[AINews] Replit Agent - How did everybody beat Devin to market?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
A fully integrated Web IDE is all you need.
AI News for 9/4/2024-9/5/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (214 channels, and 2723 messages) for you. Estimated reading time saved (at 200wpm): 303 minutes. You can now tag @smol_ai for AINews discussions!
A packed day. The annual Time 100 AI outrage piece. Maitai, AnythingLLM, Laminar launched. Melodio - new text-to-music model. Together ai announced some kernel work and speculative decoding work. Andrej Karpathy on a podcast. $2000/mo ChatGPT. We very nearly featured Matt Shumer + Sahil Chaudhary's Reflection Tuned finetune of Llama 3.1 70B as today's title story, but the 405B + paper is coming next week, so we will just give you a heads up that it is coming.
The big launch of the day is Replit Agent.
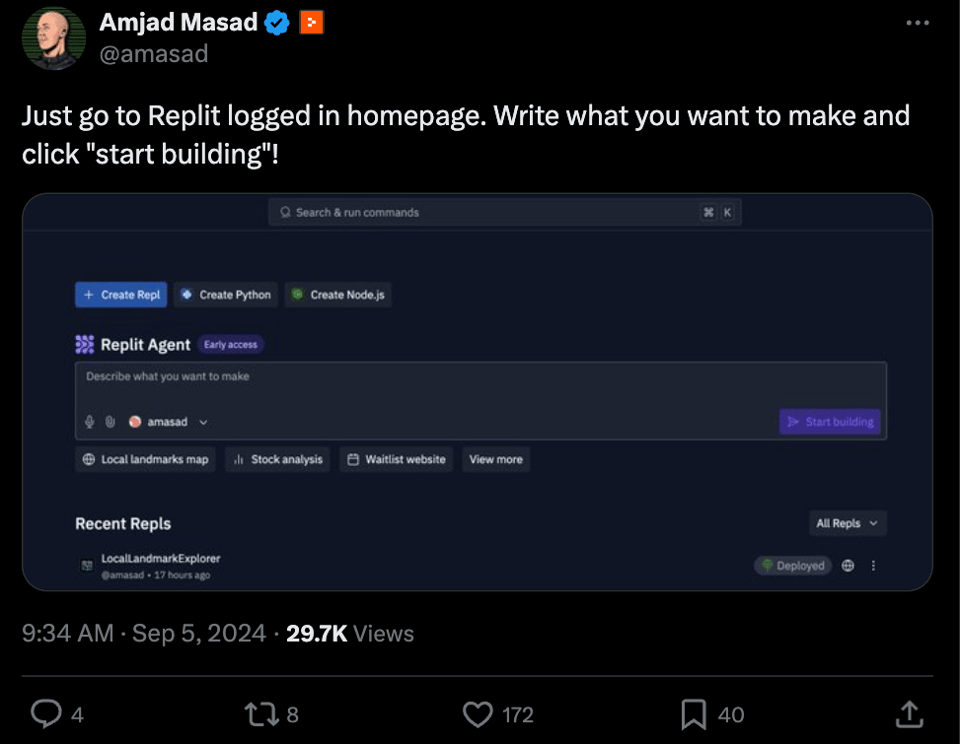
If you've been paying attention to the coding agent company launches - like Claude Artifacts, Cursor Composer, Val.town Townie, Cosie Genie, Honeycomb, and even the You.com pivot yesterday, this is pretty much what you'd expect Replit to do, just very very well executed - full text to running app generation with planning and self healing. What's laudable is the lack of waitlist - it is live today to paid users - and can deploy on a live URL with postgres backend, from people who cannot code, including on your phone. Of course, Replit Agent can even make a Replit clone.
There are unfortunately no benchmarks or even blogposts to write about. Which makes our job simple. Watch video, try it, or scroll on.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Development and Models
- Document Retrieval Techniques: @mervenoyann highlighted methods for multimodal RAG (retrieval-augmented generation), suggesting models like Donut or LayoutLM for improved structured responses from labeled data.
- AI Agents Functionality: @bindureddy explained that AI Agents can automate various tasks, such as document generation and technical image generation, enabling users to specify high-level tasks for execution by the AI.
- Image and Video Generation: @rohanpaul_ai detailed the development of JPEG-LM and AVC-LM, which utilize file encoding to enhance image and video generation. This method reduces data complexity while delivering impressive output quality.
AI Tools and Technologies
- New Enterprise Features: @rohanpaul_ai unveiled a new enterprise plan from AnthropicAI with significant features like a 500K context window and improved security measures, targeting specific use cases in marketing and engineering.
- GPU Market Trends: @LeptonAI discussed trends in the H100 GPU pricing model, predicting a drop in costs similar to that seen with the A100 GPUs, emphasizing the importance of monitoring and testing for reliability.
Philosophy and Ethics in AI
- Importance of Inquiry: @teortaxesTex criticized the lack of curiosity among scientists, suggesting a need for deeper inquiry into fundamental questions rather than accepting superficial explanations.
- Research Impact: @stanfordnlp shared recycled insights on how grad students can engage in impactful AI research, which aligns with broader discussions about meaningful contributions to the field.
