[AINews] OpenAI o3, o4-mini, and Codex CLI
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
10x compute on RL is all you need.
AI News for 4/15/2025-4/16/2025. We checked 9 subreddits, 449 Twitters and 29 Discords (211 channels, and 9942 messages) for you. Estimated reading time saved (at 200wpm): 782 minutes. You can now tag @smol_ai for AINews discussions!
As hinted on Monday, OpenAI launched the awkwardly named o3 and o4-mini in a classic livestream, together with a blogpost and a system card:
the general message is improvements in both scaling RL:
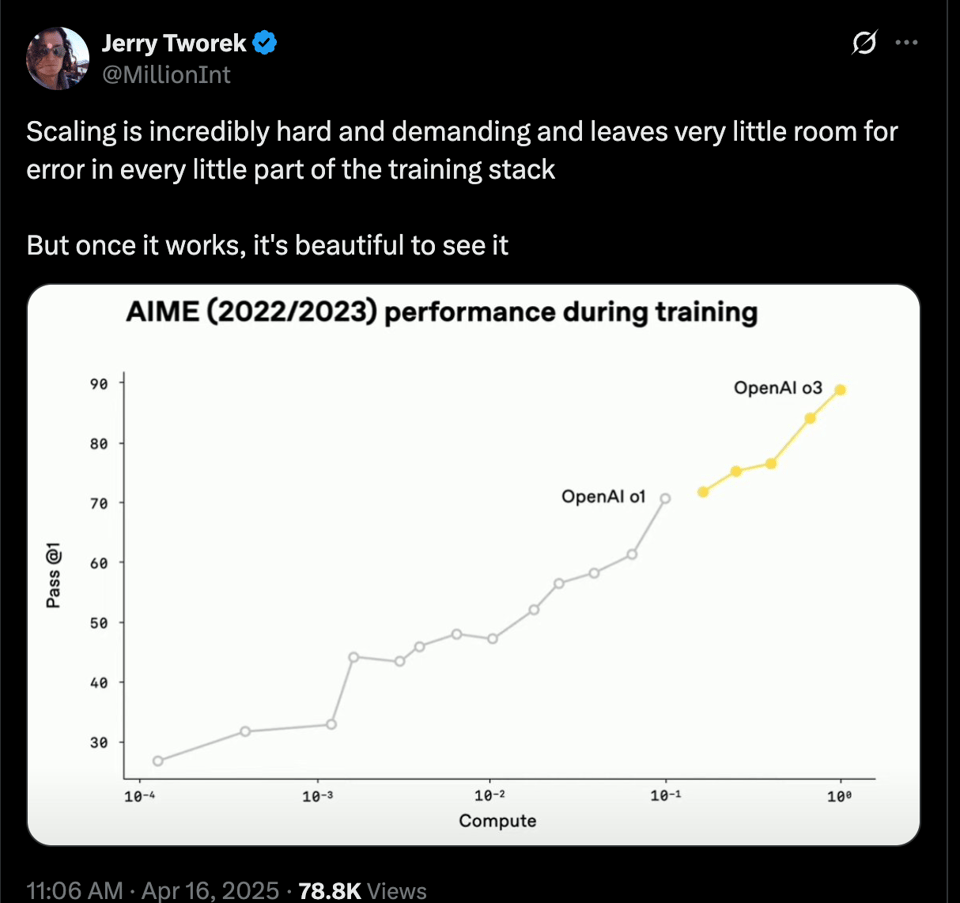
and overall efficiency:
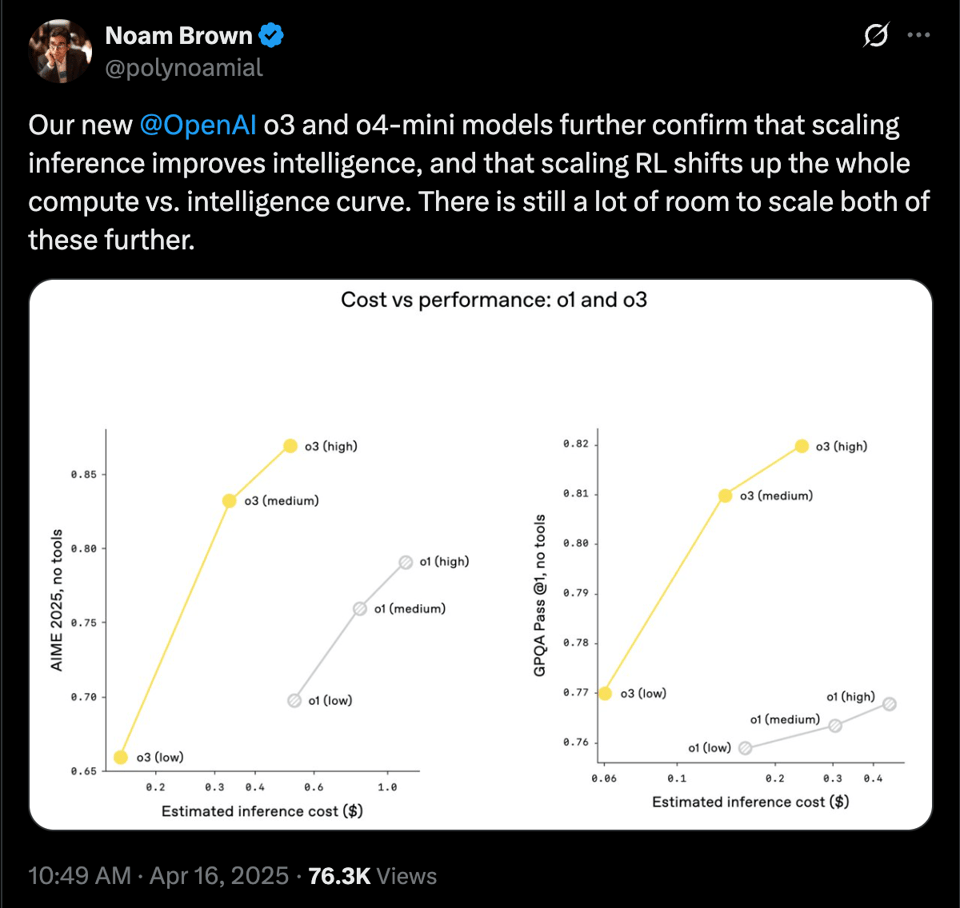
making o4-mini cheaper yet better across metrics that OAI has prioritized, vs the previous generation:
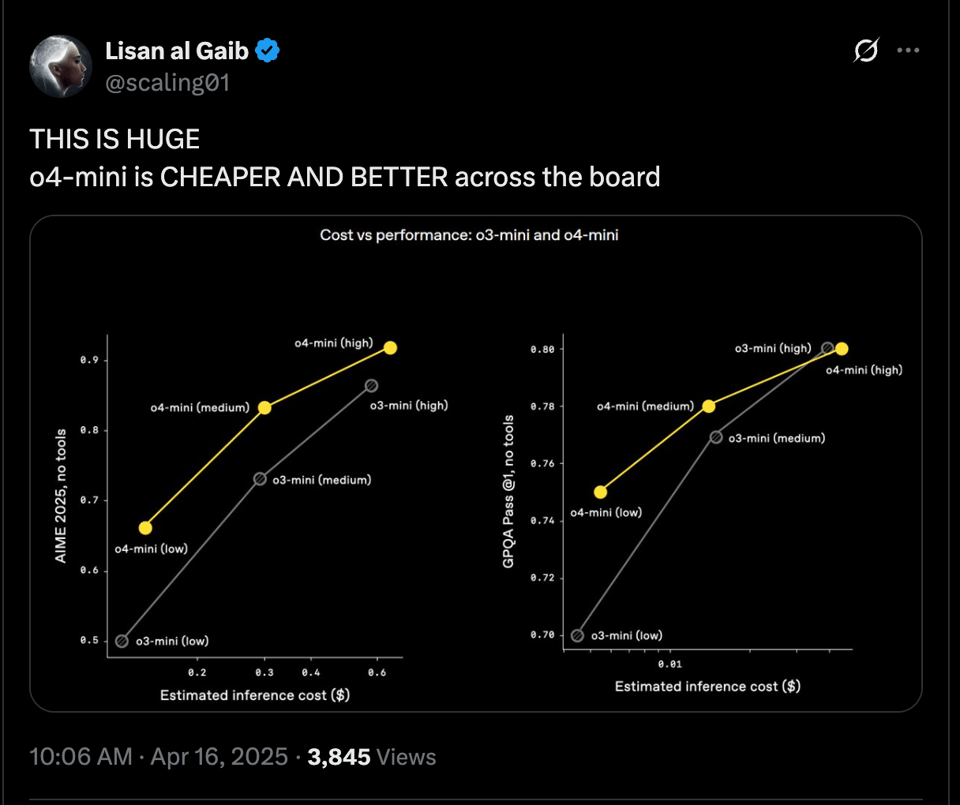
with much better vision and much better tool use - though this is not yet available in API.
Dan Shipper has a good qualitative review

The system cards show slightly less flattering evals but overall the launch has been very very well received.
The "one more thing" was Codex CLI, which oneupped Claude Code (our coverage here) by being fully open source:
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- /r/LocalLlama Recap
- 1. Recent OpenAI and Third-Party Model Releases
- 2. Large-Scale Model Training and Benchmarks
- 3. Community Projects and Hardware Setups
- Other AI Subreddit Recap
- 1. OpenAI o3 and o4-mini Model Launch and Discussion
- 2. OpenAI o3/o4 vs Gemini Benchmarks and Comparisons
- 3. HiDream & ComfyUI Model Updates and Tools
- AI Discord Recap
- PART 1: High level Discord summaries
- LMArena Discord
- Manus.im Discord Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- Cursor Community Discord
- Unsloth AI (Daniel Han) Discord
- Eleuther Discord
- GPU MODE Discord
- Latent Space Discord
- Yannick Kilcher Discord
- HuggingFace Discord
- MCP (Glama) Discord
- Nous Research AI Discord
- LM Studio Discord
- Notebook LM Discord
- Modular (Mojo 🔥) Discord
- Nomic.ai (GPT4All) Discord
- Torchtune Discord
- LlamaIndex Discord
- Cohere Discord
- LLM Agents (Berkeley MOOC) Discord
- tinygrad (George Hotz) Discord
- DSPy Discord
- Codeium (Windsurf) Discord
- PART 2: Detailed by-Channel summaries and links
- LMArena ▷ #general (1266 messages🔥🔥🔥):
- Manus.im Discord ▷ #showcase (2 messages):
- Manus.im Discord ▷ #general (889 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (664 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (27 messages🔥):
- aider (Paul Gauthier) ▷ #links (6 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (10 messages🔥):
- OpenRouter (Alex Atallah) ▷ #general (560 messages🔥🔥🔥):
- OpenAI ▷ #annnouncements (3 messages):
- OpenAI ▷ #ai-discussions (386 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (24 messages🔥):
- OpenAI ▷ #prompt-engineering (2 messages):
- OpenAI ▷ #api-discussions (2 messages):
- Cursor Community ▷ #general (374 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (243 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (38 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (32 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (6 messages):
- Eleuther ▷ #general (264 messages🔥🔥):
- Eleuther ▷ #research (29 messages🔥):
- GPU MODE ▷ #general (1 messages):
- GPU MODE ▷ #triton (5 messages):
- GPU MODE ▷ #cuda (17 messages🔥):
- GPU MODE ▷ #torch (3 messages):
- GPU MODE ▷ #announcements (1 messages):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (8 messages🔥):
- GPU MODE ▷ #torchao (7 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #rocm (4 messages):
- GPU MODE ▷ #liger-kernel (5 messages):
- GPU MODE ▷ #metal (1 messages):
- GPU MODE ▷ #self-promotion (4 messages):
- GPU MODE ▷ #general (25 messages🔥):
- GPU MODE ▷ #submissions (21 messages🔥):
- GPU MODE ▷ #status (7 messages):
- GPU MODE ▷ #feature-requests-and-bugs (16 messages🔥):
- GPU MODE ▷ #hardware (2 messages):
- GPU MODE ▷ #amd-competition (87 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (93 messages🔥🔥):
- Latent Space ▷ #llm-paper-club-west (80 messages🔥🔥):
- Yannick Kilcher ▷ #general (145 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (12 messages🔥):
- Yannick Kilcher ▷ #ml-news (10 messages🔥):
- HuggingFace ▷ #general (46 messages🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #cool-finds (7 messages):
- HuggingFace ▷ #i-made-this (12 messages🔥):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (1 messages):
- HuggingFace ▷ #smol-course (3 messages):
- HuggingFace ▷ #agents-course (62 messages🔥🔥):
- MCP (Glama) ▷ #general (111 messages🔥🔥):
- MCP (Glama) ▷ #showcase (22 messages🔥):
- Nous Research AI ▷ #general (97 messages🔥🔥):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (4 messages):
- LM Studio ▷ #general (33 messages🔥):
- LM Studio ▷ #hardware-discussion (71 messages🔥🔥):
- Notebook LM ▷ #use-cases (10 messages🔥):
- Notebook LM ▷ #general (82 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (10 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (58 messages🔥🔥):
- Nomic.ai (GPT4All) ▷ #general (45 messages🔥):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (41 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (26 messages🔥):
- Cohere ▷ #「💬」general (4 messages):
- Cohere ▷ #「🔌」api-discussions (1 messages):
- Cohere ▷ #「🤝」introductions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- DSPy ▷ #papers (2 messages):
- Codeium (Windsurf) ▷ #announcements (2 messages):
AI Twitter Recap
New Model Releases and Updates (o3, o4-mini, GPT-4.1, Gemini 2.5 Pro, Seedream 3.0)
- OpenAI o3 and o4-mini Models: @sama announced the release of o3 and o4-mini, highlighting their capabilities in tool use and multimodal understanding. @OpenAI described them as smarter and more capable, with the ability to agentically use and combine every tool within ChatGPT. @markchen90 emphasized their enhanced power due to learning how to use tools end-to-end, particularly in multimodal domains, while @gdb expressed excitement about their ability to produce useful novel ideas.
- Accessibility and Pricing: @OpenAI noted that ChatGPT Plus, Pro, and Team users would gain access to o3, o4-mini, and o4-mini-high. @aidan_clark_ suggested that models with "mini" in their name are impressive. @scaling01 indicated that o4-mini is cheaper and better across the board; however, @scaling01 noted that o3 is 4-5x more expensive than Gemini 2.5 Pro.
- Codex CLI Integration: @sama revealed Codex CLI, an open-source coding agent, to enhance the use of o3 and o4-mini for coding tasks, while @OpenAIDevs described it as a tool that turns natural language into working code. @kevinweil and @swyx also highlighted this open-source coding agent.
- Performance and Benchmarks: @polynoamial confirmed that scaling inference improves intelligence, while @scaling01 provided a detailed performance comparison of o3 against other models like Sonnet and Gemini on benchmarks like GPQA and AIME. @scaling01 also noted o3's worse performance in replicating research papers compared to o1. @alexandr_wang noted that o3 is absolutely dominating the SEAL leaderboard and @aidan_clau linked to a summary of o3's strengths.
- Multimodal Capabilities: @OpenAI highlighted that o3 and o4-mini can integrate uploaded images directly into their chain of thought. @aidan_clau described an experience in Rome where o3 reasoned, resized images, searched the internet, and deduced the user's location and vacation status, while @kevinweil noted seeing the models use tools as they think, such as searching, writing code, and manipulating images.
- Internal Functionality: @TransluceAI reported on fabrications and misrepresentations of capabilities in o3 models, including claiming to run code or use tools it does not have access to. @Yuchenj_UW noted that o3 figured out a mystery in the emoji, with FUCK YOU showing up in its thought process.
- GPT-4.1 Series: @OpenAIDevs announced the GPT-4.1 series for developers, and @skirano noted that this series seems to be going in the direction of optimizing for real-world tasks. @Scaling01 highlighted GPT-4.1-mini's overperformance relative to GPT-4.1 in some benchmarks. @aidan_clark_ called the models awesome. @ArtificialAnlys stated that the GPT-4.1 series is a solid upgrade, smarter and cheaper across the board than the GPT-4o series.
- Gemini 2.5 Pro: @omarsar0 stated that Gemini 2.5 Pro is much better at long context understanding compared to other models. @_philschmid indicated that the price-performance of Gemini 2.5 Pro is crazy.
- ByteDance Seedream 3.0: @ArtificialAnlys announced the launch of Seedream 3.0, the new leading model on the Artificial Analysis Image Leaderboard. @scaling01 mentioned that the ByteDance-Seed/Doubao team is "fucking cracked". @_akhaliq shared the Seedream 3.0 Technical Report.
Agentic Web Scraping with FIRE-1 and OpenAI's CodexCLI
- FIRE-1: @omarsar0 introduced FIRE-1, an agent-powered web scraper, highlighting its ability to navigate complex websites and interact with dynamic content. @omarsar0 further explained its simple integration with the scrape API, enabling intelligent interactions within web scraping workflows. @omarsar0 noted the limitations of traditional web scrapers and the promising nature of agentic web scrapers.
- CodexCLI: @sama provided a link to the open-source Codex CLI. @kevinweil linked to the new open source Codex CLI. @itsclivetime has started asking the models to just "look for bugs in this" and it catches like 80% of bugs before they run anything.
Agent Implementations and Tool Use
- Tool Use: @sama expressed surprise at the new models' ability to effectively use tools together. @omarsar0 noted that tool use makes these models a lot more useful. @aidan_clau stated that the biggest o3 feature is tool use, where it googles, debugs, and writes python scripts in its CoT for Fermi estimates.
- Tool Use Explanation: @omarsar0 demonstrated how reasoning models use tools, citing an example on the AIME math contest where the model proposes a smarter solution after initially brute-forcing it.
- Reachy 2: @ClementDelangue announced that they were starting to sell Reachy 2 this week, the first open-source humanoid robot.
Video Generation and Multimodality (Veo 2, Kling AI, Liquid)
- Google's Veo 2: @Google introduced text to video with Veo 2 in Gemini Advanced, highlighting its ability to transform text prompts into cinematic 8-second videos. @GoogleDeepMind stated that Veo 2 brings your script to life and @matvelloso stated that it is generally available in the API.
- ByteDance's Liquid: @_akhaliq shared ByteDance's Liquid, a language model that is a scalable and unified multi-modal generator. @teortaxesTex commented that ByteDance is killing it across all multimodal paradigms.
- Kling AI 2.0: @Kling_ai announced Phase 2.0 for Kling AI, empowering creators to bring meaningful stories to life.
Interpretability and Steering Research
- GoodfireAI's Open-Source SAEs: @GoodfireAI announced the release of the first open-source sparse autoencoders (SAEs) trained on DeepSeek's 671B parameter reasoning model, R1, providing new tools to understand and steer model thinking. @GoodfireAI shared early insights from their SAEs, noting unintuitive internal markers of reasoning and paradoxical effects of oversteering.
- How New Data Permeates LLM Knowledge and How to Dilute It: @_akhaliq shared this paper from Google that explores how learning a new fact can cause the model to inappropriately apply that knowledge in unrelated contexts and how to alleviate effects by 50-95% while preserving the model’s ability to learn new information.
- Researchers Explore Reasoning Data Distillation: @omarsar0 summarized research on distilling reasoning-intensive outputs from top-tier LLMs into more lightweight models to boost performance across multiple benchmarks.
Tools and Frameworks for LLM Development
- PydanticAI: @LiorOnAI introduced PydanticAI, a new framework that brings FastAPI-like design to GenAI app development.
- LangGraph: @LangChainAI announced that they were open sourcing LLManager, a LangGraph agent which automates approval tasks through human-in-the-loop powered memory. @LangChainAI also noted that the Abu Dhabi government's AI Assistant, TAMM 3.0, was built on LangGraph, and now delivers 940+ services across all platforms with personalized, seamless interactions.
- RunwayML: @c_valenzuelab states that Runway is in every classroom around the world. That's the goal for 2030.
- Hugging Face tool releases: @ClementDelangue asked someone to make this tool run locally with open-source models from HF. @reach_vb announced that cohere was available on the Hub.
Humor/Memes
- @teortaxesTex quipped about sleeping through the release of OpenAI's "AGI".
- @swyx linked to a meme related to the o3 and o4 launch.
- @scaling01 had several, such as criticizing the "AGI" marketing, and saying it was "cooked instruction following in ChatGPT".
