[AINews] The Last Hurrah of Stable Diffusion?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
MultiModal Diffusion Transformers are All You Need.
AI News for 6/11/2024-6/12/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (413 channels, and 3555 messages) for you. Estimated reading time saved (at 200wpm): 388 minutes. Track AINews on Twitter.
SD3 Medium was launched today with an unusually (for Stability) flashy video:

The SD3 research paper is noteworthy for it's detail on the MMDiT architecture and usage of the T5 text encoder for text rendering in images, but also for mentioning its range of models from 450M to 8B params, making the 2B parameter SD3 Medium not the most powerful SD3 version available.
If you've been diligently reading the Discord Summaries for the Stability AI discord, you'll have known that the community has been fretting about the open weights release of SD3, first announced 3 months ago, released as Paper and as API, on an almost daily basis, particularly since the exit of Emad Mostaque and Robin Rombach and many of the senior researchers involved in the original Stable Diffusion. Adding up points of related posts, it is easy to see the gradual stalling of interest from SD1 to SD2 to SD3 as the project became increasingly less default-open:
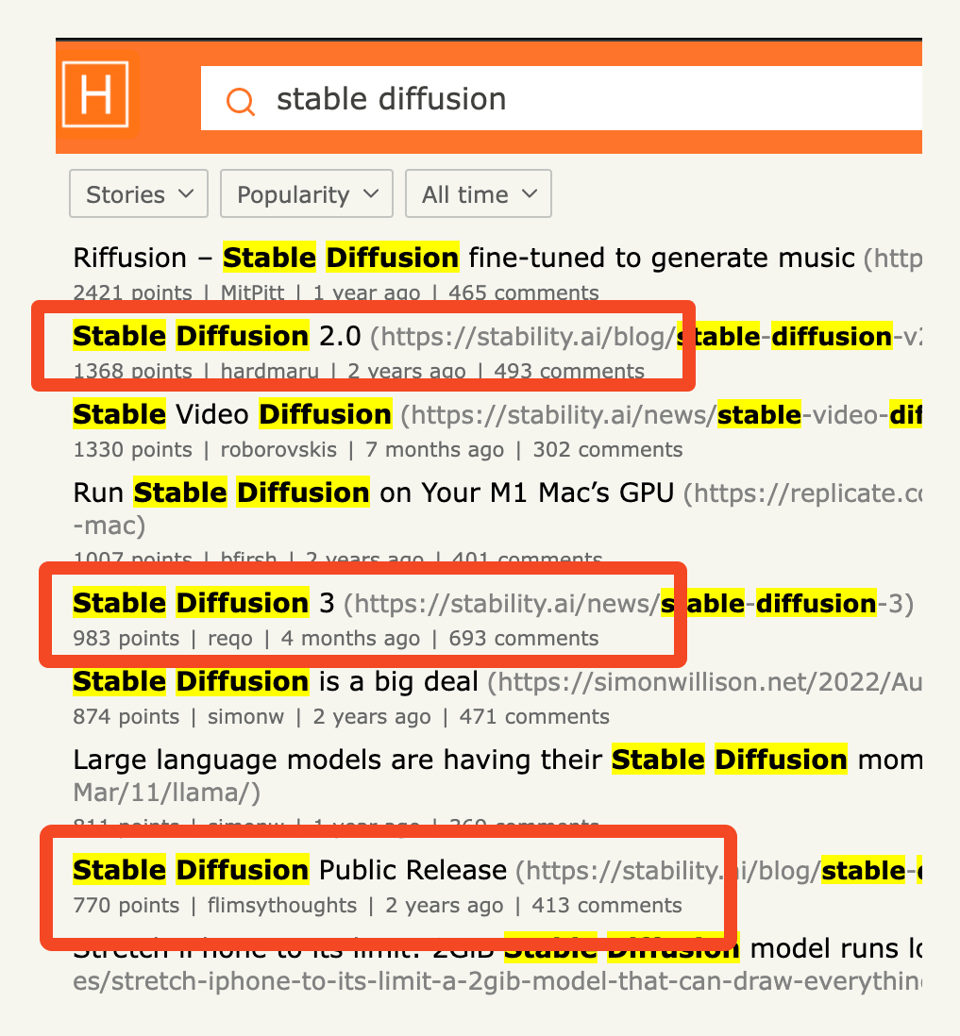
This was the last legacy of Emad's tenure at Stability - the new management must now figure out their path ahead on their own.
The Table of Contents and Channel Summaries have been moved to the web version of this email: ! (Share on Twitter.)
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- Llama 3 and Instruction Finetuning: @rasbt found Llama 3 8B Instruct to be a good evaluator model that runs on a MacBook Air, achieving 0.8 correlation with GPT-4 scores. A standalone notebook is provided.
- Qwen2 and MMLU Performance: @percyliang reports Qwen 2 Instruct surpassing Llama 3 on MMLU in the latest HELM leaderboards v1.4.0.
- Mixture of Agents (MoA) Framework: @togethercompute introduces MoA, which leverages multiple LLMs to refine responses. It achieves 65.1% on AlpacaEval 2.0, outperforming GPT-4o.
- Spectrum for Extending Context Window: @cognitivecompai presents Spectrum, a technique to identify important layers for finetuning. It can be combined with @Tim_Dettmers' QLoRA for faster training with less VRAM.
- Grokking in Transformers: @rohanpaul_ai discusses a paper showing transformers can learn robust reasoning through grokking - extended training beyond overfitting. Grokking involves a transition from a "memorizing" to a "generalizing" circuit.
Benchmarks and Datasets
- ARC Prize Challenge: @fchollet and @mikeknoop launch a $1M competition to create an AI that can adapt to novelty and solve reasoning problems, aiming to measure progress towards AGI.
- LiveBench: @micahgoldblum announces LiveBench, a general-purpose live LLM benchmark that releases new questions to avoid dataset contamination and can be judged objectively.
- Character Codex Dataset: @Teknium1 releases Character Codex, an open dataset with data on 15,939 characters from various sources for use in RAG, synthetic data generation, and roleplaying analysis.
Tools and Frameworks
- MLX 0.2: @stablequan releases MLX 0.2, providing a new LLM experience on Apple Silicon Macs with a revamped UI/UX, fully-featured chat, and faster RAG.
