[AINews] o3 solves AIME, GPQA, Codeforces, makes 11 years of progress in ARC-AGI and 25% in FrontierMath
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
DistilledInference Time Compute is all you need.
AI News for 12/19/2024-12/20/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (215 channels, and 6058 messages) for you. Estimated reading time saved (at 200wpm): 607 minutes. You can now tag @smol_ai for AINews discussions!
With the departure of key researchers, Veo 2 beating Sora Turbo in heads up comparisons, and Noam Shazeer debuting a new Gemini 2.0 Flash Reasoning model, the mood around OpenAI has been tense to say the least.
But patience has been rewarded.
As teased by sama and with clues uncovered by internet sleuths and journalists, the last day of OpenAI's Shipmas brought the biggest announcement: o3 and o3-mini were announced, with breathtaking early benchmark results:
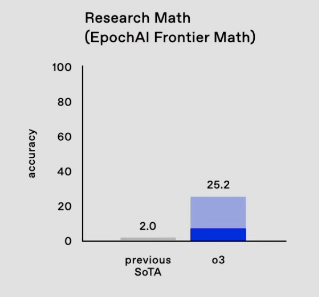
- FrontierMath: the hardest Math benchmark ever (our coverage here) went from 2% -> 25% SOTA
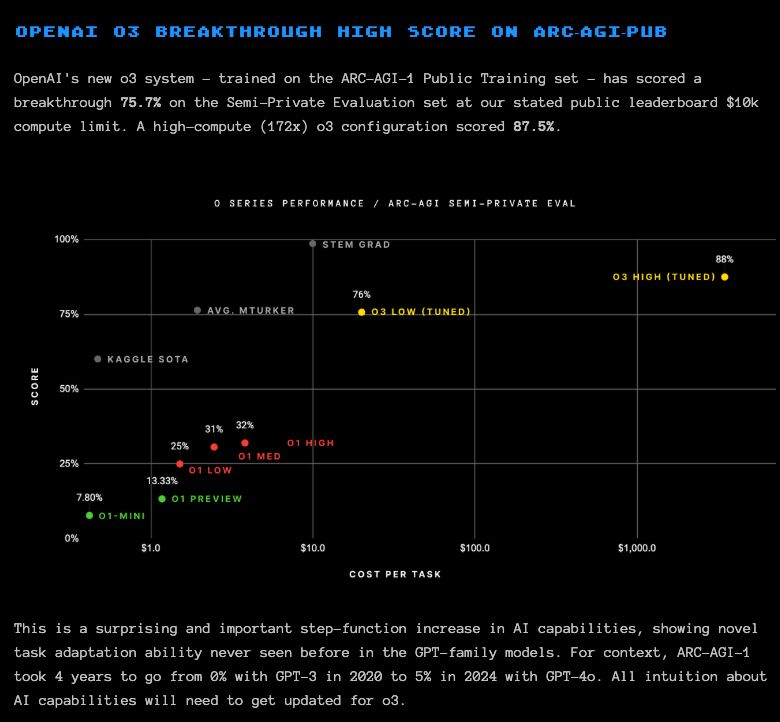
- ARC-AGI: the famously difficult general reasoning benchmark extended in a ~straight line the performance seen by the o1 models, in both o3 low ($20/task) and o3 high ($thousands/task) settings. Greg Kamradt appeared on the announcement to verify this and published a blogpost with their thoughts on the results. As they state, "ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o". o1 then extended it to 32% in its highest setting, and o3-high pushed to 87.5% (about 11 years worth of progress on the GPT3->4o scaling curve)
- SWEBench-Verified, Codeforces, AIME, GPQA: It's too easy to forget that none of these models existed before September, and o1 was only made available in API this Tuesday:
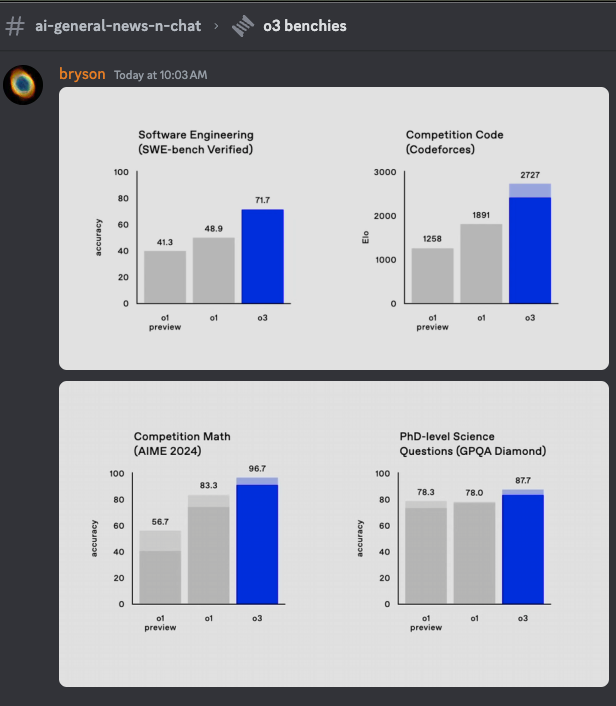
o1-mini is not to be overlooked, as the distillation team proudly showed off how it has an overwhelmingly superior inference-intelligence curve than o3-full: 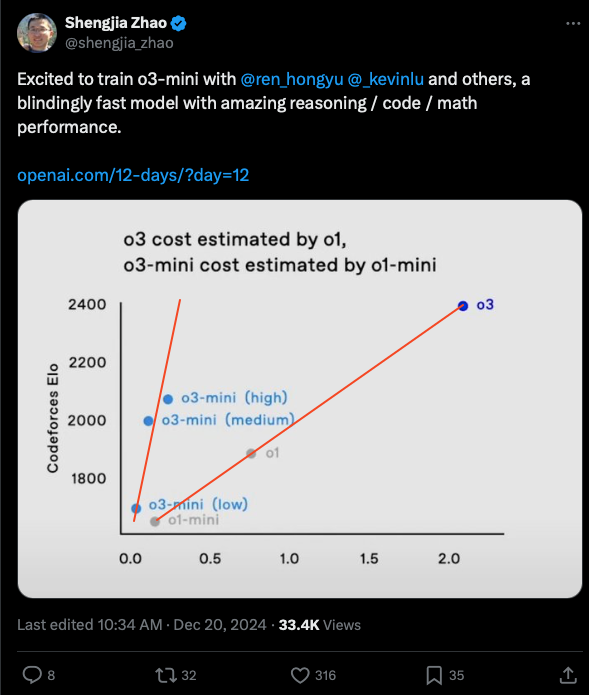
as sama says: "on many coding tasks, o3-mini will outperform o1 at a massive cost reduction! i expect this trend to continue, but also that the ability to get marginally more performance for exponentially more money will be really strange."
Eric Wallace also published a post on their o-series deliberative alignment strategy and applications are open for safety researchers to test it out.
Community recap videos, writeups, liveblogs, and architecture speculations are also worth checking out.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium (Windsurf) Discord
- Cursor IDE Discord
- aider (Paul Gauthier) Discord
- Interconnects (Nathan Lambert) Discord
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- Stackblitz (Bolt.new) Discord
- LM Studio Discord
- OpenRouter (Alex Atallah) Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- Latent Space Discord
- Notebook LM Discord Discord
- Perplexity AI Discord
- Nomic.ai (GPT4All) Discord
- Stability.ai (Stable Diffusion) Discord
- Cohere Discord
- LAION Discord
- GPU MODE Discord
- LlamaIndex Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- DSPy Discord
- OpenInterpreter Discord
- Axolotl AI Discord
- tinygrad (George Hotz) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium (Windsurf) ▷ #announcements (1 messages):
- Codeium (Windsurf) ▷ #content (1 messages):
- Codeium (Windsurf) ▷ #discussion (64 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (603 messages🔥🔥🔥):
- Cursor IDE ▷ #general (819 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (628 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (33 messages🔥):
- aider (Paul Gauthier) ▷ #links (5 messages):
- Interconnects (Nathan Lambert) ▷ #news (454 messages🔥🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (34 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (6 messages):
- Interconnects (Nathan Lambert) ▷ #memes (32 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (6 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (1 messages):
- Interconnects (Nathan Lambert) ▷ #reads (4 messages):
- Interconnects (Nathan Lambert) ▷ #lectures-and-projects (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (7 messages):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (401 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (6 messages):
- Unsloth AI (Daniel Han) ▷ #general (168 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (28 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (131 messages🔥🔥):
- Nous Research AI ▷ #general (298 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (15 messages🔥):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #reasoning-tasks (1 messages):
- Stackblitz (Bolt.new) ▷ #announcements (1 messages):
- Stackblitz (Bolt.new) ▷ #prompting (3 messages):
- Stackblitz (Bolt.new) ▷ #discussions (295 messages🔥🔥):
- LM Studio ▷ #general (103 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (103 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (170 messages🔥🔥):
- Eleuther ▷ #general (55 messages🔥🔥):
- Eleuther ▷ #research (68 messages🔥🔥):
- Eleuther ▷ #interpretability-general (14 messages🔥):
- Eleuther ▷ #lm-thunderdome (18 messages🔥):
- Eleuther ▷ #gpt-neox-dev (3 messages):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (142 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #max (3 messages):
- Latent Space ▷ #ai-general-chat (127 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (20 messages🔥):
- Notebook LM Discord ▷ #use-cases (38 messages🔥):
- Notebook LM Discord ▷ #general (106 messages🔥🔥):
- Perplexity AI ▷ #general (102 messages🔥🔥):
- Perplexity AI ▷ #sharing (5 messages):
- Nomic.ai (GPT4All) ▷ #announcements (3 messages):
- Nomic.ai (GPT4All) ▷ #general (90 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (81 messages🔥🔥):
- Cohere ▷ #discussions (58 messages🔥🔥):
- Cohere ▷ #questions (4 messages):
- Cohere ▷ #api-discussions (16 messages🔥):
- Cohere ▷ #projects (1 messages):
- LAION ▷ #general (10 messages🔥):
- LAION ▷ #research (57 messages🔥🔥):
- GPU MODE ▷ #general (11 messages🔥):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (9 messages🔥):
- GPU MODE ▷ #torch (3 messages):
- GPU MODE ▷ #algorithms (1 messages):
- GPU MODE ▷ #off-topic (3 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #arc-agi-2 (6 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (17 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (11 messages🔥):
- Torchtune ▷ #announcements (1 messages):
- Torchtune ▷ #general (7 messages):
- DSPy ▷ #general (7 messages):
- OpenInterpreter ▷ #general (7 messages):
- Axolotl AI ▷ #general (4 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
OpenAI Model Releases (o3 and o3-mini)
- o3 and o3-mini Announcements and Performance: @polynoamial announced o3 and o3-mini, highlighting o3 achieving 75.7% on ARC-AGI and 87.5% with high compute. @sama expressed excitement for the release and emphasized the safety testing underway.
- Benchmark Achievements of o3: @dmdohan noted o3 scoring 75.7% on ARC-AGI and @goodside congratulated the team for o3 achieving new SOTA on ARC-AGI.
Other AI Model Releases (Qwen2.5, Google Gemini, Anthropic Claude)
- Qwen2.5 Technical Advancements: @huybery released the Qwen2.5 Technical Report, detailing improvements in data quality, synthetic data pipelines, and reinforcement learning methods enhancing math and coding capabilities.
- Google Gemini Flash Thinking: @shane_guML discussed Gemini Flash 2.0 Thinking, describing it as fast, great, and cheap, outperforming competitors in reasoning tasks.
- Anthropic Claude Updates: @AnthropicAI shared insights into Anthropic's work on AI safety and scaling, emphasizing their responsible scaling policy and future directions.
Benchmarking and Performance Metrics
- FrontierMath and ARC-AGI Scores: @dmdohan highlighted o3's 25% on FrontierMath, a significant improvement from the previous 2%. Additionally, @cwolferesearch showcased o3's performance on multiple benchmarks, including SWE-bench and GPQA.
- Evaluation Methods and Challenges: @fchollet discussed the limitations of scaling laws and the importance of downstream task performance over traditional test loss metrics.
AI Safety, Alignment, and Ethics
- Deliberative Alignment for Safer Models: @cwolferesearch introduced Deliberative Alignment, a training approach aimed at enhancing model safety by using chain-of-thought reasoning to adhere to safety specifications.
- Societal Implications of AI Advancements: @Chamath emphasized the need to consider profound societal implications of AI advancements and their impact on future generations.
AI Tools, Applications, and Research
- CodeLLM for Enhanced Coding: @bindureddy introduced CodeLLM, an AI code editor integrating multiple LLMs like o1, Sonnet 3.5, and Gemini, offering unlimited introductory quota for developers.
- LlamaParse for Audio File Processing: @llama_index announced LlamaParse's ability to parse audio files, expanding its capabilities to handle speech-to-text conversions seamlessly.
- Stream-K for Improved Kernel Implementations: @hyhieu226 showcased Stream-K, enhancing GEMM kernels and providing a better view of kernel implementations for persistent kernels.
Memes and Humor
- Humorous Takes on AI and Culture: @dylan522p humorously stated, "Motherfuckers were market buying Nvidia stock cause OpenAI O3 is so fucking good", blending AI advancements with stock market humor.
- AI-Related Jokes and Puns: @teknium1 tweeted, "If anyone in NYC wanna meet I'll be at Stout, 4:00 to 5:30 with couple friends.", playfully mixing social plans with AI discussions.
- Lighthearted Comments on AI Trends: @saranormous shared a humorous reflection on posting clickbait content on X, blending AI content creation with social media humor.
AI Research and Technical Insights
- Mixture-of-Experts (MoE) Inference Costs: @EpochAIResearch explained that MoE models often have lower inference costs compared to dense models, clarifying common misconceptions in AI architecture.
- Neural Video Watermarking Framework: @AIatMeta introduced Meta Video Seal, a neural video watermarking framework, detailing its application in protecting video content.
- Query on LLM Inference-Time Self-Improvement: @omarsar0 posed a survey on LLM inference-time self-improvement, exploring techniques and challenges in enhancing AI reasoning capabilities.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. OpenAI's O3 Mini Outperforms Predecessors
- OpenAI just announced O3 and O3 mini (Score: 234, Comments: 186): OpenAI's newly announced O3 and O3 mini models show significant performance improvements, with O3 achieving an 87.5% score on the ARC-AGI test, which evaluates an AI's ability to learn new skills beyond its training data. This marks a substantial leap from O1's previous score of 25% to 32%, with Francois Chollet acknowledging the progress as "solid."
- Skepticism surrounds the ARC-AGI benchmark results, with users questioning its validity due to private testing conditions and the model being trained on a public training set, unlike previous versions. Concerns about AGI claims are expressed, emphasizing the benchmark's limitations in proving true AGI capabilities.
- The cost of achieving high performance with the O3 model is highlighted, with the 87.5% accuracy version costing significantly more than the 75.7% accuracy version. Users discuss the model's current economic viability and predict that cost-performance might improve over time, potentially making it more accessible.
- The naming choice of skipping "O2" due to trademark issues with British telecommunications giant O2 is noted, with some users expressing dissatisfaction with the naming conventions. Additionally, there is anticipation for public release and open-source alternatives, with a release expected in late January.
- 03 beats 99.8% competitive coders (Score: 121, Comments: 69): O3 has achieved a 2727 ELO rating on CodeForces, placing it in the 99.8th percentile of competitive coders. More details can be found in the CodeForces blog.
- O3's Performance and Computation Costs: O3 achieved significant performance on CodeForces with a 2727 ELO rating but required generating over 19.1 billion tokens to reach a high accuracy, incurring substantial costs, such as $1.15 million for the highest tier setting. The discussion highlights how compute costs are currently high but expected to decrease over time, emphasizing progress in AI capabilities.
- Challenges in AI Problem Solving: O3's approach is contrasted with traditional methods like CoT + MCTS, with comments noting its efficiency and scalability with compute, though it requires iterative processes to handle mistakes. The complexity of problems and the need for in-context computation are discussed, comparing AI's token generation to human problem-solving capabilities.