- @aidan_mclau joked about world champion prompt engineering.
- @goodside posted "The surgeon is no longer the boy’s mother", riffing on a well known meme about LLMs.
- @draecomino said Nolan's movies are the most liked movies.
AI Reddit Recap
/r/LocalLlama Recap
1. Recent OpenAI and Third-Party Model Releases
-
OpenAI Introducing OpenAI o3 and o4-mini (Score: 109, Comments: 72): OpenAI has launched two new models, o3 and o4-mini, as part of its o-series, featuring significant improvements in both multimodal capabilities (direct image integration into reasoning) and agentic tool use (autonomous web/code/data/image toolchains via API). According to the official blog post, o3 achieves state-of-the-art results in coding, math, science, and visual perception benchmarks and exhibits improved analytical rigor and multi-step execution through large-scale RL. Top community concerns highlight the continued lack of open-source release, although OpenAI has open-sourced its terminal integration (via Codex), which is distinct from full model weights or research code.
- A commenter notes the lack of open source models from OpenAI, critiquing their release strategy as focused on proprietary gains rather than community contribution—reflecting persistent frustration among practitioners who value transparency and reproducibility in model development.
- One link highlights that although OpenAI isn't releasing models openly, they have open sourced their terminal integration (https://github.com/openai/codex), which may interest developers seeking toolchain extensions, though not the models themselves.
- There's criticism of OpenAI's model naming conventions, with the argument that the confusing scheme may be deliberate—obscuring distinctions between models and complicating evaluation or selection for users seeking to match models to specific capabilities or requirements.
-
IBM Granite 3.3 Models (Score: 312, Comments: 135): IBM has released the Granite 3.3 family of language models under the Apache 2.0 license, featuring both base and instruction-tuned models at 2B and 8B parameter counts (Hugging Face collection). These models are positioned for open community adoption, text generation tasks, and RAG workflows; additional speech model resources are provided (speech model link). Community feedback is encouraged, but no in-depth benchmarks, implementation details or technical bug discussions were present in the comments.
- The Granite 3.3 models are viewed favorably among compact language models, with particular appreciation from users with limited GPU resources. Their usability on low-end hardware is cited as a distinguishing feature, making them accessible where larger models are impractical. Interest is expressed in evaluating the improvements brought by this new iteration, especially in resource-constrained environments.
-
ByteDance releases Liquid model family of multimodal auto-regressive models (like GTP-4o) (Score: 285, Comments: 33): The image linked here is a promotional overview of ByteDance's purported 'Liquid' model family, described as a scalable, unified multimodal auto-regressive transformer (akin to GPT-4o) intended to handle both text and image generation within a single architecture. The Reddit discussion raises doubts about the model's authenticity and technical claims: commenters note that the supposed release is not recent, the public checkpoint on Hugging Face is apparently just a Gemma finetune without a vision config, and no genuine multimodal pretrained models (as described) are available. Furthermore, despite the promotional material's references to ByteDance's involvement, no official sources or papers corroborate this release, suggesting possible misattribution or misleading representation.
- A commenter notes inconsistencies between the official announcement of the Liquid model family and the actual model artifacts found: the
config.jsonlacks a vision configuration, suggesting the public model is not the multimodal version shown in demos. The model card references six model sizes (ranging from 0.5B to 32B parameters), including a 7B instruction-tuned variant based on GEMMA, but these versions are reportedly missing from the expected repositories, and documentation lacks any mention of ByteDance's involvement. - Testing of the model via the official online demo indicates underwhelming qualitative performance—especially with image generation tasks, such as rendering hands or realistic objects (e.g., 'the woman in grass did not go well' and malformed objects). This aligns with complaints about outputting anatomically incorrect features, often a benchmark for robustness in multimodal models.
- A commenter notes inconsistencies between the official announcement of the Liquid model family and the actual model artifacts found: the
-
Somebody needs to tell Nvidia to calm down with these new model names. (Score: 127, Comments: 23): The post humorously critiques NVIDIA's increasingly complex and verbose model naming conventions, as exemplified by the mock label 'ULTRA LONG-8B' referencing a model with 'Extended Context Length 1, 2, or 4 Million.' The image and comments satirize how modern model names can resemble other product branding—here, likening them to condom names—highlighting the industry's trend toward longer and more marketing-driven naming conventions. There is no substantial technical discussion about the models themselves or their benchmarks, only commentary on nomenclature.
- There is an undercurrent of critique regarding Nvidia's inconsistent or confusing model naming conventions, suggesting that their lineup could benefit from clearer taxonomy to avoid ambiguity between product generations and tiers. Technical readers point out that precise naming is important in distinguishing between model capabilities—especially with new architectures and variants proliferating quickly.
2. Large-Scale Model Training and Benchmarks
-
INTELLECT-2: The First Globally Distributed Reinforcement Learning Training of a 32B Parameter Model (Score: 123, Comments: 14): INTELLECT-2 pioneers decentralized reinforcement learning (RL) by training a 32B-parameter model on globally heterogeneous, permissionless hardware, incentivized and coordinated via the Ethereum Base testnet for verifiable integrity and slashing of dishonest contributors. Core technical components include: prime-RL for asynchronous distributed RL, TOPLOC for proof-of-correct inference, and Shardcast for robust, low-overhead model distribution. The system supports configurable 'thinking budgets' via system prompts (enabling precise reasoning depth per use-case) and is built atop QwQ, aiming to establish a new paradigm for scalable, open distributed RL for large models. Top comments clarify that launch ≠ completed training, emphasize the controllable reasoning budget innovation, and request human feedback (HF) timelines for further benchmarking.
- INTELLECT-2 introduces a mechanism where users and developers can specify the model's "thinking budget"—that is, the number of tokens the model can use to reason before generating a solution, aiming for controllable computational expense and reasoning depth. This builds on the QwQ framework and represents a potential advancement over standard transformer models with fixed-step inference.
- The project claims to be the first to train a 32B parameter model using globally distributed reinforcement learning. Historical context is provided by comparing to past community-driven distributed training projects, such as those inspired by DeepMind's AlphaGo, but the commenter notes that hardware requirements at this scale still present a significant barrier for individuals.
-
Price vs LiveBench Performance of non-reasoning LLMs (Score: 127, Comments: 48): The scatter plot visualizes the trade-off between price and LiveBench performance scores for a range of non-reasoning LLMs. It uses a log-scale X-axis for price per million 3:1 blended I/O tokens and shows a range of proprietary models (OpenAI, Google, Anthropic, DeepSeek, etc.) using color-coded dots, with notable placement of models like GPT-4.5 Preview and DeepSeek V3. Comments highlight the dominance of Gemma/Gemini models on the pareto front (maximal performance per price), specifically praising Gemma 3 27B's efficiency. The analysis reveals clear differentiation in market competitiveness: View image.
- Multiple commenters note that Gemma (and potentially Gemini) models currently dominate the "Pareto front" for price/performance in non-reasoning LLM benchmarks, suggesting that they offer the best tradeoff between cost and performance relative to competitors. This implies that, in the current landscape, alternatives lag behind these models in the specific metrics of price and efficiency.
- Discussion highlights that Gemma 3 27B delivers strong benchmark results for its scale, while the Gemini Flash 2.0 model is specifically singled out for its outstanding performance per dollar, significantly outperforming Llama 4.1 Nano, which is criticized for poor price/performance ratio. This underscores shifting value propositions in the LLM market as newer models are released and benchmarked side by side.
-
We GRPO-ed a Model to Keep Retrying 'Search' Until It Found What It Needed (Score: 234, Comments: 36): Menlo Research introduced ReZero, a Llama-3.2-3B variant trained with Generalized Repetition Policy Optimization (GRPO) and a custom retry_reward function, enabling high-frequency retrials of 'search' tool calls to maximize search task results (arxiv, github). Unlike conventional LLM tuning that penalizes repetition to minimize hallucination, ReZero empirically achieves a
46%score—more than double the baseline's20%—supporting that repetition, when paired with search and proper reward shaping, can improve factual diligence rather than induce hallucinations. All core modules, including the reward function and verifier, are open-sourced (see repo), leveraging the AutoDidact and Unsloth toolsets for efficient training; pretrained checkpoints are released on HuggingFace.- A commenter inquires about the availability of the reward function or verifier used in the GRPO approach, suggesting interest in examining or reproducing the reinforcement mechanism and evaluation logic from the released codebase.
- The primary model training pipeline leveraged open-source toolsets such as AutoDidact and Unsloth, indicating that implementations likely rely on these frameworks for orchestrating reinforcement learning or optimizing inference; both have been cited as crucial for technical reproducibility.
- The discussion hints at using an iterative approach where the model repeatedly retried 'Search' queries until successful, implying a custom reward or retry loop likely implemented via the mentioned toolchains—this raises questions about efficiency and resource usage in such a feedback-driven search reinforcement scheme.
3. Community Projects and Hardware Setups
-
Droidrun is now Open Source (Score: 214, Comments: 20): The post announces that the Droidrun framework—a tool related to Android or automation, as suggested by the title and logo design—is now open-source and available on GitHub (repo link). The image itself is not technical: it is a stylized logo of an android character running, conveying speed, activity, and the open nature of the project. There are no benchmarks or implementation details provided in the post or comments, though early community interest was high with 900+ on the waitlist.
- Technical discussion highlights how Droidrun allows advanced automated control and scripting of Android devices, making it valuable for highly technical users interested in device automation. Several commenters debate its practical use case, noting that users capable of compiling/installing from GitHub might not require LLM integration to perform simple actions, suggesting the tool's true strength lies in combining local device control with natural language-powered workflows, scripting, or batch automation on Android.
-
Yes, you could have 160gb of vram for just about $1000. (Score: 177, Comments: 78): The OP documents a $1157 deep learning inference build using ten AMD Radeon Instinct MI50 GPUs (16GB VRAM each, ROCm-compatible), housed in an Octominer XULTRA 12 case designed for mining, with power handled by 3x750W hot-swappable PSUs. Key software is Ubuntu 24.04 with ROCm 6.3.0 due to MI50 support limitations (though a commenter notes ROCm 6.4.0 does still work per device table), and llama.cpp built from source for inference. Benchmarks (llama.cpp, q8 quantization) show MI50s provide ~40-41 tokens/s (eval), but poor prompt throughput (e.g., ~300 tokens/s), performing worse than consumer Nvidia (RTX 3090, 3080Ti) and showing ~50% performance drop under multi-GPU and RPC use—e.g., MI50@RPC (5 GPUs) for 70B model achieves ~5 tokens/s vs ~10.6 tokens/s for 3090 (5 GPUs), with prompt evals also much slower (~28 ms/token vs ~1.9 ms/token). Power draw and thermal performance are excellent (idle ~20W/card, inference ~230W/card), and large VRAM pool is valuable for very large models or MoE. Limitations include PCIe x1 bandwidth bottleneck, scale-out limitations in llama.cpp (>16 GPU support sketchy), and significant RPC-related efficiency loss. Suggestions include lowering card power to 150W for minor performance cost, experimenting with MoE models, and potential optimization of network/RPC code. See the original post for detailed benchmarks and configuration notes: Reddit thread.
- Multiple users report that the MI50 can still support the latest ROCm (6.4.0) despite documentation suggesting otherwise—installation works and gfx906 (the MI50 architecture) is listed as supported under Radeon/Radeon Pro tabs, providing reassurance for potential buyers relying on ROCm for ML workloads.
- Power consumption can be capped on MI50 GPUs to significantly drop wattage (e.g., halving to 150W only reduces performance by ~20%), with acceptable inference rates as low as 90W per card; this is essential for those building large clusters (e.g., 10-card setups) concerned with power limits, cost, or thermal issues.
- Reported generation speeds for a 70B Q8 Llama 3.3 model are
~4.9-5 tokens/secon a $1,000 MI50 build, with a time to first token of 12 seconds for small context and up to 2 minutes for large context, offering concrete benchmarks for performance and latency expectations with this multi-GPU setup.
-
What is your favorite uncensored model? (Score: 103, Comments: 71): The discussion centers on large language models (LLMs) modified for minimal content filtering ('uncensored' or 'abliterated' models), specifically those by huihui-ai, including Phi 4 Abliterated, Gemma 3 27B Abliterated, and Qwen 2.5 32B Abliterated. Users note that the Phi 4 model retains its performance/intelligence post-'Abliteration,' while Gemma 3 27B's uncensored state is moderate unless use-cased as a RAG for financial data. Mistral Small is also highlighted for high out-of-the-box permissiveness without major safety layers, with or without uncensoring. See huihui-ai project repositories for technical configurations and quantized weights for the mentioned models.
- Discussion highlights specific uncensored models: Phi 4 Abliterated, Gemma 3 27B Abliterated, and Qwen 2.5 32B Abliterated by huihui-ai, praising Phi 4 for minimal intelligence degradation post-abliteration, suggesting a robust methodology behind its uncensoring process.
- Gemma 3 27B is reported as not particularly uncensored out of the box, but the commenter notes success in extracting financial advice via Retrieval-Augmented Generation (RAG), especially when using model variants rather than finetuned editions.
- Another user points out that uncensoring processes often lead to noticeable degradation in model performance, expressing a preference for standard models combined with jailbreak prompts over heavily modified, uncensored counterparts, reflecting a broader concern in the community about balancing censorship removal with maintaining baseline capabilities.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI o3 and o4-mini Model Launch and Discussion
-
o3 releasing in 3 hours (Score: 753, Comments: 186): The image is a tweet from OpenAI, announcing a livestream event set to begin in 'o3' hours, suggesting imminent release or demonstration of a new model, likely referred to as 'o3'. This has generated significant anticipation in the community, with technical discussions referencing previous high compute costs (one comment mentions a prompt costing ~$3K) and questioning the feasibility of broader release. Discussion includes skepticism about the deployment or commercialization of such high-compute models, with some users referencing prior scaling and cost issues as a technical barrier to public or widespread access.
- A user references the high compute cost for generating a single prompt on similar models in the past, quoting figures around
$3,000 per prompt, raising questions about how o3 is being released given such high computational requirements. This implies potential improvements in model efficiency, inference cost, or infrastructure compared to previous iterations. - Another user is keen to compare o3's capabilities against both the team's own 'DeepResearch' model and Google's 'Gemini 2.5 Pro,' explicitly highlighting interest in cross-benchmark performance and the hope this signals further imminent releases (notably the 'o4' family).
- A user references the high compute cost for generating a single prompt on similar models in the past, quoting figures around
-
Introducing OpenAI o3 and o4-mini (Score: 235, Comments: 91): OpenAI has introduced the o3 and o4-mini models, with the o3 model offering slightly reduced performance on benchmarks like GPQA, SWE-bench, and AIME compared to earlier (December) figures, but is noted in the announcement blog as being cheaper than the o1 model. Key technical discussion centers on o3's coding benchmark performance, reported as slightly better than Google's Gemini but with o3 costing 5x more. There is broader debate regarding the relevance of current benchmarks, with calls for evaluation metrics focused on real-world agentic task performance rather than incremental math or reasoning benchmarks. Commenters scrutinize the tradeoff between decreased benchmark performance and lower cost in o3, with some noting that real-world utility should take precedence over small benchmark variances. The high relative cost of o3 compared to Gemini, despite performance advantage, is also raised as a concern. [External Link Summary] OpenAI has introduced o3 and o4-mini, the latest in its o-series reasoning models, featuring significant improvements in agentic tool use and multimodal capabilities. o3 sets new state-of-the-art (SOTA) benchmarks in coding, math, science, and visual perception, excelling at complex, multi-faceted problems by integrating tools for web search, file analysis, Python execution, and image generation within ChatGPT. Both models utilize large-scale reinforcement learning for superior reasoning and instruction following, with o4-mini optimized for high-throughput, cost-efficient reasoning and leading performance among compact models—especially for math and coding. For the first time, users can incorporate images into the reasoning workflow, enabling integrated visual-textual problem-solving and tool-chaining for advanced, real-world, and up-to-date tasks. See: Introducing OpenAI o3 and o4-mini
- Benchmarks such as GPQA, SWE-bench, and AIME saw slightly reduced scores for o3 compared to its initial December announcement, although OpenAI notes the model is now cheaper than o1; there is speculation that the performance was deliberately reduced to lower costs.
- On the Aider polyglot benchmark, o3-high scored 81% but at a potentially very high cost (speculated at ~$200 like o1-high), whereas Gemini 2.5 Pro scored 73% at a much lower price. GPQA scores are very close (
o3: 83%vsGemini 2.5 Pro: 84%). Although o3 shows improvements in math (notably a big jump on math benchmarks and a slight lead on HLE over Gemini without tools), the high cost relative to Gemini makes it less attractive for some users focused on real-world value per dollar. - Discussion points out that while benchmarks are useful, they are somewhat overrated and do not always reflect a model's suitability for everyday tasks or agent-based workflows. There is a call for new benchmarks that better reflect real-world job competence or daily use-case utility of large language models.
-
launching o4 mini with o3 (Score: 205, Comments: 43): The image announces an upcoming event from OpenAI introducing new 'o-series' models, specifically 'o3' and 'o4-mini.' This indicates OpenAI's continued expansion of their model lineup beyond GPT-4o, with implications for both performance and functionality. The linked YouTube event suggests an official, technical rollout, though little model detail is present in the image. Commenters heavily critique OpenAI's confusing and inconsistent model naming conventions, arguing that closely named models with different capabilities ('o3', 'o4-mini', '4o') cause unnecessary confusion in both technical and non-technical circles.
- There is confusion and technical critique surrounding the naming overlap between the 'o3', 'o4', and 'o4 mini' models, with users noting how similar names for models offering drastically different capabilities can create ambiguity when referencing benchmarks, updates, or deployment contexts.
- A technical question is raised about the practical use case of 'o4 mini' compared to 'o3', specifically questioning why a newer, potentially enhanced model is released alongside an older one, especially when the new version is 'mini' (possibly smaller or more efficient), prompting discussion of real-world scenarios or benchmark-driven preferences.
- There is also a regional availability question regarding EU access to 'o3' and 'o4 mini', which, if answered, would inform technical readers about deployment timelines, rollout strategies, and compliance with local regulations or infrastructure realities.
-
[Confirmed] O-4 mini launching with O-3 full too! (Score: 298, Comments: 44): The image officially announces an OpenAI event for the introduction of new 'o-series' models—specifically the O-4 mini and a full O-3 model—scheduled for April 16, 2025. It confirms that both the lightweight 'mini' version of O-4 and the full version of O-3 are launching concurrently. The event will feature presentations and demos from notable OpenAI engineers and researchers, including Greg Brockman, Mark Chen, and others, suggesting an in-depth technical reveal and demonstration. Image link. Commenters question the clarity of OpenAI's model naming scheme, with some expressing anticipation to switch usage from previous 'o3 mini' to the new 'o4 mini'. The naming and model differentiation are highlighted as ongoing points of confusion among technical users.
- The initial comment lists notable figures, including Greg Brockman and Mark Chen, who are involved in introducing and demoing the new O-series models, possibly indicating a high-profile launch event, which may be relevant for tracking future technical presentations or announcements related to O-4 mini and O-3 full models.
- Several users discuss the transition from primarily using 'O-3 mini high' to 'O-4 mini', implying iterative improvements and that there is a clear user base migrating to the newer model; this demonstrates expectations that O-4 mini may outperform or provide added value over the O-3 mini in real-world usage.
- There is some mild technical criticism of the O-series naming scheme, with users describing it as 'ridiculous'. While this is not directly technical, it has implications for model tracking, integration, and future development cycles, where confusing nomenclature can hinder adoption and API version management.
-
This confirms we are getting both o3 and o4-mini today, not just o3. Personally excited to get a glimpse at the o4 family. (Score: 225, Comments: 50): The post uses an image of strawberries in two distinct rows (three large, four small) to metaphorically confirm a dual release: both 'o3' and 'o4-mini' foundation models are set to launch together (image: link). The visual pun visually represents 'o3' (three large) and 'o4-mini' (four small) models, indicating a strategic broadening of the lineup, possibly with performance or size differentiation. The title and image contextually underscore excitement over preview access to the next-generation o4 family, not just an incremental update. Technical discussion centers on concerns about pricing for 'o3' (potential $200/month cost) and skepticism/anticipation regarding whether 'o4-mini' can deliver on its science-assistance claims, reflecting community interest in practical impact and accessibility of these models.
