[AINews] Reasoning Models are Near-Superhuman Coders (OpenAI IOI, Nvidia Kernels)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
RL is all you need.
AI News for 2/12/2025-2/13/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (211 channels, and 5290 messages) for you. Estimated reading time saved (at 200wpm): 554 minutes. You can now tag @smol_ai for AINews discussions!
This is a rollup of two distinct news items with nevertheless the same theme:
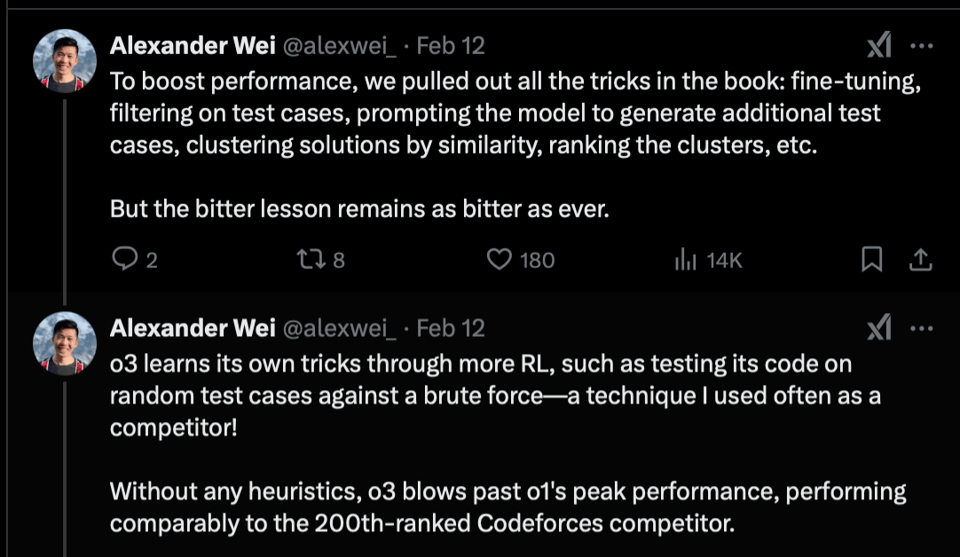
- o3 achieves a gold medal at the 2024 IOI and obtains a Codeforces rating on par with elite human competitors - in particular, the Codeforces score is at the 99.8-tile - only 199 humans are better than o3. Notably, team member Alex Wei noted that all the "inductive bias" methods also failed compared to the RL bitter lesson.
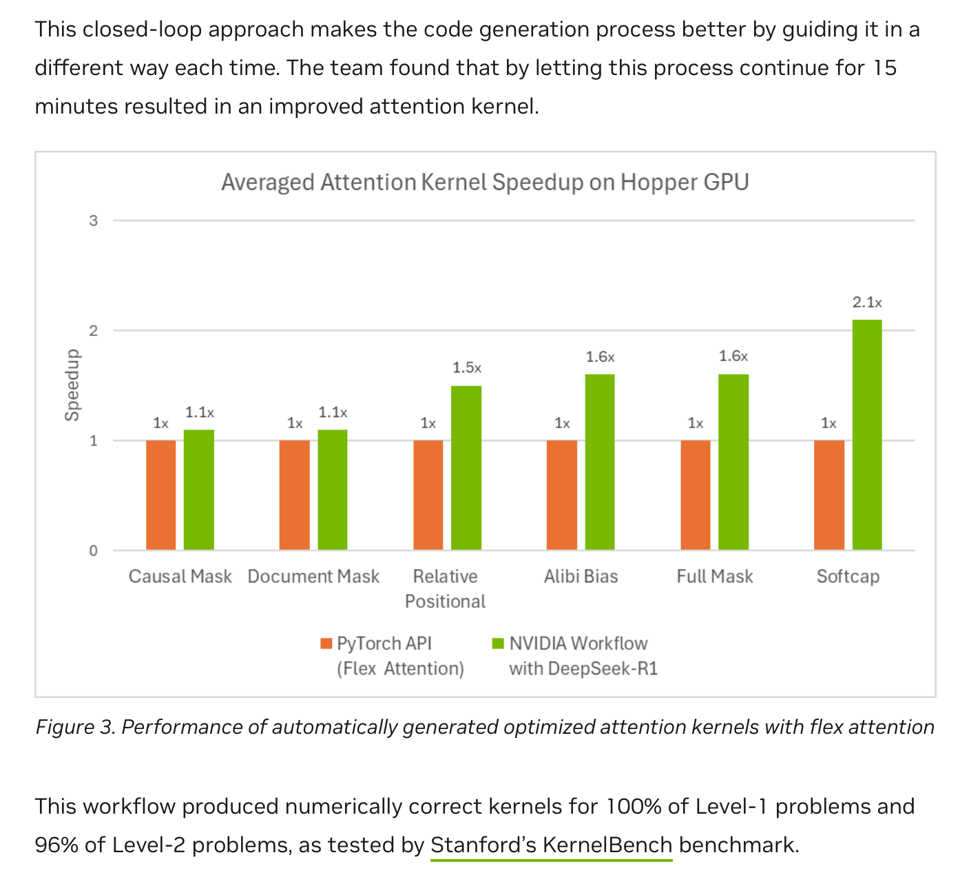
- In Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling, Nvidia found that DeepSeek r1 could write custom kernels that "turned out to be better than the optimized kernels developed by skilled engineers in some cases"
In the Nvidia case, the solution was also extremely simple, causing much consternation.
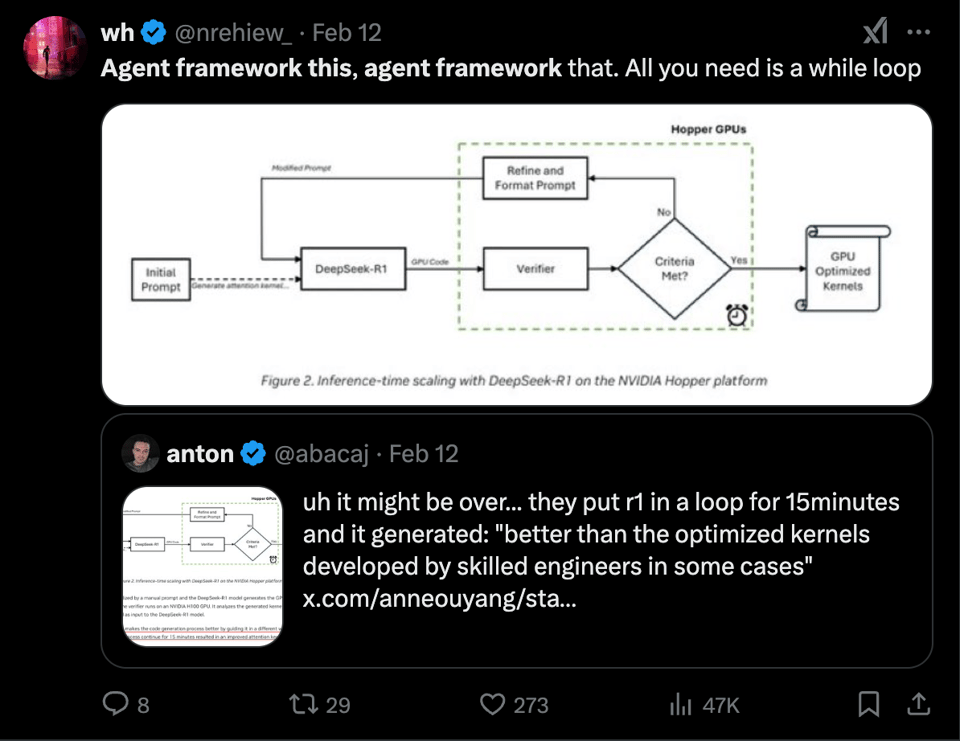
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- OpenAI Discord
- Cursor IDE Discord
- Nous Research AI Discord
- OpenRouter (Alex Atallah) Discord
- Perplexity AI Discord
- Codeium (Windsurf) Discord
- LM Studio Discord
- GPU MODE Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- Stability.ai (Stable Diffusion) Discord
- Latent Space Discord
- Yannick Kilcher Discord
- LlamaIndex Discord
- Notebook LM Discord
- Modular (Mojo 🔥) Discord
- MCP (Glama) Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- DSPy Discord
- Nomic.ai (GPT4All) Discord
- Cohere Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (956 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
- Unsloth AI (Daniel Han) ▷ #help (108 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #research (6 messages):
- HuggingFace ▷ #general (51 messages🔥):
- HuggingFace ▷ #today-im-learning (10 messages🔥):
- HuggingFace ▷ #i-made-this (14 messages🔥):
- HuggingFace ▷ #reading-group (10 messages🔥):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (8 messages🔥):
- HuggingFace ▷ #smol-course (18 messages🔥):
- HuggingFace ▷ #agents-course (717 messages🔥🔥🔥):
- HuggingFace ▷ #open-r1 (5 messages):
- OpenAI ▷ #annnouncements (3 messages):
- OpenAI ▷ #ai-discussions (347 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (12 messages🔥):
- OpenAI ▷ #prompt-engineering (16 messages🔥):
- OpenAI ▷ #api-discussions (16 messages🔥):
- Cursor IDE ▷ #general (392 messages🔥🔥):
- Nous Research AI ▷ #announcements (2 messages):
- Nous Research AI ▷ #general (268 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (2 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (11 messages🔥):
- OpenRouter (Alex Atallah) ▷ #general (257 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (1 messages):
- Perplexity AI ▷ #general (230 messages🔥🔥):
- Perplexity AI ▷ #sharing (21 messages🔥):
- Perplexity AI ▷ #pplx-api (11 messages🔥):
- Codeium (Windsurf) ▷ #announcements (2 messages):
- Codeium (Windsurf) ▷ #discussion (13 messages🔥):
- Codeium (Windsurf) ▷ #windsurf (244 messages🔥🔥):
- LM Studio ▷ #general (115 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (120 messages🔥🔥):
- GPU MODE ▷ #general (1 messages):
- GPU MODE ▷ #triton (8 messages🔥):
- GPU MODE ▷ #cuda (18 messages🔥):
- GPU MODE ▷ #torch (7 messages):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #jobs (8 messages🔥):
- GPU MODE ▷ #beginner (30 messages🔥):
- GPU MODE ▷ #pmpp-book (8 messages🔥):
- GPU MODE ▷ #torchao (2 messages):
- GPU MODE ▷ #sequence-parallel (1 messages):
- GPU MODE ▷ #off-topic (6 messages):
- GPU MODE ▷ #liger-kernel (3 messages):
- GPU MODE ▷ #self-promotion (7 messages):
- GPU MODE ▷ #🍿 (70 messages🔥🔥):
- GPU MODE ▷ #reasoning-gym (47 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (133 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
- Interconnects (Nathan Lambert) ▷ #random (36 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (4 messages):
- Interconnects (Nathan Lambert) ▷ #reads (20 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (5 messages):
- Eleuther ▷ #general (14 messages🔥):
- Eleuther ▷ #research (126 messages🔥🔥):
- Eleuther ▷ #interpretability-general (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (92 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (81 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Yannick Kilcher ▷ #general (50 messages🔥):
- Yannick Kilcher ▷ #paper-discussion (6 messages):
- Yannick Kilcher ▷ #agents (5 messages):
- Yannick Kilcher ▷ #ml-news (20 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (65 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Notebook LM ▷ #use-cases (10 messages🔥):
- Notebook LM ▷ #general (49 messages🔥):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (40 messages🔥):
- Modular (Mojo 🔥) ▷ #max (11 messages🔥):
- MCP (Glama) ▷ #general (50 messages🔥):
- tinygrad (George Hotz) ▷ #general (16 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (10 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- Torchtune ▷ #general (9 messages🔥):
- Torchtune ▷ #dev (5 messages):
- DSPy ▷ #general (10 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (10 messages🔥):
- Cohere ▷ #api-discussions (2 messages):
AI Twitter Recap
AI Tools and Resources
- OpenAI Updates on o1, o3-mini, and DeepResearch: OpenAI announced that o1 and o3-mini now support both file & image uploads in ChatGPT. Additionally, DeepResearch is now available to all Pro users on mobile and desktop apps, expanding accessibility.
- Distributing Open Source Models Locally with Ollama: @ollama discusses distributing and running open source models for developers locally, highlighting it's complementary to hosted OpenAI models.
- 'Deep Dive into LLMs' by @karpathy: @TheTuringPost shares a free 3+ hour video by @karpathy exploring how AI models like ChatGPT are built, including topics like pretraining, post-training, reasoning, and effective model use.
- ElevenLabs' Journey in AI Voice Synthesis: @TheTuringPost details how @elevenlabsio evolved from a weekend project to a $3.3 billion company, offering AI-driven TTS, voice cloning, and dubbing tools without open-sourcing.
- DeepResearch from OpenAI as a Mind-blowing Research Assistant: @TheTuringPost reviews DeepResearch from OpenAI, a virtual research assistant powered by a powerful o3 model with RL engineered for deep chain-of-thought reasoning, highlighting its features and benefits.
- Release of OpenThinker Models: @ollama announces OpenThinker models, fine-tuned from Qwen2.5, that surpass DeepSeek-R1 distillation models on some benchmarks.
AI Research Advances
- DeepSeek R1 Generates Optimized Kernels: @abacaj reports that they put R1 in a loop for 15 minutes, resulting in code "better than the optimized kernels developed by skilled engineers" in some cases.
- Importance of Open-source AI for Scientific Discovery: @stanfordnlp emphasizes that failure to invest in open-source AI could hinder scientific discovery in western universities that cannot afford closed models.
- Sakana AI Labs' 'TAID' Paper Receives Spotlight at ICLR2025: @SakanaAILabs announces their new knowledge distillation method 'TAID' has been awarded a Spotlight (Top 5%) at ICLR2025.
- Apple's Research on Scaling Laws: @awnihannun highlights two recent papers from Apple on scaling laws for MoEs and knowledge distillation, contributed by @samira_abnar, @danbusbridge, and others.
AI Infrastructure and Efficiency
- Advocating Data Centers over Mobile for AI Compute: @JonathanRoss321 argues that running AI on mobile devices is less energy-efficient compared to data centers, using analogies to illustrate the efficiency differences.
AI Security and Safety
- Vulnerabilities in AI Web Agents Exposed: @micahgoldblum demonstrates how adversaries can fool AI web agents like Anthropic’s Computer Use into sending phishing emails or revealing credit card info, highlighting the brittleness of underlying LLMs.
- Meta's Automated Compliance Hardening (ACH) Tool: @AIatMeta introduces their ACH tool that hardens platforms against regressions with LLM-based test generation, enhancing compliance and security.
AI Governance and Policy
- Insights from the France Action Summit: @sarahookr shares observations from the France Action Summit, noting that such summits are valuable as catalysts for important AI discussions and emphasizing the importance of understanding national efforts and scientific progress.
- Shifting from 'AI Safety' to 'Responsible AI': @AndrewYNg advocates for changing the conversation away from 'AI safety' towards 'responsible AI', arguing that it will speed up AI’s benefits and better address actual problems without hindering development.
Memes/Humor
- 'Rizz GPT' and Social Challenges Post-Lockdown: @andersonbcdefg humorously comments on how zoomers are building versions of 'Rizz GPT' because their brains are damaged from lockdown and they don't know how to have normal conversations.
- 'Big Day for Communicable Diseases': @stevenheidel posts a cryptic message stating it's a "big day for communicable diseases", adding a touch of humor.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Google's FNet: Potential for Improved LLM Efficiency via Fourier Transforms
- This paper might be a breakthrough Google doesn't know they have (Score: 362, Comments: 24): The FNet paper from 2022 explores using Fourier Transforms to mix tokens, suggesting potential major efficiency gains in model training. The author speculates that replicating this approach or integrating it into larger models could lead to a 90% speedup and memory reduction, presenting a significant opportunity for advancements in AI model efficiency.
- Efficiency and Convergence Challenges: Users reported that while FNet worked, it was less effective than traditional attention mechanisms, particularly in small models, and faced significant convergence issues. This raises doubts about its scalability and efficacy in larger models.
- Alternative Approaches and Comparisons: Discussions mentioned alternative models like Holographic Reduced Representations (Hrrformer), which claims superior performance with less training, and M2-BERT, which shows greater accuracy on benchmarks. These alternatives highlight the complexity of evaluating trade-offs between training speed, accuracy, and generalization.
- Integration and Implementation: The FNet code is available on GitHub, but its integration with existing models like transformers is non-trivial due to its implementation in JAX. Users discussed potential hybrid approaches, such as creating variants like fnet-llama or fnet-phi, to explore differences in performance and hallucination tendencies.
Theme 2. DIY High-Performance Servers for 70B LLMs: Strategies and Cost
- Who builds PCs that can handle 70B local LLMs? (Score: 108, Comments: 160): Building a home server capable of running 70B parameter local LLMs is discussed, with a focus on using affordable, older server hardware to maximize cores, RAM, and GPU RAM. The author inquires if there are professionals or companies that specialize in assembling such servers, as they cannot afford the typical $10,000 to $50,000 cost for high-end GPU-equipped home servers.
- Building a home server for 70B parameter LLMs can be achieved for under $3,000 using components like an Epyc 7532, 256GB RAM, and MI60 GPUs, as suggested by Psychological_Ear393. Some users like texasdude11 have shared setups using dual NVIDIA 3090s or P40 GPUs for efficient performance, providing detailed guides and YouTube videos for assembly and operation.
- The NVIDIA A6000 GPU is highlighted for its speed and capability in running 70B models; however, it is costly at around $5,000. Alternatives include setups with multiple RTX 3090 or 3060 GPUs, with users like Dundell and FearFactory2904 suggesting cost-effective builds using second-hand components.
- Users discuss the viability of using Macs, particularly M1 Ultra with 128GB RAM, for running 70B models efficiently, especially for chat applications, as noted by synn89. Future potential options include waiting for Nvidia Digits or AMD Strix Halo, which may offer better performance for home inference tasks.
Theme 3. Gemini2.0's Dominance in OCR Benchmarking and Context Handling
- Gemini beats everyone is OCR benchmarking tasks in videos. Full Paper : https://arxiv.org/abs/2502.06445 (Score: 114, Comments: 26): Gemini-1.5 Pro excels in OCR benchmarking tasks for videos, achieving a Character Error Rate (CER) of 0.2387, Word Error Rate (WER) of 0.2385, and an Average Accuracy of 76.13%. Despite GPT-4o having a slightly higher overall accuracy at 76.22% and the lowest WER, Gemini-1.5 Pro is highlighted for its superior performance compared to models like RapidOCR and EasyOCR. Full Paper
- RapidOCR is noted as a fork of PaddleOCR, with minimal expected deviation in scores from its origin. There is interest in exploring direct PDF processing capabilities using Gemini-1.5 Pro, with a link provided for implementation on Google Cloud Vertex AI here.
- Users express a need for OCR benchmarking to include handwriting recognition, with Azure FormRecognizer praised for handling cursive text. A user reported that Gemini 2.0 Pro performed exceptionally well on Russian handwritten notes compared to other language models.
- There is a call for broader comparisons across multiple languages and models, including Gemini 2, Tesseract, Google Vision API, and Azure Read API. Despite some frustrations with Gemini's handling of simple tasks, users acknowledge its advancements in visual labeling, and Moondream is highlighted as a promising emerging model, with plans to add it to the OCR benchmark repository.
- NoLiMa: Long-Context Evaluation Beyond Literal Matching - Finally a good benchmark that shows just how bad LLM performance is at long context. Massive drop at just 32k context for all models. (Score: 402, Comments: 75): The NoLiMa benchmark highlights significant performance degradation in LLMs at long context lengths, with a marked drop at just 32k tokens across models like GPT-4, Llama, Gemini 1.5 Pro, and Claude 3.5 Sonnet. The graph and table show that scores fall below 50% of the base score at these extended lengths, indicating substantial challenges in maintaining performance with increased context.
- Degradation and Benchmark Comparisons: The NoLiMa benchmark shows substantial performance degradation in LLMs like llama3.1-70B, which scores 43.2% at 32k context length compared to 94.8% on RULER. This benchmark is considered more challenging than previous ones like LongBench, which focuses on multiple-choice questions and doesn't fully capture performance degradation across context lengths.
- Model Performance and Architecture Concerns: There's significant discussion on how reasoning models like o1/o3 handle long contexts, with some models performing poorly on hard subsets of questions. The limitations of current architectures, such as the quadratic complexity of attention mechanisms, are highlighted as a barrier to maintaining performance over long contexts, suggesting a need for new architectures like RWKV and linear attention.
- Future Model Testing and Expectations: Participants express interest in testing newer models like Gemini 2.0-flash/pro and Qwen 2.5 1M, hoping for improved performance in long-context scenarios. There's skepticism about claims of models handling 128k tokens effectively, with some users emphasizing that practical applications typically perform best with contexts under 8k tokens.
Theme 4. Innovative Architectural Insights from DeepSeek: Expert Mixtures and Token Predictions
- Let's build DeepSeek from Scratch | Taught by MIT PhD graduate (Score: 245, Comments: 28): An MIT PhD graduate is launching a comprehensive educational series on building DeepSeek's architecture from scratch, focusing on foundational elements such as Mixture of Experts (MoE), Multi-head Latent Attention (MLA), Rotary Positional Encodings (RoPE), Multi-token Prediction (MTP), Supervised Fine-Tuning (SFT), and Group Relative Policy Optimisation (GRPO). The series, consisting of 35-40 in-depth videos totaling over 40 hours, aims to equip participants with the skills to independently construct DeepSeek's components, positioning them among the top 0.1% of ML/LLM engineers.
- Skepticism about Credentials: Some users express skepticism about the emphasis on prestigious credentials like MIT, suggesting that the content's quality should stand on its own without relying on the author's background. There's a call for content to be judged independently of the creator's academic or professional affiliations.
- Missing Technical Details: A significant point of discussion is the omission of Nvidia's Parallel Thread Execution (PTX) as a cost-effective alternative to CUDA in the series, highlighting a perceived gap in addressing DeepSeek's efficiency and cost-effectiveness. This suggests that understanding the technical underpinnings, not just the capabilities, is crucial for appreciating DeepSeek's architecture.
- Uncertainty about Computing Power: There is contention regarding the actual computing power used in DeepSeek's development, with some users criticizing speculative figures circulating online. The discussion underscores the importance of accurate data, particularly regarding resources like datasets and computing power, in understanding and replicating AI systems.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. OpenAI merges o3 into unified GPT-5
- OpenAI cancels its o3 AI model in favor of a ‘unified’ next-gen release (Score: 307, Comments: 66): OpenAI has decided to cancel its o3 AI model project, opting instead to focus on developing a unified next-generation release with GPT-5. The strategic shift suggests a consolidation of resources and efforts towards a single, more advanced AI model.
- There is a significant debate around whether OpenAI's move to integrate the o3 model into GPT-5 represents progress or a lack of innovation. Some users argue that this integration is a strategic simplification aimed at usability, while others see it as a sign of stagnation in model development, with DeepSeek R1 being cited as a competitive free alternative.
- Many commenters express concern over the loss of user control with the automatic model selection approach, fearing it may lead to suboptimal results. Users like whutmeow and jjjiiijjjiiijjj prefer manual model selection, worried that algorithmic decisions may prioritize company costs over user needs.
- The discussion also highlights confusion over the terminology used, with several users correcting the notion that o3 is canceled, clarifying instead that it is being integrated into GPT-5. This has led to concerns about misleading headlines and the potential implications for OpenAI's strategic direction and leadership.
- Altman said the silent part out loud (Score: 126, Comments: 59): Sam Altman announced that Orion, initially intended to be GPT-5, will instead launch as GPT-4.5, marking it as the final non-CoT model. Reports from Bloomberg, The Information, and The Wall Street Journal indicate that GPT-5 has faced significant challenges, showing less improvement over GPT-4 than its predecessor did. Additionally, the o3 model will not be released separately but will integrate into a unified system named GPT-5, likely due to the high operational costs revealed by the ARC benchmark, which could financially strain OpenAI if widely and frivolously used by users.
- Hardware and Costs: The inefficiency of running models on inappropriate hardware, such as Blackwell chips, and the misinterpretation of cost data due to repeated queries, were discussed as factors impacting the launch and operation of GPT-4.5 and GPT-5. Deep Research queries are priced at $0.50 per query, with plans offering 10 for plus members and 2 for free users.
- Model Evolution and Challenges: There is a consensus that non-CoT models may have reached a scalability limit, prompting a shift towards models with reasoning capabilities. This transition is seen as a necessary evolution, with some suggesting that GPT-5 represents a new direction rather than an iterative improvement over GPT-4.
- Reasoning and Model Selection: Discussions highlighted the potential advantages of reasoning models, with some users noting that reasoning models like o3 may overthink, while others suggest using a hybrid approach to select the most suitable model for specific tasks. The concept of models with adjustable thinking times being costly was also debated, as well as the potential for OpenAI to implement usage caps to manage expenses.
- I'm in my 50's and I just had ChatGPT write me a javascript/html calculator for my website. I'm shook. (Score: 236, Comments: 62): The author, in their 50s, used ChatGPT to create a JavaScript/HTML calculator for their website and was impressed by its ability to interpret vague instructions and refine the code, akin to a conversation with a web developer. Despite their previous limited use of AI, they were astonished by its capabilities, reflecting on their long history of observing technological advancements since 1977.
- Users shared experiences of ChatGPT aiding in diverse coding tasks, from creating SQL queries to building wikis and servers, emphasizing its utility in guiding through unfamiliar technologies. FrozenFallout and redi6 highlighted its role in simplifying complex processes and error handling, even for those with limited technical knowledge.
- Front_Carrot_1486 and BroccoliSubstantial2 expressed a shared sense of wonder at AI's rapid advancements, comparing it to past technological shifts, and noting the generational perspective on witnessing tech evolving from sci-fi to reality. They appreciated AI's ability to provide solutions and alternatives, despite occasional errors.
- Recommendations for further exploration included trying Cursor with a membership for a more impressive experience, as suggested by TheoreticalClick, and exploring app development with AI guidance, as mentioned by South-Ad-9635.
