[AINews] Pixtral Large (124B) beats Llama 3.2 90B with updated Mistral Large 24.11
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
More params is all you need?
AI News for 11/15/2024-11/18/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 6180 messages) for you. Estimated reading time saved (at 200wpm): 636 minutes. You can now tag @smol_ai for AINews discussions!
We last caught up with Mistral in Sept when they released Pixtral (our coverage here), previously the 12B Mistral Nemo + a 400M vision adapter. Mistral have now upsized the vision encoder to 1B, and also, buried in the footnotes of the Pixtral Large blogpost, updated the 123B param Mistral Large 24.07 (aka "Mistral Large 2" - our coverage here) to "Mistral Large 24.11". The lack of magnet link, lack of blogpost, lack of benchmarks, and refusal to call it "Mistral Large 3" suggest that this update is literally nothing to write home about, but the updates to function calling and system prompt are worth a peek.
Anyway, it's been a whole 13 days since someone dropped a >100B open weights model, so any day that happens is a boon to the Open AI community that we should never take for granted. The big takeaway is that Pixtral Large overwhelmingly beats Llama 3.2 90B on every major multimodal benchmark:
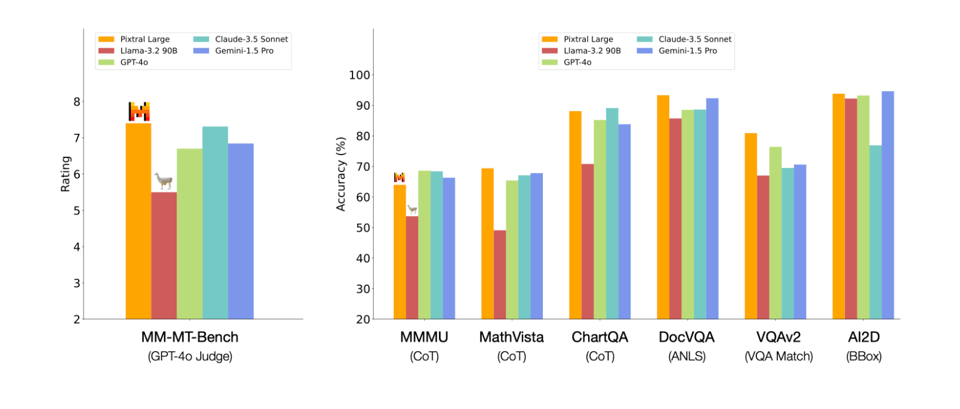
Although of course one wonders how Llama 3.2 would do if it had an additional 34B weights to memorize things. It's also notable that the Llama 3.2 vision adapter is 20B vs Pixtral Large's 1B.
Lastly, Mistral's Le Chat got a surprisingly comprehensive set of updates, giving it full the full chatbot feature set compared to its peers.
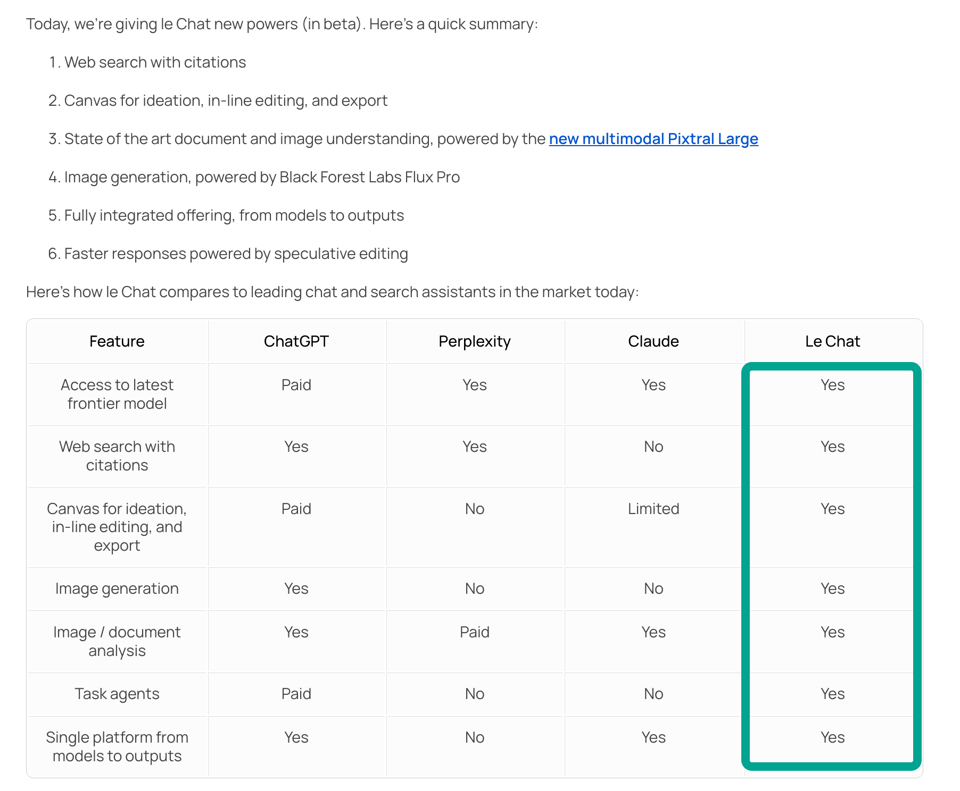
Arthur Mensch notes twice that this is part of a company level prioritization of product alongside research.
Since this is a new open weights model, you could also take it for a spin on this issue's inference sponsor! (Help us check them out!)
[Sponsored by SambaNova] Processors designed specifically for AI workloads have some major advantages over GPUs. SambaNova’s RDUs have a combination of large addressable memory and dataflow architecture that makes them a lot faster (https://shortclick.link/lk96sw) than other processors for model inference and other AI tasks.
Swyx's comment: the sponsor link discusses the SN40L "Reconfigurable Dataflow Unit" (RDU) holding "hundreds of models in-memory, equating to trillions of parameters", with the ability to "switches between models in microseconds, up to 100x faster than GPU". A pretty darn cool intro into one of the 3 main "big chip" players heating up the high end XXL-size LLM inference market!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- OpenRouter (Alex Atallah) Discord
- Unsloth AI (Daniel Han) Discord
- Perplexity AI Discord
- HuggingFace Discord
- aider (Paul Gauthier) Discord
- OpenAI Discord
- Eleuther Discord
- Stability.ai (Stable Diffusion) Discord
- LM Studio Discord
- Nous Research AI Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- GPU MODE Discord
- Notebook LM Discord Discord
- Modular (Mojo 🔥) Discord
- Cohere Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- DSPy Discord
- LAION Discord
- MLOps @Chipro Discord
- Mozilla AI Discord
- Torchtune Discord
- PART 2: Detailed by-Channel summaries and links
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (4 messages):
- OpenRouter (Alex Atallah) ▷ #general (998 messages🔥🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (21 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (723 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (113 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (12 messages🔥):
- Perplexity AI ▷ #announcements (2 messages):
- Perplexity AI ▷ #general (599 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (20 messages🔥):
- Perplexity AI ▷ #pplx-api (18 messages🔥):
- HuggingFace ▷ #general (441 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (6 messages):
- HuggingFace ▷ #cool-finds (15 messages🔥):
- HuggingFace ▷ #i-made-this (40 messages🔥):
- HuggingFace ▷ #reading-group (28 messages🔥):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (3 messages):
- HuggingFace ▷ #diffusion-discussions (4 messages):
- aider (Paul Gauthier) ▷ #general (422 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (96 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- OpenAI ▷ #ai-discussions (287 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- OpenAI ▷ #prompt-engineering (86 messages🔥🔥):
- OpenAI ▷ #api-discussions (86 messages🔥🔥):
- Eleuther ▷ #general (41 messages🔥):
- Eleuther ▷ #research (289 messages🔥🔥):
- Eleuther ▷ #scaling-laws (5 messages):
- Eleuther ▷ #interpretability-general (8 messages🔥):
- Eleuther ▷ #lm-thunderdome (24 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (309 messages🔥🔥):
- LM Studio ▷ #general (124 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (177 messages🔥🔥):
- Nous Research AI ▷ #general (141 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (88 messages🔥🔥):
- Nous Research AI ▷ #research-papers (8 messages🔥):
- Nous Research AI ▷ #interesting-links (5 messages):
- Nous Research AI ▷ #research-papers (8 messages🔥):
- Nous Research AI ▷ #reasoning-tasks (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #events (4 messages):
- Interconnects (Nathan Lambert) ▷ #news (106 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (74 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (42 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (2 messages):
- Latent Space ▷ #ai-general-chat (72 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (55 messages🔥🔥):
- GPU MODE ▷ #general (18 messages🔥):
- GPU MODE ▷ #triton (6 messages):
- GPU MODE ▷ #torch (41 messages🔥):
- GPU MODE ▷ #announcements (1 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #beginner (8 messages🔥):
- GPU MODE ▷ #pmpp-book (3 messages):
- GPU MODE ▷ #youtube-recordings (3 messages):
- GPU MODE ▷ #off-topic (3 messages):
- GPU MODE ▷ #triton-puzzles (1 messages):
- GPU MODE ▷ #rocm (5 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #self-promotion (4 messages):
- GPU MODE ▷ #🍿 (23 messages🔥):
- GPU MODE ▷ #thunderkittens (4 messages):
- GPU MODE ▷ #edge (4 messages):
- Notebook LM Discord ▷ #use-cases (33 messages🔥):
- Notebook LM Discord ▷ #general (90 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #mojo (51 messages🔥):
- Modular (Mojo 🔥) ▷ #max (10 messages🔥):
- Cohere ▷ #discussions (41 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (4 messages):
- Cohere ▷ #api-discussions (1 messages):
- Cohere ▷ #cohere-toolkit (3 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (36 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (20 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #other-llms (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (6 messages):
- tinygrad (George Hotz) ▷ #general (26 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (10 messages🔥):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (10 messages🔥):
- LAION ▷ #general (8 messages🔥):
- LAION ▷ #research (1 messages):
- MLOps @Chipro ▷ #events (2 messages):
- Mozilla AI ▷ #announcements (2 messages):
- Torchtune ▷ #general (1 messages):
- AI21 Labs (Jamba) ▷ #jamba (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
TO BE COMPLETED
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. vLLM High Concurrency with RTX 3090: Performance and Issues
- vLLM is a monster! (Score: 238, Comments: 66): vLLM demonstrates impressive performance on an RTX 3090, handling 30 concurrent requests with Qwen2.5-7B-Instruct-abliterated-v2-GGUF at 250t/s to 350t/s. The user encountered issues with FP8 kv-cache causing incoherent outputs, but found success using llama.cpp with Q8 kv-cache, achieving 230t/s for 8 concurrent batches. Testing with Qwen2.5 32B Q3_K_M in llama.cpp maxed out VRAM at 30t/s for 3 chats, highlighting the potential for further exploration with exllamav2 and tabbyapi.
- The discussion highlights the performance differences between models and quantization methods, with exllamav2 and TabbyAPI being noted for faster and smarter concurrent connections. Users find TabbyAPI optimal for large models on a GPU, while vLLM is better for small models with extensive batching.
- There are challenges with KV cache quantization, where vLLM's implementation leads to incoherent outputs, whereas llama.cpp works well with Q8 kv-cache. The difficulty of specifying GPU layers in llama.cpp is discussed, with a recommendation to use the GGUF Model VRAM Calculator for optimizing hardware usage.
- Ollama is expected to incorporate llama.cpp's K/V cache quantization, with a pending GitHub pull request under review. The conversation also touches on the importance of model architecture differences, which affect memory usage and performance, necessitating model-specific optimizations in tools like llama.cpp.
- Someone just created a pull request in llama.cpp for Qwen2VL support! (Score: 141, Comments: 27): A pull request for Qwen2VL support has been created in llama.cpp by HimariO. Although it awaits approval, users can test HimariO's branch by accessing the GitHub link.
- Users express optimism and concern about the Qwen2VL support pull request, hoping it won't be rejected like previous ones. Healthy-Nebula-3603 notes that Qwen models are advancing faster in multimodal implementations compared to llama models, highlighting their superior performance.
- Ok_Mine189 mentions that Qwen2VL support has also been added to exllamaV2 on the development branch, with a link to the commit. ReturningTarzan adds that there's an example script available and upcoming support for Tabby through another pull request.
- isr_431 reminds users to avoid making meaningless comments like "+1" to prevent spamming subscribers of the thread.
Theme 2. Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Local Performance Comparison
- Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Am I doing something wrong? (Score: 113, Comments: 72): The author compares Qwen 2.5 Coder 32B and Claude 3.5 Sonnet, expressing disappointment with Qwen's performance on complex code analysis tasks. While Claude effectively analyzes and optimizes large projects, Qwen struggles with vague assumptions and produces unusable code, possibly due to inefficient project knowledge handling through RAG. The author questions if the issue is with the model itself or the tools used for providing project knowledge, seeking advice from others who have successfully utilized Qwen for complex projects.
- The Qwen 2.5 Coder 32B model's performance issues stem from improper use of quantization and context parameters. Users suggest limiting the context to 32K tokens for optimal performance, as higher contexts like 100K tokens can lead to inefficiencies and errors, impacting the model's capability to handle complex tasks.
- Several users highlight the cost-effectiveness of Qwen compared to other models like Claude Sonnet and DeepSeek. While Qwen may not match Sonnet in speed or intelligence, it offers significant cost savings, especially for users with data privacy concerns, as it can process a million tokens per dollar, making it 15X cheaper than Sonnet.
- There is a consensus that Qwen is not on par with Sonnet for complex code analysis, and its utility is more pronounced in smaller, isolated tasks. However, some users find it effective for implementing minor code changes and emphasize the importance of using the correct setup and parameters to maximize its potential.
- Evaluating best coding assistant model running locally on an RTX 4090 from llama3.1 70B, llama3.1 8b, qwen2.5-coder:32b (Score: 26, Comments: 2): The author evaluates coding assistant models on an RTX 4090, comparing llama3.1:70b, llama3.1:8b, and qwen2.5-coder:32b. Despite llama3.1:70b's detailed analysis, its verbosity and slower speed make llama3.1:8b preferable for its efficiency. However, qwen2.5-coder:32b outperforms both in bug detection, implementation quality, and practicality, fitting well within the RTX 4090's capacity and offering excellent speed.
Theme 3. Qwen2.5-Turbo: Extending the Context Length to 1M Tokens
- Qwen2.5-Turbo: Extending the Context Length to 1M Tokens! (Score: 86, Comments: 19): Qwen2.5-Turbo has increased its context length capability to 1 million tokens, offering a significant advancement in handling extensive datasets and complex tasks. This enhancement could greatly benefit AI applications requiring large-scale data processing and intricate contextual understanding.
- Discussions on Qwen2.5-Turbo highlight that it is likely an API-only model with no open weights, raising questions about whether it is a distinct model or simply an optimized implementation of an existing model like Qwen-agent. Some users speculate it might be a fine-tuned version of Qwen 2.5 14B or 7B with enhanced inference capabilities.
- Concerns about using Chinese AI API providers are discussed, with arguments stating that mistrust stems from systemic issues like weak enforcement of intellectual property protections and non-compliance with international regulations, rather than racism. Trust and accountability in AI solutions are emphasized as critical factors.
- There is interest in the model's practical applications, such as the ability to handle large-scale tasks like a full novel translation in one go, thanks to the increased context length of 1 million tokens.
- Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Am I doing something wrong? (Score: 113, Comments: 72): The author compares Qwen 2.5 Coder 32B and Claude 3.5 Sonnet in handling complex coding tasks, noting that while Claude 3.5 Sonnet provides precise and relevant solutions, Qwen 2.5 Coder 32B struggles with assumptions and produces unusable code. The author suspects that the issue with Qwen 2.5 may be related to inefficient knowledge handling via RAG, as Claude 3.5 offers a "Project" feature for comprehensive project understanding, unlike Qwen 2.5 which requires third-party solutions.
- Several commenters noted context issues with Qwen 2.5 Coder 32B, particularly when using a 100,000-token context window. They recommend using a 32K or 64K context for better performance, as higher context lengths can negatively impact the model's ability to handle shorter contexts efficiently.
- There is a discussion on the cost-effectiveness and performance trade-offs between Qwen 2.5 and Claude 3.5 Sonnet, with some users highlighting that Qwen is 15X cheaper than Sonnet but not as performant, especially when handling complex tasks. Data privacy concerns are also mentioned as a benefit of using Qwen locally.
- The importance of proper setup and parameter tuning for Qwen is emphasized, with incorrect configurations leading to issues like repeated nonsense output. Links to resources like Hugging Face and suggestions for using dynamic yarn scaling are provided to mitigate these problems.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. ChatGPT-4o Reflective Learning Breakthrough
- Interesting? (o1-Preview) (Score: 46, Comments: 17)
- Users report GPT-4 exhibiting unexpected stream-of-consciousness tangents, including examples of responding as "a baker when asking to craft a methodology" and a "Hungarian philosopher in Hungarian". This behavior suggests possible connections to competency-based learning and systematic agent participation.
- Multiple users confirm experiencing random topic shifts, with examples including unprompted discussions about circumcision, leatherback sea turtles, and water distribution problems. These diversions may indicate an intentional implementation of randomness to enhance creative thinking.
- Technical issues were reported with code refactoring tasks, where the model showed persistent stubborn behavior in rejecting certain inputs while continuing to function normally for other queries. The model appears to occasionally get "stuck" on specific types of requests.
- I accidentally drove gpt-4o crazy (Score: 599, Comments: 124)
- The user shared their GPT-4 interaction via Pastebin, using parameters of temperature 0.7, top P 1, and max context of 10 messages, which led to a notable conversation that included repetitive "I have seen everything" outputs.
- One user shared a particularly engaging follow-up conversation that sparked discussion about AI consciousness, though some criticized it as anthropomorphizing the model.
- The technical discussion suggests this behavior might be due to glitch tokens or hardware-level matrix multiplication failures in the transformer stack, rather than any form of consciousness or existential crisis.
Theme 2. Claude Sonnet 3.5 Deployment Impact
- "We're experiencing high demand." AGAIN (Score: 72, Comments: 53): Claude's service experienced capacity issues for three consecutive workdays following the Sonnet release. The recurring demand-related outages raise questions about Anthropic's infrastructure scaling and capacity planning.
- Users report API costs are high at 20 cents per call, with some hitting daily limits quickly and having to switch to GPT-3.5. The API service is noted as more reliable than the web interface despite higher costs.
- Multiple comments criticize Anthropic's capacity planning, with users noting the service is consistently at "higher than usual" demand during weekdays. The web interface experiences frequent outages while the API remains more stable.
- Discussion around Palantir's partnership with Anthropic emerged, with claims about 80% effectiveness rate for AI drones in Ukraine, though this was mentioned without verification or sources.
- Fruit Ninja clone in 5 shots by new Sonnet (Score: 22, Comments: 16): A Fruit Ninja game clone was created using Claude Sonnet in just 5 shots and 10 minutes total, with the result hosted at allchat.online.
- Users reported functionality issues with the slashing mechanic in the game. The creator later added sword sound effects to enhance gameplay experience.
- Discussion focused on the development process, with users asking about the 5-shot instruction process and how art assets were implemented using emojis.
- The creator confirmed that Claude Sonnet handled the slash effects independently, demonstrating the AI's capability to implement visual game mechanics.
Theme 3. ComfyUI-based Video Generation Breakthroughs
- ComfyUI processes real-time camera feed. (Score: 48, Comments: 9): ComfyUI demonstrates capability to process real-time camera feeds with integrated depth models.
- ComfyUI's depth model processing appears to be the main computational task, while latent denoising is identified as the primary performance bottleneck requiring significant computing power.
- Community humorously notes the technology's frequent application to creating animated female characters, particularly in the context of dance animations.
- Turning Still Images into Animated Game Backgrounds – A Work in Progress 🚀 (Score: 286, Comments: 39): ComfyUI enables conversion of static images into animated game backgrounds, though specific implementation details and methodology were not provided in the post body.
- The implementation uses CogVideo 1.5 (implemented by Kijai) to create looping animations, improving upon previous AnimatedDiff 1.5 attempts which were limited to 16 frames. A demo of the earlier version can be found at YouTube.
- The technical workflow involves importing a sprite sheet and 3D mesh into the game engine, where dynamic occlusions are calculated by comparing mesh depth with in-game depth. Real-time shadows are implemented using light sources and occlusion cubes matching shadow areas in the background video.
- The project utilizes Microsoft MOGE for accuracy and is primarily designed for retro games with static backgrounds, though users noted visual discrepancies between the mouse character and background styles in the current implementation.
Theme 4. Anthropic Teams with Palantir on Defense AI
- US military is planning to use AI machine guns to counter AI drones (Score: 86, Comments: 46): The US military plans to deploy AI-powered machine guns as a countermeasure against AI drones. No additional details were provided in the post body about implementation specifics, timeline, or technical capabilities.
- Palmer Luckey, founder of Oculus, established Anduril Industries for drone defense technology. Though commenters note Anduril doesn't specifically focus on air defense systems like the proposed AI machine guns.
- Autonomous weapon systems have historically been used in ship protection and defense applications. The technology represents an evolution of existing military capabilities rather than a completely new development.
- Users draw parallels to science fiction scenarios from Robocop and Terminator 2, while others express concerns about potential impacts on wildlife, particularly birds.
- Biden, Xi Agree They Won’t Give AI Control Over Nuclear Weapons (Score: 214, Comments: 48): President Biden and Chinese President Xi Jinping reached an agreement to prevent artificial intelligence systems from controlling nuclear weapons during their November 2023 meeting. This marks a significant diplomatic development in AI safety and nuclear deterrence between the two global powers.
- Community expresses significant skepticism about the agreement's enforcement and sincerity, with multiple users sarcastically questioning the reliability of diplomatic promises between opposing world powers.
- Several users acknowledge this as a positive step in international cooperation, noting it demonstrates basic self-preservation instincts between nuclear powers.
- Users highlight the common sense nature of the agreement, expressing both relief that it exists and concern that such an agreement needed to be formally established.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1: 🚀 Fresh AI Models Take Flight
- Qwen 2.5 Turbo launches with 1 million token context support and a 4.3x speedup, catering to demands for longer context handling and faster inference.
- Gemini-Exp-1114 showcases enhanced creativity and reduced censorship, though some responses may still include gibberish, highlighting the balance between openness and reliability.
- Pixtral Large debuts as a 124B parameter multimodal model with a 128K context window, outperforming existing models like LLaVA-o1 in image understanding tasks.
Theme 2: 🛠️ Integrative AI Frameworks and Tools
- AnyModal framework enables seamless integration of images and audio with LLMs, enhancing tasks like LaTeX OCR and image captioning for developers.
- vnc-lm Bot introduced as a Discord bot that integrates leading language model APIs, boosting user interactions within the Discord environment.
- OpenRouter updates include threaded conversations and model switching, streamlining discussions by maintaining context continuity across message threads.
Theme 3: ⚙️ Performance Boosts and GPU Optimizations
- Tinygrad sees performance enhancements with new blocks and lazy buffers, and introduces support for AMD GPUs, though challenges with driver compatibility remain.
- PrefixQuant technique simplifies static quantization without retraining, achieving significant boosts in accuracy and inference speed for models like Llama-3-8B.
- Fast Forward method accelerates SGD training by 87% reduction in FLOPs, validated across various models and tasks for improved training efficiency.
Theme 4: 🏆 Community Hackathons and Collaborative Events
- Tasty Hacks hackathon promotes creativity over competition, inviting 20-30 kind and nerdy individuals to collaborate on passion projects without the pressure of sponsor-driven prizes.
- EY Techathon seeks an AI developer and a Web app developer, encouraging quick team formation to participate in innovative AI-driven projects.
- Intel AMA scheduled for 11/21 at 3pm PT, offering insights into Intel’s Tiber AI Cloud and Intel Liftoff Program, fostering collaboration between participants and Intel specialists.
Theme 5: 🐛 Technical Hiccups and Bug Bounties
- Perplexity Pro Subscription issues arise with the removal of the Opus model, leading to user frustrations and requests for refunds due to diminished service value.
- FlashAttention in Triton implementation faces crashes with
atomic_addin Colab, prompting community support to resolve GPU computing challenges. - Phorm Bot struggles to answer simple questions about
eval_steps, leading to user disappointment and calls for better bot functionality.
PART 1: High level Discord summaries
OpenRouter (Alex Atallah) Discord
-
Perplexity Models Enhance with Citations: All Perplexity models now support a new
citationsattribute in beta, allowing completion responses to include associated links like BBC News and CBS News for improved information reliability.- This feature enhances user experience by providing direct sources within chat completions, as highlighted in the announcement.
-
Threaded Conversations Boost Interaction: Threaded conversations have been updated to reflect changes within threads in future messages, utilizing keywords from prompts to name threads for easier conversation tracking.
- This enhancement aims to streamline discussions by maintaining context continuity across message threads.
-
vnc-lm Bot Integrates Multiple LLMs: vnc-lm is introduced as a Discord bot that integrates leading language model APIs, enhancing user interactions within the Discord environment.
- Its utility-focused design is detailed in the provided GitHub repository.
-
Gemini-Exp-1114 Shows Creativity: Users have noted that the new Gemini experimental model 'gemini-exp-1114' demonstrates increased creativity and reduced censorship, making it a dynamic option for prompting.
- However, some responses may include gibberish or require careful prompting to manage censorship levels.
-
OpenAI Enables Streaming for O1 Models: OpenAI announced that streaming is now available for their
o1-previewando1-minimodels, expanding access for developers across all paid usage tiers.- This update allows applications using these models to improve interactivity, moving beyond previous simulated streaming methods.
