[AINews] s1: Simple test-time scaling (and Kyutai Hibiki)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
"Wait" is all you need.
AI News for 2/5/2025-2/6/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (210 channels, and 4396 messages) for you. Estimated reading time saved (at 200wpm): 490 minutes. You can now tag @smol_ai for AINews discussions!
We're regrettably late to covering this paper, but late is better than never. s1: Simple test-time scaling documents a new reasoning model with 2 novel contributions:
- finetuned from Qwen 2.5 32B on just 1000 questions paired with reasoning traces distilled from Gemini 2.0 Flash Thinking, filtered for difficulty, diversity, and quality (26 mins of training on 16 H100s)
- controllable test-time compute by either forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end.

Lead author Niklas Muennighoff, who notably worked on Bloom, StarCoder, MTEB, and contributed to BIG-bench, notes that this second trick reproduces the famous o1 scaling chart:
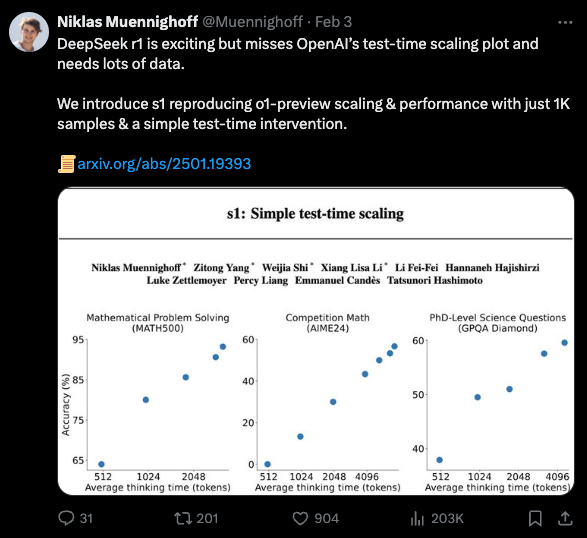
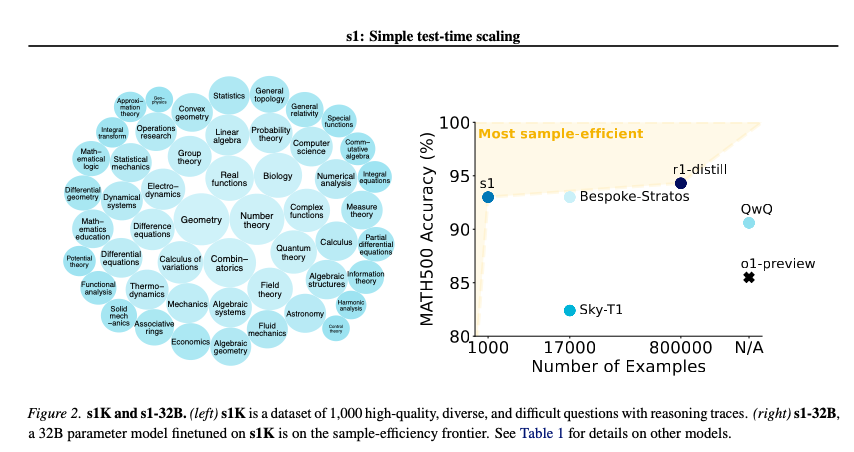
Compared to Bespoke-Stratos (our coverage here), the filtering is also remarkably sample efficient.
We would also recommend Simonw and Tim Kellogg's explainers.
Honorable mention today:
Kyutai Moshi made a splash last year (our coverage here) for its realtime voice with inner monologue, and now Hibiki shows very impressive French-English live translation offline on an iPhone. Not bad for an intern project.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
AI Models and Releases
- DeepSeek R1 and R3 Open Source Release: @teortaxesTex announced that R1-low-mid-high models are coming soon, potentially marking the first real Open Source moment in LLMs comparable to nginx, Blender, or even Linux. This release could flatten the market owned by a cartel of incumbents with proprietary tech.
- Hugging Face Releases SmolLM2: @_akhaliq shared that Hugging Face announced SmolLM2, detailed in the paper "When Smol Goes Big -- Data-Centric Training of a Small Language Model". @LoubnaBenAllal1 provided a breakdown of the SmolLM2 paper, emphasizing that data is the secret sauce behind strong performance in small LMs.
- IBM's Granite-Vision-3.1-2B Model: @mervenoyann discussed the release of Granite-Vision-3.1-2B, a small vision language model with impressive performance on various tasks. A notebook is available to test the model.
AI Research Papers and Findings
- LIMO: Less is More for Reasoning: @_akhaliq highlighted LIMO, showing that complex reasoning capabilities can emerge through minimal but precisely crafted demonstrations. @arankomatsuzaki noted that LIMO achieves 57.1% accuracy on AIME and 94.8% on MATH with only 817 training samples, significantly outperforming previous approaches.
- Token-Assisted Reasoning: @_akhaliq shared insights from the paper "Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning", discussing how combining latent and text tokens can enhance reasoning in language models.
- Advancements in Long Chains of Thought: @gneubig presented research providing insights on short vs. long chains of thought, the role of supervised fine-tuning vs. reinforcement learning, and methods to control reasoning length in language models.
AI Tools and Platforms
- Gradio DualVision App: @_akhaliq introduced DualVision, a Gradio template app for image processing featuring multi-modal predictions, GPU support, and an examples gallery for enhanced user experience.
- Le Chat by Mistral AI Now on Mobile: @sophiamyang announced the release of Le Chat, an AI assistant by Mistral AI, now available on mobile platforms with features like code interpreter and blazing-fast responses powered by the Mistral models.
- Canvas Sharing in ChatGPT: @OpenAIDevs announced that canvas sharing is now live in ChatGPT, allowing users to share, interact with, or edit canvases, enhancing collaborative capabilities.
AI Industry News and Events
- Applied ML Days Workshops with Google DeepMind: @GoogleDeepMind invited participants to two workshops at Applied ML Days focused on Building LLM Applications using Google Gemini and Natural Interactions with Foundational Models.
- Cerebras Powers Leading AI Lab: @draecomino shared that Cerebras is now powering a leading AI lab in production, showcasing advancements in AI infrastructure and computing capabilities.
- Keras Community Meeting: @fchollet announced a public Keras team community meeting, offering updates on what's new in Keras and an opportunity for developers to ask questions.
Personal Achievements and Updates
- Google Developers India Recognition: @RisingSayak expressed gratitude for being nominated and thanked @GoogleDevsIN for the recognition, highlighting a sense of fulfillment in the community.
- Philipp Schmid Joins Google DeepMind: @osanseviero welcomed Philipp Schmid to Google DeepMind, expressing excitement to work with a dream team including @DynamicWebPaige, @film_girl, and others.
Memes/Humor
- Types of Programmers: @hyhieu226 humorously categorized programmers into two types: those who write verbose type declarations and those who use 'auto' for simplicity.
