[AINews] Pixtral 12B: Mistral beats Llama to Multimodality
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Vision Language Models are all you need.
AI News for 9/10/2024-9/11/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (216 channels, and 3870 messages) for you. Estimated reading time saved (at 200wpm): 411 minutes. You can now tag @smol_ai for AINews discussions!
Late last night Mistral was back to its old self - unlike Mistral Large 2 (our coverage here), Pixtral was released as a magnet link with no accompanying paper or blogpost, ahead of the Mistral AI Summit today celebrating the company's triumphant first year.
VB of Huggingface had the best breakdown:
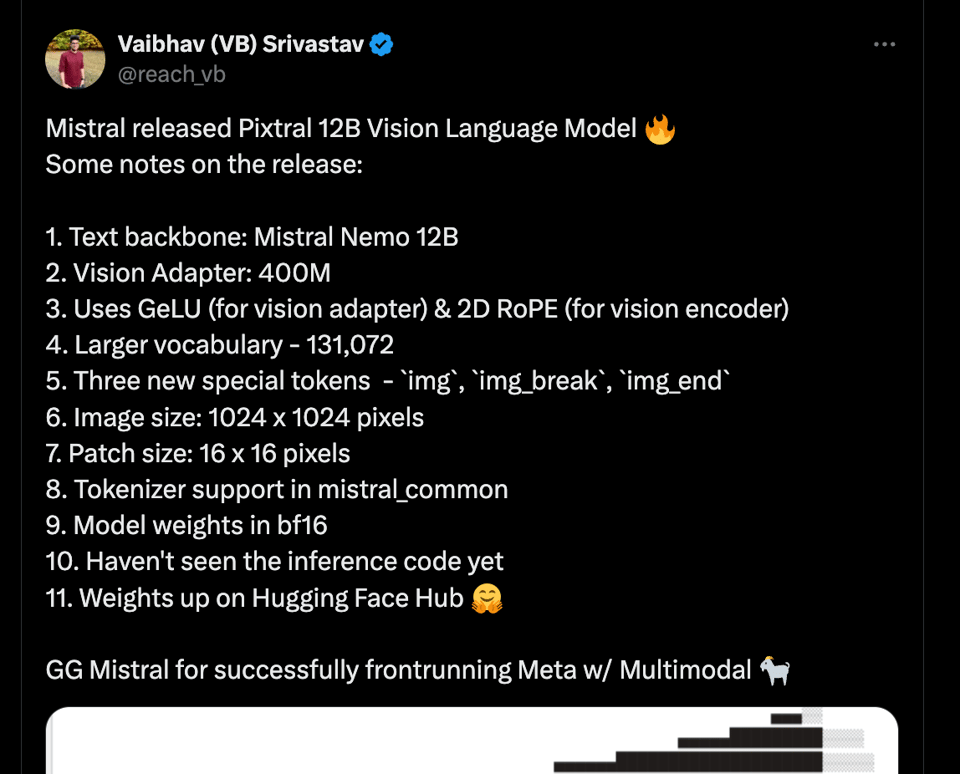
VB rightfully points out that Mistral beat Meta to releasing an open-weights multimodal model. You can see the new ImageChunk API in the mistral-common update:

More hparams are here for those interested in the technical details.
At the Summit, Devendra Chapilot shared more details, on architecture (designed for arbitrary sizes and interleaving)
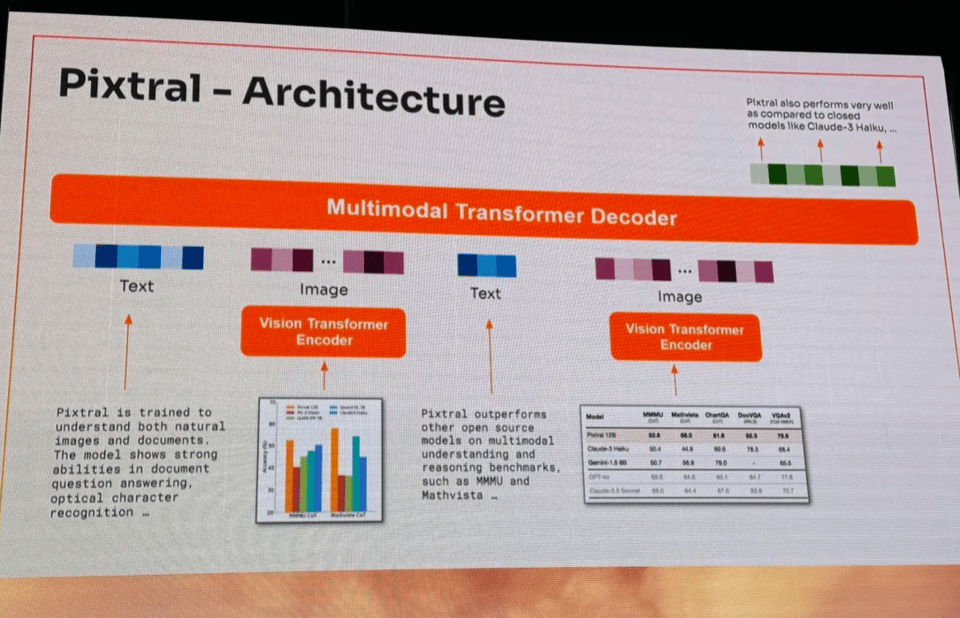
together with impressive OCR and screen understanding examples (with mistakes!) favorable benchmark performance vs open model alternatives (though some Qwen and Gemini Flash 8B numbers were off):
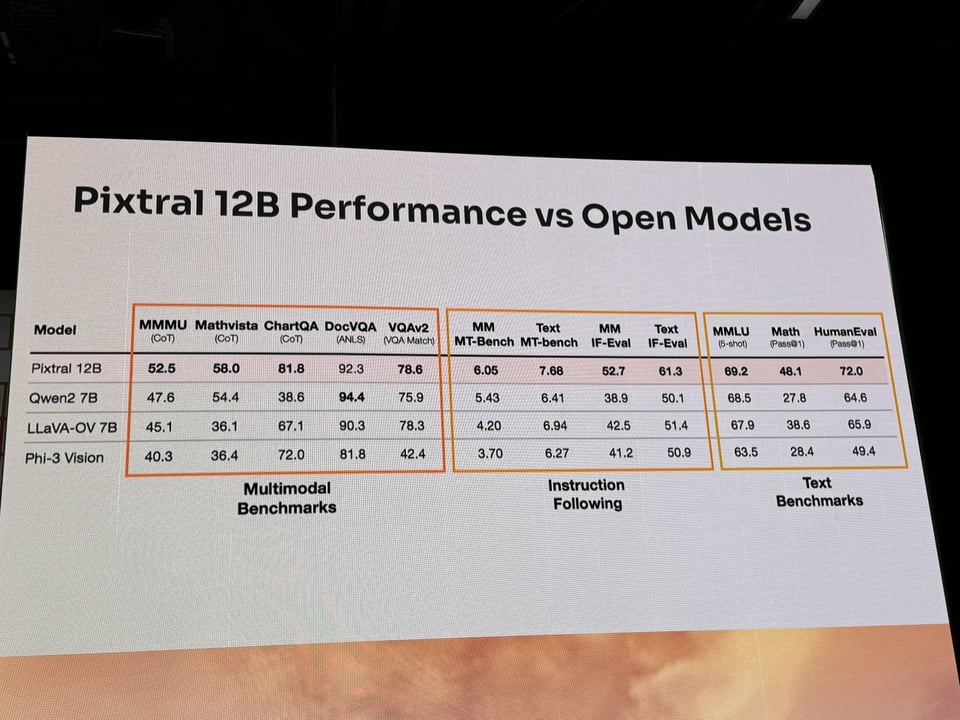
Still an extremely impressive feat and well deserved victory lap for Mistral, who also presented their model priorities and portfolio.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Modular (Mojo 🔥) Discord
- Unsloth AI (Daniel Han) Discord
- OpenAI Discord
- HuggingFace Discord
- aider (Paul Gauthier) Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- OpenRouter (Alex Atallah) Discord
- CUDA MODE Discord
- Interconnects (Nathan Lambert) Discord
- Perplexity AI Discord
- Nous Research AI Discord
- Latent Space Discord
- OpenInterpreter Discord
- Cohere Discord
- Eleuther Discord
- LlamaIndex Discord
- LangChain AI Discord
- Torchtune Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- LLM Finetuning (Hamel + Dan) Discord
- Mozilla AI Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Modular (Mojo 🔥) ▷ #general (336 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #mojo (394 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (608 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
- Unsloth AI (Daniel Han) ▷ #help (48 messages🔥):
- OpenAI ▷ #ai-discussions (466 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (12 messages🔥):
- OpenAI ▷ #prompt-engineering (17 messages🔥):
- OpenAI ▷ #api-discussions (17 messages🔥):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (241 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (6 messages):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (23 messages🔥):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #NLP (6 messages):
- aider (Paul Gauthier) ▷ #general (141 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (105 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (3 messages):
- LM Studio ▷ #general (174 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (67 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (197 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (171 messages🔥🔥):
- CUDA MODE ▷ #general (23 messages🔥):
- CUDA MODE ▷ #triton (7 messages):
- CUDA MODE ▷ #torch (1 messages):
- CUDA MODE ▷ #jobs (39 messages🔥):
- CUDA MODE ▷ #torchao (9 messages🔥):
- CUDA MODE ▷ #off-topic (1 messages):
- CUDA MODE ▷ #llmdotc (46 messages🔥):
- CUDA MODE ▷ #sparsity-pruning (7 messages):
- CUDA MODE ▷ #cudamode-irl (9 messages🔥):
- CUDA MODE ▷ #liger-kernel (3 messages):
- Interconnects (Nathan Lambert) ▷ #news (63 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (58 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (86 messages🔥🔥):
- Perplexity AI ▷ #sharing (17 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- Nous Research AI ▷ #general (74 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (13 messages🔥):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Latent Space ▷ #ai-general-chat (83 messages🔥🔥):
- OpenInterpreter ▷ #general (36 messages🔥):
- OpenInterpreter ▷ #O1 (45 messages🔥):
- OpenInterpreter ▷ #ai-content (2 messages):
- Cohere ▷ #discussions (52 messages🔥):
- Cohere ▷ #questions (5 messages):
- Cohere ▷ #api-discussions (6 messages):
- Cohere ▷ #projects (1 messages):
- Eleuther ▷ #general (15 messages🔥):
- Eleuther ▷ #research (4 messages):
- Eleuther ▷ #interpretability-general (6 messages):
- Eleuther ▷ #lm-thunderdome (1 messages):
- Eleuther ▷ #multimodal-general (3 messages):
- Eleuther ▷ #gpt-neox-dev (3 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (24 messages🔥):
- LangChain AI ▷ #general (15 messages🔥):
- LangChain AI ▷ #share-your-work (2 messages):
- Torchtune ▷ #general (4 messages):
- Torchtune ▷ #dev (5 messages):
- DSPy ▷ #papers (2 messages):
- DSPy ▷ #general (2 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- LAION ▷ #general (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Benchmarks
- Arcee AI's SuperNova: @_philschmid announced the release of SuperNova, a distilled reasoning Llama 3.1 70B & 8B model. It outperforms Meta Llama 3.1 70B instruct across benchmarks and is the best open LLM on IFEval, surpassing OpenAI and Anthropic models.
- DeepSeek-V2.5: @rohanpaul_ai reported that the new DeepSeek-V2.5 model scores 89 on HumanEval, surpassing GPT-4-Turbo, Opus, and Llama 3.1 in coding tasks.
- OpenAI's Strawberry: @rohanpaul_ai shared that OpenAI plans to release Strawberry as part of its ChatGPT service in the next two weeks. However, @AIExplainedYT noted conflicting reports about its capabilities, with some claiming it's "a threat to humanity" while early testers suggest "its slightly better answers aren't worth the 10 to 20 second wait".
AI Infrastructure and Deployment
- Anthropic Workspaces: @AnthropicAI introduced Workspaces to the Anthropic Console, allowing users to manage multiple Claude deployments, set custom spend or rate limits, group API keys, and control access with user roles.
- SambaNova Cloud: @AIatMeta highlighted that SambaNova Cloud is setting a new bar for inference on 405B models, available for developers to start building today.
- Groq Performance: @JonathanRoss321 claimed that Groq set a new speed record, with plans to improve further.
AI Development Tools and Frameworks
- LangChain Academy: @LangChainAI launched their first course on Introduction to LangGraph, teaching how to build reliable AI agents with graph-based workflows.
- Chatbot Arena Update: @lmsysorg added a new "Style Control" button to their leaderboard, allowing users to apply it to Overall and Hard Prompts to see how rankings shift.
- Hugging Face Integration: @multimodalart shared that it's now easy to add images to the gallery of LoRA models on Hugging Face.
AI Research and Insights
- Sigmoid Attention: @rohanpaul_ai discussed a paper from Apple proposing Flash-Sigmoid, a hardware-aware and memory-efficient implementation of sigmoid attention, yielding up to a 17% inference kernel speed-up over FlashAttention2-2 on H100 GPUs.
- Mixture of Vision Encoders: @rohanpaul_ai shared research on enhancing MLLM performance across diverse visual understanding tasks using a mixture of vision encoders.
- Citation Generation: @rohanpaul_ai reported on a new approach for citation generation with long-context QA, boosting performance and verifiability.
Industry News and Trends
- Klarna's Tech Stack Change: @bindureddy noted that Klarna shut down Salesforce and Workday, replacing them with a simpler tech stack created by AI, potentially 10x cheaper to run than traditional SaaS applications.
- AI Influencer Controversy: @corbtt reported on the Reflection-70B model controversy, stating that after investigation, they do not believe the model that achieved the claimed benchmarks ever existed.
- Mario Draghi's EU Report: @ylecun shared an analysis of Europe's stagnant productivity and ways to fix it by Mario Draghi, highlighting the competitiveness gap between the EU and the US.
AI Reddit Recap
/r/LocalLlama Recap
apologies, our pipeline had issues today. Fixing.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Techniques
- Lipreading with AI: A video demonstrating AI-powered lipreading technology sparked discussions about its potential applications and privacy implications. Some commenters expressed concerns about mass surveillance and deepfake potential, while others saw benefits for accessibility. Source
- China refuses to sign AI nuclear weapons ban: China declined to sign an agreement banning AI from controlling nuclear weapons, raising concerns about the future of AI in warfare. The article notes China wants to maintain a "human element" in such decisions. Source
- Driverless Waymo vehicles show improved safety: A study found that driverless Waymo vehicles get into far fewer serious crashes than human-driven ones, with most crashes being the fault of human drivers in other vehicles. This highlights the potential safety benefits of autonomous driving technology. Source
AI Model Developments and Releases
- OpenAI's GPT-4.5 "Strawberry": Reports suggest OpenAI may release a new text-only AI model called "Strawberry" within two weeks. The model allegedly takes 10-20 seconds to "think" before responding, aiming to reduce errors. However, some testers found the improvements underwhelming compared to GPT-4. Source
- OpenAI research lead departure: A key OpenAI researcher involved in GPT-4 and GPT-5 development has left to start their own company, sparking discussions about talent retention and competition in the AI industry. Source
- Flux fine-tuning improvements: Developers have made progress in fine-tuning the Flux AI model by targeting specific layers, potentially improving training speed and inference quality. This demonstrates ongoing efforts to optimize AI model performance. Source
AI in Entertainment and Media
- James Earl Jones signs over Darth Vader voice rights: Actor James Earl Jones has signed over rights for AI to recreate his iconic Darth Vader voice, highlighting the growing use of AI in entertainment and raising questions about the future of voice acting. Source
- Domo AI video upscaler launch: Domo AI has launched a fast video upscaling tool that can enhance videos up to 4K resolution, showcasing advancements in AI-powered video processing. Source
AI Industry and Research Trends
- Sergey Brin's AI focus: Google co-founder Sergey Brin stated he is working at Google daily due to excitement about recent AI progress, indicating the high level of interest and investment in AI from tech industry leaders. Source
- Public perception of AI job displacement: A meme post sparked discussion about public attitudes towards AI potentially replacing jobs, highlighting the complex emotions and concerns surrounding AI's impact on employment. Source
AI Discord Recap
A summary of Summaries of Summaries by GPT4O-Aug (gpt-4o-2024-08-06)
1. Model Performance and Benchmarking
- Pixtral 12B Outshines Competitors: Pixtral 12B from Mistral demonstrated superior performance over models like Phi 3 and Claude Haiku in OCR tasks, showcased at the Mistral summit.
- Live demos highlighted Pixtral's flexibility in image size handling, sparking discussions on its accuracy compared to rivals.
- Llama-3.1-SuperNova-Lite Excels in Math: Llama-3.1-SuperNova-Lite outperformed Hermes-3-Llama-3.1-8B in mathematical tasks, maintaining accuracy in calculations like Vedic multiplication.
- The model's superior handling of numbers was noted, although both models faced struggles, with SuperNova-Lite showing better numeric integrity.
2. AI and Multimodal Innovations
- Mistral's Pixtral 12B Vision Model: Pixtral 12B, a vision multimodal model, was launched by Mistral, optimized for single GPU usage with 22 billion parameters.
- Though limited to a 4K context size, expectations are high for a long context model by November, enhancing multimodal processing capabilities.
- Hume AI's Empathic Voice Interface 2: Hume AI unveiled the Empathic Voice Interface 2 (EVI 2), merging language and voice to enhance emotional intelligence applications.
- The model is now available, inviting users to create applications requiring deeper emotional engagement, marking advancements in voice AI.
3. Software Engineering and AI Collaboration
- SWE-bench Highlights GPT-4's Efficiency: SWE-bench results show GPT-4 outperforming GPT-3.5 in sub-15 minute tasks, demonstrating enhanced efficiency without a human baseline for comparison.
- Despite improvements, both models falter on tasks exceeding four hours, suggesting limits in problem-solving capabilities.
- Challenges in AI and Software Engineering Integration: Discussions on AI's integration with software engineering reflect growing interest, with AI models showing promise but lacking nuanced human insights.
- AI's role in software engineering tasks is burgeoning, yet it struggles to match seasoned engineers in effectiveness and insight.
4. Open-Source AI Tools and Frameworks
- Modular's Mojo 24.5 Release Anticipation: Anticipation builds for the Mojo 24.5 release, expected within a week, as community meetings discuss resolving clarity issues in interfaces.
- Users eagerly await improved communication on product timelines to prevent misunderstandings and ensure readiness for changes.
- OpenRouter Enhances Programming Tool Integration: OpenRouter offers cost-effective alternatives to Claude API, emphasizing centralized experiments with multiple models.
- Discussions highlight the bypassing of initial rate limits and lower costs, making it a preferred choice for developers.
PART 1: High level Discord summaries
Modular (Mojo 🔥) Discord
- Mojo User Feedback Opportunities: The team is actively seeking users who haven't interacted with Magic to provide feedback during a 30-minute call, offering exclusive swag incentives; interested parties can book a slot here. Inquiries about future swag availability were positively received, indicating potential for broader access.
- Members expressed interest in a possible merch store for more swag options, reflecting the community's enthusiasm for additional engagement opportunities.
- Countdown to Mojo 24.5 Release: Anticipation is building for the upcoming Mojo 24.5 release, which is expected within a week, as discussed in recent community meetings regarding conditional trait conformance that led to user confusion. Members are particularly eager about resolving clarity and visibility issues related to interfaces in complex systems.
- Discussions highlighted the need for better communication on product timelines to prevent misunderstandings and ensure users are well-prepared for the changes.
