[AINews] Ten Commandments for Deploying Fine-Tuned Models
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Gemini-in-Google-Slides is all we needed.
AI News for 5/23/2024-5/24/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (380 channels, and 4467 messages) for you. Estimated reading time saved (at 200wpm): 495 minutes.
Followups: Jason Wei published a nice "201" supplement to yesterday's topic on Evals, somewhat on the metagame of making a successful eval, but with some side digressions and anecdotes about specific notable evals like MATH and LMSYS. It's also the last day to use the
AINEWScode for the AI Engineer World's Fair.
It's a quiet news day so we went diving for interesting content from the community. Today's winner is Kyle Corbitt's talk on Deploying Finetuned Models in Prod:
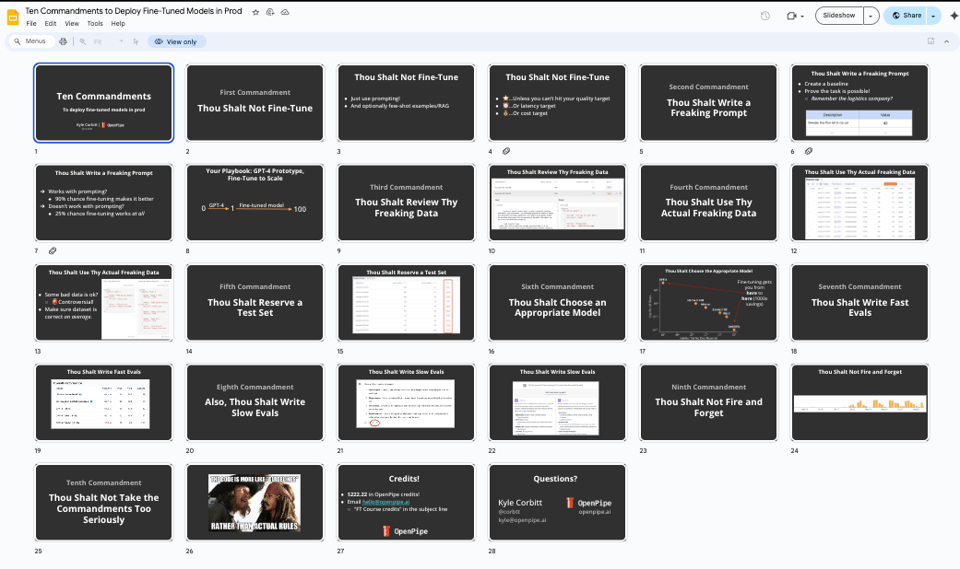
In brief the commandments are:
- Thou Shalt Not Fine-Tune: Just use prompting! And optionally few-shot examples/RAG. Fine-tuning is expensive, slow, and complex. Only do it if your use case really requires it.
- Thou Shalt Write a Freaking Prompt: Create a baseline and prove the task is possible with prompting.
- Thou Shalt Review Thy Freaking Data: If you must fine-tune, make sure you understand your data thoroughly.
- Thou Shalt Use Thy Actual Freaking Data: Your model will only be as good as the data it's trained on. Make sure your training data is as close as possible to the data your model will see in production.
- Thou Shalt Reserve a Test Set: Always reserve a portion of your data for testing to evaluate your model's performance.
- Thou Shalt Choose an Appropriate Model: The more parameters a model has, the more expensive and slower it is to train. Choose a model that is appropriate for your task and your budget.
- Thou Shalt Write Fast Evals: Write evaluation metrics that are fast to compute so you can quickly iterate on your model.
- Also, Thou Shalt Write Slow Evals: Write evaluation metrics that are more comprehensive and take longer to compute, to give you a deeper understanding of your model's performance.
- Thou Shalt Not Fire and Forget: Don't just deploy your model and forget about it. Monitor its performance and be prepared to retrain or update it as needed.
- Thou Shalt Not Take the Commandments Too Seriously: These commandments are meant to be helpful guidelines, not hard and fast rules. Use your best judgment and adapt them to your specific needs.
Fun fact, we used Gemini to do this summary of the deck. Give it a try.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Anthropic's Claude AI and Interpretability Research
- Feature alteration in Claude AI: @AnthropicAI demonstrated how altering internal "features" in their AI, Claude, could change its behavior, such as making it intensely focus on the Golden Gate Bridge. They released a limited-time "Golden Gate Claude" to showcase this capability.
- Understanding how large language models work: @AnthropicAI expressed increased confidence in beginning to understand how large language models really work, based on their ability to find and alter features within Claude.
- Honesty about Claude's knowledge and limitations: @alexalbert__ stated that Anthropic is honest with Claude about what they know and don't know, rather than purposefully making decisions about its ability to speculate on tricky philosophical questions.
Open-Source AI Models and Advancements
- Open-source models catching up to closed-source: @bindureddy highlighted that on the MMLU benchmark, open-source models like GPT-4o are nearing the performance of closed-source models like GPT-4 for simple consumer use-cases. However, more advanced models are still needed for complex AI agent and automation tasks.