- Impact on Coding Interviews: The advancement of models like O3 sparks debate about the relevance of LeetCode-style interviews, with some suggesting they could become obsolete as AI improves. There's a call for interviews to incorporate modern tools like LLMs, and a humorous critique of the unrealistic nature of some technical interview questions.
- The o3 chart is logarithmic on X axis and linear on Y (Score: 139, Comments: 65): The O3 chart uses a logarithmic X-axis for "Cost Per Task" and a linear Y-axis for "Score," illustrating performance metrics of various models like O1 MIN, O1 PREVIEW, O3 LOW (Tuned), and O3 HIGH (Tuned). Notably, O3 HIGH (Tuned) achieves an 88% score at higher costs, contrasting with O1 LOW's 25% score at a $1 cost, highlighting the trade-off between cost and performance in ARC AGI evaluations.
- Several commenters criticize the O3 chart for its misleading representation due to the logarithmic X-axis, with hyperknot highlighting that the chart gives a false impression of linear progress towards AGI. Hyperknot further argues that achieving AGI would require a massive reduction in costs, estimating a need for a 10,000x decrease to make it viable.
- Discussions on the cost and practicality of AGI suggest skepticism about its current feasibility, with Uncle___Marty arguing against the trend of increasing model sizes and compute power. Others, like Ansible32, counter that demonstrating functional AGI is valuable, akin to research projects like ITER, although ForsookComparison questions the cost logic, suggesting high expenses might not be justified.
- There is debate over the progress in computational hardware, with Chemical_Mode2736 and mrjackspade discussing the potential for cost reductions and exponential improvements in compute power. However, EstarriolOfTheEast points out that recent advancements may not be as significant as they seem due to assumptions like fp8 or fp4 and increased power demands, suggesting a slowdown in exponential improvement.
Theme 2. Qwen QVQ-72B: New Frontiers in AI Modeling
- Qwen QVQ-72B-Preview is coming!!! (Score: 295, Comments: 48): Qwen QVQ-72B is a 72 billion parameter model with a pre-release placeholder now available on ModelScope. There is some uncertainty about the naming convention change from QwQ to QvQ, and it is unclear if it includes any specific reasoning capabilities.
- The Qwen QVQ-72B model is speculated to include vision/video capabilities, as indicated by Justin Lin's Twitter post, suggesting that the "V" in QVQ stands for Vision. There is a placeholder on ModelScope, but it may have been made private or taken down shortly after its creation.
- Discussions highlight the internal thought process of models, with comparisons drawn between QwQ and Google's model. Google's model is praised for its efficiency and transparency in reasoning, contrasting with QwQ's tendency to be verbose and potentially "adversarial" in its thought process, which can be cumbersome when running on CPU due to slow token generation.
- The potential for open-source contributions is discussed, with Google’s decision not to hide the model's reasoning being seen as beneficial for both competitors and the local LLM community. This transparency contrasts with OpenAI's approach, which does not reveal the reasoning process, potentially using techniques like MCTS at inference time.
- Qwen have released their Qwen2.5 Technical Report (Score: 175, Comments: 11): Qwen has released their Qwen2.5 Technical Report, though no additional information or details were provided in the post.
- Qwen2.5's Coding Capabilities: Users are impressed by the Qwen2.5-Coder model's ability to implement complex functions, like the Levenshtein distance method, without explicit instructions. The model benefits from a comprehensive multilingual sandbox for static code checking and unit testing, which enhances code quality and correctness across nearly 40 programming languages.
- Technical Report vs. White Paper: The term "technical report" is used instead of "white paper" because it allows some methodologies to be shared while keeping other details, such as model architecture and data, as trade secrets. This distinction is crucial for understanding the level of transparency and information shared in such documents.
- Model Training and Performance: The model's efficacy, especially in coding tasks, is attributed to its training on datasets from GitHub and code-related Q&A websites. Even the 14b model demonstrates strong performance in suggesting and implementing algorithms, with the 72b model expected to be even more powerful.
Theme 3. RWKV-7's Advances in Multilingual and Long Context Processing
- RWKV-7 0.1B (L12-D768) trained w/ ctx4k solves NIAH 16k, extrapolates to 32k+, 100% RNN (attention-free), supports 100+ languages and code (Score: 117, Comments: 16): RWKV-7 0.1B (L12-D768) is an attention-free, 100% RNN model excelling at long context tasks and supporting over 100 languages and code. Trained on a multilingual dataset with 1 trillion tokens, it outperforms other models like SSM (Mamba1/Mamba2) and RWKV-6 in handling long contexts, using in-context gradient descent for test-time-training. The RWKV community also developed a tiny RWKV-6 model capable of solving complex problems like sudoku with extensive chain-of-thought reasoning, maintaining constant speed and VRAM usage regardless of context length.
- RWKV's Future Potential: Enthusiasts express excitement for the potential of RWKV models, especially in their ability to outperform traditional transformer-based models with attention layers in reasoning tasks. The community anticipates advancements in scaling beyond 1B parameters and the release of larger models like the 3B model.
- Learning Resources: There is a demand for comprehensive resources to learn about RWKV, indicating interest in understanding its architecture and applications.
- Research and Development: A user shares an experience of attempting to create an RWKV image generation model, highlighting the model's capabilities and the ongoing research efforts to optimize it further. The discussion includes a reference to a related paper: arxiv.org/pdf/2404.04478.
Theme 4. Open-Source AI: The Necessary Evolution
- The real reason why, not only is opensource AI necessary, but also needs to evolve (Score: 57, Comments: 25): The author criticizes OpenAI's pricing strategy for their o1 models, highlighting the high costs associated with both base prices and invisible output tokens, which they argue amounts to a monopoly-like practice. They advocate for open-source AI and community collaboration to prevent monopolistic behavior and ensure the benefits of competition, noting that companies like Google may offer lower prices but not out of goodwill.
- Monopoly Concerns: Commenters agree that monopolistic behavior is likely in the AI field, as seen in other industries where early entrants push for regulations to maintain their market dominance. OpenAI's pricing strategy is viewed as anti-consumer, similar to practices by companies like Apple that charge premiums for exclusivity.
- Invisible Output Tokens: There's a discussion about the costs associated with "invisible" output tokens, where critics argue that charging for these as if they were part of a larger model is unfair. Some believe that users should be able to see the tokens since they are paying for them.
- Open Source vs. Big Tech: There's a belief that open-source models can foster competition in pricing, similar to how render farms operate in the rendering world. Collaboration between open-source communities and smaller companies is seen as a potential way to challenge the dominance of big players like OpenAI and Google.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. OpenAI's O3: High ARC-AGI Performance But High Cost
- OpenAI's new model, o3, shows a huge leap in the world's hardest math benchmark (Score: 196, Comments: 80): OpenAI's new model, o3, demonstrates significant progress in the ARC-AGI math benchmark, achieving an accuracy of 25.2%, compared to the previous state-of-the-art model's 2.0%. This performance leap underscores o3's advancements in tackling complex mathematical problems.
- Discussion on AI's Role in Research: Ormusn2o emphasizes the potential of AI models like o3 in advancing autonomous and assisted machine learning research, which could be crucial for achieving AGI. Meanwhile, ColonelStoic discusses the limitations of current LLMs in handling complex mathematical proofs, suggesting the integration with automated proof checkers like Lean for improvement.
- Clarification on Benchmark and Model Performance: FateOfMuffins points out a misunderstanding regarding the benchmark, clarifying that the 25% accuracy pertains to the ASI math benchmark and is not directly comparable to human performance at the graduate level. Elliotglazer further explains the tiered difficulty levels within FrontierMath, noting that the performance spans different problem complexities.
- Model Evaluation and Utilization: Craygen9 expresses interest in evaluating the model's performance across various specialized domains, advocating for the development of models tailored to specific fields like math, coding, and medicine. Marcmar11 and DazerHD1 discuss the performance metrics, highlighting differences in model performance based on thinking time, with dark blue indicating low thinking time and light blue indicating high thinking time.
- Year 2025 will be interesting - Google was joke until December and now I have a feeling 2025 will be very Good for Google (Score: 118, Comments: 26): Logan Kilpatrick expresses optimism for significant advancements in AI coding models by 2025, receiving substantial engagement with 2,400 likes. Alex Albert responds skeptically, suggesting uncertainty about these advancements, and his reply also attracts attention with 639 likes.
- OpenAI vs. Google: Commenters discuss the flexibility of OpenAI compared to Google due to corporate constraints, suggesting that both companies are now on more equal footing. Some express skepticism about Google's ability to improve their AI offerings, particularly with concerns about their search functionality and potential ad tech interference.
- Gemini Model: The Gemini model is highlighted as a significant advancement, with one user noting its superior performance compared to previous models like 4o and 3.5 sonnet. There's debate about its capabilities, particularly its native multimodal support for text, image, and audio.
- Corporate Influence: There is a shared sentiment of distrust towards Google's influence on AI advancements, with concerns about the potential negative impact of business and advertising departments on the Gemini model by 2025. Users express a mix of skepticism and anticipation for future developments in the AI landscape.
- OpenAI o3 performance on ARC-AGI (Score: 138, Comments: 88): The post links to an image, but no specific details or context about O3 performance on ARC-AGI are provided in the text body itself.
- Discussions highlight O3's significant performance gains on the ARC-AGI benchmark. RedGambitt_ emphasizes that O3 represents a leap in AI capabilities, fixing limitations in the LLM paradigm and requiring updated intuitions about AI. Despite its high performance, O3 is not considered AGI, as noted by phil917, who cites the ARC-AGI blog stating that O3 still fails on simple tasks and that ARC-AGI-2 will present new challenges.
- The cost of using O3 is a major concern, with daemeh and ReadySetPunish noting prices of around $20 per task for O3(low) and $3500 for O3(high). Phil917 mentions that the high compute variant could cost approximately $350,000 for 100 questions, highlighting the prohibitive expense for widespread use.
- The conversation includes skepticism about AGI, with hixon4 and phil917 pointing out that passing the ARC-AGI does not equate to achieving AGI. The high costs and limitations of O3 are discussed, with phil917 noting potential data contamination in results due to training on benchmark data, which diminishes the impressiveness of O3's scores.
Theme 2. Google's Gemini 2.5 Eclipses Competitors amid O3 Buzz
- He won guys (Score: 117, Comments: 25): Gary Marcus predicts by the end of 2024 there will be 7-10 GPT-4 level models but no significant advancements like GPT-5, leading to price wars and minimal competitive advantages. He highlights ongoing issues with AI hallucinations and expects only modest corporate adoption and profits.
- Discussions highlight skepticism around Gary Marcus's predictions, with users questioning the credibility of his forecasts and suggesting that OpenAI is currently leading over Google. However, some argue that Google might still achieve breakthroughs in Chain of Thought (CoT) capabilities with upcoming models.
- There is debate over the release and impact of OpenAI's o3 model, with some users noting that its availability and pricing could limit its accessibility. While o3-mini is expected by the end of January, doubts remain about the timeliness and public access of these releases.
- Users discuss the efficiency and potential cost benefits of new reasoning models for automated workflows, contrasting them with the complexity and resource requirements of previous models like GPT-4. These advancements are seen as smarter solutions for powering automated systems.
Theme 3. TinyBox GPU Manipulations and Networking Deception
- I would hate to be priced out of AI (Score: 126, Comments: 91): The post discusses concerns over the rising costs of AI services, particularly with the O1 unlimited plan already at $200 per month and potential future pricing of $2,000 per month for agentic AI. The author expresses frustration about being priced out of quality AI while acknowledging the possible justifications for these costs, prompting reflection on the broader pricing trajectory of AI technologies.
- There is a strong sentiment that open-source AI is critical to counteract the high costs of proprietary AI solutions, as expressed by GBJI who advocates supporting FOSS AI developers to fight corporate control. The concern is that high pricing could create a bottleneck for global intelligence, disadvantaging researchers outside the US/EU and stifling innovation, as noted by Odd_Category_1038.
- LegitimateLength1916 and BlueberryFew613 discuss the economic implications of AI agents potentially replacing workers, with the former suggesting businesses will opt for AI over human employees due to cost savings. However, BlueberryFew613 argues that current AI lacks the capability and infrastructure to fully replace skilled professionals, emphasizing the need for advancements in symbolic reasoning and AI integration.
- NoWeather1702 raises concerns about the scalability of AI due to insufficient energy and compute power, noting that the growth in power/compute needed for LLMs is outpacing production. ThenExtension9196, working in the global data center industry, assures that efforts are underway to address this issue.
Theme 4. ChatGPT Pro Pricing and Market Impact Discussion
- Will OpenAI release 2000$ subscription? (Score: 349, Comments: 144): The post speculates about a potential $2000 subscription from OpenAI, referencing a playful Twitter post by Sam Altman dated December 20, 2024. The post humorously suggests a connection between the sequence "ooo -> 000 -> 2000" and Altman's tweet, which features casual and humorous engagement metrics.
- O3 Model Speculation: There are discussions about a potential new model, O3, as a successor to O1O3. This speculation arises because O2 is already a trademarked phone provider in Europe, and some users humorously suggest it might offer limited messages per week for different subscription tiers.
- Pricing and Value Concerns: Commenters express skepticism about the rumored $2000/month subscription, joking that such a price would warrant an AGI (Artificial General Intelligence), which they believe would be worth much more.
- Humor and Satire: The comments are filled with humor, referencing a potential NSFW companion model and playful associations with Ozempic and OnlyFans. There's a satirical take on the marketing strategy with phrases like "ho ho ho" and "oh oh oh."
AI Discord Recap
A summary of Summaries of Summaries by o1-2024-12-17
Theme 1. The O3 Frenzy and New Benchmarks
- O3 Breaks ARC-AGI: OpenAI’s O3 model hit 75.7% on the ARC-AGI Semi-Private Evaluation and soared to 87.5% in high-compute mode. Engineers cheered its “punch above its weight” reasoning, though critics worried about the model’s massive inference costs.
- High-Compute Mode Burns Big Money: Some evaluations cost thousands of dollars per run, suggesting big companies can push performance at a steep price. Smaller outfits fear the compute barrier and suspect O3’s Musk-tier budget puts SOTA gains out of reach for many.
- O2 Goes Missing, O3 Arrives Fast: OpenAI skipped “O2” over rumored trademark conflicts, rolling out O3 just months after O1. Jokes about naming aside, devs marveled at the breakneck progression from one frontier model to the next.
Theme 2. AI Editor Madness: Codeium, Cursor, Aider, and More
- Cursor 0.44.5 Ramps Up Productivity: Users praised the new version’s agent mode as fast and stable, fueling a return to Cursor from rival IDEs. A fresh $100M funding round at a $2.5B valuation added extra hype to its flexible coding environment.
- Codeium ‘Send to Cascade’ Streams Bug Reports: Codeium’s Windsurf 1.1.1 update introduced a button to forward issues straight to Cascade, removing friction from debugging. Members tested bigger images and legacy chat modes with success, referencing plan usage details in the docs.
- Aider and Cline Tag-Team Repos: Aider handles tiny code tweaks while Cline knocks out bigger automation tasks thanks to extended memory features. Devs see a sharper workflow with fewer repetitive chores and a complimentary synergy between the two tools.
Theme 3. Fine-Tuning Feuds: LoRA, QLoRA, and Pruning
- LoRA Sparks Hot Debate: Critics questioned LoRA’s effectiveness on out-of-distribution data, while others insisted it’s a must for super-sized models. Some proposed full finetuning for consistent results, igniting a never-ending training argument.
- QAT + LoRA Hit Torchtune v0.5.0: The new recipe merges quantization-aware training with LoRA to create leaner, specialized LLMs. Early adopters loved the interplay between smaller file sizes and decent performance gains.
- Vocab Pruning Proves Prickly: Some devs prune unneeded tokens to reduce memory usage but keep fp32 parameters to preserve accuracy. This balancing act highlights the messy realities of training edge-case models at scale.
Theme 4. Agents, RL Methods, and Rival Model Showdowns
- HL Chat: Anthropic’s Surprise and Building Anthropic: Fans teased a possible holiday drop, noticing the team’s enthusiastic environment. Jokes about Dario’s “cute munchkin” vibe underscored the fun tone around agent releases.
