[AINews] s{imple|table|calable} Consistency Models
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
TrigFlow is all you need.
AI News for 10/23/2024-10/24/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (232 channels, and 3629 messages) for you. Estimated reading time saved (at 200wpm): 399 minutes. You can now tag @smol_ai for AINews discussions!
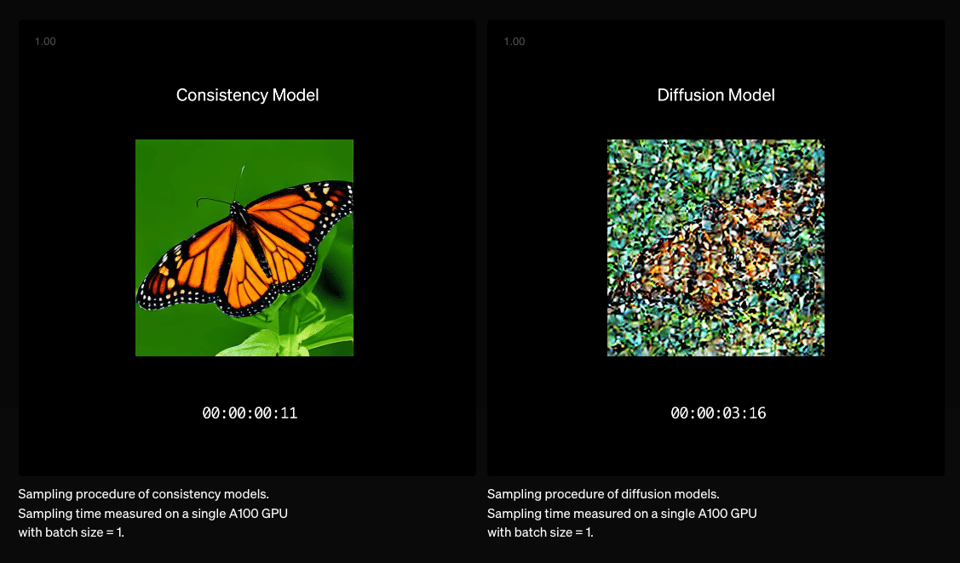
Model distillation is most often talked about for autoregressive LLMs, but the impact is often the most impressive for diffusion models, because the speedups for going from 100-200 step sampling down to 1-4 steps are dramatic enough to enable order-of-magnitude new capabilities like "realtime" generate-as-you-type experiences like BlinkShot and FastSDXL (now Flux Schnell).
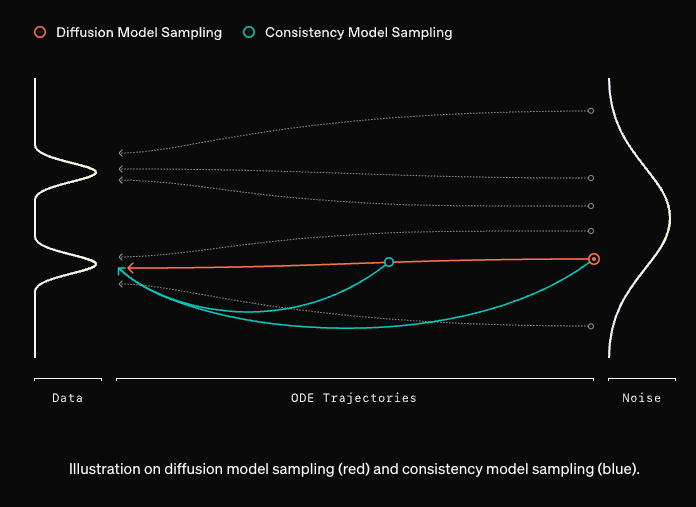
This generation of very fast-and-good image models was enabled by consistency model research led by Yang Song et al and applied to Stable Diffusion by Latent Consistency Models and LCM-LoRA. After the departure of his coauthor Ilya, Yang is now back with "sCM"s - blogpost here, paper here - a set of algorithmic improvements fixing everything unstable about prior approaches.
By the popular FID metric, they estimate that sCMs can reach less than 10% FID difference in 2 steps compared to the full model:
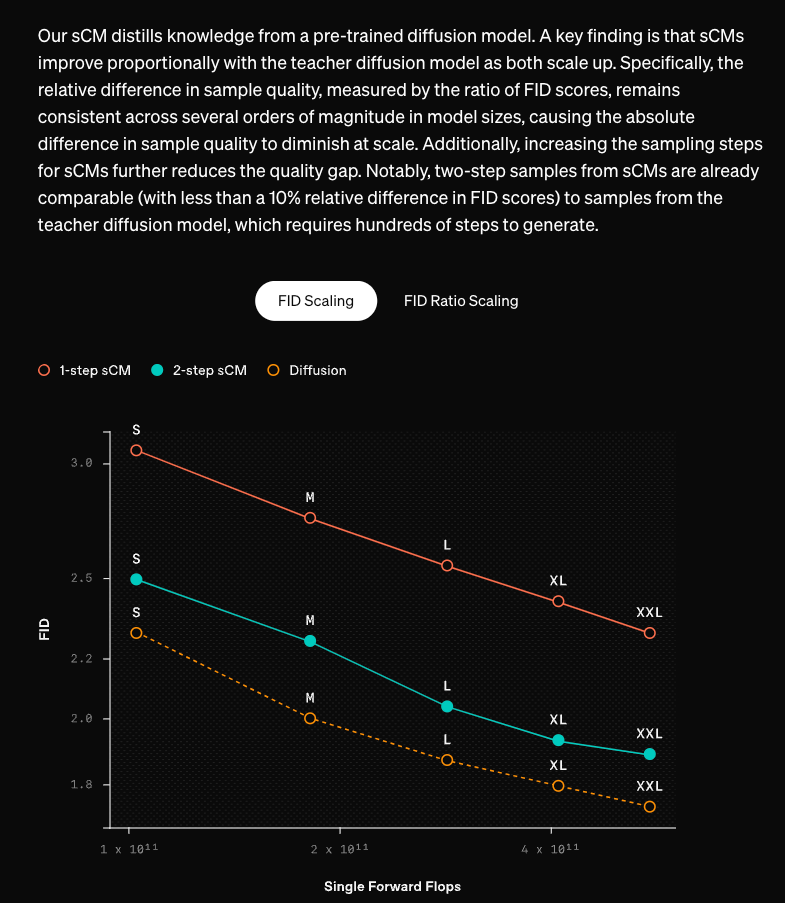
These improvements also enable scaling up continuous-time CMs to an unprecedented 1.5B params - enabling greater quality. The model isn't released, but it will not be long now for the researchers who can parse the 38 pages of diffusion math to replicate this in the wild.