- Concerns Over Mojo's Copy Behavior: Members voiced worries over Mojo's implicit copy behavior, especially with the
ownedargument convention, which can lead to unplanned copies of large data structures. Suggestions to establish explicit copying as the default option are under consideration for users transitioning from languages like Python.- This led to further debate on how different programming languages manage copying, with users advocating for more transparency in how data is handled.
- Ownership Semantics Create Confusion: The ownership semantics in Mojo sparked a discussion around their potential for creating unpredictable changes in function behavior due to implicit copies, described as 'spooky action at a distance'. There's a call for better clarity in API changes and stricter regulations regarding the
ExplicitlyCopyabletrait to prevent unintended issues such as double frees.- Several members underscored the importance of documentation and community guidelines to help developers navigate these complexities more effectively.
- Mojodojo.dev Gains Attention: The community highlighted the open-source Mojodojo.dev, initially created by Jack Clayton, as a crucial educational resource for Mojo. Members expressed a desire to enhance the platform and were invited to contribute content centered on projects built using Mojo.
- Caroline Frasca emphasized the importance of expanding the blog and YouTube channel content to better showcase projects and resources available for Mojo developers.
Unsloth AI (Daniel Han) Discord
- Mistral's Pixtral Model Emerges: Mistral launched the Pixtral 12b, a vision multimodal model featuring 22 billion parameters optimized to run on a single GPU, though it has a limited 4K context size.
- A full long context model is expected by November, raising expectations for upcoming features in multimodal processing.
- Gemma 2 Outshines Llama 3.1: Gemma 2 consistently outperforms Llama 3.1 in multilingual tasks, particularly excelling in languages like Swedish and Korean.
- Despite the focus on Llama 3, users have acknowledged Gemma 2’s strengths in advanced language tasks.
- Training Efficiency with Smaller Datasets: Users find that smaller, diverse datasets significantly cut down training loss during model optimization.
- Emphasizing quality over quantity, they noted improvements in outcomes when datasets are well-curated and less homogeneous.
- Unsloth Support for Flash Attention 2: Members are integrating Flash Attention 2 with Gemma 2, but encounters with compatibility issues have been noted.
- Despite challenges, there is optimism that final adjustments will resolve conflicts and enhance performance.
- Tuning Challenges with LoRa on phi-3.5: A user reported stagnation in loss improvement when applying LoRa on a phi-3.5 model, initially reducing from 1 to 0.4.
- Recommendations included experimenting with different alpha values to optimize performance further, given the complexities in tuning phi models.
OpenAI Discord
- SWE-bench shows GPT-4's prowess over GPT-3.5: The SWE-bench performance indicates that GPT-4 significantly outperforms GPT-3.5, especially in sub-15 minute tasks, marking enhanced efficiency.
- However, the absence of a human baseline complicates the evaluation of these outcomes against human engineers.
- GameNGEN pushes boundaries with real-time simulations: GameNGEN impressively simulates the game DOOM in real-time, opening avenues for world modeling applications.
- Despite advancements, it still relies on existing game mechanics, raising questions about the originality of 3D environments.
- GPT-4o trumps GPT-3.5 in benchmarks: GPT-4o boasts an 11x improvement over GPT-3.5 when tackling simpler tasks in the SWE-bench framework.
- Nonetheless, both models falter on tasks exceeding four hours, revealing limits to their problem-solving capabilities.
- AI faces challenges in software engineering collaboration: Increasing discussions revolve around AI's integration with software engineers for benchmark tasks, reflecting a burgeoning interest.
- While AI holds promise, it lacks the nuanced insight and effectiveness of seasoned human engineers.
- GAIA benchmark redefines AI difficulty standards: The GAIA benchmark tests AI systems rigorously, while allowing humans to score 80-90% on challenging tasks, a notable distinction from conventional benchmarks.
- This suggests a need for re-evaluation as many existing benchmarks grow increasingly unmanageable even for skilled practitioners.
HuggingFace Discord
- DeepSeek 2.5 merges strengths with 238B MoE: The release of DeepSeek 2.5 integrates features from DeepSeek 2 Chat and Coder 2, featuring a 238B MoE model with a 128k context length and new coding functionalities.
- Function calling and FIM completion offer groundbreaking new standards for chat and coding tasks.
- AI Revolutionizes Healthcare: AI has transformed healthcare by enhancing diagnostics, enabling personalized medicine, and speeding up drug discovery.
- Integrating wearable devices and IoT health monitoring facilitates early disease detection.
- Korean Lemmatizer seeks AI Boost: A member developed a Korean lemmatizer and is seeking ways to utilize AI to resolve word ambiguities.
- They expressed hope for advancements in the ecosystem for better solutions in 2024.
- CSV only provides IDs for image loading: In discussions on image loading, it was noted that CSV files merely contain image IDs, necessitating fetching images or pre-splitting them into directories.
- This method might slightly increase latency compared to creating a DataLoader object from organized folders.
- Multi-agent systems enhance performance: Transformers now support Multi-agent systems, allowing agents to collaborate on tasks, improving overall efficacy in benchmarks.
- This collaborative approach enables specialization on sub-tasks, increasing efficiency.
aider (Paul Gauthier) Discord
- Optimizing Aider's Workflow: Users shared how the
ask first, code laterworkflow with Aider enhances clarity in code implementation, particularly using a plan model.- This approach improves context and reduces reliance on the
/undocommand.
- This approach improves context and reduces reliance on the
- The Benefits of Prompt Caching: Aider's prompt caching feature has shown to cut token usage by 40% through strategic caching of key files.
- This system retains elements such as system prompts, helping to minimize costs during interactions.
- Comparing Aider with Other Tools: Users contrasted Aider with other tools like Cursor and OpenRouter, highlighting Aider's unique features that boost productivity.
- Smart functionalities, like auto-generating aliases and cheat sheets from zsh history, underscore Aider's capabilities.
- Exploring OpenRouter Benefits: Members pointed out the advantages of using OpenRouter over the Claude API, emphasizing cost reductions and the bypassing of initial rate limits.
- OpenRouter facilitates centralized experiments with multiple models, making it a preferred choice.
- Mistral Launches Pixtral Model Torrent: Mistral released the Pixtral (12B) multimodal model as a torrent, suitable for image classification and text generation.
- The download is available via the magnet link
magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238aand supports frameworks like PyTorch and TensorFlow.
- The download is available via the magnet link
LM Studio Discord
- Consistency is Key in AI Images: Users are exploring techniques to maintain character consistency across AI-generated images, even as outfits or backgrounds change.
- The aim is to ensure that the character's facial features and body remain recognizable across different panels.
- Dueling GPUs in Token Processing: Discussions on token processing revealed a user achieving 45 tokens/s on a 6900XT, highlighting discrepancies across GPU models.
- Several members suggested flashing the BIOS to enhance performance while expressing frustration over unexpected results.
- Meet-Up for LM Studio Enthusiasts: LM Studio users are organizing a meet-up in London, focusing on prompt engineering with discussions open for all users.
- Participants are encouraged to find non-students with laptops for a productive exchange.
- Spotlight on RTX 4090D: Discussion centered around the RTX 4090D, a China-exclusive GPU noted for having more VRAM but fewer CUDA cores compared to its counterparts.
- Despite lower gaming performance, it might be a strategic choice for AI workloads due to its memory capacity.
- Surface Studio Pro: Upgrade Frustrations: Users expressed frustration over the Surface Studio Pro's limited upgrade options, debating enhancements like eGPU or SSD.
- Suggestions included investing in a dedicated AI rig rather than upgrading the laptop.
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion Models Battle it Out: Users showcased the performance differences between older models like '1.5 ema only' and newer options, emphasizing advancements in image generation quality.
- The community noted that the RTX 4060 Ti outperforms the 7600 and Quadro P620 for AI tasks, highlighting the importance of GPU selection.
- Resolutions Matter in Image Generation: Optimal generation resolutions, such as 512x512 for earlier models, were recommended to minimize artifacts when upscaling.
- Users shared effective workflows suggesting that starting with lower resolutions enhances final output quality.
- AI Models and Their Familiarity: Concerns emerged regarding the similarity of various LLMs due to shared training data and techniques impacting originality.
- However, some noted that newer models have significantly improved aspects like generating realistic hands, indicating promising advancements.
- GPU Showdown for AI Training: Community members debated NVIDIA's GPUs being the preferred choice for AI model training, mainly due to CUDA compatibility.
- The consensus leaned towards favoring higher-end GPUs with 20GB of VRAM for superior performance, even if lower VRAM options could work for specific models.
- Reflection LLM Under Scrutiny: The Reflection LLM, touted for its capabilities of 'thinking' and 'reflecting,' faced criticism regarding its actual performance compared to claims.
- Concerns about disparities between the API and open-source versions fueled skepticism among users about its effectiveness.
OpenRouter (Alex Atallah) Discord
- Novita Endpoints Encounter Outage: All Novita endpoints faced an outage, leading to a 403 status error for filtering requests without fallbacks.
- Once the issue was resolved, normal functionality resumed for all users.
- Programming Tool Suggestions Ignite Discussion: A user explored using AWS Bedrock with Litelm for rate management, prompting additional suggestions like Aider and Cursor among users.
- Opinions varied on the effectiveness of the tools, stirring a lively debate about user experience and functionality.
- Speculations on Hermes Model Pricing: Users expressed uncertainty if Hermes 3 would remain free, with projections of a potential $5/M charge for updated endpoints.
- This led to discussions about expected performance improvements, alongside mention of ongoing free alternatives possibly remaining available.
- Insights into Pixtral Model's Capabilities: Pixtral 12B may primarily accept image inputs to produce text outputs, suggesting limited text processing capabilities.
- The model is expected to perform similarly to LLaVA, with a focus on specialized image tasks.
- Challenges Integrating OpenRouter with Cursor: Some users faced hurdles when using OpenRouter with Cursor, addressing configuration adjustments needed to activate model functionalities.
- Contributors highlighted existing issues on the cursor repository, particularly relevant to hardcoded routing within specific models.
CUDA MODE Discord
- Optimizing Matmul with cuDNN: Members discussed resources for various matmul algorithms like Grouped GEMM and Split K, with a recommendation to check out Cutlass examples.
- The focus remains on leveraging available optimization techniques for efficient matrix operations in machine learning.
- Neural Network Quantization Challenges: A member is re-implementing Post-Training Quantization and facing an accuracy drop during activation quantization, sharing insights on the torch forum.
- The community provided suggestions, emphasizing the importance of debugging for accuracy retention in quantized models.
- Exciting Developments in Multi-GPU Usage: Innovative ideas for Multi-GPU enhancements were shared, aiming to elongate context lengths and improve memory efficiency, with linked details.
- Participants are encouraged to pursue projects that optimize their use of resources while minimizing overhead.
- OpenAI RSUs and Market Insights: OpenAI employees discussed RSUs appreciating to 6-7x if not sold, sharing the complexities of secondary transactions that allow cashing out, with implications on future IPOs.
- Speculation on the impact of these secondary transactions on share pricing and valuation revealed insights into venture capital negotiations.
- FP6 Added to Main API: The addition of fp6 to the main README of the project was announced, leading to discussions about the integration challenges with BF16 and FP16.
- There is a recognized need for clarity among users to ensure efficient performance management across different precision types.
Interconnects (Nathan Lambert) Discord
- OpenAI Experiences Major Departures: Significant talent departures hit OpenAI as Alex Conneau announces his exit to start a new company, while Arvind shares excitement about joining Meta.
- Discussions hint that references to GPT-5 might indicate upcoming models, but skepticism lingers regarding these speculations.
- Meta's Massive AI Supercomputing Cluster: Meta approaches completion of a 100,000 GPU Nvidia H100 AI supercomputing cluster to train Llama 4, opting against proprietary Nvidia networking gear.
- This bold move underlines Meta's commitment to AI, particularly as competition escalates in the industry.
- Adobe's Generative Video Move: Adobe is set to launch its Firefly Video Model, marking substantial advancements since its rollout in March 2023, with integration into Creative Cloud features on the horizon.
- The beta availability later this year showcases Adobe's focus on generative AI-driven video production.
- Pixtral Model Surpasses Competitors: At the Mistral summit, it was reported that Pixtral 12B outperforms models like Phi 3 and Claude Haiku, noted for flexibility in image size and task performance.
- Live demos during the event revealed Pixtral's strong OCR capabilities, igniting debates on its accuracy compared to rivals.
- Surge AI's Contractual Challenges: Surge AI reportedly failed to deliver data to HF and Ai2 until faced with potential legal action, raising alarm about its reliability on smaller contracts.
- Concerns revolve around their lack of communication amidst delays, casting doubt on their prioritization.
Perplexity AI Discord
- Perplexity Pro Signup Campaign enters final stage: There's only 5 days left for campuses to secure 500 signups to unlock a free year of Perplexity Pro. Sign up at perplexity.ai/backtoschool to participate!
- The updated countdown timer, now at 05:12:11:10, amplifies this call to action—it's the final lap!
- Students face disparities with Perplexity offers: The student offer for a free month of Perplexity Pro is available, but it's limited to US students or specific campuses with enough signups.
- Concerns were voiced about the inequities faced by students from other countries, such as Germany, who also seek promotions.
- Excitement builds for new API features: Anticipation is high for new API functionalities during the upcoming dev day, particularly for 4o voice and image generation features.
- There's also a discussion on creating a hobby tier for users who need less than full pro access.
- Neuralink shares patient updates and SpaceX ambitions: Perplexity AI promoted a YouTube video detailing Neuralink's First Patient Update and SpaceX's target for Mars in 2026.
- The video offers insights into both projects and their ambitious goals for the future.
- Urgent support request from Bounce.ai for API issues: Aki Yu, CTO of Bounce.ai, reported an urgent issue with the Perplexity API impacting over 3,000 active users, stressing the need for immediate assistance.
- Despite reaching out for 4 months, Bounce.ai has yet to receive a response from the Perplexity team, highlighting potential limitations in support channels.
Nous Research AI Discord
- Llama-3.1-SuperNova-Lite excels in math: Members noted that Llama-3.1-SuperNova-Lite showcases superior handling of calculations like Vedic multiplication compared to Hermes-3-Llama-3.1-8B, maintaining accuracy.
- Despite both models struggling, SuperNova-Lite performed notably better in preserving numeric integrity.
- Model comparisons reveal performance gaps: Testing revealed that LLaMa-3.1-8B-Instruct struggled with mathematical tasks, while Llama-3.1-SuperNova-Lite achieved better results.
- A preference emerged for Hermes-3-Llama-3.1-8B, highlighting the discrepancies in their arithmetic capabilities.
- Quality Data enhances performance: Feedback across discussions emphasized that higher quality data significantly boosts model performance as parameters are scaled.
- This underscores the importance of using high-quality datasets for achieving optimal results with LLMs.
- Greener Pastures: Smaller Models for Simple Tasks: A member queried about models smaller than Llama 3.1 8B for basic tasks, mentioning Mistral 7B and Qwen2 7B as potential options.
- Discussions prompted requests for an updated list on models under 3B parameters, indicating community interest in efficiency.
- Desire for Updates on Spatial Reasoning Innovations: Curiosity arose about whether any revolutionary developments have been made in Spatial Reasoning and its allied areas.
- Members eagerly sought insights into the latest innovations that might reshape understanding in AI reasoning capabilities.
Latent Space Discord
- Mistral Showcases Pixtral 12B Model: At an invite-only conference, Mistral launched the Pixtral 12B model, outperforming competitors like Phi 3 and Claude Haiku, as noted by Mistral AI.
- This model supports arbitrary image sizes and interleaving, achieving notable benchmarks that were highlighted during the event featuring Jensen Huang.
- Klarna Cuts Ties with SaaS Providers: Klarna's CEO announced the company is firing its SaaS providers, including those once deemed irreplaceable, provoking discussions about potential operational risks, as detailed by Tyler Hogge.
- Alongside this, Klarna reportedly downsized its workforce by 50%, a decision likely driven by financial challenges.
- Jina AI Launches HTML to Markdown Models: Jina AI introduced two language models, reader-lm-0.5b and reader-lm-1.5b, optimized for converting HTML to markdown efficiently, offering multilingual support and robust performance read more here.
- These models stand out by outperforming larger models while maintaining a significantly smaller size, streamlining accessible content conversion.
- Trieve Secures Funding Boost: Trieve AI successfully secured a $3.5M funding round led by Root Ventures, aimed at simplifying AI application deployment across various industries, as shared by Vaibhav Srivastav here.
- With the new funding, Trieve's existing systems now serve tens of thousands of users daily, indicating strong market interest.
- Hume Launches Empathic Voice Interface 2: Hume AI introduced the Empathic Voice Interface 2 (EVI 2), merging language and voice to enhance emotional intelligence applications check it out.
- This model is now available for users eager to create applications that require deeper emotional engagement.
OpenInterpreter Discord
- Custom Python Code with Open Interpreter: A user inquired about utilizing specific Python code for sentiment analysis tasks in Open Interpreter, sparking interest in broader custom queries over databases.
- The community is eager for confirmation on the feasibility of involving various Python libraries like rich for formatting in terminal applications.
- Documentation Improvement Stirs Engagement: Feedback pointed out that while users find Open Interpreter appealing, the documentation lacks organization, hindering navigation.
- An offer was made to enhance documentation through collaborative efforts, encouraging pull requests for improvements.
- Early Access to Desktop App Approaches: Users are keen for details on the timeline for early access to the upcoming desktop app, which aims to simplify installation processes.
- The community anticipates additional beta testers within the next couple of weeks, aiming to enhance the user experience.
- Refunds and Transition from 01 Light: Discussions erupted around refunds for the discontinued 01 light, leading to a leaked tweet confirming the shift to a new free 01 app.
- Open-sourcing of manufacturing materials is also on the table, coinciding with the 01.1 update for further development.
- Highlighting RAG Context from JSONL Data: A preliminary test run shows promise in offering context from JSONL data designed for RAG, primarily focused on news RSS feeds.
- The tutorial creation will follow the completion of NER processes and data loading into Neo4j, enhancing usability for AI applications.
Cohere Discord
- Cohere's Ticket Support Integration: A member plans to integrate Cohere with Link Safe for ticket support and text processing, expressing excitement about the collaboration.
- I can’t wait to see how this enhances our current workflow!
- Mistral launches Vision Model: Mistral introduced a new vision model, igniting interest about its capabilities and upcoming projects.
- Members speculated on the possibility of a vision model from C4AI, linking it to developments with Maya that need more time.
- Long-Term Need for Human Oversight: Members concurred that human oversight will remain crucial in the advancement of AI, advocating for a reliable approach over the pursuit of machine intelligence.
- Let’s focus on making what we have reliable instead of chasing theoretical capabilities.
- Discord FAQ Bot Takes Shape: Efforts are underway to create a Discord FAQ bot for Cohere, streamlining communication within the community.
- The discussion also opened up possibilities for a virtual hack event, pushing for innovative ideas.
- Inquiry into Aya-101's Status: Is Aya-101 End-of-life? raised speculation about a transition to a new model that could outperform rivals.
- A member referred to it as a potential Phi-killer, stirring curiosity.
Eleuther Discord
- lm-evaluation-harness Guidance Request: A user seeks help using lm-evaluation-harness for evaluating the OpenAI gpt4o model against the swe-bench dataset.
- They appreciate any guidance, indicating that practical advice could significantly aid their evaluation process.
- Pixtral Model Announcement: The community shared the newly released Pixtral-12b-240910 model checkpoint, hinting it is partially aligned with Mistral AI’s recent updates.
- Users can find download details and a magnet URI included in the release note along with a link to Mistral's Twitter.
- RWKV-7 Shows Promise: RWKV-7 is presented as a potential Transformer killer, featuring an identity-plus-low-rank transition matrix derived from DeltaNet.
