[AINews] State of AI 2024
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
204 slides is all you need to catch up on AI.
AI News for 10/9/2024-10/10/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (231 channels, and 2109 messages) for you. Estimated reading time saved (at 200wpm): 267 minutes. You can now tag @smol_ai for AINews discussions!
It is the season of annual perspectives, whether it is SWE-bench's first year (celebrated by MLE-bench today) or Sequoia's third year, or a16z's 2nd anniversary of being cooked by roon, but the big dog here is Nathan Benaich's State of AI Report, now in year 7.
AI Engineers will probably want to skip the summaries and go straight to the slides, which recap topics we cover in this newsletter but in one place, though you'll have to dig a little to find references:

The Research and Industry sections will be most relevant, with useful 1-slide summaries of the must-know research of the year, like BitNet (our coverage here):

and even-handed presentations of both sides of the synthetic data debate:

With some of the coverage is perhaps too uncritically-accepting of bold claims at face value.
As Cerebras shapes up for IPO, the Compute Index is a nice proxy for why this is the first of its cohort to finally emerge:
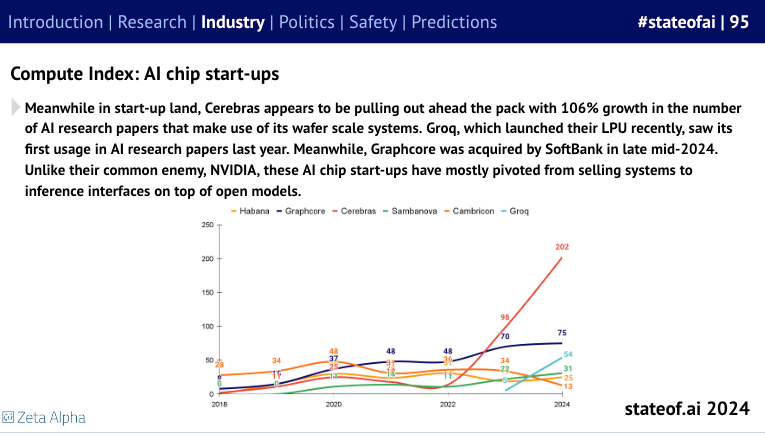
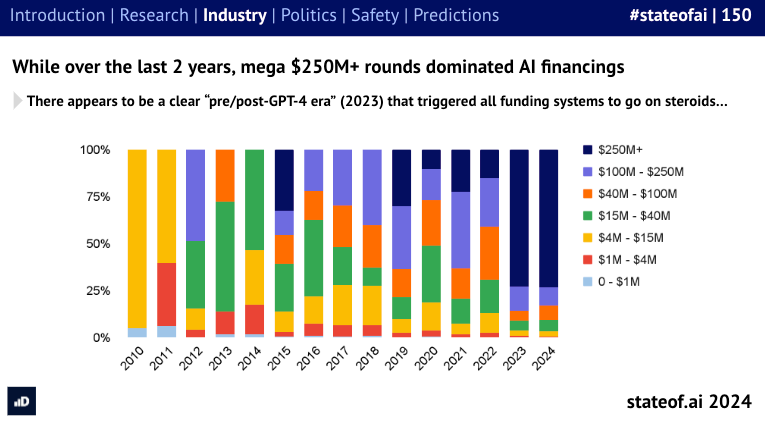
as well as good recaps of the funding landscape

Brought to you by Daily: If you’re interested in conversational voice AI (and video, too), join the team at Daily and the Open Source Pipecat community for a hackathon in San Francisco on October 19th and 20th. $20,000 in prizes for the best voice AI agents, virtual avatar experiences, UIs for multi-modal AI, art projects, and whatever else we dream up together.
Swyx commentary: They just announced that Cartesia (my fave TTS recently) and GCP have joined as sponsors AND Product Hunt is hosting a remote track as well! If you ever wanted to do anything voice + video this is the place to be next weekend!
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Nobel Prizes in Physics and Chemistry Awarded for AI Research
- Physics Prize: Geoffrey Hinton and John Hopfield awarded for work on neural networks and statistical mechanics concepts applied to AI @mark_riedl noted this recognizes the impact of deep neural networks on society @SerranoAcademy highlighted Hopfield networks and RBMs as key contributions
- Chemistry Prize: Demis Hassabis, John Jumper, and David Baker awarded for AlphaFold and protein structure prediction @ylecun commented on the tremendous impact of AlphaFold and ML-powered protein structure prediction @polynoamial expressed hope this is just the beginning of AI aiding scientific research
New AI Model Releases and Updates
- Meta released Llama 3.2 with multimodal capabilities @DeepLearningAI announced a free course on Llama 3.2 features @AIatMeta reported Llama 3.2 1B running at 250 tokens/sec on Mac
- Anthropic updated their API with new features @alexalbert__ announced support for multiple consecutive user/assistant messages and a new disable_parallel_tool_use option
AI Development and Research
- EdgeRunner: New approach for 3D mesh generation @rohanpaul_ai summarized key improvements like generating meshes with up to 4,000 faces and increased vertex quantization resolution
- TurtleBench: New benchmark for evaluating LLM reasoning @rohanpaul_ai described how it uses dynamic, real-world puzzles focusing on reasoning over knowledge recall
- HyperCloning: Method for efficient knowledge transfer between models @rohanpaul_ai reported 2-4x faster convergence compared to random initialization
AI Tools and Applications
- Tutor CoPilot: AI system for improving tutoring quality @rohanpaul_ai shared that it increased student mastery by 4 percentage points overall, with a 9 percentage point increase for lower-rated tutors
- Suno AI released new music generation features @suno_ai_ announced ability to replace sections of songs with new lyrics or instrumental breaks
AI Industry and Market Trends
- Discussions on the commoditization of AI models @corbtt suggested open-source models are becoming dominant for simple tasks, potentially extending to larger models over time
- Debates on the future of API-based vs self-built AI startups @ClementDelangue argued startups building and optimizing their own models may be better positioned than those relying on APIs
Memes and Humor
- Jokes about AI winning future Nobel Prizes @osanseviero joked about the Attention Is All You Need authors winning the Literature prize @Teknium1 quipped about AI models directly winning prizes by 2027
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Large Language Model Releases: Behemoth 123B
- Drummer's Behemoth 123B v1 - Size does matter! (Score: 48, Comments: 17): Drummer's Behemoth 123B v1, a large language model, has been released on Hugging Face. The model, with 123 billion parameters, emphasizes that size is significant in AI model performance, suggesting it may offer improved capabilities compared to smaller models.
