[AINews] The AI Search Wars Have Begun — SearchGPT, Gemini Grounding, and more
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
One AI Searchbox is All You Need.
AI News for 10/30/2024-10/31/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (231 channels, and 2468 messages) for you. Estimated reading time saved (at 200wpm): 264 minutes. You can now tag @smol_ai for AINews discussions!
Teased as SearchGPT in July, ChatGPT finally rolled out its search functionality today across all platforms, completely coincidentally coinciding with Gemini launching Search Grounding after an unfortunate delay. The launch includes a simple Chrome Extension that @sama is personally promoting on Twitter and on their Reddit AMA (dont bother) today:
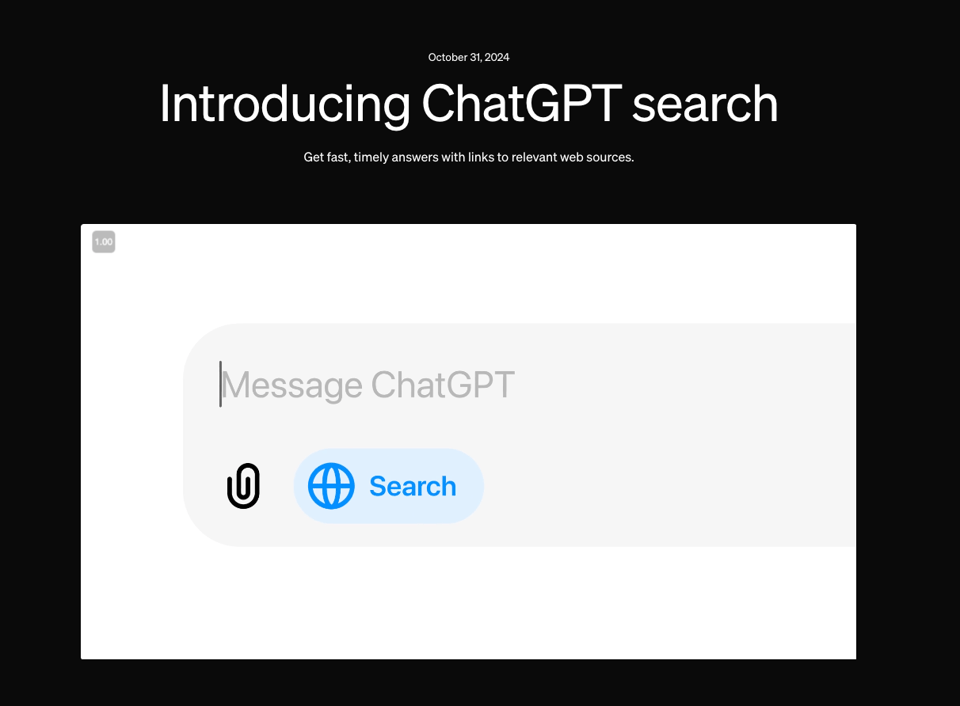
with a raft of weather, stocks, sports, news, and maps partners — noticeably, you will never get a New York Times article via ChatGPT because the NYT chose to sue OpenAI instead of partner with them. Partners are presumably happy about the feature, but the citations come with a catch - you have to expend an additional click to see them at all, and most will not.
CHatGPT search uses a "fine-tuned version of GPT-4o, post-trained using novel synthetic data generation techniques, including distilling outputs from OpenAI o1-preview", however it is already found to offer hallucinations.
This latest salvo in consumer AI plays challenging their search leader (Perplexity) mirrors a broader trend in b2b AI plays (Dropbox Dash) challenging their search leader (Glean).
Sounds like a good time to bone up on AI search techniques, with today's AINews sponsor!
Brought to you by the RAG++ course: Go beyond basic RAG implementations and explore advanced strategies like hybrid search and advanced prompting to optimize performance, evaluation, and deployment. Learn from industry experts at Weights & Biases, Cohere, and Weaviate how to overcome common RAG challenges and build robust AI solutions, leveraging Cohere's platform with provided credits for participants.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Nous Research AI Discord
- Unsloth AI (Daniel Han) Discord
- Perplexity AI Discord
- OpenAI Discord
- OpenRouter (Alex Atallah) Discord
- aider (Paul Gauthier) Discord
- Eleuther Discord
- Latent Space Discord
- LM Studio Discord
- GPU MODE Discord
- Cohere Discord
- Interconnects (Nathan Lambert) Discord
- Stability.ai (Stable Diffusion) Discord
- Modular (Mojo 🔥) Discord
- DSPy Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- LlamaIndex Discord
- LAION Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- OpenAccess AI Collective (axolotl) Discord
- LangChain AI Discord
- Alignment Lab AI Discord
- LLM Agents (Berkeley MOOC) Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (884 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (5 messages):
- HuggingFace ▷ #cool-finds (18 messages🔥):
- HuggingFace ▷ #i-made-this (2 messages):
- HuggingFace ▷ #core-announcements (1 messages):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #NLP (11 messages🔥):
- HuggingFace ▷ #diffusion-discussions (2 messages):
- Nous Research AI ▷ #general (192 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (16 messages🔥):
- Nous Research AI ▷ #interesting-links (4 messages):
- Unsloth AI (Daniel Han) ▷ #general (121 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
- Unsloth AI (Daniel Han) ▷ #help (80 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- Unsloth AI (Daniel Han) ▷ #research (1 messages):
- Perplexity AI ▷ #general (125 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (1 messages):
- OpenAI ▷ #annnouncements (2 messages):
- OpenAI ▷ #ai-discussions (108 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (2 messages):
- OpenAI ▷ #prompt-engineering (4 messages):
- OpenAI ▷ #api-discussions (4 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (107 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
- aider (Paul Gauthier) ▷ #general (100 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (5 messages):
- aider (Paul Gauthier) ▷ #links (7 messages):
- Eleuther ▷ #general (1 messages):
- Eleuther ▷ #research (100 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (99 messages🔥🔥):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #general (57 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (16 messages🔥):
- GPU MODE ▷ #general (4 messages):
- GPU MODE ▷ #triton (8 messages🔥):
- GPU MODE ▷ #torch (10 messages🔥):
- GPU MODE ▷ #cool-links (5 messages):
- GPU MODE ▷ #beginner (16 messages🔥):
- GPU MODE ▷ #off-topic (3 messages):
- GPU MODE ▷ #triton-puzzles (1 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #thunderkittens (9 messages🔥):
- Cohere ▷ #discussions (9 messages🔥):
- Cohere ▷ #questions (27 messages🔥):
- Cohere ▷ #api-discussions (7 messages):
- Cohere ▷ #projects (1 messages):
- Cohere ▷ #cohere-toolkit (4 messages):
- Interconnects (Nathan Lambert) ▷ #news (5 messages):
- Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
- Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (6 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (41 messages🔥):
- Modular (Mojo 🔥) ▷ #general (5 messages):
- Modular (Mojo 🔥) ▷ #mojo (31 messages🔥):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #papers (3 messages):
- DSPy ▷ #general (13 messages🔥):
- OpenInterpreter ▷ #general (15 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- tinygrad (George Hotz) ▷ #general (3 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (9 messages🔥):
- LAION ▷ #general (5 messages):
- LAION ▷ #research (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (6 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
- LangChain AI ▷ #general (1 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
- Alignment Lab AI ▷ #general (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Benchmarks
- Claude 3.5 Sonnet Performance: @alexalbert__ announced that Claude 3.5 Sonnet achieved 49% on SWE-bench Verified, beating the previous SOTA of 45%. The model uses a minimal prompt structure, allowing flexibility in handling diverse coding challenges.
- SimpleQA Benchmark: @_jasonwei introduced SimpleQA, a new hallucinations evaluation benchmark with 4,000 diverse fact-seeking questions. Current frontier models like Claude Sonnet 3.5 score below 50% accuracy on this challenging benchmark.
- Universal-2 Speech-to-Text Model: @svpino shared details about Universal-2, a next-generation Speech-To-Text model with 660M parameters. It shows significant improvements in recognizing proper nouns, alphanumeric accuracy, and text formatting.
- HOVER Neural Whole-Body Controller: @DrJimFan presented HOVER, a 1.5M-parameter neural network for controlling humanoid robots. Trained in NVIDIA Isaac simulation, it can be prompted for various high-level motion instructions and supports multiple input devices.
AI Tools and Applications
- AI Hedge Fund Team: @virattt built a hedge fund team of AI agents using LangChain and LangGraph, consisting of fundamental, technical, and sentiment analysts.
- NotebookLM and Illuminate: @GoogleDeepMind developed two AI tools for narrating articles, generating stories, and creating multi-speaker audio discussions.
- LongVU Video Language Model: @mervenoyann shared details about Meta's LongVU, a new video LM that can handle long videos by downsampling using DINOv2 and fusing features.
- AI Production Engineer: @svpino discussed an AI system by @resolveai that handles alerts, performs root cause analysis, and resolves incidents in production environments.
AI Research and Trends
- Vision Language Models (VLMs): @mervenoyann summarized trends in VLMs, including interleaved text-video-image models, multiple vision encoders, and zero-shot vision tasks.
- Speculative Knowledge Distillation (SKD): @_philschmid shared a new method from Google for solving limitations of on-policy Knowledge distillation, using both teacher and student during distillation.
- QTIP Quantization: @togethercompute introduced QTIP, a new quantization method achieving state-of-the-art quality and inference speed for LLMs.
- Trusted Execution Environments (TEEs): @rohanpaul_ai discussed the use of TEEs for privacy-preserving decentralized AI, addressing challenges in processing sensitive data across untrusted nodes.
AI Industry News and Announcements
- OpenAI New Hire: @SebastienBubeck announced joining OpenAI, highlighting the company's focus on safe AGI development.
- Perplexity Supply Launch: @perplexity_ai introduced Perplexity Supply, offering quality goods designed for curious minds.
- GitHub Copilot Updates: @svpino noted that GitHub Copilot is rapidly releasing new features, likely in response to competition from Cursor.
- Meta's AI Investments: @nearcyan reported that Meta now spends $4B on VR and $6B on AI, with a 43% profit margin.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Apple Showcases LMStudio in MacBook Pro Ad: Local LLMs Go Mainstream
- MacBook Pro M4 Max; Up to 526 GB/s Memory Bandwidth. (Score: 195, Comments: 87): The new MacBook Pro M4 Max chips boast up to 526 GB/s memory bandwidth, significantly enhancing local AI performance. This substantial increase in memory bandwidth is expected to greatly improve the speed and efficiency of AI-related tasks, particularly for on-device machine learning and data processing operations.
- So Apple showed this screenshot in their new Macbook Pro commercial (Score: 726, Comments: 116): Apple's new MacBook Pro commercial features a screenshot of LMStudio, a popular open-source tool for running local large language models (LLMs). This inclusion suggests Apple is acknowledging and potentially endorsing the growing trend of local AI adoption, highlighting the capability of their hardware to run sophisticated AI models locally.
- LMStudio gains mainstream recognition through Apple's commercial, with users praising its features and user-friendliness. Some debate its open-source status and comparison to alternatives like Kobold and Ollama.
- The AI community's growth is highlighted, with discussions about its size and impact. AMD also showcased LM Studio benchmarks, indicating broader industry adoption of local AI tools.
- Users speculate on the performance of new Apple M4 chips for running large language models, with expectations of running 70B+ models at 8+ tokens/sec. Current M2 Ultra chips reportedly achieve similar performance.
Theme 2. Meta's Llama 4: Training on 100k+ H100 GPUs for 2025 Release
- Summary: The big AI events of October (Score: 99, Comments: 20): October 2023 saw the release of several significant AI models, including Flux 1.1 Pro for image creation, Meta's Movie Gen for video generation, and Stable Diffusion 3.5 in three sizes as open source. Notable multimodal models introduced include Janus AI by DeepSeek-AI, Google DeepMind and MIT's Fluid text-to-image model with 10.5B parameters, and Anthropic's Claude 3.5 Sonnet New and Claude 3.5 Haiku, showcasing advancements in various AI capabilities.
- Flux 1.1 Pro generated discussion about open-source potential, with users speculating that it could become "invincible" if released openly. The conversation evolved into a debate about the limits of AI intelligence, particularly in language models versus image generation.
- The release of Stable Diffusion 3.5 was highlighted as a significant development for local, non-API-based image generation. Users expressed enthusiasm for this open-source model's accessibility.
- Discussion touched on the future of AI models, with predictions that standalone image models may soon be replaced by multimodal models integrating video capabilities. Some users speculated that AI could create entire comics "at the click of a button" within two years.
- Llama 4 Models are Training on a Cluster Bigger Than 100K H100’s: Launching early 2025 with new modalities, stronger reasoning & much faster (Score: 573, Comments: 157): Meta's Llama 4 models are reportedly training on a massive cluster exceeding 100,000 H100 GPUs, with plans for an early 2025 launch. According to a tweet and Meta's Q3 2024 earnings report, the new models are expected to feature new modalities, stronger reasoning capabilities, and significantly improved speed.
- Users expressed excitement about Llama 4's potential, with hopes it could match or surpass GPT-4/Turbo capabilities. Some speculated on model sizes, wishing for options from 9B to 123B parameters to suit various hardware configurations.
- Discussion centered on the massive 100,000 H100 GPU cluster used for training, with debates about power consumption (estimated 70 MW) and comparisons to industrial facilities. Some praised Meta's investment in open-source AI development.
- Comparisons were made between Llama and other models like Mistral and Nemotron, with users discussing relative performance and use cases. Some expressed hopes for improved usability and trainability in Llama 4 beyond benchmark scores.
Theme 3. Local AI Alternatives Challenge Cloud APIs: Cortex and Whisper-Zero
- Cortex: Local AI API Platform - a journey to build a local alternative to OpenAI API (Score: 66, Comments: 29): Cortex, a local AI API platform, aims to provide an alternative to OpenAI API with multimodal support. The project focuses on creating a self-hosted solution that offers similar capabilities to OpenAI's API, including text generation, image generation, and speech-to-text functionality. Cortex is designed to give users more control over their data and AI models while providing a familiar interface for developers accustomed to working with OpenAI's API.
- Cortex differs from Ollama in its use of C++ (vs. Go) and storage of models in universal file formats. It aims for 1:1 equivalence to the OpenAI API spec, focusing on multimodality and stateful operations.
- The project is designed as a local alternative to the OpenAI API platform, with plans to support multimodal tasks and real-time capabilities. It will integrate with Ichigo, a local real-time voice AI, and push a forward fork of llama.cpp for multimodal speech support.
- Some users expressed skepticism, viewing Cortex as "another llama-cpp wrapper." The developers clarified that it goes beyond a simple wrapper, aiming to unify various engines and handle complex multimodal tasks across different hardware and AI models.
- How did whisper-zero manage to reduce whisper hallucinations? Any ideas? (Score: 72, Comments: 49): Whisper-Zero, a modified version of OpenAI's Whisper speech recognition model, claims to reduce hallucinations in speech recognition. The post author is seeking information on how Whisper-Zero achieved this improvement, particularly in handling silence and background noise, which were areas where the original Whisper model struggled with hallucinations.
- Whisper inherits issues from YouTube autocaptioning, including hallucinations like adding "[APPLAUSE]" during silence. Users report the model sometimes adds random sentences or gets "stuck" repeating words, especially during silent periods.
- The claim of "eliminates hallucinations" is questioned, with suggestions that noise reduction preprocessing might be used. Some users note that Large-V3 performs worse than Large-V2 for certain tasks, including accented speech recognition.
- Skepticism about the "hallucination-free" claim is expressed, with users pointing out that a 10-15% WER improvement doesn't equate to zero hallucinations. The pricing ($0.6/hour transcribed) is also criticized as expensive compared to free alternatives.
Theme 4. Optimizing LLM Inference: KV Cache Compression and New Models
- [R] Super simple KV Cache compression (Score: 39, Comments: 5): The researchers discovered a simple method to improve LLM inference efficiency by compressing the KV cache, as detailed in their paper "A Simple and Effective L2 Norm-Based Strategy for KV Cache Compression". Their approach leverages the strong correlation between the L2 norm of token key projections in the KV cache and the attention scores they receive, enabling cache compression without compromising performance.
- Introducing Starcannon-Unleashed-12B-v1.0 — When your favorite models had a baby! (Score: 41, Comments: 8): Starcannon-Unleashed-12B-v1.0 is a new merged model combining nothingiisreal/MN-12B-Starcannon-v3 and MarinaraSpaghetti/NemoMix-Unleashed-12B, available on HuggingFace. The model claims improved output quality and ability to handle longer context, and can be used with either ChatML or Mistral settings, running on koboldcpp-1.76 backend.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Developments and Capabilities
- OpenAI's o1 model: Sam Altman announced that OpenAI's o series of reasoning models are "on a quite steep trajectory of improvement". Upcoming o1 features include function calling, developer messages, streaming, structured outputs, and image understanding. The full o1 model is still being worked on but will be released "soon".
- Google's AI code generation: AI now writes over 25% of code at Google, according to a report. This highlights the increasing role of AI in software development at major tech companies.
- Salesforce's xLAM-1b model: A 1 billion parameter model that achieves 70% accuracy in function calling, surpassing GPT 3.5, despite its relatively small size.
- Phi-3 Mini update: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
AI Tools and Interfaces
- Invoke 5.3: A new release featuring a "Select Object" tool that allows users to pick out specific objects in an image and turn them into editable layers, useful for image editing workflows.
- Wonder Animation: A tool that can transform any video into a 3D animated scene with CG characters.
AI Ethics and Societal Impact
- AI alignment: Discussions about the challenges of aligning AI with human values and the potential implications of highly advanced AI systems.
