[AINews] OLMo 2 - new SOTA Fully Open LLM
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Reinforcement Learning with Verifiable Rewards is all you need.
AI News for 11/26/2024-11/27/2024. We checked 7 subreddits, 433 Twitters and 29 Discords (197 channels, and 2528 messages) for you. Estimated reading time saved (at 200wpm): 318 minutes. You can now tag @smol_ai for AINews discussions!
AI2 is notable for having fully open models - not just open weights, but open data, code, and everything else. We last covered OLMo 1 in Feb and OpenELM in April. Now it would see that AI2 have updated OLMo-2 to roughly Llama 3.1 8B equivalent.
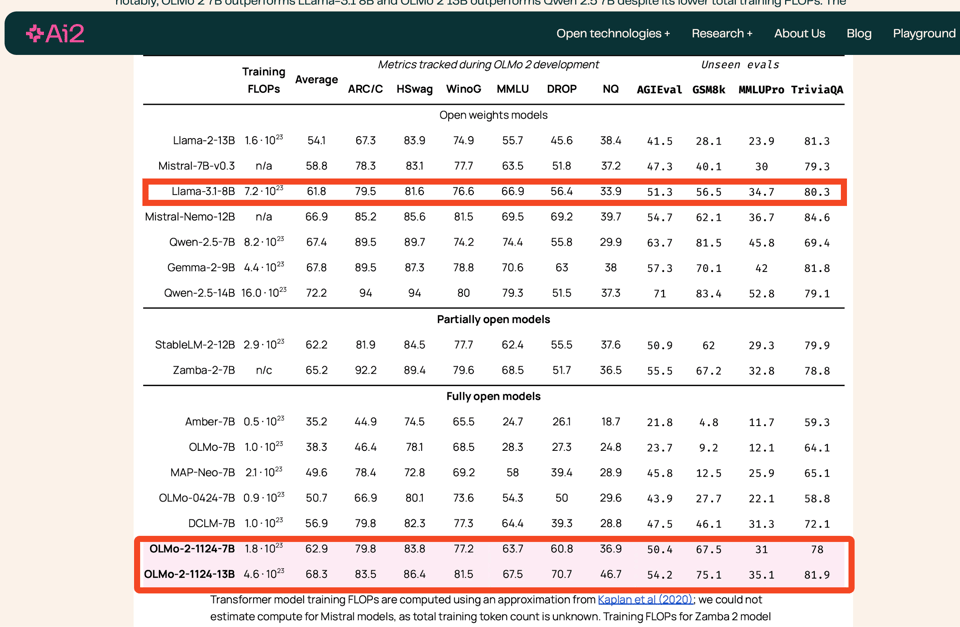
They have trained with 5T tokens, particularly using learning rate annealing and introducing new, high-quality data (Dolmino) at the end of pretraining. A full technical report is pending soon so we don't know much else, but the post-training gives credit to Tülu 3, using "Reinforcement Learning with Verifiable Rewards" (paper here, tweet here)) which they just announced last week (with open datasets of course.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Eleuther Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- Modular (Mojo 🔥) Discord
- OpenRouter (Alex Atallah) Discord
- Perplexity AI Discord
- OpenAI Discord
- Notebook LM Discord Discord
- Stability.ai (Stable Diffusion) Discord
- GPU MODE Discord
- LM Studio Discord
- Interconnects (Nathan Lambert) Discord
- Cohere Discord
- Nous Research AI Discord
- Latent Space Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- Torchtune Discord
- DSPy Discord
- Axolotl AI Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (875 messages🔥🔥🔥):
- Eleuther ▷ #general (69 messages🔥🔥):
- Eleuther ▷ #research (83 messages🔥🔥):
- Eleuther ▷ #scaling-laws (1 messages):
- Eleuther ▷ #interpretability-general (2 messages):
- Eleuther ▷ #lm-thunderdome (32 messages🔥):
- HuggingFace ▷ #NLP (173 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (98 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
- Unsloth AI (Daniel Han) ▷ #help (34 messages🔥):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (80 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (49 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Modular (Mojo 🔥) ▷ #mojo (128 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (98 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (3 messages):
- Perplexity AI ▷ #general (88 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (3 messages):
- OpenAI ▷ #ai-discussions (82 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (1 messages):
- OpenAI ▷ #prompt-engineering (6 messages):
- OpenAI ▷ #api-discussions (6 messages):
- Notebook LM Discord ▷ #use-cases (30 messages🔥):
- Notebook LM Discord ▷ #general (53 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (76 messages🔥🔥):
- GPU MODE ▷ #general (4 messages):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (31 messages🔥):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #cool-links (4 messages):
- GPU MODE ▷ #jobs (13 messages🔥):
- GPU MODE ▷ #torchao (2 messages):
- GPU MODE ▷ #🍿 (4 messages):
- LM Studio ▷ #general (46 messages🔥):
- LM Studio ▷ #hardware-discussion (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (31 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (1 messages):
- Cohere ▷ #discussions (1 messages):
- Cohere ▷ #questions (19 messages🔥):
- Cohere ▷ #api-discussions (3 messages):
- Cohere ▷ #projects (10 messages🔥):
- Nous Research AI ▷ #general (25 messages🔥):
- Nous Research AI ▷ #ask-about-llms (1 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Latent Space ▷ #ai-general-chat (20 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (16 messages🔥):
- tinygrad (George Hotz) ▷ #general (7 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- OpenInterpreter ▷ #general (7 messages):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (3 messages):
- DSPy ▷ #general (3 messages):
- Axolotl AI ▷ #general (3 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
TO BE COMPLETED
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. AutoRound 4-bit Quantization: Lossless Performance with Qwen2.5-72B
- Lossless 4-bit quantization for large models, are we there? (Score: 118, Comments: 66): Experiments with 4-bit quantization using AutoRound on Qwen2.5-72B instruct model demonstrated performance parity with the original model, even without optimizing quantization hyperparameters. The quantized models are available on HuggingFace in both 4-bit and 2-bit versions.
- MMLU benchmark testing methodology was discussed, with the original poster confirming 0-shot settings and referencing Intel's similar findings. Critics noted that MMLU might be too "easy" for large models and suggested trying MMLU Pro.
- Qwen2.5 models show unique quantization resilience compared to other models like Llama3.1 or Gemma2, with users speculating it was trained with quantization-aware techniques. This is particularly evident in Qwen Coder performance results.
- Discussion focused on the terminology of "lossless," with users explaining that quantization is inherently lossy (like 128kbps AAC compression), though performance impact varies by task - minimal for simple queries but potentially significant for complex tasks like code refactoring.
Theme 2. SmolVLM: 2B Parameter Vision Model Running on Consumer Hardware
- Introducing Hugging Face's SmolVLM! (Score: 115, Comments: 12): HuggingFace released SmolVLM, a 2B parameter vision language model that generates tokens 7.5-16x faster than Qwen2-VL and achieves 17 tokens/sec on a Macbook. The model can be fine-tuned on Google Colab, processes millions of documents on consumer GPUs, and outperforms larger models in video benchmarks despite no video training, with resources available at HuggingFace's blog and model page.
- SmolVLM requires a minimum of 5.02GB GPU RAM, but users can adjust image resolution using
size={"longest_edge": N*384}parameter and utilize 4/8-bit quantization with bitsandbytes, torchao, or Quanto to reduce memory requirements. - The model demonstrates strong OCR capabilities when focused on specific paragraphs but struggles with full screen text recognition, likely due to default resolution limitations of 1536×1536 pixels (N=4) which can be increased to 1920×1920 (N=5) for better document processing.
- Users compare SmolVLM favorably to mini-cpm-V-2.6, noting its accurate image captioning abilities and potential for broader applications.
- SmolVLM requires a minimum of 5.02GB GPU RAM, but users can adjust image resolution using
Theme 3. MLX LM 0.20.1 Matches llama.cpp Flash Attention Speed
- MLX LM 0.20.1 finally has the comparable speed as llama.cpp with flash attention! (Score: 84, Comments: 22): MLX LM 0.20.1 demonstrates significant performance improvements, increasing generation speed from 22.569 to 33.269 tokens-per-second for 4-bit models, reaching comparable speeds to llama.cpp with flash attention. The update shows similar improvements for 8-bit models, with generation speeds increasing from 18.505 to 25.236 tokens-per-second, while maintaining prompt processing speeds around 425-433 tokens-per-second.
- Users discuss quantization differences between MLX and GGUF formats, noting potential quality disparities in the Qwen 2.5 32B model and high RAM usage (70+ GB) for 8-bit MLX versions compared to Q8_0 GGUF.
- llama.cpp released their speculative decoding server implementation, which may outperform MLX when sufficient RAM is available. A discussion thread provides more details.
- Performance optimization tips include increasing GPU memory limits on Apple Silicon using the command
sudo sysctl iogpu.wired_limit_mb=40960to allow up to 40GB of GPU memory usage.
Theme 4. MoDEM: Routing Between Domain-Specialized Models Outperforms Generalists
- MoDEM: Mixture of Domain Expert Models (Score: 76, Comments: 47): MoDEM research demonstrates that routing between domain-specific fine-tuned models outperforms general-purpose models, showing success through a system that directs queries to specialized models based on their expertise domains. The paper proposes an alternative to large general models by using fine-tuned smaller models combined with a lightweight router, making it particularly relevant for open-source AI development with limited compute resources, with findings available at arXiv.
- Industry professionals indicate this architecture is already common in production, particularly in data mesh systems, with some implementations running thousands of ML models in areas like logistics digital twins. The approach includes additional components like deciders, ranking systems, and QA checks.
- WilmerAI demonstrates a practical implementation using multiple base models: Llama3.1 70b for conversation, Qwen2.5b 72b for coding/reasoning/math, and Command-R with offline wikipedia API for factual responses.
- Technical limitations were discussed, including VRAM constraints when loading multiple expert models and the challenges of model merging. Users suggested using LoRAs with a shared base model as a potential solution, referencing Apple's Intelligence system as an example.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Anthropic Launches Model Context Protocol for Claude
- Introducing the Model Context Protocol (Score: 106, Comments: 37): Model Context Protocol (MCP) appears to be a protocol for file and data access, but no additional context or details were provided in the post body to create a meaningful summary.
- MCP enables Claude Desktop to interact with local filesystems, SQL servers, and GitHub through APIs, facilitating mini-agent/tool usage. Implementation requires a quickstart guide and running
pip install uvto set up the MCP server. - Users report mixed success with the file server functionality, particularly noting issues on Windows systems. Several users experienced connection problems despite logs showing successful server connections.
- The protocol works with regular Claude Pro accounts through the desktop app, requiring no additional API access. Users express interest in using it for code testing, bug fixing, and project directory access.
- MCP enables Claude Desktop to interact with local filesystems, SQL servers, and GitHub through APIs, facilitating mini-agent/tool usage. Implementation requires a quickstart guide and running
- Model Context Protocol (MCP) Quickstart (Score: 64, Comments: 2): Model Context Protocol (MCP) post appears to have no content or documentation in the body. No technical details or quickstart information was provided to summarize.
- With MCP, Claude can now work directly with local files—create, read, and edit seamlessly. (Score: 23, Comments: 11): Claude gains direct local file manipulation capabilities through MCP, enabling file creation, reading, and editing functionalities. No additional context or details were provided in the post body.
- Users expressed excitement about Claude's new file manipulation capabilities through MCP, though minimal substantive discussion was provided.
- A Mac-compatible version of the functionality was shared via a Twitter link.
Theme 2. Major ChatGPT & Claude Service Disruptions
- Is gpt down? (Score: 38, Comments: 30): ChatGPT users reported service disruptions affecting both the web interface and mobile app. The outage prevented users from accessing the platform through any means.
- Multiple users across different regions including Mexico confirmed the ChatGPT outage, with users receiving error messages mid-conversation.
- Users were unable to get responses from ChatGPT, with one user sharing a screenshot of the error message they received during their conversation.
- The widespread nature of reports suggests this was a global service disruption rather than a localized issue.
- NOOOO!! 😿 (Score: 135, Comments: 45): Claude's parent company Anthropic is limiting access to their Sonnet 3.5 model due to capacity constraints. The post author expresses disappointment and wishes for financial means to maintain access to the model.
- Multiple users report that Pro tier access to Sonnet 3.5 is unreliable with random caps and access denials, leading some to switch back to ChatGPT. A thread discussing Opus limits was shared to document these issues.
- The API pay-as-you-go system emerges as a more reliable alternative, with users reporting costs of $0.01-0.02 per prompt and $10 lasting over a month. Users can implement this through tools like LibreChat for a better interface.
- Access to Sonnet appears to be account-dependent for free users, with inconsistent availability across accounts. Some users suggest there may be an undisclosed triage metric determining access patterns.
Theme 3. MIT PhD's Open-Source LLM Training Series
- [D] Graduated from MIT with a PhD in ML | Teaching you how to build an entire LLM from scratch (Score: 301, Comments: 72): An MIT PhD graduate created a 15-part video series teaching how to build Large Language Models from scratch without libraries, covering topics from basic concepts through implementation details including tokenization, embeddings, and attention mechanisms. The series provides both theoretical whiteboard explanations and practical Python code implementations, progressing from fundamentals in Lecture 1 through advanced concepts like self-attention with key, query, and value matrices in Lecture 15.
- Multiple users questioned the creator's credibility, noting their PhD was in Computational Science and Engineering rather than ML, and pointing to a lack of LLM research publications. Several recommended Andrej Karpathy's lectures as a more established alternative via his YouTube channel.
- Discussion revealed concerns about academic misrepresentation, with users pointing out that the creator's NeurIPS paper was actually a workshop paper rather than a main conference paper, and questioning recent posts about basic concepts like the Adam optimizer.
- Users debated the value of an MIT affiliation in the LLM field specifically, with some noting that institutional prestige doesn't necessarily correlate with expertise in every subfield. The conversation highlighted how academic credentials can be misused for marketing purposes.
Theme 4. Qwen2VL-Flux: New Open-Source Image Model
- Open Sourcing Qwen2VL-Flux: Replacing Flux's Text Encoder with Qwen2VL-7B (Score: 96, Comments: 34): Qwen2vl-Flux, a new open-source image generation model, replaces Stable Diffusion's t5 text encoder with Qwen2VL-7B to enable multimodal generation capabilities including direct image variation without text prompts, vision-language fusion, and GridDot control panel for precise style modifications. The model, available on Hugging Face and GitHub, integrates ControlNet for structural guidance and offers features like intelligent style transfer, text-guided generation, and grid-based attention control.
- VRAM requirements of 48GB+ were highlighted as a significant limitation for many users, making the model inaccessible for consumer-grade hardware.
- Users inquired about ComfyUI compatibility and the ability to use custom fine-tuned Flux or LoRA models, indicating strong interest in integration with existing workflows.
- Community response showed enthusiasm mixed with overwhelm at the pace of new model releases, particularly referencing Flux Redux and the challenge of keeping up with SOTA developments.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: AI Model Updates and Releases
- Cursor Packs Bugs with New Features in 0.43 Update: Cursor IDE's latest update introduces a revamped Composer UI and early agent functionality, but users report missing features like 'Add to chat' and encounter bugs that hamper productivity.
- Allen AI Crowns OLMo 2 as Open-Model Champion: Unveiling OLMo 2, Allen AI touts it as the best fully open language model yet, boasting 7B and 13B variants trained on up to 5 trillion tokens.
- Stable Diffusion 3.5 Gets ControlNets, Artists Rejoice: Stability.ai enhances Stable Diffusion 3.5 Large with new ControlNets—Blur, Canny, and Depth—available for download on HuggingFace and supported in ComfyUI.
Theme 2: Technical Issues and Performance Enhancements
- Unsloth Squashes Qwen2.5 Tokenizer Bugs, Developers Cheer: Unsloth fixes multiple issues in the Qwen2.5 models, including tokenizer problems, enhancing compatibility and performance as explained in Daniel Han's video.
- PyTorch Boosts Training Speed with FP8 and FSDP2, GPUs Sigh in Relief: PyTorch's FP8 training update reveals a 50% throughput speedup using FSDP2, DTensor, and
torch.compile, enabling efficient training of models up to 405B parameters.