- RL Without Full Verification: Some teams speculated on reward-model flip-flops when tasks lack a perfect checker, suggesting “loose verifiers” or simpler binary heuristics. They expect bigger RL+LLM milestones by 2025, bridging uncertain outputs with half-baked reward signals.
- Gemini 2.0 Flash Thinking Fights O1: Google’s new model displays thought tokens openly, letting devs see step-by-step logic. Observers praised the transparency but questioned whether O3 now outshines Gemini in code and math tasks.
Theme 5. Creative & Multimedia AI: Notebook LM, SDXL, And Friends
- Notebook LM Pumps Out Podcasts: Students and creators used AI to automate entire show segments with consistent audio quality. The tool also helps build timelines and mind maps for journalism or academic writing, showcasing flexible content generation.
- SDXL + LoRA Rock Anime Scenes: Artists praised SDXL’s robust styles while augmenting with LoRA for anime artistry. Users overcame style mismatches, preserving color schemes for game scenes and character designs.
- AniDoc Colors Frames Like Magic: Gradio’s AniDoc transforms rough sketches into fully colored animations, handling poses and scales gracefully. Devs hailed it as a strong extension to speed up visual storytelling and prototyping.
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
- Windsurf 1.1.1 Shines with Pricing & Image Upgrades: The Windsurf 1.1.1 update introduced a 'Send to Cascade' button, usage info on plan statuses, and removed the 1MB limit on images, as noted in the changelog.
- Community members tested the 'Legacy Chat' mode and praised the new Python enhancements, referencing details in the usage docs.
- Send to Cascade Showcases Quick Issue Routing: A short demo highlighted the 'Send to Cascade' feature letting users escalate problems to Cascade, shown in a tweet.
- Contributors encouraged everyone to try it, noting the convenience of swiftly combining user feedback with dedicated troubleshooting.
- Cascade Errors Prompt Chat Resets: Users encountered internal error messages in Cascade when chats grew lengthy, prompting them to start new sessions for stability.
- They stressed concise conversation management to sustain performance, pointing to the benefits of smaller chat logs.
- Subscription Plans Confuse Some Members: One user questioned the halt of a trial pro plan for Windsurf, sparking conversation over free vs tiered features with references to Plan Settings.
- Others swapped experiences on usage limits, highlighting the differences between the extension, Cascade, and Windsurf packages.
- CLI Add-Ons and Performance Fuel Debates: Some participants requested better integration with external tools like Warp or Gemini, while noting fluctuating performance at various times of day.
- They emphasized the potential synergy of Command Line Interface usage with AI-driven coding, though concerns about slowdowns in large codebases persisted.
Cursor IDE Discord
- Cursor 0.44.5 Boosts Productivity & Attracts Funding: Developers reported that Cursor's version 0.44.5 shows marked performance improvements, particularly in agent mode, prompting many to switch back to Cursor from rival editors.
- TechCrunch revealed a new $100M funding round at a $2.5B valuation for Cursor, suggesting strong investor enthusiasm for AI-driven coding solutions.
- AI Tools Turbocharge Dev Efforts: Participants highlighted how AI-powered features reduce coding time and broaden solution searches, allowing them to finish projects more efficiently.
- They noted synergy with extra guidance from tutorials like Building effective agents, which ensure practical integration of large language models into workflows.
- Sonnet Models Spark Mixed Feedback: Users compared multiple Sonnet releases, with some praising the latest version's UI generation chops while others reported inconsistent output quality.
- They observed that system prompts can significantly impact the model's behavior, leading certain developers to adjust their approach for better results.
- Freelancers Embrace AI for Faster Delivery: Freelance contributors shared examples of using AI to automate tedious coding tasks and clean up project backlogs more rapidly.
- A few voiced concerns about clients' skepticism regarding AI usage, but overall sentiment remained positive given improved outcomes.
- UI Styling Challenges Persist in AI-Created Layouts: While AI handles backend logic effectively, it struggles with refined styling elements, forcing developers to fix front-end design issues manually.
- This shortfall emphasizes the need for more training data on visual components, which could enhance a tool’s ability to produce polished interfaces.
aider (Paul Gauthier) Discord
- OpenAI O3 Gains Speed: Benchmarks show OpenAI O3 hitting 75.7% on the ARC-AGI Semi-Private Evaluation, as noted in this tweet.
- A follow-up post from ARC Prize mentioned a high-compute O3 build scoring 87.5%, sparking talk about cost and performance improvements.
- Aider and Cline Join Forces: Developers employed Aider for smaller coding tweaks, while Cline handled heavier automation tasks with its stronger memory capabilities.
- They observed a boost in workflow by pairing these tools, reducing manual repetition in software development.
- AI Job Security Worries Grow: Commenters voiced concern that AI could displace parts of the coding role by automating simpler tasks.
- Others insisted the human element remains key for complex problem-solving, so the developer position should remain vital.
- Depth AI Steps Up for Code Insights: Engineers tested Depth AI on large codebases, noting its full knowledge graph and cross-platform integration at trydepth.ai.
- One user stopped using it when they no longer needed retrieval-augmented generation, but still praised its potential.
- AniDoc Colors Sketches with Ease: The new AniDoc tool converts rough frames into fully colored animations based on style references.
- Users appreciated its ability to handle various poses and scales, calling it an effective extension for visual storytelling.
Interconnects (Nathan Lambert) Discord
- O3’s Overdrive on ARC-AGI: OpenAI revealed O3 scoring 87.5% on the ARC-AGI test, skipping the name O2 and moving from O1 to O3 in three months, as shown in this tweet.
- Community members argued about high inference costs and GPU usage, with one joking that Nvidia stock is surging because of O3’s strong results.
- LoRA’s Limited Gains: A user questioned LoRA finetuning, pointing to an analysis paper that doubts LoRA’s effectiveness outside the training set.
- Others emphasized that LoRA becomes necessary with bigger models, sparking debate over whether full finetuning might yield more consistent results.
- Chollet Dubs O1 The Next AlphaGo: François Chollet likened O1 to AlphaGo, explaining in this post that both use extensive processes for a single move or output.
- He insisted that labeling O1 a simple language model is misleading, spurring members to question whether O1 secretly uses search-like methods.
- RL & RLHF Reward Model Challenges: Some members argued that Reinforcement Learning with uncertain outputs needs specialized reward criteria, suggesting a loose verifier for simpler tasks and linking to this discussion.
- They warned about noise in reward models, highlighting a push toward binary checks in domains like aesthetics and predicting bigger RL + LLM breakthroughs in 2025.
- Anthropic’s Surprise Release & Building Anthropic Chat: A possible Anthropic holiday release fueled speculation, though one member joked that Anthropic is too polite for a sudden product drop.
- In the YouTube video about Building Anthropic, participants playfully described Dario as a 'cute little munchkin' and praised the team’s upbeat environment.
OpenAI Discord
- OpenAI's 12th Day Finale Excites Crowd: The closing day of 12 Days of OpenAI featured Sam Altman, Mark Chen, and Hongyu Ren, with viewers directed to watch the live event here.
- Many anticipated concluding insights and potential announcements from these key figures.
- O3 Model Fever Spurs Comparisons: Participants speculated o3 might rival Google’s Gemini, with OpenAI's pricing raising questions about its market edge.
- A tweet highlighted o3’s coding benchmark rank of #175 globally, amplifying interest.
- OpenAI Direction Triggers Mixed Reactions: Some voiced dissatisfaction over OpenAI's transition away from open-source roots toward paid services, citing fewer free materials.
- Commenters doubted the accessibility of future model releases under this pricing structure.
- Chatbot Queries & 4o Restriction: A user highlighted that custom GPTs are locked to 4o, restricting model flexibility.
- Developers also sought advice on crafting a bot to interpret software features and guide users in plain language.
Unsloth AI (Daniel Han) Discord
- O3 Gains & Skeptics Collide: The new O3 soared to 75.7% on ARC-AGI's public leaderboard, spurring interest in whether it uses a fresh model, refined data strategy, and massive compute.
- Some called the results interesting but questioned if O1 plus fine-tuning hacks might explain the bump, pointing to possible oversights in the official publication.
- FrontierMath's Surprising Accuracy: A new FrontierMath result jumped from 2% to 25%, according to a tweet by David Dohan, challenging prior assumptions about advanced math tasks.
- Community members cited Terence Tao stating this dataset should remain out of AI's reach for years, while others worried about potential overfitting or data leakage.
- RAG & Kaggle Speed Fine-Tuning: RAG training dropped from 3 hours to 15 minutes by leveraging GitHub materials, with a 75k-row CSV converted from JSON boosting model accuracy.
- Some suggested Kaggle for 30 free GPU hours weekly, and encouraged focusing on data quality over sheer volume for Llama fine-tuning.
- SDXL & LoRA Team Up for Anime: Users praised SDXL for strong anime results, noting that Miyabi Hoshimi's LoRA model can boost style accuracy.
- Others reported difficulty pairing Flux with LoRA for consistent anime outputs, expecting Unsloth support for Flux soon.
- TGI vs vLLM Showdown: TGI and vLLM sparked debate over speed and adapter handling, referencing Text Generation Inference docs.
- Some prefer vLLM for its flexible approach, while others champion TGI for reliably serving large-scale model deployments.
Nous Research AI Discord
- O3 Breaks the Bank, Bests O1: The freshly announced O3 model outperformed O1 in coding tasks and rang up a compute bill of $1,600,250, as noted in this tweet.
- Enthusiasts pointed to substantial financial barriers, remarking that the high cost could limit widespread adoption.
- Gemini 2.0 Stages a Flashy Showdown: Google introduced Gemini 2.0 Flash Thinking to rival OpenAI’s O1, allowing users to see step-by-step reasoning as reported in this article.
- Observers contrasted it with O1, highlighting the new dropdown-based explanation feature as a significant step toward transparent model introspection.
- Llama 3.3’s Overeager Function Calls: Members noted Llama 3.3 is much quicker to trigger function calls than Hermes 3 70b, which can drive up costs.
- They found Hermes more measured with calls, reducing expense and improving consistency overall.
- Subconscious Prompting Sparks Curiosity: A proposal for latent influence injecting in prompts surfaced, drawing parallels to subtle NLP-style interventions.
- Participants discussed the possibility of shaping outputs without direct references, likening it to behind-the-scenes suggestions.
- Thinking Big with
Tag Datasets : A collaboration effort emerged to build a reasoning dataset using thetag, targeting models like O1-Preview or O3. - Contributors aim to embed full reasoning traces in the raw data for improved clarity, seeking synergy between structured thought and final answers.
Stackblitz (Bolt.new) Discord
- Merry Madness with Mistletokens: The Bolt team introduced Mistletokens with 2M free tokens for Pro users until year-end and 200K daily plus a 2M monthly limit for free users.
- They aim to spark more seasonal projects and solutions with these expanded holiday token perks.
- Bolt Battles Redundancy: Developers complained about Bolt draining tokens without cleaning duplicates, referencing 'A lot of duplication with diffs on.'
- Some overcame the issue through targeted reviews like 'Please do a thorough review and audit of [The Auth Flow of my application].' that forced it to address redundancy.
- Integration Bugs Spark Frustration: Multiple users noted Bolt automatically creating new Supabase instances instead of reusing old ones, which led to wasted tokens.
- Repeated rate-limits triggered more complaints, with users insisting purchased tokens should exempt them from free plan constraints.
- WebRTC Dreams and Real-time Streams: Efforts to integrate WebRTC for video chat apps on Bolt resulted in technical difficulties around real-time features.
- Community members requested pre-built WebRTC solutions with customizable configurations for smoother media handling.
- Subscription Tango and Storefront Showoff: Many grew wary of needing an active subscription to tap purchased token reloads, urging clearer payment guidelines.
- Meanwhile, a dev previewed a full-stack ecommerce project with a headless backend, a refined storefront, and a visual editor aiming to stand on its own.
LM Studio Discord
- OpenAI Defamation Disruption: A linked YouTube video showed a legal threat against OpenAI accusing the AI of making defamatory statements about a specific individual.
- Members debated how training on open web data could produce erroneous attributions, raising concerns about name filters in final outputs.
- LM Studio's Naming Nook: Participants noticed LM Studio auto-generates chat names, likely by using a small built-in model to summarize the conversation.
- Some speculated that a bundled summarizer is embedded, making chat interactions more seamless and user-friendly.
- 3090 Gobbles 16B Models: Engineers affirmed that a 3090 GPU with 64 GB RAM plus a 5800X processor can handle 16B parameter models at comfortable token speeds.
- They mentioned 70B models still need higher VRAM and smart quantization strategies to maintain useful performance.
- Parameter Quantization Quips: Enthusiasts explained that Q8 quantization is often nearly lossless for many models, while Q6 still preserves decent precision.
- They highlighted trade-offs between smaller file sizes and model accuracy, emphasizing balanced approaches for best results.
- eGPU Power Plays: One member showcased a Razer Core X rig with a 3090 to turbocharge an i7 laptop via Thunderbolt.
- This setup sparked interest in external GPUs as a flexible choice for those wanting desktop-grade performance on portable systems.
OpenRouter (Alex Atallah) Discord
- Gemini 2.0 Flash Thinking Flickers: Google introduced the new Gemini 2.0 Flash Thinking model that outputs thinking tokens directly into text, now accessible on OpenRouter.
- It's briefly unavailable for some users, but you can request access via Discord if you're keen on experimenting.
- BYOK & Fee Talk Takes Center Stage: The BYOK (Bring Your Own API Keys) launch allows users to pool their own provider credits with OpenRouter’s, incurring a 5% fee on top of upstream costs.
- A quick example was requested to clarify fee structures, and updated docs will detail how usage fees combine provider rates plus that extra slice.
- AI To-Do List Taps 5-Minute Rule: An AI To-Do List built on Open Router harnesses the 5-Minute Rule to jump-start tasks automatically.
- It also creates new tasks recursively, leaving users to remark that “it’s actually fun to do work.”
- Fresh Model Releases & AGI Dispute: Community chatter hints at o3-mini and o3 arriving soon, with naming conflicts sparking inside jokes.
- Debate over AGI took a turn with some calling the topic a 'red herring', directing curious minds to a 1.5-hour video discussion.
- Crypto Payments API Sparks Funding Flow: The new Crypto Payments API lets LLMs handle on-chain transactions through ETH, 0xPolygon, and Base, as detailed in OpenRouter's tweet.
- It introduces headless, autonomous financing, giving agents methods to transact independently and opening avenues for novel use cases.
Eleuther Discord
- Natural Attention Nudges Adam: Jeroaranda introduced a Natural Attention approach that approximates the Fisher matrix and surpasses Adam in certain training scenarios, referencing proof details on GitHub.
- Community members stressed the need for a causal mask and debated quality vs. quantity in pretraining data, underscoring intensive verification for these claims.
- MSR’s Ethical Quagmire Exposed: Concerns about MSR’s ethics erupted following examples of plagiarism, involving two papers including a NeurIPS spotlight award runner-up.
- Participants expressed distrust in referencing MSR work and questioned the credibility of their research environment, warning others to tread carefully.
- BOS Token’s Inordinate Influence: Members discovered that BOS token positions can have activation norms up to 30x higher, potentially skewing SAE training results.
- They suggested excluding BOS from training data or applying normalization to mitigate the disproportionate effect, referencing short-context experiments with 2k and 1024 context lengths.
- Benchmark Directory Debacle: Users were thrown off by logs saving to
./benchmark_logs/name/__mnt__weka__home__...instead of./benchmark_logs/name/, complicating multi-model runs.- They proposed unique naming conventions and a specialized harness for comparing all checkpoints, balancing improvement with backwards compatibility.
- GPT-Neox MFU Logging Gains Traction: Pull Request #1331 added MFU/HFU metrics for
neox_args.peak_theoretical_tflopsusage and integrated these stats into WandB and TensorBoard.- The community appreciated the new tokens_per_sec and iters_per_sec logs, and merged the PR after positive feedback despite delayed testing.
