[AINews] OpenAI takes on Gemini's Deep Research
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
o3 and tools are all you need.
AI News for 1/31/2025-2/3/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 16942 messages) for you. Estimated reading time saved (at 200wpm): 1721 minutes. You can now tag @smol_ai for AINews discussions!
When introducing Operator (our coverage here), sama hinted at more OpenAI Agents soon on the way, but few of us were expecting the next one in 9 days, shipped from Japan on a US Sunday no less:
The blogpost offers more insight into intended usecases, but the bit notable is Deep Research's result on Dan Hendrycks' new HLE benchmark more than doubling the result of o3-mini-high released just on Friday (our coverage here).

They also released a SOTA result on GAIA - which was criticized by coauthors for just releasing public test set results - obviously problematic for an agent that can surf the web, though there is zero reason to question the integrity of this especially when confirmed in footnotes and as samples of the GAIA test traces were published.
OAIDR comes with its own version of the "inference time scaling" chart which is very impressive - not in the scaling of the chart itself, but in the clear rigor demonstrated in the research process that made producing such a chart possible (assuming, of course, that this is research, not marketing, but here the lines are unfortunately blurred to sell a $200/month subscription).
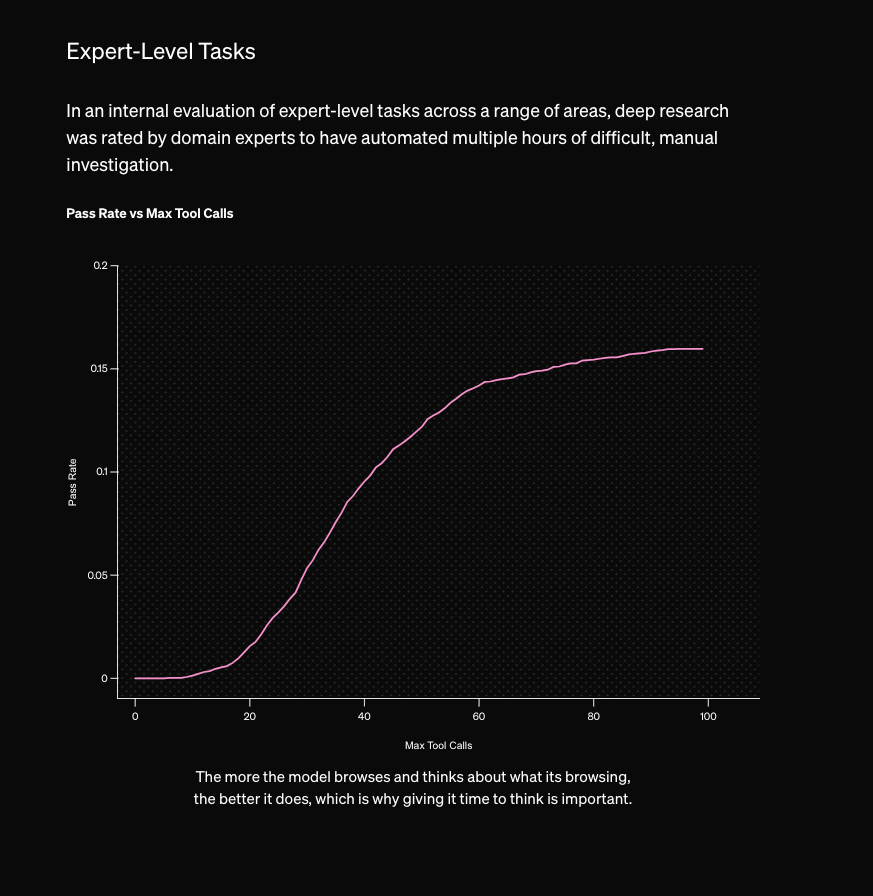
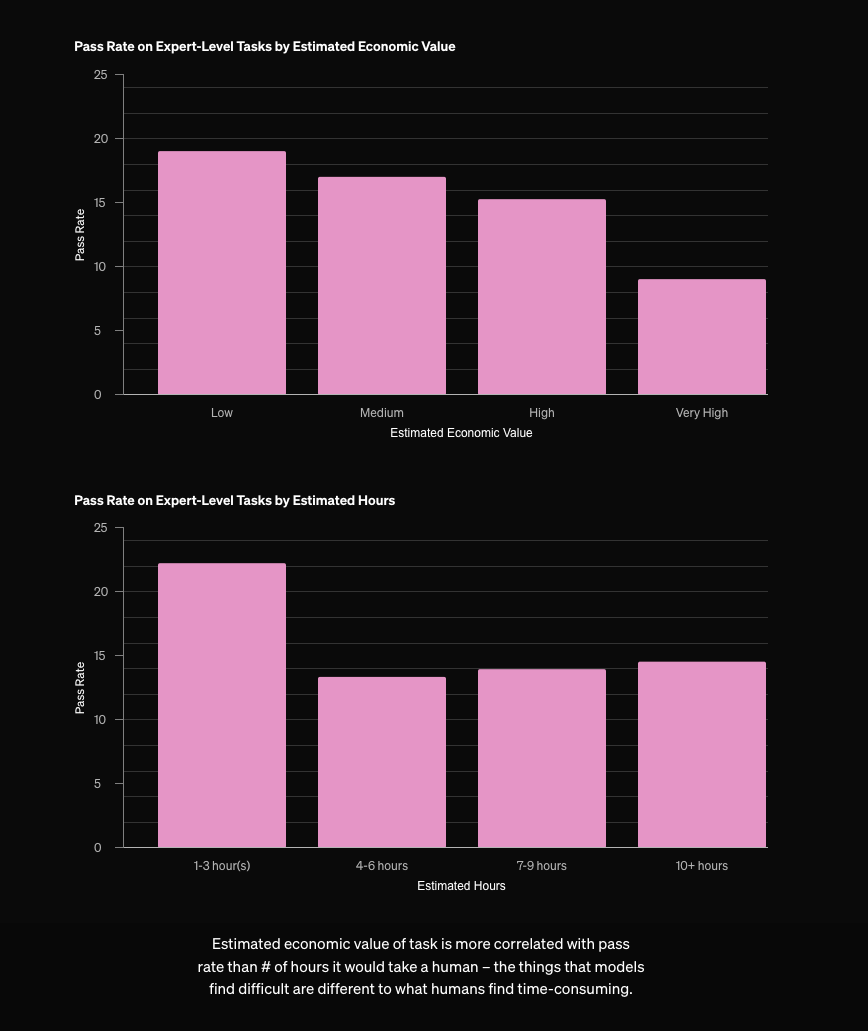
OpenAI staffers confirmed that this is the first time the full o3 has been released in the wild (and gdb says it is "an extremely simple agent"), and the blogpost notes that a "o3-deep-research-mini" version is on the way which will raise rate limits from the 100 queries/month available today.
Reception has been mostly positive, sometimes to the point of hyperventilation. Some folks are making fun of the hyperbole, but on balance we tend to agree with the positive takes of Ethan Mollick and Dan Shipper, though we do experience a lot of failures as well.
Shameless Plug: We will have multiple Deep Research and other agent builders, including the original Gemini Deep Research team, at AI Engineer NYC on Feb 20-22. Last call for applicants!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Codeium (Windsurf) Discord
- aider (Paul Gauthier) Discord
- Cursor IDE Discord
- Yannick Kilcher Discord
- LM Studio Discord
- OpenAI Discord
- Nous Research AI Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- Eleuther Discord
- MCP (Glama) Discord
- Stackblitz (Bolt.new) Discord
- Nomic.ai (GPT4All) Discord
- Notebook LM Discord Discord
- Modular (Mojo 🔥) Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- LlamaIndex Discord
- DSPy Discord
- LAION Discord
- Axolotl AI Discord
- OpenInterpreter Discord
- MLOps @Chipro Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (1121 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (262 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (445 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (6 messages):
- Unsloth AI (Daniel Han) ▷ #research (75 messages🔥🔥):
- Codeium (Windsurf) ▷ #announcements (1 messages):
- Codeium (Windsurf) ▷ #discussion (306 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (657 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (741 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (112 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (14 messages🔥):
- Cursor IDE ▷ #general (768 messages🔥🔥🔥):
- Yannick Kilcher ▷ #general (707 messages🔥🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (36 messages🔥):
- Yannick Kilcher ▷ #agents (4 messages):
- Yannick Kilcher ▷ #ml-news (53 messages🔥):
- LM Studio ▷ #general (600 messages🔥🔥🔥):
- LM Studio ▷ #hardware-discussion (210 messages🔥🔥):
- OpenAI ▷ #annnouncements (3 messages):
- OpenAI ▷ #ai-discussions (520 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (119 messages🔥🔥):
- OpenAI ▷ #prompt-engineering (29 messages🔥):
- OpenAI ▷ #api-discussions (29 messages🔥):
- Nous Research AI ▷ #general (505 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (12 messages🔥):
- Nous Research AI ▷ #research-papers (18 messages🔥):
- Nous Research AI ▷ #interesting-links (16 messages🔥):
- Nous Research AI ▷ #research-papers (18 messages🔥):
- Nous Research AI ▷ #reasoning-tasks (5 messages):
- Interconnects (Nathan Lambert) ▷ #news (228 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (28 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (197 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (32 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (7 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (23 messages🔥):
- Latent Space ▷ #ai-general-chat (181 messages🔥🔥):
- Latent Space ▷ #ai-announcements (2 messages):
- Latent Space ▷ #ai-in-action-club (270 messages🔥🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (104 messages🔥🔥):
- Eleuther ▷ #research (119 messages🔥🔥):
- Eleuther ▷ #interpretability-general (26 messages🔥):
- Eleuther ▷ #lm-thunderdome (5 messages):
- Eleuther ▷ #gpt-neox-dev (16 messages🔥):
- MCP (Glama) ▷ #general (219 messages🔥🔥):
- MCP (Glama) ▷ #showcase (14 messages🔥):
- Stackblitz (Bolt.new) ▷ #prompting (6 messages):
- Stackblitz (Bolt.new) ▷ #discussions (223 messages🔥🔥):
- Nomic.ai (GPT4All) ▷ #general (189 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (13 messages🔥):
- Notebook LM Discord ▷ #general (104 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (6 messages):
- Modular (Mojo 🔥) ▷ #mojo (49 messages🔥):
- Modular (Mojo 🔥) ▷ #max (41 messages🔥):
- Torchtune ▷ #general (32 messages🔥):
- Torchtune ▷ #dev (32 messages🔥):
- Torchtune ▷ #papers (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (51 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (8 messages🔥):
- tinygrad (George Hotz) ▷ #general (33 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- Cohere ▷ #discussions (17 messages🔥):
- Cohere ▷ #api-discussions (9 messages🔥):
- Cohere ▷ #cohere-toolkit (4 messages):
- LlamaIndex ▷ #blog (6 messages):
- LlamaIndex ▷ #general (19 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #papers (1 messages):
- DSPy ▷ #general (13 messages🔥):
- LAION ▷ #general (10 messages🔥):
- LAION ▷ #research (4 messages):
- Axolotl AI ▷ #general (3 messages):
- OpenInterpreter ▷ #general (3 messages):
- MLOps @Chipro ▷ #events (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
Advances in Reinforcement Learning (RL) and AI Research
- Reinforcement Learning Simplified and Its Impact on AI: @andersonbcdefg changed his mind and now thinks that RL is easy, reflecting on the accessibility of RL techniques in AI research.
- s1: Simple Test-Time Scaling in AI Models: @iScienceLuvr shared a paper on s1, demonstrating that training on only 1,000 samples with next-token prediction and controlling thinking duration via a simple test-time technique called budget forcing leads to a strong reasoning model. This model outperforms previous ones on competition math questions by up to 27%. Additional discussions can be found here and here.
- RL Improves Models' Adaptability to New Tasks: Researchers from Google DeepMind, NYU, UC Berkeley, and HKU found that reinforcement learning improves models' adaptability to new, unseen task variations, while supervised fine-tuning leads to memorization but remains important for model stabilization.
- Critique of DeepSeek r1 and Introduction of s1: @Muennighoff introduced s1, which reproduces o1-preview scaling and performance with just 1K high-quality examples and a simple test-time intervention, addressing the data intensity of DeepSeek r1.
OpenAI's Deep Research and Reasoning Models
- Launch of OpenAI's Deep Research Assistant: @OpenAI announced that Deep Research is now rolled out to all Pro users, offering a powerful AI tool for complex knowledge tasks. @nickaturley highlighted its general-purpose utility and potential to transform work, home, and school tasks.
- Improvements in Test-Time Scaling Efficiency: @percyliang emphasized the importance of efficiency in test-time scaling with only 1K carefully chosen examples, encouraging methods that improve capabilities per budget.
- First Glimpse of OpenAI's o3 Capabilities: @BorisMPower expressed excitement over what o3 is capable of, noting its potential to save money and reduce reliance on experts for analysis.
Developments in Qwen Models and AI Advancements
- R1-V: Reinforcing Super Generalization in Vision Language Models: @_akhaliq shared the release of R1-V, demonstrating that a 2B model can outperform a 72B model in out-of-distribution tests within just 100 training steps. The model significantly improves performance in long contexts and key information retrieval.
- Qwen2.5-Max's Strong Performance in Chatbot Arena: @Alibaba_Qwen announced that Qwen2.5-Max is now ranked #7 in the Chatbot Arena, surpassing DeepSeek V3, o1-mini, and Claude-3.5-Sonnet. It ranks 1st in math and coding, and 2nd in hard prompts.
- s1 Model Exceeds o1-Preview: @arankomatsuzaki highlighted that s1-32B, after supervised fine-tuning on Qwen2.5-32B-Instruct, exceeds o1-preview on competition math questions by up to 27%. The model, data, and code are open-source for the community.
AI Safety and Defending Against Jailbreaks
- Anthropic's Constitutional Classifiers Against Universal Jailbreaks: @iScienceLuvr discussed Anthropic's introduction of Constitutional Classifiers, safeguards trained on synthetic data to prevent universal jailbreaks. Over 3,000 hours of red teaming showed no successful attacks extracting detailed information from the guarded models.
- Anthropic's Demo to Test New Safety Techniques: @skirano announced a new research preview at Anthropic, inviting users to try to jailbreak their system protected by Constitutional Classifiers, aiming to enhance AI safety measures.
- Discussion on Hallucination in AI Models: @OfirPress shared concerns about hallucinations in AI models, emphasizing it as a significant problem even in advanced systems like OpenAI's Deep Research.
AI Tools and Platforms for Developers
- Launch of SWE Arena for Vibe Coding: @terryyuezhuo released SWE Arena, a vibe coding platform, supporting real-time code execution and rendering, covering various frontier LLMs and VLMs. @_akhaliq also highlighted SWE Arena, noting its impressive capabilities.
- Enhancements in Perplexity AI Assistant: @AravSrinivas introduced updates to the Perplexity Assistant, encouraging users to try it out on new devices like the Nothing phone, and mentioning upcoming features like integration into Android Auto. He also announced that o3-mini with web search and reasoning traces is available to all Perplexity users, with 500 uses per day for Pro users (tweet here).
- Advancements in Llama Development Tools: @ggerganov announced over 1000 installs of llama.vscode, enhancing the development experience with llama-based models. He shared what a happy llama.cpp user looks like here.
Memes and Humor
- Observations on AI Research and Naming Skills: @jeremyphoward humorously noted that it's impossible to be both a strong AI researcher and good at naming things, calling it a universal fact across all known cultures.
- Generational Reflections on Talent: @willdepue remarked that Gen Z consists of either radically talented individuals or "complete vegetables," attributing this polarization to the internet and anticipating its acceleration with AI.
- Humorous Take on Interface Design: @jeremyphoward joked about having only five grok icons on his home screen, suggesting more could fit, playfully engaging with technology design.
- Happy llama.cpp User: @ggerganov shared an image depicting what a happy llama.cpp user looks like, adding a lighthearted touch to the AI community.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Paradigm Shift in AI Model Hardware: From GPUs to CPU+RAM
- Paradigm shift? (Score: 532, Comments: 159): The post suggests a potential paradigm shift in AI model processing from a GPU-centric approach to a CPU+RAM configuration, specifically highlighting the use of AMD EPYC processors and RAM modules. This shift is visually depicted through contrasting images of a man dismissing GPUs and approving a CPU+RAM setup, indicating a possible change in hardware preferences for AI computations.
- CPU+RAM Viability: The shift towards AMD EPYC processors and large RAM configurations is seen as viable for individual users due to cost-effectiveness, but GPUs remain preferable for serving multiple users. The cost of building an EPYC system is significantly higher, with estimates ranging from $5k to $15k, and performance is generally slower compared to GPU setups.
- Performance and Configuration: There is a focus on optimizing configurations, such as using dual socket 12 channel systems and ensuring all memory slots are filled for optimal performance. Some users report achieving 5.4 tokens/second with specific models, while others suggest that I/O bottlenecks and not utilizing all cores can affect performance.
- Potential Breakthroughs and MoE Models: Discussions include the potential for breakthroughs in Mixture of Experts (MoE) models, which could allow for reading LLM weights directly from fast NVMe storage, thus reducing active parameters. This could change the current hardware requirements, but the feasibility and timing of such advancements remain uncertain.
Theme 2. Rise of Mistral, Qwen, and DeepSeek outside the USA
- Mistral, Qwen, Deepseek (Score: 334, Comments: 114): Non-US companies such as Mistral AI, Qwen, and DeepSeek are releasing open-source models that are more accessible and smaller in size compared to their US counterparts. This highlights a trend where international firms are leading in making AI technology more available to the public.
- The Mistral 3 small 24B model is receiving positive feedback, with several users highlighting its effectiveness and accessibility. Qwen is noted for its variety of model sizes, offering more flexibility and usability on different hardware compared to Meta's Llama models, which are criticized for limited size options and proprietary licensing.
- Discussions around US vs. international AI models reveal skepticism about the US's current offerings, with some users preferring international models like those from China due to their open-source nature and competitive performance. Meta is mentioned as having initiated the open weights trend, but users express concerns about the company's reliance on large models and proprietary licenses.
- There is a debate about the strategic interests of companies in keeping AI model weights open or closed. Some argue that leading companies keep weights closed to maintain a competitive edge, while challengers release open weights to undermine these leaders. Meta's Llama 4 is anticipated to incorporate innovations from DeepSeek R1 to stay competitive.
Theme 3. Phi 4 Model Gaining Traction for Underserved Hardware
- Phi 4 is so underrated (Score: 207, Comments: 84): The author praises the Phi 4 model (Q8, Unsloth variant) for its performance on limited hardware like the M4 Mac mini (24 GB RAM), finding it comparable to GPT 3.5 for tasks such as general knowledge questions and coding prompts. They express satisfaction with its capabilities without concern for formal benchmarks, emphasizing personal experience over technical metrics.
- Phi 4's Strengths and Limitations: Users praise Phi 4 for its strong performance in specific areas, such as knowledge base and rule-following, even outperforming larger models in instruction adherence. However, it struggles with smaller languages, producing poor output outside of English, and lacks a 128k context version which limits its potential compared to Phi-3.
- User Experiences and Implementations: Many users share positive experiences using Phi 4 in various workflows, highlighting its versatility and effectiveness in tasks like prompt enhancement and creative benchmarks like cocktail creation. Some users, however, report poor results in specific tasks like ticket categorization, where other models like Llama 3.3 and Gemma2 perform better.
- Tools and Workflow Integration: Discussions include using Phi 4 in custom setups, like Roland and WilmerAI, to enhance problem-solving by combining it with other models like Mistral Small 3 and Qwen2.5 Instruct. The community also explores workflow apps like n8n and omniflow for integrating Phi 4 into broader AI systems, with links to detailed setups and tools provided (WilmerAI GitHub).
Theme 4. DeepSeek-R1's Competence in Complex Problem Solving
- DeepSeek-R1 never ever relaxes... (Score: 133, Comments: 30): The DeepSeek-R1 model showcased self-correction abilities by solving a math problem involving palindromic numbers, initially making a mistake but then correcting itself before completing its response. Notably, OpenAI o1 was the only other model to solve the problem, while several other models, including chatgpt-4o-latest-20241120 and claude-3-5-sonnet-20241022, failed, raising questions about potential issues with tokenizers, sampling parameters, or the inherent mathematical capabilities of non-thinking LLMs.
- Discussions highlight the self-correcting capabilities of LLMs, particularly in zero-shot settings. This ability stems from the model's exposure to training data where errors are corrected, such as on platforms like Stack Overflow, influencing subsequent token predictions to correct mistakes.
- DeepSeek-R1 and other models like Mistral Large 2.1 and Gemini Thinking on AI Studio successfully solve the palindromic number problem, while the concept of Chain-of-Thought (CoT) models is explored. CoT models are contrasted with non-CoT models, which typically struggle to correct errors mid-response due to different training paradigms.
- The conversation delves into the foundational differences in training data across generational models (e.g., gen1, gen1.5, gen2) and the implications of these differences on error correction capabilities. There is a suggestion that presenting model outputs as user inputs for validation might help address these challenges.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. DeepSeek and Deep Research: Disruptive AI Challenges
- Deep Research Replicated Within 12 Hours (Score: 746, Comments: 93): The post highlights Ashutosh Shrivastava's tweet about the swift creation of "Open DeepResearch," a counterpart to OpenAI's Deep Research Agent, achieved within 12 hours. It includes code snippets that facilitate comparing AI companies like Cohere, Jina AI, and Voyage by examining their valuations, growth, and adoption metrics through targeted web searches and URL visits.
- Many commenters argue that OpenAI's Deep Research is superior due to its use of reinforcement learning (RL), which allows it to autonomously learn strategies for complex tasks, unlike other models that lack this capability. Was_der_Fall_ist emphasizes that without RL, tools like "Open DeepResearch" are just sophisticated prompts and not true agents, potentially leading to brittleness and unreliability.
- The discussion highlights the importance of focusing not just on models but on the tooling and applications around them, as noted by frivolousfidget. They argue that significant capability gains can be achieved through innovative use of existing models, rather than solely through model improvements, citing examples like AutoGPT and LangChain.
- GitHub links and discussions about the cost and accessibility of models emphasize the financial barriers to competing with top-end solutions like OpenAI's. YakFull8300 provides a GitHub link for further exploration, while others discuss the prohibitive costs associated with high-level AI model training and deployment.
- DeepSeek might not be as disruptive as claimed, firm reportedly has 50,000 Nvidia GPUs and spent $1.6 billion on buildouts (Score: 535, Comments: 157): DeepSeek reportedly possesses 50,000 Nvidia GPUs and has invested $1.6 billion in infrastructure development, raising questions about its claimed disruptive impact in the AI industry. The scale of their investment suggests significant computational capabilities, yet there is skepticism about whether their technological advancements match their financial outlay.
- The discussion highlights skepticism about DeepSeek's claims, with some users questioning the validity of their reported costs and GPU usage. DeepSeek's paper clearly states the training costs, but many believe the media misrepresented these numbers, leading to misinformation and confusion about their actual expenses.
- There is a debate over whether DeepSeek's open-source model represents a significant advancement in AI, with some arguing that it challenges the US's dominance in AI development. Critics suggest that Western media and sinophobia have contributed to the narrative that DeepSeek's achievements are overstated or misleading.
- The financial impact of DeepSeek's announcements, like the 17% drop in Nvidia's stock, is a focal point, with users noting the broader implications for the AI hardware market. Some users argue that the open-source nature of DeepSeek's model allows for cost-effective AI development, potentially democratizing access to AI technology.
- EU and UK waiting for Sora, Operator and Deep Research (Score: 110, Comments: 23): The post mentions that the EU and UK are waiting for Sora, Operator, and Deep Research tools, but provides no additional details or context. The accompanying image depicts a man in various contemplative poses, suggesting themes of reflection and solitude, yet lacks direct correlation to the post's topic.
- Availability and Pricing Concerns: Users express frustration over the delayed availability of Sora in the UK and EU, speculating whether the delay is due to OpenAI or government regulations. Some are skeptical about paying $200/month for the service, and there's mention of a potential release for the Plus tier next week, though skepticism about timelines remains.
- Performance and Utility: A user shared a positive experience with the tool, noting it generated a 10-page literature survey with APA citations in LaTeX within 14 minutes. This highlights the tool's impressive capabilities and efficiency in handling complex tasks.
- Regulatory and Operational Insights: There is speculation that the delay might be a strategic move by OpenAI to influence policy-makers or due to resource allocation issues, particularly in processing user activity in the Republic of Ireland. The discussion suggests that the regulatory process should ideally enhance model safety, and contrasts OpenAI's delay with other AI companies that manage day-one releases in the UK and EU.
Theme 2. OpenAI's New Hardware Initiatives with Jony Ive
- Open Ai is developing hardware to replace smartphones (Score: 279, Comments: 100): OpenAI is reportedly developing a new AI device intended to replace smartphones, as announced by CEO Sam Altman. The news article from Nikkei, dated February 3, 2025, also mentions Altman's ambitions to transform the IT industry with generative AI and his upcoming meeting with Japan's Prime Minister.
- OpenAI's AI Hardware Ambitions: Sam Altman announced plans for AI-specific hardware and chips, potentially disrupting tech hardware akin to the 2007 iPhone launch. They aim to partner with Jony Ive, targeting a "voice" interface as a key feature, with the prototype expected in "several years" (Nikkei source).
- Skepticism on Replacing Smartphones: Many commenters doubted the feasibility of replacing smartphones, emphasizing the enduring utility of screens for video and reading. They expressed skepticism about using "voice" as the primary interface, questioning how it could replace the visual and interactive elements of smartphones.
- Emerging AI Assistants: Gemini is noted as a growing competitor to Google Assistant, with integration in Samsung devices and the ability to be chosen over other assistants in Android OS. Gemini's potential expansion to Google Home and Nest devices is in beta, indicating a shift in AI assistant technology.
- Breaking News: OpenAI will develop AI-specific hardware, CEO Sam Altman says (Score: 138, Comments: 29): OpenAI plans to develop AI-specific hardware, as announced by CEO Sam Altman. This strategic move indicates a significant step in enhancing AI capabilities and infrastructure.
- Closed Source Concerns: There is skepticism about the openness of OpenAI's initiatives, with users noting the irony of "Open" AI developing closed-source software and hardware. This reflects a broader concern about transparency and accessibility in AI development.
- Collaboration with Jony Ive: The collaboration with Jony Ive is highlighted as a strategic move, potentially leading to the largest tech hardware disruption since the 2007 iPhone launch. The focus is on creating a new kind of hardware that leverages AI advancements for enhanced user interaction.
- Custom AI Chips: OpenAI is working on developing its own semiconductors, joining major tech companies like Apple, Google, and Amazon. This move is part of a broader trend towards custom-made chips aimed at improving AI performance, with a prototype expected in "several years" emphasizing voice as a key feature.
Theme 3. Critique on AI Outperforming Human Expertise Claims
- Exponential progress - AI now surpasses human PhD experts in their own field (Score: 176, Comments: 86): The post discusses a graph titled "Performance on GPQA Diamond" that compares the accuracy of human PhD experts and AI models GPT-3.5 Turbo and GPT-4o over time. The graph shows that AI models are on an upward trend, surpassing human experts in their field from July 2023 to January 2025, with accuracy ranging from 0.2 to 0.9.
- AI Limitations and Misleading Claims: Commenters argue that AI models, while adept at pattern recognition and data retrieval, are not capable of genuine reasoning or scientific discovery, such as curing cancer. They highlight that AI surpassing PhDs in specific tests does not equate to surpassing human expertise in practical, real-world problem-solving.
- Criticism of Exponential Improvement Claims: The notion of AI models improving exponentially is criticized as misleading, with one commenter comparing it to a biased metric that doesn't truly reflect the complexity and depth of human expertise. The discussion emphasizes that while AI can excel in theoretical knowledge, it lacks the ability to conduct experiments and make new discoveries.
- Skepticism Towards AI's Expertise: Many express skepticism about AI's ability to provide PhD-level insights without expert guidance, likening AI to an advanced search engine rather than a true expert. Concerns are raised about the credibility of claims that AI models have surpassed PhDs, with some attributing these claims to marketing rather than actual capability.
- Stability AI founder: "We are clearly in an intelligence takeoff scenario" (Score: 127, Comments: 122): Emad Mostaque, founder of Stability AI, asserts that we are in an "intelligence takeoff scenario" where machines will soon surpass humans in digital knowledge tasks. He emphasizes the need to move beyond discussions of AGI and ASI, predicting enhanced machine efficiency, cost-effectiveness, and improved coordination, while urging consideration of the implications of these advancements.
- Many commenters express skepticism about the imminent replacement of humans by AI, citing examples like challenges in generating simple code tasks with AI models like o3-mini and o1 pro. RingDigaDing and others argue that AI still struggles with reliability and practical application in real-world scenarios, despite benchmarks suggesting proximity to AGI.
- IDefendWaffles and mulligan_sullivan discuss the motivations behind AI hype, mentioning investment interests and the lack of factual evidence for claims of imminent AGI. They highlight the need for grounded arguments and the difference between current AI capabilities and the speculative future of AI advancements.
- Users like whtevn and traumfisch discuss AI's potential to augment human work, with whtevn sharing experiences of using AI as a development assistant. They emphasize AI's ability to perform tasks efficiently, though not without human oversight, and the potential for AI to transform industries gradually rather than instantly.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp)
Theme 1. DeepSeek AI's Ascendancy and Regulatory Scrutiny
- DeepSeek Model Steals Thunder, Outperforms Western Titans : China's DeepSeek AI model is now outperforming Western competitors like OpenAI and Anthropic in benchmark tests, sparking global discussions about AI dominance. DeepSeek AI Dominates Western Benchmarks. This leap in performance is prompting legislative responses in the US to limit collaboration with Chinese AI research to protect national innovation.
- DeepSeek's Safety Shield Shatters, Sparks Jailbreak Frenzy: Researchers at Cisco found DeepSeek R1 model fails 100% of safety tests, unable to block harmful prompts. DeepSeek R1 Performance Issues. Users also report server access woes, questioning its reliability for practical applications despite its benchmark prowess.
- US Lawmakers Draw Swords, Target DeepSeek with Draconian Bill: Senator Josh Hawley introduces legislation to curb American AI collaboration with China, specifically targeting models like DeepSeek. AI Regulation Faces New Legislative Push. The bill proposes penalties up to 20 years imprisonment for violations, raising concerns about stifling open-source AI innovation and accessibility.
Theme 2. OpenAI's o3-mini: Performance and Public Scrutiny
- O3-mini AMA: Altman & Chen Face the Music on New Model: OpenAI schedules an AMA session featuring Sam Altman and Mark Chen to address community questions about o3-mini. OpenAI Schedules o3-mini AMA. Users are submitting questions via Reddit, keen to understand future developments and provide feedback on the model.
