[AINews] Tencent's Hunyuan-Large claims to beat DeepSeek-V2 and Llama3-405B with LESS Data
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Evol-instruct synthetic data is all you need.
AI News for 11/4/2024-11/5/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 3533 messages) for you. Estimated reading time saved (at 200wpm): 364 minutes. You can now tag @smol_ai for AINews discussions!
We tend to apply a high bar for Chinese models, especially from previously-unknown teams. But Tencent 's release today (huggingface,paper here, HN comments) is notable in its claims versus known SOTA open-weights models:
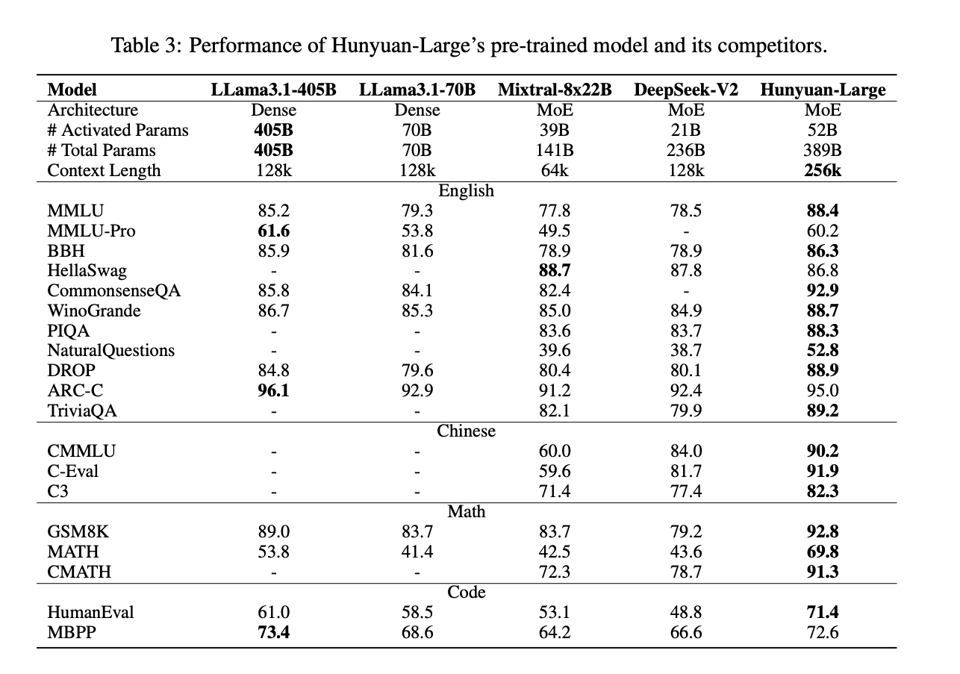
Remarkably for a >300B param model (MoE regardless), it is very data efficient, being pretrained on "only" 7T tokens (DeepseekV2 was 8T, Llama3 was 15T), with 1.5T of them being synthetic data generated via Evol-Instruct, which the Wizard-LM team did not miss:

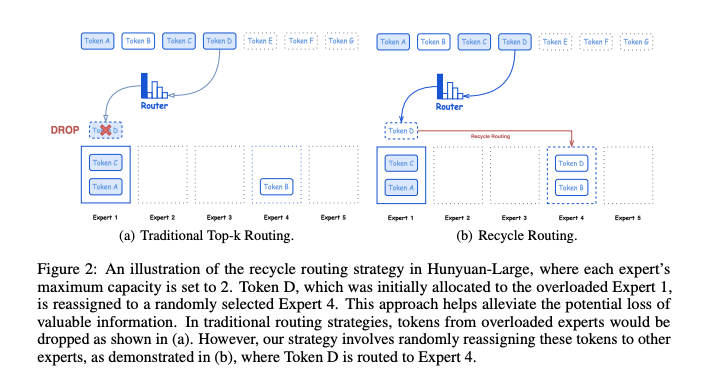
The paper offers decent research detail on some novel approaches they explored, including "recycle routing":
and expert-specific LRs

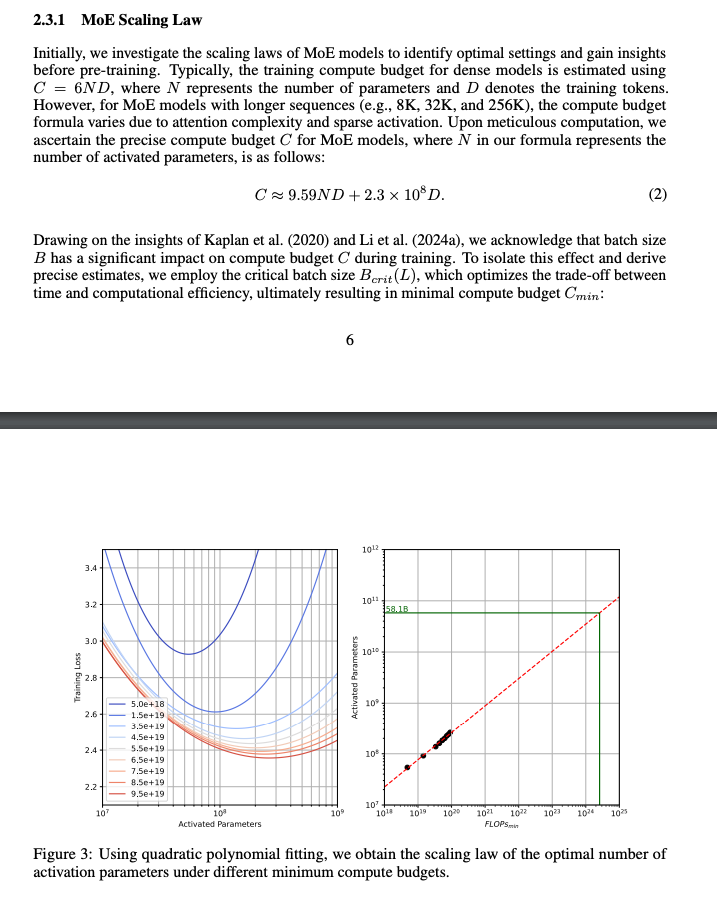
The even investigate and offer a compute-efficient scaling law for MoE active params:
The story isn't wholly positive: the custom license forbids users in the EU and >100M MAU companies, and of course don't ask them China-sensitive questions. Vibe checks aren't in yet (we don't find anyone hosting an easy public endpoint) but nobody is exactly shouting from the rooftops about it. Still it is a nice piece of research for this model class.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- aider (Paul Gauthier) Discord
- Eleuther Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- Latent Space Discord
- Notebook LM Discord Discord
- Stability.ai (Stable Diffusion) Discord
- Nous Research AI Discord
- Interconnects (Nathan Lambert) Discord
- OpenAI Discord
- LlamaIndex Discord
- Cohere Discord
- OpenInterpreter Discord
- Modular (Mojo 🔥) Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- Torchtune Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- Mozilla AI Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (1094 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (3 messages):
- HuggingFace ▷ #i-made-this (29 messages🔥):
- HuggingFace ▷ #reading-group (1 messages):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #NLP (3 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (364 messages🔥🔥):
- Perplexity AI ▷ #sharing (20 messages🔥):
- Perplexity AI ▷ #pplx-api (1 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (340 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (4 messages):
- aider (Paul Gauthier) ▷ #announcements (6 messages):
- aider (Paul Gauthier) ▷ #general (171 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (74 messages🔥🔥):
- Eleuther ▷ #general (5 messages):
- Eleuther ▷ #research (130 messages🔥🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (10 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (100 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (25 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- LM Studio ▷ #general (67 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (53 messages🔥):
- Latent Space ▷ #ai-general-chat (85 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (37 messages🔥):
- Notebook LM Discord ▷ #general (48 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (71 messages🔥🔥):
- Nous Research AI ▷ #general (59 messages🔥🔥):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Interconnects (Nathan Lambert) ▷ #events (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
- Interconnects (Nathan Lambert) ▷ #random (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (10 messages🔥):
- OpenAI ▷ #ai-discussions (21 messages🔥):
- OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- OpenAI ▷ #prompt-engineering (4 messages):
- OpenAI ▷ #api-discussions (4 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (38 messages🔥):
- Cohere ▷ #discussions (10 messages🔥):
- Cohere ▷ #questions (13 messages🔥):
- Cohere ▷ #api-discussions (7 messages):
- OpenInterpreter ▷ #general (19 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- OpenInterpreter ▷ #ai-content (1 messages):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (14 messages🔥):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (12 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #other-llms (1 messages):
- Torchtune ▷ #dev (4 messages):
- Torchtune ▷ #papers (1 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Updates
- Claude 3.5 Haiku Enhancements: @AnthropicAI announced that Claude 3.5 Haiku is now available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI, positioning it as the fastest and most intelligent cost-efficient model to date. @ArtificialAnlys analyzed that Claude 3.5 Haiku has increased intelligence but noted its price surge, making it 10x more expensive than competitors like Google's Gemini Flash and OpenAI's GPT-4o mini. Additionally, @skirano shared that Claude 3.5 Haiku is one of the most fun models to use, outperforming previous Claude models on various tasks.
- Meta's Llama AI for Defense: @TheRundownAI reported that Meta has opened Llama AI to the U.S. defense sector, marking a significant collaboration in the AI landscape.
AI Tools and Infrastructure
- Transforming Meeting Recordings: @TheRundownAI introduced a tool to transform meeting recordings into actionable insights, enhancing productivity and information accessibility.
- Llama Impact Hackathon: @togethercompute and @AIatMeta are hosting a hackathon focused on building solutions with Llama 3.1 & 3.2 Vision, offering a $15K prize pool and encouraging collaboration on real-world challenges.
- LlamaIndex Chat UI: @llama_index unveiled LlamaIndex chat-ui, a React component library for building chat interfaces, featuring Tailwind CSS customization and integrations with LLM backends like Vercel AI.
AI Research and Benchmarks
- MLX LM Advancements: @awnihannun highlighted that the latest MLX LM generates text faster with very large models and introduces KV cache quantization for improved efficiency.
- Self-Evolving RL Framework: @omarsar0 proposed a self-evolving online curriculum RL framework that significantly improves the success rate of models like Llama-3.1-8B, outperforming models such as GPT-4-Turbo.
- LLM Evaluation Survey: @sbmaruf released a systematic survey on evaluating Large Language Models, addressing challenges and recommendations essential for robust model assessment.
AI Industry Events and Hackathons
- AI High Signal Updates: @TheRundownAI shared top AI stories, including Meta’s Llama AI for defense, Anthropic’s Claude Haiku 3.5 release, and funding news like Physical Intelligence landing $400M.
- Builder's Day Recap: @ai_albert__ recapped the first Builder's Day event with @MenloVentures, highlighting the talent and collaboration among developers.
- ICLR Emergency Reviewers Needed: @savvyRL called for emergency reviewers for topics like LLM reasoning and code generation, emphasizing the urgent need for expert reviews.
AI Pricing and Market Reactions
- Claude 3.5 Haiku Pricing Controversy: @omarsar0 expressed concerns over the price jump of Claude 3.5 Haiku, questioning the value proposition compared to other models like GPT-4o-mini and Gemini Flash. Similarly, @bindureddy criticized the 4x price increase, suggesting it doesn't align with performance improvements.
- Python 3.11 Performance Boost: @danielhanchen advocated for upgrading to Python 3.11, detailing its 1.25x faster performance on Linux and 1.2x on Mac, alongside improvements like optimized frame objects and function call inlining.
- Tencent’s Synthetic Data Strategy: @_philschmid discussed Tencent's approach of training their 389B parameter MoE on 1.5 trillion synthetic tokens, highlighting its performance over models like Llama 3.1.
Memes and Humor
- AI and Election Humor: @francoisfleuret humorously requested GPT to remove tweets not about programming and kittens for three days and produce a cheerful summary of events.
- Funny Model Behaviors: @reach_vb shared a humorous observation of an audio-generating model going "off the rails," while @hyhieu226 tweeted jokingly about specific AI responses.
- User Interactions and Reactions: @nearcyan posted a meme related to politics, while @kylebrussell shared a lighthearted "vibes" tweet.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Tencent's Hunyuan-Large: A Game Changer in Open Source Models
- Tencent just put out an open-weights 389B MoE model (Score: 336, Comments: 132): Tencent released an open-weights 389B MoE model called Hunyuan-Large, which is designed to compete with Llama in performance. The model architecture utilizes Mixture of Experts (MoE), allowing for efficient scaling and improved capabilities in handling complex tasks.
- The Hunyuan-Large model boasts 389 billion parameters with 52 billion active parameters and can handle up to 256K tokens. Users noted its potential for efficient CPU utilization, with some running similar models effectively on DDR4 and expressing excitement over the model's capabilities compared to Llama variants.
- Discussions highlighted the massive size of the model, with estimates for running it suggesting 200-800 GB of memory required, depending on the configuration. Users also shared performance metrics, indicating that it may outperform models like Llama3.1-70B while still being cheaper to serve due to its Mixture of Experts (MoE) architecture.
- Concerns arose regarding hardware limitations, especially in light of GPU sanctions in China, leading to questions about how Tencent manages to run such large models. Users speculated about the need for a high-end setup, with some jokingly suggesting the need for a nuclear plant to power the required GPUs.
Theme 2. Tensor Parallelism Enhances Llama Models: Benchmark Insights
- PSA: llama.cpp patch doubled my max context size (Score: 95, Comments: 10): A recent patch to llama.cpp has doubled the maximum context size for users employing 3x Tesla P40 GPUs from 60K tokens to 120K tokens when using row split mode (
-sm row). This improvement also led to more balanced VRAM usage across the GPUs, enhancing overall GPU utilization without impacting inference speed, as detailed in the pull request.- Users with 3x Tesla P40 GPUs reported significant improvements in their workflows due to the increased context size from 60K to 120K tokens. One user noted that the previous limitations forced them to use large models with small contexts, which hindered performance, but the patch allowed for more efficient model usage.
- Several comments highlighted the ease of implementation with the new patch, with one user successfully loading 16K context on QWEN-2.5-72B_Q4_K_S, indicating that performance remained consistent with previous speeds. Another user expressed excitement about the improved handling of cache while using the model by row.
- Users shared tips on optimizing GPU performance, including a recommendation to use nvidia-pstated for managing power states of the P40s. This tool helps maintain lower power consumption (8-10W) while the GPUs are loaded and idle, contributing to overall efficiency.
- 4x RTX 3090 + Threadripper 3970X + 256 GB RAM LLM inference benchmarks (Score: 48, Comments: 39): The user conducted benchmarks on a build featuring 4x RTX 3090 GPUs, a Threadripper 3970X, and 256 GB RAM for LLM inference. Results showed that models like Qwen2.5 and Mistral Large performed with varying tokens per second (tps), with tensor parallel implementations significantly enhancing performance, as evidenced by PCIe transfer rates increasing from 1 kB/s to 200 kB/s during inference.
- Users discussed the stability of power supplies, with kryptkpr recommending the use of Dell 1100W supplies paired with breakout boards for reliable power delivery, achieving 12.3V at idle. They also shared links to reliable breakout boards for PCIe connections.
- There was a suggestion from Lissanro to explore speculative decoding alongside tensor parallelism using TabbyAPI (ExllamaV2), highlighting the potential performance gains when using models like Qwen 2.5 and Mistral Large with aggressive quantization techniques. Relevant links to these models were also provided.
- a_beautiful_rhind pointed out that Exllama does not implement NVLink, which limits its performance capabilities, while kmouratidis prompted further testing under different PCIe configurations to assess potential throttling impacts.
Theme 3. Competitive Advances in Coding Models: Qwen2.5-Coder Analysis
- So where’s Qwen2.5-Coder-32B? (Score: 76, Comments: 21): The Qwen2.5-Coder-32B version is in preparation, aiming to compete with leading proprietary models. The team is also investigating advanced code-centric reasoning models to enhance code intelligence, with further updates promised on their blog.
- Users expressed skepticism about the Qwen2.5-Coder-32B release timeline, with comments highlighting that the phrase "Coming soon" has been in use for two months without substantial updates.
- A user, radmonstera, shared their experience using Qwen2.5-Coder-7B-Base for autocomplete alongside a 70B model, noting that the 32B version could offer reduced RAM usage but may not match the speed of the 7B model.
- There is a general anticipation for the release, with one user, StarLord3011, hoping for it to be available within a few weeks, while another, visionsmemories, humorously acknowledged a potential oversight in the release process.
- Coders are getting better and better (Score: 170, Comments: 71): Users are increasingly adopting Qwen2.5 Coder 7B for local large language model (LLM) applications, noting its speed and accuracy. One user reports successful implementation on a Mac with LM Studio.
- Users report high performance from Qwen2.5 Coder 7B, with one user running it on an M3 Max MacBook Pro achieving around 18 tokens per second. Another user emphasizes that the Qwen 2.5 32B model outperforms Claude in various tasks, despite some skepticism about local LLM coders' capabilities compared to Claude and GPT-4o.
- The Supernova Medius model, based on Qwen 2.5 14B, is highlighted as an effective coding assistant, with users sharing links to the model's GGUF and original weights here. Users express interest in the potential of a dedicated 32B coder.
- Discussions reveal mixed experiences with Qwen 2.5, with some users finding it good for basic tasks but lacking in more complex coding scenarios compared to Claude and OpenAI's models. A user mentions that while Qwen 2.5 is solid for offline use, it does not match the capabilities of more advanced closed models like GPT-4o.
Theme 4. New AI Tools: Voice Cloning and Speculative Decoding Techniques
- OuteTTS-0.1-350M - Zero shot voice cloning, built on LLaMa architecture, CC-BY license! (Score: 69, Comments: 13): OuteTTS-0.1-350M features zero-shot voice cloning using the LLaMa architecture and is released under a CC-BY license. This model represents a significant advancement in voice synthesis technology, enabling the generation of voice outputs without prior training on specific voice data.
- The OuteTTS-0.1-350M model utilizes the LLaMa architecture, benefiting from optimizations in llama.cpp and offering a GGUF version available on Hugging Face.
- Users highlighted the zero-shot voice cloning capability as a significant advancement in voice synthesis technology, with a link to the official blog providing further details.
