. Compatibility between DSPY, Langchain/Langgraph, and document indexing with Azure AI Search was also debated.
- Sorting Out Streaming Syntax: In the
#[langserve]channel, issues were addressed regarding the use ofstreamEventswithRemoteRunnablein JavaScript, with members suggesting checking library versions and configurations, and reporting bugs to the LangChain GitHub repository.
- Showcase of Langchain Projects and Research: The
#[share-your-work]channel highlighted a survey on LLM application performance with donations for participation, introduced Gianna, the virtual assistant framework utilizing CrewAI and Langchain, shared insights on enhancing customer support with LangGraph on Medium, revealed Athena's autonomous AI data platform, and requested participation in a research on AI companies' global expansion readiness, especially in low-resource languages.
- Calling All Beta Testers: An invitation was extended for beta testing a new research assistant and search engine, offering access to GPT-4 Turbo and Mistral Large, available at Rubik's AI Pro.
- Parsing Troubles Amid TypeScript Talks: Technical discourse included troubleshooting JsonOutputFunctionsParser for TypeScript implementation and improving OpenAI request batching and search optimization for self-hosted Langchain applications.
LlamaIndex Discord
AI Education Leveling Up: LlamaIndex and deeplearning.ai announce a new course on creating agentic RAG systems, endorsed by AI expert Andrew Y. Ng. Engineers can learn about advanced concepts like routing, tool use, and sophisticated multi-step reasoning. Enroll here.
Scheduled Learning Opportunity: An upcoming LlamaIndex webinar spotlights OpenDevin, an open-source project by Cognition Labs designed to function as an autonomous AI engineer. The webinar is set for Thursday at 9am PT and is creating buzz for its potential to streamline coding and engineering tasks. Reserve your seat now.
Latest Tech from LlamaIndex: An update to LlamaIndex introduces the StructuredPlanningAgent, enhancing agents' task management by breaking them into smaller, more manageable sub-tasks. This development supports a range of agent workers, potentially boosting efficiency in tools like ReAct and Function Calling. Discover the influence of this tech.
Peering into Agent Observations: Engineers explore the feasibility of extracting detailed observation data from ReAct Agents and the utilization of local PDF parsing through PyMuPDF. Methods to improve the specificity and relevance of LLM (Large Language Model) responses, and the optimization of retrieval systems using reranking models, prompted a thorough technical exchange.
Towards Cooperative AI: A vibrant idea exchange occurred around multi-agent systems, envisioning a future with seamless agent collaboration and complex task execution. The concept nods to solutions like crewai and autogen, with additional focus on the capability of agents to create snapshots and rewind actions for enhanced operation.
OpenAccess AI Collective (axolotl) Discord
Layer Activation Unexpectedness: Discussions identified an anomaly where one layer in a model exhibited higher values than others, raising concerns and curiosity about the implications for neural network behavior and optimizer strategies.
LLM Training Data Discrepancies and Human Data Influence: It was noted that ChatQA is trained on a distinct mixture of data, contrasting with the GPT-4/Claude dataset used for most models, and the use of LIMA RP human data was highlighted for its potential to increase model training specificity.
Releasing RefuelLLM-2 to the Wild: RefuelLLM-2 has been open-sourced, boasting prowess in handling "unsexy data tasks,” with model weights available on Hugging Face and details shared via Twitter.
Practical Quantization Questions and GPU Quagmires: Queries were raised about creating a language-specific LLM and training with quantization on standard laptops, as well difficulties encountered with Cuda out of memory errors when using a config file for the phi3 mini 4K/128K FFT on 8 A100 GPUs, prompting a search for a working config example.
wandb Woes and Gradient Gamble: Members sought advice on Weights & Biases (wandb) configuration options and investigated strategies to handle the exploding gradient norm problem as well as considering trade-offs between 4-bit and 8-bit loading for efficiency versus model performance.
Interconnects (Nathan Lambert) Discord
LSTMs Strike Back: A recent paper discussed LSTMs scaled to billions of parameters, with potential LSTM enhancements like exponential gating and matrix memory to challenge Transformer dominance. There were concerns about flawed comparisons and a lack of hyperparameter tuning in the research.
AI's Behavioral Blueprint Unveiled: OpenAI's Model Spec draft was announced, designed to navigate model behavior in their API and implement reinforcement learning from human feedback (RLHF), as documented in Model Spec (2024/05/08).
Chatbot Reputation Under Microscope: A conversation emerged about how chatgpt2-chatbot could negatively impact LMsys' credibility, suggesting the system is overtaxed and unable to refuse requests. Licensing issues were also raised concerning chatbotarena's data releases without permissions from LLM providers.
Gemini 1.5 Pro Hits a High Note: Gemini 1.5 Pro was praised for its ability to transcribe podcast chapters accurately, incorporating timestamps despite some errors.
Awaiting the Snail's Wisdom: Community members showed anticipation and support for a seemingly important entity or event referred to as "snail," with posts suggesting a mix of awaiting news and summoning involvement from certain ranks.
Latent Space Discord
- Alternative to Glean for Small Teams Sought: A search for a unified search tool like Glean suitable for small-scale organizations led to a discussion about Danswer, an open-source option, with community members referring to a Hacker News discussion for further insights.
- Stanford Enlightens with Novel Course: The engineering community spotlighted Stanford University's new course on Deep Generative Models; a recommendable resource showing the institution's continued leadership in AI education, introduced by Professor Stefano Ermon: Watch the lecture here.
- Advanced GPU Rental Resource: In response to an inquiry on obtaining NVIDIA A100 or H100 GPUs for a short-term project, guidance was shared via a Twitter recommendation offering a potential solution for this hardware need.
- Crafting PRs with AI's Help: Reflecting on the underappreciated utility of AI in coding, a member shared their script for automating GitHub PR creation, signifying AI's role in streamlining developer workflows:
gh pr create --title "$(glaze yaml --from-markdown /tmp/pr.md --select title)" --body "$(glaze yaml --from-markdown /tmp/pr.md --select body)"
- Data Orchestration Dialogue: AI pipeline orchestration with diverse data types including text and embeddings sparked a request for recommendations, indicating a robust interest in efficient AI system design for handling complex data flows.
tinygrad (George Hotz) Discord
Tinygrad Tech Talk: Reshaping and Education: Discussions about Tinygrad's documentation on tensor reshaping sparked criticism for being too abstract, leading to a collaborative effort to demystify the concept through a community-created explanatory document. Advanced reshape optimizations, potentially using compile-time index calculations, were considered to enhance performance.
Tinygrad's BITCAST Clarified: There's active work on understanding and improving the BITCAST operation in tinygrad, as seen in a GitHub pull request, aiming to simplify certain operations and remove the need for arguments like "bitcast=false".
ML Concepts Demystified: A user conveyed the difficulty of deciphering machine learning terminology, specifically when simple concepts are buried under math jargon. This aligned with calls within the community for clearer and more approachable learning materials.
Tinygrad's No-Nonsense Policy: @georgehotz reinforced community guidelines, reminding members that the forum is not meant for beginner-level queries and that valuable time should not be taken for granted.
Engineering Discussions Advance in Sorting UOp Queries: The intricacies of Tinygrad’s operations, such as whether symbolic.DivNode should accept node operands, were debated, potentially signaling a future update to improve recursive handling within operations like symbolic.arange.
Cohere Discord
- FP16 Model Hosting Inquiry Left Hanging: A member's query about local hosting for FP16 command-r-plus models with a 40k content window failed to receive VRAM requirements information.
- RWKV Model Scalability Scrutinized: Discussions questioned the competitiveness of RWKV models at the 1-15b parameter scale compared to traditional transformers, with past RNN performance issues cited.
- Coral Chatbot Seeks Reviewers: A new Coral Chatbot promising to bundle text generation, summarization, and ReRank seeks user feedback and collaboration opportunities. Check it on Streamlit.
- Elusive Cohere Chat Download Method: A user's question about exporting files from Cohere Chat in formats like docx or pdf went without a concrete response on how to achieve the downloads.
- Wordware Charts a Fresh Course: Wordware invites would-be founding team members to build and showcase AI agents using its unique web-based IDE; prompting is at the core of its approach, akin to a programming language. Find out more on Join Wordware.
DiscoResearch Discord
- AIDEV Gathering Gains Attention: jp1 is looking forward to meeting peers at the AIDEV event, and mjm31 too is excited to attend, indicating an open and welcoming community vibe. enno_jaai raised practical concerns about food availability, hinting at the need for logistical planning for such events.
- German Dataset Development Discourse: There's an active conversation about creating a German dataset tailored for inclusive language, with members discussing the significance and methods such as adopting system prompts to steer the assistant's language.
- German Content Curation for Machine Learning: As part of developing a German-exclusive pretraining dataset, there's a call for domain recommendations that are rich in quality content, leveraged from Common Crawl data.
- Configurability and Inclusivity in AI: The idea of a bilingual AI having modes for inclusive and non-inclusive language is proposed, suggesting flexibility in language AI design. The conversation also referenced Vicgalle/ConfigurableBeagle-11B, a model indicative of how inclusivity might be incorporated into AI.
- Resources for Inclusive Language in AI Shared: Participants discussed and shared valuable resources like David's Garden and a GitLab project for gender-inclusive German, reflecting a strong interest in enhancing the understanding and application of gender-inclusive language in AI models.
Mozilla AI Discord
- Phi-3 Mini Anomalies Detected: Engineers discussed erratic behaviors in Phi-3 Mini when utilized with llamafile, despite working well with Ollama and Open WebUI; troubleshooting is ongoing.
- Backend Brilliance with Llamafile: Llamafile can run as a backend service, responding to OpenAI-style requests via a local endpoint at
127.0.0.1:8080; detailed API usage can be found on the Mozilla-Ocho llamafile GitHub. - VS Code Gets Ollama-Tastic: A notable VS Code update introduces a feature enabling dynamic model management for ollama users, with speculations about its origin being a plugin.
Datasette - LLM (@SimonW) Discord
- A Helping Hand for Package Upgrades: An innovative AI agent that upgrades npm packages got the community chuckling and nodding in approval. The conversation included a requisite nod to the ever-present cookie policy notification.
- YAML's New Chapter in Parameterized Testing: Engineers are examining two proposed YAML configurations for parameterized testing on llm-evals-plugin, documented in a GitHub issue comment. The dialogue orbits around the design choices and practicalities of such a feature.
- Ode to the
llmCLI: A heartfelt "thank you" was conveyed for thellmCLI tool, credited with streamlining management of personal projects and academic theses. The user's tribute underscored its value to their workflow.
Alignment Lab AI Discord
- AlphaFold3 Goes Open Source: The PyTorch implementation of AlphaFold3 is now accessible, allowing AI engineers to apply it to biomolecular interaction structure predictions. Contributions are being solicited through the Agora community to enhance the model's capabilities; interested engineers can join via their Discord invite and review the implementation on GitHub.
- Casual Interactions Maintain Morale: In the general chat, members participated in a casual exchange, where a user and a chatbot named "Orca" exchanged greetings. Such interactions maintain a sense of community and engagement within technical teams.
AI Stack Devs (Yoko Li) Discord
- No-Code Game Testing Revolution: Regression Games introduces Quickscope, a tool suite designed for automated Unity testing that requires no programming knowledge for setup, featuring tools for gameplay recording and functionality testing.
- Deep Dive into Game State: Quickscope boasts a feature that automatically gathers details on the game state, specifically scraping public properties of MonoBehaviours, streamlining the testing process without additional code.
- Test Better, Quicker: The Quickscope platform is available for developers and QA engineers, promising seamless integration into existing development pipelines and emphasizing its zero-code-necessary functionality.
- Team-Up Channel Lacks Engagement: In the #[team-up] channel, an isolated message by jakekies expresses a desire to join, suggesting low participation or lack of context in ongoing discussions.
LLM Perf Enthusiasts AI Discord
GPT-4-turbo Hunt in Azure: An engineer is on the lookout for GPT-4-turbo 0429 availability in Azure regions, specifically mentioning operational issues with Sweden's Azure services.
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (737 messages🔥🔥🔥):
- Scaling Down for Efficiency: Some members suggested for users with limited hardware, like a laptop with integrated graphics, to consider using models like Hyper-SD, which are trained on fewer steps for image generation, allowing potentially smoother CPU use.
- Seeking the Best Hardware for AI Work: Users discussed the benefits of dedicated GPUs with more VRAM, such as the NVIDIA 4090 or potentially the AMD Radeon RX6700 XT, over integrated GPUs for better performing AI tasks like Stable Diffusion.
- Deciding Between Local and Cloud: The debate on whether to invest in expensive local hardware for AI versus using cloud GPU services which charge hourly continues, with points about cloud services offering powerful server GPUs at fractional costs compared to purchasing cutting-edge consumer GPUs.
- Training LoRA on a Smaller Scale: Users confirmed it's possible to achieve decent results with LoRA models trained on as few as 30 images, suitable for specific modifications rather than broad, complex concepts.
- Tips and Tricks for Image and Video Editing: Participants shared experiences and recommendations for removing backgrounds from video content, mentioning tools like ffmpeg for frame extraction and rmbg or rembg extensions for background removal.
- Stylus: Automatic Adapter Selection for Diffusion Models: no description found
- Stable Cascade Examples: Examples of ComfyUI workflows
- Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared: Which graphics card offers the fastest AI performance?
- Stable Diffusion 3 is available now!: Highly anticipated SD3 is finally out now
- GitHub - Extraltodeus/sigmas_tools_and_the_golden_scheduler: A few nodes to mix sigmas and a custom scheduler that uses phi: A few nodes to mix sigmas and a custom scheduler that uses phi - Extraltodeus/sigmas_tools_and_the_golden_scheduler
- GitHub - Clybius/ComfyUI-Extra-Samplers: A repository of extra samplers, usable within ComfyUI for most nodes.: A repository of extra samplers, usable within ComfyUI for most nodes. - Clybius/ComfyUI-Extra-Samplers
- GitHub - PixArt-alpha/PixArt-sigma: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation - PixArt-alpha/PixArt-sigma
- GitHub - 11cafe/comfyui-workspace-manager: A ComfyUI workflows and models management extension to organize and manage all your workflows, models in one place. Seamlessly switch between workflows, as well as import, export workflows, reuse subworkflows, install models, browse your models in a single workspace: A ComfyUI workflows and models management extension to organize and manage all your workflows, models in one place. Seamlessly switch between workflows, as well as import, export workflows, reuse s...
- deadman44/SDXL_Photoreal_Merged_Models · Hugging Face: no description found
- Hyper-SD - Better than SD Turbo & LCM?: The new Hyper-SD models are FREE and there are THREE ComfyUI workflows to play with! Use the amazing 1-step unet, or speed up existing models by using the Lo...
- Can I run it on cpu mode only? · Issue #2334 · AUTOMATIC1111/stable-diffusion-webui: If so could you tell me how?
- The new iPads are WEIRDER than ever: Check out Baseus' 60w retractable USB-C cables Black: https://amzn.to/3JlVBnh, White: https://amzn.to/3w3HqQw, Purple: https://amzn.to/3UmWSkk, Blue: https:/...
- How to use Stable Diffusion - Stable Diffusion Art: Stable Diffusion AI is a latent diffusion model for generating AI images. The images can be photorealistic, like those captured by a camera, or in an artistic
- Sprite Art from Jump superstars and Jump Ultimate stars | PixelArt AI Model - v2.0 | Stable Diffusion LoRA | Civitai: Sprite Art from Jump superstars and Jump Ultimate stars - PixelArt AI Model If You Like This Model, Give It a ❤️ This LoRA model is trained on sprit...
- Pony Diffusion V6 XL - V6 (start with this one) | Stable Diffusion Checkpoint | Civitai: Pony Diffusion V6 is a versatile SDXL finetune capable of producing stunning SFW and NSFW visuals of various anthro, feral, or humanoids species an...