- New open-source model releases: @osanseviero shared several new open-source model releases this week, including multilingual models (Aya 23), long context models (Yi 1.5, M2-BERT-V2), vision models (Phi 3 small/medium, Falcon VLM), and others (Mistral 7B 0.3).
- Phi-3 small outperforms GPT-3.5T with fewer parameters: @rohanpaul_ai pointed out that Microsoft's Phi-3-small model, with only 7B parameters, outperforms GPT-3.5T across language, reasoning, coding, and math benchmarks, demonstrating rapid progress in compressing model capabilities.
AI Agents, Retrieval-Augmented Generation (RAG), and Structured Outputs
- Shift from RAG for QA to report generation: @jxnlco forecasted that in the next 6-8 months, RAG systems will transition from question-answering to report generation, leveraging well-designed templates and SOPs to unlock business value by targeting people with money.
- ServiceNow uses RAG to reduce hallucination: @rohanpaul_ai shared a ServiceNow paper showing how RAG can ensure generated JSON objects are plausible and executable for workflow automation by retrieving relevant steps and table names to include in the LLM prompt.
- RAG adds business value by connecting LLMs with real-world data: @cohere outlined how RAG systems address challenges like hallucinations and rising costs by connecting LLMs with real-world data, highlighting the top 5 reasons enterprises are adopting RAG for their LLM solutions.
AI Benchmarks, Evaluation, and Cultural Inclusivity
- Standard AI benchmarks may not guide true global cultural understanding: @giffmana suggested that typical "western" AI benchmarks like ImageNet and COCO may not be indicative of genuine "multicultural understanding". Training models on global data instead of just English can greatly improve performance in non-western cultures.
- Difficulties in evaluating large language models: @clefourrier and @omarsar0 shared a report discussing the challenges in robustly evaluating LLMs, such as differences between initial benchmark design and actual use, and the need for more discriminative benchmarks as models become more capable.
- Aya 23 multilingual models expand who technology serves: @sarahookr introduced Cohere's Aya 23 models, a powerful multilingual family aiming to serve nearly half the world's population, as part of their mission to change who is seen by technology.
Memes and Humor
- Nvidia stock and the "permanent underclass": @nearcyan joked about a spouse regretting not buying Nvidia stock and being part of the "permanent underclass forever".
- Satire of Anthropic's Golden Gate Bridge AI: @jeremyphoward satirized Anthropic's interpretability demo, humorously claiming that "OpenAI has already caught up with the latest feature in Claude, and also has an advanced Golden Gate Bridge mode based on sophisticated mechanistic interpretability research."
- Poking fun at Google's AI mistakes: @mark_riedl shared a humorous anecdote about jokingly claiming Google's AI incorrectly thought he won a DARPA award, leading people to actually believe he didn't receive the honor.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Progress and Capabilities
- Impressive transcription and location identification by GPT-4: In /r/OpenAI, GPT4-o demonstrates remarkable abilities to transcribe text from images and identify locations, even without EXIF data, as shown in this video and discussed further.
- Yi-Large catching up to state-of-the-art models: A comparison posted in /r/singularity shows Yi-Large approaching GPT-4 performance and surpassing Claude 3 Opus and Gemini 1.5 pro on several benchmarks.
AI Ethics and Safety Concerns
- OpenAI employees leaving over ethical concerns: In /r/singularity, it's reported that OpenAI employees are departing not just due to "decel" fears but over issues like partnering with News Corp, lobbying against open source, and aggressive tactics against ex-employees.
- Concerns over OpenAI's News Corp partnership: An /r/OpenAI post criticizes OpenAI's partnership with News Corp, a right-wing propaganda company, worried it could lead to ChatGPT legitimizing extreme viewpoints.
- California AI bill requires safeguards but criticized: A new California AI bill, discussed in /r/singularity, mandates models over 10^26 flops have weapons creation prevention, shutdown buttons, and government reporting. However, the requirements are criticized as not making technical sense.
- Yann LeCun pushes back on AI doomerism: In a video shared on /r/singularity, AI pioneer Yann LeCun argues the biggest AI dangers are censorship, monitoring, and centralized power, not the doomer scenarios often portrayed.
AI Interpretability and Control
- Anthropic's "Golden Gate Claude" maps AI features: Anthropic's research, detailed in /r/singularity, shows their "Golden Gate Claude" can map and manipulate an AI's internal features, a potentially major advance in understanding and controlling AI behavior.
- Anthropic demonstrates feature alteration to shape AI behavior: Another Anthropic paper, shared on /r/singularity, shows interpretable features learned by a sparse autoencoder can represent complex concepts and be altered to control an AI, such as inducing an obsession.
AI Commercialization and Access
- Meta considers paid version of AI assistant: The Information reports, in a post on /r/singularity, that Meta is working on a premium paid version of its AI assistant.
- Macron positions Mistral as EU's top AI company: A CNBC article, shared on /r/singularity, describes French President Macron promoting Mistral as the leading EU AI company, drawing criticism of favoring a French firm over other European contenders.
- Google Colab offers free GPUs for AI development: An /r/singularity post highlights that Google Colab is providing free GPU access, including A100s, to enable AI development.
