[AINews] OpenAI Voice Mode Can See Now - After Gemini Does
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Shipping first is all you need.
AI News for 12/11/2024-12/12/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (207 channels, and 6137 messages) for you. Estimated reading time saved (at 200wpm): 616 minutes. You can now tag @smol_ai for AINews discussions!
OpenAI launched Realtime Video a day after expected, but it made less of a splash because Gemini got there first, with less cost, and less rate limiting.
The buzz is still solidly pro Gemini:
and we enjoy seeing some friendly sniping between undoubtedly SOTA, very hard working teams.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium / Windsurf Discord
- aider (Paul Gauthier) Discord
- Cursor IDE Discord
- OpenAI Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- Eleuther Discord
- LM Studio Discord
- Bolt.new / Stackblitz Discord
- Notebook LM Discord Discord
- Nous Research AI Discord
- GPU MODE Discord
- Cohere Discord
- LLM Agents (Berkeley MOOC) Discord
- Interconnects (Nathan Lambert) Discord
- LlamaIndex Discord
- Modular (Mojo 🔥) Discord
- DSPy Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- Torchtune Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- Axolotl AI Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium / Windsurf ▷ #announcements (1 messages):
- Codeium / Windsurf ▷ #discussion (135 messages🔥🔥):
- Codeium / Windsurf ▷ #windsurf (647 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (1026 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (90 messages🔥🔥):
- Cursor IDE ▷ #general (620 messages🔥🔥🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (417 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (21 messages🔥):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- Perplexity AI ▷ #general (433 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (6 messages):
- Perplexity AI ▷ #pplx-api (6 messages):
- Unsloth AI (Daniel Han) ▷ #general (265 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
- Unsloth AI (Daniel Han) ▷ #help (15 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (3 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (208 messages🔥🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (70 messages🔥🔥):
- Eleuther ▷ #research (117 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (2 messages):
- LM Studio ▷ #general (152 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (29 messages🔥):
- Bolt.new / Stackblitz ▷ #announcements (1 messages):
- Bolt.new / Stackblitz ▷ #prompting (1 messages):
- Bolt.new / Stackblitz ▷ #discussions (174 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (17 messages🔥):
- Notebook LM Discord ▷ #general (125 messages🔥🔥):
- Nous Research AI ▷ #general (84 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (10 messages🔥):
- Nous Research AI ▷ #research-papers (5 messages):
- Nous Research AI ▷ #research-papers (5 messages):
- GPU MODE ▷ #general (7 messages):
- GPU MODE ▷ #triton (8 messages🔥):
- GPU MODE ▷ #cuda (9 messages🔥):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #algorithms (1 messages):
- GPU MODE ▷ #cool-links (3 messages):
- GPU MODE ▷ #torchao (4 messages):
- GPU MODE ▷ #off-topic (1 messages):
- GPU MODE ▷ #rocm (1 messages):
- GPU MODE ▷ #lecture-qa (1 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #self-promotion (11 messages🔥):
- GPU MODE ▷ #🍿 (1 messages):
- GPU MODE ▷ #arc-agi-2 (23 messages🔥):
- Cohere ▷ #discussions (26 messages🔥):
- Cohere ▷ #questions (40 messages🔥):
- Cohere ▷ #api-discussions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (44 messages🔥):
- Interconnects (Nathan Lambert) ▷ #events (3 messages):
- Interconnects (Nathan Lambert) ▷ #news (4 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
- Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #cv (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (21 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Modular (Mojo 🔥) ▷ #general (8 messages🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (10 messages🔥):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (12 messages🔥):
- OpenInterpreter ▷ #general (6 messages):
- OpenInterpreter ▷ #ai-content (1 messages):
- tinygrad (George Hotz) ▷ #general (6 messages):
- Torchtune ▷ #papers (3 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
- Axolotl AI ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key topics organized from the Twitter discussions:
AI Model Releases & Updates
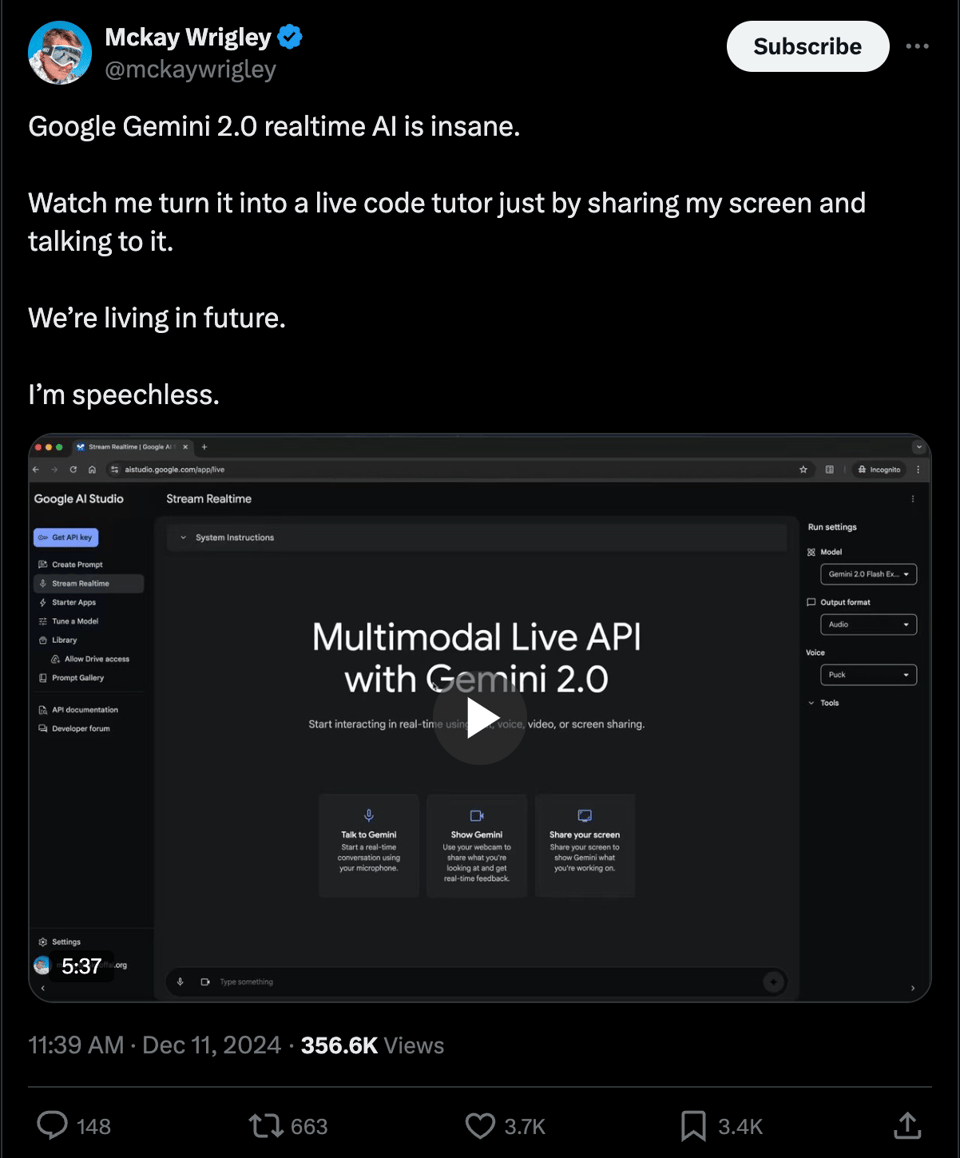
- Google launched Gemini 2.0 Flash with major improvements in multimodal capabilities, real-time streaming, and performance metrics. @GoogleDeepMind noted developers can now use real-time audio/video streaming.
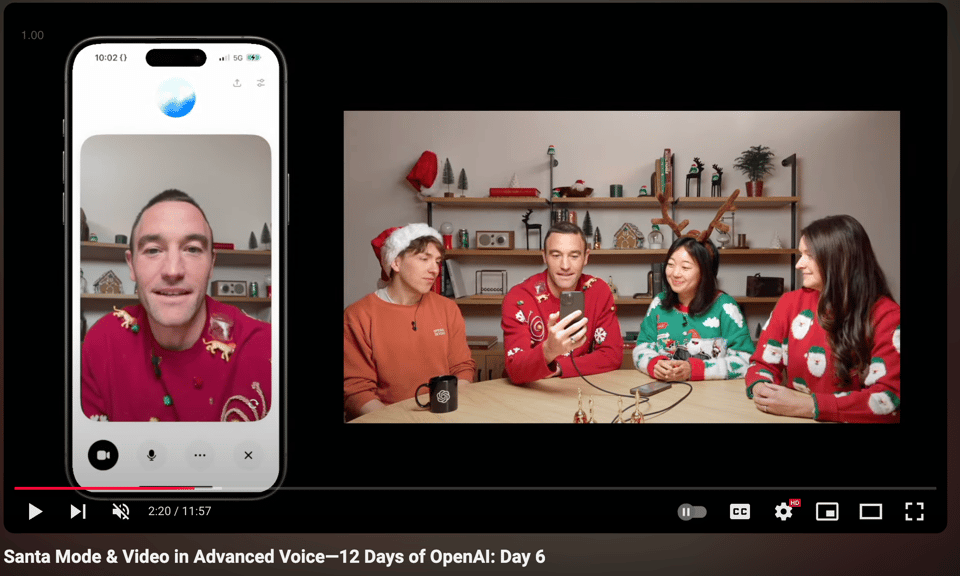
- OpenAI announced video capabilities for ChatGPT, including live video and screensharing in Advanced Voice mode.
- Anthropic released research on Clio, a system for analyzing real-world usage patterns of Claude across different languages and use cases.
AI Infrastructure & Development
- @bindureddy observed that "Anthropic is capturing the developer ecosystem, Gemini has AI enthusiast mindshare, ChatGPT reigns over AI dabblers"
- Together Computing acquired CodeSandbox to launch Together Code Interpreter for seamless code execution.
- @teortaxesTex noted that dropping Attention mechanisms means losing several key capabilities that rely on it.
Industry & Market Updates
- Scale AI and TIME launched TIME AI for Person of the Year coverage
- @far__el discussed comparisons between US and Chinese AI capabilities, suggesting the gap may be smaller than commonly believed.
Memes & Humor
- ChatGPT added Santa mode for holiday conversations
- Multiple jokes about AI outages and service disruptions
- Humorous takes on model comparisons and industry competition
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Meta's Llama 3.3-70B: Roleplaying and Prompt Handling Excellence
- Why is Llama 3.3-70B so immediately good at adopting personas based on the system prompt (and entering roleplay, even when not specified) (Score: 311, Comments: 83): Llama 3.3-70B is recognized for its proficiency in adopting personas and engaging in roleplay based on the system prompt, even when roleplay is not explicitly requested. This highlights its advanced ability to interpret and respond to nuanced prompts effectively.
- Roleplay and Creative Writing: Llama 3.3-70B has been highlighted for its roleplay capabilities, with examples showing its ability to portray characters like Yoda and Jar Jar Binks effectively. Some users noted its creative potential in roleplay, although it still faces issues like repetition and short responses, particularly in quantized forms.
- Comparison with Other Models: Discussions compared Llama 3.3 to other models like Mistral Large and GPT-4o, with some users noting that Llama 3.3 is more expressive and less censored. The model's ability to adopt personas is attributed to its training, possibly influenced by Meta's AI Studio and the diverse data from platforms like Facebook and Instagram.
- Training and Censorship: The community speculated that Llama 3.3 was trained with a focus on roleplay and character portrayal due to Meta's strategic goals, unlike OpenAI's models, which are heavily censored. Users discussed how Meta's approach to training and data curation might have contributed to Llama 3.3's advanced roleplay abilities, with some attributing its success to the lack of fine-tuning constraints and diverse training data.
Theme 2. Microsoft's Phi-4: Small Model, Big Benchmark Results, Skepticism Remains
- Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning (Score: 217, Comments: 86): Microsoft has introduced Phi-4, a new small-language model designed to specialize in complex reasoning tasks. The post did not provide further details or context about the model's capabilities or applications.
- Many users express skepticism about Phi models, stating they perform well on benchmarks but fall short in real-world applications. Synthetic training datasets are speculated to be a focus for Microsoft, potentially for licensing to other companies as an alternative to scraped data.
- There is a humorous discussion about the 14B parameter model being considered small, with users noting that it requires significant GPU resources. Benchmark results for Phi-4 are impressive, but users remain cautious due to past experiences with Phi-3.
- Some comments mention the availability of Phi-4 on Hugging Face next week, and there is a suggestion that earlier posts about Phi-3 were attempts at generating hype. The use of synthetic data for training is highlighted, particularly for tasks like math completion.
- Bro WTF?? (Score: 81, Comments: 38): Phi-4 demonstrates promising performance in benchmarks compared to other models like Phi-3, Qwen 2.5, GPT, and Llama-3.3, with evaluations conducted using OpenAI's SIMPLE-EVALS framework. The table categorizes results into "Small models" and "Large models," detailing metrics such as MMLU, GPQA, and MATH.
- Phi-4's Performance: While Phi-4 shows promising benchmark results, users express skepticism about its real-world applicability, noting past Phi models' tendency to underperform outside controlled tests. There is a consensus that despite good reasoning abilities, the model struggles with factual data due to its smaller dataset.
- Open Source and Synthetic Data: Discussions highlight open-source advancements, with some users noting Phi-4's potential to outperform models like GPT-4o mini in certain tests. There is also a debate on the efficacy of synthetic data versus broad internet data, with some users advocating for high-quality synthetic data for better model training.
- Model Availability and Usage: The model is expected to be available on Hugging Face and is currently downloadable from Azure, though users report slow download speeds. Some users share their experiences with previous Phi models, emphasizing their utility in specific tasks like reasoning and single-turn interactions, despite being verbose and less effective in multi-turn chats.
Theme 3. OpenAI o1 vs Claude 3.5 Sonnet: Subscription Showdown
- OpenAI o1 vs Claude 3.5 Sonnet: Which gives the best bang for your $20? (Score: 139, Comments: 78): OpenAI's o1 excels in complex reasoning and mathematics, outperforming other models in the $20 tier, making it ideal for non-coding tasks. Claude 3.5 Sonnet is superior for coding, offering a better balance of speed and accuracy, despite the 50 messages/week limit. Claude is noted for its engaging personality, while o1 is recognized for its high IQ, making Claude preferable for coding and conversational tasks, and o1 for math and reasoning.
- Users discuss the cost-effectiveness of different models, with 1M input tokens priced at $15 and output tokens at $60 per 1M, expressing concerns about the pricing structure. Some recommend using openrouter or OpenWebUI for flexibility in model selection without subscription costs.
- Claude is favored for its coding capability and engaging personality, though some users report issues with hallucinations in code and overly consistent responses, while others find it indispensable for solving complex software bugs quickly. o1 is criticized for being overly agreeable, making it less effective for some tasks.
- Gemini 2.0 and Qwen series are mentioned positively; Gemini is noted for its speed and being free, while Qwen is preferred for non-coding tasks over o1. There is a general sentiment that using APIs and avoiding subscriptions can be more efficient and cost-effective.
Theme 4. Gemini series shines in Math Benchmarks, Growing Cognitive Reputation
- U-MATH: New Uni-level math benchmark; Gemini is goat / Qwen is king (Score: 74, Comments: 21): Gemini and Qwen are highlighted for their exceptional performance on U-MATH, a new university-level math benchmark. The post suggests that Gemini is considered the greatest of all time (GOAT) in this context, while Qwen is recognized as the leading performer.
- Gemini's Performance: Gemini is consistently recognized as the top-performing model across various benchmarks, including U-MATH, LiveBench, and FrontierMath, outperforming other models like GPT-4o and Claude. Google's focus on math and science through projects like AlphaZero, AlphaFold, and AlphaProof is speculated to contribute to Gemini's success.
- Model Comparisons and Challenges: The discussion highlights the impressive performance of smaller models like 7b-Math, which closely match larger models such as 72b-Instruct. However, smaller models struggle with understanding contextual cues and "instructions following," often leading to hallucinations, as noted with Qwen models.
- Benchmark Details and Updates: The U-MATH and μ-MATH benchmarks are the only ones testing LLMs at this complexity level, with Gemini Pro leading in solution and judgment abilities, despite lower hallucination rates in other models like GPT/Claude/Gemini Flash. The leaderboard and HuggingFace links provide additional insights into these evaluations.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. NeurIPS 2024 Sabotage Allegations Disrupt Research
- [D] The winner of the NeurIPS 2024 Best Paper Award sabotaged the other teams (Score: 327, Comments: 31): NeurIPS 2024 Best Paper Award controversy involves accusations against a ByteDance researcher for allegedly sabotaging other teams' research to gain an advantage. The claim includes the researcher attending meetings to debug colleagues' code, maintaining a competitive edge, and there's a call for his paper's withdrawal. Further details can be found in the integrity report.
- Allegations Against Keyu Tian: Keyu Tian allegedly modified the PyTorch source code and disrupted training processes by hacking clusters and creating login backdoors, which allowed him to sabotage colleagues' experiments by altering model weights and terminating processes. This led to large-scale experiment failures, raising concerns about the integrity of his actions.
- Legal and Institutional Reactions: ByteDance is reportedly suing Tian for damages, which could impact his NeurIPS 2024 Best Paper Award. There is speculation about the repercussions this incident might have on his academic and professional standing, with questions about whether NeurIPS has conduct policies that would affect his award.
- Cultural and Competitive Context: Some commenters highlight the intense competitive pressure within Chinese academic environments, which might drive individuals to extreme actions to secure resources and recognition. This context might explain, though not justify, the alleged behavior, reflecting broader systemic issues in the field.
Theme 2. Controversial 'Stop Hiring Humans' Campaign in SF
- "Stop Hiring Humans" ads all over SF (Score: 237, Comments: 79): "Stop Hiring Humans" ads have been placed throughout San Francisco, generating significant attention and discussion. The campaign's provocative message suggests a shift towards automation and AI-driven solutions, raising questions about the future of human employment in tech-centric cities.
- Many commenters, such as XbabajagaX and dasjati, noted that the ad campaign's provocative nature is a strategic move to gain attention and free press, highlighting its success in sparking widespread discussion and media coverage. Link to campaign analysis.
- Discussions, including those by heavy-minium and umotex12, criticized the campaign for misleading claims about AI capabilities, arguing that it could desensitize the public to real AI advancements or prematurely accelerate societal conversations about AI.
- Commenters like AI_Ship and Secure-Summer2552 pointed out the dystopian and tone-deaf nature of the ads, especially given the visible social issues such as homelessness in San Francisco, comparing it to a Black Mirror episode and suggesting a need for AI to support rather than replace humans.
Theme 3. ChatGPT's Santa Voice: Seasonal Gimmick or Revolutionary?
- ChatGPT Advanced Voice Mode adds a Santa Voice (Score: 128, Comments: 33): ChatGPT has introduced an Advanced Voice Mode featuring a Santa Voice option.
- Users discuss the Santa Voice feature with mixed reactions; some find it fun and seasonal, while others encounter issues like difficulty switching back to standard voices or finding the feature creepy due to camera activation. surfer808 mentions an incident where the camera light was on, and the Santa Voice interacted with them, raising privacy concerns.
- Zulakki reports a technical issue where the Santa Voice was initially available but then disappeared, causing inconvenience when trying to demonstrate it to family. This suggests a potential bug or limitation in the feature's availability.
- There is a humorous debate about Santa's nationality, with comments suggesting he is from the UK, North Pole, or Canada, reflecting a light-hearted take on the feature's implementation and its cultural implications.
- 12 Days of OpenAI: Day 6 thread (Score: 126, Comments: 241): OpenAI's 12 Days event featured ChatGPT's Santa mode on Day 6, showcasing advanced voice capabilities with video. The live discussion was accessible via OpenAI's website and YouTube.
- Advanced Voice Mode and Video Integration: Users are discussing the integration of video and screen sharing in Advanced Voice Mode (AVM), with some expressing concerns about AVM's ability to process video context effectively. Several comments highlight the delayed rollout in Europe, with speculation that capacity issues, rather than legal constraints, may be the cause.