- Users compared Behemoth 123B to other models, with Magnum 72b praised for performance but Mistral Large 2 criticized for poor prompt adherence. The GGUF version and iMatrix version of Behemoth were shared.
- A user requested an exl2 5bpw version of the model, with another user starting the process, estimating 172 minutes for measurement pass before quantization and upload. This highlights community interest in optimizing large models for broader accessibility.
- Discussion touched on the balance between large and small models, with some advocating for more attention to smaller models like 1B, 3B, Gemmasutra, and Llama 3.2. Others noted recent trends showing continued development of sub-12B models.
Theme 2. Nvidia RTX 5090: Pricing Strategy and VRAM Concerns
- MLID $1999 - $2499 RTX 5090 pricing (Score: 107, Comments: 164): According to a leak reported by Moore's Law Is Dead (MLID), the upcoming NVIDIA RTX 5090 graphics card is expected to be priced between $1999 and $2499. The leaked information suggests that the RTX 5090 will feature 32GB of VRAM, potentially offering a significant upgrade in memory capacity compared to its predecessor.
- The RTX 5090's high price point sparked discussions about alternatives, with many suggesting multiple 3090s or 4090s as more cost-effective options. Users noted that 4x 3090s would provide 96GB VRAM for a similar price to one 5090.
- Commenters reminisced about past GPU pricing, comparing the GTX 1080's $699 launch price to current trends. Some attributed the price increases to NVIDIA's market dominance and the AI boom, while others hoped for AMD to provide competition.
- The 5070 and 5080 models' reported 12GB and 16GB VRAM respectively were criticized as insufficient, especially compared to the 4060 Ti's 16GB. This led to speculation about potential price increases for older 24GB cards like the 3090.
- 8gb vram gddr6 is now $18 (Score: 227, Comments: 119): The cost of 8GB GDDR6 VRAM has significantly decreased to just $18, prompting discussions about the pricing structure of GPUs. This price reduction raises questions about the justification for high GPU costs, especially considering that VRAM is often cited as a major component in determining overall graphics card prices.
- Nvidia's pricing strategy for GPUs with limited VRAM is criticized, with calls for increased VRAM across all tiers (e.g., 5060 = 12GB, 5070/5080 = 16-24GB, 5090 = 32GB). The company's monopoly on CUDA is cited as a key factor in maintaining high prices.
- Discussions highlight the potential for affordable GPUs with 128+ GB VRAM if manufacturers prioritized consumer needs. AMD is also criticized for not offering competitive pricing, with their 48GB card priced at $2k+, similar to Nvidia's professional options.
- Some users point to emerging competitors like Moore Threads, a Chinese GPU company offering 16GB GDDR6 cards for ~$250, as potential future challengers to Nvidia's market dominance. However, the slow pace of hardware development and software maturation is noted as a barrier to immediate competition.
Theme 3. Voice Assistant Development with Llama 3
- I'm developing a Voice Assistant (V.I.S.O.R.) with Llama3! (Score: 45, Comments: 15): The V.I.S.O.R. (Voice Assistant) project integrates Llama3 for both Android and desktop/server platforms, with development testing on a Raspberry Pi 5 (8GB). Key features include easy module creation, chat functionality with WolframAlpha and Wikipedia integration, and a custom recognizer for complex sentence recognition, while current challenges involve integrating command recognition with Llama3 responses and implementing user profiling for personalized interactions. The developer is seeking contributions and collaborations, with a long-term goal of smart home control, and encourages interested users to try out the project using Go and Android Studio for building the applications.
- The developer uses the Meta-Llama-3-8B-Instruct-Q4_K_M.gguf model from Hugging Face for the project. They express interest in fine-tuning a custom model and creating a JARVIS-like assistant in the future.
- Resources for LLM training were shared, including philschmid.de and a Reddit post about tooling for building coded datasets for code assistants.
- The project has garnered interest from potential contributors, with the codebase currently consisting of 11k lines of Java for the Android app and 7k lines of Go for the desktop/server component.
Theme 4. ARIA: New Open Multimodal Native Mixture-of-Experts Model
- ARIA : An Open Multimodal NativeMixture-of-Experts Model (Score: 187, Comments: 40): ARIA, a new multimodal Mixture-of-Experts (MoE) model with 3.9 billion active parameters and a 64K context window, has been introduced. The model demonstrates strong performance across various tasks, including vision, language, and audio processing, while maintaining efficiency through its sparse activation approach. ARIA's architecture incorporates 32 experts per layer and utilizes a native MoE implementation, allowing for effective scaling and improved performance compared to dense models of similar size.
- ARIA, an Apache 2.0 licensed multimodal MoE model, outperforms GPT4o, Gemini Flash, Pixtral 12B, Llama Vision 11B, and Qwen VL on some benchmarks. It features 3.9B active parameters (25.3B total), a 64K token context, and was trained on 7.5T tokens across four stages.
- The model's architecture includes a vision encoder with three resolution modes and an MoE decoder with 66 experts per layer. Users report better results than Qwen72, llama, and gpt4o, with successful runs on 2x3090 GPUs (using about 20GB VRAM each).
- Some users noted the lack of a released base model, opening an issue on Hugging Face. The model includes vllm and lora finetune scripts, making it potentially valuable for batched visual understanding tasks.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Breakthroughs
- Google DeepMind's AlphaFold wins Nobel Prize in Chemistry: The 2024 Nobel Prize in Chemistry was awarded to Demis Hassabis and John Jumper of DeepMind, along with David Baker, for their work on protein folding prediction. AlphaFold is seen as a groundbreaking contribution to biology and biotechnology.
- Geoffrey Hinton and John Hopfield win Nobel Prize in Physics: The 2024 Nobel Prize in Physics was awarded to Geoffrey Hinton and John Hopfield for their work on neural networks. This decision sparked some controversy, with Jurgen Schmidhuber criticizing the attribution of certain ideas.
- OpenAI's significant investment in AI research: OpenAI is spending $3 billion on training models compared to $2 billion on serving them, indicating massive investment in research and development of new AI models.
AI Safety and Ethics Concerns
- Geoffrey Hinton expresses concerns about AI safety: Stuart Russell reported that Hinton is "tidying up his affairs" due to concerns about AI development, suggesting a timeline of about 4 years before significant AI-related changes.