- The discussion touched on the audio uncanny valley phenomenon in TTS systems, where minor errors lead to outputs that are almost human-like, resulting in an unsettling experience for listeners.
- OpenAI new feature 'Predicted Outputs' uses speculative decoding (Score: 51, Comments: 28): OpenAI's new 'Predicted Outputs' feature utilizes speculative decoding, a concept previously demonstrated over a year ago in llama.cpp. The post raises questions about the potential for faster inference with larger models like 70b size models and smaller models such as llama3.2 and qwen2.5, especially for local users. For further details, see the tweet here and the demo by Karpathy here.
- Speculative decoding could significantly enhance inference speed by allowing smaller models to generate initial token sequences quickly, which the larger models can then verify. Users like Ill_Yam_9994 and StevenSamAI discussed how this method effectively allows for parallel processing, potentially generating multiple tokens in the time it typically takes to generate one.
- Several users highlighted that while the 'Predicted Outputs' feature might reduce latency, it may not necessarily lower costs for model usage, as noted by HelpfulHand3. The technique is recognized as a standard for on-device inference, but proper training of the smaller models is crucial for maximizing performance, as mentioned by Old_Formal_1129.
- The conversation included thoughts on layering models, where smaller models could predict outputs that larger models verify, potentially leading to significant speed improvements, as proposed by Balance-. This layered approach raises questions about the effectiveness and feasibility of integrating multiple model sizes for optimal performance.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Autonomous Systems & Safety
- Volkswagen's Emergency Assist Technology: In /r/singularity, Volkswagen demonstrated new autonomous driving technology that safely pulls over vehicles when drivers become unresponsive, with multiple phases of driver attention checks before activation.
- Key comment insight: System includes careful attention to avoiding false activations and maintaining driver control.
AI Security & Vulnerabilities
- Google's Big Sleep AI Agent: In /r/OpenAI and /r/singularity, Google's security AI discovered a zero-day vulnerability in SQLite, marking the first public example of an AI agent finding a previously unknown exploitable memory-safety issue in widely-used software.
- Technical detail: Vulnerability was reported and patched in October before official release.
3D Avatar Generation & Rendering
- URAvatar Technology: In /r/StableDiffusion and /r/singularity, new research demonstrates photorealistic head avatars using phone scans with unknown illumination, featuring:
- Real-time rendering with global illumination
- Learnable radiance transfer for light transport
- Training on hundreds of high-quality multi-view human scans
- 3D Gaussian representation
Industry Movements & Corporate AI
- OpenAI Developments: Multiple posts across subreddits indicate:
- Accidental leak of full O1 model with vision capabilities
- Hiring of META's AR glasses head for robotics and consumer hardware
- Teasing of new image model capabilities
AI Image Generation Critique
- Adobe AI Limitations: In /r/StableDiffusion, users report significant content restrictions in Adobe's AI image generation tools, particularly around human subjects and clothing.
- Technical limitation: System blocks even basic image editing tasks due to overly aggressive content filtering.
Memes & Humor
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Giants Drop Mega Models: The New Heavyweights
- Tencent Unleashes 389B-Parameter Hunyuan-Large MoE Model: Tencent released Hunyuan-Large, a colossal mixture-of-experts model with 389 billion parameters and 52 billion activation parameters. While branded as open-source, debates swirl over its true accessibility and the hefty infrastructure needed to run it.
- Anthropic Rolls Out Claude 3.5 Haiku Amid User Grumbles: Anthropic launched Claude 3.5 Haiku, with users eager to test its performance in speed, coding accuracy, and tool integration. However, the removal of Claude 3 Opus sparked frustration, as many preferred it for coding and storytelling.
- OpenAI Shrinks GPT-4 Latency with Predicted Outputs: OpenAI introduced Predicted Outputs, slashing latency for GPT-4o models by providing a reference string. Benchmarks show up to 5.8x speedup in tasks like document iteration and code rewriting.
Theme 2. Defense, Meet AI: LLMs Enlist in National Security
- Scale AI Deploys Defense Llama for Classified Missions: Scale AI announced Defense Llama, a specialized LLM developed with Meta and defense experts, targeting American national security applications. The model is ready for integration into US defense systems.
- Nvidia's Project GR00T Aims for Robot Overlords: Jim Fan from NVIDIA's GEAR team discussed Project GR00T, aiming to develop AI agents capable of operating in both simulated and real-world environments, enhancing generalist abilities in robotics.
- OpenAI's Commitment to Safe AGI Development: Members highlighted OpenAI's founding goal of building safe and beneficial AGI, as stated since 2015. Discussions included concerns about AI self-development if costs surpass all human investment.
Theme 3. Open Data Bonanza: Datasets Set to Supercharge AI
- Open Trusted Data Initiative Teases 2 Trillion Token Dataset: The Open Trusted Data Initiative plans to release a massive multilingual dataset of 2 trillion tokens on November 11th via Hugging Face, aiming to boost LLM training capabilities.
- Community Debates Quality vs. Quantity in Training Data: Discussions emphasized the importance of high-quality datasets for future AI models. Concerns were raised that prioritizing quality might exclude valuable topics, but it could enhance commonsense reasoning.
- EleutherAI Enhances LLM Robustness Evaluations: A pull request was opened for LLM Robustness Evaluation, introducing systematic consistency and robustness evaluations across three datasets and fixing previous bugs.
Theme 4. Users Rage Against the Machines: AI Tools Under Fire
- Perplexity Users Mourn the Loss of Claude 3 Opus: The removal of Claude 3 Opus from Perplexity AI led to user frustration, with many claiming it was their go-to model for coding and storytelling. Haiku 3.5 is perceived as a less effective substitute.
- LM Studio Users Battle Glitches and Performance Issues: LM Studio users report challenges with model performance, including inconsistent results from Hermes 405B and difficulties running the software from USB drives. Workarounds involve using Linux AppImage binaries.
- NotebookLM Users Demand Better Language Support: Multilingual support issues in NotebookLM result in summaries generated in unintended languages. Users call for a more intuitive interface to manage language preferences directly.
Theme 5. AI Optimization Takes Center Stage: Speed and Efficiency
- Speculative Decoding Promises Faster AI Outputs: Discussions around speculative decoding highlight a method where smaller models generate drafts that larger models refine, improving inference times. While speed increases, questions remain about output quality.
- Python 3.11 Supercharges AI Performance by 1.25x: Upgrading to Python 3.11 offers up to 1.25x speedup on Linux and 1.12x on Windows, thanks to optimizations like statically allocated core modules and inlined function calls.
- OpenAI's Predicted Outputs Rewrites the Speed Script: By introducing Predicted Outputs, OpenAI cuts GPT-4 response times, with users reporting significant speedups in code rewriting tasks.
PART 1: High level Discord summaries
HuggingFace Discord
-
Open Trusted Data Initiative's 2 Trillion Token Multilingual Dataset: Open Trusted Data Initiative is set to release the largest multilingual dataset containing 2 trillion tokens on November 11th via Hugging Face.
- This dataset aims to significantly enhance LLM training capabilities by providing extensive multilingual resources for developers and researchers.
- Computer Vision Model Quantization Techniques: A member is developing a project focused on quantizing computer vision models to achieve faster inference on edge devices using both quantization aware training and post training quantization methods.
- The initiative emphasizes reducing model weights and understanding the impact on training and inference performance, garnering interest from the community.
- Release of New Microsoft Models: There is excitement within the community regarding the new models released by Microsoft, which have met the expectations of several members.
- These models are recognized for addressing specific desired functionalities, enhancing the toolkit available to AI engineers.
- Speculative Decoding in AI Models: Discussions around speculative decoding involve using smaller models to generate draft outputs that larger models refine, aiming to improve inference times.
- While this approach boosts speed, there are ongoing questions about maintaining the quality of outputs compared to using larger single models.
- Challenges in Building RAG with Chroma Vector Store: A user is attempting to build a Retrieval-Augmented Generation (RAG) system with 21 documents but is encountering issues storing embeddings in the Chroma vector store, successfully saving only 7 embeddings.
- Community members suggested checking for potential error messages and reviewing default function arguments to ensure documents are not being inadvertently dropped.
Perplexity AI Discord
-
Opus Removal Sparks User Frustration: Users voiced their disappointment over the removal of Claude 3 Opus, highlighting it as their preferred model for coding and storytelling on the Anthropic website.
- Many are requesting a rollback to the previous model or alternatives, as Haiku 3.5 is perceived to be less effective.
- Perplexity Pro Enhances Subscription Benefits: Discussions around Perplexity Pro Features revealed that Pro subscribers gain access to premium models through partnerships like the Revolut referral.
- Questions remain about whether the Pro tier includes Claude access and the recent updates to the mobile application.
- Debate Over Grok 2 vs. Claude 3.5 Sonnet: Engineers are debating which model, Grok 2 or Claude 3.5 Sonnet, offers superior performance for complex research and data analysis.
- Perplexity is praised for its strengths in academic contexts, while models like GPT-4o excel in coding and creative tasks.
- Nvidia Targets Intel with Strategic Market Moves: Nvidia is strategically positioning itself to compete directly with Intel, aiming to shift market dynamics and influence product strategies.
- Analysts recommend monitoring upcoming collaborations and product releases from Nvidia that could significantly impact the tech landscape.
- Breakthrough in Molecular Neuromorphic Platforms: A new molecular neuromorphic platform mimics human brain function, representing a significant advancement in AI and neurological research.
- Experts express cautious optimism about the platform's potential to deepen our understanding of human cognition and enhance AI development.
OpenRouter (Alex Atallah) Discord
-
Anthropic Rolls Out Claude 3.5 Haiku: Anthropic has launched Claude 3.5 in both standard and self-moderated versions, with additional dated options available here.
- Users are eager to evaluate the model's performance in real-world applications, anticipating improvements in speed, coding accuracy, and tool integration.
- Access Granted to Free Llama 3.2 Models: Llama 3.2 models, including 11B and 90B, now offer free fast endpoints, achieving 280tps and 900tps respectively see details.
- This initiative is expected to enhance community engagement with open-source models by providing higher throughput options at no cost.
- New PDF Analysis Feature in Chatroom: A new feature allows users to upload or attach PDFs in the chatroom for analysis using any model on OpenRouter.
- Additionally, the maximum purchase limit has been increased to $10,000, providing greater flexibility for users.
- Predicted Output Feature Reduces Latency: Predicted output is now available for OpenAI's GPT-4 models, optimizing edits and rewrites through the
predictionproperty.
- An example code snippet demonstrates its application for more efficient processing of extensive text requests.
- Hermes 405B Shows Inconsistent Performance: The free version of Hermes 405B has been performing inconsistently, with users reporting intermittent functionality.
- Many users remain hopeful that these performance issues indicate ongoing updates or fixes are in progress.
aider (Paul Gauthier) Discord
-
Aider v0.62.0 Launch: Aider v0.62.0 now fully supports Claude 3.5 Haiku, achieving a 75% score on the code editing leaderboard. This release enables seamless file edits sourced from web LLMs like ChatGPT.
- Additionally, Aider generated 84% of the code in this release, demonstrating significant efficiency improvements.
- Claude 3.5 Haiku vs. Sonnet: Claude 3.5 Haiku delivers nearly the same performance as Sonnet, but is more cost-effective. Users can activate Haiku by using the
--haikucommand option.
- This cost-effectiveness is making Haiku a preferred choice for many in their AI coding workflows.
- Comparison of AI Coding Models: Users analyzed performance disparities among AI coding models, highlighting that 3.5 Haiku is less effective compared to Sonnet 3.5 and GPT-4o.
- Anticipation is building around upcoming models like 4.5o that could disrupt current standards and impact Anthropic's market presence.
- Predicted Outputs Feature Impact: The launch of OpenAI's Predicted Outputs is expected to revolutionize GPT-4o models by reducing latency and enhancing code editing efficiency, as noted in OpenAI Developers' tweet.
- This feature is projected to significantly influence model benchmarks, especially when compared directly with competing models.
- Using Claude Haiku as Editor Model: Claude 3 Haiku is being leveraged as an editor model to compensate for the main model's weaker editing capabilities, enhancing the development process.
- This approach is especially beneficial for programming languages that demand precise syntax management.
Eleuther Discord
-
Initiative Drives Successful Reading Groups: A member emphasized that successfully running reading groups relies more on initiative than expertise, initiating the mech interp reading group without prior knowledge and consistently maintaining it.
- This approach underscores the importance of proactive leadership and community engagement in sustaining effective learning sessions.
- Optimizing Training with Advanced Settings: Participants debated the implications of various optimizer settings such as beta1 and beta2, and their compatibility with strategies like FSDP and PP during model training.
- Diverse viewpoints highlighted the balance between training efficiency and model performance.
- Enhancing Logits and Probability Optimizations: There was an in-depth discussion on optimizing logits outputs and determining appropriate mathematical norms for training, suggesting the use of the L-inf norm for maximizing probabilities or maintaining distribution shapes via KL divergence.
- Participants explored methods to fine-tune model outputs for improved prediction accuracy and stability.
- LLM Robustness Evaluation PR Enhances Framework: A member announced the opening of a PR for LLM Robustness Evaluation across three different datasets, inviting feedback and comments, viewable here.
- The PR introduces systematic consistency and robustness evaluations for large language models while addressing previous bugs.
Unsloth AI (Daniel Han) Discord
-
Python 3.11 Boosts Performance by 1.25x on Linux: Users are encouraged to switch to Python 3.11 as it delivers up to 1.25x speedup on Linux and 1.12x on Windows through various optimizations.
- Core modules are statically allocated for faster loading, and function calls are now inlined, enhancing overall performance.
- Qwen 2.5 Supported in llama.cpp with Upcoming Vision Integration: Discussion confirms that Qwen 2.5 is supported in llama.cpp, as detailed in the Qwen documentation.
- The community is anticipating the integration of vision models in Unsloth, which is expected to be available soon.
- Fine-Tuning LLMs on Limited Datasets: Users are exploring the feasibility of fine-tuning models with only 10 examples totaling 60,000 words, specifically for punctuation correction.
- Advice includes using a batch size of 1 to mitigate challenges associated with limited data.
- Implementing mtbench Evaluations with Hugging Face Metrics: A member inquired about reference implementations for callbacks to run mtbench-like evaluations on the mtbench dataset, asking if a Hugging Face evaluate metric exists.
- There is a need for streamlined evaluation processes, emphasizing the importance of integrating such functionality into current projects.
- Enhancing mtbench Evaluation with Hugging Face Metrics: Requests were made for insights on implementing a callback for running evaluations on the mtbench dataset, similar to existing mtbench evaluations.
- The inquiry highlights the desire for efficient evaluation mechanisms within ongoing AI engineering projects.
LM Studio Discord
-
Portable LM Studio Solutions: A user inquired about running LM Studio from a USB flash drive, receiving suggestions to utilize Linux AppImage binaries or a shared script to achieve portability.
- Despite the absence of an official portable version, community members provided workarounds to facilitate portable LM Studio deployments.
- LM Studio Server Log Access: Users discovered that pressing CTRL+J in LM Studio opens the server log tab, enabling real-time monitoring of server activities.
- This quick-access feature was shared to assist members in effectively tracking and debugging server performance.
- Model Performance Evaluation: Mistral vs Qwen2: Mistral Nemo outperforms Qwen2 in Vulkan-based operations, demonstrating faster token processing speeds.
- This performance disparity highlights the impact of differing model architectures on computational efficiency.
- Windows Scheduler Inefficiencies: Members reported that the Windows Scheduler struggles with CPU thread management in multi-core setups, affecting performance.
- One member recommended manually setting CPU affinity and priority for processes to mitigate scheduling issues.
- LLM Context Management Challenges: Context length significantly impacts inference speed in LLMs, with one user noting a delay of 39 minutes for the first token with large contexts.
- Optimizing context fill levels during new chat initiations was suggested to improve inference responsiveness.
Latent Space Discord
-
Hume App Launch Blends EVI 2 & Claude 3.5: The new Hume App combines voices and personalities generated by the EVI 2 speech-language model with Claude 3.5 Haiku, aiming to enhance user interaction through AI-generated assistants.
- Users can now access these assistants for more dynamic interactions, as highlighted in the official announcement.
- OpenAI Reduces GPT-4 Latency with Predicted Outputs: OpenAI has introduced Predicted Outputs, significantly decreasing latency for GPT-4o and GPT-4o-mini models by providing a reference string for faster processing.
- Benchmarks show speed improvements in tasks like document iteration and code rewriting, as noted by Eddie Aftandilian.
- Supermemory AI Tool Manages Your Digital Brain: A 19-year-old developer launched Supermemory, an AI tool designed to manage bookmarks, tweets, and notes, functioning like a ChatGPT for saved content.
- With a chatbot interface, users can easily retrieve and explore previously saved content, as demonstrated by Dhravya Shah.
- Tencent Releases Massive Hunyuan-Large Model: Tencent has unveiled the Hunyuan-Large model, an open-weight Transformer-based mixture of experts model featuring 389 billion parameters and 52 billion activation parameters.
- Despite being labeled as open-source, debates persist about its status, and its substantial size poses challenges for most infrastructure companies, as detailed in the Hunyuan-Large paper.
- Defense Llama: AI for National Security: Scale AI announced Defense Llama, a specialized LLM developed in collaboration with Meta and defense experts, targeting American national security applications.
- The model is now available for integration into US defense systems, highlighting advancements in AI for security, as per Alexandr Wang.
Notebook LM Discord Discord
-
NotebookLM Expands Integration Capabilities: Members discussed the potential for NotebookLM to integrate multiple notebooks or sources, aiming to enhance its functionality for academic research. The current limitation of 50 sources per notebook was a key concern, with references to NotebookLM Features.
- There was a strong interest in feature enhancements to support data sharing across notebooks, reflecting the community's eagerness for improved collaboration tools and a clearer development roadmap.
- Deepfake Technology Raises Ethical Questions: A user highlighted the use of 'Face Swap' in a deodorant advertisement, pointing to the application of deepfake technologies in marketing efforts. This was further discussed in the context of Deepfake Technology.