Community and Collaboration
- Networking for NLP Events: A seminar announcement by @stanfordnlp promoted a talk on \"The State of Prompt Hacking\", inviting participation and emphasizing the importance of community engagement in discussions about NLP breakthroughs.
- Foundational Insights from Leadership: @RamaswmySridhar shared thoughts on scaling organizations, stressing the necessity for transparency and accountability as key drivers for high-growth companies.
- Mentoring and Opportunities: @aidan_mclau recognized the influence of community connections, advocating for younger engineers to leverage collaborative relationships for career growth.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. GitHub's Automated Flagging: Impact on AI Model Repositories
- Qwen repo has been deplatformed on github - breaking news (Score: 183, Comments: 75): GitHub temporarily flagged and removed the Qwen repository for unknown reasons, as reported by main contributor Junyang Lin. The project remained accessible on Gitee (Chinese GitHub equivalent) and Hugging Face, with documentation available at qwen.readthedocs.io. The post author urges the open-source community to create an archive to prevent future deplatforming incidents.
- The Qwen repository was restored on GitHub, as announced by contributor Justin Lin with the tweet: "We are fucking back!!! Go visit our github now!" Users discussed the need for backup solutions and distributed AI systems.
- Discussions arose about alternatives to GitHub, including AI-focused torrent trackers like aitracker.art and decentralized platforms such as Codeberg and Radicle. Users emphasized the importance of platform-independent solutions for code hosting and collaboration.
- Some users speculated about potential targeting of Chinese models or Microsoft's involvement, referencing the company's history of anticompetitive behavior. Others cautioned against jumping to conclusions and suggested waiting for GitHub's official explanation of the temporary removal.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Development
- Logan Kilpatrick suggests AI advancements are not slowing down if one is "paying close enough attention" (336.5 points)
- Comments note rapid improvements in AI video and image generation
- Some users express frustration with cryptic tweets and hype from AI researchers
- OpenAI co-founder Ilya Sutskever tweets "time to climb" (302.5 points)
- OpenAI tweets "we have so much to tell you" (233 points)
- Anthropic is "shipping so hard" according to a tweet (190.5 points)
- Christian Szegedy predicts superhuman AI mathematician by 2026, possibly even 2025 (140.5 points)
AI Funding and Competition
- Sutskever's new AI safety startup SSI has raised $1 billion (268 points)
- Reuters article on the funding (118 points)
- OpenAI and competitors are reportedly concerned about xAI's compute power (141 points)
AI Image Generation
- A 5-minute journey with Stable Diffusion video showcases the model's capabilities (366 points)
- Flux Icon Maker generates vector icon outputs using a custom-trained Lora and ComfyUI workflow (213 points)
- Allows direct conversion to vector graphics for scalability
- Uses the ComfyUI-ToSVG repository for vector conversion
AI Discord Recap
A summary of Summaries of Summaries by Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- DeepSeek V2.5 Launch: DeepSeek V2.5 merges its Coder and Chat models, showing significant improvements in various performance metrics, such as an ArenaHard win rate increase from 68.3% to 76.3%. Read more here.
- Users appreciate these upgrades, enhancing overall usability while maintaining instruction-following capabilities. Change Log.
- Reflection 70B Model Announcement: The new Reflection 70B model introduces Reflection-Tuning for self-correction, generating excitement in the community. Announcement by Matt Shumer.
- Members eagerly anticipate the upcoming 405B version, projected to outperform existing alternatives. Tweet.
- This innovative approach could significantly improve model performance, sparking discussions on its potential applications and implications for model design. Research Paper.
2. AI Industry News and Funding
- xAI's Cluster Sparks Competitive Concerns: Elon Musk's progress in building xAI's 100k GPU cluster has raised concerns among rival model developers, with OpenAI's Sam Altman expressing worries over potential computing power disparities.
- The news sparked discussions about the escalating AI arms race, with one community member humorously noting: 'eventually we all become GPU poor'.
- OpenAI's Ambitious Pricing Strategy: Reports emerged that OpenAI is considering subscriptions up to $2,000 per month for access to their next-generation models, suggesting potential 100x capability increases over lower-tier versions.
- The community reacted with skepticism, with one member stating: 'This will be a Vision-Pro level disaster. I hope it's a joke'. Others speculated this might be more suitable for B2B pricing models.
3. Multimodal AI Innovations
- Transfusion Model Insights: Meta released a paper on the Transfusion model, a multitasking approach integrating language and diffusion training on 1T text tokens and 692M images. Transfusion Paper.
- It was highlighted that the methodology yields better scaling performance compared to traditional discrete token training. Transfusion Paper.
- Loopy: Audio-Driven Video Generation: The paper introduces Loopy, an end-to-end audio-conditioned video diffusion model aimed at synthesizing natural motion without manual spatial templates. Loopy Paper.
- Loopy enhances audio-portrait movement correlation and showcases significant improvements in performance based on extensive experimental results. Loopy Paper.
- Comfy Rewrite Project Gains Traction: Julien Blanchon announced a minimalist Comfy rewrite from scratch, seeking to create a highly extensible user interface with no dependencies. This project invites collaboration to simplify usage while maintaining flexibility.
