[AINews] 1 TRILLION token context, real time, on device?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
SSMs are all you need.
AI News for 5/28/2024-5/29/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (389 channels, and 5432 messages) for you. Estimated reading time saved (at 200wpm): 553 minutes.
Our prior candidates for today's headline story:
- Happy 4th birthday to GPT3!
- Hello Codestral. Weights released under a Mistral noncommercial license, and with decent evals, 80 languages but scant further details.
- Schedule Free optimizers are here! We reported on these 2 months ago and the paper is now released - jury is weighing in but things look good so far - this could be a gamechanging paper in learning rate optimization if it scales.
- Scale AI launches their own elo-style Eval Leaderboards, with Private, Continuously Updated, Domain Expert Evals on Coding, Math, Instruction Following, and Multilinguality (Spanish), following their similar work on GSM1k.
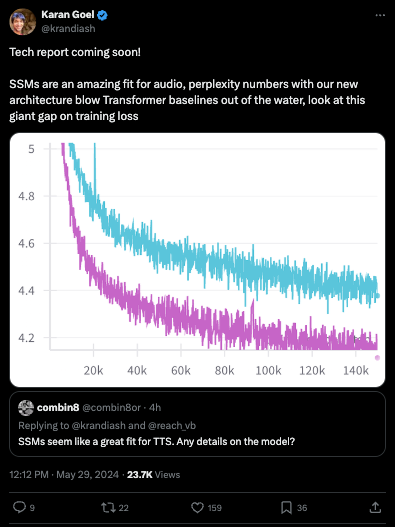
But today we give the W to Cartesia, the State Space Models startup founded by the other Mamba coauthor who launched their rumored low latency voice model today, handily beating its Transformer equivalent (20% lower perplexity, 2x lower word error, 1 point higher NISQA quality):
evidenced by a yawning gap in loss charts:
This is the most recent in a growing crop of usable state space models, and the launch post discusses the vision unlocked by extremely efficient realtime models:
Not even the best models can continuously process and reason over a year-long stream of audio, video and text: 1B text tokens, 10B audio tokens and 1T video tokens —let alone do this on-device. Shouldn't everyone have access to cheap intelligence that doesn't require marshaling a data center?
as well as a preview of what super fast on-device TTS looks like.
It is highly encouraging to see usable SSMs in the wild now, feasibly challenging SOTA (we haven't yet seen any comparisons with ElevenLabs et al, but spot checks on the Cartesia Playground were very convincing to our ears as experienced ElevenLabs users).
But comparing SSMs with current SOTA misses the sheer ambition of what is mentioned in the quoted text above: what would you do differently if you KNEW that we may soon have models can that continuously process and reason over text/audio/video with a TRILLION token "context window"? On device?
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Perplexity AI Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- LLM Finetuning (Hamel + Dan) Discord
- CUDA MODE Discord
- Nous Research AI Discord
- LM Studio Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- OpenAI Discord
- Interconnects (Nathan Lambert) Discord
- Stability.ai (Stable Diffusion) Discord
- LlamaIndex Discord
- Latent Space Discord
- OpenRouter (Alex Atallah) Discord
- LAION Discord
- LangChain AI Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- DiscoResearch Discord
- Mozilla AI Discord
- Datasette - LLM (@SimonW) Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- Perplexity AI ▷ #general (1007 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (3 messages):
- Perplexity AI ▷ #pplx-api (2 messages):
- HuggingFace ▷ #general (951 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #cool-finds (14 messages🔥):
- HuggingFace ▷ #i-made-this (8 messages🔥):
- HuggingFace ▷ #reading-group (9 messages🔥):
- HuggingFace ▷ #computer-vision (18 messages🔥):
- HuggingFace ▷ #NLP (1 messages):
- HuggingFace ▷ #diffusion-discussions (4 messages):
- Unsloth AI (Daniel Han) ▷ #general (656 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #random (3 messages):
- Unsloth AI (Daniel Han) ▷ #help (59 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #general (74 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #asia-tz (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (21 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #learning-resources (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (8 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (15 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #ankurgoyal_textsql_llmevals (53 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (141 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #whitaker_napkin_math (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (199 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #yang_mistral_finetuning (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #gradio (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #axolotl (17 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (25 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (8 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (24 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #credits-questions (46 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #eugeneyan_evaluator_model (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #fireworks (9 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #braintrust (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (7 messages):
- LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (14 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #europe-tz (25 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #announcements (3 messages):
- CUDA MODE ▷ #general (3 messages):
- CUDA MODE ▷ #triton (16 messages🔥):
- CUDA MODE ▷ #torch (19 messages🔥):
- CUDA MODE ▷ #cool-links (1 messages):
- CUDA MODE ▷ #torchao (19 messages🔥):
- CUDA MODE ▷ #off-topic (26 messages🔥):
- CUDA MODE ▷ #llmdotc (215 messages🔥🔥):
- CUDA MODE ▷ #oneapi (1 messages):
- CUDA MODE ▷ #bitnet (94 messages🔥🔥):
- Nous Research AI ▷ #ctx-length-research (2 messages):
- Nous Research AI ▷ #off-topic (12 messages🔥):
- Nous Research AI ▷ #interesting-links (9 messages🔥):
- Nous Research AI ▷ #general (256 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (16 messages🔥):
- Nous Research AI ▷ #rag-dataset (15 messages🔥):
- Nous Research AI ▷ #world-sim (6 messages):
- LM Studio ▷ #💬-general (62 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (19 messages🔥):
- LM Studio ▷ #📝-prompts-discussion-chat (5 messages):
- LM Studio ▷ #⚙-configs-discussion (3 messages):
- LM Studio ▷ #🎛-hardware-discussion (92 messages🔥🔥):
- LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- LM Studio ▷ #amd-rocm-tech-preview (9 messages🔥):
- LM Studio ▷ #model-announcements (1 messages):
- Modular (Mojo 🔥) ▷ #general (75 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
- Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- Modular (Mojo 🔥) ▷ #🔥mojo (35 messages🔥):
- Modular (Mojo 🔥) ▷ #performance-and-benchmarks (7 messages):
- Modular (Mojo 🔥) ▷ #nightly (53 messages🔥):
- Eleuther ▷ #general (24 messages🔥):
- Eleuther ▷ #research (43 messages🔥):
- Eleuther ▷ #scaling-laws (90 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (9 messages🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (100 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (30 messages🔥):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- Interconnects (Nathan Lambert) ▷ #news (60 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (30 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (4 messages):
- Interconnects (Nathan Lambert) ▷ #memes (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (7 messages):
- Interconnects (Nathan Lambert) ▷ #retort-podcast (5 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (117 messages🔥🔥):
- LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex ▷ #blog (5 messages):
- LlamaIndex ▷ #general (107 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (72 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Latent Space ▷ #llm-paper-club-west (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (51 messages🔥):
- LAION ▷ #general (23 messages🔥):
- LAION ▷ #research (17 messages🔥):
- LangChain AI ▷ #general (26 messages🔥):
- LangChain AI ▷ #langserve (1 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- OpenInterpreter ▷ #general (18 messages🔥):
- OpenInterpreter ▷ #O1 (3 messages):
- OpenInterpreter ▷ #ai-content (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (9 messages🔥):
- Cohere ▷ #general (6 messages):
- tinygrad (George Hotz) ▷ #general (4 messages):
- DiscoResearch ▷ #general (4 messages):
- Mozilla AI ▷ #llamafile (3 messages):
- Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
- Perplexity AI Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- LLM Finetuning (Hamel + Dan) Discord
- CUDA MODE Discord
- Nous Research AI Discord
- LM Studio Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- OpenAI Discord
- Interconnects (Nathan Lambert) Discord
- Stability.ai (Stable Diffusion) Discord
- LlamaIndex Discord
- Latent Space Discord
- OpenRouter (Alex Atallah) Discord
- LAION Discord
- LangChain AI Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- DiscoResearch Discord
- Mozilla AI Discord
- Datasette - LLM (@SimonW) Discord
- MLOps @Chipro Discord
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Yann LeCun and Elon Musk Debate on AI Research and Engineering
- Importance of publishing research: @ylecun argued that for research to qualify as science, it must be published with sufficient details to be reproducible, emphasizing the importance of peer review and sharing scientific information for technological progress.
- Engineering feats based on published science: Some argued that Elon Musk and companies like SpaceX are advancing technology through engineering without always publishing papers. @ylecun countered that these engineering feats are largely based on published scientific breakthroughs.
- Distinctions between science and engineering: The discussion sparked a debate on the differences and complementary nature of science and engineering. @ylecun clarified the distinctions in topics, methodologies, publications, and impact between the two fields.
Advancements in Large Language Models (LLMs) and AI Capabilities
- Strong performance of Gemini 1.5 models: @lmsysorg reported that Gemini 1.5 Pro/Advanced rank #2 on their leaderboard, nearly reaching GPT-4, while Gemini 1.5 Flash ranks #9, outperforming Llama-3-70b and GPT-4-0125.
- Release of Codestral-22B code model: @GuillaumeLample announced the release of Codestral-22B, trained on 80+ programming languages, outperforming previous code models and available via API.
- Veo model for video generation from images: @GoogleDeepMind introduced Veo, which can create video clips from a single reference image while following text prompt instructions.
- SEAL Leaderboards for frontier model evaluation: @alexandr_wang launched private expert evaluations of frontier models, focusing on non-exploitable and continuously updated benchmarks.
- Scaling insights 4 years after GPT-3: @alexandr_wang reflected on progress since the GPT-3 paper, noting that the next 4 years will be about exponentially scaling compute and data, representing some of the largest infrastructure projects of our time.
Research Papers and Techniques
- Schedule-Free averaging for training Transformers: @aaron_defazio and collaborators published a paper introducing Schedule-Free averaging for training Transformers, showing strong results compared to standard learning rate schedules.
- VeLoRA for memory-efficient LLM training: A new paper proposed VeLoRA, a memory-efficient algorithm for fine-tuning and pre-training LLMs using rank-1 sub-token projections. (https://twitter.com/_akhaliq/status/1795651536497864831)
- Performance gap between online and offline alignment algorithms: A Google paper investigated why online RL algorithms for aligning LLMs outperform offline algorithms, concluding that on-policy sampling plays a pivotal role. (https://twitter.com/rohanpaul_ai/status/1795432640050340215)
- Transformers learning arithmetic with special embeddings: @tomgoldsteincs showed that Transformers can learn arithmetic like addition and multiplication by using special positional embeddings.
Memes and Humor
- @svpino joked about the entertainment value of a particular comment thread.
- @Teknium1 humorously suggested that OpenAI's moves this week can only be saved by releasing "waifus".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Model Development
- Gemini 1.5 Pro outperforms most GPT-4 instances: In the LMSYS Chatbot Arena Leaderboard, Gemini 1.5 Pro outcompetes all GPT-4 instances except 4o. This highlights the rapid progress of open-source AI models.
- Abliterated-v3 models released: Uncensored versions of Phi models, including Phi-3-mini-128k and Phi-3-vision-128k, have been made available, expanding access to powerful AI capabilities.
- Llama3 8B Vision Model matches GPT-4: A new multimodal model, Llama3 8B Vision Model, has been released that is on par with GPT4V & GPT4o in visual understanding.
- Gemini Flash and updated Gemini 1.5 Pro added to leaderboard: The LMSYS Chatbot Arena Leaderboard has been updated with Gemini Flash and an improved version of Gemini 1.5 Pro, showcasing ongoing iterations.
AI Safety & Ethics
- Public concern over AI ethics: A poll reveals that more than half of Americans believe AI companies aren't considering ethics sufficiently when developing the technology, and nearly 90% favor government regulations. This underscores growing public unease about responsible AI development.
AI Tools & Applications
- HuggingChat adds tool support: HuggingChat now integrates tools for PDF parsing, image generation, web search, and more, expanding its capabilities as an AI assistant.
- CopilotKit v0.9.0 released: An open-source framework for building in-app AI agents, CopilotKit v0.9.0 supports GPT-4o, native voice, and Gemini integration, enabling easier development of AI-powered applications.
- WebLLM Chat enables in-browser model inference: WebLLM Chat allows running open-source LLMs like Llama, Mistral, Hermes, Gemma, RedPajama, Phi and TinyLlama locally in a web browser, making model access more convenient.
- LMDeploy v0.4.2 supports vision-language models: The latest version of LMDeploy enables 4-bit quantization and deployment of VL models such as llava, internvl, internlm-xcomposer2, qwen-vl, deepseek-vl, minigemini and yi-vl, facilitating efficient multimodal AI development.
AI Hardware
- Running Llama3 70B on modded 2080ti GPUs: By modding 2x2080ti GPUs to 22GB VRAM each, the Llama3 70B model can be run on this setup, demonstrating creative solutions for large model inference.
- 4x GTX Titan X Pascal 12GB setup for Llama3: With 48GB total VRAM from 4 GTX Titan X Pascal 12GB GPUs, Llama3 70B can be run using Q3KM quantization, showing the potential of older hardware.
- SambaNova's Samba-1 Turbo runs Llama-3 8B: SambaNova showcased their Samba-1 Turbo AI hardware running the Llama-3 8B model, highlighting specialized solutions for efficient inference.
AI Drama & Controversy
- Sam Altman's past controversies: It was revealed that Sam Altman was fired from Y Combinator and people at his startup Loopt asked the board to fire him due to his chaotic and deceptive behavior (image), shedding light on the OpenAI CEO's history.
- Yann LeCun and Elon Musk exchange: In a public discussion, Elon Musk had a weak rebuttal to Yann LeCun's scientific record, highlighting tensions between AI pioneers.
Memes & Humor
AI Discord Recap
A summary of Summaries of Summaries
-
LLM Performance and Practical Applications:
- Gemini 1.5 Pro/Advanced models from Google impressed with top leaderboard positions, outperforming models like Llama-3-70b, while Codestral 22B from MistralAI supports 80+ programming languages targeting AI engineers.
- Mistral AI's new Codestral model, an open-weight model under a non-commercial license, encouraged discussions about the balance between open-source accessibility and commercial viability. Codestral, trained in over 80 programming languages, sparked excitement over its potential to streamline coding tasks.
- Launches like the SEAL Leaderboards by Scale AI were noted for setting new standards in AI evaluations, though concerns about evaluator bias due to provider affiliations were raised.
- SWE-agent by Princeton stirred interest for its superior performance and open-source nature, and Llama3-V gathered attention for challenging GPT4-V despite being a smaller model.
- Retrieval-Augmented Generation (RAG) models are evolving with tools like PropertyGraphIndex for constructing rich knowledge graphs, while Iderkity supports translation tasks efficiently.
-
Fine-Tuning, Prompt Engineering, and Model Optimization:
- Engineers discussed Gradient Accumulation and DPO training methods, emphasizing the role of
ref_modelin maintaining consistency during fine-tuning, and tackled quantization libraries for efficient use across different systems.
- Techniques to solve prompt engineering challenges like handling "RateLimit" errors using try/except structures and fine-tuning models for specific domains were shared, underscoring practical solutions (example).
- Members debated the use of transformers versus MLPs, highlighting findings that MLPs may handle certain tasks better, and discussed model-specific issues like context length and optimizer configurations in ongoing fine-tuning efforts.
- Engineers discussed Gradient Accumulation and DPO training methods, emphasizing the role of
-
Open-Source Contributions and AI Community Collaboration:
- OpenAccess AI Collective tackled spam issues, proposed updates for gradient checkpointing in Unsloth, and saw community-led initiatives on fine-tuning LLMs for image and video content comprehension.
- LlamaIndex contributed to open-source by merging into the Neo4j ecosystem, focusing on integrating tools like PropertyGraphIndex for robust knowledge graph solutions.
- Discussions emphasized community efforts around Llama3 model training and collaborative issues submitted on GitHub for libraries like axolotl and torchao indicating ongoing developments and shared problem resolutions.
-
Model Deployment and Infrastructure Issues:
- Engineers grappled with Google Colab disconnections, Docker setup for deployment issues, and the performance benefits of using Triton kernels on NVIDIA A6000 GPUs.
- Lighting AI Studio was recommended for free GPU hours, while discussions on split GPU resources for large model productivity and tackling hardware bottlenecks highlighted user challenges.
- ROC and NVIDIA compatibility setbacks were discussed, with practical suggestions to overcome them, like seeking deals on 7900 XT for expanded VRAM setups to support larger models and transitions from macOS x86 to M1.
-
Challenges, Reactions, and Innovations in AI:
- Helen Toner's revelations on OpenAI’s management sparked debates about transparency, raising concerns about internal politics and ethical AI development (Podcast link).
- Elon Musk's xAI securing $6 billion in funding triggered discussions on the implications for AI competitiveness and infrastructure investment, while community members debated model pricing strategies and their potential impact on long-term investments in technologies.
- Cohere API sparked discussions around effective use for grounded generation and ensuring force-citation display, showing active community engagement in leveraging new models for practical use cases.
PART 1: High level Discord summaries
Perplexity AI Discord
- Web Scraping Wisdom: Discussions highlighted methods for efficient web content extraction, including Python requests, Playwright, and notably, Gemini 1.5 Flash for JavaScript-heavy sites.
- Perplexity API Woes and Wins: Engineers expressed concerns over inconsistency between Perplexity's API responses and its web app's accuracy, pondering different model choices, such as llama-3-sonar-small-32k-online, to potentially boost performance.
- Building a Rival to Rival Perplexity: A detailed project was proposed that mirrors Perplexity's multi-model querying, facing challenges related to scaling and backend development.
- Go with the Flow: Deep-dives into Go programming language showcased its effectiveness, particularly for web scraping applications, emphasizing its scalability and concurrency advantages.
- Advantage Analysis: Users shared Perplexity AI search links covering potentially AI-generated content, a clarification of a query's sensibility, and a comprehensive evaluation of pros and cons.
HuggingFace Discord
- BERT's Token Limit Has Users Seeking Solutions: A user is evaluating methods for handling documents that exceed token limits in models like BERT (512 tokens) and decoder-based models (1,024 tokens). They aim to bypass document slicing and positional embedding tweaks, without resorting to costly new pretraining.
- Diffusers Celebrate with GPT-2 Sentiment Success: The Hugging Face community hails the second anniversary of the Diffusers project, alongside a new FineTuned GPT-2 model for sentiment analysis that achieved a 0.9680 accuracy and F1 score. The model is tailored for Amazon reviews and is available on Hugging Face.
- Reading Group Eager for C4AI's Insights: A new paper reading group is queued up, with eagerness to include presentations from the C4AI community, focusing on debunking misinformation in low-resource languages. The next event is found here.
- Image Processing Queries Guide Users to Resources: Discussions cover the best practices for handling large images with models like YOLO and newer alternatives like convNext and DINOv2. A Github repository for image processing tutorials in Hugging Face was highlighted (Transformers-Tutorials).
- Medical Imaging Seeks AI Assist: Community members exchange thoughts on creating a self-supervised learning framework for analyzing unlabeled MRI and CT scans. The discussion includes leveraging features extracted using pre-trained models for class-specific segmentation tasks.
Unsloth AI (Daniel Han) Discord
- Lightning Strikes with L4: Users recommended Lightning AI Studio due to its "20-ish monthly free hours" and enhanced performance with L4 over Colab's T4 GPUs. A potential collaboration with Lightning AI to benefit the community was proposed.
- Performance Puzzles with Phi3 and Llama3: Discussions revealed mixed reactions to the Phi3 models, with
phi-3-mediumconsidered less impressive than llama3-8b by some. A user highlighted Phi3's inferior performance beyond 2048 tokens context length compared to Llama3.
- Stirring Model Deployment Conversations: The community exchanged ideas on utilizing Runpods and Docker for deploying models, with some members encountering issues with service providers. While no specific Dockerfiles were provided, a server search for them was recommended.
- Colab Premia Not Meeting Expectations: Google Colab's Premium service faced criticism due to continued disconnection issues. Members proposed moving to other platforms like Kaggle and Lightning AI as viable free alternatives.
- Unsloth Gets Hands-On In Local Development: Embarking on supervised fine-tuning with Unsloth, users discussed running models locally, particularly in VSCode for tasks like resume point generation. Links to Colab notebooks and GitHub resources for unsupervised finetuning with Unsloth were shared, such as this finetuning guide and a Colab example.
LLM Finetuning (Hamel + Dan) Discord
Fine-Tuning Frustrations and Marketplace Musings: Engineers discussed fine-tuning challenges, with concerns over Google's Gemini 1.5 API price hike and difficulties serving fine-tuned models in production. A channel dedicated to LLM-related job opportunities was proposed, and the need for robust JSON/Parquet file handling tools was highlighted.
Ins and Outs of Technical Workshops: Participants exchanged insights on LLM fine-tuning strategies, with emphasis on personalized sales emails and legal document summarization. The practicality of multi-agent LLM collaboration and the optimization of prompts for Stable Diffusion were debated.
Exploring the AI Ecosystem: The community delved into a variety of AI topics, revealing Braintrust as a handy tool for evaluating non-deterministic systems and the O'Reilly Radar insights on the complexities of building with LLMs. Discussions also highlighted the potential of Autoevals for SQL query evaluations.
Toolshed for LLM Work: Engineers tackled practical issues like Modal's opaque failures and Axolotl preprocessing GPU support problems. Queries around using shared storage on Jarvislabs and insights into model quantization on Wing Axolotl were shared, with useful resources and tips sprinkled throughout the discussions.
Code, Craft, and Communities: The community vibe flourished with talk of LLM evaluator models, the desirability of Gradio's UI over Streamlit, and the convening of meet-ups from San Diego to NYC. The vibrant exchanges covered technical ground but also nurtured the social fabric of the AI engineering realm.
CUDA MODE Discord
GPGPU Programming Embraces lighting.ai: Engineers discussed lighting.ai as a commendable option for GPGPU programming, especially for those lacking access to NVIDIA hardware commonly used for CUDA and SYCL development.
Easing Triton Development: Developers found triton_util, a utility package simplifying Triton kernel writing, useful for abstracting repetitive tasks, promoting a more intuitive experience. Performance leaps using Triton on NVIDIA A6000 GPUs were observed, while tackling bugs became a focus when dealing with large tensors above 65GB.