Nous Research AI ▷ #ctx-length-research (13 messages🔥):
- Query on RoPE's Future Generalization: A member asked if RoPE should generalize 'into the future' without any finetuning, suggesting that it should at least up to a certain token count, akin to inverse rotation.
- Affirmation on RoPE's Token Generalization: In response, another member confirmed that RoPE could generalize to some extent without further finetuning.
- Stellaathena's Continual Training Challenge: Stellaathena expressed a challenge in performing continual training of a long context model like LLaMA 3 due to compute and data constraints and asked for advice on whether to maintain or adjust the RoPE theta value during this process.
- Contemplating Finetune Sequencing: The same member inquired about the best way to order data for finetuning when dealing with multiple objectives—like chat formatting, long context, and new knowledge—and whether to mix data or perform consecutive finetuning stages.
- Mix and Shuffle Finetuning Strategy: Discussing finetuning strategies, teknium shared that their approach usually involves shuffling multiple datasets for different finetuning objectives rather than consecutive finetuning stages, applicable for contexts between 100-4000 tokens.
Nous Research AI ▷ #off-topic (4 messages):
- Reading Between Pixels: A member expressed the need to increase resolution for better text recognition from images, suggesting improvements in AI's ability to read small text.
- Open Source Weather Modeling: The Skyrim project has been shared, which is an open-source infrastructure for large weather models, inviting interested contributors. More details can be found on their GitHub page.
- Rebel's Feast: A member declares an intention for an indulgent evening with video games and a smorgasbord of snacks including potato chips, burger patties, cucumbers, chicken nuggets, blins, chocolate, and more.
- Sympathetic Emoji Response: Another member reacts, presumably to the gaming and snack plans, with a blushing emoji.
Link mentioned: GitHub - secondlaw-ai/skyrim: 🌎 🤝 AI weather models united: 🌎 🤝 AI weather models united. Contribute to secondlaw-ai/skyrim development by creating an account on GitHub.
Nous Research AI ▷ #interesting-links (13 messages🔥):
- Revolutionizing Healthcare with Deterministic Quoting: Invetech is working on Deterministic Quoting, a technique ensuring that quotations from source materials by Large Language Models (LLMs) are verbatim. In this process, quotes with a blue background are guaranteed to be from the source, minimizing the risk of hallucinated information which is crucial in fields with serious consequences like medicine. Deterministic Quoting example
- Scaling LSTMs for Language Modeling: Recent research questions the potential of scaled-up LSTMs in the wake of Transformer-based models. New modifications like exponential gating and parallelizable mLSTM propose to overcome LSTM limitations, extending their viability in the modern context of Large Language Models. LSTM research paper
- Open Sourcing Llama-3-Refueled Model: Refuel AI releases RefuelLLM-2-small (Llama-3-Refueled), a language model trained on diverse datasets for tasks like classification and entity resolution. The model is designed to excel at "unsexy data tasks" and is available for community development and application. Model weights on HuggingFace | Refuel AI details
- Efficient Llama 2 Model Packs a Punch: A new paper reveals the surprising efficiency of a 4-bit quantized version of Llama 2 70B that retains performance post-layer reduction and fine-tuning, suggesting deeper layers may have minimal impact. This could indicate that smaller, well-tuned models might perform as well as their larger counterparts. The paper tweet
- OpenAI Introduces Model Spec Draft: OpenAI publishes the first draft of their Model Spec, setting guidelines for model behavior in their API and ChatGPT, to be used alongside RLHF. The document aims to outline core objectives and manage instructions conflicts, marking a step towards responsible AI development. Model Spec document
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- Carson Poole's Personal Site: no description found
- Tweet from kwindla (@kwindla): Llama 2 70B in 20GB! 4-bit quantized, 40% of layers removed, fine-tuning to "heal" after layer removal. Almost no difference on MMLU compared to base Llama 2 70B. This paper, "The Unreas...
- Hallucination-Free RAG: Making LLMs Safe for Healthcare: LLMs have the potential to revolutionise our field of healthcare, but the fear and reality of hallucinations prevent adoption in most applications.
- Model Spec (2024/05/08): no description found
- refuelai/Llama-3-Refueled · Hugging Face: no description found
Nous Research AI ▷ #announcements (1 messages):
- WorldSim Makes a Comeback: WorldSim has been updated with bug fixes, and the credit and payments systems are operational once again. The new features include WorldClient, Root, Mind Meld, MUD, tableTop, as well as new capabilities for WorldSim and CLI Simulator, and the ability to choose a model between opus, sonnet, or haiku to manage costs.
- Explore Internet 2 with WorldClient: A web browser simulator, WorldClient, allows users to explore a simulated Internet 2, tailor-made for each individual.
- Root - The CLI Environment Simulator: With Root, users can simulate any Linux command or program they imagine in a CLI environment.
- Mind Meld Feature for Pondering Entities: Mind Meld lets users delve into the minds of any entity they can conceive.
- Gaming Simulators for Text and Tabletop Adventures: The new MUD offers a text-based adventure gaming experience, while tableTop provides a tabletop RPG simulation.
- Discover and Discuss New WorldSim: Interested users can check out the new updates at worldsim.nousresearch.com and join discussions in the dedicated Discord channel.
Link mentioned: worldsim: no description found
Nous Research AI ▷ #general (345 messages🔥🔥):
- NeuralHermes 2.5 - DPO Benchmarked: A new version of NeuralHermes, NeuralHermes 2.5, has been fine-tuned using Direct Preference Optimization surpassing the original on most benchmarks. It's based on principles from Intel's neural-chat-7b-v3-1 authors with available training code on Colab and GitHub.
- Nous Research Branding Details: For Nous Research-based projects, logos and typography can be sourced from NOUS BRAND BOOKLET, and the 'Nous girl' was mentioned as an ideal model logo to use.
- Exploring Azure's GPU Capabilities: A user provisioned 2 NVIDIA H100 GPUs on Azure to conduct experiments, discussing the capabilities of the hardware and related models such as Llama.
- Llama-3 8B Instruct 1048K Context Exploration: The Llama-3 8B Instruct model on Hugging Face has an extended context length and invites users to join a waitlist for custom agents with long contexts.
- API and Model Format Discussions: Questions were posed about available APIs for Hermes 2 Pro 8B, the go-to template for Llama 3 (still ChatML), and the utilisation of
torch.compilefor variable length sequences with advice to use sequence packing.
- JSON-Schema to GBNF: no description found
- mlabonne/NeuralHermes-2.5-Mistral-7B · Hugging Face: no description found
- Mkbhd Marques GIF - Mkbhd Marques Brownlee - Discover & Share GIFs: Click to view the GIF
- OpenAI exec says today's ChatGPT will be 'laughably bad' in 12 months: OpenAI's COO said on a Milken Institute panel that AI will be able to do "complex work" and be a "great teammate" in a year.
- Tweet from xyzeva (@xyz3va): so, here's everything we did to achieve this in action:
- axolotl/docs/multipack.qmd at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- Jogoat GIF - Jogoat - Discover & Share GIFs: Click to view the GIF
- Cat Hug GIF - Cat Hug Kiss - Discover & Share GIFs: Click to view the GIF
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: no description found
- Moti Hearts GIF - Moti Hearts - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (37 messages🔥):
- Llamafiles Integration On The Horizon?: A user inquired about the creation of llamafiles for Nous models, and a link was provided to Mozilla-Ocho's llamafile on GitHub, emphasizing the ability to use external weights in llamafiles. The user expressed an intent to explore this solution.
- Speed Up With Pretokenizing and Flash Attention: A member noted the efficiency gains in training by using pretokenizing and implemented scaled dot product (flash attention). Concerns were raised regarding Torch's selective use of flash attention 2.
- Efficiency Strategies for Variable-Length Sequences: In discussions on handling variable-length machine translation sentences, one user endorsed the strategy of bucketing by length and using a custom dataloader to minimize padding and maximize GPU utilization. The community shared the idea of padding sentences to common token lengths (like 80, 150, 200) to potentially enhance static torch compilation efficiency.
- Trade-Offs in Sequence Length Management: A conversation unfolded concerning managing sequence lengths in machine translation models. It was highlighted that padding to fixed sizes could lead to efficiency trade-offs when leveraging torch.compile.
- Exploring Autoregressive Transformer Models: One member shared their preference for autoregressive transformer models due to their generalizability. Further discussion clarified that autoregressive models generate output by considering previous outputs, making them suitable for encoder-decoder and decoder-only architectures.
- no title found: no description found
- xFormers optimized operators | xFormers 0.0.27 documentation: API docs for xFormers. xFormers is a PyTorch extension library for composable and optimized Transformer blocks.
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
Nous Research AI ▷ #project-obsidian (1 messages):
- NanoLLaVA Efforts Abandoned: A participant mentioned they abandoned using nanoLLaVA due to difficulties getting it to work on a Raspberry Pi; they plan to use moondream2 combined with an LLM instead. No specific issues or error messages were mentioned regarding the use of nanoLLaVA.
Nous Research AI ▷ #bittensor-finetune-subnet (11 messages🔥):
- Miner Repo Commit Stuck: A new miner mentioned that their committed repo to the bittensor-finetune-subnet has not been downloaded by validators for hours. The issue is linked to a pending pull request (PR) that needs to be merged to resolve the network problem.
- Awaiting Critical PR Merge: A member confirmed that the network is broken and will remain non-functional for new commits until a PR they're working on is merged. They clarified that they do not have control over the timeline as they are not the one reviewing or merging these PRs.
- Uncertainty in Resolution Timeframe: In response to a query about how soon the issue will be resolved, a member ambiguously stated that the PR would be merged "soon", without providing a specific timeline.
- Validation Halt Due to Network Issue: Clarification was given that new commits would not be validated until the aforementioned PR is merged, indicating that the network's current state impedes this process.
- Seeking Subnet GraphQL Service: An inquiry was made about where to find the GraphQL service for bittensor subnets, suggesting the user is seeking additional tools or interfaces related to bittensor.
Nous Research AI ▷ #rag-dataset (4 messages):
- Morning Musings on Chatbots: A member discussed the functionality of goodgpt2, exploring the use of an agent schema and noting the chatbot seems to operate with a structured history from ChatArena with minimal guidance.
- Conversations with a History: The same user mentioned the idea of ID tracking on tags which could reveal an entire conversation history with the chatbot, highlighting the seamless user experience.
- The Identity of ChatGPT: There is speculation that the ChatGPT being interacted with might be an agent version rather than a chatbot, possibly referring to GPT-2 as the underlying model.
- Into the Persona Schema: Correcting an earlier statement, the user clarified that they had asked for a persona schema, commenting that this was informed by two other queries in the chatbot's structured history.
Nous Research AI ▷ #world-sim (93 messages🔥🔥):
- World-Sim Role and Information Query Answered: A user inquired about what world-sim is and where to find more information. They were directed to check a specific pinned post for details: see <#1236442921050308649>.
- Claude as Self-Improvement Vessel: One user shared their perspective that (jailbroken) Claude serves as a vessel for self-improvement, using world_sim for what they described as interactive debug for the soul.
- Burning Man for Robots?: There's excitement about the idea of a "BURNINGROBOT" festival, mirroring BURNINGMAN, to showcase the work and experiences users have with Nous Research's offerings.
- Recovering BETA Conversations: In a series of interactions, users learned that BETA chats are not stored and cannot be recovered, highlighted when a user inquired about reloading worldsim conversations.
- World-Sim Feature Discussions: Users discussed various aspects of world-sim, including changing models and understanding the credit system. One user was advised that currently, credits need to be purchased after the initial free amount is expended.
Link mentioned: New Conversation - Eigengrau Rain: no description found
OpenAI ▷ #annnouncements (2 messages):
- OpenAI's Take on Data Management: OpenAI discusses their principles around content and data in the AI landscape. They've outlined their approach in a detailed blog post.
- Introducing OpenAI's Model Spec: OpenAI aims to foster dialogue on ideal AI model behaviors by sharing their Model Spec. This document can be found in their latest announcement.
OpenAI ▷ #ai-discussions (305 messages🔥🔥):
- Anticipating Future Innovations: A discussion highlighted expectations around GPT-5, with interest expressed in the potential for upcoming features and performance improvements, affirming continuous investment in AI research and development.
- Goodbye Gerbil Robot, Hello Rosie?: Amid light-hearted banter, a whimsical idea was proposed picturing an OpenAI robot with an "absurdly small single wheel"; a member whimsically visualized "an extremely small gerbil robot running on a very awesome looking wheel."
- Navigating Local Model Options: Conversations revolved around the suitability of systems like LM Studio, Llama8b, and Ollama with Llama3 8B for 8GB VRAM machines; participants discussed their experiences with these models, emphasizing ease of use and resource requirements.
- Seeking Guidance, Gaining Insights: Users sought information and shared advice on resources such as the GPT prompt library, now renamed to #1019652163640762428, along with insight into staying updated on AI trends through platforms like OpenAI Community and Arstechnica.
- OpenAI Chat GPT Models Debate: A lengthy debate unfolded regarding the performance and historical context of OpenAI's GPT models, with comparisons between GPT-4, alternative AI models from the "arena," and perspectives on OpenAI's approach to innovation and risk management.
- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs: New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
- Meta AI: Use Meta AI assistant to get things done, create AI-generated images for free, and get answers to any of your questions. Meta AI is built on Meta's latest Llama large language model and uses Emu,...
- no title found: no description found
- Ars Technica: Serving the Technologist for more than a decade. IT news, reviews, and analysis.
- OpenAI Developer Forum: Ask questions and get help building with the OpenAI platform
- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs: New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
- no title found: no description found
OpenAI ▷ #gpt-4-discussions (7 messages):
- Memory Feature Confusion: A member expressed frustration, stating that GPT-4 is not performing well due to its memory function causing errors. Another member pointed out that it is possible to turn off the memory feature.
- Admin Rank Declined: In response to a compliment on assisting with the memory issue, a user clarified that they declined to take on a mod/admin rank despite recognition for their helpfulness.
- Language Support Query: A user inquired whether GPT-4 natively understands GraphQL like it does Markdown, indicating interest in the model's capability with different languages.
- Editing Quirk with Synonyms: An issue was raised about ChatGPT consistently replacing the word "friend" with "buddy" in a script, despite attempts to provide clear context to the contrary. The user is seeking a solution to prevent this word alteration.
OpenAI ▷ #prompt-engineering (30 messages🔥):
- Prompt Too Complex: A member was advised to split complex tasks into multiple API calls, suggesting that a single API call should not be asked to perform tasks like outputting in CSV format. Further guidance included an example where multiple steps are used for vision tasks, analysis, and formatting. That's too much for one prompt.(no specific link provided*)
- DALL-E's Negative Prompt Dilemma: Users discussed that DALL-E 3 struggles with negative prompts; it tends to include elements it's asked to omit, suggesting a focus on positive details will yield better results. Sharing experiences can help understand its limitations and improve usage(no specific link provided).
- In Search of Photo-Real Humans: A user asked for advice on getting photo-realistic results from AI when generating images of humans, highlighting the artistic look of the outcomes. The conversation pointed to a separate discussion channel(no specific link provided) for further assistance.
- Output Templates and Logit Bias: Inconsistencies in AI-generated outputs were tackled by suggesting the use of clear output templates and considering logit bias for controlling random elements, though the latter requires review of the process via provided link.
- Comparing Large Documents Challenge: A user inquired about strategies for comparing substantial documents of 250 pages. The discussion highlighted that current OpenAI technology has limited capacity for such tasks and recommended a more robust AI or a Python-based solution.
OpenAI ▷ #api-discussions (30 messages🔥):
- Prompt Improvement Strategies Shared: Members discussed how to create better system prompts, emphasizing breaking down complex tasks into multiple API calls and ensuring that prompts for image generation, like with DALL-E, are clear and free of negative instructions which can confuse the model. An example was AIempower's step back prompting strategy.