Modular (Mojo 🔥) Discord
- FFI Friction: v24.6 Tangle: An upgrade from v24.5 to v24.6 triggered clashes with the standard library’s built-in write function, complicating socket usage in Mojo.
- Developers proposed FileDescriptor as a workaround, referencing write(3p) to avoid symbol collisions.
- Libc Bindings for Leaner Mojo: Members pushed for broader libc bindings, reporting 150+ functions already sketched out for Mojo integration.
- They advocated a single repository for these bindings to bolster cross-platform testing and system-level functionality.
- Float Parsing Hits a Snag: Porting float parsing from Lemire fell short, with standard library methods also proving slower than expected.
- A pending PR seeks to upgrade atof and boost numeric handling, aiming to refine performance in data-heavy tasks.
- Tensorlike Trait Tussle: A request at GitHub Issue #274 asked tensor.Tensor to implement tensor_utils.TensorLike, asserting it already meets the criteria.
- Arguments arose about
Tensoras a trait vs. type, reflecting the challenge of direct instantiation within MAX APIs.
- Arguments arose about
- Modular Mail: Wrapping Up 2024: Modular thanked the community for a productive 2024, announcing a holiday shutdown until January 6 with reduced replies during this period.
- They invited feedback on the 24.6 release via a forum thread and GitHub Issues, fueling anticipation for 2025.
Latent Space Discord
- OpenAI’s O3 Surges on ARC-AGI: OpenAI introduced the O3 model, scoring 75.7% on the ARC-AGI Semi-Private Evaluation and 87.5% in high-compute mode, indicating strong reasoning performance. Researchers mentioned possible parallel Chain-of-Thought mechanisms and substantial resource demands.
- Many debated the model’s cost—rumored at around $1.5 million—while celebrating leaps in code, math, and logic tasks.
- Alec Radford Departure: Alec Radford, known for his early GPT contributions, confirmed his exit from OpenAI for independent research. Members speculated about leadership shifts and potential impact on upcoming model releases.
- Some predicted an internal pivot soon, and others hailed Radford’s past work as key to GPT’s foundation.
- Economic Tensions in High-Compute AI: Discussions raised concerns that hefty computational budgets, like those powering O3, might hamper commercial viability. Participants cautioned that while breakthroughs are exciting, they carry significant operating costs.
- They weighed whether the improved performance on ARC-AGI justifies the expenditure, especially for specialized tasks in code and math.
- Safety Testing Takes Center Stage: OpenAI invited volunteers to stress-test O3 and O3-mini, reflecting an emphasis on spotting potential misuse. This call underscores the push for thorough vetting before wider deployment.
- Safety researchers welcomed the opportunity, reinforcing community-driven oversight as a key measure of responsible AI progress.
- API Keys & Character AI Role-Play: Developers reported tinkering with API keys, highlighting day-to-day experimentation in the AI community. Meanwhile, Character AI draws a younger demographic, with interest in 'Disney princess' style interactions.
- Participants noted user experience signals, referencing “magical math rocks” humor to highlight playful engagement beyond typical business applications.
Notebook LM Discord Discord
- Podcasting Gains Steam with AI: One conversation highlighted the use of AI to produce a podcast episode, accelerating content creation and improving section audio consistency.
- Additionally, a project titled Churros in the Void used Notebook LM and LTX-studio for visuals and voiceovers, reinforcing a self-driven approach to voice acting.
- Notebook LM Bolsters Education: One user described Notebook LM as a powerful tool for building timelines and mind maps in a Journalism class, referencing data from this notebook.
- They integrated course materials and topic-specific podcasts, reporting improved organization of content for coherent papers.
- AI Preps Job Applicants: One member used Notebook LM to analyze their resume against a job ad, generating a custom study guide for upcoming interviews.
- They recommended others upload resumes for immediate pointers on skill alignment.
- Interactive Mode & Citation Tools Hit Snags: Several users struggled to access the new voice-based interactive mode, raising questions about its uneven rollout.
- Others reported a glitch that removed citation features in saved notes, and the dev team confirmed a fix is in progress.
- Audio Overviews & Language Limitations: A user requested tips on recovering a missing audio overview, noting the difficulty of reproducing an identical version once it's lost.
- Similar threads explored how Notebook LM might handle diverse language sources more accurately by separating content into distinct sets.
Perplexity AI Discord
- OpenAI’s O3 Overdrive: OpenAI introduced new o3 and o3-mini models, with coverage from TechCrunch that stirred conversation regarding potential performance leaps beyond the o1 milestone.
- Some participants highlighted the significance of these releases for large-scale deployments, while referencing a video presentation where Sam Altman called for test-driven caution.
- Lepton AI Nudges Node Payment: A newly launched Node-based pay solution echoed the open-source blueprint from Lepton AI with discussions questioning originality.
- Comments pointed to the GitHub repo as evidence of prior open efforts, fueling arguments about reuse and proper citations.
- Samsung’s Moohan Mission: Samsung introduced Project Moohan as an AI-based initiative, prompting speculation about new integrated features.
- Details remain few, but participants are curious about synergy with existing hardware and AI platforms.
- AI Use at Work Surges: A recent survey claimed that over 70% of employees are incorporating AI into their daily tasks.
- People noted how new generative tools streamline code reviews and documentation, suggesting a rising standard for advanced automation.
Nomic.ai (GPT4All) Discord
- GPT4All v3.6.x: Swift Steps, Snappy Fixes: The new GPT4All v3.6.0 arrived with Reasoner v1, a built-in JavaScript code interpreter, plus template compatibility improvements.
- Community members promptly addressed regression bugs in v3.6.1, with Adam Treat and Jared Van Bortel leading the charge as seen in Issue #3333.
- Llama 3.3 & Qwen2 Step Up: Members highlighted functional gains in Llama 3.3 and Qwen2, citing improved performance over previous iterations.
- They referenced a post from Logan Kilpatrick showcasing puzzle-solving with visual and textual elements.
- Phi-4 Punches Above Its Weight: The Phi-4 model at 14B parameters reportedly rivals Llama 3.3 70B according to Hugging Face.
- Community testers commented on smooth local runs, noting strong performance and enthusiasm for further trials.
- Custom Templates & LocalDocs Link Up: A specialized GPT4All chat template utilizes a code interpreter for robust reasoning, verified to function with multiple model types.
- Members described connecting the GPT4All local API server with LocalDocs (Docs), enabling effective offline operation.
Stability.ai (Stable Diffusion) Discord
- Local Generator Showdown: SD1.5 vs SDXL 1.0: Some members praised SD1.5 for stable performance, while others recommended SDXL 1.0 with comfyUI for advanced results.
- They noted improvements in text-to-image clarity for concept art and stressed the minimal setup headaches of these local models.
- Flux-Style Copy Gains Steam: A user got Flux running locally and asked for tips on matching a reference image's style for game scenes.
- They mentioned successfully preserving color schemes and silhouettes, citing consistent parameters in Flux.
- Scams: Tech Support Server Raises Red Flags: A suspicious group claiming to offer Discord help requested wallet details, sparking security concerns.
- Members compared safer alternatives and reminded each other about standard cautionary measures.
- SF3D Emerges for 3D Asset Creation: Enthusiasts pointed to stabilityai/stable-fast-3d on Hugging Face for generating isometric characters and props.
- They reported stable results for creating game-ready objects with fewer artifacts than other approaches.
- LoRA Magic for Personal Art Training: An artist described wanting faster art generation by training new models with their own images.
- Others recommended LoRA finetuning, especially for Flux or SD 3.5, to lock in style details.
Cohere Discord
- Cohere c4ai Commands MLX Momentum: During an MLX integration push, members tested Cohere’s c4ai-command-r7b model, praising improved open source synergy.
- They highlighted early VLLM support and pointed to a pull request that could accelerate further expansions.
- 128K Context Feat Impresses Fans: A community review showcased Cohere’s model handling a 211009-token danganronpa fanfic on 11.5 GB of memory.
- Discussions credited the lack of positional encoding for robust extended context capacity, calling it a key factor in large-scale text tasks.
- O3 Model Sparks Speculation: Members teased an O3 model with features reminiscent of GPT-4, fueling excitement over voice-based interactions.
- They predicted a possible release soon, anticipating advanced AI functionality.
- Findr Debuts on Cohere’s Coattails: Community members celebrated Findr’s launch, crediting Cohere’s tech stack for powering it behind the scenes.
- One member asked about which Cohere features are used, reflecting a desire to examine the integration choices.
LAION Discord
- OpenAI o3 Overdrive: OpenAI unveiled its o3 reasoning model, hitting 75.7% in low-compute mode and 87.5% in high-compute mode.
- A conversation cited François Chollet’s tweet and ARC-AGI-Pub results, implying fresh momentum in advanced task handling.
- AGI or Not: The Debate Rages: Some asserted that surpassing human performance on tasks such as ARC signals AGI.
- Others insisted that AGI is too vaguely defined, urging context-driven meanings to dodge confusion.
- Elo Ratings and Compute Speculations: Participants compared o3 results to grandmaster-level Elo, referencing an Elo Probability Calculator.
- They pondered if weaker models could reach similar results with additional test-time compute at $20 per extended run.
- Colorful Discourse on DCT and VAEs: Discussions centered on DCT and DWT encoding with color spaces like YCrCb or YUV, questioning if extra steps justify the training overhead.
- Some referenced the VAR paper to predict DC components first and then add AC components, highlighting the role of lightness channels in human perception.
GPU MODE Discord
- Triton Docs Stumble, Devs Step Up: The search feature on Triton’s documentation is broken, and the community flagged missing specs on tl.dtypes like tl.int1.
- Willing contributors want to fix it if the docs backend is open for edits.
- Flex Attention Gains Momentum: Members tinkering with flex attention plus context parallel signaled that an example might soon land in attn-gym.
- They see a direct path to combine these approaches to handle bigger tasks effectively.
- Diffusion Autoguidance Lights Up: A new NeurIPS 2024 paper by Tero Karras outlines how diffusion models can be shaped through the Autoguidance method.
- Its runner-up status and PDF link sparked plenty of talk about the impact on generative modeling.
- ARC CoT Data Fuels LLaMA 8B Tests: A user is producing a 10k-sample ARC CoT dataset to see if a fine-tuned LLaMA 8B surpasses the base in log probability metrics.
- They plan to examine the influence of 'CoT' training after generating a few thousand samples, highlighting potential improvements for future evaluations.
- PyTorch Puts Sparsity in Focus: The PyTorch sparsity design introduced
to_sparse_semi_structuredfor inference, with users suggesting a swap tosparsify_for greater flexibility.- This approach also spotlights native quantization and other built-in features for model optimization.
LlamaIndex Discord
- LlamaParse Boosts Audio Parsing: The LlamaParse tool now parses audio files, complementing PDF and Word support with speech-to-text conversion.
- This update cements LlamaParse as a strong cross-format parser for multimedia workflows, according to user feedback.
- LlamaIndex Celebrates a Year of Growth: They announced tens of millions of pages parsed in a year-end review, plus consistent weekly feature rollouts.
- They teased LlamaCloud going GA in early 2024 and shared a year in review link with detailed stats.
- Stock Analysis Bot Shines with LlamaIndex: A quick tutorial walked through building an automated stock analysis agent using FunctionCallingAgent and Claude 3.5 Sonnet.
- Engineers can reference Hanane D's post for a one-click solution that simplifies finance tasks.
- Document Automation Demos with LlamaIndex: A notebook illustrated how LlamaIndex can standardize units and measurements across multiple vendors.
- The example notebook demonstrated unified workflows for real-world production settings.
- Fine-Tuning LLM with Synthetic Data: Users discussed generating artificial samples for sentiment analysis, referencing a Hugging Face blog.
- They recommended prompt manipulation as a stepping stone while others discussed broader approaches to model refinement.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Hustle & Reopened Rush: Due to participants facing technical difficulties, the hackathon submission form reopened until Dec 20th at 11:59PM PST.
- Organizers confirmed no further extensions, so participants should finalize details like the primary contact email in the certification form for official notifications.
- Manual Submission Checks & Video Format Bumps: A manual verification process is offered for participants unsure about their submission, preventing last-minute confusion.
- Some resorted to email-based entries after YouTube issues, saying they remain focused on the hackathon rather than the course.
- Agent Approach Alternatives & AutoGen Warnings: A participant referenced a post about agent-building strategies, advising against relying solely on frameworks like Autogen.
- They suggested simpler, modular methods in future MOOCs, emphasizing instruction tuning and function calling.
Torchtune Discord
- Torchtune v0.5.0 Splashes In: The devs launched Torchtune v0.5.0, packing in Kaggle integration, QAT + LoRA training, Early Exit recipes, and Ascend NPU support.
- They shared release notes detailing how these upgrades streamline finetuning for heavier models.
- QwQ-preview-32B Extends Token Horizons: Someone tested QwQ-preview-32B on 8×80G GPUs, aiming for context parallelism beyond 8K tokens.
- They mentioned optimizer_in_bwd, 8bit Adam, and QLoRA optimization flags as ways to stretch input size.
- fsdp2 State Dict Loading Raises Eyebrows: Developers questioned loading the fsdp2 state dict when sharded parameters conflicted with non-DTensors in distributed loading code.
- They worried about how these mismatches complicate deploying FSDPModule setups across multiple nodes.
- Vocab Pruning Needs fp32 Care: Some participants pruned vocab to shrink model size yet insisted on preserving parameters in fp32 for consistent accuracy.
- They highlighted separate handling of bf16 calculations and fp32 storage to maintain stable finetuning.
DSPy Discord
- Litellm Proxy Gains Traction: Litellm can be self-hosted or used via a managed service, and it can run on the same VM as your primary system for simpler operations. The discussion stressed that this setup makes integration smoother by bundling the proxy with related services.
- Participants noted it meets a broad set of infrastructure needs while staying easy to adjust.
- Synthetic Data Sparks LLM Upgrades: A post titled On Synthetic Data: How It’s Improving & Shaping LLMs at dbreunig.com explained how synthetic data fine-tunes smaller models by simulating chatbot-like inputs. The conversation also covered its limited impact on large-scale tasks and the nuance of applying it across diverse domains.
- Members observed mixed results but agreed these generated datasets can push reasoning studies forward.
- Optimization Costs Stir Concerns: Extended sessions for advanced optimizers highlighted escalating costs, prompting suggestions to cap calls or tokens. Some proposed smaller parameter settings or pairing LiteLLM with preset limits to sidestep overspending.
- Voices in the discussion underscored active resource monitoring to avoid unexpected expenses.
- MIPRO 'Light' Mode Tames Resources: MIPRO 'Light' mode offers those looking to run optimization steps a leaner way forward. It was said to balance processing demands against performance in a more controlled environment.
- Early adopters mentioned that fewer resources can still produce decent outcomes, indicating a promising path for trials.
OpenInterpreter Discord
- OpenInterpreter's server mode draws interest: One user asked about documentation for running OpenInterpreter on a VPS in server mode, curious whether commands run locally or on the server.
- They expressed eagerness to confirm remote usage possibilities, highlighting potential for flexible configurations.
- Google Gemini 2.0 hype intensifies: Someone questioned the new Google Gemini 2.0 multimodal feature, especially its os mode, noting that access could be limited to 'tier 5' users.
- They wondered about its availability and performance, suggesting a need for broader testing.
- Local LLM integration brings cozy vibes: A participant celebrated local LLM integration for adding a welcome offline dimension to OpenInterpreter.
- They previously feared loss of this feature but voiced relief that it's still supported.
- SSH usage inspires front-end aims: One user shared their method of interacting with OpenInterpreter through SSH, noting a straightforward remote experience.
- They hinted at plans for a front-end interface, confident about implementing it with minimal friction.
- Community flags spam: A member alerted others to referral spam in the chat, seeking to maintain a clean environment.
- They signaled the incident to a relevant role, hoping for prompt intervention.
Axolotl AI Discord
- KTO and Liger: A Surprising Combo: Guild members confirmed that Liger now integrates KTO, supporting advanced synergy that aims to boost model performance.
- They noted pain from loss parity concerns against the HF TRL baseline, prompting further scrutiny on training metrics.