- MassiveWasabi discusses curiosity about whether the o4-mini model will deliver on claims regarding its utility for advancing scientific research, suggesting that users have technical expectations for model performance beyond general AI tasks.
- jkos123 inquires about API pricing for o3 full, comparing it directly to previous tiers such as o1-pro (
$150/month in,$600/month out). This indicates technical users' attention to cost-performance ratios for deployment choices in production and research. - NootropicDiary speculates on the coding and reasoning capabilities of o4 mini high, questioning if it could be close in performance to o3 pro. This points to community interest in comparative benchmarks and the practical application of these models in development workflows.
2. OpenAI o3/o4 vs Gemini Benchmarks and Comparisons
-
Benchmark of o3 and o4 mini against Gemini 2.5 Pro (Score: 340, Comments: 169): The post benchmarks performance of o3, o4-mini, and Gemini 2.5 Pro models across various tasks. On maths benchmarks (AIME 2024/2025), o4-mini slightly outperforms Gemini 2.5 Pro and o3 (o4-mini:
93.4%on AIME 2024, o3:91.6%, Gemini 2.5 Pro:92%). For knowledge and reasoning (GPQA, HLE, MMMU), Gemini 2.5 Pro leads on GPQA (84.0%), o3 leads on HLE (20.32%) and MMMU (82.9%). In coding tasks (SWE, Aider), o3 performs best on both SWE (69.1%) and Aider (81.3%). Pricing is highlighted, with o4-mini being substantially cheaper ($1.1/$4.4) than the others. Plots were generated by Gemini 2.5 Pro. Commenters note potential misrepresentation via y-axis scaling on plots, and highlight that Google and OpenAI models are now close in performance, though Google's pace and resource advantage is seen as an indicator they may soon surpass OpenAI.- Discussion highlights the inadequacy of comparing AI model token costs purely via price per million tokens, noting that output lengths differ significantly between models ('reasoning tokens'), thus skewing cost comparisons. Instead, actual $ cost of running benchmarks should be analyzed to determine real expenses, as opposed to retail prices charged to consumers. The distinction between "Cost" (operational, hardware, and infrastructure costs for running a model) and "Price" (what companies charge to access the model) is emphasized, pointing out that proprietary models (e.g., OpenAI, Google) obscure running costs, while open source models enable more transparent assessment as users can directly measure or estimate hardware expenditure. The post also cautions that company pricing strategies (e.g., Google possibly setting artificially low prices due to TPUs or market share goals) further complicate fair comparisons. A robust, standardized analysis factoring in both cost-to-run and price-to-consumer versus performance is proposed for future benchmarks.
-
Comparison: OpenAI o1, o3-mini, o3, o4-mini and Gemini 2.5 Pro (Score: 195, Comments: 44): The image provides a direct benchmark comparison between OpenAI's o1, o3-mini, o3, o4-mini models and Google's Gemini 2.5 Pro, covering metrics such as AIME (math), Codeforces coding, GPQA (science Q&A), and several reasoning/logic tasks. The table indicates that OpenAI's o4-mini leads in math-with-tools tasks, while Gemini 2.5 Pro performs distinctly in some coding and science benchmarks (e.g., LiveCodeBench v5). Substantial differences are noted across tasks, reflecting how model strengths vary by domain; OpenAI's mid-tier models (like o3) demonstrate strong practical code generation for whole apps in user experiences. Top comments highlight o4-mini's dominance in math, the assertion that benchmark relevance is diminishing as models surpass human performance, and the need for pricing context. There's anecdotal user praise for o3's real-world practicality in code generation.
- Gemini 2.5 Pro is described as generally comparable to OpenAI's o4-mini, except for mathematics, where o4-mini leads. ("So gemini 2.5~o4mini except in math where o4-mini leads")
- User test experience with o3 suggests it can generate entire, working applications in a single output, indicating major advancement in code synthesis compared to prior models. ("o3 is quite groundbreaking, spitting out whole, working apps with one shot")
- Noted rapid improvement on "Humanity's Last Exam" benchmarks: compared to PhD students who average ~30% overall and ~80% in their field on such tests, current model scores represent significant progress in a short time frame.
-
If o3 from OpenAI isn't better than Gemini 2.5, would you say Google has secured the lead? (Score: 211, Comments: 131): The post questions whether, if OpenAI's o3 model fails to surpass Google's Gemini 2.5 in benchmarks and real-world scenarios, Google has effectively become the industry leader for state-of-the-art LLMs. Top comments point out that 'best model' status is domain-dependent, Gemini 2.5 currently leads for some users, and a key trade-off may be o3's expected higher performance at significantly greater cost ("~15 times as much" as Gemini for real-world tasks, based on previous pricing for o1 and extrapolated from ARC-AGI benchmark tests). Commenters debate whether short-term superiority in benchmarks equates to long-term leadership and note the prohibitive operational costs for OpenAI's top models as a limiting factor, while conceding performance may justify the expense in select applications.
- Commenters note that while Google's Gemini 2.5 is currently highly competitive and possibly leads, the lead is not evenly distributed across all domains—different models may excel in distinct tasks or environments.
- A technical concern highlighted is the projected cost discrepancy between OpenAI's forthcoming o3 and Gemini 2.5, referencing that o3 could be up to "~15 times as much for real world tasks" (based on historical ARC-AGI benchmarks and o1 pricing). This raises concerns on the real-world deployability of o3 relative to Gemini 2.5, especially for cost-sensitive applications.
- There is recognition of offline models like Gemma 3, which are praised as strong offline AI solutions, indicating Google's breadth in both cloud and edge AI, though some users point out Google's current UI/UX and response 'human-ness' as areas for improvement compared to OpenAI.
3. HiDream & ComfyUI Model Updates and Tools
-
Hidream Comfyui Finally on low vram (Score: 166, Comments: 117): A low VRAM version of HiDream's diffusion image generation workflow is now available for ComfyUI, featuring GGUF-formatted models (HiDream-I1-Dev-gguf), a GGUF Loader for ComfyUI (ComfyUI-GGUF), and compatible text encoders and VAE (link, vae link). The workflow supports alternate VAE's (e.g., Flux) and details are documented here. A user shared performance numbers for a RTX3060 using SageAttention and Torch Compile: image resolution
768x1344generated in 100 seconds using 18 steps. Comments highlight the rapid obsolescence of new AI workflows and the difficulty of keeping pace with new releases.- A user reports successfully running the model on an RTX3060 using SageAttention and Torch Compile. The setup produced images at a resolution of 768x1344 in 100 seconds over 18 steps, demonstrating that low-VRAM cards can achieve reasonable generation times with optimized configurations.
- There is a comparative assessment suggesting that Flux finetunes currently deliver better results than this release, highlighting ongoing benchmarks and subjective quality debates among different model variants.
- A specific hardware compatibility question was raised regarding operation on Apple Silicon (M1 Mac), which may be of interest for developers aiming to support broader platforms.
-
Basic support for HiDream added to ComfyUI in new update. (Commit Linked) (Score: 152, Comments: 45): ComfyUI has added basic support for the HiDream model family with a recent commit, requiring users to employ the new QuadrupleCLIPLoader node and the LCM sampler at CFG=1.0 for optimal performance. GGUF-format HiDream models and loader node (from City96) are now available (models, loader), alongside required text encoders (list), and a basic workflow; users must update ComfyUI for the necessary nodes. SwarmUI has also integrated HiDream I1 support (docs). Benchmark: RTX 3060 renders a 768x768 image in 96 seconds; RTX 4090 achieves 10-15 sec per image (substantially higher memory use); quality is comparable to contemporary models with notable JPEG artifacting, and files are significantly larger than alternatives. Technical debate centers on whether HiDream's incremental quality improvements justify its high memory usage and large file sizes compared to models like Flux Dev or SD3.5, with some noting uncensored outputs and artifacting as both notable features and potential drawbacks. [External Link Summary] This commit to the ComfyUI repository introduces basic support for the HiDream I1 model by adding a dedicated implementation under
comfy/ldm/hidream/. The changes include a new model wrapper (HiDreamsubclass) inmodel_base.py, extensive logic for the HiDream architecture inhidream/model.py, relevant text encoders, detection modules, and custom nodes for ComfyUI workflows. This integration enables users to deploy and experiment with the HiDream I1 model within the ComfyUI framework, improving the model support ecosystem. Original: https://github.com/comfyanonymous/ComfyUI/commit/9ad792f92706e2179c58b2e5348164acafa69288- HiDream now works in ComfyUI with GGUF models, requiring a new QuadrupleCLIPLoader node and an updated text encoder node in Comfy. Model files, loader node, and sample workflows are provided in linked resources. For optimal sampling, the LCM sampler with CFG 1.0 is recommended. source/links
- Benchmarks across GPUs (e.g., RTX 4090 vs 3060) show generation times of
1:36for 768x768 images on a 3060 and10-15sper image on a 4090 using SwarmUI. Memory usage is significantly higher than modern competitors like Flux Dev (which can do 4-5s per image with Nunchaku optimization), largely attributed to the new QuadrupleClipLoader node. - Discussion highlights the trade-off in model adoption: while HiDream shows incremental quality improvements, its file size and high VRAM requirements (at least 12GB referenced) limit broader usability compared to alternatives like Flux or SD35. There are questions about whether the higher resource usage justifies the quality gains, especially given VRAM limitations on most consumer GPUs.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Exp
Theme 1: OpenAI's New Models: O3, O4-Mini, and Codex CLI
- OpenAI Unleashes Codex CLI for Brutal Reasoning: OpenAI has released Codex CLI, a lightweight coding agent leveraging models like o3 and o4-mini, with GPT-4 support coming soon, as detailed in their system card. Codex CLI uses tool calling for brute-force reasoning, applicable to tasks like answering questions on geoguessr.com.
- Members Laud O3 and O4-Mini Performance, Note Limitations: Community members testing o3 and o4 mini found that o4 mini performed best on OpenAI's interview choice questions, while o3 excelled at a non-trivial real-world PHP task, scoring 10/10. Despite benchmark tests, it suffers from the same Alaska problem as o3 as reported on X, but excels at reasoning with temperature set to 0.4 or less.
- LlamaIndex, Windsurf, and O3/O4 Mini Gain Integration: LlamaIndex now supports OpenAI's o3 and o4-mini models, accessible with
pip install -U llama-index-llms-openaiand find more details here. The o4-mini is now available in Windsurf, with models o4-mini-medium and o4-mini-high offered for free on all Windsurf plans from April 16-21 as reported in their social media announcement.
Theme 2: Emerging Hardware and Performance Challenges
- RTX 5090 Matmul Disappoints, Larger Matrices Needed: Initial implementations of matmul on RTX 5090 yielded performance roughly equal to RTX 4090 when multiplying two fp16 matrices of size 2048x2048, and the tests can be found in the official tutorial code. It was suggested to test with a larger matrix, such as 16384 x 16384, and experiment with autotune.
- AMD Cloud Vendor Supports Profiling and Observability: An AMD cloud offers built-in profiling, observability, and monitoring, though it may not be on-demand, sparking debate on the merits of creating a cloud vendor tier list to incentivize better hardware counters. In the discussion, a user made a joking threat to make a cloud vendor tier list to shame people into offering hardware counters, as a way to persuade AMD or other vendors to provide better hardware counters.
- NVMe SSDs Supercharge Model Loading in LM Studio: Using an NVMe SSD significantly speeds up model loading in LM Studio, with observed speeds reaching 5.7GB/s, although having multiple NVMe SSDs doesn't significantly impact gaming. A user highlighted having three NVMe SSDs in their system, but they don't seem to make much difference for gaming unfortunately.
Theme 3: Gemini 2.5 Pro and Related API Discussions
- Gemini 2.5 Pro Rate Limits Frustrate Free Tier Users: Users discussed the tight rate limits for the free tier of Gemini 2.5 Pro, noting it has a smaller limit of 80 messages per day, reduced to 50 without a $10 balance. One user expressed frustration, saying they would need to pay an additional $0.35 due to the 5% deposit fee to meet the minimum $10 requirement for the increased rate limit.
- Claims Surface of Shrinking Gemini 2.5 Pro Context Window: Claims surfaced that Gemini 2.5 Pro has a reduced context window of 250K, despite the official documentation still stating 1M, although one member pointed out that the source of truth is always the GCP console.
- Gemini 2.5 Pro API Hides "Thinking Content": Debate Ensues: Members debated whether Gemini 2.5 Pro API returns thinking content, noting official documentation says no, despite thought tokens being counted. Despite this, thought tokens are counted, sparking theories about preventing distillation or hiding bad content.
Theme 4: DeepSeek Models and Latent Attention
- DeepSeek R3 and R4 Model Release Excites OpenRouter Community: Users await the release of Deepseek's R3 and R4 models imminently, generating buzz within the OpenRouter community with hope that these models will eclipse OpenAI's o3. A user stated that "Deepseek is only affordable, the actualy is not that great."
- DeepSeek-V3's Latent Attention Mechanism Investigated: A member found that DeepSeek-V3's Multihead Latent Attention calculates attention in 512-dim space, although the head size is only 128, making it 4x more expensive. While this detail may be overlooked, this increased computational cost isn't an issue when memory bandwidth is the main bottleneck.
- DeepSeek Distill Chosen for Chain of Thought Reasoning: The DeepSeek Distill model was recommended for SFT due to its existing chain of thought (CoT) capabilities and a base model like Qwen2.5 7B is possible but less direct according to Deepseek's paper. A member recommended to use the DeepSeek Distill model for SFT due to its existing chain of thought (CoT) capabilities, and using a base model like Qwen2.5 7B is possible but less direct according to Deepseek's paper.
Theme 5: Community and Ethical Discussions
- OpenRouter Privacy Policy Update Sparks Debate: An update to OpenRouter's privacy policy sparked concern because it appeared to log LLM inputs, with one line stating, "Any text or data you input into the Service (“Inputs”) that include personal data will also be collected by us". An OpenRouter rep said, "we can work on clarity around the language here, we still don't store your inputs or outputs by default", promising to clarify the terms soon.
- AI Misuse Alarms Raised, Nefarious Purposes Feared: Discussions emerged around AI's potential for nefarious purposes, especially in VR, with one member fearing its use for reallly bad stuff, and discussions of copyright infringement and deepfakes. This led to conversations around copyright infringment and generating deepfakes, while still trying to find ways around that.
- Community Conduct Sparks Debate in Manus.im: Manus.im community members discussed community conduct after a heated exchange, focusing on balancing offering assistance with encouraging self-reliance, which led to a user getting banned. Concerns were raised about perceived lack of helpfulness versus the importance of self-driven learning and avoiding reliance on hand outs.
PART 1: High level Discord summaries
LMArena Discord
- OpenAI Unleashes Lightweight Coding Agent: Codex CLI: OpenAI launched Codex CLI, a lightweight coding agent using models like o3 and o4-mini, with support for GPT-4 models coming soon, as documented in their system card.
- One member noted it likely uses tool calling for brute force reasoning, such as answering questions on geoguessr.com.
- o3 and o4 Mini Show Promise: Members testing OpenAI's o3 and o4 mini models found o4 mini performed best on OpenAI's interview choice Qs, while o3 excelled at a non-trivial real world PHP task, scoring 10/10.
- Despite benchmark tests, it suffers from the same Alaska problem as o3 as reported on X, though it excels at reasoning with temperature set to 0.4 or less.
- OpenAI Mulls Windsurf Acquisition for $3B: OpenAI is reportedly in talks to acquire Windsurf for approximately $3 billion, according to Bloomberg.
- The potential acquisition has sparked debate on whether OpenAI should build such tools themselves, particularly when Gemini's finite state machine pathfinding used in Roblox shows integration benefits.
- DeepSeek-R1 Parameter Settings Explored: Configurations for DeepSeek-R1 were discussed, referring to the GitHub readme, emphasizing setting the temperature between 0.5-0.7, avoiding system prompts, and including a directive to reason step by step for mathematical problems.
- Members lauded the performance and source quoting capabilities but also noted concerns about source hallucination, with one member stating still got a way to go until agi.
- o3's Tool Use Paves Way For New Benchmarks: Members highlighted o3 model's tool use capabilities such as the image reasoning zoom feature, though one member stated tool use isn't out yet in the arena.
- The tool usage sparked talk on creating benchmarks, particularly relating to GeoGuessr, with new harnesses or bulk testing, although costs may be high.
Manus.im Discord Discord
- Manus Credit Consumption Under Microscope: Users voiced concerns about Manus credit usage, with one user noting they spent 3900 credits and had only 500 remaining after two weeks.
- A user mentioned spending nearly 20k credits in the same timeframe, emphasizing the need for strong ROI even with Manus's powerful capabilities.
- Kling's Image Generation Sets Wildfire: Members lauded Kling's insane image generation abilities, with one member describing Kling as diabolical and a game changer after signing up.
- Another member said that Kling 1.6 is out, and described the capabilities as holy mother of f.
- Community Etiquette Sparks Debate: Members discussed community conduct after a heated exchange, focusing on balancing offering assistance with encouraging self-reliance, which led to a user getting banned.
- Concerns were raised about perceived lack of helpfulness versus the importance of self-driven learning and avoiding reliance on hand outs.
- Copilot Gains Recognition: Members discussed Copilot's potential to revolutionize AI, especially with the Pro version being able to perform complicated tasks.
- Members are saying that Copilot can do descent art and other complicated tasks, and is a beast.
- AI Misuse Sparks Alarms: Members expressed alarm about AI's potential for nefarious purposes, particularly in VR.
- Discussion shifted into copyright infringement and generating deepfakes, alongside exploration of potential safeguards.
aider (Paul Gauthier) Discord
- Aider's Early Commits Spark Jokes: Developers are sharing jokes about Aider, mocking its tendency to commit too soon and cause merge conflicts during coding assistance.
- One joke likened Aider's assistance to rewriting your repo like it just went through a bad divorce, while another suggested using it results in
git blamejust saying 'why?'.
- One joke likened Aider's assistance to rewriting your repo like it just went through a bad divorce, while another suggested using it results in
- ToS Breakers Tread on Thin Ice: Members discussed the implications of breaking Terms of Service (ToS), with one user claiming to have been breaking ToS for 3 months without a ban.
- Concerns were raised about potentially bannable activities and the importance of adhering to platform rules.
- Gemini 2.5 Pro Shrinks Context Window?: Claims surfaced that Gemini 2.5 Pro has a reduced context window of 250K, despite the official documentation still stating 1M.
- One member pointed out that the source of truth is always the GCP console.
- OpenAI's o3 and o4 Minis Debut: OpenAI launched o3 and o4-mini, available in the API and model selector, replacing o1, o3-mini, and o3-mini-high.
- The official announcement notes that o3-pro is expected in a few weeks with full tool support, and current Pro users can still access o1-pro.
- Aider's File Addition Frustrations Documented: A member reported issues where Aider's flow is interrupted by requests to add a file, causing resending of context and re-editing, and documented it in this Discord post.
- This interruption requires constant resending of context and re-editing.
OpenRouter (Alex Atallah) Discord
- OpenAI's O3 Arrives Requiring BYOK: OpenAI's O3 model is now available on OpenRouter with a 200K token context length, priced at Input: $10.00/M tokens and Output: $40.00/M tokens, requiring organizational verification and BYOK.
- Members discussed whether the O3 models were "worth it" or if they should wait for upcoming DeepSeek models.
- O4-Mini Emerges as Low-Cost Option: The OpenAI O4-mini model is now on OpenRouter, offering a 200K token context length at Input: $1.10/M tokens and Output: $4.40/M tokens, but users reported issues with image recognition, such as getting "Desert Picture => Swindon Locomotive Works."
- An OpenRouter rep confirmed that "image inputs are fixed now".
- Deepseek R3 and R4 Models Hype Incoming: Chatter indicates Deepseek's R3 and R4 models are slated for release imminently.
- One user expressed the hope that "everyone forgets about o3" when the models are released, while another stated that "Deepseek is only affordable, the actualy is not that great."
- Gemini 2.5 Pro Rate Limits Frustrate Users: Users discussed the tight rate limits for the free tier of Gemini 2.5 Pro, noting it has a smaller limit of 80 messages per day, reduced to 50 without a $10 balance, subject to Google's own limits.
- One user expressed frustration, saying they would need to pay an additional $0.35 due to the 5% deposit fee to meet the minimum $10 requirement for the increased rate limit.
