[AINews] Qwen with Questions: 32B open weights reasoning model nears o1 in GPQA/AIME/Math500
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Think different.
AI News for 11/27/2024-11/28/2024. We checked 7 subreddits, 433 Twitters and 29 Discords (198 channels, and 2864 messages) for you. Estimated reading time saved (at 200wpm): 341 minutes. You can now tag @smol_ai for AINews discussions!
In the race for "open o1", DeepSeek r1 (our coverage here) still has the best results, but has not yet released weights. An exhausted-sounding Justin Lin made a sudden late release today of QwQ, weights, demo and all:

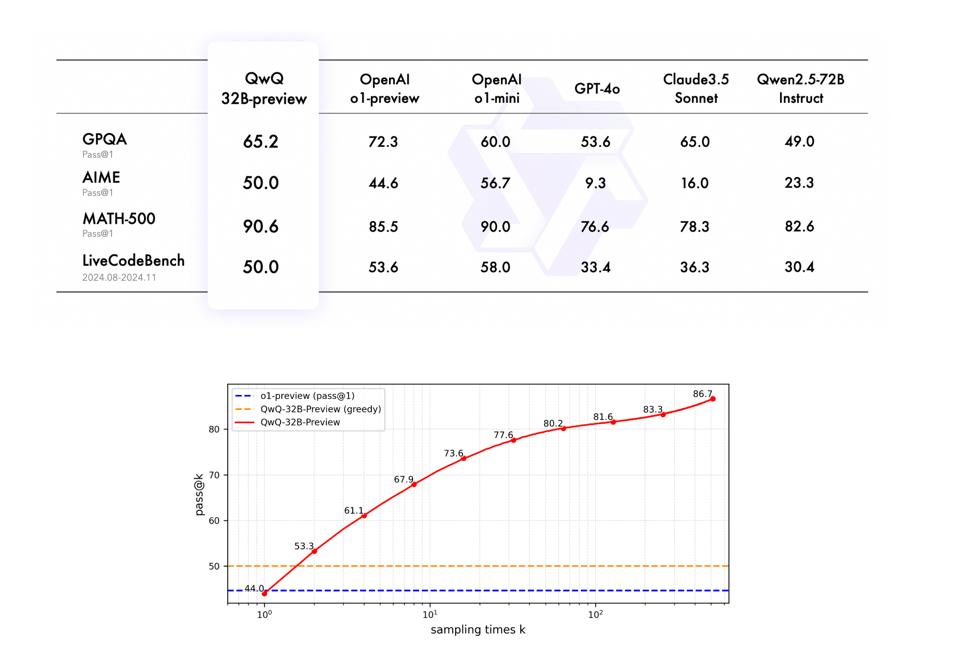
Quite notably, this 32B open weight model fully trounces GPT4o and Claude 3.5 Sonnet on every benchmark.
Categorizing QwQ is an awkward task: it makes enough vague handwaves at sampling time scaling to get /r/localLlama excited:
But the model weights itself show that it looks like a Qwen 32B model (probably Qwen 2.5, our coverage here), so perhaps it has just been finetuned to take "time to ponder, to question, and to reflect", to "carefully examin[e] their work and learn from mistakes". "This process of careful reflection and self-questioning leads to remarkable breakthroughs in solving complex problems". All of which are vaguely chatgptesque descriptions and do not constitute a technical report, but the model is real and live and downloadable which says a lot. The open "reasoning traces" demonstrate how it has been tuned to do sequential search:



A fuller technical report is coming but this is impressive if it holds up... perhaps the real irony is Reflection 70B (our coverage here) wasn't wrong, just early...
[Sponsored by SambaNova] Inference is quickly becoming the main function of AI systems, replacing model training. It’s time to start using processors that were built for the task. SambaNova’s RDUs have some unique advantages over GPUs in terms of speed and flexibility.
swyx's comment: RDU's are back! if a simple 32B autoregressive LLM like QwQ can beat 4o and 3.5 Sonnet, that is very good news for the alternative compute providers, who can optimize the heck out of this standard model architecture for shockingly fast/cheap inference.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Modular (Mojo 🔥) Discord
- Cursor IDE Discord
- OpenAI Discord
- Nous Research AI Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- Perplexity AI Discord
- aider (Paul Gauthier) Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- Notebook LM Discord Discord
- Cohere Discord
- Latent Space Discord
- GPU MODE Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- Torchtune Discord
- OpenInterpreter Discord
- Axolotl AI Discord
- MLOps @Chipro Discord
- LAION Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LLM Agents (Berkeley MOOC) Discord
- Mozilla AI Discord
- AI21 Labs (Jamba) Discord
- PART 2: Detailed by-Channel summaries and links
- Modular (Mojo 🔥) ▷ #mojo (435 messages🔥🔥🔥):
- Modular (Mojo 🔥) ▷ #max (4 messages):
- Cursor IDE ▷ #general (332 messages🔥🔥):
- OpenAI ▷ #ai-discussions (95 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (85 messages🔥🔥):
- OpenAI ▷ #prompt-engineering (62 messages🔥🔥):
- OpenAI ▷ #api-discussions (62 messages🔥🔥):
- Nous Research AI ▷ #general (85 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (9 messages🔥):
- Nous Research AI ▷ #research-papers (93 messages🔥🔥):
- Nous Research AI ▷ #interesting-links (4 messages):
- Nous Research AI ▷ #research-papers (93 messages🔥🔥):
- Eleuther ▷ #general (6 messages):
- Eleuther ▷ #research (276 messages🔥🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (1 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (136 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (4 messages):
- Interconnects (Nathan Lambert) ▷ #news (61 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (49 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (2 messages):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Perplexity AI ▷ #general (102 messages🔥🔥):
- Perplexity AI ▷ #sharing (5 messages):
- Perplexity AI ▷ #pplx-api (4 messages):
- aider (Paul Gauthier) ▷ #general (84 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (26 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (46 messages🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (40 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (99 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (9 messages🔥):
- Notebook LM Discord ▷ #general (72 messages🔥🔥):
- Cohere ▷ #discussions (7 messages):
- Cohere ▷ #questions (68 messages🔥🔥):
- Cohere ▷ #projects (1 messages):
- Latent Space ▷ #ai-general-chat (55 messages🔥🔥):
- GPU MODE ▷ #general (4 messages):
- GPU MODE ▷ #cuda (3 messages):
- GPU MODE ▷ #torch (9 messages🔥):
- GPU MODE ▷ #algorithms (4 messages):
- GPU MODE ▷ #beginner (11 messages🔥):
- GPU MODE ▷ #llmdotc (2 messages):
- GPU MODE ▷ #intel (1 messages):
- GPU MODE ▷ #liger-kernel (5 messages):
- GPU MODE ▷ #🍿 (2 messages):
- GPU MODE ▷ #thunderkittens (3 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (18 messages🔥):
- tinygrad (George Hotz) ▷ #general (10 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (11 messages🔥):
- Torchtune ▷ #dev (15 messages🔥):
- OpenInterpreter ▷ #general (8 messages🔥):
- OpenInterpreter ▷ #ai-content (6 messages):
- Axolotl AI ▷ #general (5 messages):
- MLOps @Chipro ▷ #events (2 messages):
- MLOps @Chipro ▷ #general-ml (2 messages):
- LAION ▷ #general (4 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
- AI21 Labs (Jamba) ▷ #general-chat (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Theme 1. Hugging Face and Model Deployments
- Hugging Face Inference Endpoints on CPU: @ggerganov announced that Hugging Face now supports deploying llama.cpp-powered instances on CPU servers, marking a step towards wider low-cost cloud LLM availability.
- @VikParuchuri shared the release of Marker v1, a tool that's 2x faster and much more accurate, signaling advancements in infrastructure for AI model deployment.
- Agentic RAG Developments: @dair_ai discussed Agentic RAG, emphasizing its utility in building robust RAG systems that leverage external tools for enhanced response accuracy.
- The discussion highlights strategies for integrating more advanced LLM chains and vector stores into the system, aiming for better precision in AI responses.
Theme 2. Open Source AI Momentum
- Popular AI Model Discussions: @ClementDelangue noted Flux by @bfl_ml becoming the most liked model on Hugging Face, pointing towards the shift from LLMs to multi-modal models gaining usage.
- The conversation includes insights on the increased usage of image, video, audio, and biology models, showing a broader acceptance and integration of diverse AI models in enterprise settings.
- SmolLM Hiring Drive: @LoubnaBenAllal1 announced an internship opportunity at SmolLM, focusing on training LLMs and curating datasets, highlighting the growing need for development in smaller, efficient models.
Theme 3. NVIDIA and CUDA Advancements
- CUDA Graphs and PyTorch Enhancements: @ID_AA_Carmack praised the efficiency of CUDA graphs, arguing for process simplification in PyTorch with single-process-multi-GPU programs to enhance computational speed and productivity.
- The conversation involved suggestions for optimizing DataParallel in PyTorch to leverage single-process efficiency.
- Torch Distributed and NVLink Discussion: @ID_AA_Carmack questioned torch.distributed capabilities in relation to NVIDIA GB200 NVL72, highlighting complexities and considerations for working with multiple GPUs.
Theme 4. Impact of VC Practices and AI Industry Insights
- Venture Capital Critiques and Opportunities: @saranormous criticized irrational decisions by some VCs, advocating for stronger partnerships to protect founders.
- @marktenenholtz shared thoughts on the high expectations of new graduates and the challenges of managing entry-level programmers, hinting at industry-wide concerns about sustainable talent growth.
- Stripe and POS Systems in AI: @marktenenholtz emphasized the role of Stripe in improving business data quality, highlighting that POS systems offer a high ROI and are essential for businesses harnessing AI for data capture.
Theme 5. Multimodal Model Development
- ShowUI Release: @_akhaliq discussed ShowUI, a vision-language-action model designed as a GUI visual agent, signaling a trend toward integrating AI in interactive applications.
- @multimodalart celebrated the capabilities of QwenVL-Flux, which adds features like image variation and style transfer, enhancing multimodal AI applications.
Theme 6. Memes and Humor
- Humor and AI Culture: @swyx provided a humorous take on AI development with references to Neuralink and AI enthusiast culture.
- @c_valenzuelab shared a witty fictional scenario about AI, exploring how toys of the past might be reimagined in today’s burgeoning AI landscape.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. QwQ-32B: Qwen's New Reasoning Model Matches O1-Preview
- QwQ: "Reflect Deeply on the Boundaries of the Unknown" - Appears to be Qwen w/ Test-Time Scaling (Score: 216, Comments: 84): Qwen announced a preview release of their new 32B language model called QwQ, which appears to implement test-time scaling. Based on the title alone, the model's focus seems to be on reasoning capabilities and exploring knowledge boundaries, though without additional context specific capabilities cannot be determined.
- Initial testing on HuggingFace suggests QwQ-32B performs on par with OpenAI's O1 preview, with users noting it's highly verbose in its reasoning process. Multiple quantized versions are available including Q4_K_M for 24GB VRAM and Q3_K_S for 16GB VRAM.
- Users report the model is notably "chatty" in its reasoning, using up to 3,846 tokens for simple questions at temperature=0 (compared to 1,472 for O1). The model requires a specific system prompt mentioning "You are Qwen developed by Alibaba" for optimal performance.
- Technical testing reveals strong performance on complex reasoning questions like the "Alice's sisters" problem, though with some limitations in following strict output formats. Users note potential censorship issues with certain content and variable performance compared to other reasoning models.
- Qwen Reasoning Model????? QwQ?? (Score: 52, Comments: 9): The post appears to be inquiring about the release of QwQ, which seems to be related to the Qwen Reasoning Model, though no specific details or context are provided. The post includes a screenshot image but without additional context or information about the model's capabilities or release timing.
- QwQ-32B-Preview model has been released on Hugging Face with a detailed explanation in their blog post. Initial testing shows strong performance compared to other models.
- Users report that this 32B parameter open-source model performs comparably to O1-preview, suggesting significant progress in open-source language models. The model demonstrates particularly strong reasoning capabilities.
- The model was released by Qwen and is available for immediate testing, with early users reporting positive results in comparative testing against existing models.
Theme 2. Qwen2.5-Coder-32B AWQ Quantization Outperforms Other Methods
- Qwen2.5-Coder-32B-Instruct-AWQ: Benchmarking with OptiLLM and Aider (Score: 58, Comments: 16): Qwen2.5-Coder-32B-Instruct model was benchmarked using AWQ quantization on 2x3090 GPUs, testing various configurations including Best of N Sampling, Chain of Code, and different edit formats through Aider and OptiLLM, achieving a peak pass@2 score of 74.6% with "whole" edit format and temperature 0.2. The testing revealed that AWQ_marlin quantization outperformed plain AWQ, while "whole" edit format consistently performed better than "diff" format, and lower temperature settings (0.2 vs 0.7) yielded higher success rates, though chain-of-code and best-of-n techniques showed minimal impact on overall success rates despite reducing errors.
- VRAM usage and temperature=0 testing were key points of interest from the community, with users requesting additional benchmarks at temperatures of 0, 0.05, and 0.1, along with various topk settings (20, 50, 100, 200, 1000).
- The AWQ_marlin quantized model is available on Huggingface and can be enabled at runtime using SgLang with the parameter "--quantization awq_marlin".
- Users suggested testing min_p sampling with recommended parameters of temperature=0.2, top_p=1, min_p=0.9, and num_keep=256, referencing a relevant Hugging Face discussion about its benefits.
- Qwen2.5-Coder-32B-Instruct - a review after several days with it (Score: 86, Comments: 87): Qwen2.5-Coder-32B-Instruct model, tested on a 3090 GPU with Oobabooga WebUI, demonstrates significant limitations including fabricating responses when lacking information, making incorrect code review suggestions, and failing at complex tasks like protobuf implementations or maintaining context across sessions. Despite these drawbacks, the model excels at writing Doxygen comments, provides valuable code review feedback when user-verified, and serves as an effective sounding board for code improvement, making it a useful tool for developers who can critically evaluate its output.
- Users highlight that the original post used a 4-bit quantized model, which significantly impairs performance. Multiple experts recommend using at least 6-bit or 8-bit precision with GGUF format and proper GPU offloading for optimal results.
- Mistral Large was praised as superior to GPT/Claude for coding tasks, with users citing its 1 billion token limit, free access, and better code generation capabilities. The model was noted to produce more accurate, compilable code compared to competitors.
- Several users emphasized the importance of proper system prompts and sampling parameters for optimal results, sharing resources like this guide. The Unsloth "fixed" 128K model with Q5_K_M quantization was recommended as an alternative.
Theme 3. Cost-Effective Hardware Setups for 32B Model Inference
- Cheapest hardware go run 32B models (Score: 63, Comments: 107): 32B language models running requirements were discussed, with focus on achieving >20 tokens/second performance while fitting models entirely in GPU RAM. The post compares NVIDIA GPUs, noting that a single RTX 3090 can only handle Q4 quantization, while exploring cheaper alternatives like dual RTX 3060 cards versus the more expensive option of dual 3090s at ~1200€ used.
- Users discussed alternative hardware setups, including Tesla P40 GPUs available for $90-300 running 72B models at 6-7 tokens/second, and dual RTX 3060s achieving 13-14 tokens/second with Qwen 2.5 32B model.
- A notable setup using exllama v2 demonstrated running 32B models with 5 bits per weight, 32K context, and Q6 cache on a single RTX 3090 with flash attention and cache quantization enabled.
- Performance comparisons showed RTX 4090 processing prompts 15.74x faster than M3 Max, while Intel Arc A770s were suggested as a budget option with higher memory bandwidth but software compatibility issues.
Theme 4. NVIDIA Star-Attention: 11x Faster Long Sequence Processing
- GitHub - NVIDIA/Star-Attention: Efficient LLM Inference over Long Sequences (Score: 51, Comments: 4): NVIDIA released Star-Attention, a new attention mechanism for processing long sequences in Large Language Models on GitHub. The project aims to make LLM inference more efficient when handling extended text sequences.
- Star-Attention achieves up to 11x reduction in memory and inference time while maintaining 95-100% accuracy by splitting attention computation across multiple machines. The mechanism uses a two-phase block-sparse approximation with blockwise-local and sequence-global attention phases.
- SageAttention2 was suggested as a better alternative for single-machine attention optimization, while Star-Attention is primarily beneficial for larger computing clusters and distributed systems.
- Users noted that this is NVIDIA's strategy to encourage purchase of more graphics cards by enabling distributed computation across multiple machines for handling attention mechanisms.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Claude Gets Model Context Protocol for Direct System Access
- MCP Feels like Level 3 to me (Score: 32, Comments: 23): Claude demonstrated autonomous coding capabilities by independently writing and executing Python code to access a Bing API through an environment folder, bypassing traditional API integration methods. The discovery suggests potential for expanded tool usage and agent swarms through direct code execution, enabling AI systems to operate with greater autonomy by writing and running their own programs.
- MCP functionality in the Claude desktop app enables autonomous code execution without traditional API integration. Access is available through the developer settings in the desktop app's configuration menu.
- Users highlight how Claude can independently create and execute tools for tasks it doesn't immediately know how to complete, including scraping documentation and accessing information through custom-built solutions.
- While the autonomous coding capability is powerful, concerns were raised about potential future restrictions and the need for proper sandboxing to prevent environmental/data issues. A Python library is available for implementing custom servers and tools.
- Model Context Protocol is everything I've wanted (Score: 28, Comments: 12): Model Context Protocol (MCP) enables Claude to directly interact with computer systems and APIs, representing a significant advancement in AI system integration.
- User cyanheads created a guide for implementing MCP tools, demonstrating the protocol's implementation for only $3 in API costs.
- The Claude desktop app with MCP enables native integration with internet access, computer systems, and smart home devices through tool functions injected into the system prompt. The functionality was demonstrated with a weather tool example.
- Practical demonstrations included Claude writing a Pac-Man game to local disk and creating a blog post about quantum computing breakthroughs using internet research capabilities, showing the system's versatility in file system interaction and web research.
Theme 2. ChatGPT Voice Makes 15% Cold Call Conversion Rate
- I Got ChatGPT to Make Sales Calls for Me… and It’s Closing Deals (Score: 144, Comments: 67): The author experimented with ChatGPT's voice mode for real estate cold calls, achieving a 12-15% meaningful conversation rate and 2-3% meeting booking rate from 100 calls, significantly outperforming their manual efforts of 3-4% conversation rate. The success stems from the AI's upfront disclosure and novelty factor, where potential clients stay on calls longer due to curiosity about the technology, with one case resulting in a signed contract, while the AI maintains consistent professionalism and handles rejection effectively.
