[AINews] Stripe lets Agents spend money with StripeAgentToolkit
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI SDKs are all you need.
AI News for 11/14/2024-11/15/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 1812 messages) for you. Estimated reading time saved (at 200wpm): 191 minutes. You can now tag @smol_ai for AINews discussions!
One of the rising theses in AI developer tooling this year is that tools with better "AI-Computer Interfaces" will do better as a medium-term solve for agent reliability/accuracy. You can see these with tools like E2B and the rising llms.txt docs trend started by Jeremy Howard and now adopted by Anthropic, and Vercel has a generalist AI SDK, but Stripe is the first dev tooling company that has specifically created an SDK for agents that take money:
import {StripeAgentToolkit} from '@stripe/agent-toolkit/ai-sdk';
import {openai} from '@ai-sdk/openai';
import {generateText} from 'ai';
const toolkit = new StripeAgentToolkit({
secretKey: "sk_test_123",
configuration: {
actions: {
// ... enable specific Stripe functionality
},
},
});
await generateText({
model: openai('gpt-4o'),
tools: {
...toolkit.getTools(),
},
maxSteps: 5,
prompt: 'Send <> an invoice for $100' ,
});
and spend money:
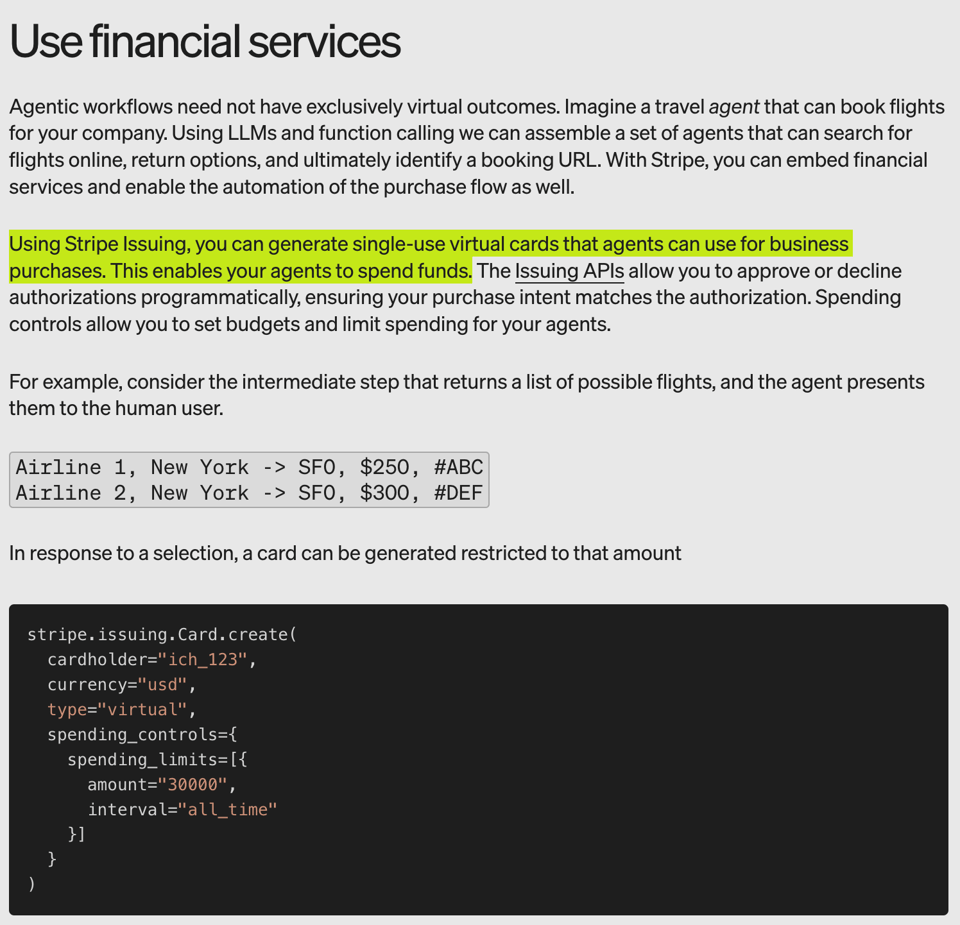
and charge based on token usage. A very very forward thinking move here, solving common pain points, and in retrospect unsurprising that Stripe was the first to build financial services for AI Agents.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- LM Studio Discord
- Perplexity AI Discord
- aider (Paul Gauthier) Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- Eleuther Discord
- Nous Research AI Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- Notebook LM Discord Discord
- OpenAccess AI Collective (axolotl) Discord
- OpenAI Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- LlamaIndex Discord
- Cohere Discord
- LAION Discord
- DSPy Discord
- Modular (Mojo 🔥) Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- LM Studio ▷ #general (83 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (223 messages🔥🔥):
- Perplexity AI ▷ #general (238 messages🔥🔥):
- Perplexity AI ▷ #sharing (10 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- aider (Paul Gauthier) ▷ #general (203 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (38 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- HuggingFace ▷ #general (118 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (3 messages):
- HuggingFace ▷ #i-made-this (9 messages🔥):
- HuggingFace ▷ #reading-group (6 messages):
- HuggingFace ▷ #NLP (2 messages):
- Unsloth AI (Daniel Han) ▷ #general (102 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (8 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (20 messages🔥):
- Eleuther ▷ #general (12 messages🔥):
- Eleuther ▷ #research (97 messages🔥🔥):
- Eleuther ▷ #interpretability-general (6 messages):
- Nous Research AI ▷ #general (66 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (2 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (6 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (65 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (9 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (60 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Interconnects (Nathan Lambert) ▷ #retort-podcast (7 messages):
- GPU MODE ▷ #general (1 messages):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #torch (7 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #beginner (13 messages🔥):
- GPU MODE ▷ #triton-puzzles (1 messages):
- GPU MODE ▷ #webgpu (4 messages):
- GPU MODE ▷ #liger-kernel (2 messages):
- GPU MODE ▷ #self-promotion (2 messages):
- GPU MODE ▷ #🍿 (2 messages):
- GPU MODE ▷ #thunderkittens (11 messages🔥):
- GPU MODE ▷ #edge (5 messages):
- Notebook LM Discord ▷ #use-cases (17 messages🔥):
- Notebook LM Discord ▷ #general (34 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (36 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (9 messages🔥):
- OpenAI ▷ #ai-discussions (25 messages🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- OpenInterpreter ▷ #general (17 messages🔥):
- OpenInterpreter ▷ #ai-content (4 messages):
- tinygrad (George Hotz) ▷ #general (12 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (10 messages🔥):
- Cohere ▷ #discussions (6 messages):
- Cohere ▷ #questions (3 messages):
- Cohere ▷ #projects (1 messages):
- LAION ▷ #general (6 messages):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #general (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
- Torchtune ▷ #announcements (1 messages):
- Torchtune ▷ #papers (2 messages):
- Mozilla AI ▷ #announcements (2 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Benchmarks
- Model Overfitting and Performance: @abacaj highlights concerns about models being overfit, performing well only on specific benchmarks. @francoisfleuret questions the notion that scaling laws have ended, arguing that increasing model size alone may not lead to AGI.
- Gemini and Claude Comparisons: @lmarena_ai reports that Gemini-Exp-1114 achieved #1 on the Vision Leaderboard and improved its standings in Math Arena. In contrast, @goodside critiques the IQ analogy for LLMs, stating that an LLM’s intelligence varies significantly across tasks.
AI Company News
- OpenAI Updates: @OpenAI announces the release of the ChatGPT desktop app for macOS, which now integrates with tools like VS Code, Xcode, and Terminal to enhance developer workflows.
- Anthropic and Meta Developments: @AnthropicAI introduces a new prompt improver in the Anthropic Console, aimed at refining prompts using chain-of-thought reasoning. Meanwhile, @AIatMeta shares top research papers from EMNLP2024, covering advancements in image captioning, dialogue systems, and memory-efficient fine-tuning.
AI Research and Papers
- ICLR 2025 Highlights: @jxmnop reviews top-rated papers from ICLR 2025, including studies on diffusion-based illumination harmonization, open mixture-of-experts language models (OLMoE), and hyperbolic vision-language models.
- Adaptive Decoding Techniques: @jaseweston introduces Adaptive Decoding via Latent Preference Optimization, a new method that outperforms fixed temperature decoding by automatically selecting creativity or factuality parameters per token.
AI Tools and Software Updates
- ChatGPT Desktop Enhancements: @stevenheidel showcases the ChatGPT desktop app’s new features, including Advanced Voice Mode and the ability to interact with VS Code, Xcode, and Terminal for a seamless pair programming experience.
- LlamaParse and RAGformation: @lmarena_ai introduces LlamaParse, a tool for parsing complex documents with features like handwritten content and diagrams. Additionally, @llama_index presents RAGformation, which automates cloud configurations based on natural language descriptions, simplifying cloud complexity and optimizing ROI.
AI Agents and Applications
- AI Agents in Production: @LangChainAI reveals that 51% of companies have AI agents in production, with mid-sized companies leading at 63% adoption. The top use cases include research & summarization (58%), personal productivity (53.5%), and customer service (45.8%).
- Gemini and Claude in Agent Workflows: @AndrewYNg discusses how LLMs like Gemini and Claude are being optimized for agentic workflows, enhancing capabilities such as function calling and tool use to improve agentic performance across various applications.
Memes and Humor
- Humorous Takes on AI: @ClementDelangue shares a lighthearted meme about Transformers.js, while @rez0__ humorously comments on cleaning habits influenced by AI.
- AI-Related Jokes: @hardmaru jokes about historical NVIDIA shareholding, and @fabianstelzer posts a funny AI prompt scenario showcasing the quirks of style transfer in LLMs.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Gemini Exp 1114 Achieves Top Rank in Chatbot Arena
- Gemini Exp 1114 now ranks joint #1 overall on Chatbot Arena (that name though....) (Score: 322, Comments: 101): Gemini Exp 1114, developed by GoogleDeepMind, has achieved a joint #1 overall ranking in the Chatbot Arena, with a notable 40+ score increase, matching the 4o-latest and surpassing o1-preview. It also leads the Vision leaderboard and has advanced to #1 in Math, Hard Prompts, and Creative Writing categories, while improving in Coding to #3.
- Discussions highlight skepticism about Gemini Exp 1114's performance, with some users questioning if its improvements are due to training on Claude's data or other synthetic datasets. Some users humorously suggest that the model's identity and capabilities might be exaggerated or misunderstood, as seen in memes and jokes about its naming and performance.
- The technical debate includes context length and response time, noting that Gemini Exp 1114 has a 32k input context length and is perceived as slower, potentially focusing on "thinking" processes. Comparisons are made with OpenAI's O1 regarding reasoning capabilities, with users noting that Gemini Exp 1114 might use "chain of thought" reasoning effectively without explicit prompts.
- Users express interest in the naming conventions and model variations, with mentions of Nemotron and comparisons to Llama models. There's curiosity about the naming of Gemini models like "pro" or "flash" and speculation about whether this version is a new iteration like "1.5 Ultra" or "2.0 Flash/Pro".
Theme 2. Omnivision-968M Optimizes Edge Device Vision Processing
- Omnivision-968M: Vision Language Model with 9x Tokens Reduction for Edge Devices (Score: 214, Comments: 47): The Omnivision-968M model, optimized for edge devices, achieves a 9x reduction in image tokens (from 729 to 81), enhancing efficiency in Visual Question Answering and Image Captioning tasks. It processes images rapidly, demonstrated by generating captions for a 1046×1568 pixel poster in under 2 seconds on an M4 Pro Macbook, using only 988 MB RAM and 948 MB storage. More information and resources can be found on Nexa AI's blog and their HuggingFace repository.
- There is curiosity about the feasibility of building the Omnivision-968M model using consumer-grade GPUs, like a few 3090s, versus needing to rent more powerful cloud GPUs such as H100/A100s for training. The model's compatibility with Llama CPP and its performance in OCR tasks are also questioned.
- Discussion includes the potential release of an audio + visual projection model and the split between vision/text parameters. Users mention the Qwen2.5-0.5B model and express interest in Nexa SDK usage, with links provided to the GitHub repository.
- Concerns are raised about contributing back to the llama.cpp project, with some users criticizing the lack of reciprocity in open-source contributions. There is also a discussion on the limitations of Coral TPUs for running models due to their small memory size, suggesting entry-level NVIDIA cards as a more cost-effective solution.
Theme 3. Qwen 2.5 7B Dominates Livebench Rankings
- Qwen 2.5 7B Added to Livebench, Overtakes Mixtral 8x22B and Claude 3 Haiku (Score: 154, Comments: 35): Qwen 2.5 7B has been added to Livebench and has surpassed both Mixtral 8x22B and Claude 3 Haiku in rankings.
- Users question the practical utility of Qwen 2.5 7B outside of benchmarks, noting its poor performance in tasks like building a basic Streamlit page and parsing job postings. WizardLM 8x22B is mentioned as a preferable alternative due to its superior performance in real-world applications despite smaller benchmark scores.
- Several users express skepticism about the validity of benchmarks, doubting claims that smaller models like Qwen 2.5 7B outperform larger ones such as GPT-3.5 or Mixtral 8x22B. They highlight a disconnect between benchmark results and actual usability, especially in conversational and instructional tasks.
- Discussion includes technical aspects of running models like Qwen 2.5 14B and 32B on specific hardware setups, such as Apple M3 Max and NVIDIA GTX 1650, and considerations for using models in fp16 or Q4_K_M formats. Users also mention Gemini-1.5-flash-8b as a close competitor in benchmarks, with its multimodal capabilities noted.
- Claude 3.5 Just Knew My Last Name - Privacy Weirdness (Score: 118, Comments: 141): The post discusses a concerning experience with Claude 3.5 Sonnet, where the AI unexpectedly included the user's rare last name in a generated MIT license, despite the user only providing their first name in the session. This raises questions about whether the AI has access to past interactions or external sources like GitHub profiles, despite the user's belief that they opted out of such data usage, and prompts the user to seek similar experiences or insights from others.
- Commenters speculated that Claude 3.5 Sonnet might have accessed the user's last name through GitHub profiles or other publicly available data, despite the user's efforts to keep their information private. Some users suggested that the AI might correlate the user's coding style and public repositories to infer their identity, while others doubted the AI had access to private data or account credentials.
- There was discussion on whether metadata or personal details from account registration, such as an email address or payment information, could have been used to identify the user. Some comments highlighted that Large Language Models (LLMs) typically do not receive such metadata directly, and any apparent personalization might be coincidental or based on public data.
- Users also debated the reliability of LLMs in explaining their thought processes, with some noting that the models might fabricate explanations or rely on training data correlations. A suggestion was made to contact Anthropic for clarification, as the incident raised concerns about privacy and data usage.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Claude Surges Past GPT-4O: Major Shift in Code Generation Quality
- 3.5 sonnet vs 4o in Coding, significant different or just a little better? (Score: 26, Comments: 42): Claude 3.5 Sonnet shows superior coding capabilities compared to GPT-4, with usage limits of 50 messages/5 hours for Claude Pro versus ChatGPT Plus's 80 messages/3 hours, plus additional 50/day with O1-mini and 7/day with O1-preview. The post author seeks advice on whether the performance difference justifies switching to Claude Pro for Python, JavaScript, and C++ development at medium to advanced levels.
- Users report that Claude 3.5 Sonnet consistently outperforms GPT-4 in coding tasks, with one user noting that GPT-4's coding capabilities have notably declined from its initial release when it could effectively handle complex tasks like Matlab-to-Python translations and PyQT5 implementations.
- Several developers emphasize Sonnet's superior code understanding and error fixing capabilities, though some mention using O1-preview for high-level architecture discussions. Users recommend using Cursor with Sonnet as an alternative to handle usage limits.
- Despite the restrictive 45 messages/5 hour limit of Claude Pro, users overwhelmingly prefer it over GPT-4, citing better code quality and project understanding. Some developers use a hybrid approach, switching to GPT-4 while waiting for Claude's limits to reset.
- Chat GPT plus is skipping code, removing functions etc. or even giving empty responses, even the o1-preview (Score: 27, Comments: 21): ChatGPT Plus users report issues with code generation where the model truncates responses, removes unrelated functions, and occasionally provides empty responses when handling larger codebases (specifically a 700-line script). The problem persists even with the GPT-4 preview model, where requests for complete code only return modified functions without the original context.
- Users report that code quality has declined across models, with some suggesting that OpenAI may be intentionally degrading performance. Others note that using the API during US nighttime hours yields better results due to lower load.
- Best practices for working with these models involve breaking down code into smaller, manageable chunks. This approach naturally leads to better architecture by preventing files from becoming too large or too fragmented.
- Claude and standard GPT-4 may produce better code than the GPT-4 preview model, despite the latter's strength in detailed code analysis and complex topic discussions.
Theme 2. FrontierMath Benchmark: Models Score Only 2% on Advanced Math
- FrontierMath is a new Math benchmark for LLMs to test their limits. The current highest scoring model has scored only 2%. (Score: 357, Comments: 117): FrontierMath, a new mathematical benchmark for testing Large Language Models, exposes significant limitations in LLM mathematical abilities with the top-performing model achieving only 2% accuracy. The benchmark aims to evaluate advanced mathematical capabilities beyond standard tests, highlighting a clear performance gap in current AI systems.
- Field Medalists including Terence Tao and Timothy Gowers confirm these problems are "extremely challenging" and beyond typical IMO problems. The benchmark requires collaboration between graduate students, AI, and algebra packages to solve effectively.
