[AINews] Perplexity starts Shopping for you
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Stripe SDK is all you need?
AI News for 11/18/2024-11/19/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 1912 messages) for you. Estimated reading time saved (at 200wpm): 253 minutes. You can now tag @smol_ai for AINews discussions!
Just 2 days after Stripe launched their Agent SDK (our coverage here), Perplexity is now launching their in-app shopping experience for US-based Pro members. This is the first at-scale AI-native shopping experience, closer to Google Shopping (done well) than Amazon. The examples show the kind of queries you can make with natural language that would be difficult in traditional ecommerce UI:
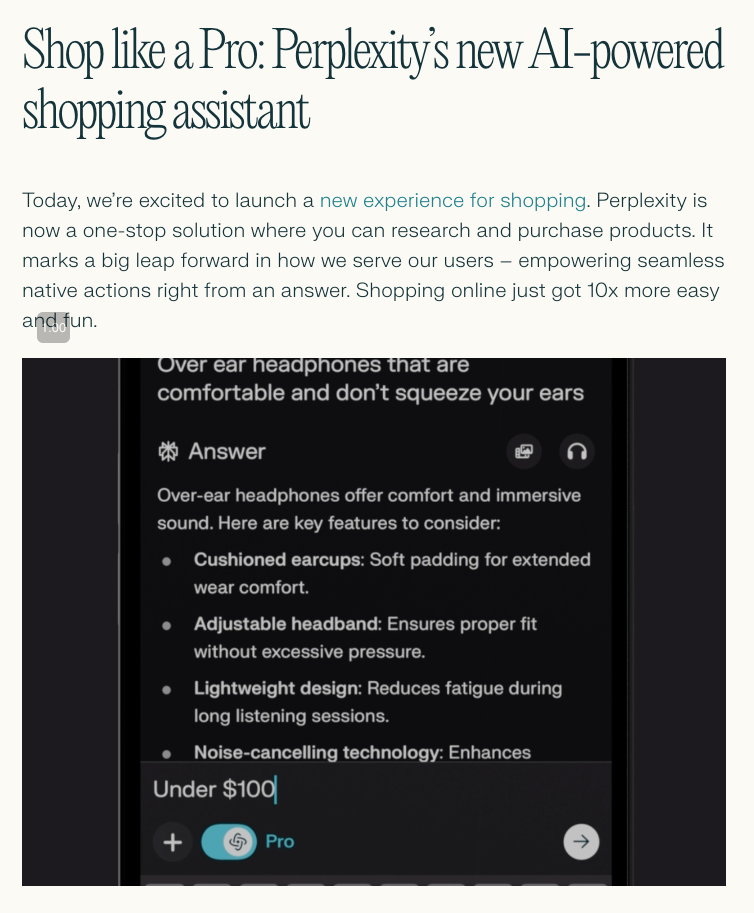
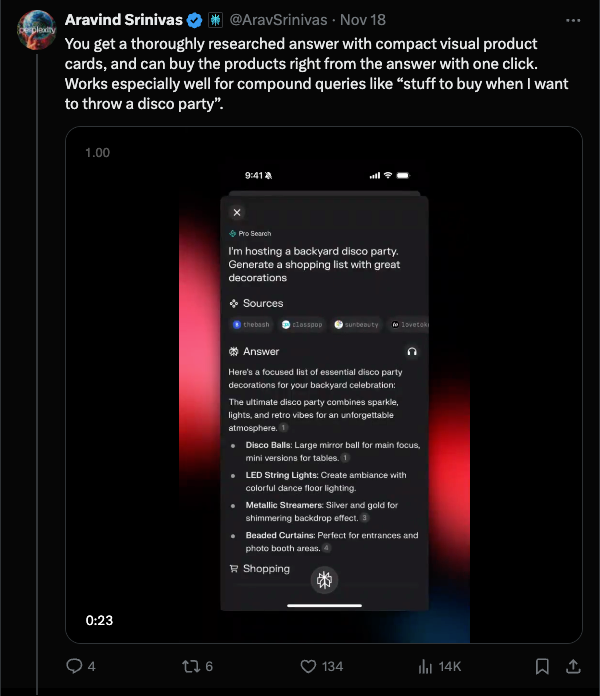
The new "Buy With Pro" program comes with one-click checkout with "select merchants" (! more on this later) and free shipping.
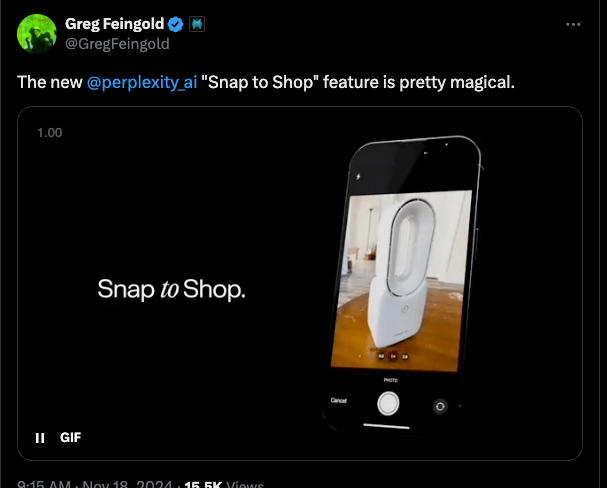
Snap to Shop is also a great visual ecommerce idea... but it remains to be seen how accurate it really is from people who don't work at Perplexity.
The Buy With Pro program is almost certainly tied to the new Perplexity Merchant Program, which is a standard free data-for-recommendations value exchange.
Both Patrick Collison and Jeff Weinstein were quick to note Stripe's involvement, though both stopped short of directly saying that Perplexity Shopping uses the exact agent SDK that Stripe just shipped.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Eleuther Discord
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- Stability.ai (Stable Diffusion) Discord
- aider (Paul Gauthier) Discord
- LM Studio Discord
- OpenRouter (Alex Atallah) Discord
- Notebook LM Discord Discord
- Nous Research AI Discord
- GPU MODE Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- OpenInterpreter Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- Modular (Mojo 🔥) Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- LAION Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Eleuther ▷ #general (73 messages🔥🔥):
- Eleuther ▷ #research (46 messages🔥):
- Eleuther ▷ #scaling-laws (12 messages🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (65 messages🔥🔥):
- OpenAI ▷ #ai-discussions (87 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (10 messages🔥):
- OpenAI ▷ #prompt-engineering (44 messages🔥):
- OpenAI ▷ #api-discussions (44 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (135 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (41 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (1 messages):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (139 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (12 messages🔥):
- HuggingFace ▷ #reading-group (9 messages🔥):
- HuggingFace ▷ #core-announcements (1 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (134 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (83 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (47 messages🔥):
- aider (Paul Gauthier) ▷ #links (3 messages):
- LM Studio ▷ #general (65 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (67 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (119 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
- Notebook LM Discord ▷ #use-cases (20 messages🔥):
- Notebook LM Discord ▷ #general (101 messages🔥🔥):
- Nous Research AI ▷ #general (78 messages🔥🔥):
- Nous Research AI ▷ #research-papers (5 messages):
- Nous Research AI ▷ #research-papers (5 messages):
- Nous Research AI ▷ #reasoning-tasks (2 messages):
- GPU MODE ▷ #general (2 messages):
- GPU MODE ▷ #triton (5 messages):
- GPU MODE ▷ #torch (17 messages🔥):
- GPU MODE ▷ #beginner (8 messages🔥):
- GPU MODE ▷ #youtube-recordings (1 messages):
- GPU MODE ▷ #off-topic (8 messages🔥):
- GPU MODE ▷ #liger-kernel (8 messages🔥):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #🍿 (16 messages🔥):
- GPU MODE ▷ #thunderkittens (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (7 messages):
- Interconnects (Nathan Lambert) ▷ #random (52 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- Latent Space ▷ #ai-general-chat (44 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (34 messages🔥):
- LlamaIndex ▷ #ai-discussion (5 messages):
- tinygrad (George Hotz) ▷ #general (25 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- Cohere ▷ #discussions (13 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (6 messages):
- OpenInterpreter ▷ #general (8 messages🔥):
- OpenInterpreter ▷ #ai-content (12 messages🔥):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (17 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (2 messages):
- Modular (Mojo 🔥) ▷ #max (12 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (7 messages):
- Torchtune ▷ #general (9 messages🔥):
- LAION ▷ #announcements (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Performance
- Mistral's Multi-Modal Image Model: @mervenoyann announced the release of Pixtral Large with 124B parameters, now supported in @huggingface. Additionally, @sophiamyang shared that @MistralAI now supports image generation on Le Chat, powered by @bfl_ml, available for free.
- Cerebras Systems' Llama 3.1 405B: @ArtificialAnlys detailed Cerebras' public inference endpoint for Llama 3.1 405B, boasting 969 output tokens/s and a 128k context window. This performance is >10X faster than the median providers. Pricing is set at $6 per 1M input tokens and $12 per 1M output tokens.
- Claude 3.5 and 3.6 Enhancements: @Yuchenj_UW discussed how Claude 3.5 is being outperformed by Claude 3.6, which, despite being more convincing, exhibits more subtle hallucinations. Users like @Tim_Dettmers have started debugging outputs to maintain trust in the model.
- Bi-Mamba Architecture: @omarsar0 introduced Bi-Mamba, a 1-bit Mamba architecture designed for more efficient LLMs, achieving performance comparable to FP16 or BF16 models while significantly reducing memory footprint.
AI Tools, SDKs, and Platforms
- Wandb SDK on Google Colab: @weights_biases announced that the wandb Python SDK is now preinstalled on every Google Colab notebook, allowing users to skip the
!pip installstep and import directly.
- AnyChat Integration: @_akhaliq highlighted that Pixtral Large is now available on AnyChat, enhancing AI flexibility by integrating multiple models like ChatGPT and Google Gemini.
- vLLM Support: @vllm_project introduced support for Pixtral Large with a simple
pip install -U vLLM, enabling users to run the model efficiently.
- Perplexity Shopping Features: @AravSrinivas detailed the launch of Perplexity Shopping, a feature that integrates with @Shopify to provide AI-powered product recommendations and a multimodal shopping experience.
AI Research and Benchmarks
- nGPT Paper and Benchmarks: @jxmnop shared insights on the nGPT paper, highlighting claims of a 4-20x training speedup over GPT. However, the community faced challenges in reproducing results due to a busted baseline.
- VisRAG Framework: @JinaAI_ introduced VisRAG, a framework enhancing retrieval workflows by addressing RAG bottlenecks with multimodal reasoning, outperforming TextRAG.
- Judge Arena for LLM Evaluations: @clefourrier presented Judge Arena, a tool to compare model-judges for nuanced evaluations of complex generations, aiding researchers in selecting the appropriate LLM evaluators.
- Bi-Mamba's Efficiency: @omarsar0 discussed how Bi-Mamba achieves performance comparable to full-precision models, marking an important trend in low-bit representation for LLMs.
AI Company Partnerships and Announcements
- Google Colab and Wandb Partnership: @weights_biases announced the collaboration with @GoogleColab, ensuring that the wandb SDK is readily available for users, streamlining workflow integration.
- Hyatt Partnership with Snowflake: @RamaswmySridhar shared how @Hyatt utilizes @SnowflakeDB to unify data, reduce management time, and innovate quickly, enhancing operational efficiency and customer insights.
- Figure Robotics Hiring and Deployments: @adcock_brett multiple times discussed Figure's commitment to shipping millions of humanoid robots, hiring top engineers, and deploying autonomous fleets, showcasing significant scaling efforts in AI robotics.
- Hugging Face Enhancements: @ClementDelangue highlighted that @huggingface now offers visibility into post engagement, enhancing the platform's role as a hub for AI news and updates.
AI Events and Workshops
- AIMakerspace Agentic RAG Workshop: @llama_index promoted a live event on November 27, hosted by @AIMakerspace, focusing on building local agentic RAG applications using open-source LLMs with hands-on sessions led by Dr. Greg Loughnane and Chris "The Wiz" Alexiuk.
- Open Source AI Night with SambaNova & Hugging Face: @_akhaliq announced an Open Source AI event scheduled for December 10, featuring Silicon Valley’s AI minds, fostering collaboration between @Sambanova and @HuggingFace.
- DevDay in Singapore: @stevenheidel shared excitement about attending the final 2024 DevDay in Singapore, highlighting opportunities to network with other esteemed speakers.
Memes/Humor
- AI Misunderstandings and Frustrations: @transfornix expressed frustrations with zero motivation and brain fog. Similarly, @fabianstelzer shared light-hearted frustrations with AI workflows and unexpected results.
- Humorous Takes on AI and Tech: @jxmnop humorously questioned why a transformer implementation error breaks everything, reflecting common developer frustrations. Additionally, @idrdrdv joked about category theory discouraging newcomers.
- Casual and Fun Interactions: Tweets like @swyx sharing humorous remarks about oauth requirements and @HamelHusain engaging in light-hearted conversations showcase the community's playful side.
- Reactions to AI Developments: @aidan_mclau reacted humorously to seeing others on social networks, and @giffmana shared laughs over AI interactions.
AI Applications and Use Cases
- AI in Document Processing: @omarsar0 introduced Documind, an AI-powered tool for extracting structured data from PDFs, emphasizing its ease of use and AGPL v3.0 License.
- AI in Financial Backtesting: @virattt described backtesting an AI financial agent using @LangChainAI for orchestration, outlining a four-step process to evaluate portfolio returns.
- AI in Shopping and E-commerce: @AravSrinivas showcased Perplexity Shopping, detailing features like multimodal search, Buy with Pro, and integration with @Shopify, aimed at streamlining the shopping experience.
- AI in Healthcare Communication: @krandiash highlighted collaborations with @anothercohen to improve healthcare communication using AI, emphasizing efforts to fix broken systems.
AI Community and General Discussions
- AI Curiosity and Learning: @saranormous emphasized that genuine technical curiosity is a powerful and hard-to-fake trait, encouraging continuous learning and exploration within the AI community.
- Challenges in AI Model Development: @huybery and @karpathy discussed model training challenges, including latency issues, layer normalizations, and the importance of model oversight for trustworthy AI systems.
- AI in Social Sciences and Ethics: @BorisMPower pondered the revolutionary potential of AI in social sciences, advocating for in silico simulations over traditional human interviews for hypothesis testing.
- AI in Software Engineering: @inykcarr and @HellerS engaged in discussions around prompt engineering for LLMs, emphasizing the superpower of 10x productivity gains through effective AI utilization.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Mistral Large 2411: Anticipation and Release Details
- Mistral Large 2411 and Pixtral Large release 18th november (Score: 336, Comments: 114): Mistral Large 2411 and Pixtral Large are set for release on November 18th.
- Licensing and Usage Concerns: There is significant discussion around the restrictive MRL license for Mistral models, with users expressing frustration over unclear licensing terms and lack of response from Mistral for commercial use inquiries. Some suggest that while the license allows for research use, it complicates commercial applications and sharing of fine-tuned models.
- Benchmark Comparisons: Pixtral Large reportedly outperforms GPT-4o and Claude-3.5-Sonnet in several benchmarks, such as MathVista (69.4) and DocVQA (93.3), but users note a lack of comparison with other leading models like Qwen2-VL and Molmo-72B. There is also speculation about a Llama 3.1 505B model based on a potential typo or leak in the benchmark tables.
- Technical Implementation and Support: Users discuss the potential integration of Pixtral Large with Exllama for VRAM efficiency and tensor parallelism, and confirm that Mistral Large 2411 does not require changes to llama.cpp for support. Additionally, there's mention of a new instruct template potentially enhancing model steerability, drawing parallels to community-suggested prompt formatting.
- mistralai/Mistral-Large-Instruct-2411 · Hugging Face (Score: 303, Comments: 81): The post discusses Mistral Large 2411, a model available on Hugging Face under the repository mistralai/Mistral-Large-Instruct-2411. No additional details or context are provided in the post body.
- Users discuss the performance of Mistral Large 2411, noting mixed results in various tasks. Sabin_Stargem mentions success in NSFW narrative generation but failures in lore comprehension and dice number tasks. ortegaalfredo finds slight improvements overall but prefers qwen-2.5-32B for coding tasks.
- There's a debate on the model's licensing and distribution. TheLocalDrummer and others express concerns about the MRL license, with mikael110 lamenting the end of Apache-2 releases. thereisonlythedance appreciates Mistral's local model access, despite licensing complaints, citing economic necessity.
- Technical discussions involve model deployment and quantization. noneabove1182 shares links to Hugging Face for GGUF quantizations and mentions the absence of evals for comparison with previous versions. segmond expresses skepticism about the lack of evaluation data and notes a slight performance drop in coding tests compared to large-2407.
- Pixtral Large Released - Vision model based on Mistral Large 2 (Score: 123, Comments: 27): Pixtral Large has been released as a vision model derived from Mistral Large 2. Further details about the model's specifications or capabilities were not provided in the post.
- Pixtral Large's Vision Setup: The model is not based on Qwen2-VL; instead, it uses the Qwen2-72B text LLM with a custom vision system. The 7B variant uses the Olmo model as a base, which performs similarly to the Qwen base, indicating the robustness of their dataset.
- Technical Requirements and Capabilities: Running the model may require substantial hardware, such as 4x3090 GPUs or a MacBook Pro with 128GB RAM. The model's vision encoder is larger (1B vs 400M), suggesting it can handle at least 30 high-resolution images, although specifics on "hi-res" remain undefined.
- Performance Benchmarks and Comparisons: Pixtral Large's performance was only compared to Llama-3.2 90B, which is considered suboptimal for its size. Comparisons with Molmo-72B and Qwen2-VL show varied results across datasets like Mathvista, MMMU, and DocVQA, indicating an incomplete picture of its capabilities against the state-of-the-art.
Theme 2. Llama 3.1 405B Inference: Breakthrough with Cerebras
- Llama 3.1 405B now runs at 969 tokens/s on Cerebras Inference - Cerebras (Score: 272, Comments: 49): Cerebras has achieved a performance milestone by running Llama 3.1 405B at 969 tokens per second on their inference platform. This showcases Cerebras' capabilities in handling large-scale models efficiently.
- Users noted that the 405B model is currently available only for enterprise in the paid tier, while Openrouter offers it at a significantly reduced cost, albeit with lower speed. The 128K context length and full 16-bit precision were highlighted as key features of Cerebras' platform.
- Discussions emphasized that Cerebras' performance gains are attributed more to software improvements rather than hardware changes, with some users pointing out the use of WSE-3 clusters and potential alternatives like 8x AMD Instinct MI300X accelerators.
- There was interest in use cases for high-speed inference, such as agentic workflows and high-frequency trading, where rapid processing of large models can offer significant advantages over slower, traditional methods.
Theme 3. AMD GPUs on Raspberry Pi: Llama.cpp Integration
- AMD GPU support for llama.cpp via Vulkan on Raspberry Pi 5 (Score: 144, Comments: 49): The author has been integrating AMD graphics cards on the Raspberry Pi 5 and has successfully implemented the Linux
amdgpudriver on Pi OS. They have compiledllama.cppwith Vulkan support for several AMD GPUs and are gathering benchmark results, which can be found here. They seek community input on additional tests and plan to evaluate lower-end AMD graphics cards for price/performance/efficiency comparisons.- Several users recommended using ROCm instead of Vulkan for better performance with AMD GPUs, but noted that ROCm support on ARM platforms is challenging due to limited compatibility. Alternatives like hipblas were suggested, though they involve complex setup processes Phoronix article.
- There was a discussion regarding quantization optimizations for ARM CPUs, specifically using
4_0_X_Xquantization levels with llama.cpp to leverage ARM-specific instructions likeneon+dotprod. This can improve performance on devices like the Raspberry Pi 5 with BCM2712 using flags such as-march=armv8.2-a+fp16+dotprod. - Benchmarking results on the RX 6700 XT using llama.cpp showed promising performance metrics with Vulkan, but highlighted power consumption concerns, averaging around 195W during tests. The discussion also touched on the efficiency of using GPUs for AI tasks compared to CPUs, with the Raspberry Pi setup consuming only 11.4W at idle.
