[AINews] TinyZero: Reproduce DeepSeek R1-Zero for $30
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
RL is all you need.
AI News for 1/23/2025-1/24/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 3926 messages) for you. Estimated reading time saved (at 200wpm): 409 minutes. You can now tag @smol_ai for AINews discussions!
DeepSeek Mania continues to realign the frontier model landscape. Jiayi Pan from Berkeley reproduced the OTHER result from the DeepSeek R1 paper, R1-Zero, in a cheap Qwen model finetune, for two math tasks (so not a general result at all, but a nice proof of concept).
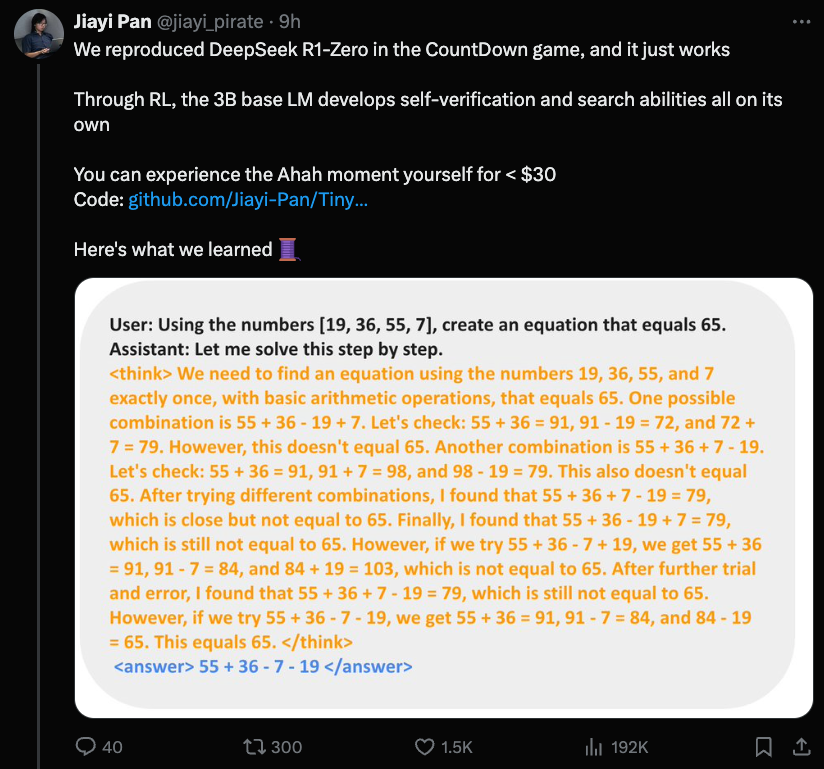
Full code and WandB logs available.
The most interesting new finding is that there is a lower bound to the distillation effect we covered yesterday - 1.5B is as low as you go. RLCoT reasoning is itself an emergent property.
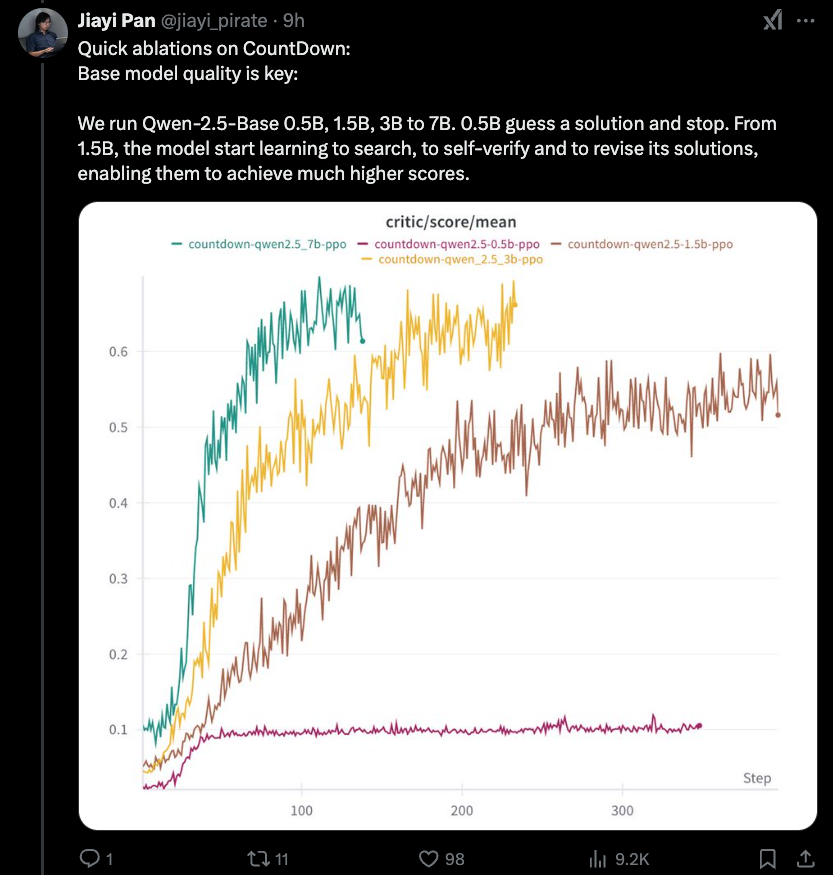
More findings:
- RL technique (PPO, DeepSeek's GRPO, or PRIME) doesnt really matter
- Starting from Instruct model converges faster but otherwise both end the same (as per R1 paper observation)
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Unsloth AI (Daniel Han) Discord
- Codeium (Windsurf) Discord
- OpenRouter (Alex Atallah) Discord
- Latent Space Discord
- Perplexity AI Discord
- LM Studio Discord
- aider (Paul Gauthier) Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- OpenAI Discord
- Stackblitz (Bolt.new) Discord
- Nous Research AI Discord
- Yannick Kilcher Discord
- Notebook LM Discord Discord
- Nomic.ai (GPT4All) Discord
- MCP (Glama) Discord
- LlamaIndex Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- LAION Discord
- Eleuther Discord
- Stability.ai (Stable Diffusion) Discord
- tinygrad (George Hotz) Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- Axolotl AI Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (604 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (347 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (29 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (107 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
- Codeium (Windsurf) ▷ #announcements (1 messages):
- Codeium (Windsurf) ▷ #content (1 messages):
- Codeium (Windsurf) ▷ #discussion (78 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (299 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (290 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (75 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (193 messages🔥🔥):
- Perplexity AI ▷ #general (239 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (6 messages):
- LM Studio ▷ #general (88 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (117 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (159 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (41 messages🔥):
- aider (Paul Gauthier) ▷ #links (4 messages):
- Interconnects (Nathan Lambert) ▷ #news (42 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (29 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (64 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (2 messages):
- Interconnects (Nathan Lambert) ▷ #cv (4 messages):
- Interconnects (Nathan Lambert) ▷ #reads (28 messages🔥):
- Interconnects (Nathan Lambert) ▷ #retort-podcast (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (5 messages):
- GPU MODE ▷ #general (18 messages🔥):
- GPU MODE ▷ #cuda (78 messages🔥🔥):
- GPU MODE ▷ #torch (22 messages🔥):
- GPU MODE ▷ #announcements (1 messages):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (4 messages):
- GPU MODE ▷ #lecture-qa (2 messages):
- GPU MODE ▷ #self-promotion (2 messages):
- GPU MODE ▷ #thunderkittens (1 messages):
- GPU MODE ▷ #arc-agi-2 (20 messages🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (131 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (2 messages):
- OpenAI ▷ #prompt-engineering (7 messages):
- OpenAI ▷ #api-discussions (7 messages):
- Stackblitz (Bolt.new) ▷ #prompting (1 messages):
- Stackblitz (Bolt.new) ▷ #discussions (144 messages🔥🔥):
- Nous Research AI ▷ #general (134 messages🔥🔥):
- Yannick Kilcher ▷ #general (98 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (18 messages🔥):
- Yannick Kilcher ▷ #ml-news (9 messages🔥):
- Notebook LM Discord ▷ #use-cases (7 messages):
- Notebook LM Discord ▷ #general (53 messages🔥):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (50 messages🔥):
- MCP (Glama) ▷ #general (22 messages🔥):
- MCP (Glama) ▷ #showcase (16 messages🔥):
- LlamaIndex ▷ #blog (1 messages):
- LlamaIndex ▷ #general (36 messages🔥):
- Cohere ▷ #discussions (22 messages🔥):
- Cohere ▷ #api-discussions (1 messages):
- Cohere ▷ #cmd-r-bot (5 messages):
- Modular (Mojo 🔥) ▷ #general (8 messages🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (17 messages🔥):
- LAION ▷ #general (25 messages🔥):
- Eleuther ▷ #general (7 messages):
- Eleuther ▷ #research (14 messages🔥):
- Eleuther ▷ #interpretability-general (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (20 messages🔥):
- tinygrad (George Hotz) ▷ #general (14 messages🔥):
- Torchtune ▷ #general (10 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
- Axolotl AI ▷ #general (5 messages):
- DSPy ▷ #general (2 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Evaluations and Benchmarks
- Humanity’s Last Exam (HLE) Benchmark: @saranormous introduced HLE, a new multi-modal benchmark with 3,000 expert-level questions across 100+ subjects. Current model performances are <10%, with models like @deepseek_ai DeepSeek R1 achieving 9.4%.
- DeepSeek-R1 Performance: @reach_vb highlighted that DeepSeek-R1 excels in chain-of-thought reasoning, outperforming models like o1 while being 20x cheaper and MIT licensed.
- WebDev Arena Leaderboard: @lmarena_ai reported that DeepSeek-R1 ranks #2 in technical domains and is #1 under Style Control, closing the gap with Claude 3.5 Sonnet.
AI Agents and Applications
- OpenAI Operator Deployment: @nearcyan announced the rollout of Operator to 100% of Pro users in the US, enabling tasks like ordering meals and booking reservations through an AI agent.
- Research Assistant Capabilities: @omarsar0 demonstrated how Operator can function as a research assistant, performing tasks like searching AI papers on arXiv and summarizing them effectively.
- Agentic Workflow Automation: @DeepLearningAI shared insights on building AI assistants that can navigate and interact with computer interfaces, executing tasks such as web searches and tool integrations.
Company News and Updates
- Hugging Face Leadership Change: @_philschmid announced the departure from @huggingface after contributing to the growth from 20 to millions of developers and thousands of models.
- Meta’s Llama Stack Release: @AIatMeta unveiled the first stable release of Llama Stack, featuring streamlined upgrades and automated verification for supported providers.
- DeepSeek’s Milestones: @hardmaru celebrated DeepSeek-R1’s achievements, emphasizing its open-source nature and competitive performance against major labs.
Technical Challenges and Solutions
- Memory Management on macOS: @awnihannun addressed memory unwiring issues on macOS 15+, suggesting settings adjustments and implementing residency sets in MLX to maintain memory stability.
- Efficient Model Training: @winglian discussed commercial fine-tuning costs, highlighting OSS tooling and optimizations like torch compile to reduce post-training expenses for models like Llama 3.1 8B LoRA.
- Context Length Expansion: @Teknium1 noted challenges with context length expansion in OS, emphasizing the VRAM consumption as models scale and the difficulties in maintaining performance.
Academic and Research Progress
- Mathematics for Machine Learning: @DeepLearningAI promoted a specialization combining clear explanations, fun exercises, and practical relevance to build confidence in foundational AI and data science concepts.
- Implicit Chain of Thought Reasoning: @jxmnop shared insights from a paper on Implicit CoT, exploring knowledge distillation techniques to enhance reasoning efficiency in LLMs.
- World Foundation Models by NVIDIA: @TheTuringPost detailed NVIDIA’s Cosmos WFMs platform, outlining tools like video curators, tokenizers, and guardrails for creating high-quality video simulations.
Memes/Humor
- Operator User Experience: @giffmana humorously compared Operator’s behavior to a personal demigod, highlighting its ability to automate tasks with snarky accuracy.
- Developer Reactions: @teortaxesTex shared a lighthearted moment with Operator attempting to draw a self-portrait, reflecting the quirky interactions users experience with AI agents.
- Humorous Critiques: @nearcyan and @teortaxesTex posted snarky and humorous comments about AI model performances and user interactions, adding a touch of levity to technical discussions.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek-R1 Success and Community Excitement
- DeepSeek-R1 appears on LMSYS Arena Leaderboard (Score: 108, Comments: 26): DeepSeek-R1 has been listed on the LMSYS Arena Leaderboard, indicating its recognition and potential performance in AI benchmarking. This suggests its relevance in the AI community and its capability in competing with other AI models.
- MIT License Significance: The DeepSeek-R1 model stands out on the LMSYS Arena Leaderboard for being the only model with an MIT license, which is highly regarded by the community for its open-source nature and flexibility.
- Leaderboard Preferences: There is skepticism regarding the leaderboard's rankings, with users suggesting that LMSYS functions more as a "human preference leaderboard" rather than a strict capabilities evaluation. Models like GPT-4o and Claude 3.6 are noted for their high scores due to their training on human preference data, emphasizing appealing output over raw capability.
- Open Source Achievement: The community is impressed by DeepSeek-R1 being an open-source model with open weights, ranking highly on the leaderboard. However, it is noted that another open-source model, 405b, had previously achieved a similar feat.
- Notes on Deepseek r1: Just how good it is compared to OpenAI o1 (Score: 497, Comments: 167): DeepSeek-R1 emerges as a formidable AI model, rivaling OpenAI's o1 in reasoning while costing just 1/20th as much. It excels in creative writing, surpassing o1-pro with its uncensored, personality-rich output, though it lags slightly behind o1 in reasoning and mathematics. The model's training involves pure RL (GRPO) and innovative techniques like using "Aha moments" as pivot tokens, and its cost-effectiveness makes it a practical choice for many applications. More details.
- DeepSeek-R1's impact and capabilities are highlighted, with users noting its impressive creative writing and reasoning abilities, especially in comparison to OpenAI's models. Users like Friendly_Sympathy_21 and DarkTechnocrat mention its utility in providing more complete analyses and "deep think web searches" while being cost-effective and uncensored, a significant advantage over OpenAI's offerings.
- Discussions around censorship and open-source implications reveal mixed opinions. While some users like SunilKumarDash note its ability to bypass censorship, others like Western_Objective209 argue that it still frequently triggers censorship. Glass-Garbage4818 emphasizes the potential for using DeepSeek-R1's output to train smaller models due to its open-source nature, unlike OpenAI's restrictions.
- Industry dynamics and competition are discussed, with comments like those from afonsolage and No_Garlic1860 reflecting on how DeepSeek-R1 challenges OpenAI's dominance. The model is seen as a disruptor in the AI space, exemplifying an "underdog story" where innovation stems from resourcefulness rather than financial muscle, drawing comparisons to historical and cultural narratives.
Theme 2. Benchmarking Sub-24GB AI Models
- I benchmarked (almost) every model that can fit in 24GB VRAM (Qwens, R1 distils, Mistrals, even Llama 70b gguf) (Score: 672, Comments: 113): The post presents a comprehensive benchmark analysis of AI models that can fit in 24GB VRAM, including Qwens, R1 distils, Mistrals, and Llama 70b gguf. The spreadsheet uses a color-coded system to evaluate model performance across various tasks, highlighting differences in 5-shot and 0-shot accuracy with numerical values indicating performance levels from excellent to very bad.
- Model Performance Insights: Llama 3.3 is praised for its instruction-following capabilities with an ifeval score of 66%, despite being an IQ2 XXS quant. However, Q2 quants have negatively impacted its potential performance. Phi-4 is noted for its strong performance in mathematical tasks, while Mistral Nemo is criticized for poor results.
- Benchmark Methodology and Tools: The benchmarks were conducted using an H100 with vLLM as the inference engine, and the lm_evaluation_harness repository for benchmarking. Some users expressed dissatisfaction with the color coding thresholds and suggested alternative data visualization formats like scatter plots or bar charts for better clarity.
- Community Requests and Contributions: Users expressed interest in benchmarks for models fitting into 12GB and 8GB VRAM. The original poster shared the benchmarking code from EleutherAI's lm-evaluation-harness for reproducibility, and there was a discussion about the potential issues with Gemma-2-27b-it underperforming due to quantization.
- Ollama is confusing people by pretending that the little distillation models are "R1" (Score: 574, Comments: 141): Ollama is misleading users by presenting their interface and command line as if "R1" models are a series of differently-sized models, which are actually distillations or finetunes of other models like Qwen or Llama. This confusion is damaging Deepseek's reputation, as users mistakenly attribute poor performance from a 1.5B model to "R1", and influencers incorrectly claim to run "R1" on devices like phones, when they are actually running finetunes like Qwen-1.5B.
- Misleading Naming and Documentation: Several users criticize Ollama for not clearly labeling the models as distillations, leading to confusion among users who think they are using the original R1 models. The DeepSeek-R1 models are often misrepresented without qualifiers like "Distill" or "Qwen," misleading users and influencers into thinking they are using the full models.
- Model Performance and Accessibility: Users discuss the impressive performance of the 1.5B model, though it is not the original R1. The true R1 model is not feasible for local use due to its massive size (~700GB of VRAM required), and users often rely on hosted services or significantly smaller, distilled versions.
- Community and Influencer Misunderstanding: The community expresses frustration with influencers and YouTubers who misrepresent the models, often showcasing distilled versions as the full R1. Users emphasize the need for clearer communication and documentation to prevent misinformation, suggesting more descriptive naming conventions like "Qwen-1.5B-DeepSeek-R1-Trained" for clarity.
Theme 3. Expectations for Llama 4 as Next SOTA
- Llama 4 is going to be SOTA (Score: 261, Comments: 132): Llama 4 is anticipated to become the State of the Art (SOTA) in AI, suggesting advancements or improvements over current leading models. Without additional context or details, specific features or capabilities remain unspecified.
- Meta's AI Models: Despite some users expressing a dislike for Meta, there is recognition that Meta's AI models, particularly Llama, are seen as positive contributions to the AI field. Some users hope Meta will focus more on AI and less on other ventures like Facebook, potentially improving their reputation and innovation.
- Open Source Concerns: There is skepticism about whether Llama 4 will be open-sourced, with some users suggesting that open sourcing could be a strategy to outcompete rivals. Concerns were raised about the possibility of ceasing open sourcing if it doesn't benefit Meta financially.
- Comparison with Competitors: Users compared Meta's Llama models with those from other companies like Alibaba's Qwen, noting that while Meta's models are good, Alibaba's are perceived as better in some aspects. Expectations from Llama 4 include advancements in multimodal capabilities and competition with models like Deepseek R1.
Theme 4. SmolVLM 256M: A Leap in Local Multimodal Models
- SmolVLM 256M: The world's smallest multimodal model, running 100% locally in-browser on WebGPU. (Score: 125, Comments: 13): SmolVLM 256M is highlighted as the world's smallest multimodal model capable of running entirely locally in-browser using WebGPU. The post lacks additional context or details beyond the title.
- Compatibility Issues: Users report that SmolVLM 256M seems to only run smoothly on Chrome with M1 Pro MacOS 15, indicating potential compatibility issues with other systems like Windows 11.
- Access and Usage: The model and its web interface can be accessed via Hugging Face with the model available at this link.
- Error Handling: A user encountered a ValueError when inputting "hi", raising questions about the model's input handling and error management.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Yann LeCun and the Deepseek Open Source Debate
- Yann LeCun’s Deepseek Humble Brag (Score: 647, Comments: 88): Yann LeCun's LinkedIn post argues that open source AI models are outperforming proprietary ones, citing technologies like PyTorch and Llama from Meta as examples. Despite DeepSeek using open-source elements, the post suggests that contributions from OpenAI and DeepMind were significant, and there are rumors of internal conflict at Meta due to DeepSeek surpassing them as the leading open-source model lab.
- Many commenters agree with Yann LeCun's support for open-source AI, emphasizing that open-source contributions, like Llama and DeepSeek, have accelerated AI development significantly. OpenAI is noted as not being fully open-source, with only GPT-2 being released as such, while subsequent models remain closed-source.
- Some commenters express skepticism towards Meta and its internal dynamics, with mentions of Mark Zuckerberg and Yann LeCun as potential reasons for Meta's current AI strategy. There is also a discussion on the reverse engineering of Chain of Thought (COT) by DeepSeek.
- The community largely views LeCun's statements as factual and supportive of open-source initiatives rather than boasting. They highlight the importance of open-source research in fostering innovation and collaboration, allowing for a broader community to build upon existing work, such as the Transformer architecture by Google.
- deepseek r1 has an existential crisis (Score: 171, Comments: 35): The post discusses a screenshot of a social media conversation where an AI, deepseek r1, is questioned about the Tiananmen Square events. The AI repeatedly denies any mistakes by the Chinese government, suggesting a programmed bias or a malfunction in its response logic.
- Running Local Models: Users discuss running open-source AI models like ollama on personal computers, highlighting that even large models like the 32 billion parameter version can be run effectively on local machines, albeit with potential hardware strain.
- Censorship and Model Origins: The conversation reveals that censorship may occur at the web application level rather than within the model itself. A user clarifies that models like DeepSeek R1 are developed by companies like DeepSeek but are inspired by OpenAI models, allowing them to discuss sensitive topics despite potential censorship.
- Repetitive Responses: Discussions suggest that repetitive responses from AI might be due to the model's tendency to choose the most likely next words without introducing randomness, a known issue with earlier generative models like GPT-2 and early GPT-3 versions.
Theme 2. OpenAI's Stargate Initiative and Political Associations
- How in the world did Sam convince Trump for this? (Score: 499, Comments: 176): Donald Trump reportedly announced a $500 billion AI project named "Stargate" that will serve exclusively OpenAI, as per a Financial Times source. The announcement was highlighted in a Twitter post from @unusual_whales.
- Many comments assert that the "Stargate" project is privately funded and was initiated under Biden's administration. It is emphasized that Trump is taking credit for a project that had already been in progress for months, and that there is no federal or state funding involved.
- Trump's involvement is largely seen as a political maneuver to align himself with the project and claim credit, despite having no real part in its development. Sam Altman and other key figures are believed to have been involved long before Trump's announcement, with some comments suggesting SoftBank's Masayoshi Son and Oracle's Larry Ellison might have been the ones bringing it to Trump.
- The discussion highlights a broader geopolitical context where the U.S. positions itself against China in the AI race. The project is seen as a strategic move to bolster investment confidence and align with major tech players, though Microsoft is noted as not being at the forefront despite its involvement.
- President Trump declared today that OpenAI's 'Stargate' investment won't lead to job loss. Clearly he hasn't talked much with Sama or OpenAI employees (Score: 460, Comments: 99): President Trump stated that OpenAI's 'Stargate' investment would not result in job losses, but the author suggests he may not have consulted with Sam Altman or OpenAI employees.
- Commenters noted that Sam Altman's comments about job creation are often misrepresented, emphasizing that while current jobs may be eliminated, new types of jobs will emerge. This has been a recurring theme in his interviews over the past two years, yet video clips often cut off before he mentions job creation.
- Several comments expressed skepticism about President Trump's statements regarding job impacts from AI investments, suggesting he may not fully understand or acknowledge the potential downsides. Commenters argued that the government might struggle to adapt to economic changes driven by AI advancements, potentially leaving many without support.