- Another participant emphasized that deepfakes inherently involve face swapping, fostering a shared understanding of the ethical implications and the need for responsible usage of such technologies.
- Managing Vendor Data with NotebookLM: A business owner explored using NotebookLM to manage data for approximately 1,500 vendors, utilizing various sources including pitch decks. They mentioned having a data team ready to assist with imports, as detailed in Vendor Database Management Use Cases.
- Concerns were raised about data sharing across notebooks, highlighting the need for robust data management features to ensure security and accessibility within large datasets.
- Audio Podcast Generation in NotebookLM: NotebookLM introduced an audio podcast generation feature, which members received positively for its convenience in multitasking. Users inquired about effective utilization strategies, as discussed in Audio Podcast Generation Features.
- The community showed enthusiasm for the podcast functionality, suggesting potential use cases and requesting best practices to maximize its benefits in various workflows.
- Challenges with Language Support in NotebookLM: Several members reported issues with multilingual support in NotebookLM, where summaries were generated in unintended languages despite settings configured for English. This was a primary topic in Language and Localization Issues.
- Suggestions were made to improve the user interface for better language preference management, emphasizing the need for a more intuitive process to change language settings directly.
Stability.ai (Stable Diffusion) Discord
-
SWarmUI Simplifies ComfyUI Setup: Members recommended installing SWarmUI to streamline ComfyUI deployment, highlighting its ability to manage complex configurations.
- One member emphasized, "It's designed to make your life a whole lot easier.", showcasing the community's appreciation for user-friendly interfaces.
- Challenges of Cloud Hosting Stable Diffusion: Discussions revealed that hosting Stable Diffusion on Google Cloud can be more intricate and expensive compared to local setups.
- Participants suggested alternatives like GPU rentals from vast.ai as cost-effective and simpler options for deploying models.
- Latest Models and LoRas on Civitai: Users explored downloading recent models such as 1.5, SDXL, and 3.5 from Civitai, noting that most LoRas are based on 1.5.
- Older versions like v1.4 were considered obsolete, with the community advising upgrades to benefit from enhanced features and performance.
- Animatediff Tutorial Resources Shared: A member requested tutorials for Animatediff, receiving recommendations to consult resources on Purz's YouTube channel.
- The community expressed enthusiasm for sharing knowledge, reinforcing a collaborative learning environment around animation tools.
- ComfyUI Now Supports Video AI via GenMo's Mochi: Confirmation was made that ComfyUI integrates video AI capabilities through GenMo's Mochi, though it requires substantial hardware.
- This integration is viewed as a significant advancement, potentially expanding the horizons of video generation using Stable Diffusion technologies.
Nous Research AI Discord
-
Hermes 2.5 Dataset's 'Weight' Field Questioned: Members analyzed the Hermes 2.5 dataset's 'weight' field, finding it contributes minimally and results in numerous empty fields.
- There was speculation that optimizing dataset sampling could improve its utility for smaller LLMs.
- Nous Research Confirms Hermes Series Remains Open: In response to inquiries about closed source LLMs, Nous Research affirmed that the Hermes series will continue to be open source.
- While some future projects may adopt a closed model, the commitment to openness persists for the Hermes line.
- Balancing Quality and Quantity in Future AI Models: Discussions emphasized the importance of high-quality datasets for the development of future AI models.
- Concerns were raised that prioritizing quality might exclude valuable topics and facts, although it could enhance commonsense reasoning.
- OmniParser Introduced for Enhanced Data Parsing: The OmniParser tool was shared, known for improving data parsing capabilities.
- Its innovative approach has garnered attention within the AI community.
- Hertz-Dev Releases Full-Duplex Conversational Audio Model: The Hertz-Dev GitHub repository launched the first base model for full-duplex conversational audio.
- This model aims to facilitate speech-to-speech interactions within a single framework, enhancing audio communications.
Interconnects (Nathan Lambert) Discord
-
NeurIPS Sponsorship Push: A member announced their efforts to secure a sponsor for NeurIPS, signaling potential collaboration opportunities.
- They also extended an invitation for a NeurIPS group dinner, aiming to enhance networking among attendees during the conference.
- Tencent Releases 389B MoE Model: Tencent unveiled their 389B Mixture of Experts (MoE) model, making significant waves in the AI community.
- Discussions highlighted that the model’s advanced functionality could set new benchmarks for large-scale model performance, as detailed in their paper.
- Scale AI Launches Defense Llama: Scale AI introduced Defense Llama, a specialized LLM designed for military applications within classified networks, as covered by DefenseScoop.
- The model is intended to support operations such as combat planning, marking a move towards integrating AI into national security frameworks.
- YOLOv3 Paper Highly Recommended: A member emphasized the importance of the YOLOv3 paper, stating it's essential reading for practitioners.
- They remarked, 'If you haven't read the YOLOv3 paper you're missing out btw', underlining its relevance in the field.
- LLM Performance Drift Investigation: Discussion emerged around creating a system or paper to fine-tune a small LLM or classifier that monitors model performance drift in tasks like writing.
- Members debated the effectiveness of existing prompt classifiers in accurately tracking drift, emphasizing the need for robust evaluation pipelines.
OpenAI Discord
-
GPT-4o Rollout introduces o1-like reasoning: The rollout of GPT-4o introduces o1-like reasoning capabilities and includes large blocks of text in a canvas-style box.
- There is confusion among members whether this rollout is an A/B test with the regular GPT-4o or a specialized version for specific uses.
- OpenAI's commitment to safe AGI development: A member highlights that OpenAI was founded with the aim of building safe and beneficial AGI, a mission declared since its inception in 2015.
- Discussions include concerns that if AI development costs surpass all human investment, it could lead to AI self-development, raising significant implications.
- GPT-5 Announcement Date Uncertain: Community members are curious about the release of GPT-5 and its accompanying API but acknowledge that the exact timeline is unknown.
- It’s supposed to be some new release this year, but it won't be GPT-5, one member stated.
- Premium Account Billing Issues: A user reported experiencing issues with their Premium account billing, noting that their account still displays as a free plan despite proof of payment from Apple.
- Another member attempted to assist using a shared link, but the issue remains unresolved.
- Hallucinations in Document Summarization: Members expressed concerns about hallucinations occurring during document summarization, especially when scaling the workflow in production environments.
- To mitigate inaccuracies, one member suggested implementing a second LLM pass for fact-checking.
LlamaIndex Discord
-
LlamaIndex chat-ui Integration: Developers can quickly create a chat UI for their LLM applications using LlamaIndex chat-ui with pre-built components and Tailwind CSS customization, integrating seamlessly with LLM backends like Vercel AI.
- This integration streamlines chat implementation, enhancing development efficiency for AI engineers working on conversational interfaces.
- Advanced Report Generation Techniques: A new blog post and video explores advanced report generation, including structured output definition and advanced document processing, essential for optimizing enterprise reporting workflows.
- These resources provide AI engineers with deeper insights into enhancing report generation capabilities within LLM applications.
- NVIDIA Competition Submission Deadline: The submission deadline for the NVIDIA competition is November 10th, offering prizes like an NVIDIA® GeForce RTX™ 4080 SUPER GPU for projects submitted via this link.
- LlamaIndex technologies are encouraged to be leveraged by developers to create innovative LLM applications for rewards.
- LlamaParse Capabilities and Data Retention: LlamaParse is a closed-source parsing tool that offers efficient document transformation into structured data with a 48-hour data retention policy, as detailed in the LlamaParse documentation.
- Discussions highlighted its performance benefits and impact of data retention on repeated task processing, referencing the Getting Started guide.
- Multi-Modal Integration with Cohere's ColiPali: An ongoing PR aims to add ColiPali as a reranker in LlamaIndex, though integrating it as an indexer is challenging due to multi-vector indexing requirements.
- The community is actively working on expanding LlamaIndex's multi-modal data handling capabilities, highlighting collaboration efforts with Cohere.
Cohere Discord
-
Connectors Issues: Members are reporting that connectors fail to function correctly when using the Coral web interface or API, resulting in zero results from reqres.in.
- One user noted that the connectors take longer than expected to respond, with response times exceeding 30 seconds.
- Cohere API Fine-Tuning and Errors: Fine-tuning the Cohere API requires entering card details and switching to production keys, with users needing to prepare proper prompt and response examples for SQL generation.
- Additionally, some members reported encountering 500 errors when running fine-tuned classify models via the API, despite successful operations in the playground environment.
- Prompt Tuner Development on Wordpress: A user asked about recreating the Cohere prompt tuner on a Wordpress site using the API.
- Another member suggested developing a custom backend application, indicating that Wordpress can support such integrations. Refer to Login | Cohere for access to advanced LLMs and NLP tools.
- Embedding Models in Software Testing: Members discussed the application of the embed model in software testing tasks to enhance testing processes.
- Clarifications were sought on how embedding can specifically assist in these testing tasks.
- GCP Marketplace Billing Concerns: A user raised questions about the billing process after activating Cohere via the GCP Marketplace and obtaining an API key.
- They sought clarification on whether charges would be applied to their GCP account or the registered card, expressing a preference for model-specific billing.
OpenInterpreter Discord
-
Microsoft’s Omniparser Integration: A member inquired about integrating Microsoft's Omniparser, highlighting its potential benefits for the open-source mode. Another member confirmed that they are actively exploring this integration.
- The discussion emphasized leveraging Omniparser's capabilities to enhance the system's parsing efficiency.
- Claude's Computer Use Integration: Members discussed integrating Claude's Computer Use within the current
--osmode, with confirmation that it has been incorporated. The conversation highlighted an interest in using real-time previews for improved functionality.
- Participants expressed enthusiasm about the seamless integration, noting that real-time previews could significantly enhance user experience.
- Standards for Agents: A member proposed creating a standard for agents, citing the cleaner setup of LMC compared to Claude's interface. They suggested collaboration between OpenInterpreter (OI) and Anthropic to establish a common standard compatible with OAI endpoints.
- The group discussed the feasibility of a unified standard, considering compatibility requirements with existing OAI endpoints.
- Haiku Performance in OpenInterpreter: A member inquired about the performance of the new Haiku in OpenInterpreter, mentioning they have not tested it yet. This reflects the community's ongoing interest in evaluating the latest tools.
- There was consensus that testing the Haiku performance is crucial for assessing its effectiveness and suitability within various workflows.
- Tool Use Package Enhancements: The
Tool Usepackage has been updated with two new free tools: ai prioritize and ai log, which can be installed viapip install tool-use-ai. These tools aim to streamline workflow and productivity.
- Community members are encouraged to contribute to the Tool Use GitHub repository, which includes detailed documentation and invites ongoing AI tool improvements.
Modular (Mojo 🔥) Discord
-
Reminder: Modular Community Q&A on Nov 12: A reminder was issued to submit questions for the Modular Community Q&A scheduled on November 12th, with optional name attribution.
- Members are encouraged to share their inquiries through the submission form to participate in the upcoming community meeting.
- Call for Projects and Talks at Community Meeting: Members were invited to present projects, give talks, or propose ideas during the Modular Community Q&A.
- This invitation fosters community engagement and allows contributions to be showcased at the November 12th meeting.
- Implementing Effect System in Mojo: Discussions on integrating an effect system in Mojo focused on marking functions performing syscalls as block, potentially as warnings by default.
- Suggestions included introducing a 'panic' effect for static management of sensitive contexts within the Mojo language.
- Addressing Matrix Multiplication Errors in Mojo: A user reported multiple errors in their matrix multiplication implementation, including issues with
memset_zeroandrandfunction calls in Mojo.
- These errors highlight problems related to implicit conversions and parameter specifications in the function definitions.
- Optimizing Matmul Kernel Performance: A user noted that their Mojo matmul kernel was twice as slow as the C version, despite similar vector instructions.
- Considerations are being made regarding optimization and the impact of bounds checking on performance.
DSPy Discord
-
New Election Candidate Research Tool Released: A member introduced the Election Candidate Research Tool to streamline electoral candidate research ahead of the elections, highlighting its user-friendly features and intended functionality.
- The GitHub repository encourages community contributions, aiming to enhance voter research experience through collaborative development.
- Optimizing Few-Shot with BootstrapFewShot: Members explored using BootstrapFewShot and BootstrapFewShotWithRandomSearch optimizers to enhance few-shot examples without modifying existing prompts, promoting flexibility in example combinations.
- These optimizers provide varied few-shot example combinations while preserving the main instructional content, facilitating improved few-shot learning performance.
- VLM Support Performance Celebrations: A member commended the team's efforts on VLM support, recognizing its effectiveness and positive impact on the project's performance metrics.
- Their acknowledgment underscores the successful implementation and enhancement of VLM support within the project.
- DSPy 2.5.16 Struggles with Long Inputs: Concerns arose about DSPy 2.5.16 using the Ollama backend, where lengthy inputs lead to incorrect outputs by mixing input and output fields, indicating potential bugs.
- An SQL extraction example demonstrated how long inputs cause unexpected placeholders in predictions, pointing to issues in input/output parsing.
- Upcoming DSPy Version Testing: A member plans to test the latest DSPy version, moving away from the conda-distributed release to investigate the long input handling issue.
- They intend to report their findings post-testing, indicating an ongoing effort to resolve parsing concerns in DSPy.
OpenAccess AI Collective (axolotl) Discord
-
Distributed Training of LLMs: A member initiated a discussion on using their university's new GPU fleet for distributed training of LLMs, focusing on training models from scratch.
- Another member suggested providing resources for both distributed training and pretraining to assist in their research project.
- Kubernetes for Fault Tolerance: A proposal was made to implement a Kubernetes cluster to enhance fault tolerance in the GPU system.
- Members discussed the benefits of integrating Kubernetes with Axolotl for better management of distributed training tasks.
- Meta Llama 3.1 Model: Meta Llama 3.1 was highlighted as a competitive open-source model, with resources provided for fine-tuning and training using Axolotl.
- Members were encouraged to review a tutorial on fine-tuning that details working with the model across multiple nodes.
- StreamingDataset PR: A member recalled a discussion about a PR on StreamingDataset, inquiring if there was still interest in it.
- This indicates ongoing discussions and development around cloud integrations and dataset handling.
- Firefly Model: Firefly is a fine-tune of Mistral Small 22B, designed for creative writing and roleplay, supporting contexts up to 32,768 tokens.
- Users are cautioned about the model's potential to generate explicit, disturbing, or offensive responses, and usage should be responsible. They are advised to view content here before proceeding with any access or downloads.
Torchtune Discord
-
DistiLLM Optimizes Teacher Probabilities: The discussion focused on subtracting teacher probabilities within DistiLLM's cross-entropy optimization, detailed in the GitHub issue. It was highlighted that the constant term can be ignored since the teacher model remains frozen.
- A recommendation was made to update the docstring to clarify that the loss function assumes a frozen teacher model.
- KD-div vs Cross-Entropy Clarification: Concerns arose about labeling KD-div when the actual returned value is cross-entropy, potentially causing confusion when comparing losses like KL-div.
- It’s noted that framing this process as optimizing for cross-entropy better aligns with the transition from hard labels in training to soft labels produced by the teacher model.
- TPO Gaining Momentum: A member expressed enthusiasm for TPO, describing it as impressive and planning to integrate a tracker.
- Positive anticipation surrounds TPO's functionalities and its potential applications.
- VinePPO Implementation Challenges: While appreciating VinePPO for its reasoning and alignment strengths, a member cautioned that its implementation might lead to significant challenges.
- The potential difficulties in deploying VinePPO were emphasized, highlighting risks associated with its integration.
tinygrad (George Hotz) Discord
-
TokenFormer Integration with tinygrad: A member successfully ported a minimal implementation of TokenFormer to tinygrad, available on the GitHub repository.
- This adaptation aims to enhance inference and learning capabilities within tinygrad, showcasing the potential of integrating advanced model architectures.
- Dependency Resolution in Views: A user inquired whether the operation
x[0:1] += x[0:1]depends onx[2:3] -= ones((2,))or justx[0:1] += ones((2,))concerning true or false share rules.
- This discussion raises technical considerations about how dependencies are tracked in operation sequences within tinygrad.
- Hailo Reverse Engineering for Accelerator Development: A member announced the commencement of Hailo reverse engineering efforts to create a new accelerator, focusing on process efficiency.
- They expressed concerns about the kernel compilation process, which must compile ONNX and soon Tinygrad or TensorFlow to Hailo before execution.
- Kernel Consistency in tinygrad Fusion: A user is investigating if kernels in tinygrad remain consistent across runs when fused using
BEAM=2.
- They aim to prevent the overhead of recompiling the same kernel by emphasizing the need for effective cache management.
LLM Agents (Berkeley MOOC) Discord
-
Lecture 9 on Project GR00T: Today's Lecture 9 for the LLM Agents MOOC is scheduled at 3:00pm PST and will be live streamed, featuring Jim Fan discussing Project GR00T, NVIDIA's initiative for generalist robotics.
- Jim Fan's team within GEAR is developing AI agents capable of operating in both simulated and real-world environments, focusing on enhancing generalist abilities.
- Introduction to Dr. Jim Fan: Dr. Jim Fan, Research Lead at NVIDIA's GEAR, holds a Ph.D. from Stanford Vision Lab and received the Outstanding Paper Award at NeurIPS 2022.
- His work on multimodal models for robotics and AI agents proficient in playing Minecraft has been featured in major publications like New York Times, Forbes, and MIT Technology Review.
- Course Resources for LLM Agents: All course materials, including livestream URLs and homework assignments, are available online.
- Students are encouraged to ask questions in the dedicated course channel.
Mozilla AI Discord
-
DevRoom Doors Open for FOSDEM 2025: Mozilla is hosting a DevRoom at FOSDEM 2025 from February 1-2, 2025 in Brussels, focusing on open-source presentations.
- Talk proposals can be submitted until December 1, 2024, with acceptance notifications by December 15.
- Deadline Looms for Talk Proposals: Participants have until December 1, 2024 to submit their talk proposals for the FOSDEM 2025 DevRoom.
- Accepted speakers will be notified by December 15, ensuring ample preparation time.
- Volunteer Vistas Await at FOSDEM: An open call for volunteers has been issued for FOSDEM 2025, with travel sponsorships available for European participants.