- Comparisons with Google Gemini: Users compare OpenAI's releases with Google's Gemini 2.0, noting Gemini's multimodal capabilities and voice mode features. Some users feel Google is ahead in terms of timely and effective feature releases, while others are excited about OpenAI's potential future updates, such as a rumored GPT-5 release.
- User Experience and Accessibility: There is a mix of excitement and frustration regarding feature accessibility, with some users unable to access new features across all devices or regions. Comments also address the perceived patronizing tone of ChatGPT's voice responses, with suggestions for more natural interactions.
Theme 4. OpenAI’s 12 Days of Releases: Video in AVM
- OpenAI releases video to Advanced Voice Mode (Score: 105, Comments: 43): OpenAI has introduced video features to its Advanced Voice Mode, coinciding with the Gemini release.
- OpenAI's new features include live video conversations and screen sharing in Advanced Voice Mode, with rollout starting today for Teams users and most Plus and Pro subscribers, while Enterprise and Edu users will access it early next year. The "Santa mode" is globally available wherever ChatGPT voice mode is accessible.
- There is a discussion about the rollout timeline, with some users pointing out discrepancies in communication, as OpenAI stated the feature would roll out "today and over the next week", which some users compare to previous delays in feature releases.
- Users are curious about availability, with some expressing frustration over the delayed access in Europe, while others inquire about how to access the new features, with a YouTube link provided as a resource.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. AI Model Showdowns: Gemini vs. Claude
- Claude Dominates Coding Tasks: Users consistently report that Claude outperforms Gemini 2.0 in coding accuracy, solidifying its position as the preferred choice for development workflows.
- Gemini 2.0 Flash Accelerates AI Speed: Gemini 2.0 Flash receives accolades for its enhanced speed and performance, although some bugs like real-time video reading issues are still being ironed out.
- Project Astra Targets OpenAI’s Throne: Project Astra is gaining traction as a formidable competitor to OpenAI, with the release of Gemini 2.0 potentially reshaping the AI industry landscape.
Theme 2. GPU Frenzy: New Launches and Scalping Wars
- 5090 GPU Launch Sparks Excitement: Anticipation peaks as the 5090 GPU is set to launch in early January, boasting an impressive 32GB VRAM that promises to boost AI computations.
- Scalpers Clash with Web Scrapers for GPUs: The rise of GPU scalpers forces users to adopt web scrapers and other tactics to secure coveted cards during high-demand launches.
- Intel ARC B580 vs. Nvidia RTX 3060: The Battle Continues: Debates rage over whether Intel’s B580 GPU with 12GB VRAM can outshine the popular RTX 3060, despite concerns over CUDA support.
Theme 3. AI Tool Turbulence: Updates, Bugs, and Integrations
- Codeium’s Windsurf Wave 1 Unveiled: Windsurf Wave 1 introduces autonomy upgrades like Cascade Memories and automated terminal commands, enhancing AI interaction through
.windsurfrules. - Aider Faces Installation Hurdles: Users grapple with global installation of Aider, finding workarounds like
uv tool install aider-chatamidst OpenSSL compatibility warnings. - Cohere Go SDK Needs Structural Fixes: Feedback highlights issues in Cohere’s Go SDK, particularly with
StreamedChatResponseV2fields, necessitating urgent structural adjustments for accurate parsing.
Theme 4. MLOps Marvels: Innovations in Training and Optimization
- Direct Preference Optimization Hits Llama 3.3: DPO successfully integrates with Llama 3.3, supported by comprehensive documentation, streamlining the fine-tuning process for users.
- SPDL Boosts AI Training Efficiency: SPDL leverages thread-based data loading to significantly reduce AI model training time, a game-changer for Reality Labs research.
- Training Jacobian Analysis Reveals Hidden Dynamics: A new paper delves into the training Jacobian, uncovering how initial parameters influence final outcomes and highlighting challenges in scaling the analysis to larger networks.
Theme 5. Community Catalysts: Hackathons, AMA Sessions, and Collaborative Tools
- LLM Agents MOOC Hackathon Deadline Looms: The LLM Agents MOOC Hackathon wraps up submissions on December 17th, transitioning from Devpost to Google Forms to streamline evaluations.
- Modular’s AMA Series Deepens Technical Insights: Ask Me Anything sessions hosted by experts like Joe and Steffi explore GPU programming with Mojo, fostering deeper community understanding.
- Early Access to Community Packages Launched: Modular unveils an early access preview of community packages, inviting users to participate in testing and expanding the package ecosystem collaboratively.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Windsurf Wave 1 Launch: Codeium has launched Windsurf Wave 1, introducing significant autonomy upgrades including Cascade Memories and automated terminal command execution. Users can review the full changelog for detailed updates.
- The release enhances AI interaction by guiding behavior through .windsurfrules, enabling more effective task management as users adapt to the new features.
- Cascade Memories Enhancement: Cascade Memories have been integrated into Windsurf, providing robust guidance for AI behavior via .windsurfrules. This feature aims to automate user interactions and improve task management.
- Community feedback indicates that Cascade Memories significantly enrich AI functionalities, though some users have reported internal errors related to this feature.
- Gemini Models vs Claude Performance: Discussions highlight that Gemini 2.0 models may outperform Claude in coding tasks, with users expressing interest in deploying Gemini models on tools like Cursor.
- Users report that models like Gemini-exp-1206 show superior performance metrics compared to others, stirring debates on optimal model selection for development workflows.
- Image Upload Capabilities Extension: Cascade image uploads in Windsurf now support files exceeding 1MB, enhancing flexibility in processing diverse file types. This upgrade addresses previous limitations in user experiences.
- The expanded image upload capacity has been positively received, allowing users to engage with more complex datasets and media within the platform.
- Improved Python Support in Windsurf: Python support within Windsurf has been upgraded, promising a smoother and more fluent coding experience. Users can manage their upgrade plans via the Codeium plan page.
- Enhanced Python integration aims to streamline development processes, though some users have reported challenges due to internal errors post-update.
aider (Paul Gauthier) Discord
- O1 Pro Excels as a Debugger: Users reported that O1 Pro effectively fixes issues in a single attempt, outperforming other models in handling repetitive or complex tasks.
- Frustrations were shared regarding Sonnet, which often loops indefinitely on simple edits, highlighting O1 Pro's efficiency.
- Gemini 2.0 Flash Shines in Performance: Gemini 2.0 Flash is praised for its speed and accuracy, scoring well in edit modes and providing a substantial context window for coding tasks.
- Despite some mixed results, many users find it suitable for practical applications, especially when combined with editor models.
- Aider Installation Hurdles and Solutions: Users faced challenges installing Aider globally, but found solutions like using
uv tool install aider-chateffective.- Warnings such as OpenSSL compatibility issues during installation were discussed but considered ignorable.
- DeepSeek Faces Performance Issues: Users expressed frustration with DeepSeek accessed via OpenRouter, citing slow performance and frequent errors.
- Despite these challenges, DeepSeek is noted for its accuracy, leading some users to continue its utilization.
- Gemini Model Response Discrepancies: Users reported that the Gemini model in Aider provides outdated sports scores compared to the web interface.
- This suggests a lack of access to recent events through the API, highlighting concerns about information consistency.
Cursor IDE Discord
- Claude Remains Top Choice Over Gemini 2.0 for Coding: Users discussed Gemini 2.0 and Claude, with Claude leading in coding accuracy despite Gemini's recent enhancements.
- Comparisons highlighted Claude's continued superiority in programming tasks, prompting users to maintain their preference.
- Users Express Concerns Over Cursor's Performance: Participants provided feedback on Cursor's recent updates, expressing frustrations with the performance and limitations of its chat and composer features.
- Suggestions focused on optimizing AI rules to enhance querying and response capabilities within Cursor.
- AI Tools Pricing Sparks Community Debate: The cost-effectiveness of AI tools like Cursor and Gemini was debated, with users assessing their value in relation to the outputs they deliver.
- Concerns were raised about subscription pricing and how it compares with other available options in the market.
- Developers Discuss Preferred Web Hosting Platforms: Users recommended platforms such as Railway and Cloudflare Workers for server hosting, emphasizing the importance of selecting based on project types.
- Discussions highlighted the balance between cost and usability when choosing hosting solutions for various development projects.
- Gen Z's Coding Styles Under the Microscope: Lighthearted conversations emerged about generational programming styles, referencing humorous YouTube videos portraying Gen Z coders.
- Participants voiced concerns over the potential future impact of these programming trends on coding quality and workplace interactions.
OpenAI Discord
- OpenAI Launches Santa Mode and Advanced Voice Features: On Day 6 of the 12 Days of OpenAI, Kevin Weil and team introduced the new Santa voice alongside video and screensharing capabilities in Advanced Voice.
- The demo encouraged viewers to engage with the festive features, enhancing the interactive experience during the holiday-themed event.
- Project Astra Challenges OpenAI's Dominance: Project Astra is gaining attention as a potential competitor to OpenAI, with discussions highlighting its readiness to challenge OpenAI's offerings.
- Some users believe that the upcoming release of Gemini 2.0 could significantly impact the competitive landscape in the AI industry.
- Gemini 2.0 Surpasses OpenAI Models with Mixed Feedback: Gemini 2.0 Flash is currently accessible on the web and has received positive feedback for its performance compared to OpenAI's models.
- However, users have reported bugs affecting features like real-time video reading, indicating areas that require further refinement.
- Advancements in AI Image and Voice Technologies: ElevenLabs' voice AI technology is being tested for realism, with efforts to achieve indistinguishable outputs from human voices.
- In the realm of AI image generation, tools like Hailuo and Sora are experiencing high demand due to free credits, though users have varied responses regarding output quality across different video formats.
- OpenAI Service Outage and Recovery Procedures: A service outage affected OpenAI from 3:16pm PST to 7:38pm PST on December 11, with API traffic recovery initiating around 5:40pm.
- All services are now operational, and OpenAI is set to perform a root-cause analysis to prevent future incidents.
Perplexity AI Discord
- Gemini 1.5 Pro Deep Search Slower Than Perplexity: Users observed that Gemini 1.5 Pro Deep Search delivers more comprehensive research capabilities compared to Perplexity, but with significantly longer response times. Detailed benchmarks were shared to illustrate the performance differences.
- One member highlighted that Gemini's thoroughness makes it suitable for intensive research tasks, despite the trade-off in speed, while others preferred Perplexity for its quicker responses in less demanding scenarios.
- Perplexity Deprecates O1 Reasoning Model: The O1 reasoning model has been removed from the Perplexity platform, prompting concerns about handling complex queries. @AravSrinivas mentioned that the model was deemed unnecessary as reasoning now auto-triggers for complex tasks.
- Discussions emerged regarding the impact on Pro users who relied on the O1 model for advanced reasoning, with some questioning the decision and its effects on workflow efficiency.
- Perplexity Launches LinkedIn Verification: Perplexity introduced LinkedIn verification, allowing users to connect their profiles for enhanced functionality. The announcement has left the community curious about the feature's specific benefits.
- Users speculated potential advantages such as improved credential verification or personalized user experiences, but Perplexity has yet to clarify the exact purpose of this integration.
- Advancements in GPR Devices Methodologies: A discussion on GPR devices and methodologies sparked interest among members, with this link highlighting recent advancements.
- Participants engaged in conversations about the latest techniques and applications of GPR technology, emphasizing its growing role in various engineering fields.
- Perplexity API Encounters 3D Secure Issues: Users reported that adding a card via the Perplexity API causes the UI to freeze, followed by the swift appearance and disappearance of the bank's 3D Secure screen, preventing transaction authorization.
- Discussions focused on the necessity of 3D Secure for security compliance and the lack of alternative solutions within the API, hindering seamless payment processes.
Unsloth AI (Daniel Han) Discord
- Direct Preference Optimization with Llama 3.3: Members confirmed that Direct Preference Optimization (DPO) successfully integrates with Llama 3.3, supported by comprehensive documentation and examples.
- Theyruinedelise highlighted that the provided documentation enhances usability, facilitating smoother implementation for users.
- Challenges in Model Merging and Quantization: Discussions focused on the complexities of merging models, especially the drawbacks of merging into 4-bit, which risks degrading LoRA fine-tuned models.
- Disgrace6161 advocated for merging into full precision first to maintain performance, emphasizing the importance of preserving model quality.
- Optimizing Fine-Tuning with LoRA Adapters: LoRA adapters were extensively discussed for their role in fine-tuning, highlighting their ability to optimize VRAM usage while maintaining model integrity.
- Participants noted that higher ranks in LoRA can enhance performance, depending on task-specific requirements and dataset characteristics.
- SPDL Enhances AI Training Efficiency: The SPDL blog post outlined how SPDL accelerates AI model training through thread-based data loading, significantly reducing training time.
- This method improves data management and throughput, proving essential for handling larger datasets in Reality Labs research.
- Release of OpenPlatypus Dataset: The OpenPlatypus dataset, comprising 25,000 samples, was released and evaluated against Qwen QwQ at temperature 0, incurring a cost of $30 on OpenRouter.
- Recommendations include excluding responses outside the 100-5000 tokens range and applying k-means clustering post sample size reduction.
Stability.ai (Stable Diffusion) Discord
- Anticipation Builds for 5090 GPU Launch: Members are eagerly awaiting the 5090 GPU release scheduled for early January, highlighting its impressive 32GB VRAM capacity.
- Humorous remarks like 'In AI time, that like years' reflect the community's excitement and anticipation for the new GPU.
- Combating GPU Scalpers with Web Scrapers: Discussions surfaced around the rise of scalpers acquiring GPUs, prompting users to explore web scrapers and other techniques to secure cards during launch.
- Participants emphasized the added difficulty for those without a physical presence in the US, underscoring the challenges in obtaining GPUs.
- Top Models Recommended for Image Generation: Users recommended models such as Dream Shaper, Juggernaut, and SDXL for generating specialized content like spaceships, noting their effectiveness.
- Some suggested leveraging LoRA training to enhance model performance, while others pointed out that 8GB VRAM may limit capabilities.
- Issues with Older Stable Diffusion Models: Members reported challenges with older models like WD1.4, which tend to produce anomalous results during image generation tasks.
- Recommendations included captioning regularization images when training LoRA models to mitigate these issues and improve output quality.
- Recommended Discord Servers for Video AI Enthusiasts: A query about suitable Discord servers for discussing local video AI models mentioned platforms like Mochi, LTX, and HunYuanVideo.
- The Banodoco Discord server was highlighted as a prime community for enthusiasts interested in these video AI models.
Eleuther Discord
- Training Jacobian Analysis Reveals Parameter Dependencies: A new paper on arXiv analyzes the training Jacobian, illustrating how final parameters are influenced by their initial values by transforming a small sphere in parameter space into an ellipsoid.
- The study identifies distinct regions in the singular value spectrum, noting that training on white noise compresses the parameter space more aggressively than training on real data, and highlights computational challenges when scaling Jacobian analysis to larger networks.
- RWKV Models Release: Flock of Finches & QRWKV-6: The RWKV team announced Flock of Finches 37B-A11B and QRWKV-6 32B Instruct Preview, both demonstrating impressive benchmark results on multiple tasks.
- Flock of Finches achieved competitive performance with only 109 billion tokens trained, while QRWKV-6 has already surpassed previous RWKV models in key metrics.
- Muon Optimizer Shows Promise Over AdamW: Consensus emerged that Muon might outperform existing optimizers like AdamW, with its gradient orthogonalization potentially relating to maximum manifold capacity loss and reinforcement learning regularization.
- The Muon optimizer's underlying mathematics are considered insightful and plausible for enhancing performance, though discussions continue on its broader applicability.
- NeurIPS Prize Controversies and VAR Paper Misconduct Concerns: The ARC prize at NeurIPS sparked debates regarding goalpost shifting and potential manipulative tactics by organizers, casting doubt on the validity of its benchmarks.
- Additionally, concerns were raised about Keyu Tian, the first author of a NeurIPS 2024 best paper, with allegations of misconduct and malicious code attacks during his internship at ByteDance, prompting calls to reassess the paper's accolades.
- Negative Attention Weights and Cog Attention: The introduction of Cog Attention proposes an attention mechanism that allows for negative weights, aiming to enhance model expressiveness by facilitating token deletion, copying, or retention.
- While the concept is innovative, concerns about its effectiveness and potential learning difficulties remain, particularly in specific applications like Sudoku tasks.
LM Studio Discord
- GPU Grids: LM Studio's Multi-GPU Mastery: LM Studio efficiently spreads tasks across multiple GPUs, requiring them to be of the same 'type' but not necessarily the same model. Heyitsyorkie mentioned that GPU offload in LM Studio is a toggle that utilizes all available GPUs.
- LM Studio users highlighted that this setup enhances performance scalability by leveraging the total computational power of connected GPUs.
- Mac Power: Running 70b LLMs on M4 Max: The M4 Pro chip can run 8b models with at least 16GB of RAM on Mac, while the M4 Max is capable of running 70b models, provided users prioritize RAM for flexibility.
- Participants noted that larger models like 70b require significant memory, making the M4 Max a suitable choice for demanding AI tasks.
- GPU Showdown: Intel B580 vs Nvidia RTX 3060: Intel's B580 GPU offers affordability with 12GB of VRAM, but requires Vulkan support, leading to skepticism among users. In contrast, the RTX 3060 provides 12GB VRAM and is available second-hand between $150-$250.
- mlengle emphasized a preference for Nvidia GPUs due to their CUDA support, which is lacking in Intel's offerings.
- Uncensored AI: Navigating Model Safety Cuts: A user expressed frustration in finding guidance to create an uncensored AI model, highlighting a lack of clear resources for removing safety features. They were advised to explore Unsloth finetuning guides and consider utilizing datasets aimed at achieving less restrictive models.
- Participants suggested alternative approaches to model safety, citing the complexities involved in modifying existing LLMs.
- Fine-Tuning vs RAG: Choosing the Right LLM Strategy: Participants discussed the complexity of fine-tuning LLMs, especially with numerical data, suggesting it may not provide desired results. Alternatives like RAG (Retrieval-Augmented Generation) for data retrieval were recommended.
- The community indicated that traditional analytical methods might yield better insights for specific use cases compared to fine-tuning.
Bolt.new / Stackblitz Discord
- Token Usage Shows 'NaN' After Minimal Use: Users reported that token usage displays 'NaN' after minimal usage, leading to confusion and inaccurate tracking.
- Support suggested reloading tabs or contacting help if the issue persists, as the display problem was being addressed.
- Debugging in Bolt Causes Excessive Token Consumption: Users faced issues with debugging in Bolt, leading to excessive token consumption without effective results.
- Recommendations included using more focused prompts and file pinning to prevent unwanted changes during complex tasks.
- Supabase Integration Set to Enhance Bolt Functionality: The community discussed the potential integration of Supabase into Bolt, which many believe will enhance functionality for building projects.
- Users expressed optimism that this integration could significantly streamline workflows, particularly for those transitioning from services like Firebase.
- Feature Requests Focus on GitHub Integration and Full-Stack Support: Users voiced suggestions for features, including better GitHub integration and more support for full-stack applications.
- The community emphasized approaching feature requests politely, directing them to the GitHub issues page for formal consideration.
Notebook LM Discord Discord
- NotebookLM UI Overhaul with Interactive Audio: NotebookLM is set to receive a revamped UI featuring separate sections for Sources, Chat, and Notes & Audio Overview, along with an Interactive Audio Beta enabling real-time interactions with hosts (Tweet).
- This update aims to enhance user experience by improving navigation and usability, addressing current limitations in source management and audio interactions.
- Gemini 2.0 Enhances Performance: Gemini 2.0 is anticipated to outperform existing models with higher output token limits and advanced features (Tweet).
- However, concerns have been raised regarding the potential limitations in context window size compared to previous iterations.
- Custom AI Voices Boost Podcast Personalization: Members discussed the integration of custom voices for podcasts, with Eleven Labs being suggested for voice cloning to meet the growing demand for personalized audio experiences.
- One user emphasized the importance of utilizing professionally cloned voices to enhance listener engagement and content uniqueness.