Nightly Torch Supports Python 3.12: The PyTorch community highlighted torch.compile issues on Python 3.12, with nightly builds providing some resolutions. Meanwhile, the deprecation of macOS x86 builds in Torch 2.3 sparked discussions about transitioning to the M1 chips or Linux.
Tom Yeh Enhances AI Fundamentals: Prof Tom Yeh is gaining traction by sharing hand calculation exercises on AI concepts. His series comprises Dot Product, Matrix Multiplication, Linear Layer, and Activation workbooks.
Quantum Leaps in Quantization: Engineers are actively discussing and improving quantization processes with libraries like bitsandbytes and fbgemm_gpu, as well as participating in competitions such as NeurIPS. Efforts on Llama2-7B and the FP6-LLM repository updates were shared alongside appreciating the torchao community's supportive nature.
CUDA Debugging Skills Enhanced: A single inquiry about debugging SYCL code was shared, highlighting the need for tools to improve kernel code analysis and possibly stepping into the debugging process.
Turbocharge Development with bitnet PRs:
Various technical issues were addressed in the bitnet channel, including ImportError challenges related to mismatches between PyTorch/dev versions and CUDA, and compilation woes on university servers resolved via a gcc 12.1 upgrade. Collaborative PR work on bit packing and CI improvements were discussed, with resources provided for bit-level operations and error resolution (BitBlas on GitHub, ao GitHub issue).
Social and Techno Tales of Berlin and Seattle: Conversations in off-topic contrasted the social and weather landscapes of Seattle and Berlin. Berlin was touted for its techno scene and startup friendliness, moderated by its own share of gloomy weather.
Tokenizer Tales and Training Talk: An extensive dialog on self-implementing tokenizers and dataset handling ensued, considering compression and cloud storage options. Large-scale training on H100 GPUs remains cost-prohibitive, while granular discussions on GPU specs informed model optimization. Training experiments continue apace, with one resembling GPT-3's strength.
Nous Research AI Discord
Playing with Big Contexts: An engineer suggested training a Large Language Model (LLM) with an extremely long context window with the notion that with sufficient context, an LLM can predict better even with a smaller dataset.
The Unbiased Evaluation Dilemma: Concerns were raised about Scale’s involvement with both supplying data for and evaluating machine learning models, highlighting a potential conflict of interest that could influence the impartiality of model assessments.
Understanding RAG Beyond the Basics: Technical discussions elucidated the complexities of Retrieal-Augmented Generation (RAG) systems, stressing that it's not just a vector similarity match but involves a suite of other processes like re-ranking and full-text searches, as highlighted by discussions and resources like RAGAS.
Doubled Prices and Doubled Concerns: Google's decision to increase the price for Gemini 1.5 Flash output sparked a heated debate, with engineers calling out the unsustainable pricing strategy and questioning the reliability of the API’s cost structure.
Gradient Accumulation Scrutiny: A topic arose around avoiding gradient accumulation in model training, with engineers referring to Google's tuning playbook for insights, while also discussing the concept of ref_model in DPO training as per Hugging Face's documentation.
LM Studio Discord
- Open Source or Not? LM Studio's Dichotomy: LM Studio's main application is confirmed to be closed source, while tools like LMS Client (CLI) and lmstudio.js (new SDK) are open source. Models within LM Studio cannot access local PC files directly.
- Translation Model Buzz: The Aya Japanese to English model was recommended for translation tasks, while Codestral, supporting 80+ programming languages, sparked discussions of integration into LM Studio.
- GPU Selection and Performance Discussions: Debates emerged over the benefits of multi-GPU setups versus single powerful GPUs, specifically questioning the value of Nvidia stock and practicality of modded GPUs. A Goldensun3ds user upgraded to 44GB VRAM, showcasing the setup advantage.
- Server Mode Slows Down the Show: Users noted that chat mode achieves faster results than server mode with identical presets, raising concerns on GPU utilization and the need for GPU selection for server mode operations.
- AMD GPU Users Face ROCm Roadblocks: Version problems with LM Studio and Radeon GPUs were noted, including unsuccessful attempts to use iGPUs and multi-GPU configurations in ROCm mode. Offers on 7900 XT were shared as possible solutions for expanding VRAM.
- A Single AI for Double Duty?: The feasibility of a model performing both moderation and Q&A was questioned, with suggestions pointing towards using two separate models or leveraging server mode for better context handling.
- Codestral Availability Announced: Mistral's new 22B coding model, Codestral, has been released, targeting users with larger GPUs seeking a powerful coding companion. It's available for download on Hugging Face.
Modular (Mojo 🔥) Discord
Mojo Gets a Memory Lane: A blog post illuminated Mojo's approach to memory management with ownership as a central focus, advocating a safe yet high-performance programming model. Chris Lattner's video was highlighted as a resource for digging deeper into the ownership concept within Mojo's compiler systems. Read more about it in their blog entry.
Alignment Ascendancy: Engineers have stressed the importance of 64-byte alignment in tables to utilize the full potency of AVX512 instructions and enhance caching efficiency. They also highlighted the necessity of alignment to prompt the prefetcher's optimal performance and the issues of false sharing in multithreaded contexts.
Optional Dilemmas and Dict Puzzles in Mojo: In the nightly branch conversations, the use of Optional with the ref API sparked extensive discussion, with participants considering Rust's ? operator as a constructive comparison. A related GitHub issue also focused on a bug with InlineArray failing to invoke destructors of its elements.
The Prose of Proposals and Compilations: The merits of naming conventions within auto-dereferenced references were rigorously debated, with the idea floated to rename Reference to TrackedPointer and Pointer to UntrackedPointer. Additionally, the latest nightly Mojo compiler release 2024.5.2912 brought updates like async function borrow restrictions with a comprehensive changelog available.
AI Expands Horizons in Open-World Gaming: An assertion was raised that open-world games could reach new pinnacles if AI could craft worlds dynamically from a wide range of online models, responding to user interactions. This idea suggests a significant opportunity for AI's role in gaming advancements.
Eleuther Discord
- A Helping Hand for AI Newbies: Newcomers to EleutherAI, including a soon-to-graduate CS student, were provided beginner-friendly research topics with resources like a GitHub gist. Platforms for basic AI question-and-answer sessions were noted as lacking, stimulating a conversation about the accessibility of AI knowledge for beginners.
- Premature Paper Publication Puzzles Peers: A paper capturing the community's interest for making bold claims without the support of experiments sparked discussion. Questions were raised around its acceptance on arXiv, contrasting with the acknowledgment of Yann LeCun's impactful guidance and his featured lecture that highlighted differences between engineering and fundamental sciences.
- MLP versus Transformer – The Turning Tide: Debate heated up over recent findings that MLPs can rival Transformers in in-context learning. While intrigued by the MLPs' potential, skepticism abounded about optimizations and general usability, with members referencing resources such as MLPs Learn In-Context and discussions reflecting back on the "Bitter Lesson" in AI architecture's evolution.
- AMD Traceback Trips on Memory Calculation: A member's traceback error while attempting to calculate max memory on an AMD system led them to share the issue via a GitHub Gist, whereas another member sought advice on concurrent queries with "lm-evaluation-harness" and logits-based testing.
- Scaling Discussions Swing to MLPs' Favor: Conversations revealed that optimization tricks might mask underperformance while spotlighting an observation that scaling and adaptability could outshine MLPs' structural deficits. Links shared included an empirical study comparing CNN, Transformer, and MLP networks and an investigation into scaling MLPs.
OpenAI Discord
- Free Users, Rejoice with New Features!: Free users of ChatGPT now enjoy additional capabilities, including browse, vision, data analysis, file uploads, and access to various GPTs.
- ImaGen3 Stirring Mixed Emotions: Discussion swirled around the upcoming release of Google's ImaGen3, marked by skepticism concerning media manipulation and trust. Meanwhile, Google also faced flak for accuracy blunders in historical image generation.
- GPT-4's Memory Issues Need a Fix: Engineers bemoaned GPT-4's intermittent amnesia, expressing a desire for a more transparent memory mechanism and suggesting a backup button for long-term memory preservation.
- RAM Rising: Users call for Optimization: Concerns over excessive RAM consumption spiked, especially when using ChatGPT on browsers like Brave; alternative solutions suggested include using Safari or the desktop app to run smoother sessions.
- Central Hub for Shared Prompts: For those seeking a repository of "amazing prompts," direct your attention to the specific channel designated for this purpose within the Discord community.
Interconnects (Nathan Lambert) Discord
- Codestral Enters the Coding Arena: Codestral, a new 22B model from Mistral fluent in over 80 programming languages, has launched and is accessible on HuggingFace during an 8-week beta period. Meanwhile, Scale AI's introduction of a private data-based LLM leaderboard has sparked discussions about potential biases in model evaluation due to the company's revenue model and its reliance on consistent crowd workers.
- Price Hike Halts Cheers for Gemini 1.5 Flash: A sudden price bump for Google's Gemini 1.5 Flash's output—from $0.53/1M to $1.05/1M—right after its lauded release stirred debate over the API's stability and trustworthiness.
- Awkward Boardroom Tango at OpenAI: The OpenAI board was caught off-guard learning about ChatGPT’s launch on Twitter, according to revelations from ex-board member Helen Toner. This incident illuminated broader issues of transparency at OpenAI, which were compounded by a lack of explicit reasoning behind Sam Altman’s firing, with the board citing "not consistently candid communications."
- Toner's Tattle and OpenAI's Opacity Dominate Discussions: Toner's allegations of frequent dishonesty under Sam Altman's leadership at OpenAI sparked debates on the timing of her disclosures, with speculation about legal constraints and acknowledgement that internal politics and pressure likely shaped the board's narrative.
- DL Community's Knowledge Fest: Popularity is surging for intellectual exchanges like forming a "mini journal club" and appreciation for Cohere's educational video series, while TalkRL podcast is touted as undervalued. Although there's mixed reception for Schulman's pragmatic take on AI safety in Dwarkesh's podcast episode, the proposed transformative hierarchical model to mitigate AI misbehaviors, as highlighted in Andrew Carr’s tweet, is sparking interest.
- Frustration Over FMTI's File Fiasco: There's discontent among the community due to the FMTI GitHub repository opting for CSV over markdown, obstructing easy access to paper scores for engineers.
- SnailBot Ships Soon: Anticipation builds for the SnailBot News update, teased via tagging, with Nate Lambert also stirring curiosity about upcoming stickers.
Stability.ai (Stable Diffusion) Discord
- Colab and Kaggle Speed Up Image Creation: Engineers recommend using Kaggle or Colab for faster image generation with Stable Diffusion; one reports that it takes 1.5 to 2 minutes per image with 16GB VRAM on Colab.
- Tips for Training SDXL LoRA Models: Technical enthusiasts discuss training Stable Diffusion XL LoRA models, emphasizing that 2-3 epochs yield good results and suggesting that conciseness in trigger words improves training effectiveness.
- Navigating ComfyUI Model Paths and API Integration: Community members are troubleshooting ComfyUI configuration for multiple model directories and discussing the integration of ADetailer within the local Stable Diffusion API.
- HUG and Stability AI Course Offerings: There's chatter about the HUG and Stability AI partnership offering a creative AI course, with sessions recorded for later access—a completed feedback form will refund participants' deposits.
- 3D Model Generation Still Incubating: Conversations turn to AI's role in creating 3D models suitable for printing, with members agreeing on the unfulfilled potential of current AI to generate these models.
LlamaIndex Discord
- Graphing the LLM Knowledge Landscape: LlamaIndex announces PropertyGraphIndex, a collaboration with Neo4j, allowing richer building of LLM-backed knowledge graphs. With tools for graph extraction and querying, it provides for custom extractors and joint vector/graph search functions—users can refer to the PropertyGraphIndex documentation for guidelines.
- Optimizing the Knowledge Retrieval: Discussions focused on optimizing RAG models by experimenting with text chunk sizes and referencing the SemanticDocumentParser for generating quality chunks. There were also strategies shared for maximizing the potential of vector stores, such as the mentioned
QueryFusionRetriever, and best practices for non-English embeddings, citing resources like asafaya/bert-base-arabic.
- Innovating in the Codestral Era: LlamaIndex supports the new Codestral model from MistralAI, covering 80+ programming languages and enhancing with tools like Ollama for local runs. Additionally, the FinTextQA dataset is offering an extensive set of question-answer pairs for financial document-based querying.
- Storage and Customization with Document Stores: The community discussed managing document nodes and stores in LlamaIndex, touching on the capabilities of
docstore.persist(), and utilization of different document backends, with references made to Document Stores - LlamaIndex. The engagement also mentioned Simple Fusion Retriever as a solution for managing vector store indexes.
- Querying Beyond Boundaries: The announced Property Graph Index underlines LlamaIndex’s commitment to expand the querying capabilities within knowledge graphs, integrating features to work with labels and properties for nodes and relationships. The LlamaIndex blog sheds light on these advances and their potential impact on the AI engineering field.
Latent Space Discord
- Gemini 1.5 Proves Its Metal: Gemini 1.5 Pro/Advanced now holds second place, edging near GPT-4o, with Gemini 1.5 Flash in ninth, surpassing models like Llama-3-70b, as per results shared on LMSysOrg's Twitter.
- SWE-agent Stirs Up Interest: Princeton's SWE-agent has sparked excitement with its claim of superior performance and open-source status, with details available on Gergely Orosz's Twitter and the SWE-agent GitHub.
- Llama3-V Steps into the Ring: The new open-source Llama3-V model competes with GPT4-V despite its smaller size, grabbing attention detailed on Sidd Rsh's Twitter.
- Tales from the Trenches with LLMs: Insights and experiences from a year of working with LLMs are explored in the article titled "What We Learned from a Year of Building with LLMs," focusing on the evolution and challenges in building AI products.
- SCALE Sets LLM Benchmarking Standard with SEAL Leaderboards: Scale's SEAL Leaderboards have been launched for robust LLM evaluations with shoutouts from industry figures like Alexandr Wang and Andrej Karpathy.
- Reserve Your Virtual Seat at Latent Space: A technical event to explore AI Agent Architectures and Kolmogorov Arnold Networks has been announced for today, with registration available here.
OpenRouter (Alex Atallah) Discord
- Temporary OpenAI Downtime Resolved: OpenAI faced a temporary service interruption, but normal operations resumed following a quick fix with Alex Atallah indicating Azure services remained operational throughout the incident.
- Say Goodbye to Cinematika: Due to low usage, the Cinematika model is set to be deprecated; users have been advised to switch to an alternative model promptly.
- Funding Cap Frustration Fixed: After OpenAI models became inaccessible due to an unexpected spending limit breach, a resolution was implemented and normal service restored, combined with the rollout of additional safeguards.
- GPT-4o Context Capacity Confirmed: Amid misunderstandings about token limitations, Alex Atallah stated that GPT-4o maintains a 128k token context limit and a separate output token cap of 4096.
- Concerns Over GPT-4o Image Prompt Performance: A user's slow processing experience with
openai/gpt-4ousingimage-urlinput hints at possible performance bottlenecks, which might require further investigation and optimization.
LAION Discord
- AI Influencers on the Spotlight: Helen Toner's comment about discovering ChatGPT on Twitter launched dialogues while Yann LeCun's research activities post his VP role at Facebook piqued interest, signaling the continued influence of AI leaders in shaping community opinions. In contrast, Elon Musk's revelation of AI models only when they've lost their competitive edge prompted discussions regarding the strategy of open-source models in AI development.
- Mistral's License Leverages Open Weights: Amidst the talks, Mistral AI's licensing strategy was noted for its blend of open weights under a non-commercial umbrella, emphasizing the complex landscape of AI model sharing and commercialization.
- Model Generation Complications: Difficulty arises when using seemingly straightforward prompts such as 'a woman reading a book' in model generation, with users reporting adverse effects in synthetic caption creation, hinting at persistent challenges in the field of generative AI.
- Discourse on Discriminator Effectiveness: The community dissected research material, particularly noting Dinov2's use as a discriminator, yet indicating a preference for a modified pretrained UNet, recalling a strategy akin to Kandinsky's, where a halved UNet improved performance, shedding light on evolving discriminator techniques in AI research.
- Community Skepticism Towards Rating Incentives: A discussion on the Horde AI community's incentivized system for rating SD images raised doubts, as it was mentioned that such programs could potentially degrade the quality of data, highlighting a common tension between community engagement and data integrity.
LangChain AI Discord
- Trouble Finding LangChain v2.0 Agents Resolved: Users initially struggled with locating agents within LangChain v2.0, with discussions proceeding to successful location and implementation of said agents.
- Insights on AI and Creativity Spark Conversations: A conversation was ignited by a tweet suggesting AI move beyond repetition towards genuine creativity, prompting technical discussions on the potential of AI in creative domains.
- Solving 'RateLimit' Errors in LangChain: The community shared solutions for handling "RateLimit" errors in LangChain applications, advocating the use of Python's try/except structures for robust error management.
- Optimizing Conversational Data Retrieval: Members faced challenges with ConversationalRetrievalChain when handling multiple vector stores, seeking advice on effectively merging data for complete content retrieval.
- Practical Illustration of Persistent Chat Capabilities: A guild member tested langserve's persistent chat history feature, following an example from the repository and inquiring about incorporating "chat_history" into the FastAPI request body, which is documented here.
Educational content on routing logic in agent flows using LangChain was disseminated via a YouTube tutorial, assisting community members in enhancing their automated agents' decision-making pathways.
OpenInterpreter Discord
- Customization is King in Training Workflows: Engineers expressed an interest in personalized training workflows, with discussions centered on enhancing Open Interpreter for individual use cases, suggesting a significant need for customization in AI tooling.
- Users Share Open Interpreter Applications: Various use cases for Open Interpreter sparked discussions, with members exchanging ideas on how to leverage its features for different technical applications.
- Hunting for Open-source Alternatives: Dialogue among engineers highlighted ongoing explorations for alternatives to Rewind, with Rem and Cohere API mentioned as noteworthy options for working with the vector DB.
- Rewind's Connectivity Gets a Nod: One user vouched for Rewind's efficiency dubbing it as a "life hack" despite its shortcomings in hiding sensitive data, reflecting a generally positive reception among technical users.
- Eliminating Confirmation Steps in OI: Addressing efficiency, a member provided a solution for running Open Interpreter without confirmation steps using the
--auto_runfeature, as detailed in the official documentation.
- Trouble with the M5 Screen: A user reported issues with their M5 showing a white screen post-flash, sparking troubleshooting discussions that included suggestions to change Arduino studio settings to include a full memory erase during flashing.
- Unspecified YouTube Link: A solitary link to a YouTube video was shared by a member without context, possibly missing an opportunity for discussion or the chance to provide valuable insights.
OpenAccess AI Collective (axolotl) Discord
"Not Safe for Work" Spam Cleanup: Moderators in the OpenAccess AI Collective (axolotl) swiftly responded to an alert regarding NSFW Discord invite links being spammed across channels, with the spam promptly addressed.
Quest for Multi-Media Model Mastery: An inquiry about how to fine-tune large language models (LLMs) like LLava models for image and video comprehension was posed in the general channel, yet it remains unanswered.
Gradient Checkpointing for MoE: A member of the axolotl-dev channel proposed an update to Unsloth's gradient checkpointing to support MoE architecture, with a pull request (PR) upcoming after verification.
Bug Hunt for Bin Packing: A development update pointed to an improved bin packing algorithm, but highlighted an issue where training stalled post-evaluation, likely linked to the new sampler's missing _len_est implementation.
Sampler Reversion Pulls Interest: A code regression was indicated by sharing a PR to revert multipack batch sampler changes due to flawed loss calculations, indicating the importance of precise metric evaluation in model training.
Cohere Discord
Rethinking PDF Finetuning with RAG: A member proposed Retrieval Augmented Generation (RAG) as a smarter alternative to traditional JSONL finetuning for handling PDFs, claiming it can eliminate the finetuning step entirely.
API-Specific Grounded Generation Insights: API documentation was cited to show how to use the response.citations feature within the grounded generation framework, and an accompanying Hugging Face link was provided as a reference.
Local R+ Innovation with Forced Citations: An engineer shared a hands-on achievement in integrating a RAG pipeline with forced citation display within a local Command R+ setup, demonstrating a reliable way to maintain source attributions.
Cohere's Discord Bot Usage Underlines Segmented Discussions: Enthusiasm around a Discord bot powered by Cohere sparked a reminder to keep project talk within its dedicated channel to maintain order and focus within the community discussions.
Channel Etiquette Encourages Project Segregation: Recognition for a community-built Discord bot was followed by guidance to move detailed discussions to a specified project channel, ensuring adherence to the guild's organizational norms.
tinygrad (George Hotz) Discord
xAI Secures a Whopping $6 Billion: Elon Musk's xAI has successfully raised $6 billion, with notable investors such as Andreessen Horowitz and Sequoia Capital. The funds are aimed at market introduction of initial products, expansive infrastructure development, and advancing research and development of future technologies.
Skepticism Cast on Unnamed Analytical Tools: A guild member expressed skepticism about certain analytical tools, considering them to have "negligible usefulness," although they did not specify which tools were under scrutiny.
New Language Bend Gains Attention: The Bend programming language was acclaimed for its ability to "automatically multi-thread without any code," a feature that complements tinygrad's lazy execution strategy, as shown in a Fireship video.
tinybox Power Supply Query: A question arose about the power supply requirements for tinybox, inquiring whether it utilizes "two consumer power supplies or two server power supplies with a power distribution board," but no resolution was provided.
Link Spotlight: An article from The Verge on xAI’s funding notably asks what portion of that capital will be allocated to acquiring GPUs, a key concern for AI Engineers regarding compute infrastructure.
DiscoResearch Discord
- Goliath Needs Training Wheels: Before additional pretraining, Goliath experienced notable performance dips, prompting a collaborative analysis and response among community members.
- Economical Replication of GPT-2 Milestone: Engineers discussed achieving GPT-2 (124M) replication in C for just $20 on GitHub, noting a HellaSwag accuracy of 29.9, which surpasses GPT-2's original 29.4 score.