- Overconfidence Warning: @qtnx_ shared a personal reflection reminding that overconfidence can lead to loss, advising to stay humble and work diligently.
- AI Lab Grifters: @scaling01 called out YouTube grifters in the AI community, highlighting a shift from dismissing AI advancements to monetizing them, implying a focus on profit over technology.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Hibiki Speech-to-Speech Translation - FR to EN Capability
- Hibiki by kyutai, a simultaneous speech-to-speech translation model, currently supporting FR to EN (Score: 448, Comments: 40): Hibiki, developed by Kyutai, is a simultaneous speech-to-speech translation model that currently supports translation from French (FR) to English (EN).
- Hibiki's Capabilities: Hibiki is praised for its real-time translation quality, naturalness, and speaker similarity, with resources available on GitHub and Hugging Face. The model's ability to preserve the speaker's voice while adapting its pace to the semantic content is highlighted, and it is noted for outperforming previous systems.
- Community Feedback and Requests: Users express admiration for the model's performance, with some desiring additional language support, particularly Spanish and Chinese. There is a desire for an on-device version for convenience and travel purposes, especially for non-English speaking regions.
- Cultural and Developmental Observations: There are humorous remarks about the French's proficiency in English and the Japanese-inspired names of the French-developed model. The open-source nature of the project, similar to Mistral, is noted, with expectations for future advancements in on-device translation capabilities.
Theme 2. Challenges with Gemini 2.0 Pro Experimental Model
- The New Gemini Pro 2.0 Experimental sucks Donkey Balls. (Score: 205, Comments: 83): The author criticizes the Gemini 2.0 Pro Experimental model for its poor performance compared to the previous 1206 model, highlighting issues like frequent mistakes and unwanted code refactoring. They express frustration with Google's pattern of releasing models that regress in quality, contrasting it with the impressive speed and efficiency of the Flesh light 2.0 for OCR tasks.
- Many users express dissatisfaction with Gemini 2.0 Pro Experimental, noting issues like decreased intelligence and increased speed at the cost of quality, with some preferring the older 1206 model or other models like Flash 2.0 for better performance in specific tasks like coding and creative writing.
- Flash 2.0 and o1 models are praised for their effectiveness, especially in handling complex queries and maintaining context over longer tasks, while newer models like o3-mini are criticized for requiring more verbose input to understand user intent, leading to inefficiencies.
- The discussion highlights a broader trend where AI models are becoming faster and more efficient but at the expense of depth and consistency, with some users pointing out the limitations of current evaluation metrics and the challenges of balancing speed with quality in real-world applications.
Theme 3. Open WebUI Releases Code Interpreter and Exa Search Features
- Open WebUI drops 3 new releases today. Code Interpreter, Native Tool Calling, Exa Search added (Score: 185, Comments: 61): Open WebUI introduced significant updates in version 0.5.8, including a Code Interpreter that executes code in real-time using Pyodide, a redesigned chat input UI, and Exa Search Engine Integration for retrieving information within the chat. Additionally, Native Tool Calling Support is now available experimentally, promising reduced query latency and improved contextual responses. Release details are available online.
- Code Interpreter and Pyodide: Users appreciate the addition of the code interpreter using Pyodide, noting its limitations but recognizing its utility for common use cases. There's a call for improvements such as integrating Gradio and enabling result downloads, like plots or processed data.
- Community Contributions: Despite many contributors, tjbck is acknowledged as the primary consistent contributor to Open WebUI, with suggestions to support them through GitHub sponsorship. The project is praised for its rapid feature updates and its competitive edge over proprietary UIs.
- Document Handling and RAG: There are criticisms regarding document handling, particularly the use of simple vector DB RAG for single document references, which often fails on simple queries. Suggestions include moving document, RAG, and search functionalities to separate pipelines to keep up with fast-moving advancements, and disabling RAG by default for better user control.
Theme 4. Over-Tokenized Transformer Enhances LLM Performance
- Over-Tokenized Transformer - New paper shows massively increasing the input vocabulary (100x larger or more) of a dense LLM significantly enhances model performance for the same training cost (Score: 324, Comments: 37): A new paper demonstrates that massively increasing the input vocabulary of a dense Large Language Model (LLM) by 100 times or more significantly boosts model performance without increasing training costs. This finding suggests a potential strategy for improving transformer efficiency by expanding the vocabulary size.
- Tokenization and Vocabulary Size: Increasing the vocabulary size to millions, as opposed to the typical 32k to 128k, can enhance model performance by using more meaningful, hierarchical tokens. This approach achieves faster convergence by combining multiple tokens into new ones, though it primarily improves training performance rather than final performance in direct proportion.
- Potential Challenges and Considerations: Concerns arise about undertrained tokens due to greedy tokenizers, which might lead to performance issues with misspellings and tasks sensitive to single character mutations, such as arithmetic or algebraic reasoning. There are also questions regarding the impact on memory usage, inference speed, and effective context size when using smaller tokens.
- Research and Comparisons: A similar study from three months ago suggested that models like Llama 2 70B should use at least 216k tokens for optimal compute use, and even larger token counts could be beneficial. The paper's findings are particularly interesting for dense models, but they did not show the same improvement for Mixture of Experts (MoE) models, highlighting a potential area for further exploration.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Altman admits reduced competitive edge for OpenAI
- Altman admits OpenAl will no longer be able to maintain big leads in AI (Score: 259, Comments: 69): Sam Altman acknowledged that OpenAI will face increased competition and will not maintain its previous lead in AI development. He noted that while OpenAI will produce better models, the competitive gap will be smaller, as reported in a Fortune.com interview. Source.
- OpenAI's Competitive Strategy: Several commenters discussed the idea that OpenAI attempted to maintain a monopoly by controlling the release of their discoveries, which gave them an advantage of about 3-4 months before competitors could replicate their work. This strategy was seen as a temporary measure to stay ahead in the competitive landscape.
- Technology Plateau and Model Training: There is a perception that AI technology may be plateauing, with users noting that OpenAI admitted to facing inevitable competition. Commenters highlighted the challenge of preventing others from using larger models' outputs to train their own, indicating that OpenAI will have to continue innovating alongside other companies.
- Media and Public Interaction: A commenter's question ended up in a Fortune article, leading to discussions about media ethics and the value of such publications. There was also appreciation for Sam Altman's openness during an AMA, despite the limitations on what he could disclose.
Theme 2. Deep Reconstruction using AI tools for complex analysis
- Give me a prompt for Deep Research and I'll run it for you! (Score: 246, Comments: 111): The user has paid $200 for access to Deep Research and is offering to run prompts for the community to evaluate its capabilities. They compare it to o3-mini-high, noting that Deep Research supports attachments but doesn't seem significantly better. They invite the community to submit serious prompts and vote on them to prioritize which ones to execute.
- Complex Prompt Challenges: Users are submitting complex, multidisciplinary prompts, such as those involving particle physics, ontological spaces, and depression subtypes. These often require clarification from the AI to proceed with research or analysis, highlighting the need for precise inputs to optimize AI responses.
