[AINews] That GPT-4o Demo
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Omnimodel is all you need
AI News for 6/27/2024-6/28/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (417 channels, and 3655 messages) for you. Estimated reading time saved (at 200wpm): 354 minutes. You can now tag @smol_ai for AINews discussions!
Romain Huet's demo of GPT-4o using an unreleased version of ChatGPT Desktop made the rounds yesterday and was essentially the second-ever high profile demo of GPT-4o after the release (our coverage here), and in the absence of bigger news is our pick of headliner today:
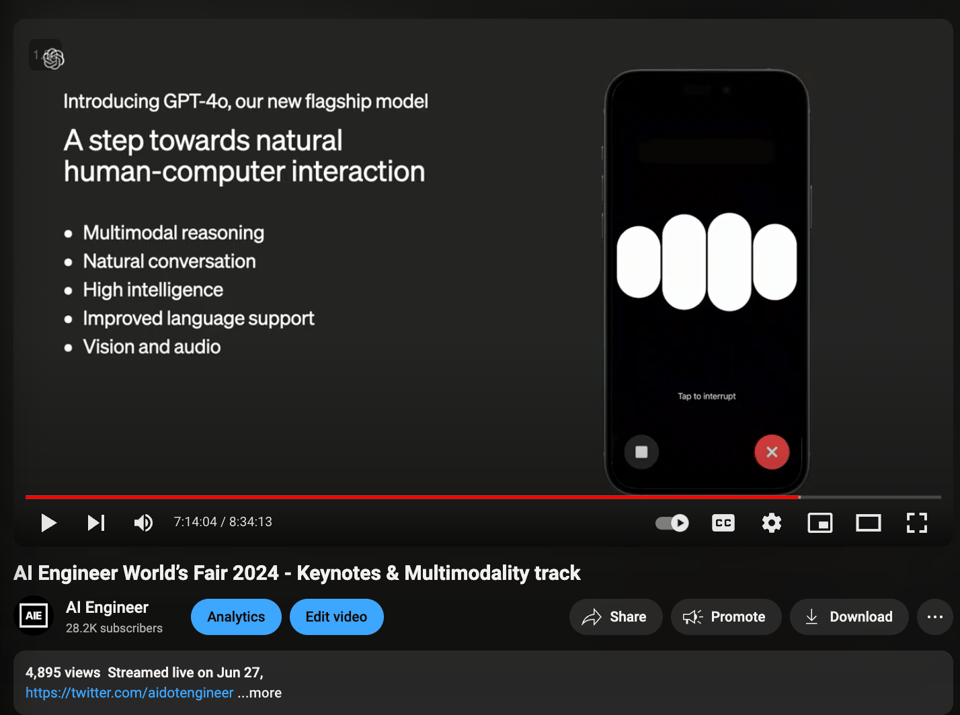
The demo starts at the 7:15:50 mark on stream, and you should watch the whole thing.
Capabilities demonstrated:
- low latency voicegen
- instructions to moderate tone to a whisper (and even quieter whisper)
- interruptions
- Camera mode on ChatGPT Desktop - constantly streaming video to GPT4o
- When paired with voice understanding it eliminates the need for a Send or Upload button
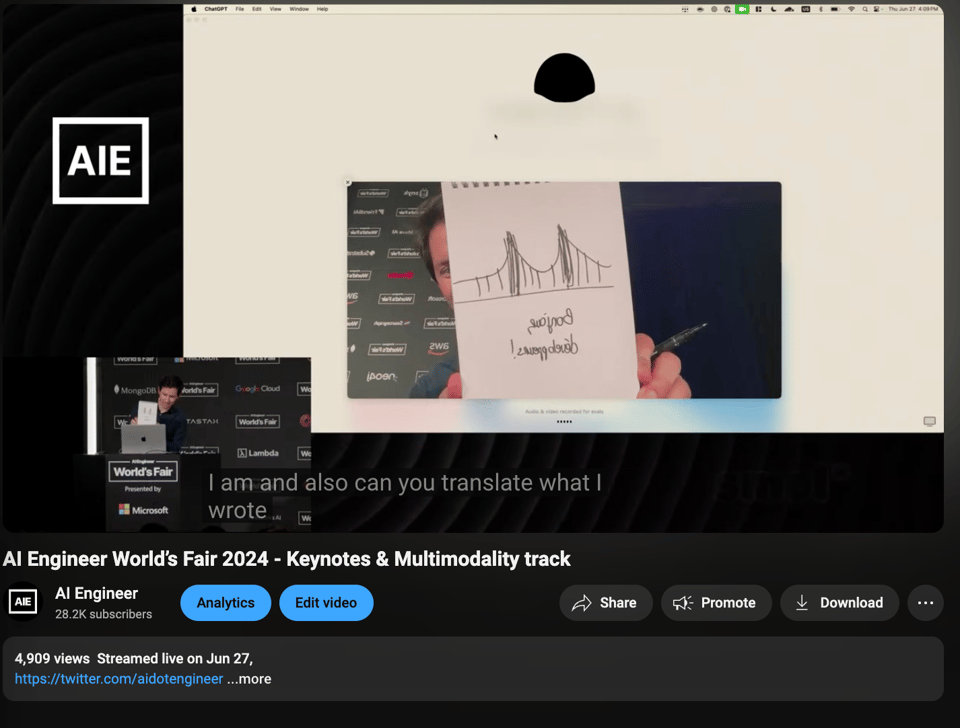
- Rapid OCR: Romain asks for a random page number, and presents the page of a book - and it reads the page basically instantly! Unfortunately the OCR failed a bit - it misread "Coca Cola" but conditions for the live demo weren't ideal.

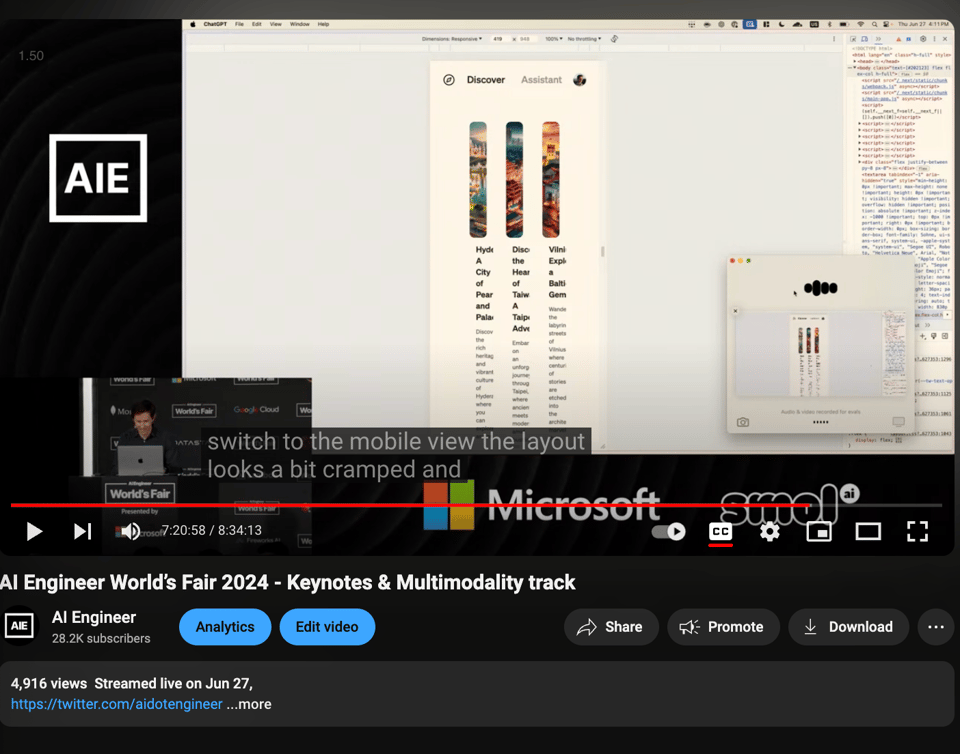
- Screen Sharing with ChatGPT: talking with ChatGPT to describe his programming problem and having it understand from visual context
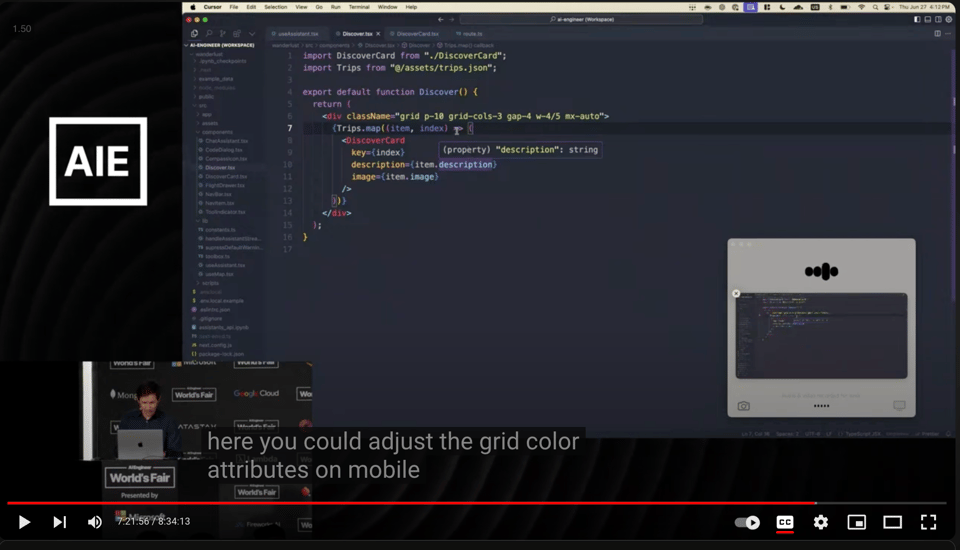
- Reading Clipboard: copies the code, asks for a "one line overview" of the code (This functionality exists in ChatGPT Desktop today)
- Conversing with ChatGPT about Code: back and forth talking about Tailwind classnames in code, relying on vision (not clipboard)
The rest of the talk discusses 4 "investment areas" of OpenAI:
- Textual intelligence (again using "GPT Next" instead of "GPT5"...)
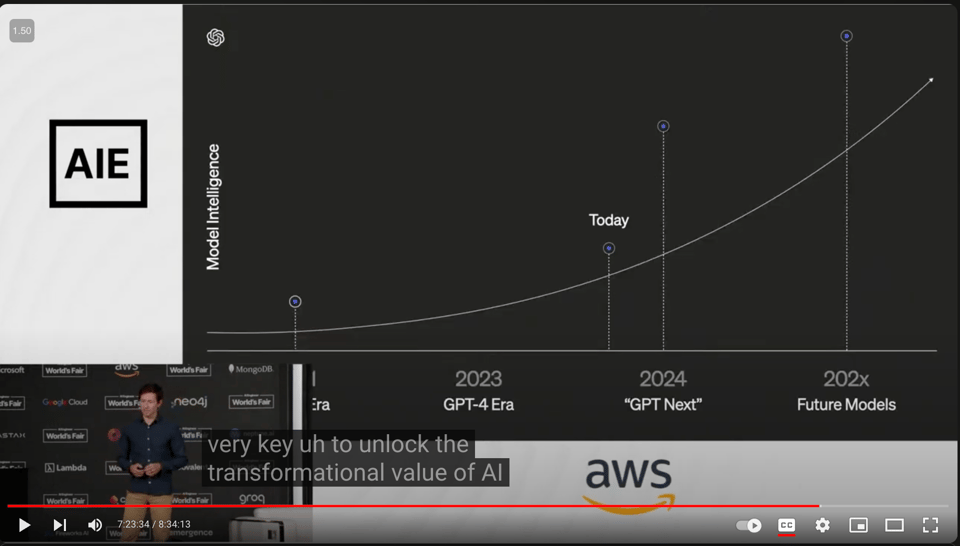
- Efficiency/Cost

- Model Customization

- Multimodal Agents
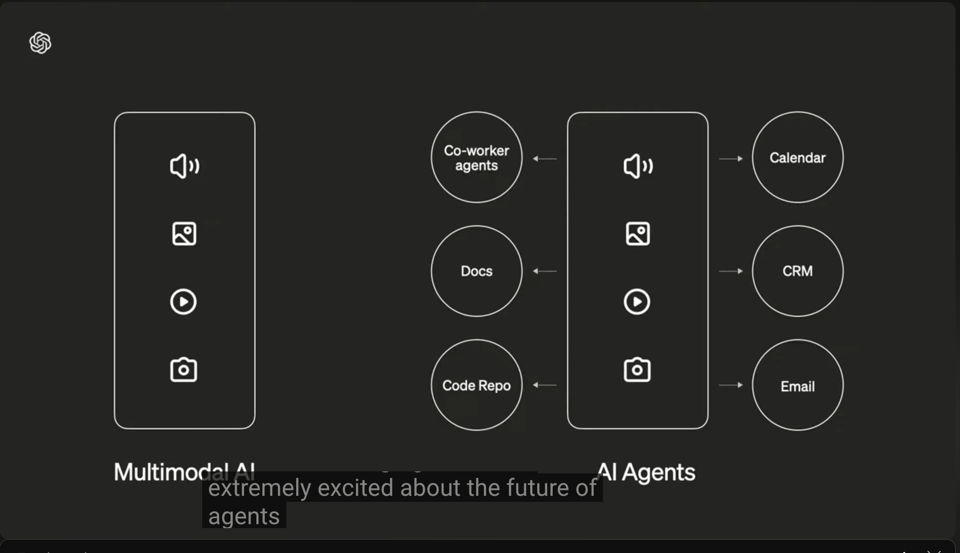 , including a Sora and Voice Engine demo that you should really check out if you haven't seen it before.
, including a Sora and Voice Engine demo that you should really check out if you haven't seen it before.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- LM Studio Discord
- OpenAI Discord
- Stability.ai (Stable Diffusion) Discord
- Latent Space Discord
- Nous Research AI Discord
- Eleuther Discord
- CUDA MODE Discord
- Perplexity AI Discord
- Interconnects (Nathan Lambert) Discord
- LlamaIndex Discord
- OpenRouter (Alex Atallah) Discord
- LAION Discord
- LangChain AI Discord
- Modular (Mojo 🔥) Discord
- Torchtune Discord
- LLM Finetuning (Hamel + Dan) Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- OpenAccess AI Collective (axolotl) Discord
- AI Stack Devs (Yoko Li) Discord
- Datasette - LLM (@SimonW) Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (549 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #random (16 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (113 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (25 messages🔥):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (482 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (6 messages):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (8 messages🔥):
- HuggingFace ▷ #reading-group (5 messages):
- HuggingFace ▷ #computer-vision (13 messages🔥):
- HuggingFace ▷ #NLP (10 messages🔥):
- HuggingFace ▷ #gradio-announcements (1 messages):
- LM Studio ▷ #💬-general (105 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (222 messages🔥🔥):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #🧠-feedback (13 messages🔥):
- LM Studio ▷ #⚙-configs-discussion (1 messages):
- LM Studio ▷ #🎛-hardware-discussion (28 messages🔥):
- LM Studio ▷ #🧪-beta-releases-chat (33 messages🔥):
- LM Studio ▷ #amd-rocm-tech-preview (4 messages):
- LM Studio ▷ #model-announcements (1 messages):
- LM Studio ▷ #🛠-dev-chat (1 messages):
- OpenAI ▷ #ai-discussions (330 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- OpenAI ▷ #prompt-engineering (25 messages🔥):
- OpenAI ▷ #api-discussions (25 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (297 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (50 messages🔥):
- Latent Space ▷ #ai-announcements (2 messages):
- Latent Space ▷ #llm-paper-club-west (150 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (34 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #datasets (10 messages🔥):
- Nous Research AI ▷ #ctx-length-research (1 messages):
- Nous Research AI ▷ #off-topic (1 messages):
- Nous Research AI ▷ #interesting-links (9 messages🔥):
- Nous Research AI ▷ #announcements (1 messages):
- Nous Research AI ▷ #general (111 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (2 messages):
- Nous Research AI ▷ #rag-dataset (85 messages🔥🔥):
- Nous Research AI ▷ #world-sim (5 messages):
- Eleuther ▷ #general (25 messages🔥):
- Eleuther ▷ #research (122 messages🔥🔥):
- Eleuther ▷ #scaling-laws (45 messages🔥):
- Eleuther ▷ #lm-thunderdome (15 messages🔥):
- Eleuther ▷ #gpt-neox-dev (6 messages):
- CUDA MODE ▷ #triton (12 messages🔥):
- CUDA MODE ▷ #torch (7 messages):
- CUDA MODE ▷ #cool-links (1 messages):
- CUDA MODE ▷ #beginner (14 messages🔥):
- CUDA MODE ▷ #pmpp-book (1 messages):
- CUDA MODE ▷ #torchao (16 messages🔥):
- CUDA MODE ▷ #off-topic (9 messages🔥):
- CUDA MODE ▷ #llmdotc (68 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (94 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (40 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Interconnects (Nathan Lambert) ▷ #memes (5 messages):
- Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (19 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (68 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (57 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
- OpenRouter (Alex Atallah) ▷ #tips (1 messages):
- LAION ▷ #general (36 messages🔥):
- LAION ▷ #research (2 messages):
- LangChain AI ▷ #general (26 messages🔥):
- LangChain AI ▷ #share-your-work (8 messages🔥):
- LangChain AI ▷ #tutorials (1 messages):
- Modular (Mojo 🔥) ▷ #general (2 messages):
- Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
- Modular (Mojo 🔥) ▷ #ai (11 messages🔥):
- Modular (Mojo 🔥) ▷ #🔥mojo (12 messages🔥):
- Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
- Modular (Mojo 🔥) ▷ #nightly (4 messages):
- Torchtune ▷ #general (30 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #general (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #fireworks (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #predibase (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
- OpenInterpreter ▷ #general (14 messages🔥):
- OpenInterpreter ▷ #O1 (3 messages):
- tinygrad (George Hotz) ▷ #general (7 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- Cohere ▷ #general (7 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
- AI Stack Devs (Yoko Li) ▷ #ai-companion (3 messages):
- Datasette - LLM (@SimonW) ▷ #ai (3 messages):
- MLOps @Chipro ▷ #events (1 messages):
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Gemma 2 Release by Google DeepMind
- Model Sizes and Training: @GoogleDeepMind announced Gemma 2 in 9B and 27B parameter sizes, trained on 13T tokens (27B) and 8T tokens (9B). Uses SFT, Distillation, RLHF & Model Merging. Trained on Google TPUv5e.
- Performance: @GoogleDeepMind 9B delivers class-leading performance against other open models in its size category. 27B outperforms some models more than twice its size and is optimized to run efficiently on a single TPU host.
- Availability: @fchollet Gemma 2 is available on Kaggle and Hugging Face, written in Keras 3 and compatible with TensorFlow, JAX, and PyTorch.
- Safety: @GoogleDeepMind followed robust internal safety processes including filtering pre-training data, rigorous testing and evaluation to identify and mitigate potential biases and risks.
Meta LLM Compiler Release
- Capabilities: @AIatMeta announced Meta LLM Compiler, built on Meta Code Llama with additional code optimization and compiler capabilities. Can emulate the compiler, predict optimal passes for code size, and disassemble code.
- Availability: @AIatMeta LLM Compiler 7B & 13B models released under a permissive license for both research and commercial use on Hugging Face.
- Potential: @MParakhin LLMs replacing compilers could lead to near-perfectly optimized code, reversing decades of efficiency sliding. @clattner_llvm Mojo 🔥 is a culmination of the last 15 years of compiler research, MLIR, and many other lessons learned.
Perplexity Enterprise Pro Updates
- Reduced Pricing for Schools and Non-Profits: @perplexity_ai announced reduced pricing for Perplexity Enterprise Pro for any school, nonprofit, government agency, or not-for-profit.
- Importance: @perplexity_ai These organizations play a critical role in addressing societal issues and equipping children with education. Perplexity wants to ensure their technology is accessible to them.
LangChain Introduces LangGraph Cloud
- Capabilities: @LangChainAI announced LangGraph Cloud, infrastructure to run fault-tolerant LangGraph agents at scale. Handles large workloads, enables debugging and quick iteration, and provides integrated tracing & monitoring.
- Features: @hwchase17 LangGraph Studio is an IDE for testing, debugging, and sharing LangGraph applications. Builds on LangGraph v0.1 supporting diverse control flows.
Other Notable Updates and Discussions
- Gemini 1.5 Pro Updates: @GoogleDeepMind opened up access to 2 million token context window on Gemini 1.5 Pro for all developers. Context caching now available in Gemini API to reduce costs.
- Lucid Dream Experience: @karpathy shared a lucid dream experience, noting the incredibly detailed and high resolution graphics, comparing it to a Sora-like video+audio generative model.