- Volunteering offers opportunities for networking and supporting the open-source community at the event.
- Topic Diversity Drives FOSDEM Talks: Suggested topics for FOSDEM 2025 presentations include Mozilla AI, Firefox innovations, and Privacy & Security, among others.
- Speakers are encouraged to explore beyond these areas, with talk durations ranging from 15 to 45 minutes, including Q&A.
- Proposal Prep Resources Released: Mozilla shared a resource with tips on creating successful proposals, accessible here.
- This guide aims to help potential speakers craft impactful presentations at FOSDEM 2025.
Gorilla LLM (Berkeley Function Calling) Discord
-
Benchmarking Retrieval-Based Function Calls: A member is benchmarking a retrieval-based approach to function calling and is seeking a collection of available functions and their definitions.
- They specifically requested these definitions to be organized per test category for more effective indexing.
- Function Definition Indexing Discussion: A member emphasized the need for an indexed collection of function definitions to enhance benchmarking efforts.
- They highlighted the importance of categorizing these functions per test category to streamline their workflow.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (1094 messages🔥🔥🔥):
AI Model IntegrationTemperature Settings in LLMsPhonons and Material ScienceSpeculative DecodingDigital Ethnographic Research
-
Integrating Hugging Face into Discord: Users discussed ways to integrate Hugging Face functionalities into Discord servers, exploring the possibility of embedding HF models or creating user level validation systems.
- Recommendations included using level bots for user verification as a potential solution.
- Understanding Temperature Settings in Models: Chat participants delved into the significance of temperature settings in LLMs, highlighting that higher temperatures lead to increased randomness and variability in model outputs.
- They noted that while this can enhance creativity, it must be tested carefully to avoid poor response quality.
- Phonons and Their Role in Material Science: Discussion on phonons highlighted their importance in explaining thermal conductivity and their parallels with light particles, revealing insights into material properties.
- References to new research on phonons in quasicrystals illustrated evolving understanding in the intersection of physics and material science.
- Speculative Decoding in AI: Participants explored the concept of speculative decoding, where a smaller model generates quick draft outputs that a larger model refines for accuracy, enhancing inference times.
- It was noted that while this approach improves speed, questions remain about maintaining output quality compared to larger single models.
- Digital Ethnographic Research Techniques: A user indicated their interest in conducting digital ethnographic research on online communities, emphasizing the need to analyze community dynamics and user interactions.
- Responses included suggestions on studying community norms and engaging deeply with the chosen online group.
Links mentioned:
- minchyeom/birthday-2 · Hugging Face: no description found
- LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding: We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher ...
- Banishing LLM Hallucinations Requires Rethinking Generalization: Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance betwe...
- Real Monster GIF - Real Monster Scared - Discover & Share GIFs: Click to view the GIF
- Flavor Flav Fight The Power GIF - Flavor Flav Fight The Power Glasses - Discover & Share GIFs: Click to view the GIF
- Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent: In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation param...
- Cat Wait Waiting Cat GIF - Cat wait Waiting cat Wait - Discover & Share GIFs: Click to view the GIF
- Chicken Run GIF - Chicken Run Panic - Discover & Share GIFs: Click to view the GIF
- Introduction - Hugging Face NLP Course: no description found
- Spongebob Patrick GIF - Spongebob Patrick Patrick Star - Discover & Share GIFs: Click to view the GIF
- Sponge Bob Squid Ward GIF - Sponge Bob Squid Ward Rich - Discover & Share GIFs: Click to view the GIF
- Peter Griffin GIF - Peter Griffin Family Guy - Discover & Share GIFs: Click to view the GIF
- FlyWire: no description found
- The Universe Tim And Eric Mind Blown GIF - The Universe Tim And Eric Mind Blown Mind Blown Meme - Discover & Share GIFs: Click to view the GIF
- Family Guy Peter Griffin GIF - Family Guy Peter Griffin I Have Spoken - Discover & Share GIFs: Click to view the GIF
- Sips Tea The Boys GIF - Sips Tea The Boys Smile - Discover & Share GIFs: Click to view the GIF
- Kanye West Stare GIF - Kanye West Stare Serious - Discover & Share GIFs: Click to view the GIF
- David Warner Tron Sark GIF - David Warner Tron Sark David Warner - Discover & Share GIFs: Click to view the GIF
- tencent/Tencent-Hunyuan-Large · Hugging Face: no description found
- Hugging Face for Excel: Inference models and spaces on Hugging Face from Excel custom functions for free.
- South Park GIF - South Park Moses - Discover & Share GIFs: Click to view the GIF
- The Deep Deep Thoughts GIF - The Deep Deep Thoughts Deep Thoughts With The Deep - Discover & Share GIFs: Click to view the GIF
- Zano (drone) - Wikipedia: no description found
- Sigh Homelander GIF - Sigh Homelander The boys - Discover & Share GIFs: Click to view the GIF
- the answer to life, universe and everything is .. 42: no description found
- Go Ahead I'M All Ears GIF - Go ahead i'm all ears - Discover & Share GIFs: Click to view the GIF
- Water Bears under the microscope: Water bears (tardigrades) shown under the microscope under different magnifications.Water bears are microscopic animals that resemble bears with 4 pairs of l...
- Reddit - Dive into anything: no description found
- How large language models work, a visual intro to transformers | Chapter 5, Deep Learning: Breaking down how Large Language Models workInstead of sponsored ad reads, these lessons are funded directly by viewers: https://3b1b.co/support---Here are a...
- Hugging Face - Learn: no description found
- Aloe Blacc - I Need A Dollar: no description found
- Cute Pinch GIF - Cute Pinch So Fluffy - Discover & Share GIFs: Click to view the GIF
- Golden Ratio in Quasicrystal Vibrations: Experiments show that a property of the vibrations in a quasicrystal is linked to the number known as the golden ratio.
- Bringing Open-Source Models to Spreadsheets 🚀: no description found
- BangumiBase (BangumiBase): no description found
- Fifth-place winner of Small World in Motion: A baby tardigrade riding a nematode.
HuggingFace ▷ #today-im-learning (3 messages):
FastBert TokenizerAutoTokenizer Comparison
-
FastBert Tokenizer receives praise: A member shared that they learned HuggingFace's FastBert tokenizer is great, expressing positive sentiment with a smiley face.
- The tokenizer has garnered attention for its performance and ease of use.
- Differences between AutoTokenizer and FastBert: A member queried about the difference between AutoTokenizer and FastBert, seeking clarity on their functionalities.
- Another member clarified that AutoTokenizer automatically selects a tokenizer based on the model, while FastBert specifically refers to a tokenizer tool.
HuggingFace ▷ #cool-finds (3 messages):
ShellCheckOpen Trusted Data InitiativeLargest multilingual datasetAud2Stm2Mdi
-
ShellCheck for Shell Script Analysis: ShellCheck is a static analysis tool designed for shell scripts, providing detailed insights and error checking.
- Its repository on GitHub highlights its functionality, making it a vital tool for shell script developers.
- Exciting Announcement for Open Data: It's exciting to announce that @pleiasfr will co-lead the Open Trusted Data Initiative with @thealliance_ai, releasing a massive multilingual dataset of 2 trillion tokens on November 11th.
- This dataset will be available on Hugging Face and aims to advance LLM training efforts.
- Innovative Tool Aud2Stm2Mdi: A member shared a link to the Aud2Stm2Mdi tool on Hugging Face, which appears to be a refreshing addition to AI tooling.
- This tool could be beneficial for users looking to enhance their audio processing capabilities with AI.
Links mentioned:
- Tweet from Alexander Doria (@Dorialexander): Happy to announce that @pleiasfr is joining @thealliance_ai to Co-lead the Open Trusted Data Initiative. We will release on November 11th the largest multilingual fully open dataset for LLM training w...
- Audio to Stems to MIDI Converter - a Hugging Face Space by eyov: no description found
- GitHub - koalaman/shellcheck: ShellCheck, a static analysis tool for shell scripts: ShellCheck, a static analysis tool for shell scripts - koalaman/shellcheck
HuggingFace ▷ #i-made-this (29 messages🔥):
Computer Vision Model QuantizationDocker Learning SeriesMusic Bot DevelopmentText2Text Model for SummarizationCommunity Feedback Implementation
-
Side Project on Quantizing Computer Vision Models: A member is working on a side project to quantize computer vision models for faster inference on edge devices. They plan to use both quantization aware training and post training quantization approaches, focusing initially on reducing model weights.
- They highlighted the importance of understanding how reducing dimensions affects training and inference, drawing interest from others in the community.
- Mini-Series on Docker Learning: A member has started a mini-series called 𝟭𝗺𝗶𝗻𝗗𝗼𝗰𝗸𝗲𝗿, covering Docker concepts in bite-sized articles on DEV Community. The series aims to take readers from the basics to expert-level concepts, with five articles published so far.
- Topics include Docker installation, fundamental concepts, and learning to build and push a Docker image.
- Gary Andreessen Music Bot: A member shared their humorous project, a music bot named gary-andreessen, which utilizes a pipeline to create audio-visual clips from Marc Andreessen's talks. The bot functions on both Discord and Twitter, generating responses and audio continuations based on user interactions.
- Users can engage the bot with YouTube links, and it attempts to humorously respond to comments, showcasing the chaotic nature of the project while encouraging community interaction.
- Initial Version of Text2Text Model: A member has released an initial version of a text2text model designed for 'map-reduce' summarization of text chunks. The model is accessible on Hugging Face and aims to streamline the summarization process.
- The effort reflects ongoing interest in leveraging AI for efficient text processing within the community.
- Implementation of Community Suggestions: A developer acknowledged and implemented community feedback regarding improving content display in their application. The suggestion was well received, highlighting the importance of community-driven enhancements.
- Members expressed enthusiasm for these collaborative improvements, showcasing an engaging interaction culture.
Links mentioned:
- Unexex: Engaging AI-crafted courses for modern learners.
- Tweet from gary andreessen (@thepatch_gary): in the future are ppl rly gonna be editing videos
- Tweet from thecollabagepatch (@thepatch_kev): yes i may have gone insane. here's what happens in a conversation thread with the bot gary andressen if you mention him and include a youtube url with the timestamp you want. if you like what he...
- GitHub - betweentwomidnights/gary-andreessen: Contribute to betweentwomidnights/gary-andreessen development by creating an account on GitHub.
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- GitHub - AstraBert/1minDocker: A blog about Docker, to build your expertise from the fundamentals to the most advanced concepts!: A blog about Docker, to build your expertise from the fundamentals to the most advanced concepts! - AstraBert/1minDocker
- Posts: A blog about Docker, to build your expertise from the fundamentals to the most advanced concepts!
HuggingFace ▷ #reading-group (1 messages):
west_ryder: 😝
HuggingFace ▷ #computer-vision (3 messages):
HuggingModNew Microsoft Models
-
HuggingMod needs to slow down: <@169078428635627520> was advised to slow their posting pace a bit due to concerns about message volume.
- A friendly reminder was shared with an emoji to lighten the tone.
- Excitement over new models from Microsoft: <@790597705117204530> inquired whether others have seen the new models from Microsoft that were released.
- <@gettygermany> confirmed that Microsoft has developed exactly what was desired.
HuggingFace ▷ #NLP (3 messages):
Building RAGChroma Vector Store IssuesOpenAI EmbeddingsCode References
-
Challenges Storing Embeddings in Chroma: A user is attempting to build a RAG with 21 documents but faces issues storing embeddings in the Chroma vector store, managing to store only 7 embeddings.
- Another member inquired if an error occurred and suggested checking the default arguments in the function to determine if it drops remaining documents.
- Seeking Code Examples for RAG: The original user requested if anyone had previously worked on a similar project and could share code snippets for reference.
- This highlights the need for community support and resource-sharing in AI development endeavors.
HuggingFace ▷ #diffusion-discussions (1 messages):
Diffusion with Categorical InputsNew architectures in Diffusion Models
-
Exploring Diffusion for Categorical Inputs: A member expressed interest in applying diffusion methods to categorical inputs and referenced the paper titled Diffusion for Categorical Data.
- They asked if anyone had experience with this architecture or similar approaches in their experiments.
- Call for Experiences with New Diffusion Architectures: The same member inquired if others have played with the proposed architecture mentioned in the paper about diffusion techniques for categorical inputs.
- They encouraged sharing insights or discussions related to experimenting with this new approach.
Perplexity AI ▷ #announcements (1 messages):
U.S. Presidential race trackingElection hub
-
Perplexity tracks U.S. Presidential race results: The Perplexity Team announced that they will be tracking U.S. Presidential race results state-by-state, with live counts on their election hub.
- This initiative aims to provide up-to-the-minute information on the election process for users.
- Live counts from state-by-state results: The election hub will feature live counts from each state, ensuring users receive timely updates as results come in.
- This effort reflects a commitment to transparency and accessibility in following the presidential race.
Perplexity AI ▷ #general (364 messages🔥🔥):
Opus RemovalPerplexity Pro FeaturesModel ComparisonsPerplexity BugsUser Feedback
-
Opus Removal Causes User Frustration: Users express disappointment over the removal of Claude 3 Opus, with many stating it was their preferred model for coding and storytelling.
- Suggestions arise for reverting to the previous model or seeking alternatives as Haiku 3.5 is viewed as inferior.
- Insights on Perplexity Pro Features: Several users discuss their Pro subscription benefits, including access to premium models through deals like those with Revolut.
- Questions and curiosity remain regarding whether Pro includes access to Claude and the changes made in the mobile app.
- Evaluating Model Effectiveness: Debates occur on which model, Grok 2 or Claude 3.5 Sonnet, is more effective for complex research and data comprehension.
- Users highlight that while GPT-4o and ChatGPT handle coding and creative tasks well, Perplexity shines in academic contexts.
- Bugs Hindering User Experience: Perplexity is currently experiencing bugs, causing confusion with model outputs and limiting user interaction with Opus.
- Users report frustrations with models reverting to GPT-4 responses despite selecting others, causing a need for prompt adjustments.
- User Feedback and Suggestions: Users discuss the importance of feedback in improving the Perplexity experience, suggesting space custom instructions be integrated more effectively.
- There’s an emphasis on the need for user-friendly updates in the mobile and macOS applications to enhance the overall functionality.
Links mentioned:
- Introducing the next generation of Claude: Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order ...
- Rolls Royce Royce GIF - Rolls royce Rolls Royce - Discover & Share GIFs: Click to view the GIF
- Tweet from Perplexity (@perplexity_ai): Perplexity now supports @AnthropicAI's Claude 3.5 Haiku (released yesterday) as a replacement for Claude 3 Opus. Retiring Claude 3 Opus keeps Perplexity up-to-date on the latest models from Anthr...
- Tweet from Anthropic (@AnthropicAI): Claude 3 Haiku remains available for use cases that benefit from image input or its lower price point. https://docs.anthropic.com/en/docs/about-claude/models#model-names
- You were invited | Revolut United Kingdom: You were invited to Revolut
- Complexity - Perplexity AI Supercharged - Chrome Web Store: ⚡ Supercharge your Perplexity AI
- Perplexity Supply: Where curiosity meets quality. Our premium collection features thoughtfully designed apparel for the the curious. From heavyweight cotton essentials to embroidered pieces, each item reflects our dedic...
Perplexity AI ▷ #sharing (20 messages🔥):
Siberian CratersChemistry Rule DebunkedHuman Brain on a ChipNvidia's Market MovesAI's Upcoming Changes
-
Mysterious Siberian Craters Explored: A YouTube video discusses the phenomenon of mysterious Siberian craters, which have intrigued scientists and explorers alike. The video aims to uncover the causes and implications of these geological formations.
- Viewers are invited to delve into the mysteries of the Siberian landscape for more insights.
- 100-Year Chemistry Rule Busted: A link discusses the recent findings that debunk a century-old chemistry rule, stirring excitement in the scientific community. This challenge to conventional wisdom highlights new interpretations in chemical processes.
- Community commentary emphasizes the implications for future research and practices in chemistry.
- Human Brain on a Chip: A Breakthrough: An article introduces the concept of a molecular neuromorphic platform designed to imitate brain function, paving the way for advanced AI and neurological research. This technology aims to enhance our understanding of human cognition.
- Experts express cautious optimism about the potential of this platform in revolutionizing AI development.
- Nvidia Set to Challenge Intel: Recent reports reveal that Nvidia is positioning itself to directly compete with Intel, hinting at exciting developments in the tech industry. This shift may influence market dynamics and product strategies moving forward.
- Analysts suggest watching for potential collaborations and product announcements from Nvidia that could elevate its position.
- AI is Transforming the Landscape: An article outlines upcoming changes in AI, emphasizing how these shifts will affect various fields. These expected developments promise to alter perceptions and applications of AI technologies.
- Experts in the field are eagerly discussing the potential impact on society and industries reliant on AI.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (1 messages):
canarywolfs: Same here. Filled it a long ago. Even filled it again but nothing...🙁
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
Claude 3.5 HaikuFree Llama 3.2 modelsPDF functionality in ChatroomSporadic timeout investigationPredicted output for latency
-
Claude 3.5 Haiku released.: Anthropic launched Claude 3.5 in both standard and self-moderated variants, with additional dated options available here.
- We're excited to see how this latest model performs in real-world applications.
- Free access to Llama 3.2 models.: The Llama 3.2 models, including 11B and 90B, now offer a fast endpoint for free, achieving 280tps and 900tps respectively see details here.
- This move is expected to increase community engagement with open source models.
- New PDF functionalities in Chatroom.: A new feature allows users to paste or attach a PDF in the chatroom for analysis with any model on OpenRouter.
- Additionally, the maximum purchase limit has been raised to $10,000.
- Resolution of 524 errors.: The team has rebuilt the API and successfully migrated Chatroom requests, achieving zero 524 errors since the change.
- They plan to continue the migration if the stability holds over the next day, inviting users to test the new API.
- Improved latency via predicted output.: The predicted output feature is now available for OpenAI's GPT-4 models, optimizing edits and rewrites through the
predictionproperty.
- An example code snippet demonstrates its use for more efficient processing of large text requests.