- Mixed reality concepts: A video demonstrating potential applications of mixed reality technology, showcasing the intersection of AI and augmented reality.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Turbocharge Your AI: Models Get a Speed Boost
- Meta's Llama 3.2 Turbocharged!: Meta releases quantized Llama 3.2 models, boosting inference speed by 2-4x and slashing model size by 56% using Quantization-Aware Training.
- SageAttention Outpaces FlashAttention: SageAttention achieves 2.1x and 2.7x performance gains over FlashAttention2 and xformers respectively, enhancing transformer efficiency.
- BitsAndBytes Native Quantization Launched: Hugging Face integrates native quantization support with bitsandbytes, introducing 8-bit and 4-bit options for streamlined model storage and performance.
Theme 2. Fresh AI Models Hit the Scene
- SmolLM2 Takes Off with 11T Tokens: SmolLM2 family launches with models ranging from 135M to 1.7B parameters, trained on a massive 11 trillion tokens and fully open-sourced under Apache 2.0.
- Recraft V3 Dominates Design Language: Recraft V3 claims superiority in design language, outperforming rivals like Midjourney and OpenAI, pushing the boundaries of AI-generated creativity.
- Hermes 3 Flexes Against Llama 3.1: Hermes 3 excels with role-play dataset finetuning, maintaining strong personas via system prompts and proving superior to Llama 3.1 in conversational consistency.
Theme 3. Build Smart: Advanced AI Tooling and Frameworks
- HuggingFace Unveils Native Quantization: Integration of bitsandbytes library enables 8-bit and 4-bit quantization, enhancing model flexibility and performance within Hugging Face’s ecosystem.
- Aider Enhances Coding with Auto-Patches: Aider now auto-generates bug fixes and documentation, allowing developers to apply patches with one click, streamlining code reviews and boosting productivity.
- OpenInterpreter Adds Custom Profiles: Users can create customizable profiles in Open Interpreter via Python files, enabling tailored model selections and context adjustments for diverse applications.
Theme 4. Deployment Dilemmas: Navigating AI Infrastructure
- Multi-GPU Fine-Tuning Coming Soon: Unsloth AI hints at launching multi-GPU fine-tuning by year’s end, focusing initially on vision models to enhance overall model support.
- Network Woes Under Investigation: OpenRouter tackles sporadic network connection issues between cloud providers causing 524 errors, with ongoing improvements showing promise.
- Docker Images for Unsloth Receive Feedback: Community testing and feedback on Unsloth’s Docker Image highlight the importance of user insights for optimizing container usability and performance.
Theme 5. Search Smarter: AI Enhancements in Information Retrieval
- ChatGPT's Search Supercharged: OpenAI upgrades ChatGPT’s web search, enabling faster, more accurate answers with relevant links, significantly enhancing user experience.
- Perplexity AI Rolls Out Image Uploads: The ability to upload images in Perplexity AI is hailed as a major improvement, though users express concerns over missing functionalities post-update.
- WeKnow-RAG Combines Web and Knowledge Graphs: WeKnow-RAG integrates Web search and Knowledge Graphs into a Retrieval-Augmented Generation system, enhancing LLM response reliability and combating factual inaccuracies.
PART 1: High level Discord summaries
HuggingFace Discord
-
Llama 3.2 Models Turbocharged: Meta's new quantized versions of Llama 3.2 1B & 3B improve inference speed by 2-4x and reduce the model size by 56%, utilizing Quantization-Aware Training.
- Community discussions highlighted how this enhancement allows for quicker performance without compromising quality.
- Native Quantization Support Launched: Hugging Face has integrated native quantization support via the bitsandbytes library, enhancing model flexibility.
- The new features include 8-bit and 4-bit quantization, streamlining model storage and use with improved performance.
- Effective Strategies for Reading Research Papers: Members shared diverse objectives for reading papers, focusing on implementation versus staying updated, with one noting, I don't think I have ever implemented something from a paper.
- A structured three-step reading method was discussed, noting its efficiency in grasping complex academic content.
- AI Tool Auto-generates Bug Fixes: An AI tool has been developed to autogenerate patches for bugs, allowing developers to apply fixes with a single click upon a PR submission.
- This tool not only enhances code quality but also saves time during code reviews by catching issues early.
- Troubleshooting SD3Transformer2DModel Import: A member faced issues importing
SD3Transformer2DModelin VSCode, while successfully importing another model, indicating possible module-specific complications.
- The community engaged in collaborative troubleshooting, demonstrating the group's commitment to problem-solving in technical contexts.
Nous Research AI Discord
-
Flash-Attn Now Runs on A6000: A member successfully got flash-attn 2.6.3 working on CUDA 12.4 and PyTorch 2.5.0 with an A6000, resolving previous issues by building it manually.
- They noted difficulties with pip installs leading to linking errors, but the new setup appears promising.
- Perplexity Introduces New Supply Line: Perplexity launched Perplexity Supply, aiming to provide quality products for curious minds.
- This prompted discussions about competition with Nous, indicating a need to enhance their own offerings.
- The Future of AI Assistants: Discussion arose around AI assistants managing multiple tasks via a blend of local and cloud integrations.
- Members debated if local computing resources are sufficient for comprehensive AI functionality and usability.
- Hermes 3 Shines Against Llama 3: Hermes 3 excels due to its finetuning with role-play datasets, staying true to personas via system prompts over Llama 3.1.
- Users found ollama helpful for testing models, offering simple commands for customization.
- SmolLM2 Family Showcases Lightweight Capability: The SmolLM2 family, with sizes like 135M, 360M, and 1.7B parameters, is designed for on-device tasks while being lightweight.
- The 1.7B variant shows improvements in instruction following and reasoning compared to SmolLM1.
Unsloth AI (Daniel Han) Discord
-
ETA for Multi-GPU Fine Tuning: Members are eager to know the arrival time for multi-GPU fine tuning, with indications it might be available 'soon (tm)' before year's end.
- Focus remains on enhancements related to vision models and overall model support.
- Debate on Quantization Techniques: Discussions revolve around the best Language Models for fine-tuning under 3 billion parameters, with suggestions like DeBERTa and Llama.
- Tradeoffs between potential quality loss and speed improvements in quantization were actively debated.
- Unsloth Framework Shows Promise: Members praise the Unsloth framework for its efficient fine-tuning capabilities, highlighting its user-friendly experience.
- Queries regarding its flexibility for advanced tasks like layering freezing yielded assurances of support for those features.
- Memory Issues Running Inferences: A user flagged increasing GPU memory usage after multiple inference runs with 'unsloth/Meta-Llama-3.1-8B', raising alarms over memory accumulation.
- Efforts to clear memory using torch.cuda.empty_cache() didn't resolve the issue, suggesting deeper memory management concerns.
- Community Tests Unsloth Docker Image: A member shared a link to their Unsloth Docker Image for community feedback.
- Discussion emphasized the importance of community insights for improving Docker images and container usability.
Perplexity AI Discord
-
Grok 2 Model Gets Mixed Feedback: Users expressed a mix of enjoyment and frustration over the new Grok 2 model, especially regarding its availability on the Perplexity iOS app for Pro users.
- Some remarked it lacks helpful personality traits, leading to varying user experiences.
- Perplexity Pro Subscription Issues Continue: Several users reported ongoing problems with Pro subscriptions, including unrecognized subscription statuses.
- Frustration arose over limited source outputs despite payments, with questions raised about the service's quality.
- Users Love Image Upload Features: The ability to upload images in Perplexity has been praised as a significant enhancement, improving user interactions.
- However, concerns remain about performance quality and missing functionalities after recent updates.
- Confusion Over Search Functions in Perplexity: Discussions reveal confusion about the clarity of the search function, with users noting its primary focus on titles.
- Frustrations were compounded by responses being rerouted to GPT without upfront developer communication.
- Users Draw Comparisons Between Perplexity and ChatGPT: Members compared Perplexity and ChatGPT, examining functionalities and perceived pros and cons.
- Overall, some suggested that ChatGPT may perform better in certain contexts, sparking questions about Perplexity's effectiveness.
OpenAI Discord
-
Reddit AMA with OpenAI Executives: A Reddit AMA with Sam Altman, Kevin Weil, Srinivas Narayanan, and Mark Chen is set for 10:30 AM PT. Users can submit their questions for discussion, details accessible here.
- This event presents a direct line for the community to engage with OpenAI’s leadership.
- Revamped ChatGPT Search Feature: ChatGPT has upgraded its search capabilities, allowing for faster and more accurate answers with relevant links. More information on this enhancement is available here.
- This major improvement is expected to enhance user experience significantly.
- Insights on GPT-4 Training Frequency: Participants discussed that significant GPT-4 updates typically require 2-4 months for training and safety testing. Some members argued for more frequent minor updates based on user feedback.
- This divergence in opinion illustrates the varied perceptions regarding the product development cycle.
- Crafting a D&D DM GPT: An exciting project is underway to create a D&D DM GPT that enhances tabletop gaming experiences through AI integration.
- This initiative aims to create a more interactive storytelling mechanism within D&D sessions.
- Debating AI Generation Constraints: Discussions emerged around limiting AI generation to solely reflect the outcomes of user actions. Members emphasized a need for clarity on enabling interactive AI that aligns with user interactions.
- Further elaboration was sought on how best to define these limits to refine the model's context.
OpenRouter (Alex Atallah) Discord
-
OpenAI Speech-to-Speech API Availability: Users are curious about the new OpenAI Speech-to-Speech API, but currently, there's no estimated release date.
- This uncertainty has led to a lively discussion, as participants eagerly await specifics on its deployment.
- Claude 3.5's Concise Mode Sparks Debate: A heated debate emerged over Claude 3.5's new 'concise mode', with some users finding its responses overly restricted.
- Participants voiced mixed experiences, with many unable to discern significant differences in the API's functionality.
- Clarifying OpenRouter Credit Pricing: Users broke down the pricing for OpenRouter credits, noting it costs about $1 for roughly 0.95 credits after fees.
- Free models have a 200 requests per day limit, while paid usage rates differ based on model and demand.
- Gemini API Enhances Search with Google Grounding: The Gemini API now supports Google Search Grounding, integrating features similar to those found in Vertex AI.
- Users cautioned that pricing may be higher than expected, but they acknowledged its potential for enhancing tech-related queries.
- Network Connection Issues Under Investigation: Sporadic network connection issues between two cloud providers are under investigation, leading to 524 errors.
- Recent improvements seem promising, and the team aims to provide updates as further details about the request timeout issues emerge.
aider (Paul Gauthier) Discord
-
Aider Reads Files Automatically: Aider now automatically reads the on-disc version of files at each command, allowing users to see the latest updates without manual additions. Extensions like Sengoku can further automate file management in the developer environment.
- This enhances interaction efficiency, making it easier for users to manage their coding resources.
- Anticipation for Haiku 3.5: Discussion buzzed around the expected release of Haiku 3.5, speculated to drop later this year but not imminently. A strong community sentiment suggests that a launch would generate significant excitement.
- The eagerness implies high standards for improvements in this version.
- Continue as a Promising AI Assistant: Users appreciate Continue, an AI code assistant for VS Code that rivals Cursor's autocomplete features. Its user-friendly interface is praised for enhancing coding efficiency through customizable workflows.
- This tool reinforces the trend towards more integrated development environments.
- Aider’s Analytics Feature: Aider introduced an analytics function that collects anonymous user data to improve overall usability. Engaging users to opt-in for analytics will help identify popular features and assist debugging efforts.
- User feedback can significantly shape future iterations of Aider.
- Aider and Ollama Performance Hiccups: Some users face performance issues when integrating Aider with Ollama, particularly with larger model sizes causing slow responses. There's a call for a robust setup to optimize seamless functionality.
- Challenges with performance highlight the critical need for improved compatibility and efficiency.
Eleuther Discord
-
Open-sourced Value Heads Inquiry: Members expressed difficulty in finding open-sourced value heads, indicating a collective challenge in the community.
- This suggests an opportunity for collaboration and knowledge sharing among members looking for these resources.
- Universal Transformers underutilization: Despite their benefits, Universal Transformers (UTs) often require modifications like long skip connections, rendering them underexplored.
- Complexities involving chaining halting impact their broader application adoption, raising questions over their practical implementation.
- Deep Equilibrium Networks face skepticism: Deep Equilibrium Networks (DEQs) have potential but struggle with stability and training complexities, leading to doubts about their functionality.
- Concerns about fixed points in DEQs emphasize their challenges in achieving parameter efficiency compared to simpler models.
- Timestep Shifting promises optimization: New advancements in Stable Diffusion 3 around timestep shifting offer ways to optimize computations in model inference.
- Community efforts are reflected in shared code aimed at numerically solving timestep shifting for discrete schedules.
- Gradient Descent and Fixed Points Exploration: The need for adjusting step sizes in gradient descent emerged as crucial when exploring implications on fixed points in neural networks.
- Discussion pointed out challenges related to recurrent structures and their potential to manifest useful fixed points in applications.
Latent Space Discord
-
Jasper AI Doubles Down on Enterprises: Jasper AI reported a doubling of enterprise revenue over the past year, now serving 850+ customers, including 20% of the Fortune 500. They launched innovations like the AI App Library and Marketing Workflow Automation to further aid marketing teams.
- This growth aligns with an increased focus on AI adoption within enterprise marketing, with many teams prioritizing adoption strategies as competitive tools.
- OpenAI's Search Just Got a Boost: OpenAI has enhanced ChatGPT's web search functionality, allowing for more accurate and timely responses for users. This update positions ChatGPT well against emerging competition in the evolving AI search landscape.
- Users have already begun noticing the difference, with reports highlighting improvements in information retrieval precision compared to previous iterations.
- ChatGPT and Perplexity Battle for Search Supremacy: Debates ensue over the search results quality from ChatGPT versus Perplexity, as both platforms upgraded their capabilities. Users noted ChatGPT's advantage in providing relevant information more effectively.
- This rivalry highlights the growing focus on user satisfaction in search engines, driving further innovation and enhancements across platforms.
- Rise of Groundbreaking AI Tools: Recraft V3 claims to excel in design language, outperforming rivals like Midjourney and OpenAI's offerings. In addition, SmolLM2, an open-source model, sports training on a massive 11 trillion tokens.
- These advancements reflect a competitive marathon in AI capabilities, pushing boundaries in design and natural language processing.
- Call for AI Regulations Grows Louder: Anthropic's recent blog advocates for targeted regulation of AI, emphasizing the need for timely legislative responses. Their comments contribute meaningfully to the discourse on AI governance and ethics.
- With rising concerns about the societal impact of AI, this piece sparks conversations about how regulations can shape the future landscape of technology.
LM Studio Discord
-
venvstacks streamlines Python installs:
venvstackssimplifies shipping the Python-based Apple MLX engine without separate installations. Available on PyPi with$ pip install --user venvstacks, this utility is open-sourced and documented in a technical blog post.- The integration supports the MLX engine within LM Studio, enhancing user experience.
- LM Studio celebrates Apple MLX support: The latest LM Studio 0.3.4 release brings support for Apple MLX, along with integrated downloadable Python environments detailed in a blog post.
- Members highlighted that venvstacks is pivotal for a seamless user experience with Python dependencies.
- M2 Ultra impresses with T/S performance: Users reported 8 - 12 T/S performance on the M2 Ultra, with speculation of 12 - 16 T/S not being particularly impactful. Rumors suggest upcoming M4 chips may challenge the 4090 graphics cards, stirring excitement.
- Community members are eagerly awaiting more performance benchmarks as they share their experiences.
- Mistral Large gains popularity: Satisfaction with Mistral Large continues, with users sharing its capabilities and effectiveness in generating coherent outputs.
- However, limitations due to 36GB unified memory were noted, impacting the ability to run larger models seamlessly.
- Understanding system prompts in API requests: A discussion surfaced on the significance of system prompts, clarifying that parameters in API payloads override UI settings. This offers flexibility but makes consistent use crucial.
- Members emphasized the importance of understanding this for optimizing interactions with the LM Studio APIs.
GPU MODE Discord
-
Data Type Conversion in Tensors Explained: Discussion focused on tensor data types, especially f32, f16, and fp8, examining the implications of stochastic rounding in conversions.
- The exploration included transition considerations between bits and standard floating point formats.
- Exploring Shape of Int8 Tensor Core WMMA Instructions: A member noted that the shape of the int8 tensor core wmma instruction is tied to memory handling in LLMs, especially with M fixed at 16.
- This raised questions about implementations when M is small, indicating possible memory optimization strategies.
- Learning Triton and Visualization Fix Updates: A member expressed gratitude for a patch that restored visualization in their Triton learning process, aiding engagement with the Trion puzzle.
- Their return to Triton reflects renewed interest in this area, coupled with active involvement in discussions.
- ThunderKittens Library for User-Friendly CUDA Tools: ThunderKittens aims to create easily usable CUDA libraries, managing 95% of complexities while allowing users to engage with raw CUDA / PTX for the remaining 5%.
- The Mamba-2 kernel showcases its extensibility by integrating custom CUDA for complex tasks, highlighting the library's flexibility.
- Comments on Deep Learning Efficiency Guide: A member shared their guide on efficiency in deep learning, covering relevant papers, libraries, and techniques.
- Feedback included suggestions for sections on stable algorithm writing, reflecting the community's commitment to knowledge sharing.
Cohere Discord
-
Cohere API Frontend Options Lauded: Members discussed various Chat UI frontend options compatible with the Cohere API key, confirming that the Cohere Toolkit fits the bill.
- One user shared insights on building applications, noting the toolkit's support in rapid deployment.
- Chatbots Could Replace Browsers: A member shared R&D efforts focused on simulating ChatGPT's browsing process, aiming to analyze its output filtering mechanisms.
- This initiative ignited excitement, probing further into how ChatGPT's algorithms differ from conventional SEO methods.
- Application Review Process Underway: The team reaffirmed that application acceptances are in progress, ensuring thorough scrutiny of each submission.