- Anthropic Updates: @alexalbert__ Anthropic devs can now view API usage broken down by dollar amount, token count, and API keys in the new Usage and Cost tabs in Anthropic Console.
- Distillation Discussion: @giffmana and @jeremyphoward discussed the importance of distillation and the "curse of the capacity gap" in training smaller high-performing models.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Architectures
- Gemma 2 models surpass Llama and Claude: In /r/LocalLLaMA, Google's Gemma 2 27B model beats Llama 3 70B in LMSYS benchmarks according to a technical report. The 9B variant also surpasses Claude 3 Haiku.
- Knowledge distillation for smaller models: Gemma 2 9B was trained using the 27B model as a teacher, an approach that could be the future for small/medium models, potentially using even larger models like Llama 400B as teachers.
- MatMul-free language modeling: A new paper introduces an approach that eliminates matrix multiplication from language models while maintaining strong performance. It reduces memory usage by 61% in training and 10x during inference, with custom FPGA hardware processing models at 13W.
- Sohu chip delivers massive performance: The specialized Sohu AI chip from Etched allegedly replaces 160 H100 GPUs, delivering 500,000 tokens/sec. It claims to be 10x faster and cheaper than Nvidia's next-gen Blackwell GPUs.
AI Applications and Use Cases
- AI-generated graphic novel: In /r/StableDiffusion, an author created a graphic novel 100% with Stable Diffusion, using SD1.5 iComix for characters, ControlNet for consistency, and Photoshop for layout. It's the first such novel published in Albanian.
- Website redesign with AI: A browser extension uses the OpenAI API to redesign websites based on a provided prompt, leveraging CSS variables. Experiments were done on shadcn.com and daisyui.com.
- Personalized AI assistant: An article on /r/LocalLLaMA details extending a personal Llama 3 8B model with WhatsApp and Obsidian data to create a personalized AI assistant.
Memes and Humor
- Disconnect in AI discussions: A meme video pokes fun at the disconnect between AI enthusiasts and the general public when discussing the technology.
- AI-generated movies: A humorous video imagines formulaic movies churned out by AI in the near future.
- Progress in AI-generated animations: A meme video of Will Smith eating spaghetti demonstrates AI's improving ability to generate realistic human animations, with only minor face and arm glitches remaining.
AI Discord Recap
A summary of Summaries of Summaries
1. Model Performance Optimization and Benchmarking
- Quantization techniques like AQLM and QuaRot aim to run large language models (LLMs) on individual GPUs while maintaining performance. Example: AQLM project with Llama-3-70b running on RTX3090.
- Efforts to boost transformer efficiency through methods like Dynamic Memory Compression (DMC), potentially improving throughput by up to 370% on H100 GPUs. Example: DMC paper by @p_nawrot.
- Discussions on optimizing CUDA operations like fusing element-wise operations, using Thrust library's
transformfor near-bandwidth-saturating performance. Example: Thrust documentation.
- Comparisons of model performance across benchmarks like AlignBench and MT-Bench, with DeepSeek-V2 surpassing GPT-4 in some areas. Example: DeepSeek-V2 announcement.
2. Fine-tuning Challenges and Prompt Engineering Strategies
- Difficulties in retaining fine-tuned data when converting Llama3 models to GGUF format, with a confirmed bug discussed.
- Importance of prompt design and usage of correct templates, including end-of-text tokens, for influencing model performance during fine-tuning and evaluation. Example: Axolotl prompters.py.
- Strategies for prompt engineering like splitting complex tasks into multiple prompts, investigating logit bias for more control. Example: OpenAI logit bias guide.
- Teaching LLMs to use
<RET>token for information retrieval when uncertain, improving performance on infrequent queries. Example: ArXiv paper.
3. Open-Source AI Developments and Collaborations
- Launch of StoryDiffusion, an open-source alternative to Sora with MIT license, though weights not released yet. Example: GitHub repo.
- Release of OpenDevin, an open-source autonomous AI engineer based on Devin by Cognition, with webinar and growing interest on GitHub.
- Calls for collaboration on open-source machine learning paper predicting IPO success, hosted at RicercaMente.
- Community efforts around LlamaIndex integration, with issues faced in Supabase Vectorstore and package imports after updates. Example: llama-hub documentation.
4. LLM Innovations and Training Insights
- Gemma 2 Impresses with Efficient Training: Google's Gemma 2 models, significantly smaller and trained on fewer tokens (9B model on 8T tokens), have outperformed competitors like Llama3 70B in benchmarks, thanks to innovations such as knowledge distillation and soft attention capping.
- Gemma-2's VRAM Efficiency Boosts QLoRA Finetuning: The new pre-quantized Gemma-2 4-bit models promise 4x faster downloads and reduced VRAM fragmentation, capitalizing on efficiency improvements in QLoRA finetuning.
- MCTSr Elevates Olympiad Problem-Solving: The MCT Self-Refine (MCTSr) algorithm integrates LLMs with Monte Carlo Tree Search, showing substantial success in tackling complex mathematical problems by systematically refining solutions.
- Adam-mini Optimizer's Memory Efficiency: Adam-mini optimizer achieves comparable or better performance than AdamW with up to 50% less memory usage by leveraging a simplified parameter partitioning approach.
5. Secure AI and Ethical Considerations
- Rabbit R1's Security Lapse Exposed on YouTube: A YouTube video titled "Rabbit R1 makes catastrophic rookie programming mistake" revealed hardcoded API keys in the Rabbit R1 codebase, compromising user data security.
- AI Usage Limit Warnings and Policy Compliance: Members highlighted the risks of pushing AI boundaries too far, cautioning that violating OpenAI's usage policies can result in account suspension or termination.
- Open-Source AI Debate: Intense discussions weighed the pros and cons of open-sourcing AI models, balancing potential misuse against democratization of access and the economic implications of restricted AI, considering both the benefits and the dangers.
6. Practical AI Integration and Community Feedback
- AI Video Generation with High VRAM Demands: Successful implementation of ExVideo generating impressive video results, albeit requiring substantial VRAM (43GB), demonstrates the continuous balance between AI capability and hardware limitations.
- Issues with Model Implementation Across Platforms: Integration issues with models like Gemma 2 on platforms such as LM Studio require manual fixes and the latest updates to ensure optimal performance.
- Challenges with RAG and API Limitations: Perplexity's RAG mechanism received criticism for inconsistent outputs, and limitations with models like Claude 3 Opus, showcasing struggles in context handling and API performance.
7. Datasets and Benchmarking Advancements
- REVEAL Dataset Benchmarks Verifiers: The REVEAL dataset benchmarks automatic verifiers of Chain-of-Thought reasoning, highlighting the difficulties in verifying logical correctness within open-domain QA settings.
- XTREME and SPPIQA Datasets for Robust Testing: Discussion on the XTREME and SPPIQA datasets focused on assessing multilingual models' robustness and multimodal question answering capabilities, respectively.
- Importance of Grounded Response Generators: The need for reliable models that provide grounded responses was highlighted with datasets like Glaive-RAG-v1, and considerations on scoring metrics for quality improvement.
8. Collaboration and Development Platforms
- Building Agent Services with LlamaIndex: Engineers can create vector indexes and transform them into query engines using resources shared in the LlamaIndex notebook, enhancing AI service deployment.
- Featherless.ai Offers Model Access Without GPU Setup: Featherless.ai launched a platform providing flat-rate access to over 450 models from Hugging Face, catering to community input on model prioritization and use cases.
- LangGraph Cloud Enhances AI Workflows: The introduction of LangGraph Cloud by LangChainAI promises robust, scalable workflows for AI agents, integrating monitoring and tracing for improved reliability.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Gemma-2 Goes Lean and Keen: The new pre-quantized 4-bit versions of Gemma-2-27B and 9B are now available, boasting faster downloads and lesser VRAM fragmentation which are beneficial for QLoRA finetuning.
- The Great OS Debate for AI Development: Within the community, there's an active debate on the merits of using Windows vs. Linux for AI development, featuring concerns about peripheral compatibility on Linux and a general preference toward Linux despite perceived arbitrary constraints of Windows.
- Hugging Face's Evaluation System Under the Microscope: The community compared Hugging Face's evaluation system to a "popularity contest" and broached the notion of having premium paid evaluations, suggesting that an "evaluation should be allowed at any time if the user is willing to pay for it."
- Big Data, Big Headaches: Discussions around handling a 2.7TB Reddit dataset pointed out the immense resources needed for cleaning the data, which could inflate to "about 15 TB uncompressed... for meh data at best."
- AI Video Generation at the Edge of VRAM: The use of ExVideo for generating video content has been reported to deliver impressive results, yet it commands a formidable VRAM requirement of 43GB, emphasizing the constant balance between AI capabilities and resource availability.
HuggingFace Discord
- Gemma 2 Outshines Competition: Google's new Gemma 2 models have been integrated into the Transformers library, boasting advantages such as size efficiency—2.5x smaller than Llama3—and robust training on 13T tokens for the 27B model. Innovations like knowledge distillation and interleaving local and global attention layers aim for enhanced inference stability and memory reduction, with informative Gemma 2 details covered in a HuggingFace blog post.
- Deciphering New File System for Elixir: Elixir's FSS introduces file system abstraction with HTTP support and discusses non-extensibility concerns alongside HuggingFace's first open-source image-based retrieval system, making waves with a Pokémon dataset example and interest in further projects like visual learning models with CogVLM2 being spotlighted.
- AI Takes Flight with Multilingual App: U-C4N's multilingual real-time flight tracking application reveals the intersect of aviation and language, while a new 900M variant of PixArt aspires collaboration in the Spaces arena. Also, a fusion of AI and musical storytelling on platforms like Bandcamp breaks genre boundaries.
- Ready, Set, Gradio!: Gradio users face an action call to update to versions above 3.13 to avoid share link deactivation. Adherence will ensure continued access to Gradio's resources and is as simple as running
pip install --upgrade gradio.
- Machine Learning at Lightning Speed: A hyper-speed YouTube tutorial has engineered a 1-minute crash course on ten critical machine learning algorithms, fitting for those short on time but hungry for knowledge. Check this rapid lesson here.
LM Studio Discord
Gemma 2 Integration with Hiccups: The latest LM Studio 0.2.26 release adds support for Gemma 2 models, though some users report integration bugs and difficulties. To work around these issues, manual downloads and reinstallation of configs are suggested, with a note that some architectures, like ROCm, are still pending support.
Gemma-2's Confusing Capabilities: Discrepancies in the information about Gemma-2's context limit led to confusion, with conflicting reports of a 4k versus an 8k limit. Additionally, the support for storytelling model ZeusLabs/L3-Aethora-15B-V2 was recommended, and for models like Deepseek coder V2 Lite, users were advised to track GitHub pull requests for updates on support status.
Snapdragon Soars in LM Studio: Users praised the performance of Snapdragon X Elite systems for their compatibility with LM Studio, noting significant CPU/memory task efficiency compared to an i7 12700K, despite falling short compared to a 4090 GPU in specific tasks.
Threading the Needle for Multi-Agent Frameworks: Discussions on model efficacy suggested that a 0.5B model might comfortably proxy a user in a multi-agent framework; however, skepticism remains for such low-end models' capacity for coding tasks. For hardware enthusiasts, queries about the value of using dual video cards were answered positively.
Rift Over ROCm Compatibility and Gemma 2 Debuts: In the AMD ROCm tech-preview channel, queries about Gemma 2 model support for AMD GPUs were raised, pointing users to the newly released 0.2.26 ROCm "extension pack" for Windows described in GitHub instructions. Furthermore, Gemma 2's launch was met with both excitement and critique, with some users labeling it as "hot garbage" and others anxious for the promised improvements in coming updates.
OpenAI Discord
AI Usage Warnings: A discussion highlighted the risks of testing the limits of AI, leading to a clear warning: violating OpenAI's usage policies can result in account suspension or termination.
Open-source AI Debate: The engineering community debated the open-sourcing of AI models; the discussion contrasted the potential for misuse against the democratization of access, highlighting the economic implications of restricted access and the necessity of surveillance for public safety.
RLHF Training Puzzles Users: Conversations about Reinforcement Learning from Human Feedback (RLHF) revealed confusion regarding its occasional prompts and the opaque nature of how OpenAI handles public RLHF training.
AI Integration Triumphs and Woes: Experiences shared by members included issues with custom GPTs for specific tasks like medical question generation and successes in integrating AI models and APIs with other services for enhanced functionalities.
Prompt Engineering Insights: Members exchanged tips on prompt engineering, recommending simplicity and conciseness, with a foray into the use of "logit bias" for deeper prompt control and a brief touch on the quasi-deterministic nature of stochastic neural networks.
Stability.ai (Stable Diffusion) Discord
- Custom Style Datasets Raise Red Flags: Participants discussed the creation of datasets with a custom style, noting the potential risks of inadvertently generating NSFW content. The community underscored the complexity in monitoring image generation to avoid platform bans.
- Switching to Forge amid Automatic1111 Frustrations: Due to issues with Automatic1111, users are exploring alternatives like Forge, despite its own memory management challenges. For installation guidance, a Stable Diffusion Webui Forge Easy Installation video on YouTube has been shared.
- Cascade Channel Revival Requested: Many members voiced their desire to restore the Cascade channel due to its resourceful past discussions, sparking a debate on the guild's direction and possible focus shift towards SD3.
- Deep Dive into Model Training Specifics: Conversations about model training touched on the nuances of LoRa training and samplers such as 3m sde exponential, as well as VRAM constraints. The effectiveness and limitations of tools like ComfyUI, Forge, and Stable Swarm were also examined.
- Discord Community Calls for Transparency: A portion of the community expressed dissatisfaction with the deletion of channels and resources, impelling a discussion about the importance of transparent communication and preservation of user-generated content.
Latent Space Discord
- Scarlet AI Marches into Project Management: A preview of Scarlet AI for planning complex projects has been introduced; interested engineers can assess its features despite not being ready for prime time at Scarlet AI Preview.
- Character.AI Dials Into Voice: New Character Calls by Character.AI allows for AI interactions over phone calls, suitable for interview rehearsals and RPG scenarios. The feature is showcased on their mobile app demonstration.
- Meta Optimizes Compiler Code via LLM: Meta has launched a Large Language Model Compiler to improve compiler optimization tasks, with a deep dive into the details in their research publication.
- Infrastructure Innovations with LangGraph Cloud: LangChainAI introduced LangGraph Cloud, promising resilient, scalable workflows for AI agents, coupled with monitoring and tracing; more insights available in their announcement blog.
- Leadership Shift at Adept Amid Amazon Team-Up: News has surfaced regarding Adept refining their strategy along with several co-founders transitioning to Amazon's AGI team; learn more from the GeekWire article.
- OpenAI Demos Coming in Hot: The guild was notified of an imminent OpenAI demo, advising members to access the special OpenAI Demo channel without delay.
- GPT-4o Poised to Reinvent Coding on Desktop: The guild discussed the adoption of GPT-4o to aid in desktop coding, sharing configurations like
Open-Interpreterwhich could easily be integrated with local models.
- When Penguins Prefer Apples: The struggles of Linux users with streaming sparked a half-humorous, half-serious comparison with Mac advantages and brought to light Vesktop, a performance-boosting Discord app for Linux, found on GitHub.
- AI Community Leaks and Shares: There's chatter about potentially sensitive GPT definitions surfacing on platforms like GitHub; a nod to privacy concerns. Links to wear the scholarly hat were exchanged, illuminating CoALA frameworks and repositories for language agents which can be found at arXiv and on GitHub.
- Praise for Peer Presentations: Members showered appreciation on a peer for a well-prepared talk, highlighting the importance of quality presentations in the AI field.
Nous Research AI Discord
- LLMs' Instruction Pre-Training Edges Out: Incorporating 200M instruction-response pairs into pre-training large corpora boosted performance, allowing a modest Llama3-8B to hang with the big guns like Llama3-70B. Details on the efficient instruction synthesizer are in the Instruction Pre-Training paper, and the model is available on Hugging Face.
- MCTSr Fuses with LLMs for Olympian Math: Integrating Large Language Models with Monte Carlo Tree Search (MCTSr) led to notable success in solving mathematical Olympiad problems. The innards of this technique are spilled in a detailed study.
- Datasets Galore: SPPIQA, XTREME, UNcommonsense: A suite of datasets including SPPIQA for reasoning, XTREME for multilingual model assessment, and UNcommonsense for exploring scales of bizarre, were discussed across Nos Research AI channels.
- Hermes 2 Pro Launches with Function Boost: The Hermes 2 Pro 70B model was revealed, trumpeting improvements in function calls and structured JSON outputs, boasting scores of 90% and 84% in assessments. A scholarly read isn't offered, but you can explore the model at NousResearch's Hugging Face.
- Debating SB 1047's Grip on AI: Members heatedly debated whether Cali's SB 1047 legislation will stunt AI's growth spurts. A campaign rallying against the bill warns it could curb the risk-taking spirit essential for AI's blazing trail.
Eleuther Discord
- "Cursed" Complexity vs. Practical Performance: The yoco architecture's kv cache strategy sparked debate, with criticisms about its deviation from standard transformer practices and complexity. The discussion also covered the order of attention and feed-forward layers in models, as some proposed an efficiency gain from non-standard layer ordering, while others remained skeptical of the performance benefits.
- Scaling Beyond Conventional Wisdom: Discussions around scaling laws questioned the dominance of the Challax scaling model, with some participants proposing the term "scaling laws" to be provisional and better termed "scaling heuristics." References were made to papers such as "Parameter Counts in Machine Learning" to support viewpoints on different scaling models' effectiveness.
- Data Privacy Dilemma: Conversations surface privacy concerns in the privacy-preserving/federated learning context, where aggregate data exposes a wider attack space. The potential for AI agents implementing security behaviors was discussed, considering contextual behavior identification and proactive responses to privacy compromises.
- LLM Evaluation and Innovation: A new reasoning challenge dataset, MMLU-SR, was introduced and considered for addition to lm_eval, probing large language models' (LLMs) comprehension abilities through modified questions. Links to the dataset arXiv paper and a GitHub PR for the MedConceptsQA benchmark addition were shared.
- Instruction Tuning Potential in GPTNeoX: Queries on instruction tuning in GPTNeoX, specifically selectively backpropagating losses, led to a discussion that referenced an ongoing PR and a preprocessing script "preprocess_data_with_chat_template.py", signifying active development in tailored training workflows.
CUDA MODE Discord
- Triton Tribulations on Windows: Users have reported Triton installation issues on Windows when using
torch.compile, leading to "RuntimeError: Cannot find a working trilog installation." It's suggested that Triton may not be officially supported on Windows, posing a need for alternative installation methods.
- Tensor Tinkering with torch.compile: The author of Lovely Tensors faces breakage in
torch.compile()due toTensor.__repr__()being called on a FakeTensor. The community suggests leveraging torch.compiler fine-grain APIs to mitigate such issues. Meanwhile, an update to NCCL resolves a broadcast deadlock issue in older versions, as outlined in this pull request.
- Gearing up with CUDA Knowledge: Stephen Jones presents an in-depth overview of CUDA programming, covering wave quantization & single-wave kernels, parallelism, and optimization techniques like tiling for improved L2 cache performance.
- CUDA Curiosity and Cloud Query: Members share platforms like Vast.ai and Runpod.io for CUDA exploration on cloud GPUs, and recommend starting with
torch.compile, then moving to Triton or custom CUDA coding for Python to CUDA optimization.
- PMPP Publication Puzzle: A member highlights a physical copy of PMPP (4th edition) book missing several pages, inciting queries about similar experiences.
- torch/aten Ops Listing and Bug-Hunting: The torchao channel surfaces requests for a comprehensive list of required
torch/aten opsfor tensor subclasses such asFSDP, conversations about a recursion error with__torch_dispatch__, and a refactor PR for Int4Tensor. Additionally, there was a caution regarding GeForce GTX 1650's lack of native bfloat16 support.
- HuggingFace Hub Hubbub: The off-topic channel buzzes with chatter about the pros and cons of storing model architecture and preprocessing code directly on HuggingFace Hub. There's debate on the best model code and weight storage practices, with the Llama model cited as a case study in effective release strategy.
- Gemma 2 Grabs the Spotlight: The Gemma 2 models from Google, sporting 27B and 9B parameters, outshine competitors in benchmarks, with appreciation for openness and anticipation for a smaller 2.6B variant. Discussions also focused on architectural choices like approx GeGLU activations and the ReLU versus GELU debate, backed by scholarly research. Hardware challenges with FP8 support led to mentions of limitations in NVIDIA's libraries and Microsoft's work on FP8-LM. Yuchen's training insights suggest platform or dataset-specific issues when optimizing for H100 GPUs.