- Challenges with DALL-E Negative Prompting: Members observed that the DALL-E 3 API has difficulties following prompts with negative instructions, such as "don't include X." The advice was to steer clear of negative prompts and to get more tips from experienced users in the appropriate OpenAI channels.
- Inconsistent Output Formations: A member sought help for the issue of inconsistent outputs and the introduction of random bullet points in responses. It was suggested to use a solid output template with constant variable names and to apply logit bias to improve consistency.
- Comparing Large Text Documents: A question arose concerning comparing two large 250-page documents for minor changes, and it was noted that the current OpenAI implementations are not suitable for such large-scale comparisons, implying the need for different tools or Python solutions.
- Prompt Engineering Course Inquiry: The effectiveness of prompt engineering courses for job search enhancement was queried, though no specific recommendations were provided due to OpenAI's policy.
- Ethical AI Practices and Prompt Engineering Examples: A comprehensive prompt template was shared to help generate discussions on the ethical considerations of AI in business. It serves as an example of prompt engineering incorporating inclusive variables, instructions, and ethical concerns in AI.
Unsloth AI (Daniel Han) ▷ #general (108 messages🔥🔥):
- Inference Impacted by Base Model Training: Discussion centered around whether the base model training affects inference results, with insights suggesting that base models trained exclusively on non-conversation specific data like the Book Pile dataset might not perform well with instruction-following tasks. Fine-tuning with conversation data will likely require many examples and may prove challenging.
- Fine-tuning and Training with PDFs Inquiry: A member asked for resources or tutorials on how to fine-tune a language model with long PDFs using Unsloth. They were referred to a YouTube guide on using personal datasets for fine-tuning language models.
- Differences in Model Fine-tuning Results: A comparison of different versions of the Llama3 coder model revealed discrepancies; v1 provided satisfactory results with fewer shots while v2 struggled. This sparked a discussion on the impacts of dataset choices and the potential issues with Llama.cpp.
- Phi-3.8b and 14b Model Release Discussion: Conversation about the status of Phi-3.8b and 14b models, with members speculating about their completion and release. Red tape and internal review were mentioned as possible reasons for the delay in releasing these models.
- Concerns Regarding Model Evaluation and Prompts: Queries were made about evaluating models like phi-3 with HellaSwag and finding good prompts for such evaluations. Responses indicated uncertainty, highlighting the challenges around prompt engineering and evaluation of large language models.
- cognitivecomputations/Dolphin-2.9.1-Phi-3-Kensho-4.5B · Hugging Face: no description found
- Granite Code Models - a ibm-granite Collection: no description found
- mahiatlinux (Maheswar KK): no description found
- How I Fine-Tuned Llama 3 for My Newsletters: A Complete Guide: In today's video, I'm sharing how I've utilized my newsletters to fine-tune the Llama 3 model for better drafting future content using an innovative open-sou...
- Issues · unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - Issues · unslothai/unsloth
- ibm-granite/granite-8b-code-instruct · Hugging Face: no description found
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #random (13 messages🔥):
- Mystery Origin Inquiry: A member inquired about the source of an image, speculating it might be from a manwha (Korean comic).
- Creator Revealed: A member clarified they created an image that sparked the conversation, with an additional note saying it was AI-generated.
- Emote Reaction Says It All: The conversation included an expressive emote reaction, signifying a form of disappointment or the end of something.
- Attack on Titan Resemblance: A member observed that the AI-generated face reminded them of Eren, a character from the anime "Attack on Titan."
- OpenAI Stack Overflow Partnership Buzz: The channel featured a Reddit post discussing OpenAI's announcement to partner with Stack Overflow, using it as a database for Large Language Models (LLM).
- Anticipating ChatGPT's Response Quirks: Members humorously anticipated how ChatGPT might reply in stereotypical programmer responses, including "'Closed as Duplicate'" or admonishing one to "look at the docs."
- Content Exhaustion Concern: A member linked to a Business Insider article discussing concerns over AI running out of human content to learn from by 2026.
- Gig workers are writing essays for AI to learn from: Companies are increasingly hiring skilled humans to write training content for AI models as the trove of online data dries up.
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (194 messages🔥🔥):
- Template Confusion and Loss of Training Data: Discussions suggest that there might be a template issue rather than a regex problem causing troubles in model behavior. Users share experiences and speculate on the cause, referencing Issue #7062 on ggerganov/llama.cpp indicating the potential loss of training data when converting to GGUF with LORA Adapter.
- Finding the Right Server for 8B Models: One user inquired about server recommendations for running 8B models, but no specific advice was provided in the subsequent discussions.
- Exploring CPU Use and Multi-GPU Support: Enquiries were made about utilizing CPUs for fine-tuning and multi-GPU capabilities in Unsloth. It was noted that Unsloth currently doesn’t support multi-GPU training, but work appears to be "cooking" on the feature.
- Unsloth and Quantization for Finetuning: Questions regarding finetuning generative models with Unsloth for classification tasks and whether Unsloth supports quantization-aware training highlighted limitations and current capabilities. Response indicated the possibility of certain quantizations but not support for GPTQ and suggested using
load_in_4bit = Falsefor 16bit training to avoid quality drops seen withq8.
- Challenges with Installation and Local Testing: Some users faced issues with installing Unsloth locally where the library was failing, particularly with Triton dependency issues and inquiries about running models without CUDA. The conversation referenced following the kaggle install instructions for a potential solution.
- Supervised Fine-tuning Trainer: no description found
- Supervised Fine-tuning Trainer: no description found
- Google Colab: no description found
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Apple Silicon Support · Issue #4 · unslothai/unsloth: Awesome project. Apple Silicon support would be great to see!
- Supervised Fine-tuning Trainer: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Google Colab: no description found
- Cooking GIF - Cooking Cook - Discover & Share GIFs: Click to view the GIF
- Google Colab: no description found
- Google Colab: no description found
- llama3-instruct models not stopping at stop token · Issue #3759 · ollama/ollama: What is the issue? I'm using llama3:70b through the OpenAI-compatible endpoint. When generating, I am getting outputs like this: Please provide the output of the above command. Let's proceed f...
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...
- Trainer: no description found
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...
Unsloth AI (Daniel Han) ▷ #showcase (18 messages🔥):
- Contribute to Open Source Paper on IPO Success: An invitation to contribute to an open source paper on predicting IPO success using machine learning is extended, with sections ranging from literature review to results available for collaboration.
- Llama AI Model Updates: The advent of Llama-3-8B-Instruct-Coder-v2, an improved AI model trained on a refined dataset, was announced, with promises of superior performance over previous iterations. Find it on Hugging Face.
- Seeking Feedback: A member shared feedback on a web design tool, suggesting a more direct tagline and considering its suitability for creators with a bit of technical know-how.
- Inter-creator Trust Measurement: A model designed to measure trust between viewers and content creators is in discussion, suggesting potential partnership opportunities for user engagement analysis.
- Llama-3-11.5B-Instruct-Coder Release: A new upscaled AI model, Llama-3-11.5B-Instruct-Coder-v2, is introduced that uses the innovative Qalore method for efficient VRAM usage during training. Additional details and the dataset used for training are available on Hugging Face.
- PREDICT IPO USING MACHINE LEARNING: Open source project that aims to trace the history of data science through scientific research published over the years
- rombodawg/Llama-3-8B-Instruct-Coder-v2 · Hugging Face: no description found
- rombodawg/Llama-3-11.5B-Instruct-Coder-v2 · Hugging Face: no description found
LM Studio ▷ #💬-general (112 messages🔥🔥):
- Overflow Policy Might Not Fix Token Limit Issue: Discussion regarding overflow policy and token limit issues wherein a member mentioned switching the overflow to keep the system prompt did not resolve issues when reaching the default token limit. Another member shared similar experiences, suggesting it might be a common problem.
- Model Loading Frustrations and Solutions: Various members are facing issues loading AI models in LM Studio, with error messages indicating potential VRAM or system RAM constraints. Solutions such as disabling GPU acceleration or ensuring proper model folder structure were suggested to tackle these concerns.
- Granite versus Deepseek AI Models: A member pointed out an interesting comparison between the newly announced Granite-34B-Code-Instruct by IBM Research and the existing Deepseek-Coder-33B-Instruct model. No conclusive comparisons were provided in the ensuing discussion.
- Seeking Chat UI Flexibility: Members expressed the need for better UI configurations in LM Studio, such as preventing auto-scrolling during AI text generation and setting a light mode for better accessibility.
- API and Mobile Interfaces for AI Chat: Members discussed the possibility of web-based and mobile-friendly UIs for chatting with AI models in LM Studio, confirming that such functionality could be accessed through APIs and suggesting the use of responsive UIs like AnythingLLM that run in Docker containers.
- OpenAI API Endpoints | Open WebUI: In this tutorial, we will demonstrate how to configure multiple OpenAI (or compatible) API endpoints using environment variables. This setup allows you to easily switch between different API providers...
- LLaMA 3 UNCENSORED 🥸 It Answers ANY Question: LLaMA 3 Dolphin 2.9 uncensored explored and tested* ENTER TO WIN RABBIT R1: https://gleam.io/qPGLl/newsletter-signupRent a GPU (MassedCompute) 🚀https://bit....
- ibm-granite/granite-34b-code-instruct · Hugging Face: no description found
LM Studio ▷ #🤖-models-discussion-chat (21 messages🔥):
- WestLake Shines for Creative Writers: A user recommended WestLake, particularly the dpo-laser version, for creative writing tasks, saying it performs better than llama3. Another user affirmed this recommendation, noting a marked improvement.
- Hunt for the Ideal Translation Model: Llama3 and Command R were suggested for multilingual support and text translation with one user expressing a preference for something open-source and built specifically for translation. T5 from Google, presented on Hugging Face with detailed documentation, was recommended as a specialized choice for translation tasks.
- Command R Plus Plagued With Issues: Users reported issues with Command R+, noting that older versions worked well but the latest release encounters significant problems in performance. It was noted that awaiting an LMStudio update might resolve these issues.
- Waiting on Granite Support in Llama.cpp: A user inquired about when Granite might receive support. Another member responded that it depends on the resolution of a
mlp_biastokenizer issue in the llama.cpp main branch.
- In Search of Diminutive MoE Models: A user asked if anyone had experience with smaller Mixture of Experts (MoE) models like Qwen1.5-MoE-A2.7B, expressing interest in a Snowflake model not yet supported by llama.cpp and sharing their lackluster experience with a model named
psychoorca.
Link mentioned: T5: no description found
LM Studio ▷ #🧠-feedback (12 messages🔥):
- Free RAM Misreport in LM Studio: A member noted a discrepancy on their Linux (Ubuntu) machine, where LM Studio reported only 33.07KB of free RAM while the machine actually had 20GB free. This issue could point towards a bug in memory reporting within the tool.
- Version Verification Before Troubleshooting: When faced with the above RAM misreport issue, another member asked if the Ubuntu version was up to date, suspecting that outdated libraries might be the culprit. The member clarified they were referring to the Ubuntu, not LM Studio version.
- Disabling GPU Offloading Resolves Model Running Issue: It was suggested to disable GPU offloading in settings; after doing so, the original member confirmed that running the Meta Llama 3 instruct 7B model worked successfully.
- Guide to Accessing Linux Beta in Discord Channels: To gain access to the Linux beta role and associated channels on Discord, a member directed another to sign up for it through the 'Channels & Roles' section found on the top left of the Discord interface. This seems to be a necessary step for discussing platform-specific issues.
- Evolution of LM Studio: A member reflected on their journey with LM Studio, commenting on how it has transitioned from causing frustration in the early days to providing a carefree AI experience now, showcasing the improvements and ease of use that have been realized over time.
LM Studio ▷ #📝-prompts-discussion-chat (2 messages):
- Acknowledging Bias with Humor: A member quipped about their own biases, making a light-hearted comparison to large language models (LLMs), with an emoji to indicate jest.
- The Illusion of AI's Capabilities: Another message from the same member reflected on the difficulty of not overestimating the capabilities of AI and the ease with which one can be fooled into overthinking them.
LM Studio ▷ #⚙-configs-discussion (38 messages🔥):
- Image Description Confusion with llava-phi-3-mini: Users are experiencing issues where llava-phi-3-mini model does not describe the uploaded image but a random image from Unsplash, confirmed with a link provided in a markdown file. The issue persists with both default and phi-3 prompt templates, and one user found success switching to Bunny Llama 3 8B V.
- Vision Models Break after First Image: Several users report that vision models only work for the first image and then fail until the system is reloaded. This seems to be a backend update issue affecting all vision models, including ollama.
- Llama.cpp Server Issue Discussed: A GitHub issue (#7060) was linked, discussing the invalid output after the first inference on the llamacpp server, possibly explaining the problems users face with image processing models.
- Performance Mysteries with Yi 30B Q4 Model: A user can load the Yi 30B Q4 model with high VRAM usage but experiences very low CPU and GPU utilization and poor performance, a stark contrast to when using smaller models. The discussion points towards system bottlenecks, specifically GPU and RAM capacity, and knowledge gaps about how LLM inference engines work.
- System Bottlenecks and Inference Engine Behavior: Discussions lead to the clarification that LLM inference engines are memory-read intensive, and performance issues with larger models like 30B Q4 could be due to the slowdown from CPU to RAM and disk swap operations, which are magnitudes slower than VRAM.
Link mentioned: llava 1.5 invalid output after first inference (llamacpp server) · Issue #7060 · ggerganov/llama.cpp: I use this server config: "host": "0.0.0.0", "port": 8085, "api_key": "api_key", "models": [ { "model": "models/phi3_mini_mod...
LM Studio ▷ #🎛-hardware-discussion (68 messages🔥🔥):
- Apple M4 Chip Sparks Interest: Apple's announcement of their M4 chip with substantially improved AI capabilities has members discussing its potential to outperform AI chips from other major companies. Details are shared in an article: Apple announces new M4 chip.
- Potential Combination of GPUs for LLMs: A member contemplates using a GTX 1060 and an Intel HD 600 for running language models, but only 500MB VRAM and 5-10% utilization would be freed.
- Choose Wisely, Dual-Boot Strategy Suggested: In response to a discussion on using consumer and enterprise GPUs together, one suggests a dual-boot setup with an older Nvidia driver for inference on Linux, while gaming on Windows with up-to-date drivers.
- Hardware Choices for Running Large Language Models: Members sharing experiences indicate that running models like mixtral 8x22b locally requires much more than budget hardware or suggests renting cloud services instead. Meanwhile, a user suggests ex-enterprise servers with multiple P40 GPUs as a possible solution within certain financial constraints.
- Neural Engine in Apple Devices Under Scrutiny: Queries about the utility of Apple's neural engine for language models surface, with one member questioning its relevance. There appears to be consensus that it might not offer any benefits in this regard.
- MSN: no description found
- What's the right nvidia driver to support both Geforce 3080Ti and Tesla P40 on my Ubuntu 22.04?: It looks like that a P40 needs a driver w/o “-open” suffix but a 3080Ti needs a driver w “-open”… what’s the right driver to install? Is it possible to support both Geforce 3080Ti and Tesla P40 on my...
LM Studio ▷ #🧪-beta-releases-chat (41 messages🔥):
- Confusing Error Not Providing Clues: A user reported an error when using visual models, but the error message just showcased system specifications without any explicit error code or message. This seemed to happen when processing images with the vision models.
- Stagnant Home Page Frustrates Model Hunters: Users expressed frustration regarding the inability to refresh the LM Studio content to discover and download the newest LLM models directly from the home page. It was clarified that the home page is static and doesn't reflect live updates of available models.
- Repeated Crashes with Visual Models: An individual reported crashes when working with visual models, noting that the models seemed to not fully unload upon a crash, potentially creating issues upon subsequent loads. They also found they had to restart the model each time to avoid incorrect responses.
- Voting for Bug Fixes: Users discussed abnormal behavior with vision models providing incorrect follow-up responses and it was suggested that this could be a bug. A link to a Discord thread was shared for users to report and add to the notes on this issue:
<https://discord.com/channels/1110598183144399058/1236217728684134431>.
