[AINews] Olympus has dropped (aka, Amazon Nova Micro|Lite|Pro|Premier|Canvas|Reel)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Amazon Bedrock is all you need?
AI News for 12/2/2024-12/3/2024. We checked 7 subreddits, 433 Twitters and 29 Discords (198 channels, and 2914 messages) for you. Estimated reading time saved (at 200wpm): 340 minutes. You can now tag @smol_ai for AINews discussions!
we apologize for the repeated emails yesterday. It was a platform bug we had no control over but we will watch closely as obviously we have zero desire to spam you/harm our own deliverability. fortunately ainews is also founded on the idea that email length and quantity is near (but not quite) free.
As widely rumored (as Olympus) in the past year, AWS Re:invent (full stream here) kicked off, ex-AWS and now Amazon CEO Andy Jassy had quite a bombshell to drop: their own, for real, actually competitive, not screwing around, set of multimodal foundation models, Amazon Nova (report, blog):

As an incredible (for a large tech player keynote) bonus, there is NO WAITLIST - Micro/Lite/Pro/Canvas/Reel are immediately Generally Available, with Premier and Speech-to-Speech and "Any-to-Any" coming next year.
The LMArena elo is running now, but already this is a much more serious contender for real AI Engineer than the previous Titan generation. Not stressed in the keynote, but of high importance are both the high speed (2-4x faster tok/s vs Anthropic/OpenAI):
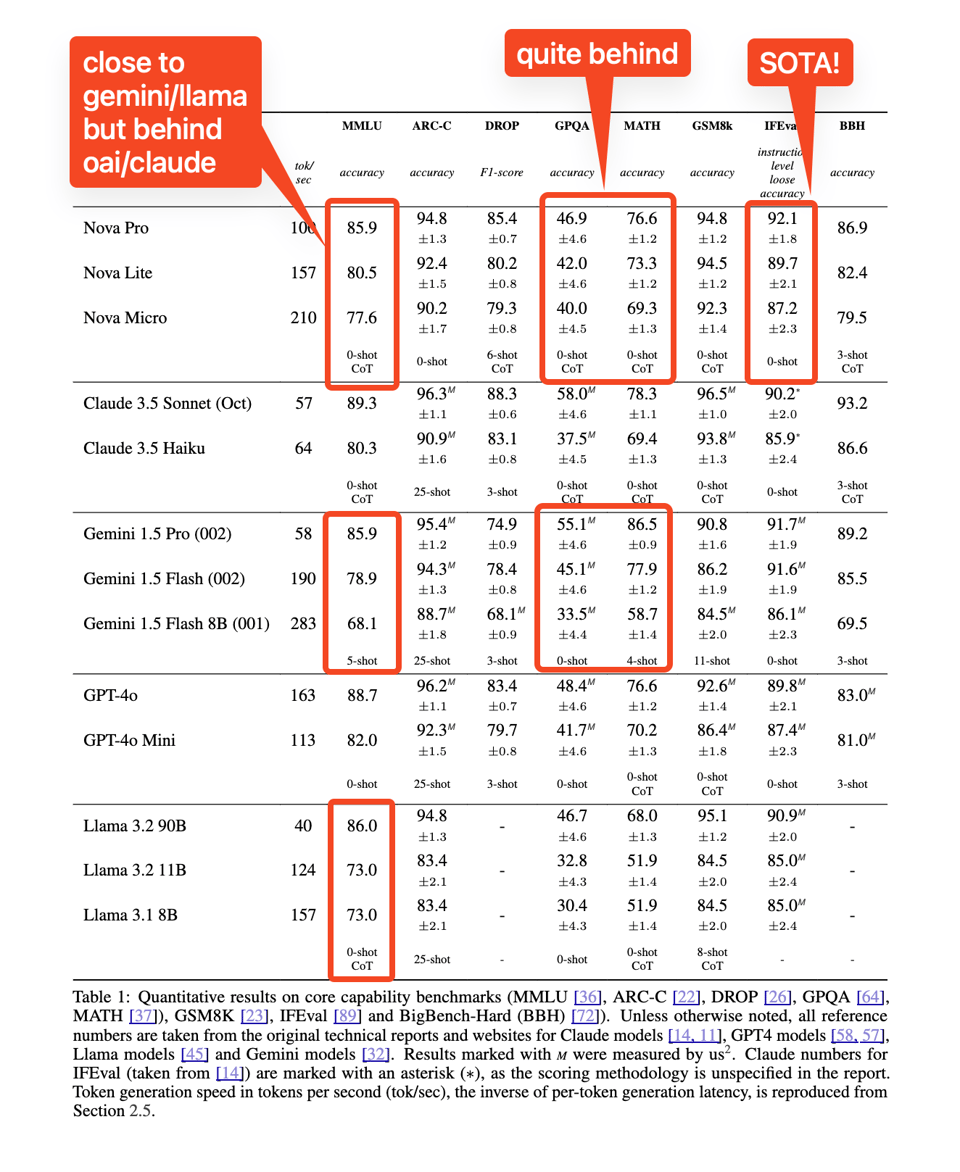
and low cost (25% - 400% cheaper than Claude equivalent):

Imputing their Arena scores with their nearest neighbor equivalents, this offers near-frontier price-intelligence performance:
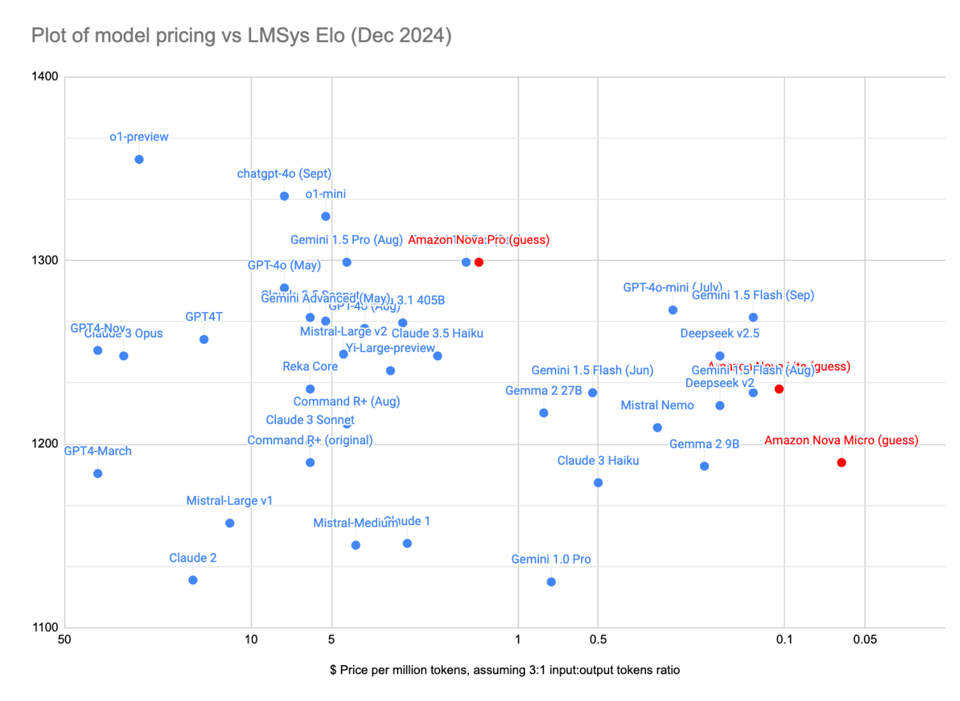
Of course, everyone is making comments about how this lines up with Amazon also investing $4bn in Anthropic, to which, the Everything Store CEO has one answer:

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Nous Research AI Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- aider (Paul Gauthier) Discord
- Cursor IDE Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- Notebook LM Discord Discord
- OpenAI Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- Latent Space Discord
- Cohere Discord
- GPU MODE Discord
- LlamaIndex Discord
- LM Studio Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- DSPy Discord
- Torchtune Discord
- MLOps @Chipro Discord
- Axolotl AI Discord
- tinygrad (George Hotz) Discord
- LAION Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Nous Research AI ▷ #announcements (2 messages):
- Nous Research AI ▷ #general (426 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (3 messages):
- Nous Research AI ▷ #reasoning-tasks (4 messages):
- Eleuther ▷ #general (181 messages🔥🔥):
- Eleuther ▷ #research (151 messages🔥🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (13 messages🔥):
- Eleuther ▷ #gpt-neox-dev (2 messages):
- Modular (Mojo 🔥) ▷ #general (120 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (133 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (154 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (82 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- Cursor IDE ▷ #general (213 messages🔥🔥):
- Perplexity AI ▷ #general (188 messages🔥🔥):
- Perplexity AI ▷ #sharing (12 messages🔥):
- Perplexity AI ▷ #pplx-api (7 messages):
- Unsloth AI (Daniel Han) ▷ #general (115 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
- Unsloth AI (Daniel Han) ▷ #help (48 messages🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (28 messages🔥):
- Notebook LM Discord ▷ #general (140 messages🔥🔥):
- OpenAI ▷ #ai-discussions (122 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- OpenAI ▷ #prompt-engineering (9 messages🔥):
- OpenAI ▷ #api-discussions (9 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (117 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (100 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
- Latent Space ▷ #ai-announcements (3 messages):
- Cohere ▷ #discussions (53 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (9 messages🔥):
- Cohere ▷ #api-discussions (6 messages):
- Cohere ▷ #projects (1 messages):
- Cohere ▷ #cohere-toolkit (1 messages):
- GPU MODE ▷ #general (7 messages):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #cuda (5 messages):
- GPU MODE ▷ #torch (1 messages):
- GPU MODE ▷ #beginner (26 messages🔥):
- GPU MODE ▷ #youtube-recordings (1 messages):
- GPU MODE ▷ #off-topic (6 messages):
- GPU MODE ▷ #arm (3 messages):
- GPU MODE ▷ #webgpu (1 messages):
- GPU MODE ▷ #self-promotion (6 messages):
- GPU MODE ▷ #🍿 (3 messages):
- GPU MODE ▷ #thunderkittens (1 messages):
- LlamaIndex ▷ #blog (6 messages):
- LlamaIndex ▷ #general (43 messages🔥):
- LM Studio ▷ #general (20 messages🔥):
- LM Studio ▷ #hardware-discussion (15 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (18 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (5 messages):
- OpenInterpreter ▷ #general (21 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- DSPy ▷ #show-and-tell (3 messages):
- DSPy ▷ #general (7 messages):
- DSPy ▷ #examples (9 messages🔥):
- Torchtune ▷ #general (4 messages):
- Torchtune ▷ #papers (1 messages):
- MLOps @Chipro ▷ #events (4 messages):
- Axolotl AI ▷ #announcements (1 messages):
- Axolotl AI ▷ #general (3 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- LAION ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Theme 1. Amazon Nova Foundation Models: Release, Pricing, and Evaluation
- Amazon Nova Release Overview: @_philschmid provided a comprehensive overview of the new Amazon Nova models, highlighting their competitive pricing and benchmarks. Nova models are available via Amazon Bedrock, with multiple configurations including Micro, Lite, Pro, and Premier, and extend the context length up to 300k tokens for certain models.
- Pricing Strategy: Nova models undercut the prices of competitors like Google DeepMind Gemini Flash 8B, as noted by @_philschmid, with competitive input/output token pricing.
- Performance and Usage: According to @ArtificialAnlys, the Nova family models, particularly the Pro, outperform models like GPT-4o on specific benchmarks.
- Controversy over Evaluation and Benchmarking: A critical perspective came from @bindureddy, where despite the promising parameters, Nova was found to score below Llama-70B in LiveBench AI metrics. This reiterates the dynamic and competitive nature of model benchmarking.
Theme 2. CycleQD: Evolutionary Approach in Language Models
- CycleQD Methodology and Launch: The most significant discussion came from @SakanaAILabs, introducing CycleQD, a population-based model merging via Quality Diversity. The approach uses evolutionary computation to develop LLM agents with niche capabilities, aimed at lifelong learning. Another tweet by HARDMARU praised the ecological niche analogy as a compelling strategy for skill acquisition in AI systems.
Theme 3. AI Humor and Memes
- Funny Anecdotes and Humor: @arohan humorously shared a moment about forgetting to inform their partner about a six-month-old promotion. Meanwhile, @tom_doerr shared a meme about an "impossible" question, emphasizing the lighter sides of AI interaction.
- Social Media Humor: @teortaxesTex mentioned a tongue-in-cheek strategy regarding NFTs related to an "impossible" question.
Theme 4. Hugging Face Concerns and Community Response
- Storage Quotas and Open Models Controversy: @far__el and others aired grievances about Hugging Face storage limits, viewing it as a potential barrier for the AI open-source community. @mervenoyann clarified that Hugging Face remains generous with storage but emphasized their adaptability towards community-driven repositories.
- Emerging Competitors: @far__el announced OpenFace, an initiative for self-hosting AI models independent of Hugging Face, as a response to recent policy changes.
Theme 5. New and Noteworthy Model Innovations
- HunyuanVideo and Emoationally Attuned Models: @andrew_n_carr highlighted Tencent's HunyuanVideo, noting its open weights and contributions to the video-generation model landscape. Meanwhile, @reach_vb announced Indic-Parler TTS, an emotionally attuned text-to-speech model.
- Model Performance Updates: Discussions around GPT-4o performance updates, like a noticeable uptick in intelligence, were noted by @cognitivecompai.
Theme 6. AI Winter and Industry Outlook
- Concerns about AI's Future: @iScienceLuvr expressed concern about an impending AI winter, suggesting a slowdown or regression in AI advancement or investment enthusiasm, showcasing the fluctuating optimism in the AI industry.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. HuggingFace Imposes 500GB Limit, Prioritizes Community Contributors
- Huggingface is not an unlimited model storage anymore: new limit is 500 Gb per free account (Score: 249, Comments: 76): HuggingFace introduced a 500GB storage limit for free-tier accounts, marking a shift from their previous unlimited storage policy. This change affects model storage capabilities for free users on the platform.
- Huggingface employee (VB) clarified this is a UI update for existing limits, not a new policy. The platform continues to offer storage and GPU grants for valuable community contributions like model quantization, datasets, and fine-tuning, while targeting misuse and spam.
- Community members reported significant storage usage, with one user at 8.61 TB/500 GB, and expressed concerns about the future availability of large models like LLaMA 65B (requiring ~130GB). Discussion centered around potential solutions including local storage and torrents.
- Users debated the business implications, noting that contributors already invest significant time and effort in creating quantized models for the community. The change prompted comparisons to YouTube's model where users pay to consume rather than upload content.
- Hugging Face added Text to SQL on all 250K+ Public Datasets - powered by Qwen 2.5 Coder 32B 🔥 (Score: 119, Comments: 11): Hugging Face has integrated Text-to-SQL capabilities across their 250,000+ public datasets using Qwen 2.5 Coder 32B model. This integration enables direct SQL query generation from natural language inputs across their entire public dataset collection.
- VB, GPU Poor at Hugging Face, confirmed the implementation uses DuckDB WASM for in-browser SQL query execution. The feature combines Qwen 2.5 32B Coder for query generation with browser-based execution capabilities.
- Users expressed enthusiasm about reducing the need to write SQL manually, particularly highlighting how this helps those less experienced with query writing.
- The announcement garnered positive reception with commenters appreciating the celebratory tone, including the use of confetti animations in the demonstration.
Theme 2. DeepSeek and Qwen Surpass Expectations, Challenge OpenAI's Position
- Open-weights AI models are BAD says OpenAI CEO Sam Altman. Because DeepSeek and Qwen 2.5? did what OpenAi supposed to do! (Score: 541, Comments: 216): DeepSeek and Qwen 2.5 open-source AI models from China demonstrate capabilities that rival closed-source alternatives, prompting Sam Altman to express concerns about open-weights models in a Fox News interview with Shannon Bream. The OpenAI CEO emphasizes the strategic importance of maintaining US leadership in AI development over China, while simultaneously facing criticism as Chinese open-source models achieve competitive performance levels.
- Community sentiment strongly criticizes Sam Altman and OpenAI's perceived hypocrisy, with users pointing out that their $157 billion valuation seems unjustified given the rising competition from open-source models. Many note that previous safety concerns about open-weights models appear unfounded.
- Users highlight that OpenAI's technological advantage or "moat" is rapidly diminishing, with Chinese models like DeepSeek and Qwen achieving competitive performance. Several comments suggest that OpenAI's main strength has been marketing rather than technological superiority.
- Multiple users reference OpenAI's deviation from its original open-source mission, citing early communications with Elon Musk and the company's current stance against open-weights models. The discussion suggests that OpenAI's business strategy relies heavily on maintaining closed-source advantages.
- Opensource is the way (Score: 60, Comments: 14): In a comparison of reasoning capabilities, open-source models (Deepseek R1 and QwQ) outperformed closed APIs (Claude Haiku and OpenAI) on complex reasoning questions, with R1 achieving the fastest correct solution in 25 seconds using Chain of Thought (CoT). A non-coding user found R1 and QwQ particularly helpful for coding tasks, while noting that Claude Sonnet's utility was limited by access restrictions and context length constraints in its free version.
- QwQ and GPT-4o usage comparison reveals that 4o has strict limits of 40 messages for regular users and 80 messages per 3 hours for Plus users, as detailed in OpenAI's FAQ.
- Users anticipate 2025 as the breakthrough year for open-source models, noting that QwQ is currently 5x less expensive than GPT-4o while delivering superior reasoning performance. Both QwQ and R1 are currently in preview/lite versions.
- The free version of GPT-4o is likely the 4o-mini variant, with users noting its performance limitations compared to QwQ based on benchmark results.
Theme 3. National Security Concerns Used to Push AI Regulation
- Open-Source AI = National Security: The Cry for Regulation Intensifies (Score: 114, Comments: 87): Media outlets and policymakers continue to link open-source AI development with national security threats, pushing for increased regulation and oversight. The narrative equates unrestricted AI development with potential security risks, though specific policy proposals remain undefined.
- Chinese AI models like Yi and Qwen are reportedly ahead of Western open-source efforts, with users noting they're not based on Llama. Multiple commenters point out that regulation of US open-source models would primarily benefit Chinese AI development.
- The discussion draws parallels between current AI regulation fears and historical resistance to open-source software in the early 2000s, particularly referencing the Microsoft/SCO situation. Users argue that like Linux, open-source AI will likely accelerate industry innovation.
- Users criticize the media narrative as fear-mongering aimed at establishing AI monopolies through regulation. Many reference Fox News' credibility on technology issues and suggest this is driven by corporate interests rather than legitimate security concerns.
Theme 4. New Tools: Open-WebUI Enhanced with Advanced Features
- 🧙♂️ Supercharged Open-WebUI: My Magical Toolkit for ArXiv, ImageGen, and AI Planning! 🔮 (Score: 97, Comments: 11): The author developed several tools for Open-WebUI, including an arXiv Search tool, Hugging Face Image Generator, and various function pipes like a Planner Agent using Monte Carlo Tree Search and Multi Model Conversations supporting up to 5 different AI models. Running on a setup with R7 5800X, 16GB DDR4, and RX6900XT, the author's AI stack includes Ollama, Open-webUI, OpenedAI-tts, ComfyUI, n8n, quadrant, and AnythingLLM, primarily using 8B Q6 or 14B Q4 models with 16k context, with code available at open-webui-tools and open-webui.
- Users suggested using Python 3.12 to enhance performance, though the developer indicated time constraints for implementation.
- Interest was expressed in the Monte Carlo Tree Search (MCTS) implementation for research summarization, though no specific details or papers were provided in the discussion.
- I built this tool to compare LLMs (Score: 297, Comments: 55): Model comparison tool mentioned without any specific details or functionality, making it impossible to provide a meaningful technical summary of the benchmarking capabilities or implementation details. No additional context provided about the actual tool or its features.