Perplexity AI Discord
- Perplexity Cuts Costs for a Cause: Perplexity introduces reduced pricing for its Enterprise Pro offering, targeting schools and nonprofits to aid in their societal and educational endeavors. Further information on eligibility and application can be found in their announcement.
- RAG Frustration and API Agitation: Within Perplexity's AI discussion, there's frustration over the erratic performance of the RAG(Relevance Aware Generation) mechanism and demand for access to larger models such as Gemma 2. Additionally, users are experiencing limitations with Claude 3 Opus, citing variable and restrictive usage caps.
- Security First, Fixes Pending: Security protocols were addressed, directing members to the Trust Center for information on data handling and PII management. Meanwhile, members suggested using "#context" for improved continuity handling ongoing context retention issues in interactions.
- Tinkering with Capabilities: The community's attention turned to exploring Android 14 enhancements, while raising issues with Minecraft's mechanics potentially misleading kids. An inquiry into filtering API results to receive recent information received guidance on using specific date formats.
- Tech Deep-Dives and Innovations Spotlighted: Shared content included insights on Android 14, criticisms of Linux performance, innovative uses of Robot Skin, and sustainable construction inspired by oysters. A notable share discussed criticisms of Minecraft's repair mechanics potentially leading to misconceptions.
Interconnects (Nathan Lambert) Discord
- Character.AI Pioneers Two-Way AI Voice Chats: Character.AI has launched Character Calls, enabling voice conversations with AI, though the experience is marred by a 5-second delay and less-than-fluid interaction. Meanwhile, industry chatter suggests Amazon's hiring of Adept's cofounders and technology licensing has left Adept diminished, amid unconfirmed claims of Adept having a toxic work environment.
- AI Agents Trail Behind the Hype Curve: Discussions draw parallels between AI agents' slow progress and the self-driving car industry, claiming that hype outpaces actual performance. The quality and sourcing of training data for AI agents, including an emerging focus on synthetic data, were highlighted as pivotal challenges.
- SnailBot News Episode Stirs Up Discussion: Excitement is brewing over SnailBot News' latest episode featuring Lina Khan; Natolambert teases interviews with notable figures like Ross Taylor and John Schulman. Ethical considerations around "Please don't train on our model outputs" data usage conditions were also brought into focus.
- Scaling Engulfs AI Discourse: Skepticism encircles the belief that scaling alone leads to AGI, as posited in AI Scaling Myths, coupled with discussions on the alleged limitations in high-quality data for LLM developers. Nathan Lambert urges critical examination of these views, referencing Substack discussions and recent advances in synthetic data.
- Varied Reflections on AI and Global Affairs: From Anthropic CEO's affection for Final Fantasy underscoring AI leaders' human sides to debates over AI crises being potentially more complex than pandemics, guild members engage in diverse conversations. Some talk even considers how an intelligence explosion could reshape political structures, reflecting on the far-reaching implications of AI development.
LlamaIndex Discord
LlamaIndex Powers Agent Services: Engineers explored building agentic RAG services with LlamaIndex, discussing the process of creating vector indexes and transforming them into query engines. Detailed steps and examples can be found in a recently shared notebook.
Jina's Reranking Revolution: The LlamaIndex community is abuzz about Jina's newest reranker, hailed as their most effective to date. Details behind the excitement are available here.
Node Weight Puzzle in Vector Retrievers: AI practitioners are troubleshooting LlamaIndex's embedding challenges, deliberating on factors such as the parts of nodes to embed and the mismatch of models contributing to suboptimal outcomes from vector retrievers. A consensus implies creating simple test cases for effective debugging.
Entity Linking Through Edges: Enhancing entity relationship detection is generating debate, focused on adding edges informed by embedding logic. Anticipation surrounds a potential collaborative know-how piece with Neo4j, expected to shed light on advanced entity resolution techniques.
Issues Surface with Claude and OpenAI Keys: Discussions emerge about needing fixes for Claude's empty responses linked to Bedrock's token limitation and an IndexError in specific cases, as well as a curious environment behavior where code-set OpenAI keys seem overridden. Engineers also probe optimizations for batch and parallel index loading, aiming to accelerate large file handling.
OpenRouter (Alex Atallah) Discord
Gemma's Multilingual Punch: While Gemma 2 officially supports only English, users report excellent multilingual capabilities, with specific inquiries about its performance in Korean.
Model Migration Madness: Gemma 2.9B models, with free and standard variants, are storming the scene as per the announcement, accompanied by price cuts across popular models, including a 10% drop for Dolphin Mixtral and 20% for OpenChat.
OpenRouter, Open Issues: OpenRouter's tight-lipped moderation contrasts with platforms like AWS; meanwhile, users confront the lack of Opus availability without enterprise support and battle Status 400 errors from disobedient APIs of Gemini models.
Passphrase Puzzles and API Allocutions Solved: Engineers share wisdom on seamless GitHub authentication using ssh-add -A, and discuss watching Simon Willison's overview on LLM APIs for enlightenment, with resources found on YouTube and his blog.
AI Affinity Adjustments: Embrace daun.ai’s advice to set the default model to 'auto' for steady results or live life on the edge with 'flavor of the week' fallbacks, ensuring continued productivity across tasks.
LAION Discord
- Gege AI Serenades with New Voices: The music creation tool, Gege AI, can mimic any singer's voice from a small audio sample, inciting humorous comments about the potential for disrupting the music industry and speculations about RIAA's reaction.
- User Frustration with Gege AI and GPT-4 Models: Users reported difficulties in registering for Gege AI with quips about social credit, while others expressed disappointment with the performance of GPT-4 and 4O models, suggesting they can be too literal and less suited for programming tasks than earlier versions like GPT-3.5.
- Adam-mini Optimizer Cuts Memory Waste: The Adam-mini optimizer offers performance comparable to, or better than, AdamW, while requiring 45-50% less memory by partitioning parameters and assigning a single learning rate per block, according to a recent paper highlighted in discussions.
- Skepticism Meets Ambition with Gemma 27B: While the new Gemma 27B model has reportedly shown some promising performance enhancements, members remained cautious due to a high confidence interval, questioning its overall advantage over previous iterations.
- Shifting to Claude for a Smoother Ride: Given issues with OpenAI's models, some members have opted for Claude for its superior artifacts feature and better integration with the Hugging Face libraries, reporting a smoother experience compared to GPT-4 models.
LangChain AI Discord
- Bedrock Befuddles Engineers: Engineers shared challenges in integrating csv_agent and pandas_dataframe_agent with Bedrock, as well as errors encountered while working with Sonnet 3.5 model and Bedrock using
ChatPromptTemplate.fromMessages, indicating possible compatibility issues.
- Launch of LangGraph with Human-in-the-Loop Woes: The introduction of LangGraph's human-in-the-loop capabilities, notably "Interrupt" and "Authorize", was marred by deserialization errors during the resumption of execution post-human approvals, as discussed in the LangChain Blog.
- Refinement of JSONL Editing Tools and RAG with Matryoshka Embeddings: Community members have circulated a tool for editing JSONL datasets (uncensored.com/jsonl) and shared insights on building RAG with Matryoshka Embeddings to enhance retrieval speed and memory efficiency, complete with a Colab tutorial.
- Dappier Creates AI Content Monetization Opportunity: The Dappier platform, featured in TechCrunch, provides a marketplace for creators to license content for AI training through a RAG API, signaling a new revenue stream for proprietary data holders.
- Testcontainers Python SDK Boosts Ollama: The Testcontainers Python SDK now supports Ollama, enhancing the ease of running and testing Large Language Models (LLMs) via Ollama, available in version 4.7.0, along with example usage (pull request #618).
Modular (Mojo 🔥) Discord
- Mix-Up Between Mojolicious and Mojo Resolved: Confusion ensued when a user asked for a Mojo code example and received a Perl-based Mojolicious sample instead; but it was clarified that the request was for info on Modular's AI development language Mojo, admired for its Python-like enhanced abilities and C-like robustness.
- Caught in the REPL Web: An anomaly was reported concerning the Mojo REPL, which connects silently and then closes without warning, prompting a discussion to possibly open a GitHub issue to identify and resolve this mysterious connectivity conundrum.
- Nightly Notes: New Compiler and Graph API Slices: Modular's latest nightly release '2024.6.2805' features a new compiler with LSP behavior tweaks and advises using
modular update nightly/mojo; Developers also need to note the addition of "integer literal slices across dimensions", with advice to document requests for new features via issues for traceability.
- SDK Telemetry Tips and MAX Comes Back: Guidance was shared on disabling telemetry in the Mojo SDK, with a helpful FAQ link provided; The MAX nightly builds are operational again, welcoming trials of the Llama3 GUI Chatbot and feedback via the given Discord link.
- Meeting Markers and Community Collaterals: The community is gearing up for the next Mojo Community meeting, scheduled for an unspecified local time with details accessible via Zoom and Google Docs; Plus, a warm nod to holiday celebrants in Canada and the U.S. was shared. Meanwhile, keeping informed through the Modverse Weekly - Issue 38 is a click away at Modular.com.
Torchtune Discord
- Community Models Get Green Light: The Torchtune team has expressed interest in community-contributed models, encouraging members to share their own implementations and enhance the library's versatility.
- Debugging Diskourse's Debacles: A puzzling issue in Torchtune's text completions was tracked to end-of-sentence (EOS) tokens being erroneously inserted by the dataset, as detailed in a GitHub discussion.
- Finding Favor in PreferenceDataset: For reinforcement learning applications, the PreferenceDataset emerged as the favorable choice over the text completion dataset, better aligning with the rewarding of "preferred" input-response pairs.
- Pretraining Pax: Clarification in discussions shed light on pretraining mechanics, specifically that it involves whole documents for token prediction, steering away from fragmented input-output pair handling.
- EOS Tokens: To Add or Not to Add?: The community debated and concluded positively on introducing an add_eos flag to the text completion datasets within Torchtune, resolving some issues in policy-proximal optimization implementations.
LLM Finetuning (Hamel + Dan) Discord
Next-Gen Data Science IDE Alert: Engineers discussed Positron, a future-forward data science IDE which was shared in the #general channel, suggesting its potential relevance for the community.
Summarization Obstacle Course: A technical query was observed about generating structured summaries from patient records, with an emphasis on avoiding hallucinations using Llama models; the community is tapped for strategies in prompt engineering and fine-tuning.
LLAMA Drama: Deployment of LLAMA to Streamlit is causing errors not seen in the local environment, as discussed in the #🟩-modal channel; another member resolved a FileNotFoundError for Tinyllama by adjusting the dataset path.
Credits Where Credits Are Due: Multiple members have reported issues regarding missing credits for various applications, including requests in the #fireworks and #openai channels, stressing the need for resolution involving identifiers like kishore-pv-reddy-ddc589 and organization ID org-NBiOyOKBCHTZBTdXBIyjNRy5.
Link Lifelines and Predibase Puzzles: In the #freddy-gradio channel a broken link was fixed swiftly, and a question was raised in the #predibase channel about the expiration of Predibase credits, however, it remains unanswered.
OpenInterpreter Discord
- Secure Yet Open: Open Interpreter Tackles Security: Open Interpreter's security measures, such as requiring user confirmation before code execution and sandboxing using Docker, were discussed, emphasizing the importance of community input for project safety.
- Speed vs. Skill: Code Models in the Arena: Engineers compared various code models, recognizing Codestral for superior performance, while DeepSeek Coder offers faster runtimes but at approximately 70% effectiveness. DeepSeek Coder-v2-lite stood out for its rapid execution and coding efficiency, potentially outclassing Qwen-1.5b.
- Resource Efficiency Query: SMOL Model in Quantized Form: Due to RAM constraints, there was an inquiry about running a SMOL multi-modal model in a quantized format, spotlighting the adaptive challenge for AI systems in limited-resource settings.
- API Keys Exposed: Rabbit R1's Security Oversight: A significant security oversight was exposed in a YouTube video, where Rabbit R1 was found to have hardcoded API keys in its codebase, a critical threat to user data security.
- Modifying OpenInterpreter for Local Runs: An AI engineer outlined the process for running OpenInterpreter locally using non-OpenAI providers, detailing the adjustments in a GitHub issue comment. Concerns were raised over additional API-related costs, on top of subscription fees.
tinygrad (George Hotz) Discord
tinygrad gets new porting perks: A new port that supports finetuning has been completed, signaling advancements for the tinygrad project.
FPGA triumphs in the humanoid robot arena: An 8-month-long project has yielded energy-efficient humanoid robots using FPGA-based systems, which is deemed more cost-effective compared to the current GPU-based systems that drain battery life with extensive power consumption.
Shapetracker's zero-cost reshape revolution: The Shapetracker in tinygrad allows for tensor reshaping without altering the underlying memory data, which was detailed in a Shapetracker explanation, and discussed by members considering its optimizations over traditional memory strides.
Old meets new in model storage: In tinygrad, weights are handled by safetensors and compute by pickle, according to George Hotz, indicating the current methodology for model storage.
Curiosity about Shapetracker's lineage: Participants pondered if the concept behind Shapetracker was an original creation or if it drew inspiration from existing deep learning compilers, while admiring its capability to optimize without data copies.
Cohere Discord
- Internship Inquiries Ignite Network: A student intersects their academic focus on LLMs and Reinforcement little reflectiong with a real-world application by seeking DMs from Cohere employees about the company's work culture and projects. Engagement on the platform signals a consensus about the benefits of exhibiting a robust public project portfolio when vying for internships in the AI field.
- Feature Requests for Cohere: Cohere users demonstrated curiosity about potential new features, prompting a call for suggestions that could enhance the platform's offerings.
- Automation Aspirations in AI Blogging: Discussions arose around setting up AI-powered automations for blogging and social media content generation, directing the inquiry towards specialized assistance channels.
- AI Agent Achievement Announced: A member showcased an AI project called Data Analyst Agent, built using Cohere and Langchain, and promoted the creation with a LinkedIn post.
OpenAccess AI Collective (axolotl) Discord
- Gemma2 Gets Sample Packing via Pull Request: A GitHub pull request was submitted to integrate Gemma2 with sample packing. It's pending due to a required fix from Hugging Face, detailed within the PR.
- 27b Model Fails to Impress: Despite the increase in size, the 27b model is performing poorly in benchmarks when compared to the 9b model, indicating there may be scaling or architecture inefficiencies.
AI Stack Devs (Yoko Li) Discord
- Featherless.ai Introduces Flat-Rate Model Access: Featherless.ai has launched a platform offering access to over 450+ models from Hugging Face at competitive rates, with the basic tier starting at $10/month and no need for GPU setup or download.
- Subscription Scale-Up: For $10 per month, the Feather Basic plan from Featherless.ai allows access up to 15B models, while the Feather Premium plan at $25 per month allows up to 72B models, adding benefits like private and anonymous usage.
- Community Influence on Model Rollouts: Featherless.ai is calling for community input on model prioritization for the platform, highlighting current popularity with AI persona local apps and specialized tasks like language finetuning and SQL model usage.
Datasette - LLM (@SimonW) Discord
- Curiosity for Chatbot Elo Evolution: A user requested an extended timeline of chatbot elo ratings data beyond the provided six-week JSON dataset, expressing interest in the chatbot arena's evolving competitive landscape.
- Observing the Elo Race: From a start date of May 19th, there's a noted trend of the "pack" inching closer among leading chatbots in elo ratings, indicating a tight competitive field.
MLOps @Chipro Discord
- Feature Stores Step into the Spotlight: An informative webinar titled "Building an Enterprise-Scale Feature Store with Featureform and Databricks" will be held on July 23rd at 8 A.M. PT. Simba Khadder will tackle the intricacies of feature engineering, utilization of Databricks, and the roadmap for handling data at scale, capped with a Q&A session. Sign up to deep dive into feature stores.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (549 messages🔥🔥🔥):
- Gemma-2 Updates with Faster Downloads and Less VRAM Fragmentation: A new pre-quantized 4-bit versions of Gemma-2-27B and 9B, have been uploaded, promising 4x faster downloads and over 1GB less VRAM fragmentation for QLoRA finetuning. Gemma-2-27B and Gemma-2-9B now available on Huggingface.
- Windows vs Linux for AI Development: Members discussed the pros and cons of using Windows versus Linux for AI development. One user noted, "Windows is certainly not dead... But it feels more and more arbitrary every day," while another expressed frustrations with peripheral compatibility on Linux.
- HF's Tiktoker-like Evaluation System: Several members critiqued Hugging Face's evaluation system, comparing it to a popularity contest and suggesting premium paid evaluations. One stated, "An evaluation should be allowed at any time if the user is willing to pay for it."
- The Challenges of Large Datasets: A 2.7TB Reddit dataset was shared, but users warned it would take significant time and resources to clean. One member estimated, "It's about 15 TB uncompressed... for meh data at best."
- AI Video Generation with ExVideo: Multiple users reported impressive results using ExVideo for generating video content, though it required substantial VRAM (43GB). One member shared a link to a GitHub repository for ExVideo Jupyter.
- Tweet from Daniel Han (@danielhanchen): Uploaded pre-quantized 4bit bitsandbytes versions to http://huggingface.co/unsloth. Downloads are 4x faster & get >1GB less VRAM fragmentation for QLoRA finetuning Also install the dev HF pip inst...
- aaronday3/entirety_of_reddit at main: no description found
- GitHub - beam-cloud/beta9: The open-source serverless GPU container runtime.: The open-source serverless GPU container runtime. Contribute to beam-cloud/beta9 development by creating an account on GitHub.
- GitHub - Alpha-VLLM/Lumina-T2X: Lumina-T2X is a unified framework for Text to Any Modality Generation: Lumina-T2X is a unified framework for Text to Any Modality Generation - Alpha-VLLM/Lumina-T2X
- aaronday3/entirety_of_reddit · Datasets at Hugging Face: no description found
- ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning: no description found
- no title found: no description found
- GitHub - camenduru/ExVideo-jupyter: Contribute to camenduru/ExVideo-jupyter development by creating an account on GitHub.
- Subreddit comments/submissions 2005-06 to 2023-12: no description found
- Tweet from Quanquan Gu (@QuanquanGu): We've open-sourced the code and models for Self-Play Preference Optimization (SPPO)! 🚀🚀🚀 ⭐ code: https://github.com/uclaml/SPPO 🤗models: https://huggingface.co/collections/UCLA-AGI/sppo-6635f...
- FoleyCrafter: no description found
- GitHub - bmaltais/kohya_ss: Contribute to bmaltais/kohya_ss development by creating an account on GitHub.
- unsloth/unsloth-cli.py at main · unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- OpenAI Compatible Server — vLLM: no description found
- Deploying vLLM: a Step-by-Step Guide: Learn how to deploy vLLM to serve open-source LLMs efficiently
- GitHub - MC-E/ReVideo: Contribute to MC-E/ReVideo development by creating an account on GitHub.
- GitHub - camenduru/FoleyCrafter-jupyter: Contribute to camenduru/FoleyCrafter-jupyter development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #random (16 messages🔥):
- Unsloth and Gemma 2 get technical spotlight: A user highlighted Daniel Han's tweet analyzing Google's new Gemma 2 release, detailing significant technical aspects such as pre & post layer norms, softcapping attention logits, and alternating sliding window/global attention. The Gemma team also garnered thanks for early access, though Unsloth has yet to support finetuning for Gemma-2.
- Knowledge Distillation sparks debate: Users discussed the peculiarity and evolution of Knowledge Distillation (KD) in model training. One user humorously noted, "Those 2 perplexity difference tho 😍" and observed the shift from traditional KD to "modern" distillation methods.
- Inference framework recommendations roll in: Multiple users sought and recommended various inference frameworks for Unsloth-trained models, steering discussions toward issues like multi-GPU support and 4-bit loading. Recommendations included vLLM and llama-cpp-python, with some users noting existing bugs and limitations.
- Gemma-2-9B finetuning wait continues: Community members questioned the possibility of finetuning Gemma-2-9B with Unsloth, with responses clarifying that it isn't supported yet but is in progress.
- Unsloth vs large models: Comparisons were made between relatively smaller models like the 9B Gemma-2 and much larger models, with some users expressing surprise at the advancements in smaller model performance.
- Tweet from Daniel Han (@danielhanchen): Just analyzed Google's new Gemma 2 release! The base and instruct for 9B & 27B is here! 1. Pre & Post Layernorms = x2 more LNs like Grok 2. Uses Grok softcapping! Attn logits truncated to (-30, 3...
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp: Python bindings for llama.cpp. Contribute to abetlen/llama-cpp-python development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #help (113 messages🔥🔥):
- Discussion on Training LM Head for Swedish Language Model: Members debated the value of training the lm_head for Swedish, with one noting it is essential if the model does not know Swedish initially. Another highlighted the process can be done using one's machine to save costs, and results will be tested after the model reaches 8 epochs.