- Members expressed interest in reforms to enhance user experience and reduce complexity, and more details are available here.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Hash Rosin Model Madness: A user seeks the best model for generating realistic hash rosin images, referencing a specific Lora that provides detailed close macro shots.
- Suggestions include pairing the Lora with models like SDXL or Flux to enhance output quality.
- ControlNet Conundrum: A user struggles with ControlNet preprocessors in ComfyUI, specifically missing options beyond the tile preprocessor.
- Users recommend experimenting with tiled ksamplers and checking setup accuracy, with tutorial resources being suggested.
- Installation Insights: Discussions revolve around trying various model combinations, with a focus on using Flux and SDXL for superior image generation.
- Participants are keen to learn how to integrate different models with Lora to achieve desired results.
- GPU Performance Predicaments: Users discuss GPU performance limitations, particularly focused on VRAM while utilizing heavy models like SDXL and Flux.
- Concerns about lengthy generation times prompt suggestions to explore cloud services for enhanced capacity and efficiency.
- Cloud Computing Curiosities: Recommendations abound for using cloud platforms like Vast.ai to access high-performance GPUs for demanding models.
- The need for cloud solutions resonates, especially among users with lower-spec machines, such as laptops.
Unsloth AI (Daniel Han) Discord
- Unsloth gets Y Combinator backing: Unsloth announced being backed by Y Combinator, marking a significant milestone in their development.
- The team is excited about future developments, including their newly celebrated 2 million monthly downloads.
- New features in Unsloth unveiled: Unsloth will launch Unsloth Studio for model fine-tuning, and Dora integration for users still requires
use_dora = Trueto utilize.- Discussion also highlighted popular model recommendations like Gemma 2 27B and Llama 3.1 8B, with community members sharing insights from their experiments.
- Illya raises $1 billion for AGI: Illya's recent $1 billion funding for Safe SuperIntelligence sparked confusion regarding its implications for scaling AGI and LLM reasoning.
- Members noted that there’s no evidence that scaling leads to AGI, pointing out that the investments are often driven by hype.
- Research on reasoning in LLMs: The community discussed the challenges of reasoning and planning in LLMs, asserting that scaling alone won't improve these capabilities.
- Insights suggested that effective reasoning may require architectural innovations or explicit reasoning mechanisms.
OpenAI Discord
- Debate on AI vs Human Cognition: A lively discussion revolved around the differences between AI reasoning and human understanding, emphasizing that LLMs utilize statistical predictions rather than authentic cognition.
- Participants pointed out that while AI simulates consciousness, it inherently lacks a true understanding that biological entities possess.
- Perplexity Emerges as a Favorite: Members frequently praised Perplexity for its speed and reliability, especially for tasks like research and projects, with the free tier deemed sufficient for many users.
- This makes Perplexity a competitive alternative to other paid subscription tools in the AI space.
- Gemini AI Performance Muddles Expectations: Users shared mixed experiences with Gemini AI, particularly noting unreliable outputs in programming tasks and hallucinations affecting response accuracy.
- Despite these setbacks, some users reported improvement in newer versions, leading them to continue exploring the tool.
- OpenAI Hits Major Subscription Milestone: OpenAI celebrated reaching 1 million paid users, driven by its business-focused offerings such as ChatGPT Team and Enterprise products.
- With subscription fees starting at $60 per user per month, this underscores significant revenue opportunities amid ongoing operational costs.
- Changing UI Draws User Confusion: Recent changes in ChatGPT’s user interface, particularly the absence of the regenerate button, have left users perplexed and uncertain about navigation.
- Some users speculate about interface elements being relocated to the model selection dropdown, affecting usability.
HuggingFace Discord
- Vision Language Models Overview: A new blogpost introduces the fundamentals of vision language models, aimed at newcomers in the field.
- It serves as a resource for understanding key principles that underpin the applications of visual and language integration.
- Streamlined Optimization for Tau LLM: The Tau LLM series examines methodologies to enhance training processes and performance metrics.
- Insights from community experts guide improvements in model efficiency and deployment strategies.
- InkubaLM-0.4B Expands Language Representation: The release of InkubaLM-0.4B addresses support for African languages, showcasing advancements in multilingual capabilities.
- This project represents a wider effort in the community to enhance diversity in AI applications.
- Kyber Odyssey Tackle Post-Quantum Encryption: The team announced acceptance of a submission at the AMA research challenge focusing on the implementation of NIST's post-quantum encryption protocols, available on GitHub.
- Their efforts prioritize accessibility for learners and communities, enhancing security protocols at minimal costs.
- Qwen2-VL-7B-Instruct Handler Released: A working handler.py and updated requirements.txt for Qwen2-VL-7B-Instruct showcase functionality on endpoints like T4, A100, and L4.
- These updates focus on maintaining compatibility and performance improvements, ensuring robust operation across different setups.
LM Studio Discord
- LM Studio 0.3.2 download error reported: Users encountered an 'unable to get local issuer certificate' error after the LM Studio 0.3.2 update, hindering model downloads. This issue may relate to corporate network security changes or SSL certificates.
- The inconvenience highlights connectivity challenges that could impact model deployment timelines in corporate environments.
