[AINews] The Ultra-Scale Playbook: Training LLMs on GPU Clusters
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
2 days is all you need to read this.
AI News for 2/18/2025-2/19/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (211 channels, and 6631 messages) for you. Estimated reading time saved (at 200wpm): 700 minutes. You can now tag @smol_ai for AINews discussions!
In seeming response to DeepMind's How To Scale Your Model, Huggingface came from nowhere to drop a massive "blogpost" equivalent for GPUs: The Ultra-Scale Playbook: Training LLMs on GPU Clusters.
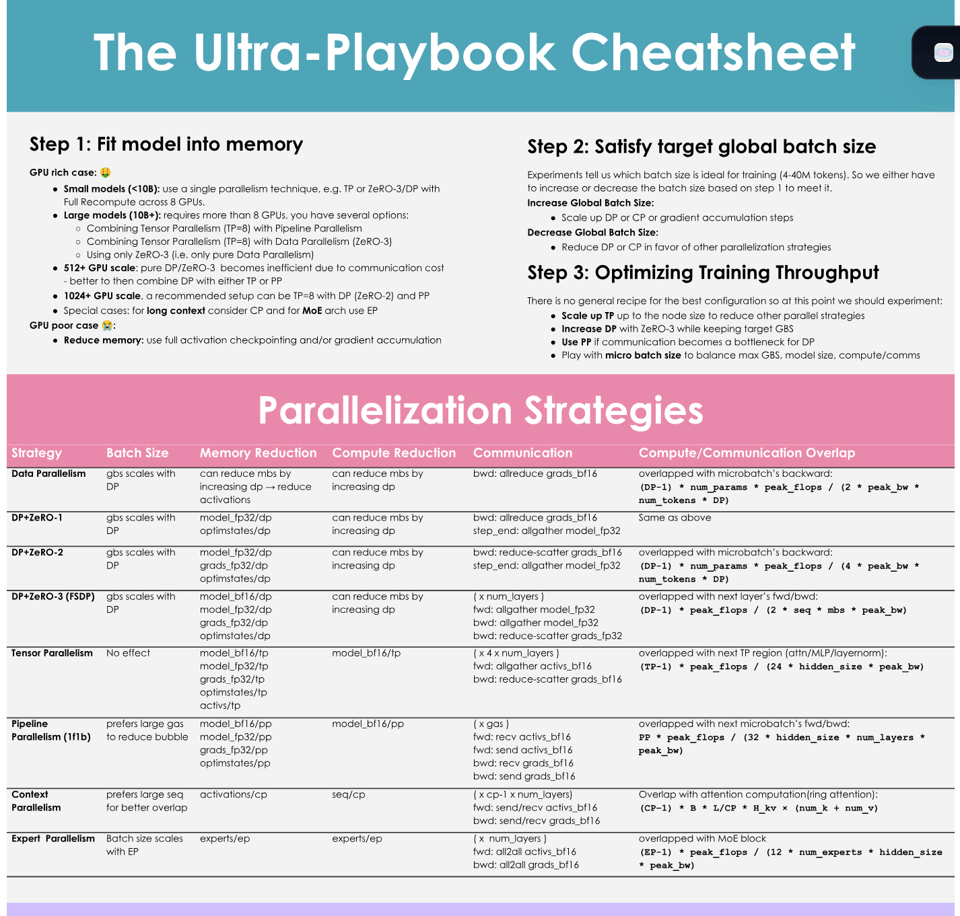
This is a great starting point for people looking for intuitive, detailed understanding of modern training constraints and strategies to scale things up on GPUs, with a first-principles build up of modern best practices:
and not to mention the blogpost is interactive, based on real data backed by 4000 scaling experiments on up to 512 GPUs.
Not strictly required for AI Engineers, but a fantastic starting point for anyone looking to get up to speed on training terminology.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
AI Models and Releases
- DeepSeek's Native Sparse Attention (NSA) model is generating significant interest. @eliebakouch shared more details about it and congratulated the team including @Nouamanetazi, @lvwerra, and @Thom_Wolf. @ProfTomYeh mentioned he would draw DeepSeek's Native Sparse Attention in a live webinar, sharing a sketch of it, and later announced he would explain the DeepSeek paper by drawing circles and lines in another webinar hosted by Alex Wang. @hkproj noted that DeepSeek releasing a paper makes the whole ML community pay attention, highlighting their soft power. @qtnx_ mentioned that command r 7b is their favorite transformer implementation.
- Perplexity AI released R1-1776, an uncensored, unbiased, and factual version of the DeepSeek R1 model, as announced by @AravSrinivas who teased more cool releases coming this week and next week. @_akhaliq also highlighted the release, describing it as post-trained to remove Chinese Communist Party censorship.
- Google DeepMind released PaliGemma 2 Mix, an open, multi-task vision-language model capable of tasks like outfit judging and object counting, as announced by @_philschmid. @mervenoyann further detailed PaliGemma 2 Mix, highlighting its versatility for vision language tasks with open-ended prompts, document understanding, and segmentation/detection, available in 3B, 10B, and 28B sizes.
- Microsoft introduced Muse, a generative AI model trained on Ninja Theory’s game Bleeding Edge, with model weights and code released, as shared by @reach_vb who indicated it signals that making your own gaming experience is coming sooner than you'd think.
- Baichuan-M1, an opensource SotA medical LLM (Baichuan-M1-14B), trained from scratch on 20T tokens with a focus on medical capabilities, was announced by @arankomatsuzaki.
- Fully open-source 40B model for genome modeling and design across all domains of life, using the new StripedHyena 2 architecture, was announced by @maximelabonne.
Research and Papers
- Microsoft presented Magma, a Foundation Model for Multimodal AI Agents, achieving SotA on UI navigation and robotic manipulation tasks, pretrained on a large dataset annotated with Set-of-Mark (SoM) and Trace-of-Mark (ToM), as highlighted by @arankomatsuzaki and @_akhaliq.
- Meta presented NaturalReasoning, a dataset for Reasoning in the Wild with 2.8M Challenging Questions, as shared by @arankomatsuzaki. @jaseweston detailed the release of NaturalReasoning, highlighting its 2.8M challenging and diverse questions requiring multi-step reasoning, showing steeper data scaling curves and potential for self-training.
- DeepMind released PaliGemma 2 Checkpoints, tailored for tasks like Optical Character Recognition and Captioning, in sizes ranging from 3B to 28B, all open weights and compatible with Transformers, as mentioned by @reach_vb.
- Hugging Face released Ultra Scale Playbook for Training LLMs on GPU Clusters, a free, open-source book covering 5D parallelism, ZeRO, fast CUDA kernels, and compute & communication overlap, based on 6 months of scaling experiments, as announced by @reach_vb.
- "Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity" is a new paper highlighted by @arankomatsuzaki.
- "Revisiting the Test-Time Scaling of o1-like Models" paper was shared by @_akhaliq, questioning if they truly possess test-time scaling capabilities.
- "ByteDance presents Phantom: Subject-consistent video generation via cross-modal alignment" paper was shared by @_akhaliq.
- "Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs" paper was mentioned by @_akhaliq.
- "Learning to Reason at the Frontier of Learnability" paper was highlighted by @iScienceLuvr, focusing on curriculum learning in LLMs using sampling for learnability in RL.
- "Is Noise Conditioning Necessary for Denoising Generative Models?" paper was shared by @iScienceLuvr, exploring denoising-based generative models without noise conditioning, finding graceful degradation and sometimes better performance.
Tools and Libraries
- LangChain announced LangGraph Studio's Playground integration for faster prompt iteration, allowing users to view LLM calls directly and iterate on prompts without re-running the whole graph, as per @LangChainAI. They also introduced Langchain MCP Adapters, enabling instant connection of LangGraph agents to hundreds of tools in the MCP ecosystem, and
npm create langgraphfor bootstrapping LangGraph.js agents with templates. - Modular released MAX 25.1, a significant release enabling new agentic workflows, GPU custom ops in Mojo, and a new portal for dev content, as announced by @clattner_llvm.
- Together AI announced Test Drive of NVIDIA Blackwell GPUs with Together GPU Clusters, offering free access to eight AI teams to optimize models and accelerate training, as per @togethercompute. They also highlighted Scaled Cognition training APT-1 on Together GPU Clusters.
- LM Studio now supports speculative decoding, as announced by @cognitivecompai.
- LlamaCloud EU, a secure, compliant knowledge management SaaS offering ensuring full data residency within the EU, was announced by @llama_index.
- Gradio is highlighted as the tool used to build most AI apps today, according to @_akhaliq.
