[AINews] Rombach et al: FLUX.1 [pro|dev|schnell], $31m seed for Black Forest Labs
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Team and $31m is all you need to recreate Stability?
AI News for 7/31/2024-8/1/2024. We checked 7 subreddits, 384 Twitters and 28 Discords (335 channels, and 3565 messages) for you. Estimated reading time saved (at 200wpm): 346 minutes. You can now tag @smol_ai for AINews discussions!
We have been covering Rombach et al's work this year closely as he shipped Stable Diffusion 3 and then left Stability AI. His new stab at the text-to-image domain is FLUX.1, and we love featuring pretty images here so here it is executing a variety of standard tasks from hyperrealistic to fantastical to photorealistic to long text prompting:

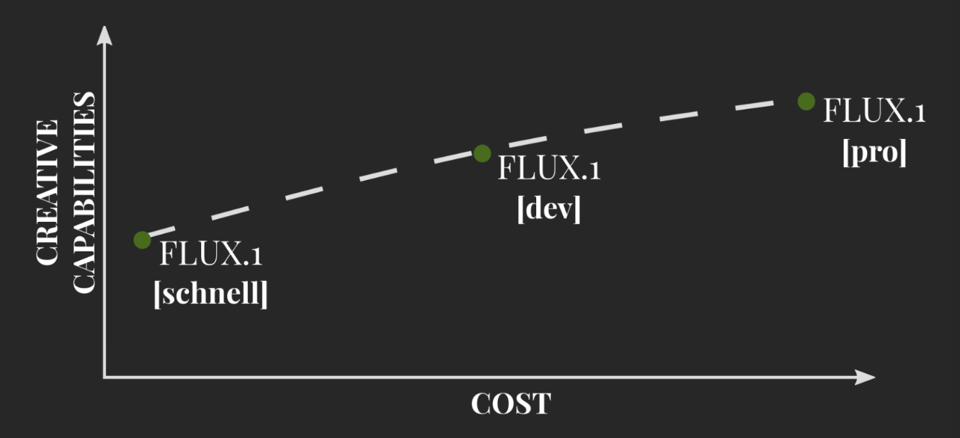
The three variants span the spectrum of size and licensing:
- pro: API only
- dev: open-weight, non-commercial
- schnell: Apache 2.0
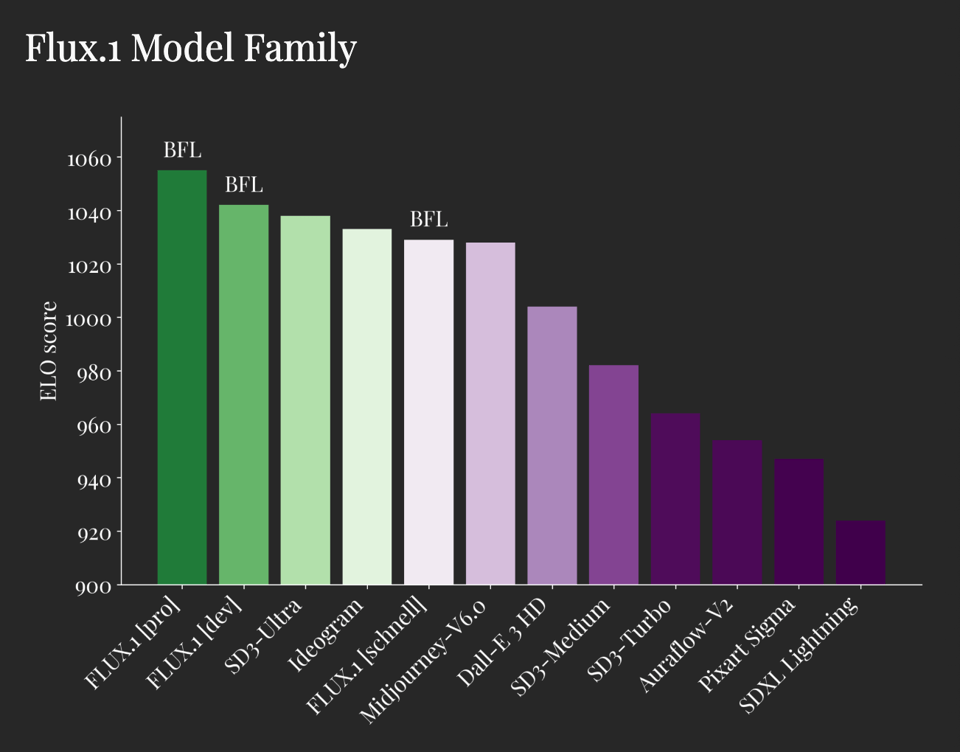
Based on Black Forest Labs' own ELO score, all three varients outdo Midjourney and Ideogram:
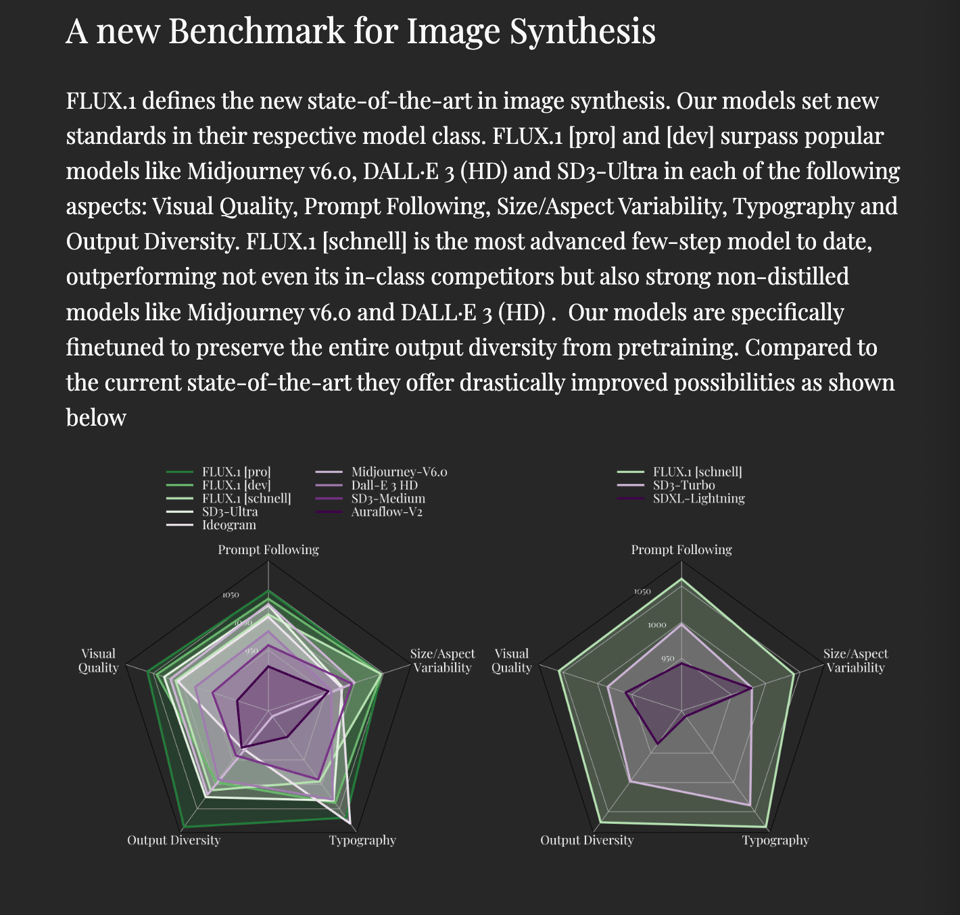
They also announced they will work on SOTA Text-to-Video next. All in all, one of the strongest and most confident model lab launches we've seen this past year.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Gemma 2 Release and AI Model Developments
Google DeepMind released Gemma 2, a new family of open-source AI models, including a 2 billion parameter model (Gemma-2 2B) that has achieved impressive performance:
- @GoogleDeepMind announced Gemma-2 2B, a new 2 billion parameter model offering best-in-class performance for its size and efficient operation on various hardware.