- Codestral-22B: Multi-Lingual Monolith: Mistral AI revealed Codestral-22B, a behemoth trained on 80+ programming languages and claimed as more proficient than predecessors, per Guillaume Lample's announcement.
- Calling All Contributors for Open GPT-4-Omni: LAION AI is rallying the community for open development on GPT-4-Omni with a blog post highlighting datasets and tutorials, accessible here.
Mozilla AI Discord
Windows Woes with Llamafile: An engineer encountered an issue while compiling llamafile on Windows, pointing out a problem with cosmoc++ where the build fails due to executables not launching without a .exe suffix. Despite the system reporting a missing file, the engineer confirmed its presence in the directory .cosmocc/3.3.8/bin, and faced the same issue using cosmo bash.
Datasette - LLM (@SimonW) Discord
- RAG to the Rescue for LLM Hallucinations: An engineer suggested using Retrieval Augmented Generation (RAG) to tackle the issue of hallucinations when Language Models (LLMs) answer documentation queries. They proposed an extension to the
llmcommand to recursively create embeddings for a given URL, harnessing document datasets and embedding storage for improved accuracy.
MLOps @Chipro Discord
A Peek Into the Technical Exchange: A user briefly mentioned finding a paper relevant to their interests, thanking another for sharing, and expressed intent to review it. However, no details about the paper's content, title, or field of study were provided.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1007 messages🔥🔥🔥):
- Scraping web content efficiently: Members discussed various methods for extracting web content, including using Python requests and Playwright. One suggested using Gemini 1.5 Flash for extracting relevant content efficiently, despite some sites requiring JavaScript.
- Issues with Perplexity's API responses: Users complained that Perplexity's API does not provide the same accuracy as the web app. Some suspected shady practices, while others suggested different models and APIs like Groq and Openrouter.
- Developing a Perplexity-like tool: A member detailed their project, which emulates Perplexity's actions by using multi-model querying and custom search pipelines to offer accurate, up-to-date responses. They discussed scaling challenges and fabricating a backend for broader infrastructure.
- Feature and capability comparisons: Responding to inquiries, members pointed out the platform's advantages and limitations in various use cases, like document search and answering complex, specific queries. Some suggested alternatives like Adobe Acrobat’s AI chat and Google’s Notebook LM for document-focused tasks.
- Technical deep-diving and Go programming: Conversations strayed to Go language techniques for improving the efficiency of web scraping and parsing methods. One member emphasized learning Go for better scalability and concurrency in building AI applications.
- Anthropic Console: no description found
- Iterate on LLMs faster | promptfoo: Tailored LLM evals for your use case. Maximize model quality and catch regressions.
- CreepJS: no description found
- PDF.ai | Chat with your PDF documents: We built the ultimate ChatPDF app that allows you to chat with any PDF: ask questions, get summaries, find anything you need!
- Oh Wah Ah Ah Ah Anthony Vincent GIF - Oh Wah Ah Ah Ah Anthony Vincent Down With The Sickness Intro - Discover & Share GIFs: Click to view the GIF
- 2024-05-29_11-44-22: World's leading screen capture + recorder from Snagit + Screencast by Techsmith. Capture, edit and share professional-quality content seamlessly.
- GitHub - projectdiscovery/katana: A next-generation crawling and spidering framework.: A next-generation crawling and spidering framework. - projectdiscovery/katana
- Perplexity Pages - Beta Access: Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
- Firecrawl: Turn any website into LLM-ready data.
- no title found: no description found
- no title found: no description found
- Our next-generation model: Gemini 1.5: Gemini 1.5 delivers dramatically enhanced performance, with a breakthrough in long\u002Dcontext understanding across modalities.
- OpenAI Plans to Challenge Google With its AI Search Engine: Another ChatGPT-powered wave incoming with the new search engine?
- Gemini 1.5 Pro - Quality, Performance & Price Analysis | Artificial Analysis: Analysis of Google's Gemini 1.5 Pro and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window & ...
- Google Gemini Pricing: 1.5 Pro and 1.5 Flash Compared: Here's how to decide which Gemini model is going to give you the most bang for your buck.
- Gemini 1.5 Flash is an Underrated Gem You Need to Try Right Now: Here's How: Gemini 1.5 Flash was lost in the buzz at Google I/O 2024, but it packs a serious punch with fast inference, multimodality, and 1 million token support.
- Japan weather May - temperature, climate, best time to visit | Selective Asia: no description found
- A Guide to Japan - May and June: Calendar, events, and about Japan in May and June
- When to travel: Which seasons are good for traveling in Japan? What is the best time to travel to Japan?
- Tokyo, Weather for May, Japan: May Weather Averages for Tokyo, Japan, Japan
- Gemini Pro 1.5 with 1 million tokens surpasses GPT-4 Turbo: What does that mean?: When it comes to Gemini 1.5 Pro, Google seems to have brought out a model that is superior and remarkably ahead of its predecessors. Gemini 1.5 Pro is the first model in the Gemini 1.5 line that the c...
- Google's Gemini 1.5 Pro Will Have 2 Million Tokens. Here's What That Means: No, not bus or arcade-game tokens. This form of token refers to the building blocks used by artificial intelligence systems.
Perplexity AI ▷ #sharing (3 messages):
- Check out AI-generated thought: A user shared a Perplexity AI search link. This link appears to lead to an AI-generated thought or search query.
- Does this make sense?: Another user posted a Perplexity AI search link. The content of the search is unclear from the message.
- Pros and cons discussion: A user contributed a link discussing the "Vor- und Nachteile," which translates to "advantages and disadvantages". This suggests a detailed exploration of a particular topic's pros and cons.
Perplexity AI ▷ #pplx-api (2 messages):
- Trying new model alias: One member suggested to another member to try switching from the model alias
sonar-small-onlinetollama-3-sonar-small-32k-online. This suggestion was made likely to test if the switch might improve performance or solve a pending issue.
HuggingFace ▷ #general (951 messages🔥🔥🔥):
- Users seek help on various technical issues: One user faced problems with Chat UI in docker, receiving the error "unexpected character" in env.local file. Another user found success with "torch compile" for multi-GPU training in PyTorch 2.4, achieving faster training with A100 configurations.
- Concerns about XP levels and bot functionality: Several users complained about losing XP levels and experiencing erratic bot behavior. Discussions revealed the issue was due to a bug affecting the levelbot's memory and its connection to a Google Sheet used for storing data.
- Interest in alternative hardware for AI training: Members discussed various hardware options such as Gaudi2, AMD, and RTX GPUs for faster and more cost-effective AI training. Shared links included details on getting a Gaudi2 rig from Supermicro for $90k and used 3090 GPUs as affordable options for LLM tasks.
- Queries on fine-tuning, memory usage, and tooling: Questions arose concerning the fine-tuning parameters for models like TinyLlama, citing learning rates like 1e-2 or 1e-3. Another user inquired about utilizing the Hugging Face CLI for reverting model versions after an accidental commit.
- Resource sharing and guidance for learning AI/ML: Newcomers sought recommendations on starting points for AI and ML, with suggestions to take NLP courses and play with inference APIs like GPT-2. A shared resource included Autotrain for fine-tuning sentence transformers.
- Tweet from abhishek (@abhi1thakur): 🚨 NEW TASK ALERT 🚨 AutoTrain now supports fine-tuning of sentence transformer models 💥 Now, you can improve and customize your RAG or retrieval models without writing a single line of code 🤗 ✅ Su...
- fishaudio/fish-speech-1 · Apply for community grant: Personal project (gpu and storage): no description found
- FLOPS - Wikipedia: no description found
- Hugging Face – The AI community building the future.: no description found
- Huh Cat GIF - Huh Cat - Discover & Share GIFs: Click to view the GIF
- Steven Universe Flattered Blush I Love You Garnet GIF - Steven Universe Flattered Blush I Love You Garnet - Discover & Share GIFs: Click to view the GIF
- reach-vb (Vaibhav Srivastav): no description found
- Cat Dont Care Didnt Ask GIF - Cat Dont Care Didnt Ask Didnt Ask - Discover & Share GIFs: Click to view the GIF
- cutycat2000 (CutyCat2000): no description found
- Interview With Sr Rust Developer | Prime Reacts: Recorded live on twitch, GET IN https://twitch.tv/ThePrimeagenOriginal: https://www.youtube.com/watch?v=TGfQu0bQTKcAuthor: https://www.youtube.com/@programme...
- Dev Deletes Entire Production Database, Chaos Ensues: If you're tasked with deleting a database, make sure you delete the right one.Sources:https://about.gitlab.com/blog/2017/02/10/postmortem-of-database-outage-...
- Electro Boom GIF - Electro BOOM - Discover & Share GIFs: Click to view the GIF
- ompl/screenshot.png at master · Beinsezii/ompl: Opinionated Music Player/Library. Contribute to Beinsezii/ompl development by creating an account on GitHub.
- 30%+ Speedup for AMD RDNA3/ROCm using Flash Attention w/ SDP Fallback · huggingface/diffusers · Discussion #7172: Yes, now you too can have memory efficient attention on AMD with some (many) caveats. Numbers Throughput for the diffusers default (SDP), my SubQuad port, and the presented Flash Attention + SDP fa...
- Accidental Launch GIF - Accidental Launch Button - Discover & Share GIFs: Click to view the GIF
- Intel Gaudi 2 Complete Servers from Supermicro for $90K: We found a hard price for an AI server configuration with Supermicro selling an 8-way Intel Gaudi 2 server for only $90K
- test_merge: Sheet1 discord_user_id,discord_user_name,discord_exp,discord_level,hf_user_name,hub_exp,total_exp,verified_date,likes,models,datasets,spaces,discussions,papers,upvotes L251101219542532097L,osansevier...
- Reddit - Dive into anything: no description found
- Dr Austin GIF - Dr Austin Powers - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
{kind=link}
{kind=link}
{kind=link}
{kind=link}
HuggingFace ▷ #today-im-learning (2 messages):
- How to access channels: A user asked how to access a specific channel. Another member responded, instructing to "head to \<id:customize> and pick the collaboration role".
HuggingFace ▷ #cool-finds (14 messages🔥):
- Monitor Inflation Trends with Nowcasting Tool: Check out Cleveland Fed's Inflation Nowcasting tool for daily estimates of inflation for the PCE and CPI indexes. This helps stay updated on monthly and yearly inflation changes.
- Fine-Tuned GPT-2 for Sentiment Analysis Live on Hugging Face: A new sentiment analysis model trained using GPT-2 is available, tailored specifically for Amazon reviews. It boasts a 96.8% accuracy rate and offers significant potential for understanding customer feedback.
- Explore Superoptimization with Mirage on Arxiv: The paper Mirage: Multi-level Superoptimizer for Tensor Programs introduces a new way to optimize tensor programs using $\mu$Graphs, significantly outperforming existing approaches.
- Efficient Quantum State Prediction via Classical Shadows: The paper Efficient method for Quantum State Prediction outlines a method to predict numerous properties of quantum states using minimal measurements, showing promising theoretical and numerical results.
- Discussion on Using GNNs for State Embeddings: Members discussed the advantages of using Graph Neural Networks (GNNs) for state embeddings in simulations, emphasizing how GNNs can encode complex relations between entities. This method might introduce some inductive bias, prioritizing distance information over other factors.
- LangFlow 1.0 Preview - a Hugging Face Space by Langflow: no description found
- ashok2216/gpt2-amazon-sentiment-classifier-V1.0 · Hugging Face: no description found
- Predicting Many Properties of a Quantum System from Very Few Measurements: Predicting properties of complex, large-scale quantum systems is essential for developing quantum technologies. We present an efficient method for constructing an approximate classical description of ...
- A Multi-Level Superoptimizer for Tensor Programs: We introduce Mirage, the first multi-level superoptimizer for tensor programs. A key idea in Mirage is $μ$Graphs, a uniform representation of tensor programs at the kernel, thread block, and thread le...
- Inflation Nowcasting: The Federal Reserve Bank of Cleveland provides daily “nowcasts” of inflation for two popular price indexes, the price index for personal consumption expenditures (PCE) and the Consumer Price Index (CP...
HuggingFace ▷ #i-made-this (8 messages🔥):
- Meet HuggingPro: Your Hugging Face Navigator: A member introduced HuggingPro, a new assistant designed to help users navigate the Hugging Face ecosystem. HuggingPro offers accurate information about models, datasets, and tools, adding a touch of humor and exclusive tips. HuggingPro.
- everything-ai v2.0.1 Features More Robust AI Capabilities: Updates include handling audio files, generating videos from text, predicting 3D structures of proteins, fine-tuning models, and exploiting larger database collections for Retrieval-Augmented Generation (RAG). The tool can be started easily with a Docker setup and is fully local. everything-ai.
- Explaining Conditional Latent Diffusion Models: A member shared a YouTube video that covers Conditional Latent Diffusion models for text-to-image generation, explaining important concepts and implementation details. Watch the video.
- Image Generator Pro Released: A new tool was introduced for text-to-image generation, sequential image generation, and image editing. The tool is available on Hugging Face Spaces. Image Generator Pro.
- Nvidia’s Embedding Model Demo: A demo for Nvidia's new embedding model, comparable to Microsoft’s e5-mistral model, is available for testing. Contributions for example use cases and functions are invited. Nvidia Embed V1.
- Image Gen Pro - a Hugging Face Space by KingNish: no description found
- Tonic's NV-Embed - a Hugging Face Space by Tonic: no description found
- Text-To-Image Generative Diffusion Models explained in 15 MUST-KNOW concepts! (+ How to code it): In just 15 points, we talk about everything you need to know about Generative AI Diffusion models - from the basics to Latent Diffusion Models (LDMs) and Tex...
- GitHub - AstraBert/everything-ai: Your fully proficient, AI-powered and local chatbot assistant🤖: Your fully proficient, AI-powered and local chatbot assistant🤖 - AstraBert/everything-ai
- everything-ai: Your fully proficient, AI-powered and local chatbot assistant🤖
- HuggingPro - HuggingChat: Use the HuggingPro assistant inside of HuggingChat
- HuggingChat: Making the community's best AI chat models available to everyone.
HuggingFace ▷ #reading-group (9 messages🔥):
- Reading group queued up: Announcing a new reading group, encouraging paper authors to present their work. Event link provided.
- Interest in low-resource language ML: A member suggested inviting the C4AI community to the reading group, highlighting their talks on debunking misinformation using LLMs in low-resource languages. They expressed enthusiasm for topics related to African languages.
- Encouragement for presentations: Lunarflu expressed interest in presentations from the C4AI community, particularly if they've authored papers or released open-source repositories. Another member confirmed they'd make an introduction and praised the quality of a recent presentation.
HuggingFace ▷ #computer-vision (18 messages🔥):
- Help with Medical Image Analysis Task: A user needed help developing a self-supervised learning framework for medical image analysis involving unlabeled MRI and CT scans. Another member suggested extracting features using pre-trained models and then running a segmentation model suitable for the identified classes.
- Image Management Guidance for Transformers: A user queried how SOTA object detection models like YOLO or SAM handle large images. Another discussion revolved around fine-tuning Transformer-based models, recommending convNext, DINOv2, or SigLIP over ViT and suggesting using a cosine learning rate scheduler with the AdamW optimizer.
- Pre-trained Model for Sheet Detection: Someone inquired about a pre-trained model to detect paper sheets in images, citing traditional methods' lack of robustness. No further details regarding solutions or specific models were provided in the discussion.
- Resources and Notebooks for Image Processing: Links were shared to helpful resources and notebooks, including how to process images using HuggingFace datasets and a GitHub repository with tutorials for specific image processing workflows.
- Process image data: no description found
- Do (Tran): no description found
- Models - Hugging Face: no description found
- Tweet from Niels Rogge (@NielsRogge): Turns out my Idefics2 notebook works just as well for PaliGemma fine-tuning :) find it here: https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma For JSON use cases, a tiny VLM ...
- GitHub - google-research/tuning_playbook: A playbook for systematically maximizing the performance of deep learning models.: A playbook for systematically maximizing the performance of deep learning models. - google-research/tuning_playbook
HuggingFace ▷ #NLP (1 messages):
- Dealing with Document Length in Classification Modeling: A member asked about classification modeling with documents exceeding token length limitations in LLMs like BERT (512 tokens) and decoder-based models (1024 tokens). They are looking for alternatives to document slicing and updating positional embeddings, avoiding costly new pretraining methods.
HuggingFace ▷ #diffusion-discussions (4 messages):
- FineTuned Model for Sentiment Analysis: A member announced the creation of a FineTuned model using GPT-2 for sentiment analysis on Amazon reviews. The model is now live on Hugging Face with notable metrics such as 0.9680 accuracy and F1 scores Check it out on Hugging Face.
- Celebrating Diffusers' Birthday: Multiple members celebrated the second anniversary of Hugging Face's Diffusers project. A commit link was shared to mark the occasion.
- ashok2216/gpt2-amazon-sentiment-classifier-V1.0 · Hugging Face: no description found
- upload some initial structure · huggingface/diffusers@0bea026: no description found
Unsloth AI (Daniel Han) ▷ #general (656 messages🔥🔥🔥):
- Lighting AI Studio Suggestion Sparks Collaboration: Members recommended Lighting AI Studio for its "20-ish monthly free hours" and faster performance with L4 compared to Colab's T4. A collaboration with Lightning is hinted as beneficial for the community.
- Fine-tuning Llama3 Chatbot Troubles: Discussion about fine-tuning llama3 models for tasks like essay completion and creating RP characters like Jesus and Donald Trump. Some members faced issues with large context sizes and batch configurations, and found synthetic datasets less effective.
- Community Resources for Fine-Tuning: Helpful resources shared include Hugging Face documentation on SFTTrainer and various guides for LoRA and hyperparameters. Members discussed creating detailed notes for fine-tuning.
- Phi3 Models and Benchmarks Debated: Mixed reviews on Phi3 models with some members finding
phi-3-mediumunderwhelming compared to llama3-8b. A user reported Phi3 performing poorly beyond 2048 tokens context length compared to Llama3’s performance. - Announcements and New Model Releases: Excitement around new models like Codestral 22B with links to HuggingFace and official announcements (Mistral AI Codestral). Discussions about waiting for Qwen2 models also highlighted.
- Finetune Phi-3 with Unsloth: Fine-tune Microsoft's new model Phi 3 medium, small & mini easily with 6x longer context lengths via Unsloth!
- DDIDU/ETRI_CodeLLaMA_7B_CPP · Hugging Face: no description found
- wttw/Llama3-8B-CPP · Hugging Face: no description found
- SimPO: Simple Preference Optimization with a Reference-Free Reward: Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance si...
- Tweet from Binyuan Hui (@huybery): I checked the download statistics of the Qwen1.5 family models on HuggingFace🤗. Qwen1.5-7B won the championship, and CodeQwen1.5-7B reached ~265k downloads in just over a month. ❤️ Thank you all for ...
- mistralai/Codestral-22B-v0.1 at main: no description found
- Codestral: Hello, World!: Empowering developers and democratising coding with Mistral AI.
- Fine-tuning Large Language Models with Sequential Instructions: Large language models (LLMs) struggle to follow a sequence of instructions in a single query as they may ignore or misinterpret part of it. This impairs their performance in complex problems whose sol...
- Tweet from Mistral AI Labs (@MistralAILabs): Announcing Codestral: our first-ever code model. - Open-weights under the new Mistral AI Non-Production License - New endpoint via La Plateforme: http://codestral.mistral.ai - Try it now on Le Chat: h...
- GitHub - the-crypt-keeper/LLooM: Experimental LLM Inference UX to aid in creative writing: Experimental LLM Inference UX to aid in creative writing - the-crypt-keeper/LLooM
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- FIx for "Couldn't invoke ptxas --version" with cuda-11.3 and jaxlib 0.1.66+cuda111 · google/jax · Discussion #6843: Hi all, Just wanted to share my solution to the "Couldn't invoke ptxas --version" error that I got after a recent install of jax using cuda-11.3. TLDR, I needed to install nvidia-cuda-to...
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- Supervised Fine-tuning Trainer: no description found
- LoRA: no description found
Unsloth AI (Daniel Han) ▷ #random (3 messages):
- Seeking Help with HTML, CSS, JS: A user asked for assistance with HTML, CSS, and JS for an interface they are working on. "Is there anyone here that can help me...?"
- Direct Message Request: The same user requested others to DM them if they could help. "DM me if you can help."
Unsloth AI (Daniel Han) ▷ #help (59 messages🔥🔥):
- Colab Disconnect Issue Stirs Frustration: Members discussed the persistent problem of Google Colab disconnecting even after upgrading to Premium level. Recommendations included switching to alternatives like Kaggle and Lightning AI which offer free computing hours.
- Local Inference with Unsloth: A user sought guidance on running Unsloth's models for tasks like resume point generation in local VSCode. It was suggested to adapt the Colab inference example by preparing a simple Python script, potentially requiring fine-tuning.
- Deploying Models with Runpods and Docker: Users exchanged ideas on deploying models using Runpods with Docker, even considering alternatives when encountering issues with providers. While specific Dockerfiles weren't readily available, searching the server was recommended.
- Continued Pretraining Clarification: The community clarified that Unsloth supports unsupervised fine-tuning (continous pretraining) natively. Relevant Colab notebooks and GitHub resources for unsupervised finetuning were provided here and here.
- Technical Errors and CUDA Version Issues: Users reported and resolved specific technical issues, such as installing the appropriate version of xformers for PyTorch 2.2 and the required CUDA version for Unsloth (
11.8). These exchanges highlighted the troubleshooting aspect within the community.
- Supervised Fine-tuning Trainer: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Google Colab: no description found
LLM Finetuning (Hamel + Dan) ▷ #general (74 messages🔥🔥):
- Channel Idea for LLM Jobs and Self-Promotion: A member suggested creating a channel dedicated to LLM-related employment, career opportunities, and self-promotion within the Discord community. This would provide a space for people to share job openings and personal achievements.
- Opinions on Fine-Tuning Debate: Members discussed the controversial inclusion of talks suggesting that "fine-tuning is dead" in a fine-tuning course. The consensus was that differing opinions are valuable for comprehensive understanding, similar to past notable talks like Joel Grus's "Why I don't like Jupyter Notebooks."
