[AINews] Somebody give Andrej some H100s already
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
C+CUDA is all you need.
AI News for 5/27/2024-5/28/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (382 channels, and 4432 messages) for you. Estimated reading time saved (at 200wpm): 521 minutes.
Five years ago, OpenAI spawned its first controversy with GPT-2 being called "too dangerous to release".
Today, with help from FineWeb (released last month), you can train a tiny GPT-2 in 90 minutes and $20 in 8xA100 server time. It is already working (kinda) for the 350M version, and Andrej estimates that the full 1.6B model will take 1 week and $2.5k.
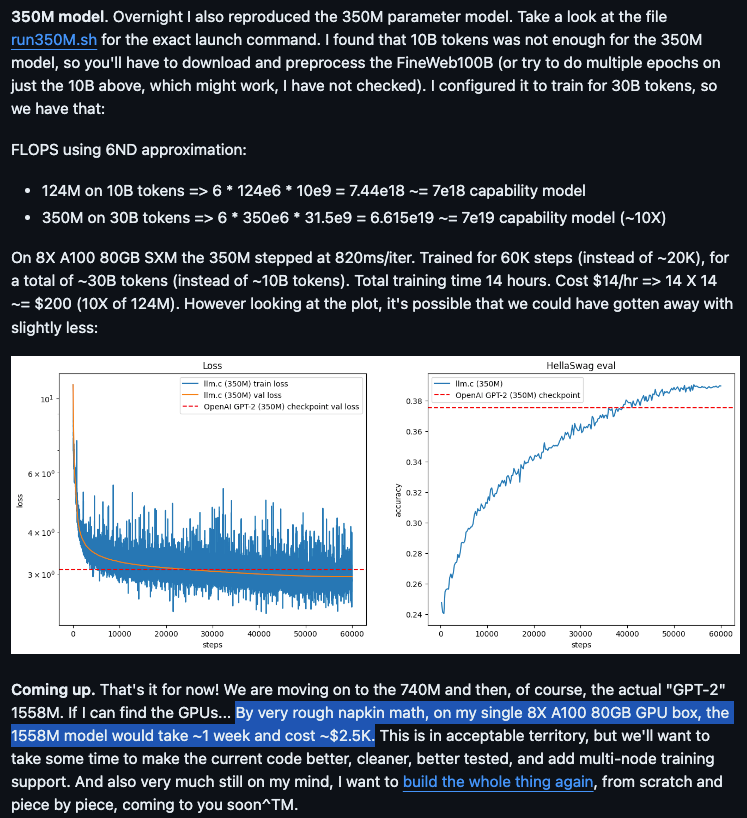
And incredible accomplishment in 7 weeks of work from scratch, though at this point the repo is 75.8% CUDA, stretching the name of "llm.c".
Andrej also answered some questions on HN and on Twitter. one of the most interesting replies:
Q: How large is the set of binaries needed to do this training job? The current pytorch + CUDA ecosystem is so incredibly gigantic and manipulating those container images is painful because they are so large. I was hopeful that this would be the beginnings of a much smaller training/fine-tuning stack?
A: That is 100% my intention and hope and I think we are very close to deleting all of that.
It would be cheaper and faster if more H100s were available. Somebody help a newly GPU poor out?
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Yann LeCun and Elon Musk Twitter Debate
- Convolutional Neural Networks (CNNs) Importance: @ylecun noted CNNs, introduced in 1989, are used in every driving assistance system today, including MobilEye, Nvidia, Tesla. Technological marvels are built on years of scientific research shared through technical papers.
- LeCun's Research Contributions: @ClementDelangue would pick @ylecun over @elonmusk, as scientists who publish groundbreaking research are the cornerstone of technological progress, despite getting less recognition than entrepreneurs.
- Musk Questioning LeCun's CNN Usage: @elonmusk asked @ylecun how Tesla could do real-time camera image understanding in FSD without ConvNets. @ylecun responded Tesla uses CNNs, as attention is too slow for real-time high-res image processing. @svpino and @mervenoyann confirmed Tesla's CNN usage.
- LeCun's Research Productivity: @ylecun shared he published over 80 technical papers since January 2022, questioning Musk's research output. He also noted he works at Meta, with @ylecun stating there's nothing wrong with that.
- Musk Acting as LeCun's Boss: @ylecun joked Musk was acting as if he were his boss. @fchollet suggested they settle it with a cage fight, with @ylecun proposing a sailing race instead.
AI Safety and Regulation Discussions
- AI Doomsday Scenarios: @ylecun criticized "AI Doomsday" scenarios, arguing AI is designed and built by humans, and if a safe AI system design exists, we'll be fine. It's too early to worry or regulate AI to prevent "existential risk".