- Unsloth: @danielhanchen announces Unsloth is now in Hugging Face AutoTrain, allowing 2x faster QLoRA finetuning of LLMs like Llama-3, Mistral, and Qwen2 with less memory.
- LangChain Integrations: @LangChainAI adds Elasticsearch capabilities for flexible retrieval and vector databases. They also ship @GroqInc support in LangSmith Playground.
Applications and Use Cases
- Brightwave AI Research Assistant: @vagabondjack announces a $6M seed round for Brightwave, an AI research assistant generating financial analysis, with customers managing over $120B in assets.
- Suno Audio Input: @suno_ai_ releases an Audio Input feature, allowing users to make songs from any sound by uploading or recording audio clips.
- Synthesia 2.0 Event: @synthesiaIO teases new features, workflows, use cases, and avatar capabilities for their AI video generator, with an event on June 24.
Discussions and Opinions
- Prompt Engineering vs. Finetuning: @corbtt argues that fine-tuned adapters will outperform prompting for better performance, control, and cheaper inference in the coming years.
- Unintended Consequences of RLHF: @rohanpaul_ai shares a paper exploring how RLHF alignment reduces model creativity and output diversity due to blocked token trajectories and mode collapse.
- Hallucinations in LLMs: @rohanpaul_ai cites a paper showing that statistically calibrated language models must hallucinate at a certain rate.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Progress and Timelines
- GPT-1 anniversary: In /r/singularity, it was noted that GPT-1 was released exactly 6 years ago, with hope expressed that by June 2030 we will be in the AGI or ASI era.
AI Companies and Products
- Tesla Optimus deployment: /r/singularity shared that Tesla has deployed two Optimus bots performing tasks autonomously in their factory.
- Musk drops OpenAI lawsuit: /r/singularity and /r/OpenAI reported that Elon Musk dropped his lawsuit against OpenAI and Sam Altman, with emails showing Musk previously agreed with the for-profit direction.
- Apple partners with OpenAI: According to /r/singularity, Apple announced Apple Intelligence, powered by OpenAI and funded by Microsoft, with on-device AI using OpenAI if local solutions fail.
- OpenAI uses Oracle Cloud: /r/OpenAI noted OpenAI selected Oracle Cloud Infrastructure to extend the Microsoft Azure AI platform.
- Ex-Google CEO criticizes open models: /r/singularity discussed the ex-Google CEO condemning open source models and arguing for government curbs on public releases, with counterarguments that this protects big tech monopolies.
AI Capabilities
- Restaurant robots advance: /r/singularity shared that restaurant robots can now cook, serve and bus meals.
- Robot dog sharpshooters: According to /r/singularity, a study found machine gun-wielding robot dogs are better sharpshooters than humans.
- AI video generation: /r/singularity noted Katalist AI Video allows turning a sentence into a storyboard and consistent video story in 1 minute, with potential for future movie production.
- AI job interviews: According to /r/singularity, AI cartoons may interview you for your next job.
- Deepfake nudes: /r/singularity warned that teens are spreading deepfake nudes of one another, causing serious issues.
AI Research
- Autoregressive image models: /r/MachineLearning and /r/singularity discussed new LlamaGen research showing autoregressive models like Llama beating diffusion for scalable image generation, with questions raised about fairly citing prior autoregressive work.
- Eliminating matrix multiplication: /r/singularity shared a revolutionary approach that eliminates matrix multiplication in language models without losing performance, using a custom FPGA solution to process billion-parameter models at 13W.
- Overtraining transformers: According to /r/singularity, research found overtraining transformers beyond the overfitting point leads to unexpected reasoning improvements.
- MaPO alignment technique: /r/MachineLearning noted MaPO is a sample-efficient reference-free alignment technique for diffusion models that improves on prior work.
- Megalodon for LLM pretraining: /r/MachineLearning shared that Megalodon allows efficient LLM pretraining and inference with unlimited context length.
Stable Diffusion
- Stable Diffusion 3.0 release: /r/StableDiffusion is highly anticipating the Stable Diffusion 3.0 release set for June 12th, with much excitement and memes from the community.
- SD3 model debate: /r/StableDiffusion is debating whether the SD3 2B or 8B model will be better, with the 8B model still training but expected to surpass 2B when finished.
- Open source training tools: According to /r/StableDiffusion, new open source tools like Kohya DeepShrink enable high-res SD training.
- SDXL vs SD3 comparisons: /r/StableDiffusion is comparing SDXL vs SD3 car images and other subjects, with SD3 showing improved proportions, reflections, and shadows.
Humor/Memes
- /r/singularity shared a meme showing Woody and Buzz as AI models, implying we are the "toys".
- /r/singularity posted a meme of the 10 commandments with "Thou shalt not take the name of the ASI in vain".
- /r/singularity shared a meme of Clippy asking if it would fold us into oblivion.
AI Discord Recap
A summary of Summaries of Summaries
1. Stable Diffusion 3 Release and Discussions
- Stability.ai released the open weights for Stable Diffusion 3 Medium, their latest text-to-image AI model promising exceptional detail, color, advanced prompt understanding using three text encoders, and superior typography rendering.
- Users reported issues with human anatomy accuracy, mixed reactions on performance compared to older versions like SD 1.5 and SDXL, and concerns over the restrictive licensing terms limiting commercial use.
- Extensive discussions around finetuning challenges, particularly for popular use cases, installation issues with existing frameworks like ComfyUI and diffusers, and the model's efficient GPU utilization.
2. Large Language Model (LLM) Advancements and Benchmarks
- Google unveiled RecurrentGemma 9B, capable of handling long sequences quickly while maintaining quality on par with Gemma, featuring base and instruct-tuned versions.
- The $1,000,000+ ARC Prize was announced to develop a solution for the ARC-AGI benchmark, measuring general intelligence through skill acquisition efficiency, sparking discussions on its significance.
- Scalable MatMul-free Language Modeling suggests eliminating matrix multiplication from LLMs while retaining strong performance, reducing memory usage during training.
3. Collaborative LLM Development and Deployment
- Members sought guidance on installing and integrating models like mistral-instruct, GPT-4o, and Codestral using tools such as llm, Datasette, and LangServe, with resources shared on Hugging Face and GitHub.