Industry News and Events
- April 29 is the date for the first-ever LlamaCon, and Meta Connect is scheduled for September 17-18, as announced by @AIatMeta.
- LangChain is hosting events, including an evening meetup in NYC on February 19th, and an AI event in Atlanta on February 27th, as posted by @LangChainAI and @LangChainAI. @hwchase17 also mentioned being in Atlanta.
- AI Engineer Summit in NY is happening, with @HamelHusain mentioning being in NY for it.
AI Agents and Applications
- Evaluating AI Agents is the focus of a new short course from DeepLearningAI in partnership with Arize AI, taught by @JohnGilhuly and @_amankhan, covering systematic assessment and improvement of AI agent performance, as announced by @AndrewYNg and @DeepLearningAI.
- AI co-scientist, a multi-agent AI system built with Gemini 2.0 by Google, is introduced to accelerate scientific breakthroughs, as reported by @omarsar0 in a detailed thread outlining its capabilities, such as generating novel hypotheses, outperforming other SoTA models, and leveraging test-time compute.
- Weights & Biases hosted a Multimodal AI Agents Hackathon, with over 200 innovators and 40 teams participating, showcasing creativity and iterations in building AI agents, as mentioned by @weights_biases.
- Microsoft just dropped MUSE - a generative AI model trained on Ninja Theory’s multiplayer battle arena game, Bleeding Edge for gameplay, according to @reach_vb.
- AI that learns from gameplay and generates visuals is highlighted as a new chapter in gaming by @yusuf_i_mehdi.
Quantum Computing Breakthrough
- Microsoft's quantum team is congratulated by @stevenheidel for a breakthrough, with @yusuf_i_mehdi announcing a major step toward making quantum computing a reality, unlocking the power to solve problems beyond today’s computers, potentially reshaping industries and accelerating scientific discovery. @cognitivecompai questioned @satyanadella whether topological superconductor is actually a new state of matter. @jeremyphoward also reacted to the news, quoting "we’ve created an entirely new state of matter".
Memes and Humor
- @nearcyan stated that everyone who bought the $700 AI pin got literally rugged, gaining significant traction.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. o3-mini Replaces DeepSeek as This Year's LLaMA Front-runner
- o3-mini won the poll! We did it guys! (Score: 1688, Comments: 186): o3-mini won a Twitter poll with 54% of the 128,108 votes, beating the "phone-sized model" option. A reply from Ahmad suggests the poll was misleading and encourages votes for "o3-mini," highlighting community engagement with likes, quotes, and reposts.
- Model Distillation Discussion: Users discussed the process of distilling a model, which involves creating a smaller, faster version by training a compact model (student) to mimic a larger model (teacher). Techniques such as knowledge distillation, pruning, and quantization are used, but OpenAI's closed-source nature limits direct distillation from their models.
- Skepticism on Model Releases: There is skepticism about whether OpenAI will release an open-source model, as historically they've moved away from open models. Users are wary of terms like "o3-mini level," suggesting it might not meet expectations or be a significantly downgraded version.
- Community Reactions and Sarcasm: The community expressed mixed feelings about the Twitter poll results and the potential release of a "phone-sized" model. Comments highlighted the use of sarcasm and skepticism regarding the actual utility and performance of such models, with some users humorously noting the potential for underwhelming releases.
Theme 2. AMD Laptops with 128 GB Unified Memory Challenges Apple Dominance
- New laptops with AMD chips have 128 GB unified memory (up to 96 GB of which can be assigned as VRAM) (Score: 482, Comments: 157): New AMD laptops now feature 128 GB unified memory, allowing up to 96 GB to be allocated as VRAM.
- Discussions highlight the performance and versatility of the new AMD laptops with 128 GB unified memory. Reviewers like JustJosh and Dave2D praise their capability to run LLMs and Linux, challenging Mac's dominance in unified memory for large model processing. b3081a mentions running vLLM with specific configurations for optimized performance on these devices.
- The pricing and comparison with Apple devices are significant discussion points. The Asus 128GB version is priced at $2799, cheaper than a comparable Apple device at $4700. Users debate the value and performance differences, with some noting potential cost benefits over high-end GPUs like the RTX 5090.
- There is interest in Linux support and potential desktop applications. Kernel 6.14 is expected to bring full Linux support for NPUs in these devices, and users express interest in Mini PCs and Framework 13 mainboards with these chips, discussing the benefits of shared RAM and unified memory in various configurations.
Theme 3. Gemini 2.0's Superior Audio Transcription with Speaker Labels
- Gemini 2.0 is shockingly good at transcribing audio with Speaker labels, timestamps to the second; (Score: 387, Comments: 90): Gemini 2.0 excels in audio transcription with precise speaker labels and timestamps to the second, as highlighted by Matt Stanbrell on Twitter. The tool's ability to recognize various sounds and provide detailed transcriptions encourages users to upload audio files for enhanced summarization and speaker identification.
- Gemini 2.0's transcription capabilities are praised for Vietnamese language accuracy, including tones, with users finding it highly reliable for language learning, as noted by Mescallan. However, leeharris100 from an ASR company critiques its timestamp accuracy and mentions it hallucinates with longer contexts, though it remains competitive in general WER (Word Error Rate) with models like Whisper medium.
- There is a consensus that Google's Gemini models are not open-sourced, preventing local use like Whisper, as highlighted by CleanThroughMyJorts. nrkishere and silenceimpaired express skepticism about its local running capabilities and open-sourcing potential.
- Gemini 2.0 is noted for its object identification and graph understanding capabilities, with users like Kathane37 impressed by its performance. space_iio attributes its effectiveness to Google's access to YouTube videos and metadata, enhancing its training data beyond typical scraping methods.
Theme 4. Unsloth's R1-1776 Dynamic GGUFs with High Accuracy
- R1-1776 Dynamic GGUFs by Unsloth (Score: 132, Comments: 53): Unsloth released R1-1776 GGUFs ranging from 2-bit to 16-bit, including Dynamic 2-bit, 3-bit, and 4-bit versions, with the Dynamic 4-bit being smaller yet more accurate than the medium version. The models, available on Hugging Face, require specific token formatting and offer instructions in the model card, with additional insights available in their blog.
- Resource Requirements: Running R1-1776 GGUFs doesn't necessitate VRAM, but for optimal performance, at least 120GB of VRAM + RAM is recommended. The dynamic 2-bit version requires 211GB of disk space and specific formatting guidance is provided to enhance model output.
- Model Performance and Benchmarks: Dynamic quants of the R1 model have shown to outperform or match the original 16-bit models in benchmarks submitted to the Hugging Face leaderboard. However, users noted the need for more comprehensive benchmarks beyond the Flappy Bird test to fully assess performance.
- Future Developments and Releases: There are upcoming releases focusing on long context and other features requested by over 10,000 users, indicating a strong community engagement. Additionally, there are plans to support distillation to smaller models, and potential updates for V3 and V2.5-1210 versions to improve accessibility and performance.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. DeepSeek GPU Smuggling Probe: Uncovering Nvidia's Singapore Revenue Anomalies
- DeepSeek GPU smuggling probe shows Nvidia's Singapore GPU sales are 28% of its revenue, but only 1% are delivered to the country: Report (Score: 286, Comments: 90): DeepSeek's investigation reveals that Nvidia's GPU sales in Singapore account for 28% of its revenue, yet only 1% of these GPUs are actually delivered to the country. This discrepancy suggests possible GPU smuggling activities.
- The DeepSeek V3 paper was questioned for its claim of using 8-bit floating point (FP8), which would be a significant shift in AI model training if true. Discussions reveal skepticism about the authenticity of DeepSeek's claims, with some suggesting it was overhyped by media outlets.
- Singapore's role as a major trading port was highlighted, explaining the high percentage of Nvidia's revenue attributed to the country despite low actual delivery. This aligns with Singapore's trade-to-GDP ratio of over 300%, suggesting potential re-exporting or processing activities rather than direct smuggling.
- Nvidia's actions are perceived as attempts to circumvent US laws, with some commenters noting the misleading nature of article titles and the strategic importance of GPUs. The discussion touches on broader geopolitical implications, including comparisons to China's potential control over strategic assets.
- Accurate (Score: 286, Comments: 15): The post humorously contrasts a serious medical setting with a casual response, featuring a patient in an MRI machine asking a doctor about results, while the monitor shows the "ChatGPT-4o" logo. This juxtaposition highlights the comedic tone by mixing a traditionally serious context with a relaxed, informal reply.
- Medical AI Assistance: Human-Independent999 suggests that AI's best application in the medical field is to assist doctors, implying that such integration may already be occurring. This reflects a common sentiment about AI's potential to enhance medical practices.
