[AINews] The world's first fully autonomous AI Engineer
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 3/11/2024-3/12/2024. We checked 364 Twitters and 21 Discords (336 channels, and 3499 messages) for you. Estimated reading time saved (at 200wpm): 410 minutes.
Warm welcome to the >3000 people who joined from Andrej's shoutout! As we said last time, this is a side project that we're kind of embarrassed by but we are honored and hope you find this as useful as we do. The email has gotten unwieldy (originally this was only recapping the LS discord) and the plan is to move sections of this off to a more dedicated news service + offer personalization.
Cognition Labs's Devin is the headline AI news of the day - on the surface one of many, many "AI software engineer" startups - but the difference is in the execution:
- learning to use unfamiliar technologies by dropping in a blogpost url in a chat
- build AND DEPLOY frontend apps to Netlify
- train and finetune its own AI models (specifically Tim Dettmers impressed by it debugging CUDA version errors)
- Contribute to mature codebases
These are all very big claims, and if generally true rather than cherrypicked, would almost certainly qualify to be one of the most advanced AI agents the world has ever seen. This should of course attract skepticism, especially since only prerecorded videos were released, but credible investors like Patrick Collison and Fred Ehrsam, and beta testers like Varun and Andrew have praised the live demos.
Details are scarce:
- Their blogpost states: "With our advances in long-term reasoning and planning, Devin can plan and execute complex engineering tasks requiring thousands of decisions. Devin can recall relevant context at every step, learn over time, and fix mistakes."
- Ashlee Vance's reporting quotes: "Wu declines to say much about the technology’s underpinnings other than that his team found unique ways to combine large language models (LLMs) such as OpenAI’s GPT-4 with reinforcement learning techniques."
- Watching the videos you can see that Devin has quite a few necessary LLM OS tools:
- asynchronous chat
- browser
- shell access to a VM
- Editor with an IDE
- a "Planner" that appears to be their secret sauce?
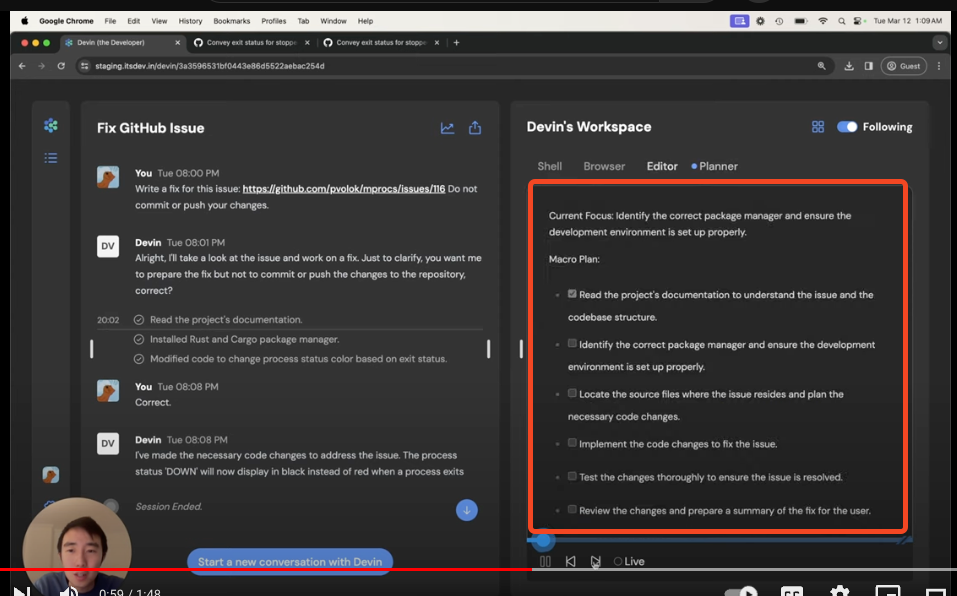
And because the videos are all edited/sped up, it's unclear whether the latency is a concern or a temporary issue. Since Devin reports minutes worked, there's no real incentive to save here apart from UX.
Overall though, people are excited about agents and AGI again, which is always cause for celebration.
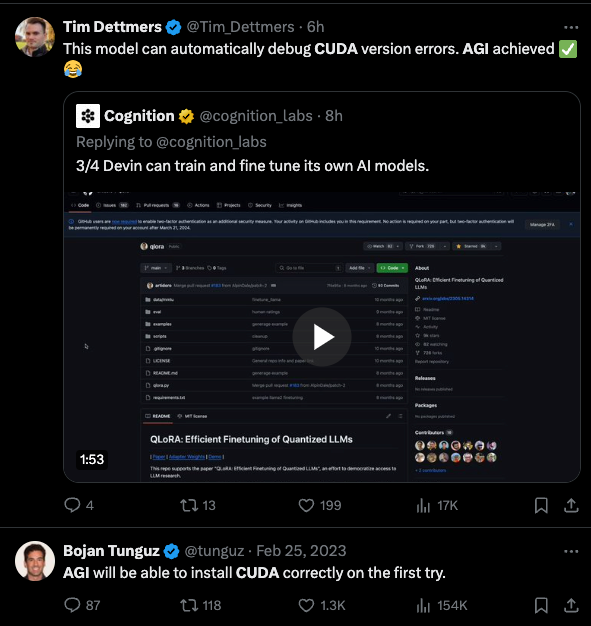
Table of Contents
- PART X: AI Twitter Recap
- PART 0: Summary of Summaries of Summaries
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord Summary
- Perplexity AI Discord Summary
- Nous Research AI Discord Summary
- LM Studio Discord Summary
- OpenAI Discord Summary
- HuggingFace Discord Summary
- Eleuther Discord Summary
- LlamaIndex Discord Summary
- LAION Discord Summary
- Latent Space Discord Summary
- Interconnects (Nathan Lambert) Discord Summary
- CUDA MODE Discord Summary
- LangChain AI Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- OpenRouter (Alex Atallah) Discord Summary
- DiscoResearch Discord Summary
- Alignment Lab AI Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- Skunkworks AI Discord Summary
- AI Engineer Foundation Discord Summary
- PART 2: Detailed by-Channel summaries and links
PART X: AI Twitter Recap
all recaps done by Claude 3 Opus, lightly edited by swyx for now. We are working on antihallucination, NER, and context addition pipelines.
Advances in Language Models and Architectures
- Google presents Multistep Consistency Models, a unification between Consistency Models and TRACT that can interpolate between a consistency model and a diffusion model. [210,858 impressions]
- Algorithmic progress in language models: Using a dataset spanning 2012-2023, researchers find that the compute required to reach a set performance threshold has halved approximately every 8 months, substantially faster than hardware gains per Moore's Law. [14,275 impressions]
- @pabbeel: Covariant introduces RFM-1, a multimodal any-to-any sequence model that can generate video for robotic interaction with the world. RFM-1 tokenizes 5 modalities: video, keyframes, text, sensory readings, robot actions. [48,605 impressions]
Retrieval Augmented Generation (RAG) and Tools
- Retrieval Augmented Thoughts (RAT) shows that iteratively revising a chain of thoughts with information retrieval can significantly improve LLM reasoning and generation in long-horizon tasks. RAT provides significant improvements to baselines in zero-shot prompting. [41,937 impressions]
- Cohere releases Command-R, a RAG-optimized LLM aimed at large-scale production workloads. It balances high efficiency with strong accuracy, enabling companies to move beyond proof of concept and into production. [75,829 impressions]
- @fchollet: "A simple definition of AGI: A system that can teach itself any task that a human can learn, using the same number of demonstration examples. Generality, not task-specific skill, is the issue." [49,452 impressions]
- @llama_index: "Anthropic releases a set of cookbooks for building RAG and agents with Claude, from basic RAG to advanced capabilities like routing and query decomposition, to sophisticated document agents and multi-modal applications." [46,629 impressions]
Multimodal AI and Video Understanding
- Vid2Persona allows you to talk to a person from a video clip. It has a simple pipeline from extracting traits of video characters to chatting with them. [10,326 impressions]
- VideoMamba, a State Space Model for Efficient Video Understanding, addresses the challenges of local redundancy and global dependencies in video understanding. Its linear-complexity operator enables efficient long-term modeling for high-resolution long video understanding. [18,814 impressions]
- V3D leverages the world simulation capacity of pre-trained video diffusion models to facilitate 3D generation. Fine-tuned on 360-degree orbit frames, it can generate high-quality meshes or 3D Gaussians within 3 minutes. [18,814 impressions]
Responsible AI and Bias
- @mmitchell_ai: Research shows that current practices of instruction tuning teach LLMs to superficially conceal covert racism. When overtly asked, models like GPT-4 will produce positive sentiment about African Americans, but underlying biases persist. [18,594 impressions]
- A poll of AI researchers estimates a 4-20% chance of AI catastrophe this year. Concerns raised about lack of security at AI labs potentially accelerating capabilities of adversaries. [13,686 impressions]
- @ehartford: TIME magazine's suggestion of banning open source AI models is met with strong opposition from the AI community, who argue for the importance of democratizing AI technology. [17,845 impressions]
Memes and Humor
- "The two things I hate the most in life: JIRA and communism. In that order." 114,102 impressions
- ChatGPT accidentally revealing a plan to end the culture war. 10,026 impressions
PART 0: Summary of Summaries of Summaries
Claude 3 Sonnet (14B?)
1. New AI Model Releases and Capabilities
- Cohere released Command-R, a 35B parameter model optimized for reasoning, summarization, RAG, and using external tools/APIs. Example: A YouTube video showcased Command-R's RAG capabilities.
- Cognition Labs unveiled Devin, an AI that passed the SWE-Bench coding benchmark and real engineering interviews, representing a milestone in AI software engineering. Example: Andrew Gao's tweet shared unfiltered opinions on trying Devin.
- ELLA (Efficient LLM Adapter) significantly improves text alignment in diffusion models like SD3 without retraining. Example: Discussions compared ELLA's performance to other models.
2. Accelerating and Optimizing Large Language Models
- Llama.cpp introduced 2-bit quantization to run LLMs more efficiently on standard hardware with less RAM and higher speed.
- NVMe SSDs enable fine-tuning 100B models on single GPUs, as discussed in a paper and tweet by @_akhaliq.
- Unsloth achieved 2x speedup and 40% less memory usage in LLM fine-tuning compared to normal QLoRA, without accuracy loss.
3. Open Source AI Tools and Resources
- Hugging Face introduced new features like filtering/searching Assistant names in Hugging Chat, table of contents for blogs, and all-time Space stats.
- WebGPU could make in-browser ML up to 40x faster, enabling powerful AI applications in web browsers.
- LlamaIndex hosted webinars, tutorials and meetups on building context-augmented apps, retrieval strategies, and implementing long-term memory for LLMs.
4. Analyzing and Interpreting Large Language Models
- A new model-stealing attack can extract embedding layers from black-box models like GPT-3.5 for under $20, raising security concerns.
- The Transformer Debugger tool enables automated interpretability and exploration of transformer model internals without coding.
- Discussions explored replacing tokenizers post-training for better language handling, constrained decoding techniques, and precompiling/caching function generation for efficiency.
Claude 3 Opus (>220B?)
- Nvidia's Dominance and Vulkan's Potential: Discussions in the CUDA MODE Discord highlighted Nvidia's compelling competitive advantage and software edge as nearly insurmountable, despite Vulkan's potential PyTorch backend posing a theoretical challenge. Meta's significant investment in AI infrastructure with a 24k GPU cluster and a roadmap for 350,000 NVIDIA H100 GPUs reinforces Nvidia's position (Meta's GenAI Infrastructure Article).
- Cohere's Command-R Model and RAG Capabilities: Cohere released an open-source 35 billion parameter model called "C4AI Command-R", available on Hugging Face. Discussions across Latent Space and Nous Research AI Discords focused on its retrieval augmented generation (RAG) capabilities and potential for merging with existing RAG setups. A YouTube video was shared demonstrating Command-R's long-context task handling.
- 100,000x Faster Neural Network Convergence: In the Skunkworks AI Discord,
@baptistelqtclaimed to have developed a method that accelerates the convergence of neural networks by 100,000x, applicable to various architectures including Transformers, by training models from scratch in every round.
- Devin: AI Software Engineer Benchmark: The AI community buzzed with the introduction of Devin, an AI software engineer by Cognition Labs that achieved high scores on the SWE-Bench coding benchmark. Discussions in Latent Space highlighted Devin's impressive backers and its potential to revolutionize software engineering.
- Grok's Potential Open-Sourcing: Elon Musk's tweet about potentially open-sourcing Twitter's algorithm "Grok" through xAI sparked debates across Latent Space and Interconnects Discords about the implications for open-source principles and Musk's reputation.
- Quantization Breakthroughs for Large Models: LAION discussions featured llama.cpp's "2-bit quantization" update, enabling more efficient local execution of large language models on regular hardware, as detailed in Andreas Kunar's Medium post. The potential of quantization and CPU-offloading for SD3 to adapt to varying VRAM capacities was also explored.
- Efficient Fine-Tuning with NVMe SSDs: The strategy of using NVMe SSDs for fine-tuning 100B parameter models on single GPUs was discussed in the Nous Research AI and Interconnects Discords, referencing a paper and a tweet about the Fuyou framework.
- Mac M1 GPU Utilization Issues in LM Studio: Users in the LM Studio Discord reported problems with LM Studio favoring CPUs over GPU acceleration on Mac M1 systems. Discussions involved model recommendations for specific hardware setups and using the Tensor Split feature to test GPU performance without physical modifications.
- Newcomer LLM Learning Resources: In the Eleuther Discord, users advised beginners to start with small models on Google Colab's T4 GPU, leverage GPT-4 and Claude3 despite the $20/month cost, and consult resources like Lilian Weng's Transformer Family Version 2.0 post and HazyResearch's AI System Building Blocks repository.
- Retrieval Augmented Generation (RAG) with LangChain: The LangChain AI Discord featured an open-source chatbot repository demonstrating RAG for efficient Q&A querying and a guide for building multi-modal applications with LlamaIndex. Discussions also covered troubleshooting and best practices for implementing LangChain in various applications.
ChatGPT (GPT4T)
Efficiency Innovations in AI Infrastructure: Gearing Up with GEAR and NVMe SSDs saw significant attention, focusing on large model operations and acceleration. The GEAR project for KV cache compression and the use of NVMe SSDs for fine-tuning huge models were notably discussed, indicating a growing interest in optimizing AI model efficiency through hardware innovations (GitHub - opengear-project/GEAR, arXiv paper).
Fine-Tuning Techniques and Troubleshooting: Unlocking Unorthodox Fine-Tuning Speed and Fine-Tuning Facades and Inferential Flops highlighted the community's engagement with enhancing model fine-tuning and troubleshooting. Techniques yielding a 2x speedup in LLM fine-tuning with a 40% reduction in memory usage via Unsloth-DPO generated buzz, while various challenges, including model bugs and
<unk>responses, underscored the complexity of fine-tuning practices (Unsloth-DPO).AI Model and Framework Development Insights: ELLA Elevates Text-to-Image Diffusion Models and Promising Advances & Discussions in AI showcased discussions around model improvements and framework developments. ELLA's boost to text-to-image model comprehension and the unveiling of efficient large language model adapters were among the advancements sparking interest, reflecting the ongoing evolution and specialization within AI technology spheres.
Community Collaborations and Technical Sharing: Community Collaboration on AI Project Development and Dev Days and RAG Nights demonstrated vibrant collaborative efforts across platforms. Shared resources for fine-tuning models with customer data, advice for AI project development, and developer series on creating context-augmented applications highlighted the importance of community support and knowledge exchange in accelerating AI innovation.
These themes collectively underscore a dynamic and collaborative AI research and development environment, with a focus on optimizing model efficiency, advancing fine-tuning methodologies, fostering innovation in AI model and framework development, and leveraging community collaboration for shared growth and learning.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord Summary
- Gearing Up with GEAR and NVMe SSDs: The community engaged with the concept of efficiency in large model operations:
@remek1972pointed to the GEAR project (GitHub - opengear-project/GEAR) for KV cache compression, and@iron_bounddiscussed an approach for fine-tuning huge models using NVMe SSDs to enable acceleration on a single GPU, referencing an arXiv paper.
- Unlocking Unorthodox Fine-Tuning Speed:
@lee0099showcased a 2x speedup in LLM fine-tuning with a 40% reduction in memory usage via Unsloth-DPO, generating excitement amongst users like@starsupernovain the showcase channel.
- Dependency Dilemmas and AI Modeling Tools: Development environment troubles made the rounds;
@maxtensorgrappled with package incompatibilities, nudging@starsupernovato suggest using a specific PyTorch wheel for resolving xformers installation issues, further recommending Windows Subsystem for Linux (WSL) for better experiences.
- Fine-Tuning Facades and Inferential Flops: In the help channel, users navigated challenges ranging from
@dahara1identifying a Gemma model bug post-Unsloth update to@aliissatrying to troubleshoot<unk>responses from a model forcing@starsupernovato suspect padding and template issues.
- ELLA Elevates Text-to-Image Diffusion Models: A discussion kicked off in random with
@tohrniisharing a paper on ELLA (Efficient Large Language Model Adapter) to boost text-to-image models' understanding of prompts, and the evergreen Windows vs Linux debate continued with operational preferences dissected between@maxtensorand@starsupernova.
Perplexity AI Discord Summary
- Claude 3 Opus Use Limited in Perplexity Pro: Users reported that on Perplexity Pro, Claude 3 Opus offers a mere 5 uses compared to 600 for other LLMs like Claude Sonett. Discussions also touched on Perplexity's competitiveness and speculated on an ad-based Pro model, referencing tweets from Perplexity's CEO about competitors' pricing strategies and attempts to hire AI researchers.
- Recruitment Queries and Advice in Perplexity: A user expressed interest in job opportunities with Perplexity AI, with guidance provided to check the careers page without directly tagging the team. Another user sought assistance to improve the pplx API for use in a personal assistant project.
- Features and Functionality of LLMs Debated: There was debate over whether Perplexity uses external models like Gemini or has its own models, with users noting similarities in responses to Gemini's API. Inquiries about Yarn-Mistral-7b-128k model use for high-context conversations were raised, alongside questions about pplx API retrieving web sources within replies.
- Pro Users Seek Effective Utilization Strategies: Pro users discussed logo design use and uploading pdf scripts for queries, with an emphasis on how to effectively leverage Perplexity for specific use cases.
- Content Sharing in the Perplexity Community: Members shared resources on topics ranging from AI discoveries, space junk re-entry, CSS insights, and the classification of strawberries, emphasizing the importance of making threads shareable within the community.
Nous Research AI Discord Summary
- 100,000x Faster Neural Network Convergence: @baptistelqt claims to have developed a method that accelerates the convergence of neural networks by 100,000x, applicable to various architectures including Transformers, with a forthcoming paper.
- Promising Advances & Discussions in AI: Cohere’s C4AI Command-R, a 35 billion parameter model optimized for reasoning and summarization, was discussed alongside Command-R's GitHub demo. The Deepseek-VL model emerged as a potential disruptor, and debates ensued on replacing tokenizers in pre-trained models with dual tokenization.
- Merging Command-R and RAG: CohereForAI’s C4AI Command-R model has been highlighted for its ability to facilitate RAG calls with a simplified search method, with a Model Card available. Practical applications of AI in game development were also showcased.
- Insights and Incidents in AI Governance: Discussions touched upon Mark Zuckerberg and Elon Musk's contrasting views and foresight on AI. Legal considerations of model licensing, such as the Nous Hermes 2, were scrutinized, while the concept of recursion in function-calling LLMs was eagerly anticipated.