- Discussions around LLM evaluation methodologies, the importance of standardized evaluations, and the potential of LLM-as-judge systems, with insights from Hailey Schoenfeld.
- Queries on LLM finetuning using Modal, Predibase, and Axolotl, covering topics like dataset preparation, resource constraints, and merging results from techniques like LoRA and qLoRA.
4. Hardware Optimization and Resource Management
- Affordable 3090 GPUs on platforms like Kijiji Canada sparked interest in building GPU rigs, with considerations for power draw, heat management, and optimizing performance metrics like flops/watts.
- Developers achieved 100% determinism in their code but faced issues like loss values hitting -inf, indicating potential bugs requiring resolution.
- Efforts to improve computational efficiency resulted in a custom matmul implementation achieving 70% speed of cuBLAS, with ongoing work to remove dependencies on cuBLASLt and tackle stable FP8 implementation.
Claude 3 Opus (>220B?)
Here is a high information density, technical summary of the top 3-4 major themes across the provided Discord content, with important key terms, facts, and URLs bolded and linked to sources where relevant:
- Unsloth AI's QWEN Models Spark VRAM and Fine-Tuning Discussions: Unsloth AI users compare VRAM requirements for Qwen2 models like the 72b variant (estimated 48GB, similar to Llama 3 70b) and share tips for converting PyTorch bins to safetensors. Fine-tuning challenges with Qwen2-1.5b using methods like Qlora and Galore are discussed, with rank 64-128 recommended to avoid failures. Performance drops after 16-bit merging are attributed to tokenizer/GGUF issues.
- LLM Fine-Tuning Course Learnings Applied and Debated: Participants reflect on Nehil's blog post applying course concepts to improve budget categorization prompts. Technical discussions cover adding pooling layers to Huggingface models, the impracticality of broad-scope chatbots vs. scoped interfaces due to security/privacy concerns, and using Modal to fine-tune LLMs for Kaggle competitions. Interest in Datasette, Anthropic Claude, and resources for transitioning from academia to industry is evident.
- GPU Market Dynamics and Creative Applications: Affordable 3090 GPUs on Kijiji Canada (~$450 USD) inspire GPU rig building plans, with power draw and heat repurposing considerations discussed. Custom CUDA development efforts, like achieving 100% determinism and implementing efficient matrix multiplication, are shared alongside the Scalable MatMul-free Language Modeling paper and implementation. The CUDA Performance Checklist lecture is re-released with video, code, and slides.
Let me know if you would like me to elaborate on any part of this summary or if you have additional questions!
GPT4T (gpt-4-turbo-2024-04-09)
Summaries:
1. Exploring LLM-Eval Harness and ARCSynthetic Challenges in EleutherAI:
- Members of EleutherAI explored LLM-Eval harness and shared insights on traditional vs. score-based evals, prompting a collaborative environment aiming to improve sensitivity and specificity regarding specific use cases.
- A new paper titled Scaling Laws for Diffusion Models was introduced, discussing the efficiency of training and utilizing diffusion methods as compared to autoregressive models.
2. Cross-Language Communication in OpenInterpreter:
- OpenInterpreter participants were enlightened with discussions on managing cross-language and cross-terminal communications effectively, utilizing NLP models for seamless interactions across diverse computing environments.
- Technical discussions highlighted the advancements in language model implementations that enhance user interface engagement through improved command interpretations.
3. Cohere's Practical Model Innovations Spotlighted:
- Cohere's platform updates were highlighted with discussions focusing on practical applications of recently introduced AI models that enhance user experience and broaden application scopes.
- Debates on model integration challenges provided insights into best practices and forthcoming innovations in AI model deployments.
4. Modular (Mojo) Embraces TPU Considerations and Compiler Updates:
- Modular's discussion on integrating TPUs and updating their compiler to version
2024.6.1205showcased ongoing efforts to enhance computational performance and flexibility. - Community feedback praised the improvements, with further anticipation for upcoming features that promise to advance scalable AI deployment scenarios using Modular's tools.
1. Model Performance Optimization and Benchmarking
- Quantization techniques like AQLM and QuaRot aim to run large language models (LLMs) on individual GPUs while maintaining performance. Example: AQLM project with Llama-3-70b running on RTX3090.
- Efforts to boost transformer efficiency through methods like Dynamic Memory Compression (DMC), potentially improving throughput by up to 370% on H100 GPUs. Example: DMC paper by @p_nawrot.
2. Fine-tuning Challenges and Prompt Engineering Strategies
- Difficulties in retaining fine-tuned data when converting Llama3 models to GGUF format, with a confirmed bug discussed.
- Importance of prompt design and usage of correct templates, including end-of-text tokens, for influencing model performance during fine-tuning and evaluation. Example: Axolotl prompters.py.
3. Open-Source AI Developments and Collaborations
- Launch of StoryDiffusion, an open-source alternative to Sora with MIT license, though weights not released yet. Example: GitHub repo.
- Release of OpenDevin, an open-source autonomous AI engineer based on Devin by Cognition, with webinar and growing interest on GitHub.
4. Multimodal AI and Generative Modeling Innovations
- Idefics2 8B Chatty focuses on elevated chat interactions, while CodeGemma 1.1 7B refines coding abilities.
- The Phi 3 model brings powerful AI chatbots to browsers via WebGPU.
5. Misc
- Stable Artisan Brings AI Media Creation to Discord: Stability AI launched Stable Artisan, a Discord bot integrating models like Stable Diffusion 3, Stable Video Diffusion, and Stable Image Core for media generation and editing directly within Discord. The bot sparked discussions about SD3's open-source status and the introduction of Artisan as a paid API service.
- Unsloth AI Community Abuzz with New Models and Training Tips: IBM's Granite-8B-Code-Instruct and RefuelAI's RefuelLLM-2 were introduced, sparking architecture discussions. Users shared challenges with Windows compatibility and skepticism over certain performance benchmarks, while also exchanging model training and fine-tuning tips.