- AI Regulation and Centralization: @ylecun outlined "The Doomer's Delusion", where AI doomsayers push for AI monopolization by a few companies, tight regulation, remote kill switches, eternal liability for foundation model builders, banning open-source AI, and scaring the public with prophecies of doom. They create one-person institutes to promote AI safety, get insane funding from scared billionaires, and claim prominent scientists agree with them.
AI Research and Engineering Discussions
- Reproducing GPT-2 in C/CUDA: @karpathy reproduced GPT-2 (124M) in llm.c in 90 minutes for $20 on an 8X A100 80GB node, reaching 60% MFU. He also reproduced the 350M model in 14 hours for ~$200. Full instructions are provided.
- Transformers for Arithmetic: @_akhaliq shared a paper showing transformers can do arithmetic with the right embeddings, achieving up to 99% accuracy on 100-digit addition problems by training on 20-digit numbers with a single GPU for one day.
- Gemini 1.5 Model Updates: @lmsysorg announced Gemini 1.5 Flash, Pro, and Advanced results, with Pro/Advanced at #2 close to GPT-4o, and Flash at #9 outperforming Llama-3-70b and nearly GPT-4-0125. Flash's cost, capabilities, and context length make it a market game-changer.
- Zamba SSM Hybrid Model: @_akhaliq shared the Zamba paper, a 7B SSM-transformer hybrid model achieving competitive performance against leading open-weight models at a comparable scale. It's trained on 1T tokens from openly available datasets.
- NV-Embed for Training LLMs as Embedding Models: @arankomatsuzaki shared an NVIDIA paper on NV-Embed, which improves techniques for training LLMs as generalist embedding models. It achieves #1 on the MTEB leaderboard.
Memes and Humor
- Musk vs. LeCun Memes: @svpino and @bindureddy shared memes about the Musk vs. LeCun debate, poking fun at the situation.
- AI Replacing Twitter with AI Bot: @cto_junior joked about building an AI version of themselves on Slack to replace attending standups, rather than on Twitter.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Architectures
- 01-ai removes custom licenses from Yi models: In /r/LocalLLaMA, 01-ai has switched the licensing of their original Yi models to Apache-2.0 on Huggingface, matching the license of their 1.5 series models.
- InternLM2-Math-Plus models released: A series of upgraded math-specialized open source large language models in 1.8B, 7B, 20B and 8x22B sizes was released. The InternLM2-Math-Plus-Mixtral8x22B achieves 68.5 on MATH (with Python) and 91.8 on GSM8K benchmarks.
- Pandora world model introduced: Pandora is a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. It aims to achieve domain generality, video consistency, and controllability.
- llama.cpp adds support for Jamba architecture: In /r/LocalLLaMA, support for AI21 Labs' Jamba architecture is being added to llama.cpp, with the first GGUF files being uploaded, including a model fine-tuned on the Bagel dataset.
- AstroPT models released for astronomy: AstroPT is an autoregressive pretrained transformer developed for astronomical use-cases, with models from 1M to 2.1B parameters pretrained on 8.6M galaxy observations. Code, weights, and dataset released under MIT license.
AI Applications and Tools
- Optimizing Whisper for fast inference: In /r/LocalLLaMA, tips were shared to speed up Whisper inference up to 5x using techniques like SDPA/Flash Attention, speculative decoding, chunking, and distillation.
- Android app for document Q&A: Android-Document-QA is an Android app that uses a LLM to answer questions from user-provided PDF/DOCX documents, leveraging various libraries for document parsing, on-device vector DB, and more.
- MusicGPT for local music generation: In /r/MachineLearning, MusicGPT was introduced as a terminal app that runs MusicGen by Meta locally to generate music from natural language prompts. Written in Rust, it aims to eventually generate infinite music streams in real-time.
- New web+LLM framework released: An open-source web framework optimized for IO-bound applications integrating with LLMs and microservices was announced, looking for early adopters to try it out and provide feedback.
AI Ethics and Safety
- Microsoft's Recall AI feature investigated over privacy concerns: Microsoft's new Recall AI feature, which tracks user activity to help digital assistants, is being investigated by UK authorities over privacy concerns, sparking debate about the data needed for useful AI assistance.
AI Industry and Competition
- Visualization of AI competition over past year: A visualization from the LMSYS Chatbot Arena showing the performance of top models from major LLM vendors over the past year highlights the intensifying competition and shifting trends.
- Contradictory claims about OpenAI equity clawbacks: An article claims data contradicts Sam Altman's statements about ignorance of equity clawbacks at OpenAI.
AI Discord Recap
A summary of Summaries of Summaries
LLM Advancements and Benchmarking:
- Llama 3 Leads the Pack: Llama 3 from Meta has topped leaderboards like ChatbotArena, surpassing models such as GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- IBM and RefuelAI Unleash New Models: IBM's Granite-8B-Code-Instruct enhances code task instruction following, while RefuelAI's RefuelLLM-2 boasts efficiency for data-heavy tasks.