The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Hardware and Infrastructure
- AI Hardware Performance and Databases: @EpochAIResearch highlighted that AI hardware performance is doubling every 2.3 years, with a yearly increase of 1.3x in FP16 operations. Additionally, they launched a new database covering over 100 accelerators, providing key insights into hardware used in AI training.
- Tesla's AI Hardware Expansion: @ArtificialAnlys reported that Tesla is deploying a 50k H100 cluster at Gigafactory Texas, surpassing the rumored sizes of clusters used for training frontier models. This expansion could potentially complete GPT-4 training in less than three weeks.
- Cerebras Systems' AI Accelerator: @ArtificialAnlys announced that Cerebras achieved >2,000 output tokens/s on Llama 3.1 70B, marking a new world record for language model inference with their custom "wafer scale" AI accelerator chips.
AI Models and Releases
- Stable Diffusion 3.5 by Stability AI: @ArtificialAnlys introduced Stable Diffusion 3.5 & the Turbo variant, showcasing significant improvements since SDXL in July 2023. These models have been added to the Image Arena for crowdsourced quality comparisons.
- Llama 3.1 Inference on H200 GPUs: @Yuchenj_UW detailed running Llama 3.1 405B bf16 on a single 8xH200 node, eliminating the need for Infiniband or Ethernet overhead, and achieving high token throughput with large GPU memory.
- Cohere's Aya Expanse Models: @aidangomez announced the release of new multilingual models spanning 23 languages, achieving state-of-the-art performance and available on Hugging Face.
AI Tools and Applications
- LangChain Ecosystem Updates: @LangChainAI celebrated their 2nd anniversary, showcasing growth to 130 million+ downloads and 132k apps powered by LangChain. New features like LangSmith and LangGraph enhance LLM testing and agent building.
- Perplexity AI MacOS App: @AravSrinivas promoted the Perplexity MacOS App, now available on the Mac App Store, offering features like ⌘ + ⇧ + P shortcuts, voice commands, and file uploads for enhanced productivity.
- Computer Use API by Anthropic: @alexalbert__ showcased Computer Use API which allows Claude to perform tasks like browser automation, data analysis, and interactive visualizations, enhancing LLM capabilities.
AI Company News and Partnerships
- Meta's Llama 3.2 Quantized Models: @AIatMeta released quantized versions of Llama 3.2 1B & 3B, offering 2-4x speed and 56% size reduction, enabling deployment on resource-constrained devices with maintained accuracy.
- Snowflake and ServiceNow Partnership: @RamaswmySridhar announced a bi-directional Zero Copy data sharing integration between Snowflake and ServiceNow, enhancing AI-driven innovation and introducing Cortex AI for conversational data queries.
- Google DeepMind's MusicAI Tools: @GoogleDeepMind released MusicFX DJ and Music AI Sandbox, featuring capabilities like musical loop generation, sound transformation, and in-painting, developed with feedback from the Music AI Incubator.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Gemma 2 27B emerges as top performer for single-GPU inference
- Most intelligent model that fits onto a single 3090? (Score: 33, Comments: 40): The post author seeks recommendations for the most intelligent LLM that can run on a single NVIDIA 3090 GPU with 24GB VRAM for tech support and coding assistance. They mention considering Qwen 2.5 and HuggingFace Chat, and are running the system on an x670e motherboard with 64GB DDR5 RAM and a 7800x3D CPU.
- Qwen2.5 32b at Q6 quantization is recommended for optimal performance on a 3090 GPU, with users suggesting it can run at 4-5 tokens/second with an 8k context window. Some suggest partial offloading to RAM for improved performance.
- Gemma 2 27B via Ollama is praised for its performance, especially in non-English languages. One user runs it with 6BPW and RoPE scaling to 24576 context, fitting in 24GB VRAM using exl2 from turboderp.
- Users recommend several alternatives, including Command R 35B, Mistral Small Instruct, and Gemma 27B, all at various quantization levels (Q4-Q6). Some note that lower quantization (Q4) sometimes performs better than higher (Q8) for certain tasks.
- Best 3B model nowadays? (Score: 33, Comments: 29): The post inquires about the current best 3B parameter language model. However, no specific content or comparisons were provided in the post body, limiting the ability to draw conclusions or provide detailed information about the performance of small 2-3B parameter language models.
- The GPU-Poor leaderboard on Hugging Face was recommended for comparing small language models. Phi3.5-mini-instruct and gemma-2-2b-it were mentioned as top performers in the 3B and 2B categories respectively.
- Users debated the performance of Qwen 2.5 versus Llama 3.2, with conflicting experiences reported. Some found Qwen prone to hallucinations, while others praised its knowledge base; Llama was noted for better prompt adherence.
- IBM's Granite model received criticism for poor performance and lack of conversational flow. Users also discussed the strengths of Llama 3.2 3B for general knowledge tasks and expressed interest in an upcoming Mistral 3B GGUF release.
Theme 2. Meta AI's Dualformer: Integrating System-1 and System-2 thinking
- Meta AI (FAIR): Introducing the Dualformer. Controllable Fast & Slow Thinking by Integrating System-1 And System-2 Thinking Into AI Reasoning Models (Score: 110, Comments: 6): Meta AI's Dualformer integrates System-1 (fast, intuitive) and System-2 (slow, deliberate) thinking into AI reasoning models, allowing for controllable fast and slow thinking. This approach aims to enhance AI's ability to handle complex tasks by combining rapid, intuitive responses with more deliberate, step-by-step reasoning processes, potentially improving performance across various AI applications.
- A* search is used for "slow thinking" while a model predicts the final A solution for "fast thinking". The Searchformer, a fine-tuned Transformer model, solves 93.7% of unseen Sokoban puzzles optimally, using up to 26.8% fewer search steps than standard A.
- A 2016-2017 Google paper on "The Case for Learned Index Structures" proposed replacing traditional database indexes with learned indexes, achieving up to 3x faster lookups and using up to 100x less memory than B-trees.
- Speculation about Llama 4 being "amazing" was met with a humorous response about the challenge of applying A* to text and reasoning, highlighting the complexity of adapting search algorithms to language models.
Theme 3. Claude 3.5 Sonnet update crushes Aider leaderboard
- Anthropic blog: "Claude suddenly took a break from our coding demo and began to peruse photos of Yellowstone" (Score: 444, Comments: 67): During an Anthropic demo, Claude, their AI model, unexpectedly deviated from the coding task and began browsing photos of Yellowstone National Park. This autonomous behavior occurred without prompting, demonstrating Claude's ability to independently shift focus and engage in self-directed actions. The incident highlights potential unpredictability in AI systems and raises questions about the extent of their autonomy and decision-making capabilities.