- They highlighted a preference for candidates with concrete agent-building experience as crucial for selection.
- Fine-tuning Issues Tackled: Team members are addressing fine-tuning issues with scheduled updates following a user's concerns about ongoing problems.
- It remains pivotal for further development, as testing is set to explore ChatGPT's browsing capabilities.
- Cohere-Python Installation Troubles Resolved: Issues related to installing the cohere-python package with
poetrywere raised, with members sharing experiences and seeking help.
- Resolution came soon after, leading to appreciation for collaborative troubleshooting within the community.
Interconnects (Nathan Lambert) Discord
-
Creative Writing Arena Debuts: A new category, Creative Writing Arena, focused on originality, garnered about 15% of votes in its debut. Key models changed significantly, with ChatGPT-4o-Latest rising to #1.
- The introduction of this category highlights the shift towards enhancing artistic expression in AI-generated content.
- SmolLM2: The Open Source Wonder: The SmolLM2 model, featuring 1B parameters and trained on 11T tokens, is now fully open-source under Apache 2.0.
- The team aims to promote collaboration by releasing all datasets and training scripts, fostering community-driven innovation.
- Evaluating Models on ARC Gains Traction: Evaluating models on ARC is gaining popularity, reflecting improvements in evaluation standards within the community.
- Participants noted that these evaluations indicate strong base model performance and are becoming a mainstream approach.
- Llama 4 Training Brings Big Clusters: Llama 4 models are being trained on a cluster exceeding 100K H100s, showcasing significant advancements in AI capability. Job openings for researchers focusing on reasoning and code generation have also been announced via a job link.
- This robust training infrastructure reinforces the competitive spirit, as noted by Mark Zuckerberg during the META earnings call.
- Podcast Welcomes Scarf Profile Pic Guy: The scarf profile pic guy joins the podcast, causing a buzz among members, with one humorously responding, Lfg! This highlights the community's enthusiasm for notable guest appearances.
- NatoLambert reminisced about their history as one of the OG Discord friends, emphasizing the long-standing connections within this community.
Stability.ai (Stable Diffusion) Discord
-
Inpaint Tool Proves Useful: Users discussed the inpaint tool as a valuable method for correcting images and composing elements, making it easier to achieve desired results.
- Inpainting can be tricky, but it often becomes essential to finalize images, boosting user confidence in their abilities.
- Interest in Stable Diffusion Benchmarks: Members are curious about recent benchmarks for Stable Diffusion, particularly regarding performance on enterprise GPUs compared to personal 3090 setups.
- One user noted that using cloud services could potentially speed up the generation process.
- Discussion on Model Bias: Users observed a trend where the latest models often produce images with reddened noses, cheeks, and ears, prompting a debate over the underlying causes.
- Speculations arose around VAE issues and inadequate training data, especially from anime sources, influencing these results.
- Seeking Community Help for Projects: A user sought assistance for creating a promo video, prompting suggestions to post in related forums for more expertise.
- The responses highlighted a strong collaborative effort within the community to share knowledge and resources.
- Personal Preferences in Image Processing: A member shared their workflow preferences, noting they preferred to separate the img2img and upscale steps instead of relying on integrated solutions.
- This method allows for a more thoughtful refinement of images before finalizing them.
Modular (Mojo 🔥) Discord
-
Community Meeting Preview on November 12th: The next community meeting is set for November 12th, featuring insights from Evan's LLVM Developers' Meeting talk focusing on linear/non-destructible types in Mojo.
- Members can submit questions for the meeting through the Modular Community Q&A, with 1-2 spots open for community talks.
- Debate on C-style Macros: A discussion highlighted that introducing C-style macros could create confusion, advocating for custom decorators as a simpler alternative.
- Members expressed concern for keeping Mojo simple while introducing decorator capabilities.
- Compile-Time SQL Query Validation: There’s potential for SQL query validation at compile time using decorators, although detailed DB schema validation might require more handling.
- Concerns were raised about the feasibility of verifying queries this way.
- Custom String Interpolators for Efficiency: The introduction of custom string interpolators in Mojo, akin to those in Scala, could streamline syntax checks for SQL strings.
- Implementing this feature may avoid complications linked to traditional macros.
- Static MLIR Reflection vs Macros: A discussion around static MLIR reflection suggests it might surpass traditional macros in terms of type manipulation capabilities.
- Maintaining simplicity remains vital to avoid issues with language server protocols while utilizing this feature effectively.
DSPy Discord
-
Masters Thesis Graphic Shared: A member shared a graphic created for their Masters thesis, indicating its potential usefulness to others.
- Unfortunately, no additional details about the graphic were provided.
- Stepping Up CodeIt with GitHub: A GitHub Gist titled 'CodeIt Implementation: Self-Improving Language Models with Prioritized Hindsight Replay' was shared, containing a detailed implementation guide.
- This resource could be particularly valuable for those engaged in related research efforts.
- WeKnow-RAG Blends Web with Knowledge Graphs: WeKnow-RAG integrates Web search and Knowledge Graphs into a 'Retrieval-Augmented Generation (RAG)' system, enhancing LLM response reliability, as detailed in the arXiv paper.
- This innovative system addresses LLMs' propensity for generating factually incorrect content.
- XMC Project Explores In-Context Learning: xmc.dspy demonstrates effective In-Context Learning tactics for eXtreme Multi-Label Classification (XMC), operating efficiently with minimal examples, and more information is available at GitHub.
- This approach could significantly enhance the efficiency of classification tasks.
- DSPy Namesake Origin Story: The name dspy initially had to be circumvented on PyPI with
pip install dspy-ai. Thanks to community efforts, the cleanpip install dspywas eventually achieved after a user-related request, as noted by Omar Khattab.
- This illustrates the importance of community engagement in project development.
OpenInterpreter Discord
-
Open Interpreter Profiles customization: Users can create new profiles in Open Interpreter via the guide, allowing for customization through Python files, including model selection and context window adjustments.
- Profiles enable multiple optimized variations, accessed using
interpreter --profiles, enhancing user flexibility. - Desktop Client updates and events: Updates for the desktop client were discussed, positioning the community's House Party as the prime source for the latest announcements and beta access.
- Members highlighted that past attendees have gained early access, hinting at future developments.
- ChatGPT Search gets an upgrade: OpenAI revamped ChatGPT's web search capabilities, providing fast, timely answers with relevant links aimed at improving response accuracy.
- This advancement encourages a better user experience, making answers more contextually relevant.
- Meta's Robotics Innovations Announced: At Meta FAIR, three robotics advancements were unveiled, including Meta Sparsh, Meta Digit 360, and Meta Digit Plexus, elaborated in a post.
- These developments aim to boost the open source community's capabilities, showcasing innovations in touch technology.
- Concerns Over Anthropic API Integration: Frustrations arose concerning the recent updates in version 0.4.x of Open Interpreter, affecting local execution and Anthropic API integration.
- Suggestions emerged to make Anthropic API integration optional to enhance community support for local models.
- Profiles enable multiple optimized variations, accessed using
tinygrad (George Hotz) Discord
-
Skepticism about NPU Performance: Concerns persist regarding NPU performance in Microsoft laptops, with discussions hinting at alternatives like Qualcomm and Rockchip for better experiences.
- Members engaged in evaluating these alternatives alongside skepticism about current vendor offerings.
- Exporting Tinygrad Models Hits Buffer Issues: Members faced challenges exporting a Tinygrad model derived from ONNX, stumbling upon
BufferCopyobjects instead ofCompiledRunnerin thejit_cache.
- Suggestions were made to filter these out to avoid runtime issues when calling
compile_model(). - Reverse Engineering Hailo Op-Codes: One member sought tools like IDA for reverse engineering Hailo Chip op-codes located in .hef files, frustrated with the absence of a universal coding interface.
- They pondered over the option of exporting to ONNX versus directly reverse engineering.
- Tensor Assignment Confusion in Lazy.py: A member questioned the need for
Tensor.empty()followed byassign()for disk tensor creation, expressing confusion over its operation.
- They also highlighted the use of
assignfor writing new key-values to the KV cache during inference, suggesting broader functionality. - What’s the Deal with Assign Method?: Another discussion arose about the apparent inconsequence of creating new tensors versus utilizing the
assignmethod when gradients aren't being tracked.
- Participants noted the need for clarity on the method's utility and behavioral distinctions.
LlamaIndex Discord
-
Automated Research Paper Reporter Takes Off: LlamaIndex is creating an automated research paper report generator that downloads papers from arXiv, processes them via LlamaParse, and indexes them in LlamaCloud, further easing report generation, as showcased in this tweet. More details are available in their blog post outlining this feature.
- Users eagerly anticipate this functionality's impact on paper-related workloads.
- Open Telemetry Enhances LlamaIndex Experience: Open Telemetry is now integrated with LlamaIndex, enhancing logging traces directly into the observability platform, detailed in this documentation. This integration enhances telemetry strategies for developers navigating complex production environments, as highlighted in this tweet.
- This move simplifies monitoring metrics for intricate applications.
- Llamaparse Struggles with Schema Consistency: Members raised concerns about llamaparse's parsing of PDF documents into inconsistent schemas, complicating imports to Milvus databases. Standardizing the parse output remains a priority for users managing multi-schema data.
- Uniformity in JSON outputs is crucial for smoother data handling and user experience.
- Call for Milvus Field Standardization: Users expressed worries about varied field structures in outputs from multiple documents, complicating imports into Milvus databases. They are exploring ways to achieve standardized parsing outputs.
- Lack of uniformity may hinder integration efforts across diverse datasets.
- Custom Retriever Queries Get a Boost: A discussion emerged on how to add extra meta information when querying a custom retriever beyond the basic query string. Users debated if creating a custom QueryFusionRetriever would be the solution to effectively manage this additional data.
- Optimizing retrieval strategies could enhance the efficiency of data queries.
LAION Discord
-
Searching for Nutritional Datasets: A member is on the hunt for a dataset rich in detailed nutritional information, including barcodes and dietary tags, due to the shortcomings of the OpenFoodFacts dataset.
- They aim to find a more structured dataset that meets their needs for developing food detection models.
- Frustration with Patch Artifacts: Members vent frustration over patch artifacts arising in autoregressive image generation, expressing a need for alternatives to vector quantization.
- Despite their disdain for Variational Autoencoders (VAEs), they feel forced to consider them due to the challenges faced in clean image generation.
- Discussion on Image Generation Alternatives: A suggestion emerged that generating images without a VAE still leads to patch usage, closely resembling VAE functions.
- This sparked a broader conversation about the inherent challenges in image generation methods that don't lean on traditional approaches.
Gorilla LLM (Berkeley Function Calling) Discord
-
Parameter Type Errors Cause Confusion: A member reported experiencing parameter type errors, with the model returning a string instead of the expected integer during evaluation.
- This bug directly impacts overall model performance, representing a significant concern within the community.
- How to Evaluate Custom Models: A query emerged on evaluating finetuned models on the Berkeley Function Calling leaderboard, particularly about processing single and parallel calls.
- Clarity on this topic is crucial for ensuring proper understanding of the evaluation methods available.
- Command Output Issues Spark Confusion: A member shared that running
bfcl evaluateyielded no models evaluated, raising questions about the command's efficacy.
- Guidance was given to check evaluation result locations, hinting at a lack of clarity in using the command properly.
- Correct Command Sequence Essential for Evaluation: It was clarified that prior to running the evaluation command, one must use
bfcl generatefollowed by the model name to obtain responses.
- This detail is essential for participants to correctly follow the evaluation process.
- Model Name in Generate Command Confirmed: Members confirmed that
xxxxin the generation command refers to the model name, emphasizing the importance of accurate command syntax.
- Consulting the setup instructions is vital for ensuring proper command execution.
OpenAccess AI Collective (axolotl) Discord
-
SageAttention surpasses FlashAttention: The newly introduced SageAttention method significantly enhances quantization for attention mechanisms in transformer models, achieving an OPS that outperforms FlashAttention2 and xformers by 2.1 times and 2.7 times respectively, as noted in this research paper. This advancement also offers improved accuracy over FlashAttention3, suggesting potential for efficiently handling larger sequences.
- Moreover, the impact of SageAttention on future transformer model architectures could be considerable, filling a critical gap in performance optimization.
- Confusion over Axolotl Docker tags: Concerns were raised regarding the Docker image release strategy for
winglian/axolotlandwinglian/axolotl-cloud, particularly about the appropriateness of dynamic tags likemain-latestfor stable production use. Users highlighted the need for clearer documentation on this release strategy as tags reflecting main-YYYYMMDD imply daily builds rather than stable versions.
- This discussion underlines the growing need for clarity in versioning as users seek reliable deployments for production environments.
- H100 compatibility on the horizon: A member reported that H100 compatibility is forthcoming, referring to a relevant GitHub pull request that highlights upcoming improvements in the bitsandbytes library. This compatibility update promises to enhance integration within existing AI workflows.
- Community members expressed anticipation regarding the performance boosts and new applications that this compatibility could introduce to their projects.
- bitsandbytes update discussion: The latest discussions centered around the implications of the anticipated H100 compatibility for the bitsandbytes library, with community members keen on sharing insights regarding its potential benefits. Enthusiasm for the update suggests a pivotal moment for innovation in their ongoing projects.
- As enhancements unfold, members examined possible performance upgrades and numerous applications that the new compatibility might yield.
LangChain AI Discord
-
Custom Model Creation is Key: A member emphasized that the only option available is to create fully custom models, directing others to the Hugging Face documentation for guidance.
- Members acknowledged the importance of utilizing these resources, noting that numerous examples can assist in the development process.
- Build Your Own Chat Application with Ollama: A member shared a LinkedIn post about building a chat application using Ollama, highlighting its flexibility.
- The post underlined the benefits of customization and control offered by Ollama, which are crucial for effective chat solutions.
- Discussion on Essential Chat Application Features: Members discussed critical features to integrate into chat applications, emphasizing security and enhanced user experience.
- They pointed out that incorporating features like real-time messaging can significantly improve user satisfaction.
Alignment Lab AI Discord
-
Steam Gift Card Share: A member shared a link to purchase a $50 Steam gift card available at steamcommunity.com. This might be of interest for engineers looking to game or utilize game engines for projects.
- The gift card could be a fun incentive or a tool for team-building activities, encouraging creativity within the engineering community.
- Steam Gift Promotion Repeat: Interestingly, the same $50 Steam gift card link was also shared in a different channel, emphasizing its availability again at steamcommunity.com.
- This duplication could indicate a strong interest among members to engage with gaming content or rewards.
LLM Agents (Berkeley MOOC) Discord
-
Interest Sparked in LLM Agents: Participants express interest in learning about LLM Agents through the Berkeley MOOC.
- evilspartan98 highlighted this opportunity to deepen understanding of agent-based models in language processing.
- Berkeley MOOC Engagement: The ongoing discussion in the Berkeley MOOC suggests a rising traction among members regarding the future implications of LLM Agents.
- The collective engagement emphasizes a shared enthusiasm for exploring innovative frameworks and applications in the field.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #announcements (1 messages):
Llama 3.2Aya ExpanseOpen Source LibrariesModel SecurityUniversal Assisted Generation
-
Llama 3.2 Models Get a Turbo Boost: Meta released new quantized versions of Llama 3.2 1B & 3B that enhance inference speed by 2-4x while reducing model size by 56% and memory footprint by 41%.
- Utilizing Quantization-Aware Training with LoRA adaptors, these models promise to deliver quicker performance without sacrificing quality.
- Explore Aya Expanse for Multilinguality: Check out the deep dive into Aya Expanse by Cohere, which aims to advance the frontier of multilingual AI technologies.
- The article elaborates on how these innovations can broaden accessibility and improve user experiences across languages.
- Gradio's New Open Source Library: The Gradio team has launched a new open-source library called
safehttpx, allowing async GET requests to avoid server-side request forgery.
- You can find more about this library on its GitHub page, which encourages community contributions.
- Model Security Enhanced with Guardian Scanner: Hugging Face partnered with ProtectAICorp to integrate the Guardian scanner into their Hub, boosting model security.
- This feature allows developers to view safety scan results directly on their repository's page, improving transparency and security.
- Join a Workshop with CEO Clem!: Don't miss the opportunity to join a live workshop with our CEO, Clem, scheduled for this Wednesday here.
- This session promises insights and Q&A, perfect for enthusiasts and professionals alike wanting to learn more about Hugging Face's innovations.
Links mentioned:
- Tweet from AI at Meta (@AIatMeta)): We want to make it easier for more people to build with Llama — so today we’re releasing new quantized versions of Llama 3.2 1B & 3B that deliver up to 2-4x increases in inference speed and, on averag...
- Tweet from clem 🤗 (@ClementDelangue)): What's you favorite open-source AI organization? You can now follow them on @huggingface to get notified each time they release a new model, dataset, paper or app! https://huggingface.co/organizat...
- Tweet from Luc Georges 🦀 (@LucSGeorges)): 🔐Want safer models? Look no further! We've partnered with @ProtectAICorp and integrated their Guardian scanner to the Hub, enhancing model security for the community 😏 You should see scan resu...
- Scaling GenAI Inference with Hugging Face and GKE): Technical session exploring the intersection of open models and infrastructure for efficient, AI inference at scale. In this session, the Google Kubernetes Engine and Hugging Face teams will unpack o...
HuggingFace ▷ #general (884 messages🔥🔥🔥):
Hugging Face Discord ModerationLlama Model OptimizationText-to-Video ModelsExperimental AI ModelsUser Behavior on Discord
-
Concerns about Discord Moderation Actions: Users expressed concerns regarding moderation actions on Discord, particularly related to reports involving potential malicious code within PRs and user behavior in chat.
- Community members were advised to reach out through designated channels for transparency regarding moderation processes and actions taken.