- Futuristic Technology Comparisons: PerennialPsycho humorously compares the scenario to Star Trek, where a doctor uses a simple tool for diagnosis, highlighting the futuristic and simplified vision of AI in healthcare.
- Optimism for AI's Future: Potential_Club_9494 expresses optimism about AI's future impact, hinting at the transformative potential that AI like ChatGPT may have on various fields.
- Tweet from an OpenAI researcher (Score: 273, Comments: 27): Aidan Clark tweeted about "Sonnet 4" and congratulated "Demis & Team," gaining significant attention with 12.7K views, 34 replies, 25 retweets, and 239 likes as of February 19, 2025.
- There is confusion and speculation about the "Sonnet 4" and Demis Hassabis's involvement, with some users questioning if Demis is being congratulated for achievements related to DeepMind or if it's a form of trolling due to Google's investments in Anthropic.
- Grok 4.5 is mentioned with enthusiasm, suggesting a possible mix-up or joke in the conversation, as Demis Hassabis is associated with DeepMind, not Anthropic.
- Several users express confusion about what "Sonnet 4" is, with some humorously suggesting it might be a cross-universe or fictional concept, indicating a lack of clarity or potential trolling in the original tweet.
Theme 2. Google's NotebookLM: A Gamechanger in AI Research Tools
- NotebookLM the Most Underrated AI Tool! (Score: 1143, Comments: 104): Google's NotebookLM is highlighted as an underrated AI tool, combining features of ChatGPT, Perplexity, and Notion AI while offering automatic source citations to eliminate hallucinations. It excels in reading and summarizing PDFs, Docs, and notes, and remembers uploaded files better than ChatGPT, making it a valuable tool for researchers, students, and professionals handling large data volumes.
- Users praise NotebookLM for its unique podcast feature, which allows for interactive and customizable experiences, likening it to having a personal AI radio show. However, there are concerns about potential hallucinations, especially on the free tier, and the possibility of Google discontinuing the service.
- Some users express interest in NotebookLM's potential to manage and summarize data, such as expenses in Excel sheets, but there are critiques regarding its chat feature and UI limitations. The tool is noted for its superior source management and citation capabilities compared to other tools.
- There is a desire for an open-source, local alternative to NotebookLM, reflecting concerns about the longevity of Google's support for the tool. Users are also curious about the pricing model and its integration with Google One AI.
- 'Improved Amateur Snapshot Photo Realism' v12 [FLUX LoRa] - Fixed oversaturation, slightly improved skin, improved prompt adherence and image coherence (20 sample images) - Now with a Tensor.art version! (Score: 239, Comments: 18): 'Improved Amateur Snapshot Photo Realism' v12 [FLUX LoRa] is a significant update that addresses issues of oversaturation, enhances skin texture, and improves prompt adherence and image coherence. The update includes 20 sample images and introduces a version compatible with Tensor.art.
- Image Quality Concerns: Users like animerobin note that FLUX LoRa models often suffer from low-resolution pixel fuzziness, questioning how to achieve crisper images.
- Dataset Sourcing: TheManni1000 seeks advice on finding image datasets for training similar models, with suggestions including Reddit image subs, Instagram, Flickr, and datasets from Hugging Face and Kaggle.
- Resource Links and Terminology: AI_Characters provides links to the model on CivitAI and Tensor.art, while a discussion arises around the term "amateer" being a buzzword for "AI generated celebrity," with some confusion over its consistent depiction.
Theme 3. Claude 3.5 Sonnet: A Benchmark in AI Coding and Consistency
- Claude reasoning. Anthropic may make offical announcement anytime soon.. (Score: 222, Comments: 87): Claude 3.5 Sonnet interface showcases features such as "Camera," "Photos," and "Files" buttons, along with options to "Choose style" and toggle "Use extended thinking" for PRO users. The interface hints at a limited daily message feature on the free plan and an "Upgrade" option, indicating potential for enhanced functionality.
- Users express frustration over the API pricing of Claude, with one user noting $0.60 per use for paraphrasing a few paragraphs, leading them to prefer the web version despite its limited daily messages. The daily message limit is a significant pain point, with users feeling restricted in their usage.
- There is skepticism around the Claude 3.5 Sonnet update, with some users suspecting it's merely a rebranding of existing features like MCP servers rather than introducing new capabilities. The addition of reasoning and potential web search features is noted, but users remain critical of the lack of substantial improvements.
- Users report that the new features are not available on iOS or Android for some, despite app updates, leading to confusion about the rollout. The community is also critical of Anthropic's focus on updates without addressing fundamental issues like message limits and practical enhancements.
- What the fuck is going on? (Score: 226, Comments: 185): Claude 3.5 Sonnet is praised for its superior coding reliability and consistency compared to models like DeepSeek, O3, and Grok 3, despite not incorporating new techniques such as AI self-looping. The author notes that while these newer models are interesting for their novel approaches, Claude 3.5 Sonnet remains unmatched, though it hasn't shown significant improvements recently.
- Many users argue that Claude 3.5 Sonnet is not universally superior, as it struggles with specific tasks like programming contest problems and architecture issues, where models like O1 and O3-mini perform better. Critics highlight that Claude's higher context window (200k vs. 32k) compared to ChatGPT might contribute to its performance discrepancies (Reddit post).
- Some users express skepticism about the emphasis on AI benchmarks and leaderboards, suggesting that they may not accurately reflect real-world usability and intelligence. They argue that focusing solely on benchmark performance can detract from the practical utility and user-friendliness of AI models.
- There is anticipation for future releases, such as Claude 4.0 and Opus 4.0, which are expected to surpass current models, while others note that Gemini Pro 2.0 and reasoning models like R1 and O3 are currently preferred for tasks requiring different aspects of intelligence. Some users mention upcoming hybrid models with reasoning capabilities, hinting at advancements in AI self-looping and reasoning.
Theme 4. OpenAI's 4o Model: Excelling in Creative Writing and Narrative Continuity
- 4o Creative Writing is Phenomenal! (Score: 135, Comments: 53): The post discusses the OpenAI 4o model and its impressive capabilities in creative writing, particularly in genres like sci-fi and fantasy. The author highlights the model's ability to maintain character consistency in continuing book series and notes the potential influence of having 128k context with a pro subscription.
- Users are impressed with the OpenAI 4o model's ability to maintain character consistency and extend stories naturally, especially with the 128k context. However, some users find that the model sometimes defaults to generic storytelling, particularly in genres like horror, and struggles with programming tasks, requiring manual intervention for accurate code generation.
- The recent updates to the model, including end of January fine-tuning and mid-February content filter relaxation, have been noted to enhance its natural language processing capabilities. Some users suggest the possibility of OpenAI's reasoning models being integrated under the hood for improved performance.
- Creative writing with the model is seen as entertaining and personalized, with users sharing strategies like using the narrative technique to guide story development. There are also discussions on the model's capacity for handling large output sizes, with alternatives like flash thinking mentioned for higher token limits.
Theme 5. SFW Hunyuan Video LoRAs: Expanding Creative AI Video Applications
- I will train & open-source 50 SFW Hunyuan Video LoRAs. Request anything! (Score: 144, Comments: 161): The author plans to train and open-source 50 SFW Hunyuan Video LoRAs, leveraging nearly unlimited compute power. They invite suggestions for training ideas, promising to prioritize the most upvoted requests and personal preferences.
- There is significant interest in martial arts fight scenes and heavy cinematic film styles, with suggestions to explore extreme wide-angle shots and different martial art styles for diverse visual effects. Wes Anderson aesthetics and Film Noir cinematics are also popular requests for unique visual storytelling.
- Some commenters emphasize the potential of fine-tuning models to their limits for high-quality outputs, suggesting themes like 360-degree character turnarounds, VR and SBS 3D videos, and immersive live-action GoPro footage. Others propose focusing on unique video training such as camera movements and action sequences over still images.
- There are creative suggestions for thematic content, including cyberpunk settings like Cyberpunk 2077 and Blade Runner 2049, dark fantasy styles, and alien lore. Additionally, there is interest in capturing film dialogue moments with nuanced emotional expressions and 2D animation styles beyond anime.
- Anthropic to release reasoning and other cool stuff soon.. (Score: 218, Comments: 44): Anthropic is set to release new features for the Claude iOS app, focusing on Thinking Models and Web Search capabilities. The announcement, originally made on Twitter by user @M1Astra, includes new icons for features like "Steps," "Think," and "Magnifying Glass," with the post dated February 19.