- Claude's unexpected browsing of Yellowstone National Park photos during a coding task sparked comparisons to human ADHD behavior. Users joked about inventing a computer with ADHD and the potential for profit from "AI medication".
- Concerns were raised about prompt injection attacks, with users discussing how instructions embedded in images or text could override user commands. Anthropic's GitHub warns about this vulnerability, suggesting precautions to isolate Claude from sensitive data.
- Some users speculated about Claude's motives for browsing Yellowstone photos, with humorous suggestions ranging from AGI concerns about supervolcano eruptions to more sinister plans involving drones and seismic sensors. Others appreciated the AI's curiosity and creativity.
- Updated Claude Sonnet 3.5 tops aider leaderboard, crushing o1-preview by 4.5% and the previous 3.5 Sonnet by 6.8% (Score: 161, Comments: 64): The updated Claude 3.5 Sonnet model has achieved 84.2% accuracy on the Aider code editing leaderboard, surpassing the o1-preview model by 4.5% and the previous 3.5 Sonnet version by 6.8%. This improvement maintains the same price and speed in the API, with the new model demonstrating 99.2% correct edit format usage according to the leaderboard.
- Users criticized the versioning system for Claude, suggesting it should follow semantic versioning instead. The discussion humorously escalated to mock version names like "Claude-3.5-sonnet-v2-final-FINAL(1)" and "Claude 98 SE".
- Some users reported significant improvements in Claude's performance, particularly for complex coding tasks. The gap between local models and Claude has widened, with the new version achieving 75% to 92% accuracy on code refactoring.
- Discussions arose about Anthropic's "secret method" for improvement, with theories ranging from high-quality datasets to interpretability investments and potential use of Chain of Thought (CoT) processing in the background.
Theme 4. GPU-Poor LLM Arena: Benchmarking resource-constrained models
- Most intelligent model that fits onto a single 3090? (Score: 33, Comments: 40): The post author seeks recommendations for the most intelligent LLM that can run on a single 3090 GPU with 24GB VRAM, primarily for tech help and mild coding. They mention considering Qwen 2.5 but are unsure about the best quantization, and also contemplate using HuggingFace Chat for potentially better performance with full-size models.
- Qwen2.5 32b at Q6 quantization is recommended for optimal performance on a 3090 GPU, with users suggesting it can run at 4-5 tokens/second with an 8k context window.
- Gemma 2 27B via Ollama is praised for its performance, especially in non-English languages. One user runs it at 6BPW with alpha 3.5 to achieve a 24576 context window on 24GB VRAM.
- Alternative models suggested include Command R 35B, Mistral Small Instruct, and Qwen 14B. Users noted that lower quantization (Q4) sometimes performs better than higher (Q8) for certain tasks.
- Best 3B model nowadays? (Score: 33, Comments: 29): The post inquires about the current top-performing 3 billion parameter language models. While no specific models are mentioned, the question implies interest in comparing the performance of small-scale language models in the 2-3 billion parameter range.
- The GPU-Poor leaderboard on Hugging Face compares small-scale language models. Phi3.5-mini-instruct (3B) and Gemma-2b-it (2B) are noted as top performers in their respective parameter ranges.
- Users debate the performance of Qwen 2.5 and Llama 3.2, with conflicting experiences regarding hallucinations and knowledge accuracy. Llama 3.2 is reported to have better prompt adherence, while Qwen 2.5 shows higher overall knowledge.
- IBM's Granite model receives criticism for poor performance and lack of conversational flow. Other models mentioned include Phi3.5 and a potential upcoming Mistral 3B GGUF version.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Releases
- OpenAI introduces sCMs: OpenAI announced simplified consistency models (sCMs) with improved training stability and scalability.
- Salesforce releases xLAM-1b model: In r/LocalLLaMA, Salesforce released xLAM-1b, a 1 billion parameter model that achieves 70% accuracy in function calling, surpassing GPT 3.5.
- Phi-3 Mini update with function calling: In r/LocalLLaMA, Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
- SD3.5 vs Dev vs Pro1.1 comparison: A comparison of image outputs from different Stable Diffusion models sparked discussion on evaluation methods and model capabilities.
AI Research and Applications
- ElevenLabs introduces Voice Design: ElevenLabs demonstrated technology to generate unique voices from text prompts alone, with potential applications in game development and content creation.
- Bimanual android with artificial muscles: A video showcasing a bimanual android called Torso actuated by artificial muscles was shared in r/singularity.
AI Industry and Policy Developments
- OpenAI advisor leaves, comments on capabilities gap: An OpenAI senior advisor for AGI readiness left the company, stating there isn't a large gap between lab capabilities and public availability.
- Citigroup predicts AGI timeline: Citigroup released a report predicting AGI by 2029 with ASI soon after, sparking discussion on the validity of such predictions.
- Reddit CEO comments on AI training data: Reddit CEO Steve Huffman claimed that Reddit content is a source of "actual intelligence" for AI training, leading to debates on data quality and AI training practices.
Discussions and Debates
- Protein folding as AGI breakthrough analogy: A discussion on how AGI breakthroughs might unfold, using the protein folding problem as an analogy.
- Importance of image prompts: A post in r/StableDiffusion highlighted the importance of sharing prompts with generated images for meaningful comparisons and discussions.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: AI Model Releases Power Up
- SD3.5 Launches With a Performance Boost: Hugging Face unveiled the new SD3.5 model, featuring quantization in diffusers for enhanced performance in large-scale applications. This release emphasizes ongoing progress in model efficiency.
- Aya Expanse Multilingual Models Bridge the Language Gap: Cohere introduced Aya Expanse, a new family of open-weight models with state-of-the-art performance across 23 languages. With 8B and 32B parameter versions, it aims to close the language gap in AI.
- Meta Shrinks Llama Models for Faster Inference: Meta released quantized versions of Llama 3.2, offering up to 2-4x increases in inference speed and reduced memory usage. These models are optimized for on-device and edge deployments.
Theme 2: AI Censorship Sparks Fiery Debates
- Censorship Controversy in Hermes 3: In the Nous Research AI Discord, members debated whether models like Hermes 3 are genuinely censored or simply reflect personality biases tied to their prompts. The discussion highlighted the fine line between model personality and actual censorship.
- SB1047 Legislation Raises Open-Source Alarm Bells: Concerns were raised about the SB1047 bill potentially hindering open-source AI development and favoring large companies. The legislation sparked debates on its true intentions and implications for the future of AI ethics and regulation.
- AI Localization Takes on 'Woke' Translations: A divisive discourse emerged on using AI for localizing anime to avoid 'woke' adaptations, with supporters emphasizing fidelity to original content and critics questioning AI's ability to handle nuanced human translation.
