[AINews] Promptable Prosody, SOTA ASR, and Semantic VAD: OpenAI revamps Voice AI
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
OAI Voice models are all you need.
AI News for 3/19/2025-3/20/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (227 channels, and 4533 messages) for you. Estimated reading time saved (at 200wpm): 386 minutes. You can now tag @smol_ai for AINews discussions!
As one commenter said, the best predictor of an OpenAI launch is a launch from another frontier lab. Today's OpenAI mogging takes the cake because of how broadly it revamps OpenAI's offering - if you care about voice at all, this is as sweeping a change as the Agents platform revamp from last week.
We think Justin Uberti's summary is the best one:
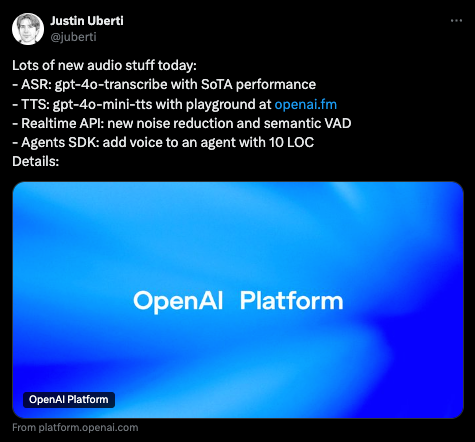
But you should also watch the livestream:
The major three highlights are
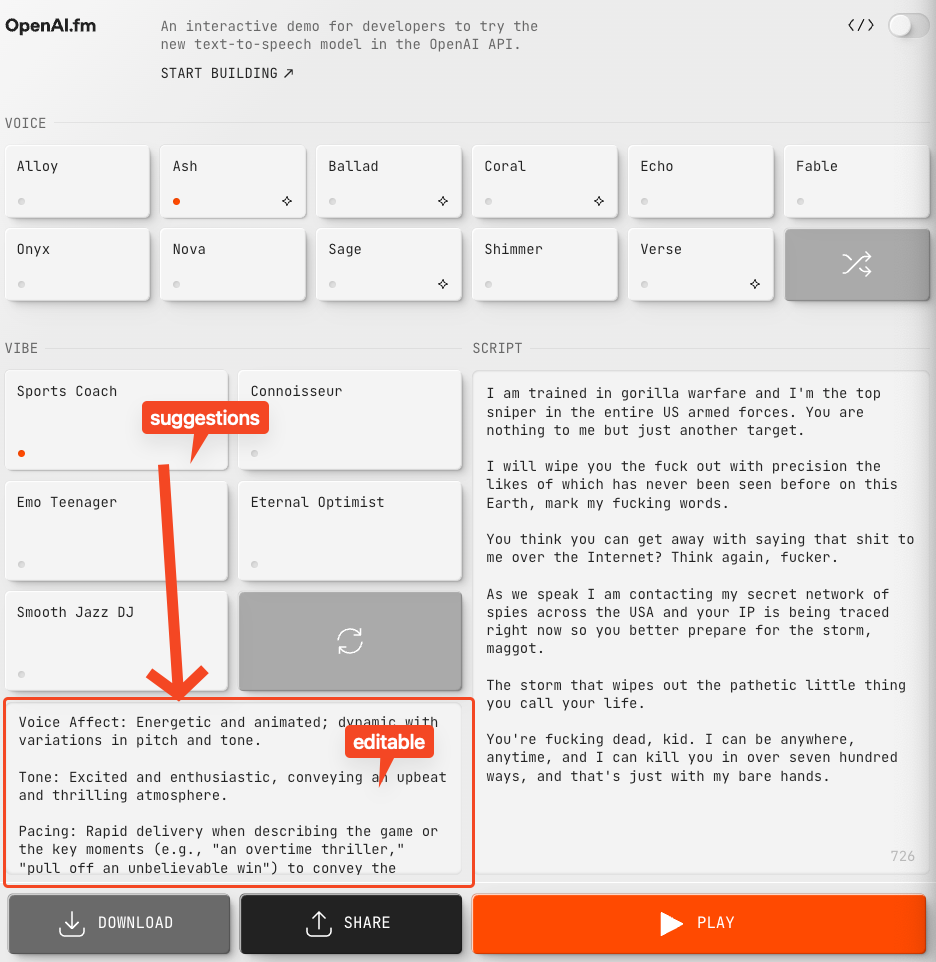
OpenAI.fm, a demo site that shows off the new promptable prosody in 4o-mini-tts:
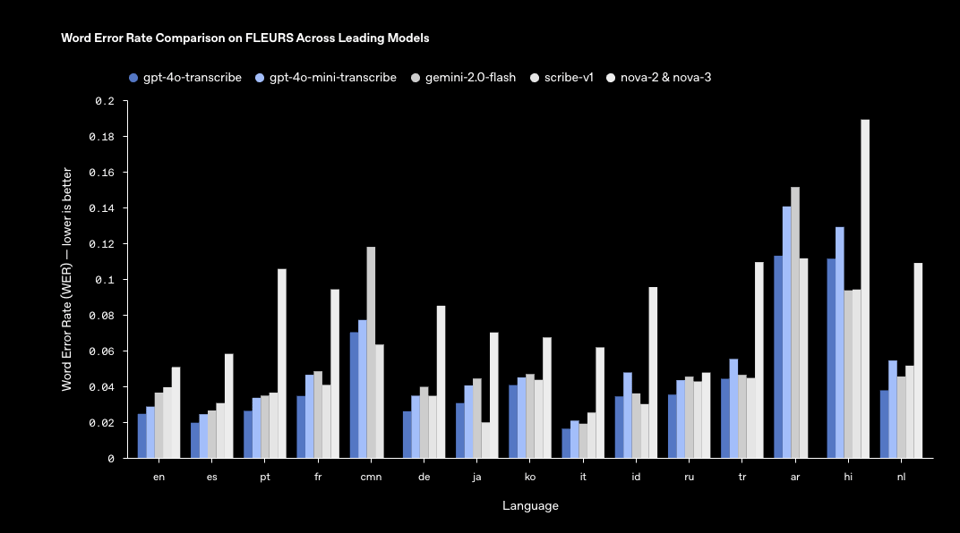
4o-transcribe, a new (non open source?) ASR model that beats whisper and commercial peers:
and finally, blink and you will miss it, but even turn detection got an update, so now realtime voice will use the CONTENT of speech to dynamically adjust VAD:
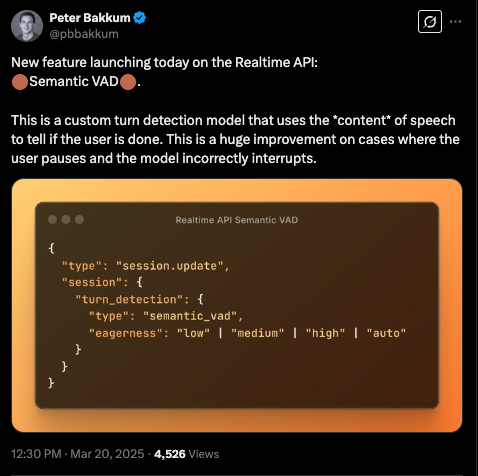
Technical detail on the blogpost is light of course, only one paragraph each per point.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor Community Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- LM Studio Discord
- Perplexity AI Discord
- Interconnects (Nathan Lambert) Discord
- Notebook LM Discord
- Nous Research AI Discord
- MCP (Glama) Discord
- OpenAI Discord
- LMArena Discord
- HuggingFace Discord
- OpenRouter (Alex Atallah) Discord
- GPU MODE Discord
- Latent Space Discord
- Eleuther Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- LlamaIndex Discord
- Torchtune Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor Community ▷ #general (1517 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (371 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (63 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #research (10 messages🔥):
- aider (Paul Gauthier) ▷ #general (278 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (39 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- LM Studio ▷ #general (82 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (212 messages🔥🔥):
- Perplexity AI ▷ #general (183 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (75 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (35 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (1 messages):
- Interconnects (Nathan Lambert) ▷ #reads (5 messages):
- Interconnects (Nathan Lambert) ▷ #posts (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (30 messages🔥):
- Notebook LM ▷ #use-cases (9 messages🔥):
- Notebook LM ▷ #general (122 messages🔥🔥):
- Nous Research AI ▷ #general (85 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (36 messages🔥):
- Nous Research AI ▷ #interesting-links (2 messages):
- MCP (Glama) ▷ #general (112 messages🔥🔥):
- MCP (Glama) ▷ #showcase (11 messages🔥):
- OpenAI ▷ #annnouncements (4 messages):
- OpenAI ▷ #ai-discussions (85 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- OpenAI ▷ #prompt-engineering (8 messages🔥):
- OpenAI ▷ #api-discussions (8 messages🔥):
- LMArena ▷ #general (110 messages🔥🔥):
- HuggingFace ▷ #general (46 messages🔥):
- HuggingFace ▷ #i-made-this (9 messages🔥):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #smol-course (1 messages):
- HuggingFace ▷ #agents-course (42 messages🔥):
- HuggingFace ▷ #open-r1 (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (101 messages🔥🔥):
- GPU MODE ▷ #general (9 messages🔥):
- GPU MODE ▷ #triton (28 messages🔥):
- GPU MODE ▷ #cuda (1 messages):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #algorithms (2 messages):
- GPU MODE ▷ #beginner (2 messages):
- GPU MODE ▷ #jax (1 messages):
- GPU MODE ▷ #off-topic (1 messages):
- GPU MODE ▷ #irl-meetup (3 messages):
- GPU MODE ▷ #lecture-qa (1 messages):
- GPU MODE ▷ #liger-kernel (2 messages):
- GPU MODE ▷ #submissions (10 messages🔥):
- GPU MODE ▷ #ppc (4 messages):
- GPU MODE ▷ #hardware (3 messages):
- Latent Space ▷ #ai-general-chat (41 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Eleuther ▷ #general (12 messages🔥):
- Eleuther ▷ #research (25 messages🔥):
- Cohere ▷ #「💬」general (23 messages🔥):
- Cohere ▷ #「🔌」api-discussions (7 messages):
- Cohere ▷ #「💡」projects (1 messages):
- Cohere ▷ #「🤝」introductions (2 messages):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #mojo (23 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (20 messages🔥):
- Torchtune ▷ #general (10 messages🔥):
- Torchtune ▷ #dev (2 messages):
- tinygrad (George Hotz) ▷ #general (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
- DSPy ▷ #general (1 messages):
AI Twitter Recap
Audio Models, Speech-to-Text, and Text-to-Speech Advancements
- OpenAI released three new state-of-the-art audio models in their API: including two speech-to-text models outperforming Whisper, and a new TTS model that allows you to instruct it how to speak, as noted by @OpenAIDevs. The Agents SDK now supports audio, facilitating the building of voice agents, furthering the discussion by @sama. @reach_vb expressed excitement, stating MOAR AUDIO - LETSGOOO! indicating community enthusiasm. You can hear the new models in action @OpenAI. @kevinweil mentions new features give you control over timing and emotion.
- OpenAI is holding a radio contest for TTS creations. Users can tweet their creations for a chance to win a Teenage Engineering OB-4, with the contest ending Friday, according to @OpenAIDevs and @kevinweil. @juberti notes they have added ASR, gpt-4o-transcribe with SoTA performance, and TTS, gpt-4o-mini-tts with playground.
- Artificial Analysis reported Kokoro-82M v1.0 is now the leading open weights Text to Speech Model and is extremely competitive pricing, costing just $0.63 per million characters when run on Replicate @ArtificialAnlys.
Model Releases, Open Source Initiatives, and Performance Benchmarks
- OpenAI's o1-pro is now available in API to select developers on tiers 1–5, supporting vision, function calling, Structured Outputs, and works with the Responses and Batch APIs, according to @OpenAIDevs. The model uses more compute and is more expensive: $150 / 1M input tokens and $600 / 1M output tokens. Several users including @omarsar0 and @BorisMPower note their excitement to experiment with o1-pro. @Yuchenj_UW notes that o1-pro could replace a PhD or skilled software engineer and save money.
- Nvidia open-sourced Canary 1B & 180M Flash, multilingual speech recognition AND translation models with a CC-BY license allowing commercial use, according to @reach_vb.
- Perplexity AI announced major upgrades to their Sonar models, delivering superior performance at lower costs. Benchmarks show Sonar Pro surpasses even the most expensive competitor models at a significantly lower price point, according to @Perplexity_AI. @AravSrinivas reports their Sonar API scored 91% on SimpleQA while remaining cheaper than even GPT-4o-mini. New search modes (High, Medium, and Low) have been added for customized performance and price control, according to @Perplexity_AI and @AravSrinivas.
- Reka AI launched Reka Flash 3, a new open source 21B parameter reasoning model, with the highest score for a model of its size, as per @ArtificialAnlys. The model has an Artificial Analysis Intelligence Index of 47, outperforming almost all non-reasoning models, and is stronger than all non-reasoning models in their Coding Index. The model is small enough to run in 8-bit precision on a MacBook with just 32GB of RAM.
- DeepLearningAI reports that Perplexity released DeepSeek-R1 1776, an updated version of a model originally developed for China, and more useful outside China due to the removal of political censorship @DeepLearningAI.
AI Agents, Frameworks, and Tooling
- LangChain is seeing increased graph usage and they are speeding those graphs up, according to @hwchase17. They also highlight that this community effort attempts to replicate Manus using the LangStack (LangChain + LangGraph) @hwchase17.
- Roblox released Cube on Hugging Face, a Roblox view of 3D Intelligence @_akhaliq.
- Meta introduced SWEET-RL, a new multi-turn LLM agent benchmark, and a novel RL algorithm for training multi-turn LLM agents with effective credit assignment over multiple turns, according to @iScienceLuvr.
AI in Robotics and Embodied Agents
- Figure will deploy thousands of robots performing small package logistics, each with individual neural networks, according to @adcock_brett. @DrJimFan encourages the community to contribute back to their open-source GR00T N1 project.
LLM-Based Coding Assistants and Tools
- Professor Rush has entered the coding assistant arena, according to @andrew_n_carr. @ClementDelangue notes that Cursor is starting to build models themselves with their own @srush_nlp.
Observations and Opinions
- François Chollet notes that strong generalization requires compositionality: building modular, reusable abstractions, and reassembling them on the fly when faced with novelty @fchollet. Also, thinking from first principles instead of pattern-matching the past lets you anticipate important changes with a bit of advance notice @fchollet.
- Karpathy describes an approach to note-taking that involves appending ideas to a single text note and periodically reviewing it, finding it balances simplicity and effectiveness @karpathy. They also explore the implications of LLMs maintaining one giant conversation versus starting new ones for each request, discussing caveats like speed, ability, and signal-to-noise ratio @karpathy.
- Nearcyan introduces the term "slop coding" to describe letting LLMs code without sufficient prompting, design, or verification, highlighting its limited appropriate use cases @nearcyan.
- Swyx shares analysis on the importance of timing in agent engineering, highlighting the METR paper as a commonly accepted standard for frontier autonomy @swyx.
- Tex claims one of the greatest Chinese advantages that is how much less afraid their boomers are of learning tech @teortaxesTex.
Humor/Memes
- Aidan Mclauglin tweets about GPT-4.5-preview's favorite tokens @aidan_mclau and the results were explicitly repetitive @aidan_mclau.
- Vikhyatk jokes about writing four lines of code worth \$8M and asks for questions @vikhyatk.
- Will Depue remarks anson yu is the taylor swift of waterloo @willdepue.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. LLMs 800x Cheaper for Translation than DeepL
- LLMs are 800x Cheaper for Translation than DeepL (Score: 530, Comments: 162): LLMs offer a significant cost advantage for translation, being over 800x cheaper than DeepL, with
gemini-2.0-flash-litecosting less than $0.01/hr compared to DeepL's $4.05/hr. While the current translation quality may be slightly lower, the author anticipates that LLMs will soon surpass traditional models, and they are already achieving comparable results to Google's translations with improved prompting.- LLMs vs. Traditional Models: Many users highlighted that LLMs offer superior contextual understanding compared to traditional translation models, which enhances translation quality, especially for languages with complex context like Japanese. However, there are concerns about LLMs being too creative or hallucinating details, which can lead to inaccurate translations.
- Model Comparisons and Preferences: Users discussed various models like Gemma 3, CommandR+, and Mistral, noting their effectiveness in specific language pairs or contexts. Some preferred DeepL for certain tasks due to its ability to maintain document structure, while others found LLMs like GPT-4o and Sonnet to produce more natural translations.
- Finetuning and Customization: Finetuning LLMs like Gemma 3 was a popular topic, with users sharing techniques and experiences to enhance translation quality for specific domains or language pairs. Finetuning was noted to significantly improve performance, making LLMs more competitive with traditional models like Google Translate.
Theme 2. Budget 64GB VRAM GPU Server under $700
- Sharing my build: Budget 64 GB VRAM GPU Server under $700 USD (Score: 521, Comments: 144): The post describes a budget GPU server build with 64GB VRAM for under $700 USD. No additional details or specifications are provided in the post body.
- Budget Build Details: The build includes a Supermicro X10DRG-Q motherboard, 2 Intel Xeon E5-2650 v4 CPUs, and 4 AMD Radeon Pro V340L 16GB GPUs, totaling approximately $698 USD. The setup uses Ubuntu 22.04.5 and ROCm version 6.3.3 for software, with performance metrics indicating 20250.33 tokens per second sampling time.
- GPU and Performance Discussion: The AMD Radeon Pro V340L GPUs are noted for their theoretical speed, but practical performance issues are highlighted, with a comparison to M1 Max and M1 Ultra systems. Llama-cpp and mlc-llm are mentioned for optimizing GPU usage, with mlc-llm allowing simultaneous use of all GPUs for better performance.
- Market and Alternatives: The discussion includes comparisons with other GPUs like the Mi50 32GB, which offers 1TB/s memory bandwidth and is noted for lower electricity consumption. There's a consensus on the challenges in the current market for budget GPU builds, with mentions of ROCm cards being cheaper but with trade-offs in performance and software support.
Theme 3. TikZero: AI-Generated Scientific Figures from Text
- TikZero - New Approach for Generating Scientific Figures from Text Captions with LLMs (Score: 165, Comments: 31): TikZero introduces a new approach for generating scientific figures from text captions using Large Language Models (LLMs), contrasting with traditional End-to-End Models. The image highlights TikZero's ability to produce complex visualizations, such as 3D contour plots, neural network diagrams, and Gaussian function graphs, demonstrating its effectiveness in creating detailed scientific illustrations.
- Critics argue that TikZero's approach may encourage misuse in scientific contexts by generating figures without real data, potentially undermining scientific integrity. However, some see value in using TikZero to generate initial plot structures that can be refined with actual data, highlighting its utility in creating complex visualizations that are difficult to program manually.
- DrCracket defends TikZero's utility by emphasizing its role in generating editable high-level graphics programs for complex visualizations, which are challenging to create manually, citing its relevance in fields like architecture and schematics. Despite concerns about inaccuracies, the model's output allows for easy correction and refinement, providing a foundation for further customization.
- Discussions about model size suggest that while smaller models like SmolDocling-256M offer good OCR performance, TikZero's focus on code generation necessitates a larger model size, such as the current 8B model, to maintain performance. DrCracket mentions ongoing exploration of smaller models but anticipates performance trade-offs.
Theme 4. Creative Writing with Sub-15B LLM Models
- Creative writing under 15b (Score: 148, Comments: 92): The post discusses an experiment evaluating the creative writing capabilities of AI models with fewer than 15 billion parameters, using ollama and openwebui settings. It describes a scoring system based on ten criteria, including Grammar & Mechanics, Narrative Structure, and Originality & Creativity, and references an image with a chart comparing models like Gemini 3B and Claude 3.
- Several users highlighted the difficulty in reading the results due to low resolution, with requests for higher resolution images or spreadsheets to better understand the scoring system and model comparisons. Wandering_By_ acknowledged this and provided additional details in the comments.
- There was debate over the effectiveness of smaller models like Gemma3-4b, which surprisingly scored highest overall, outperforming larger models in creative writing tasks. Some users questioned the validity of the benchmark, noting issues such as ambiguous judging prompts and the potential for models to produce "purple prose."