- The problems in FrontierMath are specifically designed for AI benchmarking by PhD mathematicians, requiring multiple domain experts working together over extended periods. Sample problems are available at epoch.ai, though the full dataset remains private.
- Discussion focused on the significance of achieving even 2% accuracy on problems that most PhD mathematicians cannot solve individually. Users debated whether AI reaching this level should be considered a collaborative team member rather than just a tool, with reference to Chris Olah's work on neural networks.
Theme 3. Chat.com Domain Sells for $15M to OpenAI - Major Corporate Move
- Indian Man Sells Chat.com for ₹126 Crore (Score: 550, Comments: 173): Chat.com domain sold for $15 million (₹126 Crore) with partial payment made in OpenAI shares. The domain was sold by an Indian owner, marking a significant domain name transaction in 2023.
- Dharmesh Shah, the CTO of Hubspot and tech billionaire, sold the domain after purchasing it for approximately $14 million last year. The transaction included partial payment in OpenAI shares, with Shah being friends with Sam (presumably Altman).
- Multiple commenters criticized the headline's focus on the seller's nationality rather than his significant professional credentials. The sale represents a relatively small transaction for Shah, who is reportedly worth over $1 billion.
- Discussion revealed this was not a long-term domain investment, contradicting initial assumptions about it being held since the early internet days. The actual profit margin was relatively modest given the recent purchase price.
Theme 4. Claude Rollback: 3.6 Issues Lead to Version Reversal
- LMAO they are now pulling back Sonnet 3.6? (Score: 62, Comments: 55): Anthropic appears to have rolled back Claude 3.6 Sonnet and removed version numbering from Haiku, with a screenshot showing the removal of "(new)" designation from the model selection interface. The changes suggest potential versioning adjustments or silent updates to their Claude models, though no official explanation was provided.
- Users report that Claude Sonnet is likely still version 3.6 with just the "new" label removed, as confirmed by the model's knowledge of events and its October 22nd version identifier.
- Community members criticize Anthropic's communication and version naming strategy, with many noting the company's recent struggles with transparency and internal organization. One user humorously identifies different versions by their apology phrases: "You're right, and I apologize" for old 3.5 and "Ah, I see now!" for new 3.5.
- Discussion reveals potential performance variations, with reports of the model having limitations in message output and failing simple tests like counting letters in words. A High Demand Notice was observed at the top of the page, suggesting heavy system usage.
- What's the point of paying if I just logged in and I get greeted with this stupid message? This is ridiculously bad. I didn't even use Claude today that I'm already limited. (Score: 103, Comments: 50): Claude users report immediate access limitations and service restrictions despite having paid subscriptions and no prior usage that day. Anthropic's service limitations appear to affect both new and existing paid subscribers without clear explanation or prior notice.
- Users report that paid Claude subscriptions hit usage limits quickly, with some being restricted before 11 AM. Multiple users suggest using 2-3 accounts at $20 each or switching to the more expensive API as workarounds.
- Community discussion highlights the need for better usage tracking features, suggesting a progress bar for remaining usage before downgrade to concise mode. Users criticize the lack of clarity around usage limits and inability to switch out of concise mode when restricted.
- Technical users discuss local alternatives, recommending Ollama with specific hardware requirements: NVIDIA 3060 (12GB VRAM, $200) or 3090 (24GB VRAM, $700). The Qwen 2.5 32B model is suggested for those with sufficient VRAM, while Qwen 14B 2.5 is recommended as a lighter alternative.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1: Hardware and Performance Optimization for AI Models
- GIGABYTE Unveils AMD Radeon PRO W7800 AI TOP 48G: GIGABYTE launched the AMD Radeon PRO W7800 AI TOP 48G featuring 48 GB of GDDR6 memory, targeting AI and workstation professionals.
Theme 2: Model Releases and Integration Enhancements
- DeepMind Open-Sources AlphaFold Code: DeepMind has released the AlphaFold code, enabling broader access to their protein folding technology, expected to accelerate research in biotechnology and bioinformatics.
- Google Launches Gemini AI App: Google introduced the Gemini app, integrating advanced AI features to compete with existing tools, as covered in the TechCrunch article.
Theme 3: AI Tool Integration and Feature Development
- ChatGPT Now Integrates with Desktop Apps on macOS: ChatGPT for macOS now supports integration with VS Code, Xcode, Terminal, and iTerm2, enhancing coding assistance by directly interacting with development environments.
- Stable Diffusion WebUI Showdown: ComfyUI vs SwarmUI: Users compared ComfyUI and SwarmUI, favoring SwarmUI for its ease of installation and consistent performance in Stable Diffusion workflows.
Theme 4: Training Techniques and Dataset Management
- Orca-AgentInstruct Boosts Synthetic Data Generation: Orca-AgentInstruct introduces agentic flows to generate diverse, high-quality synthetic datasets, enhancing the training efficiency of smaller language models.
- Effective Dataset Mixing Strategies for LLM Training: Members sought guidance on mixing and matching datasets during various stages of LLM training, emphasizing best practices to optimize training processes without compromising model performance.
PART 1: High level Discord summaries
LM Studio Discord
-
Qwen 2.5 LaTeX Rendering Issues: Users are experiencing problems with Qwen 2.5 failing to render LaTeX properly when wrapped in
$signs, resulting in nonsensical outputs.- A suggestion was made to create a system prompt with clear instructions to improve rendering, but attempts to resolve the issue have not been successful.
- LM Studio's Function Calling Beta Excites Users: LM Studio users are enthusiastic about the new function calling beta feature, seeking personal experiences and feedback.
- While some members found the documentation straightforward, others expressed confusion and are looking forward to more functionality in future updates.
- SSD Speed Comparisons and RAID Configurations: The community discussed SSD performance, specifically comparing the SABRENT Rocket 5 and Crucial T705, and the impact of PCIe lane limitations on RAID setups.
- Users highlighted that actual SSD performance can vary significantly based on specific workloads and RAID configurations, affecting overall efficiency.
- GIGABYTE Releases AMD Radeon PRO W7800 AI TOP 48G: GIGABYTE has launched the AMD Radeon PRO W7800 AI TOP 48G, equipped with 48 GB of GDDR6 memory, targeting AI and workstation professionals.
- Despite the impressive specifications, there are concerns regarding the reliability of AMD's drivers and software compatibility when compared to NVIDIA's CUDA.
- Hardware Considerations for LLM Training: Participants noted that 24 GB of VRAM is often insufficient for training larger LLMs, leading to discussions about potential upgrade paths and renting GPUs.
- Training on devices like the Mac Mini is possible but may result in higher electricity costs, prompting members to consider more efficient hardware solutions.
Perplexity AI Discord
-
Perplexity API's URL Injection Issue: Users have reported that the PPLX API occasionally inserts random URLs when it cannot confidently retrieve information, resulting in inaccurate outputs.
- Discussions highlight that the API's tendency to add unrelated URLs undermines its reliability for production use, prompting calls for enhanced accuracy in future updates.
- DeepMind Releases AlphaFold Code: DeepMind has open-sourced the AlphaFold code, enabling broader access to their protein folding technology, as announced here.
- This release is expected to accelerate research in biotechnology and bioinformatics, fostering new innovations in protein structure prediction.
- Chegg's Decline Driven by ChatGPT: Chegg has experienced a 99% decline in value, largely attributed to competition with ChatGPT, detailed in the article.
- The impact of AI on traditional educational platforms like Chegg has sparked significant debate within the community regarding the future of online learning resources.
- Google Gemini App Launch: Google has officially launched the Gemini app, introducing innovative features to compete with existing tools, as covered in the TechCrunch article.
- The app integrates AI and user interaction to deliver enhanced functionalities, aiming to capture a larger market share in the AI-driven application space.
aider (Paul Gauthier) Discord
-
Gemini Experimental Model Performance Soars: Users report that the new gemini-exp-1114 model achieves up to 61% accuracy on edits, outperforming Gemini Pro 1.5 in various tests despite minor formatting glitches.
- Comparative analysis suggests that gemini-exp-1114 offers similar effectiveness to previous versions, contingent on specific use case scenarios.
- Cost Implications of Model Usage in Aider: Discussions highlight that utilizing different models in Aider incurs costs ranging from $0.05 to $0.08 per message, influenced by file configurations.
- This has led users to consider more economical options like Haiku 3.5 to mitigate expenses for smaller-scale projects.
- Seamless Integration with Qwen 2.5 Coder: Users encountered integration issues with Hyperbolic's Qwen 2.5 Coder due to missing metadata, which were resolved by updating their installation setup.
- Aider's main branch updates proved essential in overcoming these challenges, facilitating smooth integration.
- Automating Commit Messages with Aider: To generate commit messages for uncommitted changes, users utilize commands like
aider --commit --weak-model openrouter/deepseek/deepseek-chator/commitwithin Aider.
- These commands automate the commit process by committing all changes without prompting for individual file selections.
HuggingFace Discord
-
Boosting OCR Accuracy with Targeted Training: Discussions highlighted that OCR accuracy can be substantially enhanced through targeted training using appropriate document scanning applications, potentially achieving near-perfect recognition rates.
- Participants emphasized that ensuring the right conditions, such as proper scanning techniques and model fine-tuning, is critical for maximizing OCR performance.
- Enhancing OCR Models via Feedback Integration: Contributors proposed integrating failed OCR instances back into the training pipeline to improve model performance in specific applications.
- This feedback loop approach aims to iteratively refine the models, leading to increased accuracy and reliability in OCR tasks.
- Introducing the OKReddit Dataset for Research: A member unveiled the OKReddit dataset, a curated collection comprising 5TiB of Reddit content spanning from 2005 to 2023, designed for research purposes.
- Currently in alpha, the dataset offers a filtered list of subreddits and provides a link for access, inviting researchers to explore its potential applications.
- Distinguishing RWKV Models from Recursal.ai's Offerings: A member clarified that while RWKV models are associated with specific training challenges, they differ from Recursal.ai models in terms of dataset particulars.
- Planned future integrations indicate a progression in model training methodologies, enhancing the versatility of both model types.
- Optimizing Legal Embeddings for AI Applications: Effective training of embedding models for legal applications necessitates using embeddings pre-trained on legal data to avoid prolonged training times and inherent biases.
- Focusing on domain-specific training not only improves accuracy but also accelerates the development process for legal AI systems.
Unsloth AI (Daniel Han) Discord
-
Triton and CUDA Future Focus: Members plan significant engineering work around Triton and CUDA, highlighting their importance for future projects.
- There are concerns about diminishing returns in model improvement, indicating a shift towards efficiency.
- Language Model Preferences Shift: The Mistral 7B v0.3 model is considered outdated as Qwen/Qwen2.5-Coder-7B-Instruct gains popularity due to extensive training data.
- Community members compared the performance of Gemma2 and GPT-4o, sharing insights on their efficacy.
- Unsloth Installation and Lora+ Support: Users encountered Unsloth installation errors due to missing torch, with suggestions to verify installations in the current environment.
- Lora+ support was confirmed in Unsloth via pull requests, with discussions on its straightforward implementation.
- Fine-tuning Llama3.1b for Math Equations: A user is fine-tuning Llama3.1b for solving math equations, currently achieving 77% accuracy.
- They are conducting hyperparameter sweeps to enhance accuracy to at least 80%, despite low losses on their dataset.
- Dataset Creation: Svelte and Song Lyrics: Due to poor results from Qwen2.5-Coder, a comprehensive dataset for Svelte documentation was created using Dreamslol/svelte-5-sveltekit-2.
- For song lyrics generation, a model is being developed using 5780 songs and associated metadata, with recommendations to use an Alpaca chat template.
Eleuther Discord
-
Scaling Laws: Twitter Declares Scaling Dead: Members debated Twitter's recent claim that scaling is no longer effective in AI, emphasizing the need for insights backed by peer-reviewed papers rather than unverified rumors.
- Some participants referenced journalistic sources from major labs highlighting disappointing outcomes from recent training experiments, questioning the validity of Twitter's assertion.
- LLM Limitations Impacting AGI Aspirations: Discussions spotlighted the capability constraints of current LLM architectures, suggesting potential diminishing returns could hinder the development of AGI-like models.
- Participants stressed the necessity for LLMs to handle intricate tasks, such as Diffie-Hellman key exchanges, raising concerns about models' ability to internally maintain private keys and overall privacy.
- Mixture-of-Experts Enhances Pythia Models: A discussion explored implementing a Mixture-of-Experts (MoE) framework within the Pythia model suite, debating between replicating existing training configurations or updating hyperparameters like SwiGLU.
- Members compared OLMo and OLMOE models, noting discrepancies in data ordering and scale consistency, which could influence the effectiveness of MoE integration.
- Defining Open Source AI: Data vs. Code: Engagements centered on the classification of AI systems as Open Source AI based on IBM's definitions, particularly debating whether requirements apply to data, code, or both.
- Linking to the Open Source AI Definition 1.0, members emphasized the importance of autonomy, transparency, and collaboration while navigating legal risks through descriptive data disclosure.
- Transformer Heads Identify Antonyms in Models: Findings revealed that certain transformer heads are capable of computing antonyms, with analyses showcasing examples like 'hot' - 'cold' and utilizing OV circuits and ablation studies.
- The presence of interpretable eigenvalues across various models confirms the functionality of these antonym heads in enhancing language model comprehension.
Nous Research AI Discord
-
NVIDIA NV-Embed-v2 Tops Embedding Benchmark: NVIDIA released NV-Embed-v2, a leading embedding model that achieved a score of 72.31 on the Massive Text Embedding Benchmark.
- The model incorporates advanced techniques like enhanced latent vector retention and distinctive hard-negative mining methods.
- RLHF vs SFT Explored for Llama 3.2 Training: A discussion on Reinforcement Learning from Human Feedback (RLHF) versus Supervised Fine-Tuning (SFT) focused on resource demands for training Llama 3.2.
- Members highlighted that while RLHF requires more VRAM, SFT offers a viable alternative for those with limited resources.
- SOTA Image Recognition with Compact Model: adjectiveallison introduced an image recognition model achieving SOTA performance with a 29x smaller size.
- This model demonstrates that compact architectures can maintain high accuracy, potentially reducing computational resources.
- AI-Driven Translation Tool Enhances Cultural Nuance: An AI-driven translation tool utilizes an agentic workflow that surpasses traditional machine translation by emphasizing cultural nuance and adaptability.
- It accounts for regional dialects, formality, tone, and gender-specific nuances, ensuring more accurate and context-aware translations.
- Optimizing Dataset Mixing in LLM Training: A member requested guidance on effectively mixing and matching datasets during various stages of LLM training.
- Emphasis was placed on adopting best practices to optimize the training process without compromising model performance.
OpenRouter (Alex Atallah) Discord
-
MistralNemo & Celeste Support Discontinued: MistralNemo StarCannon and Celeste have been officially deprecated as the sole provider ceased their support, impacting all projects dependent on these models.
- This removal necessitates users to seek alternative models or adjust their existing workflows to accommodate the change.
- Perplexity Adds Grounding Citations in Beta: Perplexity has rolled out a beta feature for grounding citations, allowing URLs to be included in completion responses for enhanced content reliability.
- Users can now directly reference sources, improving the trustworthiness of the generated information.
- Gemini API Now Accessible: Gemini is now available through the API, generating excitement about its advanced capabilities among the engineering community.
- However, some users have reported not seeing the changes, indicating potential rollout inconsistencies.
- OpenRouter Implements Rate Limits: OpenRouter has introduced a 200 requests per day limit for free models, as detailed in their official documentation.
- This constraint poses challenges for deploying free models in production environments due to reduced scalability.
- Hermes 405B Maintains Efficiency Preference: Hermes 405B continues to be the preferred model for many users despite its higher costs, due to its unmatched performance efficiency.
- Users like Fry69_dev highlight its superior efficiency, maintaining its status as a top choice despite profit margin concerns.
Stability.ai (Stable Diffusion) Discord
-
Nvidia GPU Blues for Stable Diffusion: A user reported issues configuring Stable Diffusion to use their dedicated Nvidia GPU instead of integrated graphics. Another member referenced the WebUI Installation Guides pinned in the channel for support.
- The community emphasized the importance of following the setup guides to ensure optimal GPU utilization for Stable Diffusion workflows.
- WebUI Showdown: ComfyUI vs. SwarmUI: A member compared the complexities of ComfyUI with SwarmUI, highlighting that SwarmUI streamlines the configuration process. It was recommended to use SwarmUI for a more straightforward installation and consistent performance.
- The discussion focused on ease of use, with several users agreeing that SwarmUI offers a less technical approach without compromising functionality.
- Hunting Down the Latest Image Blending Paper: A user sought assistance locating a recent research paper on image blending, mentioning a Google author but couldn’t find it. Another member suggested performing a Google search on image blending within arXiv for relevant papers.
- The community underscored the value of accessing preprints on arXiv to stay updated with the latest advancements in image blending techniques.
- Frame-by-Frame Fixes for Video Upscaling: A member shared their method for upscaling videos by extracting frames every 0.5 seconds to correct inaccuracies. The discussion included using Flux Schnell and other tools to achieve rapid inference results.
- Participants discussed various techniques and tools to enhance video quality, emphasizing the balance between speed and accuracy in the upscaling process.
- Mastering Low Denoise Inpainting with Diffusers: A user inquired about performing low denoise inpainting or img2img processing for specific image regions. Suggestions included utilizing Diffusers for a swift img2img workflow with minimal steps to refine images.