- @lmsysorg reported that Gemma-2 2B achieved a score of 1130 on the Chatbot Arena, outperforming models 10x its size and surpassing GPT-3.5-Turbo-0613 (1117) and Mixtral-8x7b (1114).
- @rohanpaul_ai highlighted that Gemma-2 2B outperforms all GPT-3.5 models on Chatbot Arena, using distillation to learn from larger models and optimized with NVIDIA TensorRT-LLM for various hardware deployments.
- @fchollet noted that Gemma 2-2B is the best model for its size, outperforming GPT 3.5 and Mixtral on the lmsys Chatbot Arena leaderboard.
The release also includes additional components:
- ShieldGemma: Safety classifiers for detecting harmful content, available in 2B, 9B, and 27B sizes.
- Gemma Scope: Uses sparse autoencoders (SAEs) to analyze Gemma 2's internal decision-making, with over 400 SAEs covering all layers of Gemma 2 2B and 9B.
AI Model Benchmarks and Comparisons
- @bindureddy criticized the Human Eval Leaderboard, claiming it's gamed and doesn't accurately represent model performance. They argue that GPT-3.5 Sonnet is superior to GPT-4o-mini, despite leaderboard rankings.
- @Teknium1 pointed out a discrepancy between Arena scores and MMLU performance for Gemma-2 2B, noting it scores higher than GPT-3.5-turbo on Arena but has an MMLU of 50 compared to 3.5-turbo's 70.
Open-Source AI and Government Stance
- @ClementDelangue shared that the United States Department of Commerce issued policy recommendations supporting the availability of key components of powerful AI models, endorsing "open-weight" models.
- @ylecun praised the NTIA report supporting open-weight/open-source AI platforms, suggesting it's time to abandon innovation-killing bills based on imaginary risks.
AI in Coding and Development
- @svpino discussed the limitations of current AI coding tools like Cursor, ChatGPT, and Claude, noting they don't significantly improve productivity in writing code.
- @svpino emphasized the potential of "passive AI" tools that work in the background, offering recommendations and identifying issues in code without requiring explicit queries.
Other Notable AI Developments
- @c_valenzuelab demonstrated real-time video generation, producing 10 seconds of video in 11 seconds.
- @mervenoyann discussed SAMv2 (Segment Anything Model 2), which introduces a new task called "masklet prediction" for video segmentation, outperforming previous state-of-the-art models.
- @rohanpaul_ai shared information about faster ternary inference, allowing a 3.9B model to run as fast as a 2B model while using only 1GB of memory.
Memes and Humor
- @bindureddy joked about Apple Vision Pro being abandoned by users and potentially being the biggest flop in Apple's history.
- @teortaxesTex shared a humorous tweet about the "Friend" gimmick.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Google's Gemma 2 Release and Ecosystem
- Google just launched 3 new Gemma products (Gemma 2 2B, ShieldGemma, and Gemma Scope) (Score: 143, Comments: 30): Google has expanded its Gemma AI lineup with three new products: Gemma 2 2B, ShieldGemma, and Gemma Scope. While specific details about these products are not provided in the post, the launch suggests Google is continuing to develop and diversify its AI offerings in the Gemma family.
- Gemma-2 2b 4bit GGUF / BnB quants + 2x faster finetuning with Flash Attention support! (Score: 74, Comments: 10): Google released Gemma-2 2b, trained on 2 trillion tokens of distilled output from a larger LLM. The post author uploaded 4bit quantized versions (bitsandbytes and GGUF) for 2b, 9b, and 27b models, and developed a method for 2x faster finetuning with 63% less VRAM usage, incorporating Flash Attention v2 support for Gemma-2. They provided links to various resources including Colab notebooks, quantized models on Hugging Face, and an online inference chat interface for Gemma-2 instruct.
- Google quietly released a sparse auto-encoder to interpret Gemma 2 and 9b. This is a google colab they put together to get you started. Super exciting, I hope Meta follows this example! (Score: 104, Comments: 22): Google has released a sparse auto-encoder for interpreting Gemma 2 and 9b models, providing a Google Colab notebook to help users get started with the tool. This release aims to enhance the interpretability of these language models, potentially setting a precedent for increased transparency in AI development that the poster hopes other companies like Meta will follow.
- The sparse auto-encoder tool allows visualization of layer activations for each token, potentially enabling research into refusal removal, induction heads, and model lying detection. Users can explore low-hanging fruit in safety research and measure fine-tuning impacts on specific concepts.
- The tool opens possibilities for runtime, low-cost fine-tuning to promote certain moods or themes in AI models. This could be applied to create dynamic AI experiences, such as an interrogation game where the model's lying probability is scored in real-time.
- Users discussed interpreting the tool's graphs, noting they show token probabilities which can quantify fine-tuning effects. The feature activations, represented as number strings, are considered more useful than the visual dashboard for analysis purposes.
Theme 2. Open Source LLM Advancements and Comparisons
- Llama-3.1 8B 4-bit HQQ/calibrated quantized model: 99.3% relative performace to FP16 and fast inference speed (Score: 156, Comments: 49): The Llama-3.1 8B model has been released in a 4-bit HQQ/calibrated quantized version, achieving 99.3% relative performance to FP16 while offering the fastest inference speed for transformers. This high-quality quantized model is available on Hugging Face, combining efficiency with performance for improved AI applications.
- Just dropping the image.. (Score: 562, Comments: 74): The image compares OpenAI's model releases with open-source alternatives, highlighting the rapid progress of open-source AI development. It shows that while OpenAI released GPT-3 in June 2020 and ChatGPT in November 2022, open-source models like BLOOM, OPT, and LLaMA were released in quick succession between June and December 2022, with Alpaca following in March 2023.
- Users criticize OpenAI's lack of openness, with comments like "OpenAI being full closed. The irony." and suggestions to rename it "ClosedAI" or "ClosedBots". Some argue OpenAI is sustained by public hype and brand recognition from being first in the space.
