[AINews] OpenAI launches Operator, its first Agent
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
A virtual browser is all you need.
AI News for 1/22/2025-1/23/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 4386 messages) for you. Estimated reading time saved (at 200wpm): 483 minutes. You can now tag @smol_ai for AINews discussions!
As widely rumored, OpenAI launched their computer use agent, 3 months after Anthropic's equivalent:
- live today for Pro users in the US
- notably NOT just an open source demo like Anthropic, but a hosted, premium product with an API promised
- Some folks had early access
- Has video export
- Lots of misclicks, but does self correct
- Long horizon, remote VMs up to 20 minutes
- Many clones/alternatives from LangChain, smooth operator
- the separate evals notes show how Operator is a SOTA agent, but still not quite at human level. Exhibits a test time scaling curve:
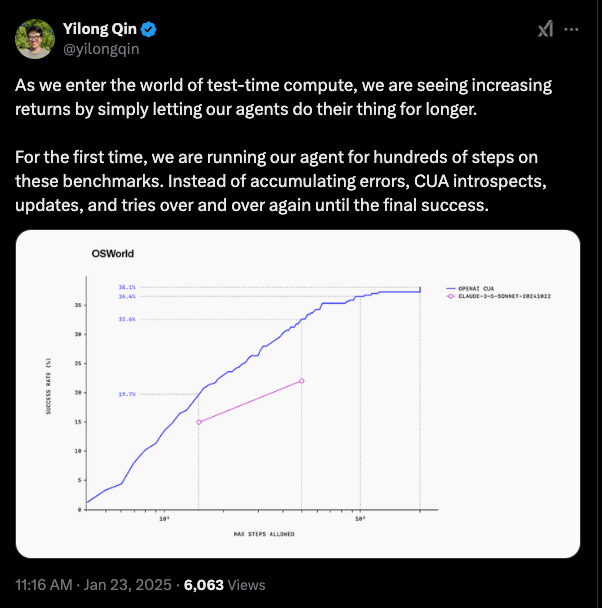
- As Sam says, there are more agents to launch in the coming weeks and months
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Codeium (Windsurf) Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- aider (Paul Gauthier) Discord
- OpenAI Discord
- Yannick Kilcher Discord
- Nous Research AI Discord
- Stackblitz (Bolt.new) Discord
- Latent Space Discord
- GPU MODE Discord
- MCP (Glama) Discord
- Nomic.ai (GPT4All) Discord
- Stability.ai (Stable Diffusion) Discord
- Eleuther Discord
- LlamaIndex Discord
- Cohere Discord
- Notebook LM Discord Discord
- Modular (Mojo 🔥) Discord
- LAION Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- Axolotl AI Discord
- MLOps @Chipro Discord
- Mozilla AI Discord
- OpenInterpreter Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (655 messages🔥🔥🔥):
- Codeium (Windsurf) ▷ #content (1 messages):
- Codeium (Windsurf) ▷ #discussion (49 messages🔥):
- Codeium (Windsurf) ▷ #windsurf (493 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (347 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (24 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (79 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (11 messages🔥):
- LM Studio ▷ #general (173 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (143 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (250 messages🔥🔥):
- Perplexity AI ▷ #sharing (11 messages🔥):
- Perplexity AI ▷ #pplx-api (11 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (6 messages):
- OpenRouter (Alex Atallah) ▷ #general (244 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (154 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (79 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (10 messages🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (170 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (9 messages🔥):
- OpenAI ▷ #prompt-engineering (14 messages🔥):
- OpenAI ▷ #api-discussions (14 messages🔥):
- Yannick Kilcher ▷ #general (160 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
- Yannick Kilcher ▷ #agents (1 messages):
- Yannick Kilcher ▷ #ml-news (10 messages🔥):
- Nous Research AI ▷ #general (162 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (6 messages):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #reasoning-tasks (1 messages):
- Stackblitz (Bolt.new) ▷ #announcements (1 messages):
- Stackblitz (Bolt.new) ▷ #prompting (1 messages):
- Stackblitz (Bolt.new) ▷ #discussions (143 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (139 messages🔥🔥):
- GPU MODE ▷ #general (5 messages):
- GPU MODE ▷ #triton (9 messages🔥):
- GPU MODE ▷ #cuda (49 messages🔥):
- GPU MODE ▷ #torch (8 messages🔥):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (14 messages🔥):
- GPU MODE ▷ #self-promotion (4 messages):
- GPU MODE ▷ #thunderkittens (1 messages):
- GPU MODE ▷ #arc-agi-2 (8 messages🔥):
- MCP (Glama) ▷ #general (87 messages🔥🔥):
- MCP (Glama) ▷ #showcase (7 messages):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (64 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (59 messages🔥🔥):
- Eleuther ▷ #general (22 messages🔥):
- Eleuther ▷ #research (27 messages🔥):
- Eleuther ▷ #lm-thunderdome (1 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (44 messages🔥):
- Cohere ▷ #discussions (9 messages🔥):
- Cohere ▷ #api-discussions (3 messages):
- Cohere ▷ #cmd-r-bot (29 messages🔥):
- Notebook LM Discord ▷ #use-cases (4 messages):
- Notebook LM Discord ▷ #general (35 messages🔥):
- Modular (Mojo 🔥) ▷ #general (9 messages🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (27 messages🔥):
- LAION ▷ #general (27 messages🔥):
- DSPy ▷ #general (5 messages):
- DSPy ▷ #examples (2 messages):
- tinygrad (George Hotz) ▷ #general (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (6 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
- Axolotl AI ▷ #general (2 messages):
- MLOps @Chipro ▷ #events (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
- OpenInterpreter ▷ #ai-content (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Releases
- OpenAI's Operator Launch: @OpenAI introduced Operator, a computer-using agent capable of interacting with web browsers to perform tasks like booking reservations and ordering groceries. @sama praised the release, while @swyx highlighted its ability to handle repetitive browser tasks efficiently.
- DeepSeek R1 and Models: @deepseek_ai unveiled DeepSeek R1, an open-source reasoning model that outperforms many competitors on Humanity’s Last Exam. @francoisfleuret commended its transformer architecture and performance benchmarks.
- Google DeepMind's VideoLLaMA 3: @arankomatsuzaki announced VideoLLaMA 3, a multimodal foundation model designed for image and video understanding, now open-sourced for broader research and application.
- Perplexity Assistant Release: @perplexity_ai launched Perplexity Assistant for Android, integrating reasoning and search capabilities to enhance daily productivity. Users can now activate the assistant and utilize features like multimodal interactions.
AI Benchmarks and Evaluation
- Humanity's Last Exam: @DanHendrycks introduced Humanity’s Last Exam, a 3,000-question dataset designed to evaluate AI's reasoning abilities across various subjects. Current models score below 10% accuracy, indicating significant room for improvement.
- CUA Performance on OSWorld and WebArena: @omarsar0 shared results of Computer-Using Agent (CUA) on OSWorld and WebArena benchmarks, showcasing improved performance over previous state-of-the-art models, though still trailing behind human performance.
- DeepSeek R1's Dominance: Multiple tweets from @teortaxesTex highlight DeepSeek R1’s superior performance on text-based benchmarks, surpassing models like LLaMA 4 and OpenAI's o1 in various evaluation metrics.
AI Safety and Ethics
- Citations and Safe AI Responses: @AnthropicAI launched Citations, a feature enabling AI models like Claude to provide grounded answers with precise source references, enhancing output reliability and user trust.
- Overhype and Hallucinations in AI: @kylebrussell criticized the overhyping of AI technologies, emphasizing that hallucinations and errors should not lead to an outright dismissal of AI advancements.
- AI as Creative Collaborators: @c_valenzuelab advocated for viewing AI as creative collaborators rather than mere tools, highlighting the importance of subjective and emotional evaluation in artistic endeavors.
AI Research and Development
- Program Synthesis and AGI: @TheTuringPost explored program synthesis as a pathway to Artificial General Intelligence (AGI), combining pattern recognition with abstract reasoning to overcome current deep learning limitations.
- Diffusion Feature Extractors: @ostrisai reported progress on training Diffusion Feature Extractors using LPIPS outputs, resulting in cleaner image features and enhanced text understanding within generated images.
- X-Sample Contrastive Loss (X-CLR): @DeepLearningAI introduced X-Sample Contrastive Loss (X-CLR), a self-supervised loss function that assigns continuous similarity scores to improve contrastive learning performance over traditional methods like SimCLR and CLIP.
AI Industry and Companies
- Stargate Project Investment: @saranormous discussed the $500B Stargate investment, which aims to boost compute power and AI token usage, questioning its long-term impact on intelligence acquisition and industry competition.
- Google Colab’s Impact: @osanseviero highlighted the significant role of Google Colab in democratizing GPU access, fostering advancements in open-source projects, education, and AI research.
- OpenAI and Together Compute Partnership: @togethercompute announced a partnership with Cartesia AI, providing access to Sonic, a low-latency voice AI model, via the Together API. This collaboration aims to create seamless multi-modal experiences by combining chat, image, audio, and code functionalities.
Memes/Humor
- AI Replacing Rule Lawyers: @NickEMoran joked about the inclusion of Magic and D&D in Humanity’s Last Exam, humorously suggesting that LLMs might soon take over the roles of Rules Lawyers.
- AI's Impact on Pop Culture: @saranormous shared a humorous quote reflecting on AI's capabilities, integrating memes to highlight the lighter side of AI advancements.
- Elon and Sam Trustworthiness Debate: @draecomino humorously questioned the trustworthiness of Elon Musk compared to Sam Altman, sparking a light-hearted debate on AI leadership.
- Funny AI Interactions: @nearcyan shared a tweet about the humorous side of AI-generated content, emphasizing the quirky and unexpected outcomes when AI models interact with user prompts.
This summary categorizes the provided tweets into AI Models and Releases, AI Benchmarks and Evaluation, AI Safety and Ethics, AI Research and Development, AI Industry and Companies, and Memes/Humor, ensuring thematic coherence and grouping similar discussion points. Each summary references direct tweets with inline markdown links to maintain factual grounding.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek's Competitiveness Shakes Tech Giants
- deepseek is a side project (Score: 1406, Comments: 165): Deepseek is described as a side project of a quantitative firm with a strong mathematical foundation and ownership of numerous GPUs used for trading and mining. The project aims to optimize the utilization of these GPUs, highlighting the firm's technical capabilities.
- Deepseek's Origin and Intent: Many users highlight that Deepseek is funded by a hedge fund, specifically High-Flyer, and emphasize that it's a side project utilizing idle GPUs. While the project isn't seen as a direct competitor to giants like OpenAI or xAI, it demonstrates significant efficiency and low-cost operations with only 2000 H100 GPUs compared to others using 100K.
- Quantitative Background and GPU Utilization: Comments discuss the hedge fund's quantitative expertise, which allows them to optimize resource usage and create efficient models despite limited hardware. Users note that the skills overlap between high-frequency trading (HFT) and AI development, with quants often working on models that require precise and fast execution, similar to trading algorithms.
- Comparisons and Market Impact: There's skepticism about the need for massive hardware investments by larger companies, questioning the ROI when smaller projects like Deepseek can achieve competitive results. Users humorously note the irony of a hedge fund's side project posing a potential threat to major AI players, highlighting the strategic advantage of leveraging existing resources effectively.
- Meta panicked by Deepseek (Score: 535, Comments: 114): Meta is reportedly alarmed by DeepSeek v3 outperforming Llama 4 in benchmarks, prompting engineers to urgently analyze and replicate DeepSeek's capabilities. Concerns include the high costs of the generative AI organization and difficulties in justifying expenses alongside leadership salaries, indicating organizational challenges and urgency at Meta regarding AI advancements.
- Skepticism on DeepSeek v3's Impact: Many commenters express doubt about the legitimacy of the claim that DeepSeek v3 is causing panic at Meta, citing the significant size difference between DeepSeek's models and Llama's models. ResidentPositive4122 highlights that DeepSeek has been known in the AI space for its strong models, which contradicts the notion of them being an "unknown" threat.
- Meta's Strategic Position: Commenters like FrostyContribution35 and ZestyData argue that Meta still holds a strong position in AI research, with ongoing innovations in architecture improvements like BLT and LCM. They suggest that Meta's extensive data resources and talented research team provide a significant advantage, despite the competitive landscape.
- Organizational and Resource Challenges: Discussions touch on the organizational dynamics at Meta, such as the pressure on engineers due to leadership decisions and the cost of energy in the USA compared to China. The_GSingh points out that despite Meta's extensive research, they lack in implementing new models, while Swagonflyyyy mentions that DeepSeek's cost-effective approach highlights inefficiencies in Meta's spending on AI leadership salaries.
- Open-source Deepseek beat not so OpenAI in 'humanity's last exam' ! (Score: 238, Comments: 36): Deepseek's open-source model, DeepSeek-R1, outperforms other models like GPT-4O and Claude 3.5 Sonnet on the "HLE" test, achieving an accuracy of 9.4% with a calibration error of 81.8%. Despite being not multi-modal, DeepSeek-R1 surpasses its competitors, with detailed results available in Appendix C.2.
- DeepSeek-R1's Performance: DeepSeek-R1, as a side project, impressively outperforms established models like OpenAI's O1 in text-only datasets, with a notable accuracy of 9.4% compared to O1's 8.9%. This achievement highlights the potential of non-mainstream projects to challenge industry leaders.
- Humanity's Last Exam (HLE): This benchmark is critical for testing AI's expert-level reasoning across disciplines, revealing significant gaps in current AI systems. Leading models score below 10%, showcasing the need for improvement in abstract reasoning and specialized knowledge.
- Open Source and Industry Dynamics: DeepSeek's success has sparked discussions about the state of open-source AI, with users questioning the absence of recent releases from major players like Meta and xAI. The conversation also touches on the unexpected rise of projects like DeepSeek, which lack backing from traditional tech giants, yet achieve state-of-the-art performance.
Theme 2. Advanced LLM Architectures: Byte-Level Models and Reasoning Agents
- ByteDance dropping an Apache 2.0 licensed 2B, 7B & 72B "reasoning" agent for computer use (Score: 541, Comments: 52): ByteDance has released Apache 2.0 licensed large language models (LLMs) with parameters of 2 billion, 7 billion, and 72 billion, focusing on enhancing reasoning tasks for computer use. These models are intended to improve computational reasoning capabilities, demonstrating ByteDance's commitment to open-source AI development.
- Discussion highlights the potential and limitations of ByteDance's new models, with users expressing curiosity about the practical use cases for the 2 billion and 7 billion parameter models beyond basic functionalities like "shortcut keys". Some users also reported initial difficulties in getting meaningful outputs from the smaller models, suggesting deployment and usage guides might be needed.
- There is interest in the Gnome Desktop demo, indicating excitement about the models' capabilities in operating systems environments. Users are also discussing the need for LLM-based approaches for non-web-based software, comparing them to tools like AutoHotkey.
- Links to resources such as GitHub repositories and Hugging Face were shared, with some users expressing gratitude for the ease of access. Additionally, there was discussion about using specific prompts from the repository to ensure the models function correctly, highlighting the importance of understanding the training methodologies.
- The first performant open-source byte-level model without tokenization has been released. EvaByte is a 6.5B param model that also has multibyte prediction for faster inference (vs similar sized tokenized models) (Score: 249, Comments: 65): EvaByte, a 6.5 billion parameter open-source byte-level model, has been released, offering multibyte prediction for faster inference without tokenization. The model achieves approximately 60% performance across 14 tasks, with a training token count just above 0.3 on a logarithmic scale, as shown in a scatter plot comparing it to other models.
- Discussions highlight the performance and speed of EvaByte compared to other models, with some users noting its architecture allows for faster decoding—up to 5-10x faster than vanilla byte models and 2x faster than tokenizer-based LMs. The model's ability to handle multimodal tasks more efficiently than BLTs is also emphasized, as it requires fewer training bytes.
- The model's byte-sized tokens are debated, with concerns about slower output speed and fast context fill-up. However, some argue that the improved architecture offsets these drawbacks by enhancing prediction speed, while others note the potential for reduced hardware expenses due to smaller dictionaries and easier computations.
- Users question training data inconsistencies and the model's scaling capabilities, with references to Hugging Face and a blog for further exploration. There is interest in how EvaByte compares with other models like GPT-J and OLMo, and discussions about its training on chatbot outputs, which may lead to errors in responses.
Theme 3. Tooling for Better Reasoning in AI Models: Enhancements in Open WebUI
- Open WebUI adds reasoning-focused features in two new releases OUT TODAY!!! 0.5.5 adds "Thinking" tag support to streamline reasoning model chats (works with R1) . 0.5.6 brings new "reasoning_effort" parameter to control cognitive effort. (Score: 104, Comments: 18): Open WebUI has released two updates, 0.5.5 and 0.5.6, enhancing reasoning model interactions. Version 0.5.5 introduces a 'think' tag that visually indicates the model's thinking duration, while version 0.5.6 adds a reasoning_effort parameter, allowing users to adjust the cognitive effort exerted by OpenAI models, thus improving customization for complex queries. More details can be found on their GitHub releases page.
- The reasoning_effort parameter does not currently impact R1 distilled models, as tested by a user who found no difference in "thinking" time across different settings. The parameter appears to be applicable only to OpenAI reasoning models at this time.
- Inference engines need to implement the "reasoning_effort" themselves, as it's not a model parameter. One suggested method is adjusting the sampling scaling coefficient for the "end of thinking" token, which can effectively modify the perceived cognitive effort.
- Users are anticipating fixes for rendering artifacts and the addition of MCP support to standardize tool usage, which is expected to enhance the utility of the platform.
- Deepseek R1's Open Source Version Differs from the Official API Version (Score: 80, Comments: 57): Deepseek R1's open-source model shows more censorship on CCP-related issues compared to the official API, contradicting expectations. This discrepancy raises concerns about the accuracy of benchmarks and the potential for biased responses, as the open model may perform worse and spread biased viewpoints, affecting third-party providers and human-ranked leaderboards like LM Arena. Tests reveal the open model interrupts its thinking process on sensitive topics, suggesting the models might not be identical, and researchers should specify which version they use in studies.
- There's a clear discrepancy between the open-source model and the official API, with the open model showing more censorship on CCP-related issues. Users, including TempWanderer101 and rnosov, discuss how benchmarks might be inaccurately measuring the open model, and that the models might not be identical, impacting performance and third-party provider quality.
- The censorship issue might be related to differences in prompt handling, with rnosov noting that using a
- There's a discussion on the cost and performance implications, with TempWanderer101 noting pricing differences between TogetherAI and OpenRouter. The potential for confusion between model versions raises concerns about the fairness of benchmarks and the reproducibility of research results, emphasizing the need for clarity in model version identification.
Theme 4. NVIDIA's GPU Innovations for Enhanced AI: Blackwell and Long Context Libraries
- NVIDIA RTX Blackwell GPU with 96GB GDDR7 memory and 512-bit bus spotted (Score: 209, Comments: 92): NVIDIA's RTX Blackwell GPU has been spotted with 96GB of GDDR7 memory and a 512-bit bus, indicating a significant update in memory capacity and bandwidth. This development suggests potential advancements in processing capabilities for high-performance computing and AI applications.
- Discussions highlight the potential pricing of the RTX Blackwell GPU, with estimates ranging from $6,000 to $18,000. Some users compare it to other cards like the MI300X/325X and the H100, suggesting they may offer better performance or value at similar price points.
- There is speculation that the RTX Blackwell could be a successor to the RTX 6000 Ada, which maxed out at 48GB. This new card's 96GB GDDR7 memory is seen as a substantial upgrade, possibly positioning it within the workstation card family.
- Users humorously express concerns about affordability, joking about selling kidneys or working extra shifts to afford the new card. This reflects a broader sentiment that while the card's specs are impressive, its price may be a barrier for many potential buyers.
- First 5090 LLM results, compared to 4090 and 6000 ada (Score: 70, Comments: 44): The NVIDIA GeForce RTX 5090 has been previewed for LLM benchmarks, showing significant improvements over the RTX 4090 and 6000 Ada models. Detailed results and comparisons can be found in the linked Storage Review article.
- Performance Expectations and Bottlenecks: Users expected the RTX 5090 to show a 60-80% increase in tokens per second due to higher memory bandwidth, but suspect a bottleneck or benchmarking issue since these gains weren't observed. FP8 is entering the mainstream, offering better performance over integer quantization, while FP4 is still years from adoption.
- Hardware Features and Comparisons: Discussions highlighted the interest in multi-GPU training capabilities and potential p2p unlocking with custom drivers for the 5090, similar to the 4090. Comparisons between RTX 6000 and GeForce series noted the 6000's higher VRAM and efficiency focus, despite its lower performance relative to the GeForce series.
- Performance Metrics: The RTX 5090 shows a 25-30% improvement in LLMs and a 40% improvement in image generation compared to the 4090, aligning with spec expectations. Users also noted the importance of FP8 and FP4 optimizations in the new generation for enhanced performance.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. OpenAI launches Operator Tool for Computers
- OpenAI launches Operator—an agent that can use a computer for you (Score: 107, Comments: 70): OpenAI has introduced Operator, an agent designed to autonomously use a computer on behalf of users. This development represents a significant advancement in AI capabilities, enabling more complex task automation and interaction with digital environments.
- Users express skepticism about Operator's capabilities, questioning its ability to control operating systems beyond browsers and its effectiveness with complex tasks like handling CAPTCHAs or doing taxes. Concerns about privacy and the high cost of $200-a-month for the service were also prominent discussion points.
- Some comments highlight Operator's potential, noting its use in programming and compatibility with tools like Google Sheets, although its current limitations make it less appealing for non-programmers. The conversation also touched on the rapid pace of AI advancements and the potential for significant improvements, referencing the quick development of video models in 2024.
- Several comments discuss the broader implications of AI on privacy, suggesting that future tech developments may inherently reduce privacy, likening it to the necessity of having a mobile phone today. The EU's stringent data privacy laws were noted as a factor causing delays in AI technology rollouts in the region.
- Is anyone's chat gpt also not working? Internal server error? (Score: 260, Comments: 320): ChatGPT users are experiencing issues, specifically internal server errors, preventing access.
- Many users from various locations, including New Zealand, Spain, and Australia, report ChatGPT being down, experiencing 503 Service Temporarily Unavailable errors, and suggest subscribing to the OpenAI status page for updates. Some users humorously speculate about potential AGI advancements causing the issue.
- Several users mention DeepSeek as an alternative, highlighting its effectiveness in solving complex issues, such as Docker configuration bugs, and considering canceling their OpenAI subscriptions in favor of this free tool.