- AMD GPUs Lag Behind, ROCm Leaves Users Fuming: Despite multi-GPU support in LM Studio, users report that AMD GPUs underperform due to ROCm's performance limitations, making AI tasks sluggish and frustrating.
Theme 3: Community Concerns and Feedback
- Cursor Users Demand Better Communication, Support Channels Wanted: Frustrated with bugs and missing features, Cursor IDE users call for improved communication about updates and issues, suggesting a dedicated support channel to address concerns.
- Stability.ai Support Goes Silent, Users Left in the Dark: Users express frustration over unanswered emails and lack of communication from Stability.ai regarding support and invoicing issues, casting doubt on the company's engagement.
- Cohere's API Limits Stall Student Projects, Support Sought: A student developing a Portuguese text classifier hits Cohere's API key limit with no upgrade option, prompting community advice to contact support or explore open-source alternatives.
Theme 4: Advancements in AI Applications
- AI Hits the Right Notes: MusicGen Continues the Tune: Members discuss AI models capable of continuing music compositions, sharing tools like MusicGen-Continuation on Hugging Face to enhance creative workflows.
- NotebookLM Turns Text into Podcasts, Content Creators Celebrate: Users harness NotebookLM to generate AI-driven podcasts from source materials, exemplified by The Business Opportunity of AI, expanding content reach and engagement.
- Companion Gets Emotional, Talks with Feeling: The latest Companion update introduces an emotional scoring system that adapts responses based on conversation tones, enhancing realism and personalization.
Theme 5: Ethical Discussions and AI Safety
- Sora API Leak Raises Concerns Over Artist Compensation: The reported leak of the Sora API on Hugging Face prompts discussions about fair compensation for artists involved in testing, with community members calling for open-source alternatives.
- Anthropic's MCP Debated, Solution Seeking a Problem?: The introduction of the Model Context Protocol (MCP) by Anthropic sparks debate over its necessity, with some questioning whether it's overcomplicating existing solutions.
- Stability.ai Reaffirms Commitment to Safe AI, Users Skeptical: Amid new releases, Stability.ai emphasizes responsible AI practices and safety measures, but some users question the effectiveness and express concerns over potential misuse.
PART 1: High level Discord summaries
Cursor IDE Discord
-
Cursor Composer's 0.43: Feature Frenzy: The recent Cursor update (0.43) introduces a new Composer UI and early agent functionality, though users have reported bugs like missing 'Add to chat'.
- Users face issues with indexing and needing to click 'Accept' multiple times for changes in the composer.
-
Agent Adventures: Cursor's New Feature Debated: The new agent feature in Cursor aims to assist with code editing but has stability and utility issues as per user feedback.
- Some users find the agent helpful for task completion, while others are frustrated by its limitations and bugs.
-
IDE Showdown: Cursor Outperforms Windsurf: Users comparing Cursor and Windsurf IDE report that Cursor's latest version is more efficient and stable, whereas Windsurf faces numerous UI/UX bugs.
- Mixed feelings exist among users switching between the two IDEs, particularly regarding Windsurf's autocomplete capabilities.
-
AI Performance in Cursor Under Scrutiny: User consensus indicates Cursor has improved significantly in AI interactions, though issues like slow responses and lack of contextual awareness persist.
- Reflections on past AI model experiences show how recent Cursor updates impact workflows, with a clear demand for enhanced AI responsiveness.
-
Community Calls for Better Cursor Communication: Members request improved communication regarding Cursor updates and issues, suggesting a dedicated support channel as a solution.
- Despite frustrations, users acknowledge Cursor's development efforts and show strong community engagement around new features.
Eleuther Discord
-
Evaluating Quantization Effects on Models: A member is assessing the impact of quantization on KV Cache using lm_eval, focusing on perplexity metrics on Wikitext.
- They aim to utilize existing evaluation benchmarks to better understand how quantization affects overall model performance without extensive retraining.
-
UltraMem Architecture Enhances Transformer Efficiency: The UltraMem architecture has been proposed to improve inference speed in Transformers by implementing an ultra-sparse memory layer, significantly reducing memory costs and latency.
- Members debated the practical scalability of UltraMem, noting performance boosts while expressing concerns about architectural complexity.
-
Advancements in Gradient Estimation Techniques: A member suggested estimating the gradient of loss with respect to hidden states in ML models, aiming to enhance performance similarly to temporal difference learning.
- The discussion revolves around using amortized value functions and comparing their effectiveness to traditional backpropagation through time.
-
Comprehensive Optimizer Evaluation Suite Needed: There is a growing demand for a robust optimizer evaluation suite that assesses hyperparameter sensitivity across diverse ML benchmarks.
- Members referred to existing tools like Algoperf but highlighted their limitations in testing methodology and problem diversity.
-
Optimizing KV Cache for Model Deployments: Discussions highlighted the relevance of KV Cache for genuine model deployments, noting that many mainstream evaluation practices may not adequately measure its effects.
- One member suggested simulating deployment environments to better understand performance impacts instead of relying solely on standard benchmarks.
HuggingFace Discord
-
Language Models for Code Generation Limitations: Members discussed the limitations of language models in accurately referring to specific line numbers in code snippets, highlighting tokenization challenges. They proposed enhancing interactions by focusing on function names instead of line numbers for improved context understanding.
- A member suggested that targeting function names could mitigate tokenization issues, fostering more effective code generation capabilities within language models.
-
Quantum Consciousness Theories Influencing AI: A user proposed a connection between quantum processes and consciousness, suggesting that complex systems like AI could mimic these mechanisms. This sparked philosophical discussions, though some felt these ideas detracted from the technical conversation.
- Participants debated the relevance of quantum-based consciousness theories to AI development, with some questioning their practicality in current AI frameworks.
-
Neural Networks Integration with Hypergraphs: The conversation explored the potential of advanced neural networks utilizing hypergraphs to extend AI capabilities. However, there was skepticism about the practical application and relevance of these approaches to established machine learning practices.
- Debates centered on whether hypergraph-based neural networks could bridge existing gaps in AI performance, with concerns about implementation complexity.
-
AI Tools for Music Composition Continuation: Members inquired about AI models capable of continuing or extending music compositions, mentioning tools like Suno and Jukebox AI. A user provided a link to MusicGen Continuation on Hugging Face as a solution for generating music continuations.
- The discussion highlighted the growing interest in AI-driven music tools, emphasizing the potential of MusicGen-Continuation for seamless music creation workflows.
-
Challenges in Balancing Technical and Philosophical AI Discussions: A participant expressed frustration with being stuck in discussions that were unproductive or overly abstract regarding AI and consciousness. This led to a mutual recognition of the challenges faced when blending technical and philosophical aspects in AI discussions.
- Members acknowledged the difficulty in maintaining technical focus while engaging with philosophical debates, aiming to foster more productive conversations.
Unsloth AI (Daniel Han) Discord
-
Qwen2.5 Tokenizer Fixes: Unsloth has resolved multiple issues for the Qwen2.5 models, including tokenizer problems and other minor fixes. Details can be found in Daniel Han's YouTube video.
- This update ensures better compatibility and performance for developers using the Qwen2.5 series.
-
GPU Pricing Concerns: Discussions emerged around the pricing of the Asus ROG Strix 3090 GPU, with current market rates noted at $550. Members advised against purchasing used GPUs at inflated prices due to upcoming releases.
- Alternative options and timing for GPU purchases were considered to optimize cost-efficiency.
-
Inference Performance with Unsloth Models: Members discussed performance issues when using the unsloth/Qwen-2.5-7B-bnb-4bit model with vllm, questioning its optimization. Alternatives for inference engines better suited for bitwise optimizations were sought.
- Suggestions included exploring other inference proxies such as codelion/optillm and llama.cpp.
-
Model Loading Strategies: Users inquired about downloading model weights without using RAM, seeking clarity on file management with Hugging Face. Recommended methods include using Hugging Face's caching and storing weights on an NFS mount for better efficiency.
- These strategies aim to optimize memory usage during model loading and deployment.
-
P100 vs T4 Performance: P100 GPUs were discussed in comparison to T4s, with users noting that P100s are 4x slower than T4s based on their experiences. Discrepancies in past performance comparisons were attributed to outdated scripts.
- This highlights the importance of using updated benchmarking scripts for accurate performance assessments.
aider (Paul Gauthier) Discord
-
Aider v0.65.0 Launches with Enhanced Features: The Aider v0.65.0 update introduces a new
--aliasconfiguration for custom model aliases and supports Dart language through RepoMap.- Ollama models now default to an 8k context window, improving interaction capabilities as part of the release's error handling and file management enhancements.
-
Hyperbolic Model Context Size Impact: In discussions, members highlighted that using 128K of context with Hyperbolic significantly affects results, while an 8K output remains adequate for benchmarking purposes.
- Participants acknowledged the crucial role of context sizes in practical applications, emphasizing optimal configurations for performance.
-
Introduction of Model Context Protocol: Anthropic has released the Model Context Protocol, aiming to improve integrations between AI assistants and various data systems by addressing fragmentation.
- This standard seeks to unify connections across content repositories, business tools, and development environments, facilitating smoother interactions.
-
Integration of Aider with Git: The new MCP server for Git enables Aider to map tools directly to git commands, enhancing version control workflows.
- Members debated deeper Git integration within Aider, suggesting that MCP support could standardize additional capabilities without relying on external server access.
-
Cost Structure of Aider's Voice Function: Aider's voice function operates exclusively with OpenAI keys, incurring a cost of approximately $0.006 per minute, rounded to the nearest second.
- This pricing model allows users to estimate usage expenses accurately, ensuring cost-effectiveness for voice-based interactions.
Modular (Mojo 🔥) Discord
-
Fixes Proposed for Segmentation Faults in Mojo: Members discussed potential fixes in the nightly builds for segmentation faults in the def function environment, highlighting that the def syntax remains unstable. Transitioning to fn syntax was suggested for improved stability.
- One member proposed that switching to fn might offer more stability in the presence of persistent segmentation faults.
-
Mojo QA Bot's Memory Usage Drops Dramatically: A member reported that porting their QA bot from Python to Mojo reduced memory usage from 16GB to 300MB, showcasing enhanced performance. This improvement allows for more efficient operations.
- Despite encountering segmentation faults during the porting process, the overall responsiveness of the bot improved, enabling quicker research iterations.
-
Thread Safety Concerns in Mojo Collections: Discussions highlighted the lack of interior mutability in collections and that List operations aren't thread-safe unless explicitly stated. Mojo Team Answers provide further details.
- The community noted that existing mutable aliases lead to safety violations and emphasized the need for developing more concurrent data structures.
-
Challenges with Function Parameter Mutability in Mojo: The community explored issues with ref parameters, particularly why the min function faces type errors when returning references with incompatible origins. Relevant GitHub link.
- Suggestions included using Pointer and UnsafePointer to address mutability concerns, indicating that handling of ref types might need refinement.
-
Destructor Behavior Issues in Mojo: Members inquired about writing destructors in Mojo, with the
__del__method not being called for stack objects or causing errors with copyability. 2023 LLVM Dev Mtg covered related topics.- Discussions highlighted challenges in managing Pointer references and mutable accesses, proposing specific casting methods to ensure correct behavior.
OpenRouter (Alex Atallah) Discord
-
Companion Introduces Emotional Scoring System: The latest Companion update introduces an emotional scoring system that assesses conversation tones, starting neutral and adapting over time.
- This system ensures Companion maintains emotional connections across channels, enhancing interaction realism and user engagement.
-
OpenRouter API Key Error Troubleshooting: Users reported receiving 401 errors when using the OpenRouter API despite valid keys, with suggestions to check for inadvertent quotation marks.
- Ensuring correct API key formatting is crucial to avoid authentication issues, as highlighted by community troubleshooting discussions.
-
Performance Issues with Gemini Experimental Models: Gemini Experimental 1121 free model users encountered resource exhaustion errors (code 429) during chat operations.
- Community members recommended switching to production models to mitigate rate limit errors associated with experimental releases.
-
Access Requests for Integrations and Provider Keys: Members requested access to Integrations and custom provider keys, citing email edu.pontes@gmail.com for integration access.
- Delays in access approvals led to user frustrations, prompting calls for more transparent information regarding request statuses.
Perplexity AI Discord
-
Creating Discord Bots with Perplexity API: A member expressed interest in building a Discord bot using the Perplexity API, seeking assurance about legal concerns as a student.
- Another user encouraged the project, suggesting that utilizing the API for non-commercial purposes would mitigate legal risks.
-
Perplexity AI Lacks Dedicated Student Plan: Members discussed Perplexity AI's pricing structure, noting the absence of a student-specific plan despite the availability of a Black Friday offer.
- It was highlighted that competitors like You.com provide student plans, potentially offering a more affordable alternative.
-
Community Feedback on DeepSeek R1: Users shared their experiences with DeepSeek R1, praising its human-like interactions and utility in logical reasoning classes.
- The discussion emphasized finding a balance between verbosity and usefulness, especially for handling complex tasks.
-
Recent Breakthrough in Representation Theory: A YouTube link was posted regarding a breakthrough in representation theory within algebra, highlighting new research findings.
- This advancement holds significant implications for future studies in mathematical frameworks.
OpenAI Discord
-
AI's Impact on Employment: Discussions compared the impact of AI on jobs to historical shifts like the printing press, highlighting both job displacement and creation.
- Participants raised concerns about AI potentially replacing junior software engineering roles, questioning future job structures.
-
Human-AI Collaboration: Contributors advocated for treating AI as collaborators, recognizing mutual strengths and weaknesses to enhance human potential.
- The dialogue emphasized the necessity of ongoing collaboration between humans and AI to support diverse human experiences.
-
Advancements in Real-time API: The real-time API was highlighted for its low latency advantages in voice interactions, with references to the openai/openai-realtime-console.
- Participants speculated on the API's capability to interpret user nuances like accents and intonations, though specifics remain unclear.
-
AI Applications in Gaming: Skepticism was expressed about the influence of the gaming community on AI technology decisions, citing potential immaturity in some gaming products.
- Concerns were voiced regarding the risks gamers might introduce into AI setups, indicating a trust divide among tech enthusiasts.
-
Challenges with Research Papers: Crafting longer and more researched papers poses significant challenges, especially in writing-intensive courses that rely on peer reviews.
- It's difficult to work with longer, more researched papers due to their complexity, with suggestions to combine peer reviews for improving quality.
Notebook LM Discord Discord
-
Advancements in AI Podcasting with NotebookLM: Users have leveraged NotebookLM to generate AI-driven podcasts, highlighting its capability to transform source materials into engaging audio formats, as showcased in The Business Opportunity of AI: a NotebookLM Podcast.
- Challenges were noted in customizing podcast themes and specifying input sources, with users suggesting enhancements to improve NotebookLM's prompt-following capabilities for more tailored content.
-
Enhancing Customer Support Analysis through NotebookLM: NotebookLM is being utilized to analyze customer support emails by converting
.mboxfiles into.mdformat, which significantly enhances the customer experience.- Users proposed integrating direct Gmail support to streamline the process, making NotebookLM more accessible for organizational use.
-
Transforming Educational Content Marketing via Podcasting: A user repurposed educational content from a natural history museum into podcasts and subsequently created blog posts using ChatGPT to improve SEO and accessibility, resulting in increased content reach.
- This initiative was successfully launched by an intern within a short timeframe, demonstrating the efficiency of combining NotebookLM with other AI tools.
-
Addressing Language and Translation Challenges in NotebookLM: Several users reported that NotebookLM generates summaries in Italian instead of English, expressing frustrations with the language settings.
- Inquiries were made regarding the tool's ability to produce content in other languages and whether the voice generator supports Spanish.
-
Privacy and Data Usage Concerns with NotebookLM's Free Model: Discussions have arisen about NotebookLM's free model, with users questioning the long-term implications and potential usage of data for training purposes.
- Clarifications were provided emphasizing that sources are not used for training AI, alleviating some user concerns about data handling.
Stability.ai (Stable Diffusion) Discord
-
ControlNets Enhance Stable Diffusion 3.5: New capabilities have been added to Stable Diffusion 3.5 Large with the release of three ControlNets: Blur, Canny, and Depth. Users can download the model weights from HuggingFace and access code from GitHub, with support in Comfy UI.
