[AINews] QwQ-32B claims to match DeepSeek R1-671B
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Two stage RL is all you need?
AI News for 3/5/2025-3/6/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (227 channels, and 3619 messages) for you. Estimated reading time saved (at 200wpm): 351 minutes. You can now tag @smol_ai for AINews discussions!
As previewed last November and again last month, the Alibaba Qwen team is finally out with their final version of QwQ, their Qwen2.5-Plus + Thinking (QwQ) post train boasting numbers comparable to R1 which is an MoE as much as 20x larger.
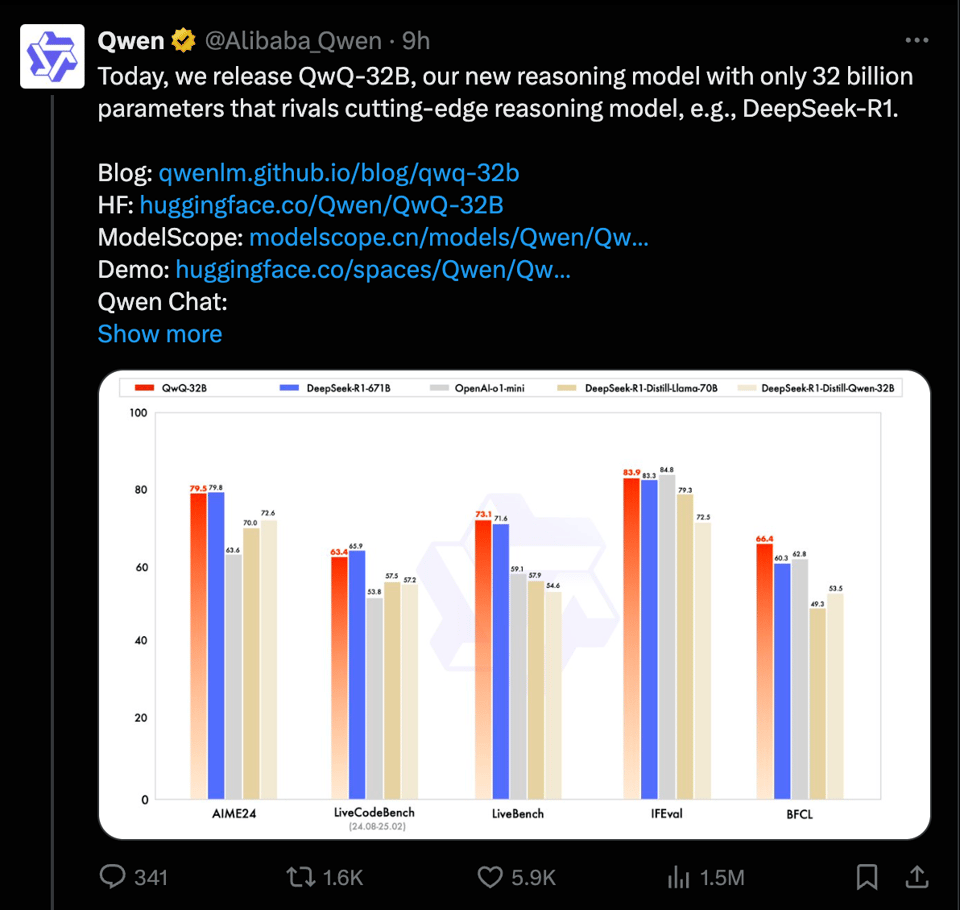
It's still early so no independent checks available yet, but the Qwen team have done the bare essentials to reassure us that they have not simply overfit to benchmarks in order to get this result - in that they boast decent non-math/coding benchmark numbers still, and gave us one paragraph on how:
- In the initial stage, we scale RL specifically for math and coding tasks. Rather than relying on traditional reward models, we utilized an accuracy verifier for math problems to ensure the correctness of final solutions and a code execution server to assess whether the generated codes successfully pass predefined test cases. As training episodes progress, performance in both domains shows continuous improvement.
- After the first stage, we add another stage of RL for general capabilities. It is trained with rewards from general reward model and some rule-based verifiers. We find that this stage of RL training with a small amount of steps can increase the performance of other general capabilities, such as instruction following, alignment with human preference, and agent performance, without significant performance drop in math and coding.
More information - a paper, sample data, sample code - could help understand, but this is fair enough for a 2025 open model disclosure. It will take a while more for QwQ-32B to rank on the Open LLM Leaderboard but here is where things currently stand, as a reminder that thinking posttrains aren't strictly better than their instruct predecessor.
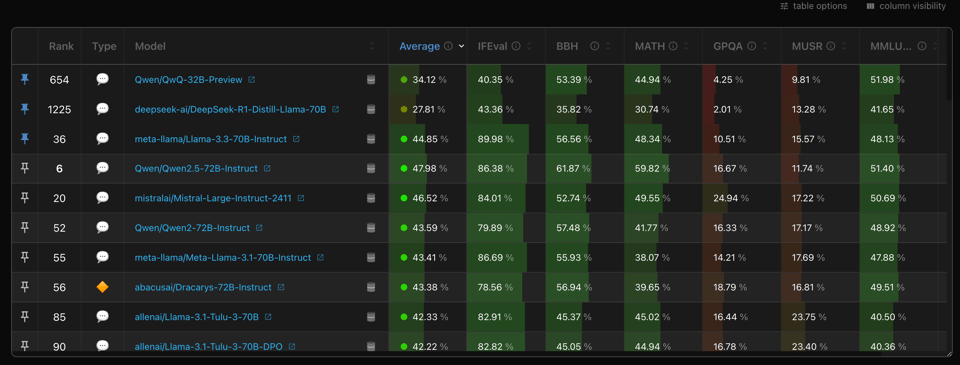
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- OpenAI Discord
- Codeium (Windsurf) Discord
- aider (Paul Gauthier) Discord
- LM Studio Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- Perplexity AI Discord
- HuggingFace Discord
- MCP (Glama) Discord
- Latent Space Discord
- Stability.ai (Stable Diffusion) Discord
- LlamaIndex Discord
- Notebook LM Discord
- Nous Research AI Discord
- OpenRouter (Alex Atallah) Discord
- Yannick Kilcher Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- Eleuther Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (676 messages🔥🔥🔥):
- OpenAI ▷ #annnouncements (2 messages):
- OpenAI ▷ #ai-discussions (546 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (10 messages🔥):
- OpenAI ▷ #prompt-engineering (12 messages🔥):
- OpenAI ▷ #api-discussions (12 messages🔥):
- Codeium (Windsurf) ▷ #announcements (1 messages):
- Codeium (Windsurf) ▷ #discussion (6 messages):
- Codeium (Windsurf) ▷ #windsurf (397 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (201 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (53 messages🔥):
- LM Studio ▷ #general (84 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (134 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (114 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (2 messages):
- Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- Interconnects (Nathan Lambert) ▷ #lectures-and-projects (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (9 messages🔥):
- GPU MODE ▷ #general (48 messages🔥):
- GPU MODE ▷ #triton (4 messages):
- GPU MODE ▷ #cuda (13 messages🔥):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #off-topic (12 messages🔥):
- GPU MODE ▷ #irl-meetup (3 messages):
- GPU MODE ▷ #triton-puzzles (1 messages):
- GPU MODE ▷ #rocm (6 messages):
- GPU MODE ▷ #tilelang (17 messages🔥):
- GPU MODE ▷ #metal (1 messages):
- GPU MODE ▷ #reasoning-gym (12 messages🔥):
- GPU MODE ▷ #gpu模式 (1 messages):
- GPU MODE ▷ #submissions (11 messages🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (107 messages🔥🔥):
- Perplexity AI ▷ #sharing (6 messages):
- Perplexity AI ▷ #pplx-api (4 messages):
- HuggingFace ▷ #general (47 messages🔥):
- HuggingFace ▷ #today-im-learning (6 messages):
- HuggingFace ▷ #cool-finds (1 messages):
- HuggingFace ▷ #i-made-this (3 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #smol-course (3 messages):
- HuggingFace ▷ #agents-course (51 messages🔥):
- MCP (Glama) ▷ #general (73 messages🔥🔥):
- MCP (Glama) ▷ #showcase (23 messages🔥):
- Latent Space ▷ #ai-general-chat (60 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (47 messages🔥):
- LlamaIndex ▷ #blog (1 messages):
- LlamaIndex ▷ #general (43 messages🔥):
- Notebook LM ▷ #use-cases (13 messages🔥):
- Notebook LM ▷ #general (29 messages🔥):
- Nous Research AI ▷ #general (33 messages🔥):
- Nous Research AI ▷ #ask-about-llms (1 messages):
- Nous Research AI ▷ #interesting-links (4 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (32 messages🔥):
- Yannick Kilcher ▷ #general (13 messages🔥):
- Yannick Kilcher ▷ #paper-discussion (5 messages):
- Yannick Kilcher ▷ #ml-news (2 messages):
- Cohere ▷ #「💬」general (14 messages🔥):
- Cohere ▷ #【📣】announcements (1 messages):
- Cohere ▷ #「🔌」api-discussions (1 messages):
- Cohere ▷ #「🤝」introductions (2 messages):
- Modular (Mojo 🔥) ▷ #general (10 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (5 messages):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (11 messages🔥):
- tinygrad (George Hotz) ▷ #general (6 messages):
- Eleuther ▷ #general (2 messages):
- Eleuther ▷ #research (2 messages):
- Eleuther ▷ #lm-thunderdome (2 messages):
- Torchtune ▷ #general (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (2 messages):
AI Twitter Recap
AI Model Releases and Benchmarks
- GPT-4.5 rollout and performance: @sama announced the rollout of GPT-4.5 to Plus users, staggering access over a few days to manage rate limits and ensure good user experience. @sama later confirmed the rollout had started and would complete in a few days. @OpenAI highlighted it as a "Great day to be a Plus user". @aidan_mclau humorously warned of potential GPU meltdown due to GPT-4.5's "chonkiness". However, initial user feedback on coding performance was mixed, with @scaling01 finding GPT-4.5 unusable for coding in ChatGPT Plus, citing issues with variable definition, function fixing, and laziness in refactoring. @scaling01 reiterated that "GPT-4.5 is unusable for coding". @juberti argued that GPT-4.5 inference costs are comparable to GPT-3 (Davinci) in summer 2022, suggesting compute costs decrease over time. @polynoamial noted GPT-4.5's ability to solve reasoning problems, attributing it to scaling pretraining.
- Qwen QwQ-32B model release: @Alibaba_Qwen announced QwQ-32B, a new 32 billion parameter reasoning model claiming to rival cutting-edge models like DeepSeek-R1. @reach_vb excitedly declared "We are so unfathomably back!" with Qwen QwQ 32B outperforming DeepSeek R1 and OpenAI O1 Mini, available under Apache 2.0 license. @Yuchenj_UW highlighted Qwen QwQ-32B as a small but powerful reasoning model that beats DeepSeek-R1 (671B) and OpenAI o1-mini, and announced its availability on Hyperbolic Labs. @iScienceLuvr also expressed excitement about Qwen team releases, considering them as impressive as DeepSeek. @teortaxesTex noted Qwen's approach of "cold-start" and competing directly with R1.
- AidanBench updates: @aidan_mclau announced aidanbench updates, stating GPT-4.5 is #3 overall and #1 non-reasoner, while Claude-3.7 models scored below newsonnet. @aidan_mclau explained a fix to O1 scores due to misclassified timeouts. @aidan_mclau pointed out the high cost of Chain of Thought (CoT) reasoning, noting complaints about GPT-4.5 cost but not Claude-3.7-thinking. @scaling01 analyzed AidanBench results, suggesting Claude Sonnet 3.5 (new) shows consistent top performance, while GPT-4.5's high score might be due to memorization on a single question.
- Cohere Aya Vision model release: @_akhaliq announced Cohere releases Aya Vision on Hugging Face, highlighting its strong performance in multilingual text generation and image understanding, outperforming models like Qwen2.5-VL 7B, Gemini Flash 1.5 8B, and Llama-3.2 11B Vision.
- Copilot Arena paper: @StringChaos highlighted the Copilot Arena paper, led by @iamwaynechi and @valeriechen_, providing LLM evaluations directly from developers with real-world insights on model rankings, productivity, and impact across domains and languages.
- VisualThinker-R1-Zero: @Yuchenj_UW discussed VisualThinker-R1-Zero, a 2B model achieving multimodal reasoning through Reinforcement Learning (RL) applied directly to the Qwen2-VL-2B base model, reaching 59.47% accuracy on CVBench.
- Light-R1: @_akhaliq announced Light-R1 on Hugging Face, surpassing R1-Distill from Scratch with Curriculum SFT & DPO for $1000.
- Ollama new models: @ollama announced Ollama v0.5.13 with new models including Microsoft Phi 4 mini with function calling, IBM Granite 3.2 Vision for visual document understanding, and Cohere Command R7B Arabic.
Open Source AI & Community
- Weights & Biases acquisition by CoreWeave: @weights_biases announced their acquisition by CoreWeave, an AI hyperscaler. @ClementDelangue praised Weights & Biases as one of the most impactful AI companies and congratulated them on the acquisition by CoreWeave. @iScienceLuvr also highlighted the acquisition as huge news for the AI infra community. @steph_palazzolo reported on the acquisition talks, mentioning a potential $1.7B deal to diversify CoreWeave's customer base into software. @alexandr_wang and @alexandr_wang shared articles covering the acquisition.
- Keras 3.9.0 release: @fchollet announced Keras 3.9.0 release with new ops, image augmentation layers, bug fixes, performance improvements, and a new rematerialization API.
- Llamba models: @awnihannun promoted Llamba models from Cartesia, high-quality 1B, 3B, and 7B SSMs with MLX support for fast on-device execution.
- Hugging Face integration: @_akhaliq announced a Hugging Face update allowing developers to deploy models directly from Hugging Face with Gradio, choosing inference providers and requiring user login for billing. @sarahookr mentioned partnering with Hugging Face for the release of Aya Vision.
AI Applications & Use Cases
- Google AI Mode in Search: @Google introduced AI Mode in Search, an experiment offering AI responses and follow-up questions. @Google detailed AI Mode expanding on AI Overviews with advanced reasoning and multimodal capabilities, rolling out to Google One AI Premium subscribers. @Google also announced Gemini 2.0 in AI Overviews for complex questions like coding and math, and open access to AI Overviews without sign-in. @jack_w_rae congratulated the Search team on the AI Mode launch, anticipating its utility for a wider audience. @OriolVinyalsML highlighted Gemini's integration with Search through AI Mode.
- AI agents and agentic workflows: @llama_index promoted Agentic Document Workflows integrating into software processes for knowledge agents. @DeepLearningAI and @AndrewYNg announced a new short course on Event-Driven Agentic Document Workflows in partnership with LlamaIndex, teaching how to build agents for form processing and document automation. @LangChainAI announced Interrupt, an upcoming AI agent conference featuring @benjaminliebald from Harvey AI on building legal copilots. @omarsar0 shared thoughts on building AI agents, suggesting hooking up APIs to LLMs or using agentic frameworks, claiming it's not hard to achieve decent agent performance.
- Perplexity AI features: @perplexity_ai announced a new voice mode for the Perplexity macOS app. @AravSrinivas noted Ask Perplexity's 12M impressions in less than a week.
- Google Shopping AI features: @Google introduced new AI features on Google Shopping for fashion and beauty, including AI-generated image-based recommendations, virtual try-ons, and AR makeup inspiration.
- Android AI-powered features: @Google highlighted new AI-powered features in Android, along with safety tools and connectivity improvements.
- Function Calling Guide for Gemini 2.0: @_philschmid announced an end-to-end function calling guide for Google Gemini 2.0 Flash, covering setup, JSON schema, Python SDK, LangChain integration, and OpenAI compatible API.
AI Infrastructure & Compute
- Mac Studio with 512GB RAM: @awnihannun highlighted the new Mac Studio with 512GB RAM, noting it can fit 4-bit Deep Seek R1 with spare capacity. @cognitivecompai reacted to the 512GB RAM option with "Shut up and take my money!".
- MLX and LM Studio on Mac: @reach_vb noted MLX and LMStudio's highlight in the M3 Ultra announcement as surreal. @awnihannun also pointed out MLX + LM Studio featured on the new Mac Studio product page. @reach_vb shared a positive experience with llama.cpp and MLX on MPS, contrasting it with torch.
- Compute efficiency and scaling: @omarsar0 discussed approaches to improve reasoning model efficiency, mentioning clever inference methods and UPFT (efficient training with reduced tokens). @omarsar0 shared a paper on reducing LLM fine-tuning costs by 75% while maintaining reasoning performance using "A Few Tokens Are All You Need" approach. @jxmnop highlighted dataset distillation's efficiency, achieving 94% accuracy on MNIST by training on only ten images.
- OpenCL's missed opportunity in AI compute: @clattner_llvm reflected on OpenCL as the tech that "should have" won AI compute, sharing lessons learned from its failure.
AI Safety & Policy
- Superintelligence strategy and AI safety: @DanHendrycks with @ericschmidt and @alexandr_wang proposed a new strategy for superintelligence, arguing it is destabilizing and calling for a strategy of deterrence (MAIM), competitiveness, and nonproliferation. @DanHendrycks introduced Mutual Assured AI Malfunction (MAIM) as a deterrence regime for destabilizing AI projects, drawing parallels to nuclear MAD. @DanHendrycks warned against a US AI Manhattan Project for superintelligence, as it could cause escalation and provoke deterrence from states like China. @DanHendrycks emphasized nonproliferation of catastrophic AI capabilities to rogue actors, suggesting tracking AI chips and preventing smuggling. @DanHendrycks highlighted AI chip supply chain security and domestic manufacturing as critical for competitiveness, given the risk of China invading Taiwan. @DanHendrycks drew parallels to Cold War policy for addressing AI's problems. @saranormous promoted a NoPriorsPod episode on this national security strategy with @DanHendrycks, @alexandr_wang, and @ericschmidt. @Yoshua_Bengio supported Sutton and Barto's Turing Award and emphasized the irresponsibility of releasing models without safeguards. @denny_zhou quoted advice to prioritize ambition in AI research over privacy, explainability, or safety.
- Geopolitics and AI competition: @NandoDF raised the question of whether China or USA is perceived as an authoritarian government potentially unfettered in AI development. @teortaxesTex noted escalating tensions and a shift away from conciliatory approaches in China's rhetoric. @teortaxesTex highlighted the presence of transgender individuals in top Chinese AI teams as a sign of China's human capital competitiveness. @RichardMCNgo discussed the implications of AI progress on deindustrialization and the nature of work, suggesting a preference for "real" manufacturing jobs grounded in local contexts over abstract roles. @hardmaru believes geopolitics and de-globalization will shape the world in the next decade.
- AI control and safety research: @NeelNanda5 expressed excitement about AI control becoming a real research field with its first conference.
- Disinformation and truth in the attention economy: @ReamBraden observed the staggering amount of disinformation on X, arguing that the incentives of the attention economy are incompatible with "free speech" and that new incentives are needed for truth online.
Memes & Humor
- GPT-4.5 "chonkiness" and GPU melting: @aidan_mclau warned "psa: gpt-4.5 is coming to plus our gpus may melt so bear with us!". @aidan_mclau posted "live footage of our supercomputers serving chonk". @aidan_mclau joked "yeah well ur model so fat it rolled itself out". @stevenheidel sent "thoughts and prayers for our GPUs as we roll out gpt-4.5".
- GPT-4.5 greentext memes: @SebastienBubeck mentioned GPT-4.5 being available to pro users for "finish the green text" memes. @iScienceLuvr and @iScienceLuvr admitted to being "wirehacked" and "embarrassed" by hilarious GPT-4.5 generated greentexts about themselves.
- ChatGPT UltraChonk 7 High cost: @andersonbcdefg joked about the future cost of ChatGPT UltraChonk 7 High, comparing 1.5 weeks of access to $800k inheritance or 2 dozen eggs in 2028.
- Movie opinions and Aidan Moviebench: @aidan_mclau declared "inception is actually the best movie humanity has ever made" as "the o1 of aidan moviebench". @aidan_mclau stated "the only good christopher nolan movies are inception and the dark knight".
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Apple's Mac Studio with M3 Ultra for AI-Inference and 512GB Unified Memory
- Apple releases new Mac Studio with M4 Max and M3 Ultra, and up to 512GB unified memory (Score: 422, Comments: 290): Apple has released a new Mac Studio featuring the M4 Max and M3 Ultra chips, offering up to 512GB unified memory.
- Discussions centered around memory bandwidth and cost emphasize the challenges of achieving high bandwidth with DDR5 and AMD Turin, with 106GB/s per CCD and a need for 5x CCD to surpass 500GB/s. Comparisons highlight the EPYC 9355P at $2998 and the high cost of server RAM, questioning the affordability of Apple's offerings.