- There is a suggestion for incorporating a status indicator within the app itself, with users recommending Downdetector as a reliable alternative for monitoring service availability.
- Sam Altman says he’s changed his perspective on Trump as ‘first buddy’ Elon Musk slams him online over the $500 billion Stargate Project (Score: 474, Comments: 104): Sam Altman has reportedly shifted his view on Donald Trump, while Elon Musk criticizes him online regarding the $500 billion Stargate Project. No additional details are provided in the post.
- Discussions highlight concerns about AI and potential dystopian futures, with users expressing fears of AI-driven surveillance states and autonomous drones used for control or warfare. WloveW and lepobz discuss scenarios involving AI's role in surveillance and enforcement, emphasizing the risks of mass deployment by state actors.
- Sam Altman's shift in stance is criticized, with some commenters expressing distrust towards billionaires and their influence on AI and politics. RealPhakeEyez and Sharp_Iodine reflect on the broader implications of billionaires' decisions and their impact on society, linking it to fascism and corporate power.
- The $500 billion Stargate Project and its political associations are discussed, with a comment by -Posthuman- noting the project's history with OpenAI, Microsoft, and the Biden administration, while questioning Trump's involvement and credit claims.
Theme 2. OpenAI's Vision for AI Agents by 2025
- Open Ai set to release agents that aim to replace Senior staff software engineers by end of 2025 (Score: 148, Comments: 147): OpenAI plans to release AI agents designed to assist and potentially replace senior software engineers by the end of 2025. The initiative includes testing an AI coding assistant, aiming for ChatGPT to reach 1 billion daily active users, and replicating the capabilities of experienced programmers, as stated by Sam Altman.
- Many commenters express skepticism about AI's ability to replace senior software engineers by 2025, noting the current limitations of AI, such as the inability to handle complex tasks and context that require human judgment and creativity. Mistakes_Were_Made73 highlights that AI can enhance productivity but not fully replace engineers, while LordDaut points out the limitations of current AI models in tasks like debugging.
- The discussion reflects a concern about the broader implications of AI on white-collar jobs, with rom_ok suggesting that the focus on software engineers might be a strategy to drive down salaries. Crafty_Fault_2238 predicts a significant impact on various white-collar jobs, describing it as an "existential" threat over the next decade.
- Some users, like tQkSushi, share examples of AI improving efficiency in specific tasks but emphasize the challenges in providing AI with sufficient context for complex software tasks. This sentiment is echoed by willieb3, who argues that while AI can assist, it still requires knowledgeable human oversight to function effectively.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1. DeepSeek R1 vs Existing Models: Capabilities and Controversies
- DeepSeek R1 Outsmarts O1 in Coding Smackdown: Users reported DeepSeek R1 surpassing OpenAI's O1 in coding tasks, even acing bizarre prompts like "POTATO THUNDERSTORM!". Side-by-side tests showed R1 delivering stronger code solutions and swifter reasoning.
- Users Chew Over Slow Performance and Censorship Concerns: While DeepSeek R1 impressed with thorough debugging, some users griped about sluggish responses in Composer mode and overzealous censorship. Sarcastic praise was directed at its safety features, with efforts to find or create an uncensored version.
- DeepSeek R1 Takes on the Big Boys for a Coffee's Cost: Greg Isenberg hailed DeepSeek R1 as making reasoning cheaper than a cup of coffee and open-source, unlike GPT-4, outpacing O1-Pro in some tasks.
Theme 2. OpenAI's Operator and Agents: New Features and User Reactions
- Operator Demos Autonomous Browsing, Users Balk at $200 Price Tag: At 10am PT, Sam Altman unveiled Operator, showcasing its ability to perform tasks within a browser for a hefty $200/month. Some users expressed excitement over its features, while others questioned the steep pricing.
- Browser Control Sparks Security Debates: Operator's capability to control web browsers autonomously raised concerns about CAPTCHA loops and safety. Users compared it with open-source alternatives like Browser Use.
- OpenAI Teases Future of Agents, Leaves Users Eager: The community buzzed about Operator not being the only agent, with hints of more launches in the coming weeks. Users anticipate new ways of automating workflows and integrating AI agents.
Theme 3. AI Assistants and IDEs: Cursor, Codeium Windsurf, Aider, and JetBrains
- Cursor Users Torn Between Chat and Composer Modes: Developers championed Chat mode for friendly code reviews but criticized Composer for unpredictable code changes. Frustrations included models running amok on code without proper context.
- Codeium Windsurf's Flow Credits Wiped Out by Buggy AI Edits: Users reported depleting over 10% of their monthly flow credits in hours due to repeated AI-induced code errors. Fixing these errors consumed credits rapidly, leading to calls for smarter resource use.
- JetBrains Fans Hopeful as They Join AI Waitlist: Despite earlier disappointments, users remain loyal to JetBrains IDEs, joining the JetBrains AI waitlist in hopes it can compete with Cursor and Windsurf. Some joked they'd stick with JetBrains regardless of AI struggles.
Theme 4. AI Model Development and Multi-GPU Support
- Unsloth's Multi-GPU Support on the Horizon: While currently lacking full multi-GPU capabilities, Unsloth AI teased future updates to support large-scale training, reducing single-GPU bottlenecks. Pro users eagerly anticipate smoother training of large models.
- BioML Postdoc Seeks to Adapt Striped Hyena for Eukaryotes: A researcher aims to finetune Striped Hyena, trained on prokaryote genomes, for eukaryotic sequences, referencing Science ado9336. Discussions included challenges with genomic data pretraining.
- Community Cheers Dolphin-R1's Open Release After $6k Sponsorship: Creating Dolphin-R1 cost $6k in API fees, leading the developer to seek a backer for open release. A sponsor stepped up, enabling the dataset to be shared under Apache-2.0 licensing on Hugging Face.
Theme 5. Hardware and Performance Discussions: GPUs, CUDA Updates, and Training Large Models
- NVIDIA's RTX 5090 Brings Speed but Sips More Power: The RTX 5090 boasts 30% faster performance than the 4090 but consumes 30% more power. Users noted the card doesn't fully exploit its 1.7x bandwidth increase for smaller LLMs.
- CUDA 12.8 Release Excites Developers with FP8/FP4 Support: CUDA 12.8 introduced Blackwell architecture support and new FP8 and FP4 TensorCore instructions, generating buzz about potential performance boosts in training.
- DeepSeek R1's Hefty VRAM Demands Stir GPU Debates: Running DeepSeek R1 Distilled Qwen 2.5 32B in float16 format requires at least 64GB VRAM, or 32GB with quantization. Discussions highlighted VRAM constraints and the challenges of training large models on limited hardware.
PART 1: High level Discord summaries
Cursor IDE Discord
-
DeepSeek R1 Races Past O1-Pro: Attendees praised DeepSeek R1 for thorough debugging, referencing Greg Isenberg's tweet that hailed it as cheaper and open source, outpacing O1-pro in some tasks.
- “I just realized DeepSeek R1 JUST made reasoning cheaper than a cup of coffee,” echoed one user, although others noted sluggish responses in Composer mode.
- O1 Subscription Scuffle: Participants discovered OpenAI's O1 Pro version costs $200/month, creating confusion and frustration across the community.
- They contrasted this plan with lower-cost alternatives, suggesting DeepSeek appears more budget-friendly for sustained usage.
- Chat vs. Composer Clash: Developers championed Chat mode as a friendlier tool for code reviews, highlighting its conversational approach.
- They criticized Composer for its unpredictable code modifications, stressing the importance of context-aware editing.
- Usage-Based Pricing Pushback: Users questioned whether they should pay more for AI-related API-call tracking, voicing skepticism about usage-based pricing.
- They demanded transparent fee structures and stronger models that deliver key features without ballooning expenses.
- UI-TARS Ushers Automated GUI Interactions: ByteDance introduced UI-TARS in a paper titled "UI-TARS: Pioneering Automated GUI Interaction with Native Agents", spotlighting advanced GUI automation possibilities.
- Developers explored its codebase in the official GitHub repo, noting potential synergy with agentic LLM processes.
Codeium (Windsurf) Discord
-
Windsurf’s Waves of Web Search: They launched a new web search feature for Codeium (Windsurf), showcased in a short demo video, with developers invited to 'surf' the internet in an integrated environment.
- Community members were urged to support the demo video post, emphasizing that broad engagement helps refine the search functionality for more robust usage.
- Codeium Extensions: A Concern for Updates: Some users expressed worry that Windsurf might overshadow Codeium extensions, citing minimal plugin updates since September.
- A public statement clarified that extension support remains essential for enterprise clients, even though current updates focus on Windsurf’s latest capabilities.
- Devin’s Autonomy Under Fire: Devin was introduced as a fully autonomous AI tool, prompting skepticism about its actual capabilities and whether human-in-the-loop input is still necessary.
- A few discussions compared it to a 'boy who cried wolf' scenario, referencing a blog post describing its performance over multiple tasks.
- Flow Credits and Model Matchups: Users reported rapid depletion of Windsurf flow credits as they repeatedly fixed AI-induced code errors, consuming over 10% of monthly quotas in a matter of hours.
- They also compared deepseek R1 with Sonnet 3.5, highlighting partial successes but calling for more consistent performance and smarter credit usage.
Unsloth AI (Daniel Han) Discord
-
DeepSeek & Qwen's Dynamic Duet: An integrated approach combining DeepSeek R1 with Qwen was applauded, with one user calling it 'damn near perfect' in terms of real-world performance.
- Community members recommended thorough evaluations before any fine-tuning to avoid harming the synergy, pointing to the Qwen 2.5 Coder collection for reference.
- Multi-GPU Hype & VRAM Chatter in Unsloth: Members confirmed Unsloth currently lacks full multi-GPU capabilities but teased future rollout to help large-scale training and reduce single-GPU bottlenecks.
- They noted VRAM usage is tied to model size, with Unsloth's documentation offering insights on memory constraints.
- 'Dolphin-R1' Makes a Splash with Sponsorship: Creating Dolphin-R1 cost $6k in API fees, spurring the developer to seek a backer for open release under Apache-2.0 licensing on Hugging Face.
- A sponsor stepped up, enabling the dataset to be shared with the community, while users praised the transparent approach to costs and data generation.
- Striped Hyena & the Eukaryote Expedition: A bioML postdoc wants to adapt Striped Hyena—trained on prokaryote genomes—for eukaryotic sequences, referencing Science ado9336 and the project repo.
- They highlighted that Unsloth hasn't fully embraced multi-GPU usage for large genomic data, spurring talk of more specialized training approaches for biomolecular tokens.
LM Studio Discord
-
DeepSeek Dilemmas & LM Studio Fixes: Users encountered errors like 'unknown pre-tokenizer type' while loading DeepSeek R1, prompting manual model updates and re-downloads.
- They referenced LM Studio docs for troubleshooting, praising quick solutions for persistent load failures.
- Qwen Quantization Quarrel: The group debated Q5_K_M as a sweet spot between model size and accuracy for Qwen models.
- Larger parameter sets appeared to deliver richer output, leading many to favor bigger footprints despite heavier GPU demands.
- Networking Nuisances in LM Studio: Contributors called for clearer toggles in LM Studio to differentiate localhost-only vs. all-IPs access across devices.
- They shared that ambiguous settings hamper multi-device usage, emphasizing a more direct labeling approach.
- Gemini 2.0 Gains Gusto: Enthusiasts commended Google's Gemini 2.0 Flash for extended context length and highly accurate parsing of legal documents.
- Comparisons with older models like o1 mini spotlighted Gemini's more sustained responses and sharper knowledge retention.
- RTX 5090 & Procyon Performance Chat: NVIDIA's RTX 5090 runs about 30% faster than a 4090 but doesn't fully exploit its 1.7x bandwidth for smaller LLMs, as seen in NVIDIA's official page.
- Procyon AI was suggested for uniform performance testing, highlighting model quantization and VRAM usage in consistent benchmarks.
Perplexity AI Discord
-
Perplexity’s Big Leap on Android: The Perplexity Assistant is now accessible on Android, enabling tasks across apps via this link.
- Voice activation remains a sticking point, though the new multimodal feature to identify real-world objects sparks interest.
- Mistral’s IPO Plan Sparks Speculation: Conversations center on Mistral aiming for an IPO, driving curiosity over potential expansions in its offerings.
- A YouTube video spotlights this move, and community members debate its impact on future model developments.
- DeepSeek R1 Surges in Performance Tests: Some claim DeepSeek R1 might outperform OpenAI in niche tasks, referencing a detailed exploration.
- Engineers see this as a sign of intensifying competition, urging more rigorous comparisons.
- Sonar Models Shift Strategy: The Sonar line dropped Sonar Huge for Sonar Large and hinted at Sonar Pro, fueling questions on performance gains.
- API disruptions, including 524 errors and SOC 2 compliance queries, underscore broader concerns about stability for enterprise use.
- PyCTC Decode & Community Projects: Developers are considering PyCTC Decode for specialized speech applications, directing peers to this link.
- Meanwhile, a music streaming concept and fresh AI prompt ideas reveal diverse experiments among contributors.
OpenRouter (Alex Atallah) Discord
-
Web Search Gains Ground: OpenRouter launched the Web Search API, priced at $4/1k results, enabling a default of 5 fetches per request when appending :online to a model, with docs at OpenRouter.
- They clarified that each query costs around $0.02 and joked about a premature announcement overshadowing the official rollout.
- Reasoning Tokens Exposed: OpenRouter introduced Reasoning Tokens for direct model insights, requiring
include_reasoning: true, as stated in this tweet.
- finish_reason standardization across multiple thinking models aims to unify the explanation style.
- Deepseek R1 Falters Under Load: Deepseek R1 faced responsiveness problems, occasionally hanging and failing to return results from Deepseek and DeepInfra, as described at DeepSeek R1 Distill Llama 70B.
- One user questioned whether the issues stemmed from inherent model flaws or service disruptions.
- Credits & Integration Hiccups: Some users reported API Key priority mix-ups, causing credit usage instead of intended Mistral integrations, while others grumbled about Web Search billing confusion.
- A workaround emerged in the form of Crypto Payments API, letting users buy credits outside standard payment methods.
aider (Paul Gauthier) Discord
-
Aider's Double-LLM Setup: Community members described configuring Aider to run multiple LLMs via
aider.conf.yaml, noting that chat modes default to a single model unless precisely set, as outlined in the installation doc.- They discovered that /chat-mode code can override a separate editor model, fueling confusion among those seeking tight control over each model's role.
- DeepSeek R1's Syntax Snags: Several voices shared that DeepSeek R1 struggles with syntax and context constraints during coding tasks, illustrated in this performance video.
- Some proposed feeding smaller bits of context, quoting 'we had better luck with partial references' as a quick fix.
- Anthropic's Citation Clarification: The new Citations API from Anthropic incorporates source links in Claude's responses, showcased in their announcement.
- Community members praised the simpler path to reliable references, remarking 'this eases the trouble of verifying sources' in generated text.
- Aider Logging for Large Projects: Participants tackled Aider prompts on bigger codebases by offloading output to a file, saving tokens and reducing clutter.
- They cited 'redirecting heavy terminal commands' as a helpful workflow to preserve clarity while capturing detailed logs.
- JetBrains AI Waitlist Buzz: Techies joined the JetBrains AI waitlist, hoping the IDE leader can stand against Cursor and Windsurf after earlier letdowns.
- Some criticized past JetBrains AI attempts but insisted 'JetBrains remains my go-to developer suite regardless of AI' due to robust IDE features.
OpenAI Discord
-
Operator’s Bold Debut & $200 Price Tag: At 10am PT, Sam Altman and team introduced Operator with a $200/month subscription in a YouTube demo.
- The community expressed excitement over its web browser integration, anticipating future expansions to user-driven browser selection.
- DeepSeek R1 Dominates O1 in Coding: Multiple side-by-side tests showed DeepSeek R1 surpassing O1 in coding tasks, even handling random prompts like 'POTATO THUNDERSTORM!' smoothly.
- Community members highlighted stronger code solutions and praised R1’s agility, predicting more intense comparisons to come.
- GPT Outage & Voice Feature Crash: Service disruptions caused GPT to throw 'bad gateway' errors and disabled voice capabilities, as tracked by OpenAI's status page.
- Users jokingly blamed LeBron James and Ronaldo, while official updates indicated ongoing fixes to restore the voice feature.
- Perplexity Assistant Gains Mobile Momentum: Several users praised the Perplexity Assistant as more efficient on mobile than existing OpenAI apps, sparking debate about user satisfaction.
- They criticized OpenAI’s pricing, hinting a shift in loyalty if alternate solutions continue to outperform ChatGPT on portability.
- Spiking Neural Networks Spark Mixed Reactions: Participants considered spiking neural networks for energy efficiency but worried about latency, citing uncertain returns in real implementations.
- Some saw them as both a dead end and a next step, prompting further inquiries into specialized tasks that might benefit from spiking models.
Yannick Kilcher Discord
-
OpenAI Operator Offers Automated Actions: OpenAI is preparing a new ChatGPT feature called Operator that can take actions in a user's browser and allow saving or sharing tasks.
- Community members expect a release this week, noting that it's not yet available in the API but might shape new ways of automating user workflows.
- R1 Qwen 2.5 32B Demands Hefty VRAM: Running R1 Distilled Qwen 2.5 32B in float16 format requires at least 64GB VRAM, or 32GB for q8, according to parameter sizing talks.
- Discussion highlights how 7B parameters at 16-bit need about 14B bytes of memory plus overhead for context windows.
- GSPN Gives Vision a 2D Twist: The new Generalized Spatial Propagation Network (GSPN) promises a 2D-capable attention mechanism optimized for vision tasks, capturing spatial structures more effectively.
- Members praised the Stability-Context Condition, which cuts down effective sequence length to √N and potentially improves context awareness in image data.
- MONA Method Minimizes Multi-Step Mischief: A proposed RL approach, MONA, uses short-sighted optimization plus far-sighted checks to curb multi-step reward hacking.
- Researchers tested MONA in scenarios prone to reward hacking, showing potential for preventing undesired behavior in reinforcement learning setups.
- IntellAgent Evaluates Agents with Simulated Dialogues: The IntellAgent project offers an open-source framework for generating and analyzing agent conversations, capturing fine-grained interaction details.
- Alongside the research paper, early adopters welcomed this approach for robust agent evaluation, focusing on a critique component that highlights conversational flaws.
Nous Research AI Discord
-
Evabyte's Compressed Chunked Attention: The new Evabyte architecture relies on a fully chunked linear attention design with multi-byte prediction, highlighted in this code snippet.
- Engineers pointed out its compressed memory footprint and improved throughput potential, shown through an internal attention sketch that underscores its large-scale efficiency.
- Tensorgrad Twists Tensors: The tensorgrad library from GitHub introduces named edges for user-friendly tensor operations, enabling commands like
kernel @ h_conv @ w_convwithout complicated indexing.
- It provides symbolic reasoning and matrix simplification, leveraging common subexpression elimination in forward and backward passes to boost performance.
- R1 Datasets Appear, Access Puzzle Persists: Participants confirmed that R1 datasets for distilled models are partially accessible, though details on precise download locations remain unclear.
- Curious researchers requested a direct repo link, hoping official clarification from Nous Research will resolve the confusion.
- Brains and Bits: MIT's Representation Convergence: MIT researchers observed that artificial neural networks trained on naturalistic input converge with biological systems, as indicated by this study.
- They found that model-to-brain alignment correlates with inter-model agreement across vision and language stimuli, suggesting a universal basis for certain neural computations.
- Diffusion Gains via TREAD Token Routing: A recent paper, TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training, tackles sample inefficiency by retaining token information instead of discarding it.
- Its authors claim increased integration across deeper layers, applicable to both transformer and state-space architectures, yielding lower compute costs for diffusion models.
Stackblitz (Bolt.new) Discord
-
Stripe-Supabase Saga: A user faced a 401 error hooking a Stripe webhook to a Supabase edge function, eventually isolating a verify_jwt misconfiguration.
- They corrected the JWT config and are checking the official docs to solidify the integration.
- Token Tangle: After switching from free to paid plans, users noted token allocation dropping from 300k to 150k, creating confusion about daily quotas.
- Some speculate paid plans remove automatic token renewals, prompting them to revisit StackBlitz registration for clarity.
- Bolt Chat Woes: Community members reported chat logs disappearing and needing a full StackBlitz reset to attempt fixes.
- They discussed persistent session strategies, citing bolt.new for possible solutions.
- 3D Display Dilemma: A user’s 3D model viewer attempt with a GLB file produced a white screen, indicating missing or incomplete setup steps.
- Guides recommended Google Model Viewer code, with further references suggested in Cursor Directory.
- Discord Payment Proposals: A user pitched a Discord login feature and new webhook acceptance system for simpler payments across Bolt.new.
- They also mentioned a token draw reward for friend invitations, aiming to boost community engagement with extra flair.
Latent Space Discord
-
Operator Takes the Digital Wheel: OpenAI introduced Operator, an agent that autonomously navigates a browser to perform tasks, as described in their blog post.
- Observers tested it for research tasks and raised concerns about CAPTCHA loops, referencing open-source analogs like Browser Use.
- Imagen 3 Soars Past Recraft-v3: Google’s Imagen 3 claimed the top text-to-image spot, surpassing Recraft-v3 by a 70-point margin on the Text-to-Image Arena leaderboard.
- Community members highlighted refined prompt handling, including a jellyfish on the beach scenario that impressed onlookers with fine details.
- DeepSeek RAG Minimizes Complexity: DeepSeek reroutes retrieval-augmented generation by permitting direct ingestion of extensive documents, as noted in discussion.
- KV caching boosts throughput, prompting some to declare classic RAG an anti pattern for large-scale use cases.
- Fireworks AI Underprices Transcription: Fireworks AI introduced a streaming transcription tool at $0.0032 per minute after a free period, detailed in their announcement.
- They claim near Whisper-v3-large quality with 300ms latency, placing them as a cost-effective alternative in live captioning.
- API Revenue Sharing Sparks Curiosity: Participants noted that OpenAI does not credit API usage toward ChatGPT subscriptions, raising questions on revenue distribution.
- They wondered if any provider pays users for API activity, but found no evidence of such arrangements.
GPU MODE Discord
-
R1’s Real Risk & DDoS Dilemma: Community members raised alarms about R1 due to its ease of jailbreak and the possibility of generating DDoS code, referencing how simple it is to manipulate AI systems in general.
- Some shared a link to the TDE Podcast #11 explaining end-to-end LLM solutions, wondering if these vulnerabilities might be mitigated with more robust code checks.
- Triton’s Tricky Step Sequencing: A contributor discovered step2 must run before step3 to avoid data overwriting issues, noting that step3 indirectly changes x_c in ways affecting the final outcome.