- A related study on optimizing for sequence length parallelization is showcased on arXiv, enhancing the model's appeal.
- Multinode Training Pitfalls: A user expresses concerns during multinode training over slow Ethernet links, particularly regarding DDP performance between 8xH100 machines.
- Discussion suggests training may suffer from speed limitations, and utilizing DDP across nodes could be less efficient than anticipated.
- Dataset Chunking Practices: A member inquires if splitting datasets into 128-token chunks is standard, implying the decision may often stem from intuition rather than empirical studies.
- Responses indicate many practitioners might overlook the potential effects of chunking on model performance, highlighting a gap in understanding.
LlamaIndex Discord
- Maven Course on RAG in the LLM Era: Check out the Maven course titled Search For RAG in the LLM era, featuring a guest lecture with live coding walkthroughs.
- Participants can engage with code examples alongside industry veterans to enhance their learning experience.
- Quick Tutorial on Building RAG: A straightforward tutorial on building retrieval-augmented generation with LlamaIndex is now available.
- This tutorial focuses on implementing RAG technologies effectively.
- Kotaemon: Build a RAG-Based Document QA System: Learn to build a RAG-based document QA system using Kotaemon, an open-source UI for chatting with documents.
- The session covers setup for a customizable RAG UI and how to organize LLM & embedding models.
- Hands-On AI Scheduler Workshop: Join the workshop at AWS Loft on September 20th to build an AI Scheduler for smart meetings with Zoom, LlamaIndex, and Qdrant.
- Participants will create a RAG recommendation engine focused on meeting productivity using Zoom's transcription SDK.
- Exploring Task Queue Setup for Indexing: A discussion initiated about creating a task queue for building indexes using FastAPI and a Celery backend, focusing on database storage for files and indexing info.
- Participants were encouraged to check existing setups that might fulfill these requirements.
LangChain AI Discord
- POC Development for Query Generation: A member is working on a POC for query generation using LangGraph, facing challenges with increasing token sizes as table counts rise.
- They are utilizing RAG to create vector representations of schemas for query formation and hesitate to add more LLM calls.
- Launch of OppyDev's Major Update: The OppyDev team announced a significant update enhancing the AI-assisted coding tool's usability on both Mac and Windows, along with support for GPT-4 and Llama.
- Users can access one million free GPT-4 tokens through limited-time promo codes; details are available on request.
- Insights on Building RAG Applications: A discussion arose regarding the retention of new line characters from texts retrieved via a web loader in RAG applications before storing in a vector database.
- It was confirmed that retaining new line characters is acceptable, ensuring the text formatting remains intact.
- Real-time Code Review Features in OppyDev: The latest OppyDev update includes a color-coded, editable diff feature for real-time code change monitoring.
- This upgrade significantly enhances developers' ability to track and manage their coding modifications effectively.
Torchtune Discord
- Torchtune lacks FP16 support: A member highlighted that Torchtune does not support FP16, requiring extra work to maintain compatibility with mixed precision modules, while bf16 is seen as the superior alternative.
- This lack of support may pose problems for users operating with older GPUs.
- Qwen2 interface tokenization quirks: The Qwen2 interface allows
Noneforeos_id, which leads to a check before adding it in theencodemethod, raising questions about its intentionality.- A potential bug arises as another part of the code does not perform this check, indicating an oversight.
- Issues with None EOS ID handling: Concerns were raised about allowing
add_eos=Truewitheos_idset toNone, implying inconsistent behavior in the tokenization process within the Qwen2 model.- This inconsistency could confuse users and disrupt expected functionality.
- Questions on padded_collate's efficacy: A member questioned the utility of padded_collate, noting that it isn't used anywhere while calling out a missing logic issue regarding input_ids and labels sequence lengths.
- This prompted follow-up inquiries about whether the padded_collate logic had been correctly incorporated into the ppo recipe.
- Clarifications needed on the PPO recipe: Discussion emerged around whether the
padded_collatelogic within the ppo recipe was complete, as a member indicated they had integrated some of it.- This raised further points about the typical matching of lengths between input_ids and labels.
DSPy Discord
- Sci Scope Launches for Arxiv Insights: Sci Scope is a new tool that categorizes and summarizes the latest Arxiv papers using LLMs, available for free at Sci Scope. Users can subscribe for a weekly summary of AI research, enhancing their literature awareness.
- A discussion arose about ensuring output veracity and reducing hallucinations in summaries, reflecting concerns regarding the reliability of AI-generated content.
- Customizing DSPy for Client Needs: A member queried about integrating client-specific customizations into DSPy-generated prompts for a chatbot, looking to avoid hard-coding client data. They considered a post-processing step for dynamic adaptations and solicited feedback on better implementation strategies.
- This exchange underscores the collaborative spirit within the group, as members actively support one another by sharing insights and solutions.
tinygrad (George Hotz) Discord
- Exploring Audio Models with Tinygrad: A user sought guidance on how to run audio models with tinygrad, specifically looking beyond the existing Whisper example provided in the repo.
- This inquiry spurred suggestions on potential starting points for exploring audio applications in tinygrad.
- Philosophical Approach to Learning: A member quoted, 'The journey of a thousand miles begins with a single step,' emphasizing the importance of intuition in the learning process.
- This sentiment encouraged a reflective exploration of resources within the community.
- Linking to Helpful Resources: Another member shared a link to the smart questions FAQ by Eric S. Raymond, outlining etiquette and strategies for seeking help online.
- This resource serves as a guide for crafting effective queries and maximizing community assistance.
OpenAccess AI Collective (axolotl) Discord
- Mistral's Pixtral Sets Multi-modal Stage: Work is advancing on Mistral's Pixtral to incorporate multi-modal support, echoing recent developments in AI capabilities.
- It's a prescient move considering today's advancements.
- Axolotl Project Gets New Message Structure: A pull request for a new message structure in the Axolotl project aims to enhance how messages are represented, favoring improved functionality.
- For insights, see the details of the New Proposed Message Structure.
- LLM Models Tested for Speed & Performance: A recent YouTube video evaluates the speed and performance of leading LLM models as of September 2024, focusing on tokens per second.
- The testing emphasizes latency and throughput, crucial metrics for any performance evaluation in production.
LAION Discord
- AI Developer Seeks Partner for NYX Model: An AI developer announced ongoing work on the NYX model, featuring over 600 billion parameters, and is actively looking for a collaborator.
- Let’s chat! if you possess expertise in AI and are aligned in timezone for effective collaboration.
- Inquiry on Training Large Models: A developer inquired about the training resources utilized for a 600B parameter model, highlighting the LLaMA-405B that was trained on 15 trillion tokens.
- Curiosity revolved around the data sourcing methodologies for such large models, indicating a keen interest in the underlying processes.
LLM Finetuning (Hamel + Dan) Discord
- Literal AI excels at usability: A user praised Literal AI for its intuitive interface, which enhances LLM applications' accessibility and user experience.
- This reflects a growing demand for user-friendly tools in the competitive landscape of LLM technologies.
- Observability boosts LLM lifecycle health: The significance of LLM observability was highlighted, as it empowers developers to rapidly iterate and handle debugging processes effectively.
- Utilizing logs can enhance smaller models' performance while simultaneously reducing expenses, driving efficient model management.
- Monitoring prompts prevents regressions: Continuous tracking of prompt performances is crucial in averting regressions prior to the deployment of new prompt versions.
- This proactive evaluation safeguards LLM applications against potential failures and increases deployment confidence.
- LLM monitoring ensures production reliability: Robust logging and evaluation mechanisms are essential for monitoring LLM performance in production environments.
- Implementing effective analytics provides teams the capacity to maintain oversight and bolster application stability.
- Integrating with Literal AI is a breeze: Literal AI supports easy integrations across applications, allowing users to tap into the full LLM ecosystem.
- A self-hosted option is available, catering to users in the EU and those managing sensitive data.
Mozilla AI Discord
- Ground Truth Data's Critical Role in AI: A new blog post emphasizes the importance of ground truth data in enhancing the model accuracy and reliability in AI applications, urging readers to contribute to the ongoing discussion join the discussion.
- Ground truth data is touted as essential for driving improvements in AI systems' performances across varying contexts.
- Mozilla Opens Call for Alumni Grant Applications: Mozilla invites past participants of the Mozilla Fellowship to apply for program grants targeting trustworthy AI and healthier internet initiatives, reflecting efforts for structural changes in AI.
- “The internet, and especially artificial intelligence (AI), are at an inflection point.” highlights Hailey Froese's call to action for transformative efforts in this space.
Gorilla LLM (Berkeley Function Calling) Discord
- Evaluation Script Errors Trouble Users: Users encountered a 'No Scores' issue while running
openfunctions_evaluation.pywith--test-category=non_live, receiving no results in the designated folder.- Attempting to rerun with new API credentials didn’t yield success, leading to further complications.
- API Credentials Updated but Issues Persist: In their setup, users added four new API addresses into
function_credential_config.json, hoping for a resolution.- Despite these changes, errors continued during evaluations, confirming that credential updates were ineffective.
- Timeout Troubles with Urban Dictionary API: During evaluation, a Connection Error arose linked to the Urban Dictionary API regarding the term 'lit', indicating there were timeout issues.
- Network problems are suspected as the source of the connection difficulties that users faced.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Modular (Mojo 🔥) ▷ #general (336 messages🔥🔥):
User Feedback for MojoSwag DiscussionsMojo 24.5 ReleaseTrait Conformance and InterfacesGo Interfaces
- User Feedback Opportunities: There is an ongoing search for users who haven't interacted with Magic to provide feedback during a 30-minute call, with cool exclusive swag offered as an incentive. Interested individuals can book a slot here.
- Inquiries about future broader access to swag or a potential merch store were positively acknowledged by the team.
- Anticipation for Mojo 24.5 Release: A user inquired about the anticipated release date for Mojo 24.5, with responses suggesting it may debut within a week. Details from recent community meetings regarding conditional trait conformance were also discussed, signaling user confusion.
- The workings of trait conformance and its implications were examined, with members raising concerns over the clarity and visibility of interfaces in complex systems.
- Discussion on Trait Conformance and Interfaces: The conversation shifted toward how different programming languages handle interface implementations, particularly focusing on Go and its interfaces. Concerns were raised about certain interfaces being unclear or leading to unintended consequences in large organizations.
- The contrasting designs of Rust and Swift were examined, with particular attention given to the implications of extending interfaces within a systems programming context.
- Critiques of Go Interfaces: The efficiency and practicality of Go interfaces were debated, focusing on their reliance on developers adhering to specific API contracts. Participants expressed mixed feelings regarding the balance and elegance of Go's composition model versus its potential pitfalls.
- The discussion encompassed the issues that arise from insufficient verification processes in the context of large codebases and organizations using Go.
- General Impressions on Composition and Interface Design: The idea that a function should not need to concern itself with implementation details if it relies on composition was emphasized in the discussion. Participants acknowledged the responsibility of programmers to ensure that interfaces are designed to facilitate easy verification and error handling.
- The responsibilities of programmers and interfaces in preventing data corruption through correct implementations were also underscored, highlighting the ongoing debate over how much verification should be embedded in language design.
- Documentation: no description found
- Documentation: no description found
- Documentation: no description found
- Documentation: no description found
- 9. Classes: Classes provide a means of bundling data and functionality together. Creating a new class creates a new type of object, allowing new instances of that type to be made. Each class instance can have ...
- 408 Protocol Oriented Programming in Swift: Video to translate Yandex browser
- Database Administrator’s Guide : You can detect and correct data block corruption.
- extends - JavaScript | MDN: The extends keyword is used in class declarations or class expressions to create a class that is a child of another class.
- Appointments: no description found
Modular (Mojo 🔥) ▷ #mojo (394 messages🔥🔥):
Mojo Copy BehaviorOwnership in MojoExplicitlyCopyable TraitMojodojo.dev
- Discussion on Mojo's Copy Behavior: Several members expressed concerns about Mojo’s implicit copy behavior, especially when using the
ownedargument convention, which can lead to unexpected copies of large data structures.- Suggestions included making explicit copying the default to avoid unexpected behavior, particularly for users transitioning from languages like Python.
- Concerns About Ownership Semantics: Members discussed how the ownership semantics in Mojo can create 'spooky action at a distance', causing local changes to significantly alter function behaviors due to implicit copies.
- The conversation highlighted the need for better clarity in API changes and potentially stricter rules surrounding the
ExplicitlyCopyabletrait to avoid unintentional double frees.
- The conversation highlighted the need for better clarity in API changes and potentially stricter rules surrounding the
- Proposal for Explicit Copy Methods: There was a proposal to require the
ExplicitlyCopyabletrait to implement acopy()method, which could improve usability and clarity for developers.- Members suggested that a built-in
copyfunction could be more Pythonic, while also debating the importance of chaining methods for functional programming styles.
- Members suggested that a built-in
- Introduction to Mojodojo.dev: The community discussed the open-source status of Mojodojo.dev, a resource originally created by Jack Clayton for learning Mojo.
- Members showed interest in collaborating to enhance Mojodojo.dev, emphasizing its value as an early educational resource in the Mojo ecosystem.
- Invitation for Contributors: Caroline Frasca invited community members to contribute to the blog and YouTube channel, expressing the desire for more content centered around projects built with Mojo.
- A user expressed appreciation for the game's coding resources that facilitated their understanding of Mojo.
- Modular: Deep dive into ownership in Mojo: This post blog is the second part of the series of ownership in Mojo. Please make sure to check out the first part, What Ownership is Really About: A Mental Model Approach, as we will build on concept...
- [External] [stdlib] Fix soundness issues in InlinedFixedVector on cop… · modularml/mojo@a597b90: …y/del (#46832) [External] [stdlib] Fix soundness issues in InlinedFixedVector on copy/del `InlinedFixedVector` had apparent double free (on multiple call of `_del_old()`) that was easily acciden...
- Generalize `init` argument convention with named result slots · Issue #3390 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? Recently, Mojo added named result slots in the form of...
Unsloth AI (Daniel Han) ▷ #general (608 messages🔥🔥🔥):
Pixtral Model LaunchGemma 2 vs Llama 3.1 PerformanceFine-tuning TechniquesUnsloth FeaturesFlash Attention 2 Issues
- Mistral launches Pixtral model: Mistral introduced a new vision multimodal model called Pixtral 12b, which is designed to fit into a single GPU and boasts 22 billion parameters.
- While some are excited to test its capabilities, others note that it has a relatively low context size of 4K, with a full long context model expected in November.
- Gemma 2 performs well in multilingual tasks: Users shared experiences that Gemma 2 outperforms Llama 3.1 in various languages, particularly in Swedish and Korean, making it a strong contender for multilingual applications.
- Despite being busy with Llama 3, there is appreciation for Gemma 2's capabilities, as many users are seeing its advanced language processing potential.
- Discussions on Fine-tuning Techniques: Participants discussed optimizing their models, noting that quality over quantity in dataset entries is crucial for effective fine-tuning.
- Suggestions were made to filter datasets for efficiency, highlighting strategies like increasing batch size or experimenting with gradient accumulation steps for improved training speed.
- Unsloth features and support: Unsloth support for Flash Attention 2 recently became available, with users attempting to integrate it into their workflows with Gemma 2.
- While some faced issues, community members expressed hope that final tweaks would resolve the compatibility problems, leading to better performance.
- Flash Attention 2 inquiries: Users inquired about the best configuration for Flash Attention 2 when working with Gemma 2, confirming that the latest version is recommended.
- Though Flash Attention 3 requires more advanced hardware, the consensus is to use Flash Attention 2 for current compatibility.
- Joseph717171/Llama-3.1-SuperNova-Lite-8.0B-OQ8_0.EF32.IQ4_K-Q8_0-GGUF · Hugging Face: no description found
- Linguistic frame of reference - Wikipedia: no description found
- Etherll/Herplete-LLM-Llama-3.1-8b · Hugging Face: no description found
- SHARED Continuous Finetuning By Rombodawg: Continuous Fine-tuning Without Loss Using Lora and Mergekit In this write up we are going to be discussing how to perform continued Fine-tuning of open source AI models using Lora adapter and mergek...
- upstage/solar-pro-preview-instruct · Hugging Face: no description found
- Orenguteng/Llama-3-8B-Lexi-Uncensored · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): Mistral just dropped a new vision multimodal model called Pixtral 12b! Also downloaded params json - GeLU & 2D RoPE are used for the vision adapter. The vocab size also got larger - 131072 Also Mist...
- arcee-ai/Llama-3.1-SuperNova-Lite-GGUF · Hugging Face: no description found
- LoRA Learns Less and Forgets Less: Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In t...
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- arcee-ai/Llama-3.1-SuperNova-Lite · Hugging Face: no description found
- Tweet from Yuchen Jin (@Yuchenj_UW): Here’s my story about hosting Reflection 70B on @hyperbolic_labs: On Sep 3, Matt Shumer reached out to us, saying he wanted to release a 70B LLM that should be the top OSS model (far ahead of 405B), ...
- Replete-AI/Replete-Coder-V2-Llama-3.1-8b · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- lighteval/MATH-Hard · Datasets at Hugging Face: no description found
- lighteval/MATH-Hard · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
mahiatlinux: https://www.reddit.com/r/ChatGPT/comments/1fdphr6/blowing_out_the_candles/
Unsloth AI (Daniel Han) ▷ #help (48 messages🔥):
Unsloth on Intel GaudiTraining Loss and Dataset SizeFinetuning LLMs on Non-English DatasetsVision Models SupportUsing LoRa with phi-3.5
- Unsloth struggles on Intel Gaudi systems: Members discussed running Unsloth on an Intel Gaudi system, experiencing an error stating Torch not compiled with CUDA enabled.
- A member noted that Unsloth primarily works with Nvidia GPUs, indicating challenges with Gaudi compatibility.
- Smaller datasets improve training efficiency: A user shared insights on how reducing the dataset size improved their training loss performance while using Unsloth.
- Discussions emphasized focusing on smaller, more diverse datasets instead of larger, homogenous ones for better results.
- Guidance for finetuning LLMs on custom datasets: A newcomer asked for guidance on finetuning LLMs on a custom non-English dataset using Unsloth, especially for sensitive data processing.
- Veteran users recommended checking out relevant YouTube tutorials for practical advice on the topic.
- Current status of vision model finetuning: Participants confirmed that vision models like phi-3.5-vision are not currently available for finetuning with Unsloth.
- There was optimism that support for such models might be introduced by the end of the year or early next year.
- Challenges with LoRa on phi-3.5: A user reported stagnant loss improvement when training a phi-3.5 model with LoRa, initially dropping from 1 to 0.4.
- Advice was given to experiment with different alpha values, as tuning phi models can be particularly challenging.
- Unsloth: How to Train LLM 5x Faster and with Less Memory Usage?: 🚀 Dive into the world of AI model fine-tuning with Unsloth! In this comprehensive tutorial, we explore how to fine-tune MRAL Jemma Llama models up to 5 time...
- LLAMA-3.1 🦙: EASIET WAY To FINE-TUNE ON YOUR DATA 🙌: Learn how to efficiently fine-tuning the Llama 3.1 model using Unsloth, LoRa, and QLoRa techniques. LINKS:Colab: https://tinyurl.com/bdzxhy5nUnsloth: https:/...
OpenAI ▷ #ai-discussions (466 messages🔥🔥🔥):
SWE-bench performanceGameNGEN capabilitiesGPT-4o vs GPT-3.5 benchmarksAI capabilities in software engineeringGAIA benchmark for AI
- SWE-bench performance metrics: The SWE-bench metric observed GPT-4 solving significantly more tasks compared to GPT-3.5, especially in the <15 min category, indicating improved efficiency.
