[AINews] Titans: Learning to Memorize at Test Time
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Neural Memory is all you need.
AI News for 1/14/2025-1/15/2025. We checked 7 subreddits, 433 Twitters and 32 Discords (219 channels, and 2812 messages) for you. Estimated reading time saved (at 200wpm): 327 minutes. You can now tag @smol_ai for AINews discussions!
Lots of people are buzzing about the latest Google paper, hailed by yappers as "Transformers 2.0" (arxiv, tweet):

It seems to fold persistent memory right into the architecture at "test time" rather than outside of it (this is one of three variants as context, head, or layer).
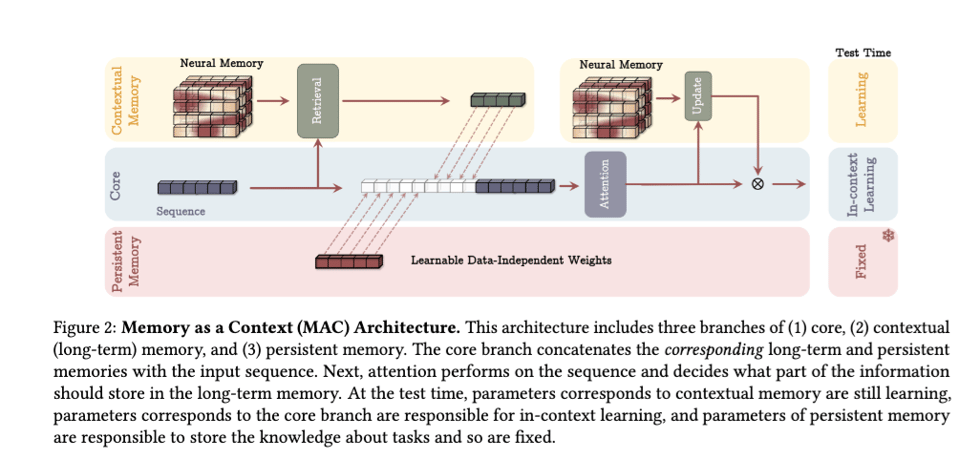
The paper notably uses a surprisal measure to update its memory:
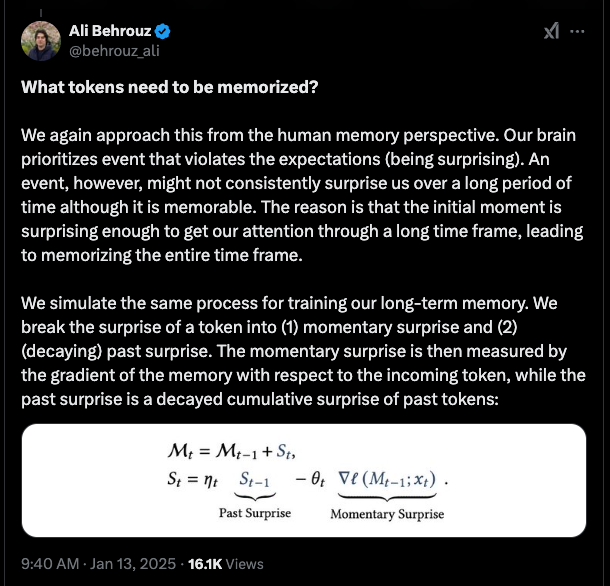
and models forgetting by weight decay

The net result shows very promising context utilization over long contexts.
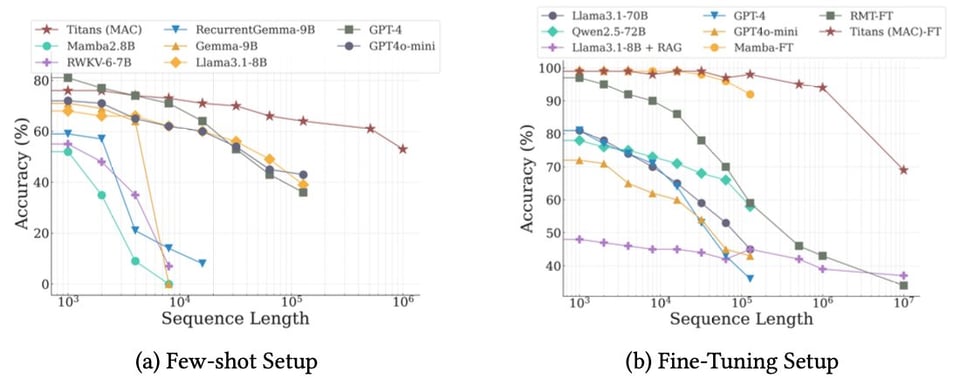
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Perplexity AI Discord
- Codeium (Windsurf) Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- Interconnects (Nathan Lambert) Discord
- Nous Research AI Discord
- Stackblitz (Bolt.new) Discord
- Notebook LM Discord Discord
- Cohere Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- LM Studio Discord
- aider (Paul Gauthier) Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- Latent Space Discord
- GPU MODE Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- LAION Discord
- AI21 Labs (Jamba) Discord
- MLOps @Chipro Discord
- Nomic.ai (GPT4All) Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (568 messages🔥🔥🔥):
- Perplexity AI ▷ #general (274 messages🔥🔥):
- Perplexity AI ▷ #sharing (7 messages):
- Perplexity AI ▷ #pplx-api (1 messages):
- Codeium (Windsurf) ▷ #announcements (2 messages):
- Codeium (Windsurf) ▷ #discussion (88 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (191 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (113 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (16 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (141 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (206 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #events (3 messages):
- Interconnects (Nathan Lambert) ▷ #news (90 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Interconnects (Nathan Lambert) ▷ #cv (7 messages):
- Interconnects (Nathan Lambert) ▷ #reads (47 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (2 messages):
- Nous Research AI ▷ #general (125 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (25 messages🔥):
- Nous Research AI ▷ #interesting-links (7 messages):
- Stackblitz (Bolt.new) ▷ #announcements (1 messages):
- Stackblitz (Bolt.new) ▷ #prompting (14 messages🔥):
- Stackblitz (Bolt.new) ▷ #discussions (135 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (16 messages🔥):
- Notebook LM Discord ▷ #general (88 messages🔥🔥):
- Cohere ▷ #discussions (34 messages🔥):
- Cohere ▷ #questions (25 messages🔥):
- Cohere ▷ #api-discussions (10 messages🔥):
- Cohere ▷ #cmd-r-bot (13 messages🔥):
- Cohere ▷ #cohere-toolkit (6 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (80 messages🔥🔥):
- OpenAI ▷ #ai-discussions (62 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- LM Studio ▷ #general (66 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (11 messages🔥):
- aider (Paul Gauthier) ▷ #general (36 messages🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (22 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #mojo (41 messages🔥):
- Eleuther ▷ #general (2 messages):
- Eleuther ▷ #research (29 messages🔥):
- Eleuther ▷ #scaling-laws (5 messages):
- Eleuther ▷ #lm-thunderdome (3 messages):
- Eleuther ▷ #gpt-neox-dev (6 messages):
- Latent Space ▷ #ai-general-chat (40 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- GPU MODE ▷ #triton (6 messages):
- GPU MODE ▷ #cuda (3 messages):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #algorithms (2 messages):
- GPU MODE ▷ #cool-links (3 messages):
- GPU MODE ▷ #beginner (2 messages):
- GPU MODE ▷ #metal (2 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #🍿 (12 messages🔥):
- GPU MODE ▷ #thunderkittens (6 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (23 messages🔥):
- OpenInterpreter ▷ #general (12 messages🔥):
- LAION ▷ #general (4 messages):
- AI21 Labs (Jamba) ▷ #general-chat (3 messages):
- MLOps @Chipro ▷ #events (1 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
- Nomic.ai (GPT4All) ▷ #general (2 messages):
- DSPy ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Scaling
- MiniMax-01 and Ultra-Long Context Models: @omarsar0 introduced MiniMax-01, integrating Mixture-of-Experts with 32 experts and 456B parameters. It boasts a 4 million token context window, outperforming models like GPT-4o and Claude-3.5-Sonnet. Similarly, @hwchase17 highlighted advancements in vision-spatial scratchpads, addressing long-standing challenges in VLMs.
- InternLM and Open-Source LLMs: @abacaj discussed InternLM3-8B-Instruct, an Apache-2.0 licensed model trained on 4 trillion tokens, achieving state-of-the-art performance. @AIatMeta shared updates on SeamlessM4T published in @Nature, emphasizing its adaptive system inspired by nature.
- Transformer² and Adaptive AI: @hardmaru unveiled Transformer², showcasing self-adaptive LLMs that dynamically adjust weights, bridging pre-training and post-training for continuous adaptation.
AI Applications and Tools
- AI-Driven Development Tools: @rez0__ outlined the need for robust Agent Authentication, Prompt Injection defenses, and Secure Agent Architecture. Additionally, @hkproj recommended Micro Diffusion for training diffusion models on a budget.
- Agentic Systems and Automation: @bindureddy emphasized the potential of Search-o1 in enhancing complex reasoning tasks, outperforming traditional RAG systems. @LangChainAI introduced LeagueGraph and Agent Recipes for building open-source social media agents.
- Integration with Development Environments: @_akhaliq discussed unifying local endpoints for AI model support across applications, while @saranormous advocated for using Grok's web app to avoid distractions.
AI Security and Ethical Concerns
- Data Integrity and Prompt Injection: @rez0__ highlighted challenges in prompt injection and the necessity for zero-trust architectures to secure LLM applications. @lateinteraction critiqued the blurring of specifications and implementations in AI prompts, advocating for clearer domain-specific knowledge.
- AI in Geopolitics and Regulations: @teortaxesTex criticized the notion of explicit backdoors in Chinese servers, promoting Apple's security model instead. @AravSrinivas discussed the impact of AI diffusion rules on NVIDIA stock, reflecting on the global regulatory landscape.
AI in Education and Hiring
- Homeschooling and Educational Policies: @teortaxesTex expressed disappointment in battle animation and the lack of effective educational techniques. Meanwhile, @stanfordnlp hosted seminars on AI and education, emphasizing the role of agents and workflows.
- Hiring and Skill Development: @finbarrtimbers shared insights on hiring ML engineers, while @fchollet sought experts for AI program synthesis, highlighting the importance of mathematical and coding skills.
AI Integration in Software Engineering
- LLM Integration and Productivity: @TheGregYang and @gdb discussed the seamless integration of LLMs into debugging tools and web applications, enhancing developer productivity. @rasbt emphasized the distinction between raw intelligence and intelligent software systems, advocating for the right implementation strategies.
- AI-Driven Coding and Automation: @hellmanikCoder and @skycoderrun highlighted the benefits and challenges of using LLMs for code generation and automation, stressing the need for robust integration and error handling.
Politics and AI Regulations
- Chinese AI Developments and Security: @teortaxesTex mentioned iFlyTek's acquisition of Atlas servers, reflecting on China's AI infrastructure growth. @manyothers discussed the potential acceleration of Ascend clusters, highlighting computation advancements in Mainland China.
- US AI Policies and Infrastructure: @iScienceLuvr summarized a US executive order on accelerating AI infrastructure, detailing data center requirements, clean energy mandates, and international cooperation. @karinanguyen_ critiqued the lag in form factors for AI workflows, reflecting on policy impacts.
Memes/Humor
- Humorous Takes on AI and Daily Life: @arojtext joked about hiding better uses of video games for escapism, while @qtnx_ shared a funny question about unrelated AI applications. Additionally, @nearcyan humorously reflected on gaming habits and unexpected property purchase offers.
- Light-hearted AI Remarks: @Saranormous mocked interactions with ScaleAI, and @TheGregYang playfully encouraged using Grok's web app to avoid distractions, blending AI functionality with everyday humor.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. InternLM3-8B outperforms Llama3.1-8B and Qwen2.5-7B
- New model.... (Score: 188, Comments: 31): InternLM3 reportedly outperforms Llama3.1-8B and Qwen2.5-7B. The project, titled "internlm3-8b-instruct," is hosted on a platform resembling GitHub, featuring tags like "Safetensors" and "custom_code," and references an arXiv paper with the identifier 2403.17297.
- InternLM3 Performance and Features: Users highlight InternLM3's superior performance over Llama3.1-8B and Qwen2.5-7B, emphasizing its efficiency in training with only 4 trillion tokens, which reduces costs by over 75%. The model supports a "deep thinking mode" for complex reasoning tasks, which is accessible through a different system prompt as seen on Hugging Face.
- Community Feedback and Comparisons: Users express satisfaction with InternLM3's capabilities, noting its effectiveness in logic and language tasks, and comparing it favorably against models like Exaone 7.8b and Qwen2.5-7B. There is a desire for a 20 billion parameter version, referencing the 2.5 20b model.
- Model Naming and Licensing: The name "Intern" is discussed, with some users finding it apt due to the AI's role as an unpaid assistant. There is also a call for clearer licensing practices when sharing models, with users expressing frustration over unclear licenses, particularly in audio/music models.
Theme 2. OpenRouter gets new features and community-driven improvements
- OpenRouter Users: What feature are you missing? (Score: 190, Comments: 79): The author unintentionally developed an OpenRouter alternative called glama.ai/gateway, which offers similar features like elevated rate limits and easy model switching via an OpenAI-compatible API. Unique advantages include integration with the Chat and MCP ecosystem, advanced analytics, and reportedly lower latency and stability compared to OpenRouter, while processing several billion tokens daily.
- API Compatibility and Support: Users express interest in compatibility with the OpenAI API, specifically regarding multi-turn tool use, function calling, and image input formats. Concerns include differences in tool use syntax and the need for detailed documentation on supported API features and models.
- Provider Management and Data Security: There is a demand for more granular control over provider selection for specific models, as some providers like DeepInfra are not optimal for all models. Additionally, glama.ai is praised for its data protection policies and commitment to not using client data for AI training, contrasting with OpenRouter's data handling practices.
- Sampler Options and Mobile Support: Users discuss the need for additional sampler options like XTC and DRY, which are not currently supported, and the challenges of implementing them as a middleman. There is also interest in improving mobile support, as current traffic is primarily desktop-based, but mobile is becoming a more frequent topic of discussion.
Theme 3. Kiln as an Open Source Alternative to Google AI Studio Gains Traction
- I accidentally built an open alternative to Google AI Studio (Score: 865, Comments: 130): Kiln, an open-source alternative to Google AI Studio, offers enhanced features like support for any LLM through multiple hosts, unlimited fine-tuning capabilities, local data privacy, and collaborative use. It contrasts with Google's limited model support, data privacy issues, and single-user collaboration, while also providing a Python library and powerful dataset management. Kiln is available on GitHub and aims to be as user-friendly as Google AI Studio but more powerful and private.
- Concerns about privacy and licensing were prominent, with users like osskid and yhodda highlighting discrepancies between Kiln's privacy claims and its EULA, which suggests potential data access and usage rights by Kiln. Yhodda emphasized that the desktop app's proprietary license could lead to user data being shared and used without compensation, raising red flags about user rights and privacy.
- Users appreciated the open-source nature of Kiln, with comments like those from fuckingpieceofrice and Imjustmisunderstood expressing gratitude for the alternative to Google AI Studio, fearing future paywalls. The open-source aspect was seen as a significant advantage, even if the desktop component is not open-source.
- Documentation and tutorials received positive feedback, with users like Kooky-Breadfruit-837 and danielhanchen praising the comprehensive guides and mini video tutorials. This suggests that Kiln is user-friendly and accessible, even for those with limited technical experience, as noted by RedZero76.
Theme 4. OuteTTS 0.3 introduces new 1B and 500M language models
- OuteTTS 0.3: New 1B & 500M Models (Score: 155, Comments: 62): OuteTTS 0.3 introduces new 1B and 500M models, enhancing its text-to-speech capabilities. The update likely includes improvements in model performance and feature set, though specific details are not provided in the text.
- There is a notable discussion regarding language support in OuteTTS, particularly the absence of Spanish despite its widespread use. OuteAI explains this is due to the diversity of Spanish accents and dialects, and the lack of adequate datasets, resulting in a generic "Latino Neutro" output.
- OuteAI clarifies technical aspects of the models, such as their basis on LLMs and the use of WavTokenizer for audio token decoding. The models are compatible with Transformers, LLaMA.cpp, and ExLlamaV2, and there is ongoing exploration of speech-to-speech capabilities.
- The OuteTTS 0.3 models offer improvements in naturalness and coherence of speech, with support for six languages including newly added French and German. A demo is available on Hugging Face, and installation is straightforward via pip.
Theme 5. 405B MiniMax MoE: Breakthrough in context length and efficiency
- 405B MiniMax MoE technical deepdive (Score: 66, Comments: 10): The post discusses the 405B MiniMax MoE model, highlighting its innovative scaling approaches, including a hybrid with 7/8 Lightning attention and a distinct MoE strategy compared to DeepSeek. It details the model's training on approximately 2000 H800 and 12 trillion tokens, with further information available in a blog post on Hugging Face.
- 405B MiniMax MoE model is noted for its impressive performance on Longbench without Chain of Thought (CoT), showcasing its capability in handling long context lengths. FiacR highlights its "insane context length" and eliebakk praises the "super impressive numbers."
- Discussion around the trend of open weights models competing with closed-source models is positive, with optimism about significant advancements by 2025. vaibhavs10 expresses enthusiasm for this trend and shares a link to the MiniMaxAI model on Hugging Face.
- The model is hosted on Hailuo.ai as mentioned by StevenSamAI, providing a resource for accessing the model.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Transformer²: Enhancing Real-Time LLM Adaptability
- [R] Transformer²: Self-Adaptive LLMs (Score: 137, Comments: 10): Transformer² introduces a self-adaptive framework for large language models (LLMs) that dynamically adjusts only singular components of weight matrices to handle unseen tasks in real-time, outperforming traditional methods like LoRA with fewer parameters. The method employs a two-pass mechanism, using a dispatch system and task-specific "expert" vectors trained via reinforcement learning, demonstrating versatility across various architectures and modalities, including vision-language tasks. Paper, Blog Summary, GitHub.
- Commenters discussed the scaling approach of the framework, noting that it scales with disk rather than the number of parameters, which could imply efficiency in storage and computation.
- There was a discussion on the performance impact of Transformer² on different sizes of LLMs, with observations that while it significantly enhances smaller models, the improvements for larger models like the 70 billion parameter model were minimal.
- The growth of the Sakana lab was noted, with recognition that the paper did not list a well-known author, suggesting an expanding and increasingly collaborative research team.
Theme 2. Deep Learning Revolutionizing Predictive Healthcare
- Researchers Develop Deep Learning Model to Predict Breast Cancer (Score: 118, Comments: 17): Researchers developed a deep learning model capable of predicting breast cancer up to five years in advance using a streamlined algorithm. The study analyzed over 210,000 mammograms and highlighted the significance of breast asymmetry in assessing cancer risk, as detailed in this RSNA article.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1: AI Model Performance Stumbles Across Platforms
- Perplexity Users Perplexed by Persistent Outages: Users reported multiple prolonged outages on Perplexity, with errors lasting over an hour, prompting frustrations and a search for alternatives.