- Google Raises Gemini 1.5 Prices: Users highlighted concerns over Google raising the price for Gemini 1.5 Flash output by 98% shortly after its release. This sparked discussions on the reliability of APIs with sudden drastic cost changes.
- Tools for JSON/Parquet Files: A user asked for recommendations on robust tools for working with arbitrary JSON/Parquet files, seeking alternatives more user-friendly than Jupyter but with database browser capabilities.
- Setting Up Regional Meetups: Members expressed interest in creating channels for regional meetups, starting with San Francisco and New York City, as a way to foster in-person connections among community members.
- Tweet from undefined: no description found
- Qwen/Qwen-Audio · Hugging Face: no description found
- Tweet from 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr): Google raised the price of Gemini 1.5 Flash output by 98% without telling anyone. This just a week after announcing the model. Output goes from 0.53/1M to 1.05/1M. How can we trust an API that dras...
- Tweet from Olivia Moore (@omooretweets): 🚨 New @a16z investment thesis! It's time for AI to reinvent the phone call - enter conversational voice agents 📱 What we're excited to invest in + market maps (from me and @illscience) 👇
- Rug Pull GIF - Rug Pull - Discover & Share GIFs: Click to view the GIF
- Aqua Voice - Voice-only Document Editor: Aqua Voice (YC W24) is a voice-driven text editor that lets you create and edit documents using just your voice.
- An evening with three AI investors · Luma: Please join us on Thursday May 30th at Solaris AI for a panel discussion about investing in AI startups. Our panelists are: - Yoko Li - Josh Buckley - Lenny…
- Tweet from Andrej Karpathy (@karpathy): # Reproduce GPT-2 (124M) in llm.c in 90 minutes for $20 ✨ The GPT-2 (124M) is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite accessible today, even for the G...
- Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 · karpathy/llm.c · Discussion #481: Let's reproduce the GPT-2 (124M) in llm.c (~4,000 lines of C/CUDA) in 90 minutes for $20. The 124M model is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite...
LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (4 messages):
- Personalized Sales Emails through LLM Fine-tuning: A user described how generating personalized first liners for sales emails can capture a recipient's attention more effectively. They emphasized that fine-tuning with a dataset of successful email openers and recipient profiles ensures aligned and compelling outreach.
- Efficient Legal Document Summarization with LLMs: Discussion centered on summarizing large numbers of discovery documents for legal proceedings using LLMs. Fine-tuning the model for specific legal domains ensures accurate and verifiable summaries, helping to streamline legal workflows.
- Multi-agent LLM Collaboration Model: Users explored the concept of a multi-agent LLM setup where each agent specializes in a niche area, operating in a continuous loop for interdisciplinary problem-solving. Suggestions include using RAG for additional context and fine-tuning each model to their domain.
- Optimizing Stable Diffusion Prompts with LLM: The topic of enhancing image generation prompts for Stable Diffusion using LLMs was discussed. Fine-tuning and few-shot learning with RAG were proposed to create more detailed and style-specific prompts, improving image outputs from simple descriptions.
LLM Finetuning (Hamel + Dan) ▷ #asia-tz (3 messages):
- Divya finds Workshop 3 high bandwidth: A new member from Singapore, Divya, shared excitement about Workshop 3, describing it as "super high bandwidth" and expressing the need for time to digest the content. She is still working on setting up her Axolotl environment and is looking forward to joint learning.
- Sid recommends starting with workshop recordings and homework: Another member, Sid, suggested beginning with the recordings and the attached homework from the workshop. He emphasized that the workshop serves more as a conference to understand general practices in building LLM applications and getting started with personal projects.
- Welcome from Pune: Gurdeep from Pune, India, joined the conversation with a greeting, saying hello to the group.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (21 messages🔥):
- Debugging Modal for Fine-Tuning: A member is facing an "opaque failure" when trying to run a finetuning example with Modal and is unsure how to debug the issue. The error appears to be related to secret configurations ("even after renaming my secrets... this persists").
- Help with Modal Secret Configuration: In response to debugging issues, another user suggested verifying secrets with the command
modal secret list. However, the original user confirmed that their issue was not related to secrets.
- Saharn Seeks Help with Training on Synthetic Data: A user named Saharn encountered an error while training on synthetic data using Modal and outlined their setup. Another member advised ensuring the dataset path is correctly placed in the
datafolder and clarified that specifying the dataset path in the configuration file is unnecessary.
- Downloading Docker Images Not Possible: In response to a query about pulling built Docker images locally, a member confirmed that this is not possible with Modal.
Link mentioned: Sign in: Welcome back to Modal! Sign in to your Modal account by selecting an identity provider below.
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (6 messages):
- O'Reilly Insights on Building with LLMs: O'Reilly Radar shares lessons from a year of building with LLMs, noting that while the barrier to entry has lowered, creating effective AI products remains challenging. The piece emphasizes informed methodologies crucial for developing LLM-based products.
- Curating Learning Resources Suggestion: A member proposed curating a list of shared resources in a repository or on a webpage. The idea includes adding thumbs up/down ratings to help users prioritize content.
Link mentioned: What We Learned from a Year of Building with LLMs (Part I): no description found
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (8 messages🔥):
- Shut down containers using Python SDK: A member suggested using the Jarvislabs Python SDK to shut down an instance since it is container-based. They shared a code snippet for how to achieve this.
- Query on using volumes inside Jarvislabs: A member inquired about the possibility of using a volume for saving files and accessing them across containers. Another member clarified that what they were asking about sounded like shared storage across multiple containers.
- Axolotl preprocessing GPU support issue: A member encountered an issue when running Axolotl preprocessing, noting that the bitsandbytes library was compiled without GPU support, forcing the operation to use CPU. They also shared a detailed log output indicating the system defaults to CPU acceleration due to lack of CUDA support.
- Follow-up on Axolotl query: To address the preprocessing issue, a member shared a related Discord discussion link indicating a similar unresolved question. The member later noted that their training script eventually ran and utilized the GPU despite initial issues.
Link mentioned: JLClient | Jarvislabs : JLClient is a Python API for Interacting with Jarvislabs.ai for the complete lifecycle of GPU instances.
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (15 messages🔥):
- Serving HF Models in Production is Frustrating: A user expressed frustration about finetuning a model using Lightning Studios and facing difficulty in serving it in production. They sought advice on converting a Pytorch model to safetensors format.
- No Knowledge on Lightning Format: One member admitted to having no knowledge about the Lightning format and suggested creating a custom handler if the inference code is known. They provided a link to the custom handler guide.
- Conversion Tutorial Shared: Another user referred to their model finetuned on a GPT2-medium base model using a tutorial from LLMs-from-scratch on GitHub. They mentioned following the tutorial for a binary classification task on a different domain.
- PTH to Safetensors Conversion: A member advised that a
.pthfile is equivalent to atorch.binfile and should be convertible to safetensors format. They shared a link to Hugging Face's guide on converting weights to safetensors.
- Email Address Clarification for Course Credits Form: A user inquired whether the email for receiving course credits could be different from the sign-up email. The response was affirmative, suggesting simply filling out the form regardless of the email used.
- Convert weights to safetensors: no description found
- GitHub - rasbt/LLMs-from-scratch: Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step: Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch
LLM Finetuning (Hamel + Dan) ▷ #ankurgoyal_textsql_llmevals (53 messages🔥):
- Workshop Highlights: Braintrust: Ankur showcased Braintrust discussing its utility for evaluating non-deterministic AI systems with tools like Autoevals for Text2SQL. The attendees appreciated the session's focus on iterative workflows and straightforward tools, with several expressing excitement to try it out.
- Shared Resources and Links: Several key links were shared, including the Braintrust cookbook, the notebook used in the presentation, and supporting datasets from Hugging Face. Enthusiasts found these resources helpful for following along and implementing Braintrust.
- Self-Hosting Recommendations: Ankur recommended self-hosting Braintrust when dealing with private databases containing sensitive information. He referred to the self-hosting guide to assist users in setting up Braintrust efficiently in their own environments.
- SQL Evaluations with Autoevals: For checking the semantic equivalence of SQL queries, Ankur shared that Autoevals uses a straightforward method and provided the template and customization documentation for users interested in tweaking the evaluation prompts.
- Autoevals and Langsmith Comparisons: Users compared Braintrust's evaluation capabilities to Langsmith, noting that Braintrust felt cleaner and easier to navigate. This prompted discussions on possibly using Langsmith for logging and tracing, while Braintrust could be ideal for evaluations due to its user-friendly interface and visual elements.
- braintrust-cookbook/examples/Text2SQL/Text2SQL.ipynb at main · braintrustdata/braintrust-cookbook: Contribute to braintrustdata/braintrust-cookbook development by creating an account on GitHub.
- Braintrust: Rapidly ship AI without guesswork
- Braintrust: Braintrust is the enterprise-grade stack for building AI products.
- braintrust-cookbook/examples/Text2SQL-Data/Text2SQL-Data.ipynb at main · braintrustdata/braintrust-cookbook: Contribute to braintrustdata/braintrust-cookbook development by creating an account on GitHub.
- LLM Eval For Text2SQL: LLM Eval For Text2SQL
- autoevals/templates/sql.yaml at main · braintrustdata/autoevals: AutoEvals is a tool for quickly and easily evaluating AI model outputs using best practices. - braintrustdata/autoevals
- Braintrust: Braintrust is the enterprise-grade stack for building AI products.
LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (141 messages🔥🔥):
- **Highly recommend John Berryman's book**: John Berryman's Prompt Engineering book on O'Reilly promises to be a comprehensive guide for developers, solidifying LLM principles and prompt engineering techniques useful for practical applications. Discover it [here](https://learning.oreilly.com/library/view/prompt-engineering-for/9781098156145/).
- **Exploring Prompt Engineering tools and frameworks**: Members shared numerous resources including links to [Hamel's notes](https://hamel.dev/notes/llm/openai/func_template.html), GoEx and reflection agent techniques via [Langchain blog](https://blog.langchain.dev/reflection-agents/), and JSON Schema details on [Notion](https://www.notion.so/matijagrcic/JSON-Schema-78055af9ce1242e8b9be27918056be2f?pvs=4).
- **Interesting insights about LLM behavior and tuning**: Members discussed how underlying principles of computation give rise to capabilities of LLMs, including references to chaining reasoning and action through frameworks like ReAct. Check the paper [ReAct: Synergizing Reasoning and Acting in Language Models](https://www.promptingguide.ai/techniques/react).
- **Copilot chatbot tips**: Several members shared experiences with AI-assisted coding tools like GitHub Copilot and Cursor, recommending examining workspace context and inline chat utilities. See [Copilot workspace context](https://code.visualstudio.com/docs/copilot/workspace-context#_tips-for-using-workspace) for optimizing workspace-based inquiries.
- **Function calling and evaluation techniques**: Discussions surfaced prompted discussions about leveraging frameworks/tools like [Anthropic's XML tags](https://docs.anthropic.com/en/docs/use-xml-tags) and how to dynamically select few-shot examples via libraries that compute Levenshtein distances or embeddings.
- Reflection Agents: Reflection is a prompting strategy used to improve the quality and success rate of agents and similar AI systems. This post outlines how to build 3 reflection techniques using LangGraph, including imp...
- Prompt Engineering Guide: A Comprehensive Overview of Prompt Engineering
- Chat using @workspace Context References: How to use Copilot's @workspace chat to ask questions against your entire codebase.
- HuggingChat: Making the community's best AI chat models available to everyone.
- ReAct: Synergizing Reasoning and Acting in Language Models: While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-though...
- Agent Smith - Evil Laugh GIF - Evil Laugh The Matrix Agent Smith - Discover & Share GIFs: Click to view the GIF
- Tool Invocation – Demonstrating the Marvel of GPT's Flexibility · Thought Box : no description found
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Use XML tags - Anthropic: no description found
- Hamel’s Blog - Function prompts: How is OpenAI formatting its prompt for function calls?
- Relevant Search: Relevant Search</i> demystifies relevance work. Using Elasticsearch, it teaches you how to return engaging search results to your users, helping you understand and leverage the internals of Luce...
- Gorilla: no description found
- Prompt Engineering v2 (Compressed): Prompt Engineering John Berryman
- Prompt Engineering for LLMs: Large language models (LLMs) promise unprecedented benefits. Well versed in common topics of human discourse, LLMs can make useful contributions to a large variety of tasks, especially now that the … ...
- Tweet from undefined: no description found
- Prompt Engineering for LLMs: Large language models (LLMs) promise unprecedented benefits. Well versed in common topics of human discourse, LLMs can make useful contributions to a large variety of tasks, especially now that the … ...
- Tweet from undefined: no description found
- Language Models are Few-Shot Learners: Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in a...
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models: We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we ...
- Large Language Models are Zero-Shot Reasoners: Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably...
- Gorilla: no description found
- Tweet from Eric Hartford (@erhartford): Cognitive Computations presents Dolphin-2.9.2-Mixtral-8x22b, trained with a new dataset SystemChat 2.0, designed to teach Dolphin to obey the System Prompt, even over a long conversation. This releas...
LLM Finetuning (Hamel + Dan) ▷ #whitaker_napkin_math (1 messages):
computer_internet_man: 🧠🍿
LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (5 messages):
- Floats are weird, period: A member highlighted the quirks of floating-point numbers, asserting that their addition is not associative. They explained that gradients, often used in AI models, require higher precision due to potential underestimation or overflow of values.
- Precision matters for gradient estimation: Discussing the precision differences, they contrasted accumulation in 8bit and 16bit floats, with 16bit providing a more accurate estimation of gradients which approximates N*eps when cast to 8bit.
- HF dataset in sharegpt format: Another contributor mentioned that the HF dataset uses the sharegpt format, which includes "from" and "value" keys.
- Fine-tuning with synthetic data conundrum: A user discussed difficulties in generating synthetic data for fine-tuning a model similar to the honeycomb example, noting their current application performs at about 66% accuracy. They pondered whether more data should be generated and sifted to find good quality examples for fine-tuning.
LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (199 messages🔥🔥):
- ChainForge breaks new ground in prompt evaluation: Members were introduced to ChainForge, an open-source visual programming environment for prompt engineering. It emphasizes easy, enjoyable prompt evaluation and offers robust testing of LLMs (ChainForge).
- Deep dive into evaluations with EvalGen and SPADE: Discussions highlighted the capabilities of EvalGen in aligning LLM-generated evaluation criteria with human requirements, and SPADE's method for synthesizing data quality assertions to handle LLM output errors (EvalGen, SPADE).
- Eugene Yan's fine-tuning insights: Eugene Yan's session was appreciated for its detailed practical approach, though some found it fast-paced. Feedback suggested expanding the size of charts and taking more time to explain concepts (Slides).
- Collected links and resources shared: A member compiled an extensive list of links shared during the session, including articles, papers, and tools related to LLM development and evaluation (What We Learned from a Year of Building with LLMs).
- Human review and annotation tools: Discussions also included recommendations for tools and vendors for setting up human review loops cost-effectively, with mentions of Argilla, pigeonXT, and cluestar to assist in annotation tasks (pigeonXT, cluestar).
- Join the llm-fine-tuning Discord Server!: Check out the llm-fine-tuning community on Discord - hang out with 1615 other members and enjoy free voice and text chat.
- Tweet from Hamel Husain (@HamelHusain): My colleagues and I distilled practical advice re: LLMs into this three-part series. Lot's of bangers. One of my favorite excerpts from this part in the screenshot Advice from: @eugeneyan, @BEBi...
- Evaluating the Factual Consistency of Large Language Models Through News Summarization: While large language models (LLMs) have proven to be effective on a large variety of tasks, they are also known to hallucinate information. To measure whether an LLM prefers factually consistent conti...
- Tweet from undefined: no description found
- SPADE: Synthesizing Data Quality Assertions for Large Language Model Pipelines: Large language models (LLMs) are being increasingly deployed as part of pipelines that repeatedly process or generate data of some sort. However, a common barrier to deployment are the frequent and of...
- Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences: Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-...
- Spellgrounds for Prodigious Prestidigitation: Spellgrounds for Prodigious Prestidigitation Dr. Bryan Bischof, Head of AI @ Hex
- GitHub - koaning/cluestar: Gain clues from clustering!: Gain clues from clustering! Contribute to koaning/cluestar development by creating an account on GitHub.
- GitHub - eugeneyan/visualizing-finetunes: Contribute to eugeneyan/visualizing-finetunes development by creating an account on GitHub.
- - Fuck You, Show Me The Prompt.: Quickly understand inscrutable LLM frameworks by intercepting API calls.
- Tweet from Hamel Husain (@HamelHusain): His talk abstract 🔥 > This talk will cover using and extending Inspect, a new OSS Python framework for LLM evals. Inspect's developer (J.J. Allaire) will walk through the core concepts and de...
- Inspect: Open-source framework for large language model evaluations
- ChainForge: A visual programming environment for prompt engineering: no description found
- GitHub - dennisbakhuis/pigeonXT: 🐦 Quickly annotate data from the comfort of your Jupyter notebook: 🐦 Quickly annotate data from the comfort of your Jupyter notebook - dennisbakhuis/pigeonXT
- Fine-tuning workshop 3 slides: Mastering LLMs A Conference For Developers & Data Scientists
- shreyashankar - Overview: CS PhD student at UC Berkeley. shreyashankar has 63 repositories available. Follow their code on GitHub.
- fast.ai Course Forums: Forums for fast.ai Courses, software, and research
- Waiting Still GIF - Waiting Still - Discover & Share GIFs: Click to view the GIF
- Langfuse: Open source LLM engineering platform - LLM observability, metrics, evaluations, prompt management.
- Bring everyone together with data | Hex : From quick queries, to deep-dive analyses, to beautiful interactive data apps – all in one collaborative, AI-powered workspace.
- Hex Magic | Smarter, faster analysis with a little Magic | Hex : Save hours every week by using Magic AI to write queries, build charts, and fix bugs.
- Task-Specific LLM Evals that Do & Don't Work: Evals for classification, summarization, translation, copyright regurgitation, and toxicity.
- Tweet from undefined: no description found
- What We Learned from a Year of Building with LLMs (Part I): no description found
- Tweet from tomaarsen (@tomaarsen): ‼️Sentence Transformers v3.0 is out! You can now train embedding models with multi-GPU training, bf16 support, loss logging, callbacks & much more. I also release 50+ datasets to train on & much more....
- USB: A Unified Summarization Benchmark Across Tasks and Domains: While the NLP community has produced numerous summarization benchmarks, none provide the rich annotations required to simultaneously address many important problems related to control and reliability....
- Prompting Fundamentals and How to Apply them Effectively: Structured input/output, prefilling, n-shots prompting, chain-of-thought, reducing hallucinations, etc.
- Scaling Up “Vibe Checks” for LLMs - Shreya Shankar | Stanford MLSys #97: Episode 97 of the Stanford MLSys Seminar Series!Scaling Up “Vibe Checks” for LLMsSpeaker: Shreya ShankarBio:Shreya Shankar is a PhD student in computer scien...
- Braintrust | The First User-Owned Talent Network: Braintrust connects organizations with top technical talent to complete strategic projects and drive innovation.
- Inspect: Open-source framework for large language model evaluations
- GitHub - traceloop/openllmetry: Open-source observability for your LLM application, based on OpenTelemetry: Open-source observability for your LLM application, based on OpenTelemetry - traceloop/openllmetry
- no title found: no description found
- Breaking Down EvalGen: Who Validates the Validators?: Everything you need to know about EvalGen, an approach to LLM-assisted evaluation. Also includes some takeaways for LLM app builders.
- johnowhitaker.dev – A few tips for working on high-surface-area problems: no description found
- SQLModel: SQLModel, SQL databases in Python, designed for simplicity, compatibility, and robustness.
- What is OpenLLMetry? - traceloop: no description found
- Welcome to pytest-vcr - pytest-vcr: no description found
- The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A": We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize...
- LLM Evaluators Recognize and Favor Their Own Generations: Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introd...
- - Your AI Product Needs Evals: How to construct domain-specific LLM evaluation systems.
- no title found: no description found
- LangSmith: Get your LLM app from prototype to production.
- Pydantic Logfire | Uncomplicated observability: Logfire is a new type of observability platform built on the same belief as Pydantic — that the most powerful tools can be easy to use.
LLM Finetuning (Hamel + Dan) ▷ #yang_mistral_finetuning (1 messages):
init27_sanyam: We have more stuff to ask about 😄 https://mistral.ai/news/codestral/
LLM Finetuning (Hamel + Dan) ▷ #gradio (1 messages):
- Struggling with CSS Customization in Gradio: A member asked for documentation on customizing the CSS of the Gradio interface. They attempted to change the gradio-container and gr-button-primary backgrounds, but only the container's background color was applied successfully, not the button's.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (17 messages🔥):
- Turning off sample packing impacts performance: A member emphasized that turning off sample packing will always make a huge difference and recommended also setting pad to sequence length to false. Another clarified, "Sample packing really shines when you have short sequences," prompting members to consider sequence length when fine-tuning.
- Debugging output inconsistencies after training: A user noticed discrepancies in model outputs using TinyLlama with the alpaca_2k_test dataset and shared their config for troubleshooting. Another advised ensuring proper prompting as per Axolotl's requirements by including the appropriate template ("Below is an instruction that describes a task...") to achieve expected results.
- Using custom metrics and multiple datasets: The feasibility of using custom metrics and meshing multiple datasets was discussed, with some suggestions that while eval datasets are supported in transformers, it’s unclear if multiple training datasets are directly supported in Axolotl.
- Troubleshooting padding errors: A user encountered a padding error during training, traced to improper input formatting in the tokenization process. Errors were identified in the process of encoding features without including 'input_ids'.
- Request for fine-tuning process architecture: One member requested a high-level architecture diagram of the fine-tuning process, detailing how different commands interact with the data and configurations for better debugging. The discussion highlighted the need for visual aids to understand data flow and process stages in Axolotl.