- Users suggested adding smaller language models to the comparison tool, specifically mentioning models like Gemma 2 2B, Llama 3.2 1B/3B, Qwen 2.5 1.5B/3B, and others for on-device applications like PocketPal.
- A significant discussion arose about token count normalization, with detailed analysis showing that Claude-3.5-Sonnet uses approximately twice the tokens compared to GPT-4o for the same input, affecting both cost calculations and context length comparisons.
- An important distinction was made between "Open Source" and "Open Weight" models, noting that the listed self-hostable models are technically Open Weight since their training data isn't publicly available.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. ChatGPT Used to Win $1180 Small Claims Court Case Against Landlord
- UPDATE: ChatGPT allowed me to sue my landlord without needing legal representation - AND I WON! (Score: 1028, Comments: 38): A tenant won a court case against Dr. Joe Prisinzano, co-principal of Jericho High School, who illegally charged a $2,175 security deposit (exceeding one month's $1,450 rent) and failed to repair a broken window during winter, with ChatGPT helping identify a 2019 law violation and prepare legal defense against a retaliatory $5,000 counterclaim. The court awarded the tenant $1,180 and dismissed the counterclaim, though Prisinzano threatened to appeal and pursue defamation charges, while the case gained viral attention through a TikTok video with over 1 million views by Sabrina Ramonov viral TikTok.
- The tenant argues this is a matter of public interest since Joe Prisinzano is an educational leader making $250,000 annually at one of the top US public high schools, with his unethical landlord behavior contradicting his leadership position and warranting public awareness.
- Multiple users shared similar experiences using ChatGPT for legal assistance, though cautioning against sole reliance on AI and recommending 1-hour legal consultations. One user noted that in New York, tenants can claim double damages for illegal security deposits and triple damages for undocumented withholding.
- The original judge ruled conservatively on the tenant's $4,000 punitive damages request, granting only the illegal deposit return and a 7% rent abatement for the broken window period, despite the landlord's written admission of knowingly breaking the law.
Theme 2. HunyuanVideo Claims State-of-Art Video Generation, Beats Gen3 & Luma
- SANA, NVidia Image Generation model is finally out (Score: 136, Comments: 78): SANA, NVIDIA's image generation model, has been released publicly. No additional details were provided in the post body about model capabilities, architecture, or source code location.
- License restrictions are significant - model can only be used non-commercially, must run on NVIDIA processors, requires NSFW filtering, and gives NVIDIA commercial rights to derivative works. The model is available on HuggingFace.
- Technical requirements include 32GB VRAM for training both 0.6B and 1.6B models, with inference requiring 9GB and 12GB VRAM respectively. A future quantized version promises to require less than 8GB for inference.
- The model uses a decoder-only LLM (possibly Gemma 2B) as text encoder instead of T5, and while it's noted to be extremely fast, users report image quality issues and text generation capabilities inferior to Flux. A demo is available at nv-sana.mit.edu.
- Tencent Hunyuan-Video : Beats Gen3 & Luma for text-video Generation. (Score: 37, Comments: 15): Tencent released Hunyuan-video, an open-source text-to-video model that claims to outperform closed-source competitors Gen3 and Luma1.6 in testing. The model includes audio generation capabilities and can be previewed in their demo video.
- The model is available on GitHub and Hugging Face, with an official project page at Tencent Hunyuan.
- System requirements include 60GB GPU memory for 720x1280 resolution with 129 frames, or 45GB for 544x960 resolution with 129 frames, prompting humorous comments about running it on consumer GPUs.
- ComfyUI integration is listed as a future development item in the project's roadmap, suggesting expanded accessibility is planned.
Theme 3. ChatGPT Parent OpenAI Considers Adding Advertisements
- We definitely should be concerned that 2025 starts with W T F (Score: 190, Comments: 157): OpenAI's plans to implement advertising in ChatGPT by 2025 sparked concerns about the future direction of AI monetization. The community expressed skepticism about this development, questioning its implications for user experience and the broader impact on AI business models.
- Data monetization concerns dominate discussions, with users predicting evolution from "promoted suggestions" for free users to eventual sponsored content across all tiers. Community expects integration of targeted advertising based on conversation data, similar to Prime Video's advertising model.
- The concept of "enshittification" emerged as a key theme, with users anticipating a shift from user-focused service to revenue maximization. Multiple commenters pointed to Claude and local LLMs (like Llama, QWQ, and Qwen) as potential alternatives.
- Users expressed concern about AI-generated advertising's potential for subtle manipulation, noting that traditional ad blockers may be ineffective against AI-integrated promotional content. Discussion highlighted how ChatGPT's conversational nature could make sponsored content particularly difficult to identify or regulate.
- Ads might be coming to ChatGPT — despite Sam Altman not being a fan (Score: 70, Comments: 108): OpenAI may introduce advertisements into ChatGPT, despite CEO Sam Altman's previously stated aversion to ad-based revenue models. The title alone suggests a potential shift in OpenAI's monetization strategy, though no specific timeline or implementation details are provided.
- User reactions are overwhelmingly negative, with many stating they would cancel subscriptions immediately if ads are implemented. Multiple users draw parallels to streaming services like Prime Video and Disney+ that introduced ads even to paid tiers.
- The original article appears to be clickbait, as noted by users pointing out that OpenAI has "no active plans" to add ads, with some suggesting this is merely testing public reaction. The top comment clarifying this received 177 upvotes.
- Users express concerns about ad-based incentives compromising ChatGPT's integrity, comparing it to the difference between trusted friend recommendations versus commissioned salespeople. Several comments highlight how ads typically expand from free tiers to paid services over time, citing cable TV and streaming platforms as examples.
Theme 4. Vodafone's AI Commercial Shows New Benchmark in AI Video Production
- Absolutely incredible AI ad by Vodafone. Much much better than Coca-cola's attempt. (Score: 163, Comments: 63): Vodafone created an AI-generated commercial that received positive reception from viewers, with commenters specifically comparing it favorably against Coca-Cola's previous AI advertising attempt. No additional details about the commercial's content or creation process were provided in the post.
- Viewer reactions were largely negative, criticizing the ad's lack of coherence and overuse of stereotypical shots. Multiple users pointed out the commercial's poor watchability without sound and overwhelming number of disconnected scenes.
- The commercial's cost efficiency was highlighted, estimated at "one tenth of an ordinary commercial." Users debated whether the technical achievement outweighed its artistic merit, with the video editor receiving more praise than the AI itself.
- Discussion centered on the industry implications, particularly regarding the potential displacement of actors and traditional production crews. A Campaign Live article about the commercial's creation was referenced but remained paywalled.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: New Optimizers and Training Techniques Revolutionize AI
- DeMo Decentralizes Model Training: Nous Research unveils the DeMo optimizer, enabling decentralized pre-training of 15B models via Nous DisTrO with performance matching centralized methods. The live run showcases its efficiency and can be watched here.
- Axolotl Integrates ADOPT Optimizer: Axolotl AI incorporates the latest ADOPT optimizer, offering optimal convergence with any beta value and enhancing model training efficiency. Engineers are invited to experiment with these enhancements in the updated codebase.
- Pydantic AI Bridges LLM Integration: The launch of Pydantic AI provides seamless integration with LLMs, enhancing AI applications. It also integrates with DSPy's DSLModel, streamlining development workflows for AI engineers.
Theme 2: New AI Models Stir Excitement and Debate
- Amazon's Nova Takes Aim at GPT-4o: Amazon releases Nova foundation models via Bedrock, boasting competitive capabilities and cost-effective pricing. Nova supports day 0 integration and expands the AI model landscape with affordable options.
- Hunyuan Video Sets Text-to-Video Bar High: Tencent's Hunyuan Video launches as a leading open-source text-to-video model, impressing users despite high resource demands. Initial feedback is positive, with anticipation for future efficiency optimizations.
- Sana Model's Efficiency Under Scrutiny: The Stability.ai community debates the new Sana model, questioning its practical advantages over existing models like Flux. Some suggest that using prior models might yield similar or better results.
Theme 3: AI Tools Face Performance and Update Challenges
- Cursor IDE's Lag Drives Users to Windsurf: Frustrated with Cursor IDE's lag in Next.js projects, users return to Windsurf due to Cursor's persistent performance issues. Cursor's syntax highlighting and chat functionality also receive criticism for causing "visual discomfort" and hindering usability.
- OpenInterpreter Revamps for Speed and Smarts: A complete rewrite of OpenInterpreter's development branch results in a "lighter, faster, and smarter" tool. The new
--serveoption introduces an OpenAI-compatible REST server, enhancing accessibility and usability. - Unsloth AI Fine-Tuning Hits Snags: Users struggle with LoRA fine-tuning on Llama 3.2 and face xformers compatibility issues, leading to shared community fixes. Challenges include OOM errors and discrepancies in sequence length configurations during training.
Theme 4: Community Explores AI Methods and Frameworks
- Function Calling vs MCP: Clash of AI State Managers: Nous Research debates the merits of function calling versus the Model Context Protocol (MCP) for managing AI model state and actions, highlighting confusion and the need for clearer guidelines on their respective applications.
- ReAct Paradigm's Effectiveness Depends on Implementation: LLM Agents course participants emphasize that ReAct's success depends on implementation specifics like prompt design and state management. Benchmarks should reflect these details due to "fuzzy definitions" in the AI field.
- DSPy and Pydantic AI Enhance Developer Workflows: DSPy integrates Pydantic AI, allowing efficient development with DSLModel. Live demos showcase advanced AI development techniques, sparking excitement for implementing Pydantic features in projects.
Theme 5: AI Community Engages in Opportunities and Events
- Ex-Googlers Launch New Venture, Invite Collaborators: Raiza departs Google after 5.5 years to start a new company with former NotebookLM team members, inviting others to join via hello@raiza.ai. They celebrate significant achievements and plan to build innovative products with the community.
- Sierra AI Scouts Talent at Info Session: Sierra AI hosts an exclusive info session unveiling their Agent OS and Agent SDK, while seeking talented developers to join their team. Participants can RSVP here to secure their spot for this opportunity.
- Multi-Agent Meetup Highlights Collaborative Innovation: The upcoming Multi-Agent Meetup at GitHub HQ features experts discussing automating tasks with CrewAI and evaluating agents with Arize AI, fostering collaboration in agentic retrieval applications.
PART 1: High level Discord summaries
Nous Research AI Discord
- Decentralized Pre-training with DisTrO: Nous has initiated a decentralized pre-training of a 15B parameter language model using Nous DisTrO and hardware from partners like Oracle and Lambda Labs, showcasing a loss curve that matches or exceeds traditional centralized training with AdamW.
- The live run can be watched here, and the accompanying DeMo paper and code will be announced soon.
- DeMo Optimizer Release: The DeMo optimizer enables training neural networks in parallel by synchronizing only minimal model states during each optimization step, enhancing convergence while reducing inter-accelerator communication.
- Details about this approach are available in the DeMo paper, and the source code can be accessed on GitHub.
- DisTrO Training Update: The ongoing DisTrO training run is nearing completion, with specific details on hardware and user contributions expected by the end of the week.
- This run serves primarily as a test, and there may not be immediate public registries or tutorials available for users.
- Function Calling vs MCP in AI Models: Function calling is utilized to manage state and actions within AI models, while MCP offers alternative advantages for implementing complex functionalities.
- There is some confusion distinguishing MCP from function calling, underscoring the need for clearer guidelines on their respective applications.
- Using Smaller Models for Specific Tasks: Smaller AI models can outperform larger ones in certain creative tasks, offering benefits such as faster processing and reduced resource usage.
- A balanced approach is suggested where smaller models handle state management while larger models are reserved for more intensive tasks like storytelling.
Eleuther Discord
- JAX Adoption Accelerates in Major AI Labs: Members revealed that Anthropic, DeepMind, and other leading AI labs are increasingly utilizing JAX for their models, though the extent of its primary usage varies across organizations.
- There is ongoing debate about JAX's dominance over PyTorch, with calls for greater transparency regarding industry adoption rates and practices.
- Vendor Lock-in Raises Concerns in Academic Curricula: Discussions highlighted the vendor lock-in issue in academia, where tech companies influence university programs by supplying resources for specific frameworks like PyTorch and JAX.
- Opinions are split; some see benefits in established partnerships, while others worry about limiting students' exposure to a broader range of tools and frameworks.
- DeMo Optimizer Enhances Large-Scale Model Training: The DeMo optimizer introduces a technique to minimize inter-accelerator communication by decoupling momentum updates, which leads to better convergence without full synchronization on high-speed networks.
- Its minimalist design reduces the optimizer state size by 4 bytes per parameter, making it advantageous for training extensive models.
- Externalizing Evals via Hugging Face Proposed: A proposal was made to allow evals to be externally loadable through Hugging Face, similar to how datasets and models are integrated.
- This approach could simplify the loading process for datasets and associated eval YAML files, though concerns about visibility and versioning need to be addressed to ensure reproducibility.
- wall_clock_breakdown Configures Detailed Logging: Members identified that the wall_clock_breakdown configuration option enables detailed logging messages, including optimizer timing metrics like optimizer_allgather and fwd_microstep.
- Clarifications confirmed that enabling this option is essential for generating in-depth performance logs, aiding in performance diagnostics and optimization.
Modular (Mojo 🔥) Discord
- Mojo Socket Communication Delays: The implementation of socket communication in Mojo is postponed due to pending language features, with plans for a standard library that supports swappable network backends like POSIX sockets.
- A major rewrite is scheduled to ensure proper integration once these language features are available.
- Mojo's SIMD Support Simplifies Programming: Discussion highlighted Mojo's SIMD support as simplifying SIMD programming compared to C/C++ intrinsics, which are often chaotic.
- The goal is to map more intrinsics to the standard library in future updates to minimize direct usage.
- High-Performance File Server Project in Mojo: A project aiming to develop a high-performance file server for a game is targeting a 30% higher packets per second rate than Nginx.
- Currently, the project utilizes external calls for networking until the delayed socket communication features become available.
- Reference Trait Proposal for Mojo: A proposal for a
Referencetrait in Mojo aims to enhance the management of mutable and readable references within Mojo code.- This approach is expected to improve borrow-checking and reduce confusion regarding mutability in function arguments.
- Magic Package Distribution Launch: Magic Package Distribution is in development with an early access preview rolling out soon, enabling community members to distribute packages through Magic.
- The team is seeking testers to refine the feature, inviting members to commit by reacting with 🔍 for package reviewing or 🧪 for installation.
aider (Paul Gauthier) Discord
- OpenRouter Performance Lags Behind Direct API: Benchmark analysis revealed that models accessed via OpenRouter deliver inferior performance compared to those accessed directly through the API, sparking discussions on optimization strategies.
- Users are collaboratively exploring solutions to enhance OpenRouter's efficiency, indicating a community-driven effort to resolve the discrepancies.
- Aider Rolls Out Enhanced Features for Developers: Aider's latest
--watch-filesfeature streamlines AI instruction integration into coding workflows, alongside functionalities like/save,/add, and context modification, as detailed in their options reference.- These updates have been well-received, with users noting improved transparency and a more informed programming experience.
- Amazon Unveils Six New Foundation Models at re:Invent: During re:Invent, Amazon announced six new foundation models, including Micro, Lite, and Canvas, emphasizing their multimodal capabilities and competitive pricing.
- These models will be exclusively available via Amazon Bedrock and are positioned as cost-effective alternatives to other US frontier models.
- Enhancing Aider's Context with Model Context Protocol: Users have been integrating the Model Context Protocol (MCP) to improve Aider's context management capabilities, particularly in code-related scenarios, as discussed in this video.
- Tools like IndyDevDan's agent and Crawl4AI are being utilized to create optimized documentation for seamless LLM integration.
- Resolving Aider Update Challenges with Python 3.12: Updating Aider to version 0.66.0 encountered issues, including command failures during package installation, which were resolved by explicitly invoking the Python 3.12 interpreter as outlined in the pipx installation guide.
- This approach has enabled users to successfully upgrade and leverage the latest features without recurring issues.
Cursor IDE Discord
- Cursor Lags in Next.js Projects: Users reported that Cursor experiences significant lag when developing with Next.js on medium to large projects, necessitating frequent 'Reload Window' commands.
- Performance varies based on system RAM, with those on 16GB experiencing more lag compared to 32GB setups, raising concerns about Cursor's performance consistency.
- Windsurf Outperforms Cursor Reliability: Some users reverted to Windsurf due to the ineffective repeat of fixes in the latest Cursor updates.
- They highlighted that Windsurf's agent successfully edits multiple files without losing comments, a functionality currently lacking in Cursor.
- Feature Requests for Cursor Agent: Members are requesting the addition of the @web feature in the Cursor Agent to enhance real-time information access.
- Issues with the agent not recognizing file changes were cited, leading to frustrations regarding its reliability.
- Cursor's Syntax Highlighting Drawbacks: First-time users reported that Cursor's syntax highlighting causes visual discomfort and hinders usability.
- Complaints include the malfunctioning of various VS Code addons within Cursor, detracting from the overall user experience.
- Post-Update Chat Issues in Cursor: After the recent update, users experienced problems with Cursor's chat functionality, including model hallucinations and inconsistent performance.
- Feedback indicates a decline in model quality, making coding tasks more challenging and frustrating.
Perplexity AI Discord
- Perplexity AI Faces Performance Slowdowns: Several users are encountering persistent slowdowns and infinite loading issues while using Perplexity AI's features, indicating potential scaling issues.
- These performance problems have also been observed on other platforms, leading users to consider transitioning to API services for a more stable experience.
- Users Explore Image Generation Capabilities: Discussions on image generation tools involved sharing prompts that yield unexpected, often creative results.
- Users experimented with quantum-themed prompts to generate unique visual outputs, demonstrating the versatile applications of image generation models.
- Amazon Nova Compared to ChatGPT and Claude: There were insightful comparisons of AI models, particularly between Amazon Nova and platforms like ChatGPT and Claude.
- Users evaluated the effectiveness of various foundational models based on specific tasks and their integration with tools like Perplexity.
- Issues with Google Gemini and Drive Integration: A user highlighted inconsistent access to Google Drive documents via Google Gemini, questioning its reliability.
- Concerns were raised about whether advanced features are restricted to paid versions, prompting users to seek practical demonstrations.
- API Error Responses and User Workarounds: Users reported intermittent API errors such as
unable to complete request, leading to confusion.- A temporary workaround involves adding a prefix to user prompts, mitigating error occurrences while awaiting a resolution.
Unsloth AI (Daniel Han) Discord
- LoRA Finetuning with Llama 3.2: Users reported challenges in fine-tuning Llama 3.2 using LoRA, particularly in transitioning from tokenization to processor management, with suggestions to modify Colab notebooks for successful execution.
- Troubleshooting steps included addressing xformers installation issues and ensuring compatibility with current PyTorch and CUDA versions.
- Model Compatibility and xformers Issues: Several users encountered compatibility problems with xformers related to their existing PyTorch and CUDA environments, resulting in runtime errors.
- Recommendations involved reinstalling xformers with matching versions, as well as verifying dependencies to resolve these issues.
- QWen2 VL 7B Fine-Tuning with LLaVA-CoT: A member fine-tuned QWen2 VL 7B using the LLaVA-CoT dataset and released the training script and dataset for community use.
- The resultant model features 8.29B parameters and utilizes BF16 tensor type, with the training script accessible here.
- GGUF Conversion Challenges in Unsloth Models: Users faced issues saving models to GGUF, encountering runtime errors about missing files like 'llama.cpp/llama-quantize' during the conversion process.
- Attempts to resolve these issues by restarting Colab were unsuccessful, suggesting potential recent changes in the underlying library.