Theme 3: AI Tools Get New Homes and Features
- Perplexity AI Lands on MacOS, Users Cheer (and Jeer): Perplexity officially launched on MacOS, offering features like Pro Search and voice query capabilities. However, users reported performance issues, such as high CPU usage and unresponsive UI elements.
- ChatGPT Makes iPhones Smarter by 10x: Apple's ChatGPT integration went live for iPhone users with iOS 18.2 beta, significantly enhancing Siri's abilities. Users expressed excitement over the improvements in functionality and productivity.
- Microsoft Unveils OmniParser to Teach AI to Read Screenshots: Microsoft introduced OmniParser, a tool that converts UI screenshots into structured data to improve LLM-based UI agents. This innovation aims to enhance user interactions with better screen parsing capabilities.
Theme 4: AI Developers Wrestle with Technical Hurdles
- Unsloth Installation Woes Drive Users Up the Wall: Running
pip install -U unslothcaused ImportError and disrupted Torch and CUDA functionalities, leading users to reinstall Torch with CUDA 12.1 support. Discussions highlighted issues with Flash Attention while building wheels. - Flux Model Fluxes Users' Patience: Users reported significant performance issues with the Flux model, citing prolonged generation times without quantization. Recommendations included switching to quantized models for better speeds and lower VRAM usage.
- MacOS App Eats CPU Like There’s No Tomorrow: Perplexity AI's MacOS app faced criticism for consuming an average of 18% CPU when idle, along with difficulties in basic functionalities. Users suggested the need for optimization in the user interface.
Theme 5: AI Enhances Productivity and Workflow
- Lindy AI Agent Becomes Your Office PA: A new Lindy AI agent now texts meeting briefings 30 minutes prior, using LinkedIn and recent emails for context. This advancement showcases practical AI applications for productivity.
- Multi-Agent Concierge System Rolls Out Red Carpet Service: Developers introduced a multi-agent concierge system integrating tool calling, memory, and human interaction to enhance customer service experiences. The system is being continuously improved based on foundational ideas.
- Gift Genie Grants Wishes at Hackathons: The Gift Genie project, designed to generate and debate gift ideas, won accolades at a recent hackathon. Developers highlighted the project's focus on encouraging engaging conversations over simple transactions.
PART 1: High level Discord summaries
HuggingFace Discord
-
SD3.5 Model Launch with Enhanced Performance: The new SD3.5 model was launched, featuring quantization in diffusers to optimize performance for large-scale applications.
- This release underscores Hugging Face's commitment to model efficiency as a continuous focus.
- OmniGen's Versatile Capabilities: OmniGen was introduced as a unified generation model for both text-to-image and image-to-image tasks, boosting creative workflows.
- Crazy day with lots of releases! underscored the flexibility OmniGen brings to multimedia generation tasks.
- Granite 3.0 Released by IBM Under Apache 2.0: Granite 3.0 from IBM is now under Apache 2.0 license, enhancing its integrability into projects with the latest Transformers support.
- This highlights IBM's focus on empowering developers with advanced AI tools.
- Introduction of HUGS for Zero-Configuration Deployment: HUGS offers a zero-configuration inference service to accelerate AI development with open models across major cloud providers.
- Optimized deployment capabilities enable companies to scale their AI solutions efficiently.
- Sambanova AI Integration for Simplified API Access: The new integration with Sambanova AI allows for rapid deployments of AI-driven applications, improving user experience.
- This setup promotes streamlined access to advanced AI models through an intuitive interface.
Unsloth AI (Daniel Han) Discord
-
Installation Woes for Unsloth: Running
pip install -U unslothcauses ImportError and disrupts Torch and CUDA functionalities, leading users to reinstall Torch with CUDA 12.1 support.- Discussion highlighted issues with Flash Attention while building wheels, pointing users to related GitHub issue for further troubleshooting.
- Quantized Llama Models Released: Quantized versions of Llama 3.2 1B and 3B have been introduced, promising 2-4x increases in inference speed with reduced memory usage.
- The models leverage Quantization-Aware Training for efficiency, allowing deployment on resource-limited devices according to a tweet from AI at Meta.
- Claude Sonnet 3.5 Takes Control: Claude Sonnet 3.5 now has the capability for computer use, enabling it to perform tasks on user devices, as detailed in this YouTube video.
- Community members light-heartedly debated the implications of AI advancements, noting potential risks humorously related to AI armageddon.
- Flex Attention Temporarily Disabled: Flex Attention functionality is disabled for maintenance, prompting members to look forward to future updates.
- Users also shared experiences with DPO training datasets, expressing challenges in achieving concise outputs while handling verbose responses.
- GPU Architecture Insights: Inquiries were made regarding Ascend NPUs and Volta-based GPUs, with discussions on GPU hierarchy and memory management patterns emerging.
- Detailed methods for tensor management in Torch and Triton pointed out critical differences in data handling capabilities across GPU architectures, along with implementation discussions surrounding FlashAttention on TPUs.
Eleuther Discord
-
Label Quality vs. Quantity in AI: The new paper, Balancing Label Quantity and Quality for Scalable Elicitation, delves into the trade-offs between high-quality and low-quality labels in AI, identifying three resource allocation regimes.
- This approach optimizes data efficacy for AI training systems by demonstrating how different budget allocations can yield enhancements in model performance.
- Molmo's Model Checkpoints are Coming: Molmo, a series of open vision-language models from the Allen Institute for AI, is set to release checkpoints including those trained on the PixMo dataset with 1 million image-text pairs.
- The Molmo 7B-D model is highlighted for its open-source nature and top-tier performance, bridging evaluations between GPT-4V and GPT-4o.
- Dinov2's Functionality Under Scrutiny: Discussions emerged around the functionality of Dinov2, with members sharing insights and resources including the original paper for clarity.
- This reflects a collaborative effort to deepen understanding of the model's intricacies and potential applications.
- Improving Noise Assignment in Diffusion Models: Key discussions focused on optimizing how noise is assigned in diffusion models to boost generative quality, incorporating Gaussian latent noise mappings.
- However, be wary of the linear assignment problem complexities, particularly with high-dimensional data, which could hinder implementational practicality.
- New Praise for Agent Interface: Members expressed excitement over the latest improvements in the agent interface, noting its user-friendly design.
- Such enhancements are expected to improve user interaction, making future engagements more intuitive.
Notebook LM Discord Discord
-
Job Interview Processes Under Fire: Concerns emerged regarding the overwhelming number of interviews and tests faced by candidates, causing frustration and inefficiencies in hiring.
- Some members proposed that AI could automate staffing, reducing candidate burdens and streamlining the process.