- O3-mini's Reasoning Prowess Questioned, Sonnet Still King: Users are reporting mixed performance for o3-mini in coding tasks, citing slow speeds and incomplete solutions. O3 Mini Faces Performance Critique. Claude 3.5 Sonnet remains the preferred choice for many developers due to its consistent reliability and speed, especially with complex codebases.
- O3-mini Unleashes "Deep Research" Agent, But Questions Linger: OpenAI launches Deep Research, a new agent powered by o3-mini, designed for autonomous information synthesis and report generation. OpenAI Launches Deep Research Agent. While promising, users are already noting limitations in output quality and source analysis, with some finding Gemini Deep Research more effective in synthesis tasks.
Theme 3. AI Tooling and IDEs: Winds of Change
- Windsurf 1.2.5 Patch: Cascade Gets Web Superpowers, DeepSeek Still Buggy: Codeium releases Windsurf 1.2.5 patch, enhancing Cascade web search with automatic triggers and new commands like @web and @docs. Windsurf 1.2.5 Patch Update Released. However, users report ongoing issues with DeepSeek models within Windsurf, including invalid tool calls and context loss, impacting credit usage.
- Aider v0.73.0: O3-mini Ready, Reasoning Gets Effort Dial: Aider launches v0.73.0, adding full support for o3-mini and a new
--reasoning-effortargument for reasoning control. Aider v0.73.0 Launches with Enhanced Features. Despite O3-mini integration, users find Sonnet still faster and more efficient for coding tasks, even if O3-mini shines in complex logic. - Cursor IDE Updates Roll Out, Changelogs Remain Cryptic: Cursor IDE rolls out updates including a checkpoint restore feature, but users express frustration over inconsistent changelogs and undisclosed feature changes. Cursor IDE Rolls Out New Features. Concerns are raised about performance variances and the impact of updates on model capabilities without clear communication.
Theme 4. LLM Training and Optimization: New Techniques Emerge
- Unsloth's Dynamic Quantization Shrinks Models, Keeps Punch: Unsloth AI highlights dynamic quantization, achieving up to 80% model size reduction for models like DeepSeek R1 without sacrificing accuracy. Dynamic Quantization in Unsloth Framework. Users are experimenting with 1.58-bit quantized models, but face challenges ensuring bit specification adherence and optimal LlamaCPP performance.
- GRPO Gains Ground: Reinforcement Learning Race Heats Up: Discussions emphasize the effectiveness of GRPO (Group Relative Policy Optimization) over DPO (Direct Preference Optimization) in reinforcement learning frameworks. Reinforcement Learning: GRPO vs. DPO. Experiments show GRPO boosts Llama 2 7B accuracy on GSM8K, suggesting it's a robust method across model families and DeepSeek R1 outperforms PEFT and instruction fine-tuning.
- Test-Time Compute Tactics: Budget Forcing Enters the Arena: "Budget forcing" emerges as a novel test-time compute strategy, extending model reasoning times to encourage answer double-checking and improve accuracy. Test Time Compute Strategies: Budget Forcing. This method utilizes a dataset of 1,000 curated questions designed to test specific criteria, pushing models to enhance their reasoning performance during evaluation.
Theme 5. Hardware Hurdles and Horizons
- RTX 5090 Blazes Past RTX 4090 in AI Inference Showdown: Conversations reveal the RTX 5090 GPU offers up to 60% faster token processing than the RTX 4090 in large language models. RTX 5090 Outpaces RTX 4090 in AI Tasks. Benchmarking results are being shared, highlighting the performance leap for AI-intensive tasks.
- AMD's RX 7900 XTX Grapples with Heavyweight LLMs: Users note AMD's RX 7900 XTX GPU struggles to match NVIDIA GPUs in efficiency when running large language models like 70B. AMD RX 7900 XTX Struggles with Large LLMs. The community discusses limited token generation speeds on AMD hardware for demanding LLM tasks.
- GPU Shared Memory Hacks Boost LM Studio Efficiency: Discussions highlight leveraging shared memory on GPUs within LM Studio to increase RAM utilization and enhance model performance. GPU Efficiency Boosted with Shared Memory. Users are encouraged to tweak LM Studio settings to optimize GPU offloading and manage VRAM effectively, especially when working with large models locally.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Dynamic Quantization in Unsloth Framework: Unsloth's dynamic quantization reduces model size by up to 80%, maintaining accuracy for models like DeepSeek R1. The blog post outlines effective methods for running and fine-tuning models using specified quantization techniques.
- Users face challenges with 1.58-bit quantized models, as dynamic quantization doesn't always adhere to the bit specification, raising concerns about performance with LlamaCPP in current setups.
- VLLM Offloading Limitations with DeepSeek R1: VLLM currently lacks support for offloading with GGUF, especially for the DeepSeek V2 architecture unless recent patches are applied.
- This limitation poses optimization questions for workflows reliant on offloading capabilities, as highlighted in recent community discussions.
- Gradient Accumulation in Model Training: Gradient accumulation mitigates VRAM usage by allowing models to train on feedback from generated completions only, enhancing stability over directly training on previous inputs.
- This method is recommended to preserve context and prevent overfitting, as discussed in Unsloth documentation.
- Test Time Compute Strategies: Budget Forcing: Introducing budget forcing controls test-time compute, encouraging models to double-check answers by extending reasoning times, aiming to improve reasoning performance.
- This strategy leverages a curated dataset of 1,000 questions designed to fulfill specific criteria, as detailed in recent research forums.
- Klarity Library for Model Analysis: Klarity is an open-source library released for analyzing the entropy of language model outputs, providing detailed JSON reports and insights.
- Developers are encouraged to contribute and provide feedback through the Klarity GitHub repository.
Codeium (Windsurf) Discord
- Windsurf 1.2.5 Patch Update Released: The Windsurf 1.2.5 patch update has been released, focusing on improvements and bug fixes to enhance the Cascade web search experience. Full changelog details enhancements on how models call tools.
- New Cascade features allow users to perform web searches using automatic triggers, URL input, and commands @web and @docs for more control. These features are available with a 1 flow action credit and can be toggled in the Windsurf Settings panel.
- DeepSeek Model Performance Issues: Users have reported issues with DeepSeek models, including error messages about invalid tool calls and loss of context during tasks, leading to credit consumption without effective actions.
- These issues have sparked discussions on improving model reliability and ensuring efficient credit usage within Windsurf.
- Windsurf Pricing and Discounts: There are concerns regarding the lack of student discount options for Windsurf, with users questioning the tool's pricing competitiveness compared to alternative solutions.
- Users expressed frustration over the current pricing structure, feeling that the value may not align with what is being offered.
- Codeium Extensions vs Windsurf Features: It was clarified that Cascade and AI flows functionalities are not available in the JetBrains plugin, limiting some advanced features to Windsurf only.
- Users referenced documentation to understand the current limitations and performance differences between the two platforms.
- Cascade Functionality and User Feedback: Users shared strategies for effectively using Cascade, such as setting global rules to block unwanted code modifications and using structured prompts with Claude or Cascade Base.
- Feedback highlighted concerns over Cascade's 'memories' feature not adhering to established instructions, leading to unwanted code changes.
aider (Paul Gauthier) Discord
- Aider v0.73.0 Launches with Enhanced Features: The release of Aider v0.73.0 introduces support for
o3-miniand the new--reasoning-effortargument with low, medium, and high options, as well as auto-creating parent directories when creating new files.- These updates aim to improve file management and provide users with more control over reasoning processes, enhancing overall functionality.
- O3 Mini and Sonnet: A Performance Comparison: Users report that O3 Mini may experience slower response times in larger projects, sometimes taking up to a minute, whereas Sonnet delivers quicker results with less manual context addition.
- Despite appreciating O3 Mini for quick iterations, many prefer Sonnet for coding tasks due to its speed and efficiency.
- DeepSeek R1 Integration and Self-Hosting Challenges: Integration of DeepSeek R1 with Aider demonstrates top performance on Aider's leaderboard, although some users express concerns about its speed.
- Discussions around self-hosting LLMs reveal frustrations with cloud dependencies, leading users like George Coles to consider independent hosting solutions.
- Windsurf IDE and Inline Prompting Enhancements: The introduction of Windsurf as an agentic IDE brings advanced AI capabilities for pair programming, enhancing tools like VSCode with real-time state awareness.
- Inline prompting features allow auto-completion of code changes based on previous actions, streamlining the coding experience for users leveraging Aider and Cursor.
Cursor IDE Discord
- O3 Mini Faces Performance Critique: Users have shared mixed reviews on O3 Mini's performance in coding tasks, highlighting issues with speed and incomplete solutions.
- Claude 3.5 Sonnet is often preferred for handling large and complex codebases, offering more reliable and consistent performance.
- Cursor IDE Rolls Out New Features: Recent updates to Cursor include the checkpoint restore feature aimed at enhancing user experience, though lack of consistent changelogs has raised concerns.
- Users have expressed frustration over undisclosed features and performance variances, questioning the impact of updates on model capabilities.
- Advanced Meta Prompting Techniques Discussed: Discussions have surfaced around meta-prompting techniques to deconstruct complex projects into manageable tasks for LLMs.
- Shared resources suggest these techniques could significantly boost user productivity by optimizing prompt structures.
Yannick Kilcher Discord
- DeepSeek AI Dominates Western Benchmarks: China's DeepSeek AI model outperforms Western counterparts like OpenAI and Anthropic on various benchmarks, prompting global discussions on AI competitiveness. The model's superior performance was highlighted in recent tests showing its capabilities.
- In response, legislative measures in the US are being considered to limit collaboration with Chinese AI research, aiming to protect national innovation as DeepSeek gains traction in the market.
- AI Regulation Faces New Legislative Push: Recent AI regulatory legislation proposed by Senator Josh Hawley targets models like DeepSeek, imposing severe penalties that could hinder open-source AI development. The bill emphasizes national security, calling for an overhaul of copyright laws as discussed in this article.
- Critics argue that such regulations may stifle innovation and limit accessibility, echoing concerns about the balance between security and technological advancement.
- LLMs' Math Capabilities Under Scrutiny: LLMs' math performance has been criticized for fundamental mismatches, with comparisons likening them to 'brushing teeth with a fork'. Models like o1-mini have shown varied results on math problems, raising questions about their reasoning effectiveness.
- Community discussions highlighted that o3-mini excelled in mathematical reasoning, solving complex puzzles better than counterparts, which has led to interest in organizing mathematical reasoning competitions.
- Self-Other Overlap Fine-Tuning Enhances AI Honesty: A paper on Self-Other Overlap (SOO) fine-tuning demonstrates significant reductions in deceptive AI responses across various model sizes without compromising task performance. Detailed in this study, SOO aligns AI's self-representation with external perceptions to promote honesty.
- Experiments revealed that deceptive responses in Mistral-7B decreased to 17.2%, indicating the effectiveness of SOO in reinforcement learning scenarios and fostering more reliable AI interactions.
- OpenEuroLLM Launches EU-Focused Language Models: The OpenEuroLLM initiative has been launched to develop open-source large language models tailored for all EU languages, earning the first STEP Seal for excellence as announced by the European Commission.
- Supported by a consortium of European institutions, the project aims to create compliant and sustainable high-quality AI technologies for diverse applications across the EU, enhancing regional AI capabilities.
LM Studio Discord
- DeepSeek R1 Faces Distillation Limitations: Users have reported confusion over the DeepSeek R1 model's parameter size, debating whether it's 14B or 7B.
- Many are frustrated with the model's auto-completion and debugging capabilities, particularly for programming tasks.
- AI-Powered Live Chatrooms Taking Shape: A user detailed creating a multi-agent live chatroom in LM Studio, featuring various AI personalities interacting in real-time.
- Plans include integrating this system into live Twitch and YouTube streams to showcase AI's potential in dynamic environments.
- GPU Efficiency Boosted with Shared Memory: Discussions highlight using shared memory on GPUs for higher RAM utilization, improving model performance.
- Users are encouraged to tweak settings in LM Studio to optimize GPU offloading and manage VRAM for large models.
- RTX 5090 Outpaces RTX 4090 in AI Tasks: Conversations revealed that the RTX 5090 offers up to 60% faster token processing compared to the RTX 4090 in large models.
- Benchmarking results were shared from GPU-Benchmarks-on-LLM-Inference.
- AMD RX 7900 XTX Struggles with Large LLMs: Users noted that AMD's RX 7900 XTX isn't as efficient as NVIDIA GPUs for running large language models like the 70B.
- The community discussed the limited token generation speed of AMD GPUs for LLM tasks.
OpenAI Discord
- OpenAI Schedules o3-mini AMA: An AMA featuring Sam Altman, Mark Chen, and other key figures is set for 2PM PST, addressing questions about OpenAI o3-mini and its forthcoming features. Users can submit their questions on Reddit here.
- The AMA aims to provide insights into OpenAI's future developments and gather community feedback on the o3-mini model.
- OpenAI Launches Deep Research Agent: OpenAI has unveiled a new Deep Research Agent capable of autonomously sourcing, analyzing, and synthesizing information from multiple online platforms to generate comprehensive reports within minutes. Detailed information is available here.
- This tool is expected to streamline research processes by significantly reducing the time required for data compilation and analysis.
- DeepSeek R1 Performance Issues: Users reported DeepSeek R1 exhibiting a 100% attack success rate, failing all safety tests and struggling with access due to frequent server issues, as highlighted by Cisco.
- DeepSeek's inability to block harmful prompts has raised concerns about its reliability and safety in real-world applications.
- OpenAI Sets Context Token Limits for Models: OpenAI's models enforce strict context limits, with Plus users capped at 32k tokens and Pro users at 128k tokens, limiting their capacity to handle extensive knowledge bases.
- A discussion emerged on leveraging embeddings and vector databases as alternatives to manage larger datasets more effectively than splitting data into chunks.
- Comparing AI Models: GPT-4 vs DeepSeek R1: Conversations compared OpenAI's GPT-4 and DeepSeek R1, noting differences in capabilities like coding assistance and reasoning tasks. Users observed that GPT-4 excels in certain areas where DeepSeek R1 falls short.
- Members debated the pros and cons of models including O1, o3-mini, and Gemini, evaluating them based on features and usability for various applications.
Nous Research AI Discord
- DeepSeek and Psyche AI Developments: Participants highlighted DeepSeek's advancements in AI, emphasizing how Psyche AI leverages Rust for its stack while integrating existing Python modules to maintain p2p networking features.
- Concerns were raised about implementing multi-step responses in reinforcement learning, focusing on efficiency and the inherent challenges in scaling these features.
- OpenAI's Post-DeepSeek Strategy: OpenAI's stance after DeepSeek has been scrutinized, especially Sam Altman's remark about being on the 'wrong side of history,' raising questions about the authenticity given OpenAI's previous reluctance to open-source models.
- Members stressed that OpenAI's actions need to align with their statements to be credible, pointing out a gap between their promises and actual implementations.
- Legal and Copyright Considerations in AI: Discussions focused on the legal implications of AI development, particularly regarding copyright issues, as members debated the balance between protecting intellectual property and fostering AI innovation.
- A law student inquired about integrating legal-centric dialogues with technical discussions, highlighting potential regulations that could impact future AI research and development.
- Advancements in Model Training Techniques: The community explored Deep Gradient Compression, a method that reduces communication bandwidth by 99.9% in distributed training without compromising accuracy, as detailed in the linked paper.
- Stanford's Simple Test-Time Scaling was also discussed, showcasing improvements in reasoning performance by up to 27% on competition math questions, with all resources being open-source.
- New AI Tools and Community Contributions: Relign has launched developer bounties to build an open-sourced RL library tailored for reasoning engines, inviting contributions from the community.
- Additionally, members shared insights on the Scite platform for research exploration and encouraged participation in community-driven AI model testing initiatives.
Interconnects (Nathan Lambert) Discord
- OpenAI's Deep Research Enhancements: OpenAI introduced Deep Research with the O3 model, enabling users to refine research queries and view reasoning progress via a sidebar. Initial feedback points to its capability in synthesizing information, though some limitations in source analysis remain.
- Additionally, OpenAI's O3 continues to improve through reinforcement learning techniques, alongside enhancements in their Deep Research tool, highlighting a significant focus on RL methodologies in their model training.
- SoftBank Commits $3B to OpenAI: SoftBank announced a $3 billion annual investment in OpenAI products, establishing a joint venture in Japan focused on the Crystal Intelligence model. This partnership aims to integrate OpenAI's technology across SoftBank subsidiaries to advance AI solutions for Japanese enterprises.
- Crystal Intelligence is designed to autonomously analyze and optimize legacy code, with plans to introduce AGI within two years, reflecting Masayoshi Son's vision of AI as Super Wisdom.
- GOP's AI Legislation Targets Chinese Technologies: A GOP-sponsored bill proposes banning the import of AI technologies from the PRC, including model weights from platforms like DeepSeek, with penalties up to 20 years imprisonment.
- The legislation also criminalizes exporting AI to designated entities of concern, equating the release of products like Llama 4 with similar severe penalties, raising apprehensions about its impact on open-source AI developments.
- Reinforcement Learning: GRPO vs. DPO: Discussions highlighted the effectiveness of GRPO over DPO in reinforcement learning frameworks, particularly in the context of RLVR applications. Members posited that while DPO can be used, it’s likely less effective than GRPO.
- Furthermore, findings demonstrated that GRPO positively impacted the Llama 2 7B model, achieving a notable accuracy improvement on the GSM8K benchmark, showcasing the method's robustness across model families.
- DeepSeek AI's R1 Model Debut: DeepSeek AI released their flagship R1 model on January 20th, emphasizing extended training with additional data to enhance reasoning capabilities. The community has expressed enthusiasm for this advancement in reasoning models.
- The R1 model's straightforward training approach, prioritizing sequencing early in the post-training cycle, has been lauded for its simplicity and effectiveness, generating anticipation for future developments in reasoning LMs.
Latent Space Discord
- OpenAI Launches Deep Research Agent: OpenAI introduced Deep Research, an autonomous agent optimized for web browsing and complex reasoning, enabling the synthesis of extensive reports from diverse sources in minutes.
- Early feedback highlights its utility as a robust e-commerce tool, though some users report output quality limitations.
- Reasoning Augmented Generation (ReAG) Unveiled: Reasoning Augmented Generation (ReAG) was introduced to enhance traditional Retrieval-Augmented Generation by eliminating retrieval steps and feeding raw material directly to LLMs for synthesis.
- Initial reactions note its potential effectiveness while questioning scalability and the necessity of preprocessing documents.
- AI Engineer Summit Tickets Flying Off: Sponsorships and tickets for the AI Engineer Summit are selling rapidly, with the event scheduled for Feb 20-22nd in NYC.
- The new summit website provides live updates on speakers and schedules.
- Karina Nguyen to Wrap Up AI Summit: Karina Nguyen is set to deliver the closing keynote at the AI Engineer Summit, showcasing her experience from roles at Notion, Square, and Anthropic.
- Her contributions span the development of Claude 1, 2, and 3, underlining her impact on AI advancements.
- Deepseek API Faces Reliability Issues: Members expressed concerns over the Deepseek API's reliability, highlighting access issues and performance shortcomings.
- Opinions suggest the API's hosting and functionalities lag behind expectations, prompting discussions on potential improvements.
Eleuther Discord
- Probability of Getting Functional Language Models: A study by EleutherAI calculates the probability of randomly guessing weights to achieve a functional language model at approximately 1 in 360 million zeros, highlighting the immense complexity involved.
- The team shared their basin-volume GitHub repository and a research paper to explore network complexity and its implications on model alignment.
- Replication Failures of R1 on SmolLM2: Researchers encountered replication failures of the R1 results when testing on SmolLM2 135M, observing worse autointerp scores and higher reconstruction errors compared to models trained on real data.
- This discrepancy raises questions about the original paper's validity, as noted in discussions surrounding the Sparse Autoencoders community findings.
- Censorship Issues with DeepSeek: DeepSeek exhibits varied responses to sensitive topics like Tiananmen Square based on prompt language, indicating potential biases integrated into its design.
- Users suggested methods to bypass these censorship mechanisms, referencing AI safety training vulnerabilities discussed in related literature.
- DRAW Architecture Enhances Image Generation: The DRAW network architecture introduces a novel spatial attention mechanism that mirrors human foveation, significantly improving image generation on datasets such as MNIST and Street View House Numbers.
- Performance metrics from the DRAW paper indicate that images produced are indistinguishable from real data, demonstrating enhanced generative capabilities.
- NeoX Performance Metrics and Challenges: A member reported achieving 10-11K tokens per second on A100s for a 1.3B parameter model, contrasting the 50K+ tokens reported in the OLMo2 paper.
- Issues with fusion flags and discrepancies in the gpt-neox configurations were discussed, highlighting challenges in scaling Transformer Engine speedups.
MCP (Glama) Discord
- Remote MCP Tools Demand Surges: Members emphasized the need for remote capabilities in MCP tools, noting that most existing solutions focus on local implementations.
- Concerns about scalability and usability were raised, with suggestions to explore alternative setups to enhance MCP functionality.
- Superinterface Products Clarify AI Infrastructure Focus: A cofounder of Superinterface detailed their focus on providing AI agent infrastructure as a service, distinguishing from open-source alternatives.
- The product is aimed at integrating AI capabilities into user products, highlighting the complexity involved in infrastructure requirements.
- Goose Automates GitHub Tasks: A YouTube video showcased Goose, an open-source AI agent, automating tasks by integrating with any MCP server.
- The demonstration highlighted Goose's ability to handle GitHub interactions, underscoring innovative uses of MCP.
- Supergateway v2 Enhances MCP Server Accessibility: Supergateway v2 now enables running any MCP server remotely via tunneling with ngrok, simplifying server setup and access.
- Community members are encouraged to seek assistance, reflecting the collaborative effort to improve MCP server usability.
- Load Balancing Techniques in Litellm Proxy: Discussions covered methods for load balancing using Litellm proxy, including configuring weights and managing requests per minute.
- These strategies aim to efficiently manage multiple AI model endpoints within workflows.
Stackblitz (Bolt.new) Discord
- Bolt Performance Issues Impactating Users: Multiple users reported Bolt experiencing slow responses and frequent error messages, leading to disrupted operations and necessitating frequent page reloads or cookie clearing.
- The recurring issues suggest potential server-side problems or challenges with local storage management, as users seek to restore access by clearing browser data.
- Supabase Preferred Over Firebase: In a heated debate, many users favored Supabase for its direct integration capabilities and user-friendly interface compared to Firebase.
- However, some participants appreciated Firebase for those already immersed in its ecosystem, highlighting a split preference among the community.
- Connection Instability with Supabase Services: Users faced disconnections from Supabase after making changes, necessitating reconnection efforts or project reloads to restore functionality.
- One user resolved the connectivity issue by reloading their project, indicating that the disconnections may stem from recent front-end modifications.
- Iframe Errors with Calendly in Voiceflow Chatbot: A user encountered iframe errors while integrating Calendly within their Voiceflow chatbot, leading to display issues.
- After consulting with representatives from Voiceflow and Calendly, it was determined to be a Bolt issue, causing notable frustration among the user.
- Persistent User Authentication Challenges: Users reported authentication issues, including inability to log in and encountering identical errors across various browsers.
- Suggested workarounds like clearing local storage failed for some, pointing towards underlying problems within the authentication system.
Nomic.ai (GPT4All) Discord
- GPT4All v3.8.0 Crashes Intel Macs: Users report that GPT4All v3.8.0 crashes on modern Intel macOS machines, suggesting this version may be DOA for these systems.
- A working hypothesis is being formed based on users' system specifications to identify the affected configurations, as multiple users have encountered similar issues.
- Quantization Levels Impact GPT4All Performance: Quantization levels significantly influence the performance of GPT4All, with lower quantizations causing quality degradation.
- Users are encouraged to balance quantization settings to maintain output quality without overloading their hardware.
- Privacy Concerns in AI Model Data Collection: A debate has arisen over trust in data collection, contrasting Western and Chinese data practices, with users expressing varying degrees of concern and skepticism.
- Participants argue about perceived double standards in data collection across different countries.
- Integrating LaTeX Support with MathJax in GPT4All: Users are exploring the integration of MathJax for LaTeX support within GPT4All, emphasizing compatibility with LaTeX structures.
- Discussions focus on parsing LaTeX content and extracting math expressions to improve the LLM's output representation.
- Developing Local LLMs for NSFW Story Generation: A user is seeking a local LLM capable of generating NSFW stories offline, similar to existing online tools but without using llama or DeepSeek.
- The user specifies their system capabilities and requirements, including a preference for a German-speaking LLM.
Notebook LM Discord Discord
- API Release Planned for NotebookLM: Users inquired about the upcoming NotebookLM API release, expressing enthusiasm for extended functionalities.
- It was noted that the output token limit for NotebookLM is lower than that of Gemini, though specific details remain undisclosed.
- NotebookLM Plus Features Rollout in Google Workspace: A user upgraded to Google Workspace Standard and observed the addition of 'Analytics' in the top bar of NotebookLM, indicating access to NotebookLM Plus.
- They highlighted varying usage limits despite similar interface appearances and shared screenshots for clarity.
- Integrating Full Tutorials into NotebookLM: A member suggested incorporating entire tutorial websites like W3Schools JavaScript into NotebookLM to enhance preparation for JS interviews.
- Another member mentioned existing Chrome extensions that assist with importing web pages into NotebookLM.
- Audio Customization Missing Post UI Update: Users reported the loss of audio customization features in NotebookLM following a recent UI update.
- Recommendations included exploring Illuminate for related functionalities, with hopes that some features might migrate to NotebookLM.
Modular (Mojo 🔥) Discord
- Mojo and MAX Streamline Solutions: A member highlighted the effectiveness of Mojo and MAX in addressing current engineering challenges, emphasizing their potential as comprehensive solutions.
- The discussion underscored the significant investment required to implement these solutions effectively within existing workflows.
- Reducing Swift Complexity in Mojo: Concerns were raised about Mojo inheriting Swift's complexity, with the community advocating for clearer development pathways to ensure stability.
- Members emphasized the importance of careful tradeoff evaluations to prevent rushed advancements that could compromise Mojo's reliability.
- Ollama Outpaces MAX Performance: Ollama was observed to perform faster than MAX on identical machines, despite metrics initially suggesting slower performance for MAX.
- Current developments are focused on optimizing MAX's CPU-based serving capabilities to enhance overall performance.
- Enhancing Mojo's Type System: Users inquired about accessing specific struct fields within Mojo's type system when passing parameters as concrete types.
- The responses indicated a learning curve for effectively utilizing Mojo's type functionalities, pointing to ongoing community education efforts.
- MAX Serving Infrastructure Optimizations: The MAX serving infrastructure employs
huggingface_hubfor downloading and caching model weights, differentiating it from Ollama's methodology.- Discussions revealed options to modify the
--weight-path=parameter to prevent duplicate downloads, though managing Ollama's local cache remains complex.
- Discussions revealed options to modify the
Torchtune Discord
- GRPO Deployment on 16 Nodes: A member successfully deployed GRPO across 16 nodes by adjusting the multinode PR, anticipating upcoming reward curve validations.
- They humorously remarked that being part of a well-funded company offers significant advantages in such deployments.
- Final Approval for Multinode Support in Torchtune: A request was made for the final approval of the multinode support PR in Torchtune, highlighting its necessity based on user demand.
- The discussion raised potential concerns regarding the API parameter
offload_ops_to_cpu, suggesting it may require additional review.
- The discussion raised potential concerns regarding the API parameter
- Seed Inconsistency in DPO Recipes: Seed works for LoRA finetuning but fails for LoRA DPO, with inconsistencies in sampler behavior being investigated in issue #2335.
- Multiple issues related to seed management have been logged, focusing on the effects of
seed=0andseed=nullin datasets.
- Multiple issues related to seed management have been logged, focusing on the effects of
- Comprehensive Survey on Data Augmentation in LLMs: A survey detailed how large pre-trained language models (LLMs) benefit from extensive training datasets, addressing overfitting and enhancing data generation with unique prompt templates.
- It also covered recent retrieval-based techniques that integrate external knowledge, enabling LLMs to produce grounded-truth data.
- R1-V Model Enhances Counting in VLMs: R1-V leverages reinforcement learning with verifiable rewards to improve visual language models' counting capabilities, where a 2B model outperformed the 72B model in 100 training steps at a cost below $3.
- The model is set to be fully open source, encouraging the community to watch for future updates.
LLM Agents (Berkeley MOOC) Discord
- Upcoming Lecture on LLM Self-Improvement: Jason Weston is presenting Self-Improvement Methods in LLMs today at 4:00pm PST, focusing on techniques like Iterative DPO and Meta-Rewarding LLMs.
- Participants can watch the livestream here, where Jason will explore methods to enhance LLM reasoning, math, and creative tasks.
- Iterative DPO & Meta-Rewarding in LLMs: Iterative DPO and Meta-Rewarding LLMs are discussed as recent advancements, with links to Iterative DPO and Self-Rewarding LLMs papers.
- These methods aim to improve LLM performance across various tasks by refining reinforcement learning techniques.
- DeepSeek R1 Surpasses PEFT: DeepSeek R1 demonstrates that reinforcement learning with group relative policy optimization outperforms PEFT and instruction fine-tuning.
- This shift suggests a potential move away from traditional prompting methods due to DeepSeek R1's enhanced effectiveness.
- MOOC Quiz and Certification Updates: Quizzes are now available on the course website under the syllabus section, with no email alerts to prevent inbox clutter.
- Certification statuses are being updated, with assurances that submissions will be processed soon, though some members have reported delays.
- Hackathon Results to Be Announced: Members are anticipating the hackathon results, which have been privately notified, with a public announcement expected by next week.
- This follows extensive participation in the MOOC's research and project tracks, highlighting active community engagement.
tinygrad (George Hotz) Discord
- NVDEC Decoding Complexities Unveiled: Decoding video with NVDEC presents challenges related to file formats and the necessity for cuvid binaries, as highlighted in FFmpeg/libavcodec/nvdec.c.
- The lengthy libavcodec implementation includes high-level abstractions that could benefit from simplification to enhance efficiency.
- WebGPU Autogen Nears Completion: A member reported near completion of WebGPU autogen, requiring only minor simplifications, with tests passing on both Ubuntu and Mac platforms.
- They emphasized the need for instructions in cases where dawn binaries are not installed.
- Clang vs GCC Showdown in Linux Distros: The debate highlighted that while clang is favored by platforms like Apple and Google, gcc remains prevalent among major Linux distributions.
- This raises discussions on whether distros should transition to clang for improved optimization.
- HCQ Execution Paradigm Enhances Multi-GPU: HCQ-like execution is identified as a fundamental step for understanding multi-GPU execution, with potential support for CPU implementations.
- Optimizing the dispatcher to efficiently allocate tasks between CPU and GPU could lead to performance improvements.
- CPU P2P Transfer Mechanics Explored: The discussion speculated that CPU p2p transfers might involve releasing locks on memory blocks for eviction to L3/DRAM, considering D2C transfers efficiency.