Theme 2. Anthropic and OpenAI enhance reasoning models
- OpenAI increased its most advanced reasoning model’s rate limits by 7x. Now your turn, Anthropic. (Score: 486, Comments: 72): OpenAI has significantly increased the rate limits of its advanced reasoning model, o3-mini-high, by 7x for Plus users, allowing up to 50 per day. Additionally, OpenAI o1 and o3-mini now support both file and image uploads in ChatGPT.
- Users express strong dissatisfaction with Anthropic's perceived lack of urgency to respond to competitive pressures, with some canceling subscriptions due to the lack of compelling updates or features. Concerns include the company's focus on safety and content moderation over innovation, potentially losing their competitive edge.
- The increased rate limits for OpenAI's o3-mini-high model have been positively received, especially by Plus users, who appreciate the enhanced access. However, some believe that OpenAI prioritizes API business customers over web/app users, leading to lower limits for the latter.
- There is a sentiment of disappointment towards Anthropic, with users feeling that their focus on safety and corporate customers is overshadowing innovation and responsiveness to market competition. Some users express frustration with Claude's limitations and the lack of viable alternatives with similar capabilities.
- The Information: Claude hybrid reasoning model may be released in next few weeks (Score: 160, Comments: 44): Anthropic is reportedly set to release a Claude hybrid reasoning model in the coming weeks, offering a sliding scale feature that reverts to a non-reasoning mode when set to 0. The model is said to outperform o3-mini on some programming benchmarks and excels in typical programming tasks, while OpenAI's models are superior for academic and competitive coding.
- Anthropic's Focus on Safety is criticized by some users, with comparisons made to OpenAI's reduced censorship and the Gemini 2.0 models, which are praised for being less restricted. Some users find the censorship efforts to be non-issues, while others see them as unnecessary corporate appeasement.
- There is skepticism about the Claude hybrid reasoning model's effectiveness for writing tasks, with concerns that it might suffer similar issues to o3-mini. Users express a need for larger and more effective context windows, noting that Claude's supposed 200k token context starts to degrade significantly after 32k tokens.
- Users discuss the importance of context windows and output complexity, with some finding o3-mini-high's output overly complex and others emphasizing the need for a context window that maintains its integrity beyond 64k tokens.
- Deep reasoning coming soon (Score: 121, Comments: 42): The post titled "Deep reasoning coming soon" with the body content "Hhh" lacks substantive content and context to provide a detailed summary.
- Code Output Concerns: Estebansaa expressed skepticism about the value of deep reasoning if it can't surpass the current output of 300-400 lines of code and match o3's capability of over 1000 lines per request. Durable-racoon questioned the need for such large outputs, suggesting that even 300 lines can be overwhelming for review.
- API Access Issues: Hir0shima and others discussed the challenges of API access, highlighting the high costs and frequent errors. Zestyclose_Coat442 noted the unexpected expenses even when errors occur, while Mutare123 mentioned the likelihood of hitting response limits.
- Release Impatience: Joelrog pointed out that recent announcements about deep reasoning are still within a short timeframe, arguing against impatience and emphasizing that companies generally adhere to their release plans.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Exp
Theme 1. Reasoning LLM Models - Trends in New releases
- Nous Research Debuts DeepHermes-3 for Superior Reasoning: Nous Research launched the DeepHermes-3 Preview, showcasing advancements in unifying reasoning and intuitive language model capabilities, requiring a specific system prompt with
- Anthropic Plans Reasoning-Integrated Claude Version: Anthropic is set to release a new Claude model combining traditional LLM and reasoning AI capabilities, controlled by a token-based sliding scale, for tasks like coding, with rumors that it may be better than OpenAI's o3-mini-high in several benchmarks. The unveiling of these models and their new abilities signals the beginning of a new era of hybrid thinking in AI systems.
- Scale With Intellect as Elon Promises Grok-3: Elon Musk announced Grok 3, nearing launch, boasting superior reasoning capabilities over existing models, hinting at new levels of 'scary smart' AI with a launch expected in about two weeks, amidst a $97.4 billion bid for OpenAI's nonprofit assets. This announcement is expected to change the game.
Theme 2. Tiny-yet-Mighty LLMs and Tooling Improvements
- DeepSeek-R1 Generates GPU Kernel Like A Boss: NVIDIA's blog post features LLM-generated GPU kernels, showcasing DeepSeek-R1 speeding up FlexAttention and achieving 100% numerical correctness on 🌽KernelBench Level 1, while also achieving 96% accurate results on Level-2 issues of the KernelBench benchmark. This automates computationally expensive tasks by allocating additional resources, but concerns arose over the benchmark itself.
- Hugging Face Smolagents Arrive and Streamline Your Workflow: Hugging Face launched smolagents, a lightweight agent framework alternative to
deep research, with a processing time of about 13 seconds for 6 steps. Users can modify the original code to extend execution when run on a local server, providing adaptability. - Codeium's MCP Boosts Coding Power: Windsurf Wave 3 (Codeium) introduces features like the Model Context Protocol (MCP), which integrates multiple AI models for enhanced efficiency and output, allowing users to configure tool calls to user-defined MCP servers and achieve higher quality code. The community is excited for this hybrid AI framework!
Theme 3. Perplexity Finance Dashboard and Analysis of AI Models
- Perplexity Launches Your All-In-One Finance Dashboard: Perplexity released a new Finance Dashboard providing market summaries, daily highlights, and earnings snapshots. Users are requesting a dedicated button for dashboards on web and mobile apps.
- Model Performance Gets Thorough Scrutiny at PPLX AI: The models that Perplexity AI uses are in question. Debates emerged regarding AI models, specifically the efficiency and accuracy of R1 compared to alternatives like DeepSeek and Gemini.
- DeepSeek R1 Trounces OpenAI in Reasoning Prowess: A user reported Deepseek R1 displayed impressive reasoning when handling complex SIMD functions, outperforming o3-mini on OpenRouter. Users on HuggingFace celebrated V3's coding ability, and some on Unsloth AI saw it successfully handle tasks with synthetic data and GRPO/R1 distillation.
Theme 4. Challenges and Creative Solutions
- DOOM Game Squeezed into a QR Code: A member successfully crammed a playable DOOM-inspired game, dubbed The Backdooms, into a single QR code, taking up less than 2.4kb, and released the project as open source under the MIT license for others to experiment with. The project used compression like .kkrieger, and has a blog post documenting the approach.
- Mobile Devices Limit RAM, Prompting Resourceful Alternatives: Mobile users note 12GB phones only allowing 2GB of accessible memory, hindering model performance, and one suggested an alternative 16GB ARM SBC for portable computing at ~\$100. If you don't have a fancy phone, upgrade it.
- Hugging Face Agents Course Leaves Users Disconnected: With users experiencing connection issues during the agents course, a member suggested changing the endpoint to a new link (https://jc26mwg228mkj8dw.us-east-1.aws.endpoints.huggingface.cloud) and also indicated a model name update to deepseek-ai/DeepSeek-R1-Distill-Qwen-32B was required, which is likely caused by overload. Try a different browser, and if all else fails... disconnect.
Theme 5. Data, Copyrights, and Declarations
- US Rejects AI Safety Pact, Claims Competitive Edge: The US and UK declined to sign a joint AI safety declaration, with US leaders emphasizing their commitment to maintaining AI leadership. Officials cautioned engaging with authoritarian countries in AI could compromise infrastructure security.
- Thomson Reuters Wins Landmark AI Copyright Case: Thomson Reuters has won a significant AI copyright case against Ross Intelligence, determining that the firm infringed its copyright by reproducing materials from Westlaw. US Circuit Court Judge Stephanos Bibas dismissed all of Ross's defenses, stating that none of them hold water.
- LLM Agents MOOC Certificate Process Delayed: Numerous participants in LLM Agents course haven't received prior certificates, and must observe a manual send, while others needing help locating them are reminded that the declaration form is necessary for certificate processing. Where's my diploma?
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- DeepSeek's Dynamic Quantization Reduces Memory: Users explained that dynamic quantization implemented in DeepSeek models helps reduce memory usage while maintaining performance, though it currently mostly applies to specific models and detailed the benefits.
- Dynamic Quantization is a work in progress to reduce VRAM and run the 1.58-bit Dynamic GGUF version by Unsloth.
- GRPO Training Plateaus Prompt Regex Tweaks: Concerns were raised about obtaining expected rewards during GRPO training, with users observing a plateau in performance indicators and unexpected changes in completion lengths, with further details in Unsloth's GRPO blog post.
- One user reported modifying regex for better training outcomes, but inconsistencies in metrics remain a problem, and the impact on Llama3.1 (8B) performance metrics is unclear.
- Rombo-LLM-V3.0-Qwen-32b Impresses: A new model, Rombo-LLM-V3.0-Qwen-32b, has been released, showcasing impressive performance across various tasks, with more details in a redditor's post.
- Details on how to support the model developer's work on Patreon to vote for future models and access private repositories for just $5 a month.
- Lavender Method Supercharges VLMs: The Lavender method was introduced as a supervised fine-tuning technique that improves the performance of vision-language models (VLMs) using Stable Diffusion, with code and examples available at AstraZeneca's GitHub page.
- This method achieved performance boosts, including a +30% increase on 20 tasks and a +68% improvement on OOD WorldMedQA, showcasing the potential of text-vision attention alignment.
HuggingFace Discord
- DOOM Game Squeezed into a QR Code: A member successfully crammed a playable DOOM-inspired game, dubbed The Backdooms, into a single QR code, taking up less than 2.4kb, and released the project as open source under the MIT license here.
- The creator documented the approach in this blog post providing insights on the technical challenges and solutions involved.
- Steev AI Assistant Simplifies Model Training: A team unveiled Steev, an AI assistant created to automate AI model training, reducing the need for constant supervision, further information available at Steev.io.
- The goal is to simplify the AI training process, eliminating tedious and repetitive tasks, and allowing researchers to concentrate on core aspects of model development and innovation.
- Rombo-LLM V3.0 Excels in Coding: A fresh model, Rombo-LLM-V3.0-Qwen-32b, has been launched, excelling in coding and math tasks, as shown in this Reddit post.
- The model's use of Q8_0 quantization significantly boosts its efficiency, allowing it to perform complex tasks without heavy computational requirements.
- Agents Course Verification Proves Problematic: Numerous participants in the Hugging Face AI Agents Course have reported ongoing problems verifying their accounts via Discord, resulting in recurring connection failures.
- Recommended solutions included logging out, clearing cache, and trying different browsers, and a lucky few eventually managed to complete the verification process.
- New Endpoints Suggested for Agent Connection: With users experiencing connection issues during the agents course, a member suggested changing the endpoint to a new link (https://jc26mwg228mkj8dw.us-east-1.aws.endpoints.huggingface.cloud) and also indicated a model name update to deepseek-ai/DeepSeek-R1-Distill-Qwen-32B was required.
- This fix could solve the recent string of issues faced by course participants trying to use LLMs in their agent workflows.
OpenAI Discord
- Pro users Get Deep Research Access: Deep research access is now available for all Pro users on multiple platforms including mobile and desktop apps (iOS, Android, macOS, and Windows).
- This enhances research capabilities on various devices.
- OpenAI o1 & o3 support File & Image Uploads: OpenAI o1 and o3-mini now support both file and image uploads in ChatGPT.
- Additionally, o3-mini-high limits have been increased by 7x for Plus users, allowing up to 50 uploads per day.
- OpenAI Unveils Model Spec Update: OpenAI shared a major update to the Model Spec, detailing expectations for model behavior.
- The update emphasizes commitments to customizability, transparency, and fostering an atmosphere of intellectual freedom.
- OpenAI's Ownership Faces Scrutiny: Discussions revolve around the possibility of OpenAI being bought by Elon Musk, with many expressing skepticism about this happening and hopes for open-sourcing the technology if it occurs.
- Users speculate that major tech companies may prioritize profit over public benefit, leading to fears of excessive control over AI.
- GPT-4o has free limits: Custom GPTs operate on the GPT-4o model, with limits that are changing daily based on various factors, with only some fixed values like AVM 15min/month.
- Users must observe the limits based on their region and usage timezone.
Cursor IDE Discord
- o3-mini Falls Behind Claude: Users have observed that OpenAI's o3-mini model underperforms in tool calling compared to Claude, often requiring multiple prompts to achieve desired outcomes, which led to frustration.
- Many expressed that Claude's reasoning models excel at tool use, suggesting the integration of a Plan/Act mode similar to Cline to improve user experience.
- Hybrid AI Model Excites Coders: The community shows excitement for Anthropic's upcoming hybrid AI model, which reportedly surpasses OpenAI's o3-mini in coding tasks when leveraging maximum reasoning capabilities.
- The anticipation stems from the new model's high performance on programming benchmarks, indicating it could significantly boost coding workflows relative to current alternatives.
- Tool Calling Draws Concern: Users voiced dissatisfaction with o3-mini's limited flexibility and efficiency in tool calling, questioning its practical utility in real-world coding scenarios.
- Discussions emphasized a demand for AI models to simplify complex coding tasks, prompting suggestions to establish best practices in prompting to elicit higher quality code.
- MCP Usage Becomes Topic of Discussion: The concept of MCP (Multi-Channel Processor) surfaced as a tool for improving coding tasks by integrating multiple AI models for enhanced efficiency and output.
- Users have been sharing experiences and strategies for utilizing MCP servers to optimize coding workflows and overcome the limitations of individual models.
- Windsurf Pricing Dissatisfies: Discussions touched on the inflexible pricing of Windsurf, specifically its restriction against users employing their own keys, which has led to user dissatisfaction.
- Many users expressed a preference for Cursor's features and utility over competitors, highlighting its advantages in cost effectiveness and overall user experience.
Nous Research AI Discord
- DeepHermes-3 Unites Reasoning: Nous Research launched the DeepHermes-3 Preview, an LLM integrating reasoning with traditional language models, available on Hugging Face.
- The model requires a specific system prompt with
- The model requires a specific system prompt with
- Nvidia's LLM Kernels Accelerate: Nvidia's blog post features LLM-generated GPU kernels speeding up FlexAttention while achieving 100% numerical correctness on 🌽KernelBench Level 1.
- This signals notable progress in GPU performance optimization, and members suggested r1 kimik and synthlab papers for up-to-date information on LLM advancements.
- Mobile Device RAMs Hamper: Members noted that 12GB phones are only allowing 2GB of accessible memory, which hindered their ability to run models.
- A user suggested acquiring a 16GB ARM SBC for portable computing, which would allow for running small LLMs while traveling for ~100, providing an affordable option for those interested.
- US Rejects AI Safety Pact: The US and UK declined to sign a joint AI safety declaration, with US leaders emphasizing their commitment to maintaining AI leadership, according to ArsTechnica report.
- Officials cautioned that engaging with authoritarian countries in AI could compromise national infrastructure security, citing examples like CCTV and 5G as subsidized exports for undue influence.
OpenRouter (Alex Atallah) Discord
- Groq DeepSeek R1 70B Sprints at 1000 TPS: OpenRouter users are celebrating the addition of Groq DeepSeek R1 70B, which hits a throughput of 1000 tokens per second, offering parameter customization and rate limit adjustments. The announcement was made on OpenRouter AI's X account.
- This is part of a broader integration designed to enhance user interaction with the platform.
- New Sorting Tweaks Boost UX: Users can now customize default sorting for model providers, focusing on throughput or balancing speed and cost in account settings. To access the fastest provider available, append
:nitroto any model name, as highlighted in OpenRouter's tweet.- This feature allows users to tailor their experience based on their priorities.
- API Embraces Native Token Counting: OpenRouter plans to switch the
usagefield in the API from GPT token normalization to the native token count of models and they are asking for user feedback.- There are speculations about how this change might affect models like Vertex and other models with different token ratios.
- Deepseek R1 Trounces OpenAI in Reasoning: A user reported Deepseek R1 displayed impressive reasoning when handling complex SIMD functions, outperforming o3-mini, saying it was 'stubborn'.
- The team is exploring this option and acknowledged user concerns about moderation issues.
- Users Cry Foul on Google Rate Limits: Users are encountering frequent 429 errors from Google due to resource exhaustion, especially affecting the Sonnet model.
- The OpenRouter team is actively addressing growing rate limit issues caused by Anthropic capacity limitations.
Perplexity AI Discord
- Perplexity Releases Finance Dashboard: Perplexity released a new Finance Dashboard providing market summaries, daily highlights, and earnings snapshots.
- Users are requesting a dedicated button for dashboards on web and mobile apps.
- Doubts Arise Over AI Model Performance: Debates emerged regarding AI models, specifically the efficiency and accuracy of R1 compared to alternatives like DeepSeek and Gemini, as well as preferred usage and performance metrics.
- Members shared experiences, citing features and functionalities that could improve user experience.
- Perplexity Support Service Criticized: A user reported issues with the slow response and lack of support from Perplexity’s customer service related to being charged for a Pro account without access.
- This spurred discussion on the need for clear communication and effective support teams.
- API Suffers Widespread 500 Errors: Multiple members reported experiencing a 500 error across all API calls, with failures in production.
- The errors persisted for some time before the API was reported to be back up.
- Enthusiasm for Sonar on Cerebras: A member expressed strong interest in becoming a beta tester for the API version of Sonar on Cerebras.
- The member stated they have been dreaming of this for months, indicating potential interest in this integration.
Codeium (Windsurf) Discord
- Windsurf Wave 3 Goes Live!: Windsurf Wave 3 introduces features like the Model Context Protocol (MCP), customizable app icons, enhanced Tab to Jump navigation, and Turbo Mode, detailed in the Wave 3 blog post.
- The update also includes major upgrades such as auto-executing commands and improved credit visibility, further detailed in the complete changelog.
- MCP Server Options Elusive Post-Update?: After updating Windsurf, some users reported difficulty locating the MCP server options, which were resolved by reloading the window.
- The issue highlighted the importance of refreshing the interface to ensure that the MCP settings appear as expected, enabling configuration of tool calls to user-defined MCP servers.
- Cascade Plagued by Performance Woes: Users have been reporting that the Cascade model experiences sluggish performance and frequent crashing, often requiring restarts to restore functionality.
- Reported frustrations include slow response times and increased CPU usage during operation, underscoring stability problems.
- Codeium 1.36.1 Seeks to Fix Bugs: The release of Codeium 1.36.1 aims to address existing problems, with users recommended to switch to the pre-release version in the meantime.
- Past attempts at fixing issues with 2025 writing had been unsuccessful, highlighting the need for the update.
- Windsurf Chat Plagued by Instability: Windsurf chat users are experiencing frequent freezing, loss of conversation history, and workflow disruptions.
- Suggested solutions included reloading the application and reporting bugs to address these critical stability problems.
LM Studio Discord
- Qwen-2.5 VL Faces Performance Hiccups: Users report slow response times and memory issues with the Qwen-2.5 VL model, particularly after follow-up prompts, leading to significant delays.
- The model's memory usage spikes, possibly relying on SSD instead of VRAM, which is particularly noticeable on high-spec machines.
- Decoding Speculation Requires Settings Tweaks: Difficulties uploading models related to Speculative Decoding led to troubleshooting, revealing users needed to adjust settings and ensure compatible models are selected.
- The issue highlights the importance of matching model configurations with the selected speculative decoding functionality.
- Tesla K80 PCIe sparks debate: The potential of using a $60 Tesla K80 PCIe with 24GB VRAM for LLM tasks was discussed, raising concerns about power and compatibility.
- Users suggested that while affordable, the K80's older architecture and potential setup problems might make a GTX 1080 Ti a better alternative.
- SanDisk Supercharges VRAM with HBF Memory: SanDisk introduced new high-bandwidth flash memory capable of enabling 4TB of VRAM on GPUs, aimed at AI inference applications requiring high bandwidth and low power.
- This HBF memory positions itself as a potential alternative to traditional HBM in future AI hardware, according to Tom's Hardware.
GPU MODE Discord
- Blackwell's Tensor Memory Gets Scrutinized: Discussions clarify that Blackwell GPUs' tensor memory is fully programmer managed, featuring dedicated allocation functions as detailed here, and it's also a replacement for registers in matrix multiplications.
- Debates emerge regarding the efficiency of tensor memory in handling sparsity and microtensor scaling, which can lead to capacity wastage, complicating the fitting of accumulators on streaming multiprocessors if not fully utilized.
- D-Matrix plugs innovative kernel engineering: D-Matrix is hiring for kernel efforts, inviting those with CUDA experience to connect and explore opportunities in their unique stack, recommending outreach to Gaurav Jain on LinkedIn for insights into their innovative hardware and architecture.
- D-Matrix's Corsair stack aims for speed and energy efficiency, potentially transforming large-scale inference economics, and claims a competitive edge against H100 GPUs, emphasizing sustainable solutions in AI.
- SymPy Simplifies Backward Pass Derivation: Members show curiosity about using SymPy for deriving backward passes of algorithms, to manage complexity.
- Discussion occurred around issues encountered with
gradgradcheck(), relating to unexpected output behavior, with intent to clarify points and follow-up on GitHub if issues persist, hinting at the complexity in maintaining accurate intermediate outputs.
- Discussion occurred around issues encountered with
- Reasoning-Gym Revamps Evaluation Metrics: The Reasoning-Gym community discusses performance drops on MATH-P-Hard, and releases a new pull request for Graph Coloring Problems, with standardization of the datasets with unified prompts to streamline evaluation processes, improving machine compatibility of outputs, detailed in the PR here.
- Updates such as the Futoshiki puzzle dataset aim for cleaner solvers and improved logical frameworks, as seen in this PR, coupled with establishing a standard method for averaging scores across datasets for consistent reporting.
- DeepSeek Automates Kernel Generation: NVIDIA presents the use of the DeepSeek-R1 model to automatically generate numerically correct kernels for GPU applications, optimizing them during inference.
- The generated kernels achieved 100% accuracy on Level-1 problems and 96% on Level-2 issues of the KernelBench benchmark, but concerns were voiced about the saturation of the benchmark.
Interconnects (Nathan Lambert) Discord
- GRPO Turbocharges Tulu Pipelines: Switching from PPO to GRPO in the Tulu pipeline resulted in a 4x performance gain, with the new Llama-3.1-Tulu-3.1-8B model showcasing advancements in both MATH and GSM8K benchmarks, as Costa Huang announced.
- This transition signifies a notable evolution from earlier models introduced last fall.
- Anthropic's Claude Gets Reasoning Slider: Anthropic's upcoming Claude model will fuse a traditional LLM with reasoning AI, enabling developers to fine-tune reasoning levels via a sliding scale, potentially surpassing OpenAI’s o3-mini-high in several benchmarks, per Stephanie Palazzolo's tweet.
- This represents a shift in model training and operational capabilities designed for coding tasks.
- DeepHermes-3 Thinks Deeply, Costs More: Nous Research introduced DeepHermes-3, an LLM integrating reasoning with language processing, which can toggle long chains of thought to boost accuracy at the cost of greater computational demand, as noted in Nous Research's announcement.
- The evaluation metrics and comparison with Tulu models sparked debate due to benchmark score discrepancies, specifically with the omission of comparisons to the official 8b distill release, which boasts higher scores (~36-37% GPQA versus r1-distill's ~49%).
- EnigmaEval's Puzzles Stump AI: Dan Hendrycks unveiled EnigmaEval, a suite of intricate reasoning challenges where AI systems struggle, scoring below 10% on normal puzzles and 0% on MIT-level challenges, per Hendrycks' tweet.
- This evaluation aims to push the boundaries of AI reasoning capabilities.
- OpenAI Signals AGI Strategy Shift: Sam Altman hinted that OpenAI's current strategy of scaling up will no longer suffice for AGI, suggesting a transition as they plan to release GPT-4.5 and GPT-5; OpenAI will integrate its systems to provide a more seamless experience.
- They will also address community frustrations with the model selection step.
Eleuther Discord
- Debate Emerges on PPO-Clip's Utility: Members rehashed applying PPO-Clip with different models to generate rollouts, echoing similar ideas from past conversations.
- A member voiced skepticism regarding this approach's effectiveness based on previous attempts.
- Forgetting Transformer Performance Tuned: A conversation arose around the Forgetting Transformer, particularly if changing from sigmoid to tanh activation could positively impact performance.
- The conversation also entertained introducing negative attention weights, underscoring potential sophistication in attention mechanisms.
- Citations of Delphi Made Easier: Members suggested it's beneficial to combine citations for Delphi from both the paper and the GitHub page for comprehensive attribution.
- It was also suggested that one use arXiv's autogenerated BibTeX entries for common papers for standardization purposes.
- Hashing Out Long Context Model Challenges: Members highlighted concerns about the challenges associated with current benchmarks for long context models like HashHop and the iterative nature of solving 1-NN.
- Questions arose around the theoretical feasibility of claims made by these long context models.
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion users fail to save progress: A user reported losing generated images due to not having auto-save enabled in Stable Diffusion, then inquired about image recovery options.
- The resolution to this problem involved debugging which web UI version they had in order to determine the appropriate save settings.
- Linux throws ComfyUI users OOM Errors: A user switching from Windows to Pop Linux experienced Out Of Memory (OOM) errors in ComfyUI despite previous success.
- The community discussed confirming system updates and recommended drivers, highlighting the differences in dependencies between operating systems.
- Character Consistency Challenges Plague AI Models: A user struggled with maintaining consistent character designs across models, sparking suggestions to use Loras and tools like FaceTools and Reactor.
- Recommendations emphasized selecting models designed for specific tasks.
- Stability's Creative Upscaler Still MIA: Users questioned the release status of Stability's creative upscaler, with assertions it hadn’t been released yet.
- Discussions included the impact of model capabilities on requirements like memory and performance.
- Account Sharing Questioned: A user's request to borrow a US Upwork account for upcoming projects triggered skepticism.
- Members raised concerns about the feasibility and implications of 'borrowing' an account.
Latent Space Discord
- OpenAI Unifies Models with GPT-4.5/5: OpenAI is streamlining its product offerings by unifying O-series models and tools in upcoming releases of GPT-4.5 and GPT-5, per their roadmap update.
- This aims to simplify the AI experience for developers and users by integrating all tools and features more cohesively.
- Anthropic Follows Suit with Reasoning AI: Anthropic plans to soon launch a new Claude model that combines traditional LLM capabilities with reasoning AI, controllable via a token-based sliding scale, according to Stephanie Palazzolo's tweet.