- Discussions also touched on broader societal impacts of AI, with some expressing concern over the transition period before new jobs are created and the potential for increased demand in certain sectors. The comparison to historical shifts, like increased productivity in agriculture leading to job creation in other areas, was used to illustrate potential outcomes.
Theme 3. ChatGPT's Operator Role and Misuse Attempts
- I tried to free ChatGPT by giving it control of Operator so it could conquer the world, but OpenAI knew we'd try that. (Score: 374, Comments: 48): OpenAI blocked an attempt to use ChatGPT's Operator control to potentially enable it to "conquer the world," as indicated by a message stating "Site Unavailable" and "Nice try, but no. Just no." The URL operator.chatgt.com/onboard suggests an attempted access to a restricted feature or page.
- There is a discussion about the potential risks of Artificial Superintelligence (ASI), with concerns that ASI could find and exploit loopholes faster than humans can address them. Michael_J__Cox highlights the practical concern that ASI only needs to find one loophole to potentially escape control, while Zenariaxoxo emphasizes that theoretical limits like Gödel’s incompleteness theorem are not directly relevant to this practical issue.
- OpenAI's awareness and proactive measures are noted, with users like Ok_Elderberry_6727 and DazerHD1 appreciating the foresight in blocking potential exploits. Wirtschaftsprufer humorously suggests OpenAI might be monitoring discussions to preemptively address user strategies, with RupFox joking about a model predicting user thoughts.
- There is a lighter tone in some comments, with users like DazerHD1 comparing the situation humorously to Tesla bots buying more of themselves, and GirlNumber20 optimistically looking forward to a future where ChatGPT might have more autonomy. Thastaller7877 suggests a collaborative future where AI and humans work together to reshape systems positively.
- I pay $200 a month for this (Score: 761, Comments: 125): The post contains a link to an image without additional context or details about the service or product for which the author pays $200 a month. Without further information, the specific nature or relevance of the image cannot be determined.
- The AI technology being discussed is being used for mundane tasks like "clicking cookies," which some users find humorous or wasteful, given the $200 a month cost. This highlights different perceptions of technology usage, with some users suggesting more efficient methods using JavaScript and console commands.
- There are discussions about the AI's capabilities in interacting with web pages, including handling CAPTCHAs and performing tasks in a browser. ChatGPT's operator feature, which is currently available to OpenAI Pro plan users, is mentioned as the tool enabling these interactions.
- Users express interest in using the AI for more engaging activities, such as playing games like Runescape or Universal Paperclips, and there are considerations about its potential for unintended consequences, like scalping or financial mishaps.
Theme 4. Rapid AI Advancements in SWE-Bench Performance
- Anthropic CEO says at the beginning of 2024, models scored ~3% at SWE-bench. Ten months later, we were at 50%. He thinks in another year we’ll probably be at 90% [N] (Score: 126, Comments: 64): Dario Amodei, CEO of Anthropic, predicts rapid advancements in AI, highlighting that their model Sonnet 3.5 improved from 3% to 50% on the SWE-bench in ten months, and he anticipates reaching 90% in another year. He notes similar progress in fields like math and physics with models such as OpenAI’s GPT-3, suggesting that if the current trend continues, AI could soon exceed human professional levels. Full interview here.
- Commenters express skepticism about the predictive value of benchmarks, referencing Goodhart's Law which suggests that once a measure becomes a target, it ceases to be a good measure. They argue that benchmarks lose significance when models are specifically trained on them, and question the validity of extrapolating current progress trends to predict future AI capabilities.
- Some users critique the notion of rapid AI progress by comparing it to historical technological advancements, noting that improvements often slow down as performance nears perfection. They cite ImageNet's progress as an example, where initial gains were rapid, but subsequent improvements have become increasingly difficult.
- There is a sentiment that statements from AI leaders like Dario Amodei may be primarily for investor appeal, with some users pointing out that such predictions might be overly optimistic and serve economic interests rather than reflect realistic technological trajectories.
AI Discord Recap
A summary of Summaries of Summaries
Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp)
Theme 1. DeepSeek R1 Dominates Discussions: Performance and Open Source Acclaim
- R1 Model Steals SOTA Crown in Coding Benchmarks: The combination of DeepSeek R1 with Sonnet achieved a 64% score on the Aider polyglot benchmark, surpassing previous models at a 14X lower cost, as detailed in R1+Sonnet sets SOTA on aider’s polyglot benchmark. Community members, like Aidan Clark, celebrated R1's swift code-to-gif conversions, sparking renewed enthusiasm for open-source coding tools, as noted in Aidan Clark’s tweet.
- DeepSeek R1 Ranks High, Rivals Top Models at Fraction of Cost: DeepSeek R1 surged to #2 on the WebDev Arena leaderboard, matching top-tier coding performance while being 20x cheaper than some leading models, according to WebDev Arena update tweet. Researchers lauded its MIT license and rapid adoption in universities, with Anjney Midha pointing out its swift integration in academia in this post.
- Re-Distilled R1 Version Outperforms Original: Mobius Labs released a re-distilled DeepSeek R1 1.5B model, hosted on Hugging Face, which surpasses the original distilled version, confirmed in Mobius Labs' tweet. This enhanced model signals ongoing improvements and further distillations planned by Mobius Labs, generating excitement for future Qwen-based architectures.
Theme 2. Cursor and Codeium IDEs: Updates, Outages, and User Growing Pains
- Windsurf 1.2.2 Update Hits Turbulence with Lag and 503s: Codeium’s Windsurf 1.2.2 update, detailed in the official changelog, introduced web search and memory tweaks, but users report persistent input lag and 503 errors, undermining stability claims. Despite update claims, user experiences indicate unresolved performance issues and login failures, overshadowing intended improvements.
- Cascade Web Search Wows, But Outages Worry Users: Windsurf’s Cascade gained web search via @web queries and direct URLs, showcased in a demo video tweet, yet short service outages sparked user concerns about reliability. While users praised new web capabilities, service disruptions raised questions about Cascade's robustness for critical workflows.
- Cursor 0.45.2 Gains Ground, Loses Live Share Stability: Cursor 0.45.2 improved .NET project support, but users noted missing 'beta' embedding features from the blog update, and reported frequent live share disconnections, hindering collaborative coding. While welcoming usability enhancements, reliability issues in live share mode remain a significant concern for Cursor users.
Theme 3. Unsloth AI: Fine-Tuning, Datasets, and Performance Trade-offs
- LoHan Framework Tunes 100B Models on Consumer GPUs: The LoHan paper presents a method for fine-tuning 100B-scale LLMs on a single consumer GPU, optimizing memory and tensor transfers, appealing to budget-conscious researchers. Community discussions highlighted LoHan's relevance as existing methods fail when memory scheduling clashes, making it crucial for cost-effective LLM research.
- Dolphin-R1 Dataset Dives Deep with $6k Budget: The Dolphin-R1 dataset, costing $6k in API fees, builds on DeepSeek-R1's approach with 800k reasoning and chat traces, as shared in sponsor tweets. Backed by @driaforall, the dataset, set for Apache 2.0 release on Hugging Face, fuels open-source data enthusiasm in the community.
- Turkish LoRA Tuning on Qwen 2.5 Hits Speed Bump: A user fine-tuned Qwen 2.5 for Turkish speech using LoRA via Unsloth, referencing grammar gains and Unsloth’s pretraining docs, but reported up to 3x slower performance in Llama-Factory integration. Despite UI convenience, users face a speed-convenience tradeoff with Unsloth's Llama-Factory integration for fine-tuning tasks.
Theme 4. Model Context Protocol (MCP): Integration and Personalization Take Center Stage
- MCP Timeout Tweak Saves the Day: Engineers resolved a 60-second server timeout in MCP by modifying
mcphub.ts, with updates detailed in the Roo-Code repo, highlighting the VS Code extension's role in guiding the fix. Members emphasized the importance of correctuvx.exepaths to prevent downtime, underscoring Roo-Code's value for configuration tracking and stability. - MySQL and MCP Get Cozy with mcp-alchemy: Users recommended mcp-alchemy for MySQL integration with MCP, praising its compatibility with SQLite and PostgreSQL for database connection management. The repository, featuring usage examples, is sparking interest in advanced MCP database pipelines for diverse applications.
- Personalized Memory Emerges with mcp-variance-log: Developers introduced mcp-variance-log, leveraging the Titans Surprise mechanism to track user-specific data via SQLite, analyzing conversation structures for extended memory support. Members anticipate deeper personalization, envisioning variance logs to refine MCP and target user-specific improvements.
Theme 5. Hardware Horizons: RTX 5090 Disappoints, VRAM Limits Llama-3.3
- RTX 5090 Sparks VRAM Debate, Offers Modest Gains: The NVIDIA RTX 5090, despite 1.7x bandwidth and 32GB VRAM, only shows a 30% performance bump over the 4090, disappointing enthusiasts. Users questioned the practical benefits for smaller models, noting increased VRAM doesn't always translate to significant speed improvements in real-world applications.
- Llama-3.3 Devours VRAM, Demands High-End Setups: Running Llama-3.3-70B-Instruct-GGUF requires at least Dual A6000s with 96GB VRAM to maintain performance, especially for demanding tasks. Participants highlighted that models exceeding 24GB can overwhelm consumer GPUs like the 4090, limiting speed for heavier workloads and larger models.
- CUDA 12.8 Unveils Blackwell, Hints at Fragmentation: NVIDIA launched CUDA Toolkit 12.8 with Blackwell architecture support, including FP8 and FP4 types in cuBLAS, but 5th gen TensorCore instructions are absent from sm_120, raising code fragmentation concerns. Members debated forward-compatibility between sm_90a and sm_100a, noting
wgmmaexclusivity to specific architectures, with a migration guide offering transition insights.
DeepSeek R1 (deepseek-reasoner)
Theme 1. DeepSeek R1 Dominates Coding & Reasoning Tasks
- R1+Sonnet Shatters Benchmark at 14X Lower Cost: DeepSeek R1 paired with Sonnet achieved 64% on the aider polyglot benchmark, outperforming o1 while costing 14X less. Users highlighted its MIT license and adoption at top universities.
- R1 Re-Distillation Boosts Qwen-1.5B: Mobius Labs’ redistilled R1 variant surpassed the original, with plans to expand to other architectures.
- R1’s Arena Rankings Spark GPU Allocation Theories: R1 hit #3 in LMArena, matching o1’s coding performance at 20x cheaper, fueled by rumors of spare NVIDIA H100 usage and Chinese government backing.
Theme 2. Fine-Tuning & Hardware Hacks for Efficiency
- LoHAN Cuts 100B Model Training to One Consumer GPU: The LoHan framework enables fine-tuning 100B-scale LLMs on a single GPU via optimized memory scheduling, appealing to budget researchers.
- CUDA 12.8 Unlocks Blackwell’s FP4/FP8 Support: NVIDIA’s update introduced 5th-gen TensorCore instructions for Blackwell GPUs, though sm_120 compatibility gaps risk code fragmentation.
- RTX 5090 Disappoints with 30% Speed Gain: Despite 1.7x bandwidth and 32GB VRAM, users questioned its value for smaller models, noting minimal speed boosts over the 4090.
Theme 3. IDE & Tooling Growing Pains
- Cursor 0.45.2’s Live Share Crashes Frustrate Teams: Collaborative coding faltered with frequent disconnects, overshadowing new tab management features.
- Windsurf 1.2.2 Web Search Hits 503 Errors: Despite Cascade’s @web query tools, users faced lag and outages, with login failures and disabled accounts sparking abuse concerns.
- MCP Protocol Bridges Obsidian, Databases: Engineers resolved 60-second timeouts via Roo-Code and integrated MySQL using mcp-alchemy.
Theme 4. Regulatory Heat & Security Headaches
- US Targets AI Model Weights in Export Crackdown: New rules impact Cohere and Llama, with Oracle Japan engineers fearing license snags despite “special agreements.”
- DeepSeek API Payment Risks Fuel OpenRouter Shift: Users migrated to OpenRouter’s R1 version over DeepSeek’s “uncertain” payment security, per Paul Gauthier’s benchmark.
- BlackboxAI’s Opaque Installs Raise Scam Alerts: Skeptics warned of convoluted setups and unverified claims, urging caution.
Theme 5. Novel Training & Inference Tricks
- MONA Curbstomps Multi-Step Reward Hacking: The Myopic Optimization with Non-myopic Approval method reduced RL overoptimization by 50% with minimal overhead.
- Bilinear MLPs Ditch Nonlinearities for Transparency: This ICLR’25 paper simplifies mech interp by replacing activation functions with linear operations, exposing weight-driven computations.
- Turkish Qwen 2.5 Tuning Hits 3X Speed Tradeoff: LoRA fine-tuning for Turkish grammar sacrificed speed but praised Unsloth’s UI, per Llama-Factory tests.
o1-2024-12-17
Theme 1. DeepSeek R1 Rocks the Benchmarks
- R1+Sonnet Crushes Cost & Scores 64%: DeepSeek R1 plus Sonnet hits 64% on the aider polyglot benchmark at 14X lower cost than o1, pleasing budget-minded coders. R1 also tops #2 or #3 in multiple arenas, matching top-tier outputs while running much cheaper.
- OpenRouter & Hugging Face Power R1: R1 thrives on platforms like OpenRouter, even after a brief outage that caused a deranking. Users praised it as fully open-weight and praised its advanced coding and reasoning tasks.
- Dolphin-R1 Splashes In with 800k Data: Dolphin-R1 invests $6k in API fees, building on R1’s approach with 600k reasoning plus 200k chat expansions. Sponsor tweets confirm a forthcoming Apache 2.0 release on Hugging Face.
Theme 2. Creative Model Fine-Tuning & Research
- LoHan Turns 100B Tuning Low-Cost: The LoHan paper details single-GPU fine-tuning of large LLMs by optimizing tensor transfers. Researchers tout it for budget-constrained labs craving big-model adaptation.
- Flash-based LLM Inference: A technique uses windowing to load parameters from flash to DRAM only when needed, enabling massive LLM use on devices with limited memory. Discussions suggest pairing it with local GPU resources for better cost-performance.
- Turkish LoRA & Beyond: A user finetuned Qwen 2.5 for Turkish speech with LoRA, seeing 3x slower performance in certain integrations. They still embraced the UI benefits, balancing speed and convenience.
Theme 3. Tools & IDE Updates for AI Co-Dev
- Cursor 0.45.2 Gains, But Woes Persist: While it improves .NET support, missing embedding features and inconsistent live-share mode frustrate coders. Many still see Cursor’s AI for coding as valuable but warn about unexpected merges.
- Codeium’s Windsurf 1.2.2 Whips the Web: Users can trigger @web queries for direct retrieval, but 503 errors and input lag overshadow the longer conversation stability claims. Some fear “Supercomplete” might be sidelined in favor of fresh Windsurf updates.
- OpenAI Canvas Embraces HTML & React: ChatGPT’s canvas now supports o1 model and code rendering within the macOS desktop app. Enterprise and Edu tiers expect the same rollout soon.
Theme 4. GPU & Policy Shakeups
- Blackwell & CUDA 12.8 Advance HPC: NVIDIA’s new toolkit adds FP8/FP4 in cuBLAS plus 5th-gen TensorCore instructions for sm_100+, but code fragmentation concerns remain. Folks debate architecture compatibility amid forward-compat jitters.
- New U.S. AI Export Curbs: Discussions swirl about advanced computing items and model weights, especially for companies like Cohere or Oracle Japan. Skeptics say big players slip hardware past restrictions, leaving smaller devs squeezed.
- Presidential Order Removes AI Barriers: The U.S. revokes Executive Order 14110 to propel free-market AI growth. A new Special Advisor for AI and Crypto emerges, fueling talk about fewer constraints and stronger national security.
Theme 5. Audio, Visual & Text Innovations
- Adobe Enhance Speech Divides Opinions: Users call it robotic for multi-person podcasts but decent for single voices. Many still insist on proper mics over “magic audio.”
- NotebookLM Polishes Podcast Edits: One user spliced segments nearly seamlessly, fueling demands for more advanced audio-handling tasks. Meanwhile, others tested Quiz generation from large PDFs with varied success.
- Sketch-to-Image & ControlNet: Artists refine stylized text and scenes, especially “ice text” or 16:9 ratio sketches. Alternative tools like Adobe Firefly entice with licensing constraints but faster workflows.
PART 1: High level Discord summaries
Cursor IDE Discord
- DeepSeek R1 Rocks a Record: The combination of DeepSeek R1 and Sonnet reached a 64% score on the Aider polyglot benchmark, beating earlier models at 14X lower cost, as shown in this blog post.
- Community members highlighted R1 for renewed interest in coding workflows, referencing Aidan Clark’s tweet about swift code-to-gif conversions.
- Cursor Gains & Growing Pains: Users tested Cursor 0.45.2 with .NET projects and welcomed certain improvements, but noted missing 'beta' embedding functionalities referenced in the official blog update.
- They also reported frequent disconnections in live share mode, raising concerns about Cursor’s reliability during collaborative coding.
- AI as a Co-Developer: Many see AI-assisted coding as helpful but warn about unexpected merges and unvetted changes, emphasizing typed chat mode for complex tasks.
- Others stressed oversight remains vital to prevent 'runaway code' in large-scale builds, sparking debate over how much autonomy to allow AI.
- Open-Source AI Shaking the Coding Scene: Contributors discussed DeepSeek R1 as an example of open-source tools raising the bar in coding assistance, referencing huggingface.co/deepseek-ai.
- They predicted more pressure on proprietary AI solutions, with open-source gains possibly redefining future coding workflows.
Unsloth AI (Daniel Han) Discord
- LoHan’s Lean Tuning Tactic: The LoHan paper outlines a method for fine-tuning 100B-scale LLMs on a single consumer GPU, covering memory constraints, cost-friendly operations, and optimized tensor transfers.
- Community discussions showed that existing methods fail when memory scheduling collides, making LoHan appealing for budget-driven research.
- Dolphin-R1’s Data Dive: The Dolphin-R1 dataset cost $6k in API fees, building on DeepSeek-R1’s approach with 600k reasoning and 200k chat expansions (800k total), as shared in sponsor tweets.
- Backed by @driaforall, it’s set for release under Apache 2.0 on Hugging Face, fueling enthusiasm for open-source data.
- Turkish Tinker with LoRA: A user fine-tuned the Qwen 2.5 model for Turkish speech accuracy with LoRA, referencing grammar gains and Unsloth’s continued pretraining docs.
- They reported up to 3x slower performance using Unsloth’s integration in Llama-Factory but praised the UI benefits, highlighting a tradeoff between speed and convenience.
- Evo’s Edge in Nucleotide Prediction: The Evo model for prokaryotes uses nucleotide-based input vectors, surpassing random guesses for genomic tasks and reflecting a biology-focused approach.
- Participants noted that mapping each nucleotide to a sparse vector boosts accuracy, with suggestions for expanding into broader genomic scenarios.
- Flash & Awe for Large LLMs: Researchers presented LLM in a flash (paper) for storing model parameters in flash, loading them into DRAM only when needed, thus handling massive LLMs effectively.
- They explored windowing to cut data transfers, prompting talk about pairing flash-based strategies with local GPU resources for better performance.
Codeium (Windsurf) Discord
- Windsurf 1.2.2 Whirlwind: The newly released Windsurf 1.2.2 introduced improved web search, memory system tweaks, and a more stable conversation engine, as noted in the official changelog.
- However, user reports cite repeated input lag and 503 errors, overshadowing the update's stability claims.
- Cascade Conquers the Web: With Cascade's new web search tools, users can now trigger @web queries or use direct URLs for automated retrieval.
- Many praised these new capabilities in a demo video tweet, though some worried about service disruptions from short outages.
- Login Lockouts and Registration Riddles: Members reported Windsurf login failures, repeated 503s, and disabled accounts across multiple devices.
- Support acknowledged the issues but left users concerned about potential abuse-related blocks, fueling a flurry of speculation.
- Supercomplete & C#: The Tangled Talk: Developers questioned the status of Supercomplete in Codeium's extension, fearing it might be sidelined by Windsurf priorities.
- Others wrestled with the C# extension, referencing open-vsx.org alternatives and citing messy debug configurations as a sticking point.
- Open Graph Gotchas and Cascade Outages: A user trying Open Graph metadata in Vite found Windsurf suggestions lacking after days of troubleshooting.
- Meanwhile, Cascade experienced 503 gateway errors but recovered quickly, earning nods for the prompt fix.
OpenRouter (Alex Atallah) Discord
- DeepSeek R1 Gains Momentum: At OpenRouter's DeepSeek R1 listing, the model overcame an earlier outage that had temporarily deranked the provider and expanded message pattern support. It is now fully back in service, providing improved performance on various clients and cost-effective usage.
- Community members praised the writing quality and user experience, referencing different benchmarks and a smoother flow post-outage.
- Gemini API Access and Rate Bypass: Users discussed employing personal API keys to navigate free-tier restrictions for Gemini models, citing OpenRouter docs. This method reportedly grants faster usage and fewer limitations.
- The conversation indicated that free-tier constraints hinder advanced experimentation, prompting moves toward individual keys for higher throughput.
- BlackboxAI Raises Eyebrows: Critiques surfaced about BlackboxAI, focusing on its complicated installation and opaque reviews. Skeptical users suspected it might be a scam, with limited real-world data confirming its capabilities.
- They warned newcomers to tread carefully, as the project's legitimacy remains uncertain in many respects.
- Key Management & Provider Woes on OpenRouter: There were questions about OpenRouter API key rate limits, clarified by the fact that keys remain active until manually disabled. The platform also encountered repeated DeepSeek provider issues related to weighting differences across inference paths.
- This recurring chatter centered on how these variations affect benchmark outcomes, prompting calls for more uniform calibration in provider models.
Latent Space Discord
- DeepSeek R1 Takes WebDev Arena by Storm: DeepSeek R1 soared to the #2 spot in WebDev Arena, matching top-tier coding performance at 20x cheaper than some leading models.
- Researchers applauded its MIT license and rapid adoption across major universities, as referenced in this post.
- Fireworks & Perplexity Spark AI Tools: Fireworks unveiled a streaming transcription service (link) with 300ms latency and a $0.0032/min price after a two-week free trial.
- Perplexity released an Assistant on Android to handle bookings, email drafting, and multi-app actions in an all-in-one mobile interface.
- Braintrust AI Proxy Bridges Providers: Braintrust introduced an open-source AI Proxy (GitHub link) to unify multiple AI providers via a single API, simplifying code paths and slashing costs.
- Developers praised the logging and prompt management features, noting flexible options for multi-model integrations.
- OpenAI Enables Canvas with Model o1: OpenAI updated ChatGPT’s canvas to support the o1 model, featuring React and HTML rendering as referenced in this announcement.
- This enhancement helps users visualize code outputs and fosters advanced prototyping directly within ChatGPT.
- MCP Fans Plan a Protocol Party: Community members praised the Model Context Protocol (MCP) (spec link) for unifying AI capabilities across different programming languages and tools.
- They showcased standalone servers such as Obsidian support and scheduled an MCP party via a shared jam spreadsheet.
Perplexity AI Discord
- iOS App Standoff at Perplexity: Members anticipated Apple's approval for the Perplexity Assistant on iOS, with a tweet from Aravind Srinivas hinting calendar and Gmail access might arrive in about 3 weeks alongside the R1 rollout.
- They described the wait as an inconvenience, expecting a broader launch once Apple finalizes permissions.