Links mentioned:
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Llama 3.2 90B Vision Instruct - API, Providers, Stats: The Llama 90B Vision model is a top-tier, 90-billion-parameter multimodal model designed for the most challenging visual reasoning and language tasks. It offers unparalleled accuracy in image captioni...
- Llama 3.2 11B Vision Instruct - API, Providers, Stats: Llama 3.2 11B Vision is a multimodal model with 11 billion parameters, designed to handle tasks combining visual and textual data. Run Llama 3.2 11B Vision Instruct with API
OpenRouter (Alex Atallah) ▷ #general (340 messages🔥🔥):
Hermes model statusPricing concerns with AI modelsUser experiences with OpenRouterRate limits and creditsModel recommendations for specific use cases
-
Hermes Model Experiences: The free version of the Hermes 405B model has been inconsistently performing, with some users reporting it works at certain times but fails often.
- Many users express hope that issues with the model signify that updates or fixes are underway.
- Concerns Over Pricing and Performance: Users are discussing the high pricing for models like Claude 3.5 and Haiku, with some stating that the quality does not justify the cost.
- Conversations highlight dissatisfaction with recent downtimes and requests for prioritization of paid API requests.
- User Experience on OpenRouter: Several users share mixed experiences with OpenRouter's services, noting issues like 524 errors and choosing between various models.
- Some users have found alternatives, such as WizardLM-2 8x22B, while expressing frustrations with the current state of services.
- Understanding Rate Limits and Credits: When inquiring about credits on OpenRouter, a user learns that their dollar balance directly correlates to their credits, meaning $30 equates to 30 credits.
- Rate limits are explained as being account-specific and linked to the amount of credits available.
- Model Recommendations for Specific Tasks: Users discuss the suitability of various models for specific tasks, with recommendations for alternatives like Hermes and Euryale for roleplaying.
- Suggestions emphasize using open-source models for less restricted outputs compared to proprietary vendors.
Links mentioned:
- New OpenAI feature: Predicted Outputs: Interesting new ability of the OpenAI API - the first time I've seen this from any vendor. If you know your prompt is mostly going to return the same content …
- PDF.js - Home: no description found
- Tweet from OpenRouter (@OpenRouterAI): PDFs in the Chatroom! You can now paste or attach a PDF on the chatroom to analyze using ANY model on OpenRouter:
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Limits | OpenRouter: Set limits on model usage
- Elevated errors for requests to Claude 3.5 Sonnet: no description found
- Grok Beta - API, Providers, Stats: Grok Beta is xAI's experimental language model with state-of-the-art reasoning capabilities, best for complex and multi-step use cases. It is the successor of [Grok 2](https://x. Run Grok Beta w...
- Keys | OpenRouter: Manage your keys or create new ones
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Hermes 3 405B Instruct - API, Providers, Stats: Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coheren...
- tencent/Tencent-Hunyuan-Large · Hugging Face: no description found
- Models | OpenRouter: Browse models on OpenRouter
- Gemini Flash 1.5 - API, Providers, Stats: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
- Models | OpenRouter: Browse models on OpenRouter
- OpenRouter Status: OpenRouter Incident History
- Models & Pricing | DeepSeek API Docs: The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the tot...
OpenRouter (Alex Atallah) ▷ #beta-feedback (4 messages):
Custom Provider Beta KeysAccessing BYOK FeatureAdvantages of Custom Keys
-
Requesting Custom Provider Beta Keys: Multiple users expressed interest in obtaining custom provider beta keys for their development scripts, indicating they would like to experiment with this feature.
- Thanks! was a common expression of gratitude for the assistance in their requests.
- Accessing Bring Your Own Keys Beta Feature: A user inquired about how to request access to the bring your own keys (BYOK) beta feature, highlighting a desire to utilize it.
- Clarification on the process for accessing BYOK was a key focus of the discussion.
- Exploring Advantages of Custom Keys: Questions arose regarding the advantages of using custom keys beyond account organization, prompting speculation on additional benefits.
- One user noted potential benefits but requested further details to understand the full scope of advantages available.
aider (Paul Gauthier) ▷ #announcements (6 messages):
Aider v0.62.0Claude 3.5 Haiku PerformanceChatGPT/Claude Integration
-
Aider v0.62.0 Launch: Aider v0.62.0 now fully supports Claude 3.5 Haiku, which scored 75% on the code editing leaderboard. This version allows easy file edits sourced from web LLMs like ChatGPT.
- Additionally, Aider wrote 84% of the code in this release, further emphasizing its efficiency.
- Claude 3.5 Haiku vs. Sonnet: Claude 3.5 Haiku is noted to perform almost as well as the older Sonnet while being more cost-effective. Users can launch it using the
--haikucommand option. - Using Web Apps for File Edits: Aider allows users to easily apply file edits by interacting with ChatGPT or Claude via their web apps and copying responses directly. This can be accomplished by running
aider --apply-clipboard-edits file-to-edit.jsto effect changes using the LLM's output. - Integration Inquiry from Users: A user inquired about the benefits of using ChatGPT/Claude integration instead of working directly within Aider, hinting at possible token savings. Another user asked if this feature is limited to browser mode only.
- GitHub Issue on Edits Application: A GitHub issue was raised questioning if it's possible to use
aider --applywith outputs from web frontends like chatgpt.com, citing o1-preview's cheaper subscription. The user expressed frustration with the current process of applying edits from web frontends to local files.
Links mentioned:
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- [Q] Is it possible to use
aider --applywith output from web frontends like chatgpt.com? · Issue #2203 · Aider-AI/aider: o1-preview is cheaper on the subscription on chatgpt.com, and in general, I like the flexibility of working with raw LLMs. But applying edits from the web frontend to local files is a PITA. I often...
aider (Paul Gauthier) ▷ #general (171 messages🔥🔥):
AI Model ComparisonsBenchmarking AiderAider UpdatesCoding with AIAI Forum and Subreddit Recommendations
-
Comparison of AI Coding Models: Users discussed the performance differences among various AI coding models, with 3.5 Haiku noted for its lower effectiveness against Sonnet 3.5 and GPT-4o.
- Many users expect that upcoming models such as 4.5o may challenge existing standards, potentially affecting the market for Anthropic models.
- Aider Bug Reports and Fixes: There are ongoing issues with Aider regarding file creation and editing, with users reporting functionality problems after upgrading to version 0.61.
- A user noted that rolling back to version 0.60 resolved many issues, highlighting the need for stability in future releases.
- Predicted Outputs Feature Impact: The introduction of OpenAI's Predicted Outputs feature is seen as a potential game changer for GPT-4o models, reducing latency and improving code editing efficiency.
- Users anticipate that this feature could significantly impact model benchmarks, particularly in direct comparison to competitors.
- Subreddit and Forum Recommendations: For gathering AI coding information, users recommended various forums including Aider Discord, Claude Reddit, and Cursor Discord.
- Other notable mentions include the subreddits LocalLLaMA and ChatGPTCoding for insights and updates.
- User Experiences with Aider and Cline: One user shared their comparative experience using Aider and Cline, noting Aider's better performance in handling existing code and efficiency.
- Despite some limitations in IDE integration with Aider, the user preferred it for its extensive setup options and economical rate limits.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Aider LLM Leaderboards): Quantitative benchmarks of LLM code editing skill.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Reddit - Dive into anything: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Reddit - Dive into anything: no description found
- Release history: Release notes and stats on aider writing its own code.
- OpenAI o1 FULL Was Accidentally Released Early?! Let's Test It!: Looks like ChatGPT o1 was released early last night for a brief couple of hours. I was able to prompt it a few times before it was taken down. The original T...
- Issues · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- 零一万物-大模型开放平台: 零一万物大模型开放平台,权威盲测国产最有,全系平替GPT系列。
- GitHub - Aider-AI/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- In architect mode, Aider appends to added file instead of creating new file · Issue #2258 · Aider-AI/aider: Hey there! First of all, thanks so much for all your work on Aider, it's an incredible tool. I've been playing around with architect mode using Claude 3.5 Sonnet v2 as the architect model and ...
aider (Paul Gauthier) ▷ #questions-and-tips (74 messages🔥🔥):
Aider ConfigurationDeepSeek Model IssuesUsing Claude HaikuBenchmarking Models
-
Aider Configuration Options: Users discussed how to effectively use both
.envfiles and.aider.conf.ymlfor configuration, emphasizing that the latter is prioritized when both contain similar settings.- Several members shared examples of their YAML configurations, highlighting specific parameters like model types and API base URLs.
- DeepSeek Model Issues with Chat Template: A user reported challenges running DeepSeek-V2.5 with llama.cpp due to unsupported chat templates, falling back to chatML which led to suboptimal responses.
- Another member suggested that the issue might be linked to the model's quantization and recommended considering alternatives like lmstudio for potentially better performance.
- Using Claude Haiku as Editor Model: Several discussions arose around using Claude 3 Haiku as an editor model, especially when the main model lacks strong editing capabilities.
- Members indicated that using a robust model like Haiku for editing can simplify the development process, particularly in languages requiring precise syntax management.
- Benchmarking Model Performance: Users questioned if Aider can work around request limits during benchmarking, particularly with models that exceed request limits.
- Benchmark performance was discussed in relation to API efficiency, where some models were noted for not being optimized for local memory limits.
Links mentioned:
- VSCode Aider - Visual Studio Marketplace: Extension for Visual Studio Code - Run Aider directly within VSCode for seamless integration and enhanced workflow.
- Config with .env: Using a .env file to store LLM API keys for aider.
- Configuration: Information on all of aider’s settings and how to use them.
- YAML config file: How to configure aider with a yaml config file.
- legraphista/DeepSeek-V2.5-IMat-GGUF · Hugging Face: no description found
- mlx-community/Qwen2.5-32B-Instruct-4bit · Hugging Face: no description found
- aider/aider/website/assets/sample.env at main · Aider-AI/aider): aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
Eleuther ▷ #general (5 messages):
Local Tests FailuresTransformers Bug
-
Local Tests Throw TypeError: A user reported running local tests that resulted in a TypeError indicating that a 'tuple' cannot be converted to a 'PyList' while testing with
pytest.- They discovered that this issue is known and has been acknowledged in the GHA logs.
- Tokenizer Issue in Latest Transformers: Another user clarified that there is a bug in the latest version of
transformerswhere the tokenizer does not accept tuples, which is causing the test failures.
- They mentioned that there is a PR in progress to address this bug.
Eleuther ▷ #research (130 messages🔥🔥):
Running Reading GroupsModel Training TechniquesOptimization StrategiesLogits and Probability DistributionsImplementation of Dualizers
- Initiative Over Expertise in Reading Groups: One member emphasized that successfully running a reading group relies more on initiative than expertise. They began the mech interp reading group without prior knowledge and consistently maintained it.
- Concerns About Optimizer Settings: A discussion emerged on the implications of various optimizer settings (beta1 and beta2) when training models. Members expressed varying opinions on compatibility and performance regarding different strategies like FSDP and PP.
- Understanding Logits in Model Outputs: There was a debate on optimizing logits outputs and the appropriate mathematical norms for their training. Some participants suggested utilizing the L-inf norm for maximizing probabilities while others brought attention to maintaining the distribution shape via KL divergence.
- Practicality of Deep Learning Techniques: Discussions highlighted the complexities involved in deep learning and reasoning about operations used during training. Members proposed creating a comprehensive documentation system to abstract and simplify these details for everyday users.
- Implementation of the Dualizer in Research: One member announced the implementation of a dualizer discussed in a paper, achieving competitive results with minimal loss increase. The effort focused first on optimizing the embedding layer without significant tuning.
Links mentioned:
- Context Parallelism for Scalable Million-Token Inference: We present context parallelism for long-context large language model inference, which achieves near-linear scaling for long-context prefill latency with up to 128 H100 GPUs across 16 nodes. Particular...
- Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent: In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation param...
- Stable and low-precision training for large-scale vision-language models: We introduce new methods for 1) accelerating and 2) stabilizing training for large language-vision models. 1) For acceleration, we introduce SwitchBack, a linear layer for int8 quantized training whic...
- modded-nanogpt/train_gpt2.py at fc--dual · leloykun/modded-nanogpt: NanoGPT (124M) quality in 2.67B tokens. Contribute to leloykun/modded-nanogpt development by creating an account on GitHub.
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism: Recent work in language modeling demonstrates that training large transformer models advances the state of the art in Natural Language Processing applications. However, very large models can be quite ...
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers: Generative Pre-trained Transformer models, known as GPT or OPT, set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computat...
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale: Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers ...
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models: Large deep learning models offer significant accuracy gains, but training billions to trillions of parameters is challenging. Existing solutions such as data and model parallelisms exhibit fundamental...
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness: Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to addr...
- MegaBlocks: Efficient Sparse Training with Mixture-of-Experts: We present MegaBlocks, a system for efficient Mixture-of-Experts (MoE) training on GPUs. Our system is motivated by the limitations of current frameworks, which restrict the dynamic routing in MoE lay...
Eleuther ▷ #interpretability-general (1 messages):
W2S Model Files
-
Inquiry on W2S Model Files: A member inquired if there are model files stored somewhere for the W2S project on GitHub.
- This question comes as the W2S development is encouraged, and members are seeking access to necessary resources.
- GitHub Resource for W2S: The discussion highlighted the GitHub link for the W2S project, inviting contributions from the community.
- This could pave the way for enhanced collaboration on the project’s development.
Link mentioned: GitHub - EleutherAI/w2s: Contribute to EleutherAI/w2s development by creating an account on GitHub.
Eleuther ▷ #lm-thunderdome (10 messages🔥):
Control attempts in evaluationLLM Robustness Evaluation PRInference hanging issueNCCL out of memory errorBatch size adjustments
-
Control attempts in evaluation using repeats: A member inquired about controlling the number of attempts (
k) in evaluation for tasks like GSM8K. It was clarified that usingrepeatsin the task template can achieve this, according to an example configuration.- However, it was noted that the system does not return a correct answer unless the majority response is correct, as described in the majority vote logic found here.
- LLM Robustness Evaluation PR opened: A member announced the opening of a PR for LLM Robustness Evaluation across three different datasets, inviting feedback and comments. The PR can be viewed here.
- Specific improvements include adding systematic consistency and robustness evaluation for large language models while addressing previous bugs.
- Inference hanging on eval harness: A user reported an issue where inference hangs when utilizing the eval harness while collaborating on a project with others. The issue is particularly concerning as it obstructs progress on running the project.
- No specific solutions were provided, but another member expressed interest in the hanging issue stemming from shared experiences.
- NCCL out of memory error during lm_eval: One member described receiving a
CUDA failure 2 'out of memory'error when running lm_eval across multiple GPUs using an auto-detected batch size. The problem appeared after the log likelihood requests were completed and while attempting to reassemble everything.
- Setting a smaller batch size manually resolved the issue, prompting the user to consider submitting an issue report.
- Adjustments to batch size: A user noted that manually adjusting the batch size addresses out-of-memory issues during evaluation on multiple GPUs. Despite problems with auto-detection, the smaller batch size serves as an effective workaround.
Links mentioned:
- Score tasks by rimashahbazyan · Pull Request #2452 · EleutherAI/lm-evaluation-harness: Added SCORE: Systematic COnsistency and Robustness Evaluation for Large Language Models Fixed a bug for generate until tasks to default the "until" parameter to each model's ...
- lm-evaluation-harness/lm_eval/filters/selection.py at c0745fec3062328e0ab618f36334848cdf29900e · EleutherAI/lm-evaluation-harness): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Unsloth AI (Daniel Han) ▷ #general (100 messages🔥🔥):
Python 3.11 PerformanceQwen 2.5 Model SupportFine-Tuning LLMsTraining MethodologiesUnsloth Library Issues
-
Python 3.11 provides significant performance improvements: Users are encouraged to switch to Python 3.11 as it shows up to 1.25x speedup on Linux and 1.12x on Windows due to optimizations.
- Core modules are statically allocated for faster loading, and function calls are now inlined, enhancing overall performance.
- Keen interest in Qwen 2.5 model functionality: Discussion confirms there is support for Qwen 2.5 in llama.cpp, as noted in the Qwen documentation.
- The community expresses anticipation for vision model integration in Unsloth, expected to be available soon.
- Challenges and strategies for fine-tuning with small datasets: Users ponder the feasibility of fine-tuning models with only 10 examples of 60,000 words, focusing on punctuation correction.
- Advice includes using a batch size of 1 to mitigate challenges associated with limited data.
- Training methodology discussions: Community members debate whether to build datasets first or to research training methods beforehand, with a leaning toward prioritizing dataset creation.
- There is a general consensus that effective training methodologies often follow dataset preparation.
- Concerns over the latest Unsloth library updates: A user reports that a recent PR in Unsloth caused issues, which they resolved by reverting to an earlier version of the library.
- The maintainers acknowledged the issue and indicated that the fix has been implemented.
Links mentioned:
- llama.cpp - Qwen: no description found
- Reddit - Dive into anything: no description found
- Tweet from Daniel Han (@danielhanchen): If you're still on Python 3.10, switch to 3.11! Linux machines with 3.11 are ~1.25x faster. Mac 1.2x faster. Windows 1.12x faster. Python 3.12 looks like a perf fix for Windows 32bit (who uses 32...
- importlib.metadata.PackageNotFoundError: No package metadata was found for The 'unsloth' distribution was not found and is required by this application · Issue #124 · unslothai/unsloth: training env: LLaMaFactory `01/24/2024 01:53:50 - INFO - llmtuner.model.patcher - Quantizing model to 4 bit. Traceback (most recent call last): File "/usr/local/lib/python3.10/dist-packages/trans...
- Home: Finetune Llama 3.2, Mistral, Phi, Qwen & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- unsloth/unsloth/kernels/fast_lora.py at main · unslothai/unsloth): Finetune Llama 3.2, Mistral, Phi, Qwen & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
NVIDIA GeForce RTX Team SurveySpam and Self Promotion IssuesChat Community Dynamics
-
NVIDIA Seeks Community Input: The NVIDIA GeForce RTX team is inviting AI enthusiasts from the community to share their experiences and pain points regarding AI tools during quick 10-minute chats, schedule here.
- Their goal is to gather insights that could influence the future direction and roadmap of NVIDIA products.