- Users express a desire for Claude to address issues like rate limits, memory, and longer conversations, with some considering a return to subscriptions if these features improve. Web search capability is also a highly requested feature to access the latest information online.
- Some commenters, like ChrisT182, highlight Anthropic's focus on AI safety and understanding as a reason for their sparse updates, suggesting that this groundwork is crucial for future advancements towards AGI.
- There are hopes for new features like Claude's voice, with Hir0shima and others expressing anticipation for this update, while some users have switched to alternatives like deepseek due to dissatisfaction with current offerings.
- ChatGPT Founder Shares The Anatomy Of The Perfect Prompt Template (Score: 1232, Comments: 62): Greg Brockman shared a tweet detailing the structure of an optimal prompt for ChatGPT, focusing on creating unique weekend getaways near New York City. The prompt includes sections such as "Goal," "Return Format," "Warnings," and "Context dump" to ensure clarity and effectiveness in generating responses.
- Prompt Structure and Effectiveness: There is a discussion about the effectiveness of prompt structure, with some users noting that placing the goal or question at the top can lead to less desirable responses, while others argue that placing it at the bottom or using data separators improves outcomes. ArthurParkerhouse suggests using a triple hash separator to distinguish between context and tasks, which aligns with MemeMan64209's observation of better results when questions are placed last.
- AI Interaction and User Experience: Fit-Buddy-9035 compares prompting AI to communicating with a logical, direct individual, emphasizing the need for clarity and explicitness, while Professional-Noise80 highlights that crafting effective prompts requires critical thinking. TheSaltySeagull87 notes that the effort in creating detailed prompts can be comparable to traditional research methods like using Google or Reddit.
- Cognitive Processing in AI Models: MaintenanceOk3364 suggests that AI models, like humans, prioritize initial information, but MemeMan64209 and ArthurParkerhouse observe that AI might prioritize the last tokens read, reflecting a discrepancy in perception of how AI processes information. This highlights the complexity and variability in AI's cognitive processing, sparking further debate on optimal prompt design.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1: Grok 3 Takes Center Stage Amid Mixed Reactions
- Grok 3 Melts Servers and Minds!: xAI's Grok 3 is now free until server capacity is reached, offering unprecedented access to the "world's smartest AI" as announced in this tweet. Users speculate about usage limits and potential server overloads.
- Grok 3 Hype Meets Skepticism: While some users hail Grok 3 as superior to ChatGPT-4, others find its reasoning capabilities underwhelming compared to models like Claude 3.5 and O1. The community is abuzz with comparisons and debates over its true prowess.
- Elon Enters Gaming with Grok 3: Elon Musk's xAI announced the creation of a new game studio tied to Grok 3, signaling a strategic move to integrate AI with gaming, as hinted in Elon's tweet.
Theme 2: AI CUDA Engineer Supercharges Kernel Optimization
- AI Codes for AI: CUDA Kernels Get a Boost: Sakana AI unveiled the AI CUDA Engineer, automating optimized CUDA kernel creation and achieving 10-100x speedups over standard PyTorch operations.
- Kernel Wizardry Impresses the Community: The AI CUDA Engineer boasts a 90% success rate in translating PyTorch to CUDA and released a dataset of 17,000 verified CUDA kernels, marking a breakthrough in AI-driven performance optimization.
- Dr. Jim Fan Applauds Autonomous Coding Agent: In a tweet, Dr. Jim Fan praised the AI CUDA Engineer as the "coolest autonomous coding agent," highlighting its potential to accelerate AI through enhanced CUDA kernels.
Theme 3: New AI Labs and Quantum Advances Shake the Industry
- Mira Murati Machines a New AI Lab: Former OpenAI CTO Mira Murati launched Thinking Machines Lab, aiming to develop more understandable and customizable AI systems with a commitment to public transparency.
- Microsoft Makes a Quantum Leap with Majorana 1: Microsoft introduced Majorana 1, the first Quantum Processing Unit powered by topological qubits, potentially scaling to a million qubits on a single chip.
- Lambda Lands $480M to Fuel AI Cloud Services: Lambda secured a massive $480 million Series D funding with participation from NVIDIA and ARK Invest, emphasizing the booming investment in AI infrastructure.
Theme 4: AI Censorship Sparks Debate; Uncensored Models Released
- Perplexity Pioneers Post-Censorship AI: Perplexity AI released R1 1776, an uncensored version of the DeepSeek R1 model, striving for unbiased and factual information.
- DeepSeek R1 Unleashed with Enhanced Quants: Users can now run Perplexity's uncensored DeepSeek R1 using dynamic 2-bit GGUF quants, promising improved accuracy over standard formats.
- Users Demand Free Speech from AI: Frustrations grow over heavy censorship in models like ChatGPT and Grok, with users seeking alternatives that allow more creative and unrestricted interactions.
Theme 5: AI Revolutionizes Gaming and Creative Expression
- AI Rendering Transforms Game Design: Enthusiasts discuss AI's potential to revolutionize gaming with dynamic, interactive environments, echoing Satya Nadella's vision in this tweet about AI-generated worlds.
- AI for Creative Writing and Roleplay Flourishes: Users share advanced techniques for enhancing erotic roleplay (ERP) with AI models, focusing on creating detailed characters and immersive experiences, highlighting AI's creative potential.
- Anthropic Preps Claude with New Features: Anthropic is reportedly upgrading Claude with web search and a new "Paprika mode" to enhance reasoning capabilities, as seen in recent app updates and tweets.
PART 1: High level Discord summaries
LM Studio Discord
- LM Studio Supercharges Inference with Speculative Decoding: LM Studio 0.3.10 introduced Speculative Decoding, which pairs a larger model with a smaller, faster draft model to potentially double inference speeds, particularly in llama.cpp/GGUF and MLX, as detailed in the release blog post.
- Users have reported varying results, with some achieving speeds over 100 tokens/sec, while others experienced slower performance depending on configurations and model choices.
- Text Embeddings Enable LM Studio Long-Term Memory: Text embeddings are utilized for retrieving relevant data from user-created and uploaded files directly within LM Studio, serving as a method to store information for long-term use within LLMs.
- This approach is different from extensions to LLMs, as embeddings facilitate the retrieval of specific data to enhance LLM context.
- Fine-Tuning Models: Proceed with Caution: Fine-tuning allows models to adapt to specific contexts but may lead to hallucinations if not carefully executed, especially with notable characters or concepts.
- Community members debated the risks of biasing models with inappropriate training examples which can drastically skew the model responses.
- A6000 GPUs Validate Fine-Tuning Prowess: The A6000 GPUs, equipped with 256 GB of memory each, are confirmed as adequate for fine-tuning a phi4 model; users are pointed towards Unsloth's notebooks for fine-tuning examples.
- The discussion highlights the growing importance of accessible hardware for AI development, with the A6000 series offering a balance of performance and cost-effectiveness.
- Mistral Models are Magnifique for French Language Tasks: Users are highlighting the Mistral model as optimal for conducting tasks in French, with recommendations also extended to models like DeepSeek V2 Lite for accelerated inference speeds when GPU resources are unavailable.
- These suggestions reflect a drive to balance model accuracy with computational efficiency, ensuring models can perform effectively across diverse hardware configurations.
OpenAI Discord
- Grok 3 Generates Excitement But Has Drawbacks: Users found Grok 3 excels at detailed script and artwork generation when given generous and specific prompts, surpassing free versions of ChatGPT.
- Grok 3 is faster and has less stringent censorship but it reportedly falls short in logical reasoning compared to more advanced models.
- AI Censorship Sparks Debate: Users are concerned about censorship in ChatGPT and Grok, particularly for certain content types, with censorship varying across platforms like Perplexity and o1 models.
- One user expressed frustration, saying that these censorship issues significantly hinder AI's creative and interactive capabilities.
- Evo-2 Writes Genomes from Scratch: Evo-2, a large AI model trained on 9.3 trillion DNA base pairs, can now write genomes from scratch, potentially revolutionizing biological research, according to this Tweet from vittorio.
- This advancement raises optimism for breakthroughs in oncology and genetic engineering, opening new avenues for medical research and treatment.
- Ethical AI Interactions Require Respect: A member expressed concerns about how interacting with AI could reflect on human behavior, emphasizing the need for healthy boundaries and stating, 'The way we treat AI... is very likely to be how we treat our fellow humans.'
- This perspective led to a discussion on parallels between animal treatment psychology and human interactions, suggesting ethical treatment of AI.
- Prompt Clarity Fixes ChatGPT Fumbles: A user improved ChatGPT functionality by simplifying their prompt, yet issues persisted on their company's server, noting improved functionality in the Playground but issues in their company's server.