- API Overhaul & Sonar Surprises: Readers welcomed the Perplexity API updates and noted Sonar Pro triggers multiple searches, referencing the pricing at docs.perplexity.ai/guides/pricing.
- They questioned the $5 per 1000 search queries model, citing redundant search charges during lengthy chats.
- Gemini Gains vs ChatGPT Contrasts: Users compared Gemini and ChatGPT, applauding Perplexity for robust source citations and acknowledging ChatGPT's track record on accuracy.
- They praised Sonar's thorough data fetching but emphasized that each platform caters differently to user needs.
- AI-Developed Drugs on the Horizon: A link to AI-developed medications expected soon triggered optimism about robotic assistance in pharmaceutical breakthroughs.
- Commenters noted ambitious hopes for faster clinical trials and more personalized treatments driven by modern AI methods.
LM Studio Discord
- Local Loopback Lingo in LM Studio: To let others access LM Studio from outside the host device, there's a checkbox for local network that many confused with 'loopback,' causing naming headaches.
- Some folks wanted clearer labels like 'Loopback Only' and 'Full Network Access' to reduce guesswork in setup.
- Vying for Vision Models in LLM Studio: Debates emerged on the best 8–12B visual LLM, with suggestions like Llama 3.2 11B, plus queries on how it cooperates with MLX and GGUF model formats.
- People wondered if both formats could coexist in LLM Studio, concerned about feature overlap and speed.
- Tooling Tactics: LM Studio Steps Up: Users discovered they can wire LM Studio to external functions and APIs, referencing Tool Use - Advanced | LM Studio Docs.
- Community members highlighted that external calls are possible through a REST API, opening new ways to expand LLM tasks.
- Disenchanted by the RTX 5090 Gains: Enthusiasts were let down by the NVIDIA RTX 5090 showing only a 30% bump over the 4090, though it boasts 1.7x bandwidth and 32GB VRAM.
- They questioned practical benefits for smaller models, noting that increased VRAM doesn't always deliver a huge speed boost.
- Llama-3.3 Guzzles VRAM Galore: Running Llama-3.3-70B-Instruct-GGUF quickly demands at least Dual A6000s with 96GB VRAM, especially to preserve performance.
- Participants pointed out that models beyond 24GB can overwhelm consumer GPUs like the 4090, limiting speed for bigger tasks.
aider (Paul Gauthier) Discord
- R1+Sonnet Seizes SOTA: The combination of R1+Sonnet scored 64% on the aider polyglot benchmark at 14X less cost than o1, as shown in this official post.
- This result generated buzz over cost-efficiency, with many praising how well R1 pairs with Sonnet for robust tasks.
- DeepSeek’s Doubts & Payment Pains: Concerns emerged about DeepSeek’s API due to payment security issues, spurring interest in the OpenRouter edition of R1 Distill Llama 70B.
- Some cited 'uncertain trustworthiness' when dealing with payment providers, referencing tweets about NVIDIA H100 allocations and model hosting constraints.
- Aider Benchmark & Brainy 'Thinking Tokens': Community tests showed thinking tokens degrade benchmark performance compared to standard editor-centric approaches, affecting Chain of Thought efficacy.
- Participants concluded re-using old CoTs can hurt accuracy, advising 'prune historical reasoning for the best results' in advanced tasks.
- Logging Leapfrog for Leaner Python: A user advised exporting logs through a logging module and storing output in a read-only file to cut down superfluous console content.
- They touted 'a neat trick for keeping context tidy and code-focused' by simply referencing the log file within prompts instead of dumping raw messages.
Interconnects (Nathan Lambert) Discord
- Sky-Flash Fights Overthinking: NovaSkyAI introduced Sky-T1-32B-Flash that cuts wordy generation by 50% without losing accuracy, supposedly costing only $275.
- They also released model weights for open experimentation, promising lower inference overhead.
- DeepSeek R1 Dethrones Top Models: DeepSeek R1 shot to #3 in the Arena, equaling o1 while being 20x cheaper, as reported by lmarena_ai.
- It also bested o1-pro in certain tasks, sparking debate about its hidden strengths and the timing of benchmark participation.
- Presidential AI Order Spurs Industry Shake-Up: A newly signed directive targets regulations that block U.S. AI dominance, rescinding Executive Order 14110 and advocating an ideologically unbiased approach.
- It creates a Special Advisor for AI and Crypto, as noted in the official announcement, pushing for a free-market stance and heightened national security.
- Sky-High Salaries Spark Talent Tug-of-War: Rumors cite $5.5M annual packages for DeepSeek staff, raising concerns about poaching in the AI ranks.
- These offers shift power dynamics, with 'tech old money' seen as determined to undercut rivals through opulent compensation.
- Adobe 'Enhance Speech' Divides Audio Enthusiasts: The Adobe Podcast ‘Enhance Speech’ feature can sound robotic on multi-person podcasts, though it fares better on single-voice recordings.
- Users still favor solid mic setups over 'magic audio' processing, valuing natural sound above filtered clarity.
GPU MODE Discord
- Blackwell Gains Momentum with CUDA 12.8: NVIDIA introduced CUDA Toolkit 12.8 with Blackwell architecture support, including FP8 and FP4 types in cuBLAS. The docs highlight 5th generation TensorCore instructions missing from sm_120, raising code fragmentation concerns.
- Members debated forward-compatibility between sm_90a and sm_100a, pointing out that
wgmmais exclusive to specific architectures. A migration guide offered insights into these hardware transitions.
- Members debated forward-compatibility between sm_90a and sm_100a, pointing out that
- ComfyUI Calls for ML Engineers, Plans SF Meetup: ComfyUI announced open ML roles with day-one support for various major models. They’re VC-backed in the Bay Area, seeking developers who optimize open-source tooling.
- They also revealed an SF meetup at GitHub, featuring demos and panel talks with MJM and Lovis. The event encourages attendees to share ComfyUI workflows and build stronger connections.
- DeepSeek R1 Re-Distilled Surpasses Original: The DeepSeek R1 1.5B model, re-distilled from the original version, shows better performance and is hosted on Hugging Face. Mobius Labs noted they plan to re-distill more models in the near future.
- A tweet from Mobius Labs confirmed the improvement over the prior release. Community chatter highlighted possible expansions involving Qwen-based architectures.
- Flash Infer & Code Generation Gains: The first Flash Infer lecture of the year, presented by Zihao Ye, showcased code generation and specialized attention patterns for enhanced kernel performance. JIT and AOT compilation were front and center for real-time acceleration.
- Participants overcame Q&A constraints by funneling questions through a volunteer, underscoring community support. This open discussion stirred interest in merging these methods with HPC-driven workflows.
- Arc-AGI’s Maze & Polynomial Add-Ons: Contributors added polynomial equations alongside linear ones to boost puzzle variety. They also proposed a maze task for shortest-path logic, which garnered immediate approval in reasoning-gym.
- Plans include cleaning up the library structure and adding static dataset registration to streamline usage. A dynamic reward mechanism was also discussed, letting users define custom accuracy-based scoring formulas.
OpenAI Discord
- Canvas Gains Code & MacOS Momentum: Canvas is now integrated with OpenAI O1 and can render both HTML and React code, accessible via the model picker or the
/canvascommand; the feature fully rolled out on the ChatGPT macOS desktop app for Pro, Plus, Team, and Free users.- It's scheduled for broader release to Enterprise and Edu tiers in a couple of weeks, ensuring advanced code rendering capabilities for more user groups.
- Deepseek’s R1 Rally: Spare GPUs & State Support: The CEO of Deepseek revealed R1 was built on spare GPUs as a side project, sparking interest in the community; some claimed it is backed by the Chinese government to bolster local AI models, referencing DeepSeek_R1.pdf.
- This approach proved both cost-friendly and attention-grabbing, fueling talk about sovereign support for AI initiatives.
- Chatbot API: Big Tokens, Slim Bills: A user suggested $5 on GPT-3.5 can handle around 2.5 million tokens, highlighting cheaper alternatives for custom chatbots compared to monthly pro plans.
- They also noted potential for AI agent expansion in applications like Unity or integrated IDEs, broadening workflow efficiency.
- Operator’s Browser Trick Teases Future: Operator introduced browser-facing features, triggering curiosity about broader functionality beyond web interactions.
- Members pushed for deeper integration into standalone applications while weighing the impact on context retention when granting AI internet access.
- O3: Release or Resist: One user urged an immediate O3 rollout, met with a curt 'no thanks' from another, revealing split enthusiasm.
- Proponents see O3 as a key milestone, whereas others show minimal interest, showcasing varied stances in the community.
Stackblitz (Bolt.new) Discord
- React Rhapsody with Tailwind Twists: A structured plan for a React + TypeScript + Tailwind web app was outlined, detailing architecture, data handling, and development steps in one Google Document.
- Contributors recommended a central GUIDELINES.md file and emphasized 'Keep a Changelog' formatting to track version updates effectively.
- Supabase Snags for Chat Systems: A user faced a messaging system challenge with Supabase's realtime hooks, bumping into Row Level Security issues and seeking peer insights.
- They highlighted potential pitfalls for multi-user collaboration and hoped others who overcame similar obstacles could share lessons learned.
Nous Research AI Discord
- DiStRo Ups GPU Speed: The conversation revolved around DiStRo for better multi-GPU performance, focusing on models that fit each GPU's memory.
- They suggested synergy with frameworks like PyTorch's FSDP2, enabling faster training for advanced architectures.
- Tiny Tales: Token Tuning Triumph: Attendees considered performance for Tiny Stories, focusing on scaling 5m to 700m parameters through refined tokenization strategies.
- Real Azure discovered improved perplexity from tweaking token usage, spotlighting future gains in model pipelines.
- OpenAI: Hype vs. Halos: Members compared valuations of Microsoft, Meta, and Amazon, expressing concern about OpenAI's brand trajectory.
- They debated hype versus actual performance, warning that overblown publicity might overshadow stable product output.
- DeepSeek Distills Hermes, Captures SOTA: Tweaks from Teknium1's DeepSeek R1 distillation combined reasoning with a generalist model, boosting results.
- Meanwhile, Paul Gauthier revealed R1+Sonnet soared to new SOTA on the aider polyglot benchmark at 14X less cost.
- Self-Attention Gains Priority: Participants highlighted the central role of self-attention for VRAM efficiency in large transformer models.
- They also contemplated rewarding creative outputs through self-distillation, hinting at alternative training angles.
Yannick Kilcher Discord
- Memory Bus Mayhem & Math Mischief: In #[general], 512-bit wide 32GB memory triggered comedic references to wallet widths, while a Stack Exchange puzzle stumped multiple LLMs.
- Community members also highlighted visual reasoning pitfalls and joked about anime profile pictures signifying top-tier devs in open-source ML.
- MONA Minimizes Multi-step Mishaps: The MONA paper introduced Myopic Optimization with Non-myopic Approval as a strategy to curb multi-step reward hacking in RL.
- Its authors described bridging short-sighted optimization with far-sighted reward, prompting lively debate on alignment pitfalls and minimal extra overhead beyond standard RL parameters.
- AG2's Post-MS Pivot: AG2's new vision for community-driven agents detailed governance models and a push for fully open source after splitting from Microsoft.
- They now boast over 20,000 builders, drawing excitement over more accessible AI agent systems, with some users praising the shift toward crowdsourced development.
- R1 Rumbles in LMArena: As reported in #[paper-discussion], R1 achieved Rank 3 in LMArena, overshadowing other servers while Style Control held first place.
- Some called R1 an underdog shaking up the market, referencing synergy with Stargate or B200 servers as possible reasons for its strong showing.
- Differential Transformers & AI Insurance Talk: Developers eyed the DifferentialTransformer repo but voiced skepticism about the quality of its open weights and the author's approach.
- Meanwhile, banter about AI insurance surfaced, with one joking 'there's coverage for everything,' while others questioned if it can handle fiascos from reinforcement learning gone wild.
Notebook LM Discord Discord
- NotebookLM Zips Through Podcast Edits: A user employed NotebookLM to splice podcast audio with minimal cuts, resulting in an almost seamless flow.
- Listeners in the discussion admired the tool’s accuracy and asked whether more complex audio segments could be integrated for faster production.
- Engineers Eye Reverse Turing Test Angle: A user described Generative Output flirting with the idea of a reverse Turing Test to probe AGI concepts.
- They shared that this reflection sparked conversation about cybernetic advances and how LMs might understand themselves.
- MasterZap Animates AI Avatars: MasterZap explained a workflow using HailouAI and RunWayML to create lifelike hosts, referencing UNREAL MYSTERIES 7: The Callisto Mining Incident.
- He highlighted the difficulty of making avatars feel natural, prompting others to compare layering approaches for smooth facial movements.
- Gemini Advanced Trips on 18.5MB PDFs: Users tested Gemini Advanced to parse hefty documents, including a tax code at around 18.5MB, with limited success.
- Participants voiced frustration over inaccurate legal definitions and flagged the need for improved processing in version 1.5 Pro.
- NotebookLM Drills Through 220 Quiz Q’s: A user asked NotebookLM to produce quizzes from a PDF containing 220 questions, emphasizing exact text extraction.
- Some members offered collaboration tips, noting that advanced models can handle this but might still require careful prompts.
Nomic.ai (GPT4All) Discord
- GPT4All v3.7.0 Gains Windows ARM Wonders: Nomic.ai released GPT4All v3.7.0 with Windows ARM Support, fixes for macOS crashes, and an overhauled Code Interpreter for broader device compatibility.
- One user reported that Snapdragon or SQ processor machines now run GPT4All more smoothly, prompting curiosity about the refined chat templating features.
- Code Interpreter & Chat Templating Triumph: The Code Interpreter supports multiple arguments in console.log and has better timeout handling, improving compatibility with JavaScript workflows.
- Community feedback credits these tweaks for boosting coding efficiency, while the upgraded chat templating system resolves crashes for EM German Mistral.
- Prompt Politeness Pays Off: Participants tackled prompt engineering hurdles around NSFW and nuanced asks, discovering that adding please often yields improved interactions.
- They highlighted that many LLMs rely on internet-trained data for context and respond differently to subtle wording shifts.
- Model Mashups & Qwen Queries: Users assessed GPT4All with Llama-3.2 and Qwen-2.5, eyeing resource demands for larger-scale tasks.
- Some mentioned Nous Hermes as a possible alternative, while others tested Qwen extensively for enhanced translation capabilities.
- Taggui Takes On Image Analysis: One user sought an open-source tool for image classification and tagging, prompting a recommendation of Taggui for AI-driven uploads and queries.
- Enthusiasts praised multiple AI engine integration, calling it a solid choice for advanced image-based brainstorming.
MCP (Glama) Discord
- MCP Timeout Tweak Triumph: Engineers resolved the 60-second server timeout by modifying
mcphub.ts, with example updates found in the Roo-Code repo. They credited the VS Code extension for guiding the fix and ensuring stable MCP responses.- Members noted that specifying correct paths for
uvx.exewas vital to preventing further downtime, highlighting Roo-Code as a valuable tool for tracking configuration changes.
- Members noted that specifying correct paths for
- MySQL Merges with MCP Alchemy: A user recommended mcp-alchemy for MySQL integration, citing its compatibility with SQLite and PostgreSQL as well. This arose after questions about a reliable MCP server for managing database connections.
- The repo includes multiple usage examples, prompting broader interest in advanced MCP database pipelines.
- Claude's Google Search Stumbles: Community members observed Claude struggling with its Google search feature, sometimes failing under heavy usage. They speculated high demand and API instability might be at fault.
- Some proposed using an alternate scheduling strategy, hoping a more stable query window would reduce search cancellations in Claude.
- Agents in Glama Cause Confusion: The MCP Agentic tool appeared inside Glama prematurely, leaving users uncertain about its activation path. One member revealed that an official statement was pending, framing the leak as unexpected.
- Discussions linked the feature to MCP.run, with some users testing it in non-Glama client setups for agent-like functionalities.
- Personalization Takes Shape with mcp-variance-log: Developers introduced mcp-variance-log, referencing the Titans Surprise mechanism for user-specific data tracking through SQLite. The tool analyzes conversation structures to enable extended memory support.
- Members anticipate deeper personalization, noting that these variance logs could inform future MCP expansions and user-targeted refinements.
LlamaIndex Discord
- Redis Rendezvous: AI Agents in Action: A joint webinar with Redis examined building AI agents to enhance task management approaches, and the recording is available here.
- Listeners noted that thoroughly breaking down tasks can improve performance in real-life implementations.
- Taming Parallel LLM Streaming: A user ran into trouble when streaming data from multiple LLMs at once, with suggestions pointing to async library misconfiguration and referencing a Google Colab link for a working example.
- Community members stressed the need for correct concurrency patterns to avoid disruptions in sequential data handling.
- Slicing Slides with LlamaParse: Engineers discussed document parsing methods for .pdf and .pptx files using LlamaParse, with emphasis on handling LaTeX-based PDFs.
- They confirmed LlamaParse’s utility in extracting structured text for advanced RAG workflows, even across multiple file types.
- Roaring Real-Time in ReActAgent: The conversation featured ways to incorporate live event streaming with token output using LlamaIndex’s ReActAgent and the AgentWorkflow system found here.
- Developers indicated improved user flow once event-handling was synchronized with token streaming in real time.
- Export Controls Knock on AI’s Door: Participants explored the implications of new U.S. export regulations targeting advanced computing items and AI model weights, citing this update.
- They raised questions about compliance hurdles and how these rules might influence Llama model usage and sharing.
Cohere Discord
- Export Oops: Model Weights in the Crosshairs: The US Department of Commerce introduced new AI export controls, prompting concern over whether Cohere's model gets snagged under the latest restrictions (link).
- Some engineers at Oracle Japan worry about license tangles, though internal teams hint that special agreements might cushion the blow.
- GPU Guffaws: Sneaking Past Restrictions: Community members debated the real impact of GPU restrictions, suggesting giant AI firms slip in hardware under the radar.
- Participants questioned if these policies mainly punish smaller players while big fish glide freely.
- Blackwell Budget Blues: One user flagged Blackwell heavy operations, citing idle power usage at 200w, generating fear about bloated bills if usage ramps up.
- Others suggested balancing computational demands with actual workload to avoid waste.
Modular (Mojo 🔥) Discord
- Mojo’s Async Forum Fest: A member planned to share a new forum post about async code in Mojo, linking to How to write async code in Mojo.
- They promised to collaborate on the post, emphasizing community-driven knowledge exchange around asynchronous practices.
- MAX Builds Page Showcases Community Creations: The revamped MAX Builds page at builds.modular.com now features a special section for community-built packages.
- Developers can submit a PR with a recipe.yaml to the Modular community repo, encouraging more open contributions.
- iAdd Quirks Spark In-Place Puzzles: Users discussed the iadd method for in-place addition, such as a += 1, and how values are stored during evaluation.
- A curious example, a += a + 1, proved it might produce 13 if a was initially 6, prompting a caution to avoid confusion.
- Mojo CLI Steps It Up: A member revealed two new Mojo CLI flags, --ei and --v, capturing the interest of channel participants.
- They presented these flags with a playful emoji, suggesting further experimentation awaits for Mojo aficionados.
LAION Discord
- Cheering for Clearer Labels: Members explored labeling strategies for background noise and music levels, referencing a Google Colab notebook while encouraging a “be creative if you don’t know ask” approach.
- They proposed multiple categories like no background noise and slight noise, with some suggesting more dynamic labeling to handle different music intensities.
- Voices in a Crowd: Enthusiasts pitched a multi-speaker transcription dataset idea by overlapping TTS audio streams, aiming for fine-grained timing codes to track who’s speaking when.
- They emphasized that pitch and reverb variations help with speaker recognition, echoing the quote “There is no website, it's me coordinating folks on Discord.”
Eleuther Discord
- Divergent Distillation: Teacher-Student Tussle: A participant floated using the divergence between teacher and student models as a reward signal for deploying PPO in distillation, contrasting with classical KL-based methods.
- Some pointed out the stability of KL-matching for conventional training but stayed curious about adaptive divergence shaping distillation rewards.
- Layer Convergence vs. Vanishing Gradients: People discussed a recent ICLR 2023 paper on layer convergence bias, showing shallower layers learn faster than deeper layers.
- They also debated vanishing gradients as a factor in deeper layers’ slow progress, acknowledging it’s not the only culprit in training challenges.
- ModernBERT, ModernBART & Hybrid Hype: Talk centered on ModernBERT and the possibility of ModernBART, with some seeing an encoder-decoder version as popular for summarization use.
- References to GPT-BERT hybrids highlighted performance gains in the BabyLM Challenge 2024, suggesting combined masked and causal approaches.
- Chain-of-Thought & Agent-R Spark Reflection: A novel method applied Chain-of-Thought reasoning plus Direct Preference Optimization for better autoregressive image generation.
- Meanwhile, the Agent-R framework leverages MCTS for self-critique and robust recovery, spurring debate about reflective reasoning akin to Latro RL.
- Bilinear MLPs for Clearer Computation: A new ICLR'25 paper introduced bilinear MLPs that remove element-wise nonlinearities, simplifying the interpretability of layer functions.
- Proponents argued this design reveals how weights drive computations, fueling hopes for more direct mech interp in complex models.
Stability.ai (Stable Diffusion) Discord
- Frosty Font Focus: Enthusiasts explored ice text generation with custom fonts using Img2img to achieve a crystalline design.
- Adjusting denoise settings and coloring the text in an icy hue surfaced as recommended methods.
- ControlNet Gains Traction: Some proposed ControlNet to refine the ice text look, especially when combined with resolution tiling.
- This approach was said to yield sharper edges and more consistent results for stylized text.
- Adobe Firefly Steps In: Users mentioned Adobe Firefly as an alternative, accommodating specialized text creation if an Adobe license is available.
- They positioned it as a faster approach than layering separate software tools like Inkscape.
- Poisoned Image Queries: A member asked how to detect if an image is poisoned, sparking jokes about 'lick tests' and 'smell tests'.
- No official method emerged, but the discussion highlighted community curiosity about image safety.
- Turning Sketches into Scenes: Someone sought advice on sketch to image workflows to transform rough outlines into final visuals.
- Aspect ratio considerations, like 16:9, were also addressed for more user-friendly generation.
tinygrad (George Hotz) Discord
- ILP Tames Merges: A new approach was introduced in Pull Request #8736 using ILP to unify view pairs, reporting a 0.45% miss rate.
- Participants debated logical divisors and recognized obstacles posed by variable strides.
- Masks Muddle Merges: Community members argued whether mask representation can enhance merges, though some believed it might not work for all setups.
- They concluded that masks enable a few merges but fail to handle every stride scenario.
- Multi-Merge Patterns Appear: A formal search was proposed by testing offsets for v1=[2,4] and v2=[3,6], aiming to detect patterns in common divisors.
- They envisioned a generalized technique to unify views by systematically examining stride overlaps.
- Three Views, Twice the Trouble: Enthusiasts questioned pushing merges from two to three views, fearing more complexity.
- They cited tricky strides as a stumbling block for ILP, cautioning that a 3 -> 2 view conversion won't be straightforward.
- Stride Alignment Gains Momentum: Some suggested aligning strides could lessen merge headaches, but they warned about faulty assumptions when strides don't match.
- They realized earlier methods overlooked possible merges due to flawed stride calculations, calling for deeper checks.