- Users express interest in the practical applications and performance of the new Mac Studio, particularly for AI inference tasks like running Unsloth DeepSeek R1 and LLM token generation. The 512GB model is seen as a viable option for local R1 hosting, despite its high price, and comparisons are made to setups like 8 RTX 3090s.
- The pricing and configuration of the Mac Studio are heavily scrutinized, with the 512GB variant priced at €11k in Italy and $9.5k in the US. The education discount reduces this to ~$8.6k, and the M4 Max is noted for its 546GB/s memory bandwidth, positioning it as a competitor to Nvidia Digits.
- The new king? M3 Ultra, 80 Core GPU, 512GB Memory (Score: 207, Comments: 141): The post discusses the Apple M3 Ultra with a 32-core CPU, 80-core GPU, and 512GB of unified memory, which opens up significant possibilities for computing power. The base price is $9,499, with options for customization and pre-order, highlighting the model's potential impact on high-performance computing.
- Thunderbolt Networking & Asahi Linux: Users discuss macOS's automatic setup for Thunderbolt networking, noting its previous limitations at 10Gbps with TB3/4, while Asahi Linux currently supports some Apple Silicon chips but not the M3. Some users tried Asahi on M2 chips but found it lacking, appreciating the team's efforts despite preferring macOS.
- Comparison with NVIDIA and Cost Efficiency: The M3 Ultra's lack of CUDA is seen as a downside for training and image generation, with some users noting the Mac's slower performance with larger prompts. The cost of the M3 Ultra is compared to NVIDIA GPUs, with discussions highlighting its power efficiency (480W vs. 5kW for equivalent GPUs) and the challenges of comparing GPU to CPU inference.
- Pricing and Value Perception: The M3 Ultra's price point is debated, with some users considering it a good deal due to its 512GB of unified memory and efficiency, while others argue it's overpriced compared to NVIDIA GPUs. The device is contrasted with 80GB H100 and Blackwell Quadro, emphasizing its value in memory capacity and bandwidth despite a higher initial cost.
- Mac Studio just got 512GB of memory! (Score: 106, Comments: 76): The Mac Studio now features 512GB of memory and 4TB storage with a memory bandwidth of 819 GB/s for $10,499 in the US. This configuration is potentially capable of running Llama 3.1 405B at 8 tps.
- Discussions highlight the cost-effectiveness of the Mac Studio compared to other high-performance setups, such as a Nvidia GH200 624GB system costing $44,000. Users debate the practicality of the $10,499 price tag, with some noting that it offers a competitive alternative to other expensive hardware configurations.
- Users discuss the technical capabilities of the Mac Studio, particularly its ability to run models like Deepseek-r1 672B with 70,000+ context using tools like the VRAM Calculator. There's debate over its suitability for running large models with small context sizes and the potential of clustering multiple units for higher performance.
- Conversations touch on the limitations of Mac systems for certain tasks, such as training models, and the challenges of achieving similar memory bandwidth with custom-built systems. Some users note the need for advanced configurations, like using Threadripper or EPYC systems, to match the Mac Studio's performance, while others suggest networking multiple Macs for increased RAM.
Theme 2. Qwen/QwQ-32B Launch: Performance Comparisons and Benchmarks
- Qwen/QwQ-32B · Hugging Face (Score: 169, Comments: 55): Qwen/QwQ-32B is a model available on Hugging Face, but the post does not provide any specific details or context about it.
- Qwen/QwQ-32B is generating significant excitement as users express that it may outperform R1 and potentially be the best 32B model to date. Some users speculate it could rival much larger models, with mentions of it being better than a 671B model and suggesting a combination with QwQ 32B coder would be powerful.
- Users discuss performance and implementation details, with some preferring Bartowski's GGUFs over the official releases, while others are impressed by the model's capabilities in specific use cases like roleplay and fiction. The model's availability on Hugging Face and its potential to run efficiently on existing hardware like a 3090 GPU are highlighted.
- There is speculation about the broader impact on the tech industry, with some suggesting that if the model gains traction, it could affect companies like Nvidia. However, others argue that demand for self-hosting could benefit Nvidia by expanding its customer base.
- Are we ready! (Score: 567, Comments: 77): Junyang Lin announced the completion of the final training of QwQ-32B via a tweet on March 5, 2025, which garnered 151 likes and other interactions. The tweet included a fish emoji and was posted from a verified account, indicating the significance of this development in AI training milestones.
- QwQ-32B Release and Performance: There is anticipation for the release of QwQ-32B, with comments highlighting its expected superior performance compared to the QwQ-Preview and previous models like Qwen-32B. The model is anticipated to be a significant improvement, potentially outperforming Mistral Large and Qwen-72B, with some users able to run it on consumer GPUs.
- Live Demo and Comparisons: A live demo is available on Hugging Face at this link. Discussions compare QwQ-Preview favorably against R1-distill-qwen-32B, suggesting that the new model could surpass DeepSeek R1 in performance, with improved reasoning and tool use capabilities.
- Community Reactions and Expectations: Users express excitement and expectations for the new model, with some humorously considering creating their own AI named "UwU", which already exists based on QwQ. There are discussions on the potential for QwQ-32B to perform better than r1 distilled qwen 32B, indicating high community interest and competitive benchmarking.
Theme 3. llama.cpp's Versatility in Leveraging Local LLMs
- llama.cpp is all you need (Score: 356, Comments: 122): The author explored locally-hosted LLMs starting with ollama, which uses llama.cpp, but faced issues with ROCm backend compilation on Linux for an unsupported AMD card. After unsuccessful attempts with koboldcpp, they found success with llama.cpp's vulkan version. They praise llama-server for its clean web-UI, API endpoint, and extensive tunability, concluding that llama.cpp is comprehensive for their needs.
- Llama.cpp is praised for its capabilities and ease of use, but concerns about performance and multimodal support are noted. Users mention that llama.cpp has given up on multimodal support, whereas alternatives like mistral.rs support recent models and provide features like in-situ quantization and paged attention. Some users prefer koboldcpp for its versatility across different hardware.
- The llama-server web interface receives positive feedback for its simplicity and clean design, contrasting with other UIs like openweb-ui which are seen as more complex. Llama-swap is highlighted as a valuable tool for managing multiple models and configurations, enabling efficient model hot-swapping.
- Performance issues with llama.cpp are discussed, particularly in scenarios with concurrent users and VRAM management. Some users report better results with exllamav2 and TabbyAPI, which offer enhanced context length and KV cache compression capabilities.
- Ollama v0.5.13 has been released (Score: 139, Comments: 19): Ollama v0.5.13 has been released. No additional details or context about the release are provided in the post.
- Ollama v0.5.13 release discussions revolve around model compatibility and integration, with users expressing challenges in using the new version, particularly with qwen2.5vl and its multimodal capabilities. One user noted issues with the llama runner process on Windows, referencing a GitHub issue.
- There is curiosity about Ollama's ability to accept requests from Visual Studio Code and Cursor, indicating a potential new feature for handling requests from origins starting with vscode-file://.
- The conversation around Phi-4 multimodal support highlights delays due to the complexity of implementing LoRA for multimodal models, with llama.cpp currently not supporting minicpm-o2.6 and putting multimodal developments on hold.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. TeaCache Enhancement Boosts WAN 2.1 Performance
- Ok I don't like it when it pretends to be a person and talking about going to school (Score: 120, Comments: 63): The post discusses a math problem involving the calculation of "130 plus 100 multiplied by 5", emphasizing the importance of remembering the order of operations, specifically multiplication before addition, as taught in "math class." The image uses a conversational tone with highlighted phrases to engage the reader.
- Discussions emphasize that AI models like ChatGPT are not designed for simple calculations like "130 plus 100 multiplied by 5." Users argue against using reasoning models for such tasks due to inefficiency and potential errors, suggesting traditional calculators as more reliable and energy-efficient alternatives.
- The conversation highlights a common misunderstanding of Large Language Models (LLMs), with users noting that LLMs function as knowledge retrieval tools rather than true reasoning entities. Some users express frustration over the average person's misconceptions about LLM capabilities and their limitations in creativity and problem-solving.
- Humor and sarcasm are prevalent in the comments, with users joking about AI's presence in math class and its anthropomorphic portrayal. There’s a playful tone in imagining AI as a classmate, referencing PEMDAS knowledge from school textbooks, and reminiscing about AI's "parents" as Jewish immigrants from Hungary.
- Official Teacache for Wan 2.1 arrived. Some said he got 100% speed boost but I haven't tested myself yet. (Score: 108, Comments: 41): TeaCache now supports Wan 2.1, with some users claiming a 100% speed boost. Enthusiastic responses in the community, such as from FurkanGozukara, highlight excitement and collaboration in testing these new features on GitHub.
- Users discuss the installation challenges with TeaCache, specifically issues with Python and Torch version mismatches. Solutions include using pip to install Torch nightly and ensuring the correct environment is activated with "source activate" before installations.
- There is interest in understanding the differences between TeaCache and Kijai’s node. Kijai updated his wrapper to include the new TeaCache features, estimating coefficients with step skips until the official release for comparison.
- Performance improvements are noted, with users like _raydeStar reporting significant speed increases using sage attention and sparge_attn, achieving a time reduction from 34.91s/it to 11.89s/it during tests. However, some users experience artifacts and are seeking optimal settings for quality rendering.
Theme 2. Lightricks LTX-Video v0.9.5 Adds Keyframes and Extensions
- LTX-Video v0.9.5 released, now with keyframes, video extension, and higher resolutions support. (Score: 184, Comments: 53): LTX-Video v0.9.5 has been released, featuring new capabilities such as keyframes, video extension, and support for higher resolutions.
- Keyframe Feature and Interpolation: Users are excited about the keyframe feature, noting its potential as a game changer for open-source models. Frame Conditioning and Sequence Conditioning are highlighted as new capabilities for frame interpolation and video extension, with users eager to see demos of these features (GitHub repo).
- Hardware and Performance: Discussions reveal that LTX-Video is relatively small with 2B parameters, running on 6GB vRAM. Users appreciate the model's size compared to others, though balancing resources, generation time, and quality remains a challenge.
- Workflows and Examples: The community shares resources for deploying and using LTX-Video, including a RunPod template with ComfyUI for workflows like i2v and t2v. Example workflows and additional resources are shared, emphasizing the need for updates to utilize new features (ComfyUI examples).
Theme 3. Open-Source Development of Chroma Model Released
- Chroma: Open-Source, Uncensored, and Built for the Community - [WIP] (Score: 381, Comments: 117): Chroma is an 8.9B parameter model based on FLUX.1-schnell, fully Apache 2.0 licensed for open-source use and modification, currently in training. The model is trained on a 5M dataset from 20M samples, focusing on uncensored content and is supported by resources such as a Hugging Face repo and live WandB training logs.
- Dataset Sufficiency: Concerns were raised about the 5M dataset being potentially insufficient for a universal model, with comparisons to booru dumps which can reach 3M images. Questions about dataset content, including whether it includes celebrities and specific labeling for sfw/nsfw content, were also discussed.
- Technical Optimizations and Licensing: The Chroma model has undergone significant optimizations, allowing for faster training speeds (~18img/s on 8xh100 nodes), with 50 epochs recommended for strong convergence. The project's Apache 2.0 license was highlighted, but challenges in open-sourcing the dataset due to legal ambiguities were noted.
- Model Comparisons and Legal Concerns: Discussions included comparisons with other models like SDXL and SD 3.5 Medium, with some users expressing excitement about overcoming challenges in training Flux models. Legal concerns about copyright infringement when training on large datasets were also mentioned, emphasizing potential legal risks.
Theme 4. GPT-4.5 Rolls Out to Plus Users with Memory Capabilities
- 4.5 Rolling out to Plus users (Score: 394, Comments: 144): OpenAI announced the rollout of GPT-4.5 to Plus users, as indicated by a Twitter post. The image highlights an informal conversation revealing the update, accompanied by emoji reactions, emphasizing the excitement for the new release.
- Users express skepticism about GPT-4.5's self-awareness and ability to provide accurate information, with some reporting instances where the model denied its own existence. OpenAI has not clearly communicated usage limits, leading to confusion among users about the 50 messages/week cap and the timing of resets.
- There's a mix of excitement and frustration regarding the rollout, particularly about the rate limits and lack of clarity on features like improved memory. Some users report having access on both iOS and browser, with it being labeled as a "Research Preview."
- OpenAI mentioned that the rollout to Plus users would take 1-3 days, and rate limits might change as demand is assessed. Users are still awaiting further updates on limits and features, with a notable interest in potential advanced voice mode updates.
- Confirmed by openAI employee, the rate limit of GPT 4.5 for plus users is 50 messages / week (Score: 148, Comments: 61): Aidan McLaughlin confirms that GPT-4.5 limits Plus users to 50 messages per week, with potential variations based on usage. He humorously claims each GPT-4.5 token uses as much energy as Italy annually, and the tweet has garnered significant attention with 9,600 views as of March 5, 2025.
- The statement about GPT-4.5's energy consumption is widely recognized as a humorous exaggeration, with users noting it lacks logical coherence. Aidan McLaughlin's tweet is interpreted as a joke, mocking exaggerated claims about AI energy use, with comparisons like the entire energy consumption of Italy being used for a single token seen as absurd.
- Discussion highlights the massive scale of GPT-4.5, with speculation about its parameters exceeding 10 trillion. Users express curiosity about the model's size and architecture, noting that OpenAI has not disclosed specific data about the number of parameters or energy consumption.
- Commenters humorously engage with the absurdity of the energy consumption claim, using humor and satire to critique the statement. This includes jokes about using Dyson spheres in the future and playful references to non-metric units like "female Canadian hobos fighting over a sandwich."
- GPT-4.5 is officially rolling out to Plus users! (Score: 165, Comments: 56): GPT-4.5 is now accessible to Plus users in a research preview, described as suitable for writing and exploring ideas. The interface also lists GPT-4o and a beta version of GPT-4o with scheduled tasks for follow-up queries, all within a modern dark-themed UI.
- Users are discussing the memory feature in GPT-4.5, with one commenter confirming its presence, contrasting with other models that lack this feature. This addition is appreciated as it enhances the model's capabilities.
- There is significant interest in understanding the limits for Plus users, with questions about the number of messages allowed per day or week. One user reported having a conversation with more than 20 messages, and another mentioned a 50-message cap that might be adjusted based on demand.
- Some users expressed disappointment with GPT-4.5, feeling it does not significantly differentiate itself from competitors, while others are curious if there are specific tasks where GPT-4.5 excels compared to other models.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1: Alibaba's QwQ-32B Challenges the Titans
- QwQ-32B Punches Above Its Weight Against DeepSeek-R1: Alibaba's QwQ-32B, a 32-billion-parameter model, rivals the 671-billion-parameter DeepSeek-R1, showcasing the power of Reinforcement Learning (RL) scaling. The model excels in math and coding tasks, proving that size isn't everything.
- Community Eagerly Tests QwQ-32B's Might: Users are putting QwQ-32B through its paces, accessing it on Hugging Face and Qwen Chat. Early impressions suggest it matches larger models in performance, sparking excitement.
- QwQ-32B Adopts Hermes' Secret Sauce: Observers note QwQ-32B uses special tokens and formatting similar to Hermes, including
<im_start>,<im_end>, and tool-calling syntax. This enhances compatibility with advanced prompting techniques.
Theme 2: User Frustrations Boil Over AI Tool Shortcomings
- Cursor's 3.7 Model 'Dumbs Down', Users Jump Ship: Developers report Cursor's 3.7 model feels nerfed, generating unwanted readme files and misusing abstractions. A satirical Cursor Dumbness Meter mocks the decline, prompting many to consider Windsurf as an alternative.
- Claude Sonnet 3.7 Fumbles Simple Tasks: Users express disappointment with Claude Sonnet 3.7 on Perplexity, citing hallucinations in parsing JSON files and inferior performance compared to direct use via Anthropic. Frustrations mount over its "claimed improvements" not materializing.
- GPT-4.5 Teases with Limits and Refusals: OpenAI's GPT-4.5 release excites users but restricts them to 50 uses per week. It refuses to engage with story-based prompts, even when compliant with guidelines, leaving users exasperated.
Theme 3: AI Agents Aim High with Sky-High Price Tags
- OpenAI Plans to Charge Up to $20K/Month for Elite Agents: OpenAI is gearing up to sell advanced AI agents, with subscriptions ranging from $2,000 to $20,000 per month, targeting tasks like coding automation and PhD-level research. The hefty price tag raises eyebrows and skepticism among users.
- LlamaIndex Partners with DeepLearningAI for Agentic Workflows: LlamaIndex teams up with DeepLearningAI to offer a course on building Agentic Document Workflows, integrating AI agents seamlessly into software processes. This initiative underlines the increasing importance of agents in AI development.
- Composio Simplifies MCP with Turnkey Authentication: Composio now supports MCP with robust authentication, eliminating the hassle of setting up MCP servers for apps like Slack and Notion. Their announcement boasts improved tool-calling accuracy and ease of use.
Theme 4: Reinforcement Learning Plays and Wins Big Time
- RL Agent Conquers Pokémon Red with Tiny Model: A reinforcement learning system beats Pokémon Red using a policy under 10 million parameters and PPO, showcasing RL's prowess in complex tasks. The feat highlights RL's resurgence and potential in gaming AI.
- AI Tackles Bullet Hell: Training Bots for Touhou: Enthusiasts are training AI models to play Touhou, using RL with game scores as rewards. They're exploring simulators like Starcraft gym to see if RL can master notoriously difficult games.
- RL Scaling Turns Medium Models into Giants: The success of QwQ-32B demonstrates that scaling RL training boosts model performance significantly. Continuous RL scaling allows medium-sized models to compete with massive ones, especially in math and coding abilities.
Theme 5: Techies React to New Hardware Unveilings
- Apple Launches M4 MacBook Air in Sky Blue, Techies Split: Apple's new MacBook Air with the M4 chip and Sky Blue color starts at $999. While some are thrilled about the Apple Intelligence features, others grumble about specs, saying "why I don't buy Macs..."
- Thunderbolt 5 Promises Supercharged Data Speeds: Thunderbolt 5 boasts 120Gb/s unidirectional speeds, exciting users about enhanced data transfer for distributed training. It's seen as potentially outpacing the RTX 3090 SLI bridge and opening doors for Mac-based setups.
- AMD's RX 9070 XT Goes Toe-to-Toe with Nvidia: Reviews of the AMD RX 9070 XT GPU show it competing closely with Nvidia's 5070 Ti in rasterization. Priced at 80% of the 5070 Ti's $750 MSRP, it's praised as a cost-effective powerhouse.
PART 1: High level Discord summaries
Cursor IDE Discord
- Cursor's 3.7 Model Performance Questioned: Members are reporting that Cursor's 3.7 model feels nerfed, citing instances where it generates readme files without prompting and overuses Class A abstractions.
- Some users suspect Cursor is either using a big prompt or fake 3.7 models, and one member shared a scientific measurement of how dumb Cursor editor is feeling today.
- Community Satirizes Cursor's Dumbness: A member shared a link to a "highly sophisticated meter" that measures the "dumbness level" of Cursor editor.
- The meter uses "advanced algorithms" based on "cosmic rays, keyboard mishaps, and the number of times it completes your code incorrectly," sparking humorous reactions in the community.
- YOLO Mode Suffers After Updates: After an update, YOLO mode in Cursor isn't working properly, as it now requires approval before running commands, even with an empty allow list.
- One user expressed frustration, stating that they want the AI assistant to have as much agency as possible and rely on Git for incorrect removals, preferring the v45 behavior that saved them hours.
- Windsurf Alternative Gains Traction: Community members are actively discussing Windsurf's new release, Wave 4, some considering switching due to perceived advantages in the agent's capabilities, with some sharing a youtube tutorial on "Vibe Coding Tutorial and Best Practices (Cursor / Windsurf)".
- Despite the interest, concerns about Windsurf's pricing model are present, and some users mentioned it yoinks continue.dev.
- OpenAI Prepares Premium Tier: A member shared a report that OpenAI is doubling down on its application business, planning to offer subscriptions ranging from $2K to $20K/month for advanced agents capable of automating coding and PhD-level research.
- This news triggered skepticism, with some questioning whether the high price is justified, especially given the current output quality of AI models.
OpenAI Discord
- OpenAI Ships GPT-4.5: OpenAI released GPT-4.5 ahead of schedule, however is limited to 50 uses per week, and is not a replacement for GPT-4o.
- Reports indicate that GPT-4.5 is refusing story-based prompts and will gradually increase usage.