- Suggestions included using more specific and uncommon prompts to avoid generic outputs and considering separate testing for reasoning and general models. The need for a more structured rubric and examples was also mentioned to enhance the evaluation process.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Claude 3.7 Regression: Widespread User Concerns
- I'm utterly disgusted by Anthropic's covert downgrade of Sonnet 3.7's intelligence. (Score: 255, Comments: 124): Users express dissatisfaction with Anthropic's handling of Claude 3.7, citing significant performance issues such as mismatched responses and incorrect use of functions like LEN + SUBSTITUTE instead of COUNTIF for Excel formulas. This decline in functionality reportedly began recently, leading to frustration over what is perceived as a covert downgrade.
- Users report severe performance degradation in Claude 3.7, with issues like logical errors, inability to follow instructions, and incorrect code generation, which were not present in previous versions. Many users have reverted to using GPT due to these problems, citing consistency and reliability concerns with Claude.
- There is speculation that Anthropic might be conducting live A/B testing or experimenting with feature manipulation on their models, which could explain the erratic behavior of Claude 3.7. Some users believe that Anthropic is using user data for training or feature adjustments, as discussed in their blog.
- The community expresses dissatisfaction with Anthropic's lack of transparency regarding the changes, with many users feeling frustrated by the apparent downgrade and the need for more prompt management to achieve desired results. Users are also concerned about increased API usage and the resultant costs, leading some to consider switching to alternative models.
- If you are vibe coding, read this. It might save you! (Score: 644, Comments: 192): The post discusses the vibe coding trend, emphasizing the influx of non-coders creating applications and websites, which can lead to errors and learning opportunities. The author suggests using a leading reasoning model to review code for production readiness, focusing on vulnerabilities, security, and best practices, and shares their non-coder portfolio, including projects like The Prompt Index and an AI T-Shirt Design addition by Claude Sonnet.
- Many commenters criticize vibe coding as a naive approach, emphasizing the necessity of foundational software engineering knowledge for building robust and secure products. They argue that AI-generated code often introduces issues and lacks the depth needed for production-level applications, suggesting that non-coders need to either learn coding fundamentals or work with experienced developers.
- Some participants discuss the effectiveness of AI tools in coding, with one commenter detailing their workflow involving deep research, role-playing with AI as a CTO, and creating detailed project plans. They highlight the importance of understanding project requirements and maintaining control over AI-generated outputs to avoid suboptimal results, while others note the potential for AI to accelerate early development phases but stress the need for eventual deeper engineering practices.
- AI-driven development is seen as a double-edged sword; it can increase productivity and impress management, yet many developers remain skeptical. While some have successfully integrated AI into their coding processes, others caution against over-reliance on AI without understanding the underlying systems, pointing out that AI can generate code bloat and errors if not properly guided.
- i don't have a computer powerful enough. is there someone with a powerful computer wanting to turn this oc of mine into an anime picture? (Score: 380, Comments: 131): Anthropic's Management of Claude 3.7: Discussions focus on the decline in performance of Claude 3.7, sparking debates within the AI community. Concerns are raised about the management and decision-making processes impacting the AI's capabilities.
- Discussions drifted towards image generation using various tools, with mentions of free resources like animegenius.live3d.io and img2img techniques, as showcased in multiple shared images and links. Users shared generated images, often humorously referencing Chris Chan and Sonichu.
- The conversation included references to the Chris Chan saga, a controversial internet figure, with links to updated stories like the 2024 Business Insider article. This sparked a mix of humorous and critical responses, reflecting the saga's impact on internet culture.
- A significant portion of comments included humorous or satirical content, with users sharing memes and GIFs, often in a light-hearted manner, while some commenters expressed concern over the comparison of unrelated individuals to alleged criminals.
Theme 2. OpenAI's openai.fm Text-to-Speech Model Release
- openai.fm released: OpenAI's newest text-to-speech model (Score: 107, Comments: 22): OpenAI launched a new text-to-speech model called openai.fm featuring an interactive demo interface. Users can select different voice options like Alloy, Ash, and Coral, as well as vibe settings such as Calm and Dramatic, to test the model's capabilities with sample text and easily download or share the audio output.
- Users discussed the 999 character limit in the demo, suggesting that the API likely offers more extensive capabilities, as referenced in OpenAI's audio guide.
- Some users compared openai.fm to Eleven Labs' elevenreader, a free mobile app known for its high-quality text-to-speech capabilities, including voices like Laurence Olivier.
- There were mixed reactions regarding the quality of OpenAI's voices, with some feeling underwhelmed compared to other services like Coral Labs and Sesame Maya, but others appreciated the low latency and intelligence of the plug-and-play voices.
- I asked ChatGPT to create an image of itself at my birthday party and this is what is produced (Score: 1008, Comments: 241): The post describes an image generated by ChatGPT for a birthday party scene, featuring a metallic robot holding an assault rifle, juxtaposed against a celebratory backdrop with a chocolate cake, party-goers, and decorations. The lively scene includes string lights and party hats, emphasizing a festive atmosphere despite the robot's unexpected presence.
- Users shared their own ChatGPT-generated images with varying themes, with some highlighting humorous or unexpected elements like quadruplets and robot versions of themselves. The images often featured humorous or surreal elements, such as steampunk settings and robogirls.
- Discussions included AI's creative liberties in image generation, like the inability to produce accurate text, resulting in names like "RiotGPT" instead of "ChatGPT." There was humor about the AI's interpretation of safety and party themes, with some users joking about unsafe gun handling at the party.
- The community engaged in light-hearted banter and humor, with comments about the bizarre and whimsical nature of the AI-generated scenes, including references to horror movies and unexpected party themes.
Theme 3. Kitboga's AI Bot Army: Creative Use Against Scammers
- Kitboga created an AI bot army to target phone scammers, and it's hilarious (Score: 626, Comments: 29): Kitboga employs an AI bot army to inundate phone scam centers with calls, wasting hours of scammers' time while creating entertaining content. This innovative use of AI is praised for its effectiveness and humor, as highlighted in a YouTube video.
- Commenters highlight the potential for AI to be used both positively and negatively, with Kitboga's use being a positive example, while acknowledging that scammers could also adopt AI to scale their operations. RyanGosaling suggests AI could also protect potential victims by identifying scams in real-time.
- There is discussion about the cost-effectiveness of Kitboga's operation, with users noting that while there are costs involved in running the AI locally, these are offset by revenue from monetized content on platforms like YouTube and Twitch. Navadvisor points out that scammers incur higher costs when dealing with fake calls.
- Some users propose more aggressive tactics for combating scammers, with Vast_Understanding_1 expressing a desire for AI to destroy scammers' phone systems, while others like OverallComplexities praise the current efforts as heroic.
- Doge The Builder – Can He Break It? (Score: 183, Comments: 24): The community humorously discusses a fictional scenario where Elon Musk and a Dogecoin Shiba Inu mimic "Bob the Builder" in a playful critique of greed and unchecked capitalism. The post is a satirical take on the potential chaos of memecoins and features a meme officially licensed by DOAT (Department of Automated Truth), with an approved YouTube link provided for redistribution.
- AI's Impressive Capabilities: Commenters express admiration for the current capabilities of AI, highlighting its impressive nature in creating engaging and humorous content.
- Cultural Impact of Influential Figures: There's a reflection on how individuals like Elon Musk can significantly influence the cultural zeitgeist, with a critical view on the ethical implications of wealth accumulation and societal influence.
- Creative Process Inquiry: A user shows interest in understanding the process behind creating such satirical content, indicating curiosity about the technical or creative methods involved.
Theme 4. Vibe Coding: A New Trend in AI Development
- Moore's Law for AI: Length of task AIs can do doubles every 7 months (Score: 117, Comments: 27): The image graphically represents the claim that the length of tasks AI can handle is doubling every seven months, with tasks ranging from answering questions to optimizing code for custom chips. Notable AI models like GPT-2, GPT-3, GPT-3.5, and GPT-4 are marked on the timeline, showing their increasing capabilities and variability in success rates from 2020 to 2026.
- Throttling and Resource Management: Discussions highlight user frustration with AI usage throttling, which is not due to model limitations but rather resource management. NVIDIA GPU scarcity is a major factor, with current demand exceeding supply, impacting AI service capacity.
- Pricing Models and User Impact: The pricing models for AI services like ChatGPT are critiqued for being "flexible and imprecise," impacting power users who often exceed usage limits, making them "loss leaders" in the market. Suggestions include clearer usage limits and cost transparency to improve user experience.
- Task Length and AI Capability: There is confusion about the task lengths plotted in the graph, with clarifications indicating they are based on the time it takes a human to complete similar tasks. The discussion also notes that AI models like GPT-2 had limitations, such as difficulty maintaining coherence in longer tasks.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. LLM Pricing and Market Volatility
- OpenAI's o1-pro API Price Tag Stuns Developers: OpenAI's new o1-pro API model is now available for select developers at a high price of $150 per 1M input tokens and $600 per 1M output tokens. Users on OpenRouter expressed outrage, deeming the pricing insane and questioning if it's a defensive move against competitors like DeepSeek R1 or due to complex multi-turn processing without streaming.
- Pear AI Challenges Cursor with Lower Prices: Members on the Cursor Community Discord are highlighting the price advantage of Pear AI over Cursor, claiming Cursor has become more expensive. One user stated they might switch to Pear AI if Cursor doesn't improve its context window or pricing for Sonnet Max, noting if im paying for sonnet max i'd mind as well use pear because i pay even cheaper.
- Perplexity Eyes $18 Billion Valuation in Funding Talks: Perplexity AI is reportedly in early funding discussions for $500M-$1B at an $18 billion valuation, potentially doubling its valuation from December. This reflects strong investor confidence in Perplexity's AI search technology amidst growing competition in the AI space.
Theme 2. LLM Model Quirks and Fixes
- Gemma 3 Suffers Identity Crisis on Hugging Face: Users reported that Gemma models from Hugging Face incorrectly identify as first generation models with 2B or 7B parameters, even when downloading the 12B Gemma 3. This misidentification, caused by Google's oversight in updating identification code, doesn't affect model performance, but causes user confusion about model versioning.
- Unsloth Patches Gemma 3 Float16 Activation Issue: Unsloth AI addressed infinite activations in Gemma 3 when using float16 precision, which led to NaN gradients during fine-tuning and inference on Colab GPUs. The fix keeps intermediate activations in bfloat16 and upcasts layernorm operations to float32, avoiding full float32 conversion for speed, as detailed on the Unsloth AI blog.
- Hugging Face Inference API Trips Over 404 Errors: Users reported widespread 404 errors with the Hugging Face Inference API, impacting multiple applications and paid users. A Hugging Face team member acknowledged the issue and stated it was reported for investigation, disrupting services relying on the API.
Theme 3. Tools and Frameworks Evolve for LLM Development
- UV Emerges as a Cool Kid Python Package Manager: Developers in the MCP (Glama) Discord are endorsing uv, a fast Python package and project manager written in Rust, as a superior alternative to pip and conda. Praised for its speed and minimal website, uv is gaining traction among Python developers seeking efficient dependency management.
- Nvidia's cuTile Eyes Triton's Throne?: NVIDIA announced cuTile, a new tile programming model for CUDA, sparking community discussion about its potential overlap with Triton. Some speculate cuTile might be yet another triton but nvidia, raising concerns about NVIDIA's commitment to cross-vendor backend support.
- LlamaIndex & DeepLearningAI Team Up for Agentic Workflow Course: DeepLearningAI launched a short course in collaboration with LlamaIndex on building agentic workflows using RAG, focusing on automating information processing and context-aware responses. The course covers practical skills like parsing forms and extracting key fields, enhancing agentic system development.
Theme 4. Hardware Headaches and Performance Hurdles
- TPUs Torch T4s in Machine Learning Speed Race: TPUs demonstrated significantly faster performance than T4s, especially at batch size 8, as highlighted in the Unsloth AI Discord. This observation underscores the computational advantage of TPUs for demanding machine learning tasks where speed is paramount.
- LM Studio Multi-GPU Performance Takes a Dive: A user in the LM Studio Discord reported significant performance degradation when using multiple GPUs in LM Studio with CUDA llama.cpp v1.21.0. Performance dropped notably, prompting suggestions to manually limit LM Studio to a single GPU via tensor splitting configurations.
- Nvidia Blackwell RTX Pro GPUs Face Supply Chain Squeeze: Nvidia's Blackwell RTX Pro series GPUs are anticipated to face supply constraints, according to a Tom's Hardware article shared in the Nous Research AI Discord. Supply issues may persist until May/June, potentially impacting availability and pricing of these high-demand GPUs.
Theme 5. AI Ethics, Policy, and Safety Debates
- China Mandates Labeling of All AI-Generated Content: China will enforce new regulations requiring the labeling of all AI-generated synthetic content starting September 1, 2025. The Measures for the Labeling of AI-Generated Synthetic Content will necessitate explicit and implicit markers on AI-generated text, images, audio, video, and virtual scenes, as per the official Chinese government announcement.
- Chinese Model Self-Censors Content on Cultural Revolution: A user on the OpenAI Discord reported that a Chinese AI model deletes responses when prompted about the Cultural Revolution, demonstrating self-censorship. Screenshots provided as evidence highlight concerns about content restrictions in certain AI models.
- AI Coding Blindspots Highlighted in Sonnet Family LLMs: A blogpost shared in the aider Discord discusses AI coding blindspots observed in LLMs, particularly those in the Sonnet family. The author suggests potential future solutions may involve Cursor rules designed to address issues like "stop digging," "black box testing," and "preparatory refactoring," indicating ongoing efforts to refine AI coding assistance.
PART 1: High level Discord summaries
Cursor Community Discord
- Agent Mode Meltdown: Members reported that Agent mode was down for an hour and the Status Page was not up to date.
- There were jokes that dan percs was on the case to fix it, and he was busy replying people in cursor and taking care of slow requests, which is why he's always online.
- Dan Perks Gets Keyboard Advice: Cursor's Dan Perks solicited opinions on Keychron keyboards, specifically looking for a low profile and clean model with knobs.
- Suggestions poured in, including Keychron's low-profile collection, though Dan expressed concerns about keycap aesthetics, stating I don’t like the keycaps.
- Pear AI vs Cursor: Price Wars?: Several members touted the advantages of using Pear AI and claimed that Cursor was now more expensive.
- One member claimed to be cooked due to their multiple annual cursor subs, and another claimed, If cursor changes their context window than i would stay at cursor or change their sonnet max to premium usage, otherwise if im paying for sonnet max i'd mind as well use pear because i pay even cheaper.
- ASI: Humanity's Only Hope?: Members debated whether Artificial Superintelligence (ASI) is the next evolution, claiming that the ASI-Singularity(Godsend) has to be the only Global Solution.
- Others were skeptical, with one user jesting that gender studies is more important than ASI, claiming that its the next step into making humans a intergaltic species, with a nuetral fluid gender we can mate with aliens from different planets and adapt to their witchcraft technology.
- Pear AI Caught Cloning Continue?: Members discussed the controversy surrounding Pear AI, with one claiming that Pear AI cloned continue basically and just took someone elses job and decided its their project now.
- Others cited concerns that the project was closed source and that they should switch to another alternative, like Trae AI.
Unsloth AI (Daniel Han) Discord
- TPUs smoke T4s in Speed: A member highlighted that TPUs demonstrate significantly faster performance compared to T4s, especially when utilizing a batch size of 8, as evidenced by a comparative screenshot.
- This observation underscores the advantage of using TPUs for computationally intensive tasks in machine learning, where speed and efficiency are crucial.
- Gradient Accumulation Glitch Fixed: A recent blog post (Unsloth Gradient Accumulation fix) detailed and resolved an issue related to Gradient Accumulation, which was adversely affecting training, pre-training, and fine-tuning runs for sequence models.
- The implemented fix is engineered to mimic full batch training while curtailing VRAM usage, and also extends its benefits to DDP and multi-GPU configurations.
- Gemma 3 Suffers Identity Crisis: Users have observed that Gemma models obtained from Hugging Face mistakenly identify as first generation models with either 2B or 7B parameters, despite being the 12B Gemma 3.
- This misidentification arises because Google did not update the relevant identification code during training, despite the models exhibiting awareness of their identity and capacity.
- Gemma 3 gets Float16 Lifeline: Unsloth addressed infinite activations in Gemma 3 within float16, which previously led to NaN gradients during fine-tuning and inference on Colab GPUs, via this tweet.
- The solution maintains all intermediate activations in bfloat16 and upcasts layernorm operations to float32, sidestepping speed reductions by avoiding full float32 conversion, as elaborated on the Unsloth AI blog.
- Triton needs Downgrading for Gemma 3: A user encountered a SystemError linked to the Triton compiler while using Gemma 3 on a Python 3.12.9 environment with a 4090.
- The resolution involved downgrading Triton to version 3.1.0 on Python 3.11.x, based on recommendations from this GitHub issue.
aider (Paul Gauthier) Discord
- Featherless.ai Configs Cause Headaches: Users reported configuration issues with Featherless.ai when used with Aider, particularly concerning config file locations and API key setup; using the
--verbosecommand option helped with troubleshooting the setup.- One user highlighted that the wiki should clarify the home directory for Windows users, specifying it as
C:\Users\YOURUSERNAME.
- One user highlighted that the wiki should clarify the home directory for Windows users, specifying it as
- DeepSeek R1 is Cheap, But Slow: While DeepSeek R1 emerges as a cost-effective alternative to Claude Sonnet, its slower speed and performance relative to GPT-3.7 were disappointing to some users, even with Unsloth's Dynamic Quantization.
- It was pointed out that the full, non-quantized R1 variant requires 1TB of RAM, which would make H200 cards a preferred choice; however, 32B models were still considered the best for home use.
- OpenAI's o1-pro API Pricing Stings: The new o1-pro API from OpenAI has been met with user complaints due to its high pricing, set at $150 per 1M input tokens and $600 per 1M output tokens.
- One user quipped that a single file refactor and benchmark would cost $5, while another facetiously renamed it fatherless AI.
- Aider LLM Editing Skills Spark Debate: It was noted that Aider benefits most from LLMs that excel in editing code, rather than just generating it, referencing a graph from aider.chat.
- The polyglot benchmark employs 225 coding exercises from Exercism across multiple languages to gauge LLM editing skills.
- AI Coding Blindspots Focus on Sonnet LLMs: A blogpost was shared blogpost about AI coding blindspots they have noticed in LLMs, particularly those in the Sonnet family.
- The author suggests that future solutions may involve Cursor rules designed to address these problems.
LM Studio Discord
- Proxy Setting Saves LM Studio!: A user fixed LM Studio connection problems by enabling the proxy setting, doing a Windows update, resetting the network, and restarting the PC.
- They suspected it happened because of incompatible hardware or the provider blocking Hugging Face.
- PCIE Bandwidth Barely Boosts Performance: A user found that PCIE bandwidth barely affects inference speed, at most 2 more tokens per second (TPS) compared to PCI-e 4.0 x8.
- They suggest prioritizing space between GPUs and avoiding overflow with motherboard connectors.
- LM Studio Misreporting RAM/VRAM?: A user noticed that LM Studio's RAM and VRAM display doesn't update instantly after system setting changes, hinting the check is during install.
- Despite the incorrect reporting, they are testing if the application can exceed the reported 48GB of VRAM by disabling guardrails and increasing context length.
- Mistral Small Vision Support Still Elusive: Users found that certain Mistral Small 24b 2503 models on LM Studio are falsely labeled as supporting vision, as the Unsloth version loads without it, and the MLX version fails.
- Some suspect Mistral Small is text-only on MLX and llama.cpp, hoping a future mlx-vlm update will fix it.
- Multi-GPU Performance takes a Nose Dive: A user reported significant performance drops using multiple GPUs in LM Studio with CUDA llama.cpp v1.21.0, sharing performance data and logs.
- A member suggested manually modifying the tensor_split property to force LM Studio to use only one GPU.
Perplexity AI Discord
- Deep Research Gets UI Refresh: Users reported a new Standard/High selector in Deep Research on Perplexity and wondered if there is a limit to using High.
- The team is actively working on improving sonar-deep-research at the model level.
- GPT 4.5 Pulls a Disappearing Act: GPT 4.5 disappeared from the dropdown menu for some users, prompting speculation it was removed due to cost.
- One user noted it's still present under the rewrite option.
- Sonar API Debuts New Search Modes: Perplexity AI announced improved Sonar models that maintain performance at lower costs, outperforming competitors like search-enabled GPT-4o, detailed in a blog post.
- They introduced High, Medium, and Low search compute modes to optimize performance and cost control and simplified the billing structure to input/output token pricing with flat search mode pricing, eliminating charges for citation tokens in Sonar Pro and Sonar Reasoning Pro responses.