- Gemma 2 from Google receives praise, with users noting its surprising quality and personality. One user describes it as "better than L3 in many ways" and expresses anticipation for Gemma 3 with potential multimodality and longer context.
- Mistral AI is commended for its rapid progress despite limited resources compared to larger companies. Users suggest normalizing comparisons based on team size and available resources to highlight Mistral's achievements.
- Google's Gemma-2-2B vs Microsoft Phi-3: A Comparative Analysis of Small Language Models in Healthcare (Score: 65, Comments: 9): A comparative analysis of Google's Gemma-2-2b-it and Microsoft's Phi-3-4k models in the medical field reveals their performance without fine-tuning. Microsoft's Phi-3-4k outperforms with an average score of 68.93%, while Google's Gemma-2-2b-it achieves 59.21% on average, as shared in a tweet by Aaditya Ura.
- Users criticized the graph color choices in the original analysis, highlighting the importance of visual presentation in data comparisons.
- Discussion arose about the specific Phi-3 model used, with speculation it was the 3.8B Mini version. Users also inquired about fine-tuning techniques for the PubMed dataset.
- Debate ensued on the relevance of evaluating small LLMs on medical QA datasets. Some argued for its importance in assessing medical knowledge, while others noted LLMs are already being used to answer medical questions, especially in areas with limited access to doctors.
Theme 3. Hardware and Inference Optimization for LLMs
- Woah, SambaNova is getting over 100 tokens/s on llama 405B with their ASIC hardware and they let you use it without any signup or anything. (Score: 247, Comments: 94): SambaNova has achieved a breakthrough in AI hardware performance, generating over 100 tokens per second on the Llama 405B model using their ASIC hardware. This technology is now accessible to users without requiring any signup process, potentially democratizing access to high-performance AI inference capabilities.
- Post your tokens per second for llama3.1:70b (Score: 61, Comments: 124): The post requests users to share their tokens per second (TPS) performance benchmarks for the Llama 3.1 70B model. While no specific performance data is provided in the post itself, it aims to collect and compare TPS metrics from different users and hardware setups running this large language model.
- 70b here I come! (Score: 216, Comments: 65): The post author is preparing to run 70B parameter models with a high-end GPU setup. They express excitement about their upcoming capability to work with large language models, as indicated by the enthusiastic title "70b here I come!"
- Users discussed thermal management, with one mentioning undervolting two 3090 FE GPUs for better performance. The original poster uses a Meshify case with good airflow and disables the 3090 when not needed.
- Performance benchmarks were shared, with one user reporting 35 tokens per second using AWQ and LMDeploy for the LLaMA 3.1 70B model. Another recommended a GitHub tool for monitoring GDDR6 memory temperatures.
- Concerns about 3090 memory overheating were raised, especially in warmer climates. One user experienced crashes with Stable Diffusion image generation and resorted to removing the case side panel for better cooling.
Theme 4. New Tools and Frameworks for LLM Development
- PyTorch just released their own llm solution - torchchat (Score: 135, Comments: 28): PyTorch has released torchchat, a new solution for running Large Language Models (LLMs) locally on various devices including servers, desktops, and mobile. The tool supports multiple models like Llama 3.1, offers Python and native execution modes, and includes features for eval and quantization, with the GitHub repository available at https://github.com/pytorch/torchchat.
- A user tested torchchat with Llama 3.1, achieving 26.47 tokens/sec on an NVIDIA GeForce RTX 3090. Comparatively, vLLM reached 43.2 tokens/s initially, and up to 362.7 tokens/s with higher batch sizes.
- Discussions focused on performance optimization, including using --num-samples for more representative metrics after warmup, --compile and --compile-prefill for PyTorch JIT engagement, and --quantize for model quantization.
- Users inquired about ROCm support for AMD GPUs, compatibility with Mamba models, and comparisons to other frameworks like Ollama and llama.cpp.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Applications
- Google DeepMind's Diffusion Augmented Agents: A new paper from Google DeepMind introduces Diffusion Augmented Agents, potentially advancing AI capabilities in complex environments. (r/singularity)
- AI outperforms doctors in prostate cancer detection: A study finds AI detects prostate cancer 17% more accurately than doctors, showcasing the potential of AI in medical diagnostics. (r/singularity)
AI Products and User Experiences
- ChatGPT Advanced Voice Mode: A video demonstration shows ChatGPT's voice mode mimicking an airline pilot before abruptly stopping due to content guidelines. (r/singularity)
- OpenAI's improved conversational AI: A user reports better conversational flow and educational capabilities in OpenAI's latest update, used during a 1.5-hour commute to learn about GitHub repositories. (r/OpenAI)
- Criticism of AI wearable device: A post criticizes a new AI wearable device, comparing it to previous failed attempts like the Humane Pin and Rabbit R1. Users discuss potential issues with the device's functionality and business model. (r/singularity)
AI and Data Rights
- Reddit CEO demands payment for AI data access: Reddit's CEO states that Microsoft should pay to search the site, sparking discussions about data rights and compensation for user-generated content. (r/OpenAI)
AI Discord Recap
A summary of Summaries of Summaries
Claude 3.5 Sonnet
1. New AI Models and Capabilities
- Llama 3.1 Launch Sparks Debate: Meta released Llama 3.1, including a new 405 billion parameter model trained on 15.6 trillion tokens, with Together AI's blog post sparking debate about implementation differences affecting model quality across providers.
- The AI community engaged in discussions about potential cherry-picking of results and the importance of rigorous, transparent evaluation methodologies. Dmytro Dzhulgakov pointed out discrepancies in Together AI's showcase examples, emphasizing the need for consistent quality testing.
- Flux Shakes Up Text-to-Image Generation: Black Forest Labs, formed by original Stable Diffusion team members, launched FLUX.1, a new suite of state-of-the-art text-to-image models including a 12B parameter version available under non-commercial and open licenses.
- The FLUX.1 model gained attention for its impressive capabilities, with users noting its strengths in rendering body extremities like hands and fingers. A pro version of FLUX.1 is already available for testing on Replicate, showcasing the rapid development in the text-to-image space.
2. AI Infrastructure and Efficiency Gains
- MoMa Architecture Boosts Efficiency: Meta introduced MoMa, a new sparse early-fusion architecture for mixed-modal language modeling that significantly improves pre-training efficiency, as detailed in their recent paper.
- According to Victoria Lin, MoMa achieves approximately 3x efficiency gains in text training and 5x in image training. The architecture employs a mixture-of-experts (MoE) framework with modality-specific expert groups for handling interleaved mixed-modal token sequences.
- GitHub Integrates AI Models: GitHub announced GitHub Models, a new feature that brings industry-leading AI tools directly to developers on their platform, aiming to bridge the gap between coding and AI engineering.
