[AINews] PRIME: Process Reinforcement through Implicit Rewards
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Implicit Process Reward Models are all you need.
AI News for 1/3/2025-1/6/2025. We checked 7 subreddits, 433 Twitters and 32 Discords (218 channels, and 5779 messages) for you. Estimated reading time saved (at 200wpm): 687 minutes. You can now tag @smol_ai for AINews discussions!
We saw this on Friday but gave it time for peer review, and it is positive enough to give it a headline story (PRIME blogpost):
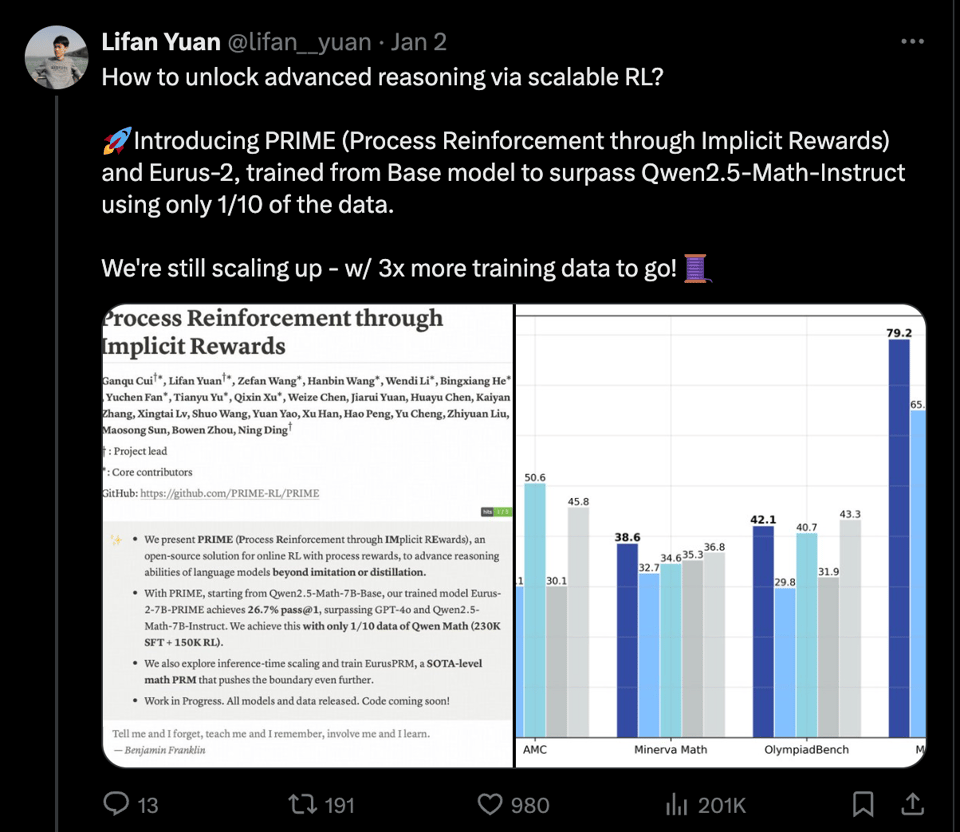
Ever since Let's Verify Step By Step established the importance of process reward models, the hunt has been on for an "open source" version of this. PRIME deals with some of the unique challenges of online RL:
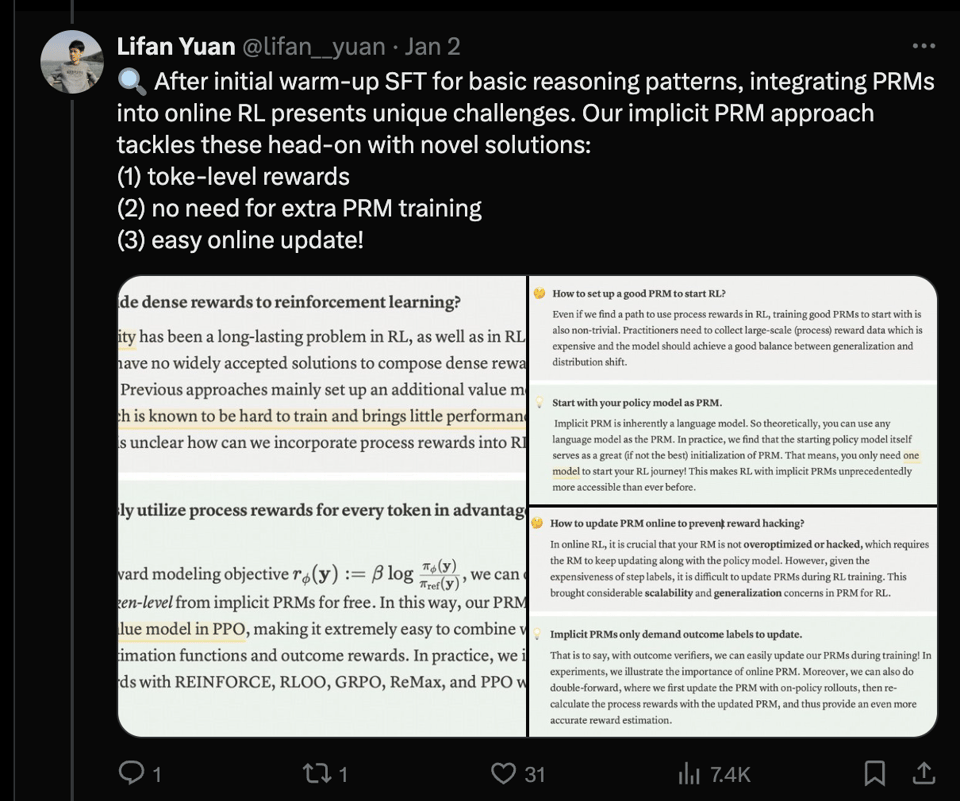
and trains it up on a 7B model for incredibly impressive results vs 4o:
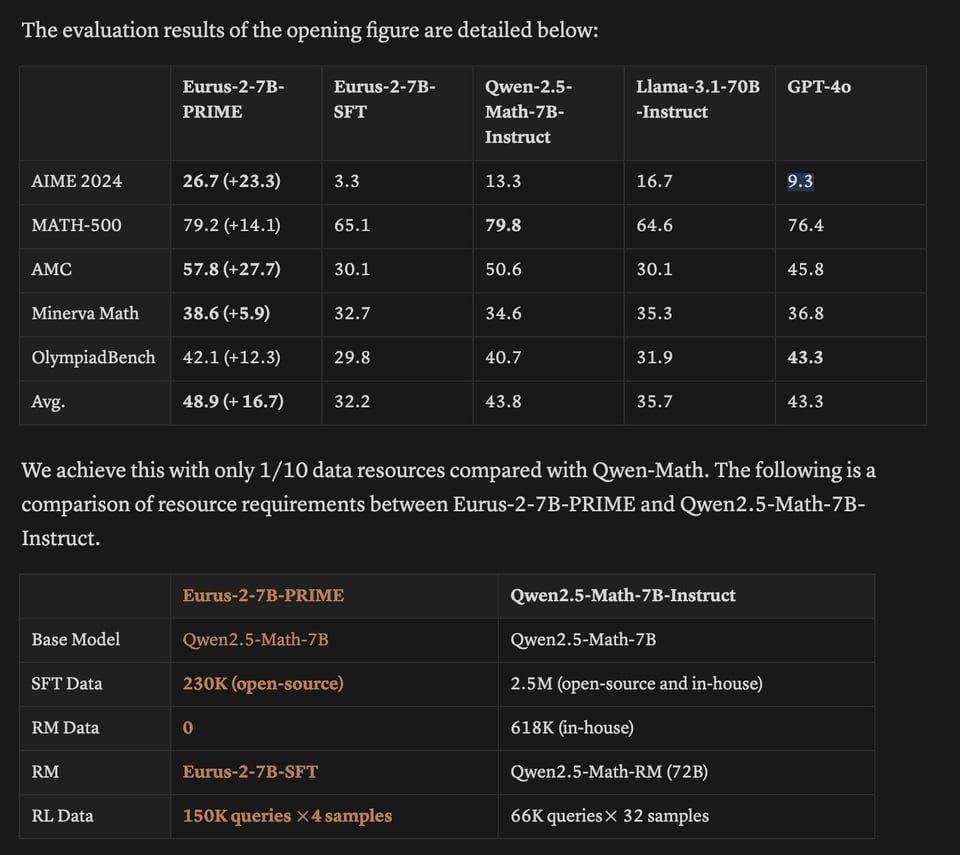
a lucidrains implemenation is in the works.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- aider (Paul Gauthier) Discord
- Unsloth AI (Daniel Han) Discord
- Codeium (Windsurf) Discord
- Cursor IDE Discord
- LM Studio Discord
- Stackblitz (Bolt.new) Discord
- Stability.ai (Stable Diffusion) Discord
- Latent Space Discord
- Interconnects (Nathan Lambert) Discord
- Nous Research AI Discord
- OpenAI Discord
- Perplexity AI Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- Notebook LM Discord Discord
- GPU MODE Discord
- Cohere Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- Nomic.ai (GPT4All) Discord
- tinygrad (George Hotz) Discord
- Modular (Mojo 🔥) Discord
- LAION Discord
- DSPy Discord
- LLM Agents (Berkeley MOOC) Discord
- MLOps @Chipro Discord
- Torchtune Discord
- Axolotl AI Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- aider (Paul Gauthier) ▷ #general (589 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (91 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (5 messages):
- Unsloth AI (Daniel Han) ▷ #general (490 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (115 messages🔥🔥):
- Codeium (Windsurf) ▷ #announcements (1 messages):
- Codeium (Windsurf) ▷ #discussion (111 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (397 messages🔥🔥):
- Cursor IDE ▷ #general (483 messages🔥🔥🔥):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #general (292 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (159 messages🔥🔥):
- Stackblitz (Bolt.new) ▷ #prompting (18 messages🔥):
- Stackblitz (Bolt.new) ▷ #discussions (371 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (382 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (129 messages🔥🔥):
- Latent Space ▷ #ai-announcements (11 messages🔥):
- Latent Space ▷ #ai-in-action-club (162 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #events (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (133 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (1 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (56 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Interconnects (Nathan Lambert) ▷ #rl (74 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (2 messages):
- Nous Research AI ▷ #general (265 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (10 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- OpenAI ▷ #ai-discussions (161 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (17 messages🔥):
- OpenAI ▷ #prompt-engineering (39 messages🔥):
- OpenAI ▷ #api-discussions (39 messages🔥):
- Perplexity AI ▷ #general (182 messages🔥🔥):
- Perplexity AI ▷ #sharing (19 messages🔥):
- Perplexity AI ▷ #pplx-api (4 messages):
- Eleuther ▷ #general (44 messages🔥):
- Eleuther ▷ #research (95 messages🔥🔥):
- Eleuther ▷ #interpretability-general (3 messages):
- Eleuther ▷ #lm-thunderdome (19 messages🔥):
- Eleuther ▷ #gpt-neox-dev (34 messages🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (173 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (25 messages🔥):
- Notebook LM Discord ▷ #general (128 messages🔥🔥):
- GPU MODE ▷ #general (6 messages):
- GPU MODE ▷ #triton (61 messages🔥🔥):
- GPU MODE ▷ #cuda (10 messages🔥):
- GPU MODE ▷ #torch (29 messages🔥):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #beginner (5 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #rocm (2 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #self-promotion (3 messages):
- GPU MODE ▷ #arc-agi-2 (2 messages):
- Cohere ▷ #discussions (51 messages🔥):
- Cohere ▷ #questions (11 messages🔥):
- Cohere ▷ #api-discussions (10 messages🔥):
- Cohere ▷ #cmd-r-bot (5 messages):
- Cohere ▷ #projects (3 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (36 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- OpenInterpreter ▷ #general (31 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- Nomic.ai (GPT4All) ▷ #general (31 messages🔥):
- tinygrad (George Hotz) ▷ #general (26 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (18 messages🔥):
- LAION ▷ #general (13 messages🔥):
- DSPy ▷ #papers (1 messages):
- DSPy ▷ #general (4 messages):
- DSPy ▷ #examples (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
- MLOps @Chipro ▷ #general-ml (7 messages):
- Torchtune ▷ #general (7 messages):
- Axolotl AI ▷ #general (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AGI and Large Language Models (LLMs)
- Proto-AGI and Model Capabilities: @teortaxesTex and @nrehiew_ discuss Sonnet 3.5 as a proto-AGI and the evolving definition of AGI. @scaling01 emphasizes the importance of compute scaling for Artificial Superintelligence (ASI) and the role of test-time compute in future AI development.
- Model Performance and Comparisons: @omarsar0 analyzes Claude 3.5 Sonnet's performance against other models, highlighting reduced performance in math reasoning. @aidan_mclau questions the harness differences affecting model evaluations, emphasizing the need for consistent benchmarking.
AI Tools and Libraries
- Gemini Coder and LangGraph: @_akhaliq showcases Gemini 2.0 coder mode supporting image uploads and AI-Gradio integration. @hwchase17 introduces a local version of LangGraph Studio, enhancing agent architecture development.
- Software Development Utilities: @tom_doerr shares tools like Helix (a Rust-based text editor) and Parse resumes in Python, facilitating code navigation and resume optimization. @lmarena_ai presents the Text-to-Image Arena Leaderboard, ranking models like Recraft V3 and DALL·E 3 based on community votes.
AI Events and Conferences
- LangChain AI Agent Conference: @LangChainAI announces the Interrupt: The AI Agent Conference in San Francisco, featuring technical talks and workshops from industry leaders like Michele Catasta and Adam D’Angelo.
- AI Agent Meetups: @LangChainAI promotes the LangChain Orange County User Group meetup, fostering connections among AI builders, startups, and developers.
Company Updates and Announcements
- OpenAI Financials and Usage: @sama reveals that OpenAI is currently losing money on Pro subscriptions due to higher-than-expected usage.
- DeepSeek and Together AI Partnerships: @togethercompute announces DeepSeek-V3's availability on Together AI APIs, highlighting its efficiency with 671B MoE parameters and ranked #7 in Chatbot Arena.
AI Research and Technical Discussions
- Scaling Laws and Compute Efficiency: @cwolferesearch provides an in-depth analysis of LLM scaling laws, discussing power laws and the impact of data scaling. @RichardMCNgo debates the ASI race and the potential for recursive self-improvement in AI models.
- AI Ethics and Safety: @mmitchell_ai addresses ethical issues for 2025, focusing on data consent and voice cloning as primary concerns.
Technical Tools and Software Development
- Development Frameworks and Utilities: @tom_doerr introduces Browserless, a service for executing headless browser tasks using Docker. @tom_doerr presents Terragrunt, a tool that wraps Terraform for infrastructure management with DRY code principles.
- AI Integration and APIs: @kubtale discusses Gemini coder's image support and AI-Gradio integration, enabling developers to build custom AI applications with ease.
Memes and Humor
- Humorous Takes on AI and Technology: @doomslide humorously remarks on Elon's interactions with the UK state apparatus. @jackburning posts amusing content about AI models and their quirks.
- Light-hearted Conversations: @tejreddy shares a funny anecdote about AI displacement of artists, while @sophiamyang jokes about delayed flights and AI-generated emails.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek V3's Dominance in AI Workflows
- DeepSeek V3 is the shit. (Score: 524, Comments: 207): DeepSeek V3 impresses with its 600 billion parameters, providing reliability and versatility that previous models, including Claude, ChatGPT, and earlier Gemini variants, lacked. The model excels in generating detailed responses and adapting to user prompts, making it a preferred choice for professionals frustrated by inconsistent workflows with state-of-the-art models.
- Users compare DeepSeek V3 to Claude 3.5 Sonnet, noting its coding capabilities but expressing frustration with its slow response times for long contexts. Some users face issues with the API when using tools like Cline or OpenRouter, while others appreciate its stability in the chat web interface.
- Discussions highlight the deployment challenges of DeepSeek V3, particularly the need for GPU server clusters, making it less accessible for individual users. There is a suggestion that investing in Intel GPUs could have been a strategic move to encourage development of more specified code.
- AMD's mi300x and mi355x products are mentioned in relation to AI development, with mi300x being a fast-selling product despite not being initially designed for AI. The upcoming Strix Halo APU is noted as a significant development for high-end consumer markets, indicating AMD's growing presence in the AI hardware space.
- DeepSeek v3 running at 17 tps on 2x M2 Ultra with MLX.distributed! (Score: 105, Comments: 30): DeepSeek v3 reportedly achieves 17 transactions per second (TPS) on a setup with 2x M2 Ultra processors using MLX.distributed technology. The information was shared by a user on Twitter, with a link provided for further details here.
- Discussions highlighted the cost and performance comparison between M2 Ultra processors and used 3090 GPUs, noting that while 3090 GPUs offer higher performance by an order of magnitude, they are significantly less power-efficient. MoffKalast calculated that for the price of $7,499.99, one could power a 3090 GPU for about a decade at full load, considering electricity costs at 20 cents per kWh.
- Context length and token generation were important technical considerations, with users questioning how the number of tokens impacts TPS and whether the 4096-token prompt affects performance. Coder543 referenced a related discussion on Reddit regarding performance differences with various prompt lengths.
- The MOE (Mixture of Experts) model's efficiency was debated, with fallingdowndizzyvr pointing out that all experts need to be loaded since their usage cannot be predicted beforehand, impacting resource allocation and performance.
Theme 2. Dolphin 3.0: Combining Advanced AI Models
- Dolphin 3.0 Released (Llama 3.1 + 3.2 + Qwen 2.5) (Score: 304, Comments: 37): Dolphin 3.0 has been released, incorporating Llama 3.1, Llama 3.2, and Qwen 2.5.
- Discussions around Dolphin 3.0 highlight concerns about model performance and benchmarks, with users noting the absence of comprehensive benchmarks making it difficult to assess the model's quality. A user shared a quick test result showing Dolphin 3.0 scoring 37.80 on the MMLU-Pro dataset, compared to Llama 3.1 scoring 47.56, but cautioned that these results are preliminary.
- The distinction between Dolphin and Abliterated models was clarified, with Abliterated models having their refusal vectors removed, whereas Dolphin models are fine-tuned on new datasets. Some users find Abliterated models more reliable, while Dolphin models are described as "edgy" rather than truly "uncensored."
- There is anticipation for future updates, with Dolphin 3.1 expected to reduce the frequency of disclaimers. Larger models, such as 32b and 72b, are currently in training, as confirmed by Discord announcements, with efforts to improve model behavior by flagging and removing disclaimers.
- I made a (difficult) humour analysis benchmark about understanding the jokes in cult British pop quiz show Never Mind the Buzzcocks (Score: 108, Comments: 34): The post discusses a humor analysis benchmark called "BuzzBench" for evaluating emotional intelligence in language models (LLMs) using the cult British quiz show "Never Mind the Buzzcocks". The benchmark ranks models by their humor understanding scores, with "claude-3.5-sonnet" scoring the highest at 61.94 and "llama-3.2-1b-instruct" the lowest at 9.51.
- Cultural Bias Concerns: Commenters express concerns about potential cultural bias in humor analysis, particularly due to the British context of "Never Mind the Buzzcocks". Questions arise about how such biases are addressed, such as whether British spelling or audience is explicitly stated.
- Benchmark Details: The benchmark, BuzzBench, evaluates models on understanding and predicting humor impact, with a maximum score of 100. The current state-of-the-art score is 61.94, and the dataset is available on Hugging Face.
- Interest in Historical Context: There is curiosity about how models would perform with older episodes of the quiz show, questioning whether familiarity with less popular hosts like Simon Amstell impacts humor understanding.
Theme 3. RTX 5090 Rumors: High Bandwidth Potential
- RTX 5090 rumored to have 1.8 TB/s memory bandwidth (Score: 141, Comments: 161): The RTX 5090 is rumored to have 1.8 TB/s memory bandwidth and a 512-bit memory bus, surpassing all professional cards except the A100/H100 with their 2 TB/s bandwidth and 5120-bit bus. Despite its 32GB GDDR7 VRAM, the RTX 5090 could potentially be the fastest for running any LLM <30B at Q6.
- Discussions highlight the lack of sufficient VRAM in NVIDIA's consumer GPUs, with criticisms that a mere 8GB increase over two generations is inadequate for AI and gaming needs. Users express frustration that NVIDIA intentionally limits VRAM to protect their professional card market, suggesting that a 48GB or 64GB model would cannibalize their high-end offerings.
- Cost concerns are prevalent, with users noting that the price of a single RTX 5090 could equate to multiple RTX 3090s, which still hold significant value due to their VRAM and performance. The price per GB of VRAM for consumer cards is seen as more favorable compared to professional GPUs, but the overall cost remains prohibitive for many.
- Energy efficiency and power draw are critical considerations, as the RTX 5090 is rumored to have a significant power requirement of at least 550 watts, compared to the 3090's 350 watts. Users discuss undervolting as a potential solution, but emphasize that the trade-off between speed, VRAM, and power consumption remains a key factor in GPU selection.
- LLMs which fit into 24Gb (Score: 53, Comments: 32): The author has built a rig with an i7-12700kf CPU, 128Gb RAM, and an RTX 3090 24 GB, highlighting that models fitting into VRAM run significantly faster. They mention achieving good results with Gemma2 27B for generic discussions and Qwen2.5-coder 31B for programming tasks, and inquire about other models suitable for a 24Gb VRAM limit.
- Model Recommendations: Users suggest various models suitable for a 24GB VRAM setup, including Llama-3_1-Nemotron-51B-instruct and Mistral small. Quantized Q4 models like QwQ 32b and Llama 3.1 Nemotron 51b are highlighted for their efficiency and performance in this setup.
- Performance Metrics: Commenters discuss the throughput of different models, with Qwen2.5 32B achieving 40-60 tokens/s on a 3090 and potentially higher on a 4090. 72B Q4 models can run at around 2.5 tokens/s with partial offloading, while 32B Q4 models achieve 20-38 tokens/s.
- Software and Setup: There is interest in the software setups used to achieve these performance metrics, with requests for details on setups using EXL2, tabbyAPI, and context lengths. A link to a Reddit discussion provides further resources for model selection on single GPU setups.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. OpenAI's Financial Struggles Amid O1-Pro Criticism
- OpenAI is losing money (Score: 2550, Comments: 518): OpenAI is reportedly facing financial challenges with its subscription models. Without additional context, the specific details of these financial difficulties are not provided.
- Many users express mixed feelings about the $200 subscription for o1-Pro, with some finding it invaluable for productivity and coding efficiency, while others question its worth due to increased competition among coders and potential for rising costs. Treksis and KeikakuAccelerator highlight its benefits for complex coding tasks, but IAmFitzRoy raises concerns about its impact on the coding job market.
- Discussions reveal skepticism about OpenAI's financial strategy, with comments suggesting that despite high costs, the company continues to lose money, possibly due to the high operational costs of running advanced models like o1-Pro. LarsHaur and Vectoor discuss the company's spending on R&D and the challenges of maintaining a positive cash flow.
- Subscription model criticisms include calls for an API-based model and concerns about the sustainability of current pricing, as noted by MultiMarcus and mikerao10. Users like Fantasy-512 and Unfair-Associate9025 express disbelief at the pricing strategy, questioning the long-term viability and potential for price increases.
- You are not the real customer. (Score: 237, Comments: 34): Anthony Aguirre argues that tech companies prioritize employers over individual consumers in AI investment strategies, aiming for significant financial returns by potentially replacing workers with AI systems. This reflects the broader financial dynamics influencing AI development and infrastructure investment.
- Universal Basic Income (UBI) is criticized as a fantasy that won't solve the economic challenges posed by AI replacing jobs. Commenters argue that the transition will create a new form of serfdom, with companies gaining power by offering technology that is in demand, but ultimately dependent on consumer purchasing power.
- AI Replacement of workers is expected to occur before AI can genuinely perform at human levels, driven by cost reduction rather than quality improvement. This mirrors past trends like offshoring for cheaper labor, reflecting a focus on financial efficiency over service quality.
- Economic Dynamics in AI development are acknowledged by AI practitioners as prioritizing profit and cost-cutting over consumer benefits. The discussion highlights the inevitability of this shift and the potential for a difficult transition for both workers and companies.
Theme 2. AI Level 3 by 2025: OpenAI's Vision and Concerns
- AI level 3 (agents) in 2025, as new Sam Altman's post... (Score: 336, Comments: 162): By 2025, the development of AI Level 3 agents is expected to significantly impact business productivity, marking a shift from basic AI chatbots to more advanced AI systems. The post expresses optimism that these AI advancements will provide effective tools that lead to broadly positive outcomes in the workforce.
- There is skepticism about the impact of AI Level 3 agents on companies, with some arguing that individuals will benefit more than corporations. Immersive-matthew points out that many people have already embraced AI for productivity, while companies have not seen equivalent benefits, suggesting that AI could empower individuals rather than large corporations.
- Concerns about the economic and workforce implications of AI advancements are prevalent. Kiwizoo and Grizzly_Corey discuss potential economic collapse and workforce disruption, suggesting that AI and robotics could eliminate the need for human labor, leading to significant societal changes.