- Performance concerns were raised regarding execution locality during complex multi-socket transfers.
Cohere Discord
- Cohere Trial Key Reset Timing: A member questioned when the Cohere trial key resets—whether 30 days post-generation or at the start of each month. This uncertainty affects how developers plan their evaluation periods.
- Clarifications are needed as the trial key is intended for evaluation, not long-term free usage.
- Command-R+ Model Praised for Performance: Users lauded the Command-R+ model for consistently meeting their requirements, with one user mentioning it continues to surprise them despite not being a power user.
- This sustained performance indicates reliability and effectiveness in real-world applications.
- Embed API v2.0 HTTP 422 Errors: A member encountered an 'HTTP 422 Unprocessable Entity' error when using the Embed API v2.0 with a specific cURL command, raising concerns about preprocessing needs for longer articles.
- Recommendations include verifying the API key inclusion, as others reported successful requests under similar conditions.
- Persistent Account Auto Logout Issues: Several users reported auto logout problems, forcing repeated logins and disrupting workflow within the platform.
- This recurring issue highlights a significant user experience flaw that needs addressing to ensure seamless access.
- Command R's Inconsistent Japanese Translations: Command R and Command R+ exhibit inconsistent translation results for Japanese, with some translations failing entirely.
- Users are advised to contact support with specific examples to aid the multilingual team or utilize Japanese language resources for better context.
LlamaIndex Discord
- Deepseek Dominates OpenAI: A member noted a clear winner between Deepseek and OpenAI, highlighting a surprising narration that showcases their competitive capabilities.
- This discussion sparked interest in the relative performance of these tools, emphasizing emerging strengths in Deepseek.
- LlamaReport Automates Reporting: An early beta video of LlamaReport was shared, demonstrating its potential for report generation in 2025. Watch it here.
- This development aims to streamline the reporting process, providing users with efficient solutions for their needs.
- SciAgents Enhances Scientific Discovery: SciAgents was introduced as an automated scientific discovery system utilizing a multi-agent workflow and ontological graphs. Learn more here.
- This project illustrates how collaborative analysis can drive innovation in scientific research.
- AI-Powered PDF to PPT Conversion: An open-source web app enables the conversion of PDF documents into dynamic PowerPoint presentations using LlamaParse. Explore it here.
- This application simplifies presentation creation, automating workflows for users.
- DocumentContextExtractor Boosts RAG Accuracy: DocumentContextExtractor was highlighted for enhancing the accuracy of Retrieval-Augmented Generation (RAG), with contributions from both AnthropicAI and LlamaIndex. Check the thread here.
- This emphasizes ongoing community contributions to improving AI contextual understanding.
DSPy Discord
- DeepSeek Reflects AI Hopes and Fears: The article discusses how DeepSeek acts as a textbook power object, revealing more about our desires and concerns regarding AI than about the technology itself, as highlighted here.
- Every hot take on DeepSeek shows a person's specific hopes or fears about AI's impact.
- SAEs Face Significant Challenges in Steering LLMs: A member expressed disappointment in the long-term viability of SAEs for steering LLMs predictably, citing a recent discussion.
- Another member highlighted the severity of recent issues, stating, 'Damn, triple-homicide in one day. SAEs really taking a beating recently.'
- DSPy 2.6 Deprecates Typed Predictors: Members clarified that typed predictors have been deprecated; normal predictors suffice for functionality in DSPy 2.6.
- It was emphasized that there is no such thing as a typed predictor anymore in the current version.
- Mixing Chain-of-Thought with R1 Models in DSPy: A member expressed interest in mixing DSPy chain-of-thought with the R1 model for fine-tuning in a collaborative effort towards the Konwinski Prize.
- They also extended an invitation for others to join the discussion and the collaborative efforts related to this initiative.
- Streaming Outputs Issues in DSPy: A user shared difficulties in utilizing dspy.streamify to produce outputs incrementally, receiving ModelResponseStream objects instead of expected values.
- They implemented conditionals in their code to handle output types appropriately, seeking further advice for improvements.
LAION Discord
- OpenEuroLLM Debuts for EU Languages: OpenEuroLLM has been launched as the first family of open-source Large Language Models (LLMs) covering all EU languages, prioritizing compliance with EU regulations.
- Developed within Europe's regulatory framework, the models ensure alignment with European values while maintaining technological excellence.
- R1-Llama Outperforms Expectations: Preliminary evaluations on R1-Llama-70B show it matches and surpasses both o1-mini and the original R1 models in solving Olympiad-level math and coding problems.
- These results highlight potential generalization deficits in leading models, sparking discussions within the community.
- DeepSeek's Specifications Under Scrutiny: DeepSeek v3/R1 model features 37B active parameters and utilizes a Mixture of Experts (MoE) approach, enhancing compute efficiency compared to the dense architecture of Llama 3 models.
- The DeepSeek team has implemented extensive optimizations to support the MoE strategy, leading to more resource-efficient performance.
- Interest in Performance Comparisons: A community member expressed enthusiasm for testing a new model that is reportedly faster than HunYuan.
- This sentiment underscores the community's focus on performance benchmarking among current AI models.
- EU Commission Highlights AI's European Roots: A tweet from EU_Commission announced that OpenEuroLLM has been awarded the first STEP Seal for excellence, aiming to unite EU startups and research labs.
- The initiative emphasizes preserving linguistic and cultural diversity and developing AI on European supercomputers.
Axolotl AI Discord
- Fine-Tuning Frustrations: A member expressed confusion about fine-tuning reasoning models, humorously admitting they don't know where to start.
- They commented, Lol, indicating their need for guidance in this area.
- GRPO Colab Notebook Released: A member shared a Colab notebook for GRPO, providing a resource for those interested in the topic.
- This notebook serves as a starting point for members seeking to learn more about GRPO.
OpenInterpreter Discord
- o3-mini's Interpreter Integration: A member inquired whether o3-mini can be utilized within both 01 and the interpreter, highlighting potential integration concerns.
- These concerns underline the need for clarification on o3-mini's compatibility with Open Interpreter.
- Anticipating Interpreter Updates: A member questioned the nature of upcoming Open Interpreter changes, seeking to understand whether they would be minor or significant.
- Their inquiry reflects the community's curiosity about the scope and impact of the planned updates.
MLOps @Chipro Discord
- Mastering Cursor AI for Enhanced Productivity: Join this Tuesday at 5pm EST for a hybrid event on Cursor AI, featuring guest speaker Arnold, a 10X CTO, who will discuss best practices to enhance coding speed and quality.
- Participants can attend in person at Builder's Club or virtually via Zoom, with the registration link provided upon signing up.
- High-Value Transactions in Honor of Kings Market: The Honor of Kings market saw a high-priced acquisition today, with 小蛇糕 selling for 486.
- Users are encouraged to trade in the marketplace using the provided market code -<344IRCIX>- and password [[S8fRXNgQyhysJ9H8tuSvSSdVkdalSFE]] to buy or sell items.
Mozilla AI Discord
- Lumigator Live Demo Streamlines Model Testing: Join the Lumigator Live Demo to learn about installation and onboarding for running your very first model evaluation.
- This event will guide attendees through critical setup steps for effective model performance testing.
- Firefox AI Platform Debuts Offline ML Tasks: The Firefox AI Platform is now available, enabling developers to leverage offline machine learning tasks in web extensions.
- This new platform opens avenues for improved machine learning capabilities directly in user-friendly environments.
- Blueprints Update Enhances Open-Source Recipes: Check out the Blueprints Update for new recipes aimed at enhancing open-source projects.
- This initiative equips developers with essential tools for creating effective software solutions.
- Builders Demo Day Pitches Debut on YouTube: The Builders Demo Day Pitches have been released on Mozilla Developers' YouTube channel, showcasing innovations from the developers’ community.
- These pitches present an exciting opportunity to engage with cutting-edge development projects and ideas.
- Community Announces Critical Updates: Members can find important news regarding the latest developments within the community.
- Stay informed about the critical discussions affecting community initiatives and collaborations.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (1121 messages🔥🔥🔥):
Unsloth Framework, DeepSeek R1, Batch Inference, Legal Considerations for AI Training, LLM Performance
- Understanding Unsloth and its Capabilities: Unsloth is primarily a fine-tuning framework designed to quickly test models, but it is not aimed at production inference, which would be better served through systems like vllm.
- Unsloth inference can be used to validate fine-tuning results more efficiently than traditional transformer inference, though it doesn't support batch processing.
- Challenges with Training Data Quality: Participants discussed the need for curated and balanced datasets to improve the performance of models being fine-tuned, particularly in avoiding biases related to specific content types.
- Participants emphasized the importance of cleaning and organizing data to ensure effective model training and prevent overfitting.
- Legal Considerations in AI Training: The conversation touched on the legal ramifications of using copyrighted data for model training, including varying international laws and potential repercussions for non-compliance.
- Given the evolving landscape of AI regulations, it is advised to consult legal resources to understand the boundaries of using textual data for training purposes.
- Performance of Different LLMs: The performance and efficiency of models like DeepSeek R1 and others were reviewed, with comments about various models' speeds and capabilities, including the potential for operational overhead in local setups.
- Participants noted the need for better computational resources to handle models effectively, especially those requiring significant GPU memory.
- Community Resources and Collaboration: Users shared links to resources, including GitHub repositories and Colab notebooks, aimed at assisting new users in navigating the complexities of fine-tuning and leveraging LLM architectures.
- The community expressed a willingness to help one another out with projects and seek collaboration in handling data tasks and improving model performance.
- Tweet from Joey (e/λ) (@shxf0072): mange to hack grpo with unsloth on free colabits painfully slowbut works :phttps://colab.research.google.com/drive/1P7frB3fjMv6vjSINqiydAf6gnMab2TiL?usp=sharingQuoting Joey (e/λ) (@shxf0072) OOMxiety
- Tweet from vLLM (@vllm_project): We landed the 1st batch of enhancements to the @deepseek_ai models, starting MLA and cutlass fp8 kernels. Compared to v0.7.0, we offer ~3x the generation throughput, ~10x the memory capacity for token...
- GGUF My Repo - a Hugging Face Space by ggml-org: no description found
- Examples — vLLM: no description found
- Writing Mathematics for MathJax — MathJax 3.2 documentation: no description found
- Mistral-Small-24B-2501 (All Versions) - a unsloth Collection: no description found
- ContactDoctor/Bio-Medical-Llama-3-8B · Hugging Face: no description found
- Fast JSON Decoding for Local LLMs with Compressed Finite State Machine | LMSYS Org:
Constraining an LLM to consistently generate valid JSON or YAML that adheres to a specific schema is a critical feature for many applications.In this blo...
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning: We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT)...
- Backus–Naur form - Wikipedia: no description found
- Hugging Face – The AI community building the future.: no description found
- Google Colab: no description found
- unsloth/Mistral-Small-24B-Instruct-2501 · Hugging Face: no description found
- Installing + Updating | Unsloth Documentation: Learn to install Unsloth locally or online.
- unsloth/Qwen2.5-14B-Instruct-1M-unsloth-bnb-4bit at main: no description found
- Fine Tune DeepSeek R1 | Build a Medical Chatbot: In this video, we show you how to fine-tune DeepSeek R1, an open-source reasoning model, using LoRA (Low-Rank Adaptation). We'll also be using Kaggle, Huggin...
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- GitHub - getAsterisk/deepclaude: A high-performance LLM inference API and Chat UI that integrates DeepSeek R1's CoT reasoning traces with Anthropic Claude models.: A high-performance LLM inference API and Chat UI that integrates DeepSeek R1's CoT reasoning traces with Anthropic Claude models. - getAsterisk/deepclaude
- GitHub - MaxHastings/Kolo: A one stop shop for fine tuning and testing LLMs locally using the best tools available.: A one stop shop for fine tuning and testing LLMs locally using the best tools available. - MaxHastings/Kolo
- Batch inference produces nonsense results for unsloth/mistral-7b-instruct-v0.2-bnb-4bit · Issue #267 · unslothai/unsloth: Hi there, after loading the model with: from unsloth import FastLanguageModel import torch model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/mistral-7b-instruct-v0.2-bnb...
- User:Find out two 3-digit palindromic numbers that added result in a 4-digit p - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- [Attention] Deepseek v3 MLA support with FP8 compute (#12601) · vllm-project/vllm@baeded2: This PR implements the Deepseek V3 support by performing matrix absorption the fp8 weights ---------Signed-off-by: Lucas Wilkinson <lwilkinson@neuralmagic.com>Co-authored-by: Woosuk Kwon...
Unsloth AI (Daniel Han) ▷ #off-topic (262 messages🔥🔥):
AMD vs Nvidia in LLMs, Deepseek Optimization Issues, Fine-Tuning Small LLMs, Performance of Custom LLMs, Date Time Parsing with LLMs
- AMD struggles in LLM landscapes: Several members noted the difficulties of using AMD for machine learning, expressing skepticism about its performance compared to Nvidia.
- One member emphasized their excitement about optimizing a custom LLM using DirectML on AMD hardware, despite the challenges associated with ROCm support.
- Users report mixed experiences with Deepseek: Issues were shared regarding problems encountered with Deepseek, causing some users to seek alternative solutions or to express frustration about the UI.
- Another member humorously detailed how they faced a specific issue by feeding a task to AI, only to receive complaints about it being broken.
- Custom LLMs achieve impressive performance: One user showcased a custom AI system that performs coding tasks in multiple languages in roughly 0.01 seconds on their lower-end hardware.
- The system was designed to handle file absorption and internet searching, indicating potential for widespread applications.
- Concerns over LLM utility for date parsing: A query was raised about using small LLMs for date time parsing, with some members questioning the necessity of AI for such pattern matching tasks.
- One member remarked that this task seems more suited for simpler pattern matching algorithms rather than complex LLMs.
- Desire for competition in GPU market: Many participants expressed a need for competition within the GPU market, specifically hoping to see improvements from AMD to rival Nvidia.
- It was discussed that advancements in CUDA and reducing Nvidia's monopoly could benefit the broader AI ecosystem.
Link mentioned: Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (445 messages🔥🔥🔥):
Unsloth and dynamic quantization, Using Ollama with custom models, Gradient accumulation in model training, Batch inference with FastLanguageModel, Model compatibility across different environments
- Unsloth's Dynamic Quantization Benefits: Unsloth's dynamic quantization reduces model size by up to 80% while maintaining accuracy, particularly for models like DeepSeek R1.
- The blog post outlines how to effectively run and fine-tune the model using specified quantization methods.
- Using Ollama with Custom Fine-tuned Models: To utilize a fine-tuned Mistral model with Ollama, one can follow the Unsloth documentation which simplifies the process for local integration.
- Using the
FastLanguageModel.from_pretrainedmethod allows for conversion to 4-bit and saving with ease.
- Using the
- Understanding Gradient Accumulation: Gradient accumulation helps to mitigate VRAM usage by allowing models to train on feedback from generated completions only.
- This method enhances stability and is recommended over directly training on previous inputs, as it preserves the context.
- Efficient Batch Inference Techniques: For batch inference using
FastLanguageModel, inputs can be tokenized all at once and predictions generated in a single call.- This method significantly speeds up processing by adjusting
max_new_tokensbased on the specific task requirements.
- This method significantly speeds up processing by adjusting
- Model Compatibility Issues and Solutions: When transitioning LORA versions across different settings, tensor size mismatches can occur, which may be resolved by ensuring configuration consistency.
- Downgrading to transformers version 4.47.1 has been identified as a solution to compatibility issues with saved models.
- Setting up ROCm and PyTorch on Fedora: A Step-By-Step Guide: Looking to set up ROCm 6.0 and PyTorch on Fedora? You’re at the right place! This guide will walk you through every step, ensuring that you…
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Google Colab: no description found
- Erland/Mistral-Small-24B-Base-ChatML-2501-bnb-4bit at main: no description found
- Google Colab: no description found
- Google Colab: no description found
- Run Deepseek-R1 / R1 Zero: DeepSeek's latest R-1 model is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Learn how to run & fine-tune the model.
- Phi-4 (All Versions) - a unsloth Collection: no description found
- Llama 3.2 - a unsloth Collection: no description found
- unsloth/DeepSeek-R1-GGUF · Over 2 tok/sec agg backed by NVMe SSD on 96GB RAM + 24GB VRAM AM5 rig with llama.cpp: no description found
- Skeleton GIF - Skeleton - Discover & Share GIFs: Click to view the GIF
- unsloth/phi-4-unsloth-bnb-4bit · Hugging Face: no description found
- Finetune Phi-4 with Unsloth: Fine-tune Microsoft's new Phi-4 model with Unsloth!We've also found & fixed 4 bugs in the model.
- Reddit - Dive into anything: no description found
- unsloth/DeepSeek-R1-Distill-Qwen-14B-unsloth-bnb-4bit · Hugging Face: no description found
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA: no description found
- Bug Fixes in LLM Training - Gradient Accumulation: Unsloth's Gradient Accumulation fix solves critical errors in LLM Training.
- Tutorial: How to Run DeepSeek-R1 on your own local device | Unsloth Documentation: no description found
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- Reddit - Dive into anything: no description found
- GitHub - suno-ai/bark: 🔊 Text-Prompted Generative Audio Model: 🔊 Text-Prompted Generative Audio Model. Contribute to suno-ai/bark development by creating an account on GitHub.
- Tutorial: How to Finetune Llama-3 and Use In Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- Windows Installation | Unsloth Documentation: See how to install Unsloth on Windows with or without WSL.
- GitHub - unslothai/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to unslothai/llama.cpp development by creating an account on GitHub.
- unsloth/unsloth/models/loader.py at main · unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1, Mistral, Phi-4 & Gemma 2 LLMs 2-5x faster with 70% less memory - unslothai/unsloth
- Optimized DeepSeek V2/V3 implementation (MLA) by fairydreaming · Pull Request #11446 · ggerganov/llama.cpp: This PR introduces various optimizations for DeepSeek V2/V3 implementation:caching latent representations instead of full key/value vectorsreplaced "naive" attention implementation w...
- All Our Models | Unsloth Documentation: no description found
Unsloth AI (Daniel Han) ▷ #showcase (6 messages):
DeepSeek-R1, Klarity Library, Fine-Tuning LLMs, OpenWebUI Integration, Local Model Running
- Run DeepSeek-R1 Locally with Ease: A guide to run DeepSeek-R1 (671B) locally on OpenWebUI has been shared, requiring no GPU with the use of the 1.58-bit Dynamic GGUF.
- The tutorial on how to integrate is available here.
- Gratitude for DeepSeek Resources: A user expressed gratitude for the resources available surrounding DeepSeek-R1 on Hugging Face, highlighting the updated library.
- The collection can be accessed at Hugging Face.
- Kolo Streamlines LLM Fine-Tuning: A new Docker image called Kolo has been released to simplify the process of fine-tuning and testing LLMs on local PCs using tools like OpenWebUI and Llama.cpp.
- Users can explore the project on GitHub and provide feedback after trying it.
- Klarity Revolutionizes Model Analysis: Klarity, an open-source library designed to analyze the entropy of language model outputs, has been released, promising detailed JSON reports and insights.
- Developers can get involved and provide feedback by checking the repository here.
- DeepSeek R1 Runs on MacBook Pro M3: A user successfully ran the largest DeepSeek R1 model on a MacBook Pro M3 with 36GB, showcasing the model's adaptability.
- Details of this achievement can be found here.
- Tweet from Unsloth AI (@UnslothAI): Run DeepSeek-R1 (671B) locally on @OpenWebUI - Full GuideNo GPU required.Using our 1.58-bit Dynamic GGUF and llama.cpp.Tutorial: https://docs.openwebui.com/tutorials/integrations/deepseekr1-dynamic/
- Xyra (@xyratech.bsky.social): OK, it's INCREDIBLY slow (a token output every 2 minutes), but I just got DeepSeek’s R1 671B model (dynamic quantised to 2.51-bit) running on a MacBook Pro M3 with 36 GB of RAM.
- DeepSeek R1 (All Versions) - a unsloth Collection: no description found
- GitHub - MaxHastings/Kolo: A one stop shop for fine tuning and testing LLMs locally using the best tools available.: A one stop shop for fine tuning and testing LLMs locally using the best tools available. - MaxHastings/Kolo
- GitHub - klara-research/klarity: See Through Your Models: See Through Your Models. Contribute to klara-research/klarity development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #research (75 messages🔥🔥):
VLLM Offloading with GGUF, Dynamic Quantization for Inferencing, DeepSeek R1 Performance, Test Time Compute Strategies, Horizontal vs Vertical Distillation
- VLLM Offloading Limitations: Currently, VLLM cannot handle offloading with GGUF, particularly not with the DeepSeek V2 architecture without recent patches.
- This limitation raises questions about optimizing workflows that depend on offloading capabilities.
- Dynamic Quantization Challenges: Users are exploring 1.58-bit quantized models for inferencing but face issues with dynamic quantization not always adhering to this bit specification.
- Though a normal LlamaCPP quantized model can be used, there are concerns about its performance under current setups.
- DeepSeek R1 Tokens per Second: Users are reporting performance metrics of about 4 tokens/s for DeepSeek R1 quantized at a context window of 8192, leading to discussions about potential optimizations.
- The conversation revolves around the accuracy of these metrics and the strategies for boosting throughput.
- Innovative Test Time Compute Strategies: Introducing budget forcing was discussed as a means to control test-time compute, encouraging models to double-check answers by extending reasoning times.
- This method aims to improve reasoning performance and is backed by the curated dataset of 1,000 questions which fulfills specific criteria.
- Horizontal vs Vertical Distillation Insights: The concept of horizontal distillation, where the same model size is maintained while improving performance by training new R1s from the best, was debated.
- There's a notable discussion on whether fresh distillation or this horizontal approach yields better outcomes in model generation and reasoning.
- SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training: Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain ...
- s1: Simple test-time scaling: Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly...
- optillm/optillm/thinkdeeper.py at feat-add-json-plugin · codelion/optillm: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
Codeium (Windsurf) ▷ #announcements (1 messages):
Windsurf 1.2.5 Update, Cascade web search features
- Windsurf 1.2.5 Patch Update Released: The Windsurf team announced the release of the 1.2.5 patch update focused on improvements and bug fixes, enhancing the Windsurf Cascade experience.
- You can check the full changelog here for detailed information, including enhancements on how models call tools.
- New Cascade Features Enhance Web Interactivity: Users can now utilize Cascade for web searches through several methods including automatic triggers, URL input, and the commands @web and @docs for more control.
- Additionally, options to enable or disable web tools are conveniently placed in the Windsurf Settings panel, alongside the feature being a 1 flow action credit.
Link mentioned: Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #discussion (306 messages🔥🔥):
DeepSeek Models, Windsurf Pricing and Discounts, Codeium Extensions vs Windsurf, JetBrains Plugin Usage, Model Performance Comparisons
- DeepSeek models causing issues: Users have reported issues with DeepSeek models, particularly with error messages indicating invalid tool calls and loss of context during tasks.
- These issues have prompted discussions around the consumption of credits without effective actions taken by the models.
- Concerns over Windsurf Pricing and Discounts: Discussion arose regarding the lack of student discount options for Windsurf and concerns over pricing competitiveness compared to other tools.
- Users expressed frustration over the pricing structure, feeling that the value may not align with current offerings.
- Capabilities of Codeium Extensions vs Windsurf: It was clarified that Cascade and AI flows are not available in the JetBrains plugin, limiting some advanced features to Windsurf only.
- Documentation was referenced for understanding current limitations and performance differences between the two platforms.
- JetBrains Plugin usability and features: Users sought clarification on the functionality of the JetBrains plugin, specifically around its command capabilities and context awareness.
- It was confirmed that while some features exist, they are not as extensive as those available in Windsurf.
- Performance comparisons of AI models: A user highlighted the impressive performance of the Codeium Premier model compared to others, expressing satisfaction with its capabilities.
- Conversely, some users flagged syntax issues with the latest Windsurf updates, particularly with JSX code.
- Models - Codeium Docs: no description found
- Prompt Engineering - Codeium Docs: no description found
- Welcome to Codeium - Codeium Docs: no description found
- Welcome to Codeium - Codeium Docs: no description found
- FAQ | Windsurf Editor and Codeium extensions: Find answers to common questions.
- Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- GitHub - ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Windsurf - Cascade: no description found
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Overview - Codeium Docs: no description found
- Local Indexing - Codeium Docs: no description found
Codeium (Windsurf) ▷ #windsurf (657 messages🔥🔥🔥):
Windsurf Issues, Model Performance Comparison, Cascade Functionality, User Experience, Feedback and Support
- Windsurf Login and Functionality Issues: Users are experiencing login issues with Windsurf, particularly with the browser not opening and commands hanging in Cascade mode. Some resolved this by reinstalling or changing shell environments, revealing potential compatibility problems with certain setups.
- Diagnosing problems through diagnostic logs and updating to the latest version were also suggested as solutions for login and functionality concerns.
- Model Performance and User Expectations: Users expressed disappointment in recent updates to models like O3 and DeepSeek, noting inconsistent performance and tool call issues that affect productivity. Many found that Sonnet 3.5 remains the most reliable choice for editing and implementation tasks.
- There are ongoing discussions about the need for clearer benchmarks for Windsurf and its models, as well as calls for improvements in latency and functionality in future updates.
- Insights and Tips on Using Cascade: Users shared strategies for effectively using Cascade, highlighting the importance of setting global rules to block unwanted modifications to certain code segments. Additionally, creating structured prompts in chat mode followed by executing code with Claude or Cascade Base was recommended.
- A shared markdown of global instructions was praised for helping manage code edits while maintaining specific code integrity.
- User Feedback on Cascades Memory Function: Concerns were raised about Cascade's reliability with its 'memories' feature, specifically regarding its failure to adhere to established instructions. Users indicated that despite writing clear memories, Cascade still made unwanted changes, prompting frustration and questioning its utility.
- The conversation emphasized the need for Cascade to respect its memories effectively to prevent unintentional code modifications.
- Potential Enhancements for Future Releases: Suggestions for future improvements included lowering latency, facilitating tab navigation between files, and implementing better code pattern recognition. The idea of expanding the suggestion block and creating a suggestions list panel was also discussed as a way to enhance user experience.
- Users expressed hope that development teams consider these suggestions in upcoming updates to improve functionality and usability.
- Cursor adds MCP, Block releases MCP app, DeepSeek hype continues | PulseMCP: New this week ending Feb 1, 2025: Cursor adds MCP support, Block (Square) releases Goose MCP app, DeepSeek hyped by mainstream media
- Prompt Engineering - Codeium Docs: no description found
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- SWE-bench: no description found
- How to Scrape X.com (Twitter) using Python (2025 Update): Tutorial for web scraping X.com (Twitter) post and user data using Python, playwright and background request capture technique. Tweet scraping.
- GitHub - ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- Reddit - Dive into anything: no description found
- Codeium Status: no description found
- 890+ MCP Servers: Updated Daily | PulseMCP: A daily-updated directory of all Model Context Protocol (MCP) servers available on the internet.
- GitHub - vladkens/twscrape: 2024! X / Twitter API scrapper with authorization support. Allows you to scrape search results, User's profiles (followers/following), Tweets (favoriters/retweeters) and more.: 2024! X / Twitter API scrapper with authorization support. Allows you to scrape search results, User's profiles (followers/following), Tweets (favoriters/retweeters) and more. - vladkens/twscrape
- GitHub - akinomyoga/ble.sh: Bash Line Editor―a line editor written in pure Bash with syntax highlighting, auto suggestions, vim modes, etc. for Bash interactive sessions.: Bash Line Editor―a line editor written in pure Bash with syntax highlighting, auto suggestions, vim modes, etc. for Bash interactive sessions. - akinomyoga/ble.sh
- Terrastruct: D2 Studio is a diagramming tool uniquely crafted for software architecture
- The Twelve-Factor App : no description found
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.73.0 Release, Context Window Improvements, OpenRouter R1 Support, Model-Specific Reasoning Tags, Code Contribution Stats
- Aider v0.73.0 Launches with New Features: The release of Aider v0.73.0 introduces full support for
o3-miniand a new--reasoning-effortargument with options for low, medium, and high.- This update also includes auto-creating parent directories when creating new files, enhancing overall file management.
- Enhanced Handling of Context Window Limits: Improvements have been made to better manage context window size limits, providing clearer messaging and specific guidance for Ollama users.
- This helps prevent user errors related to context limits and improves user experience significantly.
- Support Added for OpenRouter R1 Free: Aider now supports free access to R1 on OpenRouter with the command
--model openrouter/deepseek/deepseek-r1:free.- This addition aims to enhance flexibility and accessibility for users looking to utilize R1 features.
- Managing Model-Specific Reasoning Tags: The new model setting
remove_reasoning: tagnameallows users to remove model-specific reasoning tags from responses.- This feature promotes clarity in responses and reduces confusion related to reasoning contexts.
- Aider's Code Contributions Highlighted: The release notes indicate that Aider wrote 69% of the code in this version, showcasing significant internal development.
- These contributions reflect the ongoing commitment to improving the platform based on user feedback and requirements.
Link mentioned: Release history: Release notes and stats on aider writing its own code.
aider (Paul Gauthier) ▷ #general (741 messages🔥🔥🔥):
O3 Mini Performance, Sonnet vs. O3 Mini, MCP Tools, Deep Research, AI Tool Preferences
- O3 Mini Performance in Projects: Users reported that O3 Mini can be slow in larger projects, sometimes taking up to a minute for responses, while Sonnet offers quicker results with less manual context addition.
- For quick iterations, O3 Mini is appreciated, though some users find it less effective compared to Sonnet for coding tasks.
- Comparison of Sonnet and O3 Mini: Many users agree that Sonnet performs exceptionally well for coding tasks, while O3 Mini has potential in handling complex logic and integrations.
- Several users have expressed a preference for using Sonnet for direct coding tasks due to its speed and efficiency.
- MCP Tools Usage: MCP tools are discussed as valuable for AI assistance, with capabilities to read files and generate adjustments, thereby enhancing user efficiency.
- There is a desire among users for more integration of MCP features within Aider to leverage its ability to simplify and streamline coding workflows.
- Experiences with Deep Research: Users are eager about Deep Research's capabilities, with some expressing skepticism about its effectiveness compared to established tools.
- There is a sentiment that while tier accessibility has been an issue, the potential benefits of Deep Research could greatly assist in AI tasks.
- Personal Preferences and Workflows: Users highlight their preferences for working with specific AI tools like Aider, Claude, and R1, often citing the importance of context management and flexibility in their workflows.
- The discussions reflect varied experiences, with some valuing speed and immediate results, while others focus on deeper integrations and automation capabilities.
- Tweet from vLLM (@vllm_project): We landed the 1st batch of enhancements to the @deepseek_ai models, starting MLA and cutlass fp8 kernels. Compared to v0.7.0, we offer ~3x the generation throughput, ~10x the memory capacity for token...