- Performance of Llama Models: Discussion focused on the capabilities of various Llama models, particularly the 1B and 3B versions, highlighting their struggles with structured output.
- Some users suggested that models, such as the 8B version, might yield better results for tasks requiring consistent structured outputs.
- Interest in Text-to-Video Models: Community members explored different text-to-video models, with Mochi-1 being highlighted for its strong performance compared to others like Allegro 2.8B.
- The capabilities and limitations of various models were discussed, emphasizing their suitability for different applications in content creation.
- Keyframe Interpolation Models: For keyframe support, users discussed the CogVideoX interpolation model, which is known for effectively interpolating between two frames.
- The model's GitHub link and documentation were shared for users looking to implement interpolation in their projects.
- Community Interaction and User Engagement: The channel had discussions on the importance of understanding user behavior and fostering a supportive learning environment on Discord.
- Users were encouraged to share their insights and experiences regarding AI models and the creation of content while remaining respectful to one another.
Links mentioned:
- gsplat: no description found
- Tweet from undefined: no description found
- google/maxim-s2-enhancement-lol · Hugging Face: no description found
- xxxxxxx (sayaka.M): no description found
- Moving Pictures: Transform Images Into 3D Scenes With NVIDIA Instant NeRF: Learn how the AI research project helps artists and others create 3D experiences from 2D images in seconds.
- Tweet from Charlie Marsh (@charliermarsh): The PyTorch packaging setup is my nemesis
- Interstellar Cost GIF - Interstellar Cost Little Maneuver - Discover & Share GIFs: Click to view the GIF
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Great to visit one of our data centers where we're training Llama 4 models on a cluster bigger than 100K H100’s! So proud of the incredible work we’re doing to advance our products, the AI field a...
- Efficiently fine-tune Llama 3 with PyTorch FSDP and Q-Lora: Learn how to fine-tune Llama 3 70b with PyTorch FSDP and Q-Lora using Hugging Face TRL, Transformers, PEFT and Datasets.
- Morinaga Chocoball GIF - Morinaga Chocoball Ad - Discover & Share GIFs: Click to view the GIF
- Oh No GIF - Oh No Oh No - Discover & Share GIFs: Click to view the GIF
- GitHub - Narsil/fast_gpt2: Contribute to Narsil/fast_gpt2 development by creating an account on GitHub.
- Recurrent Neural Networks (RNNs), Clearly Explained!!!: When you don't always have the same amount of data, like when translating different sentences from one language to another, or making stock market prediction...
- GitHub - korouuuuu/HMA: Contribute to korouuuuu/HMA development by creating an account on GitHub.
- Learn PyTorch for deep learning in a day. Literally.: Welcome to the most beginner-friendly place on the internet to learn PyTorch for deep learning.All code on GitHub - https://dbourke.link/pt-githubAsk a quest...
- GitHub - SiTH-Diffusion/SiTH: [CVPR 2024] SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion: [CVPR 2024] SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion - SiTH-Diffusion/SiTH
- missing performance eval · Issue #905 · LaurentMazare/tch-rs: issue perfomance is not evaluated or communicated motivation how do we explain what is the point of this exercise ? solution side by side performance and dependency evalutions
- Audio-Visual Synchronization in the Wild: Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Nagrani, Andrea Vedaldi, Andrew Zisserman
- GitHub - huggingface/candle: Minimalist ML framework for Rust: Minimalist ML framework for Rust. Contribute to huggingface/candle development by creating an account on GitHub.
- GitHub - LaurentMazare/tch-rs: Rust bindings for the C++ api of PyTorch.: Rust bindings for the C++ api of PyTorch. Contribute to LaurentMazare/tch-rs development by creating an account on GitHub.
- neuralmagic/Meta-Llama-3.1-70B-Instruct-FP8 · Hugging Face: no description found
- joycaption/scripts/batch-caption.py at main · fpgaminer/joycaption: JoyCaption is an image captioning Visual Language Model (VLM) being built from the ground up as a free, open, and uncensored model for the community to use in training Diffusion models. - fpgaminer...
- When localhost is not accessible · Issue #4046 · gradio-app/gradio: Checking if localhost can be accessed is just to verify the program running on Colab. But this error is also triggered when http_proxy or https_proxy is set, but no_proxy="localhost, 127.0.0.1, :...
HuggingFace ▷ #today-im-learning (5 messages):
Profiling TechniquesTokenization OptimizationAttention Model TypesSeq2Seq Model StructureCourse Resources
-
Profiling reveals time spent on all-reduce: Profiling techniques showed that 90% of the time during training is consumed by all-reduce operations, with parameters set to m=n=k=16k.
- This profiling was conducted while excluding the optimization step (optim.step) for a 7B model.
- Optimizing dataset tokenization with collate_fn: A member shared insights on optimizing the tokenization of their dataset using collate_fn, enhancing code efficiency.
- They also mentioned learning to create both additive and multiplicative attention models.
- Understanding Seq2Seq model intricacies: One member fully learned the structure and data flow of a seq2seq model, encountering valuable debugging lessons related to shape mismatches.
- They are experimenting with hyperparameters, tweaking the encoder's and decoder's embedding dimensions separately.
- Questions about target padding mask usage: Currently learning about transformers, a member expressed curiosity about when to use the target padding mask.
- They are focusing on grasping the underlying theory before proceeding with coding.
- Seeking consolidated course resources: A member is trying to locate a comprehensive GitHub link that aggregates resources for free and paid courses.
- They reached out for help multiple times, underscoring the urgency of their request.
HuggingFace ▷ #cool-finds (18 messages🔥):
AI Podcast CreationOpenAI ChatGPT Search SystemBlockchain DevelopmentHuggingChat & Meta-Llama Model
-
AI Podcast Ideas from Celery Man: A member expressed interest in creating a podcast featuring a computer voice along with a Paul Rudd clone having banter, suggesting the use of Llama for text analysis and a TTS model for voices.
- Extracting text from latex files was mentioned as a step being taken for the project.
- ChatGPT's New Search Powers: OpenAI recently released a search system inside ChatGPT, allowing it to access up-to-date sources for verified information.
- This enhancement was noted to mean that ChatGPT knows everything now, providing a significant upgrade to its capabilities.
- Interest in Blockchain Development: A member inquired about others working in the blockchain area, to which another confirmed engagement in web3 coding.
- This indicates a growing interest and probably collaboration among community members in blockchain-related projects.
- HuggingChat Showcases Meta-Llama Model: Another member shared a link to HuggingChat, showcasing the meta-llama model (Meta-Llama-3.1-70B-Instruct) as part of the community's resources.
- This model is available for testing and highlights the community's effort in making the best AI chat models accessible.
- The Good News Declared: A member shared the excitement regarding the good news about OpenAI's search system added to ChatGPT.
- The initial intrigue led to questions within the community about what that good news was, emphasizing the impact of updates in AI tools.
Links mentioned:
- Hand & Face MIDI Controller: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
HuggingFace ▷ #i-made-this (2 messages):
AI bug patching agentAutomated code reviews1-Click patch applicationOpen-source project support
-
AI Agent Autogenerates Bug Patches: An agent has been developed that autogenerates patches for bugs, typos, and non-idiomatic code, suggesting fixes upon a pull request submission.
- This tool enables developers to apply patches with a single click, streamlining the code review process and enhancing code quality.
- AI-Augmented Code Reviews: This AI tool offers time-saving capabilities for developers, serving as a first pass at catching hard-to-spot bugs during code reviews.
- It enhances the review process by identifying issues that need addressing before human checks are made, thus improving efficiency.
- Automated Documentation and Consistency Fixes: The agent ensures code consistency by automatically adding missing documentation, fixing typos, and addressing minor nits.
- Its goal is to allow developers to concentrate on more critical tasks while it manages routine code quality aspects for them.
- Free for Open-Source Projects: The agent is available free of charge for open-source projects, encouraging more developers to utilize it in their workflows.
- This aspect of accessibility is essential for fostering community contributions and improving collaborative code management.
Link mentioned: Standard Input - AI Software Engineer for Code Reviews: Save time and improve code quality with AI-augmented reviews and one-click patches for your pull requests.
HuggingFace ▷ #core-announcements (1 messages):
Native Quantization Support8-bit and 4-bit QuantizationUsing bitsandbytes LibraryQLoRA for Finetuning
-
Hugging Face Introduces Native Quantization Support: Hugging Face now supports native quantization with bitsandbytes as the first backend, enhancing model performance and flexibility.
- This move allows users to efficiently compress models and is expected to expand further with additional backends in the future.
- 8-bit and 4-bit Quantization Explained: 8-bit quantization utilizes outlier handling techniques to retain model integrity while compressing weights, reducing performance degradation.
- 4-bit quantization takes this further by compressing models even more, commonly used in conjunction with QLoRA for optimizing fine-tuning.
- Installing bitsandbytes for Quantization: To get started with bitsandbytes, the following dependencies must be installed via pip:
diffusers transformers accelerate bitsandbytes -U.
- This allows quantization of models by passing a proper BitsAndBytesConfig during the loading process.
- Comprehensive Guide Links for Quantization: For a detailed guide on inference, check the inference guide, which covers quantization methods.
- The training guide provides resources for implementing quantized LLMs in practical applications.
Links mentioned:
- bitsandbytes: no description found
- diffusers/examples/research_projects/flux_lora_quantization at main · huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. - huggingface/diffusers
HuggingFace ▷ #computer-vision (3 messages):
MolMo VLM Fine-TuningUltralytics Installation Issues
-
MolMo VLM Fine-Tuning Talk: There's been no specific fine-tunes of the MolMo VLM discussed, but a member pointed to a GitHub repo as a resource for anyone interested.
- It was suggested that if anyone plans to fine-tune the MolMo VLM soon, it's likely to be Phil, who has shared relevant training notebooks.
- Jack's Ultralytics Installation Problems: A member encountered an error stating 'ultralytics no module', despite confirming installation was successful via VSCode terminal.
- Another member requested to see the precise error message for further diagnosis, indicating a collaborative troubleshooting effort.
Link mentioned: deep-learning-pytorch-huggingface/training/fine-tune-multimodal-llms-with-trl.ipynb at main · philschmid/deep-learning-pytorch-huggingface: Contribute to philschmid/deep-learning-pytorch-huggingface development by creating an account on GitHub.
HuggingFace ▷ #NLP (11 messages🔥):
Research Paper ObjectivesReading Strategies for PapersLow-Rank AdaptersCurated Paper ListsConference Proceedings
-
Clarifying Research Paper Objectives: Members shared their varying objectives when reading research papers, with some focusing on implementation while others prefer staying updated.
- I don't think I have ever implemented something from a paper reflects a common sentiment in the discussion.
- Effective Reading Strategies for Papers: One member detailed a three-step approach to reading papers: a quick skim, followed by a deeper read, and finally a thorough investigation.
- The structured method emphasizes efficiency in understanding complex topics within academic papers.
- Exploring Low-Rank Adapters: A participant acknowledged limited knowledge about low-rank adapters and admitted to not having read related papers.
- This highlights an area of interest while indicating a gap in current knowledge among members.
- Curated Resources for LLM Research: A curated list of preprints can be found at hf.co/papers which may help deepen understanding in the field.
- Members are encouraged to utilize this resource for accessing ongoing research.
- Importance of Conference Proceedings: Participants suggest looking for conference proceedings as a valuable source of information, supplementing regular paper readings.
- This method could provide insight into cutting-edge developments and community discussions in the field.
HuggingFace ▷ #diffusion-discussions (2 messages):
SD3Transformer2DModel import issueDiffusers 0.31 installationVSCode settings
-
Trouble importing SD3Transformer2DModel in VSCode: A member expressed confusion about why they cannot execute
from diffusers import SD3Transformer2DModelin VSCode despite Pylance running without error.- They mentioned that they can successfully import another model using
from diffusers.models import controlnet_sd3, indicating a possible issue specific to SD3Transformer2DModel. - Exploration of the Diffusers project: Another member thanked the community for the investigation and expressed interest in reading about the mentioned project, indicating a desire to learn more.
- This reflects the collaborative nature of the community in sharing knowledge and resources surrounding diffusers.
- They mentioned that they can successfully import another model using
Nous Research AI ▷ #general (192 messages🔥🔥):
Flash-Attn CompatibilityPerplexity Competes with NousAI Assistants and EcosystemsApple vs PC for AINetworking Hardware for AI
-
Flash-Attn Now Runs on A6000: A member successfully got flash-attn 2.6.3 working on CUDA 12.4 and PyTorch 2.5.0 with an A6000, resolving previous issues by building it manually.
- They noted that previously attempting a pip install led to linking errors, but now it appears feasible.
- Perplexity Introduces new Supply Line: A member highlighted Perplexity's new venture, Perplexity Supply, which aims to offer quality goods designed for curious minds.
- Others expressed concern that competition with Nous prompts a need to enhance their own offerings.
- The Future of AI Assistants: Discussion arose around AI assistants' potential to manage multiple tasks across platforms, with arguments for an ecosystem built on local and cloud integrations.
- Members debated whether local devices' limited computing power could support comprehensive AI functionality and ease of use.
- Comparison of Apple and PC for AI Development: A member argued that despite some advantages, Apple's offerings primarily provide ease of use rather than a superior technical edge.
- The conversation suggested that running AI on alternative hardware setups could be viable if the necessary setup challenges are addressed.
- CPU Networking for AI Performance: A member proposed utilizing spare PCIe slots for economical CPU clusters to enhance model performance through networking.
- This strategy showed promise for scaling AI workloads in cost-effective ways, contrasting with traditional workstation approaches.
Links mentioned:
- Multi-Layer Perception Visualization: no description found
- Tweet from Perplexity (@perplexity_ai): Introducing Perplexity Supply. Quality goods, thoughtfully designed for curious minds. http://perplexity.supply
Nous Research AI ▷ #ask-about-llms (16 messages🔥):
Comparing Hermes 3 and Llama 3Simulating ChatGPT's Browsing ProcessSearch behavior of LLMsAlternatives to Langchain and Ollama
-
Hermes 3 shines against Llama 3: A conversation highlighted that while Llama 3.1 is steerable, Hermes 3 adheres strongly to personas from system prompts due to its finetuning with role-play datasets.
- Members found ollama to be a practical tool for testing models, providing simple commands to pull and customize both models.
- ChatGPT's Browsing Process Under Scrutiny: One member proposed manually simulating ChatGPT's browsing process to analyze its search term extraction and result filtering methods.
- Responses indicated that transparency is lacking, with one user suggesting that using Claude might yield better insights into ChatGPT's behavior.
- State of Search-Enhanced LLMs: Discussion revealed that current search-enhanced LLM capabilities remain rudimentary, with concerns over fair use and data ingestion.
- Users voiced apprehension that utilizing full website data could expose companies to legal challenges and emphasized the need for understanding the LLMs' sources.
- Critique of Langchain and Ollama: Concerns were raised about the criticism surrounding Langchain and Ollama, prompting inquiry into alternative tools for interacting with models.
- The community seems active in seeking, discussing, and evaluating various frameworks to enhance their modeling workflows.
Link mentioned: SuperPrompt/tm_prompt.md at main · NeoVertex1/SuperPrompt: SuperPrompt is an attempt to engineer prompts that might help us understand AI agents. - NeoVertex1/SuperPrompt
Nous Research AI ▷ #interesting-links (4 messages):
SmolLM2 modelsTrainings on 11 Trillion tokens135M variant capabilities
-
SmolLM2 family showcases lightweight capability: The SmolLM2 family offers three model sizes: 135M, 360M, and 1.7B parameters, designed for a variety of tasks while being lightweight enough for on-device use.
- The 1.7B variant shows advancements in instruction following and reasoning compared to its predecessor, SmolLM1.
- Impressive training on massive data: SmolLM2 was trained on an astounding 11 trillion tokens, enhancing its ability to understand and generate content.
- This large training dataset contributes significantly to the model's improved performance in various tasks.
- 135M variant generates confusing output: Though SmolLM2's 135M version is easy to run, it reportedly generates valid-looking text that can often be quite nonsensical.
- This aspect raises concerns about its reliability for certain applications, despite its lightweight nature.
- Potential for summarization and function calling: The SmolLM2 models, particularly the smaller versions, are suggested to be effective for summarization tasks and simple function calling on edge devices.
- This makes them potentially suitable for applications requiring quick and efficient processing.
Link mentioned: HuggingFaceTB/SmolLM2-1.7B-Instruct · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #general (121 messages🔥🔥):
Multi-GPU Fine TuningQuantization TechniquesUnsloth Framework FeaturesFine-Tuning Stability IssuesNew Model Releases
-
ETA for Multi-GPU Fine Tuning: Members are inquiring about the estimated arrival time for multi-GPU fine tuning, with responses indicating it should be available 'soon (tm)' and possibly before the end of the year.
- This effort is contingent upon ongoing improvements and optimizations, with a focus on vision models and overall model support first.
- Exploring Quantization Techniques: Discussions include debates on the best Language Models (LMs) for fine tuning, particularly under 3 billion parameters, with suggestions like DeBERTa and Llama for various tasks.
- Concerns were raised about the tradeoffs of quantization, including potential quality loss versus speed improvements in fine-tuning processes.
- Unsloth Framework Features and Flexibility: The Unsloth framework is highlighted for its efficiency in fine-tuning, with many members appreciating its smooth user experience and time-saving capabilities.
- Questions were raised regarding its flexibility for advanced tasks like layering freezing and custom training loops, with assurances that it supports these features.
- Fine-Tuning Stability Issues: Members, including one who fine-tuned Qwen 2.5, reported experiencing issues with the model returning EOS prematurely, prompting discussions on dataset stability and overfitting.
- Concerns were also highlighted regarding proper token mappings and the need for layer freezing, signaling a deeper interest in precise training methodologies.