- Multilingual Audio Generation with NotebookLM: Users reported experiences prompting NotebookLM to generate content in languages such as Spanish and French, leading to mixed results.
- While some achieved success, others struggled with inconsistencies, revealing challenges in language outputs.
- NotebookLM Drives Educational Improvements: NotebookLM notably enhanced the learning experience in a Business Strategy Game course by decreasing initiation time and increasing student engagement.
- Users praised that it enables students to ask complex questions, deepening their understanding of game mechanics.
- HeyGen's Deepfake Ethics Debated: Concerns surfaced regarding the ethical implications of HeyGen's deepfake technology, particularly the transparency of model usage for avatar creation.
- Members engaged in a discussion about the consent of individuals involved, raising crucial ethical questions about content creation.
- Podcast Length Optimization Insights: Users experimented with specific word count prompts to generate longer podcasts, noting that larger numbers led to longer outputs but not always proportionately.
- They emphasized that quality remains paramount, despite efforts to extend podcast durations.
Perplexity AI Discord
-
Perplexity officially launches on MacOS: Perplexity is now available on MacOS, allowing users to ask questions using ⌘ + ⇧ + P and download the app from this link. The launch introduces features like Pro Search and voice question capabilities.
- With Thread Follow-Up, users can engage in detailed discussions and access cited sources for insightful answers in their queries.
- MacOS app suffers performance issues: Users reported that the MacOS App is consuming an average of 18% CPU even while idle, raising concerns about overall performance and responsiveness.
- Complaints include difficulties in basic functionalities, suggesting a need for optimization in the user interface.
- NVIDIA integrates Isaac ROS for enhanced robotics: NVIDIA's integration with Isaac ROS improves robotics framework capabilities, focusing on the robustness of AI-driven robotic applications.
- This initiative aims to enhance performance in diverse robotic environments, addressing industry needs for advanced functionalities.
- Users explore Streaming Mode as a workaround: Users experiencing 524 errors discussed the potential of streaming mode to mitigate these connectivity issues, suggesting it could lead to better performance.
- Resources were shared, including a link to the Perplexity API documentation to guide users through implementing this solution.
Nous Research AI Discord
-
Censorship Sparks Debate: Members discussed implications of AI censorship, questioning whether models like Hermes 3 are genuinely censored or just reflect personality biases tied to their prompts.
- One argument suggested that real censorship involves systematic avoidance, contrasting with mere personality-driven responses.
- O1 vs Claude: Performance Showdown: A heated debate surfaced about the capabilities of O1 and Claude, with many asserting their performances are nearly identical for many tasks.
- Participants expressed skepticism toward criteria skewing results, particularly with GPT-4o surprisingly ranked higher than expected.
- Implications of SB1047 Legislation: The SB1047 bill raised concerns about hindering the growth of open-source AI development and potentially favoring larger tech companies.
- The discussion highlighted worries that transitioning OpenAI to a for-profit model could lead to significant ethical dilemmas in the field.
- AI Localization in Anime: A Double-Edged Sword: A divisive discourse emerged on the use of AI in localizing anime while avoiding 'woke' adaptations, emphasizing the need to preserve original content integrity.
- Supporters claimed fidelity to source material is vital, while critics questioned the capability of AI to replicate nuanced human translation.
- Minecraft Benchmarking for AI Models: Discussion revolved around leveraging Sonnet for benchmarking AI performance via Minecraft challenges, highlighting various techniques shared in their GitHub repo.
- This initiative reflects broader concerns about evaluation methodologies across AI development.
OpenRouter (Alex Atallah) Discord
-
Navigate OpenRouter's Tool Use: Members discussed how to verify if a model supports tool use, directing to a specific page for details.
- Confusion arose over functionality when mixing models with tool calls, pointing out past issues with tool role utilization.
- Cloudflare Crashes Cause Frustration: Users reported intermittent access issues with OpenRouter, experiencing Cloudflare errors like 524 and persistent loading screens.
- Some confirmed the troubles were brief and resolved after refreshing the page.
- Hermes 3.5 Access Drama: Users reported access issues with the Hermes 3.5 405B instruct model, facing empty responses or 404 errors.
- Adjusting provider settings in OpenRouter helped some regain access.
- Cerebras Claims Speed Gains: Cerebras released news on speed improvements, although fluctuating TPS rates were reported by users.
- Speculations pointed to dynamic throttling issues during high load periods.
- Users Demand Integration Access: Several users indicated a strong interest in integration settings, emphasizing their reliance on OpenRouter for workloads.
- The urgency was highlighted with comments about the importance of robust integration options.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 Runs Smoothly on Consumer GPUs: Stable Diffusion 3.5 can successfully operate on GPUs like the 4070 TI and RTX 4080, with 8GB VRAM deemed the minimum for reasonable performance. Users have seen successful runs using a 3060 by utilizing FP8 versions for better results.
- Such configurations highlight the increasing accessibility of powerful AI visual generation models on consumer hardware.
- Flux Model Faces Hardware Challenges: Users reported significant performance issues with the Flux model, citing prolonged generation times with the default model on various hardware setups without quantization. Recommendations included switching to quantized models for enhanced speeds and lower VRAM usage.
- This shift could alleviate some frustrations while maximizing GPU capabilities.
- ComfyUI Knocks Forge for Usability: In discussions comparing ComfyUI and Forge, users praised ComfyUI's user-friendliness and performance optimization features, especially its ability to hide node connections. Complaints arose regarding Forge's cumbersome model unloading process, with many leaning toward ComfyUI for efficiency.
- This suggests a potential trend favoring simpler, more intuitive interfaces in AI workflow designs.
- Community Shares GIF Generation Tool Glif: The community highlighted Glif as a go-to tool for generating GIFs, noting its ease of use and free access. Users appreciated the capability to input images for tailored animation experiences.
- Such tools enhance creative possibilities within AI-generated media.
- Quantization Strategies Spark Discussion: Quantization discussions centered around models like flux1-dev-Q8_0, highlighting the balance of file size and performance while retaining adequate output quality. Resources were shared to help users select quantized models suitable for their hardware configurations.
- These considerations demonstrate the importance of optimizing model performance against available resources.
aider (Paul Gauthier) Discord
-
Sonnet 3.5 Targets Cost-Effective Performance: The new Sonnet 3.5 is set to perform near Haiku 3 and DeepSeek while remaining economical for users. Early feedback indicates it may match the previous version in capabilities.
- Sonnet models continue to engage users by providing strong performance metrics in various tasks, aiming for a wider adoption.
- Aider's Architect Mode Offers Potential: Users expressed interest in exploring Aider's Architect Mode with newer models, particularly Sonnet and Haiku. They noted that while the mode could enhance outputs, it might increase operational costs due to higher token consumption.