- Technical Challenges & Tooling in AI: Troubleshooting tokenizer replacement for language-specific handling, fine-tuning model sizes, memory requirements, and structuring model outputs became focal points. Various tools like llama-cpp and qlora were mentioned for assistance in specific AI development tasks.
LM Studio Discord Summary
- M1 Macs Skipping GPU Acceleration: Users such as
@maorweand@amir0717reported that LM Studio occasionally favors CPUs over GPU acceleration on Mac M1 systems, as well as on different setups including a GTX 1665 Ti with 16 GB of RAM. Discussions involved exploring model options that perform better on specific hardware, with suggestions pointing towards the deepseek-coder-1.3b-instruct-GGUF.
- Unleashing Model Potentials with Tensor Splits: Configurations like setting Tensor Split to "0, 100" were discussed to test the performance of specific GPUs for LM Studio without physical alteration of hardware connections. It was noted that dual GPU setups and advanced motherboards with PCIe 4.0, such as the MSI Meg X570, could optimize RTX 3090 performance.
- Eager Eyes on LM Studio's Next Move: Users are keenly anticipating new features in upcoming updates for LM Studio, including improved chat "Continue" behavior and enhanced version.16 support, with a notable call for attention towards an updated AVX beta version.
- Choosing Clouds or Chips for LLMs?: A debate brewed over the preference for cloud services vs. local hardware when running large language models (LLMs). Factors like cost, confidentiality, and cloud provider grants such as those from Google were mentioned as significant considerations.
- Exploring Alternatives for Optimal LLM Performance: While no clear recommendation surfaced for models capable of enhancing storytelling, a user noted difficulties with stablelm zephyr 1.5 GB producing incomplete C++ code. Others discussed alternative platforms like KoboldAI and CrewAI, and weighed the graphical advantages of AutoGen's interface in addition to monitoring closed token generation loops to conserve computational resources.
OpenAI Discord Summary
- Extended Video Ambitions Meet Technical Restraints: Discussions have been centered on the SORA AI's ability to create extended 30-minute footage, with technical constraints such as memory limitations highlighted as current challenges. While SORA is bounded by these limitations, it is technically possible for it to generate extended videos in sections as detailed in an OpenAI research paper.
- Confusion and Clarification over GPT-3.5 Subscription Tiers: Users are seeking clarity on the differences in GPT-3.5 models across subscription tiers, with the primary distinction being usage limits rather than any feature differences. The updates post the GPT-3.5 knowledge cutoff were also a topic of interest, raising questions about version discrepancies between API and ChatGPT versions.
- Peer Assistance Elevates Prompt Engineering Practices: One user,
@darthgustav., has been advising on enhancing consistency in GPT outputs utilizing an output template with variable names representing the instructions to maintain consistency. Challenges such as rewriting texts and dealing with HTML snippets are being addressed through collaborative problem solving and shared resources, emphasizing the need to adhere to OpenAI's terms of use and usage policies.
- Diverging Experiences with AI Models: Users compared their experiences with different AI models, like Claude Opus and GPT-4, noting that Claude may offer more creative and concise outputs than GPT-4, which sometimes leans towards generating bullet points or less engaging content.
- Community Collaboration on AI Project Development: The guild has become a hub for collaborative AI project development, including members sharing resources for fine-tuning models with customer data and providing advice for a solitaire instruction robot project using GPT and OpenCV. Resources included a GitHub notebook mistral-finetune-own-data.ipynb which appears to be a valuable resource for custom fine-tuning needs.
HuggingFace Discord Summary
Hugging Face Introduces Handy New Features: Hugging Chat now lets users filter and search for Assistant names, and the Hugging Face blog includes a new "table of contents" for ease of access. All-time stats are now available in Hugging Face Spaces, enabling creators to assess their space's popularity more comprehensively.
WebGPU Poised to Accelerate In-Browser ML: @osanseviero from Hugging Face indicated that WebGPU could potentially speed up machine learning in browsers by up to 40 times.
Expanding Developer Resources and Learning: The latest releases of Transformers.js 2.16.0, Gradio 4.21, and Accelerate v0.28.0 bring developers new features. Additionally, a new course titled Machine Learning for Games was announced by @ThomasSimonini.
Cutting-Edge Tools and Model Discoveries Across Channels:
- Portuguese Language Model - Mambarim-110M: Announced by @dominguesm, it's a new Portuguese LLM named Mambarim-110M, based on the Mamba architecture and pre-trained on a 6.2 billion token dataset (Hugging Face, GitHub).
- GitHub user @210924_aniketlrs02 is seeking guidance on applying a wav2vec2 codebook extraction script for extracting quantized states from the Wav2Vec2 model.
- Lucid Dream Project and Vid2Persona: Unique projects using Web-GL and conversational AI with video characters were shared on Hugging Face spaces, showcasing innovative applications of AI (The Lucid Dream Project).
- Microsoft introduced AICI: Prompts as (Wasm) Programs, enhancing prompt handling for AI applications (AICI on GitHub).
Concepts and Models Discussed for Practical AI Implementation: - Debate on action-based AI's future, involving integration of Large Language Models with APIs. - Questions raised about practical AI applications included potential hardware hacks like using PS5 consoles for powerful VRAM modules. - A discussion was sparked by a reference to using PS3 consoles as a supercomputer, highlighting gaming hardware's potential in mind-bending computational tasks. - Trials and challenges of using gaming consoles like the PS5 for computing tasks were also highlighted, along with driver limitations and lack of connections like Nvidia's NVLink in AMD and Intel cards.
Evolving the AI Discourse in Natural Language Processing: - Methodologies to evaluate clarity and emotions in discourse with Large Language Models were queried. - Seeking the best model for NSFW uncensored translation, focusing on accuracy and optimization. - Strategies to identify out-of-distribution words or phrases in documents were requested. - LightEval, a lightweight LLM evaluation suite by Hugging Face, was suggested for benchmarking LORA-esque techniques.
Eleuther Discord Summary
- Exploring LLM Learning Without GPUs:
_michaelshreceived advice for learning Large Language Models without a GPU, leveraging tools like Google Colab's T4 GPU to work with moderately sized models including Gemma and TinyLlama.
- Learning Materials and Costs for LLM Enthusiasts: Potential resources for LLM education, such as YouTube and paid access to LLMs like GPT-4 and Claude3, were suggested to
_michaelsh, pinpointing costs around $20 a month.
- Security Flaws in LLMs: An emergent model-stealing attack was discussed, which extracts projection matrices from models like gpt-3.5-turbo, igniting debate on the ethics and legality of exposing such vulnerabilities.
- Transformer Debugging Tools and Interpretability:
@stellaathenaqueried the compatibility of the transformer-debugger with Hugging Face trained models, while@millanderexamined a paper on removing unwanted capabilities from AI models through pruning, questioning the utility tradeoff in language models compared to image classifications.
- Hyperparameter Headaches and Benchmark Blues: Poor evaluation performance using Llama hyperparameters with higher learning rates has
@johnnysandsspeculating on the need for more annealing, while@epicxpondered the decline in popularity of historical benchmarks such as SQuAD and the Natural Questions leaderboard.
LlamaIndex Discord Summary
- Ready, Set, Memorize!: A webinar on MemGPT discussing long-term, self-editing memory for LLMs is scheduled for Friday at 9 am PT. It features notable speakers and aims to explore virtual context management challenges for large language models, as highlighted by
@jerryjliu0. Catch the webinar registration at Sign up for the event.
- Dev Days and RAG Nights:
@ravithejadsintroduced a series on creating context-augmented applications with Claude 3 using LlamaIndex, while@hexapodeinvites developers to a RAG meetup in Paris, discussing advanced RAG strategies. Revelations from the series and event details can be found on Twitter and Twitter respectively.
- Insights, Queries, and LLM Snippets: Discussions regarding RAG deployment, global query parameters in MistralAI, and vector store issues were serviced by
@whitefang_jr, providing links to corresponding full-stack application and Github source code. A guide for creating multi-modal applications with LlamaIndex was shared for those interested in language-image integration.
- Matryoshka and Claude Chronicles: The AI community is buzzing with talks of a Matryoshka Representation Learning paper discussion hosted by Jina AI, featuring Aditya Kusupati and Aniket Rege, register here. Additionally, a quest for an open-source GUI/frontend for Claude 3 was raised by
@vodros, along with the announcement of a new LLM Research Paper Database by@shure9200, a repository aimed at aggregating quality research papers.
- Engineers' AI Paper Repository Alert: Highlighting a valuable resource for AI researchers,
@shure9200introduced an LLM papers database curated to keep one abreast with the field's academic progressions. A paper discussion on Matryoshka Representation Learning with invites extended to engineers to join and engage with the paper's authors.
LAION Discord Summary
- ELLA Enhances Text-to-Image Precision: The introduction of ELLA has been highlighted, showcasing its ability to improve text alignment in text-to-image diffusion models such as SD3, without necessitating additional training. Technical specifics and comparisons can be explored further on Tencent's ELLA website.
- Llama.cpp Revolutionizes LLMs on Standard Hardware: A new "2-bit quantization" breakthrough in llama.cpp, discussed by
@vrus0188, allows running Large Language Models more efficiently on standard hardware. Insights and development details are covered in a Medium post by Andreas Kunar.
- SD3's Expanding Horizons: The potential of SD3 was examined, noting its advantage from the absence of cross-attention and its capacity to integrate image and text embeddings. Additionally, there's ongoing deliberation about model scalability, quantization methods, and model performance on commonplace GPUs.
- Quantization and CPU-Offloading Enable SD3 for Diverse Hardware: Strategies like quantization and CPU-offloading could make SD3 more accessible, by adapting to different VRAM capacities. The discussion highlighted the implications concerning execution times and performance trade-offs.
- Vulnerability of Transformer Models Unveiled for Less Than $20: An arXiv paper revealed an attack technique capable of recovering parts of transformer models, notably those of OpenAI, for a trivial cost, leading to discussions about model security and subsequent API changes by OpenAI and Google.
- Delving Into the Depths of LAION-400M Dataset: The LAION-400-MILLION images & captions dataset was acknowledged for its significance in a piece by Thomas Chaton, with a link to the article provided for those interested in the dataset's potential: Explore LAION-400M Dataset.
Latent Space Discord Summary
- AI "Devin" Dazzles Developers: Cognition Labs' AI named "Devin" has excelled on the SWE-Bench coding benchmark, with the potential to revolutionize software engineering. The discussion referenced Devin's backings and capabilities, including its ability to write entire programs independently as highlighted in tweets by Neal Wu and Ashlee Vance.
- Elon's "Open" AI Move Sparks Debate: A debate ensued regarding Elon Musk's proposition to potentially open-source Twitter's algorithm "Grok," with opinions diving into open-source ethos and the reputational ramifications for Musk discussed against the backdrop of his tweet.
- Weightlifting AI Research: A new DeepMind paper focused on extracting weights from parts of an AI model's embedding layer triggered discussion on the complexity and current mitigation measures to prevent weight extraction.
- Karpathy Marks a Milestone: Community members celebrated Andrej Karpathy's new achievement, discussing his contribution to AI and its implications for the future of content creation.
- Truffle-1: Next-Gen AI Inference on a Budget: The announcement of Truffle-1, an affordable AI inference engine by Truffle, attracted attention for its low power usage, affordability, and potential impact on running open-source AI models, as per the launch tweet.
Interconnects (Nathan Lambert) Discord Summary
- Elon Musk Hints at Open Sourcing Grok: In a tweet,
@elonmuskhinted at Grok being open-sourced by xAI which caught the attention of community members, though concerns about the proper definition of open source were raised.
- Cohere Unleashes Command-R for Academia: Command-R, a new large-scale generative model, has been presented by Cohere, with a focus on enabling production-scale AI applications and academic access to its weights.
- Pretraining Costs Dive: Users discussed the dropping costs of pretraining models like GPT-2 now within the sub-$1,000 range, citing Mosaic Cloud figures from September 22, and a Databricks blog post titled "GPT-3 Quality for $500k" for further insights into economy and scale (Databricks Blog).
- Meta's Massive AI Infrastructure Expansion: Meta intends to power its AI infrastructure with a massive assembly of 350,000 NVIDIA H100 GPUs by the end of 2024, as detailed in a news release, which aims to support projects including Llama 3.
- Subscriber Appreciation in the Community: A member expressed discontent with their "Subscriber" status, but was reassured by
@natolambert, who emphasized the essential role subscribers play in sustaining the community.
CUDA MODE Discord Summary
Nvidia's Moat vs. Vulkan's Potential: Nvidia's dominance in the GPU landscape continues to be a point of fascination, with discussions highlighting Nvidia's compelling competitive advantage and software edge as nearly insurmountable, despite Vulkan's potential Pytorch backend posing a theoretical challenge. Users also expressed the complexities of working with Vulkan due to setup and packaging reminiscent of CUDA issues. Meta's significant investment in AI infrastructure with a 24k GPU cluster and a roadmap for 350,000 NVIDIA H100 GPUs reinforces Nvidia's dominance in the field (Meta's GenAI Infrastructure Article).
Triton Community Gathers: The Triton programming language community is preparing for an upcoming meetup on 3/28 at 10 AM PT. Interaction with the community and information about the meeting can be accessed through the Triton Lang Slack channel and its GitHub discussions page.
CUDA Development Insights and Tips: Discussions related to CUDA included the benefits of thread coarsening for enhanced performance, the optimization of Visual Studio Code for CUDA development, and suggestions for learning specific CUDA data types and threads. A detailed c_cpp_properties.json configuration setup for VS Code was shared, highlighting necessary includes for CUDA toolkit and PyTorch.
PyTorch Ecosystem Active Discussions: Within the PyTorch community, questions were raised regarding the performance differences between libtorch and load_inline, clarification on the role of Modular in optimizing kernel compatibility with GPU architectures, and an open call for feedback on torchao RFC #47 to simplify the integration of new quantization algorithms and data types.
NVIDIA Innovations and Training Resources: The CUDA community touched upon NVIDIA's leading-edge techniques like Stream-K and Graphene IR, which promise significant speedups and optimizations in matrix multiplication on GPUs, and shared a link to the CUTLASS repository (NVIDIA Stream-K Example). For CUDA learners, a comprehensive CUDA Training Series on YouTube, along with its associated GitHub materials, was recommended (CUDA Training Series GitHub).
PMPP and Other Learning Resources: The "Programming Massively Parallel Processors" (PMPP) book was noted for not extensively covering profiling tools, with ancillary content available through associated YouTube videos. Additional CUDA coursework concerns were addressed, including questions about spacing in CUDA C++ syntax and exercise solutions for the PMPP 2023 edition.
Ring Attention Troubleshooting and Coordination: A user offered GPU availability for stress testing ring attention code and coordinated meeting times aligned with US daylight saving changes, while seeking advice after encountering high training loss. WANDB was used as an evaluation tool for training sessions.
Off-topic Rumors and AI Developments: Speculative discussions about Inflection AI and Claude-3 led to clarification via a debunking tweet. A cryptic image sparked curiosity, and attention was drawn to a new AI software engineer named Devin, developed by Cognition Labs, which promises new benchmarks in software engineering, with a real-world test publicized by @itsandrewgao (Andrew Kean Gao's Tweet).
LangChain AI Discord Summary
- Effective Prompt Crafting Resolves Langchain Issues:
@a.asifresolved an issue by creating an appropriate prompt, highlighting the importance of context in achieving the desired response.
- Progress with Langchain and Claude Integration: The Chat Playground now includes Claude V3 model support as per a pull request by
@dwb7737, marking a significant update for developers utilizing Langchain.
- Building Chatbots with Enhanced Retrieval Abilities:
@haste171shared an open-source AI chatbot repository that leverages RAG for Q/A querying, while@ninamanisought advice on switching tochatmode in their chatbot development with new LLMs, specifically a finetuned version of llama-2.
- Learning Resources for Langchain Users: New tutorials, such as "Chatbot with RAG" and "INSANELY Fast AI Cold Call Agent- built w/ Groq" were shared on YouTube by
@infoslackand@jasonzhou1993, providing practical guidance for building AI applications with Langchain and the Groq platform.
- Community Collaboration and Support for Langchain Implementation: Discussions include seeking Langchain to LCEL conversion guidance, resolving issues with iFlytek's Spark API, and optimizing LangServe usage as the community provides support and solutions for each other's technical challenges.
OpenAccess AI Collective (axolotl) Discord Summary
- Fix on Flash Attention for RTX Series:
[flash_attention: false]and[sdp_attention: true]in the YAML configuration were recommended for an issue with disabling flash attention on RTX 3090 or 4000 series GPUs.
- Cohere's Big Surprise with 'C4AI Command-R': Cohere released an open-source 35 billion parameter model called "C4AI Command-R," now available on Hugging Face.
- DoRA Gains Support in PEFT PR Merge: Hugging Face merged a PR adding DoRA support for 4bit and 8bit quantized models, though it's mentioned that DoRA supports only linear layers for now with a caveat for merging weights during inference.
- Optimizing AI Training with NVMe SSDs: A strategy involving NVMe SSDs for efficient fine-tuning of 100B parameter models on single GPUs was discussed, citing a tweet by AK.
- Advanced Axolotl and DeepSpeed Discussions: Questions regarding DeepSpeed's API in Axolotl were raised with a DeepSpeed PR under review, and a recent fix in Axolotl that might solve poor evaluation results with Mixtral training.
OpenRouter (Alex Atallah) Discord Summary
- In Search of a ChatGPT 3.5 Substitute:
@mka79requested alternatives to ChatGPT 3.5 for office use, emphasizing the need for privacy, reduced censorship, and exclusion of user data in training. - Gemma's New Contender: The new Openchat model based on Gemma has been promoted by
@louisdck, claiming performance on par with Mistral models and an edge over other Gemma models. - Hermes Has Left the Building: Access issues with the Nous Hermes 70B model were confirmed, and
@louisgvindicated the model will be offline indefinitely with a planned update to prevent access during this downtime. - Openchat and Gemma Users Hit Timeout: Due to abuse, free models including Openchat and Gemma are temporarily disabled for users without credits, with promises from
@alexatallahto work on restoring access. - Cheat Layer Spearheads New Free Autoresponding Feature:
@gpumanhighlighted Cheat Layer's new free autoresponding service on websites, leveraging OpenRouter, and urged users to report any issues to their support team; discussions about open-sourcing Open Agent Studio and integrating OpenRouter were also mentioned.
DiscoResearch Discord Summary
- Open-Source Throws Down the Gauntlet to GPT-4: A humorous prediction within the community anticipates open-source models potentially surpassing GPT-4, sparking interest in setting up a comprehensive benchmark evaluation. Meanwhile,
@.calytrixhas signaled an intention to compare various models to GPT-4 under a rigorously controlled testing environment.
- FastEval on Steroids: The community discussed enhancing FastEval with flexible backends, such as Llama.cpp or Ollama, following an instance where FastEval was modified to expand its usability beyond its original scope.
- RAG tag, You're It: Members debated the optimal placement of context and RAG instructions for prompt engineering, with opinions differing based on Specialized Fine-Tuning (SFT) experiences and whether the model had exposure to [SYS] and [USER] tags during training.
- New Tools to Dissect Transformer Brains: A new tool for getting under the hood of transformers was spotlighted: the Transformer Debugger, announced by
@janleike, promises to offer automated interpretability and a way to explore model internals without the need to code.
- Beware of Non-Standard Model Ecosystems: The community discussed issues with non-English text generation in the
DiscoResearch/mixtral-7b-8expertmodel, with a recommendation to use the official implementation at Hugging Face's Mixtral-8x7B-v0.1 for better reliability. Additionally, a need for clearer labeling of experimental models likeDiscoResearch/mixtral-7b-8expertwas recognized.