Link mentioned: axolotl/src/axolotl/prompters.py at 8a20a7b711a62d7b04e742f3d6034b4ca8aa27d2 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (25 messages🔥):
- Beneyal seeks advice on model issue: A user asked for feedback on a model issue from another member, providing a previous link to their detailed description.
- Ankur faces dependency issues with Axolotl: Ankur reported dependency issues while trying to fine-tune using Axolotl with
torch=2.1.1andpython=3.10.12, seeking assistance for correct installation steps. Another user suggested creating a separate virtual environment to resolve these issues.
- Tddammo provides detailed quantization insights: Tddammo explained quantization concepts and referred to posts such as LLM.int8() and the Hugging Face bitsandbytes integration, clarifying how different settings affect model and gradient calculations.
- Iggyal confused about dataset_prepared_path setting: Iggyal mistakenly thought leaving
dataset_prepared_pathempty would default to usinglast_run_prepared, causing a training error. Caseus_ recommended explicitly settingdataset_prepared_pathtolast_run_prepared.
- Venetis seeks confirmation on axolotl config settings: Venetis asked for a sanity check on their understanding of axolotl configuration settings related to model weights, activation, and gradient precision, involving mixed precision settings like bf16, f16, and tf32.
- A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes: no description found
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- LLM.int8() and Emergent Features — Tim Dettmers: When I attended NAACL, I wanted to do a little test. I had two pitches for my LLM.int8() paper. One pitch is about how I use advanced quantization methods to achieve no performance degradation transfo...
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (8 messages🔥):
- Chrome unveils hidden video player menu items: A user found that the embedded video player shows different menu items depending on the browser used and discovered the "3 dots" menu after switching to Chrome from Firefox.
- Heavy tasks to remain despite optimizations: Work is ongoing to optimize heavy tasks, both by the current team and the pyodide team. However, it's acknowledged these tasks will always be somewhat demanding.
- Early PoC in works with custom middleware: An early proof of concept (PoC) for a feature is working well and further development is planned. Custom middleware might be required for certain implementations, though it needs verification.
- Clarification issued for OAuth logins question: An issue has been filed on GitHub to clarify the limits on OAuth logins in Gradio, with a link to the issue. A response to the question is now available in the issue.
- Gradio praised for intuitiveness over Streamlit: In a comparison discussion, a member shared that Gradio felt far more intuitive than Streamlit, which influenced their choice when working on demos.
Link mentioned: Limit oauth logins · Issue #8405 · gradio-app/gradio: I have searched to see if a similar issue already exists. Received this question about logging in with HF on discord. Posting here for visibility: Can you limit the list of allowed logins (username...
LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (24 messages🔥):
- UK Government's Inspect Framework gets love: A member appreciated the use of
quartoin the UK Government's Inspect Framework site, praising its structure and composability. Another member expressed enthusiasm for Quarto, emphasizing its usefulness in the project.
- RStudio nostalgia and future prospects: Members reminisced about their early experiences with data science using RStudio and its impact on their careers. There was a hint from one member to stay tuned for potential new developments for Python in a similar space.
- User feedback on model critique desired: A member suggested the idea of adding a checkbox in the Inspect framework to allow users to confirm or deny the evaluator model's critique, potentially increasing user interaction and evaluation accuracy.
- Community recipes for security basics: The composability and extensions offered by Inspect are seen as an opportunity for the community to create recipes, particularly on the security front. This could make it easier for users to cover essential security basics.
- Questions about Inspect functionality: Members had questions and discussions about the functionality of Inspect, such as whether functions need to be written by the user or are included as defaults, and how to get specific windows when running evaluations.
- Frustrated Waaaaaaaa GIF - Frustrated Waaaaaaaa WWE - Discover & Share GIFs: Click to view the GIF
- Lets Go Lets Go Marvel GIF - Lets go Lets go marvel Let's go thor - Discover & Share GIFs: Click to view the GIF
- Inspect: Open-source framework for large language model evaluations
- Yes GIF - Yes - Discover & Share GIFs: Click to view the GIF
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (46 messages🔥):
- Predibase restricts signups, support suggested: Members report difficulty in signing up for Predibase due to restrictions to work email addresses. Support was advised to solve the issue.
- Only the last form submission counts: Dan confirmed that only the last submission of the credit form will be considered, addressing concerns about multiple submissions.
- Fireworks.ai added to credit sponsors: Fireworks.ai is offering credits, and members have queried whether a separate form is needed or it's included in the existing one. The form wording has been updated for clarity regarding "Account ID" versus "user-id."
- Confirmation issues with credit forms: Numerous members expressed concerns over verifying their submissions for credits and ensuring their information was correctly saved. Dan acknowledged the issue and assured that the data was not lost despite the form edits.
- Deadline clarification and comprehensive list: Dan clarified the deadline for form submission is May 30, with new enrollments cut off on May 29. A mostly comprehensive list of accounts to set up is available at the provided course link.
- Mastering LLMs: A Conference For Developers & Data Scientists by Dan Becker and Hamel Husain on Maven: An online conference for everything LLMs.
- no title found: no description found
- Hugging Face Credit Request: Before we can apply 🤗 HF credit for you to use our paid services at https://huggingface.co, we’ll need just a few quick things! Drop us a line if you have any questions at website@huggingface.co. ...
- Modal hackathon credits: To claim your Modal credits, sign up for an account at https://modal.com/ first. Then, let us know your username through this form. For support, join the Modal Slack. Here’s some examples to get s...
- Fireworks Credits - Mastering LLMs : A Conference For Developers & Data Scientists: Please fill the below form to get $250 Fireworks credits! Join our discord for questions/help or more credits ;) https://discord.gg/fireworks
LLM Finetuning (Hamel + Dan) ▷ #eugeneyan_evaluator_model (3 messages):
- **Discussion Hub Redirect**: Members identified a primary channel for questions on finetuning, suggesting that most queries might be happening in [this channel](https://discord.com/channels/1238365980128706560/1245100755787186298).
- **Training Summarization Evaluator Models**: One member shared their appreciation for a recent talk on improving summarization models by first training on a larger set (USB) before fine-tuning on a smaller, targeted dataset (FIB). The takeaway is that this method significantly boosts the evaluator model's performance on the specific dataset they care about, highlighting how "training on an additional dataset followed by the dataset we care about drastically improves performance."
LLM Finetuning (Hamel + Dan) ▷ #fireworks (9 messages🔥):
- Fireworks credit administration leadership clarified: One member will be responsible for administering Fireworks AI credits.
- Fireworks credits form released: A link to a Google form was provided for users to claim $250 in Fireworks credits. Instructions include creating a Fireworks account and submitting the Account ID.
- Community gratitude for Fireworks credits team: Multiple members expressed appreciation towards the team handling the Fireworks credits, accompanied by expressions of excitement.
- Feedback on form terminology: A potential error was highlighted regarding the use of “user-id” instead of “Account ID” for Fireworks AI. The form was subsequently edited to address this issue.
- Fireworks' unique offerings appreciated: A member noted that Fireworks is the only provider they found offering an open-source model with vision capabilities.
Link mentioned: Fireworks Credits - Mastering LLMs : A Conference For Developers & Data Scientists: Please fill the below form to get $250 Fireworks credits! Join our discord for questions/help or more credits ;) https://discord.gg/fireworks
LLM Finetuning (Hamel + Dan) ▷ #braintrust (3 messages):
- **Greetings flood the channel**: Members exchanged greetings with each other. *"Hello all 👋,"* one member said, receiving a wave of *"👋🏽" and "hi"* in response.
LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (7 messages):
- San Diego vs. San Francisco Showdown: Members discussed the merits of San Diego vs. San Francisco for local attractions. One noted San Francisco's iconic Golden Gate Bridge, while another championed San Diego's microbreweries, zoo, and beaches.
- Voice+AI meetup in San Francisco: An upcoming Voice+AI meetup in San Francisco was announced, scheduled for Thursday night. The event promises a panel discussion, demos, and pizza, with a registration link provided for attendees.
Link mentioned: An evening with three AI investors · Luma: Please join us on Thursday May 30th at Solaris AI for a panel discussion about investing in AI startups. Our panelists are: - Yoko Li - Josh Buckley - Lenny…
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (14 messages🔥):
- NYC Meetup gains interest: The idea of a meetup in NYC has sparked excitement among members. "Anyone in NYC? I’d be happy to try to arrange a meetup somewhere." "Meetup would be a great idea!"
- Members willing to travel: Some members from Philadelphia and Baltimore are open to traveling to NYC for the meetup. "I'm in Philly area but would be open to traveling to NYC for a meetup" and "P sure it's all just a train ride to each other, so I'm perfectly fine going to NYC myself."
LLM Finetuning (Hamel + Dan) ▷ #europe-tz (25 messages🔥):
- Berlin meet-up initiates interest: Multiple users including maciejgryka and lucas_vw expressed interest in meeting up in Berlin. r2d29115 and aravindputrevu possibly organizing a larger group meet-up.
- Users across Europe check-in: Users shared their locations ranging from Amsterdam, Berlin, Linz, and beyond. Various countries represented include the UK, Germany, Austria, the Netherlands, Spain, Finland, and France.
- Tech presence in Linz questioned: Someone inquired about Cloudflight (previously Catalysts) maintaining a strong presence in Linz. Confirmation was given that they are still well-known but with no further contact.
LLM Finetuning (Hamel + Dan) ▷ #announcements (3 messages):
- Keep an eye on the new announcements channel: A new announcements channel has been created for all critical updates and reminders. It is highly recommended to keep notifications on for this channel to not miss important information.
- Urgent submission of forms needed: Members are asked to fill out several important forms by 11:59PM PT on May 30 to secure vendor credits, including ones from Maven, Google Forms for Hugging Face credits, Google Forms for Modal hackathon credits, and Google Forms for Fireworks credits.
- Events category for talk schedules: Upcoming talks and events, along with their Zoom URLs, will be posted in the Events category on Discord. This section will also display the time remaining for events according to your local time zone.
- no title found: no description found
- Hugging Face Credit Request: Before we can apply 🤗 HF credit for you to use our paid services at https://huggingface.co, we’ll need just a few quick things! Drop us a line if you have any questions at website@huggingface.co. ...
- Modal hackathon credits: To claim your Modal credits, sign up for an account at https://modal.com/ first. Then, let us know your username through this form. For support, join the Modal Slack. Here’s some examples to get s...
- Fireworks Credits - Mastering LLMs : A Conference For Developers & Data Scientists: Please fill the below form to get $250 Fireworks credits! Join our discord for questions/help or more credits ;) https://discord.gg/fireworks
CUDA MODE ▷ #general (3 messages):
- Lighting.ai is highly recommended for GPGPU: A member inquired about the use of lighting.ai for GPGPU programming, citing the lack of commodity hardware for an NVIDIA card and needing to program in CUDA and SYCL. Another member affirmed, “It’s amazing yes.”
- Inquiry about Torch's approximation of erf: A member asked if anyone knows how Torch approximates the erf (error function). No response was noted in the messages provided.
CUDA MODE ▷ #triton (16 messages🔥):
- Tiny package simplifies Triton usage: A user highlighted triton_util to ease writing Triton kernels by abstracting repetitive tasks. This package aims to write Triton code in a more intuitive and less mentally draining manner.
- Enormous performance difference on A6000: Users noted the significant performance improvement of Triton on the NVIDIA A6000 GPU. They requested code examples to understand the differences in performance further.
- Issue with matrix multiplication in Triton: A user reported discrepancies in the matmul.py tutorial (link) when using specific input sizes on a GPU 3090. Another user suggested that the variances might be due to finite floating point precision in FP16, concluding it's likely not a critical issue.
- Bug with large tensors in Triton: A member discovered a bug when dealing with tensors sized 65GB+ in Triton. They explained that multiplying indices by a stride in int32 can lead to overflow, causing CUDA memory errors, highlighting the hidden complexities of tensor pointer operations in Python.
- Tweet from Umer Adil (@UmerHAdil): Make OpenAI Triton easier 🔱 😊 I find writing triton kernels involves many repetitive tasks, that can be cleanly abstracted away. This allows to write triton code much more in line with how I actua...
- GitHub - UmerHA/triton_util: Make triton easier: Make triton easier. Contribute to UmerHA/triton_util development by creating an account on GitHub.
CUDA MODE ▷ #torch (19 messages🔥):
- Missing torch.compile with Python 3.12: Several users discussed issues with torch.compile not working on Python 3.12, but noted that the nightly builds do offer some support. One member shared a GitHub issue tracking this problem and suggested using pyenv for multiple Python versions.
- Triton kernels and flash-attention workarounds: Though torch.compile is having issues, one user managed to manually install Triton kernels and found that at least flash-attention works on Python 3.12.
- Impact of new bytecodes: A user highlighted that every new Python version introduces new bytecodes, causing Dynamo interpretation issues, and hinted at future alignment of PyTorch releases with Python updates.
- macOS x86 deprecation: Users discussed their coping mechanisms following the deprecation of macOS x86 builds in Torch 2.3. Some suggested moving to M1 laptops or using Linux distros on older x86 machines, referencing the RFC GitHub issue.
- Torch compile does not work on python 3.12 · Issue #120233 · pytorch/pytorch: 🐛 Describe the bug Currently torch, as of 2.2.0 does not support torch compile with python 3.12 See following PR for example: #117853 We need to be able to use python 3.12 with torch.compile featur.....
- GitHub - pyenv/pyenv: Simple Python version management: Simple Python version management. Contribute to pyenv/pyenv development by creating an account on GitHub.
- Torch.compile support for Python 3.12 completed: Signal boosting that Python 3.12 support has been added to torch.compile and has been present in the nightly builds for a while. We anticipate that this feature will be included in the PyTorch 2.4 rel...
- [RFC] macOS x86 builds / test deprecation · Issue #114602 · pytorch/pytorch: 🚀 The feature, motivation and pitch As new Intel Mac's are no longer produced and with time fewer will remain in use, I propose stop testing and eventually building MacOS x86_64 binaries by the e...
CUDA MODE ▷ #cool-links (1 messages):
- AI by Hand Provides Essential Learning Resources: Prof Tom Yeh shares hand calculation exercises for AI, boasting a LinkedIn following of 36K and recently starting on X. The series includes Dot Product, Matrix Multiplication, Linear Layer, and Activation workbooks, aiming to make core AI concepts accessible through engaging visuals and animations.
- Tweet from Tom Yeh | AI by Hand ✍️ (@ProfTomYeh): 4. Activation - AI by Hand✍️Workbook Series I share original hand calculation exercises like this, with 36K followers on LinkedIn. I just started sharing on X. If you find this workbook he...
- Tweet from Tom Yeh | AI by Hand ✍️ (@ProfTomYeh): 5. Artificial Neuron - AI by Hand✍️Workbook Series Previous Workbooks: 4. Activation: https://x.com/ProfTomYeh/status/1794848226383655284 3. Linear Layer: https://x.com/ProfTomYeh/status/179445...
- Tweet from Tom Yeh | AI by Hand ✍️ (@ProfTomYeh): 3. Linear Layer - AI by Hand✍️Workbook Series I share original hand calculation exercises like this, with 36K followers on LinkedIn. I just started sharing on X. If you find this workbook hel...
- Tweet from Tom Yeh | AI by Hand ✍️ (@ProfTomYeh): 2. Matrix Multiplication - AI by Hand✍️Workbook Series I share original hand calculation exercises like this, with 36K followers on LinkedIn. I just started sharing on X. If you find this post he...
- Tweet from Tom Yeh | AI by Hand ✍️ (@ProfTomYeh): 1. Dot Product - AI by Hand✍️Workbook Series I share original hand calculation exercises like this, with 36K followers on LinkedIn. I just started to share on X. If you find this post helpful, [F...
CUDA MODE ▷ #torchao (19 messages🔥):
- Exploring quantization libraries: Members discussed various quantization libraries such as bitsandbytes, quanto, and fbgemm_gpu. They highlighted how bitsandbytes is unique for being a shared library with a C API and mentioned its ongoing refactoring to support
torch.compile.
- NeurIPS competition excitement: A member expressed enthusiasm about the NeurIPS competition, noting it spurred their interest in contributing. They congratulated the team for making it to the second round and predicted this year's competition would be much improved.
- Mixed-precision quantization work: Members talked about working on
Int4 weight quantization + int8 activation dynamic quantization, with progress being mentioned on 4-bit HQQ quantized weights and simulated int8 activations for Llama2-7B. They referred to a kernel available via BitBlas but noted it had not been tested: BitBlas on GitHub.
- Gratitude for the community: A member appreciated the efforts of the contributors around the torchao project and noted the value of this CUDA Discord channel compared to others, including the lackluster NVIDIA one. "This is the only good CUDA discord I've found, even the NVIDIA one kind of sucks..."
- FP6-LLM repository updates: The repository saw some updates, specifically the addition of
fp5_e2m2.
Link mentioned: GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
CUDA MODE ▷ #off-topic (26 messages🔥):
- **Seattle disappoints due to gloomy weather**: A user shared their negative experience of living in Seattle, stating it to be "the least social city" due to the dark and rainy weather for about 9 months a year. They emphasized that while Seattle is beautiful in the summer, it can be quite isolating during the rest of the year due to weather conditions.
- **Berlin shines with hacker/startup community**: Another user pointed out that Berlin has a vibrant hacker/startup community and everyone speaks English, making it easier for newcomers. They specifically mentioned Berlin’s appeal to those interested in techno parties and local cuisine like kebabs.
- **Berlin weather reality check**: Contrary to the idyllic images of Berlin shared, users warned about the long gloomy winters, with temperatures dropping as low as -10 °C. However, they noted that the spring and summer periods in Berlin are very enjoyable.
- **Tech scene in Berlin and career advice**: Suggestions included working at small startups or companies like Amazon and Zalando if moving to Berlin. However, they advised gaining big tech experience in cities like SF or NYC for better future opportunities, such as raising funding for startups.
Link mentioned: Tweet from Isa Rus (@Isarusphoto): Berlin in February
CUDA MODE ▷ #llmdotc (215 messages🔥🔥):
- Tokenizer Implementation Discussions: Members considered self-implementing a tokenizer using regex splitting, which although annoying, is deemed doable. They discussed the benefits of having raw
.binshards online to avoid additional dependencies like installing conda fortiktoken.
- Compression and Storage Options: Conversations included compressing dataset shards using zip or other lightweight alternatives to reduce download sizes. They assessed cloud storage options, including S3 pricing and other services like Zenodo for hosting datasets, and considerations around egress costs.
- H100 and Multi-Node Training Plans: Members evaluated the potential performance and costs of training on clusters with H100 GPUs. Despite available 8X A100 setups for development, larger nodes for extensive training were deemed prohibitively expensive unless significant funding was secured.
- Exploring Different GPU Specifications: Detailed technical discussions unfolded around GPU specifications, performance metrics, and tensor operations, particularly for Ampere and Ada cards. They debated values like FP32 performance and tensor core behavior across different GPUs, contributing to ongoing performance optimization.
- Continuing GPT-3 Training Experiment: One member shared ongoing results from training a 124M model on 300B tokens, similar to GPT-3. Partial results indicated a close match with GPT-3 benchmarks, raising questions about the effectiveness of the FineWeb dataset for tasks like HellaSwag.
- Transmission: no description found
- HeadlessUsage – Transmission : no description found
- eval_results.csv · HuggingFaceFW/fineweb at main: no description found
- Amazon S3 Simple Storage Service Pricing - Amazon Web Services: no description found
- Zenodo: no description found
- `softmax_autoregressive_backward_kernel` does not use share memory in the kernel by huoyushequ · Pull Request #487 · karpathy/llm.c: softmax_autoregressive_backward_kernel does not use share memory in the kernel. we do not need to launch the kernel with 256 bytes share memory, so remove it
- OpenWebText: An open-source replication of the WebText dataset from OpenAI. For more info please visit https://skylion007.github.io/OpenWebTextCorpus/ @misc{Gokaslan2019OpenWeb, title={OpenWebText Corpus}, author=...
- NVIDIA RTX A5500 Specs: NVIDIA GA102, 1665 MHz, 10240 Cores, 320 TMUs, 96 ROPs, 24576 MB GDDR6, 2000 MHz, 384 bit
CUDA MODE ▷ #oneapi (1 messages):
orion160: What are tools to debug SYCL code? In general stepping into kernel code....
CUDA MODE ▷ #bitnet (94 messages🔥🔥):
- Vayuda struggles with CUDA and PyTorch versions: Vayuda encountered
ImportError: undefined symbolerrors while working with torch2.4dev and CUDA 12.4, realizing PyPI uploads default CUDA 12.1. Marksaroufim suggested using CUDA 12.1 via conda or trying a clean install.
- Issues with compiling extensions on university server: After confirming custom C extensions weren't built properly, Vayuda faced additional errors linked to the GPU (
ptxas error: Feature '.m16n8k16' requires .target sm_80 or higher). Following several suggestions from Marksaroufim, including a "nuclear option" of deleting specific setup lines, Vayuda found upgrading to gcc 12.1 mitigated some issues.
- Collaborative work on Bitnet and Uint2Tensor PRs: Marksaroufim encouraged Vayuda and others to combine efforts on PRs related to bit packing, suggesting a prototype folder for organized development. A PR link described the implementation details, and the tests were moved to an appropriate folder for CI checks.
- Unresolved issues collected: Marksaroufim aggregated ongoing problems with custom CUDA extensions making installing ao difficult into an ao GitHub issue. Solutions involve updating device properties to add compatibility checks in tests.
- CI and Testing Coordination: Despite encountering multiple errors, some related to skipping tests on non-supported versions and CUDA availability, Vayuda ultimately ensured that tests were configured to run correctly. Marksaroufim facilitated continuous integration (CI) to run tests weekly.
- Generic packing algorithms from size N to M · Issue #284 · pytorch/ao: (Not sure how to format this but here goes) In order to support sub-byte dtypes for quantization, I (and many others) believe that it is better to pack these smaller dtypes into existing pytorch dt...
- custom cuda extensions make installing ao hard · Issue #288 · pytorch/ao: i'm collecting a few issues I've seen, I have no clear picture of how to solve them as of this moment but aggregating them in the hopes that inspiration will strike Problems Problem 1 The belo...