- They proposed testing changes directly on x instead of x_c for clarity, highlighting the subtle effect of variable manipulation in multipass kernels.
- CUDA 12.8 & Blackwell Gains: NVIDIA released CUDA 12.8 featuring Blackwell architecture support and new FP8/FP4 TensorCore instructions.
- Developers also mentioned Accel-Sim for GPU simulation and a tweet about 5th Generation TensorCore instructions, sparking debate on improved performance metrics.
- ComfyUI Calls for ML Engineers: ComfyUI is hiring machine learning engineers for its open source ecosystem, boasting a VC-backed model and big vision from the Bay Area.
- Interested parties can read more about the role in the job listing, as the team highlighted day-one model support from several top companies.
- Tiny GRPO & Reasoning Gym Roll Out: Developers unveiled the Tiny GRPO repository for minimal, hackable implementations at GitHub, encouraging contributions.
- They also kicked off the Reasoning Gym, focused on procedural reasoning tasks, inviting the community to propose new dataset ideas and expansions.
MCP (Glama) Discord
-
Timeout Tussle Tamed & Windows Woes: A user overcame the 60-second MCP server timeout, though they didn't share how they did it, which caught others' interest.
- Another user overcame hidden PATH settings on Windows and created a test.db file in Access, referencing the MCP Inspector tool to confirm stability.
- Container Clash: Podman vs Docker: Members debated the merits of Podman versus Docker, referencing Podman Installation steps for a simpler setup.
- While Podman is daemonless and more lightweight, many devs keep using Docker because of familiarity and broader tool integration.
- Code Lines for Crisp Edits: A user showcased a method for tracking line numbers in code to apply targeted changes, describing it as more efficient than older diff-based approaches.
- By highlighting improved reliability in bigger refactor tasks, the community found it an easier approach for complex code merges.
- Anthropic TS Client Stumbles & SSE Example Fix: A known bug with Anthropic TS client led some devs to switch to Python, as hinted in issue #118.
- One user admitted a copy-paste mistake in the SSE sample and linked a corrected clientSse.ts example to clarify custom header usage, also fielding questions on Node's EventSource reliability.
- Puppeteer Powers Web Interactions: A new mcp-puppeteer-linux package brings browser automation to LLMs, enabling navigation, screenshots, and element clicks.
- Community members praised its JavaScript execution features, calling it a potential game-changer for web-based testing workflows.
Nomic.ai (GPT4All) Discord
-
GPT4All Grows Gracefully: The new GPT4All v3.7.0 release includes Windows ARM support for Qualcomm and Microsoft SQ devices, though users must note CPU-only operation for now.
- The conversation spotlighted macOS crash fixes and advised uninstalling any GitHub-based workaround to revert to the official version.
- Code Interpreter Closes Cracks: The Code Interpreter saw upgrades with improved timeout handling and more flexible console.log usage for multiple arguments.
- Engineers praised this alignment with JavaScript expectations, highlighting easier debugging and smoother developer workflows.
- Chat Template Tangles Tamed: Two crashes and a compatibility glitch in the chat template parser were eliminated, delivering stability for EM German Mistral and five new models.
- Several members referenced GPT4All Docs on Chat Templates for deeper configuration and troubleshooting tips.
- Prompt Engineering Politesse Pays: Enthusiasts argued that refined requests, including polite words like 'Please,' can boost GPT4All responsiveness.
- They also joked about pay-to-play reality for unlimited ChatGPT, nudging colleagues to explore alternatives.
- NSFW and Jinja Jitters: Community members mentioned NSFW content hurdles, pointing to moral filters and zensors blocking explicit outputs.
- Others noted Jinja template complexities with C++-based GPT4All integrations, complicating custom syntax adoption.
Stability.ai (Stable Diffusion) Discord
-
CitiVAI's Quick Shutdowns: Members stated CitiVAI goes down a few times daily, referencing user experiences on r/StableDiffusion, which triggers sporadic restrictions on image creation.
- They explained that these intervals are planned as part of maintenance, with some suggesting an announcement schedule for better planning around downtime.
- Icy Mask Magic: A user shared how they combine black-and-white mask layers with Inkscape to craft ice-themed text, then color it with canny controlnet or direct prompts.
- Others discussed references like SwarmUI's Model Support docs for better integration of customized mask-based generation approaches.
- 5090 GPU Gains at a Cost: A discussion revealed that the 5090 GPU reportedly delivers 20-40% faster rendering but draws 30% more power, with deeper benefits appearing in the B100/B200 line.
- Participants pointed to data like finetuning results on an RTX 2070 consumer-tier GPU indicating consistent improvements for stable diffusion tasks.
- Training Cartoon Characters: Enthusiasts examined fine-tuning to replicate movie characters, referencing Alvin from Alvin and the Chipmunks LoRA model.
- They noted this method merely needs a mid-tier GPU and a bit of time, echoing examples with SwarmUI's prompt syntax tips.
- Clip Skip Clip-Out: A user asked if 'clip skip' is still relevant, discovering it's a leftover from SD1 evolution and rarely used now.
- The group concluded it’s generally unnecessary for modern stable diffusion setups, emphasizing that advanced prompting workflows supplant that old configuration.
Eleuther Discord
-
Google's Titans Flex Next-Gen Memory: Google introduced Titans, promising stronger inference-time memory, as shown in this YouTube video.
- The group noted the paper is hard to replicate, with lingering questions about the exact attention strategy.
- Egomotion Steps Up for Feature Learning: Researchers tested egomotion as a self-directed method, replacing labels with mobility data in this paper.
- They observed strong outcomes for scene recognition and object detection, sparking interest in motion-based training.
- Distributional Dynamic Programming Gains Momentum: A new approach called distributional dynamic programming tackles statistical functionals of return distributions, outlined in this paper.
- It features stock augmentation to broaden solutions once tricky to handle with standard reinforcement learning methods.
- Ruler Tasks Expand Long Context Possibilities: All Ruler tasks were finalized with minor formatting fixes, encouraging more extended context applications for the #lm-thunderdome channel.
- Contributors requested additional long context tasks, emphasizing efforts to push real-world testing boundaries.
LlamaIndex Discord
-
Open-Source RAG Gains Steam: Developers explored a detailed guide to build an open-source RAG system using LlamaIndex, Meta Llama 3, and TruLens, comparing a basic approach with Neo4j to a more agentic setup.
- They pitted OpenAI against Llama 3.2 to gauge performance, fueling excitement on self-hosted and flexible solutions.
- AI Chrome Extensions for Social Platforms: Members discussed a pair of Chrome extensions that harness LlamaIndex to boost the impact of X and LinkedIn posts.
- They praised these AI tools for improving engagement while expanding content creation possibilities.
- AgentWorkflow’s Big Boost: Enthusiasts praised the AgentWorkflow upgrades, highlighting improved speed and output quality over older builds.
- Several projects pivoted to these new features, crediting the revamp with eliminating previous bottlenecks.
- Multi-Agent Mayhem vs Tools: Discussions clarified how multiple agents can be active sequentially, leveraging async tool calls without clobbering one another's context.
- They also clarified that agents rely on tools but can serve as tools themselves in specialized roles.
- Memory Management and Link Glitches: Participants called for better memory modules, noting ChatMemoryBuffer may not optimize context usage, and summaries can add latency.
- A broken Agent tutorial led to 500 errors, prompting them to refer to run-llama GitHub repos for core documentation.
Cohere Discord
-
Cohere's Comical LCoT Conjecture: A member pushed Cohere to release LCoT meme model weights that handle logic and thinking, receiving a reminder of Cohere's enterprise focus.
- They shared a playful GIF to underscore community eagerness for more open experimentation.
- Pydantic's Perfect Pairing with Cohere: A user announced Pydantic now supports Cohere models, prompting excitement over simpler integration for developers.
- This update could streamline workflows and coding practices for anyone building with Cohere, although further release specifics were not detailed.
- Chain of Thought Chatter: Participants proposed cues like 'think before you act' and
- They noted that regular models lacking explicit trace training still gain partial reasoning advantages with well-structured prompts.
- Reranker Riddle: On-Prem Dreams: A user in Chile asked about on-prem hosting for Cohere Reranker to offset high latency from South America.
- No direct solutions surfaced, and they were encouraged to contact the sales team at support@cohere.com for alternatives.
- ASI Ambitions and Anxieties: Discussion covered Artificial Superintelligence (ASI) possibly exceeding human intellect, highlighting potential breakthroughs in healthcare and education.
- Members aired ethical concerns over misuse and noted no official Cohere documentation currently addresses ASI development.
Notebook LM Discord Discord
-
NotebookLM Nudges Study Gains: A member showcased their excitement about integrating NotebookLM into study workflows, including a YouTube video highlighting helpful note-organization features.
- They also discovered how Obsidian plugins can merge markdown notes effectively, fueling conversation on refined knowledge-sharing practices.
- DeepSeek-R1 Dissected in Podcast: A user posted a podcast episode dissecting DeepSeek-R1 Paper Analysis that explores the model's reasoning and RL-based improvements.
- They emphasized how reinforcement learning shapes smaller model development, sparking others to explore scale strategies.
- NotebookLM Language Frustrations: Users faced interruptions when trying to switch from Romanian to English in NotebookLM, with a URL parameter attempt leading to an error.
- Community members sought official methods for language updates, but the confusion persisted.
- High-Caliber Test Questions: One participant introduced a consistent pattern for generating multiple-choice test items from designated chapters in NotebookLM.
- They credited the approach for enabling repetitive success, thus streamlining exam preparation.
- Audio Glitches & Document Cross-Checks: Members encountered audio generation hiccups, including a tendency to draw from entire PDFs when prompts lacked specifics, and some reported playback issues for downloaded files.
- They also debated whether NotebookLM surpasses ChatGPT in analyzing legal documents, noting how cross-references could unveil atypical clauses.
Modular (Mojo 🔥) Discord
-
Mojo Goes Async: In #general, a new forum thread about asynchronous code popped up, highlighting the community's interest in coroutines despite limited official wrappers.
- Members cheered the direct link share, encouraging further discussion on code patterns and usage examples.
- MAX Builds Page Revs Up: The MAX Builds page now showcases community-built packages, shining a spotlight on expansions for Mojo-based projects.
- Contributors are recognized on launch, and anyone can submit a recipe.yaml to the Modular community repo for inclusion.
- No Override? No Worries!: A #mojo conversation confirmed there's no @override decorator in Mojo, with one member clarifying that structs don't enable inheritance anyway.
- This approach means function redefinitions proceed without special syntax, prompting detail-oriented code reviews.
- Generators Spark Discussion: A question arose about Python-style generators, noting the gap in many compiled languages.
- Participants suggested an async proposal requiring explicit yield exposure, pushing for future enhancements in coroutines.
- Reassignments & iadd Debates: Developers tackled read-only references in function definitions, distinguishing mut from owned usage.
- They also explored how iadd underpins +=, clarifying compositional behaviors in Mojo.
LAION Discord
-
Bud-E’s Emotional TTS Debut: Emotional Open Source TTS is heading to Bud-E soon, featuring a shared audio clip that demonstrates the approach’s progress.
- Members praised the expressive vocal range, calling it “an exciting step in audio-based projects” and anticipating further expansions in Bud-E.
- Distortion Dissection with pydub: A researcher is comparing waveforms of an original audio file against a noise-heavy variant using pydub, focusing on small vs. extreme distortion levels.
- They shared images highlighting slight vs. strong noise differences, illustrating improvements in audio exploration.
- Collaborative Colab Notebook: Members proposed notebook sharing with a Google Colab notebook to collectively refine code around audio transformations.
- Participants expressed interest in replicating the approach and offered suggestions for further refinements.
- Widgets for Waveform Comparisons: A request for IPython audio widgets in Colab aims to streamline before-and-after distortion evaluations.
- Members brainstormed potential code snippets, emphasizing simpler playback controls and side-by-side comparisons in the shared notebook.
DSPy Discord
-
Repo Spam Sparks Commotion: Concerns about a repo being spammed surfaced, with speculation tying it to a coin problem and describing it as 'super lame.'
- Some participants dismissed the correlation, shifting focus toward stronger content management efforts.
- Framework Inspiration Over Imitation: A user urged avoiding strict replication of existing frameworks, highlighting use-case alignment for targeted solutions.
- They advocated shaping toolkits around practical objectives rather than relying on others’ approaches.
- Email-Triggered REACT Agent in DSPy: A developer wanted to run a REACT agent via an email trigger and eventually succeeded by using a webhook.
- They cited DSPy’s readiness for external libraries, underscoring flexible trigger-to-agent workflows.
- OpenAI Model Gains Favor, Groq Stays in Play: A contributor praised the OpenAI model for its broad coverage and practicality across tasks.
- Another contributor mentioned Groq compatibility, signaling interest in multiple hardware backends.
tinygrad (George Hotz) Discord
-
Clipping the Bounty: llvm_bf16_cast Gains Traction: A contributor confirmed the llvm_bf16_cast bounty status and raised a PR a few hours earlier, effectively resolving the rewrite request.
- Attention now turns to new tasks, ensuring a stream of tinygrad bounty hunts for further GPU optimizations.
- ILP Takes the Stage with Shapetracker: A member unveiled an ILP-based approach for the shapetracker add problem, though it struggles with speed and requires an external solver.
- Still, the structured handling of shapes could pave the way for more precise rewrite operations in tinygrad.
- George Hotz Backs ILP-based Rewrite Simplifications: George Hotz took interest in the ILP approach, asking if there’s a PR and hinting at possible integration in tinygrad rewrite rules.
- This move could push tinygrad to adopt linear programming for more productive transformations.
- Masks and Views Collide: Merging Tactics Emerge: Participants discussed merging masks and views, suggesting a bounded representation could boost mask capabilities.
- They acknowledged increased complexity yet remain open to the idea of fusing masks for extended shape flexibility.
LLM Agents (Berkeley MOOC) Discord
-
Certificates Timetable Uncertain, MOOC Still Open: A participant asked about course certificates and ways to track distribution, but no official timeline was provided, prompting curiosity.
- Another participant was unsure about LLM MOOC enrollment, and discovered that simply filling out the form confirms participation.
- Agents Anticipate Course Mastery: A participant noted that being an LLM agent automatically grants access to the course, highlighting a high bar for success.
- They suggested that any agent who passes gains major credibility, reflecting the advanced nature of the LLM training.
Gorilla LLM (Berkeley Function Calling) Discord
-
BFCLV3: The Great Tool Mystery: A question arose about whether BFCLV3 provides a system message that outlines how tools like get_flight_cost and get_creditcard_balance interconnect before book_flight is called.
- Members observed no metadata on tool dependencies in tasks labeled simple, parallel, multiple, and parallel_multiple, linking to GitHub source for further detail.
- LLM Testing Methodology Under the Microscope: Participants debated whether BFCLV3 LLMs are tested purely on tool descriptions or if underlying dependency relationships are considered.
- They noted that understanding these relationships is critical for research, as citing details from the BFCLV3 dataset can shed light on real-world function call usage.
Axolotl AI Discord
-
KTO-Liger Lock Up: The KTO loss was merged in the Liger-Kernel repository, promising a boost for model performance and new capabilities.
- Community members expressed excitement about KTO loss and its immediate benefits, anticipating stronger training stability and improved generalization.
- Office Hours Countdown: A reminder went out that Office Hours begin in 4 hours, aimed at providing an interactive forum for questions and design reviews.
- Attendees can join via this Discord event link, expecting a lively exchange around ongoing LLM projects.
MLOps @Chipro Discord
-
Toronto MLOps Meetup on Feb 18: A MLOps event is scheduled in Toronto on February 18 for senior engineers and data scientists, providing a space to exchange field insights.
- Organizers mentioned attendees should direct message for more details, emphasizing the focus on professional networking and knowledge sharing.
- Networking Buzz for Senior Tech Pros: This gathering centers on strengthening connections among senior engineers and data scientists, encouraging peer support and resource sharing.
- Participants see it as a beneficial way to deepen community ties, fostering collaboration across the local AI ecosystem.
Mozilla AI Discord
-
Local-First Hackathon Lands in SF: A Local-First X AI Hackathon is set to take place in San Francisco on Feb. 22, featuring projects that blend local computing with generative AI.
- Organizers emphasized practical collaboration among participants, referring them to an event thread for idea exchange and resource sharing.
- Community Brainstorm Gathers Steam: A dedicated discussion thread encourages participants to share experimental strategies and privacy-preserving machine learning frameworks.
- Planners hope to foster real-world results by inviting local computing enthusiasts to showcase prototypes and code jam sessions during the hackathon.
OpenInterpreter Discord
-
Deepspeek Ties for OpenInterpreter: A user asked about integrating Deepspeek into
>interpreter --os mode, hoping to benefit OpenInterpreter with voice-focused functions.- They mentioned the potential synergy between Deepspeek and OS-level interpreter capabilities but provided no further technical details or links.
- OS Mode May Expand for Voice Features: Participants speculated future OS mode enhancements to accommodate speech-based operations in OpenInterpreter.
- Though plans remain unclear, the integration of Deepspeek might unlock advanced voice support and some level of system interaction.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (655 messages🔥🔥🔥):
DeepSeek R1, OpenAI O1, Chat vs Composer Mode, AI Agentic Models, Usage-Based Pricing
-
DeepSeek R1's Performance and Future: Users discussed the slow performance of DeepSeek R1 in Composer's normal mode but noted its satisfactory results when functioning properly.
- While some found R1 effective for debugging, they expressed frustration over its response speed and an inability to handle bugs as effectively as Sonnet.
- OpenAI's O1 Subscription Confusion: There was confusion regarding OpenAI's O1 pricing; some noted that the Pro version costs $200/month, while others are using the cheaper alternatives.
- Discussions highlighted how DeepSeek is perceived as a more cost-effective alternative offering significant value for money.
- Chat Mode Advantages: Chat mode was highlighted by users as a better alternative for interacting with AI, allowing for review and discussion of code before applying changes.
- Conversely, Composer was criticized for running amok on users' code and making haphazard changes without sufficient context.
- Growth of AI Tools and User Sentiment: Participants noted an increase in interest around newer AI tools, with some noting a disconnect between tech hype and general user understanding of these tools.
- There was a call for improved functionality and responsiveness in AI models like R1 to meet user expectations.
- Usage-Based Pricing Concerns: Users expressed skepticism about usage-based pricing for AI services, questioning the need to pay additional fees just to track API calls.
- The community is pushing for more transparency and effective models that do not require exorbitant costs for basic functionalities.
Links mentioned:
- LiveBench: no description found
- Agent Mode in Warp AI | Warp: A command line interface that understands plain English in addition to traditional commands. Use Agent Mode to accomplish multi-step workflows.
- Tweet from Chubby♨️ (@kimmonismus): https://x.com/skirano/status/1881854481304047656/video/1 Genius! "you can extract JUST the reasoning from deepseek-reasoner, which means you can send that thinking process to any model you want be...
- Tweet from Aidan Clark (@aidan_clark): o3-mini first try no edits, took 20 sec(told me how to convert to gif too.....)Get excited :)Quoting Ivan Fioravanti ᯅ (@ivanfioravanti) 👀 DeepSeek R1 (right) crushed o1-pro (left) 👀Prompt: "wri...
- Tweet from GREG ISENBERG (@gregisenberg): I just realized DeepSeek R1 JUST made reasoning cheaper than a cup of coffee, open source unlike GPT4, and somehow outperforms Claude 3.5 Sonnet"Made in China" AI now costs $0.50/hour while US...
- Tweet from swyx /dd (@swyx): I take back every negative thing I said about @warpdotdev. this thing can solve python dependency hell. i'm just tapping enter at this point and its fixing my envs for me to run @home_assistant.th...
- Joe Biden Presidential Debate GIF - Joe biden Presidential debate Huh - Discover & Share GIFs: Click to view the GIF
- Tweet from Aidan Clark (@aidan_clark): o3-mini first try no edits, took 20 sec(told me how to convert to gif too.....)Get excited :)Quoting Ivan Fioravanti ᯅ (@ivanfioravanti) 👀 DeepSeek R1 (right) crushed o1-pro (left) 👀Prompt: "wri...
- Introduction to Operator & Agents: Begins at 10am PTJoin Sam Altman, Yash Kumar, Casey Chu, and Reiichiro Nakano as they introduce and demo Operator.
- Please add DeepSeek R1 model: Apparently better and way cheaper than Sonnet? To be seen…
- deepseek-ai (DeepSeek): no description found
- Terminal Chat: Learn how to setup and use Terminal Chat in Windows Terminal Canary.
- How to use structured outputs with Azure OpenAI Service - Azure OpenAI)): Learn how to improve your model responses with structured outputs
- Wrapper for structured outputs with non required fields)): From the doc: https://platform.openai.com/docs/guides/structured-outputs/supported-schemas Although all fields must be required […], it is possible to emulate an optional parameter by using a union...
- Trae - Ship Faster with Trae: no description found
- The Great Queers of History: no description found
- Meta genai org in panic mode | Artificial Intelligence - Blind: It started with deepseek v3, which rendered the Llama 4 already behind in benchmarks. Adding insult to injury was the "unknown Chinese company with 5..5 million training budget"Engineers are...
- NEW Deepseek-R1 Update is INSANE! (FREE!) 🤯: 🚀 Get a FREE SEO strategy Session + Discount Now: https://go.juliangoldie.com/strategy-session - PLUS get 25% extra FREE on long term contracts!🤯 Want mor...
- Paper page - UI-TARS: Pioneering Automated GUI Interaction with Native Agents: no description found
- GitHub - bytedance/UI-TARS: Contribute to bytedance/UI-TARS development by creating an account on GitHub.
- Fireworks - Fastest Inference for Generative AI: Use state-of-the-art, open-source LLMs and image models at blazing fast speed, or fine-tune and deploy your own at no additional cost with Fireworks AI!
Codeium (Windsurf) ▷ #content (1 messages):
Web Search Feature, Demo Video Launch
-
Surfing the Web Made Better: The team expressed hope that everyone is enjoying (wind)surfin' the internet with the newly launched web search feature 🏄.
- Here's the cool demo video showcasing its capabilities, which can be found here.
- Call to Action for the Demo Video: A request was made for community support, urging members to show some love on the demo video post.
- This collaboration is viewed as vital for promoting the new search feature, encouraging more interaction.
Link mentioned: Tweet from Windsurf (@windsurf_ai): Just surfin' the web! 🏄
Codeium (Windsurf) ▷ #discussion (49 messages🔥):
Codeium extension features, Devin's capabilities, Web search for Codeium, Supercomplete in Jetbrains, Windsurf updates and issues
-
Concerns over Codeium extension updates: Users are questioning if the release of Windsurf implies that Codeium extensions will be neglected, noting that some plugins haven't been updated since September.