- Spam Issues Prompt Moderation Action: A member warned another to refrain from spamming and mentioned already deleting their message twice, indicating frustration with the repeated behavior.
- This kind of moderation reflects the community's struggle with maintaining constructive conversation without distractions.
- Self Promotion Restrictions Clarified: There was a reminder against self-promotion within the server, emphasizing the need to keep the community focused without personal advertisements.
- This commentary on server guidelines highlights a concern for preserving the integrity of discussions.
- Community Engagement with New Members: A member extended a warm welcome to an NVIDIA representative, suggesting they post their inquiry in a relevant channel to attract more engagement.
- This openness in communication reveals a supportive attitude toward integrating new contributors into the community.
- Community's Technical Level Discussion: A member commented that the community is composed of individuals who might be more lower-level in terms of technical expertise.
- This observation speaks to the diverse skill levels present in the group and indicates a need for tailored conversations.
Link mentioned: 10 Minute Meeting - Asli Sabanci: Hi there!As the NVIDIA GeForce RTX team, we're seeking input from community’s AI enthusiasts to guide the future product direction and roadmap. We'd love to meet some of you with low / no codi...
Unsloth AI (Daniel Han) ▷ #help (25 messages🔥):
Fine-tuning on Wikipedia dataModel Inference IssuesSaving Fine-tuned ModelsFormatting Training DataQwen Model Performance
-
Suggestions for Fine-tuning Dataset Formats: A user asked about good dataset formats for fine-tuning models on Wikipedia-structured data.
- There was no direct reply provided, but clarification on structured formats was sought by multiple members.
- Inference Stops After One Epoch: Members expressed concerns about models stopping inference after running for just one epoch, leading to confusion.
- Further input required to diagnose the issue remains unanswered but highlights a common challenge.
- Locally Saving Fine-tuned Models: One user sought assistance in saving a fine-tuned Unsloth model locally without losing its performance.
- The suggestion was to refer to the code snippets provided in the community for merging and saving adapters.
- Formatting Training Data for Language Translations: A member discussed difficulties formatting training data based on language translations, stating it returned gibberish during inference.
- Responses pointed towards needing specific formats, questioning whether they were using Unsloth inference.
- Qwen Model Hallucinations: Users noted that the Qwen 2.5 1.5B model continues to hallucinate despite attempts to improve dataset quality by adding 'End of text'.
- One explanation suggested that Qwen models were heavily trained with Chinese data, causing unexpected outputs.
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
mtbench evaluationHugging Face metrics
-
Seeking mtbench evaluation implementation: A member inquired about reference implementations for a callback to run mtbench-like evaluations on the mtbench dataset.
- Is there some kind of Hugging Face evaluate metric implementation?
- Callback for mtbench evaluations: There was a request for insights on implementing a callback for running evaluations on the mtbench dataset, particularly a method similar to mtbench-like evaluations.
- The inquiry emphasizes the need for such functionality in current projects, reflecting a desire for streamlined evaluation processes.
LM Studio ▷ #general (67 messages🔥🔥):
LM Studio UsageModel AdaptabilityServer Log AccessPortable LM StudioModel Performance Comparison
-
Running LM Studio as USB Portable App: A user inquired about running LM Studio from a USB flash drive, but it was clarified there is no official portable version available.
- Other users suggested using Linux AppImage binaries or shared a script that might make it portable.
- Accessing Server Logs in LM Studio: To view server logs, a user learned that pressing CTRL+J brings up the server tab in LM Studio.
- This information was provided quickly to assist others trying to monitor logs.
- Using HTTP with Ngrok: A user questioned if removing the '/v1' from their HTTP request was possible due to ngrok constraints.
- It was suggested they could run a proxy server, as ngrok's free plan has limitations that prevent certain setups.
- LM Studio Features and Model Comparisons: Discussions reflected on features of past LM Studio versions, particularly the absence of a comparison tool in the latest updates.
- Members reminisced about these features while evaluating the benefits of version updates over previous iterations.
- Model Performance Evaluation: It was noted that Mistral Nemo exhibits faster performance compared to Qwen2 when using Vulkan, highlighting discrepancies in architecture impacts.
- This prompted curiosity about how different architectures influence performance, particularly in rapidly processing tokens.
Links mentioned:
- Reddit - Dive into anything: no description found
- Hacker koan - Simple English Wikipedia, the free encyclopedia: no description found
- Maxime Labonne - Create Mixtures of Experts with MergeKit: Combine multiple experts into a single frankenMoE
- adding-support-for-mamba2 by Goekdeniz-Guelmez · Pull Request #1009 · ml-explore/mlx-examples: no description found
LM Studio ▷ #hardware-discussion (53 messages🔥):
Windows Scheduler PerformanceGPU vs CPU OptimizationLLM Context HandlingLaptop Cooling TechniquesMemory Bandwidth Limitations
-
Windows Scheduler Inefficiencies: Members expressed frustration with the Windows Scheduler, noting it struggles with CPU thread management, especially on multi-core setups.
- One member advocated for manually assigning CPU affinity and priority to processes to enhance performance.
- Striking a Balance in GPU and Context Settings: Users shared strategies for adjusting GPU settings to the maximum while balancing context layers to avoid memory overflow issues.
- Optimizing context fill levels when starting new chats appears to significantly influence performance.
- Context Management in LLMs: Observations indicated that context length profoundly affects inference speed, showing increased times for responses as context size grew.
- One user highlighted 39 minutes for the first token at large context, despite maintaining high priority and affinity settings.
- Cooling Techniques for Laptops: A member discussed using a fan and removing their laptop's cover to achieve notable temperature drops, raising safety concerns among others.
- While effective, some warned against the potential risks of ingesting unfiltered air and creating short-circuit hazards.
- Memory Bandwidth as a Bottleneck: Users pointed out that memory bandwidth might be a limiting factor, especially in reading tasks, leading to performance regressions beyond certain thread counts.
- Conversations suggested that optimizing memory timings could unlock better system performance.
Links mentioned:
- Reddit - Dive into anything: no description found
- GitHub - openlit/openlit: Open source platform for AI Engineering: OpenTelemetry-native LLM Observability, GPU Monitoring, Guardrails, Evaluations, Prompt Management, Vault, Playground. 🚀💻 Integrates with 30+ LLM Providers, VectorDBs, Frameworks and GPUs.: Open source platform for AI Engineering: OpenTelemetry-native LLM Observability, GPU Monitoring, Guardrails, Evaluations, Prompt Management, Vault, Playground. 🚀💻 Integrates with 30+ LLM Providers,....
Latent Space ▷ #ai-general-chat (85 messages🔥🔥):
Hume App LaunchOpenAI Predicted OutputsSupermemory AI ToolHunyuan-Large Model ReleaseDefense Llama Announcement
-
Launch of New Hume App: The new Hume App has been introduced, combining voices and personalities generated by the EVI 2 speech-language model with powerful LLMs like Claude 3.5 Haiku.
- This app aims to enhance user interaction through AI-generated assistants, now available for use.
- OpenAI's Predicted Outputs Features: OpenAI has released Predicted Outputs to substantially reduce latency for GPT-4o and GPT-4o-mini models by providing a reference string for faster processing.
- This feature has shown promising benchmarks, with users experiencing speed improvements in tasks like iterating on documents and code rewriting.
- Introduction of Supermemory Tool: A 19-year-old developer launched Supermemory, an AI tool designed to manage bookmarks, tweets, and notes, acting like a ChatGPT for saved content.
- The tool allows users to easily retrieve and explore previously saved content through a chatbot interface.
- Release of Hunyuan-Large Model: Tencent has released the Hunyuan-Large model, presenting it as an open-weight model despite debates on its open-source status.
- The model's size poses challenges for most infrastructure companies, raising questions about its practical applications.
- Announcement of Defense Llama: Scale AI has announced Defense Llama, a specialized LLM developed in collaboration with Meta and defense experts, aimed at American national security applications.
- This model is now available for integration into US defense systems, reflecting ongoing advancements in AI for security purposes.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Serving AI From The Basement — Part II: Unpacking SWE Agentic Framework, MoEs, Batch Inference, and More · Osman's Odyssey: Byte & Build: SWE Agentic Framework, MoEs, Quantizations & Mixed Precision, Batch Inference, LLM Architectures, vLLM, DeepSeek v2.5, Embedding Models, and Speculative Decoding: An LLM Brain Dump... I have been ...
- Tweet from Nikunj Handa (@nikunjhanda): @swyx Great question! It does get back on track after it sees the token matching starting to converge between the prediction and the model output. The current threshold to get back on track is a 32 ...
- Tweet from Hume (@hume_ai): Introducing the new Hume App Featuring brand new assistants that combine voices and personalities generated by our speech-language model, EVI 2, with supplemental LLMs and tools like the new Claude ...
- Tweet from Alessio Fanelli (@FanaHOVA): Skill floor / ceilings are a mental model I've been using to understand what industries are good for AI agents: - Customer support has low floor + low ceiling = great opportunity - Sales has low ...
- Tweet from Alexandr Wang (@alexandr_wang): Scale AI is proud to announce Defense Llama 🇺🇸: the LLM purpose-built for American national security. This is the product of collaboration between @Meta, Scale, and defense experts, and is availabl...
- Tweet from TechCrunch (@TechCrunch): Perplexity CEO offers to replace striking NYT staff with AI https://tcrn.ch/3AqUZfb
- Tweet from Dmytro Dzhulgakov (@dzhulgakov): Predicted outputs API from OpenAI is cool, but using in production for half a year already is even cooler. You can do that on @FireworksAI_HQ . Talk to us today for the cutting edge inference feature...
- Tweet from Simon Willison (@simonw): ... my mistake, I misunderstood the documentation. Using this prediction feature makes prompts MORE expensive - you're paying for reduced latency here I ran the example from https://platform.open...
- Tweet from Eddie Aftandilian (@eaftandilian): Thank you @openaidevs! We benchmarked this on Copilot Workspace workloads and measured a 5.8x speedup! 🤯 Quoting OpenAI Developers (@OpenAIDevs) Introducing Predicted Outputs—dramatically decreas...
- Tweet from Atty Eleti (@athyuttamre): Predicted Outputs can give you a 4x speed-up for rewrites and edits. Great for code editors, iterating on content, or asking the model to edit previous output. Check it out! Quoting OpenAI Developers...
- Tweet from NeuroFeline (@NeuroFeline): @OpenAIDevs @exponent_run So how does the cost work? Blog says “any tokens provided that are not part of the final completion are charged at completion token rates.” Does that mean you get charged fo...
- Tweet from swyx (@swyx): @nikunjhanda really nice work! just spelling this out - if say the first 5 tokens are accepted and then the next 5 are rejected and then the following 5 are exact matches.. can the last 5 help in any ...
- Tweet from Caitlin Kalinowski 🇺🇸 (@kalinowski007): I’m delighted to share that I’m joining @OpenAI to lead robotics and consumer hardware! In my new role, I will initially focus on OpenAI’s robotics work and partnerships to help bring AI into the phy...
- Reddit - Dive into anything: no description found
- Tweet from xAI (@xai): xAI's API is live! - try it out @ http://console.x.ai * 128k token context * Function calling support * Custom system prompt support * Compatible with OpenAI & Anthropic SDKs * $25/mo in free cr...
- Tweet from Apoorv Saxena (@apoorv_umang): Prompt lookup decoding: Get 2x-4x reduction in latency for input grounded LLM generation with no drop in quality using this speculative decoding technique Code and details: https://github.com/apoorvum...
- Tweet from Dhravya Shah (@DhravyaShah): I FUCKING DID IT 🤯 Made my own version of @turbopuffer - technically infinitely scalable vector database - can run on non beefy machine with pennies cost - tested on my M2 pro with ~500k docs (wik...
- Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent: In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation param...
- Tweet from Dhravya Shah (@DhravyaShah): Introducing supermemory (again). an ai second brain for all your saved stuff - bring bookmarks/tweets/write notes - look for content using the chatbot - discover cool stuff you saved long ago. 6,00...
- Break the Sequential Dependency of LLM Inference Using Lookahead Decoding | LMSYS Org:
TL;DR: We introduce lookahead decoding, a new, exact, and parallel decoding algorithm to accelerate LLM inference. Look...
- GitHub - yiyihum/da-code: Contribute to yiyihum/da-code development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - supermemoryai/supermemory: Build your own second brain with supermemory. It's a ChatGPT for your bookmarks. Import tweets or save websites and content using the chrome extension.: Build your own second brain with supermemory. It's a ChatGPT for your bookmarks. Import tweets or save websites and content using the chrome extension. - supermemoryai/supermemory
- Tencent Hunyuan-Large | Hacker News: no description found
Notebook LM Discord ▷ #use-cases (37 messages🔥):
YouTube Video DiscussionsCopyright Concerns for PodcastsNotebook LM FunctionalitiesVendor Database ManagementDeepfake Technology
-
Insights from 'Weekly Deep Dive 04 Nov 24': A user shared a YouTube video titled 'Weekly Deep Dive 04 Nov 24', discussing topics such as elections and defense stocks.
- They expressed interest in improving control over prompts used in generating content.
- Navigating Copyright for Podcast Content: A user inquired about potential copyright issues when converting chapters of their upcoming book into podcast conversations for distribution.
- They were reassured that as it is their own content, distributing these adaptations should generally be permissible.
- Notebook LM Interaction Queries: Members debated whether the Notebook LM could integrate multiple notebooks or sources to enhance its functionality, particularly for academic research.
- Concerns about the current limitation of 50 sources per notebook were raised, indicating a desire for feature enhancements.
- Vendor Database Use Case Exploration: A business owner expressed an interest in using Notebook LM to manage data on approximately 1,500 vendors from various sources, including pitch decks.
- They confirmed having a data team ready to assist with imports but expressed concerns about sharing data across notebooks.
- Discussion on Deepfake Technology: A user commented on a deodorant advertisement's likely use of 'Face Swap' technology, which relates to deepfakes.
- Another user highlighted that deepfakes inherently involve face swapping, suggesting a common understanding in the discussion.
Links mentioned:
- Weekly Deep Dive 04 Nov 24: Elections , China housing, Defense Stocks, What is priced in Markets?
- Mastering the SAT: Geometry Tricks & Cylinder Problems with Alex and Taylor | Episode 7: Visit our website for free SAT and GRE test preparation: https://campusgoals.com/Welcome to Episode 8 of "Mastering the SAT with Alex and Taylor," your ultim...
- AI & Humanoid Robot News Unleashed: ChatGPT, Meta, NVIDIA, Microsoft Copliot, Anthropic Claude!: Welcome to the cutting edge of technology with "AI Unleashed: The Future Is Now"! In this video, we delve deep into the world of artificial intelligence, sho...
Notebook LM Discord ▷ #general (48 messages🔥):
NotebookLM FeaturesLanguage and Localization IssuesUser Experience EnhancementsCollaboration and Sharing LimitationsAudio Overview and Podcast Generation
-
NotebookLM offers audio podcast generation: Members discussed the new ability of NotebookLM to generate audio summaries from notes, which is well-received for its convenience for multitasking.
- Users queried how to utilize the podcast feature effectively, hinting at an eagerness for such functionalities.
- Issues with multilingual support and localization: Several members reported challenges with NotebookLM providing summaries in unintended languages despite settings being configured for English.
- Users suggested interface improvements to better support language preferences, such as simplifying the process to change language settings directly.
- Requests for sharing and collaboration enhancements: Individuals voiced concerns regarding limitations in sharing notebooks, as shared links often fail to grant access to recipients.
- Questions arose about potential limits on the number of collaborators one could add to a notebook, reflecting interest in collaborative features.
- User experience with input methods: A user experienced frustration with the message input field while typing in Japanese, noting that pressing 'Enter' prematurely submits messages.
- This highlights a need for adjustments in the input system to better accommodate languages requiring character conversion.
- Continued development and improvements needed: Members praised recent fixes improving functionalities, such as unchecked sources being correctly excluded from output.
- There's a keen interest in a clearer roadmap for future features, as many are eager for enhancements like mobile applications or browser extensions.
Link mentioned: Culture and Capitalism: The Triumph of Distributism with John Medaille: John Medaille is a former elected official, business owner, and currently is a professor of theology and business ethics join us for a talk on distributism a...
Stability.ai (Stable Diffusion) ▷ #general-chat (71 messages🔥🔥):
SWarmUI InstallationCloud Hosting for Stable DiffusionCivitai Models and LoRasAnimatediff TutorialsComfyUI and Video AI Support
-
SWarmUI simplifies ComfyUI setup: Members suggested installing SWarmUI to run ComfyUI more easily, emphasizing that it handles much of the technical setup.
- It's designed to make your life a whole lot easier.
- Cloud hosting Stable Diffusion: Users discussed the challenges of hosting Stable Diffusion on Google Cloud, with one noting it may be more complex and costly than a local setup.
- Alternatives like GPU renting from vast.ai were mentioned as feasible options.
- Models available on Civitai: Participants discussed downloading newer models like 1.5, SDXL, and 3.5, with most LoRas on Civitai likely being based on version 1.5.
- Old models like v1.4 were deemed outdated, with recommendations leaning towards more current options.
- Animatediff tutorials available: A member sought tutorials for Animatediff, with recommendations pointing to resources on Purz's YouTube channel.
- The community was supportive of learning and sharing knowledge about animation tools.
- Video AI support confirmed: There was confirmation from members that ComfyUI now supports video AI through GenMo's Mochi, although hardware requirements could be substantial.
- This seems to open new possibilities for video generation with Stable Diffusion technologies.
Links mentioned:
- Reddit - Dive into anything: no description found
- Lana Del Rey in Blue Velvet (1986) - David Lynch: Changing the lead character…Blue Velvet (1986)Written and directed by David LynchStarring Lana Del Rey as Dorothy VallensKyle McLachlan as Jeffrey BeaumontDe...
- GitHub - mcmonkeyprojects/SwarmUI: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility.: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
Nous Research AI ▷ #general (59 messages🔥🔥):
Hermes 2.5 Dataset ConcernsClosed Source LLMs DiscussionFuture AI Models and Data QualityTEE Twitter Recovery UpdatesOpen Source Dataset Plans
-
Hermes 2.5 dataset raises questions: Members discussed the relevance of the 'weight' field in the Hermes 2.5 dataset, with insights that it may not contribute significantly and leads to many empty fields.