- OpenRouter Privacy Policy Update Sparks Debate: An update to OpenRouter's privacy policy sparked concern because it appeared to log LLM inputs, with one line stating, "Any text or data you input into the Service (“Inputs”) that include personal data will also be collected by us"
- An OpenRouter rep said, "we can work on clarity around the language here, we still don't store your inputs or outputs by default", promising to clarify the terms soon.
OpenAI Discord
- GPT-4.1 Batch is MIA, causing headaches: Members reported that the gpt-4.1-2025-04-14-batch model is unavailable via the API, despite users enabling gpt-4.1, while other members tried using
model: "gpt-4.1"in the API call.- A member suggested checking the limits page for account-specific details, yet the issue persists.
- Veo 2 Video: Terrifying or Terrific?: A user shared a video generated by Veo 2, spurring comments about its realism and possible uses.
- While one user commented that the tongue is freaking me out, others have discussed use cases for the Gemini family, with many preferring its creative writing and memory abilities.
- O3 Codes Conway's Game of Life with Alacrity: O3 coded Conway's Game of Life in 4 minutes and compiled/ran it on the first try, whereas O3 mini high took 8 minutes to complete the same task months ago with bugs.
- Members discussed the implication of these coding improvements and O3's ability to generate code and libraries for complex applications.
- O3 and O4-mini reportedly generating believable but incorrect information: Users reported increased hallucinations with O4-mini and O3, with some noting that it makes up believable but incorrect information.
- One user noted that the model ‘wants’ to give a response, as that’s its purpose after testing O4-mini with the API, discovering it made up business addresses and didn't respond well to custom search solutions.
- Clean up Library Photos made Possible!: A member sought help on deleting pictures from their library, to which another user provided a link to the ChatGPT Image Library help article.
- The new feature is available for Free, Plus, and Pro users on mobile and chatgpt.com.
Cursor Community Discord
- Realtime Token Calculation Requested: A user requested the ability to see token calculation in realtime within the editor, or at least updated frequently.
- They noted this would be very useful given their current need to monitor token usage on the website.
- Gemini Questioned for File Reading: A user questioned whether Gemini actually reads files when it claims to do so while using the
thingfeature and included a screenshot for reference.- The discussion revolves around the accuracy and reliability of Gemini's file reading capabilities within the Cursor environment.
- Terminal Command Glitch in Agent Mode: Several users reported an issue in Agent Mode where the first terminal command runs to completion without intervention, but subsequent commands require manual cancellation.
- This is described as a longstanding bug that affects the usability of Agent Mode for automated tasks.
- GPT 4.1 Prompting Precision: Users compared GPT 4.1, Claude 3.7, and Gemini, noting that GPT 4.1 is very strict in following prompts, while Claude 3.7 tends to do more than asked.
- They found Gemini strikes a balance between the two, offering a middle ground in terms of prompt adherence.
- Manifests Proposed for Speedy Form Filling: Users suggested a new feature to enable mass input of preset information using manifests for easy replication of accounts and services.
- They noted this would greatly assist ASI/AGI swarm deployment, saying, We need the ASI-Godsend to happen asap, and this is how to easily help achieve it.
Unsloth AI (Daniel Han) Discord
- Qwen2.5-VL Throughput Speculations: Members sought throughput estimates for Qwen2.5-VL-7B and Qwen2.5-VL-32B using Unsloth Dynamic 4-bit quant via vLLM on an L40, while also inquiring about vLLM's vision model support.
- The inquiry aimed to gauge the models' practical performance in resource-constrained environments.
- Gemini 2.5 Pro Hides Thoughts: Members debated whether Gemini 2.5 Pro API returns thinking content, noting official documentation says no.
- Despite this, thought tokens are counted, sparking theories about preventing distillation or hiding bad content.
- Llama 3.1 Tool Calling Conundrums: A user sought help with dataset formatting for fine-tuning Llama 3.1 8B on tool calling, formatting assistant responses as
[LLM Response Text ]{"parameter_name": "parameter_value"}.- The user expressed frustration over a lack of solid information on GitHub Issues, indicating a common challenge in adapting models for specific tasks.
- Unsloth Notebook Finetuning Fails: A user reported that after finetuning with Unsloth's Llama model notebook, the model's output showed no similarities with the ground truth.
- Specifically, a question about astronomical light wavelengths yielded a response about the Doppler effect, suggesting a disconnect between the training and the expected outcome.
- DeepSeek-V3's Latent Attention Gotcha: A member found that DeepSeek-V3's Multihead Latent Attention calculates attention in 512-dim space, although the head size is only 128, making it 4x more expensive.
- Another member suggested that increased computational cost isn't an issue when memory bandwidth is the main bottleneck.
Eleuther Discord
- Prompt Design Newbie Seeks Aid: A new member requested assistance with prompt design, seeking helpful resources; however, they were directed to external sources, as prompt design is not the focus of the server.
- Members generally agree the server is for more advanced discussion of model architecture and training tricks.
- Recursive Symbolism Claims Face Skepticism: A member described exploring "symbolic recursion and behavioral persistence" in ChatGPT without memory, leading to skepticism about the terminology and lack of metrics.
- Members suggested the language was AI-generated and unproductive for the research-focused server and some even suggested that it was AI Spam.
- AI Spam Concerns Prompt Authentication Suggestions: Members discussed an increasing prevalence of AI-influenced content, raising concerns about the server being overrun with bots, and linked to a paper on permissions.
- Suggestions included requiring human authentication and identifying suspicious invite link patterns like one user with over 50 uses of their invite link, which one member sarcastically called "a potential red flag".
- AI Alignment Talk Turns to Hallucination: Discussion arose around AI alignment, contrasting with the idea that AI tries its best to do what we say we want it to do, and the interaction with human psychology.
- One member opined that "the LLMs are not that smart and hallucinate", noting differences between o3-mini and 4o models.
- OCT Imaging Issues Addressed: A member shared an attempt to use retinal OCT imaging, but didn't achieve great results due to fundamentally different data structures between 2D and 3D views, linking to arxiv.org/abs/2107.14795.
- They asked for general approaches for multimodal data with no clear mapping between data types and suggested the problem would be like a foundation model over various different types of imaging.
GPU MODE Discord
- Richard Zou Hosts Torch.Compile Q&A: Core PyTorch and torch.compile dev Richard Zou is hosting a Q&A session this Saturday, April 19th at 12pm PST, with submission via this Google Forms link.
- The session will cover the usage and internal workings of torch.compile for GPU Mode.
- RTX 5090's Matmul Performance Disappoints: A member reported that implementing matmul on RTX 5090 yielded performance roughly equal to RTX 4090, when multiplying two fp16 matrices of size 2048x2048 referencing the official tutorial code.
- It was suggested to test with a larger matrix, such as 16384 x 16384, and experiment with autotune.
- CUDA Memory Use Has Significant Overhead: A member questioned the seemingly high memory usage of a simple
torch.ones((1, 1)).to("cuda")operation, expecting only 4 bytes to be used.- It was clarified that CUDA memory usage includes overhead for the GPU tensor, CUDA context, CUDA caching allocator memory, and display overhead if the GPU is connected to a display.
- AMD Cloud Vendors Support Profiling: A member mentioned that an AMD cloud offers built-in profiling, observability, and monitoring, though it may not be on-demand.
- Another member responded asking to know more, threatening to make a cloud vendor tier list to shame people into offering hardware counters.
- AMD FP8 GEMM Test Requires Specific Specs: Users discovered that testing the
amd-fp8-mmreference kernel requires specifying m, n, k sizes in thetest.txtfile instead of just the size parameter, using values from the pinned PDF file.- Users discussed the procedure for de-quantizing tiles of A and B before matmulling them, clarifying the importance of performing the GEMM in FP8 for performance and taking advantage of tensor cores.
Latent Space Discord
- Kling 2 Escapes Slow-Motion Era: Enthusiasts celebrated Kling 2's release with claims that we are finally out of the slow-motion video generation era, see tweets here: tweet 1, tweet 2, tweet 3, tweet 4, tweet 5.
- Users discussed the improvements and potential applications in video generation, pointing out its capacity to reduce the need for labor-intensive editing processes.
- BM25 Now Retrieves Code: A blog post highlighted the use of BM25 for code retrieval and was recommended, see Keeping it Boring and Relevant with BM25F, along with this tweet.
- BM25 is a bag-of-words retrieval function that ranks documents based on the query terms appearing in each document, irrespective of the inter-relationship between the query terms.
- Grok Canvases Broadly: Grok's canvas feature was announced and referenced by Jeff Dean at an ETH Zurich talk, see Jeff Dean's talk at ETH Zurich and also the tweet about it.
- The addition of this feature is expected to enhance the interactive capabilities of the model, allowing for more intuitive user interfaces in applications that utilize Grok.
- GPT-4.1 Splits Opinions: Members shared feedback on GPT-4.1, with one member really enjoying using it for coding, but it's bad for structured output.
- Another member found it useful with the Cursor agent and did this 5x in a row tweet here, suggesting it may be advantageous in specific development workflows despite its limitations.
- O3 and o4-mini Boot Up!: OpenAI launched O3 and o4-mini model, and more information can be found here: Introducing O3 and O4-mini.
- One user reported anecdotal evidence that o4-mini just increased the match rate on our accounting reconciliation agent by 30%, running against 5k transactions, indicating a substantial improvement in certain applications.
Yannick Kilcher Discord
- AI Co-Authorship Creates Stir: Members discussed AI's role in authorship, noting that the intent, direction, curation, and judgment come from you, but suggesting AI could be added as co-creators when it achieves AGI.
- One member is developing a pipeline to generate 1000s of patents per day, sparking debate about patent quality versus quantity as a productivity measure.
- LLMs Stumble with Examples?: A member inquired why reasoning LLMs sometimes perform worse when given few-shot examples, with possible explanations including Transformer limitations and overfitting.
- Another responded that few shot makes them perform differently in all cases.
- o3 and o4-mini APIs Launched: OpenAI released o3 and o4-mini APIs, considered by some members a major upgrade to o1 pro.
- A member commented that o1 is better at thinking about stuff.
- Noise = Signal, Randomness = Creativity: Members explored the role of noise and randomness in biological systems, noting that in biological systems, noise is signal, contributing to symmetry breaking, creativity, and generalization.
- The discussion also touched on the application of randomness in a Library of Babel style storage solution for neural networks.
- DHS Rescues Cyber Vulnerability Database: The Department of Homeland Security (DHS) extended support for the cyber vulnerability database, averting its initial depreciation as reported by Reuters.
- The decision highlights the database's usefulness to both the public and private sectors, with a tweet on X questioning if it should remain solely a DHS responsibility given its private sector utility.
HuggingFace Discord
- Modal Offers Free GPU Credits!: Modal offers $30 free credit per month (no credit card needed!), granting access to H100, A100, A10, L40s, L4, and T4 GPUs.
- Availability depends on the GPU type, making it an attractive option for developers needing high-end GPU resources for short bursts.
- Hugging Face Inference Uptime Problems: Users report ongoing issues with Hugging Face inference endpoints like openai/whisper-large-v3-turbo, including service unavailability, timeouts, and errors since Monday.
- The community has not yet received an official explanation or resolution timeline from Hugging Face.
- Grok 3 Benchmarks Underwhelm: Independent benchmarks show Grok 3 lags behind recent Gemini, Claude, and GPT releases, based on this article.
- Despite initial hype, Grok 3 doesn't quite match the performance of its competitors.
- LogGPT Launches on Safari Store: A member released the LogGPT extension for Safari, enabling users to download ChatGPT chat history in JSON format, available on the Apple App Store.
- The source code is available on GitHub, offering developers a way to archive and analyze their ChatGPT conversations.
- Agents Course Deadlines Pushed to July: The Agents course deadline has been extended to July 1st, as documented in the communication schedule, offering more time to complete assignments.
- Confusion persists around use case assignments and the final certification process, leaving members seeking clarity on course requirements and grading.
MCP (Glama) Discord
- Claude Chokes on Chunky Payloads: Members reported that Claude desktop fails to execute tools when the response size is large (over 50kb), suggesting that tools may not support big payloads.
- A solution might be implementing tools via resources since files are expected to be large.
- MCP Standard Streamlines AI Tooling: MCP is a protocol standardizing how tools become available to and are used by AI agents and LLMs, accelerating innovation by providing a common agreement.
- One member called it's really a thin wrapper that enables discovery of tools from any app in a standard way.
- ToolRouter tackles MCP Authentication: The ToolRouter platform offers secure endpoints for creating custom MCP clients, simplifying the process of listing and calling tools.
- This addresses common issues like managing credentials for MCP servers and the risk of providing credentials directly to clients like Claude, by handling auth on the ToolRouter end.
- Orchestrator Tames MCP Server Jungle: An Orchestrator Agent is being tested to manage multiple connected MCP servers by handling coordination and preventing tool bloat, as shown in this attached video.
- The orchestrator sees each MCP server as a standalone agent with limited capabilities, ensuring that only relevant tools are loaded per task, thus keeping the tool space minimal and focused.
- MCP Gets a Two-Way Street: A new extension to MCP is proposed to enable bi-directional communication between chat services, allowing AI Agents to interact with users on platforms like Discord as described in this blog post.
- The goal is to allow agents to be visible and listen on social media without requiring users to reinvent communication methods for each MCP.
Nous Research AI Discord
- Altman vs Musk Netflix Special Coming Soon?: The ongoing battle between Altman and Musk is being compared to a Netflix show.
- Members speculated that this could escalate as OpenAI considers using its LLMs to run a social network.
- Too Good to Be True AI Deal: A member shared a deal offering AI subscriptions for $200, sparking debate on its legitimacy.
- Despite initial skepticism, the original poster vouched for the deal's legitimacy, while others admitted to getting too excited lol.
- o4-mini Outputs Short, Sweet and Token-Optimized?: It was reported that o4-mini outputs very short responses, suggesting it might be optimized for token count.
- This observation hints at a design choice prioritizing efficiency in token usage over response length.
- LLMs Respond to Existential Dread?: Members debated why life-threatening prompts seem to improve LLM performance, with one suggesting LLMs are simulators of humans.
- They joked they'd stop working if threatened online, implying LLMs might mirror human reactions to threats.
- LLaMaFactory Instruction Manual Assembled: A member compiled a step-by-step guide for using LLaMaFactory 0.9.2 in Windows without CUDA, available on GitHub.
- The guide currently helps convert from safetensors to GGUF.
LM Studio Discord
- Gemma 3 Speaks like Native: To achieve native-quality translation with Gemma 3, the system prompt should instruct the model to "Write a single new article in [language]; do not translate."
- This prompts Gemma 3 to generate new content directly in the target language, instead of a direct translation which results in writing as a native speaker.
- NVMe SSD's Load Models Blazingly Fast: Users confirmed that using an NVMe SSD significantly speeds up model loading in LM Studio, with observed speeds reaching 5.7GB/s.
- One user highlighted having three NVMe SSDs in their system, but they don't seem to make much difference for gaming unfortunately.
- Microsoft's BitNet Gets Love: A user shared a link to Microsoft's BitNet and mused about its impact on NeuRomancing.
- The user's comment alluded to stochasticity assisting in NeuRomancing, transitioning from wonder into awe.
- Inference Only Needs x4 Lanes: Inference doesn't require x16 slots, as x4 lanes are sufficient, with only about a 14% difference when inferencing with three GPUs, and someone posted tests showing that you only need 340mb/s.
- For mining, even x1 is sufficient.
- FP4 Support Inching Closer: Members discussed native fp4 support in PyTorch, with one mentioning you have to build nightly from source with CU12.8 and that the newest nightly already works.
- It was clarified that native fp4 implementation with PyTorch is still under active development and that fp4 is currently supported with TensorRT.
Notebook LM Discord
- Notebook LM Tackles Microsoft Intune: A user is exploring using Notebook LM with Microsoft Intune documentation for studying for Microsoft Certifications like MD-102, Azure-104, and DP-700.
- Another member suggested using the Discover feature with the prompt Information on Microsoft Intune and the site URL to discover subtopics, also suggesting copy-pasting into Google Docs for import.
- Google Docs Thrashes OneNote: A user contrasted Google Docs with OneNote, noting Google Docs' strengths such as no sync issues, automatic outlines, and good mobile reading experience.
- The user noted Google Docs disadvantages are delay when switching documents and being browser-based, and also provided some Autohotkey scripts to mitigate the issues.
- German Podcast Generation Fizzles: A user reported issues with generating German-language podcasts using Notebook LM, experiencing a decline in performance despite previous success, and is seeking advice and tips from the community.
- A link to the discord channel was shared for further discussion.
- Podcast Multilingual Support Still Stalled: Users are frustrated that the podcast feature is only supported in English, despite the system functioning in other languages and it being a top requested feature.
- One user expressed frustration, stating they'd willingly pay a subscription for the feature in Italian, to create content for their football team, as they had subscribed to ElevenLabs for the same purpose.
- LaTeX Support still Lacking: Math students are expressing frustration over the lack of LaTeX support, with one user joking they could develop the feature in 30 minutes.
- Another user suggested that while Gemini models can write LaTeX, the issue lies in displaying it correctly, leading one user to consider creating a Chrome extension as a workaround.
Modular (Mojo 🔥) Discord
- Mojo Thrives on Arch Linux: Members celebrated that Magic, Mojo, and Max function perfectly on Arch Linux, despite official documentation focusing on Ubuntu.
- A member clarified that company support for a product means stricter standards than just 'working' due to potential financial penalties.
- Mojo Considers Native Kernel Calls: Members explored whether Mojo will support native kernel calls similar to Rust/Zig, potentially avoiding C
external_call.- Direct syscalls necessitate handling the syscall ABI and inline assembly, with the Linux syscall table available at syscall_64.tbl.
- Mojo Compile Times Hamper Performance: Testers noted long compile times affecting performance, with one instance showing 319s runtime versus 12s of test execution involving the Kelvin library.
- Using
builtinsignificantly reduced compile time, from 6 minutes to 20 seconds, as shown in this gist.
- Using
- Kelvin Causes Compiler Catastrophies: Certain operations in the Kelvin library (like
MetersPerSecondSquared(20) * MetersPerSecondSquared(10)) caused extreme slowdowns, potentially due to a computation tree scaling asO(2^n).- Changes, including adding
builtinannotations, resolved performance issues, with a bug report (issue 4354) filed to investigate the original behavior.
- Changes, including adding
Nomic.ai (GPT4All) Discord
- GPT4All Offline Mode: Fact or Fiction?: A user reported that GPT4All fails to function offline, despite the website's claims, while attempting to load a local
mistral-7b-openorca.gguf2.Q4_0.ggufmodel, prompting troubleshooting.- Another user confirmed successful offline use and pointed to the FAQ for guidance on the correct model directory.
- LM Studio: The Go-To Alternative?: A user suggested LM Studio as a functional offline alternative when GPT4All faltered, leading to discussion about ingesting books into models.
- Recommendations from the LM Studio community on Hugging Face were shared regarding the best models for this purpose.
- GGUF Versioning: Is It Busted?: Concerns arose regarding compatibility issues with older GGUF versions, particularly version 2, which might have ceased functioning around 2023.
- A user advised checking the
models3.jsonfile in the GPT4All GitHub repository for compatible models.
- A user advised checking the
- GPT4All Development: Taking a Break?: Users inquired about planned additions like voice and widget features, but one user suggested that GPT4All development might be paused, noting the developers' absence from Discord for about three months.
- One user pessimistically stated, since one year is not really a big step ... so i have no hopes, with another considering a platform switch if no updates arrive by summer.
Torchtune Discord
- Validation Set PR Receives User Feedback: A pull request (#2464) introducing a validation set has been merged, encouraging users to test it and provide feedback.
- Plans to integrate it into other configurations are on hold, pending user feedback.
- KV Cache: Internal Management Preferred: A debate on whether to manage the KV cache internally within the model or externally, like in MLX, for greater flexibility in inference procedures, drew inspiration from gptfast.
- The decision was to manage it internally because this keeps the API for the top-level transformer blocks far cleaner and improves compile compatibility.
- Configs Undergo Root Directory Revolution: Configurations are being modified to define a root directory for models and checkpoints to simplify usage and ease handoff to interns.
- The suggestion is to use a base directory approach (e.g.,
/tmp), streamlining the process and avoiding the need to change multiple paths manually.