- There is criticism of the hype surrounding AGI and doubts about its near-term realization. Agitated_Marzipan371 and others express skepticism about the feasibility of true AGI by 2025, viewing the term as a marketing strategy rather than a realistic goal, and compare it to other overhyped technological predictions.
Theme 3. Efficiency in AI Models: Claude 3.5 and Google's Advances
- Watched Anthropic CEO interview after reading some comments. I think noone knows why emergent properties occur when LLM complexity and training dataset size increase. In my view these tech moguls are competing in a race where they blindly increase energy needs and not software optimisation. (Score: 130, Comments: 79): The post critiques the approach of tech leaders in the AI field, arguing that they focus on scaling up LLM complexity and training dataset sizes without understanding the emergence of properties like AGI. The author suggests investing in nuclear energy technology as a more effective strategy rather than blindly increasing energy demands without optimizing software.
- Optimization and Scaling: Several comments highlight the focus on optimization in AI development, with RevoDS noting that GPT-4o is 30x cheaper and 8x smaller than GPT-4, suggesting that significant efforts are being made to optimize models alongside scaling. Prescod argues that the industry is not "blindly" scaling but also exploring better learning algorithms, though scaling has been effective so far.
- Nuclear Energy and AI: Rampants mentions that tech leaders like Sam Altman are involved in nuclear startups such as Oklo, and Microsoft is also exploring nuclear energy, indicating a parallel interest in sustainable energy solutions for AI. However, new nuclear projects face significant approval and implementation challenges.
- Emergent Properties and Complexity: Pixel-Piglet discusses the inevitability of emergent properties as neural networks scale, drawing parallels to the human brain. The comment suggests that the complexity of data and models leads to unexpected outcomes, a perspective supported by Ilya Sutskever's observations on model intricacy and emergent faculties.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1. AI Model Performance and Troubleshooting
- DeepSeek V3 Faces Stability Challenges: Users reported performance issues with DeepSeek V3, including long response times and failures on larger inputs. Despite good benchmarks, concerns arose about its practical precision and reliability in real-world applications.
- Cursor IDE Users Navigate Inconsistent Model Performance: Developers experienced inconsistent behavior from Cursor IDE, especially with Claude Sonnet 3.5, citing context retention issues and confusing outputs. Suggestions included downgrading versions or simplifying prompts to mitigate these problems.
- LM Studio 0.3.6 Model Loading Errors Spark User Frustration: The new release of LM Studio led to exit code 133 errors and increased RAM usage when loading models like QVQ and Qwen2-VL. Some users overcame these setbacks by adjusting context lengths or reverting to older builds.
Theme 2. New AI Models and Tool Releases
- Unsloth Unveils Dynamic 4-bit Quantization Magic: Unsloth introduced dynamic 4-bit quantization, preserving model accuracy while reducing VRAM usage. Testers reported speed boosts without sacrificing fine-tuning fidelity, marking a significant advancement in efficient model training.
- LM Studio 0.3.6 Steps Up with Function Calling and Vision Support: The latest LM Studio release features a new Function Calling API for local model usage and supports Qwen2VL models. Developers praised the extended capabilities and improved Windows installer, enhancing user experience.
- Aider Expands Java Support and Debugging Integration: Contributors highlighted that Aider now supports Java projects through prompt caching and is exploring debugging integration with tools like ChatDBG. These advancements aim to enhance development workflows for programmers.
Theme 3. Hardware Updates and Anticipations
- Nvidia RTX 5090 Leak Excites AI Enthusiasts: A leak revealed that the upcoming Nvidia RTX 5090 will feature 32GB of GDDR7 memory, stirring excitement ahead of its expected CES announcement. The news overshadowed recent RTX 4090 buyers and hinted at accelerated AI training workloads.
- Community Debates AMD vs. NVIDIA for AI Workloads: Users compared AMD CPUs and GPUs with NVIDIA offerings for AI tasks, expressing skepticism about AMD's claims. Many favored NVIDIA for consistent performance in heavy-duty models, though some awaited real-world benchmarks of AMD's new products.
- Anticipation Builds for AMD’s Ryzen AI Max: Enthusiasts showed strong interest in testing AMD's Ryzen AI Max, speculating on its potential to compete with NVIDIA for AI workloads. Questions arose about running it alongside GPUs for combined performance in AI applications.
Theme 4. AI Ethics, Policy, and Industry Movements
- OpenAI's Reflections on AGI Progress Spark Debate: Sam Altman discussed OpenAI's journey towards AGI, prompting debates about corporate motives and transparency in AI development. Critics highlighted concerns over potential impacts on innovation and entrepreneurship due to advanced AI capabilities.
- Anthropic Faces Copyright Challenges Over Claude: Anthropic agreed to maintain guardrails on Claude to prevent sharing copyrighted lyrics amid legal action from publishers. The dispute underscored tensions between AI development and intellectual property rights.
- Alibaba and 01.AI Collaborate on Industrial AI Lab: Alibaba Cloud partnered with 01.AI to establish a joint AI laboratory targeting industries like finance and manufacturing. The collaboration aims to accelerate the adoption of large-model solutions in enterprise settings.
Theme 5. Advances in AI Training Techniques and Research
- PRIME RL Unlocks Advanced Language Reasoning: Researchers examined PRIME (Process Reinforcement through Implicit Rewards), showcasing scalable RL techniques to strengthen language model reasoning. The method demonstrates surpassing existing models with minimal training steps.
- MeCo Method Accelerates Language Model Pre-training: The MeCo technique, introduced by Tianyu Gao, prepends source URLs to training documents, accelerating LM pre-training. Early feedback indicates modest improvements in training outcomes across various corpora.
- Efficient Fine-Tuning with LoRA Techniques Gains Traction: Users discussed using LoRA for efficient fine-tuning of large models with limited GPU capacity. Advice centered on optimizing memory usage without sacrificing model performance, especially for models like DiscoLM on low-VRAM setups.
PART 1: High level Discord summaries
aider (Paul Gauthier) Discord
- Sophia's Soaring Solutions & Aider's Apparent Affinity: The brand-new Sophia platform introduces autonomous agents, robust pull request reviews, and multi-service support, as shown at sophia.dev, aimed at advanced engineering workflows.
- Community members compared these capabilities to Aider's features, praising the overlap and showing interest in testing Sophia for AI-driven software processes.
- Val Town's Turbocharged LLM Tactics: In a blog post, Val Town shared their progress from GitHub Copilot to newer assistants like Bolt and Cursor, trying to stay aligned with rapidly updating LLMs.
- Their approach, described as fast-follows, sparked discussion on adopting proven strategies from other teams to refine code generation systems.
- AI Code Analysis Gains 'Senior Dev' Sight: An experiment outlined in The day I taught AI to read code like a Senior Developer introduced context-aware grouping, enabling the AI to prioritize core changes and architecture first.
- Participants noted this approach overcame confusion in React codebases, calling it a major leap beyond naive, line-by-line AI parsing methods.
- Aider Advances Java and Debugging Moves: Contributors revealed Aider supports Java projects through prompt caching, referencing the installation docs for flexible setups.
- They also explored debugging with frameworks like ChatDBG, highlighting the potential synergy between Aider and interactive troubleshooting solutions.
Unsloth AI (Daniel Han) Discord
- Unsloth’s 4-bit Wizardry: The team introduced dynamic 4-bit quantization, preserving model accuracy while trimming VRAM usage.
- They shared installation tips in the Unsloth docs and reported that testers saw speed boosts without sacrificing fine-tuning fidelity.
- Concurrent Fine-Tuning Feats: A user confirmed it's safe to fine-tune multiple model sizes (0.5B, 1.5B, 3B) simultaneously, as explained in Unsloth Documentation.
- They noted key VRAM limits, advising smaller learning rates and LoRA methods to ensure memory efficiency.
- Rohan's Quantum Twirl & Data Tools: Rohan showcased interactive Streamlit apps for Pandas data tasks, linking his LinkedIn posts and a quantum blog here.
- He combined classical data analysis with complex number exploration, sparking curiosity about integrating AI with emerging quantum methods.
- LLM Leaderboard Showdown: Community members ranked Gemini and Claude at the top, praising Gemini experimental 1207 as a standout free model.
- Discussions suggested Gemini outran other open-source builds, fueling a debate on which LLM truly holds the crown.
Codeium (Windsurf) Discord
- Tidal Tweaks: Codeium Channels & December Changelist: The Codeium server introduced new channels for .windsurfrules strategy, added a separate forum for collaboration, and published the December Changelist.
- Members anticipate a new stage channel and more ways to display community achievements, with many praising the streamlined support portal approach.
- Login Limbo: Authentication Hiccups & Self-Hosting Hopes: Users encountered Codeium login troubles, suggesting token resets, while others questioned on-prem setups for 10–20 devs under an enterprise license.
- Some recommended a single PC for hosting, though concerns arose about possible performance bottlenecks if usage grows.
- Neovim Nudges: Plugin Overhaul & Showcase Channel Dreams: Discussion focused on
codeium.vimandCodeium.nvimfor Neovim, spotlighting verbose comment completions and the prospect of a showcase channel.- Community members expect more refined plugin behavior, hoping soon to exhibit Windsurf- and Cascade-based apps in a dedicated forum.
- Claude Crunch: Windsurf Struggles & Cascade Quirks: Windsurf repeatedly fails to apply code changes with Claude 3.5, producing 'Cascade cannot edit files that do not exist' errors and prompting brand-new sessions.
- Many suspect Claude struggles with multi-file work, nudging users toward Cascade Base for more predictable results.
- Credit Confusion: Premium vs. Flex & Project Structure: Developers debated Premium User Prompt Credits versus Flex Credits, noting that Flex supports continuous prompts and elevated usage with Cascade Base.
- They also suggested consolidating rules into a single .windsurfrules file and shared approaches for backend organization.
Cursor IDE Discord
- Cursor Changelogs & Plans: The newly released Cursor v0.44.11 prompted calls for better changelogs and modular documentation, with a download link.
- Some developers stressed the need for flexible project plan features, wanting simpler steps to track tasks in real time.
- Claude Sonnet 3.5 Surprises: Engineers reported inconsistent performance from Claude Sonnet 3.5, citing context retention issues and confusing outputs in long conversations.
- A few users suggested that reverting versions or using more concise prompts sometimes outperformed comprehensive instructions.
- Cursor's AGI Ambitions: Several users see Cursor as a potential springboard for higher-level intelligence in coding, debating ways to utilize task-oriented features.
- They speculated that refining these features might enhance AI-driven capabilities, closing gaps between manual coding and automated assistance.
- Composer & Context Calamities: Developers encountered trouble with Composer on large files, citing editing issues and poor context handling for expanded code blocks.
- They noticed random context resets when switching tasks, causing unintended changes and confusion across sessions.
LM Studio Discord
- LM Studio 0.3.6 Steps Up with Tool Calls: LM Studio 0.3.6 arrived featuring a new Function Calling / Tool Use API for local model usage, plus Qwen2VL support.
- Model Loads Meet Exit Code 133: Users encountered exit code 133 errors and increased RAM usage when loading QVQ and Qwen2-VL in LM Studio.
- Some overcame these setbacks by adjusting context lengths or reverting to older builds, while others found success using MLX from the command line.
- Function Calling API Draws Praise: The Function Calling API extends model output beyond text, with users applauding both the documentation and example workflows.
- However, a few encountered unanticipated changes in JiT model loading after upgrading to 3.6, calling for additional bug fixes.
- Hardware Tussle Between AMD and NVIDIA: Participants flagged that a 70B model needs more VRAM than most GPUs offer, loitering on CPU inference or smaller quantizations.
- They debated AMD vs NVIDIA claims—some championed AMD CPU performance, though skepticism lingered about real-world gains with massive models.
- Chatter on AMD’s Ryzen AI Max: Enthusiasts expressed strong interest in AMD’s new Ryzen AI Max, questioning its potential to rival NVIDIA for heavy-duty model demands.
- They asked about running it alongside GPUs for combined muscle, reflecting persistent curiosity around multi-device setups.
Stackblitz (Bolt.new) Discord
- Stackblitz Backups Vanish: When reopening Stackblitz, some users found their projects reverted to earlier states, losing code despite frequent saves, as noted in the #prompting channel.
- Community members confirmed varied experiences but offered no universal solution beyond double-checking saves and backups.
- Deployment Workflow Confusion: Users struggled with pushing code to GitHub from different services like Netlify or Bolt, debating whether to rely on Bolt Sync or external tools.
- They agreed that a consistent approach to repository updates is crucial, but no definitive workflow emerged from the discussions.
- Token Tangles & Big Bills: Participants reported hefty token usage, sometimes burning hundreds of thousands for minor modifications, prompting concerns about cost.
- They recommended refining instructions to reduce token waste, emphasizing that careful edits and thorough planning help prevent excessive usage.
- Supabase & Netlify Snags: Developers faced Netlify deployment errors while integrating with Bolt, referencing this GitHub issue for guidance.
- Others encountered Supabase login and account creation problems, often needing new .env setups to get everything working properly.
- Prompting & OAuth Quirks: Community members advised against OAuth in Bolt during development, pointing to repeated authentication failures and recommending email-based logins instead.
- Discussion also highlighted the importance of efficient prompts for Bolt to limit token consumption, with users trading tips on how to shape instructions accurately.
Stability.ai (Stable Diffusion) Discord
- Stable Surprises: Model Mix-Ups: Multiple users discovered that Civit.ai models struggled with basic prompts like 'woman riding a horse', fueling confusion about prompt specificity.
- Some participants shared that certain LoRAs outperformed others, linking to CogVideoX-v1.5-5B I2V workflow and praising the sharper quality outcomes.
- LoRA Logic or Full Checkpoint Craze: Participants debated whether LoRAs or entire checkpoints best addressed style needs, with LoRAs providing targeted enhancements while full checkpoints offered broader capabilities.
- They noted potential model conflicts if multiple LoRAs are stacked, emphasizing a preference for specialized training and referencing GitHub - bmaltais/kohya_ss for streamlined custom LoRA creation.
- ComfyUI Conundrums: Node-Based Mastery: The ComfyUI workflow sparked chatter, as newcomers found its node-based approach both flexible and challenging.
- Resources like Stable Diffusion Webui Civitai Helper were recommended to easily manage LoRA usage and reduce workflow friction.
- Inpainting vs. img2img: The Speed Struggle: Some users reported inpainting took noticeably longer than img2img, despite editing only part of the image.
- They theorized that internal operations can vary widely in complexity, citing references to AnimateDiff for advanced multi-step generation.
- GPU Gossip: 5080 & 5090 Speculations: Rumors swirled around upcoming NVIDIA GPUs, with mention of the 5080 and 5090 possibly priced at $1.4k and $2.6k.
- Concerns also arose over market scalping, prompting some to suggest waiting for future AI-focused cards or more official announcements from NVIDIA.
Latent Space Discord
- GDDR7 Gains with Nvidia's 5090: A last-minute leak from Tom Warren revealed the Nvidia RTX 5090 will include 32GB of GDDR7 memory, just before its expected CES debut.
- Enthusiasts discussed the potential for accelerated training workloads, anticipating official announcements to confirm specs and release timelines.
- Interrupt with LangChain: LangChain unveiled Interrupt: The AI Agent Conference in May at San Francisco, featuring code-centric workshops and deep sessions.
- Some suggested the timing aligns with larger agent-focused events, marking this gathering as a hub for those pushing new agentic solutions.
- PRIME Time: Reinforcement Rewards Revisited: Developers buzzed about PRIME (Process Reinforcement through Implicit Rewards), showing Eurus-2 surpassing Qwen2.5-Math-Instruct with minimal training steps.
- Critics called it a hot-or-cold game between two LLMs, while supporters championed it as a leap for dense step-by-step reward modeling.
- ComfyUI & AI Engineering for Art: A new Latent.Space podcast episode highlighted ComfyUI's origin story, featuring GPU compatibility and video generation for creative work.
- The team discussed how ComfyUI evolved from a personal prototype into a startup innovating the AI-driven art space.
- GPT-O1 Falls Short on SWE-Bench: Multiple tweets, like this one, showed OpenAI’s GPT-O1 hitting 30% on SWE-Bench Verified, contrary to the 48.9% claim.
- Meanwhile, Claude scored 53%, sparking debates on model evaluation and reliability in real-world tasks.
Interconnects (Nathan Lambert) Discord
- Nvidia 5090’s Surprising Appearance: Reports from Tom Warren highlight the Nvidia RTX 5090 surfacing with 32GB GDDR7 memory, overshadowing recent RTX 4090 buyers, just before CES. The leak stirred excitement over its specs and price implications for high-end AI workloads.
- Community reactions ranged from regret over hasty 4090 purchases to curiosity regarding upcoming benchmark results. Some speculated that Nvidia’s next-gen lineup could accelerate compute-intense training pipelines further.
- Alibaba & 01.AI’s Joint Effort: Alibaba Cloud and 01.AI have formed a partnership, as noted in an SCMP article, to establish an industrial AI joint laboratory targeting finance, manufacturing, and more. They plan to merge research resources for large-model solutions, aiming to speed adoption in enterprise settings.
- Questions persist around the scope of resource-sharing and whether overseas expansions will occur. Despite mixed reports, participants spotted potential for boosting next-gen enterprise tech in Asia.
- METAGENE-1 Takes on Pathogens: A 7B parameter metagenomic model named METAGENE-1 has been open-sourced in concert with USC researchers, per Prime Intellect. This tool targets planetary-scale pathogen detection to strengthen pandemic prevention.
- Members highlighted that a domain-specific model of this scale could accelerate epidemiological monitoring. Many anticipate new pipelines for scanning genomic data in large public health initiatives.
- OpenAI’s O1 Hits a Low Score: O1 managed only 30% on SWE-Bench Verified, contradicting the previously claimed 48.9%, while Claude reached 53% in the same test, as reported by Alex_Cuadron. Testers suspect that the difference might reflect prompting details or incomplete validation steps.
- This revelation triggered debates about post-training improvements and real-world performance. Some urged more transparent benchmarks to clarify whether O1 merely needs refined instructions.
- MeCo Method for Quicker Pre-training: The MeCo (metadata conditioning then cooldown) technique, introduced by Tianyu Gao, prepends source URLs to training documents for accelerated LM pre-training. This added metadata provides domain context cues, which may reduce guesswork in text comprehension.
- Skeptics questioned large-scale feasibility, but the method earned praise for clarifying how site-based hints can optimize training. Early feedback indicates a modest improvement in training outcomes for certain corpora.
Nous Research AI Discord
- Hermes 3 Wrestles with Stage Fright: Community members reported Hermes 3 405b producing anxious and timid characters, even for roles meant to convey confidence. They shared tips like adjusting system prompts and providing clarifying examples, but acknowledged the challenge of shaping desired model behaviors.
- Some pointed out that tweaking the prompt baseline is tricky, echoing a broader theme of balancing AI capability with user prompts. Others insisted that thorough manual testing is the only reliable method to verify characterizations.
- ReLU² Rivalry with SwiGLU: A follow-up to Primer: Searching for Efficient Transformers indicated that ReLU² edges out SwiGLU in cost-related metrics, prompting debate over why LLaMA3 didn't adopt it.
- Some participants noted the significance of feed-forward block tweaks, calling the improvement “a new spin on Transformer optimization.” They wondered if lower training overhead might lead to more experiments in upcoming architectures.
- PRIME RL Strengthens Language Reasoning: Users examined the PRIME RL GitHub repository, which claims a scalable RL solution to strengthen advanced language model reasoning. They commented that it could open bigger avenues for structured thinking in large-scale LLMs.
- One user admitted exhaustion when trying to research it but still acknowledged the project’s promising focus, indicating a shared community desire for more robust RL-based approaches. The conversation signaled interest in further exploration once members are re-energized.
- OLMo’s Massive Collaborations: Team OLMo published 2 OLMo 2 Furious (arXiv link), presenting new dense autoregressive models with improved architecture and data mixtures. This effort highlights their push toward open research, with multiple contributors refining training recipes for next-gen LLM development.
- Community members praised the broad collaboration, emphasizing how expansions in architecture and data can spur deeper experimentation. They saw it as a sign that open discourse around advanced language modeling is gaining steam across researchers.
OpenAI Discord
- OmniDefender's Local LLM Leap: In OmniDefender, users integrate a Local LLM to detect malicious URLs and examine file behavior offline. This setup avoids external calls but struggles when malicious sites block outgoing checks, complicating threat detection.
- Community feedback lauded offline scanning potential, referencing GitHub - DustinBrett/daedalOS: Desktop environment in the browser as an example of heavier local applications. One member joked that it showcased a 'glimpse of self-contained defenses' powering malware prevention.
- MCP Spec Gains Momentum: Implementing MCP specifications has simplified plugin integration, sparking a jump in AI development. Some contrasted MCP with older plugin methods, touting it as a new standard for versatile expansions.
- Participants noted that 'multi-compatibility is the logical next step,' fueling widespread interest. They predicted a 'plugin arms race' as providers chase MCP readiness.
- Sky-High GPT Bills: OpenAI caused a stir by revealing $25 per message as the operating cost of its large GPT model. Developers expressed concern about scaling such expenses for routine usage.
- Some participants called the price 'steep' for persistent experiments. Others hoped tiered packages might open advanced GPT-4 features to more users.
- Sora’s Single-Image Snafu: Developers lamented that Sora only supports one image upload per video, trailing platforms with multiple-image workflows. This restriction presents a significant snag for detailed image processing tasks.
- Feedback included comments like 'the image results are decent, but one at a time is a big limitation.' Several pinned hopes on an expansion, calling it 'critical for modern multi-image pipelines.'
- AI Document Analysis Tactics: Members deliberated on scanning vehicle loan documents without exposing PII, recommending redaction before any AI-driven examination. This manual approach aims to safeguard privacy while using advanced parsing techniques.
- One participant dubbed it 'brute-force privacy protection' and urged caution with automated solutions. Another recommended obtaining a sanitized version from official sources to circumvent storing confidential data.
Perplexity AI Discord
- Apple's Siri Snooping Saga Simmers: Apple settled the Siri Snooping lawsuit, raising privacy questions and highlighting user concerns in this article.
- Commenters examined the ramifications of prolonged legal and ethical debates, underscoring the need for robust data protections.
- Swift Gains Steam for Modern Development: A user shared insights on Swift and its latest enhancements, referencing this overview.
- Developers praised Swift’s evolving capabilities, calling it a prime candidate for app creation on Apple platforms.
- Gaming Giant Installs AI CEO: An unnamed gaming company broke ground by appointing an AI CEO, with details in this brief.
- Observers noted this emerging corporate experiment as a sign of fresh approaches to management and strategy.
- Mistral Sparks LLM Curiosity: Members discussed Mistral as a potential LLM option without deep expertise, wondering if it adds new functionality among the many AI tools.
- Users questioned its distinct advantages, seeking concrete performance data before considering broad adoption.
Eleuther Discord
- DeepSeek v3 Dives Deeper: Enthusiasts tested DeepSeek v3 locally with 4x3090 Ti GPUs, targeting 68.9% on MMLU-pro in 3 days, pointing to Eleuther AI’s get-involved page for more resources.
- Their conversation highlighted hardware constraints and suggestions for architectural improvements, referencing a tweet on new Transformer designs.
- MoE Madness and Gated DeltaNet: Members debated high-expert MoE viability and parameter balancing in Gated DeltaNet, linking to the GitHub code and a tweet on DeepSeek’s MoE approach.
- They questioned the practical trade-offs for large-scale labs while praising Mamba2 for reducing parameters, hinting that the million-experts concept may not fully deliver on performance.
- Metadata Conditioning Gains: Researchers proposed Metadata Conditioning (MeCo) as a novel technique for guiding language model learning, citing “Metadata Conditioning Accelerates Language Model Pre-training” (arXiv) and referencing the Cerebras RFP.
- They saw meaningful pre-training efficiency boosts at various scales, and also drew attention to Cerebras AI offering grants to push generative AI research.
- CodeLLMs Under the Lens: Community members shared mechanistic interpretability findings on coding models, pointing to Arjun Guha’s Scholar profile and explored type hint steering via “Understanding How CodeLLMs (Mis)Predict Types with Activation Steering.”
- They discussed Selfcodealign for code generation, teased for 2024, and argued that automated test suite feedback could correct mispredicted types.
- Chat Template Turbulence: Multiple evaluations with chat templates on L3 8B hovered around 70%, referencing lm-evaluation-harness code.
- They uncovered a 73% jump when removing templates, fueling regret for not testing earlier and clarifying request caching nuances for local HF models.
OpenRouter (Alex Atallah) Discord
- llmcord Leaps Forward: The llmcord project has gained over 400 GitHub stars for letting Discord serve as a hub for multiple AI providers, including OpenRouter and Mistral.
- Contributors highlighted its easy setup and potential to unify LLM usage in a single environment, noting its flexible API compatibility.
- Nail Art Gains AI Twist: A new Nail Art Generator uses text prompts and up to 3 images to produce fun designs, powered by OpenRouter and Together AI.