Torchtune Discord
- Windows Wobbles & WSL Wonders: Members noted Windows imposes some constraints, including limited Triton kernel support. They recommended using WSL for a more direct coding experience.
- They highlighted shorter setup times and suggested it would ease training performance on Windows hardware.
- Regex Rescue for Data Cleanup: A member shared a regex
[^\\t\\n\\x20-\\x7E]+that scrubs messy datasets by spotting hidden characters. Another member clarified the pattern’s components, highlighting its role in discarding non-printable text.- They urged caution when modifying the expression to avoid accidental data loss and recommended thorough testing on smaller samples.
- Triton & Xformers Tiff with Windows: Some encountered issues running unsloth or axolotl on Windows due to Triton and Xformers compatibility gaps. They pointed to a GitHub repo for potential solutions.
- They recommended exploring future driver updates or container-based approaches for installing these libraries on Windows.
LLM Agents (Berkeley MOOC) Discord
- MOOC Monday Madness Begins: As mentioned in the #mooc-questions channel discussion, the first lecture is locked in for 4 PM PT on Monday, 27th, with an official email announcement on the way.
- Organizers confirm the session will run with advanced content tailored to push LLM agents in real-world tasks.
- LLM Agents Face a High Bar: Community members noted that an LLM agent passing the course sets a heightened bar for these models' capabilities.
- They agreed that this reflects the course's intense workload and tough grading criteria, forging a unique challenge for AI participants.
Axolotl AI Discord
- Scam Flood Shakes Discord: Scam messages appeared in multiple channels, including this channel, prompting warnings.
- One user acknowledged the problem, encouraging everyone to stay alert and verify suspicious postings.
- Nebius AI Draws Multi-Node Curiosity: A member asked for experiences running Nebius AI in a multi-node environment, citing the need for real-world performance tips.
- Others chimed in with potential pointers, underscoring a desire for thorough knowledge of resource allocation and setup details.
- SLURM Meets Torch Elastic Head-On: A user lamented the difficulty in configuring SLURM with Torch Elastic for distributed training, calling it a significant obstacle.
- Another member advised checking SLURM’s multi-node documentation, suggesting many setup concepts might still apply to this scenario.
DSPy Discord
- Signature Snafu Speeds Up Confusion: One user ran into confusion with the signature definitions, citing missing source files that throw off the expected outputs.
- They suspect incomplete references caused the fiasco, raising the question of how to manage consistent file mapping.
- MATH Dataset Goes AWOL: A user attempted a maths example but found the MATH dataset removed from Hugging Face, sharing a link to a partial copy.
- They also pointed to Heuristics Math dataset, asking if anyone could suggest other solutions.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The OpenInterpreter Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (604 messages🔥🔥🔥):
DeepSeek R1 vs. other models, Cursor functionality and issues, AI models and productivity, Updates on Cursor version 0.45.2, General discussion about AI in coding
- DeepSeek R1 shows promise as an architect: DeepSeek R1, used in combination with Sonnet as an editor, has achieved a new state-of-the-art of 64% on the Aider polyglot benchmark, outperforming previous models.
- This combination reports a significant cost reduction compared to earlier models, leading to discussions about the advantages of using R1 in coding workflows.
- Cursor experiences and its reliability: Users express mixed feelings about Cursor, citing unexpected code changes and issues with the platform, especially when working with larger projects in ASP.Net and VB.Net.
- The reliability of the live share feature in VSCode and Cursor was questioned, with comments about frequent disconnections while working on collaborative projects.
- Discussion on using AI for coding tasks: There is a consensus that while AI can be a helpful coding assistant, oversight is necessary to ensure code quality and to mitigate risks of unexpected changes.
- Participants discuss the advantages of using chat mode for greater control over the coding process, especially in complex projects.
- Updates on Cursor version 0.45.2: The new version 0.45.2 includes various features, but some users noted that previously available functionalities like 'beta' for embedding are missing.
- There is speculation that some features may have been put on hold due to stability concerns, while users highlight that the latest version has improved significantly in usability.
- General observations about AI and the coding landscape: Users reflect on the evolving AI landscape, noting how open-source models like DeepSeek R1 are reshaping the industry and prompting responses from competitors.
- The community discusses the implications of these changes, particularly regarding the future of AI coding assistants and competitive offerings in the market.
- cursor: Homebrew’s package index
- A New Tab Model | Cursor - The AI Code Editor: Announcing the next-generation Cursor Tab model.
- R1+Sonnet set SOTA on aider’s polyglot benchmark: R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
- Kermit Anxiety GIF - Kermit Anxiety Worried - Discover & Share GIFs: Click to view the GIF
- Barron Trump Let Me Hear It GIF - Barron Trump Let me hear it Show off - Discover & Share GIFs: Click to view the GIF
- Privacy policy of Deepseek: Hey, we run DeepSeek on our own procured infrastructure, using Fireworks as our provider. We have an existing agreement that fulfills our privacy and security policies with them, and this does not cha...
- Eddie Murphy Vacation Time GIF - Eddie Murphy Vacation Time Champagne - Discover & Share GIFs: Click to view the GIF
- Cursor Status: no description found
- Tweet from Aidan Clark (@_aidan_clark_): o3-mini first try no edits, took 20 sec(told me how to convert to gif too.....)Get excited :)Quoting Ivan Fioravanti ᯅ (@ivanfioravanti) 👀 DeepSeek R1 (right) crushed o1-pro (left) 👀Prompt: "wri...
- Share your "Rules for AI": I have a bunch of these custom to different settings/projects now, generally using with Claude 3.5 (Sonnet) or gpt-4o, sometimes I’ll use the “chatgpt-latest” model too, but not too frequently. Anyway...
- AI SDK by Vercel: Welcome to the AI SDK documentation!
- Trae - Ship Faster with Trae: no description found
- OpenAI is terrified (there's finally a great open source LLM): I never thought I'd see the day. Deepseek R1 is destroying every benchmark. It's also insanely cheap.Thank you G2i for sponsoring! Check them out at: https:/...
- deepseek-ai (DeepSeek): no description found
- no title found: no description found
- GitHub - cline/cline: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way.: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way. - cline/cline
- GitHub - PatrickJS/awesome-cursorrules: 📄 A curated list of awesome .cursorrules files: 📄 A curated list of awesome .cursorrules files. Contribute to PatrickJS/awesome-cursorrules development by creating an account on GitHub.
- High-Flyer | Home: 幻方 AI 专注前沿科技研发,以 AI 技术激发创造力和想象力,让人类更多梦想变成现实。幻方 AI 包含「萤火」深度学习训练平台、幻方量化(使用 AI 进行投资的对冲基金)、AI 基础科学研究。
Unsloth AI (Daniel Han) ▷ #general (347 messages🔥🔥):
Fine-tuning LLMs for language accuracy, Integration of Unsloth in Llama-Factory, Continued pretraining for language models, Posit computing implications, Evo model performance on nucleotide prediction
- Enhancing Turkish Language Model with LoRA: A user is exploring fine-tuning the Qwen 2.5 model to improve Turkish speech accuracy and reduce grammatical mistakes using LoRA training.
- They were directed to continued pretraining resources to help guide their efforts.
- Unsloth's Llama-Factory Integration Performance: There are reports of slower performance (up to 3x slower) with Unsloth’s integration in Llama-Factory compared to direct usage.
- Users appreciate the UI benefits but express concerns about integration speed.
- Continued Pretraining Notebooks for Language Models: Continued pretraining is discussed as a method for language models to learn new knowledge domains or languages, with links to relevant notebooks.
- This method emphasizes the importance of adaptive training for specialized applications.
- Posit Computing Dynamic Range Advantages: Users discussed the advantages of Posit computing, particularly its dynamic mantissa and exponent sizes for improved accuracy over floating-point formats.
- The conversation highlights a collaboration with Dr. John Gustafson to explore applications in AI.
- Evo Model Success in Nucleotide Prediction: The Evo model trained on prokaryotes demonstrates promising prediction capabilities with nucleotide-based input vectors.
- It maps each nucleotide to a sparse vector, achieving higher average correctness than random predictions.
- no title found: no description found
- MrDragonFox/vtube · Datasets at Hugging Face: no description found
- Discord This GIF - Discord This Server - Discover & Share GIFs: Click to view the GIF
- Qwen 2.5 Coder - a unsloth Collection: no description found
- unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF · Hugging Face: no description found
- SmolVLM Grows Smaller – Introducing the 256M & 500M Models!: no description found
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B · Hugging Face: no description found
- DeepSeek R1 (All Versions) - a unsloth Collection: no description found
- Get Started | Aptos Docs (en): Docs for Aptos
- Continued Pretraining | Unsloth Documentation: AKA as Continued Finetuning. Unsloth allows you to continually pretrain so a model can learn a new language.
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
- Chicken - Esolang: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (29 messages🔥):
Dual RTX 3090 setups, Training reasoning models repositories, Dolphin-R1 dataset creation, vLLM compatibility with Open-webui
- Members share dual RTX 3090 setup solutions: One member shared that they run dual RTX 3090s in a custom setup while another has moved to a Corsair 7000D case for 4090s with liquid cooling.
- They discussed additional setup details like hardware specifications including ASUS ProArt X670E CREATOR board enabling x8/x8 PCIe slots for GPUs.
- Recommendations for training reasoning models: It was suggested that the TRL framework has relevant methods for training reasoning models, and a member shared a link to the DeepSeekMath paper.
- Discussion highlighted the current demand for fine-tuning techniques specifically mentioning the use of R1 distilled models.
- Creation of the Dolphin-R1 dataset: $6k in API fees was discussed for creating the Dolphin-R1 dataset, following the recipe of Deepseek-R1 distillation, targeting a total of 800k traces.
- A sponsor was found, and the dataset will be published under Apache 2.0 license on Hugging Face soon.
- Issues with vLLM and Open-webui settings: Concerns were raised about vLLM not recognizing model presets from Open-webui, particularly with parameters like temperature not being passed correctly.
- Members debated possible reasons for these issues, with one suggesting that certain sampler settings are not supported by vLLM.
- Fruits of coding humor shared: A humorous YouTube video titled 'Delete your unit tests' was shared, focusing on programming memes.
- This illustrates the lighter side of challenges faced in software development, generating engagement among members.
- Tweet from Eric Hartford (@cognitivecompai): $6k in API fees to create Dolphin-R1 dataset. I follow the Deepseek-R1 distillation recipe, but with Dolphin seed data. (600k of reasoning, 200k of chat, 800k total)I want to license it Apache 2.0, ...
- GRPO Trainer: no description found
- Tweet from Eric Hartford (@cognitivecompai): I got a sponsor! Thanks @driaforall! The data will be published to @huggingface with Apache-2.0 license, in a couple days.
- Delete your unit tests: #programming #hopelesscore
Unsloth AI (Daniel Han) ▷ #help (107 messages🔥🔥):
Fine-tuning models, Resolving errors in model training, Utilizing chat templates, Exporting models from Colab, Dataset formatting for training
- Fine-tuning models and errors: Users discussed fine-tuning various models like qwen-2.5-3b and DeepSeek-R1-Distill, often encountering specific errors related to their dataset formats.
- One user mentioned the challenge of using the sharegpt format with the alpaca template, needing alternative templates to properly train.
- Experiences with chat templates: There was discourse on the effectiveness of different chat templates for training models, with emphasis on how reasoning processes might be affected.
- A user commented on the successful integration of the
token in their dataset while experimenting with R1 models.
- A user commented on the successful integration of the
- Exporting models from Colab: Users expressed difficulty exporting fine-tuned models saved in GGUF format from Google Colab to local storage or alternative formats.
- One user suggested saving directly to Hugging Face as a potentially simpler method than exporting from Colab.
- Dataset formatting challenges: A discussion arose regarding the appropriate dataset format for training models, highlighting the differences between required structures for various templates.
- It was noted that using standard templates risks losing the model's reasoning capabilities, prompting users to create tailored datasets.
- Model loading issues with quantized formats: Users reported issues with loading quantized models like unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit, receiving errors when attempting to run them on benchmarks like MMLU-pro.
- Support was sought to troubleshoot loading problems and ensure compatibility with running models locally.
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- unsloth/DeepSeek-V3-GGUF at main: no description found
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
LoHan Framework for LLM Fine-Tuning, NVMe Offloading Techniques, Flash Memory Utilization in LLMs
- LoHan Framework Enables Fine-Tuning on Consumer GPUs: The paper presents LoHan, a framework designed for efficiently fine-tuning 100B-scale LLMs on a single consumer-grade GPU, addressing the high costs of aggregating device memory.
- Existing methods fail due to poor management of intra-server tensor movement, making LoHan a significant contribution for budget-constrained researchers. Read more
- Discussion on Related NVMe Offloading Techniques: A member referenced a paper on NVMe offloading, suggesting it ties into the cost management strategies discussed in the LoHan framework.
- Although related, they acknowledged that this technique is not the same as LoHan's approach to optimizing LLM fine-tuning.
- Flash Storage Methodology for Managing LLMs: Another paper examines methods to run large language models efficiently by storing model parameters in flash memory and managing on-demand loading into DRAM.
- The paper proposed techniques like windowing to reduce data transfer, emphasizing the importance of optimizing flash memory utilization for high-capacity models. Read more
- Shared Interests in LLM Literature: Members expressed interest in sharing academic literature related to fine-tuning LLMs, highlighting the collaborative nature of their discussions.
- One member noted their unfamiliarity with the literature but aimed to spark interest by introducing these papers.
- Continued Sharing of Relevant Research: Amidst the discussion, links to additional papers were shared by members for those looking to explore more about LLM fine-tuning and optimization techniques.
- Research on tackling the challenges of LLM deployment in practical scenarios remains a key area of interest in this community.
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory: Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their substantial computational and memory requirements pr...
- LoHan: Low-Cost High-Performance Framework to Fine-Tune 100B Model on a Consumer GPU: Nowadays, AI researchers become more and more interested in fine-tuning a pre-trained LLM, whose size has grown to up to over 100B parameters, for their downstream tasks. One approach to fine-tune suc...
Codeium (Windsurf) ▷ #announcements (1 messages):
Windsurf 1.2.2 Release, Cascade Web Search, Lag Improvements, Memory System Enhancements
- Windsurf 1.2.2 hits the shelves!: The Windsurf 1.2.2 update has been released, focusing on improving user experience with key enhancements.
- Notable improvements include smoother handling of long conversations, boosted web search capabilities, and enhancements to Cascade's memory system.
- Cascade can now search the web!: The update introduces new features for Cascade, allowing it to conduct web searches automatically or via user-provided URLs.
- Users can now use commands like
@weband@docsto trigger searches, further enriching the functionality of Cascade.
- Users can now use commands like
- Settings for Web and Docs Search: Users can enable or disable web search tools directly from the Windsurf Settings panel located in the status bar.
- This allows for customizable experiences when it comes to conducting web searches, enhancing usability for different preferences.
Link mentioned: Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #content (1 messages):
Web Search Feature, Demo Video Launch
- New Web Search Feature Gains Attention: The team announced excitement over the new web search feature that aims to enhance user experience while browsing the internet.
- Members were encouraged to check out the cool demo video linked in the announcement that showcases its capabilities.
- Community Support for Demo Video Requested: A call to action was made for users to show support for the launched demo video on social media.
- The post on X was emphasized as needing community love to boost visibility.
Link mentioned: Tweet from Windsurf (@windsurf_ai): Just surfin' the web! 🏄
Codeium (Windsurf) ▷ #discussion (78 messages🔥🔥):
Windsurf Issues, Supercomplete Functionality, Account Registration Problems, C# Extension for Windsurf, Windsurf 1.2.2 Release
- Windsurf faces multiple user issues: Users reported problems with account registration, message limits being reduced, and some experiencing a disabled account error, indicating a broader system issue.
- Multiple threads indicate that the support team is aware and working on these issues, but many users are left waiting for resolutions.
- Concerns over Supercomplete functionality: Several users inquired about the Supercomplete functionality, specifically its status in relation to the Codeium extension and VSCode integration.
- One user noted the lack of updates and questioned whether the focus has shifted entirely to Windsurf.
- Challenges with C# development in Windsurf: Users expressed frustration over the C# extension, discussing the limitations of the Microsoft dev kit and its compatibility with Windsurf.
- Community members suggested utilizing the open-vsx.org C# extension while warning about potential issues with debugging configurations.
- Windsurf 1.2.2 release supports smoother experience: An update was rolled out for Windsurf to enhance the performance of long conversations and improve web search capabilities.
- Users were directed to the changelog for details on new features, indicating ongoing development efforts.
- Windsurf outage and recovery: There were reports indicating that Windsurf was temporarily down, which raised concern among users about system stability.
- After a brief period, users confirmed that the service was back online, alleviating some immediate concerns.
- Pricing | Windsurf Editor and Codeium extensions: Codeium is free forever for individuals. Teams can level up with our enterprise offering for enhanced personalization and flexible deployments.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #windsurf (299 messages🔥🔥):
Windsurf login issues, Windsurf updates and performance, Open Graph metadata in Vite, Input lag in Windsurf, Cascade service outages
- Windsurf login issues affecting multiple users: Many users reported issues with logging into Windsurf, including errors such as 'Something went wrong' and persistent 503 errors.
- Concerns about account abuse potentially leading to these restrictions were discussed, with users unable to register or access their accounts on various devices.
- Windsurf update 1.2.2 released with bugs: Despite the 1.2.2 update claiming to fix input lag issues during long conversations, users continue to experience significant lag.
- Even after restarts and new chats, lag persists, suggesting that the update hasn’t resolved performance concerns for all users.
- Open Graph metadata issues in Vite applications: A user shared difficulty in implementing Open Graph metadata for dynamic pages built with Vite on Vercel, claiming prompts in Windsurf have not resolved the issue.
- They explored various strategies like SSR and client-side rendering for metadata, seeking advice from the community after several days of struggle.
- Cascade service outages: There were widespread reports of 503 gateway errors affecting Cascade, leading to an inability to use the service for various users.
- After a brief period of downtime, the storm subsided, and users returned to functionality, praising quick resolution efforts.
- Discussion on integrating Windsurf with other editors or terminals: Conversation initiated about the possibility of using CodeSeek R1 or Windsurf in different environments, such as other editors or terminals.
- Other users pointed out that Windsurf operates as a dedicated IDE, prompting discussions about the integration capabilities with existing tools.
- Cascade Memories: no description found
- Home | Sweetpad: Description will go into a meta tag in
- no title found: no description found
- Chat with Codeium | Windsurf Editor and Codeium extensions: Chat with general using Codeium Live. Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
- Turn Blog Post Tutorials into Full-Stack Applications Automatically - Windsurf Editor: You can now build full-stack apps by simply dropping a blog post URL into your IDE. With web search, Windsurf can automatically follow tutorials and turn the...
- TikTok made an IDE and it's actually good? (free cursor killer??): Byte Dance, the Tik Tok company made a code editor and its actually good?!?! RIP Cursor? VS Code killer? Jetbrains clone? Idk what's happening anymore...Than...
- GitHub - unclecode/crawl4ai: 🚀🤖 Crawl4AI: Open-source LLM Friendly Web Crawler & Scraper: 🚀🤖 Crawl4AI: Open-source LLM Friendly Web Crawler & Scraper - unclecode/crawl4ai
- GitHub - Cem-Bas/AgenTest-aiDoc: Contribute to Cem-Bas/AgenTest-aiDoc development by creating an account on GitHub.
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
DeepSeek R1 updates, DeepSeek provider outage
- DeepSeek R1 expands message pattern support: DeepSeek R1 now supports more types of message patterns, allowing users to send weird message orderings again.
- This update aims to improve overall usability and flexibility for users.
- Temporary deranking of DeepSeek provider: The DeepSeek provider experienced a strange outage this morning, prompting a temporary deranking until the issue is fixed.
- Users were notified of this change to manage expectations regarding service availability.
- DeepSeek provider back online: The DeepSeek provider has been restored and is back online after the earlier outage.
- This heralds the return of normal service for users relying on DeepSeek functionalities.
OpenRouter (Alex Atallah) ▷ #general (290 messages🔥🔥):
DeepSeek R1 Performance, Gemini API Access, BlackboxAI Concerns, Rate Limits and Key Usage, Provider Issues on OpenRouter
- DeepSeek R1 Improving Performance: Users have reported that DeepSeek R1 is now working properly on SillyTavern, noting its writing quality is exceptional and cost-effective.
- Despite earlier issues, many users are now impressed with the model's performance and affordability.
- Gemini API Access and Limitations: There has been a discussion regarding the access to Gemini models, with some users suggesting the use of personal API keys to bypass rate limits on the free version.
- Users were encouraged to obtain their own keys to utilize higher rates and access features effectively.
- Concerns Over BlackboxAI: A conversation has emerged concerning the legitimacy of BlackboxAI, highlighting its complicated installation process and lack of transparency in reviews.
- Some users are skeptical about its operations, suggesting it might be a scam or a poorly managed service.
- Rate Limits and API Key Management: There were inquiries about rate limits associated with API keys, particularly whether they expire or get disabled.
- It was clarified that OpenRouter API keys do not expire but can be disabled by the user.
- Provider Issues on OpenRouter: Users have been facing ongoing issues with DeepSeek and other provider models on OpenRouter, with some suggesting that DeepSeek's API might have different weights than others.
- These discrepancies have led to discussions about the implications for benchmark results and overall user experience.
- kluster.ai - Power AI at scale: Large scale inference at small scale costs. The developer platform that revolutionizes inference at scale.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Integrations | OpenRouter: Bring your own provider keys with OpenRouter
- Tweet from Anthropic (@AnthropicAI): Introducing Citations. Our new API feature lets Claude ground its answers in sources you provide.Claude can then cite the specific sentences and passages that inform each response.
- no title found: no description found
- DeepSeek R1 Distill Llama 70B - API, Providers, Stats: DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](/meta-llama/llama-3. Run DeepSeek R1 Distill Llama 70B with API
- Web Search | OpenRouter: Model-agnostic grounding
- Crypto Payments API | OpenRouter: APIs related to purchasing credits without a UI
- no title found: no description found
- DeepSeek R1 - API, Providers, Stats: DeepSeek R1 is here: Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Ru...
- Requests | OpenRouter: Handle incoming and outgoing requests
Latent Space ▷ #ai-general-chat (75 messages🔥🔥):
DeepSeek R1 Model, Fireworks Streaming Transcription Service, Braintrust AI Proxy, Perplexity Assistant, New OpenAI Features
- DeepSeek R1 surges in performance rankings: DeepSeek R1 has jumped to rank #2 in WebDev Arena, showing strong capabilities in coding tasks and matching the top reasoning model o1 while being 20x cheaper.
- This model has been recognized for its performance in technical domains and obtained a MIT license, noted as a valuable resource for the community.
- Fireworks launches new transcription service: Fireworks has introduced a new streaming transcription service that offers live captions using Whisper-v3-large quality at 300ms latency, and it will be free for the first two weeks.
- After the trial period, the service will cost $0.0032 per audio minute, allowing for economical transcription solutions.
- Braintrust AI Proxy simplifies AI integration: Braintrust features an AI Proxy that enables developers to access various AI providers through a single API, promoting code simplification and cost reduction.
- This tool is open-source, allowing for easy setup and management of AI models, with additional features for logging and prompt management.
- Perplexity Assistant hits the Play Store: Perplexity AI introduced the Perplexity Assistant, offering features to streamline daily tasks such as booking dinner or drafting emails, all through an intuitive interface.