GPT4O (gpt-4o-2024-05-13)
Themes:
- LLM Advancements and Model Performance
- Multimodal AI and Generative Modeling Innovations
- Open-Source Tools and Community Contributions
- Technical Troubleshooting and Implementation Challenges
- Ethics and Industry Dynamics in AI
Summaries:
-
LLM Advancements and Model Performance:
- RecurrentGemma 9B by Google is praised for its super-fast performance on long sequences with both base and instruct-tuned versions, compared to Gemma.
- Members highlighted LlamaGen’s superiority in autoregressive image generation, rivaling diffusion models and supported by detailed documentation and tutorials. 2. Multimodal AI and Generative Modeling Innovations:
- Anthropic's Transformer Lens helped debug model attention, while Stable Diffusion 3 Medium sparked discussions about its image generation capabilities, yet faced criticisms regarding human anatomy accuracy.
- Idefics2 8B Chatty and CodeGemma 1.1 7B improved chat and coding interactions. Pixart Sigma combined with SDXL + PAG aimed for DALLE-3-level outputs. 3. Open-Source Tools and Community Contributions:
- Axolotl supported diverse formats for instruction tuning and pre-training LLMs. IBM’s Granite-8B-Code-Instruct excelled in code tasks.
- DeepEval allows easy integration of custom LLM evaluation metrics, enhancing capabilities in tasks like summarization and faithfulness. 4. Technical Troubleshooting and Implementation Challenges:
- Qwen2-1.5b Fine-tuning faced issues with low-rank configurations, resolved by increasing ranks (64 or 128). Members shared setup struggles for Stable Diffusion 3 in frameworks like ComfyUI, diffusers, and GPU-related discussions for RTX 2070 and P40 graphics cards.
- High Precision Requirements and stability challenges in models like PPO for RL led to shared insights on optimization techniques, tokenizer revamps and community troubleshooting on PyTorch distributed log errors. 5. Ethics and Industry Dynamics in AI:
- Ethical concerns about Nightshade technology and analyses of Perplexity AI’s alleged plagiarism (Forbes article) underscored the need for accountability.
- Microsoft’s acquisition of a 49% OpenAI stake via leveraging discussions with Tesla (Tweet) highlighted strategic moves within tech giants, while ARC Prize’s $1,000,000+ reward spurred extensive discussions on industry benchmarks.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Stable Diffusion 3 Unleashes Potentials and Problems: The newly released Stable Diffusion 3 Medium boasts better quality and advanced prompt comprehension but struggles with human anatomy accuracy, according to user reports. Discussions reveal mixed reactions to performance, with some finding it underwhelming and expressive concerns over technical hurdles in installation and finetuning.
Licence to Confuse: The licensing terms of SD3 sparked intense debate in the community over its restrictions on commercial use, with many finding them too limiting for practical application.
Photorealism Promise Meets Skepticism: Users acknowledge the efforts to enhance realism in faces and hands with SD3, but outcome consistency remains a contentious point when compared to older versions such as SD 1.5 and SDXL.
Resource Effectiveness Favorable, But Customization Could Be Costly: Engineers appreciate the efficient GPU utilization of SD3 and the customization options, although concerns about the financial and technical barriers to finetuning exist, especially for niche content.
Installation Integration Anxiety: A variety of issues related to integrating SD3 into popular frameworks like ComfyUI and diffusers have been flagged, leading to collaborative troubleshooting efforts within the community.
Unsloth AI (Daniel Han) Discord
- VRAM Demands for Large Models - No Jokes Allowed: The VRAM requirements for Qwen2 72b are akin to Llama 3 70b at roughly 48GB, with humorous suggestions of needing a supercomputer brushed aside by reality checks.
- Transfiguring Pytorch to Safetensors: Attempting to convert Pytorch bins to safetensors using this tool, users hit a snag on Google Colaboratory due to RAM limitations; a pivot to Kaggle for ample resources was advised.
- Boosting Fine-tuning Efficiency: To mitigate fine-tuning woes with low-rank configurations in Qwen2-1.5b, utilizing methods like Qlora and Galore, users recommend a minimum rank of 64 or 128.
- Troubleshooting 16-bit Merging Mishaps: A performance decline after merging a model to 16-bit calls attention to possible tokenizer and GGUF anomalies; members anticipate resolution in forthcoming patches.
- Community Effort in Documentation: Volunteers emerge to enhance documentation, pinpointing data preparation and chat notebook usage as areas ripe for improvement, and crafting video tutorials is suggested for better user engagement.
LLM Finetuning (Hamel + Dan) Discord
- Zoom Stumbles, but Blog Shines: While technical issues delayed Zoom session recordings, Nehil's blog post on budget categorization received praise for its practical application of course concepts in prompting.
- Pooling Layer Puzzles and Scope-creep Concerns: Discussions about the technicalities of adding pooling layers to models using libraries like Huggingface showcased the community's collaborative approach, while debates raged over the practicality of broad-scope chatbots versus scoped interfaces, citing concerns around data privacy and security.
- Quantum of Quantization: Excitement was palpable over Llama-recipes' "pure bf16" mode and ongoing optimizer quantization research, indicating a drive to balance model efficiency with calculation precision, evidenced by the shared optimizer library incorporating Kahan summation.
- Crediting Sparks Queries: The community saw several inquiries regarding missing or delayed credits from various platforms like OpenAI, with prompts to check pinned comments for guidance and centralized messages to streamline credit-related discussions.
- Modal Makers, Datasette Devotees, and Chatbot Chumminess: The promise of finetuning LLMs for Kaggle competitions via Modal, Datasette's command-line appeal, and character-focused AI dialogue models from Anthropic Claude agitated the technical waters, underscoring a zest for integration, analytical insights, and user experience.
Remember to check within each message history for specific links provided, such as Datasette's stable version, Simon Willison’s GitHub repository, and mentioned meetup events for more details on these topics.
Perplexity AI Discord
- Smartwatches Clash with Tradition: A playful exchange brought up the dominance of smartwatches such as WearOS versus traditional digital watches, spiced up with a tongue-in-cheek dig at Apple, highlighting individual preferences in wearable technology.
- Perplexity AI Grapples with Tech Issues: Perplexity AI users reported issues with file uploads and image interpretation features, hinting at possible downtime. However, the discussion about different language models like GPT-4o, Claude Sonnet, and Llama 3 70B focused on their performance, with members leaning towards GPT-4o as the top contender.