Theme 4. txtai 8.0: Streamlined Agent Framework Launched
- txtai 8.0 released: an agent framework for minimalists (Score: 60, Comments: 9): txtai 8.0 has been launched as an agent framework designed for minimalists. This release focuses on simplifying the development and deployment of AI applications.
- txtai 8.0 introduces a new agent framework that integrates with Transformers Agents and supports all LLMs, providing a streamlined approach to deploying real-world agents without unnecessary complexity. More details and resources are available on GitHub, PyPI, and Docker Hub.
- The agent framework in txtai 8.0 demonstrates decision-making capabilities through tool usage and planning, as illustrated in a detailed example on Colab. This example showcases how the agent uses tools like 'web_search' and 'wikipedia' to answer complex questions.
- Users inquired about the framework's capabilities, including whether it supports function calling by agents and vision models. These questions highlight the interest in extending txtai's functionality to incorporate more advanced features like visual analysis.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Flux vs SD3.5: Community Prefers Flux Despite Technical Tradeoffs
- What is the Current State of Flux vs SD3.5? (Score: 40, Comments: 99): Stable Diffusion 3.5 and Flux are being compared by the community, with initial enthusiasm for SD3.5 reportedly declining since its release a month ago. The post seeks clarification on potential technical issues with SD3.5 that may have caused users to return to Flux, though no specific technical comparisons are provided in the query.
- SD3.5 faces significant adoption challenges due to being unavailable on Forge and having limited finetune capabilities compared to Flux. Users report that SD3.5 excels at artistic styles and higher resolutions but struggles with anatomy, particularly hands.
- Community testing reveals Flux is superior for img2img tasks and realistic human generation, while SD3.5 offers better negative prompt support and faster processing. The lack of quality finetunes and LoRAs for SD3.5 has limited its widespread adoption.
- Advanced users suggest combining both models' strengths through workflows like using SD3.5 for initial creative generation followed by Flux for anatomy refinement. Flux was released in August and has maintained stronger community support with extensive finetunes available.
- Ways to minimize Flux "same face" with prompting (TLDR and long-form) (Score: 33, Comments: 5): The post provides technical advice for reducing the "same face" problem in Flux image generation, recommending key strategies like reducing CFG/Guidance to 1.6-2.6, avoiding generic terms like "man"/"woman", and including specific descriptors for ethnicity, body type, and age. The author shares a set of example images demonstrating these techniques, along with an example prompt describing a "sharp faced Lebanese woman" in a kitchen scene, while explaining how model training biases and common prompting patterns contribute to the same-face issue.
- Lower guidance settings in Flux (1.6-2.6) trade prompt adherence for photorealism and variety, while the default 3.5 CFG is maintained by some users for better prompt compliance with complex descriptions.
- The community has previously documented similar solutions for the "sameface" issue, including an auto1111 extension that randomizes prompts by nationality, name, and hair characteristics.
- Users advise against downloading random .zip files for security reasons, suggesting alternative image hosting platforms like Imgur for sharing example generations.
Theme 2. O2 Robotics Breakthrough: 400% Speed Increase at BMW Factory
- Figure 02 is now an autonomous fleet working at a BMW factory, 400% faster in the last few months (Score: 180, Comments: 63): Figure 02 robots now operate as an autonomous fleet at a BMW factory, achieving a 400% speed increase in their operations over recent months.
- Figure 02 robots currently operate for 5 hours before requiring recharge, with each unit costing $130,000 according to BMW's press release. The robots have achieved a 7x reliability increase alongside their 400% speed improvement.
- Multiple users point out the rapid improvement rate of these robots surpasses human capability, with continuous 24/7 operation potential and no need for breaks or benefits. Critics note current limitations in efficiency compared to specialized robotic arms.
- Discussion centers on economic viability, with some arguing for complete plant redesign for automation rather than human-accommodating spaces. The robots require factory lighting and maintenance costs, but don't need heating or insurance.
Theme 3. Claude vs ChatGPT: Enterprise User Experience Discussion
- Should I Upgrade to ChatGPT Plus or Claude AI? Help Me Decide! (Score: 33, Comments: 69): Digital marketing professionals comparing ChatGPT Plus and Claude AI for content creation and technical assistance, with specific focus on handling content ideation (75% of use) and Linux technical support (25% of use). Recent concerns about Claude's reliability and model downgrades have emerged, with users reporting outages and transparency issues in model changes, prompting questions about Claude's viability as a paid service option.
- OpenRouter and third-party apps like TypingMind emerge as popular alternatives to direct subscriptions, offering flexibility to switch between models and potentially lower costs than $20/month services. Users highlight the ability to maintain context and integrate with multiple APIs in one place.
- Claude's recent changes have sparked criticism regarding increased censorship and usage limitations (5x free tier), particularly affecting Spanish-language users and technical tasks. Users report Claude refusing tasks for "ethical reasons" and experiencing significant model behavior changes.
- o1-preview model receives strong praise for its integrated chain of thought capabilities and complex mathematics handling, while Google Gemini 1.5 Pro is highlighted for its 1,000,000 token context window and integration with Google Workspace.
- Claude's servers are DYING! (Score: 86, Comments: 24): Claude users report persistent server capacity issues causing workflow disruptions through frequent high-demand notifications. Users express frustration with service interruptions and request infrastructure upgrades from the Anthropic team.
- Users report optimal Claude usage times are when both India and California are inactive, with multiple users confirming they plan their work around these time zones to avoid overload issues.
- Several users suggest abandoning the Claude web interface in favor of API-based solutions, with one user detailing their journey from using web interfaces to managing 100+ AI models through custom implementations and Open WebUI.
- Users express frustration with concise responses and "Error sending messages. Overloaded" notifications, with some recommending OpenRouter API as an alternative despite higher costs.
Theme 4. CogVideo Wrapper Updated: Major Refactoring and 1.5 Support
- Kijai has updated the CogVideoXWrapper: Support for 1.5! Refactored with simplified pipelines, and extra optimizations. (but breaks old workflows) (Score: 69, Comments: 23): CogVideoXWrapper received a major update with support for CogVideoX 1.5 models, featuring code cleanup, merged Fun-model functionality into the main pipeline, and added torch.compile optimizations along with torchao quantizations. The update introduces breaking changes to old workflows, including removal of width/height from sampler widgets, separation of VAE from the model, support for fp32 VAE, and replacement of PAB with FasterCache, while maintaining a legacy branch for previous versions at ComfyUI-CogVideoXWrapper.
- Testing on an RTX 4090 shows CogVideoX 1.5 processing 49 frames at 720x480 resolution with 20 steps takes approximately 30-40 seconds, with the model being notably faster than previous versions at equivalent frame counts.
- The 2B models require approximately 3GB VRAM for storage plus additional memory for inference, with testing at 512x512 resolution showing peak VRAM usage of about 6GB including VAE decode.
- Alibaba released an updated version of CogVideoXFun with new control model support for Canny, Depth, Pose, and MLSD conditions as of 2024.11.16.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: Cutting-Edge AI Models Claim Superiority
- Cerebras Boasts Record-Breaking Speed with Llama 3.1: Cerebras claims their Llama 3.1 405B model achieves an astonishing 969 tokens/s, over 10x faster than average providers. Critics argue this is an "apples to oranges" comparison, noting Cerebras excels at batch size 1 but lags with larger batches.
- Runner H Charges Toward ASI, Outperforming Competitors: H Company announced the beta release of Runner H, claiming to break through scaling laws limitations and step toward artificial super intelligence. Runner H reportedly outperforms Qwen on the WebVoyager benchmarks, showcasing superior navigation and reasoning skills.
- Mistral Unleashes Pixtral Large with 128K Context Window: Mistral introduced Pixtral Large, a 124B multimodal model built on Mistral Large 2, handling over 30 high-res images with a 128K context window. It achieves state-of-the-art performance on benchmarks like MathVista and VQAv2.
Theme 2: AI Models Grapple with Limitations and Bugs
- Qwen 2.5 Model Throws Tantrums in Training Rooms: Users report inconsistent results when training Qwen 2.5, with errors vanishing when switching to Llama 3.1. The model seems sensitive to specific configurations, leading to frustration among developers.
- AI Fumbles at Tic Tac Toe and Forgets the Rules: Members observed that AI models like GPT-4 struggle with simple games like Tic Tac Toe, failing to block moves and losing track mid-game. The limitations of LLMs as state machines spark discussions on the need for better frameworks for game logic.
- Mistral's Models Get Stuck in Infinite Loops: Users experienced issues with Mistral models like Mistral Nemo causing infinite loops and repeated outputs via OpenRouter. Adjusting temperature settings didn't fully resolve the problem, pointing to deeper issues with model outputs.
Theme 3: Innovative Research Lights Up the AI Horizon
- Neural Metamorphosis Morphs Networks on the Fly: The Neural Metamorphosis paper introduces self-morphable neural networks by learning a continuous weight manifold, allowing models to adapt sizes and configurations without retraining.
- LLM2CLIP Supercharges CLIP with LLMs: Microsoft unveiled LLM2CLIP, leveraging large language models to enhance CLIP's handling of long and complex captions, boosting its cross-modal performance significantly.
- AgentInstruct Generates Mountains of Synthetic Data: The AgentInstruct framework automates the creation of 25 million diverse prompt-response pairs, propelling the Orca-3 model to a 40% improvement on AGIEval, outperforming models like GPT-3.5-turbo.
Theme 4: AI Tools Evolve and Optimize Workflows
- Augment Turbocharges LLM Inference for Developers: Augment detailed their approach in optimizing LLM inference by providing full codebase context, crucial for developer AI, and overcoming latency challenges to ensure speedy and quality outputs.
- DSPy Dives into Vision with VLM Support: DSPy announced beta support for Vision-Language Models, showcasing in a tutorial how to extract attributes from images, like website screenshots, marking a significant expansion of their capabilities.
- Hugging Face Simplifies Vision Models with Pipelines: Hugging Face's pipeline abstraction now supports vision language models, making it easier than ever to handle both text and images in a unified way.
Theme 5: Community Buzzes with Events and Big Moves
- Roboflow Bags $40 Million to Sharpen AI Vision: Roboflow raised an additional $40 million in Series B funding to enhance developer tools for visual AI, aiming to deploy applications across fields like medical and environmental industries.
- Google AI Workshop to Unleash Gemini at Hackathon: A special Google AI workshop on November 26 will introduce developers to building with Gemini during the LLM Agents MOOC Hackathon, including live demos and direct Q&A with Google AI specialists.
- LAION Releases 12 Million YouTube Samples for ML: LAION announced LAION-DISCO-12M, a dataset of 12 million YouTube links with metadata to support research in foundation models for audio and music.
PART 1: High level Discord summaries
Eleuther Discord
-
Muon Optimizer Underperforms AdamW: Discussions highlighted that the Muon optimizer significantly underperformed AdamW due to inappropriate learning rates and scheduling techniques, leading to skepticism about its claims of superiority.
- Some members pointed out that using better hyperparameters could improve comparisons, yet criticism regarding untuned baselines remains.
- Neural Metamorphosis Introduces Self-Morphable Networks: The paper on Neural Metamorphosis (NeuMeta) proposes a new approach to creating self-morphable neural networks by learning the continuous weight manifold directly.
- This potentially allows for on-the-fly sampling for any network size and configurations, raising questions about faster training by utilizing small model updates.
- SAE Feature Steering Advances AI Safety: Collaborators at Microsoft released a report on SAE feature steering, demonstrating its applications for AI safety.
- The study suggests that steering Phi-3 Mini can enhance refusal behavior while highlighting the need to explore its strengths and limitations.
- Cerebras Acquisition Speculations: Discussions centered around why major companies like Microsoft haven't acquired Cerebras yet, speculating it may be due to their potential to compete with NVIDIA.
- Some members recalled OpenAI's past interest in acquiring Cerebras during the 2017 era, hinting at their enduring relevance in the AI landscape.
- Scaling Laws Remain Relevant Amid Economic Feasibility Concerns: Scaling laws are still considered a fundamental property of models, but economically it's become unfeasible to push further scaling.
- A member humorously noted that if you're not spending GPT-4 or Claude 3.5 budgets, you might not need to worry about diminishing returns yet.
OpenAI Discord
-
GPT-4-turbo Update Sparks Performance Scrutiny: Members are inquiring about the gpt-4-turbo-2024-04-09 update, noting its previously excellent performance.
- One user expressed frustration over inconsistencies in the model’s thinking capabilities post-update.
- NVIDIA's Add-it Elevates AI Image Editing: Discussions highlighted top AI image editing tools like 'magnific' and NVIDIA's _Add-it _, which allows adding objects based on text prompts.
- Members expressed skepticism regarding the reliability and practical accessibility of these emerging tools.
- Temperature Settings Influence AI Creativity: In Tic Tac Toe discussions, higher temperature settings lead to increased creativity in AI responses, which can impede performance in rule-based games.
- Participants noted that at temperature 0, AI responses are consistent but not exactly the same due to other influencing factors.
- LLMs Face Challenges as Game State Machines: Users pointed out that LLMs exhibit inconsistencies when used to represent state machines in games like Tic Tac Toe.
- There’s a consensus on the need for frameworks that handle game logic more effectively than relying solely on LLMs.
- Difficulty Parameters Enhance AI Gameplay: Participants discussed introducing difficulty parameters to improve AI gameplay, such as having the AI think several moves ahead.
- Further discussions were paused as users expressed fatigue from prolonged AI conversations.
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 Model Issues: Users reported inconsistent results when training the Qwen 2.5 model using the ORPO trainer, noting that switching to Llama 3.1 resolved the errors.
- Discussion centered on whether changes in model type typically affect training outcomes, with insights suggesting that such adjustments might not significantly influence results.
- Reinforcement Learning from Human Feedback (RLHF): The community explored integrating PPO (RLHF) techniques, indicating that mapping Hugging Face components could streamline the process.
- Members shared methodologies for developing a reward model, providing a supportive framework for implementing RLHF effectively.
- Multiple Turn Conversation Fine-Tuning: Guidance was provided on formatting datasets for multi-turn conversations, recommending the use of EOS tokens to indicate response termination.
- Emphasis was placed on utilizing data suited for the multi-turn format, such as ShareGPT, to enhance training efficacy.
- Aya Expanse Support: Support for the Aya Expanse model by Cohere was confirmed, addressing member inquiries about its integration.
- The discussion did not delve into further details, focusing primarily on the positive confirmation of Aya Expanse compatibility.
- Synthetic Data in Language Models: A discussion highlighted the importance of synthetic data for accelerating language model development, referencing the paper AgentInstruct: Toward Generative Teaching with Agentic Flows.
- The paper addresses model collapse and emphasizes the need for careful quality and diversity management in the use of synthetic data.
HuggingFace Discord
-
Pipeline Abstraction Simplifies Vision Models: The pipeline abstraction in @huggingface transformers now supports vision language models, streamlining the inference process.
- This update enables developers to efficiently handle both visual and textual data within a unified framework.
- Diffusers Introduce LoRA Adapter Methods: Two new methods,
load_lora_adapter()andsave_lora_adapter(), have been added to Diffusers for models supporting LoRA, facilitating direct interaction with LoRA checkpoints.
- These additions eliminate the need for previous commands when loading weights, enhancing workflow efficiency.
- Exact Unlearning Highlights Privacy Gaps in LLMs: A recent paper on exact unlearning as a privacy mechanism for machine learning models reveals inconsistencies in its application within Large Language Models.
- The authors emphasize that while unlearning can manage data removal during training, models may still retain unauthorized knowledge such as malicious information or inaccuracies.
- RAG Fusion Transforms Generative AI: An article discusses RAG Fusion as a pivotal shift in generative AI, forecasting significant changes in AI generation methodologies.
- It explores the implications of RAG techniques and their prospective integration across various AI applications.
- Augment Optimizes LLM Inference for Developers: Augment published a blog post detailing their strategy to enhance LLM inference by providing full codebase context, crucial for developer AI but introducing latency challenges.
- They outline optimization techniques aimed at improving inference speed and quality, ensuring better performance for their clients.
Stability.ai (Stable Diffusion) Discord
-
Mochi Outperforms CogVideo in Leaderboards: Members discussed that Mochi-1 is currently outperforming other models in leaderboards despite its seemingly inactive Discord community.
- CogVideo is gaining popularity due to its features and faster processing times but is still considered inferior for pure text-to-video tasks compared to Mochi.
- Top Model Picks for Stable Diffusion Beginners: New users are recommended to explore Auto1111 and Forge WebUI as beginner-friendly options for Stable Diffusion.
- While ComfyUI offers more control, its complexity can be confusing for newcomers, making Forge a more appealing choice.
- Choosing Between GGUF and Large Model Formats: The difference between stable-diffusion-3.5-large and stable-diffusion-3.5-large-gguf relates to how data is handled by the GPU, with GGUF allowing for smaller, chunked processing.
- Users with more powerful setups are encouraged to use the base model for speed, while those with limited VRAM can explore the GGUF format.
- AI-Driven News Content Creation Software Introduced: A user introduced software capable of monitoring news topics and generating AI-driven social media posts, emphasizing its utility for platforms like LinkedIn and Twitter.
- The user is seeking potential clients for this service, highlighting its capability in sectors like real estate.
- WebUI Preferences Among Community Members: The community shared experiences regarding different WebUIs, noting ComfyUI's advantages in workflow design, particularly for users familiar with audio software.
- Some expressed dissatisfaction with the form-filling nature of Gradio, calling for more user-friendly interfaces while also acknowledging the robust optimization of Forge.
aider (Paul Gauthier) Discord
-
OpenAI o1 models now support streaming: Streaming is now available for OpenAI's o1-preview and o1-mini models, enabling development across all paid usage tiers. The main branch incorporates this feature by default, enhancing developer capabilities.
- Aider's main branch will prompt for updates when new versions are released, but automatic updates are not guaranteed for developer environments.
- Aider API compatibility and configurations: Concerns were raised about Aider's default output limit being set to 512 tokens, despite supporting up to 4k tokens through the OpenAI API. Members discussed adjusting configurations, including utilizing
extra_paramsfor custom settings.
- Issues were highlighted when connecting Aider with local models and Bedrock, such as Anthropic Claude 3.5, requiring properly formatted metadata JSON files to avoid conflicts and errors.
- Anthropic API rate limit changes introducing tiered limits: Anthropic has removed daily token limits, introducing new minute-based input/output token limits across different tiers. This update may require developers to upgrade to higher tiers for increased rate limits.
- Users expressed skepticism about the tier structure, viewing it as a strategy to incentivize spending for enhanced access.
- Pixtral Large Release enhances Mistral Performance: Mistral has released Pixtral Large, a 124B multimodal model built on Mistral Large 2, achieving state-of-the-art performance on MathVista, DocVQA, and VQAv2. It can handle over 30 high-resolution images with a 128K context window and is available for testing in the API as
pixtral-large-latest.
- Elbie mentioned a desire to see Aider benchmarks for Pixtral Large, noting that while the previous Mistral Large excelled, it didn't fully meet Aider's requirements.
- qwen-2.5-coder struggles and comparison with Sonnet: Users reported that OpenRouter's qwen-2.5-coder sometimes fails to commit changes or enters loops, possibly due to incorrect setup parameters or memory pressures. It performs worse in architect mode compared to regular mode.
- Comparisons with Sonnet suggest that qwen-2.5-coder may not match Sonnet's efficiency based on preliminary experiences, prompting discussions on training considerations affecting performance.
LM Studio Discord
-
7900XTX Graphics Performance: A user reported that the 7900XTX handles text processing efficiently but experiences significant slowdown with graphics-intensive tasks when using amuse software designed for AMD. Another user inquired about which specific models were tested for graphics performance on the 7900XTX.
- Users are actively evaluating the 7900XTX's capability in different workloads, noting its strengths in text processing while highlighting challenges in graphics-heavy applications.
- Roleplay Models for Llama 3.2: A user sought recommendations for good NSFW/Uncensored, Llama 3.2 based models suitable for roleplay. Another member responded that such models could be found with proper searching.
- The discussion highlighted the difficulty of navigating HuggingFace to locate specific roleplay models, suggesting the need for better search strategies.