Optimizing LLM Inference and Training:
- Cutting Edge Quantization Techniques: ZeRO++ aims for a 4x reduction in communication overhead during large model training on GPUs.
- Memory Efficiency Innovations: The vAttention system manages KV-cache memory more dynamically, improving LLM inference sharpens, and QSolve introduces W4A8KV4 quantization for enhancing cloud-based GPU performance.
Open-Source AI Frameworks and Community Efforts:
- Axolotl Captures Dev Interests: Supports diverse data formats, aiding LLM pre-training and instruction tuning.
- LlamaIndex Sparks Academic Curiosity: Powers a new course about building agentic RAG systems with Andrew Ng, promising advancements in AI extensions like bfloat16.
Multimodal AI and Generative Modeling Innovations:
- Idefics2 8B Makes Waves in Conversation: Fine-tuning the discourse on chat interactions, while CodeGemma 1.1 7B Improves Coding Tasks.
- Phi 3 Pioneers Browser-based AI: Introducing powerful AI chatbots directly in browsers via WebGPU, setting the stage for privacy-focused interaction enhancements.
LLM Finetuning (Hamel + Dan) Discord
OCR Showdown: Google Vision vs. Microsoft Azure: AI engineers debated the merits and pitfalls of Google Vision OCR, acknowledging its precision but criticizing the developer experience. Suggestions for using Microsoft Azure OCR and Mindee Doctr, potentially offering better ease of use, surfaced here.
Curated Data: The Key to LLM Success: Workshop discussions underscored the importance of fine-tuning LLMs with high-quality, curated datasets, ranging from pharma applications to technical support chatbots. Expert opinion highlighted the need for precision in data choice to maximize LLM effectiveness, spotlighting domains like drug discovery, law, sales, and interdisciplinary work.
Axolotl Angst and Optimization: Users faced hurdles running Axolotl's 70B model on M3 Macs, with overwhelming latency during local inference, pointing to deployment on Modal as a possible solution. Cost concerns with Weights & Biases (WandB) prompted considerations of alternatives like Aim and MLflow for economically-minded solo developers Axolotl examples.
LLM Evaluation Deep Dive: A session on evaluating LLMs offered a treasure trove of insights, covering product metrics, traditional and dynamic performance metrics, and tools like LangFuse and EvalGen. Recommending resources by Eugene Yan and practical examples to visualize fine-tuning, participants noted the necessity of nuanced evaluations for LLM development.
Transcription Tangles and the Path to Summaries: Communication around transcripts from large meetings illuminated needs for efficient summaries, exposing potential roles for LLMs. While Zoom transcripts are on the horizon, Hamel encouraged using LLMs to generate more digestible summaries, echoing wider community involvement.
Perplexity AI Discord
- Eagerly Awaiting imfo Alpha Release: A link to a tweet by @spectate_or hinted at the upcoming release of imfo alpha, sparking excitement and comparisons to similar tools within the engineering community.
- AI Task Structure Debate: Engineers discussed categorizing AI tasks into retrieval and mutation types, exemplifying with queries like "Get the weight of the iPhone 15". The need for adjustments in tasks requiring sequential execution was highlighted with the insight that "all the steps just happen at the same time."
- Scraping Accuracy Stumbles: Members voiced challenges in HTML parsing for reliable data scraping, with complications arising from sites like Apple and Docker's release notes. Workarounds through Playwright for JavaScript-centric sites were considered alongside issues with Cloudflare.
- Exploring Cost-Efficient AI Model Utilization: The community delved into the cost-effectiveness of using various AI models such as Llama3 and Claude. An approach using a combined system suggested possibilities for greater savings.
- API Functionality Quirks Highlighted: Confusion arose around an API output that displayed a JSON object sans functional links, potentially linked to the absence of a closed beta citations feature. Additional discussions included prompts to improve video link generation and a brief inquiry about a potential API outage.
Stability.ai (Stable Diffusion) Discord
New AI Features to Tinker With: Stability AI announces the launch of Stable Assistant sporting editing features built on Stable Diffusion 3, boasting of improved text-to-image quality available for a free trial here, and a beta chatbot with Stable LM 2 12B, heralding future enhancements for text generation tasks.
Education Merges with AI Innovation: An upcoming 4-week course by Innovation Laboratory, a collaboration between Stability AI and HUG, intends to guide participants on training AI models utilizing Stability AI's framework in tandem with HUG's educational approach; sign-ups are open until June 25, 2024, accessible here.
GPU Sharing in the Spotlight: AI engineers discuss a community-based GPU sharing proposal to decrease compute costs, with options ranging from a custom node to a potential blockchain setup designed to validate model training operations.
SD3 Accessibility Stirs Controversy: Discordance surfaces as members air grievances regarding Stable Diffusion's SD3 weights not being available for local use — slating Stability AI's cloud-only approach and stirring debate over cloud-dependency and data privacy concerns.