- Forbes Flames Perplexity for Plagiarism: A debate unfolded regarding a Forbes article alleging that Perplexity AI plagiarized content, illustrating the tightrope walk of ethical practices in the era of rapidly evolving AI. The topic underpins the importance of accountability and proper attribution within the AI landscape. Forbes article on Perplexity’s Cynical Theft
- AI Ethics and Industry Progress Snapshot: Ethical concerns surfaced regarding Nightshade technology and its potential abuses in sabotaging AI models, while Perplexity AI was commended for its advanced features in comparison to SearXNG. Another palpable moment in tech history was marked by the shutdown of ICQ after 28 years, showing the relentless pace of change in communication technology. ICQ Shuts Down
- API Integration Steps Confirmed: There were confirmations around the initial setup of Perplexity API with a simple acknowledgment "This seems to work," followed by directive advice to "add API key here", key for API integration - a testament to the nitty-gritty of getting digital tools up and running.
CUDA MODE Discord
- GPU Gold Rush in Canadian Markets: 3090 GPUs are hitting affordable prices, approximately 450 USD on Kijiji Canada, sparking interest in rig building among the community.
- Heat: The Byproduct with Benefits: Innovative suggestions such as using 4090 GPUs to heat hot tubs were floated, looking at GPU rigs as alternative heat sources while pondering sustainable data center designs.
- Meticulous Quest for 100% Determinism: One engineer achieved 100% determinism in their code but encountered issues such as loss values hitting -inf, indicating potential bugs needing resolution.
- Efficiency Drive in Custom Matmul Implementations: Efforts to improve computational efficiency resulted in a custom matmul achieving 70% speed of cuBLAS, with discussions ongoing about removing dependencies on cuBLASLt and tackling the difficulties of implementing stable FP8.
- Matrix Multiplication Shakeup: The Scalable MatMul-free Language Modeling paper presents a novel approach that reduces memory usage and maintains strong performance in LLMs, attracting attention and implementation efforts within the community.
HuggingFace Discord
- Whisper WebGPU Gives a Voice to Browsers: Whisper WebGPU enables rapid, on-device speech recognition in the browser, supporting over 100 languages, promising user privacy with local data processing.
- Training an Expert Finance LLM - Live!: Engineers with a yen for finance can tune into a live event featuring speaker Mark Kim-Huang, which promises insights into training an Expert Finance LLM.
- Glimpse into Google's RecurrentGemma 9B: RecurrentGemma 9B has set the community abuzz with a post highlighting its performance on long sequences. Members are keen on exploring the model's potential.
- Feasible Fusion with Fine-Tuned Mistral: Fine-tuning models on Mistral can be explored further in a detailed Medium article, offering practical guidance for engineers working with adaptable AI solutions.
- Diffusers to Support SD3 - Anticipation Peaks: The integration of
diffusersfor SD3 has the community on edge, with engineers eagerly waiting for the rollout of this advanced functionality. - Dalle 3 Dataset Provides a Creative Cache: AI that are fueled by diverse data might benefit from the 1 million+ captioned images offered by Dalle 3, available on this Dataset Card.
- Simpletuner Advocated for Diffusion Models: Amid discussions, simpletuner gains recommendation for training diffusion models, while warnings suggest that diffusers examples may need tailoring to fit the bill for specific tasks.
- Quantization Quagmires and Queries: Optimizing AI with quantization tools like quanto and optimum has engineers sharing their trials, signaling a need for more robust and error-proof solutions in model deployment.
- Google Gemini Flash Module - Show Us the Code: There's a clap of interest from the AI community for Google to open-source Google Gemini Flash, citing its potential benefits and sought-after capabilities.
OpenAI Discord
Ilya Sutskaver Strikes with Generalization Insights: Ilya Sutskaver delivered a compelling lecture at the Simons Institute on generalization, viewable on YouTube under the title An Observation on Generalization. Separately, Neel Nanda of DeepMind discusses memorization versus generalization on YouTube in Mechanistic Interpretability - NEEL NANDA (DeepMind).
Llama vs. GPT Showdown: The performance of Llama 3 8b instruct was compared with GPT 3.5, highlighting Llama 3 8b's free API on Hugging Face. GPT-4o’s coding capabilities sparked a debate regarding its performance issues.
Enterprise Tier: To Pay or Not to Pay?: Opinions were divided on the worthiness of the GPT Enterprise tier, despite benefits like enhanced context window and conversation continuity. A user conflated Teams with Enterprise, indicating a misunderstanding about the offerings.
Bootstrap or Build? That is the AI Question: Members suggested finetuning an existing AI such as Llama3 8b or seeking open-source options over building a GPT-like model from scratch, specifically tailored to one's niche.
Technical Trouble Ticket: Members faced various technical issues, including uploading PHP files to Assistants Playground despite support claims, and error messages while generating responses with unspecified solutions. A request for reducing citations from a GPT-4 assistant trained on numerous PDFs was also noted; they wish to prune citations while maintaining data retrieval.
Cohere Discord
Qualcomm's AIMET Critiqued: An individual aired grievances about the usability of Qualcomm's AIMET Library, describing it as the "worst library" encountered.
Rust Gets Cohesive with RIG: RIG, an open-source Rust library for building LLM-powered applications, was released, featuring modularity, ergonomics, and Cohere integration.
Questions Arise Over PaidTabs' AI In Integrations: There's speculation within the community about PaidTabs potentially using Cohere AI for message generation, focusing on the absence of audio capabilities in Cohere AI as per their June 24 changelog.
Musical Engineers Might Form A Band: Conversations veered into sharing musical hobbies, suggesting the potential for a community band due to the number of music enthusiasts.
Pricey Joysticks for Flight Sim Fanatics: Members debated the steep pricing of advanced joystick setups like the VPC Constellation ALPHA Prime, joking about the cost comparison to diamonds.
Eleuther Discord
- Attention Hypernetworks Enhance Generalization: An arXiv paper was shared indicating that Transformers can improve compositional generalization on intellectual tasks like the symbolic Raven Progressive Matrices by leveraging a low-dimensional latent code in multi-head attention.