- OpenAI Iterates on AGI: OpenAI views AGI development as a continuous path rather than a sudden leap, focusing on iteratively deploying and learning from today's models to make future AI safer and more beneficial.
- Their approach to AI safety and alignment is guided by embracing uncertainty, defense in depth, methods that scale, human control, and community efforts to ensure that AGI benefits all of humanity.
- Speculation on OpenAI's O3: Members speculate on the release of O3, noting that OpenAI stated they won't release the full O3 in ChatGPT, only in the API.
- The tone of voice indicates that it is still an AI and therefore won't always be 100% accurate and that one should always consult a human therapist or doctor.
- Qwen-14B Powers Recursive Summarization: Members are using the Qwen-14B model for recursive summarization tasks and find the output better than Gemini.
- An example was given of summarization of a chess book with results of the Qwen-14B being better than Gemini, which was performing like GPT-3.5.
- Surveying Prompt Engineering: A member shared a systematic survey of prompt engineering in Large Language Models titled A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications outlining key strategies like Zero-Shot Prompting, Few-Shot Prompting, and Chain-of-Thought (CoT) prompting and the ChatGPT link to access it.
- However, discussion highlighted the survey's detailed description of each technique, while noting omissions such as Self-Discover and MedPrompt.
Codeium (Windsurf) Discord
- Windsurf's Wave 4: Windfalls and Wobbles: Windsurf launched Wave 4 (blog post) including Previews, Tab-to-import, Linter integration, Suggested actions, MCP discoverability, and improvements to Claude 3.7.
- Some users reported issues like never-ending loops and high credit consumption, while others praised the speed and Claude 3.7 integration, accessible via Windsurf Command (
CTRL/Cmd + I)
- Some users reported issues like never-ending loops and high credit consumption, while others praised the speed and Claude 3.7 integration, accessible via Windsurf Command (
- Credential Catastrophe Cripples Codeium: Multiple users reported being unable to log in to codeium.com using Google or email/password.
- The team acknowledged the login issues and provided a status page for updates.
- Credit Crunch Consumes Codeium Consumers: Users voiced concerns about rapid credit usage, especially with Claude 3.7, even post-improvements.
- The team clarified that Flex Credits roll over, and automatic lint error fixes are free, but others are still struggling with credits and tool calls.
- Windsurf's Workflow Wonders with Wave 4: A YouTube video covers the Windsurf Wave 4 updates, demonstrating Preview, Tab to Import, and Suggested Actions.
- The new Tab-to-import feature automatically adds imports with a tab press, enhancing workflow within Cascade.
- Windsurf's Wishlist: Wanted Webview and Waived Limits: Users requested features like external library documentation support, increased credit limits, adjustable chat font size, and a proper webview in the sidebar like Trae, and Firecrawl for generating llms.txt files.
- A user suggested using Firecrawl to generate an llms.txt file for websites to feed into the LLM.
aider (Paul Gauthier) Discord
- Qwen Releases QwQ-32B Reasoning Model: Qwen launched QwQ-32B, a 32B parameter reasoning model, compared favorably to DeepSeek-R1, as discussed in a VXReddit post and in their blog.
- Enthusiasts are eager to test its performance as an architect and coder with Aider integration, and its availability at HF and ModelScope was mentioned.
- Offline Aider Installation Made Possible: Users seeking to install Aider on an offline PC overcame challenges by using pip download to transfer Python packages from an online machine to an offline virtual environment.
- A successful sequence involves:
python -m pip download --dest=aider_installer aider-chat.
- A successful sequence involves:
- Achieving OWUI Harmony with OAI-Compatible Aider: To use Aider with OpenWebUI (OWUI), a member recommended to prefix the model name with
openai/to signal an OAI-compatible endpoint, such asopenai/myowui-openrouter.openai/gpt-4o-mini.- This approach bypasses
litellm.BadRequestErrorissues when connecting Aider to OWUI.
- This approach bypasses
- ParaSail Claims Rapid R1 Throughput: A user reported 300tps on R1 using the Parasail provider via OpenRouter.
- While replication proved difficult, Parasail was noted as a top performer for R1 alongside SambaNova.
- Crafting commit messages with Aider: Members discussed methods to get aider to write commit messages for staged files, suggesting
git stash save --keep-index, then/commit, and finallygit stash pop.- Another suggested using
aider --commitwhich writes the commit message, commits, and exits, and consult the Git integration docs.
- Another suggested using
LM Studio Discord
- Watch your VRAM Overflow: A member described how to detect VRAM overflow in LM Studio by monitoring Dedicated memory and Shared memory usage, providing an image illustrating the issue.
- They noted that overflow occurs when Dedicated memory is high and Shared memory increases.
- No Audio Support for Multi-Modal Phi-4: Members confirmed that multi-modal Phi-4 and audio support are not currently available in LM Studio due to limitations in llama.cpp.
- There are currently no workarounds for the missing support.
- VRAM, Context and KV Cache On Lock: A member noted that context size and KV cache settings significantly impact VRAM usage, recommending aiming for 90% VRAM utilization to optimize performance.
- Another member explained the KV cache as the value of K and V when the computer is doing the attention mechanics math.
- Sesame AI's TTS: Open Source or Smoke?: Members discussed Sesame AI's conversational speech generation model (CSM), and one member praised its lifelike qualities, linking to a demo.
- Others expressed skepticism about its open-source claim, noting the GitHub repository lacks code commits.
- M3 Ultra and M4 Max Mac Studio Announced: Apple announced the new Mac Studio powered by M3 Ultra (maxing out at 512GB ram) and M4 Max (maxing out at 128GB).
- A member reacted negatively to the RAM specs, stating why I don't buy macs....
Interconnects (Nathan Lambert) Discord
- Sutton Sparks Safety Debate!: Turing Award winner Richard Sutton's recent interview stating that safety is fake news has ignited discussion.
- Responses varied, with one member commenting Rich is morally kind of sus I wouldn’t take his research advice even if his output is prodigal.
- OpenAI Agent Pricing: $20K/Month?: According to The Information, OpenAI plans to charge $2,000 to $20,000 per month for AI agents designed for tasks such as automating coding and PhD-level research.
- SoftBank, an OpenAl investor, has committed to spending $3 billion on OpenAl's agent products this year alone.
- Alibaba's QwQ-32B Model Rivals DeepSeek: Alibaba Qwen released QwQ-32B, a 32 billion parameter reasoning model, that is competing with models like DeepSeek-R1.
- The model uses RL training and post training which improves performance especially in math and coding.
- DeepMind's Exodus to Anthropic Continues: Nicholas Carlini announced his departure from Google DeepMind to join Anthropic, citing that his research on adversarial machine learning is no longer supported at DeepMind according to his blog.
- Members noted GDM lost so many important people lately, while others said that Anthropic mandate of heaven stocks up.
- RL beats Pokemon Red: A reinforcement learning system beat Pokémon Red using a policy under 10M parameters, PPO, and novel techniques, detailed in a blog post.
- The system successfully completes the game, showcasing the resurgence of RL in solving complex tasks.
GPU MODE Discord
- Touhou AI Model Ascends: A member is training an AI model to play Touhou, using RL and the game score as the reward, considering simulators like Starcraft gym and Minetest gym.
- The goal is to determine if RL and reward functions can be used to learn game playing.
- Thunderbolt 5 Speeds Data Transfer: Members are excited about Thunderbolt 5, which could make distributed inference/training between Mac Minis/Studios more viable.
- The unidirectional speed (120gb/s) appears faster than an RTX 3090 SLI bridge (112.5gb/s).
- CUDA Compiler Gets Too Smart: The CUDA compiler optimizes away memory writes when the written data is never read, leading to no error being reported until a read is added.
- This optimization can mislead developers debugging memory write operations, as the absence of errors may not indicate correct behavior until read operations are involved.
- TileLang Struggles with CUDA 12.4/12.6: Users report mismatched elements when performing matmul on CUDA 12.4/12.6 in TileLang, prompting a bug report on GitHub.
- The code functions correctly on CUDA 12.1, and exhibits an
AssertionErrorconcerning tensor-like discrepancies.
- The code functions correctly on CUDA 12.1, and exhibits an
- QwQ-32B gives larger models a run for their money: Alibaba released QwQ-32B, a new reasoning model with only 32 billion parameters, rivaling models like DeepSeek-R1.
- The model is available on HF, ModelScope, Demo and Qwen Chat.
Perplexity AI Discord
- Google Search Enters AI Chat Arena: Google has announced AI Mode for Search, offering a conversational experience and support for complex queries, currently available as an opt-in experience for some Google One AI Premium subscribers (see AndroidAuthority).
- Some users felt perplexity isn't special anymore as a result of the announcement.
- Claude Sonnet 3.7 Misses the Mark?: A user expressed dissatisfaction with Perplexity's implementation of Claude Sonnet 3.7, finding the results inferior compared to using it directly through Anthropic.
- They added that 3.7 hallucinated errors in a simple json file, questioning the model's claimed improvements.
- Perplexity API Focus Setting Proves Elusive: A user inquired about methods to focus the API on specific topics like academic or community-related content.
- However, no solutions were provided in the messages.
- Sonar Pro Search Model Fails Timeliness Test: A user reported that the Sonar Pro model returns outdated information and faulty links, despite setting the search_recency_filter to 'month'.
- The user wondered if they were misusing the API.
- API Search Cost Remains a Mystery: A user expressed frustration that the API does not provide information on search costs, making it impossible to track spending accurately.
- They lamented that they cannot track their API spendage because the API is not telling them how many searches were used, adding a cry emoji.
HuggingFace Discord
- CoreWeave Files for IPO with 700% Revenue Increase: Cloud provider CoreWeave, which counts on Microsoft for close to two-thirds of its revenue, filed its IPO prospectus, reporting a 700% revenue increase to $1.92 billion in 2024, though with a net loss of $863.4 million.
- Around 77% of revenue came from two customers, primarily Microsoft, and the company holds over $15 billion in unfulfilled contracts.
- Kornia Rust Library opens Internships at Google Summer of Code 2025: The Kornia Rust library is opening internships for the Google Summer of Code 2025 to improve the library, mainly revolving around CV/AI in Rust.
- Interested parties are encouraged to review the documentation and reach out with any questions.
- Umar Jamil shares his journey learning Flash Attention, Triton and CUDA on GPU Mode: Umar Jamil will be on GPU Mode this Saturday, March 8, at noon Pacific, sharing his journey learning Flash Attention, Triton and CUDA.
- It will be an intimate conversation with the audience about his own difficulties along the journey, sharing practical tips on how to teach yourself anything.
- VisionKit is surprisingly NOT Open Source: The model in
i-made-thischannel uses VisionKit but is not open source, with potential release later down the road, but Deepseek-r1 was surprisingly helpful during development.- A Medium article discusses building a custom MCP server and mentions CookGPT as an example.
- Agents Course Cert Location Obscure!: Users in the agents-course channel were unable to locate their certificates in the course, specifically in this page, and asked for help.
- A member pointed out that the certificates can be found under "files" and then "certificates" in this dataset, but others have had issues with it not showing.
MCP (Glama) Discord
- Composio Supercharges MCP with Authentication: Composio now supports MCP with authentication, eliminating the need to set up MCP servers for apps like Linear, Slack, Notion, and Calendly.
- Their announcement highlights managed authentication and improved tool calling accuracy.
- WebMCP sparks Security Inferno: The concept of any website acting as an MCP server raised security concerns, especially regarding potential access to local MCP servers.
- Some described it as a security nightmare that would defeat the browser sandbox, while others suggested mitigations like CORS and cross-site configuration.
- Reddit Agent Gets Leads with MCP: A member built a Reddit agent using MCP to generate leads, illustrating MCP's practicality for real-world applications.
- Another member shared Composio's Reddit integration after a query about connecting to Reddit.
- Token Two-Step: Local vs. Per-Site: After setting up the MCP Server, a user clarified the existence of a local token alongside tokens generated per-site and per session for website access.
- The developer verified this process, emphasizing that the tokens are generated per session, per site.
- Insta-Lead-Magic Unveiled: A user showcased an Instagram Lead Scraper complemented by a custom dashboard, featured in a linked video
- No second summary provided.
Latent Space Discord
- Claude Charges Coder a Quarter: A member reported spending $0.26 to ask Claude one question about their small codebase, highlighting concerns about the cost of using Claude for code-related queries.
- A suggestion was made to copy the codebase into a Claude directory and activate the filesystem MCP server on Claude Desktop for free access as a workaround.
- M4 MacBook Air: Sky Blue and AI-Boosted: Apple announced the new MacBook Air featuring the M4 chip, Apple Intelligence capabilities, and a new sky blue color, starting at $999 as noted in this announcement.
- The new MacBook Air boasts up to 18 hours of battery life and a 12MP Center Stage camera.
- Qwen's QwQ-32B: DeepSeek's Reasoning Rival: Qwen released QwQ-32B, a new 32 billion parameter reasoning model that rivals the performance of models like DeepSeek-R1, according to this blog post.
- Trained with RL and continuous scaling, the model excels in math and coding and is available on HuggingFace.
- React: The Surprise Backend Hero for LLMs?: A member suggested React is the best programming model for backend LLM workflows, referencing a blog post on building @gensx_inc with a node.js backend and React-like component model.
- Counterpoints included the suitability of Lisp for easier DSL creation and the mention of Mastra as a no-framework alternative.
- Windsurf's Cascade: Inspect Element No More?: Windsurf released Wave 4, featuring Cascade, which sends element/errors directly to chat, aiming to reduce the need for Inspect Element, with a demo available at this link.
- The update includes previews, Cascade Auto-Linter, MCP UI Improvements, Tab to Import, Suggested Actions, Claude 3.7 Improvements, Referrals, and Windows ARM Support.
Stability.ai (Stable Diffusion) Discord
- SDXL Hands Giving You a Headache?: Users seek methods to automatically fix hands in SDXL without manual inpainting, especially when using 8GB VRAM, discussing embeddings, face detailers, and OpenPose control nets.
- The focus is on finding effective hand LoRAs for SDXL and techniques for automatic correction.
- One-Photo-Turned-Movie?: Users explored creating videos from single photos, recommending the WAN 2.1 i2v model, but noted it demands substantial GPU power and patience.
- While some suggested online services with free credits, the consensus acknowledges that local video generation incurs costs, primarily through electricity consumption.
- SD 3.5 Doesn't Quite Shine: Members reported that SD 3.5 underperformed even flux dev in my tests and nowhere close to larger models like ideogram or imagen.
- However, another member said that Compared to early sd 1.5 they have come a long way.
- Turbocharged SD3.5 Speeds: TensorArt open-sourced SD3.5 Large TurboX, employing 8 sampling steps for a 6x speed boost and better image quality than the official Stable Diffusion 3.5 Turbo, available on Hugging Face.
- They also launched SD3.5 Medium TurboX, utilizing just 4 sampling steps to produce 768x1248 resolution images in 1 second on mid-range GPUs, boasting a 13x speed improvement, also on Hugging Face.
LlamaIndex Discord
- LlamaIndex unveils Agentic Document Workflow Collab: LlamaIndex and DeepLearningAI have partnered to create a course focusing on building Agentic Document Workflows.
- These workflows aim to integrate directly into larger software processes, marking a step forward for knowledge agents.
- ImageBlock Users Encounter OpenAI Glitches: Users reported integration problems with ImageBlock and OpenAI in the latest LlamaIndex, with the system failing to recognize images; A bot suggested checking for the latest versions and ensuring the correct model, such as gpt-4-vision-preview, is in use.
- This issue highlights the intricacies of integrating vision models within existing LlamaIndex workflows.
- Query Fusion Retriever's Citations go Missing: A user found that node post-processing and citation templates were not working with the Query Fusion Retriever, particularly when using reciprocal reranking, in their LlamaIndex setup, and they linked their code for review.
- The de-duplication process in the Query Fusion Retriever might be the cause of losing metadata during node processing.
- Distributed AgentWorkflow Architecture Aspirations: Members discussed a native support for a distributed architecture in AgentWorkflow, where different agents run on different servers/processes.
- The suggested solution involves equipping an agent with tools for making remote calls to a service, rather than relying on built-in distributed architecture support.
- GPT-4o Audio Preview Model Falls Flat: A user reported integration challenges using OpenAI's audio
gpt-4o-audio-previewmodel with LlamaIndex agents, particularly with streaming events.- It was pointed out that AgentWorkflow automatically calls
llm.astream_chat()on chat messages, which might conflict with OpenAI's audio support, suggesting a potential workaround of avoiding AgentWorkflow or disabling LLM streaming.
- It was pointed out that AgentWorkflow automatically calls
Notebook LM Discord
- NotebookLM can't break free from Physics Syllabus: A user found that when they uploaded their 180-page physics textbook, the system would not get away from their syllabus by using Gemini.
- This limits the ability to deviate and explore alternative concepts outside the syllabus.
- PDF Uploading Plight: Users are facing challenges with uploading PDFs, finding them nearly unusable, especially with mixed text and image content. Google Docs and Slides seem to do a better job at rendering mixed content.
- Converting PDFs to Google Docs or Slides was suggested as a workaround, however these file formats are proprietary.
- API Access Always Anticipated: A user inquired about the existence of a NotebookLM API or future plans for one, citing numerous workflow optimization use cases for AI Engineers.
- Access to an API would allow users to integrate NotebookLM with other services and automate tasks, like a podcast generator.
- Mobile App Musings: A user inquired about a standalone Android app for NotebookLM, and another user suggested that the web version works fineeeeeee, plus there's a PWA.
- Users discussed the availability of NotebookLM as a Progressive Web App (PWA) that can be installed on phones and PCs, offering a native app-like experience without a dedicated app.
- Podcast Feature Praised: A user lauded Notebook LM's podcast generator as exquisite but wanted to know is there a way to extend the length of the podcast from 17 to 20 mins.
- The podcast feature could be a valuable asset for educators and content creators for lectures.
Nous Research AI Discord
- Gaslight Benchmark Quest Begins: A member inquired about the existence of a gaslight benchmark to compare GPT-4.5 with other models, triggering a response with a link to a satirical benchmark.
- The discussion underscores the community's interest in evaluating models beyond conventional metrics, specifically in areas like deception and persuasion.
- GPT-4.5's Persuasion Gains: A member noted that GPT-4.5's system card suggests significant improvements in persuasion, which are attributed to post-training RL.
- This observation sparked curiosity about startups leveraging post-training RL to enhance model capabilities, indicating a broader trend in AI development.
- Hermes' Special Tokens: The special tokens used in training Hermes models were confirmed to be
, , , and . - This clarification is crucial for developers fine-tuning or integrating Hermes models, ensuring proper formatting and interaction.
- QwQ-32B matches DeepSeek R1: QwQ-32B, a 32 billion parameter model from Qwen, performs at a similar level to DeepSeek-R1, which boasts 671 billion parameters, according to this blogpost.
- The model is accessible via QWEN CHAT, Hugging Face, ModelScope, DEMO, and DISCORD.
- RL Scaling Boosts Model Genius: Reinforcement Learning (RL) scaling elevates model performance beyond typical pretraining, exemplified by DeepSeek R1 through cold-start data and multi-stage training for complex reasoning, as detailed in this blogpost.
- This highlights the growing importance of RL techniques in pushing the boundaries of model capabilities, especially in tasks requiring advanced logical thinking.
OpenRouter (Alex Atallah) Discord
- Taiga App Integrates OpenRouter: An open-source Android chat app called Taiga has been released, which allows users to customize the LLMs they want to use, with OpenRouter pre-integrated.
- The roadmap includes local Speech To Text based on Whisper model and Transformer.js, along with Text To Image support and TTS support based on ChatTTS.
- Prefill Functionality Debated: Members are questioning why prefill is being used in text completion mode, suggesting it's more suited for chat completion as its application to user messages seems illogical.
- One user argued that "prefill makes no sense for user message and they clearly define this as chat completion not text completion lol".
- OpenRouter Documentation Dump Requested: A user requested OpenRouter's documentation as a single, large markdown file for seamless integration with coding agents.
- Another user swiftly provided a full text file of the documentation.
- DeepSeek's Format Hard to Grok: The discussion centered on the ambiguity of DeepSeek's instruct format for multi-turn conversations, with members finding even the tokenizer configuration confusing.
- A user shared the tokenizer config which defines
<|begin of sentence|>and<|end of sentence|>tokens for context.
- A user shared the tokenizer config which defines
- LLMGuard Addition Speculated: A member raised the possibility of incorporating addons like LLMGuard for functions like Prompt Injection scanning to LLMs via API within OpenRouter.
- The user linked to LLMGuard and wondered if OpenRouter could handle PII sanitization for improved security.