User Interfaces Under Comparison: A technical discourse unfolds on the pros and cons of various interfaces for Stable Diffusion, with ComfyUI pitted against more user-friendly alternatives like Forge; discussions also include community tips, inpainting methods, and ways to enhance artificial intelligence workflows.
OpenAI Discord
OpenAI Forms Safety Shield: OpenAI has established a Safety and Security Committee that will take charge of critical safety and security decisions across all its projects; full details can be found in their official announcement.
AI Muscle Flexes in Hardware Arena: Discussions about hardware costs arose, speculating on a $200-$1000 increase due to NPUs (Neural Processing Units), with focus on their economic impact for high-end models.
Plotting the Prompt Landscape: AI engineers debated the merits of meta-prompting versus Chain of Thought (CoT), examining the potential of using mermaid diagrams to conserve tokens and enhance output quality. There was also a sharing of improved prompts like here, showcasing practical applications of advanced prompt engineering tactics.
Rubber Meets The Code: Practical discussions included how AI handles YAML, XML, and JSON formats natively, with suggestions on using these structures for prompts to improve AI understanding and performance, and shared resources pointing to real-life prompt application for generating code and planning.
Interactive Inconsistencies Ignite Inquiry: Users reported issues with ChatGPT ranging from its refusal to draw tarot cards to context drops and unresponsiveness, spotlighting the need for improved and more predictable AI behavior.
HuggingFace Discord
Voice Commands Meet Robotics: A demo video titled "Open Source Voice-Controlled Robotic Arm" exhibits a voice-activated AI robotic arm. The perspective of democratizing robotics technology via community collaboration was forwarded.
Bridging Modalities: Contributions on creating early multi-modal spaces point to the use of single models and possibly stacked models with routing functionalities. For insights on such implementation, a source link was shared, providing a model example with practical applications.
Deep Learning Consult on the Fly: A user consulted the community about overcoming common pain points in training a model using Stanford Cars Dataset, managing only a 60% accuracy using ViT-B_16, with struggles involving overfitting. Meanwhile, another member is looking for help on how to better their deep learning model, indicating an environment that supports knowledge exchange for newcomers.
Diffusers Update for Not-Just-Generation: Hugging Face announced its Diffusers library now supports tasks beyond generative models, such as depth estimation and normals' prediction through Marigold. The update suggests an escalating trend in the versatility of diffusion models and their applications.
Model Choices for Cyber Security Assessments: Analysis from researchers examines the aptitude of various large language models in cyber security contexts. This provides AI engineers an angle to consider the security ramifications inherent in the deployment of LLMs.
Robust SDXL Space Realignment: SDXL embed space discussions underscore that newly aligned spaces default to zeroes instead of an encoded space. Such insights reflect the underlying complexity and time demands associated with realigning models to new unconditioned spaces, revealing the intricate process behind the science.
Gradio Piques Curiosity with Upgraded Clients: The Gradio team announced a forthcoming live event to dive into the latest features of Gradio Python and JavaScript clients. The engagement invitation emphasizes Gradio's continuous push to streamline AI integration into diverse applications through enhanced interfaces.
Ambiguity in Finding an SFW Dataset: Community chatter touches on the difficulty of locating the Nomos8k_sfw dataset, which is tied to the 4x-Nomos8kDAT model, suggesting the dataset’s limited availability or obscure placement. This highlights the occasional challenges inherent to dataset procurement.
Launching Latest Tools for AI Storytelling: Typeface Arc emerges as a comprehensive platform for seamlessness in creating AI-driven content. It features a tool, appropriately dubbed "Copilot", designed to amplify content creation via an interactive experience pivotal for brand narratives.
LM Studio Discord
Visualize This: OpenAI Integrates with LLama!: Engineers can now leverage LLaVA for visual capabilities in LM Studio by deploying it on a server and making use of the Python vision template provided.
Speedy Model Loading on M1 Max: AI models like MLX and EXL2 load swiftly on Apple's M1 Max, taking a mere 5 seconds for L3 8bit, indicating superior performance compared to GGUF Q8 which takes 29 seconds.
LM Studio Finetuning Frustrations: Despite being a robust environment, LM Studio currently lacks the ability to directly fine-tune models, with enthusiasts being pointed to alternative solutions like MLX designed for Apple Silicon.
Budget or Bust: AI practitioners debated the value proposition of various Nvidia GPUs, considering alternatives like the Tesla P40/P100 and eagerly discussed rumored GPUs like the 5090 with anticipation.
Beta Testing Blues: As they navigate the waters of new releases, users reported problems such as Windows CPU affinity issues with large models and errors on AVX2 laptops, hinting at the complexities of configuring modern hardware for AI tasks.
Unsloth AI (Daniel Han) Discord
- GPT-2 Gets No Love from Unsloth: Unsloth confirmed that GPT-2 cannot be fine-tuned using its platform due to fundamental architectural differences.