- Image API exploration underway: Users seek free Image API providers with high limits, mentioning Stable Diffusion as a starting point. The request includes queries for alternatives offering advanced imaging tools.
- The search for expanded API capabilities reflects a growing demand for diverse imaging resources in project workflows.
- Reflection 70B model gains attention: The Reflection 70B model, known for correcting reasoning mistakes, is now available on Hugging Face. Users are eager for its integration into LM Studio following the recent upload.
- This model's capability is noted as a significant advancement for open-source LLM discussions within the community.
- User feedback on new LM Studio UI: Some users voiced criticism regarding the new UI in LM Studio 0.3.2, highlighting large elements and the lack of preset dropdowns as problems. Many expressed a desire for a more compact UI and the reintroduction of preset options.
- This feedback may guide future UI development to enhance user experience and functionality.
- Max RAM recommended for Mac users: Discussion emphasized that Apple users should aim for the largest RAM possible, with 64GB being a baseline for serious AI use. Users encouraged investing in NAS systems for efficient storage solutions.
- Ramping up RAM will facilitate enhanced model handling and performance for demanding workloads.
Nous Research AI Discord
- Reflection-Tuning for LLMs: The newly introduced method of Reflection-Tuning aims to enhance LLM capabilities by teaching models to self-correct during output generation using datasets intentionally crafted with errors.
- This innovative approach could significantly improve model performance, sparking discussions on its potential applications and implications for model design.
- Frustration with Mergekit Stalling: Users reported Mergekit stalling at 'Executing graph: 0% 0/1457' while merging fine-tuned Llama 3.1 models in Colab, preventing usable model creation.
- Guidance on resolving this issue seems essential for smooth model merging processes within the community.
- Illya's $1 Billion AGI Fundraising: Illya successfully raised $1 billion for Safe Superintelligence, aiming to tackle AGI complexity through scaling efforts.
- Members remain puzzled about whether scaling alone can address the reasoning limitations of LLMs, reflecting ongoing debates in the AI community.
- Falcon Mamba Model Released: Falcon Mamba launched by the Technology Innovation Institute under the TII Falcon Mamba 7B License 1.0, is now available on Hugging Face for open access.
- The launch blog emphasizes the model's competitive edge and integration within the Hugging Face ecosystem, inviting further exploration.
- Loopy: Advancements in Audio-Driven Video Generation: The paper introduces Loopy, an end-to-end audio-conditioned video diffusion model aimed at synthesizing natural motion without manual spatial templates.
- Loopy enhances audio-portrait movement correlation and showcases significant improvements in performance based on extensive experimental results.
Interconnects (Nathan Lambert) Discord
- xAI's GPU Cluster Raises Eyebrows: Elon Musk's 100k GPU cluster development for xAI is causing concern among rivals, with Sam Altman of OpenAI voicing his fears over competitive computing power disparities.
- One member quipped that we all inevitably become GPU poor, highlighting the escalating stakes in AI infrastructure.
- Unsloth Partners with YCombinator: Unsloth has secured backing from YCombinator to develop an integrated model creation solution, focusing on speed and accessibility using Triton and CUDA.
- Reflection Llama-3.1 Emerges as the Top Open-source LLM: Reflection Llama-3.1 70B is acclaimed as the leading open-source LLM, leveraging a technique named Reflection-Tuning for enhanced reasoning accuracy and trained with synthetic data by Glaive.
- Users can experiment with the model here.
- Quest for Effective Reasoning Datasets: A member sought recommendations for reasoning datasets, particularly those encompassing chain-of-thought reasoning, reflecting a crowded market of options.
- Prominent suggestions included the MATH and GSM8k benchmarks, revered for assessing LLM reasoning capabilities.
- OpenAI's Pricing Strategy Sparks Debate: Reports suggest that OpenAI may consider subscription fees reaching $2,000 per month, leading to skepticism regarding market viability given competitive pricing landscapes.
- Members are curious about potential B2B pricing models, questioning how such steep consumer costs could be justified in practice.
Modular (Mojo 🔥) Discord
- Magic Package Manager Takes Charge: The new Magic package manager officially supports MAX and Mojo projects with a single Conda package available now, streamlining virtual environment management.
- Users are urged to migrate to Magic or compatible tools, as the legacy
modularCLI will cease updates starting Monday.
- Users are urged to migrate to Magic or compatible tools, as the legacy
- Mojo Undergoes Performance Scrutiny: Testing reveals the ord() function in Mojo runs approximately 30 times slower than in C++ and Python, prompting calls for optimizations.
- Community discussions suggest inspecting the ord implementation and potential features like Small String Optimization to enhance performance.
- Uncertain Future for Model Serialization Format: The team has no ETA for the platform-independent model serialization format, characterized as a future enhancement expected to aid in containerization.
- Feedback highlights anticipation for this feature, which is hoped to smooth the deployment of models in Docker containers.
OpenRouter (Alex Atallah) Discord
- Infinite Bank Account Dilemma: A member humorously proposed the idea of condensing their bank account into an infinite amount, sparking lively debate about financial limits.
- This led to a philosophical discussion where another member questioned if condensing into an infinite amount truly implies expansion.