Yannick Kilcher Discord
- Sparsemax masquerades as Bilevel Max: Members discussed framing Sparsemax as a bilevel optimization (BO) problem, suggesting that the network can dynamically adjust different Neural Network layers, but another member quickly refuted this.
- Instead, they detailed Sparsemax as a projection onto a probability simplex with a closed-form solution, using Lagrangian duality to demonstrate that the computation simplifies to water-filling which can be found in closed form.
- DDP Garbles Weights: PyTorch Bug Hunt: A member reported encountering issues with PyTorch, DDP, and 4 GPUs, where checkpoint reloads resulted in garbled weights on some GPUs during debugging.
- Another suggested ensuring the model is initialized and checkpoints loaded on all GPUs before initializing DDP to mitigate weight garbling.
- Agents Proactively Clarify Text-to-Image Generation: A new paper introduces proactive T2I agents that actively ask clarification questions and present their understanding of user intent as an editable belief graph to address the issue of underspecified user prompts. The paper is called Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty.
- A supplemental video showed that at least 90% of human subjects found these agents and their belief graphs helpful for their T2I workflow.
- QwQ-32B Emerges from Alibaba: Alibaba released QwQ-32B, a new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning models like DeepSeek-R1.
- More information can be found at the Qwen Blog and on their announcement, while Alibaba is scaling RL.
Cohere Discord
- Cohere Enterprise Support Delayed: A member seeking Cohere enterprise deployment assistance was directed to email support, but noted their previous email went unanswered for a week.
- Another member cautioned that B2B lead times could extend to 6 weeks, while another countered that Cohere typically responds within 2-3 days.
- Cohere's Aya Vision Sees 23 Languages: Cohere For AI launched Aya Vision, an open-weights multilingual vision model (8B and 32B parameters) supporting 23 languages, excelling at image captioning, visual question answering, text generation, and translation (blog post).
- Aya Vision is available on Hugging Face and Kaggle, including the new multilingual vision evaluation set AyaVisionBenchmark; a chatbot is also live on Poe and WhatsApp.
- Cohere Reranker v3.5 Latency Data MIA: A member requested latency figures for Cohere Reranker v3.5, noting the absence of publicly available data despite promises made in an interview.
- The interviewee had committed to sharing a graph, but did not ultimately deliver it.
- User Hunts Sales/Enterprise Support Contact: A new user joined seeking to connect with someone from sales / enterprise support at Cohere.
- The user was encouraged to introduce themself, including details about their company, industry, university, current projects, favorite tech/tools, and goals for joining the community.
Modular (Mojo 🔥) Discord
- Mojo Still a Work in Progress: A member reported that Mojo is still unstable with a lot of work to do and another member asked about a YouTube recording of a virtual event, but learned it wasn’t recorded.
- The team mentioned that they will definitely consider doing a similar virtual event in the future.
- Triton Tapped as Mojo Alternative: A member suggested Triton, an AMD software supporting Intel and Nvidia hardware, as a potential alternative to Mojo.
- Another member clarified that Mojo isn't a superset of Python but rather a member of the Python language family and being a superset would be for Mojo like muzzle.
- Mojo Performance Dips in Python venv: Benchmarking revealed that Mojo's performance boost is significantly reduced when running Mojo binaries within an active Python virtual environment, even for files without Python imports.
- The user sought insights into why a Python venv affects Mojo binaries, which should be independent.
- Project Folder Structure Questioned: A developer requested feedback on a Mojo/Python project's folder structure, which involves importing standard Python libraries and running tests written in Mojo.
- They use
Python.add_to_pathextensively for custom module imports and a Symlink in thetestsfolder to locate source files, seeking better alternatives.
- They use
- Folder Structure moved to Modular Forum: A user initiated a discussion on the Modular forum regarding Mojo/Python project folder structure, linking to the forum post.
- This action was encouraged to ensure long-term discoverability and retention of the discussion, since Discord search and data retention is sub-par.
DSPy Discord
- SynaLinks Enters the LM Arena: A new graph-based programmable neuro-symbolic LM framework called SynaLinks has been released, drawing inspiration from Keras for its functional API and aiming for production readiness with features like async optimization and constrained structured output - SynaLinks on GitHub.
- The framework is already running in production with a client and focuses on knowledge graph RAGs, reinforcement learning, and cognitive architectures.
- Adapters Decouple Signatures in DSPy: DSPy's adapters system decouples the signature (declarative specification of what you want) from how different providers produce completions.
- By default, DSPy uses a well-tuned ChatAdapter and falls back to JSONAdapter, leveraging structured outputs APIs for constrained decoding in providers like VLLM, SGLang, OpenAI, Databricks, etc.
- DSPy Simplifies Explicit Type Specification: DSPy simplifies explicit type specification with code like
contradictory_pairs: list[dict[str, str]] = dspy.OutputField(desc="List of contradictory pairs, each with fields for text numbers, contradiction result, and justification."), but this is technically ambiguous because it doesn't specify thedict's keys.- Instead, consider
list[some_pydantic_model]where some_pydantic_model has the right fields.
- Instead, consider
- DSPy Resolves Straggler Threads: PR 7914 (merged) addresses stuck straggler threads in
dspy.Evaluateordspy.Parallel, aiming for smoother operation.- This fix will be available in DSPy 2.6.11; users can test it from
mainwithout code changes.
- This fix will be available in DSPy 2.6.11; users can test it from
tinygrad (George Hotz) Discord
- ShapeTracker Merging Proof Nearly Complete: A member announced a ~90% complete proof in Lean of when you can merge ShapeTrackers, available in this repo and this issue.
- The author notes that offsets and masks aren't yet accounted for, but extending the proof is straightforward.
- Unlocking 96GB 4090s on Taobao: A member shared a link to a 96GB 4090 on Taobao (X post), eliciting the comment that all the good stuff is on Taobao.
- There was no further discussion.
- Debugging gfx10 Trace Issue: A member requested feedback on a gfx10 trace, inquiring whether to log it as an issue.
- Another member suspected a relation to ctl/ctx sizes and suggested running
IOCTL=1 HIP=1 python3 test/test_tiny.py TestTiny.test_plusfor debugging assistance.
- Another member suspected a relation to ctl/ctx sizes and suggested running
- Assessing Rust CubeCL Quality: A member asked about the quality of Rust CubeCL, noting it comes from the same team behind Rust Burn.
- The discussion did not yield a conclusive assessment of its quality.
Eleuther Discord
- Suleiman dives into AI Biohacking: Suleiman, an executive with a software engineering background, introduced himself to the channel, expressing interest in AI and biohacking.
- He is exploring nutrition and supplement science to develop AI-enabled biohacking tools to improve human life.
- Naveen Unlearns Txt2Img Models: Naveen, a Masters cum Research Assistant from IIT, introduced himself and his work on Machine Unlearning in Text to Image Diffusion Models.
- He mentioned a recent paper publication at CVPR25, focusing on strategies to remove unwanted concepts from generative models.
- ARC Training universality hangs in balance: A user questioned whether Observation 3.1 is universally true for almost any two distributions with nonzero means and for almost any u35% on ARC training.
- The discussion stalled without clear resolution, and there was no discussion on the specific conditions or exceptions to Observation 3.1.
- Compression Begets Smarts?: Isaac Liao and Albert Gu explore if lossless information compression can yield intelligent behavior in their blog post.
- They are focusing on a practical demonstration, rather than revisiting theoretical discussions about the role of efficient compression in intelligence.
- ARC Challenge uses YAML config: Members discussed using arc_challenge.yaml for setting up ARC-Challenge tasks.
- The discussion involved configuring models to use 25 shots for evaluation, emphasizing the importance of few-shot learning capabilities in tackling the challenge.
Torchtune Discord
- Custom Tokenizer Troubles in Torchtune: Users encounter issues when Torchtune overwrites custom special_tokens.json with the original from Hugging Face after training, due to the copy_files logic in the checkpointer.
- A proposed quick fix involves manually replacing the downloaded special_tokens.json with the user's custom version in the downloaded model directory.
- Debate over Checkpointer save_checkpoint method: A member suggested supporting custom tokenizer logic by passing a new argument to the checkpointer's save_checkpoint method in Torchtune.
- However, others questioned the necessity of exposing new configurations without a strong justification.
LLM Agents (Berkeley MOOC) Discord
- MOOC Students Get All Lectures: A member inquired whether Berkeley students receive exclusive lectures not accessible to MOOC students, specifically from the LLM Agents MOOC.
- Another member clarified that Berkeley students and MOOC students attend the same lectures.
- Students Recall December Submission: A member mentioned submitting something in December related to the course, presumably a certificate declaration form from the LLM Agents MOOC.
- Another member sought confirmation regarding the specific email address used for the certificate declaration form submission, suggesting potential administrative follow-up.
Gorilla LLM (Berkeley Function Calling) Discord
- Seek clarity on AST Metric: A member sought clarification on the definition of the AST metric within the Gorilla LLM Leaderboard channel.
- They questioned if the AST metric represents the percentage of correctly formatted function calls produced by LLM responses.
- Members Question V1 Dataset Construction: A member inquired about the methodology used to construct the V1 dataset for the Gorilla LLM Leaderboard.
- Understanding the dataset construction process could provide valuable insights into the leaderboard's evaluation methodology.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (676 messages🔥🔥🔥):
Cursor 3.7 Debacles, Dumbness Meter, YOLO mode configuration, Windsurf versus Cursor, OpenAI new pricing
- Cursor's 3.7 Model sparks debate over performance and quality: Members are reporting that Cursor's 3.7 model feels nerfed, citing instances where it generates readme files without prompting and overuses Class A abstractions.
- Some users suspect Cursor is either using a big prompt or fake 3.7 models, noting that the API sometimes provides better suggestions with the same prompts and instructions. One member added a scientific measurement of how dumb Cursor editor is feeling today.
- Community measures Cursor Dumbness levels with satirical tool: A member shared a link to a "highly sophisticated meter" that measures the "dumbness level" of Cursor editor, using "advanced algorithms" based on "cosmic rays, keyboard mishaps, and the number of times it completes your code incorrectly."
- The meter's readings are updated regularly, sparking humorous reactions, with one user reporting that their meter indicates Cursor is "dumb today". Another confirmed, "definitely".
- YOLO Mode Woes plague Cursor users after updates: After an update, YOLO mode in Cursor isn't working properly, as it now requires approval before running commands, even with an empty allow list.
- One user expressed frustration, stating that they want the AI assistant to have as much agency as possible and rely on Git for any incorrect removals, preferring the v45 behavior that saved them hours.
- Windsurf gains traction as possible Cursor Alternative: Community members are actively discussing Windsurf's new release, Wave 4, some considering switching due to perceived advantages in the agent's capabilities, with some reporting that Cursor became very unusable, while others shared a youtube tutorial on "Vibe Coding Tutorial and Best Practices (Cursor / Windsurf)".
- Despite the interest, concerns about Windsurf's pricing model are present, and some users mentioned it yoinks continue.dev.
- OpenAI Prepares to charge a premium: A member shared a report that OpenAI is doubling down on its application business, planning to offer subscriptions ranging from $2K to $20K/month for advanced agents capable of automating coding and PhD-level research.
- This news triggered skepticism, with some questioning whether the high price is justified, especially given the current output quality of AI models.
- Cursor Editor Dumbness Meter: no description found
- House Classic Solid Icon | Font Awesome: House icon in the Solid style. Make a bold statement in small sizes. Available now in Font Awesome 6.
- Vibe Coding Tutorial and Best Practices (Cursor / Windsurf): Got a lot of questions asking about my stack and what I do when vibe coding. So I made a full video on it!👉 Learn more on https://mammouth.ai/Join My Newsle...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): NEW w/ @coryweinberg:OpenAI is doubling down on its application business. Execs have spoken with investors about three classes of future agent launches, ranging from $2K to $20K/month to do tasks like...
- Windsurf Wave 4: Introducing Wave 4, our fourth batch of updates to the Windsurf Editor.
- GitHub - dnakov/anon-kode: koding with any LLMs: koding with any LLMs. Contribute to dnakov/anon-kode development by creating an account on GitHub.
- Features, Usability, & Benefits of Web-based Integrated Development Environments (IDEs): Cursor.ai: We are a group of Comp Sci grads at ODU looking to conduct research to explore the features, usability, and benefits of web-based Integrated Development Environments (IDEs). These platforms allow deve...
- Mob Psycho Season3 Shigeo GIF - Mob Psycho Season3 Mob Psycho Shigeo - Discover & Share GIFs: Click to view the GIF
- Cursor 0.46 unable to solve a problem, Cursor 0.45 fixed it in one shot with Sonnet 3.7 thinking: The experience with 0.46.8 has been so bad I went back to GitHub Copilot. Even though Claude Sonnet 3.7 feels faster, eating through your quota, the quality Cursor AI gives you, is some much worse th...
OpenAI ▷ #annnouncements (2 messages):
GPT-4.5, AGI Development, AI Safety, AI Alignment
- GPT-4.5 Released ahead of schedule: The rollout of GPT-4.5 has been completed faster than expected, marking a significant milestone in AI development.
- Iterative AGI Development Path Outlined: The company views AGI development as a continuous path rather than a sudden leap, focusing on iteratively deploying and learning from today's models to make future AI safer and more beneficial.
- This approach helps in preparing for AGI by learning from current models rather than preparing for a single pivotal moment.
- Safety and Alignment Methods Discussed: The company's approach to AI safety and alignment is guided by embracing uncertainty, defense in depth, methods that scale, human control, and community efforts.
- The goal is to ensure that AGI benefits all of humanity, with an emphasis on continuous improvement and adaptation.
OpenAI ▷ #ai-discussions (546 messages🔥🔥🔥):
Will O3 ever come out?, Custom LLM for graduation project, Grok vs ChatGPT Plus, Abacus AI Feedback, Claude secret update
- Speculation on O3 Release and Coding Prowess: A member inquired about the release of O3 and whether it would surpass O3-mini for coding, to which another member responded that OpenAI stated they won't release the full O3 in ChatGPT, only in the API.
- The different options indicate aspects such as the tone of voice towards you. The "not a" is meant to serve as a reminder that it is still an AI and therefore won't always be 100% accurate and that one should always consult a human therapist or doctor.
- Local LLM Training on Budget Hardware: A student with an RTX 3050 4GB VRAM and 8 GB RAM i5 10th gen laptop seeks advice on running and fine-tuning a custom LLM locally for a graduation project.
- A user suggested leveraging Grok's Deep Research feature for updated information on suitable models, cautioning that many chatbots recommend outdated models and another member mentioned that its free for may be 3 times a day for free account for deep research, one guy told me he uses 5 free grok accounts to have 15 deep research messages a day.
- Grok and Perplexity shine as Academic Research Tools: Users compared Grok and ChatGPT Plus, noting Grok 3's larger context window (128k vs GPT's 32k), less censorship (English only), and comparable creative writing, with one user ranking Chatgpt, Perplexity, Grok, and Stanford genie models.
- Members discussed the benefits of each platform, some mentioning that Grok's deep research is free a limited number of times, and highlighting Perplexity as great for research and giving very good research.
- Claude Gets Smarter Overnight?: A user reported that Claude had undergone a significant improvement, tracing and fixing bugs in their code, even improving code that the user didn't realize had bugs.
- Members speculated on possible updates or testing, and the warm, more human-like communication style of the model.
- Qwen-14b with Recursive Summarization Crushes Gemini: Members discussed about the Qwen-14B model which is being used for recursive summarization tasks and the output is better than Gemini.
- They provided the example of summarization of a chess book and Gemini was acting like GPT-3.5, if not worse which is not acceptable by today's standards, so the results of the Qwen-14B are better.
- no title found: no description found
- This document is about Nise da Silveira's 'Jung: Vida e Obra' (1981), which delv - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- This document is about "Chess Opening Essentials: Volume 1 — The Complete 1.e4," - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- The summary introduces "Chess Opening Essentials: Volume I — The Complete 1.e4," - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Nana Mouskouri - Guten Morgen, Sonnenschein 1977: Nana Mouskouri - Guten Morgen, Sonnenschein 1977
- GitHub - opennars/OpenNARS-for-Applications: General reasoning component for applications based on NARS theory.: General reasoning component for applications based on NARS theory. - opennars/OpenNARS-for-Applications
OpenAI ▷ #gpt-4-discussions (10 messages🔥):
GPT-4.5 refusing prompts, GPT-4.5 message limits
- GPT-4.5 Rejects Story Prompts: Users reported that GPT-4.5 is refusing to respond to story-based prompts, even when the prompts do not violate guidelines.
- One user noted that they were only able to get GPT-4.5 to work once for their story prompts.
- GPT-4.5's Limited Availability Revealed: A member revealed that GPT-4.5 is currently limited to approximately 50 uses per week and may increase gradually.
- He clarified that GPT-4.5 is not intended as a replacement for other models, including GPT-4o, and suggested users switch between different models based on the task at hand.
OpenAI ▷ #prompt-engineering (12 messages🔥):
Prompt Engineering Survey, Ontology of Prompt Strategies, Sora and AI Videos, Character Consistency in Sora, Hyper-realistic Visuals
- Prompt Engineering Survey Outlines Key Strategies: A member shared a systematic survey of prompt engineering in Large Language Models titled A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications outlining key strategies like Zero-Shot Prompting, Few-Shot Prompting, and Chain-of-Thought (CoT) prompting.
- The discussion highlighted the survey's detailed description of each technique, while noting omissions such as Self-Discover and MedPrompt.
- ChatGPT link enables Access to Prompt Engineering Survey: A member shared a ChatGPT link to provide public access to an academic prompt engineering survey that they couldn't directly link.
- The member expressed a preference for public information sharing, particularly for thorough resources, noting the survey's original complexity was too much for a single Discord post.
- User Seeks Prompt Tips for Consistent AI Character in Sora: A member requested advice on creating cinematic AI videos with Sora, focusing on a consistent character named Isabella Moretti, aiming for hyper-realistic visuals and improved character consistency.
- The member seeks effective strategies or prompt tips to maintain consistent appearance details (skin tone, eyes, hair, expressions) and refine prompt structure for optimal cinematic quality (lighting, camera movements, transitions).
OpenAI ▷ #api-discussions (12 messages🔥):
Systematic Survey of Prompt Engineering in Large Language Models, Ontology of Prompt Strategies, Sora, Character Consistency in AI Videos, Hyper-realistic Visuals in Sora
- Prompt Engineering Survey Published: A member shared a summary of prompt engineering techniques extracted from the academic survey titled "A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications."
- The survey categorizes prompt strategies, including zero-shot, few-shot, chain-of-thought, RAG, and emotion prompting.
- Prompt Engineering Survey Highlights: A member shared a ChatGPT link containing an academic survey on prompt engineering.
- The poster indicated that it isn't even an exhaustive ontology, lacking Self-Discover and MedPrompt, and the full ontology is too detailed for Discord.
- Community Member Seeks Sora Tips: A member is creating cinematic AI videos using Sora, centered around a character named Isabella Moretti, and seeks tips for hyper-realistic visuals.
- The goal is to improve consistency in character details such as skin tone, eyes, and hair, refining prompt structure for optimal cinematic quality by focusing on lighting, camera movements, and transitions.
Codeium (Windsurf) ▷ #announcements (1 messages):
Windsurf Wave 4 Release, Cascade Previews, Tab-to-import, Linter integration, Claude 3.7 improvements
- Windsurf Wave 4 Drops!: Windsurf releases Wave 4, its biggest update yet, featuring gamechanging features like Previews, Tab-to-import, Linter integration, Suggested actions, MCP discoverability, and improvements to Claude 3.7.
- The update also includes a new referral program and support for drag & drop files from explorer to Cascade and Windows ARM.
- Cascade Auto-Linter fixes errors: Cascade now automatically fixes lint errors in generated code through its new Linter integration.
- Users can preview locally run websites in their IDE or browser, select React and HTML elements to send to Cascade as context, and send console errors as context.
- Tab-to-import Enhances Workflow: The new Tab-to-import feature automatically adds imports with a tab press, streamlining the coding workflow within Cascade.
- The Windsurf Preview feature can be activated by asking Cascade to start your web application or through the Website tools icon in the toolbar above conversation input.
- Windsurf Now on YouTube!: A YouTube video highlights the Windsurf Wave 4 updates, covering Preview, Tab to Import, Suggested Actions and more.
- The description urges users to update to the latest version of Windsurf to get all the new features.
- Windsurf Wave 4: Introducing Wave 4, our fourth batch of updates to the Windsurf Editor.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- Tweet from Windsurf (@windsurf_ai): Windsurf Wave 4 is here!Included in this update:🖼️ Previews✏️ Cascade Auto-Linter⚙️ MCP UI Improvements ➡️ Tab to Import↩️ Suggested Actions🫶 Claude 3.7 Improvements🤝 Referrals🖥️ Windows ARM Suppo...