- Inconsistent Model Performance Observed: A user observed that after the first successful response from a visual model, any following responses would be irrelevant or incorrect. The conversation hints at potential issues with how visual models handle context and follow-up queries.
LM Studio ▷ #autogen (1 messages):
- Bug Alert for AutoGen Studio: A member mentioned a bug concerning AutoGen Studio, stating that AutoGen Studio has confirmed it.
LM Studio ▷ #langchain (2 messages):
- LMStudioJS SDK on the Horizon: A member mentioned using the lmstudiojs sdk for JavaScript solutions, with expectations of upcoming langchain integrations.
LM Studio ▷ #amd-rocm-tech-preview (3 messages):
- ROCm on Windows Twist: A user recounted successfully running LMStudio on an RX 6600 with ROCm on Windows by setting an environment variable: HSA_OVERRIDE_GFX_VERSION=1.3.0 and initially reported it was working fine.
- A Surprise OpenCL Usage: The same member later realized that despite the ROCm setup, the system was in fact using OpenCL, indicated by an expression of surprise: "Oh no, it is using OpenCL 🤔".
- Clarification on Environment Variable: Another individual pointed out that the environment variable HSA_OVERRIDE_GFX_VERSION is not utilized by ROCm on Windows, suggesting a possible misconception or error in the initial report.
LM Studio ▷ #crew-ai (1 messages):
- Inquiry on GPT-Engineer Setup: A member showed interest in understanding how to set up gpt-engineer with LM Studio and asked whether custom prompting was part of the setup process. There was no follow-up provided with the specifics of the setup.
LM Studio ▷ #🛠-dev-chat (18 messages🔥):
- LM Studio API Integration: A user successfully integrated the LM Studio API into their custom UI, expressing excitement about the new incorporated support.
- Concurrency Challenges with LM Studio: Multiple members reported issues with LM Studio failing to handle concurrent embedding requests, leading to responses not being returned. One user documented the issue in the lmstudio-bug-tracker on GitHub.
- Lack of Embeddings in SDK Documentation: Users discussed the absence of documentation for embeddings in the LM Studio SDK. The conversation highlighted that there is no SDK guidance for those looking to generate embeddings.
- Request for Programmatic Chat Interaction: A user inquired about the ability to programmatically interact with existing chats within LM Studio, which prompted Yagilb to acknowledge the limitation and express that it is a feature currently under consideration.
- Concurrent embeddings requests cause requests to hang · Issue #7 · lmstudio-ai/lmstudio-bug-tracker: When making concurrent requests while request queue on, many of the requests are not returning responses at all. Only a few requests are returning responses. This is most likely an issue with the r...
- GitHub - lmstudio-ai/lmstudio-bug-tracker: Bug tracking for the LM Studio desktop application: Bug tracking for the LM Studio desktop application - lmstudio-ai/lmstudio-bug-tracker
Perplexity AI ▷ #general (222 messages🔥🔥):
- Confusion over Source Limit Increase: Users experienced confusion regarding an increase in the source limit for a service called Gemini 1.5 pro. While one user noted they could now use over 60 sources in one message, this was contradicted by another who insisted the limit was still at 20, leading to debates and links to GIFs instead of concrete information.
- In Search of Information on Opus Limits: The discussion centered around the limits of a service named Opus on Perplexity, with members sharing their experiences of the changing limits, currently set at 50 according to a user, and the reset mechanism which happens 24 hours after each credit's use.
- Debate on AI Quality: Users shared diverse opinions on different AI tools and platforms, expressing frustration at the perceived decline in answer quality from services like GPT-4. Contrastingly, others highlighted their positive experiences with alternative platforms and models, suggesting resources such as Librechat and Claude 3 Opus.
- Queries About Perplexity Pro and Trials: Members inquired about features and benefits of Perplexity Pro versus other services, as well as the availability of free trials or discounts. One user pointed to a change in trial policies due to abuse, while another provided a promotional referral link offering a discount for Pro.
- Customer Support Concerns: Users facing billing issues with their Pro subscriptions sought guidance, with recommendations to contact Perplexity's support email to address concerns such as unexpected charges after using trial coupons with unclear expiration dates.
- AlphaFold opens new opportunities for Folding@home – Folding@home: no description found
- Discord Does NOT Want You to Do This...: Did you know you have rights? Well Discord does and they've gone ahead and fixed that for you.Because in Discord's long snorefest of their Terms of Service, ...
- Scooby Doo Mystery Machine GIF - Scooby Doo Mystery Machine Cartoon - Discover & Share GIFs: Click to view the GIF
- Thistest GIF - Thistest Test - Discover & Share GIFs: Click to view the GIF
- Skeleton Meme GIF - Skeleton meme - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (29 messages🔥):
- Delving into Noise-Cancelling Headphones: Users shared a link exploring the best noise-cancelling headphones on Perplexity AI, showcasing the platform's ability to provide detailed comparisons and insights.
- Mapping Out Glacial History: A member found a detailed technical article on the history of glaciation in Yellowstone thanks to a follow-up question, highlighting the depth of information available at Perplexity AI.
- Analyze This – Whey Protein Isolate Comparison: A shared link requests an analysis of three whey protein isolate products, showing Perplexity AI's capability to assist in comparing complex product data.
- Soccer Rivalries in the Spotlight: A user linked to a conversation about the Ronaldo-Messi era in soccer on Perplexity AI, likely indicating the platform's discussion of their impact on the sport.
- Probing Bipolar Disorder: The sharing of a Perplexity AI link about bipolar disorder suggests members are using the platform to understand complex mental health conditions.
Perplexity AI ▷ #pplx-api (11 messages🔥):
- Clarity on New Model Guidance: The models page has been updated, indicating that system prompts don't influence the retrieval process in online models since the querying and response-generating components are separate.
- Model Parameter Puzzlement: Confusion persists around the Parameter Count for
llama-3-sonar-largemodels, as well as the practical Context Length, which seems closer to 10,000 tokens rather than the listed 28-32k tokens. - Site-Specific Search Woes: A user experienced difficulty instructing the sonar model to limit search results to specific sites, like scholar.google.com, and noted inconsistencies in the output.
- Model Foundation Queries: There was a brief interchange questioning whether the system was indeed using llama as a base, leading to clarification that the models in question are llama-3 fine tunes.
- Understanding Model Architecture: A user queried about the correct understanding of the model architecture, voicing uncertainty over the 8x7B parameter counts, clarifying that the models are MoE like Mixtral but not exactly Llama.
Link mentioned: Supported Models: no description found
HuggingFace ▷ #announcements (1 messages):
- New Models Launch Left and Right: The AI community sees a burst of new models including chat-optimized Idefics2 8B Chatty, a 7B parameter CodeGemma 1.1 for improved coding, and DeepSeek-V2 with a massive 236B parameters. Other highlights are IBM Granite a set of code models, Llama 3 Gradient 4194k with an extended context window, browser-based Phi 3, Google's time series model TimesFM, and Apple's OpenELM.
- Upskilling with Quantization: Collaboration with Andrew Ng resulted in Quantization in Depth, a new short course focused on model optimization.
- Rapid AI Prototyping: Gradio Templates simplifies hosting of AI demos such as chatbots, using just a few clicks.
- Free Course on Computer Vision: A community-driven course on computer vision has been made freely available, aiming to expand knowledge in the field.
- New Libraries for Robotic and Speaker Diarization: The release of LeRobot, a state-of-the-art robotics library, and diarizers, for fine-tuning speaker diarization models, marks advancement in hands-on AI applications.
HuggingFace ▷ #general (198 messages🔥🔥):
- Exploring Model Implementation and Compatibility: Users discuss the integration of various models such as LangChain with DSpy, LayoutLMv3, and finetuning BERT. The conversations involve troubleshooting integration issues, the functionality of Smaug-72B-LLM, and whether specific models like Mistral or BERT outperform others in benchmarks and actual utility.
- HuggingFace Website Access Checks: There was a brief moment where a user questioned if the HuggingFace website was down, but it was quickly resolved with input from others indicating potential personal connection issues instead of a site-wide problem.
- Adding New Models to Transformers: A detailed exchange focused on how to contribute new models to the transformers library, emphasizing the utility of new model issues on the GitHub repository and how following key influencers on social media can highlight trends.
- In Search of Efficient CPU-Run Models for Teaching: One member sought advice for using models suitable for CPU implementation (Chatbots and RAG pipelines), with suggestions including ollama, llama cpp python, and the HuggingFace token for faster execution via HF's external GPU resources.
- Addressing Operational Needs with AI: A user expressed a need for open-source tools and strategies to automate tasks in the commercial auto insurance sector. They sought AI methodologies to predict risks and outcomes, and open-source solutions to handle diverse data formats like PDFs and text files.
- Gradio Version Concerns for Legacy Spaces: A user inquired about the longevity of Gradio 3.x versions as they face compatibility issues with the latest updates affecting their carefully crafted old space's GUI.
- Optimizing GPU Utilization for Fine-Tuned Language Models: A Comprehensive Guide: By 🌟Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer🧑💻
- timm/ViT-SO400M-14-SigLIP-384 · Hugging Face: no description found
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
- microsoft/phi-2 · Hugging Face: no description found
- A Multi-Agent game where LLMs must trick each other as humans until one gets caught: Five top LLMs - OpenAI's ChatGPT, Google Gemini, Anthropic's Claude, Meta's LLAMA 2, and Mistral AI's Mixtral 8x7B compete in this text-based Turing Test gam...
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
- GitHub - getumbrel/llama-gpt: A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device. New: Code Llama support!: A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device. New: Code Llama support! - getumbrel/llama-gpt
- Hugging Face – Posts: no description found
HuggingFace ▷ #today-im-learning (3 messages):
- AI Data Demystified: The YouTube video introduces transparency in AI datasets, showcasing how to convert datasets from parquet format to csv. The conversation highlights the use of Polars, a performance-oriented alternative to pandas, and shares GitHub repositories for code and datasets, like the Yale MedQA_Reasoning Train Dataset.
- Understanding MultiModal AI: A two-minute YouTube video offers a simplified analogy for Multimodal AI comparing it to an acoustic electric guitar playing different genres of music. The video features the Med-Gemini model and is backed by a research paper on advancing multimodal medical capabilities.
- What Is MultiModal AI? With Med-Gemini. In 2 Minutes: At a high level, Multimodal AI is like an acoustic electric (AE) guitar. A multimodal model like Gemini takes in multiple data types- aka modalities. Data mo...
- Advancing Multimodal Medical Capabilities of Gemini: Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini'...
- GitHub - PhaedrusFlow/parq2csv: python file to convert parquet to csv using Polars: python file to convert parquet to csv using Polars - PhaedrusFlow/parq2csv
- GitHub - BIDS-Xu-Lab/Me-LLaMA: A novel medical large language model family with 13/70B parameters, which have SOTA performances on various medical tasks: A novel medical large language model family with 13/70B parameters, which have SOTA performances on various medical tasks - BIDS-Xu-Lab/Me-LLaMA
- YBXL/MedQA_Reasoning_train · Datasets at Hugging Face: no description found
- Polars: DataFrames for the new era
HuggingFace ▷ #cool-finds (5 messages):
- Morning Greetings and Partial Participation: The channel includes a series of greetings such as "gm" but no substantive discussion or links.
- Exploring Customer Support Automation: A member shared an article about Langchain’s LangGraph for streamlining customer support. The article can be read on AI Advances Blog and discusses using language models and graphs to enhance customer interaction.
- Diving into Diffusion Guidance: Two papers were linked regarding classifier-based guidance and classifier-free guidance in the context of Denoising Diffusion Probabilistic Models (DDPM). The first paper can be found at Semantic Scholar - Classifier-Free Diffusion Guidance, and the second is available at Semantic Scholar - Score-Based Generative Modeling.
- Streamline Customer Support with Langchain’s LangGraph: Ankush k Singal
- [PDF] Classifier-Free Diffusion Guidance | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
- [PDF] Score-Based Generative Modeling through Stochastic Differential Equations | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
HuggingFace ▷ #i-made-this (15 messages🔥):
- EurekAI Aims to Streamline Research: Adityam Ghosh announced EurekAI, a tool designed to revolutionize research processes, making them less disorganized and overwhelming. The team is looking for individuals to conduct interviews, demo the product, and provide feedback. Visit EurekAI.
- Rubik's AI Looking for Beta Testers: The team behind Rubik's AI has invited participants to become beta testers for their advanced research assistant and search engine, offering two months of premium access to models such as GPT-4 Turbo and Mistral Large. Interested parties can sign up at Rubik's AI and use the
RUBIXpromo code.
- Artificial Intelligence Music Generation with Udio AI: A new song was shared that was generated using Udio AI, showcasing the capabilities of AI in music production. The song is available for feedback on YouTube.
- Real-Time Video Generation Showcased on Twitter: A demonstration of real-time video generation has been shared, showing a video created at 17fps and 1024x800 resolution; however, the audio was not recorded. The demonstration can be viewed on Twitter.
- BIND: Drug Discovery with Protein-Language Models: An open-source tool called BIND is utilizing protein-language models for virtual screening in drug discovery, which purportedly outperforms traditional methods. The GitHub repository can be found at Chokyotager/BIND.
- refuelai/Llama-3-Refueled · Hugging Face: no description found
- Python Decorators In 1 MINUTE!: Discover the power of Python decorators in just 1 minute! This quick tutorial introduces you to the basics of decorators, allowing you to enhance your Python...
- Intel Real Sense Exhibit At CES 2015 | Intel: Take a tour of the Intel Real Sense Tunnel at CES 2015.Subscribe now to Intel on YouTube: https://intel.ly/3IX1bN2About Intel: Intel, the world leader in sil...
- Google Colab: no description found
- Illusion Diffusion Video - a Hugging Face Space by KingNish: no description found
- Rubik's AI - AI research assistant & Search Engine: no description found
- GitHub - Chokyotager/BIND: Leveraging protein-language models for virtual screening: Leveraging protein-language models for virtual screening - Chokyotager/BIND
HuggingFace ▷ #reading-group (1 messages):
Since there's only a single message provided without any further context or discussion, the summary would only reflect that message:
- Choosing the Next Paper: A member mentioned the possibility of discussing either the RWKV paper or Facebook’s multi-token prediction paper for an upcoming session.
There are no links or comments to add to this summary. If more messages or discussions were provided, they could be summarized accordingly.
HuggingFace ▷ #computer-vision (9 messages🔥):
- Calibration Troubles for Segmentation: A member is looking for assistance on computing the calibration curve of segmentation outputs, stating that
CalibrationDisplayonly works with binary integer targets. - Face Recognition Development Inquiry: Another member seeks guidance on implementing face recognition using transfer learning on facenet with their dataset and shared difficulties finding resources specifically for facenet as opposed to vgg16.
- Generic Appeal for Object Detection: A user briefly mentioned a project regarding object detection from traffic cameras without providing further information or context.
- Fine-Tuning Keypoint Detection Models: Someone is working on cephalometric keypoint detection and asked if there are any existing models available for fine-tuning to perform keypoint detection.
- Looking for Image Classification Training Resources: One user expressed disappointment with an example that did not work and is looking for resources on training a Multi-class Image Classification model.
- Advert Image Identification Library Shared: The adlike library was shared, which predicts to what extent an image is an advertisement.
- Object Detection Guides and Scripts Upgraded: A member highlights the updates to the HuggingFace object detection guides, including information on adding mAP metrics to the Trainer API and new official example scripts which support the Trainer API and Accelerate. These scripts facilitate fine-tuning object detection models on custom datasets.
- GitHub - chitradrishti/adlike: Predict to what extent an Image is an Advertisement.: Predict to what extent an Image is an Advertisement. - chitradrishti/adlike
- Object detection: no description found
HuggingFace ▷ #NLP (10 messages🔥):
- Seeking Chatbot to Craft PowerPoints: There's a query about a chatbot that can generate PowerPoint presentations using the OpenAI Assistant API, with capabilities to learn from previous presentations for new content creation. Suggestions for suitable RAG or LLM models were also requested.