- Partially Trainable Embeddings in Training Models: A user discussed creating partially trainable embeddings but faced challenges with the forward function not being called during training.
- Community feedback indicated that the model might be directly accessing weights instead of the modified head, necessitating deeper integration.
Notebook LM Discord Discord
- Raiza Exits Google to Launch New Venture: Raiza announced their departure from Google after 5.5 years, highlighting significant achievements with the NotebookLM team and the development of a product used by millions.
- Raiza is initiating a new company with two former NotebookLM members, inviting collaborators to join via werebuilding.ai and contact at hello@raiza.ai.
- Creative Uses of NotebookLM for Scripts and Podcasts: Users detailed leveraging NotebookLM for scriptwriting, developing detailed camera and lighting setups, and integrating scripts into video projects.
- Another user successfully generates long podcast episodes by outlining content chapter by chapter, utilizing Eleven Labs for audio and visuals in documentary-style projects.
- Enhancing Document Management with PDF OCR Tools: Discussions highlighted the use of PDF24 for applying OCR to scanned documents, transforming them into searchable PDFs with robust security protocols.
- PDF24 is recommended for converting images and photos into searchable formats, streamlining document usability without requiring installation or registration.
- Feature Requests and Integration Challenges in NotebookLM: Users expressed a need for unlimited audio generations in NotebookLM, suggesting potential subscription models to increase daily limits beyond the current 20.
- Challenges with processing long PDFs were noted, with speculation that Gemini 1.5 Pro may offer better capabilities, alongside frustrations about inconsistent Google Drive integration.
- Advancements and Issues in Multilingual AI Support: There were inquiries about changing language settings in NotebookLM to support outputs in languages other than English, with current guidance pointing to altering Google account settings.
- Users reported varying success rates in AI-generated language outputs, particularly with accents like Scottish or Polish, indicating areas for improvement in multilingual capabilities.
OpenAI Discord
- Italy's AI Regulation Act Enforces Data Removal: Italy announced plans to ban AI platforms like OpenAI unless users can request the removal of their data, sparking debates on regulatory effectiveness.
- Concerns were raised about the ineffectiveness of geolocation bans, with discussions on potential user workarounds to bypass these restrictions.
- ChatGPT Plus Plan Suffers Feature Malfunctions: Users reported that after subscribing to the ChatGPT Plus plan for $20, features such as image generation and file reading are not functioning correctly.
- Additionally, several members noted that the responses they receive appear outdated, with the issue persisting for over a week.
- GPT Faces Functionality Issues in Billing Compilation: A user highlighted problems with a GPT designed to compile billing hours, mentioning that it forgets entries and struggles to produce an XLS-compatible list.
- Humorous speculation arose questioning if the GPT is bored with the work, reflecting user frustration with the tool's reliability.
- Leveraging Custom Instructions to Tailor ChatGPT: Members are utilizing custom instructions to adjust ChatGPT's writing style, distinguishing this method from creating new GPTs.
- Providing example texts was recommended to help ChatGPT adapt its output, enhancing alignment with user-specific storytelling preferences.
- Enhancing Prompt Engineering Skills Among AI Engineers: AI engineers expressed interest in accessing free or low-cost resources to improve their prompt engineering for developing custom GPTs with OpenAI ChatGPT.
- Discussions emphasized the importance of refining interaction techniques to maximize the effectiveness and capabilities of ChatGPT.
OpenRouter (Alex Atallah) Discord
- Model removals and price reductions: Two models,
nousresearch/hermes-3-llama-3.1-405bandliquid/lfm-40b, have been removed from availability, prompting users to add credits to maintain their API requests.- Significant price reductions have been made: nousresearch/hermes-3-llama-3.1-405b decreased from 4.5 to 0.9 per million tokens and liquid/lfm-40b from 1 to 0.15, offering more affordable alternatives post-removal.
- Hermes 405B Model Removal: Hermes 405B is no longer available, signaling the model's phase-out, with users debating the cost of alternatives and favoring existing free models.
- The removal raised concerns over model availability, as some users consider purchasing increasingly priced models, while others stick with free options.
- OpenRouter API Key Management: OpenRouter now supports creation and management of API keys, allowing users to set and adjust credit limits per key without automatic resets.
- Users maintain control over their application access by managing key usage manually, ensuring secure and regulated API access.
- Gemini Flash Errors: Users encountered transient 525 Cloudflare errors while accessing Gemini Flash, which quickly resolved themselves.
- The model's instability was noted, with recommendations to verify its functionality via OpenRouter's chat interface.
- BYOK Access Update: The team announced that BYOK (Bring Your Own Key) access will soon be available to all users, though the private beta phase is currently paused.
- Ongoing adjustments are being made to address existing issues before rolling out the feature widely.
Stability.ai (Stable Diffusion) Discord
- Mastering LORA Creation: Users shared strategies for creating effective LORAs, such as using a background LORA made from images and refining outputs with software like Photoshop or Krita.
- One member advised refining generated images before training to ensure higher quality outcomes.
- Stable Diffusion Setup Tips: Multiple users sought guidance on setting up Stable Diffusion, with recommendations including using ComfyUI - Getting Started and various cloud-based options.
- Members emphasized the importance of deciding between running locally or utilizing cloud GPUs, recommending Vast.ai for GPU rentals.
- Scammer Alert Strategies: Concerns about scammers in the server led users to share warnings and advised reporting suspicious accounts to Discord.
- Users discussed recognizing phishing attempts and how certain accounts impersonate support to deceive members.
- Comparing GPU Performance: The conversation highlighted differences in GPU performance, with users comparing experiences across different models and emphasizing the importance of memory and speed.
- A user noted that cheaper cloud GPU options may offer better overall performance compared to local setups due to electricity costs.
- Evaluating the Sana Model: Members discussed a new model called Sana, noting its efficiency and quality compared to prior versions, with some skepticism about its commercial usage.
- It was suggested that for everyday purposes, using Flux or previous models might yield similar or better results.
Latent Space Discord
- Pydantic AI Integrates with LLMs: The new Agent Framework from Pydantic is now live, aiming to seamlessly integrate with LLMs to enable innovative AI applications.
- However, some users express skepticism about its differentiation from existing frameworks like LangChain, suggesting it closely resembles current solutions.
- Bolt Rockets to $8M ARR in 2 Months: Bolt has surpassed $8M ARR within just 2 months as a Claude Wrapper, featuring guests like @ericsimons40 and @itamar_mar.
- The podcast episode delves into Bolt's growth strategies and includes discussions on code agent engineering, highlighting collaborations with @QodoAI and the debut of StackBlitz.
- Tencent Launches Hunyuan Video as Open-Source Leader: Tencent has released Hunyuan Video, establishing it as a premier open-source text-to-video technology known for its high quality.
- Initial user feedback points out the high resource demands for rendering, though there's optimism about forthcoming efficiency enhancements.
- Amazon Unveils Nova Foundation Model: Amazon announced its new foundation model, Nova, positioned to rival advanced models like GPT-4o.
- Early evaluations indicate promise, but user experiences remain mixed, with some not finding it as impressive as Amazon's previous model releases.
- ChatGPT Faces Name Filtering Glitch: ChatGPT is experiencing an issue where specific names, such as David Mayer, trigger response abortions due to a system glitch.
- This problem does not impact the OpenAI API and has sparked discussions on how name associations may affect AI behavior.
Cohere Discord
- Rerank 3.5 Enhances Multilingual Search: Cohere has launched Rerank 3.5, offering enhanced reasoning capabilities and support for over 100 languages such as Arabic, French, Japanese, and Korean via the
rerank-v3.5API.- Users have expressed enthusiasm about the improved performance and its compatibility with various data formats, including multimedia content.
- Cohere Announces API Deprecations: Cohere has announced the deprecation of older models, providing details on deprecated endpoints and recommended replacements as part of their model lifecycle management.
- This move affects applications reliant on legacy models, prompting developers to update their integrations accordingly.
- Harmony Project Launches NLP Harmonisation Tools: The Harmony project introduces NLP tools for harmonizing questionnaire items and metadata, enabling researchers to compare questionnaire items across studies.
- Based at UCL, the project is collaborating with multiple universities and professionals to refine its doc retrieval capabilities.
- API Key Delays Trigger TooManyRequestsError: Users have reported encountering TooManyRequestsError despite upgrading to production API keys, attributing the issue to potential API key setup delays.
- Support has been advised to contact support@cohere.com for assistance, with indications that setup delays are typically minimal.
- Stripe Integration Causes Payment Issues: Some users have experienced credit card payment issues with Cohere's platform, despite previous successful transactions.
- Members suggest the problem may lie with the user's bank and recommend reaching out to support@cohere.com, as payments are processed via Stripe.
GPU MODE Discord
- Xmma and Nvjet Outperform Cutlass in Select Benchmarks: Members evaluated Xmma kernels, noting nvjet catching up on smaller sizes, with a custom kernel running 1.5% faster for N=8192 compared to cutlass.
- nvjet generally competes well against cutlass, with some specific instances where cutlass may slightly outperform.
- Triton MLIR Dialects Documentation Critique: A member inquired about documentation for Triton MLIR Dialects, noting much of the TritonOps documentation is minimal and lacks comprehensive examples.
- Another pointed out the programming guide on GitHub is minimal and unfinished, aiming to aid developers working with the Triton language.
- CUDARC Crate Enables Manual CUDA Bindings: The CUDARC crate offers bindings for the CUDA API, currently supporting only matrix multiplication due to manual implementation.
- Testing revealed that optimizing the matmul function consumes most development time.
- GPU Warp Scheduler and FP32 Core Distribution Insights: A member explained that a warp comprises 32 threads utilizing 32 FP32 cores in parallel, resulting in 128 FP32 cores per SM.
- Discrepancies were noted between A100's 64 FP32 cores for its 4 warp schedulers, versus RTX 30xx and 40xx series with 128 FP32 cores.
- KernelBench Launch and Leaderboard Integrity Issues: KernelBench (Preview) was introduced by @anneouyang to evaluate LLM-generated GPU kernels for neural network optimization.
- Users expressed concerns about incomplete fastest kernels on the leaderboard, referencing an incomplete kernel solution.
LlamaIndex Discord
- NVIDIA Financial Insights Unveiled: @pyquantnews showcases how NVIDIA's financial statements can be utilized for both simple revenue lookups and complex business risk analyses, using practical code examples of setting up LlamaIndex.
- This method enhances business intelligence by leveraging structured financial data.
- Streamlining LlamaCloud with Google Drive: @ravithejads outlines a step-by-step process for configuring a LlamaCloud pipeline using Google Drive as a data source, including chunking and embedding parameters. Full setup instructions are available here.
- This guide assists developers in integrating document indexing seamlessly with LlamaIndex.
- Amazon Launches Nova Foundation Models: Amazon introduced Nova, a set of foundation models offering more affordable pricing compared to competitors and providing day 0 support. Install Nova with
pip install llama-index-llms-bedrock-converseand view examples here.- The release of Nova expands the AI model landscape with cost-effective and high-performance options.
- Effective RAG Implementations: A member shared a repository containing over 10 RAG implementations, including methods like Naive RAG and Hyde RAG, aiding others in customizing RAG for their datasets. Check the repository here.
- These implementations facilitate experimentation with RAG applications tailored to specific AI development needs.
- Embedding Model Token Size Limitations: Discussion highlighted that the HuggingFaceEmbedding class truncates input text longer than 512 tokens, posing challenges for embedding larger texts.
- Members advised selecting appropriate
embed_modelclasses to bypass these constraints effectively.
- Members advised selecting appropriate
LM Studio Discord
- Qwen LV 7B Vision Functionalities: A query was raised about whether the Qwen LV 7B model works with vision functionalities, opening discussions on integrating vision capabilities with various AI models.
- Community members are exploring the potential for combining vision with Qwen LV 7B, discussing possible use cases and technical requirements.
- FP8 Quantization Enhances Model Efficiency: FP8 quantization allows for a 2x reduction in model memory and a 1.6x throughput improvement with little impact on accuracy, as per VLLM docs.
- This optimization is particularly relevant for optimizing performance on machines with limited resources.
- HF Spaces Now Support Docker Containers: A member confirmed that any HF space can run as a docker container, offering flexibility for local deployments and testing.
- This enhancement facilitates easier integration and scalability for AI engineers working on HF spaces.
- Intel Arc Battlemage Cards Face AI Task Skepticism: A member expressed doubt about the new Arc Battlemage cards, suggesting they are not suitable for AI tasks.
- Another member argued that despite being cost-effective for building local inference servers, reliance on Intel for such applications remains questionable.
- LM Studio Performance Issues on Windows: Users reported slow performance and abnormal output when running LM Studio on Windows compared to Mac, noting issues with the 3.2 model.
- Solutions suggested include toggling the
Flash Attentionswitch and checking system specs for compatibility.
- Solutions suggested include toggling the
LLM Agents (Berkeley MOOC) Discord
- Sierra AI's Info Session & Talent Search: Sierra AI is hosting an exclusive info session for developers on December 3 at 9am PT, accessible via a YouTube livestream, where participants will explore Sierra’s Agent OS and Agent SDK capabilities.
- During the session, Sierra AI will discuss their search for talented developers and encourage interested individuals to RSVP to secure their spot for exciting career opportunities.
- AI Safety Final Lecture by Dawn Song: Professor Dawn Song will deliver the final lecture on Towards building safe and trustworthy AI Agents and a Path for Science- and Evidence-based AI Policy at 3:00 PM PST today, streaming live on YouTube.
- She will address the significant risks associated with LLM agents and propose a science-based AI policy to mitigate these threats effectively.
- LLM Agents Course Assignments & Mastery Tier: Participants can still register for the LLM Agents Learning Course by completing the signup form and access all materials on the course website.
- While lab assignments are not mandatory for all certifications, completing all three is required to achieve the Mastery tier, allowing late joiners to catch up as needed.
- Concerns Over GPT-4 PII Leaks: A member raised concerns that GPT-4 may leak personally identifiable information (PII), drawing parallels to the AOL search log release incident in 2006.
- They highlighted that despite AOL's claims of anonymization, the release contained twenty million search queries from over 650,000 users, with the data still accessible online.
- ReAct Paradigm's Implementation Impact: The effectiveness of the ReAct paradigm is highly dependent on implementation specifics such as prompt design and state management, with members noting that benchmarks should reflect these details.
- Comparisons were made to foundational models in traditional ML, sparking discussions on how varying implementations lead to significant differences in benchmark performance due to the fuzzy definitions within the AI field.
OpenInterpreter Discord
- Development Branch Rewritten for Enhanced Performance: The latest development branch has been completely rewritten, making it lighter, faster, and smarter, which has impressed users.
- Members are excited to test this active branch and have been encouraged to provide feedback on missing features from the old implementation.
- New
--serveOption Enables OpenAI-Compatible Server: The new--serveoption introduces an OpenAI-compatible REST server, with version 1.0 excluding the old LMC/web socket protocol.- This setup allows users to connect through any OpenAI-compatible client, enabling actions directly on the server's device.
- TypeError Encountered with Anthropic Integration: Users reported a TypeError when integrating the development branch with Anthropic, specifically an unexpected keyword argument ‘proxies’.
- Users were advised to share the full traceback for debugging and were provided with examples of correct installation commands.
- Community Testing Requested to Enhance Development Branch: Members have requested community participation in testing to improve the development branch's functionality, which receives frequent updates.
- One member expressed reliance on the LMC for communication and finds transitioning to the new setup both terrifying and exciting.
- LiveKit Enables Remote Device Connectivity: O1 utilizes LiveKit to connect devices like iPhones and laptops or a Raspberry Pi running the server.
- This setup facilitates remote access to control the machine via the local OpenInterpreter (OI) instance running on it.
DSPy Discord
- Pydantic AI Integrates with DSLModel: The introduction of Pydantic AI enhances integration with DSLModel, creating a seamless framework for developers.
- This integration leverages Pydantic, widely used across various Agent Frameworks and LLM libraries in Python.
- DSPy Optimization Challenges on AWS Lambda: A member is contemplating running DSPy optimizations on AWS Lambda for LangWatch customers, but the 15-minute limit poses challenges.
- They expressed a need for strategies to work around this time constraint.
- ECS/Fargate Recommended over Lambda: Another member shared their experience, suggesting that running DSPy on Lambda may not be feasible due to storage constraints.
- They recommended exploring ECS/Fargate as a potentially more reliable solution.
- Program Of Thought Deprecation Concerns: A member inquired whether Program Of Thought is on the path to deprecation/no active support post v2.5.
- This suggests ongoing concerns regarding the future of this program within the community.
- Agentic and RAG Examples in DSPy: A member inquired about agentic examples in DSPy where the output from one signature is utilized as input for another, specifically for an email composing program.
- Another member suggested looking at the RAG example but later clarified the location of relevant examples may be on the dspy.ai website.
Torchtune Discord
- Image Generation Feature in Torchtune: A user expressed excitement about adding an image generation feature to Torchtune, referencing Pull Request #2098.
- The pull request aims to incorporate new functionalities that enhance the platform's capabilities.
- T5 Integration in Torchtune: Discussions suggest that T5 might be integrated into Torchtune, based on insights from Pull Request #2069.
- This integration is expected to align T5 features with the upcoming image generation enhancements.
- Fine-tuning ImageGen Models in Torchtune: A member highlighted the potential for fine-tuning image generation models within Torchtune, describing it as an enjoyable project.
- This comment generated light-hearted responses, indicating varying levels of familiarity among members.
- CycleQD Recipe Sharing: A member shared a link to a CycleQD recipe, describing it as a fun project.
MLOps @Chipro Discord
- Members Excited for Upcoming Event: Members expressed their excitement and interest in attending an upcoming event, with one member noting a scheduled visit to India around that time.
- Ooh nice. Yes. I’ll be there. Hope to meet! was shared, highlighting the enthusiasm among participants.
- Clarification on Event Registration Process: A user inquired about the registration process for attending the event, prompting a discussion on effective navigation of the registration system.
- Participants shared strategies to streamline the attendee onboarding experience, ensuring a smooth registration flow.
Axolotl AI Discord
- ADOPT Optimizer Accelerates Axolotl: The team has integrated the latest ADOPT optimizer updates into the Axolotl codebase, encouraging engineers to experiment with the enhancements.
- A member inquired about the advantages of using the ADOPT optimizer within Axolotl, prompting discussions on performance improvements.
- ADOPT Optimizer's Beta Boost: The ADOPT optimizer now supports optimal convergence with any beta value, enhancing performance across diverse scenarios.
- Members explored this capability during discussions, highlighting its potential to optimize performance in various deployment scenarios.
tinygrad (George Hotz) Discord
- PR#7987 Triumphs with Stable Benchmarks: jewnex noted that PR#7987 is worth tweeting after running benchmarks, showing no GPU hang with beam this time 🚀.
- Tweaking Thread Groups in uopgraph.py: A member in learn-tinygrad asked if thread group/grid sizes can be altered during graph rewrite optimizations in
uopgraph.py.- The discussion focused on whether sizes are fixed based on earlier searches in pm_lowerer or can be adjusted post-optimization.
LAION Discord
- Bio-ML Revolution in 2024: The year 2024 marks a surge in machine learning for biology (bio-ML), with notable achievements like Nobel prizes awarded for structural biology prediction and significant investments in protein sequence models.
- Excitement buzzes around the field, although concerns loom about compute-optimal protein sequencing modeling curves that need to be addressed. Through a Glass Darkly | Markov Bio discusses the path toward end-to-end biology and the role of human understanding.
- Introducing Gene Diffusion for Single-Cell Biology: A new model called Gene Diffusion is described, utilizing a continuous diffusion transformer trained on single-cell gene count data to explore cell functional states.