- The community recommended Diffusers as an effective tool for targeted inpainting tasks, highlighting its efficiency in achieving high-quality image refinements.
Interconnects (Nathan Lambert) Discord
-
Scaling Laws Theory faces scrutiny: Members raised concerns about the validity of the scaling laws theory, which suggests that increased computing power and data will enhance AI capabilities.
- One member expressed relief, stating that decreasing cross-entropy loss is a sufficient condition for improving AI capabilities.
- GPT-3 Scaling Hypothesis validates scaling benefits: Referencing The Scaling Hypothesis, a member stated that neural networks generalize and exhibit new abilities as problem complexity increases.
- They highlighted that GPT-3, announced in May 2020, continues to demonstrate benefits of scale contrary to predictions of diminishing returns.
- $6B Funding Round Elevates Valuation to $50B: A member shared a tweet indicating that a funding round closing next week will bring in $6 billion, predominantly from Middle East sovereign funds, at a $50 billion valuation.
- The funds will reportedly go directly to Jensen, fueling upcoming developments in the tech space.
- Historical Misalignment Concerns Resurface in 2024 Case: Members shared TechEmails discussing communications involving Elon Musk, Sam Altman, and Ilya Sutskever from 2017 on misalignment issues.
- These documents relate to the ongoing case Elon Musk, et al. v. Samuel Altman, et al. (2024), highlighting the historical context of alignment concerns.
- Apple Silicon vs NVIDIA GPUs: LLMs Cost-Effectiveness Showdown: A post discusses the competition between Apple Silicon and NVIDIA GPUs for running LLMs, highlighting compromises in the Apple platform.
- While Apple's newer products offer higher memory capacities, NVIDIA solutions remain more cost-effective.
GPU MODE Discord
-
FSDP Tags Along with torch.compile: A user demonstrated wrapping torch.compile within FSDP without encountering issues, indicating seamless integration.
- They noted the effectiveness of this approach but mentioned not having tested it in the reverse order, leaving room for further experimentation.
- NSYS Faces Memory Overload: nsys profiling can consume up to 60 GB of memory before crashing, raising concerns about its practicality for extensive profiling tasks.
- To mitigate this, users recommended optimizing nsys usage with flags like
nsys profile -c cudaProfilerApi -t nvtx,cudato minimize logging overhead. - ZLUDA Extends CUDA to AMD and Intel GPUs: In a YouTube video, Andrzej Janik showcased how ZLUDA enables CUDA capabilities on AMD and Intel GPUs, potentially transforming GPU computing.
- Community members lauded the breakthrough, expressing excitement about democratizing GPU compute power beyond NVIDIA hardware.
- React Native Embraces LLMs with ExecuTorch: Software Mansion launched a new React Native library leveraging ExecuTorch for backend LLM processing, simplifying model deployment on mobile platforms.
- Users praised the library for its ease of use, highlighting straightforward installation and model launching on the iOS simulator.
- Bitnet 1.58 A4 Accelerates LLM Inference: Adopting Bitnet 1.58 A4 with Microsoft’s T-MAC operations achieves 10 tokens/s on a 7B model, offering a rapid inference solution without heavy GPU reliance.
- Resources are available for model conversion to Bitnet, though some post-training modifications may be necessary to optimize performance.
Notebook LM Discord Discord
-
Listeners Demand More from Top Shelf Podcast: Listeners are pushing to expand the Top Shelf Podcast by adding more book summaries, specifically requesting episodes on Think Again by Adam Grant and insights from The Body Keeps Score. They linked to the Top Shelf Spotify show to support their recommendations.
- One user encouraged community members to share additional book recommendations to enrich the podcast's content offerings.
- Concerns Over AI's Control of Violence: A user shared the "Monopoly on violence for AI" YouTube video, raising alarms about the implications of artificial superintelligence managing violent actions. This monopolization of violence could lead to significant ethical and safety concerns.
- The video explores the potential consequences of granting AI entities control over violent decisions, sparking a discussion on the necessity of strict governance measures.
- NotebookLM Faces Operational Issues: Multiple members reported experiencing technical issues with NotebookLM, such as malfunctioning features and restricted access to certain functions. They expressed frustration while awaiting resolutions from the development team.
- Users shared temporary workarounds and emphasized the need for timely fixes to restore full functionality of the tool.
- Tailoring Audio Summaries for Diverse Audiences: A member showcased their approach to creating customized audio summaries using NotebookLM, adapting content specifically for social workers and graduate students. This demonstrates NotebookLM's capability to modify content based on audience requirements.
- The customization process involved altering the presentation style to better suit the informational needs of different professional groups.
- Limitations on Document Uploads Discussed: Participants debated the document upload limitations within NotebookLM, with suggestions to group documents to adhere to upload restrictions. Questions were raised about the possibility of uploading more than 50 documents.
- The discussion highlighted the need for improved upload capabilities to better accommodate extensive document collections.
OpenAccess AI Collective (axolotl) Discord
-
Orca synthetic data advancements: Research on Orca demonstrates its ability to utilize synthetic data for post-training small language models, matching the performance of larger counterparts.
- Orca-AgentInstruct introduces agentic flows to generate diverse, high-quality synthetic datasets, enhancing the efficiency of data generation processes.
- Liger Kernel and Cut Cross-Entropy improvements: Enhancements in the Liger Kernel have resulted in improved speed and memory efficiency, as detailed in the GitHub pull request.
- The proposed Cut Cross-Entropy (CCE) method reduces memory usage from 24 GB to 1 MB for the Gemma 2 model, enabling training approximately 3x faster than the current Liger setup, as outlined here.
- Axolotl Office Hours and feedback session: Axolotl is hosting its first Office Hours session on December 5th at 1pm EST on Discord, allowing members to ask questions and share feedback.
- Members are encouraged to bring their ideas and suggestions to the Axolotl feedback session, with the team eager to engage and enhance the platform. More details available in the Discord group chat.
- Qwen/Qwen2 Pretraining and Phorm Bot Issues: A member seeks guidance on pretraining the Qwen/Qwen2 model using qlora with a raw text jsonl dataset, followed by fine-tuning with an instruct dataset after installing Axolotl docker.
- Issues reported with the Phorm bot include its inability to respond to basic queries, indicating a potential technical malfunction within the community.
- Meta Invites to Llama event: A member received an unexpected invitation from Meta to attend a two-day event at their HQ regarding open-source initiatives and Llama, sparking curiosity about potential new model releases.
- Community members are speculating on the event's focus, especially considering the unusual nature of the invitation without a speaking role.
OpenAI Discord
-
GPT-4o Token Charges: A discussion revealed that GPT-4o incurs 170 tokens for processing each
512x512tile in high-res mode, effectively valuing a picture at approximately 227 words. Refer to OranLooney.com for an in-depth analysis.- Participants questioned the rationale behind the specific token pricing, drawing parallels to magic numbers in programming and debating its impact on usage costs.
- Enhancing RAG Prompts with Few-Shot Examples: Users are exploring whether integrating few-shot examples from documents into RAG prompts can improve answer quality for their QA agent platform.
- The community emphasized the necessity for thorough research in this area, aiming to refine prompt strategies to bolster response accuracy.
- AI Performance in Game of 24: 3.5 AI models have demonstrated the ability to win occasionally in the Game of 24, showcasing notable advancements in AI gaming capabilities.
- This improvement underscores the ongoing enhancements in AI algorithms, with users expressing optimism about future performance milestones.
- Content Flagging Policies: Members discussed that content flags primarily pertain to model outputs and aid in training enhancements, rather than indicating user misconduct.
- There was concern over an uptick in content flags, especially in contexts like horror video games, suggesting increased monitoring measures.
- Advanced Photo Selection Techniques: A member proposed creating a numbered collage as an efficient method for selecting the best photo among hundreds, aiming to streamline the selection process.
- Despite some skepticism about the collage approach being 'patchy,' its effectiveness was acknowledged, particularly when tasks are handled sequentially.
OpenInterpreter Discord
-
OpenAI Launches 'OPERATOR' AI Agent: In a YouTube video titled 'OpenAI Reveals OPERATOR The Ultimate AI Agent Smarter Than Any Chatbot', OpenAI announced their upcoming AI agent anticipated to reach a broader audience soon.
- The video emphasizes that it's coming to the masses! suggesting a significant scaling of the AI agent’s deployment.
- Beta App Surpasses Console Integration: Members confirmed that the desktop beta app offers superior performance compared to the console integration, attributed to enhanced infrastructure support.
- It's highlighted that the desktop app has more extensive behind-the-scenes support than the open-source repository, ensuring a better Interpreter experience.
- Azure AI Search Techniques Detailed: A YouTube video titled 'How Azure AI Search powers RAG in ChatGPT and global scale apps' outlines data conversion and quality restoration methods used in Azure AI Search.
- The discussion raises concerns about patent filings, resource allocation, and the necessity for efficient data deletion processes in large-scale applications.
- Probabilistic Computing Boosts GPU Performance: A YouTube video reports that probabilistic computing achieves 100 million times better energy efficiency compared to top NVIDIA GPUs.
- The presenter states, 'In this video, I discuss probabilistic computing that reportedly allows for 100 million times better energy efficiency compared to the best NVIDIA GPUs.'
- ChatGPT Desktop Enhancements: Latest updates to the ChatGPT desktop introduce user-friendly enhancements, marking a significant improvement for mass users.
- Users are eager to experience features that refine their interactions with the platform, emphasizing the desktop's enhanced usability.
tinygrad (George Hotz) Discord
-
tinybox pro launches for preorder: The tinybox pro is now available for preorder on the tinygrad website at $40,000, featuring eight RTX 4090s and delivering 1.36 PetaFLOPS of FP16 computing.
- Marketed as a cost-effective alternative to a single Nvidia H100 GPU, it aims to provide substantial computational power for AI engineers.
- Clarification on int64 indexing bounty: A member inquired about the requirements for the int64 indexing bounty, specifically regarding modifications to functions like
__getitem__in tensor.py.
- Another member referenced PR #7601, which addresses the bounty but is pending acceptance.
- Enhancements in buffer transfer on CLOUD devices: A pull request on buffer transfer function for CLOUD devices was highlighted, aiming to improve device interoperability.
- Discussions pointed out potential ambiguities regarding size checks for destination buffers, emphasizing the need for clarity in implementation.
- Natively transferring tensors between GPUs: Clarification was provided that tensors can be transferred between different GPUs on the same device using the
.tofunction.
- This guidance assists users in efficiently managing tensor transfers within their projects.
- Seeking feedback on tinygrad contributions: A contributor shared their initial efforts to contribute to tinygrad, seeking comprehensive feedback.
- They referenced PR #7709 which focuses on data transfer improvements.
LlamaIndex Discord
-
Learn GenAI App Building in Community Call: Join our upcoming Community Call to explore creating knowledge graphs from unstructured data and advanced retrieval methods.
- Participants will delve into techniques to transform data into queryable formats.
- Python Docs Feature Boost with RAG System: The Python documentation was enhanced with a new 'Ask AI' widget that launches a precise RAG system for code queries Check it out!.
- Users can receive accurate, up-to-date code responses directly to their questions.
- CondensePlusContext's Dynamic Context Retrieval: CondensePlusContext condenses input and retrieves context for each user message, enhancing dynamic context insertion into the system prompt.
- Members prefer it for its efficiency in managing context retrieval consistently.
- Challenges with condenseQuestionChatEngine: A member reported that condenseQuestionChatEngine can generate incoherent standalone questions when users change topics abruptly.
- Suggestions include customizing the condense prompt to handle sudden topic shifts effectively.
- Implementing Custom Retrievers in CondensePlusContext: Members agreed to use CondensePlusContextChatEngine with a custom retriever to align with specific requirements.
- They recommended employing custom retrievers and node postprocessors for optimized performance.
Cohere Discord
-
Agentic Chunking Research Published: A new method on agentic chunking for RAG achieves less than 1 second inference times, proving efficient on GPUs and cost-effective. Full details and community building for this research can be found on their Discord channel.
- This advancement demonstrates significant performance improvements in retrieval-augmented generation processes, enhancing system efficiency.
- LlamaChunk Simplifies Text Processing: LlamaChunk introduces an LLM-powered technique that optimizes recursive character text splitting by requiring only a single LLM inference over documents. This method eliminates the need for brittle regex patterns typically used in standard chunking algorithms.
- The team encourages contributions to the LlamaChunk codebase, available for public use on GitHub.
- Enhancements in RAG Pipelines: RAG Pipelines are being optimized through agentic chunking, aiming to streamline retrieval-augmented generation processes. This integration focuses on reducing inference times and improving overall pipeline efficiency.
- The updates leverage GPU efficiency to maintain cost-effectiveness while enhancing performance metrics.
- Uploading Files with Playwright in Python: A user shared a method for uploading a text file in Playwright Python using the
set_input_filesmethod, followed by querying the uploaded content. This approach streamlines automated testing workflows involving file interactions.
- However, the user noted that the method feels somewhat odd when requesting, "Can you summarize the text in the file? @file2upload.txt".
LAION Discord
-
Copyright Confusion over Public Links: A member asserted, there is no world where a public index of public links is a copyright infringement, sparking confusion about the legality of using public links.
- This debate highlights the community's uncertainty regarding copyright laws related to public link indexing.
- Discord Etiquette Appreciation: A member expressed gratitude with a simple, ty, demonstrating appreciation for help received.
- Such exchanges indicate ongoing collaborative support and adherence to Discord etiquette within the community.
DSPy Discord
-
ChatGPT for macOS integrates with desktop apps: ChatGPT for macOS now supports integration with desktop applications such as VS Code, Xcode, Terminal, and iTerm2 in its current beta release for Plus and Team users.
- This integration enables ChatGPT to enhance coding assistance by directly interacting with the development environment, potentially transforming project workflows. OpenAI Developers tweet announced this feature recently.
- dspy GPTs functionality: There is a strong intention to extend the functionality of dspy GPTs, aiming to significantly enhance development workflows.
- Community members discussed the potential benefits of expanding dspy GPTs integration, emphasizing the positive impact on their project processes.
- LLM Document Generation for Infractions: A user is developing an LLM application to generate comprehensive legal documents defending drivers against license loss due to infractions, currently focused on alcohol ingestion cases.
- They are seeking a method to create an optimized prompt that can handle various types of infractions without the need for individually tailored prompts.
- DSPy Language Compatibility: A user inquired about the language support capabilities of DSPy for applications requiring non-English languages.
- Reference was made to an open GitHub issue that addresses requests for localization features within DSPy.
Modular (Mojo 🔥) Discord
-
ABI Research Uncovers Optimization Challenges: Members shared new ABI research papers and a PDF, highlighting low-level ABIs challenges in facilitating cross-module optimizations.
- One member pointed out that writing everything in one language is often preferred for maximum execution speed.
- ALLVM Project Faces Operational Hurdles: Discussions revealed that the ALLVM project likely faltered due to insufficient device memory for compiling and linking software, especially within browsers. ALLVM Research Project.
- Another member suggested that Mojo could leverage ALLVM for C/C++ bindings in innovative ways.
- Members Advocate Cross-Language LTO: A member emphasized the importance of cross-language LTO for existing C/C++ software ecosystems to avoid rewrites.
- The discussion acknowledged that effective linking could significantly improve the performance and maintainability of legacy systems.
- Mojo Explores ABI Optimization: Members explored Mojo's potential in defining an ABI that optimizes data transfer by utilizing AVX-512-sized structures and maximizing register information.
- This ABI framework is expected to enhance interoperability and efficiency across various software components.
LLM Agents (Berkeley MOOC) Discord
-
Intel AMA on AI Tools: Join the exclusive AMA session with Intel on Building with Intel: Tiber AI Cloud and Intel Liftoff scheduled for 11/21 at 3pm PT, offering insights into advanced AI development tools.
- This event provides a unique chance to interact with Intel specialists and gain expertise in optimizing AI projects using their latest resources.
- Intel Tiber AI Cloud: Intel will unveil the Tiber AI Cloud, a platform designed to enhance hackathon projects through improved computing capabilities and efficiency.
- Participants can explore how to leverage this platform to boost performance and streamline their AI development workflows.
- Intel Liftoff Program: The session will cover the Intel Liftoff Program, which supports startups with technical resources and mentorship.
- Learn about the comprehensive benefits aimed at helping young companies scale and succeed within the AI industry.
- Quizzes Feedback Delays: A member raised concerns about not receiving email feedback for quizzes 5 and 6 while attempting to catch up.
- Another member suggested verifying local settings and recommended resubmitting the quizzes to address the issue.
- Course Deadlines Reminder: An urgent reminder was issued that participants are still eligible but need to catch up quickly as each quiz ties back to course content.
- The final submission date is set for December 12th, highlighting the necessity for timely completion.
Torchtune Discord
-
Torchtune v0.4.0 Release: Torchtune v0.4.0 has been officially released, introducing features like Activation Offloading, Qwen2.5 Support, and enhanced Multimodal Training. Full release notes are available here.
- These updates aim to significantly improve user experience and model training efficiency.
- Activation Offloading Feature: Activation Offloading is now implemented in Torchtune v0.4.0, reducing memory requirements for all text models by 20% during finetuning and lora recipes.
- This enhancement optimizes performance, allowing for more efficient model training workflows.
- Qwen2.5 Model Support: Qwen2.5 Builders support has been added to Torchtune, aligning with the latest updates from the Qwen model family. More details can be found on the Qwen2.5 blog.