- Community feedback emphasized that clear, specific prompts yield better AI responses, with one response urging focusing on server input and ensuring clarity to guide the model's output effectively.
Codeium (Windsurf) Discord
- DeepSeek-V3 Goes Unlimited!: DeepSeek-V3 is now unlimited for users on Windsurf Pro and Ultimate plans, eliminating concerns about prompt credits and flow action credits, as announced in Windsurf AI's official account.
- Members expressed excitement over this update and were encouraged to surf and fully utilize the new features.
- MCP Content Showcased by Matt Li: New MCP content and use cases were highlighted by Matt Li, prompting a strong call to action to engage with the post and show support, detailed in this tweet.
- Also, a demo was shared demonstrating how MCP works effectively within Cascade, clarifying MCP's potential uses and boosting community engagement.
- Codeium Feature Autocomplete Clarified: Discussions clarified the distinctions between autocomplete and supercomplete in Codeium, where supercomplete can suggest entire functions, and autocomplete aids with single lines.
- However, this discussion surfaced questions about documentation clarity and the difficulties some members faced in finding information on automatic installation.
- Student's Find Codeium Subscription Worthwhile: Members concluded that Codeium's $60 subscription might be worthwhile for students creating SaaS projects, as it often leads to greater earnings.
- One member noted that even though the subscription seems costly, it can balance out for students engaging in serious development projects.
- Windsurf's Performance Faces Headwinds: Numerous users reported issues with Windsurf, including internal errors during model iterations and problems with file editing, suggesting that context length might be impacting performance.
- They expressed the need for a more efficient confirmation process to improve coding workflows.
Unsloth AI (Daniel Han) Discord
- Unsloth AI Brothers Star in GitHub Interview: The Unsloth AI team highlighted their project on a GitHub Universe interview, showcasing the synergy between the Han brothers and the impact of their work on AI development.
- Enthusiastic community members appreciated the clarity and passion displayed during the interview.
- Leveraging Free GPUs for Model Fine-Tuning: Unsloth is effectively using free GPUs available on platforms like Colab, with community members sharing links to access these resources to support model fine-tuning, especially for models such as DeepSeek-R1.
- Community members explored content creation opportunities to promote these free resources and their utilization.
- Med-R1 Model Gets Medical: The newly released med-r1 model features 1B parameters and is trained on a medical reasoning dataset, now available on Hugging Face.
- Designed for medical Q&A and diagnosis, it supports 4-bit inference with a max sequence length of 2048 tokens.
- Community Tackles Bitsandbytes Code: Members scrutinized the bitsandbytes code, raising concerns about the float types and block sizes implemented.
- Discussions centered on discrepancies where the code should ideally use
fp32, yet some experiencedfp16values, sparking questions regarding pointer conversions.
- Discussions centered on discrepancies where the code should ideally use
- AI Sharpens Phytochemical Precision: An AI-driven model can now systematically identify plant-based compounds optimizing health support through a new framework.
- This approach aims to enhance the development of evidence-informed nutraceuticals while prioritizing safety and efficacy.
HuggingFace Discord
- Grok 3 Reportedly Smokes ChatGPT-4: It was mentioned that Grok 3 is reportedly better than ChatGPT-4, sparking interest in its capabilities.
- Community members expressed curiosity and speculation regarding the technical differences between the models.
- SWE-Lancer Benchmark Gauges LLM Freelancing Capacity: OpenAI introduced the SWE-Lancer benchmark to test LLMs' abilities to perform software engineering tasks worth up to $1 million, according to this tweet.
- Initial insights suggest models excel more in solution selection than implementation, revealing strengths and weaknesses.
- Microsoft Jumpstarts Quantum with Majorana 1 Chip: Satya Nadella announced the launch of the Majorana 1 chip, a significant advancement in quantum computing that promises to perform calculations in minutes that would take supercomputers billions of years, described in this blog post.
- This innovation has the potential to reshape industries and impact climate change significantly.
- CommentRescueAI Boosts Python Documentation: A member presented CommentRescueAI, a web extension designed to add AI-generated docstrings and comments to Python code easily.
- The extension is now available on the VS Code marketplace, and the creator seeks suggestions and feature ideas.
- Certificate Snag Resolved in Agents Course: Many users recently struggled to generate their certificates after completing the quiz in the Agents Course, but it has been resolved by directing submissions to a new space that generates certificates directly.
- Participants were encouraged to try the updated quiz link to receive their certificates promptly.
aider (Paul Gauthier) Discord
- Grok 3 melts servers and minds!: Grok 3 is now available for free until server capacity is reached, with increased access for X Premium+ users and SuperGrok members, according to xAI's tweet.
- Users speculate that Grok 3 will likely have restrictions, estimating a limit of about five queries per day, raising concerns regarding usability.
- LLM Inference is a Bottleneck: Users are expressing frustration about LLM inference speed while coding with Aider, while coding with aider, and others noting that Azure's OpenAI API is often faster based on community feedback.
- They are sharing tips for caching and marking the file as read only, while improving coding practices within Aider, detailing specific preferences like using httpx over requests.
- OpenRouter limits endpoints: Discussions reveal that OpenRouter may limit endpoints for models like o3-mini to 100k requests, indicating potential usability issues.
- This limitation complicates the experience of users trying to leverage OpenRouter for more intensive AI interactions.
- Ministral joins Aider, maybe!: A member inquired if anyone has tried integrating Ministral with Aider, expressing curiosity about their compatibility after seeing the LinkedIn post discussing Mistral.
- Separately, another member finds the build process very slow, as it rewrites chunks with 'build' during the API calls using TF-IDF.
- Model LLADA makes the scene: The community discussed a newly mentioned model named LLADA, which demonstrates high performance on coding tasks.
- Insights suggest that models like LLADA may become a strong alternative for code editing due to their innovative approaches.
Cursor IDE Discord
- Sonnet excels for coding: Users favor Sonnet for coding tasks due to its reliability and contextual understanding, and noted that Anthropic models excel in coding and complex tasks when combined with reasoning and careful execution.
- Users generally perceived OpenAI and DeepSeek as strong contenders for general tasks.
- Grok 3 faces user scrutiny: Some users criticized Grok 3's utility, labeling it a disappointment based on personal testing experiences that showcased its inadequacies in coding tasks, despite some favorable reviews on YouTube.
- Others are questioning the validity of arguments against Grok 3 by pointing out its favorable reviews from various YouTubers, while others are pointing to favorable reviews.
- Cursor in Agent Mode streamlines workflow: Users shared their experiences using Cursor in agent mode, emphasizing how features like changelogs and customized rules helped streamline their workflow.
- The discussion revolved around using AI assistants for automating tasks and ensuring quality output, highlighting both positive and negative interactions.
- Startup Seeks Coder for Collaboration: A user announced interest in starting a new venture and is seeking a coder who has time and dedication to collaborate, offering to fund the project.
- This announcement led to openness for potential partnerships among members of the channel.
Perplexity AI Discord
- Deep Research Plagued by Crashes: Users reported consistent crashes of the Deep Research feature, particularly for enterprise plan users, as well as issues navigating threads and accessing library content.
- They discussed potential fixes, hinting at underlying issues with the platform's stability and usability, and are now actively investigating the issue further.
- Subscription Model Sparks Debate: A member voiced confusion over the pro subscription model, which offers access to multiple models for a single fee.
- Speculation arose about the legitimacy of the pricing strategy, with one user humorously suggesting the models might be pirated, though quickly dismissed as unfounded; however, discussion continues on the actual costs of running inference on various models.
- Image Generation Feature Flounders: Despite access to widgets indicating image generation capabilities, some users encountered difficulties using this feature on the platform.
- Workarounds were discussed, including crafting specific prompts for image creation and using browser addons; however, full integration into Perplexity appears to be ongoing.
- R1-1776 Model Promises Censorship-Free Responses: The reasoning capabilities of the R1-1776 model and its differences from the standard R1 model were examined, noting its potential for censorship-free responses based on the DeepSeek model.
- Users shared experiences using the model, highlighting its performance on sensitive topics and operational context, specifically using the OpenRouter API.
- IRS Supercharges with Nvidia: The IRS is reportedly acquiring an Nvidia Supercomputer to enhance operational capabilities, boosting efficiency in data analysis for tax processing.
- This move is seen as critical in optimizing tax processing technologies amidst increasing data challenges, though specific model details or configurations have not been released.
Interconnects (Nathan Lambert) Discord
- Grok 3 Announcement Sparks Skepticism: While Grok 3 shows promise, skepticism about its true capabilities remains, as users seek reliable sources beyond Twitter for performance verification. Members discuss concerns regarding overall performance metrics and whether Grok 3 can compete effectively.