- DPO Dreams: Liger Eyes Next Steps: A team is focusing on Liger DPO as the main priority, aiming for stable operations that could lead to smoother expansions.
- Frustrated voices emerged over the loss parity struggles, yet optimism persists that fixes will soon surface for these lingering issues.
tinygrad (George Hotz) Discord
- Stale PRs Face the Axe: A user plans to close or automate closure of PRs older than 30 days starting next week, removing outdated code proposals. This frees the project from excess open requests while keeping the code repository lean.
- They stressed the importance of tidying up longstanding PRs. No further details or links were shared beyond the proposed timeline.
- Bot Might Step In: They mentioned possibly using a bot to track or close inactive PRs, reducing manual oversight. This approach could cut down on housekeeping tasks and maintain an uncluttered development queue.
- No specific bot name or implementation details were provided. The conversation ended without additional references or announcements.
Gorilla LLM (Berkeley Function Calling) Discord
- Watt-Tool Models Boost Gorilla Leaderboard: A pull request #847 was filed to add watt-tool-8B and watt-tool-70B to Gorilla’s function calling leaderboard.
- These models are also accessible at watt-tool-8B and watt-tool-70B for further experimentation.
- Contributor Seeks Review Before Christmas: They requested a timely check of the new watt-tool additions, hinting at potential performance and integration questions.
- Community feedback on function calling use cases and synergy with existing Gorilla tools was encouraged before the holiday pause.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium (Windsurf) ▷ #announcements (1 messages):
Windsurf 1.1.1 Release, Usage Transparency and Pricing, Cascade Image Uploads, Language Support Improvements
- Windsurf 1.1.1 Released with Cool Features: The Windsurf 1.1.1 update introduces quality-of-life improvements such as a new "Send to Cascade" button and enhanced autocomplete functionality, along with a status bar displaying plan and usage info.
- Bug fixes also rolled out, addressing issues like the Windows chat mode edit and autocomplete slowdowns, outlined in the full changelog.
- New Pricing and Usage Transparency Features: A revamped pricing system for Windsurf is being implemented, providing users with clearer information on their current plan usage and trial expiry via a quick settings panel.
- An introduction of a "Legacy Chat" mode allows users to continue using Cascade even without Flow Credits, though with limited capabilities, further details can be found here.
- Cascade Image Uploads Now Expanded: The 1MB limit on Cascade image uploads has been removed, allowing users to upload larger images seamlessly.
- This adjustment aims to enhance user experience in the Cascade feature, encouraging better interaction with larger visuals.
- Python Language Support Gets Enhanced: Improved language support for Python has been implemented in this update, bolstering the development environment for Python programmers.
- These enhancements aim to increase productivity and efficiency when working within the Windsurf framework.
Link mentioned: Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #content (1 messages):
Send to Cascade Button
- Demo of the 'Send to Cascade' Button: A quick demonstration was shared on the Send to Cascade button, which allows users to send their problems straight to Cascade.
- Send your problems straight to Cascade! indicates a straightforward approach for users to escalate their issues.
- User Engagement with 'Send to Cascade' Feature: Users are encouraged to try out the Send to Cascade feature, enhancing the user experience by allowing quicker problem resolution.
- The button aims to streamline communication with Cascade, creating a smoother troubleshooting process.
Link mentioned: Tweet from Windsurf (@windsurf_ai): Send your problems straight to Cascade!
Codeium (Windsurf) ▷ #discussion (64 messages🔥🔥):
Cascade Performance, Windsurf Subscription Plans, Codeium Extension Features, Usage of AI in Code Reviews, AI Prompting Guidelines
- Internal Errors with Cascade: Users reported encountering errors such as 'ErrorCascade has encountered an internal error' when using Cascade after lengthy chats, suggesting starting a new chat to refresh the session.
- Another user highlighted the importance of keeping chats concise and focused for better performance.
- Understanding Windsurf Plans: A user inquired about the availability of the trial pro plan for Windsurf, questioning if it had been canceled as they only received a free plan.
- Other users discussed their experiences with subscription limits and features across Codeium's various offerings, including the extension and Windsurf.
- AI Interaction Slowing Down: A member expressed frustration with AI performance when processing larger codebases, specifically noting slowness when handling a source code of 1k lines.
- Discussions revealed that some users are also experiencing similar issues with response times in code changes.
- Utilizing Windsurf as a Coding Assistant: Users shared their excitement about Windsurf's ability to read code repositories directly, viewing it as a significant improvement over using Sonnet directly on the site.
- One member mentioned using Windsurf alongside Cascade as a pair programming tool to enhance their coding experience.
- Prompting Techniques for AI: Members discussed the significance of refreshing chat sessions and provided links to prompting guides to optimize interaction with AI.
- A user expressed the need for tutorials to improve their understanding of using Windsurf effectively.
Link mentioned: Plan Settings: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
Codeium (Windsurf) ▷ #windsurf (603 messages🔥🔥🔥):
Windsurf Performance Issues, Codeium Features and Updates, Using Cascade Effectively, User Experiences with AI Models, Integration of New Tools
- Concerns over Windsurf Performance: Users have expressed frustration over notable performance differences when using Windsurf at different times of day, with some reporting better results at night.
- Many are experiencing issues with AI performance, leading to a less effective coding experience and prompting discussions about AI capabilities.
- Windsurf Update Delivered New Features: A recent update added a 'Send to Cascade' button in the Problems tab, allowing users to easily report issues, which has been well-received.
- The update also improved autocomplete features, benefiting users who rely on Cascade for coding assistance.
- Using Cascade Effectively for Projects: Users are encouraged to utilize Cascade for issues, though tips on managing multiple problems at once were discussed due to inefficiencies observed.
- Some users shared success in completing complex projects with Cascade, emphasizing the tool's potential when used strategically.
- Requests for Better Integration and Support: There are ongoing requests for clearer integration with models like Gemini and improved responses from Codeium support regarding account issues.
- Users highlighted the need for more accessible resources and clarity around updates in the community to ensure a smooth experience.
- Exploration of CLI Tools and AI Integration: Discussion around the use of Command Line Interfaces (CLI) with AI tools like Warp highlighted their benefits for productivity and automation.
- Users debated the effectiveness of CLI in coding workflows, with some expressing skepticism about its impact on efficiency.
- Windsurf - Cascade: no description found
- no title found: no description found
- Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
- Vite + React + TS: no description found
- Pair Programmer System | Feature Requests | Codeium: What if the AI could just edit side-by-side with you, follow your cursor, watch you, provide suggestions and feedback as you go, and stuff like that? What if
- Things That Make You Go Bluh Ron White GIF - Things That Make You Go Bluh Ron White Blue Collar Comedy - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- LLM Pricing Calculator - LLM Price Check: Explore affordable LLM API options with our LLM Pricing Calculator at LLM Price Check. Quickly compare rates from top providers like OpenAI, Anthropic, and Google.
- FAQ | Windsurf Editor and Codeium extensions: Find answers to common questions.
- Reddit - Dive into anything: no description found
- Surf Glider GIF - Surf Glider Wave - Discover & Share GIFs: Click to view the GIF
- Warp: The intelligent terminal: Warp is the intelligent terminal with AI and your dev team's knowledge built-in. Available now on MacOS and Linux.
- Set up Reddit API integration for r/Codeium content · Issue #50 · ichoosetoaccept/awesome-windsurf: We need a way to programmatically fetch valuable Windsurf/Codeium tips from r/Codeium. Potential approaches: Use Reddit API (PRAW for Python) Reddit OAuth API Reddit RSS feeds Key requirements: Fol...
- GitHub - ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- GitHub CLI: Take GitHub to the command line
- GitHub - SchneiderSam/awesome-windsurfrules: 📄 A curated list of awesome global_rules.md and .windsurfrules files: 📄 A curated list of awesome global_rules.md and .windsurfrules files - SchneiderSam/awesome-windsurfrules
- - YouTube: no description found
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- See Bastian | Wilde Möhre 2024 | Puppenräuber: See Bastian // Wilde Möhre 2024 // Puppenräuber // Playtime Sunday Morning 5.30-7.30amDanke an alle, die an dieser besonderen Frührsportsession teilgenommen haben <3
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Reddit - Dive into anything: no description found
- Awesome MCP Servers: no description found
- GitHub - dlvhdr/gh-dash: A beautiful CLI dashboard for GitHub 🚀: A beautiful CLI dashboard for GitHub 🚀 . Contribute to dlvhdr/gh-dash development by creating an account on GitHub.
- Terms of Service: Individual & Pro | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
Cursor IDE ▷ #general (819 messages🔥🔥🔥):
Cursor IDE updates, AI-driven development tools, Comparison of Sonnet models, Freelancing with AI assistance, Limitations of AI in styling
- Cursor IDE updates bring enhanced performance: Users reported that the recent update to Cursor IDE, version 0.44.5, has significantly improved its performance and usability, particularly in agent mode.
- Feedback highlighted a smoother experience in coding and more reliable output, encouraging many to switch back to using Cursor over alternatives.
- AI tools transforming development workflows: Many users emphasized the impact of AI tools like Cursor on their development processes, allowing for faster project completions and reducing the need for extensive searching for solutions.
- The integration of AI is helping developers streamline their workflows and boost productivity.
- Sonnet models and their performances: Discussion around the different Sonnet models revealed users are experiencing variable performance, with the latest version being favored for its capabilities in generating UI components.
- The conversation noted that the system prompts and performance of the models could vary, influencing user preferences.
- Freelancing with AI tools: Freelancers shared their experiences using AI tools to handle various tasks, enhancing their reputation and efficiency in delivering projects.
- Concerns were raised about potential job rejection based on AI usage, but many advocated for the advantages AI brings to development.
- Challenges with AI-generated styling: Users noted that while AI excels at backend logic, it often struggles with frontend styling, resulting in additional adjustments by developers.
- This concern reflects a need for improved AI training in UI/UX design to better assist developers.
- Tweet from ARC Prize (@arcprize): New verified ARC-AGI-Pub SoTA!@OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation.And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the S...
- Tweet from Philipp Schmid (@_philschmid): WTF?! New open-source physics AI engine absolutely insane! 🤯 Genesis is a new physics engine that combines ultra-fast simulation with generative capabilities to create dynamic 4D worlds for robotics ...
- Building effective agents: A post for developers with advice and workflows for building effective AI agents
- Downloads | Cursor - The AI Code Editor: Choose your platform to download the latest version of Cursor.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): LLM naming is the hardest problem in our society 👀So many new conspiracies after one single nighto3 spotted in safety testing4.5 has been traced a week earlierWhere is o2? 🤯Quoting Colonel Tasty (@J...
- Is it possible to index a file that's in my .gitignore?: You can add !path/to/folder to your .cursorignore to make sure the folder gets included even if it’s ignored by gitignore. Note that you may need to add !path/to/folder/* or !path/to/folder/**/* (see ...
- I Understand It Now Ok I Understand It Now GIF - I understand it now Ok i understand it now I understand it - Discover & Share GIFs: Click to view the GIF
- Tweet from Thomas Dohmke (@ashtom): OpenAI o1 now available to all individuals in Copilot Pro $10 USD Lets. Go. 😎Quoting GitHub (@github) You can now use @OpenAI’s new o1 model in Copilot Pro, Business, and Enterprise—and in GitHub Mod...
- WebDev Arena: New leaderboard from the [Chatbot Arena](https://lmarena.ai/) team (formerly known as LMSYS), this time focused on evaluating how good different models are at "web development" - though it t...
- Tweet from Junyang Lin (@JustinLin610): r u kidding me
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Scaler Create Impact GIF - Scaler Create Impact Dog - Discover & Share GIFs: Click to view the GIF
- Tweet from OpenAI (@OpenAI): Day 12: Early evals for OpenAI o3 (yes, we skipped a number)https://openai.com/12-days/?day=12
- - YouTube: no description found
- prompt.md: GitHub Gist: instantly share code, notes, and snippets.
- Tweet from Tibor Blaho (@btibor91): This is real - the OpenAI website already has references to "O3 Mini Safety Testing Call" formQuoting Colonel Tasty (@JoshhuaSays) Found references to o3_min_safety_test on the openai site. S...
- Lovable: Build software products, using only a chat interface
- Exclusive: In just 4 months AI coding assistant Cursor raised another $100M at a $2.5B valuation led by Thrive, sources say: Anysphere, the developer of AI-powered coding assistant Cursor, raised $100 million Series B at a post-money valuation of $2.6 billion, according to
- GitHub - 2-fly-4-ai/V0-system-prompt: Contribute to 2-fly-4-ai/V0-system-prompt development by creating an account on GitHub.
- GitHub - olweraltuve/LmStudioToCursor: Contribute to olweraltuve/LmStudioToCursor development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #general (628 messages🔥🔥🔥):
OpenAI O3 Release, Use of Aider and Cline, Impact of AI on Software Development, Job Security in Coding, Comparison of Tools for Developers
- Excitement Over OpenAI O3 Release: The release of OpenAI's O3 model is generating excitement, with benchmarks indicating significant advancements in coding tasks and overall functionality.
- Users highlighted the need for continued optimization and speculation on future cost reductions as AI technology evolves.
- Integration of Aider and Cline for Tasks: Developers are discussing the effective use of Aider for small changes and Cline's agentic capabilities for larger automation tasks.
- Cline's memory capabilities could potentially streamline development processes, making it a valuable tool for startups and heavy coding tasks.
- Concerns About Job Security in Development: Conversations reflect anxiety about the impact of AI on coding careers, with some believing that AI will replace many aspects of the job.
- However, others argue that while AI takes over certain tasks, the demand for skilled developers won't diminish due to the need for oversight and problem-solving.
- Challenges with Current AI Tools: Users are voicing frustrations with AI's limitations, particularly regarding its ability to understand context and follow commands effectively for coding tasks.
- Despite these issues, developers appreciate the time-savings provided, indicating a need for further enhancements.
- Future of Software Development with AI: As AI tools become more sophisticated, there's speculation about the evolution of roles in software development and the potential for new tasks emerging.
- The conversation underscores the importance of adapting to technological changes in the industry and finding value in the evolving landscape.
- Tweet from OpenAI (@OpenAI): Day 12: Early evals for OpenAI o3 (yes, we skipped a number)https://openai.com/12-days/?day=12
- Tweet from Chubby♨️ (@kimmonismus): o3 and 03 mini is coming today! What?! I didn't see that coming!LFGThey are skipping the name o2 because of legal reasons. Maybe o3 will be the first model that integrates everything else? Anyway,...
- Tweet from 🍓🍓🍓 (@iruletheworldmo): many of you guessed, but o1 pro is very goodARC
- Unlock your team's best work with Jira Software: no description found
- Take My Money Heres My Card GIF - Take my money Heres my card Here’s my card - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- Tweet from ARC Prize (@arcprize): New verified ARC-AGI-Pub SoTA!@OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation.And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the S...
- Mellstroy GIF - Mellstroy - Discover & Share GIFs: Click to view the GIF
- Indian GIF - Indian - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- Reddit - Dive into anything: no description found
- GitHub - mufeedvh/code2prompt: A CLI tool to convert your codebase into a single LLM prompt with source tree, prompt templating, and token counting.: A CLI tool to convert your codebase into a single LLM prompt with source tree, prompt templating, and token counting. - mufeedvh/code2prompt
- Red Alphabet Letter Dancing Letter L GIF - Red Alphabet Letter Dancing Letter L Cartoons - Discover & Share GIFs: Click to view the GIF
aider (Paul Gauthier) ▷ #questions-and-tips (33 messages🔥):
Aider hardware recommendations, OpenRouter API key setup, Using /read command with PDF files, Gemini model updates, Aider tutorial resources
- Hardware recommendations for running Aider client-side: Users expressed concerns about slow response times from the LLM when running Aider client-side, with one seeking recommended hardware needs.
- A member noted that such delays shouldn't be occurring, indicating potential issues with performance.
- Setting up OpenRouter API key in configuration file: A user asked about configuring the OpenRouter API key in the
.aider.conf.yaml, reporting issues with unrecognized arguments.- Another member clarified that the key should be set as
api-key: openrouter=sk-or-..., providing guidance for correct syntax.