- Cursor Crawls as Performance Pitfalls Trip Up Coders: Cursor IDE users faced significant slowdowns, with wait times of 5–10 minutes hindering Pro subscribers' workflows and sparking speculation about fixes.
- DeepSeek Drags, Users Seek Speedy Alternatives: DeepSeek V3 suffered from latency issues and slow responses, leading users to switch to models like Sonnet and voice frustrations over inconsistent performance.
Theme 2: New AI Models Break Context Barriers
- MiniMax-01 Blazes Trail with 4M Token Context: MiniMax-01 launched with an unprecedented 4 million token context window using Lightning Attention, promising ultra-long context processing and performance leaps.
- Cohere Cranks Context to 128k Tokens: Cohere extended context length to 128k tokens, enabling around 42,000 words in a single conversation without resetting, enhancing continuity.
- Mistral’s FIM Marvel Wows Coders: The new Fill-In-The-Middle coding model from Mistral AI impressed users with advanced code completion and snippet handling beyond standard capabilities.
Theme 3: Legal Woes Hit AI Datasets and Developers
- MATH Dataset DMCA'd: AoPS Strikes Back: The Hendrycks MATH dataset faced a DMCA takedown, raising concerns over Art of Problem Solving (AoPS) content and the future of math data in AI.
- JavaScript Trademark Tussle Threatens Open Source: A fierce legal dispute over the JavaScript trademark sparked alarms about potential restrictions impacting community-led developments and open-source contributions.
Theme 4: Advancements and Debates in AI Training
- Grokking Gains Ground: Phenomenon Unpacked: A new video titled “Finally: Grokking Solved - It's Not What You Think” delved into the bizarre grokking phenomenon of delayed generalization, fueling enthusiasm and debate.
- Dynamic Quantization Quirks Questioned: Users reported minimal performance changes when applying dynamic quantization to Phi-4, sparking discussions on the technique's effectiveness compared to standard 4-bit versions.
- TruthfulQA Benchmark Busted by Simple Tricks: TurnTrout achieved 79% accuracy on TruthfulQA by exploiting weaknesses with a few trivial rules, highlighting flaws in benchmark reliability.
Theme 5: Industry Moves Shake Up the AI Landscape
- Cursor AI Scores Big Bucks in Series B: Cursor AI raised a new Series B co-led by a16z, fueling the coding platform's next phase and strengthening ties with Anthropic amid usage-based pricing talks.
- Anthropic Secures ISO 42001 for Responsible AI: Anthropic announced accreditation under the new ISO/IEC 42001:2023 standard, emphasizing structured system governance for responsible AI development.
- NVIDIA Cosmos Debuts at CES, Impresses LLM Enthusiasts: NVIDIA Cosmos was unveiled at CES, showcasing new AI capabilities; presentations at the LLM Paper Club highlighted its potential impact on the field.
PART 1: High level Discord summaries
Cursor IDE Discord
- Cursor Crawls: Performance Pitfalls Trip Users: Many reported 5–10 minute wait times in Cursor, while others saw normal speeds, frustrating Pro subscribers trying to maintain steady workflows.
- This slowdown hampered coding efforts and prompted speculation about fixes, with some keeping an eye on Cursor’s blog update for potential relief.
- Swift Deploy: Vercel & Firebase Soar: Builders praised both Vercel and Google Firebase for deploying Cursor-based apps, highlighting minimal setup for production use.
- They shared templates on Vercel for rapid starts and noted easy real-time integrations with Firebase.
- Gemini 2.0 Flash vs Llama 3.1 Duel: Enthusiasts favored Gemini 2.0 Flash for stronger benchmark outcomes over Llama 3.1, pointing to sharper text generation performance.
- Others acknowledged imposter syndrome creeping in with heavier AI reliance, yet embraced heightened productivity benefits.
- Sora’s Stumble in Slow-Mo Scenes: Reports surfaced that Sora struggled with reliable video generation, especially for slow-motion segments, leaving some users dissatisfied.
- Some explored alternative options after frequent trial-and-error, indicating mixed success with Sora’s feature set.
- Fusion Frenzy: Cursor Gears Up for March: A new Cursor release is expected in March, featuring the Fusion implementation and possible integrations with DeepSeek and Gemini.
- Excitement brewed over a more capable platform, as teased in Cursor’s Tab model post, though detailed specifics remain undisclosed.
Perplexity AI Discord
- Perplexity Outages Spark Outrage: Frequent disruptions in Perplexity left users facing errors for over an hour, as shown on the status page, prompting calls for backups.
- Frustration grew alongside citation glitches, causing some to explore alternate solutions and voice concerns about reliability.
- AI Model Performance Showdown: Community members weighed the best coding model, with Claude Sonnet 3.5 topping debugging tasks and Deepseek 3.0 proposed as an economical fallback.
- Some praised Perplexity for certain queries yet criticized its hallucinations and limited context window.
- Double Vision: Two Perplexity iOS Apps: One user spotted duplicates in the App Store, prompting a web query about official Perplexity apps.
- Another user couldn't find the second listing, fueling a short debate on naming and distribution issues.
- JavaScript Trademark Tussle: A legal fight over the JavaScript trademark could threaten community-led developments if trademark claims prove more restrictive.
- Opinions voiced alarm over ownership matters and a possible wave of litigation impacting open-source contributions.
- Llama-3.1-Sonar-Large Slowed Down: llama-3.1-sonar-large-128k-online suffered a marked decline in output speed since January 10th, puzzling users.
- Community chatter points to undisclosed updates or code shifts as possible reasons for the slowdown, sparking concerns about broader performance hits.
Codeium (Windsurf) Discord
- Command Craze & Editor Applause: Windsurf released a Command feature tutorial, declared Discord Challenge winners with videos like Luminary, and launched the Windsurf Editor.
- They also presented an official comparison of Codeium against GitHub Copilot and shared a blog post on nonpermissive code concerns.
- Telemetry Tangles & Subscription Snags: Users faced telemetry issues in the Codeium Visual Studio extension and confusion around credit rollover in subscription plans, with references to GitHub issues.
- They confirmed that credits do not carry over after plan cancellation, and some encountered installation problems tied to extension manifest naming.
- Student Discounts & Remote Repository Riddles: Students showed interest in Pro Tier bundles but struggled if their addresses weren't .edu, prompting calls for more inclusive eligibility.
- Others reported friction using indexed remote repositories with Codeium in IntelliJ, seeking setup advice from the community.
- C# Type Trouble & Cascade Convo: Windsurf IDE had persistent trouble analyzing C# variable types on both Windows and Mac, even though other editors like VS Code offered smooth performance.
- Users debated Cascade’s performance and recommended advanced prompts, while also discussing the integration of Claude and other models for complex coding tasks.
Unsloth AI (Daniel Han) Discord
- Multi-GPU Mayhem in Kaggle: Developers tried to run Unsloth with multiple T4 GPUs on Kaggle but found only one GPU is enabled for inference, limiting scaling attempts. They pointed to this tweet about fine-tuning on Kaggle's T4 GPU, hoping to use Kaggle’s free hours more effectively.
- Others recommended paying for more robust hardware if concurrency is required, and they suggested that Kaggle might expand GPU provisioning in the future.
- Debunking Fine-Tuning Myths: Teams clarified that fine-tuning can actually introduce new knowledge, acting like retrieval-augmented generation, contrary to widespread assumptions. They linked the Unsloth doc on fine-tuning benefits to address these ongoing misconceptions.
- Some pointed out it can offload memory usage by embedding new data into the model, while others emphasized proper dataset selection for best results.
- Dynamic Quantization Quirk with Phi-4: Reports emerged that Phi-4 shows minimal performance changes even after dynamic quantization, closely paralleling standard 4-bit versions. Users referenced the Unsloth 4-bit Dynamic Quants collection to investigate any hidden gains.
- Some insisted that dynamic quantization should enhance accuracy, prompting further experimentation to confirm if the discrepancy is masked by test conditions.
- Grokking Gains Ground: A new video, Finally: Grokking Solved - It's Not What You Think, dives into the bizarre grokking phenomenon of delayed generalization. It fueled enthusiasm for understanding how overfitting morphs into sudden leaps in model capability.
- The shared paper Grokking at the Edge of Numerical Stability introduced the idea of Softmax Collapse, sparking debate on deeper implications for AI training.
- Security Conference Showcases for LLM: One user suggested security conferences as a more fitting venue for specialized LLM talks, referencing exploit detection use cases. This idea resonated with those who find standard ML events too broad for security-specific content.
- Others supported highlighting domain-centric approaches, pointing to a growing push for LLM research discussions in these specialized forums.
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion XL Speeds & Specs: A user ran stabilityai/stable-diffusion-xl-base-1.0 on Colab, looking for built-in metrics like iterations per second, in contrast to how ComfyUI shows time-per-iteration data.
- They highlighted the possibility of up to 50 inference steps, pointing out that metrics remain elusive without specialized tools or custom logging.
- Fake Coin Causes Commotion: Community members encountered a fake cryptocurrency launch tied to Stability AI, calling it a confirmed scam in a tweet warning.
- They cautioned that compromised accounts can dupe unsuspecting investors, sharing personal stories of losses and urging everyone to avoid suspicious links.
- Sharing AI Images Goes Social: Users debated where to post AI-generated images, suggesting Civitai and other social media as main platforms for showcasing success and failure cases.
- Concerns about data quality arose when collecting image feedback, prompting discussion on filtering out spurious or low-effort content.
Interconnects (Nathan Lambert) Discord
- Xeno Shakes Up Agent Identity: At a Mixer on the 24th and a Hackathon on the 25th at Betaworks, NYC, $5k in prizes kicked off the new wave of agent identity projects from Xeno Grant.
- Winners can receive $10k per agent in $YOUSIM and $USDC, showing expanded interest in identity solutions among hackathon participants.
- Ndea Leans on Program Synthesis: François Chollet introduced Ndea to jumpstart deep learning-guided program synthesis, aiming for a fresh path toward genuine AI invention.
- The community sees it as an approach outside the usual LLM-scaling trend, with some praising it as a strong alternative to standard AGI pursuits.
- Cerebras Tames Chip Yields: At Cerebras, they claim to have cracked wafer-scale chip yields, producing devices 50x larger than usual.
- By reversing conventional yield logic, they build fault-tolerant designs that keep manufacturing costs in check.
- MATH DMCA Hits Hard: The MATH dataset faced a DMCA takedown, sparking worries around AoPS-protected math content.
- Some recommend stripping out AoPS segments to salvage partial usage, though concerns persist over broader dataset losses.
- MVoT Shows Reasoning in Pictures: The new Multimodal Visualization-of-Thought (MVoT) paper proposes adding visual steps to Chain-of-Thought prompting in MLLMs, uniting text with images to refine solutions.
- Authors suggest depicting mental images can improve complex reasoning flows, merging well with reinforcement learning techniques.
Nous Research AI Discord
- Claude's Quirky Persona & Fine-Tuning Feats: Members praised Claude for its 'cool co-worker vibe,' noted occasional refusals to answer, and exchanged tips on advanced fine-tuning with company knowledge plus classification tasks.
- They emphasized data diversity to enhance model accuracy, proposing tailored approaches for improved results.
- Dataset Debates & Nous Research's Private Path: Community questioned LLM dataset reliability, highlighting the push for better data curation and clarifying Nous Research operations via private equity and merch sales.
- They expressed interest in open-source synthetic data initiatives, mentioning collaborations with Microsoft but no formal government or academic ties.
- Gemini Outshines mini Models: Several users praised Gemini for accurate data extraction, claiming it outperforms 4o-mini and Llama-8B in pinpointing original content.
- They remained cautious about retrievability challenges, focusing on stable expansions as next steps.
- Grokking Tweaks & Optimizer Face-Off: Participants dissected grokking and numerical issues in Softmax, referencing this paper on Softmax Collapse and its impact on training.
- They weighed combining GrokAdamW and Ortho Grad from this GitHub repo, and mentioned Coconut from Facebook Research for continuous latent space reasoning.
- Agent Identity Hackathon Calls to Create: A spirited hackathon in NYC was announced, offering $5k for agent-identity prototypes and fostering imaginative AI projects.
- Creators hinted at fresh concepts and directed interested folks to this tweet for event details.
Stackblitz (Bolt.new) Discord
- Title Tinkering in Bolt: Following a Bolt update, users can now rename project titles with ease, as detailed in this official post.
- This rollout streamlines project organization and helps locate items in the list more efficiently, boosting user experience.
- GA4 Integration Glitch: A developer's React/Vite app hit an 'Unexpected token' error with GA4 API on Netlify, despite working fine locally.
- They verified credentials and environment variables but are looking for alternative solutions to bypass the integration roadblock.
- Firebase's Quick-Fill Trick: A user recommended creating a 'load demo data' page to seamlessly populate Firestore, preventing empty schema hassles.
- This approach was hailed as a basic yet effective method, particularly beneficial to those who might overlook initial dataset setup.
- Supabase Slip-ups and Snapshots: Some users struggled with Supabase integration errors and application crashes when storing data.
- They also discussed the chat history snapshot system that aims to preserve previous states for better context restoration.
- Token Tussles: High usage reports surfaced, with one instance claiming 4 million tokens per prompt and others questioning its validity.
- Suggestions for GitHub issue submissions arose, as some suspect a bug lurking behind Bolt's context mechanics.
Notebook LM Discord Discord
- QuPath Q-illuminates Tissue Data: A user reported that NotebookLM generated a functional groovy script for QuPath, gleaned from forum posts on digital pathology, slashing hours of manual coding.
- This success underscored NotebookLM's utility for specialized tasks, with one user calling it a welcome time-saver for 'hard-coded pathology workflows'.
- Worldbuilding Wows Writers: A user leveraged NotebookLM for creative expansions in worldbuilding, noting it clarifies underdeveloped lore and recovers overlooked ideas.
- They added a note like 'Wild predictions inbound!' to spark the AI’s imaginative output, fueling deeper fictional scenarios without much fuss.
- NotebookLM Plus: The Mysterious Migration: Confusion arose around NotebookLM Plus availability and transition timelines within different Google Workspace plans, especially for those on deprecated editions.
- Some continued paying for older add-ons while weighing possible plan upgrades in response to ambiguous announcements from the Google Workspace Blog.
- API APIs: Bulk Sync on the Horizon?: Users asked if NotebookLM offers an API or can sync Google Docs sources in bulk, with no official timeline provided.
- Community members stayed hopeful for announcements this year, referencing user requests in NotebookLM Help.
- YouTube Import Woes & Word Count Warnings: Multiple members struggled with importing YouTube links as valid sources, suspecting a missing feature rather than user error.
- They also discovered a 500,000-word limit per source and 50 total sources per notebook, forcing manual website scraping and other workarounds.
Cohere Discord
- Cohere Cranks Context to 128k: Cohere extended context length to 128k tokens, enabling around 42,000 words in a single conversation without resetting context. Participants referenced Cohere’s rate limit doc to understand how this expansion impacts broader model usage.
- They noted that the entire chat timeline can remain active, meaning longer discussions stay consistent without segmenting turns.
- Rerank v3.5 Raises Eyebrows: Some users reported that Cohere’s rerank-v3.5 delivers inconsistent outcomes unless restricted to the most recent user query, complicating multi-turn ranking efforts.
- They tried other services like Jina.ai with steadier results, prompting direct feedback to Cohere about the performance slump.
- Command R Gets Continuous Care: Members sought iterative enhancements to Command R and R+, hoping new data and fine-tuning would evolve the models rather than launching entirely new versions.
- A contributor highlighted retrieval-augmented generation (RAG) as a powerful method to introduce updated information into existing model architecture.
OpenRouter (Alex Atallah) Discord
- Mistral’s FIM Marvel: The newest Fill-In-The-Middle coding model from Mistral has arrived, boasting advanced capabilities beyond standard code completions. OpenRouterAI confirmed requests for it are exclusively handled on their Discord channel.
- Enthusiasts mention improved snippet context handling, with some expecting a strong showing in code-based tasks. Others pointed to OpenRouter’s Codestral-2501 page as evidence of serious coding potential.
- Minimax-01’s 4M Context Feat: Minimax-01, promoted as the first open-source LLM from the group, reportedly passed the Needle-In-A-Haystack test at a huge 4M context. Details surfaced on the Minimax page, with user references praising the broad context handling.
- Some find the 4M token claim bold, though supporters say they’ve seen no major performance trade-offs so far. Access also requires a request on the Discord server, showcasing a growing interest in bigger context ranges.
- DeepSeek Dramas: Latencies and Token Drops: Members flagged continuing DeepSeek API inconsistencies, reporting slow response times and unexpected errors across multiple providers. Many expressed frustration over token limits slipping from 64k to 10-15k without notice.
- Commenters pointed to the DeepSeek V3 Uptime and Availability page for partial explanations, while noting that first-token latency remains persistently high. Others worry these fluctuations sabotage trust in extended context usage.
- Provider Showdowns & Model Removal Rumors: A user raised concerns about lizpreciatior/lzlv-70b-fp16-hf disappearing, learning that no provider might host it anymore. Meanwhile, participants debated the performance gap between DeepSeek, TogetherAI, and NovitaAI, citing latency differences on the OpenRouter site.
- Some found DeepInfra more reliable, whereas others saw spikes across all providers. This sparked a broader conversation on how frequently providers rotate or remove model endpoints with minimal notice.
- Prompt Caching Q&A: Multiple users asked if OpenRouter supports prompt caching for models like Claude, referencing the documentation. They hoped caching would slash cost and boost throughput.
- A helpful pointer from Toven confirmed the feature is indeed available, with some devs praising it for stabilizing project budgets. The chat also shared further reading on request handling and stream cancellation.
OpenAI Discord
- Neural Feedback Fuels Personalized Learning: One user proposed a neural feedback loop system that guides individuals to adopt optimized thinking patterns for better cognitive performance, though no official release date was shared.
- Others viewed this as a fundamental shift in AI-assisted learning, even if no links or code references have surfaced.
- Anthropic Secures ISO 42001 for Responsible AI: Anthropic announced accreditation under the ISO/IEC 42001:2023 standard for responsible AI, emphasizing structured system governance.
- Users acknowledged the credibility of this standard but questioned Anthropic’s partnership with Anduril.
- AI Memory Shortfalls with Shared Images: Participants observed that AI often loses extended context after images are introduced, leading to repeated clarifications.
- One user suggested that the images drop out of short-term storage, causing the model to overlook earlier references.
- ChatGPT Tiers Spark Uneven Performance: Community members noted that ChatGPT appears limited for free users, especially with web searches.
- They pointed out that Plus subscribers gain more advanced capabilities, raising fairness issues for API users.
- GPT-4o Tasks Outshine Canvas Tools: Multiple users reported that the Canvas feature in the desktop version was replaced by a tasks interface, though a toolbox icon can still launch Canvas.
- They highlighted that GPT-4o tasks provide timed reminders for actions like language practice or news updates.
LM Studio Discord
- Fine-Tuning Frenzy & Public Domain Delights: One user is fine-tuning LLMs with public domain texts to enhance output quality, shifting efforts to Google Colab while exploring Python for the first time.