- Remote Server Usage for LM Studio: A user sought advice on configuring LM Studio to point to a remote server. Suggestions included using RDP or the openweb-ui to enhance the user experience.
- One user expressed interest in utilizing Tailscale to host inference backends remotely, emphasizing the importance of maintaining consistent performance across setups.
- Windows vs Ubuntu Inference Speed: Tests revealed that a 1b model achieved 134 tok/sec on Windows, while Ubuntu outperformed it with 375 tok/sec, indicating a substantial performance disparity. A member suggested that this discrepancy might be due to different power schemes in Windows and recommended switching to high-performance mode.
- The community is examining the factors contributing to the inference speed differences between operating systems, considering power management settings as a potential cause.
- AMD GPU Performance Challenges: The discussion emphasized that while AMD GPUs offer efficient performance, they suffer from limited software support, making them less appealing for certain applications. A member noted that using AMD hardware often feels like an uphill battle due to compatibility issues with various tools.
- Participants are expressing frustrations over AMD GPU software compatibility, highlighting the need for improved support to fully leverage AMD hardware capabilities.
OpenRouter (Alex Atallah) Discord
-
O1 Streaming Now Live: OpenAIDevs announced that OpenAI's o1-preview and o1-mini models now support real streaming capabilities, available to developers across all paid usage tiers.
- This update addresses previous limitations with 'fake' streaming methods, and the community expressed interest in enhanced clarity regarding the latest streaming features.
- Gemini Models Encounter Rate Limits: Users reported frequent 503 errors while utilizing Google’s
Flash 1.5andGemini Experiment 1114, suggesting potential rate limiting issues with these newer experimental models.
- Community discussions highlighted resource exhaustion errors, with members recommending improved communication from OpenRouter to mitigate such technical disruptions.
- Mistral Models Face Infinite Loop Issues: Issues were raised regarding Mistral models like
Mistral NemoandGemini, specifically pertaining to infinite loops and repeated outputs when used with OpenRouter.
- Suggestions included adjusting temperature settings, but users acknowledged the complexities involved in resolving these technical challenges.
- Surge in Demand for Custom Provider Keys: Multiple users requested access to custom provider keys, underscoring a strong interest in leveraging them for diverse applications.
- In the beta-feedback channel, users also expressed interest in beta custom provider keys and bringing their own API keys, indicating a trend towards more customizable platform integrations.
Notebook LM Discord Discord
-
Audio Track Separations in NotebookLM: A member in #use-cases inquired about methods to obtain separate voice audio tracks during recordings.
- This highlights an ongoing interest in audio management tools, with references to Simli_NotebookLM for speaker separation and mp4 recording sharing.
- Innovative Video Creation Solutions: Discussion on Somli video creation tools and using D-ID Avatar studio at competitive prices was shared.
- Members exchanged steps for building videos with avatars, including relevant coding practices for those interested.
- Enhanced Document Organization with NotebookLM: A member expressed interest in leveraging NotebookLM for compiling and organizing world-building documentation.
- The request underscores NotebookLM's potential to streamline creative processes by effectively managing extensive notes.
- Customized Lesson Creation in NotebookLM: An English teacher shared their experience using NotebookLM to develop reading and listening lessons tailored to student interests.
- The approach includes tool tips as mini-lessons, enhancing students' contextual understanding through practical language scenarios.
- Podcast Generation from Code with NotebookLM: A user discussed experimenting with NotebookLM generating podcasts from code snippets.
- This showcases NotebookLM's versatility in creating content from diverse data inputs, as members explore various generation techniques.
Nous Research AI Discord
-
LLM2CLIP Boosts CLIP's Textual Handling: The LLM2CLIP paper leverages large language models to enhance CLIP's multimodal capabilities by efficiently processing longer captions.
- This integration significantly improves CLIP's performance in cross-modal tasks, utilizing a fine-tuned LLM to guide the visual encoder.
- Neural Metamorphosis Enables Self-Morphable Networks: Neural Metamorphosis (NeuMeta) introduces a paradigm for creating self-morphable neural networks by sampling from a continuous weight manifold.
- This method allows dynamic weight generation for various configurations without retraining, emphasizing the manifold's smoothness.
- AgentInstruct Automates Massive Synthetic Data Creation: The AgentInstruct framework generates 25 million diverse prompt-response pairs from raw data sources to facilitate Generative Teaching.
- Post-training with this dataset, the Orca-3 model achieved a 40% improvement on AGIEval compared to previous models like LLAMA-8B-instruct and GPT-3.5-turbo.
- LLaVA-o1 Enhances Reasoning in Vision-Language Models: LLaVA-o1 introduces structured reasoning for Vision-Language Models, enabling autonomous multistage reasoning in complex visual question-answering tasks.
- The development of the LLaVA-o1-100k dataset contributed to significant precision improvements in reasoning-intensive benchmarks.
- Synthetic Data Generation Strategies Discussed: Discussions highlighted the importance of synthetic data generation in training robust AI models, referencing frameworks like AgentInstruct.
- Participants emphasized the role of large-scale synthetic datasets in achieving benchmark performance enhancements.
GPU MODE Discord
-
Integrating Triton CPU Backend in PyTorch: A GitHub Pull Request was shared to add Triton CPU as an Inductor backend in PyTorch, aiming to utilize Inductor-generated kernels for stress testing the new backend.
- This integration is intended to evaluate the performance and robustness of the Triton CPU backend, fostering enhanced computational capabilities within PyTorch.
- Insights into PyTorch FSDP Memory Allocations: Members discussed how FSDP allocations occur in
CUDACachingAllocatoron device memory during saving operations, rather than on CPU.
- Future FSDP versions are expected to improve sharding techniques, reducing memory allocations by eliminating the need for all-gathering of parameters, with releases targeted for late this year or early next year.
- Enhancements in Liger Kernel Distillation Loss: An issue on GitHub was raised regarding the implementation of new distillation loss functions in the Liger Kernel, outlining motivations for supporting various alignment and distillation layers.
- The discussion highlighted the potential for improved model training techniques through the incorporation of diverse distillation layers, aiming to enhance performance and flexibility.
- Optimizing Register Allocation Strategies: Discussions emphasized that spills in register allocation can severely impact performance, advocating for increasing registers utilization to mitigate this issue.
- Members explored strategies such as defining and reusing single register tiles and balancing resource allocation to minimize spills, particularly when adding additional WGMMAs.
- Addressing FP8 Alignment in FP32 MMA: A challenge was identified where FP8 output thread fragment ownership in FP32 MMA doesn't align with expected inputs, as illustrated in this document.
- To resolve this misalignment without degrading performance via warp shuffle, a static layout permutation of the shared memory tensor is employed for efficient data handling.
Interconnects (Nathan Lambert) Discord
-
Runner H Beta Launch Pushes Towards ASI: The beta release of Runner H has been announced by H Company, marking a significant advancement beyond current scaling laws towards artificial super intelligence (ASI). Tweet from H Company highlighted this milestone.
- The company emphasized that with this beta release, they're not just introducing a product but initiating a new chapter in AI development.
- Pixtral Paper Sheds Light on Advanced Techniques: The Pixtral paper was discussed by Sagar Vaze, specifically referencing Sections 4.2, 4.3, and Appendix E. This paper delves into complex methodologies relevant to ongoing research.
- Sagar Vaze provided insights, pointing out that the detailed discussions offer valuable context to the group's current projects.
- Runner H Outperforms Qwen in Benchmarks: Runner H demonstrated superior performance against Qwen using the WebVoyager benchmarks, as detailed in the WebVoyager paper.
- This success underscores Runner H's edge in real-world scenario evaluations through innovative auto evaluation methods.
- Advancements in Tree Search Methods: A recent report highlights significant gains in tree search techniques, thanks to collaborative efforts from researchers like Jinhao Jiang and Zhipeng Chen.
- These improvements enhance the reasoning capabilities of large language models.
- Exploring the Q Algorithm's Foundations: The Q algorithm was revisited, sparking discussions around its foundational role in current AI methodologies.
- Members expressed nostalgia, acknowledging the algorithm's lasting impact on today's AI techniques.
Latent Space Discord
-
Cerebras' Llama 3.1 Inference Speed: Cerebras claims to offer Llama 3.1 405B at 969 tokens/s, significantly faster than the median provider benchmark by more than 10X.
- Critics argue that while Cerebras excels in batch size 1 evaluations, its performance diminishes for larger batch sizes, suggesting that comparisons should consider these differences.
- OpenAI Enhances Voice Capabilities: OpenAI announced an update rolling out on chatgpt.com for voice features, aimed at making presentations easier for paid users.
- This update allows users to learn pronunciation through their presentations, highlighting a continued focus on enhancing user interaction.
- Roboflow Secures $40M Series B Funding: Roboflow raised an additional $40 million to enhance its developer tools for visual AI applications in various fields, including medical and environmental sectors.
- CEO Joseph Nelson emphasized their mission to empower developers to deploy visual AI effectively, underlining the importance of seeing in a digital world.
- Discussions Around Small Language Models: The community debated the definitions of small language models (SLM), with suggestions indicating models ranging from 1B to 3B as small.
- There's consensus that larger models don’t fit this classification, and distinctions based on running capabilities on consumer hardware were noted.
LlamaIndex Discord
-
AIMakerspace Leads Local RAG Workshop: Join AIMakerspace on November 27 to set up an on-premises RAG application using open-source LLMs, focusing on LlamaIndex Workflows and Llama-Deploy.
- The event offers hands-on training and deep insights for building a robust local LLM stack.
- LlamaIndex Integrates with Azure at Microsoft Ignite: LlamaIndex unveiled its end-to-end solution integrated with Azure at #MSIgnite, featuring Azure Open AI, Azure AI Embeddings, and Azure AI Search.
- Attendees are encouraged to connect with @seldo for more details on this comprehensive integration.
- Integrating Chat History into RAG Systems: A user discussed incorporating chat history into a RAG application leveraging Milvus and Ollama's LLMs, utilizing a custom indexing method.
- The community suggested modifying the existing chat engine functionality to enhance compatibility with their tools.
- Implementing Citations with SQLAutoVectorQueryEngine: Inquiry about obtaining inline citations using SQLAutoVectorQueryEngine and its potential integration with CitationQueryEngine was raised.
- Advisors recommended separating citation workflows due to the straightforward nature of implementing citation logic.
- Assessing Retrieval Metrics in RAG Systems: Concerns were voiced regarding the absence of ground truth data for evaluating retrieval metrics in a RAG system.
- Community members were asked to provide methodologies or tutorials to effectively address this testing challenge.
tinygrad (George Hotz) Discord
-
tinygrad 0.10.0 Released with 1200 Commits: The team announced the release of tinygrad 0.10.0, which includes over 1200 commits and focuses on minimizing dependencies.
- tinygrad now supports both inference and training, with aspirations to build hardware and has recently raised funds.
- ARM Test Failures and Resolutions: Users reported test failures on aarch64-linux architectures, specifically encountering an AttributeError during testing.
- Issues are reproducible across architectures, with potential resolutions including integrating
x.realize()intest_interpolate_bilinear. - Kernel Cache Test Fixes: A fix was implemented for
test_kernel_cache_in_actionby addingTensor.manual_seed(123), ensuring the test suite passes.
- Only one remaining issue persists on ARM architecture, with ongoing discussions on resolutions.
- Debugging Jitted Functions in tinygrad: Setting DEBUG=2 causes the process to continuously output at the bottom lines, indicating it's operational.
- Jitted functions in tinygrad execute only GPU kernels, resulting in no visible output for internal print statements.
Cohere Discord
-
Tokenized Training Impairs Word Recognition: A member highlighted that the word 'strawberry' is tokenized during training, disrupting its recognition in models like GPT-4o and Google’s Gemma2 27B, revealing similar challenges across different systems.
- This tokenization issue affects the model's ability to accurately recognize certain words, prompting discussions on improving word recognition through better training methods.
- Cohere Beta Program for Research Tool: Sign-ups for the Cohere research prototype beta program are closing tonight at midnight ET, granting early access to a new tool designed for research and writing tasks.
- Participants are encouraged to provide detailed feedback to help shape the tool's features, focusing on creating complex reports and summaries.
- Configuring Command-R Model Language Settings: A user inquired about setting a preamble for the command-r model to ensure responses in Bulgarian and avoid confusion with Russian terminology.
- They mentioned using the API request builder for customization, indicating a need for clearer language differentiation in the model's responses.
OpenInterpreter Discord
-
Development Branch Faces Stability Issues: A member reported that the development branch is currently in a work-in-progress state, with
interpreter --versiondisplaying 1.0.0, indicating a possible regression in UI and features.- Another member volunteered to address the issues, noting the last commit was 9d251648.
- Assistance Sought for Skills Generation: Open Interpreter users requested help with skills generation, mentioning that the expected folder is empty and seeking guidance on proceeding.
- It was recommended to follow the GitHub instructions related to teaching the model, with plans for future versions to incorporate this functionality.
- UI Simplifications Receive Mixed Feedback: Discussions emerged around recent UI simplifications, with some members preferring the previous design, expressing comfort with the older interface.
- The developer acknowledged the feedback and inquired whether users favored the old version more.
- Issues with Claude Model Lead to Concerns: Reports indicated problems with the Claude model breaking; switching models temporarily resolved the issue, raising concerns about the Anthropic service reliability.
- Members questioned if these issues persist across different versions.
- Ray Fernando Explores AI Tools in Latest Podcast: In a YouTube episode, Ray Fernando discusses AI tools that enhance the build process, highlighting 10 AI tools that help build faster.
- The episode titled '10 AI Tools That Actually Deliver Results' offers valuable insights for developers interested in tool utilization.
DSPy Discord
-
DSPy Introduces VLM Support: A new DSPy VLM tutorial is now available, highlighting the addition of VLM support in beta for extracting attributes from images.
- The tutorial utilizes screenshots of websites to demonstrate effective attribute extraction techniques.
- DSPy Integration with Non-Python Backends: Members report reduced accuracy when integrating DSPy's compiled JSON output with Go, raising concerns about prompt handling replication.
- A suggestion was made to use the inspect_history method to create templates tailored for specific applications.
- Cost Optimization Strategies in DSPy: Discussions emerged on how DSPy can aid in lowering prompting costs through prompt optimization and potentially using a small language model as a proxy.
- However, there are concerns about long-context limitations, necessitating strategies like context pruning and RAG implementations.
- Challenges with Long-Context Prompts: The inefficiency of few-shot examples with extensive contexts in long document parsing was highlighted, with criticisms on the reliance of model coherence across large inputs.
- Proposals include breaking processing into smaller steps and maximizing information per token to address context-related issues.
- DSPy Assertions Compatibility with MIRPOv2: A query was raised regarding the compatibility of DSPy assertions with MIRPOv2 in the upcoming version 2.5, referencing past incompatibilities.
- This indicates ongoing interest in how these features will evolve and integrate within the framework.
OpenAccess AI Collective (axolotl) Discord
-
Mistral Large introduces Pixtral models: Community members expressed interest in experimenting with the latest Mistral Large and Pixtral models, seeking expertise from experienced users.
- The discussion reflects ongoing experimentation and a desire for insights on the performance of these AI models.
- MI300X training operational: Training with the MI300X is now operational, with several upstream changes ensuring consistent performance.
- A member highlighted the importance of upstream contributions in maintaining reliability during the training process.
- bitsandbytes integration enhancements: Concerns were raised about the necessity of importing bitsandbytes during training even when not in use, suggesting making it optional.
- A proposal was made to implement a context manager to suppress import errors, aiming to increase the codebase's flexibility.
- Axolotl v0.5.2 release: The new Axolotl v0.5.2 has been launched, featuring numerous fixes, enhanced unit tests, and upgraded dependencies.
- Notably, the release addresses installation issues from version v0.5.1 by resolving the
pip install axolotlproblem, facilitating a smoother update for users. - Phorm Bot deprecation concerns: Questions arose regarding the potential deprecation of the Phorm Bot, with indications it might be malfunctioning.
- Members speculated that the issue stems from the bot referencing the outdated repository URL post-transition to the new organization.
Modular (Mojo 🔥) Discord
-
Max Graph Integration Enhances Knowledge Graphs: An inquiry was raised about whether Max Graphs can enhance traditional Knowledge Graphs for unifying LLM inference as one of the agentic RAG tools.
- Darkmatter noted that while Knowledge Graphs serve as data structures, Max Graph represents a computational approach.
- MAX Boosts Graph Search Performance: Discussion on utilizing MAX to boost graph search performance revealed that current capabilities require copying the entire graph into MAX.
- A potential workaround was proposed involving encoding the graph as 1D byte tensors, though memory requirements may pose challenges.
- Distinguishing Graph Types and Their Uses: A user pointed out the distinctions among various graph types, indicating MAX computational graphs relate to computing, while Knowledge Graphs store relationships.
- They further explained that Graph RAG enhances retrieval using knowledge graphs and that an Agent Graph describes data flow between agents.
- Max Graph's Tensor Dependency Under Scrutiny: Msaelices questioned whether Max Graph is fundamentally tied to tensors, noting the constraints of its API parameters restricted to TensorTypes.
- This prompted a suggestion for reviewing the API documentation before proceeding with implementation inquiries.
LLM Agents (Berkeley MOOC) Discord
-
Google AI Workshop on Gemini: Join the Google AI workshop on 11/26 at 3pm PT, focusing on building with Gemini during the LLM Agents MOOC Hackathon. The event features live demos of Gemini and an interactive Q&A with Google AI specialists for direct support.
- Participants will gain insights into Gemini and Google's AI models and platforms, enhancing hackathon projects with the latest technologies.
- Lecture 10 Announcement: Lecture 10 is scheduled for today at 3:00pm PST, with a livestream available for real-time participation. This session will present significant updates in the development of foundation models.
- All course materials, including livestream URLs and assignments, are accessible on the course website, ensuring centralized access to essential resources.
- Percy Liang's Presentation: Percy Liang, an Associate Professor at Stanford, will present on 'Open-Source and Science in the Era of Foundation Models'. He emphasizes the importance of open-source in advancing AI innovation despite current accessibility limitations.
- Liang highlights the necessity for community resources to develop robust open-source models, fostering collective progress in the field.
- Achieving State of the Art for Non-English Models: Tejasmic inquired about strategies to attain state of the art performance for non-English models, particularly in languages with low data points.
- A suggestion was made to direct the question to a dedicated channel where staff are actively reviewing similar inquiries.
Torchtune Discord
-
Flex Attention Blocks Score Copying: A member reported an error when trying to copy attention scores in the flex attention's
score_modfunction, resulting in an Unsupported: HigherOrderOperator mutation error.- Another member confirmed this limitation and referenced the issue for further details.
- Attention Score Extraction Hacks: Members discussed the challenges of copying attention scores with vanilla attention due to inaccessible SDPA internals and suggested that modifying the Gemma 2 attention class could provide a workaround.
- A GitHub Gist was shared detailing a hack to extract attention scores without using triton kernels, though it diverges from the standard Torchtune implementation.
- Vanilla Attention Workarounds: It was revealed that copying attention scores with vanilla attention is not feasible due to the lack of access to SDPA internals, leading to exploration of alternatives.
- A member suggested that modifying the Gemma 2 attention class might offer a solution, as it is more amenable to hacking.
LAION Discord
-
LAION-DISCO-12M Launches with 12 Million Links: LAION announced LAION-DISCO-12M, a collection of 12 million links to publicly available YouTube samples paired with metadata, aimed at supporting basic machine learning research for generic audio and music. This initiative is detailed further in their blog post.
- The release has been highlighted in a tweet from LAION, emphasizing the dataset's potential to enhance audio-related foundation models.
- Metadata Enhancements for Audio Research: The metadata included in the LAION-DISCO-12M collection is designed to facilitate research in foundation models for audio analysis.
- Several developers expressed excitement over the potential use cases highlighted in the announcement, emphasizing the need for better data in the audio machine learning space.
Mozilla AI Discord
-
Transformer Lab Demo kicks off today: Today's Transformer Lab Demo showcases the latest developments in transformer technology.