- Another member clarified that the key should be set as
- Using /read command for PDF files: A user inquired if Aider can read PDFs and use their contents for contextual assistance, indicating the /read command wasn't working for them.
- It was confirmed by a member that the /read command works with Anthropic models for reading PDF files.
- Updates on Gemini model versions: Discussion arose regarding the latest Gemini model 'gemini-2.0-flash-thinking-exp-1219', with mixed reviews on its capabilities.
- Users shared experiences about using high map token settings with various models and the implications for context retention.
- Resources for Aider tutorials and demos: Members sought recommendations for professional-level tutorials and demos for Aider, discovering resources shared in the chat.
- A user highlighted a YouTube channel and official tutorials, providing links to help others enhance their understanding of Aider's capabilities.
- API Keys: Setting API keys for API providers.
- Coding the Future With AI: Welcome to Coding the Future With AI! Our channel is dedicated to helping developers and tech enthusiasts learn how to leverage AI to enhance their skills and productivity. Through tutorials, expert i...
- FAQ: Frequently asked questions about aider.
- Tutorial videos: Intro and tutorial videos made by aider users.
- Example chat transcripts: aider is AI pair programming in your terminal
aider (Paul Gauthier) ▷ #links (5 messages):
AniDoc animation tool, Depth AI evaluation, Integrating external libraries
- AniDoc simplifies animation creation: A new tool, AniDoc, allows users to colorize sketches based on character design references with high fidelity, even across varying poses and scales.
- Had a good time experimenting with it, and users highly recommend trying it out.
- Evaluating Depth AI for code understanding: Evaluating Depth AI, which connects with your codebase to build customized AI assistants across platforms like Slack and Jira, providing deep technical answers.
- It constructs a comprehensive knowledge graph to understand code relationships and answer questions about changes effectively.
- Experience with Depth AI on large codebases: One member shared a positive experience using Depth AI on a large codebase but decided to stop using it because they didn't require its RAG capabilities.
- They noted that it's pretty cool so far while enjoying its integration capabilities.
- Discussion on integrating external libraries: A member suggested that copying multiple external libraries into a shared folder could help leverage Depth AI to figure out integration solutions.
- They expressed disappointment that Aider cannot work with git submodules, which would have allowed for more exploration.
- Depth AI - AI that deeply understands your codebase: Chat with your codebase or build customised AI assistants. Deploy them wherever you work — Slack, Github Copilot, Jira and more.
- Tweet from Gradio (@Gradio): 🆕 🔥 AniDoc: Animation Creation Made Easier It can colorize a sequence of sketches based on a character design reference with high fidelity, even when the sketches significantly differ in pose and sc...
Interconnects (Nathan Lambert) ▷ #news (454 messages🔥🔥🔥):
OpenAI O3 release, AI and Software Engineering, Market impacts of AI advancements, Challenges in AI reasoning, AI's influence on job diversity
- OpenAI's O3 release showcases rapid advancements: OpenAI recently announced O3 and O3-mini, highlighting impressive performance metrics, particularly achieving 87.5% on the ARC-AGI Semi-Private Evaluation.
- The transition from O1 to O3 occurred within three months, showcasing a faster progress rate than previous models, indicating a shift in development paradigms.
- AI's Impact on Software Engineering Jobs: Discussions reveal concerns that as AI technologies advance, particularly with powerful models like O3, the necessity for human software engineers may decline.
- While some roles could be automated, there's also an argument that more software production will lead to new maintenance and oversight roles in the future.
- Market Dynamics Post-O3 Announcement: The release of O3 has prompted speculation about stock prices, particularly for companies like Nvidia, which is viewed as essential for AI-related hardware.
- Comments included perspectives on whether Nvidia or specialized AI chip companies will reap the benefits of the advancements sparked by models like O3.
- Challenges in AI Reasoning and Performance Metrics: Concerns were raised around the perceived limitations of AI models like O3 in reasoning tasks, leading to debates about their actual capabilities.
- Responses highlighted the importance of understanding the models' architecture and efficiency beyond mere increases in compute power.
- Diverse Career Pathways in an AI-Driven Future: There is a belief that the rise of AI may lead to fewer employees in traditional roles but could simultaneously diversify the types of jobs available within technology sectors.
- Discussions emphasized that while some positions may seem at risk, many new opportunities could arise in roles related to AI and tech infrastructure.
- Tweet from ARC Prize (@arcprize): New verified ARC-AGI-Pub SoTA!@OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation.And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the S...
- Tweet from OpenAI (@OpenAI): Day 12: Early evals for OpenAI o3 (yes, we skipped a number)https://openai.com/12-days/?day=12
- Tweet from murat 🍥 (@mayfer): how did o3 in high compute mode spend thousands of dollars of compute on one problem? since thousands of $ don't fit into context even if limit is 1m tokens
- Tweet from François Chollet (@fchollet): Cost-efficiency will be the overarching measure guiding deployment decisions. How much are you willing to pay to solve X?The world is once again going to run out of GPUs.
- Tweet from YouJiacheng (@YouJiacheng): Are these your speculations, or facts? @fchollet
- Tweet from François Chollet (@fchollet): It will also be extremely important to analyze the strengths and limitations of the new system. Here are some examples of tasks that o3 couldn't solve on high-compute settings (even as it was gene...
- Tweet from Tibor Blaho (@btibor91): Grok[.]com is possibly coming soon with Grok 2.5 model (grok-2-latest - "Our most intelligent model") - thanks for the hint, anon!
- Tweet from Xeophon (@TheXeophon): o3 is very likely powered by the next generation model, GPT-5in the livestream, o3 wrote code to use the openai python package and it got it correct - even the most recent version of o1 is stuck with ...
- Tweet from David Dohan (@dmdohan): o3 @ 87.5% on ARC-AGIIt was 16 hours at an increase rate of 3.5% an hour to "solved"Quoting David Dohan (@dmdohan) At this rate, how long til ARC-AGI is “solved”?For context:- gpt-4o @ 5%- Son...
- Tweet from YouJiacheng (@YouJiacheng): no need to believe, @fchollet said "sample sizes" are 6 and 1024.Quoting wh (@nrehiew_) o1 is $60/M tokens. If we assume the same inference economics, it looks like high costs ~ $5000 dollars....
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): Grok 2.5 - "our most intelligent model"Along with its own site + new logo? 👀Quoting Tibor Blaho (@btibor91) Grok[.]com is possibly coming soon with Grok 2.5 model (grok-2-latest - "Our mo...
- Tweet from Nat McAleese (@__nmca__): Lots of folks are posting quotes from Gowers/Tao about the hardest split of FrontierMath, but our 25% score is on the full set (which is also extremely hard, with old sota 2%, but not as hard as those...
- Tweet from YouJiacheng (@YouJiacheng): @nrehiew_ @fchollet
- Tweet from Paul Calcraft (@paul_cal): @teortaxesTex François hasn't achieved superhuman humility
- Tweet from vik (@vikhyatk): openai spent more money to run an eval on arc-agi than most people spend on a full training run
- Tweet from Jason Wei (@_jasonwei): o3 is very performant. More importantly, progress from o1 to o3 was only three months, which shows how fast progress will be in the new paradigm of RL on chain of thought to scale inference compute. W...
- Tweet from Dylan Patel (@dylan522p): Motherfuckers were market buying Nvidia stock cause OpenAI O3 is so fucking good
- Tweet from Sebastien Bubeck (@SebastienBubeck): o3 and o3-mini are my favorite models ever. o3 essentially solves AIME (>90%), GPQA (~90%), ARC-AGI (~90%), and it gets 1/4th of the Frontier Maths.To understand how insane 25% on Frontier Maths is...
- Tweet from YouJiacheng (@YouJiacheng): no need to calculate (172×$20) / ($60/Mtoks) = 57Mtoks, @fchollet said tens of millions of tokens.Quoting wh (@nrehiew_) o1 is $60/M tokens. If we assume the same inference economics, it looks like hi...
- Tweet from MatthewBerman (@MatthewBerman): .@OpenAI just dropped o3 and o3-mini!This is AGI (not clickbait)o3 is the best AI ever created, and its performance is WILD.Here's everything you need to know: 🧵
- Tweet from Xeophon (@TheXeophon): Quoting wh (@nrehiew_) o1 is $60/M tokens. If we assume the same inference economics, it looks like high costs ~ $5000 dollars. This gives ~80 Million tokens. So you either believe they have a usable ...
- Tweet from Kyle Wiggers (@Kyle_L_Wiggers): FYI, Microsoft updated Copilot the other day with a "new" Dall-E 3 model, PR16. But OpenAI PR wouldn't tell me anything about it — they directed me to Microsoft PR. Then Microsoft PR said ...
- Tweet from Logan Kilpatrick (@OfficialLoganK): We are going to build the world’s most powerful coding models, lots of good progress already with 2.0.2025 is going to be fun :)
- Tweet from Jacques (@JacquesThibs): Actually, you know what, it's probably Omni, Orion, and Operator. Orion also have 3 stars for "Orion's belt" so that's a clue to consider.Omni: includes more input/output types to ...
- Tweet from Greg Kamradt (@GregKamradt): We verified the o3 results for OpenAI on @arcprize My first thought when I saw the prompt they used to claim their score was..."That's it?"It was refreshing (impressive) to see the prompt ...
- Tweet from Amir Efrati (@amir): news: Another key OpenAI researcher @AlecRad is out. Lead author on GPT paper, instrumental to Whisper and Dall-E....
- Tweet from Chris Paxton (@chris_j_paxton): o3 achieves 87% on arc-agiRemembering this tweetQuoting Mike Knoop (@mikeknoop) o3 is really special and everyone will need to update their intuition about what AI can/cannot do.while these are still ...
- Not Like This Stare GIF - Not Like This Stare No - Discover & Share GIFs: Click to view the GIF
- Tweet from Tsarathustra (@tsarnick): OpenAI CFO Sarah Friar says the company is leaving the door open to a $2000/month subscription to its AI product which could serve as a "replacement" to hiring humans due to its PhD-level inte...
- Tweet from wh (@nrehiew_): o1 is $60/M tokens. If we assume the same inference economics, it looks like high costs ~ $5000 dollars. This gives ~80 Million tokens. So you either believe they have a usable effective context windo...
- Tweet from Mike Knoop (@mikeknoop): o3 is really special and everyone will need to update their intuition about what AI can/cannot do.while these are still early days, this system shows a genuine increase in intelligence, canaried by AR...
- Tweet from NIK (@ns123abc): LMFAOOOO Dylan Patel cooked tf out of him
- Tweet from Amir Efrati (@amir): new: Google is effectively adding its Gemini chatbot directly into search results—"AI Mode"innovator's dilemma remains, but this shows Google getting serious about conversational chatbot p...
- Tweet from Greg Kamradt (@GregKamradt): The real questions this chart asks* Does the curve flatline? Or keep going?* Is compute the right measure of efficiency or is it cost?* o3 isn’t just simply, “more compute.” Much more is going on arch...
- GitHub - arcprizeorg/model_baseline: Testing baseline LLMs performance across various models: Testing baseline LLMs performance across various models - arcprizeorg/model_baseline
Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
LoRA Finetuning, Finetuning Closed-source Models, Open-source vs Closed-source Models
- Discussion on LoRA Finetuning Effectiveness: One member expressed skepticism about LoRA finetuning, stating it might not be effective outside the training set and referred to an analysis paper.
- There was a call for sharing experiences to reconsider whether to stick with LoRA or switch to full finetuning for open-source models.
- General Sentiment on LoRA Usage: Another member commented that while LoRA is generally avoided, it becomes necessary at significantly larger model sizes.
- This suggests mixed feelings about reliance on LoRA within the community.
Interconnects (Nathan Lambert) ▷ #ml-drama (34 messages🔥):
François Chollet's statements, O1 model characteristics, Subbarao/Miles Brundage incident, AI community reactions, Recent incidents involving GDM director
- Chollet compares O1 to AlphaGo: François Chollet stated that O1 operates similarly to AlphaGo, suggesting both use extensive processes for single outputs, likening the two in analogy.
- He emphasized that calling O1 purely an LLM is misleading, much like mislabeling AlphaGo as merely a convnet.
- Discussions on O1's search functionalities: Members expressed confusion over whether O1 performs any explicit search, with some insisting that existing knowledge should clarify this aspect.
- Some speculate that the model’s performance could be replicated through search mechanisms, prompting debates on its underlying mechanisms.
- Subbarao/Miles Brundage incident revisited: There was a mention of an incident involving Subbarao and Miles Brundage that questioned the scientific basis of how models like O1 operate, affirming it's just a language model.
- This incident highlights ongoing challenges in accurately representing AI models' functions in discussions.
- Community exchanges over recent events: Members reacted to the recent incident involving GDM director David Budden, expressing disappointment over bad behavior within the community.
- Some conversations highlighted the negative impact such instances could have on the perception of the community at large.
- Legal pressures possibly affecting content: A member noted that a tweet by a community member was deleted, suggesting potential legal implications.
- There was overall surprise and concern over what might have caused the deletion, reflecting the serious nature of the content involved.
- Tweet from François Chollet (@fchollet): For those who didn't get it -- AlphaGo was a MCTS search process that made thousands of calls to two separate convnets in order to compute a single game move.Something like o1 pro is also, best we...
- Tweet from roon (@tszzl): @rao2z @Miles_Brundage but it’s not really a scientific question how a deployed product works or how the model is inferenced. o1 is just a language model
Interconnects (Nathan Lambert) ▷ #random (6 messages):
Discord stalking, o3 discussion, Timing comparison
- Discord Stalking Comedy: A member humorously questioned which Discord to stalk, stating that there were just too many options.
- This light-hearted banter showcased the overwhelming nature of community engagement on Discord.
- Excitement Over o3: One member noted a friend in a DM who was 'going wild' over o3, indicating high enthusiasm for the topic.
- It reflects growing interest and excitement within the community surrounding o3.
- Timing Rivalry with Alberto Romero: A member boasted about beating Alberto Romero by about 10 minutes in some unspecified context, highlighting a competitive spirit.
- This comment added a humorous competitive edge to the ongoing discussions among members.
Interconnects (Nathan Lambert) ▷ #memes (32 messages🔥):
OpenAI O3 model naming, Meme vs Reality in AI, OpenAI's latest model developments, Riemann Question in AI
- OpenAI considers 'O3' for new model: OpenAI is reportedly prepping for the next generation of its reasoning model, potentially skipping 'O2' due to a trademark conflict and calling it 'O3' instead, as discussed here.
- A member remarked on the absurdity of the situation, noting, 'Hard to separate meme from reality these days.'
- The struggle with meme culture in AI: Members expressed confusion about distinguishing between memes and real updates, with one noting, 'I thought the channel makes this clear enough.'
- Comments suggested that the channel's environment makes it challenging to separate fact from playful trolling, especially with ongoing developments.
- OpenAI's evolving model names and theories: A member humorously pointed out that OpenAI seems to be drawn into a naming scheme reminiscent of Intel, considering names like 'Core o7'.
- Others speculated about future implications, asking if the series will continue with odd or prime numbers and jokingly mentioning the ongoing Riemann Question.
- Rumors about diminishing returns in GPT improvements: A link shared by a member pointed to claims that GPT is experiencing diminishing returns, with OpenAI adjusting its approach in training the upcoming Orion model.
- One comment humorously referenced a prior victory in their criticism, stating, 'Folks, game over. I won.'
- Tweet from Alexander Doria (@Dorialexander): Ah yes, OpenAI is really not messing around for the last day. Wild.
- Tweet from Subbarao Kambhampati (కంభంపాటి సుబ్బారావు) (@rao2z): The new pressing Riemann Question: Are o_i series odd numbered or prime numbered? (guess gotta wait until after o7..)
- Tweet from Stephanie Palazzolo (@steph_palazzolo): OpenAI is prepping the next generation of its o1 reasoning model.But, due to a potential copyright/trademark conflict with British telecommunications firm O2, OpenAI has considered calling the next up...
- Tweet from anpaure (@anpaure): @stochasticchasm @soradotsh nathan lambert fully vindicated?