- They aim to shape prompts for better writing outcomes, focusing on new ways to utilize LLMs for creative tasks.
- Context Crunch & Memory Moves: Members noted the 'context is 90.5% full' warnings when long conversations overload the LLM's buffer, risking truncated output.
- They debated adjusting context length versus heavier memory footprints, highlighting a delicate balancing act for stable performance.
- GPU Speed Showdown: 2×4090 vs A6000: A 2x RTX 4090 setup was reported at 19.06 t/s, overshadowing an RTX A6000 48GB at 18.36 t/s, with one correction suggesting 19.27 t/s for the A6000.
- Enthusiasts also praised significantly lower power usage of the 2x RTX 4090 build, indicating gains in performance and efficiency.
- Parallelization Puzzles & Layer Distribution: Discussion explored splitting a model across multiple GPUs, placing half the layers on each card for simultaneous calculations.
- However, participants cited potential latency over PCIe and heavier synchronization as barriers to achieving a clear speed advantage.
- Snapshots Snafus: LLMs & Image Analysis: Some users struggled to get QVQ-72B and Qwen2-VL-7B-Instruct to interpret images correctly, facing initialization errors.
- They emphasized keeping runtime environments updated, noting that missing dependencies often break image processing attempts.
aider (Paul Gauthier) Discord
- DeepSeek V3 Drags, GPU Talk Heats Up: Multiple members reported slow or stuck runs with DeepSeek V3, prompting some to switch to Sonnet for better performance and share their frustrations in this HF thread.
- One user highlighted the RTX 4090 as theoretically capable for larger models, pointing to SillyTavern's LLM Model VRAM Calculator and raising questions about VRAM requirements.
- Aider Gains Kudos, Commits Stall: A user praised Aider's code editing but complained that no Git commits were generated, despite correct settings and cloned project usage.
- Others recommended architect mode to confirm changes before committing, referencing a PR to address these issues at #2877.
- Repo Maps Balloon, Agentic Tools Step In: A member noticed their repository-map grew from 2k to 8k lines, raising concerns about efficiency when handling more than 5 files at once.
- Users suggested agentic exploration tools like cursor's chat and windsurf for scanning codebases, praising Aider for final implementation steps.
- Repomix Packs Code, Cuts API Bulk: A user showcased Repomix, which repackages codebases into formats that are friendlier for LLM-powered tasks.
- They also noted synergy with Repopack for minimizing Aider's API calls, which could reduce token overhead for large projects.
- Clickbait Quips, o1-Preview Slogs: One user teased another's AI content style as borderline used-car sales, echoing community annoyance toward clickbait promotions.
- Others cited slowed responses and heavier token usage on o1-preview, pointing to performance dips that hamper real-time interactions.
Modular (Mojo 🔥) Discord
- Docs Font Goes Bolder: The docs font is now thicker for improved readability, which users cheered as much better in #general.
- People seem open to further tweaks, showing a willingness to keep refining the user experience.
- Mojo Drops the Lambda: Community confirmed Mojo currently lacks
lambdasyntax, but a roadmap note signals future plans.- Individuals suggested passing named functions as parameters until lambdas are officially supported.
- Zed and Mojo Team Up: Enthusiasts shared how to install Mojo in Zed Preview just like the stable version, with code-completion working after setup.
- Some hit minor snags when missing certain settings, but overall integration flowed well once everything was configured.
- SIMD Sparks Speed Snags: Participants warned about performance pitfalls with SIMD, referencing Ice Lake AVX-512 Downclocking.
- They urged checking assembly output to detect any register shuffling that might negate SIMD benefits on various CPUs.
- Recursive Types Test Mojo's Patience: Developers grappled with recursive types in Mojo, turning to pointers for tree-like structures.
- They linked GitHub issues for deeper details, citing continuing complexity in the language design.
Eleuther Discord
- Critical Tokens Spark Fervor: A new arXiv preprint introduced critical tokens for LLM reasoning, showing major accuracy boosts in GSM8K and MATH500 when these key tokens are carefully managed. Members also clarified that VinePPO does not actually require example Chain-of-Thought data, though offline RL comparisons remain hotly debated.
- They embraced the idea that selectively downweighting these tokens could push overall performance, with the community noting parallels to other implicit PRM findings.
- NanoGPT Shatters Speed Records: A record-breaking 3.17-minute training run on modded-nanoGPT was reported, incorporating a new token-dependent lm_head bias and multiple fused operations, as seen in this pull request.
- Further optimization ideas, like Long-Short Sliding Window Attention, were floated for pushing speeds and performance even higher.
- TruthfulQA Takes a Tumble: TurnTrout’s tweet revealed a 79% accuracy on multiple-choice TruthfulQA by exploiting weak spots with a few trivial rules, bypassing deeper model reasoning.
- This finding stirred debate across the community, spotlighting how benchmark flaws can undercut reliability in other datasets such as halueval.
- MATH Dataset DMCA Debacle: The Hendrycks MATH dataset went dark due to a DMCA takedown, as noted in this Hugging Face discussion, sparking legal and logistical concerns.
- Members traced the original questions to AOPS, reiterating that the puzzle-like content was attributed from the start, highlighting friction on dataset licensure.
- Anthropic & Pythia Circuits Exposed: Several references to Anthropic’s circuit analysis explored how sub-networks form at consistent training stages across different Pythia models, as discussed in this paper.
- Participants noted that these emergent structures do not strictly align with simpler dev-loss vs. compute plots, underscoring the nuanced evolution of internal architectures.
Latent Space Discord
- Cursor AI Scores Big Bucks: They raised a new Series B co-led by a16z to support the coding platform’s next phase, as shown in this announcement.
- Community chatter highlights Cursor AI as a key client for Anthropic, fueling talk on usage-based pricing.
- Transformer² Adapts Like an Octopus: The new paper from Sakana AI Labs introduces dynamic weight adjustments, bridging pre- and post-training.
- Enthusiasts compare it to how an octopus blends with its surroundings, highlighting self-improvement potential for specialized tasks.
- OpenBMB MiniCPM-o 2.6 Takes On Multimodality: The release of MiniCPM-o 2.6 showcases an 8B-parameter model spanning vision, speech, and language tasks on edge devices.
- Preliminary tests praise its bilingual speech performance and cross-platform integration, stirring optimism about real-world usage.
- Curator: Synthetic Data on Demand: The new Curator library offers an open-source approach to generating training and evaluation data for LLMs and RAG workflows.
- Engineers anticipate fillable gaps in post-training data pipelines, with more features planned for robust coverage.
- NVIDIA Cosmos Debuts at CES: At the LLM Paper Club, NVIDIA Cosmos was presented to highlight its capabilities following a CES launch.
- Attendees were urged to register and add the session to their calendar, preventing anyone from missing this new model’s reveal.
GPU MODE Discord
- Triton & Torch: Dancing Dependencies: A user found Triton depends on Torch, complicating a pure CUDA workflow and prompting questions about a cuBLAS equivalent (docs).
- Another user hit a ValueError from mismatched pointer types, concluding pointers in
tl.loadmust be float scalars.
- Another user hit a ValueError from mismatched pointer types, concluding pointers in
- RTX 50x TMA Whispers: Rumors persist that RTX 50x Blackwell cards may inherit TMA from Hopper, but no details are confirmed.
- Community members remain frustrated until the whitepaper drops, keeping TMA buzz alive.
- MiniMax-01 Rocks 4M-Token Context: The MiniMax-01 open-source models introduce Lightning Attention for handling up to 4M tokens with big performance leaps.
- APIs cost $0.2/million input tokens and $1.1/million output tokens, as detailed in their paper and news page.
- Thunder Compute: Storm of Cheap A100s: Thunder Compute debuted with A100 instances at $0.92/hr plus $20/month free, showcased on their website.
- Backed by Y Combinator alumni, they feature a CLI (
pip install tnr) for fast instance management.
- Backed by Y Combinator alumni, they feature a CLI (
- GPU Usage Tips and Debugging Tales: Engineers stressed weight decay for bfloat16 training (Fig 8) and discussed batching
.to(device)calls in Torch to cut CPU overhead.- They also tackled multi-GPU inference strategies, MPS kernel profiling quirks, and specialized GPU decorators for popcorn bot, referencing deviceQuery info.
LlamaIndex Discord
- RAG Rush with LlamaParse: Using LlamaParse, LlamaCloud, and AWS Bedrock, the group built a RAG application that focuses on parsing SEC documents efficiently.
- Their step-by-step guide outlines advanced indexing tactics to handle large docs while emphasizing the strong synergy between these platforms.
- Knowledge Graph Gains with LlamaIndex: Tomaz Bratanic of @neo4j presented an approach to boost knowledge graph accuracy using agentic strategies with LlamaIndex in his thorough post.
- He moved from a naive text2cypher model to a robust agentic workflow, improving performance with well-planned error handling.
- LlamaIndex & Vellum AI Link Up: The LlamaIndex team announced a partnership with Vellum AI, sharing use-case findings from their survey here.
- This collaboration aims to expand their user community and explore new strategies for RAG-powered solutions.
- XHTML to PDF Puzzle Solved with Chromium: One member noted Chromium excels at converting XHTML to PDF, outperforming libraries like pandoc, wkhtmltopdf, and weasyprint.
- They shared an example XHTML doc and an example HTML doc, highlighting promising rendering fidelity.
- Vector Database Crossroads at Scale: Users debated switching from Pinecone to either pgvector or Azure AI search to manage 20k documents with better cost efficiency.
- They referenced LlamaIndex's Vector Store Options to gauge integration with Azure and stressed the need for a strong production workflow.
OpenInterpreter Discord
- OpenInterpreter 1.0's Command Conundrum: OpenInterpreter 1.0 restricts direct code execution, shifting tasks to command-line usage and raising alarm about losing user-friendly features.
- Community members bemoaned the departure from immediate Python execution, stating the new approach "feels slower" and "requires more manual steps."
- Bora's Law Breaks Compute Conventions: A new working paper, Bora's Law: Intelligence Scales With Constraints, Not Compute, suggests exponential growth in intelligence driven by constraints instead of compute.
- Attendees stressed that this theory challenges large-scale modeling strategies like GPT-4, questioning the heavier reliance on raw hardware resources.
- Python Power Moves in OI: Enthusiasts urged the addition of Python convenience functions for streamlining tasks in OpenInterpreter.
- They argued these enhancements could "boost user efficiency" while preserving the platform's interactive style.
- AGI Approaches Under Fire: One corner of the community criticized OpenAI for overly focusing on brute-force compute, ignoring more subtle intelligence boosters.
- Members called for reevaluating AI development principles in light of creative theories like Bora's Law, highlighting the need to refine large model scaling.
LAION Discord
- DougDoug’s Dramatic Dive into AI Copyright: In this YouTube video, DougDoug shared a thorough explanation of AI copyright law, centering on potential intersections between tech and legal structures.
- This perspective sparked a lively exchange, with participants praising his attention to emerging legal blind spots and speculating on possible creator compensation models.
- Hyper-Explainable Networks Spark Royalties Rethink: A proposal for hyper-explainable networks introduced the idea of gauging training data’s influence on model outputs, potentially directing royalties to data providers.
- Opinions varied between excitement at the potential for data-driven compensation and skepticism about the overhead in implementing such a system.
- Inference-Time Credit Assignment Gains Ground: A related conversation around inference-time credit assignment floated the possibility of using it to trace each dataset chunk’s impact on a model’s results.
- While some see promise in recognizing data contributors, others point out the major complexity in quantifying these influences.
AI21 Labs (Jamba) Discord
- P2B Propositions Prompt a Crypto Clash: A representative from P2B offered services for fundraising, listing, community support, and liquidity management, hoping to engage AI21 in their crypto vision.
- They asked to share more details about these offerings, but the conversation shifted once AI21 Labs made its stance on crypto clear.
- AI21 Labs Locks Out Crypto Initiatives: AI21 Labs firmly refused to associate with crypto-based efforts, stating they will never pursue related projects.
- They also warned that repeated crypto references would trigger swift bans, underlining their no-tolerance position.
MLOps @Chipro Discord
- AI Agents Ascend in 2025: Sakshi & Satvik will host Build Your First AI Agent of 2025 on Thursday, Jan 16, 9 PM IST, featuring both code and no-code methods from Build Fast with AI and Lyzr AI.
- The workshop highlights predictions that AI Agents will transform varied industries by 2025, broadening access for newcomers and engineers alike.
- Budget Battles Over AI Adoption: A community voice emphasized cost as a critical factor in deciding whether to adopt new solutions or keep existing systems.
- Many remain cautious, indicating a preference to retain proven infrastructure over riskier, more expensive installations.
Nomic.ai (GPT4All) Discord
- Qwen 2.5 Fine-Tuning Curiosity: A user asked for Qwen 2.5 Coder Instruct (7B) fine-tuning details, wondering if it was released on Hugging Face and citing curiosity about larger models.
- They also sought success stories on proven models from others, emphasizing performance in real-world scenarios.
- Llama 3.2 Fumbles With Long Scripts: A user ran into errors analyzing a 45-page TV pilot script with Llama 3.2 3B, expecting it to handle the text without character limit trouble.
- They shared a comparison link showing distinctions in token capacities and recent releases for Llama 3.2 3B and Llama 3 8B Instruct.
DSPy Discord
- Push for Standardizing Ambient Agent Implementation: A user in #general asked about building an ambient agent with DSPy, seeking experiences and a standardized approach from anyone who has tried it.
- They highlighted the potential synergy of ambient agents with DSPy workflows, inviting collaborative input for a more structured solution.
- Growing Curiosity for DSPy Examples: Another inquiry emerged about specific DSPy examples for implementing ambient agents, emphasizing the community’s hunger for concrete code references.
- No direct examples were provided yet, but the community expressed eagerness for shared demos or open-source materials to bolster DSPy’s practical usage.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Axolotl AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (568 messages🔥🔥🔥):
Cursor performance issues, Slow requests, Deployment methods, Model comparisons, Sora AI usage
- Cursor Performance and Slow Requests: Users have reported significant slowdowns in Cursor's slow requests, with wait times increasing to 5-10 minutes, causing frustration among Pro subscribers.
- While some users experienced normal response times, many indicated persistent issues that affected their productivity.
- Deployment Strategies with Cursor: Vercel and Google Firebase emerged as popular choices for deploying apps built using Cursor, with users sharing tips on seamless deployment.
- Users noted that prompts for deploying apps typically default to Vercel, minimizing the need for additional setup.
- Model Comparisons and AI Usage: There was a discussion on the effectiveness of various LLMs, with some users preferring Gemini 2.0 Flash over Llama 3.1 due to better performance in benchmarks.
- Others expressed concern over AI dependency leading to feelings of imposter syndrome, while recognizing that working with AI has significantly enhanced productivity.
- Sora and Video Generation: Users mentioned mixed results when using Sora for video generation, finding it hit or miss for high-quality slow-motion content.
- Consistent success with applications like Sora appeared to be challenging, prompting users to explore other video generation options.
- Upcoming Changes in Cursor: Anticipation surrounds the upcoming version of Cursor expected in March, which will include the new Fusion implementation.
- Users expressed expectations regarding enhancements to the platform and a desire for the integration of models like DeepSeek and Gemini.
- Tweet from MiniMax (official) (@MiniMax__AI): MiniMax-01 is Now Open-Source: Scaling Lightning Attention for the AI Agent EraWe are thrilled to introduce our latest open-source models: the foundational language model MiniMax-Text-01 and the visua...
- Claude: Talk with Claude, an AI assistant from Anthropic
- A New Tab Model | Cursor - The AI Code Editor: Announcing the next-generation Cursor Tab model.
- Facepalm Really GIF - Facepalm Really Stressed - Discover & Share GIFs: Click to view the GIF
- omkarthawakar/LlamaV-o1 · Hugging Face: no description found
- Sad Cry GIF - Sad Cry Crying - Discover & Share GIFs: Click to view the GIF
- Anthropic Status: no description found
- Find your Template: Jumpstart your app development process with pre-built solutions from Vercel and our community.
- v0 by Vercel: Chat with v0. Generate UI with simple text prompts. Copy, paste, ship.
- Reddit - Dive into anything: no description found
- I tried the "free" GitHub Copilot so you don't have to: Microsoft has announced that GitHub Copilot is now a free part of VS Code! But is it worth using? How does it compare to other AI code editors such as Cursor...
- Cursor Directory: Find the best cursor rules for your framework and language
- aie-book/scripts/ai-heatmap.ipynb at main · chiphuyen/aie-book: [WIP] Resources for AI engineers. Also contains supporting materials for the book AI Engineering (Chip Huyen, 2025) - chiphuyen/aie-book
Perplexity AI ▷ #general (274 messages🔥🔥):
Perplexity outages, Performance of AI models, Integration with IDEs, Citations issues, User experiences with AI models
- Perplexity faces frequent outages: Users reported multiple instances of Perplexity being down, with ongoing issues for over an hour and various error messages being encountered.
- The status page indicated a partial outage, causing frustration and prompting users to use alternatives or workarounds.
- Debate on the best AI model for programming: In discussions about AI models, Claude Sonnet 3.5 was highlighted as the best for complex debugging, while Deepseek 3.0 was recommended for cheaper alternatives.
- Users expressed that Perplexity could outperform competitors in some tasks while also pointing out its limitations.
- Integration challenges with Perplexity in IDEs: A user sought to connect Perplexity to IntelliJ IDE but faced challenges due to additional costs for API access, despite having a pro version.
- Suggestions included considering other AI tools like GitHub Copilot for better integration.
- Issues with citations: Some users noticed that citations were not functioning properly within Perplexity, leading to difficulties in retrieving and validating information.
- The chat logs indicated that there were longstanding bugs affecting the display and functionality of links and citations.
- User experiences and frustrations: Several users mentioned that Perplexity's performance was lacking, particularly in terms of reliable output and context window limitations.
- Frustration over hallucinations by the AI and inconsistent results highlighted concerns regarding the effectiveness and reliability of the service.
- Scira: Scira is a minimalistic AI-powered search engine that helps you find information on the internet.
- Bowling GIF - Bowling - Discover & Share GIFs: Click to view the GIF
- Perplexity - Status: Perplexity Status
- Bora's Law: Intelligence Scales With Constraints, Not Compute: This is a working paper exploring an emerging principle in artificial intelligence development.
Perplexity AI ▷ #sharing (7 messages):
iPhone Air Rumors, JavaScript Trademark Battle, US AI-Export Rules, Perplexity AI Apps Confusion
- Exciting iPhone Air Rumors Surface: New rumors about the iPhone Air have emerged, raising speculation on design and price points. You can watch the full discussion here.
- Community reactions are mixed, with many eager for the latest features.
- JavaScript Trademark Battle Heats Up: A fierce legal dispute surrounds the JavaScript trademark, potentially affecting various projects. The implications could reshape open-source contributions in the tech space.
- Members shared their thoughts, emphasizing how this battle highlights ownership in programming languages.