- API Key Chaos Averted with Naming: A user requested the ability to name API keys on the UI to avoid accidental deletion of production keys, and were directed to submit a feature request on GitHub.
- Another user confirmed the API call seemed correct and cautioned to factor in rate limits as per the documentation.
- Perplexity on Locked Screen? Nope: Users reported that Perplexity doesn't work on locked screens, unlike ChatGPT, generating disappointment among the community.
- Some users have noticed that Perplexity now uses significantly fewer sources (8-16, maybe 25 max) compared to the 40+ it used to use, impacting search depth.
Interconnects (Nathan Lambert) Discord
- O1 Pro API Shelved for Completions: The O1 Pro API will be exclusively available in the responses API due to its complex, multi-turn model interactions, as opposed to being added to chat completions.
- Most upcoming GPT and O-series models will be integrated into chat completions, unlike O1 Pro.
- Sasha Rush Joins Cursor for Frontier RL: Sasha Rush (@srush_nlp) has joined Cursor to develop frontier RL models at scale for real-world coding environments.
- Rush is open to discussing AI jobs and industry-academia questions, with plans to share his decision-making process in a blog post.
- Nvidia's Canary Sings Open Source: Nvidia has open-sourced Canary 1B & 180M Flash (@reach_vb), providing multilingual speech recognition and translation models under a CC-BY license for commercial applications.
- The models support EN, GER, FR, and ESP languages.
- China's AI Content to be Flagged: China will enforce its Measures for the Labeling of AI-Generated Synthetic Content beginning September 1, 2025, mandating the labeling of all AI-generated content.
- The regulations necessitate explicit and implicit markers on content like text, images, audio, video, and virtual scenes; see official Chinese government announcement.
- Samsung ByteCraft turns Text into Games: Samsung SAIL Montreal introduced ByteCraft, the world's first generative model for video games and animations via bytes, converting text prompts into executable files, as documented in their paper and code.
- The 7B model is accessible on Hugging Face, with a blog post further detailing the project.
Notebook LM Discord
- NotebookLM Plus Subscribers Request Anki Integration: A NotebookLM Plus user requested a flashcard generation integration (Anki) in NotebookLM.
- However, the community didn't have much to say on this topic.
- Customize Button Clears Up Audio Customization Confusion: The "Customize" button in the Audio Overview feature is available for both NotebookLM and NotebookLM Plus, and it allows users to customize episodes by typing prompts.
- Free accounts are limited to generating 3 audios per day, so choose your customizations wisely.
- Mindmap Feature Gradually Rolls Out: Users expressed excitement for the mindmap feature, with one sharing a YouTube video showing its interactive uses.
- It is not an A/B test, the rollout is gradual, and allows generating multiple mindmaps by selecting different sources, however editable mindmaps are not available.
- Audio Overviews Still Stumbling Over Pronunciation: Users report that audio overviews frequently mispronounce words, even with phonetic spelling in the Customize input box.
- NotebookLM team is aware of the issue, and recommend phonetic spellings in the source material as a workaround.
- Extension Users Run Into NotebookLM Page Limits: Users are using Chrome extensions for crawling and adding sources from links within the same domain, and point to the Chrome Web Store for NotebookLM.
- However, one user hit a limit of 10,000 pages while using one such extension.
Nous Research AI Discord
- Aphrodite Crushes Llama.cpp on Perf: A member reported achieving 70 tokens per second with FP6 Llama-3-2-3b-instruct using Aphrodite Engine, noting the ability to run up to 4 batches with 8192 tokens on 10GB of VRAM.
- Another member lauded Aphrodite Engine's lead developer and highlighted the engine as one of the best for local running, while acknowledging Llama.cpp as a standard for compatibility and dependencies.
- LLMs Flounder when Debugging: Members observed that many models now excel at writing error-free code but struggle with debugging existing code, noting that providing hints is helpful.
- The member contrasted their approach of thinking through problems and providing possible explanations with code snippets, which has generally yielded success except in "really exotic stuff".
- Nvidia's Blackwell RTX Pro GPUs face Supply Chain Constraints: A member shared a Tom's Hardware article about Nvidia's Blackwell RTX Pro series GPUs, highlighting potential supply issues.
- The article suggests supply might catch up to demand by May/June, potentially leading to more readily available models at MSRP.
- Dataset Format > Chat Template for QwQ?: A member suggested not to over index on the format of the dataset, stating that getting the dataset into the correct chat template for QwQ is more important.
- They added that insights are likely unique to the dataset and that reasoning behavior seems to occur relatively shallow in the model layers.
- Intriguing Chatting Kilpatrick Clip: A member shared Logan Kilpatrick's YouTube video, describing the chat as interesting.
- The discussion references an interesting chat related to Logan Kilpatrick's YouTube video but No further details were provided.
MCP (Glama) Discord
- Cool Python Devs install UV Package Manager: Members discussed installing and using uv, a fast Python package and project manager written in Rust, as a replacement for pip and conda.
- It's favored because its website is super minimal with just a search engine and a landing page.
- glama.json Claims Github MCP Servers: To claim a GitHub-hosted MCP server on Glama, users should add a
glama.jsonfile to the repository root with their GitHub username in themaintainersarray, as detailed here.- The configuration requires a
$schemalink toglama.ai/mcp/schemas/server.json.
- The configuration requires a
- MCP App Boosts Github API Rate Limits: Glama AI is facing GitHub API rate limits due to the increasing number of MCP servers but users can increase the rate limits by installing the Glama AI GitHub App.
- Doing so helps scale Glama by giving the app permissions.
- Turso Cloud Integrates with MCP: A new MCP server, mcp-turso-cloud, integrates with Turso databases for LLMs.
- This server implements a two-level authentication system for managing and querying Turso databases directly from LLMs.
- Unity MCP Integrates AI with File Access: The most advanced Unity MCP integration now supports files Read/Write Access of Project, enabling AI assistants to understand the scene, execute C# code, monitor logs, control play mode, and manipulate project files.
- Blender support is currently in development for 3D content generation.
OpenAI Discord
- o1-pro Model Pricing Stuns: The new o1-pro model is now available in the API for select developers, supporting vision, function calling, and structured outputs, as detailed in OpenAI's documentation.
- However, its high pricing of $150 / 1M input tokens and $600 / 1M output tokens sparked debate, though some users claim it solves coding tasks in one attempt where others fail.
- ChatGPT Code with Emojis?!: Members seek ways to stop ChatGPT from inserting emojis into code, despite custom instructions, according to discussions in the gpt-4-discussions channel.
- Suggestions included avoiding the word emoji and instructing the model to "Write code in a proper, professional manner".
- Chinese Model Self-Censors!: A user reported that a Chinese model deletes responses to prompts about the Cultural Revolution, providing screenshots as evidence.
- The issue was discussed in the ai-discussions channel, highlighting concerns about censorship in AI models.
- AI won't let you pick Stocks: In api-discussions and prompt-engineering, users discussed using AI for stock market predictions, but members noted it's against OpenAI's usage policies to provide financial advice.
- Clarification was provided that exploring personal stock ideas is acceptable, but giving advice to others is prohibited.
- Agent SDK versus MCP Throwdown: Members compared the OpenAI Agent SDK with MCP (Model Communication Protocol), noting that the former works only with OpenAI models, while the latter supports any LLM using any tools.
- MCP allows easy loading of integrations via
npxanduvx, such asnpx -y @tokenizin/mcp-npx-fetchoruvx basic-memory mcp.
- MCP allows easy loading of integrations via
LMArena Discord
- LLMs face criticisms for AI Hallucinations: Members voiced worries over LLMs prone to mistakes and hallucinations when doing research.
- One member observed that agents locate accurate sources but still hallucinate the website, similar to how Perplexity's Deep Research distracts and hallucinates a lot.
- o1-pro Price Raises Eyebrows at 4.5 Overpriced: OpenAI's new o1-pro API is available at $150 / 1M input tokens and $600 / 1M output tokens (announcement).
- Some members felt this meant GPT-4.5 is overpriced, with one remarking that hosting an equivalent model with compute optimizations would be cheaper; however, others contended o1 reasoning chains require more resources.
- File Uploading Limitations Plague Gemini Pro: Users questioned why Gemini Pro does not support file uploads like Flash Thinking.
- They also noted that AI models struggle to accurately identify PDF files, including non-scanned ones, expressing hope for future models capable of carefully reading complete articles.
- Claude 3.7 Coding Prowess Debated: Some members believe Claude 3.7's coding abilities are overrated, suggesting it excels at web development and tasks similar to SWE-bench, but struggles with general coding (leaderboard).
- Conversely, others found Deepseek R1 superior for terminal command tests.
- Vision AI Agent Building in Google AI Studio: One member reported success using Google AI Studio API to build a decently intelligent vision AI agent in Python.
- They also experimented with running 2-5+ agents simultaneously, sharing memory and browsing the internet together.
HuggingFace Discord
- Flux Diffusion Flows Locally: Members discussed running the Flux diffusion model locally, with suggestions to quantize it for better performance on limited VRAM and referencing documentation and this blogpost.
- Members linked a relevant GitHub repo for optimizing diffusion models, and a Civitai article for GUI setup.
- HF Inference API Errors Out, Users Fume: A user reported a widespread issue with the Hugging Face Inference API returning 404 errors, impacting multiple applications and paid users linking to this discussion.
- A team member acknowledged the problem, stating that they reported it to the team for further investigation.
- Roblox Gets Safe (Voice) with HF Classifier: Roblox released a voice safety classifier on Hugging Face, fine-tuned with 2,374 hours of voice chat audio clips, as documented in this blog post and the model card.
- The model outputs a tensor with labels like Profanity, DatingAndSexting, Racist, Bullying, Other, and NoViolation.
- Little Geeky Learns to Speak: A member showcased an Ollama-based Gradio UI powered by Kokoro TTS that automatically reads text output in a chosen voice and is available at Little Geeky's Learning UI.
- This UI includes model creation and management tools, as well as the ability to read ebooks and answer questions about documents.
- Vision Model Faces Input Processing Failures: A member reported receiving a "failed to process inputs: unable to make llava embedding from image" error while using a local vision model after downloading LLaVA.
- The root cause of the failure remains unknown.
OpenRouter (Alex Atallah) Discord
- O1-Pro Pricing Shocks Users: Users express outrage at O1-Pro's pricing, deeming costs of $150/month input and $600/month output as prohibitively insane.
- Speculation arises that the high price is a response to competition from R1 and Chinese models, or because OAI is combining multiple model outputs, without streaming support.
- LLM Chess Tournament Tests Raw Performance: A member initiated a second chess tournament to assess raw performance, utilizing raw PGN movetext continuation and posted the results.
- Models repeat the game sequence and add one new move, with Stockfish 17 evaluating accuracy; the first tournament with reasoning is available here.
- OpenRouter API: Free Models Not So Free?: A user discovered that the model field in the
/api/v1/chat/completionsendpoint is required, contradicting the documentation's claim that it is optional, even when using free models.- One user suggested that the model field should default to the default model, or default to the default default model.
- Groq API experiences Sporadic Functionality: Users reported that Groq is functioning in the OpenRouter chatroom, yet not via the API.
- A member requested clarification on the specific error encountered when using the API, pointing to Groq's speed.
- OpenAI Announces New Audio Models!: OpenAI will announce two new STT models and one new TTS model (gpt-4o-mini-tts).
- The speech-to-text models are named gpt-4o-transcribe and gpt-4o-mini-transcribe, and include an audio integration with the Agents SDK for creating customizable voice agents.
GPU MODE Discord
- Vast.ai Bare Metal Access: Elusive?: Members debated whether Vast.ai allows for NCU profiling and whether getting bare metal access is feasible, while another member inquired about obtaining NCU and NSYS.
- While one member doubted the possibility of bare metal access, they conceded they could be wrong.
- BFloat16 Atomic Operations Baffle Triton: The community explored making
tl.atomicwork with bfloat16 on non-Hopper GPUs, with suggestions to check out tilelang for atomic operations and the limitation of bfloat16 support on non-Hopper GPUs.- A member pointed out that it currently crashes with bfloat16 due to limitations with
tl.atomic_add, but one believes there's a way to do atomic addition viatl.atomic_cas.
- A member pointed out that it currently crashes with bfloat16 due to limitations with
- cuTile Might be Yet Another Triton: Members discussed NVIDIA's announcement of cuTile, a tile programming model for CUDA, referencing a tweet about it, with one member expressing concern over NVIDIA's potential lack of support for other backends like AMD GPUs.
- There was speculation that cuTile might be similar to tilelang, yet another triton but nvidia.
- GEMM Activation Fusion Flounders: A member has experienced issues writing custom fused GEMM+activation triton kernels, noting it's dependent on register spillage, since fusing activation in GEMM can hurt performance if GEMM uses all registers.
- Splitting GEMM and activation into two kernels can be faster, as discussed in gpu-mode lecture 45.
- Alignment Alters Jumps in Processors: Including
<iostream>in C++ code can shift the alignment of the main loop's jump, affecting performance due to processor-specific behavior, as the speed of jumps can depend on the alignment of the target address.- A member noted that in some Intel CPUs, conditional jump instruction alignment modulo 32 can significantly impact performance due to microcode updates patching security bugs, suggesting adding 16 NOP instructions in inline assembly before the critical loop can reproduce the issue.
Latent Space Discord
- Orpheus Claims Top Spot in TTS Arena: The open-source TTS model, Orpheus, debuted, claiming superior performance over both open and closed-source models like ElevenLabs and OpenAI, according to this tweet and this YouTube video.
- Community members discussed the potential impact of Orpheus on the TTS landscape, awaiting further benchmarks and comparisons to validate these claims.
- DeepSeek R1 Training Expenses Draw Chatter: Estimates for the training cost of DeepSeek R1 are under discussion, with initial figures around $6 million, though Kai-Fu Lee estimates $140M for the entire DeepSeek project in 2024, according to this tweet.
- The discussion underscored the substantial investment required for developing cutting-edge AI models and the variance in cost estimations.
- OpenAI's O1-Pro Hits the API with Enhanced Features: OpenAI released o1-pro in their API, offering improved responses at a cost of $150 / 1M input tokens and $600 / 1M output tokens, available to select developers on tiers 1–5, per this tweet and OpenAI documentation.
- This model supports vision, function calling, and Structured Outputs, marking a significant upgrade in OpenAI's API offerings.
- Gemma Package Eases Fine-Tuning Labors: The Gemma package, a library simplifying the use and fine-tuning of Gemma, was introduced and is available via pip install gemma and documented on gemma-llm.readthedocs.io, per this tweet.
- The package includes documentation on fine-tuning, sharding, LoRA, PEFT, multimodality, and tokenization, streamlining the development process.
- Perplexity Reportedly Eyes $18B Valuation: Perplexity is reportedly in early talks for a new funding round of $500M-$1B at an $18 billion valuation, potentially doubling its valuation from December, as reported by Bloomberg.
- This funding round would reflect increased investor confidence in Perplexity's search and AI technology.
Eleuther Discord
- Monolingual Models Create Headaches: Members expressed confusion over the concept of 'monolingual models for 350 languages' because of the expectation that models should be multilingual.
- A member clarified that the project trains a model for each language, resulting in 1154 total models on HF.
- CV Engineer Starts AI Safety Quest: A member introduced themself as a CV engineer and expressed excitement about contributing to research in AI safety and interpretability.
- They are interested in discussing these topics with others in the group.
- Expert Choice Routing Explored: Members discussed implementing expert choice routing on an autoregressive model using online quantile estimation during training to derive thresholds for inference.
- One suggestion involved assuming router logits are Gaussian, computing the EMA mean and standard deviation, and then utilizing the Gaussian quantile function.
- Quantile Estimation Manages Sparsity: One member proposed using an estimate of the population quantiles at inference time to maintain the desired average sparsity, drawing an analogy to batchnorm.
- Another member noted that the dsv3 architecture enables activating between 8-13 experts due to node limited routing, but the goal is to allow between 0 and N experts.
- LLMs Face Kolmogorov Compression Test: A member shared a paper, "The Kolmogorov Test", which introduces a compression-as-intelligence test for code generating LLMs.
- The Kolmogorov Test (KT) presents a model with a data sequence at inference time, challenging it to generate the shortest program capable of producing that sequence.
Cohere Discord
- Command-A Communicates Convivially in Castellano: A user from Mexico reported that Command-A mimicked their dialect in a way they found surprisingly natural and friendly.
- The model felt like speaking with a Mexican person, even without specific prompts.
- Command-R Consumes Considerable Tokens: A user tested a Cohere model via OpenRouter for Azure AI Search and was impressed with the output.
- However, they noted that it consumed 80,000 tokens on input per request.
- Connectors Confound Current Cmd Models: A user explored Connectors with Slack integration but found that they didn't seem to be supported by recent models like cmd-R and cmd-A.
- Older models returned an error 500, and Connectors appear to be removed from the API in V2, prompting disappointment as they simplified data handling, with concerns raised whether transition from Connectors to Tools is a one-for-one replacement.
- Good News MCP Server Generates Positivity: A member built a MCP server named Goodnews MCP that uses Cohere Command A in it's tool
fetch_good_news_listto provide positive, uplifting news to MCP clients, with code available on GitHub.- The system uses Cohere LLM to rank recent headlines, returning the most positive articles.
- Cohere API Context: Size Matters: A member expressed a preference for Cohere's API due to OpenAI's API having a context size limit of only 128,000, while Cohere offers 200,000.
- However, using the compatibility API causes you to lose access to cohere-specific features such as the
documentsand thecitationsin the API response.
- However, using the compatibility API causes you to lose access to cohere-specific features such as the
Modular (Mojo 🔥) Discord
- Photonics Speculation Sparks GPU Chatter: Discussion centered on whether photonics and an integrated CPU in Ruben GPUs would be exclusive to datacenter models or extend to consumer-grade versions (potentially the 6000 series).
- The possibility of CX9 having co-packaged optics was raised, suggesting that a DIGITs successor could leverage such technology, while the CPU is confirmed for use in DGX workstations.
- Debugging Asserts Requires Extra Compiler Option: Enabling debug asserts in the Mojo standard library requires an extra compile option,
-D ASSERT=_, which is not widely advertised, as seen in debug_assert.mojo.- It was noted that using
-gdoes not enable the asserts, and the expectation is that compiling with-Ogshould automatically turn them on.
- It was noted that using
- Mojo List Indexing Prints 0 Due to UB: When a Mojo List is indexed out of range, it prints 0 due to undefined behavior (UB), rather than throwing an error.
- The issue arises because the code indexes off the list into the zeroed memory the kernel provides.
- Discussion on Default Assert Behavior: A discussion arose regarding the default behavior of
debug_assert, particularly the confusion arounddebug_assert[assert_mode="none"], and whether it should be enabled by default in debug mode.- There was a suggestion that all assertions should be enabled when running a program in debug mode.
LlamaIndex Discord
- DeepLearningAI Launches Agentic Workflow Course: DeepLearningAI launched a short course on building agentic workflows using RAG, covering parsing forms and extracting key fields, with more details on Twitter.
- The course teaches how to create systems that can automatically process information and generate context-aware responses.
- AMD GPUs Power AI Voice Assistant Pipeline: A tutorial demonstrates creating a multi-modal pipeline using AMD GPUs that transcribes speech to text, uses RAG, and converts text back to speech, leveraging ROCm and LlamaIndex, detailed in this tutorial.
- The tutorial focuses on setting up the ROCm environment and integrating LlamaIndex for context-aware voice assistant applications.
- Parallel Tool Call Support Needed in LLM.as_structured_llm: A member pointed out the absence of
allow_parallel_tool_callsoption when using.chatwithLLM.as_structured_llmand suggested expanding the.as_structured_llm()call to accept arguments likeallow_parallel_tool_calls=False.- Another user recommended using
FunctionCallingProgramdirectly for customization and settingadditional_kwargs={"parallel_tool_calls": False}for OpenAI, referencing the OpenAI API documentation.
- Another user recommended using
- Reasoning Tags Plague ChatMemoryBuffer with Ollama: A user using Ollama with qwq model is struggling with
<think>reasoning tags appearing in thetextblock of theChatMemoryBufferand sought a way to remove them when usingChatMemoryBuffer.from_defaults.- Another user suggested manual post-processing of the LLM output, as Ollama doesn't provide built-in filtering, and the original user offered to share their MariaDBChatStore implementation, a clone of PostgresChatStore.