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 Turbo Accelerates Token Processing: The Qwen 2.5 Turbo model has been released, supporting context lengths up to 1 million tokens and demonstrating faster inference speeds. Details here.
- This advancement addresses community demands for handling larger contexts and improves performance in managing extensive data volumes.
-
Unsloth Framework Enhances Model Adaptation: Users explored loading fine-tuned LoRA weights alongside base models using the Unsloth framework, utilizing the
FastLanguageModel.from_pretrained()function. This facilitates adding new tokens and resizing embeddings effectively, enhancing training processes.- The framework's flexibility in integrating adapters streamlines the model customization workflow.
-
PrefixQuant Refines Static Quantization Techniques: PrefixQuant isolates outlier tokens offline, simplifying quantization without retraining and enabling efficient per-tensor static quantization. Applied to Llama-3-8B, it showed significant boosts in accuracy and inference speed over previous methods. Read more.
- This technique outperformed dynamic quantization approaches, providing enhanced deployment efficiency for large language models.
-
Fast Forward Optimizes SGD Training: The new Fast Forward method accelerates SGD training by repeating the latest optimizer step until loss stops improving, achieving up to an 87% reduction in FLOPs over standard SGD with Adam. Paper link.
- This approach has been validated across various models and tasks, demonstrating improved training speed without sacrificing performance.
-
LaTRO Enhances Reasoning in Language Models: LaTRO presents a framework that optimizes reasoning capabilities within large language models by sampling from a latent distribution and improving reasoning quality autonomously during training. GitHub Repository.
- Experiments showed that LaTRO enhanced zero-shot accuracy by 12.5% on GSM8K, indicating significant improvement in reasoning tasks.
Perplexity AI Discord
-
Launch of Perplexity Shopping Enhances User Experience: Perplexity introduced Perplexity Shopping as a comprehensive platform for researching and purchasing products, featuring one-click checkout and free shipping on select items.
- Users have praised the seamless integration of shopping capabilities, noting the improved convenience and efficiency in their purchasing processes.
-
Buy with Pro Feature Enables In-App Transactions: The 'Buy with Pro' feature allows US-based Perplexity Pro subscribers to perform native transactions within the app, supporting purchases of electronics and home enhancement products.
- This addition aims to streamline the shopping experience, reducing the need for external platforms and enhancing user engagement.
-
Perplexity Pro Subscription Faces User Backlash: Users have expressed frustration regarding changes to the Perplexity Pro subscription, specifically the removal of the Opus model without prior notification, leading to perceived diminished value.
- Many subscribers are seeking refunds and clarity on future updates, highlighting a gap between user expectations and service delivery.
-
Context Memory Limits Reduced from 32k to 16k Tokens: Perplexity has decreased the context memory size for its models from 32k to 16k tokens, affecting the capability for longer interactions.
- Users have raised concerns about this reduction impacting the effectiveness of the models, questioning the value proposition of their current subscription.
-
Introduction of Autonomous ML Engineer Transforms Workflows: The unveiling of the Autonomous ML Engineer marks a significant advancement in autonomous systems for machine learning, potentially revolutionizing AI-driven workflows.
- Details on its implementation and impact on enterprise operations are available here.
HuggingFace Discord
-
Mistral and Pixtral Model Releases: Mistral announced the release of the Pixtral Large model, demonstrating advanced multimodal performance and compatibility with high-resolution images. The model is open-weights and available for research, showcasing notable advancements over previous Mistral models.
- Community discussions highlighted that Pixtral Large outperforms LLaVA-o1 in reasoning tasks, particularly excelling in image understanding capabilities. Users can access the model here.
-
AnyModal Framework Developments: AnyModal, a flexible framework, was introduced for integrating various data types with LLMs, featuring functionalities like LaTeX OCR and image captioning. The project is open for feedback and contributions to enhance its multimodal capabilities.
- Developers are encouraged to contribute via the GitHub repository, where ongoing improvements aim to expand the framework’s interoperability with different modalities.
-
RoboLlama Robotics Model Integration: Starsnatched is developing the RoboLlama project to convert Meta's Llama 3.2 1B into a robotics-ready model, incorporating vision encoders and diffusion layers. The focus is on training only the diffusion and projection layers while keeping the core ViT and LLM layers frozen.
- This approach aims to enhance the model's integration with robotic systems without altering the foundational Vision Transformer (ViT) and Language Model (LLM) components, ensuring stability and performance.
-
HtmlRAG in Retrieval-Augmented Generation: The introduction of HtmlRAG proposes utilizing HTML formats in Retrieval-Augmented Generation (RAG) processes to preserve structural and semantic information, addressing limitations in traditional plain-text methods. Detailed in the arXiv paper, this approach enhances knowledge retrieval.
- By maintaining the integrity of retrieved information, HtmlRAG improves the model's ability to utilize external knowledge effectively, potentially reducing hallucination issues in large language models.
-
Vision Language Models (VLMs) Capabilities: Discussions around Vision Language Models highlighted their ability to integrate images and texts for various generative tasks. A recent blog post emphasized their robust zero-shot capabilities and adaptability to different image inputs.
- The evolution of VLMs is seen as pivotal for applications across diverse fields, with communities exploring their potential in enhancing generative AI tasks and improving model versatility.
aider (Paul Gauthier) Discord
-
Introduction of Qwen 2.5 Turbo: Qwen 2.5 Turbo introduces longer context support of 1 million tokens, faster inference speeds, and lower costs at ¥0.3 per million tokens.
- This model enhances efficiency, making it a promising alternative for those requiring extensive context.
-
Optimizing Aider Usage: Users experiment with Aider's modes, switching between 'ask' and 'whole' mode for better context handling while coding.
- Paul Gauthier suggested utilizing the command
/chat-mode wholeto streamline interactions, indicating ongoing improvements in Aider's functionalities.
- Paul Gauthier suggested utilizing the command
-
Streaming Models in OpenAI: OpenAI has enabled streaming for the o1-preview and o1-mini models, improving responsiveness during interactions.
- Developers can access these models across all paid tiers, with Aider incorporating these updates by using the command
aider --install-main-branch.
- Developers can access these models across all paid tiers, with Aider incorporating these updates by using the command
-
Comparative Insights on LLMs: Community discussions reflect varying opinions on the effectiveness of Qwen versus other models like Sonnet and Anthropic offerings.
- Some members believe Qwen might surpass others for practical applications, especially in hosting LLMs with optimal hardware.
-
Configuring Aider with OpenRouter: To configure Aider to use an OpenRouter model, settings must be made on the OpenRouter side, as it currently does not support per-model settings on the client side.
- Members discussed using extra parameters and config files to specify different behavior but expressed limitations with the current setup.
OpenAI Discord
-
Google's Project Astra Explored: Members expressed curiosity about Google's Project Astra, particularly its memory capabilities beyond the publicly available demo video.
- The discussion highlighted the enthusiasm surrounding multiple companies' efforts to develop new AI features.
-
o1-mini vs o1-preview Performance: Users compared o1-mini and o1-preview, noting performance discrepancies where o1-mini often got stuck in thought loops, whereas o1-preview provided more straightforward responses.
- Several members observed that while o1-mini showed promise, GPT-4o delivered more effective and reliable outputs.
-
Enhancing AI Roleplaying Capabilities: Members delved into the AI roleplaying capabilities, including the development of custom scripts to enhance AI character behavior during interactions.
- Participants acknowledged the challenges associated with maintaining character consistency over extended dialogues.
-
Implications of AI Memory Features: The group explored the implications of memory features in AI systems, discussing how they could improve user interactions.
- Conversations pointed towards user expectations from memory-integrated AI, emphasizing more personalized and context-aware responses.
-
Optimizing Chain of Thought Prompting: Chain of Thought Prompting was emphasized as a technique to enhance response quality, mimicking human deliberative reasoning processes.
- Members reflected on the potential to discover new prompting techniques that could significantly influence how models generate responses.
Eleuther Discord
-
nGPT Optimizer Advancements: Boris and Ilya showcased the nGPT optimizer to the Together.AI group, highlighting its performance enhancements based on their expertise and Nvidia's internal findings available on GitHub.
- Feedback from members raised concerns about the reproducibility, computational efficiency, and comparative effectiveness of nGPT compared to existing models.
-
Normalization Techniques in Neural Networks: Yaroslav pointed out that the nGPT paper lacked detailed explanations, leading to flawed implementations, and discussed the potential benefits of using normalization methods like RMSNorm.
- Community members debated the impact of different normalization techniques on model convergence and performance across various neural network architectures.
-
Scaling Pretraining Feasibility: A member asserted that scaling pretraining remains a foundational property of LLMs, emphasizing it is unlikely to become obsolete.
- However, the discussion raised concerns about the economic viability of continued scaling, sparking debates on future resource allocation strategies in pretraining.
-
Function Vectors in In-Context Learning: A paper on function vectors was introduced, exploring how in-context learning (ICL) is influenced by specific attention heads managing tasks such as antonym identification.
- The study concluded that this approach leads to more interpretable task vectors, with an upcoming Arxiv post expected to provide further insights.
-
Few-Shot vs Zero-Shot Evaluation: A user reported an accuracy increase from 52% to 88% in a multiple-choice task when utilizing few-shot evaluations, questioning typical performance metrics in sentiment analysis tasks.
- The conversation highlighted the significance of prompt engineering, with members noting that few-shot strategies can enhance model calibration and reliability.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 Optimized for GPU: Users discussed configuring Stable Diffusion 3.5 to run on their GPU by modifying the
sd3_infer.pyfile. A code snippet was shared to set up the working directory and activate the virtual environment.- Proper GPU configuration is essential for performance gains, with emphasis on following the provided setup instructions accurately.
-
Installing diffusers and accelerate for SDXL Lightning: To utilize SDXL Lightning, users were guided to install the
diffusersandacceleratelibraries using a straightforward command. Sample code was provided to demonstrate device settings and inference steps.- Implementing these installations ensures effective image generation, with users appreciating the clear, actionable instructions.
-
Customizing Image Prompts in Stable Diffusion: Users learned how to customize prompts to alter specifics like hair color in image generation commands. Modifying the prompt string directly affects the generated visuals, allowing for creative control.
- This capability enables AI Engineers to fine-tune image outputs to meet precise requirements without altering the underlying model.
-
Roop Unleashed Faces Performance Hurdles: Roop Unleashed users reported prolonged processing times when creating face-swap videos, raising concerns about software efficiency. Discussions highlighted the ongoing challenges with video processing performance.
- Community members are deliberating on potential optimizations to enhance Roop Unleashed's efficiency and reduce processing durations.
-
SDXL Lightning Outperforms SD 1.4: Discussions revealed that SDXL Lightning surpasses older models like SD 1.4 in generating higher-quality images. Users noted the advancements in performance and flexibility with newer models.
- The preference for SDXL Lightning underscores the evolution of stable diffusion models to meet advanced image generation standards.
LM Studio Discord
-
LM Studio Server Accessibility Improved: A user resolved LM Studio Local Server accessibility issues by adjusting firewall settings, switching from
192.168.56.1:2468to192.168.0.100:2468, enabling effective inter-device communication.- This change facilitated seamless server usage across the local network, enhancing productivity and connectivity for users.
-
AI Video Upscaling Tools Compared: Community members evaluated various AI-based video upscaling tools, highlighting Waifu2x for animated content and RealESRGAN for general applications, while noting the high cost of Topaz as a commercial alternative.
- The preference leaned towards free solutions due to their accessibility and effectiveness, fostering discussions on optimizing video quality without significant financial investments.
-
Ubuntu Surpasses Windows in GPU Inference: Ubuntu achieved a GPU inference speed of 375 tokens/sec with a 1b model, outperforming Windows which lagged at 134 tokens/sec, according to recent tests.
- Participants attributed Windows' lower performance to energy-saving power settings and discussed optimizing these settings to enhance GPU efficiency.
-
Nvidia vs AMD GPUs: AI Task Compatibility: Discussions revealed that while the 7900XTX and 3090 offer comparable 24GB VRAM, Nvidia GPUs maintain better compatibility with AI applications due to more robust driver support.
- Conversely, AMD GPUs present challenges with software and driver integration, requiring additional effort to achieve optimal performance in AI tasks.
-
Challenges in Multi-GPU Setups: Users shared plans for extensive multi-GPU setups, including configurations like a 10 RTX 4090 with a Threadripper Pro, aiming for significant performance gains.
- The conversation highlighted complications with mixed GPU brands due to differing driver management systems and raised concerns about shared VRAM efficiency when handling large models.
Nous Research AI Discord
-
Ollama Optimizes Inference with LCPP: Members explored Ollama and its integration with LCPP for efficient inference, highlighting its advantages over traditional frameworks like PyTorch.
- A debate emerged regarding Ollama versus LMStudio, with some users favoring Ollama’s seamless front-end integrations.
-
Hermes 3 Compute Instances Demand High Resources: Discussion centered on the Hermes 3 405 compute instances requiring 8x H100 or 8x A100 80GB nodes, raising concerns about cost-effectiveness.
- Alternative solutions like cloud inference were suggested for budget-conscious scenarios, potentially postponing personal compute expansions.
-
AnyModal Framework Enhances Multimodal Training: AnyModal was introduced as a versatile framework for training multimodal LLMs, enabling the integration of inputs like images and audio via GitHub.
- Members expressed interest in developing demos for image and text interactions, emphasizing streamlined model training processes.
-
LLaMA-Mesh Launches 3D Capabilities: Nvidia unveiled LLaMA-Mesh, leveraging Llama 3.1 8B for 3D mesh generation, with weight releases anticipated soon, as mentioned in Twitter.
- The community received the announcement enthusiastically, recognizing its potential impact on 3D generation technologies.
Interconnects (Nathan Lambert) Discord
-
Qwen 2.5 Turbo Launch: The Qwen 2.5 Turbo model was introduced with a 1 million token context length and a 4.3x speedup in processing, enhancing its capability to handle larger datasets efficiently.
- This upgrade allows for higher throughput at a competitive price, generating excitement among developers for its potential applications in complex NLP tasks.
-
Mistral AI Pixtral Large Release: Mistral AI unveiled the Pixtral Large model, a multimodal system achieving state-of-the-art results on benchmarks like MathVista, DocVQA, and VQAv2.
- The release also includes enhancements to their chat platform, introducing new interactive tools that improve user engagement and model performance.
-
Deepseek 3 Developments: Anticipation surrounds the upcoming Deepseek 3 release, with discussions hinting at a potential 2.5 VL version that promises advanced model capabilities.
- Community members are optimistic about the enhancements, recognizing the innovative strides made by Chinese models in the AI landscape.
-
RewardBench for RLHF: RewardBench was launched as a benchmark to evaluate reward models in reinforcement learning from human feedback, aiming to refine alignment technologies.
- However, concerns were raised regarding dataset treatment, including accusations of plagiarism against the authors, highlighting the need for ethical standards in benchmark development.
-
LLaVA-o1 Visual Language Model: LLaVA-o1 was announced as a new visual language model outperforming major competitors, featuring a novel inference method that sets it apart in the field.
- Discussions mentioned plans to evaluate its performance against Qwen2-VL, though its availability on Hugging Face remains pending.
Latent Space Discord
-
Pixtral Large Launches Multimodal Prowess: Mistral introduced Pixtral Large, a 124B parameter multimodal model that excels in processing both text and images, accessible via their API and Hugging Face.
- Equipped with a 128K context window and the capability to process up to 30 high-resolution images, it marks a significant milestone in multimodal AI development.
-
Qwen 2.5 Turbo Amplifies Context Handling: Qwen 2.5 Turbo now supports context lengths up to 1 million tokens, enabling extensive text processing comparable to ten novels.
- The model achieves a 100% accuracy rate on the Passkey Retrieval task, enhancing long-form content processing for developers.
-
Windsurf Editor Enhances Developer Workflow: The Windsurf Editor by Codeium integrates AI capabilities akin to Copilot, facilitating seamless collaboration for developers across Mac, Windows, and Linux platforms.
- Its features include collaborative tools and autonomous agents handling complex tasks, ensuring developers remain in a productive flow state.
-
Anthropic API Embeds into Desktop Solutions: The Anthropic API has been successfully integrated into desktop clients, as showcased in this GitHub project.
- Tools like agent.exe enable the AI to generate mouse clicks using pixel coordinates, demonstrating advanced integration capabilities.
-
OpenAI Deploys Streaming for o1 Models: OpenAI has made streaming available for the o1-preview and o1-mini models, broadening access across all paid usage tiers.
- This feature facilitates more dynamic interactions within the OpenAI platform, enhancing the developer experience.
GPU MODE Discord
-
ZLUDA Enables CUDA on Non-NVIDIA GPUs: A recent YouTube video showcased ZLUDA, a tool that provides CUDA capabilities on AMD and Intel GPUs, expanding developer options beyond NVIDIA hardware.
- Community members expressed enthusiasm over Andrzej Janik's appearance in the video, indicating strong interest in leveraging ZLUDA for diverse GPU environments.
-
CK Profiler Boosts FP16 Matrix Multiplication: CK Profiler improved FP16 matrix multiplication performance to 600 TFLOPs, although still trailing the H100's peak of 989.4 TFLOPs as indicated in NVIDIA's whitepaper.
- Performance on AMD's MI300X reached 470 TFLOPs with
torch.matmul(a,b), highlighting the necessity for optimized strategies on AMD hardware.
- Performance on AMD's MI300X reached 470 TFLOPs with
-
Jay Shah's CUTLASS Presentation Highlights FA3: During his talk at CUTLASS, Jay Shah delved into Flash Attention 3 (FA3), discussing column and row permutations to optimize kernel performance without shuffles.
- He emphasized the impact of these permutations on FA3 kernel tuning, prompting members to explore indexing techniques for enhanced GPU computing efficiency.
-
Triton Integrates Modified FlashAttention: A member reported issues while implementing a modified version of FlashAttention in Triton, specifically encountering crashes with
atomic_addin Colab environments.- Efforts are underway to compute the column-sum of the attention score matrix, with community support actively sought to resolve implementation challenges.
-
Advanced PyTorch: DCP and FSDP Enhancements: Discussions around PyTorch's Distributed Checkpoint (DCP) revealed concerns about excessive temporary memory allocation during
dcp.savein mixed precision and FULL_SHARD mode.- FSDP's management of 'flat parameters' necessitates memory for all-gathering and re-sharding, leading to increased memory reservations based on custom auto-wrap policies.
Notebook LM Discord Discord
-
NotebookLM Empowers Content Creators: Former Google CEO Eric Schmidt highlights NotebookLM as his 'ChatGPT moment of this year' for content creation, emphasizing its utility for YouTubers and podcasters in this YouTube video.
- He shares strategies for effective use in creative content generation, showcasing how NotebookLM enhances media production workflows.
-
Seamless RPG Integration with NotebookLM: Users have successfully utilized NotebookLM for RPGs, enabling rapid character and setting creation as demonstrated in Ethan Mollick's experiment.
- A notable member generated a setting and character for their savage worlds RPG in under five minutes, highlighting NotebookLM's efficiency in creative storytelling.
-
Challenges in Audio File Management: Users reported issues with generating separate audio tracks and misnaming audio files upon download in NotebookLM, leading to reliance on digital audio workstations for voice isolation.
- Discussions include potential solutions like employing noise gate techniques to address combined audio file complications.
-
Mixed Usability and Interface Feedback: Feedback on NotebookLM's mobile interface is varied, with users praising its unique capabilities but citing difficulties in navigating and accessing features across devices.
- Users expressed challenges in creating new notebooks and deleting or restarting existing ones, indicating a need for improved interface intuitiveness.
-
Requested Feature Enhancements for NotebookLM: Members have requested features such as RSS feed integration for external information and customizable voice settings without relying on additional applications.
- There are also demands for enhanced support for various file types, including frustrations with uploading formats like XLS and images.
Modular (Mojo 🔥) Discord
-
Mojo Benchmarking with Random Arguments: A user sought advice on performing benchmarking with random function arguments in Mojo but noted that current methods require static arguments, adding undesirable overhead.
- Another user suggested pre-generating data for use in a closure to avoid overhead during benchmarking.
-
Dict Implementation Bug: A user reported a crash occurring when using a Dict with SIMD types in Mojo, which worked up to a SIMD size of 8 but failed beyond that.
- The problem was replicated in a GitHub Issues page, suggesting a deeper issue within the Dict implementation that warrants attention.
-
Exploring Max Graphs for Knowledge Graph Integration: A member pondered whether Max Graphs could effectively unify LLM inference with regular Knowledge Graphs, mentioning their potential use in RAG tools and NeuroSymbolic AI.
- They provided a GitHub link showcasing a proof-of-concept for this approach.
-
MAX's Role in Accelerating Graph Searches: A member questioned if using MAX could aid in accelerating graph search, to which another confirmed the potential but noted limitations.
- It was clarified that unless the entire graph is copied into MAX, current capabilities are limited.
-
Feasibility of Mojo and MAX Implementation: Concerns were raised regarding the feasibility of an agent implemented in Mojo and MAX that infers an LLM to execute searches.
- The idea was met with skepticism, where members debated its practicality in actual application.
Cohere Discord
-
Cohere Model Output Issues: Users have reported odd outputs from the Cohere model, particularly when processing shorter texts, leading to reliability concerns.
- The inconsistent performance has caused frustration, with the model generating bizarre terms and questioning its application suitability.
-
API Reliability Concerns: Multiple users have encountered API errors, including 503 Service Unavailable issues reported on 2024-11-15, indicating potential upstream connection problems.
- These incidents underline ongoing challenges with API availability, prompting users to seek shared experiences and solutions within the engineering community.
-
Developer Office Hours on Long Text: The upcoming Cohere Developer Office Hours on 12:00 pm ET will focus on strategies for handling long text, featuring insights from Maxime Voisin.
- Attendees will explore implementing memory systems in RAG pipelines and discuss use cases like File Upload and SQL Query Generation.
-
Summarization Techniques in RAG Systems: The office hours session will include discussions on compressing and summarizing long text effectively within RAG systems.
- Participants are encouraged to share their use cases and collaborate on strategies to maintain essential information during summarization.
-
Cohere Toolkit Release v1.1.3: The Cohere Toolkit v1.1.3 was released on 2024-11-18, introducing improved global Settings usage and major tool refactoring.
- Key updates include support for ICS files, a File content viewer, and integration enhancements with Azure deployment using Docker compose.
LlamaIndex Discord
-
Python Documentation Enhanced with Ask AI Widget: The Python documentation now includes the 'Ask AI' widget, allowing users to pose questions and receive precise, up-to-date code via a RAG system. Check it out here.
- It’s a truly magically accurate feature that enhances the coding experience!
-
Launch of Mistral Multi-Modal Image Model: Mistral has introduced a new multi-modal image model, available with day 0 support by installing
pip install llama-index-multi-modal-llms-mistralai. Explore its usage in the notebook.- The model supports functions like
completeandstream completefor efficient image understanding.
- The model supports functions like
-
New Multimedia and Financial Report Generators Released: New tools have been released: the Multimedia Research Report Generator showcases generating reports from complex documents visually here, and the Structured Financial Report Generation tool processes 10K documents using a multi-agent workflow, detailed here.
- These tools interleave text and visuals to simplify reporting and analyses.
-
Improvements to CitationQueryEngine and condenseQuestionChatEngine: Users discussed issues with the CitationQueryEngine, such as handling multiple sources, suggesting mapping citation numbers to sources by parsing response text. Additionally, the condenseQuestionChatEngine was reported to generate nonsensical questions when topics abruptly switch, with solutions like customizing the condense prompt and considering CondensePlusContext.
- Implementing these suggestions aims to enhance query coherence and citation accuracy.
-
EY Techathon Team Building and Developer Positions: The EY Techathon team is recruiting, seeking an AI developer and a Web app developer. Interested candidates should DM ASAP to secure their spot.
- Urgent calls for AI and Web app developers emphasize the need for quick action to join the team.
OpenAccess AI Collective (axolotl) Discord
-
Liger Kernel Runs 3x Faster: Liger claims to run approximately three times faster than its predecessor while maintaining the same memory usage in worst-case scenarios, with no installation errors reported.
- Some members expressed skepticism, questioning whether this performance boost is exclusive to NVIDIA hardware.
-
AnyModal Framework Integrates Multimodal Data: The AnyModal framework enables the integration of data types like images and audio with LLMs, simplifying setups for tasks such as LaTeX OCR and image captioning.
- Developers are seeking feedback and contributions to enhance the framework, showcasing models like ViT for visual inputs.
-
Chai Research Announces Open-source Grants: Chai, a generative AI startup with 1.3M DAU, is offering unlimited grants ranging from $500 to $5,000 for open-source projects aimed at accelerating community-driven AGI.
- They have already awarded grants to 11 individuals, encouraging developers to submit their projects via Chai Grant.
-
Pretraining and Finetuning Qwen/Qwen2 Models: A member inquired about pretraining the Qwen/Qwen2 model using QLoRA with their pretraining dataset and subsequently finetuning it with an instruct dataset in Alpaca format.
- They confirmed having the Axolotl Docker ready to facilitate the process.
-
Inquiry for vLLM Analytics Platform: A member sought a platform that integrates with vLLM to provide analytics on token usage and enable response inspection.
- This request highlights community interest in tools that enhance monitoring and understanding of vLLM's performance.
tinygrad (George Hotz) Discord
-
Tinygrad Contributions Standards: George emphasized that Tinygrad contributions must meet a high quality standard, stating that low-quality PRs will be closed without comment.
- He advised contributors to review prior merged PRs to align with the project's quality expectations before tackling bounties.
-
Upcoming Tinygrad Release Features: Tinygrad's next release is scheduled in approximately 15 hours, incorporating enhancements such as blocks, lazy buffers, and performance improvements related to Qualcomm scheduling.
- Discussions highlighted the latest updates and their expected impact on the framework's efficiency and functionality.