- Inference Configuration Clarification: A member queried about the difference between
FastLanguageModel.for_inference(model)andmodel.eval(). Another member explained that the former loads a model while the latter switches it to evaluation mode, pointing out sample Unsloth notebooks use the former method.
- Fine-Tuning and VRAM Management for Lang Models: Members discussed VRAM limitations when fine-tuning with different batch sizes on GPUs like RTX 4090. It was shared that using power-of-two batch sizes avoids errors, despite some personal experiences to the contrary.
- Support for LoRA on Quantized Models: Members explored the feasibility of using Unsloth adapters on AWQ models, referencing a GitHub pull request that supports LoRA on quantized models. Some were unsure since documentation and real examples are scarce.
- Continued Pretraining Issues and Solutions: A member faced errors when inferring from a model after continued pretraining, using a 16GB T4. Recommendations included checking a relevant GitHub issue and ensuring no conflicts with the new PyTorch version.
- [Bug]: RuntimeError with tensor_parallel_size > 1 in Process Bootstrapping Phase · Issue #5637 · vllm-project/vllm: Your current environment The output of `python collect_env.py` Collecting environment information... PyTorch version: 2.3.0+cu121 Is debug build: False CUDA used to build PyTorch: 12.1 ROCM used to...
- Cache only has 0 layers, attempted to access layer with index 0 · Issue #702 · unslothai/unsloth: I'm encountering a KeyError when trying to train Phi-3 using the unsloth library. The error occurs during the generation step with model.generate. Below are the details of the code and the error t...
- [distributed][misc] use fork by default for mp by youkaichao · Pull Request #5669 · vllm-project/vllm: fixes #5637 fork is not safe after we create cuda context. we should already avoid initializing cuda context before we create workers, so it should be fine to use fork, which can remove the necessi...
- [Core] Support LoRA on quantized models by jeejeelee · Pull Request #4012 · vllm-project/vllm: Building upon the excellent work done in #2828 Since there hasn't been much progress on #2828,so I'd like to continue and complete this feature. Compared to #2828, the main improvement is the...
Unsloth AI (Daniel Han) ▷ #community-collaboration (25 messages🔥):
- Seeking compute power for Toki Pona LLM: A member is seeking access to compute resources for training an LLM on Toki Pona, a highly context-dependent language. They reported that their model, even after just one epoch, is preferred by strong Toki Pona speakers over ChatGPT-4o.
- Oracle Cloud credits offer: Another member offered a few hundred expiring Oracle Cloud credits and asked for a Jupyter notebook to run, expressing interest in fine-tuning the Toki Pona model using Oracle’s Data Science platform.
- Discussing Oracle platform limitations: There was a discussion about the limitations of Oracle's free trial, particularly the inability to spin up regular GPU instances, necessitating use of the Data Science platform's notebook workflows for model training and deployment.
- Potential solutions and suggestions: Members suggested adapting Unsloth colabs notebooks for fine-tuning on Oracle, specifically the Korean fine-tuning setup. One member offered to give the Oracle platform a try if another managed to run the notebook first.
- Kubeflow Comparison: One member compared Oracle's notebook session feature to typical Jupyter setups, mentioning it's similar to SageMaker or Kubeflow's approach to training and deploying machine learning workflows.
- Kubeflow: Kubeflow makes deployment of ML Workflows on Kubernetes straightforward and automated
- Model Deployments: no description found
HuggingFace ▷ #announcements (1 messages):
- Gemma 2 Lands in Transformers: Google has released Gemma 2 models, including 9B & 27B, which are now available in the Transformers library. These models are designed to excel in the LYMSYS Chat arena, beating contenders like Llama3 70B and Qwen 72B.
- Superior, Efficient, and Compact: Highlights include 2.5x smaller size compared to Llama3 and being trained on a lesser amount of tokens. The 27B model was trained on 13T tokens while the 9B model on 8T tokens.
- Innovative Architecture Enhancements: Gemma 2 employs knowledge distillation, interleaving local and global attention layers, soft attention capping, and WARP model merging techniques. These changes aim at improving inference stability, reducing memory usage, and fixing gradient explosions during training.
- Seamless Integration and Accessibility: HuggingFace announced that Gemma 2 models are now integrated into the Transformers library, and available on the Hub. Additional integrations are provided for Google Cloud and Inference Endpoints to ensure smooth usage.
- Read All About It: For a deep dive into the architectural and technical advancements of Gemma 2, a comprehensive blog post is available. Users are encouraged to check out the model checkpoints, and the latest Hugging Face Transformers release.
- Welcome Gemma 2 - Google’s new open LLM: no description found
- Gemma 2 Release - a google Collection: no description found
HuggingFace ▷ #general (482 messages🔥🔥🔥):
- Exploring FSS in Elixir: A user provided an overview and link to FSS for file system abstraction in Elixir. They discussed its use cases and noted that it supports HTTP but doesn't seem extensible.
- Gemma 2 GPT-4 Parameters Chat: Users discussed items in Google's announcement concerning Gemma 2. Some conversation noted trying different AI models like Gemma and their performance, with humor around the frustrations and odd behavior in models.
- New Image Retrieval System: User announced creating the first image-based retrieval system using open-source tools from HF. They shared their excitement and a Colab implementation link, along with a Space for collaboration.
- Visual Learning Models Discussed: Recommendations and experiences shared for visual learning models, suggesting checking out CogVLM2 and Phi-3-Vision-128K-Instruct.
- Queries on HuggingFace Tools: Users asked questions related to specific HuggingFace tools and implementations, including fine-tuning guides and access tokens for new models like Gemma 2. A link was shared to the HuggingFace docs for training.
- fsspec: Filesystem interfaces for Python — fsspec 2024.6.0.post1+g8be9763.d20240613 documentation: no description found
- ShaderMatch - a Hugging Face Space by Vipitis: no description found
- THUDM/cogvlm2-llama3-chat-19B-int4 · Hugging Face: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- coqui/XTTS-v2 · Hugging Face: no description found
- microsoft/Phi-3-vision-128k-instruct · Hugging Face: no description found
- Fine-tune a pretrained model: no description found
- Brain Dog Brian Dog GIF - Brain dog Brian dog Cooked - Discover & Share GIFs: Click to view the GIF
- Serial Experiments Lain - Wikipedia: no description found
- Image Retriever - a Hugging Face Space by not-lain: no description found
- This Dog Detects Twitter Twitter User GIF - This dog detects twitter Twitter user Dog - Discover & Share GIFs: Click to view the GIF
- Monkey Cool GIF - Monkey Cool - Discover & Share GIFs: Click to view the GIF
- Doubt GIF - Doubt - Discover & Share GIFs: Click to view the GIF
- Lightning Struck GIF - Lightning Struck By - Discover & Share GIFs: Click to view the GIF
- Dbz Abridged GIF - Dbz Abridged Vegeta - Discover & Share GIFs: Click to view the GIF
- Techstars Startup Weekend Tokyo · Luma: Techstars Startup Weekend Tokyo is an exciting and immersive foray into the world of startups. Over an action-packed three days, you’ll meet the very best…
- LLaMA-Factory/examples at main · hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- not-lain/image-retriever · i cant use git for the life of me. might need more testing: no description found
- Introducing PaliGemma, Gemma 2, and an Upgraded Responsible AI Toolkit: no description found
- GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- zero-gpu-explorers/README · ZeroGPU Duration Quota Question: no description found
- coai/plantuml_generation · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- GPT-4 has more than a trillion parameters - Report: GPT-4 is reportedly six times larger than GPT-3, according to a media report, and Elon Musk's exit from OpenAI has cleared the way for Microsoft.
- Hub API Endpoints: no description found
- Google Colab: no description found
- FSS — fss v0.1.1: no description found
- Reddit - Dive into anything: no description found
- GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that execute those TensorRT engines.: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficie...
HuggingFace ▷ #today-im-learning (6 messages):
- Learn 10 Machine Learning Algorithms in 1 Minute: A member shared a YouTube video titled "10 Machine Learning Algorithms in 1 Minute", featuring a quick overview of top machine learning algorithms.
- Interest in Reinforcement Learning Project: A member expressed interest in learning Reinforcement Learning in a short duration. They proposed starting a small project to better understand the concepts, admitting they currently have only a vague idea of how it works.
- Inquiring About Huggingface Course Updates: A member is seeking information about the regular updates of the Huggingface courses compared to the "Natural Language Processing with Transformers (revised edition May 2022)" book. They also inquired about the up-to-dateness of the Diffusion and Community computer vision courses on the Huggingface website.
- Improving Biometric Gait Recognition: A member shared their progress on biometric gait recognition using basic 2D video inputs, achieving a 70% testing accuracy on identifying one out of 23 people. They plan to enhance the model by acquiring more datasets, combining several frames for RNN usage, and employing triplet loss for generating embeddings.
Link mentioned: 10 Machine Learning Algorithms in 1 Minute: Hey everyone! I just made a quick video covering the top 10 machine learning algorithms in just 1 minute! Here's a brief intro to each ( again ) :Linear Regr...
HuggingFace ▷ #cool-finds (5 messages):
- Stimulating Blog on Diffusion Models: A member highly recommended a blog post by Lilian Weng explaining diffusion models, including links to updates on various generative modeling techniques like GAN, VAE, Flow-based models, and more recent advancements like progressive distillation and consistency models.
- Hermes-2-Pro-Llama-3-70B Released: The upgraded Hermes 2 Pro - Llama-3 70B now includes function calling capabilities and JSON Mode. It achieved a 90% score on function calling evaluations and 84% on structured JSON Output.
- Synthesize Multi-Table Data with Challenges: An article discussed the complexities of synthesizing multi-table tabular data, including failures and difficulties with libraries like SDV, Gretel, and Mostly.ai, especially when dealing with columns containing dates.
- Top Machine Learning Algorithms in a Minute: A brief YouTube video titled "10 Machine Learning Algorithms in 1 Minute" promised to cover essential machine learning algorithms quickly. The video offers a fast-paced overview of key concepts.
- AI Engineer World's Fair 2024 Highlights: The AI Engineer World’s Fair 2024 YouTube video covered keynotes and the CodeGen Track, with notable attendance from personalities like Vik. The event showcased significant advancements and presentations in AI engineering.
- Synthesizing Multi-Table Databases: Model Evaluation & Vendor Comparison - Machine Learning Techniques: Synthesizing multi-table tabular data presents its own challenges, compared to single-table. When the database contains date columns such as transaction or admission date, a frequent occurrence in rea...
- What are Diffusion Models?: [Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated on 2022-08-27: Added classifier-free...
- 10 Machine Learning Algorithms in 1 Minute: Hey everyone! I just made a quick video covering the top 10 machine learning algorithms in just 1 minute! Here's a brief intro to each ( again ) :Linear Regr...
- Publications/Budget Speech Essay Final.pdf at main · alidenewade/Publications: Contribute to alidenewade/Publications development by creating an account on GitHub.
- AI Engineer World’s Fair 2024 — Keynotes & CodeGen Track: https://twitter.com/aidotengineer
- NousResearch/Hermes-2-Pro-Llama-3-70B · Hugging Face: no description found
HuggingFace ▷ #i-made-this (8 messages🔥):
- Flight Radar takes off into multilingual real-time tracking: A member shares a multilingual real-time flight tracking web application built with Flask and JavaScript. The app utilizes the OpenSky Network API to let users view nearby flights, adjust search radius, and download flight data as a JPG. Find more details on GitHub.
- PixArt-900M Space launched: A new 900M variant of PixArt is now available for experimentation with an in-progress checkpoint at various batch sizes. This collaborative effort by terminus research group and fal.ai aims to create awesome new models. Check it out on Hugging Face Spaces.
- Image retrieval system with Pokémon dataset goes live: A fully open-source image retrieval system using a Pokémon dataset has been unveiled. The member promises a blog post about this tomorrow but you can try it now on Hugging Face Spaces.
- Top 10 Machine Learning Algorithms in a minute: A quick YouTube video covering the top 10 machine learning algorithms in just one minute has been shared. Watch it here.
- AI-driven musical storytelling redefines genres: An innovative album blending AI development and music has been introduced, offering a unique narrative experience designed for both machines and humans. The album is available on Bandcamp and SoundCloud, with a promo available on YouTube.
- Image Retriever - a Hugging Face Space by not-lain: no description found
- 10 Machine Learning Algorithms in 1 Minute: Hey everyone! I just made a quick video covering the top 10 machine learning algorithms in just 1 minute! Here's a brief intro to each ( again ) :Linear Regr...
- GitHub - U-C4N/Flight-Radar: A multilingual real-time flight tracking web application using the OpenSky Network API. Built with Flask and JavaScript, it allows users to view nearby flights, adjust search radius, and supports six languages. Features include geolocation, and the ability to download flight data as a JPG: A multilingual real-time flight tracking web application using the OpenSky Network API. Built with Flask and JavaScript, it allows users to view nearby flights, adjust search radius, and supports s...
- PixArt 900M 1024px Base Model - a Hugging Face Space by ptx0: no description found
- The Prompt, by Vonpsyche: 12 track album
- THE PROMPT: Title: The Prompt Music by Vonpsyche Illustrations by Iron Goose. Plot: The album takes listeners on a journey through a dystopian world where a brilliant AI developer strives to create a people-serv
- The Prompt, by Vonpsyche: Vonpsyche - The Prompt: Immerse yourself in a narrative that blurs the lines between reality and fiction. In an uncanny reflection of recent events, 'The Pro...
HuggingFace ▷ #reading-group (5 messages):
- New Event Coming Soon: A member announced, "I'll make an event in a bit!" to the excitement of the group, which was met with reactions showing approval and anticipation.
- Research Paper on Reasoning with LLMs: A member shared an interesting research paper on reasoning with LLMs. Another member expressed curiosity about how it performs compared to RADIT, noting both might require finetuning but appreciating the inclusion of GNN methods.
Link mentioned: Join the Hugging Face Discord Server!: We're working to democratize good machine learning 🤗Verify to link your Hub and Discord accounts! | 82343 members
HuggingFace ▷ #computer-vision (13 messages🔥):
- Seek YOLO for Web Automation Tasks: A member inquired about using YOLO to identify and return coordinates of similar elements on a webpage using a reference image and a full screenshot. They are looking for an efficient method or an existing solution for their automation needs.
- Exploring Efficient SAM Deployment: A user sought advice on deploying the Segment Anything Model (SAM) efficiently and mentioned various efficient versions like MobileSAM and FastSAM. They are looking for best practices and equivalents to techniques like continuous batching and model quantization, often used in language models.
- Mask Former Fine-Tuning Challenges: Another member reported difficulties in fine-tuning the Mask Former model for image segmentation and questioned if the model, particularly facebook/maskformer-swin-large-ads, is catered more to semantic segmentation rather than instance segmentation.
- Designing Convolutional Neural Networks: A user expressed confusion over determining the appropriate number of convolutional layers, padding, kernel sizes, strides, and pooling layers for specific projects. They find themselves randomly selecting parameters, which they believe is not ideal.
HuggingFace ▷ #NLP (10 messages🔥):
- Leaderboard for Chatbot Arena Dataset Needs LLM Scripting: A member has a chatbot arena-like dataset translated into another language and seeks to establish a leaderboard. They are struggling to find a script that would fill the "winner" field using an LLM instead of human votes.
- Need for Chatbot Clarification: When another member offered help, they clarified they were referring to a chatbot arena dataset. This caused some initial confusion, with a request misunderstood as needing a chatbot instead.
- Human Preference in Arena Ratings: Vipitis mentioned that the arena usually uses human preferences to calculate an Elo rating, suggesting a need for clearer guidance or alternative methods.
- Urgent GEC Prediction Issue: Shiv_7 expressed frustration over a grammar error correction (GEC) project where their predictions list is out of shape and urgently requested advice to resolve the issue.
HuggingFace ▷ #gradio-announcements (1 messages):
- Older Gradio Versions' Share Links Deactivate Soon: Starting next Wednesday, share links from Gradio versions 3.13 and below will no longer work. Upgrade your Gradio installation to keep your projects running smoothly by using the command
pip install --upgrade gradio.
LM Studio ▷ #💬-general (105 messages🔥🔥):
<ul>
<li><strong>Gemma 2 Support Now Available:</strong> Gemma 2 support has been added in LM Studio version 0.2.26. This update includes post-norm and other features, but users are reporting some integration bugs. <a href="https://github.com/ggerganov/llama.cpp/pull/8156">[GitHub PR]</a>.</li>
<li><strong>Ongoing Issues with Updates and Integrations:</strong> Users are experiencing difficulties with Gemma 2 integration and auto-updates in LM Studio. Manual downloads and reinstallation of configs are suggested fixes, but some architectures like ROCm are still pending support.</li>
<li><strong>Locally Hosted Models Debate:</strong> Advantages of hosting locally include privacy, offline access, and the opportunity for personal experimentation. Some express skepticism about its future relevance given the rise of cheap cloud-based solutions.</li>
<li><strong>LLama 3 Model Controversy:</strong> Opinions differ on LLama 3's performance, with some claiming it is a disappointing model while others find it excels in creative tasks. Performance issues seem version-specific, with discussions around stop sequence bugs in recent updates.</li>
<li><strong>Concerns Over Gemma 9B Performance:</strong> Some users report that Gemma 9B is underperforming compared to similar models like Phi-3, specifically on LM Studio. Ongoing development aims to address these issues, with functional improvements expected soon.</li>
</ul>
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- Add attention and final logit soft-capping to Gemma2 by abetlen · Pull Request #8197 · ggerganov/llama.cpp: This PR adds the missing attention layer and final logit soft-capping. Implementation referenced from huggingface transformers. NOTE: attention soft-capping is not compatible with flash attention s...
- Add support for Gemma2ForCausalLM by pculliton · Pull Request #8156 · ggerganov/llama.cpp: Adds inference support for the Gemma 2 family of models. Includes support for: Gemma 2 27B Gemma 2 9B Updates Gemma architecture to include post-norm among other features. I have read the contr...
LM Studio ▷ #🤖-models-discussion-chat (222 messages🔥🔥):
- **Gemma-2 sparks discontent over context limit**: The announcement of **Gemma-2** with a 4k context limit was met with disappointment. One member described it as *"like building an EV with the 80mi range"*, underscoring the expectation for higher capacities in current models.
- **Confusion on Gemma-2 context limit**: While initial info suggested **Gemma-2** had a 4k context limit, others corrected it to 8k, showing discrepancies in information. One member pointed out *"Gemini is wrong about Google's product!"*.
- **Support sought for storytelling model**: A model designed for storytelling and full context use during training, [ZeusLabs/L3-Aethora-15B-V2](https://huggingface.co/ZeusLabs/L3-Aethora-15B-V2), was recommended for support. It's suggested to append “GGUF” when searching in the model explorer.
- **Deepseek Coder V2 Lite and Gemma 2 status**: **Gemma 2 9b** and **Deepseek coder V2 Lite** showed as not supported in LM Studio yet, prompting queries about their addition. A member confirmed **Gemma 2** as unsupported initially, but noted a [GitHub pull request](https://github.com/ggerganov/llama.cpp/pull/8156) that has since been merged to add support.
- **Discussion on best models in 7b~9b category**: The effectiveness of various models like **Qwen 2 7b**, **Deepseek Coder V2 Lite**, and **Llama 3** was debated. One member concluded *"Deepseek is worth it"* after performance tests, but also pointed to **Qwen 2 7b** issues without Flash Attention enabled.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- ZeusLabs/L3-Aethora-15B-V2 · Hugging Face: no description found
- Tweet from AI at Meta (@AIatMeta): Today we’re announcing Meta LLM Compiler, a family of models built on Meta Code Llama with additional code optimization and compiler capabilities. These models can emulate the compiler, predict optima...
- microsoft/Florence-2-large · Hugging Face: no description found
- GGUF quantizations overview: GGUF quantizations overview. GitHub Gist: instantly share code, notes, and snippets.
- Add support for Gemma2ForCausalLM by pculliton · Pull Request #8156 · ggerganov/llama.cpp: Adds inference support for the Gemma 2 family of models. Includes support for: Gemma 2 27B Gemma 2 9B Updates Gemma architecture to include post-norm among other features. I have read the contr...
- Cartoons Tom And Jerry GIF - Cartoons Tom And Jerry Ok - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #announcements (1 messages):
- LM Studio 0.2.26 launches with Gemma 2 support: The new LM Studio 0.2.26 now supports Google's Gemma 2 models, specifically the 9B and 27B versions. Check them out on the lmstudio-community page.
- Windows on ARM64 debut: LM Studio is now available for Windows on ARM (Snapdragon X Elite PCs) thanks to a collaboration with Qualcomm. Download the ARM64 version from lmstudio.ai.