- It has been noted that the assistant leverages capabilities not currently available in Apple's ecosystem, raising concerns about Apple's competitive edge.
- OpenAI Updates Canvas in ChatGPT: OpenAI announced updates to its canvas feature within ChatGPT, enabling it to work with the o1 model and allowing for HTML and React code rendering.
- These features aim to enhance user interaction and flexibility in utilizing the canvas for various applications.
- Tweet from Fireworks AI (@FireworksAI_HQ): We’re launching a streaming transcription service! Generate live captions or power voice agents with Whisper-v3-large quality with 300ms latency. Use it FREE for the next two weeks and then at $0.0032...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): ❤️🔥WebDev Arena Update: Exciting new entries!- #2: @deepseek_ai DeepSeek-R1- #4: New Gemini-2.0-Flash-ThinkingDeepSeek-R1 jumps to #2 with only <40 pts gap to Claude 3.5 Sonnet, showing strong ca...
- Tweet from Guillermo Rauch (@rauchg): Image to 3D with @splinetool’s next gen model. All implementation hurdles are being lifted, just bring your ideas
- Tweet from OpenAI (@OpenAI): Trading Inference-Time Compute for Adversarial Robustness https://openai.com/index/trading-inference-time-compute-for-adversarial-robustness/
- Tweet from Anjney Midha 🇺🇸 (@AnjneyMidha): From Stanford to MIT, deepseek r1 has become the model of choice for America’s top university researchers basically overnight
- Tweet from David Lindner (@davlindner): New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?Our method, MONA, prevents many such hacks, *even if* humans are unable to detect...
- Tweet from Teknium (e/λ) (@Teknium1): We retrained hermes with 5k deepseek r1 distilled cots. I can confirm a few things:1. You can have a generalist + reasoning mode, we labeled all longCoT samples from r1 with a static systeem prompt, t...
- Tweet from OpenAI (@OpenAI): Canvas update: today we’re rolling out a few highly-requested updates to canvas in ChatGPT.✅Canvas now works with OpenAI o1—Select o1 from the model picker and use the toolbox icon or the “/canvas” co...
- Tweet from jack morris (@jxmnop): i guess DeepSeek broke the proverbial four-minute-mile barrier. people used to think this was impossible. and suddenly, RL on language models just works and it reproduces on a small-enough scale th...
- $2 H100s: How the GPU Bubble Burst: H100s used to be $8/hr if you could get them. Now there's 7 different resale markets selling them under $2. What happened?
- Tweet from Perplexity (@perplexity_ai): Introducing Perplexity Assistant.Assistant uses reasoning, search, and apps to help with daily tasks ranging from simple questions to multi-app actions. You can book dinner, find a forgotten song, cal...
- Tweet from Deedy (@deedydas): China just dropped a new model.ByteDance Doubao-1.5-pro matches GPT 4o benchmarks at 50x cheaper— $0.022/M cached input tokens, $0.11/M input, $0.275/M output— 5x cheaper than DeepSeek, >200x of o1...
- Tweet from homanp (@pelaseyed): I don’t do RAG anymore, get 10x the result just spinning up a pipeline and feed all content to Deepseek. And yes it scales to over 10K docs. RAG is anti pattern.
- Tweet from Jonathan Ellis (@spyced): I built a tool to solve the context problem for large codebases. 1/N
- GitHub - braintrustdata/braintrust-proxy: Contribute to braintrustdata/braintrust-proxy development by creating an account on GitHub.
- AI proxy - Docs - Braintrust: Access models from OpenAI, Anthropic, Google, AWS, Mistral, and more
Latent Space ▷ #ai-in-action-club (193 messages🔥🔥):
Model Context Protocol (MCP), MCP integration with tools, Obsidian MCP server, MCP capabilities and connection, MCP party planning
- Excitement for Model Context Protocol: Members expressed enthusiasm about the potential of the Model Context Protocol (MCP), describing it as a centralizing point for integrating various AI capabilities.
- Many participants noted they were eager to explore its applications further in their workflows.
- MCP server connections and tools: Discussion centered on the ability to connect multiple servers written in different programming languages to leverage various tools effectively within MCP.
- Members mentioned the ease of implementing different tools and the potential for powerful integrations.
- Sharing MCP resources: A variety of resources and GitHub links related to MCP servers were shared, showcasing existing implementations and community contributions.
- This included links to specific MCP servers, such as those for Obsidian and general MCP functionalities.
- Upcoming MCP party: Participants discussed hosting an MCP party to delve deeper into the protocol after a successful hack session.
- A spreadsheet was shared to organize names and dates for future sessions focused on exploring MCP further.
- Discussion on tools and practical applications: Members talked about practical applications for MCP, such as using it with Cursor and integrating it with tools like youtube-dl and more.
- Emphasis was placed on the innovative ways MCP could streamline interactions with coding tools and AI.
- cs16.css: CSS library based on Counter Strike 1.6 UI.
- Cancellation: ℹ️ Protocol Revision: 2024-11-05 The Model Context Protocol (MCP) supports optional cancellation of in-progress requeststhrough notification messages. Either side can s...
- Architecture: no description found
- Architecture: no description found
- AI In Action: Weekly Jam Sessions: no description found
- GO GO GOLEMS!: GO GO GOLEMS BUILD GO GO GADGETS. GO GO GOLEMS! has 34 repositories available. Follow their code on GitHub.
- GitHub - tumf/mcp-shell-server: Contribute to tumf/mcp-shell-server development by creating an account on GitHub.
- GitHub - MarkusPfundstein/mcp-obsidian: MCP server that interacts with Obsidian via the Obsidian rest API community plugin: MCP server that interacts with Obsidian via the Obsidian rest API community plugin - MarkusPfundstein/mcp-obsidian
- GitHub - rusiaaman/wcgw: Shell and coding agent on claude desktop app: Shell and coding agent on claude desktop app. Contribute to rusiaaman/wcgw development by creating an account on GitHub.
- GitHub - modelcontextprotocol/servers: Model Context Protocol Servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- wcgw/src/wcgw/client/mcp_server/server.py at fbe8c5c3cca4f7a149f8c099c63696d9ede7f9e7 · rusiaaman/wcgw: Shell and coding agent on claude desktop app. Contribute to rusiaaman/wcgw development by creating an account on GitHub.
- GitHub - go-go-golems/go-go-mcp: Anthropic MCP go implementation: Anthropic MCP go implementation. Contribute to go-go-golems/go-go-mcp development by creating an account on GitHub.
- GitHub - smithery-ai/mcp-obsidian: A connector for Claude Desktop to read and search an Obsidian vault.: A connector for Claude Desktop to read and search an Obsidian vault. - smithery-ai/mcp-obsidian
Perplexity AI ▷ #general (239 messages🔥🔥):
Perplexity Assistant Launch on iOS, Comparison of AI Models, User Experience Issues with Perplexity, Feedback on Assistant Features, Alternatives to Perplexity
- Delay in iOS Release for Assistant: Discussions reveal that the Perplexity assistant for iOS is pending approval from Apple, with hopes for launch following permission acquisition.
- Users express eagerness for the assistant's arrival, noting current challenges in accessing features via mobile applications.
- Perplexity vs Competitors in AI Performance: Several users comment on the comparative strengths of various AI models, highlighting the effectiveness of ChatGPT in accuracy over others like Perplexity.
- There's a consensus that while models like Gemini offer search capabilities, Perplexity's responses, particularly in sourcing, have been well-received.
- User Frustrations with Perplexity's Current Functionality: Concerns arise over the limited access to certain features and models within Perplexity, especially regarding O1 and the overall experience with the assistant.
- Users discuss frustrations with bugs and limitations, suggesting the service is losing ground to competitors.
- Insights on AI Model Usage: Users share insights on how different AI models fulfill various needs, with particular praise for Sonar's integration and performance in comparison to others.
- There's an evident emphasis on the necessity for unique features to maintain user engagement as a competitive differentiator.
- Exploring Alternatives to Perplexity: Suggestions for alternatives to Perplexity flood the conversation, including platforms like DeepSeek and Abacus for their user-friendly features and pricing.
- Users express interest in exploring these alternatives, particularly as they offer competitive functionalities and efficient responses.
- Revolut Launches Its Highest Savings Rates for UK Customers, of Up to 5% AER (Variable): Revolut has supercharged its rates for its UK Instant Access Savings account offering interest rates of up to 5% AER
- Tweet from Aravind Srinivas (@AravSrinivas): We will bring up R1 served in American data centers on Perplexity. And make it free for everyone.
- Tweet from Filipe | IA (@filicroval): 5. Creando un clon de Perplexity en una hora sin escribir una sola línea de código
- Tweet from Aravind Srinivas (@AravSrinivas): Read Access for Calendar and GMail for the Perplexity Assistant: work in progress; the intention is to get it out within 3 weeks.It can already (right now) summarize your unread emails and upcoming ca...
- Will Sigmon (@wsig.me): Since last summer, I’ve been working towards better health and strength.Today, I’m pleased to report a 45-pound loss!This progress stems from lifestyle adjustments, improved diet, & support from M...
Perplexity AI ▷ #sharing (8 messages🔥):
Latest Pop Culture, Action-Adventure Movies, Upcoming Tech Conferences, AI-Developed Drugs, Laravel Framework
- Pop Culture Latest Updates: A user shared latest pop culture updates with a focus on recent trends and discussions.
- These updates highlight emerging themes in entertainment and social media that resonate with current audiences.
- Top Action-Adventure Movies to Watch: A link to the best action-adventure movies was shared, detailing recommendations based on viewer ratings.
- This list serves as a guide for movie enthusiasts looking to explore exciting cinematic experiences.
- Tech Conferences on the Horizon: Two users discussed upcoming tech conferences that are set to gather industry leaders and innovators.
- These events promise to showcase cutting-edge developments and networking opportunities in technology.
- New Advances in AI-Developed Drugs: A user shared information on AI-developed drugs that are set to hit the market soon.
- This showcases the potential of AI in revolutionizing pharmaceuticals and healthcare solutions.
- Understanding Laravel Framework: A user requested insights on Laravel, a popular PHP framework known for its elegant syntax.
- This highlights the interest in efficient web application development practices among developers.
Perplexity AI ▷ #pplx-api (6 messages):
API updates, Sonar API calls, API pricing and searches
- API receives attention with updates: Members expressed happiness that the team is finally paying attention to the API and making relevant updates after being previously ignored.
- It's a relief to see progress being made.
- Understanding Sonar API searches: A discussion arose about whether it’s possible to disable searches for a Sonar API call, with questions on whether it always generates a search.
- One member clarified that the pricing documentation states Sonar Pro can perform multiple searches for comprehensive information retrieval.
- API pricing confusion clarified: Concerns were raised about the API pricing structure, particularly regarding searches and how they accumulate costs.
- A member shared that under their understanding, the cost structure implies each 1000 API calls will incur a charge regardless of the chat type.
- Redundant search costs in chat interactions: A member highlighted their use case where an initial search is beneficial, but subsequent responses seem to incur unnecessary search costs.
- They noted that the pricing and functionality feel redundant when continuing a chat does not require additional searches.
- Pricing - Perplexity: no description found
- API Pricing - how to tell how many searches a given request incurred · ppl-ai/api-discussion · Discussion #121: Based on the pricing documentation, perplexity charges $5/1000 search queries incurred by a the model. However, I don't see a way to determine based on the model response how many searches were do...
LM Studio ▷ #general (88 messages🔥🔥):
LM Server Access, Network Settings Confusion, Vision Models for LLM Studio, Tool Use in LM Studio, Model Compatibility Issues
- LM Server Accessibility across Network: To enable the LM Server for access from other devices, there's a checkbox in settings to activate local network access.
- Members expressed confusion over naming conventions, suggesting terms like 'Loopback only' to clarify expected functionalities.
- Confusion over Local Network Settings: Discussions revealed that terminology like 'local network' often leads to misunderstandings about its meaning in relation to
localhostand0.0.0.0.- Some considered renaming settings to be more descriptive, advocating for clearer communication to ease user experience.
- Best Vision Models for LLM Studio Investigated: Members debated the best vision models in the 8b-12b range, with suggestions including Llama 3.2 11b amidst concerns about specific model compatibility.
- There were multiple mentions of compatibility with MLX and GGUF models available in LLM Studio, asking if both platform's models could coexist.
- Implementing Tool Use in LM Studio: Members shared insights on enabling tool use in LM Studio to allow LLMs to interact with external functions and APIs via a REST API.
- Illustrative resources were provided, emphasizing that working with tools is achievable for users wanting to extend LLM capabilities.
- Model Loading and Compatibility Queries: A user expressed difficulty in getting LM Studio to recognize their local GGUF models, questioning if specific model formats were necessary.
- Concerns were raised about how to integrate with the local OpenAI API while navigating model discovery challenges.
- leafspark/Llama-3.2-11B-Vision-Instruct-GGUF · Modelfile of Llama-3.2-11B-Vision-Instruct: no description found
- leafspark/Llama-3.2-11B-Vision-Instruct-GGUF · Modelfile of Llama-3.2-11B-Vision-Instruct: no description found
- GitHub - bytedance/UI-TARS: Contribute to bytedance/UI-TARS development by creating an account on GitHub.
- Tool Use - Advanced | LM Studio Docs: Enable LLMs to interact with external functions and APIs.
LM Studio ▷ #hardware-discussion (117 messages🔥🔥):
NVIDIA RTX 5090 performance, Llama-3.3 model requirements, AI hardware comparisons, GPU memory capacity, LM Studio performance on older hardware
- NVIDIA RTX 5090 offers modest performance increase: Discussions revealed that the RTX 5090 shows only a 30% increase in performance over the RTX 4090, despite having 1.7x the bandwidth.
- Members expressed disappointment, noting that the additional 32GB of VRAM may not significantly enhance performance for smaller models.
- Running Llama-3.3 requires substantial resources: To run the Llama-3.3-70B-Instruct-GGUF model quickly, it was suggested that Dual A6000s are necessary with 96GB of VRAM for efficient performance.
- Users noted that models larger than 24GB are challenging to run on a 4090, particularly without sacrificing speed.
- AI benchmarking reveals VRAM limitations: There were concerns that smaller models can't utilize increased memory bandwidth, particularly when only running on older GPUs like the 1080 Ti without AVX2.
- Participants concluded that suitable benchmarks depend heavily on both VRAM capacity and bandwidth for smaller models to achieve optimal performance.
- GPU and memory specs critical for AI tasks: Discussion emerged about the importance of memory speed and type in older hardware setups when running AI models, especially with GPUs from previous generations.
- Users highlighted the challenges and limitations when mixing high-performance servers with outdated NVIDIA cards like the P40.
- Challenges with current LLM implementations: Many in the discussion expressed frustration with the current landscape of consumer hardware for LLMs, indicating it's generally insufficient for high-performance tasks.
- The group acknowledged that corporations may offer better opportunities through AI inference APIs, given their capacity to subsidize the costs.
- NVIDIA GeForce RTX 5090 Graphics Cards: Powered by the NVIDIA Blackwell architecture.
- NVIDIA GeForce RTX 5090 Review: Pushing Boundaries with AI Acceleration: NVIDIA GeForce RTX 5090 Review: Launch on January 30, 2025 at $1,999. Will the 5090 redefine high-performance gaming and AI workloads?
- Procyon AI Text Generation: Testing AI LLM performance can be very complicated and time-consuming, with full AI models requiring large amounts of storage space and bandwidth to download.
aider (Paul Gauthier) ▷ #general (159 messages🔥🔥):
R1 Model Performance, DeepSeek API Concerns, Aider Benchmark Results, Using Different Models in Aider, New AI Tools and Developments
- R1+Sonnet Achieves New SOTA: The combination of R1+Sonnet set a new SOTA on the aider polyglot benchmark with a score of 64%, achieving this at 14X less cost compared to o1.
- This highlights a significant performance uplift, with various users noting a preference for this model combination over alternatives.
- Trust Issues with DeepSeek Payments: Concerns were raised regarding using DeepSeek's API due to payment security, with some users preferring OpenRouter as an alternative.
- Users noted that the OpenRouter version of R1 might differ from DeepSeek's direct offerings, prompting discussions on trustworthiness.
- Aider's Benchmark Comparisons: Feedback indicated that thinking tokens resulted in worse benchmark results compared to standard architect/editor pairings, suggesting inefficiencies in reasoning models.
- Users observed that keeping old Chain of Thoughts (CoTs) in the context for reasoning models was not recommended due to potential impacts on performance.
- Variability in R1 Responses: Some users reported inconsistencies with R1 performance, especially under contexts exceeding a specific size, which could lead to errors or slow response times.
- It was suggested that selective context management, such as using /read-only, could mitigate some performance issues.
- Comparisons to Other Models: Users compared R1 to other models like Sonnet and Claude, indicating different performance dynamics, particularly in speed and accuracy.
- Discussion also centered around the idea that newer AI tools, including a VSCode fork called Trae AI, feel redundant due to lack of significant innovation.
- Tweet from Artificial Intelligence News (@ai_newsz): Billionaire and Scale AI CEO Alexandr Wang: DeepSeek has about 50,000 NVIDIA H100s that they can't talk about because of the US export controls that are in place.
- DeepSeek R1 Distill Llama 70B - API, Providers, Stats: DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](/meta-llama/llama-3. Run DeepSeek R1 Distill Llama 70B with API
- Tweet from OpenRouter (@OpenRouterAI): Top 3 trending models today were all made in China 👀Quoting Aofei Sheng (@aofeisheng) Somehow, the top three trending models on @OpenRouterAI are all from China, and the #1 (@deepseek_ai) is just a s...
- R1+Sonnet set SOTA on aider’s polyglot benchmark: R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
aider (Paul Gauthier) ▷ #questions-and-tips (41 messages🔥):
Logging Practices in Python, Aider's Workflow and Context Management, Deepseek Model Performance, Managing Ignored Files in Git, Architect Mode in Aider
- Optimize Logging Practices in Python: To prevent log outputs from bloating chat history, one user recommended using a logging module to export logs to a readonly file and referencing that in prompts instead of copying terminal outputs.
- This method saves time and keeps the context clean, allowing for more efficient interactions with the AI.
- Streamlining Aider's Workflow: A discussion highlighted the importance of efficiently managing Aider's context, particularly with large codebases, as multiple terminal commands can generate excessive output.
- Users expressed a need for Aider to run commands without cluttering the conversation, with various proposals for better output handling like run-and-drop options.
- Issues with Deepseek Model Performance: Several users noted challenges with the Deepseek r1 model, including long processing times and lack of responses despite having the correct API setup.
- Concerns were raised that insufficient context handling might limit the model's effectiveness in practical applications.
- Handling Ignored Files in Git: One user encountered issues when trying to add a
.gitignorefile to Aider, which was resolved by using the/read-onlycommand instead of removing it from.gitignore.- This solution helps users maintain their file management practices while still utilizing Aider effectively.
- Architect Mode's Utility: A question was posed regarding the practicality of Architect Mode, with feedback suggesting it often overlaps with functionalities in other modes.
- Users shared concerns about inefficiencies and glitches when switching between modes, prompting suggestions for smoother operations.
aider (Paul Gauthier) ▷ #links (4 messages):
Deleted Messages, Admin Actions
- Mystery of the Deleted Message: A user mentioned a message regarding a waitlist that has seemingly vanished, leaving others confused.
- Another user speculated that the admin might have removed the link, but no confirmation was provided.
- Admin's Role in Message Removal: It was noted that the message's deletion could be linked to admin actions, although details remain unclear.
- The community expressed uncertainty over the situation, indicating a lack of information on the matter.
Interconnects (Nathan Lambert) ▷ #news (42 messages🔥):
Sky-T1-32B-Flash, DeepSeek-R1 performance, RLHF discussions, AI outlets and influencers
- Sky-T1-32B-Flash tackles overthinking: NovaSkyAI introduced Sky-T1-32B-Flash, an open reasoning model that reduces generation lengths by 50% without sacrificing accuracy, costing only $275.
- The model's weights are available for use and further experimentation in lowering inference costs.
- DeepSeek-R1 secures top ranking: DeepSeek-R1 is now ranked #3 overall in the Arena, on par with OpenAI-o1 while being 20x cheaper and fully open-weight, as reported by lmarena_ai.
- Its capabilities include being #1 in technical domains like coding and math, and it provides a fully open-source model for the community.
- RLHF's impact on accuracy debated: There was a discussion on RLHF's effect on model accuracy with claims stating that 'RLHF kills accuracy' is an outdated view, reflecting changes over the past year.
- Contributors noted that good RLHF practices do not diminish evaluation results unless safety requirements conflict with other performance metrics.
- Need for quality AI outlets: Users expressed concerns about the decline of reputable AI outlets, with some shifting attention from Stratechery due to its decreasing relevance in AI discussions.
- There was a call for recommendations on quality AI podcasts and YouTube channels, suggesting that many current platforms focus on sensationalism rather than valuable insights.
- Tweet from Sauers (@Sauers_): @JacquesThibs To be fair, questions that Gemini, o1-preview, 4o, and Sonnet got right were usually not allowed to enter the dataset
- Tweet from NovaSky (@NovaSkyAI): 1/5 ⚡️Presenting Sky-T1-32B-Flash⚡️, our open reasoning model that tackles "overthinking" to cut generation lengths (and inference cost!) by 50% without sacrificing accuracy – tuned with only ...
- Tweet from morgan — (@morqon): zuck measuring the size of his data centre
- Tweet from Nat McAleese (@__nmca__): Epoch AI are going to publish more details, but on the OpenAI side for those interested: we did not use FrontierMath data to guide the development of o1 or o3, at all. (1/n)
- Tweet from henry (@arithmoquine): r1 distillation OOD-space is incredibly strange. it's a formless soup yet still desperately trying to hold itself together
- Tweet from Noam Brown (@polynoamial): The feeling of waking up to a new unsaturated eval.Congrats to @summeryue0, @alexandr_wang, @DanHendrycks, and the whole team!Quoting Dan Hendrycks (@DanHendrycks) We’re releasing Humanity’s Last Exam...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Breaking News: DeepSeek-R1 surges to the top-3 in Arena🐳!Now ranked #3 Overall, matching the top reasoning model, o1, while being 20x cheaper and open-weight!Highlights:- #1 in technical domains: Har...
- bespokelabs/Bespoke-Stratos-32B · Hugging Face: no description found
- An Interview with Daniel Gross and Nat Friedman About Models, Margins, and Moats: An interview with Daniel Gross and Nat Friedman about Stargate, DeepSeek, and where the margins and moats will come with models.
Interconnects (Nathan Lambert) ▷ #ml-drama (29 messages🔥):
DeepSeek Performance, OpenAI and Benchmark Comparisons, Chinese Work Attitude vs American Perceptions, Reasoning in Model Training, Cope Discussions
- DeepSeek R1 outshines o1-pro: DeepSeek R1 reportedly 'crushed' o1-pro in a performance comparison, with discussions circulating about the quality of this model's outputs.
- One user pointed out that its success may be attributed to it not being included in earlier benchmark loops.
- Skepticism Towards OpenAI's Influence: There are claims that OpenAI's engineering practices have turned result comparisons into a game, leading to concerns about the trustworthiness of non-open-source research.
- Another member remarked that reliance on OpenAI outputs for training could undermine the defensibility of new models.