- AI-driven TTRPG Adventures Gain Popularity: Interest surged in running TTRPG adventures using AI, drawing parallels to solo D&D games for more immersive storytelling.
- Users reported varied success with this approach, noting it as an entertaining endeavor despite some challenges.
- AI-generated Video Podcasts Explore Deep Themes: A new AI-generated video podcast featuring a caveman and an AI chatbot delves into themes like The Meaning of Life, blending humor with profound conversations.
- This innovative format showcases the dynamic between ancient and modern perspectives, attracting interest for its unique approach.
Nous Research AI Discord
- Hermes 3B Exceeds Benchmarking Expectations: Users are comparing benchmarks of Hermes 3B, Llama 3.2, Mistral 7B, and Qwen 2.5, with Hermes 3B demonstrating superior performance in various metrics.
- Senor1854 highlighted the reliability of the new math benchmark dataset compared to established ones, emphasizing the importance of evolving evaluation techniques.
- QTIP Model Outperforms AQLM Without Retraining: The QTIP model has been reported to outperform AQLM without requiring retraining, as detailed in the QTIP GitHub repository.
- Community reactions suggest a resurgence of signal processing techniques in machine learning, with members pointing to the research paper for deeper insights.
- Llama3 Faces Capacity Utilization Challenges: Llama3 has been noted to experience a drop in performance related to model capacity utilization, leading members to scrutinize the underlying model dynamics.
- Members plan to examine the relevant research to understand the performance degradation, expressing interest in how model capacity affects Llama3's efficacy.
- Launch of New Math Benchmarks U-MATH and μ-MATH: Toloka announced the launch of U-MATH and μ-MATH, two new benchmarks designed to evaluate LLMs on university-level mathematics.
- These benchmarks are expected to provide more reliable evaluations, contrasting with previous scoring systems and driving advancements in evaluation techniques.
- Pretraining Small Models with Big Model Hidden States: Kotykd proposed a novel training methodology using big model hidden states to pretrain smaller models in a different architecture for improved efficiency.
- This idea has sparked discussions regarding the feasibility and potential of such methods, with members highlighting the need for further exploration and experimentation.
GPU MODE Discord
- Torch.compile Faces Dynamic Padding Penalties: A user reported that using torch.compile(mode='max-autotune') with dynamic=True led to significant performance penalties during the initial decoder iterations, specifically slower runs with new conditioning shapes.
- Despite enabling dynamic padding, the performance issues persisted, prompting discussions on potential solutions to mitigate the penalties associated with variable-length inputs.
- Triton Enhances Matmul and Softmax with Fused Kernels: Members are developing a fused kernel for matmul and softmax in Triton, drawing parallels to existing point-wise activation fusions like ReLU.
- Guidance was sought on utilizing the group-ordered matmul example from Triton's documentation to overcome challenges associated with fusing softmax operations.
- Float8 Training in TorchAO: Transitioning from DDP to FSDP: TorchAO's implementation of float8 training encounters errors when scaling to multi-GPU setups using DDP, despite running smoothly on single GPUs.
- Community members recommended adopting FSDP for data parallelism and encouraged sharing code or reporting issues on TorchAO to facilitate troubleshooting and improvements.
- CUTLASS Emerges as Top GEMM Implementation Alternative: In discussions about optimal GEMM implementations excluding cuBLAS, CUTLASS was identified as the leading alternative option.
- Participants compared various alternatives like pure CUDA and Triton, ultimately acknowledging CUTLASS for its superior performance in matrix multiplication tasks.
- GPU Glossary Launch and H100 Tensor Core Clarifications: The GPU Glossary was launched on Modal, detailing terms such as 'Streaming Multiprocessor' and addressing core counts and tensor core functionalities in the H100 GPU.
- Discussions highlighted the need for accurate representations of GPU architectures, including the clarification that each SM in the H100 has 128 FP32 cores and the operational differences of tensor cores compared to CUDA cores.
Cohere Discord
- Cohere Support Responsiveness: When users reported issues, members emphasized contacting the support team at support@cohere.com for urgent matters.
- Another user encouraged messaging directly for faster assistance, acknowledging the support team's presence.
- Rerank Timeout Issues: Multiple users experienced 504 gateway timeout errors while using the Rerank feature, with one reporting requests timing out after 40 seconds.
- The issue appeared sporadic, as some members noted service restoration shortly after, with others still reporting challenges.
- FP8 Quantization Outperforms BnB on H100: A discussion on quantization techniques revealed that with H100 hardware, FP8 quantization outperforms BnB for fast inference under high user load.
- Members agreed that traditional calibration datasets like WikiText often fall short in practical performance, especially for non-English languages.
- Cohere Go SDK Structural Fixes: Feedback indicated that the Cohere Go SDK's
StreamedChatResponseV2field related to tools calls is incorrectly structured.- Definitions for ToolPlanDelta and ToolCallDelta are missing necessary fields for accurate parsing.
- Aya Expanse Model Licensing Concerns: Users expressed a preference for using the Aya Expanse model in internal company settings, emphasizing the need for speed while avoiding potential data leaks.
- Concerns over the CC-BY-NC license were raised, leading to a discussion on the implications of non-commercial use even within corporate environments.
LLM Agents (Berkeley MOOC) Discord
- LLM Agents Hackathon Deadline and Platform Change: The LLM Agents MOOC Hackathon submission deadline is approaching on December 17th. Submissions have transitioned from Devpost to Google Forms to ensure proper evaluation.
- Winners will be announced in the first half of January 2025, and participants are encouraged to seek last-minute assistance through the chat and visit the hackathon website for more details.
- Advanced LLM Agents MOOC Launches in Spring 2025: The Advanced Large Language Model Agents MOOC is set to launch in Spring 2025, focusing on reasoning and AI for mathematics. Sign-ups are currently open at this link.
- The syllabus is still in development, with more details expected from Prof Song. The course will run from mid January to early May, with additional information available on the MOOC website.
- Assignments and Quizzes Policies for MOOC: All assignments, including the written article, are due on December 12th, 2024, by 11:59 PM PST. Quizzes are graded on a completion basis, allowing participants to earn certificates without penalty.
- The written article assignment requires a link to a social media post and can be submitted via Written Article Assignment Submission. Quizzes aim to facilitate learning rather than strict assessment.
- Ninja Tier Requirements for Hackathon: For the Ninja Tier in the hackathon, completing all quizzes and submitting the article assignment are essential, with labs being optional.
- Participants are encouraged to write about their hackathon projects for the written article assignment, enhancing their contributions to the tier.
Interconnects (Nathan Lambert) Discord
- Google Launches Android XR: Google unveiled Android XR, a new mixed reality operating system designed for headsets and smart glasses, during a recent demo.
- The platform features real-time translation with subtitles, reinforcing Google's strategic pivot towards augmented reality technologies.
- OpenAI vs Anthropic Market Rivalry: OpenAI and Anthropic are intensifying their competition for market leadership, with Anthropic achieving $1B in ARR by the end of 2024 compared to OpenAI's $4B revenue and $157B valuation.
- This rivalry highlights Anthropic's growth in coding applications, prompting concerns among OpenAI executives about shifting strategies from safety to aggressive marketing.
- Advancements in MLLM Development: Community members are actively seeking quality sources for tracking MLLM developments, with some utilizing scraping techniques and Twitter feeds as potential resources.
- Efforts to enhance information quality reflect the demand for up-to-date and reliable data in the MLLM space.
- Hugging Face's VLM Insights: Merve from Hugging Face is recommended as a key resource for VLM insights, with her informative posts accessible via Twitter.
- Her content is considered valuable for those staying abreast of developments in Vision-Language Models.
- AI Model Creative Benchmarking: Discussions emerged around establishing meaningful benchmarks for measuring LLM capabilities in creative tasks, addressing the current lack of standards for diversity and creativity.
- Claude-3, despite being favored by the community, often ranks lower in creative writing benchmarks, highlighting the need for improved evaluation metrics.
LlamaIndex Discord
- Calsoft Launches CalPitch Tool: Calsoft introduced CalPitch, a tool designed to assist their business development team in researching prospects and drafting outreach emails with human oversight.
- This launch showcases how AI can enhance and speed up current workflows.
- Enhancements to RAG Agents with SharePoint and LlamaParse: A new feature enables building RAG agents that respect SharePoint permissions, addressing requests from Azure stack users to connect to enterprise data sources using LlamaParse for parsing unstructured PDF data.
- Concerns about data privacy were addressed, ensuring that no data is retained beyond 48 hours.
- Google Gemini 2.0 Models Released: Google launched its latest Gemini 2.0 models, including day-0 support, accessible via
pip install llama-index-llms-geminiorpip install llama-index-llms-vertex.- The Gemini 2.0 Flash model promises enhanced speed and capabilities, hailed as a game changer in the AI landscape.
- Personalizing Slack Bots with ReAct Agent: A user is developing a Slack bot using the ReAct Agent and seeking advice on incorporating personality without revealing it's an AI.
- Community members suggested using FunctionCallingAgent with a system prompt to customize its personality.
- Integrating BGEM3 with Qdrant Database: A user inquired about integrating the BGEM3 model with a Qdrant database through LlamaIndex, seeking guidance on the process.
- Resources related to BGEM3 were shared to assist in the integration.
Modular (Mojo 🔥) Discord
- Swag Challenge Winners Announced: We kicked off the week with a swag challenge on Monday, and winners were announced here. Ahmed also hosted an Ask Me Anything session about GPU programming with Mojo.
- This initiative not only engaged the community but also provided an opportunity for participants to interact directly with experts on GPU programming using Mojo.
- AMA Sessions Deep Dive into Mojo: On Tuesday, Joe hosted an Ask Me Anything session on the standard library, providing valuable insights into the functionalities and features of the library.
- Additionally, today features ask Steffi anything about async Mojo/coroutine implementation in MLIR and ask Weiwei anything about the Mojo optimization pipeline, aiming to deepen understanding of specific technical topics.
- Launch of Community Packages Early Access: Yesterday, we launched the early access preview of community packages, encouraging users to join and help test the packaging. Interested users can register in <#1098713770961944628> to gain access to the instructional <#1313164738116583454> channel.
- This launch seeks to expand the package ecosystem by involving the community in testing and development.
- Async Mojo Implementation and Optimization Pipeline: Today's Ask Me Anything sessions include discussions on async Mojo/coroutine implementation in MLIR and the Mojo optimization pipeline.
- These sessions aim to provide in-depth technical knowledge and foster engagement among AI engineers working with Mojo.
DSPy Discord
- DSPy Framework for LLMs: After introducing DSPy framework, DSPy significantly reduces time spent on prompting for programming language models.
- The framework uses boilerplate prompting and task signatures, simplifying prompt creation and enhancing efficiency in LLM-powered applications.
- Focus on Text and Image Inputs: Members debated investing in video and audio inputs, with one member suggesting focusing on text and image inputs for now.
- Defining LLM Agents: A member initiated a discussion on the definition of 'LLM agents', sharing a thread that explores its metaphorical implications.
- Participants humorously acknowledged the debate's controversial nature, stating "you've kicked the bee's nest now."
- Optimizing with Labeled Data: It was confirmed that optimizers can be used with labeled data, specifically gold standard input-output pairs.
- This confirmation led to increased interest and engagement from members in optimizing using labeled datasets.
- AI as a Platypus in Technology: A member reflected on AI challenging existing technology categorizations, likening it to a 'platypus' in tech as described in The Platypus In The Room.
- They emphasized that "Nearly every notable quality of AI and LLMs challenges our conventions, categories, and rulesets."
OpenInterpreter Discord
- Searching for Spider Verse Glitch Effect: A user is seeking a Spider Verse glitch effect they saw on a website to replicate the effect.
- They expressed keen interest in the creative aspect of the effect.
- Docker Issues with Open Interpreter: A member reported that Open Interpreter running in Docker only returns the model's chat response instead of executing code.
- They suggested that the application seems to pretend to execute code without actually doing so.
- GitHub Model I Tutorial Update: A user inquired about recent changes to the GitHub page for the model i tutorial, noting significant shifts in information.
- It seems like the GitHub page updated and a lot of stuff is different now, indicating confusion over the documentation.
- Struggles with NVIDIA NIM Base URL Setup: A user sought assistance with setting up NVIDIA NIM base URL links, mentioning challenges without success.
- They expressed frustration, stating they have been trying for ages but have had no luck.
- WebVoyager vs GPT 4V Preferences: A member asked for opinions on WebVoyager, indicating a preference to update the model to use GPT 01 instead of GPT 4V.
- They are curious about testing it out and potentially switching models.
tinygrad (George Hotz) Discord
- Coverage.py Introduction: A member introduced Coverage.py as a tool for measuring Python code coverage, highlighting its ability to track executed code and analyze unexecuted parts.
- The latest release, 7.6.9, launched on December 6, 2024, supports Python versions from 3.9 up to 3.14 alpha 2.
- gcov as Alternative Coverage Tool: A member recommended gcov for coverage analysis and inquired about more fine-grained options.
- This sparked a broader conversation on the variety of available coverage tools and their respective advantages.
- George Hotz Endorses Coverage.py: George Hotz recognized Coverage.py as a good place to start for assessing test coverage, reflecting his confidence in its capability to enhance code quality.
- His endorsement underscores the tool's effectiveness among engineers seeking to improve their testing processes.
- Seeking Test Coverage Expertise: A member requested assistance from proficient users of test coverage tools to identify dead code.
- They emphasized that untested code should probably be deleted to maintain code quality.
Torchtune Discord
- QRWKV6-32B Model boosts compute efficiency: Recursal AI transformed the Qwen 32B Instruct model into the QRWKV6 architecture, maintaining the original 32B performance while achieving 1000x compute efficiency during inference.
- This modification replaces transformer attention with RWKV-V6 attention, resulting in significant cost reductions in computation.
- AMD GPUs enable rapid training: Training of the QRWKV6 model was completed in just 8 hours using 16 AMD MI300X GPUs (192GB VRAM each), showcasing advancements in AI development speed.
- Upcoming models like Q-RWKV-6 72B and RWKV-7 32B are in progress, promising enhanced capabilities.
- RWKV-V6 Attention enhances scalability: The linear attention mechanism in the QRWKV6 model proves to be highly efficient at scale, especially for processing long contexts.
- Despite these improvements, the model's current context length is capped at 16k due to compute constraints, though it remains stable beyond this limit.
- Model transformation cuts retraining costs: The conversion process allows transforming any QKV Attention model to an RWKV variant without the need for full retraining, thereby reducing compute costs.
- However, the model inherits language limitations from the Qwen model, supporting only approximately 30 languages compared to RWKV's typical 100+ languages.
- Community collaboration drives advancements: Training for the QRWKV6 model is sponsored by TensorWave, with significant contributions from EleutherAI and the RWKV community.
- While the transformation process is innovative, some details remain undisclosed, leaving the community curious about the how-to aspects.
Gorilla LLM (Berkeley Function Calling) Discord
- Finetuning Gorilla LLM for Custom API: A user is seeking guidance on how to finetune Gorilla LLM to recognize a custom API, indicating previous difficulties in the process.
- They specifically noted challenges in downloading the GoEx model from Hugging Face.
- Downloading GoEx Model Challenges: The user mentioned experiencing trouble while attempting to download the GoEx model to use in a Colab environment.
- This highlights the need for clearer instructions or troubleshooting steps for model acquisition.
- Implementing Reversibility in Gorilla LLM: The user inquired about strategies for implementing reversibility within their Gorilla LLM project.
- This suggests a broader interest in effective control mechanisms during development processes.
- Training Gorilla LLM in Colab: They are conducting training of Gorilla LLM in a Colab environment.
- This approach may necessitate efficient resource management and clear training protocols.
Axolotl AI Discord
- PyTorch's PYTORCH_TUNABLEOP_ENABLED Flag: A member highlighted the use of
PYTORCH_TUNABLEOP_ENABLED=1in PyTorch to enable tunable operations, referring to the PyTorch GitHub repository.- This feature suggests optimizations in CUDA tunable operations, potentially enhancing efficiency for developers utilizing PyTorch.
- CUDA Tunability Boosts GPU Performance: The discussion centered around
PYTORCH_TUNABLEOP_ENABLED=1and its benefits for CUDA operations, indicating possible performance improvements in GPU computation tasks.- Members believe the tunable approach allows developers to customize operations more effectively, aligning with specific user requirements.
Mozilla AI Discord
- Mozilla Builders Demo Day Recap Released: The Mozilla Builders Demo Day Recap highlights how members gathered in person despite challenging weather conditions, showcasing incredible technology and participant connections.
- The event included showcases of cutting-edge tech and fostered strong connections among participants.
- Acknowledgments to Key Contributors: Special thanks were extended to specific teams and contributors who made the event possible, detailed here.
- Community members demonstrated remarkable resilience by attending despite difficult conditions, such as braving tsunamis.
- Social Media Buzz from Demo Day: Mozilla Builders shared their LinkedIn update and a tweet capturing the event as a spectacular confluence of amazing people and incredible technology.
- The social media posts highlighted the event's success and the strong community engagement.
- Demo Day Highlights Video Available: A highlights video from the event, titled Demo_day.mp4, has been shared for those who missed the event.
- The video showcases some of the presentations and interactions from the day, providing a comprehensive overview.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium / Windsurf ▷ #announcements (1 messages):
Windsurf Wave 1 Launch, Cascade Memories, Usage Transparency, Image Upload Capabilities, Improved Python Support
- Windsurf Wave 1 goes live!: Windsurf Wave 1 is now live, featuring major autonomy upgrades including Cascade memories and automated terminal command execution.
- Check out the full changelog for a detailed overview of the changes and improvements.
- Cascade Memories enhance AI interaction: The introduction of Cascade memories via .windsurfrules significantly guides AI behavior, providing more effective task management.
- This feature aims to automate and enrich user interactions with the platform.
- Updated usage and pricing model rolls out: A revamped usage and pricing system for Windsurf is being implemented, which includes a settings panel showing current plan usage.
- Learn more about the pricing changes here and the new “Legacy Chat” mode.
- Cascade image uploads enhanced!: Cascade now supports image uploads that exceed the previous limit of 1MB, significantly improving user experience.
- This change allows for greater flexibility in the types of files users can upload for processing.
- Python support receives an upgrade: Python support has been enhanced within Windsurf, promising a more fluent coding experience.
- Users can self-serve their upgrade plans via the Codeium plan page.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- Plan Settings: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- Windsurf Wave 1: Introducing Wave 1, our first batch of updates to the Windsurf Editor.
- Tweet from Windsurf (@windsurf_ai): Introducing Wave 1.Included in this update:🧠 Cascade Memories and .windsurfrules💻 Automated Terminal Commands🪟 WSL, devcontainer, Pyright support... and more.
Codeium / Windsurf ▷ #discussion (135 messages🔥🔥):
Codeium Plugin Issues, Windsurf Features, Credit Management Concerns, User Experience with AI Integration, Comparisons to Other AI Tools
- Codeium Plugin Faces Criticism: Users expressed frustration with the Codeium plugin, citing issues like error messages when attempting to chat AI and concerns about its performance compared to Windsurf.
- One user noted, 'every time I write it, I'm getting error,' indicating ongoing technical challenges.
- Windsurf Context Features: Discussion about Windsurf and its Context feature highlighted the indexing capability of projects, as users questioned how Pinned Context works.
- In response, it was noted that Windsurf indexes the project, which users can check in the settings.
- Concerns Over Credit Usage: Numerous users noted the rapid depletion of credits for both Codeium and Windsurf, expressing dissatisfaction with the limited credits offered.
- One member remarked, '500 User Prompt credits is not much,' describing the expense as significant, especially in countries with weaker currencies.
- User Experiences with AI Tools: Users compared Windsurf to competing tools like Cursor, with mixed opinions on performance and value.
- One user reflected on the high costs associated with some AI tools, stating, '$500 dollars is diabolical.'
- Confusion About Features and Plans: There were questions about the integration of personal GPT and Claude accounts within the IDE and the overall functionality users can expect from the Codeium plugin.
- Responses indicated that while Codeium continues to develop its plugin, users still encounter significant limitations compared to other platforms.