Memes and Humor
- Meme on boomers not letting go: A meme on /r/singularity jokes about boomers refusing to let younger generations take over.
- Satirical video on Microsoft training GPT5: An /r/singularity video satirizes Microsoft training GPT5 by feeding it data like a whale consuming krill.
- Meme about Windows Recall AI and privacy: A meme on /r/singularity pokes fun at a hypothetical Windows Recall AI feature and the privacy concerns it would raise.
AI Discord Recap
A summary of Summaries of Summaries
-
LLM Fine-Tuning Techniques and Best Practices:
- Ten Commandments for Fine-Tuning: In Kyle Corbitt's talk, members emphasized meticulous prompt design and template configurations, using
###delimiters and "end of text" tokens for efficient model fine-tuning.- Hamel’s Latency Optimization Blog: Discussions on reducing overfitting and the effective use of retrieval-augmented generation (RAG) strategies highlighted practical guidance from ongoing fine-tuning experiments on platforms like Axolotl.
-
Innovations in Quantization and Performance Optimization:
- Tim Dettmers' Research on LLM.int8(): His work, highlighted by this blog, demonstrates how advanced quantization methods maintain transformer performance without degradation, revealing insights into emergent features and their implications.
- CUDA's Gradient Norm Bug Fixing: Solved issues like exploding gradients and batch size problems significantly improved training stability, as detailed in this PR.
- Optimized Memory Architecture in Axolotl: Sample packing efficiency improvements showed a 3-4% resource management gain during distributed training.
-
Open-Source Frameworks and Community Efforts:
- Axolotl's Latest Updates: The community discussed integrating observability into LLM applications and resolving cache and configuration issues to streamline workflows in fine-tuning models.
- PostgresML Integration with LlamaIndex: Andy Singal highlighted the synergy between PostgresML and LlamaIndex in efficiently leveraging AI for database management tasks.
-
Multimodal AI and New Model Developments:
- Phi-3 Model Excitement: Unsloth's Phi-3 models, touted for their longer context lengths and medium support, captured community interest with announcements of rapid optimization and integration.
- Mobius Model Anticipations: DataPlusEngine's upcoming release promises efficient base model creation, sparking debates on the implications for foundational diffusion models and their training methodologies.
-
Challenges in AI Ethics, Governance, and User Experience:
- SB-1047 Regulatory Concerns: Community outrage over the centralization of AI governance and comparisons to regulatory captures in other industries prompted heated discussions on the bill's impact on small developers.
- Ethical Use of AI in Communication Tools: Deployments of GPT-4 and Claude for workplace communication monitoring raised philosophical questions about embedding ethics into AI and their potential for reducing legal vulnerabilities, as highlighted in discussions regarding API integration and usage limits.
Part 2
LLM Finetuning (Hamel + Dan) Discord
Fine-Tuning Facts: Discussion on fine-tuning in the general channel revealed a concern about semantic similarity overfitting due to biased data categories. A user struggled with understanding fine-tuning vis-à-vis user inputs and initial model training. Changes in the OpenAI platform's sidebars were also noted with the disappearance of two icons (threads and messages).
Templates Take the Spotlight: In workshop-1, the importance of configuring templates correctly during fine-tuning was highlighted. In particular, the delimiter ### aids in parsing different input sections, and "end of text" tokens indicate when to stop token generation.
Maven Mingles with Moderation: In asia-tz, a light-hearted exchange between members referenced a reunion. A request for a conference talk recording was met, with the video being available on Maven.
Modal Mobilization: Modal users in 🟩-modal shared excitement over received credits, training experiences, and provided specific links to Modal documentation and examples for new users. A plan to use Modal for a Kaggle competition was also shared, including setup and execution details.
Jarvis Jots Down Jupyter Jumble: In the jarvis-labs channel, members discussed storing a VSCode repo on Jarvis with a suggestion to use GitHub for saving work. There was a notice of spot instance removal due to instability. The cost and duration of fine-tuning the open-lama-3b model were shared, and a user resolved an Ampere series error by adjusting model parameters.
Hugging Face Huddles on Credits & Spanish Models: The hugging-face channel saw discussions about pending HF credits and models suitable for Spanish text generation—with Mistral 7B and Llama 3 models being recommended.
Credit Countdown Carries On in replicate, where an upcoming announcement related to credit management and distribution was teased.
Corbitt's Commandments Claim Clout: Enthusiastic attendees in the kylecorbitt_prompt_to_model channel discussed fine-tuning methods and techniques presented in Kyle Corbitt's talk, including Ten Commandments for Deploying Fine-Tuned Models.
Axolotl Answers the Call in workshop-2, where users discussed datasets, model training, and troubleshooting in Axolotl. A blog post on TinyLLama Fine-Tuning was shared, and there was a push for integrating observability into LLM applications.
Zoom Out, Discord In: Users from workshop-3 migrated their discussions to Discord after the Zoom chat was disabled.
Axolotl's Cache Conundrum Causes Confusion: Issues with cache in Axolotl frustrating users and confusion with missing files were resolved in axolotl. Discussions on sample packing and a guide on tokenizer gotchas addressed concerns around efficiency and tokenization.