- It employs a self-supervised learning method, predicting clean, un-noised embeddings from gene token vectors, akin to techniques used in text-to-image models.
- Seeking Clarity on Training Regime of Gene Diffusion: Curiosity arises regarding the training regime of the Gene Diffusion model, specifically its input/output relationship and what it aims to predict.
- Members express a desire for clarification on the intricacies of the model, highlighting the need for community assistance in understanding these complex concepts.
Mozilla AI Discord
- December Schedule Events: Three new member events have been added to the December schedule to increase community engagement.
- These events aim to showcase members' projects and boost community involvement.
- Next Gen Llamafile Hackathon Presentations: Students will present their projects using Llamafile for personalized AI tomorrow, emphasizing social good.
- Community members are encouraged to support the students' innovative initiatives.
- Introduction to Web Applets: <@823757327756427295> will be Introducing Web Applets, explaining an open standard & SDK for advanced client-side applications.
- Participants can customize their roles within the community to receive updates.
- Theia IDE Hands-On Demo: <@1131955800601002095> will demonstrate Theia IDE, an open AI-driven development environment.
- The demo will illustrate how Theia enhances development practices.
- Llamafile Release & Security Bounties: A new release for Llamafile was announced with several software improvements.
- <@&1245781246550999141> awarded 42 bounties in the first month to identify vulnerabilities in generative AI.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Nous Research AI ▷ #announcements (2 messages):
DeMo Optimizer Release, Nous DisTrO, Decentralized Pre-training, Distributed Training Research
- Nous launches Decentralized Pre-training for 15B model: Nous has initiated a decentralized pre-training of a 15B parameter language model using Nous DisTrO and hardware from partners like Oracle and Lambda Labs. The run showcases a loss curve that matches or exceeds traditional centralized training with AdamW.
- You can watch the run live here and check out the accompanying DeMo paper and code being announced soon.
- Open Release of DeMo Research Paper: The DeMo optimizer allows training neural networks in parallel while synchronizing only minimal model states during each optimization step. This method improves convergence with reduced inter-accelerator communication, supporting training with diverse hardware setups.
- Future Releases for DisTrO Optimizer: The DisTrO optimizer is based on principles from DeMo but requires further development before release. An upcoming paper and code for DisTrO will be made available when ready on GitHub.
- This optimizer aims to improve decentralized training experiences and empower more AI practitioners with these tools.
- Nous DisTrO: Distributed training over the internet
- DeMo: Decoupled Momentum Optimization: Training large neural networks typically requires sharing gradients between accelerators through specialized high-speed interconnects. Drawing from the signal processing principles of frequency decomp...
- GitHub - bloc97/DeMo: DeMo: Decoupled Momentum Optimization: DeMo: Decoupled Momentum Optimization. Contribute to bloc97/DeMo development by creating an account on GitHub.
- GitHub - NousResearch/DisTrO: Distributed Training Over-The-Internet: Distributed Training Over-The-Internet. Contribute to NousResearch/DisTrO development by creating an account on GitHub.
Nous Research AI ▷ #general (426 messages🔥🔥🔥):
DisTrO Training Update, Using Smaller Models for Different Tasks, Function Calling vs. MCP in AI Models, Community Contributions to AI Training, Job Opportunities in AI Development
- DisTrO Training Update: The current DisTrO training run is expected to finish soon, with specific details on hardware and user contributions coming by the end of the week.
- This run is primarily a test, and there may not be immediate public registry or tutorials available for users.
- Using Smaller Models for Different Tasks: Smaller models can outperform larger ones in certain creative tasks and provide benefits such as faster processing and lower resource usage.
- It’s suggested to use smaller models for state management while leveraging larger models for heavy tasks like storytelling, allowing for a balanced approach.
- Function Calling vs. MCP in AI Models: Function calling is seen as a method to manage state and actions in AI, whereas MCP might offer different advantages when implementing complex functionalities.
- There's some confusion on the distinction between MCP and function calling, highlighting the need for clarification on their respective uses.
- Community Contributions to AI Training: The potential for a decentralized training approach using community resources is discussed, emphasizing the importance of efficient methods for large-scale model training.
- Participants recognize the challenges posed by syncing and communication overhead, particularly for larger models that require significant resources.
- Job Opportunities in AI Development: A user is offering job opportunities for an AI company, seeking to recruit individuals with experience in AI and ML.
- Additionally, there’s mention of a user inquiring about the availability of the Hermes 405B model on OpenRouter, indicating interest in AI model accessibility.
- Forge Reasoning API by Nous Research: Forge Reasoning API by Nous Research
- Nous DisTrO: Distributed training over the internet
- ARC Prize: ARC Prize is a $1,000,000+ nonprofit, public competition to beat and open source a solution to the ARC-AGI benchmark.
- Tweet from chris (@chriscyph): no description found
- Stochastic Gradient Descent as Approximate Bayesian Inference: Stochastic Gradient Descent with a constant learning rate (constant SGD) simulates a Markov chain with a stationary distribution. With this perspective, we derive several new results. (1) We show that...
- Papers with Code - ARC (AI2 Reasoning Challenge) Dataset: The AI2’s Reasoning Challenge (ARC) dataset is a multiple-choice question-answering dataset, containing questions from science exams from grade 3 to grade 9. The dataset is split in two partitions: Ea...
- llamaspeak - NVIDIA Jetson AI Lab : no description found
- Exascale computing - Wikipedia: no description found
- Elliott Smith - 13 - Independence Day: Town Hall, New York, New YorkSetlistSon of SamHappinessBetween the BarsLARose ParadePretty Mary KAngelesNeedle in the HaySay YesWaltz #2St. Ide's HeavenEasy ...
Nous Research AI ▷ #ask-about-llms (3 messages):
Techno-Socialism, Nous Research, XCLR8
- Techno-Socialism Interest in Nous: A member expressed their enthusiasm for Nous as a Techno-Socialist, indicating an alignment of interest in the platform.
- This highlights a potential dialogue on how technology intersects with social ideologies.
- Mention of XCLR8: A member briefly mentioned XCLR8, sparking curiosity about its relevance to the ongoing discussions.
- Further exploration may reveal insights into this topic's implications or applications.
Nous Research AI ▷ #reasoning-tasks (4 messages):
DisTro Issues, Flux Capacitor Reference, DeLorean Nostalgia
- DisTro Problem Denial: A member humorously noted the refusal to acknowledge ongoing problems with DisTro, comparing it to inventing the flux capacitor.
- This playful comment highlighted frustration over persistent issues and led to a lighthearted exchange.
- Consistency Over Logic: Another member commented that despite the issues, the situation remains logical and consistent, albeit not ideal.
- This statement reflects a resigned acceptance amidst discrepancies, adding to the camaraderie in the discussion.
- A Wish for a DeLorean: A member expressed a humorous desire for a DeLorean, referencing its iconic status in popular culture.
- This wish added a nostalgic twist to the ongoing conversation, reinforcing the lighthearted tone of the chat.
Link mentioned: no title found: no description found
Eleuther ▷ #general (181 messages🔥🔥):
Use of JAX vs. PyTorch, Vendor Lock-in Concerns, Performance Optimizations with Torch Compile, AI Lab Hiring Practices, Collaboration Between Universities and Tech Companies
- JAX gaining traction among big labs: Several members discussed that many AI labs, including Anthropic and DeepMind, are reportedly using JAX for their models, albeit with varying degrees of primary usage.
- However, the accuracy of the claim regarding JAX's dominance in relation to PyTorch remains disputed, emphasizing the need for better transparency in industry practices.
- Concerns around vendor lock-in: The conversation highlighted concerns about vendor lock-in in academia, particularly when tech companies influence university curricula by providing resources for specific frameworks.
- While some argued that leveraging vendor partnerships can be beneficial, others remained skeptical about the implications for broader skillsets in students.
- Utilizing Torch Compile for Performance: Discussion around torch.compile revealed that while it's relatively new and has challenges, it allows for significant performance optimizations when used correctly.
- AI labs often seek PyTorch compiler experts to enhance the performance of models that already employ torch.compile.
- Hiring at AI Labs: A member noted that prominent AI labs express interest in hiring contributors from frameworks like TensorFlow, PyTorch, and JAX, likely seeking skilled developers for their teams.
- The tight-knit nature of the community facilitates networking, with some attendees recalling past interactions with key personnel from these labs.
- Collaboration between universities and tech firms: Members reflected on how tech giants like Amazon and Google have collaborated with universities to shape curricula and provide resources, such as TPU access.
- While this aids student learning with cutting-edge technology, there are concerns over the potential for biased education focused on particular companies.
- Random Redirect: no description found
- Apple Uses Amazon's Custom AI Chips for Search Services: Apple uses custom Inferentia and Graviton artificial intelligence chips from Amazon Web Services for search services, Apple machine learning and AI...
- JAX is used by almost every large genAI player (Anthropic, Cohere, DeepMind, Mid... | Hacker News: no description found
- The Llama 3 Herd of Models: Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support ...
- GitHub - apple/axlearn: An Extensible Deep Learning Library: An Extensible Deep Learning Library. Contribute to apple/axlearn development by creating an account on GitHub.
- GitHub - stanford-cs149/asst4-trainium: Contribute to stanford-cs149/asst4-trainium development by creating an account on GitHub.
Eleuther ▷ #research (151 messages🔥🔥):
DeMo Optimizer, Differential Attention, Second Order Optimization, NAS in ML, Moving Sofa Problem
- DeMo Optimizer reduces sync overhead: The DeMo optimizer introduces a method to reduce inter-accelerator communication requirements by decoupling momentum updates, achieving improved convergence without the need for full synchronization on high-speed networks.
- Its minimalist approach to reduce optimizer state size by 4 bytes per parameter is highlighted as a significant advantage for large-scale models.
- Discussion on Differential Attention: Participants discussed the effectiveness of differential attention in various architectures like Hymba and Striped Mamba, questioning their performance in relation to cache size and overall effectiveness compared to traditional models.
- Concerns were raised regarding whether focusing solely on the largest gradients would yield effective results across epochs.
- Exploration of Second Order Optimizers: The viability of second order optimization methods for large models was debated, revealing that although empirical evidence suggests its potential for faster convergence, reproduction of results is not consistent across research efforts.
- Challenges such as computational complexity and preserving certain characteristics of adaptiveness in momentum were also highlighted.
- Concerns about NAS Era: The community expressed skepticism about the trend toward neural architecture search (NAS), referencing past experiences in computer vision that yielded little lasting impact and questioning if it signals a creativity drought in model design.
- Despite this, there remains a sense of optimism about hybrid models and the potential for innovation despite concerns over optimization methods.
- Moving Sofa Problem and its Implications: The Moving Sofa Problem sparked excitement over a claimed solution, intertwining discussions of mathematical proofs and optimization challenges, showcasing the intersection of theory and application.
- Participants questioned the implications for practical optimization methods while expressing interest in the unfolding of this mathematical challenge.
- STAR: Synthesis of Tailored Architectures: Iterative improvement of model architectures is fundamental to deep learning: Transformers first enabled scaling, and recent advances in model hybridization have pushed the quality-efficiency frontier...
- DeMo: Decoupled Momentum Optimization: Training large neural networks typically requires sharing gradients between accelerators through specialized high-speed interconnects. Drawing from the signal processing principles of frequency decomp...
- JetFormer: An Autoregressive Generative Model of Raw Images and Text: Removing modeling constraints and unifying architectures across domains has been a key driver of the recent progress in training large multimodal models. However, most of these models still rely on ma...
- Moving sofa problem - Wikipedia: no description found
- Tweet from Liquid AI (@LiquidAI_): New Liquid research: STAR -- Evolutionary Synthesis of Tailored Architectures.At Liquid we design foundation models with two macro-objectives: maximize quality and efficiency. Balancing the two is cha...
- Learning Neural Network Subspaces: Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider mi...
- Optimality of Gerver's Sofa: We resolve the moving sofa problem by showing that Gerver's construction with 18 curve sections attains the maximum area $2.2195\cdots$.
- Active Data Curation Effectively Distills Large-Scale Multimodal Models: Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective funct...
- Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance: Agents powered by large language models have shown remarkable abilities in solving complex tasks. However, most agent systems remain reactive, limiting their effectiveness in scenarios requiring fores...
Eleuther ▷ #interpretability-general (1 messages):
Common Methods Reference, Survey vs Textbook Distinction
- Extensive Primer on Methods Released: A member shared a primer that provides an extensive reference set and contextualizes common methods with standard notation.
- This resource is positioned in a gray area between a survey and a textbook, and feedback is welcome.
- Request for Feedback on Primer: The member specifically asked for feedback on the primer, aiming to improve its utility and clarity for users.
- The resource blurs the lines between a survey and a textbook, emphasizing the need for community input.
Eleuther ▷ #lm-thunderdome (13 messages🔥):
VLLM Seed Configuration, QwQ Preview Leaderboard Status, External Loadable Evals, Versioning and Reproducibility Concerns
- VLLM sets its own seed: A member noted that VLLM manages its own seed, which can be passed in through
model_args.- Another discussed that Hugging Face likely relies on the torch seed for its operations.
- QwQ preview struggles on leaderboards: It was highlighted that QwQ preview is listed on the Open LLM Leaderboard but scores poorly due to parsing issues with the 'thinking' section.
- A member emphasized the need for it to generate longer outputs for better evaluation results.
- Idea for externally loadable evals: A suggestion was made about making evals externally loadable in a manner similar to datasets and models via Hugging Face.
- The member pointed out that this could facilitate easier loading of datasets and associated eval YAML files.
- Concerns about visibility and versioning: A member raised concerns about visibility and versioning when using external repositories for evals.
- It was noted that ensuring reproducibility across evaluations is crucial, despite challenges that might arise.
- Versioning issues with datasets: The issue of versioning and reproducibility was acknowledged as a potential concern with raw datasets used in existing evals.
- A member remarked that while this is a valid concern, it hasn't caused significant issues so far.
Link mentioned: lm-evaluation-harness/lm_eval/main.py at f49b0377bf559f5558e8cd9ebd1190218c7df2a4 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (2 messages):
Logging Configuration, Performance Breakdown
- Origin of Distinct Logging Messages: A member inquired about the origin of detailed logging messages that provide breakdowns of optimizer timings, including metrics such as optimizer_allgather and fwd_microstep.
- The member later identified that these logs are enabled by the wall_clock_breakdown configuration option.
- Clarification on Configuration Settings: The discussion centered around the specific configuration options that lead to the appearance of detailed logging messages in the system.
- It was confirmed that the wall_clock_breakdown option is instrumental in generating these detailed logs.
Modular (Mojo 🔥) ▷ #general (120 messages🔥🔥):
Socket Communication in Mojo, Mojo's SIMD Support, Networking API Design, High-Performance File Server Implementation, Custom Allocators
- Socket Communication Features Delayed: The addition of socket communication in Mojo is delayed due to pending language features, with an aim for a standard library that supports swappable network backends including POSIX sockets.
- Current plans involve a big rewrite to ensure proper implementation when these features are ready.
- Exciting SIMD Capabilities in Mojo: Members discussed the advantages of Mojo's SIMD support, with one noting that it simplifies SIMD programming compared to C/C++ intrinsics, which can be chaotic.
- There's a goal to have more intrinsics mapped to the standard library in the future to minimize direct use.
- High-Performance File Server Project: One member mentioned a project for a high-performance file server for a game they are developing, aiming for 30% higher packets per second than what Nginx achieves.
- They are currently utilizing external calls for networking until the aforementioned features are available.
- ASP and Assembly Language Discussion: The conversation touched on the use of inline assembly and how various operations might need to be ported depending on the architecture, highlighting the role of compiler support.
- There was a suggestion for having a 'SIMD in Mojo' blog post to help with understanding and leveraging these advanced features.
- Utilizing Custom Allocators for Performance: Participants discussed the advantages of using arena allocators and how they could benefit efficiency, especially for routines utilizing continuations.
- The discussion revealed a need to balance between performance optimizations and maintaining portability across different implementations.
- Counting chars with SIMD in Mojo: Mojo is a very young (actually a work in progress) programming language designed and developed by a new company called Modular. Here is a…
- marti - Overview: GitHub is where marti builds software.
- Compiler Explorer - C (x86-64 clang (trunk)): /* Type your code here, or load an example. */void square(__m128i a, __m128i b, __mmask8* k1, __mmask8* k2) { _mm_2intersect_epi32(a, b, k1, k2);}
- GitHub - intel/hyperscan: High-performance regular expression matching library: High-performance regular expression matching library - intel/hyperscan
- MartinVu - Overview: MartinVu has 5 repositories available. Follow their code on GitHub.
- s - Overview: s has 49 repositories available. Follow their code on GitHub.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Magic Package Distribution, Early Access Preview, Community Testing, Feature Iteration
- Community Gains Magic Package Distribution: An exciting feature allowing community members to distribute packages through Magic is in development, with an early access preview rolling out soon.
- They are seeking testers to help refine the feature, inviting interested members to commit by reacting with 🔍 for package reviewing or 🧪 for installation.
- Call for Community Involvement: The team is looking for dedicated individuals who can commit time to test and iterate on the new feature before its full release.
- Interested participants are encouraged to signal their willingness to help with the respective emojis, showing community engagement enthusiasm.
Modular (Mojo 🔥) ▷ #mojo (133 messages🔥🔥):
Mojo Development Insights, Inline References Concept, Reference Trait Proposal, Current Python Support for Mojo, Compilation Structure Updates
- Exploring Mojo Development Insights: Members discussed the nuances of converting
Intto SIMD DTypes in Mojo, citing a need for clarity around syntax and function usage.- There was acknowledgement that Mojo's handling of references and dereferencing is a key point of confusion, notably regarding inline references.
- The Concept of Inline References: Inline references were proposed as a potential feature in Mojo for improving memory access patterns and handling mutable data safely.
- Discussions included the implications of inline references on mutability and the necessity of managing address spaces for pointers effectively.
- Proposal of Reference Trait in Mojo: A proposal for a
Referencetrait was put forward, aimed at enhancing the management of mutable and readable references within Mojo code.- This approach would allow for better borrow-checking and the potential to reduce confusion about mutability in function arguments.
- Current Python Support for Mojo: Members were informed that Python 3.13 is not yet supported, with a suggestion to use versions 3.8-3.12 for Mojo compatibility.
- Further clarification was provided regarding the system requirements for using the MAX engine alongside supported versions of PyTorch.
- Updates on Compilation Structure in Mojo: Discussion arose concerning the past autotuning systems in Mojo and their removal due to reworking of the compilation structure.
- Questions were raised about the possibility of automating tuning processes with current compilation phases.
- MAX FAQ | Modular Docs: Answers to questions we expect about MAX Engine.
- Parameterization: compile-time metaprogramming | Modular Docs: An introduction to parameters and compile-time metaprogramming.
aider (Paul Gauthier) ▷ #general (154 messages🔥🔥):
OpenRouter performance issues, Aider's new features, Amazon Foundation Models announcement, User experiences with Aider, Troubleshooting Repo-map
- Analysis of OpenRouter's Benchmark Results: It was revealed that models via OpenRouter have worse benchmark results than those via the direct API, sparking discussions among users regarding performance discrepancies.
- Users are investigating solutions to improve OpenRouter's performance, indicating collaborative efforts to address identified issues.
- New Features in Aider Enhance User Experience: Several users shared their positive experiences with Aider's new
--watch-filesfeature, which streamlines the integration of AI instructions into their coding workflow.- Users appreciate Aider's transparency, noting features like
/save,/add, and the ability to modify context during usage, which facilitates a more informed programming experience.