- This integration is designed to make AI more accessible to GitHub's massive developer base, potentially transforming how coding and AI interact at scale. The community speculated whether this move is an attempt to compete with platforms like Hugging Face by integrating AI capabilities into developers' existing workflows.
3. AI Ethics and Policy Developments
- NTIA Advocates for Open AI Models: The National Telecommunications and Information Administration (NTIA) issued a report supporting the openness of AI models while recommending risk monitoring to guide policymakers in the US.
- Community members noted the NTIA's direct reporting line to the White House, giving significant weight to its policy recommendations on AI model openness. This report could potentially influence future AI regulations and policy directions in the United States.
- Watermarking Debate in AI Trust: A debate emerged around the effectiveness of watermarking in solving trust issues in AI, with some arguing it only works in institutional settings and cannot prevent misuse entirely.
- The discussion suggested that better cultural norms and trust mechanisms, rather than watermarking alone, are needed to address the spread of deepfakes and misrepresented content. This highlights ongoing challenges in establishing trust and authenticity in AI-generated content.
PART 1: High level Discord summaries
HuggingFace Discord
- Fresh Web Simulators for Neural Networks: A new Neural network simulation tool invites AI enthusiasts to fiddle with different neural network configurations online.
- The simulator aims at demystifying neural network behaviors, featuring an interactive experience for users to modify and understand neural dynamics.
- Blueprints for Transferable AI Wisdom: IBM offers a detailed breakdown of Knowledge Distillation, elucidating the process of imbuing compact 'student' models with insights from bulkier 'teacher' models.
- Knowledge distillation stands out as a method for model compression and efficient knowledge transfer, pivotal for AI scalability.
- Interactive Heatmap Chronicles Model Milestones: An innovative heatmap space charts AI model releases, gaining community interest for its potential integration into Hugging Face profiles.
- This tool presents an insightful visual aggregation of model development trends, aiming to bolster visibility and understanding of AI evolution tempo.
- Crafting Semantic Parsers for Solr: A member seeks advice on teaching a Large Language Model (LLM) to interpret queries for Apache Solr, aiming to generate JSON responses with product information.
- With no training dataset at hand, the challenge lies in methodically guiding the LLM to enhance search functionality and user experience.
Nous Research AI Discord
- Chameleon Architecture Leaps Ahead: A new multi-modal architecture pioneered by the creators of Chameleon boasts substantial efficiency gains, with details available in an academic paper.
- Victoria Lin provided insights on Twitter, noting gains of approximately 3x in text training and 5x in image training, making MoMa 1.4B a standout performer (source).
- Decoding the Speculative Decoding: Speculative decoding mechanisms were a hot topic, with claims that smaller draft models can impact output distribution unless corrected by techniques like rejection sampling.
- A YouTube resource further explains speculative decoding, hinting at the balance between speed and fidelity in the process.
- Bitnet Boasts Blazing Speed: Bitnet's finetuning approach is drawing attention, achieving an impressive 198 tokens per second on a singular CPU core as reported on Reddit.
- A compact 74MB model emerged from this finetuning method, with an open-source release expected, triggering anticipation for its use in future projects (Twitter source).
- LangChain: A Key or a Kink?: Debates arose around the necessity of LangChain when using Mixtral API in the OpenAI API format.
- Some members question the requirement for LangChain, suggesting direct API interactions might suffice, sparking a discussion on tool dependencies and API conventions.
- Project Participation without the Price Tag: Members of the community inquired about ways to assist with a no-cost AI project, with steps laid out in an anticipated PR.
- The discussion affirmed the project's cost-free nature, highlighting the actionable tasks to be disclosed in a forthcoming PR, easing onboarding for new contributors.
Unsloth AI (Daniel Han) Discord
- Multi-GPU Meltdown to Victory: Discussions shed light on multi-GPU training issues, praising fixes but highlighting initial setup headaches and environmental tweaks.
- A swap to
llamafacs envwas the key to success for some, contrasting with the more hands-on approach of a manual transformers upgrade for others.
- A swap to
- Unsloth Crypto Runner Unveiled: Details on Unsloth Crypto Runner's AES/PKI-based design were reconciled, elucidating its cryptographic communication from client to server.
- The community buzzed when
MrDragonFoxunderscored the imperative of GPU usage, and Skunkworks AI's intent to open-source was revealed.
- The community buzzed when
- Continuous Qwen Refinement Realized: Qwen2-1.5B-Instruct's Continuous Fine-tuning Without Loss ushered in a blend of code FIM and instruct capabilities, marking a technical milestone.
- Community spirit was buoyed as a call for a tutorial to demystify documentation challenges echoed amongst users.
- LoRA's Binding Predicament: Merging LoRA adapters was brought to the fore, with a focus on the risks of melding leading to deceptive 16-bit representations from 4-bit models.
- Concerns bubbled up about the propagation of these faux 16-bit models within the community, prompting vigilance.
Perplexity AI Discord
- Perplexity's Prodigy Perk with Uber One: Uber One members now have access to Perplexity Pro subscription for free, valid until October 31, 2024, providing an enhanced answer engine worth $200.
- To avail this benefit, users in the US and Canada need to maintain their Uber One subscription and set up a new Perplexity Pro account. More details are at Perplexity Uber One.
- Perplexity Tops AI Search Engine Benchmarks: In a comparative assessment, Perplexity Pro outranked rivals like Felo.ai and Chatlabs, excelling in UI/UX and query responses.
- Members rated search engines on their capabilities with Pro Search appearing as a favorite, highlighted on platforms such as ChatLabs.
- Perplexity API Prompts Puzzlement: Discussions revealed user dissatisfaction regarding suboptimal outputs from Perplexity's API, feeling the result quality has declined.
- Speculation about problem prompts rose, with individuals requesting advice on improving outcomes and expressing curiosity about Perplexity References Beta access.
- Perplexity's Refined Flask Authentication: A discussion on Flask highlighted the need for secure user authentication, recommending packages such as
Flask-Login, and a secure setup guide.- Users were pointed to resources outlining model creation, user authentication routes, and encryption practices.
- OpenAI Voices Future with GPT-4o: OpenAI impressed with its launch of Advanced Voice Mode for ChatGPT, granting Plus subscribers realistic voice interactions as of July 30, 2024.
- The update allows for enhanced vocal features, like emotional tone variation and interruption handling, documented on OpenAI's update page.
OpenAI Discord
- Vivid Visionaries: GPT-4o Sparks Image Innovation: Enthusiastic debate surged on GPT-4o's image output capabilities with users comparing it to DALL-E 3, sharing examples that sparked interest over its lifelike and realistic imagery.
- Despite acclaims for GPT-4o's impressive outputs, criticisms arose on its moderation endpoint, echoing similar concerns faced by DALL-E 3.
- Versatile Vocals: GPT-4o's Vocal Prowess Under the Microscope: AI aficionados tested GPT-4o's voice model abilities, highlighting its adaptability with accents and emotional range, and its capacity to meld background tunes and effects.