- Torch.compile produces Exception: Please convert all Tensors to FakeTensors first or instantiate · Issue #127374 · pytorch/pytorch: 🐛 Describe the bug torch.compile fails on pack and unpack functions Minimal repro minimalrepo.py.zip Versions Python: 3.10.14 Torch nightly : 2.4.0.dev20240526 Error logs (ao) (base) james@instance.....
- ao/torchao/csrc/cuda/fp6_llm/ptx_mma.cuh at cbc74ee6a3dc0bae367db5b03bc58896fffe3ae0 · pytorch/ao: Native PyTorch library for quantization and sparsity - pytorch/ao
- GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- [BUG]: undefined symbol: _ZNSt15__exception_ptr13exception_ptr10_M_releaseEv · Issue #3623 · pybind/pybind11: Required prerequisites Make sure you've read the documentation. Your issue may be addressed there. Search the issue tracker and Discussions to verify that this hasn't already been reported. +1...
- Bitpacking by vayuda · Pull Request #291 · pytorch/ao: Based on this issue: #284 Adding this first iteration of packing/unpacking algorithms to support lower bit dtypes into protoype/
- [WIP] Added first bits of Uint2Tensor and BitnetTensor by andreaskoepf · Pull Request #282 · pytorch/ao: Created a UInt2Tensor class (similar to the UInt4Tensor class). Added a BitnetTensor class and a first unit test which quantizes the weights of a nn.Linear() layer and executes the matmul. Currentl...
- Hastebin: no description found
- ao/torchao/__init__.py at main · pytorch/ao: Native PyTorch library for quantization and sparsity - pytorch/ao
- ao/setup.py at main · pytorch/ao: Native PyTorch library for quantization and sparsity - pytorch/ao
- [feature request] np.packbits / np.unpackbits, general BitTensors (maybe can be just tensors with dtype torch.bits8 or have a new dtype torch.bits introduced) and bit packed tensors utilities for saving memory / accesses, support for BitTensors wherever BoolTensors are used · Issue #292 · pytorch/ao: A usecase: storing a full backtracking pointer matrix can be okay for needleman/ctc alignment (4x memory saving compared to uint8 representation), if 2bit data type is used. Currently it's possibl...
- Trinary2 dtype and quantization for Bitnet 1.58 by CoffeeVampir3 · Pull Request #285 · pytorch/ao: Motivated from issue #281 (comment) This is initial groundwork for Bitnet 1.58. After some reflection, I think it's beneficial to view this as a distinct type different than a uint2 or regular pac...
Nous Research AI ▷ #ctx-length-research (2 messages):
- Speculative idea on LLM with massive context window: A member proposed training a Large Language Model (LLM) on a very small dataset, assuming it could extrapolate well and had an extremely long context window. They suggested feeding it a pretraining dataset in-context for learning, theorizing that it could be feasible if the context window were in the trillions of tokens.
Nous Research AI ▷ #off-topic (12 messages🔥):
- Networking goldmine in Stanford and California: A member shared experiences about the abundant opportunities in San Francisco and California for networking. They emphasized the importance of attending clubs and social events to meet influential people like CEOs and VCs.
- Choosing the right classes at Stanford: It was suggested to be selective with courses at Stanford since different classes attract different types of people. For example, Probabilistic Analysis (MS&E 220) is more suited for entrepreneurial, sociable individuals.
- Feeling lazy with comfort food: One member shared their indulgent, lazy day meal consisting of 500g of pelmeni, 250g of sour cream, cucumber, chocolate milk, and halva.
- Lazy food comparison: The conversation humorously compared instant ramen noodles to the more elaborate lazy day meal, with both members showing appreciation for each other's choices.
Nous Research AI ▷ #interesting-links (9 messages🔥):
- Online Merging Optimizers unveiled before Qwen2 release: A link to a tweet discusses online merging optimizers and mentions that model merging can help mitigate alignment tax. Relevant paper and GitHub repository are provided for in-depth information.
- MoRA: High-Rank Updating method surfaces: A link to a GitHub repository introduces MoRA, a method that uses a square matrix for high-rank updating," outperforming LoRA on memory-intensive tasks while maintaining the same number of trainable parameters."
- SEAL Leaderboards launched by Scale: A link to a tweet by Alexandr Wang highlights the launch of SEAL Leaderboards, which are private, expert evaluations of leading frontier models. More details are shared on the Scale Leaderboard website focused on unbiased and continuously updated model evaluations.
- Concerns raised about Scale's involvement: A member expressed concerns about Scale’s provision of both SFT (supervised fine-tuning) and RLHF (reinforcement learning from human feedback) data for models, potentially excluding Llama 3. Comments indicate skepticism about unbiased evaluations due to this involvement.
- SEAL leaderboards: no description found
- Tweet from Alexandr Wang (@alexandr_wang): 1/ We are launching SEAL Leaderboards—private, expert evaluations of leading frontier models. Our design principles: 🔒Private + Unexploitable. No overfitting on evals! 🎓Domain Expert Evals 🏆Contin...
- Tweet from Keming (Luke) Lu (@KemingLu612): We present Online Merging Optimizers before the amazing release of Qwen2 Alignment tax is annoyed but luckily model merging can magically mitigate some. How about incorporating merging methods into t...
- GitHub - kongds/MoRA: MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning: MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning - kongds/MoRA
Nous Research AI ▷ #general (256 messages🔥🔥):
- Positional Magic and Token Prediction Limits: Members discussed the fundamental limitations of auto-regressive token prediction models, emphasizing that they lack a true understanding of math or logic and merely predict tokens. This limitation contrasts with their supposed capabilities in reasoning.
- RAG Complexity Explained: A detailed explanation on Retrieval-Augmented Generation (RAG) highlighted that it is more complex than just vector similarity search. Successful RAG implementation involves embedding, vector similarity, full-text keyword search, chunking, and re-ranking, making it akin to a recommendation engine for LLMs.
- Reward Model Clarification: Members deliberated the functionality of a reward model discussed in a linked Hugging Face repository. It was clarified that such models typically assign scores based on human preferences, supporting reinforcement learning tasks like PPO.
- Debate on New Mistral Model Licensing: The newly introduced Codestral model from Mistral, trained in 80+ programming languages, sparked debate due to its non-production licensing restricting commercial use. This move led to skepticism about its practical adoption, with comments suggesting the focus shifts to open-source alternatives as they are seen as more versatile.
- Google’s Gemini 1.5 Price Increase Criticism: There was significant criticism regarding Google’s recent price hike for the Gemini 1.5 Flash output, which nearly doubled without prior notice. Members expressed concerns about the trustworthiness and responsiveness of the service, calling it a "scam".
- Codestral: Hello, World!: Empowering developers and democratising coding with Mistral AI.
- Introducing the Mistral AI Non-Production License: Mistral AI introduces new Non-Production License to balance openness and business Growth.
- Reward Bench Leaderboard - a Hugging Face Space by allenai: no description found
- sfairXC/FsfairX-LLaMA3-RM-v0.1 · Hugging Face: no description found
- Tweet from 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr): Google raised the price of Gemini 1.5 Flash output by 98% without telling anyone. This just a week after announcing the model. Output goes from 0.53/1M to 1.05/1M. How can we trust an API that dras...
- GitHub - the-crypt-keeper/LLooM: Experimental LLM Inference UX to aid in creative writing: Experimental LLM Inference UX to aid in creative writing - the-crypt-keeper/LLooM
- GitHub - neph1/LlamaTale: Giving the power of LLM's to a MUD lib.: Giving the power of LLM's to a MUD lib. Contribute to neph1/LlamaTale development by creating an account on GitHub.
- Neuroscientists use AI to simulate how the brain makes sense of the visual world : A research team at Stanford's Wu Tsai Neurosciences Institute has made a major stride in using AI to replicate how the brain organizes sensory information to make sense of the world, opening up...
- GitHub - arenasys/Lineworks: Qt GUI for LLM assisted co-writing: Qt GUI for LLM assisted co-writing. Contribute to arenasys/Lineworks development by creating an account on GitHub.
Nous Research AI ▷ #ask-about-llms (16 messages🔥):
- Gradient Accumulation Considered Questionable: One user raised a concern about avoiding gradient accumulation and whether it is beneficial. They shared a GitHub link to Google's tuning playbook for insights on maximizing deep learning model performance.
- Reference Model in DPO Training: Users discussed the role of the
ref_modelin DPO training, whereref_modelis set to None by default, meaning a copy of the model is used as a reference. It's confirmed that the reference model can be the initial model or a different one, typically frozen, to prevent divergence from the original model as per Hugging Face's documentation.
- Definition of Agents in LLM Context: A user inquired about introductory readings on agents in the context of LLMs. Another clarified that agents perceive and affect their environment, often implemented with scripts and LLMs, like a voice conversation chatbot.
- DPO Trainer: no description found
- GitHub - google-research/tuning_playbook: A playbook for systematically maximizing the performance of deep learning models.: A playbook for systematically maximizing the performance of deep learning models. - google-research/tuning_playbook
Nous Research AI ▷ #rag-dataset (15 messages🔥):
- Noita is a welcome distraction: One member admitted to getting distracted by playing Noita in the midst of discussions.
- Discussion on RAG evaluation frameworks: A conversation emerged on the effectiveness of metrics for RAG evaluations, with popular frameworks like RAGAS, BENCH, and ARES being mentioned. Links to each framework were shared, providing resources for detailed exploration.
- Creating fusion of HyDE with multi-hop for Q/A: Members explored the concept of using HyDE with multi-hop for question-answering, contemplating methods like creating multiple sets of queries from a single query. The idea of using each step to aid the next search was also considered.
- Multimodal metrics for evaluation: The conversation covered using LLMs coupled with heuristics like n-gram and ROUGE for evaluating metrics grounded in context and query relevance. The challenge of mathematically grounding these metrics was emphasized.
- Recommendation for hybrid search in retrieval: A member recommended moving beyond simplistic cosine similarity for retrieval, suggesting a hybrid search approach integrated with insights from various experts.
- Tweet from Hamel Husain (@HamelHusain): My colleagues and I distilled practical advice re: LLMs into this three-part series. Lot's of bangers. One of my favorite excerpts from this part in the screenshot Advice from: @eugeneyan, @BEBi...
- GitHub - explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines - explodinggradients/ragas
- GitHub - arthur-ai/bench: A tool for evaluating LLMs: A tool for evaluating LLMs. Contribute to arthur-ai/bench development by creating an account on GitHub.
- GitHub - stanford-futuredata/ARES: Contribute to stanford-futuredata/ARES development by creating an account on GitHub.
Nous Research AI ▷ #world-sim (6 messages):
- Accidental AI funny mishap: A member humorously shared they tried to remove the filesystem with
rm -rf /, prompting the system to attempt transforming itself into a superintelligent AI. They joked, "Oopsie Daisy." - Terminology surprise: The same member expressed confusion over the term "AI singleton" and pondered if it would have been the system's first choice had it not known the term.
- Glitch disrupts user experience: Another member complained about the text doubling glitch in the world-sim and mentioned they would stop using it until it's fixed. Another member confirmed the glitch had not been resolved.
LM Studio ▷ #💬-general (62 messages🔥🔥):
- LM Studio's Open Source Status Confuses User: A member asked if LM Studio is open source, clarifying that only the LMS Client (CLI) and lmstudio.js (new SDK) are open source. Another member confirmed that the main LM Studio app is closed source.
- LM Studio Cannot Access Files: A user inquired about models accessing files on their PC using LM Studio, but another clarified that chatting with docs in LM Studio isn't possible and pointed to FAQ and pinned messages for more info.
- Discussion on RAG Frameworks: Members discussed low-code RAG frameworks and the integration of vector databases with RAG models, recommending llamaindex for development and considering fine-tuning models for infrequently changing data.
- Perplexity vs. LM Studio for Chat Organization: A member mentioned Perplexity's ability to create collections to save and organize chats, querying if LM Studio had a similar feature. It was confirmed that LM Studio does not support this functionality.
- File Summarization Limitations in LM Studio: Members discussed the challenges of summarizing book contents with LM Studio due to token limits and recommended using cloud-based AI like GPT4 or Claude 3 Opus for such tasks.
- Join the Mintplex Labs | AnythingLLM | VectorAdmin Discord Server!: Check out the Mintplex Labs | AnythingLLM | VectorAdmin community on Discord - hang out with 4259 other members and enjoy free voice and text chat.
- mistralai/Codestral-22B-v0.1 · Hugging Face: no description found
- bartowski/Codestral-22B-v0.1-GGUF · Hugging Face: no description found
- no title found: no description found
LM Studio ▷ #🤖-models-discussion-chat (19 messages🔥):
- Aya translation model gets a nod: A member recommended giving the Aya Japanese to English model a try for translation tasks. Both quality and efficiency were briefly highlighted.
- Highlight on Psyonic-Cetacean model: The 32 Bit Quantum Upscale of "Space Whale" was mentioned, noting significant performance improvements, including a reduction in perplexity by 932 points at a Q4KM. Learn more about this remastered version here.
- Codestral's anticipated release: Members expressed interest in Mistral's new code model, Codestral, which supports 80+ programming languages. Plans for integration into LM Studio were discussed, with a probable new app release required if the tokenizer changes.
- Hardware challenges for Aya 23 35B: Issues with the aya-23-35B-Q4_K_M.gguf model on a 4090 GPU were discussed, noting the model's need for more than 24GB of VRAM for optimal performance. Adjusting the context size was suggested as a solution to improve speed.
- Space Whale context limits checked: The context limit for the Space Whale model was confirmed by another member to be 4096 tokens. This was verified through the
llama.context_lengthconfiguration.
- Codestral: Hello, World!: Empowering developers and democratising coding with Mistral AI.
- DavidAU/Psyonic-Cetacean-Ultra-Quality-20b-GGUF · Hugging Face: no description found
LM Studio ▷ #📝-prompts-discussion-chat (5 messages):
- Switching Roles: One Model or Two?: A member inquired whether a model can perform both moderation and Q&A roles simultaneously. Another member advised that most models struggle with context switching and suggested using two separate models, while another hinted that server mode context handling could make it feasible.
LM Studio ▷ #⚙-configs-discussion (3 messages):
- Server mode is slower despite identical presets: A user noticed that results are obtained much faster when using chat mode compared to server mode, even though they used the same preset in both configurations. They checked and confirmed that the GPU is being utilized in server mode.
- Uncertainty about GPU selection on server: Another user inquired about how to select a GPU for server usage and expressed uncertainty about determining which GPU is being used. No solution or further information has been provided yet.
LM Studio ▷ #🎛-hardware-discussion (92 messages🔥🔥):
- Nvidia Bubble Debate Heats Up: Members questioned whether Nvidia's currently high valuation is justified or just a "bubble." One noted, "They could go much HIGHER!", while another suggested shorting Nvidia shares, arguing it cannot "last much longer."
- ASUS Vivobook S 15 USB Ports Impress: The ASUS Vivobook S 15 came under discussion for its impressive I/O capabilities, including "2 x USB4 ports" supporting 40Gbps data transfer. However, concerns about potential faults and recalls upon delivery were voiced.
- Goldensun3ds Upgrades to 44GB VRAM: A user outlined their setup, including a 5800X3D CPU, 64GB RAM, two RTX 4060 Ti 16GB GPUs, and an RTX 3060 12GB GPU. They debated the advantages of multiple GPUs over a single powerful GPU like the 3090, citing power consumption and VRAM as key factors.
- Motherboard and PCIe Lane Allocation Hurdles: Members discussed the complexities of running multiple GPUs efficiently, focusing on PCIe lane allocations and motherboard capabilities. "Someone needs to come out with some decent custom motherboards for AI," was a common sentiment.
- Modded GPUs Raise Eyebrows: The reliability and practicality of modded GPUs were questioned, especially a "2080ti modded 22GB." Participants pointed out, "That uses more power and has VERY questionable reliability," cautioning against their use.
- The Cathedral and the Bazaar - Wikipedia: no description found
- Reddit - Dive into anything: no description found
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- Express Gratitude: A user expressed gratitude by saying, "So true". They followed up with, "I will see what I can do, thank you all."
LM Studio ▷ #amd-rocm-tech-preview (9 messages🔥):
- iGPU support troubles LM Studio 0.2.24: A user inquired about iGPU support for ROCm in LM Studio 0.2.24, mentioning that it worked fine in version 0.2.20 but no longer does. Another user clarified that iGPUs are still unsupported in ROCm and suggested it was likely using OpenCL in the older version.
- How to revert to older version: After confirming that the previous setup was using OpenCL, a user asked for a link to the older version, 0.2.20, as it showed significantly better performance.
- Multi-GPU in OpenCL mode causes errors: A user reported success running a 7900 XT in ROCm mode but faced issues when adding a Radeon 570 to utilize extra VRAM, resulting in errors. Another user suggested that differences in card generations could be problematic.
- Adding similar generation GPUs: Considering adding a 7600 XT to the system, a user asked whether it would be compatible with a 7900 XT in ROCm mode. Another user advised to check AMD ROCm compatibility first but noted that there are good deals on 7900 XTs, suggesting a total VRAM boost might be more straightforward.
- 7900 XT deals shared: A user provided a link to a 7900 XT deal, highlighting it as a cost-effective option to expand VRAM and efficiently run larger models.
Link mentioned: Gigabyte AMD Radeon RX 7900 XT GAMING OC Graphics Card for Gaming - 20GB | Ebuyer.com: no description found
LM Studio ▷ #model-announcements (1 messages):
- Mistral's new coding model Codestral is live: The latest model from Mistral, named Codestral, is now available for download. This 22B model caters to users with larger GPUs looking for a highly powerful model to run. Check it out on Hugging Face.
Modular (Mojo 🔥) ▷ #general (75 messages🔥🔥):
- Documenting Flutter Porting Issues: A member suggested "document each thing missing when porting/writing a glue layer to Flutter" and prioritize specific feature requests. They emphasized that detailed and specific documentation is crucial to addressing blocking issues versus minor workarounds.
- C/C++ Interoperability in Mojo: Members expressed curiosity about the timeline for C/C++ Interoperability in Mojo, comparing potential approaches to Swift and discussing technical challenges and priorities. One member stated, "I'm really curious about C++ interoperability," while another noted it might not be a priority yet.
- Mojo and Clang Relationship: Discussions revealed technical details regarding Mojo's current compilation process and its reliance on LLVM. One member highlighted, "Mojo's stack is roughly mojo-(Modular compiler)- MLIR dialects- MLIR LLVM - LLVM," while another clarified that “Mojo will be able to import C/C++ headers."
- Debating ABI Compatibility: Members debated the practicalities of ABI stability and compatibility between different compilers, especially on Windows versus Linux. A member noted, "Clang implements GCC's C++ ABI because not doing so would have meant zero adoption," signaling the significant complexities involved.
- Referencing Polygeist and ClangIR Projects: Members shared resources about Polygeist and ClangIR, discussing their roles in facilitating C/C++ front-end development for MLIR. For instance, a member shared a YouTube link about a discussion on Mojo's development.
- Polygeist: no description found
- 2023 LLVM Dev Mtg - Mojo 🔥: A system programming language for heterogenous computing: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------Mojo 🔥: A system programming language for heterogenous computingSpeaker: Abdul Dakkak, Chr...
- Mojo Lang - Tomorrow's High Performance Python? (with Chris Lattner): Mojo is the latest language from the creator of Swift and LLVM. It’s an attempt to take some of the best techniques from CPU/GPU-level programming and packag...
- GitHub - llvm/Polygeist: C/C++ frontend for MLIR. Also features polyhedral optimizations, parallel optimizations, and more!: C/C++ frontend for MLIR. Also features polyhedral optimizations, parallel optimizations, and more! - llvm/Polygeist
- GitHub - llvm/clangir: A new (MLIR based) high-level IR for clang.: A new (MLIR based) high-level IR for clang. Contribute to llvm/clangir development by creating an account on GitHub.
- ClangIR · A new high-level IR for clang.: Clang IR (CIR) Clang IR (CIR) is a new IR for Clang. ClangIR (CIR) is built on top of MLIR and it's basically a mlir dialect for C/C++ based la...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1795883558608973828
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Ownership in Mojo's memory management made simple: Zapier discusses ownership in modern programming languages like Mojo, highlighting its role in providing a safe programming model for memory management while ensuring high performance. They recommend checking out Chris Lattner's deep dive video for detailed insights on how ownership is implemented in Mojo's compiler, providing further technical details. Read the full blog post here.
Link mentioned: Modular: What Ownership is Really About: A Mental Model Approach: We are building a next-generation AI developer platform for the world. Check out our latest post: What Ownership is Really About: A Mental Model Approach
Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- Taking Open-World Games Further with AI: A member proposed that open-world games could be truly revolutionary if the AI builds out custom worlds based on user interaction. They emphasized that the AI would only need a vast library of online models to choose from.
Modular (Mojo 🔥) ▷ #🔥mojo (35 messages🔥):
- Auto-dereferenced Proposal Sparks Naming Debate: A discussion ensued around a new auto-dereferenced references proposal. Suggestions included renaming Reference to TrackedPointer and Pointer to UntrackedPointer, emphasizing safety and avoiding misleading associations with terms like UnsafePointer.
- Issue with Package Path Resolution Solved: A member struggled with test code not finding definitions in their package structure. The solution involved including the
"-I ."flag with themojo run/testcommand to specify the parent path. - Tensor Initialization in Mojo Clarified: A query about easier tensor value assignment akin to numpy arrays was answered by suggesting the use of the
Indexutility. An example and further instructions were provided in this blog post. - Proposals Should be Numbered: There was a suggestion to number proposals for easier reference and order, similar to Python PEPs, though Mojo's proposals are currently less formal.
- Mojo References vs Go Pointers: A comparison between Mojo references and Go pointers highlighted that Mojo’s references are generally safer due to explicit typing and lack of nil references, unlike Go, which can have dangling pointers.
- [Proposal] New `ref` convention for returning references · modularml/mojo · Discussion #2874: Hi everyone, @lattner and I have developed an alternative "auto-deref" proposal to the one that Chris posted a few weeks ago. The new idea is to make auto-dereferencing a result convention, ...