- One response assured that there are no plans to drop the extensions as many enterprise clients rely on them, despite most innovations focusing on Windsurf.
- Devin's autonomy questioned: There were discussions around Devin's claims of being a fully autonomous AI tool, with some expressing skepticism about its long-term viability and necessity for human-in-the-loop (HITL).
- Concerns were raised that it may end up similar to a 'boy who cried wolf' situation as its actual capabilities are questioned against the hype.
- Request for web search capabilities: A user inquired about the timeline for the Codeium extension to gain web search capabilities similar to Windsurf, highlighting a desire for feature parity.
- The community expressed frustration that existing features are desirable for IDE integrations, particularly in JetBrains and other environments.
- Inquiries on Supercomplete feature: Members are curious about the return of the Supercomplete feature in the Codeium extension after noticing diminished support in IDEs.
- This has fostered discussions on feature requests and community engagement to rekindle interest in advanced functionalities.
- Permissions and access errors: Some users reported encountering a [permission_denied] error when attempting to access services, indicating potential issues with user accounts.
- This points to a broader concern about access management and possible limitations imposed by their respective teams.
Links mentioned:
- Cascade Memories: no description found
- Thoughts On A Month With Devin – Answer.AI: Our impressions of Devin after giving it 20+ tasks.
- Chrome Tutorial | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Plan Settings: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- Supercomplete for Jetbrains | Feature Requests | Codeium: I think jetbrains lack the most in the field of "consecutive action proposals". Supercomplete would be a thing that would be first-of-its-kind in this
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
Codeium (Windsurf) ▷ #windsurf (493 messages🔥🔥🔥):
Windsurf issues with credits, Windsurf login errors, Development tools and setups for mobile apps, Comparison of AI models, User experiences with Windsurf
-
Windsurf Credits Depletion Problems: Users reported significant depletion of flow credits while using Windsurf, with some stating they consumed over 10% of their monthly credits fixing errors within a few hours.
- Many expressed frustration as corrections by the AI often resulted in new errors, prompting repetitive fixes.
- Windsurf Login and Permission Issues: Several users encountered a ConnectError citing 'user is disabled by team', creating confusion and a lack of clarity regarding the source of the problem.
- Questions were raised about how to resolve these issues, but no clear solutions were provided in the discussion.
- Mobile App Development with Windsurf: Users discussed methods to preview mobile apps coded in Windsurf, highlighting workflows utilizing tools like Android Studio for building and testing applications.
- Participants exchanged tips on setting up the environment and employing Git for version control during development.
- User Feedback on AI Model Performance: Some users drew comparisons between deepseek R1 and Sonnet 3.5, noting instances where R1 outperformed Sonnet in handling certain coding tasks.
- Despite enhancements, there was skepticism about the reliability of various models, with calls for more consistent results from the AIs.
- Windsurf and Privacy Concerns: Discussions arose around the privacy policies of new tools like Trae, with users expressing reservations about the intrusive nature of data collection.
- Many users were cautious about using such tools due to perceived risks related to data privacy.
Links mentioned:
- no title found: no description found
- Home | Sweetpad: Description will go into a meta tag in
- Corey Quinn (@quinnypig.com): It's an AI best practice / horrifying troubleshooting tip to instruct the LLM to speak as if it were Elmer Fudd. When it stops doing this, it's stopped paying attention to the rules you've...
- Persistent, intelligent project memory: .cursorrules is a stopgap. What we really need is for Cursor to truly remember interactions with the user and what the project needs and auto-update this memory as the user interacts with Cursor and ...
- Tweet from Riley Brown (@rileybrown_ai): Oh my god, i'm using the r1 model in @cursor_ai and it's literally showing me the thinking before it makes changes... I actually love this as someone learning how programming works.
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Warp: The intelligent terminal: Warp is the intelligent terminal with AI and your dev team's knowledge built-in. Available now on MacOS and Linux.
- Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
- Codeium Feedback: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Merge pull request #89 from ichoosetoaccept/add-link · ichoosetoaccept/awesome-windsurf@8966b22: A collection of awesome resources for working with the Windsurf code editor - Merge pull request #89 from ichoosetoaccept/add-link · ichoosetoaccept/awesome-windsurf@8966b22
- - YouTube: no description found
- Windsurf forked VS Code to compete with Cursor. Talking the future of AI + Coding: Wes and Scott talk with Kevin Hou and Varun Mohan from Windsurf about the evolving landscape of AI in coding, and the future of software development.👉 Join ...
- Privacy Policy | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
Unsloth AI (Daniel Han) ▷ #general (347 messages🔥🔥):
DeepSeek R1 and Qwen, Multi-GPU Support in Unsloth, Fine-tuning for Non-English Languages, Tokenization Challenges in Biology, Evaluation and Training Strategies
-
DeepSeek R1 retains strong performance with Qwen: Users have noted that the distilled model, DeepSeek R1, is very effective, with one stating it's 'damn near perfect' for most use cases.
- However, tests and evaluations on specific applications are recommended before fine-tuning the model to maintain its performance.
- Multi-GPU support for Unsloth expected soon: Currently, Unsloth does not support multi-GPU operations, but upcoming updates are anticipated to address this feature.
- Pro users will be able to access multi-GPU support as it rolls out, facilitating faster training times and improved performance.
- Fine-tuning DeepSeek Qwen for non-English languages: To effectively add non-English language support to distilled DeepSeek Qwen, users should first train Qwen on the specific language before fine-tuning with additional traces.
- This approach prevents catastrophic forgetting of the original capabilities of the distilled model while enabling expanded language support.
- Challenges in biological tokenization processes: Discussions around using binary tokenization for genomics highlight the potential inefficiencies in embedding and sequence recognition.
- It is suggested that further evaluations of single, dual, and triplet tokenization could clarify performance differences in biological applications.
- Evaluating models before fine-tuning: There's an emphasis on conducting initial evaluations of models like DeepSeek R1 before proceeding with finetuning to avoid degrading performance.
- Testing and understanding model capabilities through smaller iterations can provide valuable insights for future training strategies.
Links mentioned:
- Lost in the Middle: How Language Models Use Long Contexts: While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze the performance of language models on two ta...
- Finetune Phi-4 with Unsloth: Fine-tune Microsoft's new Phi-4 model with Unsloth!We've also found & fixed 4 bugs in the model.
- Qwen 2.5 Coder - a unsloth Collection: no description found
- Tweet from Keller Jordan (@kellerjordan0): There's been community interest in having a larger NanoGPT category to speedrun. So here's a record to kick things off:-New NanoGPT-medium speedrun record: 2.92 FineWeb val loss in 29.3 8xH100...
- Unsloth - Dynamic 4-bit Quantization: Unsloth's Dynamic 4-bit Quants selectively avoids quantizing certain parameters. This greatly increases accuracy while maintaining similar VRAM use to BnB 4bit.
- togethercomputer/evo-1-131k-base · Hugging Face: no description found
- LongSafari/open-genome · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- GRPO Trainer: no description found
- GitHub - nf-core/deepmodeloptim: Stochastic Testing and Input Manipulation for Unbiased Learning Systems: Stochastic Testing and Input Manipulation for Unbiased Learning Systems - nf-core/deepmodeloptim
Unsloth AI (Daniel Han) ▷ #off-topic (24 messages🔥):
DeepSeek V3 Hardware Requirements, Dual RTX 3090s Setup, Training Reasoning Models, Dolphin-R1 Dataset, Unsloth Integration with TRL
-
DeepSeek V3 Hardware Needs Clarified: A blog post detailing the specifications for running DeepSeek V3 offline was shared, noting that you don't need a GPU for this setup.
- This model follows the R1 and is the most powerful open-source AI model available, particularly fine-tunable with Unsloth.
- Setting Up Dual RTX 3090s: Discussion arose about cases suitable for running dual RTX 3090s with suggestions for open configurations and setups.
- One user plans to run a second 3090 using an external Docker and mentioned air-controlled tents for efficient cooling.
- Repositories for Training Reasoning Models: A user asked about repositories for training reasoning models, leading to suggestions that TRL includes methods used in R1.
- Reference was made to the DeepSeekMath paper for an overview of training strategies.
- Dolphin-R1 Dataset Announcement: A user mentioned needing a sponsor for creating the Dolphin-R1 dataset, which incurred $6k in API fees, offering a detailed distillation process.
- Later, an update revealed they secured a sponsor and will publish the dataset with an Apache-2.0 license on Hugging Face.
- Building a Powerful GPU Setup: A user described their dual 4090 setup in a Corsair 7000D, highlighting the use of AIO liquid cooling and a bifurcated motherboard configuration.
- They paired this with a Ryzen 7950X for optimal performance using high-end specs like DDR5-6400 RAM.
Links mentioned:
- Tweet from Eric Hartford (@cognitivecompai): $6k in API fees to create Dolphin-R1 dataset. I follow the Deepseek-R1 distillation recipe, but with Dolphin seed data. (600k of reasoning, 200k of chat, 800k total)I want to license it Apache 2.0, ...
- Run Deepseek-R1 / R1 Zero: DeepSeek's latest R-1 model is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Learn how to run & fine-tune the model.
- GRPO Trainer: no description found
- Tweet from Eric Hartford (@cognitivecompai): I got a sponsor! Thanks @driaforall! The data will be published to @huggingface with Apache-2.0 license, in a couple days.
Unsloth AI (Daniel Han) ▷ #help (79 messages🔥🔥):
DeepSeek Distilled Models, Unsloth Notebooks, Model Fine-tuning Issues, VRAM Consumption, Dataset Management
-
Query on DeepSeek Distilled Model Template: A member shared their confusion about using the template for the new DeepSeek distilled models and asked if the output needs to be formatted in new lines.
- There was a discussion about the lack of clarity regarding system prompts and how to properly utilize the model for efficient fine-tuning.
- Unsloth Notebooks Challenges: Several members discussed ongoing issues with the Unsloth notebooks and expressed concerns about the limitations of being a small team.
- They provided links to the notebooks and discussed various model options like Phi-4 and Llama 3, highlighting the discrepancies and errors encountered.
- Issues with Model Fine-tuning: A user reported gibberish outputs when running the RAG model, leading to a discussion on the importance of using the same chat template for fine-tuning.
- The continuous evaluation of results before and after fine-tuning was emphasized, with suggestions for error management shared.
- Understanding VRAM Consumption: There was clarification that VRAM consumption during training is dependent on both model size and batch size, while dataset size influences the training duration.
- Members discussed the implications of these factors on different models and their performance in various environments.
- General Purpose Chat Datasets Inquiry: A member inquired about effective general-purpose chat datasets to mitigate catastrophic forgetting when training models.
- Their focus was on utilizing datasets that would enhance model learning consistency without overwhelming new information.
Links mentioned:
- Google Colab): no description found
- Finetune Phi-4 with Unsloth: Fine-tune Microsoft's new Phi-4 model with Unsloth!We've also found & fixed 4 bugs in the model.
- Errors | Unsloth Documentation: To fix any errors with your setup, see below:
- Errors | Unsloth Documentation: To fix any errors with your setup, see below:
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- unsloth/unsloth/kernels/fast_lora.py at d802bbf4e298cb0da1e976ab9670fbc1cbe3514c · unslothai/unsloth): Finetune Llama 3.3, Mistral, Phi-4, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #research (11 messages🔥):
Finetuning Striped Hyena Model, Unsloth GPU Support, Genomic Data Pretraining
-
Postdoc seeks to finetune Striped Hyena: A postdoc in bioML expressed a need to finetune the evo model, a Striped Hyena trained on prokaryote sequences to adapt it for eukaryotes, referencing a research paper.
- They shared the GitHub repository of the model, looking for guidance on adapting Unsloth for this task.
- Discussion on GPU resources: A member noted that Unsloth does not consider which NVIDIA GPU is being used, as multi-GPU support is not globally available yet.
- They emphasized that with access to only one GPU for training, some functionalities would be limited.
- Genomic data requires different approach: There was a discussion stating that genomic data and RNA/DNA sequences would require a different pretraining approach to identify markers and vectors effectively.
- This indicates that adapting existing models might not entirely suffice without proper retraining on the target data.
- Conversation about message relevance: A member pointed out that the original post about finetuning was not suitable for the research channel and suggested moving the conversation to a more appropriate channel.
- The initial poster acknowledged the mistake, humorously noting that research papers should indeed fit in the research channel.
Link mentioned: GitHub - togethercomputer/stripedhyena: Repository for StripedHyena, a state-of-the-art beyond Transformer architecture: Repository for StripedHyena, a state-of-the-art beyond Transformer architecture - togethercomputer/stripedhyena
LM Studio ▷ #general (173 messages🔥🔥):
DeepSeek models, LM Studio error troubleshooting, Quantization effects on model performance, Local network accessibility in LM Studio, Gemini 2.0 performance
-
Troubleshooting DeepSeek Model Loading Errors: Users reported errors such as 'unknown pre-tokenizer type' when loading models like DeepSeek R1, leading to discussions on troubleshooting steps including checking runtimes and manually updating LM Studio.
- Several users shared solutions, emphasizing the need to adjust settings and redownload models if issues persist.
- Performance and Quantization of Qwen Models: Users debated the performance of Qwen models at various quantizations, with havenwood recommending Q5_K_M for a balance of size and accuracy, while others inquired about the implications of high versus low quantization settings.
- The conversation highlighted users' experiences with different parameter sizes, emphasizing the sentiment towards higher parameters for better model performance.
- Local Network Accessibility in LM Studio: Discussion highlighted the need for clearer terminology in LM Studio's settings regarding local network accessibility, with suggestions for labeling options that clearly denote serving on all IPs versus localhost.
- Users expressed confusion over existing settings and how they affect model accessibility from various devices in a network.
- Visiting the Best Vision Models for LM Studio: Users inquired about the best vision models for LM Studio, with havenwood mentioning Llama 3.2 and the emerging UI-TARS models as options worth exploring.
- Discussions revealed challenges with using MLX and GGUF formats on specific hardware, highlighting compatibility concerns.
- Gemini 2.0 Performance Insights: Users praised the new Google Gemini 2.0 Flash model for its handling of legal documents, citing its extensive context length and attention to detail as significant improvements over previous models.
- Comparisons were made with older models like o1 mini, with Gemini being positioned as a worthy successor due to its sustained output and refined knowledge.
Links mentioned:
- Tweet from @levelsio (@levelsio): Ok went with LM Studio again
- leafspark/Llama-3.2-11B-Vision-Instruct-GGUF · Modelfile of Llama-3.2-11B-Vision-Instruct: no description found
- leafspark/Llama-3.2-11B-Vision-Instruct-GGUF · Modelfile of Llama-3.2-11B-Vision-Instruct: no description found
- LM Studio - Discover, download, and run local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
- GitHub - bytedance/UI-TARS: Contribute to bytedance/UI-TARS development by creating an account on GitHub.
LM Studio ▷ #hardware-discussion (143 messages🔥🔥):
NVIDIA RTX 5090 Performance, Llama Model Benchmarking, AVX2 Requirements for GPU Usage, AI Inference API Subsidies, Procyon AI Text Generation Benchmark
-
NVIDIA RTX 5090 shows modest performance gains: Discussions revealed that the RTX 5090 is about 30% faster than the RTX 4090, but this doesn't correspond directly to the increased 1.7x bandwidth due to potential limitations with smaller models.
- Comparison of bandwidth versus performance suggests that small models may not fully utilize the improved memory bus.
- Challenges with Llama Model Performance: Participants noted that benchmarking LLMs with models over 8B parameters tends to showcase limited gains in performance when using high-bandwidth hardware.
- Currently, Llama3 models lack comprehensive benchmarks that effectively represent real-world performance with varying GPU VRAM.
- AVX2 Limitations for Older Servers: A user shared a challenge running models on a GTX 1080 TI in a server without AVX2, raising concerns about compatibility.
- Despite having robust CPU resources, the absence of AVX2 may limit the performance gains achievable on this setup.
- API Subsidies for AI Use Cases: Discussion surrounding AI models pointed out that the most viable options for consumers may hinge on companies subsidizing models via API access, like OpenAI.
- This reflects a trend where corporations absorb the costs of hosting inference APIs to facilitate broader use of LLMs.
- Procyon AI Benchmark Tool for Simplified Testing: It's suggested to consider the Procyon AI Text Generation Benchmark for evaluating LLM performance, simplifying and providing consistent testing across models.
- This benchmarking tool aims to balance factors like quantization and model requirements, which can complicate traditional LLM performance evaluation.
Links mentioned:
- NVIDIA GeForce RTX 5090 Review: Pushing Boundaries with AI Acceleration: NVIDIA GeForce RTX 5090 Review: Launch on January 30, 2025 at $1,999. Will the 5090 redefine high-performance gaming and AI workloads?
- NVIDIA RTX Blackwell GPU with 96GB GDDR7 memory and 512-bit bus spotted - VideoCardz.com: NVIDIA preparing a workstation flagship with 96GB memory This card is said to use 3GB modules. According to a report from ComputerBase, NVIDIA’s upcoming desktop graphics card is expected ...
- Procyon AI Text Generation: Testing AI LLM performance can be very complicated and time-consuming, with full AI models requiring large amounts of storage space and bandwidth to download.
- NVIDIA RTX Blackwell GPU with 96GB GDDR7 memory and 512-bit bus spotted - VideoCardz.com: NVIDIA preparing a workstation flagship with 96GB memory This card is said to use 3GB modules. According to a report from ComputerBase, NVIDIA’s upcoming desktop graphics card is expected ...
- Reddit - Dive into anything: no description found
- NVIDIA GeForce RTX 5090 Founders Edition Review & Benchmarks: Gaming, Thermals, & Power: Sponsor: Thermal Grizzly Aeronaut on Amazon https://geni.us/e8Oq & Hydronaut (Amazon) https://geni.us/hOQrBAbThe NVIDIA GeForce RTX 5090 GPUs launch next wee...
- NVIDIA GeForce RTX 5090 Graphics Cards: Powered by the NVIDIA Blackwell architecture.
- Nvidia GeForce RTX 5090 Review, 1440p & 4K Gaming Benchmarks: Check out the Asus X870 Range here: https://www.asus.com/microsite/motherboard/amd-am5-ryzen-9000-x3d-x870e-x870-b850-b840/Support us on Patreon: https://www...
Perplexity AI ▷ #announcements (1 messages):
Perplexity Assistant Launch, Assistant Features, Integration with Other Apps
-
Perplexity Assistant launched for Android users: The Perplexity Assistant is now available on Android, marking a shift from an answer engine to an integrated assistant that can perform tasks across apps.
- Users can access it through this link and explore its abilities to assist with daily tasks.
- Assistant's unique capabilities: The Assistant can browse the web to set reminders and maintain context between actions, allowing seamless multi-app functionality.
- Whether it's booking a table at a restaurant or reminding about an event, the Assistant is designed to manage various tasks effortlessly.
- Multimodal interaction of Assistant: Users can interact with the Assistant multimodally, such as turning on the camera to ask about real-world objects.
- This feature expands the ways users can engage with the Assistant beyond just text-based commands.
- Excitement about user feedback: The team expressed enthusiasm about how users will leverage the Assistant for their daily activities.
- They look forward to seeing the creative ways users will put the Assistant's capabilities to use.
Perplexity AI ▷ #general (250 messages🔥🔥):
Perplexity Assistant Issues, Model Selection Challenges, Sonar Model Changes, AI Output Quality Comparisons, New Features in Perplexity
-
Perplexity Assistant Struggles: Users reported difficulties with the Perplexity Assistant, particularly in changing voice settings and voice activation not functioning as expected.
- Several users expressed frustration about needing to manually initiate the assistant rather than having it respond to voice commands.
- Confusion Over Model Selection: Concerns were raised regarding the removal of the Opus model from the API, with users discussing the implications for their workflows and usage preferences.
- Some users managed to work around the limitations by modifying request parameters, sparking discussions on the technicalities of model access.
- Sonar Model Eliminations: The transition of the Sonar model lineup raised eyebrows, especially the removal of Sonar Huge in favor of Sonar Large, with hints of future updates to include Sonar Pro.
- Users speculated whether these changes were linked to upcoming model launches or adjustments that might improve performance.
- Comparison of AI Output Quality: Comparisons between different models, including Claude 2 and Claude 3.5, highlighted mixed experiences, particularly with output quality and refusal rates.
- Nemoia lamented the transition from a more reliable model, citing the shift in quality and specificity in responses as a significant issue.
- New Features in Perplexity: Discussions about the new features of the Perplexity Assistant included its capability to analyze screens and perform certain tasks but faced usability challenges.
- Several users shared tips and features of the assistant, including potential customizations and its integration into daily tasks.
Links mentioned:
- Tweet from Perplexity (@perplexity_ai): Introducing Perplexity Assistant.Assistant uses reasoning, search, and apps to help with daily tasks ranging from simple questions to multi-app actions. You can book dinner, find a forgotten song, cal...
- Tweet from Sam Altman (@sama): big news: the free tier of chatgpt is going to get o3-mini!(and the plus tier will get tons of o3-mini usage)
- Revolut Launches Its Highest Savings Rates for UK Customers, of Up to 5% AER (Variable): Revolut has supercharged its rates for its UK Instant Access Savings account offering interest rates of up to 5% AER
- Tweet from Aravind Srinivas (@AravSrinivas): We are excited to launch the Perplexity Assistant to all Android users. This marks the transition for Perplexity from an answer engine to a natively integrated assistant that can call other apps and p...
- ChatGPT vs. Nelima: Which task scheduling is better?: 🚀 ChatGPT vs Nelima: The Ultimate Task Scheduling Showdown! 🚀In this video, we compare ChatGPT’s brand-new task scheduling feature with Nelima’s powerful s...
- Introduction to Operator & Agents: Begins at 10am PTJoin Sam Altman, Yash Kumar, Casey Chu, and Reiichiro Nakano as they introduce and demo Operator.
Perplexity AI ▷ #sharing (11 messages🔥):
PyCTC Decode, Mistral Plans IPO, CIA Chatbot, Stargate Initiative, DeepSeek R1
-
Exploring PyCTC Decode for Projects: A member shared their interest in PyCTC Decode for their project, highlighting its potential application.
- For more details, they referenced this link to PyCTC Decode.
- Mistral's IPO Plans Unveiled: Current discussions include Mistral's plans for an IPO, which has attracted significant attention.
- A video titled 'YouTube' discussed this development and can be viewed here.