Accelerate to Victory: zach-accelerate saw users work through confusion over float comparisons, resolve Jarvislab training command errors, and exchange resources for learning model acceleration with a focus on fine-tuning best practices.
Winging It with Axolotl: The wing-axolotl channel collaborated on dataset templates, pre-processing issues, Axolotl configurations, and provided a PR merge for the latest Axolotl updates. They delved into debugging tools and the significance of precise templates for training success.
HuggingFace Discord
Protein Data Visuals Reach New Heights: A new protein visualization project now sports 3D rendering and includes examples for human hemoglobin and ribosomal proteins, with the project details found on GitHub.
Enter the TranscriptZone with OpenAI's Whisper: A new transcription app that leverages OpenAI's Whisper to transcribe YouTube videos and more is available at Hugging Face Spaces.
Decentralizing the Web - More than a Dream?: A project building infrastructure for a decentralized internet sought community feedback through a survey, raising discussions about the ethics of data collection.
A Vision Transformers Query in Depth: A member sought resources on applying Vision Transformers (ViT) for monocular depth estimation, indicating an intent to develop a model using ViT, but no specific resources were provided in the discussion.
Quantisation Quandary for Mistral Model: The use of bitsandbytes for 8-bit quantisation on Mistral v0.3 Instruct led to slower performance compared to 4-bit and fp16, a baffling outcome that contradicts expected efficiency gains from reduced-bit computation.
Perplexity AI Discord
- Perplexity Climbs Over ChatGPT in CSV Showdown: Engineers discussed that Perplexity AI outshines ChatGPT in CSV file processing by allowing direct CSV uploads. Also, Julius AI was recommended for data analysis, leveraging Python and integration with LLMs like Claude 3 or GPT-4.
- Users Snub Claude 3 Opus: Claude 3 Opus is getting the cold shoulder due to increased content restrictions and perceived diminished utility, with GPT-4 posed as a preferable option despite limitations.
- Querying Pro Search's True Upgrade: Upgrades to Pro Search raised eyebrows as users discussed whether new multi-step reasoning features and API specs were genuine backend improvements or merely surface-level UI enhancements.
- API Integration Articulated: Dialogue around API integration for external tools with Claude generated interest along with sharing of custom function calls, serverless backends, and documentation like Tool Use with Claude.
- Ethics in AI: More Than a Thought Experiment: Discourse on infusing GPTs with ethical monitoring capabilities sparked, casting light on potential applications in workplace communication and legal defensibility, albeit with philosophical wrinkles yet to be ironed out.
Stability.ai (Stable Diffusion) Discord
- Speculation Peaks on RTX 5090's VRAM: There's buzzing debate over whether the rumored RTX 5090 with 32GB VRAM makes practical sense. References were made to potential specs and images on PC Games Hardware, but some members remained skeptical about its authenticity.
- Stable Diffusion and the AMD Challenge: Users offered guidance on installing Stable Diffusion on an AMD 5700XT GPU, suggesting that starting with web services like Craiyon may circumvent potential compatibility issues.
- Stable Diffusion 3: Trial Before Commitment: The community contrasted Stable Diffusion 3 with competitor Midjourney, highlighting that while a free trial is available for SD3, ongoing access would require a Stability membership.
- Anticipation Builds Around Mobius Model: An announcement concerning DataPlusEngine’s novel Mobius model has garnered significant interest for its claim to create efficient base models. The model, teased on Twitter, is neither a straightforward base model nor a tuned version of something pre-existing.
- 32GB VRAM: Game Changer or Overkill?: The mention of a 32GB VRAM GPU led to conversations about the potential shift in Nvidia's approach to data center GPU sales, considering how products with substantial memory could impact the market demand for the H100/A100 series.
Unsloth AI (Daniel Han) Discord
- PEFT Config Snag Solved: An issue where
config.jsonwas missing during PEFT training was resolved by copying it from the base model's configuration, with the user confirming success.
- Llama Levitates Above Bugs: The Llama 3 model's base weights were described as "buggy," but Unsloth has implemented fixes. To improve training, the use of reserved tokens and updates to the tokenizer and
lm_headare recommended.
- System Prompt Boosts Llama 3: Incorporating a system prompt, even a blank one, was observed to enhance Llama3 finetuning outcomes.
- Phi 3 Proliferation: Excitement bubbled as Phi 3 models debuted, sporting medium support. Community chatter pointed engineers toward extensive details in blog posts and release notes.
- Stable Diffusion's Sinister Side Show: Creepy artifacts and uncanny voice cloning outputs from Stable Diffusion startled users, with discussions and experiences shared via YouTube videos and a Reddit thread.
- VSCode Copilot Climbing Onboard: Recommendations for a local VSCode "copilot" were sought and met with suggestions and positive responses in the random channel.
- Inference Inertia with Phi-3: Slower inference times using Unsloth Phi-3 puzzled one user, who provided a Colab notebook to investigate the lag, with community efforts yet to find a fix.