- Members are encouraged to join and engage in the discussions to explore these advancements.
- Metadata Filtering Session Reminder: A session on metadata filtering is scheduled for tomorrow, led by an expert in channel #1262961960157450330.
- Participants will gain insights into effective data handling practices in AI.
- Refact AI Discusses Autonomous AI Agents: Refact AI will present on building Autonomous AI Agents to perform engineering tasks end-to-end this Thursday.
- They will also answer attendees' questions, offering a chance for interactive learning.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Eleuther ▷ #general (73 messages🔥🔥):
Cerebras technology speculationPre-NeurIPS meetupHyperparameter tuning toolsNovelAI service for uncensored LLMsLlama-2 70B performance
-
Questions Arise on Cerebras Acquisition: Discussions centered around why major companies like Microsoft haven't acquired Cerebras yet, speculating it may be due to their potential to compete with NVIDIA.
- Some members recalled OpenAI's past interest in acquiring Cerebras during the 2017 era, hinting at their enduring relevance in the AI landscape.
- Meet Up for EleutherAI Enthusiasts: An invitation was shared for a pre-NeurIPS meetup at Dolores Park, encouraging attendees to RSVP for snacks and drinks while networking with AI enthusiasts.
- The gathering aims to connect EleutherAI community members ahead of upcoming events, fostering discussion around AI and casual topics.
- Tool Suggestions for Hyperparameter Tuning: A participant asked for recommendations on hyperparameter tuning tools, prompting suggestions like HEBO and grid search for easier educational visuals.
- One member noted that despite grid search's inefficiency, its graphical representations could be more aesthetically pleasing.
- Exploring Uncensored LLMs with NovelAI: Members discussed uncensored LLM options for creating erotica, with suggestions for NovelAI offered and a focus on its privacy features regarding end-to-end encryption.
- Potential users were reassured about privacy practices, emphasizing no logging and secure handling of generated stories.
- Performance Insights from Cerebras WSE: The Cerebras Wafer Scale Engine (WSE) was highlighted for its impressive capabilities, reportedly achieving training speeds comparable to or faster than its inference speeds.
- Concerns were raised about the validity of performance claims and the need for independent benchmarks to substantiate the system's efficiency.
Links mentioned:
- Cerebras Now The Fastest LLM Inference Processor; Its Not Even Close: The company tackled inferencing the Llama-3.1 405B foundation model and just crushed it.
- Breaking the Molecular Dynamics Timescale Barrier Using a Wafer-Scale System: Molecular dynamics (MD) simulations have transformed our understanding of the nanoscale, driving breakthroughs in materials science, computational chemistry, and several other fields, including biophy...
- Cerebras - Wikipedia: no description found
- AI Friends @ Dolores Park (pre Neurips gathering) · Luma: RSVP if your interested! AI Friends - lets meet @ Dolores Park Its been far too long since the last gathering for EleutherAI folks (and friends) in SF 🌁 With…
- Gemini - Challenges and Solutions for Aging Adults: Created with Gemini
- Anon's Entry Level /lmg/ Guide For Clueless Newbies: AKA: The Big Spoon open wide and say "ah ah mistress" 0. Bare-Bones How-To I'll supply you with the requirements and links in order. You are expected to read all the installation...
- Models - Hugging Face: no description found
Eleuther ▷ #research (46 messages🔥):
Muon optimizer comparisonsNeural Metamorphosis
-
Muon optimizer underperforms against AdamW: Discussions highlighted that the Muon optimizer significantly underperformed AdamW due to inappropriate learning rates and scheduling techniques, leading to skepticism about its claims of superiority.
- Some members pointed out that using better hyperparameters could improve comparisons, yet criticism regarding untuned baselines remains.
- Neural Metamorphosis introduces self-morphable networks: The paper on Neural Metamorphosis (NeuMeta) proposes a new approach to creating self-morphable neural networks by learning the continuous weight manifold directly.
- This potentially allows for on-the-fly sampling for any network size and configurations, raising questions about faster training by utilizing small model updates.
- nGPT bug fixed and AI2's new project: A member shared that the bug in the nGPT has been fixed and NVIDIA is now developing this normalized transformer model further.
- Additionally, AI2 has started working on reproducing nGPT in their Olmo project, highlighting ongoing efforts to improve optimization methods.
- Concerns about data availability: Several members expressed that a lack of data is a significant hindrance for various models and methods, with discussions around optimizing activations and effective upscaling.
- It was suggested that instead of focusing on external resolution, enhancing internal resolution through better modeling could lead to improvements.
Links mentioned:
- MARS: Unleashing the Power of Variance Reduction for Training Large Models: Training deep neural networks--and more recently, large models--demands efficient and scalable optimizers. Adaptive gradient algorithms like Adam, AdamW, and their variants have been central to this t...
- Neural Metamorphosis: no description found
- Tweet from Huizhuo Yuan (@HuizhuoY): For muon on GPT2 small, we tried 2e-2, 6e-3, 3e-3, and 6e-4. For MARS on GPT2 small, we tried on the same set of learning rates. For medium and large, we scaled down learning rate by 1/2, 1/3 respecti...
- Geometric Optimisation on Manifolds with Applications to Deep Learning: We design and implement a Python library to help the non-expert using all these powerful tools in a way that is efficient, extensible, and simple to incorporate into the workflow of the data scientist...
- NVIDIA/ngpt): Normalized Transformer (nGPT). Contribute to NVIDIA/ngpt development by creating an account on GitHub.
Eleuther ▷ #scaling-laws (12 messages🔥):
Scaling laws in LLMsLLM pretraining scalabilityFinancial considerations in scalingCapabilities prediction in AIResearch on observational scaling laws
-
Scaling Laws are Not Dead Yet: Scaling is not dead - it can never be killed since it's a fundamental property of models, but economically it's become unfeasible to push further scaling.
- A member humorously noted that if you're not spending GPT-4 or Claude 3.5 budgets, you might not need to worry about diminishing returns yet.
- Discussion on LLM Pretraining Roles: There's an ongoing dialogue about transitioning roles to focus on LLM pretraining scalability and performance, which many believe remain relevant despite potential scaling limits.
- Concerns were raised about whether scaling is effectively 'done,' with users pondering if focus should shift to scalability and performance in established models.
- Diverse Perspectives on Scaling: A member pointed out the tension in narratives surrounding scaling, where, while scaling technically works, the visible performance gains for average users are slowing down.
- Links to articles from The Information and Bloomberg highlighted the ongoing struggle in developing more advanced models.
- Inquiry on Observational Scaling Laws: A member sought recommendations for papers and researchers focused on observational scaling laws and predictive evaluations, emphasizing the importance for government situational awareness.
- Contextually, there are efforts within the UK Gov's AI Safety Institute to focus on capabilities prediction, indicating wide interest in trends on scaling laws.
- Questions on Limitations of Models: In response to a discussion on scaling, another member introduced skepticism about whether language models improve on certain tasks purely as a function of scale.
- They claimed familiarity with several papers discussing these limitations within the context of scaling.
Link mentioned: Scaling realities: Both stories are true. Scaling still works. OpenAI et al. still have oversold their promises.
Eleuther ▷ #interpretability-general (1 messages):
SAE feature steeringAI safety researchPhi-3 Mini model performanceCollaboration with MicrosoftJailbreak robustness
-
SAE Feature Steering Advances AI Safety: Collaborators at Microsoft released a report on SAE feature steering, demonstrating its applications for AI safety.
- The study suggests that steering Phi-3 Mini can enhance refusal behavior while highlighting the need to explore its strengths and limitations.
- Report Compares Findings with Anthropic: The new report is pitched as a valuable complement to Anthropic's recent findings, expanding on the practical applications of their research.
- Acknowledgments were given to contributors for their Top-k SAE implementation, which supported this work.
- Exploration of Refusal Mechanisms in Phi-3: The abstract notes that steering model activations at inference is a cost-effective alternative to updating model weights for achieving safe behavior.
- The findings include that while feature steering enhances robustness against jailbreak attempts, it may negatively impact overall benchmark performance.
- Research Shared via Multiple Formats: The research is publicly available, with links to both a preprint and a direct PDF.
- Engagement in this research thread is encouraged, with a specific reference to this thread for further discussion.
Links mentioned:
- Tweet from Kyle O'Brien (@KyleDevinOBrien): Steering LMs with SAE features is a promising interpretability-driven approach for AI safety. However, its strengths and limitations remain underexplored. We study steering Phi-3 for refusal and measu...
- Steering Language Model Refusal with Sparse Autoencoders: Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behav...
Eleuther ▷ #lm-thunderdome (65 messages🔥🔥):
lm_eval config.json issuepawsx and headqa errorsglue evaluation metricsheadqa performance updateRWKV model preparation
-
lm_eval struggles with config.json: A user reported that
lm_evalattempts to downloadconfig.jsonbut it's unavailable in the main branch of the model repository.- Temporary workaround involves specifying the local model directory, but
lm_evalneeds to run on the same machine as the OpenAI-compatible server. - Errors encountered in pawsx and headqa: A member experienced issues running
pawsxandheadqawith version 0.4.5, facing unexpected errors related to task groups and configurations.
- Discussion indicated a potential bug and possible workaround by using version 0.4.4, which yielded mixed results.
- Clarifying glue evaluation metrics: Members discussed the need to aggregate metrics within glue tasks, with emphasis on averaging non-accuracy metrics like mcc for cola.
- It was concluded that macro-averaging each metric separately is likely the intended approach, while excluding cola due to its different metric.
- Updated headqa functionality: An update from the project indicated that headqa is expected to work correctly now, though earlier issues were reported.
- Users reported encountering a new error related to Arrow types but resolved this by updating the datasets library.
- RWKV model evaluation preparations: The channel's conversations hinted towards preparing for a significant release of the latest RWKV-6 model trained on an extensive dataset.
- Members expressed a desire for consistent evaluation methods relative to previous model runs, with references to historical papers.
- Temporary workaround involves specifying the local model directory, but
OpenAI ▷ #ai-discussions (87 messages🔥🔥):
Model UpdatesAI Image Editing ToolsScrolling Issues on DevicesUsing Python for InfographicsLLM Application Evaluation
-
Questions About GPT Model Updates: Members are inquiring about the current version of GPT, specifically seeking details about the 'gpt-4-turbo-2024-04-09' update, with some claiming it had excellent performance previously.
- One user expressed frustration about inconsistencies in the expected thinking capability of the model.
- State-of-the-Art AI Image Editing Tools: Discussions emerged around top AI tools for image editing, with mentions of 'magnific' and recent developments like NVIDIA's Add-it, which allows adding objects based on text prompts.
- Members expressed skepticism toward lesser-known tools, questioning their reliability and practical access.
- Scrolling Issues on Chromebooks: A user reported issues with scrolling through chat logs on their Chromebook, prompting discussions about tech limitations and RAM concerns.
- It was noted that others can scroll just fine on different devices, indicating a potential tech issue specific to the Chromebook.
- Using Python for Infographics: Members were curious about generating infographics through ChatGPT and Python, with discussions suggesting online resources such as Google Colab for executing Python code.
- One user mentioned reaching data analysis limits while experimenting, indicating a learning curve with the tool.
- Evaluating LLM Applications: A conversation took place regarding common issues with LLM applications like RAG, primarily arising from developer misunderstandings of its limitations.
- An important distinction was made between basic embedding RAG and traditional content indexing, highlighting knowledge gaps.
Link mentioned: Add-it: no description found
OpenAI ▷ #gpt-4-discussions (10 messages🔥):
Game Bots BehaviorTemperature Effect on AITic Tac Toe GPT Strategy
-
Game Bots: Shutdown Frustrations: A user expressed frustration with game bots occasionally shutting down and ignoring commands, describing the situation as infuriating.
- This highlights potential reliability issues in bot behavior during gameplay.
- Temperature Affects AI Creativity: In a discussion about Tic Tac Toe, it was noted that a higher temperature in AI models leads to increased creativity, but this can be detrimental in a rule-based game.
- As one participant stated, it's not good to be creative and random in these constrained environments.
- Low Temperature for Consistent Responses: It was shared that a temperature setting of 0 would typically cause the AI to generate similar responses for identical prompts due to limited randomness.
- However, it was also pointed out that responses aren't exactly the same because of other influencing factors.
- Understanding Temperature Impact: Users explained that temperature affects the likelihood of the AI selecting less accurate tokens, where a higher value increases the chance of such selections.
- This insight is crucial for understanding AI output variability based on temperature settings.
OpenAI ▷ #prompt-engineering (44 messages🔥):
AI performance in Tic Tac ToeChallenges with LLMs and state machinesUser frustrations with AI strategyGame logging and move trackingDifficulty parameters in AI gameplay
-
User struggles with AI blocking strategy: Users reported that the AI was not consistently blocking opponent moves in Tic Tac Toe, leading to unsatisfactory gameplay. Suggestions were made to clarify instructions, such as defining roles more strictly for the AI and user.
- One member noted that specific phrasing, like using 'You will be X and I will be O', improved AI performance.
- AI's performance declines during gameplay: It was observed that the AI's effectiveness decreases as the game progresses, leading to errors in move execution. Users discussed potential reasons such as split attention and lack of context management over longer games.
- Concerns were expressed that without structured tracking or state management, the AI may lose its strategic capability mid-game.
- Game logging as a solution: A discussion arose around whether recording moves could refresh the AI's strategic understanding. This logging might help maintain consistency throughout the game, but questions were raised about increased complexity through permutations.
- Participants acknowledged that while this might work for games like Tic Tac Toe, it wouldn't necessarily overcome the inherent limitations of LLMs.
- Limitations of LLMs for game mechanics: Members pointed out the challenges of using LLMs for representing state machines in games, suggesting they are prone to inconsistencies. There was consensus that while it’s a creative exercise, it might not yield reliable outcomes.
- The conversation highlighted the need for suitable frameworks that can effectively handle game logic rather than relying solely on LLMs.
- Exploring AI difficulties and strategies: The idea of a difficulty parameter emerged as a potential strategy for improving AI gameplay and suggesting that the AI could be asked to think several moves ahead. However, further discussion on this concept was deferred as users expressed fatigue.
- As fatigue set in, one user noted the mental toll of immersing oneself in AI-centric discussions while grappling with insomnia.
OpenAI ▷ #api-discussions (44 messages🔥):
AI Tic-Tac-Toe BotBlocking Strategy IssuesModel LimitationsState Machine RepresentationDifficulty Parameters
-
AI struggles with blocking in Tic-Tac-Toe: Users noted that their AI bot often fails to properly block opponent moves, leading to potential losses during games.
- Adjusting prompts to specify blocking priorities has improved performance, but challenges remain as mentioned by multiple users.
- Perceived decline in AI performance during gameplay: A participant observed that as a game progresses, the AI seems to exhibit decreased effectiveness in decision-making.
- Concerns were raised about whether the AI's performance can be maintained or improved through move logging or other methods.
- Limitation of LLMs as state machines: One user expressed skepticism about using LLMs to model state machines, suggesting that errors and inconsistencies are likely.
- Despite this, some see the exercise of integrating LLMs into game logic as intriguing and beneficial for understanding their capabilities.
- Challenges with future move calculations: Discussion highlighted the importance of introducing a prompt specifying how many moves ahead the AI should think to improve gameplay.
- Questions arose regarding the optimal difficulty parameters necessary for the AI to maintain competitiveness in Tic-Tac-Toe.
- User sleep deprivation during AI discussions: One user remarked on their fatigue from engaging in long hours of AI conversations, questioning their focus on Tic-Tac-Toe.
- This led to sidebar commentary about managing fatigue and the potential complexities of gaming AI during extended play sessions.
Unsloth AI (Daniel Han) ▷ #general (135 messages🔥🔥):
Qwen 2.5 model issuesUnsloth Training FAQsMultiple turn conversation fine-tuningUtilizing Azure for trainingReinforcement Learning from Human Feedback (RLHF)
-
Inconsistent results with Qwen 2.5: Several users reported issues while training the Qwen 2.5 model using the ORPO trainer, noting that switching to Llama 3.1 resolved the errors.
- Users discussed potential reasons for consistent errors, with one suggesting that changes in model type might not typically affect outcomes.
- Finetuning for Multiple Turns: Respondents provided guidance on formatting datasets for multi-turn conversations, suggesting the use of EOS tokens for stopping after each response.
- The importance of using data that suits the multi-turn format, such as ShareGPT, was emphasized as key for effective training.
- Exploring Azure for AI training: A user inquired about the feasibility of using Azure's GPUs for model fine-tuning, as they had significant credits available.
- It was confirmed that leveraging Azure's resources would be beneficial, especially since local machines like the Mac Mini M4 Pro are not supported for training.
- Implementing RLHF techniques: Discussions around integrating PPO (RLHF) were noted, indicating that mapping Hugging Face components could simplify this process.
- The community shared insights about various methodologies to develop a reward model, providing a supportive framework for newcomers.
- Model response uniformity concerns: A user expressed concerns about their model consistently producing the same outputs despite adjustments to the temperature setting.
- Suggestions were made to try increasing the temperature even further to explore variability in responses.
Links mentioned:
- GGUF Editor - a Hugging Face Space by CISCai: no description found
- rombodawg/Rombos-Coder-V2.5-Qwen-7b · Hugging Face: no description found
- Huggingface GGUF Editor · ggerganov/llama.cpp · Discussion #9268: The Huggingface GGUF Editor 🎉 Check out my latest project 🌍✨ A powerful editor designed specifically for editing GGUF metadata and downloading the result directly from any Huggingface repository yo....
- unsloth/Qwen2.5-Coder-7B-Instruct-bnb-4bit · Hugging Face: no description found
- unsloth/Qwen2.5-7B-Instruct · Hugging Face: no description found
- Dynamic Deep Learning | Richard Sutton: ICARL Seminar Series - 2024 WinterDynamic Deep LearningSeminar by Richard Sutton——————————————————Abstract:Despite great successes, current deep learning met...
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- GitHub - huggingface/trl: Train transformer language models with reinforcement learning.: Train transformer language models with reinforcement learning. - huggingface/trl
- trl dpo AttributeError: 'generator' object has no attribute 'generate' · Issue #2292 · huggingface/trl: trl dpo AttributeError: 'generator' object has no attribute 'generate' print('start training...') if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*"))...
- Google Colab: no description found
- Google Colab: no description found
- Reddit - Dive into anything: no description found
- microsoft/orca-agentinstruct-1M-v1 · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (41 messages🔥):
Using CSV for Chat ModelsAya Expanse SupportModel Finetuning IssuesContainer Installation ProblemsUnsloth Trainer Compatibility
-
Using CSV for Chat Models: A member asked if there is a notebook similar to the Titanic CSV example for using CSV in a chat-like manner.
- No specific response or solution was provided in the thread.
- Aya Expanse Support: Inquiry about whether the Aya Expanse model by Cohere will be supported was confirmed positively by another member.
- The discussion didn’t include any further details or concerns.
- Model Finetuning Issues: A user reported challenges with finetuning a model using quantization and asked if it was possible to save in different bit formats alongside the Q4 format.
- Discussion led to sharing resources and confirmations on current saving methods, but no resolution was given.
- Container Installation Problems: A member struggled with installing
bitsandbytes==0.43.1in their container built onnvidia/cuda:12.3.0-base-ubuntu20.04.
- Other members suggested possible workarounds but did not directly resolve the installation issue.
- Unsloth Trainer Compatibility: An issue was raised regarding the deprecation of 'Trainer.tokenizer' while using the ORPO trainer for Unsloth, triggering discussions on updates.
- Confirmation that the trainer still works was made, along with suggestions to update Unsloth for backward compatibility.
Links mentioned:
- Google Colab: no description found
- Home: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Hugging Face – The AI community building the future.: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #research (1 messages):
Synthetic Data in Language ModelsAgentInstruct
-
Synthetic Data's Role in Language Model Development: A discussion centered on the importance of synthetic data for accelerating the development of language models, as highlighted in the paper AgentInstruct: Toward Generative Teaching with Agentic Flows.
- The paper addresses model collapse and the need for human curation, emphasizing that effective use of synthetic data necessitates careful quality and diversity management.