- Evaluating Next-Gen LlamaGen: The LlamaGen repo suggests that autoregressive models like Llama excel in image generation, rivaling state-of-the-art performance and offering detailed explanations and tutorials.
- DPO and Autoregressive Models Battle for Multi-turn Convos: Members debated the under-researched area of Deterministic Policy Optimization (DPO) for multi-turn conversations, with suggestions to explore the Ultrafeedback dataset and MCTS-DPO approach.
- Dataset and Architecture Dust-ups: Discussions included the challenges in sourcing small coding datasets for Large Language Model (LLM) training, as well as critiques and skepticism around novel research papers and models like Griffin, Samba, and their place in efficiently handling long contexts.
- Searching for the Ultimate Pre-training Dataset: A quest for an open-source dataset similar to DeepMind's LTIP yielded a recommendation for the DataComp dataset, believed to outperform LAION for CLIP models due to its richer 1 billion image-text pair compilation.
LM Studio Discord
- Scripting Python for Chatbot Shenanigans: A member brainstormed integrating a Python script into LM Studio to allow a chatbot to mimic roleplay, directed to adhere to official LM Studio documentation for setup. The RecurrentGemma-9B was suggested for addition, backed by its Hugging Face page.
- Gripes with Glitches in LM Studio 0.2.24: Users flagged severe bugs in LM Studio 0.2.24, complaining about token counting errors and shaky model/GPU utilization. A more curious query delved into the feasibility of bot-created PowerPoint presentations using the OpenAI API.
- Zooming in on GPU and Model Match-ups: Lively debates in model and GPU matching homed in on finding the speediest options for an RTX 2070, namely Mistral7b, Codestral, and StarCoder2. Recommendations also orbited coding-specific models like Codestral, tuning tips with Unsloth, and persistence strategies using vectordb.
- GPU Market Price Pulse: Members exchanged notes on worldwide P40 graphics card pricing, diarizing deals seen on eBay for as low as $150 USD. Further commentary covered Aussie GPU prices from RTX 3060 at $450 to RTX 4090 at $3200, laying bare the realities of scarcity, power, and additional considerations.
- A Peek at the Modern UI: A snapshot was shared of the "modern UI" in the AMD ROCm tech preview frame, with a linked photo evoking kudos from one member for its stylish manifestation.
LlamaIndex Discord
- RAG's Rocky Road in Real-World Deployment: An announcement in the guild invites insight on deploying Retrieval-Augmented Generation (RAG) in enterprise environments, with Quentin and Shreya Shankar gathering feedback through interviews.
- Supercharging Graph RAG via Entity Deduplication: A tutorial shared in the guild suggests enhancing Graph RAG's efficiency by introducing entity deduplication and by employing custom retrieval methods, which can be further explored in the full tutorial.
- Elevating RAG with Excel's Spatial Rigor: A conversation emphasized the challenge of adapting RAG for use with Excel files, noting the significance of a well-organized spatial grid to ensure effective functionality, with more context provided in the referenced tweet.
- Vector Indexing Woes and Wins: Members engaged with multiple concerns including S3DirectoryReader decrypting issues, failure of
MetadataFilterin Redis index, markdown formatting challenges in the vector database, and strategies for customizing prompts inCondensePlusContextChatEngine. - Cracking the Context Code in Text-to-SQL Queries: An AI engineer in the community pointed to an issue with context recognition in text-to-SQL queries where determining the nature of an item (such as if "Q" refers to a product name) remains a challenge, leading to incorrect SQL queries being generated.
Interconnects (Nathan Lambert) Discord
- ARC Prize Stirs Discussions: The newly announced $1,000,000+ ARC Prize for developing a solution to the ARC-AGI benchmark spurred extensive talks, highlighting the benchmark's role in measuring general intelligence through skill acquisition efficiency. The industry's apparent lack of awareness about the ARC-AGI was also noted as concerning, despite its significance.
- Tech Media Gets Mixed Reviews: A TechCrunch article by Kyle Wiggers about AI was criticized for a superficial approach, while reactions to a podcast interview touching on the relationship between AI and human intelligence were mixed, with some points of contention regarding the role of genetic pedigree in determining intelligence.
- Microsoft Secures OpenAI Stake: A tweet shed light on how Microsoft acquired a 49% stake in OpenAI through leveraging discussions with Tesla, using OpenAI involvement as an incentive to potentially draw Tesla onto the Azure platform.
- Bot Development and AI Updates Generate Buzz: Issues and developments in AI tools were discussed:
june-chatbotencountering NVDA API errors indicating stability problems; "SnailBot" earning its name for sluggishness; frustrations with LMSYS; and excitement about Dream Machine’s new text-to-video capabilities from Luma Labs. - AI Reinforcement Learning Evolves: Members dissected an Apple blog post sharing their hybrid data strategy that involves human-annotated and synthetic data and discussed discrepancies in PPO (Proximal Policy Optimization) implementations from a tweet by @jsuarez5341, which contrasts with the pseudocode. Meanwhile, Tulu 2.5's performance updates and Nathan Lambert's exploration into RL practice reveal the community's deep dive into current AI methodologies.
Nous Research AI Discord
- Collaborators Wanted for Generalist Model: Manifold Research is on the lookout for collaborators to work on transformers for multimodality and control tasks, with the goal of creating a large-scale, open-source model akin to GATO. You can join their efforts via Discord, contribute on Github, or check out their expectations on Google Docs.
- Smart Factories Meet Group Chat: Discussion around GendelveChat, which showcases a simulation of group chat UX for industries like smart factories using @websim_ai, and StabilityAI releasing the open weights for Stable Diffusion 3 Medium.
- AI Developments and Data Pipeline Proposals: Apple's AI gets dissected, highlighting its 3B model and compression techniques in Introducing Apple Foundation Models. Stable Diffusion 3 Medium is announced featuring visual improvements and performance gains, while a data pipeline leveraging Cat-70B and tools like oobabooga for ShareGPT data is pitched for the Character Codex project.
- Empire of Language Models: Amid requests for Japanese language model recommendations, users suggested Cohere Aya and Stability AI models with API access, especially praising the Aya 35B for its multilingual capabilities including Japanese. For more capabilities, Cohere Command R+ (103B) was the preferred choice for Japanese model needs.