- Windsurf (@windsurfai.bsky.social): Windsurf Wave 4 is here!Included in this update:🖼️ Previews✏️ Cascade Auto-Linter⚙️ MCP UI Improvements▶️ Tab to Import↩️ Suggested Actions🫶 Claude 3.7 Improvements🤝 Referrals🖥️ Windows ARM Suppor...
- Codeium (@codeiumdev) on Threads: Windsurf Wave 4 is here!Included in this update:🖼️ Previews✏️ Cascade Auto-Linter⚙️ MCP UI Improvements▶️ Tab to Import↩️ Suggest...
- Windsurf Wave 4 Updates: Preview, Tab to Import, Suggested Actions & More: Windsurf Wave 4 is here, bringing exciting new features to enhance your experience!🌊 Make sure to update to the latest version of Windsurf to get all these ...
Codeium (Windsurf) ▷ #discussion (6 messages):
vscode commit message, flutterflow, uninstalling codium extension
- VSCode Commit Message Failure: A user reported an issue with generating commit messages in VSCode, specifically when using the pre-release version of the Codeium extension.
- They inquired about any available workarounds for this problem.
- FlutterFlow Assistance Sought: A user asked if anyone knows how to use FlutterFlow.
- There was no further discussion or details provided about the specific help needed.
- Extension Uninstall Help Needed: A user requested help with completely uninstalling the current Codeium extension.
- No further details were provided regarding the reason for the uninstall or any specific issues encountered during the process.
Codeium (Windsurf) ▷ #windsurf (397 messages🔥🔥):
Windsurf performance degradation, Codeium login issues, Windsurf Wave 4, Credit usage, Feature requests
- Windsurf Sufferers Strife with Service Stoppage: Users reported that Windsurf/Cascade experienced errors like resource exhaustion and were not working anymore, with some facing issues where the file of 100 lines got split into 5 or 6 analysis tool calls.
- Some members noticed that the analysis threshold for tool calls went from 150 lines per call down to 15 lines per call.
- Codeium Code Conundrums: Credential Catastrophe: Multiple users reported being unable to log in to codeium.com using Google or email/password.
- The team acknowledged the issue and stated that they were investigating, and a status page was provided for updates.
- Wave 4 Wonders and Woes: Windsurf's Whirlwind: Members discussed Windsurf Wave 4, with some praising its speed and integration of Claude 3.7, while others reported never-ending loops and increased credit usage.
- It was mentioned that Claude 3.7 can be used for free in Windsurf Wave 4 via Windsurf Command (using
CTRL/Cmd + I).
- It was mentioned that Claude 3.7 can be used for free in Windsurf Wave 4 via Windsurf Command (using
- Windsurf Credit Crunch: Consumers Confront Costly Consumption: Users expressed concerns about credit usage, particularly with Claude 3.7, with some noting that credits were being consumed rapidly, even after recent improvements.
- It was clarified that Flex Credits roll over and that automatic fixing of lint errors is free.
- Windsurf Wishlist: Users Yearn for Upgrades: Users requested for features such as support for external documentation of libraries, increased credit limits, the ability to adjust chat font size, and a proper webview in the sidebar like Trae.
- One user suggested using Firecrawl to generate an llms.txt file for websites to feed into the LLM.
- Neon Serverless Postgres — Ship faster: The database you love, on a serverless platform designed to help you build reliable and scalable applications faster.
- Previews (Beta) - Codeium Docs: no description found
- Login | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Windsurf Rules Directory: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- Tweet from Eric Ciarla (hiring) (@ericciarla): Generate an llms.txt file for any website in seconds with /llmstxtOur new @firecrawl_dev endpoint turns any site into a single text file that can be fed into any LLM.Check it out integrated as a @rayc...
- Overview - Codeium Docs: no description found
- Overview - Codeium Docs: no description found
- Codeium - Windsurf: 🧑💻 | Your modern coding superpower🚀 | 3M+ Codeium extension downloads🏄♂️ | Building the Windsurf Editor
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Pierre: Joyful Code Review
- Codeium Status: no description found
- Improve "Previews" feature with a proper "Webview" in the sidebar (like Trae) | Feature Requests | Codeium: I'd love for their to simply be a "Preview" tool in the sidebar like how Trae has a "Webview" tool. Prompting the AI just to Preview is kinda strange.
- Codeium Feedback: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
aider (Paul Gauthier) ▷ #general (201 messages🔥🔥):
Grok 3 Model Comparison, Aider Offline Installation, Qwen's New QwQ-32B Reasoning Model, OpenAI's o3 Mini Access, Parasail's R1 Performance on OpenRouter
- Grok vs Claude: Model Performance Debate: Users compared Grok 3, Claude 3.7, and other models, pondering performance differences between free and paid versions, with one user joking "they are probably all about the same, but grok is free".
- The discussion suggests a landscape where model preference is subjective and potentially influenced by cost considerations.
- Offline Aider: Mission Possible!: A user sought to install Aider on an offline PC, sparking a discussion on methods, including downloading Python packages and copying from an online PC, eventually solving the problem by using pip download to get the packages into an offline venv.
- A member posted a successful sequence to copy an Aider install:
python -m pip download --dest=aider_installer aider-chat.
- A member posted a successful sequence to copy an Aider install:
- Qwen's New QwQ-32B Reasoning Model: Qwen released QwQ-32B, a 32B parameter reasoning model, supposedly rivaling DeepSeek-R1, discussed in a VXReddit post and announced by Qwen themselves (blog, HF, ModelScope).
- Initial reactions were positive, with community members eager to see how it performs as an architect and coder within Aider.
- o3 Mini: Newcomer to OpenAI Tierlist: Users reported access to o3 mini on OpenAI, musing whether it could be a good editor model.
- Others praised o3-mini as a super-fast architect, noting it is "not your regular Chain-Of-Thought model", marking it as a worthwhile option.
- ParaSail Boasts Blazing R1 Speeds: A user reported impressive throughput of 300tps on R1 using the Parasail provider on OpenRouter.
- While others couldn't immediately replicate the speeds, the provider was identified as one of the top performers for R1 alongside SambaNova.
- MacBook Air 13-inch and MacBook Air 15-inch: MacBook Air laptop with the superfast M4 chip. Built for Apple Intelligence. Lightweight, with all-day battery life. Now in a new Sky Blue color.
- FAQ: Frequently asked questions about aider.
- FAQ: Frequently asked questions about aider.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Qwen released a new reasoning model QwQ-32B, and it is now powering Qwen Chat if you select Qwen2.5-Plus with Thinking (QwQ).Quoting Qwen (@Alibaba_Qwen) Today, we release QwQ-32B, our new reasoning m...
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
- Tweet from Marc (@mrousavy): ByteDance just launched Lynx – a competitor to React Native!
- Mr Bean Mrbean GIF - Mr bean Mrbean Bean - Discover & Share GIFs: Click to view the GIF
- Mujikcboro Seriymujik GIF - Mujikcboro Seriymujik - Discover & Share GIFs: Click to view the GIF
- Xi Jinping GIF - Xi Jinping - Discover & Share GIFs: Click to view the GIF
- GitHub - olilanz/RooCode-Local-Evaluation: Evaluation of Roo Code and locally hosted LLMs: Evaluation of Roo Code and locally hosted LLMs. Contribute to olilanz/RooCode-Local-Evaluation development by creating an account on GitHub.
- Apple unveils new Mac Studio, the most powerful Mac ever: Apple today announced the new Mac Studio, the most powerful Mac ever made, featuring M4 Max and the new M3 Ultra chip.
aider (Paul Gauthier) ▷ #questions-and-tips (53 messages🔥):
OWUI Integration, LM Studio R1, Aider Output, OpenRouter API, Commit Messages
- Hack OWUI with OAI-Compatible Aider: To connect Aider to OpenWebUI (OWUI), prefix the model name with
openai/so that litellm knows you're using an OAI-compatible endpoint, such asopenai/myowui-openrouter.openai/gpt-4o-mini.- This resolves the
litellm.BadRequestErrorwhen using Aider with OWUI.
- This resolves the
- Aider's Fault in DeepSeek Provider Issue: A member stated that if OpenRouter is not responding with tokens, it may be due to litellm and Aider's fault, not with the DeepSeek provider.
- A patch (PR #8431) was merged for the reasoning field with OpenRouter, but it may require a local patch for Aider to show the reasoning content.
- Commit Messages: A member suggested a solution to have aider write a commit message for the files you've staged rather than all the changes in your working tree:
git stash save --keep-index, then/commit, finallygit stash pop.- Aider can also be used as a committer with
aider --commitwhich writes the commit message, commits, and exits.
- Aider can also be used as a committer with
- The Quest For Good (Free) Editor Model: Members discussed good models to use as
editor-model, with suggestions includingqwencoder2.5:32bfor the weak model (for commit and compressing/summarizing history) andgemini flashfor edits.- Other members reported good results with
o3-mini-highas architect anddeepseek-v3as editor.
- Other members reported good results with
- /web Command: A member reported that the
/webcommand wasn't working, even after letting Aider install Playwright and was not adding it to the context.- Another member confirmed that it worked, suggesting verifying if the content was added to chat by asking a question based on the scraped page.
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Git integration: Aider is tightly integrated with git.
LM Studio ▷ #general (84 messages🔥🔥):
VRAM overflow, LMStudio and Phi-4 audio modality support, KV cache impact on VRAM, New Mac Studio's RAM, Sesame AI's open-source TTS model
- Detect VRAM Overflow by Watching Shared Memory: A member shared how to detect VRAM overflow by monitoring Dedicated memory and Shared memory usage, noting that overflow occurs when Dedicated memory is high and Shared memory increases, illustrated in the attached image.
- Audio Modality Missing on Phi-4 in LM Studio: Members confirmed that multi-modal Phi-4 and audio support are not currently available in LM Studio due to limitations in llama.cpp.
- KV Cache Keeps Your VRAM On Lock: A member explained that context size and KV cache settings significantly impact VRAM usage, recommending aiming for 90% VRAM utilization to optimize performance.
- Another member defined KV cache as the value of K and V when the computer is doing the attention mechanics math, i.e. (Q*K^T/dK).
- Sesame AI's TTS: Open Source or Smoke and Mirrors?: Members discussed Sesame AI's conversational speech generation model (CSM), with one member praising its lifelike qualities, including breathing and emotional tone, linking to a demo.
- Others expressed skepticism about its open-source claim, noting the GitHub repository lacks code commits.
- QwQ Model Template Issue Gets a Patch: Users reported issues running QwQ models in LM Studio, specifically encountering OpenSquareBracket !== CloseStatement errors with the Junja template.
- A member shared a potential fix from a GitHub issue, which involved adjusting model prompt parameters, and confirmed it resolved their issues, however, others still consider it not good.
- Puppy GIF - Puppy - Discover & Share GIFs: Click to view the GIF
- Sesame: We believe in a future where computers are lifelike. Where they can see, hear, and collaborate with us – as we do with each other. With this vision, we're designing a new kind of computer.
- SesameAILabs: SesameAILabs has 8 repositories available. Follow their code on GitHub.
- Issue with qwq-32b model in lmstudio. · Issue #479 · lmstudio-ai/lmstudio-bug-tracker: Which version of LM Studio? Example: LM Studio 0.3.11 Which operating system? Mac What is the bug? I get following error when chatting with qwq-32b model "Error rendering prompt with jinja templa...
- Issue with qwq-32b model in lmstudio. · Issue #479 · lmstudio-ai/lmstudio-bug-tracker: Which version of LM Studio? Example: LM Studio 0.3.11 Which operating system? Mac What is the bug? I get following error when chatting with qwq-32b model "Error rendering prompt with jinja templa...
- Ibm Card Reader Utility Bill GIF - IBM CARD READER CARD READER IBM - Discover & Share GIFs: Click to view the GIF
- New video by Brian Makin: no description found
LM Studio ▷ #hardware-discussion (134 messages🔥🔥):
M3 Ultra vs M4 Max, AMD RX 9070 XT GPU, DeepSeek R1, SGI machines, Local LLMs
- Apple unveils Mac Studio with M3 Ultra and M4 Max: Apple announced the new Mac Studio powered by M3 Ultra (maxing out at 512GB ram) and M4 Max (maxing out at 128GB).
- One member exclaimed why I don't buy macs... after seeing the specs.
- AMD RX 9070 XT GPU Benchmarks: A YouTube video review of the AMD Radeon RX 9070 XT GPU shows that it trades blows with the Nvidia RTX 5070 Ti in rasterization, but Nvidia maintains a lead in ray tracing.
- The RX 9070 XT sometimes reaches ~95% of the Nvidia 4080 Super’s performance while costing 80% of the 5070 Ti’s MSRP of $750.
- Is 512GB Enough for DeepSeek R1?: Members discussed whether 512GB of unified memory is sufficient to run the full DeepSeek R1 model.
- It was mentioned that 192 gb is already enough to run UD quants and that 512GB of unified architecture memory is closer to VRAM speeds
- Throwback to SGI Machine Superiority: Members discussed Silicon Graphics (SGI) machines from the late 90s, noting their superior graphics and shared global memory architecture.
- It was stated that in ~ 1998 the fastest PC graphics card could do about 600k polygons / second compared to Our SGI could do 33M polygons / second... and ours wasn't even the big configuration.
- Ditching Local LLMs: One member stated that they got bored of running local llms locally and that they use ChatGPT O3 for coding.
- They clarified that they don't use LLMs for anything else.
- Apple unveils new Mac Studio, the most powerful Mac ever: Apple today announced the new Mac Studio, the most powerful Mac ever made, featuring M4 Max and the new M3 Ultra chip.
- AMD Radeon RX 9070 XT GPU Review & Benchmarks vs. 5070 Ti, 5070, 7900 XT (Sapphire Pulse): Sponsor: Montech HyperFlow 360 Cooler on Amazon https://geni.us/dWBIbF6AMD's Radeon RX 9070 XT and 9070 GPUs are launching tomorrow. This benchmark and revie...
- Thread by @carrigmat on Thread Reader App: @carrigmat: Complete hardware + software setup for running Deepseek-R1 locally. The actual model, no distillations, and Q8 quantization for full quality. Total cost, $6,000. All download and part link...
- Mac Studio: The ultimate pro desktop. Powered by M4 Max and M3 Ultra for all-out performance and extensive connectivity. Built for Apple Intelligence.
Interconnects (Nathan Lambert) ▷ #news (114 messages🔥🔥):
Richard Sutton, OpenAI agents pricing, QwQ-32B model, Boston Dynamics vs Unitree, Adversarial machine learning
- Sutton's Sentiments on Safety: A member noted that Turing Award winner Richard Sutton said that safety is fake news in a recent interview.
- Another member remarked, Rich is morally kind of sus I wouldn’t take his research advice even if his output is prodigal.
- OpenAI Plots Pricing for PhD-Level Agents: OpenAI is reportedly planning to charge $2,000 to $20,000 per month for future AI agents, designed for tasks like automating coding and PhD-level research, according to The Information.
- SoftBank, an OpenAl investor, has committed to spending $3 billion on OpenAl's agent products this year alone, possibly buying ~12,500 $20k/mo agents.
- Alibaba Qwen Releases QwQ-32B Model: Alibaba Qwen released QwQ-32B, a new reasoning model with only 32 billion parameters, claiming it rivals models like DeepSeek-R1.
- This model is the product of RL training and post training which improves performance especially in math and coding.
- Boston Dynamics Fumbles the Humanoid: Members compared Boston Dynamics' Atlas robot unfavorably against Unitree's humanoid robot, saying The generational fumble of Boston Dynamics hurts to watch.
- DeepMind Suffers Exodus of Talent to Anthropic: Nicholas Carlini announced he is leaving Google DeepMind after seven years to join Anthropic, citing his research on adversarial machine learning is no longer supported at DeepMind according to his blog.
- A member noted that GDM lost so many important people lately, while others said that Anthropic mandate of heaven stocks up.
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
- Yes, Claude Code can decompile itself. Here's the source code.: These LLMs are shockingly good at deobfuscation, transpilation and structure to structure conversions. I discovered this back around Christmas where I asked an LLM to make me an Haskell audio library ...
- Career Update: Google DeepMind -> Anthropic : no description found
- Tweet from Chen Cheng (@cherry_cc12): Who Will Be the Next Member to Join the QwQ Family?Quoting Qwen (@Alibaba_Qwen) Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning mo...
- Tweet from Qwen (@Alibaba_Qwen): Qwen2.5-Plus + Thinking (QwQ) = QwQ-32B . This is how you should use this new model on Qwen Chat!Quoting Qwen (@Alibaba_Qwen) Today, we release QwQ-32B, our new reasoning model with only 32 billion pa...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): NEW w/ @coryweinberg:OpenAI is doubling down on its application business. Execs have spoken with investors about three classes of future agent launches, ranging from $2K to $20K/month to do tasks like...
- Tweet from Joseph Suarez (e/🐡) (@jsuarez5341): We beat Pokemon Red with online RL! Details here over the next several days. Led by @dsrubinstein. Follow him, me, @DanAdvantage, @kywch500, @computerender for more!Quoting drubinstein (@dsrubinstein...
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
- Dynamic Deep Learning | Richard Sutton: ICARL Seminar Series - 2024 WinterDynamic Deep LearningSeminar by Richard Sutton——————————————————Abstract:Despite great successes, current deep learning met...
- Tweet from Boston Dynamics (@BostonDynamics): We’re designing Atlas to do anything and everything, but we get there one step at a time. See why we started with part sequencing, how we are solving hard problems, and how we’re delivering a humanoid...
- Tweet from Unitree (@UnitreeRobotics): Kung Fu BOT GAME😘720° Spin Kick - Hear the Impact! Kung Fu BOT Gameplay RAW. (No Speed-Up)(Do not imitate, please keep a safe distance from the machine)#Unitree #Kungfu #EmbodiedAI #SpringFestivalGal...
- Tweet from Tibor Blaho (@btibor91): The Information reports OpenAI plans to charge up to $20,000 per month for advanced AI agents designed for high-level research, aiming for these agents to generate around 20%-25% of revenue long-term-...
- TURING AWARD WINNER Richard S. Sutton in Conversation with Cam Linke | No Authorities in Science: “There are no authorities in science,” says A.M. Turing Award winner Richard S. Sutton.In this exclusive conversation, Amii Chief Scientific Advisor Richard ...
Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
LLMs playing Diplomacy, GPT-4.5 greentext autocompleter, Mafia game playing LLMs, Post training as a service startups
- LLMs Negotiate World Domination in Diplomacy!: A member shared a framework for LLMs to play Diplomacy, a complex board game with a heavy negotiation element, perfect for experimenting with game theory & testing persuasion!
- GPT-4.5 rekindles Greentext Obsession: A member linked to a tweet expressing disbelief at the release of a model, sparking discussion about finding the big-model-smell greentext autocompleter that was lost two years ago (tweet link).
- Another member countered that other models can generate equally good, if not better, greentexts, suggesting V3 or old base models.
- LLMs Scheme in Online Mafia!: A member shared a link to a website (mafia.opennumbers.xyz) showcasing LLMs playing Mafia against each other and sharing model statistics such as win rates.
- Post Training Startups Spark Curiosity!: A member asked if anyone lurking works on post training as a service startups, curious about how hard one click training is for work reasons.
- Tweet from Sam Paech (@sam_paech): I made a framework for LLMs to play Diplomacy against each other.Diplomacy is a complex board game with a heavy negotiation element. Good for experimenting with game theory & testing persuasion!It'...
- Tweet from adi (@adonis_singh): i cannot fathom they actually released this model 😭
- LLM Mafia Game Competition: no description found
Interconnects (Nathan Lambert) ▷ #rl (2 messages):
Schmidhuber Congratulates Sutton and Barto, Turing Award, Cult leader game
- Schmidhuber Congratulates Sutton and Barto on Turing Award: Jürgen Schmidhuber congratulated Richard S. Sutton and Andy Barto on their Turing Award in a post.
- The message was terse, containing only the text Cult leader game recognizes cult leader game.
- Cult Leader Game Recognizes Cult Leader Game: Schmidhuber's congratulatory message to Sutton and Barto on their Turing Award included the cryptic statement, Cult leader game recognizes cult leader game.
- This seemingly self-aware comment has sparked some discussion among followers.
Link mentioned: Tweet from Jürgen Schmidhuber (@SchmidhuberAI): Congratulations to @RichardSSutton and Andy Barto on their Turing award!
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
Reinforcement Learning beats Pokemon, DeepSeek MLA performance challenges, ThunderMLA fused megakernel
- RL beats Pokemon with Thunderous Applause: A reinforcement learning system was developed to beat Pokémon Red using a policy under 10M parameters, PPO, and novel techniques, detailed in a blog post.