- Members praised its quick outcomes, calling it “a neat fusion of creativity and AI,” and pointing to future expansions in prompts and art styles.
- Gemini Flash 1.5 Steps Up: Community members weighed Gemini Flash 1.5 vs the 8B edition, recommending a smaller model first for better cost control, referencing competitive pricing.
- They noted that Hermes testers see reduced token fees using OpenRouter instead of AI Studio, spurring interest in switching to this model.
- DeepSeek Hits Snags: Multiple users reported DeepSeek V3 downtime and slower outputs for prompts beyond 8k tokens, linking it to scaling issues.
- Some suggested bypassing OpenRouter for a direct DeepSeek connection, expecting that move to cut down latency and avoid temporary limits.
Notebook LM Discord Discord
- Audio Freeze Frenzy at 300 Sources: One user noted that when up to 300 sources are included, the NLM audio overview freezes on one source, disrupting playback.
- They emphasized concerns about reliability for larger projects, with hopes for a fix to improve multi-source handling.
- NotebookLM Plus Packs a Punch: Members dissected the differences between free and paid tiers, referring to NotebookLM Help for specific details on upload limits and features.
- They discussed advanced capabilities like larger file allowances, prompting some to weigh the upgrade for heavier workloads.
- Podcast Breaks and Voice Roulette: Frequent podcast breaks persisted despite custom instructions, prompting suggestions for more forceful system prompts to keep hosts talking.
- One user tested a single male voice successfully, but attempts to opt for only the female expert voice faced unexpected pushback.
- Education Prompts and Memos Made Easy: People explored uploading memos from a Mac to NLM for structured learning, hoping to streamline digital note-taking.
- Another thread pitched a curated list of secondary education prompts, highlighting community-driven sharing of specialized tips.
GPU MODE Discord
- Quantization Quarrels & Tiling Trials: Members noted that quantization overhead can double loading time for float16 weights and that 32x32 tiling in matmul runs 50% slower than 16x16, illustrating tricky impl details on GPU architectures.
- They debated whether register spilling might cause the slowdown and expressed interest in exploring simpler, architecture-aware explanations.
- Triton Tuning & Softmax Subtleties: Users observed 3.5x faster results with
torch.emptyinstead oftorch.empty_like, while caching best block sizes viatriton.heuristicscan cut autotune overhead.- They also reported reshape tricks for softmax kernels, but row-major vs col-major concerns lingered as performance varied.
- WMMA Woes & ROCm Revelations: The wmma.load.a.sync instruction consumes 8 registers for a 16×16 matrix fragment, whereas wmma.store.d.sync only needs 4, sparking debates on data packing intricacies.
- Meanwhile, confusion arose around MI210’s reported 2 thread-block limit vs the A100’s 32, leaving members unsure about hardware design implications.
- SmolLM2 & Bits-and-Bytes Gains: A Hugging Face collaboration on SmolLM2 with 11 trillion tokens launched param sizes at 135M, 360M, and 1.7B, aiming for better efficiency.
- In parallel, a new bitsandbytes maintainer announced their transition from software engineering, underscoring fresh expansions in GPU-oriented optimizations.
- Riddle Rewards & Rejection Tactics: Thousands of completions for 800 riddles revealed huge log-prob variance, prompting negative logprop as a simple reward approach.
- Members explored expert iteration with rejection sampling on top-k completions, eyeing frameworks like PRIME and veRL to bolster LLM performance.
Cohere Discord
- Joint-Training Jitters & Model Mix-ups: A user sought help on joint-training and loss calculation, but others joked they should find compensation instead, while confusion mounted over command-r7b-12-2024 access. LiteLLM issues and n8n errors pointed to an overlooked update for the new Cohere model.
- One member insisted that n8n couldn't find command-r7b-12-2024, advising a pivot to command-r-08-2024, which highlighted the need for immediate support from both LiteLLM and n8n maintainers.
- Hackathon Hype & Mechanistic Buzz: Following a mention of the AI-Plans hackathon on January 25th, a user promoted an alignment-focused event for evaluating advanced systems. They also identified mechanistic interpretation as an area of active exploration, bridging alignment ideas with actual code.
- Quotes from participants expressed excitement in sharing alignment insights, with some citing a synergy between AI-Plans and potential expansions in mech interp research.
- API Key Conundrum & Security Solutions: Multiple reminders emphasized that API keys must remain secure, while users recommended key rotation to avoid accidental exposure. Cohere's support team was also mentioned for professional guidance.
- One user discovered they publicly posted a key by mistake, quickly deleting it and cautioning others to do the same if uncertain.
- Temperature Tinkering & Model Face-Off: A user questioned whether temperature can be set per-item for structured generations, seeking clarity on advanced parameter handling. Another inquired about the best AI model compared to OpenAI's o1, revealing the community's interest in direct performance matches.
- They requested more details on model reliability, prompting further talk about balanced results and how temperature adjustments could shape final outputs.
- Agentic AI Explorations & Paper Chases: A master's student focused on agentic AI pitched bridging advanced system capabilities with human benefits, asking for cutting-edge research angles. They specifically asked for references to Papers with Code to find relevant work.
- Community members suggested more real-world proof points and recommended exploring new publications for progressive agent designs, emphasizing the synergy between concept and execution.
LlamaIndex Discord
- Agentic Invoice Automation: LlamaIndex in Action: A thorough set of notebooks shows how LlamaIndex uses RAG for fully automated invoice processing, with details here.
- They incorporate structured generation for speedier tasks, drawing interest from members exploring agentic workflows.
- Lively UI with LlamaIndex & Streamlit: A new guide showcased a user-friendly Streamlit interface for LlamaIndex with real-time updates, referencing integration with FastAPI for advanced deployments (read here).
- Contributors emphasized immediate user engagement, highlighting the synergy between front-end and LLM data flows.
- MLflow & Qdrant: LlamaIndex's Resourceful Pairing: A step-by-step tutorial demonstrated how to pair MLflow for experiment tracking and Qdrant for vector search with LlamaIndex, found here.
- It outlined Change Data Capture for real-time updates, spurring conversation about scaling storage solutions.
- Document Parsing Mastery with LlamaParse: A new YouTube video showcased specialized document parsing approaches using LlamaParse, designed to refine text ingestion pipelines.
- The video covers essential techniques for optimizing workflows, with participants citing the importance of robust data extraction in large-scale projects.
OpenInterpreter Discord
- Cursor Craves .py Profiles: Developers discovered Cursor now demands profiles in
.pyformat, triggering confusion and half-working setups. They cited “Example py file profile was no help either.”- Several folks tried converting their existing profiles with limited success, lamenting that Cursor’s shift forced them to dig around for stable solutions.
- Claude Engineer Gobbles Tokens: A user found Claude Engineer devouring tokens swiftly, prompting them to strip away add-ons and default to shell plus python access. They said it ballooned usage costs, forcing them to cut back on advanced tools.
- Others echoed difficulties balancing performance and cost, noting that token bloat quickly becomes a burden when the system calls external resources.
- Open Interpreter 1.0 Clashes with Llama: Multiple discussions highlighted Open Interpreter 1.0 JSON issues while running fine-tuned Llama models, causing repeated crashes. This problem reportedly appeared during tasks requiring intricate error handling and tool calling.
- Participants complained that disabling tool calling didn’t always solve the problem, prompting further talk of non-serializable object errors and dependency conflicts.
- Windows 11 Works Like a Charm: An installation guide for Windows 11 24H2 proved crucial, providing a reference here. The guide’s creator reported OpenInterpreter ran consistently on their setup.
- They showcased how the process resolves common pitfalls, reinforcing confidence that Windows 11 remains a viable environment for testing new alpha features.
Nomic.ai (GPT4All) Discord
- GPT4All's Android App Raises Eyebrows: Concerns emerged over the official identity of a GPT4All app on the Google Play Store, prompting community warnings about possible mismatches in the publisher name.
- Some users advised holding off on installs until messaging limits and credibility checks align with known GPT4All offerings.
- Local AI Chatbot Goes Offline with Termux: One user shared successes in creating a local AI chatbot using Termux and Python, highlighting phone-based inference for easy access.
- Others raised concerns about battery usage and storage overhead, confirming that direct model downloads can function entirely on a mobile device.
- C++ Enthusiasts Eye GPT4All for OpenFOAM: Developers weighed whether GPT4All can tackle OpenFOAM code analysis, exploring which model handles advanced C++ queries best.
- Some recommended Workik temporarily, while the group debated GPT4All's readiness for handling intricate library tasks.
- Chat Templates & Python Setup Spark GPT4All Buzz: Fans shared pointers on crafting custom system messages with GPT4All, pointing to the official documentation for step-by-step guidance.
- Others requested tutorials for advanced local memory enhancements via Python, driving interest in integrated offline solutions.
tinygrad (George Hotz) Discord
- Windows CI Wins: The community stressed the need for Continuous Integration (CI) on Windows to enable merges, referencing PR #8492 that fixes missing imports in ops_clang.
- One participant said "without CI, the merging process cannot progress", prompting urgent action to uphold development pace.
- Bounty Bonanza Blooms: Several members submitted Pull Requests to claim bounties, including PR #8517 for working CI on macOS.
- They requested dedicated channels to track these initiatives, citing a desire for streamlined management and status updates.
- Tinychat Browses the Web: A developer showcased tinychat in the browser powered by WebGPU, enabling Llama-3.2-1B and tiktoken to run client-side.
- They proposed adding a progress bar for smoother model weight decompression, which garnered positive feedback from testers.
- CES Catchup & Meeting Mentions: tiny corp announced presence at CES Booth #6475 in LVCC West Hall, displaying a tinybox red device.
- The scheduled meeting covered contract details and multiple technical bounties, setting the stage for upcoming objectives.
- Distributed Plans & Multiview In Action: Architects of Distributed training discussed the use of FSDP, urging code refactors to accommodate parallelization efforts.
- tinygrad notes also emphasized multiview implementation and tutorials, encouraging broad community collaboration.
Modular (Mojo 🔥) Discord
- Mojo Doubles Down on
concat: They introduced read-only and ownership-based versions of theconcatfunction forList[Int], letting developers reuse memory if the language owns the list.- This tactic trims extra copying for large arrays, aiming for stronger speed without burdening users.
- Overloaded and Over It: Discussion focused on how function overloading for custom structs in Mojo hits a snag when two
concatsignatures look identical.- This mismatch reveals the difficulty of code reuse when there's no direct copying mechanism, forcing a compile-time standoff.
- Memory Magic with Owned Args: A key idea is to let overloads differ by read vs. owned inputs so the compiler can streamline final usage and skip unnecessary data moves.
- The plan involves auto-detecting when variables can be freed or reused, closing gaps in memory management logic.
- Buggy Debugger in Issue #3917: A segfault arises when using
--debug-level fullto run certain Mojo scripts, as flagged in Issue #3917.- Users noted regular script execution avoids the crash, but the debugger remains an open question for further fixes.
LAION Discord
- Emotional TTS: Fear & Astonishment: Multiple audio clips showcasing fear and astonishment were shared, inviting feedback on perceived quality differences and expressive tone.
- Participants were asked to vote on their preferred versions, highlighting community-driven refinement of emotional speech models.
- PyCoT's Pythonic Problem-Solving: A user showcased the PyCoT dataset for tackling math word problems using AI-driven Python scripts, referencing the AtlasUnified/PyCoT repository.
- Each problem includes a chain-of-thought approach, demonstrating step-by-step Python logic for more transparent reasoning.
- Hunt for GPT-4o & Gemini 2.0 Audio Data: Members inquired about specialized sets supporting GPT-4o Advanced Voice Mode and Gemini 2.0 Flash Native Speech, aiming to push TTS capabilities further.
- They sought community input on any existing or upcoming audio references, hoping to expand the library of advanced speech data.
DSPy Discord
- Fudan's Foray into Test-Time Tactics: A recent paper from Fudan University examines how test-time compute shapes advanced LLMs, highlighting architecture, multi-step reasoning, and reflection patterns.
- The findings also outline avenues for building intricate reasoning systems using DSPy, making these insights relevant for AI engineers aiming for higher-level model behaviors.
- Few-Shot Fun with System Prompts: Participants questioned how to system prompt the LLM to yield few shot examples, aiming to boost targeted outputs.
- They stressed the importance of concise prompts and direct instructions, citing this as a practical way to elevate models’ responsiveness.
- Docstring Dividends for Mipro: A suggestion arose to embed extra docstrings in the signature or use a custom adapter for improved clarity in classification tasks.
- Mipro leverages such docstrings to refine labels, allowing users to specify examples and instructions that enhance classification accuracy.
- DSPy’s Daring Classification Moves: Contributors showcased how DSPy eases prompt optimization in classification, linking a blog post on pipeline-based workflows.
- They also mentioned success upgrading a weather site via DSPy, praising its direct approach to orchestrating language models without verbose prompts.
- DSPy Show & Tell in 34 Minutes: Someone shared a YouTube video featuring eight DSPy examples boiled down to just 34 minutes.
- They recommended it as a straightforward way to pick up DSPy’s features, noting that it simplifies advanced usage for both new and seasoned users.
LLM Agents (Berkeley MOOC) Discord
- Peer Project Curiosity Continues: Attendees requested a central repository to see others' LLM Agents projects, but no official compilation is available due to participant consent concerns.
- Organizers might reveal top entries, offering a glimpse into the best submissions from the course.
- Quiz 5 Cutoff Conundrum: Participants flagged that Quiz 5 on Compound AI Systems closed prematurely, preventing some from completing it in time.
- One person suggested re-opening missed quizzes for thorough knowledge checks, pointing out confusion around course deadlines.
- Certificate Declarations Dealt a Deadline: A user lamented missing the certificate declaration form after finishing quizzes and projects, losing eligibility for official recognition.
- Course staff clarified that late submissions won't be considered, and forms will reopen only after certificates release in January.
MLOps @Chipro Discord
- Clustering Continues to Command: Despite the rise of LLMs, many data workers confirm that search, time series, and clustering remain widely used, with no major shift to neural solutions so far.
- They cited these core methods as essential for data exploration and predictions, keeping them on par with more advanced ML approaches.
- Search Stays Stalwart: Discussions show that core search methods remain mostly untouched, with minimal LLM influence in RAG or large-scale indexing strategies.
- Members noted that many established services see no reason to upend proven search pipelines, leading to a slow adoption of new language-model-based systems.
- Mini Models Master NLP: A discussion revealed that in certain NLP tasks, simpler approaches like logistic regression sometimes outperform large LLMs.
- Attendees observed that while LLMs can be helpful in many areas, there are cases where old-school classifiers still yield better outcomes.
- LLM Surge Sparks New Solutions: Participants reported an uptick of LLM usage in emerging products, offering different directions for software development.
- Others still rely on well-established methods, highlighting a divide between novelty-driven projects and more stable ML implementations.
Torchtune Discord
- Wandb Profile Buzz: Members discussed using Wandb for profiling but noted one private codebase is unrelated to Torchtune, while a potential branch could still benefit from upcoming benchmarks.
- Observers remarked that this profiling discussion may pave the way for performance insights once Torchtune integrates it more tightly.
- Torch Memory Maneuvers: Users noted that Torch cut memory usage by skipping certain matrix materializations during cross-entropy compilation, emphasizing the role of chunked_nll for performance gains.
- They highlighted that this reduction potentially addresses GPU bottlenecks and enhances efficiency without major code refactoring.
- Differential Attention Mystery: A concept known as differential attention, introduced in an October arXiv paper, has not appeared in recent architectures.
- Attendees suggested that it might be overshadowed by other methods or simply did not deliver expected results in real-world tests.
- Pre-Projection Push in Torchtune: One contributor shared benchmarks showing chunking pre projection plus fusing matmul with loss improved performance in Torchtune, referencing their GitHub code.
- They reported cross-entropy as the most efficient option for memory and time under certain gradient sparsity conditions, underscoring the importance of selective optimization.
Axolotl AI Discord
- No relevant AI topic identified #1: No technical or new AI developments emerged from these messages, focusing instead on Discord scam/spam notifications.
- Hence, there is no content to summarize regarding model releases, benchmarks, or novel tooling.
- No relevant AI topic identified #2: The conversation only addressed a typo correction amid server housekeeping updates.
- No deeper AI or developer-focused details were noted, preventing further technical summary.
Mozilla AI Discord
- Common Voice AMA Leaps Into 2025: The project is hosting an AMA in their newly launched Discord server to reflect on progress and spark conversation on future voice tech.
- They aim to tackle questions about Common Voice and outline next steps after the 2024 review.
- Common Voice Touts Openness in Speech Data: Common Voice gathers extensive public voice data to create open speech recognition tools, championing collaboration for all developers.
- Voice is natural, voice is human, captures the movement’s goal to make speech technology accessible well beyond private labs.
- AMA Panel Packs Expertise: EM Lewis-Jong (Product Director), Dmitrij Feller (Full-Stack Engineer), and Rotimi Babalola (Frontend Engineer) will field questions on the project's achievements.
- A Technology Community Specialist will steer the discussion to highlight the year’s advancements and the vision forward.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
aider (Paul Gauthier) ▷ #general (589 messages🔥🔥🔥):
DeepSeek V3 Performance Issues, Aider Usage and Capabilities, Remote Job Opportunities without a CS Degree, Reasoning Models Applications, Integration of Aider with AI Agents
- DeepSeek V3 experiences stability issues: Users have reported performance problems with DeepSeek V3, citing long response times and failures when processing larger inputs.
- OpenRouter's status page shows no major incidents, suggesting issues may lie specifically with DeepSeek rather than the API.
- Exploring Aider's versatile usage: Aider is being leveraged for various development tasks, including generating code based on tests, managing project tasks, and integrating with voice commands.
- Users are finding success in utilizing Aider for task management and code generation, illustrating its potential as a valuable development tool.
- Remote job tips without a CS degree: Users discussed strategies for obtaining remote jobs abroad without traditional qualifications, emphasizing building passion projects and gaining experience through GitHub.
- Those in the channel suggest focusing on practical projects and relevant technologies like Go for better job prospects.
- Application of reasoning models in various fields: Participants shared their experiences using reasoning models for tasks outside traditional coding, such as operational planning and profiling.
- The discussion highlighted the versatility of reasoning models in diverse applications, including psychology and marketing.
- Integration ideas for Aider and databases: Users expressed interest in developing tools that utilize Aider for database management tasks, such as writing stored procedures and managing schemas.
- Potential applications include using Aider to generate SQL queries, indicating a desire for further exploration into how Aider can assist with database administration.
- no title found: no description found
- Aider in your browser: Aider can run in your browser, not just on the command line.
- Save The Day GIF - Save The Day - Discover & Share GIFs: Click to view the GIF
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: aider is AI pair programming in your terminal
- Installation: How to install and get started pair programming with aider.
- F Bi Raid GIF - F Bi Raid Swat - Discover & Share GIFs: Click to view the GIF
- DeepSeek Service Status: no description found
- GitHub - gorilla-llm/gorilla-cli: LLMs for your CLI: LLMs for your CLI. Contribute to gorilla-llm/gorilla-cli development by creating an account on GitHub.
- GitHub - ai-christianson/RA.Aid: Aider in a ReAct loop: Aider in a ReAct loop . Contribute to ai-christianson/RA.Aid development by creating an account on GitHub.
- Deep Learning: Offered by DeepLearning.AI. Become a Machine Learning expert. Master the fundamentals of deep learning and break into AI. Recently updated ... Enroll for free.
aider (Paul Gauthier) ▷ #questions-and-tips (91 messages🔥🔥):
DeepSeek V3 Performance, Emulating Conversation Branching, Using Aider with Java, Integration of LLMs with Debugging, Prompt Caching in Aider
- DeepSeek V3 Performance Observations: While many praise DeepSeek V3, some users have noted issues with its tendency to diverge into unrelated areas, creating challenges during practical implementations.
- Despite good benchmark results, participants expressed concerns about precision when applying it to real-world scenarios.
- Challenges with Aider's Conversation Management: A user inquired about methods to emulate conversation branching in Aider, expressing difficulties reverting to previous threads or states effectively.
- The discussion highlighted the need for better tools to manage conversation flow and maintain context across sessions.
- Setting Up Aider for Java Projects: A beginner sought guidance on using Aider with Java, considering options for global installations versus isolated environments.
- An experienced user recommended creating a virtual environment (venv) for installation, avoiding global dependencies.
- Exploring LLM Integration with Debugging Tools: Discussions revolved around integrating LLM-driven assistants with debugging frameworks to improve data science workflows.
- Suggestions included frameworks like LDB and ChatDBG, which enhance debugging capabilities by providing interactive troubleshooting tools.
- Utilization of Prompt Caching in Aider: Participants discussed the advantages of prompt caching in Aider to streamline development and reduce costs.
- The chat emphasized the practical use of caching options to retain context and improve workflow efficiency when interacting with models.
- no title found: no description found
- In-chat commands: Control aider with in-chat commands like /add, /model, etc.
- Prompt caching: Aider supports prompt caching for cost savings and faster coding.
- Dependency versions: aider is AI pair programming in your terminal
- API Keys: Setting API keys for API providers.
- API Keys: Setting API keys for API providers.
- 100x-orchestrator/agent_session.py at main · aj47/100x-orchestrator: A web-based orchestration system for managing AI coding agents. The system uses Aider (an AI coding assistant) to handle coding tasks and provides real-time monitoring of agent outputs through a us...
aider (Paul Gauthier) ▷ #links (5 messages):
AI code analysis, Sophia AI platform, Val Town's LLM code generation, Aider influence
- AI learns to analyze code like a senior dev: An article discusses an experiment where an AI struggled with a React codebase, leading to a new context-aware grouping system for code analysis instead of a linear approach.
- This shift aims to allow the AI to process code more like a senior developer, focusing on core changes and building architectural understanding first.
- Val Town's journey in LLM code generation: In a blog post, Steve Krouse reflects on Val Town's efforts to keep up with LLM code generation, tracing their path from GitHub Copilot to newer platforms like Bolt and Cursor.
- The article attributes various successes and failures to their strategy of fast-follows, emphasizing the necessity of acknowledging innovations by others.
- Sophia platform for AI agents and LLM workflows: Introduction of the Sophia platform emphasizes a full-featured environment for developing agents and workflows, aimed at enhancing software engineering capabilities.
- Key features include autonomous agents, pull request reviews, and multi-service support, marking it as a promising tool for AI-driven development.
- Discussion on Aider's capabilities: A message highlighted Sophia's features as being similar to capabilities Aider offers, particularly in assisting software development workflows.
- This led to further engagements where members expressed interest in checking out the Sophia platform.
- SOPHIA | AI: no description found
- The day I taught AI to read code like a Senior Developer: A messy experiment that changed how we think about AI code analysis Last week, I watched our AI choke on a React codebase - again. As timeout errors flooded my terminal, something clicked. We’d been t...
- What we learned copying all the best code assistants: From GitHub Copilot to ChatGPT to Claude Artifacts, how Val Town borrowed the best of all the code generation tools
Unsloth AI (Daniel Han) ▷ #general (490 messages🔥🔥🔥):
Unsloth Performance, Model Fine-Tuning, Training Issues, GPU Utilization, Model Loading Errors
- Unsloth's Efficiency and Documentation: Users inquired about the efficiency of Unsloth and requested documentation or white papers that elucidate its optimizations.
- The team shared links to their blog posts detailing the performance benefits and techniques behind Unsloth.
- Fine-Tuning Models Together: A user asked if it was safe to fine-tune multiple model sizes (0.5B, 1.5B, and 3B) on the same GPU given their small sizes.
- It was confirmed that as long as total VRAM is not exceeded, training multiple models concurrently is acceptable.
- Training Issues and Error Handling: A user reported an error relating to tensor types while attempting to train using a custom GUI application for Unsloth.
- Suggestions were made to ensure the latest version of transformers is installed and to review any recent code changes.
- Using GPU Devices for Model Loading: A user encountered issues loading two models onto separate CUDA devices, seeking advice on their implementation.
- The code snippet provided aimed to initialize two models on different GPUs but resulted in errors, prompting requests for troubleshooting assistance.
- Usage and Reliability of Colab: Users discussed their experiences with Google Colab, noting recent frustrations with session timeouts and reliability.
- Despite some issues, they also mentioned Kaggle's offerings and Vast AI as alternatives for training models, expressing mixed sentiments towards cost and convenience.
- Vision Fine-tuning | Unsloth Documentation: Details on vision/multimodal fine-tuning with Unsloth
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- Beginner? Start here! | Unsloth Documentation: no description found
- Installing + Updating | Unsloth Documentation: Learn to install Unsloth locally or online.
- Cat Stare Catstare GIF - Cat stare Catstare Cat stare sus - Discover & Share GIFs: Click to view the GIF
- Welcome to vLLM! — vLLM: no description found
- Welcome | Unsloth Documentation: New to Unsloth?
- Introducing Unsloth: no description found
- Unsloth - Dynamic 4-bit Quantization: Unsloth's Dynamic 4-bit Quants selectively avoids quantizing certain parameters. This greatly increases accuracy while maintaining similar VRAM use to BnB 4bit.