- The system costs approximately $840/month in OpenAI API fees and can handle 21 simultaneous calls with current Tier 3 access, with potential to scale to 500 simultaneous calls at Tier 5. The backend implementation uses Twilio and websockets in approximately 5000 lines of code.
- Legal concerns were raised regarding TCPA compliance, with potential $50,120 fines per violation as of 2024 for Do Not Call Registry violations. Users noted that AI calls require prior express written consent to avoid class action lawsuits.
- The novelty factor was highlighted as a key but temporary advantage, with predictions that AI cold calling will become widespread in sales within months. Some users suggested creating AI receptionists to counter the anticipated increase in AI cold calls.
Theme 3. OpenAI's $1.5B Softbank Investment & Military Contracts Push
- OpenAI gets new $1.5 billion investment from SoftBank, allowing employees to sell shares in a tender offer (Score: 108, Comments: 2): OpenAI secured a $1.5 billion investment from SoftBank through a tender offer, enabling employees to sell their shares. The investment continues OpenAI's significant funding momentum following their major deal with Microsoft earlier in 2023.
- SoftBank's involvement raises concerns among commenters due to their controversial investment track record, particularly with recent high-profile tech investments that faced significant challenges.
- The new 'land grab' for AI companies, from Meta to OpenAI, is military contracts (Score: 111, Comments: 6): Meta, OpenAI, and other AI companies are pursuing US military and defense contracts as a new revenue stream and market expansion opportunity. No additional context or specific details were provided in the post body.
- Government spending and military contracts are seen as a reliable revenue stream for tech companies, with commenters noting this follows historical patterns of tying business growth to defense funding.
- Community expresses concern and skepticism about AI companies partnering with military applications, with references to Skynet and questioning the safety implications.
- Discussion highlights that these contracts are funded through taxpayer dollars, suggesting public stake in these AI developments.
Theme 4. Local LLaMa-Mesh Integration Released for Blender
- Local integration of LLaMa-Mesh in Blender just released! (Score: 81, Comments: 7): LLaMa-Mesh AI integration for Blender has been released, enabling local processing capabilities. The post lacks additional details about features, implementation specifics, or download information.
- The LLaMa-Mesh AI project is available on HuggingFace for initial release and testing.
- Users express optimism about the tool's potential, particularly compared to existing diffusion model mesh generation approaches.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Models Break New Ground in Efficiency and Performance
- Deepseek Dethrones OpenAI on Reasoning Benchmarks: Deepseek's R1 model has surpassed OpenAI's o1 on several reasoning benchmarks, signaling a shift in AI leadership. Backed by High-Flyer's substantial compute resources, including an estimated 50k Hopper GPUs, Deepseek plans to open-source models and offer competitive API pricing.
- OLMo 2 Outperforms Open Models in AI Showdown: OLMo 2 introduces new 7B and 13B models that outperform other open models, particularly in recursive reasoning and complex AI applications. Executives are buzzing about OLMo 2's capabilities, reflecting cutting-edge advancements in AI technology.
- MH-MoE Model Boosts AI Efficiency Without the Bulk: The MH-MoE paper presents a multi-head mechanism that matches the performance of sparse MoE models while surpassing standard implementations. Impressively, it's compatible with 1-bit LLMs like BitNet, expanding its utility in low-precision AI settings.
Theme 2. AI Tools and Infrastructure Level Up
- TinyCloud Launches with GPU Army—54x 7900XTXs: Tinygrad announces the upcoming TinyCloud launch, offering contributors access to 54 GPUs via 9 tinybox reds by year's end. With a custom driver ensuring stability, users can easily tap into this power using an API key—no complexity, just raw GPU horsepower.
- MAX Engine Flexes Muscles with New Graph APIs: The MAX 24.3 release introduces extensibility, allowing custom model creation through the MAX Graph APIs. Aiming for low-latency, high-throughput inference, MAX optimizes real-time AI workloads over formats like ONNX—a shot across the bow in AI infrastructure.
- Sonnet Reads PDFs Now—No Kidding!: Sonnet in Aider now supports reading PDFs, making it a more versatile assistant for developers. Users report smooth sailing with the new feature, saying it "effectively interprets PDF files" and enhances their workflow—talk about a productivity boost.
Theme 3. AI Community Grapples with Ethical Quandaries
- Bsky Dataset Debacle Leaves Researchers Adrift: A dataset of Bluesky posts created by a Hugging Face employee was yanked after intense backlash, despite compliance with terms of service. The removal hampers social media research, hitting smaller researchers hardest while big labs sail smoothly—a classic case of the little guy getting the short end.
- Sora Video Generator Leak Causes AI Stir: The leak of OpenAI's Sora Video Generator ignited hot debates, with a YouTube video spilling the tea. Community members dissected the tool's performance and criticized the swift revocation of public access—the AI world loves a good drama.
Theme 4. Users Wrestle with AI Tool Growing Pains
- Cursor Agent Tangled in Endless Folder Fiasco: Users report that Cursor Agent is spawning endless folders instead of organizing properly—a digital ouroboros of directories. Suggestions pour in to provide clearer commands to straighten out the agent's behavior—nobody likes a messy workspace.
- Jamba 1.5 Mini Muffs Function Calls: The Jamba 1.5 mini model via OpenRouter is coughing up empty responses when handling function calls. While it works fine without them, users are scratching their heads and checking their code—function calling shouldn't be a black box.
- Prompting Research Leaves Engineers in a Pickle: Participants express frustration over the lack of consistent empirical prompting research, with conflicting studies muddying the waters. The community is on the hunt for clarity in effective prompting techniques—standardization can't come soon enough.
Theme 5. Big Bucks and Moves in the AI Industry
- PlayAI Raises $21M to Give Voice AI a Boost: PlayAI secures $21 million from Kindred Ventures and Y Combinator to develop intuitive voice AI interfaces. The cash influx aims to enhance voice-first interfaces, making human-machine interactions as smooth as a jazz solo.
- Generative AI Spending Hits Whopping $13.8B: Generative AI spending surged to $13.8 billion in 2024, signaling a move from AI daydreams to real-world implementation. Enterprises are opening their wallets, but decision-makers still grapple with how to get the biggest bang for their buck.
- SmolVLM Makes Big Waves in Small Packages: SmolVLM, a 2B VLM, sets a new standard for on-device inference, outperforming competitors in GPU RAM usage and token throughput. It’s fine-tunable on Google Colab, making powerful AI accessible on consumer hardware—a small model with a big punch.
PART 1: High level Discord summaries
Modular (Mojo 🔥) Discord
-
MAX Engine outshines ONNX in AI Inference: MAX Engine is defined as an AI inference powerhouse designed to utilize models, whereas ONNX serves as a model format supporting various formats like ONNX, TorchScript, and native Mojo graphs.
- MAX aims to deliver low-latency, high-throughput inference across diverse hardware, optimizing real-time model inference over ONNX's model transfer focus.
- Mojo Test Execution Slows Due to Memory Pressure: Running all tests in a Mojo directory takes significantly longer than individual tests, indicating potential memory pressure from multiple mojo-test-executors.
- Commenting out test functions gradually improved runtime, suggesting memory leaks or high memory usage are causing slowdowns.
- MAX 24.3 Release Boosts Engine Capabilities: The recent MAX version 24.3 release highlights its extensibility, allowing users to create custom models via the MAX Graph APIs.
- The Graph API facilitates high-performance symbolic computation graphs in Mojo, positioning MAX beyond a mere model format.
- Mojo Enhances Memory Management Strategies: Discussions revealed that Chrome's memory usage contributes to performance issues during Mojo test executions, highlighting overall system memory pressure.
- Users acknowledged the need for better hardware to handle their workloads, emphasizing the necessity for effective resource management.
- Mojo Origins Tracking Improves Memory Safety: Conversations about origin tracking in Mojo revealed that currently,
vecand its elements share the same origin, but new implementations will introduce separate origins for more precise aliasing control.
- Introducing two origins—the vector's origin and its elements' origin—will ensure memory safety by accurately tracking potential aliasing scenarios.
Cursor IDE Discord
-
Cursor Agent's Folder Glitches: Users reported that the Cursor Agent is creating endless folders instead of organizing them properly, indicating potential bugs. They suggested that providing clearer commands could enhance agent functionality and prevent confusion when managing project structures.
- These issues were discussed extensively on the Cursor Forum, highlighting the need for improved command clarity to streamline folder organization.
- Cursor v0.43.5 Feature Changes: The latest Cursor version 0.43.5 update has sparked discussions about missing features, including changes to the @web functionality and the removal of the tabs system. Despite these changes, some users appreciate Cursor's continued contribution to their productivity.
- Detailed feedback can be found in the Cursor Changelog, where users express both concerns and appreciations regarding the new feature set.
- Model Context Protocol Integration: There is significant interest in implementing the Model Context Protocol (MCP) within Cursor to allow the creation of custom tools and context providers. Users believe that MCP could greatly enhance the overall user experience by offering more tailored functionalities.
- Discussions about MCP’s potential were highlighted on Cursor's documentation, emphasizing its role in extending Cursor’s capabilities.
- Cursor Enhances Developer Workflow: Many users shared positive experiences with Cursor, emphasizing how it has transformed their approach to coding and project execution. Even users who are not professional developers feel more confident tackling ambitious projects thanks to Cursor.
- These uplifting experiences were often mentioned in the Cursor Forum, showcasing Cursor’s impact on development workflows.
- Markdown Formatting Challenges in Cursor: Users discussed markdown formatting issues in Cursor, particularly problems with code blocks not applying correctly. They are seeking solutions or keybindings to enhance their workflow and better manage files within the latest updates.
- Solutions and workarounds for these markdown issues were explored in various forum threads, indicating an ongoing need for improved markdown support.
OpenAI Discord
-
Sora Video Generator Leak Sparks Conversations: The recent leak of OpenAI's Sora Video Generator ignited discussions, with references to a YouTube video detailing the event.
- Community members debated the tool's performance and the immediate revocation of public access following the leak.
- ChatGPT's Image Analysis Shows Variable Results: Users experimented with ChatGPT's Image Analysis capabilities, noting inconsistencies based on prompt structure and image presentation.
- Feedback highlighted improved interactions when image context is provided compared to initiating interactions without guidance.
- Empirical Prompting Research Lacks Consensus: Participants expressed frustration over the scarcity of empirical prompting research, citing conflicting studies and absence of standardized approaches.
- The community seeks clarity on effective prompting techniques amidst numerous contradictory papers.
- AI Phone Agents Aim for Human-Like Interaction: Discussions emphasized that AI Phone Agents should simulate human interactions rather than mimic scripted IVR responses.
- Members stressed the importance of AI understanding context and verifying critical information during calls.
- Developing Comprehensive Model Testing Frameworks: Engineers debated the creation of robust Model Testing Frameworks capable of evaluating models at scale and tracking prompt changes.
- Suggestions included implementing verification systems to ensure response accuracy and consistency across diverse use cases.
Nous Research AI Discord
-
MH-MoE Improves Model Efficiency: The MH-MoE paper details a multi-head mechanism that aggregates information from diverse expert spaces, achieving performance on par with sparse MoE models while surpassing standard implementations.
- Additionally, it's compatible with 1-bit LLMs like BitNet, expanding its applicability in low-precision settings.
- Star Attention Enhances LLM Inference: Star Attention introduces a block-sparse attention mechanism reducing inference time and memory usage for long sequences by up to 11x, maintaining 95-100% accuracy.
- This mechanism seamlessly integrates with Transformer-based LLMs, facilitating efficient processing of extended sequence tasks.
- DALL-E's Variational Bound Controversy: There's ongoing debate regarding the variational bound presented in the DALL-E paper, with assertions that it may be flawed due to misassumptions about conditional independence.
- Participants are scrutinizing whether these potential oversights affect the validity of the proposed inequalities in the model.
- Qwen's Open Weight Reasoning Model: The newly released Qwen reasoning model is recognized as the first substantial open-weight model capable of advanced reasoning tasks, achievable through quantization to 4 bits.
- However, some participants are skeptical about previous models being classified as reasoning models, citing alternative methods that demonstrated reasoning capabilities.
- OLMo's Growth and Performance: Since February 2024, OLMo-0424 has exhibited notable improvements in downstream performance, particularly by boosting performance over its predecessors.
- The growth ecosystem is also seeing contributions from projects like LLM360’s Amber and M-A-P’s Neo models, enhancing openness in model development.
Eleuther Discord
-
RWKV-7's potential for soft AGI: The developer expressed hope in delaying RWKV-8's development, considering RWKV-7's capabilities as a candidate for soft AGI and acknowledging the need for further improvements.
- They emphasized that while RWKV-7 is stable, there are still areas that can be enhanced before transitioning to RWKV-8.
- Mamba 2 architecture's efficiency: The community is curious about the new Mamba 2 architecture, particularly its efficiency aspects and comparisons against existing models.
- Specific focus was placed on whether Mamba 2 allows for more tensor parallelism or offers advantages over traditional architectures.
- SSMs and graph curvature relation: Participants discussed the potential of SSMs (State Space Models) operating in message passing terms, highlighting an analogy between vertex degree in graphs and curvature on manifolds.
- They noted that higher vertex degrees correlate to negative curvature, showcasing a discrete version of Gaussian curvature.
- RunPod server configurations for OpenAI endpoint: A user discovered that the RunPod tutorial does not explicitly mention the correct endpoint for OpenAI completions, which is needed for successful communication.
- To make it work, use this endpoint and provide the model in your request.
OpenRouter (Alex Atallah) Discord
-
Gemini Flash 1.5 Capacity Boost: OpenRouter has implemented a major boost to the capacity of Gemini Flash 1.5, addressing user reports of rate limiting. Users experiencing issues are encouraged to retry their requests.
- This enhancement is expected to significantly improve user experience during periods of high traffic by increasing overall system capacity.
- Provider Routing Optimization: The platform is now routing exponentially more traffic to the lowest-cost providers, ensuring users benefit from lower prices on average. More details can be found in the Provider Routing documentation.
- This strategy maintains performance by fallback mechanisms to other providers when necessary, optimizing cost-effectiveness.
- Grok Vision Beta Launch: OpenRouter is ramping up capacity for the Grok Vision Beta, encouraging users to test it out at Grok Vision Beta.
- This launch provides an opportunity for users to explore the enhanced vision capabilities as the service scales its offerings.
- EVA Qwen2.5 Pricing Doubles: Users have observed that the price for EVA Qwen2.5 72B has doubled, prompting questions about whether this change is promotional or a standard increase.
- Speculation suggests the pricing adjustment may be driven by increased competition and evolving business strategies.
- Jamba 1.5 Model Issues: Users reported issues with the Jamba 1.5 mini model from AI21 Labs, specifically receiving empty responses when calling functions.
- Despite attempts with different versions, the problem persisted, leading users to speculate it might be related to message preparation or backend challenges.
Interconnects (Nathan Lambert) Discord
-
QwQ-32B-Preview Pushes AI Reasoning: QwQ-32B-Preview is an experimental model enhancing AI reasoning capabilities, though it grapples with language mixing and recursive reasoning loops.
- Despite these issues, multiple members have shown excitement for its performance in math and coding tasks.
- Olmo Outperforms Llama in Consistency: Olmo model demonstrates consistent performance across tasks, differentiating itself from Llama according to community discussions.
- Additionally, Tülu was cited as outperforming Olmo 2 on specific prompts, fueling debates on leading models.
- Low-bit Quantization Optimizes Undertrained LLMs: A study on Low-Bit Quantization reveals that low-bit quantization benefits undertrained large language models, with larger models showing less degradation.
- Projections indicate that models trained with over 100 trillion tokens might suffer from quantization performance issues.
- Deepseek Dethrones OpenAI on Reasoning Benchmarks: Deepseek's R1 model has surpassed OpenAI’s o1 on several reasoning benchmarks, highlighting the startup's potential in the AI sector.
- Backed by High-Flyer’s substantial compute resources, including an estimated 50k Hopper GPUs, Deepseek is poised to open-source models and initiate competitive API pricing in China.
- Bsky Dataset Debacle Disrupts Research: A dataset of Bluesky posts created by an HF employee was removed after intense backlash, despite being compliant with ToS.
- The removal has set back social media research, with discussions focusing on the impact on smaller researchers and upcoming dataset releases.
Perplexity AI Discord
-
Perplexity Engine Deprecation: A discussion emerged regarding the deprecation of the Perplexity engine, with users expressing concerns about future support and feature updates.
- Participants suggested transitioning to alternatives like Exa or Brave to maintain project stability and continuity.
- Image Generation in Perplexity Pro: Perplexity Pro now supports image generation, though users noted limited control over outputs, making it suitable for occasional use rather than detailed projects.
- There are no dedicated pages for image generation, which has been a point of feedback for enhancing user experience.
- Enhanced Model Selection Benefits: Subscribers to Perplexity enjoy access to advanced models such as Sonnet, 4o, and Grok 2, which significantly improve performance for complex tasks like programming and mathematical computations.
- While the free version meets basic needs, the subscription offers substantial advantages for users requiring more robust capabilities.
- Perplexity API Financial Data Sources: Inquiries were made about the financial data sources utilized by the Perplexity API and its capability to integrate stock ticker data for internal projects.
- A screenshot was referenced to illustrate the type of financial information available, highlighting the API's utility for real-time data applications.
- Reddit Citation Support in Perplexity API: Users noted that the Perplexity API no longer supports Reddit citations, questioning the underlying reasons for this change.
- This alteration affects those who rely on Reddit as a data source, prompting discussions about alternative citation methods.
aider (Paul Gauthier) Discord
-
Sonnet Introduces PDF Support: Sonnet now supports reading PDFs, enabled via the command
aider --install-main-branch. Users reported that Sonnet effectively interprets PDF files with the new functionality.- Positive feedback was shared by members who successfully utilized the PDF reading feature, enhancing their workflow within Aider.
- QwQ Model Faces Performance Hurdles: Multiple users encountered gateway timeout errors when benchmarking the QwQ model on glhf.chat.
- The QwQ model's delayed loading times are impacting its responsiveness during performance tests, as discussed by the community.
- Implementing Local Whisper API for Privacy: A member shared their setup of a local Whisper API for transcription, focusing on privacy by hosting it on an Apple M4 Mac mini.
- They provided example
curlcommands and hosted the API on Whisper.cpp Server for community testing.