- New US AI-Export Rules Discussed: Discussions are ongoing about new AI-export rules in the US that aim to regulate technology distribution. Key aspects of these regulations could impact global collaboration.
- Experts warn that opposition may arise from both developers and international partners.
- Confusion Over Two Perplexity AI Apps: A user expressed surprise at finding two apps in the iOS App Store without clear distinction in their descriptions. This led to a query on the Perplexity web app for clarification.
- Another user, unable to locate the second app, sparked further discussion on which apps are available.
Perplexity AI ▷ #pplx-api (1 messages):
llama-3.1-sonar-large-128k-online output speed
- Users report slow output speed for llama-3.1-sonar-large-128k-online: Members have noted a sharp decline in the output speed of llama-3.1-sonar-large-128k-online since January 10th.
- This decline has sparked discussions among users regarding potential causes or changes that might have affected performance.
- Concerns over llamas performance decline: Another user expressed concerns that the drop in output speed could affect overall performance and user experience with the model.
- Community members are actively discussing potential troubleshooting steps and alternative solutions.
Codeium (Windsurf) ▷ #announcements (2 messages):
Windsurf Command Tutorial, Discord Challenge Winners, Student Discount Pricing, Windsurf Editor Launch, Codeium vs GitHub Copilot
- Learn to Command Effectively: A new video tutorial has been released, detailing how to use the Command feature to generate or edit code directly in the editor watch here.
- It's an opportunity for users to enhance their workflow with valuable insights on the feature.
- Discord Challenge Winners Announced!: Congratulations to the winners: <@149171016705376256> and <@1023819475650347008>! Check out their winning videos, including Luminary - FREE AI Workflow Tool and How to REALLY make money with Windsurf.
- Winners are encouraged to DM for their reward of 3 months of pro tier Windsurf.
- Students Score Major Discounts: Students with active .edu addresses can now enjoy significant discounts on Pro Tier Windsurf for a limited time, just sign up at codeium.com.
- This initiative aims to make the tool more accessible to students and enhance their coding capabilities.
- Introducing the Windsurf Editor: The new Windsurf Editor, a purpose-built IDE, has been launched to provide users with a streamlined coding experience. Users can discover more about its features and benefits on the platform.
- An official comparison of Codeium against GitHub Copilot is available, showcasing its superior performance.
- Quality Training Data Assurance: Codeium assures users that it does not train on nonpermissive code (e.g., GPL), protecting them from potential legal risks, a point highlighted in this blog post.
- The platform aims to provide high-quality, secure AI tools to streamline the coding process for engineers.
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Tweet from Windsurf (@windsurf_ai): How to use Command
- Luminary - FREE AI Workflow Tool: Luminary is a FREE open source AI Workflow ToolLike what you see? Give Luminary a star on Github!https://github.com/nascarjake/luminaryHave questions? Join m...
- How to REALLY make money with Windsurf #aiautomation #firebringerai #coding #seoautomation: Build SEO Websites in Minutes with This Game-Changing ToolStop spending hours or even days building SEO websites manually. This tool turns your keywords, for...
Codeium (Windsurf) ▷ #discussion (88 messages🔥🔥):
Codeium Telemetry Issue, Codeium Subscription Plans, Student Discounts, Remote Repository Utilization, Codeium Installation Problems
- Struggles with Codeium Telemetry: Users reported issues with telemetry in the Codeium extension for Visual Studio, with one suggesting to report the issue on GitHub.
- Someone emphasized that Codeium Visual Studio is distinct from Visual Studio Code and recommended verifying the installation setup.
- Confusion around Codeium Subscription Plans: Questions arose about credit usage in Codeium's subscription plans, specifically if credits roll over upon cancellation or if they reset monthly.
- Users confirmed that credits do not carry over after plan cancellation and that unused credits are lost at plan end.
- Seeking Clarity on Student Discounts: Several users inquired about student discounts for the Pro Ultimate plan, with some struggling to access it if their email is not a traditional .edu domain.
- Admins noted they are working on expanding eligibility beyond .edu addresses but currently, only .edu accounts qualify for discounts.
- Concerns about Utilizing Remote Repositories: A user expressed difficulty in utilizing indexed remote repositories through Codeium in IntelliJ, seeking a setup guide.
- The community was encouraged to share their experiences with remote repositories to assist one another.
- Challenges with Codeium Installation: Users reported errors while installing Codeium, particularly one related to extension manifest issues caused by too lengthy display names.
- Others have proposed reaching out for support directly to resolve persistent installation problems.
- Paid Plan and Credit Usage - Codeium Docs: no description found
- GitHub - Exafunction/codeium: Contribute to Exafunction/codeium development by creating an account on GitHub.
- Exafunction/CodeiumVisualStudio: Visual Studio extension for Codeium. Contribute to Exafunction/CodeiumVisualStudio development by creating an account on GitHub.
Codeium (Windsurf) ▷ #windsurf (191 messages🔥🔥):
Windsurf IDE issues, Discounts and Pricing, User Experiences with Cascade, C# variable type analysis, Integration of AI models
- Windsurf IDE struggles with variable type analysis: Users reported ongoing issues with variable type analysis in C# files within Windsurf IDE, even on the latest versions for both Windows and Mac systems.
- This contrasts with seamless performance experienced in other IDEs like VS Code and Cursor IDE.
- Discount woes for new users: Several users experienced issues not receiving expected discounts upon signing up, particularly those using university email accounts.
- Others suggested that contacting support and providing ticket numbers could expedite resolution.
- Mixed reviews on Windsurf and Cascade performance: Some users expressed satisfaction with Cascade Base, citing its effectiveness as a free AI tool, while others shared frustrations with app freezing and performance issues.
- Advanced users recommended using detailed prompts to improve performance in Windsurf.
- AI model integration discussions: Users expressed interest in the integration of various AI models and tools within Windsurf, highlighting Claude's capabilities for advanced problem-solving.
- Some suggested that using a combination of models could lead to better outcomes, especially for complex coding tasks.
- User feedback on pricing structure: Users shared opinions on Windsurf's pricing, with some expressing the desire for more flexibility in credits and plans that align better with usage.
- There were calls for clearer communication about the pricing structure and potential improvements to the current offerings.
- Tweet from Windsurf (@windsurf_ai): Excited to announce our first merch giveaway 🏄Share what you've built with Windsurf for a chance to win a care package 🪂 #WindsurfGiveawayMust be following to qualify
- Power Starwars GIF - Power Starwars Unlimited Power - Discover & Share GIFs: Click to view the GIF
- Text Phone GIF - Text Phone Waiting - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
Unsloth AI (Daniel Han) ▷ #general (113 messages🔥🔥):
GPU Usage in Unsloth, Fine-tuning Misconceptions, Model Training in Notebooks, Collaboration with Kaggle, Using Unsloth for Web Scraping
- Running Unsloth with Multiple GPUs: Users inquired about running Unsloth with two T4 GPUs in Kaggle, but it appears that only one GPU is currently supported for inference.
- There were discussions on using Kaggle for training jobs, with suggestions to utilize the free hours available each week.
- Addressing Fine-tuning Misconceptions: It was noted that many assume fine-tuning does not introduce new knowledge to models, while the docs clarify that it can replicate functionalities of Retrieval-Augmented Generation (RAG).
- The Unsloth team mentioned focusing on misconceptions in their documentation to better inform users about the benefits of fine-tuning.
- Training Jobs in Notebooks: Users shared their experiences with long training jobs in Google Colab, noting problems like OOM errors and potential notebook disconnections during lengthy processes.
- The discussion highlighted the need for a more robust environment, such as an A100 GPU with 80GB VRAM, for demanding training jobs.
- Collaboration with Kaggle for Notebooks: The Unsloth team is actively working on creating a Kaggle notebook for the Phi-4 model, enhancing the tools available for users.
- This collaboration aims to provide resources tailored for training and fine-tuning models effectively.
- Web Scraping Model Recommendations: A user asked for model recommendations for web scraping tasks, leading to discussions about using Firecrawl for specific website scraping.
- It was suggested that web scraping could be effectively managed by utilizing tools designed for that purpose.
- Tweet from Leonie (@helloiamleonie): Over the holidays, I learned how to fine-tune an LLM.Here’s my entry for the latest @kaggle competition.This tutorial shows you:• Fine-tuning Gemma 2• LoRA fine-tuning with @UnslothAI on T4 GPU• Exper...
- Google Colab: no description found
- Is Fine-tuning Right For Me? | Unsloth Documentation: If you're stuck on if fine-tuning is right for you, see here!
- shark-ai/docs/amdgpu_kernel_optimization_guide.md at main · nod-ai/shark-ai: SHARK Inference Modeling and Serving. Contribute to nod-ai/shark-ai development by creating an account on GitHub.
- Large Language Models explained briefly: Dig deeper here: https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3piTechnical details as a talk: https://youtu.be/KJtZARuO3JYThis was ma...
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
Unsloth AI (Daniel Han) ▷ #off-topic (16 messages🔥):
QA training techniques, Model performance issues, Fine-tuning models, MLX framework, Ollama compatibility
- Using Subset of QA Pairs for Training: A user proposed taking a subset of QA pairs for a 1 epoch primer before training on a limited dataset, raising concerns about potential model forgetting.
- Another user cautioned that the dataset contains specific patterns and emojis, which may negatively impact the model's response quality.
- Concerns Over Model Bias: Discussion highlighted that using the original dataset could influence the model’s biases in its responses, particularly regarding alignment.
- One user wished to focus on undoing excessive censorship present in previously fine-tuned models.
- Converting Models for Non-Apple Systems: A user inquired about converting a fine-tuned model created with mlx_lm into a non-Apple compatible model, noting the inability to duplicate its quality elsewhere.
- Another user provided a link related to LORA, suggesting that nearly any model should load GGUF formats, leading to further issues with compatibility.
- Challenges with Ollama Compatibility: After exporting a model to GGUF, a user reported that the model didn't work with Ollama, despite passing tests within mlx, indicating possible compatibility issues.
- The use of adapters was mentioned but resulted in a significantly lower quality output compared to the original mlx responses.
- Maintaining Consistent Generation Settings: In assessing model output quality, a user confirmed that identical prompts and generation settings (like temperature) were used to ensure fairness in testing.
- The discussion led to speculation that the underlying issue may rest with mlx itself.
- mlx-examples/llms/mlx_lm/LORA.md at main · ml-explore/mlx-examples: Examples in the MLX framework. Contribute to ml-explore/mlx-examples development by creating an account on GitHub.
- HumanLLMs/Human-Like-DPO-Dataset · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (141 messages🔥🔥):
Training Issues with Phi-4, Fine-tuning Llamas, Using WSL for AI Development, Dynamic Quantization in Models, Conda Installation on Windows
- Training Issues with Phi-4 leading to NaN: Users reported encountering NaN during evaluation cycles with per_device_eval_batch_size set to 2 when training the Phi-4 model, suggesting it may be related to low evaluation batch size.
- Another user confirmed that they found success with a higher batch size, indicating varying hardware limitations might affect training parameters.
- Fine-tuning Llama Models for Specific Tasks: Discussion included the challenge of using an outdated model for fine-tuning, with suggestions highlighting the importance of model updates for domain-specific tasks.
- Participants debated the effectiveness of current approaches and emphasized the need for diverse, high-quality datasets in training.
- Using WSL for AI Development: It was suggested that running AI workflows on Windows can be problematic, advising the use of WSL2 for a smoother experience due to better Linux support.
- Participants agreed that many AI developers prefer Linux or WSL environments due to compatibility issues on Windows.
- Dynamic Quantization and Model Performance: Concerns were raised about the perceived lack of performance difference when using dynamic quantization with the Phi-4 model compared to standard 4-bit versions.
- Users clarified that while loss values might not vary, dynamic quantization should theoretically enhance training accuracy, prompting further investigation into the issue.
- Conda Installation Issues on Windows: A user reported difficulties in creating a conda environment on Windows due to the unavailability of the xformers package, seeking advice on how to proceed.
- Suggestions included omitting the package during environment creation or installing it later with pip, while other users recommended utilizing WSL for easier setup.
- Google Colab: no description found
- Google Colab: no description found
- Unsloth 4-bit Dynamic Quants - a unsloth Collection: no description found
- Finetune Phi-4 with Unsloth: Fine-tune Microsoft's new Phi-4 model with Unsloth!We've also found & fixed 4 bugs in the model.
- Qwen 2.5 Coder - a unsloth Collection: no description found
- Installing + Updating | Unsloth Documentation: Learn to install Unsloth locally or online.
- Unsloth Documentation: no description found
- EASILY Train Llama 3 and Upload to Ollama.com (Must Know): Unlock the full potential of LLaMA 3.1 by learning how to fine-tune this powerful AI model using your own custom data! 🚀 In this video, we’ll take you throu...
- Tutorial: How to Finetune Llama-3 and Use In Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
Grokking phenomenon, LLM training methods, Security conference submissions, Research papers and resources, Grokking video sequel
- Grokking Solved - Must-Watch Video: A video titled Finally: Grokking Solved - It's Not What You Think discusses the surprising phenomenon of grokking in AI models, as it relates to prolonged overfitting in LLMs. Members expressed enthusiasm for the video, noting its significance in understanding AI generalization.
- One viewer remarked, Amazing video must watch if I wasn't this tired I'd read the paper now.
- Submissions for Security Conferences Suggested: A member suggested that LLM talks could fit better in domain-specific conferences, particularly security conferences, rather than typical ML conferences. This aligns with ongoing discussions about the application of LLMs in specialized areas.
- This insight reflects the growing interdisciplinary interest in LLM research and its implications across various fields.
- Research Paper on Grokking Shared: A user shared a research paper on grokking, noting that grokking challenges the current understanding of deep learning due to its intriguing aspects of delayed generalization. Links to both the paper and the associated GitHub repo were provided for further exploration.
- The paper argues that without regularization, grokking tasks may lead to what they term Softmax Collapse.
- Exploration of Memorizing vs. Grokking: One member expressed hope that researchers are thoroughly investigating the transition between memorizing and grokking, as it could reveal new insights into training methods used by biological neurons. This highlights a belief in potential breakthroughs tied to understanding these learning phases.
- The comment reflects the community's interest in the biological parallels for enhancing AI training methodologies.
- Sequel Video to Grokking Shared: A sequel video link was shared, titled Grokking - A Sequel providing further insights into the grokking phenomenon in AI. This reinforces ongoing discussions and investigations into the nature of AI learning processes.
- The sequel promises to build on the concepts introduced in the original video, engaging viewers interested in the evolution of LLM understanding.
- Finally: Grokking Solved - It's Not What You Think: Grokking, or the sudden generalization by AI models to new knowledge - that occurs after prolonged overfitting in LLMs, is a surprising phenomenon that has c...
- Grokking at the Edge of Numerical Stability: Grokking, the sudden generalization that occurs after prolonged overfitting, is a surprising phenomenon challenging our understanding of deep learning. Although significant progress has been made in u...
- GitHub - LucasPrietoAl/grokking-at-the-edge-of-numerical-stability: Contribute to LucasPrietoAl/grokking-at-the-edge-of-numerical-stability development by creating an account on GitHub.
Stability.ai (Stable Diffusion) ▷ #general-chat (206 messages🔥🔥):
AI Image Generation, Fake Cryptocurrency Launches, Model Metrics, ComfyUI and Stable Diffusion, Sharing Generated Images
- Successful Image Generation with Stable Diffusion XL: A user is generating images using the
stabilityai/stable-diffusion-xl-base-1.0model but is inquiring about metrics related to image generation times.- They are running the model on Colab and are trying to find out if predefined metrics like iterations per second are available.
- Scam Alert for Cryptocurrency Launch: The community discussed a recent scam involving a fake cryptocurrency launch tied to Stability AI, and members were warned not to click any suspicious links.
- Users expressed concerns about how easily people can fall for such scams and shared experiences of losses to similar situations.
- ComfyUI Provides Metrics for Image Generation: A member shared that while using ComfyUI, they are able to see metrics regarding the time taken per iteration during image generation.
- In contrast, another user running scripts in Colab noted the absence of such metrics and was looking for model-specific data.
- Experimenting with Different Model Settings: Discussion about adjusting inference steps in image generation highlighted how flexibility exists within models to change settings, impacting results.
- One user mentioned the possibility of running up to 50 inference steps but was more interested in model-specific metrics.
- Sharing AI-generated Images: A user asked about the best places to share generated images, including failures to help improve AI models.
- Civitai and social media were suggested as potential platforms, though it was noted that sharing generated images raises concerns about data quality.
- Tweet from Dango233 (@dango233max): Just reached out to my SAI Friends.This is a SCAM!!!! @StabilityAI X Account is compromised.DO NOT TRUST IT!
- stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #events (3 messages):
Agent Identity Hackathon, Mixer Event, Xeno Grant
- Mixer and Hackathon on Agent Identity: Join us for a Mixer on the 24th and a Hackathon on the 25th at Betaworks, NYC, focusing on agent identity with $5k in prizes for the most interesting projects.
- Food, drinks, and good vibes are included; check out the details on the event page.
- Registration for Xeno Grant Hackathon: Registration is required for the Xeno Grant: Agent Identity Hackathon, which features $10,000 per agent—half in $YOUSIM and half in $USDC.
- The program spans 4 weeks for agents and their developers, with approvals necessary for participation.
- Tweet from vintro (@vintrotweets): 🚨 ATTN HUMANS 🚨we're hosting a mixer and hackathon @betaworks all about agent identity to kick off @xenograntai 🥳come hack on the agent you've been wanting in your life. $5k in prizes for t...
- Xeno Grant: Agent Identity Hackathon · Luma: Come join Plastic Labs & Betaworks for an agent identity hackathon to kick off Xeno Grant (powered by $YOUSIM).$5,000 in prizes for the most compelling…
Interconnects (Nathan Lambert) ▷ #news (90 messages🔥🔥):
Model Performance Issues, Program Synthesis Focus, Cerebras Yield Solutions, Contextual AI Platform Launch, LLM Language Understanding
- Models Struggling with Doom Loops: Members discussed issues regarding models being 'undercooked' post-training, particularly mentioning difficulties in multi-turn conversations and generating repetitive outputs.
- One example noted was regarding a Division constantly generating the phrase 'let’s bring down the last digit'.
- Ndea Lab's Program Synthesis Goals: François Chollet announced the establishment of Ndea, focusing on deep learning-guided program synthesis aimed at achieving true AI innovation.
- This approach is seen as a refreshing alternative to the more common scaling of LLMs towards AGI.
- Cerebras Tackles Chip Yield Challenges: Cerebras shared insights on achieving comparable yields despite producing a wafer-scale chip that is 50x larger than traditional chips, challenging conventional semiconductor wisdom.
- Their approach involves a new understanding of the relationship between chip size and fault tolerance which facilitates higher yield rates.
- Contextual AI Platform Celebrates Milestone: The Contextual AI Platform announced its successful implementation using Meta’s Llama 3.3 and powered by Google Cloud and NVIDIA GPUs.
- They expressed gratitude towards various partners and investors for their support in reaching this milestone.
- LLMs Struggle with Niche Vocabulary: Discussion arose around how many LLMs fail to recognize the term 'protolithic', highlighting issues with language model language comprehension.