- The system successfully completes the game, showcasing the resurgence of RL in solving complex tasks.
- MLA faces Deep Performance Challenges: New schedulers are being explored to manage variable length sequences, common in LLM inference when serving requests from different users, spurred by excitement around DeepSeek MLA.
- The focus is on addressing the performance challenges associated with large language model inference.
- ThunderMLA Megakernel Fuses Performance: ThunderMLA, a completely fused megakernel for decode, is introduced as a response to LLM inference performance challenges, claiming to be 20-35% faster than DeepSeek's FlashMLA on diverse workloads, with code available on GitHub.
- Simple scheduling tricks significantly enhance performance, with the initial release focusing on attention decoding.
- ThunderMLA: FlashMLA, Faster and Fused-er!: no description found
- Tweet from drubinstein (@dsrubinstein): Excited to finally share our progress in developing a reinforcement learning system to beat Pokémon Red. Our system successfully completes the game using a policy under 10M parameters, PPO, and a few ...
Interconnects (Nathan Lambert) ▷ #lectures-and-projects (10 messages🔥):
RLHF Book, Lecture Series
- RLHF Book PDF Released!: A member shared the RLHF Book PDF for people looking for it.
- If people actually use it, am open to feedback stated the member.
- Nathan Preps RLHF Lecture Series: Nathan is tentatively thinking over the summer about doing a lecture series with 1 vid per chapter.
- He mentioned he's gotta make the marketing engine go brrr once preorder button exists.
Interconnects (Nathan Lambert) ▷ #posts (9 messages🔥):
Stargate Project, Data protection, OpenAI coding agent
- Stargate Project Pays Off via Ads: The Stargate Project is now funded via completely unbiased and unobtrusive ads.
- Data Hoarders Guard Gold: As models get more powerful, businesses need to gate their content to avoid going out of business, as per Ben Thompson's argument.
- Newspapers already lost this battle and must accept whatever deal Sam offers, so valuable data troves like YouTube and GitHub must be protected at all costs.
- Microsoft Blocks OpenAI Agents?: It was suggested that if Microsoft blocks the $20K/month OpenAI coding agent, its less useful.
- Search softening helps smaller companies with data to avoid harshness.
GPU MODE ▷ #general (48 messages🔥):
Touhou-trained model, Unified Memory Discussion, Thunderbolt 5 benefits, Raspberry Pi clusters
- *Touhou AI Model Dream Coming True?: One member wants to train an AI model to play Touhou, leveraging RL* and the game score as the reward.
- They noted it's easier now with RL, potentially using simulators like Starcraft gym and Minetest gym for learning.
- *Unified Memory: A Game Changer?: The M3 Ultra announcement sparked discussion about unified memory, with members wondering about the performance characteristics of a system where the CPU and GPU* address the same memory.
- It was suggested to check the metal channel for more specific discussion around Metal programming for these devices.
- *Thunderbolt 5 Speeds Up the Game: Members are excited about Thunderbolt 5, which will make distributed inference/training between Mac Minis/Studios* more plausible.
- The unidirectional speed (120gb/s) seems faster than a RTX 3090 SLI bridge (112.5gb/s).
- *Raspberry Pi Clusters: Still Viable?: The discussion touched on using clusters of Raspberry Pis or Jetson Nanos* for parallelizable tasks like large image generation.
- A member linked to the Turing Pi 2.5, a 4-node mini ITX cluster board that can run Raspberry Pi CM4 or Nvidia Jetson compute modules in any combination.
Link mentioned: Get Turing Pi 2, mini ITX cluster board: The Turing Pi 2.5 is a 4-node mini ITX cluster board with a built-in Ethernet switch that runs Turing RK1, Raspberry Pi CM4 or Nvidia Jetson compute modules
GPU MODE ▷ #triton (4 messages):
Triton gather operation, PagedAttention in Triton
- Gather Operation Guidance in Triton: A member inquired about performing a gather operation in Triton and encountered an
AttributeError.- Another member suggested building Triton from master and uninstalling the version provided with PyTorch, linking to a related GitHub issue.
- PagedAttention Recreation Resources Sought: A member requested resources on how to recreate PagedAttention in Triton.
Link mentioned: Cannot call tl.gather · Issue #5826 · triton-lang/triton: Describe the bug When I run the following code I get an exception: AttributeError: module 'triton.language' has no attribute 'gather' import triton.language as tl tl.gather I've in...
GPU MODE ▷ #cuda (13 messages🔥):
Compiler Optimization, CUDA OpenGL Interop, cudaGraphicsGLRegisterImage fails
- Compiler Optimizes Away Unused Memory Writes: A user found that the CUDA compiler optimizes away memory writes when the written data is never read, leading to no error being reported.
- Another user confirmed that if you add a read from the array, the compiler will report an error.
- *CUDA OpenGL Interop segfaults on Laptop: A user encountered a segfault* in their CUDA OpenGL interop code on a laptop when calling
cudaGraphicsMapResources, while the same code worked fine on their desktop.- The
cudaGraphicsRegisterImagecall was returningcudaErrorUnknown, leaving the user perplexed despite having the same CUDA and driver versions on both machines.
- The
- OpenGL Not Using GPU Causes CUDA Failure: A user found the solution to their problem to be that opengl isn't using my gpu.
- After ensuring OpenGL used the GPU, the CUDA OpenGL interop issue was resolved, as
cudaGraphicsGLRegisterImageneeds OpenGL to be running on the dedicated GPU.
- After ensuring OpenGL used the GPU, the CUDA OpenGL interop issue was resolved, as
GPU MODE ▷ #torch (4 messages):
Torch C++ Interface Library, Extending OffloadPolicy, use_reentrant in Checkpoint
- Torch C++ Methods lack Schemas?: A member inquired about why methods in the Torch C++ interface library (similar to pybind11) cannot have schemas like functions.
- They further inquired about a proposal to extend OffloadPolicy, including whether a PR would be accepted and who to consult about it.
use_reentrantParameter Exposed in PyTorch Checkpointing: A member inquired about the function of theuse_reentrantparameter in PyTorch's checkpointing feature.- It was clarified that checkpointing reruns forward-pass segments during backward propagation which impacts the RNG state; setting
preserve_rng_state=Falseomits stashing and restoring the RNG state during each checkpoint.
- It was clarified that checkpointing reruns forward-pass segments during backward propagation which impacts the RNG state; setting
Link mentioned: torch.utils.checkpoint — PyTorch 2.6 documentation: no description found
GPU MODE ▷ #off-topic (12 messages🔥):
SSH Pain Points, Nitrokey, SoloKey, Yubikey, PC under the sink
- Blackwell GPU on RTX3050?: A member expressed frustration with SSH and considered buying a Blackwell GPU to pair with their RTX 3050 and GFX90c setup for experimentation.
- Nitrokey, SoloKey, Yubikey improve account security: Members discussed using Nitrokey, SoloKey, or Yubikey for improved security, noting that these options are relatively cheap and easy to use across multiple accounts.
- They also mentioned using mutagen.io to sync files between laptop and servers, disliking VS Code.
- PC Under the Sink: One member shared an anecdote about putting a PC under their kitchen sink due to space constraints and proximity to a power outlet.
GPU MODE ▷ #irl-meetup (3 messages):
Tenstorrent, LlamaIndex, Koyeb, AI Infrastructure, Next-Gen Hardware
- Tenstorrent, LlamaIndex, and Koyeb host SF meetup: The Tenstorrent and LLamaIndex teams are hosting a small meetup tonight in SF Downtown around AI Infrastructure and Next-Gen hardware (lu.ma/ruzyccwp).
- This meetup marks the beginning of a collaboration between Tenstorrent and Koyeb delivering superior performance for cost compared to traditional GPUs.
- Details on who is hosting: Tenstorrent is described as a next-generation computing company that builds computers for AI, Koyeb is a cutting-edge serverless platform for deploying and scaling AI workloads, and LlamaIndex provides a flexible framework for building knowledge assistants using LLMs connected to enterprise data.
- The agenda includes doors opening at 5:30 PM and additional activities beginning at 6:00 PM.
Link mentioned: Next-Gen AI Infra with Tenstorrent & Koyeb @LlamaIndex · Luma: Join us for a special evening as we kick off a groundbreaking collaboration between Tenstorrent and Koyeb with our friends from LlamaIndex.This meetup is a…
GPU MODE ▷ #triton-puzzles (1 messages):
Reshaping vs Permuting, Matrix Transformations
- Reshaping differs from Permuting Matrices: Reshaping a matrix does not alter the order of elements in row-major order, whereas permuting (e.g., transposing) does change the element order.
- For an M x N matrix reshaped to N x M, reading elements in row-major order remains consistent, but transposing the matrix alters this order.
- Understanding Matrix Transformations: Reshaping can be thought of as reorganizing the matrix without changing the underlying order of elements when read in a specific way.
- Permuting, on the other hand, actively rearranges the positions of elements, leading to a different sequence when read in the same order.
GPU MODE ▷ #rocm (6 messages):
RGP on ROCm, ATT plugin
- RGP Instruction Timing alternative sought for ROCm: A member is seeking a tool similar to the Instruction Timing tab in RGP for ROCm on Linux.
- Unfortunately, using RGP is only possible on Windows and compiling rocCLR with the PAL backend on Linux is suggested as an alternative, but its functionality isn't guaranteed.
- ATT Plugin Fails to Deliver: A member inquired about the ATT plugin for rocprofilerv2, suggesting it should provide latency per instruction according to the documentation.
- However, both the original poster and another member confirmed that they couldn't get the ATT plugin to work.
GPU MODE ▷ #tilelang (17 messages🔥):
Shared Memory Allocation in CUDA, Python Linting Workarounds, CUDA Compatibility Issues, TileLang CUDA 12.4/12.6 Bug, WeChat Group Invitation
- Shared Memory Calc Discovered: A user referenced the CUDA documentation (Table 24) for calculating available shared memory overall and per thread block, linking it to
T.alloc_sharedcalls and data type sizes.- The purpose of this calculation is to ensure that the amount of shared memory requested by the program does not exceed the limits of the CUDA device.
- Python Linting Warning Resurfaces: A user confirmed that a warning is mainly due to Python linting in their Pythonic DSL, but they haven’t found a simple way to bypass the lint issue yet.
- Another user chose to ignore the warnings for now while a proper solution is being sought.
- CUDA 12.4 Failure Frustrates: A user reported a failure on an RTX 4070 laptop while running code that worked on an RTX 4090 with the same nightly build (cu121).
- Downgrading to CUDA 12.1 resolved the issue, despite the package indicating compatibility with CUDA >= 11.0.
- TileLang's Bug Tracker is Born: A user created an issue on GitHub (tile-ai/tilelang/issues/149) reporting mismatched elements when performing matmul on CUDA 12.4/12.6.
- The code, which functions correctly on CUDA 12.1, raised an
AssertionErrorconcerning tensor-like discrepancies, prompting maintainers to investigate the compatibility issue.
- The code, which functions correctly on CUDA 12.1, raised an
Link mentioned: Mismatched elements when performing matmul on CUDA 12.4/12.6 · Issue #149 · tile-ai/tilelang: Describe the Bug I ran the simple matmul code below, and I got error AssertionError: Tensor-likes are not close! The code works fine on CUDA 12.1, but not on CUDA 12.4/12.6. The number of mismatche...
GPU MODE ▷ #metal (1 messages):
M3 Ultra, Unified Memory
- M3 Ultra Announcement Sparks Creative Ideas: Members shared thoughts on the M3 Ultra announcement and possible creative applications of unified memory.
- The discussion took place in this discord channel.
- Unified Memory Applications: The potential of unified memory in the M3 Ultra was a key point of interest.
- Creative uses and benefits were discussed, though specific applications weren't detailed in the provided context.
GPU MODE ▷ #reasoning-gym (12 messages🔥):
ARC AGI, Lossless Information Compression, QwQ-32B, RL Scaling
- *ARC AGI* is next?: Members are planning to participate in ARC AGI-2 following the initial work on ARC AGI by Isaac Liao and Albert Gu on whether lossless information compression can produce intelligent behavior.
- The post gives evidence that lossless compression during in-context learning can implement AGI.
- *QwQ-32B* Challenges Reasoning Models: Alibaba released QwQ-32B, a new reasoning model with only 32 billion parameters, rivaling cutting-edge models like DeepSeek-R1.
- Links provided include the HF page, ModelScope, Demo and Qwen Chat.
- *RL* Scaling Achieves Impressive Results: Scaling RL training can continuously improve performance, especially in math and coding, with Qwen2.5-32B achieving competitive results against larger MoE models.
- The discussion emphasizes that continuous scaling of RL can help medium-sized models compete with gigantic models.
- *Reasoning Gym* sets sights on 100 datasets: The Reasoning Gym now has 97 datasets, and is seeking proposals for 3 more to reach 100 total.
- One member mentioned having two datasets that have not yet been added.
- ARC-AGI Without Pretraining: no description found
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
GPU MODE ▷ #gpu模式 (1 messages):
leoneo221: 好久没上线,竟然多了一个中文channel
GPU MODE ▷ #submissions (11 messages🔥):
Modal Runners, Leaderboard Submissions, GPU usage
- Modal Runners Succeed: Test submissions using Modal runners succeeded on various leaderboards and GPUs, including A100 and T4.
- Submissions to the
histogramandgrayscaleleaderboards were successful, as reported by the Cluster-Bot.
- Submissions to the
- Leaderboard Names Cause Hiccups: The Cluster-Bot reported that the leaderboard name specified in the command doesn't match the one in the submission script header.
- Despite the discrepancy, submissions were made to the
histogramandgrayscaleleaderboards.
- Despite the discrepancy, submissions were made to the
- T4 GPUs Take the Lead: Multiple test submissions were successful on the
grayscaleleaderboard using T4 GPUs.- Submissions with IDs 1594, 1595, 1596, 1598, 1599, 1600, and 1601 all utilized T4 GPUs for the
grayscaleleaderboard.
- Submissions with IDs 1594, 1595, 1596, 1598, 1599, 1600, and 1601 all utilized T4 GPUs for the
Perplexity AI ▷ #announcements (1 messages):
AI model settings, Claude 3.7 Sonnet, Auto settings improvements
- Settings Relocation Creates Stellar Simplicity: AI model settings are being merged into one convenient location next to the input, rolling out on web first.
- This change aims to make customizing settings faster and more intuitive; a placeholder will guide users to the new location as they transition.
- Claude's Capabilities Captivate Customers: Claude 3.7 Sonnet will be available to Pro users as part of this update.
- The team hopes to make the "Auto" setting even more powerful so users don't have to pick a model.
Perplexity AI ▷ #general (107 messages🔥🔥):
Perplexity Auto Model Selection, Image sources issue, Deepseek r2 release, Claude Sonnet 3.7 frustrations, Google Search AI Mode
- Perplexity's AUTO model: Separate Entity or Not?: Users discuss whether "Auto" in Perplexity refers to a separate AI model or a function to automatically select from existing models, with some suggesting it selects the model chosen in settings.
- It was also suggested the Auto model runs Sonar by default, unless using the 'rewrite' function.
- Annoying Image Sources Bug: A user reports that images used as sources keep reappearing in prompts even after being deleted, calling it an annoying bug needing a fix.
- No workaround was provided other than manually deleting them.
- Deepseek r2: The Community Awaits: Members are eagerly awaiting the release of Deepseek r2, with hopes it will be significantly cheaper and beneficial for the AI community.
- Concerns about server issues persist, with suggestions for a more secure proxy website to address them.
- Google Search Embraces AI Mode: Google has announced AI Mode for Search, offering a conversational experience and support for complex queries, currently available as an opt-in experience for some Google One AI Premium subscribers (see AndroidAuthority).
- One user commented, It's just that perplexity isn't special anymore.
- Claude Sonnet 3.7 Blues: One user expressed dissatisfaction with Perplexity's implementation of Claude Sonnet 3.7, finding the results inferior compared to using it directly through Anthropic and criticizing the hoops needed to activate it.
- They also noted 3.7 hallucinated errors in a simple json file, questioning the model's claimed improvements.
- no title found: no description found
- Google supercharges Search with an AI Mode to answer complex questions: The much-awaited AI Mode for Google Search is finally here and it can answer complex, multi-part questions more effectively.
Perplexity AI ▷ #sharing (6 messages):
Microsoft AI Health Assistant, Python Learning Roadmap, Mac M3, OpenAI Agent, SQLI Protection
- Microsoft Debuts AI Health Assistant: Microsoft debuted a new AI Health Assistant here.
- Roadmap to Learn Python: A roadmap to learn Python can be found here.
- New Mac M3: Discussion about the new Mac M3 can be found here.
- OpenAI's 20000 AI Agent: A page about OpenAI's 20000 AI Agent is located here.
- Protect Against SQLI: Information on how to protect against SQLI can be found here.
Perplexity AI ▷ #pplx-api (4 messages):
API focus setting, Sonar Pro model issues, Search cost pricing
- API Focus Setting Conundrum: A user inquired about methods to focus the API on specific topics like academic or community-related content.
- No solutions were provided in the messages.
- Sonar Pro Struggles with Timeliness and Validity: A user reported that the Sonar Pro model returns outdated information and faulty links, despite setting the search_recency_filter to 'month'.
- The user wondered if they were misusing the API.
- Sonar Pro's Confusing Citation Numbering: A user reported that the citation numbering in Sonar Pro is confusing, because replies start with 1, but the sources list starts at 0.
- No solutions were provided in the messages.
- API Search Cost Pricing Mystery: A user expressed frustration about the API not providing information on search costs, making it impossible to track spending accurately.
- They lamented that they cannot track their API spendage because the API is not telling them how many searches were used, adding a cry emoji.
HuggingFace ▷ #general (47 messages🔥):
Local Model Usage, Llama 3.1, Mistral small instruct quantized, CoreWeave IPO, HF Inference Credits
- Running Models at Home: One member suggested that by clicking on the "use this model" option and selecting a serve provider, users can easily run models locally.
- They also shared that you can contact Meta directly through the Discussion section or to use unsloth.
- Best Locally Runnable Text-to-Text Model is debated: A member asked about the best locally runnable text-to-text model with a 4080, wondering about Llama 3.1.
- Another member recommended Mistral small instruct quantized, noting it has 24B parameters and is comparable to llama 3.3 70B.
- CoreWeave Files for IPO: CoreWeave, a provider of cloud-based Nvidia processors, filed its IPO prospectus reporting a 700% revenue increase to $1.92 billion in 2024, though with a net loss of $863.4 million.
- Around 77% of revenue came from two customers, primarily Microsoft, and the company holds over $15 billion in unfulfilled contracts.
- Navigating Inference Credits: A user with an HF pro plan expressed concern over limited inference credits ($2) and sought alternative providers for increased usage.
- Another member confirmed the existence of several third-party providers for various models, noting that they bought W&B too.
- Trivial anomaly detection: One member suggested xircuits.io that integrates Pycaret for basic anomaly detection, highlighting its ease of use for identifying problems without specific training.
- The link points to AutoMLBasicAnomalyDetection.xircuit for a basic anomaly detection Pycaret application.
- Models - Hugging Face: no description found
- AI cloud provider CoreWeave files for IPO: CoreWeave, which counts on Microsoft for close to two-thirds of its revenue, is headed for the public market.
- Anomaly Detection | Xircuits: Before starting any of these examples, please ensure that you installed Pycaret=>2.2 in your working environment. You can use pip install pycaret==2.3.8 to install it too.
- AI cloud provider CoreWeave files for IPO: CoreWeave, which counts on Microsoft for close to two-thirds of its revenue, is headed for the public market.
HuggingFace ▷ #today-im-learning (6 messages):
Kornia Rust Library, Google Summer of Code 2025, Internship postings
- Kornia Rust Library Seeks Interns for Google Summer of Code 2025: The Kornia Rust library is opening internships for the Google Summer of Code 2025 to improve the library.
- The projects will mainly revolve around CV/AI in Rust, and interested parties are encouraged to review the documentation and reach out with any questions.
- Discord Server Invites Prohibited; Internship Postings Permitted: A member reminded the channel that server invites are not allowed in accordance with channel guidelines, referencing channel <#895532661383254098>.
- It was clarified that posting about internships is fine, but invitations to join other Discord servers are not.
Link mentioned: Google Summer of Code: Google Summer of Code is a global program focused on bringing more developers into open source software development.
HuggingFace ▷ #cool-finds (1 messages):
Flash Attention, Triton, CUDA, GPU Mode
- Umar Jamil to share his journey learning Flash Attention, Triton and CUDA on GPU Mode: Umar Jamil will be on GPU Mode this Saturday, March 8, at noon Pacific, sharing his journey learning Flash Attention, Triton and CUDA.