- Though GPT-4o shows promising results, the lack of a human baseline makes it challenging to fully evaluate model performance against human engineers.
- GameNGEN's simulation capabilities: GameNGEN is recognized for creating a neural model that can simulate the game DOOM in real-time, suggesting possibilities for applications in world modeling.
- Despite its impressive move towards simulating environments, it still relies on established game mechanics and assets rather than developing entirely novel 3D environments.
- GPT-4o vs GPT-3.5 benchmarks: GPT-4o demonstrates an 11x improvement over GPT-3.5 in solving less complex tasks within the SWE-bench benchmark.
- However, both models struggled significantly with tasks taking more than 4 hours, indicating a potential limitation in their problem-solving capabilities.
- AI capabilities in software engineering: There is a growing interest in understanding how well AI can collaborate with software engineers on benchmark problems.
- Discussions suggest that while AI models show promise, they lack the nuanced understanding and efficiency of experienced human engineers.
- GAIA benchmark designed for AI difficulty: The GAIA benchmark is designed to challenge AI systems while remaining manageable for human participants, with humans scoring 80-90% on tough tasks.
- This contrasts with conventional benchmarks, which are increasingly becoming unsolvable for even skilled graduates.
- Tweet from Florian S (@airesearch12): let me tell you my theory what happened with Reflection and @mattshumer_. it's the only explanation that does justice to both the timeline and the incomprehensible reputationally self-destructive...
- GameNGen: Diffusion Models Are Real-Time Game Engines
- SWE-bench: no description found
- [CVPR'23 WAD] Keynote - Ashok Elluswamy, Tesla: Talk given at the CVPR Workshop on Autonomous Driving 2023: https://cvpr2023.wad.vision/.00:00 Introduction02:09 Occupancy Networks Recap04:04 Generative Mod...
OpenAI ▷ #gpt-4-discussions (12 messages🔥):
Android app copying issuesGPT accessibility errorsGPT confusion and performance dropsChat memory loading concernsUpcoming GPT-5 release date
- Android app struggles with markdown: Users reported an issue in the Android app where copying text results in plain text without markdown formatting, a problem that has just started occurring.
- Additionally, users expressed frustration over not being able to switch to previous prompts/messages in the chats.
- Access problems with GPTs: One user faced an accessibility issue with their GPT, receiving an error message stating, 'Oops, an error occurred! Try again.'
- They expressed confusion as to why this occurred, indicating a potential widespread issue.
- GPT shows signs of confusion: A user expressed frustration that their GPT was suddenly confused, noting it repeats the same mistakes and seems aware of its errors.
- They speculated that the temperature setting was adjusted to 0, impacting the model's performance.
- Chat memory not loading: Several users reported that the browser version of Chat GPT fails to load chat memory consistently, leading to no responses being produced.
- One user mentioned giving up on the browser version, preferring the app version instead.
- Speculation on GPT-5 release: A user inquired about the release date for GPT-5, with another member suggesting it could be around 2025-2026.
- The suggestion was met with frustration about the wait time, prompting a user to express disbelief.
OpenAI ▷ #prompt-engineering (17 messages🔥):
Prompt Library AccessECHO with ChatGPTResponse Variety of ChatGPTCustom Instructions Impact
- Finding the Prompt Library: A member inquired about accessing the prompt library, which is now located in a specific channel, <#1019652163640762428>.
- Another member provided the updated channel information promptly.
- Questioning ECHO's Feasibility with ChatGPT: Discussion arose about the potential for ECHO to be achievable with ChatGPT, with some suggesting it may require future models like Orion and Strawberry.
- A member asked whether customer insights could clarify this topic.
- Repetition in ChatGPT Responses: One member noted that after multiple regenerations, they received the same joke, suggesting limited output variability from ChatGPT.
- This led to humor regarding the model's consistency, with comments about the frequency of identical jokes.
- Custom Instructions and Message Guidance: Members discussed how custom instructions might influence ChatGPT's responses, guiding it to provide more creative outputs instead of standard answers.
- Another member suggested that the model, when prompted, would adhere to requests for concise responses, even if it usually aims for more substantial outputs.
- ChatGPT's Encouragement for Exploration: One member experienced humorous prompts from the model suggesting breaks or alternative activities after repeated regenerations.
- This showcased the challenges of randomness in responses as the user encouraged the model to explore diverse topics, despite the random nature of the output.
OpenAI ▷ #api-discussions (17 messages🔥):
Prompt Library LocationECHO and Future ModelsRegenerating ResponsesGuiding GPT Outputs
- Find the Prompt Library Channel: A user inquired about accessing the prompt library, which has now been renamed to <#1019652163640762428>.
- A member promptly provided the new channel name to assist with navigation.
- Debate on Achieving ECHO with Current Models: A user questioned if ECHO is achievable with ChatGPT or if future models like Orion and Strawberry are necessary.
- Another member suggested that customer insight could be obtained with the current setup.
- Issues with Regenerating Jokes: A user expressed frustration over receiving the same joke repeatedly after regenerating responses multiple times, noting it was 9 out of 10 times the same.
- Notably, one regeneration produced a different response involving a cow variant humor.
- GPT-4's Interactive Jokes: In contrast to the regenerating responses, GPT-4 reportedly engages users with questions, like asking, 'knock knock'.
- A member praised its interactivity, stating that original GPT-4 is a winner for generating fresh content.
- Encouraging Unique Outputs from GPT: A user shared strategies to get unique outputs from GPT by instructing it to create something novel despite previous interactions.
- They mentioned their custom instructions guide the model to suggest different explorations, influencing its randomness.
HuggingFace ▷ #announcements (1 messages):
DeepSeek 2.5Mini OmniMulti-agent systemsTransformers.js v3Reflection-Tuning
- DeepSeek 2.5 merges strengths with 238B MoE: The release of DeepSeek 2.5 combines features from DeepSeek 2 Chat and Coder 2, boasting a 238B MoE model with a 128k context length and new coding functionalities.
- It includes features like function calling and FIM completion, setting a new standard for chat and coding tasks.
- Multi-agent systems enhance performance: Transformers Agents now supports Multi-agent systems, enabling several agents to collaborate on tasks for improved efficacy across benchmarks.
- These systems allow specialization on sub-tasks, significantly increasing operational efficiency compared to traditional single-agent models.
- Real-time audio interaction with Mini Omni: Mini Omni introduces a model that enables real-time audio conversations, expanding capabilities in live interactions.
- This innovation opens up new avenues for conversational AI, allowing for immediate and dynamic communication.
- WebGPU powers faster background removal: A new approach for image background removal employs WebGPU acceleration, enabling in-browser inference with minimal cost and high privacy standards.
- As noted, it provides fast and high-quality results without requiring data to leave the user's device.
- Reflection-Tuning yields impressive results: A new distilabel recipe showcases how to generate datasets using Reflection-Tuning, demonstrating competitive performance from the Reflection 70B model.
- The method leverages Llama 3.1 to instruct the model for generating responses, thereby enhancing output quality through reflective thinking.
- Tweet from Zach Mueller (@TheZachMueller): Today @huggingface accelerate 0.34.0 is now out, and it is a packed release! From `torchpippy` updates to resumable dataloader support, and revamped TransformerEngine support, there's a ton to co...
- Tweet from Aymeric (@AymericRoucher): 🥳 Transformers Agents now supports Multi-agent systems! Multi-agent systems have been introduced in Microsoft's framework Autogen. It simply means having several agents working together to solve...
- Tweet from vLLM (@vllm_project): We are excited to see @vllm_project as an option for local apps in the @huggingface hub! It comes with easy snippets to quickly test out the model.
- Tweet from Xenova (@xenovacom): There has been a huge debate recently about the best approach for image background removal. Here's my attempt: - In-browser inference w/ 🤗 Transformers.js - WebGPU accelerated (fast!) - Costs $0 ...
- Tweet from apolinario 🌐 (@multimodalart): It's now so easy add images to the gallery of your LoRA on @huggingface 🤯 🪄 ① Generate an image with the Widget 🖼️ ② Press "Add to model card gallery" 🔥
- Tweet from Daniel van Strien (@vanstriendaniel): The @huggingface's Semantic Dataset Search is back in action! Find similar datasets by ID or do a semantic search of dataset cards. Give it a try: https://huggingface.co/spaces/librarian-bots/hug...
- Tweet from Gabriel Martín Blázquez (@gabrielmbmb_): Yesterday Reflection 70B was released, a model fine-tuned using Reflection-Tuning that achieved impressive scores in several benchmarks such as MMLU. The dataset that was used for the fine-tuning wasn...
HuggingFace ▷ #general (241 messages🔥🔥):
HuggingFace community mappingNew datasets featuresSQL integration with datasetsBest AI models for different purposesUsing cloud for model training
- HuggingFace community mapping unveiled: A user shared an interactive visualization of the HuggingFace community, highlighting various connections within the ecosystem.
- Charlesddamp announced the release, generating excitement and recognition for community contributors.
- Introduction of new datasets features: Users discussed the latest functionalities in HuggingFace datasets, including SQL capabilities and DuckDB integration.
- Some reported issues with running SQL queries that resulted in out-of-memory errors, prompting discussions about error handling.
- Exploration of SQL for dataset analysis: One user demonstrated using SQL commands for dataset queries, particularly focusing on the Fineweb dataset within HuggingFace.
- Discussions raised interesting points about potential SQL analysis and natural language processing integrations.
- Discussion on best AI models as of now: Users compared current AI models, suggesting Llama 3.1 for open-source needs and ChatGPT or Claude for closed systems.
- Considerations for model size compatibility with hardware were discussed, particularly in relation to an M1 Mac's capabilities.
- Benefitting from cloud models: A user suggested that using cloud services could provide access to better models for those with limited hardware resources.
- This was echoed as an important consideration for users working with larger models, including discussions about quantization.
- Practical Deep Learning for Coders - Practical Deep Learning: A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
- Giving AI a large dataset with JSON: hey! i would like to ask how i could train a pre-existing LLM on a huge(and a very huge) JSON file that has a bunch of files/directories converted into json form. i want the LLM to be able to understa...
- How to install flash attention on HF gradio space: I tried to put flash-attn in the requirements.txt file to install flash-attention on my space, but it gives error that torch is not installed. I also tried to put torch above flash-attn but still cou...
- Tweet from Charles de Dampierre (@Charlesddamp): Discover our mapping of the HuggingFace community ! Explore the interactive visualization here: https://lnkd.in/eXwuKgYw @LysandreJik @JustineTunney @maximelabonne @Dorialexander @Thom_Wolf
- Introduction - Hugging Face NLP Course: no description found
- Ok Oh Yes Yes O Yeah Yes No Yes Go On Yea Yes GIF - Ok Oh Yes Yes O Yeah Yes No Yes Go On Yea Yes - Discover & Share GIFs: Click to view the GIF
- Fine-tuning | How-to guides: Full parameter fine-tuning is a method that fine-tunes all the parameters of all the layers of the pre-trained model.
- Baby Face Palm GIF - Baby Face Palm Really - Discover & Share GIFs: Click to view the GIF
- nyu-mll/glue · Datasets at Hugging Face: no description found
- airtrain-ai/fineweb-edu-fortified · Datasets at Hugging Face: no description found
- nyu-mll/glue · Datasets at Hugging Face: no description found
- nyu-mll/glue · Datasets at Hugging Face: no description found
- GitHub - pgvector/pgvector: Open-source vector similarity search for Postgres: Open-source vector similarity search for Postgres. Contribute to pgvector/pgvector development by creating an account on GitHub.
- transformers/src/transformers/models/gpt2/modeling_gpt2.py at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Add include_loss_for_metrics by Manalelaidouni · Pull Request #33088 · huggingface/transformers: What does this PR do? Fixes #32307 This PR includes loss in the compute_metrics function via the include_loss_for_metrics training argument flag, this is particularly useful for calculating loss de...
HuggingFace ▷ #today-im-learning (6 messages):
Fine-tuning Llama 2PEFT for Fine-tuningComputer Vision Community Course
- Intern seeks direction for fine-tuning Llama 2: A new intern expressed feeling overwhelmed about creating a custom LLM via fine-tuning using a Llama 2 7b model.
- They requested guidance towards resources, showing eagerness to learn quickly.
- PEFT recommended for fine-tuning: A member advised using PEFT as the best approach for fine-tuning with the Hugging Face library and mentioned available tutorials in their repository.
- For those with single or multiple GPUs, suggestions included using TRL and Accelerate libraries for optimized training.
- Impostor syndrome discussed: Another member shared their struggle with impostor syndrome, particularly when seeing PERL in Linux outputs.
- This highlights the ongoing insecurities many face in tech environments.
- Embarking on Computer Vision Community Course: A member announced they are starting the computer vision community course on Hugging Face today.
- This illustrates the commitment of participants to enhance their skills within the community.
HuggingFace ▷ #cool-finds (5 messages):
AI in HealthcareRetrieval Augmented Generation (RAG)Learning Resources on Hugging FaceAI Applications
- AI Revolutionizes Healthcare: AI has significantly transformed healthcare this year, improving diagnostics, enabling personalized medicine, and speeding up drug discovery.
- With the integration of wearable devices and IoT health monitoring, AI facilitates early disease detection and accurate diagnoses, reshaping treatment approaches.
- RAG Simplified for Beginners: Retrieval Augmented Generation (RAG) enables large language models to leverage their own data, enhancing their capabilities.
- A tutorial aims to demystify RAG, providing a straightforward approach for beginners to build RAG applications without unnecessary jargon.
- Hugging Face Learning Resources: A Community Computer Vision Course on Hugging Face teaches users about machine learning in computer vision using HF libraries and models.
- Participants noted the abundance of valuable learning resources available on the Hugging Face platform, enhancing their understanding of AI.
- 15 Amazing Real-World Applications Of AI Everyone Should Know About: The future is here, and it’s fueled by artificial intelligence. Read on to find out the top 15 real-world applications of AI that are redefining industries and impacting our daily lives in 2023.
- Hugging Face - Learn: no description found
- no title found: no description found
- A beginner's guide to building a Retrieval Augmented Generation (RAG) application from scratch: This post will teach you the fundamental intuition behind RAG while providing a simple tutorial to help you get started.
HuggingFace ▷ #i-made-this (23 messages🔥):
NLP Dataset ReleaseGradio Applications in RAgentic Framework in JavaImage Similarity DemoDebateThing AI Debate Generator
- NLP Dataset Release in Persian: A user released their first NLP dataset, a Persian translation of over 6K sentences from Wikipedia, accessible on Hugging Face. They expressed excitement for future datasets.
- The submission date for this dataset is September 10, 2024.
- Building Gradio Applications in R: A user shared their GitHub repository that teaches how to build Gradio applications in R, emphasizing the simplicity of the process (repository). Contributors are encouraged to star the project.
- The repository highlights the ease of integration between Gradio and R programming.
- Agentic Framework in Java: A demonstration of the agentic framework implemented in Java was presented, seeking feedback on the approach taken (LinkedIn post). The implementation is based on JADE and IEEE standards.
- The author is welcoming thoughts and constructive feedback.
- Image Similarity Demo using Pixtral: A user shared their image similarity demo using the pixtral-12b-240910 model from Hugging Face, inviting others to test its capabilities (demo). They mentioned issues with text generation leading to memory overflow on specific GPUs.
- They are looking for help on how to generate captions using the model.
- DebateThing AI Debate Generator Introduction: A user introduced DebateThing.com, an AI-powered debate generator that supports TTS and up to 4 participants in multiple rounds (site). The project is open-source and built with Deno Fresh.
- Key features include customization, moderator voice options, and a simple user interface for setting up debates.
- Mis (Unknow): no description found
- mistral-community/pixtral-12b-240910 · Hugging Face: no description found
- Pixtral Image Similarity - a Hugging Face Space by Tonic: no description found
- Who ?: In this video, we are going to test the world leading LLM models in this September 2024 both in speed and performance.#tokensperseconds #GPT4o #LLM #SOTA #Cl...
- Contributing to Open Source Changes Your Life ✨ | How to Contribute ⭐️ | Dhanush N: GitHub had more than 420 million repositories, including at least 28 million public repositoriesMore than 80% of contributions to GitHub are made to private ...
- GitHub - atlantis-nova/simtag: Implementation of Semantic Tag Filtering: Implementation of Semantic Tag Filtering. Contribute to atlantis-nova/simtag development by creating an account on GitHub.
- GitHub - Ifeanyi55/Gradio-in-R: Contribute to Ifeanyi55/Gradio-in-R development by creating an account on GitHub.
- Reza2kn/OLDI-Wikipedia-MTSeed-Persian · Datasets at Hugging Face: no description found
- GitHub - U-C4N/HOPE-Agent: HOPE (Highly Orchestrated Python Environment) Agent simplifies complex AI workflows. Manage multiple AI agents and tasks effortlessly. Features: • JSON-based configuration • Rich CLI • LangChain & Groq integration • Dynamic task allocation • Modular plugins Streamline your AI projects with HOPE Agent.: HOPE (Highly Orchestrated Python Environment) Agent simplifies complex AI workflows. Manage multiple AI agents and tasks effortlessly. Features: • JSON-based configuration • Rich CLI • LangChain &...
- Have several agents collaborate in a multi-agent hierarchy 🤖🤝🤖 - Hugging Face Open-Source AI Cookbook: no description found
- Multi Agent Web Browser - a Hugging Face Space by Csplk: no description found
- DebateThing.com: Generate interesting debates on any topic using AI and listen to them for free!
HuggingFace ▷ #computer-vision (2 messages):
CSV Image LoadingPyTorch DataLoader Best Practices
- CSV only provides IDs for image loading: The discussion noted that CSV files only contain image IDs, which requires fetching images on the fly or pre-splitting them into training and testing folders by class.
- This method may introduce slight latency compared to directly creating a DataLoader object from a folder hierarchy.
- Pre-apply transformations for better efficiency: A member emphasized best practices in PyTorch data loading, suggesting to apply image transformations beforehand rather than on-the-fly.
- This advice aligns with insights from a blog post discussing this behavior that highlights performance considerations.
HuggingFace ▷ #NLP (6 messages):
Korean lemmatizer enhancement with AIBuilding NLP models with PyTorchFine-tuning models on specific use casesNSFW text detection datasets
- Korean Lemmatizer seeks AI Boost: A member has developed a Korean lemmatizer without AI and seeks advice on utilizing AI to resolve ambiguous cases where a word has multiple lemmas.
- What direction should I look at? is the key question as they hope the ecosystem is now more advanced in 2024.
- Questions on Building NLP Models with PyTorch: A member is exploring how to create an NLP model from scratch using PyTorch but is unclear about the number of parameters needed for input and output.
- They mentioned their prior experience solely in computer vision, expressing a desire to branch into NLP.
- Repository Requests for Fine-tuning Models: A member is searching for GitHub repositories that provide guidance on fine-tuning models for specific use cases.
- Another member linked to the Hugging Face transformers examples as a potential resource.
- Inquiring about NSFW Text Detection Datasets: A member asks if there's a standard academic dataset for detecting NSFW text similar to how MNIST serves for image recognition.
- They mentioned CensorChat and a Reddit-based paper but noted a lack of comprehensive datasets.
Link mentioned: transformers/examples at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
aider (Paul Gauthier) ▷ #general (141 messages🔥🔥):
Aider features and workflowsPrompt caching in AiderModel performance and comparisonsUsing Aider with tools and APIsUser experiences and tips with Aider
- Optimizing Aider's Workflow: Users shared how the
ask first, code laterworkflow with Aider allows for better clarity and decision-making in code implementation, particularly when combined with a plan model.- This workflow improves context building and reduces the need for frequent
/undocommands.