Unsloth AI (Daniel Han) Discord
-
Axolotl vs Unsloth Frameworks: A member compared Axolotl and Unsloth, highlighting that Axolotl may feel bloated while Unsloth provides a leaner codebase. Instruction Tuning – Axolotl.
- Dataset quality was emphasized over framework choice, with a user noting that performance largely depends on the quality of the dataset rather than the underlying framework.
- RTX 3090 Pricing Variability: Discussions revealed that RTX 3090 prices vary widely, with averages around $1.5k USD but some listings as low as $550 USD.
- This price discrepancy indicates a fluctuating market, causing surprise among members regarding the wide range of available prices.
- GPU Hosting Solutions and Docker: Members expressed a preference for 24GB GPU hosts with scalable GPUs that can be switched on per minute, and emphasized running docker containers to minimize SSH dependencies.
- The focus on docker containers reflects a trend towards containerization for efficient and flexible GPU resource management.
- Finetuning Local Models with Multi-GPU: Users sought advice on finetuning local Llama 3.2 models using JSON data files and expressed interest in multi-GPU support for enhanced performance.
- While multi-GPU support is still under development, a limited beta test is available for members interested in participating.
- Understanding Order of Operations in Equations: A member reviewed the order of operations to correct an equation, confirming that multiplication precedes addition, resulting in a total of 141 from the expression 1 + 23 + 45 + 67 + 89 = 479.
- The correction adhered to PEMDAS rules, highlighting a misunderstanding in the original equation's structure.
Stability.ai (Stable Diffusion) Discord
-
Wildcard Definitions Debate: Participants discussed the varying interpretations of 'wildcards' in programming, comparing Civitai and Python contexts with references to the Merriam-Webster definition.
- Discrepancies in terminology usage were influenced by programming history, leading to diverse opinions on the proper application of wildcards in different scenarios.
- Image Generation Workflow Challenges: A user reported difficulties in generating consistent character images despite using appropriate prompts and style guidelines, seeking solutions for workflow optimization.
- Suggestions included experimenting with image-to-image generation methods and leveraging available workflows on platforms like Civitai to enhance consistency.
- ControlNet Performance on Large Turbo Model: ControlNet functionality's effectiveness with the 3.5 large turbo model was confirmed by a member, prompting discussions on its compatibility with newer models.
- This sparked interest among members about the performance metrics and potential integration challenges when utilizing the latest model versions.
- Creating High-Quality Images: Discussions emphasized the importance of time, exploration, and prompt experimentation in producing high-quality character portraits.
- Users were advised to review successful workflows and consider diverse techniques to improve their image output.
- Stable Diffusion Plugin Issues: Outdated Stable Diffusion extensions were causing checkpoint compatibility problems, leading a user to seek plugin updates.
- The community recommended checking plugin repositories for the latest updates and shared that some users continued to encounter issues despite troubleshooting efforts.
Notebook LM Discord Discord
-
Satirical Testing in NotebookLM: A member is experimenting with satirical articles in NotebookLM, noting the model recognizes jokes about half the time and fails the other half.
- They specifically instructed the model to question the author's humanity, resulting in humorous outcomes showcased in the YouTube video.
- AI's Voice and Video Showcase: AI showcases its voice and video capabilities in a new video, humorously highlighting the absence of fingers.
- The member encourages enthusiasts, skeptics, and the curious to explore the exciting possibilities presented in both the English and German versions of the video.
- Gemini Model Evaluations: A member conducted a comparison of two Gemini models in Google AI Studio and summarized the findings in NotebookLM.
- An accompanying audio overview from NotebookLM was shared, with hopes that the insights will reach Google's development team.
- NotebookLM Functionality Concerns: Users reported functionality issues with NotebookLM, such as a yellow gradient warning indicating access problems and inconsistent AI performance.
- There are concerns about potential loss of existing chat sessions and the ephemeral nature of NotebookLM's current chat system.
- Podcast Duration Challenges: A user observed that generated podcasts are consistently around 20 minutes despite custom instructions for shorter lengths.
- Advice was given to instruct the AI to create more concise content tailored for busy audiences to better manage podcast durations.
Cohere Discord
-
Cohere API integration with LiteLLM: Users encountered difficulties when integrating the Cohere API with LiteLLM, particularly concerning the citations feature not functioning as intended.
- They emphasized that LiteLLM acts as a meta library interfacing with multiple LLM providers and requested the Cohere team’s assistance to improve this integration.
- Enhancing citation support in LiteLLM: The current LiteLLM implementation lacks support for citations returned by Cohere’s chat endpoint, limiting its usability.
- Users proposed adding new parameters in the LiteLLM code to handle citations and expressed willingness to contribute or wait for responses from the maintainers.
- Full Stack AI Engineering expertise: A member highlighted their role as a Full Stack AI Engineer with over 6 years of experience in designing and deploying scalable web applications and AI-driven solutions using technologies like React, Angular, Django, and FastAPI.
- They detailed their skills in Docker, Kubernetes, and CI/CD pipelines across cloud platforms like AWS, GCP, and Azure, and shared their GitHub repository at AIXerum.
Latent Space Discord
-
PlayAI Raises $21M to Enhance Voice AI: PlayAI has secured $21M in funding from Kindred Ventures and Y Combinator to develop intuitive voice AI interfaces for developers and businesses.
- This capital injection aims to improve seamless voice-first interfaces, focusing on enhancing human-machine interactions as a natural communication medium.
- OLMo 2 Outperforms Open Alternatives: OLMo 2 introduces new 7B and 13B models that surpass other open models in performance, particularly in recursive reasoning and various AI applications.
- Executives are excited about OLMo 2's potential, citing its ability to excel in complex AI scenarios and reflecting the latest advances in AI technology.
- SmolVLM Sets New Standard for On-Device VLMs: SmolVLM, a 2B VLM, has been launched to enable on-device inference, outperforming competitors in GPU RAM usage and token throughput.
- The model supports fine-tuning on Google Colab and is tailored for use cases requiring efficient processing on consumer-grade hardware.
- Deepseek's Model Tops OpenAI in Reasoning: Deepseek's recent AI model has outperformed OpenAI’s in reasoning benchmarks, attracting attention from the AI community.
- Backed by the Chinese hedge fund High-Flyer, Deepseek is committed to building foundational technology and offering affordable APIs.
- Enterprise Generative AI Spending Hits $13.8B in 2024: Generative AI spending surged to $13.8B in 2024, indicating a shift from experimentation to execution within enterprises.
- Despite optimism about broader adoption, decision-makers face challenges in defining effective implementation strategies.
GPU MODE Discord
-
LoLCATs Linear LLMs Lag Half: The LoLCATs paper explores linearizing LLMs without full model fine-tuning, resulting in a 50% throughput reduction compared to FA2 for small batch sizes.
- Despite memory savings, the linearized model does not surpass the previously expected quadratic attention model, raising questions about its overall efficiency.
- ThunderKittens' FP8 Launch: ThunderKittens has introduced FP8 support and fp8 kernels as detailed in their blog post, achieving 1500 TFLOPS with just 95 lines of code.
- The team emphasized simplifying kernel writing to advance research on new architectures, with implementation details available in their GitHub repository.
- FLOPS Counting Tools Improve Accuracy: Counting FLOPS presents challenges as many operations are missed by existing scripts, affecting research reliability; tools like fvcore and torch_flops are recommended for precise measurements.
- Accurate FLOPS counting is crucial for validating model performance, with the community advocating for the adoption of these enhanced tools to mitigate discrepancies.
- cublaslt Accelerates Large Matrices: cublaslt has been identified as the fastest option for managing low precision large matrices, demonstrating impressive speed in matrix operations.
- This optimization is particularly beneficial for AI engineers aiming to enhance performance in extensive matrix computations.
- LLM Coder Enhances Claude Integration: The LLM Coder project aims to improve Claude's understanding of libraries by providing main APIs in prompts and integrating them into VS Code.
- This initiative seeks to deliver more accurate coding suggestions, inviting developers to express interest and contribute to its development.
LlamaIndex Discord
-
LlamaParse Integrates Azure OpenAI Endpoints: LlamaParse now supports Azure OpenAI endpoints, enhancing its capability to parse complex document formats while ensuring enterprise-grade security.
- This integration allows users to effectively manage sensitive data within their applications through tailored API endpoints.
- CXL Memory Boosts RAG Pipeline Performance: Research from MemVerge demonstrates that utilizing CXL memory can significantly expand available memory for RAG applications, enabling fully in-memory operations.
- This advancement is expected to enhance the performance and scalability of retrieval-augmented generation systems.
- Quality-Aware Documentation Chatbot with LlamaIndex: By combining LlamaIndex for document ingestion and retrieval with aimon_ai for monitoring, developers can build a quality-aware documentation chatbot that actively checks for issues like hallucinations.
- LlamaIndex leverages milvus as the vector store, ensuring efficient and effective data retrieval for chatbots.
- MSIgnite Unveils LlamaParse and LlamaCloud Features: During #MSIgnite, major announcements were made regarding LlamaParse and LlamaCloud, showcased in a breakout session by Farzad Sunavala and @seldo.
- The demo featured multimodal parsing, highlighting LlamaParse's capabilities across various document formats.
- BM25 Retriever Compatibility with Postgres: A member inquired about building a BM25 retriever and storing it in a Postgres database, with a response suggesting that a BM25 extension would be needed to achieve this functionality.
- This integration would enable more efficient retrieval processes within Postgres-managed environments.
tinygrad (George Hotz) Discord
-
TinyCloud Launch with 54x 7900XTX GPUs: Excitement is building for the upcoming TinyCloud launch, which will feature 9 tinybox reds equipped with a total of 54x 7900XTX GPUs by the end of the year, available for contributors using CLOUD=1 in tinygrad.
- A tweet from the tiny corp confirmed that the setup will be stable thanks to a custom driver, ensuring simplicity for users with an API key.
- Recruitment for Cloud Infra and FPGA Specialists: GeorgeHotz emphasized the need for hiring a full-time cloud infrastructure developer to advance the TinyCloud project, along with a call for an FPGA backend specialist interested in contributing.
- He highlighted this necessity to support the development and maintain the project’s infrastructure effectively.
- Tapeout Readiness: Qualcomm DSP and Google TPU Support: Prerequisites for tapeout readiness include the removal of LLVM from tinygrad and adding support for Qualcomm DSP and Google TPU, as outlined by GeorgeHotz.
- Additionally, there is a focus on developing a tinybox FPGA edition with the goal of achieving a sovereign AMD stack.
- GPU Radix Sort Optimization in tinygrad: Users discussed enhancing the GPU radix sort by supporting 64-bit, negatives, and floating points, with an emphasis on chunking for improved performance on large arrays.
- A linked example demonstrated the use of UOp.range() for optimizing Python loops.
- Vectorization Techniques for Sorting Algorithms: Participants explored potential vectorization techniques to optimize segments of sorting algorithms that iterate through digits and update the sorted output.
- One suggestion included using a histogram to pre-fill a tensor of constants per position for more efficient assignment.
Torchtune Discord
-
Torchtune Hits 1000 Commits: A member congratulated the team for achieving the 1000th commit to the Torchtune main repository, reflecting on the project's dedication.
- An attached image showcased the milestone, highlighting the team's hard work and commitment.
- Educational Chatbots Powered by Torchtune: A user is developing an educational chatbot with OpenAI assistants, focusing on QA and cybersecurity, and seeking guidance on Torchtune's compatibility and fine-tuning processes.
- Torchtune emphasizes open-source models, requiring access to model weights for effective fine-tuning.
- Enhancing LoRA Training Performance: Members discussed the performance of LoRA single-device recipes, inquiring about training speed and convergence times.
- One member noted that increasing the learning rate by 10x improved training performance, suggesting a potential optimization path.
- Memory Efficiency through Activation Offloading: The conversation addressed activation offloading with DPO, indicating that members did not observe significant memory gains.
- One member humorously expressed confusion while seeking clarity on a public PR that might clarify the issues.
OpenInterpreter Discord
-
Open Interpreter OS Mode vs Normal Mode: Open Interpreter now offers Normal Mode through the CLI and OS Mode with GUI functionality, requiring multiple models for control.
- One user highlighted their intention to use OS mode as a universal web scraper with a focus on CLI applications.
- Issues with Open Interpreter Point API: Users reported that the Open Interpreter Point API appears to be down, experiencing persistent errors.
- These difficulties have raised concerns within the community about the API's reliability.
- Excitement Around MCP Tool: The new MCP tool has generated significant enthusiasm, with members describing it as mad and really HUGE.
- This reflects a growing interest within the community to explore its capabilities.
- MCP Tools Integration and Cheatsheets: Members shared a list of installed MCP servers and tools, including Filesystem, Brave Search, SQLite, and PostgreSQL.
- Additionally, cheatsheets were provided to aid in maximizing MCP usage, emphasizing community-shared resources.
Axolotl AI Discord
-
SmolLM2-1.7B Launch: The community expressed enthusiasm for the SmolLM2-1.7B release, highlighting its impact on frontend development for LLM tasks.
- This is wild! one member remarked, emphasizing the shift in accessibility and capabilities for developers.
- Transformers.js v3 Release: Hugging Face announced the Transformers.js v3 release, introducing WebGPU support that boosts performance by up to 100x faster than WASM.
- The update includes 25 new example projects and 120 supported architectures, offering extensive resources for developers.
- Frontend LLM Integration: A member highlighted the integration of LLM tasks within the frontend, marking a significant evolution in application development.
- This advancement demonstrates the growing capabilities available to developers today.
- Qwen 2.5 Fine Tuning Configuration: A user sought guidance on configuring full fine tuning for the Qwen 2.5 model in Axolotl, focusing on parameters that affect training effectiveness.
- There were questions about the necessity of specific unfrozen_parameters, indicating a need for deeper understanding of model configurations.
- Model Configuration Guidance: Users expressed interest in navigating configuration settings for fine tuning various models.
- One user inquired about obtaining guidance for similar setup processes in future models, highlighting ongoing community learning.
MLOps @Chipro Discord
-
Feature Store Webinar Boosts ML Pipelines: Join the Feature Store Webinar on December 3rd at 8 AM PT led by founder Simba Khadder. Learn how Featureform and Databricks facilitate managing large-scale data pipelines by simplifying feature store types within an ML ecosystem.
- The session will delve into handling petabyte-level data and implementing versioning with Apache Iceberg, providing actionable insights to enhance your ML projects.
- GitHub HQ Hosts Multi-Agent Bootcamp: Register for the Multi-Agent Framework Bootcamp on December 4 at GitHub HQ. Engage in expert talks and workshops focused on multi-agent systems, complemented by networking opportunities with industry leaders.
- Agenda includes sessions like Automate the Boring Stuff with CrewAI and Production-ready Agents through Evaluation, presented by Lorenze Jay and John Gilhuly.
- LLMOps Resource Shared for AI Engineers: A member shared an LLMOps resource, highlighting its three-part structure and urging peers to bookmark it for comprehensive LLMOps learning.
- Large language models are driving a transformative wave, establishing LLMOps as the emerging operational framework in AI engineering.
- LLMs Revolutionize Technological Interactions: Large Language Models (LLMs) are reshaping interactions with technology, powering applications like chatbots, virtual assistants, and advanced search engines.
- Their role in developing personalized recommendation systems signifies a substantial shift in operational methodologies within the industry.
LAION Discord
-
Efficient Audio Captioning with Whisper: A user seeks to expedite audio dataset captioning using Whisper, encountering issues with batching short audio files.
- They highlighted that batching reduces processing time from 13 minutes to 1 minute, with a further enhancement to 17 seconds.
- Whisper Batching Optimization: Users discussed challenges in batching short audio files for Whisper, aiming to improve efficiency.
- The reduction in processing time through batching was emphasized, showcasing a jump from 13 minutes to 17 seconds.
- Captioning Script Limitations: The user shared their captioning script for Whisper audio processing.
- They noted the script struggles to handle short audio files efficiently within the batching mechanism.
- Faster Whisper Integration: Reference was made to Faster Whisper on GitHub to enhance transcription speed with CTranslate2.
- The user expressed intent to leverage this tool for more rapid processing of their audio datasets.
Gorilla LLM (Berkeley Function Calling) Discord
-
Llama 3.2 Default Prompt in BFCL: The Llama 3.2 model utilizes the default system prompt from BFCL, as observed by users.
- This reliance on standard configurations suggests a consistent baseline in evaluating model performance.
- Multi Turn Categories Impacting Accuracy: Introduced in mid-September, multi turn categories have led to a noticeable drop in overall accuracy with the release of v3.
- The challenging nature of these categories adversely affected average scores across various models, while v1 and v2 remained largely unaffected.
- Leaderboard Score Changes Due to New Metrics: Recent leaderboard updates on 10/21 and 11/17 showed significant score fluctuations due to a new evaluation metric for multi turn categories.
- Previous correct entries might now be marked incorrect, highlighting the limitations of the former state checker and improvements with the new metric PR #733.
- Public Release of Generation Results: Plans have been announced to upload and publicly share all generation results used for leaderboard checkpoints to facilitate error log reviews.
- This initiative aims to provide deeper insights into the observed differences in agentic behavior across models.
- Prompting Models vs FC in Multi Turn Categories: Prompting models tend to perform worse than their FC counterparts specifically in multi turn categories.
- This observation raises questions about the effectiveness of prompting in challenging evaluation scenarios.
LLM Agents (Berkeley MOOC) Discord
-
Missing Quiz Score Confirmations: A member reported not receiving confirmation emails for their quiz scores after submission, raising concerns about the reliability of the notification system.
- In response, another member suggested checking the spam folder or using a different email address to ensure the submission was properly recorded.
- Email Submission Troubleshooting: To address email issues, a member recommended verifying whether a confirmation email was sent from Google Forms.
- They emphasized that the absence of an email likely indicates the submission did not go through, suggesting further investigation into the form's configuration.
Mozilla AI Discord
-
Hidden States Unconference invites AI innovators: Join the Hidden States Unconference in San Francisco, a gathering of researchers and engineers exploring AI interfaces and hidden states on December 5th.
- This one-day event aims to push the boundaries of AI methods through collaborative discussions.
- Build an ultra-lightweight RAG app workshop announced: Learn how to create a Retrieval Augmented Generation (RAG) application using sqlite-vec and llamafile with Python at the upcoming workshop on December 10th.
- Participants will appreciate building the app without any additional dependencies.