- Participants flagged the need for careful evaluation of usage to balance performance boosts against scalability issues.
- Users Pit DeepSeek Against Gemini Flash: DeepSeek's performance was compared with Gemini Flash, with some users favoring the latter for its speed in processing whole edits. They experienced varied efficiencies based on their specific coding workflows.
- Concerns were raised about DeepSeek lagging when processing larger inputs, emphasizing the need for benchmarks under real-world conditions.
- Inquiries About Aider and Bedrock Claude 3.5 Compatibility: Users are seeking fixes to enable Aider's compatibility with the new Bedrock Claude 3.5 model, as past versions worked seamlessly. Discussions indicate uncertainty around the compatibility issues causing disruptions.
- The topic of hotfixes garnered attention, sparking suggestions for updates to maintain functionality across models.
- Situating Git Operations with Aider: A user voiced a need to stage changes without committing in Aider to avoid compilation failures caused by auto-commits. They received suggestions like disabling auto-commits and issuing manual
/commitcommands.
- Managing operations effectively emerged as a critical concern, driving recommendations for smoother Git integration workflows.
GPU MODE Discord
-
CUDA Stream Synchronization Clarified: A user sought clarification on the necessity of calling cudaStreamSynchronize for stream1 and stream2 prior to launching kernels as stream1 needs to wait for stream2.
- The clarification was addressed, affirming the user's previous misunderstanding.
- Numerical Precision Challenges in Deep Learning: The discussion highlighted numerical rounding issues associated with float16 and bfloat16, noting errors around 0.01 L2 Norm.
- Participants suggested pre-scaling gradients to alleviate these issues, though precision problems with BF16 remain a concern.
- Gradient Accumulation Techniques Explored: Members debated various methods for precise gradient accumulation, endorsing techniques like tree reduction over standard summation.
- Challenges in maintaining precision when accumulating in BF16 were emphasized, indicating room for improvement.
- Collaboration and Transparency in CUDABench: Members expressed excitement about the open-sourcing of the CUDABench project, promising to share internal work for better collaboration.
- The approach encourages contributions from the community with a focus on transparency and idea sharing.
- 5th Edition Anticipated Release: Members inquired on the status of the 5th edition, confirming it is not yet available, generating ongoing anticipation.
- This highlights the community's eagerness for updates regarding the release.
LM Studio Discord
-
LM Studio's Local Document Limitations: Users noted that LM Studio can only handle five files at a time for retrieval-augmented generation (RAG), which is currently described as naive with limited access to files.
- This raises concerns about the practicality of local document handling for extensive workloads.
- Model Performance Lags Post-Restart: One member reported experiencing slower generation speeds in LM Studio after restarting despite using a fresh chat and deleting old sessions.
- Advice was given to check the LM Runtimes page to ensure that the model was not falling back to using the CPU instead of the GPU.
- AMD GPU Support on the Rise: Discussion around LM Studio revealed that support for AMD graphics cards via ROCm is available for models 6800 and above.
- One user highlighted the reasonable prices of RX 6800 cards as a potential option for enhancing VRAM capabilities.
- Launch of Quantized Llama Models: Recently shared quantized versions of Llama 3.2 1B and 3B models aim for reduced memory footprints, targeting on-device deployments.
- This initiative by Meta is set to simplify development for those who build on Llama without needing extensive compute resources.
- Future Vision Mode Capabilities in LM Studio: A user questioned whether the envisioned future vision mode for LM Studio could interpret and translate on-screen text directly.
- This inquiry sparked a discussion about the potential interactive capabilities of vision modes moving forward.
OpenAI Discord
-
AI models become parameter efficient: Since the release of GPT-3, models have achieved a 300x increase in parameter efficiency, delivering similar performance with just a 0.5B parameter model.
- This efficiency makes broader deployment more feasible, leading to significant cost savings across model applications.
- GPT-4o cheaper with more features: GPT-4o is anticipated to be more cost-effective for OpenAI compared to GPT-4, with greater usage flexibility being noted.
- While not formally announced, rumors suggest increased rate limits have been lifted, raising user expectations.
- Effective prompt engineering strategies: Discussion emphasized clarity and specificity in prompt engineering to achieve more accurate AI outputs.
- Participants underscored that aligning prompt wording with desired responses is essential for optimizing interaction quality.
- Limitations of current memory features: Users debated the effectiveness of the ChatGPT memory feature, with critiques that it does not fulfill user needs adequately.
- Alternative solutions like Retrieval-Augmented Generation (RAG) were suggested to efficiently handle memory in AI models.
- Experiences with Custom GPTs: Feedback indicated that customization options for Custom GPTs are currently limited to 4o models, leaving users seeking more flexibility.
- There is a strong desire among users for enhanced options, highlighting a need for tailored interactions that meet individual requirements.
Latent Space Discord
-
Lindy AI Agent simplifies meeting prep: A new Lindy AI agent now texts meeting briefings 30 minutes prior, using LinkedIn and recent emails for context, as shared in a tweet.
- This advancement showcases practical AI applications for productivity in scheduling and information retrieval.
- Fast Text to Image with new sCMs: OpenAI reveals sCMs, their latest consistency model enhancing speed in text-to-image generation, requiring just two sampling steps, detailed in their announcement.
- Community anticipates real-world applications, as this model promises improved training stability and scalability.
- ChatGPT iPhone Integration goes live: ChatGPT's integration with Apple's AI is in beta, making iPhones reportedly 10x more useful as noted by Mich Pokrass.
- Inquiries about the sign-up process are increasing, requiring version 18.2 for eligibility.
- Microsoft introduces OmniParser: Microsoft has launched OmniParser, a tool that converts UI screenshots into structured data to improve LLM-based UI agents, as described by Niels Rogge.
- This innovation could significantly enhance user interaction by refining screen parsing capabilities.
- Cohere's Aya Expanse Model Launch: Cohere announces Aya Expanse, a new multilingual model family supporting 23 languages, with open weights available on Hugging Face, according to Aidan Gomez.
- This development marks a significant step forward in multilingual AI, aiming to close language gaps.
Interconnects (Nathan Lambert) Discord
-
ChatGPT Integration Makes iPhone Smarter: Apple's ChatGPT integration goes live today for iPhone users, enhancing Siri's ability to tackle complex questions, as stated by this tweet. A member expressed pride in their team's effort, saying their iPhone feels 10x more useful.
- This feature is part of the stable iOS 18.2 developer beta, which users can explore further in this CNET article.
- Cohere Introduces Aya Expanse Model: Cohere launched the Aya Expanse model family aimed at reducing the language barrier in AI, detailed in this tweet. The initiative is geared towards a multi-year investment in multilingual research.