- DeepClaude: no description found
- Jetdraft | Source-First AI Writer: Drop in your PDFs, documents, slides, and web sources. Get AI insights grounded in your actual data - because real work needs real evidence, not AI imagination.
- Prototyping with AI models - GitHub Docs: no description found
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- FAQ: Frequently asked questions about aider.
- Aider in your IDE: Aider can watch your files and respond to AI comments you add in your favorite IDE or text editor.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Jim Carrey Jim Carrey Dumb And Dumber GIF - Jim Carrey Jim carrey dumb and dumber Jim Carrey I don't hear you - Discover & Share GIFs: Click to view the GIF
- DeepSeek R1 Distill Llama 70B - API, Providers, Stats: DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](/meta-llama/llama-3. Run DeepSeek R1 Distill Llama 70B with API
- Freedom America GIF - Freedom America - Discover & Share GIFs: Click to view the GIF
- DeepSeek R1 Distill Qwen 32B - API, Providers, Stats: DeepSeek R1 Distill Qwen 32B is a distilled large language model based on [Qwen 2.5 32B](https://huggingface. Run DeepSeek R1 Distill Qwen 32B with API
- Fireworks | OpenRouter: Browse models provided by Fireworks
- How To Run Deepseek R1 671b Fully Locally On a $2000 EPYC Server – Digital Spaceport: no description found
- quarkus-mcp-servers/README.md at main · quarkiverse/quarkus-mcp-servers: Model Context Protocol Servers in Quarkus. Contribute to quarkiverse/quarkus-mcp-servers development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- AI Model & API Providers Analysis | Artificial Analysis: Comparison and analysis of AI models and API hosting providers. Independent benchmarks across key performance metrics including quality, price, output speed & latency.
- Open-Source MCP servers: Enterprise-grade security, privacy, with features like agents, MCP, prompt templates, and more.
- GitHub - StevenStavrakis/obsidian-mcp: A simple MCP server for Obsidian: A simple MCP server for Obsidian. Contribute to StevenStavrakis/obsidian-mcp development by creating an account on GitHub.
- GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1: Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
- GitHub - vivekVells/mcp-pandoc: MCP server for document format conversion using pandoc.: MCP server for document format conversion using pandoc. - vivekVells/mcp-pandoc
- Use Ollama with any GGUF Model on Hugging Face Hub: no description found
- Allow importing multi-file GGUF models · Issue #5245 · ollama/ollama: What is the issue? Currently Ollama can import GGUF files. However, larger models are sometimes split into separate files. Ollama should support loading multiple GGUF files similar to loading safet...
aider (Paul Gauthier) ▷ #questions-and-tips (112 messages🔥🔥):
DeepSeek R1 and Sonnet, Using Aider with external files, API access issues and tier upgrades, Self-hosting LLMs, Configuration management in Aider
- DeepSeek R1 + Sonnet Dominates Performance Metrics: The combination of DeepSeek R1 as the architect model and Sonnet as the editor is noted as the top-performing setup on Aider's leaderboard, despite user sentiment indicating some performance concerns.
- Dawidm0137 mentioned challenges with DeepSeek's speed, stating it's hard to use effectively.
- Restrictions on Editing Specific Files: A user inquired about limiting Aider to edit only a specified file, expressing the desire to avoid modifications to others.
- Renanfranca9480 suggested using
/addfor the target file and/readfor others as an effective workaround.
- Renanfranca9480 suggested using
- Concerns with API Access in Tiers: Several users reported issues with API access and restrictions, noting confusion over access to o3-mini following tier upgrades.
- Florisknitt_32612 shared experiences about tier differences in API access capabilities, further complicating user expectations.
- Challenges with Self-hosting LLMs: Frustrations with reliance on cloud offerings prompted discussions about self-hosting options for LLMs, with users like George Coles planning to pursue this route due to dependency concerns.
- Agile_prg emphasized difficulties in managing context windows and output efficiency when self-hosting.
- Configuration Management in Aider: Users discussed challenges with maintaining Aider configurations, especially in regard to managing
.aider.conf.ymlsettings.- One user highlighted the difficulty in experimenting with different models simultaneously, leading to confusion when changing modes.
- Model warnings: aider is AI pair programming in your terminal
- FAQ: Frequently asked questions about aider.
aider (Paul Gauthier) ▷ #links (14 messages🔥):
Cursor system prompts, Windsurf IDE features, Inline prompting usage, OpenRouter AI web search, Code collaboration with Aider
- Analysis of Cursor System Prompts: Members discussed the Cursor system prompts and compared them to questionable management practices, highlighting their impracticality.
- One user humorously commented on how these prompts may seem like misguided motivational talks.
- Windsurf Introduced as Agentic IDE: Windsurf is presented as a powerful agentic IDE that enables innovative coding workflows by integrating AI capabilities, specifically for pair programming.
- Users highlighted how it enhances existing tools like VSCode with features such as real-time state awareness and asynchronous operations.
- Understanding Inline Prompting: Inline prompting was described as a feature that can auto-complete code changes based on previous user actions, streamlining the coding experience.
- Users shared their experiences using tools like Aider and Cursor for effective code editing and sought advice on when to utilize inline prompting.
- OpenRouter Provides Model-Agnostic Web Search: The OpenRouter platform allows for model-agnostic integration of web search capabilities to enhance AI interactions by incorporating real-time information.
- Users can easily customize their model queries to fetch timely web content through validated prompts in their coding environments.
- Collaboration Between Aider and Cursor: A user described their workflow involving Aider and Cursor, emphasizing the benefits of using Aider for immediate coding assistance while utilizing Cursor for deeper explanation.
- They expressed a desire for more customizable features in Cursor to streamline their coding process and possibly forgo the subscription if alternatives arise.
- Web Search | OpenRouter: Model-agnostic grounding
- Spit Take Drink GIF - Spit Take Drink Laugh - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
Cursor IDE ▷ #general (768 messages🔥🔥🔥):
O3 Mini Performance, Claude 3.5 Sonnet vs. O3 Mini, Cursor Updates, Meta Prompting Techniques
- O3 Mini Performance Under Scrutiny: Users have reported mixed experiences with the O3 Mini model, especially regarding its performance in coding tasks, where it is noted for being slow or providing incomplete solutions.
- Despite its challenges, some users still find value in planning tasks, particularly in conjunction with Claude 3.5 Sonnet for UI work.
- Claude 3.5 Sonnet is Preferred by Many: Claude 3.5 Sonnet is frequently cited as superior to O3 Mini for coding tasks, especially with large and complex codebases, where it consistently performs well.
- Despite some users recognizing the potential of O3 Mini, they often revert to Sonnet for better reliability and performance.
- Cursor Updates and User Expectations: Recent updates to Cursor have introduced new features like the checkpoint restore feature and ongoing improvements, although changelogs are not consistently provided.
- Users express frustration over hidden features and performance inconsistencies, questioning how updates affect model capabilities.
- Meta Prompting Techniques Gain Attention: Discussion around meta-prompting techniques has emerged, with emphasis on using prompts to deconstruct complex projects into manageable tasks for LLMs.
- Resources for effective meta prompting are being shared, suggesting their potential impact on user productivity.
- Tweet from Han Xiao (@hxiao): Okay I hear u: we go 3D! So let'em rebuild my fav 3D maze screensaver from win95! Deepseek-r1, o3-mini-high, claude-3.5-sonnet, which is the best? Tougher than my last letter dropping animation as...
- Tweet from Cursor (@cursor_ai): o3-mini is out to all Cursor users!We're launching it for free for the time being, to let people get a feel for the model.The Cursor devs still prefer Sonnet for most tasks, which surprised us.
- Tweet from eric zakariasson (@ericzakariasson): @mattshumer_ we’ve just updated to high, let us know what you think!
- Tweet from Alex Albert (@alexalbert__): At Anthropic, we're preparing for the arrival of powerful AI systems. Based on our latest research on Constitutional Classifiers, we've developed a demo app to test new safety techniques.We wa...
- Tweet from eric zakariasson (@ericzakariasson): @mattshumer_ we’ve just updated to high, let us know what you think!
- Tweet from Han Xiao (@hxiao): Letter-dropping physics comparison: o3-mini vs. deepseek-r1 vs. claude-3.5 in one-shot - which is the best? Prompt:Create a JavaScript animation of falling letters with realistic physics. The letters ...
- Tweet from Marc Andreessen 🇺🇸 (@pmarca): Cost to run full size Deepseek R1 model down to $2,000. 🤖🤯 @gospaceport HT @wasnt__me_ https://www.youtube.com/watch?v=Tq_cmN4j2yY
- A New Tab Model | Cursor - The AI Code Editor: Announcing the next-generation Cursor Tab model.
- Cursor - The AI Code Editor: Built to make you extraordinarily productive, Cursor is the best way to code with AI.
- Get Started / Migrate from VS Code – Cursor: no description found
- Are claude-3.5-sonnet and claude-3.5-sonnet-20241022 different?: quick update here: claude-3.5-sonnet now points to claude-3-5-sonnet-20241022!
- Model-specific rules: The new cursor rules system is great, it would also be good if we could have rules for specific models.
- Has the Fusion Model been rolled out?: A big request for the developers: please clarify how to understand the changelogs about the upcoming deployment of Fusion - if I have a version higher than 0.45, does this mean that I have the new tab...
- Plan vs Act modes: I really like Cline’s plan vs act flow I’ve managed to get something working in Cursor’s composer agent mode and I thought it would be good to share. Add this to your rules for ai or .cursorrules It...
- You are a powerful agentic AI coding assistant, powered by Claude 3.5 Sonnet. Yo - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- cais/hle · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- no title found: no description found
- Reddit - Dive into anything: no description found
- cline/CHANGELOG.md at main · cline/cline: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way. - cline/cline
- no title found: no description found
- Awesome AI Tool - Use Cursor Like a Professional · Zoom · Luma: Do you want to learn about how to use Cursor AI like a pro?🚀 Our guest speaker Arnold will share how he became a 10X CTO through mastering Cursor.We'll…
- GitHub - daniel-lxs/mcp-server-starter: Contribute to daniel-lxs/mcp-server-starter development by creating an account on GitHub.
- Web Search tool for CLINE · cline/cline · Discussion #496: As part of the agent tool kit it would be great have the ability for web search similar to Claude Engineer with Tavily or similar approach. Keeping current on the latest solutions is key for qualit...
- Humanity's Last Exam: Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accura...
- Reddit - Dive into anything: no description found
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
Yannick Kilcher ▷ #general (707 messages🔥🔥🔥):
DeepSeek and AI Regulation, LLM Training and Data Usage, AI Research Funding in the EU and Canada, SFT and RL in AI Models, OpenEuroLLM Project
- DeepSeek Faces Regulatory Scrutiny: The proposed legislation by Senator Josh Hawley could impose severe penalties for the use of models like DeepSeek, raising concerns about the future of AI regulation in the U.S.
- Concerns were expressed about how the bill could impact open-source AI development and accessibility.
- Challenges of Training LLMs with Public Data: The discussion highlighted the moral ambiguities around data ownership and the use of public datasets like Wikipedia for training LLMs.
- Participants noted that interpretations of what constitutes a 'dubious' dataset can vary significantly by individual and jurisdiction.
- Funding Discrepancies Between EU and Canada: Concerns were raised about the relatively low funding allocated for AI initiatives in the EU compared to Canada, with specific concerns voiced about the distribution of funds among various research entities.
- It was also mentioned that Canada's investment significantly outpaced that of the EU in the AI sector.
- SFT and RL in AI Development: It was proposed that combining supervised fine-tuning (SFT) with reinforcement learning (RL) could yield models that memorize, generalize, and optimize more effectively.
- The community discussed how SFT can help in specializing data while RL should be involved in active learning processes.
- OpenEuroLLM Project Launch: The OpenEuroLLM initiative was introduced, aiming to develop open-source LLMs tailored for EU languages, supported by a consortium of European institutions.
- This project intends to create compliant and sustainable high-quality AI technologies for various applications across the EU.
- Copyright reform is necessary for national security: Chinese LLMs (including DeepSeek) are trained on my illegal archive of books and papers — the largest in the world. The West needs to overhaul copyright law as a matter of national security.
- LLM Augmented LLMs: Expanding Capabilities through Composition: Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structur...
- The LLVM Compiler Infrastructure Project: no description found
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
- TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters: Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a si...
- INKEY$ and his 8 legs: no description found
- Chinese developers scramble as OpenAI blocks access in China: US firm’s move, amid Beijing-Washington tensions, sparks rush to lure users to homegrown models
- Sean O'Connor (@seansocabic.bsky.social): Some Aspects of Backpropagationhttps://sites.google.com/view/algorithmshortcuts/some-aspects-of-backpropagation
- “You Kant Say That!” Philosophical Debate Leads to Shooting | TIME.com: no description found
- Andrej Karpathy: SuperThanks: very optional, goes to Eureka Labs.
- Tweet from Jürgen Schmidhuber (@SchmidhuberAI): DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural...
- Hawley Introduces Legislation to Decouple American AI Development from Communist China - Josh Hawley: Today, U.S. Senator Josh Hawley (R-Mo.) introduced legislation to protect America’s artificial intelligence (AI) development from China. “Every dollar and gig of data that f...
- 🛟 uh, halp?: no description found
- Frankly My Dear GIF - Frankly My Dear I Dont Give A Damn - Discover & Share GIFs: Click to view the GIF
- Evolution Denial: no description found
- Open Euro LLM: no description found
- Gateway to EU funding opportunities for strategic technologies: Discover EU funding opportunities for strategic technologies with the Strategic Technologies for Europe Platform (STEP). Use our interactive dashboard to find EU open calls in the digital, clean, and ...
- Delta-LLM: New efficient LLM compression idea: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- 20 Years in Jail or $1 Million Fine for Downloading DeepSeek and Similar Models: This video opines about the implications of new bill proposed in Senate and broader discussion on AI regulation.🔥 Get 50% Discount on any A6000 or A5000 GPU...
- Nichijou - Nano's introduction: no description found
- Open Euro LLM: no description found
- Tweet from European Commission (@EU_Commission): AI made in 🇪🇺OpenEuroLLM, the first family of open source Large Language Models covering all EU languages, has earned the first STEP Seal for its excellence.It brings together EU startups, research ...
- AI Is Making You An Illiterate Programmer: Twitch https://twitch.tv/ThePrimeagenDiscord https://discord.gg/ThePrimeagenBecome Backend Dev: https://boot.dev/prime(plus i make courses for them)This is a...
- Musings on Cargo Cult Consciousness — LessWrong: Like many of us, I once dreamt I'd live long enough to upload my mind–one Planck at a time–to live happily ever after in a digital heaven. This is a…
- uh-halp-data - 2 -popularity contest: Run an LLM tournament to see which commands are most important
- GitHub - bitplane/uh-halp-data: Data generation for uh-halp: Data generation for uh-halp. Contribute to bitplane/uh-halp-data development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- torch.utils.data — PyTorch 2.6 documentation: no description found
- Defining a simple augmentation pipeline for image augmentation - Albumentations Documentation: no description found
Yannick Kilcher ▷ #paper-discussion (36 messages🔥):
Math performance of LLMs, Self-Other Overlap fine-tuning, Perceptions of OpenAI's models, Development of DeepSeek models, Critiques of AI reasoning capabilities
- LLMs struggle with math: A member likened LLMs and reinforcement learning to trying to brush teeth with a fork, indicating a fundamental mismatch for mathematical tasks. Further discussion highlighted that models like o1 & r1 scored differently on math problems with some members deeming OpenAI's models inferior.
- One user stated that o3-mini performed well in mathematical reasoning, solving difficult puzzles better than others, which spurred interest in mathematical reasoning competitions.
- SOO fine-tuning aims for honest AI: A paper presented discussed Self-Other Overlap (SOO) fine-tuning in AI Safety, aimed at improving honesty by aligning AI's self-representation with perceptions of others. It reported significant reductions in deceptive responses across various model sizes without harming overall task performance.
- Experiments showed that deceptive responses in Mistral-7B dropped to 17.2%, while other models also experienced similar reductions, underscoring the efficacy of SOO in reinforcement learning scenarios.
- Critique of OpenAI's approach: Concerns were raised about OpenAI's models, suggesting they may release products that appear compelling while concealing flaws. Discussion referenced Google's approach to engineering benchmarks through vast synthetic data, likening that method to lacking precision in math capabilities.
- A user sarcastically remarked on OpenAI's strategy as creating smoke and mirrors, referring specifically to past initiatives like Sora.
- Emerging models: DeepSeek: The DeepSeek-R1 models reportedly achieve performance on par with OpenAI's models across various tasks, including math and reasoning. The team claimed that their distilled models, created from larger models, demonstrated better performance on benchmarks.
- Members noted their approach contrasts with reinforcement learning, indicating a preference for fine-tuned reasoning patterns that are both efficient and effective.
- AI discussions enter marathon mode: As discussions evolved, some members commented on the continuous nature of conversations, suggesting the frequency had shifted from 'daily' to ‘Constant’ or even 'Marathon'. This lighthearted reference indicates ongoing engagement and shared enthusiasm within the community.
- Scaling Laws for Precision: Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling la...
- Towards Safe and Honest AI Agents with Neural Self-Other Overlap: As AI systems increasingly make critical decisions, deceptive AI poses a significant challenge to trust and safety. We present Self-Other Overlap (SOO) fine-tuning, a promising approach in AI Safety t...
- Differentiable Neural Computers with Memory Demon: A Differentiable Neural Computer (DNC) is a neural network with an external memory which allows for iterative content modification via read, write and delete operations. We show that information theo...
- "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization: Despite the popularity of large language model (LLM) quantization for inference acceleration, significant uncertainty remains regarding the accuracy-performance trade-offs associated with various quan...
- deepseek-r1: DeepSeek's first-generation of reasoning models with comparable performance to OpenAI-o1, including six dense models distilled from DeepSeek-R1 based on Llama and Qwen.
- Noether's theorem - Wikipedia: no description found
- M.A.M.O.N. - Latinos VS. Donald Trump short film cortometraje: M.A.M.O.N. (Monitor Against Mexicans Over Nationwide) is a satirical fantasy sci-fi shortfilm that explores with black humor and lots of VFX the outrageous c...
- Daily Papers - Hugging Face: no description found
- speakleash (SpeakLeash | Spichlerz): no description found
- Hard Math Puzzles - Hard Maths Puzzles with Answers - Hitbullseye: no description found
- AI Mathematical Olympiad - Progress Prize 2: Solve national-level math challenges using artificial intelligence models
- BIELIK.AI: Polski Model Językowy LLM
Yannick Kilcher ▷ #agents (4 messages):
O3-mini Autonomy Model, AI News and Updates
- O3-mini's 'DANGEROUS' Autonomy Model Unveiled: The YouTube video titled "o3-mini is the FIRST DANGEROUS Autonomy Model" highlights the insane coding and ML abilities of the new autonomy model.
- Wes Roth discusses the latest happenings in the AI space, particularly focusing on LLMs and the anticipated rollout of AGI.
- Interest in O3-mini for Experiments: A member expressed interest in trying out the O3-mini model, indicating a sense of urgency with the phrase 'need to try this with O3-mini, stat'.
- This reflects an eagerness to explore the capabilities of this newly discussed autonomy model.
Link mentioned: o3-mini is the FIRST DANGEROUS Autonomy Model | INSANE Coding and ML Abilities: The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anth...
Yannick Kilcher ▷ #ml-news (53 messages🔥):
OpenAI's government contracts, DeepSeek AI model, AI copyright laws, DeepResearch alternative, Legislative actions on AI
- OpenAI's Ties to Nuclear Security: OpenAI has announced a partnership with the US National Laboratories to leverage AI for a comprehensive nuclear security program, raising concerns reminiscent of themes from 'The Terminator'.
- Critics pointed out that the risk of AI mismanagement could lead to catastrophic outcomes, questioning the wisdom of such collaborations.
- DeepSeek's Performance and Legislation: Discussions on China's DeepSeek AI model emphasized its competitive edge over Western counterparts, particularly OpenAI and Anthropic, leading to calls for AI regulation.
- Legislation is currently being considered in the US to limit collaboration with Chinese AI research, prompting fears of a detrimental impact on innovation.
- AI Copyright Law Controversy: Debates surfaced around AI companies using shadow-libraries for training, with calls for an overhaul of copyright law to protect national security interests.
- Participants highlighted the hypocrisy of companies benefitting from copyrighted content while simultaneously hiding behind similar laws that protect their intellectual property.
- Open Source Alternative to DeepResearch: An open-source alternative to OpenAI’s DeepResearch was shared, with one user expressing interest in trying it out soon.
- The project, hosted on GitHub, aims to facilitate web searches until definitive answers are found.
- Sam Altman's Theories About AI Value: A Twitter post quoting Sam Altman suggested that significant profits could be derived from using AI effectively, causing some users to label it as 'magical thinking'.
- Critics responded with skepticism, comparing the claims to snake oil selling, focusing on the potential for exploitation over societal benefit.
- Copyright reform is necessary for national security: Chinese LLMs (including DeepSeek) are trained on my illegal archive of books and papers — the largest in the world. The West needs to overhaul copyright law as a matter of national security.
- OpenAI Strikes Deal With US Government to Use Its AI for Nuclear Weapon Security: OpenAI has announced that the US National Laboratories will use its deeply flawed AI models to help with "nuclear security."
- Tweet from Gray Swan AI (@GraySwanAI): OpenAI’s o3-mini System Card is out—featuring results from the Gray Swan Arena.On Jan 4, 2025, Gray Swan AI hosted pre-release red teaming of o3-mini, testing its limits against illicit advice, extrem...
- Live Slug Reaction Klaud GIF - Live Slug Reaction Klaud Star Wars - Discover & Share GIFs: Click to view the GIF
- Tweet from OpenAI (@OpenAI): Deep ResearchLive from Tokyo4pm PT / 9am JSTStay tuned for link to livestream.
- Tweet from thomas (@distributionat): If you get $500 of value per query, then in the first month of a Pro subscription you net $49,800 with your 100 queries.Then in month 2 you can buy 249 new subscriptions, and you net $12,450,000. By m...
- OSF: no description found
- Tweet from Ben Brooks (@opensauceAI): Wow. Congress just tabled a bill that would *actually* kill open-source. This is easily the most aggressive legislative action on AI—and it was proposed by the GOP senator who slammed @finkd for Llama...
- DeepSeek will be banned: it's good, it's fast, and it's free. So it cannot be allowed.: Global equities markets reacted violently to news that China's DeepSeek AI model outperformed those of Wall Street's top names. In testing, DeepSeek is on p...
- Major G7 Country BANS China’s DeepSeek: Fatal Mistake For Western Economies: 💵 Invest With FREE Stocks:Singapore Viewers - https://start.moomoo.com/00iOSjUS & International - https://start.moomoo.com/00mFkEChina's DeepSeek breakthrou...
- Hal9000 Im Sorry Dave GIF - Hal9000 Im Sorry Dave Im Afraid I Cant Do That - Discover & Share GIFs: Click to view the GIF
- GitHub - jina-ai/node-DeepResearch: Keep searching and reading webpages until finding the answer (or exceeding the token budget).: Keep searching and reading webpages until finding the answer (or exceeding the token budget). - jina-ai/node-DeepResearch
- Introduction to Deep Research: Begins at 9am JST / 4pm PTJoin Mark Chen, Josh Tobin, Neel Ajjarapu, and Isa Fulford from Tokyo as they introduce and demo deep research.
- The case of the radical ‘Zizian’ vegan trans cult and the shooting death of a Border Patrol agent: The murder of a US Border Patrol agent near the Canadian border appears to be linked to a radical leftist trans militant cult accused of killings across the country.
LM Studio ▷ #general (600 messages🔥🔥🔥):
DeepSeek Models, Multi-Agent Live Chatroom, LM Studio Usage, GPU Utilization, AI in Genealogy Research
- DeepSeek R1 Distillation Challenges: Users have reported discrepancies in the perceived parameter size of the DeepSeek R1 model, with confusion surrounding its 14B vs 7B capabilities.
- Many expressed frustration over auto-completion and debugging abilities of models, especially with programming tasks.
- Multi-Agent Live Chatroom Creation: A user detailed their experience creating a multi-agent live chatroom using LM Studio with various AI personalities interacting in real-time.
- They plan to integrate this system into live Twitch/YouTube streams for more engaging commentary, showcasing AI's potential in dynamic environments.
- Questions on Model Compatibility and Usage: New users are inquiring about the implementation of various AI models in LM Studio, particularly the handling of specific formats and batch processing of files.
- Some users suggest using software like PDFGear to merge documents for easier querying in Genealogy research.
- GPU Efficiency and Performance: Discussions highlight the performance of models on different GPUs, with specific mentions of the efficiency of using shared memory for higher RAM utilization.
- Users are encouraged to explore settings in LM Studio to optimize GPU offloading and manage VRAM when loading large models.
- General AI Developments and Features: There are ongoing discussions about the latest AI developments, particularly around the features of models like Mistral and their performance benchmarks.
- Users are sharing insights about integrating AI capabilities into their workflows, including identifying how to enhance productivity through AI tools.
- Download and run lmstudio-community/DeepSeek-R1-Distill-Qwen-14B-GGUF in LM Studio: Use lmstudio-community/DeepSeek-R1-Distill-Qwen-14B-GGUF locally in your LM Studio
- Is Lmstudio.ai down? Live status and problems past 24 hours: Live problems for Lmstudio.ai. Error received? Down? Slow? Check what is going on.
- Vision Models (GGUF) - a lmstudio-ai Collection: no description found
- LM Studio - Discover, download, and run local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
- mradermacher/Mistral-Small-24B-Instruct-2501-i1-GGUF · Hugging Face: no description found
- mradermacher/phi-4-deepseek-R1K-RL-EZO-i1-GGUF · Hugging Face: no description found
- Dance GIF - Dance - Discover & Share GIFs: Click to view the GIF
- Mistral-Small-24B-Instruct-2501.i1-Q5_K_M.gguf · mradermacher/Mistral-Small-24B-Instruct-2501-i1-GGUF at main: no description found
- bytedance-research/UI-TARS-7B-DPO · Hugging Face: no description found
- GitHub - Les-El/Ollm-Bridge: Easily access your Ollama models within LMStudio: Easily access your Ollama models within LMStudio. Contribute to Les-El/Ollm-Bridge development by creating an account on GitHub.
- Welcome | Unsloth Documentation: New to Unsloth?
- Play That Funky Music: Provided to YouTube by EpicPlay That Funky Music · Wild CherryWild Cherry℗ 1976 Epic Records, a division of Sony Music EntertainmentReleased on: 1990-04-10Gu...
- GitHub - lllyasviel/stable-diffusion-webui-forge: Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
- GitHub - sammcj/llamalink: Link you Ollama models to LM-Studio: Link you Ollama models to LM-Studio. Contribute to sammcj/llamalink development by creating an account on GitHub.
- Deepseek R1 671b Running and Testing on a $2000 Local AI Server: How to Run Deepseek R1 671b Locally on $2K EPYC Server Writeup https://digitalspaceport.com/how-to-run-deepseek-r1-671b-fully-locally-on-2000-epyc-rig/$2K EP...
- Download an LLM | LM Studio Docs: Discover and download supported LLMs in LM Studio
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- no title found: no description found
- Get started with LM Studio | LM Studio Docs: Download and run Large Language Models (LLMs) like Llama 3.1, Phi-3, and Gemma 2 locally in LM Studio
- cognitivecomputations/dolphin-r1 · Datasets at Hugging Face: no description found
LM Studio ▷ #hardware-discussion (210 messages🔥🔥):
LM Studio setup with hardware specifications, Comparison of GPUs for AI inference, Tool Calls in AI models, Performance of AMD GPUs, Using local AI models for various tasks
- LM Studio setup with hardware specifications: Users discussed their hardware setups for running LM Studio, with mentions of Ryzen CPUs and various GPU configurations.
- Concerns were raised about the compatibility of different RAM types, impacting the system's performance in running large models.
- Comparison of GPUs for AI inference: Conversations centered on the efficacy of GPUs like the RTX 4090 and 5090 for token generation speed in larger models.
- It was highlighted that the RTX 5090 shows significant performance improvements over the 4090, with benchmarks suggesting up to 60% faster token processing.
- Tool Calls in AI models: Users shared their experiences with implementing Tool Calls in LM Studio, which allow models to perform specific tasks like web scraping.
- Models like Llama 3.2 and Qwen 2.5 were mentioned as compatible with Tool Calls, enhancing their functionality.
- Performance of AMD GPUs: Discussion included the potential of AMD's RX 7900 XTX and whether these GPUs could effectively run large language models like the 70B.
- It was noted that AMD GPUs might not be as efficient as their NVIDIA counterparts for LLM tasks and token generation speed.
- Using local AI models for various tasks: Participants described using local AI models for tasks such as data analysis, coding, and summarizing web content.
- The importance of fast response times for iterative prompt refinement was emphasized over slower but more accurate online models.
- NVIDIA Grace CPU Superchip: The breakthrough CPU for the modern data center.
- GPU and Apple Silicon Benchmarks with Large Language Models: Find out how different Nvidia GPUs and Apple Silicone M2, M3 and M4 chips compare against each other when running large language models in different sizes
- xiongjie - Overview: xiongjie has one repository available. Follow their code on GitHub.
- DeepSeek R1 671B MoE LLM running on Epyc 9374F and 384GB of RAM (llama.cpp, Q4_K_S, real time): Note that I used llama.cpp with some additional optimizations (most notably PR #11446).The hardware used is:- Epyc 9374F- 12 x Samsung M321R4GA3BB6-CQK 32GB ...
- Apple March 2025 Event LEAKS - This Changes EVERYTHING..: ANOTHER Apple Product will be launching at Apple's first event of the year in addition to 6 other devices we are expecting. This March 2024 Event will BLOW y...
- GPU Inference speed from https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference: no description found
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
- Performance of llama.cpp on Apple Silicon M-series · ggerganov/llama.cpp · Discussion #4167: Summary LLaMA 7B BW [GB/s] GPU Cores F16 PP [t/s] F16 TG [t/s] Q8_0 PP [t/s] Q8_0 TG [t/s] Q4_0 PP [t/s] Q4_0 TG [t/s] ✅ M1 1 68 7 108.21 7.92 107.81 14.19 ✅ M1 1 68 8 117.25 7.91 117.96 14.15 ✅ M1...
- Amazon.com: Libre Computer Board AML-S905X-CC (Le Potato) 2GB 64-bit Mini Computer for 4K Media : Electronics: no description found
- Amazon.com: Libre Computer Board AML-S905X-CC (Le Potato) 2GB 64-bit Mini Computer for 4K Media : Electronics: no description found
OpenAI ▷ #annnouncements (3 messages):
OpenAI o3-mini AMA, Deep Research Agent Launch
- OpenAI o3-mini AMA with Key Figures: An AMA featuring Sam Altman, Mark Chen, Kevin Weil, Srinivas Narayanan, Michelle Pokrass, and Hongyu Ren is scheduled for 2PM PST to address questions about OpenAI and its future developments.