- Investment and Economic Predictions: There is significant interest in using AI for stock market predictions and economic analysis in a post-ASI world. Users are curious about the impact of ASI on stock valuations, GDP growth, and bond markets, emphasizing the speculative nature of these inquiries and the need for AI to consider multiple scenarios and variables.
- Agricultural and Environmental Systems: The discussion includes innovative agricultural methods like the 3 sisters method and its potential expansion using AI to optimize plant cooperation systems for different climates and soil types. This reflects a broader interest in applying AI to enhance sustainable agricultural practices.
- Dear OpenAI, if I'm paying $200 per month for Deep Research, the ability to save to PDF/Markdown would be nice! (Score: 229, Comments: 40): The author expresses disappointment that OpenAI's Deep Research, despite its cost of $200 per month, lacks a feature to save reports directly to PDF or Markdown. They suggest a workaround by using the 'copy' button to obtain raw Markdown, which can then be pasted into Notion.
- Many users express frustration over OpenAI's Deep Research lacking a straightforward PDF or Markdown export feature, emphasizing that the AI should reduce busy work and facilitate easier integration with other applications like Pages and Word. The absence of these features is seen as a significant oversight given the tool's high cost of $200 per month.
- Suggestions for workarounds include using the 'copy' button for Markdown, then pasting into a Markdown Editor or using print > save as PDF. However, users find these manual processes counterintuitive to the AI's purpose of saving time and simplifying tasks.
- There is a humorous discussion around the naming conventions of AI tools, with comparisons to Gemini Deep Research and anticipation for future tools like 'Microsoft Co-pilot - In to Deep' edition. The conversation highlights a broader dissatisfaction with current AI capabilities and the expectation for more seamless functionalities in premium tiers.
Theme 3. Open Source AI for Trackable Health Diagnostics
- How I Built an Open Source AI Tool to Find My Autoimmune Disease (After $100k and 30+ Hospital Visits) - Now Available for Anyone to Use (Score: 195, Comments: 27): The author shares their journey of building an open-source AI tool to aid in diagnosing autoimmune diseases after spending $100k and visiting 30+ hospitals without clear answers. The tool allows users to upload and standardize medical records, track lab result changes, and identify patterns using different AI models, including Deepseek and GPT4/Claude. They provide resources like Fasten Health for obtaining medical records and mention plans to migrate document parsing to run locally.
- Data Security Concerns: Several commenters emphasize the critical importance of running the tool locally to avoid data breaches, especially given the sensitivity of medical records and the high value of such data on the dark market. Mithril was mentioned as a secure AI deployment option for handling medical information, highlighting the need for certifications like FISMA and HITRUST.
- Fragmented Diagnosis to Discovery: The discussion includes a personal account of receiving multiple diagnoses like herniated disc and spinal curvature, which were later unified into a diagnosis of Ankylosing Spondylitis using the tool. A suggestion to consider EDS (Ehlers-Danlos Syndrome) was also made, indicating the tool's potential in refining and discovering complex medical conditions.
- User Reactions: Strong reactions from users indicate surprise and concern about the potential for serious data breaches, with multiple comments expressing disbelief and highlighting the legal implications of mishandling sensitive medical data.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. Breakthroughs in Model Capabilities and Performance
- Hibiki Achieves Real-Time Speech Translation Like a Human: Kyutai's Hibiki model delivers simultaneous speech-to-speech translation from 🇫🇷 to 🇬🇧, adapting pace to content and preserving speaker's voice. Early reports boast Hibiki's superior quality, naturalness, and speaker similarity, rivaling professional human interpreters in real-time communication.
- Gemini 2.0 Flash Parses PDFs at Scale for Pennies: Gemini 2 Flash now efficiently parses large PDF documents for approximately $1 per 6000 tokens, marking a significant leap in document processing. This cost-effective solution unlocks new possibilities for applications requiring high-volume, high-accuracy text extraction from complex document formats.
- Unsloth's GRPO Makes DeepSeek-R1 Reasoning Accessible on 7GB VRAM: Unsloth's latest GRPO update slashes memory usage by 80%, allowing users to reproduce DeepSeek-R1's reasoning with just 7GB VRAM. This breakthrough democratizes access to advanced reasoning models, enabling local experimentation with models like Llama 3.1 (8B) and Phi-4 (14B) even on resource-constrained systems.
Theme 2. Tooling and Framework Enhancements for AI Engineers
- GitHub Copilot Awakens as an Agent, Edits Code Like a Pro: GitHub Copilot introduces agent mode and general availability of Copilot Edits, enhancing developer workflow with smarter AI assistance. This update aims to provide more proactive and effective coding support, transforming Copilot into a more integrated and powerful development partner.
- Windsurf IDE Supercharges with Gemini 2.0 Flash and Cascade Web Search: Windsurf now supports blazingly fast Gemini 2.0 Flash, consuming only 0.25 prompt credits, and Cascade gains automatic web search via @web, costing 1 flow action credit. These enhancements aim to boost developer productivity with faster models and integrated information retrieval within the IDE environment.
- Cursor IDE Unveils GitHub Agents and Architect Feature for Productivity Boost: Cursor IDE rolls out new GitHub agents and an architect feature, aiming to significantly boost developer productivity and streamline complex projects. While users are enthusiastic about these additions, some report potential bugs in command execution within the Composer tool, signaling active development and refinement of these features.
Theme 3. Navigating Challenges in Model Performance and Infrastructure
- DeepInfra Provider Plagued by 50% Failure Rate, Users Report: DeepInfra provider is currently failing to return responses 50% of the time, causing zero token completions and significant processing delays for users, particularly in applications like SillyTavern. Community members are actively sharing observations and seeking solutions to these performance issues across different models and providers on OpenRouter.
- LM Studio Users Face API Error Avalanche, Seek Debugging Guidance: LM Studio users are reporting a surge of errors like 'unknown error' and 'exit code: 18446744072635812000' when loading models, prompting calls for detailed system specs and API insights for effective debugging. State handling issues when connecting via API also highlight the need for clearer documentation and user support for API interactions.
- Codeium Jetbrains Plugin Criticized for Unresponsiveness and Frequent Restarts: Users are voicing frustrations with the Codeium Jetbrains plugin, citing frequent failures to respond and the necessity for frequent restarts, impacting developer workflow. Some users are opting to switch back to Copilot for reliability, while others report specific errors in PhpStorm, indicating persistent instability in the plugin's performance.
Theme 4. Community Driven Innovations and Open Source Contributions
- Independent Researchers Leverage JAX and TPUs for Low-Cost AI Research: Independent AI researchers are exploring realistic domains for AI/ML research, with recommendations to learn JAX for access to TPU Research Cloud, enabling resource-efficient experimentation. The community cites the OpenMoE GitHub repository as a prime example of impactful research in Mixture-of-Experts models achievable with limited resources.