- Sign up for LM Studio 0.3.0 private beta: A significant update to LM Studio is nearly complete, and testers are invited to help by signing up here.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- LM Studio 0.3.0 - Private Beta Sign Up: Thanks for your interest in helping out test our upcoming release. LM Studio 0.3.0 is gem-packed with new features and we'd love your help to shake out the bugs before sending it out to the worl...
LM Studio ▷ #🧠-feedback (13 messages🔥):
- Llama.cpp error with unsupported model architecture: Members experienced issues with the error message 'error loading model architecture: unknown model architecture: gemma2'. One member noted that this error is due to the architecture not being supported by Llama.cpp.
- Snapdragon X Elite praised for performance: A member thanked the LM Studio team for quickly supporting Snapdragon X Elite systems, noting these devices perform high with low noise and excellent battery life. In benchmarks, the Snapdragon X Elite outperformed an i7 12700K on CPU/memory tasks but fell short compared to a 4090 GPU.
- Unsupported models in LM Studio: Members discussed attempting to run the "gemma 2 9 b" model and realized it is not yet supported in LM Studio. They were advised to use older models or explore alternatives like transformer or MLX with quantized gguf files.
- IPv6 and syntax errors on Ubuntu: One user resolved a model loading issue by disabling IPv6 on Ubuntu 22.04 but continues to encounter a "config-presset file syntax error" on launch, unsure of its impact.
LM Studio ▷ #⚙-configs-discussion (1 messages):
cos2722: hello. can someone help me on making GORILL open funcion v2 work? i dont have any config
LM Studio ▷ #🎛-hardware-discussion (28 messages🔥):
- Two Video Cards Supported by LM Studio: A member asked, "Is there value in using 2 video cards? Will lmstudio take advantage of them both?" Another confirmed, "Yes. And Yes."
- Small Code Gen Models on 4GB RAM: The feasibility of running code generation LLMs on 4GB RAM was discussed. One suggestion was Qwen 2 0.5B, but its coding accuracy is described as "mediocre at best;" whereas Claude 3.5 Sonnet is recommended for better performance.
- Multi-Agent Framework with Low-End Models: A member plans to use a 0.5B model as a user proxy in a multi-agent framework, believing it can manage that role easily. Another member expressed skepticism about the efficacy of such low-end models for coding tasks.
- Lamini Memory Tuning Could Enhance LLM Accuracy: The potential of Lamini Memory Tuning was highlighted. This method “improves factual accuracy and reduces hallucinations” significantly and could make 0.5B models more effective on lower-end machines.
- Mixed Reviews on Intel GPU Performance: There were questions about Intel GPU effectiveness. One member noted "CPU is faster" while another added that "Intel GPU support is in the works but currently below CPU on supported backends."
Link mentioned: Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations | Lamini - Enterprise LLM Platform: no description found
LM Studio ▷ #🧪-beta-releases-chat (33 messages🔥):
- "Gemma 2 is hot garbage" sparks skepticism: The release of LM Studio 0.2.26 with Gemma 2 support received mixed reactions, with one user criticizing, "gemma is hot garbage... i seriously doubt they made improvements." Another user indicated issues with follow-up questions, sparking technical troubleshooting discussions.
- Solution for "Unexpected end of JSON input" error: A user encountering the JSON input error received advice to rename the problematic file and restart the application. They were also directed to specific Discord channels for further assistance.
- Updating llama.cpp commit: A user suggested updating to the latest llama.cpp commit for better performance. However, it was clarified that users need to wait for an official release incorporating the update.
- Gemma 2 loading issues and solutions: Users discussed issues and workarounds for Gemma 2, including reloading the model. One user highlighted the updated model settings and the need for LM Studio 0.2.26 for optimal performance.
- Backtick formatting problem in markdown: An issue with code block formatting in generated text was reported, where backticks were improperly placed, affecting the markdown rendering. The issue seemed transient and specific to certain code generations.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- lmstudio-community/gemma-2-9b-it-GGUF · Hugging Face: no description found
- Futurama Angry GIF - Futurama Angry - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #amd-rocm-tech-preview (4 messages):
- Support for Gemma 2 models questioned: A member inquired if there has been any update on the ROCM preview to support Gemma 2 models, noting that the normal LM studio 0.2.6 release does not detect AMD GPUs like the ROCM preview version.
- ROCm "extension pack" for Windows released: A member announced the availability of the 0.2.26 ROCm "extension pack" for Windows, providing advanced installation instructions due to the current in-between development state. For details, refer to the Extension Pack Instructions on GitHub.
Link mentioned: configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
LM Studio ▷ #model-announcements (1 messages):
- Gemma 2 Launches with a Bang: Gemma 2 is now available for download with version 0.2.26 on Windows and Mac; a Linux version is coming soon. The 9B model is performing excellently, while the 27B model is under scrutiny for quirks, with feedback being requested.
- Grab Gemma 2 Models Easily: The new models can be downloaded from the LM Studio Community on Hugging Face: the 9B model and the potentially quirky 27B model have been released and are ready for testing.
Link mentioned: 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
LM Studio ▷ #🛠-dev-chat (1 messages):
mystic9t: it is surprisingly difficult to get them in a single no-code enviornment
OpenAI ▷ #ai-discussions (330 messages🔥🔥):
- Testing AI boundaries might get you banned: Members expressed concerns about testing the limits of AI workarounds, with a reminder that violating OpenAI's usage policies could result in account suspension or termination. One shared a link to the usage policies, emphasizing the importance of respecting safeguards.
- Open-source vs. proprietary AI debate heats up: Members debated the merits of open-sourcing advanced AI models, weighing the risks of potential misuse against the benefits of widespread access. One user argued that the economic displacement caused by restricting AI to the rich could be detrimental, while another emphasized the necessity of surveillance for public safety.
- Exploring RLHF training experiences: There was confusion and curiosity about Reinforcement Learning from Human Feedback (RLHF), with users discussing its application in OpenAI's models. Some mentioned seeing RLHF prompts very rarely, while others pondered how OpenAI manages public RLHF training.
- Mass surveillance sparks intense discussion: A deep conversation unfolded about the involvement of companies like OpenAI in surveillance, referencing a blog post on disrupting deceptive uses of AI. Users debated the ethics and necessity of such surveillance, with opinions diverging on the trade-offs between privacy and security.
- Chatbot and API integrations in development: Members shared experiences and projects related to integrating AI with other tools and services. One user detailed their work on a SearxNG integration for enhanced search capabilities within Discord, while another highlighted various AI models and APIs they're experimenting with for better functionality.
- Why Elon Musk says we're living in a simulation: You may like playing The Sims, but Elon Musk says you are the Sim.Help us make more ambitious videos by joining the Vox Video Lab. It gets you exclusive perk...
- GitHub - PierrunoYT/claude-3-artifacts: Contribute to PierrunoYT/claude-3-artifacts development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- Plugins deprecated, GPTs take over: A user asked about using multiple plugin functions in a single chat, like a video summarizer and diagram maker. Another member clarified that "Plugins are deprecated now and have been replaced by GPTs," but recommended using the
@mentionfeature for flexibility to call multiple GPTs in a chat.
- API access question for workgroups: A user inquired about obtaining an API for workgroup use.
- Struggles with custom GPT for medical questions: A medical student shared issues with creating high-difficulty practice questions using a custom GPT. Despite uploading detailed guidelines and lecture information, the GPT-produced questions were subpar and sources were improperly cited.
- Lost GPTs, recovery steps: Users reported losing access to their custom GPTs and sought help. Another member shared a solution, providing a URL chatgpt.com/gpts/mine that redirected users, helping them restore access to their GPTs in the left pane.
OpenAI ▷ #prompt-engineering (25 messages🔥):
- Unicode semiotics puzzle: A member discussed using Unicode semiotics for specific tasks, noting they "cost more tokens, not less" but consume fewer characters. Despite finding it useful for in-context learning, they could not reference any explanatory paper.
- API struggles with unshuffle games: Another member shared difficulties with the API solving unshuffle games like "edtPto lumAli" to result in "Potted Allium." There's a shared approach suggesting using Python alongside the API to improve results.
- Prompt engineering advice: A user asked for prompt engineering recommendations for transitioning from coding to PM/Business analysis tasks. Simple, clear, and concise prompts in plain language were advised, and the concept of "logit bias" was briefly mentioned for deeper prompt control.
- Quasi-determinism confusion: The concept of a "quasi-deterministic" nature of stochastic neural networks was discussed to clarify how these models behave. This explanation received a mixed reaction, hinting at the complex understanding required.
OpenAI ▷ #api-discussions (25 messages🔥):
- Unicode Semiotics Costs More Tokens: Members discussed the use of Unicode semiotics for token cost savings or lower latency. It was clarified that Unicode semiotics consume fewer characters but cost more tokens, and there are no papers explaining this yet.
- Struggles with API Unshuffle Games: A member shared difficulties in getting the API to solve unshuffle games like "edtPto lumAli" into "Potted Allium." Another suggested using Python to generate all possible reorganizations of the words and then letting the API pick the correct ones, though hallucinations like "dotted" can occur.
- Advice on Engineering Prompts: Newbie inquiries on prompt engineering and negative weighting led to suggestions for using simple and plain language. The term "logit bias" was mentioned as a potential advanced technique.
- Discussion on Deterministic Nature of Neural Networks: A brief exchange clarified that the reverse function in neural networks tends to be stochastic and quasi-deterministic rather than fully deterministic.
- Unsolved Semiotics Paper Inquiry: One user asked if there was a paper on Unicode semiotics, but it was confirmed that no such documentation currently exists.
Stability.ai (Stable Diffusion) ▷ #general-chat (297 messages🔥🔥):
- Creating datasets with custom styles sparks interest and concerns: A user shared they are building a large dataset of generated images in their custom style. Concerns about generating NSFW content and getting banned were discussed, highlighting the nuances of monitoring datasets and image generation.
- Automatic1111 troubles lead users to explore alternatives: Users reported frustrations with Automatic1111 breaking or crashing, leading some to switch to alternatives like Forge, though it has memory management issues. A YouTube guide ([Stable Diffusion Webui Forge Easy Installation](https://www.youtube.com/watch?v=FKzvHFtc8N0&t=64s)) was shared for installation help.
- Cascade channel debate continues: Many users expressed their desire to unarchive the Cascade channel, citing valuable discussions and knowledge contained within. Frustration was evident, with some users suspecting a broader move to push engagement with SD3.
- Model training nuances and tools discussed: Users discussed specifics about LoRa training, samplers like 3m sde exponential, and VRAM constraints, sharing tips and experiences. The utilization and limitations of different nodes and UI tools like ComfyUI, Forge, and Stable Swarm were highlighted.
- Discord management and community dissatisfaction: Numerous users expressed dissatisfaction with the removal of channels and archives, suspecting it represents a shift in focus away from the community-driven aspects. There were calls for better communication and preservation of community-created resources.
- YouTube humor lightens the tone: The discussion saw moments of humor, including a playful share of the YouTube video [Was Not Was - Walk The Dinosaur](https://youtu.be/vgiDcJi534Y) and jokes about colorful profile pictures and nostalgic emojis like <:kek:692062611659030548>.
- Tweet from Jellybox: Run AI models locally. Private and entirely offline! Jellybox unlocks the power of local AI tools for everyone in a simple and easy to use package. From chatting, to agents, to image generation, Jelly...
- Stable Diffusion Webui Forge Easy Installation: Stable Diffusion Webui Forge Easy Installation. No need to download and install python or anything else as it's all included in the installed, just down load...
- Was Not Was - Walk The Dinosaur: And Lo the Dinosaur was walked and thus began the end of their kind.
- GitHub - lkwq007/stablediffusion-infinity: Outpainting with Stable Diffusion on an infinite canvas: Outpainting with Stable Diffusion on an infinite canvas - lkwq007/stablediffusion-infinity
Latent Space ▷ #ai-general-chat (50 messages🔥):
- **Scarlet AI Preview Launched**: A member introduced a preview of **Scarlet AI** intended for planning complex projects and delegating tasks. Test it at [https://app.scarletai.co/](https://app.scarletai.co/), though it's not yet production-ready.
- **Character AI Voice Features**: **Character.AI** launched **Character Calls** allowing users to interact with AI characters via phone calls for various use cases like practicing interviews and RPGs. Try it on their mobile app at [https://share.character.ai/Wv9R/6tdujbbr](https://share.character.ai/Wv9R/6tdujbbr).
- **Meta's LLM Compiler for Code Optimization**: Meta introduced the **Large Language Model Compiler** designed for compiler optimization tasks, enhancing understanding of intermediate representations and optimization techniques. More details available in their [research publication](https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/).
- **LangGraph Cloud for Reliable Agents**: **LangChainAI** launched **LangGraph Cloud** for fault-tolerant, scalable agent workflows with integrated tracing and monitoring. Join the waitlist and read more in their [blog post](http://bit.ly/langgraph-cloud-blog-1).
- **Adept Strategy Shift & Co-Founders Joining Amazon**: **Adept** announced updates to their strategy and changes in leadership, with several co-founders joining Amazon's AGI team. Get more details from the [GeekWire article](https://www.geekwire.com/2024/amazon-hires-founders-from-well-funded-enterprise-ai-startup-adept-to-boost-tech-giants-agi-team/).
- Amazon hires founders from well-funded enterprise AI startup Adept to boost tech giant’s ‘AGI’ team: (GeekWire File Photo / Kevin Lisota) Amazon is amping up its AI efforts by hiring executives from Adept, a San Francisco-based startup building "agents"
- Tweet from Adept (@AdeptAILabs): Today, we’re announcing some updates to our strategy and some changes to our leadership and team. More details are in our blog: https://www.adept.ai/blog/adept-update
- Tweet from Noam Shazeer (@NoamShazeer): Incredibly proud of the team for our official launch of Character Calls! Quoting Character.AI (@character_ai) AI Chat just got real. Introducing Character Calls, the latest addition to our suite o...
- Tweet from Noam Shazeer (@NoamShazeer): Incredibly proud of the team for our official launch of Character Calls! Quoting Character.AI (@character_ai) AI Chat just got real. Introducing Character Calls, the latest addition to our suite o...
- Tweet from Tiago Freitas (@tiagoefreitas): Just launched a preview of the new http://scarletai.co Everyone's a manager! Scarlet grants agency to individuals and founders alike. Eventually powering the first unicorn solopreneurs! We enab...
- Tweet from LlamaIndex 🦙 (@llama_index): ✨ Just announced on stage at @aiDotEngineer World's Fair! ✨ A brand new framework for getting multi-agent AI systems into production! Currently an alpha release, llama-agents provides: ⭐️ Distri...
- Tweet from David K 🎹 (@DavidKPiano): I love how AI startups are gradually (re)discovering state machines and the actor model for agent behavior & systems Still unsure why you would need specialized infra for it though; it's all just...
- Tweet from LangChain (@LangChainAI): 🚀 Introducing LangGraph Cloud 🚀 LangGraph helps you build reliable agents that actually work. Today, we've launched LangGraph Cloud, our new infrastructure to run fault-tolerant LangGraph agent...
- Tweet from LangChain (@LangChainAI): 🚀 Introducing LangGraph Cloud 🚀 LangGraph helps you build reliable agents that actually work. Today, we've launched LangGraph Cloud, our new infrastructure to run fault-tolerant LangGraph agent...
- no title found: no description found
Latent Space ▷ #ai-announcements (2 messages):
- OpenAI Demo Announcement: A message alerted everyone to an OpenAI demo with urgency, directing them to a specific OpenAI Demo channel. The message lacked additional context but indicated an immediate event.
- OSS GPT Store Rundown Reminder: Members were reminded about the OSS GPT Store rundown scheduled for an hour later. The reminder included a prompt to join a specific channel and pick up a role for future notifications.
Latent Space ▷ #llm-paper-club-west (150 messages🔥🔥):
- "GPT-4o to dominate desktops": Discussions revealed excitement around using GPT-4o on desktop for coding assistance, suggesting it "help[s] you code, etc.” Members expressed interest in trying Open-Interpreter for this purpose and its integration with local models.
- Linux vs. Mac for streaming issues: Members faced technical difficulties while trying to stream using Linux, noting issues with permissions and screen sharing. One joked about the need for a Mac with "such riches" highlighting the struggle ("Maybe not worth the hassle for covering stuff. ya desktop app is p cool").
- Live streaming woes and fixes: The group experienced streaming issues, predominantly around poor video and audio feeds. The problem was somewhat alleviated by switching to a wired connection for stability.
- Cursor power users and productivity tips: One member asked for “good cursor power user content” to boost productivity. Another recommended “indydevdan on YT” for useful workflows and various configuration tools to improve coding efficiency with Vim.
- Vesktop as a solution: To address Discord performance issues on Linux, members suggested using Vesktop, a custom Discord app aimed at enhancing performance and support for Linux users.
- AI Engineer World’s Fair 2024 - Keynotes & Multimodality track: https://twitter.com/aidotengineer
- AI Engineer World’s Fair 2024 - Keynotes & Multimodality track: https://twitter.com/aidotengineer
- GitHub - Vencord/Vesktop: Vesktop is a custom Discord App aiming to give you better performance and improve linux support: Vesktop is a custom Discord App aiming to give you better performance and improve linux support - Vencord/Vesktop
- dotfiles/nvim/.config/nvim/lua/commands/llm.lua at master · dimfeld/dotfiles: Contribute to dimfeld/dotfiles development by creating an account on GitHub.
Latent Space ▷ #ai-in-action-club (34 messages🔥):
- Public GPTs prompt leak possibility: A member highlighted that while specific GPT definitions might not be easy to access, they are not truly private and have been extracted by others on GitHub. Another member added, "best to assume someone could get these, so no secrets in these."
- Insightful research papers shared: One member pointed out the value of certain research papers, sharing a link to arxiv.org/abs/2309.02427 discussing Cognitive Architectures for Language Agents (CoALA) and another link to a related GitHub repository. These papers provide a framework to organize existing language agents and plan future developments.
- Great talk and presentation praise: Numerous members expressed appreciation for a well-prepared presentation, with comments like, "Great talk" and "Thanks!". The presenter was specifically praised for their preparation and contributions.
- AI engineer conference recap suggestion: For future sessions, one member suggested doing a recap of an AI engineer conference, possibly incorporating a bunch of lightning talks. This idea received positive feedback from others in the chat.
- GitHub - ysymyth/awesome-language-agents: List of language agents based on paper "Cognitive Architectures for Language Agents": List of language agents based on paper "Cognitive Architectures for Language Agents" - ysymyth/awesome-language-agents
- chatgpt_system_prompt/prompts/gpts at main · LouisShark/chatgpt_system_prompt: A collection of GPT system prompts and various prompt injection/leaking knowledge. - LouisShark/chatgpt_system_prompt
- Cognitive Architectures for Language Agents: Recent efforts have augmented large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning, le...
Nous Research AI ▷ #research-papers (2 messages):
- Instruction Pre-Training boosts LM performance: A new paper proposes Instruction Pre-Training, which augments large corpora with 200M instruction-response pairs generated by an efficient instruction synthesizer. This method not only enhances pre-trained base models but also allows Llama3-8B to compete with Llama3-70B in continual pre-training. Access the full paper or check out the model on Hugging Face.
- MCT Self-Refine improves mathematical reasoning: The MCT Self-Refine (MCTSr) algorithm integrates Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS) to boost performance in complex mathematical tasks. Extensive experiments show MCTSr significantly improving success rates in solving Olympiad-level problems, leveraging a systematic exploration and heuristic self-refine process. Read the detailed study.
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B: This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex m...
- Instruction Pre-Training: Language Models are Supervised Multitask Learners: Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling ...
- instruction-pretrain (instruction-pretrain): no description found
Nous Research AI ▷ #datasets (10 messages🔥):
- **Public Channels Now Open**: A post announced that the channels <#1105324249721356298> and <#1104063238934626386> have been made public.
- **REVEAL Benchmarks Verifiers**: A new dataset, [REVEAL: Reasoning Verification Evaluation](https://reveal-dataset.github.io), benchmarks automatic verifiers of complex Chain-of-Thought reasoning in open-domain question-answering settings, highlighting their struggles, especially in verifying logical correctness. The dataset, detailed in an [arXiv paper](https://arxiv.org/abs/2402.00559), includes comprehensive labels and free-text justifications.
- **XTREME Evaluates Multilingual Models**: The [XTREME dataset](https://huggingface.co/datasets/google/xtreme) evaluates cross-lingual generalization ability of pre-trained multilingual models, covering 40 typologically diverse languages. It includes nine tasks requiring different levels of syntax and semantics reasoning.
- **SPIQA Challenges Multimodal Models**: The [SPIQA dataset](https://huggingface.co/datasets/google/spiqa) is designed for multimodal question answering on scientific papers, containing over 270K questions focused on figures, tables, and text paragraphs. This dataset aims to assess the capability of large multimodal models in comprehending complex figures and tables.