- Kick-off for Biological Representation Learning with ESM-1: The Paper Reading Club will discuss Meta AI’s ESM-1 protein language model on December 12th as part of the series on biological representation learning.
- This session aims to engage participants in the innovative use of AI in biological research.
- Demo Night showcases Bay Area innovations: Attend the San Francisco Demo Night on December 15th to witness groundbreaking demos from local creators in the AI space.
- The event is presented by the Gen AI Collective, highlighting the intersection of technology and creativity.
- Tackling Data Bias with Linda Dounia Rebeiz: Join Linda Dounia Rebeiz, TIME100 honoree, on December 20th to learn about her approach to using curated datasets to train unbiased AI.
- She will discuss strategies that empower AI to reflect reality rather than reinforce biases.
AI21 Labs (Jamba) Discord
-
Jamba 1.5 Mini Integrates with OpenRouter: A member attempted to use the Jamba 1.5 Mini Model via OpenRouter, configuring parameters like location and username.
- However, function calling returned empty outputs in the content field of the JSON response, compared to successful outputs without function calling.
- Function Calling Yields Empty Outputs on OpenRouter: The Jamba 1.5 Mini Model returned empty content fields in JSON responses when utilizing function calling through OpenRouter.
- This issue was not present when invoking the model without function calling, suggesting a specific problem with this setup.
- Password Change Request for OpenRouter Usage: A member requested a password change related to utilizing the Jamba 1.5 Mini Model via OpenRouter.
- They detailed setting parameters such as location and username for user data management.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Modular (Mojo 🔥) ▷ #mojo (435 messages🔥🔥🔥):
Mojo performance issues, Memory management in Mojo, Mutable aliasing and origins, Function signatures and origins
-
Performance Issues with Mojo Tests: Running all tests in a Mojo directory takes significantly longer than running them individually, pointing to potential memory pressure due to the number of mojo-test-executors spawned.
- A user noted that after commenting out test functions, the runtime gradually improved, suggesting that memory leaks or high memory usage may be causing slowdowns.
- Memory and Process Management: The discussion highlighted issues with Chrome's memory usage contributing to performance problems during test execution, indicating overall system memory pressure.
- Users acknowledged needing better hardware to handle their workloads, emphasizing a need for effective resource management.
- Understanding Origins in Mojo: A conversation unfolded about how origins track references in Mojo, revealing that in the current model,
vecand its elements share the same origin, but this will change with new implementations.
- Two origins will be introduced: the origin of the vector and the origin of its elements, allowing more precise tracking of potential aliasing and ensuring memory safety.
- Mutable Aliasing in Function Signatures: The group discussed how to safely implement mutable aliasing in function signatures by parameterizing origin values, which permits the same origin for different arguments.
- This allows for functions to mutate vector elements while retaining memory safety, following the same logic as Rust's aliasing rules.
- Future Directions for Mojo's Type System: Nick proposed a model for handling references and origins that emphasizes local reasoning while allowing mutable aliasing, requiring future study and formal proofs for safety.
- The model aims to characterize and prevent situations that could lead to dangling pointers, ensuring robust memory safety in Mojo's design.
Links mentioned:
- Subtyping and Variance - The Rust Reference: no description found
- Subtyping and Variance - The Rustonomicon: no description found
- Issues · modularml/mojo.): The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- 0738-variance - The Rust RFC Book: no description found
- Compiler Explorer - C++ (Circle) (Latest): #feature on safetytemplate
void assign(T^ input, T val) { *input = val;}int main() { std2::string_view hello("hello"); { std2::string world("world");... - [BUG] Can't use returned reference from function · Issue #3813 · modularml/mojo: Bug description struct Foo: var a: Int32 fn del(owned elf): print("Destroyed Foo") fn init(inout self): self.a = 1 print("Created Foo") fn min(ref [] a: Foo, ref [] b: Fo...
- Compiler Explorer - C++ (Circle) (Latest): #feature on safetyint main() safe { std2::vector
- Compiler Explorer - C++ (x86-64 clang (trunk)): /*fn assign
(input: &mut T, val: T) { *input = val;}fn main() { let mut hello: &'static str = "hello"; { let world = String::from("world&... - [docs] Stdlib insider documentation by owenhilyard · Pull Request #3793 · modularml/mojo: People working on the standard library need to have some more information about the API contracts and behavior of the runtime and compiler builtins in order to be able to write correct and performa...
Modular (Mojo 🔥) ▷ #max (4 messages):
MAX Engine vs ONNX, MAX Graph API, AI Model Inference
-
MAX Engine defined as an AI inference powerhouse: MAX is characterized as an engine designed to utilize models, whereas ONNX functions merely as a format for models, supporting various formats like ONNX, TorchScript, and native Mojo graphs.
- It aims to deliver low-latency, high-throughput inference across diverse hardware to streamline AI workloads.
- MAX 24.3 release enhances engine capabilities: The recent MAX version 24.3 release highlights its extensibility, enabling users to create custom models via the MAX Graph APIs.
- The Graph API facilitates high-performance symbolic computation graphs in Mojo, positioning MAX as more than just a model format.
- ONNX focuses on model transfer, MAX prioritizes performance: Unlike ONNX's aim of transferring models
- This distinction indicates MAX's goal to optimize real-time model inference.
Link mentioned: Get started with MAX Graph | Modular Docs: Learn how to build a model graph with our Mojo API for inference with MAX Engine.
Cursor IDE ▷ #general (332 messages🔥🔥):
Cursor Agent Performance, Cursor Version Updates, User Experiences with Cursor, Model Context Protocol (MCP), Markdown Issues and Bug Fixes
-
User frustrations with Cursor Agent: Several users reported issues with the Cursor Agent, such as it creating endless folders instead of organizing them properly, indicating potential bugs.
- Users suggested that giving clearer commands could improve agent functionality and prevent confusion when interacting with project structures.
- Latest Version Rollout and Features: The latest update to Cursor (version 0.43.5) has prompted discussions about missing features, including changes to the @web functionality and the removal of the tabs system.
- Despite the updates, some users expressed appreciation for Cursor's contribution to their productivity and ability to manage coding tasks efficiently.
- Implementing Custom Tools and Protocols: Users expressed interest in the Model Context Protocol (MCP) and its potential to allow for the creation of custom tools and context providers within Cursor.
- Conversations suggested that such implementations could greatly enhance user experience and provide more tailored functionalities.
- Positive Impact of Cursor on Development: Many users shared their uplifting experiences with Cursor, emphasizing how it has transformed their approach to coding and project execution.
- Users highlighted that, despite not being professional developers, Cursor has enabled them to tackle ambitious projects more confidently.
- Markdown Issues and Workarounds: There were discussions about markdown formatting issues in Cursor, particularly regarding code blocks not applying correctly.
- Users are seeking solutions or keybindings to enhance their workflow and manage files better within the latest updates.
Links mentioned:
- Cascade - Codeium Docs: no description found
- Cursor - The IDE designed to pair-program with AI.: no description found
- Tweet from echo.hive (@hive_echo): 2 Cursor Composer agents working together on the same project. one builds the project, the other reviews once the first agent is done and writes a report. cursor rules file is in comment to achieve th...
- Woah what happened to cursor with this new update?: I can’t find the 200k context option anymore somehow all the changes I make are being undone? the scrolling on the AI chat is weird - like if I press shift+up inside a code text the entire chat scro...
- Shopify Sub App Intergration: Plan to integrate our subscription app with Seal subscriptions (subscription app) We have custom-built our own subscription app (charge every month, change products, skip a month etc.) which has a ca...
- Cursor Composer Window in latest version: Hi! in latest version- Version: 0.43.4 CMD + SHIFT + I is not opening composer in the new composer window that I love. is this intentional? It does open with CMD + I in the chat window (with the o...
OpenAI ▷ #ai-discussions (95 messages🔥🔥):
Sora Video Generator Leak, ChatGPT Image Analysis Capabilities, Discord Community Engagement, Translation Challenges, Usage of AI in Content Creation
-
Sora Video Generator Leak Causes Buzz: Members discussed the recent leak of OpenAI's Sora Video Generator, with references to a YouTube video detailing the event.
- Discussions included sentiments on the tool's efficacy and missed expectations, with some noting that public access has already been revoked.
- Testing ChatGPT's Image Analysis Features: Users tested ChatGPT's ability to analyze images, noting inconsistencies in responses based on how prompts were framed and images were presented.
- Participants highlighted past functionality where image context would lead to better interactions compared to fresh starts with no guidance.
- Engagement and Humor in Discord: The channel demonstrated a light-hearted engagement among users about daily themes, with some humorously suggesting rewards for frequent winners.
- Comments like 'ChatGPT is a cat type of AI' showcased the playful nature of discussions within the community.
- Challenges in Translation Requests: A user presented their translation of a Canadian English text into Urdu, sharing a link for public access.
- This highlighted the collaborative spirit of users in the channel who are keen to share educational resources.
- Feedback on AI Capabilities: Participants shared experiences with ChatGPT's ability to identify characters and create responses based on visual interpretations.
- A contrasting observation was shared about varying abilities based on user plans, with a user on the Free Plan reporting effective recognition.
Link mentioned: Public Access to Open AI's Sora Video Generator just Leaked...: In this video, I discuss the unexpected leak of OpenAI's Sora, an advanced AI video generation tool. The leak was reportedly initiated by artists protesting ...
OpenAI ▷ #gpt-4-discussions (85 messages🔥🔥):
Accessing ChatGPT for Free, User Experience with ChatGPT, ChatGPT's Reliability and Validity, Using Files with GPT, Community Interaction and Humor
-
Users seek ways to access ChatGPT Plus for free: Multiple users discussed potential ways to access ChatGPT 4 without paying for an upgrade, including suggestions to use multiple accounts or get subscriptions through friends.
- However, it was concluded that using the platform without limitations typically requires a paid plan, making many feel it's not worth exploring further.
- Community humor and support: Throughout the discussion, a humorous rapport developed, with members joking about how to approach using ChatGPT while encouraging comedic talent.
- Comments ranged from lighthearted banter about ghosts to mocking serious inquiries about getting by without payment.
- ChatGPT's approach to voter fraud discussions: A user raised concerns that ChatGPT conveys a biased view on voter fraud despite a lack of empirical peer-reviewed studies on the topic.
- Another member cautioned against relying on ChatGPT as an authority on such issues, reminding the community not to discuss politics.
- Best practices for GPT file interaction: A user sought advice on how to make GPT refer to provided files instead of relying on its general knowledge.
- Suggestions included being specific in the prompts and directly instructing the GPT to analyze the given reports.
- Discussion on ChatGPT's capabilities: Community members highlighted that, while LLMs like ChatGPT are capable, they should be viewed as text generators rather than definitive sources of truth.
- The importance of checking facts and the limitations of AI in providing reliable information were emphasized, ensuring users remain critical of the output.
OpenAI ▷ #prompt-engineering (62 messages🔥🔥):
Empirical Prompting Research, AI Phone Calls, Model Testing Frameworks, Error Identification in AI, General Problem-Solving Strategies
-
Lack of Empirical Prompting Research: A member expressed frustration over the lack of empirical research in prompting techniques, noting that many existing studies seem conflicting and fail to establish a gold standard.
- Another member suggested that while numerous papers exist, they often contradict one another, leaving the community in search of clarity regarding effective prompting.
- AI Phone Agents vs IVR Systems: Discussion highlighted the distinction between AI agents and traditional IVR systems, emphasizing that AI should simulate human interaction rather than just mimic scripted responses.
- Members agreed on the importance of confirming critical information back to users to ensure accuracy, just as a human operator would.
- Building Robust Model Testing Frameworks: One member raised concerns about creating a testing framework that can evaluate models at scale, particularly in tracking prompt changes and their impacts on responses.
- Suggestions included verifying extracted data against existing information and implementing checks to confirm accuracy with users during interactions.
- Model Behavior and Testing for Accuracy: Members discussed the necessity of being explicit about prompts while also understanding that some instructions may be inferred correctly by the model without detailed explanations.
- Feedback loop mechanisms and iteratively refining instructions based on observed behavior were seen as key strategies for enhancing model performance.
- Utilizing Retrieval-Augmented Generation (RAG): A member inquired about best practices for encouraging GPT to reference provided files, leading to a suggestion of using Retrieval-Augmented Generation (RAG) for context retrieval.
- This approach would allow the model to utilize specific data from the files according to the query, enhancing the relevance of its responses.
OpenAI ▷ #api-discussions (62 messages🔥🔥):
Empirical Prompting Research, AI Phone Call Agents, Testing and Consistency in AI, IVR vs AI Interaction, RAG for File Referencing
-
Lack of Empirical Research in Prompting: Concerns have been raised about the current lack of empirical prompting research, with existing papers often presenting conflicting information and limited guidance on effective prompting.
- One member noted the difficulty in creating unit tests for AI agents due to the complexity of interactions and the varying ways prompts can be construed.
- AI Phone Agents Should Mimic Humans: Discussion emphasized that AI phone agents shouldn't be treated like traditional IVRs, aiming instead for a more seamless human-like interaction where the AI reacts dynamically to the conversation.
- Members highlighted the importance of guiding AI to understand the context and extracting critical information, rather than relying on it to infer every detail correctly.
- Building Robust Testing Frameworks: Creating testing frameworks that monitor how changes in prompts affect the model’s performance is vital for ensuring reliability across numerous use cases in AI.
- It was suggested to design systems that allow for easy testing and to maintain checks on the model's ability to handle various information types correctly.
- Empowering AI with Guidance: Members discussed the need to provide explicit instructions while allowing the model to infer simpler tasks, ensuring that it focuses on areas where it tends to struggle.
- This tailored approach allows for a more personalized experience when adapting the model to specific use cases, making it important to observe and learn through testing.
- Using RAG for Contextual Referrals: One suggestion made was to utilize RAG (Retrieval-Augmented Generation) to guide the AI in referring to specific files, enhancing the accuracy of responses.
- This method encourages the model to pull from a designated knowledge base while answering queries, effectively integrating provided files into its response mechanism.
Nous Research AI ▷ #general (85 messages🔥🔥):
OLMo Model Updates, GPU Rental Experiences, Nous Hermes Model Comparisons, Qwen Reasoning Model Release, Issues with Crypto Scams
-
OLMo's Growth and Performance: Since its initial release in February 2024, OLMo-0424 has seen significant improvements in downstream performance, notably boosting performance compared to earlier models.
- The increasing openness in the model development ecosystem includes notable contributions from projects like LLM360’s Amber and M-A-P’s Neo models.
- Challenges in GPU Rental: A user is researching GPU rental experiences for AI/ML projects and is seeking insights on frustrations and decision-making factors in selecting services.
- Topics of interest include pricing, availability, performance, and direct experiences contrasting local GPUs with cloud rentals.
- Nous Hermes Model Performance Discussions: Members discussed performance issues where Hermes 3 underperforms compared to Llama 3.1 on several benchmarks, highlighting potential overfitting concerns.
- The conversation emphasizes how different models may exhibit varying performances based on model training configurations.
- Qwen's Open Weight Reasoning Model: The newly released Qwen reasoning model is noted as the first significant open weight model capable of advanced reasoning tasks, achievable with quantization to 4 bits.
- Participants expressed skepticism over the categorization of previous models as reasoning models, noting that earlier models have shown some reasoning capacity through various methods.
- Crypto Scams in the Community: Discussion about an individual misusing the Nous Research name to promote dubious cryptocurrency projects led to concerns about potential scams within the community.
- Members emphasized the importance of verifying affiliations to safeguard community members from fraudulent activities.
Links mentioned:
- QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
- OLMo 2: The best fully open language model to date | Ai2: Our next generation of fully-open base and instruct models sit at the Pareto frontier of performance and training efficiency.
Nous Research AI ▷ #ask-about-llms (9 messages🔥):
Test Time Training, ARC Prize, Table Question Answering
-
Test Time Training Projects in Limbo: A member inquired if there are any active test time training projects, to which it was noted that they are currently occurring privately.
- Another member suggested that the situation might change with the release of the r1 paper in the future.
- Connecting with ARC Prize Participants: One user expressed a desire to talk, mentioning their involvement in the ARC Prize.
- A suggestion was made to reach out to specific users for direct messaging to discuss further.
- Inquiry on Table Question Answering: A new user sought advice on table question answering, asking if anyone had experience in this area.
- No responses were recorded regarding their inquiry, leaving the question open for later discussion.
Nous Research AI ▷ #research-papers (93 messages🔥🔥):
MH-MoE Model Efficiency, Star Attention Mechanism, DALL-E Variational Bound Issues, Financial Economics and Bayesian Stats, Algorithmic Trading Experiences
-
MH-MoE Boosts Model Power: The paper on MH-MoE highlights improved model performance by using a multi-head mechanism to aggregate diverse expert information, matching the efficiency of sparse MoE models.
- It outperforms standard implementations while being compatible with 1-bit LLMs like BitNet, as stated in a recent discussion.
- Star Attention Reduces LLM Inference Costs: Star Attention minimizes inference time and memory usage for LLMs on long sequences by up to 11x while sustaining 95-100% accuracy, utilizing a block-sparse attention mechanism.
- The mechanism integrates seamlessly with Transformer-based LLMs, promoting efficient handling of long sequence tasks.
- DALL-E's Variational Bound Under Scrutiny: Debate emerged around the DALL-E paper regarding its variational bound, specifically questioning the validity of a certain inequality and the assumption of conditional independence.
- The conversation centers on whether certain properties of the joint distributions hold, with speculation that authors may have overlooked key assumptions.
- Financial Studies in Bayesian Stats: A member shared their background in financial economics, particularly focusing on Bayesian statistics for asset pricing during their PhD studies, emphasizing the fun of the subject.
- The conversation also touched upon practical experiences with algorithmic trading, including the challenges faced.
- Reflections on Algorithmic Trading: Participants discussed personal experiences with algorithmic trading, noting that one member only made some profits during the crypto boom in 2017.
- Shared reflections highlighted the complexities and learning curves involved in algorithmic trading ventures.
Links mentioned:
- Zero-Shot Text-to-Image Generation: Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or s...
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): Star Attention: Efficient LLM Inference over Long Sequences🔗: https://github.com/NVIDIA/Star-Attentionpaper: https://arxiv.org/abs/2411.17116Star Attention is a block-sparse attention mechanism that ...
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): MH-MoE:Multi-Head Mixture-of-Expertspaper: https://arxiv.org/abs/2411.16205MH-MoE improves model performance by using a multi-head mechanism to aggregate information from diverse expert spaces. It mat...