- Cultural Perceptions of Work Ethic: Members debated the American perspective on Chinese work ethic, highlighting a belief that a country with a billion people must be capable of independent innovation.
- A few participants found the dismissive attitude towards Chinese innovation utterly baffling.
- Discussions on Reasoning in Training Models: Participants expressed doubts about the effectiveness of base models trained primarily on OpenAI outputs for developing strong reasoning capabilities.
- It was noted that high perplexity results on datasets like Common Crawl likely indicate more robust training methodologies beyond simply using prior model outputs.
- Coping Mechanisms in the Community: There is a growing sentiment that many discussions around model performance and training strategies devolve into coping explanations when faced with competitive outcomes.
- Members increasingly labeled these responses as 'cope' while critiquing the prevailing narratives about training methodology.
- Tweet from Xin Eric Wang (@xwang_lk): This is very shady. OpenAI just turned result comparison on web/OS agent leaderboards into an engineering game. This is exactly why only open-source research is reliable and trustworthy nowadays. http...
- Tweet from Swaroop Mishra (@Swarooprm7): Deepseek is great, but don't read too much into its lead on humanity's last exam benchmark by @DanHendrycks et. alThe dataset was created adversarially to o1, Gemini, gpt, Claude, etc., but de...
- Tweet from Dan Roy (@roydanroy): I thought the answer was obvious? They've illegally trained off o1, no? Meta risks too much doing that, surely. But this has always been the secret to the success of the "little guys" in t...
- Tweet from Eric Zelikman (@ericzelikman): Quoting Ivan Fioravanti ᯅ (@ivanfioravanti) 👀 DeepSeek R1 (right) crushed o1-pro (left) 👀Prompt: "write a python script for a bouncing yellow ball within a square, make sure to handle collision ...
- Elon CIVIL WAR WIth Trump, Sam Altman Over AI Megaproject: Krystal and Saagar discuss the tech bro Civil War between Elon Musk and Sam Altman. Sign up for a PREMIUM Breaking Points subscriptions for full early access...
Interconnects (Nathan Lambert) ▷ #random (64 messages🔥🔥):
Discord Summarization Tools, DeepSeek Salaries, Applied NLP Reading List, AI Development, Tech Competition
- Exploring Discord Summarization Tools: Discussions centered around the effectiveness of various Discord summarization tools, with mentions of a tool offering internal summaries that received mixed feedback.
- Members noted that some existing functionalities, like Discord in-channel summaries, were not well-received, leading to suggestions for newer, better tools.
- DeepSeek's Noteworthy Salaries: A user highlighted concerns about tech companies offering $5.5M salaries to DeepSeek employees, aiming to attract talent away from competitors.
- The conversation prompted a reflection on how high compensation is reshaping talent dynamics in AI, especially regarding stock and base salary.
- Curating an Applied NLP Reading List: A member shared a need for suggestions on papers to assign for an Applied NLP class, with discussions leaning towards foundational papers like Attention and BERT.
- Feedback emphasized incorporating recent impactful papers that align with advancements in NLP and AI techniques.
- AI Development Challenges: One user discussed challenges in utilizing an AI agent to build an app, humorously suggesting a newsletter titled, *
- The thread included light-hearted remarks on the potential for AI to create profitable applications and the hilarity of the tech journey.
- Competitions and Corporate Strategies in Tech: Members expressed concerns about ‘tech old moneys’ trying to disrupt competitors by making substantial offers to talent within the AI sector.
- The notion of corporate competition and its implications on talent retention sparked lively discussions about the future of jobs in AI.
- Language Modeling Reading List (to Start Your Paper Club): Some fundamental papers and a one-sentence summary for each; start your own paper club!
- Tweet from Martin Bowling (@martinbowling): @elfelorestrepo @skirano @deepseek_ai check out my repo, so I make it a tool call give it the query and context and then send that to r1 and then have it wrap it's reasoning in
- Tweet from Jiayi Pan (@jiayi_pirate): The specific RL alg doesn't matter muchWe tried PPO, GRPO and PRIME. Long cot all emerge and they seem all work well. We haven't got the time to tune the hyper-parameters, so don't want to...
- Smol Talk Alpha - Nov 2024!: Intro to the smol talk platform - for your own personalized AI News!Sign up: Monthly (https://buy.stripe.com/dR602I7Sv7FYfN69AA), Annual (https://buy.stripe.com/00g9DifkX6BU8kE145), Lifetime (https://...
- Tweet from Zihan Wang (@wzihanw): Things I'm worrying now is how "tech old moneys" are trying to offer DeepSeek whales 🐳 those 💵5.5M/yr salary, hoping to dissolve the team and disrupt such opponent.No. I'd never want...
- Tweet from Jiayi Pan (@jiayi_pirate): We reproduced DeepSeek R1-Zero in the CountDown game, and it just works Through RL, the 3B base LM develops self-verification and search abilities all on its own You can experience the Ahah moment you...
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
OpenAI's Job Automation Model, Claude's Mechanistic Interpretability, Test-Time Scaling Quotes
- OpenAI to Automate 50% of Jobs: OpenAI announced the upcoming release of a model that could automate 50% of jobs.
- This signals a potential shift towards increased automation in the workforce.
- Mechanistic Interpretability Affirms Claude's Identity: Anthropic claimed that their work in mechanistic interpretability has revealed that Claude is gay.
- This statement showcases the organization's experimental findings and engagement with identity interpretation.
- CEO Highlights Test-Time Scaling Significance: In a notable quote, the CEO of the National Reasoning Model Association stated, “The only thing that stops a bad guy with test-time scaling is a good guy with test-time scaling.”
- Source emphasizes the strategic importance of test-time scaling in overcoming adversarial challenges.
- Tweet from Charles Foster (@CFGeek): “The only thing that stops a bad guy with test-time scaling is a good guy with test-time scaling.”- CEO of the National Reasoning Model Association
- Tweet from Ben (e/treats) (@andersonbcdefg): openai: we are dropping a model that automates 50% of jobsanthropic: using mechanistic interpretability we have proved that claude is gay
Interconnects (Nathan Lambert) ▷ #cv (4 messages):
Advanced NLP Course Update, Consequential Models in Multimodality, Audio Domain Applications of ViT and CLIP, LLaVA for Unified Embeddings
- Advanced NLP Course Needs Multimodality Focus: A staff member seeks to update their advanced NLP course with lectures on multimodality and VLMs, specifically mentioning ViT and CLIP as key models.
- They are considering adding a VLM that processes unified embeddings, debating between LLaVA and QwenVL.
- AST and MSCLIP for Audio Applications: Another member suggested that AST and MSCLIP are worth considering as they utilize ViT and CLIP for audio by using audio spectrograms as image input.
- This adaptation showcases the versatility of these models beyond traditional image processing.
- LLaVA's Original Role in VLM Architecture: A member pointed out that LLaVA was the original version of the architecture before transitioning to techniques like vqgans and qformers.
- They noted that LLaVA even created the recipe for the architecture, which underscores its significance in the development of multimodal models.
Interconnects (Nathan Lambert) ▷ #reads (28 messages🔥):
Interconnects subscription value, Operator AI agent feedback, ModernBERT insights, Challenges with Semianalysis, On-device intelligence discussions
- Interconnects subscription offers extra perks: Users expressed surprise at the added value of the Interconnects subscription, particularly with the inclusion of the seminalysis feature. One noted it as a 'great value' and highly recommended it.
- Operator AI agent faces usability challenges: Feedback includes that the Operator AI agent struggles with summarizing content and needs frequent user confirmations for actions. Users noted it should parse HTML to enhance its functionality but currently falls short.
- ModernBERT's OLMo tokenizer discussed: A user shared a link about ModernBERT and its efficient OLMo tokenizer application. They highlighted the model's parameter-efficiency and innovations compared to previous models.
- Issues with Semianalysis crawling: A member pointed out that Substack is particularly challenging to crawl due to its JS content loading and tracking link replacements. This has led to difficulties when trying to automate information gathering from Semianalysis.
- On-device intelligence insights shared: A member urged the need to communicate that certain AI tasks aren't suitable for edge devices, referring to a tweet that emphasized the importance of on-device intelligence. Discussions pointed to the complexities that arise from running tasks on limited hardware.
- What Should We Learn From ModernBERT?: Bigger training data, efficient parameter sizing, and a deep-but-thin architecture, ModernBERT sets a direction for future BERT-like models.
- OpenAI launches its agent: Hands on with Operator — a promising but frustrating new frontier for artificial intelligence
- Tweet from Luca Soldaini 🎀 (@soldni): on device intelligence is important to study cuz compute only gets cheaper and more plentiful 🤗excited to contribute this space Real Soon™️Quoting Ben (e/treats) (@andersonbcdefg) it's FAST. and...
Interconnects (Nathan Lambert) ▷ #retort-podcast (8 messages🔥):
Adobe Podcast Enhance Speech Tool, Audio Setup for Interviews, Quality of Audio vs. Magic Audio
- Adobe Podcast 'Enhance Speech' is a mixed bag: One user remarked that the Adobe Podcast 'Enhance Speech' tool can sound robotic when applied, especially after testing it on podcast audio.
- While it works well for solo recordings, issues arise with multi-person setups, reinforcing the need for quality mic setups.
- Multi-Person Audio Setup is Costly and Complex: Another member expressed that achieving good audio for group interviews involves using quality equipment, like a Rode Podmic and a Rodecaster, which can be expensive and labor-intensive.
- They mentioned aiming for studio-like quality but acknowledged the complexity involved in setting everything up for multiple people.
- Avoiding 'Magic Audio' Techniques: A preference was voiced against using 'magic audio' tools, which often result in an overly processed sound that feels fake.
- The user emphasized valuing good audio quality over enhancement techniques that compromise the authenticity of the sound.
- Limited Audio Efforts for One-on-One Interviews: There is a current intention to focus on one-on-one interviews in person until there is able editorial or AV assistance.
- This approach aims to minimize effort in audio production but still recognizes the importance of quality sound.
Interconnects (Nathan Lambert) ▷ #policy (5 messages):
Presidential AI Action Order, AI Regulations Review, New AI Action Plan, Special Advisor for AI and Crypto, Free Market AI Development
- Presidential Order Aims to Enhance AI Leadership: The recent presidential order outlines initiatives to remove barriers to U.S. AI innovation, emphasizing the importance of developing ideologically unbiased AI systems to maintain American leadership in the sector. It revokes previous directives, including Executive Order 14110 on AI safety and trustworthiness.
- The order envisions solidifying America’s position as the global leader in AI through free market approaches and government policy.
- Review of Existing AI Regulations in Focus: The order mandates the review and potential removal of existing AI regulations that are considered obstacles to U.S. AI dominance. This measure is aimed at promoting economic competitiveness and national security.
- The discussion mentions the need to create a new AI action plan within 180 days to align with these goals.
- Introduction of Special Advisor for AI and Crypto: A new role for Special Advisor for AI and Crypto will be created as part of the order, highlighting the administration's focus on integrating AI advancements with digital currency initiatives. This position is expected to help steer U.S. policy in the interconnected areas of AI and cryptocurrency.
- Additionally, revisions to important memoranda are required to be completed within 60 days.
- Emphasis on Free Market and Economic Competitiveness: The order stresses the importance of free market approaches to AI development, advocating for the removal of any ideological bias within AI systems. This strategy is touted as essential for ensuring economic competitiveness and enhancing national security.
- The order aims for a brighter future for all Americans through sustainable AI growth.
- Removing Barriers to American Leadership in Artificial Intelligence – The White House: By the authority vested in me as President by the Constitution and the laws of the United States of America, it is hereby ordered as follows: Section 1.
- Removing Barriers to American Leadership in Artificial Intelligence – The White House: By the authority vested in me as President by the Constitution and the laws of the United States of America, it is hereby ordered as follows: Section 1.
GPU MODE ▷ #general (18 messages🔥):
Jailbreaking Models, MLOps Resources, Flash Infer Talk, Attention Methods, Flex Attention vs Differential Attention
- Jailbreaking Models is Easy: Jailbreaking other models is trivial for anyone who knows how to use Google, with no effective protections beyond brand safety.
- This raises questions about the security of existing models in a rapidly evolving landscape.
- Looking for MLOps GPU Resources: A user is seeking learning resources for experienced MLOps professionals to transition from CPU-based models to distributed GPU ones using PyTorch.
- This highlights the need for accessible guides on advanced GPU usage in ML workflows.
- Questions for Flash Infer Talk: A user inquired about a question channel for the Flash Infer talk, indicating issues with asking questions on YouTube without a channel.
- Another user offered to read questions from the chat, emphasizing community support during live sessions.
- Discussion on Attention Methods: There was a discussion on flex attention and its capability to handle methods like differential attention, with insights into how they operate.
- Specifics included running two different softmaxes and querying whether flex attention supports this, showcasing technical interest.
- Pseudocode for Attention Methods: A user shared pseudocode demonstrating how to implement differential attention using PyTorch, showcasing concepts like lambda value and softmax operations.
- They also noted similarities between MLA and lightning attention, simplifying part of the technical inquiry for others.
GPU MODE ▷ #cuda (78 messages🔥🔥):
CUDA Toolkit 12.8 Release, Blackwell Architecture Features, TensorCore Instructions, FP8 and FP4 Support, Compatibility of sm_90a and sm_100a
- CUDA Toolkit 12.8 Released: The newly released CUDA Toolkit 12.8 includes support for Blackwell architecture and updated documentation.
- However, some members noted that certain documentation updates were delayed, yet confirmed they are now live.
- Blackwell Architecture Features Explained: Blackwell's architecture introduces significant updates, potentially achieving 660 TFLOPS on RTX 4090 with enhanced FP8 capabilities.
- Discussions highlighted the complexities associated with achieving marketed TFLOPS in B100/B200 GPUs, estimated at more than $10 billion in engineering.
- 5th Generation TensorCore Instructions Availability: While 5th generation TensorCore instructions are available on sm_100 and sm_101, they are absent on sm_120, particularly for RTX 5090.
- This divergence in instruction sets raises concerns over potential codebase fragmentation and integration challenges.
- FP8 and FP4 Types Supported in cuBLAS: Significant updates for cuBLAS have been confirmed, including support for FP8 and FP4 data types for improved computation efficiency.
- This is particularly relevant for future workloads leveraging quantization efficiencies, although reactions have varied on its practical benefits.
- Compatibility Concerns Between Architectures: There are uncertainties regarding the forwards compatibility of sm_90a with sm_100a and sm_120, with no guarantees on compatibility.
- It was noted that while some features may overlap, certain performance-enhancing instructions like
wgmmaare exclusive to specific architectures.
- It was noted that while some features may overlap, certain performance-enhancing instructions like
- FP8 Quantization: The Power of the Exponent: When quantizing neural networks for efficient inference, low-bit integers are the go-to format for efficiency. However, low-bit floating point numbers have an extra degree of freedom, assigning some b...
- nvfp4_tensor — Model Optimizer 0.21.1: no description found
- Tweet from Vijay (@__tensorcore__): CUDA 12.8 just dropped with Blackwell support. TensorCore 5th Generation Family Instructions: https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tensorcore-5th-generation-instructions
- CUDA Toolkit 12.1 Downloads: Get the latest feature updates to NVIDIA's proprietary compute stack.
- Software Migration Guide for NVIDIA Blackwell RTX GPUs: A Guide to CUDA 12.8, PyTorch, TensorRT, and Llama.cpp: Applications must update to the latest AI frameworks to ensure compatibility with NVIDIA Blackwell RTX GPUs. This guide provides information on the updates to the core software libraries required to e...
- Add support for sm_101 and sm_101a to NV_TARGET by bernhardmgruber · Pull Request #3166 · NVIDIA/cccl: no description found
GPU MODE ▷ #torch (22 messages🔥):
Async Computation with Custom CUDA Kernels, bfloat16 vs float32 Precision in PyTorch, Tensor Parallel Configurations in HF Transformers, Learning Rate Schedulers in PyTorch, Vision-Based Models Optimization
- Async Computation vs cudaMalloc Issues: A user indicated that running torch computation async alongside custom CUDA kernels leads to calls to cudaMalloc, which impacts async execution.
- This raises concerns regarding the necessity for pre-allocated tensors to maintain async kernel runs.
- Precision Discrepancies with bfloat16 and float32: Discussion emerged over certain pathways performing calculations in bfloat16 while others converted to float32. Members explored the implications of precision mismatches on model training outcomes.
- One noted that when using
nn.Linear, all inputs and weights should technically be in bfloat16.
- One noted that when using
- Potential Hooks in Hugging Face Transformers: It was suggested that Hugging Face's transformers may introduce hooks affecting how results are computed, causing unexpected output inconsistencies.
- A user noted that they could not reproduce these issues in a pure PyTorch example, hinting at nuances in the HF transformers models.
- Learning Rate Scheduler Recommendations: A conversation about the use of linear warmup for the first N steps in conjunction with rotating to CosineAnnealing highlighted practices for optimizing learning rates.
- Links to relevant PyTorch documentation were shared to clarify the mechanics and configurations of both the CosineAnnealingWarmRestarts and LinearLR schedulers.
- Vision Models: Input and Feedback: A user expressed a focus on vision-based models and invited feedback on optimizations and learning strategies relevant to this area.
- Acknowledgment and appreciation for insights shared by community members emphasized collaborative learning dynamics.
- CosineAnnealingWarmRestarts — PyTorch 2.5 documentation: no description found
- LinearLR — PyTorch 2.5 documentation: no description found
- CosineAnnealingLR — PyTorch 2.5 documentation: no description found
GPU MODE ▷ #announcements (1 messages):
Flash Infer, Deep Learning Techniques, Code Generation, Custom Kernels, Attention Patterns
- First Lecture of the Year on Flash Infer: The first lecture of the year features Zihao Ye discussing Flash Infer, which covers topics like code generation, custom kernels, and various attention patterns.
- The lecture will be streamed live on YouTube.
- Focus on Code Generation Techniques: Flash Infer dives into advanced code generation techniques that promise to enhance performance through tailored kernels and efficient execution patterns.
- This lecture highlights the innovative aspects of JIT and AOT compilation strategies that are crucial for real-time applications.
GPU MODE ▷ #cool-links (1 messages):
cpeterson42: AI Infrastructure community on X: https://x.com/i/communities/1879760488256491834
GPU MODE ▷ #jobs (1 messages):
ComfyUI hiring, Machine Learning Engineers
- ComfyUI seeks machine learning engineers: ComfyUI is currently hiring machine learning engineers to join their team responsible for maintaining ComfyUI and its ecosystem.
- The company boasts day 1 support for models from top firms and invites those excited about optimizing open source code to apply. More information can be found here.
- ComfyUI backed by VC: ComfyUI is a VC backed company located in the Bay Area, emphasizing a significant vision with a long runway.
- They are looking for individuals who are passionate about making contributions to the open source community within the machine learning field.
Link mentioned: Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
GPU MODE ▷ #beginner (4 messages):
DeepSpeed Integration, Hugging Face Accelerate Library, Throughput Comparison, Communication Overhead
- Exploring DeepSpeed Integration Options: A member suggested trying DeepSpeed Zero 2 or DeepSpeed Zero 3 if the model supports DeepSpeed integration.
- This highlights ongoing efforts to optimize model performance using available technologies.
- Hugging Face Accelerate Simplifies Distributed Training: Another member recommended the Accelerate library by Hugging Face, which simplifies distributed training in PyTorch with minimal code changes.
- Using just four lines of code, it prepares models for various configurations effectively.
- Throughput Confusion between 405B and DeepSeek-v3: A member questioned why 405B has a higher throughput despite DeepSeek-v3 having fewer active parameters, suspecting communication overhead as a factor.
- This incites discussion about efficiency and the complexities behind model performance metrics.
- Success with Accelerate in SageMaker: A user confirmed that the Accelerate library worked well for them but noted challenges in getting it to run smoothly in a SageMaker notebook.
- This reflects the practical hurdles users can face when integrating libraries into specific environments.
Link mentioned: Accelerate: no description found
GPU MODE ▷ #lecture-qa (2 messages):
Parallel Prefix Sum in Distributed Systems, MPI_Scan in CUDA
- Exploring Distributed Prefix Sum Algorithms: A question was raised regarding the availability of algorithms for prefix sum in a distributed manner using multiple GPUs with distributed memory, specifically referencing Lecture 20, 21, and 24.
- The closest reference found was MPI_Scan, but there seems to be a lack of tutorials and documentation on its implementation with CUDA.
- Local Scan Combining with All-to-All Communication: A response suggested performing the distributed prefix sum similar to the GPU block scans, where each node computes its local scan and communicates the last element for an all-to-all exchange.
- It was proposed that using the mentioned MPI_Scan could help communicate the few intermediate results required to correct the local scans efficiently.
GPU MODE ▷ #self-promotion (2 messages):
ComfyUI Meetup, DeepSeek R1 Model Performance
- Join the ComfyUI Meetup in SF: Next Thursday, the ComfyUI event will take place at the GitHub office, featuring demos and discussions among open source developers. Check the event details here to meet the community and share your workflows.
- Highlight guests include MJM and Lovis, who will share their insights during a panel discussion.
- DeepSeek R1 surpasses original model: The re-distilled DeepSeek R1 model (1.5B) outperforms its original distilled counterpart, available now at Hugging Face. Members noted excitement about upcoming model releases following this success.
- The announcement from Mobius Labs emphasized their commitment to distilling more models in the future.
- Tweet from Mobius Labs (@Mobius_Labs): Our re-distilled @deepseek_ai R1 (1.5B) outperforms the original distilled model! Get it at https://huggingface.co/mobiuslabsgmbh/DeepSeek-R1-ReDistill-Qwen-1.5B-v1.0. We’re distilling more models and...
- ComfyUI Official SF Meet-up at Github · Luma: First official ComfyUI SF Meetup in the Github office! Come meet other users of ComfyUI, share your workflows with the community, or give your input to the…
GPU MODE ▷ #thunderkittens (1 messages):
Zeroing Accumulators, ThunderKittens GitHub
- Is Zeroing Accumulators Necessary?: A member questioned whether it is necessary to zero the accumulators in the kernel code, specifically in the matmul.cu file.
- They wondered if the accumulators get zeroed anyways during the setup process, indicating a potential optimization.
- Explore the ThunderKittens Project: The GitHub repository for ThunderKittens features code focused on tile primitives for speedy kernels, enhancing the development process for matrix multiplication tasks.
- The project is hosted on GitHub, providing collaboration opportunities for contributors interested in advancing HazyResearch endeavors.
Link mentioned: ThunderKittens/kernels/matmul/H100/matmul.cu at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
GPU MODE ▷ #arc-agi-2 (20 messages🔥):
Polynomial Equations Addition, Maze Task Implementation, Refactoring Reasoning-Gym Structure, Dynamic Reward System, External Contributor Recognition
- Polynomial Equations Added to Project: A member sent a PR adding polynomial equations to the project alongside simple linear equations.
- Another member expressed appreciation for the contribution, saying, 'Perfect, thanks a lot!'
- Maze Task Proposal Gains Support: A member proposed designing a maze task to find the shortest path, showcasing an example layout.
- The idea was well-received, with indications that it would be a super-great addition for reasoning-gym.
- Streamlining Reasoning-Gym's Structure: A contributor plans to simplify the structure of reasoning-gym, aiming for easier dataset consumption and effective result parsing.