- Findings were a mix of admiration for its potential and pointers to its inconsistent performance, igniting discussions on the model's limitations and future improvements.
- Platform Conundrums: The Search for Prompt Precision: AI Engineering mavericks swapped insights on preferred platforms for prompt engineering, elevating Claude 3, Sonnet, and Artifacts + Projects as prime candidates.
- Heuristic tools for prompt evaluations grabbed the spotlight, with the Anthropic Evaluation Tool mentioned for its heuristic approach, while a collaborative Google Sheet with scripts was tabled as a sharable and efficient alternative.
- Strategic Subscription Shift: Pondering Plus's Influence: Community chatter revolved around the impact of cancelling Plus subscriptions, revealing that doing so would render custom GPTs inaccessible.
- The contemplation extended to the prerequisites for GPT monetization, spotlighting the need for substantial usage metrics and localization within the USA as criteria for revenue generation opportunities.
- The Diagram Dilemma: Charting Courses Through AI Assistance: In the world of AI diagrams, participants probed for complimentary tools adept at crafting visual aides, with a nod to ChatGPT – though its diagram-drawing talents remain up for debate.
- The dialogue also touched on the challenge LLMs face in text truncation, suggesting that seeking qualitative descriptors might be more effective than exact character or word counts.
CUDA MODE Discord
- FSDP Discord Sparks Flare: A member's critique of FSDP as 'kind of ass' sparked debate on its scalability, countered by the claim that it excels in ease of use.
- The conversation pivoted toward FSDP's situational suitability, indicating it's not a one-size-fits-all solution despite its user-friendly nature.
- Sharded LLaMA Woes and vLLM Hopes: Challenges in sharding LLaMA 405B on multiple nodes surfaced during discussions, with possible workarounds involving vLLM enhancement for larger context windows.
- Participants recommended approaches like quantization, with some avoiding vLLM, directing users to enhancement details and support for LLaMA 3.1.
- Megatron's Scholarly Appeal: The Megatron paper provoked interest among members discussing distributed training's relevance, backed by resources like the Usenix paper and explanatory MIT lecture video.
- Discourse on Megatron extended to practical insights on distributed training with references to both academically acclaimed and YouTube disseminated materials.
- Triton Tutorial's Tiled Matmul Matrix: Queries regarding the
GROUP_SIZE_Margument in the Triton tutorial surfaced, addressing its role in optimizing caching.- The debate included how setting
GROUP_SIZE_Mtoo high could lead to inefficiencies, exploring the delicate equilibrium of hardware design choices.
- The debate included how setting
- Llama 3.1: Turmoil and TorchChat Guideposts: Users voiced the need for a 10-line Python snippet to simplify Llama 3.1 model usage, with existing inference scripts deemed complex.
- In response, PyTorch unveiled TorchChat as a guide, providing the sorely needed reference implementation to run Llama 3.1.
Stability.ai (Stable Diffusion) Discord
- Stable Fast 3D's Lightning Launch: Stability AI announced Stable Fast 3D, a new model capable of converting a single image to a detailed 3D asset in just 0.5 seconds, pushing the boundaries of 3D reconstruction technology. The model's implications for gaming and VR are substantial, with a focus on speed and quality. Discover the technical details.
- 'Stable Fast 3D's incredible processing time pioneers rapid prototyping efforts in 3D frameworks.' Users benefit from additional features like optional remeshing, adding minimal time increase for broad industry applicability.
- SD3 in the Spotlight: Community discussions revolved around the utilization of Stable Diffusion 3 (SD3) Medium, tackling loading errors and exploring the model's capabilities. Shared solutions include obtaining all components and utilizing tools like ComfyUI workflows for smoother operation.
- Challenges such as 'AttributeError' were navigated through community support and adapting to various available UIs, ensuring more seamless creative experiences with SD3.
- Solving the VAE Conundrum: A common issue within the community was addressed: images turning red during rendering due to VAE settings. Collaborative efforts led to troubleshooting methods that mitigate the problem.
- Applying the '--no-half-vae' command emerged as a peer-recommended fix, easing workflows for artists crafting images with accuracy while navigating hardware-specific solutions.
- Clearing Creative Upscaler Fog: A collective effort was made to disentangle the confusion surrounding the mention of a 'Creative Upscaler' with clarification that it is not a Stability AI project. Members exchanged alternative upscaling recommendations.
- The favored techniques included ERSGAN application and adopting transformer technology, with advice pooling from various community-contributed resources for prompted challenges.
- Flux: The Next Generation in Imagery: Anticipation surrounded Black Forest Labs' release of the Flux model, with the community buzzing about enhancements in image rendition and efficient parameter usage. The announcement teased potential for the text-to-image field.
- Discourse on the model's GPU efficiency highlighted the Nvidia 4090 for optimal performance, with a special nod to the model's prowess in rendering body extremities like hands and fingers.
LM Studio Discord
- Exit Codes Expose Compatibility Clashes: LM Studio users report exit codes like 6 and 0, sparking conversations on system compatibility and the debugging labyrinth.
- This dilemma has escalated to discussions around system-specific quirks and the potential need for updated LM Studio versions.
- Gemma 2 Glitches Generate GPU Grief: Challenges in running Gemma 2 2B models emerged, particularly on dated hardware, compelling users to advocate for a new release of LM Studio.
- The community's response included both commiseration and shared strategies for circumventing the hardware hurdle.
- LLaMA: The Embedding Enigma: Enthusiasts explore embedding capabilities with projects like LLM2Vec, amidst queries on LLaMA's integration within LM Studio.
- This culminated in curated conversations on future-forward solutions for text encoders and the excitement around embedding evolution.
- Diving into LM Studio's Depths: Members unraveled bugs in LM Studio, from GPU offloading oddities to nettlesome network errors potentially tied to VPN/DNS configurations.
- Peers pitched in to pinpoint problems and proposed possible patches, promoting a collaborative climate for tackling tech troubles.
- Vision for Vivid LM Studio Features: The discourse delved into dreams of future LM Studio features, with users yearning for additions like TTS voices and RAG-supported document interactions.
- Hugging Face and approaches to Visual Question Answering (VQA) at Papers with Code garnered attention amidst these aspirations.
Eleuther Discord
- Watermark Woes: AI's Authentication Angst: Members debated watermarking's role in AI trust issues, pointing out its limited effectiveness and suggesting that establishing cultural norms** is crucial.
- The concern is that watermarking may not thwart misuse and misrepresented content without broader trust mechanisms in place.
- NTIA's Open AI Advocacy: Policy Influence Peaks**: The NTIA report promotes the openness of AI models and recommends diligent risk monitoring to guide policymakers.
- Observers note the weight of NTIA's policy recommendations owing to its direct reporting line to the White House, flagging potential shifts in AI regulation.
- GitHub's Model Mashup: Integrating AI with Code**: GitHub's introduction of GitHub Models facilitates direct access to AI models within developer workflows.