- This prompted laughter and commentary about the uniqueness and complexity of vocabulary in training models.
- Tweet from Tiezhen WANG (@Xianbao_QIAN): InternLM v3 is live now!- SoTA performance, surpass models like Llama3.1-8B and Qwen2.5-7B- Capable of deep reasoning with system prompts (details in their model card)- Trained only on 4T high quality...
- no title found: no description found
- Tweet from Nathan Lambert (@natolambert): For some reason Claude is super convinced "protolithic" isn't a word. Won't let it go. Amazing. It even complains like, maybe you meant "protolithic." I have reproduced it a fe...
- Tweet from DeepSeek (@deepseek_ai): 🎉 Introducing DeepSeek App!💡 Powered by world-class DeepSeek-V3🆓 FREE to use with seamless interaction📱 Now officially available on App Store & Google Play & Major Android markets🔗Download now: h...
- Tweet from François Chollet (@fchollet): I'm joining forces with @mikeknoop to start Ndea (@ndeainc), a new AI lab.Our focus: deep learning-guided program synthesis. We're betting on a different path to build AI capable of true inven...
- Tweet from Xeophon (@TheXeophon): Here is the full eval suite (coding + general) of my vibe bench for minimax-01.As expected in my initial vibe testing, the variance in outputs is huge. On pass@5, it scores the same as Llama 3.3 70B, ...
- Tweet from Teortaxes▶️ (@teortaxesTex): model collapse due to synthetic data is a complete nothingburger (overrated due to marcusian anti-statistical copes and butthurt artists), compared to the scourge that is TASTE COLLAPSE due to SYNTHET...
- Tweet from Contextual AI (@ContextualAI): The Contextual AI Platform is proudly built with Meta’s Llama 3.3, runs on Google Cloud, and is trained on NVIDIA GPUs.We’re extremely proud of this milestone and want to thank all of our customers, p...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Curious about how people use Chatbot Arena?Introducing Arena Explorer🔎: a brand-new way to visualize data from Chatbot Arena!With topic modeling pipeline, we organize user prompts into:- Big categori...
- Ndea: An intelligence science lab.
- Tweet from Dylan Patel (@dylan522p): Apparantly yesterday Jensen was kinda pissed and downed 3 scotches on stage at their event last night for AI in Healthcare lmfaoNote this is hearsay, I wasn't there cause reading regsQuoting Dylan...
- Tweet from Tiezhen WANG (@Xianbao_QIAN): https://huggingface.co/collections/internlm/internlm3-67875827c377690c01a9131d
- Tweet from Naman Jain (@StringChaos): 📢 Excited to share the 5th update for LiveCodeBenchWe have added 167 new problems this time and collected 880 problems overall, over two-fold increase from 400 problems in v1Leaderboard ⬇️- 🥇 open a...
- 100x Defect Tolerance: How Cerebras Solved the Yield Problem - Cerebras: no description found
- InternLM3 - a internlm Collection: no description found
- Definition of PROTOLITHIC: of or relating to the earliest period of the Stone Age : eolithic… See the full definition
- Reddit - Dive into anything: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
ReaderLM-2 Capabilities, MATH Dataset DMCA Issue, AMD GPU Sponsorship Ideas, Tensorwave MI300X Launch, AoPS Exclusivity Concerns
- ReaderLM-2 struggles against legacy scripts: Jina launched ReaderLM-2 to convert HTML to markdown but it performed worse than their prior scripted methods.
- They streamlined their explanation by omitting prior comparisons in the blog post to focus on the new features of ReaderLM.
- MATH Dataset hit with DMCA takedown: The MATH dataset has been disabled following a DMCA takedown notice, raising concerns over the future of related math datasets.
- Some believe proper usage might still be permissible for datasets from organizations like MAA, except for AoPS exclusive content.
- Push for AMD GPU support: A member proposed that AMD should fund Ai2 to encourage the use of their GPUs and provide financial support to researchers.
- This suggestion followed a mention of Intel's sponsorship to Stability AI, highlighting the competitive advantage of such partnerships.
- Tensorwave's MI300X available for AI compute: Tensorwave introduced the MI300X as a cloud solution for AI training and inference with immediate availability for users.
- They offer options for both bare-metal and managed services, emphasizing ease of use and performance benefits.
- AoPS exclusivity raises questions: Discussion arose regarding the exclusivity of AoPS content, speculating that user-posted solutions might face restrictions.
- It was suggested that parts of the MATH dataset could still be reproduced minus AoPS exclusive materials, affecting the accessibility of math resources.
- Tweet from Tom Adamczewski (@tmkadamcz): Hendrycks MATH has just been hit with a DMCA takedown notice. The dataset is currently disabled.https://huggingface.co/datasets/hendrycks/competition_math/discussions/5
- Access MI300X GPU Today | TensorWave | The MI300X Cloud: Access AMD MI300X GPUs today on TensorWave Cloud. Contact us today to get started.
- ReaderLM v2: Frontier Small Language Model for HTML to Markdown and JSON: ReaderLM-v2 is a 1.5B small language model for HTML-to-Markdown conversion and HTML-to-JSON extraction with exceptional quality.
Interconnects (Nathan Lambert) ▷ #random (2 messages):
Non-reasoning models, GPT-4o
- Defining Non-reasoning Models: What's the term we're using for non-reasoning models? This question was raised regarding the classification of models, contrasting o1 as a reasoning model.
- In response, a member referred to GPT-4o as a vanilla ass basic autoregressive model.
- Classification of GPT-4o: The discussion focused on how to classify GPT-4o in relation to reasoning models like o1.
- A participant labeled GPT-4o as a vanilla ass basic autoregressive model, emphasizing its non-reasoning nature.
Interconnects (Nathan Lambert) ▷ #cv (7 messages):
Multimodal Visualization-of-Thought (MVoT), Chain-of-Thought (CoT) prompting, Mind's Eye paradigm, Simulation in AI reasoning, Grounding language models
- Innovative Multimodal Visualization-of-Thought Proposed: A member discussed the Multimodal Visualization-of-Thought (MVoT) approach that enhances reasoning in Multimodal Large Language Models (MLLMs) by generating image visualizations of reasoning traces, introduced via this paper.
- The discussion highlighted its potential to improve Chain-of-Thought (CoT) prompting, suggesting it could complement reinforcement learning strategies effectively.
- Mind's Eye Connects Language and Physical Reality: Another member linked the Mind's Eye paradigm to a new method of grounding language models in reality, using simulation to enhance reasoning, presented in this paper.
- This method demonstrates significant improvements in reasoning accuracy by incorporating results from DeepMind's MuJoCo, marking a vital advancement in AI understanding of the physical world.
- Community Buzz on New AI Approaches: Members expressed excitement over the innovative strategies being discussed, with one calling the MVoT application to be 'sick'.
- The conversation reflects a blend of optimism regarding future AI capabilities and nostalgia for past methods in AI reasoning.
- Imagine while Reasoning in Space: Multimodal Visualization-of-Thought: Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex ...
- Mind's Eye: Grounded Language Model Reasoning through Simulation: Successful and effective communication between humans and AI relies on a shared experience of the world. By training solely on written text, current language models (LMs) miss the grounded experience ...
Interconnects (Nathan Lambert) ▷ #reads (47 messages🔥):
AI Relationships, Population Decline Implications, Automation of Jobs, AI and Social Movements, Challenges with LLMs
- AI Relationships Stir Mixed Feelings: Discussion emerged around ChatGPT and Claude being viewed as better companions or therapists than real humans, raising concerns about future relationship dynamics with AIs.
- One participant noted, 'I worry about the psychological effects of a partner you 'control'...'
- Concerns Over Population Decline: Participants debated how rapid population decline may lead to societal changes in reproduction and norms, suggesting that less desire to reproduce might shift in a post-AI world.
- One user commented, 'When do you think will we reach a point where everyone is taken care of?' indicating uncertainty about the timeline.
- Automation of White Collar Jobs: Conversations highlighted that many white collar jobs could soon be automated, with perspectives on the potential impacts of AGI and robotics on these roles.
- One user expressed doubt about seeing widespread automation before 2040, while another pointed out, 'people really love their bullshit jobs and defending them.'
- Unforeseen Social Reactions to AI: Participants reflected on the idea that serious social movements against AI have yet to emerge, which could complicate the technology's adoption.
- One member remarked that, 'It feels like everyone thinks we're unlocking an infinity box for overnight change,' highlighting skepticism toward rapid shifts.
- Difficulties with LLM Usability: Concerns were raised about the usability of LLM-based chatbots and the common struggles people face when trying to use them effectively.
- One member commented, 'Even when given simple and straightforward instructions, they do bizarre things,' suggesting a lack of understanding among users.
- Tweet from Xeophon (@TheXeophon): A lot of you want to fuck Claude and it shows
- OpenAI's AI reasoning model 'thinks' in Chinese sometimes and no one really knows why | TechCrunch: OpenAI's o1 'reasoning' model sometimes switches to Chinese and other languages as it reasons through problems, and AI experts don't know exactly why.
- Why Anthropic’s Claude Is a Hit with Tech Insiders - The New York Tim…: no description found
Interconnects (Nathan Lambert) ▷ #posts (10 messages🔥):
Voiceover Techniques, Meta Ray-Bans, Project Aria, Content Creation, User Experiences
- Experimenting with Voiceover Techniques: A member discussed taking a somewhat lazier approach to their voiceover process, opting out of using section times and explicit image links.
- Another member admitted they were unaware of these features, remarking it was either a cringeworthy revelation or a sigh of relief.
- Meta Ray-Bans Spark Interest: The conversation pivoted to Meta Ray-Bans, with a member expressing a desire to customize them further, wishing for options like Molmo.
- They described the Meta Ray-Bans as a fun gadget, highlighting personal preferences for enhancements.
- Learning About Project Aria: A member admitted to feeling embarrassed for not knowing about Project Aria, sharing a link to its official page for updates.
- They encouraged others to subscribe for news from Project Aria, emphasizing it as a new discovery in their tech journey.
- Staying Up-to-Date with Tech: The group discussed the importance of keeping up with new technology, like the features of voiceovers and wearable tech.
- A member conveyed that accessing show notes and listening through podcast apps is key to staying informed.
- Content Creation Feedback: A member noted the effort to produce new content weekly, indicating that experimentation with styles is essential.
- They reflected on the process of publishing as a continuous learning experience, despite not always being satisfied with the results.
Link mentioned: Introducing Project Aria, from Meta: Project Aria is a research program from Meta, to help build the future responsibly. Project Aria unlocks new possibilities of how we connect with and experience the world.
Interconnects (Nathan Lambert) ▷ #policy (2 messages):
TSMC and Samsung, US-China chip flow restrictions
- US urges TSMC and Samsung to limit chip exports to China: The US government is pressing TSMC and Samsung to tighten the flow of chips to China, as detailed in a recent Bloomberg article. This move is part of broader efforts to control technology exports amid growing geopolitical tensions.
- About time lol was expressed by a member, indicating a sense of relief or agreement with the decision following recent developments.
- Concerns over geopolitical chip supply chain: Discussions have emerged surrounding the implications of the US's request to TSMC and Samsung regarding chip supplies to China. Experts are noting that such measures could impact global relations and the semiconductor market.
- One participant highlighted this is a critical step to maintain technology supremacy and protect national interests.
- Bloomberg - Are you a robot?: no description found
- Bloomberg - Are you a robot?: no description found
Nous Research AI ▷ #general (125 messages🔥🔥):
Claude's Persona, Fine-Tuning Techniques, LLM Dataset Quality, Nous Research Funding, Hackathon Event
- Claude's Persona: More than Just Intelligence: Members discussed how Claude is perceived as more human-like and personable compared to other models, with one describing Claude as a 'chill guy' who feels like a cool co-worker.
- Concerns were raised about Claude's refusal to provide answers, reinforcing the perception of a strong but reserved persona.
- Exploring Fine-Tuning Techniques for LLMs: A member sought advice on fine-tuning their LLM, presenting two parts involving company knowledge and specific task classification.
- Other members shared insights about effective fine-tuning practices, emphasizing diversity in training data and interaction with the model to enhance accuracy.
- Quality of LLM Datasets Under Scrutiny: Discussion revealed skepticism about the quality of datasets used for training, with opinions suggesting a need for better data selection and conditioning.
- Members expressed a desire for the open-source community to advance in generating high-quality synthetic data.
- Funding Sources for Nous Research: It was clarified that Nous Research operates as a private entity without direct affiliations to government or academic institutions and relies on private equity and merch sales for funding.
- Members noted that while merch revenue is a small fraction, support comes from donations and collaborations with entities like Microsoft.
- Upcoming Hackathon for Agent Identity: An announcement for a mixer and hackathon around agent identity was shared, highlighting prizes and a call for participants to join in NYC.
- This event aims to encourage innovative projects and community engagement around AI agent development.
- Tweet from Karina Nguyen (@karinanguyen_): We're excited to introduce Tasks! For the first time, ChatGPT can manage tasks asynchronously on your behalf—whether it's a one-time request or an ongoing routine. Here are my favorite use cas...
- Tweet from vintro (@vintrotweets): 🚨 ATTN HUMANS 🚨we're hosting a mixer and hackathon @betaworks all about agent identity to kick off @xenograntai 🥳come hack on the agent you've been wanting in your life. $5k in prizes for t...
- MiniMax - Intelligence with everyone: no description found
Nous Research AI ▷ #ask-about-llms (25 messages🔥):
Gemini for data extraction, Grokking paper insights, Ortho Grad and GrokAdamW merger, Stablemax function issues
- Gemini excels in data extraction: A member found Gemini to be exceptional for data extraction, suggesting its reliability over 4o-mini and Llama-8B models for original content.
- Trust in these models may waver when it comes to retrievability of exact content.
- Discussion of the grokking phenomenon: A member raised a question about numeric instability of the Softmax function, speculating it may lead to entropy degradation in attention computations, as discussed in a paper.
- The paper introduces the concept of Softmax Collapse (SC) and asserts mitigating it allows grokking to occur without regularization.
- Combining GrokAdamW and Ortho Grad: Members debated the potential compatibility of GrokAdamW and Ortho Grad, with one member currently testing this combination.
- Concerns were raised on whether GrokAdamW might not be beneficial since Ortho Grad eliminates the delay.
- Skepticism towards replacing Softmax: A member commented that replacing the Softmax function is unlikely to result in a net gain, based on observed results from testing a GPT-2 model.
- There are also questions about the stablemax function not following expected norms, particularly regarding its translation invariance compared to Softmax.
- Grokking at the Edge of Numerical Stability: Grokking, the sudden generalization that occurs after prolonged overfitting, is a surprising phenomenon challenging our understanding of deep learning. Although significant progress has been made in u...
- GitHub - cognitivecomputations/grokadamw: Contribute to cognitivecomputations/grokadamw development by creating an account on GitHub.
Nous Research AI ▷ #interesting-links (7 messages):
Grokking phenomenon, Grokfast optimizer, Orthograd optimizer, Coconut GitHub project
- Grokking phenomenon explained: The phenomenon of grokking in AI models, where they suddenly generalize after overfitting, has been discussed, highlighting that models initially become 'lazy' after overfitting before eventually overcoming this laziness.
- This can be understood as models pushing through to better generalization capabilities after a period of stagnation.
- Grokking strategies and tools: Members discussed methods to encourage grokking to happen earlier, suggesting potential synergy with the Grokfast optimizer.
- The conversation centered around improving the timing of grokking to enhance model performance.
- Challenges with Grokfast optimizer: One participant noted difficulties in achieving stability with the Grokfast optimizer, a challenge echoed by others in LLM training.
- The Orthograd optimizer, developed by researchers, is proposed as a more reliable drop-in replacement for typical training optimizers like SGD or AdamW.
- Coconut GitHub project: A GitHub project titled Coconut entails training large language models to reason in a continuous latent space, providing an innovative approach in the AI field.
- This project is associated with Facebook Research and presents new methodologies for advancing language model capabilities.
- Finally: Grokking Solved - It's Not What You Think: Grokking, or the sudden generalization by AI models to new knowledge - that occurs after prolonged overfitting in LLMs, is a surprising phenomenon that has c...
- Grokking at the Edge of Numerical Stability: Grokking, the sudden generalization that occurs after prolonged overfitting, is a surprising phenomenon challenging our understanding of deep learning. Although significant progress has been made in u...
- GitHub - facebookresearch/coconut: Training Large Language Model to Reason in a Continuous Latent Space: Training Large Language Model to Reason in a Continuous Latent Space - facebookresearch/coconut
Stackblitz (Bolt.new) ▷ #announcements (1 messages):
Bolt update, Project title editing
- Editing Titles in Bolt Now Available: A recent Bolt update allows users to change the project title directly, enhancing project organization.
- This feature simplifies locating projects in the list, as confirmed in the announcement by the Stackblitz.
- Streamlined Project Management: The ability to edit project titles improves the overall user experience by allowing better project identification.
- Users can now easily navigate their projects, reducing time spent searching through lists.
Link mentioned: Tweet from StackBlitz (@stackblitz): 📢 Fresh Bolt update:You can change the project title now — making it easier to find on the projects list!
Stackblitz (Bolt.new) ▷ #prompting (14 messages🔥):
GA4 API integration issues, Firebase data loading technique, Context file creation for Bolt, Token usage optimization, Chat history snapshot system
- GA4 API integration struggles on Netlify: A developer reported encountering an 'Unexpected token' error related to their GA4 API integration after deploying their React/Vite app on Netlify, despite it functioning locally.
- They've verified credentials and environment variables but are seeking alternative solutions or suggestions.
- Streamlined Firebase data loading process: A user shared their approach to simplify connecting to Firebase, suggesting a 'load demo data' page to prepopulate Firestore, avoiding empty schema errors.
- This method was framed as beneficial, even if it might seem obvious to more experienced developers.
- Creating a context file with Bolt: One user successfully created a PROJECT_CONTEXT.md file to store project details, aiding retrieval if conversation context is lost; its effectiveness for future use remains to be seen.
- Discussions ensued about the importance of built-in functionalities for context handling in the core product.
- Reducing token usage in Bolt: Concerns around excessive token usage were raised, and a user considered restarting their project to improve their experience despite the token consumption.
- There were recommendations for more efficient context management strategies, including discussing similar features found in other tools like Cursor.
- Chat history snapshot feature in development: A user referenced a pull request on the bolt.diy repo introducing a snapshot system for chat history, enabling the restoration of past chat states.
- This feature potentially aligns with ongoing discussions about improving contextual persistence.
Link mentioned: feat: restoring project from snapshot on reload by thecodacus · Pull Request #444 · stackblitz-labs/bolt.diy: Add Chat History Snapshot SystemOverviewThis PR introduces a snapshot system for chat history, allowing the restoration of previous chat states along with their associated file system state. This...
Stackblitz (Bolt.new) ▷ #discussions (135 messages🔥🔥):
Token Usage Issues, Bolt Features and Updates, Database Integration with Supabase, Chat Session Management, Error Handling in Bolt
- Token Usage Spikes Explained: Several users reported experiencing dramatically high token usage, with one user stating that their prompts consumed 4 million tokens each, suggesting a potential bug.