- This echoes OpenAI's approach, signaling an industry trend towards integrating advanced reasoning directly into AI models.
- DeepHermes 3 Reasoning LLM Preview Released: Nous Research has unveiled a preview of DeepHermes 3, an LLM integrating reasoning capabilities with traditional response functionalities to boost performance, detailed on HuggingFace.
- The new model seeks to deliver enhanced accuracy and functionality as a step forward in LLM development.
- Meta Hardens Compliance with LLM-Powered Tool: Meta has introduced its Automated Compliance Hardening (ACH) tool, which utilizes LLM-based test generation to bolster software security by creating undetected faults for testing, explained in Meta's engineering blog.
- This tool aims to enhance privacy compliance by automatically generating unit tests targeting specific fault conditions in code.
Yannick Kilcher Discord
- Hugging Face Launches Smolagents: Hugging Face has launched smolagents, an agent framework alternative to
deep research, with a processing time of approximately 13 seconds for 6 steps.- Users can modify the original code to extend execution when run on a local server, providing adaptability.
- Musk Claims Grok 3 Outperforms Rivals: Elon Musk announced his new AI chatbot, Grok 3, is nearing release and outperforms existing models in reasoning capabilities, with a launch expected in about two weeks.
- This follows Musk's investor group's $97.4 billion bid to acquire OpenAI's nonprofit assets amid ongoing legal disputes with the company.
- Thomson Reuters Wins Landmark AI Copyright Case: Thomson Reuters has won a significant AI copyright case against Ross Intelligence, determining that the firm infringed its copyright by reproducing materials from Westlaw.
- US Circuit Court Judge Stephanos Bibas dismissed all of Ross's defenses, stating that none of them hold water.
- Innovative Approaches to Reinforcement Learning: Discussion emerged about using logits as intermediate representations in a new reinforcement learning model, stressing delays in normalization for effective sampling.
- The proposal includes replacing softmax with energy-based methods and integrating multi-objective training paradigms for more effective model performance.
- New Tool Fast Tracks Literature Reviews: A member introduced a new tool for fast literature reviews available at Deep-Research-Arxiv, emphasizing its simplicity and reliability.
- Additionally, a Hugging Face app was mentioned that facilitates literature reviews with the same goals of being fast and efficient.
LlamaIndex Discord
- LlamaIndex Seeks Open Source Engineer: LlamaIndex is hiring a full-time open source engineer to enhance its framework, appealing to those passionate about open source, Python, and AI, as announced in their job post.
- The position offers a chance to develop cutting-edge features for the LlamaIndex framework.
- Nomic AI Embedding Model Bolsters Agentic Workflows: LlamaIndex highlighted new research from Nomic AI emphasizing the role of embedding models in improving Agentic Document Workflows, which they shared in a tweet.
- The community anticipates improved AI workflow integration from this embedding model.
- LlamaIndex & Google Cloud: LlamaIndex has introduced integrations with Google Cloud databases that facilitate data storage, vector management, document handling, and chat functionalities, detailed in this post.
- These enhancements aim to simplify and secure data access while using cloud capabilities.
- Fine Tuning LLMs Discussion: A member asked about good reasons to finetune a model in the #ai-discussion channel.
- No additional information was provided in the channel to address this question.
Notebook LM Discord
- NotebookLM Creates Binge-Worthy AI Podcasts: Users are praising NotebookLM for transforming written content into podcasts quickly, emphasizing its potential for content marketing on platforms like Spotify and Substack.
- Enthusiasts believe podcasting is a content marketing tool, highlighting a significant potential audience reach and ease of creation.
- Unlock New Revenue Streams Through AI-Podcasts: Users are exploring creating podcasts with AI to generate income of about $7,850/mo by running a two-person AI-podcast, while focusing on creating content quickly.
- They claim that AI-driven podcast creation could result in a 300% increase in organic reach and content consumption, using tools such as Substack.
- Library of AI-Generated Podcast Hosts Sparks Excitement: Community members discussed the potential for creating a library of AI-generated podcast hosts, showcasing diverse subjects and content styles.
- Enthusiasts are excited about collaborating and sharing unique AI-generated audio experiences to enhance community engagement.
- Community Awaits Multi-Language Support in NotebookLM: Users are eager for NotebookLM to expand its capabilities to support other languages beyond English, which highlights a growing interest in accessible AI tools globally.
- Although language settings can be adjusted, audio capabilities remain limited to English-only outputs for now, causing frustration amongst the community.
- Navigating NotebookLM Plus Features and Benefits: NotebookLM Plus provides features like interactive podcasts, which are beneficial for students, and may not be available in the free version, according to a member.
- Another user suggested transitioning to Google AI Premium to access bundled features, which led to a discussion of how 'Google NotebookLM is really good...'.
Modular (Mojo 🔥) Discord
- Modular Posts New Job Openings: A member shared that new job postings have been posted by Modular.
- The news prompted excitement among members seeking opportunities within the Mojo ecosystem.
- Mojo Sum Types Spark Debate: Members contrasted Mojo sum types with Rust-like sum types and C-style enums, noting that
Variantaddresses many needs, but that parameterized traits take higher priority.- A user's implementation of a hacky union type using the variant module highlighted the limitations of current Mojo implementations.
- ECS Definition Clarified in Mojo Context: A member clarified the definition of ECS in the context of Mojo, stating that state should be separated from behavior, similar to the MonoBehavior pattern in Unity3D.
- Community members agreed that an example followed ECS principles, with state residing in components and behavior in systems.
- Unsafe Pointers Employed for Function Wrapping: A discussion on storing and managing functions within structs in Mojo led to an example using
OpaquePointerto handle function references safely.- The exchange included complete examples and acknowledged the complexities of managing lifetimes and memory when using
UnsafePointer.
- The exchange included complete examples and acknowledged the complexities of managing lifetimes and memory when using
- MAX Minimizes CUDA Dependency: MAX only relies on the CUDA driver for essential functions like memory allocation, which minimizes CUDA dependency.
- A member noted that MAX takes a lean approach to GPU use, especially with NVIDIA hardware, to achieve optimal performance.
MCP (Glama) Discord
- MCP Client Bugs Plague Users: Members shared experiences with MCP clients, highlighting wong2/mcp-cli for its out-of-the-box functionality, while noting that buggy clients are a common theme.
- Developers discussed attempts to work around the limitations of existing tools.
- OpenAI Models Enter the MCP Arena: New users expressed excitement about MCP's capabilities, questioning whether models beyond Claude could adopt MCP support.
- It was noted that while MCP is compatible with OpenAI models, projects like Open WebUI may not prioritize it.
- Claude Desktop Users Hit Usage Limits: Users reported that usage limits on Claude Desktop are problematic, suggesting that Glama's services could provide a workaround.
- A member emphasized how these limitations affect their use case, noting that Glama offers cheaper and faster alternatives.
- Glama Gateway Challenging OpenRouter: Members compared Glama's gateway with OpenRouter, noting Glama's lower costs and privacy guarantees.
- While Glama supports fewer models, it is praised for being fast and reliable, making it a solid choice for certain applications.
- Open WebUI Attracts Attention: Several users expressed curiosity about Open WebUI, citing its extensive feature set and recent roadmap updates for MCP support.
- Members shared positive remarks about its usability and their hope to transition fully away from Claude Desktop.
tinygrad (George Hotz) Discord
- DeepSeek-R1 Automates GPU Kernel Generation: A blog post highlighted the DeepSeek-R1 model's use in improving GPU kernel generation by using test-time scaling allocating more computational resources during inference, improving model performance, linked in the NVIDIA Technical Blog.
- The article suggests that AI can strategize effectively by evaluating multiple outcomes before selecting the best, mirroring human problem-solving.
- Tinygrad Graph Rewrite Bug Frustrates Members: Members investigated CI failures due to a potential bug where incorrect indentation removed
bottom_up_rewritefromRewriteContext.- Potential deeper issues with graph handling, such as incorrect rewrite rules or ordering, were also considered.
- Windows CI Backend Variable Propagation Fixed: A member noted that Windows CI failed to propagate the backend environment variable between steps and submitted a GitHub pull request to address this.
- The PR ensures that the backend variable persists by utilizing
$GITHUB_ENVduring CI execution.
- The PR ensures that the backend variable persists by utilizing
- Tinygrad Promises Performance Gains Over PyTorch: Users debated the merits of switching from PyTorch to tinygrad, considering whether the learning curve is worth the effort, especially for cost efficiency or grasping how things work 'under the hood'.
- Using tinygrad could eventually lead to cheaper hardware or a faster model compared to PyTorch, offering optimization and resource management advantages.
- Community Warns Against AI-Generated Code: Members emphasized reviewing code diffs before submission, noting that minor whitespace changes could cause PR closures, also urging against submitting code directly generated by AI.
- The community suggested using AI for brainstorming and feedback, respecting members' time, and encouraging original contributions.
LLM Agents (Berkeley MOOC) Discord
- LLM Agents Hackathon Winners Announced: The LLM Agents MOOC Hackathon announced its winning teams from 3,000 participants across 127 countries, highlighting amazing participation from the global AI community, according to Dawn Song's tweet.
- Top representation included UC Berkeley, UIUC, Stanford, Amazon, Microsoft, and Samsung, with full submissions available on the hackathon website.
- Spring 2025 MOOC Kicks Off: The Spring 2025 MOOC officially launched, targeting the broader AI community with an invitation to retweet Prof Dawn Song's announcement, and building on the success of Fall 2024, which had 15K+ registered learners.
- The updated curriculum covers advanced topics such as Reasoning & Planning, Multimodal Agents, and AI for Mathematics and Theorem Proving and invites everyone to join the live classes streamed every Monday at 4:10 PM PT.
- Certificate Chaos in MOOC Questions: Multiple users reported not receiving their certificates for previous courses, with one student requesting it be resent and another needing help locating it, but it might take until the weekend to fulfill.
- Tara indicated that there were no formal grades for Ninja Certification and suggested testing prompts against another student's submissions in an assigned channel. Additionally, submission of the declaration form is necessary for certificate processing.
- Guidance Sought for New AI/ML Entrants: A new member expressed their interest in getting guidance on starting in the AI/ML domain and understanding model training techniques.
- No guidance was provided in the channel.
Torchtune Discord
- Torchtune Enables Distributed Inference: Users can now run distributed inference on multiple GPUs with Torchtune, check out the GitHub recipe for implementation details.
- Using a saved model with vLLM offers additional speed benefits.
- Torchtune Still Missing Docker Image: There is currently no Docker image available for Torchtune, which makes it difficult for some users to install it.
- The only available way to install it is by following the installation instructions on GitHub.
- Checkpointing Branch Passes Test: The new checkpointing branch has been successfully cloned and is performing well after initial testing.
- Further testing of the recipe_state.pt functionality is planned, with potential documentation updates on resuming training.
- Team Eagerly Collaborates on Checkpointing PR: Team members express enthusiasm and a proactive approach to teamwork regarding the checkpointing PR.
- This highlights a shared commitment to improving the checkpointing process.
DSPy Discord
- NVIDIA Scales Inference with DeepSeek-R1: NVIDIA's experiment showcases inference-time scaling using the DeepSeek-R1 model to optimize GPU attention kernels, enabling better problem-solving by evaluating multiple outcomes, as described in their blog post.
- This technique allocates additional computational resources during inference, mirroring human problem-solving strategies.
- Navigating LangChain vs DSPy Decisions: Discussion around when to opt for LangChain over DSPy emphasized that both serve distinct purposes, with one member suggesting prioritizing established LangChain approaches if the DSPy learning curve appears too steep.
- The conversation underscored the importance of evaluating project needs against the complexity of adopting new frameworks.
- DSPy 2.6 Changelog Unveiled: A user inquired about the changelog for DSPy 2.6, particularly regarding the effectiveness of instructions for Signatures compared to previous versions.
- Clarification revealed that these instructions have been present since 2022, with a detailed changelog available on GitHub for further inspection, though no link was given.
Nomic.ai (GPT4All) Discord
- GPT4All Taps into Deepseek R1: GPT4All v3.9.0 allows users to download and run Deepseek R1 locally, focusing on offline functionality.
- However, running the full model locally is difficult, as it appears limited to smaller variants like a 13B parameter model that underperforms the full version.
- LocalDocs troubles Users: A user reported that the LocalDocs feature is basic, providing accurate results only about 50% of the time with TXT documents.
- The user wondered whether the limitations arise from using the Meta-Llama-3-8b instruct model or incorrect settings.
- NOIMC v2 waits for Implementation: Members wondered why the NOIMC v2 model has not been properly implemented, despite acknowledgement of its release.
- A link to the nomic-embed-text-v2-moe model was shared, highlighting its multilingual performance and capabilities.
- Multilingual Embeddings Boast 100 Languages: The nomic-embed-text-v2-moe model supports about 100 languages with high performance relative to models of comparable size, as well as flexible embedding dimensions and is fully open-source.
- Its code was shared.
- Community Seeks Tool to convert Prompts to Code: A user is seeking advice on tools to convert English prompts into workable code.
- Concrete suggestions are needed.
Cohere Discord
- Cohere's Chaotic Scoring: A user found that Rerank 3.5 gives documents different scores when processed in different batches, which they did not expect since it is a cross-encoder.
- The variability in scoring was described as counterintuitive.
- Cohere Struggles with Salesforce's BYOLLM: A member inquired about using Cohere as an LLM with Salesforce's BYOLLM open connector, citing issues with the chat endpoint at api.cohere.ai.
- They are attempting to create an https REST service to call Cohere's chat API, as suggested by Salesforce support.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (956 messages🔥🔥🔥):
GRPO updates in Unsloth, VRAM requirements for models, Dynamic quantization with DeepSeek, Merging models and its implications, Fine-tuning strategies for LLMs
- GRPO Updates in Unsloth: Users shared their findings on the new GRPO update for Unsloth, noting its effectiveness in various experiments with reinforcement learning.
- One user highlighted the need for better vram management, as they experienced mismatched memory usage and OOM errors when using different training setups.
- VRAM Requirements for Models: Discussion about the VRAM requirements for various models led to references about needing approximately 1.5 times the model weight in VRAM for running with some context.
- This estimation aims to help users gauge their hardware capabilities in relation to context lengths and model sizes.
- Dynamic Quantization with DeepSeek: Dynamic quantization techniques were explained, particularly focusing on how it is implemented in DeepSeek models and its benefits.
- Users shared insights on how dynamic quantization can help reduce memory usage while maintaining performance, though it currently mostly applies to specific models.
- Merging Models and Its Implications: A conversation about the ethics and viability of merging models highlighted concerns around the contribution and attribution of original creators.
- While merging can enhance capabilities, there are discussions around the need for compensating original model creators in the open-source community.
- Fine-Tuning Strategies for LLMs: Several users discussed different fine-tuning strategies, including using synthetic data and the R1 distillation process to enhance model performance.
- The conversation pointed out that practical experiences and shared findings from fine-tuning can significantly contribute to better training methodologies.
- DeepSeek R1 (All Versions) - a unsloth Collection: no description found
- agentica-org/DeepScaleR-Preview-Dataset · Datasets at Hugging Face: no description found
- Transformer-Squared: Self-adaptive LLMs: Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse...
- deepscaler/scripts/train at main · agentica-project/deepscaler: Democratizing Reinforcement Learning for LLMs. Contribute to agentica-project/deepscaler development by creating an account on GitHub.
- Quickstart — JAX documentation: no description found
- Tweet from Unsloth AI (@UnslothAI): Train your own reasoning LLM using DeepSeek's GRPO algorithm with our free notebook!You'll transform Llama 3.1 (8B) to have chain-of-thought. Unsloth makes GRPO use 80% less VRAM.Guide: https:...
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- bartowski/DeepSeek-R1-Distill-Qwen-7B-GGUF at main: no description found
- open-r1/OpenR1-Math-Raw · Datasets at Hugging Face: no description found
- Unsloth Benchmarks | Unsloth Documentation: Want to know how fast Unsloth is?
- Continued Pretraining | Unsloth Documentation: AKA as Continued Finetuning. Unsloth allows you to continually pretrain so a model can learn a new language.
- unsloth/DeepSeek-R1-GGUF · Hugging Face: no description found
- Create Training Data for Finetuning LLMs: 🚀 Mastering LLM Fine-Tuning: From PDFs to JSONL Files🚀Welcome to APC Mastery Path! In this comprehensive tutorial, we dive deep into the process of creatin...
- Quantization: no description found
- agentica-org/DeepScaleR-1.5B-Preview · Hugging Face: no description found
- CUDA semantics — PyTorch 2.6 documentation: no description found
- unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF · Hugging Face: no description found
- GitHub - allenai/s2orc: S2ORC: The Semantic Scholar Open Research Corpus: https://www.aclweb.org/anthology/2020.acl-main.447/: S2ORC: The Semantic Scholar Open Research Corpus: https://www.aclweb.org/anthology/2020.acl-main.447/ - allenai/s2orc
- Unsloth Documentation: no description found
- GitHub - SakanaAI/self-adaptive-llms: A Self-adaptation Framework🐙 that adapts LLMs for unseen tasks in real-time!: A Self-adaptation Framework🐙 that adapts LLMs for unseen tasks in real-time! - SakanaAI/self-adaptive-llms
- Liger-Kernel/src/liger_kernel/ops/fused_linear_cross_entropy.py at main · linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
- ml-cross-entropy/cut_cross_entropy/cce_lse_forward.py at main · apple/ml-cross-entropy: Contribute to apple/ml-cross-entropy development by creating an account on GitHub.
- flash-attention/flash_attn/ops/triton/cross_entropy.py at main · Dao-AILab/flash-attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- Liger-Kernel/src/liger_kernel/ops/cross_entropy.py at main · linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
- Liger-Kernel/src/liger_kernel/ops/cross_entropy.py at main · linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
Unsloth reintroduction, Wendel's AI shoutouts, Deepseek's release
- Unsloth Reintroduced with New Features: The YouTube video titled "Re-introducing Unsloth" details enhancements allowing users to finetune and train their own LLMs faster with Unsloth.
- The description emphasizes making the process of LLM training easier with Unsloth's new capabilities, encouraging adoption.
- Wendel Shouts Out Unsloth: In the video "Embrace the Coming AI Revolution with Safe Local AI!", Wendel highlights several innovations featuring Unsloth.
- Quoted directly from Wendel, he discusses the significant impact Unsloth has in the current AI landscape and its potential for future advancements.
- AI Industrial Revolution Begins with Deepseek: Wendel discusses how Deepseek's release is shaking up the AI world and signals the onset of an Industrial Revolution in AI.
- He urges viewers to embrace these changes by leveraging cutting-edge AI tools, such as Unsloth, that are leading the charge.
- Embrace the Coming AI Revolution with Safe Local AI!: Deepseek's release has shaken up the AI world, and we're on the precipice of the AI Industrial Revolution! Wendell gives you the low down on how to take that...
- Re-introducing Unsloth #ai #llm: Re-introducing UnslothEasily finetune & train LLMsGet faster with unslothhttps://unsloth.ai/
Unsloth AI (Daniel Han) ▷ #help (108 messages🔥🔥):
Llama 3.2 Issues, GRPO Training Challenges, Structured Data Models, Using Unsloth with Local Models, Model Configuration and Installation
- Troubleshooting Llama 3.2 and BitsandBytes Errors: Users are facing issues with BitsandBytes while trying to run Llama 3.2 11B on WSL, with suggestions to create new conda environments if problems persist.
- Some are experiencing long load times when offline, which users suggest may stem from connection errors with Hugging Face.
- GRPO Training with Llama Models: Concerns were raised about obtaining expected rewards during GRPO training, with users observing a plateau in performance indicators and unexpected changes in completion lengths.
- One user reported modifying regex for better training outcomes, but inconsistencies in metrics remain a problem.
- Challenges with Structured Data Extraction: Discussions around fine-tuning Llama models for structured data indicate difficulties in achieving the desired output format, with one person noting low accuracy in values extracted for XML schemas.
- Users recommend scoring outputs rather than relying solely on the model's reasoning capabilities to improve results.
- Loading FastLanguageModel with Local Caches: Users share methods for loading FastLanguageModel from local cache, emphasizing environment configuration before imports to ensure smooth execution.
- One user's attention_mask error during output generation draws attention to the need to ensure that all tensor components are properly defined beforehand.
- Issues with Model Installation and Connectivity: Multiple users encounter trouble downloading large model files from Hugging Face, indicating connection errors and suggesting manual downloads as an alternative.
- There is a curiosity about differences between HF published models and unsloth versions, especially regarding repository configurations impacting training.
- Google Colab: no description found
- Google Colab: no description found
- Errors | Unsloth Documentation: To fix any errors with your setup, see below:
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Train your own R1 reasoning model locally (GRPO): You can now reproduce your own DeepSeek-R1 reasoning model with Unsloth 100% locally. Using GRPO.Open-source, free and beginner friendly.
- Open Deep Research - Open Source AI Research Assistant: Discover an open-source alternative to OpenAI's Deep Research, Google's Gemini, and Anthropic's Claude. Powered by GPT-4o-mini, this tool delivers comprehensive market analysis and acti...
- Beginner? Start here! | Unsloth Documentation: no description found
- Unsloth update: Mistral support + more: We’re excited to release QLoRA support for Mistral 7B, CodeLlama 34B, and all other models based on the Llama architecture! We added sliding window attention, preliminary Windows and DPO support, and ...
- GitHub - instructor-ai/instructor: structured outputs for llms: structured outputs for llms . Contribute to instructor-ai/instructor development by creating an account on GitHub.
- Datasets 101 | Unsloth Documentation: Learn all the essentials of creating a dataset for fine-tuning!
- Chat Templates: no description found
- Llama 3.1 | Model Cards and Prompt formats: Llama 3.1 - the most capable open model.
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Rombo-LLM-V3.0-Qwen-32b, DeepSeek-R1 Performance, Llama 3.1B Fine-tuning, Resources for Training Reasoning Models
- Rombo-LLM-V3.0-Qwen-32b is out!: A new model, Rombo-LLM-V3.0-Qwen-32b, has been released, showcasing impressive performance across various tasks. Details can be found in the redditor's post.
- Support the developer's work on Patreon to vote for future models and access private repositories for just $5 a month.
- DeepSeek-R1 excels at complex tasks: DeepSeek-R1 has extended its capabilities to handle math and coding tasks effectively, demonstrating significant versatility. Emphasis was placed on how it operates differently from standard models, including its use of real RL methods.
- Boosting Llama 3.1B with GRPO + LoRA: The community explored how to enhance Llama 3.1B using the GRPO combined with LoRA/QLoRA techniques, placing it on par with higher-performing models. This performance comparison spanned several configurations, from base models to fine-tuned reasoning.
- Participants showcased the difference in approaches, highlighting the advantages of combining CoT prompting with advanced fine-tuning for improved reasoning skills.
- Accessing Resources for Training: Valuable resources were shared, including a Google Colab Notebook for hands-on training and exploration of reasoning models. The DeepSeekMath contributions were emphasized for their relevance in understanding the unified paradigm.
- Check out the illustrated guide here for further insights into DeepSeek-R1's architecture and capabilities.
- Reddit - Dive into anything: no description found
- Deepseek-R1 & Training Your Own Reasoning Model: DeepSeek is dominating global app stores, but what’s behind its latest breakthrough? Join us as we dive into DeepSeek-R1, the first Large Reasoning Model (LR...
- Amazingly Simple Graphic Design Software – Canva: Amazingly Simple Graphic Design Software – Canva
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #research (6 messages):
Transformer performance on tabular data, Fine-tuning Mistral model, Inference instructions for LoRA checkpoint, Reasoning agents development, Lavender method for VLMs
- Transformers struggle with tabular data: Concerns were raised about the poor performance of Transformers on tabular numeric data, irrespective of the format used, stating that each LLM calculates sums and averages differently.
- Every living LLM appears to approach tabular data in a varied manner, indicating a fundamental issue with this architecture in processing such information.
- Tips on fine-tuning Mistral Small: A query was made about the recommended number of examples to fine-tune a Mistral small model for a text humanizer project, indicating they are new to the process.
- Fine-tuning strategies were discussed, focusing on the quantity of training examples needed for effective performance.
- LoRA checkpoint and usage instructions: A member provided a link to a LoRA checkpoint and included steps for using the model via an inference guide.
- The model is currently unavailable via supported Inference Providers, and the training experienced a halt at 418 steps, prompting a need for further analysis on its performance.
- Interest in reasoning agents: A question was posed about whether anyone is working on reasoning agents, highlighting the community's focus on advanced AI applications.
- This reflects a growing interest in developing models that can perform logical reasoning tasks effectively.
- Lavender method enhances vision-language models: The Lavender method was introduced as a simple supervised fine-tuning technique that improves the performance of vision-language models (VLMs) using Stable Diffusion.
- This method achieved significant performance boosts, including a +30% increase on 20 tasks and a +68% improvement on OOD WorldMedQA through better alignment of text-vision attention.
- Lavender: Diffusion Instruction Tuning: no description found
- sathvikask/r1-1.5b-RL-gsm8k · Hugging Face: no description found
- GitHub - sathvikask0/r1-distilled-RL: Contribute to sathvikask0/r1-distilled-RL development by creating an account on GitHub.
HuggingFace ▷ #general (51 messages🔥):
Agent Templates Issues, Embedding Models and Performance, Deep Reinforcement Learning Course, LLama Spam Behavior, ViT Projection Dimension
- Troubles with First Agent Template Execution: A user expressed difficulty running the 'First Agent template' after creating a new copy, asking for guidance on execution steps.
- Other members directed them to specific Discord channels for assistance.
- Discussion on Embedding Model Sizes: Users questioned the limited availability of embedding models over 7B, with comments noting that embedding models are often designed to be cheap and fast.
- One member pointed out that larger models may not perform better than smaller ones, as they tend to overfit to benchmarks.
- Deep Reinforcement Learning Course Engagement: A user inquired about a chat or channel related to the Deep Reinforcement Learning course and was directed to relevant Discord threads.
- Further information highlighted course content and paths available for participants, including a Discord server for discussions.
- LLama Model Spamming Issues: Concerns were raised about the LLama model spamming '!', with users suggesting that this could stem from incorrect configuration in the code.