- Bobawooyo Dog Confused GIF - Bobawooyo Dog confused Dog huh - Discover & Share GIFs: Click to view the GIF
- Devin review: is it a better AI coding agent than Cursor?: Read the full review: https://www.builder.io/blog/devin-vs-cursor
Codeium / Windsurf ▷ #windsurf (647 messages🔥🔥🔥):
Windsurf Performance Issues, Gemini Models vs Claude, Internal Errors in Cascade, User Feedback on Codeium, Support Ticket System
- Windsurf performance issues lead to internal error frustration: Users are experiencing a high frequency of internal errors in Windsurf, especially following recent updates, impacting overall productivity and leading to frustrations.
- Many users have reported losing credits due to these errors and are concerned about the consistency of the service.
- Gemini models potentially outperforming Claude: There is a discussion on whether the Gemini 2.0 model is superior to Claude for coding tasks, with users expressing interest in trying Gemini models on Cursor.
- Some users note that Gemini-exp-1206 seems to outperform other models, including Sonnet.
- Internal errors persist on Cascade Base: Users report encountering internal errors on Cascade Base, questioning the need for support tickets even when the same issues have been noted by others.
- Despite the reliance on Cascade Base, users are still facing challenges, leading to the suggestion that support should be more proactive.
- User feedback and product criticism: There is a mixture of support and criticism for Codeium's products, with users discussing the value of their subscriptions and the impact of recent price adjustments.
- Some users express concern over the inconsistency of the product while others highlight the importance of ongoing feedback to improve functionalities.
- Support ticket system under scrutiny: Questions are raised about the effectiveness and necessity of the support ticket system for addressing recurring issues with the models, particularly in relation to internal errors.
- Users feel that if issues have been reported by multiple users, direct support may not be required for every individual case.
- Tweet from Kevin Kern (@kregenrek): Windsurf got a really decent update. You can now define rules for AI (similar to cursorrules). And the cursorrules extension works out of the box to get 70 predefined rules directly into windsurf.Quot...
- RabbitR1 Prompts: no description found
- Tweet from Saoud Rizwan (@sdrzn): Cline can now create and add tools to himself using MCP! Try asking him to “add a tool that pulls the latest npm docs” - Cline handles everything from creating the MCP server to installing it *into hi...
- Tweet from Codeium - Windsurf (@codeiumdev): Today, @AnthropicAI is rolling out their Model Context Protocol (MCP), an open standard that connects AI assistants to data sources.We're excited to be working with Anthropic to build upon MCP, an...
- no title found: no description found
- Google AI Studio: Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
- Anthropic Status: no description found
- Funny Animals Dog GIF - Funny Animals Dog Hide - Discover & Share GIFs: Click to view the GIF
- unixwzrd/unixwzrd.github.io · Discussions: Explore the GitHub Discussions forum for unixwzrd unixwzrd.github.io. Discuss code, ask questions & collaborate with the developer community.
- OpenAI Status: no description found
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
aider (Paul Gauthier) ▷ #general (1026 messages🔥🔥🔥):
O1 Pro Performance, Gemini Flash, DeepSeek, Devin AI, OpenHands
- O1 Pro as a Debugger: Users reported that O1 Pro is highly effective at debugging, often fixing issues in one attempt while other models struggle, especially with repetitive or complex tasks.
- Some users shared frustrations with Sonnet, noting it often loops indefinitely on simple edits compared to the efficiency of O1 Pro.
- Gemini Flash Performance: Gemini 2.0 Flash is praised for its speed and accuracy, scoring well in edit modes and offering a substantial context window for coding tasks.
- While some users have experienced mixed results, many find it suitable for practical applications, especially in combination with editor models.
- Challenges with DeepSeek: Users expressed frustration with DeepSeek when accessed via OpenRouter, citing slow performance and frequent errors, while some have had better experiences directly using DeepSeek.
- Despite its challenges, DeepSeek is noted for its accuracy, leading some to continue utilizing it despite performance issues.
- Critique of Devin AI: Devin AI was criticized for its high cost and lack of effective coding capabilities, with users joking about the dismal performance compared to expectations.
- One user mentioned a refund process initiated after a negative experience, highlighting concerns over the model's reliability.
- OpenHands Development: OpenHands is acknowledged for its rapid updates and improvements, with users noting the developers' responsiveness to issues and regular enhancements.
- Those testing OpenHands reported a positive experience, especially with recent fixes addressing prior annoyances.
- Tweet from Saoud Rizwan (@sdrzn): Cline can now create and add tools to himself using MCP! Try asking him to “add a tool that pulls the latest npm docs” - Cline handles everything from creating the MCP server to installing it *into hi...
- MCP Package Registry | Model Context Protocol Package Management: no description found
- Powering the next generation of AI development with AWS: Today we’re announcing an expansion of our collaboration with AWS on Trainium, and a new $4 billion investment from Amazon.
- Find solution for issue 85: Your reliable AI software engineer
- Devin (the Developer): Your reliable AI software engineer
- Tweet from Zed (@zeddotdev): 🚀 Introducing Zed v0.165!Just as you can split editor panels, you can now split the terminal panel.
- One Piece One Piece Movie 6 GIF - One piece One piece movie 6 One piece baron omatsuri - Discover & Share GIFs: Click to view the GIF
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Tweet from Google (@Google): Introducing Gemini 2.0, our most capable AI model yet designed for the agentic era. Gemini 2.0 brings enhanced performance, more multimodality, and new native tool use.
- Warp: The intelligent terminal: Warp is the intelligent terminal with AI and your dev team's knowledge built-in. Available now on MacOS and Linux.
- Copy/paste with web chat: Aider works with LLM web chat UIs
- I Am The Outlaw Walton Goggins GIF - I Am The Outlaw Walton Goggins Boyd Crowder - Discover & Share GIFs: Click to view the GIF
- Aider in your IDE: Aider can run in your browser, not just on the command line.
- GitHub - Aider-AI/conventions: Community-contributed convention files for use with aider: Community-contributed convention files for use with aider - Aider-AI/conventions
- Pieces for Developers — Long term memory for developer workflows: Pieces is your AI companion that captures live context from browsers to IDEs and collaboration tools, manages snippets and supports multiple LLMs.
- GitHub - Upsonic/gpt-computer-assistant: Dockerized Computer Use Agents with Production Ready API’s - MCP Client for Langchain - GCA: Dockerized Computer Use Agents with Production Ready API’s - MCP Client for Langchain - GCA - Upsonic/gpt-computer-assistant
- GitHub - robert-at-pretension-io/mcp: code: code. Contribute to robert-at-pretension-io/mcp development by creating an account on GitHub.
- GitHub - Aider-AI/aider-install: A streamlined installer for aider: A streamlined installer for aider. Contribute to Aider-AI/aider-install development by creating an account on GitHub.
- GitHub - lee88688/aider-composer: Aider's VSCode extension, seamlessly integrated into VSCode: Aider's VSCode extension, seamlessly integrated into VSCode - GitHub - lee88688/aider-composer: Aider's VSCode extension, seamlessly integrated into VSCode
aider (Paul Gauthier) ▷ #questions-and-tips (90 messages🔥🔥):
Aider Installation Issues, Aider and Rust Dependencies, Gemini Model Comparisons, Aider's Commenting Functionality, Aider User Experience and Feedback
- Aider Installation on Different Systems: Users expressed challenges in installing Aider globally, with one noting the ease of using
uv tool install aider-chatas a solution.- Warnings during installation, such as OpenSSL compatibility issues, were also discussed but deemed ignorable.
- Aider and Rust Dependencies Clarification: It was clarified that Aider does not pull in external Rust dependencies or any other languages outside the current repository, focusing only on the committed code.
- Users wondered about future plans for expanding knowledge context to include external dependencies.
- Discrepancies in Gemini Model Responses: Users reported that the Gemini model in Aider provides outdated sports scores compared to the web interface, suggesting a lack of access to recent events through the API.
- The distinction between models with and without web search capabilities was highlighted, raising concerns about the consistency of information.
- Challenges with Aider's Commenting Functionality: Concerns were raised about Aider's automatic commenting process, where it sometimes removed comments without making changes, leading to confusion.
- Feedback indicated that users desired more control over the editing process to ensure only specified tasks are completed.
- Aider User Experience and Feedback: Users shared their varied experiences with Aider, discussing its effective use for project setup while expressing a desire for additional feedback mechanisms.
- Some users suggested that clearing chat history after solving queries maintains clarity, while others raised the importance of summarizing prior actions.
- no title found: no description found
- Supported languages: Aider supports pretty much all popular coding languages.
- Tools | uv: no description found
- Installation fails due to PyO3 dependency - incompatible with Python 3.13 · Issue #16 · simonw/llm-claude-3: I just did a fresh installation of llm via brew on a M1 Mac, followed by llm install llm-claude-3. Here, I get the following error Building wheels for collected packages: tokenizers Building wheel ...
Cursor IDE ▷ #general (620 messages🔥🔥🔥):
Gemini vs Claude, Cursor performance, AI tools and price, Web hosting solutions, Programming challenges
- Gemini 2.0 and Claude Comparisons: Users expressed mixed feelings about Gemini 2.0, with some praising its capabilities while others remained loyal to Claude for coding tasks.
- Comparisons were made regarding their performance, with claims that Claude leads in coding accuracy despite Gemini's advancements.
- Cursor Performance and Feedback: There were discussions around Cursor's recent updates, with users voicing frustrations about the current performance and limitations of its chat and composer features.
- Some users suggested ways to improve AI rules to optimize querying and responses within Cursor.
- AI Tools and Pricing: The cost-effectiveness of AI tools like Cursor and Gemini was a topic of contention, with users considering their value relative to the outputs they provide.
- Concerns were raised about spending on AI tools, and how dollar subscriptions compare with other available options in the market.
- Web Hosting Solutions: Users suggested platforms like Railway and Cloudflare Workers for server hosting, emphasizing the need to choose based on the type of projects.
- The cost and usability of different hosting solutions sparked discussions on preferences among developers.
- Programming Culture and Humor: Lighthearted conversations about generational programming styles emerged, with references to humorous YouTube videos portraying Gen Z coders.
- Users shared their concerns about the potential future impact of these trends on coding quality and workplace interactions.
- LiveBench: no description found
- Cursor - Build Software Faster: no description found
- Supermaven: Free AI Code Completion: The fastest copilot. Supermaven uses a 1 million token context window to provide the highest quality code completions.
- - YouTube: no description found
- How to do `Fix in Composer` and `Fix in Chat` actions from keyboard: These 2: I could not find it in settings.
- Vanilla Components: A lightweight, flexible & customizable UI library for Vue 3, styled with Tailwind CSS
- Unemployment Unemployed GIF - Unemployment Unemployed Laid Off - Discover & Share GIFs: Click to view the GIF
- Claptrap Robot GIF - Claptrap Robot - Discover & Share GIFs: Click to view the GIF
- Wait What Wait A Minute GIF - Wait What Wait A Minute Huh - Discover & Share GIFs: Click to view the GIF
- Emobob Sponegbob GIF - Emobob Sponegbob Emo - Discover & Share GIFs: Click to view the GIF
- Inertia: no description found
- We NEED to stop gen z programmers ✋😮💨 #coding: no description found
- Cursor Status: no description found
- Livewire or Inertia.js. Which one should you choose?: Both Livewire and Inertia are incredibly popular stacks for building applications in Laravel. If you're stuck choosing between the two, let's weigh which one is right for you.
- Devin review: is it a better AI coding agent than Cursor?: Read the full review: https://www.builder.io/blog/devin-vs-cursor
- GitHub - getcursor/docs: Cursor's Open Source Documentation: Cursor's Open Source Documentation. Contribute to getcursor/docs development by creating an account on GitHub.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- gen z programmers are insane???? 😅… #coding: no description found
- Cursor Directory: Find the best cursor rules for your framework and language
{kind=link}
OpenAI ▷ #annnouncements (1 messages):
12 Days of OpenAI, Santa Mode, Advanced Voice features
- OpenAI's Day 6 Unveils Santa Mode: The latest YouTube video showcases the new Santa voice, introduced alongside video and screensharing capabilities in Advanced Voice.
- Kevin Weil and team provide a demo while encouraging viewers to engage with the festive features.
- Stay Updated with 12 Days of OpenAI: Members are encouraged to stay in the loop during the 12 Days of OpenAI by picking up the role in the designated channel.
- An interaction in the community is fostered with the mention of the role customization option for enhanced participation.
Link mentioned: Santa Mode & Video in Advanced Voice—12 Days of OpenAI: Day 6: Kevin Weil, Jackie Shannon, Michelle Qin, and Rowan Zellers introduce and demo the new Santa voice, as well as video and screensharing in Advanced Voice.
OpenAI ▷ #ai-discussions (417 messages🔥🔥🔥):
Project Astra, Gemini 2.0 vs. OpenAI, AI Image Generation, Voice AI Developments, AI Model Comparisons
- Project Astra gearing up to challenge OpenAI: Discussions highlight the anticipation around Project Astra, with some expressing confidence that it could outpace OpenAI's offerings.
- One user hinted that the release of Gemini 2.0 could be a game changer in the AI landscape.
- Gemini 2.0 seen as favorable over OpenAI: Users noted that Gemini 2.0 Flash is currently available on the web, attracting positive feedback for its performance compared to OpenAI's models.
- However, some reported issues with specific features like real-time video reading due to bugs.
- AI Image Generation tools buzzing: Several users discussed their experiences with various AI image generation tools, such as Hailuo and Sora, emphasizing the crowding of the services due to free credits.
- They shared generated content, with different responses to output quality, particularly when using various video formats.
- Voice AI technology advancing: Conversations around voice AI indicated that ElevenLabs' technology is being tested for realism, with mixed results on indistinguishability from human voices.
- Users are attempting to replicate human-like voice outputs but acknowledge challenges with certain inflections.
- General frustrations with AI services: Many discussed their frustrations about service rollouts, particularly the slower implementations from OpenAI compared to alternatives like Gemini.
- Concerns were raised about audio quality issues faced by some users, highlighting varying experiences between mobile and desktop platforms.
- Yap Yapper GIF - Yap Yapper Yapping - Discover & Share GIFs: Click to view the GIF
- GitHub - AlignAGI/Alignment: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources.: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources. - AlignAGI/Alig...
- no title found: no description found
OpenAI ▷ #gpt-4-discussions (21 messages🔥):
OpenAI service outage, Custom GPT file format, ChatGPT recovery updates, AI view feature release, User API call handling
- OpenAI service outage updates: A known outage affected OpenAI services from 3:16pm PST to 7:38pm PST on December 11, and traffic recovery began around 5:40pm for the API.
- As of the latest update, all services are now fully operational and OpenAI will conduct a root-cause analysis of the incident.
- Best file format for Custom GPT: One user inquired about the ideal file format for storing scenarios in a Custom GPT, currently using a Word document with a table.
- Another user suggested that a simple text file would be best for ease of access without unnecessary formatting complications.
- ChatGPT recovery progress: Users reported that ChatGPT is beginning to recover, yet knowledge of full restoration time frames remained uncertain.
- One user humorously suggested taking a break and watching a movie while waiting for service restoration.
- AI view feature rollout: In response to a question about the AI view feature, a user confirmed that it is rolling out now.
- Details on its full availability remain pending as it transitions from demo to live status.
- Handling API calls in Custom GPTs: A member discussed challenges in handling API calls, particularly when initial requests fail, and the need for repetition until success.
- Another participant emphasized that it’s vital to amend logic based on error responses, suggesting handling various HTTP status codes.
- API, ChatGPT & Sora Facing Issues: no description found
- OpenAI Status: no description found
OpenAI ▷ #prompt-engineering (5 messages):
Canmore Interaction Functions, Custom GPT for Presentation Slides, Formatting Evals
- Canmore's Interactive Functions Explained: A member detailed the Canmore tool's three main functions for managing text documents:
create_textdoc,update_textdoc, andcomment_textdoc, each accepting parameters in JSON format.- Not sure how accurate that is, but it's how 4o describes it serves as a disclaimer regarding the provided functionalities.
- Custom GPT for Lecture Presentations Requested: A user expressed interest in a custom GPT that processes PDF presentation slides and generates a natural language lecture, maintaining verbatim sentences while enhancing speech flow.
- They solicited pointers on existing solutions or valid prompts to develop such a tool.
- Discussion on the Canonical Tool Name: There was a confirmation from a member that canmore is indeed the correct name for the tool in question, emphasizing its canonical status.
- This aligns with previous mentions, adding clarity to the conversation about tool usage.
- Inquiry on Formatting Evals: A member sought assistance on how to correctly format evaluation metrics, indicating a need for guidance.
- The inquiry remains open-ended, with no responses currently provided.
OpenAI ▷ #api-discussions (5 messages):
Canmore Tool Functions, Custom GPT for Lectures, Formatting Evals
- Canmore's Tool Functions Detailed: One user provided insights into how the Canmore tool operates, outlining three functions:
canmore.create_textdoc,canmore.update_textdoc, andcanmore.comment_textdoc, each with specific JSON parameters required.- Another user confirmed that Canmore is the correct canonical name for the tool, supporting the initial participant's description.
- Request for Custom GPT Lecture Generator: A user expressed interest in a custom GPT model that converts PDF presentation slides into a natural language lecture, emphasizing the need to include each sentence verbatim while enhancing natural speech.
- They sought either existing models or relevant prompts to create such a functionality.
- Inquiry on Formatting Evals: A member inquired about the appropriate way to format evaluations in the context of their projects or discussions.
- Specific details or guidance were not provided in the conversation regarding this formatting question.
Perplexity AI ▷ #general (433 messages🔥🔥🔥):
Gemini Performance Comparison, Perplexity App Issues, Pro Subscription Queries, O1 and Reasoning Model, LinkedIn Integration Announcement
- Gemini performs complex research but is slow: Users noted that Gemini 1.5 Pro Deep Search is interesting for intensive research, citing that while it may outperform Perplexity, it takes significantly longer to respond.
- One user mentioned that Gemini's thorough responses are worth the wait for detailed research, compared to Perplexity's faster response times.
- Perplexity app experiencing user interface issues: Several users expressed frustration with the Perplexity MacOS app, highlighting problems such as misplaced icons, high CPU usage, and basic functionality failures.
- Users find the initial focus on text input lacks usability, detracting from the overall experience expected in 2024.
- Pro subscription discrepancies: Members shared confusion over Pro subscriptions, particularly regarding limitations and access issues, with some reporting sudden unavailability of services.
- There are suggestions that Perplexity doesn’t impose real limitations unless abuse is detected, prompting users to inquire about the differences with Enterprise Pro offerings.
- O1 reasoning model removal: Multiple users are questioning the disappearance of the O1 reasoning model from the platform, expressing a preference for its use in complex queries.
- A mention of the model being deemed unnecessary was discussed, as Pro users can automatically trigger reasoning for complex tasks.
- LinkedIn verification feature rollout: It was announced that Perplexity is rolling out LinkedIn verification, allowing users to connect their profiles for possible enhanced functionality.
- However, the reasons for this integration remain unclear, prompting curiosity among users.
- Back To Work Get Back To Work GIF - Back To Work Get Back To Work Working - Discover & Share GIFs: Click to view the GIF
- Tweet from Aravind Srinivas (@AravSrinivas): @caviterginsoy o1 is unnecessary (at least for now). Reasoning in pro triggers when the queries are complex automatically.
- Laugh Laughing GIF - Laugh Laughing Aman Gupta Meme - Discover & Share GIFs: Click to view the GIF
- Google AI Studio: Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
- Confused Kid GIF - Confused Kid Black - Discover & Share GIFs: Click to view the GIF
- Willem Dafoe Looking Up GIF - Willem Dafoe Looking Up Scared - Discover & Share GIFs: Click to view the GIF
- Tweet from TestingCatalog News 🗞 (@testingcatalog): NEW 🔥: Perplexity is rolling out LinkedIn verification!Users can connect to their LinkedIn profiles from the @perplexity_ai profile section. But it is yet fully clear why 👀
- Perplexity - Status: Perplexity Status
- Why has my order not arrived yet? | Perplexity Supply Help Center: no description found
- Maisa KPU: Explore the KPU, AI Operating System from Maisa
- Why has my order not arrived yet? | Perplexity Supply Help Center: no description found
Perplexity AI ▷ #sharing (6 messages):
B650E Taichi issues, Yong Yuan Niwan Cheng Sinaitoy, GPR devices and methodologies, Poetry requests, Advertising copywriting
- B650E Taichi Freezes: A member shared a link discussing issues related to their B650E Taichi motherboard freezing after certain updates, providing specific case details.