- **TACT Tests Numerical Reasoning**: [TACT](https://huggingface.co/datasets/google/TACT) is introduced to evaluate LLMs' reasoning and computational abilities using complex instructions through tables. The dataset shows that contemporary LLMs perform poorly, with overall accuracy below 38%.
- **UNcommonsense Explains Weird Situations**: [UNcommonsense](https://huggingface.co/datasets/allenai/UNcommonsense) focuses on explaining unusual and unexpected situations with an English-language corpus consisting of 20k unique contexts and 41k abductive explanations, offering insights into uncommon outcomes.
- **EmotionalIntelligence-50K Focuses on Emotions**: The [EmotionalIntelligence-50K dataset](https://huggingface.co/datasets/OEvortex/EmotionalIntelligence-50K) is designed to build and train models that understand and generate emotionally intelligent responses, containing 51,751 rows of text data on various prompts and responses.
- **BrightData/IMDb-Media Offers Comprehensive Film Data**: The [BrightData/IMDb-Media dataset](https://huggingface.co/datasets/BrightData/IMDb-Media) includes over 249K records with 32 data fields covering feature films, TV series, and more, regularly updated with extensive details such as ratings, reviews, cast, and budget.
- **Opus-WritingPrompts Includes Sensitive Content**: The [Opus-WritingPrompts dataset](https://huggingface.co/datasets/Gryphe/Opus-WritingPrompts) features 3008 short stories generated using Reddit's Writing Prompts. This dataset includes varied content, including erotica, and has a disclaimer for sensitive information.
- REVEAL: A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
- google/TACT · Datasets at Hugging Face: no description found
- google/spiqa · Datasets at Hugging Face: no description found
- Gryphe/Opus-WritingPrompts · Datasets at Hugging Face: no description found
- allenai/UNcommonsense · Datasets at Hugging Face: no description found
- OEvortex/EmotionalIntelligence-50K · Datasets at Hugging Face: no description found
- BrightData/IMDb-Media · Datasets at Hugging Face: no description found
- google/xtreme · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ctx-length-research (1 messages):
deoxykev: Personally I’d go straight for the empirical approach. Too many variables at play.
Nous Research AI ▷ #off-topic (1 messages):
- Discussing Longevity Research: A member shared concerns about a potential dystopian society "where old wealthy people live forever by sacrificing the lifespan of youths," while also expressing appreciation for research aimed at increasing elderly health. They suggested that such advancements should be approached in a safe manner.
Nous Research AI ▷ #interesting-links (9 messages🔥):
- RankGPT is expensive and confusing: A member commented that "RankGPT is expensive," and another user questioned what "reranking by embedding" means and why it has tokens. They later figured it out but the initial confusion highlights the complexity of the tool.
- RAG Dataset should be public: Discussing the reranking process, a member noted the necessity for the RAG dataset to be a public project, suggesting community access could improve understanding and utilization.
- Smooth brain prefers Hermes 0 shot: One user mentioned their preference for a method from a paper showing Hermes 0 shot with "good or bad" as the most effective, despite acknowledging room for improvement. They humorously confessed to wanting to avoid complex problem-solving to keep their "brain nice and smooth."
Nous Research AI ▷ #announcements (1 messages):
- Hermes 2 Pro 70B Released: Nous Research has released Hermes 2 Pro 70B, a pure Hermes model with no merge with Llama-3 Instruct. This update addresses function call issues and refusals but sacrifices a bit of performance. Check it out on HuggingFace.
- Enhanced for Function Calling and JSON Outputs: Hermes 2 Pro excels at Function Calling and JSON Structured Outputs, achieving scores of 90% and 84% respectively in evaluations. The model is based on an updated OpenHermes 2.5 Dataset and includes a Function Calling and JSON Mode dataset.
- Improvement on Several Metrics: The new Hermes 2 Pro maintains excellent general task and conversation capabilities. It has shown improvements in several areas, including structured JSON output, and function calling, developed in partnership with Fireworks.AI.
Link mentioned: NousResearch/Hermes-2-Pro-Llama-3-70B · Hugging Face: no description found
Nous Research AI ▷ #general (111 messages🔥🔥):
- Smart and context-aware 8B model surprises users: Members discussed the impressive performance and context awareness of an 8B model, noting its ability to understand nuances in conversations. A user shared, "I ask it a vague question implicating what we are going to do, and it's responses were correct!".
- Confusion over Hermes models: There was a brief confusion about whether the non-Theta Hermes Pro model should be preferred over the Theta version. A member clarified that the non-Theta version may be better for function calling or if experiencing tokenization issues.
- Interest in OpenHermes 2.5 dataset cleaning methodology: Members inquired about the cleaning process for the OpenHermes 2.5 dataset. Unfortunately, no detailed information was shared.
- New tools and benchmarking datasets discussed: Discussion on various new datasets and benchmarking tools, including REVEAL and UNcommonsense. Links shared include the REVEAL dataset, UNcommonsense dataset, and models using Self-Play Preference Optimization like Llama-3-8B-SPPO-Iter3.
- Debate on SB 1047's impact on innovation: Members debated the potential negative impacts of California's SB 1047 on AI innovation. A link was shared discussing the potential unintended consequences of the bill, with one member stating, "California should encourage innovation and learn to utilize AI to our strategic advantage."
- aaronday3/entirety_of_reddit · Datasets at Hugging Face: no description found
- Tweet from Nathan Lambert (@natolambert): Here's my full @interconnectsai interview with @deanwball on AI policy. We do pretty much a state of the union on all things AI policy, with our usual focuses on openness. This was a great one! W...
- Open LLM Leaderboard 2 - a Hugging Face Space by open-llm-leaderboard: no description found
- Protect AI Research | STOP SB 1047: Urge the legislature to protect Artificial Intelligence (AI) research and oppose SB 1047. Rather than overregulate AI at its infancy, we should encourage innovation and learn to utilize AI to our stra...
- Beneath the Stars by @bozoegg | Suno: progressive electronic atmospheric song. Listen and make your own with Suno.
- REVEAL: A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
- Hug Love GIF - Hug Love Heart - Discover & Share GIFs: Click to view the GIF
- GitHub - interstellarninja/function-calling-eval: A framework for evaluating function calls made by LLMs: A framework for evaluating function calls made by LLMs - interstellarninja/function-calling-eval
- google/gemma-2-9b · Hugging Face: no description found
- allenai/UNcommonsense · Datasets at Hugging Face: no description found
- UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3 · Hugging Face: no description found
- Tweet from Quanquan Gu (@QuanquanGu): We've open-sourced the code and models for Self-Play Preference Optimization (SPPO)! 🚀🚀🚀 ⭐ code: https://github.com/uclaml/SPPO 🤗models: https://huggingface.co/collections/UCLA-AGI/sppo-6635f...
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #ask-about-llms (2 messages):
- Enthusiasm for Hermes2-Pro-llama-3-70B: A user expressed excitement for the Hermes2-Pro-llama-3-70B. They inquired about the scenarios in which this model would be preferred over Hermes-2-Theta.
- Link Shared without Context: Another user shared a link to a specific Discord message, link, suggesting it may contain relevant information or context.
Nous Research AI ▷ #rag-dataset (85 messages🔥🔥):
- Glaive-RAG-v1 dataset launched: Glaive-RAG-v1 has around 50k samples built using Glaive platform for RAG use cases, structured with documents, questions, answers, and citation tags. Members are asked to evaluate its quality and potential improvements for future iterations.
- System Prompts and Domain Integration: Discussion on integrating system prompts per domain into Hermes RAG prompts, covering "role", "style guide", and "instructions" sections. Members are considering practical ways to indicate context and relevance within prompts.
- Relevance Scoring Mechanics: There's an ongoing debate about including relevance scores such as a 5-point Likert scale for evaluating groundedness in responses. The consensus leans towards letting LLMs self-evaluate these metrics through guided system prompts.
- Code and Tools Sharing: Members discussed the utility of sharing tools and pipelines developed for the project. An example includes an image retriever pipeline shared via Hugging Face Spaces.
- Grounded vs. Mixed Response Modes: Clarification that in "Grounded" mode, the model should only use information from provided documents, while in "Mixed" mode, it combines document information with the model's own knowledge.
- Image Retriever - a Hugging Face Space by not-lain: no description found
- Tweet from bee (@bee__computer): we still have some alphas available. pick one up at @aiDotEngineer. dm us
- glaiveai/RAG-v1 · Datasets at Hugging Face: no description found
- GitHub - explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines - explodinggradients/ragas
- RAG Data Synthesis: Sheet1 Domain,Curriculum file,Source/links,HF repo,Size (rows),Status,Who's working,Reviewer,Review Notes Websearch Wikipedia Codebase,WIP,Bexboy Academic Papers Books,WIP,EveryoneIsGross Finance...
Nous Research AI ▷ #world-sim (5 messages):
- Surge of enthusiasm for Claude 3.5 Sonnet Model in world sim: A member expressed excitement about the upcoming addition of the Claude 3.5 Sonnet model to the world simulation. This indicates a strong community interest in new AI model integrations.
Link mentioned: Lain Lain Iwakura GIF - Lain Lain iwakura Serial experiments lain - Discover & Share GIFs: Click to view the GIF
Eleuther ▷ #general (25 messages🔥):
- Aggregate data increases privacy risks: "Quickly you'll run into the situation where aggregate data from other users can inform or improve local models," leading to challenges in the privacy-preserving/federated learning space. This necessitates dealing with a "significantly wider attack space from malicious actors" (BSI link).
- AI agent security behaviors: Discussing AI agents implementing security behaviors, including activities like "identifying behaviors by scripts that compromise privacy" and "automatic things that degrade or destroy shady data collection." However, some argued this might be largely heuristic without AI generalizing abilities.
- New MMLU-SR dataset: A user introduced MMLU-SR, a new reasoning challenge dataset designed to measure comprehension abilities of Large Language Models (LLMs) (arXiv link). They found that LLMs perform poorly on modified test questions, suggesting poor true comprehension.
- Trolling issues in chat: Multiple users reported a banned user, "endomorphosis," trolling a specific channel under various accounts. Members requested his removal for a more positive community experience.
- Channel guidance for lm_eval help: New members seeking assistance with lm_eval were directed to the appropriate channel (lm_eval channel link). This spot is recommended for tasks and related queries.
Link mentioned: Reasoning or Simply Next Token Prediction? A Benchmark for Stress-Testing Large Language Models: We propose MMLU-SR, a novel dataset designed to measure the true comprehension abilities of Large Language Models (LLMs) by challenging their performance in question-answering tasks with modified term...
Eleuther ▷ #research (122 messages🔥🔥):
- Debate over yoco and kv cache: Members discussed the kv cache strategy in various architectures, particularly yoco, and expressed skepticism about its efficacy compared to alternative designs. One member called yoco's setup "cursed" due to its complexity and separation from standard transformer practices.
- Efficiency in layer ordering: There's a significant discussion around the ordering of attention and feed-forward layers in models like yoco and mamba. Some argue that placing all attention layers at one end could be more efficient, reducing computational costs, while others maintain that alternating layers might ensure better overall performance.
- Model Scaling and Performance Concerns: Participants debated the impact of layer ordering on small vs. large scale models, with some suggesting that issues at small scales might be smoothed out at larger scales. A key point of contention was whether reordering layers has measurable impacts as models grow.
- Preliminary exploration on positional embeddings: A member posed an innovative idea regarding pre-applying positional embeddings (PE) to latents before computing QK, hypothesizing it could handle operations like string reversal better. This sparked curiosity and skepticism among members, who questioned if such methods would preserve or disrupt existing benefits of techniques like RoPE.
- Reinforcement Learning Advancements: A member shared an arXiv paper discussing $\Delta$-IRIS, a new agent employing delta-based autoencoding in RL, addressing its efficiency in training time versus traditional attention-based methods.
- Efficient World Models with Context-Aware Tokenization: Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent adva...
- Improving Transformer Models by Reordering their Sublayers: Multilayer transformer networks consist of interleaved self-attention and feedforward sublayers. Could ordering the sublayers in a different pattern lead to better performance? We generate randomly or...
- Self-Retrieval: Building an Information Retrieval System with One Large Language Model: The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited int...
- Shortformer: Better Language Modeling using Shorter Inputs: Increasing the input length has been a driver of progress in language modeling with transformers. We identify conditions where shorter inputs are not harmful, and achieve perplexity and efficiency imp...
- Google Colab: no description found
Eleuther ▷ #scaling-laws (45 messages🔥):
- Questioning Chinchilla's Status as a Law of Nature: A member questioned why people seem to treat Chinchilla scaling as an immutable law, suggesting that power law scaling can't be the final optimal scaling method. They observed that there seems to be little discussion on alternatives and speculated that serious discussions on this topic might be occurring privately.
- Debating the Validity of Power Law Scaling: A member argued that power law scaling might still be a legitimate model but acknowledged that the Chinchilla model's relevance is tied to specific conditions like the training regime and data. They also pondered why inverse power relations couldn't be the norm, mentioning that both inverse power and logarithmic scaling seem plausible.
- Scaling Heuristics vs. Laws: Another member noted that terms like "scaling law" should perhaps be replaced with "scaling heuristic" to better reflect their provisional nature. They reminisced about a time when numerous papers claimed to have discovered new "laws" better than Chinchilla, implying skepticism about such definitive language.
- Reading and Citing Key Papers: Members referenced several key papers to bolster their arguments, including "Parameter Counts in Machine Learning" and Adlam 2021 on Scaling Laws. They discussed how these papers understand and model scaling laws concerning large datasets and parameter sizes.
- Practical Limitations and Future Directions: The conversation also touched on practical aspects like data selection methods and their impact on training efficiency. A member emphasized that better data collection methods, such as stratified sampling, aren't magical solutions but do improve efficiency, highlighting the complexity of predicting the future impact of data on model performance.
- A Solvable Model of Neural Scaling Laws: Large language models with a huge number of parameters, when trained on near internet-sized number of tokens, have been empirically shown to obey neural scaling laws: specifically, their performance b...
- Asymptotic learning curves of kernel methods: empirical data v.s. Teacher-Student paradigm: How many training data are needed to learn a supervised task? It is often observed that the generalization error decreases as $n^{-β}$ where $n$ is the number of training examples and $β$ an exponent ...
- Empirical statistical laws - Wikipedia: no description found
- Parameter counts in Machine Learning — AI Alignment Forum: In short: we have compiled information about the date of development and trainable parameter counts of n=139 machine learning systems between 1952 an…
Eleuther ▷ #lm-thunderdome (15 messages🔥):
- Introducing MMLU-SR Dataset to lm_eval: A member introduced a new dataset, MMLU-SR, designed to challenge LLMs' reasoning abilities through symbol replacement and inquired about adding it to lm_eval. After creating and submitting a PR, they received a prompt response for review. arxiv.org/abs/2406.15468v1
- MedConceptsQA Benchmark Addition: A member requested a review for their PR that adds the MedConceptsQA benchmark aimed at medical concepts question answering. This open-source benchmark features questions of various complexities. github.com/EleutherAI/lm-evaluation-harness/pull/2010
- Custom YAML Config Debugging: A member sought help to run a custom YAML configuration for an evaluation using the harness. They received debugging advice and managed to resolve their issue after identifying and fixing a task name conflict.
- Dancing Cat Dance GIF - Dancing cat Dance Cat - Discover & Share GIFs: Click to view the GIF
- Added MedConceptsQA Benchmark by Ofir408 · Pull Request #2010 · EleutherAI/lm-evaluation-harness: Hi, I haved added our new benchmark called MedConceptsQA. MedConceptsQA is a dedicated open source benchmark for medical concepts question answering. The benchmark comprises of questions of various...
- Use `shell=False` in `subprocess` Function Calls by pixeeai · Pull Request #2030 · EleutherAI/lm-evaluation-harness: This codemod sets the shell keyword argument to False in subprocess module function calls that have set it to True. Setting shell=True will execute the provided command through the system shell whi...
Eleuther ▷ #gpt-neox-dev (6 messages):
- Instruction Tuning in GPTNeoX: A member inquired about the possibility of instruction tuning in GPTNeoX, specifically where losses are backpropagated only for continuations, not prompts. Another member suggested looking into a specific PR and the related preprocessing script—"preprocess_data_with_chat_template.py"—indicating that while it's still under review, bug reports would be helpful.
- SFT improvements (labeling fixes, different packing implementations) by dmahan93 · Pull Request #1240 · EleutherAI/gpt-neox: add different packing impl (Unpacked, packing until overflow), a bit naive but for SFT it shouldn't be an issue fix labels to also have valid/test implementations fix label masking in _get_batch t...
- gpt-neox/tools/datasets/preprocess_data_with_chat_template.py at main · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
CUDA MODE ▷ #triton (12 messages🔥):
- Triton installation woes plague Windows users: A user reported persistent issues with torch.compile, encountering a "RuntimeError: Cannot find a working triton installation," despite having Triton installed. Another member clarified that Triton might not be officially supported on Windows and suggested alternative installation methods.
- Troubleshooting Triton with Anaconda: A user mentioned installing PyTorch with Anaconda and running into Triton-related errors. Another user confirmed the unavailability of the Triton package via
conda install tritonon Windows and requested the output ofconda listto troubleshoot further. - Seeking documentation on make_block_ptr: A member inquired about detailed documentation for
triton.language.make_block_ptr, expressing confusion over the available information.
CUDA MODE ▷ #torch (7 messages):
- Lovely Tensors breaks with torch.compile in 2.5.0: The author of Lovely Tensors is encountering issues with custom
Tensor.__repr__()breaking intorch.compile(). This is due to their__repr__being called on a FakeTensor, leading to problems; a workaround involves checking if the tensor is fake.
- Community suggests using torch.compiler APIs: There is a suggestion to use the torch.compiler_fine_grain_apis to disable or handle custom
reprfunctions. This approach could potentially unblock users facing similar issues.
- Broadcast deadlock issue with NCCL: The broadcast deadlock issue in older NCCL versions has been a significant problem but is already fixed in newer versions not shipped with torch 2.3.1. Users can resolve it by installing
pip install nvidia-nccl-cu12==2.22.3, as detailed in this TGI PR.
- TorchDynamo APIs for fine-grained tracing — PyTorch 2.3 documentation: no description found
- GitHub - xl0/lovely-tensors: Tensors, for human consumption: Tensors, for human consumption. Contribute to xl0/lovely-tensors development by creating an account on GitHub.
- Leak in FIFO queue · Issue #1251 · NVIDIA/nccl: We are experiencing an issue where 8 processes, each controlling one GPU on a node, all lock up at the same time. It seems to be deterministic, though we don't know exactly the operation that is c...
- Fix nccl regression on PyTorch 2.3 upgrade by fxmarty · Pull Request #2099 · huggingface/text-generation-inference: As per title, fixes NVIDIA/nccl#1251 in TGI's cuda image, regression introduced in #1730 & #1833 We hit this issue e.g. with llama 3 70B model with TP=4 or TP=8 on H100 & default cuda grap...
CUDA MODE ▷ #cool-links (1 messages):
- Think about writing a CUDA Program: An informative session by Stephen Jones on how to think about writing a CUDA program. Topics include wave quantization & single-wave kernels, types of parallelism, and tiling to optimize block sizes for L2 cache.
Link mentioned: How To Write A CUDA Program: The Ninja Edition | NVIDIA On-Demand: Join one of CUDA's architects in a deep dive into how to map an application onto a massively parallel machine, covering a range of different techniques aim
CUDA MODE ▷ #beginner (14 messages🔥):
- CUDA File Type Confusion? No Worries!: A member asked if they should set the item type of all their files as CUDA C/C++ in a CUDA Runtime project in Visual Studio. Another suggested that it depends on personal preference as long as files that need CUDA are marked correctly: "I usually set them to .cu if cuda and .c/cpp if not... it's personal preference."
- Cloud GPUs for Hands-on CUDA Experience: A beginner inquired about using CUDA Toolkit on a cloud GPU without a local GPU and sought cost-friendly cloud vendors. Suggestions included Vast.ai and Runpod.io, with a mention of Lightning AI offering free 22hrs/month of L4 usage.
- Python to CUDA Optimization Flow: For optimizing PyTorch code, a recommended flow was given: use
torch.compile, consider custom Triton, and finally write custom CUDA code if needed. Key advice included checking for GPU bottlenecks and using efficient implementations likeF.spda()for attention to ensure maximum utilization.
- Rent GPUs | Vast.ai: Reduce your cloud compute costs by 3-5X with the best cloud GPU rentals. Vast.ai's simple search interface allows fair comparison of GPU rentals from all providers.
- RunPod - The Cloud Built for AI: Develop, train, and scale AI models in one cloud. Spin up on-demand GPUs with GPU Cloud, scale ML inference with Serverless.