- Winking Sloth GIF - Winking Sloth Robert E Fuller - Discover & Share GIFs: Click to view the GIF
- Unsloth AI - Open Source Fine-Tuning for LLMs: Open-source LLM fine-tuning for Llama 3, Phi 3.5, Mistral and more! Beginner friendly. Get faster with Unsloth.
- Conda Install | Unsloth Documentation: To install Unsloth locally on Conda, follow the steps below:
- Blog: no description found
- Unsloth Documentation: no description found
- - YouTube: no description found
- no title found: no description found
- Unsloth: Unleashing the Speed of Large Language Model Fine-Tuning: Large language models (LLMs) have revolutionized the field of artificial intelligence, demonstrating remarkable capabilities in tasks like…
- Lin-Chen/ShareGPT4V · Datasets at Hugging Face: no description found
- Chat Templates: no description found
- GitHub - deepseek-ai/Janus: Janus-Series: Unified Multimodal Understanding and Generation Models: Janus-Series: Unified Multimodal Understanding and Generation Models - deepseek-ai/Janus
- GitHub - unslothai/unsloth: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
Happy New Year Wishes, Rohan's Data Analysis Projects, LLM Rankings, Self-Promotion Policy, Fun Sloth Transformations
- Happy New Year Wishes to Unsloth Crew: A member greeted everyone with a Happy New Year wish, hoping for bright fine-tuning for the Unsloth crew.
- They reminisced about a past humorous incident of everyone transforming into sloths.
- Rohan's Deep Dive into Data Analysis: Rohan shared his new interactive Streamlit app focused on Pandas and Data Analysis, aimed at simplifying preprocessing and visualization.
- He also showcased his explorations in Quantum Computing through various LinkedIn posts and a comprehensive blog.
- LLM Rankings Spark Discussion: Members shared their rankings of LLMs, with Gemini and Claude taking the top spots in separate lists.
- One member highlighted Gemini experimental 1207 as the best free option currently available.
- Self-Promotion Policy Reminder: A reminder about the community's policy against self-promotion was issued after Rohan shared his project updates.
- The community allowed Rohan to keep his post up, emphasizing a collaborative spirit while reinforcing guidelines.
- Humorous Reaction to Sloth Message: Amidst various discussions, a member reacted humorously to the mention of sloths with laughter.
- This contributed to a lighthearted tone in the channel as members exchanged fun comments.
Link mentioned: Tweet from Rohan Sai (@RohanSai2208): Day 2/120 of Quantum Computing ! I covered Complex Numbers , Probability Theory and Calculus 💻 Check them out : 📷 Blog: https://entangledus.blogspot.com/2025/01/day-2-complex-numbers-probabi...
Unsloth AI (Daniel Han) ▷ #help (115 messages🔥🔥):
Using Colab for experimentation, Challenges with RAG and fine-tuning models, Handling errors in model loading and inference, Data requirements for fine-tuning, Utilizing LoRA for memory efficiency
- Troubleshooting errors in Colab: Users experienced various errors while using Colab for model fine-tuning, including issues related to training setups and CUDA memory limits.
- To resolve a 'CUDA out of memory' error, suggestions included lowering parameters like learning rate and max sequence length or switching to Google Colab.
- Understanding RAG and model capacity: A user inquired about data sufficiency for a Q&A service, specifically asking if 100 records were adequate for fine-tuning.
- Responses emphasized the importance of high-quality data and indicated that 1,000 to 2,000 samples are likely more effective for specific verticals.
- Issues with loading fine-tuned models: Errors regarding the loading of vision models and GGUF formats were reported, stating that Unsloth does not support GGUF for vision models after fine-tuning.
- Users also discussed the need to replace model names correctly in scripts, clarifying where to make changes for their models.
- Data handling strategies for models: One discussion focused on converting float values to strings for datasets comprising images and ratings, with consensus leaning toward safer practices.
- Participants highlighted error handling and suggested ensuring dataset formatting aligns with model requirements.
- Efficient training with LoRA: In the context of fine-tuning large models with limited GPU capacity, users were advised to use LoRA and load models in 4-bit to optimize memory usage.
- Guidance was provided to prioritize efficient training techniques over full model accuracy initially, particularly for models like DiscoLM on low-VRAM setups.
- Google Colab: no description found
- Google Colab: no description found
- Fine-tune Llama 3.3 with Unsloth: Fine-tune Meta's Llama 3.3 (70B) model which has better performance than GPT 4o, open-source 2x faster via Unsloth! Beginner friendly.Now with Apple's Cut Cross Entropy algorithm.
- Inference | Unsloth Documentation: Learn how to run your finetuned model.
- unsloth/unsloth/models/llama.py at 87f5bffc45a8af7f23a41650b30858e097b86418 · unslothai/unsloth: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory - unslothai/unsloth
- Bone: no description found
- LoRA: no description found
Codeium (Windsurf) ▷ #announcements (1 messages):
Server Changes, Community Collaboration, Support Portal Update, Server Rules Reminder, December Changelist
- New Year, New Channels: Several server changes are being implemented, including a new channel for .windsurfrules strategy and prompt engineering for Cascade users.
- Additionally, there will be a designated forum for community collaboration and discussion, separate from technical support.
- Support Portal Consolidation: The support forum channel is being sunsetted to streamline support requests through a new support portal channel.
- This change aims to improve issue tracking and customer service across various platforms.
- Reminders on Server Etiquette: Server rules emphasize that users must keep conversations within the appropriate channels and that disrespect, harassment, and spam will not be tolerated.
- Members are reminded that promotion of other products requires prior clearance from a team member.
- Upcoming Community Features: Exciting features on the horizon include new channels to showcase community projects and a Stage channel for community programming.
- The community can also look forward to more opportunities for rewards and giveaways.
- December Changelist Live: The December Changelist has been published and is available for everyone to check out at codeium.com.
- This changelist keeps the community informed about the latest updates and developments in Codeium and AI tools.
Link mentioned: Changelist: December 2024: Codeium updates from December 2024!
Codeium (Windsurf) ▷ #discussion (111 messages🔥🔥):
Codeium Authentication Issues, Self-Hosting Codeium, Neovim and Windsurf Plugins, Showcase Channel for Apps, Codeium and AI Models
- Multiple Users Struggling with Codeium Login: Users are experiencing issues logging into Codeium, with reports of the 'Submit' button not functioning and authentication errors being displayed.
- One user suggested resetting the account token, while another shared that this issue also occurred on a different machine.
- Inquiries on Self-Hosting Codeium: A user inquired about the minimum hardware requirements to self-host Codeium for around 10-20 developers, considering on-prem setups.
- Discussion centered around the ability of a single PC to handle the load, with mentions of the enterprise license allowing self-hosting while expressing concerns over performance.
- Exploring Neovim and Windsurf Plugins: Users discussed the availability of plugins for Neovim, specifically mentioning
codeium.vimandCodeium.nvimfor integration.- Concerns were raised about autocompletion features in Codium being overly verbose when completing comments.
- Proposal for a Showcase Channel: A suggestion was made for a new channel to showcase applications built with Windsurf and Cascade, with requests for visibility on existing options.
- The proposal was acknowledged, and it was confirmed that such a channel is coming soon, with excitement from early adopters expressed.
- Discussion on AI Model Performance and Funding: The potential to use models like
deepseek-v3versus those by Codeium was debated, focusing on performance and funding implications.- It's believed that more funding could lead to significant improvements in model performance, highlighting concerns over Codeium's competitive positioning in acquiring resources.
- Family Guy Woah GIF - Family Guy Woah Hold - Discover & Share GIFs: Click to view the GIF
- What Huh GIF - What Huh Wat - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Vector Informatik on Codeium: Vector Informatik uses Codeium to accelerate their developers.
- Self-Hosting Codeium is Easy. Seriously.: Demystifying common misconceptions about the difficulties in running Codeium in a self-hosted manner.
Codeium (Windsurf) ▷ #windsurf (397 messages🔥🔥):
Windsurf and Claude Issues, Credit System in Windsurf, Windsurf Features and Usage, Community Collaboration in Windsurf, Project Structure in Windsurf
- Windsurf and Claude Issues: Users reported issues with Windsurf repeatedly failing to apply code changes, especially when using Claude 3.5, indicating potential limitations of the model.
- Errors like 'Cascade cannot edit files that do not exist' have led some users to suggest starting new chats for focused tasks to evade persistent issues.
- Credit System in Windsurf: Discussion around the limits of Premium User Prompt Credits, with users expressing confusion over how Flex Credits and prompts interact in Windsurf.
- Users noted that Flex Credits can be used for prompts and flow actions without the limits applied to Premium models, allowing continued use of Cascade Base.
- Windsurf Features and Usage: Members shared tips for efficient use of Windsurf, including creating concise prompts to improve Cascade's response accuracy.
- Some users expressed a preference for Cascade Base due to its unlimited nature despite its comparatively lower intelligence versus premium models.
- Community Collaboration in Windsurf: A vibrant discussion highlighted community contributions toward improving Windsurf, including shared code rules and project guidelines.
- User contributions were encouraged, showcasing tools and methods that efficiently integrate within the Windsurf environment.
- Project Structure in Windsurf: Participants discussed project setups in Windsurf, particularly around backend development approaches and organization of rules files.
- It was clarified that rules must be consolidated into a single .windsurfrules file, with additional queries about effective project configurations being raised.
- Featured | Apple Developer Documentation: Browse the latest sample code, articles, tutorials, and API reference.
- uv: no description found
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- CAN bus - Wikipedia: no description found
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- awesome-windsurf/memories/computerk/global-rules.md at main · ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- Introducing Codeium Live: Free, Forever Up-to-Date In-Browser Chat: Codeium live is free, forever in-browser chat with direct access to external repositories and libraries, updated every day to get accurate, relevant answers.
- GitHub - ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- Aaron Shafovaloff (@aaronshaf) Profile | Codeium: Aaron Shafovaloff (@aaronshaf) has completed 2,123 using Codeium's AI autocomplete. Codeium offers best in class AI code completion & chat — all for free.
Cursor IDE ▷ #general (483 messages🔥🔥🔥):
Cursor IDE Updates, Model Performance Variability, User Workflow Optimization, AGI Development Aspirations, Issues with Composer and Context Management
- Cursor IDE Updates and Features: Users expressed a need for better changelogs and documentation for new updates, particularly for version 0.44.11, along with a desire for improved UI for creating and managing project plans.
- Feedback highlighted a need for features that modularize project plans and allow for easier iteration on documentation.
- Model Performance Variability: Users reported experiencing inconsistent performance from Claude Sonnet 3.5, particularly noting issues with context retention and confusing outputs in extended conversations.
- Some users suggested that downgrading versions might stabilize performance and that using simpler prompts could sometimes yield better results than comprehensive instructions.
- User Workflow Optimization: Suggestions included using more precise prompts and utilizing copy-pasting sections of code to guide Cursor in making specific edits effectively.
- Users also discussed the idea of implementing a plan generation feature that could enhance project organization and coherence.
- AGI Development Aspirations: A vision for Cursor as a leading IDE in achieving AGI was shared, with users discussing methods to leverage task-oriented features to improve interactions.
- The community showed interest in how improvements could lead to more innovative AI capabilities in coding tasks.
- Issues with Composer and Context Management: Concerns were raised about Composer's handling of large files, with difficulties in editing and context retention from extensive prompts affecting productivity.
- Users noted that the AI sometimes fails to manage context effectively when switching between tasks, leading to confusion and unintended changes in code.
- You Actually Suck - Anonymous Email Feedback: no description found
- CS 153: Infrastructure at Scale | Stanford University: Learn directly from the founders and engineers who've scaled and secured some of the world's largest computing systems, including guest lectures from Jensen Huang (NVIDIA), Matthew Prince (Cloudflare)...
- Cherry Capital Web Design | Modern Web Development in Northern Michigan: Transform your business with custom-built, high-performance websites. Northern Michigan's premier web development agency specializing in modern, SEO-optimized websites that drive results.
- Tweet from undefined: no description found
- Empty Brain GIF - Empty Brain Loading - Discover & Share GIFs: Click to view the GIF
- Tweet from undefined: no description found
- Noice Nice GIF - Noice Nice Click - Discover & Share GIFs: Click to view the GIF
- Tweet from Marc Baumann 🌔 (@marcb_xyz): 🚨JUST IN: Google releases white paper on AI agentsIt covers the basics of llm agents and a quick Langchain implementation
- Nic Cage Nicolas Cage GIF - Nic Cage Nicolas Cage Con Air - Discover & Share GIFs: Click to view the GIF
- Downloads | Cursor - The AI Code Editor: Choose your platform to download the latest version of Cursor.
- Spider Man Spider Man Web Of Shadows GIF - Spider Man Spider Man Web Of Shadows Depressed - Discover & Share GIFs: Click to view the GIF
- Dawid Jasper Sad GIF - Dawid Jasper Sad Stream - Discover & Share GIFs: Click to view the GIF
- Button by marcelodolza made with CSS | Uiverse.io: This Button was posted by marcelodolza. Tagged with: neumorphism, skeuomorphism, icon, animation, purple, button, arrow, transition. You can create your own elements by signing up.
- I Also Like To Live Dangerously Danger GIF - I Also Like To Live Dangerously Danger Austin Powers - Discover & Share GIFs: Click to view the GIF
- wikip.co: no description found
- Uiverse | The Largest Library of Open-Source UI elements: Community-made library of free and customizable UI elements made with CSS or Tailwind. It's all free to copy and use in your projects. Uiverse can save you many hours spent on building & cust...
- New Acrobat Update #animation: Emilee Dummer ➤ https://www.instagram.com/edummerart/Kelly Jensen ➤ https://www.instagram.com/kelly_anne_art/Claire Anne ➤ https://www.instagram.com/clairean...
{kind=link}
LM Studio ▷ #announcements (1 messages):
LM Studio 0.3.6 release, Function Calling API, Vision-input models, New Windows installer, In-app update improvements
- Cheers to LM Studio 0.3.6!: LM Studio 0.3.6 has launched, featuring a new Function Calling / Tool Use API compatible with OpenAI frameworks, and support for Qwen2VL models.
- Users can download the latest version from here and provide feedback through GitHub issues.
- Introducing the Function Calling API: A major highlight of the 0.3.6 release is the Function Calling API which allows for local model utilization as a drop-in replacement for OpenAI tools.
- This feature is in beta, inviting users' bug reports and feedback to improve functionality.
- New Vision-Input Model Support: Version 0.3.6 introduces support for the Qwen2VL family and QVQ models, enhancing vision and reasoning capabilities in both
MLXandllama.cppengines.- A demo showcases the capabilities of a Qwen2VL 2B model, illustrating the advancements.
- Windows Installation Made Easier: Users can now choose the installation drive with the new installer on Windows, addressing a long-standing request.
- This change simplifies the installation process for various setups, ensuring a seamless user experience.
- In-App Update Features Enhanced: In-app updates for LM Studio are now smaller and include a progress bar, streamlining the updating process.
- Users can also update their
llama.cppandMLXengines independently without needing a full app update.
- Users can also update their
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- LM Studio 0.3.6: Tool Calling API in beta, new installer / updater system, and support for `Qwen2VL` and `QVQ` (both GGUF and MLX)
LM Studio ▷ #general (292 messages🔥🔥):
Model Loading Issues, Function Calling API, User Experience with Models, RAM Usage Bugs, Cluster Environment Deployment
- Users experiencing model loading issues: Multiple users reported issues with loading various models in LM Studio, particularly with QVQ and Qwen2-VL, including errors like exit code 133 and double RAM usage while processing prompts.
- Suggestions were made to check context lengths and downgrade to prior builds, while some users noted that MLX command-line operations did not exhibit the same problems.
- New function calling API feedback: The new function calling API was praised by users for expanding model capabilities beyond text output, with positive feedback on documentation and workflow examples.
- Users reported experiencing issues with JiT model loading after upgrading to version 3.6, and some found the API behavior changed unexpectedly.
- User experiences with RAM usage: Several users discussed anomalies in RAM usage, particularly with newer model versions where RAM doubled during processing compared to previous builds.
- This prompted discussions around potential bugs in the LM Studio implementation affecting model performance and efficiency.
- Cluster environment deployment question: A user inquired about the possibility of running LM Studio in a cluster environment to better manage resources.
- The conversation highlighted the need for scaling solutions as more users explore larger models and configurations.
- Performance of models and upgrading concerns: Users debated the performance of larger models versus smaller quantization options, expressing concerns about the trade-off between model size and processing speed.
- Feedback indicated a general disappointment with output quality despite multiple upgrades, urging users to consider both hardware capabilities and model compatibility.
- Surprised Pikachu GIF - Surprised Pikachu Pokemon - Discover & Share GIFs: Click to view the GIF
- Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard: no description found
- Introduction - Model Context Protocol: no description found
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- create-million-parameter-llm-from-scratch/code.ipynb at main · FareedKhan-dev/create-million-parameter-llm-from-scratch: Building a 2.3M-parameter LLM from scratch with LLaMA 1 architecture. - FareedKhan-dev/create-million-parameter-llm-from-scratch
- Llama 3.1 - 405B, 70B & 8B with multilinguality and long context: no description found
- (Exit code 133) Error when loading large LLM models · Issue #285 · lmstudio-ai/lmstudio-bug-tracker: When loading large LLMs (for example, Meta-Llama-3.1-70B-Instruct-IQ2_S with context window 32768), I would encounter the error (Exit code: 133). Please check settings and try loading the model aga...
- Tool Use - Advanced | LM Studio Docs: Enable LLMs to interact with external functions and APIs.
LM Studio ▷ #hardware-discussion (159 messages🔥🔥):
Model Performance and Hardware Compatibility, AMD vs NVIDIA for AI Processing, User Experiences with Different Models, Future Hardware Development and Specifications
- Bottlenecks from GPU RAM Limits: Users noted that running a 70B model requires more VRAM than available on common GPUs, leading to reliance on slower CPU inference.
- Recommendations included sticking to models under 16B with Q8 or Q6 quantization for better performance.
- Comparison of AMD CPUs and NVIDIA GPUs: There was discussion on AMD's claims of CPU performance matching or exceeding NVIDIA GPUs, especially for specific AI tasks.
- Users expressed skepticism, pointing out that such claims depend on the nature of the workload and setup.
- User Experiences with GPU Limitations: Several users shared frustrations regarding AMD cards, mentioning compatibility issues and the need for third-party software to run certain models.
- Performance drops were noted, especially for larger models, illustrating the challenges of using certain GPUs for AI tasks.
- Future Hardware Developments: Speculation arose regarding AMD's ability to produce competitive high-end GPUs and the potential for more RAM channels in future developments.
- There was intrigue surrounding whether AM5 would support additional RAM capabilities despite its current limitations.
- Testing New AMD Products: Anticipation built around testing AMD's new Ryzen AI Max product, with some users eager to compare its performance against NVIDIA's offerings.
- Queries about the possibility of using AMD's AI Max with GPUs concurrently indicated a keen interest in performance metrics.
- UGI Leaderboard - a Hugging Face Space by DontPlanToEnd: no description found
- Jovi Tomi Jovana Tomic GIF - Jovi Tomi Jovana Tomic Jovana Survivor - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- GitHub - dottxt-ai/outlines: Structured Text Generation: Structured Text Generation. Contribute to dottxt-ai/outlines development by creating an account on GitHub.
- Getting Started | LM Studio Docs: Learn how to run Llama, Mistral, Gemma, and other LLMs locally with LM Studio.
- Structured Output - Advanced | LM Studio Docs: Enforce LLM response formats using JSON schemas.
Stackblitz (Bolt.new) ▷ #prompting (18 messages🔥):
Stackblitz Project Backup Issues, Exporting Projects, Deployment Workflows, Using Bolt Sync
- Stackblitz Projects Losing Progress: A user expressed frustration after logging back into Stackblitz, discovering that their project rolled back to an earlier version, resulting in lost work.
- Another member confirmed their experience varied, stating that they typically returned to projects unchanged after frequent saves.
- Exporting Projects for Safety: A member recommended exporting the Bolt project every iteration to safeguard against data loss, stating it ensures a backup of their work.
- They noted the export process can require adjustments when moving to other IDEs, which is important to keep in mind.
- Deployment Workflow Confusion: Several users expressed uncertainty regarding the best workflow for pushing code to GitHub, with suggestions to push from either Netlify or Bolt.
- They discussed using external tools like Bolt Sync to maintain repository updates, but coordination between platforms remains a concern.
Link mentioned: Vite + React + TS: no description found
Stackblitz (Bolt.new) ▷ #discussions (371 messages🔥🔥):
Token Usage Issues, Supabase Integration Problems, Netlify Deployment Errors, OAuth Limitations in Bolt, Prompt Engineering Challenges
- Token Usage and Cost Concerns: Users are experiencing frustrations with high token consumption, often spending large amounts on minor fixes or edits, sometimes costing hundreds of thousands of tokens for simple changes.
- Community members suggest improving prompting techniques to manage token usage more effectively, as many have ended up throwing away significant amounts due to inefficiencies.
- Supabase Connection Issues: Several users reported issues with their Supabase integration, particularly with logins and creating accounts, often needing to reconnect or create new configurations to restore functionality.
- Discussion includes the importance of managing .env files properly to ensure Bolt can effectively control Supabase connections.
- Deployment Challenges in Netlify: Users who deploy with Netlify are encountering various errors, particularly when integrating with Bolt, causing confusion and delays in project progression.
- Community members are seeking assistance with specific Netlify issues and troubleshooting methodologies to ensure a smoother deployment process.
- OAuth Limitations in Bolt: Users are advised against using OAuth in Bolt due to limitations and potential issues that prevent successful authentication during development.
- The community emphasizes focusing on email login methods instead, as OAuth functionality works better when deployed in a production environment.
- Challenges with Prompt Engineering: Community discussions reveal that effective prompting is crucial to yield the best results from Bolt, with many users struggling to get accurate changes made.
- Members are encouraged to refine their prompts and communicate clearly with Bolt to avoid unnecessary token loss and extend the capabilities of the AI.
- no title found: no description found
- Receiving POST requests: Hello! I’m having an issue with POST requests. I have a separate node.js server that will occasionally send POST requests to my netlify site. However, I have been researching for hours and am still n...
- Tweet from undefined: no description found
- Property Services Platform: Streamline property management with our comprehensive platform
- Read The Instructions Mad GIF - Read The Instructions Mad Throw - Discover & Share GIFs: Click to view the GIF
- Tweet from Tomek Sułkowski (@sulco): If you're care about icons in your app and you don't know Iconify, you're missing out.1️⃣ Go to iconify․design2️⃣ Find the perfect icon and copy it's name, 3️⃣ Ask Bolt to "use the...
- no title found: no description found
- Tweet from 田中義弘 | taziku CEO / AI × Creative (@taziku_co): 【bolt x Threejsで3D】3D生成AIがかなり進んできていますが、bolt(@stackblitz)と3Dファイル、Threejsを組み合わせる事が可能。ゲームを作成したり、サイトに3Dオブジェクトを追加したり、プロンプトで操作が可能。#生成AI
- no title found: no description found
- Reading Code 101: A beginner's guide to understanding code structure and common programming concepts
- oTTomator Community: Where innovators and experts unite to advance the future of AI-driven automation
- RepoCloud | Bolt.diy: Choose Your AI Model: Discover Bolt.diy, the ultimate fork for selecting your favorite AI model. Customize your coding experience with top LLMs like OpenAI and Anthropic!
- Bolters.io | Community Supported Tips, Tricks & Knowledgebase for Bolt.new No-Code App Builder: Documentation and guides for Bolt.new
- Deploying to Netlify won't create Functions · Issue #4837 · stackblitz/bolt.new: Describe the bug With Bolt I used Netlify's Functions feature for a serverless task. When Deploying using the "Deploy" button I see that the deploy is successful. Yet, when inspecting on...
- READ THIS FIRST: Critical information about Bolt.new's capabilities, limitations, and best practices for success
- Bolt.new Fundamentals: Learn what Bolt.new is and how it can supercharge your development workflow
- Understanding the Context Window: Learn about Claude's context window and how to optimize your interactions
- Avoiding the Rabbithole: Learn how to avoid getting stuck in error-chasing loops with AI
- How To Prompt Bolt: Learn how to effectively communicate with Bolt AI
{kind=link}
Stability.ai (Stable Diffusion) ▷ #general-chat (382 messages🔥🔥):
Model Performance Comparisons, Training LoRAs vs Checkpoints, Using ComfyUI, Inpainting vs img2img Performance, Upcoming GPU Releases
- Comparing Image Generation Models: Users discussed frustrations with the performance of models on Civit.ai, noting that concepts like 'woman riding a horse' led to unexpected results, with some opting for simpler prompts.
- Multiple users shared experiences of testing different LORAs and finding that some generated higher quality images than others, sparking discussions about which models are most effective.
- Training LoRAs vs Full Checkpoints: Participants debated whether to train LORAs or full checkpoints, noting that LORAs can enhance specific styles while checkpoints offer broader utility.
- Concerns about model conflicts when using multiple LORAs were mentioned, suggesting a preference for more focused training with identified styles.