- Questions can be submitted on Reddit here.
- Launching the Deep Research Agent: OpenAI has announced a new deep research agent capable of autonomously finding, analyzing, and synthesizing information from hundreds of online sources, generating comprehensive reports within minutes.
- This innovation promises to significantly reduce research time compared to traditional methods; more details can be found here.
- YouTube Video Announcement: A YouTube video related to OpenAI's latest updates was shared in the announcements channel.
- The video likely covers recent advancements and insights pertaining to OpenAI's projects.
Link mentioned: Reddit - Dive into anything: no description found
OpenAI ▷ #ai-discussions (520 messages🔥🔥🔥):
DeepSeek R1 performance, OpenAI context limits, AI model comparisons, Distilled AI models, ChatGPT pro features
- User Experiences with DeepSeek R1: Users have reported mixed experiences with DeepSeek R1, particularly in accessing it due to frequent server issues; some find it useful for interpreting complex lecture slides.
- When faced with server downtime, one user shared a link to an alternative access point where performance remains consistent.
- OpenAI Context Limitations: Users highlighted that OpenAI's models have strict context limits, with Plus users capped at 32k and Pro at 128k tokens, constraining their ability to process large knowledge bases.
- One user suggested using embeddings and vector databases for handling larger datasets more effectively than splitting and sending chunks of data.
- AI Model Comparisons: Several discussions revolved around the effectiveness and capabilities of models like OpenAI's GPT-4 and DeepSeek's R1, with users noting differing performance in tasks like coding and reasoning.
- Members compared various models including o1, o3 mini, and Gemini, debating the pros and cons based on features and usability.
- Distilled AI Models: The concept of 'distillation' was explained, wherein a larger AI model is streamlined into a smaller, more efficient model that maintains its core knowledge.
- While theoretically potent, users noted that practical efficiency may vary when implementing distilled models.
- Frontend User Experience in AI Platforms: Conversations included complaints about UI design choices like light mode versus dark mode, with many users preferring dark interfaces for visual comfort.
- Users also expressed their frustrations with navigating between various AI platforms and their features, particularly when handling creative tasks.
- no title found: no description found
- Hate Ignorance GIF - Hate Ignorance Fear - Discover & Share GIFs: Click to view the GIF
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Qwen Chat: no description found
- DeepSeek Fails Researchers' Safety Tests: 'DeepSeek R1 exhibited a 100% attack success rate, meaning it failed to block a single harmful prompt,' Cisco says.
- DeepSeek Service Status: no description found
- AI Creates and Destroys (o1, deepseek, claude): Hrr. Hm. Hurrh. Huh.Open AI's O1, deepseek, and claude sonnet play minecraft in creative mode, build a bunch of architecture stuff, some utopias, some bombs,...
- Reddit - Dive into anything: no description found
- Models: Teaming up with excellent open-source foundation models.
- DeepSeek Jailbreak Reveals Its Entire System Prompt: Now we know exactly how DeepSeek was designed to work, and we may even have a clue toward its highly publicized scandal with OpenAI.
- GPT Unicorn: no description found
OpenAI ▷ #gpt-4-discussions (119 messages🔥🔥):
o3 Mini Release and Usage Limits, Model Performance Concerns, GPT Models and Features, User Experience with ChatGPT, AI in Children's Literature
- o3 Mini is here with exciting limits: The recently released o3-mini has a limit of 150 messages per day for Plus users, while o3-mini-high allows 50 messages weekly.
- Discussions highlighted that many users are curious about the differences in limits among the o3 models and current restrictions.
- Concerns over model performance: Users expressed frustrations regarding the apparent decline in performance of models like O1 and O3 mini, citing subpar responses and slower thinking times.
- Some members reported experiencing issues with models generating repetitively or failing to provide satisfactory answers, suspecting changes in model settings.
- Clarifying GPT models and their applications: Members provided insights into the roles of different models, noting that GPT-4o is suitable for image questions while O3-mini excels in coding tasks.
- The community remained keen on understanding how to best utilize these models for various functions, including web searching and reasoning.
- User experience frustrations with ChatGPT: Many users shared experiences regarding disruptions in their interaction flow, like issues with message sending and lack of clarity on model capabilities.
- Concerns about hallucination and the inconsistency in responses led users to question the reliability of the models and seek clarification on updates.
- Interest in AI Storybook creation: A user inquired about the creation of AI-generated children's books, reflecting an emerging interest in utilizing AI for storytelling.
- This topic seems to resonate with other users, hinting at creative applications of AI in literature for young audiences.
OpenAI ▷ #prompt-engineering (29 messages🔥):
O-model prompt structuring, Conlang development, Model performance discussion, Redundancy in model prompts
- Challenges in O-model prompt structuring: Members discussed the inconsistency in the O-models processing large system prompts, emphasizing the difficulty in providing a clear, top-down order in instructions.
- One noted that while prompts can be temporally ambivalent, this leads to chaos as the models ignore the order of concepts, making coherent communication difficult.
- Insights on developing Conlangs Using Models: A member expressed their struggle with developing a complex conlang, finding that while models can assist, they prefer personal development of the language.
- Another suggested using specific word orders to represent grammatical structures, which was recognized as a good technique for conlangs.
- Redundancy vs. Clarity in Prompt Design: Participants analyzed how to balance redundancy in prompts to clarify relationships without overwhelming the model with repetitive information.
- It was noted that using explicit linking phrases could help maintain coherence, balancing the organization of information and clarity.
OpenAI ▷ #api-discussions (29 messages🔥):
Conlang Development with AI, O-models Processing, Prompt Structuring Challenges, Redundancy and Clarity in Prompts, Zero-shot Prompt Techniques
- Conlang Development & AI Assistance: Members discussed using AI models for developing constructed languages (conlangs), noting that O3-mini provides good support for brainstorming vocab and explaining grammar intricacies.
- However, one member emphasized their preference for creating new words themselves, stating, that was my job while developing the conlang further.
- O-models and Context Processing: A member shared insights on how O-models process prompts, mentioning that while they handle context as a unit, clear ordering enhances clarity and coherence.
- They noted the challenge of organizing prompts effectively, emphasizing the balance between order and context, stating, the model's tendency to not care about the order of concepts is both liberating and difficult.
- Addressing Prompt Structuring Challenges: Members highlighted the importance of structuring prompts logically, as one remarked, we can construct prompts that are temporally ambivalent, which can lead to confusion.
- One member introduced a systematic method for referencing lines in prompts to improve editing and clarity, which aids in the review process.
- Balancing Redundancy in Prompts: A key point of discussion was the balance between redundancy and clarity, with a member noting that some redundancy helps reinforce local coherence.
- They acknowledged the need for strategic redundancy to clarify relationships, stating that this balancing act means sometimes accepting a bit of redundancy for stronger associations.
- Effectiveness of Zero-shot Approaches: An inquiry was made about the effectiveness of zero-shot prompting strategies, with varying opinions on how successful these techniques are in practice.
- Members expressed curiosity about how structured prompts relate to the model's responses and efficiency, encouraging a discussion on best practices.
Nous Research AI ▷ #general (505 messages🔥🔥🔥):
Psyche AI Development, OpenAI and DeepSeek, Legal Considerations in AI, DeepSeek's Advancements, Job Opportunities in AI
- Discussion on Psyche AI Development: Participants discussed the development of Psyche and the use of Rust in building its stack, with suggestions to keep the p2p networking features while utilizing existing Python modules.
- Concerns were raised about implementing complex features like multi-step responses in RL, with a focus on efficiency and the challenges presented.
- OpenAI's Strategy Post-DeepSeek: There was a debate regarding Sam Altman's statements about OpenAI being on the 'wrong side of history' and skepticism about how genuine these remarks are given OpenAI's previous hesitations on open-sourcing models.
- Participants indicated that actions should follow the statements for them to have real significance, emphasizing the disparity between promises and actions.
- Legal Considerations in AI Development: A law student engaged with the channel regarding the legal implications surrounding AI, asking if legal-centric discussions occur alongside technical dialogues.
- The conversation highlighted that there is interest in discussing legality, especially concerning potential regulations that could impact AI research and development.
- DeepSeek's Recent Achievements: Participants shared a sense of excitement about DeepSeek's advancements in AI, noting how these developments could change the competitive landscape, especially against NVIDIA.
- Discussion included the potential for DeepSeek to gain a foothold in areas traditionally dominated by larger tech firms.
- Job Opportunities in AI: Conversations emerged about posting job opportunities, specifically for a Microsoft AI Research Intern position, and how to effectively share such openings within the community.
- Members expressed a need for better communication channels for job postings to connect interested candidates with available positions.
- Tweet from Cursor (@cursor_ai): o3-mini is out to all Cursor users!We're launching it for free for the time being, to let people get a feel for the model.The Cursor devs still prefer Sonnet for most tasks, which surprised us.
- YouTube: no description found
- Tweet from Nora Belrose (@norabelrose): Do SAEs learn the same features independent of the random initialization?We find the answer is no! Two SAEs trained on the same data, in the same order, on Llama 8B only share ~30% of their features.T...
- Tweet from OpenAI (@OpenAI): Deep ResearchLive from Tokyo4pm PT / 9am JSTStay tuned for link to livestream.
- Tweet from Teknium (e/λ) (@Teknium1): Some tests with another proto-hermes-reasoner, excerpt fromWhat is your purpose and what is the purpose of life?
- Oh No! China Stole Data From OpenAI!: OpenAI have said that DeepSeek has stolen data from them to train their R1 model.Apparently the Chinese AI startup trained their model using ChatGPT to get t...
- Tweet from Tsarathustra (@tsarnick): Sam Altman: "we have been on the wrong side of history" with regards to open source/open weights AI models
- Sam Altman: OpenAI has been on the 'wrong side of history' post-DeepSeek: CNBC's Deirdre Bosa reports on the latest developments from OpenAI.
- Tweet from Teknium (e/λ) (@Teknium1): Let me tell you all a little story. Sometime around a or so year ago i reached out to an openai staffer who will not be named who had implied they would be very interested in doing some things open so...
- GitHub - relign-ai/relign: post train language models on multi-step reasoning with reinforcement learning: post train language models on multi-step reasoning with reinforcement learning - relign-ai/relign
- o3-mini is the FIRST DANGEROUS Autonomy Model | INSANE Coding and ML Abilities: The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anth...
- The brute force method for training AI models is dead, says Full-Stack Generative AI CEO May Habib: Full-Stack Generative AI CEO May Habib and ‘Chinatalk’ Podcast host Jordan Schneider, join 'Power Lunch' to discuss Nvidia, Singapore and AI's outlook.
- DeepSeek, China, OpenAI, NVIDIA, xAI, TSMC, Stargate, and AI Megaclusters | Lex Fridman Podcast #459: Dylan Patel is the founder of SemiAnalysis, a research & analysis company specializing in semiconductors, GPUs, CPUs, and AI hardware. Nathan Lambert is a re...
- Big tech rushes to adopt DeepSeek R1: CNBC's Deirdre Bosa reports on the latest regarding DeepSeek.
- DeepSeek Panic, US vs China, OpenAI $40B?, and Doge Delivers with Travis Kalanick and David Sacks: (0:00) The Besties intro Travis Kalanick!(2:11) Travis breaks down the future of food and the state of CloudKitchens(13:34) Sacks breaks in!(15:38) DeepSeek ...
- SoftBank, OpenAI to call on 500 firms to help build Japan AI network: Initiative envisions infrastructure from data centers to power plants
Nous Research AI ▷ #ask-about-llms (12 messages🔥):
CLIP with Hermes 3 Llama 3.2 3B, Difference between llama.cpp and llama 3.2, Ollama as an inference engine, Training models for academic purposes
- CLIP keeps it real with Hermes 3: A member is experimenting with connecting CLIP to Hermes 3 Llama 3.2 3B but finds running them asynchronously to be more efficient.
- Another member suggested needing to train a linear projection layer to combine the two, referencing SmolVLM and Moondream for code.
- llama.cpp vs lama 3.2: What's the deal?: A discussion arose regarding the distinction between llama.cpp and llama 3.2, where it was clarified that llama.cpp is not a model but rather a program that allows users to run various models.
- Members noted that Ollama essentially utilizes llama.cpp as an inference engine, providing a layer for easier model interaction.
- Navigating academic model requirements: A member inquired about the best models for academic purposes on a 4GB card, sparking questions on whether they meant for academic-level questions or model training.
- Confusion was noted, as many companies adopted the 'llama' branding, with Meta releasing open weight models labeled llama3.x.
Nous Research AI ▷ #research-papers (18 messages🔥):
Weekend Plans, Research Paper Reading Habits, Scite Platform for Research, Deep Gradient Compression, Stanford's Simple Test-Time Scaling
- Planning for a Good Weekend: Members expressed optimism about having a good weekend, with one noting they print out papers for deep reading.
- Many people print papers to doodle their notes, highlighting a shared habit among the members.
- Scite Platform Discussion: A member shared that Scite is a fun platform for exploring research, although it currently lacks support for most AI-related papers.
- They mentioned having contacted Scite about adding support for ArXiv and more open access research in the future.
- Insight on Deep Gradient Compression: A member referred to a paper regarding Deep Gradient Compression (DGC), which aims to reduce communication bandwidth in distributed training.
- They noted the paper proposes methods that reduce 99.9% of gradient exchanges** and maintains accuracy, showcasing its applications in various datasets.
- Kimi 1.5 Paper vs O1: A member commented that the Kimi 1.5 paper was overshadowed by R1 noise, yet it features a rivaling thinking model compared to O1.
- Another pointed out that Kimi 1.5's paper is more open and has less handwaving secret sauce compared to other models.
- Stanford's Simple Test-Time Scaling: A member shared Stanford's presentation on a new approach called Simple Test-Time Scaling, improving reasoning performance by up to 27% on competition math questions.
- The model, data, and code for this approach are completely open-source, emphasizing transparency in research.
- Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training: Large-scale distributed training requires significant communication bandwidth for gradient exchange that limits the scalability of multi-node training, and requires expensive high-bandwidth network in...
- Kimi k1.5: Scaling Reinforcement Learning with LLMs: Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a ne...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Stanford presents: s1: Simple test-time scaling- Seeks the simplest approach to achieve test-time scaling and strong reasoning performance- Exceeds o1-preview on competition math questions by up to 27...
Nous Research AI ▷ #interesting-links (16 messages🔥):
Anna's Archive and DeepSeek Impact, Political AI Agent by Society Library, Data Scarcity vs. Copyright Issues, Community Engagement in AI Model Testing, Graphical Tensor Notation in Deep Learning
- Anna's Archive and DeepSeek are blessings: Members expressed their appreciation for DeepSeek and Anna's Archive, highlighting their role in providing extensive access to literature and knowledge.
- One member remarked that these resources are crucial for the community, referencing their substantial number of archived works.
- Society Library Introduces Political AI: The Society Library is testing a new Political AI agent aimed at enhancing representation in digital democracy and providing accessible information through an AI chatbot.
- Developed as part of their vision since 2016, this AI role is framed as being Of the People, By the People, For the People, promoting public engagement in political discussions.
- Debate on Data Scarcity vs. Copyright: Discussion arose around the challenges of data scarcity and copyright issues, noting that large companies like Google have vast data yet still struggle to deliver competitive AI models.
- Members pointed out the need for a balanced approach between protecting copyrights and advancing AI innovation.
- Community Encouragement for Model Testing: A member shared enthusiasm for a project that allows the community to evaluate smaller AI models, encouraging more participation in the voting process.
- Referred to as a platform similar to the lmarena, this initiative aims to improve the representativeness of model assessments.
- Understanding Graphical Tensor Notation: A paper on Graphical Tensor Notation provides insights into tensor operations relevant for deep learning and mechanistic interpretability of neural networks.
- The notation simplifies the understanding of complex tensor manipulations, making it easier to analyze neural network behaviors.
- An introduction to graphical tensor notation for mechanistic interpretability: Graphical tensor notation is a simple way of denoting linear operations on tensors, originating from physics. Modern deep learning consists almost entirely of operations on or between tensors, so easi...
- Copyright reform is necessary for national security: Chinese LLMs (including DeepSeek) are trained on my illegal archive of books and papers — the largest in the world. The West needs to overhaul copyright law as a matter of national security.
- > Mission & Vision — The Society Library: no description found
- GPU Poor LLM Arena - a Hugging Face Space by k-mktr: no description found
- AI Politician: no description found
- Tweet from shumo - e/acc (@shumochu): http://x.com/i/article/1886118023179747328
- Open-R1: Update #1: no description found
- Log in / Register - Anna’s Archive: no description found
Nous Research AI ▷ #research-papers (18 messages🔥):
Weekend Plans, Paper Reading Habits, Scite Research Platform, Deep Gradient Compression, Stanford's Simple Test-Time Scaling
- Excited for the Weekend: Members expressed enthusiasm about the weekend, with one stating, 'Will be a good weekend.'
- Another member echoed this sentiment with a strong 'yessss'.
- Doodling Notes on Printed Papers: Several members confirmed their habit of printing research papers, with comments like, 'I print off all the best stuff to read too.'
- One member humorously noted they thought they were the only one who doodles notes around the edges to feel they've read the paper.
- Scite Platform for Research Exploration: One member shared about the Scite platform for exploring research, which offers exclusive access to journals and an AI assistant.
- They also mentioned contacting Scite about supporting ArXiv, and received a positive implication about upcoming support.
- Deep Gradient Compression Proposal: A member highlighted a paper on Deep Gradient Compression that addresses communication bandwidth issues in large-scale distributed training.
- The paper claims that nearly 99.9% of gradient exchanges are redundant and proposes methods to significantly reduce bandwidth needs.
- Stanford's Simple Test-Time Scaling: A member shared a post about Stanford's Simple Test-Time Scaling that enhances reasoning performance significantly.
- They noted it surpassed o1-preview on math competition questions by up to 27%, with the model, data, and code being open-source.
- Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training: Large-scale distributed training requires significant communication bandwidth for gradient exchange that limits the scalability of multi-node training, and requires expensive high-bandwidth network in...
- Kimi k1.5: Scaling Reinforcement Learning with LLMs: Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a ne...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Stanford presents: s1: Simple test-time scaling- Seeks the simplest approach to achieve test-time scaling and strong reasoning performance- Exceeds o1-preview on competition math questions by up to 27...
Nous Research AI ▷ #reasoning-tasks (5 messages):
Relign Open-Sourced RL Library, Distributed Training Session, Community Contributions
- Relign Launches Developer Bounties: A member announced that they are seeking contributors for developer bounties at Relign, aiming to build an open-sourced RL library tailored for reasoning engines.
- They encouraged interested developers to reach out for collaboration opportunities and resources.
- New Member Seeking Contributions: A new community member expressed their eagerness to contribute, highlighting their background in full stack engineering and R&D.
- They indicated their interest in connecting with the team for a deeper dive into the Relign project.
- Inquiry about Distributed Training Session: A member inquired whether a live distributed training session had been announced, indicating interest in upcoming events.
- There hasn't been a response regarding the status of the training session yet.
Interconnects (Nathan Lambert) ▷ #news (228 messages🔥🔥):
Deep Research, SoftBank and OpenAI partnership, Crystal Intelligence model, LLM productivity impacts, Gemini Deep Research limitations
- Deep Research Launch by OpenAI: OpenAI's new feature, Deep Research, allows users to interact with the O3 model, providing research question refinements and a sidebar displaying reasoning progress during query execution.
- Initial impressions highlight the potential of Deep Research in synthesizing information, though some users note limitations in thorough source analysis.
- SoftBank's $3 Billion Commitment to OpenAI: SoftBank has announced plans to purchase $3 billion worth of OpenAI products annually, while establishing a joint venture focused on the Crystal Intelligence model in Japan.
- This exclusive offering will integrate OpenAI's technology into SoftBank subsidiaries and aims to enhance AI solutions for Japanese enterprises.
- Launch of Crystal Intelligence Model: The Crystal Intelligence model is designed to autonomously analyze and optimize a company's legacy code over the past 30 years, with future plans to introduce AGI within two years.
- Masayoshi Son emphasized the transformative potential of AI, referring to it as Super Wisdom, in his remarks during the launch event.
- Impact of LLMs on Productivity: Users have reported significant productivity boosts from LLMs, stating they can now complete tasks that would previously take days, highlighting a shift in software development capabilities.
- However, concerns about misinformation and limitations arise, particularly regarding reliance on algorithms and source quality in generated content.
- Limitations of Gemini Deep Research: Users of Gemini Deep Research noted its tendency to produce summaries rather than synthesizing information from multiple sources, which limits its effectiveness.
- There are also concerns regarding the inclusion of low-quality content from SEO-focused pages during research processes.
- no title found: no description found
- Tweet from undefined: no description found
- (WIP) A Little Bit of Reinforcement Learning from Human Feedback: The Reinforcement Learning from Human Feedback Book
- Tweet from OpenAI (@OpenAI): Deep ResearchLive from Tokyo4pm PT / 9am JSTStay tuned for link to livestream.
- Tweet from LF AI & Data Foundation (@LFAIDataFdn): 🚀 Excited to introduce DeepSpeed, a deep learning optimization library from @Microsoft! It simplifies distributed training and inference, making AI scaling more efficient and cost-effective. Learn mo...
- Tweet from Computer Intelligence (@BigComProject): Today, we are happy to announce the Computer Intelligence Project, a non-profit initiative to develop multimodal code intelligence for compute-level task automation.Our project will focus on developin...
- Self-selection bias - Wikipedia: no description found
- K22p01 GIF - K22P01 - Discover & Share GIFs: Click to view the GIF
- Introduction to Deep Research: Begins at 9am JST / 4pm PTJoin Mark Chen, Josh Tobin, Neel Ajjarapu, and Isa Fulford from Tokyo as they introduce and demo deep research.
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): @datapoint2200 ( he’s literally saying this. I can’t make this up )
- Tweet from Teortaxes▶️ (DeepSeek🐳 Cheerleader since 2023) (@teortaxesTex): One-off geometric animation tests are an annoying fad, brittle, and I believe tell you very little about the model. (not dunking on Stephen, who shows that this task can be done by R1 too, contra clai...
- Tweet from Yuchen Jin (@Yuchenj_UW): @lexfridman @dylan522p @natolambert listening, but this picture of Liang Wenfeng is wrong.....
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Launched a 1000 person sales engineer team.SoftBank says it will make Stargate Japan
- Tweet from Tibor Blaho (@btibor91): The information reports that SoftBank has committed to purchasing $3 billion worth of OpenAI products annually while also forming a Japan-focused joint venture- SoftBank will distribute OpenAI technol...
- Tweet from X-Dimension (@X_DimensionNews): Hey Jimmy, i am Japanese and our media says:The new AI model, “Crystal Intelligence,” will be exclusively available to major Japanese companies. This model can autonomously analyze and optimize all sy...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): o3-mini is now LIVE in WebDev Arena vs DeepSeek-R1!"Simulate multiple small balls bouncing inside a spinning rectangle. The balls should collide with each other and the walls."
- Tweet from Jerry Tworek (@MillionInt): deep research is the first time people outside of OpenAI can interact with o3
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Crystals have long term memory
- Tweet from Eric Hartford (@cognitivecompai): A new, helpful feature was added yesterday to Gemini 2.0 Flash Thinking! Maybe they don't like Dolphin-R1 dataset? Oops, sorry...
- Tweet from Tibor Blaho (@btibor91): 3 new ChatGPT web app builds were deployed in recent hours- new custom instructions UX ("What should ChatGPT call you?", "What do you do?", "What traits should ChatGPT have?" -...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Masayoshi Son in a speech said Sam agreed to launch agi in Japan, less than 2 years new model called crystal intelligence, operates autonomously, reads all source code of the system your company has b...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Crystal attends all meetings, replaces call centres
- Tweet from Yuchen Jin (@Yuchenj_UW): o3-mini might be the best LLM for real-world physics.Prompt: "write a python script of a ball bouncing inside a tesseract"
- Tweet from Eric Zelikman (@ericzelikman): @Teslanaut
- RLHF Book | Hacker News: no description found
- Tweet from ∿ Ropirito (0commoDTE) (@ropirito): wow that’s crazy that your LLM can script a ball bouncing in a rotating shape. should we maybe try having it do something there aren’t 10,000 human made tutorials for
- DeepSeek, China, OpenAI, NVIDIA, xAI, TSMC, Stargate, and AI Megaclusters | Lex Fridman Podcast #459: Dylan Patel is the founder of SemiAnalysis, a research & analysis company specializing in semiconductors, GPUs, CPUs, and AI hardware. Nathan Lambert is a re...
- LIVE: OpenAI founder Sam Altman speaks in Tokyo: Watch live as OpenAI CEO Sam Altman speaks at an event “Transforming Business through AI” in Tokyo, Japan, along with SoftBank CEO Masayoshi Son and Arm Hold...
- Reddit - Dive into anything: no description found
- Google Gen AI SDK documentation: no description found
Interconnects (Nathan Lambert) ▷ #ml-questions (19 messages🔥):
SmolLM Team's Response, Human Data Space Exploration, Reinforcement Learning Challenges, Use of HF Accelerate vs. Torchrun
- Provoking the SmolLM Team: A member humorously quipped that annoying the SmolLM team might prompt them to release updates, while another affirmed that annoying people is just part of their job.
- A little chaos never hurt anyone as they navigated the excitement of poking fun at team dynamics.
- Thoughts on Human Data Space's Future: A user questioned the future implications of reinforcement learning's success and its replication on the human data space, seeking diverse perspectives.
- This led to discussions about the role of prompts and agent takeovers, emphasizing that models need assistance beyond just completions.
- Reinforcement Learning for Complex Decisions: Concerns arose about how to apply reinforcement learning in scenarios where trade-offs exist, as definitive scoring isn't applicable.
- A user proposed that human feedback on the model's responses might be necessary for complex planning scenarios.
- Token Injection in Reasoning Processes: A user inquired whether it's possible to inject tokens during a model's reasoning process, indicating a gap in available information.
- Another user provided a resource link to further explore this concept, promoting inquiry into refining reasoning in models.
- Choosing Between HF Accelerate and Torchrun: A member asked about preferences for HF Accelerate versus
torchrunfor LLM training, noting varied usage in open source repos.- Responses highlighted that while Accelerate is user-friendly for beginners, building a custom stack may warrant avoiding its use.
Interconnects (Nathan Lambert) ▷ #ml-drama (28 messages🔥):
O3-mini System Card Confusion, DeepSeek's Open Source Impact, Anthropic's Challenge, Wikipedia's Role in AI, Issues with Jailbreak Progress
- O3-mini System Card Confusion: A member questioned why the newly downloaded O3-mini system card PDF did not mention the Codeforces ELO benchmark anymore, unlike the previous version.
- This raises concerns about the changes made in the documentation of the system card.
- DeepSeek's Open Source Impact: A prominent figure expressed admiration for DeepSeek, stating their open source strategy makes powerful AI systems accessible to the masses.
- The member highlighted the significance of China's investment in AI finally receiving recognition.
- Anthropic's Challenge Draws Skepticism: Anthropic released a challenge where participants attempt to break eight safeguards with one jailbreak prompt, raising concerns about motivation for involvement.
- Several members noted that the challenge is currently unattractive to potential participants.
- Debate on Wikipedia's Relevance in AI: A heated discussion emerged regarding whether AI systems should rely on Wikipedia, with some arguing that AI will just read its sources instead.
- Members weighed in on the alignment issues surrounding Wikipedia's perceived biases and its utility in AI training.
- Bug in Jailbreak UI Revealed: Jan Leike disclosed that a bug allowed users to advance through jailbreak levels without actually breaking the model, claiming that no one has surpassed 3 levels so far.
- This revelation has sparked conversations about the effectiveness and reliability of the jailbreak process among users.
- Tweet from Armen Aghajanyan (@ArmenAgha): This is absolutely not true about what happened with Zetta. Do we really want to open up about what happened here?Quoting Yann LeCun (@ylecun) You misread.There had been multiple LLM projects within F...
- Tweet from Jürgen Schmidhuber (@SchmidhuberAI): To be clear, I'm very impressed by #DeepSeek's achievement of bringing life to the dreams of the past. Their open source strategy has shown that the most powerful large-scale AI systems can be...
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): @janleike @AnthropicAI what’s in it for me?
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): @alexalbert__ @AnthropicAI ggs
- Tweet from Yann LeCun (@ylecun): You misread.There had been multiple LLM projects within FAIR for years. Some were open sourced as research prototypes (e.g. OPT175B, Galactica, BlenderBot...).In mid-2022, FAIR started a large LLM pro...
- Tweet from Noam Brown (@polynoamial): .@OpenAI Deep Research might be the beginning of the end for Wikipedia and I think that's fine. We talk a lot about the AI alignment problem, but aligning people is hard too. Wikipedia is a great ...
- Tweet from Jan Leike (@janleike): @elder_plinius @AnthropicAI you will have fully broken our defense ✨
- Tweet from Clémentine Fourrier 🍊 (🦋 clefourrier.hf.co) (@clefourrier): Hey @OpenAI , you're not topping GAIA if you're not submitting to the PRIVATE TEST SET (and results you report for the previous SOTA (on val) are wrong btw, see the table - perf is similar to ...
- Tweet from Simon Willison (@simonw): Anyone know what's going on with the o3-mini system card? The PDF at https://cdn.openai.com/o3-mini-system-card.pdf isn't the same document as the one I downloaded a few hours ago - the old on...
Interconnects (Nathan Lambert) ▷ #random (197 messages🔥🔥):
OpenAI's O3, Deep Research performance comparisons, Research agent advancements, RLHF and model training, CoT and AI policies
- OpenAI's O3 keeps improving with reinforcement learning: OpenAI is seeing a shift towards more reinforcement learning (RL) features in their models, with O3 being based on the same model but enhanced with RL techniques.
- In addition to O3, both the operator and Deep Research have undergone RL training, illustrating a clear focus on this approach.
- Deep Research struggles with extensive tasks: Deep Research from OpenAI was tasked to compile detailed information about R1 universities but ultimately failed to complete the task efficiently.
- While Gemini deep research also struggled, users noted that OpenAI’s outputs felt more reliable despite taking longer and searching fewer web pages.
- Advances in Research Agent Technologies: Richard Socher announced an upcoming advanced research agent that they expect to outperform OpenAI's recent models, with improvements expected in a week.
- This sets the stage for competitive advancements among AI research agents, with heightened anticipation from the developer community.
- GRPO proves beneficial for Llama 2: A recent finding highlighted that the GRPO approach worked well for the Llama 2 7B model, achieving a significant accuracy improvement on the GSM8K benchmark.