- Debate over AI safety vs. profit motives: There is ongoing discussion about the balance between AI safety concerns and profit-driven development, with some researchers like Hinton criticizing companies for prioritizing profits over safety.
AI Industry Developments
- OpenAI's financial situation: Analysis of OpenAI's finances shows significant spending on research and development, with debates about the sustainability of their business model and the economics of AI development.
- AI replacing human roles: Wimbledon announced plans to replace all 300 line judges with AI technology, highlighting the ongoing trend of AI automation in various fields.
Broader Implications and Discussions
- Debates over credit and attribution in AI research: Jurgen Schmidhuber's critique of the Nobel Prize decisions sparked discussions about proper attribution and recognition in the field of AI research.
- Speculation about AGI timelines: Various posts and comments discuss potential timelines for AGI development, with some researchers and community members suggesting relatively short timelines of a few years.
- Impact of AI on scientific research: The Nobel Prizes awarded for AI-related work in both Physics and Chemistry highlight the growing influence of AI in scientific research across disciplines.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Fine-Tuning Models Enhances Performance
- Optimizing Fine-Tuning Under Resource Constraints: Engineers discussed adjusting batch sizes and epochs to fine-tune models like Qwen 2.5 effectively despite VRAM limitations. Strategies included starting with default settings and gradually tweaking based on model behavior during training.
- Addressing torch.compile and Quantization Challenges: Users highlighted issues with
torch.compilecausingTorchRuntimeErroron Windows and int8 quantization leading to slower operations. Solutions involved modifying torch.compile settings and exploring alternative quantization methods to maintain performance. - Chain-of-Thought Reasoning Without Prompting: A study revealed that LLMs can develop CoT reasoning by altering the decoding process instead of relying on traditional prompts. This approach demonstrated enhanced intrinsic reasoning abilities and higher response confidence in models.
Theme 2. Launch and Integration of New AI Models
- OpenRouter Launches Free MythoMax API: OpenRouter introduced a free MythoMax API capable of handling 10B tokens per week using int4 quantization. This release marks a significant upgrade since its inception in August 2023, facilitating broader access to MythoMax capabilities.
- Aria Multimodal MoE Outperforms Competitors: The launch of Aria - Multimodal MoE introduced a model with 3.9B active parameters and the ability to caption 256 frames in 10 seconds. Engineers praised Aria's superior performance over models like Pixtral 12B and Llama Vision 11B, highlighting its advanced training techniques.
- Llama 3.2 Models Released on Hugging Face: Llama 3.2 models, available in both 1B and 3B versions, were released on Hugging Face to enhance developer resources. These models expand the toolkit for developers, offering improved accessibility and a broader range of applications.
Theme 3. Advancements in AI Audio and Podcast Creation
- NotebookLM Facilitates Extended Audio Summaries: Users emphasized the need for longer audio summaries from NotebookLM, achieving durations up to 30 minutes. Despite concerns about hallucinations, the quality of output remained a significant focus for academic and podcast creation purposes.
- TTS Spaces Arena Launches with Enhanced Features: The TTS Spaces Arena was created to explore advanced text-to-speech (TTS) capabilities. Developers showcased new features that elevate user interaction and demonstrate the latest advancements in TTS technologies.
- Whisper Fine-Tuning Achieves Breakthrough Accuracy: Fine-tuning efforts on Whisper led to an 84% improvement in transcription accuracy, particularly benefiting air traffic control applications. This milestone underscores Whisper's potential to address challenges in automatic transcription effectively.
Theme 4. Hardware Optimization for Enhanced AI Performance
- Llama 3.1 Benchmarking on AMD MI300X GPUs: The benchmarking results for Llama 3.1 405B on 8x AMD MI300X GPUs showcased impressive performance metrics, significantly outperforming vLLM. Supported by Hot Aisle, this benchmarking emphasizes the drive towards high-efficiency models in complex tasks.
- GPU Mode Refactors TMA Interface for Optimization: The TMA interface is undergoing refactoring to enhance performance and reduce overheads related to GEMM implementations, which were consuming up to 80% of processing time. Workarounds like pre-initializing descriptors on the host were suggested, though they added complexity and were incompatible with torch.compile.
- NVIDIA RTX 4000 Series Adopts PCIe Gen 5, Drops NVLink: The new NVIDIA RTX 4000 series shifts to PCIe Gen 5 for multi-GPU setups, eliminating NVLink support. This transition allows GPUs to operate at higher speeds without interconnect limitations, enhancing multi-GPU performance for AI applications.
Theme 5. AI Ethics and Community Trends
- Debate on AGI Development and Ethics: Members engaged in discussions about the true nature of AGI, emphasizing that it relates more to learning than mere generalization. Ethical considerations around AI-generated content and censorship were prominent, especially in creating tools that assist without over-restricting capabilities.
- Transition from Crypto to AI Reflects Broader Trends: Following the collapse of FTX and the rise of ChatGPT, many professionals shifted from crypto to AI, seeking roles with more societal impact. This trend highlights the evolving priorities within the tech community, favoring sustainable and impactful fields.
- Ethical Concerns of Companionship AI for Aging Populations: The use of AI for companionship among aging populations addresses workforce shortages but raises ethical concerns regarding the anthropomorphic characteristics of such technologies. Balancing research directions to incorporate ethical implications remains a critical topic among developers.
PART 1: High level Discord summaries
Notebook LM Discord Discord
-
Audio Generation Needs Fine-Tuning: Users highlighted the need for longer audio summaries from NotebookLM, with some reaching 30 minutes, while others capped at 17 minutes.
- Despite the short duration, quality output was acknowledged, though concerns on hallucinations in audio content were raised.
- NotebookLM Offers Academic Insights: Scholars are exploring NotebookLM's potential for tracing themes among documents, identifying an alternative to Zotero keyword searches.
- However, concerns regarding hallucinations affecting accuracy sparked a debate about relying on traditional academic methods.
- Podcast Creation with NotebookLM: Users shared insights on generating podcasts, emphasizing the need for well-crafted source materials, like dedicated 'Show Notes'.
- One user achieved a 21-minute podcast by inputting multiple sources, demonstrating that depth in content is possible.
- Critical Conversations on AI Audio Bias: Discussions emerged about the possibility of negative bias in AI-generated audio, citing how easily tones can be manipulated.
- Concerns were raised that informing audio hosts could lead to awkward outputs, showcasing the challenges in guiding AI.
- User Engagement Sparks Discussions: Community members remain committed to exploring and providing feedback on NotebookLM, sharing insights from various content creation projects.