- Post-Training Data Creation for Skill Teaching: The authors propose using synthetic data for post-training, where powerful models create data to teach new skills or behaviors to other models.
- This innovative approach aims to harness the potential of synthetic data while mitigating concerns related to imitating existing models.
HuggingFace ▷ #announcements (1 messages):
Pipeline Abstraction for Vision ModelsNew Methods in DiffusersQwen 2.5 with Extended ContextPixtral Large SupportCO2 Calculations on Open LLM Leaderboard
-
Pipeline abstraction now supports vision models: The pipeline abstraction in @huggingface transformers now supports vision language models, simplifying inference.
- This enhancement makes it easier for developers to work with visual and text data simultaneously.
- Diffusers introduce new adapter methods: Two new methods,
load_lora_adapter()andsave_lora_adapter(), were added to Diffusers for models that support LoRA.
- These methods allow direct interaction with LoRA checkpoints without needing to use the previous command for loading weights.
- Qwen 2.5-Turbo processes 1M tokens swiftly: The newly released Qwen 2.5-Turbo model boasts a context length of 1 million tokens, with a 4.3x speedup in inference time.
- This upgrade ensures a faster processing speed, dropping time to first token from 4.9 minutes to just 68 seconds.
- Pixtral Large integrated into transformers: Pixtral Large is now natively supported in Hugging Face transformers, enriching the model library.
- Thanks to @art_zucker, this support enhances the versatility of the transformers framework.
- CO2 emissions tracking in LLM Leaderboard: The Open LLM Leaderboard has been updated to include CO2 calculations, allowing users to assess the environmental impact of model evaluations.
- Check out the leaderboard here and make more sustainable choices in model selection.
Links mentioned:
- Tweet from merve (@mervenoyann)): pipeline abstraction of @huggingface transformers now support vision language models for easy inference 🫰🏻
- Tweet from Sayak Paul (@RisingSayak)): Shipped two new methods in Diffusers 🧨 --
load_lora_adapter()andsave_lora_adapter()on models that support LoRA. This helps interact with a LoRA ckpt and a model more directly without going t... - Tweet from Vaibhav (VB) Srivastav (@reach_vb)): 1 Million tokens AND blazingly fast! 🔥 Try it out on @Gradio space below Quoting Qwen (@Alibaba_Qwen) After the release of Qwen2.5, we heard the community’s demand for processing longer contexts....
- Tweet from merve (@mervenoyann)): Pixtral Large is supported in @huggingface transformers 💗 grâce à @art_zucker 🎩
- Tweet from Sayak Paul (@RisingSayak)): Mochi-1 is now natively supported in
diffusers. Check out the original model card for all the details. Reminder: It's Apache 2.0! Thanks to the @genmoai team for making their amazing work ope... - Tweet from Alina Lozovskaya (@ailozovskaya)): 🌱 CO₂ calculations on the Open LLM Leaderboard! You can now check CO₂ emissions for each model evaluation! Track which models are greener and make sustainable choices🌍 🔗 Leaderboard: https://hug...
- Tweet from Daniel van Strien (@vanstriendaniel)): It's cool to see 2 of the top 10 trending @huggingface datasets derived from openly licenced content.
HuggingFace ▷ #general (139 messages🔥🔥):
Gradio API Quota IssuesHub-Stats Dataset and RankingsSynthetic Data GenerationNeurIPS ConferenceZero-Shot Classification with Hugging Face Hub
-
Gradio API Users Facing Quota Limitations: Users reported experiencing quota exhaustion while using the Gradio API for music generation, especially when logged in as PRO users, despite receiving higher limits compared to free users.
- Discussion included insights on token usage and obtaining PRO statuses to maximize usage limits in Python code.
- New Insights from Hub-Stats Dataset: The recently updated Hub-Stats dataset now includes social posts, enabling users to see their rankings, with some users boasting high ranks like #37 and #29.
- There were discussions on boosting engagement and yapping metrics, with humor about potential competitive aspects appearing in the dataset.
- Open Source Synthetic Data Generation Tools: A user inquired about open-source implementations similar to G-LLaVa and discussed existing alternatives like WizardLM's EvolInstruct.
- Members expressed interest in multimodal tools for synthetic data generation, highlighting a community need for shared resources.
- Attendance Queries for NeurIPS Conference: Users expressed their interest in attending the NeurIPS conference and inquired about finding information on side events happening during the conference.
- This sparked a brief discussion about the significance of NeurIPS in the machine learning community, indicating community engagement.
- Clarifications on Zero-Shot Classification API Usage: A user needed clarity on whether the Hugging Face Hub's endpoint client could accept multiple inputs for zero-shot classification, contrasting it with regular post requests.
- There was a call for a potential batch function for zero-shot classification, highlighting existing limitations in current client capabilities.
Links mentioned:
- Quickstart: no description found
- zero-gpu-explorers/README · use authentication in huggingface Gradio API!!!(hosting on ZeroGPU): no description found
- microsoft/orca-agentinstruct-1M-v1 · Datasets at Hugging Face: no description found
- huggingface_hub/src/huggingface_hub/inference/_client.py at main · huggingface/huggingface_hub: The official Python client for the Huggingface Hub. - huggingface/huggingface_hub
- google-bert (BERT community): no description found
- FacebookAI (Facebook AI community): no description found
- apple (Apple): no description found
- google (Google): no description found
- meta-llama (Meta Llama): no description found
HuggingFace ▷ #today-im-learning (3 messages):
EMA ScalingNeural Network in Rust
-
Exploring EMA Scaling with Video: A user is currently watching a YouTube video titled "Scaling EMA" to understand the concept of EMA Scaling.
- The video may provide insights on the topic and encourages engagement through likes and comments.
- Collaboration Request for Rust Neural Network: A member is seeking assistance in building a neural network in Rust and wants to showcase its performance benchmarks.
- They're reaching out to see if anyone has the expertise or interest to collaborate on this project.
Link mentioned: Scaling EMA: Like 👍. Comment 💬. Subscribe 🟥.🏘 Discord: https://discord.gg/pPAFwndTJdhttps://arxiv.org/pdf/2307.13813.pdfhttps://huggingface.co/papers/2307.13813#machi...
HuggingFace ▷ #cool-finds (5 messages):
Exact Unlearning in LLMsHuggingFace Feature UpdateRAG Fusion in Generative AIVoice Data Augmentation for WhisperChat Collapsing Feature
-
Exact Unlearning in LLMs: A recent paper discusses exact unlearning as a privacy mechanism that enables users to retract their data from machine learning models upon request and highlights inconsistencies in its application within Large Language Models.
- The authors argue that while unlearning can effectively manage the training phase, it does not preclude models from possessing impermissible knowledge, such as malicious information or inaccuracies.
- HuggingFace Introduces Chat Collapsing: HuggingFace rolled out a feature that collapses discussions when chat history gets too long, eliminating the need for infinite scrolling.
- This update enhances usability by making it easier to access the latest conversations during extensive chats.
- RAG Fusion Revolutionizes Generative AI: An article highlights RAG Fusion as a significant paradigm shift in generative AI, suggesting it is poised to transform the landscape of AI generation.
- The piece delves into its implications and the future of using RAG techniques in various applications.
- Voice Data Augmentation Boosts Whisper Performance: Voice data augmentation has notably improved the accuracy of Whisper small trained on the Arabic language, leading to a reduction in Word Error Rate (WER).
- This enhancement marks an accomplishment in fine-tuning models for better performance in language-specific tasks.
Link mentioned: UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI: Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate...
HuggingFace ▷ #i-made-this (12 messages🔥):
Augment Inference EngineLLM Ranking ArenaResponse Generator ChallengesQwen2-VL on ONNX RuntimePTA-1 GUI Element Localization
-
Augment tackles LLM inference latency: Augment published a post outlining their approach to building an inference engine, emphasizing that full codebase context is critical for developer AI despite causing latency issues. They discuss optimizing LLM inference to enhance speed and quality for their customers.
- The article illustrates that providing more relevant context significantly improves the quality of code processing.
- Judge Arena for LLM comparisons launched: A new platform called Judge Arena has been launched to help users rank different LLMs based on their performance as judges, fostering community engagement. Visitors can run tests and vote on which LLM they find most effective.
- This initiative aims to leverage crowdsourced feedback to determine which models excel in language evaluations, similar to LMSys's successful Chatbot Arena.
- Challenges in response generation noted: A user discussed difficulties in generating accurate responses using GPT-2 and GPT-XL, noting that the training data created was not effective in producing viable output. They expressed a desire for assistance in refining their response and recommendation generator.
- The approach thus far has involved leveraging mostly.ai for training data, but further refinement is needed to improve the generator's capabilities.
- Qwen2-VL running on ONNX Runtime: After consistent efforts, a user successfully deployed Qwen2-VL on onnxruntime-web, noting that it is currently running slowly due to some processes being on wasm. Most operations leverage webgpu, indicating potential for performance improvement.
- This implementation suggests advancements in running sophisticated models in web environments, enhancing accessibility.
- PTA-1 improves GUI element localization: The recently released PTA-1 model effectively localizes GUI elements on screenshots, allowing for swift automation on local computers with low latency. It utilizes only 270M parameters, achieving performance superior to larger models.
- The model's input consists of a screenshot combined with a description of the target element, generating bounding boxes for precise localization.
Links mentioned:
- Rethinking LLM Inference: Why Developer AI Needs a Different Approach: A technical blog post from Augment Code explaining their approach to optimizing LLM inference for code-focused AI applications. The post details how they achieved superior latency and throughput compa...
- AskUI/PTA-1 · Hugging Face: no description found
- GitHub - MaloLM/whisper-3-speach-to-text: A simple python program for audio files transcription using Whisper model.: A simple python program for audio files transcription using Whisper model. - MaloLM/whisper-3-speach-to-text
- Judge Arena - a Hugging Face Space by AtlaAI: no description found
- Judge Arena: Benchmarking LLMs as Evaluators: no description found
- streamerd/diplo-ai · Hugging Face: no description found
- GitHub - streamerd/diplo-ai: Suite of data and scripts that can classify diplomatic statements into one of 62 predefined categories and generate diplomatic responses or recommendations based on the classified statement.: Suite of data and scripts that can classify diplomatic statements into one of 62 predefined categories and generate diplomatic responses or recommendations based on the classified statement. - stre...
HuggingFace ▷ #reading-group (9 messages🔥):
GPU performance comparisonWater cooling issuesNVIDIA vs AMD for AIRadeon Instinct MI50 and MI60
-
Crazypistachecat's GPU Setup: Currently, Crazypistachecat has 3 RX 6800s in use due to a technical issue with a fourth card that caused system crashes.
- They aim to test the problematic card elsewhere, noting it is currently under a water block.
- NVIDIA vs AMD for AI Workloads: In response to a question about GPU performance, it's mentioned that NVIDIA is generally ahead in AI hardware and software.
- Finding NVIDIA cards with 16GB of VRAM can be an economical choice for those on a budget.
- Budget-Friendly Choices in GPU: Crazypistachecat chose to use RX 6800 GPUs for their price-to-performance ratio, as they were affordable and supported ROCm.
- They highlighted that options like the 3090 are too expensive, allowing for two 6800s for the cost of one.
- Exploring Radeon Instinct Options: Crazypistachecat expressed interest in transitioning to using AMD Radeon Instinct MI50 and MI60 GPUs.
- This shift indicates a growing consideration for alternative high-performance options in the AMD lineup.
HuggingFace ▷ #core-announcements (1 messages):
LoRA Model SupportNew methods for LoRA
-
Two New Methods Enhance LoRA Support: Recent updates announced the shipment of two new methods for better supporting LoRA at the model-level.
- This improvement aims to optimize performance and integration in user applications.
- Community Excitement Over LoRA Improvements: Members expressed enthusiasm about the new methods for LoRA, highlighting their potential impact on existing workflows.
- One member mentioned, 'This could really boost our model's efficiency and ease of use.'
HuggingFace ▷ #computer-vision (1 messages):
Object Detection for VideosOil and Gas Frac Site AnalysisLabeling Challenges in Object Detection
-
Seeking Object Detection Solution for Video: A user is looking for an easy way to perform object detection on a video feed from an Oil and Gas Frac site but has encountered issues with existing labels.
- They mentioned that the video is for testing purposes and expressed willingness to pay for assistance if necessary.
- Challenges with Existing Object Detection Labels: The same user noted that the labels found online do not work correctly when uploading their video for testing.
- These challenges highlight the need for more accessible and effective object detection solutions tailored to specific industrial applications.
Stability.ai (Stable Diffusion) ▷ #general-chat (134 messages🔥🔥):
Mochi and CogVideo PerformanceModel Recommendations for BeginnersUsing different WebUIs for Stable DiffusionGGUF Format vs. Large ModelAI-driven News Content Creation Software
-
Mochi vs CogVideo in Performance: Members discussed that Mochi-1 is currently outperforming other models in leaderboards despite its seemingly inactive Discord community.
- CogVideo is noted to be gaining popularity due to its features and faster processing times but is still considered inferior for pure text-to-video tasks compared to Mochi.
- Suggestions for New Stable Diffusion Users: New users are recommended to explore Auto1111 and Forge WebUI as beginner-friendly options for Stable Diffusion.
- While ComfyUI offers more control, its complexity can be confusing for newcomers, making Forge a more appealing choice.
- Optimal Model Formats for Stability: The difference between stable-diffusion-3.5-large and stable-diffusion-3.5-large-gguf relates to how data is handled by the GPU, with GGUF allowing for smaller, chunked processing.
- Users with more powerful setups are encouraged to use the base model for speed, while those with limited VRAM can explore the GGUF format.
- AI for Automated Content Generation: A user introduced a software capable of monitoring news topics and generating AI-driven social media posts, emphasizing its utility for platforms like LinkedIn and Twitter.
- The user is seeking potential clients for this service, highlighting its capability in sectors like real estate.
- Various WebUI Preferences and Experiences: The community shared experiences regarding different WebUIs, noting ComfyUI's advantages in workflow design, particularly for users familiar with audio software.
- Some expressed dissatisfaction with the form-filling nature of Gradio, calling for more user-friendly interfaces while also acknowledging the robust optimization of Forge.
Links mentioned:
- InstantX/SD3.5-Large-IP-Adapter · Hugging Face: no description found
- Video Generation Model Arena | Artificial Analysis: Compare AI video generation models by choosing your preferred video without knowing the provider.
aider (Paul Gauthier) ▷ #general (83 messages🔥🔥):
OpenAI o1 models updateIssues with qwen-2.5-coderKubernetes editing with AiderAnthropic rate limits changesModel performance comparison
-
OpenAI o1 models now support streaming: Streaming is now available for OpenAI's o1-preview and o1-mini models, allowing development across all paid usage tiers. The main branch supports this feature by default, enhancing the capabilities for developers.
- Aider's main branch will prompt for updates when new versions are released, but automatic updates are not guaranteed for developer environments.
- Challenges with qwen-2.5-coder: Users reported that the OpenRouter's qwen-2.5-coder sometimes fails to commit changes or gets stuck in loops, prompting discussions for solutions. Some members suggested this could be due to incorrect setup parameters or memory pressures.
- There is speculation regarding qwen-2.5-coder's performance under different modes, with reports indicating it performs worse in architect mode compared to regular mode.
- Exploring Aider for Kubernetes manifest edits: Discussion surfaced about using Aider to edit Kubernetes manifests with commands like 'autoscale service X'. Users are considering the model's proficiency in handling specific Kubernetes fields and the potential for guidance using reference documents.
- Suggestions included creating wrappers around the manifest types to aid in accessing relevant documentation.
- Changes to Anthropic API rate limits: Anthropic has announced the removal of daily token limits, with new minute-based input/output token limits introduced across tiers. This update could compel developers to upgrade for fewer rate limits associated with lower tiers.
- Some users expressed skepticism, viewing the tier structure as a move to incentivize spending for enhanced access.
- General model performance discussions: Users are sharing insights on the qwen model's capabilities, comparing it to Sonnet and discussing training considerations that may affect performance. Anecdotal evidence suggests that qwen may not match Sonnet's efficiency based on preliminary experiences.
- Participants are keen to explore different models' effectiveness for specific tasks, looking forward to upcoming updates and improvements.
Links mentioned:
- Model warnings: aider is AI pair programming in your terminal
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Tweet from Alex Albert (@alexalbert__): Compare the current limits to the new limits here: https://docs.anthropic.com/en/api/rate-limits
- Tweet from Alex Albert (@alexalbert__): Good news for @AnthropicAI devs: Tomorrow we will be removing the tokens per day (TPD) limit and splitting tokens per minute (TPM) into separate input/output limits across tiers on the Anthropic API.
- PEP 541 Request: aider · Issue #3296 · pypi/support: Project to be claimed aider: https://pypi.org/project/aider/ Your PyPI username paul-gauthier: https://pypi.org/user/paul-gauthier/ Reasons for the request The only releases of the project all occu...
aider (Paul Gauthier) ▷ #questions-and-tips (47 messages🔥):
Aider and OpenAI API limitationsConnecting Aider with local modelsBenchmark test skipsUsing extra_params in AiderAider with Bedrock models
-
Aider struggles with OpenAI API limitations: Concerns were raised about Aider's default output limit being set to 512 tokens, despite large context sizes available through the API.
- Members discussed the need to adjust configurations but noted the persistent issues even with the max new tokens set to 4k.
- Connecting Aider with local models issues: Several members shared frustrations about Aider's compatibility issues with local models when using an OpenAI compatible API, suggesting potential configurations of metadata JSON files.
- Discussions included the need to format these JSON files correctly to avoid conflicts and errors during use.
- Difficulty identifying skipped tests in benchmarks: A member inquired about inspecting older benchmark folder runs to determine if any tests were skipped due to timeouts.
- It was concluded that there isn't a straightforward method for verifying skipped tests within previous benchmark runs.
- Utilizing extra_params for Aider configurations: Discussion clarified that
extra_paramswithin Aider allows for adding custom parameters, including headers, for enhancing API interactions.
- It was noted that this feature doesn't support environment variable interpolation yet, but global extra_params functionality has been introduced for broader settings.
- Aider's compatibility with Bedrock models: It was mentioned that specific Bedrock models, like Anthropic Claude 3.5, are region-dependent and may lead to errors if not properly aligned with AWS configurations.
- Members shared insights about resolving these issues to run Aider smoothly, with some still facing challenges in receiving valid token outputs.
Links mentioned:
- Advanced model settings: Configuring advanced settings for LLMs.
- Advanced model settings: Configuring advanced settings for LLMs.
aider (Paul Gauthier) ▷ #links (3 messages):
Pixtral Large ReleaseDeno Project DiscussionMistral Large 2 PerformanceAider Benchmarking
-
Pixtral Large Launches with Frontier-Class Performance: Mistral has announced the release of Pixtral Large, a 124B multimodal model built on Mistral Large 2, boasting state-of-the-art performance on MathVista, DocVQA, and VQAv2.
- It can handle over 30 high-resolution images using a 128K context window and is available for testing in the API as
pixtral-large-latest. - Concerns Raised Over Deno's Future: A discussion arose regarding the Deno project and its recent criticism of NodeJS, raising doubts about its viability compared to traditional solutions.
- Concerns were expressed that a dev tool intended for websites should not compete with a runtime for production code that can build and pull in external binaries.
- Interest in Aider Compatibility with Pixtral Large: Elbie mentioned a desire to see Aider benchmarks for the new Pixtral model, noting that while the previous Mistral Large was excellent, it didn't fully fit Aider's needs.
- If the new model performs similarly but is compatible, it could significantly enhance Aider’s capabilities.
- It can handle over 30 high-resolution images using a 128K context window and is available for testing in the API as
Link mentioned: Pixtral Large: Pixtral grows up.
LM Studio ▷ #general (65 messages🔥🔥):
7900XTX Graphics PerformanceRoleplay Models for Llama 3.2Remote Server Usage for LM StudioHosting Local LLMsModel Updates in LM Studio
-
7900XTX struggles with graphics tasks: A user reported that the 7900XTX is effective with text but experiences significant slowdown with graphics-intensive tasks, particularly when using amuse software designed for AMD.