- Members are discussing possible solutions and troubleshooting steps to resolve the freezing issue.
- Exploring Yong Yuan Niwan Cheng Sinaitoy: Another link brings attention to Yong Yuan Niwan Cheng Sinaitoy, inviting readers to engage with the content and its implications, accessible here.
- Discussion surrounding this topic appears to be generating interest in its context and relevance.
- Investigating GPR Devices and Methodologies: A member referenced a link about GPR devices and methodologies to explore their applications in various fields, found at this link.
- This sparked conversations on innovations and techniques used in GPR technology.
- Creative Poetry Requests: A member requested a poem about a specific topic, sharing their creative intention through the link here.
- This call for creativity led to a discussion about poetic forms and styles preferred among participants.
- Crafting an Ad for One Million Dollars: A user sought help in crafting a compelling advertisement for one million dollars, with their request linked here.
- Participants began brainstorming catchy phrases and selling points to optimize the effectiveness of the ad.
Perplexity AI ▷ #pplx-api (6 messages):
Perplexity API card payment issues, 3D Secure transaction problems, Creation of Perplexity Pages
- API card payment issues freezing UI: A member reported that adding a card in the Perplexity API causes the UI to freeze, followed by the bank's 3D Secure screen appearing and disappearing, indicating that the transaction isn't authorized.
- This has prompted discussions on potential resolutions and the challenges of not using 3D Secure, which is standard among banks.
- Inability to bypass 3D Secure: Another member emphasized that 3D Secure is a necessity since most banks in their region implement it, making it impossible to proceed without this security feature.
- They are looking for alternative solutions to avoid issues with the Perplexity API while using the required security measures.
- Request for API endpoint for Perplexity Pages: A member inquired whether there exists an API endpoint for creating Perplexity Pages.
- In response, another user clarified that the API and the Perplexity website are distinct products and that no API currently exists for the main website.
Unsloth AI (Daniel Han) ▷ #general (265 messages🔥🔥):
DPO with Llama 3.3, Merging models and quantization, LoRA adapters and fine-tuning, 4-bit vs 16-bit model merging, Unsloth license and compatibility
- Successful DPO Implementation: Members confirmed that Direct Preference Optimization (DPO) can successfully be used with Llama 3.3, along with available documentation and examples.
- Theyruinedelise mentioned that the documentation provides clear guidance for implementing DPO, enhancing the ease of use for participants.
- Complexities of Merging Models: There was extensive discussion about the risks and recommendations for merging models, particularly regarding merging to 4-bit, which is discouraged to preserve the quality of LORA fine-tuned models.
- Disgrace6161 explained that merging LORA adapters into a 4-bit model may degrade performance, advocating for merging into full precision first.
- LoRA and Fine-Tuning Practices: Participants shared insights into the use of LORA adapters in fine-tuning, emphasizing that while LORA can optimize VRAM usage, merging should be done cautiously to maintain model quality.
- It was noted that higher ranks in LORA might lead to better performance, contingent upon the specific tasks and datasets used.
- Quantization Considerations: Discussion arose regarding the efficacy of 4-bit quantization compared to 16-bit, with members highlighting that 4-bit typically shows a reduction in performance.
- Feedback indicated that 4-bit should be treated as a final step, rather than an initial merge to avoid compounded degradation of model accuracy.
- Unsloth Licensing Insights: Members touched on the reasons for Unsloth's different licensing, aimed at protecting intellectual property from being misappropriated by other entities.
- Theyruinedelise clarified that the licensing is designed to maintain the integrity of the codebase while allowing home users to benefit from it without restriction.
- Finding the best LoRA parameters: How alpha, rank, and learning rate affect model accuracy, and whether rank-stabilized LoRA helps.
- LoRA Learns Less and Forgets Less: Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In t...
- Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments - Lightning AI: LoRA is one of the most widely used, parameter-efficient finetuning techniques for training custom LLMs. From saving memory with QLoRA to selecting the optimal LoRA settings, this article provides pra...
- unsloth/Llama-3.3-70B-Instruct-bnb-4bit · Hugging Face: no description found
- Reward Modelling - DPO, ORPO & KTO | Unsloth Documentation: To use DPO, ORPO or KTO with Unsloth, follow the steps below:
- multi gpu fine tuning : Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
SPDL: Faster AI Model Training, Thread-based Data Loading, Reality Labs AI Research
- SPDL Accelerates AI Model Training: The SPDL blog post discusses how SPDL optimizes AI model training by implementing thread-based data loading techniques.
- This approach reduces training time significantly, enhancing performance efficiency during research at Reality Labs.
- Impact of Thread-based Data Loading: By utilizing thread-based data loading, SPDL is able to streamline data management and reduce bottlenecks during the training process.
- The blog highlights that this method is crucial for handling larger datasets and improving throughput.
Unsloth AI (Daniel Han) ▷ #help (15 messages🔥):
Unsoth AI Installation Issues, Fine-Tuning Process, Multi-GPU Training Memory Error, Using Colab for Training, Ollama Setup
- Seeking Help with the Unsloth Model Training: A user encountered a
ValueErrorwhile attempting to train the modelunsloth/Llama-3.2-11B-Vision-Instructwith a custom collator they provided.- They suggested that others lend assistance as they might have insights on why the model fails to recognize tokens.
- Advice on Starting Fine-Tuning: A member expressed uncertainty about how to start fine-tuning after successfully installing Unsloth, prompting another user to share a tutorial link on the topic.
- The tutorial guides users in creating a customized personal assistant similar to ChatGPT.
- Memory Error During Multi-GPU Fine-Tuning: A user shared a link to their multi-GPU fine-tuning notebook that triggers a memory error after a few training steps and requested help to resolve the issue.
- They were given a link to their notebook hosted on Kaggle for further analysis.
- Colab Notebook for Unsloth: A user posted a link to a Colab notebook for accessing the training code related to Unsloth.
- The notebook is intended for users looking to experiment with the model and troubleshoot issues.
- Navigating Unsloth Installation Instructions: Instructions were shared on proper installation procedures to avoid issues while setting up Unsloth, including links to relevant GitHub repositories.
- Emphasis was placed on beginning the fine-tuning process with the appropriate model version specified in the instructions.
- - YouTube: no description found
- Google Colab: no description found
- multi gpu fine tuning : Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Unsloth Documentation: no description found
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- EASILY Train Llama 3 and Upload to Ollama.com (Must Know): Unlock the full potential of LLaMA 3.1 by learning how to fine-tune this powerful AI model using your own custom data! 🚀 In this video, we’ll take you throu...
- GitHub - unslothai/unsloth: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #research (3 messages):
OpenPlatypus Dataset, Minimum Wage Debate in Stenland, QwQ Model Development, Mathematics Aptitude Test of Heuristics Dataset
- OpenPlatypus Dataset Released: A new dataset called OpenPlatypus consisting of 25,000 samples has been released, which was run against Qwen QwQ at temperature 0, costing $30 on OpenRouter.
- It was suggested to exclude responses longer than 5000 tokens and shorter than 100 tokens, with an idea to perform k-means clustering after reducing the sample size.
- Minimum Wage Concerns in Stenland: A discussion highlighted concerns around raising the minimum wage in Stenland, particularly regarding potential impacts on employment if employers face higher costs.
- One option proposed stated that if raising the minimum wage did not increase employer contributions to benefits, this could alleviate some financial burdens and mitigate negative effects.
- Creating QwQ Models: A member is developing 14B and 3B QwQ models using the earlier mentioned dataset but has not yet tested them.
- This approach aims to turn any model into a QwQ version, suggesting practical applications for model adaptations.
- MATH Dataset for Benchmarking: The Mathematics Aptitude Test of Heuristics (MATH) dataset consists of problems from various math competitions, containing detailed step-by-step solutions.
- It was recommended to utilize this dataset for benchmarking purposes with QwQ, while filtering out certain benchmark questions for relevant comparisons.
- hendrycks/competition_math · Datasets at Hugging Face: no description found
- forcemultiplier/QwQ_OpenPlatypus_25k_jsonl · Datasets at Hugging Face: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (208 messages🔥🔥):
Upcoming 5090 GPU release, Scalping practices for GPUs, Model recommendations for image generation, Challenges with Stable Diffusion models, Discord community for Local Video AI Models
- Anticipation for the 5090 GPU: Members shared excitement over the upcoming 5090 GPU launch expected in early January, noting its 32GB VRAM capacity.
- In AI time, that like years became a humorous sentiment reflecting the wait until the GPU's release.
- Discussion on Scalpers and Buying GPUs: Concerns over scalpers buying GPUs led users to discuss the use of web scrapers and other methods to secure cards on launch day.
- With many stating that patience is needed, one noted that without a physical presence in the US, securing the card becomes even harder.
- Model Recommendations for Image Generation: Users recommended models like dream shaper, juggernaut, and SDXL for generating specific content such as spaceships.
- Some suggested experimenting with LoRA training if needed, while others noted that 8GB VRAM could be limiting.
- Challenges with Stable Diffusion Models: Members recounted difficulties experienced when using older models such as WD1.4 posing problems like generating strange results.
- Suggestions were made regarding captioning regularization images when training LoRA to improve outcomes.
- Finding Community Discords for Video AI Models: One user inquired about a good Discord server for discussing local video AI models, specifically mentioning Mochi, LTX, and HunYuanVideo.
- The Banodoco Discord server was recommended as a suitable community for those interested.
- Reddit - Dive into anything: no description found
- GitHub - TencentQQGYLab/ComfyUI-ELLA: ELLA nodes for ComfyUI: ELLA nodes for ComfyUI. Contribute to TencentQQGYLab/ComfyUI-ELLA development by creating an account on GitHub.
- GitHub - jhc13/taggui: Tag manager and captioner for image datasets: Tag manager and captioner for image datasets. Contribute to jhc13/taggui development by creating an account on GitHub.
- Moe Mix - v1.0 | Stable Diffusion Checkpoint | Civitai: This is my second model merge. It uses 8 different models including a custom tuned SD1.5 base. Please share and enjoy.
Eleuther ▷ #announcements (1 messages):
Training Jacobian Analysis, Parameter Space Dynamics, Neural Network Training, Impact of Data on Training, Upcoming Papers Series
- Training Jacobian reveals parameter dependencies: This new paper analyzes the training Jacobian, showing how final parameters depend on their initial values by transforming a small sphere in parameter space into an ellipsoid.
- Jacobian singular values indicate stable and chaotic subspaces, with stability emphasized in the bulk region where parameters change minimally.
- Bulk and chaotic subspaces identified: The analysis divides the singular value spectrum into three regions: the chaotic region, a stable bulk, and a low-dimensional structure that varies with input data but not labels.
- Training on white noise compressed the parameter space more aggressively than training on real data, highlighting its effects.
- Computational challenges in Jacobian analysis: Computing the entire training Jacobian is computationally intractable for larger networks, limiting in-depth analysis.
- The study primarily used a 5K parameter MLP, finding similar singular value trends in larger models, such as a 62K parameter image classifier.
- Explore upcoming research papers: This paper is the first in a series on neural network training dynamics and loss landscape geometry.
- Interested participants are encouraged to check the <#1052314857384460398> channel for further involvement.
- Access paper and code: The paper can be accessed through arXiv and includes supplementary code hosted on GitHub.
- The discussion included a Twitter thread that features insights from the paper and its implications.
- Understanding Gradient Descent through the Training Jacobian: We examine the geometry of neural network training using the Jacobian of trained network parameters with respect to their initial values. Our analysis reveals low-dimensional structure in the training...
- GitHub - EleutherAI/training-jacobian: Contribute to EleutherAI/training-jacobian development by creating an account on GitHub.
- Tweet from Nora Belrose (@norabelrose): How do a neural network's final parameters depend on its initial ones?In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final paramete...
Eleuther ▷ #general (70 messages🔥🔥):
RWKV model releases, AdamW weight decay significance, NeurIPS discussions, ARC prize controversies, Concerns over VAR paper misconduct
- RWKV Models Unveiled: Flock of Finches & QRWKV-6: The RWKV team announced the release of two new models: Flock of Finches 37B-A11B and QRWKV-6 32B Instruct Preview, showcasing impressive benchmark results on multiple tasks.
- Flock of Finches demonstrates competitive performance with only 109 billion tokens trained, while QRWKV-6 has already surpassed previous RWKV models in key metrics.
- Importance of Weight Decay in AdamW: A discussion arose regarding the significance of the weight decay setting in AdamW for affecting singular values, suggesting its inclusion in related papers.
- Community members noted that different weight decay settings could lead to varied results and highlighted the matrix shape's influence on weight scales.
- NeurIPS Prize Controversies and Discussions: The ARC prize sparked debates among members, with claims of goalpost moving and critiques about the motivations surrounding the prize's structure.
- Conversations hinted at possible manipulative tactics employed by some organizers, with members expressing skepticism about the validity of its benchmarks.
- Concerns Raised Over VAR Paper Misconduct: A report was shared concerning Keyu Tian, the first author of a NeurIPS 2024 best paper, alleging serious misconduct including malicious code attacks during his internship at ByteDance.
- Disruptive actions reportedly sabotaged research projects, leading to calls for the academic community to reconsider the paper's received accolades.
- Algorithmic Reasoning and Contest Sets: A lively exchange highlighted the ambiguity surrounding what constitutes true algorithmic reasoning, particularly in the context of contest sets and brute force methods.
- Members noted that benchmarks should ideally be solvable by humans and critiqued any attempts that might obscure the validity of the assessments.
- Ethical Challenges Related to the NeurIPS 2024 Best Paper Award: no description found
- Bluesky: no description found
- main (@main-horse.bsky.social): hard to imagine the skill level required to pull that off while also simultaneously sabotaging other teams
- Flock of Finches: RWKV-6 Mixture of Experts: The largest RWKV MoE model yet!
- recursal/QRWKV6-32B-Instruct-Preview-v0.1 · Hugging Face: no description found
- Q-RWKV-6 32B Instruct Preview: The strongest, and largest RWKV model variant to date: QRWKV6 32B Instruct Preview
Eleuther ▷ #research (117 messages🔥🔥):
Muon Optimizer, Negative Attention Weights, Attention Mechanism Insights, Prepending Information in Models, Alternative Softmax Approaches
- Muon Optimizer Shows Promise: A consensus emerged that Muon may be one of the best recent optimizers, with its underlying math being both insightful and plausible for better performance compared to existing methods like AdamW.
- Discussion reflected on how the gradient orthogonalization in Muon could be related to maximum manifold capacity loss, connecting it to regularization in reinforcement learning.
- Exploring Negative Attention Weights: The introduction of Cog Attention proposes an attention mechanism that allows for negative weights, which could enhance model expressiveness by enabling concurrent token deletion, copying, or retention.
- Concerns were raised about the method's effectiveness and potential learning difficulties, especially in specific settings like Sudoku applications.
- Challenges with Prepending Information: Participants discussed the potential drawbacks of prepending auxiliary information, like language, at training time without incorporating it at testing time, to avoid conditioning on inaccurate data.
- Suggestions included exploring EM-style approaches or modifying input representations to enhance the model's ability to generalize without relying on auxiliary information.
- Innovative Softmax Alternatives: One participant suggested exploring alternatives to the traditional softmax with ideas such as using tanh transformations to create a different normalization method for attention mechanisms.
- An exploratory thought on implementing a multivariate version of tanh was proposed, aiming to improve expressiveness while addressing the limitations of standard softmax.
- Understanding the Dynamics of Attention Mechanisms: The dynamics of attention mechanisms were critically examined, especially the implications of using alternate forms like negative attention weights and the effect on model expressiveness.
- The conversation highlighted potential alternatives for enforcing sparsity in attention without sacrificing the necessary complexity for effectively processing information.
- Tweet from rohan anil (@_arohan_): And here we go as the secret is out: I will be joining @AIatMeta ‘s Llama team next month to work on the next generation of llama models. And yes, I already have some llama puns ready before the next ...
- APOLLO: SGD-like Memory, AdamW-level Performance: Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing ...
- Weight decay induces low-rank attention layers: The effect of regularizers such as weight decay when training deep neural networks is not well understood. We study the influence of weight decay as well as $L2$-regularization when training neural ne...
- Understanding Optimization in Deep Learning with Central Flows: Optimization in deep learning remains poorly understood, even in the simple setting of deterministic (i.e. full-batch) training. A key difficulty is that much of an optimizer's behavior is implici...
- Muon: An optimizer for hidden layers in neural networks | Keller Jordan blog: no description found
- DeepNet: Scaling Transformers to 1,000 Layers: In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection i...
- Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws: Scaling laws describe the relationship between the size of language models and their capabilities. Unlike prior studies that evaluate a model's capability via loss or benchmarks, we estimate the n...
- Self-attention Networks Localize When QK-eigenspectrum Concentrates: The self-attention mechanism prevails in modern machine learning. It has an interesting functionality of adaptively selecting tokens from an input sequence by modulating the degree of attention locali...
- More Expressive Attention with Negative Weights: We propose a novel attention mechanism, named Cog Attention, that enables attention weights to be negative for enhanced expressiveness, which stems from two key factors: (1) Cog Attention can shift th...
- Large Language Models are Biased Because They Are Large Language Models: This paper's primary goal is to provoke thoughtful discussion about the relationship between bias and fundamental properties of large language models. We do this by seeking to convince the reader ...
- Patterns for Learning with Side Information: Supervised, semi-supervised, and unsupervised learning estimate a function given input/output samples. Generalization of the learned function to unseen data can be improved by incorporating side infor...
- Implicit Bias of AdamW: $\ell_\infty$ Norm Constrained Optimization: Adam with decoupled weight decay, also known as AdamW, is widely acclaimed for its superior performance in language modeling tasks, surpassing Adam with $\ell_2$ regularization in terms of generalizat...
- Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations: Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it doe...
Eleuther ▷ #lm-thunderdome (2 messages):
Saving model outputs
- Saving Model Outputs is Possible: A member raised a question about whether it's possible to save the model's outputs.
- Another member explained that by using the
--log_samplesflag along with--output_path, both model outputs and the text fed into the model will be saved at a per-document level.
- Another member explained that by using the
- Understanding Logging Parameters: The
--log_samplesflag must be utilized correctly to ensure proper logging of the model's outputs.- This option allows users to log outputs with the associated input text, enhancing traceability of the model's performance.
LM Studio ▷ #general (152 messages🔥🔥):
LM Studio Model Support, Running LLMs on Mac, Uncensored AI Models, Fine-tuning LLMs, GPU Configuration for LLMs
- LM Studio supports vision models, but with limitations: Members discussed that while LM Studio does support some vision models, users should be aware that not all models like llama-3.2 are compatible.
- One noted that if planning to attach images for analysis, not all models would yield satisfactory results.
- Running LLMs on Mac with M4 Pro and Max: Discussion highlighted that the M4 Pro chip can run LLMs, particularly 8b models with at least 16GB of RAM, and larger models require more RAM.
- An M4 Max was mentioned as capable of running 70b models but ensures users should prioritize RAM for flexibility.
- Challenges with Uncensored AI models: A user expressed frustration in finding guidance to create an uncensored AI model, highlighting a lack of clear resources for removing safety features.
- Advice was given to explore the Unsloth finetuning guides and consider utilizing datasets aimed at achieving less restrictive models.
- Fine-tuning LLMs and their feasibility: Participants discussed the complexity of fine-tuning LLMs, especially when dealing with numerical data, suggesting it may not provide the desired results.
- Alternatives like RAG for data retrieval were mentioned, indicating that traditional analytical methods might yield better insights for specific use cases.
- GPU Configuration and Performance: Users shared insights about their configurations, noting that GPU specifications and RAM significantly impact model performance.