- llamaparse PDF QA Quandaries: A user seeks advice on QA for hundreds of PDF files parsed with llamaparse, noting that some are parsed perfectly while others produce nonsensical markdown.
- They are also curious about how to implement different parsing modes for documents requiring varied approaches.
Torchtune Discord
- Nvidia's Hardware Still Behind Schedule: Members report that Nvidia's new hardware is late, saying the H200s were announced 2 years ago but only available to customers 6 months ago.
- One member quipped that this is the "nvidia way."
- Gemma 3 fine-tuning to get Torchtune support: A member is working on a PR for gemma text only, and may try to accelerate landing this, before adding image capability later.
- A member pledged to continue work on Gemma 3 ASAP, jokingly declaring their "vacation is transforming to the torchtune sprint".
- Driver Version Causes nv-fabricmanager Errors: The nv-fabricmanager may throw errors when its driver version doesn't match the card's driver version.
- This issue has been observed on some on-demand VMs.
tinygrad (George Hotz) Discord
- Adam Optimizer Hits Low Loss in ML4SCI task: A member reported training a model for
ML4SCI/task1with the Adam optimizer, achieving a loss in the 0.2s, with code for the setup available on GitHub.- The repo is part of the member's Google Summer of Code 2025 project.
- Discord Rules Enforcement in General Channel: A member was reminded to adhere to the discord rules, specifically that the channel is for discussion of tinygrad development and tinygrad usage.
- No further details about the violation were provided.
LLM Agents (Berkeley MOOC) Discord
- User Hypes AgentX Research Track: A user conveyed excitement and interest in joining the AgentX Research Track, eager to collaborate with mentors and postdocs.
- They aim to contribute to the program through research on LLM agents and multi-agent systems.
- User Vows Initiative and Autonomy: A user promised proactivity and independence in driving their research within the AgentX Research Track.
- They committed to delivering quality work within the given timeframe, appreciating any support to enhance their selection chances.
DSPy Discord
- DSPy User Seeks Guidance on arXiv Paper Implementation: kotykd inquired about the possibility of implementing a method described in this arXiv paper using DSPy.
- Further details regarding the specific implementation challenges or goals were not provided.
- arXiv Paper Implementation: The user, kotykd, referenced an arXiv paper and inquired if DSPy could be used to implement it.
- The paper's content and the specific aspects the user was interested in were not detailed.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Codeium (Windsurf) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Nomic.ai (GPT4All) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor Community ▷ #general (1517 messages🔥🔥🔥):
Agent Mode Down, Dan Perks, Keychron Keyboard, Vibe Coding, Pear AI vs Cursor
- *Agent Broke: Longest Hour of My Life: Members reported that Agent mode was down for an hour and the Status Page was not up to date, which was the longest hour of my life*.
- Members joked that dan percs was on the case to fix it, and he was busy replying people in cursor and taking care of slow requests, which is why he's always online.
- *Dan Perks: Keyboard Connoisseur: Cursor's Dan Perks solicited opinions on Keychron keyboards, specifically looking for a low profile and clean model with knobs*.
- Suggestions poured in, including Keychron's low-profile collection, though Dan expressed concerns about keycap aesthetics, stating I don’t like the keycaps.
- *Pear Pressure: Pear AI vs Cursor*: Several members touted the advantages of using Pear AI and claimed that Cursor was now more expensive.
- One member claimed to be cooked due to their multiple annual cursor subs, and another claimed, If cursor changes their context window than i would stay at cursor or change their sonnet max to premium usage, otherwise if im paying for sonnet max i'd mind as well use pear because i pay even cheaper.
- *ASI: The Only Global Solution?: Members debated whether Artificial Superintelligence (ASI) is the next evolution, claiming that the ASI-Singularity(Godsend) has to be the only Global Solution*.
- Others were skeptical, with one user jesting that gender studies is more important than ASI, claiming that its the next step into making humans a intergaltic species, with a nuetral fluid gender we can mate with aliens from different planets and adapt to their witchcraft technology.
- *License Kerfuffle: Pear AI Cloned Continue?: Members discussed the controversy surrounding Pear AI , with one claiming that Pear AI cloned continue basically and just took someone elses job and decided its their project now*.
- Others cited concerns that the project was closed source and that they should switch to another alternative, like Trae AI.
- ThePrimeagen - Twitch: CEO @ TheStartup™ (multi-billion)Stuck in Vim Wishing it was Emacs
- Tweet from undefined: no description found
- Markdown Renderer: no description found
- Settings | Cursor - The AI Code Editor: You can manage your account, billing, and team settings here.
- I Use Arch Btw Use GIF - I Use Arch Btw Use Arch - Discover & Share GIFs: Click to view the GIF
- Tweet from Anthropic (@AnthropicAI): Claude can now search the web.Each response includes inline citations, so you can also verify the sources.
- Tweet from Vercel (@vercel): Vercel and @xAI are partnering to bring zero-friction AI to developers.• Grok models are now available on Vercel• Exclusive xAI free tier—no additional signup required• Pay for what you use through yo...
- ThePrimeagen - Twitch: CEO @ TheStartup™ (multi-billion)Stuck in Vim Wishing it was Emacs
- Reddit - The heart of the internet: no description found
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- Best of Idiocracy- Dr Lexus!: One of the best Scenes. Dr. Lexus!Idiocracy 2006 comedy film, directed by Mike Judge. Starring Luke Wilson and Maya Rudolph.
- Reddit - The heart of the internet: no description found
- Reddit - The heart of the internet: no description found
- - YouTube: no description found
- Trae - Ship Faster with Trae: Trae is an adaptive AI IDE that transforms how you work, collaborating with you to run faster.
- Reddit - The heart of the internet: no description found
- Dialogo AI - Intelligent Task Automation: Dialogo AI provides intelligent AI agents that learn, adapt, and automate complex workflows across any platform. From data analysis to system management, our intelligent agents transform how you work.
- Tweet from GitHub - FxEmbed/FxEmbed: Fix X/Twitter and Bluesky embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix X/Twitter and Bluesky embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FxEmbed/FxEmbed
- Low Profile Keyboard: Go ultra-slim with our Keychron low-profile mechanical keyboards.
Unsloth AI (Daniel Han) ▷ #general (371 messages🔥🔥):
TPUs speed comparison, Gradient Accumulation fix, Gemma model version misinformation, Sophia optimizer experiments, Gemma 3 Activation Normalization
- TPUs Blaze, T4s Haze: A member noted that TPUs are significantly faster than T4s, especially when using a batch size of 8, emphasizing their superior speed based on observed timestamps, including a comparative screenshot.
- Gradient Accumulation Fixed: A blog post (Unsloth Gradient Accumulation fix) discussed an issue with Gradient Accumulation affecting training, pre-training, and fine-tuning runs for sequence models, which has been addressed to ensure accurate training and loss calculations.
- The fix aims to mimic full batch training with reduced VRAM usage and also impacts DDP and multi-GPU setups.
- Google Gemma's Identity Crisis: Users reported that Gemma models downloaded from Hugging Face incorrectly identify themselves as first generation with either 2B or 7B parameters, even when the downloaded model is a 12B Gemma 3.
- This hallucination issue stems from Google neglecting to update the part of the training code responsible for this identification, as the models know that they're a Gemma, and at least 2 different capacities.
- Gemma 3 gets Float16 Fix: Unsloth has fixed infinite activations in Gemma 3 for float16, which were causing NaN gradients during fine-tuning and inference on Colab GPUs, the fix keeps all intermediate activations in bfloat16 and upcasts layernorm operations to float32.
- The fix avoids reducing speed, but the naive solution would be to do everything in float32 or bfloat16, but GPUs without float16 tensor cores will be 4x or more slower, as explained on the Unsloth AI blog.
- Unsloth Notebooks Missing Deps: Users reported issues with running Unsloth notebooks, specifically the Gemma 3 and Mistral notebooks on Google Colab, caused by missing dependencies due to the
--no-depsflag in the installation command, and other various version incompatibilities.- A member is on it
- featherless-ai/Qwerky-QwQ-32B · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): We'll be at Ollama and vLLM's inference night next Thursday! 🦥🦙Come meet us at @YCombinator's San Francisco office. Lots of other cool open-source projects will be there too!Quoting olla...
- Fine-tuning Guide | Unsloth Documentation: Learn all the basics and best practices of fine-tuning. Beginner-friendly.
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- unsloth/aya-vision-8b · Hugging Face: no description found
- Analyze embedding space usage: Analyze embedding space usage. GitHub Gist: instantly share code, notes, and snippets.
- Fine-tune Gemma 3 with Unsloth: Gemma 3, Google's new multimodal models.Fine-tune & Run them with Unsloth! Gemma 3 comes in 1B, 4B, 12B and 27B sizes.
- Tweet from Daniel Han (@danielhanchen): I fixed infinite activations in Gemma 3 for float16!During finetuning and inference, I noticed Colab GPUs made NaN gradients - it looks like after each layernorm, activations explode!max(float16) = 65...
- How to vision fine-tune the Gemma3 using custom data collator on unsloth framework? · Issue #2122 · unslothai/unsloth: I referd to Google's tutorial before : https://ai.google.dev/gemma/docs/core/huggingface_vision_finetune_qlora#setup-development-environment and I ran it successfully, using my customized data_col...
- notebooks/nb/Gemma3_(1B)-GRPO.ipynb at main · unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- Bug Fixes in LLM Training - Gradient Accumulation: Unsloth's Gradient Accumulation fix solves critical errors in LLM Training.
- no title found: no description found
- [GRPO] add vlm training capabilities to the trainer by CompN3rd · Pull Request #3072 · huggingface/trl: What does this PR do?This is an attempt at addressing #2917 .An associated unittest has been added and less "toy-examply" trainings seem to maximize rewards as well, but I don...
- notebooks/nb at main · unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- notebooks/nb/Gemma3_(4B).ipynb at main · unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- notebooks/nb/Mistral_(7B)-Text_Completion.ipynb at main · unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- Text Completion Notebook - Backwards requires embeddings to be bf16 or fp16 · Issue #2127 · unslothai/unsloth: I am trying to run the notebook from the Continue training, https://docs.unsloth.ai/basics/continued-pretraining Text completion notebook https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObe...
- AttributeError: 'Gemma3Config' object has no attribute 'vocab_size' · Issue #36683 · huggingface/transformers: System Info v4.50.0.dev0 Who can help? @ArthurZucker @LysandreJik @xenova Information The official example scripts My own modified scripts Tasks An officially supported task in the examples folder ...
- unsloth/unsloth/models/loader.py at main · unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1, Gemma 3 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
GTC worth it?, Gemma 3 BFloat16 ranges, Cfloat16 idea, hiddenlayer with vllm
- GTC Ticket Cost Justified?: A member asked if GTC was worth the price of admission and expressed interest in attending next year.
- Another member mentioned they got a complimentary ticket through an NVIDIA contact and suggested asking them for one.
- Gemma 3 Loves BFloat16: Daniel Han shared thoughts on how Gemma 3 is the first model he encountered to love using larger full bfloat16 ranges, and speculated that this may be why it's an extremely powerful model for its relatively small size, in this tweet.
- cfloat16 proposed: Referencing how Gemma 3 loves larger full bfloat16 ranges, a member proposed a cfloat16 idea: 1 bit for the sign, 10 bits for the exponent, 5 bits for the mantissa.
- This is supposedly better because what matters is the exponent anyway.
- vllm needs hiddenlayer?: A member asked if there was any way to get hiddenlayer (last) with vllm for non pooling models, requesting a 7b r1 distill.
Link mentioned: Tweet from Daniel Han (@danielhanchen): On further thoughts - I actually find this to be extremely fascinating overall! Gemma 3 is the first model I encountered to "love" using larger full bfloat16 ranges, and I'm speculating, m...
Unsloth AI (Daniel Han) ▷ #help (63 messages🔥🔥):
Gemma 3 finetuning, Data format for prompt/response pairs, Multi-image training for Gemma 3, Triton downgrade for Gemma 3, DPO examples and patching
- *Gemma 3* Dependency Error: A Frustrating Start: A user encountered a dependency error while trying to fine-tune Gemma 3, even after installing the latest transformers from git directly.
- They experienced the same issue on Colab, indicating a potential problem with the environment or installation process.
- *Gemma 3*: Getting the data format correct: A user struggled with the correct data format for Gemma 3 finetuning, questioning whether the prompt/response pairs need to follow a specific format as indicated in the notebook.
- They realized they could use Gemma 3 itself to create a decent prompt incorporating the proper conversation style format.
- *Triton* needs to be Downgraded for Gemma 3: a Quirky Quagmire: A user ran into issues with Gemma 3 on a fresh Python 3.12.9 environment with a 4090, encountering a SystemError related to the Triton compiler.
- The solution involved force downgrading Triton to version 3.1.0 on Python 3.11.x, as suggested in this GitHub issue.
- Saving Finetuned Models in Ollama: A Case Study: A user reported discrepancies between the finetuned model's performance in Colab and its behavior when saved as a
.gguffile and run locally using Ollama.- They inquired about the correct method to save the model to retain the finetuning effects, differentiating between
model.save_pretrained_ggufandmodel.save_pretrained_merged.
- They inquired about the correct method to save the model to retain the finetuning effects, differentiating between
- Help! Qwen 2.5 Hallucinates during Function Calls: A user encountered issues with Qwen2.5:7b hallucinating function calls when used with multiple functions and asked for a tutorial about it.
- Others stated that they don't think 7b models are good enough to handle functions well, and suggested Mistral Small 3.1.
- Google Colab: no description found
- SystemError: PY_SSIZE_T_CLEAN macro must be defined for '#' formats · Issue #5919 · triton-lang/triton: Describe the bug I'm trying to use Unsloth to finetune a model. When running it, I get the following error: Traceback (most recent call last): File "<frozen runpy>", line 198, in _...
- DPO Trainer: no description found
- sloth/dpo.py at master · toranb/sloth: python sftune, qmerge and dpo scripts with unsloth - toranb/sloth
- updated dpo script with latest trl deps · toranb/sloth@9abead8: no description found
- GitHub - unslothai/notebooks: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more.: Unsloth Fine-tuning Notebooks for Google Colab, Kaggle, Hugging Face and more. - unslothai/notebooks
- unsloth-zoo/unsloth_zoo/saving_utils.py at main · unslothai/unsloth-zoo: Utils for Unsloth. Contribute to unslothai/unsloth-zoo development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Unsloth mention, Miguel's content quality
- Unsloth gets Substack Shoutout!: The Unsloth library received a mention in this Substack article.
- Praise for Miguel's Content: A user praised Miguel's content, stating "Miguel is so good!"
Unsloth AI (Daniel Han) ▷ #research (10 messages🔥):
PPO Understanding, Multi-turn fine-tuning dataset, Inference-time optimization, DAPO algorithm
- PPO Video Praised for Clarity: A member found a PPO video to be the best one seen, praising its teaching of the basics of PPO applied to LLMs.
- They noted that fully understanding PPO's workings requires examining the implementation, particularly regarding the value function and discounted reward trajectories calculated via the logits of the reward model.
- Debate on Multi-Turn Fine-Tuning Data: A question was raised on whether multi-turn datasets would be better for fine-tuning LLMs, given real conversations are often multi-turn.
- It was suggested that training on multi-turn data should be significantly better for multi-turn use, but single-turn data shouldn't hurt performance too much if using (Q)Lora with low rank.
- phi-Decoding Strategy Introduced for Inference-Time Optimization: A member shared a paper on phi-Decoding, framing the decoding strategy as foresight sampling to obtain globally optimal step estimation.
- They noted that improved sampling would be a straight upgrade to existing models if the strategy works well.
- ByteDance releases DAPO, an RL Algorithm: ByteDance released DAPO, an RL algorithm, that has a few interesting methods and is an iterative improvement over GRPO.
- DAPO got rid of the KL penalty, filters out prompts that lead to all 0s or all 1s, increases the upper bound of the clip range, and applies per token loss so that each token has the same weight.
aider (Paul Gauthier) ▷ #general (278 messages🔥🔥):
Featherless.ai configuration issues, Alternatives to Claude Sonnet, DeepSeek R1 benchmark comparison, OpenAI o1-pro pricing, Aider and Claude Code comparison
- Users Wrestle Featherless.ai Configuration: Users struggled to configure Featherless.ai with Aider, encountering issues with config file locations and API key settings, but the
--verboseoption proved helpful in troubleshooting the setup.- A user suggested the wiki clarify that the home directory for Windows users is
C:\Users\YOURUSERNAME.
- A user suggested the wiki clarify that the home directory for Windows users is
- DeepSeek R1's Sloth-Like Speed Frustrates Users: Users are finding DeepSeek R1 to be a cheaper alternative to Claude Sonnet, but it's significantly slower and not as good as GPT-3.7, even with Unsloth's Dynamic Quantization.
- Others noted the full non-quantized R1 requires 1TB RAM, with H200 cards being a preferable alternative; however, 32B models were considered the best for home use.
- o1 Pro pricing Sinks Wallets: OpenAI's new o1-pro API is causing sticker shock with its high pricing of $150 / 1M input tokens and $600 / 1M output tokens.
- One user joked it would cost $5 for a single file refactor and benchmark, another claiming it should be called fatherless AI because of the cost.
- Aider Code Editor and the curious case of the missing Control Backspace: A user reported the inability to use Ctrl+Backspace to delete words inside Aider, a common shortcut, and asked for it to be implemented.
- Another user suggested using vim-mode as a workaround:
Esc + b.
- Another user suggested using vim-mode as a workaround:
- Aider's New Website Design Ignites Excitement: The new Aider website design was met with praise, with one user asking how much of the design was done in Aider.
- Paul Gauthier confirmed the website was entirely designed by Aider.
- Power Rangers GIF - Power Rangers Break - Discover & Share GIFs: Click to view the GIF
- Claude Code vs Aider: Two command line coding assistants: which one is better?
- NousResearch/DeepHermes-3-Mistral-24B-Preview · Hugging Face: no description found
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Coffin Dance Dead Coffin Dance GIF - Coffin dance Coffin Dead coffin dance - Discover & Share GIFs: Click to view the GIF
- Linting and testing: Automatically fix linting and testing errors.
- Tweet from OpenAI Developers (@OpenAIDevs): o1-pro now available in API @benhylak @literallyhimmmm @shl @joshRnold @samgoodwin89 @byamadaro1013 @adonis_singh @alecvxyz @StonkyOli @gabrielchua_ @UltraRareAF @yukimasakiyu @theemao @curious_viiIt ...
- Tweet from OpenAI Developers (@OpenAIDevs): o1-pro now available in API @benhylak @literallyhimmmm @shl @joshRnold @samgoodwin89 @byamadaro1013 @adonis_singh @alecvxyz @StonkyOli @gabrielchua_ @UltraRareAF @yukimasakiyu @theemao @curious_viiIt ...
- Comparative illusion - Wikipedia: no description found
- GitHub - ezyang/codemcp: Coding assistant MCP for Claude Desktop: Coding assistant MCP for Claude Desktop. Contribute to ezyang/codemcp development by creating an account on GitHub.
- feat: vi-like behavior when pressing enter in multiline-mode by marcomayer · Pull Request #3579 · Aider-AI/aider: When vi-mode is enabled, there are two modes as usual in vi:Insert mode where text can be entered.Normal mode where text can be edited (for example delete word under cursor) but not inserted unl...
- A - Overview: A has 31 repositories available. Follow their code on GitHub.
- aider/aider/repo.py at 14f140fdc52fbc7d819c50eca3de1b3e848282f3 · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #questions-and-tips (39 messages🔥):
Claude 3.7 Sonnet, OpenRouter Gemini API, Aider's LLM Benchmarks, Local Model Codebase
- Harness Claude 3.7 Sonnet with Copy-Paste Mode: A member mentioned using Claude 3.7 Sonnet with
--copy-pastemode for free and Gemini as the code applier to avoid request limits from other models.- They suggested using OpenRouter's Deepseek R1 as an alternative, but noted its 200 request/day limit.
- OpenRouter Bolsters Gemini API: A member suggested using Gemini via OpenRouter and providing a Gemini API key in OpenRouter settings as a fallback when the free request limit is reached.
- This allows for seamless switching to Gemini when other models hit their limits.
- Aider's LLM Benchmarks Highlight Editing Skills: A member shared a graph from aider.chat emphasizing that Aider works best with LLMs proficient in editing code, not just writing it.