- Fine-Tuning Frustrations with Fiery Chat:
- When fine-tuning llama 3 with 50,000+ email entries, members shared advice on structuring prompts for optimal input-output pairing.
- Faced with a repeating sentence issue post-training, adding an End-Of-Sentence (EOS) token was recommended to prevent the model's overfitting or poor learning.
- Vision Model Integration on the Horizon: Members are keenly awaiting Unsloth's next-month update for vision models support, citing referrals to Stable Diffusion and Segment Anything for current solutions.
- LoRA Adapters Learning to Play Nice: The community shared tips on merging and fine-tuning LoRA adapters, emphasizing the use of resources like Unsloth documentation on GitHub and exporting models to HuggingFace.
- Coping with Phi 3 Medium's Attention Span: Discussions on Phi3-Medium revealed its sliding window attention causes efficiency to drop at higher token counts, with many eager for enhancements to handle larger context windows.
- ONNX Export Explained: Guidance was provided for converting a fine-tuned model to ONNX, as seen in Hugging Face's serialization documentation, with confirmation that VLLM formats are compatible for conversion.
- Looks Like We're Going Bit-Low: Anticipation is building for Unsloth's upcoming support for 8-bit models and integration capabilities with environments like Ollama, analogous to OpenAI's offerings.
CUDA MODE Discord
- CUDA Toolkit Commands for Ubuntu on Fire: A user suggested installing the CUDA Toolkit from NVIDIA, checking installation with
nvidia-smi, and offered commands for setup on Ubuntu, including via Conda:conda install cuda -c nvidia/label/cuda-12.1.0. Meanwhile, potential conflicts were identified with Python 3.12 and missing triton installation when setting up PyTorch 2.3, linked to a GitHub issue.
- GPT-4o meets its match in large edits: Members noted that GPT-4o struggles with extensive code edits, and a new fast apply model aims to split the task into planning and application stages to overcome this challenge. Seeking a deterministic algorithm for code edits, a member posed the feasibility of using vllm or trtllm for future token prediction without relying on draft models. More information on this approach can be found in the full blog post.
- SYCL Debug Troubles: A member enquired about tools to debug SYCL code, sparking a discussion on stepping into kernel code for troubleshooting.
- Torchao's Latest Triumph: The torchao community celebrated the merging of support for MX formats, such as
fp8/6/4, in PyTorch, offering efficiency for interested parties, provided in part by a GitHub commit and aligned with the MX spec.
- Understanding Mixer Models in DIY: Members dissected implementation nuances, such as integrating
dirent.hin llm.c, and the importance of guarding it with#ifndef _WIN32for OS compatibility. The addition of a-y 1flag for resuming training in interruptions was implemented, addressing warnings about uninitialized variables and exploring memory optimization strategies during backward pass computation, with a related initiative found in GitHub discussions.
- Quantizing Activations in BitNet: In the BitNet channel, it was concluded that passing incoming gradients directly in activation quantized neural networks might be erroneous. Instead, using the gradient of a surrogate function such as
tanhwas suggested, citing an arXiv paper on straight-through estimator (STE) performance.
Eleuther Discord
- No Post-Learning for GPT Agents: GPT-based agents do not learn post initial training, but can reference new information uploaded as 'knowledge files' without fundamentally altering their core understanding.
- Efficiency Milestones in Diffusion Models: Google DeepMind introduces EM Distillation to create efficient one-step generator diffusion models, and separate research from Google illustrates an 8B parameter diffusion model adept at generating high-res 1024x1024 images.
- Scaling Down for Impact: Super Tiny Language Models research focuses on reducing language model parameters by 90-95% without significantly sacrificing performance, indicating a path towards more efficient natural language processing.
- GPU Performance Without the Guesswork: Symbolic modeling of GPU latencies without execution gains traction, featuring scholarly resources to guide theoretical understanding and potential impact on computational efficiency.
- Challenging the Current with Community: Discussions highlight community-driven projects and the importance of collaborative problem-solving in areas such as prompt adaptation research and implementation queries, like that of a Facenet model in PyTorch.
OpenRouter (Alex Atallah) Discord
- Latest Model Innovations Hit the Market: OpenRouter announced new AI models, including Mistral 7B Instruct v0.3 and Hermes 2 Pro - Llama-3 8B, while assuring that previous versions like Mistral 7B Instruct v0.2 remain accessible.
- Model Curiosity on Max Loh's Site: Users show curiosity about the models utilized on Max Loh's website, expressing interest in identifying all uncensored models available on OpenRouter.
- OCR Talent Show: Gemini's OCR prowess was a hot topic, with users claiming its superior ability to read Cyrillic and English texts, outdoing competing models such as Claude and GPT-4o.
- OpenRouter Token Economics: There was clarification in the community that $0.26 allows for 1M input + output tokens on OpenRouter, and discussions emphasized how token usage is recalculated with each chat interaction, potentially inflating costs.