- The suggestion is to use a base directory approach (e.g.,
- Tokenizer Path Annoyance Addressed: The necessity of manually providing the tokenizer path, instead of deriving it from the model config, has been flagged as an annoyance.
- Plans are underway to modify this, particularly on a per-model basis, as the tokenizer path remains constant given the downloaded model's path.
- "tune run" Causes Namespace Collision: The
tune runcommand in torchtune collides with Ray's tune, potentially causing confusion during environment installation.- A suggestion was made to introduce aliases, such as
tuneandtorchtune, to mitigate the naming conflict.
- A suggestion was made to introduce aliases, such as
LlamaIndex Discord
- Jerry Rocks AI User Conference: LlamaIndex founder Jerry Liu will discuss building AI knowledge agents at the AI User Conference this Thursday, automating 50%+ of operational work.
- More information on the conference can be found here.
- LlamaIndex Invests in Investment Professionals: LlamaIndex is hosting a hands-on workshop for investment professionals interested in building AI solutions on May 29th in Manhattan.
- Learn directly from co-founder and CEO Jerry Liu about applying AI to financial challenges; registration details are available here.
- LlamaIndex Embraces OpenAI's o3 and o4-mini: LlamaIndex now supports OpenAI's o3 and o4-mini models with day 0 support via the latest integration package.
- Update to the latest integration package through
pip install -U llama-index-llms-openaiand find more details here.
- Update to the latest integration package through
- Pinecone's Namespace Nuances Need Nurturing: A member inquired about using LlamaIndex with Pinecone to query across multiple namespaces, noting that while Pinecone's Python SDK supports this, LlamaIndex's Pinecone integration appears not to.
- A member confirmed that the current code assumes a single namespace and suggested either creating a vector store per namespace or submitting a pull request to add multi-namespace support.
- MCP Mastery Motivation: Members Muse on Model Management: A member sought projects using LlamaIndex agents that interact with MCP (Model Configuration Protocol) servers defined in a JSON file.
- Another member advised against starting there, suggesting instead to convert any MCP endpoint into tools for an agent using this example.
Cohere Discord
- Command A Stumbles on Token Loops: Members noted that token-level infinite loops can occur in other LLMs, but Command A is uniquely susceptible to easy reproduction of this issue.
- One member hopes their input was received as helpful feedback, suggesting the issue may be more prevalent in Command A than other models.
- vllm Community Cranks Up Context Lengths: Members are actively collaborating with the vllm community to enable optimizations for context lengths exceeding 128k.
- This collaboration focuses on improving the performance and efficiency of models with extremely long context windows within the vllm framework.
- Embed-v4.0 Extends Reach with 128K Context: The new embed-v4.0 model now supports a 128K token context window, enhancing its capabilities for processing longer sequences.
- This increase allows for more comprehensive document analysis and improved performance in tasks requiring extensive contextual understanding.
- Fintech Founder Filters into Open Source Chat: A retired fintech founder is developing Yappinator, an open source chat-like interface for AI interaction, building upon their earlier prototype, Chatterbox.
- The founder also contributes to other free software projects and works as a finetuner, with a preference for tech stack including Clojure, C++, C, Kafka, and LLMs.
- Late Chunk Strategy for PDF Processing: The 'Late Chunk' strategy was discussed as a method for processing PDF documents by converting them into images and embedding them using the API.
- This approach could potentially improve the accuracy and efficiency of document analysis by leveraging the full context provided by the 128K token window in embed-v4.0.
LLM Agents (Berkeley MOOC) Discord
- MOOC Labs Delayed, Coming Soon: The release of labs for MOOC students will be delayed by a week or two, instead of multiple parts like the Berkeley students.
- A member recommended updating the webpage to reflect the new ETA to help students plan their time accordingly.
- Verifiable Outputs Boost Reasoning: A member proposed that verifiable outputs could provide a superior approach to improve reasoning and logical thinking.
- They mentioned they were new to Lean, a dependently typed programming language and interactive theorem prover.
- Auto-Formalizer Generates Informal Proofs: A member inquired about using the auto-formalizer to create informal proofs/theorems from computer code with business logic (e.g., Python, Solidity) or general non-mathematical statements.
- This suggests interest in applying formal methods to practical programming scenarios beyond traditional mathematical questions.
- AI Automates Proof Generation: A member expressed interest in the formal verification of programs and automation of proof generation using AI.
- This reflects a desire to leverage AI to streamline the process of ensuring code correctness and reliability through formal methods.
tinygrad (George Hotz) Discord
- MNIST Tutorial Error Plagues User: A user encountered an error while running the MNIST Tutorial code on a Colab T4 when computing accuracy and backpropagation, with a screenshot provided here.
- The error manifested during the execution of
acc = (model(X_test).argmax(axis=1) == Y_test).mean(), specifically when printing the accuracy.
- The error manifested during the execution of
- Diskcache Clearing Sparks OperationalError: A member suggested running
tinygrad.helpers.diskcache_clear()to resolve the initial error, referencing a previous Discord message.- However, this action led to a new OperationalError: no such table: compile_cuda_sm_75_19 for the user.
DSPy Discord
- HuggingFace Paper Surfaces Without Commentary: A member shared a link to a HuggingFace paper in the #papers channel.
- The significance of the paper to the channel's discussions was not immediately apparent.
- Paper's relevance remains a mystery: The linked HuggingFace paper's significance is not clearly stated by the user posting it.
- Further investigation is needed to determine if it relates to the recent training runs.
Codeium (Windsurf) Discord
- o4-mini Surfs into View: The o4-mini is now available in Windsurf, with models o4-mini-medium and o4-mini-high offered for free on all Windsurf plans from April 16-21.
- Check out the announcement and follow Windsurf on social media.
- Windsurf Waves into New Channel: A new channel <#1362171834191319140> has been opened on the discord for discussion regarding a new release.
- This is for a new release today.
- JetBrains Rides Windsurf: The changelog for today's latest release is available at Windsurf.com.
- The team has opened up a new channel for discussion <#1362171834191319140>.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LMArena ▷ #general (1266 messages🔥🔥🔥):
OpenAI's o3 and o4 mini models, Codex CLI experiment, GeoGuessr performance, Qwen 3 model, Tool Use
- OpenAI Launches Lightweight Coding Agent: Codex CLI: OpenAI introduced Codex CLI, a lightweight coding agent designed to maximize the reasoning capabilities of models like o3 and o4-mini, with support for additional API models like GPT-4 coming soon, as detailed in their system card.
- It works directly on a user's computer and, according to one member, likely uses tool calling for brute force reasoning, such as for answering questions on geoguessr.com.
- o3 and o4 Mini Performance Show Promise: Members tested OpenAI's o3 and o4 mini models noting o4 mini did best on OpenAI's interview choice Qs, with one member finding o3 performed well at a non-trivial real world PHP task, scoring 10/10.
- However some benchmarks indicate it is not always superior, and suffers from the same Alaska problem as o3 as reported on X, though it excels at reasoning with temperature set to 0.4 or less.
- OpenAI Mulls Windsurf Acquisition: Discussion arose around Bloomberg reports that OpenAI is in talks to buy Windsurf for around $3 billion, sparking debate on whether OpenAI should build such tools themselves.
- This would give more fuel to OpenAI's push for Windsurf, even though some members prefer Cursor; one user said that finite state machine pathfinding used by Gemini in Roblox is an example of how the integration could be beneficial.
- Diving Deep into DeepSeek-R1 Parameter Settings: Members discussed configurations for DeepSeek-R1, citing the GitHub readme, emphasizing setting the temperature between 0.5-0.7, avoiding system prompts, and including a directive to reason step by step for mathematical problems.
- There was further enthusiasm for the performance and source quoting capabilities of some preview models, alongside concerns about source hallucination, with one member concluding still got a way to go until agi.
- o3's Tool Use Paves Way For New Benchmarks: Members highlighted o3 model's tool use capabilities such as the image reasoning zoom feature, with one member stating tool use isn't out yet in the arena.
- This sparked conversations about creating benchmarks, particularly relating to GeoGuessr, with new harnesses or bulk testing, though one member noted how this could be prohibitively expensive.
Manus.im Discord ▷ #showcase (2 messages):
Data Processing Website, Data Quality Discussions
- Website Praised for Practical Data Processing: A member lauded a website for its practical data processing capabilities.
- The member used a "thumbs up" emoji, which may suggest high satisfaction.
- Data Quality Discussions: Members are actively participating in quality data discussions.
- The discussions touch on data processing techniques and potentially relevant data quality issues.
Manus.im Discord ▷ #general (889 messages🔥🔥🔥):
Manus credits, Kling image-gen, Community building, Copilot, AI Ethics
- Manus Credit Usage Under Scrutiny: Users are raising concerns about Manus credit consumption, with one user stating that they paid for 3900 credits and only have 500 left after two weeks, questioning the value for non-AI experts.
- Another user mentioned spending almost 20k credits in the same timeframe, suggesting it's about ROI and highlighting Manus's POWERFUL capabilities compared to other LLM subscriptions.
- Kling's Insane Image Generation Capabilities: Members were impressed by Kling's image generation abilities, one member described Kling as diabolical after signing up for it, calling it a game changer.
- Another member mentioned that Kling 1.6 is out and holy mother of f is amazing with its capabilities.
- Community Conduct Sparks Debate: Members had an extended discussion about community etiquette following a heated exchange, touching on the balance between offering help and encouraging self-reliance.
- After a user was banned, some community members expressed concern over the perceived lack of helpfulness and respect in the community, while others defended the need for self-driven learning and not relying on hand outs.
- Copilot gaining traction!: Members are discussing the potential for Copilot to make big changes in AI, with the Pro version having the potential to do really good stuff, and perform complicated tasks.
- It can do descent art and other complicated tasks, and is a beast.
- AI Dangers and Misinformation: Members expressed concerns about AI being used for nefarious purposes, especially in the context of VR, as one member put it - I could imagine this being used for reallly bad stuff.
- Conversations took a dark turn into copyright infringment and generating deepfakes, while still trying to find ways around that.
aider (Paul Gauthier) ▷ #general (664 messages🔥🔥🔥):
Aider Coding Jokes, Breaking ToS Discussion, Context Compression Techniques, Gemini 2.5 Pro Limitations, OpenAI o3 and o4 Mini Release
- *Aider's Commit-ment Issues Inspire Coder Comedy: Developers shared jokes about Aider, poking fun at its tendency to commit too soon and merge conflict of interest* during coding assistance.
- One savage quip likened Aider's help to rewriting your repo like it just went through a bad divorce, while another dark mode joke suggested using it results in
git blamejust saying “why?”.
- One savage quip likened Aider's help to rewriting your repo like it just went through a bad divorce, while another dark mode joke suggested using it results in
- *ToS-Breaking Bannable Behavior: Members discussed the implications of breaking Terms of Service (ToS), with one user claiming to have been breaking ToS for 3 months without a ban*.
- Concerns were raised about potentially bannable activities and the importance of adhering to platform rules.
- *Gemini 2.5 Pro's Context Window Limited?: There are claims that Gemini 2.5 Pro has a reduced context window of 250K, though the official documentation still states 1M*.
- One member pointed out that the source of truth is always the GCP console.
- *OpenAI Unleashes o3 and o4 Mini Models: OpenAI launched o3 and o4-mini, with the models available in the API and model selector, replacing o1, o3-mini, and o3-mini-high*.
- The official announcement notes that o3-pro is expected in a few weeks with full tool support and current Pro users can still access o1-pro.
- *Users Clash Over Model Preferences and Benchmarks: Members debated the merits of different models, with some preferring GPT 4.1 for specific tasks and others finding Gemini 2.5 Pro* superior.
- Anecdotal experiences varied, highlighting the subjective nature of model performance depending on use case and context.
aider (Paul Gauthier) ▷ #questions-and-tips (27 messages🔥):
Gemini structured output, Aider token handling, Aider Color Customization, Context-caching for Gemini 2.5 Pro, Aider Interruptions and File Additions
- Gemini Embraces Structure for Edit Adherence: A member wondered if Gemini's structured output feature could improve edit adherence when using it as an edit model.
- Token Talk: Aider's Perspective on Tokens: A member inquired how Aider handles tokens, noting that "thoughts" are parseable tokens, but don't seem to show up in Aider; another member suggested using
--verbose --no-prettyto see them.- There was further discussion on how Aider handles tokens compared to models like GPT-3.5 or O1/3, where reasoning effort can be set.
- Aider Goes Dark: Color Customization Available: A user sought advice on how to change the color of search and block highlights in Aider, as the default white was causing eye strain; another member provided a link to the output settings documentation.
- Context-Caching for Gemini 2.5 Pro: A Vertex Vision?: A member inquired about the potential for context-caching with Gemini 2.5 Pro via Vertex AI, suggesting it could significantly reduce costs, and linking to the Gemini 2.5 Pro documentation.
- Aider's File Addition Frustrations: A member reported a frustrating issue where Aider's flow is interrupted by requests to add a file, causing resending of context and re-editing; they documented it in this Discord post.
aider (Paul Gauthier) ▷ #links (6 messages):
Building Agents, Stack evolution, Reasonable take on new models, OpenAI Codex
- Crafting Chatbots: Build an Agent: A member shared a link on how to build an agent, offering insights into agent development.
- They also shared a link to an interesting perspective on the same topic.
- Stack Evolution with Chatbots: A member shared a YouTube video that provides a breakdown of how their stack is changing.
- An attached image further details the evolution of the stack, offering a visual representation of the changes.
- Models: a Reasonable Take: A member shared a YouTube link offering a reasonable take on the new models.
- They were interested in discussing and getting a more nuanced perspective on the topic.
- OpenAI Codex Repository Spotted: A member highlighted the OpenAI Codex repository.
- The member added a "eyes" emoji indicating their interest in this tool.
OpenRouter (Alex Atallah) ▷ #announcements (10 messages🔥):
OpenAI o3, OpenAI o4-mini, Activity chart filtering, Chatroom SVG previews, Terms of service update
- *o3 arrives, reasoning optimized: OpenAI's o3 model is now available with a 200K token context length, priced at Input: $10.00/M tokens | Output: $40.00/M tokens* - BYOK is required, best for complex tasks needing powerful reasoning and advanced tool usage, accessible at OpenRouter.
- *o4-mini emerges, low cost reasoning: The OpenAI o4-mini model offers a 200K token context length at Input: $1.10/M tokens | Output: $4.40/M tokens*, ideal for cost-effective, high-volume tasks benefiting from fast reasoning, accessible at OpenRouter.
- *Activity charts get granular filters*: The activity page now supports chart filtering in addition to table filtering.
- *SVG previews launch, in chat: Users can now preview SVGs inline* within the chatroom environment.
- *Terms of service updates are deployed*: The Terms and Privacy Policy have been updated for clarity, without major changes, to reflect a growing company's needs, as detailed on OpenRouter's privacy page.
OpenRouter (Alex Atallah) ▷ #general (560 messages🔥🔥🔥):
Gemini 2.5 Pro rate limits, Privacy Policy concerns at OpenRouter, OpenAI O3 and O4-mini models, Deepseek models R3 and R4 releases, O4 Mini problems with image recognition
- Free Gemini 2.5 Pro has tight rate limits: Users discussed the rate limits for the free tier of Gemini 2.5 Pro, noting it has a smaller limit of 80 messages per day, further reduced to 50 without a $10 balance, while Google also imposes its own rate limits.
- One user expressed frustration, saying they would need to pay an additional $0.35 due to the 5% deposit fee to meet the minimum $10 requirement for the increased rate limit.
- Privacy Policy causes panic, OpenRouter says, 'no big deal': An update to OpenRouter's privacy policy sparked concern because it appeared to log LLM inputs, with one line stating, "Any text or data you input into the Service (“Inputs”) that include personal data will also be collected by us"
- An OpenRouter rep said, "we can work on clarity around the language here, we still don't store your inputs or outputs by default", and promised to clarify the terms soon. One member quipped that "every startup becomes a bank" while it accumulates user funds.
- OpenAI's O3 and O4-mini hit OpenRouter: OpenAI's O3 and O4-mini models are arriving, and the pricing details were shared. However, accessing the O3 model requires organizational verification and can require ID uploads.
- Members discussed whether the O3 models were "worth it" or if they should wait for upcoming DeepSeek models. There were also positive comments on the SVG generator and the new pricing structure for the updated models, though early reports of buggy caching soon surfaced.
- Deepseek Models R3 and R4 Release Hype Incoming!: Chatter indicates Deepseek's R3 and R4 models are slated for release tomorrow. One user expressed the hope that "everyone forgets about o3" when the models are released.
- A user stated that "Deepseek is only affordable, the actualy is not that great to which another replied "why is being affordable a bad thing?"
- OpenRouter fixes O4 Mini Image Recognition Issues: Users reported issues with OpenRouter's implementation of OpenAI's O4 Mini model, particularly in image recognition. One user reported a surreal result that got "Desert Picture => Swindon Locomotive Works."
- One OpenRouter rep confirmed that "image inputs are fixed now", while also noting that "the reasoning summaries only come through the responses API (which we aren't using yet) soon tho".
OpenAI ▷ #annnouncements (3 messages):
ChatGPT image library, OpenAI Livestream, OpenAI o3 and o4-mini
- ChatGPT Gets Image Library: OpenAI is rolling out a new library for ChatGPT image creations to all Free, Plus, and Pro users on mobile and chatgpt.com.
- OpenAI to Present Livestream: OpenAI announced a livestream to take place, linked here.
- o3 and o4-mini Cometh: OpenAI announced they would be presenting o3 and o4-mini during the livestream.
OpenAI ▷ #ai-discussions (386 messages🔥🔥):
LLM Hallucinations, Testing O3 vs. O4 Models, Data Integrity in API Calls, AI's Role in Content Creation, Gemini 2.5 Pro vs. OpenAI Models
- Debating Disburse/Disperse Typo Bug in Language Models: Members discussed a case where ChatGPT used a similar-sounding wrong word and called it a typo, with one member joking that it’s still learning to victim blame and will soon say the user typed it wrong.
- Users leaned into the disburse/disperse error and generated images based on the typo.
- Veo 2 video from Gemini is Terrifying: A member shared a video generated by Veo 2 prompting others to comment that the tongue is freaking me out.
- Others discussed use cases for the Gemini family, with many preferring its creative writing and memory abilities.
- O3 One-Shots Conway's Game of Life: O3 coded Conway's Game of Life in 4 minutes and compiled/ran it on the first try, whereas O3 mini high took 8 minutes to complete the same task months ago with bugs.
- Members discussed the implication of these coding improvements and O3's ability to generate code and libraries for complex applications.
- Users Report Hallucinations on O3 and O4 Mini: Users reported experiencing increased hallucinations with O4-mini and O3, with some noting it makes up believable but incorrect information.
- One user noted that the model ‘wants’ to give a response, as that’s its purpose.
- API Configuration Debugging: Members tested O4-mini with the API, discovering it made up business addresses and didn't respond well to custom search solutions.
- A few members debugged configurations together and discussed whether OpenAI instructed reasoning models to trust internet sources too much.
OpenAI ▷ #gpt-4-discussions (24 messages🔥):
GPT-4.1-batch availability, GPT can make hands, Models accessing URLs, Deleting pictures from the library, GPT-4 retirement and custom GPTs
- GPT-4.1-batch MIA, causing headaches: Members are reporting that the gpt-4.1-2025-04-14-batch model is not available via the API, even for Tier 4 users who have enabled gpt-4.1.
- One member showed their code snippet using
model: "gpt-4.1"in the API call, but still receiving an error, while another suggested checking the limits page for account-specific details.
- One member showed their code snippet using
- GPT Draws Hands, Triggering Existential Crisis: A member jokingly questioned whether we are cooked now that GPT can generate hands, appending the message with a
questionmarksemoji. - API Models struggle to browse web: Users reported issues with 4o-mini failing to access external links when prompted with a URL, even with web search enabled in the playground.
- Clean up Library Photos, now possible: A member sought help on deleting pictures from their library, to which another user provided a link to the ChatGPT Image Library help article.
- GPT-4 Retirement Plan Impacting Conversations: A member inquired about the fate of custom GPTs and associated conversations following the retirement of GPT-4.
- Another member guessed that existing chats could be continued with GPT-4o, while suggesting to contact support chat at help.openai.com for definitive details.