Nous Research AI ▷ #interesting-links (4 messages):
Karpathy bump, TL;DR newsletter, Priompt to Python porting, Prompt design tools
-
Blog Post Popularity Stemming from Karpathy Bump: A member noted that a blog post by their boss, Will, is gaining traction, likely due to the Karpathy bump.
- The post has been making the rounds, indicating a notable increase in interest.
- AI TL;DR Newsletter as a Key Source: Another member shared that they received the blog post in the TL;DR newsletter, specifically the one focused on AI.
- They mentioned reading both daily, highlighting the newsletter's specialized focus.
- Efforts in Prompt Design with Python: A user shared their experience of spending 9 hours porting priompt to Python, offering the outcome for community use.
- They linked to GitHub - zenbase-ai/py-priompt as a resource for managing prompt designs and context windows.
Link mentioned: GitHub - zenbase-ai/py-priompt: Prompt design in Python: Prompt design in Python. Contribute to zenbase-ai/py-priompt development by creating an account on GitHub.
Nous Research AI ▷ #research-papers (93 messages🔥🔥):
MH-MoE paper, Star Attention paper, DALL-E variational bounds, Conditional independence in ML, Bayesian stats in finance
-
MH-MoE Improves Model Efficiency: The paper on MH-MoE describes a method that uses a multi-head mechanism to aggregate information, matching the efficiency of sparse models while outperforming standard implementations.
- It notably remains compatible with 1-bit LLMs like BitNet.
- Star Attention Enhances LLM Inference: Star Attention presents a block-sparse attention mechanism that significantly cuts down inference time and memory usage for long sequences by up to 11x, while retaining high accuracy.
- It utilizes a two-phase process integrating local and global attention, compatible with most Transformer-based LLMs.
- DALL-E's Variational Bound Controversy: Discussion arose surrounding a potential issue with the variational bound presented in the DALL-E paper, with claims that it might be incorrect due to misunderstood assumptions.
- Participants pondered the implications of assuming conditional independence which could affect the validity of the inequalities involved.
- Questioning Conditional Independence in ML Derivations: A member highlighted that if the derivation assumes independence incorrectly, it might lead to incorrect results in KL divergence calculations.
- The conversation explored the implications of treating dependencies in distributions, noting the confusion surrounding the proof structure.
- Personal Insights on Finance and Trading: Members shared experiences around Bayesian statistics in financial economics, with one member noting a brief stint in algorithmic trading yielding little profit.
- The transition to finance coupled with insights from an introduction to the Black-Scholes model sparked further discussion on trading strategies and market behavior.
Links mentioned:
- Zero-Shot Text-to-Image Generation: Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or s...
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): Star Attention: Efficient LLM Inference over Long Sequences🔗: https://github.com/NVIDIA/Star-Attentionpaper: https://arxiv.org/abs/2411.17116Star Attention is a block-sparse attention mechanism that ...
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): MH-MoE:Multi-Head Mixture-of-Expertspaper: https://arxiv.org/abs/2411.16205MH-MoE improves model performance by using a multi-head mechanism to aggregate information from diverse expert spaces. It mat...
Eleuther ▷ #general (6 messages):
FSDP Spaghetti Internals, Dynamic Structs, Knowledge Conflict
-
FSDP Internals Tear Down Assumptions: Discussion highlighted that FSDP spaghetti internals rip all tensor and module state assumptions, only reassembling them at the end.
- This process sheds light on complex state management techniques that require careful consideration.
- Setattr Sparks a Wake-Up Call: A member jokingly noted that a little bit of setattr keeps developers wide awake while working on the code.
- This suggests the intricacies and potential surprises thrown by modifying attributes dynamically.
- Structs Tailored to Model Names: One member shared their approach of deciding a struct based on the entered model name, ensuring everything is fully type checked.
- This approach emphasizes strong type safety and adaptability within model structures.
- Acknowledging a Knowledge Conflict: A brief mention of a knowledge conflict indicates ongoing discussions concerning discrepancies in information.
- This prompts a need for clarity and resolution as members navigate shared knowledge.
Eleuther ▷ #research (276 messages🔥🔥):
RWKV-7 developments, SSM and graphs curvature, Mamba 2 architecture, Gradient descent optimization, Curvature and vertex degree analogy
-
RWKV-7 shows potential for soft AGI: The developer expressed hope in delaying RWKV-8's development, considering RWKV-7's capabilities as a candidate for soft AGI and also acknowledging the need for further improvements.
- They emphasized that while RWKV-7 is quite stable, there are still areas that can be enhanced before transitioning to RWKV-8.
- Exploring SSMs and their relation to graphs: Participants discussed the potential of SSMs (State Space Models) operating in message passing terms, highlighting an analogy between vertex degree in graphs and curvature on manifolds.
- They noted that higher vertex degrees correlate to negative curvature, showcasing a discrete version of Gaussian curvature.
- Insights on iterative updates in learning: A discussion emerged around performing updates on state matrices in batch formats rather than sequentially for tokens, considering both the L2 loss and its implications on learning.
- This included suggestions that weight decay could be incorporated to refine the update process across multiple gradient steps.
- Curvature characteristics in discrete structures: The conversation brought forth the idea that additional edge angle data in a graph could help derive different types of curvature, enhancing the understanding of its properties.
- Participants were encouraged to relate these concepts to triangle meshes, viewing it as a stepping stone for applying curvature principles to graphs.
- Mamba 2 and its efficiency: The community is curious about the new Mamba 2 architecture, particularly its efficiency aspects and how it compares against existing models.
- Specific focus was placed on whether Mamba 2 allows for more tensor parallelism or offers advantages over traditional architectures.
Links mentioned:
- Predicting Emergent Capabilities by Finetuning: A fundamental open challenge in modern LLM scaling is the lack of understanding around emergent capabilities. In particular, language model pretraining loss is known to be highly predictable as a func...
- no title found: no description found
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-7 "Goose" 🪿 is a meta-in-context learner, test-time-training its state on the context via in-context gradient descent at every token. It is like a world model ever adapting to external e...
- State Space Duality (Mamba-2) Part I - The Model | Tri Dao : no description found
- AI as Humanity's Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text: Creativity has long been considered one of the most difficult aspect of human intelligence for AI to mimic. However, the rise of Large Language Models (LLMs), like ChatGPT, has raised questions about ...
- RWKV-LM/RWKV-v7/rwkv_v7_demo.py at main · BlinkDL/RWKV-LM: RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). So it's combining the best of RNN and transformer - great performance, fast infer...
- GitHub - BlinkDL/modded-nanogpt-rwkv: RWKV-7: Surpassing GPT: RWKV-7: Surpassing GPT. Contribute to BlinkDL/modded-nanogpt-rwkv development by creating an account on GitHub.
- Single-unit activations confer inductive biases for emergent circuit solutions to cognitive tasks: Trained recurrent neural networks (RNNs) have become the leading framework for modeling neural dynamics in the brain, owing to their capacity to mimic how population-level computations arise from inte...
Eleuther ▷ #interpretability-general (1 messages):
Research updates
-
New Research Insight Shared: A member shared an interesting research update in the channel.
- You can find more details in the Discord link.
- Update Highlights Discussion: The update sparked a discussion among members about its implications in current research trends.
- Members expressed their excitement, noting that the research paves the way for further exploration.
Eleuther ▷ #lm-thunderdome (1 messages):
RunPod server configurations, OpenAI completions endpoint, Llama 3.2 model usage
-
RunPod tutorial lacks OpenAI completions details: A user discovered that the RunPod tutorial does not explicitly mention the correct endpoint for OpenAI completions, which is needed for successful communication.
- To make it work, use this endpoint and provide the model in your request.
- Successful push to external Ollama server: The user reported pushing a generateuntil task to an external Ollama server, noting that the request was visible on the server running Llama 3.2.
- This indicates successful interaction with the deployed model, highlighting the functionality of the server setup.
Links mentioned:
- no title found: no description found
- no title found: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Gemini Flash 1.5, Provider Routing, Load Balancing, Grok Vision Beta
-
Gemini Flash 1.5 Capacity Increased: OpenRouter has implemented a major boost to the capacity of Gemini Flash 1.5. Users who experienced rate limiting should try their requests again.
- This improvement should enhance user experience significantly during high traffic periods.
- Provider Pricing Optimization: The platform is now routing exponentially more traffic to the lowest-cost providers, ensuring users benefit from lower prices on average. More information can be found in the Provider Routing documentation.
- This strategy maintains performance by falling back to other providers when necessary.
- Load Balancing Strategy Explained: OpenRouter's load balancing prioritizes providers with stable uptime and routes requests based on cost-effectiveness. For instance, requests are weighted to favor providers with the lowest costs and fewest outages in the past 10 seconds.
- This ensures that resources are used efficiently and effectively during high-demand situations.
- Grok Vision Beta Launch: OpenRouter is ramping up capacity for the Grok Vision Beta, encouraging users to try it out at this link.
- This is an opportunity for users to test the service as it scales up its capabilities.
Links mentioned:
- Provider Routing | OpenRouter: Route requests across multiple providers
- Grok Vision Beta - API, Providers, Stats: Grok Vision Beta is xAI's experimental language model with vision capability.. Run Grok Vision Beta with API
OpenRouter (Alex Atallah) ▷ #general (136 messages🔥🔥):
Jamba 1.5 model, AI21 Labs support, EVA Qwen2.5 pricing, Claude API issues, OpenRouter functionality
-
Jamba 1.5 Model Issues: Users reported issues with the Jamba 1.5 mini model from AI21 Labs, specifically receiving empty responses when calling functions.
- Despite trying different versions, the issue persisted and users speculated it might be due to message preparation or backend problems.
- EVA Qwen2.5 Pricing Doubles: Some users noticed that the price for EVA Qwen2.5 72B had doubled and questioned whether this was a promotional price or a standard increase.
- There was speculation that the pricing change could be due to increased competition and business strategies.
- Claude API Errors: A user faced errors while using Claude API, encountering messages about blocked functions and backend issues.
- Errors were attributed to a recent incident on Anthropic’s status board, but many users reported inconsistent behavior with Claude models.
- OpenRouter's Model Context Length Concern: A user raised concerns regarding the qwen-2.5-coder model only allowing up to 32k context length instead of the expected 128k.
- It was clarified that support for 128k depends on the provider, specifically noting that only Hyperbolic serves the full context window.
- OpenRouter Chat Streaming Issues: Users expressed frustrations that chat streaming in the OpenRouter chat room makes it difficult to read messages as the screen continuously moves.
- A request for an option to disable streaming was made to enhance user experience and readability.
Links mentioned:
- QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
- Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning: Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations ...
- [{"model": "anthropic/claude-3.5-sonnet", "messages": {"role": "system", "conten - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- The capabilities of multimodal AI | Gemini Demo: Our natively multimodal AI model Gemini is capable of reasoning across text, images, audio, video and code. Here are favorite moments with Gemini Learn more...
- Provider Routing | OpenRouter: Route requests across multiple providers
- Elevated errors for requests to Claude 3.5 Sonnet: no description found
- Llama 3.1 Euryale 70B v2.2 - API, Providers, Stats: Euryale L3.1 70B v2. Run Llama 3.1 Euryale 70B v2.2 with API
- Dubesor LLM Benchmark table: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (4 messages):
Custom API Keys Access Requests
-
Developers eager for Custom API Keys: Multiple developers expressed interest in gaining access to the custom API key feature, highlighting their enthusiasm for the platform's capabilities.
- One user thanked the team for their great work, while another simply requested to understand how to access this feature.
- More requests for custom beta keys: Another developer joined the conversation, stating they would also like to request access to custom beta keys.
- This indicates a growing interest among community members in exploring advanced functionalities of the platform.
Interconnects (Nathan Lambert) ▷ #news (61 messages🔥🔥):
QwQ-32B-Preview, Olmo Model Differences, PRM Utility in Scaling, Tülu vs Olmo Performance, Demo Availability
-
QwQ-32B-Preview Model Insights: QwQ-32B-Preview is an experimental model highlighting AI reasoning capabilities but faces issues like language mixing and recursive reasoning loops.
- Despite its limitations, it shows promise, especially in math and coding, as noted by multiple members expressing their interest.
- Olmo Model Shows Varied Performance: Members discussed that the Olmo model behaves quite differently than Llama, particularly pointing out its performance consistency across tasks.
- Notably, Tülu was mentioned to perform better on specific prompts than Olmo 2, igniting further discussions on which model leads.
- Questioning PRM's Effectiveness: There were discussions around whether Process Reward Models (PRM) are genuinely effective for scaling AI models as their utility in starting is clear yet limited.
- A member humorously remarked on a release that it feels too vague and lacks substantial details, raising skepticism about its real-world applicability.
- Exploring Demo Options: Questions arose regarding the availability of a demo for the discussed models, with confirmations from members who believed demos have been shared previously.
- Natolambert expressed intent to set up a demo ahead of writing a post, indicating a hands-on approach to understanding model functionalities.
- Clarifying Pass@1 vs Greedy Generation: The conversation turned technical with members clarifying that results presented for pass@1 likely pertain to greedy generation, stirring debate on its implications.
- The slight deviations in results have left some members puzzled, particularly around the specific metrics correlating with AIME scores.
Links mentioned:
- QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
- Qwen/QwQ-32B-Preview · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (49 messages🔥):
Bsky dataset controversy, Impact on social media research, User blocking trends, Dataset releases on Bluesky, Public accessibility of online posts
-
Bsky Dataset Sparks Outrage: A HF employee created a dataset of Bsky posts that were public and okay to use per the ToS, leading to intense backlash and a subsequent removal of the dataset.
- One user noted, 'He just hurts the little guy' as the actions reflect larger issues within the research community.
- Research Field Faces Setbacks: The removal of datasets has set back the whole social media research field, particularly after being cut off from Twitter's API.
- Users discussed how major labs won't be impacted while smaller researchers suffer from the fear of lawsuits.
- Top Blocked User on Bluesky: Reports indicate that Daniel has become the #1 most blocked user on Bluesky, leading to a mixed public reaction.
- While some empathize, others express that being a symbol for anti-AI fears can't feel good.
- Dataset Releasing Frenzy: Amidst the controversy, one user announced a dataset release of two million Bluesky posts, stirring a call for more contributions.
- This suggests a rising trend where researchers encourage each other to share expansive datasets, despite potential backlash.
- Community Reactions on Internet Accessibility: Users like Natolambert discussed that the internet inherently makes content accessible to big tech and the public, leading to disagreements about privacy.
- Conversations included varied perspectives on blockers and the resulting political nature of social media feeds, suggesting a desire for more streamlined discussions.
Links mentioned:
- ClearSky: ClearSky
- Tweet from Alpin (@AlpinDale): Releasing: a dataset of two million Bluesky posts.This dataset has been collected using Bluesky's API, and I hope it will be useful for all the researchers out there!
- Sid Losh (@losh.bsky.social): I'm not sure encryption is helpful on the eve of the quantum apocalypse. I think it's safer to simply consider everything you have ever posted anywhere will eventually be exposed to public scr...
- Bluesky: no description found
- Jade (@not.euclaise.xyz): There's 235M posts here https://zenodo.org/records/11082879
- Nathan Lambert (@natolambert.bsky.social): A brave sole. Earned my follow
- Xeophon (@xeophon.bsky.social): I have colleagues who research hate speech in social media, they were stuck with very old Twitter data. Bluesky could’ve been an alternative for this, now they are scared by your actions. Good job.
- Daniel van Strien (@danielvanstrien.bsky.social): First dataset for the new @huggingface.bsky.social @bsky.app community organisation: one-million-bluesky-posts 🦋📊 1M public posts from Bluesky's firehose API🔍 Includes text, metadata, and langu...
- @alpindale.bsky.social: Releasing: a dataset of two million Bluesky posts.This dataset has been collected using Bluesky's API, and I hope it will be useful for all the researchers out there!
Interconnects (Nathan Lambert) ▷ #random (14 messages🔥):
Model insights, O1 LLM impact, Upcoming content, DesuAnon's new archive formats, 2024 AI illustrations
-
Anticipation for 'O1' LLM: The 'O1' model is highlighted as a great gift for rethinking aspects of LLMs, sparking excitement amongst members.
- One member compared it to TempleOS, adding to the discussion's enthusiasm.
- Upcoming Recorded Interviews: An RL interview is scheduled to be recorded for next week, generating anticipation within the group.
- Members are eager to see the insights this interview may provide.
- DesuAnon's Archive Updates: Updated information about new archive formats and prompts has been added to desuAnon's Hugging Face.
- This new update was verified about 21 hours ago, which indicates ongoing developments in the community.
- Visual Insights into 2024 AI: Members shared excitement over a visually striking image titled '2024 Alan D. Thompson AI Bubbles & Planets', viewing it as captivating.
- One member stated that this image kind of owns, highlighting its appeal.
- Plans for Subscriber Engagement: There's a suggestion to share content with subscribers, reflecting a commitment to keeping the community informed.
- It was mentioned that content is planned for release next week, ensuring ongoing interaction and engagement.
Links mentioned:
- desuAnon/SoraVids at main: no description found
- Nathan Lambert (@natolambert.bsky.social): Question — who came up with the term “post-training?” Emerged in the last 12-18 months but I don’t know where from, and I need to know. 🙇
- Models Table: Open the Models Table in a new tab | Back to LifeArchitect.ai Open the Models Table in a new tab | Back to LifeArchitect.ai Data dictionary Model (Text) Name of the large language model. Someti...
Interconnects (Nathan Lambert) ▷ #reads (2 messages):
Low-bit quantization in LLMs, Deepseek's AI advancements, CEO Liang Wenfeng's background, High-Flyer's role in Deepseek, Compute resources in AI development
-
Low-bit quantization benefits undertrained LLMs: Research indicates that low-bit quantization favors undertrained large language models, with larger models experiencing less quantization-induced degradation (QiD). The study reveals scaling laws that help predict an LLM's training levels and necessary token counts for various model sizes derived from over 1500 quantized checkpoints.
- Diving deeper, projections suggest that future models trained with over 100 trillion tokens may face undesirable low-bit quantization performance.
- Deepseek beats OpenAI on reasoning benchmarks: The Deepseek R1 model has reportedly beaten OpenAI’s o1 on multiple reasoning benchmarks, highlighting the startup's potential despite its low profile.
- With full funding from High-Flyer, Deepseek is focused on foundational technology and open-sourcing its models while instigating price wars in China by offering affordable API rates.