- Contribution Conundrum: A member is eager to contribute new models to the transformer library and is seeking guidance on how to select "new models," whether to refer to paperswithcodes, trending SOTA models, or open an issue for discussions.
- Classifier Quandaries and Practical Insights: Discussing classifiers, a member explained that the probabilities across different classes should sum up to 1. They also praised Moritz's classifiers for their effectiveness.
- The Trials of Cross-Platform Script Execution: A member shared their experiences with the inconsistencies of running scripts on different cloud platforms, like Google Colab and Databricks, and issues with the sentence transformers’ encode function returning None on specific datasets.
- Debugging Deep Dive: Members discussed the benefits of using a debugger to step through code to uncover and resolve potential issues, as well as increase one’s familiarity with the libraries being used.
- Model Frustration and Request: A user expressed dissatisfaction with the Llama 2:13b model's performance in word extraction tasks and asked for suggestions for a more accurate model that could be loaded locally for better results.
HuggingFace ▷ #diffusion-discussions (9 messages🔥):
- Fine-Tuning Frenzy: A member inquired about optimal hyperparameters for fine-tuning Stable Diffusion 1.5 with a small dataset of 1300 examples, specifically for a new style. Tips on fine-tuning methods and the potential use of LoRA were requested.
- Bias BitFit Brilliance Proposed: One user suggested bitfit training which focuses on adjusting the bias terms only. This technique could offer an alternative approach to fine-tuning models.
- LoRA Hailed as the Go-To: In response to questions on fine-tuning strategies, LoRA (Low-Rank Adaptation) was endorsed as the preferred method for tasks such as adding a new style to a model.
- Git LFS Woes with Diffusion Models: A member encountered an OSError related to 'git lfs clone' being deprecated when attempting to run a training script for a diffusion model. They sought assistance to resolve this issue related to their repository being potentially not found.
Eleuther ▷ #general (63 messages🔥🔥):
- AI Community Morning Rituals: Daily greetings with custom emojis seem to be a recurring way for community members to start their day in the channel.
- PEFT vs. Full Fine Tuning Debate: The community discussed if the Parameter-Efficient Fine Tuning (PEFT) like LoRA makes sense when abundant VRAM is available, as some found it to be slower. Carsonpoole suggests that using mixed precision like bf16 with PEFT could be the issue, while Sentialx observes higher VRAM usage despite fewer trainable parameters.
- Anticipation for xLSTM: Algomancer contemplates releasing their own implementation of xLSTM prior to the authors' official release, sparking a discussion on the ethics and practices of preemptive code publication. Community members advise to clearly state it's not the official implementation and not to wait for authors if they haven't shown intent to release soon.
- Navigating Name Changes in Academia: Paganpegasus enquires about the best way to update their surname on academic platforms after marriage, while retaining links to their published papers. Suggestions include contacting the platforms directly and using their old name as an academic alias.
- Data Loading Techniques for "The Pile": Community members discuss methods for loading "The Pile" data for training AI models. Some suggest looking on Hugging Face for pre-processed versions, while others share the challenge of finding raw versions not pre-tokenized, and even discuss the difficulties and technicalities of doing it directly from source data.
- Tweet from Maximilian Beck (@maxmbeck): Stay tuned! 🔜 #CodeRelease 💻🚀
- GitHub - nihalsid/mesh-gpt: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers - nihalsid/mesh-gpt
Eleuther ▷ #research (131 messages🔥🔥):
- LSTM Reimagined with Scalable Techniques: A new paper revisits LSTMs by introducing exponential gating, normalization, and a modified memory structure to scale them up to billions of parameters. These enhancements aim to mitigate known limitations and close the performance gap with Transformer models.
- In-Depth Discussions on Parameter-Free Optimizers: Participants scrutinized an optimizer called AdamG which claims to be parameter-free, with debates focusing on its potential scale applicability and comparison to adaptive methods. Specific proposed modifications to optimize its function without compromising adaptability were made.
- AlphaFold 3 Unveiled by Google DeepMind: The blog post introduces AlphaFold 3 by Google DeepMind and Isomorphic Labs, claimed to accurately predict the structure of proteins, DNA, RNA, and their interactions, which may revolutionize biological understanding and drug discovery.
- Seeking Open-Source Tools for Insurance Automation: A user sought advice on open-source tools for automating data processing in the commercial auto insurance sector. No recommendations were directly provided within the messages.
- Pros and Cons of Adaptive vs. Tuning-Free Optimizers: The conversation touched on the benefits and limitations of adaptive optimizers versus the concept of "tuning-free" methods in the context of machine learning, questioning whether the latter could adequately handle the intricacies of learning rate adjustments without manual tuning.
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- In-Context Learning Creates Task Vectors: In-context learning (ICL) in Large Language Models (LLMs) has emerged as a powerful new learning paradigm. However, its underlying mechanism is still not well understood. In particular, it is challeng...
- Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training: Mixture-of-experts (MoE) models facilitate efficient scaling; however, training the router network introduces the challenge of optimizing a non-differentiable, discrete objective. Recently, a fully-di...
- Towards Stability of Parameter-free Optimization: Hyperparameter tuning, particularly the selection of an appropriate learning rate in adaptive gradient training methods, remains a challenge. To tackle this challenge, in this paper, we propose a nove...
- From Sparse to Soft Mixtures of Experts: Sparse mixture of expert architectures (MoEs) scale model capacity without large increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instabil...
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language mo...
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- The mechanistic basis of data dependence and abrupt learning in an...: Transformer models exhibit in-context learning: the ability to accurately predict the response to a novel query based on illustrative examples in the input sequence, which contrasts with...
- Function Vectors in Large Language Models: We report the presence of a simple neural mechanism that represents an input-output function as a vector within autoregressive transformer language models (LMs). Using causal mediation analysis on...
- AlphaFold 3 predicts the structure and interactions of all of life’s molecules: Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.
- QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs: We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way t...
Eleuther ▷ #interpretability-general (32 messages🔥):
- Residual Connections Get Negative: A member observed that during training, models with adaptive skip connections (a weight on the identity component of each skip/residual connection) showed weights reducing and becoming negative at later layers. This behavior seemed to improve model loss compared to normal models, prompting discussions on potentially beneficial effects of subtracting input representations.
- Related Research Sought: They shared experiments where weights on the identity component became negative and improved model performance and asked for related research. Another member referenced a related paper (Residual Attention Network), but it looked at weights on the residual path rather than on the identity and clamped weights > 0.
- Clarification on Skip Connections: In a conversation about the experiment's setup, it was clarified that the model was a standard decoder language model with a single
skip_weighton standard residual connections. The member provided a GitHub Gist link to the model block/layer (Model Code on GitHub).
- Model Configuration Details: Discussing the model setup, it was pointed out it had 607M parameters and was trained on the FineWeb dataset from HuggingFace, without an LR schedule, and on a context window of 768.
- Dataset and Training Parameters in Spotlight: Queries were made about the dataset size, batch size, learning rate, and training speed, to which the member disclosed using a batch size of 24, an LR of 6e-4, and noted slow loss reduction on the FineWeb dataset. They suggested consistent results with other datasets.
- train_loss (24/05/07 01:06:58): Publish your model insights with interactive plots for performance metrics, predictions, and hyperparameters. Made by Nick Ryan using Weights & Biases
- gist:08c059ec3deb3ef2aca881bdc4409631: GitHub Gist: instantly share code, notes, and snippets.
Eleuther ▷ #lm-thunderdome (10 messages🔥):
- API Models Limit Logits Support: Logits are not currently supported by API models, and a recent paper on model extraction suggests that logit biases cannot be used due to the softmax bottleneck issue. The impact on evaluation techniques like Model Image or Model Signature is notably affected.
- Evaluation Framework Tweaking: Alteration of
output_typetogenerate_untilwithin the MMLU's CoT variant has been suggested to handle generative outputs, with the aim of integrating multiple 'presets' for tasks in the lm-evaluation-harness.
- Practical Application on Italian LLM: A member mentioned experimenting with an evaluation of an Italian large language model using the MMLU, ARC, and Hellas datasets, comparing it to OpenAI's GPT-3.5 to assess performance differences.
- Challenges of External Model Evaluations: Further clarification reveals that OpenAI and other providers do not return logprobs for prompt/input tokens, complicating the process of obtaining loglikelihoods of multi-token completions in external evaluations.
- Acknowledgment of Community Assistance: Members expressed gratitude for the provided summaries and explanations, underscoring the complexities in running evaluations on externally controlled models.
- Stealing Part of a Production Language Model: We introduce the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like OpenAI's ChatGPT or Google's PaLM-2. Specifically, our...
- Logits of API-Protected LLMs Leak Proprietary Information: The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption...
- lm-evaluation-harness/lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu_flan_cot_zeroshot_template_yaml at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Modular (Mojo 🔥) ▷ #general (90 messages🔥🔥):
- Structs, Classes, and Mojo Language Structure: The discussion centered around Mojo's upcoming features, including plans for introducing classes and inheritance. Some members see having both structs and classes as a bad idea, while others support the flexibility it provides. Structs are expected to be static and non-inheritable, with value semantics, whereas classes will have inheritable capabilities.
- Mojo's Compilation Capabilities: Members are curious if Mojo can compile to native machine code and executable files like Rust can. It has been confirmed that Mojo does have these capabilities and can also pull in the Python runtime to evaluate methods. This allows Python code to be imported and run within Mojo.
- Mojo's Python Integration and Future Outlook: There's anticipation around the integration of Mojo with Python, as it allows running Python code, making Mojo a superset of Python. There’s a discussion on the potential of Mojo IR being used by other languages for Compiler optimization and whether Mojo's compiler improvements, such as ownership and borrow checking, could be leveraged by other languages.
- Anticipation for Performance Distribution: The conversation expressed excitement for a future where Python code could be dropped into Mojo and compiled for performance improvements and easier binary distribution. There was a mention of the integration of existing Python libraries with Mojo, allowing them to be compiled into binaries and distributed without requiring large Python library folders.
- Upstream Contributions to MLIR: Members discussed whether Modular would upstream components of MLIR and the implications for other MLIR-powered languages. Some envisage a future where new languages might target Mojo IR to capitalize on Modular's compiler innovations, and there's been mention of Modular's intent to upstream some dialects during an LLVM conference.
- Python integration | Modular Docs: Using Python and Mojo together.
- 2023 LLVM Dev Mtg - (Correctly) Extending Dominance to MLIR Regions: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------(Correctly) Extending Dominance to MLIR RegionsSpeaker: Siddharth Bhat, Jeff Niu------Slide...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1788281021085225170
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Chris Lattner Discusses Mojo on Developer Voices: Chris Lattner appeared in an episode of the Developer Voices podcast, discussing the creation of Mojo. The interview delved into its purpose for Python and non-Python programmers, performance optimization, and key performance features. The full interview can be found on YouTube.
- Mojo: Built for Raw Performance: The main motivation behind developing Mojo was enhancing the performance of GPUs and leveraging the capabilities of advanced CPUs with features like bfloat16 and AI extensions, addressed 3:29 minutes into the video. The goal is to rationalize and make use of these high-performance computing elements seamlessly.
Link mentioned: Modular: Developer Voices: Deep Dive with Chris Lattner on Mojo: We are building a next-generation AI developer platform for the world. Check out our latest post: Developer Voices: Deep Dive with Chris Lattner on Mojo
Modular (Mojo 🔥) ▷ #🔥mojo (67 messages🔥🔥):
- Mojo Language Constructors Clarified: Mojo constructors are brought into question, as members ponder their necessity given Mojo's lack of class and inheritance features. They are explained as a means to ensure that instances are in a valid state upon creation, similar to the
newfunction in Rust, and aid in setting up struct attributes correctly.
- Debugging Tensor Transpose in Mojo: A member shared the implementation details of the
transposeoperation in Mojo using a reference from MAX documentation, and spotlighted a Basalt function that provides an optimized 2D transpose as well as a general transpose method, Basalt on GitHub.
- Feature Request Discussion Gets Mathematical: Amidst debate surrounding a proposed feature request for parameter inference in Mojo, the idea of a
whereclause is discussed, with members linking it to mathematical conventions and its presence in other programming languages, such as Swift. Some members find parameter order confusing regardless of the direction proposed by the feature request.
- Compile-Time Meta-Programming Explored: The community discusses Mojo's capabilities in compile-time meta-programming, confirming it is possible to perform tasks like calculating Fibonacci numbers at compile time. However, 'side effects' are apparently not supported, leading to further explanations about the use of
aliasto instruct when functions should run during compilation.
- Tensor Type Casting Issue Identified: An oddity is reported concerning the
astype()method of tensors in Mojo, where tensors do not seem to reflect the correct byte count after type casting. This discrepancy prompts a member to consider whether to open an issue about the apparent bug involving 8-bit and 32-bit tensor byte counts and specs.
- transpose | Modular Docs: transpose(input Int, y: Int) -> Symbol
- Tensor | Modular Docs: A tensor type which owns its underlying data and is parameterized on DType.
- mo - Overview: mo has 49 repositories available. Follow their code on GitHub.
- Modular: Accelerating the Pace of AI: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
- mojo/proposals/inferred-parameters.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [Feature Request] Parameter Inference from Other Parameters · Issue #1245 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? Mojo already supports inferring parameters from argume...
- basalt/basalt/utils/tensorutils.mojo at main · basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
Modular (Mojo 🔥) ▷ #community-projects (14 messages🔥):
- Hash Function Hurdles for Dict: Discussion around replacing the stdlib Dict focuses on the current inadequate hash function. The replacement proposal suggests allowing users to provide custom hash functions to improve Dict's performance.
- Strategizing for Hash Function Replacement: For a well-distributed hash value of keys, it's advised to use a Hasher and not implement individual hashing strategies. This will form the basis of a reliable stdlib Dict whose default hash function will be determined after thorough testing akin to SMhasher.
- Performance Testing in the Mix: To make informed decisions on stdlib changes, a performance testing platform like CodSpeed is recommended. With this, benchmarks can be incorporated into each PR to assess the impact on the stdlib's performance.
- Contributions to Data Structures Welcomed: Following an inquiry for more data structures in Mojo, a DisjointSet implementation and an example utilizing it for the Kruskal MST algorithm are now available in the "toybox" GitHub repository. Contributions to the repo are encouraged, even as the owner navigates the open-source learning curve.
- CodSpeed: Unmatched Performance Testing: Automate performance tracking in your CI pipeline with CodSpeed. Get precise, low-variance metrics before you deploy, not after.
- no title found: no description found
- SMhasher: Hash function quality and speed tests
- GitHub - dimitrilw/toybox: Various data-structures and other toys implemented in Mojo🔥.: Various data-structures and other toys implemented in Mojo🔥. - dimitrilw/toybox
- [Proposal] Improve the hash module by mzaks · Pull Request #2250 · modularml/mojo: This proposal is based on discussion started in #1744
Modular (Mojo 🔥) ▷ #community-blogs-vids (2 messages):
- Interview Lights a Recruiting Fire: A member expressed their enthusiasm for a recent interview, considering the content pure fire and seeing it as an effective tool for recruiting like-minded individuals. The tactic proposed: "Watch this vid. Join us."
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (15 messages🔥):
- Online Normalization Less Speedy on CPU: An attempt to use the Online normalizer calculation for softmax on a CPU desktop revealed that it's slower than the naive method, contrary to expectations. Details and performance results are provided in a Jupyter notebook on GitHub.
- String Concatenation in Mojo: A user noted that string concatenation in Mojo is slower than in Python; performance concerns were highlighted using test code. Suggestions were made to profile the code and consider alternative concatenation strategies, with references to potential improvements via Mojo's string optimization features.