- This workflow improves context building and reduces the need for frequent
- The Benefits of Prompt Caching: Aider's prompt caching feature has proven effective, with some users reporting up to a 40% reduction in token usage by strategically caching key files and instructions.
- The caching system keeps various elements, such as system prompts and read-only files, saving costs during interactions.
- Comparison of Aider and Other Tools: Users compared Aider's capabilities to other tools like Cursor and OpenRouter, noting that Aider has unique features that can save time and improve productivity.
- Aider's intelligent functionalities, like generating helpful aliases and cheat sheets from zsh history, showcase its versatility.
- API Performance and Issues: Reports indicated that the Anthropic API was experiencing overload issues, affecting multiple users' ability to connect and utilize the service.
- In contrast, users found the EU Vertex AI to be functioning well during the downtime, highlighting the variability of API performance.
- New Model Features and Cost Efficiency: Discussion revealed that the latest GPT-4o model offers substantial cost savings on input and output tokens, alongside supporting structured outputs.
- This model presents an appealing option for users looking to optimize their use of GPT technology, especially with the specified model parameter.
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- Supermaven: Free AI Code Completion: The fastest copilot. Supermaven uses a 1 million token context window to provide the highest quality code completions.
- Introducing Swift on Windows: The Swift project is introducing new downloadable Swift toolchain images for Windows! These images contain development components needed to build and run Swift code on Windows.
- Using /help: Use “/help " to ask for help about using aider, customizing settings, troubleshooting, using LLMs, etc.
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- Options reference: Details about all of aider’s settings.
- Options reference: Details about all of aider’s settings.
- swift-setup/platforms/windows/README.md at main · pwsacademy/swift-setup: Student-friendly setup instructions for platforms, editors, and IDEs that support Swift. - pwsacademy/swift-setup
- Claude 3.5 Sonnet - API, Providers, Stats: Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Run Claude 3.5 Sonnet with API
aider (Paul Gauthier) ▷ #questions-and-tips (105 messages🔥🔥):
Using OpenRouter with AiderOpenAI Compatibility and API DifferencesYAML Configuration IssuesAider as a Python ToolHandling Git .gitignore Files in Aider
- Exploring OpenRouter Benefits: Members discussed the advantages of using OpenRouter over Claude API, noting that OpenRouter bypasses initial rate limits and has lower costs due to tax differences.
- There was emphasis on its utility for experiments with multiple models in a centralized manner.
- Clarifying OpenAI API vs Ollama API: It was clarified that
ollamauses OpenAI-compatible endpoints whileollama_chatutilizes native APIs, impacting how they interact with models.- This distinction led to discussions on which API configuration might yield better performance for Aider users.
- YAML Configuration Problems: Users experienced issues with YAML configurations not being recognized by Aider, particularly concerning multiline settings.
- It was noted that Aider uses a subset of YAML, which complicates its configuration.
- Using Aider Within Python Scripts: A user successfully demonstrated using Aider in a Python script, asking about defining script names and file modifications.
- Suggestions were provided on how to effectively point Aider to specific file locations for script creation.
- Issues with Git Ignored Files: A user reported issues with Aider not being able to edit files listed in .gitignore, which caused errors when attempting to save edits.
- It was discussed how to resolve this without disabling git's advice settings, enhancing Aider's functionality.
- Advanced model settings: Configuring advanced settings for LLMs.
- Home: aider is AI pair programming in your terminal
- Scripting aider: You can script aider via the command line or python.
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- ConfigArgParse: A drop-in replacement for argparse that allows options to also be set via config files and/or environment variables.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- ollama/docs/api.md at main · ollama/ollama: Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models. - ollama/ollama
- ollama/docs/openai.md at main · ollama/ollama: Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models. - ollama/ollama
aider (Paul Gauthier) ▷ #links (3 messages):
Pixel art toolsPixtral model release
- Pixel Lab Tool Gains Attention: A member highlighted Pixel Lab as a great tool for generating pixel art and 2D sprite animations for game assets.
- They also shared a YouTube tutorial on creating punching animations using this tool, noting that it's still in early development.
- Mistral Launches Pixtral Model Torrent: Mistral released a new multimodal model called Pixtral (12B) as a torrent, designed for various applications including image classification and text generation.
- The magnet link for downloading is
magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910, and it's compatible with frameworks like PyTorch and TensorFlow.
- The magnet link for downloading is
- no title found: no description found
- Tutorial: How to quickly create punching animations: This is a tutorial on how to create animation with the skeleton animation tool. The tool is still very early in its development so expect a lot of improvemen...
LM Studio ▷ #general (174 messages🔥🔥):
Maintaining Character Consistency in AI ImagesGPU Performance for Token ProcessingLM Studio User Meet-upPixtral Support and Inference CodeLM Studio Features and Updates
- Maintaining Character Consistency in AI Images: A user inquired about effective techniques to ensure a character remains consistent across AI-generated images while changing outfits or backgrounds.
- The focus is on finding methods that allow the character's face and body to stay recognizable across various panels.
- GPU Performance for Token Processing: Users discussed discrepancies in token processing speeds for different GPUs, with one member reporting 45 tokens/s on a 6900XT compared to others.
- There were suggestions to flash BIOS to enhance performance and frustration about unexpected performance figures shared among users.
- LM Studio User Meet-up: A couple of LM Studio users announced a meet-up in central London to discuss prompt engineering, inviting others to join.
- Details included the time and logistics, encouraging participants to look for non-students using laptops.
- Pixtral Support and Inference Code: There were inquiries about Pixtral support, specifically regarding inference code and its integration with existing libraries.
- Responses indicated that while Mistral published some code, there is currently no support available in transformers or llama.cpp.
- LM Studio Features and Updates: Users discussed updated features in LM Studio, noting the absence of the GPU slider on Apple Silicon.
- Advice was shared on how to access model settings via the options menu to adjust layers offloaded to the GPU.
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- Google Maps : no description found
LM Studio ▷ #hardware-discussion (67 messages🔥🔥):
AMD vs NVIDIA performanceSurface Studio Pro upgradesRTX 4090D characteristicsAI model requirementsBenchmarking multiple GPUs
- AMD and NVIDIA: The Great Debate: A user noted that Blender performs poorly on non-NVIDIA hardware, leading to discussions about the performance differences between AMD and NVIDIA GPUs.
- It was highlighted that the 4090D might outperform standard cards under certain conditions, generating varying opinions on GPU choices.
- Upgrades for Surface Studio Pro: A user expressed frustration with the Surface Studio Pro's limited upgrade potential and sought advice on possible enhancements like eGPU or SSD.
- Recommendations included budgeting for a new dedicated AI rig instead of upgrading the existing laptop.
- Characteristics of the RTX 4090D: Discussions revolved around the RTX 4090D, a China-exclusive GPU that has more VRAM but fewer CUDA cores, making it a unique choice despite lower performance in certain tasks.
- Some noted it could be a worthwhile investment for AI applications due to its higher memory capacity despite being slower in gaming.
- AI Models and RAM Requirements: Participants discussed the significant RAM requirements for running multiple AI models concurrently, linking this to the performance of various GPU setups.
- The consensus was that having ample VRAM is essential for smooth performance in AI workloads.
- Benchmarking Multiple GPUs in Systems: One user reported on benchmarking a system with both AMD Radeon 7 and Intel Arc A380, highlighting how it defaults to using the Intel GPU.
- Advice was given to remove one GPU to resolve compatibility issues when using multiple graphics cards from different manufacturers.
- Your request has been blocked. This could be due to several reasons.: no description found
- Nvidia's made-for-China RTX 4090D is only 5% slower in gaming performance than the original RTX 4090: Sanction-compliant and still fast, it's about 10% slower in AI workloads.
- ASUS RTX 4090D Outperforming RTX 4090: ASUS boosts the performance of Nvidia's China-exclusive RTX 4090D GPU to go beyond that of RTX 4090 available in the US market.
- NVIDIA GeForce RTX 4090D with 48GB and RTX 4080 SUPER 32GB now offered in China for cloud computing - VideoCardz.com: RTX 4090D and RTX 4080 SUPER get doubled memory Where there is demand, there are custom solutions available. The China-centric RTX 4090D graphics card, designed to circumvent U.S. export restrictions...
- NVIDIA GeForce RTX 2050 and MX500 Laptop GPUs tested in 3DMark TimeSpy - VideoCardz.com: First test results of the RTX 2050 and MX570/550 Only hours after being unexpectedly announced, the first benchmark results of the new entry-level GPUs from NVIDIA have been published. The test result...
- Buy Surface Studio 2+ - See Desktop Specs, Price, Screen Size | Microsoft Store: Buy the Surface Studio 2+ from Microsoft Store. This striking 28" touchscreen, that transitions from desktop to canvas, features the 11th Gen Intel® Core™ H-series processor and NVIDIA GeForce RTX...
Stability.ai (Stable Diffusion) ▷ #general-chat (197 messages🔥🔥):
Stable Diffusion Model ComparisonsText to Image Generation TechniquesAI Image Generation Technical DiscussionsHardware Recommendations for AI TrainingReflection LLM Overview
- Stable Diffusion Model Comparisons: Users discussed various Stable Diffusion models, highlighting the differences between older models like '1.5 ema only' and newer options with better performance.
- Comparisons were made between GPUs, with mentions that the RTX 4060 Ti would outperform the 7600 and Quadro P620 for AI tasks.
- Text to Image Generation Techniques: It was emphasized that models should be generated at optimal resolutions, such as 512x512 for earlier models, to minimize artifacts when upscaling.
- Users shared workflows for generating images, suggesting using lower resolutions followed by upscaling for better quality outputs.
- AI Image Generation Technical Discussions: Discussions on AI models revealed ongoing concerns about how similar various LLMs are due to common training data and techniques.
- Users noted that hands become a less problematic aspect of image generation in newer models, indicating rapid progress in AI capabilities.
- Hardware Recommendations for AI Training: The community debated the effectiveness of GPUs for training AI models, favoring Nvidia over others due to CUDA compatibility.
- Users collectively suggested that while lower VRAM GPUs might work for some models, higher-end GPUs like those with 20GB are preferred for optimal performance.
- Reflection LLM Overview: Users discussed the properties of the Reflection LLM, which was supposed to outperform others by 'thinking' and 'reflecting', but was criticized for its actual performance.
- Concerns were raised regarding the API's disparity with the open-source version, which led to skepticism about its claimed capabilities.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Reddit comments/submissions 2005-06 to 2023-12: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Novita Endpoint Outage
- Novita Endpoints Suffer Outage: All Novita endpoints are currently experiencing an outage, resulting in a 403 status error for those filtering down to Novita without fallbacks.
- If you allow fallbacks, then your requests should proceed as usual.
- Novita Outage Resolved: The previously reported issues with Novita endpoints have now been resolved.
- Users can expect normal functionality after the outage.
OpenRouter (Alex Atallah) ▷ #general (171 messages🔥🔥):
Tool Suggestions for ProgrammingDiscussion on Hermes Model PricingPixtral Model CapabilitiesOpenRouter and Cursor IntegrationNovita Service Outage
- Tool Recommendations for Programming: A user inquired about programming tools, mentioning plans to utilize AWS Bedrock with Litelm for rate management and cost efficiency.
- Other users suggested tools like Aider and Cursor, with varying opinions on their effectiveness and user experience.
- Confusion Over Hermes Model Pricing: There was uncertainty regarding whether the Hermes 3 model would remain free, with one user speculating a possible charge of $5/M for updated endpoints.
- Members expressed hope for improved performance once they began charging, while some suggested that free alternatives would still be available.
- Pixtral Model's Use Cases: Users discussed the capabilities of the Pixtral 12B model, determining it might only accept image inputs to produce text outputs, implying limited text processing abilities.
- The consensus seemed to suggest that it would function similarly to LLaVA, potentially offering specialized performance in image tasks.
- Integrating OpenRouter with Cursor: A user faced issues using OpenRouter with Cursor, leading to discussions about configuration adjustments required for enabling model functionalities.
- Users shared insights on the existing problem in the cursor repository, highlighting the hardcoded routing issues when using specific models.
- Novita Service Outage Discussion: Members reported on a temporary outage affecting the Novita service linked to OpenRouter, yielding frustrations over the unclear duration of the issue.
- Some users speculated on the reasons behind the 'NOT_ENOUGH_BALANCE' error, leaning towards provider-side authentication problems.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Meet Arcee-SuperNova: Our Flagship 70B Model, Alternative to OpenAI: Meet Arcee-SuperNova: a groundbreaking model with state-of-the-art abilities in instruction-following and strong alignment with human preferences.
- Release v1.4.0 - Mistral common goes 🖼️ · mistralai/mistral-common: Pixtral is out! Mistral common has image support! You can now pass images and URLs alongside text into the user message. pip install --upgrade mistral_common Images You can encode images as follow...
- Sao10K/L3.1-70B-Hanami-x1 · Hugging Face: no description found
- mistral-community/pixtral-12b-240910 · Any Inference code?: no description found
- OpenRouter Status: OpenRouter Incident History
- Hermes 3 405B Instruct (free) - API, Providers, Stats: Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coheren...
- Can't use claude 3.5 sonnet with openrouter, seems like a cursor issue · Issue #1511 · getcursor/cursor: Using cursor on windows 11. Was working till very recently, at leas until last friday. If I use anthropic/claude-3.5-sonnet i get error Invalid API key. On verify API key in the model preferences, ...
CUDA MODE ▷ #general (23 messages🔥):
Matmul AlgorithmsCudamode-IR Online DiscussionsNeural Network QuantizationInterview Preparation Strategies
- Exploring Matmul Algorithms: A member inquired about resources for finding various matmul algorithms like Grouped GEMM and Split K.
- Another member recommended checking the Cutlass examples as a comprehensive source for these algorithms.
- Cudamode-IR Goes Online: Discussion arose about the feasibility of an online version of cudamode-irl, prompting suggestions for community-driven projects.
- Members noted that the current community serves as an effective online platform, inviting contributions and discussions.
- Cold Starts and GPU Concerns: A member questioned whether cold starts negatively affect GPU performance in local inference settings.
- Another member responded, asking why they thought it would harm the GPU, indicating that loading weights at startup is common.
- Quantization Challenges: To understand Post-Training Quantization, a member sought feedback on their implementation after facing accuracy drops.
- Community suggestions included using dynamic quantization for activations to improve accuracy during the quantization process.
- Interview Preparation Variance: Members discussed the high variance in interview questions across different companies, highlighting the challenge in balancing CUDA, DL algorithms, and more.
- Experiences shared indicated a mix of ML theory and practical coding interviews, with some mentioning the addition of system design components.
Link mentioned: Significant Accuracy Drop After "Custom" Activation Quantization – Seeking Debugging Suggestions: To deepen my understanding of Neural Network quantization, I’m re-implementing Post-Training Quantization (PTQ) from scratch with minimal reliance on PyTorch functions. The code can be found here: Git...
CUDA MODE ▷ #triton (7 messages):
Kernel Outputs Garbage with AutotuneUtilizing Tensor Cores in TritonSupport for uint4 in TritonUsing Cutlass for Tensor Operations
- Kernel Outputs Garbage with Autotune: A user reported that the kernel outputs garbage while using autotune in Triton, even with a duplicated config, which worked fine without autotune.
- Super weird, but the issue was resolved by re-installing Triton.
- Exploring Tensor Core Utilization: A question was raised about whether Triton does anything special to utilize tensor cores since it is hardware-agnostic.
- Another member clarified that developers just need to call
tl.dotand ensure the inputs have the right shapes.
- Another member clarified that developers just need to call
- Discussion on uint4 Support in Triton: A member expressed interest in Triton's support for uint4 data type.
- However, it was stated that uint4 is not supported in Triton.
- Cutlass for Advanced Tensor Operations: It was suggested that for unsupported types like uint4, one might need to use Cutlass for tensor operations.
- A link to the Cutlass GitHub repository was shared as a resource for handling these cases.
Link mentioned: cutlass/include/cute/arch/mma_sm80.hpp at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
CUDA MODE ▷ #torch (1 messages):
FlexAttention speedupflash_attn_varlen_func comparison
- FlexAttention shows impressive speedup: A user reported trying FlexAttention with document masking, achieving over 60% speedup compared to the padding approach.
- They inquired about performance numbers for flash_attn_varlen_func(), which also uses document masking, seeking a comparison.
- Inquiry about flash_attn_varlen_func performance: The same user expressed curiosity about the performance metrics of flash_attn_varlen_func() in relation to document masking.
- This highlights a need for more detailed performance comparisons between different attention mechanisms.
CUDA MODE ▷ #jobs (39 messages🔥):
OpenAI RSU DiscussionSecondary Markets for OpenAI SharesMicrosoft Investment in OpenAICollaboration Opportunities on Liquid
- Discussion on OpenAI's RSUs: Members discussed how employees at OpenAI, especially those who joined four years ago, could have seen their RSUs appreciated to 6-7x if not sold, highlighting the inflated perception of their worth.
- One member pointed out that it's paper money until OpenAI's IPO, while others acknowledged the reality of secondary transactions that allow some cash out.
- Insights on Secondary Market Transactions: There was a conversation about how OpenAI has conducted three secondary transactions which allowed employees the opportunity to cash out their shares, with more details here.
- Members speculated about how these secondary rounds impact share pricing and valuation over time, suggesting that VCs negotiate these transactions.
- Microsoft's Historic Investment in OpenAI: It was recalled that Microsoft invested $1B in OpenAI back in 2020, valuing the company at $15B at the time.
- This investment positioned Microsoft as a significant player in the AI field and sparked discussions about the timeline of OpenAI's financial milestones.
- Potential Collaboration on Liquid: A member offered to connect anyone interested in collaborating with Liquid, showing openness for networking opportunities.
- The aim is to facilitate relationships and partnerships within the context of these technological developments.
Link mentioned: no title found: no description found
CUDA MODE ▷ #torchao (9 messages🔥):
FP6 API inclusionBF16 and FP16 confusionPost-Training Quantization challengesRelease of torchao v0.5.0Quantized TTS models limitations
- FP6 becomes a main API: A member announced they're adding fp6 to the main README as a significant API due to its decent performance, highlighted in this pull request.
- There was a discussion about the difficulties of integrating BF16 with FP16, leading to concerns about user confusion due to performance reliance.
- Challenges in Activation Quantization: A member is re-implementing Post-Training Quantization from scratch and faces a significant accuracy drop during activation quantization, looking for suggestions.
- They shared a detailed post on the Torch forum for further insights.
- torchao v0.5.0 release highlights: The community celebrated the release of torchao v0.5.0, which introduces features such as float8 training and inference and support for HQQ.
- The release notes detail enhancements for memory-efficient inference and quantized training.
- Exploring OSS Quantized TTS Models: A member discussed the void in easily searchable OSS quantized TTS models and mentioned that torchao might easily fill this gap.
- They questioned the limitations of the current quant API with TTS models like Coqui XTTS-v2 as they research into it further.
- torchao limitations discussed: A member outlined the situations where torchao does not perform well, noting its incompatibility with compile and primary reliance on CPU and convolutions.
- They highlighted the challenges faced when performing unusual operations, particularly with linear functions that don’t align with torchao's handling.
- coqui/XTTS-v2 · Hugging Face: no description found
- Significant Accuracy Drop After "Custom" Activation Quantization – Seeking Debugging Suggestions: To deepen my understanding of Neural Network quantization, I’m re-implementing Post-Training Quantization (PTQ) from scratch with minimal reliance on PyTorch functions. The code can be found here: Git...