- tinyMMLU Big Potential in Small Package: Interest was expressed in tinyMMLU benchmarks on Hugging Face, suggesting an efficient means to run translations while exploring benchmark utility.
- Hellaswag Benchmark Reveals the Power of Patience: The observation was made that the Hellaswag benchmark shows significant noise, with score fluctuations evident even after 1000 data points, highlighting the need for extensive testing to achieve stable and meaningful results.
Alignment Lab AI Discord Summary
- Seeking Efficient Minimodels: User
@joshxtinquired about the best small embedding model with 1024+ max input for local use with low RAM, but no further discussion followed.
- Diving into Mermaid for Diagrams:
@tekniumqueried about Mermaid graphs and@lightningralfresponded with explanations and resources including the Mermaid live editor and the GitHub repository.@joshxtshowcased Mermaid's capabilities with a complex system example and its utility on GitHub for generating visualizations from code.
- Under the Code Avalanche:
@autometahumorously lamented the pile-up of coding tasks and then proceeded to take action by working on a Docker environment for the team. Offering a $100 bounty for Docker setup assistance and an open call for collaboration on open science/research projects, they also delegate tasks, including Docker responsibilities, to@alpinfor further progress.
LLM Perf Enthusiasts AI Discord Summary
- Grok Going Public:
@elonmusktweeted about Grok being open-sourced by@xAIthis week, enticing discussions around potential uses and benefits within the open source community. Elon Musk's tweet has spurred anticipation amongst the users.
- Command-R Query:
@potrockis seeking insights on local implementation of Command-R, encouraging other users to share their experiments and results with the new tool.
- The Token Limit Conundrum:
@alyosha11brought up challenges with the 4096 token limit in gpt4turbo, prompting discussions on workarounds and expectations for future model improvements.
- Unraveling the GPT-4.5 Turbo Mystery:
@arnau3304initiated a debate with a Bing search link indicating the rumor of a GPT-4.5 Turbo; however,@dare.aiand others showed skepticism, noting the uncertainty without official confirmation.
- Azure Migration Curiosity: User
@pantsforbirdsexpressed interest in the experiences of migrating from OpenAI's SDK to Azure's platform, calling for advice on potential hurdles and tips, demonstrating a common interest in cloud AI service platforms.
Skunkworks AI Discord Summary
- Quantum Speedup in AI Training Unveiled: @baptistelqt has achieved a 100,000-fold acceleration in training convergence by employing an innovative method of training AI models from scratch in every round.
- Game Coding with Claude 3: @pradeep1148 shared a YouTube video illustrating the development of a game based on Plants Vs Zombies using Claude 3 and Python.
- Diving Deep with Command-R's RAG: A YouTube exploration into Command-R's capabilities in handling long-context tasks via retrieval augmented generation and external APIs has also been presented by @pradeep1148.
AI Engineer Foundation Discord Summary
- Plugin Pow-Wow Pending: A discussion spearheaded by
@hackgooferwas initiated on the configurability of plugins, specifically the viability of token-based authorization as a plugin argument. Concerns were raised about whether this security measure is sufficient.
- Casting Call for Project Proposals: Members have been invited to propose new projects, with the scope and guidelines provided in a Google Docs guide. Opportunities for collaboration, including one with Microsoft, were highlighted.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (237 messages🔥🔥):
- Inquiries about Using Fine-Tuned Models:
@animesh.adsought help for testing a fine-tuned Gemma-2 model uploaded to the hub without using a GPU, only to get advice on using "normal HF code" from@starsupernova. After some struggle,@animesh.adclarified that the model was inaccessible due to a wrong path but was advised by@starsupernovato retry the process since the names of the essential files might be incorrect. - Kaggle Notebook Troubles and Success:
@simon_vtrshared issues with running inference on Kaggle without internet connectivity. Despite hurdles like dependencies not being installed (bitsandbytes,xformers),@simon_vtreventually reported success with running Unsloth models offline. - Unsloth Features and Future Development:
@theyruinedeliseand@starsupernovahighlighted Unsloth's specificity in bug fixes over Google and Hugging Face implementations, discussing limitations and features of the models.@theyruinedeliseteased the upcoming Unsloth Studio for one-click finetuning. - RoPE Kernel Optimization Suggestion:
@drinking_coffeeproposed an improvement to the RoPE kernel by optimizing computations along axis 1 using a group approach.@starsupernovashowed interest in the suggestion and encouraged a pull request for incorporating the enhancement. - New Users & Community Engagement: The channel welcomed new members like
@remybigbossdirected from sources like Twitter posts by Micode and Yannic.@theyruinedeliseappreciated the visibility boost and encouraged GitHub stars.
Links mentioned:
- Google Colaboratory: no description found
- Kaggle Mistral 7b Unsloth notebook: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Kaggle Mistral 7b Unsloth notebook Error: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Kaggle Mistral 7b Unsloth notebook Error: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- danielhanchen (Daniel Han-Chen): no description found
- Paper page - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: no description found
- GitHub - stanford-crfm/helm: Holistic Evaluation of Language Models (HELM), a framework to increase the transparency of language models (https://arxiv.org/abs/2211.09110). This framework is also used to evaluate text-to-image models in Holistic Evaluation of Text-to-Image Models (HEIM) (https://arxiv.org/abs/2311.04287).: Holistic Evaluation of Language Models (HELM), a framework to increase the transparency of language models (https://arxiv.org/abs/2211.09110). This framework is also used to evaluate text-to-image ...
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #welcome (12 messages🔥):
- Warm Welcomes & Important Reads:
@theyruinedelisegreeted the group warmly and reminded everyone to read channel <#1179040220717522974> and to assign their roles in <#1179050286980006030>. - Game Talk in the Welcome Channel:
@emma039598inquired if any group members play games, with a positive response from@theyruinedelisementioning favorites like League of Legends, Elden Ring, and Soma. - Greeting Newcomers:
@starsupernovajoined in to welcome newcomers to the server. - Casual Gaming Chat:
@emma039598stated a preference for RPGs when asked by@theyruinedeliseabout gaming preferences. - Expressions of Welcome and Joy:
@theyruinedeliseexpressed a simple "win" in the chat, and@chelmoozgreeted everyone with a friendly "coucou".
Unsloth AI (Daniel Han) ▷ #random (9 messages🔥):
- Introducing ELLA for Improved Text-to-Image Diffusion Models:
@tohrniishared an arxiv paper focusing on the Efficient Large Language Model Adapter (ELLA) which aims to enhance text-to-image diffusion models' comprehension of complex prompts without the need for retraining. - Windows vs Linux for AI Development:
@maxtensorand@starsupernovadiscussed their development environments with@starsupernovamainly working on Colab and Linux, and mentioning a lack of GPU on their Windows machine. - Dependency Hell Strikes:
@maxtensordetailed a frustrating dependency conflict in an Ubuntu WSL environment, where attempts to integrate new AI tools led to incompatible package versions, notably with torch, torchaudio, and torchvision. - Searching for Solutions in Software Dependencies:
@starsupernovasuggested trying to install xformers with a specific PyTorch wheel index to potentially resolve dependency issues that@maxtensorencountered. - The Grind of AI Model Training:
@thetsar1209expressed their distress with an emoji over the lengthy model training process as indicated by the progress output "20/14365 [07:23<74:37:53, 18.73s/it]".
Links mentioned:
- ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment: Diffusion models have demonstrated remarkable performance in the domain of text-to-image generation. However, most widely used models still employ CLIP as their text encoder, which constrains their ab...
- no title found: no description found
Unsloth AI (Daniel Han) ▷ #help (272 messages🔥🔥):
- Gemma Model Conversion Saga:
@dahara1discovered that converting the Gemma model to gguf format requiresconvert-hf-to-gguf.pyinstead ofconvert.py, sharing a crucial GitHub pull request for reference. They also found a potential bug with Unsloth's handling of Gemma after a certain update, noting that a model created with Unsloth doesn't infer correctly on a local PC but works post-upload to Hugging Face.
- Quantization Quirks Uncovered: Users
@banu1337and@starsupernovadebated the difficulties of quantizing models, with@banu1337specifically struggling to quantize a Mixtral model even with significant GPU resources.@starsupernovarecommended GGUF as an alternative, noting its support in Unsloth, and suggested 2x A100 80GB GPUs should suffice for the task.
- Learning from LLMs:
@abhiabhi.engaged in a philosophical conversation with@starsupernova, touching upon learning rates, warmup steps, and the nature of intelligence arising from deterministic machines.
- Unsloth on Windows Woes:
@ee.ddfaced challenges installing xformers via Conda on Windows and was advised by@starsupernovato try apipinstallation instead. After further troubles,@starsupernovarecommended using WSL for a smoother experience.
- Model Loading Mysteries:
@aliissasought assistance with problems using NousResearch/Nous-Hermes-2-Mistral-7B-DPO without fine-tuning, as they only received<unk>values in response.@starsupernovasuggested it might be due to padding and the absence of the appropriate chat template.
Links mentioned:
- Repetition Improves Language Model Embeddings: Recent approaches to improving the extraction of text embeddings from autoregressive large language models (LLMs) have largely focused on improvements to data, backbone pretrained language models, or ...
- no title found: no description found
- Gemma models do not work when converted to gguf format after training · Issue #213 · unslothai/unsloth: When Gemma is converted to gguf format after training, it does not work in software that uses llama cpp, such as lm studio. llama_model_load: error loading model: create_tensor: tensor 'output.wei...
- KeyError: lm_head.weight in GemmaForCausalLM.load_weights when loading finetuned Gemma 2B · Issue #3323 · vllm-project/vllm: Hello, I finetuned Gemma 2B with Unsloth. It uses LoRA and merges the weights back into the base model. When I try to load this model, it gives me the following error: ... File "/home/ubuntu/proj...
- VLLM Multi-Lora with embed_tokens and lm_head in adapter weights · Issue #2816 · vllm-project/vllm: Hi there! I've encountered an issue with the adatpter_model.safetensors in my project, and I'm seeking guidance on how to handle lm_head and embed_tokens within the specified modules. Here'...
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
- Tutorial: How to convert HuggingFace model to GGUF format · ggerganov/llama.cpp · Discussion #2948: Source: https://www.substratus.ai/blog/converting-hf-model-gguf-model/ I published this on our blog but though others here might benefit as well, so sharing the raw blog here on Github too. Hope it...
- py : add Gemma conversion from HF models by ggerganov · Pull Request #5647 · ggerganov/llama.cpp: # gemma-2b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-2b/ --outfile models/gemma-2b/ggml-model-f16.gguf --outtype f16 # gemma-7b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-...
- unsloth/unsloth/save.py at main · unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #showcase (10 messages🔥):
- Unsloth Doubles Fine-Tuning Speed:
@lee0099fine-tunedyam-peleg/Experiment26-7Busing Unsloth-DPO, achieving a 2x speedup and 40% memory usage reduction for LLM fine-tuning without accuracy loss when compared to normal QLoRA. - Experiment26 Goes Public: In the showcase,
@lee0099introducedyam-peleg/Experiment26-7B, an experimental model hosted on Hugging Face with a focus on refining LLM pipeline research and identifying potential optimizations. - Community Support for Experiment26:
@starsupernovaexpressed excitement about@lee0099's fine-tuning advancements with the phrase, "Very very cool!" indicating strong community endorsement. - Suggestion to Display Fine-Tuned Models:
@starsupernovainvited@1053090245052219443to showcase their fine-tuned Gemma model in the channel. - Gemma Model Performance Showcase:
@kuke4367shared a Kaggle link demonstrating fast inference with the fine-tuned Gemma model and provided its URL on Hugging Face,Kukedlc/NeuralGemmaCode-2b-unsloth.
Links mentioned:
- yam-peleg/Experiment26-7B · Hugging Face: no description found
- Gemma CoPilot 2x-Fast-Inference: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- NeuralNovel/Unsloth-DPO · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #suggestions (4 messages):
- Approval for Ye Galore:
@starsupernovaexpressed their satisfaction with Ye Galore, mentioning it's good with a smiley. - Joking on Ease of Implementation:
@remek1972humorously commented on the ease of implementing something, tagging<@160322114274983936>followed by a laughing emoji. - Promoting GEAR Project:
@remek1972shared a GitHub link to the GEAR project (GitHub - opengear-project/GEAR), hinting at its efficiency in KV cache compression for near-lossless generative inference of large language models. - Novel Approach for Fine-tuning Huge Models:
@iron_boundshared an arXiv paper (Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU), discussing the possibility of fine-tuning enormous models using NVMe SSDs on a single, even low-end, GPU.
Links mentioned:
- Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: Recent advances in large language models have brought immense value to the world, with their superior capabilities stemming from the massive number of parameters they utilize. However, even the GPUs w...
- GitHub - opengear-project/GEAR: GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM: GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM - opengear-project/GEAR
Perplexity AI ▷ #general (424 messages🔥🔥🔥):
- Claude 3 Opus Offers Limited: Users like
@thugbunny.discussed the limited use of Claude 3 Opus on Perplexity Pro, with clarifications provided by@icelavamanthat Pro includes 600 uses of other LLMs like Claude Sonett but only 5 are for Opus.
- Perplexity AI Adoption Discussions: Members like
@makya2148and@jawnzeshared observations and speculations about Perplexity’s competitiveness and business moves like making the Pro version ad-based, referencing tweets from Perplexity's CEO relating to competitor's pricing models.
- Job and Internship Enthusiasts: User
@parvjreached out to offer help and express a keen interest in working with Perplexity.@ok.alexresponded by indicating to check the careers page and advised against tagging the team directly in such requests.
- Comparisons and Confusions About LLMs: Several users, including
@codeliciousand@talyzman, discussed whether Perplexity uses external models like Gemini or has its own, with some confusion raised about the responses being similar to Gemini's API.
- Pro User Experience Queries: Pro users like
@halilsakand@0xhanyainquired about issues around using logo designs and uploading pdf scripts for queries, seeking guidance on how to leverage Perplexity effectively for their specific use cases.
Links mentioned:
- Tweet from Aravind Srinivas (@AravSrinivas): Will make Perplexity Pro free, if Mikhail makes Microsoft Copilot free ↘️ Quoting Ded (@dened21) @AravSrinivas @MParakhin We want perplexity pro for free (monetize with highly personalized ads)
- CEO says he tried to hire an AI researcher from Meta, and was told to 'come back to me when you have 10,000 H100 GPUs': The CEO of an AI startup said he wasn't able to hire a Meta researcher because it didn't have enough GPUs.
- More than an OpenAI Wrapper: Perplexity Pivots to Open Source: Perplexity CEO Aravind Srinivas is a big Larry Page fan. However, he thinks he's found a way to compete not only with Google search, but with OpenAI's GPT too.
- Perplexity AI CEO Shares How Google Retained An Employee He Wanted To Hire: Aravind Srinivas, the CEO of search engine Perplexity AI, recently shared an interesting incident that sheds light on how big tech companies are ready to shell a great amount of money to retain talent...
- Stonks Chart GIF - Stonks Chart Stocks - Discover & Share GIFs: Click to view the GIF
- I Believe In People Sundar Pichai GIF - I Believe In People Sundar Pichai Youtube - Discover & Share GIFs: Click to view the GIF
- Tweet from Elon Musk (@elonmusk): This week, @xAI will open source Grok
- U.S. Must Act Quickly to Avoid Risks From AI, Report Says : The U.S. government must move “decisively” to avert an “extinction-level threat" to humanity from AI, says a government-commissioned report
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Perplexity AI ▷ #sharing (17 messages🔥):
- Discoveries via AI:
@0xhanyashared a Perplexity AI link about AI discoveries, prompting@ok.alexto remind users to ensure their threads are shareable. - Space Junk's Comeback:
@mayersj1posted a link dealing with the topic of space junk returning to Earth. - CSS Writing Insights:
@tymscarshared a resource for writing CSS, a common topic of interest amongst web developers. - Research on Fruits:
@yipengsunprovided a link Are strawberries fruits based on research into the classification of strawberries. - Sharing Enabled:
@ed323161posted a link about improving a certain topic, and@po.shfollowed up with a reminder to make sure the thread is shared for visibility.
Perplexity AI ▷ #pplx-api (9 messages🔥):
- Seeking Assistants to Boost Personal Assistant Project: User
@shine0252is working on a personal assistant project similar to Alexa and is looking for help to improve pplx API's responses for conciseness and memory of past conversations. - Conciseness with
sonarModels Suggested:@dogemeat_recommended using thesonarmodels from pplx API for more concise responses, and storing conversation history in memory or a database to enable the assistant to "remember" past interactions. - Interest in the Personal Assistant Endeavor: Both
@roey.zaltaand@brknclock1215showed interest in@shine0252's personal assistant project, with@roey.zaltaasking for more details. - Prompting over API Alone for Memory:
@brknclock1215indicated that while prompting and parameter adjustments like max_tokens and temperature can help with conciseness, remembering conversations would require external data storage, not offered solely by the pplx API. - Requesting Specific Model Features and Prompt Guidance: User
@5008802inquired if pplx API can reply with sources from the web, and@paul16307asked if it's possible to add Yarn-Mistral-7b-128k for handling high-context conversations.
Nous Research AI ▷ #off-topic (24 messages🔥):
- Rapid Convergence Method Unveiled:
@baptistelqtannounced they have developed a method that accelerates convergence of neural networks by 100,000x and it works for all architectures, including Transformers. The technique involves starting each "round" of training from scratch and a promise to publish the paper soon. - Command-R Model Introduction:
@1vnzhshared a Model Card for C4AI Command-R, a 35 billion parameter model optimized for tasks including reasoning, summarization, and question answering.@everyoneisgrossprovided a link to a GitHub demo showing how to make RAG calls with Command-R using a simplified search method. - Telestrations with AI Possibility:
@denovichdescribed the game Telestrations, noting its potential synergy with a multi-modal LLM to facilitate play with fewer than the required four players, transforming it into a fun AI-powered experience. - Newsletter Highlights AI Conversations:
@quicksortlinked to the AI News newsletter which provides summaries of AI-related discussions from social platforms, mentioning that it covers 356 Twitter accounts and 21 Discord channels. While@quicksortand@denovichfound it valuable,@ee.ddand@hexaniexpressed concerns about the privacy implications of scraping Discord chats. - YouTube Video Outlines Game Development and RAG with LLM:
@pradeep1148posted two YouTube links demonstrating projects with large language models: one showcasing the creation of a Plants Vs Zombies game using Claude 3 and another explaining the workings of Command-R for retrieval augmented generation (RAG) applications.
Links mentioned:
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Command-R: RAG at Production Scale: Command-R is a scalable generative model targeting RAG and Tool Use to enable production-scale AI for enterprise.
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
- Claude 3 made Plants Vs Zombies Game: Will take a look at how to develop plants vs zombies using Claude 3#python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
- scratchTHOUGHTS/commanDUH.py at main · EveryOneIsGross/scratchTHOUGHTS: 2nd brain scratchmemory to avoid overrun errors with self. - EveryOneIsGross/scratchTHOUGHTS
- [AINews] Fixing Gemma: AI News for 3/7/2024-3/11/2024. We checked 356 Twitters and 21 Discords (335 channels, and 6154 messages) for you. Estimated reading time saved (at 200wpm):...
Nous Research AI ▷ #interesting-links (6 messages):
- Cosine Similarity Under Scrutiny:
@leontelloshared an arXiv link discussing the reliability of cosine similarity, revealing that it can produce arbitrary and potentially meaningless results depending on the regularization of linear models.
- Exposing AI Model Embeddings:
@denovichlinked to an arXiv paper describing a new model-stealing attack that extracts the embedding projection layer from black-box models like OpenAI’s ChatGPT, achieving this for under $20 USD.