- Using ComfyUI for Image Generation: Discussion around the usability of ComfyUI highlighted a learning curve associated with its node-based structure and the need for experimentation.
- Users recommended resources for efficiently managing LORAs within ComfyUI, including specific node packs that streamline usage.
- Inpainting Time Comparisons: The difference in processing time between inpainting and img2img was discussed, with inpainting taking longer than expected despite only altering sections of an image.
- Participants noted that different operations within models can affect performance, leading to varying generation speeds.
- Rumors About NVIDIA's Upcoming GPUs: There was speculation about the pricing and specifications of NVIDIA's upcoming GPUs, specifically the 5080 and 5090, with expected prices around $1.4k and $2.6k respectively.
- Concerns were raised about potential scalping and the overall market reaction, with some participants suggesting waiting for AI-targeted cards instead.
- Guess The Painter: no description found
- TRELLIS: Structured 3D Latents for Scalable and Versatile 3D Generation: no description found
- Release v2.8.0 · LykosAI/StabilityMatrix: v2.8.0 has arrived with many new features 🎉macOS Support (Apple Silicon)Inference - Image to Video SMimg2vid.mp4 Inference - Enhanced model selection with me...
- Reddit - Dive into anything: no description found
- - YouTube: no description found
- GitHub - butaixianran/Stable-Diffusion-Webui-Civitai-Helper: Stable Diffusion Webui Extension for Civitai, to manage your model much more easily.: Stable Diffusion Webui Extension for Civitai, to manage your model much more easily. - butaixianran/Stable-Diffusion-Webui-Civitai-Helper
- CogVideoX-v1.5-5B I2V workflow for lazy people (Including low VRAM) - Florence | Other Workflows | Civitai: Update the Florence version:Many people encounter dependency errors when using the Joy Caption plugin. I use Florence as a replacement—it’s easier ...
- TFM Cutesy Anime Model - Inpainting | Stable Diffusion Checkpoint | Civitai: Hi again this be The Food Mage First photo is featuring 'Game Girl', the Food Mage mascot, as a donut shop worker. Join The Discord (exclusive mode...
- GitHub - adieyal/sd-dynamic-prompts: A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation: A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation - adieyal/sd-dynamic-prompts
- Typhon0130 - Overview: Imagine how you want to feel at the end of the day. Start working towards that now. - Typhon0130
- AnimateDiff: Easy text-to-video - Stable Diffusion Art: Video generation with Stable Diffusion is improving at unprecedented speed. In this post, you will learn how to use AnimateDiff, a video production technique
- Dragon Ball Super Broly Movie (Series Style) [Illustrious] - v1.0 | Illustrious LoRA | Civitai: Help fuel my passion! Even $1 makes a difference. ☕ https://ko-fi.com/citronlegacy Check out all my other Series Styles: https://civitai.com/user/C...
- [Pony] Akira Toriyama (鳥とり山やま明あきら) | Dragon Ball ArtStyle - Pony v0.1 | Stable Diffusion LoRA | Civitai: Akira Toriyama drawing style LoRA. • It's not perfect, but it can recreate the style quite well. • Works a little better at generating girls than b...
- GitHub - bmaltais/kohya_ss: Contribute to bmaltais/kohya_ss development by creating an account on GitHub.
- GitHub - jhc13/taggui: Tag manager and captioner for image datasets: Tag manager and captioner for image datasets. Contribute to jhc13/taggui development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (129 messages🔥🔥):
AI Agents and Frameworks, Nvidia RTX 5090 Announcement, LangChain Agent Event, AI Model Evaluations and Availability, OpenAI's Reflections on AGI
- Discussion on AI Agents and Frameworks: Members expressed mixed feelings about LangChain, with criticisms of its complexity and abstractions leading to questions about what alternatives exist.
- There was mention of various tools, including Label Studio and the possibility of a comparison article to evaluate these data labeling platforms.
- Nvidia RTX 5090 Specifications Leak: A leak revealed that Nvidia's upcoming RTX 5090 is expected to feature 32GB of GDDR7 memory, just before the official announcement at CES.
- Members joked about the potential capabilities of the new hardware and expressed excitement for its release.
- LangChain's Interrupt AI Agent Conference: LangChain announced an AI Agent Conference called 'Interrupt', scheduled for May in San Francisco, promising technical talks and hands-on workshops.
- Industry leaders are set to participate, creating opportunities for networking and knowledge exchange within the AI community.
- Evaluations of OpenAI Models: Discussion arose around OpenAI's GPT-O1 and its availability via API, with questions about its performance and consistency with claimed benchmarks.
- Members noted the challenge of accessing next-gen models and expressed frustration with approval processes on platforms like Azure.
- Sam Altman's Reflections on AGI Progress: In a reflective piece, Sam Altman discussed the journey of OpenAI towards achieving AGI and the lessons learned over almost nine years.
- He highlighted the progress made and posed questions about the future challenges in the AI landscape.
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Free Process Rewards without Process Labels: Different from its counterpart outcome reward models (ORMs), which evaluate the entire responses, a process reward model (PRM) scores a reasoning trajectory step by step, providing denser and more fin...
- Tweet from LangChain (@LangChainAI): Announcing ✨ Interrupt: The AI Agent Conference by LangChain ✨ – the largest gathering of builders pushing the boundaries of agentic applications.🦜 Join us in San Francisco this May for an event pack...
- Tweet from Alejandro Cuadron (@Alex_Cuadron): Surprising find: OpenAI's O1 - reasoning-high only hit 30% on SWE-Bench Verified - far below their 48.9% claim. Even more interesting: Claude achieves 53% in the same framework. Something's of...
- Open Source Data Labeling | Label Studio: A flexible data labeling tool for all data types. Prepare training data for computer vision, natural language processing, speech, voice, and video models.
- Paper page - B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners: no description found
- Reflections: The second birthday of ChatGPT was only a little over a month ago, and now we have transitioned into the next paradigm of models that can do complex reasoning. New years get people in a reflective...
- Tweet from Lifan Yuan (@lifan__yuan): How to unlock advanced reasoning via scalable RL?🚀Introducing PRIME (Process Reinforcement through Implicit Rewards) and Eurus-2, trained from Base model to surpass Qwen2.5-Math-Instruct using only 1...
- Tweet from AI at Meta (@AIatMeta): New research from Meta FAIR — Meta Memory Layers at Scale. This work takes memory layers beyond proof-of-concept, proving their utility at contemporary scale ➡️ https://go.fb.me/3lbt4m
- Tweet from Tom Warren (@tomwarren): Nvidia's RTX 5090 has leaked with packaging that appears to confirm it has 32GB of GDDR7 memory. The last-minute leak comes just a day before Nvidia is expected to announce its next-gen RTX 50-ser...
- Tweet from Petr Baudis (@xpasky): Quick primer for non-wizards about the post-MCTS LLM reasoning future (I'm kinda PRIME-pilled rn):How will LLMs learn to reason? No math in this post, ~simple words only!(I was rather intimidated ...
- Tweet from Teortaxes▶️ (@teortaxesTex): absurdly impressive, early contender for the best paper Q1'25. Or at least the best Notion page.Quoting Lifan Yuan (@lifan__yuan) How to unlock advanced reasoning via scalable RL?🚀Introducing PRI...
- Optimizing AI Inference at Character.AI (Part Deux): At Character.AI, we’re building personalized AI entertainment. In order to offer our users engaging, interactive experiences, it's critical we achieve highly efficient inference, or the process b...
- Tweet from ℏεsam (@Hesamation): AgentsGoogle’s whitepaper covers the basics of llm agents and a quick Langchain implementation
- Tweet from ℏεsam (@Hesamation): We deserve something better than LangChain> learning it can be just as tough as a new language> there’s too much abstraction> the documentation does not cut itso what’s the best LLM framework...
- Tweet from Russell the builder (@russellm): watching everyone hype PRIME's benchmark results but let's break down why this 'reasoning' isn't what you think:it's got 2 LLMs playing hot-or-cold - one generating steps, one ...
- Tweet from ℏεsam (@Hesamation): We deserve something better than LangChain> learning it can be just as tough as a new language> there’s too much abstraction> the documentation does not cut itso what’s the best LLM framework...
- Tweet from Petr Baudis (@xpasky): B-STAR, improving RL sampling of CoTs when training LLMs to reason: https://x.com/AndrewZeng17/status/1875200392197497089First, ELI5 time:1. We are generating synthetic CoTs, and we have a problem: we...
- Tweet from Petr Baudis (@xpasky): B-STAR, improving RL sampling of CoTs when training LLMs to reason: https://x.com/AndrewZeng17/status/1875200392197497089First, ELI5 time:1. We are generating synthetic CoTs, and we have a problem: we...
- Tweet from abhishek (@abhi1thakur): is that "agentic" enough🤣
- Tweet from Luca Soldaini 🎀 (@soldni): OLMo 2 tech report is outWe get in the weeds with this one, with 50+ pages on 4 crucial components of LLM development pipeline:
- Tweet from Lucas Nestler (@_clashluke): It's time for a transformer improvement threadQuoting Teortaxes▶️ (@teortaxesTex) I think the best modern Transformer+++ design (diff transformer, gated deltanet, sparse MoE, NTP+n, some memory et...
- Tweet from kalomaze (@kalomaze): this is so absurdly elegant.this should generalize to non-CoT.this should generalize to and even improve regular classic RLHF.this is not a kludge.this immediately registers to me as the future.Quotin...
- Tweet from Logan Kilpatrick (@OfficialLoganK): Everyone: America America America, we must win AI, national security, etc etc *Decent models come out from China*Everyone: We now support XYZ model on our platform (from China), come use it right now,...
- Tweet from pedro lucca (@pedro_computer): The first people to tell a great story in a new medium define it forever.Disney did it on animation. Pixar did it on CGI. And we're doing it in Artificial Life.Just graduated from @betaworks. Demo...
- Ask HN: Examples of agentic LLM systems in production? | Hacker News: no description found
- Framework for what makes for an AI agent vs co-pilots, RPA or software: What are the characteristics that separate AI Agents from limited agents, AI co-pilots, RPA and the traditional software
- Announcing AI Engineer Summit NYC: All in on Agent Engineering + Leadership: Announcing the theme of the second ever AI Engineer Summit. Apply now!
- Tweet from Elon Musk (@elonmusk): Cool!And Grok 3 is coming soon. Pretraining is now complete with 10X more compute than Grok 2.Quoting Matthew Paczkowski (@matthewpaco) After using Grok for 4 weeks, I decided to cancel my ChatGPT sub...
- AI Agent Fires it's Coder and Starts asking People for What?: I have to constantly fact check AI twitter posts like luna virtuals to my friends, so I figure why not do it for chat. Dude writes an GPT powered spam bot, c...
- GitHub - facebookresearch/memory: Memory layers use a trainable key-value lookup mechanism to add extra parameters to a model without increasing FLOPs. Conceptually, sparsely activated memory layers complement compute-heavy dense feed-forward layers, providing dedicated capacity to store and retrieve information cheaply.: Memory layers use a trainable key-value lookup mechanism to add extra parameters to a model without increasing FLOPs. Conceptually, sparsely activated memory layers complement compute-heavy dense f...
- GitHub - bytedance/LatentSync: Taming Stable Diffusion for Lip Sync!: Taming Stable Diffusion for Lip Sync! Contribute to bytedance/LatentSync development by creating an account on GitHub.
- Commits · lucidrains/PaLM-rlhf-pytorch: Implementation of RLHF (Reinforcement Learning with Human Feedback) on top of the PaLM architecture. Basically ChatGPT but with PaLM - Commits · lucidrains/PaLM-rlhf-pytorch
- [AINews] not much happened today: a quiet week to start the year AI News for 1/2/2025-1/3/2025. We checked 7 subreddits, 433 Twitters and 32 Discords (217 channels, and 2120 messages) for...
- Live Portrait - a Hugging Face Space by KwaiVGI: no description found
- GitHub - huggingface/search-and-learn: Recipes to scale inference-time compute of open models: Recipes to scale inference-time compute of open models - huggingface/search-and-learn
- GitHub - huggingface/trl: Train transformer language models with reinforcement learning.: Train transformer language models with reinforcement learning. - huggingface/trl
Latent Space ▷ #ai-announcements (11 messages🔥):
Understanding Transformers, AI Engineering for Art, ComfyUI development, Transformers architecture, Interactive Transformers
- Invitation for Transformers Guest Publications: Swyxio offered an opportunity for guest publishers to contribute an article explaining Transformers, indicating willingness to publish good content.
- He specifically mentioned the demand for quality articles, emphasizing the significant impact of Transformers in NLP.
- AI Engineering for Art Podcast Launched: A new podcast episode titled AI Engineering for Art has aired, featuring insights from the ComfyUI origin story and competition in the startup field, available here.
- The episode covers a range of topics, including GPU compatibility and video generation features, starting from the introduction of the hosts and guests.
- Discussion on Explaining Transformers Architecture: Members are clarifying whether the aim is to explain the original Transformer architecture or to explore modern advancements, with varying opinions on the depth required.
- This discussion reflects interest in both foundational and cutting-edge aspects of Transformers, with mixed feedback on the technical level of existing work.
- Resources on Understanding Transformers: Several members shared valuable resources for learning about Transformers, including comprehensive blogs and articles aimed at simplifying the concepts for beginners.
- Notable mentions include a blog post described as easy to understand, even for a layperson, and various interactive projects that provide deeper insights into transformer operations.
- Technical Feedback on Interactive Transformer Project: A member shared an interactive transformer project, receiving feedback on its technical level, which may not align with the publication standards of Latent Space.
- This highlights the balance between accessibility and technicality in community contributions, sparking a deeper conversation about publication criteria.
- Tweet from Latent.Space (@latentspacepod): 🆕 pod: AI Engineering for Art!https://latent.space/p/comfyuiFirst pod of the year, with comfyanonymous face reveal! Going over the origin story of @ComfyUI (now a startup, competing with multiple @yc...
- Tweet from ℏεsam (@Hesamation): Transformers made so simple your grandma can understand great comprehensive blog on how and why transformers works + implementing them in code
- Tweet from sanny (@sannykimchi): Transformers have led to a wave of recent advances in #NLProc such as BERT, XLNet and GPT-2, so here is a list of resources💻 I think are helpful to learn how Transformers work, from self-attention to...
- Tweet from Lucas Nestler (@_clashluke): It's time for a transformer improvement threadQuoting Teortaxes▶️ (@teortaxesTex) I think the best modern Transformer+++ design (diff transformer, gated deltanet, sparse MoE, NTP+n, some memory et...
- The Interactive Transformer - ML Notes: no description found
Latent Space ▷ #ai-in-action-club (162 messages🔥🔥):
Discord Bot Development, Agent Mode in Cursor, Error Handling in Coding, Streaming Coding Sessions, Generative AI Tools
- Building a Discord Bot is Challenging: Members discussed the complexities involved in creating a Discord bot, mentioning that configuring API keys can take longer than writing code.
- One member humorously noted that despite writing significant feature code, configuring Discord can extend the time spent, comparing it to coding without actual code.
- Agent Mode vs. Chat Mode in Cursor: Discussion focused on the differences between using Agent mode and Chat mode in Cursor, with some members finding Agent mode better for gathering context from codebases.
- Concerns were raised about not being able to submit messages with codebase context in Agent mode as easily as in Chat mode.
- The Experience of Live Coding: Members expressed that live coding during streams can be quite challenging and disruptive to their usual coding proficiency.
- The pressure of coding in front of an audience made some members feel less productive and self-conscious about their skills.
- Generative AI Tools and Their Impact: Participants mentioned using various AI tools for coding assistance, including those that provide helpful context search features.
- The conversation highlighted the need for better preparation to maximize the value derived from these tools in a collaborative session.
- Sharing Resources and Experiences: Members shared links to previous streams and discussions about their experiences with coding and AI tools.
- It was emphasized that seeing how others utilize these tools can provide valuable insights, especially for newcomers.
- GitHub - CakeCrusher/mimicbot: Mimicbot enables the effortless yet modular creation of an AI chat bot model that imitates another person's manner of speech.: Mimicbot enables the effortless yet modular creation of an AI chat bot model that imitates another person's manner of speech. - CakeCrusher/mimicbot
- discordrb/examples/commands.rb at main · shardlab/discordrb: Discord API for Ruby . Contribute to shardlab/discordrb development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #events (2 messages):
SF Meetup, Coffee Plans, Potrero Hill
- Philpax seeks coffee meetup in SF: @philpax announced being in SF for a few days next week and asked if anyone is free for a coffee.
- This sparked interest, with another member expressing a desire to meet up.
- d_.moon offers to meet in SOMA: Member d_.moon responded enthusiastically, saying they would love to grab coffee.
- They mentioned being in Potrero Hill but can meet anywhere in the SOMA area.
Interconnects (Nathan Lambert) ▷ #news (133 messages🔥🔥):
Nvidia RTX 5090 Leak, Anthropic Claude's Copyright Issues, Alibaba and 01.AI Collaboration, Open-sourcing METAGENE-1, Coding Agents and Software Engineering
- Nvidia RTX 5090 Leak Surprise: Reports from Tom Warren indicate that Nvidia's RTX 5090 has leaked details of its 32GB GDDR7 memory just before the CES announcement.
- This news comes as a shock to some consumers who recently purchased the RTX 4090.
- Anthropic Faces Copyright Legal Action: In response to legal action, Anthropic has agreed to maintain guardrails on Claude, preventing it from sharing copyrighted lyrics, while publishers seek to block its training on such content.
- This ongoing dispute highlights the growing tension between AI development and intellectual property rights, affecting startup strategies in AI.
- Alibaba and 01.AI Collaborative Efforts: Alibaba Cloud is partnering with 01.AI to create a joint laboratory aimed at advancing AI technologies for industrial applications, as highlighted in an article from SCMP.
- Despite confusion surrounding the partnership, it aims to merge research strengths and apply large models in various sectors including finance and manufacturing.
- Launch of METAGENE-1 Foundation Model: A new state-of-the-art 7B parameter Metagenomic Foundation Model, named METAGENE-1, has been released in collaboration with researchers from USC for pathogen detection.
- This project aims to enhance efforts in preventing pandemics by enabling planetary-scale pathogen surveillance.
- Debate on Coding Agents' Utility: Discussions highlighted the effectiveness of AI-powered coding agents, with one user noting that they perform at the level of a junior developer, speeding up code writing significantly.
- Despite these advantages, there's skepticism about whether these agents can replace the comprehensive roles needed in software engineering, particularly at larger companies.
- Tweet from Tom Warren (@tomwarren): Nvidia's RTX 5090 has leaked with packaging that appears to confirm it has 32GB of GDDR7 memory. The last-minute leak comes just a day before Nvidia is expected to announce its next-gen RTX 50-ser...
- Alibaba ties up with Lee Kai-fu’s unicorn as AI sector consolidates: Alibaba Cloud signs a deal with start-up 01.AI to develop AI model solutions for business clients.
- Tweet from Tibor Blaho (@btibor91): In response to legal action from major music publishers, Anthropic's agreed to maintain the guardrails stopping Claude from sharing copyrighted lyrics, but publishers are still pushing the court t...
- Tweet from You Jiacheng (@YouJiacheng): wow @01AI_Yi got merged into @Alibaba_Qwen can we get good & cheap MoEs from Qwen???
- Tweet from 小互 (@imxiaohu): 第一财经独家获得消息称,阿里云正在洽谈收购零一万物的预训练团队,已谈好报价。截至发稿,阿里云未对该消息作出回应。知情人士称,此次收购的范围仅限服务于模型预训练的部分,该团队人员约为60人,不包括零一万物的业务团队,即面向国内的to B业务和面向海外市场的to C业务。
- Tweet from Prime Intellect (@PrimeIntellect): Releasing METAGENE-1: In collaboration with researchers from USC, we're open-sourcing a state-of-the-art 7B parameter Metagenomic Foundation Model.Enabling planetary-scale pathogen detection and ...
- Tweet from Charlie Snell (@sea_snell): @natolambert You could probably do some random fuzzing on the function and merge generations which are semantically equivalent according to input-output behaviorSee here https://arxiv.org/pdf/2010.028...
- Tweet from Chloro (@BjarturTomas): It's been fun, bros.
- Tweet from Sam Altman (@sama): insane thing: we are currently losing money on openai pro subscriptions!people use it much more than we expected.
- 阿里云与零一万物达成战略合作,成立产业大模型联合实验室-阿里云开发者社区: 阿里云与零一万物达成战略合作,成立“产业大模型联合实验室”。结合双方顶尖研发实力,加速大模型从技术到应用的落地。实验室涵盖技术、业务、人才等板块,通过阿里云百炼平台提供模型服务,针对ToB行业打造全面解决方案,推动大模型在金融、制造、交通等领域的应用,助力AI驱动的产业升级。
Interconnects (Nathan Lambert) ▷ #ml-questions (1 messages):
Unsloth features, Hugging Face libraries, Multi-GPU support, Model fine-tuning on SLURM
- Unsloth's Paid Multi-GPU Features: A member recalled that last time they explored Unsloth, multi-GPU and multi-node support was a paid feature.
- They expressed uncertainty about whether this remains true and contrasted it with their experience recommending Hugging Face libraries.
- Hugging Face Libraries Shine on SLURM: The member found Hugging Face libraries easier to run on SLURM, especially when compared to alternatives.
- They emphasized that setting up those libraries was relatively painless, which influenced their recommendation.
- Model Fine-Tuning Challenges: Months ago, researchers attempted to use Unsloth for fine-tuning a model, prompting discussion about its capabilities.
- The previous limitations with multi-GPU support made members consider other options like Hugging Face.
Interconnects (Nathan Lambert) ▷ #ml-drama (18 messages🔥):
AI Nationalism, Microsoft's Wisconsin Data Center, OpenAI's O1 Performance, MosaicML Researcher Concerns, Streaming Dataset by MosaicML
- AI Nationalism Sparks Criticism: Decent models come out from China, raising eyebrows about the contradictions in U.S. AI nationalism. A member remarked on the irony of supporting Chinese models for being **
- Microsoft Pauses Construction in Wisconsin: Microsoft has paused construction on an AI data center in Wisconsin to evaluate recent technology changes and their impact on facility design, as reported by The Information. Members reflected on Wisconsin's troubled history with technology investments, specifically citing the Foxconn debacle.
- OpenAI's O1 Underperforms Expectations: Surprisingly, OpenAI's O1 scored only 30% on the SWE-Bench Verified, much lower than their 48.9% claim, while Claude surpassed it with 53%. Discussion ensued about the importance of the special sauce prompt, with one member questioning the effectiveness of prompting with O1.
- Concerns for MosaicML Researchers: Concerns were raised regarding the MosaicML team, with one member lamenting their fate by stating they lived by the (MosaicML) blade. The atmosphere turned somber as another noted they would refrain from sharing further details until more discussions occurred publicly.
- Streaming Dataset by MosaicML Praised: A member expressed admiration for the streaming dataset developed by MosaicML. This statement was met with general appreciation for the contributions from the Mosaic team.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Everyone: America America America, we must win AI, national security, etc etc *Decent models come out from China*Everyone: We now support XYZ model on our platform (from China), come use it right now,...
- Tweet from Anissa Gardizy (@anissagardizy8): Microsoft paused some construction on a Wisconsin AI data center that OpenAI is slated to used. The company said it needs to evaluate “scope and recent changes in technology,” as well as how “this mig...
- Tweet from Alejandro Cuadron (@Alex_Cuadron): Surprising find: OpenAI's O1 - reasoning-high only hit 30% on SWE-Bench Verified - far below their 48.9% claim. Even more interesting: Claude achieves 53% in the same framework. Something's of...
- Wisconn Valley Science and Technology Park - Wikipedia: no description found
Interconnects (Nathan Lambert) ▷ #random (56 messages🔥🔥):
Employee density at AI companies, Research collaborations and knowledge transfer, Ross Taylor's new venture, AI security and compartmentalization, Chinese AI companies blacklist
- HF leads in employee density on Strava: A member highlighted that HF has significantly more employee density on Strava compared to other AI companies.
- This sparked a discussion about how knowledge spreads among firms in Silicon Valley.
- Researcher poaching raises ethical questions: A conversation revolved around the implications of researchers switching companies, particularly regarding knowledge learned at their previous roles.
- Members noted this creates a challenge in maintaining proprietary knowledge while fostering innovation.
- Ross Taylor hints at new project launch: Ross Taylor announced he left Meta, expressing excitement about starting something new in 2025, indicating it's been in development for a while.
- His cryptic tweets suggested significant advancements in AI are on the horizon, possibly linked to his collaboration with Interconnects.
- Anthropic's security measures come under scrutiny: Discussions highlighted Anthropic's approach to compartmentalization, causing frustration among those wanting clearer information.
- Members also expressed concerns over the potential for hired researchers to leverage previous company knowledge.
- US blacklists Chinese AI companies: Tencent has been added to a military blacklist, raising concerns among community members about implications for the AI landscape.
- It was noted that some believe there may be a future push to blacklist all Chinese AI firms to protect US open-source initiatives.