- Y CLI Project Emerges as OpenRouter Terminal Chat Alternative: Y CLI, a personal project, offers a terminal-based web chat alternative for OpenRouter, storing chat data locally in jsonl files and now supporting Deepseek-r1 reasoning. Developers are actively encouraged to contribute to Y CLI via its GitHub repository, fostering community-driven development and catering to terminal enthusiasts.
- Hugging Face Community Clones DeepResearch for Open Access: HuggingFace researchers launched an open-source clone of DeepResearch, emphasizing the importance of agent frameworks and introducing the GAIA benchmark to foster community contributions. This initiative promotes transparency and collaborative development in AI agent technology, encouraging broader participation and innovation.
Theme 5. Ethical Debates and Business Model Scrutiny in AI
- OpenAI's Profit-First Approach Sparks Community Debate and Skepticism: Members are debating the motivations of AI giants like OpenAI, criticizing their prioritization of profit over public good and questioning the competitiveness of smaller companies. Skepticism surrounds OpenAI's updated chain of thought feature, with doubts about its real purpose amidst concerns about corporate agendas dominating AI development.
- AI Backlash Echoes Crypto Distrust, Fuels Ethical Concerns: Public distrust towards AI is linked to past negative experiences with cryptocurrency and NFTs, impacting the perception of AI technology and raising ethical concerns about AI development. Critics point to unlicensed AI training data and the potential for AI to disrupt labor markets, fueling broader societal anxieties about AI's ethical implications.
- Stability AI's Subscription Costs and 'Private Images' Option Spark Debate: Members are questioning the 'private images' option in Stability AI's Max subscription, debating if it implicitly caters to NSFW content, while others compare cloud service costs to local electricity expenses. These discussions reflect varying user attitudes towards the entry costs and perceived utility of different AI models, highlighting the ongoing debate about the economics of AI services.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Unsloth's GRPO now reasons with vLLM!: Unsloth's latest update on GRPO allows reproducing DeepSeek-R1's reasoning with as little as 7GB VRAM, also supporting models with reduced memory use using Colab.
- Users can experiment with the latest features and notebook updates for performance enhancements, as well as training Llama 3.1 (8B) and Phi-4 (14B) models.
- Unsloth Fine-Tunes R1 Distill Llama + Qwen!: Unsloth introduced support for fine-tuning distilled DeepSeek models, utilizing Llama and Qwen architectures and making model uploads available.
- Unsloth also supports new models such as Mistral-Small-24B-2501 and Qwen2.5, which can be found in the Hugging Face collection.
- Quantization cuts VRAM by 60%!: Recent discussions highlight effective use of BitsandBytes quantization, reducing VRAM usage by approximately 60% when selectively quantizing layers with further details available in Unsloth’s blog posts.
- Participants discussed using multi-turn conversational datasets with GRPO, emphasizing retaining reasoning contexts during model training and improving AI model reasoning capabilities with well-formatted datasets.
- OpenAI Prioritizes Profit: Members debated motivations of major AI players like OpenAI, criticizing profit prioritization over public good, along with concerns about smaller companies' competitiveness and potential alliance needs.
- A user highlighted OpenAI's updates to the chain of thought feature, linking to the announcement, but responses showed skepticism about its real purpose.
- Indie AI Researchers Tap TPUs with JAX!: Independent researchers seek realistic domains to start AI/ML research, where a member recommends learning JAX for TPU Research Cloud access, linking to the application form.
- Members cited the OpenMoE GitHub repository as a relevant example of conducting research in Mixture-of-Experts models, and even pretraining small transformers on the TinyStories dataset.
Stability.ai (Stable Diffusion) Discord
- Stability Welcomes New Community Chief: Maxfield, the new Chief Community Guy at Stability, introduced himself to improve community engagement, previously contributing at Civitai since 2022.
- Acknowledging past engagement was lackluster, Maxfield plans to launch a feature request board and encourage researchers to share project updates for improved transparency.
- Civitai Plagued by Download Errors: Users reported encountering Error 1101 when downloading models from Civitai, leading to community frustration over downtime.
- The issues raised concerns about the accessibility and reliability of accessing models via Civitai.
- Users Dissect Latent Space Intricacies: A user expressed confusion over the complexity of tools for swapping latent space parameters, suggesting a need for more user-friendly solutions.
- Discussions touched on potential implementations for newer diffusion models and the challenges of adapting existing architectures.
- AI Subscription Costs Spark Debate: Members questioned the 'private images' option in Stability's Max subscription, debating if it catered to NSFW content, while others compared cloud service costs to local electricity expenses.
- The discussions highlighted varying attitudes towards the entry costs versus the utility of different AI models.
- Engineers Seek AI Prompting Clarity: A user sought insights into prompting techniques for generative models, while others suggested external tools like brxce/stable-diffusion-prompt-generator to assist.
- The conversation underscored the difficulty in adapting to different AI model requirements and generating satisfactory prompts, especially across platforms.
Codeium (Windsurf) Discord
- Windsurf Adds Gemini 2.0 Flash: Windsurf now supports Gemini 2.0 Flash, consuming only 0.25 user prompt credits per message and flow action credits per tool call, as announced in a tweet.
- While blazingly fast and efficient, Gemini 2.0 Flash is limited in tool calling ability but excels at answering codebase-related questions.
- Windsurf Next Beta Arrives: Users can now access the latest features of Windsurf Next by downloading the beta from this link.
- The beta allows early exploration of new AI capabilities with the flexibility to switch between Next and Stable versions.
- Jetbrains Plugin Criticized by Users: Users reported frustration with the Codeium Jetbrains plugin, citing frequent failures to respond and the necessity for frequent restarts.
- One user switched back to Copilot for reliability, while another reported an error in PhpStorm related to file access.
- Users Report Windsurf Performance Issues: Users reported performance issues with Windsurf, particularly with models like O3-mini and Gemini Flash, which finish prematurely without complete suggestions.
- One user expressed frustration over the need to continuously prompt the model to 'continue', raising concerns about wasted credits.
- Cascade Learns Web Search: Cascade can now perform web searches automatically or via user commands like @web and @docs, costing 1 flow action credit, described in the Windsurf Editor Changelogs.
- This functionality supports URL input and uses web context to improve responses, aiming to provide more accurate and comprehensive information.
aider (Paul Gauthier) Discord
- Aider Users Find Port Error Fix: A user reported an invalid port error with Aider when loading model metadata, indicating a potential configuration issue.
- Another member suggested overriding the default model metadata file as a workaround to resolve this error, ensuring the tool functions correctly.
- Gemini's Unique Editing Needs: Users discussed inconsistencies with DeepSeek and Gemini models, noting Gemini's unique editing format (udiff) differs from other models.
- Aider automatically uses udiff for Google models while maintaining different defaults for others, accommodating this variation.
- Pen Testing AI Profitable, Risky: A member shared their project for pen testing using LLMs, creating a simulated hacking environment where two models collaborate.