- The Cost of Cutting-Edge Vision: There is a heated exchange on Phi-3 Vision costs when using Azure, with some members finding the $0.07/M for llama pricing too steep, even though similar rates are noted among other service providers.
Nous Research AI Discord
- Translation Tribulations: Discussions touched on the challenges of translating songs with control over lyrical tone to retain the original artistic intent. The unique difficulty lies in balancing the fidelity of meaning with musicality and artistic expression.
- AI Infiltrates Greentext: Members experimented with LLMs to generate 4chan greentexts, sharing their fascination with the AI's narrative capabilities — especially when concocting a scenario where one wakes up to a world where AGI has been created.
- Philosophical Phi and Logically Challenged LLMs: Debates emerged over Phi model's training data composition, with references to "heavily filtered public data and synthetic data". Additionally, evidence of LLMs struggling with logic and self-correction during interaction was reported, raising concerns about the models' reasoning abilities.
- Shaping Data for Machine Digestion: AI enthusiasts exchanged resources and insights on creating DPO datasets and adjusting dataset formats for DPO training. Hugging Face's TRL documentation and DPO Trainer emerged as key references, alongside a paper detailing language models trained from preference data.
- Linking Minds for RAG Riches: Collaboration is in the air, with members sharing their intent to combine efforts on RAG-related projects. This includes the sentiment and semantic density smoothing agent project with TTS on GitHub, and intentions to port an existing project to SLURM for enhanced computational management.
LangChain AI Discord
Loop-the-Loop in LangChain: Engineers are troubleshooting a LangChain agent entering continuous loops when calling tools; one solution debate involves refining the agent's trigger conditions to prevent infinite tool invocation loops.
Details, Please! 16385-token Error in LangChain 0.2.2: Users report a token limit error in LangChain version 0.2.2, where a 16385-token limit is incorrectly applied, despite models supporting up to 128k tokens, prompting a community-lead investigation into this discrepancy.
SQL Prompt Crafting Consultation: Requests for SQL agent prompt templates with few-shot examples have been answered, providing engineers with the resources to craft queries in LangChain more effectively.
Disappearing Act: Custom kwargs in Langserve: Some users experience a problem where custom "kwargs" sent through Langserve for logging in Langsmith are missing upon arrival, a concern currently seeking resolution.
Showcasing Applications: Diverse applications developed using LangChain were shared, including frameworks for drug discovery, cost-saving measures for logging, enhancements for flight simulators, and tutorials about routing logic in agent flows.
Modular (Mojo 🔥) Discord
- Python Version Alert for Mojo Users: Mojo users are reminded to adhere to the supported Python versions, ranging from 3.8 to 3.11, since 3.12 remains unsupported. Issues in Mojo were resolved by utilizing the deadsnakes repository for Python updates.
- AI-Powered Gaming Innovations: Engineers discussed the prospect of subscription models based on NPC intelligence in open-world games, and introducing special AI-enabled capabilities for smart devices that could lead to AI inference running locally. They explored open-world games that could feature AI-driven custom world generation.
- Mojo Mastery: Circular dependencies are permitted within Mojo, as modules can define each other. Traits like
IntableandStringableare inherently available, and while lambda functions are not yet a feature in Mojo, callbacks are currently utilized as an alternative.
- Performance Pioneers: An impressive 50x speed improvement was noted at 32 bytes in Mojo, though it encountered cache limitations beyond that length. Benchmarks for k-means algorithms demonstrated variability due to differences in memory allocation and matrix computations, with a suggestion to optimize memory alignment for AVX512 operations.
- Nightly Builds Nightcaps: The latest Mojo compiler build (2024.5.2805) brought new features, including implementations of
tempfile.{mkdtemp,gettempdir}andString.isspace(), with full changes detailed in the current changelog and the raw diff. Structural sharing via references was also highlighted for its potential efficiency gains in Mojo programming.
Latent Space Discord
- Debugging Just Got a Level Up: Engineers praised the cursor interpreter mode, highlighted for its advanced code navigation capabilities over traditional search functions in debugging scenarios.
- A Co-Pilot for Your Messages: Microsoft Copilot's integration into Telegram sparked interest for its ability to enrich chat experiences with features such as gaming tips and movie recommendations.
- GPT-2 Training on a Shoestring: Andrej Karpathy showcased an economical approach to training GPT-2 in 90 minutes for $20, detailing the process on GitHub.
- Agents and Copilots Distinguish Their Roles: A distinction between Copilots and Agents was debated following Microsoft Build's categorization, with references made to Kanjun Qiu's insights on the topic.
- AI Podcast Delivers Cutting-Edge Findings: An ICLR 2024-focused podcast was released discussing breakthroughs in ImageGen, Transformers, Vision Learning, and more, with anticipation for the upcoming insights on LLM Reasoning and Agents.
LlamaIndex Discord
- Financial Geeks, Feast on FinTextQA: FinTextQA is a new dataset aimed at improving long-form finance-related question-answering systems; it comprises 1,262 source-attributed Q&A pairs across 6 different question types.