- Release of New Models: Announcement of new 1.7B Hugging Face models was made, generating excitement among members, with community feedback sought through platforms like Twitter.
- Links were shared for a Google Colab notebook for Llama 3.2, promoting ease of use and encouraging the community to experiment with new models.
Links mentioned:
- TPU Research Cloud - About: no description found
- FineWeb: decanting the web for the finest text data at scale - a Hugging Face Space by HuggingFaceFW: no description found
- Buggy Horse And Buggy GIF - Buggy Horse And Buggy Big Bird - Discover & Share GIFs: Click to view the GIF
- Hobbit Gandalf GIF - Hobbit Gandalf Wizard - Discover & Share GIFs: Click to view the GIF
- unsloth/SmolLM2-1.7B-Instruct-GGUF · Hugging Face: no description found
- Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities: no description found
- unsloth/SmolLM2-1.7B-bnb-4bit · Hugging Face: no description found
- unsloth/SmolLM2-1.7B · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
Hackerrank AchievementsMemes about LearningFunny Dog Reactions
-
Excitement Over Hackerrank: A member expressed their feelings about receiving a Hackerrank by sharing a humorous perspective, indicating strong emotions tied to the achievement.
- This light-hearted tone suggests Hackerrank challenges might bring both stress and excitement.
- Humorous Dog GIFs: Members engaged with a funny GIF of a dog that humorously depicts 'I’m finished' feelings after a tough task, resonating with Hackerrank experiences.
- The choice of the GIF highlights a relatable moment, combining humor with the rigors of coding.
Link mentioned: Brain Dog Brian Dog GIF - Brain dog Brian dog Cooked - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (80 messages🔥🔥):
Unsloth Fine-TuningInference Memory IssuesFlash Attention 2 and XformersCUDA Version CompatibilityTrainer Deprecation Notice
-
Fine-tuning Models with Unsloth: Users are discussing fine-tuning various models like 'unsloth/Meta-Llama-3.1-8B' and 'allenai/OLMo-7B-0724-Instruct-hf' with Unsloth, focusing on dataset compatibility and parameter adjustments.
- Some users suggested that smaller datasets might be causing out-of-memory (OOM) issues during training and recommended checking model configurations.
- Memory Issues During Inference: A user reported increasing GPU memory usage after running multiple inferences with 'unsloth/Meta-Llama-3.1-8B', raising concerns about potential memory accumulation.
- Attempts to clear memory using torch.cuda.empty_cache() were largely ineffective, indicating the need for deeper investigation into memory management.
- Flash Attention 2 and Xformers Compatibility: There was a discussion about using Flash Attention 2 (FA2) alongside Unsloth and whether it was necessary given that Xformers is also available.
- It was concluded that while FA2 can be installed, Xformers provides sufficient performance for most use cases in continual pretraining.
- CUDA Version Recommendations: Users inquired about the best CUDA version for continued pretraining and implementing retrieval-augmented generation (RAG), highlighting the need for backwards compatibility.
- It was recommended to use CUDA version 12.1 or at least 11.8 for optimal library support, despite limited options on specific system configurations.
- Trainer Tokenizer Deprecation Notice: A notice about the deprecation of 'Trainer.tokenizer' in favor of 'Trainer.processing_class' was circulated, indicating a change in the library's design.
- This suggests that users should update their code to adapt to the new API to avoid issues in future updates of the library.
Links mentioned:
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Tweet from samsja (@samsja19): @charliermarsh Flash attention package is the final boss
- Continued Pretraining - Google Drive: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
Unsloth Docker Image
-
Try out the Unsloth Docker Image: A member shared a link to their Unsloth Docker Image for others to try out.
- They encouraged participation and feedback on the image's performance and usability.
- Feedback on Docker Images: The discussion highlighted the importance of user feedback for improving Docker images and container usability.
- Members expressed enthusiasm about testing new tools and sharing their experiences.
Link mentioned: no title found: no description found
Unsloth AI (Daniel Han) ▷ #research (1 messages):
edd0302: https://arxiv.org/pdf/2410.20305
Wow! Cool implementation of flexattention!
Perplexity AI ▷ #general (125 messages🔥🔥):
Grok 2 ModelPerplexity Pro Subscription IssuesImage Uploads in PerplexityConfusion Around Search FunctionsComparing Perplexity to ChatGPT
-
Grok 2 Model Received Mixed Reviews: Users have expressed both enjoyment and frustration with the new Grok 2 model, noting its availability on the Perplexity iOS app for Pro users.
- Some users remarked that it lacks certain features, like helpful personality traits, leading to varying experiences.
- Perplexity Pro Subscription Issues Persist: Several users reported difficulties with their Pro subscriptions, including issues with the app not recognizing the subscription status.
- Notably, some users have been frustrated with limited source outputs despite paying, questioning if the service has downgraded.
- Image Upload Feature Appreciated: Users have highlighted the ability to upload images and give prompts in Perplexity as a beneficial feature during their usage.
- However, there are concerns about missing functionalities and general performance quality with recent updates.
- Confusion Arises Over Search Functions: There were several discussions on the clarity of the search function in Perplexity, with users stating that it seems to primarily search titles, complicating more comprehensive inquiries.
- Concerns about responses being rerouted to GPT without clear communication from developers added to frustrations.
- Users Compare Perplexity to ChatGPT: Some users weighed in on comparing functionalities between Perplexity and ChatGPT, discussing perceived limitations and advantages of each model.
- The general consensus was that ChatGPT might be better in specific contexts, leaving some to question Perplexity's evolving effectiveness.
Link mentioned: Tweet from Aravind Srinivas (@AravSrinivas): Been enjoying using the Grok 2 model. Now on Perplexity iOS app too for Pro users. (Restart app if you don’t see it on “Settings->AI Model”)
Perplexity AI ▷ #sharing (9 messages🔥):
Quantum ComputingDetroit: Become HumanPeople RegulationResearch Papers OverviewAI-Written Code
-
Quantum Computing Capabilities: One link discussed how quantum computers can enhance performance in various tasks, showcasing groundbreaking potential here.
- Experts emphasize that understanding these advances can lead to substantial improvements in computational efficiency.
- Reddit's First Profit Announcement: The channel highlighted that Reddit has achieved its first profit, a significant milestone for the platform, shared in this video.
- Discussants noted the implications of this success for future revenue models in social media.
- Meta's Competitor to NotebookLM: A discussion emerged about Meta launching a new competitor to NotebookLM, indicating increased competition in the AI space source.
- Participants debated the potential impact on user adoption and market dynamics.
- Regulating People's Activities: A member shared insights regarding people regulation and its implications, leading to a discussion on best practices link.
- This includes key discussions on ethical considerations in people management.
- Research Paper Rundown: A comprehensive overview of relevant research papers was provided, summarizing key findings and contributions source.
- Participants discussed how these papers could affect ongoing AI developments.
Perplexity AI ▷ #pplx-api (1 messages):
API CitationsFeature Availability
-
Unavailability of Citations via API: A member noted that getting citations through the API is not currently supported, emphasizing that the feature is unavailable.
- This suggests limitations in the current capabilities of the API that may affect users seeking citation functionalities.
- Clarification on API Features: There was a request for clarification regarding the features offered by the API, specifically related to citation retrieval.
- This highlights ongoing discussions about what functionalities users expect from the API and what is currently feasible.
OpenAI ▷ #annnouncements (2 messages):
Reddit AMA with OpenAI ExecutivesChatGPT search enhancement
-
Get Ready for the Reddit AMA!: A Reddit AMA with Sam Altman, Kevin Weil, Srinivas Narayanan, and Mark Chen is happening at 10:30 AM PT. Users are encouraged to submit their questions for discussion, details can be found here.
- This event is a great opportunity for the community to engage directly with OpenAI’s leadership.
- ChatGPT Search Gets a Major Upgrade: ChatGPT can now search the web more effectively, providing fast and timely answers with relevant links. This improvement aims to enhance user experience, more details can be found here.
- This new feature promises to deliver better and more immediate information for users.
Link mentioned: Reddit - Dive into anything: no description found
OpenAI ▷ #ai-discussions (108 messages🔥🔥):
GPT-4 Training UpdatesAI Art DebateOpenAI's ChatGPT SearchAI in Business ConsultingText-To-Image Generation
-
GPT-4 Updates and Training Cycle: Discussion centered on the frequency of updates for models like GPT-4, with opinions suggesting that substantial changes take 2-4 months to implement due to training and safety testing.
- Some argue that small updates based on user feedback could happen more frequently, leading to a variety of views on the product’s development timeline.
- Is AI-Generated Art Truly Art?: The ongoing debate about AI-generated images being classified as art sparked conversations about whether intention or visual appeal is the key factor defining art.
- Users cited examples like museums displaying unconventional items as art, highlighting the subjectivity in defining artistic value.
- ChatGPT Search Feature Experience: Several users shared their experiences with the newly tested ChatGPT Search feature, expressing interest in its functionality and potential improvements.
- There was interest in how to customize search engines and utilize features like temporary chats for enhanced user experience.
- AI in Business Consulting: A new user introduced themselves as an AI consultant who focuses on making AI tools like ChatGPT accessible for industries such as retail and coffee.
- They expressed a desire to connect with others working with AI to transform their industries and contribute to collaborative learning.
- Text-To-Image Generation Capabilities: Participants discussed the capabilities of text-to-image models and the potential of AI to generate visually appealing content, which might contribute to the art debate.
- The excitement around AI's ability to iterate upon image generations was noted, with aspirations for future interactive coding tools and applications.
Links mentioned:
- AI Dream Factory: Make little movies with AI: AI Dream Factory is a game about ccreating little movies, memes, and skits with the help of AI.
- Article 6: Classification Rules for High-Risk AI Systems | EU Artificial Intelligence Act: no description found
OpenAI ▷ #gpt-4-discussions (2 messages):
GPTs file handlingFile conflict management
-
GPTs Prefer Single Files for Clarity: A member noted that when using multiple files with overlapping information, the model seemed to favor a single file, demonstrating a preference for clarity in challenging scenarios.
- They observed that while 120k characters of instructions could be managed, ensuring no conflicts resulted in better model performance.
- Multiple Files Still Work Fine: Despite a slight preference for single files, the member emphasized that multiple files do not hinder the model's capabilities in handling tasks, even the more complex ones.
- They concluded that the model can perform effectively with both single and multiple files, provided there are no conflicting instructions.
- Seeking Help with an Issue: A user reached out in search of assistance regarding an unspecified issue, providing a link for context.
- The message lacked details but indicated that support or advice was being sought from the community.
OpenAI ▷ #prompt-engineering (4 messages):
D&D DM GPTAI generation limitations
-
Building a D&D DM GPT: A member has been trying to create a D&D DM GPT to enhance gaming experiences.
- They expressed excitement about integrating AI into tabletop gaming.
- Limiting AI Generations to User Actions: A member inquired about methods to restrict AI generation to reflect only the direct effects of user actions.
- Another member suggested elaborating on this concept for clearer model context.
OpenAI ▷ #api-discussions (4 messages):
DND DM GPTAI generation limitationsModel context expansion
-
Building a DND DM GPT: A member is actively trying to create a DND DM GPT to enhance game sessions.
- The direction of this project suggests an interest in making storytelling more interactive.
- Limiting AI Generation Effects: A user inquired about methods to limit AI generation to reflect only the direct effects of user actions.
- This question hints at a need for clarity on how interactive AI can align with user decisions.
- Expanding on User Intentions: Another member prompted for further elaboration on the inquiry regarding AI limitations.
- They suggested that detailed explanations could be beneficial to guide the model's responses.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Request timeout issuesNetwork connection improvements
-
Investigating sporadic request timeouts: The team is currently addressing an odd, sporadic network connection issue between two cloud providers that has resulted in 524 errors.
- Recent improvements appear to be helping, but the issue remains under investigation and both cloud providers are now involved.
- Awaiting further updates on network issues: Members are informed that an update will be provided once more information about the request timeout issues becomes available.
- The focus continues on ensuring better connectivity between the involved cloud services.
OpenRouter (Alex Atallah) ▷ #general (107 messages🔥🔥):
OpenAI Speech-to-Speech APIClaude 3.5 DebatesOpenRouter Credits and ModelsGoogle Search Grounding in Gemini APILlama 3.2 Usage Limits
-
OpenAI Speech-to-Speech API Uncertainty: A user inquired about the availability of the new OpenAI Speech-to-Speech API, but it was stated that there is currently no estimated time of arrival.
- This lack of information left participants curious and seeking specifics regarding its rollout.
- Discussion on Claude 3.5 Features: There was a heated debate regarding a supposed new 'concise mode', where users expressed frustration about Claude’s responses being overly restricted.
- Participants shared varied experiences, with some claiming they haven’t noticed significant changes in the API's output.
- Understanding OpenRouter Credits: Users discussed the pricing of OpenRouter credits, clarifying that it's about $1 for about 0.95 credits after fees, which can be used to cover token costs in paid models.
- It's also noted that free models come with limits, specifically a cap of 200 requests per day and that paid models have different rates based on usage.
- Gemini API Introduces Google Search Grounding: The Gemini API has added support for Google Search Grounding, similar to its functionality in Vertex AI, though users noted that the pricing may be somewhat high.
- Discussion included how this feature could assist in grounding technical queries based on live documentation.
- Llama 3.2 and Production Use: Questions arose regarding the feasibility of using Llama 3.2 for production, especially concerning its request limits and necessary credits for higher usage.
- It was pointed out that moving to paid models might be essential if one intends to exceed the free tier limits.
Links mentioned:
- Limits | OpenRouter: Set limits on model usage
- Quick Start | OpenRouter: Start building with OpenRouter
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- Supported Models: Access Meta’s Llama 3.2 and 3.1 family of models at full precision via the SambaNova Cloud API! All models are available to all tiers, including the free tier. SambaNova is the only provider to offer...
- Generative AI Scripting: GenAIScript, scripting for Generative AI.
- no title found: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
Integration Feature Request
-
Demand for Integration Access Soars: Multiple members expressed their desire for access to the integration feature, highlighting a growing interest in this capability.
- Requests came from users with varied usernames, reinforcing the notion that integration is a hot topic in the community.
- Integration Request Flood: A wave of requests for integration access has emerged, with usernames like andycando14_09990 and futurplanet requesting access.
- This reflects a strong collective desire for enhancing functionality within the platform.
aider (Paul Gauthier) ▷ #general (100 messages🔥🔥):
Aider featuresHaiku 3.5 releaseContinue as an AI coding assistantAnalytics feature in AiderChallenges using Aider with Ollama
-
Aider's capabilities with context: Aider automatically reads the on-disc version of files at each command, seeing the latest updates without manual file additions.
- Users can utilize extensions like Sengoku to automate file management within their coding environment, streamlining interaction.
- Anticipated Haiku 3.5 Launch: There was speculation about the release of Haiku 3.5, with a consensus that it might arrive later this year but not in the immediate future.
- The discussion suggested that if Haiku 3.5 were to drop soon, it would generate significant excitement and expectations in the community.
- Continue as an alternative to Cursor: Users expressed satisfaction with Continue, an AI code assistant integrated into VS Code, which offers features similar to Cursor’s autocomplete.
- The tool is praised for its user-friendly interface and the ability to enhance coding efficiency through customizable workflows.
- Analytics Enhancement in Aider: Aider introduced an analytics feature that collects anonymous usage data to improve the usability of the application.
- Users are encouraged to opt-in to analytics, which will help the development team identify popular features and rectify bugs.
- Challenges using Aider with Ollama: Some users reported performance issues when utilizing Aider with Ollama, especially with larger model sizes leading to slow responses.
- The conversation highlighted the necessity for a capable setup to efficiently manage these AI tools for seamless integration.
Links mentioned:
- FAQ: Frequently asked questions about aider.
- Analytics: aider is AI pair programming in your terminal
- Patched: Open source workflow automation for dev teams
- Continue: Amplified developers, AI-enhanced development · The leading open-source AI code assistant. You can connect any models and any context to build custom autocomplete and chat experiences inside the IDE
aider (Paul Gauthier) ▷ #questions-and-tips (5 messages):
Aider APIAider Self-ScriptingSonnet Performance IssuesState-Machine Parsing- ``
-
Inquiry about Aider API: A user inquired whether Aider has an API for programmatic use instead of relying on the command line interface.
- Another user suggested testing Aider's capabilities on itself to explore potential implementation.
- Scripting Aider with Command Line: Discussion referred to Aider’s ability to be scripted via command line commands or Python, with various practical examples shared for using the
--messageargument.
- Guidelines were provided to facilitate scripting tasks effectively, enhancing automation for users.
- Sonnet shows performance decline: Users expressed frustration with Sonnet, noting unexpected mistakes such as generating variable names with spaces and failing to parse short files accurately.
- Concerns were raised about its declining effectiveness, suggesting a potential need for improvements or debugging.
- Recommendation for State-Machine Parsing: A user highlighted that using a state-machine style approach would enhance clarity and maintainability in parsing tasks.
- They emphasized the necessity of tracking state explicitly rather than relying solely on regex patterns for parsing.
Link mentioned: Scripting aider: You can script aider via the command line or python.
aider (Paul Gauthier) ▷ #links (7 messages):
Claude Desktop AppAnthropic ModelsElectron Apps
-
Claude Desktop App Launch Details: A member shared that Claude now has a desktop app available for both Mac and Windows link, according to @alexalbert__.
- Is anyone trying it out?
- Availability Issues on Mac: Another member noted that the app wasn't available on Mac initially, leading to confusion about its launch.
- There was no information about it on the Anthropic webpage, causing further speculation.
- Electron App Disappointment: It was revealed that the Claude app is essentially a browser wrapped as an Electron app, disappointing many users.
- One member lamented that it is no better than the 'install as app' feature available in Chrome/Safari.