- Debate ensued on whether this is a strategy to challenge competitors like Hugging Face or a natural evolution of GitHub's service offerings.
- Relaying the Double Descent: Scaling Laws Under Scrutiny: AI researchers discussed anomalies in validation log-likelihood in scaling law experiments, particularly when models with 1e6 sequences underperformed**.
- This prompted references to the BNSL paper, shedding light on similar patterns and sparking curiosity about dataset size impacts.
- Prompt Overproducing Mystery: lm-eval's Unexpected Multiples: lm-eval's behavior of using more prompts than benchmarks specify, as observed in benchmarks like gpqa_main**, incited technical inquiry and debugging efforts.
- Clarification emerged that the progress bar in lm-eval accounts for
num_choices * num_docs, reconciling perceived discrepancies and aiding in understanding tool behavior.
- Clarification emerged that the progress bar in lm-eval accounts for
Interconnects (Nathan Lambert) Discord
- Grok's Growth: xAI Unlikely to Capture Character AI: Rumors of xAI acquiring Character AI to enhance its Grok models have been circulating, but Elon Musk denied these claims, calling the information inaccurate.
- The community pondered the truth behind Musk's statements, referencing prior instances where official denials preceded confirmed acquisitions.
- Black Forest Labs Emerges from Stable Diffusion's Roots: The founding team of Stable Diffusion sparked excitement with the launch of Black Forest Labs, specializing in advanced generative models.
- Black Forest Labs' Flux demonstrates creative prowess, and early testers can try it out on fal, signaling potential disruptions in the generative landscape.
- GitHub Models Meshes Devs with AI Prowess: GitHub makes a splash in AI by introducing GitHub Models, offering powerful AI tools to its massive developer base.
- This new suite aims to democratize AI usage for developers, potentially transforming how coding and AI interact on a grand scale.
- Apple Intelligence Puts a Twist in Tech's Future: Apple's latest AI advancements promise to weave apps together more seamlessly, enhancing daily tech interactions.
- Skeptics in AI labs question the groundbreaking status of Apple Intelligence, while others see it as a significant multiplier for tech utility.
- Rejection Sampling Finds Home in Open Instruct: Open Instruct embraces rejection sampling, a method set to fine-tune training by avoiding common pitfalls.
- The move could signal improved efficiencies in model training and a step forward for methodologies within the AI training spectrum.
Latent Space Discord
- Llama 3.1 Touches Nerve in Quality Debate: Together AI blog spurred debate on Llama 3.1 by spotlighting variances in performance due to different implementation practices by inference providers, raising concern for model consistency.
- Dmytro Dzhulgakov drew the community’s attention to potential result cherry-picking and emphasized the cruciality of clear methodologies in model evaluation, igniting extensive discussion on this thread.
- Sybill Secures Millions for AI-Enhanced Selling: Sybill has secured a potent $11M Series A to refine their personal assistant AI for sales reps, with prominent backers like Greystone Ventures (announcement details).
- The AI sales tool spectrum is seeing a spark of innovation with Sybill's solution, cloning sales reps' voices to engineer more relevant follow-ups.
- Black Forest Labs Breaks Ground with FLUX.1: Black Forest Labs, featuring ex-Stable Diffusion wizards, debut their groundbreaking text-to-image model FLUX.1, inclusive of a robust 12B parameter version (see announcement).
- The pro iteration of FLUX.1 is currently live on Replicate for trials, displaying an edge over others in the space.
- LangGraph Studio Unveils New Horizons for Agentic Apps: LangChain propels IDE innovation with the launch of LangGraph Studio, built to streamline the creation and debugging of agentic applications (announcement tweet).
- The agent-focused IDE marries LangSmith, boosting efficiency and teamwork for developers in the realm of large language models.
- Meta MoMa Transforms Mixed-Modal Modeling: Meta's novel MoMa architecture accelerates the pre-training phase for mixed-modal language models, employing a mixture-of-experts approach (accompanying paper).
- The architecture is tailored to juggle and make sense of mixed-modal sequences effectively, marking a step forward in the domain.
LlamaIndex Discord
- Async Advances Accelerate BedrockConverse: New asynchronous methods for BedrockConverse have been integrated, resolving outstanding issues as seen in pull request #14326, notably #10714 and #14004.
- The community expressed appreciation, highlighting the contribution's significant impact on enhancing user experience with BedrockConverse.
- Insights from the LongRAG Paper: The LongRAG paper, authored by Ernestzyj, introduced techniques for indexing larger document chunks to harness the potential of long-context LLMs.
- Opening new possibilities, this method simplifies the retrieval-augmented generation process, garnering interest from the community.
- Workflows Work Wonders in LlamaIndex: Newly introduced workflows in llama_index empower the creation of event-driven multi-agent applications.
- The community applauded this innovation for its readable, Pythonic approach to complex orchestration.
- Stabilizing the Codebase Conundrum: Conversation revolved around determining the stable version of LlamaIndex, clarified by directing users to installations via pip as the safeguard for stability.
- The term 'stable' emerged as a focal point, associating stability with the most recent releases available on PyPI, sparking further debate.
- Prompt Playing with DSPy and LlamaIndex: Members evaluated DSPy's prompt optimization against LlamaIndex's rewriting features.
- Enthusiasm was noted for the comparative exploration between these two tools, considering their application in improving prompt performance.
Cohere Discord
- Embed with Zest: Content Structures Clarified: In a technical discussion, Nils Reimers clarified that embedding models automatically remove new lines and special symbols, reinforcing that preprocessing text is not essential.
- This revelation indicates the models’ robustness in handling noisy data, allowing AI engineers to focus on model application rather than extensive text preprocessing.
- Citations Boost Speed; Decay Dilemmas: A perceptive user linked slower responses with high citation_quality settings in Ukrainian/Russian language on Cohere Cloud, noting that shifting from fast to accurate resolved character issues.
- While the stable output was attained, the trade-off in response speed has become a topic for potential optimization conversation among engineers.
- Arabic Dialects in LLMs: A Linguistic Leap: Surprise was expressed when LLM Aya generated accurate text in various Arabic dialects, prompting questions about dialect training in an English-based prompt environment.
- The community's experience with LLMs in dialect handling reinforces the notion of advanced contextual understanding, stoking curiosity about the training mechanisms.
- Devcontainer Dilemma: Pydantic Ponders: AI engineers faced a bottleneck when pydantic validation errors aborted setup of a Cohere toolkit repository, highlighting issues in the
Settingsclass with missing fields like auth.enabled_auth.- A swift response from the team promised an imminent fix, demonstrating agility and commitment to toolkit maintenance and usability.
- "Code and Convene": AI Hackathon Series: Enthusiasm bubbled as community members discussed participation in the AI Hackathon Series Tour at Google, spanning 3 days of AI innovation and competition.
- The tour aims to highlight AI advancements and entrepreneurial ventures, culminating in PAI Palooza, a showcase of emerging AI startups and projects.