- Another user inquired about which specific models were tested for graphics performance on the 7900XTX.
- Seeking NSFW Models for Roleplay: A user asked for recommendations on good NSFW/Uncensored, Llama 3.2 based models for roleplay, to which another responded that they could be found with proper searching.
- A discussion ensued about the difficulty of navigating HuggingFace for these models.
- Remote Server Accessibility for LM Studio: A user sought advice on pointing LM Studio to a remote server, with suggestions including using RDP or the openweb-ui for a better experience.
- One user expressed interest in using Tailscale to host inference backends remotely, emphasizing consistent performance.
- Hosting Local LLMs Discussion: Users exchanged thoughts on hosting local LLMs, mentioning that LM Studio provides a significant portion of that capability and suggesting SillyTavern as additional UI.
- One user noted the benefit of using a local SSD for storage, clarifying that while it may help initial load times, inference speed remains unaffected.
- Updating Models in LM Studio: A user inquired if they could update a downloaded model without deleting it, to which another user confirmed that models must be downloaded afresh when updated.
- This led to further discussions about the specifics of model handling and troubleshooting within LM Studio.
Links mentioned:
- Sideload models - Advanced | LM Studio Docs: Use model files you've downloaded outside of LM Studio
- microsoft/orca-agentinstruct-1M-v1 · Datasets at Hugging Face: no description found
LM Studio ▷ #hardware-discussion (67 messages🔥🔥):
Windows vs Ubuntu Inference SpeedAMD GPU Performance ChallengesRTX 4090 Configuration OptionsBenchmarking Results on AMD W7900
-
Windows vs Ubuntu Inference Speed Revealed: Tests showed that on Windows, a 1b model achieved 134 tok/sec, while Ubuntu outpaced it with 375 tok/sec, suggesting a significant performance gap.
- A member proposed that the discrepancy might be due to differing power schemes in Windows, recommending switching to high-performance mode.
- AMD GPUs: Great Hardware, Tough Software: Discussion highlighted that while AMD GPUs offer efficient performance, they suffer from a lack of software support, making them less appealing for certain applications.
- One member noted that using AMD hardware often feels like an uphill battle due to compatibility issues with tools.
- RTX 4090 Setup Causing a Stir: Enthusiasts mentioned impressive configurations with multiple RTX 4090s directly connected to a motherboard, enhancing their benchmarking capabilities substantially.
- Another member humorously noted they could mount their setup on wood since they couldn't afford a case.
- Benchmarking AMD W7900 Against Nvidia: A user sought to re-evaluate the AMD W7900, recalling previous benchmarks that showed it performed slightly slower than a 3090 when using certain prompts.
- Members agreed to share results from their tests in the chat, highlighting a collaborative benchmarking effort.
- Juiced-Up Dual AMD CPUs Speculated: A member described plans for a dual 128-core Bergamo AMD CPU setup alongside water-cooled RTX 4090s for a robust configuration that's both powerful and resource-intensive.
- They humorously noted that they are mounting the hardware on wood due to budget constraints for traditional cases.
Link mentioned: Don't ask to ask, just ask: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Activity page outage
-
Activity Page Outage Investigation: The Activity page experienced an outage, prompting an ongoing investigation into the issue.
- An update was provided stating that it was back up and running at 12:31 PM ET.
- Activity Page Restoration Update: The team communicated that the outage on the Activity page has been resolved and service is restored as of 12:31 PM ET.
- Users can now access the page normally following the brief disruption.
OpenRouter (Alex Atallah) ▷ #general (119 messages🔥🔥):
O1 Preview and Streaming SupportGemini Model IssuesMistral API LimitationsOpenRouter Error ReportsDeveloper Requests and Suggestions
-
O1 Streaming now Available: Discussion revealed that OpenAI's
o1-previewando1-minimodels now support real streaming capabilities, as confirmed by OpenAIDevs. This change opens up access for developers across all paid usage tiers.- Members noted past limitations with 'fake' streaming methods and expressed interest in better clarity around updates.
- Frequent Errors with Gemini Models: Users reported high error rates, particularly 503 errors, while using Google's
Flash 1.5andGemini Experiment 1114, indicating potential rate limiting issues. Some community members speculated about potential bugs related to the newer experimental models.
- Additionally, errors related to resource exhaustion were common, prompting suggestions for improved communication from OpenRouter.
- Mistral Model Limitations: A user expressed issues when using Mistral models with OpenRouter, particularly regarding infinite loops and repeated outputs. This seems to be a recurring pattern across multiple models, including
Mistral NemoandGemini.
- Community members suggested adjustments, like lowering temperature settings, but acknowledged the challenges in addressing these technical difficulties.
- OpenRouter Dashboard Errors: Users faced issues accessing the OpenRouter settings panel, particularly in the Brave browser, citing missing Redis configuration parameters. Alex addressed these concerns, confirming investigation and announcing that the panel was back online.
- Other users noted similar issues in Chrome, highlighting discrepancies across different browsers.
- Developer Feature Requests: Community members discussed potential enhancements to the OpenRouter platform, including a request for a 'copy' button for code outputs and a feature to review account activity. These requests reflect users' desire for improved usability and functionality.
- Suggestions were well-received, with some members indicating the reasonableness of implementing such features.
Links mentioned:
- Large Enough: Today, we are announcing Mistral Large 2, the new generation of our flagship model. Compared to its predecessor, Mistral Large 2 is significantly more capable in code generation, mathematics, and reas...
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Models | OpenRouter: Browse models on OpenRouter
- How generative AI expands curiosity and understanding with LearnLM: LearnLM is our new Gemini-based family of models for better learning and teaching experiences.
- Self Report Among Us GIF - Self report Among us Troll - Discover & Share GIFs: Click to view the GIF
- Cerebras Now The Fastest LLM Inference Processor; Its Not Even Close: The company tackled inferencing the Llama-3.1 405B foundation model and just crushed it.
- DOJ Will Push Google to Sell Chrome to Break Search Monopoly - Bloomb…: no description found
- no title found: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
Custom Provider KeysBeta Custom Provider KeysBring Your Own API Keys
-
Requests for Custom Provider Keys flood in: Several users have requested access to custom provider keys, expressing a keen interest in utilizing them for various applications.
- One user noted, ‘I’d like to request access for custom provider keys please’, showing a clear demand for these resources.
- Interest in Beta Custom Provider Keys: A user specifically requested access to beta custom provider keys, highlighting a desire for the latest features available.
- The phrasing offers insight into a growing trend of users seeking early access or testing new capabilities in the project.
- Bring Your Own API Keys: Another user mentioned a desire to request access to bring their own API keys, indicating a push for more customizable solutions.
- This reflects a shift towards user-defined integrations within the platform.
- Plus One for Custom Provider Key Access: A user showed support for custom provider keys with a simple '+1', emphasizing community backing for key access requests.
- Such endorsements may suggest a growing consensus on the importance of these keys among the users.
Notebook LM Discord ▷ #use-cases (20 messages🔥):
Audio Track SeparationsVideo Creation ToolsNotebookLM for Document OrganizationTeaching with NotebookLMPodcast Experimentation with Code
-
Inquiry on Separating Voice Audio Tracks: A member asked if anyone has figured out how to obtain two separate audio tracks of voices during a recording.
- This reflects ongoing interest in tools that manage audio intricacies within platforms like NotebookLM.
- Exploring Video Creation Solutions: Discussion on video creation tools led to a sharing of methods using avatars from Somli at a competitive price.
- Steps were shared on how to build videos using D-ID Avatar studio with appropriate coding mentioned for those interested.
- Using NotebookLM for Document Organization: A member expressed interest in using NotebookLM to compile and organize world-building documentation effectively.
- The desire for better organization of notes hints at NotebookLM's potential to streamline creative processes.
- Creating Customized Lessons with NotebookLM: An English teacher shared their experience using NotebookLM to develop reading and listening lessons tailored to student interests.
- The approach includes tool tips as mini-lessons, enhancing contextual understanding of language in practical scenarios.
- Experimenting with Podcast Generation from Code: A user expressed curiosity about the kind of podcast NotebookLM might generate if presented with code snippets.
- This experimentation showcases the versatility of NotebookLM in generating content from diverse data inputs.
Links mentioned:
- The best games of 2024: no description found
- Starfish English Lessons: no description found
- GitHub - jjmlovesgit/Simli_NotebookLM: A project to take an audio file and separate it into speakers and play it with avatars and save the recording as an mp4 for sharing on social etc. Ideal for Deep Dive podcasts from Google NotebookLM: A project to take an audio file and separate it into speakers and play it with avatars and save the recording as an mp4 for sharing on social etc. Ideal for Deep Dive podcasts from Google Notebook...
Notebook LM Discord ▷ #general (101 messages🔥🔥):
NotebookLM UI ConfusionData Source LimitationsUsing NotebookLM for StudyingMobile Access and App UpdatesPodcast Generation Feature
-
Users Face Confusion with NotebookLM UI: Many users expressed confusion about the location of the 'GENERATE' feature in NotebookLM, with several not realizing they needed to click on the 'notebook guide' button in the bottom right to access it.
- Users highlighted that the naming of certain buttons and features in the UI could lead to misunderstandings about their functions.
- Issues with Data Source Availability: A user reported problems with accessing citations in NotebookLM, where the sources showed question mark boxes instead of readable content, indicating formatting problems.
- Suggestions included converting documents to different formats to resolve these display issues.
- NotebookLM Assists with Studying: Some users utilize NotebookLM for studying by generating podcasts while reading their notes and slides, though some express concern regarding the reliability of audio summaries.
- One user mentioned they prepare summaries beforehand and then listen to the podcasts for better understanding during their studies.
- Mobile Access and Upcoming Improvements: Users inquired about the best ways to access NotebookLM on mobile, with suggestions to save shortcuts until a dedicated mobile app is released.
- Improvements to mobile web access are expected soon, while the app is still in the future.
- Podcast Generation Limitations: Users found that only one podcast can be generated per notebook, leading to confusion when trying to create multiple podcasts without deleting previous ones.
- Workarounds were discussed, including combining sources into single documents to optimize output.
Link mentioned: AI Note Taking & Transcribe & Summarizer | AI Notebook App: Generate transcripts and AI summarize for College Students in lectures. Specializing in YouTube Video Summarizer, PDF Summarizer, Article Summarizer. Save key insights and review with study guides, qu...
Nous Research AI ▷ #general (78 messages🔥🔥):
Recent AI/ML Research PapersAI Model FeedbackOpportunities for High School Students in AI/MLSecurity Concerns in Job PostingsForge API Access Requests
-
Exploring New AI/ML Research Papers: Members discussed multiple influential AI/ML research papers including topics like 'Cut Your Losses in Large-Vocabulary Language Models' and 'LLMs Can Self-Improve in Long-context Reasoning'. This shows ongoing interest in advancements within the field and reflects recent developments.
- Some researchers expressed their interest in using work from these papers as a basis for their own projects and experiments.
- Feedback on Hermes AI's Responses: One user raised concerns regarding the Hermes AI's expressions of speed, suggesting it may lead to confusion about AI sentiments or consciousness. Responses like these should be re-evaluated to maintain clarity about the nature of AI capabilities.
- This sparked a discussion about the appropriateness of such language in AI interactions, highlighting user sensitivity to perceived sentience.
- Advice for Aspiring AI/ML Students: A high school student sought advice on standing out in AI/ML, while another younger member shared their experience writing a paper on inference time compute. The conversation turned towards specialization in various AI areas and starting from foundational knowledge.
- Advice emphasized avoiding highly abstract frameworks in favor of a strong grasp of core principles, with recommendations for learning resources and personal initiatives.
- Security Issues with Job Postings: A discussion unfolded concerning the risks of scams related to job postings, particularly in the web3 space. A user highlighted precautions to take when interacting with potential suspect offerings.
- The exchange pointed to a broader issue of trust within online job opportunities, advising users to be vigilant and prioritize security.
- Requests for Forge API Access: Several members expressed interest in accessing the Forge API, with some participants already signing up on the waitlist and direct messaging for access. The conversation underscored a growing demand for integration in their projects.
- Users were encouraged to reach out for access requests while confirming that the API is currently in a small beta phase.
Links mentioned:
- chatgpt2dataset.py: GitHub Gist: instantly share code, notes, and snippets.
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others): Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Research updates: Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
Nous Research AI ▷ #research-papers (5 messages):
LLM2CLIPNeural MetamorphosisAgentInstruct
-
LLM2CLIP Enhances Visual Representation: The paper proposes LLM2CLIP, which harnesses LLM capabilities to improve the CLIP model by refining its textual handling, particularly in managing complex image captions, as detailed in the study.
- This approach dramatically boosts CLIP's performance in cross-modal tasks by utilizing a fine-tuned LLM as a guide for CLIP's visual encoder.
- Neural Metamorphosis Innovates Neural Network Training: Introducing Neural Metamorphosis (NeuMeta), the paper describes a method for creating self-morphable neural networks by learning a continuous weight manifold of models, allowing weights to be sampled for various configurations without retraining, as explained here.
- This new paradigm utilizes neural implicit functions as hypernetworks to generate weights dynamically, enhancing model flexibility.
- AgentInstruct Automates Synthetic Data Generation: The AgentInstruct framework produces diverse and high-quality synthetic data automatically, facilitating Generative Teaching by leveraging raw data sources to create extensive datasets, including a remarkable 25M pairs for language model training, mentioned in the paper.
- Post-training with this data led to substantial performance improvements across benchmarks for the Orca-3 model compared to its predecessor, with enhancements such as a 40% improvement on AGIEval.
Link mentioned: Neural Metamorphosis: This paper introduces a new learning paradigm termed Neural Metamorphosis (NeuMeta), which aims to build self-morphable neural networks. Contrary to crafting separate models for different architecture...
Nous Research AI ▷ #research-papers (5 messages):
LLM2CLIPNeural MetamorphosisAgentInstructCross-modal representationSynthetic data generation
-
LLM2CLIP enhances visual representation: The paper proposes LLM2CLIP, leveraging large language models to improve CLIP's multimodal capabilities by enabling efficient processing of longer captions.
- By fine-tuning LLMs in the caption space, the method allows for remarkable advancements in cross-modal tasks and visual encoder performance.
- Neural Metamorphosis introduces self-morphable networks: Neural Metamorphosis (NeuMeta) offers a learning paradigm that produces self-morphable neural networks by sampling directly from a continuous weight manifold.
- This innovative approach allows for weight generation for unseen configurations without retraining models, with a focus on the smoothness of the learned manifold.
- AgentInstruct automates synthetic data generation: The AgentInstruct framework automates the creation of synthetic data for training language models, producing 25 million diverse prompts and responses from raw data sources.
- When post-training Mistral-7b with this dataset, the resulting Orca-3 model demonstrated significant benchmark improvements, outperforming models like LLAMA-8B-instruct and GPT-3.5-turbo.
Link mentioned: Neural Metamorphosis: This paper introduces a new learning paradigm termed Neural Metamorphosis (NeuMeta), which aims to build self-morphable neural networks. Contrary to crafting separate models for different architecture...
Nous Research AI ▷ #reasoning-tasks (2 messages):
LLaVA-o1Vision-Language ModelsReasoning capabilitiesVisual question-answeringInference-time scaling
-
LLaVA-o1 introduces structured reasoning in VLMs: The paper introduces LLaVA-o1, a novel Vision-Language Model designed for autonomous multistage reasoning, improving performance in complex visual question-answering tasks. It engages in stages of summarization, visual interpretation, logical reasoning, and conclusion generation.
- The authors claim significant improvements in precision on reasoning-intensive tasks through the development of a comprehensive dataset, LLaVA-o1-100k, comprising samples from diverse VQA sources.
- Comparison to existing reasoning models: In the discussion, a member inquired if LLaVA-o1's approach is similar to techniques used in the existing reasoning model. This highlights an interest in cross-comparative analysis of different reasoning methodologies in AI.
Link mentioned: LLaVA-o1: Let Vision Language Models Reason Step-by-Step: Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, curr...
GPU MODE ▷ #general (2 messages):
Colexicographical OrderCutlass/Cute API Behavior
-
Understanding Colexicographical Order in Coordinates: One member discussed their confusion regarding the colexicographical order in the context of coordinate mapping, stating that for a coordinate like (A, (B, C)), the expected iteration order is inner A, B, outer C.
- They noted a discrepancy with Cutlass/Cute's API behavior, which appears to follow a different extraction order, leading to further questioning.
- Cutlass/Cute API Confusion: Another member pointed out the inconsistency between the iteration order observed in Cutlass/Cute and its API's description, particularly with the
getmethod.
- They highlighted the extraction method in the API that suggests an inner-outter iteration sequence that contradicts their understanding of the colexicographical process.
Link mentioned: cutlass/media/docs/cute/01_layout.md at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
GPU MODE ▷ #triton (5 messages):
Triton spellingTriton CPU backendGitHub Pull Request
-
Laughter Over Triton Spelling: A member humorously remarked, 'Can barely spell triton,' eliciting laughter from others in the chat.
- This light-hearted exchange highlighted the community's camaraderie and shared experiences.
- Introduction of Triton CPU Backend: A member shared a GitHub Pull Request that aims to add Triton CPU as an Inductor backend to PyTorch.
- The goal of this integration is to use Inductor-generated kernels to stress test the new Triton CPU backend.
Link mentioned: Add Triton CPU as an Inductor backend by int3 · Pull Request #133408 · pytorch/pytorch: Stack from ghstack (oldest at bottom): -> Add Triton CPU as an Inductor backend #133408 The goal is to use Inductor-generated kernels to stress test the new Triton CPU backend. cc @XilunWu @H...
GPU MODE ▷ #torch (17 messages🔥):
DCP Saving MechanicsFSDP Memory AllocationsState Dict AnalysisTransformer Block Auto-Wrap PolicyFuture of FSDP Improvements
-
DCP Save Function Insight: A member shared a simple script based on the DCP tutorial to illustrate their use of
dcp.save.- They emphasized that checkpointing involves CPU memory allocation as tensors are copied to disk, which can pose challenges during distributed training.
- FSDP's Device Memory Allocations: A discussion clarified that the allocations seen during saving are actually from
CUDACachingAllocatorand take place on device memory, not CPU memory.
- Members expressed confusion over large memory allocations despite expectations, attributing them to the new allocations needed for parameter 'unflattening'.
- State Dict Memory Usage: The involvement of the
get_state_dictfunction in memory usage was explored, leading to the observation that it requires allocations for flat parameters during the all-gather process.
- A member noted that the efficiency of this process might depend on the customized auto-wrap policy used.
- Transformer Block Auto-Wrap Scrutiny: Discussions revealed that the
FlatParameterconcept in FSDP refers to each transformer block's atomic unit of communication, influencing the memory reserved when usingget_state_dict.
- Capturing model weights and optimizer state in blocks means understanding memory allocation intricacies at the transformer block level.
- Future Enhancements for FSDP: Members confirmed that upcoming FSDP versions would aim for improved sharding techniques that do not require all-gathering of parameters, which will reduce memory allocations.
- Predicted releases are slated for late this year or early next year, promising significant advancements in memory management.
Links mentioned:
- Getting Started with Distributed Checkpoint (DCP) — PyTorch Tutorials 2.5.0+cu124 documentation: no description found
- pytorch/torch/distributed/checkpoint/filesystem.py at e80b1b2870ad568aebdbb7f5205f6665f843e0ea · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First Principles: Given some interest, I am sharing a note (first written internally) on the PyTorch Fully Sharded Data Parallel (FSDP) design. This covers much but not all of it (e.g. it excludes autograd and CUDA cac...
GPU MODE ▷ #beginner (8 messages🔥):
Rewriting Aten kernelsKernel fusion benefitsTorch.compile limitations
-
Rewriting Aten kernels with Triton and CUDA: When using Triton or CUDA kernels, we are indeed replacing Torch Aten kernels, which are more generic to handle various use cases.
- This allows for optimizations tailored to specific problem constraints.
- Benefits of Kernel Fusion: Kernel fusion enhances performance by combining multiple operations to minimize memory reads and writes, which is a key advantage of frameworks like Dynamo and TorchInductor.