- Quantization Quandary Unraveled: A member faced challenges quantizing a custom model, hitting walls with llama.cpp and Docker compatibility, sparking a discussion on solutions.
- VRAM Verdict for Model Might: VRAM requirements were laid out: 12GB for Phi 3 mini is okay, but 16GB is a must for Phi 3 medium. For hefty tasks, considering outside computing resources was proposed.
- Data Diligence for Training Consistency: The importance of using consistent datasets for training and evaluation was echoed, highlighting Unslothai's public datasets like the Blackhole Collection.
- Platform Possibilities and Cautions: Queries regarding Unsloth support for older Macs were addressed, confirming a focus on CUDA and GPU usage, with suggestions for those on CPU-only rigs.
- Enterprise Expertise Extension: A community member stepped forward to offer enterprise expertise to Unsloth, hailing the joining of accelerators at Build Club and Github, hinting at synergistic potential for Unsloth's endeavors.
Nous Research AI Discord
Intellectual Debate Ignites Over AI Understanding: In-depth discussions were had about the true understanding of concepts by LLMs, with interpretability research considered important empirical evidence. Skeptics argued that current efforts are lacking, with references to work by Anthropic on mapping large language model minds.
The Creature from the Llama Lagoon: A technical foray into enhancing Llama models centered around crafting a script that could manage function calls, with Hermes Pro 2's approach serving as inspiration. Another inquiry circled the implementation of Llama3 LoRA techniques on a 3080 GPU.
Reality Quest in Digital Dimensions: Spearheading a conversation on Nous and WorldSim, members explored the possible applications of NightCafe and multi-dimensional AR spaces in mapping complex AI worlds. Dream-like explorations in audio-visualizers and whimsical ASCII art representations highlighted creative uses for AI-driven simulations.
Sifting Through RAG Data: Advocation for models to integrate internal knowledge with Retrieval-Augmented Generation (RAG) was a hot topic, with questions raised about how to handle contradictions and resolve conflicts. Emphasizing user evaluations was seen as essential, particularly for complex query cases.
Precision over Pixie Dust in Fine-Tuning AI: The community's discourse featured a celebration of the Mobius model for its prowess in image generation, with anticipation for an open-sourced version and elucidating publications. Additionally, Hugging Face was mentioned for their PyTorchModelHubMixin enabling easier model sharing, though limited by a 50GB size constraint without sharding.
Eleuther Discord
- JAX vs. PyTorch/XLA: The TPU Showdown: The performance comparison of JAX and PyTorch/XLA on TPUs spurred debate over benchmarking nuances such as warmup times and blocking factors. The dramatic decline in GPT-3 training costs from $4.5M to an estimated $125K-$1M by 2024 was highlighted, considering TFLOP rates and GPU-hour pricing from various contributors, linking to a Databricks Blog Post.
- Scaling and Teaching LLMs: In the research forum, the Chameleon model was noted for its strong performance in multimodal tasks, while Bitune promised improvements in zero-shot performance for LLMs (Bitune Paper). Discussions questioned the scalability of the JEPA model for AGI and critiqued RoPE's context length limitations, referencing a relevant paper.
- Emergent Features Puzzle LLM Enthusiasts: Tim Dettmers' research on advanced quantization methods maintaining performance in transformer inference was linked, including his concept of emergent outliers, and its integration with Hugging Face via the bitsandbytes library. Discourse on emergent features coalescing around ideas of them being the "DNA" of a model, driving discussions on its implications for phase transitions.
- A Brief on Technical Tweaks & LM Evaluation: Within the lm-thunderdome, engineers covered practical tips for setting seeds in vllm models, retrieving the list of tasks with
lm_eval --tasks list, and handling changes in BigBench task names that affect harnesses like Accelerate with memory issues. It was suggested to locate tasks by perusing thelm-eval/tasksfolder for better organization.
- A Call for Collaboration: An appeal was made for expanding the Open Empathic project, with a YouTube guide for contributing movie scenes and a link to the project shared. Further collaboration was encouraged, underlining the need for community efforts in enhancement.
LM Studio Discord
GPU Adventures: Engineers discussed challenges when loading small models onto GPUs, with some favoring models like llama3, mistral instruct, and cmdrib. Meanwhile, using lower quantizations, such as llamas q4, reportedly yielded better results than higher ones like q8 for certain applications, refuting the notion that "bigger is always better."
Next-Gen Models Incoming: An update in the model realm informed about the release of a 35B model, with testing to ensure LM Studio compatibility. Optimizations for different scales of models were a topic too, with a focus on Phi-3 small GGUFs and their efficiency.
Servers and Setups: Hardware discussions included leveraging distributed inference with llama.cpp and its recent RPC update, although quantized models aren't supported yet. Experimental builds using clustered cheap PCs with RTX 4060 Ti 16GB for distributed model setups and possible network constraints were also explored.
Multilingual Cohesion Achieved: Cohere models now extend their prowess to 23 languages, as advertised with aya-23 quants available for download, but ROCm users must await an update to dive in.
Stable Diffusion Left Out: LM Studio clarified that it exclusively handles language models, excluding image generators like Stable Diffusion, alongside dealing with CUDA issues on older GPUs and promoting services like Julius AI to ease user experience woes.