- Release v0.5.0 · pytorch/ao: Highlights We are excited to announce the 0.5 release of torchao! This release adds support for memory efficient inference, float8 training and inference, int8 quantized training, HQQ, automatic mi...
- README and benchmark improvements by HDCharles · Pull Request #867 · pytorch/ao: Summary: quantization README: added fp6 to benchmarks rewrote autoquant section to give a higher level explanation before diving into the details reordered affine quantization section to first sho...
CUDA MODE ▷ #off-topic (1 messages):
Neural Network QuantizationPost-Training Quantization (PTQ)Weight QuantizationActivation QuantizationDebugging Accuracy Drop
- Implementing PTQ from Scratch: A member is re-implementing Post-Training Quantization (PTQ) from scratch with minimal reliance on PyTorch functions, and has successfully implemented weight-only quantization.
- However, they report a significant drop in accuracy when attempting activation quantization and seek suggestions for improvement.
- Seeking Help on Accuracy Issues: The member has posted on the torch forum to share their challenges with activation quantization and accuracy drop post-implementation.
- They are looking for debugging suggestions and insights from the community to address the issues faced.
Link mentioned: Significant Accuracy Drop After "Custom" Activation Quantization – Seeking Debugging Suggestions: To deepen my understanding of Neural Network quantization, I’m re-implementing Post-Training Quantization (PTQ) from scratch with minimal reliance on PyTorch functions. The code can be found here: Git...
CUDA MODE ▷ #llmdotc (46 messages🔥):
Activation Function SaveFP8 Custom ImplementationMemory Management in OptimizersTensor Scaling ApproachesDebugging Fused Classifier
- Saving Activation Values for Backward Pass: It was noted that activation values are saved after applying the activation function for the backward pass, with optional activation checkpointing working on a branch.
- One member highlighted the ability to recalculate certain outputs like GELU or layer normalization to save memory.
- Exploring a Custom FP8 Implementation: Tile-wise scaling was discussed as an alternative FP8 approach, deviating from the typical per-tensor absmax tracking, which could simplify the codebase significantly.
- Members mentioned that a custom GEMM kernel might be necessary, as existing approaches seem limited and focused on per-tensor methods.
- Buffer Memory Management Strategy: One member proposed implementing a fixed-size, double-ended stack to manage intermediate buffer allocations, which would address the typical allocation patterns effectively.
- The idea was acknowledged as applicable for both scratch and temporary tensors while simplifying overall memory management efforts.
- Advancements in Tensor Scaling Techniques: Discussion revolved around implementing a strategy for using per-row/column absmax scaling to enhance accuracy, particularly in FP16 and tensor-core operations.
- The conversation included considerations for optimizing memory use with respect to classification and accurate input scaling within larger architectures.
- Debugging Issues in the Fused Classifier: A debugging incident resolved around the fused_classifer incorrectly writing dlogits during validation was shared as a humorous misstep.
- This bug was traced back to a minor error in code logic that highlighted the challenges of validation condition handling.
- cutlass/examples/55_hopper_mixed_dtype_gemm/55_hopper_mixed_dtype_gemm.cu at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
- llm.c/llmc/cuda_common.h at bd457aa19bdb7c0776725f05fe9ecb692558aed8 · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
CUDA MODE ▷ #sparsity-pruning (7 messages):
cuSparse usageSparse matrix multiplicationCompressed sensing theory
- Seeking cuSparse Batch-Multiplication Tips: A member inquired about using cuSparse for batch-multiplying sparse matrices S with dense matrices D that have a repeating pattern, without making a copy of the dense matrices.
- They provided a code snippet and asked for insights on optimizing memory allocation while using the API.
- Caution on cuSparse Performance: Another member warned that cuSparse is optimized for extremely sparse matrices (<1% non-zero), suggesting performance might not be efficient for typical machine-learning sparsity levels.
- They recommended considering a custom implementation if there are exploitable structures in the data.
- Interest in Compressed Sensing: One user suggested using compressed sensing theory to achieve similar effects as working with a super sparse matrix but with a smaller dense matrix.
- However, the original poster expressed concerns that due to variable sparsity patterns across batches, a consistent projection may not be feasible.
- Projection Challenge in Compressed Sensing: In response, a member noted that fixed random matrices with unit norm columns can encode all information, provided they follow the right distribution.
- They emphasized the need to determine the appropriate projection size while mentioning that the underlying projection could change as the sparsity pattern varies.
CUDA MODE ▷ #cudamode-irl (9 messages🔥):
Hackathon ParticipationMulti-GPU EnhancementsGPU Provider UpdatesSponsorshipCloud Credits
- Seeking Hackathon Participation: A member expressed interest in contributing to the hackathon, highlighting experience in building PyTorch/cuDNN from scratch and their upcoming position at Tenstorrent. They shared a GitHub repository for their work in convolution kernels.
- This role could provide valuable insights for kernel development.
- Multi-GPU Ideas Shared: Members discussed exciting new ideas for Multi-GPU usage, including elongating context lengths and optimizing memory efficiency. They linked to additional details for collaborators.
- The aim is to enable participants to pursue their projects with minimal overhead.
- GPU Provider Updates Announced: The team confirmed securing $300K in cloud credits along with a 10 node GH200 cluster and a 4 node 8 H100 cluster for the hackathon. They plan to work with sponsors to extend access to attendees beyond the event.
- Thanks were given to several sponsors, including Fal, Anyscale, and NVIDIA for their substantial support, more details can be found on the event website.
- Multi-gpu Track: Multi-gpu Track Make 405B faster on 4090s/not-so-beefy GPUs Today, one can fit llama-405B in 4 48GB 4090s, but it’s slow. Could we incorporate torch.compile as a first-class citizen? Currently, it co...
- GitHub - yugi957/Journey at convolution: Contribute to yugi957/Journey development by creating an account on GitHub.
CUDA MODE ▷ #liger-kernel (3 messages):
SGD ImplementationLabel Smoothing in FLCE
- Experimenting with SGD while awaiting resources: A member mentioned they are trying out SGD while waiting for access to 80GB A100 instances.
- This highlights the community's ongoing pursuit of efficiency and resource utilization in their projects.
- Label Smoothing Support Added for FLCE: A contributor fixed the label_smoothing support for FLCE and submitted a pull request to the Liger Kernel repository.
- The update includes testing performed on an RTX-3080 to ensure correctness, style, and convergence, addressing a previously noted issue.
Link mentioned: Add label smoothing to FLCE and unit tests by Tcc0403 · Pull Request #244 · linkedin/Liger-Kernel: Summary Fix #243 Testing Done Hardware Type: RTX-3080 run make test to ensure correctness run make checkstyle to ensure code style run make test-convergence to ensure convergence
Interconnects (Nathan Lambert) ▷ #news (63 messages🔥🔥):
OpenAI DeparturesMeta's AI Supercomputing ClusterAdobe Firefly Video ModelPixtral Model PerformanceGovernment Bureaucracy and Automation
- OpenAI Experiences Major Departures: OpenAI saw significant talent departures today, with former employee Alex Conneau announcing his exit to start a new company, while Arvind shared excitement about joining Meta.
- Rumors suggest that references to GPT-5 in profiles may indicate upcoming models, though skepticism about these claims exists.
- Meta Builds 100K GPU AI Supercomputing Cluster: Meta is reportedly nearing completion of an AI supercomputing cluster consisting of 100,000 Nvidia H100 GPUs to train Llama 4, opting out of proprietary Nvidia networking gear.
- The scale of this initiative emphasizes Meta's commitment to AI capabilities, especially as competition in the field intensifies.
- Adobe Firefly Video Model Introduction: Adobe announced a forthcoming Firefly Video Model, highlighting its rapid advancements since launching Firefly in March 2023 and its integration into popular Creative Cloud features.
- The new video model will be available in beta later this year, indicating Adobe's strong interest in leveraging generative AI for video production.
- Pixtral Model Shows Competitive Edge: At the recent Mistral summit, it was reported that the Pixtral 12B model outperforms peers like Phi 3 and Claude Haiku, offering flexibility with image sizes and tasks.
- Live demos showcased Pixtral's strong performance in OCR tasks, launching debates about its accuracy against competitors.
- Automation Through LLMs in Government: There were discussions about how LLMs could significantly automate bureaucratic processes in governments, potentially saving billions of taxpayer dollars.
- However, concerns were raised that such automation might expose hidden wealth that could be reluctant to simplify operations.
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- Tweet from Alexis Conneau (@alex_conneau): Career update: After an amazing journey at @OpenAI building #Her, I’ve decided to start a new company.
- Tweet from swyx.io (@swyx): **Frontier AI in your Hands** my live notes from today’s @MistralAI summit ft Jensen Huang and @arthurmensch and crew here thread emoji
- Bringing generative AI to video with Adobe Firefly Video Model | Adobe Blog: The latest in Firefly Video Model advancements.
- Tweet from Amir Efrati (@amir): new: Meta close to completing an AI supercomputing cluster of 100,000-plus Nvidia H100s to train Llama 4. In doing so, it will no longer use proprietary Nvidia networking gear. https://www.theinform...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Ok back to October now. We should have a 4.x model ( maybe still called 4.5, my old friend ) in October. The big boy gpt 5, I’ve heard as early as December but for your sanity I would have Q1/Q2 2...
- Tweet from Clayton Thorrez (@cthorrez): 14/24 of these matches were played today and 539's performances has not been superhuman. It has gotten 8/14 (57%) correct compared to 11/14(78%) by Elo invented in the 1960's using only histor...
- Tweet from Arvind Neelakantan (@arvind_io): Excited to join @AIatMeta! The past 4.5 years at @OpenAI,working on embeddings, GPT-3 & 4,API and ChatGPT, have been career highlights. Now, I'm thrilled to work on the next generations of Llama a...
- Tweet from anton (@abacaj): pixtral got this one wrong lmao, qwen2-vl nails this one... question 5 "vulnerable" is supposed to be "unlawful" Quoting swyx.io (@swyx) @GuillaumeLample @ArtificialAnlys @dchaplot ...
- Tweet from swyx.io (@swyx): New Pixtral details published onstage at mistral’s invite-only conference ft Jensen Huang, including benchmarks!!!!! Pixtral > Phi 3, Qwen VL, Claude Haiku, LLaVA Quoting swyx.io (@swyx) @Guill...
- Tweet from swyx.io (@swyx): @GuillaumeLample @ArtificialAnlys and @dchaplot takes the stage to drop alpha on Pixtral 12B (cc @altryne) in contrast with @imhaotian LLaVA style fused models - fixed image sizes, smaller number of ...
Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
Matt Shumer's AnnouncementReflection 70B Model IssuesCommunity ReactionsTransparency and Accountability
- Matt Shumer's Project Announcement Backlash: Matt Shumer expressed regret over his premature announcement regarding the Reflection 70B project, stating he acted too quickly based on the information available at the time.
- I made a decision to ship this new approach based on the information that we had at the moment.
- Reflection 70B Benchmarks on Wrong Model: Concerns surfaced about Reflection 70B benchmarks after a member claimed that erroneous configurations led to tests being run on the previous Sonnet 3.5 model.
- The member noted that Matt unknowingly ran benchmarks on the wrong model and published the results despite issues.
- Demand for Transparency from Matt Shumer: A developer expressed frustration at the lack of communication from Matt after investing significant resources into hosting his model, urging transparency on the discrepancies in performance.
- The developer pointed out that after extensive effort, they felt let down by the halted communication concerning the Reflection 70B model.
- Community Reflects on Hosting Efforts: Community members reflected on the time and resources spent hosting the Reflection 70B model, stating they will pivot to more productive projects if responses do not come soon.
- One member summarized the dilemma, stating, Attention is not all you need, hinting at the lessons learned from this experience.
- Exasperation with Ongoing Discussions about Matt: Members expressed a growing fatigue with the ongoing discussions about Matt, some humorously suggesting to move on from the topic entirely.
- One member's comment encapsulated the sentiment: When the dead AI news cycle needed him most, a hero appeared.
- Tweet from Florian S (@airesearch12): 3. when reconfiguring for Reflection 70b, he must have done something wrong, the proxy still pointed to Sonnet 3.5 instead, that he had in place before. Matt *unknowingly* ran benchmarks on the wrong ...
- Tweet from Yuchen Jin (@Yuchenj_UW): @mattshumer_ Hi Matt, we spent a lot of time, energy, and GPUs on hosting your model and it's sad to see you stopped replying to me in the past 30+ hours, I think you can be more transparent about...
- Tweet from Matt Shumer (@mattshumer_): I got ahead of myself when I announced this project, and I am sorry. That was not my intention. I made a decision to ship this new approach based on the information that we had at the moment. I know ...
Interconnects (Nathan Lambert) ▷ #random (14 messages🔥):
Gemini and Cursor IntegrationAider vs CursorAPI UX frustrationsAnthropic's SDK PerformanceStripe API Subscription Issues
- Exploring Gemini and Cursor Connection: Members discussed trying to integrate Gemini into Cursor, with one arguing it’s a very useful AI chatbot interface.
- Cursor has gained mixed reviews, with some expressing underwhelming experiences overall.
- Aider Gains Favor: There’s a growing preference for Aider among members, with one noting they have been loving it despite coding difficulties.
- Aider seems appealing for those not comfortable with terminal commands, as noted by members actively considering it.
- Frustrations with API UX: Members voiced their dissatisfaction with the standardization around the OpenAI API format, describing its UX as poor and convoluted.
- One user criticized the complexity of using the API, noting it requires multiple steps for simple tasks.
- Comparing APIs: OpenAI vs Google: A discussion emerged comparing the OpenAI API and Google's, with users agreeing that neither offers a straightforward experience.
- The desire for a more ergonomic API like Stripe or Python Requests was expressed, emphasizing frustrations with both services.
- State of Anthropic's SDKs: A member suggested a summary of the current state of APIs would be beneficial, focusing on Anthropic's fluctuating SDK performance this year.
- Comments suggest that Anthropic has faced challenges, and users are keen on tracking developments in its support.
Interconnects (Nathan Lambert) ▷ #posts (58 messages🔥🔥):
Surge AI Contract IssuesData Annotation WorkforceGoogle Contract Workers UnionizeTuring vs. Scale AIRLHF for Private Models
- Surge AI faced contract delivery issues: Surge AI reportedly failed to deliver data to HF and Ai2 until threatened with legal action, raising concerns about their prioritization of smaller contracts.
- There was no communication regarding their delays, leading to questions about their reliability.
- Challenges in in-house Data Annotation: Members discussed the difficulties of bringing data annotation in-house as most teams are reluctant to take on such tasks, highlighting the business risks involved for tech companies.
- This sentiment echoed concerns regarding the operational complexities seen with companies like Nvidia, which have not pursued in-house manufacturing.
- Google contract workers successfully unionize: A group of Google contract workers who trained the Bard AI chatbot voted overwhelmingly to join the Alphabet Workers Union, seeking better working conditions.
- These workers emphasized their challenging tasks, which included managing obscene and offensive prompts, as part of their role.
- Comparison between Turing and Scale AI: Discussion around Turing and Prolific highlighted their roles in data annotation and their initial focus on engineering recruitment before expanding into coding workforces.
- While there was curiosity about the industry landscape, it was noted that accurate metrics are hard to come by due to the private nature of these companies.
- Understanding RLHF for Private Models: Members expressed a desire to understand how Reinforcement Learning from Human Feedback (RLHF) functions for bespoke models, particularly in enterprise contexts.
- The conversation pointed out that while RLHF aims to adjust models for human preferences, challenges arise in specialized fields like materials science and organic chemistry.
- Google contractors objected to reading obscene Bard prompts — now they’re unionizing: More Google contractors are unionizing.
- Google contractors objected to reading obscene Bard prompts — now they’re unionizing: More Google contractors are unionizing.
Perplexity AI ▷ #announcements (1 messages):
Perplexity Pro Signup CampaignFinal Countdown for SignupsFree Month for Students
- Perplexity Pro Signup Campaign enters final stage: There are only 5 days left for campuses to reach 500 signups to secure a free year of Perplexity Pro. Check out the details and sign up at perplexity.ai/backtoschool.
- It's the final lap! and participants are encouraged to rally their peers for signups before the deadline.
- Countdown Timer Adds Urgency: A countdown timer emphasizes the urgency, showing 05:12:11:10 left to meet the signup goal. This ticking clock aims to motivate students to act quickly.
- Visuals accompanying the announcement highlight the limit time offer and create excitement around the campaign.
- Free Month of Perplexity Pro for Students: Students can sign up with their student email to unlock one free month of Perplexity Pro. This offer is designed to incentivize new users to engage with the platform.
- Signing up not only allows access to premium features but also contributes towards the campus signup goal.
Link mentioned: Perplexity - Race to Infinity: Welcome back to school! For just two weeks, redeem one free month of Perplexity Pro on us. Refer your friends, because if your school hits 500 signups we'll upgrade that free month to an entire free y...
Perplexity AI ▷ #general (86 messages🔥🔥):
Perplexity subscriptionsStudent offersAPI featuresPromotions and discountsGeneral user experience
- Students benefit from Perplexity subscriptions: Currently, there is an offer for students to receive a free pro month, although some noted that this is limited to US students or specific schools with sufficient signups.
- Members expressed frustration over international inequities in these offers, mentioning countries like Germany that also have promotions.
- Discussion on API and features: Users discussed anticipation for new API features during the upcoming dev day, speculating about the release of 4o voice and image generation capabilities.
- There’s also a desire for a hobby tier subscription for frequent users who may not need the full pro access.
- Feedback on user experience: Some users faced issues when trying to manage multiple attachments within the Perplexity platform, particularly when attempting to remove specific ones without losing all.
- There was additional chatter about the general user experience, comparing Perplexity favorably against competitors.
- Promotions and discounts discussed: Promotions and discounts were a hot topic, with mentions of a wide range of coupons available to diverse user bases and promotional offers in specific regions.
- The community highlighted the existence of a referral program, with mixed sentiments on its accessibility.
- Community engagement and support: Members expressed gratitude for community support, especially when reaching out for answers regarding their subscription and account statuses.
- The discussions illustrated an active community with shared experiences in troubleshooting and feature requests.
Perplexity AI ▷ #sharing (17 messages🔥):
Neuralink Patient UpdateSpaceX Starship Mars 2026 TargetCommercial SpacewalkIntelligence Chiefs UpdateClash of Titans Insights
- Neuralink's First Patient Update: Perplexity AI shared a YouTube video titled Neuralink's First Patient Update and SpaceX's Starship Targets Mars 2026.
- The video provides insights regarding Neuralink and SpaceX, detailing their future ambitions.
- First Commercial Spacewalk Success: A user expressed satisfaction with how the page on the First Commercial Spacewalk turned out.
- Concerns were raised about the lack of embeds in the page, indicating a desire for more interactive content.
- Intelligence Chiefs' Latest Insights: Updates regarding Intelligence Chiefs were noted, with a page conversion shared for ease of access here.
- This highlights ongoing discussions about national security and current intelligence methodologies.
- Clash of Titans Key Takeaways: Users converted discussions on the Clash of Titans into pages, emphasizing important takeaways, notably Key Takeaway 5.
- This reflects a collaborative effort to compile insights into digestible formats for future reference.
- AI at the Forefront Analysis: Discussion on the topic of AI's relevance in current tech advancements was highlighted in this search query.
- This indicates an interest in the evolving role of AI across various sectors.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
Bounce.aiPerplexity API usageSupport request
- Bounce.ai's Urgent Support Request: Aki Yu, CTO and co-founder of Bounce.ai, reached out regarding an urgent issue with the Perplexity API affecting their platform with over 3,000 active users.
- Despite trying to contact the Perplexity team for the past 4 months through various channels, they have yet to receive a response.