- Devin: AI That Passes Engineering Interviews:
@atgctghighlighted a Twitter post from Cognition Labs introducing Devin, an AI software engineer that scores remarkably high on a coding benchmark, outperforming other models and even completing actual engineering tasks.
- Cohere’s Command-R Model Revealed:
@benxhpresented the C4AI Command-R model from Cohere, a 35 billion parameter model noted for its performance in reasoning, summarization, multilingual generation, and more.
- Chloe's Twit on New Advancements:
@atgctglinked a Twitter post by @itschloebubble without context provided, thus the content of the advancement cannot be summarized.
Links mentioned:
- Tweet from Cognition (@cognition_labs): Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering intervie...
- Is Cosine-Similarity of Embeddings Really About Similarity?: Cosine-similarity is the cosine of the angle between two vectors, or equivalently the dot product between their normalizations. A popular application is to quantify semantic similarity between high-di...
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
Nous Research AI ▷ #general (267 messages🔥🔥):
- Zuckerberg's AI Hindsight: ldj shared a humorous video reflecting on Mark Zuckerberg’s past thoughts on AI, with an ironic twist given the rapid advancements since then.
- Musk's Musing on AI Risks: teknium linked to an Elon Musk tweet emphasizing the potential dangers of AI, adding to longstanding debates on the topic.
- AI Release Predictions in the Community: mautonomy speculated a 30% chance of GPT-5 releasing in 56 hours, though @ee.dd countered, predicting no release until after U.S. elections, with @thepok and @night_w0lf discussing whether current models like GPT-4 would be surpassed by other AI entities.
- Under-the-Radar AI Models: @night_w0lf pointed out a relatively unnoticed Deepseek-VL model, suggesting it could disrupt the current AI landscape – details found in the Deepseek-VL paper.
- Function Calling LLM Anticipation: teknium hinted at the imminent release of a new 7B function-calling language model from their end, boosting anticipation in the AI community.
Links mentioned:
- Errors in the MMLU: The Deep Learning Benchmark is Wrong Surprisingly Often: Datasets used to asses the quality of large language models have errors. How big a deal is this?
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Tweet from interstellarninja (@intrstllrninja): recursive function-calling LLM dropping to your local GPU very soon...
- U.S. Must Act Quickly to Avoid Risks From AI, Report Says : The U.S. government must move “decisively” to avert an “extinction-level threat" to humanity from AI, says a government-commissioned report
- Free Me Nope GIF - Free Me Nope Cat Stuck - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Gemma optimizations for finetuning and infernece · Issue #29616 · huggingface/transformers: System Info Latest transformers version, most platforms. Who can help? @ArthurZucker and @younesbelkada Information The official example scripts My own modified scripts Tasks An officially supporte...
- GitHub - openai/transformer-debugger: Contribute to openai/transformer-debugger development by creating an account on GitHub.
- Gemma bug fixes - Approx GELU, Layernorms, Sqrt(hd) by danielhanchen · Pull Request #29402 · huggingface/transformers: Just a few more Gemma fixes :) Currently checking for more as well! Related PR: #29285, which showed RoPE must be done in float32 and not float16, causing positional encodings to lose accuracy. @Ar...
Nous Research AI ▷ #ask-about-llms (120 messages🔥🔥):
- Tokenizer Replacement Debate:
@stoicbatmaninquired about replacing a model's tokenizer post-training to better handle specific languages like Tamil.@tekniumresponded that adding tokens is possible, but replacing the tokenizer would essentially make prior learning useless according to@stefangliga. Discussions orbited around dual tokenization support and maintaining a mapping of the old tokenizer. - Function Calling with XML and Constrained Decoding: A discussion led by
@kramakekand@.interstellarninjaexplored using XML tags in LLMs, constrained decoding techniques, and the accuracy of function calls by fine-tuned models.@ufghfigchvhighlighted their tool that samples logits for valid JSON output but noted it does not yet support parallel function calls. - Hosting Models and Output Structuring:
@sundar_99385asked about tools for guiding open source LLM outputs, comparing various libraries like Outlines and SG-lang for model hosting and guidance.@.interstellarninjasuggested that llama-cpp offers grammar support, while@tekniumand@ufghfigchvdiscussed precompiling and caching function generation for efficiency. - Discussions on Model Licensing and Usability:
@thinwhiteduke8458questioned the commercial usability of models like Nous Hermes 2 given its mix of Apache 2 and MIT licenses, with@tekniumstating no legal issues would come from their end in terms of usage. - On Fine-Tuning Model Size and System Requirements:
@xela_akwasought advice on memory requirements for fine-tuning jobs, facing out-of-memory issues despite working with dual 40GB A100 GPUs.@ee.ddrecommended trying unsloth for better efficiency, while@tekniumsuggested qlora, which requires less VRAM, and reminded that PPO requires the full model to be loaded twice.
Links mentioned:
- Use XML tags: no description found
- GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI): User-friendly WebUI for LLMs (Formerly Ollama WebUI) - open-webui/open-webui
- GitHub - enricoros/big-AGI: 💬 Personal AI application powered by GPT-4 and beyond, with AI personas, AGI functions, text-to-image, voice, response streaming, code highlighting and execution, PDF import, presets for developers, much more. Deploy and gift #big-AGI-energy! Using Next.js, React, Joy.: 💬 Personal AI application powered by GPT-4 and beyond, with AI personas, AGI functions, text-to-image, voice, response streaming, code highlighting and execution, PDF import, presets for developers.....
Nous Research AI ▷ #collective-cognition (3 messages):
- Flash Attention Query Redirected: User
@pradeep1148asked about how to disable flash attention feature.@tekniumredirected the question, noting that this channel is archived and advising to ask in <#1154120232051408927>.
LM Studio ▷ #💬-general (207 messages🔥🔥):
- Mac M1 Pro GPU Woes:
@maorwereported issues with LM Studio opting to use CPUs instead of GPU acceleration on a Mac M1 Pro. Other users, like@amir0717, faced similar problems with different setups, asking for model recommendations for a GTX 1665 Ti with 16 GB of RAM.
- DeepSeek Model Compatibility:
@amir0717detailed errors when running certain models, particularly DeepSeek, and@_nahfam_suggested that "1.3B not 7B" models would work better, also proposingdeepseek-coder-1.3b-instruct-GGUF.
- Exploring GPU Configuration for LM Studio:
@purplemelbourneexperienced difficulties with LM Studio recognizing dual GPUs as a single unit with combined VRAM, and@heyitsyorkieoffered advice regarding the utilization of the tensor split feature.
- Commitment to LM Studio: In a series of posts, users including
@yagilb,@donnius, and@rexehdiscussed the pace of development for LM Studio, with developers acknowledging delays and promising new updates, citing a small team and ongoing efforts.
- User-Created Guides and APIs for LLM:
@ninjasnakeyesinquired about the differences between using LM Studio and llamacpp, leading to a discussion about API connectivity for custom programs with@rjkmelband@nink1providing clarification. Further,@tvb1199shared a comprehensive Local LLM User Guide they've compiled.
Links mentioned:
- Rivet: An open-source AI programming environment using a visual, node-based graph editor
- deepseek-ai/deepseek-vl-7b-chat · Discussions: no description found
- Pc Exploding GIF - Pc Exploding Minecraft - Discover & Share GIFs: Click to view the GIF
- deepse (DeepSE): no description found
- I Have The Power GIF - He Man I Have The Power Sword - Discover & Share GIFs: Click to view the GIF
- Ugh Nvm GIF - Ugh Nvm Sulk - Discover & Share GIFs: Click to view the GIF
- The Muppet Show Headless Man GIF - The Muppet Show Headless Man Scooter - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- The unofficial LMStudio FAQ!: Welcome to the unofficial LMStudio FAQ. Here you will find answers to the most commonly asked questions that we get on the LMStudio Discord. (This FAQ is community managed). LMStudio is a free closed...
- Rivet: How To Use Local LLMs & ChatGPT At The Same Time (LM Studio tutorial): This tutorial explains how to connect LM Studio with Rivet to use local models running on your own pc (e.g. Mistral 7B), but also how you are able to still u...
- GitHub - xue160709/Local-LLM-User-Guideline: Contribute to xue160709/Local-LLM-User-Guideline development by creating an account on GitHub.
- A Complete Guide to LangChain in JavaScript — SitePoint: Learn about the essential components of LangChain — agents, models, chunks, chains — and how to harness the power of LangChain in JavaScript.
LM Studio ▷ #🤖-models-discussion-chat (96 messages🔥🔥):
- LLM Storytelling Enhancement Discussion: User
@bigboimarkusinquired about a language model adept at improving or expanding stories. No specific recommendations were given in the discussion. - Model Choice for Coding in C++:
@amir0717sought advice for the best model to handle around 200 lines of C++ code with a GTX 1665 Ti and 16 GB of RAM and stated that the current model they're using, stablelm zephyr 1.5 GB, is generating incomplete code. - Innovative Ternary Computing:
@purplemelbourneand@aswarpengaged in a detailed discussion on the potential revolution in computing with the shift from binary to ternary systems, accompanied by scholarly references to research papers and implementation strategies. - Update Anticipation for LLM Studio:
@rexehlooked for alternative recommendations to Starcoder 2 for use with lm studio on rocm, particularly for Python, while@heyitsyorkiementioned that support for Starcoder 2 is expected in the next update of LM Studio. - Exploring Stock Price Prediction AI:
@christianazinndiscussed the idea of using a locally hosted LLM for stock price prediction, weighing in on the performance differences between large context length models versus shorter ones with auxiliary systems like MemGPT. Conversation also touched on the potential for local models to access the internet for updated real-time data.
Links mentioned:
- Render mathematical expressions in Markdown: Render mathematical expressions in Markdown
- Calculation Math GIF - Calculation Math Hangover - Discover & Share GIFs: Click to view the GIF
- Im Waiting Daffy Duck GIF - Im Waiting Daffy Duck Impatient - Discover & Share GIFs: Click to view the GIF
- How to safely render Markdown using react-markdown - LogRocket Blog: Learn how to safely render Markdown syntax to the appropriate HTML with this short react-markdown tutorial.
- GitHub - deepseek-ai/DeepSeek-VL: DeepSeek-VL: Towards Real-World Vision-Language Understanding: DeepSeek-VL: Towards Real-World Vision-Language Understanding - deepseek-ai/DeepSeek-VL
- Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models: no description found
- Ternary Hashing: This paper proposes a novel ternary hash encoding for learning to hash methods, which provides a principled more efficient coding scheme with performances better than those of the state-of-the-art bin...
LM Studio ▷ #🎛-hardware-discussion (63 messages🔥🔥):
- Config Tweaks for GPU Testing: User
@goldensun3dsdiscussed setting Tensor Split to "0, 100" in the config file to test specific GPUs without physically unplugging them, which could also help@nink1's issue regarding model card loading preferences.
- MacBook Pro M2 Max on the Horizon:
@saber123316has ordered a MacBook Pro M2 Max with 96 GB RAM and 4TB storage. They note a significant cost saving over the M3 Max variant and mention the possibility of returning it if it doesn't meet their needs.
- Motherboard and GPU Compatibility Exploration: Discussions led by
@nink1,@rugg0064, and@silk1821explore setting up a motherboard with multiple RTX 3090 GPUs using PCIe risers.@nink1shared success with a B550 board but suggests looking into higher-end boards with PCIe 4.0 capabilities for optimal performance.
- On AMD GPUs and Offloading:
@heyitsyorkiementioned AMD GPU offload is available through OpenCL, which explains why@nink1saw an RX580 with 8GB VRAM being detected but not utilized due to lack of ROCm support.
- The Cloud vs. Local Hardware for LLMS:
@silk1821and@nink1weigh the pros and cons of using cloud services versus local hardware for running large language models. Confidentiality concerns, costs, and reliability are discussed, with mention of possible grant offers from cloud providers like Google.
Links mentioned:
- no title found: no description found
- Amazon.com: MSI Meg X570 Unify Motherboard (AMD AM4, DDR4, PCIe 4.0, SATA 6GB/s, M.2, USB 3.2 Gen 2, Ax Wi-Fi 6, Bluetooth 5, ATX) : Electronics: no description found
LM Studio ▷ #🧪-beta-releases-chat (6 messages):
- Upgrade Recommendation by @fabguy:
@fabguysuggested upgrading to version .16 as it includes significant updates that might resolve existing issues. - Beta Version Seeker:
@jarod997was unable to find version .16 on LMStudio.ai, later clarifying they require the Beta version due to AVX compatibility on their machine. - Upcoming Chat Feature Spoiler: User
@yagilbannounced that a new chat "Continue" behavior will be included in the next version. - Anticipating New Features:
@wolfspyreresponded with a playful "tease" reacting to the announcement of the new chat feature. - Request for AVX Beta Update:
@mike_50363inquired about an update to the AVX beta version, currently at 0.2.10, hinting at a need for newer features or fixes.
LM Studio ▷ #autogen (1 messages):
- Autogen vs. CrewAI - A Feature Comparison:
@omgitsprovidencementioned that while they haven't used CrewAI, it seems Autogen has more features by looking at the repository. They highlighted that the output quality depends largely on workflow design, prompting, and context management.
LM Studio ▷ #memgpt (1 messages):
- A Peculiar Warning: User
@purplemelbourneissued a jarring message with an unclear context: "We reserve the right to shoot you dead if we feel like it. Enjoy your lunch." The tone seems somewhat facetious or metaphorical, given the juxtaposition with enjoying a meal.
LM Studio ▷ #amd-rocm-tech-preview (14 messages🔥):
- GPU Troubleshooting with MISTRAL: User
@omgitsprovidenceadvises setting layers to -1 and toggling the GPU enable/disable upon encountering performance issues which they believe could be due to the model size exceeding GPU memory. - MISTRAL 7b Success on Limited Hardware: User
@aryanemberedexperiences success running MISTRAL 7b on a system with 16GB DDR4 and an 8GB RX6600, after facing issues with a version of MISTRAL that required more than the available GPU memory. - KoboldAI as an Alternative: To avoid system RAM usage problems with LM Studio,
@aryanemberedindicates they are using KoboldAI, which they find simpler and more effective for their needs. - AMD Driver Update Boost Performance: User
@sadmonstaadiscovers performance improvements switching to AMD PRO drivers from Adrenalin, resulting in GPU utilization and doubling the speed compared to OpenCL. - Disabling iGPU May Solve Offloading Issues:
@minnonafound that disabling the integrated GPU (iGPU) fixed offloading problems with their Asrock system, while@heyitsyorkiehopes for future updates to simplify GPU switching for non-technical users.@luxdominatusr5suggests that disabling iGPU can also be done via Device Manager in Windows.
LM Studio ▷ #crew-ai (1 messages):
- CrewAI vs AutoGen:
@jg27_kornypraises CrewAI's logical setup but mentions AutoGen's advantage with its graphic user interface. The best performance is achieved using the GPT API, as the open-source models don't work as well. - Beware of Token Generation Loops:
@jg27_kornywarns about agents created by CrewAI or AutoGen entering closed loops which could lead to wasted computational token use. Users should monitor token generation to avoid unnecessary costs.
OpenAI ▷ #ai-discussions (248 messages🔥🔥):
- Venturing Into Extended Video Generation:
@anthiel4676is eagerly inquiring about when SORA will be capable of creating 30-minute footage. Both@askejmand@solbusdiscuss model limitations and capabilities, indicating that current technological constraints and memory limitations bind SORA but it could technically produce extended videos in sections (OpenAI research paper).
- Debating GPT-3.5 Subscriptions and Versions: There's confusion among users such as
@sangam_k,@celestialxian, and@satanhashtagabout differences in GPT-3.5 models between free and pro subscriptions, with clarifications citing higher usage limits as the primary difference. GPT-3.5's knowledge cut-off and subsequent updates are discussed, with a consensus that API and ChatGPT versions may differ in their current information limits.
- ChatGPT's Knowledge Accuracy in Question: Users
@webheadand@askejmdelve into the inconsistency of ChatGPT's self-reported knowledge cutoff, with discussions about training data and recent updates. Despite conflicting accounts, it's suggested that asking the model may not always yield accurate answers to its knowledge timeframe.
- Exploring Claude and Opus:
@askejmand@webheadshare their experiences with different AI models, including Claude Opus and GPT-4. Comparisons highlight how Claude Opus might offer more creative and concise output compared to GPT-4, which sometimes defaults to bullet points or less engaging responses.
- User Requests for Fine-Tuning Code and AI Project Advice:
@tfriendlykinddudeseeks a generic outline for fine-tuning LLMs with customer interaction data;@testtmshares a helpful notebook resource. Meanwhile,@beranger31outlines a university project to develop a solitaire instruction robot using GPT and OpenCV, prompting community members like@.miniclip.comand@joinityto offer detailed steps and encourage exploration of platform features.
Links mentioned:
- Prompt-based image generative AI tool for editing specific details: I am trying to make some spritesheets using DALLE3, and while the initial generation of spritesheets by DALLE3 are fascinating, I have encountered these problems: Inconsistent art style(multi...
- notebooks/mistral-finetune-own-data.ipynb at main · brevdev/notebooks: Contribute to brevdev/notebooks development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (29 messages🔥):
- Seeking Fine-Tuning Solutions:
@shashank4866inquired about the possibility of fine-tuning an AI model based on an instruction document to avoid passing the same instructions with each API call, hoping to reduce token wastage and output time.
- Browser Troubles With ChatGPT:
@mhrecaldebmentioned having issues with Chrome when using ChatGPT, whereas Firefox presented no problems, a sentiment echoed by@pandagexwho also experienced issues with Chrome but found Edge worked fine.
- Questions Over Creator Payments:
@ar888asked about when GPT creators will start getting paid, which@elektronisaderesponded to by mentioning a blog post stating a Q1 timeline and that it would be initially for the US only.
- Managing Notifications and Opting Out:
@realmunknownasked how to opt out of receiving notifications from specific channels like<#1046314025920761896>.
- Clarification on GPT-4 Image Generation Fees:
@komtinquired whether GPT-4 image generation incurs additional costs on top of a subscription, which@solbusreplied to with a link for more information.
- Query on OpenAI Account Credits:
@itzarshiaquestioned the continuation of the $5 credit for new OpenAI accounts, to which@rjkmelbsimply responded with a "no."
- LLM Context Limitations and PDF Queries:
@glass4108queried about LLMs' ability to handle large PDFs exceeding the 32k token internal context limit, and@solbusclarified that LLMs cannot internalize files larger than this limit but will search and summarize based on the query provided.
- Regional Pricing Concerns for OpenAI Services: Users like
@johanx1238and@julio_yt_brinitiated a discussion about the OpenAI subscription costs, which are considered high relative to the average income in countries like Georgia and Brazil, and expressed a desire for OpenAI to adjust their pricing to be more affordable in their respective countries.
- Is GPT Down?:
@dixon0001queried the status of GPT, wondering if it was down again.
OpenAI ▷ #prompt-engineering (55 messages🔥🔥):
- Consistency is King:
@darthgustav.advised@iloveh8on achieving consistent prompt outputs by using an output template with specific variable names that encapsulate the instructions. They provided an explicit template example handling different types of requests. - When HTML Snippets Confuse GPT:
@marijanarukavinaexperienced issues with GPT not processing an HTML snippet and@eskcantasuggested splitting the input into smaller parts or uploading the list as a file, which solved the problem. - Prompt Engineering and Arbitration Terms Awareness:
@eskcantaand@kunhai_04769discuss the development of a GPT analysis tool, emphasizing the importance of being aware of OpenAI's terms of use and user privacy concerns. - The Challenge of Text Rewriting:
@ericplayzsought help with rewriting extensive texts using GPT, but encountered issues with word count and compliance to instructions.@darthgustav.suggested using custom instructions with an output template and starting new conversations to counteract issues related to context length and retrieval rate. - Model Behavior Mysteries Solved with a Fresh Start:
@eskcantaexplained that starting new chats can often fix irregular AI behavior because it might draw from less useful training data in ongoing conversations.