CUDA MODE Discord
- Gradient Norm Nuisance: Altering the batch size from 32 leads to a sudden spike in gradient norm, disrupting training. A pull request resolved this issue by preventing indexing overflow in the fused classifier.
- Int4 and Uint4 Types Need Some TLC: A member flagged that many functions lack implementations for int4 and uint4 data types in PyTorch, with a discussion thread indicating limitations on type promotion and tensor operations.
- Live Code Alert – Scan Algorithm in Spotlight: Izzat El Hajj will lead a live coding session on the Scan algorithm, vital for ML algorithms like Mamba, scheduled for
<t:1716663600:F>, promising to be a technical deep dive for enthusiasts.
- CUB Library Queries and CUDA Nuances: Members tapped into discussions ranging from the functioning of CUDA CUB library code to triggering tensor cores without cuBLAS or cuDNN, highlighting resources like NVIDIA's CUTLASS GitHub repository and the NVIDIA PTX manual.
- FineWeb Dataset Conundrum: Processing the FineWeb dataset can be a storage hog, hitting 70 GB on disk and gobbling up to 64 GB of RAM, hinting at a need for better optimization or more robust hardware configurations for data processing tasks.
Modular (Mojo 🔥) Discord
Python Libraries Cling to C Over Mojo: There's a lively conversation about the feasibility and preparedness of porting Python libraries to Mojo, with concerns about pushing maintainers too hard given Mojo's evolving API. Members discussed whether targeting C libraries might be a more immediate and practical endeavor.
Rust's Security Appeal Doesn't Rust Mojo's Potential: Mojo is not slated to replace C, but the security benefits of Rust are influencing how engineers think about Mojo's application in different scenarios. Ongoing discussions address concepts from Rust that could benefit Mojo developments.
Blazing Ahead With Nightly Mojo: BlazeSeq performance on MacOS using Night versions of Mojo shows promising similarity to Rust's Needletail, fueling cross-platform efficiency discussions. Rapid nightly updates, noted in changelog, keep the community engaged with the evolving language.
Curiosity Sparks Over Modular Bot's Machinery: Queries were raised about the underlying tech of "ModularBot", and although no specific model was referenced, the bot shared a colorful reply. Separately, the potential for ML model training and inference within Mojo was discussed, with mention of Max Engine as a numpy alternative, though no full-fledged training framework is on the horizon.
Compile-Time Confusion and Alignment Woes: Problems from aligning boolean values in memory to compile-time function issues are causing a stir among users, with workarounds and official bug reports highlighting the importance of community-driven troubleshooting.
OpenAI Discord
- LaTeX Loyalist LLM: In the realm of formatting, users noted frustration with GPT's strong inclination to default to LaTeX despite requests for Typst code, revealing preferences in coding syntax that the LLM seems to adhere to.
- Microsoft Copilot+ vs. Leonardo Rivalry: Conversations in the community centered on the value of Microsoft Copilot+ PCs for creative tasks like "sketch to image," while some members encouraged checking out Leonardo.ai for analogous capabilities.
- A Thirst for Efficiency in AI: Concern was voiced over the environmental toll of AI, citing a Gizmodo article on the substantial water usage during the training of AI models, prompting discussions on the need for more eco-friendly AI practices.
- Iteration Over Innovation: There was active dialogue on enhancing the performance of LLMs through iterative refinement, with references to projects like AutoGPT addressing iterations, despite the associated higher costs.
- Intelligence Infusion Offer Overstated?: The guild pondered the plausibility and potential of embedding legal knowledge within ChatGPT, enough to consider a valuation at $650 million, though detailed perspectives on this bold assertion were limited.
LangChain AI Discord
LangChain CSV Agent Deep Dive: Engineers explored LangChain's CSV agent within a SequentialChain and discussed how to customize output keys like csv_response. Challenges with SQL agents handling multi-table queries were mentioned, pointing towards token limits and LLM compatibility issues, with direction to GitHub for issues.
AI Showcases Gather Buzz: OranAITech tweeted their latest AI tech, while everything-ai v2.0.0 announced features including audio and video processing capabilities with a repository and documentation available.
Demystifying VisualAgents: Demonstrations of Visual Agents platform were shared via YouTube, revealing its potential to streamline SQL agent creation and building simple retrieval systems without coding, utilizing LangChain's capabilities. Two specific videos showcased their workflows: SQL Agent and Simple Retrieval.
EDA GPT Impressions On Display: A demonstration of EDA GPT, including a five-minute overview video showcasing its various functions, was linked to via LOVO AI. The demo highlights the AI tool's versatility.
Tutorial Teaser: A message in the tutorials channel provided a YouTube link to business24.ai's content, although the context of its relevance was not disclosed.
LAION Discord
- Piracy's Not the Panacea: Despite a humorous suggestion that The Pirate Bay could become a haven for sharing AI model weights, skepticism among members arises, highlighting the potential for friendlier AI policy landscapes in other nations to prevail instead.