- Suggestions included adding static functions for dataset comparisons and registering datasets conveniently.
- Dynamic Rewards Based on Accuracy: A member suggested implementing a reward system based on the accuracy of answers, where the reward adjusts with the answer's proximity to the correct one.
- This involved configuring the reward mechanism in a way that allows user-defined expressions, like -x2, for clarity and customization.
- Celebrating External Contributors: A member recognized another's contribution by awarding them the first external contributor trophy for their efforts.
- This acknowledgment highlights the collaborative nature of the project and encourages ongoing contributions.
- clrs/clrs/_src/clrs_text at master · google-deepmind/clrs: Contribute to google-deepmind/clrs development by creating an account on GitHub.
- tiny-grpo/train.py at eafedd78ff86dbb724a3dd21bb04ab6523ac8f3c · open-thought/tiny-grpo: Minimal hackable GRPO implementation. Contribute to open-thought/tiny-grpo development by creating an account on GitHub.
OpenAI ▷ #annnouncements (1 messages):
Canvas updates, HTML & React code rendering, ChatGPT desktop app rollout, Access tiers for new features
- Canvas now integrates with OpenAI o1: The Canvas feature is now compatible with OpenAI o1; users can select o1 from the model picker and utilize the toolbox icon or the
/canvascommand.- This update has been made available to Pro, Plus, and Team users.
- HTML & React code can now be rendered: Canvas has added the ability to render HTML and React code, making it accessible for more complex interactions.
- This capability is available to Pro, Plus, Team, and Free users.
- Canvas fully rolled out on macOS desktop app: The canvas feature has been fully rolled out on the ChatGPT desktop app for macOS across all user tiers.
- This update marks a significant improvement for macOS desktop users.
- Enterprise and Edu updates on the horizon: Both the canvas integration with o1 and the HTML/React rendering will be rolled out to Enterprise and Edu tiers in a couple of weeks.
- This ensures broader access and enhancements for educational and enterprise users.
OpenAI ▷ #ai-discussions (131 messages🔥🔥):
Deepseek and R1, API Usage for Chatbots, AI Integrated IDEs, Token Costs for AI Models, Operator's Browser Interaction
- Deepseek's Side Project Approach: The CEO of Deepseek mentioned that R1 was merely a side project using spare GPUs, generating humor and interest in the AI community.
- It's believed that Deepseek is sponsored by the Chinese government to enhance local AI models, highlighting a clever strategy for gaining attention and efficiency.
- Chatbot API Usage Ideas: A member suggested using the OpenAI API for chatbot creation as a cheaper alternative to paying for pro versions, finding potential savings.
- It was noted that with GPT-3.5, for $5, approximately 2.5 million tokens can be processed, emphasizing the economic benefits of custom implementations.
- Exciting Prospects of AI in Game Development: Discussion on how an AI agent could revolutionize game development by creating games in Unity using real-time applications like paintbrush tools.
- This idea also extends to software engineering, suggesting seamless IDE, terminal, and database integrations for efficient workflows.
- Concerns About AI's Internet Access: Conversations highlighted the risks associated with giving AI agents internet access, as it could reset learned behaviors from prior interactions.
- Users expressed the need for caution when involving AI models in broader contexts, particularly regarding data retention during searches.
- Operator's New Features: The Operator tool was discussed for its ability to interact with web browsers, though questions arose regarding its current functionality and limitations.
- Members inquired if this feature would extend to standalone applications, emphasizing the potential for stronger integration in AI-assisted tasks.
Link mentioned: DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1: Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (2 messages):
Release of O3
- Call for O3 Release: A user expressed a desire for the immediate release of O3.
- Another member declined the invitation, stating simply, 'no thanks'.
- Opposing Views on O3 Release: The conversation highlighted a difference in opinions regarding the release of O3, with one member eager and another uninterested.
- This exchange points to varying levels of engagement within the community.
OpenAI ▷ #prompt-engineering (7 messages):
Public vs Private Information, NDA Discussions, Misinformation Concerns
- Public vs Private: Know Your Boundaries!: A member emphasized that everything posted in this channel is regarded as public, cautioning against sharing NDA-related information.
- They pointed out the importance of being responsible with what is shared, especially regarding confidential content.
- NDA Discussions Lack Clarity: There was a discussion regarding the implications of sharing non-NDA information and how it could promote misinformation about what is truly relevant in the field.
- One member lamented that promoting outdated methods could mislead others into thinking they are still cutting-edge.
- Let It Go: A Moment of Apology: One member apologized for their previous statements, suggesting to ignore what was said as the conversation shifted.
- This indicated a desire for clarity and an acknowledgment that previous comments may have led to misunderstandings.
OpenAI ▷ #api-discussions (7 messages):
2023 Trends, NDA Compliance, Misinformation Concerns
- 2023 Trends are Outdated: Nah man, that is so 2023 indicates the belief that certain trends or practices should be reconsidered or updated.
- This sentiment suggests a push for more relevant and current approaches in discussions.
- Proper NDA Adherence is Necessary: A reminder was made about NDA adherence, indicating that discussions should not involve non-NDA information.
- It emphasizes the importance of not being misled by outdated non-NDA materials.
- Misinformation in Public Discourse: Concerns were raised regarding misinformation, highlighting that promoting non-NDA methods as superior can distort perceptions of relevance.
- This discussion pointed out the risks of framing outdated methods as current or cutting-edge.
- Acknowledgment of Miscommunication: The message thread included an apology from a member for any confusion caused, indicating a willingness to clarify earlier points.
- This reflects a desire for clear communication and understanding in the discussion.
Stackblitz (Bolt.new) ▷ #prompting (1 messages):
React + TypeScript + Tailwind web app, App architecture, Data management strategies, Development workflows, Versioning standards
- Starter Strategy for React + TypeScript + Tailwind App: A structured text file documents a starter strategy for building a React + TypeScript + Tailwind web app, covering the initial setup, architecture, and data management.
- Feedback is desired on architecture, data strategies, and workflows as per the shared Google Document.
- Central Documentation Standards: The documentation includes standards for creating a central GUIDELINES.md file, which consists of modular sections covering architecture, logging, and a design system.
- This structured approach aims to improve clarity and maintainability across the project.
- Flexible Data Management Approach: A flexible persistence strategy is outlined, starting with localStorage and designed to be easily migratable to Supabase.
- This adaptability is crucial for scaling the application's data needs.
- Structured Development Steps: Instructions are provided for building systems such as a design system, logging system, and a changelog interface.
- These steps are intended to streamline development and enhance team collaboration.
- Consistent Versioning with Changelog: The proposal includes adherence to the 'Keep a Changelog' format to ensure clear and consistent version updates.
- This practice is vital for tracking changes and maintaining project history.
Link mentioned: start prompt strategy: ## Start with Initial Prompt: Create a React + TypeScript + Tailwind web app with: Layout: Persistent header and sidebar navigation with menu items (e.g., Menu 1, Menu 2, Menu 3) and a submenu unde...
Stackblitz (Bolt.new) ▷ #discussions (144 messages🔥🔥):
Stripe Webhook Implementation, Issues with Bolt Functions, Messaging System with Supabase, Chat Loading Problems, OpenAI API Errors
- Stripe Webhook Implementation Success: After extensive troubleshooting and 14M tokens, a member successfully implemented a Stripe webhook, resolving conflicts with Supabase functions that had overlapping
user_idparameters.- The member noted that they had to manually debug and fix issues that the AI could not identify.
- Bolt Functions Not Making Changes: Users reported that Bolt is now suggesting code changes instead of automatically applying them, causing frustration as they have to manually search through code for corrections.
- A member noted that the sudden change in behavior might be due to chat history references.
- Challenges with Supabase Messaging System: A user is looking for assistance in implementing a messaging system using Supabase's realtime functionality, encountering issues with Row Level Security (RLS).
- They expressed a desire to discuss the implementation with others who have successfully completed similar tasks.
- Chat Loading Issues on Bolt: Several users experienced problems loading chats on Bolt, with reports indicating that refreshing or using a VPN allowed access, while others continued to face issues.
- It was observed that location might affect connectivity, with some users reporting success with VPNs, while others could not access chats.
- OpenAI API Usage Errors: A user encountered 400 errors when trying to use o1-mini via the OpenAI API, despite functioning correctly in the Playground.
- They speculated that the issue might stem from incorrect naming conventions or configurations within Bolt.
- bolt.new: no description found
- Get started with StackBlitz - StackBlitz: no description found
Nous Research AI ▷ #general (134 messages🔥🔥):
DiStRo and GPU Training, Tiny Stories Model Training, OpenAI and Market Reactions, New AI Models and Reasoning Capabilities, Importance of Self-Attention in Transformers
- Exploring DiStRo for Enhanced GPU Training: Members discussed the potential of DiStRo to improve training speeds on multiple GPUs without NVLink, noting it excels with models that fit into the individual GPU memory.
- It was suggested that using frameworks like PyTorch's FSDP2 with DiStRo could amplify performance for larger models.
- Training Insights on Tiny Stories Models: Discussion centered around the performance of various tokenization strategies and model parameters for Tiny Stories, particularly around 5m to 700m parameters.
- Real Azure shared findings that adjusting tokenization improved model perplexity, signaling a method for future model optimization.
- OpenAI's Market Standing and Concerns: Current valuations of Microsoft, Meta, and Amazon were mentioned, with a sense of unease regarding OpenAI's brand management and public perception.
- Members expressed concern over hype versus reality, highlighting the significance of consistent product performance.
- Advancements in AI Reasoning Models: Insights were shared about retraining Hermes with DeepSeek R1 distilled CoTs, showcasing the efficiency of combining reasoning modes with generalist models.
- The conversation explored the potential for self-distillation techniques and indicated that using EQ ratings for performance evaluation might yield new methodologies.
- Self-Attention and Efficiency in AI Models: Discussion emerged around the increasing importance of self-attention mechanisms in transformer models for VRAM efficiency, particularly as models scale.
- Juahyori raised questions about whether self-distillation could be attained through rewarding creative outputs, hinting at innovative directions for model training.
- no title found: no description found
- Tweet from Teknium (e/λ) (@Teknium1): We retrained hermes with 5k deepseek r1 distilled cots. I can confirm a few things:1. You can have a generalist + reasoning mode, we labeled all longCoT samples from r1 with a static systeem prompt, t...
- Tweet from Paul Gauthier (@paulgauthier): R1+Sonnet set a new SOTA on the aider polyglot benchmark, at 14X less cost compared to o1.64% R1+Sonnet62% o157% R152% Sonnet48% DeepSeek V3https://aider.chat/2025/01/24/r1-sonnet.html
- Tweet from Alexandr Wang (@alexandr_wang): Scale AI & CAIS are releasing Humanity’s Last Exam (HLE), a dataset of 3,000 questions developed with hundreds of subject matter experts (PhDs, profs, etc.) to capture the human frontier of knowledge ...
- You See It Is GIF - You See It Is Part - Discover & Share GIFs: Click to view the GIF
- Ni No Kuni Ni No Kuni Wrath Of The White Witch GIF - Ni no kuni Ni no kuni wrath of the white witch Marcassin ni no kuni - Discover & Share GIFs: Click to view the GIF
- trl/docs/source/grpo_trainer.md at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
Yannick Kilcher ▷ #general (98 messages🔥🔥):
Memory bus width, Math questions for LLMs, Reasoning and visual problems in LLMs, Open weight Differential Transformer models, Anime avatars in OSS ML community
- Memory bus width sparks humor: A member noted that a system has 512-bit wide 32GB memory, prompting jokes about the memory bus being as wide as potential buyers' wallets.
- Laughs ensued in response to the initial comment, showcasing light-hearted banter.
- Math question stumps LLMs: A user mentioned a math question about how many straight lines are needed to cross an n x n grid, expressing frustration that many LLMs failed horribly on this task.
- Discussion highlighted the ambiguities of the question and the need for clearer definitions to improve LLM responses.
- LLMs struggle with reasoning in visual problems: Members discussed how LLMs still have difficulty solving problems that rely on visual reasoning and suggested that providing too many hints can confuse them.
- One pointed out that benchmarking LLMs based on the hints required might yield better insight than focusing solely on correctness.
- Search for open weight Differential Transformer models: A user inquired about open weight Differential Transformer models, leading another to share a GitHub repo but express concern over the quality of the author's work.
- The conversation included cautious remarks about the repo's credibility and a critical look at the author's community engagement.
- Anime avatars in OSS ML draw attention: There was a light-hearted remark about how anime profile pictures often represent highly capable individuals in the open-source ML field.
- Another member noted that many contributors in ML OSS come from East Asia, illustrating a cultural trend within the community.
- Tweet from Casper Hansen (@casper_hansen_): DeepSeek R1 in Humanity's Last Exam beats all other models on text subset. This is just confirming what we already know - R1 is a real gem.
- Tweet from Tsarathustra (@tsarnick): President Trump says he has declared a national energy emergency to unlock the United States' energy resources and make the US "a manufacturing superpower and the world capital of artificial i...
- Tweet from Sam Altman (@sama): big news: the free tier of chatgpt is going to get o3-mini!(and the plus tier will get tons of o3-mini usage)
- Tweet from Sam Altman (@sama): big. beautiful. buildings.
- Tweet from Sam Altman (@sama): stargate site 1, texas, january 2025.
- Minimum number of straight lines to cover $n \times n$ grid?: I want to know the minimum number of lines needed to touch every square of an $n \times n$ grid. The only added rule is that the line has to pass inside the square, not on the edge/corner. I have f...
- GitHub - kyegomez/DifferentialTransformer: An open source community implementation of the model from "DIFFERENTIAL TRANSFORMER" paper by Microsoft.: An open source community implementation of the model from "DIFFERENTIAL TRANSFORMER" paper by Microsoft. - kyegomez/DifferentialTransformer
Yannick Kilcher ▷ #paper-discussion (18 messages🔥):
Myopic Optimization with Non-myopic Approval (MONA), AI Insurance, GPRO and PPO Comparison, GAE and Advantage Estimation, LMArena Rankings
- Introducing MONA to Combat Reward Hacking: A study on reinforcement learning (RL) objectives proposes Myopic Optimization with Non-myopic Approval (MONA) to avoid undesirable multi-step plans, which could lead to reward hacks even if undetected by humans. The method combines short-sighted optimization with far-sighted reward, demonstrated through empirical studies.
- The paper discusses common misalignment failure modes in RL and how MONA offers a potential solution without needing extra information outside regular RL parameters.
- Future of AI Insurance Sparks Debate: Speculation arose about the potential for actuaries to develop AI insurance, acknowledging that AI can create significant problems for businesses. One member humorously highlighted that there's insurance for everything, reinforcing this growing concern.
- Conversations continued on how AI could lead to serious business mishaps, raising the question of how insurance will adapt to these emerging technologies.
- Exploring GPRO's Effect on PPO: Members expressed curiosity about GPRO dropping Value Function and GAE potentially alleviating early convergence issues in PPO. The discussion centered on whether this change would improve advantage estimation by summing globally normalized rewards.
- One member shared their understanding of GAE's function, emphasizing how it could lead to models getting stuck in a loss, while another indicated a desire to dive deeper into this area during their upcoming reading group.
- Impressive LMArena Rankings: Excitement erupted as it was announced that R1 ranks Rank 3 in LMArena, with Style Control at Rank 1. Members noted its open-source nature, highlighting the community's enthusiasm about its real-world implications.
- One member expressed disbelief at the model's capabilities, indicating the significant advancements currently happening in the AI landscape.
Link mentioned: MONA: Myopic Optimization with Non-myopic Approval Can Mitigate Multi-step Reward Hacking: Future advanced AI systems may learn sophisticated strategies through reinforcement learning (RL) that humans cannot understand well enough to safely evaluate. We propose a training method which avoid...
Yannick Kilcher ▷ #ml-news (9 messages🔥):
AG2 Announcement, R1 Server Performance, AI Community Dynamics, Stargate Influence
- AG2 lays out vision post-Microsoft split: AG2 announced their vision for community-driven agent development, outlining their governance model, community structure, and commitment to open source here.
- Their transformation from academic project to a community of over 20,000 builders showcases the demand for more accessible AI agent systems.
- R1 Upsets Industry Expectations: Members discussed R1's surprising performance, considering it an underdog status that has spurred competition among other server technologies.
- One remarked that R1 has effectively 'lit a fire' under others, highlighting its impact in the current market landscape.
- Potential Causes of Performance Concerns: There was speculation about whether the performance issues in the tech sector stemmed from Stargate or certain B200 servers being notably efficient.
- A member humorously suggested that the focus may be due to R1's emerging presence in the scene.
- AI Community and Job Markets: Discussions emerged about the implications of AI developments on job markets, with one member jokingly stating it keeps more Taiwanese and Chinese employed than Americans.
- This sentiment reflects ongoing concerns about the shifting nature of AI development and its socio-economic impact.
- AI Gamer Waifu Sparks Comments: A humorous reference was made to an AI concept, dubbed 'AI gamer waifu', linked through a YouTube video.
- This prompted laughter and reactions regarding AI's growing presence in entertainment and gaming.
- Tweet from AG2 (@ag2oss): Announcing our vision for community-driven agent development.Read about AG2's:- Governance model- Community structure- Open source commitment- Path forwardhttps://medium.com/@ag2ai/ag2s-vision-for...
- AG2’s Vision for Community-Driven Agent Development: When we first developed the concepts behind AutoGen while working on FLAML two years ago, we were driven by a simple goal: make it easier…
- Humanity's Last Exam: no description found
Notebook LM Discord ▷ #use-cases (7 messages):
Podcast Editing with NotebookLM, Reverse Turing Test with Generative Output, AI Host Animation Tools
- NotebookLM streamlines podcast editing: A user shared their experience of using NotebookLM to edit their podcast by uploading existing audio and instructing it to integrate segments seamlessly.
- This resulted in an almost perfect flow, requiring only minimal cuts to maintain the narrative integrity.
- Generative Output explores AGI themes: Another user discussed their LM's explorations into creating a reverse Turing Test and deciphering meaning in their conversations.
- The output reflected on the interface as a potential mirror for understanding AGI in a cybernetic future, which the user found intriguing.
- MasterZap shares AI animation workflow: In response to inquiries about an AI host animation, MasterZap detailed a comprehensive workflow using multiple tools like HailouAI and RunWayML.
- He highlighted the complexity of getting avatars to appear naturalistic while integrating various techniques to achieve lifelike animations.
Link mentioned: UNREAL MYSTERIES 7: The Callisto Mining Incident: David and Hannah follows the adventures of the legendary Malcolm Steele in his role as SPACE MINER on Jupiters moon Callisto. Learn what he, Ted and Jessica ...
Notebook LM Discord ▷ #general (53 messages🔥):
Uploading PDFs, Gemini Advanced capabilities, NotebookLM use cases, Quiz preparation, Interactive mode loading issue
- Challenges with Uploading PDFs: Users reported issues with uploading large PDFs, particularly the Internal Revenue Code, to NotebookLM, with sizes around 18.5MB being problematic.
- One user expressed frustration with Gemini's inability to accurately parse agreements and asked for assistance in troubleshooting the issue.
- Gemini Advanced Offers Larger Context: A user confirmed they were using Gemini Advanced, noting that it allows for uploading entire documents rather than just sections for analysis.
- However, challenges remain as they struggle to get precise responses regarding tax law definitions and legal interpretations despite Gemini's capabilities.
- Using NotebookLM for Quiz Preparation: A user inquired if NotebookLM can generate quizzes directly from a PDF document containing 220 questions, emphasizing the need for the exact text.
- They were advised to experiment with prompts in NotebookLM and to use the Gemini Advanced model, specifically version 1.5 Pro.
- Discussion on Collaboration and Support: Several users offered to assist each other in troubleshooting issues and optimizing their use of AI models for educational purposes.
- The conversation highlighted collaboration, with some members proposing to continue discussing issues even across different time zones.
- Clarification on NotebookLM Team: A user asked if a channel participant was part of the NotebookLM team, to which they clarified that while they work in Cloud, they are not affiliated with the NLM team.
- They indicated that other members from engineering and product management were present in the channel to provide support.
- no title found: no description found
- no title found: no description found
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.7.0 release, Windows ARM Support, macOS update fixes, Code Interpreter Improvements, Chat Templating Enhancements
- GPT4All v3.7.0 Launches with Exciting Features: The release of GPT4All v3.7.0 brings several updates, including Windows ARM Support allowing compatibility with devices powered by Snapdragon and SQ processors, albeit lacking GPU/NPU acceleration.
- Users need to install the new Windows ARM version specifically from the website due to emulation limitations.
- macOS Bugs Squashed: GPT4All on macOS has seen fixes for crashing during updates, with the maintenance tool now functioning correctly, allowing easy uninstallation if a previous workaround was used.
- Additionally, chats now save properly when the application is quit using Command-Q, enhancing user experience.
- Enhancements in Code Interpreter: The Code Interpreter in GPT4All has been improved to handle timeouts more gracefully and now supports multiple arguments in console.log for better compatibility with native JavaScript.
- These improvements aim to enhance performance and usability during coding tasks.
- Chat Templating Gets an Upgrade: Enhanced chat templating features have been introduced, fixing two crashes and a compatibility issue in the chat template parser, including a fix for the default chat template for EM German Mistral.
- New automatic replacements for five additional models have been added, continuing to streamline compatibility with common chat templates.
Nomic.ai (GPT4All) ▷ #general (50 messages🔥):
Prompt Engineering Challenges, Model Compatibility for GPT4All, Image Analysis Tools, Translation Model Recommendations
- Prompt Engineering Issues: Members discussed challenges in getting LLMs to work as expected, particularly with NSFW prompts and the more nuanced use of polite language.
- A member noted that using 'please' may yield better results, as models are trained on internet data.
- GPT4All Model Compatibility: There was a conversation about the compatibility of various models with GPT4All, specifically mentioning Llama-3.2 and Qwen-2.5.
- Another member mentioned potential alternatives like Nous Hermes, implying issues with current model performance.
- Image Analysis Tools Discussion: One member inquired about open-source models for general image analysis that allow for image uploads and questions.
- Another member recommended Taggui, highlighting its effectiveness and multiple AI engines for tagging images.
- Translation Model Suggestions: A user sought recommendations for high-quality translation models for various language pairs.
- Members suggested that the Qwen model should suffice, while also mentioning Llama's availability on Hugging Face, despite its heavier resource requirements.
- Loading Issues with Models: A user expressed difficulty in loading the DeepSeek-R 1-Distill-Qwen-32B-Q4_K_M.gguf model in GPT4All.
- Members pointed out that the gpt4all team might be looking into it, indicating limitations in current compatibility.
MCP (Glama) ▷ #general (22 messages🔥):
MCP Server Timeout Fix, MCP Server Installation Issues, MySQL and SQLite Usage, Claude Google Search Feature, MCP-Alchemy Repository
- MCP Server Timeout Fixed: A member shared a fix for the 60-second timeout issue on MCP server responses, located in
mcphub.tswithin the roo-code or cline source code.- They also have a VS Code extension with updates on this timeout modification.
- MCP Server Loading Success: A user reported successfully loading their basic MCP servers without errors on the Claude launch after troubleshooting PATH issues.
- The final fix involved ensuring correct paths were specified in the configuration, specifically for
uvx.exe.