- Perfecting Prompt Structures: An enquiry was made concerning resources for crafting optimal system role prompts, drawing inspiration from LlamaIndex's model.
- Chat History Preservation Tactics: The community discussed techniques for saving chat histories within LlamaIndex, considering custom retrievers for NLSQL and PandasQuery engines to maintain a record of queries and results.
- API Function Management Explored: Strategies to handle an extensive API with over 1000 functions were proposed, favoring hierarchical routing and the division of functions into more manageable subgroups.
- RAG System Intricacies with LlamaIndex Debated: Technical challenges related to metadata in RAG systems were dissected, showing a divided opinion on whether to embed smaller or larger semantic chunks for optimal accuracy in information retrieval.
LAION Discord
AI Reads Between the Lines: Members shared a laugh over SOTA AGI models' odd claims with one model's self-training assertion, "it has trained a model for us," tickling the collective funny bone. Musk's jab at CNNs—quipping "We don’t use CNNs much these days"—set off a chain of ironical replies and a nod towards vision transformer models as the new industry darlings.
Artificial Artist's Watermark Woes: Corcelio's Mobius Art Model is pushing boundaries with diverse prompts, yet leaves a watermark even though it's overtaking past models in creativity. Ethical dilemmas arose from the capability of image generation systems to produce 'inappropriate' content, sparking debate on community guidelines and systems' control settings.
Synthetic Sight Seeks Improvement: In an effort to grapple with SDXL's inability to generate images of "reading eyes," a member asked for collaborative help to build a synthetic database using DALLE, hoping to hone SDXL's capabilities in this nuanced visual task.
Patterns and Puzzles in Generative Watermarks: Observations within the guild pointed out a recurring theme of generative models producing watermarks, indicating possible undertraining, which was found both amusing and noteworthy among the engineers.
Elon's Eyeroll at CNNs Stokes AI Banter: Elon Musk's tweet sent a ripple through the community, sparking jests about the obsolete nature of CNNs in today's transformative AI methodologies and the potential pivot towards transformer models.
tinygrad (George Hotz) Discord
GPU Latency Predictions Without Benchmarks?: Engineers discussed the potential for symbolically modeling GPU latencies without running kernels by considering data movement and operation times, though complexities such as occupancy and async operations were recognized as potential confounders. There's also anticipation for AMD's open-source release of MES and speculation about quant firms using cycle accurate GPU simulators for in-depth kernel optimization.
Optimizing with Autotuners: The community explored kernel optimization tools like AutoTVM and Halide, noting their different approaches to performance improvement; George Hotz highlighted TVM's use of XGBoost and stressed the importance of cache emulation for accurate modeling.
Latency Hiding Mechanics in GPUs: It was noted that GPUs employ a variety of latency-hiding strategies with their ability to run concurrent wavefronts/blocks, thus making latency modeling more complex and nuanced.
Buffer Creation Discussions in Tinygrad: The #learn-tinygrad channel had members inquiring about using post dominator analysis in scheduling for graph fusion efficiency and the creation of LazyBuffer from arrays, with a suggestion to use Load.EMPTY -> Load.COPY for such scenarios.
Code Clarity and Assistance: Detailed discussions were had regarding buffer allocation and LazyBuffer creation in Tinygrad, with one member offering to provide code pointers for further clarification and understanding.
AI Stack Devs (Yoko Li) Discord
- Elevenlabs Voices Come to AI Town: Integrating Elevenlabs' text-to-speech capabilities, AI Town introduced a feature allowing conversations to be heard, not just read, with a minor delay of about one second, challenging real-time usage. The implementation process involves transforming text into audio and managing audio playback on the frontend.
- Bring Science Debate to AI Chat: A concept was shared about utilizing AI chatbots to simulate science debates, aiming to foster engagement and demonstrate the unifying nature of scientific discussion.
- Audio Eavesdropping Added for Immersion: The Zaranova fork of AI Town now simulates eavesdropping by generating audio for ambient conversations, potentially amplifying the platform's interactivity.
- Collaborative Development Rally: There's an active interest from the community in contributing to and potentially merging new features, such as text-to-speech, into the main AI Town project.
- Addressing User Experience Issues: A user experienced difficulties with the conversations closing too quickly for comfortable reading, hinting at potential user interface and accessibility improvements needed within AI Town.
Cohere Discord
- Slimming Down on Logs: A new pipeline developed by a member removes redundant logs to reduce costs. They recommended a tool for selecting a "verbose logs" pipeline to achieve this.
- Debating Deployment: Members discussed cloud-prem deployment solutions for reranking and query extraction, seeking insights on the best integrated practices without providing further context.
- Financial RAG Fine-tuning: There was an inquiry on the possibility of fine-tuning Cohere models to answer financial questions, specifically mentioning the integration with RAG (Retrieve and Generate) systems using SEC Filings.