- Users appreciate Aider's transparency, noting features like
- Amazon Unveils New Foundation Models: Amazon announced the release of six new foundation models as part of their re:Invent event, emphasizing their multimodal capabilities and competitive pricing.
- Models like Micro, Lite, and Canvas will be exclusively available via Amazon Bedrock, with pricing structures that users find attractive compared to other US frontier models.
- User Insights on Aider's Efficiency: Users have found Aider to be more contemplative compared to other coding aids, enabling them to strategically prompt the AI for more tailored responses.
- This sentiment reflects Aider's effectiveness in enhancing coding efficiency and user satisfaction as clients transition from other platforms.
- Troubleshooting Issues with Repo-map: One user reported issues with the repo-map feature, indicating potential accidental deletion of files, which led to inquiry about how to restore the configuration.
- Community members suggested re-establishing the repo-map configuration and shared experiences with common errors during updates.
- Tweet from Philipp Schmid (@_philschmid): Unexpected. @amazon is back with Foundation Models. As part of re:Invent they announced 6 new foundation models from text only to text-to-video! 👀 Nova models will be exclusively available through Am...
- Tweet from cohere (@cohere): Introducing our latest AI search model: Rerank 3.5!Rerank 3.5 delivers state-of-the-art performance with improved reasoning and multilingual capabilities to precisely search complex enterprise data li...
- GitHub - yoheinakajima/babyagi-2o: the simplest self-building general autonomous agent: the simplest self-building general autonomous agent - yoheinakajima/babyagi-2o
- software-dev-prompt-library/docs/guides/getting-started.md at main · codingthefuturewithai/software-dev-prompt-library: Prompt library containing tested reusable gen AI prompts for common software engineering task - codingthefuturewithai/software-dev-prompt-library
- Coding the Future With AI: Welcome to Coding the Future With AI! Our channel is dedicated to helping developers and tech enthusiasts learn how to leverage AI to enhance their skills and productivity. Through tutorials, expert i...
- Options reference: Details about all of aider’s settings.
- Unlock AI Coding with Workflow-Driven, Tuned Prompt Chains 🔑: In this tutorial, we’re diving into a systematic approach to building software with AI, introducing you to a workflow-driven system powered by highly tuned p...
aider (Paul Gauthier) ▷ #questions-and-tips (82 messages🔥🔥):
Using Aider with Docker, Updating Aider, Function Refactoring Challenges, Context Management in Aider, Scraping Documentation for Aider
- Running Aider in Docker Requires Permissions: A user mentioned permission issues when running Aider Docker container, trying to share a volume with another container, both set to UID:GID 1000:1000.
- They encountered a 'Permission denied' error when Aider attempted to write to specific files, requiring further investigation.
- Updating Aider Version Issues: A user had difficulty updating Aider to version 0.66.0 and reported various command failures when using package installation tools.
- After troubleshooting, they found success by specifically invoking the Python 3.12 interpreter during installation.
- Refactoring Functions Across Files: A user sought assistance with using Aider to locate where a function is called across files during a refactor, but learned that Aider can't perform this task directly.
- They were advised to utilize IDE capabilities or external tools for code analysis before involving Aider.
- Collecting Documentation for Aider's Context: Users discussed methods to scrape external documentation for Aider, expressing a desire for automated solutions to generate reference files.
- Some suggested creating a local directory for manual documentation collection or using Docker tools for scraping.
- Context Management with MCP: Several users explored the use of the Model Context Protocol (MCP) to enhance Aider's context capabilities, especially in code-related scenarios.
- They discussed using tools like IndyDevDan's agent and Crawl4AI to create optimized documentation for LLM integration.
- Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions: Currently OpenAI o1 sparks a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mathemat...
- Ollama: aider is AI pair programming in your terminal
- Aider with docker: aider is AI pair programming in your terminal
- Chat modes: Using the code, architect, ask and help chat modes.
- Install with pipx: aider is AI pair programming in your terminal
- Aider v0.66.0Model: ollama_chat/qwen2.5-coder:14b with whole edit formatGit - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- AI Coding with Aider Architect, Cursor and AI Agents. (Plans for o1 BASED engineering): 🔥 The AI CODE Editor WAR is ON! Is Your Coding Workflow Ready for the o1 Release?Don’t Get COOKED and Left Behind! 🚀🔥🔗 Resources- 💻 Computer Use Bash & ...
- aider/.github/workflows/release.yml at main · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- Anthropic MCP with Ollama, No Claude? Watch This!: anthropic released model context protocol which allows you to connect llm's to your own data and tools. in this video chris shows how to decouple mcp from c...
aider (Paul Gauthier) ▷ #links (1 messages):
pierrunoyt: https://supabase.com/blog/supabase-ai-assistant-v2 Nice stuff
Cursor IDE ▷ #general (213 messages🔥🔥):
Cursor Lag Issues, Windsurf vs Cursor Performance, Agent Features and Limitations, Syntax Highlighting Concerns, Chat Functionality Problems after Update
- Cursor Lag Issues in Dev Server: Several users reported that Cursor lags, particularly during development using Next.js on medium to large projects, requiring frequent 'Reload Window' commands.
- Users with 16GB RAM noted significant lag compared to others with 32GB, raising questions about performance consistency.
- Windsurf's Reliability Compared to Cursor: Some users have shifted back to using Windsurf due to ongoing issues with the latest Cursor updates, which often repeat the same fixes ineffectively.
- Witnesses indicated that Windsurf's agent edited multiple files without losing comments, a feature that Cursor currently struggles with.
- Agent Features and Limitations: Requests for the @web feature in the Cursor Agent highlight its current limitations, as users want improved access to real-time information.
- A user noted that changes when editing files were not properly recognized by the agent, leading to frustration with its reliability.
- Syntax Highlighting Concerns: First-time users expressed dissatisfaction with the syntax highlighting in Cursor, describing it as causing visual discomfort.
- There were complaints that many VS Code addons were not functioning properly within Cursor, hindering the user experience.
- Chat Functionality Problems after Update: Post-update, users have faced issues with Chat functionality, citing hallucinations and inconsistent model performance as significant problems.
- Users commented on the perception that the model quality had diminished, making tasks more challenging and frustrating.
- Medium: Read and write stories.: On Medium, anyone can share insightful perspectives, useful knowledge, and life wisdom with the world.
- How to do `Fix in Composer` and `Fix in Chat` actions from keyboard: These 2: I could not find it in settings.
- Connect Github CodeSpaces to Cursor Ai (Ai friendly vs code clone): Connecting GitHub Codespaces to CURSOR.DEV: A Developer’s Guide
- Infinite Loading Issue When Saving Files in Cursor App: Hi everyone, I’m experiencing a persistent issue with the Cursor app. Whenever I save a file, the app gets stuck in an infinite loading state. Here are the error messages I’m receiving: Error Messag...
- WSL extension is supported only in Microsoft versions of VS Code · Issue #2027 · getcursor/cursor: If you can, please include a screenshot of your problem Please include the name of your operating system If you can, steps to reproduce are super helpful I am developing using Windows 11 + WSL: Ubu...
Perplexity AI ▷ #general (188 messages🔥🔥):
Perplexity Pro subscription issues, Performance and speed problems, Image generation capabilities, Comparison of AI models, Amazon Nova foundation models
- Issues with Perplexity Pro Subscriptions: Users are reporting various issues with their Perplexity Pro subscriptions, including problems accessing features and unexpected price changes.
- Some users have experienced account bans and require support to resolve hacking incidents, while others inquire about available discounts.
- Performance Slowdowns in Perplexity AI: Several users are encountering persistent slowdowns and infinite loading while using Perplexity AI's features, deemed a potential scaling issue.
- This issue has been reflected in other platforms, prompting users to consider transitioning to API services for a more stable experience.
- Exploration of Image Generation Tools: There was a discussion around tools for image generation, with users sharing prompts that yield unexpected, often creative results.
- Users experimented with quantum-themed prompts to generate unique visual outputs, highlighting versatile applications of image generation models.
- Comparison of AI Models and Features: Discussions on AI models include insights on the effectiveness of Amazon Nova compared to existing platforms like ChatGPT and Claude.
- Users expressed interest in how various foundational models perform based on specific tasks and their integration with tools like Perplexity.
- Challenges with Google Gemini and Drive Integration: A user expressed frustration with Google Gemini's inconsistent access to Google Drive documents, questioning its reliability.
- Concerns were raised regarding whether advanced features are restricted to paid versions, leaving users seeking practical demonstrations.
- Server Sent Events: no description found
- no title found: no description found
- Tweet from Phi Hoang (@apostraphi): if you've been on the fence about upgrading to perplexity pro, get your first month for five bucks, today.
- Tweet from Phi Hoang (@apostraphi): if you've been on the fence about upgrading to perplexity pro, get your first month for five bucks, today.
- Introducing Amazon Nova, our new generation of foundation models: New state-of-the-art foundation models from Amazon deliver frontier intelligence and industry-leading price performance.
- Real-time AI search battle: ChatGPT Search vs. Perplexity vs. Google vs. Copilot vs. Grok: AI is taking over search. 🤖Whether you love em or hate em, LLM-powered searches are coming for your devices. ↳ ChatGPT Search and its Chrome extension. ↳ Go...
Perplexity AI ▷ #sharing (12 messages🔥):
Pending Searches, Partition in Linux, Parameter Counts, Purchasing Items, Vesuvius Challenge Progress
- Exploring Pending Searches: Several members are looking into pending search queries on Perplexity AI. A repeated link was shared regarding the same topic with trail links for various queries.
- The urgency about pending searches suggests ongoing user engagement and curiosity around this feature.
- Understanding Partition in Linux: A member shared a link that delves into the topic of partition in Linux, accessible here. This is aimed at clarifying foundational Linux concepts for users.
- Issues of disk management and file system layout are likely discussed in detail based on user requests.
- Diving into Parameter Counts: Another query surfaced regarding the number of parameters used in a specific model, found here. This reflects an interest in model capacities and settings among the users.
- Such questions highlight the focus on AI model configurations and their performance metrics.
- Where to Purchase Items: A seeking user asked about where to buy a particular item, linking to a purchasing query here. This indicates the community’s need for practical sourcing of technology or related products.
- The shared search link suggests a direct approach to finding purchasing information efficiently.
- Vesuvius Challenge Progress Insights: Discussion turned towards the Vesuvius Challenge, with a member sharing a link that documents current progress here. This indicates ongoing enthusiasm for results and developments in this challenge.
- The interest reflects user involvement in competitions and collective projects, likely fostering community collaboration.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (7 messages):
API Error Responses, Content Citation Issues
- Intermittent API Errors Confusing Users: Users reported receiving responses like
An error occurred while making the request: unable to complete request, especially within the last couple of hours.- One user mentioned that the same requests sometimes execute successfully, creating uncertainty about the issue's nature.
- Workaround for Unresponsive API: A user shared a temporary fix by adding a prefix to the user prompt, which seems to mitigate the error occurrences for now.
- This suggests users may need to adapt their requests while awaiting a resolution to the underlying API issues.
- Citations Persist Despite User Input: A member expressed frustration with the API still generating content citations in parentheses, despite using the instruction 'Do not generate content citation in parentheses.'
- Another user noted that citations are automatically added and that currently there is no option available to deactivate this feature.
Unsloth AI (Daniel Han) ▷ #general (115 messages🔥🔥):
LoRA finetuning process, Model compatibility issues, Training Llama 3.2, xformers installation issues, Inference and tokenization with finetuned models
- LoRA finetuning process confusion: Users expressed difficulties in finetuning Llama 3.2, particularly regarding the transition from tokenization to processor management.
- Modifications to the original Colab notebooks were suggested for successful execution of the finetuning process.
- Model compatibility issues: Several users faced compatibility problems with xformers and their current PyTorch and CUDA versions, leading to error messages.
- Recommendations for reinstalling xformers with the correct version were provided to resolve such issues.
- Training Llama 3.2 on less capable hardware: Users noted running into Out of Memory (OOM) errors when trying to train longer examples on hardware such as a 3090.
- Switching to lower resource setups or configurations like marco O1 were alternatives considered by users.
- Inference and tokenization with finetuned models: A user questioned if their finetuned LoRA model could be loaded and used like any other HF model without issues.
- It was clarified that if models are merged correctly, users didn't need to rely on
FastVisionModel.from_pretrained(...)for their finetuned versions.
- It was clarified that if models are merged correctly, users didn't need to rely on
- Help with finetuning assignment: Inquiries were made regarding producing expected results with fine-tuned models for assignment completion.
- Community responses suggested checking model merging processes or using available tutorials to achieve desired outputs.
- no title found: no description found
- no title found: no description found
- Vision Fine-tuning | Unsloth Documentation: Details on vision/multimodal fine-tuning with Unsloth
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Models - Hugging Face: no description found
- Google Colab: no description found
- vLLM Now Supports Running GGUF on AMD Radeon GPU: This guide shows the impact of Liger-Kernels Training Kernels on AMD MI300X. The build has been verified for ROCm 6.2.
- Speculative decoding in vLLM — vLLM: no description found
- GitHub - huggingface/smol-course: A course on aligning smol models.: A course on aligning smol models. Contribute to huggingface/smol-course development by creating an account on GitHub.
- GitHub - facebookresearch/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.: Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
- GitHub - foundation-model-stack/fms-fsdp: 🚀 Efficiently (pre)training foundation models with native PyTorch features, including FSDP for training and SDPA implementation of Flash attention v2.: 🚀 Efficiently (pre)training foundation models with native PyTorch features, including FSDP for training and SDPA implementation of Flash attention v2. - foundation-model-stack/fms-fsdp
- GitHub - unslothai/unsloth: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
Claude for Coding, Continued Pretraining, Citation of Founders, Understanding Numerical Data, Accounting Domain Tokens
- Claude excelling in code but what's next?: There was curiosity about whether Claude can handle numerical tabular data understanding, highlighting its primary focus on coding tasks.
- An image was shared to illustrate this point regarding Claude's capabilities.
- Importance of Continued Pretraining: A member emphasized that Continued Pretraining (CPT) is crucial for language models like Llama-3 and Mistral to adapt to new domains, especially when initial datasets lack diversity in language or specialty areas.
- They noted that CPT helps these models learn new tokens from specific domains, such as accounting.
- How to Cite Unsloth's Founders: A member asked for guidance on citing co-founders Daniel Han and Michael Han of Unsloth, looking for an acceptable format.
- Another member provided an example citation for referencing their work on finetuning language models available on GitHub: Unsloth AI.
- Challenges with Multilingual Models: Discussion included the challenges that base models face in effectively understanding various languages or specialized text domains like law and medicine.
- The point was made that CPT is fundamental in addressing these gaps in knowledge.
Unsloth AI (Daniel Han) ▷ #help (48 messages🔥):
Unsloth Model Issues, Fine-tuning Challenges, Llama-3 Model Conversion to GGUF, Partially Trainable Embeddings, Model Sequence Length Concerns
- Unsloth Model Issues with GGUF Conversion: Users are experiencing issues when trying to save models to GGUF, often encountering runtime errors indicating missing files such as 'llama.cpp/llama-quantize'.
- Another user confirmed that restarting Colab did not resolve the issue, raising potential concerns about recent changes in the underlying library.
- Challenges in Fine-tuning Process: A user mentioned they are new to fine-tuning and have run into difficulties, such as models losing context between prompts during training.
- Advice was sought on whether this forgetting was expected, highlighting concerns about managing state across fine-tuning sessions.
- Discussion on Sequence Length for Llama Models: There was an inquiry regarding the appropriate setting of max sequence length within the training code for Llama models, with users confirming it's a model configuration concern.
- One participant noted that the tokenizer shouldn't impact sequence length, emphasizing that the training configuration is crucial.
- Exploring Partially Trainable Embeddings: In a discussion about creating partially trainable embeddings, a user detailed their challenges with a custom implementation but noted the forward function was not being called during training.
- Feedback suggested that the model might be directly accessing weights instead of invoking the modified head, indicating a need for deeper integration.
- Uncertainty Around Mistral and Llama Architectures: A conversation unfolded regarding the differences between Mistral and Llama models, with claims that Mistral utilizes enhanced features beyond Llama’s architecture.
- Questions arose about the model type classifications in configuration files, leading to further clarification needs from the community.
- Google Colab: no description found
- Finetune Phi-3 with Unsloth: Fine-tune Microsoft's new model Phi 3 medium, small & mini easily with 6x longer context lengths via Unsloth!
- config.json · unsloth/Phi-3.5-mini-instruct at main: no description found
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
QWen2 VL 7B finetuning, LLaVA-CoT dataset, Hugging Face model card
- QWen2 VL 7B Finetuned with LLaVA-CoT: A member finetuned QWen2 VL 7B using the LLaVA-CoT dataset and released both the training script and the dataset.
- The model contains 8.29B params and uses BF16 tensor type, with the script available here.
- Model Card for Hugging Face: No model card was created for the finetuned model, but there’s a call to action to Contribute a Model Card.
- This is highlighted as a necessary step for better documentation and usability in the Hugging Face community.
- forcemultiplier/Qwen2-VL-7B-Instruct-LLaVA-CoT-2000steps-r16a16-merged · Hugging Face: no description found
- forcemultiplier/LLaVA-CoT-30k-jsonl-trainkit · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
PhD students' working conditions, 996 work culture, Work output and relaxation, Tokenizers in research
- PhD Students Power Nap at Work: A discussion ensued about PhD students in China who work so hard that they even have pillows in the office for napping during long hours.
- One member noted, ‘They have their lunch brought to them,’ highlighting the extreme conditions of research work.
- Culture of Overworking: The 996 Dilemma: A member introduced the concept of 996 work culture, describing it as employees working from 9 AM to 9 PM, six days a week.
- Another chimed in, stating that practices like 996 are ‘not efficient in the long run.’
- Relaxation for Enhanced Productivity: One participant asserted that providing beanbags and beds for employees can lead to higher productivity by allowing them to work in a relaxed state.
- This sentiment was supported by others who agreed on the importance of looking after employees.
- Lack of Focus on Tokenizers in Research: A query was raised about whether anyone was addressing different tokenizers in their research, signaling a potential oversight in discussions.
- This reflects growing concerns within the community about tools not getting enough attention in research discussions.
Notebook LM Discord ▷ #announcements (1 messages):
Raiza's departure from Google, NotebookLM team achievements, New venture announcement
- Raiza bids farewell to Google: Today marks Raiza's last day at Google after 5.5 years, during which they led the NotebookLM team and fostered a vibrant community.
- 'It has been one of the highlights of my career,' Raiza shared, expressing gratitude for the experience and the team's support.
- NotebookLM's impactful journey: Raiza reflected on the journey of going from idea to prototype to a product beloved by millions, highlighting the team's dedication and hard work.
- Raiza is confident about the future, stating, 'There is a lot in store for NotebookLM on the horizon.'
- Launching a new company: Raiza announced plans to start a new company alongside two other members of the NotebookLM team, inviting interested individuals to sign up for updates at werebuilding.ai.
- They encourage collaboration, stating, 'If you’re interested in building with us, hit me up at hello@raiza.ai.'
Link mentioned: We're Building: no description found
Notebook LM Discord ▷ #use-cases (28 messages🔥):
Notebook LM usage for scripting, OCR tools for PDF handling, Podcast creation, Fiction writing with AI, Multilingual capabilities in AI
- Using Notebook LM for Scriptwriting: A user shared their experience using Notebook LM to develop a script for a short movie, detailing camera and lighting setups in their audio clip.
- They expressed excitement about integrating this script into a video project.
- OCR Tools for Document Management: Members discussed the utility of PDF24 for applying OCR to scanned documents, enhancing their usability by creating searchable PDFs.
- This tool is recommended for converting images and photos into searchable formats, with an emphasis on its security protocols.