LangChain AI Discord
- Pydantic Puzzles in LangChain Programming: Confusion arose with a ValidationError due to a version mismatch of Pydantic, causing type inconsistencies when working with LangChain.
- The conflict was highlighted by input mismatches and validations that led to execution failures, spotlighting the necessity for api_version harmony.
- API Access Angst for LangSmith Users: A user experienced a
403 Forbiddenerror when attempting to deploy an LLM using LangSmith, suggesting potential API key misconfiguration.- Community discussion circled around the proper setup for the key and seeking assistance through various LangChain channels.
- Streaming Solutions for FastAPI Fabulousness: Proposing a pattern for asynchronous streaming with FastAPI in LangChain applications, a user advocated using Redis for smooth message brokering.
- This would maintain current synchronous operations while empowering LangChain agents to share outcomes in real-time.
- Jump-Start Resources for LangChain Learners**: The discourse delved into available resources for mastering LangChain, highlighting alternatives and repositories for effective learning.
- Members exchanged GitHub examples and various API docs to advantageously navigate common deployment and integration puzzles.
- LangGraph's Blueprints Unveiled: An innovative LangGraph design pattern was shared, aimed at user-friendly integration into apps like web-chats and messenger bots, with a GitHub example showcasing the integration process.
- Additionally, an invitation was extended for beta testing Rubik's AI new features, inclusive of top-tier models like GPT-4o and Claude 3 Opus, through a special promotional offer.
OpenRouter (Alex Atallah) Discord
- Digital Detox Diet: Moye's Method: Moye Launcher's minimalistic design promotes digital wellbeing by intentionally making apps less accessible, championing behavioral shifts towards less screen time.
- The developer targets three contributors to excess usage, such as auto-clicks and a lack of accountability, aiming to forge habits for focused app engagement through design and user feedback.
- BEAMing Personalities: Big-agi's Big Play: Big-agi's 'persona creator' lets users spin up character profiles from YouTube inputs and the BEAM feature merges outputs of multiple models, increasing response diversity.
- Still, Big-agi feels the pinch of absent server save and sync functions, hindering an otherwise smooth model interaction experience.
- Msty Merges Memory and Web Mastery: Msty's integration with Obsidian and website connectivity garners user praise for its ease of use but faces criticism for its forgetful parameter persistence.
- Some users look to swap to Msty despite its need for a polish, thanks to its sleek interfacing capabilities.
- Llama 405B Walks FP16 Tightrope: OpenRouter lacks a FP16 avenue for Llama 405B, while Meta-recommended FP8 quantization proves more efficient.
- Although SambaNova Systems offers similar services, they're hemmed in by a max 4k context limit and cost-intensive bf16 hosting.
- OpenRouter's Beta Guarantees Gateway to APIs: OpenRouter teases an API integration beta, welcoming support emails for rate limit fine-tuning and threading OpenAI and Claude APIs into user endeavours.
- While its website sometimes stumbles with regional troubles, the OpenRouter status page acts as a beacon, guiding users through operational tempests.
OpenInterpreter Discord
- Open Interpreter Stuck in the Slow Lane: Concern is mounting over Ben Steinher's delayed response from Open Interpreter, who missed his mid-July response deadline.
- Despite the delay, the community lauded a new PR for Groq profile contribution as an impactful way to support Open Interpreter, highlighting a GitHub PR by MikeBirdTech.
- Techies Tune in for Accessibility Talk: An Accessibility Roundtable is set for August 22nd to stir discussion and engagement, with an open invite for the community to share insights.
- Anticipation is high for the upcoming House Party event, after sorting initial time-zone tangles, with participants directed to the event link.
- Model Selection Muddles Minds: Discussion arose about the necessity of an OpenAI API key and the right model string when using '01 --local', evidencing a need for clearer guidelines.
- Inquisitive threads continue, probing whether OpenInterpreter can save and schedule workflows, with answers still pending in the community.
- iKKO Earbuds Amplifying AI Possibilities: Buzz is building about integrating OpenInterpreter on iKKO ActiveBuds, merging high-resolution audio with AI, as detailed on iKKO's website.
- Shipment updates for 01 spark urgency within the community, with an unanswered call for updated information as August ticks by.
- Earbuds with a Vision: Camera Talk: A novel idea emerged for earbuds equipped with cameras, bolstering interaction by capturing visual context during conversations with LLMs.
- Community members pondered the integration, contemplating a tap feature to activate the camera for an enhanced HCI experience.
Modular (Mojo 🔥) Discord
- Mojo Misses the Thread: In a conversation about Mojo's capabilities, a member clarified that Mojo does not currently expose thread support directly to users.
- It was mentioned that utilizing fork() is a workaround for achieving threading within the compiled environments.
- MAX & Mojo's Packing Proclamation: Upcoming changes to MAX and Mojo packaging have been revealed, starting with version 0.9 of the
modularCLI, dropping the need for authentication to download MAX and Mojo.- Mojo will be merged with MAX nightly builds, with the announcement suggesting a shift to the new
magicCLI for seamless Conda integration.
- Mojo will be merged with MAX nightly builds, with the announcement suggesting a shift to the new
- Charting a Tier of Confusion: Members expressed bewilderment over a tier chart, debating its accurate representation and criticizing it for not reflecting the intended 'level of abstraction'.
- Some advocated for simplifying the visual with a fire emoji, indicating the expectation of a clear and effective communication tool.
- Unicode Unleashed in CrazyString: The CrazyString gist was updated, introducing Unicode-based indexing and boasting full UTF-8 compatibility.
- The conversation touched upon Mojo string's small string optimization and the increased usability due to the updates.
- Max Installation Maze on M1 Max: Challenges arose for a member attempting to install max on their Mac M1 Max device, with the community stepping in to provide potential fixes.
- A shared resource suggested a specific Python installation workaround could help to navigate the installation issue.
OpenAccess AI Collective (axolotl) Discord
- Axolotl's Ascent with Auto-Stopping Algorithms: Axolotl introduced an early stopping feature in response to queries about halting training when loss plateaus or validation loss surges.
- Community members engaged in a brief exchange regarding the abilities to manually terminate runs while saving the current LoRA adapter state.
- Masked Learning Leap for SharedGPT: A member put forward an "output mask" field for each turn of SharedGPT, aimed at targeted training through selective output masking.
- This innovation sparked discussion about its potential to refine learning through processed output errors.
- Chat Templates Call for Clarity: Issues with deciphering new chat templates prompted members to call for better documentation to aid in understanding and customization.
- A member volunteered to share personal notes on the topic, suggesting a community-driven update to the official documents.
- Pacing Pad Token Problems: Training troubles talked about the frequent occurrence of
<pad>token repetition, hinting at inefficiencies in sampling methods.- The conversation contributed a tip: ensure pad tokens are cloaked from labels to prevent recurring redundancies.
- Gemma2's Eager Edge Over Flash: An endorsed tip for Gemma2 model training surfaced, suggesting 'eager' over 'flash_attention_2' to solidify stability and performance.