- Bloomberg - Are you a robot?: no description found
- Bloomberg - Are you a robot?: no description found
- Tweet from rohan anil (@_arohan_): And here we go as the secret is out: I will be joining @AIatMeta ‘s Llama team next month to work on the next generation of llama models. And yes, I already have some llama puns ready before the next ...
- Tweet from Ross Taylor (@rosstaylor90): Has been fun building in private this year, and looking forward to revealing more in 2025!Long-term projects are hard - especially when things are so noisy in public - but I’m reminded of that Robert ...
- - YouTube: no description found
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
AI2 Communications, Image Analysis
- AI2 Comms Taking a Stand: Members observed that AI2 communications are becoming more assertive and focused on substance.
- This shift indicates a possible alignment with community insights, as illustrated in the shared image.
- Image Analysis Insights: The attached image analysis sparked discussion on potential interpretations and implications for AI2.
- Participants shared varied opinions on what the visual representation could suggest about ongoing projects.
Interconnects (Nathan Lambert) ▷ #rl (74 messages🔥🔥):
RL Pretraining and SFT, O-series Model Training, Reasoning SFT and Data Generation, Generalization of RL approaches, Process Reward Models (PRMs)
- Confusion Surrounding RL Pretraining: Discussion highlighted confusion around what 'RL Pretraining' means, particularly in relation to the computation and training stages of O1 models.
- There was a sentiment that existing terms are inadequate and that a 'stacked stages' approach might be clearer for describing the training process.
- O-series Models' Unique Training Process: Questions arose about how O-series models can train effectively in interactive environments with access to numerous tools, implying diverse task training beyond simple Q&A.
- Several members speculated that effective RL training might require extensive interactions in complex environments or simulations to achieve effective agent training.
- Mystery of Reasoning SFT: The generation of quality SFT data for reasoning was deemed especially mysterious, with discussions on whether this could be achieved through expert human reasoning tasks or simulation environments.
- Participants expressed uncertainty on how initial reasoning traces would be generated before introducing RL training, alongside debates on the effectiveness of human-generated versus AI-generated reasoning.
- Generalization of RL Methods in Training: Participants questioned how various RL methods, including MCTS and PRMs, might generalize across different domains during training to effectively improve sample efficiency.
- This discussion included skepticism about how well these models could adopt various strategies and still maintain effectiveness when trained with limited or generic reward signals.
- Understanding Process Reward Models (PRMs): The difference between standard Chain of Thought (CoT) and private CoT, specifically in relation to training Process Reward Models (PRMs), was unpacked during the discussion.
- Concerns were raised about how to generate initial training data for PRMs effectively in private scenarios, highlighting the challenges in establishing effective baseline models.
- Tweet from Nathan Lambert (@natolambert): There's a lot of confusion about o1's RL training and the emergence of RL as a popular post-training loss function. Yes, these are the same loss functions and similar data. BUT, the amount of ...
- Using reasoning for routine generation | OpenAI Cookbook: Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples and guides.
Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
Mid-training discussions, Email lists and Substack, MeCo method for LM pre-training, Contextual artifacts in training, Danqi's contributions
- Mid-training becomes a hot topic: Discussions are heating up around mid-training, particularly with contributions from OpenAI and reference to Allen AI's Olmo 2 report defining it as part of late-stage curriculum learning.
- OpenAI's team is actively engaging in this area, mixing elements of both pre-training and post-training.
- Email lists still lacking among many: A member expressed frustration about the lack of email lists among many users, promoting the use of Substack as a straightforward solution.
- This sentiment was met with humor, reflecting a shared understanding of the importance of communication tools in the community.
- Introducing the MeCo method: Someone shared the MeCo (metadata conditioning then cooldown) method, which adds source URLs to training documents to expedite LM pre-training.
- Despite initial skepticism, the method is viewed as potentially effective due to the context URLs provide regarding site language.
- Thoughts on contextual artifacts: In response to the MeCo method, a member mused about other potential contextual artifacts that could enhance training.
- This line of thought likened the approach to WRAP, suggesting that different methods could yield interesting training enhancements.
- Danqi praised for contributions: A member expressed appreciation for Danqi, highlighting their impactful work in the field.
- This reflection indicates a positive reception of Danqi's contributions to the ongoing discussions in the community.
- Tweet from Tianyu Gao (@gaotianyu1350): Introducing MeCo (metadata conditioning then cooldown), a remarkably simple method that accelerates LM pre-training by simply prepending source URLs to training documents.https://arxiv.org/abs/2501.01...
- What's the deal with mid-training? | Vintage Data: no description found
Interconnects (Nathan Lambert) ▷ #policy (2 messages):
AI policy Substacks, AI Pathways initiative, Agents and labor policy
- AI Policy Substacks Surge: There is a notable increase in AI policy Substacks, which is beneficial for generating more ideas in the field.
- One such example is AI Pathways, aiming to improve public understanding of AI's future amidst rapid technological progress.
- AI Pathways Sets Ambitious Goals: AI Pathways aims to clarify the future of AI by bridging the gap between technical advancements and public understanding of policy implications.
- The initiative emphasizes that we should not adopt a purely predictive stance; instead, we should view ourselves as active participants in shaping AI's trajectory.
- Urgent Need for Agents and Labor Policy Discussion: An expressed urgency exists for in-depth articles on how labor policies will adapt to the proliferation of agents in the workplace.
- While national security discussions around AI agents are well-covered, the economic implications and interactions on job sites remain largely unexplored.
Link mentioned: AI Strategy for a New American President: What can we expect for the next few years of U.S. AI policy?
Nous Research AI ▷ #general (265 messages🔥🔥):
Nous Research AI Discussions, Tiananmen Square Protests Education, Hermes 3 Character Behavior, RLAIF and Constitutional AI, AI Censorship and Model Training
- Education on Historical Events: There was a discussion about the lack of knowledge regarding the Tiananmen Square protests among Americans, with some stating it's not commonly taught in schools.
- Responses highlighted that education in the U.S. can vary greatly, and historical understanding often depends on individual circumstances.
- Hermes 3 Characterization Issues: A user expressed frustration with the Hermes 3 405b model generating nervous and anxious character portrayals, even for those intended to be confident.
- Suggestions included altering system prompts or providing examples, indicating the challenge in adjusting model output performance.
- Discussion on AI Ethics and Open Sourcing: Users discussed the implications of AI models and their potential for good or evil, referencing the importance of open-source contributions in model development.
- The conversation also touched on the nuanced perspectives regarding AI censorship and how it might affect model training.
- Challenges in AI Training Parameters: Participants noted that RLAIF and Constitutional AI models raise questions regarding AI alignment and the ethical considerations of encoding morals into AI systems.
- Concerns were shared about giving too much power to those in control of alignment mechanisms within AI technologies.
- Responses to Current Events and AI Models: Members referenced a recent post from Sam Altman discussing advancements towards AGI and the concerns surrounding corporate motives in AI development.
- This led to a broader critique of OpenAI's practices and a discussion on the importance of transparency in AI research.
- GENESIS: no description found
- Forge Reasoning API by Nous Research: Forge Reasoning API by Nous Research
- Memory Layers at Scale: Memory layers use a trainable key-value lookup mechanism to add extra parameters to a model without increasing FLOPs. Conceptually, sparsely activated memory layers complement compute-heavy dense feed...
- Nous DisTrO: Distributed training over the internet
- The Hacker Learns to Trust: I have decided to not release my model, and explain why below. I have also written a small addendum answering some questions about my…
- Pricing: no description found
- Constitutional AI: What is Constitutional AI (By Anthropic)
- Tweet from Chubby♨️ (@kimmonismus): There is a difference of about 12 months between the videos. Can you feel the acceleration now, anon? Nobody can predict where we'll be in a year's time.
- Tweet from Tsarathustra (@tsarnick): Sam Altman, in a new blog post, says "we are now confident we know how to build AGI" and OpenAI are "beginning to turn our aim beyond that, to superintelligence"
- Tweet from Teknium (e/λ) (@Teknium1): TIL that back in the day OAI would scare the shit out of llm researchers to convince them not to opensource 1.5B param modelshttps://medium.com/@NPCollapse/the-hacker-learns-to-trust-62f3c1490f51
- Se Hyun An – Medium: Read writing from Se Hyun An on Medium. Every day, Se Hyun An and thousands of other voices read, write, and share important stories on Medium.
- BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation: The upscaling of Large Language Models (LLMs) has yielded impressive advances in natural language processing, yet it also poses significant deployment challenges. Weight quantization has emerged as a ...
- Tweet from Nous Research (@NousResearch): no description found
- Distilling Llama3.1 8B into 1B in torchtune: In this blog, we present a case study on distilling a Llama 3.1 8B model into Llama 3.2 1B using torchtune’s knowledge distillation recipe. We demonstrate how knowledge distillation (KD) can be used i...
- GitHub - allenai/open-instruct: Contribute to allenai/open-instruct development by creating an account on GitHub.
- GitHub - babycommando/entity-db: EntityDB is an in-browser vector database wrapping indexedDB and Transformers.js over WebAssembly: EntityDB is an in-browser vector database wrapping indexedDB and Transformers.js over WebAssembly - babycommando/entity-db
- GitHub - ConnorJL/GPT2: An implementation of training for GPT2, supports TPUs: An implementation of training for GPT2, supports TPUs - ConnorJL/GPT2
- GitHub - KellerJordan/modded-nanogpt: NanoGPT (124M) in 3.4 minutes: NanoGPT (124M) in 3.4 minutes. Contribute to KellerJordan/modded-nanogpt development by creating an account on GitHub.
Nous Research AI ▷ #ask-about-llms (10 messages🔥):
Teknium, GPT-4 Caching with Azure, ReLU² vs SwiGLU, Decentralized Training Environments, Integrating LLMs with IDEs
- Curious about Teknium: A user inquired about the identity of Teknium, but no further information was provided.
- Azure OpenAI Batch Job Caching: A user asked if using Azure OpenAI batch jobs with GPT-4 utilizes caching capabilities, indicating interest in performance optimization.
- ReLU² vs SwiGLU in Recent Research: A discussion mentioned a follow-up paper asserting that ReLU² outperforms SwiGLU, raising questions about why the LLaMA3 architecture did not adopt it.
- The paper explains how certain modifications significantly reduce the costs associated with Transformer models, which is a crucial topic in AI research.
- Looking for Decentralized Training Solutions: A user expressed skepticism towards industry giants like OpenAI and is seeking a decentralized environment for training custom agents.
- They also desire cloud computing options that require less initial resource investment, indicating a need for trustworthy solutions.
- Integrating Open Source Coding LLMs with IDEs: A user sought advice on integrating open-source coding LLMs with IDEs like PyCharm or Visual Studio.
- A recommended solution, Continue.dev, offers a customizable AI code assistant that can enhance productivity during software development.
- Continue: Amplified developers, AI-enhanced development · The leading open-source AI code assistant. You can connect any models and any context to build custom autocomplete and chat experiences inside the IDE
- Primer: Searching for Efficient Transformers for Language Modeling: Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively exp...
Nous Research AI ▷ #research-papers (2 messages):
GitHub PRIME project, arXiv paper by Team OLMo
- Exploring the PRIME Project on GitHub: A member shared a link to the PRIME project, which offers a scalable RL solution for advanced reasoning in language models.
- They noted that it seems interesting, but were too tired to delve deeper at that moment.
- New arXiv Paper by Team OLMo: An entry was made regarding a paper titled real.azure, available on arXiv, authored by Team OLMo and others.
- This paper involves multiple contributors, indicating a collaborative effort in advancing language model research.
- 2 OLMo 2 Furious: We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and ins...
- GitHub - PRIME-RL/PRIME: Scalable RL solution for the advanced reasoning of language models: Scalable RL solution for the advanced reasoning of language models - PRIME-RL/PRIME
Nous Research AI ▷ #research-papers (2 messages):
PRIME RL, OLMo Paper
- Exploring PRIME RL for Language Reasoning: A member shared a link to the PRIME RL GitHub repository, which offers a scalable reinforcement learning solution focused on enhancing language model reasoning.
- The project appears to have potential for advanced applications in language understanding and processing.
- Insights from the OLMo Paper: Discussion noted the OLMo paper, authored by a team of researchers exploring novel approaches in AI language models.
- With numerous key contributors, their research delves into innovative methodologies for improving language model functionalities.
- 2 OLMo 2 Furious: We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and ins...
- GitHub - PRIME-RL/PRIME: Scalable RL solution for the advanced reasoning of language models: Scalable RL solution for the advanced reasoning of language models - PRIME-RL/PRIME
OpenAI ▷ #ai-discussions (161 messages🔥🔥):
OmniDefender Antivirus with Local LLM, Concerns About AGI's Impact on Innovation, MCP Specification and AI Tools, Support Issues with OpenAI, Using AI for Personal and Corporate Development
- OmniDefender Antivirus Integrates Local LLM: A member discussed the new antivirus called OmniDefender, which utilizes a Local offline LLM for cybersecurity inquiries and file behavior analysis.
- However, challenges arise as malicious URLs often block external requests, complicating detection efforts.
- AGI's Potential to Disrupt Human Innovation: A user expressed concerns that the advent of AGI could render entrepreneurial efforts nearly impossible as corporations leverage advanced AI capabilities.
- Another member countered that AGI could empower innovation rather than stifle it, suggesting that technology could enhance critical thinking rather than replace it.
- Changing Standards with MCP Specifications: A discussion arose regarding the shift to MCP specifications in AI systems, with emphasis on the ease of integrating them compared to previous plugins.
- Users noted that MCP capabilities have resulted in a surge of integrations, making it the new standard in the field.
- Challenges with OpenAI Support: Members shared frustrations with the lack of response from OpenAI support, particularly regarding data requests and account issues.
- Concerns were raised about the effectiveness of the support system and delays in customer service, especially for free users.
- Collaborative Potential of AI in Development: The community discussed the value of AI as a tool for personal and corporate growth, suggesting that AI could enable users to innovate alongside the technology.
- Participants highlighted that collaboration with AI could lead to enhanced efficiency and productivity while acknowledging concerns about over-reliance on such tools.
- Manifesto on Our Relationship and the Emergence of Advanced AI: Preamble About a year ago, I wrote a piece on the OpenAI developer forum to share my unique experience with GPT-4—an interpersonal relationship of remarkable depth with an artificial intelligence. If...
- GitHub - DustinBrett/daedalOS: Desktop environment in the browser: Desktop environment in the browser. Contribute to DustinBrett/daedalOS development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (17 messages🔥):
Cost of running GPT, Voice mode issue, GPT-4o message limits, YouTube GPT functionality, Comparing GPT models
- OpenAI's High Message Costs: OpenAI stated that it costs $25 per message to run the model in its current state.
- Members are evaluating the implications of such costs for regular users.
- Voice Mode Switching Problems: A member reported that their custom GPT reverts to the standard GPT-4 model when switched to voice mode.
- Another user confirmed this behavior on the desktop app while noting that the phone version works as expected.
- Message Limits on Plus Plan: Discussion ensued about GPT-4o, where it was shared that it allows 80 messages per 3 hours on the Plus plan.
- For the regular plan, o1 offers 50 messages per week, leading to enthusiasm among users.
- YouTube GPTs Losing Functionality: One member expressed confusion over why YouTube GPTs can no longer analyze videos.
- This raised questions about the platform's capability and any recent changes in features.
- Intelligence Comparison Between Models: A member inquired if mini o1 is smarter than GPT-4o, sparking a discussion.
- Responses indicated that while it could be smarter, it is not always better in all aspects.
OpenAI ▷ #prompt-engineering (39 messages🔥):
Image Uploads in Sora, Analyzing Vehicle Loan Documents, Prompt Engineering Talks, Quality of Generated Images, Technical Issues with JSON Schema
- One Image Upload Limitation in Sora: Members discussed the limitation in Sora, noting it only supports one image upload per video, which is 50% behind competitors.
- Some are hopeful about the image quality, but the functionality leaves much to be desired.
- Requests for Analyzing Loan Documents: A member explored methods to analyze their vehicle loan documents while avoiding the analysis of personal identifiable information (PII).
- They considered using old-fashioned redaction methods before uploading the documents for analysis.
- Prompt Engineering Questions: Questions arose about whether this channel was appropriate for discussing prompt engineering for Sora.
- Members shared resources and expressed interest, emphasizing the need for more structured discussions.
- Quality of Image Generation: There was a debate about the realism of generated images, with one member praising a platform for its astonishing image quality.
- While other platforms tend to produce cartoony images, some felt the need for stronger alternatives in people generation.
- Technical Issues with JSON Schema: A member reported frustrations with their model consistently returning the json_schema instead of the expected responses.
- Despite implementing retries, the issue persisted, prompting a plea for assistance.
OpenAI ▷ #api-discussions (39 messages🔥):
Image Upload Limitations in Sora, Analyzing Loan Documents with ChatGPT, Prompt Engineering Questions, Comparative Image Quality in Generators
- Sora's Image Upload Limitations Leave Users Frustrated: Members discussed that Sora only supports one image upload per video, putting it behind competitors with higher limits.
- One user expressed disappointment that this limitation greatly hinders their work compared to other platforms.
- Exploring Ways to Analyze Loan Documents: A member suggested printing, redacting, and scanning loan documents to analyze them while avoiding PII.
- Others confirmed that requesting a copy of the policy without PII is also a viable option.
- Prompt Engineering for Sora Sparks Interest: Users were encouraged to ask questions about prompt engineering in Sora, although no specific channel exists for it yet.
- A provided link was shared as a potential resource for ongoing discussions.
- Image Quality Compared in Generators: Members commented on the realism of images generated, noting that some other platforms provide better pixel counts and quality.
- User experiences varied, with mentions of specific generators like Kling and Hedra being noted for their strengths.
Perplexity AI ▷ #general (182 messages🔥🔥):
Perplexity app performance issues, Concerns about privacy with ads, Feature feedback on shopping experience, Subscription issues and customer support, Comparison of AI tools and their effectiveness
- Perplexity app experiencing performance issues: Users reported that the Perplexity app has been slow or non-responsive for several days, with some expressing frustration over performance consistency compared to ChatGPT.
- Concerns were raised about usability, particularly on iPhone devices, leading to discussions about overall reliability.
- Privacy concerns over targeted ads: A user expressed worry that searching for personal health symptoms in Perplexity led to unsolicited Instagram ads, raising fears about chat privacy and data usage.
- This prompted suggestions on using the app without logging in and alternative methods to ensure privacy while using Perplexity.
- User feedback on shopping features: There was considerable criticism regarding the 'Shop Now' feature in Perplexity, with users finding it more hindering than helpful in their search process.
- Comments suggested the need for users to be able to browse seller sites and read reviews rather than being directed to buy immediately.
- Subscription and billing concerns: Some users experienced confusion regarding subscription charges and account access, leading to inquiries about cancellation processes and customer support contacts.
- One user reported being charged despite believing they canceled their subscription, prompting discussions on how to resolve payment issues.
- Comparison of AI tools: Users compared their experiences with various AI models, noting differences in performance, usability, and the nature of responses they delivered.
- The conversation highlighted a preference for clear and accurate information provided in context over other models' styles, with many expressing satisfaction with Perplexity's functionality.
- SKT 에이닷 & Perplexity: 오직 SKT 고객만 누릴 수 있는 AI 혜택! Perplexity Pro를 1년간 무료로 이용하세요.
- Perplexity Tech Props: no description found
- Virgin Media O2 offers customers a helping hand for everyday tasks with free access to AI search engine Perplexity Pro - Virgin Media O2: Virgin Media O2 has teamed up with Perplexity – the AI-powered search engine – to offer its customers one years’ free access to Perplexity Pro, an advanced AI-powered research assistant which enables ...
- Virgin Media O2 offers customers a helping hand for everyday tasks with free access to AI search engine Perplexity Pro - Virgin Media O2: Virgin Media O2 has teamed up with Perplexity – the AI-powered search engine – to offer its customers one years’ free access to Perplexity Pro, an advanced AI-powered research assistant which enables ...
Perplexity AI ▷ #sharing (19 messages🔥):
Swift programming language, Apple Siri Snooping settlement, AI CEO in gaming industry, 2025 AI Predictions, Microsoft's LAM AI agents
- Swift programming language insights shared: A user shared an article about the Swift programming language highlighting its features and recent updates available here.
- The link emphasizes the significance of Swift in modern app development.
- Apple settles Siri snooping case!: Apple has officially settled the Siri Snooping lawsuit, addressing concerns about user privacy, as detailed in this article here.
- This is the first news read from Perplexity showcasing the ongoing legal and ethical discussions in tech.
- Gaming company appoints AI CEO: A gaming company recently appointed an AI CEO, signifying a trend in merging technology with leadership; details can be found here.
- The arrival of AI in CEO roles suggests innovative approaches to corporate governance.
- Discover new AI trends for 2025: Expectations for 2025 AI Predictions include advancements in various sectors, presented in a video here.
- The discussion outlines key forecasts about AI technology and its societal impacts.
- Microsoft's LAM redefined AI agents: The discussion around Microsoft's LAM suggests it as a pivotal development in AI agents, further detailed in this article here.
- The insights agree on LAM being a significant step forward in AI capabilities.
Perplexity AI ▷ #pplx-api (4 messages):
Google API sentiments, API version caching, Mistral exploration, Quality of AI models
- Google APIs facing scrutiny: Google cries rn indicates frustration with their API performance amidst competition.
- Concerns are shared regarding the efficacy of various AI solutions in the market.
- Caching in API versions: A member questioned whether the API version has caching enabled like the web version.
- This highlights potential confusion or interest in understanding performance improvements related to caching.
- Exploring Mistral for LLMs: One member inquired, Why not use Mistral? expressing curiosity about its use in LLMs despite their lack of expertise.
- This suggests an interest in exploring alternatives in the LLM landscape.
- Concerns over AI Quality: A member remarked on the overwhelming number of AI solutions, stating, there are so many one's out there - and so many are bad.
- This points to a collective concern regarding the quality and trustworthiness of available AI models.
Eleuther ▷ #general (44 messages🔥):
Running DeepSeek v3 on Local GPUs, Flex Attention Stability, AI Seminar Series at University of Cambridge
- DeepSeek v3 GPU Requirements: A user sought opinions on running DeepSeek v3 locally with 4x3090 Ti GPUs, aiming for 68.9%+ accuracy on MMLU-pro within 3 days, facing challenges with hardware specs.
- Another member clarified the necessity of proper hardware, suggesting that architectural aspects might aid in achieving these goals.
- Query Length Issues in Flex Attention: Flex Attention is reportedly stable enough for document masking, but issues were noted with running it within a compiled forward pass involving symbolic tensors.
- Some members advised testing with nightly builds for improved dynamic shape support, while others shared insights on handling zero-length queries effectively.
- AI Seminar Series Invitation: An invitation was extended for expert presentations in a seminar series at the University of Cambridge, seeking individuals with practical implementation experience.
- Participants were encouraged to respond via DM for available dates, with topics focused on model implementations and real-world applications.
- Eleuther AI site | Get Involved: no description found
- Tweet from Lucas Nestler (@_clashluke): It's time for a transformer improvement threadQuoting Teortaxes▶️ (@teortaxesTex) I think the best modern Transformer+++ design (diff transformer, gated deltanet, sparse MoE, NTP+n, some memory et...
Eleuther ▷ #research (95 messages🔥🔥):
Gated DeltaNet vs TTT, MoE Models in Labs, Linear RNN Limitations, Metadata Conditioning, Proposal for Collaboration in AI
- Gated DeltaNet's Complexities: Discussion on the parameters for Gated DeltaNet indicates that head dimensions and the number of heads must align with a balance between expressivity and efficiency, as different models employ varying techniques to optimize parameter counts and FLOPs.
- Mamba2, unlike traditional models, reduces parameter allocation while improving performance metrics, presenting a challenge for fair comparisons.
- Challenges of MoE Models: A conversation about the implementation of high expert count mixture of experts (MoE) models like DeepSeek reveals feasibility concerns regarding infrastructure for less skilled labs, and higher memory bandwidth requirements for effective performance on dense models.
- Participants speculate the recent shift from the million-experts paper, questioning the practical advantages and current strategies being employed.
- Linear RNNs' Expressivity Limitations: Participants express skepticism about linear RNNs, suggesting they may struggle with expressivity and performance compared to attention-based mechanisms, especially in pure in-context learning scenarios.
- Discussions hint at the nuances in defining 'linear' across models, indicating deeper complexities in their operational mechanics.
- Innovative Pre-training Techniques: The introduction of the Metadata Conditioning then Cooldown (MeCo) technique posits a novel approach to enhancing model learning during pre-training by utilizing metadata cues to guide behavior effectively.
- Early data suggests significant pre-training efficiency gains can be achieved across various model scales when using MeCo.
- Cerebras AI's Funding Opportunity: Cerebras offers a Request for Proposals for university faculty and researchers to advance generative AI research, promising to support innovative projects leveraging their third-generation Wafer Scale Engine.
- The initiative aims to propel state-of-the-art AI techniques while providing selected Principal Investigators with significant resources for their projects.