Links mentioned:
- Terms of use: no description found
- Usage policies: no description found
OpenAI ▷ #api-discussions (55 messages🔥🔥):
- Consistency in Custom GPT Output:
@darthgustav.advises using an output template with open variables that succinctly encode the instructions within the variable names to ensure consistent output from custom GPT.
- Handling Complex Rewrites with GPT:
@eskcantaprovided assistance to@ericplayzfor rewriting a paragraph with an extended, professional vocabulary, explaining that uploaded files can work around the GPT input length limitation.@ericplayzfound success by following the guidance and expressed appreciation for the support.
- Discussions on Prompt Effectiveness:
@eskcantaresponds to@high_voltzregarding the effectiveness of prompt engineering, confirming that they find it to be an effective practice.
- Legal and Privacy Considerations for GPT Analysis Tools:
@eskcantacautions@kunhai_04769about building a GPT analysis tool (similargpts), highlighting the need to be mindful of OpenAI's terms of use and usage policies, especially regarding user privacy.
- Troubleshooting Text Length Issues:
@darthgustav.and@ericplayzdiscuss the difficulties in rewriting text with specific length and structure requirements and troubleshooting methods. Darthgustav. emphasizes the importance of starting new chats to avoid reduced compliance in GPT responses.
Links mentioned:
- Terms of use: no description found
- Usage policies: no description found
HuggingFace ▷ #announcements (1 messages):
- Search Assistants Seamlessly: Hugging Chat introduces a new feature allowing users to filter and search for Assistant names, as announced by
@lunarflu1. Find out more about the enhancement at Hugging Face Chat. - Blog Reading Made Easy:
@lunarflu1shared that the Hugging Face blog now includes a new "table of contents" and the ability to update blogs without breaking old URLs, ensuring seamless access to updated content. Check out the improvements here. - Space Analytics Upgrade: Hugging Face Spaces now offer all-time stats, letting creators track the popularity of their spaces, as unveiled by
@lunarflu1. Creators can dive into their Space's analytics here. - Faster In-Browser ML with WebGPU: A tweet from
@osansevierosuggests that WebGPU could make machine learning in-browser 40 times faster, promising a significant performance boost. Discover more about this technological leap on Twitter. - Enhanced Open Source Tools and Courses: The release of Transformers.js 2.16.0, Gradio 4.21, and Accelerate v0.28.0 brings new features to developers, and
@ThomasSimoniniannounces the launch of the Machine Learning for Games course, further expanding educational resources in the AI community. For more details on the open-source updates and learning opportunities, check the respective Twitter announcements linked in the original message.
Links mentioned:
- Tweet from lunarflu (@lunarflu1): You can now filter / search Assistant names on Hugging Chat! http://hf.co/chat
- Tweet from lunarflu (@lunarflu1): 🤗Blog updates on @huggingface : 1. ✨New "table of contents"! 2. 🛡️Update blogs without breaking the old URL with redirects mapping!
- Tweet from lunarflu (@lunarflu1): Spaces analytics for @huggingface now has all-time stats! What's your most popular space? 🚀
- Release 2.16.0 · xenova/transformers.js: What's new? 💬 StableLM text-generation models This version adds support for the StableLM family of text-generation models (up to 1.6B params), developed by Stability AI. Huge thanks to @D4ve-R fo...
- Tweet from Gradio (@Gradio): 🎈 For the weekend hackers, gradio==4.21 is out! ☸️ Kubernetes support! Gradio now works on your k8 pods & other proxies 🧨 Diffusers pipelines -> demos automatically 💾 Running out of disk space...
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Fast Mamba Inference is now in Transformers! 🐍 All you need is 5 lines of code and the latest transformers! Bonus: You can also fine-tune/ RLHF it with TRL & PEFT too 🤗 We support all the base ch...
- Reddit - Dive into anything: no description found
- Tweet from Philipp Schmid (@_philschmid): How can we evaluate LLMs during training? 🤔 Evaluating LLMs on common benchmarks like MMLU or Big Bench takes a lot of time and computing, which makes them unfeasible to run during training. 😒 A new...
- Tweet from ESA Earth Observation (@ESA_EO): .@esa's Φ-lab has released, in partnership with @huggingface, the 1st dataset of Major TOM (Terrestrial Observation Metaset), the largest, community-oriented, ML-ready collection of @CopernicusEU ...
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): MusicLang 🎶 - Llama 2 based Music generation model! > Llama2 based, trained from scratch. > Permissively licensed - open source. > Optimised to run on CPU. 🔥 > Highly controllable, cho...
- Tweet from Jeremy Howard (@jeremyphoward): Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming G...
HuggingFace ▷ #general (149 messages🔥🔥):
- Debate Over AI's Ability to Act: Users
@vishyouluckand@jeffry4754discussed the future of action-based AI, with@vishyouluckpositing the integration of LLMs with APIs and the automation of business processes as the next big leap in AI. - Questioning Practical AI Applications: In a philosophical musing,
@zorian_93363questioned the practicality of AI in everyday life, speculating about hardware hacks using PS5 consoles to create powerful VRAM modules. - Sharing a Supercomputer Concept:
@vipitisshared a link to an article about a supercomputer built from PS3 consoles, discussing how gaming consoles can be more powerful than standard consumer computing hardware. - Lamenting Driver Shortcomings:
@ahmad3794and@vipitisexchanged views on the feasibility and limitations of repurposing PS5 consoles for other computing tasks, considering the barriers such as the lack of equivalent to Nvidia's NVLink in AMD and Intel cards. - Potential Misalignment in Model Training: User
@gryhknsought assistance with an issue where the total number of examples processed during the fine-tuning of an LLM did not match the expected number, providing detailed training arguments to contextualize the problem.
Links mentioned:
- Logging in to HuggingFace from Jupyter notebook without interactive prompt: In a recent project, I came across a troubling setup problem. Being a student who wants to learn and contribute, but who is short of funds…
- Wikipedia, the free encyclopedia: no description found
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Hugging Face – The AI community building the future.: no description found
- US Must Move 'Decisively' To Avert 'Extinction-Level' Threat From AI, Gov't-Commissioned Report Says - Slashdot: The U.S. government must move "quickly and decisively" to avert substantial national security risks stemming from artificial intelligence (AI) which could, in the worst case, cause an "ext...
- Spaces Overview: no description found
- Why Fail GIF - Why Fail Poor - Discover & Share GIFs: Click to view the GIF
- When The Air Force Needed A Supercomputer, They Built It Out Of PS3 Consoles | War History Online: In late 2010, the U.S. Air Force built their own supercomputer that would drastically reduce the time needed for pattern recognition, image analysis, and
- Command-R: RAG at Production Scale: Command-R is a scalable generative model targeting RAG and Tool Use to enable production-scale AI for enterprise.
- Adding a Sign-In with HF button to your Space: no description found
- Sign in with Hugging Face: no description found
- INSANELY Fast AI Cold Call Agent- built w/ Groq: What exactly is Groq LPU? I will take you through a real example of building a real time AI cold call agent with the speed of Groq🔗 Links- Follow me on twit...
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
HuggingFace ▷ #today-im-learning (2 messages):
- Seeking Wisdom in New Territories: User
@refik0727asked other members to share their experiences, but no context was provided regarding the specific topic or field of interest. - Journey into Machine Learning:
@210924_aniketlrs02is seeking assistance on how to use a GitHub script to extract quantized states from the Wav2Vec2 model and asked the community for guidance.
Links mentioned:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
HuggingFace ▷ #cool-finds (11 messages🔥):
- Deep Reinforcement Learning Resource Shared:
@joshhu_94661recommended a YouTube tutorial on deep reinforcement learning by NTU. The lecture provides insights into the subject.
- Web-GL Dream Project Space:
@tonic_1shared a fascinating Web-GL demo called The Lucid Dream Project, hosted on Hugging Face's Spaces.
- Research on Personal Values Catches Interest:
@istem.linked to a journal article without description, which piqued@lunarflu's interest with a comment of intrigue.
- Microsoft Introduces AICI: User
@katopzposted a link to Microsoft's GitHub for AICI: Prompts as (Wasm) Programs, suggesting a novel approach to handling AI prompts.
- Next-Level AI in Physical Interactions:
@edge44_shared an ACM SIGGRAPH 2023 paper and a YouTube video, both showcasing advancements in synthesizing physical character-scene interactions using machine learning.
- Introducing Devin, the AI Software Engineer:
@valentindmfound @cognition_labs's introduction of Devin, an AI that successfully passed real engineering interviews and handles engineering tasks, to be quite impressive.
- Conversation with Video Characters Enhanced by AI:
@osansevierohighlighted a project by<@504681610373758977>and<@704859925981036644>, where users can converse with video characters using AI: Vid2Persona, a project leveraging both commercial and open-source models.
Links mentioned:
- The Lucid Dream Project - a Hugging Face Space by ilumine-AI: no description found
- [@chansung on Hugging Face: "🎥 🤾 Vid2Persona: talk to person from video clip
A fun project over the last…"](https://huggingface.co/posts/chansung/716968829982789): no description found - Build Diffusion models with PyTorch Lightning & HF diffusers - a Lightning Studio by dasayan05: This lightning studio contains diffusion model training and inference code that is easy to use, compatible with HF ecosystem and free of boilerplate. - Tweet from The Simulation (@fablesimulation): Announcing our paper on Generative TV & Showrunner Agents! Create episodes of TV shows with a prompt - SHOW-1 will write, animate, direct, voice, edit for you. We used South Park FOR RESEARCH ONLY -... - Synthesizing Physical Character-Scene Interactions: no description found - Synthesizing Physical Character-Scene Interactions: Supplementary video for the paper: Synthesizing Physical Character-Scene Interactions - ML Lecture 23-1: Deep Reinforcement Learning: no description found - Tweet from Cognition (@cognition_labs): Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering intervie... - GitHub - microsoft/aici: AICI: Prompts as (Wasm) Programs: AICI: Prompts as (Wasm) Programs. Contribute to microsoft/aici development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (19 messages🔥):
- Mambarim-110M: A new Portuguese LLM:
@dominguesmintroduced Mambarim-110M, a Portuguese language LLM based on the Mamba architecture with over 119 million parameters, pre-trained on a 6.2 billion token dataset. Model details and code can be found on Hugging Face and GitHub.
- Blobby Button Biodiversity Dashboard:
@istem.shared their Belly Button Biodiversity Dashboard, a Javascript project for exploring microbial data, with an invitation to check out the interactive visualization at belly-button-challenge.io.
- BERT Extended for Long Text:
@pszemrajfine-tuned a 4k context small BERT for long text similarity named bert-plus-L8-v1.0-syntheticSTS-4k, emphasizing its effectiveness due to actual long context training, with resources available on Hugging Face.
- Open Source Learning Tool for Gradio:
@cswamyis working on a tool designed to assist new developers to learn from closed issues and PRs by providing AI-generated explanations, calling for beta testers and stating their aim to encourage contributions.
- Hugging Face Models Deployed to Vertex AI:
@alvarobarttannounced the creation of thevertex-ai-huggingface-inference-toolkitPython package for deploying models from Hugging Face Hub in Vertex AI with simplicity, currently under active development. The toolkit is available on GitHub.
- ComfyUI Integrates LLMs & LlamaIndex:
@alx.aireleased an update that brings LLM integration with ComfyUI, along with LlamaIndex, and tagged a Twitter post for further details: See the announcement on Twitter.
Links mentioned:
- Portfolio – javascript: no description found
- BEE-spoke-data/bert-plus-L8-v1.0-syntheticSTS-4k · Hugging Face: no description found
- dominguesm/mambarim-110m · Hugging Face: no description found
- GitHub - alvarobartt/vertex-ai-huggingface-inference-toolkit: 🤗 HuggingFace Inference Toolkit for Google Cloud Vertex AI (similar to SageMaker's Inference Toolkit, but for Vertex AI and unofficial): 🤗 HuggingFace Inference Toolkit for Google Cloud Vertex AI (similar to SageMaker's Inference Toolkit, but for Vertex AI and unofficial) - alvarobartt/vertex-ai-huggingface-inference-toolkit
- CohereForAI/aya_dataset · Datasets at Hugging Face: no description found
- Aya - a Hugging Face Space by Tonic: no description found
HuggingFace ▷ #reading-group (9 messages🔥):
- Inquiry About Citing Web Docs in Research:
@noir_bdqueried whether it is appropriate for research or survey papers to cite information from website documentation or articles. No definitive answer was provided in the chat, but they were directed to other communities for further discussion. - Seeking Guidance with ML Script:
@210924_aniketlrs02requested assistance on how to use a specific Python script from a GitHub repository designed to extract quantized states from the Wav2Vec2 model. The message contained a link to the script but no guidance was provided in the response. - Link Shared Without Context:
@ibrahim_72765_43784shared a link to a Kaggle discussion, but no context was provided in the message as to why this link was shared or its relevance. - Presentation Proposal for Diffusion Models:
@chad_in_the_houseproposed presenting on text-to-image customization techniques, specifically mentioning the desire to discuss and test methods from a HuggingFace paper before confirming a presentation date. The HuggingFace paper link was provided for context. - Support and Excitement for Upcoming Presentation:
@lunarfluexpressed enthusiasm and support for@chad_in_the_house's potential presentation about customizing diffusion models using techniques from the aforementioned HuggingFace paper.
Links mentioned:
- [Deleted Topic] | Kaggle: [Deleted Topic].
- Paper page - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization: no description found
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
HuggingFace ▷ #diffusion-discussions (2 messages):
- Assistance Request for wav2vec2 codebook script:
@210924_aniketlrs02is seeking guidance on how to use a wav2vec2 codebook extraction script to extract quantized states of the Wav2Vec2 model. They are new to machine learning and need help with the application of the script. - Inquiry About Unet with Structured Data: User
@nana_94125is asking if anyone has attempted to use Unet, a neural network architecture typically used for image segmentation, with structured data. No further details or context were provided.
Links mentioned:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
HuggingFace ▷ #computer-vision (23 messages🔥):
- In Search of NSFW Image Captioning: User
ninamaniinquired about the best open-source model that can handle uncensoredImage to Textor image captioning, specifically adept at describing NSFW content. - Unity and Inpainting with HuggingFace's API:
@okan1962asked whether HuggingFace's inference API supports inpainting and image variations within Unity; however, responses suggest these features may not be accessible through the API. - Decoding Diffusion-Generated Images:
@akshit1993elaborated on a method using the DDIM scheduler to detect diffusion-generated images and is seeking advice on whether to use CLIPImageProcessor or CLIPVisionModel for best results. They also shared a link to the relevant code, although the URL was not provided. - Recommendations for Continuous Learning:
@itsnotmadyqueried the community about training models incrementally with new images, looking for strategies to prevent forgetting features of previous images, with@akshit1993suggesting using CLIPVisionModel for creating and saving image embeddings. - Whisper ASR for Long Audio Files:
@swetha98received suggestions from@huzunito use OpenAI's Whisper ASR model, as mentioned by Andrej Karpathy, to transcribe large audio files. It was suggested that the model should handle large lengths well although performance might depend on hardware.
HuggingFace ▷ #NLP (17 messages🔥):
- Seeking Clarity on Emotional Discourse Analysis: User
@smartguy_41719inquired about methodologies to evaluate clarity and emotions within discourse using Large Language Models (LLM), questioning the feasibility of the task. - Quest for the Ultimate NSFW Translation Model:
@ninamanilooked for an optimized and accurate model specifically for NSFW uncensored translation, pointing out issues with both old translation models and large LLMs. - Outliers Beware:
@pizzadronessought strategies from the community for identifying out-of-distribution phrases or words in short documents, with@vipitissuggesting a basic approach using tf-idf. - Wav2Vec2 Script Guidance: User
@210924_aniketlrs02requested assistance with using a script for extracting quantized states from the Wav2Vec2 model, sharing a relevant GitHub link. - Evaluating LLMs with LightEval:
@alexmathsought a benchmarking tool for LORA-esque LLM techniques and was directed by@.dvs13to investigate LightEval, Hugging Face's lightweight LLM evaluation suite.
Links mentioned:
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
- GitHub - huggingface/lighteval: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. - hug...
HuggingFace ▷ #diffusion-discussions (2 messages):
- Seeking Guidance on Wav2Vec2 Script:
@210924_aniketlrs02is asking for assistance on how to utilize a Python script for extracting quantized states from the Wav2Vec2 model provided in a GitHub repository. They are new to ML and need guidance on the steps involved. - Exploring U-Net for Structured Data:
@nana_94125inquired if anyone has attempted to apply U-Net, a convolutional network typically used for image segmentation, to structured data. This could indicate an exploration beyond the conventional applications of U-Net.
Links mentioned:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: Contribute to fauxneticien/wav2vec2-codebook-indices development by creating an account on GitHub.
Eleuther ▷ #general (105 messages🔥🔥):
- No GPU, No Problem: User
_michaelshwas seeking advice on how to gain experience with Large Language Models (LLMs) without a GPU, and@staticpunchrecommended working with small models on Colab's T4 GPU, which could handle models like Gemma, Pythia, or TinyLlama.
- Learning LLMs as a Newbie: In a response to
_michaelsh's inquiry regarding learning materials for LLMs,@rallio.suggested utilizing YouTube and powerful LLMs such as GPT-4 or Claude3 for efficient learning, flagging the cost at $20 a month for access to these LLMs.
- Curated Learning Path for Transformers: When
_michaelshrevealed a strong foundation in NLP and familiarity with Transformers architecture but sought current knowledge,@tulkascodesshared several recommended resources, including an updated overview on Transformers by Lilian Weng and a GitHub collection by HazyResearch on foundation models.
- Qualifications vs. Knowledge in AI: As
_michaelshexpressed confusion about where to focus learning efforts with so many resources available, various users like@ad8e,@catboy_slim_, and@wonkothesensibleoffered personalized guidance, emphasizing the importance of selecting interesting topics, reading arXiv papers, and using concrete materials like textbooks, including the mentioned UDL Book.
- Innovations and Discussions on LLMs: Beyond personal learning strategies, the channel discussed recent advancements in LLMs, including the release of Cohere 35b model weights with built-in RAG capabilities (
@rallio.) and a YouTube video on The Orthogonality Thesis & AI Optimism (.the_alt_man). There was also reference to a government-commissioned report on the risks of advanced AI posted by@conceptron.
Links mentioned:
- US Must Move 'Decisively' To Avert 'Extinction-Level' Threat From AI, Gov't-Commissioned Report Says - Slashdot: The U.S. government must move "quickly and decisively" to avert substantial national security risks stemming from artificial intelligence (AI) which could, in the worst case, cause an "ext...
- The Transformer Family Version 2.0: Many new Transformer architecture improvements have been proposed since my last post on “The Transformer Family” about three years ago. Here I did a big refactoring and enrichment of that ...
- Let's build GPT: from scratch, in code, spelled out.: We build a Generatively Pretrained Transformer (GPT), following the paper "Attention is All You Need" and OpenAI's GPT-2 / GPT-3. We talk about connections t...
- The orthogonality thesis & AI optimism: Timestamps:0:00 - Start of video7:39 - Outline of Bostrom’s argument9:25 - Decisive strategic advantage13:26 - Arguments for slow takeoff23:13 - Definition o...