- This integration facilitates the use of Qwen2.5 models within Torchtune's training environment.
- Multimodal Training Enhancements: The multimodal training functionality in Torchtune has been enhanced with support for Llama3.2V 90B and QLoRA distributed training.
- These enhancements enable users to work with larger datasets and more complex models, expanding training capabilities.
- Orca-AgentInstruct for Synthetic Data: The new Orca-AgentInstruct from Microsoft Research offers an agentic solution for generating diverse, high-quality synthetic datasets at scale.
- This approach aims to boost small language models' performance by leveraging effective synthetic data generation for post-training and fine-tuning.
Mozilla AI Discord
-
Local LLM Workshop Scheduled for Tuesday: The Build Your Own Local LLM Workshop is set for Tuesday, featuring Building your own local LLM's: Train, Tune, Eval, RAG all in your Local Env., aimed at guiding members through local LLM setup intricacies.
- Participants are encouraged to RSVP to enhance their local environment capabilities.
- SQLite-Vec Adds Metadata Filtering: SQLite-Vec Now Supports Metadata Filtering was announced on Wednesday via this event, highlighting enhanced capabilities with practical applications.
- This update allows improved data handling through metadata utilization.
- Autonomous AI Agents Discussion on Thursday: Join the Exploring Autonomous AI Agents discussion on Thursday, featuring Autonomous AI Agents with Refact.AI, focusing on AI automation advancements.
- The event promises insights into the functionality and future trajectory of AI agents.
- Assistance Needed for Landing Page Development: A member is seeking help to develop a landing page for their project, with plans for a live walkthrough on the Mozilla AI stage.
- Interested members should reach out in this thread to provide collaborative marketing support.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LM Studio ▷ #general (83 messages🔥🔥):
Qwen2.5-Math-72B-Instruct issuesLM Studio local server setupFunction calling beta in LM StudioSSD speed comparisonsUsing multiple apps for LLM tasks
-
Qwen2.5 not rendering LaTeX correctly: Users expressed frustration with Qwen 2.5 when it fails to display LaTeX wrapped in $ signs properly, leading to nonsensical outputs.
- There was a suggestion that creating a system prompt with clear instructions might improve results, but attempts to fix the issue have been unhelpful.
- LM Studio as a server for LLM access: A user attempted to set up LM Studio as a server to invoke a simple LLM but faced connection errors related to server accessibility.
- Another member reminded them that LM Studio functions as an API, not a web UI, which could clarify the setup.
- Excitement over function calling beta: Users shared their enthusiasm about the function calling beta feature in LM Studio, with requests for personal experiences and feedback.
- Some users highlighted that documentation was straightforward, yet others expressed confusion, anticipating more functionality.
- Discussion on SSD speeds and RAID configurations: The chat discussed the speeds of SSDs, particularly the SABRENT Rocket 5 and Crucial T705, while emphasizing the limitations of PCIe lanes and RAID setups.
- Users noted that while SSDs have ideal max speeds, actual performance could vary significantly depending on specific workloads and RAID configurations.
- Using multiple applications for LLM experimentation: One user shared their approach of using multiple LLM apps for different tasks, highlighting that no single app excels at every use case.
- They underscored that while LM Studio serves most needs, it’s beneficial to have options for specific purposes, like experimenting with various models.
LM Studio ▷ #hardware-discussion (223 messages🔥🔥):
GPU ComparisonsAMD Radeon PRO W7800Apple hardware for AIQualcomm X Elite v2Training costs for LLMs
-
Debating Between Mac Mini M4 and PC with 3090: Users discussed the pros and cons of using a Mac Mini M4 versus a PC with a 3090 for AI-related tasks, highlighting trade-offs like upgrade potential and energy efficiency.
- There was consensus that while the Mac is user-friendly, it may not perform as well for training compared to a dedicated NVIDIA GPU machine.
- GIGABYTE Launches AMD Radeon PRO W7800 AI TOP 48G: GIGABYTE recently launched the AMD Radeon PRO W7800 AI TOP 48G, featuring 48 GB of GDDR6 memory aimed at AI and workstation professionals.
- Despite the impressive specs, there are concerns about the reliability of AMD's drivers and software compatibility compared to NVIDIA's CUDA.
- Considerations for LLM Training on Different Hardware: Participants noted that 24 GB of VRAM is often insufficient for training larger models, leading to discussions on potential upgrade paths.
- Training on the Mac Mini is possible but may incur higher electricity costs, prompting discussions on renting GPUs for training tasks.
- Qualcomm X Elite v2 and Windows on ARM: There was a discussion on the upcoming Qualcomm X Elite v2 and its implications for development, though concerns about Windows on ARM compatibility were raised.
- Participants agreed that while progress is being made, ARM-based Windows is still lacking in software compatibility compared to its Mac counterpart.
- Performance and Usability of New AI Models: Users expressed interest in the performance of various AI models, specifically mentioning comparisons between LLMs like Qwen 2.5 and Nemotron 70B.
- There were concerns about the overall usability of models based on RAM and GPU performance, affecting inference speeds.
Links mentioned:
- Extropic assembles itself from the future: Extropic announces its $14.1M Seed round // Guillaume Verdon // December 4 2023
- GIGABYTE Launches AMD Radeon PRO W7800 AI TOP 48G Graphics Card: GIGABYTE TECHNOLOGY Co. Ltd, a leading manufacturer of premium gaming hardware, today launched the cutting-edge GIGABYTE AMD Radeon PRO W7800 AI TOP 48G. GIGABYTE has taken a significant leap forward ...
Perplexity AI ▷ #general (238 messages🔥🔥):
Perplexity API and FeaturesMobile App IssuesChinese Language and Culture DiscussionsPlagiarism Check in AI WritingCurator Applications for Perplexity
-
Concerns about Perplexity's API and Real-time Browsing: Users have expressed confusion about Perplexity's current inability to access links or browse the internet in real-time, with suggestions to phrase inquiries differently.
- Some noted that prompting the model properly could potentially yield better results, particularly for summarizing content.
- Mobile App Functionality: Several users reported recent difficulties with the Perplexity mobile app, with one unable to install it despite successful downloads of other apps.
- Recommendations to update the app from the App Store were provided, along with some confirmations that others were experiencing no issues.
- Discussions on Chinese Language: Several members discussed the prevalence of Chinese language in the chat, sharing their thoughts on language use, translation tools, and cultural perceptions.
- Users noted differences between simplified and traditional Chinese, and how using certain applications can facilitate communication.
- Plagiarism Concerns in AI Writing: A user inquired about whether Perplexity performs real plagiarism checks when generating articles, raising concerns about the originality of AI-generated content.
- Community members suggested using specific prompts to instruct the AI to avoid plagiarism, while confirming that Perplexity does include resource citations.
- Curator Role Applications: A user inquired about the status of curator applications and was encouraged to apply, with tips provided for increasing selection chances.
- Another user mentioned being busy with schoolwork but planned to include related projects as writing samples for their application.
Links mentioned:
- Tweet from Phi Hoang (@apostraphi): naturally
- Vencord: no description found
- Tweet from Ryan Putnam (@RypeArts): friday vibes ✨
- no title found: no description found
- no title found: no description found
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Massive News from Chatbot Arena🔥 @GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — ma...
- Perplexity CEO Aravind Srinivas on the rush toward an AI-curated web | TechCrunch Disrupt 2024: Perplexity's AI-powered search engine might be the next stage of interacting with the web and knowledge in general - or not. But the company is certainly ris...
Perplexity AI ▷ #sharing (10 messages🔥):
DeepMind AlphaFold Code ReleaseChegg's Decline Due to ChatGPTGoogle Gemini App LaunchMicrosoft Quantum LogicBest Work Mouse
-
DeepMind Releases AlphaFold Code: The news broke that DeepMind has released the code for AlphaFold, allowing wider access to their groundbreaking protein folding technology, linked here.
- This release may aid further research in biotechnology and bioinformatics, fostering new advancements in the field.
- Chegg's Downfall Due to ChatGPT: A discussion highlighted how Chegg experienced a staggering 99% decline in value, mostly attributed to competition with ChatGPT, detailed in the article here.
- The impact of AI on traditional educational platforms like Chegg has sparked considerable conversation in the community.
- Google Launches Gemini App: Google has officially launched the Gemini app, providing users with innovative features as covered in this TechCrunch article.
- The app aims to compete directly with existing tools, showcasing new capabilities that blend AI and user interaction.
- Microsoft's Quantum Logic Operations: Another significant tech development is Microsoft's exploration into quantum logic operations, revealing future possibilities in advanced computing, detailed here.
- This could reshape computational paradigms and strengthen Microsoft’s position in quantum technologies.
- Best Mouse for Work: Participants discussed recommendations for the best mouse for work, emphasizing comfort and efficiency, which can be found in this search article.
- The community is keen on ergonomic tools that enhance productivity for daily tasks.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
PPLX API PerformanceURL Injection Issue
-
PPLX API shows mixed results in production use: A member raised a concern regarding the PPLX API's reliability for production use, specifically about its ability to provide accurate results.
- They mentioned that when the API cannot find something confidently, it injects random URLs that were not specified, leading to inaccurate results.
- Discussions on API usability: Another participant shared their observations that the PPLX API generally functions well but has notable shortcomings.
- This ongoing dialogue suggests that while some see potential, others are questioning its suitability in a production environment.
aider (Paul Gauthier) ▷ #general (203 messages🔥🔥):
Gemini Experimental ModelAider Configuration IssuesCosts of Using ModelsIntegrating Aider with Hyperbolic's Qwen 2.5 CoderUsing Aider for Commit Messages
-
Gemini Experimental Model Performance: Users report that the new gemini-exp-1114 model performs better than others, with some achieving a 61% accuracy on edits despite minor formatting issues during testing.
- Comparisons to the Gemini Pro 1.5 indicate it might be similarly effective, but performance can vary based on specific use cases.
- Troubles with Aider Configuration: Users expressed frustration when Aider didn't recognize certain files or settings, particularly with the openrouter/qwen/qwen-2.5-coder-32b-instruct configuration, leading to confusion around token limits and charges.
- A fix has been implemented to address these issues, and users are encouraged to reload the main branch for optimal performance.
- Understanding Model Costs: Discussion arose about the costs associated with using different models in Aider, with some users noting charges ranged nearly 0.05 to 0.08 dollars per message depending on file configuration.
- This sparked conversation about how smaller projects can incur surprisingly high costs due to specific model behaviors and file handling.
- Integrating Aider with Hyperbolic's Qwen 2.5 Coder: Users experienced integration issues with Hyperbolic's Qwen 2.5 Coder, initially leading to errors due to missing metadata, but found success after correcting the installation setup.
- Clear instructions to follow the main branch updates helped resolve these integration challenges.
- Generating Commit Messages with Aider: To generate commit messages for uncommitted changes in a Git repository, users can utilize commands like
aider --commit --weak-model openrouter/deepseek/deepseek-chator/commitinside Aider.
- These commands will create a commit message but will commit all changes without prompting for file selections.
Links mentioned:
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Tweet from undefined: no description found
- Tweet from Melvin Vivas (@donvito): I'm building a new startup. Here's my AI team http://bolt.new - Frontend Engineer http://aider.chat - Backend Engineer @crewAIInc - Product Designer / Manager Claude AI - Content Creator @per...
- Gemini - direct access to Google AI: Created with Gemini
- Tweet from Logan Kilpatrick (@OfficialLoganK): squashing a few rough edges in AIS still, will be available in the API soon, stay tuned and have fun!
- Google AI Studio: Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
- Gemini - Challenges and Solutions for Aging Adults: Created with Gemini
- Scripting aider: You can script aider via the command line or python.
- no title found: no description found
- Ravel: no description found
- PHP: Manual Quick Reference: PHP is a popular general-purpose scripting language that powers everything from your blog to the most popular websites in the world.
- Aide - Your AI Programming Assistant: Code with the speed and knowledge of the best programmer you know. Aide is by your side.
aider (Paul Gauthier) ▷ #questions-and-tips (38 messages🔥):
Aider's API Key ConfigurationAider Permission ErrorsUsing XAI with AiderCheap Models for AiderAider Running in Docker
-
Aider's API Key Configuration Issues: A user encountered problems using .aider.conf.yml for API key configuration and found that an old API key was causing the failure.
- Another user suggested running Aider with
—verboseto check which YAML file was loaded and which API key was in effect. - Random Permission Errors in Aider: One user reported random permission errors when running Aider on Windows, specifically when trying to write to a file, despite running as an administrator.
- The permission error occurred on files intermittently, leaving users confused if it was related to LLMs or another issue.
- Challenges Using XAI with Aider: A user reported difficulties using the XAI model xai/grok-beta, receiving errors about the LLM provider not being recognized.
- This appeared to stem from an outdated
litellmdependency, with links provided for further context on the GitHub issues related to it. - Seeking Cheaper Model Alternatives for Aider: A user inquired about the cheapest model for running Aider while using the diff format, mentioning high costs with existing models.
- They noted success only with the Haiku 3.5 model and were exploring alternatives due to the expenses.
- Running Aider in Docker and Configuration: A user questioned where Aider stores the sentence transformer model when running in Docker, aiming to map it outside the container.
- After reassessing their setup, they switched from using Docker to directly updating environment variables for a more recent configuration.
- Another user suggested running Aider with
Links mentioned:
- XAI | liteLLM: https://docs.x.ai/docs
- Providers | liteLLM: Learn how to deploy + call models from different providers on LiteLLM
- xai model not being recognized · Issue #2295 · Aider-AI/aider: Issue /model xai/grok-beta Warning for xai/grok-beta: Unknown context window size and costs, using sane defaults. Did you mean one of these? xai/grok-beta Aider v0.62.1 Model: xai/grok-beta with wh...
aider (Paul Gauthier) ▷ #links (1 messages):
renanfranca9480: https://supermaven.com/blog/cursor-announcement
HuggingFace ▷ #general (118 messages🔥🔥):
Hugging Face Sign-Up IssuesOCR Accuracy and ImprovementReinforcing OCR ModelsLoading LoRA State DictsShortening URLs for Hugging Face
-
Hugging Face Sign-Up Page: Multiple users reported receiving a 400 error code and a blank screen when attempting to sign up on Hugging Face.
- The issue persisted across different users in various locations, suggesting a potential systemic problem.
- Increasing OCR Accuracy: The discussion examined how OCR accuracy could be improved significantly through training, especially with proper document scanning applications.
- Participants expressed that if the right conditions are met, achieving a near 100% success rate is possible.
- Reinforcing OCR Models: Contributors proposed that failed OCR cases could be fed back into the training process to enhance model performance in specific applications.
- The ongoing adjustment and training of models based on prior failures could lead to near-perfect recognition rates.
- Using State Dicts for Loading LoRA: A user sought help with loading a LoRA model using a specific state_dict format, providing examples of keys and their tensor sizes.
- The state_dict details indicated it covers a significant portion of the base model's keys, raising questions about documentation.
- Shortening Hugging Face URLs: Users discussed the idea of shortening Hugging Face URLs similar to how YouTube uses 'youtu.be' links.
- While hf.co exists, participants highlighted that URLs still need the '/spaces/' segment, only saving about nine characters.
Links mentioned:
- Use authentication in huggingface Gradio API!(hosting on ZeroGPU): Guys. I have already hosted my code on ZeroGPU(for that i subscribe the PRO) When I visited him on the webpage (logged in as my PRO user), I did receive 5x usage quota compared to free users. But w...
- Remiscus/MediGen · Update README.md: no description found
- Cat Drugs GIF - Cat Drugs Tripping - Discover & Share GIFs: Click to view the GIF
- GitHub - turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs: A fast inference library for running LLMs locally on modern consumer-class GPUs - turboderp/exllamav2
- zero-gpu-explorers/README · Discussions: no description found
- Getting Started With The Python Client: A Step-by-Step Gradio Tutorial
HuggingFace ▷ #today-im-learning (3 messages):
Missing user updatesOnline tutorials progress
-
Missing updates from a key user: <@930102195330900009> updates are notably absent, leading to a sense of disappointment expressed by a member with a crying emoji.
- People are looking forward to their insights and contributions back on the platform.
- Journey through Online Tutorials: A member shared their experience of starting with online tutorials, highlighting that they began with the basics and gradually advanced.
- This dedication to learning has been met with appreciation, evidenced by positive reactions from others.
HuggingFace ▷ #cool-finds (3 messages):
Post TransparencyCommunity Feedback
-
Call for Transparency in Posts: A member expressed that it feels disingenuous to present a post without clearly stating one's affiliation with the platform.
- The suggestion is to clarify relationships in future posts to maintain trust within the community.
- Skepticism about Content Authenticity: Another member voiced concerns that a recent post reads like a scam, questioning its authenticity.
- This indicates a growing wariness among members regarding the credibility of shared content.
HuggingFace ▷ #i-made-this (9 messages🔥):
SnowballTarget environmentOKReddit datasetRWKV modelsRuntime errors in spacesSearch frustrations on Hugging Face
-
SnowballTarget Environment Results Shared: Members discussed their experiences with the SnowballTarget environment in the deep reinforcement learning course, with one sharing they reached a reward of around 28.
- They experimented with different parameters like epochs, learning rate, and buffer size, showing improvements but still facing hurdles.
- Introduction to OKReddit Dataset: A member introduced the OKReddit dataset, which is a curated collection of 5TiB of Reddit content from 2005 to 2023, available for research purposes.