- Suggestions included refining approach to improve user understanding of NotebookLM's capabilities and addressing technical issues.
Unsloth AI (Daniel Han) Discord
-
Fine-tuning models under resource constraints: Users discussed optimal settings for fine-tuning models, emphasizing adjustments in batch size and epochs to improve performance. Many suggested starting with defaults and making gradual tweaks based on model behavior during training.
- A conversation about VRAM limitations followed, recommending lower bit precision as a solution to prevent crashes during training while still maintaining quality.
- Qwen 2.5 faces memory hurdles: Users reported challenges in fine-tuning Qwen 2.5 at 32k context, often encountering out of memory (OOM) errors during evaluations, despite successful training phases. Problems were linked to inconsistencies in dataset context lengths.
- To handle eval memory issues, participants discussed adjusting max sequence lengths and utilizing evaluation accumulation strategies, especially for high context sizes on H100 NVL GPUs.
- Anticipating multimodal model support: Excitement brewed around upcoming support for multimodal models like Llama3.2 and Qwen2 VL, expected to enhance OCR capabilities. Users are looking forward to integrating these models into their workflows for improved performance.
- The dialogue included notable references to community notions of how new models would shape data interaction and output quality.
- CoT reasoning pushes boundaries: A paper presented findings on Chain-of-Thought (CoT) reasoning emerging from changes in the decoding process rather than relying solely on traditional prompts. This approach showcases the intrinsic reasoning abilities of LLMs.
- Despite the paper's age, members agreed that the discussion around its implications reflects the rapid evolution in the AI research community, with many acknowledging the fast-paced changes prevalent in the field.
OpenAI Discord
-
AGI Development Sparks Debate: AGI has more to do with learning than being more general, as members discussed evolving AI capabilities and model training challenges.
- The community anticipates significant improvements in models' adaptability, albeit acknowledging that AGI remains unrealized.
- OpenAI's Voice Model Disappoints: Members expressed disappointment in the Advanced Voice Model, noting it lacks showcased features like singing and vision.
- Concerns arose regarding its inconsistent voice mimicry, highlighting limitations in user interaction capabilities.
- Vision O1 Release Uncertainties: A user inquired about the upcoming Vision O1, but no information has emerged regarding the potential product launch.
- The community remains in a state of anticipation for further announcements on this development.
- Mistral AI's European Promise: Discussion around Mistral AI revealed enthusiasm for its API and recognition of advancements in Europe’s AI landscape.
- Members highlighted a blend of optimism and caution over the competitive landscape, particularly against American firms like OpenAI.
- Improving ChatGPT Prompts: Users shared techniques for enhancing ChatGPT prompts, such as instructing it to 'respond like a friend' for more engaging interaction.
- Resistance to character descriptions noted; specificity in inquiries is recommended for better responses.
OpenRouter (Alex Atallah) Discord
-
MythoMax API Free Launch: OpenRouter launched a free API endpoint for MythoMax 🎁, leveraging TogetherCompute Lite with int4 quantization.
- This MythoMax API can handle 10B tokens per week, marking a significant upgrade since its inception in August 2023.
- NotebookLM Podcast Buzz: A user praised the NotebookLM Deep Dive podcast and is creating notebooks for easy, mobile access to paper summaries.
- The conversation shifted towards automation, highlighting new tools like ai-podcast-maker and groqcasters to enhance podcast management.
- Gemini's Moderation Dilemma: Concerns were raised about Gemini moderating user inputs and the potential for bans due to behavior.
- It was clarified that Gemini has stringent filters, but OpenRouter does not enforce bans, inciting deeper discussions about moderation flags.
- Claude Model Error Discussions: Users encountered Claude 3.5 returning 404 errors, fueling speculation over their cause and solutions.
- The prevailing theory suggests these might be due to rate limits linked to server overload, affecting some users while others succeeded with requests.
- Grok Model Integration Hopes: Discussion around the potential integration of the Grok model surfaced, with enthusiasm for upcoming meetings.
- Members urged others to support a Grok integration thread to signal demand for resource expansion in their toolkit.
HuggingFace Discord
-
TTS Spaces Arena Launches with New Features: TTS Spaces Arena has been created, allowing users to explore TTS capabilities with exciting new features driven by enthusiastic developers.
- The project enhances user interaction and showcases advancements in text-to-speech technologies.
- Llama 3.1 Outperforms in Benchmarking: The benchmarking results for Llama 3.1 405B on 8x AMD MI300X GPUs reveal impressive performance metrics, significantly outperforming vLLM.
- Facilitated by Hot Aisle, the benchmarking emphasizes the drive towards high-efficiency models in complex tasks.
- FluxBooru 12B Brings Innovative Demo: The FluxBooru 12B demo showcases cutting-edge advancements in generative modeling, adding depth to AI-generated visual content.
- This initiative fuels ongoing discussions about enhancing visual content generation capabilities through novel AI applications.
- Whisper Fine-Tuning Achieves Significant Accuracy: Fine-tuning efforts on Whisper have led to an 84% improvement in transcription accuracy, particularly benefitting air traffic control applications.
- This breakthrough highlights Whisper's potential to tackle challenges in automatic transcription effectively.
- Access to 7 Million Wikipedia Images for Developers: A dataset of 7 million Wikipedia images is now available for free use, paving the way for diverse visual resources accessible to researchers and developers.
- This initiative greatly enhances resource availability without restrictions for AI projects.
GPU MODE Discord
-
TMA Interface Refactoring in Progress: The team is actively refactoring the TMA interface, which is expected to lead to enhancements and optimizations.
- Members encouraged keeping an eye out for updates, indicating that improvements are on the horizon.
- GEMM Implementation Performance Issues: An open issue on GitHub discusses performance overheads related to the GEMM implementation and TMA descriptors, reportedly consuming up to 80% of processing time.
- Members suggested pre-initializing descriptors on the host as a workaround, although this approach adds complexity and is incompatible with torch.compile.
- torch.compile Faces Adaptation Challenges: Issues reported with
torch.compileon Windows include compatibility problems with dynamic tensor subclasses, leading toTorchRuntimeError.
- These challenges are affecting model exports, and there are calls for resolving these compatibility issues to enhance usability.
- int8 Quantization Performance Concerns: Testing revealed that using int8 quantization results in slower operations at 6.68 seconds per iteration, even when applying
torchao.
- Despite successful quantization, the ongoing performance issues linked to compilation persist and remain unaddressed.