- Console and Open-source Queries in WorldSim: A recent update has made writing and editing longer console prompts more user-friendly on both mobile and desktop interfaces. Curiosity arose regarding WorldSim's open-source status, but no confirmation was provided in the queried time frame.
LAION Discord
Elon Musk Battles Apple and OpenAI: Elon Musk reportedly took action against Apple's Twitter account following their partnership with OpenAI, a development highlighted with a link to a post by Ron Filipkowski on Threads.net.
Google's Gemma Goes Recurrent: Google's RecurrentGemma 9B is out, capable of handling long sequences quickly while maintaining quality on par with the base Gemma model, as heralded by Omar Sanseviero.
Transformer Learning Challenged by ‘Distribution Locality’: The learnability of Transformers faces limits due to 'distribution locality,' which is explored in a paper on arXiv, indicating challenges for models in composing new syllogisms from known rules.
Revising CC12M dataset with LlavaNext Expertise: The CC12M dataset received a facelift using LlavaNext, resulting in a recaptioned version now hosted on HuggingFace.
Global Debut of a TensorFlow-based Machine Learning Library: An engineer announced the launch of their TensorFlow-centric machine learning library capable of parallel and distributed training, supporting a slew of models like Llama2 and CLIP, introduced on GitHub.
Modular (Mojo 🔥) Discord
TPUs in Mojo's Future: Members discussed the possibility of Mojo utilizing TPU hardware if Google provided a TPU backend for MLIR or LLVM, indicating future support for diverse architectures without waiting for official updates due to planned extensibility.
Up-to-Date with Modular Releases: A new Mojo compiler version 2024.6.1205 was released, featuring conditional conformance that received positive commentary, along with inquiries about recursive trait bounds capabilities. Updating instructions and details can be found in the latest changelog.
Diving into Mojo's Capabilities and Quirks: A code change from var to alias offered no performance gain, while issues with outdated Tensor module examples were addressed and a successful pointer conversion solution was introduced in a recent Pull Request.
Modular's Multimedia Updates: Modular has been active across platforms with a new YouTube video release and a tweet update from their official Twitter account.
Community Discussions and Resources: Exchanges ranged from recommendations for learning Mojo through VSCode, with a potential resource at Learn Mojo Programming Language, to reflections on tech influencers serving as modern-day programming critics, highlighting a Marques and Tim interview among shared content.
OpenInterpreter Discord
Zep Eases Memory Concerns Within Free Boundaries: Participants identified Zep as an ace for memory management, provided that usage remains within its free tier limitations.
Apple Tosses Freebies into the Tech Ring: Apple's move to offer certain services free of charge stirred conversations, with members acknowledging it as a significant competitive edge.
OpenAI's API Wallet-Friendly Pricing: Debate emerged over the OpenAI API's pricing, with mentions suggesting a range of $5-10 per month, highlighting the affordability of OpenAI's offerings for engineers.
Configuring GCP for Advanced Models: A user successfully implemented GPT-4o on their GCP account, though flagged high costs and troubles when changing the default model to gemini-flash or codestral.
OpenInterpreter Gains Momentum: Comprehensive resources were spotlighted, including a GitHub repository, Gist for code, and a uConsole and OpenInterpreter video, with users brainstorming about enhancing voice interactions potentially via a mini USB mic.
OpenRouter (Alex Atallah) Discord
Custom Metrics for LLMs Made Easy: DeepEval allows users to smoothly integrate custom evaluation metrics for language models, enhancing capabilities in G-Eval, Summarization, Faithfulness, and Hallucination.
Transparent AI with Uncensored Models: A heated discussion identified the growing interest in uncensored models among users, acknowledging their value in providing unfiltered AI responses for diverse applications.
WizardLM-2's Surprisingly Low Price Tag: Queries around WizardLM-2’s affordability led to insights that it might save on costs by utilizing fewer parameters and strategic GPU rentals, sparking discussions among members on the model’s efficiency.
Self-Hosting vs. OpenRouter: Debating the trade-offs, members concluded that self-hosting large language models (LLMs) might only make economic sense under constant high demand or if offset by pre-existing hardware capabilities, compared to solutions like OpenRouter.
GPU Rentals for Batch Inference: The guild exchanged ideas on the viability of renting GPUs for batch inference, touching on cost benefits and efficiency, and suggesting tools such as Aphrodite-engine / vllm for optimizing large-scale computations.
OpenAccess AI Collective (axolotl) Discord
- Testing the Bounds of Local Model Training: An engineer tested running a 7 billion parameter model locally using the mlx library and reported it as "slow af, but works lmao," while others suggested trying llama.cpp for better performance. Another member looked for insights on training QWEN 2 with 1.5 billion parameters, but no specific performance data was provided in the discussions.
- Runpod's Perplexing Path Persistence: Members discussed an issue on Runpod where mounting a data volume to /workspace often results in the overwrite of /workspace/axolotl, necessitating reinstallation or re-cloning of Axolotl - a persistent annoyance noted in the development environment setup.
- Step Aside, Redundant Instructions: Within the documentation channel, it was noted that "Step 2" is superfluous in the model upload process, as the repository is created automatically, indicating an update to documentation may be warranted.
- PyTorch Distributed Drama: An engineer encountered a ChildFailedError when using PyTorch's distributed launcher, prompting advice to check environmental setup, verify configurations, and potentially increase shared memory, with further troubleshooting steps available in the Accelerate documentation.
- LoRA's Learning Curve: Queries were made about utilizing LoRA for transitioning from completion format to instruction format training and merging qLoRA training results on Mistral 7B within a 24GB GPU system, suggesting a discussion about handling resource limitations is in play.
Latent Space Discord
- Google Plays Its Next Hand with RecurrentGemma 9B: Google's RecurrentGemma 9B promises breakthroughs in processing long sequences swiftly, boasting similar prowess to Gemma while introducing base and instruct-tuned versions. The model's details and its comparison to its predecessor can be found in the collection here and the underlying research in the Griffin paper.
- Granular Analysis on Alexa AI's Pitfalls: Mihail Eric pulled back the curtain on Alexa AI's failures, citing technical disconnect and organizational inefficiencies as key roadblocks to innovation, backed by deep resources yet resulting in few public breakthroughs. The detailed thread sheds light on behind-the-scenes challenges and is available here.