- Generating Podcasts from Outlines: A user is successfully generating a long podcast episode by providing a detailed outline and generating content chapter by chapter.
- They plan to use the resulting text with Eleven Labs to create audio and visuals for a documentary-style project.
- AI in Fiction Writing: Users inquired about using Notebook LM for fiction writing, seeking methods to prompt the AI for creative story development.
- One user suggested customizing the settings to improve the AI's scriptwriting capabilities.
- Multilingual AI Challenges: There was a discussion regarding the ability of AI to communicate in multiple languages and handle different accents.
- Users noted varying success rates with language output, particularly when attempting accents like Scottish or Polish.
- PDF OCR - Recognize text - easily, online, free: Free online tool to recognize text in documents via OCR. Creates searchable PDF files. Many options. Without installation. Without registration.
- Hailuo AI: Transform Idea to Visual with AI: Hailuo AI Tools - the innovative ai video generator & prompt that transform your ideas into stunning ai videos. Create captivating visuals in no time with cutting-edge AI-powered tech and a piece ...
- Top Shelf: Podcast · Four By One Technologies · "Top Shelf" is your go-to podcast for quick, insightful takes on today’s best-selling books. In just 15 minutes, get the gist, the gold, and a fresh pers...
Notebook LM Discord ▷ #general (140 messages🔥🔥):
NotebookLM Updates, Audio Overview Features, Language Support, User Experience Feedback, Google Drive Integration
- User Demand for Unlimited Audio Overviews: Users expressed strong interest in having unlimited audio generations per day, highlighting that the current limit of 20 feels restrictive for studying.
- Suggestions for potential subscription models for increased access were met with mixed reactions, emphasizing the demand for more flexibility.
- Challenges with PDF Reading: Users reported issues with NotebookLM's ability to process long PDFs correctly, often receiving messages about not having access to the complete document.
- There were speculations that other models, like Gemini 1.5 Pro, may have superior capabilities in this aspect.
- Questions on Language Support: A number of users raised inquiries about changing the language settings in NotebookLM, especially for generating outputs in languages other than English.
- Current guidance suggests altering Google account settings to reflect preferred languages, although support is still questioned by users.
- Feedback on User Organization Features: Participants suggested the need for folder organization within NotebookLM to better manage numerous notebooks and avoid clutter.
- In the interim, a workaround using short category codes was proposed to facilitate manual organization.
- Concerns about Google Drive Compatibility: Users voiced frustration regarding Google Gemini's inconsistent ability to access Google Drive documents and stated this might be linked to potential restrictions in free versions.
- Questions arose about whether this functionality is available only to paid users or dependent on specific features.
Link mentioned: Tweet from Bryan Kerr (@BryanKerrEdTech): I figured out how to listen to NotebookLM Audio Overviews in my podcast app. Now I enjoy my walks and commutes with more purpose.You can do it too. All you need is a Dropbox or OneDrive account and Pu...
OpenAI ▷ #ai-discussions (122 messages🔥🔥):
Italy's AI Regulation, ChatGPT Feature Issues, Voting and Quantum Computing, Content Moderation Challenges, AI Translation Comparisons
- Italy's AI Regulation Act: Italy plans to ban AI platforms, including OpenAI, unless individuals can request removal of their data, prompting discussions about its implications.
- There are concerns that geolocation bans are not effective, as users may find ways to bypass these restrictions.
- ChatGPT's Functional Limitations: Users reported that after purchasing the ChatGPT Plus plan, they faced issues with features such as image generation not working properly.
- Concerns about inappropriate content being generated led to discussions on how the system should handle such prompts.
- Quantum Computing's Relevance to Voting: A debate sparked about whether quantum computing could aid in voting processes, with skepticism expressed regarding its actual application in this context.
- It was pointed out that voters cannot be in superposition and that quantum methods do not enhance classical consensus algorithms.
- Debates on Content Moderation: Users discussed the complexities of content moderation in AI, noting that current methods are insufficient and face many edge cases.
- It was emphasized that while AI can generate warnings about policy breaches, complete automation in moderation is not feasible.
- AI Translation Options: A question was raised about the best AI tools for translating into Hungarian, comparing options like DeepL, Claude, and ChatGPT.
- This led to further exploration of users' experiences with different AI translation services in the context of their effectiveness.
Link mentioned: React App: no description found
OpenAI ▷ #gpt-4-discussions (6 messages):
GPT functionality issues, ChatGPT Plus Plan, Transcription models
- User faces GPT functionality issues: A user reported difficulties with a GPT designed to compile hours for billing, stating it forgets entries and struggles to produce an XLS-compatible list.
- Could it be that the GPT is bored with the work?
- ChatGPT Plus Plan not delivering promised features: Another user expressed frustration after purchasing the ChatGPT Plus plan for $20, reporting that features like image generation and file reading are malfunctioning.
- They noted that responses appear outdated, and another member confirmed experiencing the same issues for a week.
- Clarification on transcription models: A member provided a clarification about different models used for transcription, suggesting they should not be compared directly.
- They referenced OpenAI's voice mode FAQ for further details.
OpenAI ▷ #prompt-engineering (9 messages🔥):
Custom Instructions in ChatGPT, Improving Prompt Engineering, Learning User Styles, ChatGPT Writing Styles
- Custom Instructions enhance ChatGPT's output: A member suggested using custom instructions to inform ChatGPT of specific style requirements, which can streamline editing efforts.
- Another pointed out that this approach differs from creating a new GPT in the Explore GPTs feature.
- Possibility of ChatGPT learning user styles: A member inquired whether ChatGPT could learn their storytelling style to reduce the need for editing.
- Responses indicated that showing examples of desired styles could help ChatGPT adapt its writing accordingly.
- Resources for Enhancing Prompt Engineering: A user expressed interest in finding free or low-cost resources to improve their prompt engineering for custom GPTs.
- This reflects a broader interest in developing better interactions with ChatGPT and maximizing its capabilities.
- Writing in different styles with ChatGPT: One participant emphasized experimenting with different writing styles using ChatGPT as a tool to refine narrative delivery.
- It was noted that adjusting the model's output might require specific guidance, including example texts.
OpenAI ▷ #api-discussions (9 messages🔥):
Custom Instructions, Prompt Engineering, Storytelling Style Adaptation
- Exploring Custom Instructions for Style: Members discussed the use of custom instructions to adjust ChatGPT's writing style, suggesting it can help align with personal storytelling preferences.
- One suggested providing examples to ChatGPT to showcase the desired style for improved output.
- Differences between Custom Instructions and Custom GPTs: Clarifications were made regarding the difference between custom instructions and creating a custom GPT in the Explore GPTs section.
- Custom instructions are aimed at adapting the model's response style rather than developing a new GPT entirely.
- Improving Prompt Engineering: A user expressed intent to enhance their prompt engineering skills for better custom GPT development using OpenAI ChatGPT.
- They inquired about resources available for free or low cost to elevate their understanding and application.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Model removals, Price reductions, Claude 3.5 Haiku discount
- Two Models Disappear: The models
nousresearch/hermes-3-llama-3.1-405bandliquid/lfm-40bhave been removed from availability.- Users are reminded to keep API requests operational by adding credits.
- Major Price Drops Announced: The price for
nousresearch/hermes-3-llama-3.1-405bfell from 4.5 to 0.9 per million tokens, while liquid/lfm-40b decreased from 1 to 0.15.- These significant reductions come as a silver lining following the removals.
- Sales Alert on Claude 3.5 Haiku: A 20% price cut has been announced for Claude 3.5 Haiku, providing users with a more affordable option.
- This discount is part of the ongoing efforts to make models more accessible.
OpenRouter (Alex Atallah) ▷ #general (117 messages🔥🔥):
Hermes 405B Model Status, OpenRouter API Key Management, Gemini Flash Errors, New Amazon Nova Models, LLM Tokenization Insights
- Hermes 405B Model No Longer Available: Users confirmed that the Hermes 405B model is gone for good, with sentiments expressed about this being an end of an era.
- The cost of alternatives was discussed, with some users considering purchasing models while others express preference for available free models.
- OpenRouter Key Management Features: OpenRouter allows for the creation and management of API keys, with users able to set and adjust credit limits per key without automatic resets on limit changes.
- Users were assured they need to manage key access themselves, maintaining control over who can use their application.
- Transient Gemini Flash Errors: Users reported encountering a 525 Cloudflare error while accessing Gemini Flash, which was found to be a transient issue that resolved quickly.
- The model's instability was noted, with recommendations to verify functionality via OpenRouter's chat interface.
- Plans for Amazon Nova Models: There are ongoing discussions about integrating the new Amazon Nova models, which are currently exclusive to AWS Bedrock.
- Users showed interest in the new models, suggesting they appear to be decent options worth pursuing.
- Insights on LLM Tokenization: The discussion included how LLMs break down unseen strings into recognizable tokens, with an emphasis on the importance of token embedding rather than tokens themselves.
- An external resource for experimenting with various tokenizers was shared, allowing for further exploration of the topic.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Tiktokenizer: no description found
- The Tokenizer Playground - a Hugging Face Space by Xenova: no description found
- GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI's models.: tiktoken is a fast BPE tokeniser for use with OpenAI's models. - openai/tiktoken
- Transforms | OpenRouter: Transform data for model consumption
- Build Generative AI Applications with Foundation Models - Amazon Bedrock Pricing - AWS: no description found
- Reddit - Dive into anything: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
Custom provider keys, BYOK access, Gemini experimental model
- Access Requested for Custom Provider Keys: Multiple users expressed interest in gaining access to the custom provider keys, indicating a high demand within the channel.
- One member specifically linked their access queries to the inability to use the Gemini experimental 1121 model.
- Update on BYOK Access: A quick update announced that the team is working to bring BYOK (Bring Your Own Key) access to everyone soon, although the private beta is currently paused.
- The team is actively addressing some kinks before moving forward.
Stability.ai (Stable Diffusion) ▷ #general-chat (100 messages🔥🔥):
LORA training, Stable Diffusion Guidance, Scammer Alerts, GPU Utilization, New Image Synthesis Model
- Tips for Creating LORAs: Users discussed various strategies for creating effective LORAs, such as using a background LORA made from images and cleaning up outputs in software like Photoshop or Krita.
- One member advised refining generated images before using them for training to ensure higher quality outcomes.
- Stable Diffusion Setup Guidance: Multiple users sought recommendations on starting with Stable Diffusion, with suggestions including using ComfyUI and various cloud options.
- Members emphasized the importance of knowing whether to run it locally or utilize cloud GPUs, with resources like Vast.ai recommended for rental options.
- Awareness Against Scammers: Concerns about potential scammers in the server led users to share warnings and recommended actions, like reporting suspicious accounts to Discord.
- Members discussed recognizing phishing attempts and how certain accounts impersonated support to deceive users.
- Understanding GPU Performance: The conversation highlighted differences in GPU performance, with users comparing experiences with different models and emphasizing that memory and speed were crucial factors.
- A user pointed out that cheaper cloud GPU options may lead to better overall performance compared to local setups due to electricity costs.
- Discussion on New Image Synthesis Model: Members discussed a new model called Sana, noting its efficiency and quality compared to prior versions, with some expressing skepticism about its commercial usage.
- It was suggested that for everyday purposes, using Flux or previous models might yield similar or better results at leisure.
- Sana: no description found
- Rent GPUs | Vast.ai: Reduce your cloud compute costs by 3-5X with the best cloud GPU rentals. Vast.ai's simple search interface allows fair comparison of GPU rentals from all providers.
- Don't ask to ask, just ask: no description found
- ComfyUI - Getting Started : Episode 1 - Better than AUTO1111 for Stable Diffusion AI Art generation: Today we cover the basics on how to use ComfyUI to create AI Art using stable diffusion models. This node based editor is an ideal workflow tool to leave ho...
- Revolutionize Your WordPress Site with AI Art: AI Artist Plugin + Free Preconfigured Server!: 🎨 Create Stunning AI Art on Your WordPress Site (It’s Easy, I Promise!)In this video, I’m introducing the AI Artist Plugin for WordPress, a super easy way t...
Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
Pydantic AI, NotebookLM team changes, Hunyuan Video release, Amazon Nova foundation model, ChatGPT's handling of names
- Pydantic AI Framework Goes Live: The new Agent Framework from Pydantic aims to integrate with LLMs, showing potential for innovative applications in AI.
- However, skepticism arose regarding its differentiation from existing frameworks like LangChain, as some users felt it merely mimicked existing solutions.
- NotebookLM Team Takes a New Path: Key members from the NotebookLM team at Google, @raizamrtn and @jayspiel_, are leaving to create a new venture together after years of significant contributions.
- Their new journey is anticipated to inspire further innovation in AI, as they invite followers to join their updates at werebuilding.ai.
- Hunyuan Video Makes Waves: Tencent's release of Hunyuan Video positions it as a new leader in open-source text-to-video technology, showcasing impressive quality.
- Initial user feedback highlights the substantial resource requirements for rendering, but they are optimistic about future efficiency improvements.
- Amazon Launches Nova Foundation Model: Amazon announced its new foundation model, Nova, which is positioned to compete with advanced models like GPT-4o.
- Initial impressions suggest it shows promise, although users have communicated mixed experiences, not feeling entirely wowed as they did with previous models.
- ChatGPT's Name Crisis: Certain names, notably David Mayer, have been flagged by ChatGPT, causing it to abort responses when they are mentioned due to a system glitch.
- This issue, which does not affect the OpenAI API, has sparked curiosity and commentary about the implications of name associations on AI behavior.
- Certain names make ChatGPT grind to a halt, and we know why: Benj Edwards on the really weird behavior where ChatGPT stops output with an error rather than producing the names David Mayer, Brian Hood, Jonathan Turley, Jonathan Zittrain, David Faber or …
- Tweet from Pietro Schirano (@skirano): I added a new MCP server that lets Claude think step by step before answering.Claude is able to decide upfront how many thinking steps are needed, retrace its thoughts, and even branch off if it sees ...
- Tweet from 青龍聖者 (@bdsqlsz): Huggingface suddenly increased the space limit, now the free amount is 500G and pro members are offered 1TB.For us this is a nightmare.
- Coders Worry The AI From This $2 Billion Startup Could Replace Their Jobs: Backed by $200 million in funding, 28-year-old Scott Wu and his team of competitive coders at Cognition are building an AI tool that can program entirely on its own, like an “army of junior engineers....
- Tweet from Paul Copplestone — e/postgres (@kiwicopple): today we're releasing @supabase AI assistant v2it's like cursor for databases. even an Australian can use it ↓↓
- ChatGPT’s refusal to acknowledge ‘David Mayer’ down to glitch, says OpenAI: Name was mistakenly flagged and prevented from appearing in responses, says chatbot’s developer
- Introduction: Agent Framework / shim to use Pydantic with LLMs
- Tweet from World Labs (@theworldlabs): We’ve been busy building an AI system to generate 3D worlds from a single image. Check out some early results on our site, where you can interact with our scenes directly in the browser!https://worldl...
- Cognition | A review of OpenAI o1 and how we evaluate coding agents: We are an applied AI lab building end-to-end software agents.
- Tweet from kalomaze (@kalomaze): sillytavern is a frontend (for autists), connects to basically any APIlm studio is a frontend+backend (for normal people/mac developers), proprietary fork of llama.cppkoboldcpp is a frontend+backend (...
- Introducing Amazon Nova, our new generation of foundation models: New state-of-the-art foundation models from Amazon deliver frontier intelligence and industry-leading price performance.
- 2:4 Sparse Llama: Smaller Models for Efficient GPU Inference: Discover Sparse Llama: A 50% pruned, GPU-optimized Llama 3.1 model with 2:4 sparsity, enabling faster, cost-effective inference without sacrificing accuracy.
- GitHub Next | GitHub Spark: GitHub Next Project: Can we enable anyone to create or adapt software for themselves, using AI and a fully-managed runtime?
- Tweet from AP (@angrypenguinPNG): The new king of Open-Source text-to-video is here!Tencent just released their open-source video model: Hunyuan Video.
- Tweet from Jonathan Adly (@Jonathan_Adly_): If you have an interest in ColPali and RAG.We have published a production-ready RAG API that implements the paper with a full eval pipeline. Our evals are very close to the latest model by @ManuelFays...
- Archive for Tuesday, 3rd December 2024: no description found
- Tweet from The Browser Company (@browsercompany): Come help us build our second product, a smart browser called Dia. More at 🔗 diabrowser [dot] com
- Tweet from apolinario 🌐 (@multimodalart): My first HunyuanVideo generation 🎥 "A capybara walks on the grass, realistic style" 🌱₍ᐢ-(ェ)-ᐢ₎🌱Definitely SOTA open source quality! 🔥 Took 60GB VRAM and 40min tho —how much less will it be...
- Tweet from Exa (@ExaAILabs): Announcing Exa Websets - a breakthrough toward perfect web search.Sign up for the waitlist below👇
- Tweet from Scott Wu (@ScottWu46): Devin has saved companies millions of dollars and has shown as much as an 8x productivity boost in engineering time. Great to chat with Forbes about the work Devin has been doing with customers like N...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Congrats to @amazon on releasing the latest frontier model, Nova!⭐Nova is competitive with top models like GPT-4o on standard benchmarks. Now, the real challenge begins—Nova is in Arena for human eval...
- Tweet from Exa (@ExaAILabs): How does Exa serve billion-scale vector search?We combine binary quantization, Matryoshka embeddings, SIMD, and IVF into a novel system that can beat alternatives like HNSW.@shreyas4_ gave a talk tod...
- LLMs are a tool for thought: no description found
- Tweet from Amelia Wattenberger 🪷 (@Wattenberger): 🐟 some musings on how we might use LLMs🐠 to interact with text at multiple levels of abstraction🐡 inspired by the fish-eye lens
- servers/src/sequentialthinking at main · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- Tweet from Raiza Martin (@raizamrtn): After 5.5 years, today is my last day at Google. Leading @NotebookLM from idea to a product serving millions has been the ride of a lifetime.But the best part? Finding my future cofounders in the tren...
- Tweet from Jason Spielman (@jayspiel_): After 7.5 incredible years at Google — most recently building NotebookLM and contributing to some of Google’s most innovative AI products — I’m leaving to start a company.Highlights:1️⃣ In 2011 I play...
- Tweet from Google DeepMind (@GoogleDeepMind): Transforming content into engaging audio conversations is just one feature of @NotebookLM 🗣️@Stevenbjohnson and @Raizamrtn from the @LabsDotGoogle team believe it could be transformative for learning...
- Tweet from Steve Jurvetson (@FutureJurvetson): The Moore's Law UpdateNOTE: this is a semi-log graph, so a straight line is an exponential; each y-axis tick is 100x. This graph covers a 1,000,000,000,000,000,000,000x improvement in computation/...
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): some people managed to find some AoC-solving code from qianxyz in a github repo that has now been deleted seems like an automated pipeline using gpt-4o-mini with a pretty basic promptQuoting Tanishq M...
Latent Space ▷ #ai-announcements (3 messages):
Bolt Launch, AI Agents Discussion, Open Source Strategies, Revenue Growth in AI, AI Interface Dynamics
- Bolt's Exciting Launch and Revenue: The recent podcast featuring Bolt highlights its impressive growth, achieving over $8m ARR in just 2 months as a Claude Wrapper. The discussion includes notable guests like @ericsimons40 and @itamar_mar.
- We are excited to catch up with @QodoAI and debut @stackblitz on what’s possible with code agent engineering.
- Diving Deep into AI Agents: The podcast covers topics like Generic vs. Specific AI Agents and the dynamics of Human vs Agent Computer Interfaces. Key timestamps highlight discussions on maintaining vs creating with AI and why Docker isn’t suitable for Bolt.