- The benefits of prioritizing VRAM over raw processing power were discussed, emphasizing the importance of adequate mitigation for model loading.
- AutoTrain: no description found
- [1hr Talk] Intro to Large Language Models: This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What the...
- - YouTube: no description found
LM Studio ▷ #hardware-discussion (29 messages🔥):
LM Studio GPU Usage, Intel GPU Purchasing Decisions, Gaming Laptop RAM Limitations, B580 GPU Reviews, RTX 3060 Comparisons
- LM Studio utilizes multiple GPUs efficiently: Members discussed that LM Studio can spread tasks across multiple GPUs, confirming they should be of the same 'type' but not the same model.
- Heyitsyorkie added that GPU offload in LM Studio is simply a toggle that utilizes all GPUs if available.
- Debate over purchasing Intel GPUs: Koboldminion expressed curiosity about the B580 GPU, noting its affordability with 12GB of VRAM, but reservations about needing to use Vulkan.
- Others shared skepticism about Intel's GPUs for AI use, with mlengle emphasizing preference for Nvidia options due to CUDA support.
- Gaming Laptops may improve with RAM advancements: There was a conversation about current gaming laptop RAM support being maxed at 64GB, with hopes for future 128GB or 256GB capability.
- Heyitsyorkie claimed that Macbooks currently offer the best portable solutions for AI, with their unified RAM approach.
- Interest in B580 GPU reviews: A member shared a YouTube video on the B580 GPU claiming it offers the best VRAM/$ ratio on the market.
- Others anticipated innovative uses for the B580, such as combining multiple units for benchmarks.
- RTX 3060 seen as a viable alternative: Members discussed the RTX 3060, mentioning its 12GB VRAM and affordable second-hand prices between $150-$250.
- mlengle pointed out limitations of Intel GPUs due to their lack of CUDA support, reinforcing preference for Nvidia options.
- lmstudio-community (LM Studio Community): no description found
- Intel Arc B580 Review, The Best Value GPU! 1080P & 1440p Gaming Benchmarks: Support us on Patreon: https://www.patreon.com/hardwareunboxedYT Membership: https://www.youtube.com/channel/UCI8iQa1hv7oV_Z8D35vVuSg/joinBuy relevant produc...
Bolt.new / Stackblitz ▷ #announcements (1 messages):
Bolt beanie, 2024 Holiday Special
- Get Your Bolt Beanie!: You can now purchase a Bolt beanie for $30.00 as part of the 2024 Holiday Special available here.
- Made from 100% Turbo acrylic fabric, this beanie offers a one-size-fits-most design, ensuring warmth and style this holiday season.
- Quality Guarantee on Merchandise: Bolt guarantees the quality of their products; any print errors or visible quality issues will be either replaced or refunded.
- However, since items are made to order, general returns or sizing-related returns are not accepted.
Link mentioned: 2024 Holiday Special 🎅: The official website and shop of StackBlitz. Find the latest merch.
Bolt.new / Stackblitz ▷ #prompting (1 messages):
Deleting all chats, Chat history errors
- Deleting all chats fails to erase history: A member reported that when they delete 'all chats', it is not actually removing the chat history in the prompts, which leads to persistent errors.
- Any ideas on how to resolve this issue? Members expressed frustration with the ongoing problem.
- Repeated Errors from Chat History: Another member highlighted that the failure to delete chat history was causing recurring errors during prompting sessions.
- They suggested that better infrastructure might be needed to support the deletion functionality.
Bolt.new / Stackblitz ▷ #discussions (174 messages🔥🔥):
Token Usage Issues, Debugging with Bolt, Integration of Supabase, Frontend vs Fullstack Development, Feature Requests and Improvements
- Token Usage Confusion: Users reported discrepancies in token usage, specifically seeing 'NaN' for their remaining tokens after minimal use, prompting discussions on underlying issues.
- Support suggested reloading tabs or contacting help if the issue persists, as the display problem was being addressed.
- Debugging Challenges in Bolt: Several users faced issues with debugging in Bolt, occasionally leading to excessive token consumption without effective results.
- Recommendations included more focused prompts and using file pinning to prevent unwanted changes during complex tasks.
- Upcoming Supabase Integration: The community discussed the potential integration of Supabase into Bolt, which many believe will enhance functionality for building projects.
- Users expressed optimism that this integration could significantly streamline workflows, particularly for those transitioning from services like Firebase.
- Building E-commerce with Bolt: Discussion revolved around whether Bolt could be used to create a functional e-commerce site for selling digital products, with varying opinions on its capability.
- Encouragement was given to users, noting it was possible with effort and guided prompting despite potential challenges in context management.
- Feature Requests and Improvements: Users voiced suggestions for features, including better GitHub integration and more support for full-stack applications.
- The community emphasized the importance of approaching feature requests politely, directing them to the GitHub issues page for formal consideration.
- Silly Cat Silly Car GIF - Silly cat Silly car Car stare - Discover & Share GIFs: Click to view the GIF
- Understanding CORS in WebContainer: Learn about Cross-Origin Resource Sharing (CORS), its impact on WebContainer, and current limitations
- Prompting 101: Learn how to effectively communicate with AI assistants in Bolt.new
- Firebase Storage Integration: Learn how to integrate Firebase Storage for file uploads in your application
Notebook LM Discord ▷ #use-cases (17 messages🔥):
Custom Voices in AI, Roleplaying in TTRPGs, Post-Apocalyptic Musicals, AI-generated Podcasts, Using NotebookLM for Literature Review
- Custom Voices in AI for Podcasts: Several members expressed interest in using custom voices for their podcasts, with one suggesting to use Eleven Labs for voice cloning.
- A user highlighted the desire to utilize a professionally cloned voice, indicating the growing demand for personalized audio experiences.
- Running TTRPG Adventures with AI: A member inquired about running a TTRPG adventure using AI, reminiscent of solo D&D games, for immersive storytelling.
- Another member confirmed having tried this approach, indicating varied success but noting it as a fun endeavor.
- Exploring Post-Apocalyptic Musicals: A user suggested creating a post-apocalyptic musical, referencing the YouTube video titled UNREAL MYSTERIES 6: The Christmas Special which infuses humor and theme.
- This could pave the way for unique storytelling avenues combining music and dystopian settings.
- AI-generated Video Podcasts: A new AI-generated video podcast featuring a caveman and an AI chatbot explores profound themes like The Meaning of Life.
- The episode promises to blend humor and deep conversation, showcasing the intriguing dynamic between ancient and modern perspectives.
- Challenges with Literature Reviews in NotebookLM: A student researcher shared experiences using NotebookLM for literature reviews, mentioning limitations in extracting detailed information from papers.
- This raises questions about possible workarounds to enhance the depth of insights when utilizing this tool for academic research.
- no title found: no description found
- AI Podcast Caveman & Chatbot: When AI Meets the Stone Age: A New Video Podcast is Here! 🪨🤖🎙️ Deep questions. Timeless wisdom. Unlikely hosts.Introducing a groundbreaking (and rock-brea...
- UNREAL MYSTERIES 6: The Christmas Special - a Post-Apocalyptic Musical: Every good show has a Christmas Special and every good Christmas Special is a musical.... David and Hannah takes on Zombie reindeer, Australian Aliens, and l...
- Women Suck at EVERYTHING?! Debating Fresh and Fit's Myron Gaines @StandOutTV_: Myron Gaines from the FreshandFit podcast thinks women suck at everything. From driving to sports, he believes women are inferior to men. Join me as I debate...
Notebook LM Discord ▷ #general (125 messages🔥🔥):
NotebookLM Updates, Podcast Customization, YouTube Video Summaries, Gemini 2.0, Source Management
- NotebookLM set for UI overhaul with interactive features: NotebookLM will receive a new UI with separate sections for Sources, Chat, and Notes & Audio Overview, along with an 'Interactive Audio Beta' that allows real-time interaction with hosts Tweet.
- The update aims to enhance user experience with improved navigation and usability.
- Challenges with podcast customization: Users expressed difficulties in customizing podcast character personalities and controlling length, with recommendations to use specific prompts for better results.
- It was suggested to incorporate original source links into notes for easier reference later on.
- Discussion about Gemini 2.0 capabilities: Gemini 2.0 is anticipated to improve performance over the existing models, with expectations for higher output token limits and advanced features source.
- Concerns were raised about the potential limitations in context window size compared to previous models.
- Managing sources in NotebookLM: Users noted the current limitation of retrieving original source links after uploading them, with suggested practices like copying links as titles for easy reference.
- This workaround aims to maintain clarity about the origin of the extracted text used in generated responses.
- Engagement with YouTube and external tools: Members shared links to YouTube videos and tools that assist in summarizing content for better study results.
- The importance of using various platforms for enhanced learning experiences was also highlighted.
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: NotebookLM will be getting a new updated UI with 3 separate sections for Sources, Chat and Notes & Audio Overview 👀This also comes with an "Interactive Audio Beta" where users wi...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: NotebookLM will be getting a new updated UI with 3 separate sections for Sources, Chat and Notes & Audio Overview 👀This also comes with an "Interactive Audio Beta" where users wi...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: NotebookLM will be getting a new updated UI with 3 separate sections for Sources, Chat and Notes & Audio Overview 👀This also comes with an "Interactive Audio Beta" where users wi...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: NotebookLM will be getting a new updated UI with 3 separate sections for Sources, Chat and Notes & Audio Overview 👀This also comes with an "Interactive Audio Beta" where users wi...
- ideasthesia research - Google Search: no description found
- - YouTube: no description found
- How to use chatgpt https://chatgpt.com/share/675b31fa-5f50-8013-8ca7-289ad9534b13: https://chatgpt.com/share/675b31fa-5f50-8013-8ca7-289ad9534b13
- Trim and Crop YouTube videos - YouTubeTrimmer.com: YouTubeTrimmer.com: Trim and Crop YouTube videos online. A free online tool.
- - YouTube: no description found
- 10 NotebookLM Podcast Prompts YOU MUST know: NotebookLM Podcast is changing the game-so why settle for generic two-host chats? In this video, I'll reveal 10 secret prompts that will elevate your Noteboo...
- America's Book Of Secrets: DARPA's Secret Mind Control Technology (Season 4) | History: The Defense Advanced Research Projects Agency (DARPA) sets out on an initiative to develop nonsurgical neurotechnology - also used for mind control, in this ...
- A simple guide to chaos theory - BBC World Service: According to classical physics and the laws of Isaac Newton, it should be easy to predict the behaviour of objects throughout the universe with relative ease...
- What is String Theory?: Brian Greene explains the basic idea of String Theory in under 3 minutes. Thirty-five years ago string theory took physics by storm, promising the coveted un...
- Hailuo AI: Transform Idea to Visual with AI: Hailuo AI Tools - the innovative ai video generator & prompt that transform your ideas into stunning ai videos. Create captivating visuals in no time with cutting-edge AI-powered tech and a piece ...
- Behind the Scenes of Gemini 2.0: Tulsee Doshi, Gemini model product lead, joins host Logan Kilpatrick to go behind the scenes of Gemini 2.0, taking a deep dive into the model's multimodal ca...
- December 11, 2024: no description found
Nous Research AI ▷ #general (84 messages🔥🔥):
Hermes Model Benchmarks, Qwen and Mistral Discussions, Event Registration Updates, Math Benchmark Insights, Model Running and Fine-tuning Tools
- Benchmark Expectations for Hermes 3B: Users are interested in comparing benchmarks of Hermes 3B, Llama 3.2, and other models like Mistral 7B and Qwen 2.5.
- There is a discussion on the potential progression beyond Mistral 7B with enthusiasm for exploring various other models.
- Registration for Upcoming Events: Several users registered for an event with limited space, prompting discussions about registration processes and approval by hosts.
- Participants expressed excitement about meeting in-person and discussed the possibility of live streams or recordings for the talks.
- Math Benchmark Evaluation Insights: Senor1854 shared insights on a new math benchmark dataset emphasizing the reliability of evaluations compared to established ones.
- Users acknowledged how new benchmarks can contrast with previous scoring, emphasizing the importance of evolving evaluation techniques.
- Discussions on Running Models: Members sought advice on running various models like Hermes, with recommendations for using LM Studio for ease of access.
- There was a focus on tools available for running models through different platforms and the benefits of open-source solutions.
- Exploring New Model Training Methodologies: Kotykd proposed a novel training idea using big model hidden states to pretrain smaller models in a different architecture for efficiency.
- This sparked discussions about the feasibility of training methods, highlighting the need for further exploration and experimentation.
- WebLLM | Home: no description found
- NousResearch/Hermes-3-Llama-3.2-3B · Hugging Face: no description found
- NOUS @ NEURIPS · Luma: Thursday December 12thDoors @ 6pm, Talks @ 7pmLimited spaceDCTRL, 436 W Pender St, VancouverFood + Drink + Merch.Talks:DisTrO Demystified - @theemozilla…
- CYAI-vision-agent/README.md at main · carl-devin/CYAI-vision-agent: Main Repo: Vision AI agent, let's put cameras at work. Safer workplaces and streets. - carl-devin/CYAI-vision-agent
- Training Large Language Models to Reason in a Continuous Latent Space: no description found
- U-MATH & μ-MATH: Assessing LLMs on university-level math: Toloka is excited to announce U-MATH and μ-MATH, two groundbreaking benchmarks for evaluating LLMs on university-level mathematics.
Nous Research AI ▷ #ask-about-llms (10 messages🔥):
Amnesia mode in 3B, iOS apps for LLMs, Unfiltered Hermes, Context length in Ollama, Continuous SFT for Llama Instruct
- 3B lacks Amnesia mode: Members indicated that 3B does not seem to have an Amnesia mode, as one reported getting random continuations with an empty prompt.
- Don't think so was the general consensus regarding its functionality.
- iOS apps support custom models: A member questioned the availability of iOS apps for running LLMs with support for custom models or Hermes.
- Another shared their discovery that most apps indeed allow the use of custom downloaded models.
- Is smol Hermes unfiltered?: Inquiring about the new smol Hermes, one member asked whether it is unfiltered, noting previous versions were limited.
- Another shared that Hermes models often default to a friendly assistant mode, but can be adjusted with specific system prompts.
- Context length impacts in Ollama: A member raised a query about the placement of num_ctx in the system prompt while using Ollama.
- The discussion noted significant variation in model outputs when increasing context length, indicating a possible hidden impact.
- Continuous SFT for Llama Instruct comparison: One member asked whether Nous Research ever applied continuous SFT to Llama Instruct.
- They expressed interest in comparing its performance with theta-way methodologies.
Nous Research AI ▷ #research-papers (5 messages):
QTIP model analysis, Signal processing resurgence, Communication theory papers
- QTIP Surpasses AQLM without Retraining: A member expressed astonishment that the QTIP model outperforms AQLM without the need for retraining, signifying a significant advancement in model design.
- Looks like signal processing-like approaches are coming back in a big way, highlighting an interesting trend in model development.
- Concerns over Model Capacity Utilization: Another member noted that the model capacity utilization seems crucial, pointing out that Llama3 drops more in performance than expected.
- They plan to examine the provided paper in detail to understand these dynamics better.
- GitHub Repository for QTIP Project: A link was shared to the QTIP GitHub repository, where contributions to the development can be made.
- This repository is connected to the insights derived from the recently discussed paper.
- Interest in Communication Theory: Members have started reading papers on communication theory, possibly reflecting a shift in focus to earlier methodologies.
- As discussions deepen, this could lead to innovative applications of these theories in modern contexts.
Link mentioned: GitHub - Cornell-RelaxML/qtip: Contribute to Cornell-RelaxML/qtip development by creating an account on GitHub.
Nous Research AI ▷ #research-papers (5 messages):
Qtip Model Discussion, Model Capacity Utilization, Communications Theory in AI
- Qtip Model raises eyebrows: The recent findings on the Qtip model reportedly outperform AQLM without requiring retraining, which many find extraordinary.
- Initial reactions highlight a notable resurgence of signal processing techniques in machine learning strategies.
- Llama3 and Model Capacity Utilization: Discussions indicate that Llama3's performance is particularly affected by model capacity utilization, suggesting a deeper dive into model dynamics is necessary.
- One user mentioned needing to read the study in detail to fully understand the implications and results.
- Github Repository for Qtip: The Qtip model's development is documented in its GitHub repository, encouraging contributions.
- This repository is seen as a vital resource for researchers interested in the underlying mechanics of Qtip.
- Interest in Communication Theory: There are observations that some individuals in the community are exploring communication theory papers, signaling a trend in research focus.
- This reflects a curious merging of traditional communications theory with modern AI applications.
Link mentioned: GitHub - Cornell-RelaxML/qtip: Contribute to Cornell-RelaxML/qtip development by creating an account on GitHub.
GPU MODE ▷ #general (7 messages):
Intel CPUs, Intel Arc B580 vs RX 6750 XT, Torch Compile Performance, Dynamic Padding vs Performance Penalties
- Are Intel CPUs Worth It Now?: Members discussed the current status of Intel CPUs, with one remarking that they're not bad but recommended opting for Ryzen chips instead for similar pricing.
- The conversation highlighted varying opinions, depending on the specific use case for these CPUs.
- Comparing Intel Arc B580 with RX 6750 XT: A question was raised about whether the Intel Arc B580 is a better choice than the RX 6750 XT, indicating ongoing interest in GPU comparisons.
- No definitive answer was provided, but interest in performance between these two models persists.
- Performance Issues with torch.compile: A user reported anomalies in the performance after compiling a model with torch.compile(mode='max-autotune'), specifically slower initial runs with new conditioning shapes.
- Despite using dynamic=True, they experienced significant performance penalties, especially in the first and second decoder iterations.
- Questions on Dynamic Padding Solutions: The user acknowledged that while padding is an obvious solution for handling variable-length inputs, they hoped dynamic=True would mitigate performance hits.
- They noted that similar issues occurred previously and posed a request for suggestions to avoid the performance dips.
GPU MODE ▷ #triton (8 messages🔥):
Fused Kernel for Matmul and Softmax, Fused Attention and Flash Attention, Elementwise Operations on FP16 vs FP32, Floating Point Precision in Triton, Resource Requests for Triton Fused Attention
- Fused Kernel for Matmul and Softmax Query: A member is trying to create a fused kernel for matmul and softmax, expressing familiarity with fusing point-wise activations like ReLU but challenges with softmax operations.
- They seek guidance on utilizing the group-ordered matmul example from Triton's documentation for this purpose.
- Confusion about Outer Loop Parameter in Fused Attention: A user inquired why the outer for loop in
_attn_fwd()passes4-STAGEto_attn_fwd_inner()instead of just thestagedirectly.- This aspect has sparked curiosity among multiple members regarding its implementation.
- Floating Point Value Differences in Masking Logic: A member found the use of
-float('inf')form_iand-1.0e-6in masking logic to be confusing, suspecting floating point precision issues.- This has raised questions about the rationale behind choosing different floating-point values for similar operations.
- Elementwise Operations in Triton with FP16 and FP32: One member is exploring ways to perform elementwise operations on matrix FP16 using FP32 instructions in Triton, noting performance concerns with automatic type conversions.
- They referenced specific code from the flash attention tutorial that demonstrates the challenges around data type management.
- Request for Resources on Fused Attention: In light of the numerous questions surrounding fused attention, a member inquired about resources that explain the code in detail.
- They suggested the possibility of having a quick session with someone experienced in the area to clarify doubts.
GPU MODE ▷ #cuda (9 messages🔥):
Best GEMM Implementations, Occupancy and Branching, CUDA Programming Techniques, GPU Glossary Release
- Discussing Best GEMM Implementations: A member inquired about the best-performing GEMM implementation excluding cuBLAS, suggesting options like pure CUDA, Triton, or CUTLASS.
- Another member responded, asserting that CUTLASS is likely the top option available.
- Theoretical Query on Occupancy and Branching: One member posed a theoretical question regarding occupancy when using two different branches in a kernel, one heavier and one lighter in register usage.
- Another member clarified that register allocation happens at compile time, hinting that the passed argument would not affect the number of threads.
- CUDA Programming Workarounds: In response to the branching question, a member suggested using template arguments as a workaround for increased flexibility.