- Practical guidance was given, with code provided to demonstrate setting
eagerattention inAutoModelForCausalLM.
- Practical guidance was given, with code provided to demonstrate setting
DSPy Discord
- Discussions Ignite around DSPy and Symbolic Learning: Members buzz with anticipation over integrating DSPy with symbolic learners, speculating on the groundbreaking potential.
- Optimism sparks as participants expect substantial advancements from such a combination in AI capabilities.
- Self-Adapting Agents Step into the Spotlight: The Microsoft Research blog brought self-adapting AI agents to the fore, showcasing an article with promising workplace applications.
- Insights link the games industry as a catalyst to AI advancement, now materializing in tools like ChatGPT and Microsoft Copilots.
- Enter Agent Zero: A Foray into User-Tested AI: Agent Zero makes its debut as the first user-tested production version, showing off its AI prowess.
- Feedback insinuates a shift towards AI occupying more diverse roles in professional settings.
- LLMs Self-Improve with Meta-Rewarding: A new Meta-Rewarding technique enhances LLMs' self-judgment, revealed in an arXiv paper, improving their performance.
- Significant win rate increases are reported on AlpacaEval 2, indicating that models like Llama-3-8B-Instruct also benefit.
- MindSearch Paper Explores LLM-Based Multi-Agent Frameworks: A paper published on arXiv presents MindSearch, emulating human cognitive processes in web searches using LLM-driven agents.
- The study tackles information seeking challenges and aims to refine modern search-assisted models.
tinygrad (George Hotz) Discord
- NVIDIA Grabs Taxpayer Dough: A message showed enthusiasm for NVIDIA receiving public funds, detailing the value for the taxpayer's investment.
- This topic stirred conversation on investment priorities and implications for tech development.
- George Hits Hotz Button on Discord Decorum: George Hotz issued a reminder about the server's rules, funneling focus towards tinygrad development.
- Hotz's nudge was a call to maintain a professional and on-topic dialogue within the community.
- Argmax Chokes GPT-2 Speed: A deep dive into GPT-2 performance found that embedding combined with
argmaxsignificantly throttles execution speed, as observed in Issue #1612.- The inefficiency traced back to an O(n^2) complexity issue, sparking discussions on more efficient algorithmic solutions.
- Embedding Bounty: Qazalin's Got a Quest: Talks of a bounty for enhancing embeddings in tinygrad surfaced, exclusively directed towards a user named Qazalin.
- The bounty generated buzz and motivated other contributors to seek different optimization opportunities within tinygrad.
- Cumsum Conundrum: Challenges with the
cumsumfunction's O(n) complexity were tackled in Issue #2433, inciting innovative thought among developers.- George Hotz rallied the troops, advocating for practical experiments to discover possible optimization strategies.
LAION Discord
- Polyglot ChatGPT's Vocal Feats: A member showcased ChatGPT Advanced Voice Mode adeptly reciting poetry in Urdu and storytelling in several languages including Hebrew, Norwegian, and Georgian.
- This display included narratives in lesser-known dialects like Moroccan Darija, Amharic, Hungarian, Klingon, wowing the engineering community.
- Spectacular Reveal of Black Forest Labs: Enthusiasm erupted over the launch of Black Forest Labs, with a mission focused on innovative generative models for media.
- The initiative took off with FLUX.1, a model that promises to enhance creativity, efficiency, and diversity in generating visuals.
- FLUX.1 Model Debuts Impressively: The community turned their attention to FLUX.1, a new model whose debut on Hugging Face was met with acclaim.
- Discussions emerged on how this model could potentially shift the landscape of generative learning, with features termed as refreshing and super good.
- Innovative Activation Function Twists: AI enthusiasts delved into experiments with varied normalization and activation functions on complex-valued activations, tagging the exercises as 'kinda fun!'.
- This practical exploration led to sharing of insights and potential applications in complex domains.
- The Overhyped Regularization Riddle: A user pointed out, using a Medium article, that extensive methods like data augmentation and dropout fail to curb overfitting significantly.
- Probing the effectiveness of various regularization techniques, the community pondered on methods beyond traditional tricks to advance machine learning models.
Torchtune Discord
- Topping the Charts with Top_p: A member discovered that setting top_p=50 met their performance standards with substantial results.
- They compared the 0.8 online model against their own, noting the online variant's superior outcome.
- Debugging Delight with Generate Recipe: Clarification was brought that generate recipe is geared for debugging purposes, targeting an accurate portrayal of the model.
- Any discrepancies with benchmarks should prompt the submission of an issue, with evaluations affirming the recipe's efficacy.
- FSDP2's New Feature Fusion: A member shared that FSDP2 now handles both quantization for NF4 tensor and QAT, boosting its versatility.
- While QAT recipes seem compatible, compiling with FSDP2 may present challenges, marking an area for potential refinement.
- Merging PRs with Precision: The upcoming merger of a PR has been flagged as dependent on a prior one, with PR #1234 under review, thereby paving the way for sequential improvements.
- This anticipates enhanced fine-tuning datasets, with a focus on grammar and samsum, advancing Torchtune's methodical evolution.
MLOps @Chipro Discord
- Data Phoenix Ascends with AI Webinar: The Data Phoenix team announced a webinar titled 'Enhancing Recommendation Systems with LLMs and Generative AI,' featuring Andrei Lopatenko set for August 8 at 10 a.m. PDT.
- This webinar aims to unveil how LLMs and Generative AI are transforming personalization engines, with a webinar registration made available.
- dlt Elevates ELT Know-how with Workshop: A 4-hour workshop on ELT with dlt is slated to school data enthusiasts on constructing robust ELT pipelines, resulting in a 'dltHub ELT Engineer' certification.
- Scheduled online for 15.08.2024 at 16:00 GMT+2, the session starts with dlt basics and registrations can be made here.
- Conferences Showcase NLP & GenAI Dominance: Two ML conferences placed a heavy accent on NLP and genAI, overshadowing presentations on models like Gaussian Processes and Isolation Forest.
- The trend underscores a strong community tilt towards NLP and genAI technologies, leaving some niche model discussions in the shadows.
- ROI from genAI Under Community Microscope: A lively debate questioned whether the ROI for genAI will live up to the lofty expectations set by some in the field.
- The conversation pointed out the gap between expectations and realities, stressing the need for grounded anticipation of returns.
LLM Finetuning (Hamel + Dan) Discord
- LangSmith Credits Conundrum: Digitalbeacon reported an issue accessing LangSmith credits after adding a payment method, using a different email address from his organization ID 93216a1e-a4cb-4b39-8790-3ed9f7b7fa95.
- Danbecker recommended contacting support for credit-related troubles, implying a need for direct resolution with customer service.
- Payment Method Mayhem for LangSmith: Digitalbeacon inquired about a zero credit balance in LangSmith post payment method update, even after timely form submission.
- The situation suggests a system glitch or user misstep, necessitating further investigation or support intervention.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!