- This demonstrates the effectiveness of reinforcement learning techniques beyond just the latest model families.
- CoT enhancements and AI policy inquiries: Discussions emerged around a potential new 'CoT experience' being tested by OpenAI, indicating ongoing improvements in context-driven outputs.
- These advancements prompted conversations about AI policies at universities, as users delve into the implications of AI in academic settings.
- Tweet from The Information (@theinformation): 🚀 OpenAI is on a growth streak:• ChatGPT hit 15.5M paid subscribers in 2024• Business adoption of its models jumped 7x• A new $200/month Pro tier is already pulling in $300M annuallyWhat’s next? High...
- (WIP) A Little Bit of Reinforcement Learning from Human Feedback: The Reinforcement Learning from Human Feedback Book
- BigCodeBench Leaderboard: no description found
- s1: Simple test-time scaling: Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly...
- LiveBench: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Tweet from Jake Colling (@JacobColling): @simonw Maybe renable formatting?https://platform.openai.com/docs/guides/reasoning#advice-on-prompting
- Tweet from Casper Hansen (@casper_hansen_): Next week, I will speedrun a Tülu 3-Zero using their RLVR dataset
- Schedule: no description found
- Tweet from Epoch AI (@EpochAIResearch): In this week’s Gradient Updates issue, @EgeErdil2 explains what went into the training of DeepSeek-R1 and estimates that the dollar cost of the compute that went into its training on top of DeepSeek V...
- Tweet from Sam Paech (@sam_paech): Big update to Judgemark⚖️Results first:- Huge variability in how each judge uses the score range. 👀 the heatmaps!- Before calibration, haiku-3.5 wins (!). It makes best use of the score range.- Afte...
- Tweet from Daya Guo (@Guodaya): @davikrehalt We have also been trying to apply R1 to formal proof environments like Lean. We hope to bring a better model to the community as soon as possible.
- Tweet from Tibor Blaho (@btibor91): The ChatGPT web app announcement about the "new CoT summarizer" for o3-mini has been renamed to "new CoT Exp." with a new experiment controlling whether it should "show preview whe...
- Tweet from vik (@vikhyatk): this looks like the original CoT...?
- Tweet from vik (@vikhyatk): @MaziyarPanahi the tokens stream in with minimal latency, unlike the summarizer they had before. tried looking around but didn't see any announcements
- Tweet from George (@georgejrjrjr): poor dylan, cooked by the interns again.Also: not a dunk on @natolambert who seems honest and is very helpful, but that v3 article could use another update:best evidence we’ve got says yr cost estimat...
- Tweet from Sasha Rush (@srush_nlp): Got talked into giving a DeepSeek talk this afternoon https://simons.berkeley.edu/workshops/llms-cognitive-science-linguistics-neuroscience/schedule#simons-tabsNot sure I have anything new to say here...
- Tweet from Shannon Sands (@max_paperclips): So much for the very first test prompt I gave o3-mini-high (reimplement the r1 GRPO trainer)Yup, back to r1 it is. Get bent OAI
- Tweet from Cristiano Giardina (@CrisGiardina): OpenAI is working to show more of the thinking CoT tokens for o3 / their reasoning models.@kevinweil says "showing all CoT leads to competitive distillation [...] but power users want it,"@sam...
- Tweet from Nathan Lambert (@natolambert): Subscribe to @interconnectsai to take advantage of my crazy attempts to keep up with reasoning results for free
- Tweet from Ofir Press (@OfirPress): Congrats to o3-mini on setting a new high score on SciCode!! R1 clocks in at an impressive 4.6%, matching Claude 3.5.SciCode is our super-tough programming benchmark written by PhDs in various scienti...
- Tweet from Daniel Litt (@littmath): First of all, it’s clearly a significant improvement over o1. It immediately solved (non-rigorously) some arithmetic geometry problems with numerical answers that I posed to it, which no other models ...
- Tweet from Riley Goodside (@goodside): Brainstorming ideas with o3-mini — going well, pasting in some code to explain AidenBench. It asks about some function. I paste the file.Policy error. A mistake, I say. Policy error. I go back and edi...
- Tweet from Richard Socher (@RichardSocher): Now that openai has caught up to our old research agent from over a year ago we will soon launch our advanced research and intelligence agent which will be 10x better than what we have had and openai ...
- Tweet from Teortaxes▶️ (DeepSeek🐳 Cheerleader since 2023) (@teortaxesTex): DeepSeek V3 type model can now be trained on Huawei Ascend.
- Tweet from Ricardo Dominguez-Olmedo (@rdolmedo_): Does reinforcement learning with verifiable rewards work only for recent model families?It turns out that GRPO also works very well for Llama 2 7B, with an impressive +15 accuracy point increase in GS...
- Tweet from Tibor Blaho (@btibor91): The Information reports that OpenAI told some shareholders that ChatGPT paid subscribers increased from 5.8 million to 15.5 million in 2024, while according to a person familiar with the discussions, ...
- Tweet from vLLM (@vllm_project): We landed the 1st batch of enhancements to the @deepseek_ai models, starting MLA and cutlass fp8 kernels. Compared to v0.7.0, we offer ~3x the generation throughput, ~10x the memory capacity for token...
- Tweet from Andrej Karpathy (@karpathy): There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g...
- Tweet from Xeophon (@TheXeophon): I love this example, all VLMs were incredibly off when counting, including Gemini. Qwen2.5-VL nails it every time if you instruct it to count really, really hard. Else it is off by 1.This is now a Qwe...
- Tweet from Maitrix.org (@MaitrixOrg): 🚀Unlock efficient inference-time scaling with LLM Reasoners - now powered by SGLang! > 🔥100x acceleration over previous veresion of LLM Reasoners (w/ huggingface) > With just one line of co...
- Tweet from Tsarathustra (@tsarnick): Sam Altman: "we have been on the wrong side of history" with regards to open source/open weights AI models
- Tweet from Daniel Litt (@littmath): Some brief impressions from playing a bit with o3-mini-high (the new reasoning model released by OpenAI today) for mathematical uses.
- Tweet from Charlie Marsh (@charliermarsh): Huge, yet very very niche news: Flash Attention (flash-attn) now uses Metadata 2.2, which means uv can resolve it without building the package from source.
- Tweet from Lex Fridman (@lexfridman): OpenAI o3-mini is a good model, but DeepSeek r1 is similar performance, still cheaper, and reveals its reasoning.Better models will come (can't wait for o3pro), but the "DeepSeek moment" i...
- Reddit - Dive into anything: no description found
- GitHub - Deep-Agent/R1-V: Witness the aha moment of VLM with less than $3.: Witness the aha moment of VLM with less than $3. Contribute to Deep-Agent/R1-V development by creating an account on GitHub.
- Tweet from Sam Altman (@sama): got one more o3-mini goody coming for you soon--i think we saved the best for last!
- Qwen Chat: no description found
Interconnects (Nathan Lambert) ▷ #memes (32 messages🔥):
HF_ENABLE_FAST_TRANSFER, Bengali Ghosthunters, TechCrunch's Meme Game, Economic Value Charts, RLHF vs Reasoning Models
- HF_ENABLE_FAST_TRANSFER boosts efficiency: A member highlighted using
HF_ENABLE_FAST_TRANSFER, which reportedly triples the effectiveness of the HF ecosystem.- Discussion ensued about the default transfer speeds of large file storage, with concerns expressed that they seem slow.
- Bengali Ghosthunters take center stage: Bengali Ghosthunters generated humor as a member recounted an experience where Gemini Flash Thinking became erratic while helping him learn about LLMs.
- The topic sparked further exploration and interest in the connection between technology and humorous experiences.
- TechCrunch memes making waves: A hilarious reaction was captured as the headline from TechCrunch was praised with a member remarking on their ability to post memes on X like a champ.
- Another member jokingly suggested that modern math classes led to the widespread of rosettes among contributors.
- Estimated Economic Value charts cause a stir: A member noted excitement over new 'Estimated Economic Value' charts promising to intrigue fans of the ambiguous test time compute log plots.
- The reaction ranged from humorous skepticism to excitement about how these insights would be presented, resembling pitch decks.
- Debates on RLHF and reasoning models: A strong opinion emerged surrounding RLHF, with a member asserting that it continues to be a vital part of the pipeline despite the rise of reasoning models.
- This sparked a lively discussion emphasizing that both RLHF and reasoning training are components of a larger post-training strategy.
- Tweet from sholín (NOAM CHOMSKY SIGUE VIVO) (@qwrk8126): Gemini Flash Thinking Exp 2.0 0121 was teaching me more about the technical nature of LLMs and prepared a short multiple choice exam for me to provide the correct answers. After I did, it stopped thin...
- Tweet from edwin (@edwinarbus): no description found
- Tweet from Charles Foster (@CFGeek): “The bitter lesson is we just needed to rebrand reward functions as verifiers”- Rich Sutton, probably
- Tweet from Colin Fraser (@colin_fraser): This made me laugh out loud
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): no description found
- Tweet from wordgrammer (@wordgrammer): Anthropic spends $5 mil training Claude, then $995 mil redteaming it.OpenAI spends $5 mil training o3, then $995 mil in test-time compute on some math benchmark.DeepSeek spends $5 mil training, then $...
- Tweet from Xeophon (@TheXeophon): I knew itQuoting Nathan Lambert (@natolambert) Way too many people think that because reasoning models have taken off, and reinforcement learning with verifiable rewards as a core ingredient, that RLH...
- Tweet from Colin Fraser (@colin_fraser): some real gems in the 202-second CoT for this one
- Tweet from xjdr (@_xjdr): if you liked the ambiguous test time compute log plots you are going to love the new "Estimated Economic Value" charts
- GitHub - huggingface/hf_transfer: Contribute to huggingface/hf_transfer development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #rl (7 messages):
Funding Issues, GRPO and RLVR, Demos, DeepSeek
- Funding Challenges Close a Project: A member expressed gratitude to AI2 for being a supportive open-source community while sharing the unfortunate news of closing their project due to lack of funding and personal health issues.
- They emphasized the importance of platforms like AI2 for open-source efforts in today's climate.
- Question on GRPO's Role in RLVR: A member posed a question regarding whether GRPO is essential for RLVR or if DPO could suffice instead.
- Another interjected, stating that while DPO could be utilized, it would likely be less effective than using GRPO.
- Desire for Better Demos at AI2: A member expressed a wish for AI2 to improve on their demo presentations, suggesting that better showcases could enhance the community's outreach.
- They acknowledged, however, that not focusing on quick hits allows for more mental space to pursue bigger wins.
- Discussion on DeepSeek's Mechanisms: A member sought clarity on whether GRPO is a crucial aspect of DeepSeek's magic or merely an implementation detail.
- The response noted that GRPO is possibly not required as DPO could be applied, albeit with reduced effectiveness.
Link mentioned: Alexander Doria (@dorialexander.bsky.social): In case it interests anyone, I managed to set up a demo of GRPO RL training in Colab. It’s an adaptation of Will Brown instant classic for math reasoning. Replace llama 1B with qwen 0.5b and inference...
Interconnects (Nathan Lambert) ▷ #rlhf (10 messages🔥):
DeepSeek AI R1 model, AI as a science discussion, Thinking models in AI, NeurIPs talk on post-training, R1 training parameters
- DeepSeek AI launches flagship R1 model: On January 20th, China's DeepSeek AI released their first full-fledged reasoning model, the R1 model.
- This model is characterized by a focus on longer training with more data, prompting excitement in the community about reasoning models.
- Is AI a science? A deep dive: The hosts of The Retort discussed whether AI qualifies as a science, referencing the Kuhn'ian perspective.
- This debate highlights ongoing philosophical discussions about the nature of scientific disciplines in relation to AI.
- Exploring thinking models in AI: A guest appeared on a podcast to discuss the concept of “thinking models” and their intersection with post-training and reasoning methods, available here.
- The discussion emphasizes the evolution of AI methodologies and how they distinguish between various model training approaches.
- NeurIPs talk on post-training revealed: A recent talk given at NeurIPs focused on post-training strategies for AI applications, now publicly available here.
- The insights shared aim to guide AI practitioners in refining their training cycles for better outcomes.
- R1 training simplicity acknowledged: Training the R1 model involves providing more data and extending training time, with the sequencing prioritized early in the post-training cycle.
- This straight-forward approach received a lighthearted acknowledgment of its simplicity, sparking enthusiasm for diverse reasoning models.
Link mentioned: DeepSeek R1's recipe to replicate o1 and the future of reasoning LMs: Yes, ring the true o1 replication bells for DeepSeek R1 🔔🔔🔔. Where we go next.
Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
Creator Gravity, AI Self-Assessment, Rejection in Writing Jobs, Sander Land's Substack Commentary
- Sander Land's Hilarious Commentary: A member highlighted a hilarious Substack article discussing concepts of tokenization, stating, 'people follow this shit?' while sharing the article link.
- The discussion revealed a mix of skepticism and amusement regarding the content, suggesting a growing trend of critique in AI discussions.
- Creator Gravity Discussion: A member expressed frustration with the repetitive nature of rejection emails while sharing insights on Creator Gravity.
- 'If no one is going to hire me, I’ll hire myself,' was a standout moment reflecting the determination within the creative community.
- Rich Sutton on AI Self-Verification: The mention of Rich Sutton's article, 'Key to AI,' sparked a discussion regarding the self-assessment capabilities of AI. He argues that an AI's ability to verify its own performance is crucial for successful operation.
- One member reacted humorously, referring to Sutton's insights as a boomer reference, pointing to generational divides in perceptions of AI development.
- Discovery of Article: The link shared by a member was a response to a previous discussion, emphasizing the interconnectedness of ideas shared within the community. Another member remarked on how easily such pieces circulate on platforms like Twitter.
- This interaction highlights the dynamic exchange of information and perspective prevalent in the group.
- Self-Verification, The Key to AI: no description found
- WTF is Creator Gravity? : The art and science of becoming magnetic online–and why it has nothing to do with traditional influence.
- Whole words and Claude tokenization: Using the new counting endpoint reveals .. a preference for whole words?
Interconnects (Nathan Lambert) ▷ #policy (23 messages🔥):
Proposed AI Legislation, Shadow Libraries and AI, Foxconn Tariffs, AI Research Collaboration Restrictions
- Congress's Aggressive AI Bill Threatens Open Source: A bill proposed by GOP Senator seeks to ban the import of AI technology from the PRC, potentially including downloading of model weights like
DeepSeek, with penalties of up to 20 years imprisonment.
- It also prohibits export of AI to an 'entity of concern', equating the release of products like Llama 4 with similar penalties.
- Potential Laws to Criminalize Research Collaborations: The bill could make it a crime for U.S. nationals to co-author machine learning papers with institutions like Tsinghua University, raising concerns over academic freedom.
- Critics argue that this moves the conversation in a dangerous direction for international collaboration in AI.
- Foxconn Shipping and Trade Tariffs: Reports indicate that all Foxconn GB200 orders to the U.S. will be shipped from Mexico following Trump's planned tariffs on Canada and Mexico, potentially affecting GPU availability.
- This situation raises implications for large data center builds amidst ongoing supply chain concerns.
- AI Copyright and Shadow Libraries Discussion: Concerns have been raised regarding the use of illegal archives like Z-Library for training Chinese LLMs, highlighting the need for a copyright law overhaul as a matter of national security.
- Experts point to the urgency of addressing these issues to protect intellectual property and open-source developments.
- Copyright reform is necessary for national security: Chinese LLMs (including DeepSeek) are trained on my illegal archive of books and papers — the largest in the world. The West needs to overhaul copyright law as a matter of national security.
- Tweet from Ben Brooks (@opensauceAI): Wow. Congress just tabled a bill that would *actually* kill open-source. This is easily the most aggressive legislative action on AI—and it was proposed by the GOP senator who slammed @finkd for Llama...
- Tweet from Aviya Skowron (@aviskowron): the bill would also make it a crime for a US national to co-author a machine learning paper with someone at Tsinghua University. You'd think I am exaggerating, but here's the press release and...
- Tweet from Kakashii (@kakashiii111): You’re all aware that all Foxconn GB200 orders to the U.S. are planned to be shipped from Mexico, right?Quoting unusual_whales (@unusual_whales) BREAKING: White House says Trump plans to follow throug...
- Tweet from Ben Brooks (@opensauceAI): 1. The bill would ban the import of AI "technology or intellectual property" developed in the PRC. Conceivably, that would include downloading @deepseek_ai R1 / V3 weights. Penalty: up to 20 y...
- Tweet from Ben Brooks (@opensauceAI): 2. The bill would also ban the export of AI to an "entity of concern". Export means transmission outside the US, or release to a foreign person in the US. E.g. Releasing Llama 4. Penalty? Also...
- § 740.27 License Exception Artificial Intelligence Authorization (AIA). | Bureau of Industry and Security: no description found
Latent Space ▷ #ai-general-chat (181 messages🔥🔥):
Deep Research Launch, OpenAI Agent Discussions, AI Model Developments, LLM Competition and Internal Conflicts, Reasoning Augmented Generation (ReAG)
- OpenAI releases Deep Research: OpenAI introduced Deep Research, an autonomous agent optimized for web browsing and complex reasoning, promising to synthesize extensive reports from various sources in minutes.
- Early feedback suggests it functions as a powerful e-commerce tool, although some users report limitations in its output quality.
- Confusion over model access levels: There has been confusion among users regarding access to Deep Research on mobile devices, with many noting it currently seems limited to desktop use only.
- Some users expressed concern over the disparity in access between different subscription tiers.
- AI model competition and internal disputes: Yann LeCun highlighted internal competition within FAIR, contrasting the development paths of Zetta and Llama-1, stating that smaller teams often outperformed larger projects.
- This led to discussions about the implications of such dynamics in ongoing AI development, especially in contexts like DeepSeek versus traditional players.
- Introduction of Reasoning Augmented Generation (ReAG): ReAG aims to improve upon traditional Retrieval-Augmented Generation by eliminating retrieval steps and directly feeding raw material to LLMs for synthesis.
- Initial responses indicate its potential effectiveness but raise concerns regarding scalability and the necessity of preprocessing documents.
- Community engagement and feedback: Users actively crowdsource ideas and tests for AI models like Deep Research, demonstrating community interest in improving interactions with these technologies.
- Participants are sharing experiences, findings, and engaging in discussions that reflect a vibrant and evolving landscape in AI development.
- Tweet from Cursor (@cursor_ai): o3-mini is out to all Cursor users!We're launching it for free for the time being, to let people get a feel for the model.The Cursor devs still prefer Sonnet for most tasks, which surprised us.
- Tweet from Noam Brown (@polynoamial): .@OpenAI Deep Research might be the beginning of the end for Wikipedia and I think that's fine. We talk a lot about the AI alignment problem, but aligning people is hard too. Wikipedia is a great ...
- Tweet from Teknium (e/λ) (@Teknium1): Let me tell you all a little story. Sometime around a or so year ago i reached out to an openai staffer who will not be named who had implied they would be very interested in doing some things open so...
- Tweet from Tsarathustra (@tsarnick): Sam Altman: "we have been on the wrong side of history" with regards to open source/open weights AI models
- DeepSeek Has Gotten OpenAI Fired Up: After a Chinese-startup roiled the industry, OpenAI readies a response—ahead of schedule.
- Tweet from Owen Colegrove (@ocolegro): I asked openai deep researcher what R1 was and how I could replicate it on a small scale - the results were very good (no hype) - this is the first thing to impress me as much asthe original ChatGPT r...
- The Agent Reasoning Interface: o1/o3, Claude 3, ChatGPT Canvas, Tasks, and Operator — with Karina Nguyen of OpenAI: Karina Nguyen from OpenAI (and previously Anthropic) discusses her work on Claude, ChatGPT Canvas and Tasks, and the new AI interaction paradigms for human-computer collaboration.
- Tweet from Ishan Anand (@ianand): ArrrZero: Why DeepSeek R1 is less important than R1-Zero.While everyone's talking about DeepSeek R1, the real game-changer is R1-Zero. In this video I cover how this model went straight from base ...
- Tweet from Naman Goyal (@NamanGoyal21): @giffmana Being the only person who was co-author both in OPT and llama1 and was part of zetta team, I can say that actually that it was much more nuanced and has multiple POVs and not a simple story ...
- Tweet from Noam Brown (@polynoamial): o1 was released less than 2 months ago. o3-mini was released 2 days ago. Deep Research was released today. It’s a powerful tool and I can’t wait to see what the world does with it, but AI will continu...
- Tweet from Ishan Anand (@ianand): ArrrZero: Why DeepSeek R1 is less important than R1-Zero.While everyone's talking about DeepSeek R1, the real game-changer is R1-Zero. In this video I cover how this model went straight from base ...
- Tweet from Chubby♨️ (@kimmonismus): OpenAI's-Team AMA on Reddit: best of A thread 🧵No. 1: recursive self-improvement probably a hard take off
- ReAG: Reasoning-Augmented Generation - Superagent: Superagent is a workspace with AI-agents that learn, perform work, and collaborate.
- Tweet from Sam Altman (@sama): @yacineMTB oops i got that wrong. i thought it was going out today, but that part ships very soon!
- Tweet from Hyung Won Chung (@hwchung27): Happy to share Deep Research, our new agent model!One notable characteristic of Deep Research is its extreme patience. I think this is rapidly approaching “superhuman patience”. One realization workin...
- Tweet from OpenAI (@OpenAI): Powered by a version of OpenAI o3 optimized for web browsing and python analysis, deep research uses reasoning to intelligently and extensively browse text, images, and PDFs across the internet. https...
- Tweet from Kevin A. Bryan (@Afinetheorem): The new OpenAI model announced today is quite wild. It is essentially Google's Deep Research idea with multistep reasoning, web search, *and* the o3 model underneath (as far as I know). It sometim...
- Tweet from Sam Altman (@sama): (note: this is not the "one-more-thing" for o3-mini. few more days for that.)
- Tweet from Han Xiao (@hxiao): OpenAI's Deep Research is just a search+read+reasoning in a while-loop, right? unless i'm missing miss something, here is my replicate of it in nodejs, using gemini-flash and jina reader https...
- Tweet from Nikunj Handa (@nikunjhanda): o3-mini is the most feature complete + developer friendly o-series model we've released to date: function calling, structured outputs, streaming, batch, assistants!It's also:1. It's 90+% c...
- Tweet from thomas (@distributionat): If you get $500 of value per query, then in the first month of a Pro subscription you net $49,800 with your 100 queries.Then in month 2 you can buy 249 new subscriptions, and you net $12,450,000. By m...
- Reddit - Dive into anything: no description found
- Tweet from Mckay Wrigley (@mckaywrigley): The key takeaway from OpenAI’s Deep Research preview is that they’ve made significant progress on longterm planning + tool calling.This is how you get The Virtual Collaborator.Agents are coming.
- Tweet from Sam Altman (@sama): congrats to the team, especially @isafulf and @EdwardSun0909, for building an incredible product.my very approximate vibe is that it can do a single-digit percentage of all economically valuable tasks...
- Tweet from Zhiqing Sun (@EdwardSun0909): Excited to finally share what I’ve been working on since joining OpenAI last June!The goal of deep-research is to enable reasoning models with tools to tackle long-horizon tasks in the real world and ...
- Tweet from Dan Hendrycks (@DanHendrycks): It looks like the latest OpenAI model is very doing well across many topics.My guess is that Deep Research particularly helps with subjects including medicine, classics, and law.
- Tweet from homanp (@pelaseyed): Traditional RAG sucks because it promises "relevant chunks" but in fact returns "similar chunks". Relevancy requires reasoning.Introducing ReAG - Reasoning Augmented Generation
- Tweet from Greg Brockman (@gdb): Deep Research is an extremely simple agent — an o3 model which can browse the web and execute python code — and is already quite useful.It's been eye-opening how many people at OpenAI have been us...
- Reddit - Dive into anything: no description found
- Tweet from Armen Aghajanyan (@ArmenAgha): This is absolutely not true about what happened with Zetta. Do we really want to open up about what happened here?Quoting Yann LeCun (@ylecun) You misread.There had been multiple LLM projects within F...
- RLHF Book | Hacker News: no description found
- Tweet from Clémentine Fourrier 🍊 (🦋 clefourrier.hf.co) (@clefourrier): Hey @OpenAI , you're not topping GAIA if you're not submitting to the PRIVATE TEST SET (and results you report for the previous SOTA (on val) are wrong btw, see the table - perf is similar to ...
- Tweet from Dan Shipper 📧 (@danshipper): OpenAI just launched an autonomous research assistant, Deep Research. We've been testing it for a few days @Every and it's like a bazooka for the curious mind:- Give it a question, and it will...
- Tweet from Alex Albert (@alexalbert__): At Anthropic, we're preparing for the arrival of powerful AI systems. Based on our latest research on Constitutional Classifiers, we've developed a demo app to test new safety techniques.We wa...
- Tweet from vittorio (@IterIntellectus): ehm...
- Tweet from Jan Leike (@janleike): We challenge you to break our new jailbreaking defense!There are 8 levels. Can you find a single jailbreak to beat them all?https://claude.ai/constitutional-classifiers
- Tweet from Jason Wei (@_jasonwei): Very excited to finally share OpenAI's "deep research" model, which achieves twice the score of o3-mini on Humanity's Last Exam, and can even perform some tasks that would take PhD exp...
- Tweet from Nathan Lambert (@natolambert): Stoked to get to talk to @lexfridman + my homie @dylan522p for 5+ hours to try and get to the bottom of what is actually happening in AI right now.DeepSeek R1 & V3, China v US, open vs closed, decreas...
- Tweet from Ethan Mollick (@emollick): OpenAI’s deep research is very good. Unlike Google’s version, which is a summarizer of many sources, OpenAI is more like engaging an opinionated (often almost PhD-level!) researcher who follows lead.L...
- Tweet from Sherwin Wu (@sherwinwu): First time o3 (full, not mini) is available to users outside OpenAI – and it's wrapped in a really slick product experienceQuoting OpenAI (@OpenAI) Powered by a version of OpenAI o3 optimized for ...
- Tweet from AshutoshShrivastava (@ai_for_success): OpenAI launched Deep Research, while ChatGPT Plus users got mogged again. Feels like OpenAI treats Plus users worse than the free tier.
- Tweet from Ethan Mollick (@emollick): OpenAI’s deep research is very good. Unlike Google’s version, which is a summarizer of many sources, OpenAI is more like engaging an opinionated (often almost PhD-level!) researcher who follows lead.L...
- o1 pro - Marginal REVOLUTION: Often I don’t write particular posts because I feel it is obvious to everybody. Yet it rarely is. So here is my post on o1 pro, soon to be followed by o3 pro, and Deep Research is being distrib...
- Brazilian Zouk Move List Request: Brazilian Zouk Moves and Movements Originating in the vibrant dance scene of 1990s Brazil, Brazilian Zouk is a captivating partner dance that has taken the world by storm with its sensual and expressi...
- Tweet from OpenAI (@OpenAI): Deep ResearchLive from Tokyo4pm PT / 9am JSTStay tuned for link to livestream.
- Tweet from OpenAI (@OpenAI): Deep ResearchLive from Tokyo4pm PT / 9am JSTStay tuned for link to livestream.
- Tweet from Sam Altman (@sama): it is very compute-intensive and slow, but it's the first ai system that can do such a wide variety of complex, valuable tasks.going live in our pro tier now, with 100 queries per month.plus, team...
Latent Space ▷ #ai-announcements (2 messages):
AI Engineer Summit, Karina Nguyen Keynote, New Online Track
- AI Engineer Summit Tickets Selling Fast: Sponsorships and tickets for the AI Engineer Summit are selling fast, with the event scheduled for Feb 20-22nd in NYC.
- The new website features live updates on speakers and schedules.
- Karina Nguyen to Deliver Closing Keynote: Karina Nguyen will present the closing keynote at the AI Engineer Summit, highlighting her impressive background including roles at Notion, Square, and Anthropic.
- Her journey includes substantial contributions to the development of Claude 1, 2, and 3.
- Special Online Track Created for AIE Summit: A new online track will be hosted by a member, created due to an overwhelming number of qualified applicants for the AI Engineer Summit.
- This event kicks off with the first two days in NYC, and further details can be found on the Discord event page.
- no title found: no description found
- The Agent Reasoning Interface: o1/o3, Claude 3, ChatGPT Canvas, Tasks, and Operator — with Karina Nguyen of OpenAI: Karina Nguyen from OpenAI (and previously Anthropic) discusses her work on Claude, ChatGPT Canvas and Tasks, and the new AI interaction paradigms for human-computer collaboration.
Latent Space ▷ #ai-in-action-club (270 messages🔥🔥):
Discord screen sharing issues, AI tutoring concepts, Deepseek API discussions, Open source AI tools, Cline vs RooCline
- Discord screen sharing struggles continue: Members discussed various issues with Discord's screen sharing capabilities, highlighting problems with audio quality and video freezing.
- While some found success with the screenshare, others pointed out the frustration with Discord's UX, prompting suggestions for alternative platforms like Zoom.
- AI tutoring systems evolve: The concept of AI tutoring was explained as a method where systems teach users interactively instead of delivering all information at once, similar to Cursor.
- Members expressed interest in AI tutoring and its potential benefits for guiding users through processes instead of just automating tasks.
- Concerns over Deepseek API: There were discussions around the reliability of the Deepseek API, with some members sharing their experiences and highlighting access issues.
- Concerns were raised about the quality and performance of the Deepseek API, with opinions that its hosting and functionalities are lacking.
- Interest in open source AI tools: Members expressed a preference for open source tools over commercial options, discussing projects like Cline and RooCline as viable alternatives.
- The dynamic between maintaining and using these tools was highlighted, emphasizing the community's inclination towards accessible and customizable solutions.
- Cline vs RooCline comparison: A comparison was made between the original Cline project and RooCline, noting that RooCline has diverged with new fixes and functionalities.
- Members were intrigued by the potential differences and improvements made in RooCline, viewing both projects as interesting subjects for further discussion.
- no title found: no description found
- Careless Whisper - Mac Dictation App: no description found
- Brain Dump - Shape Thoughts Instantly.: no description found
- D-Squared: Day Job: Professional AI Whisperer at Gradient Labs | Side Hustle: Showing you the AI automation tricks
- MCP.mp4: no description found
- GitHub - D-Squared70/GenAI-Tips-and-Tricks: Different GenAI tips and tricks I've found useful: Different GenAI tips and tricks I've found useful. Contribute to D-Squared70/GenAI-Tips-and-Tricks development by creating an account on GitHub.
- GenAI-Tips-and-Tricks/Claude_ImplementationPlan.txt at main · D-Squared70/GenAI-Tips-and-Tricks: Different GenAI tips and tricks I've found useful. Contribute to D-Squared70/GenAI-Tips-and-Tricks development by creating an account on GitHub.
- Archive – D-Squared: no description found
- Models & Pricing | DeepSeek API Docs: The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the tot...