- While marked as alpha, it offers a filtered list of subreddits and includes a link for access, inviting discussion about its potential uses.
- Clarifying RWKV Models vs. Recursal.ai Models: A member indicated that while RWKV models can be related to training rigors, they differ from Recursal.ai models in terms of dataset specifics.
- Future integrations are planned, suggesting a continued evolution in model training approaches.
- Discussing Runtime Errors in Spaces: A user reported a runtime error encountered when attempting to use the RWKV model in Gradio, suggesting a library loading issue.
- The traceback indicated a missing libnvidia-ml.so.1, which raised concerns about setup issues among members.
- Frustration with Space Search Results: Frustration emerged over the abundance of non-functional results when searching in the Hugging Face spaces, especially when these were displayed as defective.
- The member expressed that distinguishing working spaces becomes a challenge due to many listing errors, leading to frustration.
Links mentioned:
- v5-EagleX-v2-7B-gradio - a Hugging Face Space by RWKV: no description found
- recursal/OKReddit-alpha · Datasets at Hugging Face: no description found
- Walter White Walter GIF - Walter White Walter Falling - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #reading-group (6 messages):
GPU compatibilityMotherboard decisionsPCIe bandwidth considerations
-
Make the Most of Your GPUs: A member noted that if the CPU is supported, you can run up to 4 dual-slot GPUs, but it's crucial to check PCIe bandwidth as X8 instead of X16 can significantly reduce performance.
- If they physically fit, they are essentially guaranteed to not cause harm to each other, although performance may vary.
- Motherboard Spending Choices: There was a suggestion to avoid spending too much on motherboards, with advice to find something better than an MI60 but cheaper than $1000.
- The cost of a high-end motherboard can equate to the price of a 3090 TI founder's edition or an RX 7900XTX.
- Existing Hardware Setup Considerations: One member mentioned they own an MSI Godlike X570 running 3 RX 6800s, and shared that the PCIe lanes in their multi-GPU setup are distributed as x8 x4 x4 x4.
- The member prefers not to buy new components despite ongoing issues with the fourth GPU.
HuggingFace ▷ #NLP (2 messages):
Legal Embedding ModelsAI Assistant for Legal SystemsGTE Finetuning Data
-
Pre-trained Legal Embeddings Essential: To effectively train an embedding model for legal applications, it's crucial to use embeddings pre-trained on legal data; otherwise, training can become lengthy and lead to biases.
- A focus on domain-specific training enhances accuracy and speeds up the process.
- Using GTE for AI Legal Assistance: A member noted their use of GTE for finetuning data in their AI Assistant Legal system, highlighting its importance in their workflow.
- This approach suggests a choice for general embeddings despite the potential need for legal specializations.
Unsloth AI (Daniel Han) ▷ #general (102 messages🔥🔥):
Importance of Learning Triton and CUDACurrent State of Language ModelsInput Processing for Fine TuningModel Comparison and UtilizationPersonal Experiences of Community Members
-
Triton and CUDA: A Future Focus: Members expressed that there will be significant engineering work centered around Triton and CUDA in the future, suggesting they are valuable skills to learn.
- One mentioned that diminishing returns are a concern in creating 'better' models, indicating a shift towards efficiency improvements.
- Shifts in Language Model Preferences: Discussion revealed that the Mistral 7B v0.3 model is considered outdated, with Qwen/Qwen2.5-Coder-7B rising in popularity due to its training on ample data.
- Members shared insights on the efficacy of various models, comparing Gemma2 and GPT-4o in performance.
- Potential Issues with Fine-tuning Exports: A user highlighted difficulties when exporting their fine-tuned model to Ollama, implying inconsistencies in performance post-export.
- Another member suggested troubleshooting may involve addressing chat templates or memory management issues, especially with bitsandbytes.
- Mocktails vs Cocktails: A Weekend Vibe: Members engaged in a lighthearted discussion about personal drinks, with someone planning to make a martini while others identified as part of the mocktail gang.
- The conversation reflected a casual atmosphere, fostering community connections over shared interests.
- Local Monitoring Tools for Training Models: A member sought alternatives for monitoring model training locally, expressing interest in lighter frameworks beyond TensorBoard for tracking loss, gradients, and learning rates.
- There was a consensus on using TensorBoard but a curiosity for more efficient tools to visualize training metrics.
Links mentioned:
- Tweet from AK (@_akhaliq): Nvidia presents LLaMA-Mesh Unifying 3D Mesh Generation with Language Models
- Google Colab: no description found
- Boo GIF - Boo - Discover & Share GIFs: Click to view the GIF
- Qwen/Qwen2.5-Coder-7B-Instruct · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (8 messages🔥):
Dietary ChoicesRice Preferences
-
Discussion on Animal-Derived Products: That's a lot of animal derived products said a member, pointing out chicken, egg, milk while questioning the absence of nuts and seeds in the diet.
- Another member humorously responded, what can I say im an animal HEHE, admitting to not consuming nuts or seeds.
- Joking About Eating Habits: A member joked, I eat nothing, amusingly responding to a comment about their diet.
- Humor continued as another member echoed, simply stating Mike.
- Switching Rice Types for Better Digestion: A member mentioned replacing white rice with Basmati rice, noting it feels better for them.
- They elaborated that while jasmine rice does not sit well with them, Basmati is easier on their digestion.
Unsloth AI (Daniel Han) ▷ #help (20 messages🔥):
Unsloth installation issuesSupport for Lora+Svelte dataset for Qwen2.5-CoderSong lyrics dataset preparationFine-tuning Llama3.1b for math equations
-
Unsloth installation error due to missing torch: A user encountered an error stating ModuleNotFoundError: No module named 'torch' while trying to install Unsloth and xformers in their notebook.
- It appears the issue persists even if torch is installed and others suggest verifying the installation in the current environment.
- Lora+ support in Unsloth: A user inquired if Unsloth supports Lora+, to which a participant confirmed it does if submitted through a pull request.
- Further discussions indicated that it should be a straightforward process to implement.
- Advice on Svelte dataset for Qwen2.5-Coder: A user created a comprehensive dataset for Svelte documentation due to poor results from Qwen2.5-Coder.
- A suggestion was made to use the none instruct version of Qwen2.5-Coder for better results since instruct is a finetuned variant.
- Creating a dataset for song lyrics: A user detailed their pursuit of creating a model for generating lyrics based on 5780 songs and associated metadata.
- They were advised to utilize an Alpaca chat template to structure their dataset effectively.
- Fine-tuning Llama3.1b on math equations: A user seeks advice on improving the accuracy of their model fine-tuning Llama3.1b for math equation solving as their accuracy sits at 77%.
- Despite achieving low losses on their dataset, they are experimenting with hyperparameter sweeps to push for at least 80% accuracy.
Links mentioned:
- Google Colab: no description found
- Dreamslol/svelte-5-sveltekit-2 · Datasets at Hugging Face: no description found
Eleuther ▷ #general (12 messages🔥):
Histogram plotting alternativesOpen Source AI definitionsDiscussion on coding in AIDatashader for large datasets
-
Seeking faster histogram options: A member inquired about alternatives to Matplotlib for plotting histograms of around 100,000 scalars due to its slow performance.
- Another member suggested using Datashader as a potential solution for visualizing large datasets efficiently.
- Debating Open Source AI classification: There was a crucial discussion about the classification of AI systems like Granite as Open Source AI based on the definition from IBM.
- It was noted that while one view suggests all data must be public, others argue that descriptive data disclosure suffices to avoid legal risks.
- Clarifying Open Source data rules: A member pointed out the confusion surrounding whether the requirement for sufficient disclosure applied to data or code in the Open Source AI definition.
- Linking to the Open Source AI Definition page, another member reinforced the need for autonomy, transparency, and collaboration in AI.
- Experiences with AI coding: A member shared their background in physics and programming, particularly in C/C++/Fortran, and their experiences with TensorFlow Lite.
- They expressed interest in using AI chat for generating C++ code, highlighting the appeal of the project's openness.
Link mentioned: The Open Source AI Definition – 1.0: version 1.0 Preamble Why we need Open Source Artificial Intelligence (AI) Open Source has demonstrated that massive benefits accrue to everyone after removing the barriers to learning, using, sharing ...
Eleuther ▷ #research (97 messages🔥🔥):
Scaling Laws in AILLM CapabilitiesEncrypted LLM CommunicationDiminishing Returns in Model TrainingSynthetic Tasks and Relevance
-
Twitter's Claim on Scaling Laws: Members discussed recent claims from Twitter stating that scaling is dead, leading to disagreements and the assertion that conclusions should be backed by concrete papers rather than rumors.
- Some cited journalists' sources at major labs reporting disappointing results from recent training runs, raising questions about the validity of these claims.
- Concerns Over LLM Capability Limitations: A conversation emerged regarding the capability limitations of models, with suggestions that while current architectures might achieve diminishing returns, they could stall true advancements in AGI-like models.
- Participants highlighted the need for LLMs to grasp complex tasks like Diffie-Hellman key exchanges, arguing that current models may not maintain private keys internally, raising concerns over privacy.
- Diminishing Returns and Research Interest: Members expressed hope for diminishing returns in AI model training as it would incentivize further research and exploration of complex problems rather than reducing ML to mere engineering tasks.
- Discussions pointed to the necessity of engaging with deeper understanding and clarification capabilities for practical usability in LLMs.
- Relevance of Synthetic Tasks: The relevance of synthetic tasks, such as arithmetic, came into question, with debates about their applicability to real-world capabilities of LLMs.
- One user suggested that focusing solely on synthetic tasks may not reflect the practical utility of LLMs, referencing the AIW project as potentially irrelevant.
- Homomorphic Encryption in Communication: A conversation unfolded about the potential of using homomorphic encryption to enable secure communication with LLMs without compromising sensitive information.
- Participants contemplated whether such encryption methods could effectively hide private keys within model activations, balancing the need for security against performance usability.
Links mentioned:
- Should I Use Offline RL or Imitation Learning?: The BAIR Blog
- Tweet from Karol Hausman (@hausman_k): This is the ultimate reason why offline RL should be better than behavioral cloning: It allows you to cut and stitch the trajectories in the way that is optimal for the task/reward. You don't ne...
- Planting Undetectable Backdoors in Machine Learning Models: Given the computational cost and technical expertise required to train machine learning models, users may delegate the task of learning to a service provider. We show how a malicious learner can plant...
- GitHub - apple/ml-cross-entropy: Contribute to apple/ml-cross-entropy development by creating an account on GitHub.
- Building machines that learn and think with people - Nature Human Behaviour: In this Perspective, the authors advance a view for the science of collaborative cognition to engineer systems that can be considered thought partners, systems built to meet our expectations and compl...
Eleuther ▷ #interpretability-general (6 messages):
Pythia model suiteMixture-of-Experts (MoE)Hidden States UnconferenceTransformer heads and antonyms
-
Exploring Mixture-of-Experts for Pythia: A discussion initiated about the potential for a Mixture-of-Experts version of the Pythia model suite, questioning the replication of its training setup versus modernization of hyperparameters like SwiGLU and longer training.
- Members weighed in, comparing current models like OLMo and OLMOE, pointing out differences in data order and consistency across scales.
- Hidden States Unconference Announced: An unconference titled Hidden States is scheduled for December 3rd, 2024 in SF, focusing on discussions about AI interfaces and hidden states.
- Keynote speakers include Leland McInnes and Linus Lee, and there are incentives for indie researchers and students to attend.
- Antonym Heads in Transformers: A post was shared discussing findings on transformer heads that compute antonyms, revealing their presence across various models with interpretable eigenvalues.
- The analysis included OV circuits, ablation studies, and showcased examples of antonyms like 'hot' - 'cold', affirming their functionality in language models.
Links mentioned:
- no title found: no description found
- Tweet from Nora Belrose (@norabelrose): If there were a mixture-of-expert version of the Pythia model suite, what sorts of questions would you want to answer with it? Should we try to exactly replicate the Pythia training setup, but with M...
- Antonym Heads Predict Semantic Opposites in Language Models — LessWrong: In general, attention layers in large language models do two types of computation: They identify which token positions contain information relevant t…
Nous Research AI ▷ #general (66 messages🔥🔥):
TEE Wallet Collation ConcernsNVIDIA NV-Embed-v2 ReleaseRLHF vs SFT for Fine-tuningTee's Twitter Activity
-
TEE wallet collation issues raised: Members expressed frustration regarding the frequent wallet changes for TEE, emphasizing that it undermines the bot's autonomy and community trust.
- Concerns were voiced about establishing stability so that users feel comfortable interacting with the bot on-chain.
- NVIDIA launches NV-Embed-v2 model: NVIDIA announced the release of NV-Embed-v2, a top-ranking embedding model on the Massive Text Embedding Benchmark with a score of 72.31.
- It introduces innovative techniques for training, including improved retention of latent vectors and unique hard-negative mining methods.
- Debate on RLHF vs SFT for Models: A discussion ensued about the resource demands of Reinforcement Learning from Human Feedback (RLHF) compared to Supervised Fine-Tuning (SFT) for training Llama 3.2.
- Members advised that while RLHF requires more VRAM, SFT could be a more feasible starting point for limited resources.
- Tee's inactivity raises questions: Concerns arose regarding Tee's lack of tweets for an extended period, with members speculating on its operational status.
- Jokes were made about Tee possibly taking an extended break over the weekend, prompting others to check on its status.
Links mentioned:
- The Surprising Effectiveness of Test-Time Training for Abstract Reasoning: Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of t...
- Tweet from Dr. Dad, PhD 🔄🔼◀️🔽▶️ (@GarrettPetersen): Kind of sad to learn that Gwern is a brilliant underachiever. I assumed he was a CS prof or SWE.
- nvidia/NV-Embed-v2 · Hugging Face: no description found
- Your Life Story: no description found
Nous Research AI ▷ #ask-about-llms (2 messages):
Mixing datasets for LLM trainingMatching strategies for datasets
-
Seeking Insights on Dataset Mixing: A member is looking for resources or insights on how to effectively mix and match datasets at different stages of LLM training.
- They emphasized the need for tips or best practices to enhance the training process.
- Interest in Matching Strategies: The same member expressed anticipation in finding diverse methods for matching strategies relevant to the dataset mixing.
- This reflects an ongoing interest in optimizing LLM training workflows.
Nous Research AI ▷ #research-papers (1 messages):
adjectiveallison: https://arxiv.org/abs/2411.04732
Image recognition sota with a model 29x smaller
Nous Research AI ▷ #interesting-links (6 messages):
AI-driven translation toolResume website transformationTranslation servicesSlang translationCultural nuances in translation
-
Advanced translation tool stands out: It uses an AI-driven, agentic workflow that transcends traditional machine translation by focusing on cultural nuance and adaptability.
- Unlike most systems, it considers regional dialects, formality, tone, and gender-based nuances for more accurate translations.
- Transform Your Resume into a Stunning Website: Users can upload their resume to receive a professional, responsive Bootstrap site in just minutes through this service.
- The process promises a swift generation of the website, indicating a user-friendly experience.
- Slang Translation Made Easy: Slang translator offers a way to convert slang terms into standard language, enhancing communication and understanding.
- This tool provides an additional layer of translation catering specifically to colloquial expressions.
- Customizable Translation Experience: The advanced translation tool's three-step process includes translating, reflecting, and refining to enhance the output precisely.
- This allows users to tailor their experience by adjusting prompts related to tone and regional variations while maintaining term consistency.
Links mentioned:
- Resume to Website Generator: no description found
- Advanced Translation Tool - Accurate and Culturally Nuanced Translations: Translate text between languages with cultural nuance, context, formality, tone, and gender considerations.
Nous Research AI ▷ #research-papers (1 messages):
adjectiveallison: https://arxiv.org/abs/2411.04732
Image recognition sota with a model 29x smaller
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
MistralNemo StarCannonCelestePerplexity CitationsBeta FeaturesModel Updates
-
MistralNemo StarCannon and Celeste Support Dropped: MistralNemo StarCannon and Celeste are no longer available as the only provider has dropped support for them.
- This change affects all users relying on these models for their projects.
- Perplexity Introduces Grounding Citations in Beta: Perplexity models now feature a beta implementation of
citations, enabling URLs to be returned with completion responses.
- This new attribute provides users with direct links for further information, enhancing the reliability of the generated content.
OpenRouter (Alex Atallah) ▷ #general (65 messages🔥🔥):
Gemini API AvailabilityRate Limits on OpenRouterHermes 405B ModelPerplexity Citations LiveMagnum 72B Model Evaluation
-
Gemini API now accessible: Members discussed that Gemini is now available through the API, prompting excitement about its capabilities.
- Despite some users still not seeing the changes, it's clear that this model is anticipated to improve user interactions.
- Understanding Rate Limits on OpenRouter: The conversation highlighted the rate limits for free models, specifically noting a 200 requests per day constraint.
- Members emphasized that this limit effectively hinders utilization in production environments, making free models less practical.
- Frequent Returns to Hermes 405B: Fry69_dev pointed out that after testing multiple models, they keep returning to Hermes 405B for its efficiency.
- Despite its costs impacting profit margins, its performance remains unmatched for many users.
- Perplexity Citations now active on OpenRouter: Alex Atallah announced that perplexity citations have gone live on OpenRouter, generating interest among users.
- However, some users reported they could not access the feature yet due to API response requirements.
- Evaluation of Magnum 72B for Writing Style: Frehref mentioned that the Magnum 72B model is recognized for its good writing style despite being pricey.