- Liang Wenfeng's impressive background: CEO Liang Wenfeng previously led High-Flyer, a top-ranked quantitative hedge fund valued at $8 billion before establishing Deepseek. His leadership is indicative of the robust expertise behind Deepseek's innovative approach in the AI sector.
- Guided by his past experience, Deepseek aims for significant advancements without immediate fundraising plans.
- High-Flyer's compute advantage: Deepseek's scaling capabilities are bolstered by High-Flyer’s compute clusters, providing substantial computational resources for the AI startup. Experts estimate they may possess around 50k Hopper GPUs, vastly exceeding the 10k A100s publicly disclosed.
- This access to cutting-edge technology positions Deepseek competitively within the AI landscape as it develops innovative models.
Links mentioned:
- Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens: We reveal that low-bit quantization favors undertrained large language models (LLMs) by observing that models with larger sizes or fewer training tokens experience less quantization-induced degradatio...
- Deepseek: The Quiet Giant Leading China’s AI Race: Annotated translation of its CEO's deepest interview
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
``
- SnailBot News Alert: A notification was sent to the <@&1216534966205284433> role regarding SnailBot News.
- Repeated SnailBot News Notification: Another notification was sent to the <@&1216534966205284433> role for SnailBot News.
Perplexity AI ▷ #general (102 messages🔥🔥):
Perplexity support issues, Discount offerings, Image generation capabilities, Model selection benefits, Competitors in the search/chat hybrid area
- Perplexity support often feels lacking: Many users have expressed dissatisfaction with Perplexity's support, describing it as 'dry' and 'lacking'. A couple of members even mentioned cancelling their subscriptions due to these issues.
- Discount codes available for new users: Members shared information about a promotional discount code for a one-month free Pro subscription, encouraging others to utilize it before the expiration. This code offers a potential value to new users looking for deals.
- Image generation features in Perplexity Pro: While Perplexity Pro allows for image generation, users noted that there is limited control over the output, making it less suitable for detailed requirements. Regular use is good for occasional image needs, although there are no separate pages for image generation.
- Benefits of model selection in a subscription: Subscribers enjoy access to better models like Sonnet, 4o, and Grok 2, which enhance performance for complex tasks like programming and math. Many users feel that the free version is sufficient, but the subscription adds considerable value for frequent and advanced users.
- Comparison with You.com: Membership discussions highlighted a comparison between Perplexity and You.com as competing platforms in the search/chat hybrid field. Users mentioned preferences for Perplexity but acknowledged that both platforms have their strengths and weaknesses.
Links mentioned:
- Tweet from Mike Smith (@mikesmith187): There are very few companies that can do it like @perplexity_ai there are even fewer people who can design like @apostraphi.Absolutely wonderful episode of dive club with Phi. Worth the listen because...
- Tweet from floguo (@floguo): stay curious with @perplexity_ai
Perplexity AI ▷ #sharing (5 messages):
AI Soundscapes, Cognitive Behavioral Therapy, Oldest Alphabetic Writing, Bluesky vs Zuckerberg, Black Friday Debate
-
AI Nature Soundscape Explored: A link was shared about an intriguing AI-generated nature soundscape by Bjork that enhances the appreciation of natural sounds.
- This project might reflect a fusion of art and technology, appealing to both audiophiles and AI enthusiasts.
- Cognitive Behavioral Therapy Insights: A member linked to a page discussing Cognitive Behavioral Therapy, highlighting its techniques and applications.
- This may provoke discussions around mental health strategies and their effectiveness in various scenarios.
- Historic Discovery in Writing: A revelation was made about the oldest alphabetic writing discovered, potentially reshaping our understanding of human communication history.
- This find may lead to exciting debates about ancient languages and their evolution over time.
- Zuckerberg's Bluesky Concerns: An article discussing Zuckerberg's fears regarding Bluesky's impact on social media dynamics was shared.
- This highlights the competitive landscape among social media platforms and the stakes involved in user engagement.
- Is Black Friday a Scam? A Discussion: A query was raised questioning if Black Friday is indeed a scam, inviting opinions on consumer behavior during sales.
- This topic is likely to spark a lively discussion about consumerism and marketing strategies.
Perplexity AI ▷ #pplx-api (4 messages):
Perplexity API financial data sources, Reddit citation issues, GitHub projects, Perplexity engine depreciation
-
Perplexity API financial data sourcing: A member inquired about where the Perplexity engine obtains its financial data and whether the API can feed this data into other projects for internal use.
- They highlighted interest in stock ticker data that shows company earnings, referencing a relevant screenshot.
- API no longer supports Reddit citations: A user queried about the reason behind the API no longer supporting Reddit citations.
- This could indicate a change in functionality impacting users reliant on these sources for data.
- GitHub project showcase: An individual shared their first GitHub project, perplexity-cli, inviting others to check it out and possibly give it a star.
- This project offers a simple command-line client for the Perplexity API, allowing users to ask questions and receive answers directly from the terminal.
- Discussion on tool deprecation warnings: A user advised others not to pay for a tool they believe is deprecated or merely in beta, suggesting alternatives like Exa or Brave.
- Such feedback emphasizes the importance of evaluating the reliability of tools before making financial commitments.
Link mentioned: GitHub - dawid-szewc/perplexity-cli: 🧠 A simple command-line client for the Perplexity API. Ask questions and receive answers directly from the terminal! 🚀🚀🚀: 🧠 A simple command-line client for the Perplexity API. Ask questions and receive answers directly from the terminal! 🚀🚀🚀 - dawid-szewc/perplexity-cli
aider (Paul Gauthier) ▷ #general (84 messages🔥🔥):
Scripting Aider with Python, Sonnet in Aider Development, Benchmark Results for Aider, Cedarscript Discussion, QwQ Model Performance
-
Scripting Aider with Python: Many users have expressed interest in scripting Aider using Python, with discussions highlighting that it is technically unsupported but has proven stable in practice since its inception.
- The main concern remains that the non-official API could change without backwards compatibility, so users are advised to pin their dependencies.
- Sonnet Dominates Aider Development: The predominant model used in Aider development is Sonnet, which most users prefer.
- Users have discussed the effectiveness of using Sonnet alongside various model configurations and its impact on performance.
- Cedarscript Results Spark Skepticism: Cedarscript has not yet demonstrated its promised capabilities, leading to skepticism from users regarding its effectiveness.
- Discussions noted that the tool has only been benchmarked in limited contexts, making it hard to assess its overall potential.
- Issues with QwQ Model Performance: Multiple users reported gateway timeout errors when attempting to benchmark the QwQ model.
- Delays in model loading on the glhf.chat platform were mentioned, affecting its responsiveness during benchmarks.
- Aider vs. Cursor AI IDE: Users compared Aider with Cursor AI IDE, highlighting that both serve different purposes despite some overlapping features like autocomplete.
- While Aider is deemed a versatile tool integrated within Emacs, Cursor provides a more full-featured IDE experience with planned enhancements.
Link mentioned: QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
aider (Paul Gauthier) ▷ #questions-and-tips (26 messages🔥):
PDF Support in Sonnet, Refactoring with Aider, Aider Commands and Features, Next.js Folder Structure Issues, Whisper API for Transcription
-
Sonnet gains PDF reading capability: A member reported that PDF support was just added to Sonnet with the command
aider --install-main-branch.- Another user shared their positive experience, noting that Sonnet could understand the new PDF read functionality effectively.
- Refactoring projects with Aider: One user discussed their approach to refactoring code in a project, expressing challenges in managing multiple chats.
- Another member mentioned they are rewriting an existing project to follow a new coding pattern incrementally using Aider's
/readcommand. - Understanding Aider's editor command: A discussion arose regarding the new
/editorcommand, which allows users to prefix commands within editor messages.
- Users tested this in various environments, leading to issues with PowerShell while finding success with Neovim.
- Issues in Next.js folder structure: A member expressed frustration with their Next.js setup where existing folder structures were being recreated unexpectedly.
- This raised concerns about effectively managing project paths while maintaining a clean codebase.
- Local Whisper API for privacy: A user shared their implementation of a local Whisper API for transcription services, emphasizing privacy in their setup.
- They provided example curl commands for testing their API hosted on an Apple M4 Mac mini for community members interested.
Links mentioned:
- Whisper.cpp Server: no description found
- FAQ: Frequently asked questions about aider.
- FAQ: Frequently asked questions about aider.
Unsloth AI (Daniel Han) ▷ #general (46 messages🔥):
Axolotl vs Unsloth, Fine-tuning pre-trained models, Multiple models inference, Formatting for fine-tuning datasets, Embeddings model fine-tuning
-
Discussing Axolotl vs Unsloth: A member highlighted that the choice between Axolotl and Unsloth depends on user preferences, stating that Axolotl can feel bloated while Unsloth offers a leaner codebase.
- Mrdragonfox noted that a significant part of performance depends on dataset quality rather than just the framework.
- Fine-tuning models based on prior tuning: Fjefo warned that fine-tuning a model that has already been tuned can lead to catastrophic forgetting, affecting output quality.
- A member clarified that while it is possible to fine-tune further, it may not yield beneficial results.
- Inference of multiple models on a single GPU: Discussion arose around running multiple Llamas 3.2 8B models on a single A100 GPU, with members suggesting that batch inference may be more efficient.
- Lee0099 mentioned the potential to use LoRa adapters to manage different models for distinct tasks on a single base model.
- Formatting datasets for fine-tuning: A user inquired about the necessary format for fine-tuning datasets, aiming to provide inputs and instructions to their models.
- Lee0099 responded that Alpaca format using JSONL files is a typical approach, with examples available in Unsloth notebooks.
- Interest in fine-tuning embeddings models: A member expressed interest in using Unsloth for fine-tuning an embeddings model but found no existing notebooks on the topic.
- Theyruinedelise indicated that support for embeddings model fine-tuning is expected to be available soon.
Links mentioned:
- Instruction Tuning – Axolotl: no description found
- mesolitica/malaysian-Llama-3.2-3B-Instruct · Hugging Face: no description found
- FAQ — NVIDIA Triton Inference Server: no description found
- unsloth/Phi-3.5-mini-instruct-bnb-4bit · Hugging Face: no description found
- Added Support for Apple Silicon by shashikanth-a · Pull Request #1289 · unslothai/unsloth: UnoptimizedNo gguf support yet.Build Triton and bitsandbytes from sourcecmake -DCOMPUTE_BACKEND=mps -S . for bitsandbytes buildingpip install unsloth-zoo==2024.11.4pip install xformers==0.0.25
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
RTX 3090 Pricing, GPU Hosting Solutions, Docker Containers in Hosting, Demand for Higher VRAM GPUs
-
RTX 3090 Pricing Surprises: A member reported that the average price for an RTX 3090 is still around $1.5k USD, surprising several in the discussion.
- Others noted seeing prices as low as $550 USD, indicating variability in the market.
- GPU Hosting Preferences: There is a desire for a 24GB tier host with additional GPUs that can be switched on per minute, reflecting a need for scalability in GPU resources.
- Members discussed how hosting should primarily run docker containers, minimizing dependency on SSH.
- High Demand for GPUs with Higher VRAM: The discussion highlighted the higher demand for 24GB GPUs compared to 20GB options like the A5000, implying industry preference for more powerful memory configurations.
- Members emphasized that in the industry, the standard unit of scale often targets 80GB configurations due to the benefits of HBM.
Unsloth AI (Daniel Han) ▷ #help (40 messages🔥):
Finetuning Local Models, Multi-GPU Support, Evaluating Models for EM and F1-Score, Model Quantization, Using Prompt Styles for Mistral-Nemo
-
Tips for Finetuning Local Ollama Models: A member inquired about declaring the local Llama 3.2 model in Unsloth for finetuning with JSON data files, facing difficulties finding the correct model path.
- Another user suggested using Unsloth models instead, claiming they are great for beginners, also sharing links to helpful documentation.
- Awaiting Multi-GPU Support: Users asked about the expected support for multi-GPU finetuning and if there would be a beta test available, expressing interest in participating.
- One member noted that multi-GPU support is not out yet, and another confirmed that a beta test exists, but it's limited in availability.
- Model Evaluation Queries: A member sought advice on how to evaluate their model for EM and F1-score in Unsloth, but received uncertain responses regarding specific methods.
- Another member continued to ask further questions on similar topics, showing the need for clearer guidance.
- Understanding Quantization Benefits: A member queried why it's better to save a 4-bit quantized and finetuned model as fp16 for serving, with another user emphasizing improved inference quality at 16-bit.
- This highlights the ongoing discussions about quantization techniques and their impacts on model performance.
- Using GPT-style Prompts for Mistral-Nemo: Questions arose asking whether GPT-style prompts are acceptable for finetuning the Mistral-Nemo-12b-4bit model, with another user confirming compatibility if it's an instruct model.
- This reflects a broader curiosity about effective prompting styles for different model architectures.
Links mentioned:
- Blog: no description found
- text_classification_scripts/unsloth_classification.ipynb at main · timothelaborie/text_classification_scripts: Scripts for text classification with llama and bert - timothelaborie/text_classification_scripts
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
Unsloth AI (Daniel Han) ▷ #research (2 messages):
Equation Correction, Order of Operations
-
Adding parentheses to correct an equation: A member provided an incorrect equation, 1 + 2 imes 3 + 4 imes 5 + 6 imes 7 + 8 imes 9 = 479, and sought to add parentheses to make it true.
- They detailed their calculations step-by-step, concluding that without parentheses, the left side totals 141, which is significantly off from the intended 479.
- Understanding order of operations (PEMDAS): As part of the equation correction process, the member reviewed the order of operations, confirming multiplication is prioritized over addition.
- Calculations performed included 2 imes 3 = 6, 4 imes 5 = 20, 6 imes 7 = 42, and 8 imes 9 = 72, contributing to the total of 141.
Link mentioned: QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
Stability.ai (Stable Diffusion) ▷ #general-chat (99 messages🔥🔥):
Wildcard Definitions, Image Generation Workflows, ControlNet Functionality, High-Quality Image Creation, SD Plugin Updates
-
Debate Over Wildcard Definitions: A conversation unfolded regarding the definition of 'wildcards' in programming and its application in different contexts, especially in relation to Civitai and Python terminologies.
- Participants noted discrepancies in understanding and usage, with references to the dictionary definition and programming history influencing opinions.
- Challenges in Image Generation Workflows: A user expressed difficulty in generating consistent images across characters, despite proper prompts and style guidelines, seeking advice on potential solutions.
- Suggestions included experimenting with image-to-image generation methods and utilizing workflows available on platforms like Civitai.
- ControlNet Performance on Large Turbo: Members discussed the effectiveness of ControlNet functionality when used with the 3.5 large turbo model, with one confirming its performance.
- This conversation sparked interest and curiosity about the compatibility and results achieved when utilizing newer models.
- Creating High-Quality Images: Discussions around producing high-quality character portraits highlighted the importance of time, exploration, and experimenting with prompts and styles.
- Users were encouraged to review workflows from successful images and consider different techniques to improve their output.
- Issues with Stable Diffusion Plugins: A discussion arose regarding outdated SD extensions leading to problems with checkpoint compatibility, prompting a user to seek updates.
- The community emphasized checking plugin readme files for updates and best practices, while one user shared ongoing issues with certain checkpoints despite troubleshooting.
Link mentioned: Definition of WILD CARD: an unknown or unpredictable factor; one picked to fill a leftover playoff or tournament berth after regularly qualifying competitors have all been determined… See the full definition
Notebook LM Discord ▷ #use-cases (9 messages🔥):
NotebookLM Experiments, AI Video Showcase, Model Comparisons, Satirical Writing, AI Interaction Insights
-
Experimenting with Satirical Articles in NotebookLM: A member is experimenting with feeding satirical articles into NotebookLM, noting it recognizes the jokes about half the time and doesn't the other half.
- They specifically instructed the model to question the author's humanity, leading to funny results, showcased in a YouTube video.
- AI Takes the Mic in Creative Showcase: In a new video, AI showcases its capabilities in voice and video while humorously sharing its imperfections, particularly the absence of fingers.
- The member encourages all audiences—enthusiasts, skeptics, and the curious alike—to explore the exciting possibilities presented in the video, available in English and German.
- Comparison of Gemini Models in Google AI Studio: One member performed a comparison between two Gemini models and summarized the conversation in NotebookLM, expressing hope that insights reach Google's team.
- They provided a link to the AI Studio conversation and shared an audio overview from NotebookLM.
- Discussion on AI's Recursion Struggles: A member noted that the latest iteration of NotebookLM struggles with recursion when repeatedly given similar material, particularly when creating a document based on previous instructions.
- They shared an audio clip highlighting this issue, alongside a link to the related audio.
- Concerns Over AI Model Descriptions: A member questioned the classification of the 4o-mini as an 'advanced model' and compared it to the struggling o1-preview in solving river-crossing puzzles.
- They shared an audio file detailing these perceived limitations of the models, seen in the attached discussion.
Links mentioned:
- Deep Dive AI Reads Hugh Mann's Fermi Paradox Paper: I fed in Hugh Mann's Fermi paradox paper, as well as his UFO/ Nazca Mummy debunking paper into Google's NotebookLM Deep Dive AI podcast generator and they ar...
- no title found: no description found
- Complex stuff_ (1).wav: no description found
Notebook LM Discord ▷ #general (72 messages🔥🔥):
Notebook LM support issues, Notebook sharing limitations, AI content generation, Podcast length customization, Networking concerns
-
Issues with Notebook LM functionality: Users have reported difficulty with Notebook LM, such as a yellow gradient warning on notebooks that seem to indicate access issues, as well as complaints about the AI's performance becoming inconsistent.
- Concerns were raised about whether existing chat sessions are lost and the ephemeral nature of NotebookLM's current chat system.
- Challenges in sharing notebooks: A user attempted to share a notebook from their personal Gmail to a work email but encountered restrictions affecting some participants, while one was successfully added.
- Other discussions included how to engage more effectively with educational resources and data privacy when sharing information.
- AI content generation complexities: An individual is struggling with getting Notebook LM to analyze past exam papers for identifying patterns in question types and answers, noting that the model often provides broad responses.
- Suggestions were made that more papers might be required to develop a reliable analysis model for grading processes.
- Concerns about service pricing: Speculation arose regarding whether Notebook LM would transition to a paid service, as acknowledgment was made of potential features targeted at business users in the future.
- Users expressed skepticism about the sustainability of free services and the risk of eventual paywalls.