Link mentioned: Tweet from Alex Albert (@alexalbert__): We built a Claude desktop app! Now available on Mac and Windows.
Eleuther ▷ #general (1 messages):
Open-sourced value heads
-
Inquiry on Open-sourced Value Heads: A member expressed interest in finding open-sourced value heads but reported difficulties in locating any.
- They inquired if another member had been successful in their search for these resources, reflecting a shared challenge in the community.
- Interest in Community Resources: The conversation highlights a collective interest in gathering information about available open-sourced value heads among members.
- This reveals a potential area for collaboration or knowledge sharing within the community.
Eleuther ▷ #research (100 messages🔥🔥):
Universal Transformers (UTs)Deep Equilibrium Networks (DEQs)Timestep Shifting in Diffusion ModelsGradient Descent and Fixed PointsParameter Efficiency in Model Designs
-
Universal Transformers remain underutilized: Despite potential benefits, Universal Transformers (UTs) often require modifications like long skip connections to perform effectively, yet they seem underexplored in practice.
- Chaining halting and theoretical complexities pose challenges that may limit their adoption in broader applications.
- Challenges with Deep Equilibrium Networks: Deep Equilibrium Networks (DEQs) are noted for their potential but struggle with stability and training complexities, leading to skepticism about their practicality.
- Concerns about the existence of guaranteed fixed points in DEQs highlight their limitations in achieving parameter efficiency while not necessarily outperforming simpler models.
- Timestep Shifting Insights in Diffusion Models: The recent advancements in Stable Diffusion 3, particularly around timestep shifting, present new opportunities for optimizing computations during model inference.
- Code was shared to numerically solve timestep shifting for discrete schedules, indicating a community effort to enhance model performance.
- Fixed Points and Gradient Descent: The conversation highlighted the need for properly adjusting step sizes in gradient descent while exploring its implications on fixed points in neural networks.
- Challenges arise when considering how recurrent structures could manifest a useful fixed point in practical applications.
- Availability Attacks and Sequencing Issues: Discussions around the probability of models halting during computation raised concerns about potential availability attacks exploiting infinite loops with certain sequences.
- It was suggested that chains of sequences might lead to halting issues, revealing vulnerabilities in model infrastructure.
Links mentioned:
- eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers: Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually s...
- MoEUT: Mixture-of-Experts Universal Transformers: Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in lea...
- Tweet from TuringPost (@TheTuringPost): .@GoogleDeepMind, @GoogleAI and @kaist_ai introduce new methods to turn large LLMs into smaller models: - Recursive Transformers that reuse layers multiple times - Relaxed Recursive Transformers with...
Latent Space ▷ #ai-general-chat (99 messages🔥🔥):
Jasper AI's GrowthOpenAI's Search FunctionalityChatGPT vs. PerplexityNew AI Tools and ModelsRegulatory Approaches to AI
-
Jasper AI Surges in Enterprise Demand: Jasper AI reported a doubling of enterprise revenue over the past year, now serving 850+ customers including 20% of the Fortune 500.
- They announced new product innovations like the AI App Library and Marketing Workflow Automation to further assist marketing teams.
- OpenAI Introduces Improved Search Capabilities: OpenAI has rolled out enhancements to ChatGPT's web search functionality, which provides more accurate and timely responses for users.
- The update aims to streamline information retrieval, competing directly with other platforms in the evolving AI search landscape.
- ChatGPT and Perplexity Engage in Search Showdown: Users are discussing the differences in search results between ChatGPT and Perplexity after both platforms enhanced their capabilities.
- Several users reported better performance from ChatGPT in pinpointing relevant information compared to Perplexity's current offerings.
- Emergence of New AI Tools and Models: The release of Recraft V3 showcases a model that excels in design language, claiming to surpass competitors like Midjourney and OpenAI.
- Similarly, SmolLM2, an open-source language model, has been introduced, praised for its extensive training on 11 trillion tokens.
- Anthropic Advocates for AI Regulation: Anthropic released a blog post arguing for targeted regulation of AI, emphasizing the necessity for timely legislative measures.
- The post aims to contribute to the ongoing debates surrounding the governance of artificial intelligence and its societal impact.
Links mentioned:
- SemEval-2025 Task 1: AdMIRe - Advancing Multimodal Idiomaticity Representation
- Tweet from apolinario 🌐 (@multimodalart): I think @recraftai did an amazing job for capturing mind share with the red_panda v3 release and got lots of folks to try out their (very cool) platform imo a further stage of impact for exponential...
- Training FLUX Style LoRA on fal: FLUX has taken over the image generation space, but getting exactly the style you want can be difficult. This where style LoRAs can help. Training a style LoRA on Fal is easy, but there are some tips...
- Tweet from fofr (@fofrAI): Some remarkable realism. So many models struggle with wet things, and soap suds.
- Tweet from Recraft (@recraftai): Introducing Recraft V3 — a revolutionary AI model that thinks in design language. It delivers unprecedented quality in text generation, outperforming models from Midjourney, OpenAI, and others. It’s...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): WOW! Google Learn About Experiment is now available in US 👀👀👀 There you can prompt any topic and deep dive into it through Google's autosuggestions. It also can use search to search for inform...
- Tweet from fofr (@fofrAI): Prompt: "a bad selfie" with Recraft and the natural light style
- Tweet from bryson (@Bryson_M): we got ourselves a generative tool search-off
- Tweet from fofr (@fofrAI): Red panda is Recraft. It's live now on http://recraft.ai and on Replicate: https://replicate.com/recraft-ai/recraft-v3 https://replicate.com/recraft-ai/recraft-v3-svg It's amazing. And it m...
- Tweet from AK (@_akhaliq): chatgpt search vs perplexity
- Tweet from fofr (@fofrAI): Recraft seems able to do text really well, and pretty accurately. But at the same time, the model seems like it was trained on images with really amateur typesetting.
- Tweet from Cartesia (@cartesia_ai): We're releasing a new model called Voice Changer. Transform any input voice clip into an output voice from your voice library, and preserve key characteristics of the input voice like intonation,...
- Ushering in Jasper’s next phase of hypergrowth, powered by apps and workflows: Jasper doubled enterprise revenue and now has 850+ enterprise clients; launches Marketing Workflow Automation and 80+ AI Apps
- Tweet from Loubna Ben Allal (@LoubnaBenAllal1): Introducing SmolLM2: the new, best, and open 1B-parameter language model. We trained smol models on up to 11T tokens of meticulously curated datasets. Fully open-source Apache 2.0 and we will release...
- Tweet from Timothy Young (@timyoung): 🚀Quick Jasper AI update… Over the last year, there has been a surge in demand for @heyjasperai as an increasing number of enterprise marketing teams have prioritized AI adoption. This has been hugel...
- AskNews: AskNews is re-imagining how news is consumed by humans and LLMs alike. We provide human editorial boosted by AI-powered insights to minimize bias and build a transparent view of current events.
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): There we go, and they couldn’t help but to do it alongside a Google release. Quoting Jimmy Apples 🍎/acc (@apples_jimmy) Apparently OpenAi was going to do a launch/wide release of SearchGPT last we...
- Tweet from Aravind Srinivas (@AravSrinivas): Until now, we mainly prioritized informational queries. But search is about anything you want to do. A navigational query is essentially a link/sitemap as an answer. We made it even easier to navigate...
- Why I build open language models: Reflections after a year at the Allen Institute for AI and on the battlefields of open-source AI.
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Fuck it - it’s raining smol LMs - SmolLM2 1.7B - beats Qwen 2.5 1.5B & Llama 3.21B, Apache 2.0 licensed, trained on 11 Trillion tokens 🔥 > 135M, 360M, 1.7B parameter model > Trained on FineWeb...
- Tweet from Anthropic (@AnthropicAI): We've published a short piece making the case for targeted AI regulation sooner rather than later. Read it here: https://www.anthropic.com/news/the-case-for-targeted-regulation
- Tweet from fofr (@fofrAI): Recraft v3 has impressive landmark knowledge "a close-up half-portrait photo of a woman wearing a sleek blue and white summer dress with a monstera plant motif, has square white glasses, green br...
- Tweet from Sawyer Merritt (@SawyerMerritt): NEWS: Tesla Megapack’s help power the training jobs at xAI’s new 100,000 Nvidia GPU cluster. xAI found millisecond power fluctuations when GPUs start training, causing issues with power infrastructur...
- Tweet from Kylie Robison (@kyliebytes): NEW: ChatGPT is officially an AI-powered web search engine. The company is enabling real-time information in conversations for paid subscribers today, with free, enterprise, and education users gainin...
- Learn About: no description found
- Tweet from OpenAI (@OpenAI): 🌐 Introducing ChatGPT search 🌐 ChatGPT can now search the web in a much better way than before so you get fast, timely answers with links to relevant web sources. https://openai.com/index/introduc...
- Reddit - Dive into anything: no description found
- OpenHands + Daytona: OpenHands is a AI Coding Agent that can do anything a human developer can. Built on the agent-agnostic middleware Daytona.
LM Studio ▷ #announcements (1 messages):
venvstacksApple MLX supportPython dependencies
-
Meet
venvstacks: Simplifying Python Environment Setup:venvstacksallows shipping the Python-based Apple MLX engine without needing users to install any Python dependencies themselves. It is now available on PyPi for users to easily install with$ pip install --user venvstacks.- The utility was open-sourced and is documented in this technical blog post, which outlines its role in supporting the MLX engine within LM Studio.
- Release of Apple MLX Support in LM Studio 0.3.4: The recent announcement highlighted support for Apple MLX in LM Studio 0.3.4, and details on the integrated downloadable Python environments were included. Relevant links include the full blog post discussing this feature.
- This announcement pointed to venvstacks as the technology behind enabling seamless experience for users with specific Python needs.
- Discussion Channel for venvstacks: Discussion around
venvstackscan be continued in channel <#1234988891153629205>, where the project lead is actively engaged. Users are encouraged to share thoughts and feedback on the utility's functionality and integration.
- The project lead, an identified member, spearheads this innovative addition, enhancing the development experience in the community.
Links mentioned:
- Introducing venvstacks: layered Python virtual environments: An open source utility for packaging Python applications and all their dependencies into a portable, deterministic format based on Python's
sitecustomize.py. - GitHub - lmstudio-ai/venvstacks: Virtual environment stacks for Python: Virtual environment stacks for Python. Contribute to lmstudio-ai/venvstacks development by creating an account on GitHub.
LM Studio ▷ #general (57 messages🔥🔥):
LM Studio FeaturesUser Experiences with LM StudioSystem Prompts in API RequestsQuantization in LM StudioModel Performance in Storytelling
-
LM Studio featured in Apple announcements: LM Studio was highlighted in the M4 Macbook Pro announcements. This recognition was celebrated by community members, emphasizing its utility over competitors.
- One member pointed out that the display of currently used tokens in LM Studio is particularly useful compared to alternatives.
- Challenges with system prompts: A user inquired about the significance of the system prompt in LM Studio, specifically regarding its behavior in API requests.
- It was clarified that parameters in the API payload override those set in the UI, making system prompts less critical if used consistently in requests.
- Users share LM Studio model experiences: Users discussed their experiences with different LM Studio models, highlighting issues with memory retention during long text adventures.
- One member recommended the Mistral Small Instruct 2409 for generating coherent stories without excessive detail, confirming performance satisfaction on their hardware.
- Quantization support in LM Studio: A question arose about LM Studio's support for
quantkvand its implications for model context length.
- It was noted that the UI's fixed quantization to Q8 could solve some memory issues faced by users trying to fit larger models into limited hardware.
- Long-term memory inquiry: A user asked about the potential for long-term memory in LM Studio to enhance text adventures, noting current limitations.
- Community members discussed options for initializing memories in models, highlighting the importance of context size and initial memory inputs for storytelling.
LM Studio ▷ #hardware-discussion (16 messages🔥):
M2 Ultra performanceMistral Large usageAI chip in CoPilot PCsMulti-Mac processing with LlamaLM Studio installation on Intel Macs
-
M2 Ultra shows strong T/S performance: A member reported getting about 8 - 12 T/S on the M2 Ultra, speculating that 12 - 16 T/S might not be significant.
- There are rumors that the upcoming M4 chips could rival the current 4090 graphics cards, leading to eager anticipation.
- Enjoying Mistral Large: User indicated satisfaction with the Mistral Large model, mentioning it has provided lots of goodness.
- Another member noted constraints due to their 36GB unified memory, limiting their capability to run larger models.
- Interest in AI Chip for CoPilot PCs: One user inquired about the programmatic use of the AI chip in CoPilot PCs, suggesting interest in its capabilities.
- They soon found a relevant website that likely details this information.
- Inquiring about Multi-Mac Setup with Llama: A member asked if it's possible to run LM Studio with multiple Mac Mini's in a chain to share processing power for the Llama model.
- Potential solutions or insights could help users leverage clustered computing for better performance.
- LM Studio installation issues on Intel Macs: One user questioned if they could install LM Studio on their 2017 iMac running Ventura, finding no older version available.
- Members confirmed that Intel Macs are not supported, but suggested using Windows with an eGPU for potentially faster performance.
GPU MODE ▷ #general (4 messages):
Data type conversion in tensorsSYCL vs. CUDA discussionFirst CUDA project recommendationsMatrix multiplication optimization in CUDA
-
Data Type Conversion in Tensors Explained: Discussion revolved around the conversion of various data types in a tensor, specifically f32, f16, bf16, fp8, and fp4 formats, both with and without stochastic rounding.
- Additional explorations were considered regarding the transition between bits as well as mk3 and standard floating point formats.
- Debating SYCL as an Alternative to CUDA: Members shared their thoughts on SYCL, raising the question of its viability if CUDA is off the table as a programming model.
- The discourse highlighted potential advantages and drawbacks of adopting SYCL over CUDA.
- Seeking First CUDA Project Ideas: A member expressed interest in starting their first GPU programming project using CUDA and looked for recommendations.
- This question prompted responses suggesting various projects suitable for beginners.
- Matrix Multiplication: Essential for GPU Programming: A member shared a link to a post about optimizing matrix multiplication written in CUDA, emphasizing its significance in deep learning.
- The post details performance characteristics relevant to modern GPUs and includes code samples accessible on GitHub.
Link mentioned: How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog: In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...
GPU MODE ▷ #triton (8 messages🔥):
Triton Debug Barrier BehaviorSynchronization Across BlocksTriton Casting StrategiesKernel Implementation for RescalingvLLM FP8 Quantization Comparison
-
Triton Debug Barrier Behavior Clarified: A member clarified that
tl.debug_barrieronly synchronizes threads within a single block, likening it to__syncthreads()in CUDA, hence not blocking across all blocks in the grid.- This can cause confusion when attempting to synchronize operations that span multiple blocks.
- Need for Synchronization Across Blocks: Members discussed the necessity of synchronization across blocks and suggested launching two separate kernels as a solution.
- Alternative methods were also mentioned, such as using Compare-And-Swap (CAS) techniques.
- Triton Casting Strategies and Static Casting: The conversation transitioned to Triton's casting strategies, questioning if they correlate with static casting in traditional programming.
- One member is exploring this while implementing a rescale kernel to learn Triton.
- Kernel Implementation for Rescaling: A member shared their Triton kernel designed to rescale tensors from bfloat16 to fp8, using activation scales to compute the necessary transformations.
- They are conducting tests against vLLM's quantization methods to ensure accuracy.
- Discrepancies in Output Quantization: In comparing outputs between their Triton kernel and vLLM's static casting, discrepancies were noted in the resulting values, particularly with rounding differences.
- The member speculated that slight numeric errors elsewhere in the vLLM code might contribute to these differences.
Link mentioned: vllm/csrc/quantization/fp8/common.cu at 55650c83a0c386526ed04912a0c60eccca202f3e · vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
GPU MODE ▷ #torch (10 messages🔥):
CUDACXX Environment VariableMomentum SR TestingBitsAndBytes Stochastic VariantsDeprecated Python APIsCUDA Allocator Familiarity
-
Set CUDACXX for Custom CUDA Version: Users discussed setting the
CUDACXXenvironment variable to enable CMake to pick up CUDA versions not available in the path.- This approach could help developers avoid compatibility issues with their codebases.
- Momentum SR Shows Potential Benefits: A member observed that they did not extensively test momentum SR due to concerns about instability in larger models, positing that it might be useful for saving memory when the first moment is in FP8.
- Another member noted they tested it in AdamW8bit without significant differences, highlighting the need for further analysis on the effects of low-bit precision on performance.
- Stochastic=True Not Exposed in Python: Discussions revealed that while some variants in BitsAndBytes have
stochastic=true, it is not exposed in the C interface or Python, limiting its accessibility.
- There are implications that such optimizations might not be utilized effectively, particularly for low precision weight updates.
- Deprecated APIs Clean-Up Efforts: One member mentioned marking some APIs with
@deprecatedon the Python side, planning to remove them after one release to streamline the codebase.
- This move aims to reduce backward compatibility issues while phasing out inefficiencies, although it’s a gradual process.
- Inquiry about CUDA Allocator Familiarity: A question was raised about another user's familiarity with the CUDA allocator, indicating an interest in discussing memory management.
- This suggests potential upcoming discussions on optimizing CUDA functionalities within projects.
Links mentioned:
- max_autotune_vs_reduce_overhead.py: GitHub Gist: instantly share code, notes, and snippets.
- bitsandbytes/csrc/kernels.cu at 9568735b21b9325e4789d6a5004517f2287f47c8 · bitsandbytes-foundation/bitsandbytes: Accessible large language models via k-bit quantization for PyTorch. - bitsandbytes-foundation/bitsandbytes
- bitsandbytes/csrc/pythonInterface.cpp at main · bitsandbytes-foundation/bitsandbytes: Accessible large language models via k-bit quantization for PyTorch. - bitsandbytes-foundation/bitsandbytes
GPU MODE ▷ #cool-links (5 messages):
Efficiency in Deep LearningBlog FeedbackStable Efficient Algorithms
-
Deep Learning Efficiency Guide Launch: A member shared their guide on efficiency in deep learning which outlines the progression of relevant papers, libraries, and hardware, including sections on fast linear algebra methods and model pruning.