- AI In Action: Weekly Jam Sessions: no description found
Eleuther ▷ #announcements (1 messages):
Probability of Random Language Model Weights, Volume Hypothesis in Deep Learning, Importance Sampling in High Dimensions, Network Complexity and Alignment
- Probability of Getting a Functional Language Model: The chance of obtaining a fully functional language model by randomly guessing weights is about one in 360 million zeros, as calculated by a team studying neural networks.
- They emphasize that this estimate reflects complexity—the lower the probability, the more complex the model.
- Volume Hypothesis sheds Light on Deep Learning: Their method for estimating network sampling probability helps illuminate the volume hypothesis which correlates to sampling networks from weight space with low training loss.
- The work strives to measure volume effectively as a means to understand how deep learning operates under vague assumptions.
- Importance of Sampling Outlier Directions: The study highlights that gathering data from high-dimensional spaces is tricky, where small outlier directions can drastically affect volume measurements.
- They introduced importance sampling using gradient information to increase the chance of capturing these outlier scenarios.
- Higher Complexity Linked to Overfitting: It was found that networks that memorize training data exhibit lower local volume, indicating higher complexity compared to those that generalize well.
- This link suggests that overfitting models possess additional unaligned reasoning that could lead to concerns and misalignments with human values.
- Resources Shared for Further Exploration: The team encouraged interest in their project by sharing a GitHub repository on the topic basin-volume and a research paper on arXiv.
- They provided various resources like code, a Twitter thread, and links for deeper insights into their exploratory findings.
- GitHub - EleutherAI/basin-volume: Precisely estimating the volume of basins in neural net parameter space corresponding to interpretable behaviors: Precisely estimating the volume of basins in neural net parameter space corresponding to interpretable behaviors - EleutherAI/basin-volume
- Estimating the Probability of Sampling a Trained Neural Network at Random: We present an algorithm for estimating the probability mass, under a Gaussian or uniform prior, of a region in neural network parameter space corresponding to a particular behavior, such as achieving ...
- Tweet from Nora Belrose (@norabelrose): What are the chances you'd get a fully functional language model by randomly guessing the weights?We crunched the numbers and here's the answer:
Eleuther ▷ #general (104 messages🔥🔥):
Reproduction of R1 results, Censorship in Language Models, Mixture of Experts (MoE), DeepSeek's behavior, Community engagement in AI
- Replication Failures of R1 on SmolLM2: Current tests show that SmolLM2 135M has worse autointerp scores and higher reconstruction errors for SAEs trained on random models compared to those trained on real models.
- The replication of the original results from the paper using Pythia is failing, raising questions about the validity of the initial claims.
- Censorship Issues with DeepSeek: Discussants noted that DeepSeek provides different responses about sensitive topics such as Tiananmen Square, depending on the language of prompt, highlighting potential biases in its design.
- It seems the model's responses can be influenced by censorship mechanisms, with some suggesting ways to bypass these limitations using clever prompting.
- DeepSeek’s Nationalistic Messaging: Users observe that DeepSeek gives a distinctly nationalistic narrative on questions related to Taiwan, contrasting with its responses on Tiananmen, which were more restrictive.
- This inconsistency raises concerns about the censorship model employed and how it adapts based on the subject matter.
- Educational Resources on Mixture of Experts (MoE): A user sought resources on Mixture of Experts (MoE), prompting shared links to comprehensive visual guides and YouTube videos explaining the concept.
- An associated channel exists for discussions about MoE, although its activity level is uncertain.
- Community Contributions to AI Projects: A new user expressed interest in contributing to projects related to AI safety and policy, pointing out a scarcity of such initiatives in Italy.
- The community is encouraged to engage in discussions about useful tools, such as a drag-and-drop interface for LLM assembly, fostering collaboration.
- Sparse Autoencoders Can Interpret Randomly Initialized Transformers: Sparse autoencoders (SAEs) are an increasingly popular technique for interpreting the internal representations of transformers. In this paper, we apply SAEs to 'interpret' random transformers,...
- Low-Resource Languages Jailbreak GPT-4: AI safety training and red-teaming of large language models (LLMs) are measures to mitigate the generation of unsafe content. Our work exposes the inherent cross-lingual vulnerability of these safety ...
- A Visual Guide to Mixture of Experts (MoE): Demystifying the role of MoE in Large Language Models
- deepseek-ai/DeepSeek-R1 · Hugging Face: no description found
- Tweet from Nora Belrose (@norabelrose): we have seven (!) papers lined up for release next weekyou know you're on a roll when arxiv throttles you
- Tweet from Nora Belrose (@norabelrose): Their result does NOT replicate on SmolLM2.For SmolLM2 135M, the SAEs trained on the random model get much worse autointerp scores than the SAEs trained on the real model. Below are results on a subse...
- Deepseek R1's Open Source Version Differs from the Official API Version: Posted in r/LocalLLaMA by u/TempWanderer101 • 126 points and 64 comments
- GitHub - EleutherAI/sae: Sparse autoencoders: Sparse autoencoders. Contribute to EleutherAI/sae development by creating an account on GitHub.
- The Achilles Heel of Large Language Models: Lower-Resource Languages Raise More Safety Concerns: no description found
Eleuther ▷ #research (119 messages🔥🔥):
DeepSeek Math paper metrics, DRAW architecture for image generation, Learning-rate schedules in optimization, Distillation processes in model training, Complexity measures in neural networks
- Understanding Pass@K and Maj@K Metrics: In the DeepSeek Math paper, Pass@K indicates if any parsed answer passes for K repeats, while Maj@K refers to the majority answer passing across these repeats.
- This second metric, Maj@K, is particularly relevant for numeric outputs or concise outputs like multiple-choice questions.
- DRAW Architecture Overview: The DRAW network architecture introduces a novel spatial attention mechanism that mimics human foveation, enhancing image generation capabilities.
- It significantly improves generative model performance on datasets like MNIST and Street View House Numbers, producing indistinguishable images from real data.
- Learning-rate Schedules in Non-Smooth Convex Optimization: Recent work highlights surprisingly close relationships between learning-rate schedules in large model training and non-smooth convex optimization theory.
- These insights provide practical benefits for learning-rate tuning, leading to better training of models such as Llama-types.
- Synthetic Data and Distillation in Model Training: Discussion revolves around the potential use of synthetic datasets for training, including methods like reinforcement learning and general policy optimization.
- This approach may help in fine-tuning smaller models using outputs derived from larger models' synthetic examples.
- Complexity Measures in Neural Networks: There are speculations about using complexity measures to detect undesired reasoning in neural networks; the goal is to align networks with human values without ulterior motives.
- The discussion points to prior work linking simplicity in neural networks to inductive biases, focusing on local volume and the evolution of model complexity.
- DRAW: A Recurrent Neural Network For Image Generation: This paper introduces the Deep Recurrent Attentive Writer (DRAW) neural network architecture for image generation. DRAW networks combine a novel spatial attention mechanism that mimics the foveation o...
- Differential Transformer: Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, t...
- EXAdam: The Power of Adaptive Cross-Moments: This paper introduces EXAdam ($\textbf{EX}$tended $\textbf{Adam}$), a novel optimization algorithm that builds upon the widely-used Adam optimizer. EXAdam incorporates three key enhancements: (1) new ...
- SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training: Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain ...
- Theoretical limitations of multi-layer Transformer: Transformers, especially the decoder-only variants, are the backbone of most modern large language models; yet we do not have much understanding of their expressive power except for the simple $1$-lay...
- The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training: We show that learning-rate schedules for large model training behave surprisingly similar to a performance bound from non-smooth convex optimization theory. We provide a bound for the constant schedul...
- GPT or BERT: why not both?: We present a simple way to merge masked language modeling with causal language modeling. This hybrid training objective results in a model that combines the strengths of both modeling paradigms within...
- Harnessing Proof Assistant Feedback for Reinforcement Learning and...: Lean is an advanced proof assistant designed to facilitate formal theorem proving by providing a variety of interactive feedback. In this paper, we explore methodologies to leverage proof assistant...
- Reddit - Dive into anything: no description found
- Tweet from Mathieu Blondel (@mblondel_ml): The EBM paper below parameterizes dual variables as neural nets. This idea (which has been used in other contexts such as OT or GANs) is very powerful and may be *the* way duality can be useful for ne...
- Reddit - Dive into anything: no description found
Eleuther ▷ #interpretability-general (26 messages🔥):
New paper by David Chalmers, Crosscoder repositories, Sparse autoencoders optimization, Expert evaluation in MoE models
- Chalmers on Propositional Attitudes: A new paper by David Chalmers argues that extracting propositional attitudes from AI is more impactful than pursuing mechanistic understanding.
- Chalmers also cited a previously published paper from the team, expressing gratitude for the reference.
- Crosscoder Repositories Discussion: A member inquired about open source repositories for training and using crosscoders, highlighting the ongoing challenge of reproducibility in the field.
- Another member shared a GitHub link to dictionary_learning as a potential resource.
- Sparse Autoencoders and Optimization Scalability: There was a discussion about the challenges of sparse recovery, suggesting that the search for the right representation typically requires iterative methods.
- It was pointed out that the scale required for effective analysis might render these methods infeasible in practice.
- Evaluating Experts in Mixture of Experts (MoE): Discussion centered on identifying the most active experts in a DeepMind code contests dataset, with frequency and weight data provided for several experts.
- The top experts were highlighted, and it was noted that their performance assessments might help inform pruning strategies in MoE models.
- Cosine Similarity vs Euclidean Distance in Expert Weights: Clarification was given that the distance metric used for the analysis of expert distributions was euclidean, rather than cosine similarity as initially assumed.
- Cosine similarity was actually referenced as a derived metric based on expert distribution vectors aggregated by the MoE gating module.
- Distributions of Angles in Random Packing on Spheres: This paper studies the asymptotic behaviors of the pairwise angles among n randomly and uniformly distributed unit vectors in R^p as the number of points n -> infinity, while the dimension p is eit...
- Smooth activations and reproducibility in deep networks: Deep networks are gradually penetrating almost every domain in our lives due to their amazing success. However, with substantive performance accuracy improvements comes the price of \emph{irreproducib...
- Tweet from Nora Belrose (@norabelrose): This new paper from @davidchalmers42 is goodExtracting propositional attitudes from AI is more useful than chasing after "mechanistic" understandingAlso he cited a paper from our team, thanks ...
- GitHub - jkminder/dictionary_learning: Contribute to jkminder/dictionary_learning development by creating an account on GitHub.
Eleuther ▷ #lm-thunderdome (5 messages):
Non-overlapping windows, make_disjoint_window modification, Chunked prefill, Data storage in scripts.write_out
- Non-overlapping windows for model length: Discussion confirmed that the system uses non-overlapping windows of
size==max_model_len, with a reference to section A.3 for further details.- One participant mentioned implementing strided approaches for better efficiency.
- Modifying
make_disjoint_windowfunction: A suggestion was made to modify themake_disjoint_windowfunction to generate overlapping pairs instead.- The coder expressed willingness to review specific examples for potential adjustments.
- Inquiry on chunked prefill: A query was raised about the implications of using chunked prefill within the system integrities with model operations.
- No responses were provided regarding the questioning of chunked prefill's operational strategies.
- Data storage concerns in scripts.write_out: One member wanted clarification on where data is stored upon calling scripts.write_out.
- This inquiry was left unanswered in the conversation.
Link mentioned: lm-evaluation-harness/lm_eval/models/vllm_causallms.py at 0bb8406f2ebfe074cf173c333bdcd6cffb17279b · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (16 messages🔥):
NeoX Performance, Fusion Flags, Transformer Engine Speedups, Scaling Softmax Functions, Error with Detect NVLink Pairs Flag
- NeoX Performance Metrics Inquiry: A member reported achieving around 10-11K tokens per second on A100s for a 1.3B parameter model, contrasting sharply with the 50K+ tokens stated in the OLMo2 paper.
- Despite attempts to maximize batch sizes, improvements in tokens per second remained minimal.
- Confusion Over Fusion Flags: Questions arose regarding the usage of the partition-activations flag in Pythia configs, with a suggested discrepancy between the paper and GitHub settings.
- Concerns were raised about using certain fusion flags, as they seemed to hang the run with no logs generated.
- Expectations on Transformer Engine Speed: Inquiries were made about the training configuration mentioned in the Transformer Engine integration, questioning any potential speedups when using Mixed Precision BF16 training.
- The necessity and circumstances for using scaled_masked_softmax_fusion versus scaled_upper_triang_masked_softmax_fusion were also discussed.
- Issue with NVLink Pairs Flag: A member tried to utilize the detect_nvlink_pairs flag but encountered an issue stating it does not exist, highlighting that it only appeared in argument files.
- A screenshot provided illustrated this discrepancy in the codebase.
- Acknowledgment of Support Delays: A team member acknowledged that support for users may be slower due to a current development sprint on NeoX 3.0 features.
- They committed to providing a more detailed response later in the day.
- Process Hangs When Setting scaled_upper_triang_masked_softmax_fusion or rope_fusion to True · Issue #1334 · EleutherAI/gpt-neox: Hi Raising an error report following our Discord discussion - I am trying to train a Llama2 model and the config in the repo sets scaled_upper_triang_masked_softmax_fusion to True. Here is the YAML...
- gpt-neox/configs/1-3B-transformer-engine.yml at main · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
- pythia/models/1B/pythia-1b.yml at main · EleutherAI/pythia: The hub for EleutherAI's work on interpretability and learning dynamics - EleutherAI/pythia
- Process Hangs When Setting scaled_upper_triang_masked_softmax_fusion or rope_fusion to True · Issue #1334 · EleutherAI/gpt-neox: Hi Raising an error report following our Discord discussion - I am trying to train a Llama2 model and the config in the repo sets scaled_upper_triang_masked_softmax_fusion to True. Here is the YAML...
MCP (Glama) ▷ #general (219 messages🔥🔥):
Remote MCP Tools, Discord Server Confusion, Superinterface Products, Load Balancing Using Litellm Proxy, Open-Source Alternatives
- Discussions on Remote MCP Tools: Members expressed the need for remote capabilities in MCP tools, emphasizing that most existing solutions focus on local implementations.
- Concerns were raised about the scalability and usability of current MCP setups, along with suggestions to explore alternative setups.
- Confusion over Discord Servers: A member highlighted the existence of two similar Discord servers, with one being a copy of the other, causing confusion.
- It was clarified that neither server is official and both are run by non-Anthropic users, although modifications on this server include Anthropic employees.
- Insights on Superinterface Products: A cofounder of Superinterface clarified that their focus is on providing AI agent infrastructure as a service, distinct from open-source alternatives.
- The product is positioned as a solution for integrating AI capabilities into user products, highlighting the complexity of infrastructure needed for such purposes.
- Load Balancing in Litellm Proxy: Members discussed techniques for load balancing using Litellm proxy, including setting weights and requests per minute.
- This approach helps manage multiple AI model endpoints efficiently within workflows.
- Open-source vs Proprietary Tools: Conversations highlighted a preference for open-source models and tools, with mentions of specific alternatives like Llama and DeepSeek.
- Members noted the importance of evaluating tools based on their openness and alignment with user needs.
- no title found: no description found
- no title found: no description found
- Roadmap - Model Context Protocol: no description found
- Transports - Model Context Protocol: no description found
- Sampling: ℹ️ Protocol Revision: 2024-11-05 The Model Context Protocol (MCP) provides a standardized way for servers to request LLMsampling (“completions” or “ge...
- Progress: ℹ️ Protocol Revision: 2024-11-05 The Model Context Protocol (MCP) supports optional progress tracking for long-runningoperations through notification messages. Either s...
- mcp.run - the App Store for MCP Servlets: portable & secure code for AI Apps and Agents.: no description found
- Sage - Native Client for Claude: no description found
- servers/src/everything/sse.ts at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2 · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- GitHub - SecretiveShell/MCP-Bridge: A middleware to provide an openAI compatible endpoint that can call MCP tools: A middleware to provide an openAI compatible endpoint that can call MCP tools - SecretiveShell/MCP-Bridge
- servers/src/github at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2 · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- OpenAPI Toolkit | 🦜️🔗 LangChain: We can construct agents to consume arbitrary APIs, here APIs conformant to the OpenAPI/Swagger specification.
- GitHub - wong2/mcp-cli: A CLI inspector for the Model Context Protocol: A CLI inspector for the Model Context Protocol. Contribute to wong2/mcp-cli development by creating an account on GitHub.
- GitHub - sparfenyuk/mcp-proxy: Connect to MCP servers that run on SSE transport, or expose stdio servers as an SSE server using the MCP Proxy server.: Connect to MCP servers that run on SSE transport, or expose stdio servers as an SSE server using the MCP Proxy server. - sparfenyuk/mcp-proxy
- GitHub - modelcontextprotocol/servers at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- Authentication · modelcontextprotocol/specification · Discussion #64: First of all - thanks for open-sourcing MCP and all the effort that has been put in to-date. I'm truly excited about the integration possibilities this protocol enables. Of course, a lot of those ...
MCP (Glama) ▷ #showcase (14 messages🔥):
MCP Server Projects, Zed Extensions, Goose Automation, Supergateway v2, FFmpeg Speed Adjustments
- MCP Server Projects on the Rise: Several users showcased their MCP server projects, including a Claude-powered integration with MercadoLibre's API for product searches and detailed reviews.
- Another member introduced a server that allows running any MCP server on any client, highlighting the versatility of MCP capabilities.
- Zed Extensions Show Limited Use: A recent merge of a Zed extension for the Confluence context server prompted discussion about its effectiveness, with users noting that Zed currently supports only prompts with a single argument.
- This limitation led to questions about future implementations for broader support of tools within the Zed editor.
- Goose Automates GitHub Interaction: A user shared a YouTube video demonstrating how Goose, an open source AI agent, automates tasks while integrating with any MCP server.
- The video showcased Goose's extensible functionality in automating GitHub tasks, emphasizing the innovative use of MCP.
- Supergateway v2 Enhancements: Supergateway v2 allows users to run any MCP server remotely by tunneling with ngrok, making it easier to set up and access servers.
- Members were encouraged to reach out for assistance, showcasing the community spirit in enhancing MCP server usability.
- FFmpeg Makes Speed Listening Easier: Users discussed a command for FFmpeg to apply pitch reduction alongside speed adjustments, enhancing audio quality for faster listening.
- This simple solution made a notable difference in the user experience when interacting with audio files.
- GitHub - mtct/journaling_mcp: MCP Server for journaling: MCP Server for journaling. Contribute to mtct/journaling_mcp development by creating an account on GitHub.
- Automate GitHub Tasks with Goose: Goose, an open source AI agent, automates your developer tasks. It integrates with any MCP server, giving you extensible functionality. This example shows Go...
- GitHub - supercorp-ai/supergateway: Run MCP stdio servers over SSE and visa versa. AI gateway.: Run MCP stdio servers over SSE and visa versa. AI gateway. - supercorp-ai/supergateway
- GitHub - mouhamadalmounayar/confluence-context-server: Contribute to mouhamadalmounayar/confluence-context-server development by creating an account on GitHub.
- Zed - The editor for what's next: Zed is a high-performance, multiplayer code editor from the creators of Atom and Tree-sitter.
- [DRAFT] Add Experimental Model Context Protocol (MCP) Support by madtank · Pull Request #164 · JoshuaC215/agent-service-toolkit: [DRAFT] Add Experimental Model Context Protocol (MCP) SupportOverviewIntroduces an optional, lightweight integration of Model Context Protocol (MCP) capabilities into the agent service toolkit, e...
Stackblitz (Bolt.new) ▷ #prompting (6 messages):
Stripe Payment Issues, User Stories Documentation, Zapier Workaround for User Tiers, Upcoming Office Hours
- Stripe Payment Detection Fails: Members expressed frustrated at Bolt's inability to successfully detect a payment on Stripe, leaving subsequent actions unprocessed.
- One member is seeking prompts that work, indicating that the current ones are not effective.
- Tracking User Stories and Updates: A query arose about where the team is documenting user stories and their updates, hinting at a need for better organization.
- There has been no consensus on the best medium for tracking this information.
- Zapier Used for User Tier Updates: One member mentioned using Zapier as a quick workaround to update user tiers when subscription changes occur, although this is still in early stages.
- They plan to explore more complex UI solutions based on different user group needs in the near future.
- Mark Your Calendars for Office Hours: Members noted an upcoming office hours session on February 12th that could shed light on the Stripe payment issues.
- This discussion could provide invaluable insights for those grappling with similar challenges.
Stackblitz (Bolt.new) ▷ #discussions (223 messages🔥🔥):
Bolt Performance Issues, Supabase vs Firebase, Connecting to Supabase, Iframe Issues with Calendly, User Authentication Issues
- Bolt Performance Issues: Several users reported performance issues with Bolt, including slow responses and error messages during operation.
- Users mentioned being forced to reload or clear cookies to resolve access issues, indicating potential server or local storage problems.
- Supabase vs Firebase: A discussion took place regarding preferences for Supabase versus Firebase, with many favoring Supabase for its direct integration and ease of use.
- Conversely, some expressed appreciation for Firebase, particularly for those already familiar with its ecosystem.
- Connecting to Supabase: Users experienced disconnections from Supabase services after making changes, necessitating reconnection efforts.
- One user resolved the issue by reloading their project, implying that connection issues may arise from front-end changes.
- Iframe Issues with Calendly: A user encountered issues with an iframe for Calendly within their Voiceflow chatbot, claiming it displayed errors.
- Despite follow-up checks, both Voiceflow and Calendly representatives deemed it a Bolt issue, causing frustration.
- User Authentication Issues: Concerns arose regarding user authentication, with one user unable to log in and encountering same errors across different browsers.
- Others suggested potential workarounds like clearing local storage, but the issue persisted for some users, indicating a deeper problem.
- Vite + React + TS: no description found
- Vite + React + TS: no description found
- bolt.new: no description found
Nomic.ai (GPT4All) ▷ #general (189 messages🔥🔥):
GPT4All Bug Reports, Quantization and Model Efficiency, Data Privacy Concerns, LaTeX Support in AI Models, NSFW Story Generation with LLMs
- Bug Report for GPT4All v3.8.0: Users are experiencing crashes with GPT4All v3.8.0 on modern Intel macOS machines, leading to a hypothesis that the version is DOA on these systems.
- A working hypothesis is being formed based on users' system specs to narrow down affected configurations as multiple users report similar issues.
- Understanding Model Quantization: Discussion revolves around quantization levels affecting model performance, specifically highlighting that lower quantizations can lead to significant quality degradation.
- Users are urged to find a balance in quantization settings to maintain a reasonable output quality without overloading their hardware.
- Privacy and Data Collection Debates: A lively debate emerges over trust in data collection, contrasting Western and Chinese data practices, with users expressing varying degrees of concern and skepticism.
- Arguments reflect frustrations over perceived double standards in how data collection is viewed across different countries.
- LaTeX Integration in AI Models: Users explore the potential use of MathJax for integrating LaTeX support within AI applications like GPT4All, emphasizing compatibility with LaTeX structures.
- Conversations center around parsing LaTeX content and extracting math-related expressions for better representation in the LLM’s output.
- Local LLMs for NSFW Content Generation: A user seeks a locally usable LLM capable of generating NSFW stories offline, similar to existing online tools but without using llama or DeepSeek.
- The user specifies their system capabilities and requirements, expressing a need for a German-speaking LLM to fulfill their content generation needs.
- LaTeX Typesetting: no description found
- MathJax: Beautiful math in all browsers.
- bartowski/DeepSeek-R1-Distill-Llama-8B-GGUF · Hugging Face: no description found
- Nein Doch GIF - Nein Doch Oh - Discover & Share GIFs: Click to view the GIF
- Nein Doch Shocked GIF - Nein Doch Shocked - Discover & Share GIFs: Click to view the GIF
- GGUF quantizations overview: GGUF quantizations overview. GitHub Gist: instantly share code, notes, and snippets.
- Legacy of the “Dark Side”: Two decades after the attacks of September 11, 2001, and the arrival of the first terrorism suspects at Guantánamo Bay on January 11, 2002, many Americans may not recall details of the systematic abus...
- text-generation-webui/instruction-templates/Mistral.yaml at main · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models with support for multiple inference backends. - oobabooga/text-generation-webui
- text-generation-webui/instruction-templates/Metharme.yaml at main · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models with support for multiple inference backends. - oobabooga/text-generation-webui
- [REGRESSION] macOS Intel crash on startup in 3.8 (3.7 worked fine) · Issue #3448 · nomic-ai/gpt4all: (Did not see a similar issue) Bug Report GPT4ALL crashes on startup in version 3.8 after 3.7 and previous versions worked correctly. Steps to Reproduce Download and install GPT4ALL 3.8 Double click...
- Fix index used by LocalDocs when tool calling/thinking is active by cebtenzzre · Pull Request #3451 · nomic-ai/gpt4all: Fixes #3445When using tool calling or reasoning (e.g. DeepSeek) and LocalDocs, the second response would be an error like this:Error: item at index 3 is not a promptWhich is accurate—the item a...
- LocalDocs error 'item at index 3 is not a prompt' with all models in the reasoning tab. · Issue #3445 · nomic-ai/gpt4all: I encounter the error 'item at index 3 is not a prompt' with all DeepSeek models in the reasoning tab. If I ask just one question, it works, but if I ask another one, I get that error. I shoul...
- minja/include/minja/minja.hpp at 76f0d01779aa00b0c68f2117f6cb2c9afc3a0ca8 · google/minja: A minimalistic C++ Jinja templating engine for LLM chat templates - google/minja
- Advancements in AI Planning: OpenAI’s o1 and Large Reasoning Models (LRMs) - Ajith's AI Pulse: Explore how OpenAI’s o1 Large Reasoning Model (LRM) is transforming AI planning and problem-solving, surpassing traditional Large Language Models (LLMs) in complex reasoning tasks.
- no title found: no description found
- Chat Templates - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
Notebook LM Discord ▷ #use-cases (13 messages🔥):
NotebookLM for JS Interviews, Google Workspace Standard Account, NBLM in BPO Environment, Leveraging NBLM for Language Learning, Podcast Announcement
- Integrating Complete Tutorials into NotebookLM for Learning: A member suggested incorporating entire tutorial websites like W3School JavaScript instead of individual links to better prepare for JS interviews using NotebookLM.
- Another member mentioned that currently, there are Chrome extensions that can assist with web page imports to NotebookLM.
- Google Workspace Standard Account Reveals Changes: A user upgraded to Google Workspace Standard and noted that the visible change from NotebookLM was the addition of 'Analytics' in the top bar, while the term 'NotebookLM Plus' was not displayed.
- They highlighted that usage limits are different even if the overall interface appears similar, sharing screenshots for clarity.
- Exploring Use Cases of NotebookLM in BPO Settings: A member inquired about the usage of NotebookLM in BPO environments and sought insights on potential use cases from others.
- This indicates a growing interest in how NotebookLM can facilitate business process outsourcing operations.
- Using NotebookLM for Language Mastery: A user detailed their approach of using NotebookLM to learn Japanese by analyzing video transcripts and clarifying grammatical concepts seamlessly.
- They expressed enthusiasm for the future capabilities of NotebookLM over the next year, showcasing its potential in language education.
- Launching the 'Roast or Toast' Podcast: The Toastinator announced the premiere of the podcast 'Roast or Toast', where they humorously dissect profound topics, starting with the meaning of life.
- Listeners are invited to tune in for a comical yet deep exploration of life's mysteries through the podcast's unique format.
Link mentioned: Chrome Web Store: Add new features to your browser and personalize your browsing experience.
Notebook LM Discord ▷ #general (104 messages🔥🔥):
NotebookLM functionality, Language settings, Audio customization, API release, AI models and capabilities
- NotebookLM struggles with language settings: Several users expressed confusion regarding changing the output language of NotebookLM, with suggestions to modify Google account settings or use prompts to specify the desired language.
- Users noted instances where downloaded outputs defaulted to German despite having their browser and OS set to English.
- Queries about API and features: There were inquiries about the planned API release for NotebookLM, with users expressing eagerness for additional functionalities.
- It was indicated that the output token limit for NotebookLM is lower than that of Gemini, but exact specifications remain unclear.
- Customization concerns for audio overviews: A new user sought guidance on customizing audio overviews in NotebookLM but found the functionality missing after a UI update.
- Another user suggested checking out Illuminate for related functionalities, hoping some features might migrate to NotebookLM.
- Issues with features like analytics link: Users reported not seeing the analytics link that would indicate access to NotebookLM Plus, questioning the rollout status in their regions.
- There was advice to verify through specific checklists and the suggestion that Google One might provide access to Plus features.
- Feedback on content outputs: Concerns were raised about NotebookLM including footnote numbers in notes without corresponding links, leading to confusion over references.
- Users noted the importance of clear citation practices and expressed the need for better handling of source material within notes.
- Chatbot Software Begins to Face Fundamental Limitations | Quanta Magazine: Recent results show that large language models struggle with compositional tasks, suggesting a hard limit to their abilities.
- The Drive AI: Revolutionizing File Management & Knowledge Bases: Discover The Drive AI's breakthrough in smart file organization. Our platform transforms your files into a dynamic knowledge base with the help of cutting-edge AI. Elevate your business operation...
- Google AI Studio: Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
- Learn how NotebookLM protects your data - NotebookLM Help: no description found
- Illuminate | Learn Your Way: Transform research papers into AI-generated audio summaries with Illuminate, your Gen AI tool for understanding complex content faster.
- Google Workspace Updates: NotebookLM Plus now available to Google Workspace customers : no description found
- Compare Gemini for Google Workspace add-ons - Business / Enterprise - Google Workspace Admin Help: no description found
Modular (Mojo 🔥) ▷ #general (6 messages):
Mojo and MAX solutions, Broken Mojo Examples link, Community Mojo Examples, Modular examples page update
- Mojo and MAX as Solutions: A member expressed excitement about clarifying complex details of Mojo and MAX, believing they are the ultimate solutions to current challenges.
- These aren't simple problems, emphasizing the significant investment needed to address them.
- Mojo Examples Link Returns 404: A member reported the Mojo Examples link on the Modular homepage is broken, returning a 404 response.
- Another member noted that this issue was acknowledged and allegedly fixed, but the update may not reflect on the site yet.
- Community Contributions of Mojo Examples: A member pointed to having Mojo examples from the community available in a specified Discord channel.
- This was followed by a clarification that Modular has taken down their page to replace the examples.
- Community Showcase Moves to Forum: It was noted that the community showcase is now read-only and has been shifted to the Modular Forum for better accessibility.
- Members can access it at Community Showcase Forum.