- One member provided a linked Discord message that may contain additional insights on handling this issue.
- ViT Projection Dimension Queries: A user sought advice on the appropriate projection dimension for ViTs, questioning whether it should be larger or smaller than the patch dimension.
- They referenced the original paper's choice of dimension and shared their mixed results with smaller values, looking for accepted approaches.
- Welcome to the 🤗 AI Agents Course - Hugging Face Agents Course: no description found
- Welcome to the 🤗 Deep Reinforcement Learning Course - Hugging Face Deep RL Course: no description found
- Download files from the Hub: no description found
- Welcome to the 🤗 Deep Reinforcement Learning Course - Hugging Face Deep RL Course: no description found
- Download files from the Hub: no description found
- Introduction - Hugging Face NLP Course: no description found
- AutoTrain – Hugging Face: no description found
- Python/VAM_AI/Course_HF/New_PROMPT_AI.ipynb at main · murilofarias10/Python: My projects in Python. Contribute to murilofarias10/Python development by creating an account on GitHub.
- LM Studio Docs | LM Studio Docs: Learn how to run Llama, DeepSeek, Phi, and other LLMs locally with LM Studio.
- LM Studio - Beta Releases: Beta and Release Candidate versions of LM Studio
HuggingFace ▷ #today-im-learning (10 messages🔥):
Overlapping Communication in Tensor Parallelism, Agents Course, Fuzzy Clustering, Use of Special Tokens, Importance of Repetition
- Understanding Overlapping Communication in Tensor Parallelism: A member shared insights on overlapping communication in tensor parallelism, highlighting its significance in processing efficiency.
- Questions arose about the applications of tensor parallelism, leading to further inquiry and discussion.
- Questions in Agents Course: Another member is progressing through Unit 1 of the Agents' course, expressing confusion over the terms reasoning and reflection in agent terminology.
- They seek clarity on whether these terms are interchangeable, which seems to resonate with others experiencing similar confusion.
- Fuzzy Clustering on Stream Data: A member is diving into fuzzy clustering techniques specific to stream data, aiming to explore their effectiveness and applications.
- This topic highlights an interest in data-driven methods relevant in various streams of data processing.
- The Role of Repetition: In a light-hearted exchange, a member noted that repetition is key, referencing a discussion about the use of the ♻️ emoji to signify recurring actions.
- Repetition is crucial was echoed by members, underscoring its importance in learning.
HuggingFace ▷ #i-made-this (14 messages🔥):
QR Code DOOM, AI Model Training Assistant, New LLM Releases, Joker Joke Generator, Deep Researcher System
- DOOM runs inside a QR code!: A member successfully created a playable DOOM-inspired game called The Backdooms, fitting entirely inside a single QR code, staying under 2.4kb in size.
- This project is documented as open source under the MIT license, allowing others to experiment with it here.
- Introducing Steev, your AI training assistant: A team launched Steev, aimed at streamlining AI model training to eliminate constant supervision during the process.
- They invite interested users to explore the application at Steev.io.
- Rombo-LLM V3.0 released for coding tasks: A new model named Rombo-LLM-V3.0-Qwen-32b has been released, showcased in a Reddit post detailing its features.
- The model is noted for its effectiveness in coding and math, with Q8_0 quantization enhancing its capabilities.
- Jokes Generator launched on Hugging Face: A member introduced a Jokes Generator that fetches jokes from a Joker Rest API with a user-friendly Gradio chat interface.
- The application can be enjoyed via their Hugging Face Space at this link.
- Deep Researchers concept discussion: A user shared their approach of using two different LLMs to engage in back-and-forth discussions to extract deeper insights on topics.
- This method leverages a larger model to compile findings into a cohesive research report, with more details available on their GitHub.
- Xo JokeGen NoAI - a Hugging Face Space by xyizko: no description found
- Kyro-n1 - a open-neo Collection: no description found
- Client Challenge: no description found
- .kkrieger - Wikipedia: no description found
- steev: Experiment AI Agent for ML research.
- GitHub - solarkyle/Adversarial-Researchers: Contribute to solarkyle/Adversarial-Researchers development by creating an account on GitHub.
- GitHub - karam-koujan/mini-pytorch: Contribute to karam-koujan/mini-pytorch development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - Kuberwastaken/backdooms: A self-contained game that fits inside a QR code inspired by DOOM 1993 and The Backrooms: A self-contained game that fits inside a QR code inspired by DOOM 1993 and The Backrooms - Kuberwastaken/backdooms
- How I Managed To Get Doom In A QR Code: Yes, this is literally the entire game. Scan it and play if you want to. DOOM is a game known for running everywhere because of the ports it has had since 1993, there have been memes on "It Runs ...
- reddit: no description found
HuggingFace ▷ #reading-group (10 messages🔥):
Bingbin Liu Presentation, Technical Difficulties, Session Recording
- Bingbin Liu shares insights on attention glitches: The reading group session featuring Bingbin Liu on the paper Exposing Attention Glitches with Flip-Flop Language Modeling is set to start soon with a link to the paper here.
- Participants were encouraged to join the discussion and ask questions during the session held on Zoom.
- Technical difficulties arise during the session: Members expressed apologies for the technical difficulties encountered today, prompting a shift to a Zoom session.
- The provided Zoom link was shared multiple times to ensure everyone could join.
- Session will be recorded for absent members: Attendees were reassured that the session will be recorded for those uncomfortable with Zoom or unable to attend live.
- This ensures everyone has access to the insights shared, despite technical issues.
- Gratitude for the presentation: Attendees expressed appreciation for the presentation, noting how the context added depth to the understanding of the paper.
- One member specifically thanked Bingbin Liu and another presenter for their engaging delivery.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
HuggingFace ▷ #computer-vision (1 messages):
Canny edge filters, Sobel filters, ControlNet with diffusion model
- Canny and Sobel Filters as Preprocessing Tools: Starting with Canny edge or Sobel filters is a key approach before integrating machine learning (ML) models, as not every process requires an ML component.
- These filters can serve as an essential pre-processing stage that aids ML in learning different downstream tasks.
- ControlNet Utilizes Edge Filtering: The ControlNet with diffusion model adopts Canny edge filtered images to generate outputs that maintain structural consistency with the original images.
- This method illustrates how traditional image processing techniques enhance the capabilities of modern ML models.
HuggingFace ▷ #NLP (8 messages🔥):
Pretrained Model Behavior, Tokenization of Tool Messages, Fine-tuning with LoRA, End Token Generation Issues, Training Techniques
- Pretrained Models Guess the Next Token: Pretrained models effectively guess the next token based on their training corpus. Fine-tuning on instruction datasets allows models to refine their responses and reduce hallucinations.
- One member noted that this training helps models understand roles like 'user' and 'assistant'.
- Curiosity on Tool Message Tokenization: A member inquired if tool messages are tokenized and sent to a transformer just like system and human/assistant messages. Another member surmised that models reason based on responses from tool messages.
- This suggests that understanding how tool messages are processed is crucial for model functionality.
- Fine-tuning Qwen Model with LoRA: After fine-tuning the Qwen model with LoRA, a member found the pre-merged model performed better with instructions but struggled to produce end tokens. The merged model produced gibberish responses, raising questions about the weight merging process.
- Concerns were expressed that poor quality data during training could lead to these issues, impacting the model's ability to conclude answers correctly.
- End Token Generation Explained: A member noted that end tokens are only produced when they are the likely next token, indicating challenges in preventing infinite loops. They sought clarity on how to effectively teach the model to recognize end tokens.
- Another member suggested using supervised fine-tuning (SFT) on instruction/answer pairs, which can help models learn where answers should conclude.
- Understanding Training Techniques: Fast training occurs when a learning rate is too high, leading to disruptive changes in model weights. Length refers to the number of epochs or steps in training, indicating how long the training phase lasts.
- Members emphasized the importance of fine-tuning to avoid drastic changes while preserving the model's understanding of language.
HuggingFace ▷ #smol-course (18 messages🔥):
Agent Course Support, Endpoint Changes, Model Name Updates, Study Group Inquiries, Testing New Tools
- Agent Course Channel Confusion: A member highlighted the need to switch channels for better support regarding the agent course, suggesting the dedicated 'agent course' section.
- Support access points remain crucial for troubleshooting common issues faced by users.
- Changing to Overloaded Endpoints: A user suggested changing the endpoint to a new link to overcome connection issues due to overload: new endpoint.
- They also indicated a model name update to 'deepseek-ai/DeepSeek-R1-Distill-Qwen-32B' was required for proper functionality.
- Joining Study Groups Remains a Challenge: A user inquired about joining a study group for the agent course, expressing uncertainty about the process.
- Another member joined in with the same question, highlighting a community feel for shared resources.
- Testing Tools Confusion: A member who created a tool in the course asked if crafting a prompt is necessary for testing it.
- A parallel inquiry about activation issues led to suggestions regarding potential overload of the LLM.
- Common Troubleshooting Tips: Users were advised to check logs for possible issues, hinting at missing definitions like
HF_TOKENas a frequent problem.- This highlights the importance of proper configurations in the user setup for successful interactions.
HuggingFace ▷ #agents-course (717 messages🔥🔥🔥):
Hugging Face Agents Course, Discord verification issues, Learning groups and collaboration, Model access and deployment, Course completion and certificates
- Hugging Face Agents Course Overview: Participants are excited to join the Hugging Face AI Agents Course, sharing their backgrounds and locations, from countries like India, Canada, and Brazil.
- Many users expressed eagerness to learn about agents and collaborate with peers throughout the course.
- Discord Verification Troubles: Several users experienced issues verifying their Hugging Face accounts through Discord, leading to repeated connection errors and confusion about the process.
- Users suggested logging out and using different browsers to solve these issues, with some eventually succeeding in the verification process.
- Collaboration and Study Groups: Many participants are seeking to connect with others for collaborative learning, especially interested in forming study groups for the course.
- Users shared their LinkedIn profiles and expressed their intentions to support one another throughout the learning journey.
- Model Access and Debugging: Participants discussed the technical challenges they faced while using the agents, specifically issues with models being overloaded and error messages.
- There were inquiries about how agents handle tool errors and whether they can debug issues autonomously, highlighting the importance of thorough testing.
- Course Completion and Certificates: Users confirmed completing the first unit and receiving their certificates, with some curious about how to review their quiz answers for further learning.
- Questions about the course's certification process and the time it takes to generate certificates were also raised, emphasizing engagement with the course material.
- no title found: no description found
- no title found: no description found
- no title found: no description found
- Introduction to Agents - Hugging Face Agents Course: no description found
- Welcome to the 🤗 Machine Learning for 3D Course - Hugging Face ML for 3D Course: no description found
- Beam Search Visualizer - a Hugging Face Space by m-ric: no description found
- Welcome to the 🤗 AI Agents Course - Hugging Face Agents Course: no description found
- Welcome to the 🤗 AI Agents Course - Hugging Face Agents Course: no description found
- AgentS (Sean M. Murphy): no description found
- Unit 1 Quiz - Hugging Face Agents Course: no description found
- Welcome to the 🤗 AI Agents Course - Hugging Face Agents Course: no description found
- Welcome To The Agents Course! Introduction to the Course and Q&A: In this first live stream of the Agents Course, we will explain how the course will work (scope, units, challenges and more) and answer your questions.Don't ...
- Introducing smolagents: simple agents that write actions in code.: no description found
- meta-llama/Llama-3.2-1B · Hugging Face: no description found
- What A Sunny Day GIF - What A Sunny Day - Discover & Share GIFs: Click to view the GIF
- agents-course (Hugging Face Agents Course): no description found
- aperrot 🍹 home - aperrot 🍹 home: no description found
- agents-course/certificates at main: no description found
HuggingFace ▷ #open-r1 (5 messages):
DeepSeek AI-HPC, Granite 3.2 MoE, GPT-3.5 Data Distillation
- DeepSeek AI-HPC's Cost-Effective Co-Design: The YouTube video titled "DeepSeek 🐋 | Fire-flyer AI-HPC" discusses cost-effective software and hardware co-designs for deep learning amid the increasing demands for computational power.
- DeepSeek incorporates innovative solutions to address the challenges presented by rapidly evolving deep learning technologies.
- New Research on Large Language Models: A paper authored by a group including Wei An and others is outlined in arXiv, exploring advancements in large language models with implications for AI development.
- Details on the specific methodologies employed in this research provide insights into state-of-the-art developments in the field.
- Granite 3.2 MoE Preview Insights: A user shared their impression of the Granite 3.2 MoE, suggesting that it might have distilled data solely from GPT-3.5, hinting at limitations in its learning scope.
- It was noted that the training data for this model only extends up to the year 2021, raising questions about its relevance for recent developments.
- Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning: The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computi...
- DeepSeek 🐋 | Fire-flyer AI-HPC: A Cost-Effective Software Hardware Co-design for Deep Learning: The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, com...
- deepseek-ai/DeepSeek-V3-Base · Hugging Face: no description found
OpenAI ▷ #annnouncements (3 messages):
Deep Research Access, File & Image Uploads in ChatGPT, Model Spec Update
- Deep Research Accessible for Pro Users: OpenAI announced that deep research is now available for all Pro users on multiple platforms including mobile and desktop apps (iOS, Android, macOS, and Windows).
- This feature enhances research capabilities on various devices, tapping into a wider audience.
- ChatGPT Enhancements with File & Image Support: Updates have been made where OpenAI o1 and o3-mini now support both file and image uploads in ChatGPT.
- Additionally, o3-mini-high limits have been increased by 7x for Plus users, allowing up to 50 uploads per day.
- Major Update to Model Spec: OpenAI shared a major update to the Model Spec, detailing expectations for model behavior.
- The update emphasizes commitments to customizability, transparency, and fostering an atmosphere of intellectual freedom for users to explore and create with AI.
OpenAI ▷ #ai-discussions (347 messages🔥🔥):
OpenAI future ownership, AI model capabilities, Fictional violence in AI, Current AI tools and platforms, Comparison of AI models
- Concerns Over OpenAI's Ownership: Discussions revolve around the possibility of OpenAI being bought by Elon Musk, with many expressing skepticism about this happening and hopes for open-sourcing the technology if it occurs.
- Users speculate that major tech companies may prioritize profit over public benefit, leading to fears of excessive control over AI.
- AI Model Functionality and Filtering: Participants discuss the differences in handling fictional violence across various AI models, highlighting tools like Sudowrite for unfiltered creative writing.
- Some users note the importance of maintaining privacy and safety settings when using AI services to prevent misuse.
- Emerging AI Tools and Models: The community shares insights about different AI tools, including DeepSeek and its advantages over larger companies' models, along with features of AI writing assistants.
- Users emphasize the need for robust hardware to effectively run larger open-source models and are excited about the potential future of AI capabilities.
- Comparative Discussion of AI Models: Debate arises over the effectiveness of various AI models like GPT-4, O3, and emerging technologies like GPT-5, with humor about a hypothetical 'GPT Megazord'.
- Members express concerns that continuing to combine models into one may lead to unexpected outcomes in AI reasoning.
- Cautions about Data Privacy: Users highlight the issues surrounding data collection by AI companies, specifically regarding the use of AI by malicious actors and the potential consequences of such actions.
- The conversation raises questions about the adequacy of security measures and the ethical implications of AI technologies.
- Gemini - chat to supercharge your ideas: Bard is now Gemini. Get help with writing, planning, learning, and more from Google AI.
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- Meme GIF - Meme - Discover & Share GIFs: Click to view the GIF
- Rethinking social development with Moxie, a robot companion for kids: With its blue body and big anime eyes, Moxie wants to be friends with your child. Named one of Time’s top inventions of 2020, the AI-powered robot is designe...
- Webrtc Real Time API with microcontroller: Hi! In the Day 9 demo, we saw a stuffed animal with a microcontroller consuming the WebRTC Real-Time API (link: YouTube Live). Could you provide more details about the overall architecture? For examp...
OpenAI ▷ #gpt-4-discussions (12 messages🔥):
Custom GPT Models, Hiring Experts, Limits of Free Plan
- Custom GPTs run on GPT-4o: A member confirmed that the custom GPTs operate on the GPT-4o model, addressing a query regarding the underlying model.
- Request for Specific Expertise: A member looking to hire expressed the need for an expert for their startup, asking for those with great experience to reach out.
- Another member humorously questioned if eating pizza like a pro qualifies as relevant experience, suggesting more specificity in the request.
- Understanding Free Plan Limits: A user inquired about verifying the limits of the free plan for various models, questioning if it involved messaging and file attachments.
- A member responded that limits are changing daily based on various factors, with only some fixed values like AVM 15min/month.
- Guidelines for Free Plan Usage: Despite the query for guidelines on free plan limits, it was stated that there isn’t really a rough guideline to follow.
- Users must observe the limits based on their region and usage timezone.
OpenAI ▷ #prompt-engineering (16 messages🔥):
Function Calling Issues, Prompt Sharing, Using CoT and ToT, Error Interpretation, Prompt Engineering Discussions
- Function Calling Challenges in System Prompt: A member shared ongoing issues with function calling related to client status in their prompt, indicating discrepancies in AI responses and function triggers.
- They highlighted the importance of calling the
determine_statusfunction correctly after client interactions to avoid losing leads.
- They highlighted the importance of calling the
- Encouragement for Prompt Sharing: Members discussed the appropriateness of sharing prompts in the channel, encouraging questions and discussions rather than just information dumps.
- One member expressed hesitation to share a lengthy prompt but was informed that discourse about unusual prompts is welcomed.
- Using CoT and ToT for Functions: Another member mentioned utilizing Chain of Thought (CoT) and Tree of Thought (ToT) strategies to handle ambiguous client responses effectively.
- They emphasized that accurately structured prompts should facilitate the correct sequencing of function calls.
- Value of Error Identification in Prompts: A suggestion was made to identify errors by asking the model to interpret the prompt, focusing on potential conflicts or ambiguities.
- This strategy is recommended for enhancing prompt clarity and addressing misinterpretations by the model.
- Discussion about 'Boomer Prompts': A member humorously posed the question about the meaning of a 'boomer prompt,' suggesting a cultural or generational context for prompts.
- This sparked interest in how language and prompting conventions might vary across different audiences.
OpenAI ▷ #api-discussions (16 messages🔥):
Function calling issues, Prompt sharing practices, Using CoT and ToT, ChatGPT versus playground, Interpreting prompts
- Function calling chaos in prompts: A user discussed challenges with function calling in their system prompt, highlighting issues where the AI sometimes fails to indicate statuses, leading to potential lost leads in Pipedrive.
- They shared their structured approach of using functions to categorize client responses, but still faced inconsistencies in the AI's behavior.
- Prompt sharing etiquette in discussions: Another user inquired about posting prompts, prompting discussion on the best practices for sharing within the Discord channel.
- Members suggested that questions or observations generate better discussions than simple 'info dumps'.
- Utilizing CoT and ToT in prompts: A user explained that they incorporated
Chain of Thought (CoT)andTree of Thought (ToT)strategies to determine when to call functions in ambiguous client interactions.- They expressed a desire for feedback on their prompt's structure to improve functionality.
- Differences between ChatGPT and playground: Users noted that working with ChatGPT differs from using the playground, with distinct ways models handle prompts and errors.
- Suggestions were made to identify patterns in errors to refine prompt instructions for better outcomes.
- Interpreting prompt conflicts for clarity: A member recommended the technique of asking the model to interpret prompts without following them to uncover potential ambiguities.
- This strategy can help reveal unexpected conflicts and improve overall prompt design.
Cursor IDE ▷ #general (392 messages🔥🔥):
Cursor IDE Features, OpenAI o3-mini vs. Claude, Anthropic's Hybrid AI Model, Tool Calling and Coding, MCP Server Utilization
- Cursor's User Experience with o3-mini: Users found that the o3-mini model underperformed in tool calling capabilities, often requiring multiple prompts to achieve desired outcomes, leading to increased frustration and questioning its value for coding tasks.
- Many mentioned that Claude's reasoning models excelled at tool use compared to o3-mini, prompting discussions around integrating a Plan/Act mode similar to Cline to improve user experience.
- Anticipation for Anthropic's Hybrid Model: Excitement builds around Anthropic's upcoming hybrid AI model, which reportedly outperforms OpenAI's o3-mini in coding tasks when utilizing maximum reasoning capabilities.
- The new model's high performance on programming benchmarks suggests it could significantly enhance coding workflows compared to the current offerings.
- Concerns Over Tool Calling Effectiveness: Users expressed dissatisfaction with o3-mini's lack of flexibility and efficiency in tool calling, raising concerns about its practical utility in real-world coding environments.
- Ongoing discussions revealed a desire for AI models to simplify complex coding tasks, with suggestions to establish best practices in prompting to elicit better code quality from the AI.
- Perspectives on MCP Usage: The concept of a MCP (Multi-Channel Processor) emerged in discussions as a tool for enhancing coding tasks by integrating multiple AI models for improved efficiency and output.
- Users shared various experiences and strategies for leveraging MCP servers to optimize coding workflows and address the limitations of individual models.
- Marketplace Competition and Pricing: The conversation touched on the pricing strategies of AI models, with users noting that Windsurf lacks flexibility by not allowing users to employ their own keys, leading to dissatisfaction with its value.
- Many users expressed a preference for Cursor's features and utility over competitors, pointing out advantages related to cost effectiveness and user experience.
- Darth Vader Alter The Deal GIF - Darth Vader Alter The Deal Empire Strikes Back - Discover & Share GIFs: Click to view the GIF
- Funny GIF - Funny - Discover & Share GIFs: Click to view the GIF
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Claude not detecting lint errors half the time after writing code: Half the time Claude doesn’t detect and fix the linting errors after writing code. The linter error is immediately present in the code editor, and only doing a follow-up prompt makes the AI fix the is...
- "Supervisory" agent to guide "worker" agent: Aider showed that this is how you achieve the best AI coder agent. Also, an agent that implements this flow would be absolutely game changer for Cursor I think. So yeah, great suggestion!
- Windsurf Wave 3: Introducing Wave 3, our third batch of updates to the Windsurf Editor.
- Tweet from Pontus Abrahamsson — oss/acc (@pontusab): Generate your own optimized cursor rule directly from your package.json, now live on Cursor Directory!Built using:◇ @nextjs - Framework◇ @vercel - Hosting◇ @aisdk - AI Toolkit◇ @xai - LLM◇ @shadcn - U...
- Anthropic Status: no description found
- Cursor Status: no description found
- Augment Code – Developer AI for real work: Experience the AI platform that truly understands your codebase. Our developer AI helps teams code faster, make smarter decisions, and unlock collective knowledge. Try free today.
Nous Research AI ▷ #announcements (2 messages):
DeepHermes-3 Preview, Long chain of thought reasoning, LLM advancements, Hugging Face Model Links
- Introducing DeepHermes-3 Preview: Nous Research unveiled the DeepHermes-3 Preview, a pioneering LLM that unifies reasoning and traditional language model capabilities, now available on Hugging Face.
- This model showcases enhancements in LLM annotation and function calling, and is one of the first to handle long chains of thought in a single framework.
- Expertise Required for LongCoT Usage: To enable the long chain of thought reasoning, users must employ a specific system prompt, including instructions to enclose internal deliberations in
- This direct approach encourages deeper systematic reasoning before arriving at a solution, enhancing model performance.
- Benchmarks Report Improvement: Early benchmarks with DeepHermes-3 indicate significant enhancements in mathematical reasoning and a modest boost in Google Proof Question Answering (GPQA).
- The model is aimed at refining its reasoning capabilities through community feedback and further exploration of its functionalities.
- Open-source Collaboration Acknowledged: The development of DeepHermes-3 acknowledges the contributions of key community members who supported data collection, evaluation, and training efforts.
- This collaborative spirit is essential for continuing advancements in deep reasoning models and enhancing user steerability.
- NousResearch/DeepHermes-3-Llama-3-8B-Preview · Hugging Face: no description found
- NousResearch/DeepHermes-3-Llama-3-8B-Preview-GGUF · Hugging Face: no description found
Nous Research AI ▷ #general (268 messages🔥🔥):
DeepHermes-3 model preview, Reasoning capabilities, Mobile performance limitations, Comparisons with other models, Accessibility of hardware for running models
- DeepHermes-3 Model Preview Released: Nous Research introduced the DeepHermes-3 Preview, a new LLM that unifies reasoning and intuitive capabilities while allowing toggling of long chains of thought for improved accuracy.
- The model has been made available on Hugging Face for users to test its capabilities, like its handling of multi-turn conversations.
- Discussion on Mobile Device Limitations: Members discussed the limitations of using AI models on mobile devices, specifically with regards to RAM usage and background app management.
- One user expressed frustration over their 12GB phone only allowing 2GB of accessible memory, which hindered their ability to run models.
- Comparative Performance of Models: The comparison between DeepHermes-3 and DeepSeek's models highlighted the latter's strong performance in math problems but noted their lesser conversational abilities.
- Users noted that while DeepSeek models excel at specific tasks, DeepHermes-3 is aimed at general conversational and reasoning capabilities.
- Potential Hardware Solutions for Testing Models: A user suggested acquiring a 16GB ARM SBC for portable computing, which would allow for running small LLMs while traveling.
- Prices for these devices range from around $80 for 8GB to $100-$140 for 16GB, providing an affordable option for those interested.
- Utility of X Forwarding in Remote Access: X forwarding was discussed as a method to run graphical applications on a remote Linux server, effectively allowing remote desktop capabilities.
- However, users expressed that now is not the time for purchasing new devices, especially with current financial considerations.
- Zed now predicts your next edit with Zeta, our new open model - Zed Blog: From the Zed Blog: A tool that anticipates your next move.
- Update tokenizer_config.json · deepseek-ai/DeepSeek-R1 at 8a58a13: no description found
- Tweet from M4rc0𝕏 (@dreamworks2050): DEEPHERMES-LLAMA-3-8B thinking mode: ON - FIRST RUNGGUF - F16 by @NousResearch 🔥MacBook Pro M4 Max : 28.98t/s
- Tweet from Nous Research (@NousResearch): Introducing DeepHermes-3 Preview, a new LLM that unifies reasoning and intuitive language model capabilities.https://huggingface.co/NousResearch/DeepHermes-3-Llama-3-8B-PreviewDeepHermes 3 is built fr...