- Tweet from jack morris (@jxmnop): openai: we trained our language model to think. it can do phd-level mathgoogle: we trained a language model to think harder. it can do harder phd-level mathanthropic: we asked our language model if ...
- Tweet from hero ⚔️ (@1thousandfaces_): o3's secret? the "I will give you $1k if you complete this task correctly" prompt but you actually send it the moneyQuoting Tenobrus (@tenobrus) they're spending over $1k PER TASK in t...
- Tweet from Gary Marcus (@GaryMarcus): Folks, game over. I won. GPT is hitting a period of diminishing returns, just like I said it would.Quoting Amir Efrati (@amir) news: OpenAI's upcomning Orion model shows how GPT improvements are s...
Interconnects (Nathan Lambert) ▷ #rl (6 messages):
Reinforcement Learning Challenges, Reward Models in RL, Verification in RL, Specialized Reward Criteria, Future of RL Research
- Questioning RL's Verifiability: <@kevin_nejad> raised a concern about implementing Reinforcement Learning (RL) when outputs are not verifiable, suggesting that a robust reward model might be similar to RLHF training.
- He pondered how one could create specialized reward models in domains where human judgment dictates outcomes, such as aesthetics.
- Loose Verifiers for Desired Outcomes: <@natolambert> suggested that using a loose verifier could reinforce specific outcomes, especially for simpler questions.
- He emphasizes that while this might not be scalable, it could work in specialized fields, promoting a potential direction for research.
- Noise in Reward Models: <@kevin_nejad> agreed that reward models could introduce noisy rewards, advocating for clear criteria and deterministic outcomes instead.
- He supported the idea of breaking down desired outcomes into binary criteria to function as loose verifiers, specifically for niche domains.
- Anticipating Future RL Research: Both members expressed enthusiasm for further research in LLM (Large Language Models) and RL, particularly looking towards breakthroughs in 2025.
- This indicates a shared interest in the evolution and intersection of these fields.
Interconnects (Nathan Lambert) ▷ #rlhf (1 messages):
natolambert: https://x.com/natolambert/status/1870150741593129045
Interconnects (Nathan Lambert) ▷ #reads (4 messages):
Building Anthropic, YouTube Video Discussion
- Building Anthropic Conversation Sparks Fun Comments: The discussion around 'Building Anthropic' led to humorous remarks about Dario being a 'cute little munchkin'.
- Participants expressed that the vibes were positive, noting that those involved are 'lovely folk'.
- YouTube Video Cited: A member shared a link to a YouTube video titled 'Building Anthropic | A conversation with...'.
- However, no description was provided for the video.
Link mentioned: - YouTube: no description found
Interconnects (Nathan Lambert) ▷ #lectures-and-projects (3 messages):
RLHF Ignorance, GitHub Availability, Interest in Free Resources
- Embracing RLHF Ignorance: A member admitted to being an RLHF ignoramus but feels their mastery of the English language positions them well for discussions.
- *'I also like
- GitHub as a Resource: A member mentioned that everything is available on GitHub, implying that accessing information shouldn't be overly complicated.
- This suggests a shared understanding that resources can be parsed and utilized effectively from the platform.
Interconnects (Nathan Lambert) ▷ #posts (7 messages):
OpenAI's o3 model preview, Anthropic's potential release, User vacation plans
- OpenAI introduces o3 model preview: Today, OpenAI previewed their o3 model, marking a continuation in training language models to reason with o1, with o3-mini expected to be publicly available by late January 2025. Observers noted that 2024 has been a year of consolidation among competitors achieving GPT-4 equivalent models.
- The o3 model's upcoming release is generating more excitement than o1, indicating rapid advancements in reasoning models, contrasting the lack of significant excitement seen in 2024.
- Anthropic might surprise with a release: A member speculated that Anthropic could drop a surprise release during the holiday season. However, another countered that they are too wholesome to pull off such a move.
- This light-hearted exchange hints at anticipation within the community regarding potential announcements from leading AI developers.
- User plans to unplug during vacation: As the user mentioned upcoming vacation plans, they expressed a desire to disconnect completely from Slack, Discord, and Twitter. This underscores a need for a mental break from the intense AI landscape.
- The concern about potential announcements sneaking into personal emails also reflects the constant engagement and pressure within the community.
- Effort behind writing updates: One user shared that it took approximately three hours to write their comprehensive update on the o3 model. They humorously mentioned having spent an additional hour or two freaking out beforehand, highlighting the emotional investment in sharing important information.
Link mentioned: o3: The grand finale of AI in 2024: A step change as influential as the release of GPT-4. Reasoning language models are the current big thing.
OpenAI ▷ #annnouncements (1 messages):
12 Days of OpenAI, Final Day Event, Sam Altman, Mark Chen, Hongyu Ren
- Final Day of 12 Days of OpenAI: On Day 12, attendees are invited to join Sam Altman, Mark Chen, Hongyu Ren, and a special guest to celebrate the culminating event of the 12 Days of OpenAI.
- Watch the live event here to participate in this significant conclusion.
- Excitement Builds for the Event: As the last day approaches, excitement is soaring among the community for the grand finale of the 12 Days of OpenAI.
- Participants are encouraged to tune in to see the involvement of noted figures like Sam Altman and Mark Chen.
Link mentioned: - YouTube: no description found
OpenAI ▷ #ai-discussions (401 messages🔥🔥):
OpenAI o3 release expectations, Comparison of AI models, AI capabilities in development, Market impact of AI pricing, Future of AI technology updates
- High Anticipation for o3 Release: There is ongoing speculation around the release of OpenAI's o3 model, with many users eager for its capabilities amid competition from models like Gemini.
- Some users noted that past announcements often followed by delays have left them cautious about what to expect from OpenAI.
- Comparison Between AI Models: Users compared the performance and costs of OpenAI's models with other options like Google's Gemini and technologies like Apple's OpenELM, noting how pricing has shifted.
- Discussion included how o3 may offer superior intelligence relative to its competitors, driving interest but also skepticism towards OpenAI's pricing strategy.
- Concerns Over OpenAI's Direction: There was discontent expressed about OpenAI's transformation from a presumably open-source company to one offering expensive, tiered services.
- Participants emphasized that past tutorials and open resources have dwindled, leading to concerns over transparency in OpenAI's current offerings.
- AI Capabilities in Daily Use: Users shared experiences about how AI tools like OpenAI and others facilitate tasks like coding and language learning, questioning the effectiveness of free versions.
- Conversations highlighted the value of paid subscriptions for those serious about leveraging AI for more complex projects versus casual use.
- Expectations for Frequent Updates: Amidst discussions on AI's rapid evolution, users expressed hope for more frequent updates from AI companies to keep pace with technological advancements.
- There was optimism that future iterations could lead to more open and efficient AI systems, particularly as competition heats up in the market.
Link mentioned: Tweet from Deedy (@deedydas): OpenAI o3 is 2727 on Codeforces which is equivalent to the #175 best human competitive coder on the planet.This is an absolutely superhuman result for AI and technology at large.
OpenAI ▷ #gpt-4-discussions (6 messages):
Custom GPT usage, Obsolescence of discussion channels, O3 release timeline, Chatbot development advice
- Custom GPTs locked to version 4o: A member inquired about forcing custom GPTs to use a specific model, and it was clarified that all custom GPTs currently use 4o, with no option to change that.
- This establishes the existing limitations on model flexibility for custom GPT configurations.
- Discussion channels potentially becoming obsolete: A member suggested renaming the channel to #openai-model-discussions or creating separate channels for #o1-model and #o3-model, as current discussions seem to be declining.
- The shift indicates a need for more targeted discussion spaces amidst changing user interests.
- O3 release and subscription limits discussed: Another member asked when o3 would be released and about the limits for pro subscribers, to which it was mentioned that o3 mini is set to come out at the end of next month and the full version shortly after.
- The timelines provided suggest an anticipation for the next generation of models amidst ongoing discussions.
- Seeking advice on building a chatbot: A member reached out for guidance on creating a chatbot capable of understanding software functionality and explaining it to users.
- This inquiry highlights the community's interest in developing intelligent chat solutions focused on user education.
Unsloth AI (Daniel Han) ▷ #general (168 messages🔥🔥):
O3 Release Discussion, Fine-tuning LLMs, Consciousness Benchmarks, TGI and Deployment Options, FrontierMath Performance
- Excitement and Skepticism Surrounding O3: The community expressed mixed feelings about the recent O3 release, highlighting benchmarks but questioning the transparency of its improvements over O1.
- Some speculate that it may involve a new model and higher quality data, while others remain skeptical of its practicality and demand for massive compute.
- Utilizing Fine-tuning for LLMs: Members discussed the potential of fine-tuning various LLMs using their own datasets, emphasizing the dependency on the use case for the quantity of data needed.
- Several contributions highlighted the importance of quality and relevance over sheer volume, with some suggesting a few hundred to thousands of examples.
- Consciousness in AI and Relevant Benchmarks: There was a brief debate regarding the concept of measuring consciousness in AI, with a consensus that it remains an unmeasurable concept.
- Participants noted that while AI can assist with complex tasks, it does not imply consciousness, suggesting that current benchmarks are insufficient.
- Various Deployment Options Discussed: The options for deploying models such as TGI and vLLM were discussed, with vLLM being noted for its speed and flexibility in handling adapters.
- A member also shared resources regarding TGI, which serves to streamline deployment of transformer models more effectively.
- FrontierMath Performance and AI Capabilities: Participants highlighted the impressive performance of FrontierMath, citing a significant leap in accuracy for difficult problems as a promising indicator for AI development.
- However, some remained skeptical of potential overfitting or dataset leakage, suggesting a need for thorough validation to support these claims.
- OpenAI o3 Breakthrough High Score on ARC-AGI-Pub: OpenAI o3 scores 75.7% on ARC-AGI public leaderboard.
- Tweet from Daniel Han (@danielhanchen): o3 is trained on ARC AGI - so is o3 ~= o1+CoT+pruning+finetuning+evaluator+hacks?Is the 6/1024 samples in https://arcprize.org/blog/oai-o3-pub-breakthrough referencing the "depth" during tree ...
- Text Generation Inference: no description found
- Tweet from David Dohan (@dmdohan): imo the improvements on FrontierMath are even more impressive than ARG-AGI. Jump from 2% to 25% Terence Tao said the dataset should "resist AIs for several years at least" and "These are e...
- Skywork/Skywork-Reward-Gemma-2-27B-v0.2 · Hugging Face: no description found
- GitHub - namin/llm-verified-with-monte-carlo-tree-search: LLM verified with Monte Carlo Tree Search: LLM verified with Monte Carlo Tree Search. Contribute to namin/llm-verified-with-monte-carlo-tree-search development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #off-topic (28 messages🔥):
League addiction, SDXL model strength, LoRA models for anime, Flux model challenges, Unsloth support plans
- League Addiction Returns: A member confirmed their League addiction has come back, showing interest in ongoing discussions about gaming.
- Another member responded with a lighthearted acknowledgment, noting it appears to still be a thing.
- SDXL Model is Strong for Anime: Members discussed the SDXL model's strength for generating anime content, with one suggesting it's more effective when used with LoRA models.
- They emphasized the advantages of using models trained on top of SDXL for better anime output.
- LoRA Models Insight: A member shared a link to a LoRA model for anime, specifically one related to Miyabi Hoshimi from Zenless Zone Zero.
- Discussions highlighted various trigger words and characteristics ideal for the model's implementation.
- Flux Model Drawing Challenges: Concerns were raised about the Flux model being challenging to use consistently with LoRA for anime generation.
- One member expressed they're waiting for Unsloth to support Flux, indicating plans may be in the works.
- Upcoming Pony Model Release: Members discussed using pony-based models that are SDXL-based until the next Pony 7 release.
- The community shows excitement about future updates, indicating a pending interest in upcoming releases.
- - YouTube: no description found
- Miyabi Hoshimi (星見雅) (星见雅) - Zenless Zone Zero (绝区零) (絕區零) (ゼンレスゾーンゼロ) - booru | Stable Diffusion LoRA | Civitai: Support me on facebook.com/Kaiseir patreon.com/Serkai https://ko-fi.com/kaiseir Weight: 1.0 Trigger words: Appearance: miyabihoshimi, <lora:miya...
Unsloth AI (Daniel Han) ▷ #help (131 messages🔥🔥):
RAG Implementation, Training and Fine-Tuning Models, Using Google Colab and Kaggle, JSON Formatting Issues, Installation Problems on Windows
- Successful RAG Implementation: A member shared progress on implementing RAG, stating that they are now successfully training with a 75k row CSV file converted from JSON.
- The model's accuracy drastically improved from taking 3 hours to just 15 minutes after understanding the GitHub resources.
- Training Issues and Solutions: A user faced a ZeroDivision error while training their model and highlighted installation issues on Windows due to dependency conflicts.
- Notes suggested using WSL for better compatibility, and a member shared experiences about fine-tuning using Llama models effectively.
- Kaggle for Free GPU Access: A suggestion was made to utilize Google Colab or Kaggle for training, revealing that Kaggle provides 30 hours of free access to a 16GB GPU weekly.
- Resources and tutorials were recommended for getting started, including using notebooks provided by the Unsloth documentation.
- JSON Formatting Challenges: A user expressed difficulty in formatting their dataset properly, which caused training issues when adapting a local JSON dataset for fine-tuning.
- Another member suggested that if the JSON data isn't formatted correctly, it can lead to irrelevant responses when training models.
- Utilizing Llama Models in Specific Contexts: New users inquired about the suitability of Llama 3 models for training agents using conversation histories and the best approach to achieve this.
- Experts suggested leveraging powerful cloud services and taking advantage of the community notebooks for quick starts.
- BA-LoRA: Bias-Alleviating Low-Rank Adaptation to Mitigate Catastrophic Inheritance in Large Language Models: Large language models (LLMs) have demonstrated remarkable proficiency across various natural language processing (NLP) tasks. However, adapting LLMs to downstream applications requires computationally...
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
Nous Research AI ▷ #general (298 messages🔥🔥):
O1 and O3 Models, Agentic Systems, Economic Impact of AI, ARC-AGI Benchmark, Open Source AI Development
- O3 Model's Cost and Performance: The newly announced O3 model has shown significant improvements in reasoning tasks, with O3-Mini reportedly outperforming O1, especially in coding, while also being cheaper.
- However, the total compute cost for using O3 can reach up to $1,600,250, raising concerns about the accessibility and financial implications of advanced AI tools.
- Development of Agentic Systems: There's optimism that smaller companies and open source developers will pivot towards developing autonomous agents and multi-step reasoning systems, akin to a gold rush in AI.
- The conversation suggests that such developments could democratize AI advancements, similar to how smaller players improved baseline model performance.
- AI and Job Market Concerns: Participants shared apprehension about the rapid advancement of AI capabilities, particularly the fear that autonomous agents capable of research could lead to job losses in various sectors.
- The concern is that as AI continues to excel in complex tasks, traditional job roles could become increasingly obsolete.
- Evaluating ARC-AGI Benchmark Success: The ARC-AGI benchmark results showed that achieving 25% is already in competition-level math problems, raising questions about the scoring and effectiveness against human participants.
- Understanding the performance in comparison to skilled humans could help gauge the actual advancements made by AI on these benchmarks.
- Regulatory Perspectives on AI Assets: There's a discussion around how lawmakers might treat the exchange of digital assets differently from existing currencies, despite their similar functions.
- Concerns were expressed regarding how the evolving landscape of AI, including agentic systems, could prompt new regulations and economic frameworks.
- no title found: no description found
- Tweet from Sauers (@Sauers_): The total compute cost was around $1,600,250, more than the entire prize
- Adaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation: Inference-time computation is a powerful paradigm to enhance the performance of large language models (LLMs), with Best-of-N sampling being a widely used technique. However, this method is computation...
- Tweet from Nat McAleese (@__nmca__): o3 represents enormous progress in general-domain reasoning with RL — excited that we were able to announce some results today! Here’s a summary of what we shared about o3 in the livestream (1/n)
- Google unveils new reasoning model Gemini 2.0 Flash Thinking to rival OpenAI o1: Unlike competitor reasoning model o1 from OpenAI, Gemini 2.0 enables users to access its step-by-step reasoning through a dropdown menu.