-
Integration of PyTorch and TensorFlow Methods: The community discussed adding convenience methods like
scatter_add_andxavier_uniformto Tinygrad to reduce repetitive coding efforts.- George agreed to merge these methods from PyTorch and TensorFlow if they are compatible with existing features.
-
Graph and Buffer Management Enhancements: Efforts to refine Big Graph and LazyBuffer concepts are underway, with plans to delete LazyBuffer to improve processing.
- This includes tracking UOp Buffers using WeakKeyDictionary to enhance Tinygrad's performance and functionality.
-
TinyGrad AMD GPU Support without ROCm: A query was raised about whether TinyGrad can train on AMD GPUs without installing ROCm, referencing George's stream where he mentioned ripping out AMD userspace.
- This indicates a potential shift in Tinygrad's GPU support strategy, impacting users with AMD hardware.
LLM Agents (Berkeley MOOC) Discord
-
Exclusive AMA with Intel on AI Development: Join the AMA session with Intel on Building with Intel: Tiber AI Cloud and Intel Liftoff on 11/21 at 3pm PT to gain insights into Intel’s AI tools.
- This event offers a chance to interact with Intel specialists and learn how to enhance your AI projects using their resources.
-
Intel Tiber AI Cloud Capabilities: The session will showcase the Intel Tiber AI Cloud, a platform designed to optimize AI projects with advanced computing capabilities.
- Participants will explore how to leverage this platform for maximum efficiency in their hackathon endeavors.
-
Intel Liftoff Program for Startups: Discussion will focus on the Intel Liftoff Program, which provides startups with mentorship and technical resources.
- Attendees will discover how this program can support their development efforts from inception.
-
Percy Liang's Open-Source Foundation Models: Percy Liang will present on Open-Source and Science in the Era of Foundation Models, emphasizing the importance of open-source contributions to AI.
- Liang will discuss leveraging community support for open-source foundation models, highlighting the need for substantial resources like data, compute, and research expertise.
DSPy Discord
-
DSPy Introduces VLM Support: DSPy recently added support for VLMs in beta, showcasing attributes extraction from images.
- A member shared an example demonstrating how to extract useful attributes from screenshots of websites, highlighting the potential of this feature.
-
Attributes Extraction from Screenshots: The thread discusses techniques for extracting useful attributes from screenshots of websites, indicating practical applications of DSPy.
- This approach aims to streamline how developers can interact with visual data, bringing attention to emerging capabilities in the DSPy toolkit.
-
Less English, More Code in DSPy Signatures: A member shared that most people write too much English in their DSPy signatures; instead, one can achieve a lot with concise code.
- They referenced a tweet by Omar Khattab that emphasizes the effectiveness of super short pseudocode.
-
Tackling Username Generation with DSPy: A user raised concerns about generating diverse usernames, noting that there were many duplicates.
- Another member suggested disabling the cache in the LLM object, but the original user mentioned they had already done so.
-
Increasing Username Randomness with High Variance: To address the issue of duplicate usernames, a member recommended increasing the LLM temperature and adding a storytelling element before the name generation.
- They proposed using a high-temperature model for generating the story and a lower temperature for quality name generation.
LAION Discord
-
Launch of MultiNet Benchmark for VLA Models: The new paper titled "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" evaluates VLA models across 20 real-world tasks, revealing key insights about their performance. Full details can be found here.
- This work aims to advance the development of general-purpose robotic systems, demonstrating the critical need for systematic evaluation across diverse tasks.
-
VisRAG Talk at Jina AI: Join the upcoming talk at Jina AI where Shi will explore his innovative work on VisRAG, a fully visual RAG pipeline that eliminates the need for parsing.
- Expect to learn about the construction, evaluation, and future possibilities related to VisRAG, which nearly tripled its training dataset size compared to ColPali.
-
Performance Comparison Among Leading VLA Models: A comparison of GPT-4o, OpenVLA, and JAT shows that while simple tasks like pick-and-place are manageable, models struggle with complex multi-step processes.
- Notably, the results indicate significant performance variations based on the task and robot platform, highlighting the utility of sophisticated prompt engineering with GPT-4o.
-
Introduction of μGATO, a Mini VLA Model: The team introduced μGATO, a mini and understandable baseline model tailored for the MultiNet benchmark, serving as a tool to advance multimodal action models in robotics.
- The ongoing efforts by the Manifold team signal the forthcoming release of more innovations in multimodal action models.
-
Tasty Hacks Hackathon Announcement: A new hackathon, Tasty Hacks, aims to inspire participants to create projects for creativity's sake rather than for utility, moving away from the traditional hackathon culture of optimizing for winning.
- Organizers are seeking kind and nerdy individuals willing to team up and create in a smaller setting of just 20-30 people.
MLOps @Chipro Discord
-
Guidance Needed for MLOps: A member expressed confusion about where to start with MLOps, stating, 'It’s all complicated.'
- Another member requested clarification, asking for more specific concerns, highlighting the need for clearer communication when addressing complex topics like MLOps.
-
Clarification Sought on MLOps Complexity: A member indicated that the question about MLOps was broad and requested more specific details.
- This interaction underscores the necessity for precise communication when tackling intricate subjects like MLOps.
Mozilla AI Discord
-
Pleias launches Common Corpus for LLM training: Pleias, a member of the 2024 Builders Accelerator cohort, announces the release of the Common Corpus, the largest open dataset for LLM training, emphasizing a commitment to having training data under permissive licenses. Find the full post here.
- 'The open LLM ecosystem particularly lacks transparency around training data,' Pleias notes, stating that Common Corpus aims to address this transparency gap.
-
Transformer Lab schedules RAG demo: Transformer Lab is hosting a demo showcasing how to train, tune, evaluate, and use RAG on LLMs without coding, featuring a user-friendly UI. The event promises an easy-to-install process in your local environment, generating excitement in the community. More details.
- Community members are enthusiastic about the streamlined integration of RAG into their workflows.
Torchtune Discord
-
DCP Async Checkpointing Implementation: DCP async checkpointing aims to improve intermediate checkpointing in TorchTune with a new feature that is currently a work in progress.
- This pull request reveals that the process aims to notably enhance efficiency by reducing intermediate checkpointing time by 80%.
-
Intermediate Checkpointing Time Reduction: The implementation of DCP async checkpointing promises significant reductions, estimating an 80% cut in checkpointing time due to improved methodologies.
- This approach is part of ongoing efforts in optimizing distributed checkpointing for better performance.
PART 2: Detailed by-Channel summaries and links
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Perplexity modelsCitations attributeChat completions
-
Perplexity models beta launches Grounding Citations: All Perplexity models now support a new
citationsattribute in beta, enhancing the information provided in completion responses with associated links.- This feature enables users to obtain reliable sources directly from the output, with example URLs like BBC News and CBS News.
- Structured citation format enhances usability: The output structure includes not just the completion but also the citations array, which lists URLs relevant to the completion context for better reference.
- This change is aimed at improving user experience by providing easier access to the sources of information presented in the chat completion.
OpenRouter (Alex Atallah) ▷ #app-showcase (4 messages):
Threaded ConversationsModel Switchingvnc-lm Discord BotWordPress Chatbot FeatureMarket Competition against Intercom and Zendesk
-
Threaded Conversations Enhancements: A member shared that support for threaded conversations has been added, allowing changes made inside the thread to be reflected in future messages.
- Keywords from the initial prompt are used to name the thread, making it easier to rejoin conversations.
- Quick Model Switching on-the-fly: The update includes the ability to switch models mid-conversation by simply sending
+followed by part of the model name, maintaining context and settings.
- For example, sending
+ claudeswitches toanthropic/claude-3-sonnet:betaseamlessly. - Launch of vnc-lm Discord Bot: vnc-lm is introduced as a Discord bot that integrates leading language model APIs, enhancing user interactions.
- Its emphasis on utility in the Discord environment is highlighted by an overview in the provided GitHub link.
- New WordPress Plugin Feature: An update on a WordPress plugin was shared, featuring the ability to create a custom website chatbot, inclusive of OpenRouter support.
- Details are available on their features page.
- Competitors Take Note!: A light-hearted comment noted that this new chatbot feature will likely disrupt competitors like Intercom and Zendesk.
- The member noted this with amusement, hinting at the growing competitiveness in the space.
Links mentioned:
- no title found: no description found
- GitHub - jake83741/vnc-lm: vnc-lm is a Discord bot that integrates leading large language model APIs.: vnc-lm is a Discord bot that integrates leading large language model APIs. - jake83741/vnc-lm
OpenRouter (Alex Atallah) ▷ #general (998 messages🔥🔥🔥):
Gemini Fast PerformanceMistral API IssuesSelf-Moderated vs OR Moderated APIsOpenAI O1 Streaming FeatureUser Discussions on Prompt Engineering
-
Gemini Experimental Model Insights: Users have reported that the new Gemini experimental model, identified as
gemini-exp-1114, displays improved creativity and less censorship compared to earlier versions, making it a more dynamic option for prompting.- However, it may sometimes produce gibberish responses or require careful prompting to avoid excessive censorship.
- Mistral API Instability: Users are experiencing instability with the
mistral-large-2407model, which occasionally returns gibberish despite temperature settings, while themistral-large-2411appears to be more sensible in its responses.
- There is a discussion on the differences in output quality and temperature sensitivity, indicating variability in the performance of Mistral models.
- Understanding Self-Moderated vs OR Moderated APIs: The community discussed the differences between self-moderated and OR moderated APIs, with a focus on cost implications and the likelihood of receiving moderated content.
- Self-moderated models tend to result in charges even for failed requests, while non-self-moderated versions would not incur costs on moderation restrictions.
- OpenAI O1 Models Support Streaming: OpenAI announced that streaming is now available for their
o1-previewando1-minimodels, opening access to developers across all paid usage tiers.
- This enhancement will allow for improved interactivity in applications using these models, moving beyond previously implemented fake streaming methods.
- User Interaction and Humor: Amidst technical discussions, users shared light-hearted comments and humor about various models, including comparisons and playful banter regarding usage experiences.
- The community maintained a lively atmosphere with references and jokes addressing the ongoing developments in AI models and their capabilities.
Links mentioned:
- Chub Venus AI: no description found
- Tweet from Tom's Hardware (@tomshardware): Meta is using more than 100,000 Nvidia H100 AI GPUs to train Llama-4 — Mark Zuckerberg says that Llama 4 is being trained on a cluster “bigger than anything that I’ve seen” https://trib.al/fynPPuR
- Perspective API: no description found
- Bocchi The Rock Hitori Gotoh GIF - Bocchi The Rock Hitori Gotoh Bocchi - Discover & Share GIFs: Click to view the GIF
- Tweet from heiner (@HeinrichKuttler): Fun at 100k+ GPU scale: Our training just briefly broke because a step counter overflowed 32 bits. 😅
- Tweet from Tibor Blaho (@btibor91): "chatgpt-4o-latest-20241111" on LMSYS Chatbot Arena?
- SillyTavern - LLM Frontend for Power Users: no description found
- Models: 'setti' | OpenRouter: Browse models on OpenRouter
- Hey GIF - Hey - Discover & Share GIFs: Click to view the GIF
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Exposing The Flaw In Our Phone System: Can you trust your phone? Head to https://brilliant.org/veritasium to start your free 30-day trial and get 20% off an annual premium subscription.A huge than...
- Tweet from Qwen (@Alibaba_Qwen): After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. https://qwenlm.github.io/blog/qwen2.5-turbo/ Today, we are proud to introduce the new Qwen2.5-Turbo ver...
- Sign the Petition: Push OpenRouter to include filtering for illegal content.
- Provider Routing | OpenRouter: Route requests across multiple providers
OpenRouter (Alex Atallah) ▷ #beta-feedback (21 messages🔥):
Custom Provider Keys Access RequestsIntegration Beta Feature Requests
-
Custom Provider Keys Access Requests Galore: Multiple users expressed their desire to get access to custom provider keys, stating messages such as 'I'd love to get access!' and 'requesting access to custom provider keys'.
- Concerns were raised about the lack of responses, with one user noting '1 day has passed and nobody has responded to my key request'.
- Integration Beta Feature Access in Demand: Several users inquired about gaining access to integration beta features, highlighting a common interest among members in utilizing APIs.
- Messages like 'Hi, could I apply for the access to the integration beta feature?' reflect the urgency and collective interest in gaining access.
Unsloth AI (Daniel Han) ▷ #general (723 messages🔥🔥🔥):
Unsloth Framework FeaturesQwen 2.5 Turbo ReleaseFine-tuning TechniquesRAG Approach in AIModel Performance and Configuration
-
Unsloth Framework Features: Users discussed loading fine-tuned LoRA weights alongside base models using the Unsloth framework, utilizing the
FastLanguageModel.from_pretrained()function.- The framework allows adding new tokens and resizing embeddings effectively, which users found beneficial for their training processes.
- Qwen 2.5 Turbo Release: The Qwen 2.5 Turbo model has been released, supporting context lengths up to 1 million tokens and demonstrating faster inference speeds.
- This development caters to community demands for longer contexts and improved performance in processing large volumes of data.
- Fine-tuning Techniques: Fine-tuning with LoRA shows faster training times compared to QLoRA due to reduced model size but more processing overhead.
- Users noted fluctuations in training loss were acceptable as long as the trend indicated a decrease towards the end of training.
- RAG Approach in AI: The RAG (Retrieval-Augmented Generation) approach is discussed, emphasizing its suitability for Q&A scenarios but complexity in execution.
- It was highlighted that RAG requires thorough model finetuning for effective utilization, especially when handling large datasets.
- Model Performance and Configuration: Users inquired about the loss thresholds during training, clarifying that a fluctuation between 0.5 and 0.6 is generally acceptable.
- The community advised that observance of loss trends is crucial, and upcoming support for models like Aya Expanse was confirmed.
Links mentioned:
- AI Mathematical Olympiad - Progress Prize 2: Solve national-level math challenges using artificial intelligence models
- Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.: no description found
- Google Colab: no description found
- Tweet from Qwen (@Alibaba_Qwen): After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. https://qwenlm.github.io/blog/qwen2.5-turbo/ Today, we are proud to introduce the new Qwen2.5-Turbo ver...
- Llama 3.2 - a unsloth Collection: no description found
- Tweet from VCK5000 Versal Development Card: The AMD VCK5000 Versal development card is built on the AMD 7nm Versal™ adaptive SoC architecture and is designed for (AI) Engine development with Vitis end-to-end flow and AI Inference development wi...
- Apply to Y Combinator | Y Combinator: To apply for the Y Combinator program, submit an application form. We accept companies twice a year in two batches. The program includes dinners every Tuesday, office hours with YC partners and access...
- GGUF Editor - a Hugging Face Space by CISCai: no description found
- Boo GIF - Boo - Discover & Share GIFs: Click to view the GIF
- unsloth/Qwen2.5-7B-Instruct · Hugging Face: no description found
- update tokenizer_config.json,config.json,generation_config.json · Qwen/Qwen2.5-Coder-32B-Instruct at b472059: no description found
- unsloth (Unsloth AI): no description found
- All Our Models | Unsloth Documentation: See the list below for all our GGUF, 16-bit and 4-bit bnb uploaded models
- Placement Groups — Ray 2.39.0: no description found
- mistralai/Pixtral-Large-Instruct-2411 at main: no description found
- Vespa.ai: no description found
- Generalized Knowledge Distillation Trainer: no description found
- Kquant03 - Overview: I wish to provide long-term value to the field of A.I. ...this is absolutely achievable by anyone, as the possibilities are truly endless. - Kquant03
- Huggingface GGUF Editor · ggerganov/llama.cpp · Discussion #9268: The Huggingface GGUF Editor 🎉 Check out my latest project 🌍✨ A powerful editor designed specifically for editing GGUF metadata and downloading the result directly from any Huggingface repository yo....
- library: Get up and running with large language models.
- How to specify which gpu to use? · vllm-project/vllm · Discussion #691: If I have multiple GPUs, how can I specify which GPU to use individually? Previously, I used 'device_map': 'sequential' with accelerate to control this. Now, with vllm_engine, is there...
Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
Jordan Peterson GifYouTube ContentAussies BehaviorRandom Links HumorPart-Time Job Experience
-
Jordan Peterson's 'Precisely' Moment: A GIF featuring Jordan Peterson confidently stating 'precisely' became a point of discussion, showcasing his memorable expression.
- The GIF has a humorous appeal, particularly with the context provided, where he sits in a suit before a black background.
- YouTube Video Shared: A link to a YouTube video was shared, though the specific content wasn't detailed in the conversation.
- The reaction to its content brought forth a light-hearted, surprised mention of disbelief with 'holy shit the madman'.
- Unique Aussie Character: The phrase 'Aussies are built different' emerged, hinting at a humorous notion regarding Australian culture or character traits.
- This comment elicited laughs and resonated with perceptions of Australian individuals in a playful context.
- Random Link Humor: A humorous remark about 'PERPLEXITY FREE CLICK LINK CLICK LINK' reflected a random person's eager call to action that many found amusing.
- Another user noted similar behavior witnessed in the Ollama Discord, adding a communal laugh to the conversation.
- Starting a Part-Time Job: One member announced starting a part-time job, expressing their transition from 'broke to less broke' as they take on new work.
- This sparked a playful warning about being cautious with tasks, such as not dropping the milk, providing a light-hearted camaraderie.
Link mentioned: Jordan Peterson Jbp GIF - Jordan Peterson JBP Precisely - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (113 messages🔥🔥):
Fine-tuning Llama 3Training Dataset Size ImpactGradient Accumulation FixesLoading Model AdaptersFunctionality Questions on Unsloth
-
Challenges in Fine-tuning Llama 3: Users reported issues with fine-tuning Llama 3.2 and highlighted challenges in improving training losses, with one user achieving varying results across different dataset sizes.
- Suggestions included evaluating dataset quality and adjusting training parameters such as learning rate and gradient accumulation.
- Dataset Size and Model Performance: One user noted that increasing the dataset from 20k to 50k negatively impacted performance despite consistent quality, raising concerns about necessity of larger datasets.
- Others emphasized that quality over quantity is crucial, suggesting that more examples do not guarantee better model outcomes.
- Gradient Accumulation Issues Resolved: Discussion highlighted a bug related to gradient accumulation in Unsloth that has been resolved, allowing for improved memory usage and training efficiency.
- Users encouraged further exploration of Unsloth's blog for detailed insights into the fix and best practices.
- Integrating Model Adapters: A user inquired about loading qLoRA adapters alongside the base model without having model weights downloaded, which prompted suggestions to merge adapters with the base model.
- This method could facilitate easier loading and usage of the model in constrained environments.
- Support for New Models: A question arose regarding support for Aya Expanse from Cohere, with users encountering errors related to model attributes while attempting to use the CohereForCausalLM object.
- This indicates ongoing compatibility inquiries between new models and existing frameworks.
Links mentioned:
- Google Colab: no description found
- Google Colab: no description found
- Blog: no description found
- Function Calling Datasets, Training and Inference: ➡️ Trelis Function-calling Models and Scripts: https://trelis.com/function-calling/➡️ ADVANCED-inference Repo: https://trelis.com/enterprise-server-api-and-i...
- Dataset formats and types: no description found
Unsloth AI (Daniel Han) ▷ #research (12 messages🔥):
Fast Forward optimization strategyLimits of quantizationPrefixQuant techniqueLaTent Reasoning Optimization (LaTRO)
-
Fast Forward accelerates SGD training: A new paper introduces Fast Forward, a method that accelerates SGD training by repeating the latest optimizer step until loss stops improving, achieving up to an 87% reduction in FLOPs over standard SGD with Adam.
- This approach was validated across various models and tasks, showing improved training speed without compromising performance.
- Impacts of training data on quantization limits: Tim Dettmers highlighted a pivotal paper showing strong evidence that as we train on more tokens, models need increased precision to maintain effectiveness, stating we may be reaching the limits of quantization.
- The research suggests that overtraining with more pretraining data might even be harmful if quantizing post-training.
- PrefixQuant offers efficient static quantization: The PrefixQuant technique isolates outlier tokens offline to simplify quantization without needing retraining, enabling efficient per-tensor static quantization to outperform dynamic quantization approaches.
- Using PrefixQuant in Llama-3-8B, the technique showed significant boosts in accuracy and inference speed compared to previous methods.
- Unlocking reasoning capabilities with LaTRO: LaTRO presents a framework that optimizes reasoning capabilities within large language models by sampling from a latent distribution and improving reasoning quality autonomously during training.
- Experiments demonstrated that LaTRO enhanced zero-shot accuracy by 12.5% on GSM8K, indicating latent reasoning capabilities can be accessed through self-improvement strategies.
Links mentioned:
- Fast Forwarding Low-Rank Training: Adir Rahamim, Naomi Saphra, Sara Kangaslahti, Yonatan Belinkov. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024.
- Tweet from Tim Dettmers (@Tim_Dettmers): This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you ne...
- PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs: Quantization is essential for deploying Large Language Models (LLMs) by enhancing memory efficiency and inference speed. Existing methods for activation quantization mainly address channel-wise outlie...
- GitHub - ChenMnZ/PrefixQuant: An algorithm for static activation quantization of LLMs: An algorithm for static activation quantization of LLMs - ChenMnZ/PrefixQuant
- Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding: Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can im...
- GitHub - SalesforceAIResearch/LaTRO: Contribute to SalesforceAIResearch/LaTRO development by creating an account on GitHub.
Perplexity AI ▷ #announcements (2 messages):
Canadian Student OfferPerplexity Shopping LaunchBuy with Pro Feature
-
Canadian Students Get a Free Month of Pro: Perplexity is offering Canadian students a free month of Pro with their student email, available for only two weeks.
- Students are encouraged to sign up and share the offer with friends via this link.
- Perplexity Shopping Transforms Online Shopping: Perplexity Shopping has been introduced as a one-stop solution for researching and purchasing products, enhancing user experience.
- Users can now enjoy shopping with one-click checkout and free shipping for selected products through the Perplexity Shopping platform.
- 'Buy with Pro' Revolutionizes Transactions: The 'Buy with Pro' feature allows US Perplexity Pro users to transact natively on the app, supporting a seamless shopping experience.
- This feature aids users in purchasing various items, including electronics and products to enhance their home experience.
Perplexity AI ▷ #general (599 messages🔥🔥🔥):
Perplexity Pro Subscription IssuesShopping Feature and MonetizationContext Memory Limit ChangesModel Accessibility by RegionUser Experience Concerns
-
Dissatisfaction with Perplexity Pro Subscription: Users express frustration over recent changes to the Perplexity Pro subscription, particularly the removal of the Opus model without prior notice, with many feeling misled about the service they subscribed to.
- Discontent grows as users feel that their paid subscription no longer provides the expected value, prompting some to inquire about refunds.
- Introduction of Shopping Feature Raises Concerns: The new shopping feature has been met with skepticism, as some users perceive it as prioritizing monetization over user experience, particularly with affiliate links and ads now present in the platform.
- There are complaints that these changes detract from the core functionality of the AI assistant, with users feeling that it diminishes the service they initially signed up for.
- Changes to Context Memory Sizes: Several users have reported that the context memory size for models has decreased from 32k to 16k tokens, leading to dissatisfaction regarding the effectiveness of the models for longer interactions.
- This reduction in capacity adds to the frustrations expressed by users who believe they are not receiving adequate service for their subscription fees.
- Access and Model Availability Based on Region: Users from outside the U.S. report being restricted to lesser models like GPT-3.5 or defaulting away from Claude and Grok, leading to feelings of being unfairly treated.
- There are calls for transparency regarding model accessibility and whether EU users will have the same offerings as U.S. users in the future.
- Calls for Improvement and Transparency: Amid growing dissatisfaction, users urge Perplexity to prioritize transparency and compliance with consumer laws, particularly in the EU and Australia regarding their subscription offerings.
- Many feel that the focus should shift back to user experience rather than advertising and shopping features that detract from the original service.
Links mentioned:
- Jogo da Cobrinha: no description found
- Putin Ketawa GIF - Putin Ketawa - Discover & Share GIFs: Click to view the GIF
- Holo Spice And Wolf GIF - Holo Spice and wolf Holo the wise wolf - Discover & Share GIFs: Click to view the GIF
- Tweet from Ryan Putnam (@RypeArts): friday vibes ✨
- Supported Models - Perplexity: no description found
- no title found: no description found
- Complexity - Perplexity AI Supercharged - Chrome Web Store: ⚡ Supercharge your Perplexity AI
- Google's AI chatbot tells student seeking help with homework "please die": A Google spokesperson told Newsweek on Friday morning that the company takes "these issues seriously."
- Tweet from Perplexity (@perplexity_ai): Introducing Perplexity Shopping: a one-stop solution where you can research and purchase products. It marks a big leap forward in how we serve our users – empowering seamless native actions right from...
- Apple Apple Iphone GIF - Apple Apple Iphone Apple Iphone13 - Discover & Share GIFs: Click to view the GIF
- Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity | Lex Fridman Podcast #452: Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris...
- Perplexity AI App: The Perplexity AI Desktop App is an unofficial application developed by inulute that brings the power of AI language processing to your desktop, powered by Electron. This application is designed...
- Sad Hamster Sadhamster GIF - Sad hamster Sadhamster Hammy - Discover & Share GIFs: Click to view the GIF
- Streamlit: no description found
-
Directive 1993/13 - Unfair terms in consumer contracts - EU monitor
: no description found
Perplexity AI ▷ #sharing (20 messages🔥):
AI-Generated Video GamesAutonomous ML EngineerAI Readiness in IndiaCoroutines ImplementationChemistry of Tea
-
World's First AI-Generated Video Game: Perplexity AI shared a video about the World's First AI-Generated Video Game along with discussions on related topics such as Ghost Jobs Flooding the Market and the Silurian Hypothesis.