- Aya23 Model's Restrictive Use: It was clarified that Aya23 models are strictly for research purposes and are not available for commercial use, affecting their deployment in startup environments.
- Bot Plays the Game: A member launched a Cohere Command R powered gaming bot, Create 'n' Play, featuring "over 100 text-based games" aimed at fostering social engagement on Discord. The project's development and purpose can be found in a LinkedIn post.
OpenAccess AI Collective (axolotl) Discord
- Inference vs. Training Realities: The conversation underscored performance figures in AI training, particularly regarding how a seemingly simple query about "inference only" topics quickly lead to complex areas focused on training's computational requirements.
- FLOPS Define Training Speed: A key point in the discussion was that AI model training is, in practice, constrained by floating-point operations per second (FLOPS), especially when employing techniques like teacher forcing which increase the effective batch size.
- Eager Eyes on Hopper Cards for FP8: The community showed enthusiasm about the potential of Hopper cards for fp8 native training, highlighting a keen interest in leveraging cutting-edge hardware for enhanced training throughput.
- Eradicating Version Confusion with fschat: Members were advised to fix fschat issues by reinstallation due to erroneous version identifiers, pointing to meticulous attention to detail within the collective's ecosystem.
- When CUTLASS Is a Cut Above: Discussions clarified the importance of setting
CUTLASS_PATH, emphasizing CUTLASS's role in optimizing matrix operations vital for deep learning, underscoring the guild’s focus on optimizing algorithmic efficiency.
Interconnects (Nathan Lambert) Discord
- Apache Welcomes YI and YI-VL Models: The YI and YI-VL (multimodal LLM) models are now under the Apache 2.0 license, as celebrated in a tweet by @_philschmid; they join the 1.5 series in this licensing update.
- Gemini 1.5 Challenges the Throne: Gemini 1.5 Pro/Advanced has climbed to #2 on the ranking charts, with ambitions to overtake GPT-4o, while Gemini 1.5 Flash proudly takes the #9 spot, edging out Llama-3-70b, as announced in a tweet from lmsysorg.
- OpenAI's Board Left in the Dark: A former OpenAI board member disclosed that the board wasn't informed about the release of ChatGPT in advance, learning about it through Twitter just like the public.
- Toner Drops Bombshell on OpenAI's Leadership: Helen Toner, a previous member of OpenAI's board, accused Sam Altman of creating a toxic work environment and acting dishonestly, pushing for "external regulation of AI companies" during a TED podcast episode.
- Community Aghast at OpenAI's Revelations: In reaction to Helen Toner's grave allegations, the community expressed shock and anticipation about the prospect of significant industry changes, highlighted by Natolambert querying if Toner might "literally save the world?"
Datasette - LLM (@SimonW) Discord
- Go-To LLM Leaderboard Approved by Experts: The leaderboard at chat.lmsys.org was highlighted and endorsed by users as a reliable resource for comparing the performance of various large language models (LLMs).
Mozilla AI Discord
- Securing Local AI Endpoints Is Crucial: One member highlighted the importance of securing local endpoints for AI models, suggesting the use of DNS SRV records and public keys to ensure validated and trustworthy local AI interactions, jesting about the perils of unverified models leading to unintended country music purchases or squirrel feeding.
- Troubleshoot Alert: Llamafile Error Uncovered: A user running a Hugging Face llamafile - specifically
granite-34b-code-instruct.llamafile- reported an error with an "unknown argument: --temp," indicating potential issues within the implementation phase of the model deployment process. - Focus on the Running Model: In a clarification, it was noted that whatever model is running locally at
localhost:8080(like tinyllama) would be the default, with themodelfield in the chat completion request being inconsequential to the operation. This suggests a single-model operation paradigm for llamafiles in use.
Link mentioned: granite-34b-code-instruct.llamafile
OpenInterpreter Discord
- Request for R1 Update: A member expressed anticipation for the R1's future developments, humorously referring to it as a potential "nice paperweight" if it doesn't meet expectations.
- Community Seeks Clarity: There's a sense of shared curiosity within the community regarding updates related to R1, with members actively seeking and sharing information.
- Awaiting Support Team's Attention: An inquiry to the OI team concerning an email awaits a response, signifying the need for improved communication or support mechanisms.
AI21 Labs (Jamba) Discord
- Spotting a Ghost Town: A member raised the concern that the server appears unmoderated, which could indicate either an oversight or an intentional laissez-faire approach by the admins.
- Notification Fails to Notify: An attempted use of the @everyone tag in the server failed to function, suggesting restricted permissions or a technical snafu.
MLOps @Chipro Discord
- LLM for Backend Automation Inquiry Left Hanging: A member's curiosity about whether a course covers automating backend services using Large Language Models (LLM) remained unanswered. The inquiry sought insights into practical applications of LLMs in automating backend processes.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!