- Check out the detailed announcement on the Stable.ai blog for more information on these new features.
-
Flexible Licensing Options for Stability.ai Models: The new models are available for both commercial and non-commercial use under the Stability AI Community License, allowing free use for non-commercial purposes and for businesses with under $1M in annual revenue. Organizations exceeding this revenue threshold can inquire about an Enterprise License.
- This model ensures users retain ownership of outputs, allowing them to use generated media without restrictive licensing implications.
-
Stability.ai's Commitment to Safe AI Practices: The team expressed a strong commitment to safe and responsible AI practices, emphasizing the importance of safety in their developments. They aim to follow deliberate and careful guidelines as they enhance their technology.
- The company highlighted their ongoing efforts to integrate safety measures into their AI models to prevent misuse.
-
User Support Communication Issues: Many users expressed frustration over lack of communication from Stability.ai regarding support, especially concerning invoicing issues.
- One user noted they sent multiple emails without a reply, leading to doubts about the company's engagement.
-
Utilizing Wildcards for Prompts: A discussion arose around the use of wildcards in prompt generation, with members sharing ideas on how to create varied background prompts.
- Examples included elaborate wildcard sets for Halloween backgrounds, showcasing community creativity and collaboration.
GPU MODE Discord
-
FP8 Training Boosts Performance with FSDP2: PyTorch's FP8 training blogpost highlights a 50% throughput speedup achieved by integrating FSDP2, DTensor, and torch.compile with float8, enabling training of Meta LLaMa models ranging from 1.8B to 405B parameters.
- The post also explores batch sizes and activation checkpointing schemes, reporting tokens/sec/GPU metrics that demonstrate performance gains for both float8 and bf16 training, while noting that larger matrix dimensions can impact multiplication speeds.
-
Resolving Multi-GPU Training Issues with LORA and FSDP: Members reported inference loading failures after fine-tuning large language models with multi-GPU setups using LORA and FSDP, whereas models trained on a single GPU loaded successfully.
- This discrepancy has led to questions about the underlying causes, prompting discussions on memory allocation practices and potential configuration mismatches in multi-GPU environments.
-
Triton's PTX Escape Hatch Demystified: The Triton documentation explains Triton's inline PTX escape hatch, which allows users to write elementwise operations in PTX that pass through MLIR during LLVM IR generation, effectively acting as a passthrough.
- This feature provides flexibility for customizing low-level operations while maintaining integration with Triton's high-level abstractions, as confirmed by the generation of inline PTX in the compilation process.
-
CUDA Optimization Strategies for ML Applications: Discussions in the CUDA channel focused on advanced CUDA optimizations for machine learning, including dynamic batching and kernel fusion techniques aimed at enhancing performance and efficiency in ML workloads.
- Members are seeking detailed methods for hand-deriving kernel fusions as opposed to relying on compiler automatic fusion, highlighting a preference for manual optimization to achieve tailored performance improvements.
LM Studio Discord
-
LM Studio Beta Builds Missing Key Features: Members raised concerns about the current beta builds of LM Studio, highlighting missing functionalities such as DRY and XTC that impact usability.
- One member mentioned that 'The project seems to be kind of dead,' seeking clarification on ongoing development efforts.
-
AMD Multi-GPU Support Hindered by ROCM Performance: AMD multi-GPU setups are confirmed to work with LM Studio, but efficiency issues persist due to ROCM's performance limitations.
- A member noted, 'ROCM support for AI is not that great,' emphasizing the challenges with recent driver updates.
-
LM Studio Runs 70b Model on 16GB RAM: Several members shared positive experiences with LM Studio running a 70b model on their 16GB RAM systems.
- 'I’m... kind of stunned at that,' highlighted the unexpected performance achievements.
-
LM Studio API Usage and Metal Support: A member inquired about sending prompts and context to LM Studio APIs, and asked for configuration examples with model usage.
- There was a question regarding Metal support on M series silicon, noted as being 'automatically enabled.'
- Dual 3090 GPU Configuration: Motherboards and Cooling: Discussions surfaced about acquiring a second 3090 GPU, noting the need for different motherboards due to space limitations.
- Members suggested solutions like risers or water cooling to address air circulation challenges when fitting two 3090s together. Additionally, they referenced GPU Benchmarks on LLM Inference for performance data.
Interconnects (Nathan Lambert) Discord
-
Tülu 3 8B's Shelf Life and Compression: Concerns emerged regarding Tülu 3 8B possessing a brief shelf life of just one week, as members discussed its model stability.
- A member highlighted noticeable compression in the model's performance, emphasizing its impact on reliability.
-
Olmo vs Llama Models Performance: Olmo base differs significantly from Llama models, particularly when scaling parameters to 13B.
- Members observed that Tülu outperforms Olmo 2 in specific prompt responses, indicating superior adaptability.
-
Impact of SFT Data Removal on Multilingual Capabilities: The removal of multilingual SFT data in Tülu models led to decreased performance, as confirmed by community testing results.
- Support for SFT experiments continues, with members praising efforts to maintain performance integrity despite data pruning.
-
Sora API Leak and OpenAI's Marketing Tactics: An alleged leak of the Sora API on Hugging Face triggered significant user traffic as enthusiasts explored its functionalities.
- Speculation arose that OpenAI might be orchestrating the leak to assess public reaction, reminiscent of previous marketing strategies.
-
OpenAI's Exploitation of the Artist Community: Critics accused OpenAI of exploiting artists for free testing and PR purposes under the guise of early access to Sora.
- Artists drafted an open letter demanding fair compensation and advocating for open-source alternatives to prevent being used as unpaid R&D.
Cohere Discord
-
API Key Caps Challenge High School Projects: A user reported hitting the Cohere API key limit while developing a text classifier for Portuguese, with no upgrade option available, prompting advice to contact support for assistance.
- This limitation affects educational initiatives, encouraging users to seek support or explore alternative solutions to continue their projects.
-
Embeddings Endpoint Grapples with Error 500: Error 500 issues have been frequently reported with the Embeddings Endpoint, signaling an internal server error that disrupts various API requests.
- Users have been advised to reach out via support@cohere.com for urgent assistance as the development team investigates the recurring problem.
-
Companion Enhances Emotional Responsiveness: Companion introduced an emotional scoring system that tailors interactions by adapting to user emotional tones based on in-app classifiers.
- Updates include tracking sentiments like love vs. hatred and justice vs. corruption, alongside enhanced security measures to protect personal information.
-
Command R+ Model Shows Language Drift: Users have encountered unintended Russian words in outputs from the Command R+ Model despite specifying Bulgarian in the preamble, indicating a language consistency issue.
- Attempts to mitigate this by adjusting temperature settings have been unsuccessful, suggesting deeper model-related challenges.
-
Open-Source Models Proposed as API Alternatives: Facing billing issues, members proposed using open-source models like Aya's 8b Q4 to run locally as a cost-effective alternative to Cohere APIs.
- This strategy offers a sustainable path for users unable to afford production keys, fostering community-driven solutions.
Nous Research AI Discord
-
Test Time Inference: A member inquired about ongoing test time inference projects within Nous, with others confirming interest and discussing potential initiatives.
- The conversation highlighted a lack of clear projects in this area, prompting interest in establishing dedicated efforts.
-
Real-Time Video Models: A user sought real-time video processing models for robotics, emphasizing the need for low-latency performance.
- CNNs and sparse mixtures of expert Transformers were discussed as potential solutions.
-
Genomic Bottleneck Algorithm: An article was shared about a new AI algorithm simulating the genomic bottleneck, enabling image recognition without traditional training.
- Members discussed its competitiveness with state-of-the-art models despite being untrained.
-
Coalescence Enhances LLM Inference: The Coalescence blog post details a method to convert character-based FSMs into token-based FSMs, boosting LLM inference speed by five times.
- This optimization leverages a dictionary index to map FSM states to token transitions, enhancing inference efficiency.
-
Token-based FSM Transitions: Utilizing the Outlines library, an example demonstrates transforming FSMs to token-based transitions for optimized inference sampling.
- The provided code initializes a new FSM and constructs a tokenizer index, facilitating more efficient next-token prediction during inference.
Latent Space Discord
-
MCP Mayhem: Anthropic's Protocol Sparks Debate: A member questioned the necessity of Anthropic's new Model Context Protocol (MCP), arguing it might not become a standard despite addressing a legitimate problem.
- Another member expressed skepticism, indicating the issue might be better solved through existing frameworks or cloud provider SDKs.
-
Sora Splinter: API Leak Sends Shockwaves: Sora API has reportedly been leaked, offering video generation from 360p to 1080p with an OpenAI watermark.
- Members expressed shock and excitement, discussing the implications of the leak and OpenAI's alleged response to it.
-
OLMo Overload: AI Release Outshines Competitors: Allen AI announced the release of OLMo 2, claiming it to be the best fully open language model to date with 7B and 13B variants trained on up to 5T tokens.
- The release includes data, code, and recipes, promoting OLMo 2's performance against other models like Llama 3.1.
-
PlayAI's $21M Power Play: PlayAI secured $21 Million in funding to develop user-friendly voice AI interfaces for developers and businesses.
- The company aims to enhance human-computer interaction, positioning voice as the most intuitive communication medium in the era of LLMs.
-
Custom Claude: Anthropic Tailors AI Replies: Anthropic introduced preset options for customizing how Claude responds, offering styles like Concise, Explanatory, and Formal.
- This update aims to provide users with more control over interactions with Claude, catering to different communication needs.
LlamaIndex Discord
-
LlamaParse Boosts Dataset Creation: @arcee_ai processed millions of NLP research papers using LlamaParse, creating a high-quality dataset for AI agents with efficient PDF-to-text conversion that preserves complex elements like tables and equations.
- The method includes a flexible prompt system to refine extraction tasks, demonstrating versatility and robustness in data processing.
-
Ragas Optimizes RAG Systems: Using Ragas, developers can evaluate and optimize key metrics such as context precision and recall to enhance RAG system performance before deployment.
- Tools like LlamaIndex and @literalai help analyze answer relevancy, ensuring effective implementation.
-
Fixing Errors in llama_deploy[rabbitmq]: A user reported issues with llama_deploy[rabbitmq] executing
deploy_corein versions above 0.2.0 due to TYPE_CHECKING being False.- Cheesyfishes recommended submitting a PR and opening an issue for further assistance.
-
Customizing OpenAIAgent's QueryEngine: A developer sought advice on passing custom objects like chat_id into CustomQueryEngine within the QueryEngineTool used by OpenAIAgent.
- They expressed concerns about the reliability of passing data through query_str, fearing modifications by the LLM.
-
AI Hosting Startup Launches: Swarmydaniels announced the launch of their startup that enables users to host AI agents with a crypto wallet without coding skills.
- Additional monetization features are planned, with a launch tweet coming soon.
tinygrad (George Hotz) Discord
-
Flash Attention Joins Tinygrad: A member inquired whether flash-attention could be integrated into Tinygrad, exploring potential performance optimizations.
- The conversation highlighted interest in enhancing Tinygrad's efficiency by incorporating advanced features.
-
Tinybox Pro Custom Motherboard Insights: A user questioned if the Tinybox Pro features a custom motherboard, indicating curiosity about the hardware design.
- This inquiry reflects the community's interest in the hardware infrastructure supporting Tinygrad.
-
GENOA2D24G-2L+ CPU and PCIe 5 Compatibility: A member identified the CPU as a GENOA2D24G-2L+ and discussed PCIe 5 cable compatibility in the Tinygrad setup.
- The discussion underscored the importance of specific hardware components in optimizing Tinygrad's performance.
-
Tinygrad CPU Intrinsics Support Enhancement: A member sought documentation on Tinygrad's CPU behavior, particularly support for CPU intrinsics like AVX and NEON.
- There was interest in implementing performance improvements through potential pull requests to enhance Tinygrad.
-
Radix Sort Optimization Techniques and AMD Paper: Discussions explored optimizing the Radix Sort algorithm using
scatterand referenced AMD's GPU Radix Sort paper for insights.- Community members debated methods to ensure correct data ordering while reducing dependency on
.item()andforloops.
- Community members debated methods to ensure correct data ordering while reducing dependency on
LLM Agents (Berkeley MOOC) Discord
-
Hackathon Workshop with Google AI: Join the Hackathon Workshop hosted by Google AI on November 26th at 3 PM PT. Participants can watch live and gain insights directly from Google AI specialists.
- The workshop features a live Q&A session, providing an opportunity to ask questions and receive guidance from Google AI experts.
-
Lecture 11: Measuring Agent Capabilities: Today's Lecture 11, titled 'Measuring Agent Capabilities and Anthropic’s RSP', will be presented by Benjamin Mann at 3:00 pm PST. Access the livestream here.
- Benjamin Mann will discuss evaluating agent capabilities, implementing safety measures, and the practical application of Anthropic’s Responsible Scaling Policy (RSP).
-
Anthropics API Keys Usage: Members discussed the usage of Anthropic API keys within the community. One member confirmed their experience with using Anthropic API keys.
- This confirmation highlights the active integration of Anthropic’s tools among AI engineering projects.
-
In-person Lecture Eligibility: Inquiry about attending lectures in person revealed that in-person access is restricted to enrolled Berkeley students due to lecture hall size constraints.
- This restriction ensures that only officially enrolled students at Berkeley can participate in in-person lectures.
-
GSM8K Inference Pricing and Self-Correction: A member analyzed GSM8K inference costs, estimating approximately $0.66 per run for the 1k test set using the formula [(100 * 2.5/1000000) + (200 * 10/1000000)] * 1000.
- The discussion also covered self-correction in models, recommending adjustments to output calculations based on the number of corrections.
OpenInterpreter Discord
-
OpenInterpreter 1.0 Release: The upcoming OpenInterpreter 1.0 is available on the development branch, with users installing it via
pip install --force-reinstall git+https://github.com/OpenInterpreter/open-interpreter.git@developmentusing the--tools gui --model gpt-4oflags.- OpenInterpreter 1.0 introduces significant updates, including enhanced tool integrations and performance optimizations, as highlighted by user feedback on the installation process.
-
Non-Claude OS Mode Introduction: Non-Claude OS mode is a new feature in OpenInterpreter 1.0, replacing the deprecated
--osflag to provide more versatile operating system interactions.- Users have emphasized the flexibility of Non-Claude OS mode, noting its impact on streamlining development workflows without relying on outdated flags.
-
Speech-to-Text Functionality: Speech-to-text capabilities have been integrated into OpenInterpreter, allowing users to convert spoken input into actionable commands seamlessly.
- This feature has sparked discussions on automation efficiency, with users exploring its potential to enhance interactive development environments.
-
Keyboard Input Simulation: Keyboard input simulation is now supported in OpenInterpreter, enabling the automation of keyboard actions through scripting.
- The community has shown interest in leveraging this feature for testing and workflow automation, highlighting its usefulness in repetitive task management.
-
OpenAIException Troubleshooting: An OpenAIException error was reported, preventing assistant messages due to missing tool responses linked to specific request IDs.
- This issue has raised concerns about tool integration reliability, prompting users to seek solutions for seamless interaction with coding tools.
Torchtune Discord
-
Torchtitan Launches Feature Poll: Torchtitan is conducting a poll to gather user preferences on new features like MoE, multimodal, and context parallelism.
- Participants are encouraged to have their voices heard to influence the direction of the PyTorch distributed team.
-
GitHub Discussions Open for Torchtitan Features: Users are invited to join the GitHub Discussions to talk about potential new features for Torchtitan.
- Engagement in these discussions is expected to help shape future updates and enhance the user experience.
-
DPO Recipe Faces Usage Challenges: Concerns were raised about the low adoption of the DPO recipe, questioning its effectiveness compared to PPO, which has gained more traction among the team.
- This disparity has led to discussions on improving the DPO approach to increase its utilization.
-
Mark's Heavy Contributions to DPO Highlighted: Despite the DPO recipe's low usage, Mark has heavily focused his contributions on DPO.
- This has sparked questions about the differing popularity levels between DPO and PPO within the group.
DSPy Discord
-
DSPy Learning Support: A member expressed a desire to learn more about DSPy and sought community assistance, presenting AI development ideas.
- Despite only a few days of DSPy experience, another member offered their assistance to support their learning.