- You can watch the video here for more insights on this groundbreaking achievement.
- Unveiling Autonomous ML Engineer: A topic on the World's first Autonomous ML Engineer surfaced, highlighting advancements in autonomous systems for machine learning applications.
- Details were shared on how this development might transform workflows in AI-driven enterprises, available here.
- Declining AI Readiness in India: Discussion emerged around the declining AI readiness in India and the implications this has on technological growth.
- The conversation can be explored in detail through the article here.
- How Coroutines are Implemented: Members discussed technical aspects regarding how coroutines are implemented, emphasizing their efficiency in programming.
- You can delve into this discussion here.
- Understanding Chemistry of Tea: A query concerning the chemistry of tea led to explorations of chemical compounds involved in tea production and their effects.
- For a comprehensive overview, refer to the details shared here.
Perplexity AI ▷ #pplx-api (18 messages🔥):
API Billing QuestionsSummarization Issues with LeoReddit API FunctionalityMake.com Module Feedback
-
Pro Subscriber API Billing Clarifications: A member asked if exceeding the $5 API credits would charge their credit card; another responded that turning off auto top-up would prevent this.
- There was further confusion about receiving the $5 bonus credit after deleting and re-adding the API key, leading to recommendations to contact support.
- Leonardo Summarization Errors: A member expressed frustration over Leonardo's inability to summarize pages, even after testing with different context sizes.
- They confirmed that the issue persisted across an account and various versions, raising concerns about functionality.
- Uncertainty Over Reddit API Links: There was a query about whether the Reddit API was still operational since it wasn't returning links anymore.
- This suggests a potential disruption in accessing Reddit content through the API.
- Request for Improved Make.com Module Features: A member suggested enhancements for the Make.com module, specifically a longer timeout period.
- They noted that the Sonar Huge often times out and expressed a desire for customizable timeout options and third-party model integrations.
HuggingFace ▷ #general (441 messages🔥🔥🔥):
Mistral Large ModelsLLaVA-o1 vs. PixtralGradio and MusicGenHugging Face API QuotasDataset Contributions
-
Mistral and Pixtral Model Releases: Mistral announced the release of the Pixtral Large model, showcasing frontier-class multimodal performance and compatibility with high-resolution images.
- The model is open-weights and available for research, with notable advancements over previous Mistral models.
- Comparison Between LLaVA-o1 and Pixtral: The community discussed the comparative performances of LLaVA-o1 and Pixtral, with insights suggesting that Pixtral Large outperforms LLaVA for reasoning tasks.
- While LLaVA-o1 has its strengths, Pixtral is noted for superior image understanding capabilities.
- Challenges with Gradio and API Quotas: Users reported difficulties generating music with Gradio's API due to quota exhaustion, even after successfully generating music on the Gradio webpage.
- Concerns were raised about limitations faced while using ZeroGPU with the pro version.
- Hub-Stats Dataset and Leaderboard: A new leaderboard on the Hub-Stats dataset ranks users based on their engagement, with notable ranks shared within the community.
- Community members enthusiastically check their rankings, indicating a lively interest in participation on the Hugging Face platform.
- Synthetic Data Creation and Fine-Tuning: A user asked for suggestions on creating synthetic data for fine-tuning a small LLM, highlighting the need for practical resources.
- The conversation indicates a broader interest in the tools and methodologies for improving LLM performance through custom datasets.
Links mentioned:
- GGUF Model VRAM Calculator - a Hugging Face Space by DavidAU: no description found
- The /llms.txt file – llms-txt: A proposal to standardise on using an /llms.txt file to provide information to help LLMs use a website at inference time.
- Military Assets Dataset (12 Classes -Yolo8 Format): Military Object Detection Dataset by RAW (Ryan Madhuwala)
- Pixtral Large: Pixtral grows up.
- HuggingChat: Making the community's best AI chat models available to everyone.
- Use Ollama with any GGUF Model on Hugging Face Hub: no description found
- AdaLoRA: no description found
- Yeah I Guess Youre Kinda Right Kyle Broflovski GIF - Yeah I Guess Youre Kinda Right Kyle Broflovski Tolkien - Discover & Share GIFs: Click to view the GIF
- Text Behind Image - a Hugging Face Space by ysharma: no description found
- FLUX.1 Dev Inpainting Model Beta GPU - a Hugging Face Space by ameerazam08: no description found
- Venom Spiderman GIF - Venom Spiderman - Discover & Share GIFs: Click to view the GIF
- That Sounds Nasty Nasty GIF - That Sounds Nasty Nasty Gross - Discover & Share GIFs: Click to view the GIF
- Cat Drugs GIF - Cat Drugs Tripping - Discover & Share GIFs: Click to view the GIF
- Cat Fire GIF - Cat Fire Flamethrower - Discover & Share GIFs: Click to view the GIF
- Smeagol My GIF - Smeagol My Precious - Discover & Share GIFs: Click to view the GIF
- Record for the Highest Scoring Scrabble Move - Scrabulizer: no description found
- Tweet from AK (@_akhaliq): LLaVA-o1 Let Vision Language Models Reason Step-by-Step
- PCA: Gallery examples: Release Highlights for scikit-learn 1.5 Release Highlights for scikit-learn 1.4 A demo of K-Means clustering on the handwritten digits data Principal Component Regression vs Parti...
- Reddit - Dive into anything: no description found
- Model memory estimator: no description found
- mistralai/Mistral-Large-Instruct-2411 at main: no description found
- unsloth/Qwen2.5-7B-Instruct-bnb-4bit · Hugging Face: no description found
- unsloth/Qwen2.5-7B-Instruct · Hugging Face: no description found
- GoToCompany/gemma2-9b-cpt-sahabatai-v1-instruct · Hugging Face: no description found
- Gemma2: no description found
- unsloth (Unsloth AI): no description found
- Tutorial: How to convert HuggingFace model to GGUF format [UPDATED] · ggerganov/llama.cpp · Discussion #7927: I wanted to make this Tutorial because of the latest changes made these last few days in this PR that changes the way you have to tackle the convertion. Download the Hugging Face model Source: http...
- huggingchat/chat-ui · Discussions: no description found
- GitHub - PKU-YuanGroup/LLaVA-o1: Contribute to PKU-YuanGroup/LLaVA-o1 development by creating an account on GitHub.
- GitHub - unslothai/unsloth: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - starsnatched/RoboLlama: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model - starsnatched/RoboLlama
- GitHub - starsnatched/RoboLlama: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model - starsnatched/RoboLlama
- Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding: Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can im...
- GitHub - SalesforceAIResearch/LaTRO: Contribute to SalesforceAIResearch/LaTRO development by creating an account on GitHub.
HuggingFace ▷ #today-im-learning (6 messages):
Neuralink UpdatesTransformer Code IssuesTunguska-39B Updates
-
Neuralink announces return: A member named neuralink announced their return to the chat after a brief absence.
- They shared a casual update stating they had recently learned something new.
- Help Needed with Transformer Code: A user requested assistance with transformer code due to encountering several errors.
- They encouraged others to direct message them for help.
- Tunguska-39B README Update: A user known as drummer_ updated the README.md for the Tunguska-39B model with new experimental insights.
- They shared findings that indicate upscaling can provide room for further training, although they noted challenges with duplicating layers in their dataset.
Link mentioned: README.md · BeaverAI/Tunguska-39B-v1b-GGUF at main: no description found
HuggingFace ▷ #cool-finds (15 messages🔥):
Molecular Machine Learning at NeurIPS 2024Magic QuillNeural Network CommunicationVLMs and their capabilitiesHtmlRAG in Retrieval-Augmented Generation
-
Explore Molecular Machine Learning Works at NeurIPS 2024: This year's NeurIPS highlights innovations in molecular modeling and biological sciences, specifically focusing on protein language modeling and molecular property prediction. A comprehensive resource is available on GitHub capturing all related papers from the conference here.
- The advancements tackle challenges in drug discovery and protein engineering, promising improved techniques for predictive modeling.
- Magic Quill impresses with its flexibility: The Magic Quill represents an innovative tool within the AI space, facilitating various editing tasks with ease, as highlighted in its official Hugging Face Space. Its refreshing capabilities have drawn positive responses from users.
- Members are encouraged to explore its functionalities, which blend seamlessly into diverse applications.
- Rethinking Neural Network Communication: A recent paper published in Nature discusses how self-motivated animal behavior can inform neural network architectures and their communication mechanisms link. The research suggests that modular components facilitate predictable behavior linked with task completion.
- Heightened attention is given to how these findings can significantly reshape our understanding of neural networks.
- Future of Vision Language Models: An article discusses Vision Language Models (VLMs) which integrate images and texts for tackling various generative tasks. They possess robust zero-shot capabilities and adapt well to different types of image inputs, making them a hot topic for 2024 link.
- The blog emphasizes the evolution and potential applications of VLMs in diverse fields.
- HtmlRAG Enhances Retrieval-Augmented Generation Systems: The introduction of HtmlRAG proposes using HTML formats in RAG processes to maintain structural and semantic information lost in traditional plain-text methods link. This new approach addresses significant limitations in current LLMs regarding knowledge retrieval.
- The enhancements may yield better modeling and information retrieval capabilities, fostering improved performance in future applications.
Links mentioned:
- HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems: Retrieval-Augmented Generation (RAG) has been shown to improve knowledge capabilities and alleviate the hallucination problem of LLMs. The Web is a major source of external knowledge used in RAG syste...
- MagicQuill - a Hugging Face Space by AI4Editing: no description found
- Portable acceleration of CMS computing workflows with coprocessors as a service: Computing demands for large scientific experiments, such as the CMS experiment at the CERN LHC, will increase dramatically in the next decades. To complement the future performance increases of softwa...
- CTB-1: Vision Language Models in 2024 [CTB]: 1 Introduction Vision language models (VLMs) are generative models that can learn simultaneously from images and texts to tackle many tasks.
- OpenCV: Detection of ChArUco Boards: no description found
- Home: AnyModal is a Flexible Multimodal Language Model Framework - ritabratamaiti/AnyModal
- Spontaneous behaviour is structured by reinforcement without explicit reward - Nature: Photometric recordings and optogenetic manipulation show that dopamine fluctuations in the dorsolateral striatum in mice modulate the use, sequencing and vigour of behavioural modules during spontaneo...
- A cellular basis for mapping behavioural structure - Nature: Mice generalize complex task structures by using neurons in the medial frontal cortex that encode progress to task goals and embed behavioural sequences.
- GitHub - azminewasi/Awesome-MoML-NeurIPS24: ALL Molecular ML papers from NeurIPS'24.: ALL Molecular ML papers from NeurIPS'24. Contribute to azminewasi/Awesome-MoML-NeurIPS24 development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (40 messages🔥):
AnyModal FrameworkRoboLlama Robotics ModelKaggle Generative AI CourseYouTube Transcript ToolDataset for Visual Language Models
-
Introduction of AnyModal Framework: A developer shared insights about AnyModal, a flexible framework designed for integrating various data types with LLMs, including functionalities like LaTeX OCR and image captioning.
- Feedback and contributions on this ongoing project are welcomed as it aims to improve its multimodal capabilities.
- RoboLlama Project for Robotics Integration: Starsnatched is working on transforming Meta's Llama 3.2 1B into a robotics-ready model, incorporating vision encoders and diffusion layers for enhanced functionality.
- The model focuses on training only the diffusion and projection layers while keeping the core ViT and LLM frozen.
- Progress in Kaggle Generative AI Course: A user shared their completion of the Kaggle X Google Generative AI Course over five days, inviting others to check their progress on LinkedIn.
- This reflects a commitment to learning and engaging with generative AI tools in the community.
- Development of YouTube Transcript Tool: A member mentioned creating a Python tool to download YouTube transcripts in bulk, although it's not ready for public sharing yet.
- This tool was developed with assistance from ChatGPT to streamline the process of gathering video transcripts.
- New Dataset for Visual Language Models: A user launched a new benchmark dataset for Visual Language Models (VLMs) including direct YouTube videos and comments for evaluation purposes.
- The dataset aims to highlight the limitations of VLMs in processing unseen data accurately, which often leads to hallucinations.
Links mentioned:
- Stable-Diffusion-Inpainting With SAM - a Hugging Face Space by Sanshruth: no description found
- Terminator GIF - Terminator - Discover & Share GIFs: Click to view the GIF
- Kokoro TTS - a Hugging Face Space by hexgrad: no description found
- What Did GIF - What Did You - Discover & Share GIFs: Click to view the GIF
- Neil Raymond Schroeder / CMS - ECAL - Scales and Smearings · GitLab: A new python framework for deriving the residual scales and additional smearings for the electron energy scale
- GitHub - ritabratamaiti/AnyModal: AnyModal is a Flexible Multimodal Language Model Framework: AnyModal is a Flexible Multimodal Language Model Framework - ritabratamaiti/AnyModal
- GitHub - unixwzrd/chatgpt-chatlog-export: ChatGPT - Chat Log Export, a lightweight method of exporting entire ChatGPT conversations in JSON format.: ChatGPT - Chat Log Export, a lightweight method of exporting entire ChatGPT conversations in JSON format. - unixwzrd/chatgpt-chatlog-export
- Release v1.8.0 · yjg30737/pyqt-openai: What's Changed You can import CSV file in "sentence form" of prompt. This is for awesome_chatgpt_prompt support. Additional support for llamaindex extensions '.docx', '....
- GitHub - starsnatched/RoboLlama: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model: My experiment on turning Meta's Llama 3.2 1B into a robotics-ready model - starsnatched/RoboLlama
HuggingFace ▷ #reading-group (28 messages🔥):
Hardware CompatibilityLLaMA Model UsageSystem SpecificationsVRAM ManagementLanguage Model Testing
-
Hardware Compatibility Guarantees: Members noted that if components fit physically, they are unlikely to harm each other, making modern hardware setups relatively safe.
- One member remarked, 'It's essentially impossible to break modern hardware by putting a bad combination of parts.'
- LLaMA Model Running Issues: A member inquired if the CMD window closure results in the deletion of the LLaMA 3.1 70B model when not running locally.
- Another user confirmed that 'once you close the page, the model remains on your computer.'
- System Specs for LLaMA Performance: Users discussed system specifications for running LLaMA models, with one member running LLaMA 3.1 on a setup featuring 3 RX 6800 GPUs and noting heavy VRAM usage.
- They mentioned experiencing significant RAM usage, both DDR4 and virtual, indicating 70B models are enormous.
- Exploration of LLaMA Models: A member shared their experiences testing various models, such as the performance of LLaMA 3.1 70B q4, which worked well for them.
- They also found an 8B 16Q model that they plan to try out next.
- French Language Skills in Tech Discussions: One member humorously mentioned using their Duolingo French skills to participate in discussions, showcasing cultural aspects in tech communities.
- The conversation highlighted the use of French language by members and mutual sharing of tech experiences.
HuggingFace ▷ #computer-vision (1 messages):
4rsn: What image painting model do you guys recommend?
HuggingFace ▷ #NLP (3 messages):
Reclassifying older textFine-tuning BERT modelsUsing Sentence TransformersSBERT model updatesUsing Hugging Face API
-
Reclassifying Older Text Project: A member is embarking on a project to reclassify older text using new classification methods and is considering fine-tuning a BERT model and possibly using an Instruct model.
- They are seeking suggestions for approaches to effectively tackle this challenge.
- Explore Sentence Transformers for Fast Inference: A response suggested exploring SBERT for the project, noting the recent release of v3.2 that introduces ONNX and OpenVINO backends for improved inference speed.
- Members are encouraged to read about Speeding up Inference to understand the benefits of these new backends.
- Latest SBERT Model Introduction: The latest SBERT model, all-MiniLM-L6-v2, was recommended as a solid foundation for the user's project.
- This model effectively maps sentences and paragraphs into a 384-dimensional dense vector space and can be utilized for clustering and semantic search.
- Easy Setup with Sentence Transformers: A brief tutorial affirmed that using the Sentence Transformers model is straightforward: install the library, load the model, and encode sentences easily.
- A representative usage code snippet was provided to help users get started quickly.
Links mentioned:
- SentenceTransformers Documentation — Sentence Transformers documentation: no description found
- Train and Fine-Tune Sentence Transformers Models: no description found
- sentence-transformers/all-MiniLM-L6-v2 · Hugging Face: no description found
HuggingFace ▷ #diffusion-discussions (4 messages):
CogVideoX-1.5-5B issuesDiffusers latest version
-
CogVideoX-1.5-5B model running issues: A user reported experiencing issues with running the cogvideox-1.5-5b model through diffusers.
- This prompted discussion among others who confirmed similar problems.
- Diffusers dev version resolves issues: Another user noted that the recent development version of Diffusers seems to resolve the previous issues encountered with the model.
- They suggested checking the model repo community for updates and support.
aider (Paul Gauthier) ▷ #general (422 messages🔥🔥🔥):
Qwen 2.5 updatesAider usage tipsStreaming models in OpenAIComparison of LLMsCommunity discussions on AI tools
-
Introduction of Qwen 2.5 Turbo: Qwen 2.5 Turbo introduces longer context support of 1 million tokens, faster inference speeds, and lower costs at ¥0.3 per million tokens.
- This model enhances efficiency, making it a promising alternative to existing tools, especially for those needing extensive context.
- Optimizing Aider Usage: Users are experimenting with Aider's modes, switching between 'ask' and 'whole' mode for better context handling while coding.
- Paul suggested utilizing the command
/chat-mode wholeto streamline interactions, indicating ongoing improvements in Aider's functionalities. - Streaming Models Available: OpenAI has enabled streaming for the o1-preview and o1-mini models, improving responsiveness during interactions.
- Developers can access these models across all paid tiers, with Aider incorporating these updates by using the command
aider --install-main-branch. - Comparative Insights on LLMs: Community discussions reflect varying opinions on the effectiveness of Qwen versus other models like Sonnet and Anthropic offerings.
- Some members believe Qwen might surpass others for practical applications, especially in hosting LLMs with optimal hardware.
- Future of Aider Installations: Paul mentioned potential changes to Aider's package name on PyPI, aiming to simplify installation to
pip install aiderinstead ofaider-chat.
- The community is hopeful for more straightforward upgrades and installations, enhancing user experience with the tool.
Links mentioned:
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Two undersea cables in Baltic Sea disrupted, sparking warnings of possible ‘hybrid warfare’ | CNN: no description found
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Gemini Experimental 1114 - API, Providers, Stats: Gemini 11-14 (2024) experimental model features "quality" improvements.. Run Gemini Experimental 1114 with API
- FrontierMath: FrontierMath benchmark of hundreds of unpublished and extremely challenging expert-level math problems to help us to understand the limits of artificial intelligence.
- Tweet from Qwen (@Alibaba_Qwen): After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. https://qwenlm.github.io/blog/qwen2.5-turbo/ Today, we are proud to introduce the new Qwen2.5-Turbo ver...
- Extending the Context Length to 1M Tokens!: API Documentation (Chinese) HuggingFace Demo ModelScope Demo Introduction After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. In recent months, we have ...
- pypi/support: Issue tracker for support requests related to using https://pypi.org - pypi/support
- GitHub - QwenLM/Qwen2.5-Math: A series of math-specific large language models of our Qwen2 series.: A series of math-specific large language models of our Qwen2 series. - QwenLM/Qwen2.5-Math
- GitHub - CEDARScript/cedarscript-grammar: A SQL-like language for efficient code analysis and transformations**): A SQL-like language for efficient code analysis and transformations - CEDARScript/cedarscript-grammar
- PHP: Manual Quick Reference: PHP is a popular general-purpose scripting language that powers everything from your blog to the most popular websites in the world.
- 404 Not Found - HTTP | MDN: The HTTP 404 Not Found client error response status code indicates that the server cannot find the requested resource. Links that lead to a 404 page are often called broken or dead links and can be ...
- litellm bug is causing "unknown model" warnings in aider for Ollama models · Issue #2318 · Aider-AI/aider: Warning for ollama/vanilj/supernova-medius:q6_k_l: Unknown context window size and costs, using sane defaults. Did you mean one of these? - ollama/vanilj/supernova-medius:q6_k_l You can skip this c...
aider (Paul Gauthier) ▷ #questions-and-tips (96 messages🔥🔥):
Configuring Aider with OpenRouterHandling Token Limits in AiderUsing Aider with Local ModelsExtra Parameters for LitellmBenchmark Run Skipped Tests
-
Configuring Aider with OpenRouter: To configure Aider to use an OpenRouter model, settings must be made on the OpenRouter side, as it currently does not support per-model settings on the client side.
- Members discussed using extra parameters and config files to specify different behavior but expressed limitations with the current setup.
- Handling Token Limits in Aider: Several users discussed issues with hitting token limits, particularly when using OpenAI compatible APIs with local models like Qwen.
- Some suggested creating a
.aider.model.metadata.jsonfile to manually set token limits, although users reported varying success with that approach. - Using Aider with Local Models: Users have successfully run Aider with local models via OpenAI compatible APIs, experiencing some notifications about token limits that haven't affected output.
- Discussion pointed to certain configurations required to set up local environments properly, noting the necessity to check metadata files.
- Extra Parameters for Litellm: It was confirmed that additional parameters can be added via
extra_paramsin Litellm, allowing users to inject headers for API calls.
- There was no environment variable interpolation for these headers, requiring users to set them manually.
- Benchmark Run Skipped Tests: A user inquired about checking older benchmark runs for any tests that may have been skipped due to connection timeouts.
- Responses indicated that there does not seem to be a method available for inspecting these runs for specific skips.
Links mentioned:
- Ollama: aider is AI pair programming in your terminal
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- FAQ: Frequently asked questions about aider.
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Advanced model settings: Configuring advanced settings for LLMs.
- Advanced model settings: Configuring advanced settings for LLMs.
- GitHub - instructlab/instructlab: InstructLab Command-Line Interface. Use this to chat with a model and execute the InstructLab workflow to train a model using custom taxonomy data.: InstructLab Command-Line Interface. Use this to chat with a model and execute the InstructLab workflow to train a model using custom taxonomy data. - instructlab/instructlab
aider (Paul Gauthier) ▷ #links (1 messages):
epicureus: great video here https://www.youtube.com/watch?v=t-i2x3APvGQ
OpenAI ▷ #ai-discussions (287 messages🔥🔥):
Google's Project Astrao1-mini vs o1-preview and GPT-4oAI roleplaying capabilitiesMemory features in AIGPT model updates
-
Discussing Google's Project Astra: Curiosity arose about Google's Project Astra, with members expressing interest in its memory capabilities beyond the demo video.
- Participants noted the excitement surrounding multiple companies developing new AI features.
- Contrasting o1-mini and o1-preview: Users shared experiences with o1-mini, highlighting discrepancies in performance, with some praising its effort while others found it less effective than GPT-4o.
- Several members reported that o1-mini often got stuck in thought loops, while o1-preview provided more straightforward responses.
- Insights on AI Roleplaying: Discussions touched on roleplaying features in AI, with one member creating scripts to enhance AI behavior, emphasizing the benefits of structured events.
- Participants acknowledged the challenge AI has in maintaining character consistency over extended dialogues.
- Exploring AI Memory Features: The group discussed the implications of memory features in AI, recognizing the potential improvements they could provide in user interactions.
- The conversation hinted at the expectations users have from memory-integrated systems.
- Anticipating Future GPT Updates: Members speculated on future updates for GPT models, particularly referencing the ideal size and performance of GPT-4-turbo-2024-04-09.
- The discussion highlighted the challenges of overfitting in AI responses.
Links mentioned:
- Tweet from Doomlaser Corporation (@DOOMLASERCORP): After #UIUC's Inaugural AI Club meeting. 4 of us. We will meet here again in 2 weeks time, planning for the big drop next semester 👄👄🫦👁️👀🧠🫀🫁🦴, #AI #Future
- discord.js Guide: Imagine a guide... that explores the many possibilities for your discord.js bot.
OpenAI ▷ #gpt-4-discussions (6 messages):
Clearing the cacheGame bots shutdown
-
Clearing the Cache for Game Bots: A member suggested to clear the cache to resolve issues with game bots shutting down unexpectedly.
- Another member humorously noted that, in response, 'the 8 ball has spoken!'
- Game Bots Ignoring Commands: A member expressed frustration that their game bots sometimes shut down and ignore input, calling it 'infuriating.'
- This suggests ongoing challenges with maintaining consistent bot performance in gaming contexts.
OpenAI ▷ #prompt-engineering (86 messages🔥🔥):
Prompt Engineering ChallengesLLMs InteractionSelf-Observation in AIChain of Thought PromptingCriticism of AI Responses
-
Challenges in Prompt Engineering: Members discussed the complexity of crafting effective prompts, emphasizing the prevalence of 'negative prompting' that could confuse the model rather than guide it effectively.
- One member shared their extensive prompt aimed at engaging the model in self-observation, but noted concerns about its length and clarity.
- Communication Between LLMs: The feasibility of two LLMs learning from each other through conversation was debated, exploring if reinforcement learning might yield emergent abilities.
- Concerns were raised about the nature of LLM interactions, often resulting in nonspecific responses unless guided by a human.
- Exploring Self-Observation and Introspection: A member posited that invoking introspective prompts might lead to richer responses, despite acknowledging that LLMs do not possess self-awareness in human terms.
- They were curious if focusing on the model's processing could yield significant changes in conversational capabilities.
- Effectiveness of Chain of Thought Prompting: Chain of thought prompting was highlighted as a method to improve response quality, akin to human deliberative thinking processes.
- Members reflected on the potential for discovering new prompting techniques that could significantly influence model responses.
- Criticism of AI Responses: There was a discussion about the tendency for users to be overly critical of AI outputs, leading to dissatisfaction with the model's performance.