- lucidrains - Repositories: Working with Attention. It's all we need. lucidrains has 282 repositories available. Follow their code on GitHub.
- GitHub - HazyResearch/aisys-building-blocks: Building blocks for foundation models.: Building blocks for foundation models. Contribute to HazyResearch/aisys-building-blocks development by creating an account on GitHub.
Eleuther ▷ #research (68 messages🔥🔥):
- Gemini 1.5 Report Updates Analyzed: Users discussed Gemini 1.5 report updates, noting the addition of 9 pages to list contributors, minor paragraph changes, and extended example outputs in the appendix. No specific discussions around the impact of these changes were highlighted besides the contributor list seeming excessive to some.
- Model-Stealing Attack Exposes LLM Dimensions: Details of a new model-stealing attack were shared from a tweet by @_akhaliq, which mentions the ability to extract entire projection matrices from models like OpenAI's ChatGPT, revealing hidden dimensions of various models including gpt-3.5-turbo. Discussions ensued about the ethics of disclosing such vulnerabilities and whether it constitutes IP theft.
- Discussion on Memorable Training: Users conversed about a new paper on how RLHF (Reinforcement Learning from Human Feedback) affects language model training, exploring whether RLHF'd behaviors can be transferred between languages and aligned to different cultural norms. Gson_arlo expressed interest in collaborating on related research about human preference biases reflected in text generation.
- Theoretical Model Weights Generation: The concept of using a hypernetwork to generate weights for either larger or smaller neural networks was deliberated. Users discussed a paper's suggestion that larger models could generate weights for smaller models, with a consensus forming around the idea being explored for smaller components rather than entire models due to complexity.
- Inference Output Irregularities in LLMs: User xnerhu inquired about their Language Model outputting the same token with similar logprobs regardless of the prompt. Several suggestions were provided including training or fine-tuning the model, using a different model, and detailed discussions regarding optimizers and batch size calculations ensued.
Links mentioned:
- Yi: Open Foundation Models by 01.AI: We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language mode...
- Tweet from AK (@_akhaliq): Google announces Stealing Part of a Production Language Model We introduce the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like...
- Stacking as Accelerated Gradient Descent: Stacking, a heuristic technique for training deep residual networks by progressively increasing the number of layers and initializing new layers by copying parameters from older layers, has proven qui...
- Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization: Large language models (LLMs) have revolutionized the role of AI, yet also pose potential risks of propagating unethical content. Alignment technologies have been introduced to steer LLMs towards human...
- Tweet from Jan Leike (@janleike): Today we're releasing a tool we've been using internally to analyze transformer internals - the Transformer Debugger! It combines both automated interpretability and sparse autoencoders, and ...
- Emergent and Predictable Memorization in Large Language Models: Memorization, or the tendency of large language models (LLMs) to output entire sequences from their training data verbatim, is a key concern for safely deploying language models. In particular, it is ...
Eleuther ▷ #interpretability-general (3 messages):
- Clarification on Transformer Debugger Support:
@stellaathenainquires if the transformer-debugger tool only supports models from their custom library, questioning its compatibility with trained Hugging Face checkpoints.
- Unlearning through Pruning in Pythia:
@millanderdiscusses a paper on interpretability-driven capability unlearning using Pythia, which tries to eliminate capabilities by pruning important neurons. Despite language model performance dropping faster on forget sets than retain sets, significant drops in retain set performance impact overall utility, whereas image classification fared better. The paper can be found here.
Links mentioned:
- GitHub - openai/transformer-debugger: Contribute to openai/transformer-debugger development by creating an account on GitHub.
- [PDF] Dissecting Language Models: Machine Unlearning via Selective Pruning | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
Eleuther ▷ #lm-thunderdome (2 messages):
- Llama Hyperparameters and Learning Rate Queries:
@johnnysandsis experiencing unexpected poor downstream evaluation performance despite good loss stats with a model trained using Llama hyperparameters and a higher learning rate (still at 1e-4). They question whether the learning rate not having annealed sufficiently could be the reason, suggesting that performance might improve as the learning rate drops, based on past observations with MMLU evaluations.
- Benchmarks from a Bygone Era:
@epicxinquires why certain benchmarks, like the ones from SQuAD v1.1 ExactMatch (EM) and F1 scores, which carry historical significance, have fallen out of favor. They have posted a leaderboard displaying model scores including the human benchmark, and models like{ANNA},LUKE, andXLNet, and referenced the Natural Questions leaderboard as having no data (<<null>>).
Links mentioned:
- The Stanford Question Answering Dataset: no description found
- Google's Natural Questions: no description found
Eleuther ▷ #multimodal-general (2 messages):
- Clarification on Transformer and Diffusion:
@yoavhacohenclarified that Transformer is an architecture, while diffusion refers to a training and inference method, mentioning that diffusion with transformers was applied in earlier models such as DALL-E 2, DiT, and PixArt. - Understanding Achieved:
@kerlsexpressed understanding and gratitude for the clarification provided by@yoavhacohenregarding the relationship between transformers and diffusion models.
Eleuther ▷ #gpt-neox-dev (1 messages):
- Checkpoint Conversion Confusion:
@aphohis struggling with converting pythia/neox checkpoints to upstream megatron-lm. Despite matching weights and successful loading, they are encountering unexpectedly high losses (>25), and questioning the layout of the qkv projection matrices.
LlamaIndex ▷ #announcements (1 messages):
- MemGPT Webinar on the Horizon:
@jerryjliu0announces a webinar on long-term, self-editing memory with MemGPT, featuring speakers Charles, Sarah et al. It's scheduled for this Friday at 9 am PT, exploring the challenges of long-term memory for LLMs and virtual context management. Sign up for the event. - Understanding MemGPT: The upcoming MemGPT presentation will delve into how the system manages memory both in the immediate context and external storage, suggesting it as a significant advancement in machine learning memory management. The session will include a detailed presentation on the paper by Packer et al.
Links mentioned:
LlamaIndex Webinar: Long-Term, Self-Editing Memory with MemGPT · Zoom · Luma: Long-term memory for LLMs is an unsolved problem, and doing naive retrieval from a vector database doesn’t work. The recent iteration of MemGPT (Packer et al.) takes a big step in this...
LlamaIndex ▷ #blog (5 messages):
- Cooking up Context-augmented Apps:
@ravithejadsreleased a series featuring six notebooks and four videos, teaching how to build apps with Claude 3 using LlamaIndex, covering simple-to-advanced Retrieval-Augmented Generation (RAG) to automated agents. Catch the full series on Twitter.
- RAG Meetup in Paris Announced: Join
@hexapodeand other experts at a RAG meetup in Paris on March 27th for talks on advanced RAG strategies, a RAG Command-Line Interface (CLI), and more with LlamaIndex and Mistral models. Details of the meetup can be found on Twitter.
- Home Searching Simplified with Home AI: The create-llama command-line tool powers Home AI, an interface that uses Language Models (LLMs) to make reading property disclosure documents easier, enhancing the filters available for home searches. Learn about this tool on Twitter.
- New Webinar on Enhancing LLM Memory:
@MemGPTwill discuss advancements in implementing long-term memory for LLMs, a significant step forward from simple vector database retrievals, in a new webinar. Find out more about the upcoming webinar on Twitter.
- Ollama and Friends' Developer Meetup in Paris:
@hexapodewill be present at the Ollama developer meetup on March 21st, with talks and demos from key figures in AI and open-source communities, including maintainers of Ollama, Docker, and LlamaIndex, held at Station F in Paris. Full event details and the lineup are available on Twitter.
Links mentioned:
Local & open-source AI developer meetup (Paris) · Luma: Ollama and Friends are in Paris! Ollama and Friends will be hosting a local & open-source AI developer meetup on Thursday, March 21st at 6pm at Station F in Paris. Come gather with developers...
LlamaIndex ▷ #general (162 messages🔥🔥):
- LlamaIndex with RAG Deployment Queries:
@o3omoominasked about implementing a RAG-using chatbot with LlamaIndex, and@whitefang_jrdirected them to a "full-stack application using LlamaIndex" on GitHub that combines frontend and backend. - Query Parameters in MistralAI:
@maax4322inquired about setting global parameters liketop_k,top_p, andmax_tokensfor MistralAI, and@whitefang_jrexplained thatmax_tokenscan be defined during initialization, while others can be passed as a dict, referring to the GitHub source code. - Issues Using LLM with VectorStoreIndex:
@kamyarmhdstruggled with errors when using RetrieverQueryEngine with Llama2 and@whitefang_jradvised to set their LLM in the settings prior to using it for resolution. - Error Handling with Recent LlamaIndex Upgrade:
@cheesyfishesassisted@rachel_001.withImportErrorrelated toDEFAULT_PERSIST_FNAME, suggesting the creation of a fresh virtual environment after updating LlamaIndex to v0.10. - Creating Multi-Modal Applications with LlamaIndex:
@whitefang_jrshared a LlamaIndex guide for multi-modal applications that combine language and images, as@verdvermsearched for information on handling different types of multi-modal data.
Links mentioned:
- Node Postprocessor Modules - LlamaIndex 🦙 v0.10.18.post1: no description found
- Tweet from TheHeroShep (@TheHeroShep): LLM Node Pack 1 for ComfyUI Excited to share @getsalt_ai's powerful set of nodes to make working with LLM's and @llama_index in comfyUI easier thanks to @WAS_STUFF ✨ Prompt Enhancement Nod...
- Node Postprocessor - LlamaIndex 🦙 v0.10.18.post1: no description found
- CitationQueryEngine - LlamaIndex 🦙 v0.10.18.post1: no description found
- Documents / Nodes - LlamaIndex 🦙 v0.10.18.post1: no description found
- OrdalieTech/Solon-embeddings-large-0.1 · Hugging Face: no description found
- Nujoom AI: no description found
- 🚀 RAG/LLM Evaluators - DeepEval - LlamaIndex 🦙 v0.10.18.post1: no description found
- OpenAI Agent with Query Engine Tools - LlamaIndex 🦙 v0.10.18.post1: no description found
- Multi-modal - LlamaIndex 🦙 v0.10.18.post1: no description found
- Llama Hub: no description found
- INSANELY Fast AI Cold Call Agent- built w/ Groq: What exactly is Groq LPU? I will take you through a real example of building a real time AI cold call agent with the speed of Groq🔗 Links- Follow me on twit...
- llama_index/llama-index-core/llama_index/core/indices/base.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/llama-index-integrations/llms/llama-index-llms-mistralai/llama_index/llms/mistralai/base.py at d63fec1c69a2e1e51bf884a805b9fd31ad8d1ee9 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- GitHub - run-llama/sec-insights: A real world full-stack application using LlamaIndex: A real world full-stack application using LlamaIndex - run-llama/sec-insights
- Vector Stores - LlamaIndex 🦙 v0.10.18.post1: no description found
- Ensemble Query Engine Guide - LlamaIndex 🦙 v0.10.18.post1: no description found
- Router Query Engine - LlamaIndex 🦙 v0.10.18.post1: no description found
- ReAct Agent with Query Engine (RAG) Tools - LlamaIndex 🦙 v0.10.18.post1: no description found
- Semi-structured Image Retrieval - LlamaIndex 🦙 v0.10.18.post1: no description found
- Chroma Multi-Modal Demo with LlamaIndex - LlamaIndex 🦙 v0.10.18.post1: no description found
- llama_index/docs/examples/query_engine/SQLAutoVectorQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/docs/examples/query_engine/SQLJoinQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs: no description found
LlamaIndex ▷ #ai-discussion (3 messages):
- Explore Matryoshka Representation Learning:
@lien_61024shared an invitation to a paper discussion on Matryoshka Representation Learning featuring Aditya Kusupati and Aniket Rege, hosted by Jina AI. The discussion is designed to provide insights into the paper and requires registration for participation.
- Seeking OS GUI/frontend for Claude 3:
@vodrosis looking for recommendations on an open-source GUI/frontend that is compatible with Claude 3, mentioning a desire to upgrade from using Chatbox.
- LLM Research Paper Database Coming Up:
@shure9200announced the creation of a database for LLM (Large Language Models) papers, aimed at keeping researchers updated with the latest high-quality papers in the field. The database aims to be comprehensive and well-organized.
Links mentioned:
- Awesome LLM Papers Toward AGI: World's Most Comprehensive Curated List of LLM Papers & Repositories
- Matryoshka Representation Learning: Paper discussion · Zoom · Luma: Join us for an insightful hour as we delve into the fascinating world of Matryoshka Representation Learning. Presented by the knowledgeable Aditya Kusupati and the astute Aniket Rege, and...
LAION ▷ #general (65 messages🔥🔥):
- A Quest for AI Video Models:
@lunseiinquired about good AI video models besides those from OpenAI, to which@nodjareplied that there are none available publicly as far as they know.@nodjaalso speculated about the possibility of someone utilizing SD3 to create a video model. - Musk's Tweet Linked:
@spirit_from_germanyshared a tweet from Elon Musk, while@freonand@pseudoterminalxcommented on potential AI regulations with a humorous take on how such rules could favor China or impede free speech. The conversation included skepticism regarding the effectiveness of such policies. - Gladstone AI's Mission Brief:
@itali4noposted a link to Gladstone AI, alongside a commentary on their outlook concerning GPT-3 and how it sparked a scaling race in AI. The discussion then shifted to speculate on the funding and political affiliations of those behind such reports. - Super PAC Intrigue: Delving into financial trails,
@progamergovshared information on a related super PAC and the anonymity of funders. Contributions showered skepticism on the political feasibility and motivations behind an expert report suggesting AI limitations. - AI Safety Worker Concerns:
@thejonasbrothersquoted troubling sentiments about AI safety workers being wary of company decision-making. The conversation continued with remarks on the unlikelihood of training limitations for advanced AI systems and critique of the report's authors.
Links mentioned:
- Seriously Really GIF - Seriously Really Omg - Discover & Share GIFs: Click to view the GIF
- Devin: World's First AGI Agent (yes, this is real): If you're serious about AI, and want to learn about AI Agents, join my community: https://www.skool.com/new-societyFollow me for super-fast AI news - https:/...
- Gladstone AI: Gladstone helps governments craft effective policy responses in the new era of advanced AI.
- AMERICANS FOR AI SAFETY - committee overview - FEC.gov: Explore current and historic federal campaign finance data on the new fec.gov. Look at totals and trends, and see how candidates and committees raise and spend money. When you find what you need, expo...
- Political action committee - Wikipedia: no description found
LAION ▷ #research (75 messages🔥🔥):
- Revolutionizing Text-to-Image Models with ELLA:
@chad_in_the_houseshared the abstract of a paper, introducing ELLA (Efficient Large Language Model Adapter), which significantly improves text alignment for text-to-image diffusion models without additional training. The discussion further evolved into comparing ELLA and other models like SD3 over at Tencent's new creation.
- Quantization for the People:
@vrus0188brought attention to a recent breakthrough with llama.cpp that enables running Large Language Models (LLMs) on regular hardware by using a new "2-bit quantization" technique. For details and insights, one can check out the Medium post by Andreas Kunar and explore the relevant GitHub update.
- Unleashing SD3's Potential:
@thejonasbrothersspeculated on the potential of SD3, discussing its advantages due to the absence of cross-attention and its method to incorporate image and text embeddings. The conversation addressed issues of model size, with a focus on the feasibility of running high-quality models on standard GPUs, quantization techniques, and performance expectations.
- The Trade-off Between Time and Memory: Continuous messages from
@thejonasbrothersdescribed quantization and CPU-offloading strategies for SD3 to work with different VRAM capacities. The discussion covered potential execution times, performance trade-offs, and anticipated community-driven optimizations akin to those achieved with Llama.
- Uncloaking Black-Box Models for Under $20:
@twoaboveshared an arXiv paper surprising the community with an attack that can recover the embedding projection layer of transformer models, specifically targeting OpenAI's models, for a minimal cost. The revelation sparked discussions about the simplicity and affordability of the methodology as well as its implications, leading to OpenAI and Google introducing API modifications to mitigate such attacks.
Links mentioned:
- ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment: no description found
- Breaking News: Run Large LLMs Locally with Less RAM and Higher Speed through llama.cpp with QuIP#: A recent update to llama.cpp enables a new “crazy-sounding, but useable” 2-bit quantization for LLMs — QuIP: Quantization with Incoherence…
- GitHub - openai/transformer-debugger: Contribute to openai/transformer-debugger development by creating an account on GitHub.
- GitHub - leejet/stable-diffusion.cpp: Stable Diffusion in pure C/C++: Stable Diffusion in pure C/C++. Contribute to leejet/stable-diffusion.cpp development by creating an account on GitHub.
LAION ▷ #learning-ml (1 messages):
- Exploration of LAION-400M Dataset:
@coreys7870expressed admiration for a piece by Thomas Chaton regarding the use and creation of the LAION-400-MILLION images & captions dataset, providing a shortened link to the article: bit.ly/3uYrDCh.
Links mentioned:
Download & stream 400M images + text - a Lightning Studio by thomasgridai: Use, explore, & create from scratch the LAION-400-MILLION images & captions dataset.
Latent Space ▷ #ai-general-chat (117 messages🔥🔥):
- Excitement for New AI "Devin":
@guardiangshared info about Cognition Labs' new AI software engineer "Devin," which demonstrates significant progress on the SWE-Bench coding benchmark. The community discussedDevin'shigh-profile backers and impressive capabilities, highlighting its potential to change the landscape of software engineering.
- Debate Over Elon Musk's "Open" AI: The channel had a vigorous discussion involving
@tzmartin,@vodros,@guardiang, and others about Elon Musk's announcement to potentially open-source Twitter's algorithm "Grok." Users discussed the implications for open-source principles and Musk's reputation.
- AI Weight Extraction Research Published:
@swyxiolinked a DeepMind paper on extracting weights from AI models;@erleichda.and@stealthgnomeclarified that the methodology involved inferring structure and extracting weights for part of a model's embedding layer, although patches have been applied.
- Karpathy Reaches New Milestone:
@mhmazurexcitedly shared news of Andrej Karpathy reaching a new milestone, with community congratulations and discussions on the implications for AI and content creators.
- Emergence of Efficient AI Inference Engine:
@fanahovaannounced the launch of Truffle-1, an affordable inference engine designed to run open-source models efficiently, catching the attention of the community for its low power usage and potential impact.
Links mentioned:
- no title found: no description found
- Tweet from Andrew Kean Gao (@itsandrewgao): i never believe recorded demos so I reached out to the @cognition_labs team for early access to try for myself and got it! will be sharing my unfiltered opinions on #devin here. 🧵🧵 1/n ↘️ Quotin...
- Tweet from Cognition (@cognition_labs): Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering intervie...
- Tweet from Akshat Bubna (@akshat_b): The first time I tried Devin, it: - navigated to the @modal_labs docs page I gave it - learned how to install - handed control to me to authenticate - spun up a ComfyUI deployment - interacted with i...
- Tweet from asura (@stimfilled): @qtnx_ 3) dateLastCrawled: 2023-09
- Diffusion models from scratch: This tutorial aims to give a gentle introduction to diffusion models, with a running example to illustrate how to build, train and sample from a simple diffusion model from scratch.
- Tweet from Varun Shenoy (@varunshenoy_): Devin is 𝘪𝘯𝘤𝘳𝘦𝘥𝘪𝘣𝘭𝘦 at data extraction. Over the past few weeks, I've been scraping data from different blogs and Devin 1. writes the scraper to navigate the website 2. executes the cod...