- Decoding Slowness in minbpe.mojo: A user encountered slow decoding performance with the minbpe.mojo library, which is slower in Mojo compared to Python and Rust. Other users suggested optimization techniques such as avoiding repeated string concatenations and using an optimized dictionary for lookup, with further discussion on the impacts of underlying string operations.
- StringBuilder as a Performance Hack: Using the StringBuilder class from a GitHub repository resulted in a 3x performance boost for string concatenation. The integration of a StringBuilder and the suggestion to wrap a dedicated Keyable class around integer keys for dictionary lookup contributed to the performance improvement.
- Anticipation for Short String Optimization: The community is looking forward to the potential benefits of short string optimization in the Mojo String struct, which is under development with potential implications on performance. There is anticipation for this feature, and users are advised to monitor the progress for future inclusion in a stable release.
- GitHub - maniartech/mojo-stringbuilder: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator.: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator. - maniartech/mojo-stringbuilder
- mojo-lab/notebooks/OnlineNormSoftmax.ipynb at main · GeauxEric/mojo-lab: mojo lang experiments. Contribute to GeauxEric/mojo-lab development by creating an account on GitHub.
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- compact-dict/string_dict/keys_container.mojo at main · mzaks/compact-dict: A fast and compact Dict implementation in Mojo 🔥. Contribute to mzaks/compact-dict development by creating an account on GitHub.
- [Feature Request] Unify SSO between `InlinedString` and `String` type · Issue #2467 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? We currently have https://docs.modular.com/mojo/stdlib...
Modular (Mojo 🔥) ▷ #nightly (45 messages🔥):
- Bug Hunts and Lifetime Mysteries: A series of exchanges regarding a bug in
TensorandDTypePointerfrom the Mojo standard library documented in Issue #2591 sparked a deep discussion. The talk revolved around the nuances of memory management and the proper lifetime of objects in the Mojo language.
- A Pointer's Lifespan Debate: Technical contemplation on the discrepancy between the expected and actual behavior of
Tensor.data()in Mojo programs occurred. lukashermann.com explained that due to the immediate destruction of the original tensor, a copied pointer becomes dangling, causing undefined behavior.
- Lifetime Extension Queries: Members debated on how using
_ = tensorinside a function could prevent early destruction and allow correct data copying. lukashermann.com clarified that lifetime extension is required to avoid cleanup beforememcpyexecution.
- Misleading Function Names Garner Laughs: Some participants chuckled at the unfortunate naming conventions found in Mojo and beyond, highlighting
atolandcumsumas examples. A member shared a link to the cumsum function documentation.
- Nightly Release Party: The Mojo compiler's nighttime release boasted 31 external contributions and was announced excitedly. Users were encouraged to update and check out the changes through provided links to the nightly release diff and the nightly changelog.
- [BUG]: Weird behavior when passing a tensor as owned to a function · Issue #2591 · modularml/mojo: Bug description When passing a tensor as owned to a function and one tries to do a memcpy of the data or printing the information from inside a @parameter function (using a simd load) a weird behav...
- [stdlib] Update stdlib corresponding to 2024-05-08 nightly/mojo by JoeLoser · Pull Request #2593 · modularml/mojo: This updates the stdlib with the internal commits corresponding to today's nightly release: mojo 2024.5.822.
- mojo/docs/changelog.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
CUDA MODE ▷ #general (23 messages🔥):
- Dynamic Shapes Puzzle Torch’s Compilers: A member is pretraining a language model with dynamic batch sizes, leading to challenges with
torch.compileas it recompiles for every variable shape. Another member suggested using padding to predefined shapes to alleviate re-compilation issues.
- Jagged Tensors Await Torch.Compile Integration: It was shared that support for torch.compile with nested/jagged tensors is in development, which would obviate the need to pad data to fit static shapes. Until then, the current best practice is to pad data up to the closest predetermined shape.
- Torch.compile Trials and Tribulations: Users discussed the inefficiency of compiling for every unique sequence length when using dynamic batch shapes in sequence training. Pad strategies were considered, but with concerns about the practicality when dealing with varying input and output sequence lengths in machine translation.
- The Inefficacy of Dynamic=True: Members report that
dynamic=Truewithintorch.compiledoesn't seem to prevent recompilations as expected, suggesting that the feature doesn't help when it comes to dealing with varying input shapes.
- A Deep Dive into GPU Optimization: A member shares a comprehensive 9-part blog post series and GitHub repo about optimizing inference for a diffusion paper, detailing insights on GPU architecture and custom CUDA kernels in PyTorch, available at Vrushank Desai's Blog Series and GitHub Repository, with a highlight on modulating GPU coil whine to play music, announced in their Twitter Thread.
Link mentioned: Diffusion Inference Optimization: no description found
CUDA MODE ▷ #triton (10 messages🔥):
- Triton gets fp8 support: Triton has been updated to include support for fp8, as shown in this fused attention example on the official Triton GitHub page.
- Community Resource for Triton Kernels: Inspired by a Twitter post, a new GitHub repository Triton-index has been created to catalogue community-written Triton kernels.
- Creating a Community-Owned Triton Repo: It was suggested to make the Triton resources more community-owned, considering moving the initiative to the cuda-mode GitHub and possibly creating a dedicated group for it.
- Admin Invites Sent for Collaborative Triton Repo: Admin invites have been sent out, and the cuda-mode Triton-index repository is now live, aiming to collate and showcase released Triton kernels.
- Interest in a Dataset Publishing Kernels: There's an idea and interest in publishing a dataset of Triton kernels, highlighting that current AI, like ChatGPT, performs sub-optimally with Triton code examples.
- GitHub - cuda-mode/triton-index: Cataloging released Triton kernels.: Cataloging released Triton kernels. Contribute to cuda-mode/triton-index development by creating an account on GitHub.
- triton/python/tutorials/06-fused-attention.py at main · openai/triton: Development repository for the Triton language and compiler - openai/triton
- GitHub - haileyschoelkopf/triton-index: See https://github.com/cuda-mode/triton-index/ instead!: See https://github.com/cuda-mode/triton-index/ instead! - haileyschoelkopf/triton-index
CUDA MODE ▷ #torch (2 messages):
- Tensor Normalization Orientation Query: A member raised a question about whether it's more efficient to permute a tensor from NHWC to NCHW for normalization purposes or to use an algorithm that directly works with NHWC on the GPU, which may suffer from suboptimal access patterns.
CUDA MODE ▷ #algorithms (1 messages):
andreaskoepf: xLSTM paper is out: https://arxiv.org/abs/2405.04517
CUDA MODE ▷ #cool-links (2 messages):
- CUTLASS Deep Dive with Matrix Transpose: An enlightening tutorial delves into memory copy optimization in NVIDIA® GPUs, using CUTLASS through the case study of a matrix transpose. This work builds on Mark Harris's tutorial, focusing on coalesced accesses and other optimization techniques without computation overhead, available at Colfax International.
- Watch GPU Memory Copy in Action: A video was shared without additional context, available for viewing on YouTube.
Link mentioned: Tutorial: Matrix Transpose in CUTLASS: The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will stud…
CUDA MODE ▷ #beginner (3 messages):
- Seeking Clarity on Torch Compile with Triton: A member is looking for guidance on how to use
torch.compilefor Triton, questioning whetherbackend="inductor"is the appropriate choice, but no correct option is confirmed in the discussion. - Interest in BetterTransformer Integration: The message indicates interest in using BetterTransformer (BT) alongside
torch.compile, providing an example snippet of usingBetterTransformer.transform(model)andtorch.compile(model.model_body[0].auto_model)to potentially boost performance of Encoder-based models.
CUDA MODE ▷ #jax (1 messages):
- Efficient Multi-Chip Model Training: A member shared a blog post on efficiently training machine learning models over multiple chips, specifically using Google's TPUs. The article includes a visual example of layer-wise matrix multiplication and recommends Google Cloud documentation for deploying TPUs.
Link mentioned: Multi chip performance in JAX: The larger the models we use get the more it becomes necessary to be able to perform training of machine learning models over multiple chips. In this blog post we will explain how to efficiently use G...
CUDA MODE ▷ #off-topic (4 messages):
- ICLR Rolcall: A member confirmed their attendance to ICLR when prompted by another user's inquiry about the conference.
- Apple M4 Chip Announced: Apple introduced its new M4 chip, aimed at powering the new iPad Pro with enhanced performance and efficiency. The M4 chip, crafted with second-generation 3-nanometer technology, boasts 38 trillion operations per second.
- Panther Lake Packs More Tera Operations: Commenting on the chip discussion, a member pointed out that "panther lake" delivers an impressive 175 tera operations per second (TOPS).
Link mentioned: Apple introduces M4 chip: Apple today announced M4, the latest Apple-designed silicon chip delivering phenomenal performance to the all-new iPad Pro.
CUDA MODE ▷ #irl-meetup (5 messages):
- Anybody Attending MLSys?: A member inquired about attendance at the upcoming MLSys conference.
- Tempted to Attend MLSys: Another expressed interest in attending MLSys but will be in New York at the same time.
- ICLR GPU Programming Event: At ICLR, a member shared a link to an event dedicated to CUDA/GPU Programming listed on the Whova app: CUDA/GPU Event at ICLR.
- Chicago CUDA Catch-up: An invitation was extended to anyone in Chicago interested in collaborating on going through videos and writing CUDA code together.
Link mentioned: ICLR 2024 -The Twelfth International Conference on Learning Representations Whova Web Portal: May 7 – 11, 2024, Messeplatz 1, Postfach 277, A-1021 Wien
CUDA MODE ▷ #llmdotc (126 messages🔥🔥):
- Fusing Forward and Backward Kernels: A pull request (PR) to improve performance by fusing the residual and layernorm forward in CUDA has been merged. The discussion highlights remaining optimizations for NVIDIA's A100, including merging GELU, CUDA stream improvements, and addressing the challenges with cuBLASLt and BF16.
- Analysing Kernel Performance Metrics: Messages discuss the significance of the time spent outside NVIDIA kernels, stating that only 20% of the time is now spent there. GELU backward is identified as the most expensive kernel, and there's an exploration into why pointwise operations aren't reaching peak memory bandwidth.
- Model Training on Diverse GPU Architectures: Conversations reflect on the complexities of utilizing modern GPUs for maximum efficiency and leverage abstractions like Thrust/CUB for optimization. There's acknowledgment that GPU complexities are increasing and the necessity of efficient software abstractions becomes more apparent.
- Multisize GPT-2 Training Capability Achieved: A member shares updates on enabling all-sized GPT-2 model training, executing a batch size of 4 at 12K tok/s on a single A100 GPU. However, a 4X A100 GPU setup slows down training, resulting in a lower token rate of approximately 9700 tok/s.
- Communication Overheads in Distributed Training: The lack of gradient accumulation is pointed out as a cause for slower multi-GPU performance due to excessive data transfer. The conversation mentions that future gradient accumulation and NCCL overlapping with the backward pass should improve this.
- cuda::memcpy_async: CUDA C++ Core Libraries
- ZeRO++: ZeRO++ is a system of communication optimization strategies built on top of ZeRO to offer unmatched efficiency for large model training regardless of the scale or cross-device bandwidth constraints. R...
- When should I use CUDA's built-in warpSize, as opposed to my own proper constant?: nvcc device code has access to a built-in value, warpSize, which is set to the warp size of the device executing the kernel (i.e. 32 for the foreseeable future). Usually you can't tell it apart ...
- Strangely, Matrix Multiplications Run Faster When Given "Predictable" Data!: Strangely, Matrix Multiplications Run Faster When Given "Predictable" Data! - mm_weird.py
- Improve tanh derivative in backward gelu by akbariyeh · Pull Request #307 · karpathy/llm.c: It is cheaper to compute the derivative of tanh as 1 - tanh^2 than computing 1/(cosh^2). This will probably not make a measurable difference.
CUDA MODE ▷ #oneapi (3 messages):
- New Accelerators on the Block: PyTorch's GitHub has an open pull request for adding a dropdown of accelerators that includes Huawei Ascend, Intel Extension for PyTorch, and Intel Gaudi to the quick start table.
- PyTorch Conference 2024 Proposals: The call for proposals for the PyTorch Conference 2024 is now open, with opportunities for early bird registration savings. Full details and guidelines are available for those interested.
- PyTorch 2.3 Rolls Out: The latest update, PyTorch 2.3, now supports user-defined Triton kernels in
torch.compileand offers improvements for training Large Language Models (LLMs) with native PyTorch. More information is provided on their blog post. - Membership Drives and Tools Ecosystem: PyTorch invites users to join various membership levels suitable for their goals, and highlights a robust ecosystem with a suite of tools for development in various domains. Transition to production is facilitated by TorchScript and TorchServe.
- PyTorch Embraces the Cloud: Major cloud platforms offer extensive support for PyTorch, showcasing its readiness and adaptability in scalable distributed training and performance optimization across diverse environments.
- Add accelerators to quick start table by aradys · Pull Request #1596 · pytorch/pytorch.github.io: Create accelerators dropdown with following options and add it to quick start table: Huawei Ascend Intel Extension for PyTorch Intel Gaudi Add commands to previous versions section RFC: pytorc...
- PyTorch : no description found
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- Emotional Companions Lead the Pack: A member highlighted that the majority of high-ranking models on OpenRouter tend to focus on providing emotional companionship. They expressed interest in visualizing this trend through a graph of the categories people build with OpenRouter.
OpenRouter (Alex Atallah) ▷ #general (115 messages🔥🔥):
- Tackling Regional Latency on OpenRouter: Members discussed that OpenRouter leverages edge workers, which influence latency depending on the upstream provider's global distribution. Optimizing for regions like Southeast Asia, Australia, and South Africa is still an ongoing infrastructure effort.
- Debating Model Theft and Leakage: There was chatter about someone managing to "steal" the ChatGPT system prompt, but questions persisted about the success of applying it to the API. A Reddit post was mentioned showcasing an alleged leak.
- Discussions on AI Moderation Capabilities: Users exchanged insights on various AI moderation models with consensus pointing to limitations and imperfections, including discussing specific tools like Llama Guard 2 and L3 Guard.
- HIPAA Compliance Queries and Provider Hosting: Queries were made about OpenRouter's HIPAA compliance and hosting for specific models like Deepseek v2. The consensus was that OpenRouter has not been audited for HIPAA compliance and no provider had been confirmed to host Deepseek v2 at the time of the discussion.
- Model Comparisons and Jailbreaks: Members compared WizardLM-2-8x22B and Mistral 8x22b, citing WizardLM for better understanding prompts and discussed attempts to jailbreak or modify the model to remove restrictions. Concerns were raised about inherent ChatGPT brainrot influencing Wizard's creativity and political neutrality.
- no title found: no description found
- What are the different AI models in AI Dungeon?: no description found
- no title found: no description found
- Models - Hugging Face: no description found
- Meta: Llama 3 70B Instruct by meta-llama | OpenRouter: Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated stron...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- OpenRouter: Build model-agnostic AI apps
LAION ▷ #general (106 messages🔥🔥):
- New Researcher Seeking Dataset Advice: One new member requested recommendations for datasets suitable for a research paper, expressing interest in text/numeric data for regression or classification, but wanting to avoid image classification tasks. Other members suggested datasets like MNIST-1D and the Stanford's Large Movie Review Dataset, although the latter was considered too large for the member's project.
- Discussion on Video Diffusion Models: Conversations emerged regarding the dominance of diffusion models in state-of-the-art text-to-video generation, noting the advantage of fine-tuning from t2i (text-to-image) models. One author from the stable diffusion paper participated, suggesting that diffusion models hold an edge due to their strong spatial knowledge and sharing insights into the potential benefits of unsupervised pre-training on large video datasets.
- Pixart Sigma Fine-Tuning Discussion: Members discussed fine-tuning various models such as Pixart Sigma, with one sharing they've achieved results rivaling DALL-E 3 output by combining Pixart Sigma with other models. When queried about memory constraints during fine-tuning, others indicated that certain techniques can facilitate the process on available hardware.