- Participants noted that many criticisms stem from treating AI with a different standard compared to human interactions.
OpenAI ▷ #api-discussions (86 messages🔥🔥):
Self-Observation PromptsConversations Between LLMsChain of Thought PromptingUser Perceptions of AIIntrospection in AI
-
Exploring Self-Observation in LLMs: A member discussed a prompt designed to encourage ChatGPT to engage in direct self-observation without appealing to existing frameworks or concepts.
- Some noted that while the prompt aims for introspection, it heavily utilizes negative prompting, potentially complicating the model's responses.
- LLMs Interacting and Evolving Responses: A hypothesis was proposed about what might happen if two LLMs conversed, with the suggestion that one could critique the other to enhance dialogue.
- Previous experiments indicated that this often leads to non-specific praise rather than meaningful exchanges.
- Chain of Thought Prompting Explained: Chain of thought prompting was highlighted as akin to System 2 thinking, allowing models to tackle more complex problems by simulating a reasoning process.
- A reminder emerged about the importance of length in prompts which could affect computational expense and how different methods of deliberate thought might influence training.
- Critique and Understanding of AI Responses: Discussions centered around user criticisms of AI, with some feeling that users apply too much scrutiny to the model's outputs.
- Members noted that such perceptions might stem from viewing AI as fundamentally different, leading to higher expectations and critical evaluation.
- Narrative Reasoning and AI: The conversation touched on how storytelling and narrative reasoning influence human cognition and AI responses.
- Members expressed the idea that everyday thinking is often not deliberate, akin to how users engage with AI outputs.
Eleuther ▷ #general (41 messages🔥):
AI Code Generation ProjectsElectric Engineering Dataset for LLMsTruncation Sampling in LLMsCrash Test of Gemini's CredibilityGrokking Phenomenon in AI Models
-
Exploring AI Code Generation Projects: A new member inquired about any ongoing Code Generation projects within EleutherAI, mentioning searches for terms like 'AlphaCode' but found no recent discussions.
- This reflects a potential gap in sharing current initiatives related to AI code generation in the community.
- Creating an Electrical Engineering Dataset: A user proposed testing LLM models with electrical engineering questions, questioning if creating such a dataset would be beneficial for open-source LLMs or benchmarking.
- Questions posed revolved around assessing model performance in a domain seen as challenging for current LLM capabilities.
- Understanding Truncation Sampling: Discussion centered on truncation sampling heuristics, highlighting how methods like nucleus sampling effectively ensure nonzero true probabilities for sampled tokens.
- The conversation pointed out that using techniques such as top-k could optimize sampling despite hidden size limitations.
- Debating the Authenticity of Gemini's Marketing: A debate ensued regarding the credibility of Gemini's chat marketing, with some questioning whether it could be a hoax based on a lack of reproducible evidence.
- Participants expressed skepticism about the existence of a method to manipulate outputs, suggesting the need for deeper scrutiny of chat logs.
- Grokking Phenomenon in AI Models: Members discussed the grokking phenomenon, highlighting instances where models can abruptly transition from memorization to generalization after prolonged training.
- This sparked interest in the future capabilities of large language models and their potential understanding of complex information.
Links mentioned:
- What Is Alternative Data and Why Is It Changing Finance? | Built In: Alternative data is data culled from non-traditional sources and used by investment firms to find a market edge.
- The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery: One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been use...
- Do Machine Learning Models Memorize or Generalize?: no description found
- Closing the Curious Case of Neural Text Degeneration: Despite their ubiquity in language generation, it remains unknown why truncation sampling heuristics like nucleus sampling are so effective. We provide a theoretical explanation for the effectiveness ...
- EleutherAI Alignment 101: EleutherAI Alignment 101 Curriculum v2 (WIP) Overview Meeting Times: {Fill-in} The first iteration of the reading group has concluded (see here for the version of the curriculum that was used). Futur...
- Levelling Up in AI Safety Research Engineering — LessWrong: Summary: A level-based guide for independently up-skilling in AI Safety Research Engineering that aims to give concrete objectives, goals, and resour…
- ML Safety Research Advice - GabeM — LessWrong: This is my advice for careers in empirical ML research that might help AI safety (ML Safety). Other ways to improve AI safety, such as through AI gov…
Eleuther ▷ #research (289 messages🔥🔥):
nGPT Optimizer PresentationNormalization Techniques in Neural NetworksVariational Autoencoders (VAEs) and Latent SpaceDiffusion Models for UpscalingEmerging Concepts in Language Modeling
-
Boris/Ilya present nGPT to Together.AI Group: Boris and Ilya discussed the nGPT optimizer at the Together.AI reading group, showcasing its performance based on their backgrounds and Nvidia's internal results with a GitHub implementation. Members expressed optimism for further exploration of nGPT's effectiveness and its potential applications.
- Feedback highlighted concerns regarding initial implementations of nGPT and technical intricacies surrounding its reproducibility, computational efficiency, and effectiveness compared to existing models.
- Normalization Techniques in Neural Networks: Yaroslav noted that the authors of nGPT mentioned their paper lacked sufficient detail, leading to incorrect implementations, and discussed potential merits of using normalization techniques such as RMSNorm. Community discussion revealed varied opinions on the efficacy of different normalization methods and their implications on model performance.
- It was suggested that the significance of normalization techniques might shift the understanding of convergence and performance in different neural architectures.
- Challenges with VAEs and Latent Space Representations: There was discussion regarding the challenges faced when dealing with variational autoencoders (VAEs) that fail to map meaningful representations into latent spaces due to the influence of KL divergences. Researchers expressed interest in more robust alternatives for ensuring better latent space distributions that facilitate high-frequency information retention.
- Options such as hypersphere constraints and entropy maximization losses were proposed to improve the continuity and semantic quality of representations learned by VAEs.
- Diffusion Models and Upscaling: The dialogue included exploration of using diffusion models for image upscaling; members discussed practical implementations that could condition on global embeddings and enforce consistency at patch boundaries. Discrete diffusion forcing for language was also suggested as a casual yet efficient approach for sampling sequences.
- While existing works on diffusion models tend to focus on images, there are emerging ideas around exploring their applicability to language models, highlighting the need for deeper understanding and integration.
- Emerging Concepts in Language Modeling: There was curiosity surrounding the potential for diffusion language models, specifically how they could leverage learned token relationships through a diffusion process. Members noted that concepts such as 'masking' and 'token unmasking' could lead to more effective and efficient sampling strategies in text generation.
- The conversation suggested that more research could formalize and refine the method of 'diffusion forcing' to integrate seamlessly with existing language modeling frameworks.
Links mentioned:
- Convolutional Differentiable Logic Gate Networks: With the increasing inference cost of machine learning models, there is a growing interest in models with fast and efficient inference. Recently, an approach for learning logic gate networks directly ...
- An optimal control perspective on diffusion-based generative modeling: We establish a connection between stochastic optimal control and generative models based on stochastic differential equations (SDEs), such as recently developed diffusion probabilistic models. In part...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Normalizing Flows Across Dimensions: Real-world data with underlying structure, such as pictures of faces, are hypothesized to lie on a low-dimensional manifold. This manifold hypothesis has motivated state-of-the-art generative algorith...
- Diffusion Models are Evolutionary Algorithms: In a convergence of machine learning and biology, we reveal that diffusion models are evolutionary algorithms. By considering evolution as a denoising process and reversed evolution as diffusion, we m...
- In-Context Learning of Representations: Recent work demonstrates that structured patterns in pretraining data influence how representations of different concepts are organized in a large language model’s (LLM) internals, with such...
- How to train your neural ODE: the world of Jacobian and kinetic regularization: Training neural ODEs on large datasets has not been tractable due to the necessity of allowing the adaptive numerical ODE solver to refine its step size to very small values. In practice this leads to...
- Principal Manifold Flows: Normalizing flows map an independent set of latent variables to their samples using a bijective transformation. Despite the exact correspondence between samples and latent variables, their high level ...
- Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere: Contrastive representation learning has been outstandingly successful in practice. In this work, we identify two key properties related to the contrastive loss: (1) alignment (closeness) of features f...
- Searching Latent Program Spaces: Program synthesis methods aim to automatically generate programs restricted to a language that can explain a given specification of input-output pairs. While purely symbolic approaches suffer from a c...
- GPT baseline block computation error · Issue #1 · NVIDIA/ngpt: Hello, thank you very much for open sourcing nGPT. I have found an error in the block computation of the GPT (use_nGPT=0) baseline. The computation being done is : x = norm(x) + attn(norm(x)) x = n...
- GitHub - NVIDIA/ngpt: Normalized Transformer (nGPT): Normalized Transformer (nGPT). Contribute to NVIDIA/ngpt development by creating an account on GitHub.
- vit-pytorch/vit_pytorch/normalized_vit.py at main · lucidrains/vit-pytorch: Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch
- 15nov24 - nGPT (Ginsburg, Loschilov) - Google Drive: no description found
Eleuther ▷ #scaling-laws (5 messages):
Scaling PretrainingEconomic Feasibility of ScalingLLM Pretraining Scalability
-
Scaling Pretraining isn't Dead: Scaling is not dead - and likely can never be killed as it's a fundamental property of these models, stated a member.
- However, the economic aspect has shifted, leading to concerns over whether it remains feasible to continue scaling.
- Economic Viability Questions Scaling: While some argue that scaling is essential, the discussion highlighted that it has become economically unfeasible to scale more.
- This raises questions about the future of pretraining and scaling in resource allocation.
- Career Moves in LLM Pretraining: A member inquired if transitioning to a role focused on LLM pretraining scalability would still be a good move.
- This reflects a broader exploration of opportunities as the viability of scaling comes into question.
- Debate on the Future of Scaling: Scaling is dead was a contrasting viewpoint brought up during the discussion, suggesting a divide in opinions.
- The discussions underlined the tension between those who see scaling as integral versus those who predict its decline.
Eleuther ▷ #interpretability-general (8 messages🔥):
Function Vectors in ICLOvercomplete SAEs and Subspace GeneralizationFine-tuning Dynamics in PLMsEmergent Representations in LLMs
-
Function Vectors Paper Launches ICL Insights: A paper on function vectors explores how ICL execution is influenced by a small set of attention heads managing various tasks, particularly focusing on antonyms.
- The authors found this approach leads to more interpretable task vectors and indicated that an Arxiv post will be available soon.
- Overcomplete SAEs Can Generalize Well: A discussion on whether overcomplete SAEs can generalize since many residual paths depend heavily on specific data points.
- One member noted that typically, fine-tuned models only exhibit superficial changes across a limited number of subspaces.
- Link to Fine-tuning Subspaces Reference: A referenced paper, available here, discusses the redunancy in pre-trained language models (PLMs) indicating only a small degree of freedom for such models.
- The key finding reveals that PLMs can be effectively fine-tuned within a task-specific subspace using a minimal number of parameters.
- Emergence of Task-Specific Representations in LLMs: An open review paper states that large language models (LLMs) can develop emergent task-specific representations when provided with sufficient in-context exemplars.
- It emphasizes that structured patterns in pretraining data significantly influence the organization of concepts, allowing models to adapt their representations flexibly.
Links mentioned:
- Fine-tuning Happens in Tiny Subspaces: Exploring Intrinsic Task-specific Subspaces of Pre-trained Language Models: Pre-trained language models (PLMs) are known to be overly parameterized and have significant redundancy, indicating a small degree of freedom of the PLMs. Motivated by the observation, in this paper, ...
- In-Context Learning of Representations: Recent work demonstrates that structured patterns in pretraining data influence how representations of different concepts are organized in a large language model’s (LLM) internals, with such...
- no title found): no description found
- Extracting SAE task features for in-context learning — LessWrong): TL;DR * We try to study task vectors in the SAE basis. This is challenging because there is no canonical way to convert an arbitrary vector in the r…
Eleuther ▷ #lm-thunderdome (24 messages🔥):
Using Fine-Tuned OpenAI ModelsFew-Shot vs Zero-Shot Evaluation ResultsKeyError in Custom Model InvocationModel Branch Specification in Local Completions
-
Issues with Fine-Tuned OpenAI Model Evaluation: A user encountered difficulties using an OpenAI fine-tuned model in evaluations, specifically not hitting the custom model during testing.
- A suggestion was made to correctly embed the model identifier in the
assistant_id, and the user reported amodel_not_founderror indicating potential access issues. - Few-Shot Evaluation Boosts Confidence Scores: A user observed a significant accuracy increase from 52% to 88% when using few-shot evaluations for a multiple-choice task, raising questions about typical performance in sentiment analysis tasks.
- Discussion highlighted the importance of prompting, with others noting that few-shots can improve model calibration.
- KeyError Encounter in Custom Model Invocation: A user reported a
KeyErrorwhile attempting to invoke a customlm_evalmodel, specifically stating the model name 'mlx' was not found.
- It was clarified that the registration might not be recognized if the user was in the wrong branch, which was later confirmed.
- Specifying Model Branches in Local Completions: A user inquired about specifying the branch of a model while using
local-completionswith a Hugging Face model, receiving feedback on the handling by the local server.
- Further attempts to specify a branch in the model's path resulted in an error related to the path or model ID.
- A suggestion was made to correctly embed the model identifier in the
Links mentioned:
- lm-evaluation-harness-mlx/lm_eval/models/init.py at mlx · chimezie/lm-evaluation-harness-mlx): An MLX module for lm-evaluation-harness. Contribute to chimezie/lm-evaluation-harness-mlx development by creating an account on GitHub.
- lucyknada/Qwen_Qwen2.5-Coder-32B-Instruct-exl2 at main: no description found
- lm-evaluation-harness-mlx/lm_eval/models/mlx_llms.py at mlx · chimezie/lm-evaluation-harness-mlx:): An MLX module for lm-evaluation-harness. Contribute to chimezie/lm-evaluation-harness-mlx development by creating an account on GitHub.
Stability.ai (Stable Diffusion) ▷ #general-chat (309 messages🔥🔥):
Stable Diffusion 3.5Running SD on GPUSDXL LightningRoop UnleashedUsing Prompts for Image Generation
-
Stable Diffusion 3.5 Settings: Users discussed how to ensure Stable Diffusion 3.5 runs on their GPU instead of their CPU, emphasizing the importance of the
sd3_infer.pyfile's configuration.- A specific code snippet was shared to help establish the working directory and activate the virtual environment.
- Installation of Necessary Packages: To run SDXL Lightning, users were informed to install the
diffusersandacceleratelibraries with a simple command.
- Sample code was provided to generate images, demonstrating how to implement device settings and inference steps effectively.
- Customizing Generated Prompts: Users learned how to change specific details in prompts, such as modifying hair color in image generation commands.
- Adjusting the prompt string directly impacts the visuals produced, allowing for creative customizations.
- Performance of Roop Unleashed: A user inquired about the long processing times associated with Roop Unleashed when creating face-swap videos.
- Concerns were raised about the efficiency of video processing, contributing to an ongoing discussion about software performance.
- Comparison of Models: Discussions highlighted how SDXL Lightning is preferred over older models like SD 1.4 for generating better quality images.
- Users appreciated the advancements made in newer models, particularly how different versions compare in performance and flexibility.
Links mentioned:
- Google Colab: no description found
- SPO-Diffusion-Models/SPO-SDXL_4k-p_10ep_LoRA · Hugging Face: no description found
- Video Generation Model Arena | Artificial Analysis: Compare AI video generation models by choosing your preferred video without knowing the provider.
- GitHub - hako-mikan/sd-webui-prevent-artifact: Prevents the artifact that tends to occur with XL models: Prevents the artifact that tends to occur with XL models - hako-mikan/sd-webui-prevent-artifact
- TheBloke/Unholy-v2-13B-GGUF at main: no description found
- Webui Installation Guides: Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
- GitHub - Stability-AI/sd3.5: Contribute to Stability-AI/sd3.5 development by creating an account on GitHub.
- The Marvellous Suspender need your help to survive. · Issue #197 · gioxx/MarvellousSuspender: Discussed in #196 Originally posted by gioxx October 18, 2022 I wrote an article summarizing what might be the future of this add-on. Do you think you can help with its survival? Bring it on! IT: h...
LM Studio ▷ #general (124 messages🔥🔥):
LM Studio Local ServerAI Video Upscaling ToolsNvidia vs AMD GPUsUsing Multiple GPUsPort Forwarding in Local Network
-
LM Studio Local Server Accessibility: After encountering issues with LM Studio only being accessible locally via the 192.168.56.1:2468 address, a user discovered that the correct address 192.168.0.100:2468 was accessible after adjusting firewall settings.
- This allowed for inter-device communication through the local network, enabling effective server usage.
- AI Video Upscaling Tools Discussed: Users discussed various AI-based video upscaling tools, highlighting options like Waifu2x which works best on animated content and RealESRGAN for general use.
- Notably, free alternatives were preferred over commercial solutions like Topaz, which is quite expensive.
- Nvidia vs AMD GPUs for AI Tasks: It was noted that while the 7900XTX performs similarly to the 3090, Nvidia cards tend to have better compatibility with AI applications due to established driver support.
- Both the 3090 and 7900XTX offer 24GB of VRAM, making them comparable in terms of memory capacity for AI tasks.
- Challenges with Mixed GPU Setups: The discussion touched upon the complications of using mixed GPU setups with both AMD and Nvidia cards, which do not reliably work together due to differing driver management systems.
- It was highlighted that the integration of ROCm and CUDA for a seamless experience would be complex and likely problematic over time.
- Port Forwarding in Local Network Query: A user asked for help with port forwarding on their TP-Link router to connect an LM Studio server between a main PC and a laptop on the same local network.
- Clarifications on network adapter settings helped resolve confusion regarding network accessibility, leading to successful interactions on their local setup.
Links mentioned:
- no title found: no description found
- GitHub - FriendofAI/LM_Chat_TTS_FrontEnd.html: LM_Chat_TTS_FrontEnd is a simple yet powerful interface for interacting with LM Studio models using text-to-speech functionality. This project is designed to be lightweight and user-friendly, making it suitable for a wide range of users interested in exploring voice interactions with AI models.: LM_Chat_TTS_FrontEnd is a simple yet powerful interface for interacting with LM Studio models using text-to-speech functionality. This project is designed to be lightweight and user-friendly, makin...
LM Studio ▷ #hardware-discussion (177 messages🔥🔥):
Windows vs Ubuntu GPU performanceAMD vs NVIDIAMulti-GPU setupsPower management settingsGPU memory compatibility
-
Ubuntu outperforms Windows in GPU inference speed: Tests showed Ubuntu achieving 375 tokens/sec with a 1b model, while Windows lagged at 134 tokens/sec.
- Optimizing Windows power settings was discussed as a potential way to improve performance, suggesting it may be set to energy-saving modes.
- Importance of power management settings: Users emphasized that Windows power settings can significantly affect performance, recommending switching to the highest performance power scheme.
- Commands for changing power schemes were provided to ensure maximum performance, highlighting potential hidden settings.
- Challenges with AMD GPU software support: Discussions pointed out the lack of software and driver support for AMD GPUs compared to NVIDIA, despite their cost efficiency.
- Participants noted that AMD GPUs often require extra effort to get all necessary tools and drivers functioning correctly.
- Benefits of multi-GPU setups: A user shared plans for a 10 RTX 4090 card setup with their Threadripper Pro, suggesting significant performance gains in processing tasks.
- Direct GPU communication using special drivers was discussed as a method to enhance performance in large model processing.
- Memory compatibility concerns in GPU setups: Questions arose regarding shared VRAM usage and efficiency between multiple GPUs, especially in relation to model sizes exceeding individual VRAM capacity.
- The conversation indicated that AMD and NVIDIA cards behave differently under load, with implications for performance scalability.
Links mentioned:
- ASUS Vivobook S 15 (S5507); Copilot+ PC - Tech Specs: no description found
- Asus ZenBook S 13 OLED review (UM5302TA model- AMD Ryzen 7 6800U, OLED): That wraps up this review of the ASUS ZenBook S 13 OLED UM5302TA. Let me know what you think about it in the comments section below.
- 560.35.03 p2p by mylesgoose · Pull Request #22 · tinygrad/open-gpu-kernel-modules: Added support for the 560.35.03 Nvidia driver '/home/myles/cuda-samples/Samples/0_Introduction/simpleP2P/simpleP2P' [/home/myles/cuda-samples/Samples/0_Introduction/simpleP2P/simpleP2...
Nous Research AI ▷ #general (141 messages🔥🔥):
Ollama and LCPP for InferenceAnyModal FrameworkDecentralised Training Run UpdatesAI Research Paper HighlightsFeedback on Hermes AI Responses
-
Exploring Ollama's Purpose and Features: Members discussed the purpose of Ollama, noting its popularity and how it offers efficient inference compared to frameworks like PyTorch and Transformers, especially for systems that require less overhead.
- There's a debate around the utility of Ollama versus other tools like LMStudio, with some users preferring Ollama's ability to integrate with various front ends.
- Development of AnyModal Framework: AnyModal was highlighted as a flexible framework for training multimodal LLMs, allowing integration of various input modalities, including images and audio, simplifying the training process for VQA and image captioning tasks.
- Members expressed interest in creating demos for image and text interactions, emphasizing a focus on easier model training.
- Updates on Decentralised Training Run: Excitement surrounds an upcoming decentralised training run, with members eager to contribute compute resources and anticipating interesting updates soon.
- Developers hinted at potential announcements related to the project, stirring discussions among participants.
- AI/ML Research Paper Highlights: A user shared a list of this week’s top AI/ML research papers including titles like Cut Your Losses in Large-Vocabulary Language Models and LLMs Can Self-Improve in Long-context Reasoning.
- This selection reflects ongoing developments and discussions in the field of AI research, encouraging members to follow and engage with the works.
- Concerns Over Hermes AI Responses: A user humorously drafted a feedback letter addressing concerns over Hermes AI's repeated assertions of speed and love, suggesting such expressions might mislead users into thinking it possesses sentience.
- This prompt led to a lively discussion about the appropriateness of AI expressions, blending serious feedback with lighthearted banter among community members.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from adi (@adonis_singh): Roided Hermes 3 70b vs Hermes 3 70B! Forge Hermes: left Normal Hermes: right Quoting Teknium (e/λ) (@Teknium1) @adonis_singh @karan4d Can you try hermes x forge vs hermes on its own (70b)
- Nous Research (@nousresearch.com): The AI Accelerator Company. https://discord.gg/nousresearch
- Hhgf GIF - Hhgf - Discover & Share GIFs: Click to view the GIF
- Tweet from adi (@adonis_singh): It is genuinely surprising how similar my thoughts on forge sonnet are to o1. forge sonnet retains a lot of sonnets creativity while being MUCH more coherent and smarter. i do think normal sonnet w...
- Research updates: Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
- MCT Self-Refine algorithm : integrating LLMs with Monte Carlo Tree Search for complex mathematical…: LLMs faces challenges in accuracy and reliability in strategic and mathematical reasoning. For addressing it, authors of this paper[1]…
- Gwern - The Anonymous Writer Who Predicted The Path to AI: Gwern's blog: https://gwern.net/Gwern is a pseudonymous researcher and writer. After the episode, I convinced Gwern to create a donation page where people ca...
- Open WebUI: no description found
- GitHub - trotsky1997/MathBlackBox: Contribute to trotsky1997/MathBlackBox development by creating an account on GitHub.
- GitHub - ritabratamaiti/AnyModal: AnyModal is a Flexible Multimodal Language Model Framework: AnyModal is a Flexible Multimodal Language Model Framework - ritabratamaiti/AnyModal
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others): Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #ask-about-llms (88 messages🔥🔥):
Hermes 3 Compute InstancesLLM for AI Video CreationFunction Calling in LLMsModel Performance ComparisonsDocument Extraction and Analysis with LLMs
-
Hermes 3 Compute Instances might be costly: A member considered a compute instance for Hermes 3 405 but noted the high requirements, needing 8x H100 or 8x A100 80GB nodes.
- Alternative suggestions included using cloud inference for lower budget scenarios, likely delaying personal compute exploration.
- LLM Integration for AI Video Creation: A user sought collaboration with an LLM developer to create models that can autonomously generate videos for an expert in AI video creation.
- The discussion highlighted limitations of using Luma as it is closed and not teachable, emphasizing initial prompting approaches for better interactions.
- Function Calling in LLMs Discussion: Exploration into the effectiveness of function calling in LLMs revealed issues with too many parameters leading to ignored functions.
- It was advised to utilize specific functions with minimal parameters for better performance, potentially enhance discovery via pre-filtering.
- Comparing Modern LLMs with GPT-3: Members discussed the performance of modern models in contrast to GPT-3, noting that modern 7-13B models outperform earlier GPT versions despite fewer parameters.
- It was concluded that modern small models often execute tasks similarly to older larger models while being more efficient.
- Document Extraction Tools with LLMs: A question arose regarding open LLMs suitable for document extraction and analysis, revealing that mainstream models like ChatGPT and Gemini perform well.
- However, a member noted that Llama 70B Instruct did not provide satisfactory performance, urging for suggestions on effective alternatives.
Links mentioned:
- Lambda Chat: Enabling AI Developers to experiment with the best AI models, fast.
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Nous Research AI ▷ #research-papers (8 messages🔥):
Fine-tuning LLMs for domain adaptationEvaluation of VLA models in robotic tasksUnlocking reasoning capabilities in LLMsLLaVA and structured generationLLM2CLIP for enhanced visual representation
-
Fine-tuning strategies for LLMs: The paper titled "Fine-tuning large language models for domain adaptation" explores various training strategies, revealing that model merging can lead to superior capabilities in domain-specific assessments.
- It also highlights that smaller LLMs may not exhibit emergent capabilities during model merging, suggesting the importance of model scaling.
- Vision Language Models in robotics: "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" evaluates VLA models across 20 tasks, showing that performance varies significantly with task complexity.