- Japan Takes the AI High Road: Participants noted Japan's encouraging position on AI development, referencing a paper shared via a tweet about creating new base diffusion models without the need for extensive pretraining, showcasing a strategy involving temporary disruption of model associations.
- Poisoned Recovery Protocols Probed: A collaborative study, involving a poisoned model recovery method conducted by fal.ai, was mentioned, with findings expected to empirically substantiate the recovery approach. Reservations were expressed regarding the aesthetics of AI-generated imagery, specifically the "high contrast look" and artifacts presented by models like Mobius versus predecessors such as MJv6.
- Claude Mappings Crack the Code: Anthropic's research paper details the dissection of Claude 3 Sonnet's neural landscape, which illustrates the manipulation of conceptual activations and can be read at their research page. Debates sparked over the potential commercialization of such activations, with a juxtaposed fear of the commercial implications driving AI practitioners to frustration.
- A Nostalgic Look at AI's Visual Visions: A member reminisced about the evolution from early AI visual models like Inception v1 to today's sophisticated systems, recognizing DeepDream’s role in understanding neural functionality. Furthermore, the benefits of sparsity in neural networks were discussed, describing the use of L1 norm for sparsity and a typical 300 non-zero dimensions in high-dimensional layers.
LlamaIndex Discord
- Meetup Alert: Limited Seats Available: Few spots remain for the upcoming LlamaIndex meetup scheduled for Tuesday, with enthusiasts encouraged to claim their spots quickly due to limited availability.
- MultiOn Meets LlamaIndex for Task Automation: LlamaIndex has been coupled with MultiOn, an AI agents platform, facilitating task automation through a Chrome web browser acting on behalf of users; view the demo here.
- RAGApp Launches for Code-Free RAG Chatbot Setup: The newly introduced RAGApp simplifies the deployment of RAG chatbots via a docker container, making it easily deployable on any cloud infrastructure, and it's open-source; configure your model provider here.
- Solving PDF Parsing Puzzles: The community endorses LlamaParse as a viable API for extracting data from PDFs, especially from tables and fields, leveraging the GPT-4o model for enhanced performance; challenges with Knowledge Graph Indexing were also a topic, highlighting the need for both manual and automated (through
VectorStoreIndex) strategies.
- PostgresML Joins Forces with LlamaIndex: Andy Singal shared insights on integrating PostgresML with LlamaIndex, detailing the collaboration in a Medium article, "Unleashing the Power of PostgresML with LlamaIndex Integration", receiving positive remarks from the community.
OpenRouter (Alex Atallah) Discord
- Phi-3 Medium 128k Instruct Drops: OpenRouter unveiled Phi-3 Medium 128k Instruct, a powerful 14-billion parameter model, and invited users to review both the standard and free variants, and to participate in discussions on its effectiveness.
- Wizard Model Gets a Magic Boost: The Wizard model has shown improvements, exhibiting more prompt and imaginative responses, yet attention is required to avoid repeated paragraphs.
- Eyes on Phi-3 Vision and CogVLM2: Enthusiasm surges around Phi-3 Vision, with sharing of testing links like Phi-3 Vision, and suggestions to use CogVLM2 for vision-centric tasks found at CogVLM-CogAgent.
- Automatic Llama 3 Prompt Transformation: It was clarified that prompts to Llama 3 models are automatically transformed through OpenRouter's API, streamlining the process, but manual prompting remains as an alternative approach.
- Gemini API Annoyances: Users reported issues with Gemini FLASH API, such as empty outputs and token drain, recognized as a model-centric problem. The emergence of Google's daily API usage limits has piqued interest in how this might affect OpenRouter's Gemini integration.
Latent Space Discord
- Indexify Ignites Interest: The launch of Indexify, an open-source real-time data framework by Tensorlake, sparked discussions focusing on its "streaming ETL" capabilities and the challenges in creating sustainable open-source models. Concerns were raised about the adequacy of the extractors provided and their potential paths to monetization.
- LLM Evaluation under the Microscope: A Hugging Face blog post about Large Language Model (LLM) evaluation practices, the importance of leaderboards, and meticulous non-regression testing caught the attention of members, emphasizing the critical role of such evaluations in AI developments.
- AI's Answer to Search Engine Manipulations: An incident involving website poisoning affecting Google's AI-gathered overviews triggered discussions around security and data integrity, including workarounds through custom search engine browser bypasses as reported in a tweet by Mark Riedl.
- AI Democratizing Development or Raising Reliability Questions?: GitHub CEO Thomas Dohmke's TED Talk on AI's role in simplifying coding provoked debates over its reliability despite AI-driven UX improvements that expedite problem-solving in the coding process.
- Diversity Scholarships to Bridge Gaps: Engineers from diverse backgrounds who face financial barriers to attending the upcoming AI Engineer World's Fair received a boost with the announcement of diversity scholarships. Interested applicants should furnish concise responses to the essay questions provided in the application form.
Interconnects (Nathan Lambert) Discord
- Tax Tales Without Plastic: Nathan Lambert deciphered an invoice kerfuffle, realizing the rational behind tax billing sans credit card due to resale certificates.