- Despite high token usage, professional pen tests can be extremely lucrative, suggesting a potential financial benefit.
- HuggingFace Clones DeepResearch: HuggingFace researchers created an open-source clone of DeepResearch, as detailed in their blog post.
- This initiative emphasizes the importance of agent frameworks and introduces the GAIA benchmark, to foster community contributions.
- R1 Model Dumps Junk
- Recommendations included configuring model settings to minimize these tokens in commit messages and keep commits clean.
OpenAI Discord
- Gemini 2.0 Pro Sparking Excitement: Users are excited about Gemini 2.0 Pro with its 2 million token context, which facilitates complex interactions, but raised concerns about its usability compared to Google AI Studio.
- Free alternatives offer extensive customization and might give users better results on certain tasks, and the community suggests weighing effort against perceived value of additional features in premium models.
- DeepSeek Tangles with ChatGPT for Chess Title: A potential chess match between DeepSeek and ChatGPT is piquing user's interest given the models' limitations on reasoning, which promises to be highly amusing.
- Humorous contrasts were drawn between the pricing of DeepSeek’s $1 chess game versus OpenAI's $100 chess game, suggesting some prefer the cheaper, yet still challenging, game.
- Gemini Flash 2.0 and Copilot Shine as Coding Tools: In discussions about coding, members recommended Gemini Flash 2.0 and Microsoft Copilot for their features and cost-effectiveness, particularly for advanced mathematics.
- Users noted that Copilot offers a free trial, making it easier to explore without immediate financial commitment and allows engineers to 'try before they buy'.
- Deep Research Chat Eagerly Awaited by Plus Users: Several members expressed eagerness for the Deep Research chat feature to be available for Plus users soon, noting their need for it in the coming days.
- A member inquired if anyone had shared information about Deep Research chats, obviously looking for insights, and prompted others to express similar anticipation regarding the feature coming to Plus subscriptions.
- Fine Tuning AI with Iterative Editing: A member suggested using Python to count words and iterate to ensure better response length, but noted this may impact creativity when attempting to control Response Length in AI responses.
- Members also noted the importance of editing inputs using the edit button to sculpt the AI's output effectively by adjusting your input until satisfied before proceeding to ensure coherent context in the conversation.
Cursor IDE Discord
- Cursor IDE Gets GitHub Agents, Architect Feature: Users are excited about the new GitHub agents and the architect feature in Cursor IDE, which aims to boost productivity.
- However, some users reported a potential bug with running commands within the Composer tool after recent updates, as noted in the Cursor forum.
- Gemini 2.0 Self-Learning Solid, But Not Top Dog: Users find Gemini 2.0 performs well for self-learning tasks due to its affordability and context management, some discussion mentioned it was solid but not superior to Sonnet for coding.
- The community noted its effective context use makes it appealing for handling large codebases, potentially shaking up AI testing tools like Momentic.
- Clipboard Comparison Tool Recommendations: The community is recommending a VSCode extension for clipboard comparisons, which allows users to compare against clipboard content as documented in Microsoft's VSCode documentation.
- Users are also drawing comparisons between VSCode's local history and JetBrains' Timeline, suggesting Timeline offers greater efficiency, and the Partial Diff extension from the VSCode Marketplace.
- MCP Server Configs Demand Better Context: A user is seeking assistance with MCP server configurations and accessing keys for Supabase, noting limited access with some keys and the github repo for mcp-starter.
- The community is generally highlighting the need for improved context management within Cursor, particularly for managing complex projects, using the releases from daniel-lxs/mcp-starter.
- Cursor's Context Crunch Spurs Debate: Concerns are surfacing about context limitations in Cursor, with some users preferring models like Cline or Google models for their larger context windows, perhaps because they are reading Andrej Karpathy's tweets on vibe coding.
- There's ongoing debate on how context size impacts the effectiveness of AI models, specifically how larger context windows could boost performance in broader applications, and the role of model specific rules as discussed in the cursor forum.
Perplexity AI Discord
- Focus Mode Gets the Chop: Users noticed the temporary removal of Focus Mode in Perplexity AI, sparking debate on the necessity to explicitly mention sources like Reddit in prompts.
- Some users expressed concerns about the complication this adds to their ability to direct the AI's information sourcing effectively.
- Decoding Model Use in Perplexity Pro: Users are trying to clarify if Pro mode fully uses models like Claude 3.5 end-to-end or integrates R1 for reasoning, suggesting a more complex, multi-model approach.
- Insights indicate that undisclosed models conduct initial searches before handing off to chosen models for the final answer generation.
- ByteDance Dives Deep with Deepfakes: ByteDance's release of new deepfake technology has ignited discussions on the ethical implications and potential for misuse within the AI community.
- Community members are actively speculating on the ramifications of this technology, weighing its innovative possibilities against its capacity for harm.
- Desire for Model Transparency Swells: Users are urging Perplexity AI for clearer communication about model specifications and updates, particularly regarding changes that impact functionality and performance.
- Greater transparency is expected to diminish user confusion and improve interaction with the platform’s AI functionalities.
- Sonar Pro Devs on Hot Seat for Security: An urgent call went out for contact with the Sonar Pro reasoning developers due to the discovery of a security issue.
- Users were directed to email api@perplexity.ai to address the vulnerability.
OpenRouter (Alex Atallah) Discord
- DeepSeek Insurance gets even deeper: OpenRouter now insures DeepSeek R1 requests that receive no completion tokens, so you won't be charged even if the upstream provider does.
- The completion rate for Standard DeepSeek R1 has improved from 60% to 96% over time, making it a more reliable option.
- Kluster's Cancellation Catastrophe Corrected: A Kluster integration issue caused delayed completion tokens and unexpected charges due to failure to cancel timed-out requests.
- This issue has since been addressed, resolving the problem of users being charged despite apparent timeouts on OpenRouter's end.
- Qwen Quitting Quietly: Novita is deprecating their Qwen/Qwen-2-72B-Instruct model, with OpenRouter set to disable it around the same time.
- Users should transition away from this model to avoid disruption when the model becomes unavailable.
- Y CLI yearns for your attention: Y CLI, a personal project and web chat alternative, stores all chat data in single jsonl files and has added Deepseek-r1 reasoning content support, evidenced in this asciinema recording.
- Developers are encouraged to contribute to Y CLI via its GitHub repository, with a call for fellow terminal fans.
- DeepInfra Deeply Inconsistent: Users reported that DeepInfra is currently failing to return responses 50% of the time due to an increase in processing delays, often causing zero token completions when utilized with applications like SillyTavern.
- The community is sharing observations about performance differences between models and providers, including suggestions for improvements.
LM Studio Discord
- User face LM Studio API Error Avalanche: Users reported errors like 'unknown error' and 'exit code: 18446744072635812000' when loading models in LM Studio, needing system specs and API details for debugging.
- One user struggled with state handling when connecting to local models via API, indicating the need for better guidance on API interactions.