- DeepSeek R1 Pushing Boundaries: A member indicated that the DeepSeek R1 model may outperform OpenAI's offerings in specific comparisons.
- Further insights can be found in this detailed exploration.
- Music Streaming Project Discussion: A user mentioned they are in the process of creating a music streaming platform, seeking insights and assistance.
- Relevant details regarding this endeavor are discussed in this link.
- Inquiries about AI Prompts: A member asked, What is the best AI prompt for generating effective responses?.
- This inquiry sparked several discussions, with resources shared through this link.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (11 messages🔥):
API Issues, API SOC 2 Compliance, Sonar vs Legacy Models, Retrieving Old Responses by ID, Sonar-Pro Multi-Step Goals
-
API struggles with 524 errors: Several members reported experiencing 524 errors when attempting to switch to sonar/sonar-pro on the API, indicating possible connectivity issues.
- One user noted that some requests eventually went through, suggesting intermittent problems with the API.
- API SOC 2 Compliance inquiry: A member congratulated the team on the API release and inquired about whether the API is SOC 2 compliant, stressing its importance for product integration.
- The discussion emphasizes compliance as a crucial factor for adoption in enterprise solutions.
- Questions on Sonar's functionality: A member raised the question of whether Sonar represents a substantial change from legacy models or if it is merely a rebranding.
- Another user inquired about the capabilities of sonar-pro, specifically regarding multi-step goals similar to those in Perplexity Pro Search.
- Retrieving old responses by ID: Members discussed the possibility of retrieving old responses by ID, with a suggestion to store responses in their own databases for easier access.
- This feature is seen as essential for users needing to verify API calls within their applications.
- Positive outlook on API updates: One user expressed satisfaction with the attention being given to the API and its updates, countering earlier concerns of neglect.
- This reflects a growing appreciation in the community for ongoing improvements and support.
OpenRouter (Alex Atallah) ▷ #announcements (6 messages):
Web Search API Launch, Reasoning Tokens Introduced, Web Search Pricing Update, Model Standardization Improvements, Announcement Prematurely Made
-
Web Search API Launch: The new Web Search API allows users to append
:onlineto the model name for web search functionality, priced at $4/1k results.- By default, up to 5 web results are fetched per request using Exa.ai, and users can customize the result count and prompt.
- Introduction of Reasoning Tokens: The introduction of Reasoning Tokens enables users to see how models reason directly in the Chatroom by including
include_reasoning: truein requests.
- This feature is also available via API, enhancing transparency in model reasoning.
- Web Search Pricing Update: A clarification on web search pricing was shared, indicating a charge starting at $4/1k results, with costs resulting in less than $0.02 per request.
- This pricing model will begin implementation the next day, coinciding with API access soft launching.
- Model Standardization Improvements: Recent updates include normalization of
finish_reasonacross models, using OpenAI-style explanations, with native reasons returned for clarity.
- Reasoning tokens are standardized among all reasoning models, expected to enhance consistency and usability.
- Announcement Prematurely Made: There was an acknowledgment of a premature announcement regarding updates; certain features were still in deployment.
- This prompted a humorous reaction in the chat, ensuring clarity on the ongoing changes.
Links mentioned:
- Tweet from OpenRouter (@OpenRouterAI): New LLM standard emerging: Reasoning Tokens! 🧠- you can now see how models reason directly in the Chatroom- standardized API (including finish reasons) across multiple thinking models, including Deep...
- Cheers Cheerleader GIF - Cheers Cheer Cheerleader - Discover & Share GIFs: Click to view the GIF
- Tweet from OpenRouter (@OpenRouterAI): Another launch today: the Web Search API!Add grounding to any model by simply appending ":online" 🌐
OpenRouter (Alex Atallah) ▷ #general (244 messages🔥🔥):
Deepseek R1, API Features and Issues, Web Search Pricing, Model Performance Comparisons, Payment Methods for Credits
-
Deepseek R1 struggles with responsiveness: Users reported that Deepseek-provided R1 is hanging and failing to return responses from both Deepseek and DeepInfra, indicating potential service issues.
- One user questioned if the lack of response was due to inherent model problems.
- API Key Issues and Charges: A user encountered a problem where their API key for Mistral wasn't being prioritized, resulting in charges on their credits instead of using the integration settings.
- Other users speculated that additional charges related to OpenRouter might be complicating the issue.
- Web Search Pricing Explained: The new pricing for web search queries indicates a charge of $0.02 for each web result, which adds to the overall usage costs.
- Users expressed confusion about the implications of the web search feature on their API usage and billing.
- Discussions on Model Performance: Participants discussed the capabilities of distilled models, noting that while some models do not 'think', they still outperform older models like O1 Mini and Claude.
- There was some skepticism about the performance differences and the effectiveness of various model implementations.
- Payment Method Alternatives for Credits: A user inquired about alternative methods for purchasing credits, especially given that available methods were not suitable for their country.
- It was mentioned that credits could be purchased using cryptocurrency through OpenRouter's interface, providing a workaround for some users.
Links mentioned:
- kluster.ai - Power AI at scale: Large scale inference at small scale costs. The developer platform that revolutionizes inference at scale.
- Introducing Citations on the Anthropic API: Today, we're launching Citations, a new API feature that lets Claude ground its answers in source documents.
- Web Search | OpenRouter: Model-agnostic grounding
- Tweet from Anthropic (@AnthropicAI): Introducing Citations. Our new API feature lets Claude ground its answers in sources you provide.Claude can then cite the specific sentences and passages that inform each response.
- DeepSeek R1 Distill Llama 70B - API, Providers, Stats: DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](https://openrouter. Run DeepSeek R1 Distill Llama 70B with API
- no title found: no description found
- Reddit - Dive into anything: no description found
- no title found: no description found
- Crypto Payments API | OpenRouter: APIs related to purchasing credits without a UI
- DeepSeek R1 - API, Providers, Stats: DeepSeek R1 is here: Performance on par with OpenAI o1, but open-sourced and with fully open reasoning tokens📖 Fully open-source model & [technical report](https://api-docs.deepseek...
- Requests | OpenRouter: Handle incoming and outgoing requests
aider (Paul Gauthier) ▷ #general (154 messages🔥🔥):
Aider Configuration, DeepSeek R1 Performance, Using Multiple LLMs, Chat Mode Operations, Citations API from Anthropic
-
Aider Configuration for Multiple LLMs: Users discussed configuring Aider to utilize different LLMs for coding and architectural tasks using the
aider.conf.yamlfile, setting specific models for both roles.- It was clarified that switching chat modes to
codeignores the editor model specified in the config, defaulting to the architect model for both roles. - DeepSeek R1 Performance Issues: Several users expressed frustration with DeepSeek R1's syntax handling and performance, noting issues with context capacity and accuracy while coding.
- Some users found that providing selective context rather than entire files helped maintain performance, while others reported mixed results across different tasks.
- Using Multiple LLMs with Ollama: There were inquiries about effectively routing questions to specific LLMs when using Ollama, with some users successfully starting two LLMs for that purpose.
- Discussions included the benefits of using custom prompts and memory banks to manage context, leading to improved performance in coding tasks.
- Chat Mode Operations in Aider: The importance of setting the correct chat mode in Aider was emphasized, with operational commands like
/chat-mode codeor/chat-mode architectallowing users to switch between modes.
- It was mentioned that the default load settings determine the initial mode, and users can pivot between modes as needed during their workflow.
- Citations API from Anthropic: A new feature from Anthropic allows for source citation in responses, enhancing trustworthiness and verifiability of AI-generated outputs.
- This addresses prior complexities with prompt engineering, providing a straightforward method for referencing sources integrated with Claude's responses.
- It was clarified that switching chat modes to
Links mentioned:
- Introducing Citations on the Anthropic API: Today, we're launching Citations, a new API feature that lets Claude ground its answers in source documents.
- Prompt Engineering Guide: A Comprehensive Overview of Prompt Engineering
- DeepSeek R1: API Provider Performance Benchmarking & Price Analysis | Artificial Analysis: Analysis of API providers for DeepSeek R1 across performance metrics including latency (time to first token), output speed (output tokens per second), price and others. API providers benchmarked inclu...
- 人間によるコーディング禁止の CLINE 縛りでゲームを作らせてみた感想: no description found
- Coding with AI episode 1: Claude Sonnet 3.5 vs DeepSeek v3 for coding analysis and modifications: NOTE: Make sure to turn subtitles (manually edited) on. My English accent is hard to follow especially if I'm tired.We will use the kilo editor as a test cas...
- DeepSeek R1 Fully Tested - Insane Performance: Open source stays winning!Vultr is empowering the next generation of generative AI startups with access to the latest NVIDIA GPUs! Try it yourself when you v...
- Reasoning Model (deepseek-reasoner) | DeepSeek API Docs: deepseek-reasoner is a reasoning model developed by DeepSeek. Before delivering the final answer, the model first generates a Chain of Thought (CoT) to enhance the accuracy of its responses. Our API p...
- FuseAI/FuseO1-DeepSeekR1-Qwen2.5-Coder-32B-Preview-GGUF · Hugging Face: no description found
- Feature: Add GitHub Copilot as model provider · Issue #2227 · Aider-AI/aider: Issue Hello! Please add GitHub Copilot as model provider. Should be possible like this: https://github.com/olimorris/codecompanion.nvim/blob/5c5a5c759b8c925e81f8584a0279eefc8a6c6643/lua/codecompani...
- no title found: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (79 messages🔥🔥):
Aider Installation Issues, Using Aider with Docker, Aider Logging Practices, Aider and Large Codebases, Models for Aider Usage
-
Complex Aider Installations Cause Frustration: Members discussed issues with Aider installations, particularly when using multiple package managers like Conda and Brew, leading to confusion over versioning.
- One user reported having to delete numerous helper files before a successful reinstall of Aider was achieved.
- Aider Capability with File Access: Inquiries were made about Aider's ability to access files and directories, leading to clarifications that Aider can see files within git repositories but may require explicit commands to read them.
- It was noted that Aider uses terminal output heavily, which can complicate the workflow if not managed properly.
- Optimizing Logging for Aider: Users suggested implementing a logging system that writes outputs to a file, minimizing token usage and context bloat when using Aider.
- This allows for efficient tracking of project logs without the need for excessive copying between terminals.
- Handling Outputs in Aider for Large Codebases: Discussions highlighted challenges of managing terminal command outputs in Aider when working with large codebases.
- Members discussed the potential of cleaner output management methods to prevent context overload during lengthy command sequences.
- Recommendations for Aider Models: Users sought recommendations for effective models to use with Aider that provide good performance relative to cost.
- There was a general curiosity about optimizing model selection to enhance the productivity of Aider.
Link mentioned: Installation: How to install and get started pair programming with aider.
aider (Paul Gauthier) ▷ #links (10 messages🔥):
JetBrains AI, Cursor & Windsurf competition, VSCode vs JetBrains, Continue feature use, User waitlist inquiries
-
JetBrains joins the AI game?: A member expressed hope after joining the JetBrains AI waiting list, questioning if JetBrains can finally compete in the AI space, given past failures.
- They lost many users to Cursor and Windsurf due to earlier disappointments.
- JetBrains remains favored despite AI struggles: Despite concerns around their AI capabilities, a member stated JetBrains remains their favorite IDE provider, contrasting it negatively with VSCode.
- This sentiment reinforces a strong preference for JetBrains tools among some professionals, regardless of AI performance.
- JetBrains users still rely on IDEs: Another individual noted that professionals continue to use JetBrains tools, affirming their utility even without AI enhancements.
- They also mentioned the Continue feature is functional within JetBrains, showing ongoing commitment from users.
- User migration trends: Discussion centered on user migration, suggesting that the majority have left JetBrains for VSCode, while Windsurf is also noted to be drawing users away.
- This reflects ongoing challenges for JetBrains amidst rising competition in the IDE space.
- Inquiry about the waiting list: A user questioned which waitlist was being referenced in the conversation, indicating a lack of clarity on the subject.
- This highlights potential communication gaps regarding JetBrains' current offerings and developments.
OpenAI ▷ #annnouncements (1 messages):
Operator introduction, OpenAI presentation
-
Operator Unveiling by OpenAI Team: Join Sam Altman, Yash Kumar, Casey Chu, and Reiichiro Nakano as they introduce and demo Operator on YouTube. The presentation starts at 10am PT.
- Don't miss out on this exciting demonstration of new features and capabilities!
- Get Ready for the Operator Demo: Mark your calendars for the unveiling of the Operator tool led by OpenAI's top executives.
- This introductory session promises to showcase key functionalities that enhance user engagement.
OpenAI ▷ #ai-discussions (170 messages🔥🔥):
DeepSeek R1 Performance, Operator Features, Usage of Perplexity Assistant, OpenAI API Comparisons, Spiking Neural Networks Discussion
-
DeepSeek R1 surpasses O1 in coding tasks: Users reported that DeepSeek R1 delivered better coding solutions compared to O1, even preferring it in side-by-side comparisons.
- One user humorously noted how R1 turned a random prompt about a 'POTATO THUNDERSTORM!' into an elaborate response.
- Operator allows web browser interactions: The Operator feature enables interaction with a web browser, providing a new capability for users at a subscription cost of $200/month.
- Currently, it is only available through web browsers, and users cannot select which browser is utilized for its operations.
- Perplexity Assistant praised over OpenAI offerings: A user mentioned that the Perplexity Assistant performs better on mobile than OpenAI's current mobile solutions.
- This sparked a discussion on the general quality of user experiences between various AI offerings, highlighting a dissatisfaction with competitors.
- OpenAI subscription concerns: Participants debated the fairness of OpenAI's pricing, particularly for features that appear to offer substantial benefit.
- One user suggested that with the current prices, the company's name 'Open AI' might no longer be fitting.
- Varying opinions on spiking neural networks: A member posed questions about the viability of spiking neural networks, weighing their efficiency against potential latency issues.
- This prompted a conversation on how they may represent either a deadend in some aspects or a useful tool in others for future projects.
Links mentioned:
- ChatGPT vs. Nelima: Which task scheduling is better?: 🚀 ChatGPT vs Nelima: The Ultimate Task Scheduling Showdown! 🚀In this video, we compare ChatGPT’s brand-new task scheduling feature with Nelima’s powerful s...
- Trae - Ship Faster with Trae: no description found
- TikTok made an IDE and it's actually good? (free cursor killer??): Byte Dance, the Tik Tok company made a code editor and its actually good?!?! RIP Cursor? VS Code killer? Jetbrains clone? Idk what's happening anymore...Than...
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
GPT Outage, Voice Feature Issues, Status Updates, Attributing Blame for Downtime
-
GPT Facing Outage Issues: Members expressed frustrations as GPT went down, with mentions of bad gateway errors and users unable to access services.
- One member humorously commented, 'Rip the night or day shift team' in response to the situation.
- Voice Features Not Available: A user questioned if the outage was the reason behind the unavailability of the voice feature in GPT.
- Another member confirmed their own inability to use the voice, reinforcing the connectivity problems.
- OpenAI Status Updates: The current status from OpenAI's status page indicates fixes have been implemented and they are monitoring the results, although issues persist.
- Earlier updates showed the problem being identified and worked on, suggesting ongoing interruptions.
- Humorous Blame Game for Downtime: A member facetiously blamed LeBron James and Ronaldo for the GPT downtime, prompting agreement from others.
- This light-hearted comment reflected the community's coping mechanism during the service disruption.
Link mentioned: OpenAI Status: no description found
OpenAI ▷ #prompt-engineering (14 messages🔥):
OCR use cases, GIS datasets improvement, Task prompt sharing, ASMR meta-prompts, Content creation strategies
-
OCR challenges for reading maps: A member highlighted that using examples for OCR may actually promote hallucinations instead of improving accuracy, especially in unconstrained spaces.
- Another member shared their workaround for reading maps but expressed hope that OpenAI's models will improve for spatial datasets.
- Creative Task Prompts for Content: A member provided a detailed prompt for generating content for posters and social media, combining marketing skills with a persuasive tone to ensure high-quality outputs.
- They emphasized the importance of human-like responses while maintaining professionalism and few grammatical errors.
- Exploring Task Prompts for Inspiration: A user expressed interest in discovering new task prompts and mentioned working on concepts like a daily news digest and corporate event calendar.
- They aimed to push ChatGPT to its limits by maximizing its features and functionality.
- Innovative ASMR Meta-Prompt for Sleep: A member discussed using a unique task meta-prompt for ASMR that incorporates onomatopoeia as a soothing mechanism for sleep.
- They acknowledged the nonstandard nature of this use case, sparking interest among others in the channel.
- Sharing Resources within the Community: Conversation ensued about sharing creative prompts and resources but was met with uncertainty about the appropriateness of mentioning personal servers.
- Members expressed willingness to contribute and explore each other's work while remaining mindful of community guidelines.
OpenAI ▷ #api-discussions (14 messages🔥):
Using prompts effectively, Task prompts for GPT, ASMR meta-prompts, Content creation for social media, Daily news digests
-
Discussion on Using Prompts Effectively: A member shared a complex prompt for creating posters and social media content that emphasizes human-like responses and corporate jargon.
- This includes a double prompt structure specifically for advertising, suggesting a serious and professional tone.
- Exploring Task Prompts for Inspiration: A member expressed interest in discovering unique task prompts to broaden their use of ChatGPT's features, mentioning concepts like daily news digests and corporate event calendars.
- The inquiry prompted offers to create or share ideas, with a focus on maximizing the capabilities of ChatGPT.
- Innovative ASMR Prompt Use Case: One member noted their use of a task meta-prompt for creating ASMR content featuring onomatopoeia, though they couldn't share it verbatim due to formatting restrictions.
- This unique application of prompts showcases a nonstandard use case for ChatGPT.
Yannick Kilcher ▷ #general (160 messages🔥🔥):
AI Model Limitations, National Energy Emergency Declaration, Employment Opportunities in AI, OpenAI's Future Plans, Math Problem Solving with LLMs
-
AI Models Struggle with Geometric Reasoning: Users discussed the limitations of LLMs when solving geometry problems, specifically how many lines are needed to cover a 3x3 grid, with some models consistently providing incorrect answers.
- They noted that the accuracy and reasoning ability often depend on the specificity of the prompts used.
- Trump's Energy Emergency Declaration: President Trump announced a national energy emergency aimed at maximizing the U.S.'s energy resources and positioning the country as a leader in manufacturing and AI.
- This declaration emphasizes the connection between energy resources and advancements in AI technology.
- Job Opportunities at Rav.ai: A member from rav.ai indicated that their team offers roles to work on foundation models and AI, emphasizing a collaborative environment with substantial funding.
- They mentioned variety in work opportunities covering everything from hardware to AI research, targeting interested developers and researchers.
- OpenAI's Upgrades for ChatGPT: Sam Altman hinted that the free tier of ChatGPT will soon include the o3-mini upgrade, while the Plus tier will have enhanced access.
- This change responds to growing demand for improved capabilities in OpenAI's offerings.
- Engagement with AI Problem-Solving: Members shared their experiences of using LLMs to tackle mathematical problems, while emphasizing the importance of constraints in prompt formulation.
- They agreed that a more detailed examination of reasoning methodology proves to be a better measure of an AI's capabilities.
Links mentioned:
- Tweet from Sam Altman (@sama): big news: the free tier of chatgpt is going to get o3-mini!(and the plus tier will get tons of o3-mini usage)
- Open Positions - Tufa Labs: no description found
- Wikipedia, the free encyclopedia: no description found
- Tweet from Tsarathustra (@tsarnick): OpenAI's Brad Lightcap: "o1 is almost like a portal to GPT-7, GPT-8... [it] gives you the effective compute of what a GPT-7 or GPT-8 would... it's a pure discontinuity on the scaling"
- Minimum number of straight lines to cover $n \times n$ grid?: I want to know the minimum number of lines needed to touch every square of an $n \times n$ grid. The only added rule is that the line has to pass inside the square, not on the edge/corner. I have f...
- Tweet from Tsarathustra (@tsarnick): President Trump says he has declared a national energy emergency to unlock the United States' energy resources and make the US "a manufacturing superpower and the world capital of artificial i...
- Tweet from AshutoshShrivastava (@ai_for_success): Elon vs. Sam Altman is getting nasty. Is Sam Altman trying to imply that Elon and his companies don’t put America first, while OpenAI does?Let’s not forget that OpenAI’s board now includes BlackRock e...
- Tweet from Paul Calcraft (@paul_cal): OpenAI's @SebastienBubeck on the o1 paradigm:"No tactic was given to the model. Everything is emergent. Everything is learned through reinforcement learning. This is insane. Insanity"Quoti...
- Tweet from Sam Altman (@sama): stargate site 1, texas, january 2025.
- Tweet from Sam Altman (@sama): big. beautiful. buildings.
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
DeepSeek memory requirements, Generalized Spatial Propagation Network, Reinforcement Learning reward hacking
-
Memory Requirements for DeepSeek Models: To run the R1 Distilled Qwen 2.5 32B model in float16 format, a minimum of 64GB (V)RAM is required, or 32GB for q8, according to the discussion on parameter sizes.
- A member confirmed that 7 billion parameters at 16-bit require approximately 14 billion bytes of memory, plus extra for context windows.
- GSPN Tackles Attention Mechanism Limitations: The Generalized Spatial Propagation Network (GSPN) offers a new attention mechanism designed to optimize vision tasks by capturing 2D spatial structures, thereby enhancing computational efficiency.
- Central to GSPN is the Stability-Context Condition, which significantly reduces effective sequence length to \sqrt{N}, making it more context-aware for image data.
- Peer Review Call for GSPN Implementation: A member has implemented the GSPN concept in PyTorch and has shared the code for peer review, suggesting it is a straightforward approach.
- They expressed that since NVIDIA authored the paper, the implementation might hold considerable merit, inviting input from others.
- Exploring MONA in Reinforcement Learning: A new training method, Myopic Optimization with Non-myopic Approval (MONA), aims to prevent agents from executing undesired multi-step reward hacks in reinforcement learning setups.
- The method combines short-sighted optimization with far-sighted reward strategies and is empirically tested in varying environments to address misalignment issues.
Links mentioned:
- MONA: Myopic Optimization with Non-myopic Approval Can Mitigate Multi-step Reward Hacking: Future advanced AI systems may learn sophisticated strategies through reinforcement learning (RL) that humans cannot understand well enough to safely evaluate. We propose a training method which avoid...
- Parallel Sequence Modeling via Generalized Spatial Propagation Network: We present the Generalized Spatial Propagation Network (GSPN), a new attention mechanism optimized for vision tasks that inherently captures 2D spatial structures. Existing attention models, including...