- Llama 3.1 Benchmark Results on AMD GPUs: A benchmark on the inference performance of Llama 3.1 405B using 8x AMD MI300X GPUs was conducted, with supportive details available in the benchmark article.
- The benchmark emphasized real-time versus batch inference use cases, supported by Hot Aisle's bare metal machine.
Eleuther Discord
-
Crypto Professionals Flee to AI: A significant number of individuals are transitioning from crypto to AI, especially following the collapse of FTX and the emergence of ChatGPT.
- This shift reflects a broader trend where tech experts seek societal impact in their work.
- Exploring the Web5 Concept: A member is investigating a new networking paradigm called Web5, which currently lacks comprehensive information online.
- Jokingly, members suggested that the nomenclature might continue to escalate, humorously hinting at a future Web8.
- Best Practices for Paper Writing: Advice was shared on structuring research papers effectively, focusing on clarity in sections like the abstract and results.
- The community was encouraged to check out this video resource for further insights.
- Recruiters Show Interest in Tech: Members reported an influx of recruiter messages related to tech roles, particularly highlighting opportunities in crypto startups.
- Concerns were expressed over lower responses for ML roles, with many recruiters focused on enterprise and finance positions.
- LUMI's Performance Queries: Inquiries arose regarding the performance benchmarks for neox on LUMI, especially concerning tests conducted by EAI.
- Members showed interest in sharing insights to compile necessary data on LUMI's capabilities.
Perplexity AI Discord
-
Perplexity's Responses Take a Hit: Users expressed frustration with Perplexity's response quality, reporting that outputs are now more 'condensed' and less informative than before. Concerns arose that token limits may have contributed to this reduction in depth.
- One user lamented, 'I used to run the same query with a variable input for months and get high-quality responses. Now, it's just a one-paragraph response.'
- AI Struggles with Video Generation: Discussions centered on the feasibility of AI generating coherent videos, with some participants indicating that full automation remains out of reach. One noted, 'I don't feel that AI is quite currently capable of generating an entire video automatically.'
- Participants acknowledged the evolving technology but remained skeptical of its current limitations.
- Financial Health of Perplexity Under Scrutiny: Multiple users raised concerns about Perplexity's financial sustainability amidst ongoing expenses related to servers and staff. One user humorously reflected, 'my bank account is at -$9,' which sparked discussions about financial pressures.
- This highlights a broader worry regarding the long-term viability of their services.
- Investigation into Fraud Detection Tools: A member shared insights on various techniques for fraud detection, pointing to a resource that discusses current methodologies for improved accuracy in AI applications. The shared link offers a comprehensive view on evolving fraud prevention strategies.
- This could play a crucial role in developing robust AI systems capable of better decision-making under uncertainty.
- Exa vs. Perplexity AI Showdown: Members engaged in a comparative discussion between Exa and Perplexity AI, focusing on their respective search query efficiency. Considerations included better documentation for Exa, alongside reports of superior results from Perplexity.
- This debate suggests varying use cases for both systems, drawing attention to the need for adequate documentation to facilitate user experience.
aider (Paul Gauthier) Discord
-
SambaNova Meets Aider: Members discussed integrating SambaNova models with Aider, noting that models can be manually added if the API is OpenAI-compatible. A successful addition of
/model sambanova/Meta-Llama-3.1-405B-Instructraised questions about costs, highlighting a lack of pricing transparency.- 'Only 3 reflections allowed, stopping,' becomes a common snag when Aider's updates are half-applied, prompting users to retry or manually code. This issue stems from limitations in Aider's ability to handle complex changes effectively.
- Deno 2 Streamlines Development: Deno 2 has arrived, aiming to simplify web development and ensure compatibility with Node.js and npm ecosystems. Developers can expect a zero-config setup and an all-in-one toolchain enhancing both JavaScript and TypeScript development.
- The enhanced Jupyter support allows users to utilize JavaScript/TypeScript instead of Python, further allowing image, graph, and HTML outputs via
deno jupytercommands. - Palmyra X 004 Enhances Workflows: The newly released Palmyra X 004 model promises potential improvements in enterprise workflows. Users are especially interested in its functionalities for automating tasks and effective data integration within external systems.
- Ryan Dahl showcased new notebook support in Deno 2, emphasizing the installation of the Jupyter kernel with
deno jupyter --install, marking a significant upgrade for Deno users. - Function Calling Woes in Smaller Models: Challenges arise when using smaller models for function calling in AI, as discussions compare their capabilities to Claude. It seems these models are less trained for generating XML outputs, creating hurdles.
- Development discussions referenced release notes addressing these limitations, leading to community efforts in sharing resources to enhance model capabilities.
Nous Research AI Discord
-
GAIR-NLP's O1 Replication Journey: The O1 Replication Journey report details GAIR-NLP's efforts to replicate OpenAI's O1 model, achieving an 8% improvement in performance with just 327 training samples using a novel journey learning paradigm.
- This transparent approach documents both successes and challenges, fostering community engagement in model replication efforts.
- Pyramid Flow Sets the Stage for Video Generation: The Pyramid Flow repository introduces an Autoregressive Video Generation method via Flow Matching, capable of generating high-quality 10-second videos at 768p resolution and 24 FPS.
- Anticipated features include a technical report and new model checkpoints, signaling progress in video synthesis techniques.
- Model Merging Strategies Show Promise: A study investigates the interaction between model size and model merging methods such as Task Arithmetic, indicating that merging boosts generalization capabilities with stronger base models.
- Findings suggest that merging expert models enhances performance, providing insights into effective merging techniques.
- RNNs Face Challenges with Long Contexts: Research highlights limitations of recurrent neural networks (RNNs) in processing long contexts, including state collapse and memory issues, examined in the paper Stuffed Mamba.
- Proposed strategies aim to bolster RNN effectiveness for long sequences, challenging the dependence on transformer models for extended context handling.
- Chain-of-Thought Reasoning Revolutionized: Recent findings on Chain-of-Thought reasoning suggest that it can emerge from methodological changes in the decoding process of LLMs, improving reasoning capabilities without prompt reliance as detailed in the paper Chain-of-Thought Reasoning Without Prompting.
- The research highlights that CoT paths correlate with higher response confidence, reshaping our understanding of intrinsic reasoning in LLMs.