- Opus Outshines Sonnet in Specific Tasks: A member highlighted that Opus outperforms Sonnet on particular prompts, such as calculating angles on a digital clock display.
- However, many contend that comprehensive benchmarks still favor Sonnet, creating a split in performance evaluation.
- DeepSeek V2.5 Model Hits Higher Marks: The launch of DeepSeek V2.5, merging its Coder and Chat models, showcases significant metric improvements, like an ArenaHard win rate jump from 68.3% to 76.3%.
- Users appreciate these upgrades, enhancing overall usability while maintaining instruction-following capabilities.
- Reflection 70B Model Announcement: The new Reflection 70B model is set to introduce Reflection-Tuning for self-correction, generating excitement in the community.
- Members are eagerly anticipating the upcoming 405B version, projected to outperform existing alternatives, according to Matt Shumer's announcement.
- AI Studio Key Configuration Fails: AI Studio users reported a critical issue where the key entry does not save configurations, reverting back to Not Configured.
- While Hyperbolic and Lambda keys function properly, this inconsistency raises concerns among users regarding reliability.
Perplexity AI Discord
- Perplexity offers Free Membership for Students: Perplexity announced a free 1-year pro membership for colleges reaching 500 student signups with
.eduemails, raising questions on eligibility and sign-up criteria.- Users must register by a specific date, and the conversation highlighted uncertainty about their university's participation.
- xAI's Colossus Steals the Show: Perplexity AI introduced the World's Most Powerful Supercomputer, xAI's Colossus, alongside discussions on the Oldest Known Board Game, Senet.
- For more about this groundbreaking discovery, check out the YouTube video here.
- File Uploads Made Easy with Perplexity API: A member outlined a method to implement file uploads in Flask using the Perplexity API, detailing both client-side and server-side configurations.
- This method modifies the /query route to accept file data, allowing for seamless integration into API prompts.
- Cold Showers Gain Traction: Members dived into the benefits of cold showers, highlighting health advantages like improved circulation and mood enhancement.
- This trend sparked discussions about daily routines and their mental benefits.
- Boosting Perplexity API Response Quality: A user sought advice on configuring Perplexity API requests to emulate the response quality of the Perplexity website.
- While no specific solutions were offered, the quest for enhanced API responses indicates a community interest in model performance.
CUDA MODE Discord
- Cursor AI Tool Yields Mixed Reviews: While discussing the Cursor AI coding tool, several members expressed skepticism, saying it feels unhelpful, although it excels at code retrieval compared to the free tier.
- One member noted, 'Does anyone actually try to use it for tickets right?' questioning its effectiveness in practical scenarios.
- New Reflection 70B Marks Milestone in Open-Source LLMs: The launch of Reflection 70B, an open-source LLM refined through Reflection-Tuning, excited many, with a follow-up model, 405B, expected next week to set new standards.
- A community member shared a tweet from Matt Shumer, emphasizing the model's capabilities to self-correct mistakes.
- Diving into Pallas Kernels: Members explored various kernels implemented in Pallas, available on GitHub, showcasing transformations for Python+NumPy programs.
- The Splash Attention kernel was highlighted, with its implementation linked here for in-depth review.
- Exploring Open Sora's CUDA Implementation: A member is tackling the implementation of Open Sora in CUDA and C++, noting the difficulty and slow progress on this extensive project.
- They expressed a wish for more advancements in graphics, indicating a desire for progress in the technical domain.
- Memory-Bound Performance Analysis in Triton: Performance remains limitingly slow in memory-bound setups while achieving speeds near FP16 with larger batch sizes, indicating ongoing efforts for efficiency.
- The conversation also leaned towards using autotuning to potentially enhance speed, as batch sizes grew.
Eleuther Discord
- MCTS in Image Generation: A Debate: The discussion on applying Monte Carlo Tree Search (MCTS) in image tasks opened questions about its logic reversal when compared to models like AlphaZero and AlphaProof.
- One participant emphasized how MCTS relies heavily on previous steps, pointing out its focus on enhancing policies rather than generating them.
- Creative AI Workshop Interest: Members are seeking information on upcoming creative AI workshops, aiming to leverage insights from their recent paper on diffusion models.
- Skepticism arose regarding their relevance for the ICCV timeframe, especially given looming submission deadlines.
- Scaling Parameters: A Pitfall: Concerns emerged about the inefficiencies in scaling parameter counts without a corresponding increase in dataset size, with references to the Chinchilla paper.
- One user suggested examining the paper's formulas for a clearer understanding of the implications of scaling.
- Transfusion Model Insights: Discussion centered around the Transfusion paper, which offers insights into training multi-modal models on both discrete and continuous data.
- It was highlighted that the methodology yields better scaling performance compared to traditional discrete token training.
- AI Boosts Developer Productivity: Findings from a paper titled The Effects of Generative AI on High Skilled Work showed a 26.08% increase in task completion among developers using AI tools like GPT 3.5.
- This suggests significant productivity improvements linked to the infusion of AI technologies in development.
Latent Space Discord
- SSI Inc secures massive $1B funding: SSI Inc has successfully acquired $1B in a funding round, alongside Sakana's $100M achievement.
- Speculation arose regarding potential allocations from this funding towards Nvidia in engineering discussions.