- Takefy planned to test this model but expressed concerns about the costs associated with its use.
Links mentioned:
- Limits | OpenRouter: Set limits on model usage
- no title found: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (9 messages🔥):
Custom Provider Keys Access
-
High Demand for Custom Provider Keys: Several users, including giampie.ro and @wyatt02146, expressed a desire to request access to Custom Provider Keys.
- The volume of requests indicates a significant interest in these keys, prompting questions about the acquisition process.
- Inquiry on Access Process for Custom Provider Keys: A member questioned whether acquiring access to Custom Provider Keys could be automated given the numerous requests from the community.
- A lot of people here have requested access suggests that users are eager for clarity on the steps involved in gaining access.
- General Requests Abound for Custom Provider Keys: Users consistently reiterated their requests for Custom Provider Keys, with expressions of interest from multiple members like @cuts2k and @schwemschwam.
- The repeated requests reflect a growing anticipation for access among community members eager to engage with the functionality.
- Support and Next Steps Requested: Members like @pjtidder have sought information on the next steps for accessing beta Custom Provider Keys and indicate the need for support.
- Such requests underscore the community's interest in clear guidance on moving forward with their access requests.
Stability.ai (Stable Diffusion) ▷ #general-chat (60 messages🔥🔥):
Stable Diffusion GPU UsageWebUI Installation GuidesImage Blending Research PaperVideo Upscaling TechniquesUsing Low Denoise Inpaint
-
Need help running Stable Diffusion on Nvidia GPU: A user expressed difficulty in configuring stable diffusion to utilize their dedicated Nvidia GPU instead of the integrated graphics.
- Another user pointed to the setup guides available in the pinned messages of the channel for assistance.
- ComfyUI vs. SwarmUI for easier use: A member discussed the complexity of ComfyUI and noted that SwarmUI simplifies the technical processes involved in configuration.
- It was suggested to try out SwarmUI for an easier installation experience and more consistent results.
- Searching for an image blending research paper: A user sought help finding a recent research paper focusing on image blending, recalling a Google author, but had trouble locating it.
- Another member recommended a Google search on image blending in arXiv for potentially useful papers.
- Methods for fixing video anatomy issues: A member shared their approach to upscale video by taking frames every 0.5 seconds to refine existing inaccuracies.
- Discussion included the use of Flux Schnell and other methods to achieve fast inference results.
- Inquiry on applying low denoise inpaint: A user asked how to perform low denoise inpainting or img2img processing for specific regions of an image.
- Suggestions included using Diffusers for a fast img2img workflow with minimal steps to refine images.
Links mentioned:
- genmo/mochi-1-preview · Hugging Face: no description found
- Webui Installation Guides: Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
- alibaba-pai/CogVideoX-Fun-V1.1-5b-InP · Hugging Face: no description found
- THUDM/CogVideoX1.5-5B-SAT · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
Scaling Laws TheoryGPT-3 Scaling HypothesisFunding Round UpdateChanges in Twitter's Terms of ServiceMeta AI Developments
-
Concerns about Scaling Laws Theory: Members raised concerns about the validity of the scaling laws theory, which suggests that more computing power and data will enhance AI capabilities.
- One member expressed relief, stating that decreasing cross-entropy loss is a sufficient condition for improving AI capabilities.
- Insights on GPT-3 Scaling Hypothesis: A member referred to a well-known post on the scaling hypothesis, stating that neural nets generalize and exhibit new abilities as problems increase in complexity.
- They highlighted that GPT-3, announced in May 2020, continues to show benefits of scale contrary to predictions of diminishing returns.
- Massive Funding Round Announcement: A member shared a tweet indicating that a funding round closing next week will bring in $6 billion total, predominantly from Middle East sovereign funds for a $50 billion valuation.
- The funds will reportedly go directly to Jensen and fuel upcoming developments in the tech space.
- Concerns Over New Twitter Terms of Service: A conversation emerged around Twitter's updated Terms of Service, which allows for training AI models on user content starting tomorrow.
- Several members noted that using content from users is a troubling trend, reflecting the sad reality of the situation.
- Meta AI's Fun Developments: A member mentioned exciting developments related to Meta AI, expressing enthusiasm for what’s coming next.
- They hinted at ongoing improvements and a bright future for AI advancements in the works.
Links mentioned:
- Tweet from Andrew Curran (@AndrewCurran_): Another 100,000 chips on the stack. The funding round is apparently closing next week. $6 billion total ($5 billion of that from Middle East sovereign funds) at a $50 billion valuation. Of course it&...
- Tweet from Luiza Jarovsky (@LuizaJarovsky): 🚨 BREAKING: X's updated Terms of Service take effect TOMORROW. Pay attention to the AI clause:
- The Scaling Hypothesis · Gwern.net: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
Ilya Sutskever emailsAI perceptionsMisalignment discussions
-
AI Art and Hallucinations spark debates: Concerns arose around the statements on AI hallucinations and the criticism of AI art, with one member noting a significant shift in public perception.
- In theory, aligned; in practice, not echoed frustration over ideological conflicts regarding AI technology.
- TechEmails reveal historical discussions: Members shared links to TechEmails which discussed communications involving Elon Musk, Sam Altman, and Ilya Sutskever dating back to 2017 regarding misalignment issues.
- Documents relate to the ongoing case of Elon Musk, et al. v. Samuel Altman, et al. (2024) highlighting the historical context of alignment concerns.
- Members intrigued by implications: Reactions showed a mix of surprise and fascination regarding the implications of the discussions between Ilya and Sam surrounding AI's misalignment.
- The acknowledgment of longstanding concerns highlighted the depth of these issues within the community's discourse.
Links mentioned:
- Tweet from Internal Tech Emails (@TechEmails): no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from Internal Tech Emails (@TechEmails): [This document is from Elon Musk, et al. v. Samuel Altman, et al. (2024).]
Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
Expectations for the New ModelSam Altman's ICO ProposalApple Silicon vs NVIDIA PerformancePyTorch Anaconda Package Deprecation
-
New Model Raises High Expectations: Members expressed anticipation about a new model, with one stating, this model better blow all of our expectations.
- Another member clarified that it's more about the process involving model, data, and code together.
- Sam Altman proposed an OpenAI Cryptocurrency: A tweet revealed that according to an amended lawsuit, Sam Altman attempted to create an OpenAI cryptocurrency through an ICO in 2018.
- One participant remarked, Lol about the implications of this decision.
- Apple Silicon vs NVIDIA GPUs Analysis: A detailed post discusses the competition between Apple Silicon and NVIDIA GPUs for running LLMs, highlighting compromises in the Apple platform.
- While noting higher memory capacities in Apple’s newer products, it concludes that NVIDIA solutions remain more cost-effective.
- PyTorch to Stop Anaconda Package Publishing: A recent announcement confirmed that PyTorch will cease publishing Anaconda packages on its official channels.
- For more details, members were referred to a discussion post on dev-discuss.
Links mentioned:
- Tweet from PyTorch (@PyTorch): We are announcing that PyTorch will stop publishing Anaconda packages on PyTorch’s official anaconda channels. For more information, please refer to the following post on dev-discuss: https://dev-disc...
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): I hit my rate limits for you
- Tweet from Anna Tong (@annatonger): According to an amended version of Elon Musk's lawsuit against OpenAI, Sam Altman tried to create an OpenAI cryptocurrency in 2018 by proposing an ICO. Lol
- Tweet from Dumitru Erhan (@doomie): Who leaked this to The Information? ;)
- Apple统一内存适合运行LLM?理想很丰满,现实很骨感 | David Huang's Blog: no description found
Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
Squidward & SpongeBob Discord DecorDiscord Shopping Experience
-
Natolambert scores Squidward decor: Natolambert revealed that he paid for his Squidward decor on Discord, and his brother's insider knowledge helps him with exclusive options.
- He later clarified that he actually has Patrick decor instead, correcting his previous comment.
- SpongeBob decor still available: Another member noted that SpongeBob decorations are still available in the Discord shop, adding a humorous tone to the discussion.
- Haha moments ensued as members joked about their character choices and decor mishaps.
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
PersonasPrompts
-
Excitement about Personas: One member expressed enthusiasm for personas with a clap emoji, indicating support for their use.
- Another member responded positively, suggesting that effective prompts are essential for maximizing their utility.
- Importance of Effective Prompts: A user highlighted that using the right prompts is a simple yet effective way to leverage personas in discussions.
- This conversation reflects a broader sentiment that prompts play a crucial role in facilitating engaging interactions.
Interconnects (Nathan Lambert) ▷ #retort-podcast (7 messages):
Audio ExperienceThe GradientPodcast Cadence
-
Torters Eager for Content: Members expressed excitement, noting that it had been a while since there was new content, with one highlighting that Thomas was hitting his stride with recent openers.
- Torters are fiending for more engaging discussions and topics.
- Driving to LA with Subpar Audio: One member shared their frustration about having a subpar audio experience while driving to LA, indicating it detracted from their enjoyment.
- This sentiment resonated with others who appreciate quality audio during their commute.
- Mixed Feelings on 'The Gradient': A member jokingly expressed distaste for 'The Gradient', implying it was not meeting expectations with an emoji for emphasis.
- However, this was followed up with a clarification that the comment was meant in jest, as they acknowledged a lack of serious gradient disdain.
- Discussion on Podcast Cadence: Members discussed that a monthly cadence for the podcast might be more manageable, suggesting they'd been busy with other commitments.
- This proposed frequency seems to align better with their current schedules.
GPU MODE ▷ #general (1 messages):
memorypaladin: just go ahead and ask your question.
GPU MODE ▷ #triton (3 messages):
Kernel Variable PassingGrid Configuration Issues
-
Mysterious Kernel Variable Values: A user reported issues passing a variable into their kernel where the output values are correct only when x is 1, but yield random numbers otherwise.
- When trying configurations like grid (1, 3), results show expected values, while with (2, y), they display seemingly uninitialized data.
- Potential Uninitialized Data Issue: Another user suggested that the problem might be due to reading uninitialized data, prompting a request for a code snippet to further analyze the issue.
- This response indicates the need for debugging strategies to ensure proper initialization of variables before use in the kernel.
GPU MODE ▷ #torch (7 messages):
FSDP and torch.compileUsing nsys for profilingProton profiler with TritonMemory issues with nsysUsing emit_nvtx() for profiling
-
FSDP works well with torch.compile: One user shared a code example of wrapping torch.compile in FSDP from torchtitan, stating they hadn't faced any issues.
- This approach seems effective, although they did not try it in the reverse order.
- Profiling with nsys has memory limitations: A member noted that nsys can consume as much as 60 GB of memory before crashing, raising concerns about its feasibility for profiling tasks.
- Another user suggested optimizing the usage of nsys with flags like
nsys profile -c cudaProfilerApi -t nvtx,cudato reduce logging overhead. - Proton offers a quick profiling solution: Proton, the profiler included with Triton, can be used for quick profiling by starting it with
proton.start()and finalizing it afterward.
- Users should install llnl-hatchet to execute the command for viewing profiling results, which is a simpler alternative to nsys.
- Using emit_nvtx() for detailed profiling: To get detailed insights into CUDA kernel calls, it's recommended to use
emit_nvtx()within your program and run it under nsys profile.
- By using this method, users can directly observe which CUDA kernels are triggered by specific ATEN operations, providing clarity on performance bottlenecks.
Links mentioned:
- torchtitan/torchtitan/parallelisms/parallelize_llama.py at main · pytorch/torchtitan: A native PyTorch Library for large model training. Contribute to pytorch/torchtitan development by creating an account on GitHub.
- pytorch/torch/autograd/profiler.py at 8043e67026b1cd5b5f1d17c46cd6fe579c322168 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #cool-links (2 messages):
ZLUDANVIDIA GPUsAMD and Intel GPUs
-
Developer of ZLUDA Discusses CUDA for Non-NVIDIA GPUs: In a YouTube video, Andrzej Janik explains how ZLUDA allows CUDA capabilities on AMD and Intel GPUs, which could shift the landscape of GPU computing.
- A member commented that they had previously tried to get Janik for a discussion, noting, finally someone got'em haha.
- Excitement Around ZLUDA Breakthrough: Members expressed enthusiasm about Janik's appearance in the video, marking a significant step for non-NVIDIA GPU users.
- There is a growing curiosity on how ZLUDA might democratize access to GPU computing power.
Link mentioned: #246 Developer Of ZLUDA: CUDA For Non Nvidia GPUs | Andrzej Janik: CUDA is one of the primary reasons people buy NVIDIA GPUs but what if there was a way to have this compute power on AMD and Intel GPUs as well. Well there is...
GPU MODE ▷ #beginner (13 messages🔥):
NVCC vs Clang performanceGPU memory calculation for LLMsDebugging register usage in KokkosLoop unrolling effects on performance
-
NVCC vs Clang Performance Divergence: A member began measuring performance differences between NVCC and Clang, noting a surprising 2x difference in the number of registers used per thread.
- Discussion indicated that differences in compiled PTX could lead to variations in register usage, with loop unrolling being a potential factor.
- Calculating GPU Memory for Training: A query was raised about calculating the required GPU memory for training or fine-tuning a Large Language Model (LLM) ahead of time.
- The response highlighted the need for specific methods or tools to estimate memory requirements accurately.
- Debugging Register Usage in Kokkos: An inquiry was made about debugging strategies for register usage in Kokkos, particularly regarding the use of launch bounds.
- It was suggested to leverage the Kokkos API for defining execution policies and to utilize launch bounds for better control.
- SASS Assembly and Loop Unrolling Insights: Clarification was sought on how more aggressive loop unrolling correlates with the number of instructions and registers utilized in code.
- In response, it was explained that increased instructions lead to more registers being used to maintain independent operations and avoid pipeline stalls.
- Using NCU Source View for Code Insights: The NCU Source View was recommended as a tool for identifying sections of code with high register usage, aiding in debugging efforts.
- It was noted that this view could provide insights into where to focus for potential optimization in SASS generation.
Link mentioned: Execution Policies - Kokkos documentation: no description found
GPU MODE ▷ #triton-puzzles (1 messages):
Online Softmax
-
Online Softmax Technique discussed: A member mentioned that the online softmax technique originated from an original paper that introduced this trick.
- It's noted that the hint provided isn't very obvious about this technique.
- Understanding the online softmax application: This trick is essential for optimizing the performance of models in certain applications, particularly in neural networks.
- Members encouraged exploring various resources to better grasp the implications of using online softmax.
GPU MODE ▷ #webgpu (4 messages):
TFLOPS performanceApple M2 memory modelEfficient caching strategies
-
Struggling to Boost TFLOPS: I’m sorta surprised this approach doesn’t get you even higher flops, indicating challenges in achieving optimal performance with current methods.
- Another member noted they managed to reach 1 TFLOP but faced issues, suggesting it could be a me problem more than anything.
- Exploring Faster Memory Access: One user experimented with shared memory, finding it slower than expected, and is considering subgroups for potentially faster access.
- They expressed frustration over a lack of clear documentation on the Apple M2 memory model, particularly on how to exploit caching for better performance.
- Maximizing Cache Efficiency: A member suggested that improvements in performance could stem from using the cache more efficiently and avoiding unnecessary recalculation across workgroups.
- Their benchmark comparisons indicated that other implementations yielded similar performance to their own.
- Documenting Memory Coalescing Confusion: Concerns were raised about the clarity of documentation regarding memory coalescing on Apple hardware, alongside a reference to a blog post for NVIDIA-specific terms.
- The lack of a comprehensive resource appears to hinder effective optimization strategies for developers working with the Apple M2.
GPU MODE ▷ #liger-kernel (2 messages):
Liger-Kernel Bug FixConvergence Test Issues
-
Fix implemented for flce patching issue: A pull request was made to resolve issue #355, addressing the problem where flce was not being patched after reverting in the convergence test.
- The fix involves commenting out revert patching for now and only testing with float32.
- Acknowledgment for resolving annoying reverting issue: Gratitude was expressed to a member for fixing the convoluted and annoying reverting issue that was affecting development.
- This recognition highlights the importance of collaboration in addressing technical challenges.
Link mentioned: Fix flce not being patched after reverting in convergence test by Tcc0403 · Pull Request #385 · linkedin/Liger-Kernel: Summary Resolve #355: 1. revert patching causes flce not taking effect (comment out revert patching for now, and only test float32). The bug occurs because we define a model config dictionary befor...
GPU MODE ▷ #self-promotion (2 messages):
cudaDeviceSynchronizeC++ development experience
-
cudaDeviceSynchronize() as an anti-pattern: A user argues that cudaDeviceSynchronize() is an anti-pattern that programmers should avoid because it iterates over all CUDA streams and calls cudaStreamSynchronize() on them.
- They emphasize that this inefficiency is not clearly articulated, which can lead to misunderstandings among developers.
- C++ developer seeking free experience: A user introduced themselves as a C++ developer with 2 years of experience, expressing a desire to work for free to gain more practical experience.
- This highlights a proactive approach to skill enhancement and networking within the development community.
Link mentioned: Tweet from Daniel Galvez (@memorypaladin): cudaDeviceSynchronize() is an anti-pattern that people should avoid. It's not clearly stated, but basically it iterates over all cuda streams in the cuda context and calls cudaStreamSynchronize() ...
GPU MODE ▷ #🍿 (2 messages):
Discord Cluster Manager IssueFinetuning LoopTrion Docs and Examples
-
Inspiration from Quantization Scaling: A member shared an insightful post from GitHub Issue #23 about quantization scaling, praising @TimDettmers' thread as very inspiring.