- ARC Prize Forges New Frontier in AI Benchmarking: A prize connected to the ARC task dataset, which now includes over 4,100 interaction histories, aims to elevate understanding and development regarding human problem-solving methods in AI. Resources such as videos and multiple datasets are available with invitation for participation opened through this link.
- Google Unveils Healthcare-Specific Language Model: Google's latest addition, the Personal Health Large Language Model, harnesses wearables data to deliver tailored health insights, reportedly surpassing industry experts. In-depth information about this model's capabilities and design can be found here.
- Stanford Shares Insights on AI's Rapid Evolution: A lecture at Stanford by hwchung27 offered a valuable glimpse into the state-of-the-art in AI, drawing attention to the transformative impact of cheaper compute resources and the growth of Transformer architectures. Watch the insightful lecture and review the accompanying slides for a detailed narrative.
tinygrad (George Hotz) Discord
- Bounty Hunting for RetinaNet on MLPerf: George Hotz has announced a $600 bounty for implementing RetinaNet on the MLPerf benchmark, promising to double it if the contribution is accepted into MLPerf. See the pull request related to this here.
- Hungry for Efficient Data Loading: Engineers have voiced concerns over the time sink associated with optimising data loading in PyTorch, especially on HPC clusters, suggesting WebDataset as a viable solution.
- Drafting TinyGrad's Data Loader: George Hotz shared plans for TinyGrad's data loader API, which includes a function to load records, shuffle buffer size, and batch size, mentioning Comma's "gigashuffle" for reference.
- TinyGrad Evolves with 0.9.0: TinyGrad version 0.9.0 is now available in the Nix repository, as confirmed by the GitHub Pull Request, and features the inclusion of gpuctypes directly in the codebase.
- MLPerf Benchmarking and Community Buzz: The latest MLPerf results are published, featuring tinybox red/green benchmarks, alongside media coverage like a German article on TinyGrad which can be read on Heise.de, with further discussions hinting at a future blog post comparing TinyGrad's speed to theoretical limits.
Mozilla AI Discord
- LLMs Require Structured Output: Members highlighted the necessity for LLMs (Large Language Models) to have defined grammar or JSON schemas to be effectively utilized as agents. The standardization of outputs to be parsable by external programs has been noted as critical for usefulness in the application layer.
- Streamlining llamafile with Integrated Schemas: The conversation on optimizing
llamafileusage proposed a two-step streamline process: first converting JSON schema to grammar, and then integrating that grammar for utility, with a command example given:llamafile --grammar <(schemaify <foo.sql). - Efficient Packaging of Shared Objects: A technical discussion emerged concerning the most effective method for including
ggml_cuda.soandggml_rocm.soinllamafiledistributions, including a shared Bash script and a mention of necessary manual adjustments for different libraries such as AMD and tinyblas. - Magit as a Sync Solution: A humorous referral to a video titled "Interview with an Emacs Enthusiast in 2023 [Colorized]" was made to exemplify the use of Magit, a Git interface for Emacs, demonstrating its application for syncing files like
llama.cpp. - Schema Applications in LLMs: The dialog underlined a community interest in applying structured data schema to improve the output of Large Language Models, signaling a trend in engineering circles toward enhancing LLM integration with downstream systems.
Datasette - LLM (@SimonW) Discord
- Apple Interfacing Prospects with LORA Analogue: Apple's adapter technology has been compared to LORA layers, suggesting a dynamic loading system for local models to perform a variety of tasks.
- The Contorting Web of HTML Extraction: AI engineers explored different tools for HTML content extraction, like htmlq, shot-scraper, and
nokogiri, with Simonw highlighting the use ofshot-scraperfor efficient JavaScript execution and content extraction. - Shortcut to Summation Skips Scrutiny: Chrisamico found it more efficient to bypass technical HTML extraction and directly paste an article into ChatGPT for summarization, foregoing the need for a complicated
curlandllmsystem. - Simon Says Scrape with shot-scraper: Simonw provided instructions on utilizing
shot-scraperfor content extraction, advocating the practicality of using CSS selectors in the process for those proficient in JavaScript. - Command Line Learning with Nokogiri: Empowering engineers to leverage their command line expertise, Dbreunig shared insights on using
nokogirias a CLI tool, complete with an example for parsing and extracting text from HTML documents.
LangChain AI Discord
LangChain Postgres Puzzles Programmers: Engineers reported issues with LangChain Postgres documentation, finding it lacks a checkpoint in the package which is crucial for usage. The documentation can be found here, but the confusion continues.
GPT-4 Gripes in LangChain: A member flagged an error using GPT-4 with langchain_openai; guidance was offered to switch to ChatOpenAI because OpenAI uses a legacy API not supporting newer models. More information about the OpenAI API can be found here.
Sharing Snafu in LangServe: Difficulty sharing conversation history in LangServe's chat playground was discussed, with users experiencing an issue where the "Share" button leads to an empty chat rather than showing the intended conversation history. This problem is tracked in GitHub Issue #677.
No Cost Code Creations at Nostrike AI: Nostrike AI has rolled out a new free python tool allowing easy creation of CrewAI code with future plans to support exporting Langgraph projects, inviting users to explore it at nostrike.ai.
Rubik's AI Recruits Beta Testers: Rubik's AI, touted as an advanced AI research assistant and search engine, seeks beta testers with the enticement of a 2-month free trial using the promo code RUBIX, covering models like GPT-4 Turbo and Claude 3 Opus. Check it out here.
Torchtune Discord
Discord Amps Up with Apps: Members can now enhance their Discord experience by adding apps across servers and direct messages starting June 18. Detailed information and guidance on app management and server moderation can be found in the Help Center article and developers can create their own apps with the aid of a comprehensive guide.
Cache Conundrums in Torchtune: A dialogue has opened up regarding the increased use of cache memory by Torchtune during each computational step, with community members probing deeper to understand this performance characteristic.
Tokenizer Revamp on the Horizon: An RFC detailing a significant overhaul of tokenizer systems sparked conversations about multimodal feature integration and design consistency, which is available for review and contribution on GitHub.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!