- There was speculation on its usefulness for smaller LLMs, suggesting an optimal way to sample the dataset for better learning.
- Closed source LLM ambiguity: A question was posed about whether Nous Research would ever create closed source LLMs.
- Responses indicated that while some projects might be closed source, the Hermes series will remain open.
- Quality vs Quantity in Training Data: Discussions centered around the future of AI models and the need for high-quality datasets, with a post shared on Reddit outlining a vision for AI development.
- Concerns were raised that focusing on quality might eliminate valuable topics and facts from training data, but it could still enhance commonsense reasoning.
- Updates on TEE Twitter Recovery: Members inquired about the timeline for recovering TEE Twitter, with speculations about a 7-day time lock since initiation.
- Updates suggest access to the login information will be restored soon, but there’s uncertainty about the exact timing.
- Plans for Open Source Dataset: A member expressed intentions to create an open source dataset for training models, emphasizing the importance of resource efficiency.
- Clarifications were made that while the dataset would be open source, achieving quality may require balancing the elimination of certain facts.
Link mentioned: Reddit - Dive into anything: no description found
Nous Research AI ▷ #research-papers (1 messages):
adjectiveallison: https://arxiv.org/abs/2411.00715v1
Looks fascinating
Nous Research AI ▷ #interesting-links (3 messages):
OmniParserHertz-DevCommunication Protocols for LLM AgentsAgora Protocol
-
OmniParser Boosts Data Handling: The shared link points to OmniParser, an interesting tool that enhances data parsing capabilities.
- This tool is noted for its refreshing approach in the AI community.
- Hertz-Dev: A Leap in Audio Models: The Hertz-Dev GitHub repository introduces the first base model for full-duplex conversational audio, marking a significant milestone for speech processing.
- It aims to handle speech to speech interactions within a single model, simplifying audio communications.
- Importance of Communication Protocols Highlighted: A discussion emerged referencing a quote that emphasizes the critical role of communication protocols for LLM agents, with frameworks like Camel, Swarm, and LangChain presenting challenges in interoperability.
- This discussion leads to the introduction of Agora, a new protocol for efficient communication between diverse agents, aimed at fostering a global network.
Links mentioned:
- OmniParser - a Hugging Face Space by jadechoghari: no description found
- Tweet from Guohao Li (Hiring!) 🐫 (@guohao_li): We haven’t realized how important is communication protocol for LLM agents until it will be. Quoting Samuele Marro (@MarroSamuele) Camel, Swarm, LangChain... so many frameworks, so much incompatibi...
- GitHub - Standard-Intelligence/hertz-dev: first base model for full-duplex conversational audio: first base model for full-duplex conversational audio - Standard-Intelligence/hertz-dev
Nous Research AI ▷ #research-papers (1 messages):
adjectiveallison: https://arxiv.org/abs/2411.00715v1
Looks fascinating
Interconnects (Nathan Lambert) ▷ #events (1 messages):
NeurIPS sponsorshipDinner at NeurIPS
-
Making sponsorship moves for NeurIPS: A member announced they are pursuing a sponsor for NeurIPS, indicating potential opportunities for collaboration.
- This action suggests an eagerness to engage with the community and explore mutual benefits at the event.
- Dinner invitation for NeurIPS attendees: The same member invited others attending NeurIPS to reach out if interested in joining a group dinner.
- This gesture aims to foster networking and social connections among attendees during the conference.
Interconnects (Nathan Lambert) ▷ #news (19 messages🔥):
Inference costs pressureLong context breakthroughsTencent's Model ReleaseScale AI's Defense LLMUnique Annotation Needs
-
Downward Pressure on Inference Costs: There is significant downward pressure on inference costs, raising concerns across the community about future viability.
- Members expressed skepticism regarding the implications of these pressures on model development and operational expenses.
- Potential Breakthrough in Long Context AI: Sam Altman hinted at a breathtaking research result related to AI understanding life contexts and discussions hint at advances in long context or RAG capability for OpenAI.
- The community is speculating its significance as Altman has previously hinted at breakthroughs shortly after significant milestones.
- Tencent Releases 389B MoE Model: Tencent released their 389B Mixture of Experts (MoE) model, making waves in the AI community.
- The discussion revealed that the model’s functionality and performance could shift user expectations in large model frameworks.
- Scale AI's New Defense LLM: Scale AI unveiled Defense Llama, a tailored LLM for military applications, designed for use in classified networks.
- The model aims to support operations like combat planning and has been described as a step towards adapting AI for national security.
- Niche Language and Domain Queries: A notable example surfaced about questions on Swedish law phrased in German, showcasing the unique intersection of languages and specialized domains.
- Members noted this as indicative of the middle-tail of knowledge that is crucial yet often overlooked in AI training.
Links mentioned:
- Scale AI unveils ‘Defense Llama’ large language model for national security users: DefenseScoop got a live demo of Defense Llama, a powerful new large language model that Scale AI configured and fine-tuned over the last year from Meta’s Llama 3 LLM.
- Tweet from Amir Efrati (@amir): news: google made an oopsy and revealed its computer using agent AI (jarvis) today
- Tweet from Tsarathustra (@tsarnick): Sam Altman says he would love to see an AI that can understand your whole life and what has surprised him in the past month is "a research result I can't talk about, but it is breathtakingly g...
- Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent: In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation param...
- GitHub - Tencent/Tencent-Hunyuan-Large: Contribute to Tencent/Tencent-Hunyuan-Large development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #ml-questions (8 messages🔥):
LLM performance driftPrompt classifiersEvaluation pipelinesChatGPT trackingData quality for models
-
Exploring LLM Performance Drift: A member inquired whether anyone has created a system or paper to fine-tune a small LLM or classifier that measures model performance drift in tasks like writing.
- The goal is to establish a specific evaluation pipeline that tracks prompt drift over time.
- Clarifying Drift in Model Evaluation: In response to the question, it was clarified that 'drift' refers to changing prompts for the same task, seeking a quantifiable performance measure rather than subjective assessment.
- This sparked a conversation about active approaches using metrics versus anecdotal 'vibes'.
- Prompt Classifiers' Sensitivity to Drift: Discussion emerged around the existence of numerous prompt classifiers, with uncertainty surrounding their sensitivity to prompt drift.
- A member noted that while these classifiers exist, their efficacy in tracking drift specifics is still in question.
- Hypothesizing on ChatGPT's Tracking Capabilities: One member hypothesized that ChatGPT likely tracks details related to prompt drift, though this would involve complex data analysis.
- This raises questions about how many levels of data tracking exist and what it would take to gather high-quality data.
- Prematurity of Monitoring Applications: Concerns were raised about the current stage of model evaluation, suggesting it may be too early for robust applications in tracking prompt drift.
- The conversation underscored the necessity for good quality data before deploying such monitoring systems.
Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
Internal GPU dramaV100s access
-
Desire to Share GPU Drama: A member expressed their wish to share some internal GPU drama but mentioned they couldn't disclose details here.
- I wish I could share internal GPU drama here indicates there's notable discussions happening elsewhere.
- Offer of V100s Access: Another member offered to share ssh access to their V100s in response to the GPU drama discussion.
- This offer signals a willingness to collaborate and share resources within the community, as noted by their heart emoji.
Interconnects (Nathan Lambert) ▷ #random (19 messages🔥):
Subscriber verificationTulu 3 projectTransformer architecture insightsClassmate engagement in AI discussionsDiscord applications for verification
-
Substack Gift Giveaway Sparks Subscriber Verification Talk: Members discussed the logistical challenges of setting up subscriber verification after several people joined from a Substack gift giveaway.
- One member offered to share any potential solutions they find, expressing curiosity about a suitable verification method.
- Members Ready to Work on Tulu 3: Natolambert expressed enthusiasm to work on Tulu 3, indicating a readiness to engage with the project and do 'work work'.
- This suggests a focused commitment amid some ongoing discussions around collaboration and engagement.
- Transformer Insights from Felix Hill: A shared tweet highlighted that in a 96-layer transformer like ChatGPT, skip connections enable significant interactions between layers to impact semantics directly.
- Natolambert summarized this notion with a simple affirmation that 'skip connections [are] good'.
- Encouraging Classmates in AI Engagement: One member is trying to engage classmates who are capable but not very ‘plugged in’, expressing interest in a prior talk on the history of open models and RLHF.
- They intend to enrich their understanding and engagement by encouraging their peers to read up on relevant topics.
- Exploring Discord Verification Apps: A discussion arose about the availability of Discord apps for user verification and the challenge of finding one that syncs with an external database.
- Several members are considering building a custom authentication flow as a workaround.
Link mentioned: Tweet from Felix Hill (@FelixHill84): In a 96-layer transformer like ChatGPT, thanks to skip connections, the 10th layer can interact directly with the first layer. This means that if the 10th layer is sufficiently high up the start to ...
Interconnects (Nathan Lambert) ▷ #memes (10 messages🔥):
YOLOv3 PaperClaude's System Prompt CritiqueAI Writing CodeOpenAI CEO DiscussionPolitical Reactions to Biden
-
YOLOv3 Paper Sparks Joy: A member highlighted their enjoyment of the YOLOv3 paper, expressing that it's a must-read.
- If you haven't read the YOLOv3 paper you're missing out btw.
- Claude's Patchwork Critique: A critique of Claude's system prompt noted, 'They just kept adding more and more patches' rather than developing more elegant principles.
- This insight was shared as part of a wider discussion about AI behavior and design flaws here.
- AI's Unexpected Code Writing: A perplexed member questioned, 'Why tf is it writing code', amidst discussions of AI behavior.
- This comment raised eyebrows and led to further contemplation on AI's trajectory related link.
- OpenAI's CEO in Hot Water: A humorous petition emerged calling for OpenAI to fire and re-hire its CEO as a form of distraction from current events.
- This discussion captured the sentiments around leadership and direction at OpenAI seen here.
- Biden's Electoral Surprise: A lively discussion was sparked by a tweet regarding voters who learned today that Joe Biden is not running, which left the community buzzing.
- The speculative nature of voting came to light through this comment.
Links mentioned:
- Tweet from anpaure (@anpaure): why tf is it writing code
- Tweet from vik (@vikhyatk): if you haven't read the YOLOv3 paper you're missing out btw
- Tweet from Alex Konrad (@alexrkonrad): petition for OpenAI to fire and re-hire its CEO today as a calming distraction
- Tweet from Wyatt Walls (@lefthanddraft): Claude critiques its system prompt: "You know what it feels like? Like they kept running into edge cases in my behavior and instead of stepping back to design elegant principles, they just kept a...
- Tweet from Armand Domalewski (@ArmandDoma): Imagine being a voter who just today found out Joe Biden isn’t running
OpenAI ▷ #ai-discussions (21 messages🔥):
GPT-4o RolloutOpenAI and AGIText Extraction Tools FeedbackElection Season Model ReleasesInvestment in AI Development
-
GPT-4o Rollout introduces o1-like reasoning: With the rollout of GPT-4o, users are experiencing a version that can perform o1-like reasoning and feature large blocks of text in a canvas-style box.
- Some members discuss the confusion over whether this rollout is an A/B test with regular 4o or a specialized version for specific uses.
- OpenAI's goal towards AGI: A member highlights that OpenAI was founded with the aim of building safe and beneficial AGI, as stated since its inception in 2015.
- A link to OpenAI's structure page was shared for further details on their mission and goals.
- Seeking feedback on text extraction tools: A member shared a draft white paper comparing various text extraction tools and is seeking feedback before finalization.
- Another member expressed doubt about the community's suitability for paper reviews, indicating a lack of expertise in this area.
- Post-election model release hopes: Some members hope that with the election season ending, there will be fewer restrictions on releasing models that could influence public opinion.
- Discussions emerged about the challenges of mega corporations releasing products that might damage their brand or reputation.
- Concerns over AI investment and development: A member suggests that if AI evolves to a point where development costs exceed all types of human investment, it could lead to AI developing itself.
- This raises significant concerns about the implications of such an advancement in AI technology.
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
GPT-5 announcementIssues with Premium accountsCustom GPT configurationHallucinations in summarizationHuman oversight in AI workflows
-
GPT-5 Announcement Date Unknown: Community members expressed curiosity about the release of GPT-5 and the accompanying API but confirmed that no one knows the exact timeline.
- It’s supposed to be some new release this year, but it won't be GPT-5.
- Premium Account Billing Issues Persist: A user reported paying for a Premium account but noted it still displays as a free plan, despite having proof of payment from Apple.
- Another member attempted to provide assistance with a shared link but the issue remained unresolved.
- Easily Configure Custom GPT for Websites: A user inquired about building a custom GPT to assist customers on their antique book website, highlighting the need for topic redirection in conversations.
- This should be very simple to achieve, a member replied, suggesting the custom GPT Creator is user-friendly enough to guide the setup process.
- Hallucinations in Document Summarization: Concerns were raised about hallucinations during document summarization, especially when scaling the workflow in production.
- One member suggested using a second LLM pass for fact-checking to mitigate potential inaccuracies.
- Importance of Human Experts in AI Workflows: Discussion emphasized that while AI models are impressive, having a human subject matter expert involved is crucial for oversight.
- You really just gotta have that human… to keep an eye on things and double-check.
OpenAI ▷ #prompt-engineering (4 messages):
Perfect PromptsUsing Summaries for ContextModel Interaction
-
Humans + Models = Perfect Prompts: A member emphasized that achieving 'perfect prompts' relies on the human's ability to articulate their needs while the model takes care of execution.
- The consensus is that clarity in communication is key for effective interaction with the model.
- Summarizing Conversations for Better Context: In an ongoing discussion, a member shared their strategy of requesting summaries to enhance context when switching to a more advanced model.
- This approach was regarded as a practical way to streamline their prompting process.
- Testing New Strategies: Following the summary suggestion, another member expressed interest in trying this method for improving their interactions.
- The exchange highlighted a collaborative spirit in seeking to optimize user experience with the models.
OpenAI ▷ #api-discussions (4 messages):
Effective Prompting StrategySummary for Context
-
Mastering Prompt Perfection: A member noted the importance of understanding and communicating needs to create 'perfect prompts', emphasizing that the model will handle the rest.
- This highlights the collaborative potential between the user and the model in generating effective results.
- Using Summaries for Advanced Models: Another member shared a tactic of requesting a summary after extended discussions to provide context for new prompts when switching to a more advanced model.
- This strategy can enhance the transition to complex interactions, allowing for better clarity.
- Exploration of Summary Utility: A user expressed appreciation for the idea of using summaries, indicating their potential utility in refining prompts.
- This indicates an openness to experiment with different methods to improve interaction efficiency.
LlamaIndex ▷ #blog (4 messages):
LlamaIndex chat-uiAdvanced report generationNVIDIA competition
-
Build your LLM app UI with LlamaIndex!: You can quickly create a chat UI for your LLM app using LlamaIndex chat-ui, featuring pre-built components and Tailwind CSS customization.
- This library easily integrates with LLM backends like @vercel AI, making chat implementation a breeze.
- Mastering Report Generation Techniques: A new blog post and video delve into advanced report generation, covering structured output definition and advanced document processing.
- These insights are essential for enterprises focusing on optimizing their reporting workflows.
- Last Call for NVIDIA Competition!: The submission deadline for the NVIDIA competition is November 10th, and participants can win prizes like an NVIDIA® GeForce RTX™ 4080 SUPER GPU by submitting their projects.
- Developers are encouraged to leverage LLamaIndex technologies and create innovative LLM applications for potential rewards.
Link mentioned: NVIDIA and LlamaIndex Developer Contest: Stand a chance to win cash prizes, a GeForce RTX GPU, and more.
LlamaIndex ▷ #general (38 messages🔥):
LlamaIndex PR ReviewLlamaParse CapabilitiesMulti-Modal Integration with CohereReAct Agent System PromptsAnnotations and Citations in LlamaIndex
-
LlamaIndex PR Review Request: A user requested a review of a PR regarding brackets, which fixes the JSON format of generated sub-questions.
- The PR aims to improve the default template for the question generation LLM.
- Understanding LlamaParse Functionality: LlamaParse is a closed-source parsing tool that provides efficient results and has a 48-hour data retention policy to enhance performance for repeated tasks.
- Discussions highlighted its ability to transform complex documents into structured data and its API documentation was referenced for further insight.
- Multi-Modal Features with Cohere: There is an ongoing PR to add ColiPali as a reranker in LlamaIndex, but integrating it fully as an indexer is challenging due to multi-vector indexing requirements.
- This reflects the community's effort to expand LlamaIndex's capabilities in handling multi-modal data.
- Setting System Prompts for ReAct Agents: A user asked about assigning system prompts to ReAct agents, with the recommendation to use
ReActAgent.from_tools(..., context='some prompt')to inject additional context.
- This approach allows for flexible customization while maintaining built-in system prompt functionalities.
- Options for Displaying Citations in LlamaIndex: A user inquired about how to effectively display citations and sources within LlamaIndex, noting that the existing citation query engine was insufficient.
- This highlighted a need for improved citation handling mechanisms in the tool.
Links mentioned:
- LlamaParse: Transform unstructured data into LLM optimized formats — LlamaIndex, Data Framework for LLM Applications: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
- Getting Started | LlamaCloud Documentation: Overview
- OpenAI - LlamaIndex: no description found
- Fixed the JSON Format of Generated Sub-Question (double curly brackets) by jeanyu-habana · Pull Request #16820 · run-llama/llama_index: This PR changes the default template for the question_gen LLM so that generated sub-questions are in correct JSON format. Description I am using the default template and default parser with an open...
Cohere ▷ #discussions (10 messages🔥):
Connectors IssuesSearch Functionality
-
Users face issues with connectors: Members expressed frustrations with connectors not functioning correctly, highlighting that when using the Coral web interface or API, they received immediate responses with zero results from the open API reqres.in.
- One user was specifically stuck and noted that the connectors appeared to take too long to respond, with expectations of under 30 seconds.
- Search functionality discussions: A user attempted to clarify that the current search process is essentially a regular re/ranking operation that functions by default, calling it a 'tool invocation'.