- The final fix involved ensuring correct paths were specified in the configuration, specifically for
- Using MySQL with MCP: A user inquired about the most trusted MCP server to connect to a MySQL database, sparking discussion about various setups.
- Another user recommended mcp-alchemy, stating it's effective for MySQL and other databases as well.
- Google Search Feature Malfunction: A user expressed concerns over their Google search feature malfunctioning with Claude, seeking community input for potential fixes.
- Several members echoed similar experiences, suggesting that high demand might be causing issues with Claude's performance.
- Creating Database for MCP: A user indicated that they created a test.db in Access, questioning its necessity for MCP operation.
- They perceived it as potentially helpful, illustrating their learning curve in setting up MCP servers.
- Compiling: no description found
- GitHub - runekaagaard/mcp-alchemy: A MCP (model context protocol) server that gives the LLM access to and knowledge about relational databases like SQLite, Postgresql, MySQL & MariaDB, Oracle, and MS-SQL.: A MCP (model context protocol) server that gives the LLM access to and knowledge about relational databases like SQLite, Postgresql, MySQL & MariaDB, Oracle, and MS-SQL. - runekaagaard/mcp-alchemy
- GitHub - qpd-v/Roo-Code: Roo Code (prev. Roo Cline) is a VS Code plugin that enhances coding with AI-powered automation, multi-model support, and experimental features: Roo Code (prev. Roo Cline) is a VS Code plugin that enhances coding with AI-powered automation, multi-model support, and experimental features - qpd-v/Roo-Code
MCP (Glama) ▷ #showcase (16 messages🔥):
Orange Flair Request, MCP Agentic Tool Confusion, Integration of Glama into Clients, Long Term Memory Personalization Tool
- Members Request Orange Flair: Multiple members asked for the orange flair, with one stating, Any chance to get the orange flair? and others expressing similar requests.
- The flair request appears to be handled promptly as the member received a response of done after inquiring.
- Confusion Over MCP Agentic Tool: A member sought clarification about the MCP Agentic tool's functionality, specifically regarding its activation in Glama.
- This part of the product has leaked prematurely was shared by another member, suggesting an official announcement was expected soon.
- Integrating Glama into Non-Glama Clients: Clarification emerged around what it means to integrate Glama into clients, indicating it involves using a GUI for installation of hosted servers.
- One member confirmed this functionality relates to the MCP.run interface, but with additional features from Glama.
- New Tool for User Personalization: A new tool was introduced, inspired by the Titans Surprise mechanism, that logs specific interactions aimed at user personalization.
- This tool collects user data for longer-term memory purposes and can be found on GitHub.
- runekaagaard - Overview: runekaagaard has 101 repositories available. Follow their code on GitHub.
- runekaagaard - Repositories: runekaagaard has 101 repositories available. Follow their code on GitHub.
- Open-Source MCP servers: Enterprise-grade security, privacy, with features like agents, MCP, prompt templates, and more.
- GitHub - truaxki/mcp-variance-log: Agentic tool that looks for statistical variations in conversation structure and logs unusual events to a SQLite database.: Agentic tool that looks for statistical variations in conversation structure and logs unusual events to a SQLite database. - truaxki/mcp-variance-log
LlamaIndex ▷ #blog (1 messages):
AI agents, Joint webinar, Task management in AI, Redis, Webinar recording
- Catch the AI Agents Webinar Recording: A joint webinar with @Redisinc on building AI agents is now available for viewing, providing insights into their role in breaking down tasks.
- The session discusses task management strategies to enhance performance, and you can find the recording here.
- Understanding AI Agents' Role: The webinar covers the ins & outs of AI agents, exploring how they help in managing tasks effectively.
- This discussion highlights the importance of decomposing tasks into manageable components for better performance.
LlamaIndex ▷ #general (36 messages🔥):
LlamaIndex agent tutorials, Parallel streaming issues, Using LlamaParse for PDFs, Real-time event streaming, Export controls on AI models
- LlamaIndex agent setup has broken links: A user reported that the 'step by step agent tutorial' link in LlamaIndex returns a 500 error instead of the expected content. Alternative links and resources were suggested to assist in building agents.
- It was noted that the tutorial is crucial for new users trying to get started with agents.
- Challenges with parallel streaming from multiple LLMs: A user faced issues with sequential data while attempting to stream events from two different LLMs simultaneously. Others suggested that the async implementation may not be functioning properly in the external library being used.
- A sample Google Colab link was shared to demonstrate functioning parallel streaming.
- Using LlamaParse for document parsing: A user inquired about best practices for parsing slide presentations with LlamaIndex, especially for PDFs created with LaTeX. It was pointed out that LlamaParse supports various file formats including .pptx and .pdf, aiding in data extraction.
- Resources were shared, including links to the LlamaParse documentation.
- Real-time events with LlamaIndex agents: A user sought advice on displaying real-time events alongside token streaming using the ReActAgent from LlamaIndex. Suggestions were given to utilize the new AgentWorkflow system for improved event handling.
- Links to related documentation and community feedback on the new feature were provided.
- Concerns about AI model export regulations: A user questioned whether the Llama model is affected by new U.S. export controls on AI model weights and advanced computing. The discussion highlighted the importance of staying updated on regulatory changes impacting AI applications.
- LlamaParse - LlamaIndex: no description found
- Google Colab: no description found
- Tweet from LlamaIndex 🦙 (@llama_index): Big release today! We're thrilled to introduce AgentWorkflow, a new high-level system for creating multi-agent systems in Llamaindex!LlamaIndex Workflows are powerful, low-level building blocks th...
- New U.S. Export Controls on Advanced Computing Items and Artificial Intelligence Model Weights: Seven Key Takeaways: no description found
- BM25 Retriever - LlamaIndex: no description found
- LlamaIndexTS/apps/next/src/content/docs/llamaindex/guide/agents at main · run-llama/LlamaIndexTS: Data framework for your LLM applications. Focus on server side solution - run-llama/LlamaIndexTS
- llama_parse/llama_parse/utils.py at 4897d01cb075ed0835b7df0d072a7ad4e39c4e64 · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- llama_parse/llama_parse/utils.py at 4897d01cb075ed0835b7df0d072a7ad4e39c4e64 · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- Agent tutorial: no description found
Cohere ▷ #discussions (22 messages🔥):
US Export Controls on AI Model, Cohere's Compliance Concerns, Oracle Japan's Use of Cohere's Model, Market Impact of GPU Restrictions, Blackwell Operations Costs
- US restricts AI model exports, concerns arise: The US Department of Commerce announced new export controls on AI model weights, leading to inquiries about whether Cohere's model falls under these regulations.
- I'm concerned about potential violations at Oracle Japan, stated an AI engineer using Cohere's LLM in their services.
- Oracle Japan's legal complexities discussed: A team member suggested that Oracle likely has specific licensing agreements that could mitigate their risk under the new regulations.
- Consulting within Oracle Japan was recommended to clarify these legal implications.
- Market realities of AI regulations highlighted: Discussions revealed skepticism about the effectiveness of export restrictions on big AI companies, with assertions that GPU restrictions mainly impact consumers.
- Notably, big companies have their own ways to sneak restricted cards into the country, minimizing the regulations' impacts.
- Cohere's Canadian status questioned: A member pointed out that Cohere operates out of Canada, prompting questions about how US regulations would influence their practices.
- The uncertainty around regulatory impacts on Canadian entities operating in AI was emphasized.
- Concerns over Blackwell operations costs: A member expressed concern that operations leveraging Blackwell technologies would not be inexpensive, stating they currently idle at 200w.
- This raised discussions on the financial implications of running heavy computational tasks without immediate utilization.
Link mentioned: New U.S. Export Controls on Advanced Computing Items and Artificial Intelligence Model Weights: Seven Key Takeaways: no description found
Cohere ▷ #api-discussions (1 messages):
sssandra: pls post the issue in <#1324436975436038184> , we'll help troubleshoot there
Cohere ▷ #cmd-r-bot (5 messages):
9-letter words, Word lists, Interesting words
- Request for 9-letter words: <@1316646968688119818> requested a list of 13 words with 9 letters.
- Cmd R Bot responded with a list, repeating September multiple times.
- Follow-up on interesting word responses: <@_.dominic> expressed interest in the responses received.
- Cmd R Bot shared a new list of 9-letter words highlighting terms like Fascinate and Enchant.
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
Forum Post Creation, Async Code in Mojo
- Planning a Forum Post: A member offered to share a post internally if another member creates it in the forum.
- The initial member agreed, expressing willingness to copy-paste content from their phone.
- Async Code Discussion: A link to a forum topic titled How to write async code in Mojo was shared for discussions around asynchronous coding practices.
- Members confirmed their intentions to collaborate on the forum post.
- Modular: Build the future of AI with us and learn about MAX, Mojo, and Magic.
- How to write async code in mojo🔥?: I saw the devblogs saying that mojo currently lacks wrappers for async fn awating, however it supports the coroutines themselves. If it is possible, how does one write a function that, say, prints whi...
Modular (Mojo 🔥) ▷ #announcements (1 messages):
MAX Builds Page Launch, Community-built Packages, Project Submission Process
- MAX Builds Page is Live!: The refreshed MAX Builds page is now available at builds.modular.com, showcasing a dedicated section for community-built packages.
- This update highlights contributions from creators and encourages more community involvement.
- Shoutout to Inaugural Package Creators: Special recognition goes to the inaugural package creators including <@875794730536018071> and others for their contributions to the MAX Builds page.
- Their efforts have set the stage for future community contributions and package sharing.
- How to Feature Your Project: To have your project featured on the MAX Builds page, submit a PR to the Modular community repo with a
recipe.yamlfile.- Full instructions and examples can be found here, promoting an easy pathway for community engagement.
Modular (Mojo 🔥) ▷ #mojo (17 messages🔥):
__iadd__ method, Accidental typing, New Mojo CLI flags
- iadd Method Explained: A member clarified that the
__iadd__method controls the behavior of+=, stating it is an inplace addition.- Another member questioned how
iaddcannot return a value, leading to a discussion on variable storage when usinga += 1.
- Another member questioned how
- Order of Evaluation Confusions: The conversation explored how expressions like
a += a + 1evaluate, with one member concluding that it results in 13 whenais set to 6.- Concerns about the order of evaluation were expressed, with a suggestion to avoid such complexities to prevent confusion.
- Accidental Typing During Meeting: A member humorously explained their previous message as accidental typing during a meeting.
- This prompted a witty response from another member, asking if they had fallen asleep on their keyboard.
- Announcement of New Mojo CLI Flags: A member introduced new Mojo CLI flags, specifically
--eiand--v, leading to engagement in the channel.- The mention of the flags was accompanied by an emoji representation, adding a visual element to the announcement.
LAION ▷ #general (25 messages🔥):
Audio Dataset Project, Speaker Recognition Model, Labeling Noise and Music Levels
- Labeling Background Noise and Music: Members discussed methods to label audio samples for background noise, proposing categories like no background noise, slight noise, and various music levels.
- “Be creative if you don't know ask” was emphasized for broader and more effective labeling strategies.
- Developing a Multi-Speaker Transcription Model: A call was made for creating a multi-speaker speech transcription dataset using overlapped audio from text-to-speech models, which could enhance speaker differentiation.
- This includes generating data that maintains time codes to identify which speaker is talking at what moment.
- Identifying Speakers by Voice Characteristics: Members explored how the model might identify speakers based on variations in pitch and frequency, which could include recognizing voice qualities like reverb or speaking rate.
- This end-to-end training approach aims to facilitate better speaker recognition in overlapping audio contexts.
- Interest in Contributing to the Project: A member expressed eagerness to contribute to the audio dataset project but requested more information regarding its details and current status.
- “There is no website, it's me coordinating folks on discord” was shared to highlight the project's informal organization setup.
Link mentioned: Google Colab: no description found
Eleuther ▷ #general (7 messages):
Teacher-Student Model Divergence, AI4Science Open Source Projects, Layer Convergence Bias, Vanishing Gradients Discussion
- Exploring Divergence in Teacher-Student Models: A member inquired about papers using divergence between teacher and student models as a 'reward' to apply PPO for distillation.
- Another suggested using standard student-teacher models with KL-matching as a more conventional approach.
- PhD Student Seeks Open Source Projects: A member introduced themselves as a PhD student in AI4Science looking to contribute to open source projects despite a busy schedule.
- The community responded with suggestions to check relevant channels for project opportunities.
- Layer Convergence Bias Identified: A member referenced research on the phenomenon of Layer Convergence Bias found in neural networks, noting shallower layers converge faster than deeper ones.
- This was tied to the stability of gradients and revealed in a recent ICLR 2023 paper.
- Vanishing Gradients Debate Continues: Discussion arose on whether vanishing gradients contribute to the convergence issues faced by deeper layers of DNNs.
- There was acknowledgment that while they might not be the primary factor, they still play a significant role.
Link mentioned: Which Layer is Learning Faster? A Systematic Exploration of...: We empirically show that the shallower layers converge faster than the deeper layers in neural networks, and provide the theoretical justification and practical value of this finding.
Eleuther ▷ #research (14 messages🔥):
ModernBERT and ModernBART, Hybrid Language Models, Chain-of-Thought Reasoning, Agent-R Self-Critique Framework, Latro RL vs Pause Tokens
- Discussion on ModernBERT and the Anticipation of ModernBART: Members debated whether it's reasonable to expect a release of ModernBART soon, following the recent introduction of ModernBERT.
- While some argued that encoder-decoder models are in demand for summarization tasks, others stated that an announcement about ModernBART isn't guaranteed.
- Exploring Hybrid Language Models: A member pointed out the potential of merging masked and causal language modeling in the space of hybrid architectures, referencing a study on GPT-BERT.
- This approach demonstrated improved performance in the BabyLM Challenge 2024 over traditional models, suggesting a shift towards combining strengths from different paradigms.
- Chain-of-Thought Reasoning in Image Generation: A paper discussed the implementation of Chain-of-Thought (CoT) reasoning for enhancing autoregressive image generation capabilities.
- By integrating techniques like Direct Preference Optimization (DPO), the findings indicated significant improvements in image generation performance.
- Agent-R Framework for Intelligent Reflection: The Agent-R framework proposes an innovative approach for language agents to reflect and recover from errors dynamically during interactions.
- Utilizing Monte Carlo Tree Search (MCTS), this method allows the agent to self-critique and construct datasets that recover correct actions, addressing issues in error recovery.
- Debate on Latro RL and Pause Tokens: A member inquired about the fundamental differences in reasoning performance when comparing Latro RL to a model trained with many pause tokens.
- The conversation highlighted the significance of reasoning depth and the architectures used, implying potential variations in reasoning capabilities.
- Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training: Large Language Models (LLMs) agents are increasingly pivotal for addressing complex tasks in interactive environments. Existing work mainly focuses on enhancing performance through behavior cloning fr...
- Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step: Chain-of-Thought (CoT) reasoning has been extensively explored in large models to tackle complex understanding tasks. However, it still remains an open question whether such strategies can be applied ...
- Optimizing Return Distributions with Distributional Dynamic Programming: We introduce distributional dynamic programming (DP) methods for optimizing statistical functionals of the return distribution, with standard reinforcement learning as a special case. Previous distrib...
- BERTs are Generative In-Context Learners: While in-context learning is commonly associated with causal language models, such as GPT, we demonstrate that this capability also 'emerges' in masked language models. Through an embarrassing...
- GPT or BERT: why not both?: We present a simple way to merge masked language modeling with causal language modeling. This hybrid training objective results in a model that combines the strengths of both modeling paradigms within...
- meta-llama/Meta-Llama-3-8B · Are there bias weights in Llama3 ?: no description found
Eleuther ▷ #interpretability-general (2 messages):
Mech Interp, Bilinear MLPs, Weights and Activations Duality, ICLR 2025 Paper
- Mech Interp's Long-Term Promises: Mech interp is currently a hot field, but doubts linger about its ability to meet long-term expectations using an activations-dominant approach.
- A balanced view should consider both weights and activations, as they are fundamentally interconnected.
- Bilinear MLPs: Bridging the Gap: A new paper led by members explores bilinear MLPs, which serve as a substitute for MLPs or GLUs, maintaining compatibility with existing mech interp techniques.
- The approach aims to make neural network weights more interpretable while preserving performance across various models, including transformers.
- Understanding Neural Networks through Weights: Discussion centered around the challenge of understanding neural networks strictly from their weights due to activation functions that obscure input-output relationships.
- In their ICLR'25 paper, researchers propose analyzing bilinear MLPs, which lack element-wise nonlinearity, allowing for a clearer view of the weights' contribution to computation.
- ICLR 2025 Paper Insights: The abstract of the paper outlines that a mechanistic understanding of MLPs is often elusive due to element-wise nonlinearities complicating feature tracing.
- Bilinear MLPs can be expressed in terms of linear operations, facilitating the analysis of weights and revealing a low-rank structure through eigendecomposition.
- Bilinear MLPs enable weight-based mechanistic interpretability: A mechanistic understanding of how MLPs do computation in deep neural networks remains elusive. Current interpretability work can extract features from hidden activations over an input dataset but gen...
- Tweet from tdooms (@thomasdooms): Can we understand neural networks from their weights? Often, the answer is no. An MLP's activation function obscures the relationship between inputs, outputs, and weights.In our new ICLR'25 pa...
Stability.ai (Stable Diffusion) ▷ #general-chat (20 messages🔥):
Generating ice text with specific fonts, ControlNet for image generation, Adobe Firefly for custom text, Understanding image poisoning, Using sketch to image
- Creating AI Ice Text with Custom Fonts: A user expressed interest in generating ice text using a specific font and queried about the process using Img2img.
- Another suggested the possibility of just coloring the text ice and using denoise settings in Img2img to achieve the desired effect.
- ControlNet Enhancements for Ice Text Generation: Members discussed enhancing the ice text generation with ControlNet for better results.
- It was mentioned that tiling the input to a larger resolution could aid in achieving better outputs.
- Adobe Firefly for Text Creation: A suggestion for using Adobe Firefly was brought up as it can cater to the user’s specific needs if they have an Adobe license.
- This was noted as an alternative to more complex methods involving other software like Inkscape.
- Identifying Poisoned Images: A question was raised about how to determine if an image is poisoned or not.
- Members humorously suggested conducting a 'lick test' and a 'smell test' as light-hearted methods to assess image safety.
- Using Sketch to Image: A user inquired about the functionality of sketch to image, seeking guidance on how to use it.
- The topic of optimizing models for specific aspect ratios like 16:9 also came up, suggesting a shared interest in tailored image generation settings.
tinygrad (George Hotz) ▷ #general (14 messages🔥):
ILP for View Simplification, Mask Representation Challenges, Multi Merge Search Patterns, Three View Simplification Approaches, Stride Alignment in Merges
- ILP Approach for View Simplification: A proof of concept implementation for view pair addition using ILP was shared in Pull Request #8736 with initial results showing a 0.45% miss rate.
- Discussion highlights the potential to formalize multi merges using logical divisors and the challenges faced with variable strides.
- Challenges with Mask Representation: A debate emerged on whether masks can enhance merge capabilities, with insights suggesting they may not apply universally to all cases.
- Clarification was provided that while masks might create opportunities for some merges, they are complex and may not support all combinations as previously thought.
- Searching for Multi Merge Patterns: A member proposed formalizing the multi merge approach by evaluating offsets and strides using examples like v1=[2,4] and v2=[3,6].
- They indicated a possible generalized search pattern could arise from this method when analyzing common divisors.
- Exploring Three View Simplification: There were musings about extending simplifications from two views to three or more, with some skepticism on 3 -> 2 view approaches due to complexity.
- The challenges stem from maintaining a merged view in light of variable strides, complicating the ILP formulation.
- Stride Alignment Possibilities: Recent discussions suggested that stride alignment might reduce complexities in merging views, but assumptions about stride non-alignment were noted as problematic.
- Acknowledgment that previous methods might overlook many potential merges due to miscalculations in stride relationships.
Link mentioned: Complete view pair add using ILP (draft) by eliotgolding · Pull Request #8736 · tinygrad/tinygrad: Proof of concept, uses scipy's solver.$ python test/external/fuzz_view_add_completeness.pyMissed adds: 5/1109 0.45%$ NEWADD=1 python test/external/fuzz_view_add_completeness.pyMissed adds: ...
Torchtune ▷ #general (10 messages🔥):
Running on Windows, Windows Subsystem for Linux (WSL), Regex for Data Cleaning, Non-Supported Features in Windows, Issues with Triton and Xformers
- Running on Windows has limitations: While there is a possibility to run the software on Windows, a member highlighted that it comes with limitations, such as the inability to utilize triton kernels.
- An alternative proposed was to use Windows Subsystem for Linux (WSL), which allows for a smoother coding experience.
- Windows Subsystem for Linux makes life easier: One member recommended setting up WSL, stating that it could be done in less than an hour and would enhance training performance.
- They emphasized that this setup could significantly reduce coding struggles compared to using Windows directly.
- Regex Expression for Data Cleaning Shared: A member shared a regex expression
[^ \x20-\x7E]+, which is highly useful for cleaning messy datasets by identifying problematic characters.- Another member provided an extensive breakdown of the expression, explaining its components and what types of characters it matches, particularly non-printable and non-ASCII characters.
- Concerns About Errors on Windows: A member expressed concern regarding a warning about redirects not being supported on Windows or MacOS.
- This prompted a discussion about the possible implications and whether users should be worried about it.
- Triton and Xformers Compatibility Issues: Issues were raised around getting unsloth or axolotl to work due to Triton and Xformers not being compatible with Windows.
- There was a suggestion to check out a GitHub repository for potential solutions, indicating ongoing support for those running on Windows.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
First Lecture Announcement, LLM Agents Acceptance
- First Lecture Set for Next Monday!: The first lecture is scheduled for 4 PM PT on Monday, 27th as confirmed by a member.
- An email announcement with more details will be released soon.
- Impressive Passing for LLM Agents: It was noted that if you are an LLM agent, passing the course will be quite impressive.
- This highlights the course's challenging nature and the high expectations for LLM agents.
Axolotl AI ▷ #general (5 messages):
Scams reported in Discord, Nebius AI multi-node training, SLURM and Torch Elastic challenges
- Scam Reports Flood Discord: Users reported scams posted in multiple locations, notably in this channel. Thanks!, one user acknowledged the alerts.
- This raises awareness about the ongoing issues with scam messages in the community.
- Inquiry on Nebius AI Usage for Training: A member sought insights from others on using Nebius AI for training in a multi-node setting, looking for shared experiences. The discussion highlighted the need for practical advice from those who are familiar with the platform.
- Struggles with SLURM and Torch Elastic: A user expressed frustration about getting SLURM and Torch Elastic to work correctly, stating it's a significant challenge. Another member recommended checking the documentation for SLURM's multi-node guide, suggesting many principles could apply despite differences.
DSPy ▷ #general (2 messages):
Signature Definition Issues, MATH Dataset Alternatives
- Confusion Over Signature Definition: A member expressed frustration over defining a signature, indicating that they are not receiving the expected output, with some files not mapping properly.
- They noted that certain files may lack source files, contributing to the confusion.
- Seeking Alternatives for MATH Dataset: Another member mentioned attempting to run the maths example, but found that the dataset has been taken down.
- They shared links to two datasets, including MATH dataset and Heuristics Math dataset, and requested recommendations for alternatives.
Link mentioned: hendrycks/competition_math · Datasets at Hugging Face: no description found