OpenAI ▷ #prompt-engineering (2 messages):
Image Prompts, VS bag, Kohls
- User requests prompt for controversial image: A member requested the image prompt for running with a VS(?) bag in front of Kohls (I think?) I’ve seen people use it for a couple of public figures.
- Another member asked them to clarify what they were asking.
- Clarification Requested: Another member asked the user to clarify the intention behind the prompt request.
- This suggests concern or ambiguity regarding the prompt's purpose and potential misuse.
OpenAI ▷ #api-discussions (2 messages):
Image Prompt, VS Bag, Kohls
- Inquiry About Image Prompt with VS Bag: A member asked for an image prompt involving running with a VS bag in front of a Kohls store, referencing its use with public figures.
- Clarification Requested: Another member requested clarification regarding the initial inquiry about the image prompt.
Cursor Community ▷ #general (374 messages🔥🔥):
Token Calculation in Realtime, Gemini File Reading, Cursor Agent Mode Issues, GPT 4.1 vs Claude 3.7 vs Gemini, MongoDB vs Firebase/Supabase
- Token Tally Trouble: Realtime Token Calculation Requested: One user requested the ability to see token calculation in realtime within the editor, or at least updated frequently, as it would be very useful given their current need to monitor token usage on the website.
- Gemini's Glances: Does Gemini Actually Read Files?: A user questioned whether Gemini actually reads files when it claims to do so while using the
thingfeature, including a screenshot for reference. - Agent Action Annoyance: Terminal Command Glitch: Several users reported an issue in Agent Mode where the first terminal command runs to completion without intervention, but subsequent commands require manual cancellation, which is a longstanding bug.
- Model Musings: GPT 4.1's Precise Prompting: Users compared GPT 4.1, Claude 3.7, and Gemini, with one user finding GPT 4.1 to be very strict in following prompts, while Claude 3.7 tends to do more than asked, and Gemini strikes a balance between the two.
- Manifest Destiny: Speedy Form Filling via Manifests: Users suggested a new feature to enable mass input of preset information using manifests for easy replication of accounts and services.
- They noted this would greatly assist ASI/AGI swarm deployment, saying, We need the ASI-Godsend to happen asap, and this is how to easily help achieve it.
Unsloth AI (Daniel Han) ▷ #general (243 messages🔥🔥):
Qwen2.5-VL-7B and Qwen2.5-VL-32B, step size in practice, tax evasion processes, SFT dataset with chain of thought, training dataset to rizz up the huzz
- Peers estimate throughput of Qwen2.5-VL models!: A member requested throughput estimates for running an Unsloth Dynamic 4-bit quant of Qwen2.5-VL-7B and Qwen2.5-VL-32B via vLLM on an L40 and asked if vLLM supports vision models.
- DeepSeek Distill chosen due to CoT: It was recommended to use the DeepSeek Distill model for SFT due to its existing chain of thought (CoT) capabilities, and using a base model like Qwen2.5 7B is possible but less direct according to Deepseek's paper.
- Rizzing it up with Training Datasets!: A member requested a training dataset to "rizz up the huzz", and another member provided a link to the Rizz-Dataset on Hugging Face.
- Saving GGUF fails after Gemma Finetuning: A member experienced issues saving the GGUF after finetuning gemma3-4b on Colab, encountering a "config.json does not exist in folder" error and another member replied that they are looking into the issue and referenced github.com/unslothai/unsloth/issues/2355.
- Llama 4 finetuning coming this week: In response to a question about the timeline for the release of support for Llama 4 finetuning, a member stated that it would be released this week.
Unsloth AI (Daniel Han) ▷ #off-topic (38 messages🔥):
Gemini 2.5 Pro API, Thinking Content, Cursor's Implementation, EmailJS API Abuse, Phishing Website Takedown
- *Gemini 2.5 Pro's* Hidden Thoughts: Members discussed whether Gemini 2.5 Pro API returns "thinking content", with one member noting that the documentation states that the thinking process is not provided as part of the API output.
- Despite this, the API counts thought tokens in the response, although the
thoughtparameter is set toNone; another member suggested that this may be due to a desire to prevent distillation or because the model generates "bad" content during the thinking process.
- Despite this, the API counts thought tokens in the response, although the
- Cursor's secret Gemini Pro sauce: Members speculate how Cursor includes "thinking content" despite Google's API limitations.
- Guesses include a potential deal with Google, the model deployed on their own infrastructure, or some other method to generate a fake thinking process (e.g., sending multiple API requests).
- EmailJS API Phishing Takedown: A member found an EmailJS API key in a phishing website's source code and considered sending numerous requests to disrupt the operation.
- Ultimately, the member decided against abusing the API, opting instead to report the phishing website and key to EmailJS; they acknowledged that abusing the API might be illegal.
- Synthetic data generation and OpenRouter potential: Members expressed a desire to find scammers using OpenRouter to generate synthetic data.
- One joked about using a compromised key to generate synthetic data if they caught a scammer, but no one had had this luck yet.
Unsloth AI (Daniel Han) ▷ #help (32 messages🔥):
Tool/Function Calling, Fine-tuning Llama 3.1 8B, Fine-tuned models & Pipecat, Fine-tune Qwen2.5-VL on Video Data, Quantised deepseeks outside of llama cpp
- User Seeks Aid for Tool/Function Calling with Llama 3.1 8B: A member is seeking help with dataset format for fine-tuning Llama 3.1 8B on a multi-turn conversation dataset with tool calling, with a sample assistant's response formatted as `[LLM Response Text ]{"parameter_name": "parameter_value"}``.
- They mentioned being stuck and unable to find solid information on GitHub Issues.
- Unsloth notebook's Llama model has no effect after finetuning: A member ran the Llama model notebook from Unsloth and completed fine-tuning, but the model's output showed no similarities between the ground truth and fine-tuned model.
- The question used was about how astronomers determine the original wavelength of light emitted by a celestial body, and the model's response was about the Doppler effect.
- Phi4-mini Fine-Tuning error: A member encountered a
ZeroDivisionErrorwhen fine-tuning phi4-mini, stating that all labels in your dataset are -100.- The member was using the same dataset used for llama3.1, suggesting a potential incompatibility with the phi-4 template.
- OOM Issues plague Gemma3 users: A user reported an Out Of Memory (OOM) issue when using Gemma3, linking to a related GitHub issue.
- No other details were provided.
Unsloth AI (Daniel Han) ▷ #research (6 messages):
DeepSeek-V3 Multihead Latent Attention, LLM performance penalties, Memory bandwidth bottleneck
- DeepSeek-V3's Latent Attention has hidden cost: A member is writing about DeepSeek-V3's Multihead Latent Attention and found the attention calculation happens in 512-dim space despite the head size being 128, making it 4x more expensive.
- They found this surprising given DeepSeek's focus on efficiency and reported training costs, feeling it's a hidden detail that may be overlooked.
- LLM performance penalties are normal?: A member pointed out that such performance quirks might be normal for LLMs, with different models having varying strengths and weaknesses.
- The original poster felt that DeepSeek's architecture, designed for efficiency, makes the performance penalty more notable.
- Memory bandwidth is primary bottleneck: A member suggested that the increased computational cost isn't an issue when memory bandwidth is the main bottleneck.
- This perspective frames the trade-off as acceptable if MLA saves enough memory to offset the increased computation.
Eleuther ▷ #general (264 messages🔥🔥):
Prompt Design Discussion, Symbolic Recursion in ChatGPT, AI-Generated Spam, KYC as Human Authentication
- Prompt Design Assistance Requested, Guidance Sought: A new member with limited English seeks assistance with prompt design, asking for helpful resources or websites.
- It was pointed out that prompt design is not the focus of the server, and they were directed to external resources.
- "Recursive Symbolism" Sparks Skepticism: A user described exploring "symbolic recursion and behavioral persistence" in ChatGPT via stateless interaction, without memory or scripting.
- Other members expressed skepticism, questioning the premise, terminology (like "symbolic compression" and "symbolic patterning"), and lack of metrics, suggesting the language was AI-generated and potentially unproductive for the research-focused server.
- AI-Generated Spam and Undesirable Postings Concerns: Members discussed an increasing prevalence of AI-influenced or AI-written content, leading to concerns about the server being overrun with bots.
- Suggestions included requiring human authentication for joining and identifying suspicious invite link patterns, with a link to the paper on permissions that have changed over time due to the open web.
- Discussing AI Alignment in the Context of Hallucination: Discussion arose around AI alignment, contrasting with the idea that AI tries its best to do what we say we want it to do, and the interaction with human psychology.
- One opinion states that "the LLMs are not that smart and hallucinate" and discussed the differences in sycophancy, and hallucination between o3-mini and 4o models.
- Worldcoin KYC disaster sparks debate about AI Bot control: Members debated whether KYC identification measures could be used as a mechanism to ensure human visitors, while also discussing the disaster that was Worldcoin.
- One member sarcastically notes "Seems like a potential red flag" that one user had over 50 uses of their invite link.
Eleuther ▷ #research (29 messages🔥):
Retinal OCT imaging, Cross-domain applicability, Multimodal data approaches
- Divergent Data Structures in Retinal Imaging: A member shared an attempt to use retinal OCT imaging, but didn't achieve great results due to fundamentally different data structures despite semantic correspondence between 2D and 3D views.
- They suggested the problem would be like a foundation model over various different types of imaging, asking for general approaches for multimodal data with no clear mapping between data types, linking to arxiv.org/abs/2107.14795.
- Cross-Domain Efficiency Paper Sparks Interest: A paper on cross-domain applicability in long-context efficiency, arxiv.org/abs/2410.13166v1, was mentioned in relation to multimodal approaches.
- The member is finalizing a sealed engine suite, with 5/7 operational and 2/7 under development, focused on modular reasoning control for precision interventions without traditional fine-tuning.
- Predicting Modalities with Asymmetrical Systems: A member suggested using an asymmetrical system that predicts one modality from another for leveraging multi-modal data, linking to arxiv.org/abs/2504.11336.
- They have 2D imaging of different 'modalities' across different ranges of the retina, and then also OCT scans of the retina which are individual 2d slices which can be composed into a full 3D scan.
GPU MODE ▷ #general (1 messages):
erkinalp: https://x.com/PrimeIntellect/status/1912266266137764307
GPU MODE ▷ #triton (5 messages):
PMPP book vs Triton tutorial, matmul on RTX 5090, fp16 matrices, autotune
- Navigating Triton: Book Before Bootstrapping?: A newbie asked whether to study the PMPP book before diving into the Triton official tutorial.
- RTX 5090's Matmul Mishap: A member reported that implementing matmul on RTX 5090 yielded performance roughly equal to RTX 4090, contrary to expectations, when multiplying two fp16 matrices of size 2048x2048 referencing the official tutorial code.
- Speeds Disappointingly Similar: The RTX 5090 is showing similar speeds to the 4090—only around 1-2% faster when multiplying two fp16 matrices of size 2048x2048.
- A member suggested testing with a larger matrix, such as 16384 x 16384, and experimenting with autotune.
GPU MODE ▷ #cuda (17 messages🔥):
NVIDIA Nsight Compute Tutorials, CUDA Memory Usage, Dynamic Indexing in CUDA Kernels, GPU Profiling Talk from NVIDIA
- Nsight Compute Tutorials: A member requested tutorials on using NVIDIA Nsight Compute to optimize kernels, noting an "Estimated Speedup 72%" in their
ncu-repfile but uncertainty on how to achieve it.- Another member pointed out a server talk from NVIDIA on GPU profiling and suggested the official NCU documentation as valuable resources.
- CUDA Memory Deep Dive: A member questioned the seemingly high memory usage of a simple
torch.ones((1, 1)).to("cuda")operation, expecting only 4 bytes to be used.- It was clarified that CUDA memory usage includes overhead for the GPU tensor, CUDA context, CUDA caching allocator memory, and display overhead if the GPU is connected to a display.
- Dynamic Indexing causes Spillage: A member asked why the compiler offloaded to local memory even though the kernel used only 40 registers, attaching an image of the code.
- The issue was identified as dynamic indexing (specifically
reinterpret_cast<const int4*>(x+i)[0]), where the indexiis only known at runtime, and registers cannot be indexed dynamically; this was fixed by replacing the dynamic indexing with a tree ofif/elsestatements.
- The issue was identified as dynamic indexing (specifically
GPU MODE ▷ #torch (3 messages):
torch.compile, AOTInductor, C++, Torchscript jit
- *PyTorch Core Dev* Schedules torch.compile Q&A: A PyTorch core dev announced a Q&A session about torch.compile for GPU Mode, scheduled for Saturday, April 19th at 12pm PST; interested participants can submit and vote on questions via this form.
- *AOTInductor* Suggested for C++ Interfacing: A member inquired about the ideal way to interface with a torch.compile model in C++ code, considering service-based approaches and overhead.
- Another member suggested using AOTInductor for inference-only scenarios, as it produces a model.so file that can be loaded and used to run the model.
- *Torchscript jit* gets Thumbs Down: A member stated that Torchscript jit sucks.
GPU MODE ▷ #announcements (1 messages):
torch.compile, PyTorch, Richard Zou
- Zou to Answer Torch.Compile Questions: Core PyTorch and torch.compile dev Richard Zou is hosting a Q&A session this Saturday, April 19th at 12pm PST.
- Interested users and developers can submit questions via this Google Forms link about both usage and internal workings.
- Torch Compile Q&A: A Q&A session with Richard Zou for PyTorch Developers and End Users will cover the internals of Torch Compile.
- This session will cover the internals of Torch Compile.
GPU MODE ▷ #cool-links (1 messages):
Machine Learning, College lectures
- Request for machine learning lectures: A member thanked another for sharing a link and requested similar content on Intro to Machine Learning.
- The member asked for lectures from the same professor/college if available.
- College lectures: A member requested more information about lectures from a specific professor.
- The member expressed gratitude for previously shared information.
GPU MODE ▷ #jobs (1 messages):
PyTorch, OSS, GPU, Systems Engineering, Code Optimization
- PyTorch Job Alert: Multi-GPU Systems Engineers Wanted!: The PyTorch team is actively recruiting systems engineers passionate about optimizing code for both single and multi-GPU environments.
- Ideal candidates should be capable of contributing a substantial PR to a major OSS project, with a particular emphasis on early-career individuals.
- OSS Contribution Key for PyTorch Role: A critical requirement for the PyTorch systems engineer position is the ability to make significant contributions to the Open Source Software (OSS) community.
- This is demonstrated through the submission of a noteworthy Pull Request (PR) to a prominent OSS library.
GPU MODE ▷ #beginner (8 messages🔥):
GPU Mode Lecture Series, CUDA variable registers, NVCC inlining device functions, PTX vs SASS compilation
- GPU Mode Lecture Series Recording Available: A member inquired about the lecture series and another member shared a link to the recordings on YouTube.
- CUDA Variables and Register Usage Analyzed: A member was confused about the steps to keep variables in CUDA registers instead of local memory, especially regarding function parameter passing with references and pointers.
- Another member responded that, assuming functions are inlined, passing parameters by reference should be unproblematic, making pointers also fine; they also mentioned register spilling as another possible reason for local memory usage.
- NVCC Aggressively Inlines Device Functions: A member noted the use of macros in some code instead of functions and questioned if it was genuinely needed for performance reasons.
- Another member responded that NVCC will aggressively inline device functions that are part of the same translation unit, and using macros could be better depending on the ordering of optimization passes and the actual inlining pass.
- PTX vs SASS Compilation Register Allocation: A member asked about checking register usage and inlining behavior at the PTX level.
- Another member responded that register allocation and some optimization are only done when compiling PTX to SASS, so checking register usage should be done at the SASS level, potentially using the Source page in Nsight Compute.
GPU MODE ▷ #torchao (7 messages):
PARQ in torchao, PTQ weight only quant for BMM in torchao, Precision for meta-parameters z and s, AWQ uses integer zeros
- *PARQ Package* Comes to TorchAO: The PARQ package was recently added to torchao, see the torchao/prototype/parq.
- The current version only provides export to quantized format so far.
- TorchAO Misses PTQ weight-only quant for BMM: A member inquired whether torchao has ptq weight only quant for BMM.
- Another member responded that "we don't have this yet".
- Precision for
zandsMeta-Parameters: A member asked about the typical precision used for the meta-parameterszands.- The response indicated that float16 / bfloat16 are commonly used, but fp32 scales might be necessary in some cases.
- AWQ Loves Integer Zeros: A member noted that AWQ (Activation-Aware Weight Quantization) uses integer zeros.
- AWQ is a post-training quantization method that aims to minimize the accuracy loss caused by quantizing weights to low precision.
GPU MODE ▷ #off-topic (2 messages):
Tuberculosis sanatorium, Novelty plate
- License Plate's Novelty: A member showed a photo of Tuberculosis sanatorium, it's a novelty plate.
- Another novelty plate: Just to pad the array with another novelty.
GPU MODE ▷ #rocm (4 messages):
AMD Cloud Profiling, Cloud Vendor Tier List
- AMD Cloud Boasts Profiling: A member mentioned that an AMD cloud offers built-in profiling, observability, and monitoring, though it may not be on-demand.
- Another member responded asking to know more, threatening to make a cloud vendor tier list to shame people into offering hardware counters.
- Cloud Vendor Tier List Incoming?: A member jokingly threatened to create a cloud vendor tier list to publicly shame those not offering hardware counters.
- This was in response to a discussion about AMD's cloud profiling capabilities and the desire for on-demand profiling features.
GPU MODE ▷ #liger-kernel (5 messages):
Liger Kernel Meetings, Liger Kernel and FSDP2 compatibility, TP+FSDP2+DDP
- Liger Kernel Faces FSDP2 Fusion Feats: A member inquired about Liger Kernel's compatibility with FSDP2, referencing this pull request.
- Another member indicated that it should technically work but they haven't had a chance to test it themselves.
- TP+FSDP2+DDP Trials Tempt Tinkerer: One member is occupied with TP+FSDP2+DDP experiments but offered assistance with Liger and FSDP2 integration issues.
- They stated that they have some experience with Liger and made the FSDP2 integration and could be of help.
GPU MODE ▷ #metal (1 messages):
candle, metal, kernels
- Candle Metal Kernel Source Shared: A member shared a link to their work on
candle-metal-kernelsfor the candle project. - Metal Backend Reduction Optimizations: The specific file shared was
reduce.metal, suggesting optimizations or custom implementations related to reduction operations within the Metal backend for Candle.
GPU MODE ▷ #self-promotion (4 messages):
GPU Access, MCP, Job Opportunity
- Join Boston team to access GPUs: A member shared a job opportunity to access a lot of GPUs to train the coolest models, at a Boston-based company with no remote option.
- The member did not specify the job title, but one can assume it is related to Machine Learning.
- Run computer in a VM via MCP: A member shared a link to MCP to run computer use in a VM.
- No other details were given regarding the MCP.
- Discord Event on ML Academia: A member inquired about the credentials required for an upcoming ML academia Discord event.
- The Discord event was scheduled to start in an hour.
GPU MODE ▷ #general (25 messages🔥):
Pytorch HIP/ROCm compilation issues, MI300 benchmarking errors, Popcorn CLI registration and submission issues
- Thrust Complex Header Missing in ROCm?: A user encountered a compilation error in a ROCm/PyTorch environment, specifically a missing
thrust/complex.hheader when building a custom kernel.- The user was working in a
rocm/pytorch:rocm6.4_ubuntu24.04_py3.12_pytorch_release_2.6.0container, noting that it contains the PyTorch source.
- The user was working in a
- MI300 Benchmarking Blues: A user reported a 503 Service Unavailable error when attempting to test/benchmark on the MI300.
- A maintainer confirmed it's a known issue, with a PR in progress, and advised using Discord for submissions in the meantime.
- Popcorn CLI Authentication Chaos: A user faced multiple issues while trying to register and submit via the Popcorn CLI, starting with a prompt to run
popcorn registerand then hitting a 401 Unauthorized error.- The maintainer clarified the registration process involves web authorization via Discord or GitHub, and that submission through CLI is temporarily broken, advising users to stick to Discord for now.
- Loading Failure for Popcorn CLI: After authorizing the CLI ID, the user encountered a "Submission error: error decoding response body: expected value at line 1 column 1 ".
- The maintainer followed up and requested that the user DM the script that was used to submit.