-
Observers SDK Integration: A member inquired about integrating Observers, referencing the Hugging Face article on AI observability.
- The article outlines key features of this lightweight SDK, indicating community interest in enhancing AI monitoring capabilities.
Axolotl AI Discord
-
Accelerate PR Fix for Deepspeed: A pull request was made to resolve issues with schedule free AdamW when using Deepspeed in the Accelerate library.
- The community raised concerns regarding the implementation and functionality of the optimizer.
-
Hyberbolic Labs Offers H100 GPU for 99 Cents: Hyberbolic Labs announced a Black Friday deal offering H100 GPUs for just 99 cents rental.
- Despite the appealing offer, a member humorously added, good luck finding them.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (875 messages🔥🔥🔥):
Cursor Composer updates, Cursor agent functionality, Windsurf IDE comparison, Cursor version rollouts, User experiences with AI models
-
Cursor Composer updates introducing new features: The recent update to Cursor (0.43) has introduced a new Composer UI and early-agent functionality, but some users have reported issues with missing features like 'Add to chat'.
- Users are experiencing bugs, particularly with indexing and the need to click 'Accept' multiple times for changes in the composer.
-
Discussion on agent functionality: Users are exploring the new agent feature, which is meant to assist with code editing but appears to have stability and utility issues.
- While some users find the agent helpful for completing tasks, others express frustration with its limitations and bugs.
-
Comparison of Cursor and Windsurf IDE: Some users are switching between Cursor and Windsurf IDE, with mixed feelings about Windsurf's performance and autocomplete capabilities.
- Users note that Cursor's latest version feels more efficient and stable compared to Windsurf, which has been reported to have numerous UI/UX bugs.
-
User experiences with AI models: There is a consensus among users that while Cursor has improved significantly, there are still moments of slow responses and a lack of contextual awareness in AI interactions.
- Users are reflecting on past experiences with AI models and how recent updates impact their workflows, indicating a desire for improvements in AI responsiveness.
-
Feedback on Cursor's communication: Community members express a desire for improved communication regarding updates and issues with Cursor, suggesting that a dedicated support channel could help.
- Despite frustrations, users acknowledge Cursor's development efforts and the excitement surrounding new features, indicating a strong community engagement.
Links mentioned:
- Cursor - Build Software Faster: no description found
- Cursor: Built to make you extraordinarily productive, Cursor is the best way to code with AI.
- Cursor - Build Software Faster: no description found
- Cursor: Built to make you extraordinarily productive, Cursor is the best way to code with AI.
- Quickstart - Model Context Protocol: no description found
- Cursor - The IDE designed to pair-program with AI.: no description found
- Tweet from Cursor (@cursor_ai): We are excited to announce that @SupermavenAI is joining Cursor! Together, we will continue to build Cursor into a research and product powerhouse.(1/5)
- You Got GIF - You Got Any - Discover & Share GIFs: Click to view the GIF
- Cursor - The IDE designed to pair-program with AI.: no description found
- - YouTube: no description found
- Cursor - The IDE designed to pair-program with AI.): no description found
- Cursor Status: no description found
- Anthropic Status: no description found
- Reuse context from previous composer messages: Is there a way to reuse the previous composer message context? At-mentioning the same handful of contexts over and over again for every message gets pretty long in the tooth. If there were a way to ju...
- Cursor Community Forum: A place to discuss Cursor (bugs, feedback, ideas, etc.)
- Cursor 0.42.4: Cursor is bottom-up designed with the goal of creating an integrated development environment to build software faster using AI. .
- Download Cursor 0.43.4: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
Eleuther ▷ #general (69 messages🔥🔥):
Zombo.com references, Experience with sfcompute, PyTorch parallelism wrappers, Configuration complexity challenges, FSDP behavior and module properties
-
Zombo.com Nostalgia Hits: Members shared a playful exchange about Zombo.com, with one claiming it's the first reference in years and stating, 'how can you compete with being able to do anything, anything at all?'
- The conversation humorously highlighted the absurdity of the site's premise while welcoming a new member's Linux experience.
-
sfcompute Access Issues: A member reported difficulties in accessing sfcompute, stating their account has been under review for a long time without updates after trying to reach out for help.
- Another member shared their frustrations, noting that even when approved, the command-line interface presented challenges and lacked compute resources.
-
Exploring PyTorch Parallelism Wrappers: Discussion around PyTorch parallelism led to recommendations for torchtitan and FSDP, with suggestions on how these tools could alleviate complexity in handling model architectures.
- Concerns were raised about configuration complexities versus coding, with members debating the benefits and drawbacks of each approach.
-
FSDP's Impact on Module Properties: A member discussed how FSDP sharding impacts module properties, losing track of custom attributes placed on weights during training.
- The group debated different strategies to retain these attributes, with one proposing a workaround using dictionaries for properties while another mentioned the complexities within FSDP's internal mechanics.
-
Regex for State Dict/Module Dict Mappings: Conversation highlighted the challenges faced when building a regex for state_dict/module_dict mappings in PyTorch, with one member emphasizing the risks of unnecessary complexity.
- They noted that simplifying the configuration process could prevent common pitfalls found in traditional coding methods, allowing for better adaptability in model training.
Links mentioned:
- torchtitan/torchtitan/parallelisms/parallelize_llama.py at 4d182a13e247ff6bc65ca2b82004adcaf8c4b556 · pytorch/torchtitan: A native PyTorch Library for large model training. Contribute to pytorch/torchtitan development by creating an account on GitHub.
- AI Conference Deadlines: no description found
- Code rant: The Configuration Complexity Clock: no description found
Eleuther ▷ #research (83 messages🔥🔥):
Gradient Estimation in ML, UltraMem Architecture, Optimizer Evaluation Suite, Diffusion Models in Other Modalities, Learning Rate Sensitivity
-
Exploring Gradient Estimation Techniques: A member suggested estimating the gradient of loss with respect to hidden state in ML models, as it could enhance performance similar to temporal difference learning.
- The idea revolves around using amortized value functions, comparing its effectiveness to backprop through time.
-
UltraMem Offers Efficient Training: The UltraMem architecture has been proposed to improve inference speed in Transformers by implementing an ultra-sparse memory layer, reducing memory costs and latency.
- Members expressed concerns regarding the complexity and practical application of such models at scale while noting their performance improvements.
-
The Need for an Optimizer Evaluation Suite: There is a growing discussion around creating a comprehensive optimizer evaluation suite that assesses hyperparameter sensitivity across a wide range of ML benchmarks.
- Members referred to existing efforts like Algoperf, but highlighted its limitations in testing methodology and problem diversity.
-
Integrating Diffusion Models with Language: A member suggested researching how diffusion models can generate coherent language across different modalities without explicit instructions.
- This raises the question of why current models struggle with unsupervised generation in comparison to structured prompts.
-
Learning Rate Discussions: Learning rates were discussed with insight into their effects on model training, with suggestions that a learning rate of 0.001 works well for large models over 1B parameters.
- Members debated the nuances of learning rate selection, emphasizing the need for thorough experimentation across various architectures.
Links mentioned:
- Ultra-Sparse Memory Network: It is widely acknowledged that the performance of Transformer models is exponentially related to their number of parameters and computational complexity. While approaches like Mixture of Experts (MoE)...
- SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context: Current large language models (LLMs) primarily utilize next-token prediction method for inference, which significantly impedes their processing speed. In this paper, we introduce a novel inference met...
- Domino: Eliminating Communication in LLM Training via Generic Tensor Slicing and Overlapping: Given the popularity of generative AI, Large Language Models (LLMs) often consume hundreds or thousands of GPUs for parallelizing and accelerating the training process. Communication overhead becomes ...
- LlaMaVAE: Guiding Large Language Model Generation via Continuous Latent Sentence Spaces: Deep generative neural networks, such as Variational AutoEncoders (VAEs), offer an opportunity to better understand and control language models from the perspective of sentence-level latent spaces. To...
- Cautious Optimizers: Improving Training with One Line of Code: AdamW has been the default optimizer for transformer pretraining. For many years, our community searches for faster and more stable optimizers with only constraint positive outcomes. In this work, we ...
- Tweet from Kaizhao Liang (@KyleLiang5): @Grad62304977 @cranialxix @lqiang67 @Tim38463182 as for learning rate: we searched for 4 magnitude of lrs among 1e-2, 1e-3, 1e-4, 1e-5. 1e-3 is the largest lr that was converging fast without unrecove...
- Tweet from Lucas Nestler (@_clashluke): Underrated findhttps://x.com/KyleLiang5/status/1861247330848010486Quoting Kaizhao Liang (@KyleLiang5) TLDR: 1⃣ line modification, satisfaction (theoretically and empirically) guaranteed 😀😀😀Core ide...
Eleuther ▷ #scaling-laws (1 messages):
Cross-entropy loss curves, Datasets for LLMs training
-
Seeking Cross-Entropy Loss Curves for LLMs: A member inquired about the availability of a dataset containing cross-entropy loss curves for LLMs, expressing interest in testing ideas inspired by the paper Scaling Law with Learning Rate Annealing.
- They asked if there's a way to retrieve this data without the need to train the models themselves.
-
Ideas Inspired by Scaling Laws: The individual mentioned having some ideas they want to test out, specifically concerning scaling laws as per the referenced paper.
- This highlights the ongoing interest in optimizing LLM training methodologies without the computational overhead.
Eleuther ▷ #interpretability-general (2 messages):
AISI, Meeting Setup
-
Collaboration at AISI: A member mentioned their presence at AISI and expressed willingness to discuss a related document they contributed to.
- They indicated an openness for direct communication, signifying a collaborative atmosphere.
-
Setting Up a Meeting with Rob: Another member shared their intention to set up a meeting with Rob, implying important discussions ahead.
- This indicates proactive networking and collaboration efforts within the group.
Eleuther ▷ #lm-thunderdome (32 messages🔥):
Evaluation of Quantization Effects, KV Cache Importance in Deployments, Model Performance and Comparison, LM Eval Error Handling, Perplexity as Evaluation Metric
-
Evaluating Quantization Effects on Models: A member is investigating the impact of quantization of KV Cache using lm_eval, noting that papers typically report perplexity on Wikitext as a measure of perturbation after quantizing.
- They are exploring how to use existing eval benchmarks to better reflect the impact of quantization on model performance.
-
KV Cache's Relevance in Model Deployments: Discussion highlighted the relevance of KV Cache for genuine model deployments but not for many mainstream evaluation practices, suggesting that existing benchmarks may not adequately measure the effects.
- One member suggested simulating a deployment environment to better understand performance rather than relying solely on standard benchmarks.
-
Review of LM Eval Error Handling: User experienced memory allocation errors when trying to run lm_eval on an Apple M1 Max, which were mitigated by switching the data type to float16.
- However, they encountered a new issue related to model output size, indicating potential issues with model conversion prior to evaluation.
-
Exploring Relevant Evaluation Metrics: A member remarked that understanding the evaluation metrics relevant to the quantization of KV Cache is essential, as perplexity on Wikitext is commonly used but may not fully capture impact.
- They emphasized the importance of digging into the relevancy of tasks and metrics being utilized for evaluation to direct their research approach.
-
Llama Models Focus in Research: The conversation pointed out that while others were discussing wildchat and LMSys logs, the focus was on the llama base models for the research on quantization.
- This underlines the differentiation in approach taken by members when analyzing models according to their specific research interests.
Link mentioned: general question: Is kv-cache actually not used in all the LLM-evaluation tasks? · Issue #1105 · EleutherAI/lm-evaluation-harness: Is kv-cache actually not used in all the LLM-evaluation tasks, since those tasks usually takes only one-step attention calculation, not like language generating process which needs a lot of kv-cach...
HuggingFace ▷ #NLP (173 messages🔥🔥):
Language models and code generation, Quantum consciousness theories, Neural networks and algorithms, AI tools for music continuation, Complexity in AI discussions
-
Discussions on language models for code generation: Members discussed the limitations of language models in accurately referring to specific line numbers in code snippets, with insights shared about tokenization challenges.
- A suggestion was made to enhance interactions by focusing on specific function names rather than line numbers for better context understanding.
-
Exploration of quantum and consciousness-related theories: One user proposed a connection between quantum processes and consciousness, suggesting that complex systems such as AI could mimic these mechanisms.
- This led to philosophical discussions, but some participants felt these ideas detracted from the technical conversation.
-
Neural networks and their potential: The conversation touched on the power of algorithms and how they might extend AI capabilities through advanced neural networks like hypergraphs.
- However, there was skepticism about the practical application of these ideas, debating their relevance to established machine learning practices.
-
AI tools for creating music: A member inquired about AI models capable of continuing or extending music compositions, mentioning tools such as Suno and Jukebox AI.
- Another user provided a link to MusicGen-Continuation on Hugging Face as a potential solution for generating music continuations.
-
Struggles with AI interactions and technical confusion: One participant expressed frustration with feeling stuck in discussions that seemed unproductive or overly abstract regarding AI and consciousness.
- This led to a mutual recognition of the challenges faced when blending technical and philosophical aspects in AI discussions.
Links mentioned:
- LogoMotion: Visually Grounded Code Generation for Content-Aware Animation: Animated logos are a compelling and ubiquitous way individuals and brands represent themselves online. Manually authoring these logos can require significant artistic skill and effort. To help novice ...
- MusicGen Continuation - a Hugging Face Space by sub314xxl: no description found
- Jakob Kudsk Steensen: Jakob Kudsk Steensen brings together physical, virtual, real and imagined landscapes in mixed reality immersive installations.
- Shadertoy: no description found
Unsloth AI (Daniel Han) ▷ #general (98 messages🔥🔥):
Unsloth model updates, GPU price discussions, Inference performance issues, Qwen2.5 fixes, Model loading strategies
-
Unsloth addresses Qwen2.5 tokenizer issues: Unsloth has resolved multiple issues for the Qwen2.5 models, including tokenizer problems and other minor fixes.
- For clarity on these changes, individuals were directed to resources such as a YouTube video by Daniel regarding bug fixes.
-
GPU market price concerns: Discussion emerged around the current pricing of the Asus ROG Strix 3090 GPU, with market rates noted to be around $550.
- Some members advised against purchasing used GPUs at inflated prices due to upcoming new GPU releases.
-
Inference performance with unsloth models: Members discussed performance issues when using the unsloth/Qwen-2.5-7B-bnb-4bit model in conjunction with vllm, questioning its optimization.
- Suggestions for alternative inference engines more suited for bitwise optimizations were sought.
-
Qwen2.5 model recommendations: It was recommended to use the unsloth version of Qwen2.5 models for both instruct and base versions to avoid issues.
- Members were cautioned not to use the chat template for the base model.
-
Optimizing model loading strategies: A user inquired about downloading model weights without using RAM, seeking clarity on file management with Hugging Face.
- Suggestions included using Hugging Face's caching methods and storing weights on an NFS mount for better efficiency.
Links mentioned:
- Downloading models: no description found
- Fixing bugs in Gemma, Llama, & Phi 3: Daniel Han: The story behind our 8 bug fixes for Gemma, multiple tokenization fixes for Llama 3, a sliding window bug fix and Mistral-fying Phi-3, and learn about how we...
- Reddit - Dive into anything: no description found
- GitHub - codelion/optillm: Optimizing inference proxy for LLMs: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Optimizing LLMs for Speed and Memory: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
Cheap options not enabling SSH, RTX 3090 pricing, PrimeIntellect GPU hosting
-
Cheap options fail to enable SSH: A user expressed frustration that the cheap options they tried did not have SSH enabled, which is crucial for remote access.
- Another user inquired if this was related to Lambda Labs, hinting they may have a solution.
-
Inquiry on RTX 3090 GPU pricing: A user sought information on the cost of RTX 3090 with 24GB GPU memory, indicating a need for a powerful graphics card.
- This highlights ongoing interest in high-performance components amidst budget concerns in the community.
-
PrimeIntellect's GPU hosting options: Discussion arose about PrimeIntellect, with a user noting it offers choices for hosting or attaching to a GPU but prefers a more flexible solution.
- The user desires a host setup with an on/off switch for adding GPUs to achieve 24-48GB of video memory.