- You.com shifts strategies with $50M boost: You.com transitions from AI search ventures to focus on deeper productivity agents, powered by a recent $50M funding round.
- Founder Richard Socher emphasized that competing with Google on simple queries is less effective than enhancing complex query capabilities.
- Karpathy champions Tesla in autonomous driving: In a captivating podcast, Andrej Karpathy predicts that Tesla will lead in self-driving tech, despite Waymo's advancements, citing a vital software versus hardware challenge.
- He highlighted the transformative potential of Optimus, Tesla's humanoid robot, for future factory applications.
- OpenAI contemplates a $2000/month model: OpenAI is reportedly considering a $2000/month subscription for accessing their next-gen model, suggesting possible 100x capability increases over lower-tier versions.
- Discussions hint at either significant model performance enhancements or the need to cover escalating operational costs.
- Replit Agent automates dev tasks: Replit has launched the Replit Agent to automate software development tasks, including setting up development environments during early access.
- This initiative aims to strengthen Replit's offerings by integrating AI more deeply into programming workflows.
OpenInterpreter Discord
- Open Interpreter Marks Another Year: Members celebrated the birthday of Open Interpreter, highlighting its achievements in AI-human collaboration and prompting a humorous remark about 'AGI achieved, we can all go home now'.
- This reflective moment underscored the tool’s relevance in today’s AI discourse.
- Teaching the Open Interpreter New Tricks: Discussion centered around Teach Mode, where users can say, 'I want to teach you something' to help the system develop new skills based on user input.
- The system’s adaptability aligns with principles shared by Rabbit Tech, demonstrating its potential in diverse applications.
- Open Repos Encourage Collaboration: The Open Interpreter and 01 repositories are now open-source, inviting developers to integrate innovative functionalities into their applications.
- One user expressed aspirations to automate web tasks by leveraging these open resources.
- AGI Buzz in the Air: A curious member raised a question regarding the AGI announcement, provoking a mix of excitement and skepticism among participants, reiterated by 'AGI achieved, we can all go home now'.
- This chatter reflects a vibrant community engagement around advanced AI concepts.
- Fulcra App: Still Waiting to Explore: Interest simmered around the international launch of the Fulcra app, with expectations high from users outside New Zealand.
- The anticipated release timeline remains unclear, keeping users on edge.
Torchtune Discord
- PyTorch 2.4 Compile Errors Emerge: Members reported compile errors with PyTorch 2.4, particularly with fake tensors, suggesting use of
os.environ['TORCH_COMPILE_BACKEND'] = 'aot_eager'to mask errors in CI.- A possible CI issue regarding the default backend was raised, stressing the need for updated gcc installations for CI workers.
- Input Padding Hits Performance Hard: Testing revealed that input padding with the Alpaca dataset incurred a substantial drop in speed, despite showing improved memory footprint.
- The suggestion to report both padded and unpadded tokens aimed to quantify the performance impact of padding more effectively.
- Enhancements to DeepFusionModel Tests: The latest updates for DeepFusionModel included added tests for kv caching, with a pull request shared for detailed review and feedback.
- Pull Request #1449 proposes overrides for max cache sequence length, prompting discussions on its necessity.
- Unsloth Gains Y Combinator Support: Unsloth has secured backing from Y Combinator, igniting excitement around prospective support for community initiatives.
- Anticipation grew as one member expressed hope for similar opportunities, highlighting the shifting landscape of community projects.
- Clarification on Meta Employment: A member clarified misconceptions regarding employment at Meta, emphasizing that not all participants are affiliated with the company.
- One member noted that Salman is doing it purely for the love of the game, dispelling assumptions of professional ties.
Cohere Discord
- Tackling System Prompt Errors: A user faced issues optimizing their system prompt, receiving errors stating Could not parse & validate the given body.
- Another member advised providing detailed prompts in a designated channel for focused help.
- What's Cooking with Cohere?: Members are eager to learn about the latest updates from Cohere, with one pointing to the Cohere blog for fresh insights.
- This resource highlights customer use cases and recent developments crucial for understanding ongoing improvements.
- Implementing Text Suggestions Like Gmail: A member sought advice on replicating a text suggestions feature akin to Gmail's Smart Compose using Cohere models.
- Another member suggested the importance of contextual prompting to make this feature feasible.
- Using LLM Agents for Reports: There's interest in leveraging LLM agents to generate stakeholder reports, drawing from previous writing styles and meeting notes.
- Suggestions ranged from RAG with Nimble rerank for meeting notes to meta prompting techniques to retain writing style consistency.
- OpenSesame 2.0 Debuts Major Updates: OpenSesame 2.0 launched with enhancements like no longer requiring ground truth input and integration with vector DBs for semantic searches.
- It also supports multiple models, including functionalities for platforms like OpenAI, Gemini, and Cohere.
LlamaIndex Discord
- Netchex AI Revolutionizes Employee Support: Netchex implemented AskHR + Netchex AI using LlamaIndex, transforming employee support for small to medium-sized businesses in just one month with two engineers. They used advanced RAG pipelines for context-aware responses, showcasing rapid development in the HR sector. Read more here.