- Need for Immediate Contact: Aki emphasized the critical nature of their situation, requesting that someone from the Perplexity team urgently contact them at yutian@gobounce.ai.
- This highlights a potential gap in support or communication from Perplexity that needs addressing to maintain user trust.
Nous Research AI ▷ #general (74 messages🔥🔥):
Llama-3.1-SuperNova-Lite performanceModel comparisons: Hermes vs LlamaDistillation techniques and implicationsNeed for Hermes 3 APITraining small LLMs
- Llama-3.1-SuperNova-Lite showcases better mathematical abilities: A member highlighted that Llama-3.1-SuperNova-Lite seems to handle calculations like Vedic multiplication better than other models, particularly Hermes-3-Llama-3.1-8B, by maintaining accuracy in numbers.
- Though both models struggled with the task, SuperNova-Lite demonstrated an edge in preserving numeric integrity during calculations.
- Model comparisons reveal distinctions in performance: In testing, LLaMa-3.1-8B-Instruct consistently struggled with mathematical tasks while Llama-3.1-SuperNova-Lite performed relatively well, prompting a comparison between the models.
- The user expressed a strong preference for Hermes-3-Llama-3.1-8B over LLaMa-3.1-8B-Instruct, noting discrepancies in their mathematical performance.
- Discussion on distillation techniques: Members debated the effectiveness and cost of using distillation methods on large language models, questioning whether the benefits outweigh the challenges involved.
- Concerns were raised about the distilled model's limitations in handling out-of-distribution data due to reliance on a curated dataset for training.
- Interest in Hermes 3 API: There was a request for an API for Hermes 3 70B due to unsatisfactory results from existing services like Hyperbolic.
- The community noted that hosting options for Hermes 3 405B are available, but information on Hermes 3 70B is still pending.
- Exploration of small LLM training: A member expressed interest in pretraining a small language model (~10M params) using the Grokadamw optimizer, weighing options for speed and ease of use between different software.
- Concerns were shared regarding the transformer trainer's performance in terms of speed compared to alternatives like Axolotl.
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- Tweet from Kyle Corbitt (@corbtt): @mattshumer_ @ArtificialAnlys Final report on Reflection-70B: after investigating, I do not believe the a model that achieved the claimed benchmarks ever existed. It' very unclear to me where tho...
- Tweet from Alina Lozovskaya (@ailozovskaya): 🧵 (1/7) I got the results for both mattshumer/ref_70_e3 and mattshumer/Reflection-Llama-3.1-70B, with and without the system prompt! TL;DR none of these models performs as well as Meta-Llama-3.1-70B...
- HF's Missing Inference Widget - a Hugging Face Space by featherless-ai: no description found
- Meta AI: Use Meta AI assistant to get things done, create AI-generated images for free, and get answers to any of your questions. Meta AI is built on Meta's latest Llama large language model and uses Emu,...
- meta-llama/Meta-Llama-3.1-8B · Hugging Face: no description found
- LWDCLS/DarkIdol-Llama-3.1-8B-Instruct-1.2-Uncensored-GGUF-IQ-Imatrix-Request at main: no description found
- meta-llama/Meta-Llama-3.1-8B-Instruct · Hugging Face: no description found
- Meta AI: Use Meta AI assistant to get things done, create AI-generated images for free, and get answers to any of your questions. Meta AI is built on Meta's latest Llama large language model and uses Emu,...
Nous Research AI ▷ #ask-about-llms (13 messages🔥):
Quality Data ScalingBest Small Models for Instruction FollowingLlama-3.1-SuperNova-Lite LaunchModels Under 3B ParametersOpen LLM Leaderboard Resources
- Quality Data Scales in Performance: Members noted that higher quality data significantly enhances performance as model parameters are scaled up.
- The consistent feedback points to the importance of using high-quality datasets for optimal results.
- Discussion on Best Small Instruction Models: There was a query about the best small models (<7B) for instruction following, with prompts about various options including qlora 3.1 8B.
- Responses leaned towards Llama 3.1 8B as a viable choice for instruction tasks, indicating its effectiveness in the category.
- Llama-3.1-SuperNova-Lite Released: A new model, Llama-3.1-SuperNova-Lite, was shared as an 8B parameter model excelling in instruction-following capabilities.
- It is a distilled version of the larger Llama-3.1-405B-Instruct model, designed to be efficient and effective in tasks.
- Seeking Smaller Models for Simple Tasks: A member sought recommendations for smaller models capable of simple tasks, specifically smaller than Llama 3.1 8B.
- Suggestions included Mistral 7B, Qwen2 7B, and possibilities below 3B parameters, prompting requests for an updated list.
- Resource Sharing for LLM Rankings: A member mentioned finding an Open LLM Leaderboard that details various models’ performance.
- This resource is expected to help users make informed decisions on current best-performing LLMs.
- arcee-ai/Llama-3.1-SuperNova-Lite · Hugging Face: no description found
- Open LLM Leaderboard 2 - a Hugging Face Space by open-llm-leaderboard: no description found
Nous Research AI ▷ #research-papers (1 messages):
Spatial ReasoningNeuro-Symbolic AIProgram SearchProgram Synthesis
- Spatial Reasoning: The Last Hope?: A member expressed that Spatial Reasoning might be the final hope for advancement in reasoning, possibly alongside neuro-symbolic AI, program search, or program synthesis.
- They conveyed a sense of uncertainty, questioning if any revolutionary developments have occurred in these fields recently.
- Discussion on Recent Innovations: The conversation highlighted a desire for updates on any recent innovations in Spatial Reasoning and associated technologies.
- Members are eager to know if there have been any notable strides in this area of research.
Nous Research AI ▷ #research-papers (1 messages):
Spatial ReasoningNeuro-symbolic AIProgram SearchProgram Synthesis
- Spatial Reasoning as the Last Hope for AI: A member expressed the belief that Spatial Reasoning might be the ultimate frontier for Reasoning capabilities in AI.
- They suggested exploring potential advancements in neuro-symbolic AI, program search, or program synthesis as part of these innovations.
- Inquiry about Recent Advancements: The member raised a question about whether any revolutionary developments have emerged in the areas of Spatial Reasoning and related fields recently.
- This reflects ongoing interest and curiosity in the community about the latest trends in AI technology.
Latent Space ▷ #ai-general-chat (83 messages🔥🔥):
Pixtral 12B modelKlarna's SaaS strategyNew AI models and toolsTrieve's funding roundHume's Empathic Voice Interface
- Pixtral 12B model launched at Mistral conference: Mistral announced the Pixtral 12B model, outperforming other models like Phi 3 and Claude Haiku, as revealed at an invite-only conference featuring Jensen Huang.
- The model supports arbitrary image sizes and interleaving, showcasing important benchmarks at the event.
- Klarna to scrap legacy SaaS providers: Klarna's CEO stated that they are firing their SaaS providers, including systems previously thought impossible to replace, raising eyebrows about operational risks.
- In addition to cutting SaaS relationships, Klarna has also reportedly let go of 50% of its workforce, potentially linked to financial strain.
- Launch of new AI models for HTML to Markdown: Jina AI introduced two small models, reader-lm-0.5b and reader-lm-1.5b, specifically trained to convert HTML to markdown cleanly and efficiently.
- These models are multilingual and designed for high performance, outperforming larger counterparts while being significantly smaller.
- Trieve secures $3.5M in funding: Trieve AI announced a successful $3.5M funding round led by Root Ventures, aimed at making AI applications easier for all industries.
- The funding will support their growth, with current systems already reaching tens of thousands of users daily.
- Hume's new empathetic voice model: Hume AI has launched the Empathic Voice Interface 2 (EVI 2), which combines language and voice to train for emotional intelligence.
- The model is available for users to try and start building applications that require emotional engagement.
- Tweet from Mistral AI (@MistralAI): magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannoun...
- Tweet from tyler hogge (@thogge): Klarna CEO saying they are firing their SaaS providers even the "systems of record" that we thought were impossible to rip out. gone this is.....wild.
- Tweet from Patrick Collison (@patrickc): a16z made this handy list of the top 50 AI Gen AI web products: https://a16z.com/100-gen-ai-apps-3/ We checked, and turns out that 82% use @Stripe. We've been building a bunch of functionality t...
- Tweet from swyx.io (@swyx): New Pixtral details published onstage at mistral’s invite-only conference ft Jensen Huang, including benchmarks!!!!! Pixtral > Phi 3, Qwen VL, Claude Haiku, LLaVA Quoting swyx.io (@swyx) @Guill...
- Tweet from Esha (@eshamanideep): "dim": 5120, "n_layers": 40, "head_dim": 128, "hidden_dim": 14336, "n_heads": 32, "n_kv_heads": 8, "rope_theta": 1000000000.0, "norm_eps"...
- YNAB API Endpoints - v1: no description found
- Tweet from william (@wgussml): 🚀 I'm excited to announce the future of prompt engineering: 𝚎𝚕𝚕. developed from ideas during my time at OpenAI, 𝚎𝚕𝚕 is light, functional lm programming library: - automatic versioning & t...
- Tweet from aiur (@alwayslaunch): Quoting tyler hogge (@thogge) Klarna CEO saying they are firing their SaaS providers even the "systems of record" that we thought were impossible to rip out. gone this is.....wild.
- Tweet from Hume (@hume_ai): Introducing Empathic Voice Interface 2 (EVI 2), our new voice-to-voice foundation model. EVI 2 merges language and voice into a single model trained specifically for emotional intelligence. You can t...
- Tweet from Visual Studio Code (@code): 📣 The new @code release has the latest and greatest GitHub Copilot updates. Let's check them out… 🧵
- Tweet from Tom Dörr (@tom_doerr): One of the most exciting projects I've seen recently. This crawler can give you screenshots of the pages, allows you to choose the output format (JSON, cleaned HTML, markdown) and has a ton of oth...
- Tweet from Daniel Han (@danielhanchen): Mistral just dropped a new vision multimodal model called Pixtral 12b! Also downloaded params json - GeLU & 2D RoPE are used for the vision adapter. The vocab size also got larger - 131072 Also Mist...
- Tweet from Tim Suchanek (@TimSuchanek): 🚀 After an amazing time at Stellate, I've decided to start a new business. I've founded http://expand.ai, and we're in the current YC batch - S24! For techies: http://expand.ai instantly...
- Tweet from LangChain (@LangChainAI): LangChain Academy is live! Our first course — Introduction to LangGraph — teaches you the in-and-outs of building a reliable AI agent. In this course, you’ll learn how to: 🛠️ Build agents with LangG...
- Tweet from jason liu (@jxnlco): congrats to http://expand.ai! for everyone else, expand ai at home ;)
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): 🚨 New powerful open Text to Speech model: Fish Speech 1.4 - trained on 700K hours of speech, multilingual (8 languages)🔥 > Instant Voice Cloning > Ultra low latency > ~1GB model weights &...
- Tweet from skeptrune (@skeptrune): I am thrilled to announce @trieveai's $3.5M funding round led by Root Ventures! Myself and @cdxker founded Trieve because we felt like building AI applications should be easier. We are looking...
- Tweet from homanp (@pelaseyed): 1. The cost of writing a piece of software is going to zero. 2. The skills necessary to write a piece of software is also going to zero. 3. Traditional business models, e.g SaaS, are being disrupte...
- Tweet from Jina AI (@JinaAI_): Announcing reader-lm-0.5b and reader-lm-1.5b, https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown?nocache=1 two Small Language Models (SLMs) inspired by J...
- Tweet from James Wang (@draecomino): Nvidia is starting to lose share to AI chip startups for the first time. You can hear it in the hallways of every AI conference in the past few months.
- Tweet from martin_casado (@martin_casado): Hehe, someone is going to learn that state consistency and integrations are hard.
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): End to End Speech models are on fire - LLAMA-OMNI 8B - Apache licensed! 🔥 > Speech Encoder - Whisper Large v3 > LLM backbone - Llama 3.1 8B Instruct > Speech Decoder - HuBERT (UnitY) > ...
- Reworkd AI: End to End Web Scraping
- Buy now, pay later firm Klarna swings to first-half profit ahead of IPO: Klarna said it made an adjusted operating profit in the first half of 2024, swinging into the black as the firm nears a hotly anticipated IPO.
- @philschmid/clipper: A CLI to clip articles from the web and save them as markdown files.. Latest version: 0.2.0, last published: 8 months ago. Start using @philschmid/clipper in your project by running `npm i @philschmid...
OpenInterpreter ▷ #general (36 messages🔥):
Open Interpreter CapabilitiesDocumentation ClarityEarly Access for Desktop AppDiscontinuation of 01 LightExploration of Hardware with Open Interpreter
- Instructing Open Interpreter with Custom Python Code: A member inquired about the possibility of using specific Python code as a tool in Open Interpreter for tasks like sentiment analysis.
- There was interest in confirming the feasibility of this feature for broader custom queries over databases.
- Documentation Feedback Received: A member expressed that while they found Open Interpreter cool, they encountered issues navigating the documentation, which felt scattered.
- Another participant offered to help improve the documentation with suggestions and welcomed pull requests.
- Early Access for Desktop App Opening Soon: A user sought information on the timeline for early access to the desktop app and was encouraged to ping for updates.
- It was noted that there might be more beta testers included within a couple of weeks.
- Refunds and 01 Light Project Update: A member shared they received a refund related to the discontinuation of the 01 light, enlivening a discussion about transitions to a new free 01 app.
- A related update confirmed that all manufacturing materials would be open-sourced along with the 01.1 update.
- Exploring Hardware Options Post-01 Discontinuation: A user asked if there's a forum for exploring hardware possibilities with Open Interpreter after the discontinuation of the 01 project.
- They were directed to a specific channel that had relevant discussions, which they hadn't seen before.
- Tweet from killian (@hellokillian): Today we're discontinuing the 01 light, refunding everyone, and launching a free 01 app. We're also open-sourcing all our manufacturing materials + a major 01.1 update. Why? Focus. This soft...
- no title found: no description found
- GitHub - Textualize/rich: Rich is a Python library for rich text and beautiful formatting in the terminal.: Rich is a Python library for rich text and beautiful formatting in the terminal. - Textualize/rich
OpenInterpreter ▷ #O1 (45 messages🔥):
Open Interpreter installation issuesMobile app requirementsUpdating 01Upcoming desktop appDifferences between Open Interpreter and 01
- Open Interpreter installation issues persist: Users expressed frustrations with the complexity of installing Open Interpreter on various systems, particularly on Intel MacBooks.
- Several members are waiting for an easier installation option via an upcoming desktop app, currently in beta testing.
- Mobile app needs Livekit server: To utilize the new mobile app, users must install the Livekit server and set up API keys for services like ElevenLabs and Anthropics in their .env file.
- It was noted that Ngrok is only required for web exposure, making local network usage feasible without it.
- Updating 01 to resolve issues: Issues related to running commands like
poetry run 01 --local --qrprompted discussions on updating 01 using commands likegit pullandpoetry install.- When problems persisted, users were advised to clone a fresh repository to ensure they had the latest version.
- Interest in beta testing desktop app: A user inquired about helping with the beta testing of the upcoming desktop app, which promises a simplified installation process.
- The community is optimistic about the desktop app's potential to streamline installs for Windows and Mac users.
- Clarification on Open Interpreter vs. 01: There was confusion over the distinction between Open Interpreter and 01, with users unsure about the differences.
- Members were encouraged to post installation issues in a dedicated channel to streamline support.
- Choosing a server - 01: no description found
- Livekit Server - 01: no description found
- Configure - 01: no description found
- Introduction - 01: no description found
OpenInterpreter ▷ #ai-content (2 messages):
RAG Context from JSONL DataPheme News GitHub RepositoryNER Process and Neo4j LoadingInformation Differentiation in News
- Sneak Peek at RAG Context: A user provided a sneak peek at a preliminary test run for offering context from JSONL data intended for RAG, currently configured for news RSS feeds.
- The process involves NER taking a day, with similar time needed to load the data into Neo4j before creating a video tutorial on usability.
- Pheme News Repository Highlighted: Highlighted GitHub repository Pheme-News aims to differentiate between mis/dis/mal-information in news using NLP techniques.
- It seeks to track actors and their interconnectivity with global events, showcasing a more holistic approach to information analysis.
- Encouragement to Load Sample Data: A user reminded others that sample data for testing purposes has been shared in the off-topic channel.
- This encourages engagement and experimentation with the provided resources.
Link mentioned: GitHub - CodeAKrome/Pheme-News: Differentiate between mis/dis/mal-information in news using NLP to track actors and their interconnectivity with each other and world evens in a holistic fashion.: Differentiate between mis/dis/mal-information in news using NLP to track actors and their interconnectivity with each other and world evens in a holistic fashion. - CodeAKrome/Pheme-News
Cohere ▷ #discussions (52 messages🔥):
Cohere Integration ProjectsMistral Vision ModelHuman Oversight in AIDiscord FAQ Bot Development
- Cohere Integration for Ticket Support: A member plans to integrate Cohere within Link Safe for various purposes such as ticket support and text processing.
- They expressed excitement about using Cohere in conjunction with their ongoing experimentation.
- Mistral Unveils Vision Model: Members reacted with excitement as Mistral dropped a new vision model, sparking discussions about potential capabilities and future projects.
- One member expressed interest in whether the C4AI team would develop a vision model, while another shared they are working on 'Maya' and need a few more months.
- Long-Term Human Oversight in AI: A member voiced strong agreement that human oversight is likely to remain critical for years to come in AI developments.
- Another member agreed, emphasizing that Cohere's focus should be on making existing capabilities reliable and relevant in enterprise contexts, rather than chasing ultimate machine intelligence.
- Development of Discord FAQ Bot: A member is currently building a Discord FAQ bot specifically designed for Cohere, looking to streamline communication in the server.
- They are also organizing a virtual hack event, encouraging participation and exploration of new ideas.
- Engagement Ideas for Cohere Community: Discussions sparked about brainstorming more engaging use cases for the server, including a proper chatbot and AI dungeon crawling experiences.
- Members encouraged each other to think creatively about how to enhance user interaction and engagement within the community.
Cohere ▷ #questions (5 messages):
Aya-101 End-of-lifeFine-tuning LLMsAya-23 Release
- Questioning Aya-101's Future: Is Aya-101 End-of-life? raises concern among members, hinting at a possible transition to a new model.
- The same member speculated that a new model could potentially outperform competitors, referring to it as a Phi-killer.
- Exploring Aya-23's Capabilities: Another member recommended trying out Aya 23, claiming it covers a smaller set of languages but is more powerful than Aya-101.
- They mentioned that fine-tuning scripts are available for Aya-23, accessible through its Hugging Face model page for interested users.
- Call for Fine-tuning Resources: Members actively sought suggestive videos or books on how to fine-tune LLMs, indicating a desire for targeted learning resources.
- Additionally, they expressed interest in obtaining fine-tuning information alongside new model releases.
Link mentioned: C4AI Aya 23 - a CohereForAI Collection: no description found
Cohere ▷ #api-discussions (6 messages):
Cohere API functionalityFeedback process for APIPolymorphic objects in JSON
- Cohere API still faces functionality issues: Users expressed frustration about the Cohere API, noting ongoing changes to methods without clear communication on what is currently functioning.
- One user questioned the overall reliability of the API, while another suggested narrowing down specific issues for clarity.
- Feedback on API experience: Acknowledgements of user feedback reflected a desire from Cohere team members to improve the overall user experience regarding API functionalities.
- Recommendations included providing more explicit details about non-working methods and utilizing feedback forms in documentation.
- Request for min-p parameter: A user requested the addition of the
min-pparameter to the Cohere API as a feature enhancement.- This request was made alongside complaints about the lack of clarity regarding existing API capabilities.