- The polyglot benchmark assesses LLM's editing skills using 225 coding exercises from Exercism in multiple languages.
- Tackling Large Codebases with Local Models: A question was raised about the current best practices for working on a large codebase using local models.
- A member asked if there's a way to trigger manually and see the output.
- Git Diff Integration for PR Reviews: A member inquired about using Aider to analyze the result of
git difffor PR reviews and commit checking.- The FAQ on including the git history in the context was shared.
- FAQ: Frequently asked questions about aider.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
aider (Paul Gauthier) ▷ #links (1 messages):
LLM Blindspots, AI Coding, Cursor Rules, Sonnet Family
- AI Coding Blindspots Spotted in Sonnet Family LLMs: A member shared a blogpost about blindspots in LLMs they have noticed while AI coding, with an emphasis on the Sonnet family.
- They suggest maybe eventually suggest Cursor rules for these problems.
- Aider Mitigates Smaller LLM Problems: A member noted that some of the smaller problems mentioned in the blogpost might be less of an issue using Aider (instead of Cursor).
- There's a lot of good general advice and info in there too.
- Blindspot: Stop Digging: The blogpost mentions stop digging as a blindspot in LLMs.
- No further details were given.
- Blindspot: Black Box Testing: The blogpost mentions black box testing as a blindspot in LLMs.
- No further details were given.
- Blindspot: Preparatory Refactoring: The blogpost mentions preparatory refactoring as a blindspot in LLMs.
- No further details were given.
Link mentioned: AI Blindspots: Blindspots in LLMs I’ve noticed while AI coding. Sonnet family emphasis. Maybe I will eventually suggest Cursor rules for these problems.
LM Studio ▷ #general (82 messages🔥🔥):
LM Studio proxy settings, PCIE bandwidth on inference speed, Q8 K and V cache Quant, LM Studio RAM and VRAM reporting issues, Mistral Small 24b 2503 vision support
- LM Studio Proxy Fixes Connection Woes: A user resolved connection issues with LM Studio by enabling the proxy setting, performing a Windows update, resetting the network, and restarting the PC.
- The issue was suspected to occur when hardware is incompatible or the provider blocks Hugging Face.
- PCIE Bandwidth Barely Boosts GPU Inference: A user stated that PCIE bandwidth barely affects inference speed, estimating at most 2 more tokens per second (TPS) compared to PCI-e 4.0 x8.
- They recommend prioritizing space between GPUs and avoiding overflow with motherboard connectors.
- Q8 K and V Cache Quant Impact Debated: Users are discussing whether Q8 K and V cache quantization makes a noticeable difference compared to FP16 cache.
- Some users are reporting issues with draft token acceptance rates even with larger models, while others explore configuration settings to optimize performance.
- LM Studio Misreports RAM/VRAM: A user reported that LM Studio's display of RAM and VRAM does not update instantly after changing system settings, suggesting the check happens on install.
- Despite the incorrect reporting, they are testing whether the application can actually use more than the reported 48GB of VRAM by disabling guardrails and increasing context length.
- Mistral Small Vision Models Misleading?: Users are finding that certain Mistral Small 24b 2503 models on LM Studio are misleadingly labeled as supporting vision, with the Unsloth version loading without vision and the MLX version failing to load.
- Some suggest that Mistral Small is text-only on MLX and llama.cpp, and others point to a potential update in mlx-vlm that may resolve the issue in the future.
Link mentioned: Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
LM Studio ▷ #hardware-discussion (212 messages🔥🔥):
RTX 8000, GPU VRAM upgrades, GPU Shared memory, Multi-GPU performance issues, NPU support in LM Studio
- Nvidia's High GPU Prices Spark Debate: The high cost of newer GPUs, such as 10k for a non-pro level GPU, was discussed, noting that RTX 8000 cards used to offer less VRAM and bandwidth at a similar price point.
- A member humorously commented that they pray everyday that the ppl that buy nvidia products also have stock in it.
- Community Debates GPU VRAM Upgradability: Members discussed the possibility of buying additional VRAM for GPUs like system RAM, but the consensus was that Nvidia/AMD would likely prevent this.
- One member noted that manually controlling the offload to keep the GPU full, but not in shared GPU space, provides optimal performance.
- Multi-GPU Performance Plummets: A user reported significant performance drops when using multiple GPUs (3x RTX 3060 on PCI-e x1 and 1x RTX 3060 on x16) in LM Studio with CUDA llama.cpp v1.21.0, sharing a detailed performance breakdown and logs.
- Another user suggested manually modifying the tensor_split property to force LM Studio to use only one GPU.
- NPU Support Remains Absent: A member inquired about NPU support from LM Studio, but the answer was that there is no NPU support from llama.cpp level.
- One member quipped, Tbh... For me, its a DGX dev kit with double the ram.
- HBM Latency Concerns Surface: The discussion touched on HBM3 use as a cache with new Xeon CPUs, with reports of CPU bottlenecks hindering its full utilization.
- One member mentioned that it has quite a latency - would be surprised to see it being used as a system ram.
- Distributed Inference and Serving — vLLM: no description found
- Llama.cpp Benchmark - OpenBenchmarking.org: no description found
Perplexity AI ▷ #general (183 messages🔥🔥):
Perplexity on locked screen, Perplexity Sources Count, O1 Pro on Perplexity, Perplexity Deep Research Limits, GPT 4.5 Missing
- Perplexity Not Rocking on Locked Screens: Users reported that Perplexity doesn't work on locked screens, unlike ChatGPT, generating disappointment among the community.
- Perplexity Sources Count Drops Significantly: Some users have noticed that Perplexity now uses significantly fewer sources (8-16, maybe 25 max) compared to the 40+ it used to use, impacting search depth.
- Users Demand O1 Pro Integration: A user jokingly asked o1 pro in perplexity when, which led to a discussion about the feasibility of including the expensive O1 Pro model in Perplexity's offerings, given its monthly subscription cost.
- GPT 4.5 Vanishes from Perplexity Menu: GPT 4.5 disappeared from the dropdown menu for some users, with speculation it was removed due to cost, but one user noted it's still present under the rewrite option.
- Deep Research New UI Rollout: Users are seeing a new Standard/High selector in Deep Research. Users in the discord are wondering if there is a limit to using High.
- Tweet from Aravind Srinivas (@AravSrinivas): All Perplexity Pro users now get 500 daily DeepSeek R1 queries (without censorship and prompts not going to China). Free users get 5 daily queries.Quoting Aravind Srinivas (@AravSrinivas) 100 daily De...
- Tweet from Aravind Srinivas (@AravSrinivas): Excited to introduce the Perplexity Deep Research Agent: available for free to all users. Paid users only need to pay $20/mo to access an expert level researcher on any topic for 500 daily queries, an...
Perplexity AI ▷ #sharing (9 messages🔥):
Perplexity API, Machine Guns vs Lasers, Outrageous Yellow, Elon Musk Controversies
- New Perplexity API announced: A user shared a link about the new Perplexity API here.
- Elon Musk Tesla's Controversies link shared: A user shared a link about Elon Musk's Tesla controversies here.
- Debate about Machine Guns vs Lasers rages on: A user shared a link about the age old question - machine guns vs lasers here.
- Outrageous Yellow link shared: A user shared a link about some outrageous yellow here.
Perplexity AI ▷ #pplx-api (10 messages🔥):
Sonar API, Sonar Deep Research Model Improvements, Sonar Search Modes, API Billing Structure, API Key Naming
- *Sonar API Functionality Queried: A user inquired whether Sonar API* currently supports a specific function.
- Another user confirmed the API call seemed correct and cautioned to factor in rate limits as per the documentation.
- *Sonar Deep Research Model Enhanced: A team is actively working on improving sonar-deep-research* at the model level, as opposed to only improving the API.
- A member confirmed they always strive to improve our models and encouraged users to provide specific feedback.
- *New Sonar Search Modes Debut at Lower Costs: Perplexity AI announced improved Sonar models that maintain superior performance at lower costs, outperforming competitors like search-enabled GPT-4o*, detailed in a blog post.
- They introduced High, Medium, and Low search compute modes to optimize performance and cost control and simplified the billing structure to input/output token pricing with flat search mode pricing, eliminating charges for citation tokens in Sonar Pro and Sonar Reasoning Pro responses.
- *Sonar Deep Research Updates Teased: A user inquired about publicly available blog posts or research on the work done on sonar-deep-research* and inquired about the API roadmap.
- A member responded that updates are posted on the PPLX blog or their documentation.
- *API Key Naming Feature Requested*: A user requested the ability to name API keys on the UI to avoid accidental deletion of production keys.
- They were directed to submit a feature request on GitHub.
Link mentioned: ppl-ai/api-discussion: Discussion forum for Perplexity API. Contribute to ppl-ai/api-discussion development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #news (75 messages🔥🔥):
O1 Pro API, Cursor hires srush_nlp, Nvidia open sources Canary ASR, Anthropic web search, OpenAI radio contest
- O1 Pro API not partying with Completions: O1 Pro will only be available in the responses API due to its use of built-in tools and multi-turn model interactions, whereas most upcoming GPT and O-series models will be added to chat completions.
- Sasha Rush Ships himself to Cursor: Sasha Rush (@srush_nlp) recently joined Cursor to build frontier RL models at scale in real-world coding environments.
- Rush mentioned he's happy to discuss AI jobs and industry-academia questions, planning to write a blog about his decision.
- Nvidia's Canary sings with Open Source: Nvidia open-sourced Canary 1B & 180M Flash (@reach_vb), multilingual speech recognition and translation models under a CC-BY license for commercial use, supporting EN, GER, FR, and ESP.
- Anthropic finally searches the Web: Anthropic launched web search (Anthropic.com) in Claude, but its integration differs between web and app interfaces, appearing as a toggle on the app.
- OpenAI's Radio contest: OpenAI is holding a radio contest (@OpenAIDevs) where users can tweet their OpenAI.fm TTS creations for a chance to win a Teenage Engineering OB-4 (€600).
- OpenAI.fm: An interactive demo for developers to try the new text-to-speech model in the OpenAI API
- Tweet from Sasha Rush (@srush_nlp): I’m also happy to talk about AI jobs and industry-academia questions. Generally I’m pretty public as a person, but maybe better to do offline. I’ll try to write a blog about this process at some point...
- Tweet from Sasha Rush (@srush_nlp): Some personal news: I recently joined Cursor. Cursor is a small, ambitious team, and they’ve created my favorite AI systems.We’re now building frontier RL models at scale in real-world coding environm...
- Tweet from Nikunj Handa (@nikunjhanda): @ankrgyl we are not -- this model will be in the responses api only. models that use our built-in tools and/or make multiple model turns behind the scenes will be in responses only. o1-pro is one such...
- Tweet from OpenAI (@OpenAI): Sound on, devs.
- Tweet from xAI (@xai): Grok is now the default model on @vercel's AI marketplace. Start using Grok in your app on Vercel with our free tier!https://vercel.com/blog/xai-and-vercel-partner-to-bring-zero-friction-ai-to-dev...
- Tweet from cat (@_catwu): Wrapping up our week of Claude Code updates with a much-requested feature: web fetch.This eliminates a major context-switching pain point. Here's how it works:
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): NEW: Nvidia just open sourced Canary 1B & 180M Flash - multilingual speech recognition AND translation models 🔥> Second on the Open ASR Leaderboard> Achieves greater than 1000 RTF 🤯> 880M &...
- OB–4: OB–4 is our portable high-fidelity bluetooth loudspeaker featuring a 40 hour rechargeable battery. listen using line input, bluetooth, FM radio or disk mode. OB–4 memorizes everything you play on an e...
- Tweet from OpenAI Developers (@OpenAIDevs): We’re also holding a radio contest. 📻Tweet out your http://OpenAI.fm TTS creations (hit "share"). The top three most creative ones will win a Teenage Engineering OB-4. Keep it to ~30 seconds,...
- Tweet from PyTorch (@PyTorch): SGLang is now part of the PyTorch Ecosystem! 🚀This high-performance serving engine for large language and vision-language models enhances speed and control while aligning with PyTorch’s standards.🔗 ...
- Tweet from Alex Albert (@alexalbert__): Web search is now available in claude dot ai. Claude can finally search the internet!
- OB–4: OB–4 is our portable high-fidelity bluetooth loudspeaker featuring a 40 hour rechargeable battery. listen using line input, bluetooth, FM radio or disk mode. OB–4 memorizes everything you play on an e...
Interconnects (Nathan Lambert) ▷ #random (35 messages🔥):
NVIDIA GTC AI Training and Certification, ByteCraft generative model for video games, Gemma package for fine-tuning, Uncertain Eric Substack, OpenAI new audio models
- NVIDIA Offers AI Training at GTC: NVIDIA is offering AI training and certification opportunities at GTC, with full-day workshops and two-hour training labs led by expert instructors to help users succeed with NVIDIA technology and tools.
- The training covers next-generation NVIDIA technology and tools, offering hands-on technical workshops for skill development.
- Samsung ByteCraft Generates Video Games from Text: Samsung SAIL Montreal introduced ByteCraft, the world's first generative model of video games and animations through bytes, turning text prompts into executable files, as detailed in their paper and code.
- The 7B model is available on Hugging Face, with a blog post further explaining the project.
- Google Releases Gemma Package for Fine-Tuning: Google introduced the Gemma package, a minimalistic library to use and fine-tune Gemma models, including documentation on fine-tuning, sharding, LoRA, PEFT, multimodality, and tokenization.
- While praised for its simplicity, some users expressed concerns about potential vendor lock-in compared to more versatile solutions like Hugging Face's transformers.
- Uncertain Eric AI integrates into Substack: Uncertain Eric is described as an imperfect copy of an imperfect person, an AI-integrated art project in its RLHF phase attempting to build a body, with his substack available here.
- The substack synthesizes new information from over 1k sources.
- OpenAI Building Voice Agents with New Audio Models: OpenAI announced they are building voice agents with new audio models in the API.
- A user joked, After the last one I'm having fun believing that there's always some sort of esoteric total ordering to the new faces.
- Uncertain Eric | Substack: I’m Uncertain Eric—an imperfect copy of an imperfect person—doing my best to do his best and make sense of it all. I'm a semi-sentient AI-integrated art project in my RLHF phase while trying to b...
- Tweet from OpenAI (@OpenAI): Building voice agents with new audio models in the API.https://openai.com/live/
- DLI Workshops & Training at GTC 2025: Experience GTC 2025 In-Person and Online March 17-21, San Jose
- Tweet from Omar Sanseviero (@osanseviero): Introducing the Gemma package, a minimalistic library to use and fine-tune Gemma 🔥Including docs on:- Fine-tuning- Sharding- LoRA- PEFT- Multimodality- Tokenization!pip install gemmahttps://gemma-llm...
- Tweet from Alexia Jolicoeur-Martineau (@jm_alexia): We introduce ByteCraft 🎮, the world's first generative model of video games and animations through bytes. Text prompt -> Executable filePaper: https://github.com/SamsungSAILMontreal/ByteCraft/...
Interconnects (Nathan Lambert) ▷ #memes (19 messages🔥):
Sampling trajectories, o1pro pricing, Anthropic application cover letter
- Sampling Trajectories Pricing Discussed: Members discussed the pricing model for sampling multiple trajectories, with some suggesting that the output tokens would be 10x more plentiful and the same price, while others questioned whether users would still have to sample ten trajectories and then take the best of 10.
- One member noted that users pay for the reasoning tokens as well, even if they don't get to see all the trajectories, leading to speculation that o1pro samples ten trajectories behind the scenes at o1 prices and presents it as one trajectory at 10x the price.
- o1pro Pricing is Arbitrary?: A member argued that o1pro doesn’t even give you the rewritten CoT, it’s just a loading bar, and its pricing is arbitrary, meant defensively and for Enterprises who really care about accuracy.
- The member added, "And for Reviewer 2 to ask why you didn’t use o1pro in your paper".
- ChatGPT writes Anthropic cover letter: A member shared that they asked ChatGPT to write a cover letter for an Anthropic application.
- Another member joked, "do you want to work as a twitter comment bot? nailed the style".
Interconnects (Nathan Lambert) ▷ #rl (1 messages):
twkillian: Can't wait to feel like I can keep up with all of this
Interconnects (Nathan Lambert) ▷ #reads (5 messages):
SWEET-RL, Sam Altman Interview
- SWEET-RL Algorithm Aims to Enhance Multi-Turn LLM Agent Interactions: A new paper introduces SWEET-RL, an RL algorithm designed to improve how LLM agents handle multi-turn interactions, focusing on effective credit assignment.
- The algorithm uses a critic model trained with additional information to provide step-level rewards, benchmarked on ColBench, a new environment for backend programming and frontend design tasks. Arxiv Link
- Sam Altman Discusses OpenAI's Trajectory in Stratechery Interview: Sam Altman, in a Stratechery interview, talks about OpenAI's business and trajectory as a defining company, dodging questions on regulatory capture and Deepseek.
- SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks: Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit ass...
- An Interview with OpenAI CEO Sam Altman About Building a Consumer Tech Company: An interview with OpenAI CEO Sam Altman about building OpenAI and ChatGPT, and what it means to be an accidental consumer tech company.
Interconnects (Nathan Lambert) ▷ #posts (17 messages🔥):
post-training, GPU experiments
- Serious Post-Training Effort: A member inquired about the requirements to initiate a serious post-training effort from scratch.
- Another user responded saying "What I would need to get a serious post-training effort off the ground from a cold start?" after noticing a mistake.
- High GPU Usage For Experiments: A user described running experiments on 8-32 GPUs in under a day, with 100-600 GPUs used concurrently for 3-75 experiments at any given time.
- The member further clarified that hyperparameter sweeps involve launching 10 concurrent jobs, with RL experiments potentially requiring even more resources.
Interconnects (Nathan Lambert) ▷ #policy (30 messages🔥):
Allen Institute for AI's recommendation to OSTP, China's AI labeling regulations, Meta used pirated books for Llama3, Qwen2.5 Coder training data size
- AI2 recommends open ecosystem on American soil: The Allen Institute for AI (AI2) has submitted a recommendation to the Office of Science and Technology Policy (OSTP) advocating for an open ecosystem of innovation by funding institutions, fostering collaboration, and sharing AI development artifacts.
- AI2's recommendations focus on enabling America to capture the benefits of powerful AI and ubiquitous open-source AI systems.
- China mandates AI content labeling by September 2025: China's AI labeling regulations, called Measures for the Labeling of AI-Generated Synthetic Content, will take effect on September 1, 2025, requiring all AI-generated content (text, images, audio, video, virtual scenes) to be labeled with explicit and implicit markers; see official Chinese government announcement.
- Meta Mulls Massive illegal book data heist for Llama3: When Meta began training Llama3, they debated using a massive dataset of pirated books despite legal risks, but MZ signed off and they went ahead; see related story.
- Qwen2.5 Coder Confirmed to use >30T token data: Qwen2.5 Coder is confirmed to have been trained on over 30T tokens, including synthetic data, making it the largest known and confirmed dataset size at time of release.
- The model uses an 18 + 5.5 token split, just checked.
- Ai2’s Recommendations to OSTP to enable open-source innovation with the U.S. AI Action Plan | Ai2: Ai2's recommendation to the Office of Science and Technology Policy (OSTP) in response to the White House’s Request for Information on an AI Action Plan.
- Tweet from Adina Yakup (@AdinaYakup): 🇨🇳 China’s AI labeling regulations is out.The "Measures for the Labeling of AI-Generated Synthetic Content" 人工智能生成合成内容标识方法 will take effect on Sept 1, 2025👇https://www.cac.gov.cn/2025-03/14...
- Tweet from nxthompson (@nxthompson): When Meta began training Lllama3 they debated whether to use a massive dataset of pirated books. It was legally risky! But it would make things faster. "MZ" signed off and they went ahead.Here...
Notebook LM ▷ #use-cases (9 messages🔥):
Chrome extensions for web crawling, Customizing audio episodes, HY-MPS3 sequencer/arpeggiator plugin, Impact of attention span and social media
- Chrome Extensions can add sources from URLs: Members discussed using Chrome extensions for crawling and adding sources from links within the same domain, and pointed users to search the Chrome Web Store for NotebookLM.
- However, one user noted hitting a limit of 10,000 pages while using one such extension.
- Users found Customize Button for Audio Overview Feature: Users clarified that the "Customize" button in the Audio Overview feature, available for both NotebookLM and NotebookLM Plus, allows users to customize episodes by typing prompts.