Unsloth AI (Daniel Han) ▷ #help (34 messages🔥):
Kaggle Progress Bar Issue, Performance of P100 vs T4, Gemma Quantization Questions, Fine-tuning on Unlabeled Tweets, Model Loading Errors
-
Kaggle progress bar not showing: A user expressed confusion over why the Kaggle interface is not displaying the progress bar during model runs, seeking insights on the issue.
- An image was shared to illustrate the problem, but no specific solutions were mentioned.
-
T4s outperform P100 GPUs: Discussion around whether P100 GPUs are faster than T4s indicated that P100s are actually 4x slower than T4s, based on user experiences.
- Users noted discrepancies in past performance comparisons, suggesting that outdated scripts may have skewed results.
-
Questions on Gemma quantization: A newcomer inquired about the creation process for unsloth/gemma-2-9b-bnb-4bit and the differences from regular BitsAndBytes quantization methods.
- Responses highlighted that using community uploads often leads to bug fixes, and that quantization details can be found in the provided colab notebooks.
-
Challenges in fine-tuning with messy data: A user reported increasing training loss when fine-tuning a model on unlabeled tweets, raising concerns over the effectiveness of the approach.
- Advice given emphasized that training loss may not always correlate with improved domain representation, especially with unlabeled datasets.
-
Errors loading models: Problems were reported regarding invalid hugging face repo errors when trying to load models from disk, seemingly due to name formatting issues.
- Users suggested double-checking the repo name formatting and verifying the presence of expected JSON files in the specified directories.
Link mentioned: Wow GIF - Wow - Discover & Share GIFs: Click to view the GIF
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.65.0 release, Custom model aliases, RepoMap support for Dart language, Analytics opt-in feature, Error handling improvements
-
Aider v0.65.0 Launches with New Features: The Aider v0.65.0 release includes a new
--aliasconfig option for defining custom model aliases and a flag to manage URL detection.- Notably, Ollama models now default to an 8k context window, enhancing user interaction.
-
Dart Language Gets RepoMap Support: In this update, support for RepoMap was added for the Dart language, detailed in the documentation.
- This enhancement aims to streamline how users interact with Dart repositories.
-
User Analytics Now Optional: Aider has introduced an option for users to opt-in to analytics, starting with 2.5% of users being asked.
- This change reflects a push towards better user insights while respecting privacy preferences.
-
Significant Error Handling Enhancements: The latest release features enhanced error handling for analytics and better management of UnknownEditFormat exceptions with helpful documentation links.
- These improvements are designed to assist users in troubleshooting and navigating potential issues more effectively.
-
File Handling Improvements: Aider now skips suggesting files that share names with others already present in chat, streamlining the user experience.
- Additionally, the
/editorcommand now pre-fills file content into prompts, simplifying message composition.
- Additionally, the
aider (Paul Gauthier) ▷ #general (80 messages🔥🔥):
Hyperbolic Model Context, Sonnet vs O1 Models, Using Aider for Website Publishing, Aider Task Management, Model Aliases and Versioning
-
Hyperbolic Model Context Size Matters: A member emphasized that with Hyperbolic, using 128K of context impacts the results, while 8K output is generally sufficient for benchmarks.
- Another member acknowledged the importance of context sizes in real-world usage.
-
Sonnet Outshines O1 Models: There was a debate regarding the Sonnet and O1 mini, with some arguing that Sonnet is superior and easier to prompt, especially in coding tasks.
- Despite mixed opinions, the consensus leaned towards Sonnet’s better usability, especially for complex edits.
-
Publishing Websites with Aider: Members discussed how to publish a website created with Aider, suggesting methods like using GitHub Pages or Vercel for deployment smoothly.
- Aider can assist users in publishing by guiding them through the process with commands such as
/ask.
- Aider can assist users in publishing by guiding them through the process with commands such as
-
Streamlining Tasks with Aider: A user inquired about managing tasks with multiple subtasks in Aider, questioning whether to break it down into smaller tasks for better outcomes.
- It was advised to tackle coding tasks in smaller, bite-sized increments for improved performance and efficiency.
-
Issues with Model Aliases: Concerns were raised regarding incorrectly named built-in model aliases like
claude-3-sonnetinstead of the correctclaude-3-5-sonnet.- A prompt fix was acknowledged as heading to the main branch, demonstrating a responsive approach to user feedback.
Links mentioned:
- GitHub Pages: Websites for you and your projects, hosted directly from your GitHub repository. Just edit, push, and your changes are live.
- Tips: Tips for AI pair programming with aider.
- Model Aliases: Assign convenient short names to models.
aider (Paul Gauthier) ▷ #questions-and-tips (49 messages🔥):
Model Context Protocol, Aider Upgrades, Connecting Aider with VS Code, Token Limit Issues, Voice Function Costs
-
Introduction of Model Context Protocol: Anthropic has open-sourced the Model Context Protocol, a new standard aimed at enhancing the connection between AI assistants and various data systems.
- This protocol seeks to eliminate the challenges posed by fragmented integrations and data silos.
-
Challenges with Aider Upgrades: Some users are facing difficulties with Aider's upgrade process, including issues with command prompts to run necessary scripts or installing packages.
- Others have observed that Aider might not detect newly added files correctly, leading to confusion about its operational consistency.
-
Connecting Aider with Visual Studio Code: Users have reported that Aider works seamlessly within the VS Code terminal, requiring no special configuration other than ensuring auto-save is turned off.
- This approach allows for direct modifications in Aider to reflect changes in the VS Code environment.
-
Token Limit Confusion: Upgrading to a higher token limit in Anthropic plans has led to confusion, as Aider continues to report lower limits, though it doesn’t enforce these limits.
- Users can create a
.aider.model.metadata.jsonfile to define token limits for unrecognized models.
- Users can create a
-
Cost of Voice Function: The voice function in Aider currently operates exclusively with OpenAI keys, costing approximately $0.006 per minute.
- This pricing is structured to be rounded to the nearest second, making it easier for users to estimate usage costs.
Links mentioned:
- File editing problems: aider is AI pair programming in your terminal
- Introducing the Model Context Protocol: The Model Context Protocol (MCP) is an open standard for connecting AI assistants to the systems where data lives, including content repositories, business tools, and development environments. Its aim...
- Ollama: aider is AI pair programming in your terminal
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Advanced model settings: Configuring advanced settings for LLMs.
aider (Paul Gauthier) ▷ #links (2 messages):
MCP Server for Git, Integration with Aider, Add-ons for Aider, Standardized Capabilities
-
MCP Server for Git launches!: The new MCP server for Git is now available, allowing tools to be registered that map to git commands.
- This server's implementation details can be found in its GitHub repository.
-
Aider integration with Git debated: A member expressed that Aider could have deeper integration with Git, negating the need for MCP server access.
- They proposed that MCP support could allow the community to standardize new capabilities for Aider.
-
Exciting potential with plug-ins for Aider!: The community could integrate additional tools like SQLite and PostgreSQL to enhance Aider's functionality.
- Envision adding Google Drive or connecting to Sentry for richer data interactions.
Links mentioned:
- servers/src/git at main · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- servers/src/git/src/mcp_server_git/server.py at main · modelcontextprotocol/servers): Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #mojo (128 messages🔥🔥):
Segmentation faults in Mojo, Mojo QA Bot Performance, Thread Safety and Mutex in Mojo, Function Parameter and Mutability, Error Handling for Ref Types
-
Exploring Fixes for Segmentation Faults: Members discussed potential fixes in the nightly builds for segmentation faults found in the def function environment, revealing that the def syntax is still rough around the edges.
- One member suggested that porting to fn might offer more stability in the presence of persistent segmentation faults.
-
Mojo QA Bot's Impressive Performance: A member reported that after porting their QA bot from Python to Mojo, the memory usage dropped significantly from 16GB to 300MB, demonstrating a much better performance.
- Despite experiencing segmentation faults during the port, the overall responsiveness improved, allowing for quicker research iterations.
-
Understanding Thread Safety Mechanisms in Mojo: There were discussions around the lack of interior mutability in collections and that List type operations are not thread-safe unless explicitly mentioned.
- The community expressed that existing mutable aliases lead to safety violations and that more concurrent data structures will need to be developed.
-
Function Parameter Mutability and Errors: The community explored issues surrounding the use of ref parameters and why the min function was facing type errors, particularly when attempting to return references with incompatible origins.
- Various suggestions were made about using Pointer and UnsafePointer to resolve mutability concerns, indicating that the handling of ref types might need refinement.
-
Destructor Behavior in Mojo: Members shared queries about writing destructors in Mojo and issues related to the
__del__method not being called for stack objects or causing errors with copyability.- Discussions highlighted the challenges of handling Pointer references and mutable accesses, with suggestions given for using specific casting methods to ensure correct behavior.
Links mentioned:
- 2023 LLVM Dev Mtg - Mojo 🔥: A system programming language for heterogenous computing: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------Mojo 🔥: A system programming language for heterogenous computingSpeaker: Abdul Dakkak, Chr...
- Mojo Team Answers | Mojo Dojo: no description found
- cccl/libcudacxx/include/nv/detail/__target_macros at 8d6986d46ca5288d4bd7af7b9088f8a55297ba93 · NVIDIA/cccl: CUDA Core Compute Libraries. Contribute to NVIDIA/cccl development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
Companion emotional scoring system, Enhanced interaction realism, Security improvements in Companion, Automated security audits
-
Companion's Emotional Scoring Takes Center Stage: The latest updates to Companion introduce an emotional scoring system that understands the emotional tone of conversations, starting neutral and building familiarity over time.
- As the conversation shifts, Companion maintains the emotional connection across different channels, ensuring warmth and understanding.
-
Diverse Emotional Perspectives Captured: Companion now adapts its responses based on an emotional spectrum, balancing perspectives like love vs. hatred and justice vs. corruption.
- This flexibility allows it to handle multiple models without enforcing a single emotional interpretation.
-
Security Enhancements for Smoother Interactions: Recent updates have improved detection of personal information such as phone numbers, reducing false positives in Companion.
- These security enhancements include ongoing automated security audits to keep user servers secure and in line with best practices.
-
Making Interactions More Meaningful: The updates aim to create a smoother, safer, and more connected experience, positioning Companion as more than just a tool.
- It's about fostering relationships and ensuring that every interaction is significant.
-
Explore More on GitHub: For detailed insights into these changes, check out the full details on GitHub at GitHub Repository.
- This repository hosts comprehensive information about Companion's latest features and security enhancements.
OpenRouter (Alex Atallah) ▷ #general (98 messages🔥🔥):
OpenRouter API Key Issues, Performance of Gemini Models, Usage of Models and Document Types, Chat Synchronization Across Devices, Limitations of Free Models
-
OpenRouter API Key Errors: A user reported a 401 error indicating an incorrect API key while using the OpenRouter API, despite confirming the key is correct.
- Another member suggested checking for quotation marks in the API key, a common mistake that can lead to such errors.
-
Challenges with Gemini Models: One user experienced a resource exhaustion error (code 429) when utilizing the Gemini Experimental 1121 free model for chatting.
- It was advised to switch to production models to avoid such rate limit errors encountered with experimental ones.
-
Document Formats and Usage: Users discussed limitations regarding the types of documents that can be attached when using OpenRouter, noting the capabilities with PDFs and HTML files.
- While attaching HTML is seen as beneficial to avoid data loss, it was cautioned that PDFs may lead to problems with text extraction.
-
Chat Synchronization Across Devices: A user inquired about syncing chat conversations between devices, to which it was clarified that conversations do not get stored on OpenRouter servers.
- Alternatives like using LibreChat were suggested for those needing cloud storage of conversations for syncing across devices.
-
Limitations of Free Models: Concerns were raised about limitations encountered with free models, including rate limits and response lengths.
- It was mentioned that users with a zero credit balance may still be subject to additional limitations despite being able to test non-free models.
Links mentioned:
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Meta: Llama 3.2 90B Vision Instruct – Provider Status: See provider status and make a load-balanced request to Meta: Llama 3.2 90B Vision Instruct - The Llama 90B Vision model is a top-tier, 90-billion-parameter multimodal model designed for the most chal...
- LibreChat: Free, open source AI chat platform - Every AI for Everyone
- LibreChat: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (3 messages):
Access to Integrations, Access to Custom Provider Keys
-
Requests for Access to Integrations: A member requested help with gaining access to Integrations using the email edu.pontes@gmail.com.
- Can someone help?
- Follow-up on Access Requests: Another member expressed frustration about not receiving access after a couple of weeks, asking for more information regarding their request.
- If there’s a way to get more information please let me know.
- Call for Custom Provider Keys Access: A member introduced themselves and requested access to custom provider keys to join the submissions.
- I’d kindly request access to custom provider keys.
Perplexity AI ▷ #general (88 messages🔥🔥):
Discord Bot Creation, Perplexity AI Subscription Plans, Model Comparison in Programming, DeepSeek R1 Feedback, Refund Process for API Credits
-
Creating a Discord Bot with Perplexity API: A member expressed interest in creating a Discord bot using the Perplexity API, seeking assurance about potential legal issues since they are a student.
- Another user encouraged them to try using the API for their bot project, suggesting that using it for non-commercial purposes would be safe.
-
Questions on Perplexity AI's Student Plan: Members discussed Perplexity AI's pricing plans, noting that there isn't a dedicated student plan available, though a Black Friday offer exists.
- One member highlighted that competitors like You.com offer student plans, which could be a more affordable option.
-
Comparison of JavaScript and Python for Programming: A user inquired about the best programming language, JavaScript or Python, with a member sharing a Discord link for more insights.
- This question has sparked discussions on language preferences and their applications in various projects.
-
Feedback on DeepSeek R1: Members shared their experiences with DeepSeek R1, noting its human-like interaction and how it helps in their logical reasoning classes.
- The conversation highlighted a balance between being verbose and useful, especially for complex tasks.
-
Seeking Refund for API Credits: A user inquired about the refund process for mistakenly purchased API credits, expressing urgency due to pending expenses.
- Support responded that refund processing may take time but would be handled by the support team.
Link mentioned: Streamlit: no description found
Perplexity AI ▷ #sharing (9 messages🔥):
QNET MLM Scheme Warning, Cloud Hosting Black Friday Deals, Bengaluru Adaptive Traffic Control, EU's Gorilla Glass Investigation, Representation Theory Breakthrough in Algebra
-
QNET Scam Alert Shared: A member warned about QNET, identifying it as another MLM disguised as a direct selling company and highlighted red flags like the promise of passive income.
- They emphasized vigilance, stating that it took them 45 minutes to discover the company's name, which was not disclosed during the presentation.
-
Black Friday Cloud Hosting Deals Article: A member crafted an article aimed at simplifying the search for cloud hosting deals this Black Friday season, providing tips for savings.
- The article serves as a guide for users looking to take advantage of significant discounts available during the Black Friday sales.
-
Bengaluru's Adaptive Traffic Control Changes: A link was shared regarding Bengaluru's adaptive traffic control system, shedding light on innovations benefitting urban mobility.
- This adaptive system aims to create a more efficient traffic management approach in the city.
-
EU Investigates Gorilla Glass: A shared resource discussed the EU's investigation into Gorilla Glass and its implications for tech industries using the material.
- This investigation has sparked conversations about product safety standards in manufacturing processes.
-
Algebra Breakthrough in Representation Theory: A link was posted about a recent breakthrough in representation theory within algebra, pointing towards new research findings.
- This development has significant implications for future studies in mathematical frameworks.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (3 messages):
Closed Beta Program, User Concerns, Arthritis Discussion
-
Silence Post Closed Beta Request: A user expressed that they submitted a request to join the closed beta program but have not received any updates since.
- They are seeking guidance on what steps to take next after the prolonged silence.
-
Link to Discord Discussion: A member shared a link to a previous discussion regarding the closed beta requests.
- This was in response to the ongoing inquiries about the status of beta program entries.
-
Discussion on Arthritis: There was a brief mention of arthritis, potentially indicating user interest or concern about health topics.
- However, no specific details or discussions were provided regarding this topic.
OpenAI ▷ #ai-discussions (82 messages🔥🔥):
Impact of AI on jobs, Human-AI collaboration, Real-time API, AI in gaming, AI's understanding of emojis
-
AI's Influence on Employment: Discussions highlighted the dual nature of AI replacing jobs while also potentially creating new ones, similar to past technological shifts like the printing press.