- fnands - Parsing PNG images in Mojo: no description found
- Null References: The Billion Dollar Mistake : Tony Hoare introduced Null references in ALGOL W back in 1965 "simply because it was so easy to implement", says Mr. Hoare. He talks about that decision considering it "my billion-dolla...
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (7 messages):
- Align your table for AVX512 efficiency: "Make sure that the entire table is 64 byte aligned. This gives you faster versions of most of AVX512's loads and stores, and it makes sure you aren't wasting half of a cache line somewhere." Alignment is critical to pack as much of the table into your cache space and optimize performance.
- Optimizing prefetching with aligned memory: A large block of memory with aligned accesses is "screaming at the prefetcher to keep it hot." This emphasizes the importance of aligned memory for performance.
- False sharing only in multithreaded scenarios: The issue of false sharing is only problematic in multithreaded environments. Aligning memory can help mitigate this issue.
- Exploring alignment for Lists: A user expressed interest in aligning a List used to store tables, noting that DTypePointer has an alignment argument in its alloc but UnsafePointer (used by List) does not. "Maybe there is a way, I'll have to go scratch around a bit."
Modular (Mojo 🔥) ▷ #nightly (53 messages🔥):
- Navigating
Optionalin Mojo's ref API: Discussions about the newrefAPI highlighted challenges when using it withDict, as dereferencing remains awkward for key-value pairs. Members debated the merits of exceptions versusOptional, citing Rust's use of the?operator and exploring the possibility of special treatment for empty payloads.
- Feedback on Mojo's contributing guide: After encountering linter issues while proposing a new
refAPI, a member suggested improving the contributing guide. The recommendation was to emphasize the importance of installing pre-commit hooks to avoid CI errors, as clarified by a contributor.
- Bug in
InlineArraydestructor: A member asked for a fix for the issue whereInlineArraydoes not invoke the destructors of its elements, referencing GitHub issue #2869.
- Nightly Mojo compiler release: The new nightly Mojo compiler version
2024.5.2912was released with various updates including async function borrow restrictions and renaming of several standard library functions. The full changelog and raw diff between versions were shared.
- Discussion on changing default branch to nightly: A member suggested making the nightly branch the default on GitHub for a better development experience. The project manager explained that currently, 75% of users use the released versions, and changing the default branch could confuse less experienced users.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/CONTRIBUTING.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [Feature Request] DX: Change the default branch of modularml/mojo from `main` to `nightly` · Issue #2556 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? I would like a modularml admin to go to the settings o...
- [stdlib] [BUG] `InlineArray` does not invoke the destructors of its elements · Issue #2869 · modularml/mojo: InlineArray contains values of AnyType and copies on construction but does not invoke the destructors of its elements. We need to fix this.
Eleuther ▷ #general (24 messages🔥):
- EleutherAI welcomes new member inquiries: A new member, nearing the end of an undergraduate CS degree, sought advice on how to get started with EleutherAI. Other members suggested beginner-level research topics, providing a GitHub gist and other resources, noting some problems are accessible without extensive backgrounds.
- Research and question clarification challenges: Members discussed the difficulty in finding platforms where newcomers can ask basic questions without facing gaps in available knowledgeable respondents. Alternatives like ChatGPT were mentioned but noted for their occasional reliability issues.
- Exploration of multimodal AI research: A member expressed curiosity about the scarcity of professors specializing in multimodal AI, wondering if it's considered a subfield of CV and NLP. No substantial response clarified this.
- SPAR highlighted as a resource: The Supervised Program for Alignment Research (SPAR) was recommended as a valuable opportunity for developing AI safety skills. Although the current application deadline had passed, the program runs multiple times a year, offering ongoing opportunities.
- Tweet from Stella Biderman (@BlancheMinerva): Many people seem to think they can't do interesting LLM research outside a large lab, or are shoehorned into crowded topics. In reality, there are tons of wide-open high value questions. To prove ...
- Supervised Program for Alignment : SPAR provides a unique opportunity for early-career individuals and professionals to contribute to AI safety research by participating in mentorship, either as a mentor or mentee, in alignment researc...
- some simple topics for beginners in machine learning: some simple topics for beginners in machine learning - a.txt
Eleuther ▷ #research (43 messages🔥):
- Controversial Research Paper Lacks Experiments: Members were disappointed with a paper that presented intriguing results in the abstract but admitted in the content that "we haven't done any of the experiments yet actually lol." This raised questions about why the paper was published on arXiv.
- Debate Over Yann's Scientific Contributions: A heated discussion unfolded around Yann LeCun's standing in the scientific community, with some questioning his Turing Award and others defending his mentorship and earlier work. A member emphasized that his name on recent papers is not merely symbolic, citing positive feedback from his students.
- Comparisons to Megabyte Model: There was speculation about a model in the paper resembling the Megabyte model. A member noted, "its just megabyte no?" but others suggested there must be some differences.
- Constant Learning Rate Schedule Discussion: Members discussed the merits of using constant learning rate schedules versus fixed ones, sparked by a recent paper. One member summarized their preference for warmup schedules, highlighting past successes.
- Yann LeCun's Lecture on Engineering vs. Sciences: A member shared a YouTube link featuring Yann LeCun's lecture on "Engineering sciences vs. Fundamental sciences," contrasting this with his ongoing and past contributions to AI research.
- Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations: Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setu...
- The Epistemology of Deep Learning - Yann LeCun: Deep Learning: Alchemy or Science?Topic: The Epistemology of Deep LearningSpeaker: Yann LeCunAffiliation: Facebook AI Research/New York UniversityDate: Febru...
Eleuther ▷ #scaling-laws (90 messages🔥🔥):
- MLPs challenge Transformer dominance: Members discussed how recent research demonstrates that multi-layer perceptrons (MLPs) can perform in-context learning (ICL) competitively with Transformers and sometimes better on relational reasoning tasks. "These results suggest that in-context learning is not exclusive to Transformers and highlight the potential of exploring this phenomenon beyond attention-based architectures."
- Skepticism and optimization issues: Despite promising results from MLPs, some members expressed skepticism about their generalizability and pointed to potential weaknesses in the study's Transformer models. "Though i will say that their transformer is a bit suboptimal: they use post-layernorm with absolute positional encodings."
- Debate over sequence length and causality in MLPs: The discussion touched on how MLP-Mixer models handle sequence length and causality, similar to RNNS and Transformers. However, the necessity for tricks like weight-sharing and memory management raised concerns. "It seems like many weird tricks are needed to make the MLP model work with any sequence length and causal."
- MLPs in practical applications: Members discussed the practical applicability of MLP-Mixers, especially the ways these models handle input-dependent pooling and memory requirements. "It is very interesting tho, i might try it out at some point."
- Bitter lesson on model architecture: The broader theme of the conversation revolved around the idea that scaling and adaptability might be more crucial than the specific architecture, echoing the "Bitter Lesson" about the evolution of machine learning models. "Another example of the Bitter Lesson, and the one which will be memorable now that all the CNN dudes have aged out and been replaced by 'Transformers are magic pixie dust!' types."
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Efficient Language Modeling with Sparse all-MLP Sparse all-MLP improves LM PPL and obtains up to 2x improvement in training efficiency compared to Transformer-based MoEs as well as dense Transformers...
- Do Deep Convolutional Nets Really Need to be Deep and Convolutional?: Yes, they do. This paper provides the first empirical demonstration that deep convolutional models really need to be both deep and convolutional, even when trained with methods such as distillation th...
- Fully-Connected Neural Nets · Gwern.net: no description found
- A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP: Convolutional neural networks (CNN) are the dominant deep neural network (DNN) architecture for computer vision. Recently, Transformer and multi-layer perceptron (MLP)-based models, such as Vision Tra...
- Scaling MLPs: A Tale of Inductive Bias: In this work we revisit the most fundamental building block in deep learning, the multi-layer perceptron (MLP), and study the limits of its performance on vision tasks. Empirical insights into MLPs ar...
- MLPs Learn In-Context: no description found
- MLPs Learn In-Context: In-context learning (ICL), the remarkable ability to solve a task from only input exemplars, has commonly been assumed to be a unique hallmark of Transformer models. In this study, we demonstrate that...
Eleuther ▷ #lm-thunderdome (9 messages🔥):
- Traceback on AMD trying to calculate max memory: A member experienced a traceback on AMD when attempting to calculate max memory and questioned if it was an environmental issue. They linked a GitHub Gist containing the error and noted that specifying max_memory_per_gpu circumvents the issue.
- Running concurrent queries with lm-evaluation-harness: A member using lm-evaluation-harness with vLLM instances noted the benchmark runs one query at a time and asked if batch processing is possible. They also inquired about running logits-based tests despite 'local-chat-completions' not supporting them and requested pseudo-code explaining the use of logits/logprobs in extracting textual answers.
- Question about maj1@k in gsm8k evaluation: A member working on fine-tuning for the gsm8k dataset sought clarification on the acc@1 reported in a paper and queried about the unspecified value of k. Another member responded, suggesting to refer to the reported llama2 results, indicating it was likely maj1@1.
Link mentioned: gist:0004bf39a3cec65262cf72f556c316c4: GitHub Gist: instantly share code, notes, and snippets.
OpenAI ▷ #annnouncements (1 messages):
- ChatGPT Free users get new features: "All ChatGPT Free users can now use browse, vision, data analysis, file uploads, and GPTs." This includes browse, vision, data analysis, file uploads, and GPTs capabilities.
OpenAI ▷ #ai-discussions (100 messages🔥🔥):
- Google's ImaGen3 set for release, users skeptical: Discussions arose about the beta testing of ImaGen3, announced at Google I/O, replacing an older version amidst concerns of manipulation and public trust issues. One user humorously noted, "they had one job."
- Custom GPTs misbehaving: Users shared frustrations with custom GPTs not remembering things well and being generally unresponsive. One user mentioned, “Mine are refusing to remember things and generally being lazy.”
- Google AI controversies continue: Heated discussions pointed out that Google's AI image generator had issues with generating accurate historical images, with instances like “Nzi black women” discussed as examples of poor filter calibration. One user noted, “Google dropped the ball so hard on AI."*
- Visibility in AI research and development: Use of OpenAI models and legal implications were discussed, with users debating whether OpenAI would go after personal projects using their data. Concerns about scams and fraud involving OpenAI also surfaced.
- Mathematics and AI revolution: A user shared thoughts on an article titled "Why Mathematics is Set to be Revolutionized by AI" and engaged in a discussion about a challenge posed by a professor on whether AI can replicate complex mathematical proofs across different dimensions.
OpenAI ▷ #gpt-4-discussions (30 messages🔥):
- Headache from Disappearing Memories: Many users shared frustrating experiences with general memory in ChatGPT, reporting it as often disappearing and then later reappearing. One user suggested that long-term memory could benefit from transparency and a backup option, saying, "I deeply wish the principles/rules/protocols for the memory system were transparent. And a backup button."
- RAM Usage Overload Annoys Users: Users reported high RAM usage when engaging in lengthy conversations with ChatGPT, notably on Brave where memory usage spiked up to 32GB and caused crashes. One tip was to use Safari or the desktop app which reportedly handle large chats better.
- GPT Store Access for Free Users: Some users celebrated free access to the GPT Store, though it was noted that GPTs would only run on the 3.5 version for free users.
- Annoying Word Salad Outputs: A user complained that GPT-4 tends to generate "word salad" after prolonged use, where initial coherent responses degrade into a jumble of buzzwords and nonsensical phrases. They shared an example where the response started logically and then devolved into gibberish.
OpenAI ▷ #prompt-engineering (3 messages):
- Prompt Sharing Channel Highlighted: A member inquired, "Are all amazing prompts shared somewjere?". Another user referred them to the #1019652163640762428 channel for shared prompts.
OpenAI ▷ #api-discussions (3 messages):
- Prompt Resources Available in Specific Channel: A user asked if all "amazing prompts" are shared somewhere, and another user directed them to channel <#1019652163640762428>. This suggests a dedicated place for sharing high-quality prompts within the Discord community.
Interconnects (Nathan Lambert) ▷ #news (60 messages🔥🔥):
- OpenAI's alignment discussion triggers mixed reactions: A user linked a tweet from Jan Leike discussing alignment, which others mentioned muting due to the prevalence of "doomerism and bait" tweets. Another user stated they find blocking more effective than muting.
- Mistral launches Codestral, a new 22B code model: Codestral is an open-weight model fluent in over 80 programming languages and designed for code generation tasks. Codestral is available on HuggingFace and for free during an 8-week beta period.
- Scale AI debuts LLM leaderboard: Scale AI launched a new LLM leaderboard with heldout private data. A user voiced concerns about potential biases, citing the company’s incentives and the use of the same crowd workers for evaluations and paid client data.
- Google's Gemini 1.5 Flash faces pricing controversy: Google was criticized for nearly doubling the price of Gemini 1.5 Flash output without notice shortly after the model's launch. Users debated whether this price adjustment was an overreaction, noting the initial praise for its cost-effectiveness.
- Codestral: Hello, World!: Empowering developers and democratising coding with Mistral AI.
- Tweet from Ross Taylor (@rosstaylor90): Credit rating agencies had misaligned incentives in the 2000s: the providers of the products they rated were the ones paying them. (My first job was regulating CDOs post-crisis, lol) Similarly a comp...
- Tweet from xjdr (@_xjdr): with the 22B code model, there should be enough datapoints to extract a single 22B dense model from the 8x22B MoE (not sure what that would do to the licenses) it probably wouldnt need any additional ...
- Tweet from Nathan Lambert (@natolambert): @TheXeophon @Teknium1 DON'T PUS HME TOO FAR BABY
- Tweet from Mistral AI Labs (@MistralAILabs): Request Codestral access at https://console.mistral.ai/codestral. It's free during a beta period of 8 weeks!
- Tweet from 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr): Google raised the price of Gemini 1.5 Flash output by 98% without telling anyone. This just a week after announcing the model. Output goes from 0.53/1M to 1.05/1M. How can we trust an API that dras...
- Tweet from Nathan Lambert (@natolambert): i'm so over these plots for marketing. here's a version if you scale the y axis from 0 to 100 on HumanEval thx chatgpt :) Quoting Theophile Gervet (@theo_gervet) We just released our first...
- Tweet from Qian Liu 🔭 (@sivil_taram): Congratulations on the new release of Codestral, and welcome the new powerful coding model to join the open source community! A small patch to the figure: add CodeQwen1.5 🤔 Disclaimer: I am not the...
Interconnects (Nathan Lambert) ▷ #ml-drama (30 messages🔥):
- Helen Toner spills the tea on OpenAI: A former OpenAI board member, Helen Toner, revealed shocking details about Sam Altman’s firing, citing frequent dishonesty and a toxic work environment. The podcast discussed balancing innovation with oversight in fast-developing AI (link to podcast).
- Board blindsided by ChatGPT launch: Helen mentioned that the board learned about ChatGPT via Twitter, reflecting gaps in communication and transparency within OpenAI management. This lack of advance notice was a key concern for the board.
- Mixed feelings on information release: Members debated why Helen Toner didn’t release her information sooner, with some attributing it to legal constraints. There was general agreement that internal politics and external pressures likely influenced the board’s communications.
- Sam Altman's defense: The board's formal response to these accusations was that there were no real issues with product safety or finances justifying Sam's firing. They emphasized their mission to ensure Artificial General Intelligence (AGI) benefits everyone and highlighted their commitment to moving forward.
- Firing rationale questioned: Despite Helen's compelling accusations, members noted that the board's stated reason for the firing—"not consistently candid communications"—seemed weak. They speculated that legal considerations limited the board's ability to fully disclose reasons.
- Tweet from Tibor Blaho (@btibor91): @TheXeophon https://dts.podtrac.com/redirect.mp3/chtbl.com/track/48D18/dovetail.prxu.org/6792/49695742-c50c-4a16-83ba-407f75b3f301/TED_AI_E02_Helen_Toner_Seg_A_-_YES_COMMENT_2024-05-28.mp3
- Tweet from Bilawal Sidhu (@bilawalsidhu): ❗EXCLUSIVE: "We learned about ChatGPT on Twitter." What REALLY happened at OpenAI? Former board member Helen Toner breaks her silence with shocking new details about Sam Altman's firing....
Interconnects (Nathan Lambert) ▷ #random (4 messages):
- FMTI uses CSV instead of markdown: A user expressed frustration about the FMTI GitHub repository storing scores as CSV files instead of markdown. They stated, "they closed it because they’re uploading the scores as csv in each batch of the paper into a new folder."
- Personalized study music with generative models: A suggestion was made about using generative audio models to create personalized study music, specifically tailored for coding, reading, or writing. Another user humorously added that such a system might optimize playlists for completions instead, reflecting concerns over productivity-focused designs.
Interconnects (Nathan Lambert) ▷ #memes (10 messages🔥):
- Mini journal club idea gains interest: A member proposed forming a "mini journal club" and discussed potential formats. Another member was interested but pointed out the need for a structured format, stating that a "casual podcast format is not that interesting."
- Cohere's educational series stands out: Discussions unfolded about educational resources, with some members expressing fondness for Cohere's educational video series. One member suggested that it would be helpful if researchers could "walk through the paper in 30-45 mins sharing their key takeaways / highlights."
- TalkRL podcast underrated: A member shared that the TalkRL podcast is "super underrated." Another member agreed, highlighting that ML Street Talk sometimes "gets heavy very quickly and hard to follow" due to its philosophical context.
- Mixed reception of Schulman episode: A conversation emerged around the recent Dwarkesh's podcast episode with Schulman. Some members found it dry and noted a lack of sync between host and guest, impacting the overall discussion quality.
Interconnects (Nathan Lambert) ▷ #rl (3 messages):
- Enthusiasm for DMC-GB2 GIFs: A member shared their excitement about the GIFs in the DMControl Generalization Benchmark 2 (DMC-GB2) repository. They praised the visual appeal, stating "the gifs in this repo are just so good."
- Affection for Reinforcement Learning: Expressing nostalgia, a member remarked "i miss rl." Another member comforted them by saying, "RL is there for you with open arms."
Link mentioned: GitHub - aalmuzairee/dmcgb2: Official release of the DMControl Generalization Benchmark 2 (DMC-GB2): Official release of the DMControl Generalization Benchmark 2 (DMC-GB2) - GitHub - aalmuzairee/dmcgb2: Official release of the DMControl Generalization Benchmark 2 (DMC-GB2)
Interconnects (Nathan Lambert) ▷ #posts (7 messages):
- Stickers Discussion Underway: Amid a light-hearted conversation about stickers, Nathan Lambert mentioned, "Need to figure out good stickers… Haven’t figured it out yet." He later mentioned they are "working on stickers. Not nathan lambert tho lol."
- SnailBot News Update Incoming: SnailBot News tagged a role with, "<@&1216534966205284433>". More details about SnailBot were not provided in this excerpt.
Interconnects (Nathan Lambert) ▷ #retort-podcast (5 messages):
- Tom's Rousseau Reference Strikes a Chord: A member enjoyed the latest episode and appreciated Tom's background, particularly mentioning the thought-provoking Rousseau reference. They marked Discourse on Inequality as a noteworthy discussion point.
- Hierarchy-Informed Model Spec: A user linked to Andrew Carr’s tweet discussing OpenAI's alignment research that incorporates "instruction hierarchy" to mitigate jailbreaking attacks. The modular prompt structures and hierarchical privileges were noted as crucial elements.
- Transformative Exceptions Raise Eyebrows: There was a discussion about the grey areas in policies regarding transformative exceptions. The anticipation of new model releases with extensive context windows was mentioned as possibly influencing these policies due to high costs in running classifiers.
Link mentioned: Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): cool new alignment research from OpenAI. they generate synthetic data that encourages "instruction hierarchy" where system prompts are treated as more important by the model. this then pre...
Stability.ai (Stable Diffusion) ▷ #general-chat (117 messages🔥🔥):
- Colab and Kaggle suggested for faster image generation: Users discussed their experiences with various online hosting services, recommending Kaggle or Colab for better and faster image generation. One user noted that "1 img takes 1:30m or 2m on Colab with 16GB VRAM".
- Training Stable Diffusion XL LoRA Models: Members exchanged tips on training SDXL LoRA models, discussing optimal steps, epochs, and the importance of the number of training images. "2-3 epochs recommended" and "short trigger words work better" for training.
- Auto1111 and ComfyUI model path issues: Members sought advice on configuring ComfyUI extra model paths to load models from multiple directories. Additionally, inquiries about integrating ADetailer within the local Stable Diffusion API were raised.
- HUG and Stability AI Course: Discussion about the HUG and Stability AI collaboration for a creative AI course, where sessions will be recorded and accessible after live streaming. Completion of the course and a feedback form is required to refund the deposit.
- 3D Models with Stable Diffusion: Users talked about the potential for AI-generated 3D models and their applicability to 3D printing. One member stated, “No, it doesn't at all. Yet,” reflecting the current limitations.
- Yas Hyped GIF - Yas Hyped Lit - Discover & Share GIFs: Click to view the GIF
- HUG x Stability AI Innovation Laboratory — HUG: Discover your own unique innovation with Stability AI and receive real-time strategic, marketing, and creative education from HUG.
LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex introduces PropertyGraphIndex: A new feature for building knowledge graphs with LLMs was announced in collaboration with Neo4j. The tweet and blog post provide more details.
- Sophisticated tools for knowledge graph construction: The feature includes tools to extract and query knowledge graphs using various retrievers like keywords, vector search, and text-to-cypher. Users can now perform joint vector search and graph search, regardless of graph store compatibility with vectors.
- Customization and flexibility emphasized: It allows for defining custom extractors and retrievers, making it intuitive to work with labeled property graphs. Each node/relationship can have labels and properties, enabling robust knowledge graph structures.
- Detailed guides and examples available: Comprehensive guidance and example notebooks are provided in the docs, with both basic and advanced use cases thoroughly documented. Integration with Neo4j is also covered in the usage guide.
- Collaboration with Neo4j hailed: Significant contributions were made by Neo4j experts including @tb_tomaz to create integration guides and refactor abstractions for seamless functionality.