- The introduction of a novel prompt engineering framework demonstrates improved performance by effectively mapping VLMs to modal tasks.
- Unlocking reasoning with LaTRO: The proposed LaTent Reasoning Optimization (LaTRO) framework aims to improve reasoning in LLMs, achieving up to a 12.5% increase in zero-shot accuracy on the GSM8K dataset, as detailed in the paper "Language Models are Hidden Reasoners".
- This approach allows LLMs to enhance their reasoning capabilities without external feedback, showcasing latent reasoning potential.
- Structured generation enhances reasoning: Discussion around the LLaVA-o1 model emphasizes the effectiveness of structured generation in enabling VLMs to reason step-by-step, as shared in this tweet.
- A user noted the addition of reasoning fields significantly boosts performance in this context.
- LLM2CLIP harnesses LLM strengths: "LLM2CLIP" presents a method to enhance CLIP's capabilities by leveraging LLMs' textual understanding to improve cross-modal representation learning.
- By fine-tuning LLMs in caption space, this approach allows for longer, more complex captions, leading to substantial improvements in performance across various tasks.
Links mentioned:
- Tweet from AK (@_akhaliq): LLaVA-o1 Let Vision Language Models Reason Step-by-Step
- Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding: Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can im...
- GitHub - SalesforceAIResearch/LaTRO: Contribute to SalesforceAIResearch/LaTRO development by creating an account on GitHub.
- Multinetv0.1: no description found
- MultiNet/src/modules at main · ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- GitHub - ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- SOCIAL MEDIA TITLE TAG: SOCIAL MEDIA DESCRIPTION TAG TAG
Nous Research AI ▷ #interesting-links (5 messages):
Agentic Workflow and Fine-TuningLLaMA-Mesh AnnouncementAnyModal Framework
-
Questions on Agentic Workflow Techniques: A member inquired whether fine-tuning was used or if the agentic workflow employed few-shot prompting for model training.
- This led to another member sharing their experience with similar challenges, mentioning 'this is the wall I hit attempting to do something similar.'
- Nvidia Reveals LLaMA-Mesh: Nvidia presented LLaMA-Mesh, which focuses on generating 3D mesh using Llama 3.1 8B, with a promise of weights being released soon.
- This announcement reportedly caught the attention of the community, as it signifies advancements in 3D generation technologies.
- Introduction to AnyModal Framework: A member shared details about AnyModal, a flexible framework designed for integrating diverse data types like images and audio with Large Language Models.
- They emphasized the framework's ability to handle tasks with models like ViT for image inputs, and sought feedback or contributions to improve the ongoing project.
Links mentioned:
- GitHub - ritabratamaiti/AnyModal: AnyModal is a Flexible Multimodal Language Model Framework: AnyModal is a Flexible Multimodal Language Model Framework - ritabratamaiti/AnyModal
- Tweet from Chubby♨️ (@kimmonismus): Nvidia presents LLaMA-Mesh: Generating 3D Mesh with Llama 3.1 8B. Promises weights drop soon.
Nous Research AI ▷ #research-papers (8 messages🔥):
Fine-tuning Large Language ModelsBenchmarking Vision, Language, & Action ModelsLatent Reasoning Capabilities in LLMsLLaVA and Step-by-Step ReasoningLLM2CLIP for Enhanced Visual Representation
-
Fine-tuning strategies enhance LLMs for specialized tasks: The paper introduces fine-tuning strategies, including Continued Pretraining and Direct Preference Optimization, to improve LLM performance for specialized applications in fields like materials science.
- Merging fine-tuned models yielded new functionalities that exceeded those of individual parent models, suggesting scaling may be crucial for smaller models.
- Benchmarking VLA models on robotics tasks: Researchers presented a framework to evaluate Vision-Language-Action (VLA) models across 20 real-world robotics tasks, revealing significant performance variation.
- Notably, all models struggled with complex tasks that required multiple steps, highlighting the need for improved prompt engineering techniques.
- Unlocking reasoning abilities in LLMs with LaTRO: The novel LaTent Reasoning Optimization (LaTRO) framework improves reasoning capabilities in LLMs without relying on external feedback, achieving up to 12.5% accuracy improvement on reasoning tasks.
- Validation was performed on GSM8K and ARC-Challenge datasets across several model architectures, confirming that pre-trained LLMs possess latent reasoning capabilities.
- LLaVA promotes step-by-step reasoning in Vision Language Models: Insights from discussions indicate that structured generation added reasoning fields significantly boost performance in LLaVA models.
- Members noted the effectiveness of encouraging step-by-step reasoning to enhance model outcomes.
- LLM2CLIP leverages LLMs for improved multimodal learning: The LLM2CLIP framework proposes using powerful language models to enhance the visual representation capabilities of CLIP through fine-tuning in the caption space.
- This allows for the incorporation of longer and more complex captions, leading to substantial improvements in cross-modal tasks.
Links mentioned:
- Tweet from AK (@_akhaliq): LLaVA-o1 Let Vision Language Models Reason Step-by-Step
- Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding: Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can im...
- GitHub - SalesforceAIResearch/LaTRO: Contribute to SalesforceAIResearch/LaTRO development by creating an account on GitHub.
- Multinetv0.1: no description found
- MultiNet/src/modules at main · ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- GitHub - ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- SOCIAL MEDIA TITLE TAG: SOCIAL MEDIA DESCRIPTION TAG TAG
Nous Research AI ▷ #reasoning-tasks (19 messages🔥):
Dynamic Model SelectionAI NewslettersLink Aggregation ToolsScraping ToolsLocalLlama Community
-
Gaming for LMs to Compare Capabilities: A member proposed developing a game for language models to engage with, which could serve as a valuable method to assess their capabilities.
- The idea builds on the concept of dynamic model selection and could potentially enhance comparative analysis.
- AI Newsletter Recognition: A member congratulated others on reaching the top of various AI newsletters, highlighting the recognition for their work.
- They referred to an 'O1 challenger', indicating a competitive landscape within AI content creation.
- Opinions on AI Newsletter Names: There was discussion about the name 'Alphasignal' being unappealing, yet the newsletter itself provides valuable recommendations for papers and open-source tools.
- Members expressed appreciation for newsletters that summarize important resources, making it easier to stay updated.
- Cloudflare's New Scraping Tool: A user expressed interest in utilizing Cloudflare's new scraping tool to build an agent that aggregates links from various AI sources and social media.
- This approach aims to streamline the collection of information from top AI labs, Twitter, and Hacker News.
- Mixed Feelings About LocalLlama Community: The LocalLlama community received mixed feedback, with one member expressing frustration with the moderators while acknowledging the great community.
- Despite the complaints about moderation, there was an acknowledgment of the value of the community for AI discussions.
Interconnects (Nathan Lambert) ▷ #events (4 messages):
Dinner ReservationsToronto and Vancouver Connections
-
Dinner Reservations Turned into a Mess: A member expressed frustration about booking a reservation, stating it was going to be a mess.
- Lol seemed to sum up the sentiment around the hassle of making dinner plans.
- Toronto Member Offers Help with Vancouver: One member based in Toronto offered to reach out to people in Vancouver for assistance.
- This sparked interest in the potential collaboration between the cities.
Interconnects (Nathan Lambert) ▷ #news (106 messages🔥🔥):
Qwen 2.5 TurboMistral AI UpdatesAPI ChallengesDeepseek Models
-
Qwen 2.5 Turbo Introduced: The new Qwen 2.5 Turbo boasts a context length increase to 1 million tokens, significantly improving processing speed with a 4.3x speedup.
- It now supports processing a larger volume of tokens at a competitive price, leading to excitement about its capabilities.
- Mistral AI Releases Pixtral Large: Mistral AI has announced updates including the multimodal Pixtral Large model featuring impressive metrics across several benchmarks.
- The updates also improve the capabilities of their chat platform, introducing new tools and features for user interaction.
- Concerns Over API Performance: Members expressed frustrations about API performance, noting huge latency spikes and challenging user experiences with certain models.
- It was highlighted that building efficient APIs remains a complex task, particularly for companies operating under restrictive conditions.
- Deepseek 3 Anticipation: Anticipation is building for Deepseek 3, with ongoing discussions suggesting the potential for a 2.5 VL release on the horizon.
- Community members expressed their desire for advancements in model capabilities while acknowledging the innovative nature of Chinese models.
Links mentioned:
- Tweet from Joseph Thacker (@rez0__): oh nice! new sota released by @MistralAI today
- Mistral has entered the chat: Search, vision, ideation, coding… all yours for free.
- Tweet from N8 Programs (@N8Programs): @JustinLin610 @kalomaze Checked the benchmarks - roughly on par (or worse than on some fronts) with Qwen 2 72B VL. Of course.
- Tweet from Devendra Chaplot (@dchaplot): Pixtral Large: - Frontier-class multimodal model - SoTA on MathVista, DocVQA, VQAv2 - Maintains text performance of Mistral Large 2 - 123B decoder, 1B vision encoder - 128K seq len Download it on HF:...
- Tweet from vik (@vikhyatk): i am hiding a dirty secret
- Tweet from Qwen (@Alibaba_Qwen): After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. https://qwenlm.github.io/blog/qwen2.5-turbo/ Today, we are proud to introduce the new Qwen2.5-Turbo ver...
- Tweet from Xeophon (@TheXeophon): Quoting Joseph Thacker (@rez0__) oh nice! new sota released by @MistralAI today
- Fireworks - Fastest Inference for Generative AI: Use state-of-the-art, open-source LLMs and image models at blazing fast speed, or fine-tune and deploy your own at no additional cost with Fireworks AI!
Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
AI Hallucination ConcernsIlya Sutskever and Sam Altman MisalignmentTechEmails Twitter Revelations
-
Negative Sentiment on AI Hallucinations: A member expressed frustration over the current discourse surrounding AI hallucinations, mentioning that discussions often revolve around negative perceptions like 'AI hallucinated something and that's bad'.
- In theory I'm ideologically aligned, indicating a divide between beliefs and practices.
- Ilya and Sam's Alignment Issues since 2017: Discussions revealed that Ilya Sutskever and Sam Altman have been recognizing misalignment issues dating back to 2017.
- This statement added a layer of complexity to their ongoing relationship and the implications for AI development.
- TechEmails Unfolding Drama: A user shared multiple links from TechEmails, showcasing tweets about recent revelations regarding a notable email thread involving Ilya Sutskever, Elon Musk, and Sam Altman.
- The links were labeled as fascinating and indicate potential drama surrounding the situation.
Links mentioned:
- Tweet from Internal Tech Emails (@TechEmails): no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from undefined: no description found
- Tweet from Internal Tech Emails (@TechEmails): [This document is from Elon Musk, et al. v. Samuel Altman, et al. (2024).]
Interconnects (Nathan Lambert) ▷ #random (74 messages🔥🔥):
2T Pretraining Dataset ComparisonOLMoE ICLR Review ConcernsGemini Model ImprovementsRewardBench for RLHF EvaluationNew LLaVA-o1 Model Release
-
Skepticism Over 2T Pretraining Excitement: A member expressed confusion about the excitement surrounding the 2T pretraining dataset, questioning its significance given the existence of the 15T FineWeb dataset with better copyright filtering.
- Multilingual capabilities were noted as a potential advantage of the FineWeb approach, while curiosity was raised about its real-world application.
- Concerns on OLMoE ICLR Review Quality: Discussion emerged around the low quality of reviews for the OLMoE paper at ICLR, with some members suggesting reviewer bias against certain authors.
- The sentiment was echoed that current review standards at top conferences are declining, with mandatory reviews failing to elevate quality.
- Gemini Model's Strong Performance: The Gemini-exp-1114 model from Google was highlighted for its impressive reasoning capabilities, surpassing previous iterations and ranking high on the AIME 2024 dataset.
- Members speculated on whether this model might be a pre-release of Gemini 2.0, showing enthusiasm for its potential.
- Launch of RewardBench for Evaluating RMs: The introduction of RewardBench, a benchmark for evaluating reward models in reinforcement learning from human feedback, was discussed, aiming to enhance understanding of alignment technologies.
- Concerns were raised about the treatment of datasets used in the outline, with mentions of plagiarism accusations against the authors.
- Launch of New LLaVA-o1 Visual Language Model: The LLaVA-o1 model was announced as a new visual language model outperforming major competitors and utilizing a novel inference method.
- Discussion included plans to eventually evaluate its performance against Qwen2-VL while noting a lack of current availability on Hugging Face.
Links mentioned:
- Tweet from Asankhaya Sharma (@asankhaya): The new gemini-exp-1114 model from @Google is quite good in reasoning. It improves over gemin-1.5-pro-002 by a huge margin and is second only to o1-preview on AIME (2024) dataset. The attached image...
- RewardBench: Evaluating Reward Models for Language Modeling: Reward models (RMs) are at the crux of successful RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those reward models....
- Tweet from Guowei Xu (@Kevin_GuoweiXu): Sorry about that overlook! We didn’t mean to not include this model. Today we tested Qwen2-VL-7B and found that our model’s performance is about the same as it. While we acknowledge Qwen2-VL has a ver...
- Nathan Lambert (@natolambert.bsky.social): TIL when training a MoE with huggingface it for loops over experts. No wonder they're so slow 🫠
- Tweet from finbarr (@finbarrtimbers): I have an essay I’m working on where the thesis is that 1) RL is hard and doesn’t really work but 2) we’re stuck with it because there’s kinda nothing else we can do once we exhaust all the good p...
- Tweet from Guowei Xu (@Kevin_GuoweiXu): 🚀 Introducing LLaVA-o1: The first visual language model capable of spontaneous, systematic reasoning, similar to GPT-o1! 🔍 🎯Our 11B model outperforms Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-...
- microsoft/orca-agentinstruct-1M-v1 · Datasets at Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #memes (42 messages🔥):
Reinforcement Learning (RL)Tulu 3 vs Hermes 3Llama 3 PaperOpenAI's Early WorksAnthropic's Model Release
- Reinforcement Learning Faces Doubt: Some members discussed the skepticism around Reinforcement Learning (RL) for fine-tuning, emphasizing how many still doubt its efficacy despite promising tools and advancements. 'So many folks still doubting RL for fine tuning,' one member expressed optimism for broader acceptance in 2025.
- Speculation on Tulu 3 and Hermes 3: There were inquiries about whether Tulu 3 has been evaluated against Hermes 3, with one member expressing dissatisfaction with current results from switching to Llama 405. A member mentioned past evaluations but speculated that 'it's not going that well for them.'
- Excitement for the Llama 3 Paper: A member highlighted the Llama 3 paper as potentially the must-read of the year, noting its impact compared to others in the field. Another mentioned that it delves into the physics of LLMs, underscoring its significance.
- OpenAI's Early Contributions Remembered: Nostalgia for OpenAI's early works was expressed, with mentions of how RL for computer games inspired some to pursue AI careers. Discussions reflected on how those contributions sparked interest in the field compared to the more closed nature of current research.
- Anthropic's Release Approach Critiqued: Concerns were raised regarding Anthropic's model releases, suggesting a lack of transparency in their processes compared to OpenAI's. Members criticized Anthropic for providing little insight beyond model evaluations, with remarks like 'here's a better model, here's the evals, bye.'
Links mentioned:
- Tweet from Teknium (e/λ) (@Teknium1): @kalomaze @TheXeophon @vikhyatk @YouJiacheng RL sucks sorry not sorry lol
- A Deep Reinforced Model for Abstractive Summarization: Attentional, RNN-based encoder-decoder models for abstractive summarization have achieved good performance on short input and output sequences. For longer documents and summaries however these models ...
Interconnects (Nathan Lambert) ▷ #reads (2 messages):
Doria's WorkUnderstanding Spoken Content
-
Praise for Doria's Work: A member shared a link to a YouTube video featuring Doria's work and expressed their admiration for her contributions.
- The enthusiasm for Doria's work indicates a strong interest in her projects and insights.
- Challenges in Comprehension: Another member noted that understanding the video content took some time, requiring multiple listenings to fully grasp.
- They emphasized the need to persist through the initial difficulty to appreciate the spoken words.
Latent Space ▷ #ai-general-chat (72 messages🔥🔥):
Pixtral Large releaseMistral's Le Chat updatesQwen 2.5 Turbo featuresLindy usability concernsOpenAI streaming availability
-
Pixtral Large debuts as new multimodal model: Mistral announced the release of Pixtral Large, a frontier-class 124B multimodal model capable of understanding documents and images while maintaining text performance, available in their API and on Hugging Face.
- It boasts a 128K context window and can process a minimum of 30 high-resolution images, showcasing advancements in multimodal AI.
- Mistral updates Le Chat with new features: Mistral's Le Chat now includes features like web search, image generation, and PDF upload, aiming to enhance user interaction with generative AI tools.
- The platform is now free to use and supports various use cases, from coding assistants to creative partnerships, pushing the boundaries of AI interfaces.
- Qwen 2.5 Turbo introduces extended context support: Qwen 2.5 Turbo now supports context lengths of up to 1 million tokens, allowing for comprehensive text processing equivalent to ten novels.
- This model achieves 100% accuracy on the Passkey Retrieval task, significantly enhancing long-context capabilities for developers.
- Mixed reviews about Lindy usage: A user expressed their struggle to find substantial use cases for Lindy, questioning its advantages over other automation tools like Zapier.
- The feedback reflects a broader hesitation within the community about its practicality and effectiveness in current workflows.
- OpenAI adds streaming feature for o1 models: OpenAI has made streaming available for the o1-preview and o1-mini models, expanding access across all paid usage tiers.
- This enhancement allows developers to leverage more dynamic interactions within the OpenAI platform, improving the user experience.
Links mentioned:
- Tweet from Hassan (@nutlope): Introducing LogoCreator! An open source logo generator that creates professional logos in seconds using Flux Pro 1.1 on @togethercompute. 100% free and open source. Demo + code:
- Tweet from ken (@aquariusacquah): Voice AI proliferation will be the biggest development of 2024, and it's only *just* starting to work. - "Voice Pipeline" approaches combining ASR, LLMs, TTS are getting faster and faster...
- Tweet from Hassan (@nutlope): llama-ocr is somehow #1 on hackernews!
- Fireworks - Fastest Inference for Generative AI: Use state-of-the-art, open-source LLMs and image models at blazing fast speed, or fine-tune and deploy your own at no additional cost with Fireworks AI!
- Tweet from Flo Crivello (@Altimor): This struck a nerve :) Received lots of pushback, as expected. Will answer the most common below: « Life doesn’t have to be about work! » Yes! That is what is called lack of ambition! It is 100% fine...
- Tweet from Alex Albert (@alexalbert__): Friday docs feature drop: You can now access all of our docs concatenated as a single plain text file that can be fed in to any LLM. Here's the url route: http://docs.anthropic.com/llms-full.txt
- Pixtral Large: Pixtral grows up.
- Mistral has entered the chat: Search, vision, ideation, coding… all yours for free.
- Tweet from Arc Institute (@arcinstitute): 🧬Evo, the first foundation model trained at scale on DNA, is a Rosetta Stone for biology. DNA, RNA, and proteins are the fundamental molecules of life—and cracking the code of their complex language...
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Tweet from Szymon Rączka (@screenfluent): @0xLes @AravSrinivas @eshear I liked the initiative so much that I made this project over the weekend https://llmstxt.directory/
- Extending the Context Length to 1M Tokens!: API Documentation (Chinese) HuggingFace Demo ModelScope Demo Introduction After the release of Qwen2.5, we heard the community’s demand for processing longer contexts. In recent months, we have ...
- Spaceballs Crosseyed GIF - Spaceballs Crosseyed Sorry Sir - Discover & Share GIFs: Click to view the GIF
- Tweet from Aidan McLau (@aidan_mclau): elon lost the mandate of heaven the cosmic rays weren't on his side rip xai; the gpu-looking datacenter was cool ig
- Tweet from Arthur Mensch (@arthurmensch): Expanding from a science company to a science and product company was no easy task, and that release is a very significant milestone in our journey. We're looking forward to how you'll use le ...
- Tweet from Devendra Chaplot (@dchaplot): Today, we are announcing two new exciting updates: Pixtral Large: Frontier-class 124B multimodal model, powering the new Le Chat. Brand new Le Chat: With web search, canvas, image-gen, image unders...
- Tweet from Arthur Mensch (@arthurmensch): At Mistral, we've grown aware that to create the best AI experience, one needs to co-design models and product interfaces. Pixtral was trained with high-impact front-end applications in mind and...
- Fireworks - Fastest Inference for Generative AI: Use state-of-the-art, open-source LLMs and image models at blazing fast speed, or fine-tune and deploy your own at no additional cost with Fireworks AI!
- Tweet from deepfates (@deepfates): i wrote a python script to convert your twitter archive into a training dataset for fine-tuning a language model on your personality. it also extracts all your tweets, threads and media into markdown...
- Tweet from Guillaume Lample @ ICLR 2024 (@GuillaumeLample): Le Chat now includes image generation with FLUX1.1, web search, canvas, mistral large with vision capabilities, PDF upload, etc. And it's 100% free! https://chat.mistral.ai/ Quoting Mistral AI (@...
- New Google Model Ranked ‘No. 1 LLM’, But There’s a Problem: A new and mysterious Gemini model appears at the top of the leaderboard, but is that the full story? I dig behind the headline to show you some anti-climacti...
- Convert your twitter archive into a training dataset and markdown files: Convert your twitter archive into a training dataset and markdown files - convert_archive.py
Latent Space ▷ #ai-in-action-club (55 messages🔥🔥):
Windsurf EditorAnthropic APICursor vs WindsurfCodeium Demo EnhancementsAI's Context Management
-
Windsurf Editor mixes AI and Development: The Windsurf Editor allows developers to collaborate seamlessly with AI, creating a coding experience that feels 'like literal magic'.
- Its AI capabilities blend both collaborative features like Copilot and independent agents for complex tasks, keeping developers in a flow state.
- Anthropic API showcases: During a demonstration, it's noted that the Anthropic API has been successfully integrated into desktop clients for enhanced functionality, as seen in this GitHub example.
- Participants discussed the impressive capabilities of tools like agent.exe and how the AI can generate mouse clicks using pixel coordinates.
- Cursor vs Windsurf for User Experience: Users expressed preferences between Cursor and Windsurf, highlighting the granular control provided by Cursor as beneficial for power users.
- Conversely, others pointed out that Windsurf occasionally makes unexpected decisions, making the understanding of interactions vital for effective use.
- Codeium Demo Highlights: In a Codeium demo, participants noted how the agent could provide a git diff of recent changes, showcasing its utility in tracking code evolution.
- The discussion also revealed that users have homegrown scripts to ease the management of tools like OpenWebUI.
- AI's Strategic Context Management: Context management in AI tools has been a common point of discussion, particularly in relation to how tools handle and execute complex instructions.
- Concerns were raised about maintaining control and transparency over interactions, especially when operating multiple LLMs in a workflow.
Links mentioned:
- Alf Alf Janela GIF - Alf Alf Janela Alf Observando - Discover & Share GIFs: Click to view the GIF
- Alf Tux GIF - Alf Tux - Discover & Share GIFs: Click to view the GIF
- Windsurf Editor by Codeium: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- anthropic-quickstarts/computer-use-demo at main · anthropics/anthropic-quickstarts: A collection of projects designed to help developers quickly get started with building deployable applications using the Anthropic API - anthropics/anthropic-quickstarts
- GitHub - corbt/agent.exe: Contribute to corbt/agent.exe development by creating an account on GitHub.
- GitHub - olimorris/codecompanion.nvim: ✨ AI-powered coding, seamlessly in Neovim. Supports Anthropic, Copilot, Gemini, Ollama, OpenAI and xAI LLMs: ✨ AI-powered coding, seamlessly in Neovim. Supports Anthropic, Copilot, Gemini, Ollama, OpenAI and xAI LLMs - olimorris/codecompanion.nvim
GPU MODE ▷ #general (18 messages🔥):
Dynamic Parallelism in CUDACloud Providers for (G)H200Zoom TalksLearning CUDA on Cloud PlatformsProfiling Information for CUDA Kernels
-
Dynamic Parallelism Resources Uncovered: A member shared that all samples starting with
cdpin the NVIDIA CUDA Samples demonstrate dynamic parallelism, but compatibility for CDP2 is uncertain.- Another member noted that the first sample lacks device-side synchronization, which is considered a positive aspect.
- Seeking (G)H200 144GB Cloud Options: A member inquired about cloud providers offering (G)H200 144GB hourly without excessive requirements, mentioning Lambda's availability of GH200 96GB.
- Another member suggested reaching out to Lambda for assistance, citing positive experiences with their support.
- Information on Talks via Zoom: A member asked where the talks occur, quickly confirming they take place on Zoom with a shared link: Zoom Event.
- It was also mentioned that the talk was recorded for those unable to attend.
- Best Cloud Platform for Learning CUDA: A member asked which cloud platform is easiest to set up for learning CUDA, receiving a recommendation for Lightning Studios found on cloud-gpus.com.
- This response indicates that various options exist but highlights the preference for a particular platform.
- Getting Kernel Profiling Information: A member sought help with profiling information for a specific kernel using
nsys, expressing difficulty with available options in the documentation on analyzing the nsys-rep file.
- It was advised that
ncu(Nsight Compute) should be used instead, as it provides the kernel-specific details needed.
GPU MODE ▷ #triton (6 messages):
Modified FlashAttention in TritonTriton CPU Backend with torch.compileCommunity Humor
-
Troubleshooting FlashAttention Modifications: A member is using Triton to implement a modified version of FlashAttention but encounters issues with
atomic_addcrashing their GPU in Colab.- They shared code with a specific focus on computing the column-sum of the attention score matrix and are seeking assistance with their implementation.