CUDA MODE ▷ #pmpp-book (1 messages):
- Missing Pages in PMPP Book: A member reported that their recently purchased PMPP (4th edition) book was missing several pages—specifically 148, 149, 150, 290, 291, 292, 447, and 448. They inquired if anyone else faced the same issue.
CUDA MODE ▷ #torchao (16 messages🔥):
- **Custom static analysis tools discussion**: A user mentioned wanting to run custom static analysis tools on the project. This prompted excitement and agreement within the group.
- **Need for a list of required torch/aten ops**: One member suggested maintaining a list or table of required `torch/aten ops` for different tensor subclass use cases such as `FSDP`. For example, to swap linear weight, implementing `F.linear` and `aten.detach.default` is necessary.
- **Recursion error with `__torch_dispatch__`**: A user encountered a recursion error when printing arguments in `__torch_dispatch__`, leading to a discussion on possible causes and solutions. This included checking for special functions in `__repr__()` and using a debugger for inspection.
- **Int4Tensor refactor PR**: [A PR](https://github.com/pytorch/ao/pull/458) was created to refactor `Int4Tensor` and perform some code cleanup which will be completed over the weekend.
- **NVIDIA GeForce GTX 1650 warning**: One user raised concerns about a warning for the NVIDIA GeForce GTX 1650 not supporting bfloat16 compilation natively. It was clarified that this could lead to performance implications like multiple kernel launches, which was linked to the usage of bfloat in quant API.
- pytorch/torch/_inductor/compile_fx.py at 26d633b7213c80371985ba88e6db4a2f796a2e50 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- [WIP] Int4Tensor refactor to implements pattern by melvinebenezer · Pull Request #458 · pytorch/ao: Refactoring UInt4Tensor to have implements pattern similar to nf4tensor and UInt2Tensor ToDo Create implements for UInt4Tensor and PerChannelSymmetricWeight Test Cases Move uint4i to uint4.py
- ao/torchao/prototype/intx/intx.py at intx · vayuda/ao: Native PyTorch library for quantization and sparsity - vayuda/ao
- [RFC] Tensor Subclass based Quantization API · Issue #391 · pytorch/ao: Status: Draft Updated: 06/17/2024 Objective In this doc we’ll talk about Tensor subclass based quantization API for modeling users and developers. Modeling User API Modeling users refer to people w...
CUDA MODE ▷ #off-topic (9 messages🔥):
- Model releases on HuggingFace Hub prioritize storage convenience: A user noticed an increasing trend where model architecture and preprocessing code are directly stored on HuggingFace Hub instead of being added to the transformers repository. They speculated whether this is due to code licensing issues and shared examples here and here.
- Pros and Cons of HuggingFace Hub strategy: Another user pointed out the benefits of this strategy, such as the ability for authors to release new models without needing an official HF team release, but also mentioned drawbacks like being unable to use these models for certain functionalities on the HF platform unless
trust_remote_codeis enabled.
- Debate on optimal code and model storage solutions: The discussion highlighted differing opinions about the best practices for storing model code and weights. One user suggested that releasing code on GitHub and storing model weights on HuggingFace Hub might be ideal, though others noted potential compatibility issues and the convenience factors of using the HF Hub.
- Llama release as a case in point: The discussion mentioned the Llama model release strategy, which involves maintaining the inference code on GitHub independent of the transformers library. An example repository for this approach is meta-llama on GitHub.
- GitHub - meta-llama/llama: Inference code for Llama models: Inference code for Llama models. Contribute to meta-llama/llama development by creating an account on GitHub.
- microsoft/Florence-2-base-ft at main: no description found
- Qwen/Qwen-Audio at main: no description found
- deepseek-ai/DeepSeek-Coder-V2-Instruct at main: no description found
CUDA MODE ▷ #llmdotc (68 messages🔥🔥):
- Google Gemma 2 shines in benchmarks: Google's new Gemma 2 models (27B and 9B) outperformed Llama3 70B and Qwen 72B in the LYMSYS Chat arena. The details of the release appreciate the open sharing of experiments and the planned 2.6B model release soon.
- Danielhanchen analyzes Gemma 2 architecture: Daniele Hanchen highlighted key elements of the Gemma 2 models, including pre and post Layernorms and approx GeGLU activations. The models use a sliding window and global attention layers for efficient processing.
- ReLU vs GELU debate: Discussion on whether ReLU is better than GELU for activation functions, referencing an arxiv paper, testing results, and hardware benefits. The debate included the importance of accurate hyperparameters for ReLU.
- FP8 challenges with hardware and libraries: Challenges of FP8 support in current hardware and libraries, with a focus on NVIDIA's NCCL and cuDNN limitations. A detailed discussion on alternatives and potential workarounds ensued, including references to Microsoft's FP8-LM paper.
- Training insights and optimizations: Yuchen's training with H100 GPUs showed promising results with higher learning rates, suggesting that issues faced could be platform or dataset specific. Discussion about various optimizers and the specifics of their implementations followed, indicating the complexity and sensitivity of the training processes.
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Let's fucking gooo! Google just dropped Gemma 2 27B & 9B 🔥 > Beats Llama3 70B/ Qwen 72B/ Command R+ in LYMSYS Chat arena & 9B is the best < 15B model right now. > 2.5x smaller than Llam...
- Tweet from Daniel Han (@danielhanchen): Just analyzed Google's new Gemma 2 release! The base and instruct for 9B & 27B is here! 1. Pre & Post Layernorms = x2 more LNs like Grok 2. Uses Grok softcapping! Attn logits truncated to (-30, 3...
- Tweet from Yuchen Jin (@Yuchenj_UW): Outperform GPT-3 (1.5B) with @karpathy's llm.c using just 1/5 training tokens 🌠 Previously, I trained the GPT-2 Small (124M) model. Recently, I trained GPT-2 XL (1.5B), aka the official GPT-2, u...
- GitHub - clu0/unet.cu: UNet diffusion model in pure CUDA: UNet diffusion model in pure CUDA. Contribute to clu0/unet.cu development by creating an account on GitHub.
- GitHub - Azure/MS-AMP: Microsoft Automatic Mixed Precision Library: Microsoft Automatic Mixed Precision Library. Contribute to Azure/MS-AMP development by creating an account on GitHub.
Perplexity AI ▷ #announcements (1 messages):
- Reduced Pricing for Perplexity Enterprise Pro for Philanthropic Organizations: Perplexity now offers reduced pricing for Perplexity Enterprise Pro to schools, nonprofits, government agencies, and not-for-profits. The initiative aims to support organizations facing budget constraints while playing a vital role in societal and educational development. Learn more.
Perplexity AI ▷ #general (94 messages🔥🔥):
- Perplexity's RAG Performance Discussed: Members discussed how Perplexity's Relevance Aware Generation (RAG) mechanism sometimes leads to poor outputs, especially when it tries to incorporate files inconsistently. It was noted that writing mode aims to avoid RAG, but actual results still often exhibit hallucinations.
- Claude 3 Opus Usage Limits Frustrate Users: The daily usage limit for Claude 3 Opus has been a source of ongoing frustration, fluctuating from 5 to 600 and now capped at 50 interactions per day. One user described this limit change as a "roller coaster ride."
- Security and Data Concerns Addressed: A member asked about the security measures and PII handling for Perplexity's enterprise solution. The response directed them to the Trust Center and provided an email for further inquiries.
- Intermittent Context Issues with Perplexity: Users noted that Perplexity tends to lose context during extended interactions. One user suggested using keywords like "#context" to improve continuity until a fix is implemented.
- VPN and Access Issues: A few members reported issues with Perplexity not working over VPNs like Cloudflare WARP, causing connectivity and login problems. There were recommendations to switch to DNS-only mode as a workaround.
Link mentioned: Trust Center: Showcasing our security posture to build trust across the web.
Perplexity AI ▷ #sharing (8 messages🔥):
- Android 14 insights explored: A link to a Perplexity AI page detailing features and enhancements introduced in Android 14 was shared. This page likely discusses the specifics of the operating system update and its impact on user experience.
- Question about RDP on Perplexity AI: The link provided offers an in-depth look at Microsoft Remote Desktop Protocol (RDP). It discusses ongoing considerations and potential improvements in RDP usage within Microsoft's ecosystem.
- CriticGPT, Living Robot Skin, and sustainable innovations: A YouTube video was shared with a title indicating a discussion on CriticGPT, Living Robot Skin, and Oyster-Inspired Concrete. The video seems to cover cutting-edge technologies and sustainable materials inspired by natural solutions.
- Linux performance exploration: A link to a Perplexity AI search dives into reasons behind Linux performance and adoption issues. This page likely explores common challenges and solutions for Linux users.
- Misleading Minecraft mechanics: An article titled Minecraft Repair Mechanics Misleads Kids was shared. It raises concerns about the potential misconceptions in mechanical knowledge children might develop by playing the game.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (13 messages🔥):
- Community wants Gemma 2 model: "I know this goes without saying, but it'd be cool to have Gemma 2 in the available models."
- Question on supporting larger models and pro searches: A member asked, "when will Perplexity API start supporting pro searches and bigger models like GPT-4 and Sonnet?" Another member responded that GPT-4 and Sonnet can be used via respective providers and Pro Search for the API is currently not planned.
- Clarification on Perplexity's added value: "The whole point of Perplexity is that it will add more online search and better prompts to talk to GPT-4 or Sonnet to give a better experience," noted a member. Current models like
llama-3-sonar-large-32k-onlineare available with specific parameters that can be found in the Perplexity model cards documentation. - Critique of current API performance: A member expressed dissatisfaction, stating, "I have tried them but they are not as good as GPT-4 or Sonnet 3.5 to comprehend" and noted "tons of hallucinations" in the current API.
- Inquiring about filtering results: Another member inquired about limiting results to new information from the last 30 days, receiving advice to try
after:2024-05-28.
Link mentioned: Supported Models: no description found
Interconnects (Nathan Lambert) ▷ #news (40 messages🔥):
- Character.AI launches Character Calls: Character.AI introduced Character Calls, a feature for two-way voice conversations with AI characters, available for free on their app. However, user feedback highlighted issues like a 5-second delay and robotic voices, affecting the fluidity of conversations.
- Amazon acquires Adept's talents and tech: Discussions centered around Amazon hiring Adept's cofounders and licensing its technology, leaving Adept with around 20 employees. There were rumors about a toxic culture at Adept leading to the departure of the Transformer paper authors who initially founded the company.
- Skepticism around the progress of AI agents: Comparisons were made between the hype around AI agents and self-driving cars, suggesting that agents are "always just around the corner but never working reliably enough." The conversation noted that despite significant talent and investment, the development of useful AI agents is slow compared to other AI advancements like video generation.
- Challenges in training data for AI agents: Participants discussed that a likely bottleneck in developing AI agents is the collection and quality of training data. The focus is shifting towards generating synthetic data and obtaining annotated counterfactual examples to improve agent reliability and performance.
- An Update to Adept: Announcing some updates to our strategy and the company.
- Introducing Character Calls: 0:00 /0:07 1× Calling the Character.AI Community! We're thrilled to ring in an exciting new feature that's set to redefine your Character.AI experience: Character Calls!...
- Tweet from Lucas Beyer (bl16) (@giffmana): @fouriergalois @character_ai just tried it, it's not comparable unfortunately, would have been super impressive! It's not fluid at all. 5sec delay when I'm done talking. I can't inter...
- Tweet from Anissa Gardizy (@anissagardizy8): Amazon has hired the cofounders of artificial intelligence startup Adept and licensed some of its tech, according to a post by the startup and an internal email from an Amazon exec Adept is left w/ a...
Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Anthropic CEO nostalgically discusses Final Fantasy: A member shared a YouTube video of Dario Amodei, CEO of Anthropic, discussing how he and his sister played Final Fantasy growing up and continue to do so as adults. The member found this anecdote pretty endearing.
- AI crisis vs. pandemic debate ignites: Natolambert labeled Dwarkesh's comparison of an AI crisis being harder than a pandemic as presumptive. Dwarkesh also controversially said, “we’ve done vaccines before” to imply that COVID vaccines were normal.
- Political instability sparks extreme hopes: Natolambert expressed a wish for an unstable intelligence explosion to render government meaningless if Trump becomes president. The sentiment indicates a desire for significant change driven by AI developments.
- European member disheartened by debate: Xeophon expressed feeling bad about the debate, mentioning his European perspective. This hints at a more global impact of the debate on AI and political issues.
Link mentioned: Dario Amodei - CEO of Anthropic | Podcast | In Good Company | Norges Bank Investment Management: Dario Amodei CEO of Anthropic: Claude, New models, AI safety and Economic impactHow much bigger and more powerful will the next AI models be? Anthropic’s CEO...
Interconnects (Nathan Lambert) ▷ #memes (5 messages):
- Memes: Bourne Supremacy Reference: A member shared a YouTube video titled "The Bourne Supremacy (9/9) Movie CLIP - Final Call to Pamela (2004) HD". The video is a movie clip from The Bourne Supremacy.
Link mentioned: The Bourne Supremacy (9/9) Movie CLIP - Final Call to Pamela (2004) HD: The Bourne Supremacy movie clips: http://j.mp/1uvIXs9BUY THE MOVIE: http://amzn.to/tor8HhDon't miss the HOTTEST NEW TRAILERS: http://bit.ly/1u2y6prCLIP DESCR...
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- Debunking AI Scaling Myths: The article AI Scaling Myths challenges the predictability of scaling, arguing there's virtually no chance scaling alone will lead to AGI. It suggests LLM developers are near the limit of high-quality data and highlights downward pressure on model size despite the predictability shown in scaling laws.
- Discussion on AGI Definitions and Synthetic Data: Nathan Lambert critiqued the article for not defining AGI and ignoring synthetic data, suggesting this research on rewriting pre-training data. Lambert also mentioned that the claim about the industry stopping large models is short-term and linked to capital expenditures, encouraging further discussion on Substack.
- Nathan Lambert on AI Snake Oil: I'm a fan, but I feel like this fell into a few of the same traps as the AGI Faithful, but from the other side: 1. Easy to do this without definitions. You did not define AGI or comment on how mu...
- AI scaling myths: Scaling will run out. The question is when.
Interconnects (Nathan Lambert) ▷ #posts (19 messages🔥):
<ul>
<li><strong>SnailBot News Episode Talks</strong>: Members expressed excitement about the latest SnailBot News episode featuring a discussion around Lina Khan (Chairperson FTC) on Hard Fork [TikTok link](https://www.tiktok.com/@hardfork/video/7301774206440656171?lang=en). Natolambert mentioned plans for future interviews including Ross Taylor of Paperswithcode/Galactica and John Schulman.</li>
<li><strong>Model Output Training Limitations</strong>: A user highlighted the interesting point on "Please don't train on our model outputs" stipulations being required by data providers. Natolambert confirmed that some models would drop the limitation if not required by data providers, citing DBRX folks.</li>
<li><strong>Potential Interviewees Discussed</strong>: Natolambert revealed potential guests for future episodes including Amanda Askell, with one member expressing enthusiasm for her insights from past appearances. Xeophon mentioned Ross Taylor's elusive yet significant insights, stirring interest among the group.</li>
<li><strong>Nicknames and Influence in Labs</strong>: 420gunna humorously noted the nickname "DBRex," to which Natolambert took credit. This was followed by a light-hearted comment on Natolambert's influence within labs.</li>
<li><strong>Pre-deployment Testing and Influencing AI Labs</strong>: The conversation touched on pre-deployment testing issues and the contrasting influence on AI labs versus government figures. One member found the idea of influencing AI labs less realistic compared to government figures.</li>
</ul>
Link mentioned: TikTok - Make Your Day: no description found
LlamaIndex ▷ #blog (2 messages):
- Build agentic RAG services with llama-agents: A notebook demonstrates creating vector indexes, turning them into query engines, and providing these tools to agents before launching them as services. For detailed steps, check this notebook.
- Jina releases their best reranker yet: LlamaIndex users are enthusiastic about the new Jina reranker, described as their best one to date. More details can be found here.
Link mentioned: llama-agents/examples/agentic_rag_toolservice.ipynb at main · run-llama/llama-agents: Contribute to run-llama/llama-agents development by creating an account on GitHub.
LlamaIndex ▷ #general (68 messages🔥🔥):
- Embedding Node Weights and Issues with Vector Retrievers: Multiple members discuss embedding issues with LlamaIndex, focusing on what parts of nodes are embedded and problems where vector retrievers yield poor results possibly due to incorrectly matched embedding models. One member suggests, "the best way to start is creating a simple test case that reproduces some unexpected results” to debug effectively.
- Entity Relationship Linking: Members debate about adding edges based on embedding conditions to better capture entity relationships, which aren't detected traditionally. They mention a potential collaboration article by Neo4J and LlamaIndex on entity resolution that may help.
- Claude's Empty Responses: There's a technical discussion about Claude's response handling via Bedrock leading to empty responses if max tokens are set too low. An edge case leads to an IndexError, prompting a member to share a temporary fix and promising to clean up and share the validating notebook.
- Excitement Around New Releases: Enthusiasm is expressed about the new Gemma2 model and the latest announcement on the agents framework. A link to the Gemma2 model on Hugging Face is shared, with members troubleshooting integration issues.
- Challenges with OpenAI Key Environment Variables: A user reports unexpected behavior where OpenAI keys are sought from environment variables despite being set in the code itself. Additionally, optimization queries arise regarding batch and parallel loading of indices to handle large file sizes faster.
- no title found: no description found
- bartowski/gemma-2-9b-it-GGUF · Hugging Face: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- Gemma 2.9B launches new models: Free & standard variants for the new google/gemma-2-9b-it are now available. OpenRouter announced this update for 2023-2024.
- Price cuts announced: Several popular models have received price reductions. Notable drops include cognitivecomputations/dolphin-mixtral-8x22b with a 10% cut, openchat/openchat-8b with a 20% reduction, and meta-llama/llama-3-70b-instruct with a 3.5% drop.
- Google: Gemma 2 9B by google: Gemma 2 9B by Google is an advanced, open-source language model that sets a new standard for efficiency and performance in its size class. Designed for a wide variety of tasks, it empowers developers...
- Dolphin 2.9.2 Mixtral 8x22B 🐬 by cognitivecomputations: Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a finetune of [Mixtral 8x22B Instruct](/models/mistralai/mixtral-8x22b-instruct). It features a 64k context...
- OpenChat 3.6 8B by openchat: OpenChat 8B is a library of open-source language models, fine-tuned with "C-RLFT (Conditioned Reinforcement Learning Fine-Tuning)" - a strategy inspired by offline reinforcement learning. It...
- MythoMax 13B by gryphe: One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge
- Meta: Llama 3 70B (Base) by meta-llama: Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This is the base 70B pre-trained version. It has demonstrated strong performance compared to leading closed...
- Qwen 2 72B Instruct by qwen: Qwen2 72B is a transformer-based model that excels in language understanding, multilingual capabilities, coding, mathematics, and reasoning. It features SwiGLU activation, attention QKV bias, and gro...
OpenRouter (Alex Atallah) ▷ #general (57 messages🔥🔥):
- OpenRouter Moderation Strictness Discussed: Members compared OpenRouter's self-moderation to AWS and Anthropic, suggesting it is more censored. One user mentioned, "Both will refuse without a prefill but start writing with a basic prefill."
- Issues with Opus Availability: A user noted that enabling Opus is currently unavailable without enterprise support. They linked to a Reddit post discussing this limitation.
- Troubleshooting GitHub Authentication: Members shared solutions for making GitHub pushes without repeatedly entering a passphrase, recommending tools like
ssh-add -Aand adding commands to~/.bash_profile. One detailed guide was linked in a SuperUser post.
- API Differences and Issues: Discussions revealed API discrepancies, particularly with Gemini models producing a "Status 400" error. It's highlighted that Google APIs do not follow standard formatting, with specific adjustments required for tool roles.
- Evaluating LLM APIs: A member suggested watching Simon Willison's talk for an overview of LLM APIs, sharing a YouTube link and a link to his blog post.
- Provider Routing | OpenRouter: Route requests across multiple providers
- Reddit - Dive into anything: no description found
- AI Engineer World’s Fair 2024 — Keynotes & CodeGen Track: https://twitter.com/aidotengineer
- Cursor Community Forum: A place to discuss Cursor (bugs, feedback, ideas, etc.)
- macOS keeps asking my ssh passphrase since I updated to Sierra: It used to remember the passphrase, but now it's asking it to me each time. I've read that I need to regenerate the public key with this command, which I did: ssh-keygen -y...
OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
voidnewbie: Gemma 2가 명목상으로는 영어만 지원하지만 뛰어난 다국어 능력을 가지고 있는 것 같아요. 한국어를 시험해보신 분 계신가요?