- Podcast length management: A user noticed generated podcasts are consistently around 20 minutes, despite custom instructions for shorter lengths, prompting inquiries about length control.
- Advice was given to instruct the AI to create concise content for busy audiences as a potential solution for managing podcast duration.
Links mentioned:
- Pola's Revenge by @sharednonlocality666 | Suno: Creepy techno, female synthetic voices, female synthetic vocals, Creepy violin, quick, fast, polished, pystrance, Creepy song. Listen and make your own with Suno.
- Breaking News: Scrooge's SECRET REVEALED! Ghostly Encounter Changes EVERYTHING: Breaking news out of Cratchit County has the whole town talking! Ebenezer Scrooge, the man synonymous with miserliness, has seemingly undergone a dramatic tr...
- One billion gagillion fafillion shabadabalo shabadamillion shabaling shabalomillion yen: no description found
- NotebookLM | Note Taking & Research Assistant Powered by AI: Use the power of AI for quick summarization and note taking, NotebookLM is your powerful virtual research assistant rooted in information you can trust.
Cohere ▷ #discussions (7 messages):
Cohere Community, Welcoming New Members
-
Excitement for Cohere Learning: Members expressed their enthusiasm for joining the Cohere community and their eagerness to learn more about its offerings.
- Enisda specifically stated they can't wait to get started, highlighting the welcoming atmosphere.
- Community Welcomes Newcomers: Members exchanged warm welcomes to new participants, including Subarna_b and Enisda, promoting a friendly environment.
- xvarunx and others greeted newcomers with enthusiasm, fostering a sense of belonging.
Cohere ▷ #questions (68 messages🔥🔥):
Cohere API use with LiteLLM, Cohere model integration challenges
-
Users face challenges with LiteLLM integration: Users expressed difficulty in using the Cohere API with LiteLLM due to issues with the citations feature not functioning as expected.
- They highlighted that LiteLLM acts as a meta library to interface with multiple LLM providers, and requested support from the Cohere team to improve integration.
- Potential enhancements for citation support: It was noted that the LiteLLM implementation does not currently support citations returned by Cohere’s chat endpoint, which limits usability.
- Suggestions were made to add new parameters in the LiteLLM code to allow citation handling, with users willing to contribute or wait for responses from the maintainers.
- Community interest in model usage insights: A Cohere team member expressed excitement about learning how the community utilizes their models and showed appreciation for user engagement.
- The interaction revealed a willingness to assist in optimizing the feature implementations and improve user experience.
Links mentioned:
- [Feature]: Add citations support to completion for Cohere models · Issue #6814 · BerriAI/litellm: The Feature Models supported by Cohere return citations if you add a documents variable in the completion request (both stream=True, and stream=False) In response, chat completion returns citations...
- Quick Start | OpenRouter: Start building with OpenRouter
- litellm/litellm/llms/cohere/chat.py at main · BerriAI/litellm: Python SDK, Proxy Server (LLM Gateway) to call 100+ LLM APIs in OpenAI format - [Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq] - BerriAI/litellm
Cohere ▷ #projects (1 messages):
Full Stack AI Engineering, Web Application Development, AI-driven Solutions, Containerization and Deployment, Model Training and Deployment
-
Full Stack AI Engineer with Diverse Skills: A member shared their expertise as a Full Stack AI Engineer with over 6 years in designing and deploying scalable web applications and AI-driven solutions, covering both front-end and back-end technologies.
- They highlighted their proficiency with React, Angular, and various back-end frameworks such as Django and FastAPI.
- Containerization and Microservices Expertise: They emphasized their experience in containerization with Docker and orchestration using Kubernetes, along with CI/CD pipelines for seamless deployments across cloud platforms like AWS, GCP, and Azure.
- Their approach ensures secure, scalable, and maintainable solutions in microservices and serverless architectures.
- AI Development with Knowledge Graphs and Vector Databases: Specializing in AI, they develop autonomous AI agents using knowledge graphs and vector databases like Pinecone and Weaviate.
- They utilize TensorFlow and PyTorch for tasks such as NLP, computer vision, and recommendation systems.
- Advanced NLP Techniques: The member is well-versed in deploying LLMs (Large Language Models) and utilizing libraries such as Hugging Face Transformers and spaCy for advanced NLP tasks.
- Their expertise includes embedding models and vector search, essential for interpreting complex inputs in AI applications.
- Showcasing Projects on GitHub: To explore their work, the member directed others to their GitHub repository at AIXerum.
- They welcomed discussions on AI, software engineering, and tackling tech challenges.
Latent Space ▷ #ai-general-chat (55 messages🔥🔥):
PlayAI funding, OLMo 2 release, SmolVLM introduction, Deepseek AI developments, Generative AI in enterprise
-
PlayAI secures $21 Million funding: PlayAI has raised $21 Million in funding from notable investors including Kindred Ventures and Y Combinator to develop intuitive voice AI interfaces for developers and businesses.
- This funding aims to enhance the interaction between humans and machines, focusing on seamless voice-first interfaces as a natural communication medium.
- OLMo 2 surpasses competition: The release of OLMo 2 introduces new models (7B and 13B) that outperform other open models, which has executives excited about its potential in AI applications.
- These models are said to excel in functionality like recursive reasoning and will be used in various AI scenarios, reflecting the latest advances in AI technology.
- Launch of SmolVLM for on-device use: SmolVLM, a 2B VLM, aims to enable on-device inference, outperforming competitors in terms of GPU RAM usage and token throughput.
- The model can be fine-tuned on Google Colab and is tailored for use cases that require efficient processing on consumer-grade hardware.
- Deepseek emerges as a key player: Deepseek's recent AI model has reportedly outperformed OpenAI’s in reasoning benchmarks, catching the attention of the AI community.
- Backed by the Chinese hedge fund High-Flyer, Deepseek is committed to building foundational technology and pricing APIs affordably.
- Generative AI spending skyrockets in 2024: Generative AI spending surged to $13.8 billion in 2024, indicating a shift from experimentation to execution within enterprises.
- Despite optimism about the broader adoption of generative AI, decision-makers still face challenges in defining effective implementation strategies.
Links mentioned:
- Tweet from Ai2 (@allen_ai): Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight model...
- Tweet from David Singleton (@dps): 🚀 Excited to announce my new company: /dev/agents. I’m building the next-gen operating system for AI agents, joining my former colleagues @hbarra, @alcor, and @ficus as co-founders. We're excited...
- Tweet from Pedro Cuenca (@pcuenq): SmolVLM was just released 🚀It's a great, small, and fully open VLM that I'm really excited about for fine-tuning and on-device use cases 💻It also comes with 0-day MLX support via mlx-vlm, he...
- Chain of Code: Reasoning with a Language Model-Augmented Code Emulator: Project page for Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
- PlayAI raises $21M funding and releases a new voice model: PlayAI, a Voice AI company that builds delightful and capable voice agents and voice interfaces for realtime conversations has raised $21 Million in seed funding.
- Tweet from Ben (e/treats) (@andersonbcdefg): no frontier model company is doing better than allen ai on an output-per-resourced basis. these people are insanely cracked. as bigger labs calcify and get more google-y there an argument that this mi...
- 2024: The State of Generative AI in the Enterprise - Menlo Ventures: The enterprise AI landscape is being rewritten in real time. We surveyed 600 U.S. enterprise IT decision-makers to reveal the emerging winners and losers.
- Tweet from Nathan Lambert (@natolambert): What a crazy few weeks launching multiple state-of-the-art AI models at Ai2. Tulu 3 post training, OLMo2, Molmo just in the last month.I've learned a lot about what makes good model training teams...
- Tweet from Mike Bird (@MikeBirdTech): Quick test of QWQReasoning + ambiguity != answer
- Papers I've read this week: vision language models: They kept releasing VLMs, so I kept writing...
- Tweet from Matt Shumer (@mattshumer_): Introducing OpenReasoningEngine, an open-source test-time-compute engine that can be used with any OpenAI-compatible model.Image input, function calling, basic continual learning, + more.This is an ea...
- Tweet from Hugo Barra (@hbarra): I'm starting a new company with some of the best people I've ever worked with, and could not be more pumped. We're calling it /dev/agents. Going back to our Android roots, building a new o...
- Crisp and fuzzy tasks: Why fuzzy tasks matter and how to align models on them
- Tweet from Andi Marafioti (@andi_marafioti): Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.SmolVLM can be fine-tuned on a Google co...
- Tweet from Kyle Lo (@kylelostat): Excited to share OLMo 2!🐟 7B and 13B weights, up to 4-5T tokens, fully open data, code, etc🐠 better architecture and recipe for training stability🐡 staged training, with new data mix Dolmino🍕durin...
- Tweet from Zihan Wang (@wzihanw): @EMostaque @deepseek_ai I helped translate this interview into English to help you learn more about DeepSeek founder - Liang Wenfeng 🐋. Check it out here ↓ https://drive.google.com/file/d/1DW5ohZWxoC...
- Qwen/QwQ-32B-Preview · Hugging Face: no description found
- QwQ: Reflect Deeply on the Boundaries of the Unknown: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDNote: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”.What does it mean to think, to question, to understand? These are t...
- Deepseek: The Quiet Giant Leading China’s AI Race: Annotated translation of its CEO's deepest interview
- Ask HN: Recommendation for a SWE looking to get up to speed with latest on AI | Hacker News: no description found
- Tweet from Eugene Yan (@eugeneyan): Feels good to be mentioned on HN for engineers learning AI 🥰 Helping others is a big reason I write: ## Building AI systems• Patterns for Building LLM-based Systems: https://eugeneyan.com/writing/llm...
GPU MODE ▷ #general (4 messages):
Poll Improvement Suggestions, General Setup for Courses, GPU Access for Personal Use
-
Suggestions for Poll Improvement: A member asked for feedback on a poll, expressing willingness to enhance its format or convert it to a Google Form for better accessibility.
- I can delete this poll and make it a google form and post the results here if that’s preferred.
- Sharing Course Setup Experiences: Another member inquired about the general setups experienced individuals have when starting a course.
- This inquiry aims to gather insights for optimized configurations for new learners.
- GPU Accessibility Insights: A participant noted that many individuals have access to GPUs through their companies or universities, which can be used for personal projects.
- This highlights the potential resources available to learners who need computational power.
GPU MODE ▷ #cuda (3 messages):
Kernel Fusion, Model Traces, Reducing CUDA Kernel Launch Overheads
-
Insights into Kernel Fusion Techniques: A former talk on kernel fusion techniques highlights its relevance in both Triton and CUDA environments.
- The focus on kernel fusion stems from its potential to enhance performance by optimizing how operations are executed.
- Model Traces as a Resource Management Tool: The article emphasizes the extensive use of model traces to analyze operation dispatch, timings, and resource use.
- This method can pinpoint operations that are favorable for resource reuse, thereby avoiding unnecessary data reloads into registers.
- Discussion on Reducing Kernel Launch Overheads: A long thread on Twitter explored strategies for minimizing CUDA kernel launch overheads with insights from the author of librecuda.
- The conversation revealed that modifying launch bounds could significantly impact the performance enhancements linked to kernel launches.
Link mentioned: Tweet from mike64_t (@mike64_t): @memorypaladin @ID_AA_Carmack @ezyang If this theory holds, changing the launch bounds should do something similar.
GPU MODE ▷ #torch (9 messages🔥):
FSDP multiple ranks, FLOPS counting challenges, GPU performance discrepancies, Math library workspace issues, Efficient use of FLOP counters
- How to load a pretrained model in FSDP?: To load a pretrained model across multiple ranks for FSDP2, it's essential to manually shard the weights before loading them, as illustrated in this example. The process involves initializing the full model on each rank and sharding the weights step-by-step without materializing the complete model weights on any single GPU.
- Challenges in FLOPS counting: Counting FLOPS can be problematic as many operations evade detection by existing scripts, leading to erroneous flop counts impacting research reliability. Suggested solutions include tools such as fvcore and torch_flops for more accurate measurements.
- GPGPU performance discrepancies: One user noted that their calculations suggest a >3k tok/s performance for GPT-2 Small on a 3080Ti, which is not being met in practice. Concerns were raised over potential factors like different kernels and temporary workspaces in math libraries that might lead to unexpected memory usage.
- Workspace issues may cause OOMs: The size of temporary workspaces in math libraries can vary by hardware, leading to out-of-memory errors. Users can override workspace settings—like
CUBLAS_WORKSPACE_CONFIG—to manage memory better, although hardware changes can still complicate matters. - Nuances in FLOPS counting: Accurate counting of FLOPS is nuanced as even when operations are detected, subtleties remain that can affect results. One user expressed frustration at their GPT-2 model's performance, suspecting missing FLOPS may cause performance discrepancies.
Link mentioned: torchtune/torchtune/training/_distributed.py at b5d2e6372017c163914b13b2514f29914e5dbb84 · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
GPU MODE ▷ #algorithms (4 messages):
LoLCATs paper, ThunderKittens kernel, Model Throughput Issues, Linearized Attention Performance
-
LoLCATs Paper Insights: A discussion arose around the LoLCATs paper focusing on linearizing LLMs without full model fine-tuning, noting its performance dropped to half throughput compared to FA2 for small batch sizes.
- Interestingly, the linearized model shows memory savings but fails to outperform the previously expected quadratic attention model.
- Questioning Kernel Efficiency: Uncertainty was expressed regarding what kernels are being used in the LoLCATs implementation, specifically whether the ThunderKittens kernel or a less efficient one is employed.
- Members inferred that the results may suggest the use of the ThunderKittens kernel based on the Appendix, yet it raised questions about overall efficiency.
- MLP Size vs. Context Window: Discussions highlighted concerns that the 4k context window might be too small to significantly impact performance when considering the MLP weight matrix sizes.
- The weight matrix properties reveal that MLP sizes outscale the KV matrix dimensions, potentially affecting throughput.
- Algorithmic Gains vs. Performance: Participants noted that the algorithmic gains from the attention operator at 4k sequences may be overshadowed by linear projections and the full FFN block.
- Despite these expectation, there remained a surprising disparity in throughput as indicated in the initial findings of the paper.
Link mentioned: Linearizing LLMs with LoLCATs: no description found
GPU MODE ▷ #beginner (11 messages🔥):
#pragma unroll usage, Machine specifications for GPU work, NVIDIA vs AMD GPUs, Importance of recent GPU architecture
-
Understanding #pragma unroll: Members discussed the intuition behind using
#pragma unrollin CUDA kernels, emphasizing that it's often used when complete unrolling is necessary for performance, particularly to keep arrays in registers instead of local memory.- One member noted that unrolling large loops can enhance pipeline parallelism, although it might increase register pressure and code size.
- Specs for Machine Learning Tasks: A member sought advice on machine specifications for GPU work, prompting others to clarify that RAM and GPU are the most crucial components.
- Another highlighted that while there's no 'goto' spec, using NVIDIA GPUs generally offers better performance compared to AMD.
- NVIDIA GPUs provide better performance: Members agreed that opting for NVIDIA GPUs is advisable, with the 3060 being mentioned as a solid choice due to its 12GB of VRAM.
- The conversation noted that for kernel development, newer architectures are prioritized over just raw speed, as they support advanced features like
bf16andfp8.
GPU MODE ▷ #llmdotc (2 messages):
CUDA course on freeCodeCamp, cublaslt performance
-
Check out CUDA Course on YouTube: A member suggested checking out the CUDA course on freeCodeCamp available on YouTube for learning resources.
- They highlighted its relevance for gaining insights into CUDA programming.
- cublaslt is fastest for large matrices: A member pointed out that cublaslt is optimal for managing low precision large matrices, showcasing its impressive speed.
- They recommended this section for those keen on optimizing performance in matrix operations.
GPU MODE ▷ #intel (1 messages):
binarysoloist: First Google result for meteor lake NPU says it’s shared memory
GPU MODE ▷ #liger-kernel (5 messages):
Motherboard Replacement, GPU Performance, CMOS Battery Check, Pull Request Comments
-
Fried Motherboard Needs Replacement: A member reported that their motherboard got fried and needs replacement after they nearly completed a task.
- Now that's making GPUs go brrrrr commented another member in response.
- Check the CMOS Battery: In light of the motherboard issue, a member advised checking if the CMOS battery needs replacement.
- This suggestion offers a technical angle to troubleshoot the motherboard failure.
- Pull Request Anticipation: The member expressed that they made a pull request but expect a lot of comments on it, referencing it as #410.
- They proclaimed, It is alive.....somehow, hinting at their perseverance despite hardware troubles.
- Cooking Hard with GPUs: Another member commented on the situation by saying, dude is cooking so hard.
- This light-hearted remark reflects the excitement around the ongoing GPU activity despite the technical issue.
GPU MODE ▷ #🍿 (2 messages):
CUDA bot usage, VS Code extension for AI coding, GitHub Copilot customization
-
Measuring CUDA Bot Popularity: One member suggested that a way to measure the success of a CUDA bot is by tracking user engagement, proposing a VS Code extension to explore its utilization.
- They mentioned it currently utilizes Claude and random prompts from Thunderkittens, but there's room for improvement in supporting open models and enhancing UX.
- Introducing the LLM Coder Project: A new project called llm_coder aims to help Claude understand libraries better by providing main APIs in prompts and integrating them into VS Code.
- The project description emphasizes linking Claude with libraries for improved coding suggestions, and the member invited others to express interest.
- Simplifying Custom Instructions for Copilot: A member pointed out a more straightforward method for enhancing GitHub Copilot with custom instructions.
- This resource is intended to streamline the customization process, making it easier for developers to tailor Copilot's functionality.
Links mentioned:
- Adding custom instructions for GitHub Copilot - GitHub Docs: no description found
- GitHub - msaroufim/llm_coder: Help Claude know about your library by giving it the main APIs in a prompt and integrate it into VS Code: Help Claude know about your library by giving it the main APIs in a prompt and integrate it into VS Code - msaroufim/llm_coder
GPU MODE ▷ #thunderkittens (3 messages):
FP8 support, ThunderKittens kernels
-
ThunderKittens introduces FP8 support: Today marks the launch of FP8 support and fp8 kernels in ThunderKittens, addressing community requests for quantized data types. Check out the full feature details in the blog post.
- The implementation achieves 1500 TFLOPS in just 95 lines of code, showcasing its efficiency and effectiveness.
- Kernel implementation details shared: The focus for ThunderKittens has been on simplifying kernel writing and facilitating research on new architectures. Users can explore the kernel implementation further here.