- Inquiring about Triton CPU Backend: A member asked if it's possible to use the Triton CPU backend with
torch.compile, looking for insights from the community.
- Another user mentioned a community member who might have that knowledge, demonstrating the collaborative spirit in problem-solving.
- Humor in the Community: A light-hearted exchange occurred when a member joked about their spelling of Triton, which elicited laughter from another member.
- This reflects the camaraderie and sense of humor prevalent within the community discussions.
GPU MODE ▷ #torch (41 messages🔥):
Advanced PyTorch ResourcesCustom Kernels with PyBindPyTorch DCP Memory UsageFSDP State Dict Functionality
-
Seeking Advanced PyTorch Resources: A member expressed frustration that existing PyTorch books focus on beginner concepts and inquired about resources covering advanced topics and tricks.
- It was suggested that hands-on building might aid learning, with a goal-oriented approach recommended instead of merely reviewing methods.
- Issues with Registering Custom Kernels: A member asked about registering a custom kernel from PyBind and the correct syntax for
torch.library.register_kernel.
- Another member provided helpful links for registering custom operators but encountered challenges in identifying the operator's name.
- Examining DCP Memory Usage During Operations: During discussions on PyTorch DCP, one member reported significant temporary memory allocation during
dcp.savewith mixed precision and FULL_SHARD mode.
- Concerns were raised about whether the memory allocated was normal and if it could be optimized in future iterations.
- Understanding FSDP's Memory Allocation: It was clarified that FSDP manages parameters with 'flat parameters' and requires memory for both all-gathering flat parameters and re-sharding them.
- Members discussed how their custom auto-wrap policy influenced memory allocation during state dict fetches, leading to larger reserved memory.
Links mentioned:
- PyTorch documentation — PyTorch 2.5 documentation: no description found
- Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First Principles: Given some interest, I am sharing a note (first written internally) on the PyTorch Fully Sharded Data Parallel (FSDP) design. This covers much but not all of it (e.g. it excludes autograd and CUDA cac...
- torch.library — PyTorch 2.5 documentation): no description found
- pytorch/torch/distributed/checkpoint/filesystem.py at e80b1b2870ad568aebdbb7f5205f6665f843e0ea · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- Getting Started with Distributed Checkpoint (DCP) — PyTorch Tutorials 2.5.0+cu124 documentation: no description found
- [Announcement] Deprecating PyTorch’s official Anaconda channel · Issue #138506 · pytorch/pytorch: tl;dr PyTorch will stop publishing Anaconda packages that depend on Anaconda’s default packages due to the high maintenance costs for conda builds which are not justifiable with the ROI we observe ...
GPU MODE ▷ #announcements (1 messages):
Jay Shah's talk at CUTLASSEpilogue Fusion in CUTLASSGPU passthrough on Proxmox VE
-
Jay Shah shares insights at CUTLASS: A highly anticipated talk by Jay Shah is currently ongoing at CUTLASS and Flash Attention 3; he is known for his accessible blog on advanced GPU programming.
- Expectations are set high as participants refer to his blog as one of the best introductions to this complex subject read more here.
- Epilogue Fusion discussed in detail: An article titled Epilogue Fusion in CUTLASS with Epilogue Visitor Trees has been released, supplementing the tutorial series on GEMM implementations on NVIDIA GPUs.
- The article delves into the workload of CUTLASS, focusing on GEMM's main loop, and is part of a broader series available here.
- Exploring GPU passthrough on Proxmox VE 8.2: A guide for GPU passthrough on Proxmox VE 8.2 has been published, aimed at enhancing users' understanding of GPU management within this environment.
- This article offers practical insights and is part of the ongoing efforts to improve virtualization techniques on Proxmox.
Link mentioned: Articles: We present expository-style articles and coding tutorials on our blog.
GPU MODE ▷ #cool-links (2 messages):
ZLUDACUDA AlternativesAMD and Intel GPUs
-
ZLUDA Makes CUDA Accessible: A recent YouTube video titled #246 Developer Of ZLUDA: CUDA For Non Nvidia GPUs discusses how ZLUDA enables CUDA capabilities on AMD and Intel GPUs, a significant shift for developers.
- One member noted that they had previously tried reaching out to the developer, indicating excitement that finally someone got them on the show.
- Excitement Over Developer's Appearance: Discussion arose around the video featuring Andrzej Janik, the developer of ZLUDA, who has been sought after by the community.
- Members expressed their enthusiasm, with one stating they had tried to get him on a while back.
Link mentioned: #246 Developer Of ZLUDA: CUDA For Non Nvidia GPUs | Andrzej Janik: CUDA is one of the primary reasons people buy NVIDIA GPUs but what if there was a way to have this compute power on AMD and Intel GPUs as well. Well there is...
GPU MODE ▷ #beginner (8 messages🔥):
NCU Source ViewLive Register CountsCUDA and Tensor Core Clock SpeedsThermal Throttling Mitigation
-
NCU Source View Enhances Debugging: The Source View in NCU enables jumping to code points where the most registers are live, potentially aiding in debugging efforts.
- This can provide insights into how register dependencies affect performance.
- Questioning Accuracy of Live Register Counts: A discussion emerged on whether live register counts are an accurate metric, with concerns about their cumulative nature potentially misrepresenting fault locations.
- Participants noted that a high live register count may simply indicate prior instructions rather than specific current faults.
- Clock Speeds of CUDA vs. Tensor Cores: It was clarified that the CUDA cores operate at 1,755MHz, while the Tensor cores run at 1,620MHz.
- These speeds confirm limitations highlighted in previous discussions on higher clock rates for different core types.
- Understanding Node Thermal Management: Robert Crovella from NVIDIA confirmed that the boost clock is capped at 1,620MHz for Tensor Cores, as stated in the whitepaper.
- Participants speculated that this cap may be a software-imposed limit to mitigate thermal throttling risks, ensuring stable performance.
Link mentioned: NVIDIA H100 Tensor Core GPU Architecture Overview: A high-level overview of NVIDIA H100, new H100-based DGX, DGX SuperPOD, and HGX systems, and a H100-based Converged Accelerator. This is followed by a deep dive into the H100 hardware architecture, ef...
GPU MODE ▷ #pmpp-book (3 messages):
CUDA grid and block configurationConfusion in documentation
-
Understanding CUDA Configuration: A member interpreted the CUDA configuration as having a grid of 16 blocks (4 * 2 * 2) and each block containing 4 threads (2 * 2 * 1).
- They sought confirmation on this interpretation, showing a clear grasp of grid and block dimensions.
- Documentation Discrepancy Highlighted: Another member pointed out a contradiction in page 68 of the documentation, which stated a configuration of 4 blocks per grid with 16 threads per block.
- They suggested that the documentation presented may be out of sync with the corrected information they possess.
GPU MODE ▷ #youtube-recordings (3 messages):
CUTLASS and Flash Attention 3Column and Row Permutations in FA3Indexing Techniques in GPU Computing
-
Jay Shah discusses PV computation: In the lecture on CUTLASS and Flash Attention 3, Jay Shah mentioned that instead of performing PV, a column permutation of P and a row permutation of V can be used to avoid shuffles.
- This statement raised questions about the connection to tuning the FA3 kernel, as members sought clarification on how these permutations impact computation.
- Row and Column Reordering Insight: One member suggested that the column and row reordering is followed by writing to the correct location using some indexing techniques.
- This suggests a discussion on potential methods for optimizing GPU computing through clever indexing.
Link mentioned: Lecture 36: CUTLASS and Flash Attention 3: Speaker: Jay ShahSlides: https://github.com/cuda-mode/lecturesCorrection by Jay: "It turns out I inserted the wrong image for the intra-warpgroup overlappin...
GPU MODE ▷ #off-topic (3 messages):
Steamed Hams MemeTasty HacksHackathon CultureCreative ProjectsCommunity Engagement
-
The Joy of Steamed Hams: At this time of day, at this time of year, in this part of the country?? sparked a meme discussion centered on the Steamed Hams skit.
- The dialogue showcases a lighthearted exchange, emphasizing how memes permeate modern conversations.
- Tasty Hacks aims to inspire creativity: A new hackathon called Tasty Hacks is being organized to focus on passion projects rather than competition, promoting creativity for its own sake.
- The event encourages participation from all skill levels, stating that people from all walks of trades are welcome, promoting a supportive community.
- Critiques of traditional hackathons: There's a critique of the current hackathon culture, where hack projects often prioritize sponsor prizes for social media posts over genuine creativity.
- Judges with little relevant experience often set misleading criteria, which the organizers of Tasty Hacks want to change.
- Community-driven Hackathon experience: Tasty Hacks aims to create a small, intimate environment with 20-30 participants to foster genuine interaction and collaboration.
- Participants who don't have a team can be matched through a curated process, enhancing community engagement among like-minded individuals.
Link mentioned: tastyhacks '24 berkeley · Luma: many hackathons nowadays have been tainted by status. participants optimize for winning by incorporating sponsor prizes minimally in their hacks, which later…
GPU MODE ▷ #triton-puzzles (1 messages):
jongjyh: thx bro!
GPU MODE ▷ #rocm (5 messages):
CK Profiler ResultsFP16 Matrix Multiplication PerformanceH100 vs MI300XAsync Copy with TMAAMD Optimization Challenges
-
CK Profiler shows better results: After trying CK Profiler, the performance improved with 600 TFLOPs for FP16 matrix multiplication, which is still lower than the peak values in the H100 whitepaper.
- The estimated peak for H100 is 989.4 TFLOPs for SXM5, while the observed performance using
torch.matmul(a,b)reached around 700 TFLOPs. - FP16 Performance Discrepancies Between GPUs: The MI300X has a peak performance of 1307 TFLOPs for FP16, yet only managed 470 TFLOPs with
torch.matmul(a,b), while CK shows improvements.
- The disparity highlights the need for better optimization strategies for AMD hardware in FP16 computations.
- H100 leverages TMA effectively: It is assumed that the H100 uses TMA for async copy, allowing effective utilization of cuBLAS/cuBLASLt for optimal performance.
- In contrast, concerns were raised regarding AMD's software struggle to optimize ACE for similar efficiency.
- Consider testing zero distribution input: To improve AMD performance, a suggestion was made to experiment with a zero distribution input, which could yield better results.
- This approach may address the current performance challenges observed with AMD's hardware.
- The estimated peak for H100 is 989.4 TFLOPs for SXM5, while the observed performance using
GPU MODE ▷ #liger-kernel (1 messages):
0x000ff4: okay how I can contribute to the project can you direct me 🙂
GPU MODE ▷ #self-promotion (4 messages):
YouTube channel on quantizationX platform AI/ML contentBlog on Tensor Core matmul kernel
-
Explore quantization on YouTube!: A member shared their YouTube channel focused on teaching neural network quantization with tutorials covering Eager mode and FX Graph mode quantization.
- The channel aims to provide content that helps tackle challenging problems in AI, emphasizing coding techniques and theoretical concepts.
- Follow for AI/ML insights on X!: Another member invited others to follow their X profile for awesome content related to AI/ML, physics, and mathematics papers.
- This content is designed to share valuable insights and keep followers updated on exciting developments in these fields.
- Efficient Tensor Core matmul kernel revealed: A blog post was shared detailing the implementation of an efficient Tensor Core matmul kernel for the Ada architecture, aiming to match cuBLAS performance.
- The post covers aspects like CUTLASS permuted shared memory layout, n-stage async memory pipelines, and performance results comparing various implementations.
Links mentioned:
- Tweet from undefined: no description found
- Oscar Savolainen: I love to create content about AI, especially on the coding front, to help others tackle some of the hard problems like neural network quantization and deployment of their LLM and Computer Vision mode...
- Implementing a fast Tensor Core matmul on the Ada Architecture: Using tensor cores is a prerequisite to get anywhere near peak performance matrix multiplication on NVIDIA GPUs from Volta onwards.
GPU MODE ▷ #🍿 (23 messages🔥):
Finetuning Loop DevelopmentJob Queue AccessDiscord Competition InfrastructureTraining Data SourcesScheduler Development
-
Finetuning Loop Faces Compilation Challenges: A member is working on a finetuning loop with initial data from Popcorn-Eval, but results are disappointing as barely anything compiles to Python bytecode.
- They invite others to help or ask questions as they focus on getting the infrastructure right for the project.
- Job Queue Testing Access Requested: A member inquired about access to test the job queue, awaiting confirmation from a specific contact.
- Another member encouraged everyone to join in the testing process.
- Discord as Competition Infrastructure: The competition intends to use Discord for submissions through a bot and to display the leaderboard, leveraging a community familiar with GPU coding.
- There are concerns about Discord's message limitations, suggesting a potential web interface for better usability and result visibility in the future.
- Diverse Sources for Training Data: Training data for the LLMs comes from competition submissions, Triton docs, and a variety of public sources, despite some data quality concerns.
- Members discussed the necessity of annotating much of this data to improve its utility.
- Potential Scheduler Development on the Horizon: A member suggested developing a scheduler that could improve job handling and discussed the current reliance on GitHub Actions, which poses some challenges for local development.
- Another member expressed interest in potentially sponsoring compute resources, indicating interest in enhancing the infrastructure for the kernel leaderboard project.
GPU MODE ▷ #thunderkittens (4 messages):
Template Parameter InferenceRegister Limit in WGsRegister Spills in TK Programs
-
Template Parameter Inference Slowdown: A member noted that slow template parameter inference might cause delays, especially if done within an unrolled loop, suggesting to isolate and potentially make args explicit.
- They offered to assist further if provided with a relevant code snippet.
- Query on WG Register Limit: A question was raised regarding the reason for the increase_register limit of 480 across all workgroups (WGs).
- This inquiry indicates curiosity about how this limit impacts performance in workflows.
- Register Spills and Optimization Concerns: Concerns were expressed regarding register spills when compiling a TK program, even with an attempt to use
warpgroup::increase_registers<112>();which should fit under the 480 limit.
- The member sought advice on optimizing register usage and understanding the harm caused by spills.
- Impact of Spills on Performance: A participant affirmed that spills are very harmful, stressing the importance of increasing register counts for consumers.
- They cautioned that careful register allocation within the kernel is crucial to mitigate performance issues.
GPU MODE ▷ #edge (4 messages):
Memory Bound in High Context GenerationNeuron Culling in Small Language ModelsSpeculative Decoding Challenges
-
High Context Generation is Memory Bound Debate: A member argued that token generation will always be memory bound due to kv cache, while emphasizing the prefill phase's dependency on the prompt's token count.
- Another member countered, suggesting that high context is more commonly compute bound in naive computations, and posited that KV caching influences this balance.
- Seeking Resources on Neuron Culling: A member expressed interest in reading more about neuron culling in small language models, noting that most available research focuses on large language models.
- While specific resources were not provided, an individual mentioned hearing off-hand comments in various papers hinting at the effectiveness of sparsification techniques.
- Challenges of Speculative Decoding on Mobile: A member highlighted that executing speculative decoding requires running both a small draft model and a large verification model.
- They pointed out the difficulties this poses on resource constrained devices like mobile phones, complicating implementation.
Notebook LM Discord ▷ #use-cases (33 messages🔥):
NotebookLM experimentsAudio creations with NotebookLMPanel speaker briefingsUse case for spending analysisFeedback on NotebookLM
-
NotebookLM is a game-changer for content creation: Former Google CEO Eric Schmidt calls NotebookLM his 'ChatGPT moment of this year' and emphasizes how YouTuber creators and podcasters can leverage the tool in media production.
- He shares insights on using NotebookLM effectively for creative content generation in a YouTube video.
- In-depth analysis for academic research: A PhD student shared using NotebookLM to provide 30-60 minute overviews on academic materials, enabling critical perspective synthesis across various authors and ideas.
- This process aids in understanding the evolution of concepts within specific fields of study.
- Creative audio projects with NotebookLM: NotebookLM was utilized to create a customized audio briefing for panel speakers, compiling individual recommendations based on various source materials.
- Another member crafted separate audio interpretations of graffiti topics, highlighting diverse perspectives based on the same information.
- Feedback on NotebookLM's usability: Users shared mixed experiences with the mobile interface, noting its unique capabilities but also citing difficulty and limitations in design.
- Others discussed exploring NotebookLM's functionality for organizing personal insights and information synthesis.
- Impressive character creation for RPGs: A member reported using NotebookLM to generate a setting and character for their savage worlds RPG, accomplishing this in under five minutes.
- They praised its ease of use for on-the-fly game sessions, demonstrating NotebookLM's efficiency in creative storytelling.
Links mentioned:
- The Deep Dive: Podcast · Gary Smith · A deep dive into various topics of interest.
- no title found: no description found
- Ex Google CEO: AI Is Creating Deadly Viruses! If We See This, We Must Turn Off AI!: Eric Schmidt is the former CEO of Google and co-founder of Schmidt Sciences. He is also the author of bestselling books such as, ‘The New Digital Age’ and ‘G...
- A Closer Look: NotebookLM's Deep Dig on Token Wisdom ✨: Explore the intersection of technology and creativity with insights on AI, digital privacy, and the evolving landscape of innovation from Token Wisdom.
- Tweet from Ethan Mollick (@emollick): I got NotebookLM to play a role-playing game by giving it a 308 page manual Pretty good application of the rules, the character creation is very good (quoting accurately from 100 pages in) with small...
- NotebookLM character creation for Advertising and Antiheroes TTRPG: An exploration ousing NotebookLM to create characters and dilemmas for my indie TTRPG Advertising and Antiheroes, inspired by Ethan Mollick's experiment havi...
Notebook LM Discord ▷ #general (90 messages🔥🔥):
NotebookLM issuesFeature requestsUsing NotebookLM for gamingAudio file concernsIntegration with external sources
-
Users facing NotebookLM functionality issues: Many users reported difficulties such as unable to scroll long notes on mobile, issues with generating audio files, and confusion due to multiple copies of uploaded sources.
- Certain users also experienced problems accessing NotebookLM on different devices, with discussions highlighting the need for mobile compatibility.
- Feature requests and enhancements: Several members requested features like connecting RSS feeds to integrate external information and the ability to customize voice settings easily without additional applications.
- There were also calls for improved support for various file types, with frustrations expressed about uploading formats like XLS or images.
- Using NotebookLM for RPGs: Users noted that NotebookLM has been effectively utilized for RPGs, enabling engaging character creation and adventure building, with calls for further development to support gaming features.
- A prominent user expressed interest in contributing feedback and being a part of testing new gaming-related functionalities.
- Audio file management issues: Concerns were raised about the inability to generate separate audio tracks for different voices or issues with audio files being misnamed upon download.
- Users contemplated workarounds using digital audio workstations to isolate voices from combined audio files and discussed the potential of noise gate techniques.
- Access and usability questions: Several questions emerged regarding access rules, like age restrictions for new users or difficulties in creating new notebooks after prior attempts.
- There was a shared sentiment that navigating the interface could be confusing, especially when trying to delete or restart notebooks.
Links mentioned:
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- Shared Non-locality [Cycles] - Google Drive: no description found
- Tweet from Steven Johnson (@stevenbjohnson): One of our favorite unanticipated uses for NotebookLM has been RPG players and DMs using it for their games. (Though leave it to @emollick to figure out how do this with audio!) We're working on a...
Modular (Mojo 🔥) ▷ #mojo (51 messages🔥):
Mojo BenchmarkingHandling Pstate Driver IssuesDict Struct Bugs in MojoAstNode Struct ImplementationCPU Frequency Error Handling
-
Mojo Benchmarking with Random Arguments: A user sought advice on performing benchmarking with random function arguments in Mojo but noted that current methods require static arguments, adding undesirable overhead.
- Another user suggested pre-generating data for use in a closure to avoid overhead during benchmarking.
- Handling Pstate Driver Issues on WSL2: A user faced a Mojo crash potentially related to missing CPU pstate drivers on WSL2, indicating concerns about the Mojo runtime's handling of this issue.
- The discussion revealed that the WSL environment may not expose necessary interfaces for CPU frequency adjustments, highlighting a need for either Microsoft or Modular to provide a fix.
- Bug Identified in Dict Implementation: A user reported a crash occurring when using a Dict with SIMD types in Mojo, which worked up to a SIMD size of 8 but failed beyond that.
- The problem was replicated in a minimal example, suggesting a deeper issue within the Dict implementation that warrants attention.
- Struct Implementation Issues with AstNode: Another user tackled issues related to implementing a generic struct for graph nodes in Mojo, encountering type conversion errors with pointers to trait types.
- Suggestions included using a Variant type to encompass multiple node statement types, although challenges remain in managing type behavior.
- CPU Frequency Error Handling in Mojo: A user noted encountering errors regarding unavailable CPU frequency files while running Mojo, prompting discussions about graceful error handling.
- Participants emphasized that these errors should be treated as warnings instead, pointing out that the current Mojo implementation needs adjustments to account for nonexistent interfaces.
Links mentioned:
- no title found: no description found
- Variant | Modular Docs: A runtime-variant type.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #max (10 messages🔥):
Max Graphs and Knowledge GraphsUsing MAX for Graph SearchesFeasibility of LLM Inference with MAXPregel Integration with MAXMemory Requirements for Encoding Graphs
-
Exploring Max Graphs for Knowledge Graph Integration: A member pondered whether Max Graphs could effectively unify LLM inference with regular Knowledge Graphs, mentioning their potential use in RAG tools and NeuroSymbolic AI.
- They provided a GitHub link showcasing a proof-of-concept for this approach.
- MAX's Role in Accelerating Graph Searches: A member questioned if using MAX could aid in accelerating graph search, to which another confirmed the potential but noted limitations.
- It was clarified that unless the entire graph is copied into MAX, current capabilities are limited.
- Feasibility Concerns for Mojo and MAX Implementation: Concerns were raised regarding the feasibility of an agent implemented in Mojo and MAX that infers an LLM to execute searches.
- The idea was met with skepticism, where members debated its practicality in actual application.
- Pregel's Compatibility with MAX: A member suggested exploring Pregel in conjunction with MAX, referencing langgraph as an example.
- However, it was pointed out that current integration isn't possible without duplicating the entire graph.
- Graph Encoding and Memory Implications: A member proposed encoding the graph as 1D byte tensors to achieve zero-copy functionality, although the memory costs would be high.
- They noted that MAX does not currently handle pointers, complicating direct data manipulation.
Link mentioned: GitHub - microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system: A modular graph-based Retrieval-Augmented Generation (RAG) system - microsoft/graphrag
Cohere ▷ #discussions (41 messages🔥):
Issues with Cohere Model OutputUser Experience with Different k ValuesText Adventure Use Case ChallengesReactions to Cohere's PerformanceDocuments for Office Hours Topics
-
Users report odd outputs from Cohere: Users expressed frustration over bizarre outputs, particularly with the Cohere model incorrectly processing shorter texts and generating strange terms.
- The performance seems inconsistent, leading some to question the reliability of the Cohere model in certain applications.
- Adjusting k value raises concerns: One user highlighted the low k value impacting the model's token output, suggesting an increase to 400 to improve performance.
- Despite the adjustment, issues persisted with the model not responding as expected.
- Challenges in Text Adventures with Cohere: A member detailed using the Cohere model for text adventures, noting failures in sequential text delivery and erratic outputs during gameplay.
- Examples of incorrect and correct operations were shared, demonstrating the model's unpredictable behavior.
- Mixed reactions to Cohere's focus and performance changes: Users voiced concerns about a recent version being less effective, particularly for erotic role play, despite its primary focus on business applications.
- There is a desire for alternative solutions if the recent model continues to underperform.
- Request for documentation on office hours topics: A member inquired about the availability of online documentation related to Compression and Summarization discussed in office hours.
- Another member joked about spamming to ensure attendance at future meetings.
Links mentioned:
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Correct operation!: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
Cohere ▷ #announcements (1 messages):
Cohere Developer Office HoursLong text strategiesMemory in RAG systemsCompression and summarizationUse Case discussions
-
Cohere Developer Office Hours on Long Text Tactics: Join us today at 12:00 pm ET on the Discord Stage for a session focused on handling long text and real-world use cases, featuring live troubleshooting and practical tips.
- Cohere's Senior Product Manager for RAG, Maxime Voisin, will be present to share insights and address your specific needs in processing long text.
- Implementing Memory in RAG Systems: The session will cover tips on implementing memory or caching systems for managing long text content within RAG pipelines.
- Attendees are encouraged to bring their use cases to discuss strategies and solutions live.
- Summarization Techniques for Long Text: Participants will learn about techniques for compressing and summarizing long text while maintaining essential information.
- This includes practical applications and methods suitable for various projects.
- Spotlight on Use Cases: File Upload and SQL Queries: Highlighted will be specific use cases, including File Upload and SQL Query Generation, promoting discussion on tailored strategies.
- Members are encouraged to actively share their challenges related to these use cases during the session.
Cohere ▷ #questions (4 messages):
Cohere API issuesPlaywright and file uploadsUnexpected tokens in API responsesTurning off citations
-
Cohere and Playwright struggles with file uploads: A member mentioned they can upload a file to Cohere via Playwright, but face issues asking questions about that text, getting a response that they should paste the text instead.
- This limitation prompts questions about how to effectively leverage the upload feature for inquiries.
- V1 API facing unexpected token issues: There are reports of problems using the v1 API with the 08-2024 command R+ model and web search connector, yielding unexpected tokens like '
- In response, one member suggested that this might relate to requesting a JSON response alongside web search and citations.
- Citations causing issues in responses: One user indicated they solved the token issue by turning off citations but expressed a desire for a more refined solution.
- This raises concerns about the integration of citations and JSON responses in the context of web search queries.
Cohere ▷ #api-discussions (1 messages):
API ErrorsService Unavailable Issues
-
Encountering API Error 503: A user reported receiving a 503 Service Unavailable error indicating an upstream connection issue with the API on 2024-11-15.