Cohere Discord
-
Nobel Prize Clamor: Mixed Reactions: The Royal Swedish Academy of Sciences faced buzz over rumors of awarding the 2024 Nobel Prize in Literature to the authors of Attention Is All You Need, stirring excitement on Twitter. Despite the buzz, skepticism emerged regarding the authenticity of these claims.
- Eventually, participants highlighted a confirmation from The Guardian that the prize was actually awarded to South Korean author Han Kang, debunking the earlier rumors.
- Google Drive Connectivity Woes: Connection issues with Google Drive have been on the rise, as reported by a member experiencing problems with both enterprise and personal accounts. Suggestions were made that the troubles might stem from Google's end, urging users to contact support.
- The community discussed the significance of reliable connections for productivity, underscoring the challenges faced during such outages.
- AI Confronts Emotional Challenges: Developers are tackling the complexities of creating an AI capable of understanding emotional context, working under restrictive censorship policies that impact training data. This effort aims to enhance the therapeutic experience for professionals lacking direct interaction with patients.
- Emerging techniques include assigning an emotional score to inputs, striving for more genuine AI responses while acknowledging issues stemming from user reluctance to engage meaningfully with AI interfaces.
- Companionship AI: A Two-Edged Sword: The dialogue explored AI's potential in offering companionship for aging populations, addressing workforce shortages, yet raising important ethical concerns about the anthropomorphic characteristics of such technologies. Balancing research direction encompasses these ethical implications.
- The quest for support in navigating these ethical waters remains a critical topic as members advocate for responsible AI development.
- Independent Research on Personal AI Projects: A member clarified their ongoing personal AI projects as independent from any university affiliation, showcasing an often unrecognized landscape of research. This revelation sparked a discussion on how external support structures could enhance innovation in personal endeavors.
- The conversation highlighted the need for a collaborative academic environment to foster more engagement in the field of AI.
Interconnects (Nathan Lambert) Discord
-
LMSYS transitions to a company: Members discussed the exciting news that LMSYS is becoming a company, noting the shift in focus from academic incentives to potential financial gains.
- One member preferred non-profit status, adding that for profit is more predictable.
- Aria - Multimodal MoE shakes things up: The launch of Aria - Multimodal MoE was announced, boasting impressive features with 3.9B active parameters and the ability to caption 256 frames in 10 seconds.
- Members highlighted Aria's superior performance over models like Pixtral 12B and Llama Vision 11B.
- Debate on o1 Reasoning Trees: Concerns arose regarding the functionality of o1 without intermediate scoring from a PRM, suggesting that tree pruning could enhance performance.
- A member expressed confusion about the implementation details, indicating a need for clarification.
- ButtBench Alignment Project showcases new logo: Exciting developments unfold as the ButtBench Alignment Project debuts an official logo, despite still being far from achieving human performance.
- Luca Soldaini remarked, 'we are still far from human performance,' reinforcing the challenges faced by the project.
- Setting Up Systems Seems Simple: One member indicated that setting up the system wouldn't be too hard, yet they expressed uncertainty about some complexities involved.
- This implies that while the process seems straightforward, there are intricacies that could arise during implementation.
Stability.ai (Stable Diffusion) Discord
-
Deforum Alternatives Explored: Members discussed finding free alternatives to Deforum after its ban from Google Colab, with suggestions including renting GPUs from RunPod, priced around $0.3/hour.
- The cost considerations raised important questions about the viability of using external GPU services for model experimentation.
- CogVideoX Shines for Video Tasks: CogVideoX has emerged as the best open-source model for video generation, installable via Comfy UI or Diffusers, catering to demand for animation tools.
- This model showcases robust capabilities in handling various video generation tasks, highlighting the community's shift towards open-source solutions.
- Navigating Flux Model Use: A user requested help setting up grid generation with the Flux checkpoint, clarifying they are working within the development version of Flux.
- The inquiry indicates a growing interest in utilizing advanced features of the Flux model, particularly regarding integration with Loras.
- AI Product Recreation Challenges: Members shared insights on recreating product images with AI, specifically using tools to blend generated products into backgrounds without traditional compositing methods, referencing a workflow for a background swapper.
- This approach emphasizes AI's capabilities in creative tasks, sparking enthusiasm for automation in product design.
- Optimizing KJNodes in Comfy UI: A member engaged in using KJNodes within Comfy UI for grid generation, recommending specific nodes for label addition and text generation automation.
- This insight reflects users' continuous exploration of Comfy UI functionalities to streamline workflows, enhancing productivity in image processing.
Modular (Mojo 🔥) Discord
-
Rust's Provenance APIs Validated: Discussion centered around Rust's Provenance APIs, exploring how they could potentially 'legalize'
int -> ptrcasts crucial for the io_uring API, enhancing buffer management capabilities.- Participants suggested a compiler builtin for pointer tracking to streamline operations and enable optimizations.
- Efficient Event Handling with io_uring: The io_uring API facilitates pointer management for event completions using the
user_datafield, which can hold an index or pointer to a coroutine context, enhancing state handling.
- This design allows for effective management of stack-allocated coroutines, a notable engineering decision in modern architecture.
- Addressing in Modern Servers Stands Limited: The limits of 48 and 57-bit addressing in current computing were discussed, noting vast memory spaces are theoretically supported, but real-world applications often encounter constraints.
- CXL-based storage servers were highlighted, reflecting on challenges with 'sparse' memory usage in future disaggregated architectures.
- Historical Issues with Coherent Memory Interconnects: A deep dive revealed the historical challenges faced by coherent memory interconnects, where intense pressure on cache coherence algorithms resulted in reduced utilization.
- While alternatives like IBM’s interconnects exist, practical limits on node connectivity hinder broader implementation.
- Relevance of Distributed Shared Memory: The ongoing importance of distributed shared memory (DSM) was emphasized, allowing separate memories to function under a unified address space despite its complexities.
- IBM's strategies highlighted the critical need for proximity between compute nodes to enhance performance metrics.
LM Studio Discord
-
LMX outperforms Ollama: With identical settings, LMX in LM Studio is recorded to be an average of 40% faster than Ollama in q4 models.
- This performance gap surprised members, who expected only slight improvements from the new integration.
- Configuration Steps for GPU Acceleration: A member detailed the steps for configuring CUDA/Vulkan/ROCM to optimize GPU acceleration based on GPU type.
- Users shared adjustments needed to enhance performance through setting changes.
- Support for Llama 3.2 Model: Llama 3.2 models with vision capabilities like 11b or 90b necessitate running in vllm or transformers with a minimum of 24GB of VRAM.