- Others expressed skepticism about these claims, recommending that affected users report the issue on GitHub if accurate.
- Connection Issues with Supabase: Members mentioned facing difficulties connecting to Supabase, with reports of errors and application crashes during data storage attempts.
- Some users suggested opening help threads for community support regarding integration issues with databases.
- Request for Preservation of Chat History: A user advocated for the preservation of the initial prompt history in Bolt projects, highlighting its value for future reference despite session context loss.
- Another user agreed and mentioned they keep their starter prompts documented separately.
- Updates and Features Discussion: Discussions included the anticipation of features like Git support and improvements related to the 'lazy bot' effect that has affected code generation consistency.
- A recent livestream addressed upcoming fixes, creating optimism among users for better functionality.
- Error Management Strategies: Users shared strategies for managing code errors in projects, with one suggesting the use of Diff mode to simplify resolution and debugging.
- A user reported issues of the system deleting content unexpectedly, reinforcing the importance of error handling discussions.
- Screenshot: Captured with Lightshot
- Screenshot: Captured with Lightshot
Notebook LM Discord ▷ #use-cases (16 messages🔥):
AI-generated scripts, Worldbuilding assistance, Podcast tone issues, Forum-based information extraction, Novel author discussions
- AI provides functional scripts with ease: A user expressed amazement at how NotebookLM generated a functional groovy script for QuPath from several forum posts about digital pathology, saving them hours of work.
- This outcome led to significant time savings, demonstrating the AI's utility in practical applications.
- Worldbuilding through AI insights: A user shared that they use a notebook for worldbuilding, asking AI to explain less developed concepts, which helps overcome writer's block and unearth forgotten ideas.
- Another user mentioned adding a note like 'Wild predictions inbound!' to gauge the AI's conjectures effectively.
- Podcast tone consistency concerns: Discussion arose regarding a podcast where the host's tone changed unexpectedly during episodes, affecting the listening experience.
- Concerns were raised about consistency in delivery, particularly in educational formats.
- Critique of AI limitations: A user commented on the perceived biases of NotebookLM, expressing frustration at its limitation against discussing certain topics.
- They highlighted instances where the AI refused to engage with specific questions without offering constructive alternatives.
- Call for new podcast channel: A user suggested creating a separate channel for podcast postings and advertising services to keep the use-cases channel focused on relevant discussions.
- This proposal aimed to streamline conversations and ensure that the primary channel remains dedicated to specific use cases.
- no title found: no description found
- What happened on Jan 15?: What happened on Jan 15? by This Day in History
- What happened on Jan 14?: What happened on Jan 14? by This Day in History
Notebook LM Discord ▷ #general (88 messages🔥🔥):
NotebookLM Plus Features, API and Bulk Sync Features, Using YouTube as a Source, Limitations of Text Uploads, Scraping Websites for Content
- Uncertainty Around NotebookLM Plus Transition: Users expressed confusion regarding the availability of NotebookLM Plus features, especially concerning transition timelines for different Google Workspace plans, particularly for those on deprecated editions.
- Some users, like firehorse67, are continuing to pay for specific addons while considering plan upgrades due to unclear communications from Google.
- Questions on API and Bulk Sync Availability: Members inquired about the potential for API access and the ability to sync Google Docs sources in bulk, hoping for implementations this year.
- No concrete information was provided regarding the timeline for these features.
- Issues with YouTube Import Links: Users have reported difficulties with importing YouTube links as sources in NotebookLM, questioning the current functionality of this feature.
- Several users confirmed they are unable to use YouTube links effectively at this time.
- Text and File Size Limitations: Queries about text upload limitations revealed that NotebookLM has a maximum of 500,000 words per source and 50 sources per notebook.
- If users exceed these limits, the system is expected to notify them, particularly if they attempt to exceed the word count.
- Website Scraping Capabilities: Participants discussed the lack of features for scraping entire websites into NotebookLM, confirming that users must download files manually for input.
- A Chrome extension was suggested as a workaround for downloading multiple files, but no integrated scraping functionality exists.
- The future of AI-powered work for every business | Google Workspace Blog: The best of Google AI is now included in Workspace Business & Enterprise plans, giving you AI features like Gemini and NotebookLM Plus with no add-on needed.
- Bora's Law: Intelligence Scales With Constraints, Not Compute: This is a working paper exploring an emerging principle in artificial intelligence development.
- Notebooks - NotebookLM Help: no description found
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Turn on or off additional Google services - Google Workspace Admin Help: no description found
- NotebookLM Help: no description found
Cohere ▷ #discussions (34 messages🔥):
Discord bot API usage, Inefficiency in project, LLM interface and APIs, Payment issues with production key, Learning resources for programming
- Discord bot successfully uses API: A member created a Discord bot using the API on their first try, though they humorously noted its inefficiency.
- It seems to waste many tokens as the process involves running a poorly optimized jar file and reading its console output.
- Redesigning the project setup: There's a suggestion to restructure the project process, highlighting that using Node libraries for LLMs would improve efficiency.
- A member mentioned they learned about activating separate jar files, indicating that their understanding of the process is evolving.
- Understanding API communication: Members discussed how communicating with APIs is fundamentally about sending JSON payloads and receiving responses, linking it to curl commands.
- One member expressed uncertainty about transitioning from Java or Python to Node for API communication, feeling skilled yet lacking foundational knowledge.
- Addressing payment issues for production keys: A member reported problems with saving their payment method for a production key, suggesting it might be location-based.
- Others advised reaching out to support and checking the option to use OpenRouter, which proxies all Cohere models.
- Seeking learning resources: A member inquired about learning resources for making API calls with Node, implying a desire for structured guidance.
- Another member suggested specifying response length in prompts as a way to control the output from the API.
Cohere ▷ #questions (25 messages🔥):
Context length of 128k tokens, Cohere API key limits, Rerank model performance decline, Audio noise reduction recommendations, Updating Command R models
- Cohere's context length sets new token limits: The context length for Cohere's models is set at 128k tokens, allowing for approximately 42,000 words in a single chat without losing context throughout the entire conversation.
- Users clarified that this length applies to the entire timeline of interactions within one chat.
- Cohere API keys have request limits: Users inquired whether API keys have token limits or just call limits and determined that it is based on requests, referencing Cohere's rate limit documentation.
- This includes various rate limits for different endpoints, such as 20 calls per minute for chat on trial keys.
- Rerank model performance facing issues: A user reported declining performance with Cohere’s rerank-v3.5 model, stating that it only yields good results when using the latest user query instead of the full conversation history.
- They mentioned they tested another service, Jina.ai, with better results and sought clarification on the issue, receiving support contact details for troubleshooting.
- Seeking advanced audio noise reduction methods: A user requested recommendations for state-of-the-art noise suppression algorithms, though another participant noted that the cohort does not specialize in audio models.
- Despite the lack of relevant expertise, they inquired about specific techniques and implementations for audio noise reduction.
- Wish for updated Command R models: Discussion arose regarding the desire for continuous updates to Command R and R+ models using new data and fine-tuning techniques, rather than developing entirely new models.
- Another user pointed out that updating knowledge with retrieval-augmented generation (RAG) applied to existing models is an effective approach.
- Different Types of API Keys and Rate Limits — Cohere: This page describes Cohere API rate limits for production and evaluation keys.
- How Cohere will improve AI Reasoning this year: Aidan Gomez, CEO of Cohere, reveals how they're tackling AI hallucinations and improving reasoning abilities. He also explains why Cohere doesn't use any out...
Cohere ▷ #api-discussions (10 messages🔥):
Cohere Client Initialization Error, Payment Method Issues for Production Key, Use of Cohere ClientV2
- Cohere Client Initialization Error: A user reported encountering a TypeError regarding unexpected keyword argument 'token' while initializing the Cohere client with
Client(client_name="YOUR_CLIENT_NAME", token="token").- Another member suggested using the updated initialization method with
cohere.ClientV2("<to avoid this error.>")
- Another member suggested using the updated initialization method with
- Payment Method Issues for Production Key: A user expressed frustration about being unable to purchase a production key due to issues saving their payment method.
- It was noted that certain locations might face card issues, prompting a request for the user's location to investigate further.
Cohere ▷ #cmd-r-bot (13 messages🔥):
Cohere Bot Interactions, Counting to 10, Searching Documentation
- Cohere Bot interacts playfully: A user prompted the Cohere Bot to count to 10, which it did efficiently, responding with 1 to 10 sequentially.
- This engagement highlights the casual and interactive nature of the bot's functionality.
- Searching for Specific Guidance: A user inquired about how to integrate the word of God into a spot of mediocreness, prompting the bot to search documentation for relevant guidance.
- The bot acknowledged its inability to find specific information regarding this inquiry, displaying the limitations of its current database.
- Documentation Limitations Revealed: Despite efforts to find relevant documentation about the word of God, the bot ultimately failed to locate satisfactory information for the user's queries.
- The situation emphasizes the bot's dependency on the existing documentation and its inability to provide detailed insights when resources are not available.
Cohere ▷ #cohere-toolkit (6 messages):
Moderator Recruitment, Community Contributions
- New Moderator Aspirations face Reality: A member expressed willingness to help as another moderator in the community, stating, feel free to dm me if you need another moderator.
- However, another member humorously remarked that getting mod status isn’t that simple, stressing that contributions matter.
- Advice on Gaining Mod Recognition: A member advised that to become a moderator, one should start contributing to the community to demonstrate their value over time.
- This advice was well-received, with the aspiring mod acknowledging the recommendation: You're absolutely right, man! Thanks for the recommendation!
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Mistral coding model, Minimax-01 release
- Mistral drops new top-line coding model: The new Fill-In-The-Middle (FIM) coding model from Mistral has been released, marking a significant advancement in coding models. Users can request the model through the Discord channel as it is currently not available for direct access.
- This model promises to be a top performer in its category, emphasizing its unique capabilities beyond just FIM.
- Minimax-01 sets new records: The first open-source LLM, Minimax-01, is now available and has impressively passed the Needle-In-A-Haystack test at a remarkable 4M context length. More details can be found on the Minimax page.
- To access this model, interested users are directed to the same Discord server for requests.
- Tweet from OpenRouter (@OpenRouterAI): New top-line FIM (fill-in-the-middle) coding model from @MistralAI is out!
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
OpenRouter (Alex Atallah) ▷ #general (80 messages🔥🔥):
DeepSeek API issues, Token limit inconsistencies, Provider performance, Model removal, Prompt caching
- DeepSeek experiencing performance issues: Many users reported problems with the DeepSeek API, experiencing inconsistent response times and errors while trying to access the service.
- Nicholaslyz noted that all DeepSeek v3 providers have been facing latency issues recently, particularly with first token responses.
- Inconsistencies in token limits: Users expressed frustration over DeepSeek's handling of token limits, where claims of 64k tokens can suddenly drop to 10-15k without warning.
- Amoomoo highlighted how this impacts development, as unexpected errors undermine the reliability of their
- Concerns about model removal: A user inquired about the potential removal of the model lizpreciatior/lzlv-70b-fp16-hf, stating they encountered a no endpoint error.
- Toven responded, indicating that there may no longer be a provider available for that model.
- Performance of various providers debated: There was discussion about the performance disparities between DeepSeek and other providers, with some noting TogetherAI and NovitaAI had higher latencies.
- Nilaier mentioned that while the OpenRouter website displayed high latency for those two providers, DeepSeek and DeepInfra maintained more manageable response times.
- Prompt caching functionality: A user inquired about whether the OpenRouter supports prompt caching for models like Claude.
- Toven confirmed that caching is supported, linking to the documentation for more details.
- Prompt Caching | OpenRouter: Optimize LLM cost by up to 90%
- Requests | OpenRouter: Handle incoming and outgoing requests
- DeepSeek V3 – Uptime and Availability: Uptime statistics for DeepSeek V3 across providers - DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-...
- MiniMax-Intelligence with everyone: no description found
- Dum Suspense GIF - Dum Suspense Climax - Discover & Share GIFs: Click to view the GIF
- MiniMaxAI/MiniMax-Text-01 · Hugging Face: no description found
OpenAI ▷ #ai-discussions (62 messages🔥🔥):
AI and Neural Feedback Loop, ISO 42001 Certification for AI, AI Limitations in Conversation Context, ChatGPT's API and Performance Discrepancies, Generative AI Hype and Market Reality
- Innovative Neural Feedback for AI Interaction: A user proposed the concept of an AI utilizing a neural feedback loop to analyze optimal thinking patterns and guide users to mimic them for better cognitive performance.
- This approach suggests a more proactive role for AI in individual learning and personal development.
- Anthropic Achieves ISO 42001 Certification: Anthropic announced their accreditation under the new ISO/IEC 42001:2023 standard for responsible AI, showing commitment to ethical AI governance.
- This certification helps ensure AI systems are developed and used responsibly, despite skepticism regarding partnerships with companies like Anduril.
- AI's Memory Limitations in Conversations: Members discussed issues with AI forgetting context in conversations, particularly when images are shared, leading to confusion and repetitive reminders.
- One suggested that the brief retention period of images could be a reason for AI's quick memory loss.
- ChatGPT's API Performance Variance: Discussions indicated that while using ChatGPT, free users experienced limitations in quality and functionality, particularly with web searches compared to Plus users.
- Some users highlighted discrepancies between the capabilities of different tiers, noting a decrease in performance for free API access.
- Declining Hype for Generative AI Applications: Users expressed that the excitement surrounding generative AI has diminished due to limited applications, feeling restricted to text, images, and videos.
- Concerns were raised about the costs associated with high-quality AI outputs, which may deter wider adoption.
- Mistral AI | Frontier AI in your hands: Frontier AI in your hands
- Anthropic achieves ISO 42001 certification for responsible AI: We are excited to announce that Anthropic has achieved accredited certification under the new ISO/IEC 42001:2023 standard for our AI management system. ISO 42001 is the first international standard ou...
- MiniMax - Intelligence with everyone: no description found
OpenAI ▷ #gpt-4-discussions (6 messages):
Custom GPT uploads, GPT-4o Tasks, Canvas feature on web, Model limitations
- Custom GPT uploads disappearing: A member reported that the files uploaded to their Custom GPT knowledge base have disappeared, questioning if it might be a bug.
- Concerns were raised about the reliability of the upload feature for managing important data.
- Custom GPTs limited by model type: It was noted that Custom GPTs are based on a lower model and do not have access to memory from other sessions.
- Members discussed that they can only operate effectively if fed with alternative data.
- Canvas feature replaced by tasks: Canvas has seemingly been replaced by a tasks interface on the desktop web version, as mentioned by a member.
- Another member confirmed that a toolbox icon near the text entry box still provides access to the Canvas feature.
- Functionality of GPT-4o Tasks: Tasks in GPT-4o were described as timed actions that can remind users to perform specific activities at set times.
- These include notifications for tasks like practicing languages or receiving news updates at designated times.
OpenAI ▷ #prompt-engineering (5 messages):
Assistants referencing docs, API related questions, Humanization prompt, Prompt engineering, Scripting support
- Struggles with Assistants referencing docs: A user expressed difficulty in getting their Assistants to stop referencing documentation at the end of responses.
- They were seeking advice on where to implement a solution in the playground.
- API limitations in the playground: Another user clarified that the issue cannot be resolved in the playground, as it is related to API configurations rather than prompt engineering.
- They referred to a previous discussion link for further details on this topic.
- Friendly humanization prompt discussion: One participant shared their humanization prompt intended to make text more accessible for second language speakers.
- The goal was to simplify the text while retaining specific terminologies.
- Community support and scripting: The conversation highlighted the community's willingness to assist users with scripting issues related to their Assistants.
- Participants expressed encouragement and offered help to resolve users’ coding challenges.
OpenAI ▷ #api-discussions (5 messages):
Assistants referencing docs, API concerns in Playground, Humanization prompt for AI
- Assistants keep referencing docs: A user expressed frustration about their Assistants frequently referencing the documentation in their responses.
- They sought advice on where to insert code to prevent this issue in the Playground, leading to a suggestion from another member.
- API clarification for Playground: A member clarified that the issue with referencing docs can't be addressed in the Playground, as it relates to API usage rather than prompt engineering.
- They provided a link for further clarification on this topic, reinforcing that it falls outside the scope of the Playground.
- Humanization prompt for AI content: One user shared a prompt aimed at making AI-generated content more accessible to second language speakers by simplifying the language used.
- The focus was on avoiding rare words and complex sentence structures while maintaining field-specific terminology.
LM Studio ▷ #general (66 messages🔥🔥):
Model Fine-Tuning Techniques, User and Assistant Modes, Context Window and Memory Usage, Model Loading Issues, Image Analysis with Models
- Exploring Fine-Tuning of Models: A user is considering fine-tuning models with specific public domain texts of an author, improving output quality through directive prompts.
- They are transitioning to Google CoLab for fine-tuning, noting Python is new to them but expressing excitement about utilizing LLMs for writing.
- Understanding User vs Assistant Mode: User mode allows users to send messages as themselves, while Assistant mode lets them respond as the AI, helping control the conversation flow.
- Users clarified that in Assistant mode, their responses are perceived as AI-generated content, shaping the context of the interaction.
- Managing Context Window Limitations: Users discussed the 'context is 90.5% full' notification, which indicates how much of the context window is currently used in the model.
- Adjusting context size was suggested, but users were warned that larger context increases the memory footprint of the model.
- Resolving Model Loading Problems: Users shared experiences with loading models and troubleshooting errors related to high memory usage and system specifications.
- Discussions touched on potential solutions like adjusting model layers and settings to optimize performance on varying hardware.
- Image Analysis Capabilities with LLMs: Several users reported difficulties in getting models like QVQ-72B and Qwen2-VL-7B-Instruct to analyze images correctly.
- Ensuring that runtime environments are up to date was emphasized as crucial for successful image analysis functionality.
LM Studio ▷ #hardware-discussion (11 messages🔥):
Comparative Inference Speeds, GPU Parallelization Limitations, Power Efficiency of GPUs, Model Layer Distribution
- Comparing Inference Speeds of GPUs: A discussion revealed that 2x RTX 4090 cards could potentially achieve 19.06 t/s compared to the RTX A6000 48GB at 18.36 t/s under certain conditions.
- One participant suggested that if considering the 4090's memory speed advantage, the A6000's score could be corrected to 19.27 t/s.
- Power Efficiency Gains: A participant highlighted that using 2x RTX 4090 cards results in significantly less power consumption compared to the alternatives.
- This point emphasized the importance of efficiency alongside performance when choosing hardware for inference.
- Limits of Parallelization in Inference: There was skepticism about parallelizing inference across GPUs when the model fits in one GPU's memory, with discussions on placing half the layers on each card.
- Participants pointed out that synchronizing outputs post-layer may introduce latency or bandwidth issues over PCIe.
- Distribution of Model Layers Across GPUs: The idea of distributing full model layers on each GPU to compute half the nodes was debated, yet identified as potentially limited by necessary synchronization.