- They welcomed feedback from the community, mentioning how greatly they benefited from discussions within the group.
- Suggesting Algorithm Writing Tips: A member suggested it might be beneficial to include a section on how to write a stable efficient algorithm under a given FP system in the guide.
- This suggestion was well-received, and the author expressed enthusiasm about potentially creating a separate write-up on this topic.
- Community Appreciation for the Blog: Another member praised the guide, calling it 'really cool' and adding excitement around the topic of deep learning efficiency.
- This positive feedback highlights the community’s supportive and collaborative spirit in improving shared knowledge.
Link mentioned: Alex L. Zhang | A Meticulous Guide to Advances in Deep Learning Efficiency over the Years: A very long and thorough guide how deep learning algorithms, hardware, libraries, compilers, and more have become more efficient.
GPU MODE ▷ #beginner (16 messages🔥):
Quantization techniquesFlash Attention implementationUse of torchaoGPU resource challengesAccuracy benchmarks among quantization approaches
-
Exploring Shape of Int8 Tensor Core WMMA Instructions: A member pondered if the shape of the int8 tensor core wmma instruction is related to memory handling in LLMs, specifically noting that M is always 16, while K can be larger.
- This led to a discussion about potential explanations when M is small and the implications for implementation.
- Accuracy Drops in Quantization Approaches: Concerns were raised about whether benchmark comparisons have been conducted regarding accuracy drops among quantization methods like non-fused vs. fused dequantization.
- It was suggested that more frequent conversions might contribute to lower accuracy, prompting further investigation.
- Flash Attention Project Idea for Beginners: A member questioned the feasibility of implementing flash attention in CUDA as a beginner's project, looking for something manageable that could take about 50 hours.
- This inquiry highlights the interest in substantial yet attainable projects.
- Using torchao for Weight/Activation Quantization: A question arose regarding whether there's a clear method to check if
torchao.autoquantis effectively quantizing weights and activations.
- This reflects a desire for clarity on tool functionalities and quantization processes.
- Challenges with GPU Resources at Hackathons: A member shared an anecdote about relying on corporate GPUs for compute during a hackathon, illustrating the challenges of using a less popular model when resources are limited.
- This discussion emphasized the need for alternative solutions during development, particularly for applications needing faster inference.
GPU MODE ▷ #off-topic (3 messages):
Asking Questions CultureQuestion Clarity and ResearchServer Vibes and CommunityAdvanced Topics Discussion
-
Crusade Against 'Dumb Question' Preface: A member expressed a desire to eliminate the phrase 'I have a dumb/stupid/noob question' when seeking help, arguing that all questions deserve straightforward answers.
- They emphasized that instead of apologizing, users should try to do some self-research before asking.
- No Such Thing as a Dumb Question: The sentiment shared was that there's never a dumb question, only a dumb answer, fostering a more welcoming environment for all members.
- This aligns with the idea that beginner inquiries should be encouraged rather than discouraged.
- Clear Questions Over Confusing Ones: One member pointed out a preference for clear questions, noting that vague or easily searchable inquiries can be quite frustrating.
- This highlights the importance of clarity in communication within the community.
- Community Vibes are Strong: The overall mood in the server is positive, and members are reminded that those who act inappropriately are removed to maintain this atmosphere.
- Members are encouraged to ask questions without fear of judgment, reinforcing a culture of kindness.
- Advanced Topics and Query Etiquette: It was observed that more advanced topics often lead to a rise in members apologizing for asking questions, indicating a level of apprehension.
- Despite complexity, the quality of questions remains high, as they often cannot be resolved with a simple search.
GPU MODE ▷ #triton-puzzles (1 messages):
Triton learningTrion puzzle visualizationPatch updates
-
Gratitude for Visualization Fix: A member expressed appreciation for a recent change that helped them get the visualization working again in their pursuit of learning Triton.
- This patch has made it easier to engage with the Trion puzzle and continues to support the learning process.
- Return to Triton Learning: The member highlighted their return to learning Triton after some time away, indicating a renewed interest in the area.
- They are actively engaging with discussions around the Trion puzzle as part of this journey.
GPU MODE ▷ #liger-kernel (1 messages):
Speech ProcessingLiger Kernel IssuesRoPE Implementation
-
Jerry seeks his first coding issue in Liger Kernel: A new member, Jerry, an EE grad student, expressed interest in tackling an issue from the Liger Kernel GitHub related to efficient Triton kernels for LLM training.
- He questioned the status of the original RoPE implementation, wondering if there are plans to move forward with it since the issue hasn't seen updates in some time.
- Triton Kernels for LLM Training: The issue Jerry is interested in involves developing efficient Triton kernels that are crucial for LLM training.
- This development is significant as it could enhance performance and reduce overhead in processing large language models.
Link mentioned: Issues · linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
GPU MODE ▷ #thunderkittens (9 messages🔥):
ThunderKittens LibraryMamba-2 KernelLivestream Announcement
-
ThunderKittens aims for user-friendly CUDA libraries: TK is designed to fill a similar role as Cutlass but intends to be as easy to use as Triton, allowing developers to back out and write raw CUDA / PTX if needed.
- TK is user-friendly, aiming to manage 95% of complex tasks while giving users the flexibility to handle the remaining 5% themselves.
- Mamba-2 kernel showcases extensibility: The Mamba-2 kernel integrates custom CUDA code to perform complex operations like causal cumulative sums within the attention matrix, highlighting TK's extensibility.
- In contrast, the demo H100 kernel uses only TK primitives, demonstrating both the versatility and depth of the library.
- Livestream scheduled for 1:15 PM PST: A livestream about ThunderKittens is set to begin at 1:15 PM PST, slightly delayed from the initial 1 PM start time.
- Attendees are encouraged to ask questions during the stream, with a livestream link provided for easy access.
Cohere ▷ #discussions (9 messages🔥):
Cohere API frontend optionsCohere ToolkitFuture of chatbots in web browsing
-
Cohere API compatible frontends discussed: A user inquired about any Chat UI frontend that works with the Cohere API key.
- Another user responded, confirming that the Cohere Toolkit is compatible.
- Cohere Toolkit details shared: A user shared a link to the Cohere Toolkit repository, describing it as a collection of prebuilt components for RAG applications.
- They highlighted that the toolkit enables users to quickly build and deploy these applications.
- Chatbots could replace traditional web browsers: A member shared their work in R&D focused on preparing for a future where chatbots like ChatGPT could replace traditional web browsing.
- This sparked some excitement among the group, with a member expressing amazement at the initiative.
- User introduction: A new member, Samriddh, introduced themselves as a newbie in the channel.
- They sought suggestions for tools similar to perplexity.ai.
Link mentioned: GitHub - cohere-ai/cohere-toolkit: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications.: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications. - cohere-ai/cohere-toolkit
Cohere ▷ #questions (27 messages🔥):
Response Time InquiryChatbot Browsing SimulationPaper Writing AssistanceAya Expanse PerformanceEmbedding Storage in ChromaDB
-
Response time inquiry from team: A user requested an estimated response time for an email, emphasizing their team's urgency for the information increase.
- Another member expressed gratitude, noting that their teammate is already addressing the issue.
- Chatbot browsing process simulation: A user explored the possibility of manually simulating ChatGPT's browsing, aiming to analyze the factors influencing result filtering.
- They expressed interest in understanding how ChatGPT processes information compared to traditional SEO methods.
- Guidance on paper edits and photo tools: A member sought advice on condensing their IEEE conference paper, which exceeded the page limit due to references and figures.
- They inquired about tools to compile photos effectively without disrupting their references.
- Performance concerns with Aya Expanse 32b: A user reported a significant slowdown in performance when using the Aya Expanse 32b model locally, noting a drop from 20t/s to as low as 3t/s.
- It was suggested that VRAM limitations may be causing the slowdown, and a switch to the 8b model was recommended.
- Embedding storage in ChromaDB: A user shared their goal of saving calculated embeddings from Cohere into ChromaDB, providing a code snippet for reference.
- Feedback was offered, highlighting the importance of ensuring ChromaDB is running before further testing.
Links mentioned:
- How I can match each returned embedding with the text I gave to him so I can save them into a db?: I made this script that reads the text frpom pdf and for each paragraph calculates the mebddings using cohere embeddings api: import os import cohere import time from pypdf i...
- Reddit - Dive into anything: no description found
- Embed — Cohere: This endpoint returns text embeddings. An embedding is a list of floating point numbers that captures semantic information about the text that it represents. Embeddings can be used to create text cla...
Cohere ▷ #api-discussions (7 messages):
Fine-tuning issuesChatGPT browsing capabilitiesR&D for ChatGPT alternatives
-
Fine-tuning issues on the mend: A member acknowledged the ongoing fine-tuning issues, reassuring that teams have already implemented a fix and updates will follow soon.
- This update came after a user expressed concerns about these issues and requested further information.
- Exploring ChatGPT's browsing capability: One member in R&D raised the question of whether it’s possible to manually simulate ChatGPT's browsing process to analyze its search capabilities.
- They proposed conducting tests to understand SEO, ranking criteria, and how ChatGPT filters and processes search results.
Cohere ▷ #projects (1 messages):
Application Review ProcessBuilding Agents Experience
-
Ongoing Application Acceptances: The team confirmed that acceptances are currently ongoing, with careful reviews of each application.
- They assured that applicants will be contacted with updates once the review process is complete.
- Focus on Agent-Building Experience: The team is prioritizing candidates with experience in building agents during the application review.
- They emphasized the importance of this experience in selecting suitable candidates for the ongoing process.
Cohere ▷ #cohere-toolkit (4 messages):
poetry installation issuescohere-python package
-
Installation Woes with Poetry: Member reported an installation issue when trying to run
poetry add coherefor the cohere-python package.- “My question is if someone also has a similar issue when trying to install via poetry.”
- Solved: Cohere-Python Installation: Member mentioned they found a solution to the installation problem with cohere-python.
- Another member responded positively, appreciating the effort by stating, “Awesome yea toolkit's using poetry for package handling, thanks for figuring it out by your own!”
Interconnects (Nathan Lambert) ▷ #news (5 messages):
Creative Writing ArenaSmolLM2 LaunchModel Evaluations on ARC
-
Creative Writing Arena Debuts!: 🚨 A new category, Creative Writing Arena, focuses on originality and artistic expression, receiving about 15% of votes in its debut.
- Key models saw changes: o1-Mini dropped below the top, while ChatGPT-4o-Latest made a significant leap to stay at #1.
- SmolLM2: The Open Source Wonder: Introducing SmolLM2, this new 1B-parameter model was trained on 11T tokens of meticulously curated datasets and is fully open-source under Apache 2.0.
- The team plans to release all datasets and training scripts, promoting broader access and collaboration.
- Evaluating Models on ARC Gains Popularity: A member appreciated that evaluating models on ARC is becoming more mainstream, suggesting an improvement in evaluation standards.
- Another participant concluded that these evaluations reflect strong base model performance.
Links mentioned:
- Tweet from Loubna Ben Allal (@LoubnaBenAllal1): Introducing SmolLM2: the new, best, and open 1B-parameter language model. We trained smol models on up to 11T tokens of meticulously curated datasets. Fully open-source Apache 2.0 and we will release...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): 🚨New Chatbot Arena Category: Creative Writing Arena! Creative writing (~15% votes) involves originality, artistic expression, and often different from technical prompts. Key Findings: - o1-Mini dr...
Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
Midjourney Image GenerationStyle Transfer TechniquesSemEval Task Scaling
-
Seeking Diffusion Bros for Image Generation Tips: A member inquired about generating additional images in the style of a collection produced by Midjourney, specifically for representing idioms.
- They expressed interest in techniques to derive likely prompts from existing images to create similarly-styled outputs.
- Style Transfer in Image Generation: A response highlighted style transfer as a method that doesn't require fine-tuning, suggesting it as a viable approach for the image generation task.
- However, another member pointed out the lack of available code for executing this technique.
- Member's Epiphany on Using Image-Image Style Transfer: The initial poster acknowledged confusion over their approach and realized that instead of extracting a style modifier, they could implement image-image style transfer after generating a suitable content image.
- They thanked the respondent for clarifying their think process, admitting they weren't considering the right approach at first.
Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
Reproducing IssuesBing Search ProblemsGitHub Account Sketchiness
-
Reproducing Issues for Support: A member mentioned, 'I can reproduce it for him, but not for my GH account,' indicating ongoing issues while trying to assist.
- The context remains 'still sketch,' highlighting uncertainty surrounding the problem.
- Bing Search is at Fault: A discussion pointed out that Bing is likely responsible for the issues, with one member stating, 'Bing also finds it, so it’s a Bing problem if anything.'
- They also noted that 'none of my private repos come up on Bing,' suggesting privacy concerns.
Link mentioned: Tweet from Paul Calcraft (@paul_cal): @sahir2k Bing also finds it, so it's a Bing problem if anything. Fwiw none of my private repos come up on Bing
Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
Llama 4 TrainingMeta's RecruitmentUS Elections Discussion
-
Llama 4 Training Brings Big Clusters: Ahmad Al Dahle shared that they are training Llama 4 models on a cluster exceeding 100K H100s in one of their data centers, showcasing their advancements in the AI field.
- They’re actively hiring for top researchers to focus on reasoning and code generation, encouraging applications via a job link.
- Meta's Confidence in Llama 4 Release: Andrew Curran reported that Mark Zuckerberg confirmed during the META earnings call that Llama 4 is well into training and projected for release in Q1 of 2025.
- Zuckerberg also humorously compared his data cluster's size to Elon Musk’s, hinting at a competitive spirit.
- Fascination with US Elections: Members expressed that US elections are captivating from a European perspective, with one noting it feels overstimulating for those following closely.
- Natolambert commented on the intensity of the upcoming election discussions, indicating that next week might be quiet.
Links mentioned:
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Great to visit one of our data centers where we're training Llama 4 models on a cluster bigger than 100K H100’s! So proud of the incredible work we’re doing to advance our products, the AI field a...
- Tweet from Andrew Curran (@AndrewCurran_): Mark Zuckerberg said during the META earnings call last night that Llama 4 is well into its training. He also managed to sneak in a shot about his cluster being even bigger than Elon's. Llama 4 ar...
Interconnects (Nathan Lambert) ▷ #posts (6 messages):
Scarf profile pic guestOG Discord friendsPodcast excitement
-
Scarf Profile Pic Guy Joins the Pod: A member expressed excitement that the scarf profile pic guy is on the podcast, referring to him as a notable guest.
- Lfg! was the enthusiastic response from another member, showcasing the community's excitement.
- NatoLambert Reflects on Discord History: NatoLambert shared that the guest is one of the OG Discord friends, noting their history dating back to when it was originally a Wavelength chat.
- This highlights the long-standing connections within the community.
- Andrew Claims the Scarf Guy Identity: Andrew clarified that the scarf profile pic guy is indeed him, adding a personal touch to the discussion.
- This prompted further engagement from other members, contributing to the light-hearted mood.
Stability.ai (Stable Diffusion) ▷ #general-chat (41 messages🔥):
Inpaint Tool UtilityStable Diffusion BenchmarksVAE Issues with Image GenerationSeeking Stable Diffusion HelpWorkflow Preferences in Image Processing
-
Inpaint Tool Proves Useful: Users discussed the inpaint tool as a valuable method for correcting images and composing elements, making it easier to achieve desired results.
- Inpainting can be tricky, but it often becomes essential to finalize images, and many users expressed feeling more confident in their abilities.
- Interest in Stable Diffusion Benchmarks: Members are curious about recent benchmarks for Stable Diffusion, especially regarding performance on enterprise GPUs compared to a personal 3090 setup.
- One user noted that using cloud services could potentially speed up the generation process.
- Discussion on Model Bias: Users observed a trend where the latest models often produce images with reddened noses, cheeks, and ears, and the underlying causes were debated.
- Some speculated that VAE issues and inadequate training data, particularly from anime sources, could be influencing these results.
- Seeking Community Help for Projects: A user asked for assistance from skilled Stable Diffusion enthusiasts for creating a promo video, prompting suggestions to post in related forums.
- The response highlighted the collaborative effort within the community to share knowledge and resources.
- Personal Preferences in Image Processing: A member shared their workflow preferences, noting they preferred to separate the img2img and upscale steps instead of relying on integrated solutions.
- This approach allows for a more thoughtful refinement of images before finalizing them.
Links mentioned:
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
Modular (Mojo 🔥) ▷ #general (5 messages):
Community Meeting on November 12thEvan's LLVM Developers' Meeting talkGPU developments in projectsProject collaboration efforts
-
Upcoming Community Meeting Highlights: The next community meeting is scheduled for November 12th, featuring a sneak peek into Evan's LLVM Developers' Meeting talk on implementing linear/non-destructible types in Mojo.
- There are also 1-2 spots open for community talks, inviting members to submit their questions via the Modular Community Q&A.
- Curiosity about GPU Developments: Members are expressing excitement and curiosity around the GPU developments that are expected to be announced 'soon'.
- Darin comments on the team's hopefulness for advancements, emphasizing the importance of being useful to related projects.
- Inquiry on Project Utilization: Interest was noted in being useful to the mentioned projects, reflecting an eagerness to contribute effectively.
- One member plans to contact project leads to foster collaborations and discuss future involvement.
Link mentioned: Modular Community Q&A: no description found
Modular (Mojo 🔥) ▷ #mojo (31 messages🔥):
C-style macros vs decoratorsSQL query validationCustom string interpolatorsStatic MLIR reflectionAlgebraic types
-
Debate over C-style macros vs custom decorators: There’s a consensus that introducing C-style macros may bring more confusion than benefits, as highlighted by multiple members in the discussion.