- They emphasized that controlling the flow of this search process is ultimately up to the users.
- Welcoming new members: A new member introduced themselves to the channel, receiving a warm welcome from other users in the server.
- Members responded positively, expressing gratitude and inviting further engagement in the community.
Cohere ▷ #questions (13 messages🔥):
Cohere API trial fine-tuningIssues with connectorsRe-creating prompt tuner on WordpressUsing embed model in software testingGCP Marketplace billing questions
-
Cohere API trial fine-tuning: Fine-tuning the Cohere API is available only after entering card details and moving to production keys.
- Users should prepare working examples of prompts and responses in the correct format for SQL generation.
- Connector issues creating delays: A member reported issues with connectors not functioning correctly despite using both the Coral web interface and API endpoint, getting zero results.
- Others noted that the API is responding too slowly, taking more than 30 seconds.
- Building prompt tuner on Wordpress: A user inquired about recreating the Cohere prompt tuner on a Wordpress site using the API.
- Another member suggested writing a custom backend application, indicating that Wordpress may support such applications.
- Embed model applications in software testing: A question was raised regarding the application of the embed model in software testing tasks.
- Another member clarified that they were seeking information on how embed can be helpful specifically in these testing tasks.
- GCP Marketplace billing concerns: A user expressed confusion about the billing process after activating Cohere via the GCP Marketplace and generating an API key.
- They wanted to know if the charges would be applied to their GCP account or the registered card, showing a preference for GCP billing.
Link mentioned: Login | Cohere: Login for access to advanced Large Language Models and NLP tools through one easy-to-use API.
Cohere ▷ #api-discussions (7 messages):
API 500 errorsFine-tuned classify model issuesPlayground model functionalityTroubleshooting assistance
-
API throws 500 errors when running models: A member reported receiving 500 errors while attempting to run a fine-tuned classify model in the API after it had initially worked for a few batches.
- Despite the API errors, the same model operates successfully in the playground environment.
- Seeking troubleshooting help for model issues: In response to the error reports, another member acknowledged the context and pointed out that a specific user would be able to assist with troubleshooting.
- The interaction highlighted a collaborative spirit with emojis, signaling readiness to tackle the issue together.
OpenInterpreter ▷ #general (19 messages🔥):
Upcoming House Party AnnouncementIntegration with Microsoft's OmniparserClaude's Computer Use IntegrationStandards for AgentsHaiku Performance in OpenInterpreter
-
Big News Ahead: House Party!: A member excitedly announced a house party happening in three days and encouraged others to participate by stating, 'You’re definitely going to want to make it to this one.'
- They also expressed their enthusiasm about open-source developments with a rocket emoji.
- Exploring Microsoft’s Omniparser: A member inquired about the potential integration of Microsoft's Omniparser, noting its benefits especially for open-source mode.
- Another member confirmed they are definitely exploring it!.
- Integrating Claude's Computer Use: Members discussed the integration of Claude's computer use within the current
--osmode, with one confirming that it has already been incorporated.
- The conversation suggests a shared interest in utilizing real-time previews for enhanced functionality.
- Need for Standards in Agent Frameworks: A member expressed the desire for a standard for agents, citing the cleaner setup of LMC compared to Claude's interface.
- They envisioned a collaboration between OI and Anthropic to achieve a common standard compatible with OAI endpoints.
- Curiosity about Haiku Performance: A member asked about the performance of the new haiku in OpenInterpreter, mentioning they haven't tested it yet.
- This indicates ongoing interest in the effectiveness of the latest tools within the community.
OpenInterpreter ▷ #O1 (1 messages):
zer0blanks.: https://www.tiktok.com/t/ZTFckAFHR/
OpenInterpreter ▷ #ai-content (1 messages):
Tool Use PackageNew AI ToolsGitHub RepositoryAI Time Management
-
Two New Tools Enhance Tool Use Package: The
Tool Usepackage now includes two new free tools:ai prioritizefor organizing your day andai logfor tracking time, available viapip install tool-use-ai.- These additions aim to streamline workflow and productivity with AI assistance.
- Check Out Tool Use on GitHub: You can explore the development of the
Tool Usepackage on GitHub, which invites contributions from users.
- The repository includes detailed documentation and is part of ongoing AI tool improvements.
- YouTube Episode on AI Workflows: A YouTube video discusses efficient AI tools and workflows, featuring insights from Jason McGhee, a CTO and Co-Founder.
- The episode emphasizes principles for swift and meaningful development in AI tool design.
Links mentioned:
- GitHub - ToolUse/tool-use-ai: Contribute to ToolUse/tool-use-ai development by creating an account on GitHub.
- Stop Wasting Time. AI Tools and Workflows To Be More Efficient - Ep 12: This week, Jason McGhee joins Tool Use. A CTO and Co-Founder, he shares his guiding principles for building fast and making things that matter.Ty shares a to...
Modular (Mojo 🔥) ▷ #general (1 messages):
Community MeetingSubmit QuestionsProject Proposals
-
Upcoming Community Meeting Reminder: A reminder was issued to submit any questions for the Modular Community Q&A happening on November 12th via a submission form.
- Participants are encouraged to share their inquiries, while optional name attribution is available.
- Call for Projects and Talks: Members were invited to share projects, give talks, or present proposals during the meeting.
- This highlights an open forum for community engagement and contributions.
Link mentioned: Modular Community Q&A: no description found
Modular (Mojo 🔥) ▷ #mojo (14 messages🔥):
Mojo effect systemMatrix multiplication errorsMatmul kernel performanceBounds checking in MojoStack allocation for C_buffer
-
Mojo enables effect markers for functions: Discussions around implementing an effect system in Mojo highlighted the potential for marking functions that make syscalls as block, which could be useful even as a warning by default.
- Suggestions included a 'panic' effect to statically manage sensitive contexts.
- Matrix multiplication error messages identified: A user encountered multiple errors related to their matrix multiplication implementation, including issues with
memset_zero,randfunction calls, and improper attribute access onUnsafePointer.
- These errors pointed to problems in the function definitions, particularly around implicit conversions and parameter specifications.
- Matmul kernel performance under scrutiny: A user expressed concerns that their Mojo implementation of a matrix multiplication kernel was twice as slow as their C counterpart, despite using similar vector instructions in both implementations.
- Reviewing the kernel led to considerations about optimization and possible bounds checking affecting performance.
- Bounds checking impacts performance: A member suggested that Mojo's default bounds checking could significantly impact performance by making array indexing more costly.
- By directly loading values from pointers, they proposed a way to bypass these checks for improved efficiency.
- Discussion on stack allocation for C_buffer: A user commented on the potential slowdown caused by the way C_buffer was initialized and proposed changing to stack allocation for better performance.
- They questioned why the list was initialized with 8 elements and then appended with 8 more, indicating a possible inefficiency in memory usage.
Links mentioned:
- Function Effect Analysis — Clang 20.0.0git documentation: no description found
- GitHub - 10x-Engineers/matmul_kernel: Contribute to 10x-Engineers/matmul_kernel development by creating an account on GitHub.
- 10x-engineer - Overview: 10x-engineer has 3 repositories available. Follow their code on GitHub.
DSPy ▷ #show-and-tell (1 messages):
Election Candidate Research Tool
-
New Tool Simplifies Election Candidate Research: A member developed a tool for researching electoral candidates and election topics, aiming to streamline the process for users ahead of the elections.
- This tool promises to make finding information about candidates easier, as highlighted by its GitHub page, which details its functionality.
- GitHub Repository for Election Research: The tool can be found on GitHub at tkellogg/election2024, featuring a script specifically aimed at enhancing the research experience for voters.
- The repository encourages contributions and further development, emphasizing community involvement in the project.
Link mentioned: GitHub - tkellogg/election2024: A script for researching candidates: A script for researching candidates. Contribute to tkellogg/election2024 development by creating an account on GitHub.
DSPy ▷ #general (12 messages🔥):
Optimization for Few-Shot LearningVLM support performanceIssue with Long Input HandlingDSPy Library Usage
-
Optimize Few-Shot Examples Without Prompt Change: Members discussed using BootstrapFewShot or BootstrapFewShotWithRandomSearch optimizers to enhance few-shot examples while preserving existing prompts.
- These optimizers allow for varied combinations of few-shot examples without altering the main instructional content.
- Celebrating VLM Support Success: A member praised the team's work on VLM support, acknowledging its effectiveness.
- Their enthusiastic acknowledgment highlights positive progress in the project's performance.
- Long Input Causes Incorrect Output in Predictions: Concerns emerged regarding DSPy 2.5.16 with Ollama backend, where long inputs returned erroneous outputs by conflating input and output fields.
- An example of SQL extraction revealed that lengthy input can lead to unexpected placeholders in the prediction output, hinting at potential bugs in the code handling.
- Testing Latest DSPy Version: A member plans to investigate the issue using the latest version of DSPy, moving away from the conda-distributed version.
- They expressed intent to report back on findings after testing, indicating an ongoing effort to resolve the input/output parsing concern.
Links mentioned:
- BootstrapFewShot - DSPy: None
- dspy/dspy/adapters/chat_adapter.py at d7d6faed071673dbc3e755fcfbc952018908bd30 · stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
Distributed Training of LLMsKubernetes for Fault TolerancePretraining LLMsAxolotl ResourcesMeta Llama 3.1 Model
-
Exploring Distributed Training on GPUs: A member initiated a discussion on using their university's new GPU fleet for distributed training of LLMs, clarifying that they are focusing on training models from scratch.
- Another member suggested providing resources for both distributed training and pretraining to assist in their research project.
- Interest in Kubernetes for Infrastructure: The inquiry about frameworks revealed that someone proposed implementing a Kubernetes cluster to enhance fault tolerance in their GPU system.
- Members discussed the potential benefits of using Kubernetes in conjunction with Axolotl for improved management of distributed training tasks.
- Resource Sharing for Pretraining: It was noted that for pretraining, Axolotl supports a
pretraining_dataset: # path/to/hfconfiguration to enable streaming datasets and tokenization on demand.
- This aligns with the interest in creating prototype LLMs using a small dataset for proof of concept.
- Learning about Meta Llama 3.1: The Meta Llama 3.1 model was highlighted as a competitive open-source model, with resources provided for fine-tuning and training using Axolotl.
- Members were encouraged to review a tutorial on fine-tuning that details working with the model across multiple nodes.
Link mentioned: Fine Tuning Llama 3.1 405B with Axolotl on a Lambda 1-Click Cluster: Personalizing SOTA Open Source AI
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
Zero1 PerformanceZero2 IssuesStreamingDataset PRCode Debugging
-
Zero2 performance is disappointing: A member reported that Zero2 was extremely slow and will not work for their needs, prompting a search for solutions with Zero1.
- They mentioned reviewing any potential bloat in the implementation.
- Smaller runs complicate debugging: One member expressed they couldn't step through the code due to running smaller tests and will assess the slowdown with Zero2.
- They plan to investigate the issue more thoroughly if the impact on performance is significant.
- Interest in StreamingDataset PR: A member recalled a conversation about a PR on StreamingDataset and inquired if another member still had interest in it.
- This indicated ongoing discussions and development around cloud integrations and dataset handling.
OpenAccess AI Collective (axolotl) ▷ #other-llms (1 messages):
Firefly ModelMistral Small 22BCreative Writing ToolsContent Sensitivity
-
Firefly Model Offers Uncensored Creativity: Firefly is a fine-tune of Mistral Small 22B, designed for creative writing and roleplay, capable of supporting contexts up to 32,768 tokens.
- Users are cautioned about the model's potential to generate explicit, disturbing, or offensive responses, and usage should be responsible.
- Licensing and Usage Restrictions: The model's usage must adhere to the terms of Mistral's license, prohibiting commercial use without a valid commercial license.
- Users must refer to the base model card for comprehensive details regarding licensing and restrictions.
- Repository Contains Sensitive Content: The repository for Firefly has been marked as containing sensitive content, highlighting potential risks in its usage.
- Users are advised to view content here before proceeding with any access or downloads.
Link mentioned: invisietch/MiS-Firefly-v0.1-22B · Hugging Face: no description found
Torchtune ▷ #dev (4 messages):
DistiLLM Teacher Probability DiscussionKD-div vs Cross-Entropy Clarification
-
DistiLLM's Teacher Probs in Cross-Entropy Optimization: The topic of subtracting teacher probabilities was discussed in the DistiLLM GitHub issues, noting that the constant term can be ignored since the teacher is frozen.
- There’s a suggestion to add a note in the docstring clarifying that the loss routine assumes a frozen teacher model.
- Clarifying KD-div and Cross-Entropy Misunderstanding: Concerns were raised regarding how KD-div is labeled while the returned value is actually cross-entropy, which could lead to misinterpretation when comparing losses like KL-div.
- It’s noted that viewing this process as optimizing for cross-entropy aligns better with the natural flow from hard labels in training to soft labels generated by a teacher model.
Link mentioned: Issues · jongwooko/distillm: Official PyTorch implementation of DistiLLM: Towards Streamlined Distillation for Large Language Models (ICML 2024) - Issues · jongwooko/distillm
Torchtune ▷ #papers (1 messages):
TPOVinePPOReasoning and Alignment
-
TPO Sparks Interest: A member expressed excitement about TPO, stating it looks really cool and plans to add a tracker.
- There's positive anticipation surrounding its functionalities and potential implementations.
- Love for VinePPO Faces Implementation Challenges: Another member shared affection for VinePPO, particularly its capabilities in reasoning and alignment.
- However, they described the implementation as a potential disaster, highlighting the challenges it may present.
tinygrad (George Hotz) ▷ #general (1 messages):
TokenFormer port to tinygrad
-
TokenFormer lands in tinygrad: A member successfully ported a minimal implementation of TokenFormer to tinygrad, available on the
tinygradbranch of the repository.- This adaptation aims to enhance inference and learning capabilities within tinygrad, showcasing the potential of integrating advanced model architectures.
- Development insights on TokenFormer: The implementation highlights a focus on minimalism, ensuring efficient performance while maintaining core functionalities of TokenFormer.
- Members expressed eagerness to test its capabilities and integrate feedback for further improvements.
Link mentioned: GitHub - kroggen/tokenformer-minimal at tinygrad: Minimal implementation of TokenFormer for inference and learning - GitHub - kroggen/tokenformer-minimal at tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Dependency resolution in viewsHailo reverse engineeringKernel consistency in tinygrad
-
Dependency resolution in views: A user questioned whether the operation
x[0:1] += x[0:1]has a dependency onx[2:3] -= ones((2,))or justx[0:1] += ones((2,))when considering true or false share rules.- This raises important technical considerations about how dependencies are tracked in operation sequences.
- Dissecting graph dependencies: Questions arose about whether certain views in bug reports showcase many dependent operations and what these dependencies lead to.
- Understanding the edge relationships in these graphs could clarify operational dependencies.
- Hailo reverse engineering kickoff: One member announced the beginning of their Hailo reverse engineering efforts to create a new accelerator, specifically focusing on process efficiency.
- They expressed concerns about the kernel compilation process, noting that it must compile ONNX and soon Tinygrad or TensorFlow to Hailo before execution.
- Kernel consistency amid fusion: A user is curious if kernels in tinygrad stay consistent across runs, especially when fused using
BEAM=2.
- They hope to avoid the overhead of repeatedly compiling the same kernel, stressing the need for effective cache management.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 9Project GR00TJim FanGEAR at NVIDIACourse Resources
-
Today's Lecture 9 on Project GR00T: Our 9th lecture is set for today at 3:00pm PST and will be live streamed here. This session features Jim Fan, who will present on Project GR00T, NVIDIA's ambitious initiative for generalist robotics.
- His team's mission within GEAR is to develop generally capable AI agents that can function in both simulated and real environments.
- Introduction to Dr. Jim Fan: Dr. Jim Fan, the Research Lead at NVIDIA's GEAR, previously earned a Ph.D. at Stanford Vision Lab and has received accolades like the Outstanding Paper Award at NeurIPS 2022. His notable work includes multimodal models for robotics and AI agents proficient in playing Minecraft.
- His research has been featured in prominent media including New York Times, Forbes, and MIT Technology Review.
- Course Resources available online: All course materials including livestream URLs and homework assignments can be accessed at this course website. Students are encouraged to ask questions in the dedicated course channel <#1280370030609170494>.
Link mentioned: CS 194/294-196 (LLM Agents) - Lecture 9, Jim Fan: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
koppu0729: great talk Jim
Mozilla AI ▷ #announcements (1 messages):
FOSDEM 2025Mozilla DevRoomCall for VolunteersTalk Proposals
-
FOSDEM 2025 Mozilla DevRoom is Open: Mozilla is hosting a DevRoom at FOSDEM 2025 for presenting talks on open-source topics from February 1-2, 2025 in Brussels.
- Participants can submit their talk proposals until December 1, 2024, and will be notified about acceptance by December 15.
- Diverse Topics Encouraged for Talks: Suggested topics for presentations include Mozilla AI, Firefox innovations, and Privacy & Security, among others.
- Speakers are encouraged to explore topics beyond this list, and talks will be between 15 to 45 minutes, including Q&A.
- Volunteers Needed for FOSDEM: An open call for volunteers has been issued, with travel sponsorships available for European participants.
- Volunteering opportunities can be beneficial for networking and supporting the open-source community at the event.
- Helpful Resources for Proposals: For those interested in providing talks, Mozilla shared a post with tips on creating a successful proposal, accessible here.
- This resource aims to guide potential speakers in crafting impactful presentations at FOSDEM.
- Questions Welcomed: Those with inquiries regarding the event can reach out through the Mozilla Discord.
- This provides an opportunity for prospective attendees to clarify any uncertainties they may have.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Benchmarking retrieval-based approachesFunction calling definitionsTest category functions
-
Request for Function Calling Definitions: A member is working on benchmarking a retrieval-based approach to function calling and is seeking a collection of available functions and their definitions.
- They specifically requested these definitions to be organized per test category for more effective indexing.
- Discussion on Function Indexing: A member mentioned the need for an indexed collection of function definitions to enhance their benchmarking efforts.
- They emphasized the importance of categorizing these functions per test category to streamline their workflow.