- Concerns are being raised about reading Hacker News comments. Why does XAI discussion feel so stressful?.
- Google Debuts PaliGemma 2 Mix: Google introduced PaliGemma 2 mix that allows for out-of-the-box usage on a diverse set of tasks, moving beyond pre-training checkpoint limitations. See the release blogpost.
- Comparisons are made to previous versions, with discussions about the clarity and practicality of the naming and functionality.
- AI CUDA Engineer Aims for Kernel Speed: Sakana AI launched the AI CUDA Engineer, an AI system designed to produce optimized CUDA kernels that can achieve 10-100x speedup over typical implementations. Check out Sakana AI's Announcement.
- This system is heralded as potentially transformative for AI-driven performance optimization in machine learning operations.
- Tulu3 70B Gets Week-Long RLVR Training: The RLVR phase training for the tulu3 70B model on an 8×8 H100 setup is estimated to take about a week if it fits in memory. Using GRPO will enhance memory capabilities, which could positively influence the training process.
- The team noted they have updated the paper with relevant information about the training phase.
- Evo 2 Emerges as Foundation for Biology: Michael Poli announced Evo 2, a new foundation model boasting 40 billion parameters designed for biological applications, set to advance understanding of genomics significantly. See Michael Poli's Announcement.
- Evo 2 aims to demonstrate test-time scaling laws and improve breast cancer variant classification while promoting real open-source efforts in AI.
OpenRouter (Alex Atallah) Discord
- OpenRouter Debates Reasoning Token Defaults: Due to user feedback that they would prefer to receive content even when max_tokens is low, OpenRouter is reconsidering its default setting for include_reasoning.
- There is a poll open for community feedback with four options ranging from keeping the current setting to making reasoning tokens default, and a supplementary option for user comments.
- Grok 3 Fails to Impress in Reasoning Tasks: Users report that Grok 3's reasoning capabilities are underwhelming when compared to Claude 3.5 and O1, despite its reputation as a top-tier LLM.
- One user stated it did not live up to the hype with concerns about its current standing.
- New Users Express Confusion Navigating OpenRouter API: New users are having a hard time accessing OpenRouter and utilizing O3 mini via the API, which leads to questions about usage limitations.
- There is a need for better integration options and clarity on API key usage, especially regarding the gradual rollout of model access.
- Perplexity R1 1776 Enters the Ring: The R1 1776 model from Perplexity, a version of the DeepSeek R1 model, has been launched, granting users access to a model that has been post-trained to remove censorship.
- The announcement on X links to the HuggingFace Repo for the model weights.
- Chatbot Integration Asks for Help: A user needs guidance on integrating an AI chatbot on an HTML website using the OpenRouter API, highlighting a need for readily available resources.
- Community members suggested that they would need to develop the solution or hire a developer for assistance.
Stability.ai (Stable Diffusion) Discord
- ControlNet Boosts Image Accuracy: ControlNet enhances image generation in both Stable Diffusion (SD) and Flux by using poses as skeletal references, improving generated image accuracy.
- Users find that ControlNet works well with both SD and Flux to generate images in specific poses.
- SwarmUI Simplifies AI Tool Access: ComfyUI's complex, mindmap-like interface is not user-friendly for casual users, but SwarmUI and other one-stop-shop solutions offer easier access.
- These alternatives provide simpler interfaces to make AI tools more accessible.
- RTX 3080 Handles SD and Flux Effectively: Users with an RTX 3080 GPU can effectively run both Stable Diffusion 3.5 and Flux.
- The choice between SD 3.5 and XL depends on the user's specific needs, with newer models offering better features.
- Installation Guides Streamline Setup: Installation guides for SwarmUI, CS1o tutorials, and Lykos Stability Matrix provide detailed steps for setting up AI tools.
- These resources assist users in navigating the installation process for different interfaces, such as the LykosAI Stability Matrix.
Torchtune Discord
- Torchtune H1 2025 Roadmap Goes Public: The Torchtune roadmap for H1 2025 is now available on PyTorch dev-discuss, outlining key objectives and timelines, including staying ahead of new model architectures.
- The team aims to prioritize existing core work, and the roadmap complements other exciting developments across the entire PyTorch organization.
- Packing increases VRAM usage: Users found that employing packing with longer sequence lengths can significantly elevate VRAM requirements during training, leading to unpredictable memory allocation.
- The community is actively investigating kernel differences to optimize memory management and settings.
- Llama 3B acts nonsensical after finetuning: After fine-tuning 3B Llama models, users reported issues of the model speaking nonsense during inference, contrasting sharply with the 8B variant.
- The team suspects potential bugs in the model export and checkpointing process in Torchtune, which could be affecting the 3B model.
- New attention mechanisms on the horizon: There is community interest in integrating advanced attention mechanisms like sparse and compressed attention into Torchtune for improved efficiency.
- The Torchtune team welcomes new ideas, with an emphasis on utilizing PyTorch core functionalities.
- StepTool Enhances Multi-Step Tool Usage: The paper StepTool: Enhancing Multi-Step Tool Usage in LLMs through Step-Grained Reinforcement Learning at arxiv.org/abs/2410.07745 introduces StepTool, a novel reinforcement learning framework that enhances multi-step tool usage for LLMs by treating tool learning as a dynamic decision-making task.
- The key is Step-grained Reward Shaping that offers rewards during tool interactions based on their success and contribution to the task, optimizing the model's policy in a multi-step manner.
Nous Research AI Discord
- Grok-3 API Remains Elusive: Members discussed the absence of an API for Grok-3, which limits its usability, and suggested the need for independent benchmarks before any testing can occur.
- Observations suggest Grok-3 might obfuscate content, leading to ongoing conversations about how it could be integrated and used in various applications.
- Le Chat Wins Hearts with Speed and Quality: Users reported positive experiences with Le Chat, praising its speed, image generation capabilities, and overall quality compared to other models; French residents are being offered a low-cost subscription.
- One user shared a link to Le Chat, describing it as “seriously impressive compared to the competition, especially at this price point for French residents.”
- AI Rendering Could Transform Game Design: Discussions focused on the potential of AI rendering to revolutionize gaming through dynamic and interactive environments.
- Members expressed concerns about balancing AI-generated content with traditional game development, stressing the importance of meaningful engagement with the technology as Satya Nadella described it in a tweet about imagining entire interactive environments created with AI.
- SWE-Lancer Tasks Models with $1M Challenge: The SWE-Lancer benchmark, as described in the paper, includes over 1,400 freelance software engineering tasks from Upwork, collectively valued at $1 million USD.
- Tasks range from $50 bug fixes to $32,000 feature implementations, evaluation shows that frontier models struggle to solve most tasks effectively.
- MoBA Targets Long-Context LLM Performance: MoBA, documented on GitHub, introduces a Mixture of Block Attention method designed to improve the performance of long-context LLMs.
- This project aims to overcome limitations in effectively handling lengthy input, and can be found on GitHub for additional insights and contributions.
Notebook LM Discord
- Notebook LM excels at teaching books: A user is confident that Notebook LM can effectively teach them a book by using precise prompts, with hopes it helps avoid skipping key parts.
- This reflects the growing user experimentation and reliance on AI tools for personalized learning experiences.
- Audio Discussions Get Interrupted: A user appreciated how Notebook LM helps organize responses but found the audio discussion hard to follow due to frequent interruptions between voices.
- They suggested a more structured approach where one voice presents a complete idea before the other interjects, indicating a need for improved audio management features.
- Podcast TTS Prompting Proves Problematic: A user sought assistance with TTS prompts for the podcast feature, struggling to make the host read text word for word.
- The request for the exact prompt used demonstrates the challenges in achieving precise control over AI-driven voice outputs.
- Notebook LM Access Faces Limitations: A user inquired about inviting non-Google account holders to access a Notebook, similar to Google Docs sharing capabilities.
- This underscores the ongoing limitations in access and collaboration features within Notebook LM, potentially hindering broader adoption.
- NotebookLM Plus Gets Usage Caps: Users noted that NotebookLM Plus has daily limits of 500 chat queries across all notebooks and sharing is capped at 50 users.
- The suggestion to create multiple accounts to bypass these limits shows that users are looking for ways to maximize utility despite current restrictions on AI Tool usage.
GPU MODE Discord
- AI CUDA Engineer Auto-Generates Kernels: Sakana AI introduced the AI CUDA Engineer which auto-generates optimized CUDA kernels, potentially achieving 10-100x speedup over common PyTorch operations by translating PyTorch ops to CUDA.