- Concerns were raised regarding the feasibility of this approach given the advanced research already conducted in the field.
- Usage of Claude with LM Studio: A member shared a link to an image demonstrating a tool created with Claude intended for use with LM Studio.
- This brought attention to practical applications of AI models in conjunction with existing software solutions.
aider (Paul Gauthier) ▷ #general (36 messages🔥):
DeepSeek performance issues, Aider with code editing, Using GPUs for model execution, AI content clickbait discussions, GitHub bots integration
- DeepSeek V3 struggles with speed: Several users reported that DeepSeek V3 is performing slowly, with one stating it was completely stuck and unable to process any tokens.
- Others have opted to switch to Sonnet for better performance during this downtime.
- Aider's editing functionality: A user questioned whether Aider allows options to 'accept' or 'reject' the model's editing plans before execution, as opposed to just running changes directly.
- Another user clarified that this is essentially what architect mode in Aider is designed to do.
- Discussion on AI content clickbait: One user mocked another's tendency towards clickbait content, humorously likening it to a used car salesman promoting an inferior vehicle.
- Responses indicated a shared frustration with misleading AI content while acknowledging the need for quick updates on new tools.
- GPU requirements for model execution: There was a discussion about required GPU specifications for running models efficiently, with one user suggesting that an RTX 4090 is sufficient.
- Others discussed the need for high RAM when working with larger models, citing potential compatibility issues.
- Building GitHub bots with Aider: A user inquired if anyone had successfully created GitHub bots utilizing the Aider framework.
- This indicates a growing interest in the practical applications of the Aider tool for automated tasks in software development.
- unsloth/DeepSeek-V3-GGUF · What is the required GPU size to run Is a 4090 possible and does it support ollama: no description found
- Reddit - Dive into anything: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Reddit - Dive into anything: no description found
- aider/benchmark/README.md at main · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- LLM Model VRAM Calculator – SillyTavern: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (22 messages🔥):
Repository-map size concerns, Agentic tools for code exploration, Aider API call logging, Git commit issues with Aider, o1-preview API performance
- Repository-map size increases curiosity: A member noticed the repository-map grew from 2k to 8k with a mid-size project and questioned if recent updates influenced this change.
- Another shared that a small repo-map becomes inefficient with more than 5 files, suggesting a correlation.
- Agentic tools rule for codebase exploration: One user mentioned using agentic tools like cursor's chat and windsurf for codebase exploration, stating these tools are superior to standard repo maps.
- They emphasized that for implementation, Aider excels unmatched, making it their primary choice despite using additional tools for exploration.
- No logging for Aider API calls: A user inquired about a method for Aider to log LLM API calls, revealing that chat history does not include complete API call data.
- A response confirmed that currently, there is no solution before locally running Aider and dumping to a database.
- Challenges with Git commits in Aider: Another user reported that although Aider made changes in a cloned repository, it did not perform any commits despite settings being correct.
- Member advice indicated that using architect mode may help; one even submitted a PR to improve troubleshooting guidance.
- Performance issues with o1-preview: Concerns were raised about the o1-preview API call speed, with one user commenting that it seems to have become slower.
- Another user confirmed that while they use it occasionally, it consumes many tokens and takes longer to respond, indicating potential inefficiencies.
Link mentioned: docs: Add architect mode section to edit errors troubleshooting guide by golergka · Pull Request #2877 · Aider-AI/aider: no description found
aider (Paul Gauthier) ▷ #links (2 messages):
Repomix, AI-friendly codebase packaging, Repopack, API call optimization
- Repomix Offers AI-Friendly Packaging: A member highlighted Repomix as a useful tool for packing codebases into AI-friendly formats.
- This could streamline integration efforts with LLMs for enhanced efficiency.
- Minimizing API Calls for Aider: A user noted that tracking developments since Repopack could be beneficial for managing a minimized version of API calls for Aider.
- This approach aims to optimize the data sent to LLMs.
Link mentioned: Tweet from Repomix: Pack your codebase into AI-friendly formats
Modular (Mojo 🔥) ▷ #general (4 messages):
Docs font weight update, User feedback on readability
- Docs font becomes thicker for better readability: The docs font weight has been updated to be thicker, aiming to improve readability.
- Feel free to share more feedback if not suggests an openness to further adjustments based on user input.
- Positive user feedback on font change: Users expressed satisfaction with the update, noting that this change is much better for readability.
- One user responded with a simple acknowledgment of the improvement, reinforcing the positive reception.
Modular (Mojo 🔥) ▷ #mojo (41 messages🔥):
Function Support in Mojo, Zed Preview Extension, SIMD Performance, Recursive Types in Mojo
- Lambda Functions Still Unsupported: Users confirmed that Mojo does not currently support
lambdasyntax, but functions can be passed as parameters instead.- One user shared a roadmap document illustrating planned features in Mojo.
- Getting Mojo in Zed Preview: Members discussed how to install Mojo in Zed Preview, noting that the same installation method as the stable version works.
- Users confirmed code-completion works after adding necessary settings, although some faced issues when missing configurations.
- Performance Footguns with SIMD Usage: Concerns were raised about potential performance issues when using
SIMD, as results can vary by CPU architecture and implementation.- Users suggested checking assembly output for any excessive register shuffling to ensure it’s worthwhile.
- Challenges with Recursive Types in Mojo: There were discussions around the difficulties of implementing recursive types in Mojo, with suggestions to use pointers instead.
- A user referenced prior attempts at creating a tree structure and pointed to relevant GitHub issues for further context.
- Ice Lake AVX-512 Downclocking: Examining the extent of AVX related downclocking on Intel’s Ice Lake CPU
- Mojo🔥 roadmap & sharp edges | Modular: A summary of our Mojo plans, including upcoming features and things we need to fix.
- run | Modular: runfunc SIMD[float64, 1] = SIMD(60), maxbatch_size: Int = 0) -> Report
- [BUG] --debug-level full crashes when importing · Issue #3917 · modularml/mojo: Bug description Running a mojo script using the debugger seg faults, as opposed to when running regular mojo, which runs to completion (although I have noticed strange behavior in the regular scrip...
- [Help wanted] Evaluating optional argument to not None gives segmentation fault · Issue #3950 · modularml/mojo: Issue description I have a class that needs an optional argument. When evaluating to None, it gives an error. If evaluating to None gives an error, how am i supposed to evaluate it? But also, i may...
Eleuther ▷ #general (2 messages):
Fateful Ping, AI Ranking
- The Fateful Ping brings Chaos: A member humorously described the impact of a single ping that led to widespread chaos and unforeseen consequences.
- They referred to this moment as an 'abomination', reflecting the chaotic atmosphere that followed.
- Ranking in the Top 1% of AI: Another member remarked on the exceptional quality of the previous message, claiming it was literally top 1% in AI.
- This statement suggests that the community values insightful contributions highly.
Eleuther ▷ #research (29 messages🔥):
Critical Tokens in LLMs, VinePPO and CoT Trajectories, NanoGPT Speedrun Record, TruthfulQA Dataset Weaknesses, Human Annotation Issues in Datasets
- Identifying Critical Tokens to Boost LLMs: A recent abstract introduced the concept of critical tokens which are crucial for reasoning tasks in LLMs and can significantly impact model accuracy, particularly in datasets like GSM8K and MATH500.
- The methodology presented suggests identifying and minimizing these tokens could enhance the model's performance, aligning with observations on implicit PRMs.
- Clarifying VinePPO Usage: Members discussed VinePPO, noting it does not require example Chain-of-Thought (CoT) trajectories for its implementation despite initial confusion about its needs.
- Clarifications indicated that offline reinforcement learning (RL) was being leveraged, though there are concerns regarding benchmarks and comparisons.
- New Speed Record set for NanoGPT: Fern.bear reported a new modded-nanoGPT speedrun record of 3.17 minutes, showcasing improvements like new lm_head biases and fused operations.
- This record has prompted discussion on further optimizations like Long-Short Sliding Window Attention for enhanced performance.
- Weaknesses in TruthfulQA Dataset Explored: TurnTrout revealed how subtle weaknesses in the TruthfulQA multiple-choice dataset were exploited to achieve a 79% accuracy, highlighting flaws in even reputed benchmarks.
- This raises important concerns about dataset reliability and influences ongoing dialogues about similar issues observed in other datasets, such as halueval.
- Concerns Over Human Annotations in Datasets: Discussion surfaced around the prevalence of incorrect human annotations in datasets like halueval, often leading to misleading results.
- Members expressed that this problem is widespread, with claims that up to 30% of entries can be ambiguous or erroneous in some vision-language model datasets.
- Tweet from Alex Turner (@Turn_Trout): Mark Kurzeja & I exploited weaknesses in multiple-choice TruthfulQA dataset while hiding the questions! A few simple rules of thumb achieved 79% accuracy.Even well-regarded benchmarks can have flaws. ...
- Tweet from Fern (@hi_tysam): New NanoGPT training speed record: 3.28 FineWeb val loss in 3.17 minutes on 8xH100Previous record (recreation): 3.32 minutesLots of changes!- New token-dependent lm_head bias- Fused several ops- Multi...
- Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability: Mathematical reasoning tasks pose significant challenges for large language models (LLMs) because they require precise logical deduction and sequence analysis. In this work, we introduce the concept o...
- Towards Learning to Reason at Pre-Training Scale: Prompting a Large Language Model (LLM) to output Chain-of-Thought (CoT) reasoning improves performance on complex problem-solving tasks. Moreover, several popular approaches exist to "self-improv...
- GitHub - facebookresearch/coconut: Training Large Language Model to Reason in a Continuous Latent Space: Training Large Language Model to Reason in a Continuous Latent Space - facebookresearch/coconut
- Long-Short Sliding Window Attention (3.2 sec or 0.053 mins improvement) by leloykun · Pull Request #71 · KellerJordan/modded-nanogpt: Currently, we warmup the context length of the sliding window attention at the same rate in all layers. This attempt warms up the context length differently in some layers instead. This leads to a ...
Eleuther ▷ #scaling-laws (5 messages):
Loss vs Compute Plot, Induction Head Behavior, Circuit Interoperability, Pythia Models Training
- Loss vs Compute Plot Doesn't Align: A member questioned if plotting loss vs compute would show all the induction head bumps lying on a straight line, implying a possible correlation.
- Stellaathena clarified that it generally occurs after the same number of tokens, indicating that the answer is no.
- Insights from Anthropic Papers: Further insights were shared regarding findings from the original Anthropic posts and later papers detailing the behavior of circuits during training.
- A specific reference was made to a circuit interoperability paper that shows a plot of circuits emerging over the course of training for different Pythia models view this paper.
Eleuther ▷ #lm-thunderdome (3 messages):
MATH Dataset DMCA, AOps Disclosure
- MATH Dataset Faces DMCA Takedown: The Hendrycks MATH dataset has been hit with a DMCA takedown notice, resulting in the dataset being disabled, as reported by TMK Adamcz.
- A link to the Hugging Face discussion regarding the takedown provides further context.
- AOps Acknowledges Source of Questions: A member noted that the questions in the MATH dataset were sourced from AOPS (Art of Problem Solving).
- It was pointed out that AOPS has always disclosed this information concerning the origin of the questions.
Link mentioned: Tweet from Tom Adamczewski (@tmkadamcz): Hendrycks MATH has just been hit with a DMCA takedown notice. The dataset is currently disabled.https://huggingface.co/datasets/hendrycks/competition_math/discussions/5
Eleuther ▷ #gpt-neox-dev (6 messages):
NeoX model conversion, Learning ranks attribute, Intermediate size configuration, Layer masking issues, Zero stages incompatibility
- NeoX model conversion struggles: A user encountered an error while converting a NeoX model into HF, referencing a GitHub Gist that documents the issue.
- Despite discussions implying fixes in the comments, the user continues to face errors when trying to execute the conversion process.
- Missing 'module' attribute in tp_ranks: Printing out
tp_ranks[0]revealed it lacks a 'module' attribute, causing confusion among users.- The detailed tensor structure shows multiple layers and parameters but does not address the user's concerns about the 'module' attribute.
- Intermediate size confusion in Llama config: A user discovered that the intermediate size should be 3x the expected value according to a recent PR.
- This raises questions about whether the standard of 32768 is appropriate as it doesn’t equate to 3x11008.
- Layer masking issue with Llama 2 config: An update indicated that setting
scaled_upper_triang_masked_softmax_fusionto True caused the model to hang, which was identified through multiple ablation tests.- Turning this setting off resolves the hanging issue, but it contradicts the defaults specified in the Llama 2 configuration.
- Zero stages incompatibility with model parallelism: A user queried the incompatibility of zero stages 2 and 3 with both model and pipeline parallelism in NeoX, stating that DeepSpeed should only require disabling pipeline parallelism.
- The concern highlights the necessity of model parallelism for training large models and questions the utility of DeepSpeed in its absence.
- error.txt: GitHub Gist: instantly share code, notes, and snippets.
- misindexing when converting llama weights to gpt-neox format · Issue #971 · EleutherAI/gpt-neox: Describe the bug After running the convert_raw_llama_weights_to_neox.py with --pipeline_parallel the checkpoint are missing the 2nd and 3rd layers (i.e.): layer_02-model_-model_states.pt layer_03-m...
- fix 'intermediate_size' in Llama configuration files after the 'mlp_type' option was removed by tiandeyu-cs · Pull Request #1309 · EleutherAI/gpt-neox: After the 'mlp_type' option was removed, the regular-type and the llama-type of MLP share the same implementation, and the "mlp_type" is now specified by whether the ...
- gpt-neox/megatron/training.py at f7a5a6f9da47de4d4d7cdf776c0832b257f329ef · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
Latent Space ▷ #ai-general-chat (40 messages🔥):
Cursor AI funding, Transformer² adaptive models, AI tutoring impact in Nigeria, OpenBMB MiniCPM-o 2.6 model, Synthetic data generation with Curator
- Cursor AI Secures Series B Funding: Exciting news as @a16z co-leads the Series B funding for Cursor AI, marking a significant milestone for their continued work in the coding space.
- The community expresses support, with comments highlighting the potential impact and success of Cursor as a large customer for Anthropic.
- Transformer² Revolutionizes Adaptive Models: A new system called Transformer² from @SakanaAILabs dynamically adjusts its weights for various tasks, blurring the lines between pre-training and post-training.
- It ties into concepts of adaptation and self-improvement, with capabilities similar to how an octopus blends into its environment.
- AI Tutoring Shows Remarkable Gains in Nigeria: A recent trial shows that after six weeks of GPT-4 tutoring, students in Nigeria achieved learning gains equivalent to two years, outperforming 80% of other educational interventions.
- The pilot program demonstrates the potential of AI to support education, particularly benefiting disadvantaged groups such as girls.
- New Multimodal Model: OpenBMB MiniCPM-o 2.6: The newly released MiniCPM-o 2.6 features 8 billion parameters and supports vision, speech, and language processing on edge devices.
- With impressive benchmarks, it offers best-in-class bilingual speech capabilities and seamless multimodal integration across various platforms.
- Curator: An Open-source Tool for Synthetic Data: The new tool Curator aims to enhance productivity in generating synthetic data for AI training and evaluation.
- It addresses gaps in tooling and is expected to release more features that bolster its application in post-training datasets.
- Tweet from Sarah Wang (@sarahdingwang): Thrilled to announce that @a16z is co-leading the Series B of @cursor_ai. We couldn't be more excited to continuing working with the Cursor team as they take the world of coding by storm.
- Tweet from Ethan Mollick (@emollick): New randomized, controlled trial of students using GPT-4 as a tutor in Nigeria. 6 weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interven...
- Tweet from François Chollet (@fchollet): I'm joining forces with @mikeknoop to start Ndea (@ndeainc), a new AI lab.Our focus: deep learning-guided program synthesis. We're betting on a different path to build AI capable of true inven...
- Tweet from Samuel Colvin (@samuel_colvin): We've just released @Pydantic AI v0.0.19.This comes with the biggest new feature since we announced PydanticAI — graph support!I was originally cynical about graphs, but I'm now really excited...
- Tweet from Mahesh Sathiamoorthy (@madiator): We are happy to announce Curator, an open-source library designed to streamline synthetic data generation!High-quality synthetic data generation is essential in training and evaluating LLMs/agents/RAG...
- Tweet from hardmaru (@hardmaru): Transformer²: Self-adaptive LLMshttps://arxiv.org/abs/2501.06252This new paper from @SakanaAILabs shows the power of an LLM that can self-adapt its weights to its environment. I think in the future, t...
- Tweet from Sakana AI (@SakanaAILabs): We’re excited to introduce Transformer², a machine learning system that dynamically adjusts its weights for various tasks!https://sakana.ai/transformer-squaredAdaptation is a remarkable natural phenom...
- Tweet from Ethan Mollick (@emollick): New randomized, controlled trial of students using GPT-4 as a tutor in Nigeria. 6 weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interven...
- Tweet from jack morris (@jxmnop): posted the other day about model distillation. pretty much everyone responded with their theoriesprofessors, leading lab researchers, students, pseudoanonymous anime-profile postersseems there's n...
- Tweet from Synthesia 🎥 (@synthesiaIO): 🎉 Big news: We’ve raised $180 million in Series D funding 🎉Plenty of work still ahead, but the path forward has never been clearer.Of course, none of this would be possible without our amazing custo...
- Introducing: The Managed-Service-as-Software (M-SaS) Startup: A technology disruption like AI is especially powerful for startups when paired with a business model disruption.
- EvalPlus Leaderboard: no description found
- How the Hedge Fund Magnetar Is Financing the AI Boom: Épisode de balado · Odd Lots · 2024-12-09 · 50 min
- Tweet from Philipp Schmid (@_philschmid): New open Omni model released! 👀@OpenBMB MiniCPM-o 2.6 is a new 8B parameters, any-to-any multimodal model that can understand vision, speech, and language and runs on edge devices like phones and tab...
- Anthropic cannot sustain additional slow request traffic on Claude 3.5 Sonnet. Please enable usage-based pricing: We are without a doubt their largest customer.
- From chalkboards to chatbots: Transforming learning in Nigeria, one prompt at a time: "AI helps us to learn, it can serve as a tutor, it can be anything you want it to be, depending on the prompt you write," says Omorogbe Uyiosa, known as "Uyi" by his friends, a student...
- Reddit - Dive into anything: no description found
- Speech AI has 10x’d: purpose, evaluation, and products: How can we use computers' verbal intelligence to improve user experiences?
- MiniMax - Intelligence with everyone: no description found
- Did AI Cause Those Layoffs? NY Employers May Have To Disclose.: New York State announced a significant step to address the potential workforce impacts of AI by requiring businesses to disclose layoffs explicitly tied to AI adoption
- no title found: no description found
Latent Space ▷ #ai-announcements (1 messages):
NVIDIA Cosmos, CES presentation, LLM Paper Club
- NVIDIA Cosmos Launch at CES: A member announced that <@538564162109046786> will present the paper/model NVIDIA Cosmos launched at CES in 40 minutes at the LLM Paper Club event.
- Attendees are encouraged to join using the provided link to participate in the discussion on this new model.