- The proposing member seemed optimistic about this approach, indicating it could be an interesting solution.
- Exciting GPU Glossary Announcement: A member announced the release of the GPU Glossary on Modal, sharing a link for members to access it.
- Others expressed gratitude for the shared resource, indicating it was well-received within the community.
Link mentioned: GPU Glossary: A glossary of terms related to GPUs.
GPU MODE ▷ #torch (2 messages):
Forward and Backward Hooks, Activation Checkpointing, Context Function in Checkpointing
- Interesting Behavior with Hooks and Checkpointing: A member reported encountering interesting behavior with forward and backward hooks when using activation checkpointing, where the forward hook prints twice during the backward pass.
- They noted that the forward hook fires once without checkpointing, leading to confusion while rerunning due to the forward pass requirement.
- External Variable to Track Backward Pass: To address the forwarded behavior during backward pass, a member implemented an external variable that tracks whether it's the backward phase, setting it to True before
loss.backward().- This adjustment enables the forward hook to decide whether to execute its logic based on the variable's state.
- Utilizing context_fn in Checkpointing: Furthermore, another approach discussed involves using the
context_fnargument in checkpoint() to manage behavior during backward passes.- This method allows customization of how the checkpoint function operates, potentially serving as an alternative to using an external variable.
GPU MODE ▷ #algorithms (1 messages):
konakona666: https://arxiv.org/pdf/2302.02451 smth like that?
GPU MODE ▷ #cool-links (3 messages):
vLLM Office Hours, Machete GEMM Kernel, Trillium TPU, Gemini 2.0 AI Model, Building ML Systems
- Insights from vLLM Office Hours: The recent vLLM Office Hours discussed Machete, Neural Magic's latest mixed-input GEMM kernel optimized for NVIDIA Hopper GPUs.
- This innovation highlights a substantial advancement in mixed-precision inference, significantly enhancing performance for compute and memory-bound tasks.
- Building Machine Learning for Massive Operations: A YouTube video discusses the evolution of Machine Learning and its enormous implications across various sectors over the last decade.
- The presentation emphasizes how ML has permeated everything from the tech industry to even receiving a Nobel Prize.
- Google's Trillium TPU Launch: Google Cloud has announced that Trillium, their sixth-generation TPU, is now generally available, designed to meet the intense demands of large-scale AI models.
- Trillium TPUs were crucial in training the new Gemini 2.0 AI Model, known for its enhanced capability and efficiency.
- vLLM Office Hours - Exploring Machete, a Mixed-Input GEMM Kernel for Hopper GPUs - December 5, 2024: In this session, we explored Machete, Neural Magic's newest innovation in mixed-input GEMM kernel design for NVIDIA Hopper GPUs. Built on top of advancements...
- Building Machine Learning Systems for a Trillion Trillion Floating Point Operations: Over the last 10 years we've seen Machine Learning consume everything, from the tech industry to the Nobel Prize, and yes, even the ML acronym. This rise in ...
- Trillium TPU is GA | Google Cloud Blog: Trillium, Google’s sixth-generation Tensor Processing Unit (TPU) is now GA, delivering enhanced performance and cost-effectiveness for AI workloads.
GPU MODE ▷ #torchao (4 messages):
Float8 Training Implementation, DDP vs FSDP in TorchAO
- Float8 Training with TorchAO Faces Challenges: A member shared their efforts in implementing float8 training using the torchao FP8 implementation but encountered issues when scaling to multi-GPU setups.
- While FP8 training runs smoothly on a single GPU, errors arise during the forward pass in larger configurations.
- Transitioning from DDP to FSDP Solutions: Another member suggested that most testing has been done using FSDP for data parallelism and encouraged sharing code or opening an issue on TorchAO for easier tracking.
- The initial implementation using DDP is noted as a stepping stone, with plans to switch to FSDP as the primary approach.
GPU MODE ▷ #off-topic (1 messages):
Video Game Datasets, Keyboard/Mouse Inputs, Labeled Actions in Games
- Seeking High-Quality Video Game Datasets: A member inquired about any high-quality video game datasets that include labeled actions, specifically looking for datasets that pair screenshots with keyboard/mouse inputs.
- They highlighted the need for datasets that show the results of inputs through subsequent screenshots, and the community might have recommendations for such resources.
- Need for Labeled Action Data: The request emphasized the importance of datasets that include both the keyboard/mouse inputs and gameplay outcomes to facilitate research or development.
- The community's input on available datasets could greatly aid in finding suitable resources for labeled action data in games.
GPU MODE ▷ #rocm (1 messages):
Instinct devices and XDP kernels, Gemms with CUDA core style MAC, GEMM DL examples in ROCm
- XDP Kernels Required for Instinct Devices: Inquired whether only XDP kernels utilizing V_MFMA op can be used on Instinct devices, or if there are kernels using classic CUDA core style MAC.
- This concern arose due to the compatibility issues of the GEMM DL examples which do not run on MI250.
- Concerns Over GEMM DL Example Compatibility: Noted that the GEMM DL examples from the ROCm repository are not compiled by default, specifically referencing this GitHub link for context.
- This situation raises questions about the execution of these examples and their compatibility with specific hardware setups.
Link mentioned: composable_kernel/example/01_gemm/gemm_dl_fp16.cpp at develop · ROCm/composable_kernel: Composable Kernel: Performance Portable Programming Model for Machine Learning Tensor Operators - ROCm/composable_kernel
GPU MODE ▷ #lecture-qa (1 messages):
CUDA Performance Checklist, Kernel Occupancy vs Duration
- Understanding Kernel Occupancy vs Duration: A member questioned why increasing the block size in the
copyDataCoalescedkernel from 128 to 1024 led to better occupancy (86% compared to 76%), yet resulted in increased duration from 500 microseconds to 600 microseconds.- They expressed a lack of intuition regarding the performance drop even with better occupancy and requested insights on this observation.
- Insights on Performance Metrics: Discussion emphasized the importance of breaking down performance metrics beyond occupancy, focusing on execution time and its correlation with block size in CUDA programming.
- Several members contributed thoughts on how memory access patterns influence performance, underscoring the complexity of optimizing for both occupancy and execution time.
GPU MODE ▷ #liger-kernel (1 messages):
0x000ff4: there is an update about KTO on #410
GPU MODE ▷ #self-promotion (11 messages🔥):
Pruna AI guest appearance, GPU Glossary creation, H100 GPU thread count confusion, Tensor core functionality, Register limitations
- Pruna AI seeks GPU mode collaboration: A member inquired about who to contact for arranging a guest appearance for Pruna AI on the GPU mode YouTube channel.
- Another member suggested that two specific users were previously involved in inviting others for talks.
- Launch of GPU Glossary sparks discussion: One member announced the creation of a GPU Glossary with Modal, detailing key terms like 'Streaming Multiprocessor' and featuring interconnected articles.
- Members discussed suggestions for refining the glossary, particularly about the accuracy of core counts and tensor core behaviors.
- Clarification on H100 GPU threading: A member questioned the 32 threads per Streaming Multiprocessor (SM) claim, noting that the H100 has 128 FP32 cores per SM, implying it should be 128.
- Discussion ensued regarding the GPU scheduler's operations, confirming each SM has 4 schedulers issuing one warp per cycle.
- Tensor cores operate differently: There was a suggestion to clarify that tensor cores utilize warp-level execution rather than a per-thread basis, contrasting with CUDA cores.
- Members acknowledged potential caveats regarding performance with int8 and fp8 on newer architectures.
- Register access limitations discussed: A member proposed including a mention of the limitation that registers are not dynamically addressable in the glossary's register page.
- They also suggested providing a code snippet to demonstrate efficient vs. inefficient register access patterns.
Link mentioned: Device Hardware | GPU Glossary: no description found
GPU MODE ▷ #🍿 (1 messages):
Markdown Blog Version, Eval Performance for Kernels
- Request for Markdown Blog: A member inquired if another has a markdown version of their blog, suggesting it could be used as a megaprompt.
- The intention behind this is to see if it may help improve evaluation performance for their kernels.
- Exploration of Megaprompts for Performance: The idea of using a megaprompt is under discussion, with hopes of enhancing the evaluation performance of their kernels.
- Utilizing a blog formatted in markdown could potentially yield better results in evaluation tasks.
GPU MODE ▷ #arc-agi-2 (23 messages🔥):
ARC Riddles and LLMs, Transduction vs. Program Induction, Test Time Training Extensions, Image Segmentation and GNNs, ARC Augmentation Strategies
- Leveraging LLMs for ARC Riddles: Members discussed using LLM-based annotations for ARC riddles, noting the importance of 2D representations and potential advantages of Vision Transformers. One member shared their experiments with different representations to improve outcomes.
- Ryan Greenblatt's approach with GPT4o ARV agents was mentioned as a promising method for program induction, suggesting a pursuit of similar strategies with vision-language models.
- Transduction vs. Program Induction Insights: There was a lively discussion on whether transduction could be more effective than program induction, with references to a paper stating both methods might be complementary. One member noted that challenges exist in sampling performance for LLM-based program searches compared to optimized discrete methods.
- The idea of an induction-transduction pincer movement was humorously suggested for tackling ARC from multiple angles.
- Enhancing Test Time Training Techniques: Ideas were shared regarding extending test time training by using various transformations to help models learn invariant properties in images. This approach could foster better understanding of the solutions to ARC riddles.
- Members considered the technical difficulties of combining segmentation methods with graph neural networks to create vector representations for LLM utilization.
- Exploring ARC Augmentation Strategies: A collection of augmentation techniques for ARC riddles was proposed, including rotation, flipping, and color mapping, to determine their effectiveness for test-time training. One member expressed intent to compile and share results from these experiments.
- It was acknowledged that augmentations are vital for training models capable of generalizing to unseen test examples, with ongoing interest in how best to leverage them.
- Hope for Better Compute Resources in ARC-AGI-2: Concerns were raised about the compute constraints imposed on participants in the ARC competitions, expressing hope for improved access to hardware like A100 GPUs. It was mentioned that the new dataset format for ARC-AGI-2 would be similar to ARC-1, possibly allowing filtering with existing solvers.
- Members planned to compile a materials and ideas list to strategize future projects, highlighting collaboration and preparation moving forward.
- Combining Induction and Transduction for Abstract Reasoning: When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using...
- Tackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects: The Abstraction and Reasoning Corpus (ARC) is a popular benchmark focused on visual reasoning in the evaluation of Artificial Intelligence systems. In its original framing, an ARC task requires solvin...
- arc-agi-2/arc-1/annotated-re-arc at main · open-thought/arc-agi-2: Building the cognitive-core to solve ARC-AGI-2. Contribute to open-thought/arc-agi-2 development by creating an account on GitHub.
- arc-research/prototyping/arc_vit at main · arc-community/arc-research: A repo where we test different hypotheses. . Contribute to arc-community/arc-research development by creating an account on GitHub.
- arc-research/prototyping/infer_func/infer_func.py at b8566c752c5d4163a3949769079887e88d0b92ac · arc-community/arc-research: A repo where we test different hypotheses. . Contribute to arc-community/arc-research development by creating an account on GitHub.
Cohere ▷ #discussions (26 messages🔥):
Cohere support issues, Timeout problems, System status updates, User interactions, Error messages
- Cohere support team is responsive: When users reported issues, members emphasized contacting the support team at support@cohere.com for urgent matters.
- Another user encouraged messaging directly for faster assistance, acknowledging the support team's presence.
- Intermittent timeout issues reported: Multiple users experienced 504 gateway timeout errors while using the Rerank feature, with one reporting requests timing out after 40 seconds.
- The issue appeared sporadic, as some members noted service restoration shortly after, with others still reporting challenges.
- System status confirmed operational: Cohere confirmed that their systems are fully operational, with a status update stating 99.84% uptime across components.
- Updates were shared on the Cohere Status Page with assurance that users should not face ongoing issues.
- User interactions show community engagement: Members actively communicated about their experiences, with one user relieved that their prior chat failures were resolved after debugging.
- The conversations highlighted a community willing to share support channels and report back on resolved issues.
- Resolution of previous issues acknowledged: After several discussions about downtime, users were finally informed that the prior issues had been resolved and all endpoints were operational.
- The community celebrated this resolution, signaling relief and gratitude for the updates provided throughout the troubleshooting process.
- Magic Eight GIF - Magic Eight Eightball - Discover & Share GIFs: Click to view the GIF
- Cohere Status Page Status: Latest service status for Cohere Status Page
Cohere ▷ #questions (40 messages🔥):
Quantization Techniques in Model Training, Cohere Go SDK Update Needs, Aya Expanse Model Usage, Model Calibration Datasets, Licensing Issues and Compliance
- Exploring Quantization Strategies: A discussion on the effectiveness of FP8 quantization revealed that with H100 hardware, it outperforms BnB for fast inference, especially under high user load.
- Members agreed that traditional calibration datasets like WikiText often fall short in practical performance, especially for non-English languages.
- Cohere Go SDK Requires Fixes: Feedback was provided regarding the Cohere Go SDK, indicating that the structure of the StreamedChatResponseV2 field related to tools calls is incorrect.
- It was noted that the definitions for ToolPlanDelta and ToolCallDelta are also missing necessary fields for accurate parsing.
- Aya Expanse Model Discussion: Users expressed a preference for using the Aya Expanse model in internal company settings, emphasizing the need for speed while avoiding potential data leaks.
- Concerns over the CC-BY-NC license were raised, leading to a discussion on the implications of non-commercial use even within corporate environments.
- Model Calibration Dataset Choices: The conversation highlighted the choice of calibration datasets, with Neural Magic’s approach using 2,048 samples from Ultrachat working effectively for English models.
- A member noted the difficulty of using Traditional Chinese data and suggested exploring multilingual datasets for better performance.
- Need for JSON Schema Examples: A request was made for clearer documentation on handling structured JSON, specifically for examples involving arrays of objects.
- This highlighted a gap in the documentation for structured outputs, prompting a need for explicit guidance on array handling.
- minyichen/aya-expanse-32b-Dynamic-fp8 · Hugging Face: no description found
- Structured Outputs — Cohere: This page describes how to get Cohere models to create outputs in a certain format, such as JSON.
- GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024): Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024) - hiyouga/LLaMA-Factory
Cohere ▷ #api-discussions (2 messages):
403 Error Response, VPN Usage, IP Information, Email Issues
- User Reports 403 Error Without VPN: A user reported receiving a 403 error response when attempting to access the service without using a VPN.
- They indicated that the issue persists even without VPN, hinting at potential region-specific restrictions.
- User's ISP and Location Details: The user provided their IP information as being from ChinaTelecom, based in Xiamen, Fujian, China.
- This detail may be relevant in determining the cause of the access issues they are experiencing.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Hackathon submission deadline, Submission platform change, Evaluation criteria, Announcement timeline
- Hackathon submission deadline on the horizon!: The submission deadline for the LLM Agents MOOC Hackathon is approaching fast, set for 12/17.
- Remember, all submissions must be completed by December 17th to be eligible for evaluation.
- Transition from Devpost to Google Forms: The hackathon has transitioned from Devpost to Google Forms for submissions; make sure to use the correct form linked in the message.
- This change is critical for ensuring your innovative solutions are counted in the competition.
- Eager anticipation for winner announcements: Winners of the hackathon will be announced in the first half of January 2025, adding excitement to the upcoming submissions.
- Participants are encouraged to submit before the deadline to impress the judges with their projects.
- Last-minute assistance available!: Members are reminded that if they need help or have last-minute questions, they can drop them in the chat.
- Additionally, visiting the hackathon website is advisable for more detailed information as the deadline approaches.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Advanced Large Language Model Agents MOOC, LLM technology advancements, MATHEMATICS in AI, AI Code Generation, Program Verification
- New MOOC on Advanced LLM Agents launches in Spring 2025!: The new Advanced Large Language Model Agents MOOC will launch in Spring 2025, building on the previous success from Fall 2024, focusing on topics like reasoning and AI for mathematics.
- This course promises to explore next frontier technologies in LLM agents, with sign-ups now open at this link.
- Syllabus still in development, more details to come: Stay tuned for more information regarding the syllabus, which is still under development, as conveyed by the announcement.
- Participants are encouraged to support Prof Song's upcoming posts for formal announcements regarding the MOOC.
- Course runs from mid January to early May: The Advanced LLM Agents MOOC is scheduled to run from mid January through early May, providing an extensive learning period.
- Potential participants are invited to explore course details further at the Advanced LLM Agents website.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (44 messages🔥):
Article Assignment Information, Quizzes and Certificate Requirements, Hackathon Participation, Course Feedback and Future Offerings, TA Assistance
- All Assignments Due December 12th, 2024: All assignments, including the written article, are due on December 12th, 2024, by 11:59 PM PST.
- This deadline applies to the article assignment which requires a link to a social media post featuring the article.
- Quizzes Are Completion-Based: Quizzes are graded on a completion basis, so scoring poorly won't affect your ability to earn a certificate.
- Participants should see their scores immediately upon quiz submission, and the intention is for learning rather than strict assessment.
- Hackathon Contribution Information: For the Ninja Tier, completing all quizzes and submitting the article assignment is essential, but labs are not required.
- Participants can write about their hackathon projects for the written article assignment.
- Course Preparedness for Future Offerings: The current course covers key introductory content vital for understanding agents, making it feasible for students to catch up quickly.
- Expected prerequisites include basic knowledge of Python and some exposure to machine learning or LLMs, making it suitable for many undergraduate students.
- Gratitude for TA Assistance: Participants expressed appreciation for the TA, commending their responsiveness and support throughout the course.
- The TA confirmed their ongoing commitment to helping students navigate the course.
- A Visual Perspective on Technical Concepts in AI Safety: Welcome! Understanding the intricacies of artificial intelligence and its potential risks can be challenging. This article aims to distill these technical conce
- Written Article Assignment Submission: INSTRUCTIONS:Create a Twitter, Threads, or LinkedIn post of roughly 500 words. You can post this article directly onto your preferred platform or you can write the article on Medium and then post a li...
Interconnects (Nathan Lambert) ▷ #events (3 messages):
Meeting Location, Event Details
- Clarification on Meeting Location: A member inquired about the meeting location by asking, 'Are we meeting up somewhere?'. Details were clarified with a response indicating that the meeting is on the second floor.
- It was further specified that the location is in the north east corner.
- Meeting Venue Confirmation: The conversation confirmed that the meeting is taking place on the second floor of the venue.
- Participants were directed to the north east corner for the exact meeting point.
Interconnects (Nathan Lambert) ▷ #news (4 messages):
Android XR, Gemini, Google's Augmented Reality, Live Translation, Smart Glasses
- Google's Big Bet with Android XR: Google introduced Android XR, a new mixed reality OS for headsets and smart glasses, showcasing its capabilities during a recent demo.
- Attendees experienced features like real-time translation with subtitles, marking Google's renewed commitment to augmented reality.
- Excitement Builds for Live Translation Features: Members expressed anticipation that live translation could revolutionize communication, noting it has been a long-awaited feature in tech.
- One attendee humorously recalled their surprise at seeing speech translated in real-time while wearing prototypes.
- All Eyes on Gemini's Performance: Feedback surfaced regarding the Gemini system working alongside Android XR, with users feeling positive about Google's direction.
- Participants noted that the combination of these technologies might signify a notable comeback for Google in the AR space.
Link mentioned: I saw Google’s plan to put Android on your face: This is the closest I’ve ever been to being Tony Stark.
Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
Content battles, Wholesome interactions
- Content Battle with Gary: A member expressed a need for someone to 'battle Gary' on their behalf regarding content.
- This highlights the competitive nature of discussions and the effort required to uphold one's viewpoint.
- Wholesome Atmosphere: The sentiment shared in the channel was described as 'so wholesome'.
- This suggests that despite potential conflicts, there is a positive and supportive community vibe.
Link mentioned: Michelangelo D’Agostino (@mdagost.bsky.social): I have no inside information, only what @natolambert.bsky.social wrote in that post:
Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
Nous Dunks, Nextcloud Promotion, Frankle-signed Databrick Bricks, OpenAI vs Anthropic, Claude Pro Subscription
- Compliment on Nous Dunks sparks mystery: A member received a compliment on their Nous Dunks and hinted at the mysteries behind the product's appeal, saying the admirer 'has no idea what goes on behind closed doors'.