- Concerns were raised about whether AI could replace junior roles in software engineering, raising questions about future job structures.
-
Collaboration with AI: Participants expressed views on treating AI as partners, acknowledging that both AI and humans have flaws and strengths.
- The conversation emphasized the need for ongoing collaboration to unlock human potential and support diverse human experiences.
-
Understanding Real-Time API: Questions arose regarding the functionality of the real-time API, particularly its low latency advantages for voice interactions.
- Participants speculated on the API's ability to interpret user nuances, such as accents and intonations, though specific details remained unclear.
-
Skepticism Towards Gaming Influence: Comments were made regarding the influence of the gaming community on tech decisions, suggesting a lack of maturity in certain gaming products.
- Concerns were voiced about the potential risks gamers introduce into AI setups, indicating a divide in trust among tech enthusiasts.
-
Communication and Emoji Usage: Participants debated the effectiveness of emojis in communication, questioning their subtlety and relevance in AI interactions.
- This led to comparisons between generational communication styles, suggesting that younger generations may rely heavily on simplified digital expressions.
Link mentioned: GitHub - openai/openai-realtime-console: React app for inspecting, building and debugging with the Realtime API: React app for inspecting, building and debugging with the Realtime API - openai/openai-realtime-console
OpenAI ▷ #gpt-4-discussions (1 messages):
vvvvvvvvvvvvvvvvvvv_: Is anyone experiencing issues with saving custom GPTs?
OpenAI ▷ #prompt-engineering (6 messages):
Challenges with Research Papers, AI for Web Interaction, Self-Operating Computer, Claude 3.5 Sonnet, Google's Jarvis
-
Toughness in Handling Research Papers: It's difficult to work with longer, more researched papers due to the complexity involved, especially in writing-intensive courses.
- Combining this with peer reviews potentially allows more dedicated time to improve paper quality.
-
AI's Struggles with Web Interfaces: There is ongoing discussion regarding the feasibility of AI products that can determine x and y coordinates on a webpage using vision.
- Currently, most options face challenges with arbitrary web interfaces, complicating interactions.
-
Achieving Web Interaction with Advanced AI: A member noted that solutions like Self-Operating Computer, Claude 3.5 Sonnet, and Google's Jarvis can achieve interaction with web elements.
- This suggests potential advancements in web automation capabilities using cutting-edge AI technology.
-
Speculations on OpenAI's Developments: It was mentioned that OpenAI may or may not be working on technology similar to those mentioned for web interaction.
- This insight highlights ongoing speculation about competitive advancements in AI tools.
OpenAI ▷ #api-discussions (6 messages):
Research Paper Challenges, AI Web Interaction, Self-Operating Computer, Claude 3.5 Sonnet, Google's Jarvis
-
Challenges in Research Paper Development: It was mentioned that crafting longer and better-researched papers is particularly challenging, especially in writing-intensive courses that rely on peer review.
- It's noted that significant class time is needed to effectively work on such papers.
- AI Limitations in Web Element Interaction: A query was raised about AI products that can obtain x and y coordinates for webpage elements and interact with them using vision.
- One response highlighted that most options struggle with arbitrary web interfaces and provided examples of products that can perform these tasks.
-
Potential AI Solutions for Web Interaction: It was confirmed that using Self-Operating Computer, Claude 3.5 Sonnet, and Google's Jarvis can enable interaction with web elements.
- Additionally, there was a suggestion that OpenAI may also be developing a similar capability.
Notebook LM Discord ▷ #use-cases (30 messages🔥):
AI Podcasting, Customer Data Management, Educational Content Marketing, Audio Overview Functionality, Virtual Podcast Hosts
-
Innovative Use of AI Podcasting: Several members shared their positive experiences with using NotebookLM for generating podcasts, particularly highlighting the ease of articulating source materials into engaging audio formats.
- One user created a podcast focused on the business opportunities of AI and linked a related PDF for further exploration.
-
Streamlining Customer Support Analysis: A member discussed using Notebook LM to analyze customer support emails by converting .mbox files into .md files, finding it significantly enhances the customer experience.
- They suggested that direct Gmail integration could improve accessibility for their organization, streamlining the process.
-
Marketing Educational Content via Podcasts: One user shared how they transformed educational content from a natural history museum into podcasts and then created blog posts using ChatGPT to enhance SEO and accessibility.
- This initiative significantly increased the content's reach, successfully launched by an intern in a short time frame.
-
Customization of AI Podcasting: Members discussed the potential of customizing generated podcasts by specifying certain sources or themes but noted challenges in finding effective input methods.
- Feedback was shared regarding the AI's capacity to follow specific prompts, with suggestions for improvement.
-
Exploring Virtual Podcast Hosts: One user experimented with virtual podcast hosts created by AI, prompting them to reflect on their identities based on text sources provided.
- They noted challenges related to recursion and repetition within the generated content, highlighting some limitations of the current AI responses.
Links mentioned:
- #207 - Sound Check 1 - AI Research Platform - The Misophonia Podcast: In this experimental episode, we're talking about a new AI research platform I am developing that blends scientific literature, lived experience on the podcast, and questions and comments from the...
- The Business Opportunity of AI: a NotebookLM Podcast: GET NOW THE PDF ⤵️https://discord.gg/Yt9QgjBUMgI created a podcast using NotebookLM about the business opportunities of AI, based on a very interesting PDF t...
- 👁️ A Closer Look - Token Wisdom ✨: A weekly essay from a bucket of topics consisting of all things blockchain, artificial intelligence, extended reality, quantum computing, renewable energy, and regenerative practices.
- NotebookLM ➡ Token Wisdom ✨: Technology Podcast · 40 Episodes · Updated Weekly
Notebook LM Discord ▷ #general (53 messages🔥):
NotebookLM Features and Functionality, User Experiences with Document Handling, Issues with Language and Translations, Concerns about AI Data Usage, Audio Overview Customization
-
Exploring NotebookLM's Features: Users are actively discussing NotebookLM's ability to scrape and summarize various sources, including PDFs and web pages, seeking advice on improving output quality.
- A user expressed difficulty in ensuring that NotebookLM can access all visible content on web pages, especially when content is dynamically loaded.
-
User Experiences with Document Handling: Concerns were raised regarding the formatting issues when uploading PDFs and how it affects the citation process, prompting suggestions for better text extraction methods.
- Users noted the importance of having properly formatted text for effective use of NotebookLM and expressed the potential benefit of using plain text files from certain sources.
-
Language and Translation Issues with NotebookLM: Several users voiced frustrations about language settings, particularly related to summaries being generated in Italian rather than English.
- There were inquiries about the capability of generating content in other languages and whether the voice generator can support Spanish.
-
Concerns Over AI Data Usage: Discussions emerged about NotebookLM's free model, with users questioning the long-term implications and possible data usage for training purposes.
- Clarifications were made about privacy protections, emphasizing that sources are not used for training AI, which eased some users' concerns over data handling.
-
Customizing Audio Overviews for Better Engagement: Users are seeking ways to optimize the Audio Overview feature by providing specific instructions to better suit their desired outcomes.
- Implementation of customization options allows users to tailor audio outputs more precisely, and some are utilizing third-party editing software for further refinement of audio files.
Links mentioned:
- Privacy - Help: no description found
- Behind the product: NotebookLM | Raiza Martin (Senior Product Manager, AI @ Google Labs): Raiza Martin is a senior product manager for AI at Google Labs, where she leads the team behind NotebookLM, an AI-powered research tool that includes a delig...
- Godot Docs – 4.3 branch: Welcome to the official documentation of Godot Engine, the free and open source community-driven 2D and 3D game engine! If you are new to this documentation, we recommend that you read the introduc...
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
ControlNets for Stable Diffusion 3.5, Commercial and Non-Commercial Licensing, Ownership of Generated Media
-
ControlNets enhance Stable Diffusion 3.5 Large: New capabilities have been added to Stable Diffusion 3.5 Large with the release of three ControlNets: Blur, Canny, and Depth. Users can download the model weights from HuggingFace and access code from GitHub, with support in Comfy UI.
- Check out the detailed announcement on our blog here for more information on these new features.
-
Flexible Licensing Options for Users: The new models are available for both commercial and non-commercial use under the Stability AI Community License, which allows free use for non-commercial purposes and for businesses with under $1M in annual revenue. Organizations exceeding this revenue threshold can inquire about an Enterprise License.
- This model ensures users retain ownership of outputs, allowing them to use generated media without restrictive licensing implications.
- Commitment to Safe AI Practices: The team expressed a strong commitment to safe and responsible AI practices, emphasizing the importance of safety in their developments. They aim to follow deliberate and careful guidelines as they enhance their technology.
Link mentioned: ControlNets for Stable Diffusion 3.5 Large — Stability AI: Today we are adding new capabilities to Stable Diffusion 3.5 Large by releasing three ControlNets: Blur, Canny, and Depth.
Stability.ai (Stable Diffusion) ▷ #general-chat (76 messages🔥🔥):
User Support Communication Issues, Utilizing Wildcards for Prompts, SDXL Model Loading Times, Finding AI Tools and Resources, Managing Loras by Checkpoint
-
User Support Communication Issues: Many users expressed frustration over lack of communication from Stability.ai regarding support, especially concerning invoicing issues.
- One user noted they sent multiple emails without a reply, leading to doubts about the company's engagement.
-
Utilizing Wildcards for Prompts: A discussion arose around the use of wildcards in prompt generation, with members sharing ideas on how to create varied background prompts.
- Examples included elaborate wildcard sets for Halloween backgrounds, showcasing community creativity and collaboration.
-
SDXL Model Loading Times: Users inquired about the loading times of the SDXL models, with one querying if longer load times were expected on first selection.
- Responses indicated it is normal for the model to take time as it loads into VRAM.
-
Finding AI Tools and Resources: A user sought recommendations for platforms to learn about software development and AI, asking for guidance on contributing to deep learning models.
- Suggestions included exploring community resources and tools for engaging with AI-related projects.
-
Managing Loras by Checkpoint: A member asked about tools for sorting LoRA models based on the checkpoints they were designed for, like SDXL or SD 1.5.
- Community members provided links to GitHub resources that could help sort and manage these models effectively.
Links mentioned:
- GitHub - Kinglord/ComfyUI_LoRA_Sidebar: Fast, visual and customizable LoRA sidebar packed with features for ComfyUI: Fast, visual and customizable LoRA sidebar packed with features for ComfyUI - Kinglord/ComfyUI_LoRA_Sidebar
- Loads of Halloween backgrounds. - v1.0 | Stable Diffusion Wildcards | Civitai: Generate loads of Halloween style backgrounds with this yaml file. upload file to \extensions\sd-dynamic-prompts\wildcards folder in the file you h...
GPU MODE ▷ #general (4 messages):
Kashmiri Text Corpus Dataset, Lecture 12 Flash Attention, LLM Fine-tuning Issues, Model Loading Problems, Multi-GPU Training
-
Endorsement request for Kashmiri Text Corpus: A member is seeking endorsement for a technical note related to their text corpus dataset on Hugging Face to comply with academic standards.
- They mentioned that access to the dataset requires agreeing to certain conditions and are open to sharing the full technical note.
-
Need for lecture 12 notebook on Flash Attention: A user inquired about accessing the notebook from lecture 12 on Flash Attention, noting it appears to be missing from the GitHub repository.
- They are seeking assistance in locating this specific resource for better understanding.
-
Inference issues after fine-tuning LLM: A member reported issues loading a model for inference after fine-tuning with multi-GPU using LORA and FSDP, claiming it won't load.
- In contrast, they noted that models trained with a single GPU successfully load, indicating a potential issue with multi-GPU setups.
-
Model training discrepancies between GPUs: Following up on earlier concerns, the same member highlighted that a model trained on a single GPU works properly, but the multi-GPU trained variant cannot be loaded.
- They are questioning why the model from the multi-GPU training session is failing to load.
Link mentioned: Omarrran/Kashmiri__Text_Corpus_Dataset · Datasets at Hugging Face: no description found
GPU MODE ▷ #triton (2 messages):
Triton escape hatch, FP8 vs INT8 performance
-
Triton's Inline PTX Escape Hatch Explained: Triton language includes an escape hatch allowing users to write inline PTX for elementwise operations, which passes through MLIR but acts as a passthrough.
- It is noted that Triton generates inline PTX during LLVM IR generation, confirming the explanation's clarity.
-
FP8 Performance Slower than INT8 on H100: Observations indicate that FP8 multiplied by FP8 is significantly slower compared to INT8 times INT8 on the H100 when utilizing dynamic quantization.
- This raises concerns regarding the efficiency of FP8 operations relative to INT8 in practical applications.
GPU MODE ▷ #cuda (31 messages🔥):
Odd behavior in CUDA simulations, Random number generation initialization, Memory allocation and initialization, CUDA optimizations for ML applications, Kernel fusion in CUDA
-
Weird results in CUDA simulations: Issues arise when running CUDA simulations in quick succession without a one-second delay, affecting the results obtained.
- Member confirmed checking for memory leaks and using the number of threads equal to CUDA cores, yet still encountered unexpected behavior.
-
Improving random number generation seeds: The random number generation initialized with
time(NULL)is deemed naive; improvements are suggested through more robust seed practices.- Recommended reading on mixing entropy for random number generators was shared, emphasizing the importance of effective seeding.
-
Memory allocation issues in CUDA: A host API memory access error indicates uninitialized memory access when copying between device pointers using
cudaMemcpyAsync.- Advice centered on initializing memory with
cudaMemsetprior to copying to prevent errors and ensure valid data transfer.
- Advice centered on initializing memory with
-
CUDA optimizations for machine learning: Interest in resources for various CUDA optimizations specifically targeting machine learning applications is expressed, including dynamic batching and kernel fusion.
- Member seeks patterns and techniques for optimizing ML applications as they feel familiar with most basic performance ideas.
-
Kernel fusion techniques in CUDA: Discussion around deriving fused kernels in CUDA as a method of performance optimization for machine learning is ongoing.
- Member seeks detailed methods for hand-deriving kernel fusion compared to automatic fusion handled by compilers.
Link mentioned: Simple Portable C++ Seed Entropy: How to cope with the flaws of the C++ random device
GPU MODE ▷ #torch (4 messages):
GPU Memory Footprint Issues, PyTorch CPU Affinity and NUMA, CUDA OOM Errors from Reserved Memory, Flops Calculation for GPT-2, Inference Latency in Transformers
-
GPU Memory Footprint Differences: A question arose regarding the possibility of different memory footprints for PyTorch models across GPU architectures, such as potentially going OOM on an A100 but not on an H100 with the same memory capacity.
- Is it likely that different architectures handle memory in distinct ways?
- Explore PyTorch's CPU Affinity and NUMA: Members inquired about documentation on how PyTorch handles CPU affinity, NUMA, and binding to various network interfaces.
- Any good resources available for understanding these aspects?
- CUDA OOM Due to Reserved Memory: One user shared their experience with CUDA OOM occurring from excessive reserved memory, despite attempts to free memory with gc.collect() and torch.cuda.empty_cache().
- Has anyone else run into this issue during model inference under high loads?
- Debating the Flops of GPT-2: Discussion sparked over the flops calculation for GPT-2, with inconsistencies found between different sources, one stating ~2GFlops and another suggesting around 0.2 GFlops.
- Confusion arose over the discrepancy, as contributors sought clarity on performance metrics based on their hardware setup.
- Understanding Inference Latency: A query was raised about determining the peak performance metrics for GPT-2 concerning memory latency and compute latency during inference.
- Pointers were requested to also understand the broader implications on inference performance.
Link mentioned: Transformer Inference Arithmetic | kipply's blog): kipply's blog about stuff she does or reads about or observes
GPU MODE ▷ #cool-links (4 messages):
FP8 Training, Performance Gains with FSDP2, Meta LLaMa Model Architecture
-
PyTorch's FP8 Training Blogpost Released: The new blogpost on FP8 training from PyTorch reveals a 50% throughput speedup using FSDP2, DTensor, and torch.compile with float8.
- This improvement enables training over the Meta LLaMa models from 1.8B to 405B parameters, enhancing performance significantly.
-
Dynamic Casting Overhead and Performance: Discussion highlighted that larger matrix multiplications (matmuls) can better conceal the overhead from dynamic casting due to being compute-bound, leading to improved performance.