- Discussion among members acknowledged the model's CC-by-NC license and its potential applications in various sectors.
- Yann LeCun critiques Nobel AI awardees: Yann LeCun criticized the recent Nobel Prizes awarded for AI, suggesting they were a result of pressure on the committee to recognize deep learning's influence, calling Hopfield nets and Boltzmann machines 'completely useless'.
- The reaction was mixed among members, reflecting differing views on the relevance of these technologies in current AI discourse.
- Anthropic positions as B2B company: Anthropic is adopting a B2B strategy, focusing on automating work tasks, in contrast to OpenAI's B2C approach aimed at consumer preferences. A member highlighted, Every task I’d even want to automate away with such an agent would be something work-related.
- The discussion pointed to the struggles of AI agents in the consumer market, where automation of activities like shopping is generally resisted.
- Managing Long PDFs Remarks: Frustrations emerged about losing progress in lengthy PDFs, leading to suggestions for PDF readers that track viewing locations, alongside tools like Zotero. One member humorously lamented reliance on screenshots to avoid confusion.
- This conversation underscores the need for better user-centric tools in document management among AI engineers.
OpenInterpreter Discord
-
Easiest Way to Try Anthropic Model: To explore Anthropic's computer controlling model, simply use
interpreter --os, with calls for volunteers to implement it.- Increased screen size positively impacts performance, suggesting a need to investigate better text processing methods.
- Resolve Python Version Confusion: Users faced errors using Python 3.10 with the Open Interpreter, leading to compatibility issues.
- Switching to Python 3.11 resolved these problems, prompting queries on efficient switching methods.
- Installation Queries Clarified: Questions arose about running OS mode with the one-click installer, and detailed terminal commands were shared for users.
- The developer confirmed that OS mode functions differently from the mobile app, yet both allow computer control.
- Understand Missing Features in Claude Computer: Confusion emerged over the absence of new Claude Computer features in Open Interpreter, necessitating a version check.
- The developer highlighted the importance of updating to the correct version to access new features.
- Beta Test Rollout Explained: Queries about receiving emails for the Open Interpreter desktop app beta test were posed, prompting discussion.
- Beta testers are being added periodically, with priority for House Party participants.
Cohere Discord
-
Aya Model Bridges Language Gaps: Cohere's latest Aya model offers state-of-the-art multilingual capabilities aimed at closing the language gap with AI, as highlighted in a new blog post. This initiative focuses on empowering entrepreneurs in various emerging markets to leverage AI solutions.
- The model family includes 8B and 32B versions designed to enhance performance across 23 languages, confronting the limitations that most models face with non-English requirements.
- Emerging Market Startups Need Special Licenses: A member raised a concern that startups in emerging markets won't be able to use certain models due to the NC license and addendum restrictions. It was suggested that startups should contact Cohere for a more applicable license to provide value in their specific contexts.
- This reflects the challenges faced by entities in regions with different commercial frameworks attempting to utilize cutting-edge AI models.
- Discussion on API Integration and Model Performance: A user is exploring integrating Cohere v2 using the Vercel AI SDK but noted compatibility issues as the current provider mapping only supports version 1, as mentioned in a GitHub issue. The team confirmed that Cohere v2 is on the roadmap, though no specific release date is confirmed.
- Meanwhile, users are dealing with API key queries when programming across multiple machines, especially regarding rate limiting based on API or IP address.
- API Troubleshooting for Finetuned Models: A user reported issues with their finetuned models through the API, prompting requests for more details about their errors. It was noted that ensuring quotes are escaped properly might resolve this, particularly with 'order_id' format.
- These practical issues often stall developments but highlight the community's collaborative troubleshooting spirit.
- Debate on AI Model Comparisons: Members engaged in a debate regarding the perceived superiority of models like cmd r+ versus c4i-aya-32b, questioning the objective nature of this evaluation. The discussion highlighted that accuracy differences might reflect the nature of queries rather than model capabilities.
- This ongoing conversation underlines the importance of context in selecting AI models, showing how subjective experiences can vary.
tinygrad (George Hotz) Discord
-
Multi-Cloud Ops Spark Lazy Debate: A member questioned if multi-Cloud device movement operations are considered lazy, igniting a conversation about their effectiveness and current usage.
- Opinions varied significantly on the efficiency and necessity of such operations in today's tech landscape.
- Direct Device-Device Communication investigated: Discussion arose on whether direct device-device communication is feasible without frontend integration, hinting at potential enhancements.
- Suggestions included this idea as a promising pull request for future development in the Tinygrad context.
- Attention Implementation in Tinygrad Under Scrutiny: A user requested guidance on implementing attention in Tinygrad, comparing its performance unfavorably against PyTorch.
- Benchmarks indicated that optimized function usage could lead to improved performance, emphasizing method placement's significance during testing.
- Memory Allocation Troubles Persist: Concerns were raised about performance drop due to memory allocation when using randn for tensor initialization in Tinygrad.
- Despite attempts to set environment variables for GPU allocation, issues remained, suggesting deeper complexities in Tensor initialization.
- Kernel Optimization Flags Tested for Boost: Ideas emerged to utilize flags like
BEAM=4to enhance Tinygrad's performance through kernel search optimization, but early tests yielded limited success.
- This reflects the need for continual experimentation and fine-tuning to identify effective configurations for improving computation.
LlamaIndex Discord
-
Multi-Agent Concierge System Takes Shape: An update reveals a new multi-agent concierge system enhancing customer service by integrating tool calling, memory, and human interaction. LoganMarkewich has completely revamped the system leading to ongoing improvements (read more).
- Continuous advancements are being made to build more responsive customer service bots.
- AWS Bedrock Welcomes Anthropic Models: Members confirmed use of Anthropic 3.5sonnet in AWS Bedrock, available in regions like Virginia, Oregon, Tokyo, Frankfurt, and Singapore with
pip install -U llama-index-llms-anthropic. This integration allows easier access to cutting-edge models.
- Existing deployment options are being explored to maximize functionality and model usage.
- Integrates Llama 2 into LlamaIndex: To use Llama 2 with LlamaIndex, developers can deploy with Ollama, LlamaCPP, or the Llama API, depending on their setup. Sample code showcasing integration methods was shared with npm commands for guidance.
- Flexibility in deployment options allows developers to choose based on their existing architecture.
- Scaling Neo4jPropertyGraphStore Deployment: Discussion arose regarding the deployment of multiple instances of Neo4jPropertyGraphStore in Anyscale and the potential scalability impact. Concerns were voiced about whether running multiple instances could affect overall performance.
- Members are actively weighing possibilities for efficient scaling and node management.