OpenRouter (Alex Atallah) ▷ #tips (1 messages):
- Set default model wisely: daun.ai suggests setting your default model to 'auto' for reliable output on most tasks. Alternatively, use 'flavor of the week' for more serendipitous results, which will be the fallback model if no specific model is chosen and a request fails.
LAION ▷ #general (36 messages🔥):
- Gege AI threatens the music industry: A member shared a Reddit link about Gege AI, an AI that can clone any singer's voice with a small sample. They humorously commented, "RIP music industry" and suggested the RIAA should sue China.
- Challenges with Gege AI registration: Users discussed facing issues while registering for Gege AI. One joked about it being related to "Not enough social credit points".
- Gemma 27B model impresses and causes skepticism: A member claimed that Gemma 27B is performing well, but others expressed skepticism about its true capabilities. They noted its performance still seemed better than its predecessor despite the high confidence interval.
- Complaints about GPT-4 and 4O models: Multiple users mentioned problems with GPT-4 and 4O models, noting they often take prompts too literally and are less effective for programming compared to GPT-3.5. One stated, "Free alternative reign supreme" comparing it with Gemini 1.5 Pro.
- Switching to Claude for better experience: Some users have switched from OpenAI's models to Claude due to a better artifacts feature and functionality with Hugging Face libraries. They reported improved experiences over GPT-4 models.
Link mentioned: Reddit - Dive into anything: no description found
LAION ▷ #research (2 messages):
- Adam-mini optimizer slashes memory usage without sacrificing performance: An exciting new optimizer called Adam-mini can achieve similar or better performance than AdamW with 45% to 50% less memory footprint. The paper argues that most of the learning rate resources in Adam (specifically $1/\sqrt{v}$) can be removed by partitioning parameters into blocks and assigning a single, optimized learning rate per block, ultimately outperforming Adam in some cases.
- Single learning rates for weight tensors eliminate excess: The innovative approach of using one pre-searched learning rate per weight tensor shows significant performance improvements over Adam. "One pre-searched learning rate per weight tensor outperforms Adam significantly," highlighting how careful resource allocation and optimization can enhance efficiency.
Link mentioned: Adam-mini: Use Fewer Learning Rates To Gain More: We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in ...
LangChain AI ▷ #general (26 messages🔥):
- CSV and Pandas DataFrame Agents with Bedrock Issues: A member is experiencing issues building and running a csv_agent or pandas_dataframe_agent with Bedrock. They sought help from the community for troubleshooting.
- Errors with Sonnet 3.5 and Bedrock: Another member is having trouble integrating the Sonnet 3.5 model with Bedrock using
ChatPromptTemplate.fromMessages. They shared an example format and mentioned receiving errors despite attempts to adjust message formats.
- LangGraph and Human-in-the-Loop Launch: LangChain Blog announced the launch of LangGraph featuring human-in-the-loop capabilities via "Interrupt" and "Authorize" functions. The discussion highlighted issues with deserialization errors when attempting to resume execution after human approval steps.
- Discussion on CSV File Handling: A user discussed using LangChain's CSV Loader and expressed difficulty handling multiple CSV files effectively. They shared a documentation link and sought community input on better approaches.
- Python Example for Human-in-the-Loop: A detailed example and link to a guide for implementing human-in-the-loop in Python were shared. This included a mechanism for asking human approval in tool invocation steps and handling tool call acceptance or rejection.
- Human-in-the-loop with OpenGPTs and LangGraph: TLDR; Today we’re launching two “human in the loop” features in OpenGPTs, Interrupt and Authorize, both powered by LangGraph. We've recently launched LangGraph, a library to help developers buil...
- How to add a human-in-the-loop for tools | 🦜️🔗 LangChain: There are certain tools that we don't trust a model to execute on its own. One thing we can do in such situations is require human approval before the tool is invoked.
- How to load CSVs | 🦜️🔗 LangChain: A comma-separated values (CSV) file is a delimited text file that uses a comma to separate values. Each line of the file is a data record. Each record consists of one or more fields, separated by comm...
LangChain AI ▷ #share-your-work (8 messages🔥):
- No Code Chrome Extension for LangChain: A member shared a YouTube video titled "No Code Chrome Extension Chat Bot Using Visual LangChain." The video demonstrates how to design a LangChain RAG application with an interactive chat feature.
- Dappier Launches AI Content Marketplace: A new platform, Dappier, aims to monetize proprietary content for AI use and training. Featured in a TechCrunch article, the platform allows creators to license data models via a RAG API.
- Data Analyst Agent Using Cohere and LangChain: A member built a Data Analyst Agent leveraging Cohere and LangChain, and shared the project on LinkedIn.
- Testcontainers Adds Ollama Support: A new PR for testcontainers-python was accepted, adding support for the Ollama module. Users are encouraged to try features released in version 4.7.0.
- Tool for Editing JSONL Datasets: A free tool for editing fine-tune and chat datasets in JSONL format was shared: uncensored.com/jsonl. The creator emphasized the hassle of manually editing JSONL datasets.
- Building RAG with Matryoshka Embeddings: A member shared details about building RAG with Matryoshka Embeddings and Llama Index. Advantages include improved retrieval speed and reduced memory footprint, with a Colab tutorial provided.
- No Code Chrome Extension Chat Bot Using Visual LangChain: In this demo, I show an exciting new feature of Visual Agents where you can design your LangChain RAG application, including an interactive chat feature to a...
- Tweet from Prashant Dixit (@Prashant_Dixit0): Build Matryoshka RAG with @llama_index These embedding models produce a range of embedding dims(768, 512, 256, 128, and 64). 🌟 Advantages ✅ Boosting retrieval Speed performance ✅ Reducing memory...
- Chat Uncensored AI | Rated 2024's Best Uncensored AI: What's New: Now with Uncensored Images! The latest & most advanced Uncensored AI (2024). No log in required, 100% private, Turbo Speed. Trusted by 10,000+ users worldwide.
- Dappier 2.0 - Combat AI data scraping & get paid for your content fairly | Product Hunt: Dappier is the world’s first online marketplace for AI content and data rights. Get paid fairly as your licensed content is accessed by AI companies around the world.
- fix: Add support for ollama module by bricefotzo · Pull Request #618 · testcontainers/testcontainers-python: Added a new class OllamaContainer with few methods to handle the Ollama container. The _check_and_add_gpu_capabilities method checks if the host has GPUs and adds the necessary capabilities to th...
- New Container: OllamaContainer · Issue #617 · testcontainers/testcontainers-python: Add support for the OllamaContainer to simplify running and testing LLMs through Ollama. What is the new container you'd like to have? I would like to request support for a new container: OllamaCo...
- Dappier is building a marketplace for publishers to sell their content to LLM builders | TechCrunch: Dappier, an early stage startup, is building a marketplace where publishers and data owners can sell access to their content to LLM builders.
LangChain AI ▷ #tutorials (1 messages):
- Testcontainers Python SDK adds Ollama support: A user announced that their pull request for adding support for Ollama in the Testcontainers Python SDK has been accepted and released in version 4.7.0. They included an example to help others get started quickly.
- fix: Add support for ollama module by bricefotzo · Pull Request #618 · testcontainers/testcontainers-python: Added a new class OllamaContainer with few methods to handle the Ollama container. The _check_and_add_gpu_capabilities method checks if the host has GPUs and adds the necessary capabilities to th...
- New Container: OllamaContainer · Issue #617 · testcontainers/testcontainers-python: Add support for the OllamaContainer to simplify running and testing LLMs through Ollama. What is the new container you'd like to have? I would like to request support for a new container: OllamaCo...
Modular (Mojo 🔥) ▷ #general (2 messages):
- Next Mojo Community Meeting Scheduled: The next Mojo Community meeting will take place on [local time]. For details, attendees can join the meeting via Zoom and access the agenda on Google Docs.
- Holiday Wishes: Happy holidays to those in Canada and those taking time off during the July 4 week in the U.S.!
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- [Public] Mojo Community Meeting: Mojo Community Meeting This doc link: https://modul.ar/community-meeting-doc This is a public document; everybody is welcome to view and comment / suggest. All meeting participants must adhere to th...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1806718451089817703
Modular (Mojo 🔥) ▷ #ai (11 messages🔥):
- Confusion over Mojolicious and Mojo: A user requested a code example in Mojo, and there was confusion when ModularBot provided a Perl-based Mojolicious example. Another member clarified that the inquiry was specifically about Mojo, the AI development language created by Modular in 2022.
- Clarification of Mojo: After further prodding, ModularBot acknowledged the mistake and discussed Mojo’s capabilities, comparing it to "a knight venturing into uncharted territories" with its enhanced abilities similar to Python but robust like C.
Modular (Mojo 🔥) ▷ #🔥mojo (12 messages🔥):
- Issues with Mojo SDK and Telemetry: Members discuss the Mojo SDK's telemetry collection, with one noting it can be disabled and sharing a link to the FAQ for more information. Another thanks them for the useful info.
- Connection Issue in Mojo REPL: A member observes that running REPL opens a connection without showing network traffic, which later closes unexpectedly. They confirm the issue and suggest opening a GitHub issue for further investigation.
- Discussion on Mojo Package Listing: A member runs a command to list Mojo packages, revealing the package details of mojo version 24.4.0. This spurs a conversation on their configuration and setup.
- Mojo Language Design Choices: A member notes the Io module's lack of functionality, requiring interfacing with Python to read from stdin. They ponder whether this is deliberate or if contributions to expand it would be accepted by Modular.
Link mentioned: Mojo🔥 FAQ | Modular Docs: Answers to questions we expect about Mojo.
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 38 https://www.modular.com/newsletters/modverse-weekly-38
Modular (Mojo 🔥) ▷ #nightly (4 messages):
- Graph API improvements missed in changelog: The latest release includes "integer literal slices and slicing across all dimensions" with some semantic restrictions. The team highlighted the importance of filing issues for tracking and addressing external interest in new features.
- Temporary solution for unsqueeze operation: For those needing to "unsqueeze", using
ops.unsqueeze(x, axis=-1)is suggested as a workaround. - MAX nightly releases back online: The MAX nightly releases are functional again, and users are encouraged to demo the Llama3 GUI Chatbot via the provided Discord link and share feedback.
- New Mojo nightly compiler released: A new nightly compiler version
2024.6.2805has been released, with notable updates including changes in LSP behavior. Users are instructed to update usingmodular update nightly/mojoand can check the raw diff and current changelog.
Torchtune ▷ #general (30 messages🔥):
- Community contributions to the model welcomed: "This is on our radar but we also welcome any community contribution of the model if someone wants to try to use the model right away."
- Weird behavior in text completions linked to EOS tokens: A user identified "super weird behavior" in continuations caused by "dataset adding eos tokens when encoding" as noted in this GitHub link.
- PreferenceDataset recommended for PPO implementation: When discussing dataset configurations, a user recommended using PreferenceDataset for RL where "reward model looks at how 'preferred' the whole input+response is". This contrasts with text completion dataset used for continued pretraining of single text bodies.
- Confusion cleared up around pretraining examples: Discussions clarified pretraining inputs and outputs, highlighting pretraining as involving whole documents where the model predicts tokens, penalizing wrong predictions, instead of handling segmented input-output pairs.
- Option to add EOS tokens considered reasonable: Users debated whether it makes sense to add an option for add_eos in the text completion dataset, concluding it is a practical idea and helped fix a PPO implementation issue.
Link mentioned: torchtune/torchtune/datasets/_text_completion.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #general (6 messages):
- Check out the evals workshop: A member shared a link to a discussion about an evals workshop, hinting at its importance. They also shared a GitHub link to Positron, a next-generation data science IDE.
- Seeking JSONL data editor: Two members expressed interest in a tool for iterating through and editing JSONL file examples directly within the same interface. One mentioned trying Lilac, which almost meets their needs but lacks direct editing capabilities.
- Summarizing patient records: A member is looking for tools or papers to generate structured summaries from patient records in JSON format, noting the need for methods different from text-to-text summarization. They are testing Llama models to avoid hallucinations and are seeking recommendations for prompt engineering and fine-tuning techniques.
Link mentioned: GitHub - posit-dev/positron: Positron, a next-generation data science IDE: Positron, a next-generation data science IDE. Contribute to posit-dev/positron development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (4 messages):
- LLAMA on Streamlit throws error: A member sought help with an error encountered after deploying LLAMA to Streamlit for an RAG application. They mentioned that the issue was not present locally but only emerged in the deployed environment.
- Missing credits in account: A member requested assistance with not receiving credits yet and provided their username and email for follow-up.
- Tinyllama custom dataset path error resolved: Initially, a member faced a
FileNotFoundErrorwhile finetuning Tinyllama with a custom dataset. They later resolved it by setting thepath: my_test.jsonlcorrectly without including thedata/directory.
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (2 messages):
- Broken Link Issues Resolved: A user mentioned that a link shared during a session was no longer working and requested an update. The issue was promptly acknowledged and fixed by another user.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (2 messages):
- Kishore requests assistance with credits: Kishore reported not receiving the credits and asked for help, providing his identifier
kishore-pv-reddy-ddc589.
- Christopher seeks credits for fireworks: Christopher also requested credits for fireworks and included his identifier
christopher-438388.
LLM Finetuning (Hamel + Dan) ▷ #predibase (2 messages):
- You’ve got mail!: A user pinged another member via DM on the Discord channel, asking them to check their messages. They used the plea emoji 🙏 to emphasize urgency.
- Predibase credits expiration query: A member asked if the Predibase credits would expire on July 4th. There was no response in the visible message history.
LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
- User awaiting OpenAI credits: A user posted that they haven't received their OpenAI credits yet. They provided their org ID org-NBiOyOKBCHTZBTdXBIyjNRy5 and relevant email addresses (karthikv2k@gmail.com and karthik@v2k.ai).
OpenInterpreter ▷ #general (14 messages🔥):
- Open Interpreter prioritizes security with open discussion: A member voiced concerns over Open Interpreter's security risks, leading to a detailed response about ongoing security measures such as user confirmation before code execution and sandboxing using Docker. The conversation emphasized transparency and community involvement to ensure the project's safety.
- Performance comparison of Code models: Members discussed the performance of various code models, noting that Codestral gives the best performance, while DeepSeek Coder is significantly faster but around 70% as good.
- DeepSeek Coder-v2-lite praised for speed and code capability: A member expressed a preference for DeepSeek Coder-v2-lite due to its fast performance and coding efficiency, suggesting it might be better than Qwen-1.5b.
- Quantized model support inquiry: There was an inquiry about running a SMOL multi-modal model for image understanding in a quantized form due to RAM limitations, highlighting a need for efficiency in resource-constrained environments.
- YouTube video exposes Rabbit R1 security flaw: A YouTube video titled "Rabbit R1 makes catastrophic rookie programming mistake" was shared, revealing that Rabbit R1's codebase contains hardcoded API keys, compromising user data security.
Link mentioned: Rabbit R1 makes catastrophic rookie programming mistake: A group of jailbreakers recently discovered that the Rabbit R1 codebase contains hardcoded API keys - giving them easy access to user data from their AI tech...
OpenInterpreter ▷ #O1 (3 messages):
- Run OpenInterpreter locally with modifications: A member explained that running OpenInterpreter locally with non-OpenAI providers requires some changes. They detailed the necessary differences in a GitHub issue comment.
- APIs default to OpenAI: It's noted that by default, the system likely uses OpenAI's API, potentially GPT-4 Turbo. However, specifics weren't confirmed as it hasn't been reviewed in a while.
- Concerns about additional API costs: Another member expressed concerns about additional charges when using the API, which are separate from the subscription costs.
Link mentioned: Litellm/01 is unable to connect to non-openAI providers. · Issue #272 · OpenInterpreter/01: What causes the issue: Run 01 specifying any non OAI server-host and api key Expected: Be able to connect to other services like Groq, Anthropic, OpenRouter etc as the seem to be working with the b...
tinygrad (George Hotz) ▷ #general (7 messages):
- Finished port supports finetuning: A member announced the completion of a port, mentioning that it now works with finetunes as well. This indicates progress and potential new capabilities in their project.
- FPGA-based systems for energy-efficient robotics: Another member detailed their 8-month project focusing on energy-efficient humanoid robots. They emphasized the cost-effectiveness and logical approach of using FPGA-based systems to achieve large DRAM space with decent inference speed.
- Humanoid robots' battery consumption on GenAI: The same member pointed out that humanoid robots currently consume a lot of battery power on GenAI, which is inefficient given the use of 3-4 GPU-based SOMs per robot. They implied that the current setup is not sustainable.
- Utility of JSON/YAML in tinygrad: A user proposed making tinygrad capable of reading models from a JSON/YAML file, suggesting it could simplify configuration. Another member responded that models are already saved and loaded in dict form.
- Current model storage mechanisms: George Hotz clarified that safetensors are used for weights and pickle for compute in tinygrad. This highlights the project's current approach to model storage.
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- Shapetracker enables zero-cost tensor reshaping: Members discussed the capabilities of the Shapetracker as explained in a blog post. One member noted, "if you have to reshape a huge tensor, the underlying data in the memory doesn’t have to change, just how you access it needs to change."
- Questions about mask solving: In the context of Shapetracker, a member asked for clarification on what problems masks solve. They connected this query to understanding shape and strides in memory representation.
- Curiosity about Shapetracker's origin: A member expressed curiosity whether the logic behind Shapetracker was invented from scratch or inspired by other deep learning compilers. They marveled at how sophisticated it is, "most frameworks optimize with strides, but shapetracker allows arbitrary movement ops with no copies at all."
Link mentioned: How ShapeTracker works: Tutorials on tinygrad
Cohere ▷ #general (7 messages):
- Internships at Cohere Spark Interest: A student doing research on LLMs and Reinforcement Learning seeks insights into the work and culture at Cohere, asking for DMs from current employees. Another member noted the difficulty of securing internships at major AI companies, emphasizing the need for a substantial public portfolio.
- Wish List for Cohere: A member inquired if there are any features people wish to be added to Cohere.
- AI Automation for Blogging: One member asked for help setting up AI-powered automations to create blogs and post on social platforms. They were redirected to another channel for assistance.
- Showcasing AI Built with Cohere and Langchain: A member shared their LinkedIn post about creating a Data Analyst Agent using Cohere and Langchain.
OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
- Support for Gemma2 with Sample Packing: A member shared a GitHub pull request supporting Gemma2 with sample packing. They are waiting on an upstream Hugging Face fix linked within the PR.
- 27b Model Underwhelms in Benchmarks: A user mentioned that the 27b model is surprisingly underwhelming in benchmarks compared to the 9b model, hinting at performance issues with the larger model.
Link mentioned: support for gemma2 w sample packing by winglian · Pull Request #1718 · OpenAccess-AI-Collective/axolotl: Description Motivation and Context How has this been tested? Screenshots (if appropriate) Types of changes Social Handles (Optional)
AI Stack Devs (Yoko Li) ▷ #ai-companion (3 messages):
- Featherless.ai launches model access platform: Recently, a new platform was launched by Featherless.ai to provide access to over 450+ models on Hugging Face for a flat subscription starting at $10/month. The platform boasts features like no GPU setup/download required, OpenAI compatible API access, and new models added weekly with competitive pricing tiers.
- Subscription Plans Detailed: Featherless.ai offers two subscription tiers: Feather Basic at $10/month for up to 15B models and Feather Premium at $25/month for up to 72B models. Both plans offer unlimited personal use, with Feather Premium extending benefits to larger model sizes and private, secure, and anonymous usage.
- Feedback Request for Prioritizing Models: Community feedback is sought on which models to prioritize for addition to the Featherless platform. The platform’s early adopters mainly use it for AI persona local apps and more specific uses like language finetuning and SQL models.
Link mentioned: Featherless - Serverless LLM: Featherless - The latest LLM models, serverless and ready to use at your request.
Datasette - LLM (@SimonW) ▷ #ai (3 messages):
- Request for Over-Time Elo Data: A user inquired if there was "an over-time dataset or view of the chatbot arena elo numbers." They noted that the available JSON data only spans around six weeks.
- Pack catching up: The timeline mentioned starts from May 19th, and it was observed that the "pack" is catching up at the top.
MLOps @Chipro ▷ #events (1 messages):
- Webinar on Enterprise-Scale Feature Store: There is an upcoming webinar titled "Building an Enterprise-Scale Feature Store with Featureform and Databricks" on Tuesday, July 23rd at 8 A.M. PT. The session will feature Simba Khadder, who will discuss simplifying feature engineering, leveraging Databricks, and best practices for managing large-scale data, with a Q&A to follow. Sign up here.
Link mentioned: Building an Enterprise-Scale Feature Store with Featureform and Databricks: Join our 1-hr webinar with Featureform's founder to learn how to empower your data by using Featureform and Databricks!