- For instance, fusing linear and activation operations prevents intermediate activation values from being written to main memory, significantly speeding up the process.
- Torch.compile's Automatic Fusion: In simple cases, torch.compile can automatically handle kernel fusion, potentially reducing the need for manually writing fused kernels.
- However, limitations exist, as torch.compile cannot optimize all patterns due to its hard-coded nature and specific code structure it recognizes.
GPU MODE ▷ #youtube-recordings (1 messages):
FP8 and FP32 MMA alignmentWarp shuffle performance issuesStatic layout permutation
-
FP8 Mismatch in FP32 MMA: The discussion revolves around how the output thread fragment ownership for FP8 in FP32 MMA does not align with expected input, particularly illustrated in page 8, figures 3 & 4.
- Elements requiring ownership from different threads in the same location highlight an issue in data handling during processing.
- Warp Shuffle Not Ideal for Fragment Alignment: A naive approach to fixing thread ownership alignment through warp shuffle could degrade performance if applied to every element in a fragment.
- This concern emphasizes the need for efficient data handling to ensure optimal operation while managing thread ownership.
- Using Static Layout Permutation for Efficiency: To prevent performance degradation, a static layout permutation of the shared memory tensor is employed to align thread ownership without incurring performance costs.
- This method allows for a more suitable arrangement of data that matches expected input requirements for subsequent operations.
GPU MODE ▷ #off-topic (8 messages🔥):
Travel TipsFlight Searching ToolsOpenAI o1 Technical DiscussionYouTube ContentDiscount Travel Strategies
-
OpenAI o1 Technical Tutorial Video: Check out the YouTube video titled "Speculations on Test-Time Scaling (o1)" for a tutorial on the technical background behind OpenAI o1, featuring slides available on GitHub. This talk, written with Daniel Ritter, delves into the implications of 'large' in LLM.
- The video promises to enrich understanding of OpenAI's innovations in a concise format.
- Advice on Cheaper Flight Tickets: A member shared effective tips for finding cheaper flights, recommending tools like Google Flights and Skiplagged. Key strategies include setting flight alerts, using a VPN to avoid price hikes, and considering travel reward credit cards.
- The conversation highlighted that using a rewards card can significantly save money when booking flights, as illustrated with personal examples.
Link mentioned: Speculations on Test-Time Scaling (o1): Tutorial on the technical background behind OpenAI o1. Talk written with Daniel Ritter.Slides: https://github.com/srush/awesome-o1Talk: The “large” in LLM is...
GPU MODE ▷ #liger-kernel (8 messages🔥):
Strange Model OutputsLiger Kernel Distillation LossKaggle Collaborations
-
Strange Outputs from Qwen2.5 Model: A user reported strange results when using the Qwen2.5 model in the Liger Kernel after successfully installing it on Kaggle, with nonsensical output produced.
- In contrast, swapping to AutoModelForCausalLM yielded a coherent step-by-step explanation of solving an equation, highlighting potential issues with the initial model.
- Implementation Request for Liger Kernel Features: A user pointed out an issue regarding the implementation of new distillation loss functions in the Liger Kernel, sparking interest in additional features.
- Details were provided in an issue on GitHub outlining the motivation behind supporting various alignment and distillation layers.
- Kaggle Collaboration for Liger Kernel: A user expressed interest in sharing a Kaggle notebook to help troubleshoot Liger Kernel issues, mentioning the challenges faced in getting it to run effectively for the competition.
- They were looking for a Kaggle handle to facilitate sharing, indicating a community effort to solve common problems.
Link mentioned: [RFC] Liger FlexChunkLoss: Alignment and Distillation loss · Issue #371 · linkedin/Liger-Kernel: 🚀 The feature, motivation and pitch We want to support various alignment and distillation loss functions. Refer this PR on ORPO: #362 Progress Alignment ORPO #362 CPO #382 DPO #378 SimPO #386 IRPO .....
GPU MODE ▷ #self-promotion (1 messages):
NVIDIA Virtual Connect with ExpertsCUDA Core Compute Libraries
-
Join NVIDIA's Expert Panel on CUDA Libraries: Don't miss the NVIDIA Virtual Connect with Experts event on Friday, November 22, 2024 at 10am PT, focusing on CUDA Core Compute Libraries.
- An expert panel will cover topics including Thrust, CUB, and libcudacxx, with more details available on their GitHub page.
- Spread the Word for the Upcoming Event: Participants are encouraged to share the event details with friends and colleagues via social media platforms like LinkedIn and Facebook.
- The announcement emphasizes community engagement and invites everyone interested in CUDA development to join.
- Connect with CUDA Developers on X: A post on X shared that attendees can directly connect with a panel of CUDA developers during the virtual event on November 22 at 10-11:30am Pacific.
- The post provides informational links and invites viewers to learn more about the event here.
Links mentioned:
- accelerated-computing-hub/connect-with-experts at main · NVIDIA/accelerated-computing-hub: NVIDIA curated collection of educational resources related to general purpose GPU programming. - NVIDIA/accelerated-computing-hub
- no title found: no description found
- Tweet from NVIDIA HPC Developer (@NVIDIAHPCDev): Connect directly with a panel of #CUDA developers at NVIDIA. 👀 We'll be discussing CUDA Core Compute Libraries like Thrust, CUB, and libcudacxx. Join us for a virtual CUDA event 📆 Nov. 22 at 1...
GPU MODE ▷ #🍿 (16 messages🔥):
Scheduler DevelopmentModal IntegrationRemote Authentication
-
Scheduler Implementation Success: A member developed a scheduler with a quick fix that resolved an issue where a modal was trying to run the bot code instead of a user-submitted file, now pushing the new branch.
- This scheduler is now reported to be the fastest one they have, showcasing improved performance.
- Discussion on Compute Resources: A member inquired about using their own compute resources with Modal, which was explained to only provide compute for its users, except potentially for large enterprises in the future.
- Another member offered to add $5k in credits for a nicer GPU, emphasizing support for upgrading.
- Remote Authentication with Modal: A member asked for ways to authenticate to Modal from a remote machine like Heroku without browser authentication, seeking to use environment variables instead.
- It was suggested to copy the
.modal.tomlfile or set environment variables likeMODAL_TOKEN_IDandMODAL_TOKEN_SECRET, which was successfully implemented. - CLI Token Setting for Modal: Another member noted the command to set the token via the CLI as
modal token set, offering an alternative method for authentication.
- This method adds flexibility to the authentication process for users who are integrating Modal from various environments.
Link mentioned: modal branch by msaroufim · Pull Request #25 · gpu-mode/discord-cluster-manager: Still has an annoying bug where modal is trying to run the bot code itself instead of the train.py Logging statements though show that the filename and contents are correct And I know a toy example...
GPU MODE ▷ #thunderkittens (2 messages):
Register AllocationSpill Prevention StrategiesNsight Compute Profiling
-
Spills in Register Allocation are Harmful: Spills are very harmful in terms of performance, emphasizing the importance of increasing registers for consumers effectively.
- One member noted the need to be cautious with register allocation within the kernel to prevent performance degradation.
- Strategy for Register Allocation: A member inquired about strategies for careful register allocation, detailing their experience defining a single register tile and reusing it to minimize spills.
- They reported that spills emerged only after adding additional WGMMAs, indicating a balance must be struck between resource utilization and performance.
- Utilizing Nsight Compute for Profiling: Discussion arose on whether an Nsight Compute profile could provide insights for optimizing register allocation strategies.
- Tips were requested on what to specifically look for in the profile to enhance implementations in TK.
Interconnects (Nathan Lambert) ▷ #news (7 messages):
Runner H Navigation SkillsPixtral Paper DiscussionRunner H Performance EvaluationRunner H Beta ReleaseComparisons with Qwen
-
Runner H Navigation Skills are Exceptional: @laurentsifre highlighted that Runner H navigation skills are powered by their internal VLM, known for its state-of-the-art capabilities in UI element localization, while remaining significantly smaller and cheaper than competing models.
- This emphasizes Runner H's technological advantage in practical applications.
- Insights from the Pixtral Paper: @Sagar_Vaze pointed out that there's a detailed discussion on relevant points in the Pixtral paper, specifically referencing Sections 4.2 and 4.3, along with Appendix E.
- Such resources provide valuable insights into the complexities discussed within the context of their research.
- Runner H Shows Strong Performance Against Competitors: A research update detailed the performance of Runner H 0.1 agents against competitors using the WebVoyager benchmarks, indicating success in real-world scenario evaluations.
- This was made possible through auto evaluation methods as described in the original WebVoyager paper.
- Runner H Beta Release Marks New Advances: In the announcement of the beta release for Runner H, it was stated that this development is pushing past the limitations of plateauing scaling laws, moving towards artificial super intelligence (ASI).
- They proclaimed that with this release, they are not merely launching a product, but opening a new chapter in AI.
- Runner H Compared to Qwen: It was noted that Runner H does indeed compare its performance against Qwen, reflecting a competitive landscape in current AI advancements.
- Such comparisons are critical for understanding the effectiveness of AI models in the industry.
Links mentioned:
- Tweet from H Company (@hcompany_ai): With the beta release of Runner H, we are breaking through the limitations of plateauing scaling laws, taking a step toward artificial super intelligence (ASI). With Runner H, we’re not just introduci...
- Tweet from Sagar Vaze (@Sagar_Vaze): @TheXeophon We've got detailed discussion on this point in the Pixtral paper: https://arxiv.org/abs/2410.07073 See Secs 4.2 and 4.3, and particularly Appendix E.
- The Tech Behind Runner’s State-of-the-Art Results: The promise of autonomous agents first fulfilled by H on the web. Our evaluation of Runner H versus competitors on WebVoyager benchmarks is proof that the tech is topping the leaderboard on real-world...
- Tweet from Laurent Sifre (@laurentsifre): Runner H navigation skills are powered by our internal VLM which is state-of-the-art on UI element localization, while being orders of magnitude smaller and cheaper to serve compared to the other foun...
Interconnects (Nathan Lambert) ▷ #random (52 messages🔥):
Tulu DiscussionsGoogle Employee PerspectivesGrok UpdatesThreelu Naming IdeaTime Zone Challenges
-
Tulu Night Plans Spark Buzz: Tulu tonight became a lively topic of discussion, with multiple members joking about their plans and time zones. One noted that their tonight aligns with someone else's next day, showcasing the group's playful banter.
- Despite the lighthearted conversation, some expressed reluctance over late-night meetings, contributing to a running joke of collective burnout.
- Mixed Feelings on Google's Culture: Members shared their contrasting experiences with Google, highlighting that while individual employees are friendly, there seem to be organizational issues. One commented, the org is broken somehow, indicating a disconnect within the company's structure.
- Others echoed similar sentiments, suggesting that Google’s overall operation has its challenges despite having amazing employees.
- Curious about Grok Updates: A member lamented the lack of Grok updates that evening, stating they would have to deal with two updates the next day instead. This sparked concerns about the ongoing development and expectations surrounding Grok.
- The absence of updates led to playful banter, showing that while updates are missed, the group finds ways to keep the conversation engaging.
- Naming Ideas for Threelu Float Around: There was a lighthearted debate over naming a project ‘Threelu’ or going with alternatives like ‘Tulululu’. One member suggested that Tulu looks prettier than Threelu, reflecting the humorous nature of the discussion.
- The naming conversations sparked memes and nostalgia within the chat, including past jokes like Clong for context models.
- Time Zone Struggles Shared: Members exchanged comments about the difficulties of working across multiple time zones, with one recalling their experience working with people in +9 time zones. This highlighted a relatable challenge faced by those in the tech industry.
- The camaraderie in sharing such experiences underscored the community's strong bonds despite geographical differences.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from Binyuan Hui (@huybery): @KMatiDev1 Both are fine. I just don’t want to be overlooked, like often being excluded from comparisons when new models are released.
- Tweet from Yaroslav (@512x512): Sorry, no Grok updates tonight, meaning we'll have 2 tomorrow.
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
Tree Search GainsTree of ThoughtsQ* Algorithm
-
Significant Report on Tree Search Gains: A recent report discusses notable advancements in tree search methods, showcasing gains not previously observed in the field.
- It attributes these improvements to collaborative efforts from a diverse group of authors, including Jinhao Jiang and Zhipeng Chen.
- Reflection on Tree of Thoughts: A member reminisced about the 'good ol days' referring to the Tree of Thoughts method, indicating its positive impact.
- This sparks interest in revisiting past strategies that shaped current methodologies.
- Nostalgia for Q Algorithm: A mention of the Q algorithm invoked nostalgia among members for its foundational role in discussions around AI techniques.
- This highlights a continued appreciation for historical algorithms as they contribute to ongoing developments.
Link mentioned: Technical Report: Enhancing LLM Reasoning with Reward-guided Tree Search: Recently, test-time scaling has garnered significant attention from the research community, largely due to the substantial advancements of the o1 model released by OpenAI. By allocating more computati...
Latent Space ▷ #ai-general-chat (44 messages🔥):
Cerebras Inference PerformanceOpenAI Voice FeaturesRoboflow Series B FundingSmall Language Models
-
Cerebras' Llama 3.1 Inference Speed: Cerebras claims to offer Llama 3.1 405B at 969 tokens/s, significantly faster than the median provider benchmark by more than 10X.
- Critics argue that while Cerebras excels in batch size 1 evaluations, its performance diminishes for larger batch sizes, suggesting that comparisons should consider these differences.
- OpenAI Enhances Voice Capabilities: OpenAI announced an update rolling out on chatgpt.com for voice features, aimed at making presentations easier for paid users.
- This update allows users to learn pronunciation through their presentations, highlighting a continued focus on enhancing user interaction.
- Roboflow Secures $40M Series B Funding: Roboflow raised an additional $40 million to enhance its developer tools for visual AI applications in various fields, including medical and environmental sectors.
- CEO Joseph Nelson emphasized their mission to empower developers to deploy visual AI effectively, underlining the importance of seeing in a digital world.
- Discussions Around Small Language Models: The community debated the definitions of small language models (SLM), with suggestions indicating models ranging from 1B to 3B as small.
- There's consensus that larger models don’t fit this classification, and distinctions based on running capabilities on consumer hardware were noted.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): Streaming is now available for OpenAI o1-preview and o1-mini. 🌊 https://platform.openai.com/docs/api-reference/streaming And we’ve opened up access to these models for developers on all paid usage t...
- Tweet from Artificial Analysis (@ArtificialAnlys): Cerebras is capable of offering Llama 3.1 405B at 969 output tokens/s and they have announced they will soon be offering a public inference endpoint 🏁 We have independently benchmarked a private end...
- Exclusive: Roboflow, vision AI startup, raises $40 million Series B: Roboflow has raised $40 million for its Series B, led by GV, Fortune has exclusively learned.
- Inference, Fast and Slow: When System 1/System 2 analogies are not enough: The 6 types of LLM inference
- Goddammit! GIF - Ryan Reynolds Goddammit Damn - Discover & Share GIFs: Click to view the GIF
- Tweet from swyx in 🇸🇬 (@swyx): I propose T-shirt sizing for LLM weight classes: XXLLM: ~1T (GPT4, Claude2, PanGu) XLLM: 300~500B (PaLM, PaLM2) LLM: 20~100B (GPT3, Claude, UL2)
zone of emergenceMLM: 7~14B (T5, LLaMA, MPT) SL... - Tweet from OpenAI (@OpenAI): Another Advanced Voice update for you—it’s rolling out now on http://chatgpt.com on desktop for all paid users. So you can easily learn how to say the things you're doing an entire presentation o...
- Tweet from Joseph Nelson (@josephofiowa): Roboflow has raised an additional 40M to continue progress in computer vision the ability to see is fundamental to experiencing the world. but software barely leverages sight. we're investing f...
- I'm a happily-paying customer of Groq but they aren't competitive against Cerebr... | Hacker News: no description found
- Tweet from Tim Dettmers (@Tim_Dettmers): Just to clarify this benchmark. This is an apple to oranges comparison. - Cerebras is fast for batch size 1 but slow for batch size n. - GPUs are slow for batch size 1 but fast for batch size n. I ...
LlamaIndex ▷ #blog (2 messages):
Local Agentic RAG ApplicationLlamaIndex WorkflowsLlama-DeployLlamaIndex Azure IntegrationMicrosoft Ignite
-
Build Your Own Local RAG Application: Join our friends at AIMakerspace on November 27 to learn how to set up an 'on-prem' LLM app stack for report generation using open-source LLMs, covering LlamaIndex Workflows and Llama-Deploy.
- The event promises hands-on training and insights for building a robust local application.
- LlamaIndex Azure Solution Unveiled at Ignite: We're excited to announce an end-to-end solution integrating LlamaIndex with Azure at #MSIgnite this week, featuring Azure Open AI, Azure AI Embeddings, and Azure AI Search.
- If you're attending Microsoft Ignite, connect with @seldo for more details on this powerful integration.
LlamaIndex ▷ #general (34 messages🔥):
Document Processing in S3RAG App FunctionalitySQLAutoVectorQueryEngine CitationsChat History in RAGIterating on Prompts
-
S3 Document Processing Issues: A user reported difficulties in processing PDF documents with an S3 reader, receiving an error about file paths.
- Another user suggested modifying the PDF reader and using a custom
PDFParserto overcome compatibility issues. - Challenges in Implementing RAG Functionality: A user inquired about integrating chat history functionality in a RAG application using Milvus and Ollama's LLMs, citing their custom indexing method.
- They were directed to a chat engine functionality that could be modified for use with their existing tools.
- Citations with SQLAutoVectorQueryEngine: A user queried about obtaining in-line citations using SQLAutoVectorQueryEngine and whether it could integrate with CitationQueryEngine.
- They were advised to separate workflows for citations, given the simplicity of implementing citation logic.
- Testing RAG with Quality Retrieval Metrics: A participant raised concerns about the lack of ground truth data for testing the quality of retrieval metrics in their RAG system.
- They asked the community for methodologies or tutorials to effectively approach this challenge.
- Iterating on Prompts Efficiently: A user asked for advice on efficiently iterating on prompts once integrated into a service, stating their current use of Jupyter notebooks felt inefficient.
- They are seeking better methods or tools to improve their workflow in this regard.
- Another user suggested modifying the PDF reader and using a custom
Links mentioned:
- no title found: no description found
- Add neo4j generic node label (#15191) · run-llama/llama_index@77bd4c3: no description found
- Workflows - LlamaIndex): no description found
- Pandas - LlamaIndex: no description found
- Milvus Vector Store - LlamaIndex: no description found
- Module Guides - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (5 messages):
RAG systemsAgent invocation strategiesPreventing spam in channels
-
Understanding RAG System Response Mechanism: A user inquired how a RAG system decides whether to search vector embeddings again or refine previous answers, using the example of displaying a list of leaves in a table.
- The question highlighted the need for mechanisms to differentiate between new queries and refinement of existing responses.
- Agents Utilizing Tool Invocation: Another member clarified that agents choose to invoke tools, like a vector database search, based on chat history and utilize trained protocols from various LLMs.
- Some LLMs employ prompting strategies such as ReAct, chain-of-code, and chain-of-abstraction to facilitate tool invocation.
- Reminder Against Spamming Channels: A member cautioned against spammy behavior in the channel, urging that excessive questioning could lead to blocking.
- This reminder encourages members to maintain a respectful and focused dialogue without unnecessary disruptions.
tinygrad (George Hotz) ▷ #general (25 messages🔥):
tinygrad 0.10.0 ReleaseTesting Failures on ArchitecturesMeeting Access and NotesKernel Cache in Action TestInterpolation Test on ARM
-
Release of tinygrad 0.10.0: The team announced the release of tinygrad 0.10.0, which includes over 1200 commits and an update focused on minimizing dependencies.
- Besides simplicity, tinygrad now supports both inference and training, with aspirations to build hardware in the future, having recently raised funds.
- Intermittent Test Failures on ARM: A user reported that while updates work smoothly on
x86_64-linux, they faced numerous test failures onaarch64-linux, particularly with anAttributeErrorduring testing.