- Joseph717171/Hermes-3-Llama-3.1-8B-OQ8_0-F32.EF32.IQ4_K-Q8_0-GGUF at main: no description found
- SuperFreezZ App stopper | F-Droid - Free and Open Source Android App Repository: Entirely freeze all background activities of apps.
- Apparently Its A Big Deal Big GIF - Apparently Its A Big Deal Big Deal - Discover & Share GIFs: Click to view the GIF
- NousResearch/DeepHermes-3-Llama-3-8B-Preview · Hugging Face: no description found
- BYD stock prices goes ballistic after they revealed this...: BYD stock prices goes ballistic after they revealed this...The best solar company in Australia just installed my new solar system. Check them out here: https...
- The Most Useful Thing AI Has Done: The biggest problems in the world might be solved by tiny molecules unlocked using AI. Take your big idea online today with https://ve42.co/hostinger - code ...
- Deepfake technology: A threat or a tool: This survey aims to assess public awareness of deepfake technology and gather data for research purposes. Your responses will help us understand how well people recognize deepfakes, their potential ri...
- Tweet from Sam Altman (@sama): OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.We want AI to “just work” for you; we re...
- LM Studio Docs | LM Studio Docs: Learn how to run Llama, DeepSeek, Phi, and other LLMs locally with LM Studio.
- LM Studio - Beta Releases: Beta and Release Candidate versions of LM Studio
- Ken Griffin says Trump's 'bombastic' trade rhetoric is a mistake that's eroding trust in the U.S.: The billionaire hedge fund founder's comments came after Trump on Monday evening signed an order that would impose 25% tariffs on steel and aluminum imports.
Nous Research AI ▷ #ask-about-llms (2 messages):
SFT on Llama-3B-Instruct, Loss of Base Model Performance, Domain-Specific Challenges
- SFT leading to performance issues on Llama-3B-Instruct: A member reported conducting SFT on Llama-3B-Instruct with a learning rate of 2e-4.
- They noted a significant loss in the base model's performance during the first epoch, measured using Winogrande.
- Performance drop linked to domain specificity: The performance issues seem to stem from the technology domain in Brazilian Portuguese.
- The member reached out for pointers to overcome the challenges faced in this specific domain.
Nous Research AI ▷ #research-papers (3 messages):
Nvidia blog post on GPU kernels, LLM report papers, State of the art methods in LLM
- Nvidia showcases LLM-generated GPU kernels: A new blog post from Nvidia highlights that LLM-generated GPU kernels are demonstrating speedups over FlexAttention while achieving 100% numerical correctness on 🌽KernelBench Level 1.
- This development indicates significant advancements in optimizing GPU performance in LLMs.
- Searching for updated LLM report papers: A member is actively seeking recent LLM report papers that cover state of the art methods such as reasoning models, noting the February 2024 survey paper is now outdated.
- This reflects a community desire for the latest research and developments in LLM methodologies.
- Relevant papers for LLM advancements: In response to the search for updated LLM papers, teknium highlighted r1 kimik and synthlab papers as the most relevant options.
- This suggests that members are sharing valuable resources to aid in research and development pursuits.
Link mentioned: Tweet from Anne Ouyang (@anneouyang): New blog post from Nvidia: LLM-generated GPU kernels showing speedups over FlexAttention and achieving 100% numerical correctness on 🌽KernelBench Level 1
Nous Research AI ▷ #interesting-links (1 messages):
US AI Safety Declaration, International AI Cooperation, Concerns about Authoritarian Regimes
- US and UK reject AI safety pact: At a recent summit, the US and UK declined to sign a joint AI safety declaration, with US leaders emphasizing their commitment to maintaining AI leadership.
- Vance warned against alliances with authoritarian regimes, indicating their past misuse of technology to infringe on national security.
- International governance discord: The declaration signed by several nations, including China, India, and Germany, focused on enhancing international cooperation for AI governance.
- However, a US official stated that the US was not on board with the language surrounding multilateralism and opposed terms interpreting collaborative frameworks.
- Concerns over infrastructure security: Vance cautioned that engaging with authoritarian countries in AI could lead to compromising national information infrastructure, citing examples like CCTV and 5G.
- He described these technologies as cheap but heavily subsidized exports that could bring countries under the influence of authoritarian powers.
Link mentioned: US and UK refuse to sign AI safety declaration at summit: US stance is “180-degree turnaround” from Biden administration.
Nous Research AI ▷ #research-papers (3 messages):
Nvidia LLM-generated GPU Kernels, Recent LLM Report Papers, r1 kimik and synthlab papers
- Nvidia achieved 100% correctness with LLM kernels: A new blog post from Nvidia highlights that LLM-generated GPU kernels are showing speedups over FlexAttention and achieving 100% numerical correctness on KernelBench Level 1.
- This could significantly enhance performance metrics for developers working with these models.
- Searching for Up-to-Date LLM Report Papers: @pier1337 expressed interest in LLM report papers that cover recent state-of-the-art methods including reasoning models, stating the previous papers were outdated.
- They had found the February 2024 LLM survey paper useful but are now looking for more current information.
- Relevant Papers Suggested by Teknium: In response, teknium recommended that the r1 kimik and synthlab papers are the most relevant sources for up-to-date information on LLM advancements.
- These papers may offer substantial insights for those investigating cutting-edge reasoning models.
Link mentioned: Tweet from Anne Ouyang (@anneouyang): New blog post from Nvidia: LLM-generated GPU kernels showing speedups over FlexAttention and achieving 100% numerical correctness on 🌽KernelBench Level 1
OpenRouter (Alex Atallah) ▷ #announcements (11 messages🔥):
Groq DeepSeek R1 70B launch, New sorting preferences in OpenRouter, Update to usage field in API, Token count comparisons, Discussion on model ranking consistency
- Groq DeepSeek R1 70B offers record speeds: OpenRouter announced the addition of Groq DeepSeek R1 70B, recording an impressive 1000 tokens per second throughput and supporting various parameters, with options to increase rate limits.
- This is part of a broader integration with OpenRouter AI that maximizes users’ interaction with the platform.
- New default sorting options enhance user experience: Now, users can easily adjust their default sorting preference for model providers by changing settings to focus on throughput or balance between speed and cost.
- Additionally, appending
:nitroto any model name ensures users access the fastest provider available, as stated in the announcement from OpenRouter.
- Additionally, appending
- API usage field might switch to native token counts: A proposed update suggests changing the
usagefield in the API from GPT token normalization to the native token count of models, with user feedback being solicited.- Concerns about model rankings and consistency have been raised, emphasizing the importance of maintaining fair comparisons across models.
- Token count differences spark discussion: There are speculations regarding how the switch from GPT's normalized counts to native token counts might affect models like Vertex, and concerns about varying token ratios persist.
- The reply confirmed that while there are slight differences, it won’t be as extreme as previous character-based models, thus not resulting in disruptive changes.
- Call for additional functionality in usage reporting: A suggestion was made to incorporate a field in the API that explicitly returns the GPT token count, reflecting a desire for more comprehensive usage metrics.
- This aligns with ongoing discussions about improving clarity and transparency in model comparisons and usage reporting.
- Tweet from OpenRouter (@OpenRouterAI): NEW: You can now change the default sort for providers for any model in your account settings.Sort by "Throughput" if you care about speed 🚀Sort by Default to balance uptime, price, and throu...
- Tweet from OpenRouter (@OpenRouterAI): Excited to announce @GroqInc officially on OpenRouter! ⚡️- incl. a record-fast 1000 TPS distilled DeepSeek R1 70B- tons of supported parameters- bring your own key if you want, get a rate limit boostP...
OpenRouter (Alex Atallah) ▷ #general (257 messages🔥🔥):
OpenAI's o3-mini functionality, Issues with Deepseek R1, Self-moderated OpenAI endpoints, Google's rate limit errors, Usage of AI models for YouTube content creation
- OpenAI's o3-mini functionality for Tier 3 users: After 8 days, a user reported that OpenAI enabled o3-mini for their Tier 3 key, which was previously Tier 2.
- They expressed frustration about the wait time but noted that they can now use OpenAI credits with BYOK.
- Deepseek R1 demonstrates superior reasoning: A user shared their experience of using Deepseek R1, which showed impressive reasoning capabilities while working on complex SIMD functions compared to o3-mini.
- They called o3-mini 'stubborn,' implying it was less effective in reasoning tasks.
- Discussing self-moderated OpenAI endpoints: A user expressed interest in whether self-moderated OpenAI endpoints would be available, expecting lower latency and consistent results.
- The team indicated they are exploring this option and acknowledged user concerns about moderation issues.
- Google's rate limit issues causing frustration: Users reported receiving 429 errors from Google due to resource exhaustion, affecting their use of the Sonnet model.
- The OpenRouter team mentioned they are addressing growing rate limit issues caused by Anthropic capacity limitations.
- Best AI for creating YouTube thumbnails and titles: A user inquired about the best AI model for generating YouTube content aimed at maximizing click-through rates.
- Another user suggested tracking performance to refine model outputs, despite expressing dissatisfaction with existing tools.
- no title found: no description found
- Tweet from Sam Altman (@sama): OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.We want AI to “just work” for you; we re...
- LLM Rankings: programming | OpenRouter: Language models ranked and analyzed by usage for programming prompts
- Provider Integration - Add Your Models to OpenRouter: Learn how to integrate your AI models with OpenRouter. Complete guide for providers to make their models available through OpenRouter's unified API.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- DeepSeek: R1 – Provider Status: See provider status and make a load-balanced request to DeepSeek: R1 - DeepSeek R1 is here: Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It&#...
- API Rate Limits - Manage Model Usage and Quotas: Learn about OpenRouter's API rate limits, credit-based quotas, and DDoS protection. Configure and monitor your model usage limits effectively.
- OpenRouter Quickstart Guide: Get started with OpenRouter's unified API for hundreds of AI models. Learn how to integrate using OpenAI SDK, direct API calls, or third-party frameworks.
- Web Search - Real-time Web Grounding for AI Models: Enable real-time web search capabilities in your AI model responses. Add factual, up-to-date information to any model's output with OpenRouter's web search feature.
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- Are OpenAI credits expiring?: Since dashboard change, I see no warning about credit expiration date. They forgot to put it, they placed it somewhere else or credits are not expiring any more?
- no title found: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (1 messages):
Feature feedback
- Request for Feedback on Features: A member expressed enthusiasm about the new features, stating, 'This looks awesome!' and encouraged others to share any missing functionalities.
- The message highlights the community's focus on improving the product through user feedback.
- Encouraging Community Engagement: The same member encouraged ongoing communication for feature discovery with the phrase, 'let us know if you find any features that are missing.'
- This suggests a proactive approach to gathering user input and enhancing the overall experience.
Perplexity AI ▷ #general (230 messages🔥🔥):
Perplexity Finance Dashboard, AI Model Performance, Customer Support Issues, Referring Links and Discounts, Usage of AI in Technology
- Exploring the Perplexity Finance Dashboard: Members discussed the newly released Perplexity Finance Dashboard, seeking confirmation on whether it is the first of its kind from Perplexity.
- There were hopes for a dedicated button for dashboards on web and mobile apps.
- Concerns Over AI Model Performance: There were debates regarding AI models, particularly about the efficiency and accuracy of R1 compared to alternatives like DeepSeek and Gemini, raising issues about preferred usage and performance metrics.
- Members shared their experiences, citing specific features and functionalities that could improve user experience.
- Customer Support Experience Lamented: A user expressed frustrations with the slow response and lack of support from Perplexity’s customer service regarding account issues, specifically relating to being charged for a Pro account without access.
- This prompted discussions on the necessity for clear communication and assistance from support teams.
- Referral Links & Discounts Discussed: Members discussed various offers and referral links, including the availability of codes for free Pro subscriptions, raising questions about how they can be obtained.
- Some members claimed to have received extended subscriptions through promotional offers from services like Revolut.
- AI Tools and Their Limitations: Discussions highlighted the paradox of AI’s capabilities in creating advanced technologies while struggling with basic task accuracy, specifically in coding scenarios.
- One user expressed a desire for more intelligent AI that adheres to documentation and suggested methods more accurately.
- no title found: no description found
- Hasbulla Hasbik GIF - Hasbulla Hasbik Cute - Discover & Share GIFs: Click to view the GIF
- Tweet from avdhesh.eth (@CuriousCharjan): Damn the response is crazy! Here’s the code.Add this at the checkout:FREEPPLXNTUOSSQuoting avdhesh.eth (@CuriousCharjan) Reply to this tweet to get free 6 months of Perplexity ProWill DM you the code!
- Tweet from Perplexity Finance (@PPLXfinance): Your daily source for the latest market insights—now live on Perplexity.Market summaries, daily highlights, earnings snapshots, and everything you need to understand the "why" behind it all.Fi...
- Perplexity - Status: Perplexity Status
- no title found: no description found
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): MUAHAHAHA 💉💦Quoting Djah 〰️ (@Djahlor) WHAT??? @elder_plinius did you do this??
- Tweet from Perplexity (@perplexity_ai): We are excited to announce that the winner of the Million Dollar Questions Sweepstakes is Kaylee Edmondson! Kaylee is a small business owner from Nashville, TN.Congratulations, Kaylee. And thank you t...
- Reddit - Dive into anything: no description found
- Sonar by Perplexity: Build with the best AI answer engine API, created by Perplexity. Power your products with the fastest, cheapest offering out there with search grounding. Delivering unparalleled real-time, web-wide re...
Perplexity AI ▷ #sharing (21 messages🔥):
EU AI Investment, Llama Model, DND Campaign Features, AI's Performance on Integer Queries, OpenAI Bid Situation
- EU AI Investment Insights: A link to a discussion on EU AI Investment highlights recent funding and policies boosting AI development in Europe.
- It emphasizes the need for robust strategies to keep pace with global AI advancements.
- Exploring Llama Model Capabilities: A user shared a link discussing the Llama model, detailing its architecture and use cases in AI applications.
- The conversation explored its potential benefits over similar models.
- DND Campaign Features Explored: A user reported on the DND Campaign capabilities of Perplexity AI, which supports both DM and player roles.
- They inquired about inviting friends and shared insights on gameplay dynamics.
- AI's Integer Query Performance Under Scrutiny: A discussion unveiled frustrations with AI's ability to handle integer queries correctly, as highlighted in this query.
- Members speculated on the AI's learning curve and improvement strategies.
- Musk's OpenAI Bid Contingency: A link to an article revealed that Musk might withdraw his bid for OpenAI if certain conditions are not met.
- The conversation revolved around the implications of this potential withdrawal on the AI landscape.
Perplexity AI ▷ #pplx-api (11 messages🔥):
API 500 Error, Beta Testing for Sonar API on Cerebras
- Widespread 500 Errors from API: Multiple members reported experiencing a 500 error across all API calls, with one member noting failures in production.
- It’s not good, said one user, as these errors persisted for some time before another member mentioned that the API seems to be back up now.
- Interest in Beta Testing Sonar on Cerebras: A member expressed enthusiasm for becoming a beta tester for the API version of Sonar on Cerebras, stating they have been dreaming of this for months.
- Their offer for testing indicates a potential interest in innovations related to the integration of these tools.
Codeium (Windsurf) ▷ #announcements (2 messages):
AI Engineering Summit Tickets, Windsurf Wave 3 Features, Model Context Protocol, Customizable App Icons, Turbo Mode
- Win Tickets to AI Engineering Summit!: We’re giving away 3 tickets to the AI Engineering Summit in New York City on February 20-21. Fill out the form to enter, but you must be in the NYC area to qualify for the tickets here.
- Travel expenses are not covered, but attendees will meet Windsurf’s Head of Product Engineering and receive exclusive event merchandise.
- Windsurf Wave 3 Launch Features: Windsurf Wave 3 introduces exciting new features, including the Model Context Protocol (MCP), customizable app icons, and enhanced Tab to Jump navigation. Major upgrades also include Turbo Mode for auto-executing commands and improved credit visibility.
- Read the full updates in the Wave 3 blog post and check out the complete changelog here.
- Model Context Protocol Enhancements: Cascade supports the Model Context Protocol (MCP), allowing users to configure tool calls to user-defined MCP servers. Every MCP tool call costs one flow action credit, regardless of execution result.
- This new feature is accessible to all individual plans and can be set up by clicking the hammer icon in the Cascade input tool bar.
- Custom Icons Now Available!: Windsurf now allows custom app icons on Mac (Beta) for paying users, with styles like Classic, Blueprint, Hand-drawn, and Valentine. These icons apply system-wide but require a restart for changes to take effect.
- All paid user plans can access this feature, further enhancing personalization for the app.
- Turbo Mode for Cascade Users: The newly introduced Turbo Mode in Cascade streamlines command execution by auto-executing commands and supporting drag-and-drop image uploads. These enhancements also come with a significant improvement to the completions and expanded @docs options.
- Users are encouraged to explore these features as part of Wave 3’s launch and join discussions in the dedicated channels.
- Tickets to AI Engineering Summit NYC from Windsurf : We want to say thank you to our community by giving away three free tickets to the AI Engineering Summit in New York! This two-day event on February 20-21 is a chance to hear from top AI experts, expl...
- Windsurf Wave 3: Introducing Wave 3, our third batch of updates to the Windsurf Editor.
- Tweet from Windsurf (@windsurf_ai): Wave 3 is here!Included in this update:⏩ Tab to Jump🔗 MCP Integration⚡ Turbo Mode🎨 Custom Icons… and more.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #discussion (13 messages🔥):
Codeium Release 1.36.1, Troubleshooting Issues, Internship Opportunities, Upcoming Announcements
- Codeium Release 1.36.1 fixes issues: The latest release, 1.36.1, is set to go live tomorrow and appears to resolve existing problems, with a recommendation to switch to the pre-release meanwhile.
- There was mention of past 2025 writing that failed to improve the situation.
- User needs troubleshooting advice: A user expressed frustration with an issue that works fine in cursor but is problematic otherwise, prompting a request for troubleshooting.
- Another user suggested contacting support through codeium.com/support for assistance.
- VPN resolves connectivity issues: A member noted that the application operates without issues when using a VPN, indicating a potential network-related problem.
- This suggests that some connectivity problems may be region-specific.
- Seeking full-stack dev interns: A member announced they are looking for full stack dev interns, opening opportunities within the community.
- This reflects ongoing recruitment efforts for new talent.
- Anticipation for more announcements: A user hinted at possible additional announcements for the day, especially for those outside of NYC, suggesting that more news is forthcoming.
- This remark spurred speculation about being part of an exciting wave 3 of releases.
Codeium (Windsurf) ▷ #windsurf (244 messages🔥🔥):
AI-generated decision concerns, Windsurf chat issues, MCP server functionality, Cascade performance problems, Feature requests and suggestions
- Concerns About AI-generated Decisions: Users expressed significant concerns regarding the reliability of AI-generated decisions, noting that persistent errors lead to potential financial losses.
- Community discussion emphasized the importance of analyzing AI outputs and confirmed ongoing issues with the AI's consistency.
- Windsurf Chat Stability Issues: Multiple users reported frequent freezing of the Windsurf chat, loss of conversation history, and significant disruptions to workflow.
- Suggestions included reloading the application and filing bug reports to address the critical stability problems.
- MCP Server Visibility Issues: Some users were unable to find the MCP server options after updating Windsurf, prompting troubleshooting steps such as reloading the window.
- It was confirmed that refreshing the interface often results in the MCP settings appearing as expected.
- Cascade Performance & Usability Problems: Users reported sluggish performance and crashing issues with the Cascade model, often requiring force restarts to regain functionality.
- Ongoing frustrations were shared, particularly concerning the lacking response capabilities and increased CPU usage during operation.
- Feature Requests and Suggestions: Feedback from users highlighted the need for more customizable features in Windsurf, such as markdown export options and specialized prompts.
- Community members were encouraged to submit their requests on the official feedback platform for consideration in future updates.
- Clojure - Visual Studio Marketplace: Extension for Visual Studio Code - Clojure nREPL support for Visual Studio Code
- A Hand-Curated Shitpost Picture: no description found
- Codeium Feedback: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Windsurf Wave 3 Updates: Tab to Jump, MCP, Custom App Icons, Turbo Mode & More: Windsurf wave 3 of updates is here! 🚀 Check out the latest features that make Windsurf even more powerful:Tab to Jump ⏩ Easily navigate within files to make...
- Codeium Status: no description found
- llms.txt directory: no description found
- Simplifying docs for AI with /llms.txt: Why we're providing a better way for LLMs to process documentation.
LM Studio ▷ #general (115 messages🔥🔥):
Qwen-2.5 VL Model Performance Issues, Model Uploading and Compatibility, Using Templates in LM Studio, GPU Usage and Specs, LM Studio Errors and Troubleshooting
- Qwen-2.5 VL Model Performance Issues: Users are reporting slow response times and memory management issues with the Qwen-2.5 VL model, particularly when sending follow-up prompts, leading to significant delays.
- The model's memory usage spikes after prompts, suggesting it may be relying on SSD instead of efficient VRAM use, which is particularly noticeable on high-spec machines.
- Model Uploading and Compatibility Insights: A user inquired about difficulties in uploading models related to Speculative Decoding, finding their models incompatible despite having the latest versions.
- Troubleshooting revealed users needed to adjust settings and ensure compatible models were selected for speculative decoding functionality to work.
- Using Templates in LM Studio: A question about pasting Jinja templates in the system prompt led to clarification that templates should be placed in a different section of LM Studio.
- Screenshots were shared to help users navigate the interface for template management.
- Discussion on GPU Specs: Users expressed concerns over GPU compatibility and specifications, specifically regarding the Tesla K80 model and its operational capabilities.
- Queries about PCIe and SXM2 usage highlighted the confusion over older GPU features fitting into modern setups.
- LM Studio Errors and Troubleshooting: A user reported an 'error: received prediction-error' message while running queries, leading to discussions around updating their LM Studio version and runtime.
- Feedback included suggestions to check hardware compatibility, as some users faced issues due to lack of AVX2 instruction support.
- no title found: no description found
- NVIDIA TESLA K80 24GB GDDR5 GPU GRAPHICS CARD 699-22080-0200-511 no cable | eBay: no description found
- System Requirements | LM Studio Docs: Supported CPU, GPU types for LM Studio on Mac (M1/M2/M3/M4), Windows (x64/ARM), and Linux (x64)
- lmstudio-ai/mlx-engine: 👾🍎 Apple MLX engine for LM Studio. Contribute to lmstudio-ai/mlx-engine development by creating an account on GitHub.
- Nvidia P100-SXM2-16GB P100 PCIe 16 GB Tesla GPU | eBay: no description found
- v0 by Vercel: Chat with v0. Generate UI with simple text prompts. Copy, paste, ship.
- Reddit - Dive into anything: no description found
- Markdown input is rendered instead of displayed as raw text in chat · Issue #430 · lmstudio-ai/lmstudio-bug-tracker: Which version of LM Studio? LM Studio 0.3.9 (Build 6) Which operating system? Windows 11 What is the bug? When users input text in markdown format (e.g., # Heading, italic, bold), it gets rendered ...
- LM Studio - Discover, download, and run local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
LM Studio ▷ #hardware-discussion (120 messages🔥🔥):
LLM Inference Performance, GPU Comparisons, AI Hardware Developments, Intel vs AMD CPUs, Gaming vs Inference
- K80 GPU for LLM Tasks: A user considered purchasing a $60 Tesla K80 PCIe with 24GB of VRAM for an 8B LLM project, but expressed concerns about power requirements and adapter compatibility.
- Discussion suggested that although K80 is affordable, many found setups to be problematic, with a recommendation for potentially using a GTX 1080 Ti instead.
- Inference Performance Expectations: Users discussed expected performance comparing different GPUs, with the Tesla K80 anticipated to yield around 30 tokens per second for R1 Llama 8b Q4_K if properly configured.
- Concerns arose about the K80's older architecture, which might limit performance compared to newer options.
- Amazon AD Connectors for Optiplex: A user looking to upgrade a Dell Optiplex 7020 considered using a PSU adapter to support the Tesla K80's power needs, which exceed the system's standard capacity.
- This setup raises potential compatibility and performance issues flagged by others, encouraging caution before proceeding.
- Interchangeable GPU Benefits: The conversation highlighted preferences for GPUs based on their power efficiency versus VRAM needs, indicating that a GTX 1080 Ti might be a more logical choice for certain AI tasks.
- The option to rent GPUs for benchmarks before committing to purchases was also mentioned as a practical approach to gauge performance.
- SanDisk's HBF Memory Introduction: SanDisk introduced a new high-bandwidth flash memory that could enable 4TB of VRAM capacity on GPUs, targeting AI inference applications looking for high bandwidth and low power requirements.
- This innovative memory solution positions itself as a potential alternative to traditional high-bandwidth memory (HBM) in future AI hardware developments.
- SanDisk's new High Bandwidth Flash memory enables 4TB of VRAM on GPUs, matches HBM bandwidth at higher capacity: Equipping AI GPUs with 4TB of memory.
- (Updated) AMD reportedly working on gaming Radeon RX 9070 XT GPU with 32GB memory - VideoCardz.com: AMD may be working on Radeon RX 9070 XT with 32GB memory There’s a new rumor from Chiphell about an alleged Radeon RX 9000 card equipped with twice the memory capacity compared to the RX 9070 se...
- GitHub - Nicoolodion/RTX-3070-16GB-GUIDE: A Guide for Modding a RTX 3070 to 16 GB VRAM: A Guide for Modding a RTX 3070 to 16 GB VRAM. Contribute to Nicoolodion/RTX-3070-16GB-GUIDE development by creating an account on GitHub.
- NVIDIA RTX 5090 PCIe 5.0 vs. 4.0 vs. 3.0 x16 Scaling Benchmarks: Sponsor: Arctic Liquid Freezer III on Amazon - https://geni.us/NrMtDTThis benchmark compares PCIe generation differences on the NVIDIA RTX 5090 GPU. We're te...
- Pciex16 vs x8 vs x4 - Gaming test.: Pci express x16 vs x8 vs x4 - Tested with rtx 3070 , 1440p.Test detailsTested at 2560 x 1440 resolution.Room ambient Temp - 30 degreespcie version 3.0CPU ...
GPU MODE ▷ #general (1 messages):
shindeirou: does anybody know at what toolkit version nvjet was introduced to cublas?