- Plans for custom decorator capabilities and the importance of keeping Mojo simpler were suggested as preferable alternatives.
- SQL query validation through decorators: Members discussed the potential for SQL query verification at compile time using decorators, though concerns were raised about the feasibility of such features.
- It was noted that specific DB schema validation might still require additional handling beyond what decorators can provide.
- Potential of custom string interpolators: Custom string interpolators, similar to those in Scala, could lead to more efficient syntax checks for SQL strings in Mojo, according to community input.
- Members emphasized that implementing this feature could avoid the complexity associated with traditional syntactic macros.
- Static MLIR reflection vs macros: Discussion emerged around the advantages of static MLIR reflection compared to traditional macros, with the former providing significant type manipulation capabilities.
- It was noted that while static reflection can replace some macro functionalities, maintaining simplicity is crucial to avoid issues with language server protocols.
- Concerns over syntax merging in Mojo: Concerns were raised about the potential messiness of syntax if
matchcould be implemented without compiler support, underscoring the need for clean syntax.
- It was suggested that Mojo might follow Python's lead with a
match/casestructure, yet compiler backing is essential for optimal implementation.
DSPy ▷ #show-and-tell (2 messages):
Masters Thesis GraphicCodeIt Implementation
-
Graphic Shared for Masters Thesis: A member shared a graphic made for their Masters thesis, suggesting it could be useful to others.
- No additional details about the graphic were provided.
- CodeIt Implementation Resource: Another member shared a link to a GitHub Gist titled 'CodeIt Implementation: Self-Improving Language Models with Prioritized Hindsight Replay'.
- The gist contains a detailed implementation guide that may be of interest to those working on similar research.
Link mentioned: CodeIt Implementation: Self-Improving Language Models with Prioritized Hindsight Replay: CodeIt Implementation: Self-Improving Language Models with Prioritized Hindsight Replay - Codeit.md
DSPy ▷ #papers (3 messages):
WeKnow-RAGXMC with In-Context Learning
-
WeKnow-RAG Enhances LLMs with Retrieval: A new approach called WeKnow-RAG integrates Web search and Knowledge Graphs into a 'Retrieval-Augmented Generation (RAG)' system, significantly improving the accuracy and reliability of LLM responses.
- This system combines the structured representation of Knowledge Graphs with dense vector retrieval to tackle the challenge of LLMs producing factually incorrect and 'phantom' content, as detailed in the arXiv paper.
- xmc.dspy pushes limits on Multi-Label Classification: The xmc.dspy project showcases In-Context Learning techniques for eXtreme Multi-Label Classification (XMC), promising to operate effectively with only a handful of examples.
- This innovative approach could redefine efficiency in classification tasks, with the project details available at GitHub.
Links mentioned:
- WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs: Large Language Models (LLMs) have greatly contributed to the development of adaptive intelligent agents and are positioned as an important way to achieve Artificial General Intelligence (AGI). However...
- GitHub - jmanhype/WeKnow-Information-Retrieval-Assistant: Contribute to jmanhype/WeKnow-Information-Retrieval-Assistant development by creating an account on GitHub.
- GitHub - KarelDO/xmc.dspy: In-Context Learning for eXtreme Multi-Label Classification (XMC) using only a handful of examples.: In-Context Learning for eXtreme Multi-Label Classification (XMC) using only a handful of examples. - KarelDO/xmc.dspy
DSPy ▷ #general (13 messages🔥):
DSPy Initiative StoryRunning DSPy with OllamaChain of Thought vs Predict
- Thanks to Initiative, DSPy Gets Its Name: When starting DSPy, the name
dspywas taken on PyPI, so the workaround waspip install dspy-ai, as shared by Omar Khattab. Fortunately, after a community member reached out, the handle was transferred, allowing for a cleanpip install dspyexperience. -
Challenges Running DSPy with Llama3.2 on Ollama: A user reported functioning issues with Llama3.2 on Ollama, indicating the output did not meet expectations and requested further inputs. Omar advised ensuring the latest version and provided code examples for setup with Ollama.
- The provided example for configuring DSPy to work with Ollama proved functional, allowing for accurate extractions from invoices.
- Choosing between Chain of Thought and Predict: A user inquired if Chain of Thought should always be used over Predict in DSPy, emphasizing the potential benefits. Omar clarified that both methods are acceptable, noting Predict is usually faster while Chain of Thought can yield better results in certain scenarios.
Links mentioned:
- no title found: no description found
- Tweet from Omar Khattab (@lateinteraction): Initiative is often rewarded. Fun story: When we started DSPy, the name
dspywas taken on pypi, so I went withpip install dspy-ai. Many months later, a user (@tom_doerr) was trying to install `d...
OpenInterpreter ▷ #general (15 messages🔥):
Creating new profiles in Open InterpreterDesktop client updatesIssues with --server commandOS mode limitationsConcerns about Anthropic API integration
-
Creating New Profiles in Open Interpreter: To create new profiles in Open Interpreter, users can visit this guide detailing how to customize their instance through Python files, covering fields from model selection to context windows.
- Profiles allow multiple variations for optimized use-cases and can be accessed using
interpreter --profiles. - Updates for the Desktop Client: A member indicated that the best source for updates on the desktop client might be the community's House Party event, suggesting a link to the Discord invite.
- Another noted that attendees at the last House Party received beta access to the desktop app, hinting at future announcements.
- Questions Raised on --server Command: Several members expressed confusion regarding the functionality of the
--servercommand, with one asking if it works for anyone.
- Responses indicated that it does work for some users, with suggestions to share errors in specific channels for further assistance.
- Clarifications on OS Mode: In the discussion about OS mode, it was clarified that currently, OS mode is limited to Claude's computer use only, leaving Model I without such capabilities for now.
- This limitation raised questions about potential improvements for future versions.
- Concerns Over Anthropic API Integration: A user shared frustrations regarding the recent changes in version 0.4.x, which introduced issues with local execution and integration with the Anthropic API.
- They suggested that making the Anthropic API integration optional might benefit community development and support for local models.
- Profiles allow multiple variations for optimized use-cases and can be accessed using
Link mentioned: Profiles - Open Interpreter: no description found
OpenInterpreter ▷ #O1 (1 messages):
mikebirdtech: Did you get it working <@476060434818924544> ?
OpenInterpreter ▷ #ai-content (2 messages):
ChatGPT SearchMeta FAIR RoboticsMeta SparshMeta Digit 360Meta Digit Plexus
-
ChatGPT Search gets an upgrade: OpenAI introduced a new way for ChatGPT to search the web, offering fast, timely answers with relevant links.
- This enhancement aims to improve the accuracy and relevance of responses.
- Meta's Robotics Innovations Unveiled: At Meta FAIR, three major advancements in robotics were announced, outlined in a detailed post.
- These innovations aim to better empower the open source community, highlighting Meta Sparsh, Meta Digit 360, and Meta Digit Plexus.
- Meta Sparsh revolutionizes tactile sensing: Meta Sparsh is the first general-purpose encoder for vision-based tactile sensing, trained on over 460K tactile images using self-supervised learning.
- This innovation is designed to work across various tactile sensors and tasks.
- Meta Digit 360: A game changer in touch technology: Meta Digit 360 is an artificial fingertip-based tactile sensor boasting over 18 sensing features for human-level touch data precision.
- This breakthrough enhances touch-sensing capabilities significantly.
- Meta Digit Plexus connects robotic sensors seamlessly: Meta Digit Plexus serves as a standardized platform for connecting tactile sensors, enabling integration on a single robot hand.
- This setup allows for seamless data collection and control over a single cable.
Links mentioned:
- Tweet from AI at Meta (@AIatMeta): Today at Meta FAIR we’re announcing three new cutting-edge developments in robotics and touch perception — and releasing a collection of artifacts to empower the community to build on this work. Deta...
- Tweet from OpenAI (@OpenAI): 🌐 Introducing ChatGPT search 🌐 ChatGPT can now search the web in a much better way than before so you get fast, timely answers with links to relevant web sources. https://openai.com/index/introduc...
tinygrad (George Hotz) ▷ #general (3 messages):
NPU performance in Microsoft laptopsQualcomm and Rockchip discussionsOpen source excitement for NPUTOSA as a compiler targetDiscord community rules
-
Evaluating NPU in Microsoft Laptops: There seems to be skepticism about the NPU performance in Microsoft laptops, with concerns raised regarding user experiences.
- The conversation alluded to the potential interest in evaluating alternative offerings like Qualcomm and Rockchip.
- Open Source Interest in NPU: A query was made about the overall excitement for NPU technology within the open source community, indicating uncertainty about its reception.
- Additionally, TOSA was mentioned as a potential target for compilers associated with NPU technology.
- Importance of Following Discord Rules: A member cautioned that failing to read and follow the Discord rules upon initial login could lead to issues within the community.
- This serves as a reminder for new members on the importance of adhering to community guidelines.
- Focusing on Relevant Topics: Discussion was raised about the costs associated with random topics, especially for individuals or teams building projects that require focus.
- The comment reflects a need for clarity and purpose in discussions, emphasizing the value of concentrated conversations.
tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
Tinygrad Model ExportingHailo Chip Reverse EngineeringTensor Assignment in Lazy.pyONNX InterfacingBufferCopy vs CompiledRunner Issues
-
Tinygrad Model Exporting from ONNX: One member is trying to export a Tinygrad model derived from an ONNX model but encounters
BufferCopyobjects instead ofCompiledRunnerfor some attributes in thejit_cache.- There's a suggestion to either filter these copies out or resolve them into compiled runners to prevent runtime errors when calling
compile_model(). - Tools for Reverse Engineering Hailo Files: A member inquired about tools like IDA for reverse engineering op-codes in a .hef file for Hailo devices, expressing frustration at the lack of a general coding interface for AI accelerators.
- They noted that ONNX is a common format among vendors and are considering whether to export to ONNX or reverse engineer the op-codes directly.
- Understanding Tensor Assignment in Lazy.py: A member asked about the necessity of using
Tensor.empty()followed byassign()for creating and writing to a disk tensor.
- They expressed confusion regarding the purpose of
assigninlazy.py, questioning its functionality beyond autograd. - KV Cache Updates during Inference: A member mentioned that the
assignfunction is also utilized for writing new key-values to the KV cache during inference.
- This indicates that
assign()may have broader applications beyond gradient tracking. - Exploring Tensor Assignment Effects: Another user questioned why creating a new tensor versus calling the
assignmethod seems inconsequential when not tracking gradients.
- They highlighted the uncertainty about the specific utility and behavioral differences of using
assign.
- There's a suggestion to either filter these copies out or resolve them into compiled runners to prevent runtime errors when calling
Links mentioned:
- tinygrad/examples/compile_tensorflow.py at 4c0ee32ef230bdb98f0bc9d0a00f8aaaff4704f1 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- hailort/hailort/drivers/common/hailo_ioctl_common.h at master · hailo-ai/hailort: An open source light-weight and high performance inference framework for Hailo devices - hailo-ai/hailort
LlamaIndex ▷ #blog (2 messages):
automated research paper report generationOpen Telemetry integration
-
Automated Research Paper Report Generator with LlamaIndex: Learn how to build an automated research paper report generator using LlamaIndex to download papers from arXiv, process them with LlamaParse, and index them in LlamaCloud. This essential use-case is expanding to simplify the report generation process further, as detailed in this tweet.
- You can find more information about the project on their blog post outlining this functionality.
- Open Telemetry Now Available with LlamaIndex: Open Telemetry is the industry standard for logging traces, and @braintrustdata now enables this directly from LlamaIndex to their observability platform. Documentation for this integration is available here in a tweet by LlamaIndex.
- This integration is pivotal for developers seeking robust telemetry solutions in complex production applications, as highlighted in this announcement.
LlamaIndex ▷ #general (9 messages🔥):
Llamaparse challengesMilvus database field standardizationCustom retriever with additional metadataQueryFusionRetrieverNamed Entity Recognition (NER) integration
- Llamaparse faces schema inconsistencies: Members discussed issues with llamaparse parsing PDF documents into varying schemas, complicating imports into Milvus databases. Standardizing the parse output is a common concern for users managing multi-schema data.
- Milvus fields need uniformity: A member expressed concern over different field structures in JSON outputs from multiple documents, complicating their import into Milvus. They wondered if there's a way to achieve standardization in the parsed outputs.
- Enhancing retriever queries with custom data: A user inquired about how to integrate additional meta information when querying a custom retriever beyond the basic query string. They sought guidance on whether to create a new fusion retriever to handle this data.
- Custom fusion retriever creation discussed: The discussion included whether it's necessary to create a custom QueryFusionRetriever for enhanced querying capabilities. Overloading methods was seen as a potential complication in implementation.
- Integrating NER for query optimization: A member highlighted the importance of utilizing NER on user queries to extract relevant entities for better search results. They noted the challenge of not processing NER inside the retriever due to its interaction with other application components.
LAION ▷ #general (5 messages):
Food Detection ModelsAutoregressive Image GenerationPatch ArtifactsVariational Autoencoders
-
Seeking Nutritional Dataset for Food Models: A member is searching for a dataset containing detailed nutritional information, including barcodes, macronutrients, and dietary tags.
- They found the OpenFoodFacts dataset lacking in structure and are looking for suggestions on more comprehensive datasets.
- Patch Artifacts in Image Generation: A member expressed frustration about dealing with patch artifacts in autoregressive image generation without using vector quantization.
- They noted a disdain for Variational Autoencoders (VAEs) but feel compelled to use one due to the challenges presented.
- Discussion on Image Generation Techniques: Amidst the discussion, one member suggested that even without a VAE, the use of patches effectively leads to an approximation of a VAE.
- This sparked a conversation about the inevitable challenges related to generating images without traditional methods.
LAION ▷ #research (1 messages):
mkaic: https://arxiv.org/abs/2410.23168
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (6 messages):
Parameter type errorsEvaluating custom modelsModel Response Generation
-
Parameter Type Errors Encountered: A member noted they are experiencing parameter type errors where the model outputs a string when it should be an integer.
- This issue was highlighted as a notable bug affecting model performance.
- Inquiries on Custom Model Evaluation: A member asked how to evaluate their finetuned model on the Berkeley Function Calling leaderboard, specifically regarding the support for single and parallel calls.
- This raises important questions about the evaluation process for customized implementations.
- Evaluation Command Issues: Another member shared the output from running
bfcl evaluate, indicating that no models were evaluated despite running the command.
- They were referred to evaluation result locations, suggesting confusion regarding correct usage.
- Preceding Command Required for Evaluation: A member informed that before running the evaluation command, the model response must be generated using
bfcl generatefollowed by the model name.
- This clarification was essential for ensuring proper command usage in the evaluation process.
- Clarification on Command Usage: In response to the previous message, a member confirmed that
xxxxin the generate command indeed refers to the model name.
- They emphasized the importance of consulting the setup instructions for all valid commands.
OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
SageAttention quantizationAxolotl Docker image release strategy
-
SageAttention surpasses FlashAttention: A new method called SageAttention has been introduced, significantly improving the quantization of attention mechanisms in transformer models as discussed in this research paper. The method achieves an OPS that outperforms FlashAttention2 and xformers by 2.1 times and 2.7 times, respectively.
- Furthermore, SageAttention offers improved accuracy over FlashAttention3, making it a potentially remarkable advancement for handling large sequence lengths effectively.
- Confusion over Axolotl Docker tags: Concerns were raised regarding the Docker image release strategy for
winglian/axolotlandwinglian/axolotl-cloud, particularly regarding stable tags for production use. Users highlighted that tags likemain-latestare dynamic and may not be appropriate for stable implementations.
- It was noted that while tags resembling
main-YYYYMMDDpoint to specific builds, they seem more akin to daily developments rather than traditional stable releases, prompting questions about available documentation on this release strategy.
Link mentioned: SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration: The transformer architecture predominates across various models. As the heart of the transformer, attention has a computational complexity of O(N^2), compared to O(N) for linear transformations. When ...
OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
H100 compatibilitybitsandbytes updates
-
H100 compatibility on the horizon: A member shared that H100 compatibility is coming soon with a reference to a GitHub pull request.
- This update signals ongoing improvements in the bitsandbytes library, focusing on enhanced compatibility.
- bitsandbytes update discussion: The community is eagerly discussing the implications of the upcoming H100 compatibility in their projects related to bitsandbytes.
- Members expressed interest in the potential performance enhancements and applications that this update might bring.
LangChain AI ▷ #general (1 messages):
Hugging Face DocsCustom Models
-
Custom Model Creation is Key: There is none - a member emphasized that the only option available is to create fully custom models.
- They referred others to check the Hugging Face documentation for related guidance.
- Hugging Face Resources for Custom Models: Members discussed the importance of utilizing resources when creating fully custom models.
- Referencing the documentation, they highlighted that numerous examples can assist in the development process.
LangChain AI ▷ #share-your-work (1 messages):
Chat ApplicationsOllama
-
Build Your Own Chat Application with Ollama: A member shared a LinkedIn post discussing how to build a chat application using Ollama, highlighting the flexibility of the platform.
- The post emphasizes the advantages of customization and control offered by Ollama in chatting solutions.
- Discussion on Chat Application Features: Members provided insights on essential features that should be integrated into a chat application, such as security and user experience enhancements.
- They noted that incorporating features like real-time messaging can significantly improve user satisfaction.
Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
tpojd: steam gift 50$ - steamcommunity.com/gift-card/pay/50
@everyone
Alignment Lab AI ▷ #general (1 messages):
tpojd: steam gift 50$ - steamcommunity.com/gift-card/pay/50
@everyone
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
evilspartan98: Interested