- Obsidian's Smart Connections Extension Causes Turmoil: Users faced errors connecting Obsidian's Smart Connections extension to LM Studio, citing conflicts with other extensions and missing required fields in API responses.
- Troubleshooting involved uninstalling conflicting plugins and rebuilding caches, though ongoing errors persisted even after setting up a connection.
- TheBloke Models Still a Standard: Members inquired about the safety and reliability of downloading AI models from TheBloke, even with his reduced community presence.
- It was confirmed that TheBloke's models remain a standard in the industry, with users encouraged to monitor community channels for availability updates.
- DDR5 6000 EXPO Timings are Conservative: A user found their DDR5 6000 EXPO timings to be conservative, observing a peak memory bandwidth of 72 during inference.
- After completing 4 passes of memtest86, another member suggested trying TestMem5 for a more rigorous assessment of stability.
- DeepSeek R1 Model Support GPU Acceleration?: Inquiries arose about GPU acceleration for the DeepSeek R1 Distill Qwen 7B model, with uncertainty about which models support GPU use.
- It was clarified that only specific models like Llama have known support for acceleration, leaving some ambiguity for the DeepSeek model.
MCP (Glama) Discord
- Home Assistant Gets Functional MCP Client: A user released a Home Assistant with MCP client/server support and plans to add an animated talking head avatar via met4citizen/TalkingHead for better user interaction.
- The project is still in development, as they balance paid work with open source development. Also, there was curiosity about usage statistics of the Home Assistant MCP bridging with tools like Claude.
- Goose MCP Client Honks Loudly: Users shared positive experiences using the Goose MCP Client in testing, highlighting its effectiveness.
- A pull request to enhance its logging features, block/goose@162c4c5, is in progress, with a fix to include cached tokens in usage count logs in Goose.
- Claude Grapples Image Display: A user reported challenges displaying images as tool results on Claude Desktop, encountering an input error.
- The error has led to speculation that converting image results to embedded resources might be a potential workaround.
- PulseMCP Boasts Use Cases: A new showcase of practical PulseMCP Use Cases debuted, featuring instructions and videos for using various client apps and servers, and launched the use-cases on PulseMCP.
- It highlights uses of Gemini voice, Claude, and Cline for managing Notion, converting Figma designs, and creating knowledge graphs.
- Mobile MCP options discussed: Members suggested that Sage supports iPhones, while options for Android users may require using web clients like LibreChat or MCP-Bridge.
- This conversation underscores interest in extending MCP functionality beyond desktop environments.
Yannick Kilcher Discord
- Gemini 2.0 Pro Creates SVGs: Members discussed that Gemini 2.0 Pro demonstrates impressive performance in creating SVGs, surpassing models such as o3-mini and R1, as noted in Simon Willison's blog.
- Several members also observed its enhanced SQL query capabilities, hinting at significant progress by Google with Gemini Flash 2.0.
- DeepSpeed Dataloader Batch-size Woes: A user reported confusion regarding the need to manually define batch_size in Dataloader while utilizing DeepSpeed's auto batch size configuration.
- Another member proposed the integration of DeepSpeed tags into the Dataloader for optimization and suggested potential performance modifications for specific nodes.
- Harmonic Loss Paper Lacks Punch: Community members expressed skepticism towards the harmonic loss paper, deeming it hastily assembled and failing to provide meaningful performance improvements despite its theoretical advantages.
- One member indicated that the GitHub repository associated with the paper offers more valuable information than the paper itself.
- Gemini 2.0 Flash leaves mark: Users trying the new Gemini 2.0 Flash model through LlamaIndex reported incredible speeds, although not as fast as Groq.
- One user stated that the model struggled with returning valid JSON formats, concluding it may not be suitable for tasks needing reliability in output.
- S1 Model emerges under $50: The S1 reasoning model was discussed, highlighting its performance compared to models like OpenAI's o1 but at a fraction of the cost, under $50.
- The S1 model and its tools are available on GitHub and was developed through distillation from Gemini 2.0.
Eleuther Discord
- Adobe Seeks LLM Agent Research Partners: A senior ML Engineer at Adobe is looking for collaboration on LLM agent research projects.
- Interested individuals are invited to join discussions to explore potential partnerships.
- Deepspeed Batch Size still required: When using Deepspeed with auto batch sizing, the batch_size needs to be specified for the data loader.
- This requirement persists despite auto batch sizing configuration.
- Thematic Generalization Benchmark Emerges: A member shared a GitHub repository detailing a thematic generalization benchmark for evaluating LLMs in category inference from examples and anti-examples.
- The benchmark's correlation with the performance of SAE autointerp was questioned.
- New Architectures are Cookin' at RWKV: The RWKV team is actively developing some new architectures, showing their proactive stance.
- One user grappling with scaling issues has invited discourse about prospective collaboration.
- MATS 8.0 Cohort Applications Now Open: Applications for the MATS 8.0 cohort are open until Feb 28, offering opportunities for paid full-time mechanistic interpretability research, apply here.
- Previous mentees have significantly contributed, evidenced by their involvement in 10 top conference papers.
Nous Research AI Discord
- Deep Research Excites Users: Members laud OpenAI's Deep Research for efficiently gathering relevant connections and sources, boosting their cognitive bandwidth.
- One user highlighted its ability to explore obscure online communities and gather unexpected data.
- AI Backlash Echoes Crypto Concerns: Public distrust towards AI stems from past issues with cryptocurrency and NFTs, impacting the perception of AI technology, according to some members.
- Critics are concerned about AI training data being unlicensed and the disruptive effects of AI on labor markets, as articulated in Why Everyone Is Suddenly Mad at AI.
- Purpose AI Agent in Legal Limbo: A user aims to develop a purpose-driven AI agent within a legal trust framework, aiming to pioneer legal discourse around AI personhood.
- Feedback centered on the engineering complexity, including integrating fiscal management functions while emphasizing the potential for custom software solutions like the ones shown in I Built the Ultimate Team of AI Agents in n8n With No Code (Free Template).
- Model Merging Mania: Members discussed strategies for merging AI models, sharing insights on improving model instruction tuning and reasoning performance.
- Various fine-tuning methods were explored, highlighting the benefits of innovative techniques in AI training to enhance model performance with tools like Unsloth Documentation.
- Synthetic Data Dream: A member seeks resources on synthetic data generation, focusing on seed-based approaches similar to Self-Instruct, after facing challenges with Magpie outputs.
- They discovered the Awesome-LLM-Synthetic-Data GitHub repository, offering a list of resources on LLM-based synthetic data generation.
Interconnects (Nathan Lambert) Discord
- Schulman Shuffles from Anthropic: Leading AI researcher and OpenAI co-founder John Schulman has left Anthropic after around five months, prompting speculation about his next career steps link.
- Potential destinations mentioned include Deepseek and AI2, according to sources.
- Copilot Becomes Agent: GitHub Copilot introduced agent mode, enhancing developer assistance along with general availability of Copilot Edits link.
- This update seeks to provide more effective coding support through AI.