- This implementation demonstrates the effective use of AI in enhancing employee interactions, marking a significant evolution in the HR landscape.
- create-llama Introduces Multi-Agent Workflow: The latest update to create-llama offers a multi-agent workflow in Python, emphasizing its role in rapid deployment for various use cases. An example utilizes three agents to generate a blog post, demonstrating its flexibility and efficiency. Check it out!.
- This feature aims to streamline content creation processes, empowering developers to innovate with AI capabilities easily.
- Launch of llama-deploy for Microservices: llama-deploy enables seamless microservice deployment based on LlamaIndex Workflows, marking a substantial improvement in deployment efficiency. This launch builds on lessons from llama-agents and Workflows, enhancing capabilities for developers. Get details here.
- The system aims to simplify the deployment of AI-centric applications, crucial for scaling services quickly.
- Installing llama-index-experimental-param-tuner: To install the experimental package, run
pip install llama-index-experimentalfor llama-index version 0.11.3. One user confirmed that this installation step is necessary for the functionality.- This package is expected to offer advanced features for users seeking to leverage the latest improvements in LlamaIndex.
- Setting up Claude with LlamaIndex: A comprehensive guide was shared for utilizing Claude's latest models in LlamaIndex, including setup instructions and tokenizer settings. The models range from Claude 3 Opus to Claude 3 Haiku, emphasizing adherence to documentation.
- This integration opens opportunities for building sophisticated applications that utilize advanced language models.
LangChain AI Discord
- Community Input Sought for AI Agent Platform: A member is exploring a platform to build, deploy, and monetize AI agents and is requesting insights from other builders during the research phase.
- They are offering beta access in return for a brief chat, aiming to refine features based on community feedback.
- Document-Driven Chatbot Challenges: Assistance is requested for a chatbot that needs to interact using content from two PDF files, with an emphasis on user experience.
- Key requirements include document loading, response generation, and efficient conversation management.
- Exploring Advances in Vision Language Models: A blog post reveals the journey from early models like CLIP to sophisticated solutions such as Flamingo and LLaVA, emphasizing joint training with vision and text data.
- Gamified Learning with CodeMaster App: The CodeMaster app has launched, aimed at enhancing coding skills through gamification and science-backed learning techniques.
- Community feedback praises its spaced repetition feature, significantly boosting user engagement and knowledge retention.
- Shifting from SQLite to Cloud Solutions: Options for transitioning from SQLite to Postgres or MySQL for a ReAct agent deployed on GCP AppEngine were discussed.
- Concerns about losing local SQLite context with redeployments were also raised.
LAION Discord
- Comfy Rewrite Project Gains Traction: Julien Blanchon announced a minimalist Comfy rewrite from scratch, seeking to create a highly extensible user interface with no dependencies. This project invites collaboration to simplify usage while maintaining flexibility.
- Members expressed interest in reforms to enhance user experience and reduce complexity, and more details are available here.
- Reflection 70B Claims Self-Correction Ability: Reflection 70B is announced as the top open-source model capable of fixing its own mistakes through Reflection-Tuning. Reports indicate it outperforms models like GPT-4o across benchmarks, with a 405B version on the horizon.
- The AI community buzzes with excitement, as a noteworthy tweet highlights its revolutionary features.
- Transfusion Model Combines Modalities: Meta released a paper on the Transfusion model, a multitasking approach integrating language and diffusion training on 1T text tokens and 692M images. It shows potential for future extensions to audio and potentially video.
- The study proposes innovative use of VAE for seamless media transitions, which could have broad implications for multi-modal AI developments, as described in the arXiv paper.
- SwarmUI Focuses on Modular Accessibility: The SwarmUI project aims to provide a modular web user interface for Stable Diffusion, prioritizing user-friendliness and performance enhancements. A GitHub link was shared, highlighting its goal to make power tools easily accessible.
- Members noted its extensibility is a key feature, catering to users who seek streamlined operations in their AI applications. More can be explored on its GitHub page.
- Unified Multi-modal Model Proposed: Members discussed the vision of a Transfusion+GameNGen model that integrates language, vision, audio, and gaming engines into a singular framework. Such an advancement could redefine interactions across AI and modalities.
- This concept sparked debate on the future of integrated AI solutions, with many keen on exploring the practical implications of this type of model.
tinygrad (George Hotz) Discord
- Bounty Payments Completed: All individuals who emailed to claim bounties have been paid, and recipients are encouraged to report if they have not received their compensation.
- This promotes transparency and efficiency in managing user rewards within the tinygrad community.
- Tinyboxes Rental Proposal Takes Shape: A concept was shared regarding manufacturing tinyboxes for sale or rental from a data center, emphasizing an upgrade path for hardware.
- The plan aims to sell outdated hardware to keep stock fresh for consistent rentals.
- Discussion on Pricing Models for Performance: Members explored pricing models, recommending costs be expressed as $/exaflops and $/tflops*month.
- This highlights the complexity of pricing structures and how they cater to different user needs.
- Confusion Over phi Operation in IR: A member inquired about the phi operation in the IR, asking how it compares to LLVM IR's placements in loop bodies.
- Discussion clarified it's not a true phi operation, with suggestions to rename it to ASSIGN or UOps.UPDATE.