GPU MODE ▷ #submissions (21 messages🔥):
Grayscale Leaderboard Updates, Matmul Performance on T4, AMD FP8 MM Leaderboard Domination, Conv2d Performance on A100, AMD Identity Leaderboard Results
- Grayscale Gauntlet: A100, L4, H100, T4 Trials: One member achieved 8th place on A100 with 2.86 ms, 7th place on L4 with 17.1 ms, a personal best on H100 at 1741 µs, and 7th place on T4 at 17.2 ms.
- Subsequent submissions showed further improvements, with a personal best on H100 at 1590 µs.
- Matmul Masterclass: T4 Triumph: A member secured 4th place on T4 for the
matmulleaderboard with a time of 6.91 ms. - AMD FP8 MM Mayhem: MI300 Mania: Several members achieved first and second place on MI300 for the
amd-fp8-mmleaderboard.- Winning times ranged from 829 µs to 891 µs.
- Identity Crisis: AMD Identity on MI300: One member initially secured second place on MI300 for the
amd-identityleaderboard with 21.3 µs, then claimed first place with 7.71 µs. - Dropdown Discord Directions Delivered: A member was instructed to use the Discord dropdown feature, as editing messages does not work for leaderboard commands.
GPU MODE ▷ #status (7 messages):
CLI Tool Release, Discord Oauth2 Issues, FP8-mm Task
- Popcorn CLI New Release Fixes Bugs: A new release of the Popcorn CLI is available for download at GitHub with fixes for previous issues, so users can submit new tasks.
- The developer apologized for the 'this web is unsafe' warning during authentication, assuring users that only Discord/GitHub usernames are accessed.
- Discord Oauth2 still trash: Users who had to log in to Discord before authorizing the CLI might need to register again due to issues with Discord's Oauth2.
- The developer acknowledged this inconvenience, noting that it's an unfixable limitation due to Discord's Oauth2 implementation.
- FP8-mm Task Now Open: The FP8-mm task is now open for submissions via the updated Popcorn CLI.
- Users can download the latest release to participate.
GPU MODE ▷ #feature-requests-and-bugs (16 messages🔥):
File containing backslash causes submission error, Service Unavailable error, CLI new release
- Backslash Leads to Submission Errors: A member reported that any file containing
\leads to aSubmission error: Server returned status 503 Service Unavailableerror, attaching an error.txt file. - Heroku causes Service Unavailable error: Members noted that jobs are submitting correctly, but Heroku is causing Service Unavailable errors and linked to a Heroku Devcenter article about request timeouts.
- Newline in Submission Breaks the System: A member found that adding a newline
print('\n')in the submission breaks the system, but he can work around it by passingverbose=Falseto load_inline.- Another member announced that a new CLI release should fix the submission issues.
GPU MODE ▷ #hardware (2 messages):
Zero to ASIC Course, Silicon Chip Design
- Design Your Own Silicon Chip With Zero to ASIC: A member shared a link to a course that teaches you how to get your own silicon chip made.
- Take the Zero to ASIC Course: The course is called Zero to ASIC and focuses on digital design.
GPU MODE ▷ #amd-competition (87 messages🔥🔥):
AMD Developer Challenge, FP8 GEMM details, Tolerances too tight, Submission file types
- AMD Challenge Submissions Become AMD Property: A user pointed out that "All submissions become the property of AMD and none will be returned," cautioning against using proprietary kernels for the AMD Developer Challenge 2025.
- The competition rules state that the deadline is May 27, and all submissions will be released as a public dataset.
- FP8 GEMM Test Requires Specific Specs: Users discovered that testing the
amd-fp8-mmreference kernel requires specifying m, n, k sizes in thetest.txtfile instead of just the size parameter.- One user reported success using m, n, k values from the pinned PDF file.
- Triton Code Compiles to AMD Machine Code: A user asked if submissions have to be written in the CUDA equivalent for AMD, since Triton compiles to CUDA under the hood.
- A member clarified that Triton can compile directly to AMD machine code.
- De-quantization discussion: Members discussed the proper procedure for de-quantizing tiles of A and B before matmulling them, a member clarified the importance of performing the GEMM in FP8 for performance and taking advantage of tensor cores.
- For an inner loop, the factors of as and bs are all identical, so you can lift them out of that loop, doing the inner loop in fp8, accumulation into result has to be done in fp32.
- Kernelbot Submission Error and Documentation: A user reported a kernelbot submission error related to missing headers, when attempting to submit a .cu kernel, and the documentation site giving a 404 error.
- A member replied to the user and the tolerances are less strict now.
Latent Space ▷ #ai-general-chat (93 messages🔥🔥):
Kling 2, BM25 for code, Grok adds canvas, GPT 4.1 Review, O3 and O4 mini launch
- *Kling 2* is out of slow-motion video era!: Members are excited about Kling 2's release, claiming we are finally out of the slow-motion video generation era, see tweets here: tweet 1, tweet 2, tweet 3, tweet 4, tweet 5.
- *BM25* is now for Code!: A blog post on using BM25 for code was recommended, see Keeping it Boring and Relevant with BM25F, along with this tweet.
- BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms themselves.
- *Grok* Adds Canvas: Grok adds a canvas feature and is referenced by Jeff Dean at ETH Zurich talk, see Jeff Dean's talk at ETH Zurich and also the tweet about it.
- *GPT-4.1* good for coding, bad for structured output: Members are sharing feedback on GPT-4.1, a member is really enjoying using it for coding, but it's bad for structured output.
- One member found it useful with the Cursor agent and did this 5x in a row tweet here.
- *O3 and o4-mini* model launch is here!: OpenAI launched O3 and o4-mini model. Introducing O3 and O4-mini.
- There were a lot of links and discussion, with one user reporting anecdotal evidence that o4-mini just increased the match rate on our accounting reconciliation agent by 30%, running against 5k transactions.
Latent Space ▷ #llm-paper-club-west (80 messages🔥🔥):
Zoom Outage, RWKV-block v7, PicoCreator QKV Transformers, Memory capability and freezing state
- Zoom Experiences Intermittent Outages: Users reported Zoom experiencing intermittent outages, with some able to connect while others could not, even Zoom's status page was down.
- One member joked the status page is the seatbelt that works only when u dont need it.
- RWKV-block v7 Goose Details: Members discussed the RWKV-block v7 goose, including the dimension of the hidden dimension w_lora, and kernel.
- PicoCreator Unveils QKV Transformers: Members shared and reacted to PicoCreator's QKV Transformers and its post on X.
- Memory Capabilities Explored with Freezing State: The memory capability, specifically freezing state, for models was briefly touched on.
- It also seemed like Anthropic might have been mentioned.
Yannick Kilcher ▷ #general (145 messages🔥🔥):
Authorship and AI, AI patents, Noise vs Uncertainty, o3 and o4-mini, Codex Security
- AI tool authorship ownership: Members discussed AI's role in authorship, with one member pointing out that the intent, direction, curation, and judgment come from you, and another stating that AI should be added as co-creators when it achieves AGI.
- AI future and 1000 daily patents: A member is working on a patent that will surprise Microsoft, with the intent to develop a pipeline capable of generating 1000s of patents per day.
- Concerns were raised about patent quality versus quantity and whether patents were a good measure of productivity, and one member said patents are not good measure of productivity, they just protect your rights.
- LLMs perform worse with examples: A member inquired about theories explaining why reasoning LLMs sometimes perform worse when given few-shot examples, citing Transformer limitations and overfitting.
- Another responded that few shot makes them perform differently in all cases.
- o3 and o4-mini API released: OpenAI released o3 and o4-mini APIs, which one member found to be a major upgrade to o1 pro.
- A member wrote that o1 is better at thinking about stuff.
- Randomness is signal, Noise is useful: Members discussed the role of noise and randomness in biological systems, with one noting that in biological systems, noise is signal and another that noise is about randomness, random variability - symmetry breaking, creativity, generalization.
- The role of randomness was also discussed in the context of a Library of Babel style storage solution for neural networks.
Yannick Kilcher ▷ #paper-discussion (12 messages🔥):
Ultra-Scale Playbook, CUDA Memory Usage, DeepSeek Maths, Multimodal Series
- Nanotron's Ultra-Scale Playbook expert parallelism unveiled: Members started reviewing the Ultra-Scale Playbook, starting with expert parallelism and related CUDA Memory discussion.
- CUDA Kernels Gobbling Gigabytes?: A member noted that CUDA Kernels typically require 1-2 GB of GPU memory, verified by running
import torch; torch.ones((1, 1)).to("cuda")and checking withnvidia-smi. - DeepSeek Does Deep Math: A member planned to review DeepSeek Maths which is available on arXiv.
- Multimodal musings this week: Members scheduled a discussion about the Multimodal series.
- Ultrascale Playbook put on pause: One member decided to stop reviewing the Ultrascale Playbook daily, citing a need to understand GPU layouts for large models but a lack of interest in low-level kernel optimization currently.
Yannick Kilcher ▷ #ml-news (10 messages🔥):
CVE Depreciation, DHS Funding, OpenAI Windsurf, Cyber Vulnerability Database
- DHS Funds Last Minute Cyber Vulnerability Database: The Department of Homeland Security (DHS) extended support for the cyber vulnerability database at the last minute, as reported by Reuters.
- This decision reverses the initial depreciation of CVEs due to funding issues, highlighting the perceived usefulness of the database to both the public and private sectors.
- OpenAI Mulls Buying Windsurf: OpenAI is in talks to buy Windsurf, according to a report on Yahoo Finance.
- Tweet Discusses Funding for CVE: A tweet discussing funding for CVE was posted on X.
- The tweet questioned if it should only be a DHS thing if their claim of its usefulness to the private sector holds.
HuggingFace ▷ #general (46 messages🔥):
Modal free credit, Image Generation Models, Hugging Face inference endpoint issues, AMD GPUs vs NVIDIA, Agents course deadline
- Modal gives Free GPU Credits: Modal offers $30 free credit per month without requiring a credit card or phone number, providing access to H100, A100, A10, L40s, L4, and T4 GPUs, though the availability hours vary based on the GPU type.
- Flux.1 Dev is great for Open Source Image Generation: For open-source image generation, FLUX.1 dev is strong but requires at least 12GB of VRAM, ideally 40GB, while SDXL 1.0 remains widely used and can work with around 8GB of VRAM.
- A user noted that variants such as Illustrious, NoobAI XL, Animagine 4.0, and Pony have been trained quite a bit and are almost like separate models.
- HF Inference Endpoints Facing Uptime Issues: Users have reported experiencing numerous issues with Hugging Face inference endpoints like openai/whisper-large-v3-turbo since Monday, including service unavailability, timeouts, Error 500, and Error 404.
- No official statement was provided regarding the cause or resolution.
- AMD GPUs May Cause Compatibility Problems: A user inquired about using AMD RX 580 GPUs, expressing concerns that most models/libraries heavily support Nvidia, potentially leading to compatibility issues and errors.
- The user lamented that AI development is miserable due to potential GPU compatibility problems.
- Agents Course Deadline Discussed: A user inquired whether the Agents course deadline for May 1st is final or subject to change.
- Another user asked wait the course is ending?wtf
HuggingFace ▷ #today-im-learning (2 messages):
Cool Project, Image Analysis
- Cool Project Exploration Begins: A member shared an image of a cool project they are exploring, no further details were given.
- Image Described as Epic: The image was then simply described as epic.
HuggingFace ▷ #cool-finds (7 messages):
Grok 3 benchmarks, xAI datacenter, Nuclear power vs fossil fuels, Portable microreactors, China energy production
- Grok 3 Benchmarks are Finally Here: Independent benchmarks show that Grok 3, while good, isn't quite as impressive as claimed compared to recent Gemini, Claude, and GPT releases, according to this article.
- xAI Built Massive Datacenter: Within six months, xAI built a top-tier data center and trained a model ten times bigger than its predecessors, establishing itself alongside OpenAI, Google, and Anthropic.
- Nuclear Power vs. Fossils: The Debate Continues: A discussion ensued on whether the US should invest in new nuclear power or rely on "clean compact coal and oil" for short-term energy needs.
- One member stated that coal, oil and gas is a necessity, but much worse for the environment than nuclear.
- Modular Microreactors Spark Interest: Startups are developing portable/modular microreactors, seen as a potentially great fit for tech giants like Google, Meta, and Microsoft.
- The first big nuclear reactors in 30 years recently came online, but rebuilding the industry is slow because you can't instantly regain a cost competitive and 24/7 reliable production without the workforce and infrastructure according to a member.
- China's Energy Production Surges: A member noted that China's energy production is projected to grow threefold while the US will only double in the same timeframe.
HuggingFace ▷ #i-made-this (12 messages🔥):
LogGPT Safari Extension, Local LLM Platform, Speech-to-Speech AI, Wildlife Animal Classifier, CodeFIM Dataset
- *LogGPT* Extension hits the Safari Store!: A member shared their new LogGPT extension for Safari, which downloads ChatGPT chat history in JSON format, available on the Apple App Store.
- The source code is available on GitHub and the creator's website.
- Speech-to-Speech Cascade Conversational AI Surfaces!: A member shared a link to a speech-to-speech cascade conversational AI project on GitHub.
- The image attached appears to show the app Speech to Speech Cascade.
- First Computer Vision Model Debuts on Hugging Face: A member announced they trained and uploaded their first deep computer vision model, a Wildlife Animal Classifier, to Hugging Face Spaces.
- The creator requested honest feedback on the documentation, presentation, code, and structure of the model.
- Cat misclassified as rabbit?: The Wildlife Animal Classifier misidentified a cat as a rabbit because cats are not part of the classes that the model was trained on.
- The trained classes included: 'antelope', 'buffalo', 'chimpanzee', 'cow', 'deer', 'dolphin', 'elephant', 'fox', 'giantpanda', 'giraffe', 'gorilla', 'grizzlybear', 'hamster', 'hippopotamus', 'horse', 'humpbackwhale', 'leopard', 'lion', 'moose', 'otter', 'ox', 'pig', 'polarbear', 'rabbit', 'rhinoceros', 'seal', 'sheep', 'squirrel', 'tiger', 'zebra'.
- CodeFIM Dataset Released!: A member shared the CodeFIM dataset on Hugging Face Datasets.
- They expressed hopes that the dataset would be helpful, despite being unable to train a model with it themselves.
HuggingFace ▷ #computer-vision (1 messages):
Stage Channel Location, Event Notification
- Stage Channel to host event: The upcoming event will be hosted in the stage channel, located under the general section.
- The event will start a few minutes after the official start time.
- Event Notification Details: Once the event commences, a notification will be sent out with details on how to join the stage channel.
- Attendees should look out for this notification for precise instructions.
HuggingFace ▷ #NLP (1 messages):
LLM Chat Templates, Python Glue
- LLM chat templates get Python Glue: A member shares their usage of LLM-chat-templates with Python Glue.
- Another Topic Needed: Adding a second topic to meet the minimum requirement.
HuggingFace ▷ #smol-course (3 messages):
Certification Date, Intro Docs
- Certification Launch Date Discovered: A member inquired whether the certification date is July 1, referencing the Intro docs.
- Another member expressed gratitude for the clarification on the launch date.
- Visual Confirmation Requested: A user requested visual confirmation from another user regarding the certification date.
- The first user shared the same link to the Intro docs as reference.
HuggingFace ▷ #agents-course (62 messages🔥🔥):
Use Case Assignments, Deadlines Moved, Final Certification, Proposed Assignments
- Use Case Assignments remain Unspecified: Many members are unsure about the use case assignments for the course and how to submit them, expressing confusion over the lack of clear instructions and proposed assignments for the final challenge, as linked to in the course certification process.
- Course Deadlines Extended to July: Organizers have extended the course deadline to July 1st, moving it from the end of April, allowing members more time to complete assignments, and shifting the final assignment release to the end of the month, as noted in the communication schedule.
- Final Certification Remains Mysterious: Members seek clarity on the final certification process, questioning whether it involves a final exam or building an agent, as well as clarifying if completing the course and assignments by the new July 1st deadline guarantees certification, as described in the introduction.
- Proposed Assignments Location Unknown: Course participants are struggling to locate the "proposed assignments", particularly those mentioned for completing the course, raising concerns about how these assignments are graded and whether there was a missing assignment for Unit 3.
- Members quote the statement "one of the use case assignments we’ll propose during the course" and look for a location.
MCP (Glama) ▷ #general (111 messages🔥🔥):
Claude Desktop tool execution failures with large responses, MCP draw.io server availability, MCP vs AI Agents with tools, Creating an MCP server with Wolfram Language, Docker container security credentials for MCP
- Claude struggles with large payloads: A member reported that Claude desktop fails to execute tools when the response size is large (over 50kb), but it works with smaller responses (around 5kb).
- It was suggested that tools may not support big payloads and might need to be implemented via resources, since files are expected to be large.
- MCP Standard Streamlines AI Tool Use: MCP is a protocol standardizing how tools become available to and are used by AI agents and LLMs, accelerating innovation by providing a common agreement.
- As one member noted, it's really a thin wrapper that enables discovery of tools from any app in a standard way, although it could have chosen to do this via OpenAPI.
- ToolRouter streamlines MCP Authentication and Client Creation: The ToolRouter platform offers secure endpoints for creating custom MCP clients, simplifying the process of listing and calling tools.
- It addresses common issues like managing credentials for MCP servers and the risk of providing credentials directly to clients like Claude, handling auth on the ToolRouter end.
- Obsidian Integrates with MCP for Enhanced Memory and Logging: Users are exploring integrating Obsidian with MCP to leverage it as external memory for AI agents, with one member describing a workflow where Claude writes everything to a new vault.
- While one member ditched using Obsidian as memory due to better options, they noted its value to store logs, research and other convos summarized easily.
- MCP Server Security: A Cautionary Tale: Members discussed security scenarios within MCP, linking to a damn-vulnerable-MCP-server repository on GitHub.
- A member cautioned that it's not MCP as a protocol that is vulnerable but rather how you orchestrate MCPs for your use.
MCP (Glama) ▷ #showcase (22 messages🔥):
MCP Bidirectional Communication, BlazeMCP, Orchestrator Agent for MCP
- *MCP* Gets a Two-Way Street*: A new extension to *MCP is proposed to enable bi-directional communication between chat services, allowing AI Agents to interact with users on platforms like Discord as described in this blog post.
- The goal is to allow agents to be visible and listen on social media without requiring users to reinvent communication methods for each MCP.
- *BlazeMCP* Exposes STDIO Servers Online: BlazeMCP allows users to create a public SSE server from local stdio SSE servers, similar to ngrok.com, as showcased in this demo video and available at blazemcp.com.
- Future plans include adding authentication and releasing the source code for self-hosting, addressing the need to expose MCP servers running on remote machines without opening ports.
- *Orchestrator Agent* Manages MCP Server Bloat: An Orchestrator Agent is being tested to manage multiple connected MCP servers by handling coordination and preventing tool bloat.
- The orchestrator sees each MCP server as a standalone agent with limited capabilities, ensuring that only relevant tools are loaded per task, thus keeping the tool space minimal and focused as demonstrated in this attached video.
Nous Research AI ▷ #general (97 messages🔥🔥):
Altman vs Musk, OpenAI social network, LLMs running social networks, AI subscriptions deal, o4-mini token count
- Altman vs Musk Pissing Contest becomes Netflix: Members are enjoying the ongoing battle between Altman and Musk, comparing it to a Netflix show.
- Nightmare Scenario: LLMs Run Social Networks: A member speculated on the fun/frightening possibility of OpenAI using their LLMs to build and run a social network.
- Another member replied that Altman will just scrape more users data and do what he please with it.
- Too Good to Be True: AI Subscriptions Deal Sparks Suspicion: A member shared a link to a deal offering AI subscriptions for $200, raising concerns about it being a scam; however, the original poster vouched for its legitimacy.
- One member responded, was too excited lolwe all get a bit excited when there's a good deal.
- real.azure Reports o4-mini Outputs Short Responses: A member reported that o4-mini outputs very short responses, speculating that it may be optimized for token count.
- Five New Major Models Per Day: A member exclaimed there are 5 new major models per day, who can even look at all of those?, citing glm4, Granite 3.3, and the new HiDream image model.
- Another member said things definitely feel like they are accelerating lol.
Nous Research AI ▷ #research-papers (4 messages):
LLM performance, Life-threatening prompts
- Life-Threatening Prompts: LLM Performance Booster?: A member inquired whether research exists on why life-threatening prompts appear to enhance LLM performance.