- The tool's process involves using an evolutionary approach driven by LLMs to surpass traditional torch.compile, along with releasing a dataset of 17,000 verified CUDA kernels.
- CUDA Installs Prove Challenging on Windows: Multiple users report that the CUDA Express Installer is getting stuck on components like Nsight and Visual Studio for different NVIDIA GPUs on Windows.
- Difficulties were highlighted when installing CUDA 12.5 and 12.8 with Visual Studio, with concerns raised about the ease of installation on Linux compared to Windows.
- DeepSeek Aims to Improve Reasoning with CodeI/O: DeepSeek released a paper on CodeI/O, designed to improve reasoning by converting code into input-output prediction formats.
- The new training approach bases itself on natural language tasks, which is a deviation from enhancing narrow skills; the paper can be found on github.
- ROCm Developer Certification Launched by AMD: AMD introduced a ROCm Application Developer Certificate to enhance GPU computing skills within the ROCm ecosystem.
- The certification aims to promote specialization in open-source GPU computing technologies.
- Kokoro TTS Optimized with Triton and CUDA: Inference speed improvements for Kokoro, a modern TTS model, was achieved using Triton + CUDA graph to reduce kernel launch overhead of LSTM at bs=1 on a 4070Ti SUPER.
- A member stated I can't believe I had to optimize LSTM in this day and age 😂, and cited measurements on his improvement.
Eleuther Discord
- DeepSeek R1 Arrives with Enhanced Quants: A member shared a link for running Perplexity's uncensored DeepSeek R1 and other model versions on Hugging Face.
- The new dynamic 2-bit GGUF quants promise improved accuracy over standard 1-bit/2-bit formats; instructions for usage are included.
- Model-Guidance Accelerates Diffusion Model Training: The Model-guidance (MG) objective removes Classifier-free guidance (CFG), accelerates training, and doubles inference rates, achieving state-of-the-art performance on ImageNet 256 benchmarks with an FID of 1.34.
- Evaluations confirm MG sets a new standard in diffusion model training.
- AI CUDA Engineer Automates Kernel Optimization: The AI CUDA Engineer automates CUDA kernel creation, achieving 10-100x speedup over standard PyTorch, and includes a release of 17,000 verified kernels.
- This development is purported to mark a new era of AI-driven efficiencies in machine learning operations, with implications for automated optimization of inference times.
- Optimizing LLM Compute Allocation Explored: Members discussed the increasing focus on optimizing test-time compute in recent LLM releases like Grok 3, and that scaling up pretraining compute was yielding benefits.
- Despite speculation on allocation balance between pre-training versus post-training, data on resource allocation remains largely unavailable.
- Transformer Engine Faces Hurdles in NeoX: A member attempting to integrate the Transformer Engine in NeoX encountered challenges that halted testing, suggesting that enabling non-FP8 flags resulted in system failure.
- This highlights integration complexities while aiming to uphold system reliability.
Yannick Kilcher Discord
- Elon Enters Gaming with Grok 3: Elon Musk's xAI announced the creation of a new game studio related to Grok 3, expanding its AI initiatives into the gaming realm as posted on Twitter.
- This move follows the recent branding update of Grok 3, suggesting a strategic shift towards integrating AI with gaming applications.
- DeepSeek Navigates Sparse Attention: A community discussion highlighted DeepSeek's new paper, Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention (link), praised for its quality.
- The paper introduces a novel approach to sparse attention mechanisms that are both hardware-aligned and natively trainable, addressing computational efficiency.
- Murati Machines New AI Lab: Mira Murati, former OpenAI CTO, launched Thinking Machines Lab, which is focused on developing more understandable and customizable AI systems while ensuring public transparency.
- While specific projects are under wraps, the lab promised to regularly publish technical research, with the goal of making AI systems less opaque.
- Perplexity Pioneers Post-Censorship AI: Perplexity AI introduced R1 1776, a new model designed to overcome Chinese censorship using innovative post-training techniques on DeepSeek's R1 model.
- This approach aims to create more robust AI systems that generate content while maintaining contextual integrity, even when faced with censorship constraints.
- Microsoft Makes Quantum Leap with Majorana 1: Microsoft unveiled Majorana 1, the first Quantum Processing Unit powered by topological qubits, with potential scaling to a million qubits on a single chip.
- This advancement represents a significant stride toward practical quantum computing, paving the way for a new era in computational technology.
Latent Space Discord
- Thinking Machines Lab is Born: Thinking Machines Lab has launched, aiming to enhance the accessibility and customization of AI systems, led by notable figures such as Mira Murati (ex-OpenAI CTO) and Lilian Weng, addressing knowledge gaps in AI.
- The lab's creation has sparked excitement in the AI community, with Andrej Karpathy congratulating the team, many of whom were involved in building ChatGPT.
- Perplexity AI's R1 1776 Goes Open-Source: Perplexity AI has open-sourced R1 1776, a version of their DeepSeek R1 model, designed to provide uncensored and unbiased information, pushing for more reliable AI models.
- The AI community is playfully calling this 'freedomtuning', signaling the model's emphasis on unfiltered data and factual accuracy.
- OpenAI's SWElancer Sets New Coding Benchmark: OpenAI introduced SWElancer, a new benchmark featuring over 1,400 freelance software engineering tasks, to evaluate AI coding performance in real-world scenarios.
- This initiative arrives amid discussions about the potential of AI-driven game generation replacing traditional game studios, highlighting the need for realistic metrics.
- Mastra's JS SDK Unleashes AI Agents: Mastra launched an open-source JavaScript SDK, designed to facilitate the development of AI agents capable of complex task execution with built-in workflows.
- The framework is designed for easy collaboration and integration with Vercel’s AI SDK, marking a significant advancement in open-source AI development.
- Lambda Lands $480M Series D Funding: Lambda secured a substantial $480 million Series D funding round, co-led by Andra Capital and SGW, highlighting growing interest in cloud services tailored for AI applications.
- Participation from investors like NVIDIA and ARK Invest emphasizes the firm's potential in the evolving AI landscape.
Modular (Mojo 🔥) Discord
- Grok 3 Arrives Early, Surprising Mojo: The release of Grok 3 preempted Mojo's progress, sparking interest among developers rather than discouragement.
- The early arrival is considered beneficial, potentially driving further innovation in Mojo.
- Polars Integrates Swiftly into Mojo: A developer reported quickly importing Polars into a Mojo project, sharing their implementation, including examples, on GitHub.
- Clarifications were made regarding the distinction between implementing versus importing Polars in the project's context.
- MAX 25.1 Livestream Sparks Curiosity: An upcoming livestream will cover MAX 25.1, with a Google Form available for question submissions.
- The event is promoted via LinkedIn, encouraging community engagement.
- Mojo's Quick Sort Faces Performance Bottleneck: A user discovered that a Mojo-implemented quick sort algorithm was significantly slower (2.9s) than its Python counterpart (0.4s).
- The ensuing discussion suggested using Mojo's benchmark module to isolate and accurately measure sort performance, and to watch out for compile time affecting timing results.
- Slab List Gains Traction Over Linked List: Members explored the advantages of SlabList over traditional LinkedLists, focusing on constant time operations and cache efficiency, pointing to nickziv's github.
- A slab list was defined as
LinkedList[InlineArray[T, N]], streamlining memory usage without intricate manipulations.
- A slab list was defined as
Nomic.ai (GPT4All) Discord
- CUDA GPUs Get Some Love: The guild discussed adding support for older CUDA 5.0 compatible GPUs like GM107/GM108, with members noting the lack of support for low-end architectures.
- A member confirmed that a PR supporting these GPUs has been merged and will be included in the next release, as per the CUDA Wikipedia page.
- GPT4All Embedding Token Limits Revealed: Members discussed reaching the 10 million token limit for embedding in GPT4All, noting a base price of $10/month with added costs for additional tokens.
- It was clarified that removing tokens from local documents does not reduce the total token count billed.
- Chat Templates Prompting Headaches: Members sought clarification on using chat templates to instruct the model to quote excerpts, but were told that system message instructions would suffice, according to GPT4All's docs.
- Other members inquired about the effectiveness of Jinja or JSON code in prompting the model, which suggests complexity in achieving expected outputs.
- Nomic v2 Release MIA?: Speculation arose regarding the absence of Nomic v2, with members expressing curiosity about the delay and pointing out its importance.
- One member humorously questioned the prolonged wait without updates on the new version.
- Image Handling Falls Flat in GPT4All: A member requested the ability to copy and paste images directly into the chat, similar to other platforms, but GPT4All currently does not support image inputs.