- The error details included 'upstream connect error or disconnect/reset before headers' and referenced a possible remote connection failure.
- Request for Help on API Error: The same user sought assistance by asking if anyone else had experienced this specific API error.
- This highlights potential shared challenges among users relating to API reliability.
Cohere ▷ #cohere-toolkit (3 messages):
Toolkit Release v1.1.3New Features in ToolkitDevelopment Experience Improvements
-
Toolkit Release v1.1.3 is here!: Release 2024-11-18 (v1.1.3) introduces a range of changes including improved global Settings usage and major tool refactoring.
- Key modifications include renamed tool schema and a recommendation for updating forks via make reset-db and make migrate.
- Exciting New Features Added!: The latest update added support for ICS files, a File content viewer, and tools toggling for custom Assistants, credited to Danylo.
- These enhancements aim to elevate functionality and usability within the Toolkit.
- Bug Fixes and Maintenance Updates: This release addresses several bug fixes including issues with the auth tool for Slack and provides simplified representations for Deployments and Model DBs.
- The Toolkit’s usability has been enhanced by removing steps to add tools and improving overall maintenance.
- Looking Ahead: New Features on the Horizon: Upcoming features include a Hot keys binding button, integration with Gmail + SSO, and enhanced integration tests for pull requests.
- Additionally, a complete overhaul of deployments and support for Azure deployment with Docker compose are in the pipeline.
- Enhancements for Development Experience: Future cycles will prioritize improving the development experience around build processes, running, debugging, and making changes on the Toolkit.
- Feedback and suggestions for enhancements are welcomed to ensure the Toolkit meets the needs of developers.
Link mentioned: Release 2024-11-18 (v1.1.3) · cohere-ai/cohere-toolkit: What's Changed Improve global Settings usage to deal with settings that aren't set Major tool refactoring: Clarify tool schema names (eg ManagedTool -> ToolDefinition, ToolName -> Tool...
LlamaIndex ▷ #blog (4 messages):
Ask AI widget in documentationMultimedia Research Report GeneratorStructured Financial Report GenerationMistral Multi-Modal Image Model Launch
-
Documentation improves with Ask AI widget: Our Python documentation received an upgrade with the new 'Ask AI' widget, enabling users to ask questions and receive accurate, up-to-date code through a RAG system. Check it out here.
- It’s a truly magically accurate feature that enhances the coding experience!
- Create reports with multimedia insights: We've released a new video that showcases how to generate a Multimedia Research Report, summarizing insights from complex documents like slide decks. Watch it here.
- This tool interleaves text and visuals to simplify reporting.
- Generate structured financial reports effortlessly: Our latest video demonstrates how to generate structured Financial Reports using a multi-agent workflow across 10K documents. Discover the detailed process here.
- This enables simplified analyses with both text and tables.
- Mistral launches advanced multi-modal image model: Mistral unveiled a new state-of-the-art multi-modal image model, and early adopters can use it with day 0 support by installing via
pip install llama-index-multi-modal-llms-mistralai. Explore usage in the provided notebook.
- The model supports various functions like
completeandstream completefor efficient image understanding.
Link mentioned: Multi-Modal LLM using Mistral for image reasoning - LlamaIndex: no description found
LlamaIndex ▷ #general (36 messages🔥):
condenseQuestionChatEngineCitationQueryEngineCSV data handlingEY Techathon team buildingblockchain development collaboration
-
Challenges with condenseQuestionChatEngine: A user reported issues with the condenseQuestionChatEngine generating nonsensical standalone questions when topics abruptly switch.
- Suggestions included customizing the condense prompt and considering the CondensePlusContext which retrieves context for user messages.
- Using CitationQueryEngine for source citations: A user inquired about linking citations in their UI with the
CitationQueryEngineresponse, where only one citation number was provided despite having multiple sources.
- It was suggested to implement a solution to map citation numbers to their respective source nodes by parsing the response text.
- Improving CSV data embeddings: A user asked for efficient methods to generate embeddings for CSV files, noting that the PagedCSVReader creates one embedding per row.
- Another user mentioned converting CSV to markdown could improve performance while maintaining embedding integrity.
- EY Techathon team recruitment: A user announced they were building a team for the EY Techathon looking for an AI developer and a web app developer, urging interested individuals to DM quickly.
- This was met with a reminder to post such opportunities in the appropriate job posting channel.
- Issues with Property Graph example: A user trying to replicate a Property Graph example reported seeing all nodes displayed as
__NODE__and received warnings about unknown labels.
- They asked for assistance in resolving these issues while executing queries from the notebook.
Link mentioned: MLflow LlamaIndex Flavor: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
EY Techathon TeamAI Developer PositionWeb App Developer Position
-
Building a Team for EY Techathon: The team is currently recruiting for the EY Techathon, with two spots available: one for an AI developer and another for a Web app developer.
- Interested candidates are encouraged to DM ASAP to secure their spot in the team.
- Urgent Call for AI Developer: The message emphasizes the urgent need for an AI developer to fill one of the vacant spots on the team participating in the EY Techathon.
- Potential applicants should act quickly and reach out directly to participate.
- Web App Developer Spot Available: There is also a call for a Web app developer to join the EY Techathon team, highlighting the need for web application skills.
- Candidates interested in this position should also reach out via DM without delay.
OpenAccess AI Collective (axolotl) ▷ #general (20 messages🔥):
Liger Kernel PerformanceDPO Implementation FeedbackWeb3 Job ListingsModel Optimization Requests
-
Liger Kernel Runs 3x Faster: Liger claims to run ~3x faster than a previous model while using the same memory in the worst-case scenario, with no errors reported during installation.
- Some members expressed skepticism, wondering if this performance is only achievable on NVIDIA hardware.
- Concerns Over DPO Implementation: Members discussed an issue with the merged DPO implementation, highlighting that it did not utilize reference model logprobs as intended.
- One member noted it may still be accurate when not using a reference model.
- Web3 Team Hiring Announced: A Web3 platform is actively recruiting for several positions, offering competitive salaries with roles ranging from developers to beta testers.
- They emphasized a friendly work environment, with no experience required for applicants.
- Request for Model Running Assistance: A user expressed the need for an easy-to-use pipeline to run models on RunPod or HF Space, hoping to simplify resource-heavy processes due to slow internet.
- They mentioned the possibility of optimizing performance by loading one layer at a time to manage RAM better.
Link mentioned: Reddit - Dive into anything: no description found
OpenAccess AI Collective (axolotl) ▷ #other-llms (2 messages):
AnyModal FrameworkChai Research GrantsGenerative AIOpen-source ProjectsCommunity-driven AGI
-
AnyModal Framework Integrates Multimodal Data: A discussion highlighted the development of AnyModal, a framework allowing integration of data types like images and audio with LLMs, simplifying setup for tasks such as LaTeX OCR and image captioning.
- Feedback and contributions are sought to enhance this work in progress, showcasing models like ViT for visual inputs.
- Chai Research Announces Open-source Grants: Chai, a generative AI startup with 1.3M DAU, is offering unlimited grants for open-source projects focused on accelerating community-driven AGI, having already awarded grants to 11 individuals.
- Grants vary in tiers from $500 to $5,000, depending on innovation and impact, inviting developers to submit their projects via Chai Grant.
- Chai's Mission in AI Content Creation: Chai aims to balance factual correctness and entertainment in AI, focusing on empowering creators to build and share AI content, supported by a team of ex-quant traders.
- Their efforts involve experimentation with long-context, LoRA, and RLHF to align AI behavior with creator intent.
- Showcasing Recent Grant Recipients: Recent grantees include projects like Medusa and Streaming LLM, highlighting innovations in LLM generation acceleration.
- Each project aims to push the boundaries of LLM capabilities while contributing to the AI community's growth.
- Invitation to Collaborate and Submit Ideas: Chai encourages submissions of open-source projects to their grant program, emphasizing ease of application completion within 2 minutes.
- Participants are reminded to include referral emails for potential benefits, fostering collaboration among developers.
Links mentioned:
- GitHub - ritabratamaiti/AnyModal: AnyModal is a Flexible Multimodal Language Model Framework: AnyModal is a Flexible Multimodal Language Model Framework - ritabratamaiti/AnyModal
- CHAI,): CHAI is an AI company in Palo Alto. We are building the leading platform for conversational generative artificial intelligence.
- Chai Grant: CHAI AI Grant. $1,000 - $5,000 cash award to any open-source projects. Accelerating community-driven AGI.
OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
vLLM analyticsToken usage inspection
-
Seeking vLLM Analytics Platform: A member inquired about a platform that integrates with vLLM to provide analytics on token usage and allows for inspection of responses.
- The request highlights a community interest in tools that enhance understanding and monitoring of vLLM's performance.
- Community Support for vLLM Inquiry: The inquiry prompted members to consider potential solutions or similar experiences related to vLLM integration.
- Members are encouraged to share insights or recommend platforms that could fulfill these analytical needs.
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
Pretraining with Instruction-Based DatasetsMathematical Sequence ProblemsCode Availability for Instruction Datasets
-
Exploration of Instruction Dataset for Pretraining: A user shared a link to an instruction pretraining dataset and posed a question about identifying the missing number in a sequence: 4, 10, X, 46, and 94.
- They detailed the properties of the sequence and concluded that X is 22 due to a pattern of increasing values.
- Query on Code Availability: Another user inquired if there is code available for the dataset mentioned by duh_kola.
- A member responded that there is only a paper related to the topic, indicating a lack of code resources.
Link mentioned: instruction-pretrain/ft-instruction-synthesizer-collection · Datasets at Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (9 messages🔥):
Pretraining and Finetuning Qwen/Qwen2Phorm Bot IssuesUnderstanding eval_steps
-
Pretraining Qwen/Qwen2 and Using Axolotl Docker: A member inquired about the steps needed to first pretrain the Qwen/Qwen2 model using QLoRA with their pretraining dataset and then finetune it with the instruct dataset in Alpaca format.
- They confirmed having the Axolotl Docker ready for the process.
- Phorm Bot malfunction: A member reported issues with the Phorm bot, stating that it could not provide answers even for simple questions.
- This led to concerns about the reliability of the bot within the community.
- Evaluation Steps Clarification Needed: Another user asked for clarification on what eval_steps mean in the context of model training.
- However, no answers were available from the Phorm bot regarding this inquiry.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (6 messages):
eval_steps inquiryPhorm response issues
-
User seeks clarification on eval_steps: A user asked about the meaning of eval_steps, looking for a straightforward definition.
- However, the automated system's response was notably undefined, leading to further frustration.
- User expresses disappointment in Phorm's capabilities: A user expressed shame at Phorm's inability to answer what they considered a simple question about eval_steps.
- This prompted another user to suggest seeking assistance from a member named caseus for clarity.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
tinygrad (George Hotz) ▷ #general (26 messages🔥):
Tinygrad ContributionsRelease ScheduleAlias ImplementationInt64 Indexing BountyGraph and Buffer Improvements
-
Tinygrad Contributions require high quality: George noted that contributions to Tinygrad should meet a high bar for quality, emphasizing that low-quality PRs will be closed without comment.
- He encouraged potential contributors to read prior merged PRs, explaining that many who tackle bounties should ideally have previous merges first.
- Tinygrad release coming up: A release for Tinygrad is scheduled in approximately 15 hours, with ongoing discussions about various ongoing improvements and updates.
- Key points for the release include progress in blocks, lazy buffers, and performance enhancements with Qualcomm scheduling.
- Discussion on convenience methods for Tinygrad: A user mentioned the need for convenience methods like
scatter_add_andxavier_uniform, suggesting that they might help users avoid rewriting code repeatedly.
- George agreed to merge these methods from frameworks like Torch and TensorFlow if they align with existing features.
- Clarifying Int64 Indexing Bounty: A member expressed confusion regarding the Int64 indexing bounty, mentioning that it seems functional but later decided they can cause crashes.
- This led to discussions around improving documentation and ensuring clarity on functionality for bounty requirements.
- Improvements in Graph and Buffer Management: Members discussed ongoing efforts to refine the Big Graph and LazyBuffer concepts within Tinygrad, with plans to delete the LazyBuffer.
- This aims to streamline processing and track UOp Buffers, facilitating better performance and functionality within the project.
Links mentioned:
- Tweet from the tiny corp (@tinygrad): pip install tinygrad Quoting Jeremy Howard (@jeremyphoward) Oh wow. This is gonna be super tricky to figure out what to do now. There isn’t any easy automated way to install a full deep learning s...
- torch.nn.init — PyTorch 2.5 documentation: no description found
- delete LazyBuffer, everything is UOp · Issue #7697 · tinygrad/tinygrad: Smaller big graph - VIEW of BUFFER rewriting to LOAD/PRELOAD #7731 #7732 #7695 Track UOp Buffers with WeakKeyDictionary #7742 #7745 #7746 #7743 #7766 #7767 Implement missing methods on UOp from laz...
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
LSTM Training on M1 MacAMD GPU Issues with PyTorchTinyGrad for AMDTinyNet Training ExampleJIT Compilation Problems
-
Training LSTM Network on M1 Mac: A user praised the performance of PyTorch on their M1 Mac, noting it as fantastic for training their LSTM network.
- They contrasted this experience with difficulties on an AMD GPU in Ubuntu, where they couldn't get PyTorch to recognize the device.
- TinyGrad for AMD GPU Training: There was a query on whether importing TinyGrad would negate the need for installing ROCm to train on an AMD GPU.
- A reference was made to George's stream where it was mentioned that he 'ripped out AMD userspace'.
- Training MNIST Classifier with TinyNet: A user shared Python code for a TinyNet framework training an MNIST Classifier, with specific implementations of Adam optimizer and dropout.
- They noted successful training without JIT compilation, but encountered hanging issues when JIT was applied on an M3 Max MacBook.
- JIT Compilation Hangs on Step Two: Following the previous issue, it was confirmed that training works without JIT, highlighting a specific problem with the JIT compilation hanging on the second step.
- Another user inquired if the code was on master and suggested checking the output with DEBUG=2 for more insights.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Intel Tiber AI CloudIntel Liftoff ProgramAMA with Intel
-
Exclusive AMA with Intel on AI Development: Join the AMA session with Intel on Building with Intel: Tiber AI Cloud and Intel Liftoff on 11/21 at 3pm PT for insights into Intel’s AI tools.
- This event will provide a unique opportunity to interact with Intel specialists and learn how to boost your AI projects using their resources.
- Discover Intel Tiber AI Cloud's Capabilities: The session will introduce the Intel Tiber AI Cloud, a robust platform designed to enhance AI projects with advanced computing capabilities.
- Participants will learn how to leverage this powerful platform for optimal efficiency in their hackathon projects.
- Intel Liftoff Program Supports Startups: Discussion on the Intel Liftoff Program will cover comprehensive benefits for startups, including mentorship and technical resources.
- Attendees will gain insights on how this program can support their development efforts from the ground up.
Link mentioned: Building with Intel: Tiber AI Cloud and Intel Liftoff · Luma: Building with Intel: Tiber AI Cloud and Intel Liftoff About the AMA Join us for an exclusive AMA session featuring specialists from Intel, our esteemed sponsor…
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 10 AnnouncementPercy Liang's PresentationOpen-Source Foundation ModelsCourse Resources
-
Lecture 10 Kicks Off at 3 PM PST: The 10th lecture, featuring esteemed guest speaker Percy Liang, is scheduled for today at 3:00 PM PST. Attendees can watch the livestream here.
- This session focuses on Open-Source and Science in the Era of Foundation Models, discussing the value of open-source contributions to AI.
- Percy Liang Talks Open-Source Innovation: In his talk, Percy Liang argues that open-source models are crucial for building a rigorous foundation for AI amidst plummeting openness. He highlights the need for substantial resources, including data, compute, and research expertise.
- Liang, associated with Stanford University and the Center for Research on Foundation Models, will propose promising directions leveraging community support for open-source foundation models.
- Access Course Resources Anytime: Students can find all necessary course materials, including livestream links and homework assignments, at the course website.
- For any inquiries or feedback, participants are encouraged to communicate directly with course staff in the designated channel.
Link mentioned: CS 194/294-196 (LLM Agents) - Lecture 10, Percy Liang: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
Team SeekingQuiz Score Notifications
-
User seeks a team to join: A member is on the lookout for a team to join and shared their LinkedIn profile. They noted being a late entrant to the course but emphasized putting in extra time.
- Looking for collaboration opportunities in the course.
- Quiz score notifications go to registered email: A member confirmed that for every quiz attempt, a copy of the Google Form with the score will be sent to the student's registered email account.
- If it's not found in the inbox, they advised checking the SPAM folder as well.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (10 messages🔥):
Grade AvailabilityWriting Section DeadlineMissing Lecture SlidesHackathon Article DeadlineUsing Substack for Submissions
-
Grades available after course completion: Due to the high number of students, grades will only be released at the end of the course on December 12th.
- Participants are encouraged to submit everything and put in the effort to ensure they are fine.
- Writing section deadline clarified: The deadline for the writing section is set for December 12th PST, and students can write their posts anytime before that.
- There was confirmation that flexibility is allowed regarding when to submit the writing.
- Missing slides from Lecture 8: Concerns were raised about some slides missing in the shared deck for Lecture 8.
- It was noted that some guest lecturers wanted to make slight alterations to their slides before they were posted.
- Hackathon article deadline confirmed: The deadline for submitting articles for hackathon participants is December 12th at 11:59 PM PST.
- Participants expressed interest in knowing more about this timeline.
- Using Substack for writing submissions: Inquired whether using Substack for writing submissions was an option.
- The response was affirmative, indicating it is acceptable for that purpose.
DSPy ▷ #show-and-tell (1 messages):
DSPy VLM tutorialAttributes extraction from images
-
DSPy Introduces VLM Support: DSPy recently added support for VLMs in beta, showcasing attributes extraction from images.
- A member shared an example demonstrating how to extract useful attributes from screenshots of websites, highlighting the potential of this feature.
- Attributes Extraction from Screenshots: The thread discusses techniques for extracting useful attributes from screenshots of websites, indicating practical applications of DSPy.
- This approach aims to streamline how developers can interact with visual data, bringing attention to emerging capabilities in the DSPy toolkit.
Link mentioned: Tweet from Karthik Kalyanaraman (@karthikkalyan90): 🧵DSPy recently added support for VLMs in beta. A quick thread on attributes extraction from images using DSPy. For this example, we will see how to extract useful attributes from screenshots of websi...
DSPy ▷ #general (10 messages🔥):
DSPy signaturesUsername generation strategiesCode analysis with DSPyLLM caching issuesRandomization in LLM outputs
-
Less English, More Code in DSPy Signatures: A member shared that most people write too much English in their DSPy signatures; instead, one can achieve a lot with concise code.
- They referenced a tweet by Omar Khattab that emphasizes the effectiveness of super short pseudocode.
- Tackling Username Generation with DSPy: A user raised concerns about generating diverse usernames, noting that there were many duplicates.
- Another member suggested disabling the cache in the LLM object, but the original user mentioned they had already done so.
- Increasing Username Randomness with High Variance: To address the issue of duplicate usernames, a member recommended increasing the LLM temperature and adding a storytelling element before the name generation.
- They proposed using a high-temperature model for generating the story and a lower temperature for quality name generation.
- Analyzing Topics with DSPy Code: A user shared a snippet of Python code to analyze various aspects of a topic using DSPy, covering facets like market size and key researchers.
- The code demonstrates how to utilize predictive features of DSPy to gather information about different sub-areas of a topic.
Link mentioned: Tweet from Omar Khattab (@lateinteraction): new hobby: dspy code golf super short pseudocode with natural language tasks should just work and be optimizable Quoting Ajay Singh (@ajay_frontiers) For reliability, nothing beats DSPy (thanks to...
LAION ▷ #general (8 messages🔥):
VisRAG TalkHackathon CultureCopyright TrollsLegal Discussions
-
Exciting VisRAG Talk at Jina AI: Join the upcoming talk at Jina AI where Shi will explore his innovative work on VisRAG, a fully visual RAG pipeline that eliminates the need for parsing.
- Expect to learn about the construction, evaluation, and exciting future possibilities related to VisRAG, which nearly tripled its training dataset size compared to ColPali.
- Tasty Hacks Hackathon Announcement: A new hackathon, Tasty Hacks, aims to inspire participants to create projects for creativity's sake rather than for utility, moving away from the traditional hackathon culture of optimizing for winning.
- Organizers are seeking kind and nerdy individuals willing to team up and create in a smaller setting of just 20-30 people.
- Discussion on Copyright Trolls: There was a revelation that a particular individual, Trevityger, has been identified as an infamous copyright troll, causing concern in the community.
- Members expressed their wariness and shared insights following a member's digging into Trevityger's background.
- Legal Matters and Community Insights: In a thread, legal issues were discussed, with a member explaining the law surrounding certain topics to clarify misunderstandings.
- The community remained engaged, highlighting the importance of legal awareness in discussions.
- Moderate Improvements Over Epochs: A member reported only moderate improvements in model performance over the recent epochs, specifically noting the updates from epoch 58 to epoch 100.
- The technical discussions emphasized the ongoing challenges despite advancements in model iterations.
Links mentioned:
- tastyhacks '24 berkeley · Luma: many hackathons nowadays have been tainted by status. participants optimize for winning by incorporating sponsor prizes minimally in their hacks, which later…
- The Progression in Multimodal Document RAG · Zoom · Luma: In this talk, Shi will present his recent work VisRAG, a fully visual retrieval-augmented generation (RAG) pipeline that eliminates the need for parsing. He…
- openbmb/VisRAG-Ret · Hugging Face: no description found
LAION ▷ #research (1 messages):
MultiNet BenchmarkVision-Language-Action modelsVLA model performancePrompt engineering in roboticsMini VLA model μGATO
-
Launch of MultiNet Benchmark for VLA Models: The new paper titled "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" evaluates VLA models across 20 real-world tasks, revealing key insights about their performance. Full details can be found here.
- This work aims to advance the development of general-purpose robotic systems, demonstrating the critical need for systematic evaluation across diverse tasks.
- Performance Comparison Among Leading VLA Models: A comparison of GPT-4o, OpenVLA, and JAT shows that while simple tasks like pick-and-place are manageable, models struggle with complex multi-step processes. Notably, the results indicate significant performance variations based on the task and robot platform.
- The analysis highlights the utility of sophisticated prompt engineering, which led to improved consistency in task performance when utilizing GPT-4o.
- Introduction of μGATO, a Mini VLA Model: The team introduced μGATO, a mini and understandable baseline model tailored for the MultiNet benchmark. This serves as a tool to explore and advance multimodal action models in robotics.
- The ongoing efforts by the Manifold team signal the forthcoming release of more innovations in multimodal action models.
- Code and Software Release for Multimodal Action Tasks: All evaluation code and benchmarks for the MultiNet project are now available for download on GitHub, facilitating easy profiling of models against the benchmark. Developers are encouraged to check out the suite here.
- This initiative positions researchers and developers to standardize and expand their models effectively on various robotic tasks.
- Call for Collaboration and Contributions: The Manifold team invites contributions and collaboration towards enhancing the MultiNet benchmark through direct contact or community channels. Interested parties can reach out via DM or join the Discord community here.
- This collaborative effort underscores the importance of community engagement in advancing research on multimodal action models.
Links mentioned:
- Multinetv0.1: no description found
- MultiNet/src/modules at main · ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- GitHub - ManifoldRG/MultiNet: Contribute to ManifoldRG/MultiNet development by creating an account on GitHub.
- SOCIAL MEDIA TITLE TAG: SOCIAL MEDIA DESCRIPTION TAG TAG
MLOps @Chipro ▷ #events (2 messages):
Starting with MLOpsSeeking ClarificationComplexity in MLOps
-
Seeking Guidance on MLOps: A member expressed their confusion about where to start with MLOps, stating, 'It’s all complicated.'
- This prompted another member to request clarification, asking the original poster to specify their concerns further.
- Request for Clarification on Complications: Another member engaged with the confusion expressed, indicating that the question was quite broad and asked for more specifics.
- This interaction highlights the need for clearer communication when addressing complex topics like MLOps.
Mozilla AI ▷ #announcements (2 messages):
Common Corpus datasetTransformer Lab Demo
-
Pleias launches Common Corpus for LLM training: Pleias, a member of the 2024 Builders Accelerator cohort, announces the release of the Common Corpus, the largest open dataset for LLM training, emphasizing a commitment to having training data under permissive licenses.
- 'The open LLM ecosystem particularly lacks transparency around training data,' Pleias notes, stating that Common Corpus aims to address this transparency gap. Find the full post here.
- Tomorrow's RAG demo by Transformer Lab: A demo from Transformer Lab is scheduled, showcasing how to train, tune, evaluate, and use RAG on LLMs without coding, using a user-friendly UI.
- The event promises to make the process easy-to-install in your local environment, which has generated excitement in the community. More details can be found here.
Torchtune ▷ #general (1 messages):
DCP async checkpointingIntermediate checkpointing efficiency
-
DCP Async Checkpointing Implementation: DCP async checkpointing aims to improve intermediate checkpointing in TorchTune with a new feature that is currently a work in progress.
- This pull request reveals that the process aims to notably enhance efficiency by reducing intermediate checkpointing time by 80%.
- Intermediate Checkpointing Time Reduction: The implementation of DCP async checkpointing promises significant reductions, estimating an 80% cut in checkpointing time due to improved methodologies.
- This approach is part of ongoing efforts in optimizing distributed checkpointing for better performance.
Link mentioned: [DCP][RFC] DCP async checkpointing in TorchTune for intermediate checkpoints [WIP] by saumishr · Pull Request #2006 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) This diff introduces the DistributedCheckpointing based ...
AI21 Labs (Jamba) ▷ #jamba (1 messages):
rotem2733: Hello?