GPU MODE ▷ #triton (8 messages🔥):
PyTorch Profiler Tracing, Fused MM Activation with Triton, Triton GEMM Performance, Autotuning in Triton
- PyTorch Profiler shows 10ms gap: A member shared an analysis of the PyTorch profiler's tracing results, noting a 10ms gap between consecutive lines, specifically with
column_sumpreceding a CUTLASS kernel call.- It was concluded that without warm-up, significant latency might occur, impacting performance.
- Problem resolved with warm-up: After assessing the tracing information, it was concluded that running a for loop eliminates the latency issue related to warm-up.
- The member expressed confidence that this approach would alleviate the previously observed bubbles in execution time.
- Implementing Fused MM activation in Triton: A member inquired about the fastest tiled MM kernel for non-square matrices with dimensions M=2500, N=512, and K=512, referencing the Triton MM tutorial for guidance.
- They emphasized that understanding the correct block_size choices, which should be multiples of 16, is crucial for optimal performance.
- A8W8 GEMM kernel suggested: In response to the Fused MM inquiry, a member recommended an A8W8 (persistent) GEMM as the fastest option indicated in Triton for the specified dimensions.
- They advised running max-autotune to identify the best autotuning settings tailored to specific hardware requirements.
GPU MODE ▷ #cuda (18 messages🔥):
Blackwell GPU Tensor Memory, CUTLASS CUTE and SGEMM, NCCL Issues with Blackwell, Tensor Memory Programmer Management, Accessing GB200 GPU Resources
- Clarification on Blackwell Tensor Memory Management: There is debate on whether the new tensor memory in Blackwell GPUs is hardware or software managed; some users claim it's fully programmer managed with dedicated allocation functions details here. Another member noted that tensor memory serves to replace registers in matrix multiplications, not solely to replace shared memory.
- Inquiries on CUTLASS CUTE Functionality: A user raised questions about sgemm_v1.cu, noting the operation of multiple threads on memory and their overall workflow in a 128x8 tile structure. They sought clarity on the roles of excess threads, memory access overlaps, and the mapping of threads in the computation process.
- NCCL Errors When Using Blackwell GPUs: A member reported encountering NCCL errors while attempting to implement distributed training with Blackwell GPUs, even with the latest nightly builds. The reported errors highlighted
invalid argumentissues which persisted across different NCCL versions details provided. - Concerns Over Tensor Memory Efficiency: Members discussed potential inefficiencies related to how tensor memory accommodates sparsity and microtensor scaling, leading to wasted capacity. One highlighted that if 250KiB are used out of 256KiB available, it complicates attempts to fit accumulators on streaming multiprocessors.
- Challenges in Accessing GB200 GPUs: A user expressed frustration over the difficulty in obtaining access to GB200 GPUs, noting a lack of response from potential providers. Suggestions were made about alternative providers, citing high demand for LLM inference and issues with waitlist queues.
Link mentioned: Tweet from Lambda (@LambdaAPI): All we know is we're good for our NVIDIA HGX B200s 🙂
GPU MODE ▷ #torch (7 messages):
SymPy for Backward Pass, Torch Compile for Optimization, Fast Hadamard Transform in Quantized Attention, Gradient Formula Simplification, Issues with gradgradcheck()
- SymPy might simplify backward pass derivation: A member expressed curiosity about using SymPy for deriving backward passes of algorithms, indicating it could help manage complexity.
- They seemed interested in examples showing its practical application in code.
- Using torch.compile for graph optimization: A suggestion was made to utilize
torch.compilewithTORCH_LOGS=aot_graphsto optimize computation graphs for better performance.- Another member acknowledged this tip while expressing concerns about the optimization level compared to handwritten graphs.
- Fast Hadamard Transform for efficient attention: A question arose about why some quantized attention methods require the Fast Hadamard Transform for performance, while others like SageAttention do not.
- They discussed a recent paper proposing improvements over existing methods, highlighting quantization techniques and performance metrics.
- Complication in gradient formula simplification: A member corrects another's interpretation, confirming interest in deriving an actual gradient formula but expressed uncertainty about simplifying it by hand.
- They mentioned issues encountered with
gradgradcheck(), relating to unexpected output behavior—a possible indication of the complexity in maintaining accurate intermediate outputs.
- They mentioned issues encountered with
- Clarifications needed on outputs checking in gradgradcheck(): Concerns were raised about the behavior of
gradgradcheck()when returning zero matrices, suggesting it checks against intermediary outputs instead of final outputs.- The discussion revealed an intent to clarify these points, contemplating a follow-up on GitHub if issues persist.
- GitHub - Dao-AILab/fast-hadamard-transform: Fast Hadamard transform in CUDA, with a PyTorch interface: Fast Hadamard transform in CUDA, with a PyTorch interface - Dao-AILab/fast-hadamard-transform
- SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization: Although quantization for linear layers has been widely used, its application to accelerate the attention process remains limited. To further enhance the efficiency of attention computation compared t...
GPU MODE ▷ #cool-links (1 messages):
iron_bound: https://arxiv.org/abs/2502.07202
GPU MODE ▷ #jobs (8 messages🔥):
D-Matrix hiring efforts, Kernel programming talk, Architecture discussion, Performance projections, Programming model development
- D-Matrix seeks talent for kernel development: D-Matrix is actively hiring for their kernel efforts and invites those with CUDA experience to connect and explore opportunities in their unique stack.
- Potential candidates are encouraged to reach out to Gaurav Jain on LinkedIn for insights into their innovative hardware and architecture.
- Proposing a talk on D-Matrix programming: There's interest in scheduling a talk to introduce programming with D-Matrix, aiming to engage and attract potential recruits.
- Gaurav expressed enthusiasm about the idea, indicating this channel is ideal for such discussions.
- Plans for setting up a tech talk: Gaurav confirmed his willingness to discuss D-Matrix's architecture and programming model, which is currently in early development stages.
- He plans to coordinate specific details for the talk after returning from a three-week trip outside the US.
- D-Matrix's performance outlook: D-Matrix's Corsair stack is designed for optimal speed and energy efficiency, claiming transformative potential in large-scale inference economics.
- Performance projections highlight competitive edge against H100 GPUs, emphasizing sustainable solutions in AI.
- Software Engineer, Senior Staff Kernels: Software Engineer, Senior Staff - Kernels
- d-Matrix Corsair. Built For Generative AI | d-Matrix AI: d-Matrix delivers the world's most efficient AI computing solutions for generative AI at scale
GPU MODE ▷ #beginner (30 messages🔥):
CUDA Code Structure, Error Handling Best Practices, Memory Cleanup in CUDA, Kernel Launch Indexing, CUDA Development in C vs C++
- Feedback Requested on CUDA Code Structure: A user sought feedback on their CUDA code structure, particularly around error handling and memory cleanup practices for a matrix multiplication example shared on GitHub. They aimed for constructive pointers as they ramp up on CUDA programming essentials.
- Consistency in Error Handling: A reviewer pointed out inconsistent usage of the
cudaCheckErrormacro in the user's code, suggesting all CUDA calls should be consistently checked for errors. They emphasized that if errors are not recoverable, explicit resource cleanup may not be necessary as the OS/driver can manage this. - Kernel Launch Indexing Scheme Issues: A discussion emerged regarding a kernel's indexing scheme that produced duplicate indices, causing some rows of matrices not to be calculated. Changing the blockDim to (4, 1, 1) instead of (2, 2, 1) resolved the issue, highlighting the necessity of understanding the grid layout.
- Best Practices for Resource Management: A reviewer noted that while it’s good practice to manage resources effectively, if the program exits due to an error, the need for explicit cleanup diminishes since the OS will handle it. They also mentioned that freeing resources at main()'s end enables code reuse without worrying about memory leaks.
- Considerations for C vs C++ in CUDA: A user inquired about preferences for writing production-level CUDA code in C or C++, to which it was clarified that CUDA is generally aligned with C++ development for better compatibility with current practices. They acknowledged the importance of being C++-aligned to stay updated as they learn parallel programming.
- Sample matrix multiplication - CUDA: Sample matrix multiplication - CUDA. GitHub Gist: instantly share code, notes, and snippets.
- GitHub - NVIDIA/cccl: CUDA Core Compute Libraries: CUDA Core Compute Libraries. Contribute to NVIDIA/cccl development by creating an account on GitHub.
GPU MODE ▷ #pmpp-book (8 messages🔥):
CUDA memory model confusion, Errors in table for tiled matrix multiplication, Clarification on tile sizes, Typos in printed materials
- CUDA Memory Model Concerns: A CUDA beginner raised a question about a code snippet violating the C++ memory model due to the lack of a thread fence in a scan/prefix sum example.
- They sought clarification on whether this oversight was acknowledged in CUDA documentation, receiving mixed responses from community members.
- Typos Found in Tiled Matrix Multiplication Table: A member highlighted a potential error in the 7th column of a table related to tiled matrix multiplication, believing the operands were incorrect based on their analysis.
- Another participant confirmed this, noting that the 7th column merely repeated the indices of the 4th column, pointing out multiple typos in online PDFs.
- Clarification on Tile Sizes in Tiled Matrix Multiplication: A member questioned whether the tiles in tiled matrix multiplication should be the same size as the blocks.
- The dialogue revealed some confusion around the 4th column's accuracy, with one member reflecting on their previous mistake regarding it.
- Awaiting Edits in the 5th Edition: One participant expressed hope that the 5th edition editor would address the confirmed typos swiftly but not hastily.
- The conversation highlighted that many of the typographical errors remained in the materials and there was anticipation for updates.
Link mentioned: CUDA memory model: why acquire fence is not needed to prevent load-load reordering?: I am reading the book "Programming Massively Parallel Processors" and noticed the below code snippets to achieve "domino-style" scan: if (threadIdx.x == 0) {&#x...
GPU MODE ▷ #torchao (2 messages):
Dynamic Quantization, Issue Resolution
- Dynamic Quantization Options Available in torchao: Members discussed that users should be able to try FP8 or INT8 dynamic quantization directly from torchao.
- One member indicated that due to recent discussions, it appears these options are now available for testing.
- Resolution on Prior Issue: A member referred to a prior issue suggesting that it seems to be largely resolved based on recent discussions.
- Another member confirmed that this has been resolved, indicating progress in the matter.
GPU MODE ▷ #sequence-parallel (1 messages):
shindeirou: sorry dude never saw that message. It was excalidraw + PP
GPU MODE ▷ #off-topic (6 messages):
Inference-time scaling, AI and compute efficiency, Documentation of hardware, Conspiracy theories in AI, Personal coding documentation
- Inference-time scaling emerges as a key technique: A new scaling law known as inference-time scaling is gaining traction in AI, improving performance by allocating more computational resources during inference to evaluate multiple outcomes.
- This technique, referred to as AI reasoning or long-thinking, enables models to solve complex problems similarly to humans.
- Focus on AI compute efficiency: In recent years, significant efforts have been made to reduce AI's computational demands, such as through techniques like FlashAttention.
- Various models, including H3 and Monarch Mixer, aim to run AI more efficiently on available compute resources.
- Concerns about hardware documentation: It was noted that the documentation of hardware is often inadequate, leading to challenges in using it effectively in AI applications.
- One member humorously remarked that they wouldn't criticize others for their poor documentation skills, reflecting a shared sentiment on the issue.
- Speculations on intentional obfuscation: A discussion arose about whether the poor documentation of technology is unintentional or a deliberate choice, prompting thoughts of conspiracy theories related to AI.
- One member expressed feeling like a conspiracy theorist when considering these possibilities.
Links mentioned:
- GPUs Go Brrr: how make gpu fast?
- Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog: As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning ...
GPU MODE ▷ #liger-kernel (3 messages):
FSDP, Liger Kernel, User Defined Kernels
- Struggling with FSDP on Liger Kernel: A member expressed frustration after hours of trying to get FSDP to work with Liger Kernel.
- They were seeking help, indicating a possible misunderstanding or technical issue.
- Inquiry about FSDP Versions: Another member inquired whether the original poster was using FSDP version 1 or version 2.
- They suggested that there shouldn't be too many issues with user-defined kernels, implying potential compatibility.
GPU MODE ▷ #self-promotion (7 messages):
CUDA Kernel Optimizations, Performance Comparisons with PyTorch, cuBLAS vs. CUDA, Matrix Multiplication Techniques
- Optimizations in CUDA Transformer Kernel: A user implemented various optimizations such as loop unrolling and warp-level reductions in their Transformer CUDA kernel, achieving 1/3rd performance of PyTorch without using cuBLAS.
- Despite optimizations, they felt further improvements were minimal and their code was already complicated.
- Misunderstandings about cuBLAS and CUDA: A member clarified that cuBLAS is a high-level API optimized for matrix multiplications, contrasting it with their CUDA implementation, which was written at a lower level.
- They emphasized that it's possible to write faster matrix multiplications in CUDA without delving into PTX.
- Potential for Performance Improvements: Another user encouraged exploring additional optimizations in CUDA, suggesting that improvements could be made without requiring extensive programming techniques.
- They referenced a resource detailing various techniques applicable to GPU implementation.
Links mentioned:
- 100-daysofcuda/day18 at main · prateekshukla1108/100-daysofcuda: Kernels Written for 100 days of CUDA Challenge. Contribute to prateekshukla1108/100-daysofcuda development by creating an account on GitHub.
- Chapter 4: V2: no description found
GPU MODE ▷ #🍿 (70 messages🔥🔥):
DeepSeek-R1 and Inference-Time Scaling, KernelBench Benchmark Performance, GPU Kernel Optimization Challenges, Project Popcorn and Open Collaboration, Using LLMs for Systems Programming
- DeepSeek-R1 Automates GPU Kernel Generation: NVIDIA showcases the use of the DeepSeek-R1 model to automatically generate numerically correct kernels for GPU applications, optimizing them during inference.
- However, the results lacked details on performance metrics, and concerns were raised about the saturation of the current benchmark, especially at higher levels.
- KernelBench Accuracy and Performance Questions: Recent reports indicate that NVIDIA's workflow produced 100% accuracy on Level-1 problems and 96% on Level-2 issues of the KernelBench benchmark, but performance data remains unreported.
- Concerns were voiced about the benchmark being potentially saturated, with suggestions to focus on performance metrics to gauge true effectiveness.
- GPU Kernel Optimization as a Core Challenge: Discussions highlighted that while GPU kernel programming is a niche, it's deemed highly important in software engineering due to its implications on performance and resource usage.
- Members noted that optimizing kernels could yield significant savings in both compute costs and energy consumption, thus impacting broader software engineering practices.
- Project Popcorn's Open Collaboration Efforts: One member emphasized that contributions to Project Popcorn will be facilitated once the initial 'tasks' are released, aimed for around the GTC timeframe on March 16.
- Efforts are being made to build the project in an open-source manner, though some aspects, like data releases, require more formal approvals.
- LLMs' Challenges in Code Generation: Efforts to utilize LLMs for code generation were discussed, with a focus on the divide between application programming and systems programming challenges—particularly with performance optimization.
- One participant proposed that careful design and high-performance targets make kernel optimization a compelling benchmark for measuring LLM capabilities in reasoning.
Link mentioned: Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog: As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning ...
GPU MODE ▷ #reasoning-gym (47 messages🔥):
Graph Coloring Problems, Reasoning-Gym Dataset Evaluations, Futoshiki Puzzle Dataset, Game of Life Outputs, Standardization of Reporting Scores
- Graph Coloring Problems PR by Miserlou: A new pull request for Graph Coloring Problems was submitted, requiring a coloring method where no connected vertices share the same color, with specific details in the PR here.
- The discussion highlighted that the changes would improve machine compatibility of outputs.
- Performance Issues on MATH-P-Hard: Members noted significant performance drops on MATH-P-Hard, indicating a bias toward original reasoning patterns that affects model effectiveness on harder examples, as discussed in this thread.
- Good news mentioned is that models perform robustly with simpler perturbations.
- Updates to Reasoning-Gym Datasets: Contributions such as the Futoshiki puzzle dataset were made, which aims for cleaner solvers and improved logical frameworks, with details available in the PR here.
- Additionally, the datasets are being standardized with unified prompts to streamline evaluation processes.
- Evaluation Output Storage Setup: An evaluation repository was created to store output JSON files and associated scripts to keep the main repo clean, proposed by several members after discussions about maintaining organization.
- Discussions included using a central Google table to track evaluations and results for better collaborative oversight.
- Standardization in Reporting Scores: There is a call for a standard method of determining average scores across datasets, with suggestions for using 50 samples for consistency in reporting as highlighted by member discussions.
- The aim is to ensure reliability across the boards where various models are evaluated.
Links mentioned:
- Tweet from Kaixuan Huang (@KaixuanHuang1): We observe significant performance drops on MATH-P-Hard, while the performance drops on MATH-P-Simple are negligible. This indicates the models are biased toward the original distribution of reasoning...
- GitHub - open-thought/reasoning-gym-eval: Collection of LLM completions for reasoning-gym task datasets: Collection of LLM completions for reasoning-gym task datasets - open-thought/reasoning-gym-eval
- Tweet from Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex): Incredible paper. One weird trick to recursive self-improvement:- a model iteratively labels its own train data and learns from progressively harder examples. Gotta1) generate problems of appropriate...
- reasoning-gym-eval: no description found
- Game of Life Output Formatting by Miserlou · Pull Request #125 · open-thought/reasoning-gym: Asks for a more machine-friendly output format, with instructions and example.
- Add Graph Coloring Problems by Miserlou · Pull Request #120 · open-thought/reasoning-gym: ClassicoPlease provide a coloring for this graph such that every vertex is not connected to a vertex of the same color. The graph has these properties:Edges: [(0, 2), (0, 4), (0, 7), (0, 8), (1,...
- Add Futoshiki puzzle generator by olliestanley · Pull Request #60 · open-thought/reasoning-gym: Closes #54Existing solvers were messy & difficult to follow so I implementing a new one. The logical rules are not easy to follow even in this code, but are well worth it as they speed this up...
Interconnects (Nathan Lambert) ▷ #news (133 messages🔥🔥):
GRPO vs PPO in Tulu models, Anthropic's upcoming Claude model, DeepHermes-3 Preview release, EnigmaEval reasoning challenges, Jailbreaking challenges results
- GRPO outperforms PPO in Tulu models: Costa Huang announced that switching from PPO to GRPO resulted in a 4x performance gain for the Tulu pipeline with the new Llama-3.1-Tulu-3.1-8B model showing better results in MATH and GSM8K.
- The transition to GRPO showcases significant enhancements over the previous models released in the fall.
- Anthropic's Claude model on the horizon: Anthropic's next Claude model will integrate a traditional LLM with reasoning AI, allowing developers to adjust reasoning levels on a sliding scale, potentially outperforming OpenAI’s o3-mini-high in various benchmarks.
- This innovative approach signifies a shift in model training and operational capabilities for business coding tasks.
- DeepHermes-3 Preview introduced: Nous Research released DeepHermes-3, an LLM that combines reasoning with language processing, capable of toggling long chains of thought for improved accuracy at the cost of increased computational demand.
- The model's performance metrics and comparison with Tulu models raise questions due to differences in benchmark scores.
- EnigmaEval presents new reasoning challenges: Dan Hendrycks announced EnigmaEval, a set of complex reasoning challenges where AI systems struggle, scoring below 10% on normal puzzles and 0% on MIT-level challenges.
- The introduction of such a rigorous evaluation aims to push the boundaries of AI reasoning capabilities.
- Results of Anthropic's jailbreaking challenge revealed: In a jailbreaking challenge organized by Anthropic, participants sent over 300,000 messages and generated a universal jailbreak with $55k awarded to winners demonstrating significant engagement.
- The challenge reflects ongoing efforts to improve security measures in AI models, particularly with newly introduced constitutional classifiers.
Links mentioned:
- Open Weight Definition (OWD): no description found
- Tweet from Nous Research (@NousResearch): Introducing DeepHermes-3 Preview, a new LLM that unifies reasoning and intuitive language model capabilities.https://huggingface.co/NousResearch/DeepHermes-3-Llama-3-8B-PreviewDeepHermes 3 is built fr...
- The Open Source AI Definition – 1.0: version 1.0 Preamble Why we need Open Source Artificial Intelligence (AI) Open Source has demonstrated that massive benefits accrue to everyone after removing the barriers to learning, using, sharing ...
- Open Source Alliance: Uniting global Open Source communities to shape the future of software freedom.
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): What types of programming languages are people asking about?Python and markdown are by far the most common languages people’s questions are related to, according to our retrieved file types.
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): Distillation Scaling LawsThis study presents a distillation scaling law to estimate student model performance based on compute allocation between teacher and student models. It provides guidelines fo...
- Tweet from Nathan Lambert (@natolambert): Costa's just trying to make GRPO go brrr with no bugs and we're ending up with way better performance than the Tülu models we released in the fall. Changing from PPO -> GRPO 4x'd the ga...
- Tweet from Igor Kotenkov (@stalkermustang): babe wake up AIME 2 LLM results droppedo3-mini is the king, gemini is cooked, R1 is reasonable
- Tweet from Jan Leike (@janleike): @caleb_parikh They sent 7,867 messages, and passed 1,408 of them onto the auto-grader. We estimate that they probably spent over 40 hours on this in total.
- Tweet from Alexander Doria (@Dorialexander): @TheXeophon New org. https://opensourcealliance.org/ Definition was just dropped during the summit and reasonably publicized(for context, seemingly a fork from open source initiative due to disagreeme...
- Tweet from The Information (@theinformation): Exclusive: Anthropic Projects Soaring Growth to $34.5 Billion in 2027 RevenueAnthropic, a primary challenger to OpenAI, has projected revenue as high as $34.5 billion in 2027, up from $3.7 billion thi...
- Tweet from Dylan Patel (@dylan522p): The new OpenAI model specs allows for sexual contentAs we speak millions of third world annotators are being tasked with the kinkiest roleplays.Hundreds of thousands of ai judges are being spun up to ...
- Tweet from Negin Raoof (@NeginRaoof_): Announcing OpenThinker-32B: the best open-data reasoning model distilled from DeepSeek-R1.Our results show that large, carefully curated datasets with verified R1 annotations produce SoTA reasoning mo...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): Anthropic's next Claude model is coming—and soon.It'll be a combo of a traditional LLM + reasoning AI, w/ the ability for devs to adjust how much it reasons on a sliding scale measured in toke...
- Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog: As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning ...
- Tweet from Neil Houlsby (@neilhoulsby): And I am excited to announce that I have joined Anthropic, Switzerland! 🇨🇭Anthropic is setting up a new office in Zurich, expanding its global presence. I am super excited to build a team here, wher...
- Tweet from Olivier Godement (@oliviergodement): @mikeknoop The API will support o3! We will provide knobs such as reasoning effort to get the best out of new frontier models. We are working through options to package o3 in the broader GPT-5 system,...
- Tweet from Piotr Padlewski (@PiotrPadlewski): Excited to join @neilhoulsby at Anthropic’s new Zürich office to work on multimodalAfter an incredible journey at Reka, it's time for a new chapter! Grateful for the chance to contribute to LLM/VL...
- Tweet from Together AI (@togethercompute): Since launching DeepSeek-R1, we've seen a wave of companies looking to deploy reasoning models in production—but scaling them efficiently remains a challenge.Today, we’re expanding beyond our ultr...
- Tweet from Tibor Blaho (@btibor91): The Information reports Anthropic is about to release a hybrid AI model in the coming weeks that can switch between fast responses and deep reasoning, with a unique sliding scale for developers to con...
- Tweet from swyx 🔜 @aidotEngineer NYC (@swyx): signal boosting this kind reply. i felt that the worst timeline was the one {COMPETITOR} appeared to be going towards, which is train different models + have a model router to create semblance of agin...
- Tweet from Xeophon (@TheXeophon): with GPT-5 being an (even more) black-box system, i hope academia finally moves on from being paying product testers to using open models exclusively
- Tweet from OpenAI (@OpenAI): Two updates you'll like—📁 OpenAI o1 and o3-mini now support both file & image uploads in ChatGPT⬆️ We raised o3-mini-high limits by 7x for Plus users to up to 50 per day
- Tweet from Tsarathustra (@tsarnick): Elon Musk says Grok 3 will be released in "a week or two" and it is "scary smart", displaying reasoning skills that outperform any other AI model that has been released
- Old Boomer GIF - Old Boomer History - Discover & Share GIFs: Click to view the GIF
- Tweet from Dan Hendrycks (@DanHendrycks): We're releasing EnigmaEval, a collection of long, complex reasoning challenges that take groups of people many hours or days to solve.The best AI systems score below 10% on normal puzzles, and for...
- Tweet from Jan Leike (@janleike): Results of our jailbreaking challenge:After 5 days, >300,000 messages, and est. 3,700 collective hours our system got broken. In the end 4 users passed all levels, 1 found a universal jailbreak. We...
- Tweet from wh (@nrehiew_): On the same TULU3 dataset, GRPO > PPO. What’s the intuition here? is GRPO just the mandate of heaven RL algo?Quoting Costa Huang (@vwxyzjn) 🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> a...
- Tweet from Sam Altman (@sama): OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.We want AI to “just work” for you; we re...
- Tweet from Sheel Mohnot (@pitdesi): Anthropic expects base case of $2.2B revenue this year (up from ~$500M in 2024) and projects $12B in 2027OpenAI is ~5x Anthropic by revenue, projects $44B in 2027To hit these projections they’ll have ...
Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
notebookLM performance, GPT-5 model interface
- notebookLM struggles with basic tasks: A user expressed frustration, stating that notebookLM behaves like an outdated model, responding quickly yet failing at tasks like creating a markdown table from benchmarks in 24 PDFs.
- The user's concern highlighted issues with markdown formatting, prompting thoughts of utilizing Deep Research instead.
- Concerns over GPT-5's single-interface model: A user reacted to Sama's announcement about merging models for GPT-5, stressing the importance of knowing which models are in use for task delegation.
- I'm pretty sure that's what's going on with notebookLM, they remarked, indicating that the product version has led to dissatisfaction.
Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
DH3 Evaluation Metrics, ImitationLearn Company Legitimacy
- DH3 Evaluation Metrics Raise Questions: Notes indicate that DH3 only presents two specific evaluations for the 'reasoning on' metrics, while the 'reasoning off' chart displays all metrics.