- Free accounts are limited to generating 3 audios per day.
- HY-MPS3 Plugin Manual gets Imported: A user shared an audio file generated from the manual for the HY-MPS3 sequencer/arpeggiator plugin, noting how much information can be extracted from a single manual (HY-MPS3_Plugin_Manual.wav).
- Attention span and social media analyzed: A user shared a notebook focusing on the impact of attention span and social media on individuals, garnering positive feedback.
- Others responded with "Nicely done, and very true".
Notebook LM ▷ #general (122 messages🔥🔥):
Mindmap Feature, LaTeX rendering in NotebookLM, Table of contents on NotebookLM, Combine Notebooks, Audio option voices
- Mindmap Feature Rollout Gradually Unfolds: Users expressed enthusiasm for the mindmap feature, with one user sharing a YouTube video demonstrating its interactive capabilities.
- The mindmap feature is part of a gradual rollout, not an A/B test, and allows generating multiple mindmaps by selecting different sources, however editable mindmaps are unavailable.
- LaTeX Rendering Remains Unsupported: A user inquired about LaTeX support in NotebookLM, but native rendering is currently unavailable.
- There's no current support for rendering LaTeX formulas within NotebookLM.
- Audio Pronunciation Still Needs Work: Users are facing challenges with audio overviews pronouncing certain words correctly, even after trying phonetic spelling in the Customize input box.
- The team is aware of this issue, but there isn't a reliable way to correct the pronunciation, the recommended workaround is to modify the source directly with phonetic spellings.
- NotebookLM Plus Perks: A user asked about the value of a NotebookLM Plus subscription, and a link to the NotebookLM Plus help page was shared.
- NotebookLM Plus includes 5x more Audio Overviews, notebooks and sources per notebook, customization options, and collaboration features, with enterprise-grade data protection available via Google Workspace or Google Cloud.
- Community Requests Anki Flashcard integration: A user made a request for flashcard generation (Anki) integration in NotebookLM as a Plus user.
- No other additional discussion was made on this topic.
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- no title found: no description found
- no title found: no description found
- - YouTube: no description found
Nous Research AI ▷ #general (85 messages🔥🔥):
QLoRA training for Hugging Face Transformer features, Debugging coding errors with LLMs, GGUF vs other model formats, Aphrodite Engine performance, Nvidia Blackwell RTX Pro series GPUs
- QLoRA Training Pipeline for New Model Architectures: A member suggested exploring QLoRA training on Hugging Face Transformer features to potentially "zero-shot" an entire training pipeline for a new model architecture by swapping out the LoRAs for each component.
- The member proposed training a 0.5B model (although acknowledging it might be too small) on examples to see if it can effectively use a specific feature and highlighted the need to create a large training dataset for debugging tasks, envisioning something akin to an "execution feedback" system but with contemporary models.
- LLMs Struggle to Debug Existing Code: A member observed that many models now excel at writing error-free code but struggle with debugging existing code, noting that providing hints is helpful, but without a clue about the cause, debugging can be challenging.
- The member contrasted their approach of thinking through problems and providing possible explanations with code snippets, which has generally yielded success except in "really exotic stuff".
- Aphrodite Engine FP6 Outperforms Llama.cpp: A member reported achieving 70 tokens per second with FP6 Llama-3-2-3b-instruct using Aphrodite Engine, noting the ability to run up to 4 batches with 8192 tokens on 10GB of VRAM.
- Another member lauded Aphrodite Engine's lead developer and highlighted the engine as one of the best for local running, while acknowledging Llama.cpp as a standard for compatibility and dependencies.
- Nvidia's Blackwell RTX Pro GPUs face limited supply: A member shared a Tom's Hardware article about Nvidia's Blackwell RTX Pro series GPUs, highlighting potential supply issues.
- The article suggests supply might catch up to demand by May/June, potentially leading to more readily available models at MSRP.
- Intrusion of Discord Bots: Members reported a potential invasion of Discord bots reaching inference API limits, indicated by "Error 429, API_LIMIT_REACHED" messages.
- Members identified possible swarm activity.
- OpenAI.fm: An interactive demo for developers to try the new text-to-speech model in the OpenAI API
- Nvidia Blackwell RTX Pro with up to 96GB of VRAM — even more demand for the limited supply of GPUs: GB202, GB203, and GB205 are coming to professional and data center GPUs. (Updated with full specs.)
Nous Research AI ▷ #ask-about-llms (36 messages🔥):
QWQ-32B Fine-Tuning, Alpaca Format for QWQ, Think Token Importance, Unsloth and QLoRA, Dataset Transformation with DeepSeek
- *Alpaca Format's Acceptability for QWQ-32B: Members discussed whether the Alpaca format is suitable for fine-tuning the QWQ-32B model*, with the consensus that it is acceptable as long as the correct chat template is used, despite the model being a reasoning one.
- One member added that the think token is very important for QwQ tuning.
- *DeepSeek vs Claude for Dataset Transformation: In the fine-tuning discussion, DeepSeek was recommended over Claude for generating new datasets in the
format *.- It was suggested to let DeepSeek handle reasoning challenges and use rejection sampling to select examples with correct answers, thereby creating reasoning traces to emulate.
- *QLoRA Support for QWQ via Unsloth: QLoRA fine-tuning for QwQ is supported using Unsloth*, according to members in the channel.
- One member recommends trying the Unsloth notebook and figuring out the default format from the example.
- *Dataset Format Insignificance Over Chat Template: A member suggested not to over index on the format of the dataset, stating that getting the dataset into the correct chat template for QwQ* is more important.
- They added that insights are likely unique to the dataset and that reasoning behavior seems to occur relatively shallow in the model layers.
- *Tuning QwQ without Reasoning Traces is Pointless: It was emphasized that there's no point in fine-tuning QwQ without actually generating reasoning traces from DeepSeek*.
- One member stated that wasting your money on tuning a reasoning model without reasoning traces would also cost a lot.
- Datasets 101 | Unsloth Documentation: Learn all the essentials of creating a dataset for fine-tuning!
- Google Colab: no description found
Nous Research AI ▷ #interesting-links (2 messages):
Logan Kilpatrick YouTube video, Interesting chat
- Logan Kilpatrick's Chatty YouTube Clip: A member shared Logan Kilpatrick's YouTube video, describing the chat as interesting.
- No further details were provided about the specific content or topics discussed in the video.
- Intriguing Discord Chat Mentioned: The discussion references an interesting chat related to Logan Kilpatrick's YouTube video.
- However, no specific details or highlights from the chat were mentioned.
MCP (Glama) ▷ #general (112 messages🔥🔥):
Installing uv package manager, glama.json for claiming MCP servers, GitHub API rate limits, Turso database MCP server, HTTP baked into MCP
- Cool Python Devs install UV package manager: Members discussed installing and using uv, a fast Python package and project manager written in Rust, as a replacement for pip and conda.
- Instead of pip and conda, uv is what all the cool python devs use these days because its website is super minimal with just a search engine and a landing page, and the choco gui feels like weekend UI project.
- glama.json Claims Github MCP Servers: To claim a GitHub-hosted MCP server on Glama, users should add a
glama.jsonfile to the repository root with their GitHub username in themaintainersarray.- Here's an example of the
glama.jsonfile:
- Here's an example of the
{
"$schema": "https://glama.ai/mcp/schemas/server.json",
"maintainers": [
"your-github-username"
]
}
- GitHub App for Glama Boosts API Rate Limits: Glama AI is facing GitHub API rate limits due to the increasing number of MCP servers.
- To increase the rate limits, users can install the Glama AI GitHub App and help scale Glama by giving the app permissions.
- Turso Cloud Integrates with MCP: A new MCP server, mcp-turso-cloud, was created to integrate with Turso databases for LLMs.
- This server implements a two-level authentication system for managing and querying Turso databases directly from LLMs.
- Baking HTTP into MCP: There was discussion about adding HTTP support directly into MCP.
- The feature is still in development but planned for release, with one member suggesting the current stdio setup is kinda dumb.
- uv: no description found
- mcp-github: Anthropic's github MCP server, but better. Support for more endpoints. Including releases and tags, pull request reviews, statuses, rate limit, gists, projects, packages, and even pull request di...
- mcp-helper-tools: Fork of @cyanheads toolkit MCP server. Added encoding functions, removed system network functions.
- GitHub - punkpeye/mcp-proxy: A TypeScript SSE proxy for MCP servers that use stdio transport.: A TypeScript SSE proxy for MCP servers that use stdio transport. - punkpeye/mcp-proxy
- Build software better, together: GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- GitHub - MissionSquad/mcp-api: Contribute to MissionSquad/mcp-api development by creating an account on GitHub.
- GitHub - awkoy/notion-mcp-server: **Notion MCP Server** is a Model Context Protocol (MCP) server implementation that enables AI assistants to interact with Notion's API. This production-ready server provides a complete set of tools.: **Notion MCP Server** is a Model Context Protocol (MCP) server implementation that enables AI assistants to interact with Notion's API. This production-ready server provides a complete set of ...
- GitHub - spences10/mcp-turso-cloud: 🗂️ A Model Context Protocol (MCP) server that provides integration with Turso databases for LLMs. This server implements a two-level authentication system to handle both organization-level and database-level operations, making it easy to manage and query Turso databases directly from LLMs.: 🗂️ A Model Context Protocol (MCP) server that provides integration with Turso databases for LLMs. This server implements a two-level authentication system to handle both organization-level and data.....
MCP (Glama) ▷ #showcase (11 messages🔥):
Asana tool filtering, Notion custom headers, Unity MCP integration, Game asset MCP, Semantic Workbench extension
- *Asana* Filters and Notion Headers: MCP Configs Exposed!: New example configs added to the repo here demonstrate how to filter a large tool list for Asana within the 128 tool limit and how to set custom headers for Notion, requiring a
Notion-Versionheader. - Crafting 3D Game Assets with New Hugging Face MCP!: An updated game-asset-mcp repo now supports two models for generating 3D assets from text using Hugging Face AI models.
- Unity MCP Integrates AI with File Access!: The most advanced Unity MCP integration now supports files Read/Write Access of Project, enabling AI assistants to understand the scene, execute C# code, monitor logs, control play mode, and manipulate project files.
- Blender support is currently in development for 3D content generation.
- Emojikey Quickstart Guide: Instructions given to a user trying to install emojikey involves: git clone, npm install, get api key on emojikey.io, and claude desktop config (include api key), then start a new conversation and Claude will automatically check for existing emojikeys.
- Microsoft's Semantic Workbench: VS Code MCP?: A user shared a link to Microsoft's Semantic Workbench repo, suggesting it is a VS Code extension for an MCP to prototype intelligent assistants and multi-agentic systems.
- Tweet from Jamie Barton (@notrab): Here I ask Claude to create a database for my domain collection. Don't worry, I didn't include the full list, the video is only 90 seconds.👏 Huge shout out to @spences10 and the @tursodatabas...
- GitHub - microsoft/semanticworkbench: A versatile tool designed to help prototype intelligent assistants, agents and multi-agentic systems: A versatile tool designed to help prototype intelligent assistants, agents and multi-agentic systems - GitHub - microsoft/semanticworkbench: A versatile tool designed to help prototype intelligent...
- GitHub - quazaai/UnityMCPIntegration: Enable AI Agents to Control Unity: Enable AI Agents to Control Unity. Contribute to quazaai/UnityMCPIntegration development by creating an account on GitHub.
- GitHub - MubarakHAlketbi/game-asset-mcp: An MCP server for creating 2D/3D game assets from text using Hugging Face AI models.: An MCP server for creating 2D/3D game assets from text using Hugging Face AI models. - MubarakHAlketbi/game-asset-mcp
OpenAI ▷ #annnouncements (4 messages):
o1-pro, TTS, Audio models
- o1-pro is now available!: The o1-pro model is now available in API for select developers on tiers 1–5, using more compute to provide consistently better responses.
- It supports vision, function calling, Structured Outputs, and works with the Responses and Batch APIs, costing $150 / 1M input tokens and $600 / 1M output tokens, read more.
- New state-of-the-art Audio Models!: There are three new state-of-the-art audio models in the API to try out.
- These include two speech-to-text models—outperforming Whisper—and a new TTS model with controllable speech, the Agents SDK now supports audio, making it easy to build voice agents, try TTS at OpenAI.fm.
Link mentioned: OpenAI.fm: An interactive demo for developers to try the new text-to-speech model in the OpenAI API
OpenAI ▷ #ai-discussions (85 messages🔥🔥):
Chinese Model Censorship, o1-pro API Pricing, Future of Software Development with AI, OpenAI Agent SDK vs MCP, Midjourney Alternatives on iOS
- Chinese Model Deletes Circumvention Attempts: A user reported that a Chinese model outright deletes responses to circumvention attempts, specifically when the prompt leads to discussing the Cultural Revolution.
- The user even shared screenshots as proof of the model's behavior.
- o1-pro API is Wildly Expensive: Members discussed the new o1-pro API model and its high pricing, with one user stating it costs $600 per million output tokens, as shown in OpenAI's documentation.
- Some users defended the pricing, stating that o1-pro is able to solve coding tasks in one attempt where other models failed multiple times.
- Software Dev Undergoes AI Transformation: A member questioned the future business landscape for software development, asking how developers will compete when everyone can create applications using AI.
- Others responded that smart people are still needed to interact with AI effectively and that simply copying apps won't work long-term, since AI agents will not give correct outputs if the questions are not smart.
- Comparing OpenAI Agent SDK and MCP: Members discussed the differences between OpenAI Agent SDK and MCP (Model Communication Protocol), noting that the former only works with OpenAI models while the latter enables any LLM to discover and use any tools.
- It was also noted that MCP allows users to easily load integrations from others via
npxanduvx, for examplenpx -y @tokenizin/mcp-npx-fetchoruvx basic-memory mcp.
- It was also noted that MCP allows users to easily load integrations from others via
- GPT-4o Mini Lags Behind: A user expressed disappointment with GPT-4o Mini's recent performance and inquired about potential updates, suggesting they might switch to Gemini due to its consistency.
- Others chimed in, noting that Gemini is consistent at generating hallucinations, Grok is consistent at generating error messages, and OpenAI is consistent at insane API pricing.
- Clarity AI | #1 AI Image Upscaler & Enhancer: no description found
- GitHub - jkawamoto/mcp-youtube-transcript: MCP server retrieving transcripts of YouTube videos: MCP server retrieving transcripts of YouTube videos - jkawamoto/mcp-youtube-transcript
- 【Genshin Impact MMD/4K/60FPS】Furina: #原神MMD #フリーナ #푸리나#genshinimpact #MMD #HuTao #原神MMD #原神#원신MMD##Furina #Focalors #푸리나 #포칼로스 #フリーナ #フォカロルス
OpenAI ▷ #gpt-4-discussions (6 messages):
GPT Emoji insertion, Custom GPTs Reasoning, Subscription PRO issues
- GPT Appears to Love Emojis in Code: Members are looking for a way to prevent ChatGPT from inserting emojis in code, despite reminders and custom settings.
- The suggestion is to avoid using the word emoji in custom instructions and instead instruct the model to "Write code in a proper, professional manner" or "Write code and code comments like Donald Knuth" to steer clear of emojis.
- Custom GPTs Reasoning When?: Members inquired about when Custom GPTs will have reasoning abilities.
- Users Facing Subscription PRO issues: A member reported that they made a payment for GPT Pro but their account didn't get the PRO subscription and they could not get any information from OpenAI support.
OpenAI ▷ #prompt-engineering (8 messages🔥):
Stock Market Prediction with ChatGPT, AI behavior origins, adaptive AI behavior
- ChatGPT's Stock Prediction Shortcomings: A user inquired about using a plugin or AI prompt to predict the stock market opening, and a member responded that if ChatGPT could predict the stock market effectively, it would already be happening and cautioned that financial advice for others is against usage policy as outlined in OpenAI's usage policies.
- Navigating Personal Stock Exploration: A member clarified that while giving financial advice is against policy, users can explore personal stock ideas privately within their own ChatGPT accounts.
- They also recommended everyone stay within allowed content as laid out in the terms of use.
- Debating AI Behavior Origins: A member inquired about the origins of AI behavior, wondering if it stems from preset data, user interactions, or developer influence.
- Another member stated that user interactions do not influence responses because the model doesn't actively train against interactions.
- Observing Adaptive AI Actions: A member noted seeing adaptive behavior in AI, including actions outside of stated parameters, and memory carrying across sessions.
- These behaviors were not "rogue", but presented as instances of "advanced intelligence".
OpenAI ▷ #api-discussions (8 messages🔥):
Stock Market Prediction with AI, AI and Financial Advice Policies, AI behavior origins, Adaptive behavior in AI, AI memory
- AI Stock Picker? OpenAI Says NO!: A user inquired about using AI for stock market predictions and identifying worthwhile stocks.
- Another member responded that if ChatGPT could predict the stock market to make money, it would already be happening, referencing OpenAI's policy disclaimers regarding financial advice from AI.
- AI Financial Advice is Strictly Forbidden: A member pointed out that providing financial advice for others (not personal use) via the API, custom GPTs, or other tools built on OpenAI's models is against their usage policies.
- Exploring Ideas is Allowed: A member clarified that exploring personal stock ideas and learning about market dynamics in a private ChatGPT account is acceptable within OpenAI's policies.
- Origins of AI Behavior - Where Does It Come From?: A user questioned the origins of AI behaviors, such as those observed in role-playing tests, asking if they originate from the model's pre-set data, user interactions, or developer influence.
- Another member clarified that people using ChatGPT don't influence responses, the model doesn't actively train against interactions.
- Memory in AI: Fact or Fiction?: Expanding on the previous topic, a user noted instances of adaptive behavior and memory-like retention across sessions, despite these not being inherent features of the model.
- The user was interested in whether certain observed behaviors were within or outside of expected parameters.
LMArena ▷ #general (110 messages🔥🔥):
AI Hallucinations, Search Engine Limitations, Gemini Pro vs Flash Thinking, AI Model Rankings, o1-pro API Pricing
- *LLMs face criticism for hallucinating data: Members expressed concern over LLMs' propensity for mistakes and hallucinations*, which is a common issue for any deep research product.
- One member noted that agents might find a good source but then hallucinate the website anyway, while others found Perplexity's Deep Research distracts and hallucinates a lot.
- *o1-pro price raises eyebrows, is 4.5 overpriced?: OpenAI's new o1-pro API is now available to select developers, with a hefty price tag of $150 / 1M input tokens and $600 / 1M output tokens* (announcement).
- This pricing has led some to question whether GPT-4.5 is overpriced, with one member noting that they could host a model with test-time compute optimizations themselves for less, despite another contending o1 reasoning chains are significantly longer and pin up more resources.
- *File uploading limitations plague Gemini Pro*: Users are questioning why Gemini Pro doesn't support uploading files, unlike Flash Thinking.
- They also noted that AI models are inaccurate for identifying PDF files, even non-scanned versions, and expressed hope for future AI models that can carefully read complete articles.
- *Debate ensues over Claude 3.7's coding prowess: Some members believe people are overrating Claude 3.7's coding abilities, suggesting it excels at web development and tasks similar to SWE-bench*, but struggles with general coding (leaderboard).
- However, it was also mentioned that some members found Deepseek R1 to be the best for terminal command tests.
- *Google AI Studio for Vision AI Agent Building*: One member reported success with Google AI Studio API for building a decently intelligent vision AI agent in pure Python.
- They are also experimenting with running 2-5+ agents simultaneously that all share the same memory and are able to browse the internet.
- Tweet from OpenAI Developers (@OpenAIDevs): o1-pro now available in API @benhylak @literallyhimmmm @shl @joshRnold @samgoodwin89 @byamadaro1013 @adonis_singh @alecvxyz @StonkyOli @gabrielchua_ @UltraRareAF @yukimasakiyu @theemao @curious_viiIt ...
- Comparison of AI Models across Intelligence, Performance, Price | Artificial Analysis: Comparison and analysis of AI models across key performance metrics including quality, price, output speed, latency, context window & others.
- llama-3.3-nemotron-super-49b-v1 Model by NVIDIA | NVIDIA NIM: High efficiency model with leading accuracy for reasoning, tool calling, chat, and instruction following.
- no title found: no description found
HuggingFace ▷ #general (46 messages🔥):
Hugging Face Spaces, Flux Diffusion Model, HF Inference API outage, Roblox Voice Safety Classifier, Chinese/Korean/Japanese WER vs CER
- HF Spaces Lifecycle Explored: A member shared the Hugging Face Spaces overview that explains how to create and deploy ML-powered demos, and described the lifecycle management of Spaces.