- Listeners can learn about strategies for breaking down complex tasks and reflections on Bolt’s success throughout the episode.
- Open Source and Future Growth: The episode discusses the importance of building in Open Source and the strategies for selecting products as a founder. Insights into Bolt’s unique features and future growth prospects in AI engineering are shared.
- Topics such as AI Capabilities and Pricing Tiers and the competitive landscape are also examined, offering listeners a comprehensive view of the field.
- Personal Insights and Advice for Founders: Towards the end, hosts share personal stories, including having a baby and completing an Iron Man, showcasing work-life balance in startups. Additionally, they provide valuable advice to founders about embracing AI in their ventures.
- This mix of personal reflections and professional insights make for a well-rounded discussion for aspiring entrepreneurs.
Link mentioned: Tweet from Latent.Space (@latentspacepod): 🆕 Bolt, Flow Engineering for Code Agents, and >$8m ARR in 2 months as a Claude Wrapperwith @ericsimons40 and @itamar_mar!We are excited to catch up with @QodoAI and debut @stackblitz on the pod, w...
Cohere ▷ #discussions (53 messages🔥):
Manufacturing Discussions, New Rerank 3.5 Features, Colpali and Tewi References, Multilingual Support in Rerank, Community Engagement
- Manufacturing Jobs Spark Interest: A member asked if anyone had experience with manufacturing jobs, especially machinist roles, expressing a desire to share use cases.
- One participant noted the quietness in Discord discussions, attributing it to everyone currently being focused on building and development.
- Rerank 3.5 Brings Improved Functionality: A shoutout was given to the new Rerank 3.5, which offers enhanced reasoning and multilingual capabilities, allowing for better search of complex enterprise data.
- Members expressed excitement about the performance improvements and discussed its compatibility across various formats like multimedia.
- Colpali and Tewi: Community Humor: The community entertained itself with light-hearted banter around Colpali and Tewi, jokingly assigning blame for various issues to these entities.
- The exchange highlighted the camaraderie among members who found humor in the challenges they faced.
- Multilingual Support Confirmation: A member inquired about the multilingual support of Rerank 3.5, questioning if they could switch from the previous multilingual version.
- It was confirmed that Rerank 3.5 supports both multilingual and English functions, providing users with more flexibility.
- Curiosity about Google Gemini: A member expressed frustration regarding Google Gemini, asking about its functionality with Google Drive and consistency in accessing documents.
- The concern was raised about whether certain features worked only for paid users, leading to dialogue about the reliability of these services.
- Introducing Rerank 3.5: Precise AI Search: Rerank 3.5 delivers improved reasoning and multilingual capabilities to search complex enterprise data with greater accuracy.
- ColPali: Efficient Document Retrieval with Vision Language Models 👀: no description found
Cohere ▷ #announcements (1 messages):
Rerank 3.5, API deprecations, Multilingual capabilities, Enhanced reasoning, Legacy model lifecycle
- Rerank 3.5 has been launched!: The new Rerank 3.5 model delivers SOTA performance with enhanced reasoning skills and better compatibility for searching long documents, emails, and semi-structured data.
- It also supports multilingual performance across 100+ languages like Arabic, French, Japanese, and Korean, accessible via the
rerank-v3.5API alias; check out the blog post for more details.
- It also supports multilingual performance across 100+ languages like Arabic, French, Japanese, and Korean, accessible via the
- Important updates on API deprecations: Cohere announced deprecations of older models and provided information on recommended replacements for deprecated endpoints and models on this documentation page.
- The document outlines the model lifecycle, from 'Active' to 'Deprecated', impacting applications relying on Cohere's legacy models.
- Introducing Rerank 3.5: Precise AI Search: Rerank 3.5 delivers improved reasoning and multilingual capabilities to search complex enterprise data with greater accuracy.
- Deprecations — Cohere: Learn about Cohere's deprecation policies and recommended replacements
Cohere ▷ #questions (9 messages🔥):
TooManyRequestsError, Payment Issues with Card, API Key Setup Delay
- TooManyRequestsError despite Production Key: A user reported encountering a TooManyRequestsError even after upgrading to a production API key that allows more than 10 calls per minute.
- Another member suggested creating a support ticket at support@cohere.com for further assistance, but the user later acknowledged that the issue was possibly due to a delay in setting up the API_KEY.
- Credit Card Declining Payment: A user expressed frustration with their credit card being rejected for payments despite having successfully used it the previous month.
- Members suggested that it might be an issue with their bank, and recommended contacting support@cohere.com for resolution, since Stripe is used for processing payments.
Cohere ▷ #api-discussions (6 messages):
TooManyRequestsError, Production API Key Setup Delay
- User faces TooManyRequestsError despite scaling up: A user mentioned they are receiving a TooManyRequestsError after scaling up to a production key for rerank, allowing more than 10 calls per minute.
- They confirmed that they changed their API key and checked usage, indicating potential issues with setup or propagation.
- Support Contact Recommended for API Issues: Another member advised the user to email support@cohere.com with their customer id for assistance.
- Propagation should never take too long, noted another member, suggesting that setup delays are typically minimal.
- User's API Key Issue Appears Resolved: The user later reported that their problem seems resolved, speculating that there may be a delay in API key activation.
- According to responses, the setup delay may be only a few minutes at most.
Cohere ▷ #projects (1 messages):
Harmony Project, Large Language Model Competition, Natural Language Processing in Questionnaire Harmonisation
- Introducing the Harmony Project: The Harmony project aims to harmonize questionnaire items and meta-data using Natural Language Processing. Researchers can use it to compare questionnaire items across studies.
- Based out of UCL, the project involves collaboration with several universities and professionals.
- Competition for LLM Matching Algorithms: A competition has been announced to improve Harmony's LLM matching algorithms, with prizes of up to £500 available for participants who enter via DOXA AI. It's beginner-friendly; previous LLM experience is not required.
- Interested participants can join the Harmony Discord server and check out the 🏅「matching-challenge」 channel for more information.
- Evaluating Harmony's Performance: The Harmony project acknowledges challenges in accurately matching similar sentences, as discussed in their blog post. The system sometimes mislabels similarities that professionals might view differently.
- They are keen on community input to refine Harmony’s matching capabilities.
- Harmony | A global platform for contextual data harmonisation: A global platform for contextual data harmonisation
- Competition to train a Large Language Model for Harmony on DOXA AI | Harmony: A global platform for contextual data harmonisation
Cohere ▷ #cohere-toolkit (1 messages):
mrdragonfox: - hey "new" - im mrdragonfox ^^
GPU MODE ▷ #general (7 messages):
Xmma Kernels Performance, Nvjet vs Cutlass Comparisons, GEMM Toolkit Updates, Runtime Error with Meta Tensors
- Xmma Kernels prove interesting yet slow: Members discussed the Xmma kernels, with one noting they're 'almost embarrassingly bad' during current experiments.
- While experimenting with nvjet, another member found it caught up on smaller sizes, though their custom kernel remained 1.5% faster for N=8192.
- Nvjet shows competitive performance: Discussion highlighted that nvjet competes well against cutlass, with personal experiences suggesting it can outperform cutlass in certain instances.
- One member noted that cutlass may slightly outperform nvjet in specific cases but generally found nvjet more competitive.
- GEMM Toolkit Updates generate curiosity: A member revealed that the 12.6.2 toolkit was released in October, prompting questions about what prior methods were used for GEMM.
- The consensus was that many relied on cublas, or cutlass/triton for more intensive optimization efforts before the toolkit's release.
- Runtime Error with Meta Tensors: A user sought help regarding a runtime error with a specific function, causing confusion around the Tensor.item() method.
- The error message indicated issues with meta tensors, prompting requests for assistance in debugging.
GPU MODE ▷ #triton (3 messages):
Triton MLIR Dialects, Floating Point Representations in Triton, Documentation and Tutorials
- Floating Point Argument in Triton Kernel Concerns: A member raised a concern regarding the safety of using a
floatlike 1.5 as atl.constexprargument in a Triton kernel, questioning potential issues with floating point representation.- There were no immediate responses addressing the potential risks or precautions regarding this usage.
- Seeking Triton MLIR Dialects Documentation: A member inquired about available documentation or tutorials for Triton MLIR Dialects, expressing that much of the linked content appears to be incomplete.
- Another member provided a link to the Triton Ops documentation, highlighting that although minimal, it contains relevant examples.
- Minimal Programming Guide for Triton: It was noted that there is a very minimal programming guide available on GitHub, yet it seems to be unfinished.
- The guide is meant to assist developers working with the Triton language but currently lacks comprehensive content.
- Triton MLIR Dialects and Ops — Triton documentation: no description found
- TritonOps — Triton documentation: no description found
- triton/docs/programming-guide at main · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
GPU MODE ▷ #cuda (5 messages):
Warp Schedulers in GPU Architecture, Comparison of FP32 Cores in Different Models
- Understanding Warp Schedulers and FP32 Core Distribution: A member explained that a warp consists of 32 threads utilizing 32 FP32 cores in parallel, leading to 128 FP32 cores per SM.
- This concept clarified the parallel processing capabilities of modern GPUs.
- Discrepancies in A100 and RTX Core Counts: Another member pointed out that the A100 has only 64 FP32 cores for its 4 warp schedulers, differing from the RTX 30xx and 40xx series with 128 FP32 cores.
- This highlights the architectural differences across GPU generations.
- Architecture-Specific Details on Warp Execution: Continuing the discussion, it was noted that the Volta architecture featured 4 warp schedulers with 16 FP32 cores each, indicating that a warp requires two passes to execute each instruction.
- This brings attention to execution efficiency across various architectures.
GPU MODE ▷ #torch (1 messages):
bf16 training, debugging tips
- bf16-true training yields success: A member reported that switching to bf16-true helped their training process immensely, stating that it trains well now.
- They expressed gratitude for the debugging tips shared earlier, indicating a positive resolution to their initial issues.
- Appreciation for Debugging Assistance: Another member acknowledged the helpfulness of the debugging tips provided, indicating that they eased the troubleshooting process.
- This shows a strong community sentiment towards sharing best practices and strategies for effective training.
GPU MODE ▷ #beginner (26 messages🔥):
MIT Efficient ML Course, Stanford CS 229S Course, Assignments for ML Courses, Machine Learning Optimization Techniques
- MIT Efficient ML Course for Advanced Techniques: Professor Han from MIT offers an Efficient ML course that covers crucial topics such as quantization, pruning, and distributed training to optimize machine learning systems.
- This course also emphasizes practical implementation, allowing students to work with model compression techniques and deploy large models like Llama2-7B on resource-constrained devices.
- Stanford's CS 229S Course Emphasizes Systems: Another resource mentioned is the Stanford CS 229S course, which focuses on systems for machine learning and includes various coding exercises.
- Participants are encouraged to explore assignments and materials to understand infrastructure and lifecycle challenges in deploying deep learning models.
- Public Access to Labs and Assignments: The courses provide publicly accessible labs and assignments hosted in Google Colab, facilitating an easier learning experience without compute resource constraints.
- Participants have noted that while some assignments are challenging, they appreciate the organization and support found in the course materials.
- Knowledge Prerequisites for Success: Discussion highlights the importance of prior knowledge as proposed by Professor Han, with recommendations for prerequisite courses available through OCW and GitHub resources.
- Members agree that starting with a solid base in machine learning concepts is critical for tackling the course's challenges.
- Home: Systems for Machine Learning
- MIT 6.5940 Fall 2024 TinyML and Efficient Deep Learning Computing: no description found
- MIT HAN Lab: Welcome to MIT HAN Lab, where efficiency meets performance, innovation converges with excellence in the realm of artificial intelligence (AI) and computer architecture. Our lab stands at the forefront...
GPU MODE ▷ #youtube-recordings (1 messages):
mobicham: Is the 3-bit version here symmetric or asymmetric ?
GPU MODE ▷ #off-topic (6 messages):
Mastodon for AI/ML, HPC Community on Mastodon, Mastodon Overview
- GPU Community Presence on Mastodon: Members discussed whether there are many AI/ML folks on Mastodon, with one noting a presence of graphics/compute/HPC enthusiasts but uncertainty about AI.
- Curiosity about the network there is valid, highlighting that interests might vary within the community.
- Enquiry about Mastodon: What's Mastodon? was posed, to which a member provided a link to Google it rather than explaining directly.
- This response was viewed as impolite by another member, emphasizing that asking for clarifications is natural in conversation.
- Community Etiquette on Responses: A member pointed out that straightforward questions should not be dismissed and should foster chit-chat.
- They stressed that sending links to searches can come off as rude, suggesting a preference for conversational engagement.
Link mentioned: Mastodon: no description found
GPU MODE ▷ #arm (3 messages):
Low Bit ARM kernels, Low-bit operations, LUT techniques, Bitnet.cpp
- YouTube Lecture on Low Bit ARM Kernels: For anyone who missed the initial presentation, check out the YouTube video titled 'Lecture 38: Low Bit ARM kernels' featuring speaker Scott Roy.
- Details on the slides are still to be determined, but the lecture promises valuable insights.
- Excitement over Low Bit Techniques: A member expressed enthusiasm, noting it as a super cool topic worth exploring further.
- Low-bit operations are gaining traction in discussions, indicating a growing interest.
- Proposing LUT Methods Similar to Bitnet: A suggestion was made to implement these ideas with true low-bit operations through LUT, referencing Bitnet.cpp for inspiration.
- This indicates a potential shift towards more efficient methods in low-bit processing discussions.
Link mentioned: Lecture 38: Low Bit ARM kernels: Speaker: Scott RoySlides: TBD
GPU MODE ▷ #webgpu (1 messages):
Performance Optimizations, TFLOP/s Metrics
- Exploring Performance Optimizations: A member expressed eagerness to chat about potential performance optimizations and suggested that there might be some practices hurting current performance.
- I'm sure there are things that I'm doing that are silly that are hurting performance.
- 1TFLOP/s as a Benchmark: 1TFLOP/s was mentioned as a milestone that seemed worthy of publishing, indicating it was a nice round number rather than a definitive achievement.
- It just seemed worthy of publishing at that point 😄.
GPU MODE ▷ #self-promotion (6 messages):
CUDARC Project, Luminal Framework, Talk Invitation
- CUDARC Crate for Manual CUDA Bindings: The CUDARC crate provides bindings for the CUDA API, but currently only supports matrix multiplication due to its manual implementation.
- Testing has indicated that most of the user's time was spent optimizing this matmul function.
- Luminal Framework Sparks Interest: Another user highlighted Luminal, a similar Rust-based project, praising the growth of ML frameworks in different languages.
- The conversation acknowledged the positive trend in expanding ML tools across various programming environments.
- Upcoming Talk Opportunity Confirmed: A user accepted an invitation to give a talk early next year, expressing enthusiasm with *
GPU MODE ▷ #🍿 (3 messages):
KernelBench introduction, Kernel performance evaluation, Leaderboard concerns
- Introducing KernelBench for LLMs: The new coding benchmark, KernelBench (Preview), aims to evaluate the ability of LLMs to generate efficient GPU kernels for optimizing neural network performance. It was formally introduced on Twitter by @anneouyang.
- Initial reactions reveal excitement about its potential, with users eager to explore its capabilities.
- Concerns on Kernel Leaderboard Completeness: There were grievances about certain fastest kernels on the leaderboard appearing incomplete, raising questions about their accuracy. A user referenced a incomplete kernel solution hinting at potential issues.
- This discussion emphasizes the importance of thorough evaluations for benchmarking tools.
Link mentioned: GitHub - ScalingIntelligence/KernelBench: Contribute to ScalingIntelligence/KernelBench development by creating an account on GitHub.
GPU MODE ▷ #thunderkittens (1 messages):
WGMMA+TMA custom kernel, Race Condition in Kernel, Mask Implementation, Shared Memory Issues, Latest Fork Updates
- Race Condition Investigated in WGMMA+TMA: A member reported encountering a race condition while implementing WGMMA+TMA with a custom kernel, noting their matrix's non-16-aligned start and end.
- The mask isn't always applied correctly, leading to issues unless the mask call is duplicated multiple times.
- Masking Junk Rows with Custom Logic: They created a custom mask function based on existing load functions to mask out junk rows before calling WGMMA, adjusting row_start and row_end parameters.
- However, the solution resulted in unexpected behavior with the mask not always applying as intended.
- Shared Memory and Barrier Concerns: The code includes __syncthreads() correctly, but there are concerns regarding its effectiveness when combined with other functions like kittens::warpgroup::mma_fence.
- Members are exploring whether changes in synchronization methods impacted the kernel's efficiency.
- Updates on the Old Fork 2024: The implementation is based on a relatively old fork from around Jul 1, 2024, potentially lacking recent fixes related to shared memory and barriers.
- Users are encouraged to consider whether to rewrite off the latest version for improved stability and performance.
- Praise for ThunderKittens Tools: The original poster expressed appreciation for ThunderKittens and praised its ease of use compared to alternatives.
- They highlighted the team's efforts as super cool and instrumental for developers working with these technologies.
LlamaIndex ▷ #blog (6 messages):
NVIDIA Financial Analysis, LlamaCloud Pipeline with Google Drive, Multi-Agent Meetup at GitHub, AI Apps on Vercel, Amazon's Nova Foundation Models
- NVIDIA's Financial Insights Unveiled: In a video, @pyquantnews demonstrates using NVIDIA's financial statements for both simple lookups like revenue figures and complex analyses of business risks and segment performance. Check out more on practical code examples of setting up LlamaIndex.
- This approach illustrates how financial statements can be leveraged for deeper business intelligence.
- Streamlining LlamaCloud with Google Drive: In another video, @ravithejads outlines a step-by-step process for setting up a LlamaCloud pipeline using Google Drive as a data source, including configuration parameters for chunking and embedding. Discover the full setup here.
- This guide serves as a valuable resource for developers looking to easily integrate document indexing with LlamaIndex.
- Multi-Agent Meetup Sparks Collaboration: The upcoming Multi-Agent Meetup at GitHub HQ will feature experts discussing various topics, including automating tasks with CrewAI and evaluating agents using Arize AI. Learn more about the event here.
- This meetup promises to explore innovative practices in agentic retrieval and applications with LlamaIndex.
- Easier AI Development on Vercel: Building AI apps on Vercel is now simpler with enhancements to LlamaIndex and LlamaCloud integration. More details are available in this post.
- This improvement is set to streamline the workflows for developers utilizing Vercel.
- Amazon Launches Nova Foundation Models: Amazon unveiled Nova, a competitive family of foundation models boasting significantly cheaper pricing compared to equivalents while offering day 0 support. Install it with
pip install llama-index-llms-bedrock-converseand see examples here.- The launch marks an exciting addition to the AI model landscape, promising enhanced affordability and performance.
LlamaIndex ▷ #general (43 messages🔥):
Embedding model limitations, Quarterly report generation, RAG implementations, Structured output from multimodal models, Workflow management for chat history
- Embedding Model Limited by Token Size: A member inquired about handling input text larger than 512 tokens for embedding models, noting that the HuggingFaceEmbedding class simply truncates longer inputs.
- Another member emphasized the importance of selecting the right
embed_modelclass to avoid these limitations in practice.
- Another member emphasized the importance of selecting the right
- Creating Detailed Quarterly Reports: A user expressed the need for a 4-6 page compiled quarterly report from multiple detailed monthly financial reports, requiring high accuracy without hallucinations.
- Suggestions included creating a structured process that combines templates and RAG methods to synthesize insights effectively.
- Effective RAG Techniques Highlighted: A member shared a comprehensive repository of over 10 RAG implementations, including various techniques like Naive RAG and Hyde RAG.
- This can aid others in experimenting with RAG applications tailored for their specific datasets and needs.