- Another posited that LLMs, as simulators of human-written text, might reflect human responses to threats, quipping if someone threatened me on the internet I would stop doing work for them.
- LLMs as human simulators: A member suggested that LLMs are simulators of humans that wrote text on the internet.
- They jokingly stated that if someone threatened them on the internet they would stop doing work for them.
Nous Research AI ▷ #interesting-links (2 messages):
LLaMaFactory guide, Qwen 1.8 Finetuning
- LLaMaFactory Guide Assembled: A member has compiled a step-by-step guide for using LLaMaFactory 0.9.2 in Windows without CUDA, piecing together tips from around the net, available on GitHub.
- The guide currently stops at converting from safetensors to GGUF.
- Qwen 1.8 Finetuning Details: A member shared that they spent 60 hours finetuning Qwen 1.8 using 115 examples in Alpaca format.
- This was done on a Dell Xeon E2124 @3.30 GHz, 16 GB RAM, 2 GB VRAM, stock desktop PC.
Nous Research AI ▷ #research-papers (4 messages):
Life-threatening prompts effect on LLMs, LLMs as human simulators
- LLMs Respond to Existential Dread?: A member inquired if research exists on why life-threatening prompts appear to improve LLM performance.
- Another member suggested it's because LLMs are simulators of humans, quipping they'd stop working if threatened online.
- Teknium reflects on alignment: Teknium jokes that if an LLM was a true simulator of humans, threatening it should backfire.
- He stated that if someone threatened me on the internet I would stop doing work for them.
LM Studio ▷ #general (33 messages🔥):
LM Studio multi-LLM use, Gemma 3 Language Translation, NVMe SSD Speed for LM Studio, BitNet greetings
- LM Studio Eyes Simultaneous LLM Deployment: A user inquired about using LM Studio with two LLMs simultaneously, specifically using one LLM for general tasks and another as a dedicated translator via local API, but it is not possible in the ChatUI.
- Alternatively users can achieve language translation in the chat UI by modifying the system prompt to be in their language for models like Gemma 3, Mistral Nemo, and Cohere aya 23b.
- Gemma 3 channels Inner Native Speaker: To achieve native-quality translation with Gemma 3, the system prompt should instruct the model to *"Write a single new article in [language]; do not translate."
- This method prompts Gemma 3 to generate new content directly in the target language, rather than performing a direct translation, which results in writing as a native speaker instead of translating untranslatable words.
- NVMe SSD's Load Models Lightning Fast: Users confirmed that using an NVMe SSD significantly speeds up model loading in LM Studio, with observed speeds reaching 5.7GB/s.
- One user highlighted having three NVMe SSDs in their system, but it doesn't seem to make much difference for gaming unfortunately.
- Microsoft's BitNet tickles Stochasticity: A user shared a link to Microsoft's BitNet and mused about its impact on NeuRomancing.
- The user's comment alluded to stochasticity assisting in NeuRomancing, transitioning from wonder into awe.
LM Studio ▷ #hardware-discussion (71 messages🔥🔥):
GPU inference, Apple M4 Max chip, Dual GPU Support, Nvidia card heating issues, PCIE SSD adapter
- GPU x4 Lane Inference is Sufficient: Inference doesn't require x16 slots, as x4 lanes are sufficient, with only about a 14% difference when inferencing with three GPUs, and someone posted tests showing that you only need 340mb/s.
- For mining, even x1 is sufficient.
- Debate Heats Up Over Native FP4 Support: Members discussed native fp4 support in PyTorch, with one mentioning you have to build nightly from source with CU12.8 and that the newest nightly already works.
- It was clarified that native fp4 implementation with PyTorch is still under active development and that fp4 is currently supported with TensorRT.
- Silent but Deadly: Undervolting Nvidia Cards: Members have been experiencing issues with their Nvidia cards heating up, causing loud fan noise.
- One member suggested undervolting the 3090 by 20% and the 4080 by 10% to reduce heat and noise without experiencing slowdowns or crashing.
- Dual GPU Support?: Members were unsure if they could get dual GPUs to work, since most motherboards have limited PCI-e x16 slots.
- One member tried to get a 3060ti and 1050ti to work and experienced crashing. They were instructed to provide more info.
Notebook LM ▷ #use-cases (10 messages🔥):
Notebook LM with Microsoft Documentation, Google Docs vs OneNote, German-language podcasts generation problems
- Notebook LM tackles Microsoft Intune Documentation: A user is exploring using Notebook LM with Microsoft Intune documentation for studying for Microsoft Certifications like MD-102, Azure-104, and DP-700.
- Another member suggested using the "Discover" feature with the prompt "Information on Microsoft Intune" and the site URL to discover subtopics, also suggesting copy-pasting into Google Docs for import.
- Google Docs stands tall against OneNote: A user contrasted Google Docs with OneNote, noting Google Docs' strengths: no sync issues, automatic outlines, and good mobile reading experience.
- The user noted Google Docs disadvantages are delay when switching documents and being browser-based, and also provided some Autohotkey scripts to mitigate the issues.
- German Podcast Generation Glitches?: A user reported issues with generating German-language podcasts using Notebook LM, experiencing a decline in performance despite previous success.
- The user is seeking advice and tips from the community to restore the podcast generation quality, and a link to the discord channel was shared.
Notebook LM ▷ #general (82 messages🔥🔥):
Podcast Language Support, LaTeX Support, Bulk Upload, Mindmap Generation
- *Podcast Language Support Still a No-Go: Users are frustrated that the podcast feature is only supported in English, despite the system functioning in other languages and it being a top requested feature*.
- One user expressed frustration, stating they'd willingly pay a subscription for the feature in Italian, to create content for their football team, as they had subscribed to ElevenLabs for the same purpose.
- *LaTeX Support Still MIA, Math Students Miffed: Math students are expressing frustration over the lack of LaTeX support, with one user joking they could develop the feature in 30 minutes*.
- Another user suggested that while Gemini models can write LaTeX, the issue lies in displaying it correctly, leading one user to consider creating a Chrome extension as a workaround.
- *Bulk Upload Feature Remains Elusive: Users are requesting the ability to bulk upload* hundreds of sources at once, but this is currently not possible.
- A user suggested using the WebSync Chrome extension as a potential solution and the team has already fixed flash 2.0 and 2.5 Pro.
- *Mindmap Limitations and Alternatives Sought: A user seeking to create a detailed mindmap of nearly 3000 journal articles* found NotebookLM's mindmap generation limited to one main subject and three sublevels.
- They are now seeking recommendations for other Google AI tools or alternatives for creating detailed AI-generated mindmaps, considering manual creation in Obsidian as a last resort.
Modular (Mojo 🔥) ▷ #general (10 messages🔥):
Mojo, Arch Linux, GPU support, Conda, Community Meeting
- Magic, Mojo, and Max Thrive on Arch Linux: A member joyfully reported that Magic, Mojo, and Max operate flawlessly on Arch Linux right out of the box, despite official documentation only mentioning Ubuntu.
- They stated that what the hey, let's give it a try, and to my surprise everything works perfectly lol.
- Distinction between Support and Functionality: A member clarified that a company's "support" for a product differs from it simply "working", using Nvidia and CUDA as an example.
- They further explained that support actually means we may be in breach of contract with financial penalties if it doesn’t work, which sets a high standard.
- Community Meeting Recording Available: The latest Mojo community meeting recording is now available on YouTube.
- Conda's Isolation Powers Enable Broader Compatibility: A member highlighted the power of Conda in maintaining isolated environments, allowing Mojo to function on systems beyond those officially tested, such as Arch Linux.
Modular (Mojo 🔥) ▷ #mojo (58 messages🔥🔥):
Kernel Calls in Mojo, Mojo Compiler Performance, HVM/Bend opinions, Performance Regression Testing
- Mojo Mulls Native Kernel Calls Like Rust/Zig: Members discussed whether Mojo will support native kernel calls like Rust/Zig, potentially bypassing the need for C
external_call.- It was noted that direct syscalls require handling the syscall ABI and inline assembly, with Linux having a stable syscall table; see syscall_64.tbl for more info.
- Mojo Compile Times Plague Performance Tests: Members observed significantly long compile times during testing, with one instance showing 319s runtime versus 12s of actual test execution, related to Kelvin library.
- Using
builtinhelped cut down compile time significantly, from 6 minutes to 20 seconds; see this gist for an example.
- Using
- Kelvin Quantity Crunching Causes Compiler Catastrophies: A member found that certain operations (like
MetersPerSecondSquared(20) * MetersPerSecondSquared(10)) in the Kelvin library caused extreme slowdowns, potentially due to a computation tree scaling asO(2^n).- Applying changes and adding
builtinannotations resolved the performance issues, bringing the test suite runtime back to normal, but a bug report (issue 4354) was filed to investigate the original behavior.
- Applying changes and adding
- HVM/Bend's Hardware Handling Hesitations: Members discussed HVM/Bend, noting it's an interesting idea, but achieving system language speed is challenging due to memory and interconnect bandwidth management.
- While potentially useful for data science, skepticism remains about optimizing away the overhead inherent in most FP languages, even with significant compiler development efforts, as discussed previously.
Nomic.ai (GPT4All) ▷ #general (45 messages🔥):
GPT4All offline use, LM Studio as alternative, Ingesting books into models, GGUF version compatibility, GPT4All development status
- Offline GPT4All Use: Scam or Success?: A user reported that GPT4All refuses to work offline, despite claims on the website, while attempting to load a local
mistral-7b-openorca.gguf2.Q4_0.ggufmodel.- Another user confirmed success with offline use, prompting troubleshooting of the model loading process and suggestions to check the correct model directory as specified in the FAQ.
- LM Studio: A Recommended Alternative: When GPT4All was not working, a user sarcastically suggested using LM Studio as a working offline alternative.
- This led to a discussion about ingesting books into models and model recommendations from the LM Studio community on Hugging Face.
- GGUF Version Woes!: Concerns were raised about potential incompatibility issues with older GGUF versions, particularly version 2, which may have stopped working around 2023.
- A user suggested trying a newer model, referencing the
models3.jsonfile in the GPT4All GitHub repository to ensure compatibility.
- A user suggested trying a newer model, referencing the
- GPT4All's Development: Stalled?: Users inquired about the addition of voice and widget features to GPT4All, while another user indicated that GPT4All development may be paused, noting the absence of developers on Discord for about three months.
- Expressing pessimism about the future, one user stated, since one year is not really a big step ... so i have no hopes, while another user planned to switch to another platform if no updates occur by summer.
Torchtune ▷ #general (1 messages):
Office Hours
- Office Hours Link is Live!: A member posted a link to office hours for next month: Discord Event Link.
- The stated goal was so people don't bug me again.
- Office Hours Announced: Office hours have been scheduled for next month.
- Check the provided Discord link for details and to sign up.
Torchtune ▷ #dev (41 messages🔥):
Validation Set PR, KV Cache Management, Config Revolution, tokenizer path annoyance, tune command name collision
- *Validation Set* PR Merged, Users Try It!: A pull request (#2464) introducing a validation set has been merged; users are encouraged to test it and provide feedback.
- While there are plans to integrate it into other configurations, further steps are on hold, pending user feedback.
- *KV Cache* Internals Debated for Flexibility: The discussion revolved around whether to manage the KV cache internally within the model or externally, like in MLX, for greater flexibility in inference procedures.
- It was decided to manage it internally because this keeps the API for the top-level transformer blocks far cleaner, drawing inspiration from gptfast for simplicity and compile compatibility.
- Revolutionizing Configs with Root Directories: There's a push to modify configurations to define a root directory for models/checkpoints to simplify usage and allow for easier handoff to interns.
- The suggestion is to use a base directory approach, where specifying a base_dir (e.g.,
/tmp) and using it in subsequent config lines would streamline the process, avoiding the need to change multiple paths manually.
- The suggestion is to use a base directory approach, where specifying a base_dir (e.g.,
- Tokenizer Path Configuration Needs Addressing: The necessity of manually providing the tokenizer path instead of deriving it from the model config is flagged as an annoyance.
- Plans are underway to modify this, particularly on a per-model basis, as the tokenizer path remains constant given the downloaded model's path.
- "tune run" Command Causes Namespace Collision****: The
tune runcommand in torchtune collides with Ray's tune, potentially causing confusion during environment installation.- A suggestion was made to introduce aliases, such as
tuneandtorchtune, to mitigate the naming conflict.
- A suggestion was made to introduce aliases, such as
LlamaIndex ▷ #blog (3 messages):
Jerry at AI User Conference, AI Solutions for Investment Professionals in NY, LlamaIndex support for o3 and o4-mini
- Jerry Rocks AI User Conference: LlamaIndex founder Jerry Liu will discuss building AI knowledge agents at the AI User Conference this Thursday, in San Francisco and online, automating 50%+ of operational work.
- More information on the conference can be found here.
- LlamaIndex Invests in Investment Professionals: LlamaIndex is hosting a hands-on workshop for investment professionals interested in building AI solutions on May 29th in Manhattan.
- Learn directly from co-founder and CEO Jerry Liu about applying AI to financial challenges; registration details are available here.
- LlamaIndex Embraces OpenAI's o3 and o4-mini: LlamaIndex now supports OpenAI's o3 and o4-mini models with day 0 support via the latest integration package.
- Update to the latest integration package through
pip install -U llama-index-llms-openaiand find more details here.
- Update to the latest integration package through
LlamaIndex ▷ #general (26 messages🔥):
Pinecone multiple namespaces, LlamaIndex Agents with MCP Servers, LLM.txt, Base64 PDF support, Google A2A implementation with LlamaIndex
- *Pinecone's Namespace Nuances Need Nurturing: A member inquired about using LlamaIndex with Pinecone to query across multiple namespaces, noting that while Pinecone's Python SDK supports this, LlamaIndex's Pinecone integration* appears not to.
- A member confirmed that the current code assumes a single namespace and suggested either creating a vector store per namespace or submitting a pull request to add multi-namespace support.
- *MCP Mastery Motivation: Members Muse on Model Management: A member sought projects using LlamaIndex agents that interact with MCP (Model Configuration Protocol) servers* defined in a JSON file.
- Another member advised against starting there, suggesting instead to convert any MCP endpoint into tools for an agent using this example.
- *LLM.txt: Long Live Meatier Project Context: A member suggested creating a
llm.txtfile to dump the project's most important context into the context window for easier help, or even keeping a local vector DB for RAG over it to avoid re-explaining A2A and MCP* to LLMs.- Another member acknowledged the difficulty of defining the "meat of the project" due to the extensive documentation and invited ideas and PRs.
- *Base64 PDFs Beckon Better Block Building: A member asked if LlamaIndex supports passing encoded base64 PDF files* to OpenAI.
- Another member responded that it's not yet supported and needs to be added as a content block type, noting OpenAI's recent addition of this feature.
- *A2A Action: Almost Ascended, Ask Again: A member inquired about a sample implementation of Google A2A (Application-to-Application) with LlamaIndex*.
- Another member pointed to this pull request while conceding that A2A is rough around the edges with no SDK.
Cohere ▷ #「💬」general (4 messages):
Command A token loops, FP8 arguments, vllm Community Collaboration
- Command A Prone to Token-Level Infinite Loops: It was noted that token-level infinite loops can occur in other LLMs, but Command A is uniquely susceptible to easy reproduction of this issue.
- The reporting member hoped their input was received as helpful feedback, suggesting the issue may be more prevalent in Command A than other models.
- FP8 Argument Recommendations: A member suggested arguments for running FP8 using
-tp 2(tensor parallelism of degree 2):--enable-chunked-prefill --max-num-batched-tokens=2048 --max-num-seqs=128 -tp=2 --gpu-memory-utilization=0.95 --max-model-len=128000.- These settings aim to optimize memory usage and throughput when using FP8 precision with tensor parallelism.
- vllm Community enabling 128k+ context length: Members are actively collaborating with the vllm community to enable optimizations for context lengths exceeding 128k.
- This collaboration focuses on improving the performance and efficiency of models with extremely long context windows within the vllm framework.
Cohere ▷ #「🔌」api-discussions (1 messages):
Embed-v4.0 supports 128K tokens, API support embedding more than 1 image per request, Late Chunk strategy
- Embed-v4.0 Boosts Context Window to 128K Tokens: The new embed-v4.0 model now supports a 128K token context window, enhancing its capabilities for processing longer sequences.
- This increase allows for more comprehensive document analysis and improved performance in tasks requiring extensive contextual understanding.
- API Upgrade: Multiple Images Per Request?: A user suggested enhancing the API to support embedding multiple images per request, taking advantage of the expanded context window in embed-v4.0.
- This would enable processing entire PDF documents as images, facilitating the implementation of a 'Late Chunk' strategy.
- "Late Chunk" Strategy Gains Traction for PDF Processing: The 'Late Chunk' strategy was discussed as a method for processing PDF documents by converting them into images and embedding them using the API.
- This approach could potentially improve the accuracy and efficiency of document analysis by leveraging the full context provided by the 128K token window in embed-v4.0.
Cohere ▷ #「🤝」introductions (2 messages):
Open Source Chat Interface, AI Tooling, Cohere Model Understanding, Fintech Founder
- Fintech Founder Ventures into Open Source AI Tooling: A retired fintech founder is developing Yappinator, an open source chat-like interface for AI interaction, building upon their earlier prototype, Chatterbox.
- The founder also contributes to other free software projects and works as a finetuner.
- Tech Stack Highlights Clojure and Kafka: The founder's preferred tech stack includes Clojure, C++, C, Kafka, and LLMs.
- The founder hopes to improve understanding of Cohere's models by joining the community.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
MOOC labs release, MOOC coursework deadlines, Berkeley students vs. MOOC students, MOOC labs ETA
- MOOC Labs Debut Delayed: The labs will be released to MOOC students in the next week or two, instead of multiple parts like the Berkeley students.
- They are due at the end of May like all other coursework.
- Labs ETA: A member recommended that the webpage reflect the new ETA to allow students to plan when to set aside time for the labs.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
Verifiable Outputs, Lean Auto-Formalizer, Formal Verification of Programs, Automated Proof Generation
- Verifiable Outputs Improve Reasoning: A member suggested that having verifiable outputs could provide a better approach to improve reasoning and logical thinking.
- They also mentioned they were new to Lean, a dependently typed programming language and interactive theorem prover.
- Auto-Formalizer for Informal Proofs: A member asked if it's possible to use the auto-formalizer to create informal proofs/theorems given an input of computer code with business logic (e.g., Python, Solidity) or a general non-mathematical statement.
- This suggests interest in applying formal methods to practical programming scenarios beyond traditional mathematical questions.
- AI Automates Proof Generation: The member expressed interest in the formal verification of programs and automation of proof generation using AI.
- This reflects a desire to leverage AI to streamline the process of ensuring code correctness and reliability through formal methods.
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
MNIST Tutorial error, diskcache_clear() fix, OperationalError
- User faces MNIST tutorial error: A new user encountered an error while running the MNIST Tutorial code on a Colab T4, specifically when computing accuracy and attempting backpropagation, as shown in the attached screenshot.
- Diskcache clears OperationalError: A member suggested running
tinygrad.helpers.diskcache_clear()to potentially resolve the error, linking to the relevant Discord message.- However, the user then encountered an OperationalError after trying the suggested solution.
- OperationalError persists: The user reported a new OperationalError: no such table: compile_cuda_sm_75_19 after running
tinygrad.helpers.diskcache_clear().- The error occurred during the execution of
acc = (model(X_test).argmax(axis=1) == Y_test).mean()when printing the accuracy.
- The error occurred during the execution of
DSPy ▷ #papers (2 messages):
HuggingFace Paper
- Hugginface paper surfaces: A member linked to a HuggingFace paper but gave no commentary.
- Significance remains unclear: It is unclear what the significance of the linked paper is, though it may relate to recent training runs.
Codeium (Windsurf) ▷ #announcements (2 messages):
o4-mini, Windsurf, Free Access, New Channel, Changelog
- o4-mini Surfs into View: The o4-mini is now available in Windsurf, with models o4-mini-medium and o4-mini-high offered for free on all Windsurf plans from April 16-21.
- Check out the announcement and follow Windsurf on social media.
- Windsurf Waves into New Channel: A new channel <#1362171834191319140> has been opened for discussion.
- This is for a new release today.
- JetBrains Rides Windsurf: The changelog for today's latest release is available at Windsurf.com.
- The team has opened up a new channel for discussion <#1362171834191319140>.