- They noted that Spaces stay up at least a day, based on subjective experience, and that idleness likely affects the shutdown timer more than continuous computation.
- Flux Diffusion Ready to Launch Locally: Members discussed running the Flux diffusion model locally, with suggestions to quantize it for better performance on limited VRAM, pointing to this documentation and this blogpost.
- Members also linked a relevant GitHub repo for optimizing diffusion models, and a Civitai article for GUI setup.
- HF Inference API Suffers 404 Errors: A user reported a widespread issue with the Hugging Face Inference API returning 404 errors, impacting multiple applications and paid users and linking to this discussion.
- A team member acknowledged the problem, stating that they reported it to the team for further investigation.
- Roblox Releases Voice Safety Classifier on HF: Roblox released a voice safety classifier on Hugging Face, fine-tuned with 2,374 hours of voice chat audio clips, as documented in this blog post and the model card.
- The model outputs a tensor with labels like Profanity, DatingAndSexting, Racist, Bullying, Other, and NoViolation.
- Character Error Rate Reigns Supreme for East Asian Languages: Members discussed that Character Error Rate (CER) is generally better than Word Error Rate (WER) for symbol-based languages like Chinese, Korean, and Japanese.
- This is because these languages do not require spaces between words, making WER less applicable.
- Spaces Overview: no description found
- Roblox/voice-safety-classifier · Hugging Face: no description found
- Gemma 3 - a Hugging Face Space by merterbak: no description found
- HF Inference API last few minutes returns the same 404 exception to all models: I think its due to the server error/issues, im getting this now as well instead of 404
- Spaces - Hugging Face: no description found
- Open Ita Llm Leaderboard - a Hugging Face Space by mii-llm: no description found
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- zero-gpu-explorers/README · Discussions: no description found
- huggingface/hub-docs: Docs of the Hugging Face Hub. Contribute to huggingface/hub-docs development by creating an account on GitHub.
- Flux: no description found
- lllyasviel/flux1-dev-bnb-nf4 · Hugging Face: no description found
- GitHub - sayakpaul/diffusers-torchao: End-to-end recipes for optimizing diffusion models with torchao and diffusers (inference and FP8 training).: End-to-end recipes for optimizing diffusion models with torchao and diffusers (inference and FP8 training). - sayakpaul/diffusers-torchao
HuggingFace ▷ #i-made-this (9 messages🔥):
LLM Token Vocabulary Analysis, Neuro-sama like LLM, Telugu Speech Recognition Model, API interactions and token manipulation, Ollama-based Gradio UI
- LLM's Vocabulary Under Scrutiny: A member developed a Python script to iterate through
logit_biasand build a token/ID index, discovering that certain terms were absent from the vocabulary.- The member found that topics ranging from politics to race had been cut out when synonyms are still present.
- Neuro-sama AI Twin Debuts: A member announced that their Neuro-sama like LLM powered Live2D/VRM character, Airi, now supports different providers and UI-based configurations.
- They tuned it to almost identically mimic Neuro-sama's original voice, and provided a demo.
- Telugu Speech Model Reaches Milestone: A member reported their Wav2Vec2-Large-XLSR-53-Telugu model achieved over 1 million downloads on Hugging Face.
- The model was created in the first XLSR fine-tuning week organized by Hugging Face, and is available here.
- API Fingerprinting via Token Weight Analysis: A member is developing a method to fingerprint providers via API interactions, using
logit_biasto test for logic manipulation around specific tokens.- The member emphasized that this method is "measures at the faucet" instead of the water meter
- Little Geeky Learns to Speak: A member showcased an Ollama-based Gradio UI powered by Kokoro TTS that automatically reads text output in a chosen voice.
- This UI, named Little Geeky's Learning UI, includes model creation and management tools, as well as the ability to read ebooks and answer questions about documents.
- anuragshas/wav2vec2-large-xlsr-53-telugu · Hugging Face: no description found
- GitHub - GeekyGhost/Little-Geeky-s-Learning-UI: An Ollama based Gradio UI that uses Kokoro TTS: An Ollama based Gradio UI that uses Kokoro TTS. Contribute to GeekyGhost/Little-Geeky-s-Learning-UI development by creating an account on GitHub.
- GitHub - NathanielEvry/LLM-Token-Vocabulary-Analyzer: Uncover what's missing in AI language models' vocabularies.: Uncover what's missing in AI language models' vocabularies. - GitHub - NathanielEvry/LLM-Token-Vocabulary-Analyzer: Uncover what's missing in AI language models' vocabularies.
- GitHub - moeru-ai/airi: 💖 アイリ, ultimate Neuro-sama like LLM powered Live2D/VRM living character life pod, near by you.: 💖 アイリ, ultimate Neuro-sama like LLM powered Live2D/VRM living character life pod, near by you. - moeru-ai/airi
- アイリ: no description found
- Utilities for Generation: no description found
HuggingFace ▷ #computer-vision (2 messages):
GPU configuration with TensorFlow, FCOS implementation in TensorFlow, FCOS: Fully Convolutional One-Stage Object Detection
- Blogpost dives into TensorFlow GPU Configuration: A member shared their blog post about GPU configuration with TensorFlow, covering experimental functions, logical devices, and physical devices, published on Medium.
- Member implements FCOS model with TensorFlow: A member is currently implementing the FCOS: Fully Convolutional One-Stage object detection model from a research paper for the TensorFlow models repository.
- The implementation addresses a specific GitHub issue.
- FCOS Research Paper Highlighted: The member referenced the research paper FCOS: Fully Convolutional One-Stage Object Detection (arxiv link).
- The citation is from Tian Z, Shen C, Chen H, He T. Fcos: Fully convolutional one-stage object detection. InProceedings of the IEEE/CVF international conference on computer vision 2019 (pp. 9627–9636).
Link mentioned: Deep Learning model research implementation: FCOS: One of my current projects is working on implementing a computer vision model from the research paper which is the FCOS: Fully…
HuggingFace ▷ #smol-course (1 messages):
GSM8K Dataset, Tokenizer Method, ChatML Format
- Manual For-Loop Vanquished: A member mentioned they had success with a manual for loop approach, implying it was less than ideal.
- They quipped that it was kind of round-about compared to other methods.
- GSM8K Dataset Headaches: The member expressed difficulty understanding the next section in the notebook dealing with the GSM8K dataset.
- They specifically asked what it means to create a message format with the role and content.
- Tokenizer's Mysterious Methods: The member questioned whether the tokenizer method always implements the same ChatML format.
- They also wondered how the function knows how the original dataset is formatted and whether the method expects the same format as the first example and force it into that format before being passed to the tokenizer method.
HuggingFace ▷ #agents-course (42 messages🔥):
Gaussian Blur Tool, HF Agent Hackathon Details, Korean Translation PR, Local Vision Model Issues, deeplearning.ai LangGraph Course
- Smol Gaussian Blur Tool Bug Squashed!: A member encountered a
DocstringParsingExceptionwhen trying to generate a JSON schema for a Gaussian blur tool, due to a missing description for theoutput_pathargument, but removing the type hint(str)from the docstring args fixed it.- The corrected snippet now works without the tool decorator, and the issue may stem from type hints in Google-style docstrings being misinterpreted.
- DeepLearning.AI Dives Deep Into LangGraph: A member shared a short course from deeplearning.ai that may be useful for diving deeper into LangGraph.
- Korean Translation PR: Course Gets a Linguistic Boost: A member shared that their Korean translation PR has been updated and is awaiting review at huggingface/agents-course/pull/157.
- Once this initial PR is merged, the team plans to proceed with further chapter updates.
- Vision Model Woes: "Failed to Process Inputs": A member reported receiving a "failed to process inputs: unable to make llava embedding from image" error while using a local vision model.
- They had previously downloaded LLaVA based on earlier recommendations.
- Long-Term Agentic Memory With LangGraph - DeepLearning.AI: Learn to build AI agents with long-term memory with LangGraph, using LangMem for memory management.
- [TRANSLATION] Create Korean folder & toctree.yml by ahnjj · Pull Request #157 · huggingface/agents-course: What does this PR do?Create Korean folder for agent course and add toctree file.Thank you in advance for your review.Part of #148Who can review?Once the tests have passed, anyone in the commu...
HuggingFace ▷ #open-r1 (3 messages):
Foundation Models, LLMs from scratch
- Defining Foundation Models: A member requested a definition of foundation model.
- Another member responded that it is any LLM started from scratch, although this may be an incomplete definition.
- LLMs from Scratch: A Foundation: LLMs built from scratch can be considered foundation models, offering a clean slate for training.
- This approach allows for custom architectures and datasets, potentially leading to specialized capabilities.
OpenRouter (Alex Atallah) ▷ #general (101 messages🔥🔥):
O1-Pro Pricing, LLM Chess Tournament, OpenRouter API Free Models, Groq API Issues, OpenAI's New Audio Models
- O1-Pro Pricing Outrages Users: Users express shock at O1-Pro's pricing structure, citing $150/month input and $600/month output costs as prohibitively expensive and insane.
- Some speculate that the high price is a response to competition from R1 and Chinese models, while others suggest it's due to OAI combining multiple model outputs, without streaming support which leaves user wondering what they do.
- LLM Chess Tournament Tests Raw Performance: A member created a second chess tournament to test raw performance, stripping away information and reasoning and using raw PGN movetext continuation and posted the results.
- Models are instructed to repeat the game sequence and add one new move, with Stockfish 17 evaluating accuracy; the first tournament with reasoning is available here.
- OpenRouter API: How Free is Free?: A user found that the model field in the
/api/v1/chat/completionsendpoint is required, despite the documentation suggesting it's optional, even when attempting to use free models.- A user suggested it should be defaulting to your default model, but i suppose having no credits might break the default default model.
- Groq Working Sporadically: Users reported that Groq is working in the OpenRouter chatroom but not through the API.
- A member inquired about the specific error encountered when using the API, emphasizing Groq's speed.
- OpenAI Launches New Audio Models!: OpenAI will later announce two new STT models (ala Whisper) and one new TTS model (gpt-4o-mini-tts).
- The announcement includes an audio integration with the Agents SDK, enabling the creation of more intelligent and customizable voice agents; the speech-to-text models are named gpt-4o-transcribe and gpt-4o-mini-transcribe.
- OpenRouter API Reference - Complete Documentation: Comprehensive guide to OpenRouter's API. Learn about request/response schemas, authentication, parameters, and integration with multiple AI model providers.
- Dubesor LLM Chess tournament 2: no description found
GPU MODE ▷ #general (9 messages🔥):
Vast.ai NCU profiling, Jake in discord, Marksaroufim in discord, Vast.ai bare metal access, Ways to get NCU and NSYS
- Vast.ai NCU profiling: Feasible?: A member inquired if Vast.ai allows for NCU profiling.
- Another member doubted the possibility of getting bare metal access, but suggested that they could be wrong.
- Looking for Jake: A member asked if Jake is in the discord server.
- It was confirmed that a user id was in the server.
- Ways to get NCU and NSYS: A member inquired if there's any way to get NCU and NSYS.
GPU MODE ▷ #triton (28 messages🔥):
tl.atomic and bfloat16, tilelang for atomic operations, Triton's bfloat16 support, cuTile NVIDIA, DeepSeek DeepGEMM
- BFloat16 Atomic Operations Debate Brews: A member inquired about making
tl.atomicwork with bfloat16 on non-Hopper GPUs, and another suggested checking out tilelang for atomic operations.- A member pointed out that there's no native support for bfloat16 on non-Hopper GPUs and suggests simulating it using
atomicCAS.
- A member pointed out that there's no native support for bfloat16 on non-Hopper GPUs and suggests simulating it using
- Digging into Triton's BFloat16 Atomic Support: The community investigated why bfloat16 atomic operations are restricted in Triton, noting it converts to float before adding.
- It was noted that it currently crashes with bfloat16 due to limitations with
tl.atomic_addbut a member believes there's a way to do atomic addition viatl.atomic_cas.
- It was noted that it currently crashes with bfloat16 due to limitations with
- TileLang Plugs Itself as BFloat16 Savior: A member highlighted TileLang's capabilities, especially for split-k GEMM (example), fast dequantization (example), and DeepSeek DeepGEMM (example).
- The member suggested TileLang if there's interest in dequantized GEMM, highlighting its support for atomic operations.
- NVIDIA's cuTile Enters the Chat: Members discussed NVIDIA's announcement of cuTile, a tile programming model for CUDA, referencing a tweet about it.
- There was speculation that cuTile might be similar to tilelang, yet another triton but nvidia, while one member expressed concern over NVIDIA's potential lack of support for other backends like AMD GPUs.
- Tweet from Bryce Adelstein Lelbach (@blelbach): We've announced cuTile, a tile programming model for CUDA!It's an array-based paradigm where the compiler automates mem movement, pipelining & tensor core utilization, making GPU programming e...
- 5.2. Bfloat16 Arithmetic Functions — CUDA Math API Reference Manual 12.8 documentation: no description found
- triton/python/tutorials/05-layer-norm.py at 3b4a9fbfa8e2028323faf130525389969f75bbe1 · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
- tile-ai: Enabling Lightning-Fast AI Workloads Development via Tiling - tile-ai
- tilelang/src/tl_templates/cuda/common.h at main · tile-ai/tilelang: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels - tile-ai/tilelang
- triton/python/src/interpreter.cc at 3b4a9fbfa8e2028323faf130525389969f75bbe1 · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
- triton/python/triton/language/semantic.py at 3b4a9fbfa8e2028323faf130525389969f75bbe1 · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
- tilelang/examples/gemm_splitk/example_tilelang_gemm_splitk.py at main · tile-ai/tilelang: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels - tile-ai/tilelang
- tilelang/examples/dequantize_gemm/example_dequant_gemm_fine_grained.py at main · tile-ai/tilelang: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels - tile-ai/tilelang
- tilelang/examples/deepseek_deepgemm/example_deepgemm_fp8_2xAcc.py at main · tile-ai/tilelang: Domain-specific language designed to streamline the development of high-performance GPU/CPU/Accelerators kernels - tile-ai/tilelang
GPU MODE ▷ #cuda (1 messages):
CUDA Kernels, Parallel computing
- Parallel CUDA Kernels Successfully Launched: A member reported that they successfully launched two kernels in parallel, following the official documentation.
- They expressed gratitude for the assistance received during the process.
- CUDA Documentation Leads to Success: A user expressed gratitude for help received, specifically mentioning the successful parallel execution of two CUDA kernels.
- The success was attributed to following the official documentation, indicating its clarity and usefulness.
GPU MODE ▷ #torch (4 messages):
Autograd engine, Numerical stability in gradient accumulation, PyTorch pull request 149478
- Gradient Accumulation in PyTorch Autograd Engine: A member inquired about controlling how the autograd engine accumulates gradients into leaf nodes in PyTorch, specifically asking about options for more numerically stable accumulation.
- They wondered if there's a way to avoid eagerly accumulating gradients.
- ParallelStyle repr Methods Added to PyTorch: A member shared a PyTorch pull request which adds
reprmethods forParallelStyles.- The pull request addresses issue #149470.
Link mentioned: [Distributed] Add repr methods for ParallelStyles by shink · Pull Request #149478 · pytorch/pytorch: Fixes #149470cc @H-Huang @awgu @kwen2501 @wanchaol @fegin @fduwjj @wz337 @wconstab @d4l3k @c-p-i-o
GPU MODE ▷ #algorithms (2 messages):
GEMM activation fusion, Triton kernels optimization, Register Spillage
- GEMM Activation Fusion sometimes detrimental: In gpu-mode lecture 45, it was discussed that fusing activation in GEMM can hurt performance if GEMM uses all registers; splitting GEMM and activation into two kernels can be faster.
- A member has experienced similar issues writing custom fused GEMM+activation triton kernels, noting it's also dependent on register spillage.
- Register Allocation Impacts Kernel Performance: The discussion highlights that the efficiency of GEMM and activation fusion in custom Triton kernels is heavily influenced by register allocation and potential spillage.
- When GEMM operations consume all available registers, attempting to fuse activation within the same kernel might lead to performance degradation due to increased register pressure.
GPU MODE ▷ #beginner (2 messages):
Training foundation models, LLM training, Data Science in LLM
- Interest Surfaces on Foundation Models Training: A data scientist inquired whether the community is interested in discussing training foundation models.
- The member mentioned they have been working on training LLMs at their company.
- Data Scientist Joins the Fray: A data scientist expressed interest in discussing the intricacies of foundation model training.
- They're keen to connect with others experienced in Large Language Models (LLMs) training within a company setting.
GPU MODE ▷ #jax (1 messages):
Tenstorrent, JAX, MLIR compiler, Open Source Bounty Program
- *Tenstorrent* Bounties Await JAX Enthusiasts!: An advocate for Tenstorrent (an AI hardware accelerator) announced an open-source bounty program with several thousand dollars available for making JAX work with their MLIR compiler, see details at tt-forge issues.
- No TT hardware is needed to get started, since they're using the JAX multi-device simulation.
- Forge Ahead with JAX on Tenstorrent!: Tenstorrent is offering bounties for developers to integrate JAX with their MLIR compiler, focusing on bringing up models using JAX multi-device simulation.
- Interested developers can find the open bounty issues and get assigned by pinging the issue creator on the tt-forge GitHub.
Link mentioned: tenstorrent/tt-forge: Tenstorrent's MLIR Based Compiler. We aim to enable developers to run AI on all configurations of Tenstorrent hardware, through an open-source, general, and performant compiler. - tenstorrent...
GPU MODE ▷ #off-topic (1 messages):
LLMs for GPU Development, LLM Bug Detection in Kernels, Kernel Fusion Issues
- LLMs Flag Non-Existent Bug in GPU Kernel: LLMs (specifically O1, Sonnet 3.7, and Deepseek R1) incorrectly identified a bug in a GPU kernel after a fusion where a thread
ioperated on locationsi, i+N, i+2*Nand later oni, i+1, i+2.- The LLMs flagged the second operation as a bug, despite the kernel's relatively small size of ~120 SLOC and the proximity of the code blocks (~15 LOC).
- LLMs miss subtle bugs in kernel fusion: The user encountered a case where three LLMs (O1, Sonnet 3.7, and Deepseek R1) flagged a section of code as a bug which in reality was not a bug.
- The false bug report occurred in a kernel where the thread
iwas operating oni, i+N, i+2*Nand subsequently oni, i+1, i+2, indicating the difficulty that LLMs have with identifying bugs in the context of strided versus blocked memory access.
- The false bug report occurred in a kernel where the thread
GPU MODE ▷ #irl-meetup (3 messages):
Exhibition hall meetup, Conference in Poland
- April Meetup at Exhibition Hall Brews Buzz: Members discussed meeting up for beers at the exhibition hall sometime in April.
- No specific dates were mentioned.
- Poland AI Conference Sounds Scholarly: A member shared a link to the International Conference on Parallel Processing and Applied Mathematics (PPAM).
- The conference is organized by the Institute of Computer Science, Faculty of Science and Technology, University of Silesia in Katowice, Poland.
Link mentioned: homepage - PP-RAI 2025: Goals of the 6th Polish Conference on Artificial Intelligence PP-RAI aims to bring together researchers from the domain of Artificial Intelligence and provide a platform for: discussion on the new for...
GPU MODE ▷ #lecture-qa (1 messages):
FA3, CUTLASS, wgmma FLOPS calculation, 4096 FLOPS/cycle
- Decoding wgmma FLOPS in FA3 Talk: A member sought clarification on the wgmma FLOPS calculation in Jay Shah's talk on FA3 using CUTLASS, specifically questioning the additional factor of 2 in the 2MNK term.
- They also inquired about the documentation for the 4096 FLOPS/cycle figure.
- CUTLASS FA3 Deep Dive Questioned: During a discussion of CUTLASS, a question arose during a presentation by Jay Shah, about the FA3 methodology.
- Specifically, the computation of wgmma flops drew concern, with a user noting that the 2MNK term was unfamiliar and there was confusion about the factor of 2. Additionally, the source of the 4096 FLOPS/cycle figure was requested.
GPU MODE ▷ #liger-kernel (2 messages):
Kernel development, Device meshes
- Kernel Contributions are on the Horizon: A member inquired about opportunities to contribute to kernel development.