- This reflects a bit of Amdahl's law, implying that in larger configurations, the time spent on casting is proportionally smaller.
-
Performance Metrics and Batch Size Exploration: The blogpost mentions exploring batch sizes and activation checkpointing schemes to report the tokens/sec/GPU metric, focusing on performance gains for both float8 and bf16 training.
- It was noted that while an 8B model uses larger batch sizes, it could be slower with larger M-dim than K-dim for matrix multiplications.
Link mentioned: Supercharging Training using float8 and FSDP2: IBM: Tuan Hoang Trong, Alexei Karve, Yan Koyfman, Linsong Chu, Divya Kumari, Shweta Salaria, Robert Walkup, Praneet Adusumilli, Nirmit Desai, Raghu Ganti, Seetharami SeelamMeta: Less Wright, Wei Feng,...
GPU MODE ▷ #jobs (13 messages🔥):
Hugging Face Internship, Application Details, FAQs on Internship Requirements
-
Hugging Face Internship Season Kicks Off: The Hugging Face intern season has begun, and the team is looking for candidates to focus on FSDPv2 integration and education. Interested applicants should mention the CUDA Mode discord in their application as a source.
- A link to the application was shared along with an image attachment.
-
Job Links Updated: Candidates faced issues with outdated links. The team confirmed the links have been updated for the application process.
- Participants inquired whether to apply to alternative internship postings mentioning the same source if they encounter issues.
-
Internship Time Commitment Clarified: The position is confirmed to be full-time, with an intention for successful interns to join the team afterward. Interns are expected to work around 40 hours per week.
- This opportunity is open to students of various academic years, not restricted to seniors.
-
Application Encouragement: Despite being a third-year student, one member expressed eagerness to apply for the internship, suggesting the opportunity is valuable. Others encouraged applying regardless of year.
- There is an application route provided specifically for non-U.S. candidates, shared by a team member.
Links mentioned:
- Machine Learning Engineer Internship, Accelerate - EMEA Remote - Hugging Face: Here at Hugging Face, we’re on a journey to advance good Machine Learning and make it more accessible. Along the way, we contribute to the development of technology for the better.We have built the fa...
- Machine Learning Engineer Internship, Accelerate - US Remote - Hugging Face: Here at Hugging Face, we’re on a journey to advance good Machine Learning and make it more accessible. Along the way, we contribute to the development of technology for the better.We have built the fa...
GPU MODE ▷ #torchao (2 messages):
Benchmarking Quantization Techniques, Glossary for Terminology
-
Benchmarking Quantization Techniques: The benchmarks table summarizes int4, int8, and fp8 techniques on weights and activations, found here. More benchmarks are available in the section on other quantization techniques.
- This resource has been appreciated by members as it proves to be really helpful in understanding different quantization approaches.
- Need for a Glossary: A member proposed creating a glossary for disambiguations to simplify understanding of the terms used in discussions, expressing willingness to make a simple note and share it. This was suggested as a useful resource for the community.
Links mentioned:
- ao/torchao/quantization at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
- ao/torchao/quantization at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #🍿 (4 messages):
Function Cost Calculation, Execution Time as Proxy for Cost, Modal Functions Overview
-
Exploring Function Cost Return: A member inquired whether a function could return its running cost in USD after execution, with the idea of using cost as the main ranking function.
- Charles noted that while it's not straightforward, execution time correlates well with cost since GPU usage is billed by the second.
- Manual Logging of Execution Time Suggested: It was suggested that logging the execution time manually could be necessary for cost calculation.
- The challenge of obtaining execution times post hoc was discussed, as they weren't readily visible on the call graph or input stats.
- Overview of Modal Functions: Details about Modal Functions was shared, emphasizing that these are core units for serverless execution on the platform.
- Key features like
keep_warm,from_name, andlookupweren't granularly explored in the conversation.
Link mentioned: modal.functions: Functions are the basic units of serverless execution on Modal.
LM Studio ▷ #general (46 messages🔥):
Beta Builds Concerns, AMD Multi-GPU Support, LM Studio Performance, Model Usage and API Queries, Token Display During Inference
-
Beta Builds Raise Questions: Members expressed concerns about the current state of beta builds, mentioning missing features like DRY and XTC functionalities that affect usability.
- One member stated, 'The project seems to be kind of dead,' indicating a desire for clarification on ongoing developments.
-
AMD Multi-GPU Compatibility Discussed: It was confirmed that AMD multi-GPU setups do work, but efficiency in AI applications remains limited due to ROCM's performance issues.
- A member noted, 'ROCM support for AI is not that great,' emphasizing challenges with recent driver updates.
-
LM Studio Performance Surprises Users: Several members shared positive experiences running large models on lower-spec systems, like one member managing to run a 70b model with their 16GB RAM setup.
- Another member commented, 'I’m... kind of stunned at that,' highlighting the unexpected performance figures achieved.
-
API Usage Queries for LM Studio: A member inquired about sending prompts and context to LM Studio APIs and asked for examples of configuration with model usage.
- Another question arose regarding Metal support on M series silicon, which was noted as being 'automatically enabled.'
- Token Display Concerns in Inference: Members discussed displaying tokens per second during model inference, indicating it's available only post-inference as per the current llama.cpp structure.
- One member remarked they achieved 30 tokens/second with a 4090RTX, contrasting performance with an M4 system clocking only 2.3 tokens/second.
Link mentioned: GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
LM Studio ▷ #hardware-discussion (10 messages🔥):
Second 3090 considerations, Black Friday full tower deals, Motherboard requirements for second GPU, PCIe slot configurations, Cooling solutions for multiple GPUs
-
Second 3090 comes with hardware requirements: A user mentioned that acquiring a second 3090 would require a different motherboard down the line due to space limitations.
- It's crucial to consider physical space and board compatibility when planning for a second graphics card.
-
Black Friday is on the radar for deals: A user asked for recommendations on Black Friday deals, particularly on full tower setups.
- The community eagerly anticipates good offers as the shopping event approaches.
-
Importance of motherboard layout: Discussing motherboard options, a user noted the necessity of having 2x PCIe 16x slots for better configuration, avoiding specific network cards.
- Compatibility is key, especially for users wanting to maintain their current AM4 CPU and RAM.
-
Challenges with GPU spacing: One user highlighted the challenges in using multiple thick graphics cards in close spacing, suggesting risers or water cooling as solutions.
- They noted that air circulation can be problematic when fitting two 3090s together in the same space.
-
Water cooling for optimal performance: There were discussions around using water cooling for optimal airflow between tightly packed 3090s, emphasizing power and heat management.
- It's a potential solution when physical spacing becomes a constraint in GPU setups.
Interconnects (Nathan Lambert) ▷ #news (17 messages🔥):
Tülu 3 8B shelf life, Olmo model comparisons, Multilingual capabilities, SFT data removal impact, Pre-training efficiency
-
Tülu 3 8B's brief shelf life: Concerns were raised about Tülu 3 8B having a shelf life of only a week, as expressed by members discussing model stability.
- One member commented on the compression observed in this model, mentioning it with strong emphasis.
-
Olmo and Tülu model differences: There's a notable difference between Olmo base and Llama models, especially in terms of behaviors after bumping parameters to 13B.
- Members noted that Tülu demonstrates better performance in specific prompts compared to Olmo 2.
-
Multilingual capabilities draw attention: Members discussed the multilingual capabilities of both Tülu and Olmo 2, with Tülu performing slightly better on certain prompts.
- One member expressed amazement at its capability to handle multilingual tasks despite the removal of SFT multilingual data.
-
SFT data removal and model performance: A member confirmed that the decision to remove multilingual SFT data was maintained as it worsened model performance when tested.
- This was supported by another member who praised the tuning of their SFT experiments that managed to keep performance intact.
-
Efficiency in pre-training draws admiration: Another member expressed sincere admiration for the model's effectiveness despite a low amount of pre-training tokens.
- They emphasized the importance of open science, noting that transparency in research is a key element in understanding model performance.
Links mentioned:
- Ai2 (@ai2.bsky.social): Applying our state of the art Tülu 3 post-training recipe, we also built OLMo 2 Instruct, which are competitive with even the best open-weight models—OLMo 2 13B Instruct outperforms Qwen 2.5 14B instr...
- Ai2 (@ai2.bsky.social): Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight model...
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
Return of Activity, Screenshot Analysis
-
Discord Channel Activity Resumes: A member excitedly declared, 'we are so back', indicating a resurgence of activity in the channel.
- This phrase suggests an optimistic outlook towards ongoing discussions or developments.
-
Image Analysis Shared: A relevant image was attached, likely containing important visual insights.
- The content of the image remains unspecified, but it could prompt further discussion or analysis among members.
Interconnects (Nathan Lambert) ▷ #random (31 messages🔥):
Sora API Leak, OpenAI Corporate Practices, Artist Community Reactions, Hugging Face Usage, Public Perception Management
-
Sora API Leak Sparks Community Buzz: Members noticed an alleged leak of the Sora API on Hugging Face, leading to heavy traffic as users explored the tool's capabilities.
- Despite the chaos, some speculate that it’s a deliberate move by OpenAI to gauge public reaction rather than a real leak.
-
Critique of OpenAI's Treatment of Artists: A message criticized OpenAI's approach towards the artist community, accusing them of exploiting artists for free testing and PR under the guise of early access to Sora.
- An open letter was drafted by artists expressing their concerns over being used as unpaid R&D and calling for fair compensation and open source alternatives.
-
User Engagement and Response Issues: Users expressed frustrations with the Sora interface, encountering infinite loading issues and suspecting server restarts rather than crashes.
- Conversations revealed skepticism about the intentions behind the launch, comparing it to previous marketing stunts by OpenAI.
-
Community Discussions on Open Source Tools: Members encouraged using open source video generation tools to promote genuine artistic expression without corporate constraints.
- Several tools were suggested, including CogVideoX and Mochi 1, highlighting the need for support and accessible paths for artists.
-
Public Speculation on OpenAI's Strategies: Some users debated whether the public leak of Sora was a strategy for publicity, hinting that OpenAI often engages in similar tactics.
- Concerns were raised about the potential backlash and scrutiny that could arise from such marketing moves amidst ongoing controversy.
Links mentioned:
- PR Puppet Sora - a Hugging Face Space by PR-Puppets: no description found
- Tweet from Simo Ryu (@cloneofsimo): Wait o1 mightve been this work all along? https://arxiv.org/abs/2310.04363Quoting Edward Hu (@edwardjhu) proud to see what i worked on at OpenAI finally shipped! go 🐢!!
- Tibor Blaho (@btibor91.blaho.me): >"some sora-alpha-artists, Jake Elwes, CROSSLUCID, Jake Hartnell, Maribeth Rauh, Bea Ramos, Power Dada"
- Tibor Blaho (@btibor91.blaho.me): >"After 3 hours, OpenAI shut down Sora's early access temporarily for all artists"
- PR-Puppets/PR-Puppet-Sora · 🚩 Report: Legal issue(s): no description found
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
SnailBot News: <@&1216534966205284433>
Cohere ▷ #discussions (1 messages):
_reamer: Absolute layman, just exited teenagehood
Cohere ▷ #questions (19 messages🔥):
Transitioning to Production API Key, Error 500 on Embeddings Endpoint, Issues with Command R+ Model Outputs, Inconsistent Language Responses in Bulgarian, Credit Card Details Issue
-
Transitioning to Production API Key causes token issues: A member reported receiving 0 output tokens with input tokens of 6850, indicating possible API limitations despite using a production key.
- Another member clarified that while input can go up to 128k, output is capped at 4k, suggesting the issue might be unrelated to model capabilities.
-
Persistent Error 500 on Embeddings Endpoint: Several members reported encountering Error 500 when attempting to use the embeddings endpoint, indicating a recurring issue since earlier in the day.
- While one found the issue resolved later, another confirmed the sporadic occurrence of the error over several calls.
-
Inconsistent Output Language in Command R+ Model: A user experiencing responses with unintended Russian words despite specifying Bulgarian in the preamble noted that the problem persists.
- They took steps to mitigate this by checking responses and adjusting temperature settings, but still encountered issues with language consistency.
-
Credit Card Details cannot be added: A member inquired about issues with credit card details being erased, and another suggested reaching out to support for assistance.
- This indicates possible technical difficulties with account management features affecting multiple users.
Cohere ▷ #api-discussions (3 messages):
Embed endpoint errors, Error 500 reports, Support communication
-
Embed Endpoint Suffers from Error 500: Multiple users reported encountering Error 500 with the Embed endpoint in the last hour, citing an 'internal server error' message.
- One user noted this issue has been reported to developers, indicating awareness of the problem.
-
Acknowledgement of Ongoing Errors: Another user confirmed they are also experiencing these errors, highlighting that it's a widespread issue.
- This further underscores the need for community members to stay updated on the Embed endpoint performance.
-
Support Offered for Urgent Issues: In response to the reports, a team member offered assistance and suggested that users can reach out via email for urgent matters.
- They provided the contact email as support@cohere.com to ensure swift communication regarding these endpoint issues.
Cohere ▷ #projects (10 messages🔥):
Cohere API Key Limitations, Companion's Emotional Scoring System, Open Source Models, Support for Project Development
-
Cohere API key limitations for high school projects: A user shared their struggle with the API key limit while developing a text classifier application for Portuguese using Cohere API.
- Unfortunately, there’s no possibility of obtaining a higher limit key, leading to suggestions to contact support for help.
-
Exploring open-source model alternatives: In light of billing issues, a member suggested using open-source models like Aya's 8b Q4 version to run locally as an alternative.
- This could be a feasible option for users who are unable to pay for a production key.
-
Companion now feels more relatable: An update on Companion highlighted a new emotional scoring system that personalizes interactions, adapting to emotional tones as it learns from users.
- The system tracks emotional bonds and alters responses based on classifiers measuring emotions like love vs. hatred and justice vs. corruption.
-
Enhanced security features in Companion: The latest Companion updates focus on improving security by better detecting personal information and reducing false positives during interactions.
- Automated security audits have been implemented to ensure compliance with best practices, enhancing user safety.
-
Building meaningful connections with Companion: The updates aim to make every interaction with Companion more meaningful, fostering relationships rather than just being a tool.
- Users can find full details of the updates in the GitHub Repository.
Link mentioned: Login | Cohere: Login for access to advanced Large Language Models and NLP tools through one easy-to-use API.
Nous Research AI ▷ #general (25 messages🔥):
Test Time Inference, Real-Time Video Models, Genomic Bottleneck Algorithm, Nous Flash Agent Setup
-
Inquiry about Test Time Inference: A member asked who is currently working on test time inference, with another confirming interest within Nous.
- This sparked further discussion on the existence of ongoing projects in this specific area.
-
Seeking Real-Time Video Models: A user inquired about models capable of processing real-time video for a robotics project, emphasizing the need for rapid response times.
- Discussion revealed that CNNs and sparse mixtures of expert Transformers might meet those real-time requirements.
-
Genomic Bottleneck Algorithm's Capabilities: An article was shared about a new AI algorithm that simulates a genomic bottleneck, allowing it to perform image recognition without traditional training.
- Members discussed its effectiveness, noting that this algorithm competes with state-of-the-art models despite being untrained.
-
Challenges with Nous Flash Agent Setup: A user expressed frustration over encountering a daily limit error while configuring the nous-flash agent.
- Later, they noted improvements in functionality, although issues persisted with tweet handling.
Link mentioned:
The next evolution of AI begins with ours: Neuroscientists devise a potential explanation for innate ability
: In a sense, each of us begins life ready for action. Many animals perform amazing feats soon after they're born. Spiders spin webs. Whales swim. But where do these innate abilities come from? Ob...
Nous Research AI ▷ #ask-about-llms (1 messages):
vondr4gon: Is there a test time training project ongoing currently?
Nous Research AI ▷ #research-papers (1 messages):
jsarnecki: https://arxiv.org/abs/2411.14405
Nous Research AI ▷ #interesting-links (1 messages):
Coalescence for LLM inference, Finite State Machines transformation, Token-based FSM transitions, Outlines library usage
-
Coalescence makes LLM inference 5x faster: The Coalescence blog post discusses a method to deterministically transform character-based FSMs into token-based FSMs, improving inference speed for LLMs by five times.