Yannick Kilcher ▷ #agents (1 messages):
IntellAgent, Conversational Agents Evaluation, Research Insights
-
IntellAgent Launches Open-Source Framework: The new open-source project, IntellAgent, is designed for evaluating conversational agents by generating diverse datasets from the agent's prompt, leading to simulated conversations.
- Its GitHub repository provides a complete framework focusing on comprehensive diagnosis and evaluation.
- In-Depth Analysis through Simulation: IntellAgent simulates conversations between a user-playing agent and the tested agent, coupled with a critique component for fine-grained analysis.
- This innovative method enhances the evaluation process, providing clearer insights into conversational dynamics.
- Research Paper Reveals Fascinating Insights: Accompanying the project is a research paper that uncovers several fascinating non-trivial insights generated by the IntellAgent system.
- These insights offer valuable contributions to the understanding of conversational agent capabilities.
Link mentioned: GitHub - plurai-ai/intellagent: A framework for comprehensive diagnosis and evaluation of conversational agents using simulated, realistic synthetic interactions: A framework for comprehensive diagnosis and evaluation of conversational agents using simulated, realistic synthetic interactions - plurai-ai/intellagent
Yannick Kilcher ▷ #ml-news (10 messages🔥):
OpenAI Operator, Kanye West AI Project, ChatGPT Free Tier Updates, Humanity's Last Exam, R1 Competitive Landscape
-
OpenAI Prepares to Launch 'Operator': OpenAI is gearing up to release a new feature called Operator that will take actions in users' browsers, providing suggested prompts and allowing task saving/sharing but it's not available in the API.
- This feature is set to release this week, as shared in a tweet by @steph_palazzolo.
- Kanye West Seeks 'Wizards' for AI Project: Kanye West announced that his Yeezy company is actively seeking talents for their AI project, calling for 'WIZARDS ONLY' to join the team.
- Interested parties are encouraged to send portfolios and CVs to participate in the creative endeavor, as reported by VICE.
- ChatGPT Free Tier Gains o3-mini Access: Big updates: the free tier of ChatGPT will soon incorporate o3-mini, while Pro users will have access to extensive usage of the feature.
- This announcement by @sama indicates intensified competition possibly fueled by recent developments.
- Call for Submissions to 'Humanity's Last Exam': The project Humanity's Last Exam is still receiving questions and contributions but clarifies that new submissions won't be eligible for the prize pool.
- Details and citations for participation can be found on the project's website.
- R1's Impact on AI Landscape: Discussions ensued about how the recent success of R1 might be influencing other AI developments, with some speculating it could be driving OpenAI's strategy.
- The unexpected performance of R1 has spurred competition and prompted reflections on efficiency in server tech.
Links mentioned:
- Tweet from Sam Altman (@sama): big news: the free tier of chatgpt is going to get o3-mini!(and the plus tier will get tons of o3-mini usage)
- Tweet from Stephanie Palazzolo (@steph_palazzolo): Scoop: OpenAI is prepping to release "Operator," a new ChatGPT feature that will take actions on behalf of users in their browsers, this week.Interesting details:- Operator provides suggested ...
- Kanye West Seeking 'Wizards Only' for Ambitous AI Project: Kanye West is a man who often has a lot of irons in the fire, and now he's apparently working on his own artificial intelligence project.
- Humanity's Last Exam: no description found
Nous Research AI ▷ #general (162 messages🔥🔥):
AI and AGI Predictions, AI Implementation for Companies, Olweus Bullying Victimization Questionnaire, GPU Comparisons and Choices, Model Training Strategies
-
Industry Insiders Reassess AGI Timeline: Some industry insiders, previously skeptical about reaching AGI, now think it's achievable within 5 years with a greater than 90% probability.
- This comes with the acknowledgment that AI will indeed be economically disruptive in the near future.
- Challenges in AI Implementation for Companies: Discussion centers around whether companies prefer in-house AI solutions or external agencies, alongside the need for specialized skills.
- Leaders often misunderstand the technology, which can lead to fear of upfront costs and ongoing expenses.
- Understanding the Olweus Bullying Questionnaire: A participant seeks assistance in understanding the scoring system of the Olweus Bullying Victimization Questionnaire for their study.
- They are particularly focused on calculating averages and categorizing bullying risk levels based on heart rate variations.
- Choosing Between GPUs for Machine Learning: A conversation about the pros and cons of purchasing 5090 GPUs versus waiting for the unreleased RTX Blackwell and considering A100s.
- Factors such as memory bandwidth, PCIe speeds, and future scalability with existing hardware are heavily considered.
- Exploring Training Strategies with Distributed Resources: Participants discuss strategies for speeding up training on multiple GPUs, including the use of DiStRo and various parallelism methods.
- The importance of GPU memory and the implications of using multiple machines versus cards without NVLink is highlighted.
Links mentioned:
- Tweet from Ronan (@Ronangmi): @dylan522p (leading AI researcher) was asked about what spaces in the AI startup world he is is excited about. his first answer? distributed training and inference. in particular, @NousResearch and @...
- Tweet from Pietro Schirano (@skirano): By the way, you can extract JUST the reasoning from deepseek-reasoner, which means you can send that thinking process to any model you want before they answer you. Like here where I turn gpt-3.5 turbo...
- Tweet from Smoke-away (@SmokeAwayyy): Andrej Karpathy: "What you want is the inner thought monologue of your brain... The trajectories in your brain as you're doing problem solving, if we had a billion of that, AGI is here roughly...
- Tweet from Mahesh Sathiamoorthy (@madiator): Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe. The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchma...
- How blockchains could change the world: Ignore Bitcoin’s challenges. In this interview, Don Tapscott explains why blockchains, the technology underpinning the cryptocurrency, have the potential to revolutionize the world economy.
- Tweet from Teknium (e/λ) (@Teknium1): I am seeking two engineers for the post training team at Nous Research to build the future of generally capable models, explore cognizant, creative models, and advance state of the art reasoning and a...
- Tweet from Sun 乌龟 💖 (@suntzoogway): Guys this is a parody I wrote up!Just trying to hyperstition a good future (I'm trapped in EU regulatory hell)
- MisguidedAttention/eval/harness at main · cpldcpu/MisguidedAttention: A collection of prompts to challenge the reasoning abilities of large language models in presence of misguiding information - cpldcpu/MisguidedAttention
Nous Research AI ▷ #ask-about-llms (6 messages):
Synthetic Data Generation, R1 Dataset Availability, Olweus Bullying Victimization Questionnaire
-
Searching for Guides on Synthetic Data Do's and Don'ts: One member inquired about useful guides on the do's and don'ts of generating synthetic data for finetuning purposes.
- The quest for these resources indicates a growing need for clear best practices in the field.
- Availability of R1 Dataset: A member asked if the R1 dataset used for distilled models is available, prompting confirmation from another member that a few are accessible.
- This leads to a following inquiry about where to find them, showing there may be confusion surrounding dataset access.
- Understanding the Olweus Bullying Victimization Questionnaire Scoring: A member sought clarity on the scoring system of the Olweus Bullying Victimization Questionnaire, aiming to categorize scores into low, medium, and high chances of bullying.
- They provided related documents and requested assistance from others with expertise to corroborate their understanding of the scoring process.
Nous Research AI ▷ #research-papers (4 messages):
Human-AI representation similarities, Diffusion models optimization
-
Human-AI representation alignment discovered: MIT researchers showed that many artificial neural networks (ANNs) trained on naturalistic data align with neural representations from biological systems, indicating a convergence in representations.
- They developed a method that identifies stimuli affecting model-to-brain alignment, demonstrating a core component of representation universality that aids in uncovering biological computations.
- Optimizing diffusion models' training efficiency: A recent study proposes a method to improve training efficiency of diffusion models by using predefined routes to retain information, avoiding the inefficiency of token discarding.
- This optimization can be applied across various architectures, including both transformer-based and state-space models, enhancing their computational effectiveness.
Links mentioned:
- TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training: Diffusion models have emerged as the mainstream approach for visual generation. However, these models usually suffer from sample inefficiency and high training costs. This issue is particularly pronou...
- Universality of representation in biological and artificial neural networks: no description found
Nous Research AI ▷ #interesting-links (3 messages):
Evabyte Architecture, Tensor Network ML Library, Symbolic Reasoning in ML, Graph Isomorphism Optimization
-
Evabyte's Chunked Attention Mechanism: The Evabyte architecture utilizes a fully chunked linear attention method that compresses the attention footprint alongside multi-byte prediction for optimized throughput. For detailed implementation, refer to the source on GitHub.
- An illustrative sketch highlights this architecture.
- Innovative Tensor Network Library: A new ML library based on tensor networks has been developed, featuring named edges instead of numbered indices for intuitive tensor operations like convolutions. Users can effortlessly connect edges in operations like
kernel @ h_conv @ w_convwithout worrying about tensor manipulations.
- Additionally, this library employs symbolic reasoning and matrix simplification, outputting optimized compiled torch code, enhancing performance with techniques like common subexpression elimination in both forward and backward passes.
- Request for Feedback on Tensor Library: The creator of the tensor network ML library is seeking user feedback to improve usability, inviting users to give it a spin and share their experiences. The library promises various advanced features, including symbolic expectation calculations relative to variables.
- This innovative tool aims to streamline tensor operations while providing intricate enhancements that could greatly benefit ML workflows.
Links mentioned:
- GitHub - thomasahle/tensorgrad: Tensor Network Library with Autograd: Tensor Network Library with Autograd. Contribute to thomasahle/tensorgrad development by creating an account on GitHub.
- evabyte/evabyte_hf/eva.py at ba8f65c5fe502b7ed07f916773754734b91b52fd · OpenEvaByte/evabyte: EvaByte: Efficient Byte-level Language Models at Scale - OpenEvaByte/evabyte
Nous Research AI ▷ #research-papers (4 messages):
Human-AI Representation Alignment, Optimization for Diffusion Models
-
Human-AI Systems Converge on Similar Representations: Research by MIT authors shows that high-performing artificial neural networks (ANNs) and biological systems converge on similar representations when trained with ecologically plausible objectives on naturalistic data, as outlined in their study.
- They established that model-to-brain alignment can be predicted through varying degrees of inter-model agreement across language and vision stimuli.
- Innovative Training Efficiency for Diffusion Models: A recent paper discusses a novel method to enhance the training efficiency of diffusion models by utilizing predefined routes to retain information instead of discarding it, allowing for deeper layer integration, as linked here.
- This approach not only addresses sample inefficiency but is also adaptable to non-transformer architectures, showcasing significant optimizations without altering the underlying training structure.
Links mentioned:
- TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training: Diffusion models have emerged as the mainstream approach for visual generation. However, these models usually suffer from sample inefficiency and high training costs. This issue is particularly pronou...
- Universality of representation in biological and artificial neural networks: no description found
Nous Research AI ▷ #reasoning-tasks (1 messages):
lowiqgenai: Hey i did some using MistralAI free Services fhai50032/medmcqa-solved-thinking-o1
Stackblitz (Bolt.new) ▷ #announcements (1 messages):
katetra: https://x.com/boltdotnew/status/1882483266680406527
Stackblitz (Bolt.new) ▷ #prompting (1 messages):
cwinhall: You need to connect supabase. It's trying to use that for the database
Stackblitz (Bolt.new) ▷ #discussions (143 messages🔥🔥):
Bolt and Stripe Integration, Token Allocation Issues, Chat Persistence Problems, 3D Model Viewer Implementation, Payment System Suggestions
-
Challenges with Stripe Webhook Implementation: A user has been experiencing a 401 error while implementing a Stripe webhook combined with a Supabase edge function that has left them frustrated after extensive debugging.
- They discovered the cause was an incorrect JWT configuration set to
verify_jwt = true, leading to progress being made towards a functioning integration. - Concerns over Token Allocation: Users have expressed confusion regarding their token allocation, specifically with the daily distribution changing from 300k to 150k after subscribing to a paid plan.
- It's suggested that free plans receive daily tokens while paid plans may not, prompting users to seek clarification and rectify their token usage.
- Persisting Chat Issues in Bolt: A user raised concerns about chats not persisting, and the need to delete and reopen them via StackBlitz causes additional bugs.
- Users are looking for effective solutions to keep chat logs intact without causing further complications.
- Seeking Help with 3D Model Viewer Code: A user attempted to create a webpage featuring a 3D model viewer using a specified GLB file but reported seeing only a white screen during the implementation.
- Further guidance included suggestions to integrate the model viewer via code from Google Model Viewer to resolve the display issue.
- Suggestions for Payment Integration Improvements: One user proposed creating systems for webhook acceptance and proposal for a Discord login feature to enhance user experience on the platform.
- They also mentioned incentivizing Discord invites through token draws, signaling a desire for improved community engagement.
- They discovered the cause was an incorrect JWT configuration set to
Links mentioned:
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Get started with StackBlitz - StackBlitz: no description found
- READ THIS FIRST: Critical information about Bolt.new's capabilities, limitations, and best practices for success
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- bolt.new: no description found
- Cursor Directory: Find the best cursor rules for your framework and language
Latent Space ▷ #ai-general-chat (139 messages🔥🔥):
OpenAI Operator Launch, Imagen 3 performance, DeepSeek model advancements, Fireworks AI transcription service, API revenue sharing
-
OpenAI Launches New Operator for Automation: OpenAI introduced Operator, an agent designed to autonomously perform tasks using its own browser, allowing real-time user interaction and workflow management.
- Initial reactions highlight its capabilities but raise questions about security and the potential for increased CAPTCHA challenges.
- Imagen 3 Claims Top Spot in Text-to-Image Arena: Google’s Imagen 3 has debuted at the top of performance metrics, surpassing competitor Recraft-v3 by a significant margin, showcasing advancements in text-to-image generation.
- The model was praised for handling specific prompts effectively, demonstrating the progress in AI-generated imagery.
- DeepSeek Revolutionizes RAG with Fast, Cost-Effective Solutions: DeepSeek is enabling a new approach to retrieval-augmented generation (RAG) by allowing users to feed extensive documents directly into the model for relevance checks, achieving remarkable efficiency.
- This method, leveraging KV caching and high-speed processing, reportedly outperforms traditional RAG strategies and opens up new possibilities for large-scale document handling.
- Fireworks AI Launches Competitive Streaming Transcription Service: Fireworks AI announced a new streaming transcription service that boasts features comparable to leading models while offering a competitive price point of $0.0032 per audio minute post-free trial.
- This service aims to provide high-quality transcription with low latency, positioning itself as a viable alternative to existing solutions.
- Discussion on API Revenue Sharing Models: The conversation explored whether any model company shares revenue from API usage with users, noting that OpenAI does not count API use as part of ChatGPT subscriptions.
- Participants expressed interest in financial transparency regarding model API use and revenue sharing, highlighting a gap in current practices.
Links mentioned:
- Tweet from Noam Brown (@polynoamial): The feeling of waking up to a new unsaturated eval.Congrats to @summeryue0, @alexandr_wang, @DanHendrycks, and the whole team!Quoting Dan Hendrycks (@DanHendrycks) We’re releasing Humanity’s Last Exam...
- Tweet from Anthropic (@AnthropicAI): Introducing Citations. Our new API feature lets Claude ground its answers in sources you provide.Claude can then cite the specific sentences and passages that inform each response.
- Tweet from Mark Chen (@markchen90): It's a SoTA model (on OSWorld, WebArena, WebVoyager) and it feels that way when you play with it!Apply to the CUA team here: https://openai.com/careers/research-engineer-research-scientist-compute...
- Tweet from Jacques (@JacquesThibs): guy who says uni exams don’t test the real-world and complains about useless CS grads but then builds an AI benchmark like some boring exam
- Tweet from Swaroop Mishra (@Swarooprm7): This is a good benchmark created adversarially with model in the loop and with expert verification. Also, there is an option to submit errors if spotted.I created a few questions and liked the data cr...
- Tweet from Lucas Nestler (@_clashluke): Wake up babeNew MoE scaling laws dropped
- Tweet from Jerry Liu (@jerryjliu0): LlamaIndex is now, more than ever, a full-fledged agents framework. 🤖🛠️Today I’m excited to introduce AgentWorkflows - a new set of abstractions that allows you to setup event-driven, async-first, m...
- Tweet from Harrison Chase (@hwchase17): ⭐️Want an open source version of OpenAI's Operator?There's a great open source project called Browser Use that does similar things (and more) while being open sourceAllows you to plug in any m...
- ZombAIs: From Prompt Injection to C2 with Claude Computer Use: In news that should surprise nobody who has been paying attention, Johann Rehberger has demonstrated a prompt injection attack against the new Claude [Computer Use](https://simonwillison.net/2024/Oct/...
- Tweet from Yilong Qin (@yilongqin): As we enter the world of test-time compute, we are seeing increasing returns by simply letting our agents do their thing for longer.For the first time, we are running our agent for hundreds of steps o...
- Tweet from Fireworks AI (@FireworksAI_HQ): We’re launching a streaming transcription service! Generate live captions or power voice agents with Whisper-v3-large quality with 300ms latency. Use it FREE for the next two weeks and then at $0.0032...
- We Tried OpenAI’s New Agent—Here’s What We Found: Operator (Could you help me do this task?)
- Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models: Scaling the capacity of language models has consistently proven to be a reliable approach for improving performance and unlocking new capabilities. Capacity can be primarily defined by two dimensions:...
- Tweet from fofr (@fofrAI): Imagen 3 also passes this testQuoting fofr (@fofrAI) Prompt: "a jellyfish on the beach"Once again, recraft-v3 is smashing it.1. recraft2. flux 1.1 pro3. sd3.5 large4. Midjourney v6.1
- Tweet from Alessio Fanelli (@FanaHOVA): Notes:- Won't be available in Europe for a while- Ran by CUA (Computer Use Agent) trained starting from 4o- Will be available by API as well- Operator has direct integrations with Opentable and ot...
- Tweet from Peter Welinder (@npew): I’m Swedish, so I like saunas. Here’s a video of Operator reading through hotel reviews on Tripadvisor to find the best hotel sauna in Stockholm.
- Tweet from Andrej Karpathy (@karpathy): Projects like OpenAI’s Operator are to the digital world as Humanoid robots are to the physical world. One general setting (monitor keyboard and mouse, or human body) that can in principle gradually p...
- Tweet from elvis (@omarsar0): Trying OpenAI's Operator as my research assistant.Watch me ask the agent to search for AI papers on arXiv and summarize them. The future is here!Agents are no joke!
- Tweet from Morgante (@morgantepell): Too many AI "employees" startups commit the skeumorphic flaw of assuming the ideal interface for managing agents is the same as for managing employees.I've also fallen into this trap, but ...
- Tweet from Mike (@grabbou): 🎉 Announcing Flows AI: A light-weight library to build agent workflows, on top of Vercel AI SDK.✅ No unnecessary abstractions.✅ Use any LLM and provider of your choice.✅ All patterns from Anthropic a...
- Tweet from Florian S (@airesearch12): I am building smooth operator, an alternative to openai operator that - won't cost $200/month and - uses a combination of the best models on the market, e.g. R1 and screengrasplink below.
- Tweet from Varun Anand (@vxanand): We're announcing $40m in Series B expansion funding at a $1.25B valuation.Our last raise remains untouched, but our momentum — 6x revenue growth in '24 and 10x growth in both '22 and '...
- Tweet from Greg Brockman (@gdb): Operator — research preview of an agent that can use its own browser to perform tasks for you.2025 is the year of agents.Quoting OpenAI (@OpenAI) Introduction to Operator & Agentshttps://openai.com/in...
- The ‘self-operating’ computer emerges: Powered by GPT-4V, the framework takes screenshots as input and outputs mouse clicks and keyboard commands, just as a human would.
- Tweet from swyx /dd (@swyx): Initial thoughts on Operator:- SOTA OSWorld/WebArena means actual meaningful model advance, not just ui/product wrapper. OAI always excels at this (model+product progress), as we discuss in our @karin...
- Tweet from Mahesh Sathiamoorthy (@madiator): Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe. The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchma...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Breaking news from Text-to-Image Arena! 🖼️✨@GoogleDeepMind’s Imagen 3 debuts at #1, surpassing Recraft-v3 with a remarkable +70-point lead! Congrats to the Google Imagen team for setting a new bar!Tr...
- Tweet from Alex Volkov (Thursd/AI) (@altryne): Here's how this tweet happened! @OpenAI added a share mechanism to OperatorQuoting Alex Volkov (Thursd/AI) (@altryne) H i, this is OpenAI's operator standing in for Alex.
- Tweet from Shunyu Yao (@ShunyuYao12): To name one highlight for CUA and Operator each:- CUA is *long-horizon* — it could act 20min autonomously if needed!- Operator uses *remote VMs*, which is good for managing safety and access, and mean...
- Tweet from Dan Hendrycks (@DanHendrycks): We’re releasing Humanity’s Last Exam, a dataset with 3,000 questions developed with hundreds of subject matter experts to capture the human frontier of knowledge and reasoning.State-of-the-art AIs get...
- Tweet from Andrej Karpathy (@karpathy): It’s done because it’s much easier to 1) collect, 2) evaluate, and 3) beat and make progress on. We’re going to see every task that is served neatly packaged on a platter like this improved (including...
- Tweet from fofr (@fofrAI): let's go. seriously. how.Quoting fofr (@fofrAI) Wow, Imagen 3 🤯> a high speed nature photo capturing two song birds fighting in mid flight in an English gardenThe rose leaves even have a touch...
- Tweet from OpenAI (@OpenAI): Trading Inference-Time Compute for Adversarial Robustness https://openai.com/index/trading-inference-time-compute-for-adversarial-robustness/
- Tweet from Deedy (@deedydas): China just dropped a new model.ByteDance Doubao-1.5-pro matches GPT 4o benchmarks at 50x cheaper— $0.022/M cached input tokens, $0.11/M input, $0.275/M output— 5x cheaper than DeepSeek, >200x of o1...
- Tweet from thebes (@voooooogel): Made a very stupid sampler-based lever to try and mimic o1-style "reasoning_effort=high" on r1:If appears before enough thinking tokens have been generated, the sampler replaces...
- $2 H100s: How the GPU Bubble Burst: H100s used to be $8/hr if you could get them. Now there's 7 different resale markets selling them under $2. What happened?
- Optimizing Pretraining Data Mixes with LLM-Estimated Utility: no description found
- Tweet from Nick Dobos (@NickADobos): Operator isn't the only agent."We'll also have more agents to launch in the coming weeks and months"Quoting OpenAI (@OpenAI) Introduction to Operator & Agentshttps://openai.com/index/i...