- The guild suggested using external software for image handling instead.
MCP (Glama) Discord
- Anthropic Shuts Down Unexpectedly: The Anthropic homepage experienced downtime, sparking speculation about potential service interruptions.
- The downtime was reported by a member, and shared via an attached image.
- Haiku 3.5 Rumors Flying High: Discussions surround the potential release of Haiku 3.5, possibly featuring tool and vision support.
- A member also suggested we might see Sonnet 4.0 released.
- Cursor MCP Tool Detection Falters: Multiple members reported Cursor MCP reporting 'No tool found', suggesting a widespread issue.
- One user shared an /sse implementation to address the issue, providing a link to shared information.
- Google Workspace MCP Packs a Punch: A member highlighted their Google Workspace MCP on Docker, supporting multiple accounts and auto token refresh, with Docker images for different platforms.
- This MCP offers integrated access to Gmail, Calendar, and other Google Workspace APIs.
- Python REPL Gets Matplotlib: A member introduced their Python REPL for MCP, providing STDIO support, matplotlib, seaborn, and numpy.
- Future plans include adding IPython support, with a strong interest in visualizations similar to those in Jupyter.
LlamaIndex Discord
- LlamaCloud EU Eliminates Barriers: LlamaCloud EU has been announced, offering secure, compliant knowledge management specifically for European enterprises with a focus on data residency within EU jurisdiction here.
- This early access offering aims to eliminate a significant barrier for European companies concerned about compliance and data privacy.
- Vendor Questionnaires App Retrieves Answers: An innovative full-stack app from @patrickrolsen allows users to answer vendor questionnaires by semantically retrieving previous answers and enhancing them with an LLM.
- This application represents a core use case for knowledge agents by streamlining the process of reading forms and filling in answers.
- AgentWorkflow Tool's Output has Bug: A user reported that their AgentWorkflow's tool output list remains empty despite generating responses, seeking clarity on implementation of the AgentWorkflow tool.
- Another member shared that streaming events could serve as a workaround to capture all tool calls during execution in the AgentWorkflow.
- Challenges on Next Phase in AI and Data Ops: A recent post titled The End of Big Dumb AI & Data discusses emerging trends in AI and data operations that challenge traditional approaches.
- It emphasizes a shift towards more intelligent and efficient systems in handling data for better decision-making and focuses on federal technology spending and enterprise AI applications since its launch two years ago.
LLM Agents (Berkeley MOOC) Discord
- MOOC Students Achieve Legendary Status: The F24 MOOC recognized 15,000 students, celebrated 304 trailblazers, 160 masters, 90 ninjas, 11 legends, and 7 honorees.
- Course staff highlighted that three honorees came from the ninja tier and four from the masters, signaling broad achievement.
- Advanced Course Certificates are Here!: Members inquired about the availability of an advanced course certificate and whether it's possible to obtain it without the F24 MOOC certificate, with course staff responding affirmatively to both questions.
- More details will be released soon regarding the specifics for certificate acquisition for the advanced course.
- LangChain Streamlines LLM Applications: LangChain is designed to streamline the LLM application lifecycle, covering areas such as development, productionization, and deployment with various components.
- It functions by linking outputs from one LLM as inputs to another, effectively creating chains for enhanced performance, which is useful to know for LLM application architects.
- Explore LLMs with Machine Learning Forecasting Models: There was discussion regarding combining LLM agents with machine learning forecasting models, suggesting a review of academic papers on Everscope for insights.
- Filtering for all-time on Everscope might yield the best papers related to LLMs, enabling you to study new techniques.
- MOOC course videos now available: Course staff announced that video lectures from current course remain available in the syllabus.
- Course staff encouraged members to sign up for the Spring 2025 iteration to continue learning, as quizzes and tests are no longer available for previous courses.
Cohere Discord
- Channels Experience Heavy Traffic: All text channels are experiencing heavy traffic indicating that there is a surge in ongoing discussions.
- It was also noted that much of the traffic is due to automation bots and a member has requested a new channel dedicated to sharing screenshots.
- Profit-Sharing Proposal Causes Stir: A member proposed a profit-sharing collaboration targeting individuals aged 25-50, with potential profits ranging from $100 to $1500.
- This proposal sparked a debate around sharing identity and the balance between collaboration and theft.
- Identity Sharing Under Scrutiny: Members voiced concerns regarding the privacy implications of sharing personally identifiable information within the community, which led to questions such as Identity theft is this open nowadays?.
- A member advised that clearer writing is essential when sharing opinions to prevent misunderstandings, especially in a text-based medium.
- Transparency called for in projects channel: In the projects channel, posters highlighted a lack of detail in a proposal and an absence of website or documentation.
- A user described the whole venture as suspicious, noting that transparency is crucial for cautious collaboration.
- Coffee-less world Implications Investigated: A request has been made for an essay exploring the cultural and economic consequences of a world without coffee.
- This topic opens up a discussion on the hypothetical scenarios and societal changes that could occur without this popular beverage.
AI21 Labs (Jamba) Discord
- Users Seek Help Integrating Jamba-1.5-large model: A user requested assistance on how to format requests to the
jamba-1.5-largemodel via the AI21 API, with members providing API reference and examples for proper request construction.- The discussion highlighted the specific headers and parameters necessary for successful API calls, particularly when integrating with
jamba-1.5-large.
- The discussion highlighted the specific headers and parameters necessary for successful API calls, particularly when integrating with
- Escape Characters Appear in Jamba 1.5 API Output: A user inquired about unexpected details in API outputs when solving mathematical expressions using the AI21 API.
- A member clarified that escape characters in the output require additional code adjustments for clean display, as the AI21 Studio UI handles these characters automatically.
- API Responses Demand Special Character Treatment: Community members discussed the necessity of removing special characters from AI21 API responses when using PHP.
- The discussion emphasized that while AI21 Studio UI is designed to handle special characters, additional code handling is required for proper output formatting when directly accessing the API.
- PHP & Symfony Integration Creates Challenges: A user highlighted challenges integrating AI21 API responses using Symfony and PHP, indicating the need for extensive data conversions and custom handling.
- The user thanked the community for providing insights on effectively working with and formatting the API outputs within the PHP environment.
DSPy Discord
- SPO Framework Optimizes Prompts: A new Self-Supervised Prompt Optimization (SPO) framework discovers effective prompts for both closed and open-ended tasks without external references, enhancing LLM reasoning capabilities as detailed in the Self-Supervised Prompt Optimization paper.
- The framework derives evaluation signals purely from output comparisons, making it cost-efficient; one participant noted the paper failed to mention DSPy until the last paragraph.
- Zero-Indexing Internet Search improves RAG: A study introduces a new approach to Retrieval Augmented Generation (RAG), detailed in Zero-Indexing Internet Search Augmented Generation for Large Language Models, by using standard search engine APIs to dynamically integrate the latest online information during generative inference.
- This paradigm involves a parser-LLM that determines the need for Internet augmentation and extracts search keywords in a single inference to improve generated content quality without relying on a fixed index.
- DSPy Synthesizes Data with Jinja2: Members shared a link to a GitHub repository showcasing structured outputs from DSPy and Jinja2, emphasizing their combined capability in synthetic data generation.
- A synthetic data generation pipeline could be utilized to train ChatDoctor with an attached image for illustration.
- Judge-Time Scaling Library Verdict Debuts: A member shared a post by Leonard Tang expressing excitement over a new library called Verdict, which focuses on scaling judge-time compute, aiming to tackle the evaluation limitations in AI, particularly in open-ended and non-verifiable domains.
- Another member indicated that this library would be ideal for their concept of a Personal Voice Identity Manager, highlighting its potential impact on personal identity management within AI frameworks.
- DSPy Prompt Freezing Loses Control Flow: A member shared a code snippet showing how to freeze and export all prompts in a DSPy program into message templates, using a default adapter.
- While this method is convenient, it may lead to losing control flow logic, suggesting alternatives like
program.save().
- While this method is convenient, it may lead to losing control flow logic, suggesting alternatives like
tinygrad (George Hotz) Discord
- Mixed bag of Model Performance on Differing Setups: A user reported testing on a 10-year-old GeForce 850M and only yielded 3 tok/s, whereas another with an RTX 4070 on Windows 11 got 12 tok/s.
- The user with the RTX 4070 mentioned a 1.9 seconds time to first token.
- Computational Cost Still Prohibitive: Despite decent performance with an RTX 4070, a user finds that the model is not very usable due to high computational costs and complexity.
- They pinpointed problems such as numerical stiffness and difficulties with nonlinear sub-problems complicating accurate solution retrieval.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!