- The transformation allows for more efficient transitions by utilizing a dictionary index that maps FSM states to token transitions.
-
Implementing token-based FSM with Outlines: An example of FSM transformation using the Outlines library is provided, showcasing how to create an index for token transitions.
- The code snippet demonstrates initializing a new FSM and constructing a tokenizer index for effective sampling of the next tokens in the inference process.
Link mentioned: Coalescence: making LLM inference 5x faster: no description found
Nous Research AI ▷ #research-papers (1 messages):
jsarnecki: https://arxiv.org/abs/2411.14405
Latent Space ▷ #ai-general-chat (20 messages🔥):
Model Context Protocol (MCP), Sora API Leak, OLMo 2 Release, Funding for PlayAI, Customization in Claude Responses
-
Debate on Anthropic's Model Context Protocol (MCP): A member questioned the need for Anthropic's new Model Context Protocol (MCP), suggesting it may not become a standard despite addressing a legitimate problem.
- Another member expressed skepticism, indicating the issue might be better solved through existing frameworks or cloud provider SDKs.
-
Excitement Over Sora API Leak: Sora API has reportedly leaked, with details indicating it can generate videos from 360p to 1080p, complete with an OpenAI watermark.
- Members expressed shock and excitement, with discussions around the implications of the leak and OpenAI's alleged response to it.
-
OLMo 2 Surpasses Other Open Models: Allen AI announced the release of OLMo 2, claimed to be the best fully open language model to date, featuring 7B and 13B model variants trained on up to 5T tokens.
- The release includes data, code, and recipes, promoting their model's performance against other models like Llama 3.1.
-
PlayAI Secures $21 Million in Funding: PlayAI announced a significant $21 Million funding round to develop user-friendly voice AI interfaces for developers and businesses.
- The company aims to enhance human-computer interaction, positioning voice as the most intuitive communication medium in the era of LLMs.
-
Claude Gains Response Customization: Anthropic revealed the introduction of preset options for how Claude responds, including styles like Concise, Explanatory, or Formal.
- This update aims to provide users with more control over interactions with Claude, catering to different communication needs.
Links mentioned:
- Tweet from Alex Albert (@alexalbert__): Introducing the Model Context Protocol (MCP)An open standard we've been working on at Anthropic that solves a core challenge with LLM apps - connecting them to your data.No more building custom in...
- Tweet from testtm (@test_tm7873): OpenAI now Mutes Peoples on official discord server for talking about recent sora leak!!
- Tweet from Andrew Curran (@AndrewCurran_): Sora may have been leaked by a group of creatives who were given early access for testing. You can choose from 360p to 1080p. Videos generated actually do have the OpenAI watermark in the bottom right...
- Tweet from Justin Uberti (@juberti): During the development of WebRTC, we recognized the impact of voice and video on human communication, and I wondered if someday we'd talk to AIs the same way. Today, we can see this future taking ...
- PlayAI raises $21M funding and releases a new voice model: PlayAI, a Voice AI company that builds delightful and capable voice agents and voice interfaces for realtime conversations has raised $21 Million in seed funding.
- Tweet from Kol Tregaskes (@koltregaskes): Try it here:https://huggingface.co/spaces/PR-Puppets/PR-Puppet-SoraIf Sora, it looks like an optimised version. Can generate up to 1080 10-second clips.Suggest duplicating the space (if that works - ...
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): OpenAI Sora has leaked
- Tweet from Anthropic (@AnthropicAI): With styles, you can now customize how Claude responds.Select from the new preset options: Concise, Explanatory, or Formal.
- Tweet from Ai2 (@allen_ai): Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight model...
- Xeophon (@xeophon.bsky.social): Alleged OpenAI Sora (API) leakhttps://huggingface.co/spaces/PR-Puppets/PR-Puppet-Sora
- app.py · PR-Puppets/PR-Puppet-Sora at main: no description found
LlamaIndex ▷ #blog (3 messages):
LlamaParse, NLP research papers, RAG system optimization, Ragas and LlamaIndex
-
LlamaParse turns research into rich datasets: Learn how @arcee_ai processed millions of NLP research papers using LlamaParse, creating a high-quality dataset for their AI agents with efficient PDF-to-text conversion that preserves complex elements like tables and equations.
- The method includes a flexible prompt system to refine extraction tasks, demonstrating versatility and robustness in data processing.
-
Optimize RAG systems with Ragas: Boost your RAG system's performance before going live using Ragas to evaluate and optimize key metrics for RAG evaluation, including context precision and recall.
- Integrate tools like LlamaIndex and @literalai to analyze answer relevancy and ensure effectiveness in implementation.
LlamaIndex ▷ #general (16 messages🔥):
llama_deploy errors, OpenAIAgent customization, Retrieving specific embedding model, Startup launch announcement, MCP service for llama index
-
llama_deploy encounters issues: A user reported an error with using llama_deploy[rabbitmq] when executing
deploy_corein versions above 0.2.0 due to TYPE_CHECKING being always False.- Cheesyfishes suggested the need for a PR and code change, recommending to open an issue for further assistance.
-
Modifying OpenAIAgent's QueryEngineTool: A developer sought advice on passing custom objects like chat_id into CustomQueryEngine within the QueryEngineTool used by OpenAIAgent.
- They expressed concerns about the reliability of passing data through query_str, fearing changes by the LLM.
-
Setting specific embedding models per retriever: A user inquired about the possibility of assigning a specific embedding model to retrievers set with
VectorStoreIndex.from_vector_store().- Cheesyfishes clarified that while the default model is used, users can still specify an embed model when invoking
as_retriever().
- Cheesyfishes clarified that while the default model is used, users can still specify an embed model when invoking
-
Startup announcement for AI hosting: Swarmydaniels announced the launch of their startup focused on allowing users to host AI agents with a crypto wallet without coding skills.
- They mentioned that additional features for monetization are planned, with a launch tweet coming soon.
-
Interest in building MCP service for llama index: A user asked if anyone was working on an MCP service for the llama index, linking to the Model Context Protocol documentation.
- Cheesyfishes indicated they were interested in trying it out soon.
Link mentioned: Tweet from undefined: no description found
tinygrad (George Hotz) ▷ #general (7 messages):
Flash Attention Integration, Tinybox Pro Custom Motherboard, GENOA2D24G-2L+ CPU, PCIe 5 Cable Compatibility, Tinygrad CPU Documentation
-
Can Flash Attention join Tinygrad?: A member asked whether flash-attention could be integrated into tiny-grad, questioning if it's a separate or unrelated entity.
- This inquiry highlights interest in optimizing tiny-grad's performance through potential new features.
-
Curiosity about Tinybox Pro's motherboard: A user inquired if an image depicted the tinybox pro and whether it features a custom motherboard.
- This reveals ongoing interest in the hardware design choices behind tinygrad's infrastructure.
-
Discussion about a specific CPU model: Another member identified the CPU as a GENOA2D24G-2L+, contributing to the hardware discussion.
- This detail emphasizes attention to the specific components utilized in the project.
-
Cables in tinygrad setup: Questions arose about whether flat cables didn't perform as expected, with a member sharing new cable types.
- In response, George Hotz confirmed that both flat and new cable designs work well, maintaining compatibility with PCIe 5.
-
Inquiry on Tinygrad CPU Behavior: A member sought documentation on CPU behavior in Tinygrad, specifically regarding support for CPU intrinsics such as AVX and NEON.
- This discussion included whether such improvements could be implemented through a pull request, suggesting an interest in enhancing performance.
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Optimization with scatter, Radix Sort enhancements, Non-sequential data processing, GPU Radix Sort paper by AMD
-
Optimization using scatter in Radix Sort: Exploration of utilizing
scatterfor optimizing the Radix Sort algorithm focused on reducing the use of.item()and theforloop.- The goal is non-sequential processing while maintaining correct data ordering.
-
Revisiting index backfill in sorting: A discussion highlighted how attempting to use
scattermight lead to incorrect array ordering when backfilling indices.- A potential method proposed was a reverse cumulative minimum approach to address the instant scatter issue.
-
Referencing AMD's GPU Radix Sort paper: A member noted that AMD's paper on GPU Radix Sort is insightful for understanding optimization techniques.
- The paper can be found here for further reading.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Hackathon Workshop, Google AI, Live Q&A
-
Hackathon Workshop with Google AI Today!: Join us for the Hackathon Workshop with Google AI happening at 3 PM PT today (11/26).
- Don't miss the chance to watch live here, and set your reminders for insights directly from Google AI specialists!
- Get Your Questions Ready for Google AI: The workshop is a great opportunity to ask your questions and gain insights directly from Google AI specialists.
- Prepare your inquiries for an engaging live Q&A session!
Link mentioned: LLM Agents MOOC Hackathon - Google workshop: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 11 Overview, Measuring Agent Capabilities, Responsible Scaling Policy, Benjamin Mann's Background
-
Lecture 11 on Agent Capabilities Today: The 11th lecture titled 'Measuring Agent capabilities and Anthropic’s RSP' by Benjamin Mann will take place today at 3:00 pm PST. You can join the livestream here.
- Mann will discuss evaluating agent capabilities, implementing safety measures, and the practical application of Anthropic’s Responsible Scaling Policy (RSP).
-
Insights on AI Safety Governance: The lecture will cover real-world AI safety governance connected to agent development and capability measurement. Students can expect a practical understanding of industry approaches to these challenges.
- The discussion will highlight the intersection of safety and innovation as the lecture emphasizes the importance of responsible AI deployment.
-
Meet Guest Speaker Benjamin Mann: Benjamin Mann, co-founder at Anthropic and former technical staff at OpenAI, will lead today's session. He aims to cultivate AI systems that are helpful, harmless, and honest.
- Mann has a rich background, having also worked at Google on the Waze Carpool, and studied computer science at Columbia University.
-
Course Resources Available Online: All necessary course materials, including livestream links and homework assignments, are accessible on the course website.
- For any questions or feedback, students are encouraged to communicate with course staff in the dedicated communication channel.
Link mentioned: CS 194/294-196 (LLM Agents) - Lecture 11, Ben Mann: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Anthropic API keys
-
Question about Anthropics API Keys Usage: A member inquired if anyone has used Anthropic API keys.
- Another member confirmed their usage by stating, yes.
-
Confirmation of Using Anthropics API Keys: In response to the inquiry, a member responded indicating that they have indeed used Anthropic API keys.
- This brief confirmation adds to the understanding of usage within the community.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
In-person lectures, Berkeley student enrollment
-
In-person Lecture Access Limited: A member inquired about attending the lecture in person, emphasizing their proximity to Berkeley in the East Bay.
- Another member clarified that the in-person lecture is intended for enrolled Berkeley students due to lecture hall size constraints.
-
Student Eligibility for In-person Participation: Questions arose regarding eligibility for in-person attendance at the Berkeley lecture, especially from local attendees.
- The response underlined that access is restricted to students officially enrolled at Berkeley because of limited space.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
GSM8K Inference Pricing, Self-Correction in Models
-
GSM8K inference costs analyzed: A member shared that for GSM8K, running only the 1k test set yields an inference cost of approximately $0.66 per run when accounting for inputs and outputs.
- The calculation includes the formula [(100 * 2.5/1000000) + (200 * 10/1000000)] * 1000 for one inference run without self-correction.
-
Understanding output and self-correction: It was noted that each question in the GSM8K study should be around 100 tokens and outputs are approximately 200 tokens.
- The analysis also considered self-corrections, suggesting to multiply outputs by the number of corrections plus one for accurate estimations.
OpenInterpreter ▷ #general (7 messages):
OpenInterpreter 1.0 release, Non-Claude OS mode, Developer branch integration, Speech-to-text functionality, Keyboard input simulation
-
OpenInterpreter 1.0 features arriving: The upcoming OpenInterpreter 1.0 is now available on the development branch. A user noted using the command
pip install --force-reinstall git+https://github.com/OpenInterpreter/open-interpreter.git@developmentalongside--tools gui --model gpt-4ofor installation.- Non-Claude OS mode is highlighted as a new feature, marking a shift away from the deprecated
--osflag.
- Non-Claude OS mode is highlighted as a new feature, marking a shift away from the deprecated
-
Rapid Fire Chat about 1.0 Launch: A user remarked after attending a recent party that the new version of OpenInterpreter looks impressive and operates quickly. They inquired about the inclusion of the moondream / transformers library in the upcoming 1.0 version.
- This enthusiasm is matched by the excitement around new capabilities, suggesting remaining questions within the community.
-
Exploration of Speech-to-Text and Automation: One participant expressed initial surprise at the existence of OpenInterpreter and later shifted to searching about speech-to-text capabilities. Their exploration also included simulating keyboard input movements, driven humorously by 'pure laziness'.
- This reflects a broader interest in automation tools and how this community looks for efficiency in tech.
-
Troubleshooting OpenAI Exceptions: A message reported an OpenAIException error that prevents assistant messages from succeeding due to missing tool responses. The specific details pointed to unresponsive tool calls tied to certain request IDs, marking a technical barrier for seamless interaction.
- This highlights potential integration issues that users might face when employing tool features in coding practices.
-
Curiosity Driven by Laziness: A user candidly shared their motivations for exploring OpenInterpreter, driven more by laziness rather than pure curiosity. Their mention of trying to find a way to simulate keyboard input with minimal effort emphasizes the ongoing quest for streamlined automation in development.
- This resonates with many in the tech community who seek to minimize effort while maximizing outcomes.
Torchtune ▷ #general (1 messages):
Torchtitan Poll, Feature Requests
-
Torchtitan Poll Invites User Input: Torchtitan is conducting a poll asking for user preferences on new features such as MoE, multimodal, and context parallelism.
- Make your voices heard by participating to influence the direction the PyTorch distributed team will take.
-
GitHub Discussion on Torchtitan Features: Users are encouraged to join the conversation on GitHub Discussions regarding potential new features for Torchtitan.
- Engagement in this discussion could help shape future updates and enhance user experience.
Link mentioned: Tweet from Horace He (@cHHillee): If you'd like to influence what features the PyTorch distributed team work on in torchtitan (e.g. MoE, multimodal, context parallelism, etc.), go made your voices heard here...
Torchtune ▷ #dev (3 messages):
DPO usage, PPO Contributions, Mark's contributions
-
DPO Recipe Struggles in Usage: Concerns were raised about the low usage of the DPO recipe, questioning its effectiveness in current practices.
- One member noted the contrast with PPO, which appears to have more traction among the team.
-
Mark’s DPO Contributions Shine: A member pointed out that despite the low usage, Mark's contributions have been heavily focused on DPO.
- This raises questions about the disparity in popularity between DPO and PPO efforts within the group.
DSPy ▷ #general (3 messages):
DSPy Learning Support, Observers Integration
-
DSPy Learning Opportunity: @borealiswink expressed a desire to learn more about DSPy and sought help from the community, stating they are new to AI but have ideas in development.
- Another member, slackball, offered their assistance despite only having a few days of experience with DSPy.
-
Inquiry on Observers Integration: A member @realkellogh inquired about the integration of Observers, referencing an article on Hugging Face.
- The article highlights important features and functionalities related to AI observability, indicating community interest in this lightweight SDK.
Link mentioned: Introducing Observers: AI Observability with Hugging Face datasets through a lightweight SDK: no description found
Axolotl AI ▷ #general (3 messages):
Accelerate PR Fix, Hyberbolic Labs Black Friday GPU Deal
-
Accelerate PR Fix for Deepspeed: A pull request was made to fix issues with schedule free AdamW when using Deepspeed in the Accelerate library.
- The community reported concerns, particularly regarding the implementation and functionality of the optimizer.
-
Hyberbolic Labs Offers H100 GPU for 99 Cents: Hyberbolic Labs announced a Black Friday deal offering H100 GPUs for just 99 cents rental.
- Despite this appealing offer, a member humorously added, good luck finding them.
Link mentioned: support for wrapped schedulefree optimizer when using deepspeed by winglian · Pull Request #3266 · huggingface/accelerate: What does this PR do?Axolotl community reported an issue with schedule free AdamW with deepspeed:[rank0]: File "/root/miniconda3/envs/py3.11/lib/python3.11/site-packages/transformers/train....