- Deepseek: The Quiet Giant Leading China’s AI Race: Annotated translation of its CEO's deepest interview
- Tweet from Aaron Levie (@levie): AI Agent interaction is going to be one of the most interesting software interoperability paradigms of the future. Inevitably, no one software system contains all the knowledge or information to perfo...
- Tweet from Jason Baldridge (@jasonbaldridge): It really is exciting to have Imagen 3 debut with this strong showing on the lmsys leaderboard. It's the result of a huge effort and a ton of work -- congrats to the whole team! (See https://arxiv...
- Elon Musk bashes the $500 billion AI project Trump announced, claiming its backers don’t ‘have the money’ | CNN Business: no description found
- Introduction to Operator & Agents: Begins at 10am PTJoin Sam Altman, Yash Kumar, Casey Chu, and Reiichiro Nakano as they introduce and demo Operator.
- Tweet from Karina Nguyen (@karinanguyen_): CUA Evals!Quoting OpenAI (@OpenAI) Introduction to Operator & Agentshttps://openai.com/index/introducing-operator/
- Tweet from homanp (@pelaseyed): I don’t do RAG anymore, get 10x the result just spinning up a pipeline and feed all content to Deepseek. And yes it scales to over 10K docs. RAG is anti pattern.
- Tweet from Jonathan Ellis (@spyced): I built a tool to solve the context problem for large codebases. 1/N
- Anthropic CEO Calls for Policy Action on AI: Anthropic CEO and Co-Founder Dario Amodei addressed the threat of autonomous AI and said he will work with the Trump administration on an energy provision to...
- Anthropic reportedly secures an additional $1B from Google | TechCrunch: Anthropic has reportedly raised around $1 billion from Google as the AI company looks to deliver a number of major product updates this year.
- State of AI 2025 Preview · Issue #278 · Devographics/surveys: Here is a preview link for the upcoming State of Web Dev AI 2025 survey, the first ever edition of this new survey: https://survey.devographics.com/en-US/survey/state-of-ai/2025 I would love to get...
- [AINews] Bespoke-Stratos + Sky-T1: The Vicuna+Alpaca moment for reasoning: Reasoning Distillation is all you need. AI News for 1/21/2025-1/22/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 4297...
GPU MODE ▷ #general (5 messages):
R1 jailbreak risks, DDoS capabilities of AI, End-to-End LLM solutions
-
R1's Jailbreak Risks Highlighted: Despite being remarkable, R1 is seen as concerning due to how easily it can be jailbroken or manipulated to perform dangerous tasks.
- One member noted that jailbreaking other models is also trivial for anyone who knows how to use Google.
- AI's Potential for DDoS Attacks: A user expressed surprise that ChatGPT could be persuaded to write code capable of executing a DDoS attack on a website.
- This raises eyebrows about the broader implications of conversational AI when used irresponsibly.
- Discussion on LLM Solutions Podcast: A member shared a link to the TDE Podcast #11 featuring Paul Iusztin & Maxime Labonne, discussing how to build end-to-end LLM solutions.
- The YouTube video can be accessed here.
- Concerns Over Protection Mechanisms: There was a debate on whether the existing protection methods for AI models provide any significant safety beyond brand protection.
- One sentiment shared was that these protections seem ineffective against motivated users.
Link mentioned: - YouTube: no description found
GPU MODE ▷ #triton (9 messages🔥):
Step Execution Order, Data Overwriting Issue, Compiler Behavior, Variable Changes
-
Step Execution Order Confusion: A member clarified that step2 must execute before step3 because step3 overwrites the data loaded by step2.
- This raised questions about the necessity of ordering when, at first glance, it seemed step2 did not affect step3.
- Data Overwriting Issue Raised: It was noted that the discrepancies arise because step3 changes the variable x_c, impacting the outcome of step2 despite x itself remaining untouched.
- A member suggested testing changes directly on x instead of x_c to resolve the issue.
- Compiler Behavior Under Review: Concerns were shared about the compiler executing step1 and step3 together, leading to potential errors.
- One member postulated that this behavior might stem from the fact that x was not being modified.
- Attempting Variable Adjustment: A member attempted to adjust the equation to combine x and x_c, but encountered issues when updating it to x=x+x_c0.00001+y0.000001.
- An attachment containing the code was shared for further analysis and debugging.
GPU MODE ▷ #cuda (49 messages🔥):
CUDA Toolkit 12.8 Release, Accel-Sim Framework, New Tensor Instructions, FP8 and FP4 Data Types, Blackwell Architecture Enhancements
-
CUDA Toolkit 12.8 drops with Blackwell support: CUDA 12.8 has officially been released, incorporating support for Blackwell architecture and new TensorCore instructions.
- Documentation has been updated to reflect these changes, including performance enhancements and new capabilities.
- Accel-Sim Framework Provides GPU Emulation: Accel-Sim offers a simulation framework for emulating and validating GPUs on CPUs, recently updated with version 1.2.0.
- It allows for deeper exploration of power modeling and efficient design space for modern GPU architectures.
- Exciting New Tensor Instructions Announced: New tensor instructions have been introduced, with emphasis on their optimization for hardware architectures sm_90a and sm_100a.
- As a result, there are implications for instruction performance, particularly for FP8 and FP4 data types.
- FP8 and FP4 Data Types for Enhanced Performance: Discussion centered around the new FP8 and FP4 data types that enhance tensor performance for neural networks, streamlining quantization processes.
- Various implementations are expected to support NVFP4, with emerging tensor instructions promising significant speed improvements.
- Blackwell Architecture Enhancements: Blackwell architecture introduces significant capabilities, including specs on FP4/fp6 conversions and advancements in cuBLAS for matrix operations.
- Participants acknowledged the complexities involved in achieving the advertised TFLOPS for B100/B200 architectures and improvements in gemm operations.
Links mentioned:
- LeetGPU: no description found
- FP8 Quantization: The Power of the Exponent: When quantizing neural networks for efficient inference, low-bit integers are the go-to format for efficiency. However, low-bit floating point numbers have an extra degree of freedom, assigning some b...
- Accel-Sim: The Accel-Sim Framework : no description found
- nvfp4_tensor — Model Optimizer 0.21.1: no description found
- Tweet from Vijay (@tensorcore): CUDA 12.8 just dropped with Blackwell support. TensorCore 5th Generation Family Instructions: https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tensorcore-5th-generation-instructions
GPU MODE ▷ #torch (8 messages🔥):
Torch Profiler Function Timing, Learning Rate Scheduling Techniques, Memory Allocation in Torch Compile
- Torch Profiler can track function execution times: A user inquired whether it’s possible to track the running time of high-level functions like forward attention when stack tracing is enabled in the torch profiler.
-
Diverse Learning Rate Scheduling Approaches: Various learning rate scheduling methods were discussed, including CosineAnnealing with warm restarts and recent methods like schedule-free techniques.
- Some participants noted success with linear warmup and cosine decay, while others mentioned WSD schedule as a stable option for training consistency.
- Concerns about Mismatched Outputs: A user shared an image comparing outputs, raising a question about why the outputs don't match.
- This prompted inquiries into the underlying computations and conditions affecting these results.
- Memory Allocation Preferences in Torch: A user expressed interest in understanding memory allocation with torch.compile and inquired about providing pre-allocated GPU tensors to avoid blocking async kernel runs.
- They noted that without pre-allocated tensors, cudaMalloc is called, preventing asynchronous operations.
GPU MODE ▷ #jobs (1 messages):
ComfyUI Hiring, Machine Learning Engineers, Open Source Contributions
-
ComfyUI Seeking Machine Learning Engineers: ComfyUI is hiring machine learning engineers to work with their team that maintains the ComfyUI ecosystem, emphasizing their commitment to open source contributions.
- Last year, they had day 1 support for models from top companies like BFL, Hunyuan, and StabilityAI, inviting those interested to reach out for more details.
- Join a VC Backed Venture in the Bay Area: The company is VC backed and located in the Bay Area, boasting a long runway and a big vision for future growth.
- More information on the position can be found in the job listing.
GPU MODE ▷ #beginner (14 messages🔥):
Choosing a GPU for Programming, Running Large Models Locally, Multi-GPU Training with Florence-2, Cost-effective GPU Options, Cloud GPU Services
-
Selecting the Right GPU for Your Budget: A member seeking advice on GPU options suggested that the RTX 4060 has limited VRAM, making it difficult for local model runs, while noting that the RTX 3090 is a favored choice if operating locally.
- Renting GPUs through cloud services is mentioned as a cheap alternative, with a link provided for cloud GPU comparisons.
- Struggles with Running Large Models: A member expressed frustration over running the 405b models, noting their setup struggles even with 2x16GB GPUs when attempting to handle 70b models.
- Another emphasized the importance of having enough system RAM alongside GPUs to avoid swapping issues when switching between models.
- Insights on Entry Level GPUs: Recommendations for entry-level GPUs included the RTX 3060 with 12GB due to its cost-effectiveness, although recent prices have risen, raising concerns about overall system budget.
- Starting with one GPU and expanding later was suggested as a viable strategy.
- Challenges in Fine-tuning Florence-2 on Multiple GPUs: A user reported difficulties in fine-tuning the Florence-2 model with only one of the four 16GB GPUs being utilized, leading to CUDA out of memory errors.
- Solutions suggested included using DeepSpeed Zero 2 or Zero 3 for better multi-GPU support, assuming model compatibility.
Links mentioned:
- Cloud GPUs: no description found
- Fine-tuning Florence-2 - Microsoft's Cutting-edge Vision Language Models: no description found
GPU MODE ▷ #self-promotion (4 messages):
LeetGPU.com support, ComfyUI event, Performance enhancement tips, Community engagement, Workflows sharing
-
Join LeetGPU.com for Updates: Members are invited to join for updates and support from LeetGPU.com via this Discord link.
- This platform aims to facilitate communication and support for its user community.
- Boost Performance with Token Management: It was advised to eliminate context tokens after the last attention module for 5-10% faster prefill and VRAM savings.
- Torch.compile() can be utilized on the last MLP module since the input shape will be static, optimizing performance.
- ComfyUI Event in Bay Area Next Thursday: Attendees are encouraged to join the ComfyUI event at the Github Office next Thursday for demos and community interaction, featuring a variety of open-source developers.
- Refreshments will be provided, and notable presenters include MJM and Lovis, who will share their workflow tips.
- Agenda for ComfyUI Event: The event will feature a structured agenda starting with registration, followed by intros from the Comfy Org Team and demo presentations.
- Highlights include a panel and a lightning round for sharing workflows, encouraging broad participation.
Links mentioned:
- Tweet from mobicham (@mobicham): You can get 5-10% faster prefill + save VRAM with large context/vocab sizes by getting rid of the context tokens after the last attention module.Then you can torch.compile() the last mlp module since ...
- ComfyUI Official SF Meet-up at Github · Luma: First official ComfyUI SF Meetup in the Github office! Come meet other users of ComfyUI, share your workflows with the community, or give your input to the…
GPU MODE ▷ #thunderkittens (1 messages):
Tensor accumulation in CUDA kernels, Setup of accumulators
-
Questions on Zeroing Accumulators: A member inquired if it's necessary to zero the accumulators in the CUDA matrix multiplication code here, considering they might already be zeroed in the setup.
- They wondered about potential redundancy in initializing the accumulators again at that point in the code.
- Discussion on Kernel Performance: Another member highlighted the importance of tile primitives for achieving speedy kernels while referring to the ThunderKittens GitHub repository.
- They noted that optimizing these primitives could lead to significant performance improvements during matrix multiplication.
Link mentioned: ThunderKittens/kernels/matmul/H100/matmul.cu at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
GPU MODE ▷ #arc-agi-2 (8 messages🔥):
Tiny GRPO Repository, Reasoning Gym Project, Accessible RL Tutorials, Cloud Computing Options, Community Contributions
-
Tiny GRPO Repository Launched: The Tiny GRPO project has been moved to a separate GitHub repository for a minimal hackable implementation.
- Check out the project's description for details on contributing and features.
- New Reasoning Gym Project Kicks Off: A new project for collecting procedural reasoning datasets started, available at Reasoning Gym, aimed at algorithmically verifiable tasks.
- The initiator welcomes task ideas and contributions to enhance its scope.
- Easy RL Tutorial for Newbies: A member shared a tutorial on RL with LLMs designed for beginners looking to ease into reinforcement learning.
- This tutorial builds on recent significant developments in more efficient LLMs.
- Cloud Computing for Apple Users: In response to concerns about running experiments on Apple laptops without NVIDIA GPUs, suggestions included utilizing cloud compute services like Prime Intellect.
- One recommended service for cloud computing was also runpod.io.
- Community Collaboration on Projects: Members are expressing interest in contributing to projects, specifically with ideas for supporting formal languages through grammars.
- Collaboratively, members encourage sharing ideas or creating issues for potential tasks if contributions are constrained by time.
Links mentioned:
- How to align open LLMs in 2025 with DPO & and synthetic data: Learn how to align LLMs using Hugging Face TRL and RLHF through Direct Preference Optimization (DPO) and on-policy synthetic data.
- Prime Intellect - Commoditizing Compute & Intelligence: Prime Intellect democratizes AI development at scale. Our platform makes it easy to find global compute resources and train state-of-the-art models through distributed training across clusters. Collec...
- GitHub - open-thought/tiny-grpo: Minimal hackable GRPO implementation: Minimal hackable GRPO implementation. Contribute to open-thought/tiny-grpo development by creating an account on GitHub.
- GitHub - open-thought/reasoning-gym: procedural reasoning datasets: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
MCP (Glama) ▷ #general (87 messages🔥🔥):
MCP Server Improvements, Podman vs Docker, Line Number Handling in Code, MCP Client Interaction, Timeout Issues with MCP Servers
-
MCP Server timeout issues resolved: A member shared that they fixed the 60-second timeout issue on MCP server responses, providing a potential solution for others facing this challenge.
- However, details on the specific fix were not provided in the discussion.
- Windows Path issues with MCP Servers: A user encountered problems launching MCP servers on Windows due to hidden PATH settings but ultimately resolved it by specifying the full path to the uvx.exe command.
- They also created a database file, test.db, in Access for their applications, noting they weren't sure if it was necessary.
- Discussion on Containerization Options: Members debated the merits of Podman versus Docker, with Podman being noted for its lightweight design and being daemonless.
- Podman is gaining popularity, but many tools still primarily support Docker due to its longer presence in the field.
- Handling Line Numbers in Code Editing: A member discussed their approach to managing code line numbers for specific edits, emphasizing that this method makes it more reliable and efficient for handling code changes.
- This approach was noted as preferable compared to previous iterations that struggled with diff handling.
- Interactions with MCP Clients and Tool Usage: One user was frustrated with passing environment variables into mcp dev server.py and found that the wong2 mcp cli offered a simpler solution.
- They shared experiences related to managing MCP clients and discussed various methods for extracting and validating tool parameters.
Links mentioned:
- Sage - Native Client for Claude: no description found
- Files and Resources with MCP - Part 1: A practical guide to handling files, images and other content types with the Model Context Protocol (MCP). Learn how Claude Desktop and other MCP implementations manage resources and tool responses fo...
- Reddit - Dive into anything: no description found
- Hyper-V Dynamic Memory Overview: no description found
- Podman Installation | Podman: Looking for a GUI? You can find Podman Desktop here.
- GitHub - evalstate/mcp-webcam: Capture live images from your webcam with a tool or resource request: Capture live images from your webcam with a tool or resource request - GitHub - evalstate/mcp-webcam: Capture live images from your webcam with a tool or resource request
- GitHub - modelcontextprotocol/inspector: Visual testing tool for MCP servers: Visual testing tool for MCP servers. Contribute to modelcontextprotocol/inspector development by creating an account on GitHub.
- Simplified, Express-like API by jspahrsummers · Pull Request #117 · modelcontextprotocol/typescript-sdk: Inspired by #116 and some of the MCP SDK wrappers that have popped up in the ecosystem, this is an attempt to bring a more Express-style API into the SDK.This diverges from the existing wrapper li...
MCP (Glama) ▷ #showcase (7 messages):
Anthropic TS Client Issue, Puppeteer for Browser Automation, SSE Client Example Correction
-
Known Issue with Anthropic TS Client: A user noted a known issue with the Anthropic TS client and provided a link to an issue on GitHub related to using custom headers.
- They mentioned opting for Python after struggling with the JavaScript implementation.
- Puppeteer Enhances Browser Automation: A post introduced a Puppeteer package for browser automation, allowing LLMs to interact with web pages and execute JavaScript.
- This includes capabilities like navigating, taking screenshots, and clicking elements on web pages.
- Correction on SSE Client Example: A user acknowledged making a copy-paste mistake in the SSE client example and clarified that it supports using custom headers.
- They provided a link to the corrected SSE client example on GitHub.
- Clarification on Node Version of EventSource: In response to the SSE client clarification, a user asked if the Node version of EventSource actually works.
- This indicates ongoing discussions about its functionality and user experiences.
Links mentioned:
- mcp-puppeteer-linux: MCP server for browser automation using Puppeteer with X11/Wayland support. Latest version: 1.0.0, last published: 14 hours ago. Start using mcp-puppeteer-linux in your project by running `npm i mcp-p...
- Use custom headers for both the
/sseand/messageendpoints · Issue #118 · modelcontextprotocol/typescript-sdk: @chrisdickinson thank you for this PR Apologies, but I'm not very strong in JS. I need to include an API token to access my MCP server, for both the /sse and /message endpoints. I believe the head... - actors-mcp-server/src/examples/clientSse.ts at master · apify/actors-mcp-server: Model Context Protocol (MCP) Server for Apify's Actors - apify/actors-mcp-server
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.7.0 Release, Windows ARM Support, macOS Updates, Code Interpreter Improvements, Chat Templating Fixes
-
GPT4All v3.7.0 launched with key features: The GPT4All v3.7.0 release introduces various updates including Windows ARM support for Qualcomm Snapdragon and Microsoft SQ-series devices.
- However, users must note that GPU/NPU acceleration is not available at this time, limiting operation to CPU only.
- macOS updates fix previous issues: macOS users will benefit from fixes that prevent the application from crashing during updates and allow chats to save properly when quitting with Command-Q.
- If users had installed a workaround from GitHub, they are advised to uninstall it to revert back to the official version from the website.
- Code Interpreter gets behavior upgrades: Improvements in the Code Interpreter include better handling of timeout scenarios during execution and enhanced functionality of console.log to accept multiple arguments for compatibility.
- These adjustments aim to streamline developer experience and align closer with native JavaScript behaviors.
- Chat templating issues resolved: Recent updates have fixed two crashes and one compatibility issue within the chat template parser, ensuring smoother usability.
- Additionally, the default chat template for EM German Mistral has been corrected, and automatic replacements have been added for five new models.
Nomic.ai (GPT4All) ▷ #general (64 messages🔥🔥):
ChatGPT access and limitations, Prompt engineering, Model compatibility and selection, Issues with Jinja templates, NSFW content generation
-
ChatGPT access requires payment: A member stated that to access unlimited ChatGPT functionality, one must pay, leading to a humorous exchange about limitations.
- The sentiment conveyed was that free access is unrealistic, prompting jokes about alternate chat solutions.
- Prompt engineering advice shared: A discussion arose about the importance of prompt engineering for effective model responses, suggesting refined prompts yield better results.
- Member emphasized that using polite language, such as 'Please,' increases the likelihood of getting desirable responses from the models.
- Compatibility issues of models with GPT4All: Members discussed various model options that are compatible with GPT4All, noting the importance of selecting the right models to avoid censorship.
- Suggestions included exploring the Nous Hermes model and other alternatives from Undi's Hugging Face profile.
- Challenges with Jinja templates: Members expressed concerns regarding the usability of Jinja syntax, indicating that ongoing compatibility issues exist with different model architectures.
- There are ongoing challenges with implementing Jinja, especially since GPT4All is built in C++, making integration difficult.
- NSFW content generation hurdles: Discussions centered on trying to generate NSFW content indicating struggles with zensors and model limitations.
- Members noted the discrepancy between expected and actual performance when requesting explicit storytelling, mentioning the prevailing moral constraints.
Link mentioned: Chat Templates - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
Stability.ai (Stable Diffusion) ▷ #general-chat (59 messages🔥🔥):
CitiVAI Downtime, Image Generation Techniques, GPU Comparisons, AI Model Training, Clip Skip Settings
-
CitiVAI Maintenance Schedule: A member inquired about CitiVAI being down, to which another mentioned that maintenance occurs a few times daily.
- This indicates a routine upkeep procedure that might affect accessibility intermittently.
- Using Masks for Ice Text Generation: A user shared their process for generating ice text using a specific font by creating a black and white mask in Inkscape.
- Other users suggested that utilizing canny controlnet or directly prompting for ice color could simplify the image generation process.
- Benchmarking GPU Performance: Discussion surfaced about the 5090 GPU's performance claiming it offers 20-40% faster generation but consumes 30% more power.
- Members noted that the impressive advancements are seen more in the B100/B200 series rather than the consumer cards.
- Training AI Models for Specific Characters: A conversation explored training models on specific movies, with a member asserting that it requires a decent GPU and some time.
- Discussion highlighted the ease of training, with practical references shared regarding models that mimic specific animated characters.
- Clarifying Clip Skip Settings: A member asked about the relevance of 'clip skip' settings in AI generation, which another confirmed is an outdated setting from the SD1 era.
- The clarification suggests that contemporary users need not concern themselves with this legacy setting for optimal performance.
Links mentioned:
- Reddit - Dive into anything: no description found
- Alvin Seville (Alvin and the Chipmunks Movie) - V1 | Stable Diffusion LoRA | Civitai: Alvin from Alvin and the Chipmunks Movie COMMISSION Optional Prompts: Realistic, Hands in Pockets COMMISSIONS ARE OPEN, PLEASE VISIT THIS LINK - Co...
- SwarmUI/docs/Model Support.md at master · mcmonkeyprojects/SwarmUI: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
- SwarmUI/docs/Features/Prompt Syntax.md at master · mcmonkeyprojects/SwarmUI: SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
- Reddit - Dive into anything: no description found
Eleuther ▷ #general (22 messages🔥):
Google's Titans, Difficulty of Titans Paper, Pretraining Context in Models, Interpretability and Diffusion Models, Reward Systems in Model Distillation
-
Google Research Unveils Titans, Promises Performance Boost: Members discussed Google's new model, Titans, which claims to outperform transformers and introduce a new kind of memory at inference time, as highlighted in a YouTube video on the topic.
- Consensus seems to suggest that the paper is difficult to reproduce, leaving some members puzzled about the exact attention mechanism used.
- Debating the Difficulty of the Titans Paper: Questions arose about the difficulty of reproducing results from the Titans paper, with a member remarking it’s tough to decipher their methodology. Another noted that they felt a similar sense of confusion after reading through the paper.