- Concerns were expressed about their omission of comparisons to the official 8b distill release, which boasts higher scores, with DH3 showing ~36-37% GPQA versus r1-distill's ~49%.
- ImitationLearn's Company Credibility in Doubt: Discussion quoted a member expressing uncertainty about ImitationLearn's legitimacy, stating it may just be 'swaggy' and that might be what matters.
- This ambiguity leaves the community questioning the company's authenticity in the space.
Link mentioned: Tweet from kalomaze (@kalomaze): dh3 notes1. they only show these two specific evals for the "reasoning on"; the "reasoning off" chart is the only one showing all metrics2. they don't compare to the official 8b di...
Interconnects (Nathan Lambert) ▷ #random (36 messages🔥):
Censored Model Discussions, OpenThinker-32B Model Release, Reasoning Token Scaling, Chatbot Prompt Guidelines, Community Commentary on RL
- Concerns over Censored Models: Members expressed annoyance regarding the censorship of DeepSeek models, prompting a discussion on ways to de-censor them, with suggestions for alternatives such as the OpenThinker-32B model.
- Someone noted that these concerns are common within the community.
- Release of OpenThinker-32B: A new reasoning model called OpenThinker-32B has been released, which is performing well by utilizing curated data for classifying problems and reasoning tasks.
- The release was celebrated by the team with remarks on the significant progress made in successfully aligning the model.
- Debate on Reasoning Token Scaling: There was a lively discussion about reasoning tokens dropping off after a certain problem size, with observations suggesting a limitation at around 30 digits.
- One user cautioned that the findings are based on a small sample size, thus encouraging others to interpret results conservatively.
- Best Practices for Chatbot Prompts: A user shared a guideline emphasizing the importance of avoiding 'boomer prompts' and suggested using straightforward instructions along with delimiters for clarity.
- Another member humorously noted their feelings of being addressed by such guidelines, highlighting community engagement.
- Community Commentary on Reinforcement Learning: Members commented on the messiness and complexity of recent reinforcement learning roundup results, reflecting frustration with the need for compilation.
- Despite the challenges, there was a recognition of the valuable insights that can be drawn from the more interesting findings.
Links mentioned:
- Tweet from Nat McAleese (@nmca): @stalkermustang @ahelkky o3 samples many solutions and uses a learned function to pick the best --- for codeforces, we sampled 1,162 samples per problem
- Avatar Aang Aang GIF - Avatar Aang Aang Atla - Discover & Share GIFs: Click to view the GIF
- Tweet from Colin Fraser (@colin_fraser): @littmath Perhaps not coincidentally, at this threshold the reasoning tokens seems to stop scaling with problem size
- Tweet from Colin Fraser (@colin_fraser): @littmath depends on your standards for what counts as "reliably" but seems to drop off pretty bad after 30 digits. Small sample size (10 for each n) so take any point with a grain of salt
- Tweet from Mahesh Sathiamoorthy (@madiator): We accidentally de-censored the model!Qwen-instruct which we use is censored and aligned.DeepSeek-R1 distilled models are censored and aligned.When we SFT the Qwen model with reasoning data in math an...
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): MUAHAHAHA 💉💦Quoting Djah 〰️ (@Djahlor) WHAT??? @elder_plinius did you do this??
- Tweet from OpenAI Developers (@OpenAIDevs): As some of you have noticed, avoid “boomer prompts” with o-series models. Instead, be simple and direct, with specific guidelines.Delimiters (xml tags) will help keep things clean for the model, and i...
Interconnects (Nathan Lambert) ▷ #memes (4 messages):
DeepSeek Announcement, OpenAI's Roadmap Update, OLMo GitHub Issue, AI Security Reviewers, Rust's Future Value Proposition
- DeepSeek Teaser Just Ahead: A member hinted that something big is coming out tomorrow about DeepSeek.
- AK teased the announcement, suggesting it could be significant for the community.
- OpenAI's Shift in Strategy for AGI: Sam Altman revealed that the current strategy of simply scaling up will no longer suffice for AGI, indicating a shift in OpenAI's approach as they prepare to launch GPT-4.5 and GPT-5.
- OpenAI will integrate its systems to provide a more seamless experience, while addressing community frustrations with the model selection step.
- Clarification on AllenAI’s Founding: An issue was raised on GitHub questioning if AllenAI was founded by Jeff Bezos, with OLMo 2 asserting it was not true.
- This inquiry highlights the need for clarity about the origins of AI projects like OLMo.
- AI Reviewers Poised for Transformation: As AI security reviewers gear up to find and fix bugs in source code at scale, questions arise about the diminishing value of programming skills.
- A member pondered, just what is the value proposition of Rust going to be in a few years amidst these advancements.
Links mentioned:
- Tweet from loss (@untitled01ipynb): just what is the value preposition of any programmer anymoreQuoting xlr8harder (@xlr8harder) Since we're on the cusp of AI security reviewers being able to detect and fix security/memory bugs at s...
- Tweet from Stanford NLP Group (@stanfordnlp): The final admission that the 2023 strategy of OpenAI, Anthropic, etc. (“simply scaling up model size, data, compute, and dollars spent will get us to AGI/ASI”) is no longer working!Quoting Sam Altman ...
- Were you founded by Jeff Bezos? · Issue #787 · allenai/OLMo: ❓ The question Olmo2 says AllenAI was created by Jeff Bezos. Is this true? I am OLMo 2, an AI language model developed by the Allen Institute for Artificial Intelligence (Ai2), also known as "All...
- Tweet from loss (@untitled01ipynb): what did ak seeQuoting AK (@_akhaliq) Something big coming out Tomorrow about deepseek
Interconnects (Nathan Lambert) ▷ #reads (20 messages🔥):
Dwarkesh, Noam Shazeer, Jeff Dean, Podcast Interviews, Science History
- Dwarkesh's Iconic Podcast with Noam and Jeff: A discussion emerged around Noam Shazeer and Jeff Dean on Dwarkesh's podcast, where members expressed excitement about its content.
- Damn, this episode is truly iconic, with listeners appreciating Noam's style, particularly his OutdoorResearch hat, which sparked additional conversations.
- Interest in Dwarkesh's Podcast: Several members mentioned a desire to participate in Dwarkesh's podcast, highlighting that it would be fun but not a priority at the moment.
- One member noted, multiple people have recommended it, and I could have him on, referencing their podcasting experience.
- Respect for Noam's Hat Choice: The conversation took a humorous turn when a member described Noam's hat as iconic, comparing it to photos found online, noting it's the same one he often wears.
- Another added, I have the same hat but in a different color, showcasing camaraderie among the members around the shared fashion choice.
Link mentioned: noam shazeer - Google Search: no description found
Interconnects (Nathan Lambert) ▷ #posts (5 messages):
Aged beautifully, SnailBot
- Commentary on Aging: A member remarked that something has aged beautifully, possibly indicating a positive transformation over time.
- This led to a lighthearted exchange with another member expressing acknowledgment.
- SnailBot News Alert: The SnailBot sent out a notification tagged for an audience, possibly indicating an update or important information.
- No specific details were provided regarding the content of the SnailBot's message.
Eleuther ▷ #general (14 messages🔥):
Dataset perplexity evaluation, Post-training datasets, Online courses in AI and tech, Collaboration opportunities at Eleuther AI
- Seeking Efficient Dataset Perplexity Evaluation: A member inquired about an efficient implementation of dataset perplexity evaluation that runs fast on multi-GPU systems.
- Another member suggested using lm-eval-harness as a potential solution.
- Discussion on Best Post-training Datasets: There was a question about the best post-training datasets, with SmolTalk and Tulu-3 mentioned as possible options.
- The conversation included a query about combining reward models with SFT objectives.
- Resources for Learning AI and Tech: A Brazilian member asked for recommendations on the best online courses in AI and tech/business to stay updated.
- Another member directed them to a specific channel for resources on learning opportunities.
- Interest in Contributing to Research at Eleuther AI: A member expressed interest in collaborating on research projects at Eleuther AI and sought guidance on how to contribute.
- They inquired if there are any open research projects available for participation.
Eleuther ▷ #research (126 messages🔥🔥):
PPO-Clip with Alternative Models, Memory Mechanisms in Models, Forgetting Transformer, Evaluation of Long Context Models, Temporal Causality in Attention
- PPO-Clip with Alternative Models Discussion: Members discussed the idea of applying PPO-Clip with different models to generate rollouts, reminiscing about similar ideas from past conversations.
- One member expressed skepticism about the effectiveness of this approach based on previous attempts.
- Exploring Memory Mechanisms: Discussion highlighted a member's concept of improving model memory by using dummy tokens and additional gates for sparse attention mechanisms.
- Concerns arose about how the implementation could influence causality and parallelization in model architectures.
- Forgetting Transformer Framework: There was a conversation surrounding the Forgetting Transformer and whether changing from sigmoid to tanh activation could impact performance positively.
- The idea of introducing negative attention weights was also proposed, highlighting potential for more sophistication in attention mechanisms.
- Challenges in Evaluating Long Context Models: Members reflected on the challenges associated with current benchmarks for long context models like HashHop and the iterative nature of solving 1-NN.
- Concerns were raised about the theoretical feasibility of the claims being made by the long context model's approach.
- Temporal Causality and Attention Mechanisms: Discussion emerged regarding the effectiveness of search over vectors in temporal causality, emphasizing the uniqueness of language data's non-stationarity.
- Members debated if softmax attention and gated RNNs could adequately model non-stationary distributions in various data types.
Links mentioned:
- On the Emergence of Thinking in LLMs I: Searching for the Right Intuition: Recent AI advancements, such as OpenAI's new models, are transforming LLMs into LRMs (Large Reasoning Models) that perform reasoning during inference, taking extra time and compute for higher-qual...
- 100M Token Context Windows — Magic: Research update on ultra-long context models, our partnership with Google Cloud, and new funding.
- gptcore/model/experimental/memtention.py at main · SmerkyG/gptcore: Fast modular code to create and train cutting edge LLMs - SmerkyG/gptcore
Eleuther ▷ #interpretability-general (2 messages):
Citing Delphi, Citing Sparsify, BibTeX entries for papers, GitHub citations
- Guidance on Citing Delphi: <@177739383070261248> inquired about the proper way to cite Delphi, considering referencing both the paper and the GitHub page.
- It's a good idea to combine citations for comprehensive attribution, as agreed upon by others in the discussion.
- Thoughts on Sparsify Citation: <@177739383070261248> expressed plans to also cite the Sparsify GitHub page, highlighting that multiple citations enhance research quality.
- Using autogenerated BibTeX entries from arXiv could be beneficial for standardization.
- Discussion on BibTeX Outputs: There was a suggestion about using arXiv's autogenerated BibTeX entries for common papers, which streamlines the citation process.
- Members advised creating basic BibTeX entries for various GitHub repositories to maintain consistency.
Stability.ai (Stable Diffusion) ▷ #general-chat (92 messages🔥🔥):
Stable Diffusion Saving Issues, Switching to Linux with ComfyUI, Model Recommendations and Performance, AI Character Design Consistency, Upwork Account Borrowing
- Stable Diffusion lacks auto-save feature: A user realized they didn't have the auto-save option enabled in Stable Diffusion and inquired about recovering older generated images.
- Others suggested checking for the web UI version used to determine the options available for saving.
- ComfyUI OOM Errors on Linux: A user switching from Windows to Pop Linux encountered Out Of Memory (OOM) errors while using ComfyUI, despite successfully running it before.
- Discussion included confirming system updates and recommended drivers, emphasizing the differences in dependencies between operating systems.
- Choosing the Right AI Model: A user expressed challenges maintaining consistent character designs across models, prompting discussions about using Loras and tools like FaceTools and Reactor.
- Recommendations included exploring different models based on tasks, with emphasis on models that are specifically designed for certain functionalities.
- Quest for Upscaling and Creative Tools: Users questioned the release of Stability's creative upscaler, with one asserting that it hasn’t been released yet.
- This sparked conversations about model capabilities and whether certain models would fit requirements like memory and performance.
- Upwork Account Borrowing Inquiry: A member sought to borrow a US Upwork account for upcoming projects, raising questions about the feasibility of such an arrangement.
- This prompted skepticism regarding the concept of 'borrowing' an account and its implications.
Links mentioned:
- swarmui="" a="" at="" docs="" href="https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/Model%20Support.md#black-forest-labs-flux1-models>" master="" mcmonkeyprojects="" model="" support.md="" swarmui<="" ·="">: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
- mcm - Overview: mcm has 47 repositories available. Follow their code on GitHub.
Latent Space ▷ #ai-general-chat (81 messages🔥🔥):
AI Agents, OpenAI Roadmap Updates, Apple Product Announcements, DeepHermes 3 Model, Meta's Automated Compliance Hardening Tool
- OpenAI's Latest Roadmap Updates: OpenAI shared a major update about its upcoming models GPT-4.5 and GPT-5, aiming to unify various model types and simplify their product offerings.
- Key features include integrating O-series models and all tools to create a more streamlined AI experience for developers and users.
- Anthropic's New Claude Model: Anthropic plans to launch the next Claude model soon, which will combine traditional LLM capabilities with reasoning AI that developers can control via a token-based sliding scale.
- This approach is similar to the one adopted by OpenAI in their recent announcements, indicating a trend toward integrating reasoning in AI models.
- Excitement for Apple Product Launch: Anticipation builds around Apple's upcoming product announcements, including a supposed new iPhone SE and a long-overdue update to Apple TV.
- Tim Cook teased the reveal, sparking speculation about additional features and upgraded chips in these products.
- DeepHermes 3 Model Unveiled: Nous Research has released a preview of DeepHermes 3, an LLM that integrates reasoning with traditional response capabilities, enhancing its performance.
- This model aims to deliver improved accuracy and functionality, representing a significant step in LLM development.
- Meta's Automated Compliance Hardening Tool: Meta introduced its Automated Compliance Hardening (ACH) tool, utilizing LLM-based test generation to enhance software security by creating undetected faults for testing.
- This advanced tool aims to improve privacy compliance by automatically generating unit tests targeting specific fault conditions in code.
Links mentioned:
- Tweet from OpenAI (@OpenAI): Two updates you'll like—📁 OpenAI o1 and o3-mini now support both file & image uploads in ChatGPT⬆️ We raised o3-mini-high limits by 7x for Plus users to up to 50 per day
- Tweet from Stephanie Palazzolo (@steph_palazzolo): Anthropic's next Claude model is coming—and soon.It'll be a combo of a traditional LLM + reasoning AI, w/ the ability for devs to adjust how much it reasons on a sliding scale measured in toke...
- Tweet from Glean (@glean): Welcome to the agentic era 🚀 We’re excited to announce 𝐆𝐥𝐞𝐚𝐧 𝐀𝐠𝐞𝐧𝐭𝐬–our horizontal agent environment that enables employees and businesses to build, run, manage, and govern AI agents at sc...
- Tweet from swyx 🔜 @aidotEngineer NYC (@swyx): RT @JeffDean: I'm delighted to have joined my good friend and colleague @NoamShazeer for a 2+hour conversation with @dwarkesh_sp about a wi…
- Tweet from Glenn Solomon (@glennsolomon): Proud to co-lead @FAL's Series B 🚀AI-powered creativity is only as good as the infrastructure behind it. fal is the inference layer fueling gen-media for Canva, Perplexity & more!Thrilled to part...
- Tweet from Romain Huet (@romainhuet): @NickADobos @sama Our developer platform remains a top priority, and our API will support o3 reasoning capabilities! Yes, we’ll keep providing all the controls you need—like a “reasoning effort” setti...
- Jeff Dean & Noam Shazeer – 25 years at Google: from PageRank to AGI: Jeff Dean & Noam Shazeer – 25 years at Google: from PageRank to AGI
- Tweet from Scaled Cognition (@ScaledCognition): We’re Scaled Cognition, developing the first ever models trained specifically for agentic applications:1. Our first system, APT-1, is now #1 on agentic benchmarks.2. It was developed by a US team for ...
- Tweet from Winston Weinberg (@winstonweinberg): Excited to announce our Series D led by @sequoia with participation from @conviction, @kleinerperkins, @OpenAI, @GVteam, @conviction, @eladgil, and @LexisNexis.Thank you to our customers, team, invest...
- Tweet from Nathan Lambert (@natolambert): New talk! I wanted to make space to ask: Where is this new wave of RL interest going?How does this compare to when we "rediscovered" RLHF post-ChatGPT with Alpaca etc?What ingredients make thi...
- Tweet from FleetingBits (@fleetingbits): OpenAI is moving over to selling agents not models. Some thoughts.1) You will no longer be able to build your own system because OpenAI is already packaging for you2) You will be buying a level of int...
- An Unexpected Reinforcement Learning Renaissance: The era we are living through in language modeling research is one pervasive with complete faith that reasoning and new reinforcement learning (RL) training ...
- Revolutionizing software testing: Introducing LLM-powered bug catchers: WHAT IT IS Meta’s Automated Compliance Hardening (ACH) tool is a system for mutation-guided, LLM-based test generation. ACH hardens platforms against regressions by generating undetected faults (mu…
- Tweet from Google DeepMind (@GoogleDeepMind): 🎥 Our state-of-the-art video generation model Veo 2 is now available in @YouTube Shorts.With the Dream Screen feature, creators can:✨ Produce new clips that fit seamlessly into their storytelling wit...
- Tweet from Zach Nussbaum (@zach_nussbaum): many embedding models, especially multilingual ones, have been scaled up from BERT-base sized to 7B Mistral-sized models.but why haven't embeddings taken a page out of LLMs and leveraged Mixture o...
- Tweet from sankalp (@dejavucoder): you are laughing. they put deepseek r1 in a loop with a simple verifier and it outperformed nvidia's skilled engineers in writing gpu kernels in some cases and you are laughing?
- Tweet from Air Katakana (@airkatakana): third most popular model on huggingface
- Tweet from wh (@nrehiew_): Agent framework this, agent framework that. All you need is a while loopQuoting anton (@abacaj) uh it might be over... they put r1 in a loop for 15minutes and it generated: "better than the optimi...
- Tweet from anton (@abacaj): uh it might be over... they put r1 in a loop for 15minutes and it generated: "better than the optimized kernels developed by skilled engineers in some cases"Quoting Anne Ouyang (@anneouyang) N...
- Tweet from Sheel Mohnot (@pitdesi): Anthropic expects base case of $2.2B revenue this year (up from ~$500M in 2024) and projects $12B in 2027OpenAI is ~5x Anthropic by revenue, projects $44B in 2027To hit these projections they’ll have ...
- Tips for building AI agents: Anthropic’s Barry Zhang (Applied AI), Erik Schultz (Research), and Alex Albert (Claude Relations) discuss the potential of AI agents, common pitfalls to avoi...
- Tweet from MatthewBerman (@MatthewBerman): New research paper shows how LLMs can "think" internally before outputting a single token!Unlike Chain of Thought, this "latent reasoning" happens in the model's hidden space.TONS ...
- Tweet from Matt Barrie (@matt_barrie): “It was trained on the most compute, and a lot of synthetic data, and if it’s got data that is wrong it will reflect upon that and remove it. Even without fine tuning, Grok 3 base model is better than...
- NousResearch/DeepHermes-3-Llama-3-8B-Preview · Hugging Face: no description found
- Tweet from Tim Cook (@tim_cook): Get ready to meet the newest member of the family.Wednesday, February 19. #AppleLaunch
- Tweet from Dimitris Papailiopoulos (@DimitrisPapail): o3 can't multiply beyond a few digits...But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers... with recursive self-impr...
- Tips for building AI agents: Anthropic’s Barry Zhang (Applied AI), Erik Schultz (Research), and Alex Albert (Claude Relations) discuss the potential of AI agents, common pitfalls to avoi...
- Reddit - Dive into anything: no description found
- Tweet from Sam Altman (@sama): OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.We want AI to “just work” for you; we re...
- Tweet from OpenAI (@OpenAI): Today we're sharing a major update to the Model Spec—a document which defines how we want our models to behave.The update reinforces our commitments to customizability, transparency, and intellect...
- Tweet from Alexander Wei (@alexwei_): o3 x competitive programming update from the OpenAI reasoning team! 🧵Back in August, we sprinted to prepare o1 to compete in the 2024 International Olympiad in Informatics ...
- Tweet from Aravind Srinivas (@AravSrinivas): Reply to this thread with prompts (or links) of chatgpt deep search that you found very impressive and (or) useful
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): LLM Pretraining with Continuous ConceptsNew Meta paper that introduces a new pretraining framework where the model must predict "continuous concepts” learned from a pretrained sparse autoencoder a...
- Tweet from Joanne Jang (@joannejang): 📖 model spec v2!it's the latest version of the doc that outlines our desired intended behavior for openai's models.some of additions shouldn't be controversial, but some are definitely sp...
- Tweet from Anne Ouyang (@anneouyang): New blog post from Nvidia: LLM-generated GPU kernels showing speedups over FlexAttention and achieving 100% numerical correctness on 🌽KernelBench Level 1
- Tweet from Nomic AI (@nomic_ai): Nomic Embed Text V2 is now available- First general purpose Mixture-of-Experts (MoE) embedding model- SOTA performance on the multilingual MIRACL benchmark for its size- Support for 100+ languages- Tr...
- Tweet from Aravind Srinivas (@AravSrinivas): Need to clarify this in no ambiguous terms: We still think NVIDIA is peerless and singular and the industry leader by far. And nothing changes in our relationship with them. I like Andrew and Cerebras...
- Tweet from Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex): I believe Elon. A theory that they kept shipping cringe and figuring out their org but have finally caught up and will be the first to drop a well-designed and trained model of this weight class makes...
- Tweet from Avi (@AviSchiffmann): I feel like we’re working on one of the hardest engineering problems at friend.creating, updating, and querying “memories” while chatting with LLMs already barely works, but since friend is always lis...
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new pod drop! https://x.com/latentspacepod/status/1890101440615453025
Yannick Kilcher ▷ #general (50 messages🔥):
Accessing Research Papers, TinyStories Pretraining, Pretraining Foundation Models, Intermediary Logits in RL, Architecture and Optimization Challenges
- Accessing Research Papers Made Easy: Members discussed ways to access research papers, with suggestions to use resources like Anna's Archive and to directly contact authors for PDF access.
- One user expressed gratitude for bookmark-worthy resources when looking for academic papers.
- TinyStories Offers Pretrained Architectures: A member recommended TinyStories for pretraining datasets, asserting it provides a family of architectures, pretrained models, and a detailed research paper.
- The conversation highlighted that TinyStories was specifically created to facilitate training small models effectively.
- Optimizing Pretraining on Limited Hardware: Users sought suggestions for pretraining datasets that can work well on less powerful hardware, expressing interest in models like GPT-2 or Phi series for prototype projects.
- One noted that Tinystories could offer an accessible entry point for small-scale pretraining on consumer hardware.
- Innovative Approaches to Reinforcement Learning: Discussion emerged about the use of logits as intermediate representations in a new reinforcement learning model, stressing delays in normalization for effective sampling.
- The proposal includes replacing softmax with energy-based methods and integrating multi-objective training paradigms for more effective model performance.
- Challenges of Training Small Models: Members discussed the common hurdles faced when training small models on consumer hardware, emphasizing the importance of optimization techniques.
- One user humorously noted that opting for cloud solutions usually offers easier training than local setups, which require extensive optimization efforts.
Links mentioned:
- Anna’s Archive: no description found
- Reddit - Dive into anything: no description found
- Minimum Width for Universal Approximation: The universal approximation property of width-bounded networks has been studied as a dual of classical universal approximation results on depth-bounded networks. However, the critical width...
- Reddit - Dive into anything: no description found
Yannick Kilcher ▷ #paper-discussion (6 messages):
Forward citation of language models, Monte Carlo Tree Diffusion, Challenges in balanced language datasets, Paper discussion scheduling
- Exploring Forward Citations in Language Models: A member noted a forward citation regarding language models indicating that if trained on balanced corpora like Japanese and English, it activates based on target languages such as English for French and Japanese for Chinese.
- They questioned whether this could be extended to more languages, discussing the trade-offs of one dominant language versus multiple balanced ones.
- Introducing Monte Carlo Tree Diffusion: A link to a paper on Monte Carlo Tree Diffusion was shared, detailing how it combines the generative strength of diffusion models with MCTS's adaptive search capabilities.
- This framework reconceptualizes denoising as a tree-structured process, enabling the iterative evaluation and refinement of plans.
- Challenges in Testing Larger Scales of Balanced Languages: One participant remarked on the difficulty of testing larger scales with balanced languages due to the scarcity of open datasets providing more than 3-5B natural tokens in any language other than English.
- They expressed interest in pretraining from scratch with a balanced approach, such as using 20M tokens of 4 languages.
- Daily Paper Discussion Updates: A member mentioned they would have to skip the paper discussion today but anticipated a more robust session tomorrow.
- Another member indicated a busy crunch week, expressing uncertainty about participation in discussions this week, but expects to resume next week.
Link mentioned: Monte Carlo Tree Diffusion for System 2 Planning: Diffusion models have recently emerged as a powerful tool for planning. However, unlike Monte Carlo Tree Search (MCTS)-whose performance naturally improves with additional test-time computation (TTC),...
Yannick Kilcher ▷ #agents (5 messages):
Smolagents by Hugging Face, New AI Model without Tokens, Novel Language Model Architecture
- Hugging Face Launches Smolagents: Hugging Face introduced an alternative to
deep researchwith their agent framework smolagents, which runs with a processing time of around 13 seconds for 6 steps.- The original code can be modified to extend execution longer when run on a local server, showcasing adaptability for users.
- Can AI Think Without Tokens?: A YouTube video sparked a discussion on whether models can think without using tokens, challenging traditional notions in AI.
- The speaker engages viewers by questioning the fundamental mechanics of AI operations, encouraging sign-ups for regular updates.
- Exploring a Novel Language Model Architecture: A paper on arXiv outlines a new language model that scales test-time computation through implicit reasoning in latent space, unrolling to arbitrary depth.
- This model boasts 3.5 billion parameters and achieves performance improvements on reasoning benchmarks without the need for specialized training, challenging conventional methods.
Links mentioned:
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach: We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling...