- Insights on cstyle Renderer: George Hotz directed attention to the cstyle renderer for a better understanding of its role in the ongoing discussion.
- This was acknowledged as a useful reference by members seeking deeper comprehension.
OpenAccess AI Collective (axolotl) Discord
- Unsloth Phi converts seamlessly to Llama: The Unsloth Phi architecture now converts to Llama, allowing for the use of a Llama3 configuration for more efficient experimental setups.
- This adjustment offers a potential boost in experimentation efficiency.
- Ongoing discussions about Phi3 challenges: While Phi3 is considered safe, there are challenges that need consistent attention highlighted in the Discord history.
- Members suggest that while it functions, it may require further investigation due to ambiguities in performance.
- Invisietch looks for a small model: Invisietch seeks a small model for rapid experimentation, reflecting a need for accessible resources in the community.
- This pursuit showcases a wider interest in agile development tactics.
- Dora support is officially confirmed: Axolotl now officially supports Dora by using the parameter
peft_use_dora: true, as noted in a GitHub issue.- Members are encouraged to review prior discussions to explore similar feature requests.
- Llama-3.1-8B turns into a Molecular Design Engine: Fine-tuning and DPO successfully transformed Llama-3.1-8B into a model for generating molecules based on user-defined properties.
- This advancement enables on-demand molecule creation with minimal input instructions.
DSPy Discord
- DSPy Usecase List Revealed: The DSPy usecase list has been officially announced, detailing insights into nearly 100 products built with Large Models (LMs) in production, as shared in a tweet.
- This initiative, led by key contributors, aims to gather community input and explore current deployments within a DSPy context.
- ColPali Enhances Document Retrieval: A new method named ColPali has launched, efficiently enhancing document retrieval through a late interaction mechanism for visually rich documents, as described here.
- Developed by Manuel Faysse and Hugues Sibille, ColPali addresses limitations in existing systems by incorporating non-textual elements like tables and figures.
- Visual Document Retrieval Benchmark Introduced: The Visual Document Retrieval Benchmark (ViDoRe) has been introduced, designed to assess retrieval performance across diverse languages and document types.
- This benchmark aims to enhance evaluation methods by integrating a broader spectrum of document elements beyond plain text.
- Livecoding Sessions in Full Swing: A reminder about ongoing livecoding sessions encourages members to participate via this link.
- These sessions are intended to bolster hands-on coding skills within the community.
- New Paper Alert: A link to a new research paper was shared, found here, highlighting topics relevant to AI and model developments.
- This contribution adds to the ongoing discourse surrounding advancements in the field.
DiscoResearch Discord
- Member Seeks Experience with Multimodal LLMs: A member inquired about experiences with multimodal LLMs that incorporate both text and speech inputs, particularly focusing on training and finetuning efforts.
- This reflects an escalating interest in weaving speech capabilities into LLM frameworks.
- YouTube Video on Multimodal Insights: A member shared a YouTube video that presumably covers aspects of multimodal models.
- This resource could serve as a valuable introduction for those aiming to operationalize multimodal capabilities in their projects.
LLM Finetuning (Hamel + Dan) Discord
- Meeting Needs a Transcript: Participants emphasized the necessity of a transcript of the entire meeting, including attendee names, to improve accountability.
- This could enhance reference accuracy and accountability for future discussions.
- Focused Proof of Concept in Development: One member is developing a proof of concept for a report, indicating a hands-on approach to project implementation.
- This moves towards practical implementation while keeping the scope manageable.
- Complexities of Agent Workflows: The conversation included ideas about leveraging agents' workflows, hinting at a potential shift in project methodology.
- However, concerns emerged regarding the complexity of evaluating agents, stemming from a lack of established standards.
MLOps @Chipro Discord
- AI Enterprise Summit Set for SF: The AI Enterprise Summit is scheduled for October 2, 2024, in San Francisco, targeting executives and AI enthusiasts focused on scaling AI products. Use code AIR50 for a $50 discount on tickets to this exclusive event.
- Expected to draw a crowd of ambitious professionals, the summit aims to facilitate connection and learning opportunities among attendees.
- Industry Leaders to Take the Stage: Keynote speakers for the summit include Paul Baier (CEO of GAInsights), Ted Shelton (COO of Inflection AI), and Jeremiah Owyang (Blitzscaling Ventures), providing insights on practical business applications.
- These leaders will offer valuable perspectives from the industry, making it a significant learning experience for all participants.
- Networking for AI Professionals: The summit promotes a curated gathering where AI professionals can network and collaborate on AI product development. This environment aims to foster constructive dialogues among leaders in the field.
- Participants will have the chance to engage directly with thought leaders, ensuring a productive exchange of ideas and fostering potential collaborations.
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla LLM Issue Acknowledgment: A member acknowledged the issue regarding Gorilla LLM and assured they would take a look at it.
- No additional details were provided, but this indicates engagement in addressing potential improvements.
- Berkeley Function Calling Insights: Discussion around Berkeley Function Calling included inquiries about the utility of this approach in Gorilla LLM integration.
- Although specific comments were not available, the interest reflects a trend towards enhancing function calls and interfaces in newer models.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!