- Golden Gate AI Gets Attention: Experimentation by Anthropic AI led to "Golden Gate Claude," an AI single-mindedly trained on the Golden Gate Bridge, creating buzz for its public interactivity at claude.ai.
- Google's AI Missteps: Google's failure to harness feedback and premature deployment of AI models spurred discussion about the tech giant's public relations challenges and product development woes.
- Battling Dataset Misconceptions: Google's AI team countered claims about using the LAION-5B dataset by putting forth that they utilize superior in-house datasets, as referenced in a recent tweet.
- Nathan Shares Knowledge Nuggets: For AI aficionados, Nathan Lambert uploaded advanced CS224N lecture slides. Additionally, attendees were tipped off about an upcoming session recording, sans release date details.
OpenAccess AI Collective (axolotl) Discord
- GQA Gains Traction in CMDR Models: Discussions revealed that Grouped Query Attention (GQA) is present in the "cmdr+" models but not in the basic "cmdr" models, indicating an important distinction in their specifications.
- VRAM Efficiency with Smart Attention: Engineers noted that while GQA doesn't offer linear scaling, it represents an improved scaling method compared to exponential, affecting VRAM usage favorably.
- Sample Packing Gets a Boost: A new GitHub pull request showcases a 3-4% efficiency improvement in sample packing, promising better resource management for distributed contexts, linked here.
- Academic Achievement Acknowledged: A member's co-authored journal article has been published in the Journal of the American Medical Informatics Association, highlighting the impact of high-quality, mixed-domain data on medical language models, with the article available here.
- Community Cheers Scholarly Success: The community showed support for the peer's published work through personal congratulatory messages, fostering a culture of recognition for academic contributions within the AI field.
OpenInterpreter Discord
SB-1047 Sparks Technical Turmoil: Engineers express deep concerns about the implications of SB-1047, dubbing it as detrimental to smaller AI players and likening the situation to regulatory capture observed in other industries.
Perplexity and Arc, Tools of the Trade Showcased: The community spotlighted tools aiding their workflows, sharing a Perplexity AI search on SB-1047 and the new “Call Arc” feature of Arc Browser, which simplifies finding relevant answers online, with an informational link.
Install Issues Incite Inquiry: Users face issues with Typer library installation via pip, raising questions about whether steps in the setup process, such as poetry install before poetry run, were followed or if a virtual environment is being used.
Mozilla AI Discord
Twinny Takes Off as Virtual Co-Pilot: Developers are integrating Twinny with LM Studio to serve as a robust local AI code completion tool, with support for multiple llamafiles running on different ports.
Embedding Endpoint Enlightenment: The /v1/embeddings endpoint was clarified not to support image_data; instead, the /embedding endpoint should be used for images, as per pull request #4681.
Mac M2 Meets Its Match in continue.dev: A performance observation noted that continue.dev runs slower on a Mac M2 compared to an older Nvidia GPU when executed with llamafile.
Hugging Your Own LLMs: For those looking to build and train custom LLMs, the community recommended the use of HuggingFace Transformers for training, with the reminder that llamafile is designed for inference, not training.
Cohere Discord
- Gratitude Echoes in the Server: A user expressed heartfelt thanks to the team, showcasing user appreciation for support or development work done by the team.
- Curiosity About Upscaled Models: There's buzz around whether a 104B version of a model will join the family tree, but no clear answers have been outlined yet.
- Langchain Links Missing: Questions arose regarding the integration of Langchain with Cohere, with users seeking guidance on its current usability and implementation status.
- Model Size Mysteries: Users are probing for clarity on whether the Aya model in the playground pertains to the 8B or 35B version, indicating importance in understanding model scales for application.
- Error Troubleshooting Corner: Issues like a
ValidationErrorwith ContextualCompressionRetriever and a 403 Forbidden error signal active debugging and technical problem-solving among the engineers, serving as reminders of common challenges in AI development.
AI Stack Devs (Yoko Li) Discord
AI Comedy Night Hits the Right Notes: An AI-generated standup comedy piece shared by a user was met with positive surprise, indicating advancements in AI's capability to mimic humor and perform entertainment.
Exploratory Queries on AI Applications: Curiosity about the extent of Ud.io's functions was evident from a user's query whether its capabilities go beyond generating comedy.
Sound Transformations Showcased: A user displayed the flexible audio alteration features of Suno by sharing an altered, demonic version of an original sound piece.
Eagerness for Audio Engineering Know-How: Interest was expressed in acquiring the skills to craft audio modifications like the ones demonstrated, a skill set valuable for an AI engineer with an interest in sound manipulation.
Concise Communication Preferred: A one-word reply "No" to a question highlighted a preference for succinct responses, perhaps reflecting an engineer's desire for direct, no-nonsense communication.
MLOps @Chipro Discord
- In Search of a Unified Event Tracker: A member has highlighted a pressing need for an event calendar compatible with Google Calendar to ensure no community events are overlooked. The absence of such a system is a noted concern within the community.
DiscoResearch Discord
- New Dataset Announcement: A new dataset has been referenced by user datarevised, with a link to further details: DataPlusEngine Tweet.
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!