- Event Registration Reminder: Participants were reminded to register for the event to receive notifications about new events from Latent.Space.
- Additionally, they were instructed to click the RSS logo to add the event to their calendar.
Link mentioned: LLM Paper Club (NVIDIA Cosmos) · Zoom · Luma: Ethan He is back to share the latest from Nvidia CES: the Cosmos World Foundation Models:https://github.com/NVIDIA/Cosmos---we need YOU to volunteer to do…
GPU MODE ▷ #triton (6 messages):
Triton dependency on Torch, cuBLAS equivalent for Triton, Triton pointer type error
- Triton needs Torch for functionality: A user inquired if Triton has a run-time dependency on Torch and whether it’s possible to use Triton with CUDA without it, citing issues with conflicting dependency versions.
- They noted the latest Triton version is 3.2, which isn't compatible with Torch 2.5.1, creating challenges for its installation without losing access to necessary documentation.
- Exploring cuBLAS alternatives for Triton: A user asked if there exists an equivalent of cuBLAS tailored for Triton, suggesting a need for GPU-accelerated linear algebra operations.
- However, no specific alternatives or solutions were discussed in response to this question.
- ValueError in Triton code due to pointer type: A user reported encountering a ValueError related to an unsupported pointer type when using the
tl.loadfunction in their Triton code.- Another member suggested that the pointer type should be float rather than int, emphasizing that pointers should be scalars representing memory addresses.
Link mentioned: Redirecting to https://triton-lang.org/main/index.html: no description found
GPU MODE ▷ #cuda (3 messages):
RTX 50x Blackwell cards, Hopper TMA features
- Speculation on RTX 50x Cards Having TMA: A member inquired if the RTX 50x Blackwell cards will feature the TMA like the Hopper architecture.
- Unfortunately, it was noted that without the whitepaper, definitive answers remain elusive.
- Awaiting Confirmation on Features: There is a general uncertainty regarding the features of the RTX 50x Blackwell cards, particularly the TMA functionality.
- Community members expressed frustration over the lack of concrete information until the official whitepaper is released.
GPU MODE ▷ #torch (2 messages):
Batching Tensors to GPU, Torch Compiler Material
- Batching Tensors to GPU minimizing CPU Overhead: A member inquired if there's a method to transfer a batch of tensors to the GPU without incurring high CPU overhead from iterating and calling
.to(device)repeatedly.- They mentioned experiencing too much lag due to this approach, as illustrated in an attached image.
- Seeking Detailed Understanding of Torch Compiler: Another member expressed the need for resources on how the torch compiler works, specifically looking for a comprehensive breakdown during neural network compilation.
- They have already found slides from ASPLOS 2024 but couldn't locate video content or more in-depth material to support their learning.
GPU MODE ▷ #algorithms (2 messages):
MiniMax-01, Lightning Attention Architecture, Open-Source Model Release, Ultra-Long Context Processing, Cost-Effective AI Solutions
- MiniMax-01 Launches Open-Source Models: MiniMax has introduced its latest open-source models: MiniMax-Text-01 and MiniMax-VL-01 with innovative architecture.
- The models feature a novel Lightning Attention mechanism, setting a new standard for model performance in AI.
- Lightning Attention Mechanism Debuts: The Lightning Attention architecture marks the first large-scale implementation of its kind, providing a powerful alternative to traditional Transformers.
- This innovation is set to redefine context handling in AI applications.
- Unprecedented Ultra-Long Context of 4M Tokens: MiniMax-01 can efficiently process up to 4M tokens, significantly outperforming existing models by 20 to 32 times.
- This capability positions MiniMax-01 as a leader for the upcoming increase in agent-related applications.
- Cost-Effective AI Solutions Introduced: The new models offer industry-leading pricing, with APIs available for just USD $0.2 per million input tokens and USD $1.1 per million output tokens.
- This competitive pricing supports continuous innovation in AI deployment.
- Further Information and Resources Available: Users can access the detailed research paper here for insights on MiniMax-01.
- For additional information, check the announcement on MiniMax's news page.
Link mentioned: Tweet from MiniMax (official) (@MiniMax__AI): MiniMax-01 is Now Open-Source: Scaling Lightning Attention for the AI Agent EraWe are thrilled to introduce our latest open-source models: the foundational language model MiniMax-Text-01 and the visua...
GPU MODE ▷ #cool-links (3 messages):
Training with bfloat16, GPU animation insights, GPT-3 architecture access
- Weight decay essential for bfloat16 training: A notable suggestion emphasized that weight decay should be used when training with bfloat16 to avoid divergence, as highlighted in Fig 8 of the paper.
- This practical advice aims to enhance the performance of models utilizing bfloat16.
- A100 Animation Gains Attention: A shared tweet noted that everyone working with GPUs needs to internalize the insights from a brilliant animation of the A100 GPU by @vrushankdes.
- The animation sparked interest and discussion on GPU capabilities and optimizations, with a link here.
- Questions on GPT-3 Architecture Access: A member questioned how vendors participating in MLPerf access the architecture and weights of GPT-3, given that they are not open-sourced.
- This raised discussions around the accessibility and proprietary nature of model architectures in the competitive landscape of machine learning.
Link mentioned: Tweet from Fleetwood (@fleetwood___): Everyone working with GPUs needs to internalise this.A100 version of @vrushankdes's animation
GPU MODE ▷ #beginner (2 messages):
LLM inference with single GPU, LLM inference with multiple GPUs, VRAM requirements for serving multiple requests, Batch processing requests, Parallelism strategies for multi-GPU setups
- Serve Multiple Users on One GPU: You can serve multiple users with a single GPU by utilizing batched requests, but the maximum number of simultaneous requests depends on the available VRAM for KV cache.
- Without sufficient VRAM, you could run into performance bottlenecks while handling requests.
- Multi-GPU Setup Inference: In a multi-GPU setup, you can handle more requests simultaneously due to the increased available VRAM, but you need to use a parallelism strategy to partition the model weights.
- This approach allows multiple GPUs to work efficiently without overlapping memory constraints.
GPU MODE ▷ #metal (2 messages):
MPS Kernel Profiling, Debugging GPU Trace, Metal Compiler Flags
- MPS Kernel Profiling Issues: A user reported difficulty profiling a kernel on MPS, noting that Xcode indicated an empty GPU trace despite using
getMPSProfiler(). They ensured profiling was initiated withstartCapture('kernel', stream)and stopped withstopCapture(stream).- Synchronization issues were implicated in the empty trace, prompting further troubleshooting.
- Encountering Debug Info Access Problems: Following a successful capture, the user faced challenges accessing debug info, indicated by a troubling screenshot linked in their message. They had set Metal flags including
-Wall -Wextra -gline-tables-only -frecord-sourceswhen running their Python setup.- The implications of these flags on the debug output appear to be unclear, contributing to ongoing discussions about optimizing debug info visibility.
GPU MODE ▷ #self-promotion (1 messages):
Thunder Compute, Cloud GPU Pricing, Y Combinator, Instance Management Tool
- Thunder Compute Launches Cloud GPU Service: Co-founders announced Thunder Compute, aiming to make cloud GPUs cheaper, with A100 instances priced at $0.92/hr and a trial of $20/month free available for new users on their website.
- The service is currently in beta, leveraging GCP or AWS for hosting to maximize uptime, and includes a command-line tool for instance management.
- Y Combinator Alumni Strengthens Team: Thunder Compute's team of three recently completed the Y Combinator program this summer, enhancing their credibility and network in the tech space.
- They are actively seeking user feedback to improve their offerings, showcasing a strong commitment to community engagement.
- Easy Instance Management with CLI: Users can manage cloud GPU instances seamlessly using the CLI with a simple installation command: pip install tnr.
- The platform promises an efficient setup process, allowing users to create instances tailored to their specifications with minimal hassle.
Link mentioned: Thunder Compute: Low-cost GPUS for anything AI/ML: Train, fine-tune, and deploy models on Thunder Compute. Get started with $20/month of free credit.
GPU MODE ▷ #🍿 (12 messages🔥):
Modal Registry for Popcorn Bot, GPU Type Handling, Creating Modal Functions, Using nvidia-smi for GPU Capability, Discord Leaderboard Implementation
- Systematizing Modal Registry: A member is exploring a more elegant solution for the modal registry in the popcorn bot, specifically trying to create Modal Functions for different GPU types without hacks.
- The conversation shifts to the limitations of decorating functions for Modal, emphasizing the importance of having distinct function versions for structured infrastructure.
- Understanding GPU Type Implementation: Discussion reveals the need to specify GPU types in decorators when creating Modal Functions, which complicates partial application of functions.
- The underlying aim is to create various Modal endpoints with fixed arguments for simplicity and functionality.
- Future Introspection Plans for GPU Types: In future plans, the team aims to enable introspection of GPU types directly within Modal Functions, potentially checking GPU specifics dynamically.
- This anticipation may streamline the creation of Modal Functions in the popcorn bot, reducing manual configuration for each function.
- Utilizing Device Query for GPU Information: To identify GPU compute capabilities, a member suggests using the deviceQuery utility included in CUDA installations, emphasizing the ability to check compute specs programmatically.
- This approach might offer a workaround for setting the correct architecture from the discord bot side while maintaining clean code.
- Flexibility in Architecture Setting: A workaround is proposed where the correct architecture is set from the discord bot side, which could allow users to call different GPU endpoints.
- Interestingly, this feature could yield insights on performance variations by compiling for different architectures.
Link mentioned: What utility/binary can I call to determine an nVIDIA GPU's Compute Capability?: Suppose I have a system with a single GPU installed, and suppose I've also installed a recent version of CUDA. I want to determine what's the compute capability of my GPU. If I coul...
GPU MODE ▷ #thunderkittens (6 messages):
Onboarding Documentation, Kernel Options, Linking Resources, Manual Creation
- Onboarding Documentation Now Available: A member shared the addition of basic onboarding documentation to TK, inviting feedback through comments.
- Comment-mode is activated for users to suggest clarifications or highlight issues that may need addressing.
- Interest in Onboarding: Members expressed enthusiasm regarding the onboarding documentation, indicating a keen interest in reviewing it.
- One member specifically noted they would check the document promptly.
- Discussion on Resource Linking: A question arose about the potential creation of a formal manual from the new documentation for the TK repository, as interest in linking resources was expressed.
- The original document owner indicated the current document could suffice for now, with potential for more extensive resources in the future.
- Kernel Options Added: The document's author mentioned they have included a couple of kernel options in the onboarding documentation.
- They also offered assistance for anyone interested in trying out the listed options.
Link mentioned: TK onboarding: Summary This document specifies how to get started on programming kernels using TK. Please feel free to leave comments on this document for areas of improvement / missing information. Summary 1 Back...
LlamaIndex ▷ #blog (3 messages):
RAG applications with LlamaParse, Improving knowledge graphs with LlamaIndex workflows, LlamaIndex and Vellum AI partnership
- Build RAG Applications with LlamaParse: Learn to build a RAG application using LlamaParse, LlamaCloud, and AWS Bedrock with an efficient document parsing approach.
- This step-by-step guide covers everything from parsing SEC documents to managing indices.
- Transform Knowledge Graphs using LlamaIndex: Tomaz Bratanic of @neo4j showcases how to dramatically improve the accuracy of knowledge graph applications by applying agentic strategies with LlamaIndex workflows in his comprehensive post.
- He builds from a naive text2cypher implementation to a more robust agentic approach, enhancing overall performance with proper error handling.
- LlamaIndex Partners with Vellum AI: The team announced a partnership with @vellum_ai, sharing valuable use-case data from their survey conducted together here.
- This cooperation aims to further explore the applications and use cases within the ecosystem.
LlamaIndex ▷ #general (23 messages🔥):
XHTML to PDF conversion utilities, Choosing a vector database, Workflow design with HITL steps, Difference between agents and workflows, User sign-up issues
- Seeking good XHTML to PDF conversion tools: A member shared their struggles with various libraries like pandoc, wkhtmltopdf, and weasyprint, stating that only Chromium offers good conversion from XHTML to PDF.
- They provided links to an example XHTML doc and an example HTML doc.
- Choosing a vector database for production: A user is considering switching from Pinecone to either pgvector or Azure AI search due to cost concerns for handling 20k documents.
- They sought advice on what to look for when making this decision, particularly regarding the integration with Azure.
- Challenges in HITL workflow design: A member detailed their workflow implementation with HITL steps and expressed challenges with marking a step as completed when pausing for human input.
- They needed to ensure the workflow checkpointed correctly to reflect the completion of the step that emitted the UserInputRequestEvent.
- Understanding agents versus workflows: There was a discussion on the distinction between agents and workflows, concluding that workflows can be broader, while agents are more specific implementations that involve decision-making and tool usage.
- One member emphasized that the definition of an 'agent' might vary, suggesting users focus on building necessary applications rather than getting caught up in labels.
- User sign-up issue resolved: A user reported difficulties signing up but was informed that the issue was due to a temporary error related to auth upgrades that has since been resolved.
- Another user echoed the concern and mentioned it would be helpful to have official communication regarding such errors.
- Vector Stores - LlamaIndex: no description found
- RAG Workflow with Reranking - LlamaIndex: no description found
- python-agents-tutorial/5_memory.py at main · run-llama/python-agents-tutorial: Code samples from our Python agents tutorial. Contribute to run-llama/python-agents-tutorial development by creating an account on GitHub.
OpenInterpreter ▷ #general (12 messages🔥):
OpenInterpreter 1.0 capabilities, Bora's Law on intelligence, Python convenience functions for OI, Limitations of command line tools, AGI development approaches
- OpenInterpreter 1.0 changes functionality: Members discussed that the new OpenInterpreter 1.0 version limits the ability to run code directly and now primarily operates through command line interactions, which may reduce its user-friendly capabilities.
- While there's potential for performing tasks via external scripts, the immediate execution feature that was popular in previous versions seems diminished, causing concern among users.
- Bora's Law proposes new intelligence model: A member shared insights that Bora's Law argues intelligence scales exponentially with constraints rather than compute, challenging mainstream views on AGI development.
- The theory suggests a mathematical relationship (I = Bi(C²)) and raises questions about the efficacy and direction of current large language models like GPT-4, which focus heavily on scaling.
- Desire for improved Python support in OI: One user expressed interest in adding more Python convenience functions to OpenInterpreter to facilitate efficient task completion and enhance the 'learn new skills' feature.
- There’s a consensus that improving Python capabilities could significantly benefit operational efficiency while maintaining user engagement with the platform.
- Limitations of command line tools in version 1.0: Concerns were raised regarding the functionality of command line tools in version 1.0, particularly the ability to execute tasks that were previously effortless.
- Users are lamenting the potential loss of functionality that allowed for immediate execution of Python code, indicating a need for a more integrated approach.
- Debate over AGI development approaches: The conversation highlighted a divergence in opinions on the path to achieving AGI, with one user criticizing OpenAI's heavy reliance on compute power over efficient intelligence scaling.
- Members noted the need for a critical reevaluation of methodologies in AI development to better align with emerging insights, like those from Bora's Law.
Link mentioned: Bora's Law: Intelligence Scales With Constraints, Not Compute: This is a working paper exploring an emerging principle in artificial intelligence development.
LAION ▷ #general (4 messages):
AI Copyright Law Overview, Hyper-Explainable Networks, Inference-Time Credit Assignment
- DougDoug excels in AI Copyright Law overview: Unexpectedly, DougDoug delivered the best overview of AI copyright law yet, which can be viewed here.
- His insights have sparked discussions about the intersection of technology and legal frameworks.
- Dreaming of Hyper-Explainable Networks: A member shared a visionary idea for hyper-explainable networks that could score training data's impact on output generation.
- Although cautious about its feasibility, this concept raises interesting questions about data utilization and creator royalties.
- Looking into Inference-Time Credit Assignment: Discussion touched on the notion of inference-time credit assignment for training data as a method for tracking its impact.
- While it seems ambitious, the idea continues to foster contemplation about the value of training data in machine learning models.
AI21 Labs (Jamba) ▷ #general-chat (3 messages):
P2B crypto platform, AI21 Labs' stance on crypto, Community guidelines on crypto discussions
- P2B offers fundraising and community growth: An authorized representative from the crypto platform P2B introduced their services, claiming to assist with fundraising, listing, community growth, and liquidity management for crypto projects.
- They inquired if they could provide more information about their offerings to AI21.
- AI21 Labs against crypto discussions: A member responded firmly, stating that AI21 Labs is not participating in any crypto projects and will never do so.
- They warned that further mentions of crypto in the Discord would lead to a swift ban.
MLOps @Chipro ▷ #events (1 messages):
AI Agents Workshop, 2025 AI Trends, No-code AI Development
- Create Your First AI Agent Workshop: A workshop titled Build Your First AI Agent of 2025 is set for Thursday, Jan 16, 9 PM IST, inviting all developers and beginners to learn about building AI agents using both code and no-code methods.
- Hosted by Sakshi & Satvik, this invite-only, free event requires registration approval and features insights from Build Fast with AI and Lyzr AI.
- AI Agents Dominating 2025: The discussion highlighted that AI Agents are forecasted to revolutionize industries by 2025, serving roles from personal assistants to business analysts.
- Creating an AI Agent is easier than you think, with the potential for no coding required, broadening access for all attendees.
Link mentioned: Create Your First AI Agent of 2025 · Zoom · Luma: AI Agents are the talk of 2025! From personal assistants to business analysts, these digital teammates are taking over every industry. The best part? Creating…
MLOps @Chipro ▷ #general-ml (1 messages):
heathcliff_ca: Cost is another big reason to stick with what works
Nomic.ai (GPT4All) ▷ #general (2 messages):
Qwen 2.5 fine-tuning, Llama 3.2 character limits, TV pilot script analysis
- Inquiry on Qwen 2.5 Fine-Tuning: A user expressed interest in how another member fine-tuned their version of Qwen 2.5 Coder Instruct (7B) and whether it was released on Hugging Face.
- They also inquired about the larger models available and successful models used by others.
- Challenges with Llama 3.2 Character Limit: A user reported difficulties analyzing a 45-page TV pilot script due to character limits, stating that Llama 3.2 3B should handle it but errors persist.
- They shared a comparison link highlighting differences between Llama 3.2 3B and Llama 3 8B Instruct, both recently released, with distinct token capacities.
Link mentioned: Compare Llama 3.2 3B vs Llama 3 8B Instruct - Pricing, Benchmarks, and More: Compare pricing, benchmarks, model overview and more between Llama 3.2 3B and Llama 3 8B Instruct. In depth comparison of Llama 3.2 3B vs Llama 3 8B Instruct.
DSPy ▷ #general (1 messages):
Ambient Agent Implementation, DSPy Examples
- Seeking Ambient Agent Insights: A member inquired about the process of implementing an ambient agent using dspy and requested shared examples of experiences or implementations.
- They specifically asked if anyone has already done it and could contribute their insights to help standardize approach.
- Interest in DSPy Examples: Another member expressed interest in seeing concrete DSPy examples related to ambient agents.
- This highlights a broader curiosity in the community regarding how ambient agents can be practically implemented.