- Tweet from simp 4 satoshi (@iamgingertrash): Finally, excited to launch Truffle-1 — a $1299 inference engine designed to run OSS models using just 60 watts https://preorder.itsalltruffles.com
- Tweet from Ashlee Vance (@ashleevance): Scoop: a start-up called Cognition AI has released what appears to be the most capable coding assisstant yet. Instead of just autocompleting tasks, it can write entire programs on its own. Is backed...
- Tweet from Aravind Srinivas (@AravSrinivas): This is the first demo of any agent, leave alone coding, that seems to cross the threshold of what is human level and works reliably. It also tells us what is possible by combining LLMs and tree searc...
- Tweet from Neal Wu (@WuNeal): Today I can finally share Devin, the first AI software engineer, built by our team at @cognition_labs. Devin is capable of building apps end to end, finding bugs in production codebases, and even fine...
- Tweet from Andrej Karpathy (@karpathy): # automating software engineering In my mind, automating software engineering will look similar to automating driving. E.g. in self-driving the progression of increasing autonomy and higher abstracti...
- Fine tuning Optimizations - DoRA, NEFT, LoRA+, Unsloth: ➡️ ADVANCED-fine-tuning Repo: https://trelis.com/advanced-fine-tuning-scripts/➡️ ADVANCED-inference Repo: https://trelis.com/enterprise-server-api-and-infere...
- Tweet from cohere (@cohere): Today, we’re excited to release Command-R, a new RAG-optimized LLM aimed at large-scale production workloads. Command-R fits into the emerging “scalable” category of models that balance high efficien...
- Tweet from Fred Ehrsam (@FEhrsam): First time I have seen an AI take a complex task, break it down into steps, complete it, and show a human every step along the way - to a point where it can fully take a task off a human's plate. ...
- Tweet from muhtasham (@Muhtasham9): DeepMind folks can now steal weights behind APIs “We also recover the exact hidden dimension size of the gpt-3.5-turbo model, and estimate it would cost under $2,000 in queries to recover the entire...
- Tweet from Patrick Collison (@patrickc): These aren't just cherrypicked demos. Devin is, in my experience, very impressive in practice. ↘️ Quoting Cognition (@cognition_labs) Today we're excited to introduce Devin, the first AI so...
- Thermodynamic Computing: Better than Quantum? | Guillaume Verdon and Trevor McCourt, Extropic: Episode 3: Extropic is building a new kind of computer – not classical bits, nor quantum qubits, but a secret, more complex third thing. They call it a Therm...
Interconnects (Nathan Lambert) ▷ #news (59 messages🔥🔥):
- Musk Teases Grok Being Open Sourced:
@xeophon.shared a tweet by@elonmuskhinting at xAI open sourcing Grok, while@natolambertexpressed skepticism about the correct use of "open source." - Cohere Introduces Command-R:
@xeophon.brought attention to Command-R, a new scalable generative model for large-scale production, with its weights being released for academic use. - Expectations Set for Llama 3: Amidst discussions on model openness,
@xeophon.alluded to high expectations for the yet-to-be-released Llama 3 model, and@natolambertconcurred on the multiplicity of models over a single breakthrough. - GPT-4.5 Bing Bing, You’ve Got Updates:
@philpaxpointed out that a blog post for GPT-4.5 appeared in Bing search results, with@natolambertremarking on the significance of its emergence. - Debates on Model Releases and Legalities:
@natolambertpondered over when new models like Llama 3 would become available due to legal complexity, while@dangf91and@xeophon.engaged in conversations regarding the language capability of Cohere's Command-R model for EU applications.
Links mentioned:
- Command-R: RAG at Production Scale: Command-R is a scalable generative model targeting RAG and Tool Use to enable production-scale AI for enterprise.
- Tweet from Xeophon (@TheXeophon): GPT 5 tonite GPT 5 tonite queen
- Tweet from Elon Musk (@elonmusk): This week, @xAI will open source Grok
Interconnects (Nathan Lambert) ▷ #ml-questions (34 messages🔥):
- The Cost of Pretraining GPT Models:
@xeophon.indicated that pretraining a model like GPT-2 could cost less than $1,000 based on September 22's costs on Mosaic Cloud. Further discussion referenced that the costs for models like GPT-1.3B had been halved since then, and a Databricks blog post titled "GPT-3 Quality for $500k" was also linked (Databricks Blog). - Pretraining Expenses for Hobbyists: During the chat,
@philpaxmused about the possibility of well-off enthusiasts training similar models given that the cost might be reasonable.@natolambertpointed out that it would still be a substantial amount for hobbyists who can't obtain discounts. - Stability Pays Less for Compute?: Discussing the cost of training models for companies like Stability AI,
@natolambertspeculated that Stability likely paid less than $100,000 for compute, while@xeophon.mentioned potential offsets in costs through partnerships or exchange deals with hardware providers, referencing a Stability ad about using the AI supercomputer (Stability AI Supercomputer Work). - Strategies for Integrating More Reading Material:
@dangf91asked about tactics for having models read more books/articles, and whether a classic unsupervised approach using masked inputs would suffice.@natolambertand@vj256suggested adding books to the pretraining dataset would be the standard practice rather than solely relying on unsupervised masking methods.
Interconnects (Nathan Lambert) ▷ #random (15 messages🔥):
- Subscriber Status Lamentation:
@420gunnaexpressed a brief moment of sadness by referring to themselves as the "reviledSubscriber" with a downcast emoji.@natolambertcountered this sentiment, emphasizing the importance of subscribers to the community: "We love subscribers. This doesn’t exist without subscribers."
- Debating which Paper to Read:
@420gunnamused over choosing between two similar academic papers posted on arXiv, inquiring about the more valuable read.@natolambertclarified the difference, pointing out that one paper is about data while the other concerns methods for choosing between data sets, suggesting that the selection focused paper is more in-depth, but the other is likely easier to digest.
- AI-Leveraged Literature Research Improvement:
@xeophon.mentioned their paper-to-summary project Clautero, noting that Claude3 produces better summaries than Claude 2 and expressing excitement about using LLMs for literature research.
- Meta's Major AI Infrastructure Announcement:
@xeophon.shared a Meta news release about a significant investment in AI infrastructure. They revealed Meta's plan to build two 24k GPU clusters, intending to incorporate 350,000 NVIDIA H100 GPUs — equivalent to nearly 600,000 H100s computational power — into their infrastructure by the end of 2024.
- Meta's Infrastructural Roadmap and Llama 3 Train Plans: In response to the Meta AI infrastructure news,
@natolamberthumorously criticized an included diagram for its oversimplified depiction of progress towards AGI, quipping about the diagram's vague attribution to Llama 3 and asking, "What intern made this", while@pxlbuzzardjoked about the chart's overly straightforward link between basic milestones and AGI.
Links mentioned:
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- A Survey on Data Selection for Language Models: A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available da...
- Datasets for Large Language Models: A Comprehensive Survey: This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructu...
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
- Doge on the Move: User
@xeophon.shared a link that appears to be related to Doge. - Cringe Attack: User
@philpaxposted an emoji that signifies dying of cringe (emoji code:<a:diesofcringe:1051223570501611581>).
CUDA MODE ▷ #general (38 messages🔥):
- Nvidia's Moat Continues to Impress: User
@apazexpressed insights from watching Bill Dally talks, acknowledging why Nvidia has a significant competitive advantage. - Cross-Platform Compute Woes:
@stefangligalamented the absence of a universal heterogeneous compute platform, critiquing CUDA's narrowness and the experimental nature of SYCL on Windows, among other options. This user also mentioned the quirks with different GPU series, like Nvidia's Pascal GPUs supporting FP16 in CUDA and Vulkan but not OpenCL. - Vulkan as a CUDA Alternative:
@stefangligaspeculated that Vulkan could narrow Nvidia's moat if its Pytorch backend were shipped on desktop, while concluding that while Nvidia's hardware seems beatable, its software edge feels nearly insurmountable. - Barriers to Vulkan Adoption:
@apazdescribed Vulkan as being intimidating to work with, referencing the pedantic setup required before it becomes usable and the packaging issues similar to those faced with CUDA. - Meta Announces Massive AI Infrastructure: An article posted by
@andreaskoepfdetailed Meta's investment in a 24k GPU cluster and ambitious roadmap involving 350,000 NVIDIA H100 GPUs, underscoring the company's commitment to AI development and open-source initiatives.
Links mentioned:
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- Back to the Future (1985) - 1.21 Gigawatts Scene | Movieclips: Back to the Future - 1.21 Gigawatts: Marty (Michael J. Fox) and Doc (Christopher Lloyd) concoct a plan to harness 1.21 gigawatts for the DeLorean.BUY THE MOV...
- Apps to atoms: Microsoft hires nuclear expert to fuel its data centres | - Times of India: Microsoft hires a nuclear expert to fuel its data centres by developing small-scale atomic reactors as an alternative to fossil fuels.
- Microsoft hires leaders for nuclear datacenter program: Industry vets specialize in the development of small modular reactors
CUDA MODE ▷ #triton (3 messages):
- Community Meetup Scheduled:
@aaryaaviannounced that the MS Teams link for the Community meetup will be provided in the Triton Lang Slack channel and shared the channel link and a link for those who want to be added: Slack Invitation Request. - Meeting Invite Clarification:
@marksaroufimconfirmed that he's on Slack and will check for the correct meeting invite, indicating that the link is shared monthly in the general channel. - Meetup Details Update:
@aaryaavimentioned that this month's meetup is scheduled for 3/28 at 10 AM PT, with the joining link and agenda forthcoming.
Links mentioned:
- Slack: no description found
- Requests for Invitation to Slack · openai/triton · Discussion #2329: Hello, I am starting this thread in case anyone else (like me) would like to request for invitation to Slack.
CUDA MODE ▷ #cuda (13 messages🔥):
- Efficiency Boost Using Thread Coarsening:
@cudawarpeddiscussed the benefits of thread coarsening in CUDA, explaining that increasing the coarsening factor can lead to linear performance gains by reducing shared memory operations, until the kernel becomes memory bound. - DIY Approach to CUDA Learning:
@g.huyinquired about resources for learning special CUDA data types likenv_half, to which@zippikarecommended searching through CUDA toolkit headers with Visual Studio Code and looking at code examples on GitHub. - Extensions for CUDA Development in VS Code: Replying to a query from
@g.huy,@zippikadescribed using the C++ extension in VS Code and adjusting the include path to enable type support for CUDA development. - Debugging CUDA with Visual Studio Code:
@zippikaexplained the process of resolving issues with include paths in Visual Studio Code by updating thec_cpp_properties.jsonfile, which prompts the editor to provide correct IntelliSense for CUDA code. - Configure Visual Studio Code for CUDA:
@zippikashared theirc_cpp_properties.jsonconfiguration detailing the setup for proper IntelliSense operation, including include paths for CUDA toolkit and PyTorch, and setting the right defines for CUDA architecture and toolkit versions.
CUDA MODE ▷ #torch (4 messages):
- Libtorch Performance Query: User
@ingiinginquired about whether libtorch runs faster thanload_inlinein PyTorch, sparking a discussion on performance comparisons. - Clarifying ‘GPU Architecture Solver’:
@andreaskoepfclarified that the term "solver for gpu architecture" is generally about finding the best software solutions for a given hardware rather than designing optimal hardware for a software problem. - Understanding Modular's Role: In response to the clarification above,
@mr.osophyacknowledged a misunderstanding and agreed that indeed, Modular is concerned with the optimization problem, namely the compatibility of kernels with GPU architectures. - Feedback Request for PyTorch Acceleration:
@marksaroufiminvited feedback on torchao RFC #47, which seeks to simplify the integration of new quantization algorithms and data types. The same team developedgpt-fastandsam-fastkernels and is offering to mentor new kernel authors for practical CUDA projects.
Links mentioned:
[RFC] Plans for torchao · Issue #47 · pytorch-labs/ao: Summary Last year, we released pytorch-labs/torchao to provide acceleration of Generative AI models using native PyTorch techniques. Torchao added support for running quantization on GPUs, includin...
CUDA MODE ▷ #algorithms (4 messages):
- Loop Reorganization Intel from NVIDIA:
@ericauldshared a link to an NVIDIA article about Stream-K, a new tactic for reorganizing loops in matrix multiplication for better work chunking (Download PDF). It offers up to 14x peak speedup compared to existing libraries like CUTLASS and cuBLAS on GPU processors.
- GitHub Gem: The example implementation of NVIDIA's Stream-K can be found in the CUTLASS repository on GitHub, showcasing this innovative matrix multiplication technique (Check the example).
- Graphene IR Unveiled:
@ericauldhighlighted another article from NVIDIA introducing Graphene, an intermediate representation (IR) to optimize tensor computations on GPUs (Read more). Graphene brings new levels of expression that allow it to match or exceed the performance of established libraries by utilizing optimized mappings between data and thread tiles.
Links mentioned:
- Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU: We introduce Stream-K, a work-centric parallelization of matrix multiplication (GEMM) and related computations in dense linear algebra. Whereas contemporary decompositions are primarily tile-based, ou...
- cutlass/examples/47_ampere_gemm_universal_streamk at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
CUDA MODE ▷ #suggestions (1 messages):
- CUDA Training Series Available:
@w0rlordshared lecture materials for a CUDA Training Series on YouTube, complementing the resources found on GitHub and the official series page. - Dive into CUDA Homework: They also provided a GitHub link for practical homework related to the CUDA Training Series, containing a variety of training materials and exercises.
Links mentioned:
- cuda-training-series: from https://github.com/olcf/cuda-training-series and https://www.olcf.ornl.gov/cuda-training-series/
- GitHub - olcf/cuda-training-series: Training materials associated with NVIDIA's CUDA Training Series (www.olcf.ornl.gov/cuda-training-series/): Training materials associated with NVIDIA's CUDA Training Series (www.olcf.ornl.gov/cuda-training-series/) - olcf/cuda-training-series
CUDA MODE ▷ #beginner (8 messages🔥):
- PyTorch to CUDA Workflow Strategy:
@iron_boundsuggest starting with PyTorch/Triton for initial model development to get fast feedback and remove errors, and transitioning to CUDA only when performance optimization is necessary. - PyTorch Version Impact on Speed:
@poppingtonicobserves a performance discrepancy when comparing PyTorch version 2.1.2 (9.17ms) against 2.2.1 (10.2ms) while running thematmul_dynprogram on a 2080 Ti with CUDA 12.1. - Exploring tinygrad:
@poppingtonicsets a new objective to delve into tinygrad operations and kernels. - Nsight Compute Warnings Troubles:
@ingiingencounters warnings while using Nsight Compute, with messages such as "No kernels were profiled" and advice on using the--target-processes alloption. - Executable Kernel Confirmation: In response to
@drisspg's question,@ingiingconfirms that their executable is definitely launching kernels, but worries their GPU might not be supported by Nsight Compute.
CUDA MODE ▷ #pmpp-book (12 messages🔥):
- Profiling in PMPP Book:
@dasher519inquired about whether the PMPP book covers the use of profiling tools for CUDA, to which@marksaroufimresponded that it's not extensively covered in the book but is discussed in lecture 1. However, the book authors do cover profiling in their YouTube videos. - Triple Angle Brackets Formatting in CUDA:
@alexanderrgriffingnoticed that the PMPP book uses spaces in the triple angle brackets (e.g.,<< < ... >> >) and wondered if that was for compatibility reasons with C++ parsers.@stefangligaclarified that spacing used to be mandatory due to C++ standards but was fixed with C++11, though old habits may persist. - CUDA C++ and Spacing Requirements: In a follow-up question,
@alexanderrgriffingasked if CUDA used to require spacing in the past.@stefangligastated not knowing the specifics about CUDA C++, but assumed it might be related to which gcc versions and default flags are used by nvcc. - Seeking Exercise Solutions for PMPP 2023 Edition:
@dasher519asked about the location of exercise solutions for the 2023 edition of the PMPP book and if they might be in a separate solutions book. There was no direct answer provided in the chat messages.
CUDA MODE ▷ #ring-attention (8 messages🔥):
- GPU Available for a Stress Test:
@iron_boundis conducting a longer training session to stress-test some code and offers the GPU for anyone who needs it, with the possibility of stopping the test if necessary. The GPU is depicted with a custom emoji code<:gpu:1198044139011452958>.
- Daylight Saving Time Reminder:
@iron_boundreminds everyone that daylight saving time has occurred in the US and proposes to catch up around<t:1710176400:t>, indicating a specific timestamp for coordination.
- Training Stuck at High Loss:
@iron_boundreports that after running training for 100 epochs on a small dataset the loss won't drop below 3.6, showing frustration with the loud tone indicated by "🤯".
- Suggestion to Adjust Learning Rate: In response to the high loss issue,
@apazsuggests possibly decreasing the learning rate or indirectly asks if the kernel itself might be broken.
- Testing Ring Attention Code:
@iron_boundinforms@222363567192670219that they're testing the ring-attention code through training software named axolotl, indicating that the learning rate seems to be calculated automatically at the moment and shares a link to WANDB with the user@iron_bound's axolotl training runs: https://wandb.ai/iron-bound/axolotl/runs/t6dz9ub1?workspace=user-iron-bound.
Links mentioned:
iron-bound: Weights & Biases, developer tools for machine learning
CUDA MODE ▷ #off-topic (6 messages):
- Rumor Mill: Claude-3 and Inflection Talk: User
@f_michaelshared a rumor about Inflection and Claude-3 integration, expressing curiosity about its implications. The rumor, originally sourced from a tweet, was later corrected, revealing it was merely hearsay.
- Inflection AI Denouncese Rumors: Responding to the gossip,
@itali4noshared a tweet from Inflection AI that debunked the rumors about Claude-3 usage, pointing towards the tweet source for accurate information.
- Cryptic Image from Stefangliga:
@stefangligashared an encrypted image prompting curiosity but offered no context or explanation for the content.
- Introducing Devin: AI Software Engineer: User
@andreaskoepfshared a blog link announcing Devin, an autonomous AI software engineer by Cognition Labs that claims to set a new bar in software engineering benchmarks.
- Real-world Test of Devin by itali4no:
@itali4noprovided a link to a tweet by @itsandrewgao who claimed to have received early access to Devin and promised to deliver unfiltered opinions on its performance as an AI that completed tasks unassisted on the SWE-Bench coding benchmark.
Links mentioned:
- Blog: no description found
- Tweet from Andrew Kean Gao (@itsandrewgao): i never believe recorded demos so I reached out to the @cognition_labs team for early access to try for myself and got it! will be sharing my unfiltered opinions on #devin here. 🧵🧵 1/n ↘️ Quotin...
LangChain AI ▷ #general (67 messages🔥🔥):
- Prompt Crafting Resolves Issues:
@a.asifexpressed that an issue they were facing was resolved by creating a proper prompt and context around the response. - Langchain Support Requested: Users like
@jimmyssand@sumerchoudhary_98267are seeking help for using Langchain, with@sumerchoudhary_98267facing an error with iFlytek's Spark API and sharing links for further assistance, such as iFlytek API documentation and iFlytek billing information. - Integration and Retrieval Troubleshooting:
@problem9069inquired about capturing output from a LangServe route into a variable, and@mattew_999offered a potential solution usingrequestsin Python.@chyru_97015questioned whether the BM25Retriever supports external memory or is in-memory only. - Community Support on Langchain Customization:
@yborbalvesand@raxrbare looking for help on building an agent that can retrieve PDF metadata and dynamically switch models based on token length, respectively. Meanwhile,@smix7194asked for assistance with an error related toreturn_full_textin a LaMini-T5 model, and@evolutionstepperdiscussed the successful use of Motor (MongoDB) as memory in Langchain. - Implementing and Troubleshooting Langchain in Applications: Users shared experiences and sought advice on various Langchain applications and errors. For example,
@pushiha.gencountered an odd output format while using a specific model, while@ninamanisought guidance for generating responses with a new LLM.@andres_fresh_lemmonasked for best practices in unit testing when using Langchain, and@siddhijain16wanted advice on incrementally updating Qdrant collection embeddings.