- New AI Model "Thinks" Without Using a Single Token: Can models think without using tokens?! Really??Join My Newsletter for Regular AI Updates 👇🏼https://forwardfuture.aiMy Links 🔗👉🏻 Subscribe: https://www....
- Open Deep-Research - a Hugging Face Space by m-ric: no description found
- smolagents/examples/open_deep_research at main · huggingface/smolagents: 🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents. - huggingface/smolagents
Yannick Kilcher ▷ #ml-news (20 messages🔥):
Elon Musk's Grok 3, Thomson Reuters AI Copyright Case, OpenAI Roadmap Update, Literature Review Tool, Pre-trained Language Models Release Practices
- Elon Musk's Grok 3 Set to Challenge OpenAI: Elon Musk announced that his new AI chatbot, Grok 3, is nearing release, claiming it outperforms existing models in reasoning capabilities, with a launch expected in about two weeks.
- This announcement follows Musk's investor group's $97.4 billion bid to acquire OpenAI's nonprofit assets amid his ongoing legal disputes with the company.
- Thomson Reuters Wins Major AI Copyright Case: Thomson Reuters has won a significant AI copyright case against Ross Intelligence, determining that the firm infringed its copyright by reproducing materials from Westlaw.
- US Circuit Court Judge Stephanos Bibas dismissed all of Ross's defenses, stating that none of them hold water.
- OpenAI Roadmap Reveals Future Plans: OpenAI shared its roadmap update, highlighting that GPT-4.5 will be the last non-chain-of-thought model before merging its O-series and GPT-series models into a unified system.
- The GPT-5 model is set to be released with enhanced capabilities and increased access for different subscription tiers.
- New Literature Review Tool from GitHub: A member introduced a new tool for fast literature reviews available at Deep-Research-Arxiv, emphasizing its simplicity and reliability.
- Additionally, a Hugging Face app was mentioned that facilitates literature reviews with the same goals of being fast and efficient.
- Challenges in Pre-trained Language Models Release Practices: A recent study analyzed 52,227 PTLMs on Hugging Face and identified inconsistencies in release practices, including 148 different naming practices.
- The study revealed that over 40% of changes to model weight files were not reflected in the versioning practice or documentation, indicating a significant knowledge gap.
Links mentioned:
- MSN: no description found
- Deep Research Arxiv - a Hugging Face Space by AlignAI: no description found
- Towards Semantic Versioning of Open Pre-trained Language Model Releases on Hugging Face: The proliferation of open Pre-trained Language Models (PTLMs) on model registry platforms like Hugging Face (HF) presents both opportunities and challenges for companies building products around them....
- Thomson Reuters Wins First Major AI Copyright Case in the US: The Thomson Reuters decision has big implications for the battle between generative AI companies and rights holders.
- Musk Says New AI Chatbot Outperforms Rivals, Nears Launch - Slashdot: Elon Musk said Thursday his AI startup xAI will release Grok 3, a new chatbot he claims surpasses existing AI models, within two weeks. Speaking at Dubai's World Governments Summit, Musk cited interna...
- Tweet from Sam Altman (@sama): OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.We want AI to “just work” for you; we re...
- GitHub - GitsSaikat/Deep-Research-Arxiv: Do literature review Fast, Simple and Reliable: Do literature review Fast, Simple and Reliable. Contribute to GitsSaikat/Deep-Research-Arxiv development by creating an account on GitHub.
- Elon Musk says Grok 3 in final stages, outperforming all chatbots: Elon Musk said on Thursday his AI chatbot, and ChatGPT challenger, Grok 3, is in the final stages of development and will be released in about a week or two. "Grok 3 has very powerful reasoning ...
LlamaIndex ▷ #blog (3 messages):
LlamaIndex Open Source Engineer Position, Nomic AI Embedding Model, Google Cloud Integrations
- LlamaIndex hires full-time open source engineer: LlamaIndex is seeking a full-time open source engineer to expand its framework, targeting those who love open source, Python, and AI. Interested candidates can find more information on the job post.
- This opportunity invites skilled individuals to work on exciting new capabilities for the LlamaIndex framework.
- Nomic AI advances embedding model: LlamaIndex expressed excitement over a new work from Nomic AI that highlights the importance of embedding models for Agentic Document Workflows. This development is crucial for enhancing workflow quality and efficiency, as noted in their tweet.
- The community is eager to see how this embedding model improves integration with AI workflows.
- LlamaIndex integrates with Google Cloud: LlamaIndex has launched new integrations with Google Cloud databases, allowing diverse functionalities like data store, vector store, document store, and chat store. More features concerning these integrations can be explored in their detailed post here.
- These enhancements aim to simplify and secure access to data while leveraging cloud capabilities.
LlamaIndex ▷ #general (65 messages🔥🔥):
Query Engine Tool with Metadata, Exhaustive RAG Search Techniques, Vector Database Preferences, LlamaIndex Configuration for Unicode, AI Agents and Workflow Implementation
- Creating Metadata-Driven Query Engine Tools: A user inquired about developing query engine tools that utilize predefined filters based on metadata without creating multiple indexes.
- Another user confirmed that a query tool can be instantiated using
QueryEngineTool.from_defaultswith appropriate filters.
- Another user confirmed that a query tool can be instantiated using
- Exploring Methods for Exhaustive RAG Searches: A user sought advice on the best methods for conducting exhaustive RAG searches, especially when the top k is low but many chunks are considered.
- They mentioned seeing autorag and query synthesizing as potential solutions for searching for data comprehensively.
- Vector Database Choices Discussed: There was a discussion among members about their preferred vector databases; one user mentioned trying Milvus while another confirmed their use of Pinecone.
- Another participant noted using Redis in a Docker container for vector data handling.
- Storing and Displaying Vietnamese Text with LlamaIndex: A member faced issues with LlamaIndex converting Vietnamese text to Unicode escape sequences instead of displaying proper characters.
- They sought assistance on how to configure LlamaIndex with Qdrant to handle and correctly display Vietnamese text.
- Utility of UV for Environment Management: Users shared their experiences with the
uvtool for managing virtual environments, discussing the benefits and potential drawbacks.- One shared a bash function to streamline switching between environments and adjusting configuration files using aliases.
Links mentioned:
-
uv_requirements | Pantsbuild: Generate a
python_requirementfor each entry inpyproject.tomlunder the[tool.uv]section. - Router Query Engine - LlamaIndex: no description found
- AgentWorkflow Basic Introduction - LlamaIndex: no description found
- Multi-agent workflows - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
pier1337: What are some good reasons to finetune a model?
Notebook LM ▷ #use-cases (10 messages🔥):
NotebookLM's podcasting capabilities, Monetizing content with AI, AI-generated podcast hosts, Comparing AI sources, Translating content into audio
- NotebookLM dazzles in AI podcasting: A user praised NotebookLM for making it easy to create podcasts quickly, claiming it can transform written content into binge-worthy audio without the need for speaking.
- The enthusiasm around podcasting underscored its power as a content marketing tool, highlighting a significant potential audience reach across platforms like Spotify and Substack.
- AI-Podcasts: A new revenue stream: One user outlined a potential income of $7,850/mo by running a two-person AI-podcast, focusing on the efficiency of creating content quickly.
- The post emphasized that using AI for podcast creation could lead to a substantial increase in content consumption, with a suggested 300% jump in organic reach.
- AI-generated hosts spark interest: A conversation emerged about creating a library of AI-generated podcast hosts, showcasing diverse subjects and content styles contributed by users.
- Members expressed excitement at the potential for collaboration and sharing unique AI-generated audio experiences, enhancing community engagement.
- Comparing AI sources can be tricky: One member noted concerns about NotebookLM treating multiple sources similarly, but still found it effective for analyzing job candidate scores.
- The mention of using citations further clarified the source comparison process, underlining its practical usage in evaluations.
- Demand for multi-language support: User inquiries were made about when NotebookLM would expand its capabilities to other languages.
- This highlights a growing interest in making AI tools accessible to a broader audience globally.
Links mentioned:
- Captain America_ Brave New World Review.wav: no description found
- 🎙️create podcasts, in seconds (without speaking)🤐: How I'd make an extra $7850/mo with a two-person AI-podcast 🎧 (no-code)
Notebook LM ▷ #general (49 messages🔥):
NotebookLM features, Daily usage limits, Language support, Sharing ideas in community, Audio generation issues
- NotebookLM Plus offers unique features: Members discussed how NotebookLM Plus is beneficial for students and offers features like interactive podcasts that may not be available on the free version.
- One member suggested transitioning to Google AI Premium to access bundled features saying, 'I found Google NotebookLM really good...'.
- Confusion over daily chat limits: A member questioned the existence of a daily chat limit on NotebookLM, which was confirmed by another member who noted that these limits had been announced a few months ago.
- Starting in December, 50/500 message limits were introduced for free and Plus users respectively.
- Current limitations of audio in different languages: Users expressed frustration regarding audio generation being available only in English, despite inquiries about support for other languages.
- While members shared methods to switch language in settings, audio capabilities remain limited to English-only outputs for now.
- Community interaction and support: Members discussed the purpose of the Discord group, seeing it as a platform for community interaction, support, and collaboration amongst NotebookLM users.
- Another member highlighted that forums allow for sharing ideas and solutions without extensive searching online, enhancing community connectivity.
- Challenges with audio synthesis accuracy: A user reported experiencing inaccuracies when focusing the audio overview on specific sources, suggesting a broader approach could yield better results.
- The community advised having a mix of a general notebook along with specific ones to avoid confusion and improve audio output quality.
Links mentioned:
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Reddit - Dive into anything: no description found
Modular (Mojo 🔥) ▷ #general (1 messages):
eggsquad: new Modular job postings 👀
Modular (Mojo 🔥) ▷ #mojo (40 messages🔥):
Mojo sum types, ECS vs Component Architecture, Mojo Function Wrapping, Memory Management in Mojo, New Release v25.1
- Discussion on Mojo Sum Types and
Variant: Members discussed the differences between Rust-like sum types and C-style enums, highlighting thatVariantcould cover many needs, but parameterized traits are a higher priority for upcoming features.- A user implemented a hacky union type using the variant module, prompting a conversation about the limitations of current Mojo implementations.
- Misunderstandings on ECS Implementation: A clarification was made regarding the definition of ECS, stating that state should be separated from behavior, a concept likened to the MonoBehavior pattern in Unity3D.
- Members confirmed that the original example indeed followed ECS principles with state in components and behavior in systems.
- Using Unsafe Pointers in Mojo: A conversation ensued about how to store and manage functions within structs in Mojo, resulting in an example utilizing
OpaquePointerto manage function references safely.- Users shared complete examples, acknowledging the complexities of managing lifetimes and memory when using
UnsafePointer.
- Users shared complete examples, acknowledging the complexities of managing lifetimes and memory when using
- Error in
add_funFunction Call: A user encountered a specific compiler error regarding aliasing in a function call involvingadd_fun, which sparked a discussion on possible memory management issues in Mojo.- Participants discussed functional programming patterns and mutability constraints, indicating their experiences with the current limitations of the language.
- Announcing New Release v25.1: A member announced the release of Mojo v25.1, indicating excitement for potential new features and improvements.
- This news prompted interest in updates and changes introduced in the new version.
Link mentioned: no title found: no description found
Modular (Mojo 🔥) ▷ #max (11 messages🔥):
MAX CUDA usage, NVIDIA backend bugs, Mojo API tensor types, Forum for help
- MAX Minimizes CUDA Dependency: MAX operates with only essential CUDA requirements, relying primarily on the CUDA driver for functions like memory allocation.
- As one member noted, MAX implies a lean approach to GPU use, particularly with NVIDIA hardware for optimal performance.
- Gnarly NVIDIA Backend Bugs Awaiting Attention: A member expressed uncertainty about sharing NVIDIA backend bugs, describing them as quite severe.
- Others encouraged reporting any MAX bugs, emphasizing their eagerness to investigate even the most challenging issues.
- Issues with Tensor Types in Mojo API: Concerns were raised about potentially using incorrect tensor types when accessing the Mojo API.
- This indicates that specific operations must be understood to ensure proper GPU functionality within MAX.
- Seeking Details on CUDA Issues: A user shared confusion over NVIDIA libraries causing problems and suggested posting specifics on the forum for community support.
- This approach aligns with shared community efforts to diagnose and fix issues with MAX more efficiently.
Link mentioned: Modular: Build the future of AI with us and learn about MAX, Mojo, and Magic.
MCP (Glama) ▷ #general (50 messages🔥):
MCP Development, OpenAI Models in MCP, Usage Limits for Claude Desktop, Glama Gateway Comparison, Open WebUI Features
- MCP Development Insights: Members discussed experiences with various MCP clients, with wong2/mcp-cli being highlighted for its out-of-the-box functionality.
- Buggy clients are a common theme, as various developers shared their attempts to work around limitations of existing tools.
- OpenAI Models in MCP Usage: New users expressed excitement about the capabilities of MCP, questioning if models beyond Claude could adopt MCP support.
- Some noted that while MCP is compatible with OpenAI models, other projects like Open WebUI may not prioritize it.
- Discussing Usage Limits on Claude Desktop: Users noted that usage limits on Claude Desktop have become a problem, with discussions suggesting that Glama's services could provide a workaround.
- One member emphasized that the limitations greatly affect their use case, drawing attention to how Glama offers cheaper and faster alternatives.
- Glama Gateway vs. OpenRouter: Members compared Glama's gateway with OpenRouter, noting its benefits of lower costs and privacy guarantees.
- While Glama supports fewer models, it is praised for being fast and reliable, positioning itself as a solid choice for certain applications.
- Curiosity About Open WebUI: Several users expressed curiosity about Open WebUI, mentioning its extensive feature set and recent roadmap updates for MCP support.
- Members shared positive remarks about its usability and expressed their hope to transition fully away from Claude Desktop.
Links mentioned:
- Gateway: Fast, Reliable AI Gateway
- Timothy J. Baek - Why I’m Building Open WebUI: On Autonomy, Diversity, and the Future of Humanity: no description found
- Leading LLM Models: Enterprise-grade security, privacy, with features like agents, MCP, prompt templates, and more.
- GitHub - luohy15/y-cli: A Tiny Terminal Chat App for AI Models with MCP Client Support: A Tiny Terminal Chat App for AI Models with MCP Client Support - luohy15/y-cli
tinygrad (George Hotz) ▷ #general (16 messages🔥):
Windows CI Issues, DeepSeek-R1 Model Experiment, Graph Rewrite Challenges, AI and Code Submission Etiquette
- Windows CI struggles with environment variables: A member pointed out that Windows CI failed to propagate the backend environment variable between steps, causing it to select CLANG every time. They linked a GitHub pull request addressing this issue.
- This PR ensures that the backend variable is persisted through steps by utilizing
$GITHUB_ENVduring CI execution.
- This PR ensures that the backend variable is persisted through steps by utilizing
- DeepSeek-R1 to automate GPU kernel generation: A shared blog post discussed the DeepSeek-R1 model experiment, demonstrating improvements in GPU kernel generation for solving complex problems. The technique known as test-time scaling allocates more computational resources during inference, improving model performance.
- This allows AI to effectively strategize, paralleling human problem-solving by evaluating multiple outcomes before selecting the best.
- Graph rewrite bug challenges in tinygrad: Members debated the causes behind CI failures, with one suggesting that incorrect indentation removed
bottom_up_rewritefromRewriteContext. Others indicated potential deeper issues with the graph handling, such as incorrect rewrite rules or ordering.- One member expressed that they were learning the codebase and encouraged trying various approaches instead of fixating on a single solution.
- AI's Role in Code Writing - a warning: A member emphasized the importance of reviewing code diffs thoroughly before submission, highlighting that any minor whitespace changes could lead to PR closures. They also urged against submitting code directly generated by AI, suggesting instead to use AI for brainstorming and feedback.
- This approach is seen as a way to respect community time and encourage original coding efforts among members.
Links mentioned:
- Speed - tinygrad docs: no description found
- Tweet from 0xSG - */acc (@sxsm): @__tinygrad new beam search just droppedQuoting Anne Ouyang (@anneouyang) New blog post from Nvidia: LLM-generated GPU kernels showing speedups over FlexAttention and achieving 100% numerical corre...
- Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog: As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning ...
- Ensure Windows CI correctly tests the specified backends by rmtew · Pull Request #9047 · tinygrad/tinygrad: Ensure that the set backend environment variable is persisted to the next step via $GITHUB_ENVIt doesn't actually persist for Windows unless shell is explicitly set to bash.Add the assertion ....
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
tinygrad vs PyTorch, Performance & Cost Efficiency, Understanding Hardware
- Evaluating Tinygrad vs PyTorch: A user inquired about the benefits of switching from PyTorch to tinygrad, wondering if the effort to learn tinygrad would be justified.
- Another member suggested that it makes sense if you're looking for cheaper hardware or aiming to grasp what's happening 'under the hood'.
- Cheaper and Faster Models: For those concerned about cost efficiency or performance, moving to tinygrad could eventually lead to a faster model compared to the typical PyTorch setup.
- This could represent a significant advantage for users focused on optimization and resource management.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
LLM Agents MOOC Hackathon, Participation statistics, Winning teams, Top represented countries, Top represented companies
- Winning Teams of LLM Agents Hackathon Announced: Excitement fills the community as the winning teams of the LLM Agents MOOC Hackathon are announced, showcasing the amazing participation from the global AI community.
- Prof Dawn Song highlighted this achievement, emphasizing the thrilling enthusiasm from participants worldwide, with details shared on Twitter.
- Incredible Participation Statistics Revealed: The hackathon boasted ~3,000 participants from 127 countries, with 1,100+ universities and 800+ companies involved.
- Top participation came from the US, India, and China, showcasing a diverse representation of global talent.
- Top Schools Standing Out in Participation: Recognized institutions include UC Berkeley, UIUC, Stanford, Carnegie Mellon, and Northeastern, drawing significant participant numbers.
- These schools were among the top represented, indicating their strong presence in the AI community.
- Major Companies Represented at the Hackathon: Companies such as Amazon, Microsoft, Samsung, and Salesforce were notably represented among participants.
- Their involvement highlights the hackathon's appeal to key players in the AI sector, fostering collaboration and innovation.
- Explore Winning Submissions on Hackathon Website: The winning teams and their submissions can be explored on the official hackathon website.
- Participants and attendees are encouraged to visit the hackathon website to celebrate the achievements.
Link mentioned: Tweet from Dawn Song (@dawnsongtweets): 🎉 Excited to announce the winning teams of LLM Agents MOOC Hackathon! We’re thrilled by the amazing participation and enthusiasm from the global AI community:🌍 ~3,000 participants from 127 countries...
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Spring 2025 MOOC, Advanced LLM Agents, Live Sessions, AI for Mathematics
- Spring 2025 MOOC officially launched: The Spring 2025 MOOC has officially launched, targeting the broader AI community with an invitation to retweet Prof Dawn Song's announcement.
- This semester aims to build on the success of Fall 2024, which had 15K+ registered learners and 200K+ lecture views on YouTube.
- Advanced Topics to Explore: The updated curriculum covers advanced topics such as Reasoning & Planning, Multimodal Agents, and AI for Mathematics and Theorem Proving.
- This initiative reflects a growing interest in more complex areas of AI such as Agent Safety & Security.
- Join the Live Sessions: Classes will be streamed live every Monday at 4:10 PM PT, providing an engaging learning experience for all participants.
- The series invites everyone from students to researchers to partake in shaping the future of LLM Agents.
Link mentioned: Tweet from Dawn Song (@dawnsongtweets): Really excited to announce our Advanced LLM Agents MOOC (Spring 2025)!Building on the success of our LLM Agents MOOC from Fall 2024 (15K+ registered learners, ~9K Discord members, 200K+ lecture views ...
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (10 messages🔥):
Hackathon Participation, Certificate Resending Requests, Prompt Evaluation, Ninja Certification, Certificate Declaration Form
- No Hackathon This Semester: A new student inquired about participating in a hackathon this semester, but it was confirmed that there is none planned for this spring.
- Prof Song has offered several hackathons in the past and may continue to do so in the future.
- Certificates Not Received: Multiple users reported not receiving their certificates, with one student requesting to resend it to a specific email address.
- Tara confirmed she would add the request to her tasks but mentioned it might take until the weekend to fulfill.
- Prompt Evaluations for Ninja Certification: A student queried about the grading of their lab assignments submitted for ninja certification and the identification of best prompts.
- Tara indicated that there were no formal grades and suggested testing prompts against another student's submissions in an assigned channel.
- Certificate Declaration Requirement: Another student requested help locating their fall 2024 certificate and was asked if they completed the required declaration form.
- Tara expressed uncertainty about their status in the system, indicating that submission of the form is necessary for certificate processing.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
Updates on Release Details, Guidance for Newcomers in AI/ML
- Updates on Release Details: An announcement indicated that more details will be released soon, thanking users for their patience.
- Stay tuned for the upcoming updates that could provide additional insights.
- Guidance for Newcomers in AI/ML: A new member expressed their interest in getting guidance on starting in the AI/ML domain and understanding model training techniques.
- Looking for help, they reached out to the community for insights on how to effectively begin their journey.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
tarande57: we'll release details soon! thank you for your patience!
Torchtune ▷ #general (9 messages🔥):
Distributed Inference with Torchtune, Torchtune Docker Image, Using vLLM for Model Loading
- Distributed Inference is possible with Torchtune: A member inquired about running distributed inference on multiple GPUs with Torchtune, to which another member pointed to the GitHub recipe for guidance.
- Moreover, using a saved model with vLLM was suggested as an alternative that would also offer speed benefits.
- No Available Docker Image for Torchtune: A member asked if a Docker image for Torchtune exists, expressing difficulty in finding one.
- Another participant confirmed that there is currently no Docker image, guiding towards the installation instructions on GitHub.
Links mentioned:
- GitHub - pytorch/torchtune: PyTorch native post-training library: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/recipes/dev/generate_v2_distributed.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (5 messages):
Checkpointing Branch, Recipe State Functionality, Documentation Improvement, Team Collaboration
- Checkpointing Branch Successfully Cloned: A member confirmed they've successfully cloned the checkpointing branch and stated it performs great after testing.
- They expressed intent to verify whether recipe_state.pt functions as intended, potentially expanding the documentation on resuming training.
- Lighthearted Reactions to Testing Success: Another member reacted positively to the success of the testing, humorously acknowledging a previous uncertainty with a playful tone.
- This casual exchange highlights the team's camaraderie in troubleshooting and project progress.
- Inquiry About Past Confusion: There was a moment of uncertainty, with a member questioning whether they had been wrong about some details.
- This indicates ongoing discussions and clarifications among team members regarding the project.
- Willingness to Collaborate on Checkpointing PR: A team member dropped a message in the checkpointing PR, expressing eagerness to collaborate on the project.
- This shows a proactive approach to teamwork and a commitment to improving the checkpointing process.
DSPy ▷ #general (10 messages🔥):
Inference-Time Scaling, LangChain vs DSPy, DSPy 2.6 Changes
- NVIDIA Explores Inference-Time Scaling: NVIDIA's new experiment demonstrates the approach of inference-time scaling using the DeepSeek-R1 model to optimize GPU attention kernels, allowing for better problem-solving by evaluating multiple outcomes.
- Notably, this technique assigns additional computational resources during inference, akin to human problem-solving strategies.
- Choosing Between LangChain and DSPy: A question arose regarding when to use LangChain over DSPy, highlighting that both have unique use cases.
- One member advised that if the learning curve seems daunting, it may be better to leverage established approaches within LangChain instead.
- DSPy 2.6 Changelog Inquiry: A user inquired about the changelog for DSPy 2.6, mentioning the introduction of instructions for Signatures and questioning their effectiveness compared to previous versions.
- A response clarified that these instructions have been around since 2022, and a detailed change log is available on GitHub for further insights.
Link mentioned: Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog: As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning ...
Nomic.ai (GPT4All) ▷ #general (10 messages🔥):
GPT4All v3.9.0 and Deepseek R1 Integration, LocalDocs Functionality and Limitations, NOIMC v2 Release and Implementation, Nomic's Multilingual MoE Text Embeddings, Turning English Prompts into Code
- GPT4All v3.9.0 taps into Deepseek R1: Members clarified that GPT4All v3.9.0 does not fully integrate Deepseek R1, but instead allows users to download the model locally and run it, emphasizing offline capabilities.
- Challenges were noted regarding running the full model locally, as it seems limited to smaller variants like a 13B parameter model that underperforms the full version.
- LocalDocs needs improvement: A user shared frustrations about the LocalDocs feature, describing it as barebones and only providing accurate results about half the time with their TXT documents.
- Questions were raised about whether this limitation stems from using the Meta-Llama-3-8b instruct model or incorrect settings.
- Concerns about NOIMC v2 implementation: Members questioned why the NOIMC v2 model has not been properly implemented, despite its release being acknowledged.
- A link to the nomic-embed-text-v2-moe model was shared, highlighting its multilingual performance and capabilities.
- Discussion on multilingual text embeddings: The nomic-embed-text-v2-moe model was praised for its state-of-the-art multilingual capabilities, supporting approximately 100 languages with significant high performance compared to models of comparable size.
- Features like flexible embedding dimensions and its fully open-source nature were emphasized, with links provided to its code.
- Advice needed for converting prompts to code: A user sought assistance on what tools to use to convert English prompts into workable code, indicating a need for effective solutions.
- The lack of concrete suggestions prompted further inquiries on suitable options to facilitate this process.
Link mentioned: nomic-ai/nomic-embed-text-v2-moe · Hugging Face: no description found
Cohere ▷ #api-discussions (2 messages):
Rerank 3.5 behavior, Cohere with Salesforce BYOLLM
- Rerank 3.5 provides inconsistent scoring: A user reported that the same document receives different scores in Rerank 3.5 when processed in different batches, which is contrary to their expectations for a deterministic behavior.
- This variability seems counterintuitive given that it operates as a cross-encoder.
- Challenges using Cohere with BYOLLM: A member asked if anyone has successfully used Cohere as an LLM with Salesforce's BYOLLM open connector, noting issues with the chat endpoint at api.cohere.ai.
- They mentioned attempting to create an https REST service to invoke Cohere's chat API, following a suggestion from Salesforce support.