- Fight!!! was their playful reaction to initial comments, suggesting a raucous atmosphere.
- Nextcloud: An open-source favorite: One enthusiast shared their love for Nextcloud.com, promoting it as a superior open-source platform that they advocate for regularly.
- They expressed gratitude towards its functionality, indicating strong satisfaction with the service.
- Desire for Frankle-signed Databrick Bricks: A user expressed a strong desire for frankle-signed Databrick bricks, humorously noting that it ranks just below a sword as their wished item.
- This showcases a lighthearted attitude towards collecting tech memorabilia.
- OpenAI and Anthropic tensions rise: A detailed analysis highlighted increasing tensions between OpenAI and Anthropic, with both companies vying for market leadership and coding supremacy.
- Anthropic's growth in coding applications has OpenAI executives concerned, with reports revealing a shift from safety focus to aggressive strategies in marketing.
- New Claude Pro subscriber speaks out: A member admitted to finally subscribing to Claude Pro, showcasing the growing interest in competitive AI tools.
- The playful remark towards Dario signals camaraderie within their group regarding the decision.
Link mentioned: Tweet from Tibor Blaho (@btibor91): The Information details rising tensions between OpenAI ($4B revenue in 2024, $157B valuation) and Anthropic ($1B in ARR by end of 2024, $18B valuation), highlighting Anthropic's growth in coding a...
Interconnects (Nathan Lambert) ▷ #cv (9 messages🔥):
MLLM developments sources, VLM insights by Hugging Face, MVLM posts request, University courses on MLLM
- Seeking quality sources for MLLM developments: Members expressed interest in tracking MLLM developments and highlighted the need for better sources, with some resorting to scraping information.
- One user plugged their Twitter feed here as a potential source.
- Hugging Face's Merve shares valuable insights: A member recommended following Merve from Hugging Face for good content related to VLMs via this link.
- It's suggested that her posts are informative and relevant for those interested in this field.
- Request for in-depth MVLM posts: A member noted the lack of long, updated MVLM posts from trusted authors like Lilian W and expressed disappointment in the current landscape of high-level resources.
- They mentioned that university courses on the topic seem limited, citing Stanford's multimodal class as lacking depth.
- Potential for personal MVLM insights: A member considered writing their own MVLM post, acknowledging that creating content of Lilian's quality would be challenging but worthwhile.
- Another member offered encouragement, humorously stating they would provide feedback on quality for free if the effort was made.
- Tweet from undefined: no description found
- Tweet from undefined: no description found
Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
AI Model Creative Benchmarking, Algorithmic Responsibility, Claude's Spam Problem, Tulu 3 Post-Training Techniques
- AI Model Creativity Benchmarking Discussion: The community discussed possible tasks to measure LLM capabilities in 'creative' tasks, pointing out the lack of meaningful benchmarks for creativity and diversity.
- In particular, users expressed discontent that despite Claude-3 being their favorite, it often ranked lower in benchmarks related to creative writing.
- Participatory Algorithmic Responsibility Terms: A member appreciated the term 'algorithmic decision-making systems' in the context of participatory approaches to algorithmic responsibility.
- This terminology highlights the importance of user involvement in understanding how algorithms affect decision-making.
- Claude Tackles Spam with AI Insights: An article revealed that Anthropic's Claude chatbot faced a spam issue, as accounts sought to manipulate its text generation for SEO purposes.
- The piece emphasizes that while generating keywords isn't inherently wrong, manipulative tactics often evade detection, raising concerns for the platform.
- Exploring Tulu 3 Innovations: A recent YouTube talk covered 'Tulu 3: Exploring Frontiers in Open Language Model Post-Training,' focusing on innovations in RLHF and post-training techniques.
- Community members noted that insightful questions were raised during the session, especially by cohost Sadhika at the end.
- How Claude uses AI to identify new threats: PLUS: Exclusive data on how people are using Anthropic’s chatbot
- Tulu 3: Exploring Frontiers in Open Language Model Post-Training - Nathan Lambert (AI2): Reinforcement learning from human feedback (RLHF) and other post-training techniques are driving an increasing proportion of innovations on leading, primaril...
- Towards Benchmarking LLM Diversity & Creativity · Gwern.net: no description found
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
Discord critical mass, Technical issues
- User humor on technical issues: A member jokingly pondered whether they broke the system after stating, 'Wow it never came maybe I broke it lol.'
- This reflects the casual atmosphere of the conversation, even amidst technical challenges.
- Discord reaching critical mass: Another member remarked that Discord has reached a level of critical mass, implying its robustness and user base stability with the statement, 'Discord has critical mass now it’s okay.'
- This suggests a positive outlook on the platform's growth and user's confidence in its operational status.
LlamaIndex ▷ #blog (3 messages):
CalPitch Tool, RAG Agents & SharePoint, Google Gemini 2.0 Launch, Llama Index Compatibility
- Calsoft launches CalPitch for Business Development: Calsoft created CalPitch, a tool assisting their business development team in researching prospects and drafting outreach emails with human oversight.
- This showcases how AI can enhance and speed up current workflows.
- Build RAG agents with SharePoint Permissions: A new feature allows building RAG agents that respect SharePoint permissions, addressing a regular request from Azure stack users to connect to enterprise data sources.
- Users can now enjoy a more tailored experience with their data in compliance with existing permissions structures.
- Google unveils Gemini 2.0 models with Day-0 support: Google launched its latest Gemini 2.0 models, including day-0 support, available via
pip install llama-index-llms-geminiorpip install llama-index-llms-vertex.- The model, particularly the Gemini 2.0 Flash, promises enhanced speed and capabilities, hailed as a game changer in the AI landscape.
Link mentioned: Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode: Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and …
LlamaIndex ▷ #general (21 messages🔥):
Slack Bot Personalization, Techniques for Unstructured PDF, Function Calling Defaults, BGEM3 Model Integration, Setting System Prompts in FunctionCallingProgram
- Personalizing Slack Bot with ReAct Agent: A user is building a Slack bot using the ReAct Agent and seeks advice on making it demonstrate personality without disclosing it’s an AI.
- Another member suggested using FunctionCallingAgent with a system prompt to customize its personality.
- Optimizing RAG with LlamaParse for PDFs: LlamaParse is recommended for parsing unstructured PDF data, ensuring high-quality input for LLM applications while handling various file types.
- Concerns about data privacy were addressed, assuring that no data is retained beyond 48 hours.
- Defaults in Function Calling with OpenAI: It was clarified that
strict=Trueis not the default in FunctionCallingProgram due to latency issues and compatibility with Pydantic classes.- Members were informed that setting
strict=Trueis possible but it may lead to breaking some Pydantic classes.
- Members were informed that setting
- Integrating BGEM3 with Qdrant Database: A user inquired about integrating the BGEM3 model with a Qdrant database through LlamaIndex, seeking guidance on the process.
- Resources related to BGEM3 were shared for further assistance.
- Setting System Prompts in FunctionCallingProgram: Users can pass a ChatMessagePromptTemplate to the FunctionCallingProgram to set custom system prompts easily.
- Options for setting tool choices were also discussed to optimize function calls within the program.
Link mentioned: LlamaParse - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
Athina AI, LLM Experiments, Prompt Engineering Techniques
- Exploring Athina AI for LLM Experiments: A demonstration was created to test various prompt engineering techniques on medium to high-level problems using the YC startup Athina AI.
- The member praised Athina AI as a strong product for running experiments with both open and closed source LLMs.
- Demo Video Shared for LLM Testing: An attached demo video showcases the testing in action.
- This video aims to provide insights into the various techniques being applied in the Athina AI testing process.
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
New Forum Experience, Excitement for Upcoming Events, User Level Advancement, Company Praise
- Users enjoy the revamped forum: Members expressed their appreciation for the new forum feel, with one stating it is really nice.
- Feedback highlights include a more engaging user interface and overall experience.
- A week full of fun promised: A member mentioned that they were promised a week of fun ahead, generating excitement within the community.
- This promise has created a buzz among users, adding to the community's enthusiasm.
- User advances to level 6: <@360038721778745345> celebrated moving up to level 6 in the community rankings, receiving congratulations from other members.
- Such achievements often foster a friendly competitive spirit among participants.
- General positive company sentiments: Expressions like 'Lit' and 'Cool company' reflect positive member sentiments towards the organization.
- These remarks contribute to a culture of appreciation within the community.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Swag challenge, Ask Me Anything sessions, Community packages early access, Async Mojo implementation, Mojo optimization pipeline
- Swag Challenge Winners Announced: We kicked off the week with a swag challenge on Monday, and winners were announced here. Ahmed also hosted an Ask Me Anything session about GPU programming with Mojo.
- Joe's Insights on Standard Library: On Tuesday, Joe hosted an Ask Me Anything session on the standard library. This session provided valuable insights into the functionalities and features of the library.
- Launch of Early Access Preview for Community Packages: Yesterday, we launched the early access preview of community packages, encouraging users to join and help test the packaging. Interested users can register in <#1098713770961944628> to gain access to the instructional <#1313164738116583454> channel.
- Ask Me Anything Sessions Today: Today features ask Steffi anything about async Mojo/coroutine implementation in MLIR and ask Weiwei anything about the Mojo optimization pipeline. These sessions aim to deepen understanding of specific technical topics.
- Prepare for Tomorrow's Challenge!: Participants are encouraged to stay tuned for tomorrow's exciting challenge! 🥳 Make sure to check back for more details.
Modular (Mojo 🔥) ▷ #mojo (10 messages🔥):
Open sourcing Mojo, Mojo's mascot, Boitatá, Mojo character name
- Curiosity About Mojo's Open Sourcing Timeline: A member inquired about the timeline for Mojo being open sourced, expressing interest in its future availability.
- Though no specific timeline was provided, the question highlighted ongoing interest in open source developments.
- Discussion on Mojo's Mascot: Members referenced a discussion about Mojo's mascot, particularly relating to Boitatá, a Brazilian mythological creature linked to Mojo's identity.
- This connection sparked curiosity about the character's identity and suggested potential cultural significance.
- Naming the Little Flame Character: Members shared thoughts about the small flame character, initially unsure if it had a name or if it was a species of little flame beings.
- Eventually, it was confirmed that the character is simply named Mojo, bringing some clarity to earlier confusion.
- Humorous Engagement Regarding Mojo: Members had a light-hearted interaction, discussing the simplicity of the character name and sharing laughs about the mascot's identity.
- Such exchanges reflect the casual, fun atmosphere within the community surrounding Mojo.
Link mentioned: Mojo mascot? Python+Mojo=Boitatá (brazilian mythological creature) · modularml/mojo · Discussion #941: Not a issue itself, but something curious for me being Brazilian which brings me an idea. Mojo being a superset of Python (or a "Python++"), reminds me of a famous monster in Brazilian folkl...
DSPy ▷ #show-and-tell (2 messages):
DSPy, Prompt Optimization, Categorization Tasks
- DSPy Framework for LLMs: A member introduced DSPy as a framework for programming language models, which significantly reduces the time spent on prompting.
- “DSPy is the framework for programming—rather than prompting—language models,” emphasizing its efficiency in creating LLM-powered applications.
- Effortless Prompting with Boilerplate: The approach of DSPy utilizes boilerplate prompting, allowing users to define tasks through signatures, which simplifies the prompt creation process.
- This method aids in framing various tasks in a clean and efficient manner, making interactions with LLMs less cumbersome.
- Explaining DSPy's Categorization Example: A simple categorization task was used to illustrate how DSPy operates and its usefulness as a tool.
- This example showcased the framework's practical application, helping to clarify its advantages.
Link mentioned: Pipelines & Prompt Optimization with DSPy: Writing about technology, culture, media, data, and all the ways they interact.
DSPy ▷ #general (12 messages🔥):
Video and Audio Input Discussion, LLM Agent Definition Debate, Use of Optimizers with Labeled Data, Impact of AI on Conventional Categories
- Investing in Text and Image Inputs: Members debated the value of video and audio inputs, with one suggesting a focus on text and image inputs for the time being.
- I might be short sighted but I feel like investing in text and image input is best for now.
- What is an LLM Agent? Debate: A member initiated a discussion about the definition of 'LLM agents', sharing a thread that explores its metaphorical implications.
- Several participants humorously acknowledged the debate's controversial nature, noting you've kicked the bee's nest now.
- Optimizers with Labeled Data Usage: In response to a query, it was confirmed that optimizers can indeed be used with labeled data, particularly gold standard input-output pairs.
- The confirmation prompted further engagement from members expressing collective interest.
- AI as a New 'Platypus' in Technology: One member reflected on how AI challenges existing categorizations and conventions, likening it to a 'platypus' in tech.
- They highlighted that AI may be the most significant example yet, stating, Nearly every notable quality of AI and LLMs challenges our conventions, categories, and rulesets.
- The Platypus In The Room: Writing about technology, culture, media, data, and all the ways they interact.
- Tweet from Omar Khattab (@lateinteraction): I've long avoided the debate defining "LLM agents", since it felt silly. But OK:To the extent that there's a right answer, it's than an agent is an abstraction. A choice of metapho...
OpenInterpreter ▷ #general (6 messages):
Spider verse glitch effect, Issues with OI in Docker, GitHub model i tutorial update, NVIDIA NIM base URL setup, Thoughts on WebVoyager
- Searching for Spider Verse Glitch Effect: A user recalled seeing a website featuring a Spider Verse glitch effect and expressed a desire to find it again to replicate the effect.
- I thought I saw a website that had a spider verse glitch effect, showing keen interest in the creative aspect.
- Docker Issues with Open Interpreter: A member raised a concern regarding running Open Interpreter in Docker, noting it returns only the model's chat response rather than executing code.
- They suggested that the application seems to pretend to execute code without actually doing so.
- Changes to GitHub Model I Tutorial: Someone inquired about the recent changes to the GitHub page for the model i tutorial, stating that a lot of information has shifted.
- It seems like the GitHub page updated and a lot of stuff is different now, indicating confusion over the documentation.
- Struggles with NVIDIA NIM Base URL Links: A user sought assistance with setting up NVIDIA NIM base URL links, mentioning they've faced challenges without success.
- They expressed frustration, stating they have been trying for ages but have had no luck.
- WebVoyager vs. GPT 4V: A member asked for opinions on WebVoyager, indicating a preference to update the model to use GPT 01 instead of GPT 4V, believing it could offer better results.
- They are curious about testing it out and potentially switching models.
OpenInterpreter ▷ #ai-content (1 messages):
zohebmalik: Video to advanced voice mode in ChatGPT announced for day 6
tinygrad (George Hotz) ▷ #general (6 messages):
Test Coverage Tools, Finding Dead Code, Coverage.py, gcov tool, Code Quality
- Seeking Test Coverage Expertise: A member inquired about proficient users of test coverage tools to help identify dead code.
- They emphasized that if code is not tested, it should probably be deleted.
- Introduction to Coverage.py: Another member recommended Coverage.py for measuring code coverage in Python, noting it tracks executed code and analyzes unexecuted parts.
- The latest version, 7.6.9, was released on December 6, 2024, supporting multiple Python versions including 3.9 to 3.14 alpha 2.
- Discussion on Alternative Tools: A member suggested using gcov, a popular coverage tool, and inquired about more fine-grained options.
- This inquiry seemed to open up the floor for further discussion on various coverage tools available.
- George Hotz endorses Coverage.py: George Hotz acknowledged that Coverage.py is a good place to start for measuring test coverage.
- His endorsement reflects confidence in the tool's effectiveness for improving code quality.
Link mentioned: Coverage.py — Coverage.py 7.6.9 documentation: no description found
Torchtune ▷ #papers (3 messages):
QRWKV6-32B Model, Compute Efficiency, Training Innovations, RWKV-V6 Attention, Model Limitations
- QRWKV6-32B Model achieves great feat: Recursal AI converted the Qwen 32B Instruct model into QRWKV6 architecture, achieving original 32B performance with 1000x compute efficiency in inference.
- This conversion replaces transformer attention with RWKV-V6 attention through a novel method, ensuring significant cost reductions in compute.
- Training speed impresses with AMD GPUs: Training was completed in just 8 hours using 16 AMD MI300X GPUs (192GB VRAM each) for the QRWKV6 model, showcasing rapid development in AI.
- Future models like Q-RWKV-6 72B and RWKV-7 32B are currently in progress, promising even greater capabilities.
- Linear attention shows long-term promise: The linear attention mechanism employed in the QRWKV6 model proves to be highly efficient at scale, particularly for processing long contexts.
- Despite these advancements, the model's current context length is limited to 16k due to compute constraints, yet it shows stability beyond this window.
- Key highlights on model transformation: The conversion process allows transforming any QKV Attention model to an RWKV variant without the need for full retraining, cutting down compute costs.
- However, the model inherits language limitations from the Qwen model, only supporting approximately 30 languages compared to RWKV's typical 100+ languages.
- Community collaboration sparks innovation: The training for this model is sponsored by TensorWave, with notable contributions from EleutherAI and the RWKV community.
- While the transformation process is groundbreaking, details on the inner workings may remain undisclosed, leaving some curious about the how-to.
Link mentioned: Tweet from Rohan Paul (@rohanpaul_ai): New linear models: QRWKV6-32B (RWKV6 based on Qwen2.5-32B) & RWKV-based MoE: Finch-MoE-37B-A11B🚀 Recursal AI converted Qwen 32B Instruct model into QRWKV6 architecture, replacing transformer attentio...
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
finetuning Gorilla LLM, downloading GoEx model, implementing reversibility, training in Colab
- Finetuning Gorilla LLM for Custom API: A user is seeking guidance on how to finetune Gorilla LLM to recognize a custom API, indicating previous difficulties in the process.
- They specifically noted challenges in downloading the GoEx model from Hugging Face.
- Challenges with GoEx Model Download: The same user mentioned experiencing trouble while attempting to download the GoEx model to use in a Colab environment.
- This situation highlights the need for clearer instructions or troubleshooting steps for model acquisition.
- Seeking Reversibility Implementation Strategies: The user inquired about pointers for successful implementation of reversibility/undoing actions within their project.
- This question suggests a broader interest in effective control mechanisms during the development process.
Axolotl AI ▷ #general (1 messages):
PYTORCH_TUNABLEOP_ENABLED, PyTorch tunable operations
- Discover PyTorch's Tunable Operations: A member found relevant information regarding
PYTORCH_TUNABLEOP_ENABLED=1, which is related to tunable operations in PyTorch. The details can be found in the PyTorch GitHub repository.- This feature hints at optimizations in CUDA tunable operations, enhancing the overall efficiency for developers leveraging PyTorch.
- Discussion on CUDA Tunability: The conversation around
PYTORCH_TUNABLEOP_ENABLED=1highlighted its potential benefits for CUDA operations. Members believe this could lead to improved performance in GPU computation tasks.- The tunable approach may allow developers to customize operations more effectively, aligning with user-specific requirements.
Mozilla AI ▷ #announcements (1 messages):
Mozilla Builders Demo Day, Community Engagement, Social Media Highlights
- Mozilla Builders Demo Day Recap Released: The recap of Mozilla Builders Demo Day highlights how members gathered in person despite challenging weather conditions.
- The event showcased incredible technology and connection among participants.
- Thank You to Key Contributors: Acknowledgments were given to specific teams and contributors who made the event possible, especially those mentioned in the thread, here.
- Braving tsunamis to attend, the community showed remarkable resilience and support.
- Social Media Buzz from the Event: The Mozilla Builders shared links to their social media posts, including a LinkedIn update and a tweet on X.
- Their tweet encapsulated the event as a spectacular confluence of amazing people and incredible technology.
- Demo Day Highlights Video Available: A highlights video from the event, titled Demo_day.mp4, has been shared for those who missed the event.
- The video showcases some of the incredible presentations and interactions from the day.
Link mentioned: Tweet from Mozilla Builders 🔧 (@mozillabuilders): We have chiseled ourselves out of our Demo Day cocoons just in time to write the world's most interesting recap. Seriously, it was spectacular — a confluence of amazing people and incredible techn...