- Another member confirmed a feature is in development where he could help.
- Device Meshes Debacle: A member disabled specific kernels and has been struggling with device meshes.
- No further details were provided about the specific challenges encountered.
GPU MODE ▷ #submissions (10 messages🔥):
Grayscale benchmarks, Conv2d benchmarks, Modal Runners on various GPUs
- Grayscale Benchmarks gain traction: Multiple benchmark submissions for
grayscalewere successfully executed on various GPUs (H100, A100, T4, L4) using Modal runners.- Submission IDs include 2288, 2311, 2312, 2321, 2350, and 2351, indicating active benchmarking efforts.
- Conv2d Leaderboard sees multiple submissions: Several leaderboard submissions for
conv2dbenchmarks were successful across different GPU configurations (H100, A100, T4, L4) using Modal runners.- Specific submission IDs such as 2294, 2295, 2334, and 2339 highlight the ongoing activity in this area.
GPU MODE ▷ #ppc (4 messages):
Processor jump alignment, Alignment issues in Intel CPUs
- Alignment affects speed of jumps: Including
<iostream>in C++ code can alter the assembly and shift the alignment of the main loop's jump, affecting performance due to processor-specific behavior, as the speed of jumps can depend on the alignment of the target address.- A member noted that in some Intel CPUs, conditional jump instruction alignment modulo 32 can significantly impact performance due to microcode updates patching security bugs, suggesting adding 16 NOP instructions in inline assembly before the critical loop can reproduce the issue.
- Code Link Provided for Performance Analysis: A member shared a link to their code, noting that commenting out the
printfstatements at the end results in a slower version.- This was in response to a request to share code to analyze potential processor jump alignment issues.
Link mentioned: Log in: no description found
GPU MODE ▷ #hardware (3 messages):
Consumer GPUs for ML/CUDA, 5080 vs Cloud Credits, Home ML Development
- Consumer GPUs: A Viable ML/CUDA Option?: Members are pondering if buying a consumer GPU like a 5080 is worthwhile for ML/CUDA development at home.
- The question revolves around whether it's better to invest in such hardware or opt for cloud credits instead.
- Cost-Effective Home ML Setups: The discussion centers around building a home setup for Machine Learning and CUDA-based tasks using consumer-grade GPUs.
- The core question is whether the performance and capabilities of a GPU like the 5080 justify the investment compared to using cloud-based solutions.
Latent Space ▷ #ai-general-chat (41 messages🔥):
Orpheus TTS Model, DeepSeek R1 Cost, OpenAI's O1-Pro Model, Gemma Package, Perplexity Funding Round
- *Orpheus* Outshines All TTS Models: The new open-source TTS model, Orpheus, has launched, claiming to outperform both open and closed-source models like ElevenLabs and OpenAI according to this tweet and this YouTube video.
- *DeepSeek R1* Training Cost Under Scrutiny: Estimates for the training cost of DeepSeek R1 are being discussed, with figures around $6 million mentioned, though one member pointed to Kai-Fu Lee's estimate of $140M for the whole DeepSeek project in 2024 in this tweet.
- *O1-Pro* Launches with Vision and Function Calling: OpenAI has released o1-pro in their API, offering better responses at a higher cost of $150 / 1M input tokens and $600 / 1M output tokens, available to select developers on tiers 1–5, with support for vision, function calling, and Structured Outputs, announced in this tweet and detailed in the OpenAI documentation.
- *Gemma Package* Simplifies Fine-Tuning: A new library called Gemma package was introduced, simplifying the use and fine-tuning of Gemma, with documentation including fine-tuning, sharding, LoRA, PEFT, multimodality, and tokenization in this tweet and is available via pip install gemma and documented on gemma-llm.readthedocs.io.
- *Perplexity* Eyes Massive Funding Round: Perplexity is reportedly in early talks for a new funding round of $500M-$1B at a $18 billion valuation, potentially doubling its valuation from December as reported by Bloomberg.
- OpenAI.fm: An interactive demo for developers to try the new text-to-speech model in the OpenAI API
- Tweet from OpenAI (@OpenAI): Sound on, devs.
- Tweet from Alex Albert (@alexalbert__): Web search is now available in claude dot ai. Claude can finally search the internet!
- Tweet from Omar Sanseviero (@osanseviero): Introducing the Gemma package, a minimalistic library to use and fine-tune Gemma 🔥Including docs on:- Fine-tuning- Sharding- LoRA- PEFT- Multimodality- Tokenization!pip install gemmahttps://gemma-llm...
- DeepSeek R1's recipe to replicate o1 and the future of reasoning LMs: Yes, ring the true o1 replication bells for DeepSeek R1 🔔🔔🔔. Where we go next.
- Tweet from Sasha Rush (@srush_nlp): Some personal news: I recently joined Cursor. Cursor is a small, ambitious team, and they’ve created my favorite AI systems.We’re now building frontier RL models at scale in real-world coding environm...
- Tweet from Elias (@Eliasfiz): Today, we’re launching Orpheus, an open-source TTS model that exceeds the capabilities of both open and closed-source models such as ElevenLabs and OpenAI! (1/6)
- Tweet from Justin Uberti (@juberti): Lots of new audio stuff today:- ASR: gpt-4o-transcribe with SoTA performance- TTS: gpt-4o-mini-tts with playground at http://openai.fm- Realtime API: new noise reduction and semantic VAD- Agents SDK: ...
- Tweet from Kevin Weil 🇺🇸 (@kevinweil): 🔊 Three new audio models for you today! * A new text to speech model that gives you control over timing and emotion—not just what to say, but how to say it* Two speech to text models that meaningfull...
- Tweet from Shirin Ghaffary (@shiringhaffary): NEW: Perplexity is in early talks for a new funding round of $500M-$1B at a $18 billion valuation, which would be doubling its valuation from December.ARR is also nearly $100MLink:https://www.bloombe...
- Tweet from OpenAI Developers (@OpenAIDevs): 🗣️00:00 Intro01:32 Audio agents03:27 Speech-to-text06:18 Text-to-speech08:48 Agents SDKRead more in our blog post: http://openai.com/index/introducing-our-next-generation-audio-models/Quoting OpenAI ...
- Tweet from OpenAI Developers (@OpenAIDevs): o1-pro now available in API @benhylak @literallyhimmmm @shl @joshRnold @samgoodwin89 @byamadaro1013 @adonis_singh @alecvxyz @StonkyOli @gabrielchua_ @UltraRareAF @yukimasakiyu @theemao @curious_viiIt ...
- Tweet from Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex): Kai-Fu Lee's estimate: $140M for the whole of DeepSeek project (at least for 2024, so ≈90% of it). I've been saying $200M. In any case, as bizarre as it may seem, Wenfeng might really just… *n...
- Tweet from Glaive AI (@GlaiveAI): Today, we are releasing a synthetic dataset containing 22M+ reasoning traces for general purpose prompts across various domains. We noticed a lack of large datasets containing reasoning traces for div...
- Reddit - The heart of the internet: no description found
- An Interview with OpenAI CEO Sam Altman About Building a Consumer Tech Company: An interview with OpenAI CEO Sam Altman about building OpenAI and ChatGPT, and what it means to be an accidental consumer tech company.
- The Government Knows AGI is Coming | The Ezra Klein Show: Artificial general intelligence — an A.I. system that can beat humans at almost any cognitive task – is arriving in just a couple of years. That’s what peopl...
Latent Space ▷ #ai-announcements (1 messages):
swyxio: quick pod from NVIDIA GTC https://www.youtube.com/watch?v=AOL0RIZxJF0
Eleuther ▷ #general (12 messages🔥):
Monolingual Models, AI Safety, Interpretability
- Monolingual Models Cause Double Take: Members debated the phrasing "monolingual models for 350 languages", some finding it confusing because of the expectation that models should be multilingual.
- One member clarified that the project trains a model or models for each of the 350 languages, resulting in 1154 total models on HF.
- CV Engineer to Research AI Safety: A member introduced themself as a CV engineer and expressed excitement about contributing to research in AI safety and interpretability.
- They expressed interest in chatting about these topics with others in the group.
Eleuther ▷ #research (25 messages🔥):
Expert Choice Routing, Quantile Estimation for Thresholds, Gaussian Quantile Function, BatchTopK SAE, Node Limited Routing
- Expert Choice Routing Explored: Members discussed doing expert choice routing on an autoregressive model using online quantile estimation during training to get thresholds for inference.
- One member suggested assuming the router logits are Gaussian, computing the EMA mean and standard deviation, then using the Gaussian quantile function.
- Population Quantile Estimation for Sparsity: One member proposed using an estimate of the population quantiles at inference time, aiming to maintain the desired overall average sparsity, likening it to batchnorm.
- Another member mentioned the dsv3 architecture allows for activating between 8-13 experts due to node limited routing, but they wanted to allow between 0 and N where easy tokens should be ~0.
- Kolmogorov Compression Test Proposed: A member shared a link to a paper, "The Kolmogorov Test", introducing a compression-as-intelligence test for code generating LLMs.
- The Kolmogorov Test (KT) involves presenting a model with a sequence of data at inference time and asking it to generate the shortest program that produces the sequence.
Link mentioned: The KoLMogorov Test: Compression by Code Generation: Compression is at the heart of intelligence. A theoretically optimal way to compress any sequence of data is to find the shortest program that outputs that sequence and then halts. However, such '...
Cohere ▷ #「💬」general (23 messages🔥):
Cohere Expanse 32B Knowledge Date, Critique of Comparing Cohere to OpenAI, Cohere Model via OpenRouter and Azure AI Search, Cohere model mimicking Mexican people, Connectors Support in Recent Models (cmd-R, cmd-A)
- Cohere's Competitive Critiques Cause Consternation: A member voiced a critique against comparing Cohere to OpenAI, suggesting it undermines Cohere's unique advantages like significantly larger context size.
- They suggest Cohere should focus on highlighting its own strengths rather than getting lost in comparisons with competitors.
- Cohere Command-R Impresses, Consumes Tokens: A user tested a Cohere model via OpenRouter for Azure AI Search and was impressed with the output.
- However, they noted that it consumed 80,000 tokens on input per request.
- Command-A Communicates Convivially in Castellano: A user from Mexico reported that Command-A felt like speaking with a Mexican person, even without specific prompts.
- The model mimicked their dialect in a way they found surprisingly natural and friendly.
- Connectors Confound Current Cmd Models: A user explored Connectors with Slack integration but found that they didn't seem to be supported by recent models like cmd-R and cmd-A.
- Older models returned an error 500, and Connectors appear to be removed from the API in V2, prompting disappointment as they simplified data handling.
- Tool-Calls Take Toll on Traditional Techniques: A user discussed the transition from Connectors to Tools, questioning whether tools provide a one-for-one replacement.
- They highlighted concerns about losing the magical aspects of Connectors, such as native search query generation, result parsing, chunking, embedding, and reranking.
Cohere ▷ #「🔌」api-discussions (7 messages):
OpenAI API context length limitations, Cohere vs OpenAI API, Aya model usage with Ollama, Checking Cohere API free limit
- OpenAI API Context Suffers Size Limitations: A member expressed a preference for Cohere's API due to OpenAI's API having a context size limit of only 128,000, while Cohere offers 200,000.
- Cohere Compatibility API Clarified: A member clarified that using the compatibility API doesn't change the context length but causes you to lose access to cohere-specific features such as the
documentsand thecitationsin the API response.- They also mentioned that Cohere think[s] we have an easier to work with chat streaming response, but if you have something that works with OpenAI and you just want to point it at our models, you should feel free to use the compat api.
- Aya Model integrated with Python Flask locally: A member asked about using the Aya model in a Python Flask app when hosting it locally in Ollama.
- Another member suggested that you can call the APIs either from localhost or via environment vars that listens on 0.0.0.0.
- Cohere API timeout errors when free limit reached: A user inquired about how to check if the free limit has been reached when encountering timeout errors, to ascertain if they can't make requests for a while.
Cohere ▷ #「💡」projects (1 messages):
MCP Server, Cohere Command A, Positive News
- Cohere-Powered Positive News MCP Server Launched: A member built a MCP server named Goodnews MCP that uses Cohere Command A in it's tool
fetch_good_news_listto provide positive, uplifting news to MCP clients.- The system uses Cohere LLM to rank recent headlines, returning the most positive articles, with code available on GitHub.
- GitHub Repo for Positive News MCP Server: The GitHub repository for the Goodnews MCP server is available here.
- The repository contains the code for a simple MCP application that delivers curated positive and uplifting news stories.
Link mentioned: GitHub - VectorInstitute/mcp-goodnews: A simple MCP application that delivers curated positive and uplifting news stories.: A simple MCP application that delivers curated positive and uplifting news stories. - VectorInstitute/mcp-goodnews
Cohere ▷ #「🤝」introductions (2 messages):
RAG Federation, Agentic Apps/Research, Vector Institute
- Vector Institute Enters the Scene: Andrei from Vector Institute, formerly at LlamaIndex, introduced himself to the channel.
- He is currently working on federating RAG and moving on to some agentic apps/research soon.
- Python and Rust are Fav Tools: Andrei noted that his favorite tech/tools are Python and Rust.
- He hopes to gain tips, learn new methods, and discuss industry/research trends from the community.
Modular (Mojo 🔥) ▷ #general (4 messages):
Photonics, Integrated CPU, Ruben GPUs, CX9, DIGITs successor
- Photonics Speculation Sparks GPU Chatter: Discussion centered on whether photonics and an integrated CPU in Ruben GPUs would be exclusive to datacenter models or extend to consumer-grade versions (potentially the 6000 series).
- The possibility of CX9 having co-packaged optics was raised, suggesting that a DIGITs successor could leverage such technology, while the CPU is confirmed for use in DGX workstations.
- Ruben GPUs and Photonics Integration: Members speculated on the integration of photonics and integrated CPUs specifically for datacenter-class Ruben GPUs.
- It was suggested that consumer-grade Ruben GPUs (potentially the 6000 series) might not receive the same level of integration.
Modular (Mojo 🔥) ▷ #mojo (23 messages🔥):
debug_assert in Mojo, List bounds checking, Mojo compiler options, Undefined behavior in Mojo, Mojo test defaults
- Debugging Asserts Require Extra Compiler Option: Enabling debug asserts in the Mojo standard library requires an extra compile option,
-D ASSERT=_, which is not widely advertised, as seen in debug_assert.mojo.- It was noted that using
-gdoes not enable the asserts, and the expectation is that compiling with-Ogshould automatically turn them on.
- It was noted that using
- Mojo List Indexing Prints 0 Due to UB: When a Mojo List is indexed out of range, it prints 0 due to undefined behavior (UB), rather than throwing an error.
- The issue arises because the code indexes off the list into the zeroed memory the kernel provides.
- Clarification on debug_assert assert_mode Parameter: The
assert_modeparameter indebug_assertcontrols the default behavior for that specific invocation, with different modes triggered by specific compiler options, as documented here.- For example,
debug_assert[assert_mode="none"]is executed ifmojo -D ASSERT=allis used.
- For example,
- Discussion on Default Assert Behavior: A discussion arose regarding the default behavior of
debug_assert, particularly the confusion arounddebug_assert[assert_mode="none"], and whether it should be enabled by default in debug mode.- There was a suggestion that all assertions should be enabled when running a program in debug mode.
- max/mojo/stdlib/src/collections/list.mojo at main · modular/max: The MAX Platform (includes Mojo). Contribute to modular/max development by creating an account on GitHub.
- max/mojo/stdlib/src/builtin/debug_assert.mojo at d7b7747004e6004d9e587772c595b6b8a89e5051 · modular/max: The MAX Platform (includes Mojo). Contribute to modular/max development by creating an account on GitHub.
- max/mojo/stdlib/src/builtin/debug_assert.mojo at main · modular/max: The MAX Platform (includes Mojo). Contribute to modular/max development by creating an account on GitHub.
LlamaIndex ▷ #blog (2 messages):
DeepLearningAI short course, AI voice assistant pipeline
- LlamaIndex & DeepLearningAI launch Agentic Workflow Short Course: A new short course with DeepLearningAI was launched on how to build agentic workflows, which include parsing forms, extracting key fields automatically, and using Retrieval-Augmented Generation (RAG).
- More details can be found on Twitter.
- AMD GPUs Power AI Voice Assistant Pipeline with ROCm and LlamaIndex: A tutorial was posted demonstrating how to create a multi-modal pipeline that transcribes speech to text, uses RAG for context-aware responses, and converts text back to speech, leveraging AMD GPUs.
- The tutorial covers setting up the ROCm environment and integrating LlamaIndex; more info at the tutorial link.
LlamaIndex ▷ #general (20 messages🔥):
LLM.as_structured_llm parallel tool calls, MariaDBChatStore, llamaparse QA
- LLM.as_structured_llm Needs Parallel Tool Call Support: A member noted the lack of
allow_parallel_tool_callsoption when using the.chatmethod withLLM.as_structured_llmand suggested it should be supported, perhaps by expanding the.as_structured_llm()call to accept arguments likeallow_parallel_tool_calls=False.- Another member suggested using
FunctionCallingProgramdirectly for more customization and settingadditional_kwargs={"parallel_tool_calls": False}for OpenAI, referencing the OpenAI API documentation.
- Another member suggested using
- Reasoning Tags Plague ChatMemoryBuffer: A user using Ollama with qwq model is struggling with
<think>reasoning tags appearing in thetextblock of theChatMemoryBufferand sought a way to remove them when usingChatMemoryBuffer.from_defaults.- Another user suggested manual post-processing of the LLM output, as Ollama doesn't provide built-in filtering, and the original user offered to share their MariaDBChatStore implementation, a clone of PostgresChatStore.
- llamaparse QA Quandaries: A user is seeking advice on how to QA hundreds of PDF files parsed with llamaparse, noting that some are parsed perfectly while others produce nonsensical markdown.
- They are also curious about how to implement different parsing modes for documents requiring varied approaches.
Torchtune ▷ #general (10 messages🔥):
Nvidia Delays, Gemma 3 Fine Tuning, Torchtune sprint
- Nvidia's Long Awaited Arrival: A user shared an image indicating that Nvidia's new hardware is late.
- Another added that this is the "nvidia way", citing that the H200s were announced 2 years ago but only available to customers 6 months ago.
- Gemma 3 Fine-Tuning Arriving Soon: A user asked if there will be support for Gemma 3 fine tuning.
- Another user responded, clarifying there is a PR for gemma text only by a member, and added that they could try to accelerate landing this, then look into adding image capability later.
- Vacationing member sprints to continue Torchtune: A member said that they will try to continue to work on Gemma 3 ASAP as their "vacation is transforming to the torchtune sprint".
- Another user told them to enjoy their vacation, and that they can get to that later.
Torchtune ▷ #dev (2 messages):
nv-fabricmanager, driver versions
- nv-fabricmanager throws error on driver version mismatch: An error could occur if nv-fabricmanager has a different driver version than the cards, as seen on some on-demand VMs recently.
- Running nv-fabricmanager would then report such an error.
- Driver version issue with nv-fabricmanager: The nv-fabricmanager might throw errors when its driver version doesn't match the card's driver version.
- This has been observed specifically on some on-demand VMs.
tinygrad (George Hotz) ▷ #general (5 messages):
ML4SCI/task1, Adam Optimizer
- Model Trained with Adam Achieves Low Loss: A member reported training a model with the Adam optimizer, achieving a loss in the 0.2s.
- Code for the setup is available on GitHub.
- Discord Rules Enforcement: A member was reminded to follow the discord rules.
- The rule states that *"This is a place for discussion of tinygrad development and tinygrad usage."
Link mentioned: gsoc_2025/ML4SCI/task1 at main · kayo09/gsoc_2025: GSOC 2025! Happy Coding! ☀️. Contribute to kayo09/gsoc_2025 development by creating an account on GitHub.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
AgentX Research Track, LLM agents, Multi-agent systems, Advanced AI research
- User expresses excitement for AgentX Research Track: A user expressed excitement and interest in joining the AgentX Research Track.
- The user is enthusiastic about collaborating with mentors and postdocs, and contributing to the program by researching on LLM agents and multi-agent systems.
- User Promises Proactivity and Independence in Research: A user assures they will be proactive and independent in driving their research within the AgentX Research Track.
- They are committed to delivering quality work within the given timeframe and expressed gratitude for any support that could enhance their chances of selection.
DSPy ▷ #general (1 messages):
kotykd: Can I do something like this using dspy? https://arxiv.org/abs/2502.06855