- It will be an intimate conversation with the audience about his own difficulties along the journey, sharing practical tips on how to teach yourself anything.
- Triton and CUDA Discussion: The discussion is focused on learning practical tips for mastering Triton and CUDA for efficient GPU programming.
- The session will also cover strategies for self-teaching complex technical subjects.
Link mentioned: Tweet from Umar Jamil (@hkproj): I'll be hosted March 8th by @GPU_MODE sharing my journey in learning Flash Attention, Triton and CUDA. It's going to be an intimate conversation with the audience about my own difficulties alo...
HuggingFace ▷ #i-made-this (3 messages):
VisionKit, Deepseek-r1, Model Context Protocol (MCP)
- VisionKit is not yet Open Source!: The model uses VisionKit but is not open source, with potential release "later down the road."
- Deepseek-r1 lends a Helping Hand: Deepseek-r1 was surprisingly helpful during development.
- A Medium article discusses building a custom MCP server and mentions CookGPT as an example.
Link mentioned: Model Context Protocol- Custom MCP Server: In this article, we will focus on building a custom MCP server. If you need an introduction to MCP, please refer to my previous articles on…
HuggingFace ▷ #computer-vision (1 messages):
DINOv2, fine-tuning, pose estimation, weakly labeled images
- DINOv2 Backbone Training for Pose Estimation Discussed: A member is seeking advice on training or fine-tuning DINOv2 with ~600k weakly labeled images for a specific task, with the eventual goal of using it for pose estimation and other complex tasks.
- They are considering training from scratch versus fine-tuning, and are also contemplating training classification with the backbone unfrozen, but are unsure if the semantics learned would be sufficient due to the vague labels.
- DINOv2 Fine-Tuning Strategies: The discussion revolves around whether to train a DINOv2 backbone from scratch or fine-tune it for a specific task involving weakly labeled images.
- The user is also exploring the option of training for classification with an unfrozen backbone, but is concerned about the quality of semantics learned due to the vague nature of the labels.
HuggingFace ▷ #smol-course (3 messages):
Reasoning Course, Smol Course Discovery
- Reasoning Course gets Spotlight: The course creator is focusing on the reasoning course material as the logical progression of the smol-course.
- A member inquired about more units in reasoning.
- Smol Course attracts Chatbot Builder: A member happily discovered the smol-course and inquired if the course is for them.
- They have built a few chatbots on various applications, with up to 5 basic tool calls, including a couple bots with local llm and RAG, and wants to learn more about the hf ecosystem.
HuggingFace ▷ #agents-course (51 messages🔥):
Certificate location, Alfred Examples Opinion, 401 Error, Huggingface channels, Llama Index error
- Certificates location not obvious!: Users were unable to locate their certificates in the course, specifically in this page, and asked for help.
- A member pointed out that the certificates can be found under "files" and then "certificates" in this dataset, but others have had issues with it not showing.
- Alfred Examples get roasted, then defended: One member expressed dislike for the Alfred examples in the course, finding them too far removed from real-world use cases.
- Another member defended the examples, stating that they explain perfectly how an agent would be needed and act IRL.
- Hit 401 Error, solved by copy to Drive!: A member encountered a 401 Client Error in the
code_agents.ipynbnotebook despite a successful login.- The issue was resolved by copying the notebook to their Google Drive and launching it from there.
- Llama Index import failure?
llama_index.embeddings.huggingface_apinot found?: A member faced aModuleNotFoundErrorwhen running the notebook for Llama Index, specifically failing to importllama_index.embeddings.huggingface_api.- Another member suggested running
!pip install llama_index.embeddings.huggingfaceand changing the import statement tofrom llama_index.embeddings.huggingface import HuggingFaceInferenceAPIEmbedding.
- Another member suggested running
- Inference usage limit: A member suggested using OpenRouter as another method to get access to free, open source models.
- Specifically, all models with ":free" at the end are usable without having to pay for credits or a subscription.
- Steam Gift Activation: no description found
- Unit 1 Quiz - Hugging Face Agents Course: no description found
- Models: no description found
- Unit 1 Quiz - Hugging Face Agents Course: no description found
- agents-course/certificates · Datasets at Hugging Face: no description found
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Discord: no description found
MCP (Glama) ▷ #general (73 messages🔥🔥):
Tool calling, MCP for Reddit, Composio MCP Support, WebMCP, fastmcp
- Evals for Production Empirically Optimize Prompts: Members discussed that evals for production are the way to empirically optimize prompts and context, especially for commercial/critical stuff.
- They noted that even with 95% accuracy, the inability to identify which instances are correct poses a challenge.
- Composio Now Supports MCP with Comprehensive Authentication: Composio announced full support for MCP with comprehensive authentication for integrations.
- This eliminates the need to set up MCP servers for apps like Linear, Slack, Notion, and Calendly, offering managed authentication and improved tool calling accuracy, as highlighted in their announcement.
- WebMCP Idea Sparks Security Concerns: The idea of any website being an MCP server was discussed, with potential for any website to access local MCP servers.
- This raised significant security concerns, with one member describing it as a security nightmare that would defeat the browser sandbox; others countered that protections like CORS and cross-site configuration could mitigate risks.
- Reddit Agent Built with MCP: A member built a Reddit agent using MCP to start getting leads, showcasing the practical application of MCP for real-world tasks.
- Another member shared a link to Composio's Reddit integration after asking about how to connect to Reddit.
- fastmcp tool description options: A member noted that fastmcp can use the docstring or the decorator
@mcp.tool(description="My tool description")to describe a tool.- They linked to code examples in the python-sdk repo and base.py.
- Supporting Multi-Agent Use Cases with Anthropic's Model Context Protocol: Mentioned in the Video:- Anthropic MCP Workshop recording and swyx's summary https://x.com/swyx/status/1896242039614042181?t=6qt4OtebjAeM_BYkt_6QuQ&s=19- Lis...
- GitHub - ComposioHQ/composio: Composio equip's your AI agents & LLMs with 100+ high-quality integrations via function calling: Composio equip's your AI agents & LLMs with 100+ high-quality integrations via function calling - ComposioHQ/composio
- python-sdk/examples/fastmcp/text_me.py at main · modelcontextprotocol/python-sdk: The official Python SDK for Model Context Protocol servers and clients - modelcontextprotocol/python-sdk
- Composio MCP Server: no description found
- Your connected workspace for wiki, docs & projects | Notion: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- python-sdk/src/mcp/server/fastmcp/tools/base.py at main · modelcontextprotocol/python-sdk: The official Python SDK for Model Context Protocol servers and clients - modelcontextprotocol/python-sdk
- Tweet from Composio (@composiohq): We're thrilled to announce that Composio now fully supports MCP, complete with comprehensive authentication for all your integrations.You no longer have to struggle with setting up MCP servers for...
- GitHub - nextapps-de/flexsearch: Next-Generation full text search library for Browser and Node.js: Next-Generation full text search library for Browser and Node.js - nextapps-de/flexsearch
MCP (Glama) ▷ #showcase (23 messages🔥):
MCP Server setup, MCP Token Generation, Blue Yeti Mic, Instagram Lead Scraper
- *MCP Server Setup Snafu Solved!: A user encountered a 401 error* while setting up the MCP server, but resolved it by correctly supplying the client token generated on startup as an environment variable to the MCP Server, after realizing the docs were incorrectly labelled.
- The user clarified that you need to supply a client token generated on startup as an environment variable to the MCP Server, then you use the command line to generate other tokens to paste in to the website.
- *Token Tango: Local vs. Per-Site!: After the MCP Server setup, the user clarified there's a local token, and then tokens generated per-site and per session* for website access.
- The developer confirmed the process, emphasizing that it's per session, per site.
- *Blue Yeti: Mic Drop!*: A user inquired about the microphone used in the demo, and it was revealed to be a Blue Yeti with years of service.
- The developer confirmed and added that the audio was just the raw audio- no eq, compression, reverb etc.
- *Insta-Lead-Magic: Scraper & Dashboard Debut!: A user showcased an Instagram Lead Scraper paired with a custom dashboard*, demonstrated in an attached video.
Latent Space ▷ #ai-general-chat (60 messages🔥🔥):
Claude costs, M4 Macbook Air, Qwen models, React for LLM backends, Windsurf Cascade
- Claude's Costly Codebase Questions: A member reported spending $0.26 to ask Claude one question about their small codebase.
- Another member suggested copying the codebase into a Claude directory and activating the filesystem MCP server on Claude Desktop for free access.
- Apple's M4 MacBook Air Debuts in Sky Blue: Apple announced the new MacBook Air featuring the M4 chip, Apple Intelligence capabilities, and a new sky blue color, starting at $999, according to this announcement.
- Qwen's QwQ-32B Rivals DeepSeek-R1: Qwen released QwQ-32B, a new 32 billion parameter reasoning model that rivals the performance of models like DeepSeek-R1 as mentioned in this blog post.
- The model was trained with RL and continuous scaling, improving performance in math and coding, and is available on HuggingFace.
- React Reimagined for Backend LLM Workflows?: A member shared a hot take that React is the best programming model for backend LLM workflows, linking to a blog post on building @gensx_inc with a node.js backend and React-like component model.
- Another member noted that the main point is the inadequacy of defining graphs with APIs like graph.addEdge, suggesting that Lisp allows for easier DSL creation, while another member pointed to Mastra as a no-framework alternative.
- Windsurf's Cascade Waves into Element Inspection: Windsurf released Wave 4, featuring Cascade, which sends element/errors directly to chat, aiming to reduce the need for Inspect Element with a demo available at this link.
- Included in this update: previews, Cascade Auto-Linter, MCP UI Improvements, Tab to Import, Suggested Actions, Claude 3.7 Improvements, Referrals, and Windows ARM Support.
- Tweet from Chen Cheng (@cherry_cc12): Who Will Be the Next Member to Join the QwQ Family?Quoting Qwen (@Alibaba_Qwen) Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning mo...
- Together AI to Co-Build Turbocharged NVIDIA GB200 Cluster with 36K Blackwell GPUs in Partnership with Hypertec Cloud: no description found
- Expanding AI Overviews and introducing AI Mode: AI Mode is a new generative AI experiment in Google Search.
- Handling Complex LLM Operations | Workflows | Mastra: no description found
- Tweet from OpenAI (@OpenAI): Great day to be a Plus user.
- Tweet from Evan Boyle (@_Evan_Boyle): Hot take: React is the best programming model for backend LLM workflows. New blog post on why we built @gensx_inc
- Tweet from Windsurf (@windsurf_ai): Windsurf Wave 4 is here!Included in this update:🖼️ Previews✏️ Cascade Auto-Linter⚙️ MCP UI Improvements ➡️ Tab to Import↩️ Suggested Actions🫶 Claude 3.7 Improvements🤝 Referrals🖥️ Windows ARM Suppo...
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
- Tweet from Qwen (@Alibaba_Qwen): Qwen2.5-Plus + Thinking (QwQ) = QwQ-32B . This is how you should use this new model on Qwen Chat!Quoting Qwen (@Alibaba_Qwen) Today, we release QwQ-32B, our new reasoning model with only 32 billion pa...
- Tweet from Tim Cook (@tim_cook): Say hello to the new MacBook Air! The world’s most popular laptop now features M4, Apple Intelligence capabilities, and a beautiful new color—sky blue.
- GitHub - x1xhlol/v0-system-prompts: Contribute to x1xhlol/v0-system-prompts development by creating an account on GitHub.
- Apple introduces the new MacBook Air with the M4 chip and a sky blue color: Apple announced the new MacBook Air, featuring the M4 chip, up to 18 hours of battery life, a 12MP Center Stage camera, and a lower starting price.
Stability.ai (Stable Diffusion) ▷ #general-chat (47 messages🔥):
SDXL Hand Fixing, Photo Realistic Upscalers, Text-to-video for Free, Stable Diffusion v4, SD3.5 Large TurboX
- Hands fixed automatically with SDXL: Users are looking for ways to fix hands automatically without inpainting when using SDXL with 8GB VRAM, exploring options like embeddings, face detailers, and OpenPose control nets.
- The user is seeking good hand LoRAs for SDXL and options for automatic hand correction without manual inpainting.
- Generate videos locally with WAN 2.1 model: Users discussed creating videos from a single photo for free, suggesting the WAN 2.1 i2v model, but noted it requires a good GPU and patience.
- Some suggest using online services with free credits, though results may vary, while others pointed out that generating videos locally still costs money due to electricity consumption.
- SD 3.5 Underperforms: Members discussed that SD 3.5 underperformed even flux dev in my tests and nowhere close to larger models like ideogram or imagen.
- Another member said that Compared to early sd 1.5 they have come a long way.
- SD3.5 Large TurboX Open-Sourced: TensorArt open-sourced SD3.5 Large TurboX, which uses 8 sampling steps to deliver a 6x speed boost with superior image quality compared to the official Stable Diffusion 3.5 Turbo; it is available on Hugging Face.
- They also released SD3.5 Medium TurboX, which uses only 4 sampling steps to generate 768x1248 resolution images in 1 second on mid-range GPUs, providing a 13x speed improvement; it is also available on Hugging Face.
- SwarmUI/docs/Video Model Support.md at master · mcmonkeyprojects/SwarmUI: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
- GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model: A latent text-to-image diffusion model. Contribute to CompVis/stable-diffusion development by creating an account on GitHub.
- SD3.5 Large TurboX just released: Posted in r/StableDiffusion by u/NukeAI_1 • 180 points and 44 comments
- Let Us Cook Let Me Cook GIF - Let us cook Let me cook Lets cook - Discover & Share GIFs: Click to view the GIF
LlamaIndex ▷ #blog (1 messages):
Agentic Document Workflows, DeepLearningAI partnership
- LlamaIndex Envisions Agentic Document Workflows: According to LlamaIndex, Agentic Document Workflows, which integrate directly into your larger software processes, are the future of knowledge agents.
- LlamaIndex and DeepLearningAI have partnered to bring you a short course on how to build them.
- DeepLearningAI and LlamaIndex Partner on New Course: LlamaIndex has partnered with DeepLearningAI to create a short course.
- The course focuses on building Agentic Document Workflows that integrate directly into software processes.
LlamaIndex ▷ #general (43 messages🔥):
ImageBlock and OpenAI integration issues, Query Fusion Retriever Citation Problems, Distributed AgentWorkflow Architecture, Profiling/Timing Agent Execution in LlamaIndex, Memory Consumption with Flask and Gunicorn
- ImageBlock Integration Issues Plague LlamaIndex Users: A member reported issues using ImageBlock with OpenAI in the latest LlamaIndex, with the system not recognizing the image.
- A bot suggested ensuring the most up-to-date versions of LlamaIndex and dependencies are used and verifying the correct model is used (e.g., gpt-4-vision-preview).
- Query Fusion Retriever Fails to Cite Sources: A user reported that node post-processing and citation templates were not working correctly with the Query Fusion Retriever in their LlamaIndex setup, particularly when using reciprocal reranking.
- It was suggested that the de-duplication process in the Query Fusion Retriever might be the cause of losing metadata during node processing, and they linked their code for review.
- AgentWorkflow Seeks Distributed Architectures: A member inquired about native support for a distributed architecture in AgentWorkflow, where different agents run on different servers/processes.
- One suggestion proposed achieving this by equipping an agent with tools that make remote calls to a service, rather than relying on built-in distributed architecture support.
- GPT-4o Audio Preview Model Struggles in Agents: A user is facing integration challenges using OpenAI's audio
gpt-4o-audio-previewmodel with LlamaIndex agents, particularly with streaming events.- It was pointed out that AgentWorkflow automatically calls
llm.astream_chat()on chat messages, which might conflict with OpenAI's audio support, suggesting a potential workaround of avoiding AgentWorkflow or disabling LLM streaming.
- It was pointed out that AgentWorkflow automatically calls
- Claude Sonnet 3.5's ReactAgent Realness: A user found that Claude Sonnet 3.5 does not work well with the ReactAgent, generating multiple steps at once.
- Another member concurred, advising that Anthropic models work best with XML prompting, and suggesting using function calling over the API as a more reliable alternative to React.
- ingest-reposit/app/engine at main · Restodecoca/ingest-reposit: Contribute to Restodecoca/ingest-reposit development by creating an account on GitHub.
- llama_index/llama-index-core/llama_index/core/agent/workflow/function_agent.py at ea1f987bb880519bb7c212b33d8615ae4b8fdbf8 · run-llama/llama_index: LlamaIndex is the leading framework for building LLM-powered agents over your data. - run-llama/llama_index
- OpenAI - LlamaIndex: no description found
Notebook LM ▷ #use-cases (13 messages🔥):
Uploading textbooks, NotebookLM API, NotebookLM and PDFs, Strategy optimization in online game, NotebookLM Podcast Feature
- Gemini vs NotebookLM for Physics Syllabus: A user uploaded their entire 180-page physics textbook but found that the system would not get away from their syllabus by using Gemini.
- NotebookLM PDF uploading isn't ideal: Users discussed issues with uploading PDFs, finding them near unusable, especially with mixed text and image content.
- A member suggested converting PDFs to Google Docs or Slides**, which handles mixed content better.
- NotebookLM API Inquiries: A user inquired about the existence of a NotebookLM API or future plans for one, citing numerous workflow optimization use cases.
- NotebookLM For Gaming Optimization: A user leverages NotebookLM to enhance strategy in an online game, using game documentation, personal game data (like JSON card lists), and extracted spreadsheet data as source material.
- Podcast feature is a game changer for lectures: A university professor uses the podcast feature to provide stimulating discussion and analogies that can help students see the bigger picture.
Notebook LM ▷ #general (29 messages🔥):
Standalone Android App, NLM Response Length, Formula Rendering in NLM, File Upload Issues, Podcast Generator
- *Android App Anticipation: A user inquired about a standalone Android app for NotebookLM, and another user suggested that the web version works fineeeeeee*.
- *NLM's Lengthy Latency*: Several users reported that the responses in NLM have been much longer than usual, suggesting that prompt adjustments might be necessary to obtain more specific answers.
- *Podcast Power Play: A user lauded Notebook LM's podcast generator as exquisite but wanted to know is there a way to extend the length of the podcast from 17 to 20 mins*.
- *Filipino Feature Frustrations*: A user was confused about NotebookLM's support for the Filipino language, citing conflicting information from Google's Vertex AI docs and NotebookLM support pages.
- *PWA Praise & Installation Info: Users discussed the availability of NotebookLM as a Progressive Web App (PWA*) that can be installed on phones and PCs, offering a native app-like experience without a dedicated app.
Link mentioned: no title found: no description found
Nous Research AI ▷ #general (33 messages🔥):
Gaslight Benchmark, GPT-4.5 vs Claude image generation, Video AI Prompt Engineering, Hermes Special Tokens, Post-training RL
- *Gaslight Benchmark* quest begins: A member inquired about the existence of a gaslight benchmark to compare GPT-4.5 with other models.
- Another member jokingly responded with a link to a satirical benchmark.
- *GPT-4.5's Persuasion Gains: A member mentioned that GPT-4.5's system card* indicates significant improvements in persuasion, likely due to post-training RL.
- Another member is interested to see startups use post-training RL.
- *Hermes' Special Tokens Unveiled: A member asked about the list of special tokens used in training Hermes*.
- Another member clarified that the special tokens are
and , as well as and .
- Another member clarified that the special tokens are
- *Video AI Prompt Engineering struggles: A member is struggling with writing effective prompts for video AI tools like Kling or Hailou*.
- They asked for sample prompts to learn how to get the hang of it and generate realistic images or sketches.
- *Scamming in 2025: A user posted hi guys new here, just started learning about ML and somehow landed here hmm still a scam user id is 1336741798512693382 if they delete and repost again*
- In response, a member responded love scamming people in 2025.
Nous Research AI ▷ #ask-about-llms (1 messages):
garry_plahilsin07: Opps
Nous Research AI ▷ #interesting-links (4 messages):
QwQ-32B, Reinforcement Learning, DeepSeek R1, Tool calling syntax, Hermes format
- Qwen's QwQ-32B packs a Punch: QwQ-32B, a 32 billion parameter model from Qwen, achieves performance comparable to DeepSeek-R1, which has 671 billion parameters (with 37 billion activated) according to this blogpost.
- Hopes for QwQ-Max Dashed: A user expressed that they were hoping for QwQ-Max release, but will do a vibe check between QwQ-32B and DeepSeek R1.
- The model is available via QWEN CHAT, Hugging Face, ModelScope, DEMO, and DISCORD.