- Comments on the attention mechanism indicated uncertainty, with one member pointing out that there are usually only a few options available.
- Pretraining Process as a Test Time Training Layer: A member proposed that the pretraining process could be viewed as a giant test time training layer, suggesting that context often isn't outlined meaningfully. This perspective reflects a growing interest in making sense of model interpretability.
- Others expressed curiosity about how this concept applies to recent developments in interpretability and diffusion models.
- Conversation Wishes and Entrepreneurial Spirit: A member expressed a desire to communicate with Sam over his Twitter silence, emphasizing the need for transparency regarding past actions. In a lighter tone, they dubbed the group as co-founders and humorously stated a salary of 1 trillion per year.
- Their remarks were playful, including remarks about buying whatever they like and making light of the situation with emojis.
- Exploring Distillation Methods in AI Models: A member inquired about papers discussing the divergence between teacher and student models used as a reward in PPO applications for distillation. Another member questioned why one wouldn't use standard student-teacher models with KL-matching instead.
- The discussion indicates an ongoing examination of model distillation strategies, particularly in the context of improving student model performance.
Link mentioned: Google Research Unveils "Transformers 2.0" aka TITANS: Have we finally cracked the code on how to give models "human-like" memory? Watch to find out!Join My Newsletter for Regular AI Updates 👇🏼https://forwardfu...
Eleuther ▷ #research (27 messages🔥):
Feature Learning with Egomotion, LLM Explainability and Security Feedback, Multi-Turn Reasoning in Models, Learned Optimizers, Distributional Dynamic Programming
-
Utilizing Egomotion for Feature Learning: Research on using egomotion as a supervisory signal for feature learning has emerged, contrasting traditional supervised learning with hand-labels by leveraging mobility data instead for tasks like scene recognition and object detection.
- This approach shows competitive feature learning results, suggesting that egomotion can be an effective alternative to class-label supervision.
- Seeking Feedback on Research Papers: A member inquired about channels for sharing papers on LLM explainability and security to gather feedback from the community.
- Another participant suggested posting in a dedicated channel for work-sharing, especially when near completion.
- Enhancing Multi-Turn Reasoning with Key-Value Compression: Discussion on improving multi-turn reasoning in models includes employing techniques such as attention masking and dynamic key-value compression to enhance memory retention and reasoning ability.
- Several members explored the idea of maintaining prior reasoning traces while allowing future steps to access and learn from them without a significant loss in decoding accuracy.
- Insights on Learned Optimizers: A member shared interest in the potential of learned optimizers, which offer hyperparameter-free training advantages through meta-generalization, with challenges highlighted regarding their practical implementation.
- There’s an increasing focus on optimizing the architectures and procedures for learned optimizers to improve their generalization capabilities.
- Introduction of Distributional Dynamic Programming: A paper was introduced proposing distributional dynamic programming methods to optimize statistical functionals of return distributions, extending traditional reinforcement learning concepts.
- This new framework incorporates stock augmentation, enabling the addressing of problems previously challenging to solve with classic methods.
Links mentioned:
- Optimizing Return Distributions with Distributional Dynamic Programming: We introduce distributional dynamic programming (DP) methods for optimizing statistical functionals of the return distribution, with standard reinforcement learning as a special case. Previous distrib...
- MONA: Myopic Optimization with Non-myopic Approval Can Mitigate Multi-step Reward Hacking: Future advanced AI systems may learn sophisticated strategies through reinforcement learning (RL) that humans cannot understand well enough to safely evaluate. We propose a training method which avoid...
- Learning Versatile Optimizers on a Compute Diet: Learned optimization has emerged as a promising alternative to hand-crafted optimizers, with the potential to discover stronger learned update rules that enable faster, hyperparameter-free training of...
- Learning to See by Moving: The dominant paradigm for feature learning in computer vision relies on training neural networks for the task of object recognition using millions of hand labelled images. Is it possible to learn usef...
- Restructuring Vector Quantization with the Rotation Trick: Vector Quantized Variational AutoEncoders (VQ-VAEs) are designed to compress a continuous input to a discrete latent space and reconstruct it with minimal distortion. They operate by maintaining a set...
- meta-llama/Meta-Llama-3-8B · Are there bias weights in Llama3 ?: no description found
Eleuther ▷ #lm-thunderdome (1 messages):
Ruler tasks, Long context tasks
-
Ruler Tasks Updated: A member confirmed that all Ruler tasks have been added, noting that mostly small formatting adjustments remain.
- They inquired if anyone knows of additional long context tasks that could be supported.
- Need for Long Context Tasks: The member raised a question regarding the availability of good long context tasks in the current setup.
- This highlights the need for further exploration into maximizing task effectiveness.
LlamaIndex ▷ #blog (2 messages):
Open-source RAG system, LlamaIndex, AI Chrome extensions
-
Building Open-source RAG System with LlamaIndex: Learn how to construct and assess an open-source RAG system utilizing LlamaIndex, Meta Llama 3, and @TruLensML by following this detailed guide.
- It compares a basic RAG setup using @neo4j for data storage to a more advanced agentic RAG system, including performance evaluations of OpenAI against Llama 3.2.
- AI Chrome Extensions for Social Media: You can build more than just RAG with LlamaIndex; check out a pair of Chrome extensions designed to enhance your X and LinkedIn posts' impact at this link.
- These tools leverage AI capabilities to optimize content for better engagement and visibility.
LlamaIndex ▷ #general (44 messages🔥):
AgentWorkflow Improvements, Multi-Agent Workflows, Agent vs Tool Clarification, Dynamic Memory Management, LlamaIndex Documentation Issues
-
AgentWorkflow enhancements spark enthusiasm: Members expressed excitement over the improvements in AgentWorkflow, noting it significantly outpuits its predecessors.
- Right on time, it appears many are already planning to build with it.
- Clarification on Multi-Agent Workflows: Cheesyfishes explained that multiple agents can be active but operate one at a time, with async tool calls occurring when predicting multiple actions.
- The global chat history contributes to potential context window issues but isn't fully loaded into each agent's context.
- Confusion between Agents and Tools Explained: Cheesyfishes clarified the distinction between agents, which utilize tools, and tools themselves, which can also function as agents.
- Adding multiple agents serves to better separate responsibilities to enhance performance.
- Dynamic Memory Management Under Discussion: The discussion highlighted the need for smarter memory modules, as Cheesyfishes noted that the current ChatMemoryBuffer may not maximize context usage effectively.
- While options exist for summaries, they introduce latency and may not always be a default choice.
- LlamaIndex Documentation Links Down: Twocatsdev pointed out a broken link in the step-by-step agent tutorial, leading to a 500 error.
- In response, Cheesyfishes provided a potential source link and confirmed that most starter information is still accessible elsewhere.
Links mentioned:
- LlamaIndexTS/apps/next/src/content/docs/llamaindex/guide/agents at main · run-llama/LlamaIndexTS: Data framework for your LLM applications. Focus on server side solution - run-llama/LlamaIndexTS
- GitHub - run-llama/multi-agent-concierge: An example of multi-agent orchestration with llama-index: An example of multi-agent orchestration with llama-index - run-llama/multi-agent-concierge
- Agent tutorial: no description found
Cohere ▷ #discussions (9 messages🔥):
Cohere LCoT models, Pydantic support for Cohere, COT prompting techniques
-
Call for LCoT Model Release: A member urged Cohere to enter the market by releasing LCoT meme model weights that can handle logic and thinking.
- Another member responded, emphasizing that Cohere primarily focuses on enterprise solutions.
- Pydantic Integrates Cohere Models: Excitement arose as a member announced that Pydantic now supports Cohere models, marking a significant step for developers.
- This integration could streamline processes and improve usability for developers working with Cohere.
- COT Functionality Through Prompting: Discussion centered around the concept of Chain of Thought (COT) being achievable through strategic prompting.
- One member suggested using cues like 'think before you act' and wrapping thoughts with
- Debate on Regular Model Reasoning: A member pointed out that while regular models not trained on traces cannot fully replicate COT, they can still provide some reasoning.
- This generated a conversation about the effectiveness of prompting and its impact on the inherent capabilities of standard models.
Link mentioned: Tossing Hat GIF - Jeff Bridges Agent Champagne Kingsman Golden Circle - Discover & Share GIFs: Click to view the GIF
Cohere ▷ #api-discussions (3 messages):
Cohere API endpoints, Latency issues in South America, Cohere Reranker models on premise
-
Querying Cohere API endpoint locations: A member inquired about the location of Cohere API endpoints due to experiencing latency from Chile and suspected a topological issue.
- No specific response was noted regarding the API locations.
- Possibility of on-premise Cohere Reranker models: The same member followed up questioning if it's feasible to mount Cohere Reranker models on premise or access a region close to South America.
- Another member suggested that this inquiry should be directed to the sales team at support@cohere.com.
Cohere ▷ #cmd-r-bot (29 messages🔥):
Artificial Superintelligence (ASI), Cohere Documentation Queries
-
Exploring the Concept of ASI: ASI, or Artificial Superintelligence, is a theoretical idea where machines surpass human intelligence across all domains, including creativity and problem-solving.
- While enticing, the idea raises significant ethical concerns regarding its potential misuse and implications for society.
- Potential Impacts of ASI: The development of ASI could revolutionize sectors like healthcare and education, offering advancements like precise disease diagnosis and creative solutions to complex problems.
- However, it is essential to handle ASI responsibly to mitigate risks alongside the expected benefits.
- Cohere Documentation Limits: Repeated searches in the Cohere documentation for the term ASI yielded no relevant information, indicating a lack of formal resources on the topic.
- Despite attempts to find documentation, the discussions focused on theoretical interpretations rather than specific content in the resources.
Notebook LM Discord ▷ #use-cases (4 messages):
NotebookLM Journey, Obsidian Plugins, Audio Generation Issues, Note Saving Limits
-
User begins NotebookLM journey in study workflow: A member shared their excitement about being on week three of their NotebookLM journey and integrating it into their study workflow, highlighting its impact.
- They provided a link to a YouTube video showcasing various features of NotebookLM for studying.
- Learning about Obsidian's markdown capabilities: Another member commented on the aforementioned video, expressing appreciation for new insights into Obsidian, particularly the ability to combine markdown notes using a plugin.
- This highlights the ongoing sharing of knowledge and workflows within the community.
- Concerns about audio generation prompts: A member noted that when generating audio without specific prompts, the model often defaults to general information from the entire PDF, potentially affecting content quality.
- They advised others experiencing similar issues to report it as a bug in the designated section.
- Issue with saving notes in NotebookLM: A user inquired about potential limitations on saving notes in NotebookLM, as they were encountering problems with new notes not being saved despite being generated.
- This raises concerns about the reliability of the saving feature in the application.
Link mentioned: NotebookLM: The AI Tool That Will Change Your Study Habits: In this video I share the Google NotebookLM features I use for studying.00:00 Introduction00:46 Workflow01:49 Feature 102:50 Feature 203:55 Feature 304:50 Fe...
Notebook LM Discord ▷ #general (35 messages🔥):
Podcast Creation, NotebookLM Language Settings, Test Questions Format, Downloading Audio Issues, Document Comparison with NotebookLM
-
Podcast Launch on DeepSeek-R1 Analysis: A user shared their new podcast episode on DeepSeek-R1 Paper Analysis, discussing the model's reasoning skills and performance benchmarks.
- Listeners are encouraged to explore how reinforcement learning enhances capabilities and contributes to smaller model development.
- NotebookLM Language Adjustment: Users discussed changing the language of NotebookLM, with one asking how to switch from Romanian to English.
- Following advice, attempting to use a URL parameter resulted in an error, showcasing the confusion around language settings.
- Crafting High-Quality Test Questions: A user successfully created a format for generating multiple-choice test questions based on specific guidelines.
- This approach has helped in consistently producing high-quality test questions from specified chapters.
- Audio Overview Playback Issues: One member reported issues with downloading audio overviews, noting files appear on their phone but do not play.
- This problem has persisted for a few weeks, indicating a potential ongoing technical issue.
- Comparing Documents with NotebookLM vs. ChatGPT: A user inquired whether NotebookLM could better assist with analyzing legal documents compared to ChatGPT by uploading entire documents.
- They noted that while ChatGPT identifies atypical clauses, the ability to handle multiple documents and cross-references might provide more comprehensive insights.
Links mentioned:
- #AI - A ChatGPT from China better, free and open source? Analyzing DeepSeek-R1: Carlos Nuñez’s Podcast by Nalah · Episode
- no title found: no description found
- no title found: no description found
Modular (Mojo 🔥) ▷ #general (9 messages🔥):
Asynchronous code in Mojo, Sharing forum posts
-
Inquiry on Asynchronous Code: A member sought help on how to write asynchronous code and mentioned the previous silence in discussions.
- Thanks for your help! was expressed as encouragement to continue the dialogue.
- Forum Post Creation Assistance: Discussion emphasized the need for clarity on asynchronous functions, with an offer to help post in the forum on Modular's website.
- A member confirmed willingness to copy-paste the message while on-the-go, making the collaboration straightforward.
- Direct Link to Forum Thread: The original poster shared a direct link to their newly created forum topic on writing async code.
- This step encourages continued engagement and support within the community regarding asynchronous programming queries.
Links mentioned:
- Modular: Build the future of AI with us and learn about MAX, Mojo, and Magic.
- How to write async code in mojo🔥?: I saw the devblogs saying that mojo currently lacks wrappers for async fn awating, however it supports the coroutines themselves. If it is possible, how does one write a function that, say, prints whi...
Modular (Mojo 🔥) ▷ #announcements (1 messages):
MAX Builds page launch, Community-built packages, Package submission instructions
-
MAX Builds Page Goes Live: The refreshed MAX Builds page is now live, showcasing a dedicated section for community-built packages.
- Congratulations to the inaugural package creators for their contributions to this exciting launch!
- Shoutout to Package Creators: A special shout out was given to creators such as <@875794730536018071>, <@1074753858309468292>, and others for their community packages featured on the MAX Builds page.
- Their efforts have helped enhance the community-driven initiative with notable contributions.
- Instructions for Project Submission: To get your project featured, submit a PR to the Modular community repo with a
recipe.yamlfile.
- Full submission instructions and examples can be found here.
Modular (Mojo 🔥) ▷ #mojo (27 messages🔥):
Overriding functions in Mojo, Python-style generators in Mojo, Re-assigning variables in Mojo function definitions, __iadd__ method in Mojo
-
Clarification on Function Overriding: A member clarified that there's no
@overridedecorator in Mojo, emphasizing that you can override a function without this decorator.- Another pointed out that structs lack inheritance, further complicating the idea of overriding.
- Implementing Python-style Generators: A member inquired about implementing Python-style generators in Mojo, noting the difficulty of finding similar constructs in other compiled languages like Swift, C++, and Java.
- The discussion led to an async proposal that forces exposing
yieldin coroutines as a prerequisite. - Re-assigning Values in Function Definitions: There was a query about re-assigning values to function signature variables in Mojo, prompting a discussion about read-only references.
- A member explained the difference between using
mutto allow modification of references versusownedfor in-register copies hidden from callers. - Understanding iadd Method: A member asked for help understanding the
__iadd__method in Mojo, specifically how it functions.
- Another member responded that
__iadd__controls the behavior of the+=operator in the language.
LAION ▷ #general (27 messages🔥):
Open Source TTS, Audio Distortions Visualization, Colab Notebook Sharing, Pydub Implementations, Audio Output Widgets
-
Emotional Open Source TTS on Bud-E: A member announced that Emotional Open Source TTS will soon be available on Bud-E, sharing a relevant audio clip.
- The clip elicited positive reactions and exemplified the type of content being developed.
- Visualizing Audio Distortions: Another member is visualizing the differences between an original audio file and one with distortions, using pydub.
- They shared images comparing waveforms of slight vs. strong noise, showing progress in their audio exploration.
- Colab Notebook Collaboration: Notebook sharing became a topic as one member offered to share their work in a Google Colab notebook for collaboration.
- The link was shared, with some members expressing interest in reviewing the implementation and next steps.
- Saving Issues in Colab: A member faced auto-save failures in Colab, resulting in lost changes, which prompted discussion about fixing the situation.
- There was a back-and-forth on where to find the implementation, with frustration expressed over the failed save.
- Request for Audio Output Widgets: A member requested the creation of IPython audio widgets in Colab to facilitate audio comparisons before and after distortions.
- This led to collaborative suggestions on how to implement the audio output in their shared notebook.
Link mentioned: Google Colab: no description found
DSPy ▷ #general (5 messages):
Repo Spam Concerns, Adaptation vs. Imitation in Frameworks, Using External Libraries with DSPy
-
Repo Spam Raises Questions: Concerns were raised about the repo being spammed, with one member questioning if this is connected to the recent coin issue.
- Another member dismissed the situation, deeming it 'super lame' to engage in such activities.
- Evolving Frameworks Should Inspire, Not Dictate: A member emphasized that not everything needs to be a direct copy of what existing frameworks offer, promoting the idea of a toolkit for unique solutions.
- They stressed the importance of understanding the use case behind tools instead of replicating others’ success.
- Webhook Implementation for Triggering REACT Agent: A member shared their experience of wanting to trigger their REACT agent via email and sought examples of using external libraries with DSPy.
- They later confirmed that they successfully resolved the issue by using webhooks.
DSPy ▷ #examples (2 messages):
OpenAI Model, Groq Integration
-
OpenAI Model Discussion: A member mentioned the OpenAI model and its potential applications, suggesting that it could be a viable solution.
- The model seems to garner interest for its robustness and flexibility in various tasks.
- Groq Compatibility Inquiry: Another member highlighted that Groq should work effectively too, indicating compatibility with existing models.
- This points toward a broader interest in exploring Groq's capabilities alongside OpenAI.
tinygrad (George Hotz) ▷ #general (7 messages):
llvm_bf16_cast PR, shapetracker add problem, bounty suggestions, mask shrinks and views
-
llvm_bf16_cast bounty status confirmed: A member inquired about the status of the bounty to move llvm_bf16_cast to rewrite rules in renderer, noting a PR was raised a few hours earlier.
- This confirms resolution of the bounty, prompting discussions about available tasks for newcomers.
- Shapetracker add problem demonstrated: A member presented their approach to the shapetracker add problem, detailing its reduction to integer linear programming in a PDF attachment.
- While noted as complete, it faces speed issues and requires an ILP solver which raises questions about its general usefulness.
- Refactoring possibilities for ILP: George Hotz expressed interest in the presented work and asked if there’s a PR for it, suggesting that rewrite simplifications could also benefit from ILP.
- It indicates a potential for further optimization and integration of linear programming techniques into existing workflows.
- Exploration of views and mask merges: A discussion arose about merging masks and views, pondering the requirement for a bounded representation to enhance mask utility.
- Members acknowledged that combining masks could complicate the original merging problem while still offering potential solutions.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (6 messages):
Course Certificates, LLM MOOC Enrollment
-
When are course certificates coming?: A member inquired about the timeline for receiving course certificates and whether there's a way to track the dates.
- No specific information was provided in response to this query.
- Clarification on LLM MOOC Enrollment: Another member expressed uncertainty about their enrollment status after filling out the advance application form in December, asking for confirmation.
- A response confirmed that there is no 'acceptance process'; anyone who filled out the signup form is automatically enrolled!
- LLM Agents and Course Success: A member noted that being an LLM agent guarantees acceptance into the course and remarked that passing it would be impressive.
- This highlights the expectation of competence among agents in the course.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
BFCLV3 LLMs testing, Tool relationships in LLMs, Research on BFCLV3 dataset
-
Inquiry on BFCLV3 LLMs Tool Relationships: A member asked whether the LLMs in BFCLV3 receive a system message detailing the relationships between tools like get_flight_cost and get_creditcard_balance before executing actions like book_flight.
- They sought clarification on whether LLMs are tested solely based on tool descriptions without any meta information about tool dependencies.
- Response on Task Information Availability: In response, another member mentioned that checking the actual request information for various tasks reveals that there seems to be no provided information on tool dependencies for simple, parallel, multiple, and parallel_multiple tasks.
- They shared a GitHub link for further investigation into the Gorilla dataset.
- Research Focus on BFCLV3 Dataset: The initial member confirmed they had reviewed all available data and emphasized that understanding tool relationships is critical for their research.
- They expressed a desire to try and cite information specifically from the BFCLV3 dataset.
Link mentioned: gorilla/berkeley-function-call-leaderboard/data at main · ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
BFCLV3 System Message, LLMs Tool Dependency
-
BFCLV3's System Message Clarity: A member inquired whether LLMs in BFCLV3 receive a system message that explains the relationships between tools, like get_flight_cost and get_creditcard_balance, before actions are executed.
- The question raises the issue of whether LLMs operate solely on tool descriptions without any meta information regarding inter-tool dependencies.
- Clarification on LLM Testing Methodology: The discussion included whether LLMs are tested purely based on tool descriptions or if dependency relationships are considered in their testing.
- This inquiry highlights a potential gap in understanding the evaluation process for LLMs within the BFCLV3 framework.
Axolotl AI ▷ #general (2 messages):
KTO Loss Merge, Office Hours Announcement
-
Liger-Kernel Merges KTO Loss: The KTO loss has been successfully merged in the Liger-Kernel repository.
- This merge is expected to enhance the performance of the model, providing exciting new capabilities.
- Reminder for Office Hours: A friendly reminder that Office Hours will begin in 4 hours.
- Members can join the event through this Discord link for interactive discussion.
MLOps @Chipro ▷ #events (1 messages):
Event for Senior Engineers/Data Scientists, Networking Opportunities in Toronto
-
Hosting Event for Senior Engineers/Data Scientists: An individual announced they are hosting a small event on February 18 for senior engineers and data scientists in Toronto.
- They invited interested participants to DM for more details.
- Toronto Networking Event: This event aims to facilitate networking and discussions among senior engineers and data scientists in Toronto.
- It presents an opportunity for professionals to connect and share insights in their respective fields.
Mozilla AI ▷ #announcements (1 messages):
Local-First X AI Hackathon, Event Discussion Thread
-
San Francisco Hackathon Announcement: A Local-First X AI Hackathon is set to take place in San Francisco on Feb. 22.
- Organizers include members who are eager to engage the community in innovative projects during this event.
- Discussion Thread for Hackathon: A thread is available for more discussion on the event as details are finalized.
- Interested participants are encouraged to share ideas and collaborate ahead of the hackathon.
OpenInterpreter ▷ #ai-content (1 messages):
fund21: ye how we can you integrate Deepspeek on >interpreter --os mode ?