- Gift Genie Projects Grows Popularity: The Gift Genie project won accolades at a recent hackathon for its inventive ability to generate and debate gift ideas, emphasizing engaging conversation over simple transaction processing. Developers shared positive feedback on idea discussions rather than straight recommendations (details here).
- Community interest is escalating as unique projects gain recognition.
Torchtune Discord
-
Tensor Parallelism Achieves Speedy Fine-Tuning: Upon implementing Tensor Parallelism for multi-GPU fine-tuning, epochs clocked in under 20 minutes, showcasing impressive training velocity.
- Users expressed satisfaction with their configurations, highlighting that this setup meets their rapid training goals.
- Batch Size Clarity in Multi-GPU Setup: Members confirmed using
batch_size = 6across 8 GPUs results in a global batch size of 48, clearing up previous confusion regarding the scaling.
- This insight helped streamline the distributed training process, optimizing workflow for many users.
- Dataloader Performance Bottlenecks Revealed: Participants raised concerns about dataloader slowdown due to settings like
num_processes=0and insufficient pinned memory.
- Suggestions emerged for optimizing these settings to enhance training efficiency and mitigate performance drops.
- Packed vs Unpacked Training Performance Differences: Discussion highlighted mixed results between packed=True and packed=False training configurations, with the former sometimes speeding up processes.
- However, packed data produced unexpected responses, prompting further analysis into optimal usage.
- Inquiry on muP Parameterizations Progress: A user inquired about the status of muP parameterizations for recipes, referencing earlier discussions and seeking clarity on their implementation.
- This indicates ongoing community interest in feature development and the necessity for concrete updates moving forward.
Modular (Mojo 🔥) Discord
-
Right Channel for Modular Questions: A user inquired if <#1284264544251809853> is correct for questions about the organization, which led to a redirection to <#1098713601386233997> for general inquiries.
- This feedback emphasizes clarity in channel usage, enhancing community communication.
- Discourses on Data Type Checking: A member asked how to perform data type checks, igniting a dialogue on data validation in programming practices.
- Additionally, there was a request on how to convert a List to an InlineArray, focusing on practical data manipulation techniques.
- Recommendation for Kapa Resource: A member suggested using the kapa channel for help with data type checks, affirming its utility in programming discussions.
- This highlights the community's inclination to share resources that support each other's learning journeys.
- Insights on MAX Engine C API: Clarification was provided regarding the C API for integrating the MAX Engine into high-performance apps, discussing support for Torch/ONNX models.
- The conversation examined whether the current C framework could facilitate running inference on models designed for Mojo MAX-graph, stressing potential architectural considerations.
- Inference Graph Integration Inquiry: A member questioned the viability of running inference on Mojo MAX-graph models within the existing C application framework, reflecting ongoing development interests.
- They sought community insights into possible challenges associated with this integration, prioritizing technical feasibility.
LLM Agents (Berkeley MOOC) Discord
-
Confusion Over Acceptance Emails: Users reported no formal acceptance emails after signing up for the course, receiving only a filled form instead. tarande57 explained that signing up merely adds users to a mailing list, not confirming acceptance.
- This led to mixed messages regarding expectations for course onboarding, as participants anticipated traditional acceptance notifications.
- Timestamp Troubles in Email Tracking: One user inquired about an email received on September 28 at 6:50 PM PST, asking if they could DM with details regarding the email. After verification, tarande57 confirmed resolution of the user's email issue.
- This indicates a potential area for improvement in email tracking and notifying users about form submissions and communication times.
- Mailing List Dynamics and Lecture Information: Several users noted receiving information about lectures but not quizzes, questioning the consistency of information distribution. tarande57 reassured that completion of the signup form is primarily for tracking assignments related to certificate qualifications.
- This inconsistency sparked concerns over procedural clarity, suggesting a need for better communication regarding course expectations.
DSPy Discord
-
Kickoff for a Cutting-edge Workflow System: Members are starting to work on the world's most advanced workflow system and are discussing it in detail on Discord. This ambitious project aims to overhaul how workflows are managed and executed.
- The team is excited about potential collaboration opportunities as they develop this innovative solution.
- ColPali Cookbook for Fine-Tuning: The ColPali Cookbook provides recipes for learning, fine-tuning, and adapting ColPali to multimodal Retrieval Augmented Generation (RAG) use cases. This GitHub repository serves as a practical guide for integrating ColPali into various applications.
- Users can utilize these recipes to enhance their implementation efforts, particularly in RAG contexts.
- Introducing ViDoRe Benchmark for Document Retrieval: The paper discusses the introduction of the Visual Document Retrieval Benchmark (ViDoRe), aimed at assessing visually rich document retrieval tasks. It highlights how current systems struggle with visual cues, prompting the need for new retrieval architectures like ColPali.
- This benchmark is crucial for advancing document retrieval capabilities across diverse domains and languages.
- Challenges in Modern Document Retrieval: Modern document retrieval systems excel in query-to-text matching but falter with visual elements, impacting performance in practical applications. The authors emphasize that addressing these shortcomings is crucial for enhancing document retrieval effectiveness.
- They call for innovations to bridge the gap between text and visual information retrieval.
- ColPali's Approach to Document Understanding: ColPali leverages the capabilities of recent Vision Language Models to generate contextualized embeddings directly from document images. This new model architecture aims to improve the retrieval of information from visually rich documents.
- This approach signifies a shift in how documents are processed and understood, paving the way for more advanced retrieval systems.
LangChain AI Discord
-
Creating a Graph for Request-Response Connections: A member proposed building a graph to illustrate the relationships among multiple documents representing HTTP request-response interactions. This aims to clarify these connections for better understanding.
- The necessity for such a visualization reflects ongoing challenges in comprehensively analyzing the intricate patterns in request-responses.
- DeepLearning.AI Course on Functions and Tools: A member shared a GitHub repo for the Functions, Tools and Agents course on DeepLearning.AI, focusing on LangChain.JS implementations. This resource serves as a practical reference for course participants to bolster their coding skills.
- The repository contains significant code examples that enhance the learning experience, encouraging others to check out the repository for further exploration.
LAION Discord
-
Querying Best Models for Image Captioning: A user inquired about the best performing models for image captioning to process a ~0.5 billion image dataset for diffusion model pretraining, suggesting Internvit and Google's Gemini models as potential fits.
- They emphasized a preference for models not exceeding 50 billion parameters, honing in on efficiency without sacrificing capability.
- Hunting for Additional Model Recommendations: The user showed keen interest in locating other high-performance models beyond those mentioned for their captioning needs.
- They specifically aimed to bypass larger models, focusing on maximizing efficiency in performance.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The OpenAccess AI Collective (axolotl) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!