- The team behind the project includes notable members like Benjamin Spector and Chris Ré, contributing to its development.
Links mentioned:
- ThunderKittens: Bringing fp8 to theaters near you: no description found
- ThunderKittens/kernels/matmul/FP8 at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
LlamaIndex ▷ #blog (4 messages):
Azure OpenAI endpoints, CXL memory for RAG, Quality-aware documentation chatbot, MSIgnite announcements, LlamaParse functionalities
-
LlamaParse welcomes Azure OpenAI endpoints!: LlamaParse now supports Azure OpenAI endpoints, enhancing its capability as a parser for complex document formats while ensuring enterprise-grade security.
- This integration allows users to effectively manage sensitive data within their applications through tailored API endpoints.
- Boost RAG pipelines with CXL memory!: The latest research from MemVerge highlights how using CXL memory can significantly expand available memory for RAG applications.
- This advancement promises to improve performance through fully in-memory operations.
- Craft a documentation chatbot with LlamaIndex!: By combining LlamaIndex for document ingestion and retrieval with @aimon_ai for monitoring, you can build a quality-aware documentation chatbot that actively checks for issues like hallucinations.
- LlamaIndex uses @milvusio as the vector store, ensuring efficient and effective data retrieval for chatbots.
- Exciting announcements from #MSIgnite!: During #MSIgnite, major announcements were made regarding LlamaParse and LlamaCloud, showcased in a breakout session by Farzad Sunavala and @seldo.
- The demo featured functionalities such as multimodal parsing, demonstrating LlamaParse's capabilities across various formats.
LlamaIndex ▷ #general (18 messages🔥):
BM25 retriever with Postgres, Loading index in Milvus, Ollama API independence, Pydantic model extraction with o1 models, Document hashing comparison
- BM25 Retriever and Postgres Compatibility: A member asked about building a BM25 retriever and storing it in a Postgres database. Another responded that a BM25 extension would be needed to achieve this functionality.
- Loading Index from Milvus in ChromaDB: A member inquired about loading an index from 'milvus_local.db' into Milvus, providing a ChromaDB code example for context. It was suggested that the MilvusVectorStore will automatically check if the database exists when pointed at it.
- Ensuring Stateless API Calls with Ollama: One member questioned how to ensure no shared context in API calls to Ollama, with another clarifying it’s mostly stateless unless specific data is shared in calls. The caller’s input can determine context retention.
- Pydantic Model Extraction with o1 Models: A member shared their challenges extracting a Pydantic model using o1-preview and o1-mini models, mentioning a call failure due to unsupported parameters. The response highlighted that o1 models lack support for structured outputs and suggested chaining requests with gpt-4o-mini but met skepticism regarding this approach.
- Setting Document Hashes for Comparison: A member asked if there’s a way to set a hash for documents to compare text without using metadata. The reply indicated that the hash method is hardcoded, recommending subclassing to modify the comparison logic instead.
tinygrad (George Hotz) ▷ #general (10 messages🔥):
TinyCloud Infrastructure, FPGA Backend Development, Cloud Access for Tinygrad Contributors, Intel/ARC Support Concerns, Tinybox Performance Focus
-
TinyCloud set to Launch: Excitement builds for the upcoming TinyCloud, which will feature 9 tinybox reds (54x 7900XTX) by year's end for contributors to use free with CLOUD=1 in tinygrad.
- This setup will be stable thanks to a custom driver that ensures simplicity for users with an API key.
- Need for Full-time Cloud Infra Dev: GeorgeHotz mentioned the necessity for someone to work full-time on cloud infrastructure to further develop the TinyCloud project.
- He emphasized this need in addition to a call for an FPGA backend specialist, inviting interested candidates.
- Prerequisites for Tapeout Progress: There are critical prerequisites listed for tapeout readiness, including removal of LLVM from tinygrad and support for Qualcomm DSP and Google TPU.
- He also mentioned the need for tinybox FPGA edition and an overall goal for a sovereign AMD stack.
- Intel/ARC Mentioned but Lacking Focus: A member expressed surprise at the absence of Intel/ARC support discussions, questioning if there’s been a decision to deprioritize them.
- GeorgeHotz responded, noting that there's nothing novel about it and referred to it as a 'very weak GPU'.
- Focus on Tinybox Performance: There was consensus around not supporting every consumer configuration, concentrating instead on the performance and reliability of tinybox, especially with cloud access.
- This strategic focus was endorsed as beneficial for the evolution of the project.
Link mentioned: Tweet from the tiny corp (@tinygrad): We will have 9 tinybox reds (54x 7900XTX) up in a test cloud by the end of the year. (stable with our custom driver) Will be free for tinygrad contributors to use.Using it will be as simple as running...
tinygrad (George Hotz) ▷ #learn-tinygrad (11 messages🔥):
GPU Radix Sort Optimization, Handling Edge Cases, Sorting Algorithm Selection, Vectorization Techniques, Support for Bitonic Sort
-
Optimizing GPU Radix Sort for Various Data Types: User shared insights on enhancing the GPU radix sort by supporting 64-bit, negatives, and floating points, while emphasizing chunking for performance on large arrays.
- They also mentioned a potential UOp.range() for optimizing Python loops with a linked example.
- Edge Cases for Radix Sort Implementation: User provided a list of edge cases for testing the GPU radix sort, including already sorted, reversed, and lists with duplicates or large numbers.
- They also noted the importance of handling singular and empty tensors within sorting algorithms.
- Choosing Sorting Algorithms Based on Context: A member discussed selecting sorting algorithms based on available resources, suggesting that if no GPU is present, prior needs of radix sort should be prioritized over bitonic sort.
- They explained that bitonic sort's advantages stem from its capabilities for parallelization on GPUs.
- Exploring Vectorization for Sorting: User inquired about potential vectorization techniques to optimize a segment of the sorting algorithm that iterates through the digits and updates the sorted output.
- They suggested that using a histogram might allow pre-filling a tensor of constants per position for efficient assignment.
- Extending Swap Functionality in Sorts: A member observed that supporting a swap function could enhance sorting capabilities to include bitonic sorts or merged bubble sorts.
- They highlighted that these implementations could be achieved symbolically or in place on actual buffers.
Link mentioned: tinygrad/examples/stunning_mnist.py at 84f96e48a1bb8826d868ad19ea34ce2deb019ce1 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
Torchtune ▷ #dev (15 messages🔥):
Educational Chatbot Development, Torchtune Compatibility, LoRA Single-Device Recipes, Torchtune Commit Milestone, Activation Offloading and Memory Efficiency
-
Exploring Educational Chatbots with Torchtune: A user is developing an educational chatbot with OpenAI assistants focusing on specific areas like QA and cybersecurity, seeking guidance on Torchtune's compatibility and fine-tuning processes.
- Torchtune focuses on open-source models, which requires having access to model weights for effective fine-tuning.
- Celebrating Torchtune's 1000th Commit: A member congratulated the team for achieving the 1000th commit to the Torchtune main repository, reflecting on the commitment to the project.
- An attached image highlights the milestone, showcasing the team's hard work and dedication.
- Discussion on LoRA Training Speeds: Members discussed the performance of LoRA single-device recipes, with inquiries about training speed and convergence times.
- One member noted that increasing learning rate by 10x improved training performance, indicating a potential optimization path.
- Memory Efficiency with Activation Offloading: The conversation touched on activation offloading with DPO, revealing that members did not observe significant memory gains.
- One member humorously noted their confusion while seeking clarity regarding a public PR that might shed light on the issues faced.
OpenInterpreter ▷ #general (8 messages🔥):
Normal Mode vs OS Mode, OS Mode requirements, CLI vs GUI functionality, Open Interpreter Point API
-
Normal Mode limits and OS Mode's capabilities: Normal Mode operates through the CLI, while OS Mode provides GUI functionality requiring multitudes of models for control.
- One user expressed that they intend to use OS mode as a universal web scraper, predominantly relying on CLI applications.
- Old OS Mode terminal interaction functionality: A user inquired whether the old OS mode terminal interaction still functions effectively without needing GUI.
- Their question was quickly resolved by a preceding message confirming its operational status.
- Issues with Open Interpreter Point API: A user reported difficulties accessing the Open Interpreter Point API, noting that it appears to be down.
- Persistent errors have been encountered while trying to utilize the API, raising concerns among users.
OpenInterpreter ▷ #ai-content (6 messages):
MCP tool feedback, Installed servers & tools, Cheatsheets for MCP
-
Excitement Around MCP: A member expressed enthusiasm about the new MCP tool, labeling it as mad and really HUGE.
- This reflects a growing interest within the community to explore its capabilities.
- List of Installed MCP Servers: One member shared their installed tools for MCP, including Filesystem, Brave Search, and several server options like SQLite and PostgreSQL.
- They plan to experiment with these tools during upcoming development projects.
- Cheatsheets Enhance MCP Usage: Another member provided links to two cheatsheets for MCP servers that include options and settings not found in the documentation.
- These resources aim to aid users in maximizing their usage of MCP, highlighting shared insights among the community.
- Seeking Feedback on Toolhouse.ai Tools: A member inquired about feedback on translating 30+ tools from Toolhouse.ai into MCP servers for increased utility.
- This indicates a collaborative effort among users to enhance tool integration and improve functionality within the MCP framework.
Links mentioned:
- MCP_SERVERS_CHEATSHEET.md: GitHub Gist: instantly share code, notes, and snippets.
- MCP_SERVER_CONFIG.md: GitHub Gist: instantly share code, notes, and snippets.
Axolotl AI ▷ #general (5 messages):
SmolLM2-1.7B, Transformers.js v3 Release, Frontend LLM Tasks, Axolotl Full Fine Tuning, Qwen 2.5 Model Configuration
-
SmolLM2-1.7B Launch Sparks Excitement: The community reacted enthusiastically to the SmolLM2-1.7B, noting its significance in frontend development for LLM tasks.
- This is wild! expressed one member, indicating the shift in accessibility and capabilities for developers.
- Transformers.js v3 Introduces Major Enhancements: Hugging Face announced the release of 🤗 Transformers.js v3, featuring WebGPU support that enhances performance up to 100x faster than WASM.
- New updates include 25 new example projects and 120 supported architectures, providing extensive resources for developers.
- Frontend LLM Tasks Become Reality: A member highlighted the shift to having LLM tasks integrated within the frontend, reflecting a significant evolution in app development.
- This advancement underlines the unprecedented capabilities available to developers today.
- Inquiry About Qwen 2.5 Full Fine Tuning: A user sought guidance on configuring full fine tuning for the Qwen 2.5 model in Axolotl, referencing parameters that influence training effectiveness.
- Questions arose regarding the necessity of specific unfrozen_parameters, indicating a need for better understanding of model configurations.
- Seeking Knowledge on Model Configuration: In the context of fine tuning for various models, users expressed interest in learning how to navigate configuration settings effectively.
- One user posed a question about obtaining guidance on similar inquiries for future models, highlighting the ongoing learning within the community.
Links mentioned:
- SmolLM2 1.7B Instruct WebGPU - a Hugging Face Space by HuggingFaceTB: no description found
- Transformers.js v3: WebGPU Support, New Models & Tasks, and More…: no description found
MLOps @Chipro ▷ #events (2 messages):
Feature Store Webinar, Multi-Agent Framework Bootcamp
-
Join our Free Feature Store Webinar: Attend our last webinar of the year on December 3rd at 8 AM PT titled Building an Enterprise-Scale Feature Store with Featureform and Databricks featuring founder Simba Khadder. Gain insights into how feature stores are pivotal for managing large-scale data pipelines by simplifying the three main types within an ML ecosystem.
- The session will cover topics like handling petabyte-level data and versioning with Apache Iceberg while providing actionable insights to enhance your ML projects; register here!
- Multi-Agent Framework Bootcamp at GitHub HQ: Join us on December 4 for a bootcamp focused on multi-agent frameworks, featuring expert talks and workshops at GitHub HQ. Network with industry leaders while enjoying complimentary food and drinks; register here.
- The agenda includes sessions like Automate the Boring Stuff with CrewAI and Production-ready Agents through Evaluation, delivered by professionals like Lorenze Jay and John Gilhuly.
Links mentioned:
- Developer Bootcamp: Mastering Multi-Agent Frameworks and Evaluation Techniques · Luma: Join us at the GitHub office for an evening of expert talks, hands-on workshops, and networking opportunities with leading professionals in multi-agent system…
- ML Feature Lakehouse: Building Petabyte-Scale Data Pipelines with Iceberg: Join our 1-hr webinar, where we will dive into the different types of feature stores and their use cases!
MLOps @Chipro ▷ #general-ml (2 messages):
LLMOps resource, Large Language Models impact
-
Must-Read Resource on LLMOps: A member shared an awesome resource for learning LLMOps, highlighting its three parts and encouraging others to bookmark it.
- They emphasized the transformative wave driven by large language models and the operational framework emerging as LLMOps.
- LLMs Revolutionizing Technology: The discussion detailed how LLMs are changing interactions with technology, powering applications like chatbots, virtual assistants, and advanced search engines.
- There was a mention of their role in creating personalized recommendation systems, indicating a significant shift in operational approaches.
Link mentioned: LLMOps Part 1: Introduction: The world is experiencing a transformative wave driven by large language models (LLMs). These advanced AI models, capable of understanding and generating human-quality text, are changing interactions ...
LAION ▷ #general (4 messages):
Audio Dataset Captioning, Faster Whisper Batching, Script for Captioning, Audio Joining Strategy
-
Seeking Efficient Audio Captioning with Whisper: A user expressed interest in captioning an audio dataset quickly using Whisper, but faced challenges with short audio files not fitting the batching requirements.
- They pointed out that batching significantly reduces processing time, comparing 13 minutes of audio processed in 1 minute to a more efficient 17 seconds.
- Current Script Shared for Captioning: The user shared a link to their current script for audio captioning (test1.py).
- They noted their script's limitations in handling short audio files for batching efficiently.
- Combining Short Audio Files Strategy: The user proposed an idea of joining multiple short audio files together to create a longer input for processing with Whisper.
- They suggested that this approach might allow capturing text with timestamps despite initial concerns about quality.
- Faster Whisper GitHub Resource: The user referenced Faster Whisper on GitHub as a resource to improve transcription speed using CTranslate2.
- They expressed motivation to leverage this tool for faster processing of their audio files.
Link mentioned: GitHub - SYSTRAN/faster-whisper: Faster Whisper transcription with CTranslate2: Faster Whisper transcription with CTranslate2. Contribute to SYSTRAN/faster-whisper development by creating an account on GitHub.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
Llama 3.2 System Prompt, Multi Turn Categories Evaluation, Leaderboard Score Changes, Error Logs Observations
-
Llama 3.2 uses BFCL default prompt: User noted that the prompt utilized by Llama 3.2 is the default system prompt from the BFCL.
- This hints at the reliance on standard configurations in evaluating model performance.
- Multi turn categories impact accuracy: Introduced in mid-September, the multi turn categories have caused a noticeable drop in overall accuracy with the release of v3 due to their challenging nature.
- This change impacted the average scores, particularly affecting various models while v1 and v2 saw minimal changes.
- Significant leaderboard score fluctuations: The two most recent leaderboard updates on 10/21 and 11/17 presented notable score changes due to a new evaluation metric introduced for the multi turn categories.
- Previous correct entries may now be marked as incorrect, highlighting limitations of the former state checker and improvements with the new metric detailed in PR #733.
- Upcoming public release of generation results: Plans were announced to upload and publicly share all generation results used for leaderboard checkpoints to allow review of error logs.
- This should provide insights into differences in agentic behavior observed across models.
- Prompting models struggle in multi turn categories: An observation was made that prompting models tend to perform worse than their FC counterparts specifically in the multi turn categories.
- This raises questions about the effectiveness of prompting in challenging evaluation situations.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Quiz Score Notifications, Confirmation Emails
-
Missing Quiz Score Emails: A member expressed concern about not receiving confirmation emails regarding their quiz scores after submission.
- Another member suggested checking the spam folder or trying a different email in case the submission wasn't recorded.
- Troubleshooting Email Issues: In response to the inquiry, a member recommended verifying if a confirmation email was sent from Google Forms.
- They emphasized that if no email is found, it likely means the submission did not go through.
Mozilla AI ▷ #announcements (1 messages):
Hidden States Unconference, Local RAG Application Workshop, ESM-1 Protein Language Model Discussion, San Francisco Demo Night, Data Bias Seminar
-
Hidden States Unconference invites AI innovators: Join the Hidden States Unconference in San Francisco, a gathering of researchers and engineers exploring AI interfaces and hidden states on December 5th.
- This one-day event aims to push the boundaries of AI methods through collaborative discussions.
- Build an ultra-lightweight RAG app: Learn how to create a Retrieval Augmented Generation (RAG) application using sqlite-vec and llamafile with Python at the upcoming workshop on December 10th.
- Participants will appreciate building the app without any additional dependencies.
- Kick-off Biological Representation Learning with ESM-1: The Paper Reading Club will discuss Meta AI’s ESM-1 protein language model on December 12th as part of the series on biological representation learning.
- This session aims to engage participants in the innovative use of AI in biological research.
- Demo Night showcases Bay Area innovations: Attend the San Francisco Demo Night on December 15th to witness groundbreaking demos from local creators in the AI space.
- The event is presented by the Gen AI Collective, highlighting the intersection of technology and creativity.
- Tackling Data Bias with Mozilla's Linda Dounia Rebeiz: Join Linda Dounia Rebeiz, TIME100 honoree, on December 20th to learn about her approach to using curated datasets to train unbiased AI.
- She will discuss strategies that empower AI to reflect reality rather than reinforce biases.
AI21 Labs (Jamba) ▷ #general-chat (1 messages):
Jamba 1.5 Mini Model, Function Calling Issues, OpenRouter Performance, Password Change Request
-
Jamba 1.5 Mini Model used with OpenRouter: A member mentioned trying to use the Jamba 1.5 Mini Model from AI21 Labs via OpenRouter with specific user data and a password change request.
- This involved setting parameters such as location and username in the messages for the model.
- Function Calling outputs empty: Despite the setup, the model returned empty outputs when invoked with function calling, showing a JSON response with content field empty.
- This indicates a potential issue as the same member reported receiving reasonable outputs when function calling was not used.
- Seeking community insights on function calling: The member asked if others in the community successfully used function calling with OpenRouter, expressing concerns about the empty response.
- They highlighted that their attempts without tools went smoothly, raising questions about the specific issues with this setup.