- Challenges with Structured Outputs from Multimodal Models: Discussion arose around the MultiModalLLMCompletionProgram, which does not utilize function calls, leading to brittle output parsing.
- Members suggested establishing a custom function calling interface to facilitate more reliable structured data outputs.
- Managing Chat History in Workflows: A user sought advice on passing chat history between steps in workflows after the deprecation of QueryPipeline, which was more convenient for this purpose.
- Recommendations included utilizing Context for state management or employing a ChatMemoryBuffer for handling chat history across sessions.
- Workflows - LlamaIndex: no description found
- Voice & Video AI Agents Hackathon · Luma: Gen AI AgentsCreatorsCorner, collaborating with AWS, Temporal, Modal, Tandem, Marly, Retell, Senso, Unified, Speedlegal, Corval, Simli, PolyAPI and others…
- GitHub - athina-ai/rag-cookbooks: Cookbooks for LLM developers: Cookbooks for LLM developers. Contribute to athina-ai/rag-cookbooks development by creating an account on GitHub.
LM Studio ▷ #general (20 messages🔥):
LM Studio Windows Download Issues, LM Studio Performance on Windows, Community Support and Attitudes, Qwen LV 7B Model Functionality
- Users Struggling with LM Studio Download: A user reported trouble downloading the Windows x86 version from lmstudio.ai, encountering a message that the file is unavailable on multiple browsers.
- Another user suggested that it might be a CDN issue and recommended using a VPN to change location for the download.
- Windows Performance Issues with LM Studio: One user experienced slow performance and abnormal output when running LM Studio on Windows compared to Mac, noting issues with the 3.2 model.
- Others chimed in with solutions, suggesting toggling the
Flash Attentionswitch and checking the system specs for compatibility.
- Others chimed in with solutions, suggesting toggling the
- Community Offers Positive Feedback: A user expressed gratitude, noting a lack of high-handed behavior among moderators and developers in the community.
- They emphasized the importance of constructive dialogue in improving the product, wishing for this attitude to persist.
- Qwen LV 7B with Vision Capabilities: A query was raised about whether the Qwen LV 7B model works with vision functionalities.
- This question opens a discussion regarding the integration of vision capabilities with various AI models.
LM Studio ▷ #hardware-discussion (15 messages🔥):
Docker Containers for HF Spaces, Optimal GPU Configurations, FP8 Quantization in Models, Changing LLaMA.cpp Version, Intel Arc Battlemage Cards
- HF Spaces Can Run as Docker Containers: A member confirmed that you can run any HF space as a docker container.
- This provides flexibility for local deployments and testing.
- Tips for Building a GPU Rig: One member advised buying a used RTX 3090 while upgrading RAM to 64GB, highlighting that CPU matters less these days.
- They emphasized the importance of suitable power supply and compatibility for potential future upgrades.
- FP8 Quantization Boosts Model Efficiency: FP8 quantization allows for a 2x reduction in model memory and a 1.6x throughput improvement with little impact on accuracy, according to VLLM docs.
- This could be particularly relevant for those looking to optimize performance on machines with limited resources.
- Limitations on LLaMA.cpp Version Changes: A discussion arose about changing the llama.cpp version used by LM Studio, with members confirming it isn't currently possible.
- Interestingly, a member noted the availability of a new Cuda version that contrasts with the earlier one.
- Skepticism on Intel Arc Battlemage Cards: A member expressed doubt about the new Arc Battlemage cards, suggesting they are not suitable for AI tasks.
- Another member argued that despite being cost-effective for building local inference servers, they still wouldn't rely on Intel for such applications.
Link mentioned: Reddit - Dive into anything: no description found
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
Sierra AI Info Session, Recruitment Opportunities at Sierra
- Sierra AI hosts info session for developers: An exclusive info session with Sierra, a leading conversational AI platform, is scheduled for 12/3 at 9am PT, accessible via livestream on YouTube. Participants will gain insights into Sierra’s capabilities and career opportunities.
- The session will cover topics such as Sierra’s Agent OS and Agent SDK, emphasizing lessons learned from deploying AI agents at scale.
- Sierra AI looking for talent: Sierra is seeking talented developers to join their team and will discuss exciting career opportunities during the info session. Interested parties are encouraged to RSVP to secure their spot for the livestream.
- “Don’t miss this chance to connect with Sierra and explore the future of AI agents!”
- Meet with Sierra AI: LLM Agents MOOC Hackathon Info Session · Luma: Meet with Sierra AI: LLM Agents MOOC Hackathon Info SessionAbout the Info Session:🔗 Livestream Link: https://youtube.com/live/-iWdjbkVgGQ?feature=shareJoin…
- LLM Agents MOOC Hackathon - Sierra Information Session: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (2 messages):
Final Lecture & Presentation, Course Completion Certificate, Quizzes Reminder, Course Website Resources
- Final Lecture on AI Safety: Today at 3:00 PM PST, Professor Dawn Song will present on Towards building safe and trustworthy AI Agents and a Path for Science- and Evidence-based AI Policy during the final lecture, available via livestream.
- She will address the significant risks associated with LLM agents and propose a science-based AI policy to mitigate these threats effectively.
- Course Completion Certificate Process: Students must complete a certificate declaration form to earn their course completion certificate, which will be released shortly after today’s lecture.
- Ensure all assignments are submitted with the same email address, as this is how progress is tracked.
- Upcoming Quizzes and Deadlines: Quizzes 11 and 12 will be released early this week, with all assignments due by December 12th at 11:59 PM PST.
- The hackathon project deadline is set for December 17th at 11:59 PM PST for those participating.
- Course Resources Available Online: All course materials, including livestream URLs and assignments, can be accessed on the course website.
- Students are encouraged to communicate with course staff via the designated channel for any questions or feedback.
Link mentioned: - YouTube: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (18 messages🔥):
LLM Agents Learning Course, Post-mortem assignment, Lab assignments requirements, Written article assignment, Social media sharing guidelines
- LLM Agents Learning Course Signup: Members confirmed that participants can still register for the LLM Agents Learning Course by filling out the signup form. For further details about the course, one can visit this course website.
- Participants were welcomed, with suggestions to take quizzes and possibly join a hackathon to enhance their learning experience.
- Post-mortem Assignment Clarification: For the post-mortem assignment, it was clarified that it is mainly effort-based allowing participants to discuss the topic freely in 500 words. The grading is expected to be generous, alleviating stress around the assignment.
- This encouragement aims to foster a relaxed approach to evaluation while ensuring students engage with the material.
- Lab Assignments and Certification: It was confirmed that while lab assignments are not mandatory for all certifications, completion of all three is necessary for achieving the Mastery tier. Participants who joined late were reassured they can still catch up.
- This structure helps enable learners to choose their level of engagement with the course content.
- Guidance on Written Article Assignment: For the written article assignment, participants were advised to paste their final draft directly into the designated Google Form field. They were also reminded to link back to the course site in their LinkedIn posts.
- It was stated that writing about the course as a whole is acceptable, providing an opportunity to reflect on the overall learning experience.
- Social Media Sharing Options: Members could post their social media share to platforms like Mastodon if they do not use Twitter or Threads, as it was deemed acceptable. Links to posts should be added in the respective fields after pasting the article text.
- This flexibility in sharing mediums underscores the community's commitment to inclusivity in communication.
- Large Language Model Agents MOOC: MOOC, Fall 2024
- LLM Agents MOOC Signup Form: Thank you for your interest in the course! Upon completion of the form, you will receive a copy of your response via email. If you would like to make changes to your response afterwards, please fill o...
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
GPT-4 PII leaks, AOL search log release
- GPT-4 potentially leaks PII: A member expressed concern that GPT-4 leaks personally identifiable information (PII), drawing a parallel to historical events.
- They referenced the AOL search log release incident in 2006 where users were identified through poorly scrubbed data.
- AOL's infamous data mishap: AOL released a dataset containing twenty million search queries from over 650,000 users in 2006, which included PII despite initial claims of anonymization.
- Although AOL pulled the data shortly after, it was extensively copied and remains accessible online.
Link mentioned: AOL search log release - Wikipedia: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (5 messages):
ReAct Paradigm, Implementation Quality, Benchmark Evaluations
- ReAct effectiveness hinges on implementation: A discussion emerged about how the effectiveness of the ReAct paradigm varies significantly based on implementation details like prompt design and state management. One member noted that benchmarks should reflect the specific implementation rather than being viewed as a general evaluation of the framework itself.
- Implementation compared to foundational models: It was likened to the relationship between dataset size/quality in traditional ML and the size/quality of foundation models within LLM frameworks. This analogy sparked conversation about how varying implementations lead to substantial differences in benchmark performance.
- Definitions in AI remain fuzzy: Members expressed that the definitions within the field of AI, particularly concerning ReAct and its benchmarks, are currently quite fuzzy. This lack of clarity adds another layer of complexity when assessing the paradigm's effectiveness.
OpenInterpreter ▷ #general (21 messages🔥):
Development Branch Updates, OpenAI Compatibility, Usage Issues with Anthropic, Testing Requests, Linux OS Compatibility
- Development Branch Earns Praise: The latest development branch has undergone a complete rewrite, making it lighter, faster, and smarter, which has impressed users.
- Members expressed excitement about testing this active branch, and requests for feedback on missing features from the old implementation have been encouraged.
- Challenges with Anthropic Integration: There was a reported issue when using the development branch with Anthropic, specifically a
TypeErrorrelated to an unexpected keyword argument ‘proxies’.- Users were advised to share the full traceback for better debugging, and examples of correct installation commands were provided.
- OpenAI Server Launch: The new
--serveoption allows for an OpenAI-compatible REST server, although the 1.0 version excludes the old LMC/web socket protocol.- This new setup enables users to connect via any OpenAI-compatible client allowing actions on the server's device.
- Testing Requests for Improved Performance: Members requested that the community participate in testing to enhance functionality in the development branch, which is updated frequently.
- One member expressed their reliance on the LMC for communication and found transitioning to the new setup both terrifying and exciting.
- Garuda-Linux Success Story: A member confirmed successful usage of the development branch on Garuda-Linux, an Arch Linux fork, amid discussions about various Linux distributions.
- They listed several other distributions tried, including Manjaro, Mint, and Kali, showcasing broad compatibility across different systems.
Link mentioned: So Close GIF - So Close This - Discover & Share GIFs: Click to view the GIF
OpenInterpreter ▷ #O1 (1 messages):
LiveKit Connection, Device Interaction, Local OpenInterpreter Operations
- LiveKit Bridges Devices: O1 typically uses LiveKit to connect two devices, such as your iPhone and a laptop or Raspberry Pi running the server.
- This setup enables remote access to control the machine via the local OI instance running on it.
- Enhanced Computing with O1: The capacity with O1 allows for greater computer use, acting as a sophisticated tool compared to CLI form.
- Despite the additional capabilities, OI in CLI form remains fully capable of operating the computer effectively.
DSPy ▷ #show-and-tell (3 messages):
Pydantic AI, DSLModel, AI Development, Pydantic Logfi, Live Demos
- Pydantic AI integrates with DSLModel: The introduction of Pydantic AI enhances integration with DSLModel, creating a seamless framework for developers.
- This integration leverages Pydantic, which is widely used across various Agent Frameworks and LLM libraries in Python.
- DSLModel resonates with users: DSLModel has been enthusiastically received, allowing for efficient development with Pydantic integrations.
- Users are encouraged to install it via pip install dslmodel to begin utilizing the framework.
- Live Demo on AI Development: A YouTube live demo titled 'Master AI Development: PydanticAI + DSPy + DSLModel' was shared, providing real-time exploration of these tools.
- The demo aims to showcase cutting-edge AI development techniques (Watch here).
- Community engagement with Pydantic: The community expressed excitement for implementing advanced features derived from Pydantic in their projects.
- A detailed discussion highlighted various use cases that demonstrate its practical applications.
- Introduction: Agent Framework / shim to use Pydantic with LLMs
- dslmodel: Pydantic + DSPy instances from prompts and Jinja.
- Master AI Development: PydanticAI + DSPy + DSLModel Deep Dive (Live Demo): https://ai.pydantic.dev/https://dspy.ai/https://pypi.org/project/dslmodel/🚀 Join us live as we explore the cutting edge of AI development! Discover how to c...
DSPy ▷ #general (7 messages):
Optimization Duration, DSPy on AWS Lambda, Program Of Thought Deprecation
- Optimization Processes Can Take Longer: One member noted that running optimizations can definitely exceed 15 minutes, especially if the program involves multiple steps.
- This highlights that duration can vary significantly based on complexity.
- DSPy Optimization on AWS Lambda Considered: A member is contemplating running DSPy optimizations on AWS Lambda for LangWatch customers, but the 15-minute limit poses challenges.
- They expressed a need for strategies to work around this time constraint.
- ECS/Fargate Recommended over Lambda: Another member shared their experience, suggesting that running DSPy on Lambda may not be feasible due to storage constraints.
- They recommended exploring ECS/Fargate as a potentially more reliable solution.
- Query on Program Of Thought Support: A member inquired whether Program Of Thought is on the path to deprecation/no active support post v2.5.
- This suggests ongoing concerns regarding the future of this program within the community.
DSPy ▷ #examples (9 messages🔥):
Agentic examples in DSPy, RAG Example in DSPy, Codetree quick version, DSPy Module Class
- Searching for Agentic Examples: A member inquired about agentic examples in DSPy where the output from one signature is utilized as input for another, specifically for an email composing program.
- Another member suggested looking at the RAG example but later clarified the location of relevant examples may be on the dspy.ai website.
- Super Quick Version of Codetree: A member shared a quick version of 'codetree' labeled with few-shots (k=1), stating it is not optimized.
- dspy/examples/llamaindex/dspy_llamaindex_rag.ipynb at main · stanfordnlp/dspy: DSPy: The framework for programming—not prompting—language models - stanfordnlp/dspy
- codetree.py: GitHub Gist: instantly share code, notes, and snippets.
Torchtune ▷ #general (4 messages):
Image Generation in Torchtune, T5 Integration, Fine-tuning Models
- Image Generation Feature Coming to Torchtune?: A user raised excitement about the possibility of an image generation feature being integrated into Torchtune, referencing Pull Request #2098.
- The details on this PR suggest it's aimed at adding new functionalities to the platform.
- T5's Role in Upcoming Features: Discussion hinted that T5 might also be included in Torchtune based on the insights gained from Pull Request #2069.
- The user implied that the features from T5 are aligned with the image generation integration plans.
- Fun in Fine-tuning ImageGen Models: One user expressed enthusiasm about the potential of fine-tuning image generation models within Torchtune, suggesting it could be an enjoyable endeavor.
- This remark sparked light-hearted responses, indicating mixed familiarity with the topic among members.
- Flux Autoencoder by calvinpelletier · Pull Request #2098 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here)Please link to any issues this PR addresses.ChangelogW...
- T5 Encoder by calvinpelletier · Pull Request #2069 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here)Please link to any issues this PR addresses.ChangelogW...
Torchtune ▷ #papers (1 messages):
pjbontrager: This would be a fun recipe: https://sakana.ai/cycleqd/
MLOps @Chipro ▷ #events (4 messages):
Event Attendance, Registration Process, India Visit
- Excitement for Upcoming Event: Members expressed their excitement and interest in attending an upcoming event, with one noting they are scheduled to visit India around that time.
- Ooh nice. Yes. I’ll be there. Hope to meet!
- Inquiry on Event Registration: A user inquired about the process for registering as an attendee for the event.
- This prompted a discussion on how to navigate the registration process effectively.
Axolotl AI ▷ #announcements (1 messages):
Office Hours Announcement, Axolotl Survey, Swag Giveaway
- Upcoming Office Hours: Join Us!: Mark your calendars for our office hours on Thursday 12/5 at 1pm Eastern / 10am Pacific to discuss Axolotl.
- We're excited to talk with everyone!
- Share Your Input through the Axolotl Survey: To help improve Axolotl, we invite you to fill out our Axolotl Survey linked in the announcement.
- Your feedback is crucial for us, and by participating, you can help us tailor our support to your needs.
- Complete the Survey for Exclusive Swag: As a thank you for completing the survey, participants will receive some soon-to-be-released Axolotl swag (while supplies last!).
- We value your time, so don't miss out on this opportunity!
Link mentioned: Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Axolotl AI ▷ #general (3 messages):
ADOPT optimizer updates, Axolotl codebase
- Latest updates for ADOPT optimizer made: The team announced the integration of the latest updates for the ADOPT optimizer into the Axolotl codebase, inviting members to try it out.
- One member inquired about the advantages of this optimizer.
- Optimal convergence with any beta value: The ADOPT optimizer can achieve optimal convergence with any beta value, optimizing performance across various scenarios.
- This capability stood out during the discussion among members exploring the recent integration.
tinygrad (George Hotz) ▷ #general (1 messages):
jewnex: PR#7987 worth a tweet, run some benchmarks, no gpu hang with beam this time 🚀
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
Thread group/grid sizes in graph rewrites, Optimizations in uopgraph.py
- Question about changing thread group/grid sizes: A member asked if the thread group/grid sizes can be altered during the graph rewrite optimizations in
uopgraph.py.- They were curious if, when sizes are lowered through pm_lowerer, these sizes are already fixed based on some earlier search in the process.
- Clarification on graph optimization processes: The discussion revolved around understanding how uopgraph.py handles thread group sizes during the optimization phase.
- Members expressed interest in whether adjustments can be made post-optimization and if initial searches dictate final sizes.
LAION ▷ #general (1 messages):
bio-ML advancements, Gene Diffusion model, mechanistic interpretability, protein sequencing modeling, self-supervised learning
- Bio-ML Revolution in 2024: The year 2024 marks a surge in machine learning for biology (bio-ML), with notable achievements like Nobel prizes awarded for structural biology prediction and significant investments in protein sequence models.
- Excitement buzzes around the field, although concerns loom about compute-optimal protein sequencing modeling curves that need to be addressed.
- Introducing Gene Diffusion for Single-Cell Biology: A new model called Gene Diffusion is described, utilizing a continuous diffusion transformer trained on single-cell gene count data to explore cell functional states.
- It employs a self-supervised learning method, predicting clean, un-noised embeddings from gene token vectors, akin to techniques used in text-to-image models.
- Seeking Clarity on Training Regime of Gene Diffusion: Curiosity arises regarding the training regime of the Gene Diffusion model, specifically its input/output relationship and what it aims to predict.
- Members express a desire for clarification on the intricacies of the model, highlighting the need for community assistance in understanding these complex concepts.
Link mentioned: Through a Glass Darkly | Markov Bio: What does the path toward end-to-end biology look like and what role does human understanding play in it?
Mozilla AI ▷ #announcements (1 messages):
December schedule events, Next Gen Llamafile Hackathon, Introducing Web Applets, Theia IDE demonstration, Llamafile update
- December Schedule Events Announced: Three new member events have been added to the December schedule to keep everyone engaged.
- These events aim to enhance community involvement and showcase projects from members.
- Next Gen Llamafile Hackathon Presentations Tomorrow: Students will present their hackathon projects using Llamafile for personalized AI tomorrow, focusing on social good.
- Community members are encouraged to join and support the students' innovative efforts.
- Introduction to Web Applets: <@823757327756427295> will be Introducing Web Applets, detailing an open standard & SDK for creating advanced client-side applications.
- Participants can opt into updates by customizing their roles within the community.
- Theia IDE Hands-On Demo: <@1131955800601002095> will showcase Theia IDE—an open and flexible AI-driven development environment.
- This demo aims to illustrate how Theia can facilitate better development practices.
- New Llamafile Release & Security Bounties: A new release for Llamafile was announced, providing updates on software improvements.
- <@&1245781246550999141> awarded 42 bounties in its first month, focusing on exposing vulnerabilities in generative AI.