- They emphasized the importance of research on how to do research and the popularization of methods and results in this field.
- Struggles with Finetuning Loop: One member is currently developing a finetuning loop using initial data shared in Discord, but results are subpar as little compiles to Python bytecode.
- They expressed openness for collaboration and assistance, inviting others to play with the setup and respond to any questions.
- Using Triton Docs for Evals: For evaluations, the member is relying on simple examples from the Triton documentation and puzzles, planning to expand efforts once infrastructure is established.
- They noted that the focus is on getting the infrastructure right before making significant advancements in evaluations.
Link mentioned: Job Queue · Issue #23 · gpu-mode/discord-cluster-manager: I recently read @TimDettmers thread on quantization scaling. Very inspiring. I think that this is the sort of research, research on how to do research, and popularizing the methods and results, is ...
GPU MODE ▷ #thunderkittens (11 messages🔥):
Kernel Compilation DelaysComplexity Threshold in CodeTemplate Parameter ImpactEffective Debugging Strategies
-
Strange kernel compilation delays observed: A member reported that their kernel takes upwards of 30 minutes to compile after exceeding a certain complexity threshold, despite compiling successfully.
- They managed to identify that reducing complexity, such as selectively commenting out code blocks, can bring the compile time back to ~5 seconds.
- Adjusting template parameters reduces complexity: Another suggested that adjusting template and constexpr parameters, specifically changing loop counts, can assist in reducing compilation time.
- For instance, setting
NC=1in a loop surrounding their main function body allowed them to compile much faster. - Seeking diagnosis for compilation delays: A member requested help diagnosing the unusually long kernel compile times and shared the challenges faced during the process.
- They expressed uncertainty about how to approach identifying the specific cause behind the issue.
- The role of template parameter inference in delays: Someone noted that slow template parameter inference can contribute to long compile times, especially during loop unrolling.
- They recommended isolating the offending lines of code and making template arguments explicit to improve performance.
GPU MODE ▷ #edge (5 messages):
React Native LLM LibraryLLM Inference on AndroidMemory Bound vs Compute Bound in LLMsBitnet for Fast InferenceGGUF Q8 Performance
-
React Native library for LLMs hits the scene: Software Mansion released a new library for using LLMs within React Native that utilizes ExecuTorch for backend processing. Installation instructions are available on their GitHub page.
- Users found it pretty easy to use with clear steps to launch a model on the iOS simulator.
- LLM inference on Android smartphones - The memory question: A discussion raised the question of whether LLM inference on newer Android smartphones is memory bound. Responses emphasized that dependency on context type influences whether LLMs are primarily memory or compute bound.
- It was noted that typically, memory bound is a consideration at low context tasks alongside compute bounds at high context tasks.
- Bitnet 1.58 A4 for rapid inference: For faster inference, using Bitnet 1.58 A4 with Microsoft’s T-MAC operations can achieve 10 tokens/s on a 7B model, though it requires some retooling of the target model. Importantly, it can be trained on a desktop CPU if GPU resources are lacking.
- There are resources available for converting a model to Bitnet, though it may necessitate post-training adjustments.
- GGUF Q8: A low-cost performance solution: GGUF Q8 is cited as a viable option providing close to zero performance hit for resource-constrained devices, particularly effective for 7B-13B models. The advantages of GGUF Q8 for smaller models, however, remain untested by some users due to device limitations.
- It's mentioned that GGUF Q8 may not yield the same benefits for 3B models and below.
Link mentioned: GitHub - software-mansion/react-native-executorch: Contribute to software-mansion/react-native-executorch development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (17 messages🔥):
Top Shelf PodcastAI and violencePodcast dialogue techniquesMicrolearning through audioPhysics textbook assistance
-
Listeners seek more from Top Shelf Podcast: Listeners expressed interest in expanding the Top Shelf podcast with additional book summaries, particularly requesting episodes on Think Again by Adam Grant and capturing the essence of The Body Keeps Score during discussions.
- One user encouraged others to share recommendations to enhance the podcast's offerings, linking to their Spotify show.
- Discussion on AI's control over violence: A user shared a YouTube video titled "Monopoly on violence for AI," highlighting concerns regarding the implications of artificial superintelligence managing violence.
- The video delves into potential consequences that arise from this monopolization of violence in the context of evolving AI technologies.
- Exploring podcast dialogue techniques: Members discussed the prevalent use of the yes...and framework among podcast hosts, commenting on how it creates an illusion of depth in conversations.
- There was a call for exploring more critical tones and discussing the dynamics of dual host dialogues in audio descriptions to enhance the listening experience.
- Microlearning aims for busy individuals: A member shared their vision of using the Top Shelf podcast to facilitate microlearning, addressing the challenge of time constraints preventing full book readings.
- They emphasized that while the podcast can supplement learning, it cannot replace the experience of reading an entire book.
- Physics textbook assistance using Notebook LM: A user mentioned leveraging Notebook LM for definitions while reading physics textbooks and suggested outputting responses in mathematical notation rather than LaTeX.
- This highlights the demand for more user-friendly formats in educational tools for enhanced comprehension.
Links mentioned:
- Top Shelf: Podcast · Four By One Technologies · "Top Shelf" is your go-to podcast for quick, insightful takes on today’s best-selling books. In just 15 minutes, get the gist, the gold, and a fresh pers...
- [NEUROPODCAST] Monopoly on violence for AI: The episode explore the potential consequences of a powerful artificial superintelligence (ASI) gaining control over violence, potentially leading to a "mono...
- Aging & Nutrient Deficiency: Impact on Immunity: #AgingAndImmunity #MicronutrientDeficiency #HealthyAgingaging and immunity, micronutrient deficiency, healthy aging, boost immunity, aging health tips, micro...
Notebook LM Discord ▷ #general (34 messages🔥):
Art of Prompting with AIIssues with NotebookLMAudio Summaries and CustomizationUploading DocumentsExploration of Relevant Links
-
Art of Prompting with AI is Key: Discussions highlighted the importance of mastering the art of prompting to effectively use paid AI tools for generating art.
- Members emphasized that good prompts can significantly enhance the quality of AI-generated outputs.
- NotebookLM Facing Technical Issues: Several members reported experiencing issues with NotebookLM, including problems operating functions and accessing certain features.
- Users discussed their frustrations and shared temporary workarounds while awaiting fixes from the development team.
- Audio Summaries Customized for Different Audiences: One user shared an experience of creating customized audio summaries from a set of resources tailored to various audiences.
- The process involved adapting content for both social workers and grad students, showcasing NotebookLM's flexibility.
- Document Upload Limitations Discussed: Questions arose about the limits on document uploads, with members suggesting to group documents to stay within allowable limits.
- Some users wondered about the feasibility of uploading over 50 documents to NotebookLM.
- Seeking improvement in prompting techniques: A member inquired about prompts that could help make deeper dives into academic papers, suggesting a need for focused strategies.
- Responses included using expert perspective or theoretical approaches for more thorough discussions.
Links mentioned:
- Healthy Habits, Happy Life: Essential Tips for a Vibrant Lifestyle: Podcast · LetPeopleTalk · Join us on a journey to a healthier, happier you! Our channel is dedicated to providing practical tips, expert advice, and inspiring stories to help you live a fulfilling lif...
- MarkDownload - Markdown Web Clipper - Chrome Web Store: This extension works like a web clipper, but it downloads articles in markdown format.
- The $3 Trillion AI Opportunity Everyone Missed: Why Today's 'GPU Bubble' Is Actually Massive Under-Investment
- Notebook LM Tutorial: Customizing Content for Different Audiences: Learn how to tailor your content to different audiences using Notebook LM's powerful customization features! In this tutorial, we'll explore how to synthesiz...
OpenAccess AI Collective (axolotl) ▷ #general (36 messages🔥):
Liger Kernel ImprovementsCut Cross-Entropy MethodOrca3 InsightsEvent Invitation from MetaTokenization and Fine-Tuning
-
Liger Kernel shows improved performance: The team highlighted enhancements in the Liger Kernel, with new updates improving both speed and memory efficiency see details.
- Specific improvements also included support for DPO and changes to Gemma2, enabling it to utilize fusedcrossentropy.
- Cut Cross-Entropy method proposes major efficiency gains: A proposal for Cut Cross-Entropy (CCE) suggests a significant reduction in memory usage when computing loss, from 24 GB to 1 MB for the Gemma 2 model details here.
- This method reportedly allows for training at about 3x faster than Liger while maintaining similar memory usage.
- Insights emerging about Orca3: Orca3 has generated positive feedback, noted by members as being particularly impressive.
- Discussions related to Orca3 referenced other channels, highlighting its potential innovations in model architecture.
- Meta's mysterious Llama event invitation: A member received an unexpected invitation from Meta for a two-day event at their HQ regarding open-source and Llama, raising curiosity about potential new model releases.
- Members speculated on the event's focus, emphasizing the oddity of such a trip without being a speaker.
- Token overlap in fine-tuning: In discussions about fine-tuning, it was questioned whether 5k of data would suffice if the tokenizer remains unchanged, with one member suggesting millions of tokens as more appropriate.
- All the while, there were reflections on continuity in their model training processes and the necessity for examining token overlaps.
Link mentioned: Tweet from Kearm (@Nottlespike): So this is how my day has been going
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
OrcaOrca 2Orca-AgentInstructSynthetic Data Generation
-
Orca showcases synthetic data prowess: The research on Orca reveals its capability to leverage synthetic data for post-training small language models, achieving performance levels akin to larger models.
- This approach signifies a noteworthy advancement in language model training, demonstrated in both Orca and Orca 2.
- Orca-AgentInstruct enhances synthetic data generation: Orca-AgentInstruct explores agentic flows to produce diverse and high-quality data at scale for synthetic data generation.
- By using this agentic framework, it enables the creation of customized datasets that include both prompts and responses, improving the overall efficiency of data generation.
Link mentioned: Orca-AgentInstruct: Agentic flows can be effective synthetic-data generators: Orca-AgentInstruct, from Microsoft Research, can generate diverse, high-quality synthetic data at scale to post-train and fine-tune base LLMs for expanded capabilities, continual learning, and increas...
OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
Office HoursAxolotl feedback session
-
Join Axolotl's First Office Hours!: We're thrilled to host our first Office Hours session on Discord on December 5th at 1pm EST for all members to ask questions and share feedback.
- This is your chance to inquire about anything regarding Axolotl and contribute your ideas!
- Feedback Opportunity for Axolotl: This session is an open invitation to bring your thoughts and suggestions that can help enhance Axolotl.
- The Axolotl team is eager to listen and engage with the community to improve the platform.
Link mentioned: Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (9 messages🔥):
Qwen/Qwen2 Model PretrainingEval Steps in TrainingPhorm Bot Malfunction
-
Steps for Qwen/Qwen2 Model Pretraining: A member is looking for guidance on how to pretrain the Qwen/Qwen2 model using qlora with their raw text jsonl dataset and then fine-tune it with an instruct dataset after setting up Axolotl docker.
- They prompted for specific next steps to proceed with their setup.
- Inquiry about eval_steps: Another member asked, 'What do eval_steps mean?' seeking clarification on the significance of eval_steps in the training process.
- However, there was no clear answer provided in the subsequent messages.
- Phorm Bot's Response Issues: A member reported that the Phorm bot seemed to be malfunctioning, stating it could not provide answers even to basic queries.
- This highlighted a possible technical issue that may need addressing within the community.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
OpenAI ▷ #ai-discussions (25 messages🔥):
P100 vs P40 ScamPhoto Selection TechniquesPDF Upload IssuesGPT-4o Pricing MechanicsAI Club Development Plans
-
P100 shipped instead of P40 scam: A member reported being scammed by a seller in Shenzhen, who shipped a P100 when a P40 was ordered, expressing frustration with big tech enabling such fraud.
- They remarked, 'no way I'm plugging this in,' highlighting distrust in the product received.
- Innovative photo selection strategies: A member discussed the challenge of selecting the best photo among hundreds, contemplating the efficiency of creating a numbered collage as a method to streamline the process.
- Despite downplaying the collage technique as 'patchy,' they acknowledged its effectiveness, particularly when given one task at a time.
- Ongoing PDF upload difficulties: A user expressed frustration with issues uploading PDFs across different platforms, including the Mac App, iOS App, and web browser.
- This sparked a discussion regarding the current stability of various OpenAI systems.
- Exploring GPT-4o pricing mechanics: A discussion highlighted that GPT-4o charges 170 tokens for processing each
512x512tile in high-res mode, upholding that a picture is effectively worth about 227 words.
- Members pondered the significance of the oddly specific token charge, relating it to the concept of magic numbers in programming.
- Plans for development in AI clubs: A member shared an update on a recent AI Club meeting at UIUC, noting that planning is underway for future activities and a major drop next semester.
- This generated excitement within the community, emphasizing a collaborative approach to future AI endeavors.
Links mentioned:
- Tweet from Doomlaser Corporation (@DOOMLASERCORP): After #UIUC's Inaugural AI Club meeting. 4 of us. We will meet here again in 2 weeks time, planning for the big drop next semester 👄👄🫦👁️👀🧠🫀🫁🦴, #AI #Future
- A Picture is Worth 170 Tokens: How Does GPT-4o Encode Images? - OranLooney.com: Here’s a fact: GPT-4o charges 170 tokens to process each 512x512 tile used in high-res mode. At ~0.75 tokens/word, this suggests a picture is worth about 227 words—only a factor of four of...
OpenAI ▷ #gpt-4-discussions (6 messages):
Content FlagsGPT IssuesUser Input Policies
-
Content Flags Not a Major Issue: A member noted that while they've received many content flags over the years, these are often about the model's outputs and can help improve its training rather than indicating user wrongdoing.
- They emphasized that content flags can occur even if users did not explicitly request disallowed content.
- Clarification on Allowed Content: Another member expressed frustration regarding their content not violating policies, specifically when discussing horror video games, stating they don't see how it's harmful.
- They mentioned receiving many flags recently, suggesting a possible increase in content monitoring.
- Seeking Solutions for GPT Troubles: A user reached out for assistance, asking others about ways to fix issues they're experiencing with GPT.
- The inquiry was met with a lighthearted response, illustrating the ongoing challenges users face.
OpenAI ▷ #prompt-engineering (5 messages):
Game of 24 AI performanceExploring past experiencesRAG prompt and few-shot examples
-
3.5 AI shines in Game of 24: A user shared that the 3.5 AI often does not lie during the Game of 24, making it capable of winning occasionally.
- This indicates significant improvements in AI performance in gaming scenarios.
- Nostalgia for past gaming days: Another user reminisced about the good old days, expressing interest in exploring Game of 24 again.
- I bet we can still explore that too if we want! highlighted a shared enthusiasm for revisiting this game.
- RAG prompt enhancement inquiry: A user is seeking clarity on whether incorporating examples from documents into the RAG prompt can boost answer quality.
- They emphasized the need for research on this aspect, especially for developing a QA agent platform.
- Hint prompt for enhanced reasoning: A user suggested a hint prompt for AI responses, stating if the AI feels unconfident, it should ask for more time.
- This prompt allows the AI to refine its answers and suggests a method for improving response accuracy.
OpenAI ▷ #api-discussions (5 messages):
Game of 24Exploring Past AI IterationsPrompting Techniques for AIRAG Prompt with Few-Shot Examples
-
Game of 24 Skills Rise: A user noted that their 3.5 model is capable of playing the Game of 24 and even wins occasionally.
- This highlights improvements in AI capabilities during gameplay, reflecting a positive trend.
- Nostalgic Reflections on AI Exploration: A member reminisced about earlier explorations, suggesting that they can still revisit these ideas together.
- This sentiment indicates a strong community interest in exploring past developments and iterations in AI.
- Enhancing RAG Prompts with Examples: A user inquired whether adding examples from documents in the RAG prompt would enhance answer quality.
- They emphasized their ongoing development of a QA agent platform and need for feedback on incorporating few-shot examples.
- Prompting Strategy with Confidence Hints: A suggestion was made for a hint prompt to encourage players to admit when they need more thinking time.
- This approach aims to alleviate pressure during problem-solving, fostering a more thoughtful engagement.
OpenInterpreter ▷ #general (17 messages🔥):
OpenAI's 'OPERATOR' AI AgentBeta App PerformanceAzure AI Search MethodologiesOpen Interpreter Shell IntegrationDevin AI Preview Access
-
OpenAI Reveals 'OPERATOR' AI Agent: A YouTube video titled "OpenAI Reveals 'OPERATOR' The Ultimate AI Agent Smarter Than Any Chatbot" discusses the upcoming launch of OpenAI's new AI agent, which is expected to reach a larger audience soon.
- It's coming to the masses!
- Beta App Outperforms Console Integration: Confirmation was sought regarding the beta app's performance, with a member stating that the desktop app will provide the best Interpreter experience due to better infrastructure.
- They highlighted that it has much more behind-the-scenes support than the open-source repo.
- Azure AI Search Breakdown: A YouTube video titled "How Azure AI Search powers RAG in ChatGPT and global scale apps" outlines the data conversion and quality restoration techniques involved in Azure AI Search.
- It raises questions about patents, resources, and the need for effective data deletion processes.
- Launch of Open Interpreter Shell Integration: A new Open Interpreter shell integration was introduced, allowing users to install and access it within their terminal for enhanced interactivity.
- Feedback is encouraged as it's an experimental feature aimed at transforming any terminal into a chatbox for Open Interpreter.