- Currently, there's no support from llama.cpp or MLX for these larger models.
- NVIDIA RTX 4000 Series Drops NVLink Support: The new NVIDIA RTX 4000 series eliminates NVLink support, shifting to use PCIe Gen 5 for enhanced multi-GPU setups.
- This upgrade emphasizes operating at higher speeds without interconnect limitations, inciting discussions about performance benefits.
- AVX2 Requirement for Model Running: To efficiently run models, an AVX2 compatible CPU is mandatory, but this feature's availability in VMs raises questions.
- Users suggested verifying AVX2 activation in an Ubuntu VM through CPUID or similar tools.
OpenAccess AI Collective (axolotl) Discord
-
Hugging Face Token Usage Simplified: To use a Hugging Face authentication token, set the
HUGGINGFACE_HUB_TOKENenvironment variable in your scripts or log in via the Hugging Face CLI to save the token securely.- This method prevents embedding sensitive information directly into scripts, improving security and ease of use.
- Tweaks for Axolotl Config File: Members reported issues with the Axolotl config file, noting it contains unusual fields and hardcoded tokens that should be avoided.
- Recommendations include using environment variables for sensitive data and eliminating any unnecessary fields to streamline configurations.
- Multi-GPU Setup with Axolotl: To leverage multiple GPUs with Axolotl, configure the
acceleratelibrary for distributed training, adjusting the number of processes to match available GPUs.
- Fine-tuning settings via environment variables, such as
CUDA_VISIBLE_DEVICES, can enhance control over GPU allocation. - Significance of GPU Rental Queries: A member inquired about hosts offering 10xA100 or 10xH100 nodes for rent, highlighting the acute demand for high-performance GPU resources.
- They raised concerns over the feasibility of 10x configurations, questioning CPU support for that many PCI x16 lanes.
- Login to Hugging Face from Jupyter: The
notebook_loginfunction from thehuggingface_hublibrary simplifies using a Hugging Face token securely in Jupyter Notebooks.
- Alternatively, setting the token as an environment variable presents security risks if the notebook is broadly shared.
LlamaIndex Discord
-
LlamaIndex Voice Agent Empowers Interaction: Watch a demo where an AI agent converses via voice through LlamaIndex and the OpenAI realtime API client, showcasing powerful interactive capabilities.
- This project is open source, allowing the community to create their own voice agents.
- Argilla Enhances Dataset Quality: The introduction of Argilla, a tool for generating and annotating datasets, now supports fine-tuning, RLHF, and integrates seamlessly with LlamaIndex.
- Check the demo notebook here to see how it helps improve data quality.
- AWS Bedrock Faces API Maintenance Issues: AWS Bedrock users reported maintenance complications due to API changes from the provider, which complicates data handling in LlamaIndex.
- There's a strong community push for a unified API to ease integration workflows.
- Clarification Needed on Qdrant Node Usage: A member posed questions about storing JSON data in a Qdrant Database, revealing misunderstandings between nodes and documents during ingestion.
- The community clarified that nodes and documents are largely semantic and interchangeable, allowing custom nodes from JSON.
- Hugging Face Inference API Accessibility Confirmed: Discussion confirmed that LlamaIndex supports accessing Hugging Face model inference endpoints via both inference API and endpoint models.
- Helpful documentation links were shared to aid users in implementation.
Latent Space Discord
-
Sierra hits a $4B valuation: Bret Taylor's AI startup Sierra has garnered a staggering valuation of $4 billion following a new deal highlighted by massive revenue multiples.
- This valuation has sparked conversations about the advantages of having reputed leaders like Taylor at the helm, as shared in a tweet.
- UGround Enables Human-like Agents: Introducing UGround, a universal grounding model that allows agents to perceive the digital world through visual perception only, providing SOTA performance across six benchmarks.
- This approach simplifies the creation of multimodal agents, eliminating the need for cumbersome text-based observations, as discussed in a detailed explanation.
- State of AI Report 2024 Released: The highly anticipated State of AI Report 2024 is now available, featuring a comprehensive overview of research, industry, safety, and politics in AI.
- Nathan Benaich's tweet highlights the director's cut and an accompanying video tutorial for further insights.
- AMD Launches New AI Chip: AMD unveiled the Instinct MI325X AI chip, positioning it directly against Nvidia's offerings by starting production by the end of 2024.
- The launch aims to challenge Nvidia's 75% gross margins in a rapidly growing market demanding advanced AI processing capabilities, covered in a CNBC article.
- Writer.com Develops Competitive AI Model: AI startup Writer has launched a new model aimed to compete with offerings from OpenAI and others, notable for its low training cost of about $700,000.
- Writer is currently raising up to $200 million at a valuation of $1.9 billion, reflecting significant investor interest as reported by CNBC.
LLM Agents (Berkeley MOOC) Discord
-
Hackathon Focus Stirs Excitement: Members discussed that ninja and legendary tier students should prioritize hackathon submissions, enhancing overall quality and focus.
- This decision aims to maximize impact and engagement during the submissions period.
- Lab 1 Download Problems Surface: Reports indicate issues with downloading Lab 1 from the email link, often resulting in empty files for users.
- Members suggested switching to the course website link for better reliability.
- RAG Framework Recommendations Requested: A member sought advice on the easiest RAG framework to work with, showing interest in integration ease and feature satisfaction.
- This inquiry indicates an appetite for optimizing coding workflows within projects.
- Web Browser Agents Bring Buzz: The conversation explored experiences with web browser agents, highlighting Web Voyager as a particularly promising tool.
- This reflects an interest in enhancing agent functionality within browsers.
- Brainstorming Channel Gains Traction: Members initiated a brainstorming session in <#1293323662300155934>, agreeing to use the channel for collaborative idea generation.
- The consensus emphasizes a commitment to fostering collaboration and creative discussions.
Torchtune Discord
-
Small Models Signal Potential Issues: A member raised concerns over the reliability of ideas from small models, suggesting those results may not significantly shape future concepts.
- They noted that while these papers serve as the seed stage, their actual influence remains questionable.
- Mixed Optimizations Under Scrutiny: The discussion questioned the real-world impact of mixed optimizations alongside successful small models, hinting at potential limitations.
- Members implied even effective methods might show minimal differences in practice.
- SOAP Outshines AdamW but Faces Real-World Issues: The SOAP optimizer outperformed AdamW in running on Alpaca, but encountered challenges with distributed contexts and bf16.