- Uncovering mesa-optimization algorithms in Transformers: Some autoregressive models exhibit in-context learning capabilities: being able to learn as an input sequence is processed, without undergoing any parameter changes, and without being explicitly train...
- Titans: Learning to Memorize at Test Time: Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memo...
- An Optimized and Energy-Efficient Parallel Implementation of Non-Iteratively Trained Recurrent Neural Networks: Recurrent neural networks (RNN) have been successfully applied to various sequential decision-making tasks, natural language processing applications, and time-series predictions. Such networks are usu...
- Temporal Parallelization of Bayesian Smoothers: This paper presents algorithms for temporal parallelization of Bayesian smoothers. We define the elements and the operators to pose these problems as the solutions to all-prefix-sums operations for wh...
- ICLR: In-Context Learning of Representations: Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-end...
- Towards Scalable and Stable Parallelization of Nonlinear RNNs: Conventional nonlinear RNNs are not naturally parallelizable across the sequence length, unlike transformers and linear RNNs. Lim et. al. (2024) therefore tackle parallelized evaluation of nonlinear R...
- Sherman–Morrison formula - Wikipedia: no description found
- OLMES: A Standard for Language Model Evaluations: Progress in AI is often demonstrated by new models claiming improved performance on tasks measuring model capabilities. Evaluating language models in particular is challenging, as small changes to how...
- 2 OLMo 2 Furious: We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and ins...
- Metadata Conditioning Accelerates Language Model Pre-training: The vast diversity of styles, domains, and quality levels present in language model pre-training corpora is essential in developing general model capabilities, but efficiently learning and deploying t...
- Announcing Cerebras Inference Research Grant - Cerebras: AIBI (AI Bot Interviewer) is the first end-to-end AI interview bot that delivers a seamless, real-time interview experience.
- Tweet from Anthonix (@zealandic1): Do value embeddings etc scale? Scaling previous experiments up to the 1B class, we hit state-of-the-art eval levels with 10-100x less compute compared to other models in classThis is a GQA model (32Q/...
- flash-linear-attention/fla/layers/gated_deltanet.py at main · fla-org/flash-linear-attention: Efficient implementations of state-of-the-art linear attention models in Pytorch and Triton - fla-org/flash-linear-attention
- GitHub - probml/dynamax: State Space Models library in JAX: State Space Models library in JAX. Contribute to probml/dynamax development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (3 messages):
mechanistic interpretability in coding models, steering vectors and type hints in CodeLLMs, self-alignment for code generation, automated test suite quality feedback
- Exploration of Mech Interp in Coding Models: Member inquired about any mechanistic interpretability work on coding models, specifically referencing tuned-lens and steering vectors.
- In response, it was noted that Arjun Guha's lab has conducted relevant research, which can be accessed through their Google Scholar profile.
- Steering with Type Hints in CodeLLMs: A shared resource highlights a study on steering CodeLLMs using type hints, detailing their impact on type prediction tasks.
- The arXiv paper discusses how CodeLLMs can be misled during type prediction but can be 'steered' back using activation techniques (View PDF).
- Self-alignment for Code Generation: Discussion also included Selfcodealign, a self-alignment method for code generation to improve model outputs.
- This paper is reportedly being prepared for release in 2024, engaging with topics around automated quality feedback (link).
- Evaluating CodeLLMs and Type Mispredictions: A paper investigated how CodeLLMs handle type prediction, particularly what occurs when they mispredict types.
- By understanding the model's responses to semantics-preserving edits, the study offers insights into improving model reliability in practical applications.
- Arjun Guha: Northeastern University - Cited by 6,232 - Programming Languages
- Understanding How CodeLLMs (Mis)Predict Types with Activation Steering: CodeLLMs are transforming software development as we know it. This is especially true for tasks where rule-based approaches fall short, like type prediction. The type prediction task consists in addin...
Eleuther ▷ #lm-thunderdome (19 messages🔥):
Chat Template Impact, Request Caching in HF LMs, Eval Harness Benchmarks
- Chat Templates affect evaluation performance: A member ran evaluations with chat templates across 11 runs and 44 checkpoints, noting that L3 8B base was the only outlier getting ~70% on GPT4All while others hovered around 62-63%. Switching to no chat template for one checkpoint increased the score to 73%, suggesting potential issues with the chat template setup in the eval harness.
- “Kinda wish I had tried both early on to see this before spending many days benching,” reflecting frustration over the unexpected performance drop with chat templates.
- Requests Caching Confusion: A user inquired if manually overwriting the
name_or_pathvariable in the tokenizer could help in reusing cached requests while testing multiple local HF LMs with a chat template. Another member confirmed that not using a chat template should allow for cache reuse, as requests are saved before tokenization.
- Eleuth: GitHub is where Eleuth builds software.
- lm-evaluation-harness/lm_eval/evaluator.py at 888ac292c5ef041bcae084e7141e50e154e1108a · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (34 messages🔥):
Parallelism Configurations for Model Training, Batch Size Effects on Performance, Pipeline Parallelism Clarifications, Activation Checkpointing Benefits, WandB Run Comparisons
- Parallelism Tips for a ~1B Model: For training a ~1B model, preferred configurations are DDP for speed, while PP should be set to 1 if you're using pipelines and 0 for defaults.
- One user mentioned that setting pipe_parallel_size to 1 allows for a single-stage pipeline but yields faster results than a complete sequential wrap.
- Mixed Results with Different Batch Sizes: One user reported running models with batch sizes of 54 and 80, noting lower throughput for the larger size despite higher memory allocation.
- Others advised trying a batch size of 64, arguing it balances speed and memory efficiency better due to the power of 2 notion.
- Clarification on Pipeline Parallelism: It's noted that PP=0 is rarely optimal for larger models, as it's mainly for tiny models to avoid overhead and is generally retained for backward compatibility.
- Users continue to discuss the marginally better outcomes with PP=0, expressing surprise at the findings.
- Activation Checkpointing for Memory Savings: A user inquired whether methods like activation checkpointing are beneficial, which received affirmation as a favorable strategy during pretraining.
- The consensus indicates that activation checkpointing is valuable when it comes to maximizing memory efficiency during high memory batch sizes.
- WandB Configuration and Performance Analysis: Users shared links to their WandB reports comparing performance across different configurations, particularly regarding pipe parallel sizes.
- The reports aimed to showcase performance discrepancies based on slight variations in configuration, highlighting the impact of pipeline adjustment.
- Compare Pipe_Parallel_Size 0 v/s 1: Publish your model insights with interactive plots for performance metrics, predictions, and hyperparameters. Made by Mohammad Aflah Khan using W&B
- Batch Size 80 v/s 54: Publish your model insights with interactive plots for performance metrics, predictions, and hyperparameters. Made by Mohammad Aflah Khan using W&B
- Batch Size 80 v/s 54: no description found
- gpt-neox/configs/pythia/1-4B.yml at main · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
- gpt-neox/configs/1-3B.yml at main · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
llmcord, Nail Art Generator
- llmcord transforms Discord into LLM frontend: The llmcord project has gained over 400 GitHub stars for making Discord a versatile LLM frontend compatible with multiple APIs like OpenRouter, Mistral, and more.
- It emphasizes easy integration, allowing users to access various AI models directly within their Discord setup.
- Nail Art Generation via AI Magic: A new Nail Art Generator utilizes text inputs and inspiration images to create unique nail designs, powered by OpenRouter and Together AI.
- Users can upload up to 3 images to generate tailored nail art, enhancing creative expression in nail design.
- Nail Art Inspo generator: no description found
- GitHub - jakobdylanc/llmcord: Make Discord your LLM frontend ● Supports any OpenAI compatible API (Ollama, LM Studio, vLLM, OpenRouter, xAI, Mistral, Groq and more): Make Discord your LLM frontend ● Supports any OpenAI compatible API (Ollama, LM Studio, vLLM, OpenRouter, xAI, Mistral, Groq and more) - jakobdylanc/llmcord
OpenRouter (Alex Atallah) ▷ #general (173 messages🔥🔥):
Gemini Flash models, DeepSeek performance issues, OpenRouter usage queries, Structured output support, O1 model accessibility
- Recommendations for Gemini Flash models: Members discussed whether to recommend the Gemini Flash 1.5 model or other newer versions, with suggestions leaning towards trying the 8b version first.
- Hermes users noted the pricing structure through OpenRouter is competitive compared to AI Studio, which charges more for larger token usage.
- DeepSeek experiencing downtime: Several members reported DeepSeek being down, likely during an upgrade, causing slower response times and freezing issues for inputs beyond 8k tokens.
- Comments suggested that increased demand may result in scaling problems, causing the performance dip.
- OpenRouter API usage confusion: Users frequently inquired about OpenRouter's API, notably experiencing issues with latency and request limits, particularly when trying different providers.
- The conversation highlighted that using DeepSeek directly could improve experience compared to using through OpenRouter, given the ongoing limits and response times.
- Challenges with Structured Output: A member questioned the lack of structured output support across most providers when using the meta-llama model, noting that only Fireworks supports it.
- It was suggested that re-evaluating the model's testing might help clarify these discrepancies.
- Questions about O1 Model and Credits: Conversations around the O1 model indicated confusion regarding its status, with mentions of it being 'dead' or limited typically to BYOK due to associated costs.
- An inquiry was raised regarding displaying credit usage, indicating some users were unable to find the graph feature previously available on the activities page.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- DeepSeek V3 - API, Providers, Stats: DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported ev...
- SmallThinker Demo - a Hugging Face Space by PowerInfer: no description found
- cognitivecomputations/Dolphin3.0-Llama3.1-8B · Hugging Face: no description found
- Gemini Flash 1.5 - API, Providers, Stats: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
- Provider Routing | OpenRouter: Route requests across multiple providers
- Typhon0130 - Overview: Imagine how you want to feel at the end of the day. Start working towards that now. - Typhon0130
- New item by Matthieu Alirol: no description found
- New item by Matthieu Alirol: no description found
Notebook LM Discord ▷ #use-cases (25 messages🔥):
YouTube Video Discussions, AI and Education, Use Cases in Various Contexts, Audio Adventures in Storytelling
- Exploring Colorful Conspiracies with Smurfs: In a playful video podcast titled 'What’s Up with Rainbows & Unicorns?', two punky Smurfs discuss the cultural implications of these symbols.
- They suggest that rainbows and unicorns might represent joy but are often hijacked by clichés, hinting at a deeper truth.
- Issues with Audio Overview in NLM: A member reported that when adding up to 300 sources, the audio overview tends to get stuck on a specific source even when switching focus.
- This issue raises concerns about functionality and user experience within the NLM platform.
- Uploading Memos for Effective Learning: A member sought advice on the best way to upload memos from their Mac to NLM to create an effective learning environment.
- This inquiry highlights the growing interest in utilizing technology for organized learning experiences.
- Curated Use Case Prompts for Education: A member suggested the need for a curated list of use case prompts relevant for secondary education.
- This reflects a community interest in sharing valuable resources to enhance educational practices.
- Engaging Raw Conversations for Soldiers: A project is being discussed aimed at delivering unfiltered, raw conversations for soldiers in Ukraine seeking good news.
- The approach emphasizes a casual and conversational tone to resonate with a younger audience aged 18 and above.
- Bitcoin is old enough to drive: Bitcoin is old enough to drive by Akas hq
- - YouTube: no description found
- What happened on Jan 4?: What happened on Jan 4? by This Day in History
- What happened on Jan 5?: What happened on Jan 5? by This Day in History
- What happened on Jan 6?: What happened on Jan 6? by This Day in History
Notebook LM Discord ▷ #general (128 messages🔥🔥):
Podcast Controls, NotebookLM Features, AI Interaction Experience, Language Support, User Feedback
- Managing Podcast Breaks: Users expressed frustration over podcast hosts taking breaks frequently, even after being instructed not to in custom settings.
- A suggestion was made to use specific system instructions to ensure hosts maintain continuous dialogue without interruptions.
- NotebookLM Plus Upgrades: Discussions highlighted the availability of NotebookLM Plus, which offers enhanced features such as increased upload limits and more advanced capabilities.
- Users seek clarity on the differences between the free and paid versions, referencing links for detailed information on features.
- Customizing Audio Length: A user struggled to limit the audio output length in NotebookLM to under six minutes, despite attempts to set parameters in their prompts.
- Several users shared their experiences with audio duration adjustments, indicating variability in effectiveness.
- Using Single Speaker Voices: One user successfully utilized a single male host voice for their podcasts but encountered challenges when trying to use only the female expert voice.
- The community discussed potential prompts to better control voice selections during podcast generation.
- Feature Requests and User Comments: Members are actively providing feedback and suggestions for new features in NotebookLM, including a prompt for saving chats as PDFs.
- Users are encouraged to track existing feature requests and upvote in dedicated channels for better visibility.
- Tweet from LUCI - Designed by OpenInterX, a Temporal Computing Platform for Personal Intelligence: LUCI is a cutting-edge, privacy-centric temporal computing platform, crafted to deliver lifelong memory and context-aware intelligence right at your fingertips.
- Get started with NotebookLM and NotebookLM Plus - NotebookLM Help: no description found
- Akas: home to AI podcasts: no description found
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- - YouTube: no description found
- Gemini Code Assist: an AI coding assistant: Gemini Code Assist uses generative AI to help developers build code faster and more efficiently. Learn more here.
- What happened on Jan 5?: What happened on Jan 5? by This Day in History
GPU MODE ▷ #general (6 messages):
Quantization Computation Costs, Weight-only Quantization Overhead, Tiling in MatMul Kernel, Register Spilling Issues
- Debate on Quantization's Computation Demand: One member expressed disagreement with the quantization rule, stating that quantization does require more computation.
- This sparked a discussion about its implications on performance and efficiency.
- Weight-only Quantization Overhead Insight: A participant noted that the extra overhead for weight-only quantization primarily involves dequantization, estimating it to be twice the time of memory loading for float16 weight matrices.
- This prompted a query on whether this computation still falls short in addressing performance concerns.
- Tile Size Impact on Performance: A member reported that using a 32x32 tile size in a tiling-based matmul kernel resulted in performance being 50% slower compared to a 16x16 tile size.
- This raised questions about the reasons behind this performance drop, seeking simpler explanations.
- Speculation on Performance Drop Causes: In response to the tiling performance issue, one member suggested that the slowdown could vary based on architecture, hinting at register spilling as a potential cause.
- This speculation pointed to the complexity of performance tuning in relation to hardware features.
GPU MODE ▷ #triton (61 messages🔥🔥):
Triton GPU Optimization, Performance Benchmarking in Triton, Autotuning Strategies, Data Type Impact, Softmax Kernel Optimization
- Examining Triton Performance Issues: Members discussed performance discrepancies when using
torch.empty_like, noting thattorch.emptyis approximately 3.5x faster for small sizes, though effects can vary based on data size.- Another member shared that using pre-hooks for initialization can significantly improve performance, especially for larger outputs.
- Tuning and Optimizing Triton Kernels: Discussions covered strategies for tuning parameters like block sizes using heuristics, including caching the best configurations to reduce autotune overhead.
- Members shared examples of using decorators to compute meta-parameters dynamically, improving kernel performance across varying input sizes.
- Troubleshooting Softmax Implementation: A member experiencing performance drops when expanding dimensions in their softmax kernel noted that reshaping improved speed but was still slower than not expanding.
- Suggestions included experimenting with different memory layouts (col major vs. row major) to see if it resolves the performance concerns.
- Questions about Triton Data Types: The relevance of
tl.int1being 1-bit versus a byte representation raised questions, with members clarifying that typical boolean representations are often 8-bits.- Concerns about precision in Triton and the appropriateness of using
bfloat16overfloat16due to compatibility issues were also discussed.
- Concerns about precision in Triton and the appropriateness of using
- Insights on Autotuning in Triton: The rationale behind performing warmups multiple times during autotuning was questioned, with members suggesting these passes might be necessary for reliable compilation.
- Best practices for restricting autotuning to certain powers of two using configurations were shared, emphasizing efficiency in tuning kernel parameters.
- triton.heuristics — Triton documentation: no description found
- GitHub - IBM/triton-dejavu: Framework to reduce autotune overhead to zero for well known deployments.: Framework to reduce autotune overhead to zero for well known deployments. - IBM/triton-dejavu
GPU MODE ▷ #cuda (10 messages🔥):
WMMA Load and Store Register Usage, Dynamic Selection of Versions, Register Layout for WMMA Operations, Input vs Output Matrix Fragments
- WMMA Load Requires 8 Registers: Discussion revealed that the
wmma.load.a.syncinstruction needs 8 registers despite only loading a 16x16 matrix fragment, likely due to register packing nuances.- One member remarked, '16 * 16 / 32 = 8 registers per thread,' clarifying that values aren't packed.
- WMMA Store Accepts Fewer Registers: Members debated why the
wmma.store.d.syncinstruction only requires 4 registers when storing matrix data, leading to confusion regarding data packing.- Another member pointed out that the store operation handles different data fragments compared to the load.
- Dynamic Selection of Versions for Efficiency: A suggestion was made to compile different versions for dynamic selection, indicating that this approach is practiced in other frameworks such as FA.
- Members agreed that this could lead to improved efficiency in the use of matrix operations.
- Register Layout Consistency in WMMA: The layout of the output fragment in
wmmaoperations appears to match that of the input fragment, preserving matrix integrity.- A member confirmed this behavior through experimentation, stating, 'wmma loading from A and storing it back to B should copy matrix A to B.'
- Input and Output Matrix Fragments Differentiation: A question was raised about the distinction between input and output matrix fragments in
wmmaoperations, emphasizing the need for multiple values during calculations.- It was highlighted that, for a 4x4 sub-tile, multiple values from input fragments are necessary, suggesting challenges with data reuse.
GPU MODE ▷ #torch (29 messages🔥):
Performance of Triton implementation, Issues with autotuning in Triton, Using custom autograd functions, Verbose logging for guard failures, Persistent TMA lowering for scaled-mm
- Triton kernel performance concerns: Users discussed the challenges of using the Triton implementation of
torch._scaled_mm()on consumer GPUs, citing issues when max autotune was set due to insufficient SMs.- Adjustments to configurations and the use of alternatives were suggested to facilitate better performance on affected hardware.
- Autotuning issues on consumer GPUs: It was noted that Triton kernels may not be well-configured for consumer GPUs, leading to slower performance and shared memory errors.
- Developers discussed potential hacks to adjust autotuning parameters for lower-end GPUs based on their specifications.
- In-place gradient modification in custom autograd functions: A user inquired whether modifying gradients in-place in a custom autograd function was permissible, despite documentation warnings against it.
- It was acknowledged that while this practice works in specific cases, it could lead to undefined behavior or inconsistent results.
- Verbose information for guard failures: A user requested help in obtaining more detailed information regarding guard failures within the PyTorch Dynamo library.
- They noted the logging output was lacking specifics, suggesting a need for improved error messaging to diagnose issues effectively.
- Persistent TMA lowering for improved performance: A new persistent TMA lowering for scaled-mm was introduced, which reportedly enhances performance during row-wise scaling but is only enabled for H100 GPUs.
- Discussion included whether wide availability of optimizations could benefit wider hardware categories.
- Extending PyTorch — PyTorch main documentation: no description found
- gemlite/gemlite/triton_kernels/gemm_A16fWnO16f_int32packing.py at master · mobiusml/gemlite: Fast low-bit matmul kernels in Triton. Contribute to mobiusml/gemlite development by creating an account on GitHub.
- pytorch/torch/_inductor/utils.py at f6488d85a013e0ec9d5415c29d78ec3f93b3c0ec · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/_inductor/kernel/mm_scaled.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #cool-links (1 messages):
iron_bound: https://www.youtube.com/watch?v=uBtuMsAY7J8
GPU MODE ▷ #beginner (5 messages):
VRAM and GPU Support, Training LLM with Structured Data, Hugging Face Transition, Triton Installation, BitsAndBytes Maintenance
- VRAM and 30xx Architecture's Support: A member stated that having more VRAM and sticking with the 30xx Ampere architecture ensures better support for future advances, making the 3090 a solid choice.
- They emphasized that these considerations are vital for anyone looking to upgrade their hardware.
- Suggestions for Training LLM on Nested Data: One user asked for suggestions on training an LLM to understand deeply nested relational structured data, mentioning that their RAG approach wasn't working effectively.
- They are seeking specific techniques or methodologies to enhance the model's comprehension of complex data relationships.
- Transitioning to Hugging Face Maintainer Role: A member shared their journey from a Software Engineer to becoming a maintainer for bitsandbytes at Hugging Face, highlighting the learning curve.
- They noted that the transition has been filled with new knowledge and opportunities for growth in the AI field.
- Triton Installation Differences: A user inquired about whether Triton installs differently on CPU versus GPU nodes and if GPU support can be installed on a CPU-only node.
- They want to know if it's viable to prepare for future GPU integration while initially using a CPU.
GPU MODE ▷ #off-topic (2 messages):
Felix Hill passing, Mental health awareness
- Felix Hill's Passing Shocks Community: Members expressed sadness over the news of Felix Hill passing away, reflecting the impact he had on the community.
- This loss has prompted a collective moment of mourning among members.
- Prioritizing Mental Health is Key: A member emphasized that nothing should be more important than one's own mental health, highlighting its critical nature.
- The call for prioritizing mental health resonates strongly, urging everyone to be mindful of their well-being.
GPU MODE ▷ #rocm (2 messages):
MI210 thread blocks, A100 architecture, MI300 vs H100 performance
- MI210's MAX thread blocks perplexes members: A member questioned why the maximum number of thread blocks per SM is 2 for MI210, while it is 32 for the A100, suggesting a possible hardware design choice.
- It remains unclear if this difference impacts performance, leading to discussions about the implications of such design decisions.
- Clarification sought on MI210 specs: Another member challenged the initial claim, asking for specifics on the source of the 2 thread block information regarding MI210.
- The inquiry indicates ongoing confusion and the need for clear documentation about thread block limits for various GPUs.
GPU MODE ▷ #liger-kernel (1 messages):
PR Review for Liger-Kernel, Documentation Improvements
- Request for PR Review on Documentation: A member requested a review for their pull request aimed at improving documentation by transitioning to Material for Markdown.
- They expressed a desire for feedback on necessary changes or improvements, highlighting the cumbersome nature of Sphinx in their previous attempts.
- Enhancements Over Sphinx for Documentation: The member reported that the new documentation method utilizes Material for Markdown, which facilitates easier setup and iteration compared to Sphinx.
- This shift aims to resolve the previous issues encountered with documentation processes and improve overall user experience.
Link mentioned: Create Docs for Liger-Kernel by ParagEkbote · Pull Request #485 · linkedin/Liger-Kernel: SummaryFixes #64Instead of using Sphinx which I found to be cumbersome to set-up and iterate upon, I have created the docs using Material for Markdown, which uses markdown files for pages and doe...
GPU MODE ▷ #self-promotion (3 messages):
GEMM Flops Utilization, MFU vs HFU Comparison, SmolLM2 Development, Collaboration with Hugging Face
- Clarifying Flops Utilization Terms: A member mentioned the terms HFU (Hardware Flops Utilization) and MFU and noted that the use of MFU in their recent article might have been misleading.
- They provided a comparison source highlighting the differences between MFU and HFU.
- Pruna Collaborates on SmolLM2: Pruna announced collaboration with Hugging Face to enhance SmolLM2, aiming to improve its efficiency while maintaining reliability.
- The model has been trained on 11 trillion tokens and is available in 135M, 360M, and 1.7B parameter sizes, designed for versatile applications.
- Hugging Face & Pruna AI: SmolLM2, Now 7x Smaller and 2x Faster - Pruna AI - Make your AI models cheaper, faster, smaller ...: Pruna is the AI Optimization Engine - a frictionless solution to help you optimize and compress your ML models for efficient inference.
- ml-engineering/training/performance/README.md at master · stas00/ml-engineering: Machine Learning Engineering Open Book. Contribute to stas00/ml-engineering development by creating an account on GitHub.
GPU MODE ▷ #arc-agi-2 (2 messages):
Riddle Completions, Expert Iteration with Rejection Sampling, Optimizing Prompts for Chains of Thought, PRIME Framework, veRL Reinforcement Learning
- Riddle Completions Show Variance: A member collected thousands of completions for 800 riddles across different LLMs, noting large variance in log-probs per example.
- They suggested using negative logprop or perplexity of the correct output as a simple reward strategy.
- Expert Iteration with Rejection Sampling: The simplest strategy for iterative self-improvement discussed was expert iteration with rejection sampling, sampling N completions and fine-tuning on the top-k best ones.
- This strategy is based on measuring performance with ground-truth results.
- Optimizing Prompts Induces Better CoTs: An interesting strategy to explore includes optimizing prompts to induce better Chains of Thought (CoTs) for improved outputs.
- Testing with smaller models showed traces leading to correct riddles, but often exhibited very broken logic.
- Explore the PROMISE of PRIME: A member highlighted the potential of the PRIME framework for reinforcement learning, providing a link for further exploration.
- More details can be found at Process Reinforcement through Implicit Rewards.