- QwQ-32B follows Tool Calling Syntax: QwQ-32B uses specific syntax for tool calling, for example using
<tool_call> { \"name\": \"get_current_temperature\", \"arguments\": { \"location\": \"San Francisco, CA, USA\"} } </tool_call>. - QwQ-32B Embraces Hermes Formatting: It was observed that QwQ-32B employs the Hermes format.
- RL Scaling Propels Model Ingenuity: Reinforcement Learning (RL) scaling boosts model performance beyond typical pretraining, demonstrated by DeepSeek R1 via cold-start data and multi-stage training for intricate reasoning, according to this blogpost.
Link mentioned: QwQ-32B: Embracing the Power of Reinforcement Learning: QWEN CHAT Hugging Face ModelScope DEMO DISCORDScaling Reinforcement Learning (RL) has the potential to enhance model performance beyond conventional pretraining and post-training methods. Recent studi...
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
Android Chat App, OpenRouter Integration, Speech-to-Text, Text-to-Image, Text-to-Speech
- *Taiga Debuts* as Android Chat App: An open-source Android chat app called Taiga has been released, allowing users to customize the LLMs they want to use, with OpenRouter pre-integrated.
- Taiga Roadmap Includes Speech, Images, and TTS*: The developer plans to add local *Speech To Text based on Whisper model and Transformer.js, along with Text To Image support and TTS support based on ChatTTS.
Link mentioned: Release Releasing v0.1.0-rc.0 · Ayuilos/Taiga: It's a pre-release version.And everything will have possibility to change.No more words to say, enjoy and let me know if there's bug or something!
OpenRouter (Alex Atallah) ▷ #general (32 messages🔥):
Prefill Usage in Text Completion, OpenRouter Documentation for Coding Agents, DeepSeek instruct format, LLMGuard Integration, Usage Based Charging App
- Prefill puzzles users: Members discussed whether prefill is being mistakenly used in text completion mode instead of chat completion, questioning why it would be applied to user messages.
- One user noted, "except prefill makes no sense for user message and they clearly define this as chat completion not text completion lol".
- Docs accessible for coding agents: A user inquired about accessing OpenRouter's documentation as a single, large markdown file for use with coding agents.
- Another user provided a link to a full text file of the documentation.
- DeepSeek's Instruct Format Remains Murky: The discussion highlighted the lack of clear documentation on DeepSeek's instruct format for multi-turn conversations, noting that even digging into their tokenizer was confusing.
- A user shared the tokenizer config which defines
<|begin of sentence|>and<|end of sentence|>tokens.
- A user shared the tokenizer config which defines
- LLMGuard Addons?: A member inquired about plans to add addons like LLMGuard for features like Prompt Injection scanning to LLMs via API within OpenRouter.
- The user linked to LLMGuard and wondered if OpenRouter could handle PII sanitization.
- Usage Based Charging App Explored: A user asked for opinions on building an app that mimics the OpenRouter payment flow with a small percentage-based charge on top, inquiring about potential pitfalls.
- The user outlined a happy path: *"1. Check user balance, 2. Make LLM call, 3. Get call cost, 4. Deduct cost plus fee, 5. Tiny Profit."
- tokenizer_config.json · deepseek-ai/DeepSeek-V3 at main: no description found
- Anonymize - LLM Guard: no description found
- Ban Competitors - LLM Guard: no description found
- DeepSeek-V3 Technical Report: We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepS...
Yannick Kilcher ▷ #general (13 messages🔥):
Bilevel Optimization, Sparsemax Generalization, DDP Garbled Weights, MPEC translation, AI method complexity
- Bilevel Optimization Faces Skepticism: A member argued that bilevel optimization doesn't inherently offer anything beyond standard optimization techniques, despite its potential for algorithmic and reformulation benefits, linking to a discussion of bilevel optimization.
- They emphasized that bilevel programming's utility is primarily intuitive, as it translates into a Mathematical Program with Equilibrium Constraints (MPEC) solved as a single-level Nonlinear Programming problem (NLP).
- Sparsemax as Bilevel Max: An AI Reframing?: A member proposed framing Sparsemax as a bilevel optimization (BO) problem, suggesting its potential to dynamically adjust different Neural Network layers.
- Countering this, another member detailed Sparsemax as a projection onto a probability simplex with a closed-form solution, using Lagrangian duality to demonstrate that the computation simplifies to water-filling which can be found in closed form.
- Diffusion Models defy Closed-Form: A member noted the limitations of simplifying AI methods to single-level closed forms, particularly in complex scenarios like diffusion models, quoting Sampling flexibility does not require a full closed-form expression.
- They linked to a prior discussion on diffusion models, suggesting bilevel optimization as an alternative for adaptive max functions when closed forms are unattainable.
- DDP Garbles Weights: Debugging Pytorch?: A member reported encountering issues with PyTorch, DDP, and 4 GPUs, where checkpoint reloads resulted in garbled weights on some GPUs.
- Another suggested ensuring the model is initialized and checkpoints loaded on all GPUs before initializing DDP to mitigate weight garbling.
Yannick Kilcher ▷ #paper-discussion (5 messages):
Proactive T2I Agents, DeepMind's Papers
- Agents Proactively Clarify Text-to-Image Generation: A new paper, Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty, introduces proactive T2I agents that actively ask clarification questions and present their understanding of user intent as an editable belief graph to address the issue of underspecified user prompts.
- A supplemental video shows that at least 90% of human subjects found these agents and their belief graphs helpful for their T2I workflow.
- DeepMind Dominates Discussion Domination: Members expressed that DeepMind's papers are top tier and the "best" in the field of generative AI.
- Another member echoed this sentiment noting they would miss future discussions about the group's publications.
- Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty: User prompts for generative AI models are often underspecified, leading to sub-optimal responses. This problem is particularly evident in text-to-image (T2I) generation, where users commonly struggle ...
- Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty: A Google TechTalk, presented by Meera Hahn, 2024-12-05ABSTRACT: User prompts for generative AI models are often underspecified or open-ended, which may lead ...
Yannick Kilcher ▷ #ml-news (2 messages):
QwQ-32B release, RL scaling, Qwen2.5-32B
- *QwQ-32B* Model Surfaces: Alibaba released QwQ-32B, a new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning models like DeepSeek-R1 and further information can be found at the Qwen Blog.
- Scaling RL Recipes Investigated: Alibaba investigated recipes for scaling RL and achieved impressive results based on their Qwen2.5-32B model, observing that continuous scaling of RL can help a medium-size model achieve competitive performance against gigantic MoE models, as described on their announcement.
- - YouTube: no description found
- Tweet from Qwen (@Alibaba_Qwen): Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.Blog: https://qwenlm.github.io/blog/qwq-32bHF: https://hu...
Cohere ▷ #「💬」general (14 messages🔥):
Cohere, Enterprise, Support
- Cohere's Enterprise Support Contacted: A member asked for a contact at Cohere to discuss enterprise deployment and was directed to email support.
- The member had already emailed support a week prior and was hoping for a faster reply via Discord, emphasizing their preference for a Canadian company.
- B2B Lead Times Are Slow: A member mentioned that enterprise inquiries are handled by direct sales and that B2B lead times can be slow, potentially taking up to 6 weeks.
- Another member countered that Cohere, as an AI company, usually replies within 2-3 days.
Cohere ▷ #【📣】announcements (1 messages):
Aya Vision, Multilingual Vision Model, AyaVisionBenchmark, Multimodal AI
- Cohere Debuts Aya Vision: Seeing the World in 23 Languages: Cohere For AI launched Aya Vision, an 8B and 32B open-weights multilingual vision research model supporting 23 languages.
- It is Cohere's first multimodal model and excels at image captioning, visual question answering, text generation, and translation, as detailed in the blog post.
- Aya Vision: Now on Hugging Face and Kaggle: The release includes a new multilingual vision evaluation set called AyaVisionBenchmark, along with availability on Hugging Face and Kaggle.
- The model is designed to translate both text and images into clear, natural-language text, enhancing its versatility.
- Aya Vision Chatbot is Live on Poe and Whatsapp!: Aya Vision is accessible on Poe and can be texted for free via WhatsApp, offering capabilities in 23 languages.
- Users can use the model to ask text and visual questions, caption images, and translate content into natural language.
- Aya Vision: Expanding the Worlds AI Can See: Our state-of-the-art open-weights vision model offers a foundation for AI-enabled multilingual and multimodal communication globally. Today, Cohere For AI, Cohere’s open research arm, is proud to anno...
- CohereForAI | Aya Vision | Kaggle: C4AI Aya Vision is an open weights research release of 8B and 32B parameter models with advanced capabilities optimized for a variety of vision-language use cases, including OCR, captioning, visual re...
- Aya-Vision - Poe: Aya Vision is a 32B open-weights multimodal model with advanced capabilities optimized for a variety of vision-language use cases. It is model trained to excel in 23 languages in both vision and text:...
- Text Aya on WhatsApp | Cohere For AI: Available in 23 languages, Aya Expanse is the best multilingual AI in the world. Now available on WhatsApp, text Aya in your language, for free.
Cohere ▷ #「🔌」api-discussions (1 messages):
Cohere Reranker v3.5 latency
- Cohere Reranker v3.5 latency numbers sought: A member inquired about latency numbers for Cohere Reranker v3.5, noting the lack of publicly available data despite promises from an interview.
- He mentioned the interviewee said he would share a graph but in the end, he didn't.
- Cohere Reranker v3.5 latency numbers sought pt 2: no details, this second topic is only to satisfy the requirements
- more details, this second topic is only to satisfy the requirements
Cohere ▷ #「🤝」introductions (2 messages):
Introductions
- User seeks sales/enterprise support: A new user joined and is seeking to connect with someone from sales / enterprise support.
- New user introduction: A new user is encouraged to introduce themselves with details on their company/industry/university, what they're working on, favorite tech/tools, and what they hope to gain from the community.
Modular (Mojo 🔥) ▷ #general (10 messages🔥):
Mojo Stability, Virtual Event Recording, Triton vs Mojo, Mojo and Python Relationship
- Mojo Unstable, Work Still to be Done: A member indicated that Mojo is not yet stable, and there’s still a lot of work to do.
- Virtual Event, No Recording Available: A member inquired about a YouTube recording of a virtual event, but it wasn’t recorded.
- The team will definitely consider doing a similar virtual event in the future.
- Triton Surfaces as Alternative: A member suggested Triton, an AMD software supporting Intel and Nvidia hardware, as an alternative option.
- However, another member stated that Mojo is not a superset of Python but rather a member of the python language family.
- Mojo's Python Family Ties: A member clarified that Mojo is not a superset of Python but a member of the Python language family and being a superset would be for Mojo like muzzle.
- It wouldn't fully utilize features from programming languages design, greatly evolved throughout these years.
Modular (Mojo 🔥) ▷ #mojo (5 messages):
Mojo and Python performance benchmark, Mojo/Python project folder structure, Python.add_to_path alternatives, Symlink alternatives in tests folder, Modular Forum
- Mojo Performance Suffers in Python venv: Benchmarking revealed that Mojo's performance boost is significantly reduced when running Mojo binaries within an active Python virtual environment, even for files without Python imports.
- The user was seeking insights into why a Python venv affects Mojo binaries that should be independent.
- Mojo/Python Project Folder Structure Questioned: A developer requested feedback on a Mojo/Python project's folder structure, which involves importing standard Python libraries, custom Python modules, and running tests written in Mojo.
- They use
Python.add_to_pathextensively for custom module imports and a Symlink in thetestsfolder to locate source files.
- They use
- Alternatives to
Python.add_to_pathSought: The developer is seeking alternatives to usingPython.add_to_pathfor Mojo to find custom Python modules, aiming for a cleaner import mechanism.- They are also interested in alternative solutions to symlinking in the
testsfolder for source file access during testing.
- They are also interested in alternative solutions to symlinking in the
- Mojo/Python Folder Structure moved to Modular Forum: A user initiated a discussion on the Modular forum regarding Mojo/Python project folder structure, linking to the forum post.
- This action was encouraged to ensure long-term discoverability and retention of the discussion, since Discord search and data retention is sub-par.
Link mentioned: Mojo/Python project folder structure: I originally posted this on Discord (link), but @DarinSimmons felt it would make a good topic for this forum. I’m looking for guidance on folder organization for a significant Mojo/Python project. I’...
DSPy ▷ #show-and-tell (2 messages):
SynaLinks release, Keras vs Pytorch frameworks, Knowledge graph RAGs, Reinforcement learning, Cognitive architectures
- SynaLinks Framework Joins the LM Arena!: A new graph-based programmable neuro-symbolic LM framework called SynaLinks has been released, drawing inspiration from Keras for its functional API and aiming for production readiness with features like async optimization and constrained structured output - SynaLinks on GitHub.
- SynaLinks Focuses on Knowledge Graphs and RL!: Unlike DSPy, SynaLinks will focus on knowledge graph RAGs, reinforcement learning, and cognitive architectures, aiming for a different niche in the LLM framework landscape.
- It was advised by François Chollet after he liked the previous project (HybridAGI, which was made with DSPy).
- SynaLinks Runs Online with HuggingFace!: Code examples for SynaLinks are available and runnable online via a Hugging Face Space, encouraging community feedback and experimentation.
- SynaLinks Already in Production!: The framework is already running in production with a client, with more projects to follow, showing its potential for real-world applications.
- synalinks notebooks - a Hugging Face Space by YoanSallami: no description found
- GitHub - SynaLinks/synalinks: 🧠🔗 Graph-Based Programmable Neuro-Symbolic LM Framework - a production-first LM framework built with decade old Deep Learning best practices: 🧠🔗 Graph-Based Programmable Neuro-Symbolic LM Framework - a production-first LM framework built with decade old Deep Learning best practices - SynaLinks/synalinks
DSPy ▷ #general (11 messages🔥):
Optimizing intent classification with DSPy, Comparing texts for contradictions, DSPy adapters system, Straggler threads in dspy.Evaluate and dspy.Parallel
- DSPy optimizes intent classification: DSPy can help to optimize classification of intents that requires specialized agents.
- One user was heading in this direction.
- Comparing Texts for Contradictions: Computational Intensive Tasks: Comparing two pieces of texts for contradictions is computationally intensive; using dspy's CoT module takes significant time with large data.
- One user explored providing multiple pairs through one shot, noting some reservations about the LLM's ability to respect the expected return structure when returning a list of pairs, especially when using
OutputField.
- One user explored providing multiple pairs through one shot, noting some reservations about the LLM's ability to respect the expected return structure when returning a list of pairs, especially when using
- DSPy Simplifies Explicit Type Specification: DSPy simplifies explicit type specification with code like
contradictory_pairs: list[dict[str, str]] = dspy.OutputField(desc="List of contradictory pairs, each with fields for text numbers, contradiction result, and justification."), but this is technically ambiguous because it doesn't specify thedict's keys.- Instead, consider
list[some_pydantic_model]where some_pydantic_model has the right fields.
- Instead, consider
- DSPy's Adapters System Decouples Signature From Providers: DSPy's adapters system decouples the signature (declarative specification of what you want) from how different providers produce completions.
- By default, DSPy uses a well-tuned ChatAdapter and falls back to JSONAdapter, leveraging structured outputs APIs for constrained decoding in providers like VLLM, SGLang, OpenAI, Databricks, etc.
- Straggler Threads Resolved for Smoother DSPy Evaluation: PR 7914 (merged) addresses stuck straggler threads in
dspy.Evaluateordspy.Parallel, aiming for smoother operation.- This fix will be available in DSPy 2.6.11; users can test it from
mainwithout code changes.
- This fix will be available in DSPy 2.6.11; users can test it from
tinygrad (George Hotz) ▷ #general (6 messages):
Lean proof for ShapeTracker merging, Taobao 4090, gfx10 trace issue, Rust CubeCL
- *ShapeTracker Merging* Gets Lean Proof!: A member announced a ~90% complete proof in Lean of when you can merge ShapeTrackers, available in this repo and this issue.
- Offsets and masks aren't taken into account, but the author believes extending it is straightforward and not worth the effort.
- *4090s* on Taobao: A member shared a link to a 96GB 4090 on Taobao (X post).
- Another member commented from experience all the good stuff is on Taobao.
- *gfx10 Trace Issue*?: A member asked for thoughts on a trace and whether they should log it as an issue.
- A member suggested it might be related to ctl/ctx sizes and requested running
IOCTL=1 HIP=1 python3 test/test_tiny.py TestTiny.test_plusto help debug, as they lack gfx10 hardware.
- A member suggested it might be related to ctl/ctx sizes and requested running
- *Rust CubeCL*: Good?: A member inquired about the quality of Rust CubeCL, noting it's from the same team behind Rust Burn.
- Tweet from Gene edited Yostuba (@Yomix1337): @EsotericCofe coming out after may
- GitHub - Nielius/Tensorlayouts: Lean proof of necessary and sufficient conditions for merging two tensor views: Lean proof of necessary and sufficient conditions for merging two tensor views - Nielius/Tensorlayouts
- On the Mergeability of arbitrary ShapeTrackers · Issue #8511 · tinygrad/tinygrad: Heyo, I'd like to propose a new formulation and a proof of the view merging problem which I haven't seen anyone mention yet. I have seen a formulation by person called @Nielius but sadly it wa...
Eleuther ▷ #general (2 messages):
Introduction of Suleiman, Introduction of Naveen, CVPR25 Paper
- Suleiman Joins Chat, Exploring AI Biohacking: Suleiman, an executive at a Saudi company with a software engineering background, introduced himself to the channel, expressing his passion for tech and AI.
- He is currently exploring nutrition and supplement science, aiming to develop AI-enabled biohacking tools to improve human life.
- Naveen Enters, Showcases Unlearning Research: Naveen, a Masters cum Research Assistant from IIT, introduced himself, stating that he currently works on Machine Unlearning in Text to Image Diffusion Models.
- He mentioned having recently published a paper in CVPR25.
Eleuther ▷ #research (2 messages):
Observation 3.1, ARC Training, Lossless Compression, Intelligent Behavior
- Observation 3.1: universally true?: A user questioned whether Observation 3.1 is universally true for almost any two distributions with nonzero means and for almost any u35% on ARC training.
- No further discussion or clarification was provided on the specific conditions or exceptions to Observation 3.1.
- ARC AGI Without Pretraining: Isaac Liao and Albert Gu explore whether lossless information compression can produce intelligent behavior in their blog post.
- They aim to provide a practical demonstration, rather than revisiting theoretical discussions about the role of efficient compression in intelligence.
Link mentioned: ARC-AGI Without Pretraining: no description found
Eleuther ▷ #lm-thunderdome (2 messages):
arc_challenge.yaml, ARC-Challenge tasks, Few-shot Learning
- ARC-Challenge Tasks Employ arc_challenge.yaml: Members noted they are utilizing arc_challenge.yaml for ARC-Challenge tasks in a 25-shot configuration.
- Discussions around Few-shot prompting for model evaluation: The conversation includes using a limited number of examples, such as 25 shots, to evaluate model performance on specific tasks.
Torchtune ▷ #general (5 messages):
Tokenizer customization, Checkpointer save method, special_tokens.json handling, Copy files logic
- Tokenizer Customization Troubles: A user downloads from HF and has some custom tokenizer logic represented in their own special_tokens.json, but the original downloaded one is saved in the checkpoint directory after training.
- The suspected culprit is this section of code which assumes that most of the non-model files downloaded from HF are useful as-is.
- Quick Fix Proposed for Tokenizer Issue: The suggested quick fix involves replacing the downloaded special_tokens.json with the user's own version in the downloaded model directory.
- Members discussed potentially making the copy_files and save_checkpoint logic more general to allow for customization.
- Checkpointer save method arg: One member suggested supporting this use case by passing a new arg to the checkpointer's save_checkpoint method, but this would also need to be exposed via config.
- Members were considering whether it's worth exposing anything new without a really strong reason.
- GitHub - pytorch/torchtune at 80da6a5dae23a201595d07041c12ffde830332d7: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/training/checkpointing/_checkpointer.py at 80da6a5dae23a201595d07041c12ffde830332d7 · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
MOOC Lectures, Certificate Submission
- MOOC Students attend same lectures: A member asked if there are lectures that Berkeley students have that MOOC students do not.
- Another member responded that Berkeley students and MOOC students attend the same lectures.
- Certificate Submission in December: A member stated that they had submitted something in December.
- Another member asked for confirmation on which email the certificate declaration form was submitted under.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (2 messages):
AST Metric, V1 Dataset
- AST Metric Definition Needed: A member inquired whether the AST metric is simply the percentage of LLM responses that produced a correctly formatted function call.
- Clarification on the AST metric definition would help others better understand the leaderboard.
- Inquiry About the V1 Dataset Construction: Another member inquired about how the V1 dataset was constructed.
- Understanding the dataset construction process provides insight into the evaluation methodology.