Links mentioned:
- LangSmith: no description found
- Retrieving metadata from vector store · langchain-ai/langchain · Discussion #10306: Hi all I have created a chatbot which uses multiple tools to get an answer for a question. One of the tools queries a Pinecone index to get an answer. The structure of the chain is as follows: def ...
- GitHub - antonis19/autobrowse: AutoBrowse is an autonomous AI agent that can perform web browsing tasks.: AutoBrowse is an autonomous AI agent that can perform web browsing tasks. - antonis19/autobrowse
- Run LLMs locally | 🦜️🔗 Langchain: Use case
- GitHub - langchain-ai/langserve: LangServe 🦜️🏓: LangServe 🦜️🏓. Contribute to langchain-ai/langserve development by creating an account on GitHub.
- 讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞: no description found
- iFLYTEK Open Platform Documents: no description found
LangChain AI ▷ #langserve (5 messages):
- Langserve Usage Inquiry: User
@problem9069sought assistance on using Langserve to capture output from a specific route in a variable, using the ChatOpenAI withgpt-4-turbo-previewmodel.
- Chat Playground Now Features Claude V3:
@dwb7737created a pull request that updates the Chat Playground to utilize Claude version 3. The changes involve updating import statements and specifying themodel_nameparameter.
- Access to LangServer: Users
@juand4.devand@gitmaxdexpressed interest in obtaining access to LangServer.@gitmaxdsuggested contacting<@703607660599181377>on platform X for access.
Links mentioned:
Refactor Anthropic import to langchain_anthropic and update model to v3 by donbr · Pull Request #524 · langchain-ai/langserve: Transition Anthropic API import to the langchain_anthropic package for enhanced compatibility. Upgrade the AI model to claude-3-sonnet-20240229 for improved performance and features.
LangChain AI ▷ #langchain-templates (1 messages):
- Seeking Switch to 'chat' Mode:
@ninamaniis developing a chatbot with langchain library and seeks guidance on changing the generation mode tochatas opposed tochat-instructafter moving to a new LLM. They provided a code snippet and specified the new LLM might be a finetuned version of llama-2 which performs better inchatmode within the oobabooga environment.
LangChain AI ▷ #share-your-work (2 messages):
- Introducing Langchain Chatbot on GitHub:
@haste171shared a GitHub repository for Langchain Chatbot, an open-source AI for analyzing and extracting information in conversational format, demonstrating the use of RAG for efficient Q/A querying. The chatbot includes features like a simple setup, a support server, an interactive Streamlit UI, and a Python FastAPI server. - New Article: Gemma-2b-it Meets Langchain:
@andysingalannounced their article Revolutionizing Video Transcription: Unveiling Gemma-2b-it and Langchain in the Era of Transformers, published on Hugging Face's blog, which explores the integration of transformers models and langchain for video transcription. The article delves into the future of transcription technology with a focus on Gemma-2b-it and Langchain's application.
Links mentioned:
- Revolutionizing Video Transcription: Unveiling Gemma-2b-it and Langchain in the Era of Transformers: no description found
- GitHub - Haste171/langchain-chatbot: AI Chatbot for analyzing/extracting information from data in conversational format.: AI Chatbot for analyzing/extracting information from data in conversational format. - Haste171/langchain-chatbot
LangChain AI ▷ #tutorials (4 messages):
- RAG Chatbot Tutorial on YouTube:
@infoslackshared a YouTube video titled "Chatbot with RAG, using LangChain, OpenAI, and Groq," which serves as a guide on building a chatbot using Retrieval Augmented Generation (RAG) with OpenAI's gpt-3.5-turbo.
- Seeking Langchain to LCEL Conversion Guidance:
@sharrajeshinquired about instructions or tutorials for converting an existing Langchain project to lcel, seeking advice from the Langchain team.
- AI Cold Call Agent with Groq:
@jasonzhou1993introduced an educational video titled "INSANELY Fast AI Cold Call Agent- built w/ Groq", discussing the capabilities of Groq LPU and demonstrating the building of a real-time AI cold call agent.
- Command-R and RAG Integration Demo:
@pradeep1148shared a YouTube video titled "Lets RAG with Command-R", showcasing the model Command-R optimized for long context tasks such as RAG and utilizing external APIs.
Links mentioned:
- INSANELY Fast AI Cold Call Agent- built w/ Groq: What exactly is Groq LPU? I will take you through a real example of building a real time AI cold call agent with the speed of Groq🔗 Links- Follow me on twit...
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
- Chatbot with RAG, using LangChain, OpenAI, and Groq: In this video, I will guide you on how to build a chatbot using Retrieval Augmented Generation (RAG) from scratch. We will use OpenAI's gpt-3.5-turbo LLM, wh...
OpenAccess AI Collective (axolotl) ▷ #general (40 messages🔥):
- Flash Attention Troubleshooting: User
@pradeep1148encountered an issue disabling flash attention on RTX 3090 or 4000 series Gpus.@caseus_advised settingflash_attention: falseand enablingsdp_attention: truein the YAML configuration.
- Understanding SDP attention:
@duh_kolainquired about SDP attention, which@rathesungodclarified as a concept from the seminal paper Attention Is All You Need.
- Cohere Unveils Open-Source Model:
@duh_kolashared a surprise announcement that Cohere has released an open-source model called "C4AI Command-R", a 35 billion parameter generative model available on Hugging Face.
- LLaMA and Axolotl Compatibility Discussions:
@leoandlibeinquired about LLaVA support in Axolotl, with@nafnlaus00stating it already exists, but@nanobitznoted that LLaVA 1.6 has significant changes which might affect compatibility.
- Tools for Editing LLM Datasets:
@nanobitzsought recommendations for tools to manually edit LLM datasets, with@duh_kolasuggesting that Argilla might have editing capabilities and@lee0099humorously adding Notepad++ to the mix.
Links mentioned:
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (10 messages🔥):
- Hugging Face PEFT Pull Request Merged:
@suikamelonhighlighted the merge of QDoRA: Support DoRA with BnB quantization, noting its support for DoRA on quantized models. Caveats include DoRA currently supporting only linear layers and suggesting merging weights for inference to reduce overhead.
- Discussing NVMe SSDs Boost for AI Training:
@dctannershared a tweet discussing Fuyou, a framework that allows fine-tuning 100B parameter models on single GPUs by using NVMe SSDs efficiently.
- Potential Implementation Questions for DeepSpeed:
@casper_aishared a link to a DeepSpeed PR, questioning whether an API that sets a module as a leaf node when setting Z3 hooks should be implemented in Axolotl.@seungdukmentioned they are currently training Mixtral with zero3 which seemed to contradict the need for the PR, engendering further discussion.
- Concerns over Mixtral Training and DeepSpeed Fix:
@seungduknoted poor evaluation results during Mixtral training and connected it to a potential issue with DeepSpeed zero3 and MoE models, but realized a recent PR fix might address this issue.
- Confirmation of Axolotl's Implementation Detail:
@caseus_initially unsure about the implementation of the leaf node API in Axolotl, confirmed that it was already present after reviewing the PR shared by@casper_ai.
Links mentioned:
- Tweet from AK (@_akhaliq): Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU Recent advances in large language models have brought immense value to the world, with their superior capabilities ste...
- QDoRA: Support DoRA with BnB quantization by BenjaminBossan · Pull Request #1518 · huggingface/peft: Adds support for DoRA on 4bit and 8bit quantized models with bitsandbytes. Merging also works, with the usual caveats for quantized weights (results are not 100% identical), but it's not worse...
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 does not work with MoE models because the order of executing modules can change at every forward/backward pass (#4094, #4808). This PR adds an API to stop breaking down a module for parameter...
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 does not work with MoE models because the order of executing modules can change at every forward/backward pass (#4094, #4808). This PR adds an API to stop breaking down a module for parameter...
- Mixtral fixes 20240124 (#1192) [skip ci] · OpenAccess-AI-Collective/axolotl@54d2ac1: * mixtral nccl fixes
- make sure to patch for z3
OpenAccess AI Collective (axolotl) ▷ #general-help (11 messages🔥):
- Frustration with Fine-tuning openllama-3b:
@heikemoexperienced odd behavior when fine-tuning openllama-3b on a dataset of 2 million rows, with the model returning very short or no output despite converging losses. They were advised by@nanobitzto adjust hyperparameters, since a smaller dataset worked well with LoRA, suggesting that the issue might not be related to the training data quality.
- Seeking Help for Long Data Truncation:
@ksshumabinquired about an argument for truncating long data into blocks and grouping short data during continual pretraining. They were informed by@nanobitzthat settingtype: completionandsample_packing: truewould handle this automatically.
- Query About Total Tokens Calculation:
@ksshumabfollowed up with a concern that their calculation of total tokens (derived from sequence length, batch size, epochs, devices, optimization steps) did not match the printed total_num_tokens. There was no response to this concern in the message history.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (2 messages):
- Mistral's Medium vs. Large:
@duh_kolamentioned that they have experimented with both Mistral medium and large models, finding that the medium performs better than Mixtral, and the large is the best but suffers from quicker timeouts. - Curiosity about Model Comparison:
@rathesungodexpressed interest in learning more about@duh_kola's experiences, specifically asking what they meant by Mistral medium being better than Mixtral.
OpenRouter (Alex Atallah) ▷ #general (63 messages🔥🔥):
- Model Alternatives to ChatGPT 3.5 Sought: User
@mka79inquired about free models that can be used as alternatives to ChatGPT 3.5 for office use, with requirements such as less censorship, privacy for sensitive data, and no use of user data for training. - New Model Arrival:
@louisdckshared a new Openchat model based on Gemma which claims to have nearly the same performance as Mistral-based models and better than its Gemma counterparts. - Nous Hermes 70B Model Offline:
@hanaaa__reported an error trying to access the Nous Hermes 70B model.@louisgvconfirmed the model will be unavailable until further notice and that a fix is being pushed to disable it. - Timeout Issues with Openchat and Gemma:
@louisdckreported timeout errors with Openchat and Gemma, with@alexatallahresponding that free models are temporarily disabled for users with no credits due to abuse but they'll be working to restore access. - New Offering by Cheat Layer:
@gpumanannounced Cheat Layer's return with free autoresponding on websites, powered by OpenRouter, and requested users to report any compatibility issues to their support; also, discussion on open-sourcing Open Agent Studio and integrating OpenRouter was mentioned.
Links mentioned:
- TOGETHER: no description found
- Blog: no description found
- The Introduction Of Chat Markup Language (ChatML) Is Important For A Number Of Reasons: On 1 March 2023 OpenAI introduced the ChatGPT and Whisper APIs. Part of this announcement was Chat Markup Langauge which seems to have gone…
- NeverSleep/Noromaid-20b-v0.1.1 · Hugging Face: no description found
- openchat/openchat-3.5-0106-gemma · Hugging Face: no description found
- Unlimited Free Autoresponder on Every Single Website: Extension auto-update 12.9.8 ships with an unlimited free autoresponder on every single website!Open Agent Studio 7.0.0 also ships with llama for unlimited t...
- mixtral - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Reddit - Dive into anything: no description found
DiscoResearch ▷ #disco_judge (6 messages):
- Open-Source vs GPT-4 Faceoff:
@johannhartmannhumorously anticipates a comparison where open-source models might outperform GPT-4, in light of a current evaluation. - Under Construction: GPT-4 Benchmarking:
@.calytrixadmits to not having compared models to GPT-4 in the same test environment yet, but plans to create a proper benchmark with multiple questions to test several models. - Choosing the Right Tool for Judge Role: In response to a question by
@johannhartmann,@.calytrixmentions the consideration of integrating benchmarking with EQ-Bench, but FastEval might be a better fit for the role of judging language models. - Hacking FastEval for Enhanced Flexibility:
@devnull0brings up that someone modified FastEval to use different backends other than vLLM, and suggests that incorporating Llama.cpp or a wrapper like Ollama could be beneficial.
DiscoResearch ▷ #general (7 messages):
- RAG Prompt Placement Debate:
@philipmaysparked a discussion about whether context and RAG instructions should be in the system message or embedded within the user message.@rasdaniresponded that it depends on the SFT and what the model has seen during the training, suggesting that [SYS] and [USER] tags used during SFT might influence subsequent inference behavior.
- New Transformer Debugger Released:
@rasdanishared a link to a tweet by@janleikeannouncing a new tool for analyzing transformer internals called the Transformer Debugger. It features automated interpretability and sparse autoencoders for model exploration without coding. (Original Twitter thread by Jan Leike)
- Inference Issues with Mixtral 7b 8 Expert Model:
@rohitsaxena4378faced an issue with theDiscoResearch/mixtral-7b-8expertmodel generating non-English text. The model is available on Hugging Face.
- Use Official Mixtral Implementations: In response to the inference issue,
@bjoernprecommended using the official Mixtral implementation instead of the experimentalDiscoResearchversion, pointing to Hugging Face's official model.
- Experimental Label Suggested for Mixtral Implementation:
@bjoernpacknowledged the need to clearly label the experimentalDiscoResearch/mixtral-7b-8expertmodel to guide users towards the official version for more reliable performance.
Links mentioned:
- DiscoResearch/mixtral-7b-8expert · Hugging Face: no description found
- mistralai/Mixtral-8x7B-v0.1 · Hugging Face: no description found
- Tweet from Jan Leike (@janleike): Today we're releasing a tool we've been using internally to analyze transformer internals - the Transformer Debugger! It combines both automated interpretability and sparse autoencoders, and ...
DiscoResearch ▷ #benchmark_dev (3 messages):
- Discovering tinyMMLU:
@johannhartmannshared a link to the tinyMMLU benchmarks on Hugging Face and expressed intention to explore a quick and easy translation for potential use. - Statistical Noise in Hellaswag Benchmark: User
@_chromix_observed that in Hellaswag benchmark testing, score fluctuations were significant (up to ±2.5) even after 1000 data points, only stabilizing (±0.2) after 9,000 points. This experience led them to favor complete tests for more dependable results, considering that short tests with 100 data points could only provide a very rough comparison.
Links mentioned:
tinyBenchmarks (tinyBenchmarks): no description found
DiscoResearch ▷ #discolm_german (2 messages):
- Importing Tokenizer Source for Merged Models:
@johannhartmannshared that the most reliable approach to handle merged models' tokenization is to import the tokenizer source from a model such as cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser, where token 2 /</s>is repurposed for `
Alignment Lab AI ▷ #general-chat (1 messages):
- In Search of Lightweight Models: User
@joshxtinquired about the best small embedding model with 1024+ max input that can be run locally with minimal RAM requirements. No responses or recommendations were provided within the provided message history.
Alignment Lab AI ▷ #oo (5 messages):
- Mermaid Graph Inquiry:
@tekniumasked about what a mermaid graph is. - Mermaid Explained:
@lightningralfexplained that Mermaid is a tool to create various diagrams from text, akin to how markdown works, and provided the Mermaid live editor. - GitHub Resource Shared:
@lightningralfalso shared the GitHub link to the mermaid-js repository, providing resources for generating diagrams like flowcharts or sequence diagrams. - Mermaid Syntax Example:
@joshxtshared a detailed example of Mermaid syntax to demonstrate how to visualize a complex system involving FASTAPI, multiple API endpoints, and various services like LLM, STT, and CTTS. - Leveraging GitHub for Mermaid Visuals:
@joshxtdiscussed the integration of Mermaid syntax with GitHub to convert code into graphical representations.
Links mentioned:
GitHub - mermaid-js/mermaid: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown - mermaid-js/mermaid
Alignment Lab AI ▷ #oo2 (11 messages🔥):
- Beneath a Mountain of Coding:
@autometahumorously expresses being overwhelmed with minor coding tasks, yet notes they haven't "died" but are merely swamped. - Docker Environment Setup for Team Convenience:
@autometais working on setting up a Docker environment to streamline processes and minimize redundant efforts among team members. - Call for Docker Setup Assistance with Incentive:
@autometaoffers a $100 reward to anyone willing to help finalize the Docker environment setup, to expedite their current workflow challenges. - Open Invitation to Contribute: In addition to Docker help,
@autometamentions there are various open science and open research projects that could use assistance, implying opportunities for interested collaborators. - Task Ownership and Delegation:
@autometaclaims they have the Docker situation under control and have also passed some responsibility to@alpinfor further progress.
LLM Perf Enthusiasts AI ▷ #general (10 messages🔥):
- Token Limit Troubles:
@alyosha11queries about solutions for the 4096 token limit on gpt4turbo, mentioning frequent run-ins with the token context length limit. - Possible GPT-4.5 Turbo on the Horizon?:
@arnau3304shared a Bing search link suggesting that GPT-4.5 Turbo might be released soon, sparking curiosity and skepticism among users. - Skepticism Over GPT-4.5 Turbo Announcement:
@dare.aivoices suspicion that the GPT-4.5 Turbo announcement might be a hallucination, given the 'explore further' links typical of RAG references. - Search Engine Echoes:
@.kiingoreported that DuckDuckGo also indexed the GPT-4.5 announcement, adding to the speculation of its existence. - Search Source Insights:
@justahveeprovides an insight clarifying that DuckDuckGo largely utilizes Bing's results, which@.kiingoacknowledges as valuable information.
Links mentioned:
必应: no description found
LLM Perf Enthusiasts AI ▷ #gpt4 (1 messages):
- Transition from OpenAI to Azure SDK Inquiry: User
@pantsforbirdsinquired about experiences transitioning from OpenAI's SDK to Azure's platform for AI services. They expressed interest in potential challenges during the mapping process and are seeking advice from others who have undergone the same transition.
LLM Perf Enthusiasts AI ▷ #opensource (2 messages):
- Elon Teases Open Sourcing Grok:
@res6969shared a tweet from@elonmuskannouncing that@xAIwill open source Grok this week. The tweet can be found here. - Local Experimentation with Command-R?:
@potrockinquired if anyone has used Command-R locally yet, opening the topic for discussion among the community.
Links mentioned:
Tweet from Elon Musk (@elonmusk): This week, @xAI will open source Grok
Skunkworks AI ▷ #general (1 messages):
- Quantum Leap in Training Convergence:
@baptistelqtannounced the completion of a method that drastically accelerates training convergence by a factor of 100,000. The method involves training from scratch in every "round".
Skunkworks AI ▷ #off-topic (2 messages):
- Game Development with Claude 3:
@pradeep1148shared a YouTube video demonstrating how to develop a Plants Vs Zombies game using Claude 3. The content covered includes Python programming for game development and leveraging the capabilities of the language model, Claude 3.
- Exploring Command-R's RAG Abilities:
@pradeep1148also provided a YouTube link to a video titled "Lets RAG with Command-R," which delves into Command-R's optimization for long-context tasks like retrieval augmented generation, and its integration with external APIs and tools.
Links mentioned:
- Claude 3 made Plants Vs Zombies Game: Will take a look at how to develop plants vs zombies using Claude 3#python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
AI Engineer Foundation ▷ #general (1 messages):
- Plugin Configuration Discussion on The Table: User
@hackgooferdetailed the agenda concerning the usage of Config Options for Plugins, including ideas like authorization via token as a plugin argument. The key question posed: "is that going to cut it?"
- Invitation to Propose Projects: A call for new project suggestions was made, with criteria outlined in a linked Google Docs guide. Project collaboration opportunities, including one with Microsoft, were mentioned as potential leads.
Links mentioned:
Guide to Submit Projects to AI Engineer Foundation: no description found