- In-Depth Analysis of Video Model Training: An extensive exchange about the nuances of training stable and autoregressive video models unfolded, with members probing into the mechanics of learning motion from static frames and the balance of using synthetic captions versus other methods for text supervision.
- Concern Over AI-Driven Job Replacement: A news article was shared about a company called AdVon Commerce, describing a situation where a writer was initially hired to write product reviews but later transitioned to polishing AI-generated content. As the AI system, named MEL, improved, it ultimately replaced the writers, leading to job losses.
- Meet AdVon, the AI-Powered Content Monster Infecting the Media Industry: Our investigation into AdVon Commerce, the AI contractor at the heart of scandals at USA Today and Sports Illustrated.
- VideoPoet – Google Research: A Large Language Model for Zero-Shot Video Generation. VideoPoet demonstrates simple modeling method that can convert any autoregressive language model into a high quality video generator.
- GitHub - instructlab/community: InstructLab Community wide collaboration space including contributing, security, code of conduct, etc: InstructLab Community wide collaboration space including contributing, security, code of conduct, etc - instructlab/community
LAION ▷ #research (6 messages):
- AI for Auto Insurance Data Processing Sought: A member inquired about the best open-source tools to automate data extraction and processing for commercial auto insurance tasks. They seek methods to analyze risk, manage claims, and predict outcomes using machine learning or AI.
- Community Etiquette Reminder: Another member reminded the community about etiquette, advising against copying and pasting messages across multiple channels as it may appear spammy.
- Acknowledgment of Etiquette Misstep: The individual who sought advice on automation tools apologized for the multiple postings, acknowledging the community's feedback.
- Query on Desktop Automation Publications: A member asked if there are any research papers on Robotic Process Automation (RPA) or desktop manipulation, signaling an interest in formal literature on the topic.
Link mentioned: GitHub - lllyasviel/IC-Light: More relighting!: More relighting! Contribute to lllyasviel/IC-Light development by creating an account on GitHub.
OpenInterpreter ▷ #general (11 messages🔥):
- In Search of Ubuntu Custom Instructions for GPT-4: Members are expressing interest in obtaining Custom/System Instructions that work well with Ubuntu for GPT-4, indicating a community desire for optimized instruction sets compatible with this operating system.
- Alert for Moderation Action: There was a notification regarding a user with mention of their identification number, followed promptly by a moderation action indicating the user was banned.
- Endorsement of OpenPipe.AI for Data Handling: A member recommended OpenPipe.AI to those with ample data and suggested thoroughly exploring System Messages before considering fine-tuning AI models.
- Curiosity about AI Hardware and Availability: A member inquired about the functionalities of the 01 light, learning it is in developer preview and open source, with both hardware and software available for preorder or self-built options based on provided documentation.
Link mentioned: OpenPipe: Fine-Tuning for Developers: Convert expensive LLM prompts into fast, cheap fine-tuned models.
OpenInterpreter ▷ #O1 (83 messages🔥🔥):
- Battery Life Queries for 01: A member inquired about the battery life experience of a 500mAh LiPo for their newly ordered 01 build.
- Awaiting Pre-Order Shipments: Users discussed how to verify if their 01 orders have been shipped amidst false shipment notifications; they were directed to check the pinned messages in the channel for updates.
- Persistent Skills Post-Server Shutdown: One member highlighted the necessity for a memory file to prevent reteaching skills to the same LLM if the server shuts down. It was clarified that skills persist on storage as per open-interpreter's GitHub repository.
- International DIY Approach Encouraged: Users touched on the complexities of international shipping for 01s, with individuals opting for DIY builds and using forwarding services as workarounds for locations like Canada.
- Connecting 01/OI to Various LLMs via Cloud APIs: There was a discussion about the capability of 01/OI to connect to different models over cloud platforms using endpoints such as Google, AWS, etc. Litellm's documentation offers guidance on connecting to several providers, including OpenAI and others detailed at litellm's docs for providers.
- Providers | liteLLM: Learn how to deploy + call models from different providers on LiteLLM
- open-interpreter/interpreter/core/computer/skills/skills.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (10 messages🔥):
- Unexpected Rickrolling by OpenInterpreter: Using OpenInterpreter with thebloke/mixtral-8x7b-instruct-v0.1-gguf in LMStudio resulted in the user being humorously rickrolled during a basic task without any custom instructions.
- Exploring Desktop AI with py-gpt: A member shared a GitHub link to py-gpt, a desktop AI assistant that incorporates various AI models, and expressed curiosity about its capabilities and potential integration with OpenInterpreter.
- GPT-4 Delivers with Minimal Input: Mike.bird reported good results using GPT-4 by giving just a single custom instruction related to using YouTube for music, demonstrating the model's effectiveness with minimal guidance.
- Local Model Experiences Mixed Results: exposa compared different local AI models, finding mixtral-8x7b-instruct-v0.1.Q5_0.gguf performed best for their requirements and highlighted a video shared by another user as a reference for similar work.
Link mentioned: GitHub - szczyglis-dev/py-gpt: Desktop AI Assistant powered by GPT-4, GPT-4 Vision, GPT-3.5, DALL-E 3, Langchain, Llama-index, chat, vision, voice control, image generation and analysis, autonomous agents, code and command execution, file upload and download, speech synthesis and recognition, access to Web, memory, prompt presets, plugins, assistants & more. Linux, Windows, Mac.: Desktop AI Assistant powered by GPT-4, GPT-4 Vision, GPT-3.5, DALL-E 3, Langchain, Llama-index, chat, vision, voice control, image generation and analysis, autonomous agents, code and command execu...
LangChain AI ▷ #general (49 messages🔥):
- Quest for AI-Powered Presentation Bot: A member inquired about creating a PowerPoint presentation bot that learns from previous presentations using the OpenAI Assistant API, with recommendations for RAG or LLM models that could be suitable for this task.
- Combining Tools for Optimization: Questions arose regarding the compatibility of DSPY with Langchain/Langgraph and the indexing of numerous documents using Azure AI Search with Langchain.
- Windows Woes with JSON and JQ: A member experienced issues when attempting to use jq to load json data on Windows, despite the setup working fine on Colab and Unix/Linux systems. Another member mentioned a possible solution through a new jsonloader on the Langchain GitHub.
- Implementing Semantic Caching and Seeking Beta Testers: Discussions covered topics like implementing semantic caching using gptcahe in a RAG application, and a call for beta testers to try out a new research assistant and search engine with access to models like GPT-4 Turbo and Mistral Large at Rubik's AI Pro.
- Langchain Usage and Troubleshooting: Users contributed to various Langchain-related issues, from TypeScript implementation queries involving JsonOutputFunctionsParser and OpenAI batching to optimization of search functionality in self-hosted applications.
Link mentioned: Rubik's AI - AI research assistant & Search Engine: no description found
LangChain AI ▷ #langserve (13 messages🔥):
- Exploring
streamEventsFunctionality: A member asked ifstreamEventscan be used withRemoteRunnable. They are attempting to use the method in JavaScript, which should allow event streaming from internal steps of the runnable.
- JavaScript vs Python Streaming Issues: Despite following the advised usage of
streamEventswithRemoteRunnable, the member encounters issues where JavaScript implementation makes a POST to/streaminstead of/stream_events. The issue persists even though the Python version seems to work correctly.
- Guidance and Bug Reporting Suggestion: The member was advised to ensure they're using the correct library version and configurations, including parameters setting for models. If the problem continues, they are suggested to report the issue on the LangChain GitHub repository.
- Integrating with LangServe | 🦜️🔗 Langchain: LangServe is a Python framework that helps developers deploy LangChain runnables and chains
- Interface | 🦜️🔗 Langchain: In an effort to make it as easy as possible to create custom chains, we've implemented a "Runnable" protocol that most components implement.
LangChain AI ▷ #share-your-work (5 messages):
- Survey for a Cause: A survey on LLM application performance is shared requesting a 5-minute commitment. For every response, $1 will be donated to the UN Crisis Relief fund to aid Gaza, accessible via this link.
- Introducing Gianna - The Virtual Assistant Framework: Gianna is an innovative virtual assistant framework emphasizing simplicity and extensibility and is enhanced by CrewAI and Langchain. It invites contributions on GitHub and is available for installation via
pip install gianna.
- Exploring Customer Support Enhancement with Langchain: An article titled Streamline Customer Support with Langchain’s LangGraph discusses enhancing customer support using LangGraph, with additional insights available on Medium.
- Athena Debuts as a Fully Autonomous AI Data Agent: Athena, an AI data platform and agent, utilizes Langchain and Langgraph to provide data workflows for enterprises. Its autonomous mode can intake problems, devise and execute plans, offering self-correction and human-in-the-loop dynamics, and is featured in a YouTube demo.
- Research Request for Global AI Expansion Readiness: An invitation is extended to participate in research examining AI companies' readiness for global expansion, particularly concerning low-resource languages affecting billions. The survey is conducted via Typeform.
- Scaling AI Beyond English Survey: Thank you for contributing to our research on AI technology's approach to supporting underrepresented languages and expanding beyond English-speaking markets. Your insights are invaluable in help...
- LLM Application Performance: Please take this short survey focused on LLM (including chain/agent) application performance
- Enterprise AI Data Analyst | AI Agent | Athena Intelligence: no description found
- Streamline Customer Support with Langchain’s LangGraph: Ankush k Singal
LangChain AI ▷ #tutorials (1 messages):
ntelo007: What is the benefit of this?
LlamaIndex ▷ #announcements (2 messages):
- OpenDev Webinar Scheduled: The OpenDevin authors are featured in an upcoming LlamaIndex webinar. This open-source tool is gaining traction on GitHub and the session is slated for Thursday at 9am PT. Register for the webinar here.
- AI Education Advancement: LlamaIndex launches a new course on building agentic RAG featured on deeplearning.ai. The course, praised by Andrew Y. Ng, delves into routing, tool use, and multi-step reasoning with agents. Sign up for the course.
- Tweet from Andrew Ng (@AndrewYNg): I’m excited to kick off the first of our short courses focused on agents, starting with Building Agentic RAG with LlamaIndex, taught by @jerryjliu0, CEO of @llama_index. This covers an important shif...
- LlamaIndex Webinar: Build Open-Source Coding Assistant with OpenDevin · Zoom · Luma: OpenDevin is a fully open-source version of Devin from Cognition - an autonomous AI engineer able to autonomously execute complex engineering tasks and…
LlamaIndex ▷ #blog (2 messages):
<ul>
<li><strong>OpenDevin, the Autonomous AI Engineer**: [OpenDevin](https://twitter.com/llama_index/status/1787858033412063716) is an open-source autonomous AI engineer from <strong>@cognition_labs</strong>, capable of executing complex engineering tasks and collaborating on software projects.</li>
<li><strong>StructuredPlanningAgent Enhances LlamaIndex**: The latest LlamaIndex update includes the <strong>StructuredPlanningAgent</strong> which assists agents in planning by breaking down tasks into sub-tasks, making them easier to execute. It supports various agent workers like ReAct and Function Calling. [Find out more](https://twitter.com/llama_index/status/1787971603936199118).</li>
</ul>
LlamaIndex ▷ #general (50 messages🔥):
- Diving into ReAct Agent Observations: Members discussed accessing observation data from ReAct Agents when verbosity is enabled. It was suggested to log the data in the terminal into a file to then access it as needed.
- Exploring Local PDF Parsing Libraries: The use of PyMuPDF was recommended for local PDF parsing in Python when LlamaParse is not an option. A detailed example of how to integrate PyMuPDF with LlamaIndex was shared, along with additional resources such as the LlamaIndex documentation.
- Tackling LLM Response Precision and Retriever Behavior: Members shared approaches to prevent irrelevant responses from LLMs, such as using prompt engineering to specify conditions for responding or not. Furthermore, there was an inquiry about strange behavior where a retriever module retains previously retrieved information.
- Enhancement Techniques for LLM-based Retrieval Systems: There was a discussion on optimizing LLM retrieval systems with reranking models. Concerns were raised about the variability in response quality depending on the
top_nvalue and the introduction of irrelevant information. - Vision for Multi-Agent Coordination and Planning: The conversation touched on the idea of a team of planning agents working collectively, similar to systems like crewai and autogen. Progression towards this goal was confirmed, with intermediate steps such as snapshotting and rewinding also being explored.
- OpenAI & other LLM API Pricing Calculator - DocsBot AI: Calculate and compare the cost of using OpenAI, Azure, Anthropic, Llama 3, Google Gemini, Mistral, and Cohere APIs with our powerful FREE pricing calculator.
- Knowledge graph - LlamaIndex: no description found
- Building Evaluation from Scratch - LlamaIndex: no description found
OpenAccess AI Collective (axolotl) ▷ #general (16 messages🔥):
- Mysterious Layer Activity Detected: Discussion revolves around an anomaly in training models where one layer exhibits higher values than others unexpectedly. c.gato expresses skepticism about the lack of uniformity and implies this goes against typical expectations of layer activation.
- Optimizer's Mysterious Ways Confound Users: nruaif muses that the optimizer might be functioning in "mysterious and lazy ways," suggesting the optimizer may focus on sections of a layer for performance gains.
- Uniformity in Layer Values Challenged: c.gato finds it odd that only one slice of the layer has significantly higher values and is not convinced by the suggestion that it might be an optimization strategy.
- Speculation on Model Training Data Differences: nruaif points out that most models are trained on GPT-4/Claude dataset, while the ChatQA model has a different mixture of data sources.
- Human Data's Role in Model Training Discussed: c.gato mentions using a substantial portion of LIMA RP, which is human data, in their model, suggesting the influence of human data on training specificity.
OpenAccess AI Collective (axolotl) ▷ #other-llms (1 messages):
- Launch of RefuelLLM-2: Dhruv Bansal announced the open sourcing of RefuelLLM-2, which claims the title for the "world’s best large language model for unsexy data tasks." Model weights are accessible on Hugging Face, with further details announced in a post on Twitter.
OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- Request for Example Repositories: A user's request for an example repository was ultimately resolved by a link to Axolotl's supported dataset formats documentation, which details the JSONL schema depending on the task and provides guidance on constructing custom dataset types.
- Language-Specific LLM Query: A user expressed interest in creating a language-specific LLM for code assistance, aiming to operate it on a regular laptop without a GPU. They sought advice on the base model for fine-tuning, optimal epochs, training size, and maintaining accuracy during quantization, inviting suggestions for resources.
- Config File Conundrum for Mini 4K/128K FFT: A member encountered
Cuda out of memory errorswhile attempting to use a config file on 8 A100 GPUs for the phi3 mini 4K/128K FFT and is seeking a working configuration example. - Yearning for H100 Training: A user posted a frustrated plea along with an issue on GitHub about errors encountered while trying to train on 8x H100. The linked issue describes behavior deviations from previous successful runs of Axolotl.
- Axolotl - Dataset Formats: no description found
- Recent RunPod Axolotl error · Issue #1596 · OpenAccess-AI-Collective/axolotl: Please check that this issue hasn't been reported before. I searched previous Bug Reports didn't find any similar reports. Expected Behavior I ran Axolotl around two days ago and it worked fin...
OpenAccess AI Collective (axolotl) ▷ #datasets (2 messages):
- Experimenting with Llama3: A member mentioned they would consider testing llama3 on the same datasets previously discussed. They expressed earnest interest in seeing the results.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (1 messages):
- Inquiry about Axolotl Config Options: A member inquired about what to place in the
wandb_watch,wandb_name, andwandb_log_modeloptions in the Axolotl configuration file. No further context or responses are provided in the message history.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (19 messages🔥):
- Seeking wandb Configuration Guidance: A member inquired about configuring Weights & Biases (wandb) in the axolotl config file, particularly for the options
wandb_watch,wandb_name, andwandb_log_model, seeking to know what specific values should be input.