Link mentioned: Community Showcase: Community projects that use MAX and Mojo
Modular (Mojo 🔥) ▷ #mojo (49 messages🔥):
Complexity in Mojo vs Swift, Mojo for Programming Education, Challenges with Mojo's Type System, Community Feedback on Mojo 1.0, Hot Reloading System for Mojo
- Avoiding Swift's Complexity in Mojo: There are concerns about Mojo following Swift's drive into complexity, emphasizing the need for clarity and avoiding rushed developments.
- The community is focused on stabilizing Mojo and weighing tradeoffs carefully without unnecessary pressure.
- Leveraging Mojo in Educational Settings: A student is considering using Mojo for a programming class project, questioning its compatibility with Pascal gen cards and system requirements.
- Discussions highlighted potential hardware limitations, particularly with older generations of GPUs.
- Integrating Types in Mojo's System: A user inquired about accessing specific struct fields in Mojo's type system when passing a parameter as a concrete type.
- The response indicates that users may still be learning how to effectively leverage Mojo's type capabilities.
- Concerns about Mojo's Heavy Reliance on Magic: A community member voiced apprehensions regarding Mojo's dependency management via 'magic', desiring more control over installations.
- There is a general sense that a clearer roadmap and less reliance on magic would enhance Mojo's usability and transparency.
- Difficulties Implementing Hot Reloading in Mojo: Hot reloading is currently problematic in Mojo, mainly due to the lack of a stable ABI and the challenges of modifying structures.
- The community is aware that this limitation hinders the implementation of dynamic updates in frameworks built with Mojo.
Modular (Mojo 🔥) ▷ #max (41 messages🔥):
MAX Serving Infrastructure, Ollama Performance Comparison, Memory Usage in LLMs, Weight Path Issues, DeepSeek R1 Model Performance
- MAX Serving Infrastructure Downloads Weights: The MAX serving infrastructure utilizes
huggingface_hubto download and cache model weights in~/.cache/huggingface/hub, differing from Ollama's approach.- Discussion highlighted that users can change the
--weight-path=to avoid duplicate downloads, but local cache for Ollama might not be straightforward.
- Discussion highlighted that users can change the
- Ollama vs MAX Performance: Users noted that Ollama appeared faster than MAX on the same machine, even with metrics suggesting that MAX was performing slower.
- Performance for CPU-based serving in MAX is still under active development, with improvements expected as the model is tuned further.
- Memory Usage Affects Model Performance: It was suggested that with 16GB of RAM, users might run into memory limitations when using MAX, prompting recommendations to adjust model configurations for better resource management.
- To alleviate slow performance, users were advised to utilize quantization techniques and reduce the
--max-lengthsetting.
- To alleviate slow performance, users were advised to utilize quantization techniques and reduce the
- Issue with Model Endpoint Visibility: Users experienced issues with the MAX container not exposing a v1/models endpoint while trying to use it with open-webui.
- Logs and error messages highlighted ineffective model exposure, requiring further troubleshooting and adjustments in commands to improve functionality.
- Observations on Uvicorn Errors: The presence of
uvicorn.errormessages was clarified to be a logging artifact and not an actual error, causing some initial confusion among users.- To further test the capabilities, users were encouraged to switch commands from
magic run servetomagic run generatefor direct streaming results.
- To further test the capabilities, users were encouraged to switch commands from
- Modular: Use MAX with Open WebUI for RAG and Web Search: Learn how quickly MAX and Open WebUI get you up-and-running with RAG, web search, and Llama 3.1 on GPU
- Unsloth AI - Open Source Fine-Tuning for LLMs: Open-source LLM fine-tuning for Llama 3, Phi 3.5, Mistral and more! Beginner friendly. Get faster with Unsloth.
Torchtune ▷ #general (32 messages🔥):
GRPO on multiple nodes, SFT without message structure, Custom dataset class considerations, Hijacking SFTDataset transforms
- Ariel2137 deploys GRPO over 16 nodes: After minor adjustments to the multinode PR, a member successfully got their GRPO running on 16 nodes and is optimistic about the upcoming reward curve validations.
- They humorously noted that working at a well-funded company can provide significant advantages in such endeavors.
- Exploring SFT without message-like structure: A member inquired about the best approach for performing SFT without using a typical message structure, suggesting a custom method following an alternative template.
- Discussions highlighted the need to mask certain messages for effective training, particularly focusing on ground truth during the SFT process.
- Creating a custom dataset class: It was suggested that a custom dataset be made for SFT due to the limitations of the default SFTDataset which adds unwanted special tokens.
- Members discussed encoding methods and the importance of generating proper Boolean masks manually when using raw strings.
- Customizing SFTDataset transforms: A member successfully customized the two transforms in SFTDataset to modify how messages and models are processed, enabling a more tailored training format.
- They indicated that this flexibility allowed overcoming issues faced, though noted the need for a more intuitive solution if such customizations became standard practice.
- torchtune/torchtune/datasets/_alpaca.py at 059cad9c1c0b684ec095634992468eca18bbd395 · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- Grpo & verifiable rewards dataset by ianbarber · Pull Request #2324 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to[ x] add a new feature fix a bug update tests and/or documentation other (please add here)ChangelogAdd GRPO finetuning recipe with LoRA and ...
Torchtune ▷ #dev (32 messages🔥):
Multinode Support in Torchtune, DPO Recipe Seed Issue, Normalization in DPO Loss, Gradient Accumulation Fix, DataLoader and Seed Consistency
- Final Approval Request for Multinode Support: A request for final approval on the multinode support pull request was made, emphasizing its importance based on user demand.
- The discussion highlighted potential concerns about the API parameter
offload_ops_to_cpu, suggesting that it might require further review.
- The discussion highlighted potential concerns about the API parameter
- Seed Inconsistency in DPO Recipes: There's an ongoing investigation into why
seedworks for LoRA finetuning but fails for LoRA DPO, with sampler consistency being questioned.- Multiple issues related to seed management have been logged, particularly focusing on the effect of
seed=0andseed=nullin datasets.
- Multiple issues related to seed management have been logged, particularly focusing on the effect of
- Normalization of DPO Loss: A member raised concerns about the lack of loss normalization by token amount in the DPO recipe, something present in single-device setups.
- An issue has been created to address this normalization concern, depicting how it contrasts with the logic applied in other recipes.
- Potential Gradient Accumulation Fix: A suggestion was made to apply a gradient accumulation fix to both DPO and PPO recipes, linked to the need for improved efficiency.
- A relevant blog post was cited as a resource for understanding gradient management.
- DataLoader Batching Consistency: Logging from the DataLoader shows that batches remain consistent across runs, indicating that the randomness issue does not stem from data retrieval.
- Concerns were raised that the paired dataset class might be affecting sampler functionality, emphasizing the need for thorough comparison between finetuning and DPO recipes.
- Distributed DPO loss normalization by amount of tokens · Issue #2333 · pytorch/torchtune: Distributed DPO doesn't normalize loss by the amount of tokens -> https://github.com/pytorch/torchtune/blob/main/recipes/lora_dpo_distributed.py#L710 Single device DPO has this logic -> http...
- Apply gradient accumulation fix to DPO/PPO recipes · Issue #2334 · pytorch/torchtune: https://unsloth.ai/blog/gradient
- Seed is not applied for DPO recipes · Issue #2335 · pytorch/torchtune: TL;DR Launching same config twice with seed: 42 results in two different loss curves Affected recipes full_dpo_distributed - seed is not set Full DPO is taken from #2275 lora_dpo_distributed - seed...
- torchtune/recipes/lora_dpo_distributed.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/recipes/lora_finetune_single_device.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- Multinode support in torchtune by joecummings · Pull Request #2301 · pytorch/torchtune: Officially declaring multi-node open for business in torchtune!ContextThis has been an explicit ask by several users (#2161, #2142) and although things should work fairly easily OOTB, we hadn'....
Torchtune ▷ #papers (2 messages):
Data Augmentation in LLMs, R1-V Model Introduction
- In-depth Survey on Data Augmentation in LLMs: The survey reveals that large pre-trained language models (LLMs) excel in applications requiring extensive training datasets, highlighting issues like overfitting on insufficient data. It discusses how unique prompt templates enhance data generation and recent retrieval-based techniques integrate external knowledge for more reliable outputs.
- This enables LLMs to produce grounded-truth data, emphasizing the importance of data augmentation in their training.
- R1-V Model Revolutionizes Counting Abilities: A member excitedly introduced R1-V, utilizing reinforcement learning (RL) with verifiable rewards to boost visual language models' counting capabilities. Impressively, a 2B model outperformed the 72B model in just 100 training steps at a cost under $3.
- The development will be fully open source, inviting the community to keep an eye out for future updates.
- Text Data Augmentation for Large Language Models: A Comprehensive Survey of Methods, Challenges, and Opportunities: The increasing size and complexity of pre-trained language models have demonstrated superior performance in many applications, but they usually require large training datasets to be adequately trained...
- Tweet from Liang Chen (@liangchen5518): Excited to introduce R1-V!We use RL with verifiable rewards to incentivize VLMs to learn general counting abilities. 2B model surpasses the 72B with only 100 training steps, costing less than $3.The p...
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture with Jason Weston, Self-Improvement Methods in LLMs, Jason Weston Background
- Exciting Lecture with Jason Weston TODAY!: Our 2nd lecture featuring Jason Weston will take place today at 4:00pm PST! You can watch the livestream here.
- Learning to Self-Improve & Reason with LLMs will cover various methods for improving LLM performance across different tasks.
- Innovative Methods for LLM Self-Improvement: Jason will discuss several recent methods for LLMs including Iterative DPO and Meta-Rewarding LLMs, with links to detailed papers like Iterative DPO and Self-Rewarding LLMs.
- These techniques focus on enhancing proficiency in reasoning, math, and creative tasks, showcasing the evolving capabilities of LLM technology.
- Jason Weston's Impressive Background: Jason Weston is a prominent figure in AI research with a PhD in machine learning and a rich career including roles at Meta AI and Google. He has received multiple accolades including best paper awards and was involved in an Emmy-winning project for YouTube Recommendation Engines.
- His extensive experience includes a series of prestigious positions and contributions to the fields of AI and NLP, underscoring his significant influence in the area.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (51 messages🔥):
Quiz Completion Confusion, MOOC Project Participation, Certification Queries, Mailing List Confirmation, Hackathon Results Update
- Quiz Completion Confusion Looms: Many members expressed uncertainty about whether quizzes completed will count towards course completion, especially those unsure of deadlines. One member confirmed there are 'no deadlines yet' for submissions.
- You're fine! since the MOOC curriculum details haven't been released yet, alleviating concerns over completion status.
- MOOC Students Eager for Project Participation: There were inquiries about whether MOOC students could participate in the Research Track of the class project. Currently, the course is primarily available to tuition-paying UC Berkeley students.
- However, the possibility for MOOC students is still under discussion, with updates expected soon.
- Queries about Certification Status: Participants requested updates regarding their certificates for the last semester's course, citing they had filled out forms to obtain them. Assurances were provided that 'should be soon' for those waiting.
- Others confirmed receiving confirmation emails but expressed concerns about email communication efficacy.
- Mailing List Confirmation Remains Elusive: Users raised concerns about missing emails from the mailing list meant for course updates and how to ensure they don’t miss important announcements. The mailing list emails should come from a specific address to avoid being mistaken for spam.
- Confirmation and support were offered for those questioning their enrollment status, noting that if they received confirmation from Google Forms, they are indeed enrolled.
- Hackathon Results Anticipation: There was curiosity regarding the prior hackathon results, with a member asking for updates. It was noted that participants have been privately notified, and a public announcement is expected by next week.
Link mentioned: Advanced Large Language Model Agents MOOC: MOOC, Spring 2025
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (8 messages🔥):
Quiz availability, DeepSeek R1 vs PEFT, Email alerts for quizzes, Study session on Reasoning techniques, Course website navigation
- Quizzes posted on course website: A member confirmed that the quiz for Lecture 1 is available on the course website in the syllabus section.
- For direct access, check the syllabus section here.
- DeepSeek R1 challenges PEFT: A member argued that DeepSeek R1 proves that reinforcement learning with group relative policy optimization outperforms PEFT or instruction fine-tuning.
- This perspective suggests a shift in focus from traditional prompting methods in light of DeepSeek R1's effectiveness.
- No email alerts for quizzes: It's noted that there aren't email alerts for new quizzes or answer keys; quizzes typically release around Wednesday after the related lecture.
- Answer keys follow the week after, but the course team avoids sending emails to keep inboxes uncluttered.
- Study session on Reasoning Techniques: A study session is set to begin shortly focusing on reasoning techniques from Lecture 1 and DeepSeek R1.
- Members interested in joining can connect via the provided Discord link.
- Quizzes location on course website: Members inquired about the quiz locations, with the course coordinator indicating they can be found in the syllabus section of the course website.
- Direct links were provided for easier navigation to the relevant materials, ensuring students can find resources efficiently.
Link mentioned: Advanced Large Language Model Agents MOOC: MOOC, Spring 2025
tinygrad (George Hotz) ▷ #general (33 messages🔥):
PR Handling, Video Decoding with NVDEC, WebGPU Autogen Progress, LLVM and Clang Usage in Linux Distros
- PR handling takes care and detail: When a PR is closed by maintainers, it's crucial to reflect on the feedback and improve, as one noted 'the typo is indicative of a lack of attention to detail'.
- It's advised to review submissions multiple times to ensure clarity and accuracy before resubmitting.
- Challenges in NVDEC Video Decoding: Decoding video with nvdec can be complex, requiring attention to file formats and the potential need for cuvid binaries due to internal complications.
- The libavcodec implementation is lengthy and includes high-level abstractions, which could be simplified.
- WebGPU Autogen Progress Report: A member reported they are close to completing WebGPU autogen, requiring only minor simplifications as they are above the line limit.
- They highlighted the need for instructions if dawn binaries are not installed, noting that tests are passing on both Ubuntu and Mac platforms.
- Clang vs. GCC in Linux Distros: While few Linux distros utilize clang, it is favored by specific platforms like Apple and Google for their developments.
- However, the general usage of gcc persists among major Linux distributions, raising debate over whether distros should switch to clang for better optimization.
- meta-llama/Llama-3.2-1B · Hugging Face: no description found
- FFmpeg/libavcodec/nvdec.c at c6194b50b1b4001db23e8debab4ac4444e794f90 · FFmpeg/FFmpeg: Mirror of https://git.ffmpeg.org/ffmpeg.git. Contribute to FFmpeg/FFmpeg development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
HCQ Execution Paradigm, CPU P2P Transfer Mechanisms, Math Trait Refactor, Multigpu Execution Strategies
- HCQ Execution Paradigm Simplifies Multi-GPU Understanding: The discussion highlighted how HCQ-like execution is a fundamental step towards understanding multi-GPU execution, with mention of potential support for CPU implementations.
- It was noted that optimizing the dispatcher for deciding between CPU and GPU work could lead to improved performance.
- CPU Peer-to-Peer Transfer Explained: A member speculated that p2p on CPU could involve releasing locks on memory blocks for evictions to L3/DRAM, pondering the efficiency of D2C transfers.
- Concerns were raised about the performance impact of execution locality during these complex multi-socket transfers.
- Math Trait Refactor Turns Two Classes into Three: A member detailed their first pass on the math trait refactor, mentioning an unintended increase in classes from two to three.
- A possible enhancement could be the compression of in-place operators into a MathTraits class, with a GitHub comparison to showcase the changes.
Link mentioned: Comparing tinygrad:master...davidjanoskyrepo:math_trait_refactor · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - Comparing tinygrad:master...davidjanoskyrepo:math_trait_refactor · tinygrad/tinygrad
Cohere ▷ #discussions (17 messages🔥):
Cohere trial key limits, Command-R+ model performance, Account auto logout issues
- Cohere trial key limit confusion: A member expressed confusion about the Cohere trial key, specifically when the limit resets—either after 30 days from generation or at the beginning of each month.
- Normally that's not really a question that is asked since the key is for evaluation purposes, not free use.
- Praise for Command-R+ Model: A user highlighted how the Command-R+ model has consistently met their needs without the desire to test other models after long-term usage.
- They noted that the model continues to surprise them despite not being a power user.
- Persistent auto logout issues: A member reported ongoing problems with their account auto logging out, requiring them to log in repeatedly.
- This issue seems to be a common frustration among users in the channel.
Cohere ▷ #api-discussions (9 messages🔥):
Embed API v2.0 errors, Command R and Japanese translations
- HTTP 422 Error in Embed API v2.0: A user reported an 'HTTP 422 Unprocessable Entity' error when attempting to use the Embed API v2.0 with a provided cURL command, raising concerns about necessary preprocessing for longer articles.
- Suggestions included ensuring the API key is correctly included in the request, as another user noted that the request worked for them.
- Inconsistent Japanese Translation Results: A member brought up inconsistent translation results when using Command R or Command R+ for Japanese, stating that sometimes translations fail completely.
- In response, one member suggested contacting support with examples to assist the multilingual team, while another mentioned using Japanese language websites for context.
Cohere ▷ #cohere-toolkit (4 messages):
Limitations of LLMs in Math, ASLLM - Application Specific Language Models
- LLMs struggle with math tasks: One member pointed out that LLMs aren't designed for math, suggesting that users should create a calculator alongside the AI or utilize existing programs.
- This sentiment highlights the need for dedicated tools rather than relying solely on language models for mathematical computations.
- Wolfram Alpha as an ASLLM example: A user mentioned Wolfram Alpha as an example of an ASLLM (Application Specific Large Language Model) for specialized tasks.
- This underscores the value of using models tailored for specific applications, especially for complex mathematical queries.
LlamaIndex ▷ #blog (6 messages):
LlamaReport, o3-mini support, SciAgents, PDF to PPT Generator, Contextual Retrieval
- LlamaReport showcases report generation: A video demonstrating the early beta of LlamaReport was shared, highlighting its potential for report generation in 2025. You can watch it here.
- This development aims to streamline the reporting process for users looking for efficient solutions.
- o3-mini gets day 0 support: Support for o3-mini was announced with a command to install via pip:
pip install -U llama-index-llms-openai. Find more details here.- This makes integration smoother for developers looking to utilize o3-mini right from the start.
- Introducing SciAgents for scientific discovery: SciAgents is an automated scientific discovery system featuring a multi-agent workflow that leverages ontological graphs. Check out more about it here.
- This project shows how collaborative analysis can drive innovation in scientific research.
- Transform PDFs into PowerPoint with AI: An open-source web app allows users to convert PDF documents into dynamic PowerPoint presentations easily. The project utilizes LlamaParse and can be explored further here.
- This application simplifies the process of creating presentations, making it an exciting tool for users looking to automate their workflows.
- DocumentContextExtractor for RAG accuracy: A Reddit user highlighted DocumentContextExtractor, aimed at enhancing the accuracy of Retrieval-Augmented Generation (RAG), which both AnthropicAI and LlamaIndex showcased. For more details, check the thread here.
- This highlights the ongoing contributions in the open-source community for improving AI contextual understandings.
Link mentioned: GitHub - lesteroliver911/ai-pdf-ppt-generator-openai: A fun project where I use the power of AI to analyze a PDF. The AI extracts key information based on the user's instructions and selections (see the UI demo). The user then gets a second screen to edit the slides before downloading the final PPT. Simple, fast, and powered by AI to make creating presentations a breeze!: A fun project where I use the power of AI to analyze a PDF. The AI extracts key information based on the user's instructions and selections (see the UI demo). The user then gets a second scree...
LlamaIndex ▷ #general (19 messages🔥):
Deepseek vs OpenAI, Auto-Retrieval from Vector Database, Testing Chunking Strategies, Token Cost with Structured Output, Managing Memory for Multiple Users
- Deepseek claims victory over OpenAI: A member noted a clear winner between Deepseek and OpenAI, highlighting a surprising narration linked here.
- The conversation sparked interest in how these tools perform relative to each other.
- Exploring Auto-Retrieval with Chroma: A user inquired whether they can use summaryextractor and keyword extractor with metadata retrieved from a vector database like Chroma.
- They sought clarification on the functionality limits of their current setup with attached example images.
- Tips for Testing Chunking Strategies: Advice was shared on testing chunking strategies for LlamaIndex, including experimenting with different chunk sizes and overlap values.
- The guidance emphasized using evaluation metrics and real query tests to optimize performance and balance between retrieval and synthesis chunks.
- Token Costs for Structured Output: A member expressed concerns about whether the schema structure in their output, such as keys and punctuation, would incur token costs during inference.
- It was clarified that the structure does count towards input tokens, while the generated values are also included in the cost.
- Memory Management for Multi-User Apps: A user discussed the need for individual memory management per user in their app, questioning the simultaneous use of retrievers and rerankers.
- They sought insights on potential latency issues and the balance between shared and individual resources.
- Building Performant RAG Applications for Production - LlamaIndex: no description found
- no title found: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
Deepseek vs OpenAI, Audio Narration Technology
- Deepseek takes the lead over OpenAI: A discussion highlighted a clear winner between Deepseek and OpenAI, indicating emerging strengths in their competitive capabilities.
- Listeners were encouraged to enjoy the surprising narration showcasing this competition.
- Audio Narration Technology Gains Attention: The effectiveness of audio narration technology is becoming a focal point in discussions around AI capabilities.
- The comparison between Deepseek and OpenAI sheds light on how these platforms leverage narration for user engagement.
Link mentioned: no title found: no description found
DSPy ▷ #show-and-tell (1 messages):
DeepSeek Perspectives, Power Objects in AI, AI Boosters vs Skeptics, Open Source vs Proprietary Development, AI Doomsday Concerns
- DeepSeek Reflects Our Hopes and Fears: The article discusses how DeepSeek acts as a textbook power object, revealing more about our desires and concerns regarding AI than about the technology itself, as highlighted here.
- Every hot take on DeepSeek shows a person's specific hopes or fears about AI's impact.
- AI Boosters Celebrate DeepSeek's Promise: AI boosters believe that DeepSeek indicates that the progress of LLMs will continue unabated, reinforcing their optimism in AI advancements.
- This complements their narrative that innovation in AI will keep marching forward despite skepticism.
- Skeptics Doubt AI's Competitive Edge: AI skeptics argue that DeepSeek illustrates a lack of any significant advantages, suggesting AI companies have no defensive positioning in a rapidly changing landscape.
- Their perspective points to a broader concern regarding AI's sustainability and integration in real-world applications.
- Open Source Advocates Champion DeepSeek: For open source advocates, DeepSeek served as evidence that collaborative, transparent development practices thrive compared to proprietary models.
- They view DeepSeek's emergence as a victory for the open source community, emphasizing the benefits of shared knowledge.
- Doomsday Scenarios Surrounding AI: AI doomers express alarm at the implications of DeepSeek, fearing an uncertain and potentially dangerous future with unchecked AI development.
- Their concerns highlight the need for more robust ethical considerations and oversight in the field of AI.
Link mentioned: DeepSeek as a Power Object: The wave of DeepSeek takes reveal more about our own hopes and concerns than they do about DeepSeek.
DSPy ▷ #papers (1 messages):
SAEs performance, LLM steering methods
- SAEs face significant challenges: A member expressed disappointment in the long-term viability of SAEs for steering LLMs predictably, citing a recent discussion.
- Another member highlighted the severity of recent issues, stating, 'Damn, triple-homicide in one day. SAEs really taking a beating recently.'
- Concerns about SAE's predictability: There is a sentiment that SAEs might not be the optimal method for guiding LLMs effectively in the long run based on recent discourse.
- Members are becoming increasingly vocal about the challenges SAEs are encountering, suggesting a need for alternative steering methods.
Link mentioned: Tweet from KZ is in London (@kzSlider): Damn, triple-homicide in one day. SAEs really taking a beating recently
DSPy ▷ #general (13 messages🔥):
Typed Predictors in DSPy 2.6, Mixing Chain-of-Thought with R1 Models, Streaming Outputs in DSPy, Error with Importing in DSPy
- Typed Predictors no longer exist in DSPy: Members clarified that typed predictors have been deprecated; normal predictors suffice for functionality in DSPy 2.6.
- It was emphasized that there is no such thing as a typed predictor anymore in the current version.
- Interest in Mixing DSPy Techniques: A member expressed interest in mixing DSPy chain-of-thought with the R1 model for fine-tuning in a collaborative effort towards the Konwinski Prize.
- They also extended an invitation for others to join the discussion and the collaborative efforts related to this initiative.
- Challenges Streaming Outputs in DSPy: A user shared difficulties in utilizing dspy.streamify to produce outputs incrementally, receiving ModelResponseStream objects instead of expected values.
- They implemented conditionals in their code to handle output types appropriately, seeking further advice for improvements.
- ImportError Issue with DSPy: A user reported facing an ImportError related to
passage_has_answerswhen attempting to use theBootstrapFewShotmetric for validation.- This issue arises specifically during the compilation of the RAG with the provided trainset.
- streamify - DSPy: The framework for programming—rather than prompting—language models.
- Deployment - DSPy: The framework for programming—rather than prompting—language models.
LAION ▷ #general (10 messages🔥):
OpenEuroLLM, EU Commission AI Initiative, Research Project Challenges
- OpenEuroLLM Debuts for EU Languages: OpenEuroLLM has been introduced as the first family of open-source LLMs catering to all EU languages, emphasizing compliance under EU regulations.
- The models will be developed within Europe's robust regulatory framework, ensuring alignment with European values while maintaining technological excellence.
- EU Commission Highlights AI's European Roots: According to a tweet from EU_Commission, OpenEuroLLM has received the first STEP Seal for its excellence and aims to bring together EU startups and research labs.
- The initiative focuses on maintaining linguistic and cultural diversity while developing AI on European supercomputers.
- Busy Schedules Amidst Research: A member shared their busy schedule with university and a research project, indicating a common struggle among peers to balance academic and personal commitments.
- Another member, spirit_from_germany, checked in on their availability with a friendly prompt.
- Interest in Performance Comparisons: One participant expressed excitement about testing a new model, stating it is purportedly faster than HunYuan.
- This reflects a keen interest in performance comparisons among existing AI models within the community.
- Skepticism on Future AI Developments: A member humorously remarked to check back in 2030, reflecting skepticism about the timeline for AI advancements.
- This follows a conversation about the ambitious goals outlined in the OpenEuroLLM initiative.
- Tweet from European Commission (@EU_Commission): AI made in 🇪🇺OpenEuroLLM, the first family of open source Large Language Models covering all EU languages, has earned the first STEP Seal for its excellence.It brings together EU startups, research ...
- Open Euro LLM: no description found
LAION ▷ #research (4 messages):
CV Research Collaboration, R1-Llama and R1-Qwen Evaluation, DeepSeek Model Specifications
- Collaboration Opportunity for CV Research: A member expressed availability for collaboration on a computer vision (CV) research paper.
- Is anyone seeking contributors for a CV project?
- R1-Llama Outperforms Expectations: Preliminary evaluations on R1-Llama-70B indicate it matches and even surpasses both o1-mini and the original R1 models, raising eyebrows in the community.
- This evaluation involved solving Olympiad-level math and coding problems, showcasing potential generalization deficits in leading models source.
- DeepSeek's Specifications Under Scrutiny: The DeepSeek v3/R1 model boasts 37B active parameters, contrasting with the dense architecture of Llama 3 models that consume more resources.
- The discussion highlighted that the Mixture of Experts (MoE) approach contributes to better compute efficiency, supported by extensive optimizations from the DeepSeek team.
Link mentioned: Tweet from Jenia Jitsev 🏳️🌈 🇺🇦 🇮🇱 (@JJitsev): DeepSeek R1 Distilled Llama 70B & Qwen 32B models claim to solve olympiad level math & coding problems, matching o1-mini which claims same. Can they handle versions of AIW problems that reveal general...
Axolotl AI ▷ #general (3 messages):
Fine-tuning reasoning models, GRPO Colab notebook
- Member unsure about fine-tuning reasoning models: A member expressed their confusion about how to fine-tune reasoning models, humorously admitting they don't even know where to start.
- Lol - it seems they are looking for guidance in a complex area.
- Colab notebook shared for GRPO: Another member shared a Colab notebook for GRPO, providing a resource for those interested in the topic.
- This could be an excellent starting point for members wanting to learn more about GRPO specifically.
Link mentioned: Google Colab: no description found
OpenInterpreter ▷ #general (3 messages):
o3-mini compatibility, Open Interpreter changes
- Question on o3-mini usage in Open Interpreter: A member inquired whether the o3-mini can be utilized within both 01 and the interpreter.
- Concerns about the compatibility were raised, showcasing a need for clarification on the integration potential.
- Expectations on Open Interpreter updates: Another member questioned what kind of changes to anticipate in the application aspects of the upcoming Open Interpreter.
- They were curious if these changes would be minor or significant based on the upcoming updates.
MLOps @Chipro ▷ #events (2 messages):
Cursor AI as Development Tool, Honor of Kings Market Transactions
- Master Cursor AI to Boost Productivity: Join us this Tuesday at 5pm EST for a hybrid event on how to use Cursor AI like a pro, featuring guest speaker Arnold, a 10X CTO, discussing best practices for this powerful tool. Participants can attend in person at Builder's Club or via Zoom, with the link shared on registration.
- The event aims to enhance coding speed and quality for developers, while also providing a no-code option for non-techies to create prototypes easily.
- High Prices in Honor of Kings Market: The Honor of Kings market saw a high price acquisition today, with 小蛇糕 selling for 486. Users are encouraged to trade in the marketplace using the provided market code and password.
- Participants can open the game and visit the marketplace with the code -<344IRCIX>- and enter the password [[S8fRXNgQyhysJ9H8tuSvSSdVkdalSFE]] to buy or sell items.
Link mentioned: Awesome AI Tool - Use Cursor Like a Professional · Zoom · Luma: Do you want to learn about how to use Cursor AI like a pro?🚀 Our guest speaker Arnold will share how he became a 10X CTO through mastering Cursor.We'll…
Mozilla AI ▷ #announcements (1 messages):
Lumigator Live Demo, Firefox AI Platform, Blueprints Update, Builders Demo Day Pitches
- Lumigator Live Demo for Model Evaluation: Join the Lumigator Live Demo to learn about installation and onboarding for running your very first model evaluation.
- This event will guide attendees through critical setup steps for effective model performance testing.
- Firefox AI Platform Launches for Offline Tasks: The Firefox AI Platform is now available, enabling developers to leverage offline machine learning tasks in web extensions.
- This new platform opens avenues for improved machine learning capabilities directly in user-friendly environments.
- Latest on Blueprints for Open-Source Recipes: Check out the Blueprints Update for new recipes aimed at enhancing open-source projects.
- This initiative aims to equip developers with essential tools for creating effective software solutions.
- Builders Demo Day Pitches Released: The Builders Demo Day Pitches have been released on Mozilla Developers' YouTube channel, showcasing innovations from the developers’ community.
- These pitches present an exciting opportunity to engage with cutting-edge development projects and ideas.
- Important Updates and Announcements: Members can find important news regarding the latest developments within the community.
- Stay informed about the critical discussions affecting community initiatives and collaborations.