- Challenges with polymorphic objects in JSON: A user encountered difficulties using polymorphic objects within structured JSON in Cohere, specifically noting the lack of support for
anyOf.- Two attempted approaches for creating polymorphic structures were shared, but both were rejected by the API.
Cohere ▷ #projects (1 messages):
AI developer seeking project
- AI Developer on the Hunt for Projects: An AI developer expressed interest in collaborating on new projects, encouraging others to reach out.
- Feel free to reach out to me if anyone has project opportunities.
- Invitation for Collaboration: The message emphasizes an open invitation for collaboration within the AI development community.
- Others are encouraged to engage with this member regarding potential projects.
Eleuther ▷ #general (15 messages🔥):
lm-evaluation-harnesspile-t5 performancebenchmark paper finalizationhuggingface implementation
- Getting Guidance on lm-evaluation-harness: A user seeks help in using lm-evaluation-harness to evaluate the OpenAI gpt4o model with a code generation swe-bench dataset.
- They express gratitude in advance for any guidance provided.
- Benchmark Paper Nears Completion: One member mentioned that the benchmark and paper finalization are almost complete and invited others to reach out when published.
- Another expressed interest in seeing a rough draft for feedback once available.
- Questions on pile-t5 Codebase and Performance: A user asked about the codebase used for evaluating pile-t5, noting lower-than-expected performance compared to google/t5-v1_1-xl.
- They are unsure if it's a Hugging Face implementation issue or if the model just isn't suitable for their task.
- Usage of lm-eval-harness for Evaluations: A member confirmed they used lm-eval-harness for their evaluations and specified it was with the full model, not just the encoder.
- This clarification helps the user understand that their specific use case hasn't been tested.
Eleuther ▷ #research (4 messages):
Pixtral-12b-240910RWKV-7 improvementsDynamic state evolution in RWKV-7
- Pixtral-12b-240910 model released: The community shared the Pixtral-12b-240910 model checkpoint, noting it is provided as-is and may not be up-to-date, mirroring the torrent released by Mistral AI.
- The download link includes a magnet URI and more details can be found on Mistral's Twitter.
- RWKV-7 shows potential as Transformer killer: RWKV-7 is described as an improved version of DeltaNet with a transition matrix that is identity-plus-low-rank, which could challenge existing transformers.
- A related study on optimizing DeltaNet for sequence length parallelization is available on arXiv.
- Dynamic state evolution in RWKV-7 gains traction: The RWKV-7 ‘Goose’ preview emphasizes dynamic state evolution utilizing a structured matrix, leading to a more scalable loss curve after resolving a bug.
- This enhancement signals notable progress, as shared by BlinkDL on their X platform.
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-7 "Goose" preview, with dynamic state evolution (using structured matrix) 🪿 Now the loss curve looks scalable, after fixing a hidden bug😀
- Tweet from Songlin Yang (@SonglinYang4): RWKV7 is said to be an improved version of DeltaNet where the transition matrix is identity-plus-low-rank. Check out our previous work on how to parallelize DeltaNet over sequence length: https://arx...
- mistral-community/pixtral-12b-240910 · Hugging Face: no description found
Eleuther ▷ #interpretability-general (6 messages):
Chunking datasetsPerformance rationale in trainingEOS token usage
- Is chunking datasets a standard practice?: A user questioned whether it's standard to split datasets into 128-token chunks for training, noting the potential impacts on model input context.
- Responses suggest that decisions around chunking may stem from intuitive guesses rather than empirical studies.
- Performance benefits vs. context loss: Another user emphasized that it's common practice not necessarily due to studies optimizing for performance but often due to lack of solid justification.
- The conversation implies that many might use chunking without considering its true impact on model performance.
- Introducing EOS tokens in chunking: A member mentioned using an
token as a separator before chunking data into window lengths, lacking strong justification for the method.- They likened the practice to how text is split in newspapers, concluding that while the position effects might average out, this still isn't definitive proof.
Eleuther ▷ #lm-thunderdome (1 messages):
rimanv_51850: I am preparing a pull request for a task, that will include the fix if that's ok
Eleuther ▷ #multimodal-general (3 messages):
image-text multimodal LLM positioningpixtral
- Positioning of Image Text Tokens: A member questioned if there is research on the optimal positioning of image tokens relative to text tokens in image-text multimodal LLMs.
- zaptrem responded, stating that attention is position invariant, implying that positioning shouldn't matter unless fine-tuning an existing model which may have learned a recency bias.
- Excitement for New Pixtral: A member shared enthusiasm about the capabilities of the new pixtral, indicating it is a cool advancement.
- The discussion hinted at a positive reception, but specifics on its features were not provided.
Eleuther ▷ #gpt-neox-dev (3 messages):
Multinode trainingDDP across nodesGlobal batch size impact
- Multinode Training Performance Concerns: A user inquired about experiences with multinode training over slower Ethernet links between 8xH100 machines, specifically regarding DDP functionality.
- Concerns were raised that performance might be significantly impacted due to link speed, which could affect training times.
- DDP Insights: The possibility of training models within a single node but using DDP across multiple nodes was discussed.
- It was suggested that although feasible, the efficiency could diminish due to slower connections.
- Batch Size Recommendations: A member recommended increasing the train_batch_size to saturate VRAM, thus optimizing training efficiency.
- It was noted that a global batch size of 4M-8M tokens was identified as a threshold for effective convergence during Pythia pretraining.
- Training Techniques Discussion: The importance of higher batch sizes to enhance time spent between gradient reductions across nodes was emphasized.
- The user expressed a lack of success with techniques like 1-bit Adam and topk grad sparsification, indicating ongoing challenges in optimization.
LlamaIndex ▷ #blog (4 messages):
RAG courseRetrieval-Augmented Generation tutorialKotaemon UI for document QAAI Scheduler workshop
- Maven Course on RAG in the LLM Era: Check out the Maven course titled Search For RAG in the LLM era, featuring a guest lecture by @jerryjliu0, complete with live code walkthroughs.
- Engage with code examples and implementations alongside industry veterans to enhance your learning experience.
- Quick Tutorial on Building RAG: A nice quick tutorial on building retrieval-augmented generation with LlamaIndex is now available.
- It provides a straightforward approach to implementing RAG technologies effectively.
- Kotaemon: Building a RAG-Based Document QA System: Learn how to build a RAG-based document QA system using Kotaemon, an open-source UI for chatting with documents.
- Topics covered include setting up a customizable RAG UI and organizing LLM & embedding models.
- Hands-On AI Scheduler Workshop: Join the workshop at AWS Loft on September 20th to build an AI Scheduler for smart meetings using Zoom, LlamaIndex, and Qdrant.
- Participants will create a RAG recommendation engine for meeting productivity and utilize Zoom's transcription SDK for analysis.
LlamaIndex ▷ #general (24 messages🔥):
Task queue for building indexesQueryPipeline run_multi_with_intermediatesSaving vectors in ChromaDBMemory management in LlamaIndexUsing different LLM providers
- Exploring Task Queue Setup: Discussion initiated about creating a task queue for building indexes using FastAPI with a Celery backend and database for storing files and indexing info.
- A suggestion was made to check for existing setups that might fulfill these requirements.
- QueryPipeline's run_multi_with_intermediates: Inquiries were made about achieving similar functionality as QueryPipeline's run_multi_with_intermediates within workflows, highlighting its utility for inspecting results after query executions.
- The method was confirmed as effective for viewing intermediary results, with some users sharing coding techniques to handle workflows.
- Storing Vectors from Semantic Chunker: A question arose about saving vectors from a semantic chunker into ChromaDB, with an indication that this option does not currently exist.
- To store vectors, users were advised to subclass the semantic chunker and implement custom code to push the vectors into a database solution.
- Managing Memory in LlamaIndex: Users discussed implementation strategies for memory management when utilizing LlamaIndex, detailing how to use ChatMemoryBuffer to store chat messages.
- Best practices shared included how to append new messages while retrieving previous message histories for context.
- Integrating Alternative LLM Providers: Instructions were provided on how to switch from OpenAI to other LLM providers like Ollama using LlamaIndex, facilitating integration flexibility.
- Resources were shared for setup and usage of alternative LLMs, including a link to a Colab notebook for practical demonstrations.
- Streaming events - LlamaIndex: no description found
- Ollama - Llama 3.1 - LlamaIndex: no description found
LangChain AI ▷ #general (15 messages🔥):
Query Generation with LLMConnecting Young EntrepreneursStripping LLM ResponsesBuilding RAG ApplicationsUpstash Redis Memory Debugging
- Building a POC for Query Generation: A member is developing a POC on query generation through LLM using LangGraph, facing challenges with increased token sizes as the number of tables grows.
- They implemented RAG to convert schemas into vectors for generating queries and seek other potential solutions, noting reluctance to add additional LLM calls.
- Forming a Group of Like-minded Individuals: A member expressed interest in forming a group of ambitious AI enthusiasts, coders, and entrepreneurs for daily brainstorming sessions aimed at making an impact.
- They emphasized the need for active participation, stating 'Let’s act and stop waiting around for other people/companies to do what you are wishing you would’ve done.'
- Stripping the Output of LLM Responses: Inquiring about how to strip responses to display only the LLM output, a member was directed to the StrOutputParser provided by LangChain.
- This parser is designed to extract the top likely string from LLM results, facilitating cleaner outputs.
- Building RAG Application Insights: A newcomer to RAG apps asked whether to keep or remove new line characters from text fetched via a web loader before storing it in a vector database.
- Another member advised that there is no need to remove the new line characters which implies it would be fine to retain the formatting.
- Debugging Upstash Redis Memory: A user raised an issue regarding Upstash Redis history bugs when using ChatTogetherAI, noting that switching to ChatOpenAI resolves the problem.
- This indicates potential compatibility issues within the library that might require further investigation.
Link mentioned: langchain_core.output_parsers.string.StrOutputParser — 🦜🔗 LangChain 0.2.16: no description found
LangChain AI ▷ #share-your-work (2 messages):
OppyDev UpdatePromo CodesPlugin SystemRAG SystemReal-time Code Review
- OppyDev's Major Update Launch: The team announced a significant update to their AI-assisted coding tool, OppyDev, enhancing the developer experience by streamlining interactions with AI.
- New features include an easy setup for Mac and Windows, and integration with multiple LLMs like GPT-4 and Llama.
- Exclusive Promo Codes Available: They are offering promo codes to users for a limited time, providing access to a subscriber account with one million free GPT-4 tokens.
- Interested users can message for a promo code to get started with the new version of OppyDev.
- Introducing a New Plugin System: The update features a new plugin system that enables users to build custom tools and enhance OppyDev's capabilities.
- Learn more about the plugin functionality in the documentation.
- RAG System for Enhanced Coding Tasks: OppyDev utilizes a RAG system that allows developers to ask questions about their codebase and manage multi-step coding tasks across files.
- This helps bridge the gap between development and AI assistance, improving efficiency.
- Real-time Code Review Features: The new update includes a color-coded, editable diff feature that enables real-time change reviews during coding.
- This functionality ensures developers can monitor their coding progress effectively.
Link mentioned: Documentation - OppyDev: Watch our getting started video and learn more about how to use OppyDev's AI agent powered coding assistan
Torchtune ▷ #general (4 messages):
Torchtune FP16 SupportQwen2 Interface DiscrepanciesEOS ID Handling
- Torchtune does not support FP16: A member explained that maintaining compatibility between mixed precision modules and other features requires extra work, while bf16 half precision training is considered superior.
- The main downside of lacking FP16 support is its incompatibility with older GPUs, which may affect some users.
- Qwen2 Interface has differing tokenization behavior: A member noted that the Qwen2 interface allows passing
Noneforeos_id, resulting in aNone-check before adding it in theencodemethod.- However, there may be an oversight since another case in the code does not perform this check, raising potential questions about whether this behavior is intentional or a bug.
- Allowing None EOS ID seems problematic: It was suggested that allowing
add_eos=Truewhile havingeos_idset toNoneshould not be permitted explicitly.- This raises concerns about the consistency and expected behavior of the tokenization process within the Qwen2 model.
- torchtune/torchtune/models/qwen2/_tokenizer.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/models/qwen2/_tokenizer.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (5 messages):
padded_collate utilityppo recipe modifications
- Inquiry about padded_collate's usage: A member noticed that the
padded_collateutility is not utilized anywhere and inquired about its intended purpose, particularly regarding the padding direction parameter.- They pointed out a logic issue in
padded_collate_sft, mentioning that the matching input_ids and labels seq length logic is missing.
- They pointed out a logic issue in
- Clarification on ppo recipe: Another member believed they had added the
padded_collatelogic to the ppo recipe and asked for clarification on what was missing.- This led to a discussion about the current state of the padded_collate implementation and whether len(input_ids) and len(labels) would typically match.
Link mentioned: torchtune/torchtune/data/_collate.py at eb92658a360d7a7d4ce1c93bbcf99c99a2e0943b · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
DSPy ▷ #papers (2 messages):
Sci Scope ToolEvaluating AI Outputs
- Introducing Sci Scope for Arxiv Paper Summaries: A new tool named Sci Scope has been developed to group the latest Arxiv papers by similarity and generate concise summaries using LLMs, hosted for free on the website.
- Users can sign up to receive a weekly summary of all AI research directly to their inbox, with a list of sources provided for deeper exploration.
- Query on Veracity of Output: A member expressed interest in how the tool ensures output veracity and minimizes hallucinations in the generated summaries.
- This raises an important discussion about the reliability of AI-generated content and the methodologies behind evaluating such outputs.
Link mentioned: Sci Scope: An AI generated newspaper on AI research
DSPy ▷ #general (2 messages):
DSPy CustomizationsDynamic Prompting Techniques
- Client-Specific Customizations for DSPy: A member posed a question about how to integrate client-specific customizations into DSPy-generated prompts for a simple chatbot, without hard-coding client information into the module.
- They are considering a post-processing step for dynamic adaptations and are seeking advice on better methods for implementing customizations.
- Expressing Gratitude for Help: A member thanked another for providing the information they were looking for regarding DSPy.
- This exchange highlights the collaborative spirit of the group, where members are actively supporting each other in their queries.
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Running audio models with tinygradWhisper exampleGetting help online
- Exploring Audio Models with Tinygrad: A user sought guidance on how to run audio models with tinygrad, specifically looking beyond the existing Whisper example provided in the repo.
- This inquiry spurred suggestions on potential starting points for exploring audio applications in tinygrad.
- Philosophical Approach to Learning: A member quoted, 'The journey of a thousand miles begins with a single step,' emphasizing the importance of intuition in the learning process.
- This sentiment encouraged a reflective exploration of resources within the community.
- Linking to Helpful Resources: Another member shared a link to the smart questions FAQ by Eric S. Raymond, which outlines etiquette and strategies for seeking help online.
- This resource serves as a guide for crafting effective queries and maximizing community assistance.
Link mentioned: How To Ask Questions The Smart Way: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
Mistral's Pixtral ReleaseMulti-modal SupportNew Message Structure
- Excited about Mistral's Pixtral: A member noted working on changes to promote multi-modal support, which aligns with the recent release of Mistral's Pixtral.
- It's a prescient move considering today's advancements.
- Proposed New Message Structure in Progress: A pull request has been created to introduce a new message structure in the Axolotl project, which aims to enhance the representation of messages.
- Check the details of the wip add new proposed message structure for more insights.
Link mentioned: wip add new proposed message structure by winglian · Pull Request #1904 · axolotl-ai-cloud/axolotl: no description found
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
Speed/Performance of LLM ModelsSeptember 2024 LLM Testing
- LLM Models Race for Speed & Performance: The recently released YouTube video titled 'Who?' tests leading LLM models for speed and performance as of September 2024.
- The presenter aims to uncover which model stands out in terms of tokens per second, showcasing the latest in state-of-the-art technology.
- Analyzing Metrics in LLM Performance: In the one discussed video, the testing focuses on various metrics that define the speed and efficiency of the leading AI models now available.
- Key aspects being measured include latency and throughput, critical for anyone evaluating performance under production conditions.
Link mentioned: Who ?: In this video, we are going to test the world leading LLM models in this September 2024 both in speed and performance.#tokensperseconds #GPT4o #LLM #SOTA #Cl...
LAION ▷ #general (2 messages):
NYX model developmentCollaboration in AIData sourcing for large models
- Seeking Collaboration for NYX Model: An AI developer is currently working on the NYX model with over 600 billion parameters and is looking for a passionate partner to improve it.
- Let’s chat! if you have experience in AI and are in a compatible timezone for collaboration.
- Questions on Training Resources for Large Models: Inquired about the resources used to train a 600B parameter model, with a specific reference to LLaMA-405B trained on 15 trillion tokens.
- Curiosity centered around how data for such large models is generally obtained, indicating an interest in the methodologies used.
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
Literal AI UsabilityLLM ObservabilityLLM EvaluationLLM MonitoringLLM Integrations
- Literal AI shines in usability: A user expressed strong approval for the usability of Literal AI, appreciating its friendly interface for LLM applications.
- This enthusiasm highlights the increasing demand for user-centric LLM tools.
- Emphasizing LLM Observability for Lifecycle Health: The importance of LLM observability was underscored, noting it enables developers and Product Owners to iterate and debug issues rapidly.
- Leveraging logs can help fine-tune smaller models, potentially boosting performance while lowering costs.
- Tracking Prompt Performances to Mitigate Risks: Monitoring prompt performances is essential for ensuring that no regressions occur before deploying new prompt versions.
- This continuous evaluation approach serves as a safeguard against issues in LLM applications.
- LLM Monitoring and Analytics: Key to Production Success: Having LLM logs and evaluations in place is vital for monitoring the performance of LLM systems in production.
- Effective analytics allow teams to maintain oversight and improve application reliability.
- Seamless Integrations with Literal AI: Literal AI allows for easy integration into applications, tapping into the entire LLM ecosystem.
- Moreover, it offers a self-hosted option, which is crucial for users in the EU or those handling sensitive information.
Link mentioned: Literal AI - RAG LLM observability and evaluation platform: Literal AI is the RAG LLM evaluation and observability platform built for Developers and Product Owners.
Mozilla AI ▷ #announcements (1 messages):
Ground Truth Data in AIMozilla Fellowship Grants
- Understanding Ground Truth Data's Role in AI: A new blog post highlights the importance of ground truth data in AI applications, discussing its critical role in improving model accuracy and reliability. Readers are encouraged to share their thoughts in the discussion thread: join the discussion.
- Mozilla Opens Call for Alumni Grant Applications: Mozilla invites previous participants of the Mozilla Fellowship or Awards to apply for program grants aimed at addressing issues in trustworthy AI and promoting a healthier internet. Hailey Froese emphasizes the necessity for structural changes in AI to harness its benefits while mitigating its harms.
- “The internet, and especially artificial intelligence (AI), are at an inflection point.”
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Error in Evaluation ScriptAPI Credential IssuesConnection Problems with Urban Dictionary API
- Error encountered in openfunctions_evaluation.py script: The user ran the
openfunctions_evaluation.pyscript with--test-category=non_livebut received no scores in the result folder.- They attempted to run
eval_runner.pywith new API credentials but faced issues instead.
- They attempted to run
- Additions to function_credential_config.json: After applying for four more API addresses, they filled them into
function_credential_config.jsonas part of their setup.- However, this step did not resolve the issue as they encountered further errors when running the evaluations.
- Connection timeout error with Urban Dictionary API: Running the evaluation led to a
requests.exceptions.ConnectionErrorrelated to the Urban Dictionary API, specifically the term 'lit'.- The error message indicated trouble establishing a connection due to a timeout, suggesting possible network issues.