- LRM Test-Time Scaling Terminology Troubles: Members questioned the term test-time scaling for Long-Range Models (LRMs), emphasizing that models decide their own output link.
- It was pointed out that scaling occurs during the training phase, rendering the term misleading; a member called the whole concept fundamentally flawed.
- Qwen Achieves Magical Results: Qwen 2.5 models are showing impressive results with minimal training data, as noted by members discussing their findings link.
- Aran Komatsuzaki remarked that Qwen models seem to have a magical quality, achieving notably good performance with limited data.
- Scale AI Faces Adaptation Challenge: Members recognized that adaptation is possible for Scale AI, but challenges remain due to current operational models and valuations link.
- The consensus was a bleak outlook without significant changes to their approach amid a shifting landscape.
Notebook LM Discord
- NotebookLM Mobile Users Limited to One Model: Users cannot change the model within the mobile version of NotebookLM, a limitation causing frustration for those expecting greater flexibility.
- This restriction hinders the user experience on mobile devices, leading to confusion among users accustomed to managing models on the web platform.
- Gemini Shines with Sheets, NotebookLM Stumbles: Members voiced concerns about using NotebookLM for analyzing spreadsheet data, suggesting tools like Gemini within Google Sheets are more suitable.
- As Engadget reported, Gemini can use Python code to generate insights and charts, reinforcing NotebookLM's strength as primarily a text analysis tool.
- Sliders Could Refine AI Creativity: A user proposed integrating sliders for tuning AI's creativity, similar to features in the Gemini API, inspired by discovering an exploit related to the AI's features.
- This functionality would allow users to adjust parameters, offering greater control over the creative output of AI models.
- NotebookLM Summarizes Legal Testimony at NY Budget Hearing: A user employed NotebookLM to capture testimony at the New York State Legislature’s Budget hearing on Environmental Conservation.
- The user highlighted the challenge of sharing this extensive document due to licensing, while the notes are available here.
- Max Headroom Glitches Back, Critiques AI: The iconic Max Headroom makes a return with a new video, showcasing a unique approach to AI interaction.
- As seen on Youtube, the new content humorously critiques corporate AI practices, urging viewers to share and engage.
LLM Agents (Berkeley MOOC) Discord
- Fall 2024 MOOC Certificates Finally Drop: The Fall 2024 MOOC certificates were released today at 8am PT, after the resolution of technical challenges.
- Some participants were downgraded to the Trailblazer tier due to incomplete coursework, with no makeups offered.
- Certificate Timeline Elusive: Members expressed uncertainty regarding the certificate issuance timeline, hoping for delivery within a week or two due to unforeseen technical issues being resolved.
- A member noted discrepancies in certificate receipt, indicating a potential soft bounce issue affecting communications.
- Quiz Availability Creates Confusion: Concerns arose over the availability of answers for Quiz-1 as Quiz-2 was launched, prompting members to seek clarification on the new policy regarding answer releases.
- Community members clarified that score visibility for Quiz-1 was possible through the original submission link.
- Certificate Tier Distribution: It was revealed that there are 301 Trailblazer, 138 Masters, 89 Ninjas, 11 Legends, and 7 Honorees amongst the participants.
- Clarification was provided that only the honorary tier would be noted if both an honorary and a specific tier were achieved.
- Course Experience Earns Praise: The community expressed gratitude for the support received during the course, especially acknowledging the team handling grading and certificate queries.
- Participants shared enthusiasm for the course, with one member reflecting on their learning journey and the significance of their certificate for future endeavors.
GPU MODE Discord
- NVIDIA Blackwell gets OpenAI Triton: The Triton compiler now supports the NVIDIA Blackwell architecture due to ongoing collaboration between NVIDIA and OpenAI, enhancing performance and programmability via cuDNN and CUTLASS.
- This advancement enables developers to optimize matrix multiplication and attention mechanisms for modern AI workloads, improving efficiency and capabilities.
- Minimize AI Research Costs: Members shared that independent researchers can conduct efficient work on LLMs and vision tasks while fine-tuning models on a limited budget, economizing AI research via stability with low-bit training weights.
- The success of GPT-2 speedruns with Muon was highlighted as a prime example of impactful research using limited resources.
- FP8 Attention requires Hadamard: A member observed that FP8 Attention for video models performed significantly better when utilizing the Hadamard Transform, drastically reducing error rates; the Flash Attention 3 paper suggests that this approach is crucial for operations in FP8.
- Another member recommended using the fast-hadamard-transform repository to implement Hadamard before the attention mechanism for enhanced performance.
- Reasoning Gym Embraces Sokoban Puzzles: A pull request was submitted to add Sokoban puzzles to reasoning-gym, demonstrating a new puzzle format for users to solve, including a graphic explanation of the puzzle setup along with example moves.
- Members are also discussing collaboratively building a basic gym for the Rush Hour game integration into the reasoning-gym to encourage joint coding efforts.
- Linear Attention faces Distillation Challenges: A member attempted to distill a small LLM to a linear attention model following a recipe from Lolcats but the model only produced repeating characters.
- The member reached out for help specifically from the Lolcats team, highlighting the community support aspect often relied upon in AI model development.
Nomic.ai (GPT4All) Discord
- O3 Remains Ahead Despite Pricing: Despite pricing concerns, O3 continues to outperform other models, with Llama 4 being anticipated as the next potential challenger, according to discussions in the general channel.
- Links comparing DeepSeek-R1 vs o3 are available online and o3-mini vs DeepSeek-R1 are also available.
- DeepSeek Constrained in Political Discussions: Users found that DeepSeek has greater limitations than ChatGPT and O3-mini in sensitive political discussions, often resulting in unexpected deletions or evasions.
- This highlights potential constraints in language models when prompted with sensitive political topics.
- DeepSeek's Cutoff Date Raises Questions: Reportedly, DeepSeek's knowledge cutoff date is July 2024, which raises questions about its current relevance given that we are now in 2025.
- The Time Bandit method, for extracting information by leveraging temporal context, was discussed in relation to DeepSeek, with more details on its system prompt available online.
Torchtune Discord
- GRPO Implementation Scores Big: A member reported a successful implementation of GRPO training, achieving training scores ranging from 10% to 40% on GSM8k.
- While debugging, they noted challenges with deadlocks and memory management, and are planning improvements and opening the project for contributions.
- Kolo Extends to Torchtune: Kolo officially announced support for Torchtune on their GitHub page.
- The project delivers a comprehensive solution for fine-tuning and testing LLMs locally using the best available tools.
- Llama 3.1 and Qwen 2.5 stumble on Configs: Members identified FileNotFoundError issues downloading and fine-tuning Llama 3.1 and Qwen 2.5 due to mismatched path configurations.
- One member created a GitHub issue to address the incorrect default paths and propose fixes.
- Hugging Face Fast Tokenizers Get Support: The community discussed the prospect of using Hugging Face fast tokenizers, with members indicating current limitations but ongoing progress.