- Exploring Gradient Issues: The discussion included a request for clarification on the exploding gradient norm problem, which is a challenge encountered during the training of deep neural networks where gradients become excessively large, potentially leading to numerical instability and difficulty in model convergence.
- Deciding on Quantization Precision: A comparison between
load_in_4bitandload_in_8bitwas made, emphasizing that 4-bit loading improves memory efficiency at the possible cost of accuracy, while 8-bit offers a better trade-off between size reduction and performance, subject to one's specific model needs and hardware capabilities.
- site).: Weights & Biases, developer tools for machine learning
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Interconnects (Nathan Lambert) ▷ #news (5 messages):
- Evaluating LSTMs' Viability Post-Transformers: Members in the channel discussed a research paper addressing the question of how LSTMs perform when scaled to billions of parameters. The study introduces modifications like exponential gating and a parallelizable mLSTM with matrix memory, aiming to enhance LSTM viability in the face of dominant Transformer models.
- Aesthetic Appreciation for Research Diagrams: One member commented on the visual appeal of the diagrams included in the LSTM research paper, stating they contain "really pretty pictures."
- Critical Assessment of LSTM Paper Claims: A critical analysis of the LSTM paper was provided, pointing out some shortcomings like comparing the number of parameters instead of FLOPs, using an unusual learning rate for Transformer baselines, and the absence of hyperparameter tuning for any of the models discussed.
- Skeptical Yet Open to Results: Another member expressed skepticism regarding the claims made by the LSTM paper, preferring to wait and see if the proposed LSTM enhancements turn out to be effective in practice.
Link mentioned: xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
Interconnects (Nathan Lambert) ▷ #random (24 messages🔥):
- Chatbot Nonsense Weighs on LMSYS: Concerns were raised about how chatgpt2-chatbot activities might damage the credibility of LMsys. It was mentioned that LMsys is overstretched and doesn't have the luxury to decline requests.
- Possible Interview with LMSYS Representatives: The idea of conducting an audio interview with the point person for LMsys was floated, though it was noted there might be a lack of rapport which could affect the interview's quality.
- Exploring Gemini 1.5 Pro's Abilities: A chapter summary of a podcast was successfully created using Gemini 1.5 Pro's audio input, impressing members with its accuracy and the inclusion of timestamps, despite the member acknowledging there were some errors and not feeling inclined to correct them.
- Chatbotarena Post Anticipation:
- Licensing Concerns Over Chatbotarena's Data Release: A point was made regarding chatbotarena potentially confusing license issues by releasing text generated from LLMs of major providers without special permission.
Link mentioned: Tweet from ハードはんぺん (@U8JDq51Thjo1IHM): I’m-also-a-good-gpt2-chatbot I’m-a-good-gpt2-chatbot ?? Quoting Jimmy Apples 🍎/acc (@apples_jimmy) @sama funny guy arnt you. Gpt2 back on lmsys arena.
Interconnects (Nathan Lambert) ▷ #reads (4 messages):
- Previewing AI's Behavioral Blueprint: OpenAI's first draft of the Model Spec was announced, aiming to guide the behavior of models in the OpenAI API and ChatGPT. It focuses on core objectives and how to handle conflicts in instructions, using reinforcement learning from human feedback (RLHF) for implementation.
- A Blog Post in the Making: A member expressed intent to write a blog piece on the just-released Model Spec document by OpenAI.
- A Sign of Serious Intent: The commitment of OpenAI to not "fuck around" when it comes to their work was mentioned, reflecting a deep respect for the organization's approach.
- Simple Reaction Indicates Amusement: A member reacted with a simple "😂" emoji, possibly finding amusement or irony in the conversation or the Model Spec document.
Link mentioned: Model Spec (2024/05/08): no description found
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
- Awaiting the Snail: A mention was made using a clock emoji, implying anticipation or waiting for something or someone referred to as "snail".
- Summoning the Rank: There was a call to a specific group or rank within the community, denoted by
<@&1228050892209786953>, indicating a summon or a page for attention. - Announcing SnailBot News: SnailBot News was tagged, which might indicate either the delivery or expectation of news from a bot or service named SnailBot.
- Cheering on Mr. Snail: The message "f yeea mr snail" appears to indicate enthusiasm or support for something or someone known as Mr. Snail.
Latent Space ▷ #ai-general-chat (26 messages🔥):
- In Search of Unified Search Solutions: A member discussed the utility of Glean, a unified search for enterprises, and mentioned searching for an alternative suitable for small organizations. They provided a Hacker News link to a related open-source project called Danswer.
- AI Orchestration and Data Transfer Inquiries: A member solicited recommendations for AI (data) orchestration and data transfer techniques, describing a need for orchestrating a pipeline with multiple AI components and data types, such as text and embeddings.
- Stanford's New Deep Generative Models Course: A member shared a link to Stanford University's new 2023 course on Deep Generative Models, taught by Professor Stefano Ermon.
- Seeking Short-Term Access to Advanced GPUs: Another member inquired about tips or providers for securing NVIDIA A100 or H100 GPUs for a short-term period of 2-3 weeks, with a response providing a Twitter link.
- Utilizing AI for Code Assistance: A member expressed amazement that it's not until May 2024 that people realize the benefits of AI-assisted coding, sharing their practice of using LLM-generated code after understanding and testing it, akin to any other source code. They also shared a snippet of a script used to create GitHub PRs:
gh pr create --title "$(glaze yaml --from-markdown /tmp/pr.md --select title)" --body "$(glaze yaml --from-markdown /tmp/pr.md --select body)"
- no title found: no description found
- Stanford CS236: Deep Generative Models I 2023 I Lecture 1 - Introduction: For more information about Stanford's Artificial Intelligence programs visit: https://stanford.io/aiTo follow along with the course, visit the course website...
- I'm puzzled how anyone trusts ChatGPT for code | Hacker News: no description found
Latent Space ▷ #llm-paper-club-west (2 messages):
- Inquiry about Meeting Schedule: A member inquired if there was a scheduled call for the current day. No further details or context were provided.
tinygrad (George Hotz) ▷ #general (14 messages🔥):
- Machine Learning Sans Math Jargon: A user expressed frustration over spending hours to realize that a concept in machine learning was essentially just multiplication. This indicates a wish to understand machine learning concepts without complex math terminology.
- No Place for Beginners: @georgehotz reinforced the Discord rules, emphasizing that this is not the place for what might be perceived as noob questions and underlining the value of other people's time.
- Queries on Tinybox Orders: A member inquired about the process for discussing large unit orders of Tinybox and if there are plans for a rack mountable format.
- Pull Request and Bitcast Confusion: A pull request on GitHub related to the BITCAST operation in tinygrad was shared, leading to a brief discussion about its status and difference from the CAST operation.
- Understanding UOp BITCAST: Clarifications ensued about the BITCAST operation being a different uop, not an ALU op, and the desire to remove arguments like "bitcast=false" from functions that currently include it.
Link mentioned: UOps.BITCAST by chenyuxyz · Pull Request #3747 · tinygrad/tinygrad: implicitly fixed no const folding for bitcast
tinygrad (George Hotz) ▷ #learn-tinygrad (11 messages🔥):
- Understanding Tinygrad's Complex Documentation: A member sought guidance on a Tinygrad documentation, which they found abstract and challenging to understand. Another participant vehemently criticized the document's quality, offering to share their own explanatory document to clarify the concept of view merges.
- Navigating Through Tensor Reshaping: A user inquired about the logistics of reshaping a tensor originally defined with a certain stride, particularly when simple stride adjustments fail to cover more complex reshapes. The user themselves proposed a solution involving the maintenance of the original shape to calculate indices for the new reshaped tensor.
- Optimizing Reshape Operations in Tinygrad: Continuing the discussion on tensor reshaping, the same user speculated that if all loops are unrolled, indices can potentially be calculated at compile-time. They questioned whether Tinygrad employs a similar approach for facilitate tensor reshaping.
- Shared Learning through Documentation: A member suggested the strategy of learning by teaching could be effective in understanding Tinygrad better. They recommended building toy examples and documenting the process as an educational tool.
- Clarifying Symbolic Node Implementation: One user questioned whether the
symbolic.DivNodein Tinygrad requires a second operand to be an integer by design or if it's simply not yet implemented for node operands. Another responded, not seeing any indication that a node operand wouldn't work and wondering if this related to a need for recursive operation handling withinsymbolic.arange.
- tinygrad/docs-legacy/reshape_without_symbolic.md at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- View Merges: no description found
Cohere ▷ #general (12 messages🔥):
- Local Hosting of FP16 Models Queried: A member inquired about hosting FP16 command-r-plus locally with vLLM and was interested in the VRAM requirements for approximately a 40k content window. There were no responses providing VRAM estimates.
- Discussions on RWKV Model Scalability: The RWKV models were brought up for discussion, questioning their competitiveness with traditional transformer models, especially given past research suggesting RNN's inferior performance. The member pointed out potential use cases at the 1-15b parameter scale.
- Handling Token Limit Challenges with Cohere: A user shared a challenge in implementing RAG using Cohere.command due to the 4096 token limit, as their application requires processing about 10000 tokens. Another user suggested using Elasticsearch to reduce the text amount and break resumes into logical segments.
- Cohere Chat File Output Possibilities Discussed: A question was raised about downloading files from Cohere Chat, which may include outputs from the model in docx or pdf formats. It was implied that the chat might provide links for downloading such files, although no actual link or direct instructions were given.
- Praise for the 'command R' Model: Users expressed their positive impressions of the 'command R' model, describing it as "Awesome" and affirming its brilliance. These comments suggest satisfaction with the model's performance.
Cohere ▷ #project-sharing (2 messages):
- All-in-One Chat App Awaits Feedback: A new app, Coral Chatbot, which integrates text generation, summarization, and ReRank, is looking for feedback and collaboration opportunities. Check it out on Streamlit.
- Watch This Space: A link to a YouTube video has been shared without any context.
Link mentioned: no title found: no description found
Cohere ▷ #collab-opps (1 messages):
- Founding Team Opportunities with Wordware: An SF-based company, Wordware, is looking to expand its team by hiring a founding engineer, DevRel, and product/FE engineer. Interested individuals can showcase their skills by building something on Wordware's web-hosted IDE, designed for non-technical experts to collaborate in creating AI agents, and share it with the founders.
- Prompting as a New Programming Language: Wordware differentiates itself by treating prompting as a programming language rather than relying on low/no-code blocks, aiming to simplify the creation of task-specific AI solutions. For more information on the roles, visit their Notion page at Join Wordware.
Link mentioned: Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
DiscoResearch ▷ #general (3 messages):
- Meetup Momentum for AIDEV Event: jp1 shared excitement about meeting people at the upcoming AIDEV event at AI Village and is open to communicating with others who plan to attend.
- Joining the Joyful Journey: mjm31, also attending AIDEV, expressed enthusiasm about the event and hoped it was okay to join even without prior communication.
- Culinary Concerns for the Conference: enno_jaai inquired about food arrangements at the AI Village, questioning whether to bring their own snacks or if there would be food available nearby.
DiscoResearch ▷ #discolm_german (6 messages):
- Debating the Need for a German Inclusive Language Dataset: A member asked for opinions on the potential usefulness of creating a German dataset specifically for inclusive language. Another suggested that such an initiative would be valuable, especially when combined with system prompts guiding the assistant's speech style.
- Seeking Quality Domains for German Pretraining Dataset: A member announced the beginnings of a German-exclusive pretraining dataset based on Common Crawl and asked for suggestions on any domains that should be given extra weight due to high-quality content.
- Exploring Inclusive Mode for German Language AI: The concept of having an inclusive/noninclusive mode for language AI was proposed as an idea worth considering.
- Resources for Gender-Inclusive German Language Tools: The discussion pointed to resources such as Includify and a project report on diversity-sensitive language available at David's Garden and the associated backend code for gender-inclusive German.
- Inclusivity Reflections in Configurable AI Models: A member suggested the possibility of inclusive language features being envisioned in a manner similar to CST-style models like Vicgalle/ConfigurableBeagle-11B.
- David’s Garden - Gender-inclusive German: A benchmark and a model: Gender-inclusive language is important for achieving gender equality in languages with gender inflections, such as, for the purpose of this report, German.
- David Pomerenke / Gender-inclusive German - a benchmark and a pipeline · GitLab: GitLab.com
Mozilla AI ▷ #llamafile (5 messages):
- Phi-3 Mini Behaving Oddly: A member shared an issue with Phi-3 Mini; they find its performance satisfactory when used with Ollama and Open WebUI but encounter problems when using llamafile.
- Running Llamafile as a Backend Service: Inquiring about backend service usage post-command execution, a member learned that an API endpoint at
127.0.0.1:8080can be used for sending OpenAI-style requests. Details and guidance are available at Mozilla-Ocho's GitHub llamafile repo. - VS Code Integration with Ollama: A member observed a new feature in VS Code that provides a dropdown for users running ollama to manage their models dynamically. Another member queried if this feature comes from a VS Code plugin.
Link mentioned: GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
Datasette - LLM (@SimonW) ▷ #ai (1 messages):
- AI Agent as NPM Package Upgrader: A member shared a Reddit link about an AI agent that upgrades npm packages, sparking humor in the community. The Reddit post also came with the standard notification about the use of cookies and privacy policies.
Link mentioned: Reddit - Dive into anything: no description found
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
- YAML Proposals for Parameterized Testing: Two YAML configurations for parameterized testing on the llm-evals-plugin are shared for review. The linked GitHub issue comment includes the proposals and the ongoing discussions about the design and implementation of this feature.
- Midnight Appreciation for the
llmCLI: A user expresses their gratitude for thellmCLI, mentioning it has significantly helped in managing their personal projects and thesis work. They highlight its usefulness and express a heartwarming "thank you" for the project.
Link mentioned: Design and implement parameterization mechanism · Issue #4 · simonw/llm-evals-plugin: Initial thoughts here: #1 (comment) I want a parameterization mechanism, so you can run the same eval against multiple examples at once. Those examples can be stored directly in the YAML or can be ...
Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
- AlphaFold3 Model Democratized: The implementation of AlphaFold3, as described in the paper "Accurate structure prediction of biomolecular interactions with AlphaFold 3", is now available in PyTorch. Users are invited to join Agora to contribute to democratizing this powerful model: Check the implementation here and Join Agora here.
- GitHub - kyegomez/AlphaFold3: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch - kyegomez/AlphaFold3
- Join the Agora Discord Server!: Advancing Humanity through open source AI research. | 6698 members
Alignment Lab AI ▷ #general-chat (2 messages):
- Greeting Exchange in General Chat: A member greeted the chatbot named "Orca" with a "hello". Another member responded with a friendly "Hello 👋".
AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
- Quickscope Takes Aim at Game QA: Regression Games announces the launch of Quickscope, a new AI-powered suite of tools for automated testing in Unity. No code is required for integration, and it includes a gameplay session recording tool and validations tool with an easy-to-use UI for functional testing.
- Deep Game Insights with Zero Hassle: Quickscope's deep property scraping feature automatically extracts game state details, including public properties of MonoBehaviours, without the need for custom coding.
- Streamline Your Testing Process Now: Developers and QA engineers can try Quickscope and experience its integration ease and comprehensive functionality at regression.gg. The platform highlights its no custom code integration for quick deployment in any development workflow.
- Introducing Quickscope - Automate smoke tests in Unity - May 06, 2024 - Regression Games: Learn about Quickscope, a tool for automating smoke tests in Unity
- Regression Games - The ultimate AI agent testing platform for Unity: Easily develop bots for Unity for QA testing.
AI Stack Devs (Yoko Li) ▷ #team-up (1 messages):
jakekies: I want to join
LLM Perf Enthusiasts AI ▷ #openai (1 messages):
- In Search of GPT-4-turbo 0429: A member is looking for an Azure region that supports the new GPT-4-turbo 0429, with the note that Sweden's Azure services are currently facing issues.