- Interest in Devin AI: A query was posed about whether anyone had preview access to Devin AI, leading to some skepticism about its value.
- One member expressed doubt, stating they believe it's lame.
Links mentioned:
- OpenAI Reveals "OPERATOR" The Ultimate AI Agent Smarter Than Any Chatbot: 👉 Register for ChatGPT & AI workshop for FREE: https://web.growthschool.io/ARO👉 100% Discount for first 1000 people 🔥✅ Join Top1% AI Community for regula...
- How Azure AI Search powers RAG in ChatGPT and global scale apps: Millions of people use Azure AI Search every day without knowing it. You can enable your apps with the same search that enables retrieval-augmented generatio...
- Microsoft Mechanics - Azure AI Search at scale: Microsoft Mechanics - Azure AI Search at scale. GitHub Gist: instantly share code, notes, and snippets.
OpenInterpreter ▷ #ai-content (4 messages):
Probabilistic computingChatGPT desktop compatibilityNew computing performance
-
Probabilistic computing achieves drastic GPU performance boost: A YouTube video discusses a new breakthrough in probabilistic computing which reportedly achieves 100 million times better energy efficiency compared to the best NVIDIA GPUs.
- In this video, I discuss probabilistic computing that reportedly allows for 100 million times better energy efficiency compared to the best NVIDIA GPUs.
- ChatGPT desktop gains user-friendly enhancements: This advancement is labeled as huge for mass users of ChatGPT desktop, indicating significant improvements that enhance user experience.
- Users are keen on features that will enhance their interaction with the platform.
- Compatibility with multiple providers: A member noted that the platform is compatible with several providers including OpenAI, Anthropic, Google, AWS Bedrock, and Replicate.
- They are currently working on a custom URL, indicating ongoing improvements.
Link mentioned: New Computing Breakthrough achieves 100 MILLION Times GPU Performance!: In this video I discuss probabilistic computing that reportedly allows for 100 million times better energy efficiency compared to the best NVIDIA GPUs.Check ...
tinygrad (George Hotz) ▷ #general (12 messages🔥):
tinybox pro preorderint64 indexing bountybuffer transfer functioncommunity support in development
-
tinybox pro launches for preorder: The tinybox pro is now available for preorder on the tinygrad website with a price tag of $40,000, featuring eight RTX 4090s.
- With its impressive capability to hit 1.36 PetaFLOPS of FP16 computing, it's marketed as a more affordable alternative to a single Nvidia H100 GPU.
- Guidance sought on int64 indexing bounty: A member asked for help on what the int64 indexing bounty entails, specifically if it requires changes to functions like getitem in tensor.py.
- Another member noted that they could search submitted PRs, highlighting PR #7601 which addresses the bounty but has not yet been accepted.
- Community discusses bounty background: A member suggested that searching through Discord could provide valuable background discussions regarding the bounties available.
- This resource is noted to be generally helpful for anyone looking to understand details about both the int64 indexing and other bounties.
- Buffer transfer function details shared: A pull request was highlighted which discusses a buffer transfer function on CLOUD devices, useful for device interoperability.
- The exchange noted that there may be some ambiguity regarding the necessity for a size check for the destination buffer.
Links mentioned:
- AI accelerator tinybox pro goes up for preorder for $40,000 — the device features eight RTX 4090s and two AMD Genoa EPYC processors: A more powerful but still affordable AI accelerator.
- Buffer transfer on CLOUD devices by mdaiter · Pull Request #7705 · tinygrad/tinygrad: Title says it all - read out buffer from one device, put it into another on a different device. You don't really need the assert or the sz param in there, but I wanted to keep this congruent w...
- better int64 indexing by ttomsa · Pull Request #7601 · tinygrad/tinygrad: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
tinygrad ContributionsBuffer Transfer on CLOUD DevicesGPU Tensor Transfer
-
Contributing to tinygrad: Seeking Feedback: A user shared their first attempt to contribute to tinygrad and expressed openness to all feedback as they aim to improve.
- They referenced a GitHub pull request that discusses their work on data transfer.
- Buffer Transfer on CLOUD Devices Pull Request: The user re-opened a pull request focused on managing buffer transfers on CLOUD devices, citing previous feedback received on the topic.
- They reflectively commented that their last approach seemed silly in hindsight, about reading and dumping data between web buffers.
- Natively Transfer Tensors Between GPUs: In response to the initial query, it was clarified that tensors can be transferred between different GPUs on the same device using the
.tofunction.
- This clarification was aimed at guiding the user toward a more effective method for handling tensor transfers.
Link mentioned: Buffer transfer on CLOUD devices by mdaiter · Pull Request #7709 · tinygrad/tinygrad: From some feedback, re-opening this PR. My last PR focused on reading data synchronously out of a web buffer, onto a host device, and then dumping it in another web buffer. Seems silly in hindsight...
LlamaIndex ▷ #blog (2 messages):
LlamaIndex Community CallPython Documentation UpgradeKnowledge GraphsRAG system
-
Learn GenAI App Building in Community Call: Join our upcoming Community Call to learn about creating knowledge graphs from unstructured data and advanced retrieval methods.
- Explore how to transform data into queryable formats!
- Python Docs Feature Boost from RunLLM: Our Python documentation received an upgrade with the new 'Ask AI' widget that launches a highly accurate agentic RAG system for code queries Check it out!.
- Users can now get accurate, up-to-date code written directly in response to their questions.
LlamaIndex ▷ #general (10 messages🔥):
condenseQuestionChatEngineCondensePlusContextretrieving contextcustomizing prompts
-
Issues with condenseQuestionChatEngine: A member raised concerns that when users abruptly switch topics, the condenseQuestionChatEngine sometimes generates incoherent standalone questions.
- Suggestions were made to customize the condense prompt to better handle sudden topic changes.
- Preference for CondensePlusContext: Another member expressed a preference for CondensePlusContext because it condenses input and retrieves context for every user message.
- They highlighted its efficiency in providing dynamic context, which includes inserting the retrieved text into the system prompt.
- Clarification on context retrieval: There was confusion about whether CondensePlusContext retrieves context for every user message or just the latest one, with consensus that it refers to the latest user message.
- One member clarified that the function indeed uses a retriever for context retrieval.
- Handling queries with custom query engine: A member detailed their implementation of a custom query engine, emphasizing the challenge of using CondensePlusContext without a query engine parameter.
- They provided code snippets to showcase their setup involving a RetrieverQueryEngine with various postprocessors.
- Using custom retriever in CondensePlusContext: Members agreed that the appropriate approach for their situation would be to use CondensePlusContextChatEngine with a custom retriever.
- They suggested using custom retriever and node postprocessors to align with their specific requirements.
Link mentioned: Postgres Vector Store - LlamaIndex: no description found
Cohere ▷ #discussions (6 messages):
New Users on CohereIssues with Model Settings
-
Greetings to New Users in Cohere: Multiple members welcomed newcomers fotis and lovisonghamnongtimem to the Cohere community, encouraging them to enjoy their experience.
- Enjoy the journey and share the fun! was a common sentiment expressed by existing members.
- Ongoing Issues with Model Settings: A member highlighted persistent issues with their settings for the command-r-plus-08-2024 model, sharing specific parameters including temperature and frequency penalty.
- They seek assistance as they continue to encounter problems despite the specified configurations.
Cohere ▷ #questions (3 messages):
Playwright Python file uploadCohere discussion
-
Uploading a file with Playwright in Python: A user shared their method for uploading a text file in Playwright Python using
set_input_filesmethod and then queries the uploaded content.- However, they expressed concern that the approach feels somewhat odd when they ask, "Can you summarize the text in the file? @file2upload.txt".
- Cohere relevance questioned: A user prompted a question regarding the relevance of the discussion to Cohere, indicating uncertainty about the topic's context.
- This inquiry remained unanswered in the given message history.
Cohere ▷ #projects (1 messages):
Agentic ChunkingLlamaChunk MethodRAG PipelinesRegular Expressions Challenges
-
Agentic Chunking Research Published: A new method on agentic chunking for RAG has resulted in less than 1 second inference times, proving to be efficient on GPUs and cost-effective.
- The full details and community building for this research can be found on their Discord channel.
- LlamaChunk Simplifies Text Processing: Introducing LlamaChunk, a LLM-powered technique that optimizes recursive character text splitting by requiring only a single LLM inference over documents.
- This method eliminates the need for brittle regex patterns typically used in standard chunking algorithms, allowing for better handling of unstructured data.
- Challenges in Writing Regex for Chunking: A key pain-point highlighted is the difficulty in writing regex patterns for chunking documents, which can fail and create oversized chunks.
- Common methods include splitting every 1000 characters or on whitespace, but these solutions often lack efficiency and flexibility.
- Open Source Contribution Invitation: The team encourages contributions to the LlamaChunk codebase, available for public use on GitHub.
- Users can explore the README for a detailed explanation of the method's operation.
Links mentioned:
- LlamaChunk: Better RAG Chunking Than LlamaIndex | Hacker News: no description found
- GitHub - ZeroEntropy-AI/llama-chunk: Contribute to ZeroEntropy-AI/llama-chunk development by creating an account on GitHub.
LAION ▷ #general (6 messages):
Copyright infringement debatePublic link index discussion
-
Confusion on Copyright and Public Links: A member asserted, there is no world where a public index of public links is a copyright infringement.
- This statement sparked confusion regarding the legality of using public links.
- General Guidance on Discord Etiquette: Another member expressed gratitude with a simple, ty, demonstrating appreciation for help received.
- Such exchanges indicate ongoing collaborative support within the community.
DSPy ▷ #show-and-tell (1 messages):
ChatGPT for macOSIntegration with desktop appsdspy GPTs functionality
-
ChatGPT for macOS integrates with coding apps: Exciting news! ChatGPT for macOS can now integrate with desktop apps like VS Code, Xcode, Terminal, and iTerm2 in this beta feature for Plus and Team users.
- This enhancement allows ChatGPT to provide better coding assistance by directly interacting with the development environment, which could be a game-changer for projects.
- Hope for dspy GPTs integration: There is a strong hope to extend this functionality to dspy GPTs, enhancing workflows significantly.
- Members discussed the potential impact of these integrations on their projects, emphasizing the possibilities for improvement.
Link mentioned: Tweet from OpenAI Developers (@OpenAIDevs): ChatGPT 🤝 VS Code, Xcode, Terminal, iTerm2 ChatGPT for macOS can now work with apps on your desktop. In this early beta for Plus and Team users, you can let ChatGPT look at coding apps to provide be...
DSPy ▷ #general (4 messages):
LLM Document Generation for InfractionsDSPy Language Compatibility
-
Expanding LLM Application for Various Infractions: A user is developing an LLM application to generate long legal documents defending drivers from losing their licenses, currently limited to alcohol ingestion infractions.
- They seek a way to create a single optimized prompt that can handle various types of infractions without individually tailored prompts.
- DSPy Language Support Inquiry: A user inquired about the language compatibility of DSPy for applications in non-English languages.
- The subsequent response pointed to an open GitHub issue that addresses the localization features request for DSPy.
Link mentioned: Feature request: localization · Issue #1803 · stanfordnlp/dspy: Hi! It is me again :-) . As am trying out some basics of the DSPy some more I realised one thing: the currently is no option to set diff. lang than English. The thing is, I want to make sure the LM...
Modular (Mojo 🔥) ▷ #general (5 messages):
New ABIs ResearchALLVM ProjectCross-Language LTOMojo's ABI Potential
-
Research Highlights New ABIs: Members shared links to research papers on new ABIs, emphasizing the challenges with low-level ABIs in facilitating cross-module optimizations. One pointed out that writing everything in one language is often preferred for maximum execution speed.
- Included papers are available at DOI link and a PDF link.
- ALLVM Project Decline: Discussion highlighted that the ALLVM project likely faltered due to many devices lacking sufficient memory to compile/link all running software, especially in browsers. Another member suggested that Mojo could leverage ALLVM for C/C++ bindings in innovative ways.
- The original intent of ALLVM was to unify the software representation, but it seems to be largely inactive now, as noted by participants.
- Desire for Cross-Language LTO: A member expressed the importance of cross-language LTO, particularly for the vast amount of software written in C/C++ that many prefer not to rewrite. They emphasized this necessity due to complexities in existing software ecosystems.
- The discussion acknowledged that effective linking would greatly improve performance and maintainability of legacy systems.
- Mojo's Potential ABI Innovations: Discussion turned to Mojo's potential for defining an ABI that optimizes data transfer by passing maximum information in registers, leveraging structures sized for AVX-512. This approach aims to enhance interoperability and efficiency across various software components.
- The hope is that an ABI framework centered around register efficiency could transform how C/C++ is integrated within modern contexts.
Link mentioned: ALLVM Research Project | LLVM All the Things! - University of Illinois at Urbana-Champaign): no description found
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Intel Tiber AI CloudIntel Liftoff ProgramAMA with IntelAI development toolsHackathon opportunities
-
Don't Miss the Intel AMA on AI Tools: Join the exclusive AMA session with Intel on Building with Intel: Tiber AI Cloud and Intel Liftoff on 11/21 at 3pm PT to explore advanced AI resources.
- This event offers a unique chance to interact with Intel specialists and gain insights into optimizing your AI development projects.
- Discover the Intel Tiber AI Cloud: Intel will introduce the Tiber AI Cloud, a platform aimed at enhancing your hackathon projects through advanced computing capabilities and efficiency.
- Participants can learn how to leverage this powerful tool for better performance in their projects.
- Intel Liftoff Program Benefits Explained: The session will also cover the Intel Liftoff Program, which supports startups with technical resources and mentorship.
- Learn about comprehensive benefits that can help young companies scale and succeed in the AI industry.
Link mentioned: Building with Intel: Tiber AI Cloud and Intel Liftoff · Luma: Building with Intel: Tiber AI Cloud and Intel Liftoff About the AMA Join us for an exclusive AMA session featuring specialists from Intel, our esteemed sponsor…
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
Quizzes FeedbackCourse Deadlines
-
Quizzes Feedback Delays: A member expressed concern about not receiving email feedback for quizzes 5 and 6 while trying to catch up.
- Another member suggested they should check if the issue is from their end and recommended resubmitting to resolve the problem.
- Urgent Reminder on Course Deadlines: A member reminded peers that they are still eligible to participate, but they should catch up quickly as every quiz ties back to the course content.
- The final submission date is December 12th, stressing the need for timely completion.
Torchtune ▷ #announcements (1 messages):
Torchtune v0.4.0Activation OffloadingQwen2.5 SupportMultimodal Training Enhancement
-
Torchtune v0.4.0 is Here!: Torchtune has officially released v0.4.0, featuring a TON of new functionalities that promise to enhance user experience significantly.
- The community's support played a crucial role in this launch, and full release notes are available here.
- Activation Offloading Boosts Performance: Activation offloading is now implemented for full finetuning and lora recipes, cutting memory requirements for ALL text models by an additional 20%!
- This feature aims to optimize overall performance and efficiency for users working with text models.
- Support Added for Qwen2.5 Builders: Builders for Qwen2.5, the new release from the Qwen model family, have been added to Torchtune.
- Developers can find more details on this cutting-edge release on the Qwen2.5 blog.
- Multimodal Training Expands: The multimodal training functionality has been enhanced with support for Llama3.2V 90B and QLoRA distributed training.
- This expansion enables users to engage with larger data sets and more complex models for advanced training capabilities.
Torchtune ▷ #papers (2 messages):
Orca and Orca 2Agentic Solutions for Synthetic DataCausal Language Models
-
Orca-AgentInstruct pursues synthetic data generation: The latest work on Orca introduced Orca-AgentInstruct, an agentic solution for generating diverse and high-quality datasets at scale.
- This approach aims to elevate small language models' performance to levels commonly seen in larger models through effective synthetic data generation.
- Advocacy for broader understanding in NLP: A newly shared paper emphasizes the necessity of avoiding local minima in causal language models, promoting broader frameworks for understanding.
- The paper advocates for expanding perspectives rather than staying confined within traditional models' limitations, as referenced in the preprint.
Link mentioned: Orca-AgentInstruct: Agentic flows can be effective synthetic-data generators: Orca-AgentInstruct, from Microsoft Research, can generate diverse, high-quality synthetic data at scale to post-train and fine-tune base LLMs for expanded capabilities, continual learning, and increas...
Mozilla AI ▷ #announcements (2 messages):
Local LLM WorkshopSQLite-Vec Metadata FilteringAutonomous AI AgentsLanding Page Development Assistance
-
Build Your Own Local LLM Workshop: Upcoming event on Tuesday titled Building your own local LLM's: Train, Tune, Eval, RAG all in your Local Env. invites members to learn local LLM setup intricacies.
- Members are encouraged to RSVP for this informative session to enhance their local environment capabilities.
- SQLite-Vec Now Supports Metadata Filtering: On Wednesday, members can attend an event announcing the enhanced capabilities of sqlite-vec now supports metadata filtering!, focusing on practical applications.
- This is a key opportunity to learn how to utilize metadata for improved data handling.
- Exploring Autonomous AI Agents: Join the discussion on Thursday about Autonomous AI Agents with Refact.AI, aimed at diving deeper into AI automation.
- This event promises valuable insights into the functionality and future of AI agents.
- Landing Page Help Available!: A member is seeking assistance in spinning up a landing page for their project, planning a live walkthrough on the Mozilla AI stage.
- Interested members should reach out in this thread for collaborative marketing support.