Link mentioned: Tweet from LlamaIndex 🦙 (@llama_index): We’re excited to launch a huge feature making @llama_index the framework for building knowledge graphs with LLMs: The Property Graph Index 💫 (There’s a lot of stuff to unpack here, let’s start from ...
LlamaIndex ▷ #blog (5 messages):
- **FinTextQA dataset converges on finance**: The FinTextQA dataset offers **1,262 high-quality, source-attributed question-answer pairs** and covers six different question types. It provides a robust context for document-based financial question answering [source](https://t.co/emhQYXY1S4).
- **PostgresML integrates with LlamaIndex**: If you're into Postgres and AI applications, check out [PostgresML](https://t.co/G7WTrSdt0B). It allows for **local embedding, model training, and fine-tuning** in Python and JavaScript.
- **LlamaIndex launches the Property Graph Index**: The Property Graph Index offers new tools for constructing and querying knowledge graphs with LLMs (**Large Language Models**). This new feature aims to position LlamaIndex as a comprehensive framework for building knowledge graphs [source](https://t.co/X9D3Wl0Hyv).
- **Codestral code-gen model now available**: The new **Codestral** model from MistralAI supports over **80 programming languages** and can run locally. LlamaIndex offers **day 0 support** along with a detailed [notebook](https://t.co/k2nHDiMnwD) to demonstrate its usage.
- **Ollama enhances Codestral support**: As a bonus, the Codestral model is fully supported by [Ollama](https://t.co/gsPHHF4c0K), enabling users to run it locally with first-class support.
LlamaIndex ▷ #general (107 messages🔥🔥):
- Semantic Chunking Debate in RAG Models: Members discussed the trade-off between large and small semantic text chunks in RAG (Retrieval Augmented Generation) models. They considered embedding multiple versions of the same text for better retrieval and pointed out challenges like co-reference resolution in chunking strategies.
- LlamaIndex Enhancements and Support: Members shared experiences and queries regarding using LlamaIndex for various purposes, such as ArangoDB support and customized tokenizer settings. One mentioned the GitHub repository for the Semantic Document Parser to generate high-quality text chunks for RAG.
- Embedding and Retrieving Models: There was a discussion on setting up and using different embedding models, especially for non-English texts. Members recommended models from HuggingFace for specific language tasks, such as Arabic Data embedding.
- Combining and Managing Vector Stores: A user sought help merging Qdrant vector store indexes, and a solution involving
QueryFusionRetrieverfrom LlamaIndex documentation was suggested. Another query involved the chat memory buffer for multi-modal input using GPT-4o.
- Saving and Extracting Nodes in LlamaIndex: Members inquired about managing nodes in LlamaIndex, including saving nodes using
docstore.persist()and extracting nodes with theget_all_documents()method. They discussed using different document store backends like RedisDocumentStore and MongoDocumentStore.
- asafaya/bert-base-arabic · Hugging Face: no description found
- GitHub - isaackogan/SemanticDocumentParser: Advanced parser to generate high quality text chunks for RAG.: Advanced parser to generate high quality text chunks for RAG. - isaackogan/SemanticDocumentParser
- Document Stores - LlamaIndex: no description found
- ">no title found: no description found
- Arango db - LlamaIndex: no description found
- Multi-Modal Applications - LlamaIndex: no description found
- Simple Fusion Retriever - LlamaIndex: no description found
Latent Space ▷ #ai-general-chat (72 messages🔥🔥):
- **Gemini 1.5 impresses with performance**: After the release of the Gemini 1.5 results, it was noted that **Gemini 1.5 Pro/Advanced** ranks second, closely trailing GPT-4o, and **Gemini 1.5 Flash** ranks ninth, outperforming models like Llama-3-70b. The comprehensive breakdown can be found on [LMSysOrg's Twitter](https://x.com/lmsysorg/status/1795512202465845686).
- **Insights from building with LLMs**: The article "[What We Learned from a Year of Building with LLMs](https://www.oreilly.com/radar/what-we-learned-from-a-year-of-building-with-llms-part-i/)" discusses the rapid advancement of LLMs and the challenges in building effective AI products beyond demos.
- **Excitement over SWE-agent's potential**: After Princeton researchers unveiled the **SWE-agent**, claims about its superior performance and its open-source nature sparked interest. More details were shared on [Gergely Orosz's Twitter](https://x.com/GergelyOrosz/status/1794743519954731331) and the [SWE-agent GitHub](https://github.com/princeton-nlp/SWE-agent).
- **New open-source VLM model - Llama3-V**: The **Llama3-V** model claims to outperform **LLaVA** and compete closely with models like GPT4-V, emphasizing its efficiency with a significantly smaller model size. Details and access links were provided on [Sidd Rsh's Twitter](https://x.com/siddrrsh/status/1795541002620727439).
- **Scale announces SEAL Leaderboards for LLM evaluations**: **Scale's SEAL Leaderboards** aims to offer private, expert evaluations to ensure robust and non-exploitable model assessments. The initiative was highlighted by [Alexandr Wang](https://x.com/alexandr_wang/status/1795857651592491281) and received commendation from [Andrej Karpathy](https://x.com/karpathy/status/1795873666481402010).
- What We Learned from a Year of Building with LLMs (Part I): no description found
- Why you shouldn't use AI to write your tests (Changelog News #96): Swizec’s article on not using AI to writes tests, LlamaFs is a self-organizing file system with Llama 3, a Pew Research analysis confirmed that the internet is full of broken links, Sam Rose built a s...
- How aider scored SOTA 26.3% on SWE Bench Lite: Aider achieved this result mainly through its existing features that focus on static code analysis, reliable LLM code editing, and pragmatic UX for AI pair programming.
- Tweet from Arthur Mensch (@arthurmensch): With Codestral, our newest state-of-the-art code model, we are introducing the Mistral AI non-production license (MNPL). It allows developers to use our technology for non-commercial use and research....
- Tweet from Gergely Orosz (@GergelyOrosz): If building an AI coding agent performing ~4x better than the best LLMs has a billion-dollar potential: Here are 7 Princeton researchers who did this. It's all open source, and called SWE-agent....
- Tweet from Siddharth Sharma (@siddrrsh): Introducing Llama3-V, a SOTA open-source VLM model We feature: • Outperforms LLaVA • Comparable performance to GPT4-V, Gemini Ultra, Claude Opus with a 100x smaller model • SOTA open source VLM for L...
- Tweet from Alexandr Wang (@alexandr_wang): 1/ We are launching SEAL Leaderboards—private, expert evaluations of leading frontier models. Our design principles: 🔒Private + Unexploitable. No overfitting on evals! 🎓Domain Expert Evals 🏆Contin...
- Tweet from lmsys.org (@lmsysorg): Big news – Gemini 1.5 Flash, Pro and Advanced results are out!🔥 - Gemini 1.5 Pro/Advanced at #2, closing in on GPT-4o - Gemini 1.5 Flash at #9, outperforming Llama-3-70b and nearly reaching GPT-4-01...
- Tweet from OpenAI (@OpenAI): All ChatGPT Free users can now use browse, vision, data analysis, file uploads, and GPTs. Quoting OpenAI (@OpenAI) We're opening up access to our new flagship model, GPT-4o, and features like b...
- Tweet from Alexandr Wang (@alexandr_wang): 1/ We are launching SEAL Leaderboards—private, expert evaluations of leading frontier models. Our design principles: 🔒Private + Unexploitable. No overfitting on evals! 🎓Domain Expert Evals 🏆Contin...
- Tweet from Rohan Pandey (e/acc) (@khoomeik): 📢 Excited to finally be releasing my NeurIPS 2024 submission! Is Chinchilla universal? No! We find that: 1. language model scaling laws depend on data complexity 2. gzip effectively predicts scaling...
- Tweet from Mistral AI Labs (@MistralAILabs): Announcing Codestral: our first-ever code model. - Open-weights under the new Mistral AI Non-Production License - New endpoint via La Plateforme: http://codestral.mistral.ai - Try it now on Le Chat: h...
- DocArray: no description found
- Tweet from Andrej Karpathy (@karpathy): Nice, a serious contender to @lmsysorg in evaluating LLMs has entered the chat. LLM evals are improving, but not so long ago their state was very bleak, with qualitative experience very often disagre...
Latent Space ▷ #ai-announcements (1 messages):
- AI Agent Architectures and KANs event at 12 PM PT: Latent Space is hosting an event on AI Agent Architectures and Kolmogorov Arnold Networks today at 12 PM PT. Event registration and details are available and attendees are encouraged to add the event to their calendars via the RSS logo on the event page.
Link mentioned: LLM Paper Club (AI Agent Architectures + Kolmogorov Arnold Networks) · Zoom · Luma: a 2-for-1! Eric Ness will cover https://arxiv.org/abs/2404.11584 (The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A…
Latent Space ▷ #llm-paper-club-west (2 messages):
There are no messages to summarize for the channel llm-paper-club-west.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenAI faces temporary downtime: "OpenAI usage is temporarily down for many users," with Azure and Azure fallback still operational. The issue was resolved quickly with an update: "EDIT: it's back."
- Cinematika model to be deprecated: The Cinematika model is being discontinued due to very low usage. Users are advised to migrate to a new model immediately: "Please switch to a new one!"
OpenRouter (Alex Atallah) ▷ #general (51 messages🔥):
- OpenAI Models Hit Spending Limit: Members discussed issues with OpenAI models being inaccessible due to hitting spending limits unexpectedly. Alex Atallah promised an announcement and a fix, mentioning that normal OpenAI usage was restored with additional checks being put in place.
- Prompting Gemini Models Request: A member asked for a guide on prompting Gemini models but did not receive a response. This request indicates ongoing interest and potential areas for user support or documentation.
- Media Attachments Policy: Cupidbot.ai inquired about the restriction on sending media. Alex Atallah explained that media was restricted to a specific channel to control spam and promised to allow elevated roles to post attachments, with Louisgv agreeing to the change.
- GPT-4o Context and Token Limits: A concern was raised about the GPT-4o context limit being reduced to 4096 tokens. Alex Atallah clarified that the context limit is 128k, with a maximum of 4096 output tokens.
- Slow Image Processing with GPT-4o: A user reported slow image processing while using
openai/gpt-4owithimage-urlinput, taking minutes per prompt. This points to potential performance issues needing attention.
- Oh No Homer GIF - Oh No Homer Simpsons - Discover & Share GIFs: Click to view the GIF
- Streamlit: no description found
- lluminous: no description found
LAION ▷ #general (23 messages🔥):
- Helen Toner on ChatGPT: Users shared a link to a Reddit post where Helen Toner mentions they "learned about ChatGPT on Twitter".
- LeCun's Publishing Status: There was a discussion on whether Yann LeCun, a well-known AI figure, stopped publishing papers after becoming VP at Facebook. Some felt LeCun was still actively contributing.
- Elon Musk's AI Models Positioning: Members debated Elon Musk's stance on open-source models, noting that Musk only released models when they were no longer competitive. A link to xai-org on Hugging Face was shared as part of the discussion.
- Mistral AI Model Licensing: The Mistral AI model was highlighted for its business approach of having "open weights" despite being under a non-commercial license. Related links and other updates were shared to provide more details.
- Muting Elon Musk on Twitter: A user mentioned muting Elon Musk on Twitter due to his controversial statements and behavior. This spurred others to talk about their reactions to Musk's purchase of Twitter, with one deleting their account.
Link mentioned: Reddit - Dive into anything: no description found
LAION ▷ #research (17 messages🔥):
- Compel Process Issues with Synthetic Captions: Conversations highlight that using ‘a woman reading a book’ as a prompt in the compel process leads to problems, even with strong synthetic captions. A user mentioned, “bad things start to happen”, indicating challenges in generating accurate outputs.
- Dinov2 and UNet Configuration in Research Paper: There was an exchange of insights about a research paper, arxiv.org/abs/2405.18407, noting the use of Dinov2 as a discriminator. However, it was found that “a pretrained unet with a network on top was better,”, similar to the approach taken by Kandinsky where they “cut the unet in half and trained it as a discriminator.”
- Horde Community’s Incentivized Rating System: A user inquired about the Horde AI community’s tools for rating SD images, offering kudos for contributions which can be used to generate more images. However, another user showed disinterest in the system, and concerns were raised that “incentives for rating will almost always lead to poorer data.”
Link mentioned: Phased Consistency Model: The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in ...
LangChain AI ▷ #general (26 messages🔥):
- Langchain v2.0 agents confusion: A user expressed difficulty in locating agents in LangChain v2.0 but later confirmed they found them.
- Innovative AI discussions: A member shared a tweet about allowing machines to redefine creativity and innovate beyond repetitive tasks, inciting thoughts on AI creativity (Tweet).
- Handling RateLimit errors in LangChain: For handling "RateLimit" errors in LangChain, standard try/except mechanisms in Python were suggested, with an example provided to guide error handling.
- ConversationalRetrievalChain issue: A member reported incomplete content retrieval using ConversationalRetrievalChain with multiple vectorstores and sought a resolution for data merging issues.
- CSV dataset to Vectorstore for retrieval: Detailed instructions were shared on how to process a CSV dataset into a vectorstore for retrieval, including loading the CSV file and creating the vectorstore using
langchainlibraries (More info).
- Handling tool errors | 🦜️🔗 LangChain: Using a model to invoke a tool has some obvious potential failure modes. Firstly, the model needs to return a output that can be parsed at all. Secondly, the model needs to return tool arguments that ...
- Tweet from Dorsa Rohani (@Dorsa_Rohani): How do we allow machines to express themselves? Right now, AI copies. Repeats. I want to build AI that innovates and creates the novel. But how do we get AI to test the limits and redefine creativit...
- Lantern | 🦜️🔗 LangChain: Lantern is an open-source vector similarity search for Postgres
- Infinispan | 🦜️🔗 LangChain: Infinispan is an open-source key-value data grid, it can work as single node as well as distributed.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langserve (1 messages):
- Langserve Example with Chat History: A member is testing chat history with langserve using a provided example from GitHub. They seek assistance on how to "include my chat_history in the body" with details provided in the FastAPI documentation.
Link mentioned: langserve/examples/chat_with_persistence_and_user/client.ipynb at main · langchain-ai/langserve: LangServe 🦜️🏓. Contribute to langchain-ai/langserve development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (1 messages):
- Routing Logic in Agent Flows with Visual Agents: A YouTube video titled "How to Route Logic in Your Agent Flows" was shared. The video provides a simple example of using routing logic in agent flows with Visual Agents, built on LangChain. You can check it out here.
Link mentioned: How to Route Logic in Your Agent Flows: Simple example of how to use routing logic in your agent flows with Visual Agents, built on LangChain.https://visualagents.aihttps://langchain.ai
OpenInterpreter ▷ #general (18 messages🔥):
- Personalize training workflows: A member expressed the desire to do their own training, highlighting that "each of us have our own workflows and our own use cases."
- Open Interpreter use cases: Another member asked the community about their use cases for Open Interpreter, sparking a discussion about various applications.
- Open-source Rewind alternatives: Members discussed alternatives to Rewind, with one mentioning Rem and another sharing their experience using Rewind’s free version in combination with the Cohere API for querying the vector DB.
- Phidata and Rewind connectivity praised: A member shared their positive experience with Rewind, noting that although it doesn't hide passwords or credentials, they find its "life hack" capabilities invaluable.
- Running OI without confirmation: A member inquired about running Open Interpreter without needing confirmation, discussing potential solutions like using pyautogui and eventually finding a solution with the
--auto_runfeature, as pointed out in the documentation.
Link mentioned: All Settings - Open Interpreter: no description found
OpenInterpreter ▷ #O1 (3 messages):
- Flashing the M5 using Arduino hits roadblock: A user managed to flash the M5 using Arduino and opened the captive portal successfully. However, after server setup, the device now shows a white screen when accessed, with no options to connect to a Wi-Fi network or server, even after re-flashing.
- Suggestions for resolving white screen on M5: Another user suggested setting Arduino studio settings to erase memory when flashing as a potential fix for the issue.
OpenInterpreter ▷ #ai-content (1 messages):
mikebirdtech: https://www.youtube.com/watch?v=sqwtk18pw14
OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
- NSFW Discord invite spam alert: A member alerted moderators about NSFW Discord invite links being spammed in multiple channels. They mentioned not being sure if the moderator ping was effective.
- Moderator response to NSFW spam: A moderator acknowledged and took action on the spam issue, thanking the member for the report.
- Inquiry on fine-tuning LLMs for multimedia understanding: A member asked for guidance on fine-tuning large language models (LLMs) for images and videos understanding, specifically referencing models like LLava models. No responses were provided within the message history.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (9 messages🔥):
- Proposal for Updating Gradient Checkpointing in Unsloth: A member suggested updating the gradient checkpointing code in Unsloth to support MoE and shared the proposed code update. They received confirmation to proceed with a PR once verified.
- Untrained Token Fix Consideration: There was a discussion about the untrained token fixes, where a member confirmed no double bos_token issues exist but suggested considering untrained token fixes.
- Efficient Bin Packing Update: Another member mentioned the updated bin packing being much more efficient and inquired about issues with distributed training. A user experienced training getting stuck after the first evaluation, possibly due to the new sampler not implementing
_len_est.
- Call for Backend Developer with Specific Skills: A member requested someone knowledgeable in backend development and Google's protobuf, seeking expertise similar to a reverse engineer, malware analyst, or bug bounty hunter. They offered payment for the assistance.
- Reverted Multipack Batch Sampler Changes: The PR to revert multipack batch sampler changes was shared by a member, indicating the loss calculations in the previous implementation were off by an order of magnitude. PR #1672 - Revert multipack batch sampler changes.
Link mentioned: revert multipack batch sampler changes by winglian · Pull Request #1672 · OpenAccess-AI-Collective/axolotl: The loss isn't quite right w/ #1619, off by an order of magnitude.
Cohere ▷ #general (6 messages):
- Consider RAG instead of JSONL finetuning for PDFs: A member suggested using a Retrieval Augmented Generation (RAG) approach for PDFs to avoid the need for finetuning. "You might want to consider a RAG approach, which removes the need to finetune on the pdf."
- How to access response.citations in API: The response.citations feature is reportedly accessible only through the API. An example was provided to illustrate this grounded generation approach.
- Local R+ implementation includes force citations: One member shared their success in building a pipeline for RAG within a local implementation of Command R+, which ensures citations are included. "In my application powered by local R+, I built a pipeline for RAG and force showing citations obtained by locally running embedding model."
- Discord bot using Cohere praised but needs proper channel: A member appreciated another member's Discord bot but suggested moving the discussion to the appropriate project channel. "I love your discord bot, and its use of Cohere! It’s just that we have a channel for projects!"
Link mentioned: CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
tinygrad (George Hotz) ▷ #general (4 messages):
- Elon Musk's xAI gets big funding boost: xAI announced raising 6 billion in funding to "bring the startup's first products to market, build advanced infrastructure, and accelerate R&D of future technologies." Backers include Andreessen Horowitz, Sequoia Capital, and Saudi Arabian Prince Al Waleed bin Talal, among others.
- Doubt about analytical tools: One member stated that tools discussed in the channel are of "negligible usefulness" without specifying what tools they were referring to.
- Fireship video impresses with Bend language: Another member praised the Bend language featured in a Fireship video, highlighting its ability to "automatically multi-thread without any code," which aligns well with tinygrad's lazy execution.
- Query about tinybox power supply: There was a question asked about whether the tinybox uses "two consumer power supplies or two server power supplies with a power distribution board."
Link mentioned: Elon Musk’s xAI raises $6 billion to fund its race against ChatGPT and all the rest: How much of that money is going to be spent on GPUs?
DiscoResearch ▷ #general (4 messages):
- Goliath sees performance drops before continued pretraining: A member asked if there were large performance drops in Goliath before continued pretraining. This sparked interest and tagged responses from other users.
- GPT-2 replication in llm.c noted: A discussion on GitHub detailed reproducing GPT-2 (124M) in llm.c for $20 and achieving a HellaSwag accuracy of 29.9, surpassing GPT-2's 29.4. The comparison was made to GPT-3 models which were trained for significantly longer.
- Mistral AI launches Codestral-22B, its first code model: Guillaume Lample announced the release of Codestral-22B, a model trained on more than 80 programming languages. It outperforms previous models and is available on their API platform, VScode plugins, and Le Chat.
- LAION AI seeks community help with open GPT-4-Omni: LAION AI shared a blog post asking for assistance in building an open GPT-4-Omni. They provided promising directions, datasets, and tutorials in the post here.
- Tweet from LAION (@laion_ai): Help us build an open GPT-4-Omni! With this blog post we show promising directions (including data sets and tutorials) https://laion.ai/notes/open-gpt-4-o/
- Tweet from Guillaume Lample @ ICLR 2024 (@GuillaumeLample): Today we are releasing Codestral-22B, our first code model! Codestral is trained on more than 80 programming languages and outperforms the performance of previous code models, including the largest on...
- Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 · karpathy/llm.c · Discussion #481: Let's reproduce the GPT-2 (124M) in llm.c (~4,000 lines of C/CUDA) in 90 minutes for $20. The 124M model is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite...
Mozilla AI ▷ #llamafile (3 messages):
- Compilation Error with llamafile on Windows: A user shared difficulties compiling llamafile on Windows, encountering an error related to
cosmoc++. Specifically, the build toolchain fails due to the way executables are launched when they lack a.exeextension. - File Existence Issue: The user noted that despite the error message indicating a missing file, the file definitely exists in
.cosmocc/3.3.8/bin. The compilation attempt using cosmo bash also blocks similarly.
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- **Retrieval Augmented Generation can solve hallucination**: A member mentioned frequently using **LLMs** to answer documentation-related questions but facing issues with hallucinations and inaccuracies. They suggested that *pulling the docs, storing embeddings, and using similarity search ("Retrieval Augmented Generation")* could mitigate this and inquired about extending `llm` to create embeddings for a URL recursively.
MLOps @Chipro ▷ #general-ml (1 messages):
yellowturmeric: I haven't. thanks for sharing. I'll take a read of this paper.