- After investigation, it was confirmed that the issue was reproducible across architectures with possible resolutions being discussed.
- Meeting Access Only for Red Members: A discussion took place about updating meeting notes, with George Hotz granting @zibokapi access to post as a 'red' member.
- This access was necessary to add notes to the recording channel for meetings.
- Fixing test_kernel_cache_in_action Issues: A user identified that adding
Tensor.manual_seed(123)before certain operations intest_kernel_cache_in_actionresolved previously failing tests.
- This fix was confirmed to allow the full test suite to pass, except for one remaining issue on ARM architecture.
- Interpolation Test Failure Diagnosis: The remaining failure on
aarch64-linuxwas traced back to an interpolation test, specificallytest_interpolate_bilinear, with references shared for further examination.
- It was proposed that integrating
x.realize()might enhance the existing test implementations.
Links mentioned:
- tinygrad: You like pytorch? You like micrograd? You love tinygrad! <3
- test_kernel_cache_in_action: fix test by GaetanLepage · Pull Request #7792 · tinygrad/tinygrad: Fixes a regression introduced in c100f3d. self =
p = Program(name='E_\x1b[34m4194304\x1b[0m\x1b[90m_\x1b[0m\x1b[... - Release tinygrad 0.10.0 · tinygrad/tinygrad: A significant under the hood update. Over 1200 commits since 0.9.2. At 9937 lines. Release Highlights VIZ=1 to show how rewrites are happening, try it 0 python dependencies! Switch from numpy ran...
- tinygrad/tinygrad/engine/realize.py at v0.10.0 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
-
add support and tests for nearest modes in interpolate, adapt uint8 b… · tinygrad/tinygrad@7de4eac: …ilinear to torch implementation (#6308) * add
nearestmode to interpolatematching pytorch
nearestwhich is knowingly buggy- relevant TestsOps
- add
nearest-exactmode to interpol... - default threefry (#6116) · tinygrad/tinygrad@c100f3d: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
DEBUG outputJitted functions behavior
-
Understanding DEBUG=2 Output: A member asked about the output when setting DEBUG=2 and whether it's on master. Another member indicated that the bottom lines just repeat when the process is running.
- If bottom lines keep going, it's running indicates that the code is operational despite the repetition.
- Clarification on Jitted Functions: Discussion revealed that the jitted function only executes GPU kernels, meaning no output will be visible for prints inside it. This led to a clearer understanding of how debugging operates within these functions.
Cohere ▷ #discussions (13 messages🔥):
Tokenized Training in AI ModelsName and Symbol RecognitionLanguage Model Training ChallengesAPIs and Language Response Settings
-
Tokenized Training's Impact on Word Recognition: A member pointed out that the word 'strawberry' is tokenized during training, affecting its recognition due to it being broken down into smaller components.
- This issue has been observed in models like GPT-4o and Google’s Gemma2 27B, highlighting similar challenges across different systems.
- Discussion on Name Recognition Capabilities: A member expressed curiosity regarding Aya's ability in name and syllable recognition, implying its potential strength in this area.
- It was noted that due to tokenization, the models may struggle with accurate recognition of certain words.
- Morning Greetings in the Channel: Members exchanged morning greetings, with several users responding to prabhakar171's 'gm' with similar greetings.
- This light interaction reflected camaraderie among users in the discussion.
- Language Settings in API Requests: A user inquired about configuring the command-r model to respond in Bulgarian while avoiding confusion with Russian terminology.
- They mentioned using the API request builder for this customization, indicating the need for clearer language differentiation.
Cohere ▷ #announcements (1 messages):
Beta Program for Cohere ToolResearch and Writing ToolUser Feedback Importance
-
Final Call to Join Our Beta Program!: Sign-ups for the Cohere research prototype beta program are closing tonight at midnight ET, offering early access to a new tool designed for research and writing tasks.
- Participants are encouraged to contribute detailed feedback to help shape the tool's features, focusing on tasks such as complex reports and summaries.
- Opportunity for Text-Based Deliverables Creators: The beta program is aimed at those who frequently create text-based deliverables like reports, summaries, or blog posts.
- Testers will have the chance to influence the development of the tool, ensuring it effectively assists in real-world tasks.
Link mentioned: Research Prototype - Early Beta Sign Up Form: Thank you for your interest in participating in the beta testing phase of our research prototype — a tool designed to help users tackle research and writing tasks such as: creating complex reports, do...
Cohere ▷ #questions (6 messages):
Rate limits in APILanguage setting for models
-
Clarification on API Rate Limiting: A member inquired whether the rate limit established in the docs is enforced per API key or per account.
- The discussion seeks clarity on the mechanics of the rate limit, but a definitive answer has yet to materialize.
- Bulgarian Language Model Configuration: One user asked how to set a preamble or variant of the command-r model to ensure it responds specifically in Bulgarian and avoids confusion with Russian words.
- They mentioned utilizing the API request builder for this purpose, indicating a need for clearer language handling in the model.
OpenInterpreter ▷ #general (8 messages🔥):
Development Branch StatusOpen Interpreter Skills GenerationUI SimplificationsClaude Model Issues
-
Development Branch appears WIP: A member noted that the development branch, or beta, seems to be in a work-in-progress state as the
interpreter --versionshows 1.0.0, suggesting a possible regression in UI and features.- Another member offered to help fix any issues, indicating the last commit was 9d251648.
- Help needed for skills generation in Open Interpreter: A member requested assistance in generating skills within Open Interpreter, mentioning that the expected folder is empty and seeking suggestions on how to proceed.
- It was suggested to follow instructions from GitHub about teaching the model, as future versions will also utilize this functionality.
- UI simplifications spark mixed reactions: A discussion arose about recent UI simplifications, with one member expressing preference for the old design and noting that they were accustomed to it.
- The developer acknowledged feedback on the UI changes and inquired if users liked the old version more.
- Claude model issues get attention: A member reported issues with the Claude model breaking, indicating that switching models resolved the problem and raised concerns about the Anthropic service.
- This prompted inquiries into whether these issues were recurrent across different versions.
OpenInterpreter ▷ #ai-content (12 messages🔥):
10 AI Tools PodcastTool Use PodcastServer EtiquetteCommunity Engagement
-
Ray Fernando Shares AI Tools Insights: In a recent YouTube episode, Ray Fernando discusses how he utilizes AI tools to enhance his build process, featuring 10 AI tools that help build faster.
- The conversation is detailed in the video titled '10 AI Tools That Actually Deliver Results,' providing valuable insights for developers interested in tool usage.
- Discussion on Tool Use Podcast: Members expressed their appreciation for the Tool Use Podcast, highlighting the engaging content and co-hosts Mike and Ty, while discussing the use of mentions in the server.
- It's noted that the use of @everyone tags should be reserved for important communications to respect community members' time and attention.
- Encouraging Career Changes: One member shared how learning about Mike's coding journey in Ep 5 of Tool Use Podcast was very encouraging, having transitioned careers at a later age.
- This personal story resonated with others, illustrating the podcast's impact on individuals considering significant life changes.
- Valuing Community Engagement: Community members emphasized the importance of engaging with content on their own terms, expressing gratitude for shared insights and encouragement towards maintaining respectful communication.
- There’s a mutual understanding of the need to balance community involvement with personal rhythms and attention management.
- Keeping Up with New Content: A member expressed love for the Tool Use Podcast, stating that the reminders are helpful amidst busy schedules to catch the latest episodes.
- The sentiment reflects a broader appreciation within the community for facilitators who help others stay informed about relevant content.
Links mentioned:
- 10 AI Tools That Actually Deliver Results (ft. Ray Fernando) - Ep 14: Join us for an in-depth conversation with Ray Fernando, a former Apple engineer turned live streamer, as we explore the world of AI-powered tools and transcr...
- GitHub - gregpr07/browser-use: Make websites accessible for AI agents: Make websites accessible for AI agents. Contribute to gregpr07/browser-use development by creating an account on GitHub.
DSPy ▷ #show-and-tell (1 messages):
DSPy VLM tutorialAttribute extraction from images
-
DSPy Introduces VLM Support: A new DSPy tutorial is now available, highlighting the recent addition of VLM support in beta for extracting attributes from images.
- The tutorial uses screenshots of websites to demonstrate how to effectively utilize this feature, as detailed in this Twitter thread.
- Attributes and Image Processing Made Easy: In the tutorial, practical examples are shown for extracting useful attributes from images, specifically focusing on screenshots of websites.
- This marks a substantial enhancement in DSPy's capabilities, as explained by the author in their informative thread.
Link mentioned: Tweet from Karthik Kalyanaraman (@karthikkalyan90): 🧵DSPy recently added support for VLMs in beta. A quick thread on attributes extraction from images using DSPy. For this example, we will see how to extract useful attributes from screenshots of websi...
DSPy ▷ #general (17 messages🔥):
DSPy integration with non-PythonCost reduction with DSPyChallenges with long-context promptsTesting DSPy code for React agentsDSPy assertions compatibility with MIRPOv2
-
DSPy output struggles with non-Python backends: A member is experiencing lower accuracy when integrating DSPy's compiled JSON output with Go, expressing concerns about replicating the prompt handling.
- Another member suggested using the inspect_history method to build templates tailored for specific applications.
- Cost-saving strategies with DSPy: Members discussed how DSPy could help reduce prompting costs, particularly through prompt optimization and potentially employing a small language model as a proxy.
- However, concerns were raised about long-context limitations and the need for strategies like context pruning and RAG implementations to improve efficiency.
- Long-context prompt optimization quandary: The discussion highlighted the inefficiencies of few-shot examples with large contexts in long document parsing, criticizing reliance on model coherence across extensive input.
- A member proposed breaking processing into smaller steps and maximizing information per token as potential solutions to mitigate context-related issues.
- Seeking DSPy samples for React agents: One member is searching for DSPy code samples to test a tool wrapper aimed at improving React agents' performance, specifically those that have exhibited issues.
- They clarified that they are looking for examples of agents that have not been functioning well, particularly in handling unexpected outputs and multi-turn conversations.
- MIRPOv2 compatibility inquiries: A member questioned the compatibility of DSPy assertions with MIRPOv2 in the upcoming version 2.5, recalling previous incompatibilities.
- The query suggests ongoing interest in how these features will evolve and integrate within the framework.
OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
Mistral Large / Pixtral modelsMI300X trainingbitsandbytes integrationWeb3 platform job openings
-
Exploring Mistral Large / Pixtral models: Members discussed their interest in trying the latest Mistral Large and Pixtral models, seeking insights from those who have experience.
- The conversation reflects ongoing curiosity and experimentation within the community surrounding these AI models.
- MI300X training is operational: Training with the MI300X has been successful for a significant period, with several changes reportedly upstreamed.
- One member emphasized the importance of upstream contributions to ensure consistent performance and reliability during the training process.
- Bitsandbytes requires import adjustment: Concerns were raised about the necessity of importing bitsandbytes even when not actively used during training, suggesting it should be optional.
- A member proposed using a context manager to suppress import errors, enhancing flexibility in the codebase.
- ROCm compatibility for bitsandbytes: A member pointed out that ROCm support is available in a branch of the main bitsandbytes repository.
- Another member referred to a fork which provides bnb support, aiding in the integration for ROCm compatible platforms.
- Web3 platform seeking team members: A Web3 platform is hiring for various positions, including developers, moderators, and beta testers with competitive pay.
- The team promotes a friendly environment with no experience necessary, appealing to potential candidates in the community.
Links mentioned:
- Bash script to setup axolotl+FA2+BnB+liger-kernel on Runpod MI300X: Bash script to setup axolotl+FA2+BnB+liger-kernel on Runpod MI300X - axolotl_ROCm_setup_v2.sh
- GitHub - arlo-phoenix/bitsandbytes-rocm-5.6: 8-bit CUDA functions for PyTorch Rocm compatible: 8-bit CUDA functions for PyTorch Rocm compatible. Contribute to arlo-phoenix/bitsandbytes-rocm-5.6 development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
faldore: <@257999024458563585> did you implement this one yet?
https://arxiv.org/abs/2410.05258
OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
Axolotl v0.5.2 releaseOptimizer supportUpgraded dependenciesFSDP gradient accumulation fix
-
Axolotl v0.5.2 launches with significant fixes: The newly released v0.5.2 includes a plethora of fixes, improved unit tests, and various upgrades to underlying dependencies.
- Notably, the release resolves issues encountered with
pip install axolotlthat plagued the previous version, v0.5.1. - New optimizer support features added: Axolotl v0.5.2 introduces support for schedule-free optimizers and the ADOPT optimizer for enhanced performance.
- This includes rectifications for FSDP+gradient accumulation in the upstream transformers library.
- Upgraded core components bolster performance: With this release, essential components such as liger and datasets have been significantly upgraded.
- Moreover, the integration of autoawq is also noted as a highlight of the v0.5.2 release.
- Previous version yanked addressing installation issues: The v0.5.1 release was yanked due to installation issues via
pip install axolotl, now resolved in v0.5.2.
- This move ensures that users can smoothly transition to the more stable v0.5.2 without installation hurdles.
- Anticipation builds for future updates: The announcement hinted that there are more improvements and features on the horizon, saying 'there's more to come soon!'.
- This suggests ongoing development and commitment to enhancing the overall user experience.
- Notably, the release resolves issues encountered with
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (2 messages):
Phorm Bot deprecationRepository URL issues
-
Phorm Bot possibly deprecated: A user inquired whether the phorm bot is deprecated, suggesting it might be broken.
- Another member speculated that it could be due to it pointing to the old repo URL which hasn't been updated after the transition to the new organization.
- Repository URL concerns: Discussion revealed that the repository URL for the phorm bot is outdated.
- It was noted that a necessary swap never happened after moving to the new organization, potentially causing the bot's issues.
Modular (Mojo 🔥) ▷ #max (12 messages🔥):
Max Graphs and Knowledge GraphsUsing MAX for Graph SearchGraph RAG SystemMojo and Max Agent Implementation
-
Max Graphs facilitate Knowledge Graph integration: An inquiry was raised about whether Max Graphs can enhance traditional Knowledge Graphs for unifying LLM inference as one of the agentic RAG tools.
- Darkmatter noted that while Knowledge Graphs serve as data structures, Max Graph represents a computational approach.
- Efforts to use MAX for accelerated graph searches: Discussion on utilizing MAX to boost graph search performance revealed that current capabilities require copying the entire graph into MAX.
- A potential workaround was proposed involving encoding the graph as 1D byte tensors, though memory requirements may pose challenges.
- Clarifying graph types and their purposes: A user pointed out the distinctions among various graph types, indicating MAX computational graphs relate to computing, while Knowledge Graphs store relationships.
- They further explained that Graph RAG enhances retrieval using knowledge graphs and that an Agent Graph describes data flow between agents.
- Max Graph's tensor dependency concerns: Msaelices questioned whether Max Graph is fundamentally tied to tensors, noting the constraints of its API parameters restricted to TensorTypes.
- This prompted a suggestion for reviewing the API documentation before proceeding with implementation inquiries.
Link mentioned: GitHub - microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system: A modular graph-based Retrieval-Augmented Generation (RAG) system - microsoft/graphrag
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Google AI WorkshopGemini IntegrationHackathon Insights
-
Google AI Workshop on Gemini: Join us for a special Google AI workshop on 11/26 at 3pm PT focusing on building with Gemini during the LLM Agents MOOC Hackathon.
- The event includes live demos of Gemini and an interactive Q&A session with Google AI specialists for direct advice.
- Unlocking Gemini's Capabilities: Participants will gain valuable insights into the potential of Gemini and Google's suite of AI models and platforms.
- Don't miss this opportunity to enhance your hackathon projects with cutting-edge technologies.
Link mentioned: Workshop with Google AI: Building with Gemini for the LLM Agents MOOC Hackathon · Luma: Workshop with Google AI: Building with Gemini for the LLM Agents MOOC Hackathon About the Workshop Join us for an exclusive workshop at the LLM Agents MOOC…
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 10 AnnouncementPercy Liang's PresentationOpen-Source Foundation ModelsCourse Logistics
-
Lecture 10 starts at 3:00pm PST: The 10th lecture is scheduled for today at 3:00pm PST, with a livestream available here.
- This lecture will feature exciting developments in the realm of foundation models.
- Percy Liang to discuss openness in AI: Percy Liang, an Associate Professor of Computer Science at Stanford, will present on 'Open-Source and Science in the Era of Foundation Models'. He emphasizes that open-source is crucial for advancing AI innovation despite currently limited accessibility.
- Liang highlights the need for community resources to develop robust open-source models.
- Course resources located online: All necessary materials, including livestream URLs and assignments, can be accessed on the course website. This centralizes resources essential for successful course completion.
- Students are encouraged to visit the site for the latest updates and materials.
- Communication with course staff: For questions, feedback, or concerns, participants are directed to communicate directly with the course staff in designated channels. This ensures that everyone receives timely responses regarding course-related issues.
- Engagement through the appropriate channels will facilitate smoother communication.
Link mentioned: CS 194/294-196 (LLM Agents) - Lecture 10, Percy Liang: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (7 messages):
Non-English modelsState of the art performanceLow data point challenges
-
Achieving State of the Art for Non-English Models: Tejasmic inquired about approaches to attain state of the art performance for non-English models, especially in languages with low data points.
- There was a suggestion to pose the question in a dedicated channel as staff were actively reviewing content there.
- Best Lecture Praise: Another member, zbrn_07683, declared it the best lecture, indicating overall positive reception.
- This highlights a sense of community engagement and approval regarding the lecture's content.
Torchtune ▷ #general (9 messages🔥):
Flex Attention LimitationsAttention Score HacksVanilla Attention Strategies
-
Flex Attention cannot copy scores: A member encountered an error while attempting to copy attention scores to a global variable in the flex attention's
score_modfunction, stating Unsupported: HigherOrderOperator mutation error.- Another member confirmed this limitation exists within flex attention, noting the issue can be checked here.
- Possible Vanilla Attention workaround: Discussion revealed that copying attention scores with vanilla attention is also not feasible due to a lack of access to SDPA internals.
- A member pointed out that modifying the Gemma 2 attention class could offer a solution, highlighting that it is more hackable.
- Discovery of score extraction hack: One member shared a GitHub Gist that details a hack for getting attention scores without using triton kernels.
- Further discussion acknowledged that while this hack works, it diverges from using the standard torchtune implementation.
Links mentioned:
- Repro.py: GitHub Gist: instantly share code, notes, and snippets.
- Issues · pytorch-labs/attention-gym: Helpful tools and examples for working with flex-attention - Issues · pytorch-labs/attention-gym
LAION ▷ #announcements (1 messages):
LAION-DISCO-12MYouTube samples for ML
-
LAION-DISCO-12M Launches with 12 Million Links: LAION announced LAION-DISCO-12M, a collection of 12 million links to publicly available YouTube samples paired with metadata, aimed at supporting basic machine learning research for generic audio and music.
- This initiative is detailed further in their blog post.
- Metadata Enhancements for Audio Research: The metadata included in the LAION-DISCO-12M collection is designed to facilitate research in foundation models for audio analysis.
- Several developers expressed excitement over the potential use cases highlighted in the announcement, emphasizing the need for better data in the audio machine learning space.
Link mentioned: Tweet from LAION (@laion_ai): We announce LAION-DISCO-12M - a collection of 12 million links to publicly available YouTube samples paired with metadata to support basic machine learning research in foundation models for generic au...
Mozilla AI ▷ #announcements (1 messages):
Transformer Lab DemoMetadata FilteringRefact AIAutonomous AI Agents
-
Transformer Lab Demo is starting: Today's Transformer Lab demo is about to begin, showcasing the latest developments in transformer technology.
- Members are encouraged to join and be part of the exciting discussions.
- Reminder for Metadata Filtering Session: Tomorrow, a session on metadata filtering will be led by <@533894367354552330> in channel <#1262961960157450330>.
- Participants can gain valuable insights into effective data handling practices in AI.
- Refact AI Takes the Floor on Thursday: On Thursday, Refact AI will discuss building Autonomous AI Agents to perform engineering tasks end-to-end.
- They will also be answering questions from attendees, providing a great opportunity for interactive learning.