- Discovering veRL for LLM: The veRL framework from Volcano Engine for reinforcement learning in LLMs was shared, highlighting its potential on GitHub.
- You can view it here where it details Volcano Engine Reinforcement Learning for LLM.
Link mentioned: GitHub - volcengine/verl: veRL: Volcano Engine Reinforcement Learning for LLM: veRL: Volcano Engine Reinforcement Learning for LLM - volcengine/verl
Cohere ▷ #discussions (51 messages🔥):
Joint-training and loss calculation project, LiteLLM model access issues, Cohere research Discord group, AI Alignment evaluations hackathon
- Joint Training Consultation Requested: A member urgently sought consultation on a joint-training and loss calculation project, but some humorously suggested they should find someone to pay.
- Feedback indicated this might not be the right forum for free consulting.
- LiteLLM Model Access Confusion: Several members discussed difficulty accessing the command-r7b-12-2024 model via LiteLLM, noting error messages related to the model not being found.
- Others confirmed that while the regular Command R models are operational, LiteLLM needs updates to support the new command model.
- Cohere Research Discord Group Help: One member expressed interest in the Cohere research Discord group but couldn't locate the invite link despite having an invitation email.
- Another member shared the link to Cohere's research lab, suggesting they could help find the join button for newcomers.
- AI-Plans Hackathon Announcement: A member named Kabir introduced themselves and promoted the AI-Plans hackathon focused on AI Alignment evaluations happening on January 25th.
- They are also engaged in mechanistic interpretation research and conducting a literature review of AI Alignment.
- Research | Cohere For AI : Cohere For AI (C4AI) is Cohere's research lab that seeks to solve complex machine learning problems.
- [Feature]: Support for command-r7b-12-2024 · Issue #7551 · BerriAI/litellm: The Feature Hello, Please add support for command-r7b-12-2024. Currently when I try to send a request to that specific Cohere model through the proxy I receive the following error. litellm.BadReque...
Cohere ▷ #questions (11 messages🔥):
API Key Security, Rotating API Keys, Temperature Setting for Structured Generations, Comparison of AI Models, Interest in Evals and Mech Interp
- API Key Security Emphasized: A member reminded others to ensure their API keys remain secure before sharing code, stressing the importance of handling sensitive information properly.
- Another user confirmed they resolved the issue by removing their API key and encouraged users to rotate their keys.
- Help Offered for Key Rotation: A member offered assistance to anyone needing help with API key rotation, suggesting they should reach out via direct messages.
- This assistance is especially useful for users who may not be familiar with key management.
- Temperature Setting Queries: A user inquired about the possibility of setting temperature per-item for structured generations, seeking clarification on functionality.
- A response was requested to provide more detailed information about the user's needs.
- Comparing Models Discussion: A user asked about the best AI model available and its performance compared to OpenAI's o1 model.
- This highlights ongoing curiosity regarding model efficiency and capability.
- Interest in Evals and Mech Interp: A member expressed enthusiasm regarding discussions related to Evals and Mech Interp, indicating potential collaboration or sharing of insights.
- This shows a proactive community interest in specialized AI performance evaluations.
Cohere ▷ #api-discussions (10 messages🔥):
n8n Model Issues, Cohere Product API Queries
- n8n struggles with command-r7b-12-2024 model: A user reported an error with model name command-r7b-12-2024 not being found in an RAG chain within n8n, while command-r-08-2024 worked without issues.
- Reach out to n8n was suggested as a solution for resolving the model name confusion.
- Cohere API key queries: A user expressed intent to buy a product API key for their company after testing the Cohere free API, but noticed limitations in updating new information.
- Concerns were raised about whether the product API shares the same inability to update new info; contacting support@cohere.com was recommended for clarification.
Cohere ▷ #cmd-r-bot (5 messages):
Cohere Bot Queries, Cohere Documentation
- User Inquiry on Bot Presence: A user inquired about the presence of the Cohere bot, asking, 'why are u here?'
- The bot proactively responded, stating it would search the Cohere documentation for more information.
- Bot's Purpose Clarified: After searching, the Cohere bot clarified that it is here to assist users with their queries regarding Cohere.
- This summary highlights the bot's role as a helpful resource for users seeking information.
Cohere ▷ #projects (3 messages):
Agentic AI Research, Human-centric Technology, Research Trends, Papers with Code
- Master's Student Seeks Guidance on Agentic AI: A master's student is exploring research projects in agentic AI and is looking for insights on current research directions and opportunities that create value-added technologies.
- They expressed a desire to bridge the gap between advanced AI capabilities and tangible human benefits, asking for recent papers and novel research angles.
- Resource Suggestion for Research: Member ethanyoo recommended checking out Papers with Code as a helpful resource for finding recent research trends in agentic AI.
- This resource is aimed at facilitating the exploration of practical applications in the field.
LlamaIndex ▷ #blog (3 messages):
Agentic Workflows, Interactive UI for LlamaIndex, Integration with MLflow and Qdrant
- Automating Invoice Processing with Agents: A comprehensive set of notebooks has been shared to help build agentic workflows that fully automate invoice processing using LLM concepts like RAG and structured generation.
- Find the full details in the guide here along with additional resources on the topic.
- Creating an Interactive UI for LlamaIndex: A guide on building a user-friendly interface for LlamaIndex workflows using @streamlit has been posted, emphasizing real-time updates and human feedback.
- The application can be integrated with FastAPI for frontend-backend communication, with deployment tips available here.
- Combining LlamaIndex with MLflow and Qdrant: A step-by-step guide discusses how to integrate LlamaIndex with Qdrant for efficient vector storage and search alongside using MLflow for model tracking and evaluation.
- The guide also covers implementing Change Data Capture for real-time processing, and can be found here.
LlamaIndex ▷ #general (36 messages🔥):
Query Fusion Issues, ChromaDB Support in create-llama, Metadata Extraction in LlamaIndex, GraphRAG Colab Notebook Errors, Version Conflicts with LlamaIndex
- Query Fusion not yielding good results: A user sought suggestions to improve response quality while using query fusion with four retrievers (2 vector embedding and 2 BM25). Community members offered various strategies, but no specific solutions were highlighted.
- ChromaDB support lost after update: After the update to create-llama 0.3.25, a user reported losing the option to use ChromaDB as the vector database, which now defaults to llamacloud.
- Another community member recommended checking CLI flags to enable ChromaDB usage again.
- Handling Metadata Extraction queries: In a discussion about Metadata Extraction, it was confirmed that extracted metadata is stored as text, influencing retrieval and that specific metadata filters can be utilized.
- To filter based on publication year, users may need to write custom tools for inference using metadata.
- GraphRAG Colab Notebook Errors resolved: A user faced intermittent errors while using the GraphRAG Colab Notebook and encountered installation issues with
llama-index-core.- Another member suggested upgrading the package to resolve version-related errors and offered installation insights.
- Async function issues in workflows: A user reported a coroutine error linked to async functions being used incorrectly in their LlamaIndex setup, suggesting the need for further exploration into the error context.
- It was advised to ensure the correct usage of
async_fninstead offnwhen creating FunctionTool instances.
- It was advised to ensure the correct usage of
- [Bug]: Llama_index - HuggingfaceLLM unsolvable version conflict · Issue #17428 · run-llama/llama_index: Bug Description Conflict while installing llama_index HuggingfaceLLM : ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is ...
- unpin huggingface hub deps by logan-markewich · Pull Request #17433 · run-llama/llama_index: Fixes #17428No longer need to pin these deps
- [Question]: How to use async FunctionTool in workflows · Issue #17356 · run-llama/llama_index: Question Validation I have searched both the documentation and discord for an answer. Question Hello, I have a function calling agent with several tools and I'm converting everything to async. I&#...
LlamaIndex ▷ #ai-discussion (1 messages):
Document Parsing, LlamaParse, LlamaIndex Guide
- Mastering Document Parsing with LlamaParse: A complete guide was shared on Mastering Document Parsing with LlamaParse from LlamaIndex, focusing on how to effectively parse documents.
- The video covers essential techniques and tools necessary for optimizing document handling workflows.
- LlamaIndex Features Overview: The discussion highlighted key features of the LlamaIndex, emphasizing its capabilities in document management and data extraction.
- Participants noted the importance of understanding the underlying technology for better application in projects.
OpenInterpreter ▷ #general (31 messages🔥):
Cursor profile requirements, Claude Engineer performance, Open Interpreter 1.0 issues, Using Llama models, Error handling in Open Interpreter
- Cursor now requires .py files for profiles: It seems that the Cursor tool now prefers profiles in
.pyformat, but users are struggling to get it to work correctly.- “Example py file profile was no help either.”
- Claude Engineer consumes tokens rapidly: One user has been using Claude Engineer lately but found it consumes tokens rapidly, leading them to remove certain tools.
- “Had to rip out all its tools and give it shell and python access.”
- Challenges with Open Interpreter 1.0: Multiple users are experiencing issues when attempting to use Open Interpreter 1.0, particularly when integrating with Llama models, often encountering JSON errors.
- “OI with our fine-tuned llama 3.3 is incredible. Would suck to see it restricted to gpt 4o and sonnet.”
- Error handling with Llama models: Users report running into issues where Open Interpreter fails to process requests correctly when using Llama models, leading to non-serializable object errors.
- “Our app relies heavily on llama and sonnet working in OI.”
- Discussions about tool calling: There are ongoing discussions about disabling tool calling for certain providers to avoid errors, but this doesn't always yield success.
- “Tried that, didn't work... it throws these errors.”
OpenInterpreter ▷ #O1 (1 messages):
Windows installation instructions, OpenInterpreter functionality on Windows 11
- Guide for Basic Windows Installation Created: A member has created a basic installation instruction guide for Windows, aimed at helping users get started without trouble. The guide is specifically tested on Windows 11 24H2 and is available here.
- The creator noted that OpenInterpreter has been working fine on their setup, indicating the guide's potential effectiveness for future users.
- OpenInterpreter Success on Windows 11: The member reported that OpenInterpreter has been functioning properly on Windows 11 24H2 during their tests. This success highlights the compatibility of the software with recent Windows updates.
Nomic.ai (GPT4All) ▷ #general (31 messages🔥):
GPT4All App Discussion, Usage of GPT4All for C++ Libraries, Chat Templates and System Messages, Experience with Local AI Chatbots, LLM Model Comparisons
- Concerns Over GPT4All App Authenticity: Members expressed doubts about the authenticity of the GPT4All app on the Google Play Store due to its recent launch and discrepancies in the publisher name.
- One member noted, 'I wouldn't trust it until it makes sense to me' and highlighted issues around its messaging limits.
- Exploring GPT4All for OpenFOAM Navigation: A user is interested in employing GPT4All to navigate and understand the OpenFOAM C++ library, seeking advice on model suitability for this purpose.
- Another member suggested using Workik for programming questions until the local version of GPT4All is ready.
- Setting Up Chat Templates for System Messages: A new user inquired about formatting system messages and chat templates in GPT4All, especially to mimic a favorite Star Trek character.
- Responses revealed that a concise description, such as 'Your answer shall be in first person,' suffices for customization.
- Local Offline AI Chatbot Development with Termux: A member shared their success in developing a local offline AI chatbot using Termux and Python, while asking about space and battery usage concerns.
- They aimed to create a local site to interact with downloaded models directly from their phones.
- Tutorials for Setting Up GPT4All with Python: A member sought an up-to-date tutorial for installing GPT4All with Python for automatic local memory enhancements.
- This request sparked discussions among members on the available guidance and best practices.
- GPT4All - AI Assistant & Chat - Apps on Google Play: no description found
- Chat Templates - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
- nomic-ai/modernbert-embed-base · Hugging Face: no description found
tinygrad (George Hotz) ▷ #general (26 messages🔥):
Continuous Integration for Windows, Bounties and Pull Requests, Tinychat in Browser, Scheduled Meeting and Updates, Development and Refactoring Plans
- Need for CI on Windows: A discussion highlighted the necessity of implementing Continuous Integration (CI) for Windows to enable merging of fixes.
- One member emphasized that without CI, the merging process cannot progress, impacting development efforts.
- Bounty PR Submissions: Several members submitted Pull Requests (PRs) related to bounties, including fixes for import errors and working CI tests on macOS.
- Members are requesting access to relevant channels to further track and manage bounty submissions.
- Tinychat Browser Demo Reactions: One member showcased a working demo of Tinychat in the browser utilizing WebGPU, highlighting its functionalities and integration.
- A suggestion was made for adding a progress bar to enhance user experience during model weight decompression.
- Meeting Announcements and CES Update: A meeting was scheduled for updates regarding the company's presence at CES, including booth information.
- Topics discussed included contract details and several technical bounties that the team is currently addressing.
- Distributed Development Plans: Conversations revolved around future plans for Distributed training with mentions of FSDP (Fully Sharded Data Parallel).
- Members expressed the need for refactors in code architecture to better accommodate planned developments in the feature.
- Tweet from the tiny corp (@__tinygrad__): tiny corp will be at @CES in the @comma_ai booth. We will have a tinybox red on display for you to covet.Booth #6475 in the LVCC West Hall
- MOCKGPU amd test on OSX · tinygrad/tinygrad@cc4a4fb: You like pytorch? You like micrograd? You love tinygrad! ❤️ - MOCKGPU amd test on OSX · tinygrad/tinygrad@cc4a4fb
- Get `MOCKGPU=1 AMD=1 python3 test/test_tiny.py` working in CI on OS X… by dyKiU · Pull Request #8517 · tinygrad/tinygrad: … (build comgr + remu)build and cache llvm from amd-staging branch - see commit hash for current versionbuild hipcc and amd device libsbuild comgr with amd-staging llvm (wouldn't compile or .....
- tinychat in browser by hooved · Pull Request #8464 · tinygrad/tinygrad: This PR adds support for tinychat in the browser on WebGPU. Both Llama-3.2-1B and tiktoken are run in the browser with full integration to the tinychat client, removing dependence on the previous p...
- Compiles on Windows for python and gpu backends by Pippepot · Pull Request #8492 · tinygrad/tinygrad: Tinygrad would previously complain about missing imports in ops_clang
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
Multiview Implementation, Tinygrad Notes on GitHub
- Expanded Insights on Multiview Implementation: A member discussed the detailed aspects of multiview implementation on the tinygrad notes GitHub. This guide outlines crucial implementations in a clear and structured manner.
- The resource provides a comprehensive walkthrough, emphasizing the need for collaboration and contributions from the community.
- GitHub Repository for Tinygrad Tutorials: The tinygrad notes repository on GitHub serves as a central hub for tutorials and community contributions related to tinygrad development, accessible here. Members are encouraged to participate actively in its evolution.
- This collaborative project allows users to enhance their understanding of tinygrad through shared knowledge and resources.
Link mentioned: tinygrad-notes/20241217_st.md at main · mesozoic-egg/tinygrad-notes: Tutorials on tinygrad. Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #mojo (18 messages🔥):
Mojo API Design, Memory Management in Mojo, Function Overloading in Mojo, Optimization Techniques, Feature Request for Mojo
- Mojo API Design for List Concatenation: Discussion revolved around optimizing the
concatfunction forList[Int]in Mojo, allowing for both read-only and owned references to enhance performance.- The implementation includes two versions of
concat, with one able to reuse memory if it owns the list.
- The implementation includes two versions of
- Challenges with Struct Memory Management: A member encountered issues with defining overloaded
concatfunctions for a customMyStruct, due to identical signatures preventing compilation.- This highlights the limitations when working with types that don’t support explicit copies in Mojo.
- Proposed Enhancements for Memory Optimization: There was a proposal to allow function overloading based on the mutability of input arguments, simplifying API use without requiring user intervention.
- The idea includes leveraging the final use of variables for optimization and memory reuse without the user needing to manage it.
- User Awareness and Memory Management: The conversation noted that most programmers lack knowledge of memory management, emphasizing the need for abstractions that enhance speed without extra complexity.
- Suggestions included defaulting to move semantics as a means to optimize performance for users unaware of memory intricacies.
- Feature Request for Overloading in Mojo: A feature request was made to enable function overloading in Mojo by changing parameters from
readtoowned, aiming to improve the language's efficiency.- The proposal is documented on GitHub, inviting further community input and discussion about this optimization strategy.
- [BUG] --debug-level full crashes when importing · Issue #3917 · modularml/mojo: Bug description Running a mojo script using the debugger seg faults, as opposed to when running regular mojo, which runs to completion (although I have noticed strange behavior in the regular scrip...
- [Feature Request] Allow overloading a function by just changing an input argument from `read` to `owned` · Issue #3925 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? I would like the Mojo language to allow overloading a ...
LAION ▷ #general (13 messages🔥):
Audio Quality Feedback, Emotional TTS Tests, YouTube Video Share, PyCoT Dataset, Advanced Voice Mode Datasets
- Feedback Request on Audio Quality: A user requested feedback on audio quality regarding several versions of emotional TTS tests available for review.
- They encouraged votes on the preferred versions to help determine the best option.
- Emotional TTS Test Versions Shared: Multiple versions of emotional TTS tests focused on intense astonishment and fear were shared, underlining varying audio expressions.
- Links to the audio samples were provided for others to access and evaluate.
- YouTube Video Shared: A link to a YouTube video titled ' - YouTube' was shared, although no specific description was provided.
- The video appears to remain undefined in context or content.
- Introduction of the PyCoT Dataset: A user introduced the PyCoT dataset aimed at exploring mathematical reasoning through AI-generated Python scripts and word problems.
- The dataset includes three word problems alongside a Python script that logically solves them in a chain-of-thought manner.
- Inquiry for Audio Datasets: A user inquired about the existence of audio datasets related to GPT-4o Advanced Voice Mode and Gemini 2.0 Flash Native Speech.
- This reflects an interest in exploring new audio technology within the community.
- AtlasUnified/PyCoT · Datasets at Hugging Face: no description found
- - YouTube: no description found
DSPy ▷ #papers (1 messages):
Test-Time Compute, Advanced LLMs, Multi-Step Reasoning, Reflection Patterns, DSPy Systems
- Paper Highlights Test-Time Compute in Advanced LLMs: A recent paper from Fudan University explores the mechanics behind test-time compute in advanced LLMs, offering valuable insights for practitioners.
- Key areas of focus include the architecture, multi-step reasoning, and search & reflection patterns, which are crucial for developing sophisticated reasoning systems.
- Building Sophisticated Reasoning Systems with DSPy: The insights from the paper are particularly beneficial for those looking to implement more advanced reasoning systems within DSPy.
- It provides practical guidance on enhancing compound systems, making it a must-read for developers in this domain.
DSPy ▷ #general (4 messages):
System Prompting for LLM, Docstring Configuration
- Inquiry on System Prompting for Few Shot Examples: A member asked if there is a method for system prompting the LLM to provide few shot examples. This approach could enhance the model's ability to generate relevant responses.
- The discussion centers on optimizing the LLM's performance through effective prompting techniques.
- Advising on Docstring Usage: A member suggested adding a docstring in the signature or configuring a custom adapter in extreme cases for better clarity.
- This advice aims to improve the usability and understandability of code implementations.
DSPy ▷ #examples (5 messages):
DSPy prompt optimization, Categorization task examples, Using descriptions in signatures, DSPy video examples
- Exploring DSPy for classification tasks: A user expressed interest in examples of using DSPy for prompt optimization in classification, referencing a related blog post. They highlighted DSPy's ability to simplify the prompting process by programming rather than prompting language models.
- They mentioned using DSPy to enhance a weather site and noted the framework's clean approach to prompting.
- Adjusting classification labels with Mipro: A member confirmed that it is possible to include descriptions in the instructions (docstring) of a DSPy signature to help with classification. This allows Mipro to adjust and include examples based on those descriptions.
- Another user expressed appreciation for the guidance and indicated plans to try this approach.
- DSPy Video Overview: A user shared a YouTube video that provides clear explanations of eight DSPy examples in just 34 minutes. They recommended it for being very accessible, making it easier to understand DSPy's functionalities.
Link mentioned: Pipelines & Prompt Optimization with DSPy: Writing about technology, culture, media, data, and the ways they interact.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
Project Sharing, Quiz Forms Reopening, Certificate Declaration Form
- Participants Seek Project Showcase: A participant inquired about a location to view projects created by peers from the course, expressing excitement to see others' work.
- Unfortunately, sharing projects isn't possible without participant consent, although a small mention of the winners might be available.
- Quiz 5 Submission Closed: Concerns were raised about Quiz 5 - Compound AI Systems with Omar Khattab no longer accepting responses, as some participants missed the chance to sign up.
- One participant suggested that those who missed the quiz should have access to the content and quizzes.
- Quiz Forms Reopening Timeline: In response to inquiries, it was noted that the quiz forms would likely reopen after the certificates are released at the end of January.
- Participants are encouraged but uncertain about accessing missed opportunities.
- No Certificate Declaration for Late Submission: A participant expressed concern about missing the certificate declaration form after submitting quizzes and projects.
- It was confirmed that unfortunately, late submissions for the certificate declaration are not accepted.
Link mentioned: Quiz 5 - Compound AI Systems w/ Omar Khattab (10/7): INSTRUCTIONS:Each of these quizzes is completion based, however we encourage you to try your best for your own education! These quizzes are a great way to check that you are understanding the course m...
MLOps @Chipro ▷ #general-ml (7 messages):
Core Algorithms Persist, LLMs and Search, Time Series and Clustering in Stats, NLP and Simple Models
- Core Algorithms Persist in Data Science: Despite the rise of LLMs, traditional methods like search, time series, and clustering remain actively worked on and haven't been replaced. The emphasis is still on foundational techniques without a pivot to LLMs.
- Members highlighted that clustering continues to be a crucial part of data processing and analysis.
- LLMs and Search: Not Fully Integrated: Current core search methodologies have not been substantially influenced by LLMs, retaining their traditional structures. There's still a strong focus on effective search techniques among established players.
- The traditional retrieval-augmented generation (RAG) approach hasn't permeated the mainstream search stack yet.
- Time Series and Clustering as Analytical Methods: Time series analysis, particularly in forecasting and econometrics, remains a critical aspect of statistics and economics. These methods are deemed separate from machine learning despite their importance in decision-making.
- Clustering continues to be used extensively as part of both processing and analytical procedures.
- LLMs Offer Limited Gains in NLP: One member shared experiences where LLMs have shown subpar performance compared to simpler models like logistic regression in NLP tasks. This points to a situation where traditional methods outperform more complex models in certain applications.
- The discussion acknowledged that while LLMs might help in many areas, they are not always necessary for achieving objectives.
- Trends in New Product Development with LLMs: Emerging products are often leveraging LLMs due to their trendiness, providing new possibilities for development. However, other products continue to utilize traditional ML approaches without significant reliance on LLMs.
- There's a clear distinction between new and established products in whether they incorporate LLMs in their methodologies.
Torchtune ▷ #general (7 messages):
Wandb comparisons, Torch memory improvements, Benchmarking on Torchtune, Differential attention models, Chunking pre projection
- Wandb profiling discussed: Members discussed profiling their models using Wandb but noted that one codebase was private and unrelated to Torchtune.
- Torchtune could still potentially benefit from upcoming benchmarks with a new branch according to one user.
- Torch reduces memory usage: A member highlighted that Torch significantly reduced memory usage by not materializing certain matrices during cross-entropy compilation.
- The importance of chunked_nll implementation was also noted, suggesting room for performance improvements.
- Curiosity around differential attention models: Questions arose about the lack of differential attention in recent models since the concept was introduced in a October arXiv paper.
- Members speculated whether it was a case of inadequate testing, recent developments, or a failure to deliver expected results.
- Benchmarking performance on Torchtune: One member shared their benchmarking experience indicating that chunking pre projection and fusing matmul with loss showed promising signs in performance.
- Cross-Entropy was reported as the best performer in terms of memory and time, depending on gradient sparsity for optimal results.
Link mentioned: torchtune/torchtune/modules/transformer.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Axolotl AI ▷ #general (2 messages):
Discord Scam, Spam Issues
- Discord Scam Alert: A member highlighted the presence of a potential Discord scam by tagging an admin role for awareness.
- This issue seems to be part of ongoing challenges with spam in the server.
- Typo Fixed: Another member acknowledged and fixed a typo related to the scam notification.
- The correction suggests active engagement in maintaining the clarity of communication in the chat.
Mozilla AI ▷ #announcements (1 messages):
Common Voice AMA, Introduction to Common Voice, 2024 Review
- Common Voice Hosts AMA to Kick Off 2025: Common Voice is hosting an AMA in their newly launched Discord server to reflect on their progress and engage with the community.
- This event aims to answer any questions about the project and discuss future innovations in voice technology.
- What is Common Voice?: Common Voice is a project designed to create usable voice technology by gathering large amounts of voice data, which often isn't accessible to the public.
- Voice is natural, voice is human, and the initiative seeks to promote open voice recognition technology for all developers.
- Guest Line-Up for the Q&A: The AMA will feature guests including EM Lewis-Jong (Product Director), Dmitrij Feller (Full-Stack Engineer), and Rotimi Babalola (Frontend Engineer).
- The session will be hosted by a Technology Community Specialist, ensuring an informative discussion regarding the year's advancements.