- A member mentioned that Evan is actively enabling support, as detailed in this GitHub pull request.
- Full DPO Distributed PR Faces Hurdles: A user reported issues with GitHub checks on their Full DPO Distributed PR, with specific errors related to GPU and OOM issues.
- The error,
ValueError: ProcessGroupNCCL is only supported with GPUs, no GPUs found!, prompted the user to seek assistance from the community.
- The error,
Modular (Mojo 🔥) Discord
- Mojo Pivots from Python, Focuses on GPU: In a recent community meeting, Modular clarified that Mojo is not currently a superset of Python, but focuses on leveraging GPU and performance programming.
- This shift emphasizes enhancing Mojo's efficiency in its designed applications rather than broadening its language framework.
- Parser Revision Balances Branching Costs: A member suggested that the parser needs adjustment for handling multiple slices of data, weighing the costs of branching and noting that branching may be cheaper than significant data transfers.
- This is a valid consideration for those not focusing on higher performance needs.
- Msty Simplifies Local Model Access: A member introduced Msty, an OpenAI-compatible client that simplifies local model interactions compared to using Docker and other complex setups, highlighting its ease of use and features for accessing AI models seamlessly with Msty's Website.
- The importance of offline usability and privacy with Msty was emphasized, suggesting it is highly favorable for users who wish to avoid complex configurations.
- MAX Serve CLI Mimics Ollama's Features: Members discussed building a CLI similar to ollama on top of MAX Serve, noting that MAX Serve can already handle many functionalities offered by Ollama with a docker container.
- The discussion highlighted the hope for better performance running local models compared to Ollama.
- Community Reports OpenAI API Incompatibilities: A user reported missing features in the OpenAI completions API with max serve (v24.6), such as generation stopping at specified tokens, suggesting that they file issues on the GitHub repo to highlight these missing elements.
- The group acknowledged ongoing issues with OpenAI API compatibility, particularly referencing the v1/models endpoint, and other missing functionalities like token stopping and prompt handling in this GitHub issue.
Latent Space Discord
- Hibiki Champions Real-time Translation: Kyutai's Hibiki model achieves real-time speech-to-speech translation from 🇫🇷 to 🇬🇧, preserving the speaker's voice and adapting to context.
- Early reports claim Hibiki excels in quality, naturalness, and speaker similarity, rivaling human interpreters.
- Melanie Mitchell Raises Agent Concerns: @mmitchell_ai's latest paper argues against developing Fully Autonomous Agents, emphasizing ethical considerations.
- The piece sparked debates within the AI community, acknowledging her balanced perspective amidst fervent discussions.
- Mistral AI's Le Chat Enters the Scene: Mistral AI launched Le Chat, a versatile AI assistant tailored for daily personal and professional tasks, accessible on web and mobile.
- The tool is set to redefine user interaction with AI, potentially impacting workflows and personal routines.
- OpenAI Enhances o3-mini Capabilities: OpenAI rolled out enhanced chain of thought features in o3-mini and o3-mini-high (source), benefiting both free and paid subscribers.
- The updates promise improved performance and a smoother user experience, reaffirming OpenAI's commitment to continuous service evolution.
- PDF Parsing Achieves Breakthrough: PDF parsing is now efficiently solved at scale; Gemini 2 Flash can parse large documents for approximately $1 per 6000 tokens, according to @deedydas.
- This advancement in processing complex documents unlocks new possibilities for applications needing high-caliber text extraction.
LlamaIndex Discord
- Gemini 2.0 is now generally available: Gemini 2.0 from @google launched with day 0 support, developers can install the latest integration package with
pip install llama-index-llms-geminiand read more in the announcement blog post.- The updated 2.0 Flash is available to all users in the Gemini app on desktop and mobile.
- LlamaParse Tackles Complex Financials: Hanane D showcased the parsing of complex financial documents accurately and cost-effectively using LlamaParse 'Auto' mode, using @OpenAI embeddings as shared in this link.
- Her demonstration highlights the advancements in parsing technology for extracting relevant insights from intricate data, charts and tables.
- Embedding Print Troubles LlamaIndex: A member requested deletion of the embedding print from the LlamaIndex documentation due to excessive space usage and readability issues, see GitHub issue.
- Another member offered to create a Pull Request (PR) to address the embedding print removal.
MLOps @Chipro Discord
- LLMs Classify Well, But Noise Makes Them Falter: Members discussed that although LLMs are effective for classification, noisy data requires additional techniques like dense embeddings and autoencoder rerankers to improve performance.
- This suggests the necessity of a more intricate strategy when handling challenging data scenarios.
- Latency Concerns Dampen LLM Enthusiasm: The discussion revealed that although LLMs classify effectively, their suitability might diminish in scenarios with strict latency requirements due to their processing limits.
- The suitability of LLMs depends on the specific latency constraints of a given application.
- Business Requirements Highlight ML Misfits: A member noted that a missed opportunity occurred in properly framing the business requirements during the transition to an ML solution.
- It should have been evident from the onset that if low-latency is paramount, traditional LLMs might not be the ideal choice.
Cohere Discord
- Cohere Fine-Tuning Limits Spark Concern: A user encountered a BadRequestError (Status code: 400) in Cohere, indicating the training configuration surpassed the maximum of 250 training steps, with a batch size limit of 16.
- A member questioned if this restricts fine-tuning to 4000 examples, highlighting that this limitation wasn't previously in place.
- AIML System Design Interview Questions Requested: A member inquired about system design interview questions specific to AI/ML in the Cohere channel.
- Another member acknowledged the request and indicated it would be collected, implying team collaboration on this topic.
Gorilla LLM (Berkeley Function Calling) Discord
- Request for Canonical System Prompts Arises: A member requested clarification on the canonical system prompts for fine-tuned tool-using models, noting the Gorilla paper lacked this detail.
- The goal is to ensure the models reliably return responses or JSON for function calls, suggesting a need for standardized prompt engineering practices.
- Hugging Face Datasets Seek Transformation: A member aimed to streamline experimentation by transforming data and using
datasets.mapon Hugging Face, signalling a move towards more flexible data manipulation.- This highlights ongoing efforts to improve the usability and accessibility of datasets for research and development purposes.
- Dataset Format Issue with Hugging Face: A member reported a dataset format mismatch within Hugging Face, where .json files actually contained jsonl data, leading to compatibility problems.
- The suggested solution involves renaming the file suffix to .jsonl and adjusting the dataset config files to align with the actual data format.
DSPy Discord
- Paper Posted on DSPy: A member shared a link to a paper on DSPy.
- The paper was shared in the #papers channel.
- Member Asks About Git Repo: In the #examples channel, a member inquired about the availability of a Git repo for their work, indicating interest in accessing related code or resources.
- The member did not specify which project it was referring to.
- Colab Notebook Surfaces: In response to the Git repo query, a member provided a link to a Colab notebook.
- Accessing the notebook requires signing in and it is likely related to the DSPy discussion.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!