- One member noted that tuning AdamW's learning rate was necessary to navigate its complexities.
- Preconditioning Poses Implementation Challenges: Preconditioning optimizers demand careful management of weight and gradient matrices, complicating distributed setups.
- A member pointed to the Facebook research repository for insights on these issues.
- Entropix Gains Momentum with Unique Approach: The Entropix method, which avoids token output with high entropy logits, surged to 2k stars within a week.
- A member shared a project update, highlighting its effective token prediction strategy.
OpenInterpreter Discord
-
OS Mode Perfected for MacOS Performance: The OS mode appears to significantly enhance performance specifically for MacOS, with tools optimized for this platform.
- mikebirdtech emphasized that this will lead to a much better user experience on Mac.
- AI Agent Rocks the Terminal: A shared GitHub repo showcases an AI agent that harnesses local tools and vision capabilities directly in the terminal.
- It can run shell commands and execute code, proving valuable for tertiary development tasks.
- Calypso Makes Waves with Voice Features: Excitement surged for Calypso, an autonomous AI streamer project that features a refined voice capability, leaving users thrilled.
- Designed to integrate three AI models, it aims to deliver a lifelike performance that's hard to match.
- ElevenLabs Creator Plan Pricing Revealed: An analysis revealed that the ElevenLabs Creator Plan provides 100k credits monthly, costing around $0.18 per minute of audio.
- This structure translates to approximately 2 hours of audio production monthly, making it clear for audio service users.
LAION Discord
-
Vision-Language Intelligence Takes Shape: A recent paper titled A Spark of Vision-Language Intelligence proposes an autoregressive transformer aimed at efficient fine-grained image generation.
- This approach indicates a promising trend in merging vision and language capabilities in AI.
- Connections to Visual Autoregressive Models: Discussion highlighted parallels to Visual Autoregressive Modeling, which focuses on scalable image generation via next-scale prediction.
- References were made to Apple's Matryoshka Diffusion Models, showcasing similar innovations.
- Shift Towards Coarse-to-Fine Techniques: A member remarked that the effective autoregression direction for images should be coarse to fine instead of the conventional 'top-left to bottom-right'.
- This insight emphasizes generating images in a more structured manner.
- Innovative Autoencoder Concept with Gradiated Dropout: A novel idea proposed involves training an image-to-vector-to-image autoencoder using 'gradiated dropout' on the latent vector.
- In this method, dropout probability increases progressively across elements, fostering friendly latents for progressive decoding.
DSPy Discord
-
Excitement for the DOTS Algorithm: A member expressed enthusiasm for the DOTS paper, emphasizing its dynamic reasoning approach over static methodologies, with plans to implement DOTS through the DSPy framework.
- The implementation will utilize Signatures for atomic actions and integrate custom modules to enhance dynamic decision-making capabilities.
- DOTS 24 Game Implementation: A DOTS 24 game script was shared, coupled with a reference to the DOTS paper, showcasing the innovative aspects of reasoning for large language models.
- The paper details enhancing LLM capabilities using tailored dynamic reasoning trajectories instead of static reasoning actions, marking a significant shift.
- YouTube Resource on DOTS: A member linked a YouTube video that provides additional insights into the DOTS algorithm discussion.
- This resource may help understand the implementation and broader implications of the DOTS algorithm within the LLM community.
LangChain AI Discord
-
AI Chat Assistant Takes on Piñata Challenge: A user showcased their AI Chat Assistant project as part of the Piñata Challenge, aiming to motivate fellow developers.
- They encouraged community members to like the post if it resonates with them, fostering a culture of active engagement and feedback.
- Engagement through Likes Boosts Community: The call to action for users is to like the post if it resonates with them, creating a feedback loop for helpful content.
- This approach encourages active participation and appreciation among developers in the community.
tinygrad (George Hotz) Discord
-
Inquiry on Hugging Face Diffusers: A user asked if anyone in the channel had experience using
diffusersfrom Hugging Face, prompting a discussion around its capabilities and applications.- This inquiry highlights the growing interest in generative models and practical tools that facilitate their implementation, central to many AI engineering projects.
- Interest in Techniques for Diffusion Models: The mention of
diffuserssuggests a rising curiosity about state-of-the-art techniques, particularly in image generation and text-to-image art, related to these models.
- Participants might soon share their experiences with various parameters and dataset configurations for experimenting with Hugging Face's offerings.
Mozilla AI Discord
-
Llama 3.2 hits Hugging Face: Llama 3.2, available in both 1B and 3B versions, is now released on Hugging Face to enhance developer resources.
- This release focuses on improving accessibility and offering users a broader toolkit for leveraging Llama models.
- Mozilla Accelerator funds 14 projects: Mozilla's new accelerator program announced funding for 14 innovative projects, each capable of receiving up to $100,000 to support open-source AI work.
- The projects range from drug discovery initiatives to a Swahili LLM, aiming to spotlight community-driven innovations.
- Lumigator MVP brings clarity to model selection: Mozilla.ai launched the Lumigator MVP, designed to streamline and clarify the model selection process for developers.
- By offering task-specific metrics, Lumigator helps users identify not just any model, but the most suitable one for their specific project needs.
Gorilla LLM (Berkeley Function Calling) Discord
-
BFCL-V3 Enhances Handling of Missing Fields: BFCL-V3 is focusing on improving model responses to missing fields in multi-round conversations to create a more coherent dialogue experience.
- Members are looking forward to Gorilla LLM optimizing this functionality, which promises to refine interaction quality.
- Excitement for Upcoming Gorilla Features: Discussion highlighted members' enthusiasm for upcoming features in Gorilla LLM, particularly within the context of handling conversational complexities.
- There’s a buzz about how these enhancements might influence user interactions, indicating a shift towards more robust conversational AI.
AI21 Labs (Jamba) Discord
-
CUDA Error in AI21-Jamba-1.5-Mini: A user encounters a CUDA initialization error: Cannot re-initialize CUDA in forked subprocess while working with the Hugging Face model AI21-Jamba-1.5-Mini under Docker on Ubuntu with CUDA 12.4.
- The user's setup leverages
torch.multiprocessingutilizing the 'spawn' method, raising concerns on how to resolve the issue specific to their Docker environment. - Request for CUDA Error Solutions: The user seeks guidance on rectifying the CUDA error during the model's execution, highlighting the significance of their Docker and torch.multiprocessing configuration.
- They are looking for targeted solutions that accommodate their specific technical setup.
- The user's setup leverages
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!