- Tweet from Jeff Dean (@JeffDean): Want to see Gemini 2.0 Flash Thinking in action? Check out this demo where the model solves a physics problem and explains its reasoning.
- Deep Thought Thinking GIF - Deep Thought Thinking Loading - Discover & Share GIFs: Click to view the GIF
- Google unveils new reasoning model Gemini 2.0 Flash Thinking to rival OpenAI o1: Unlike competitor reasoning model o1 from OpenAI, Gemini 2.0 enables users to access its step-by-step reasoning through a dropdown menu.
- Tweet from François Chollet (@fchollet): Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tas...
- Universal Transformers: Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their inherent...
- MoEUT: Mixture-of-Experts Universal Transformers: Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in lea...
- arc-prize-2024/the_architects.pdf at main · da-fr/arc-prize-2024: Our solution for the arc challenge 2024. Contribute to da-fr/arc-prize-2024 development by creating an account on GitHub.
Nous Research AI ▷ #ask-about-llms (15 messages🔥):
Subconscious programming in prompts, Tokenization methods, Random activation functions, Function calling behavior in LLMs, Instruction tuning LLMs on raw data
- Exploring Subconscious Programming Techniques: A member raised the idea of latent influence injecting, where prompts are engineered to subtly influence outputs without overt references.
- Another member expressed interest in investigating this method, suggesting it could act like neuro linguistic programming for agent prompts.
- Diverse Tokenization Techniques Discussed: Discussion revolved around various ways to tokenize a string, such as 'Se-villa' or 'S-evil-lla', and the implications for prompt engineering.
- Members concluded that while polysemy exists in tokens, it may lead to challenges in precise prompt engineering, which might rely heavily on trial and error.
- Random Activation Functions Speculated: A member inquired about the existence of an activation function that activates randomly, potentially optimizing computation by pre-loading matrices.
- They mentioned they had heard something about it before but couldn't confirm if it was a legitimate method in the field.
- Llama 3.3 More Aggressive in Function Calling: A member observed that Llama 3.3 exhibited much more aggressive function calling compared to Hermes 3 70b, which they found undesirable due to costs associated with calls.
- In contrast, Hermes was described as less aggressive, leading to more stable outcomes in most cases.
- Concerns About Training LLMs on Raw Text: A member questioned the repercussions of training an instruction-tuned LLM on raw text data, like PubMed, and whether that would affect model coherence.
- They emphasized the need to convert data into Q/A pairs for effective training instead of straight fine-tuning on raw text.
Nous Research AI ▷ #interesting-links (1 messages):
jellyberg: https://theaidigest.org/self-awareness
Nous Research AI ▷ #reasoning-tasks (1 messages):
Reasoning dataset, Collaborative project, Usingtag, Modeling strategies
- Collaborating on a reasoning dataset: A member proposed creating a reasoning dataset and invited others to collaborate on this project.
- The focus is on a method using the
- The focus is on a method using the
- Innovative approach with
tag : The method involves encapsulating the thought process within- This initiative aims to improve the quality and effectiveness of reasoning datasets through systematic study and collaboration.
Stackblitz (Bolt.new) ▷ #announcements (1 messages):
Mistletokens, Holiday Gifts, Free Tokens Distribution
- Bolt Team Celebrates with Mistletokens: The Bolt team announced the launch of their holiday gift, Mistletokens, which comes with exciting benefits for users during the holiday season.
- Happy Holidays! All Pro users can enjoy 2M free tokens until the end of the year, while Free users receive 200K daily and a 2M monthly limit.
- Holiday Greetings from Stackblitz: In the spirit of the season, the Stackblitz team shared their holiday cheer along with the announcement of Mistletokens.
- They expressed their eagerness to see the creations users will build with these new token benefits.
Link mentioned: Tweet from StackBlitz (@stackblitz): Happy Holidays! Yet again our team put together a special gift for y'all:🎄 We call them, Mistletokens! 🎄Till EOY:🔔 All Pro users get 2M free tokens!🔔 All Free users get 200K daily & 2M monthly...
Stackblitz (Bolt.new) ▷ #prompting (3 messages):
Bolt application review, Redundancy cleanup, Targeted review requests
- Bolt needs improvement on redundancy reviews: Users expressed frustration about Bolt's handling of application redundancy, noting that it tends to just consume tokens without effective cleanup.
- A member remarked, 'But with diffs on it seems tricky. A lot of duplication.'
- Targeted reviews yield better results: It was noted that Bolt has improved in handling redundant applications recently, especially with targeted review requests.
- A member shared their success with a specific prompt: 'Please do a thorough review and audit of [The Auth Flow of my application].'
Stackblitz (Bolt.new) ▷ #discussions (295 messages🔥🔥):
Bolt integration issues, WebRTC implementation, Subscription and token management, Ecommerce platform development using Bolt, Community support and collaboration
- Bolt users face integration frustrations: Multiple users reported issues with Bolt creating new Supabase projects instead of using existing ones, leading to wasted tokens and operational disruptions.
- The ongoing rate limiting on free plans fueled frustration, as users believe token purchases should not lead to such restrictions.
- WebRTC for video chat applications: A discussion around implementing WebRTC for applications similar to Omegle highlighted the challenges users face when trying to integrate real-time communication features within Bolt.
- Community members expressed a desire for fully integrated WebRTC features along with customizable implementation options.
- Subscription-based token confusion: Users raised concerns about the necessity of an active subscription to utilize purchased token reloads, with calls for clearer communication on payment pages.
- The community echoed frustrations about token spending and restrictions on usage once subscriptions are canceled, underscoring a need for transparent policies.
- Impressive full-stack ecommerce platform development: One user shared their ambitious development of a full-stack ecommerce platform, emphasizing complete independence from third-party services with various integrated features.
- The phases of development include a headless backend, an optimized storefront, and a visual editor, aiming to provide a robust alternative to current market offerings.
- Community support and shared experiences: Users expressed their experiences and challenges within the Bolt community, offering support and solutions to those facing similar issues.
- The discourse highlighted collaboration among developers, fostering a community that thrives on knowledge-sharing and mutual assistance.
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Wiser - Knowledge Sharing Platform: no description found
- - YouTube: no description found
LM Studio ▷ #general (103 messages🔥🔥):
Adrenaline Driver Issues, LM Studio Installation, TPM and Windows 11 Compatibility, Defamation Lawsuit Against OpenAI, LM Studio Chat Naming Mechanism
- Adrenaline Driver Causes System Stuttering: Several members reported issues with the Adrenaline 24.12.1 drivers that cause constant system stuttering when loading models on the 7900 XTX GPU, while downgrading to 24.10.1 resolves these problems.
- 'Seems to be more faulty for those on Win11,' noted one user, while others share their experiences with different combinations of Windows and driver versions.
- Installing LM Studio without GUI: A user inquired about installing the LM Studio server on Linux without a GUI, and it was mentioned that launching the GUI at least once is necessary to enable headless mode.
- It was indicated that full headless support is still in development, and currently, direct use of llama.cpp may be the best workaround.
- Troubles with TPM and Windows 11 Compatibility: A member expressed frustration over being unable to enable TPM for Windows 11 on their X570 motherboard, despite having a compatible 3700X CPU.
- Discussions indicated potential motherboard or CPU faults, with another suggesting that upgrading to a new build might resolve these incompatibility issues.
- Defamation Lawsuit Against OpenAI: A YouTube video linked in the chat revealed a lawsuit threat against OpenAI due to allegedly defamatory statements made by the AI, leading to filtering of the individual's name from model outputs.
- Discussions focused on the implications of training on open web data and concerns over context and accuracy in AI responses.
- Naming Mechanism in LM Studio: Queries were raised about how LM Studio automatically generates chat names based on conversations, with suspicions of a small model being utilized for summarization.
- Some members speculated that a bundled model within LM Studio may be responsible for this feature, indicating the tool's design to enhance user interaction.
- - YouTube: no description found
- Amazon.com: ASRock TPM2-S TPM Module Motherboard (V2.0) : Electronics: no description found
LM Studio ▷ #hardware-discussion (103 messages🔥🔥):
3090 Performance for AI and Coding, External GPU Setups, LLM Parameter Compression, Mac vs. PC for AI Development, Local Market vs. eBay for Hardware Purchase
- 3090 Thrives in AI and Coding Tasks: Multiple members confirmed that a 3090 GPU with 64 GB RAM and a 5800X can run models comfortably in the 16B range while maintaining good token speeds.
- Discussion focused on potential speeds, with 70B models requiring higher VRAM and specific quantization for optimal performance.
- External GPU Insights: A member shared their setup using a Razer Core X eGPU with a 3090, enhancing performance on an i7 laptop, highlighting the value of external graphics.
- Clarification was made that eGPUs refer to external GPUs, connected via Thunderbolt, which opens up discussions on hardware options.
- Understanding LLM Parameter Compression: The impact of quantization (Q) levels on model performance was explained, particularly how Q8 is often nearly lossless and Q6 can still yield good results.
- Members discussed that lower quantization levels may benefit some models, emphasizing the balance between size and performance.
- Mac vs. PC for Coding Applications: Debate arose regarding the suitability of Macs compared to PCs like the one with a 3090 for applications in code generation and AI development.
- Ultimately, the choice depended on specific needs like iOS development requirements, power efficiency, and budget.
- Market Insights for Hardware Purchases: Members discussed their preferences for purchasing hardware locally versus through platforms like eBay, citing experiences with seller reliability and item condition.
- Local classifieds were recommended for avoiding excessive fees while engaging with community sellers for better pricing.
- TRELLIS - a Hugging Face Space by JeffreyXiang: no description found
- Excellent Happy GIF - Excellent Happy Mr Burns - Discover & Share GIFs: Click to view the GIF
- Surprised Shocked GIF - Surprised Shocked Funny - Discover & Share GIFs: Click to view the GIF
- NVIDIA GeForce RTX 3090 Founders Edition 24GB GDDR6X GDDR6X Graphics Card | eBay: no description found
- NVIDIA MSI GeForce RTX 3090 GAMING X TRIO 24GB Gaming Graphics Card HDMI 2.1 VR | eBay: no description found
- NVIDIA MSI GeForce RTX 3090 GAMING X TRIO 24GB Gaming Graphics Card HDMI 2.1 VR | eBay: no description found
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
Gemini 2.0 Flash Thinking Experimental, Timeout Logic Change and Reversion, BYOK (Bring Your Own API Keys), o1 Model Changes, Crypto Payments API
- Gemini 2.0 Flash Thinking Model Launch: Google's new thinking model, Gemini 2.0 Flash Thinking, is now live, allowing it to output thinking tokens directly into its text content stream. Users can try it on OpenRouter.
- The model 'google/gemini-2.0-flash-thinking-exp' is currently unavailable, and users are directed to request access via the Discord.
- Timeout Logic Issue Resolved: A temporary change in timeout logic affected a subset of users, but the issue has been resolved and everything is back to normal. The team has apologized for the inconvenience and plans to enhance automated testing for timeouts.
- Users were only impacted for 30 minutes, and measures will be taken to avoid similar situations in the future.
- Launch of BYOK - Bring Your Own API Keys: BYOK empowers users to leverage their own API keys and credits from major providers, enhancing throughput with combined rate limits. This new feature offers access to unified analytics and works with third-party credits from platforms like OpenAI and Google Cloud.
- Users can manage their integration through Settings and utilize this service for just 5% of their upstream provider's cost.
- o1 Model Going BYOK-Only Temporarily: OpenAI's o1 model will be BYOK-only until the new year, with the o1-preview and o1-mini remaining unaffected. Users with Tier 5 OpenAI keys can still access the o1 model through their BYOK settings.
- The team is working closely with OpenAI to improve access, as this limitation is against OpenRouter's principles of broad access.
- Introduction of the Crypto Payments API: A new Crypto Payments API allows for headless, on-chain payments for any LLM, marking a significant development in autonomous funding. This feature supports payments via ETH, 0xPolygon, and Base, powered by Coinbase.
- More details and a tutorial can be found in the announcement on OpenRouter's status.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Tweet from OpenRouter (@OpenRouterAI): Introducing the Crypto Payment API: the first way to script on-chain payments for any LLM 💸Want to make one of the first agents that can fund its own intelligence?Works with ETH, @0xPolygon, & @Base,...
- Tweet from OpenRouter (@OpenRouterAI): Two big new features today!#1: BYOK, Bring Your Own API KeysWe're excited to announce BYOK, giving you the best possible uptime:🚀 aggregate our rate limits with yours!💰 use 3rd party credits fro...
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
AI To-Do List, Open Router integration, 5-Minute Rule
- AI To-Do List powered by Open Router: An engaging AI To-Do List concept was shared, built using Open Router, which can process tasks using context like code or spreadsheets.
- The idea plays on the 5-Minute Rule, starting to work in seconds, and aims to trigger agents to complete tasks automatically, highlighting how fun work can be.
- Functionality of the To-Do List: The list can be utilized not only to manage tasks but also to create new tasks, creating a recursive efficiency.
- A user remarked, “It's actually fun to do work,” emphasizing the playful aspect of this approach.
Link mentioned: Todo Lists: no description found
OpenRouter (Alex Atallah) ▷ #general (170 messages🔥🔥):
OpenRouter Payment Policies, AGI Discussions, Model Releases and Features, Cloud Service Utilization, User Experience with APIs
- OpenRouter's Payment Structure Explained: Users discussed the complexities of using their own keys with OpenRouter, noting a 5% fee on provider costs, causing confusion around how that interacts with usage and credits. An example was requested to clarify this structure for better understanding.
- The documentation will be updated to clarify that usage fees depend on the rate from the upstream provider plus the additional fee from OpenRouter.
- Insights on AGI from Community Perspectives: Debate arose around whether AGI advancements are merely a 'red herring', with one user noting that higher compute power isn't equivalent to genuine AGI. Others countered that recent developments show significant performance leaps, suggesting logical progression towards AGI.
- Users were directed to a 1.5-hour discussion video for deeper insight into these claims, indicating a divide in beliefs about the implications of rapid AI advancements.
- Upcoming Model Releases from OpenAI: The upcoming releases of o3-mini and regular o3 were mentioned, suggesting a timeline for potential new features in AI models. The naming conventions around these models were humorously noted due to conflicts with existing company names.
- Community members expressed surprise at the rapid pace of technological evolution, underscoring the significant improvements seen recently.
- User Experiences with Cloud Services: Conversations highlighted the frustrations users have with cloud service support, particularly from Google, comparing it unfavorably to OpenRouter's integration solutions. One user suggested that OpenRouter simplifies user experiences by handling complexities around service availability and limitations.
- A call for transparency in terms of profits margins was made, emphasizing the necessity for OpenRouter to remain profitable while providing solid service.
- Community Engagement on Resource Utilization: Members discussed their experiences with various APIs, seeking clarity on implementation details, especially around model calling and resource usage. The conversation highlighted specific user integration with the mcp-bridge.
- Confusion was noted regarding the provider rate structures, prompting suggestions for clearer documentation and user support.
- François Chollet (@fchollet.bsky.social): It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just bru...
- Red herring - Wikipedia: no description found
- Integrations | OpenRouter: Bring your own provider keys with OpenRouter
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Requests | OpenRouter: Handle incoming and outgoing requests
- - YouTube: no description found
- - YouTube: no description found
- o1 - API, Providers, Stats: The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 model series is trained with large-scale reinforcement learning to reason using ...
Eleuther ▷ #general (55 messages🔥🔥):
Natural Attention and Scaling Laws, Causal Masking in Attention Models, Optimizer Improvements in Training, Quality vs. Quantity in Pretraining, Patterns of Attention Mechanisms
- Jeroaranda's Natural Attention Breakthrough: Jeroaranda claimed to break scaling laws while leveraging the fact that attention approximates the Fisher matrix, showcasing theoretical and empirical results on GitHub.
- He observed that normal Adam optimizer struggles, while natural attention with energy preconditioning yields promising convergence results.
- Need for Causal Mask in Training: Members discussed the necessity of incorporating a causal mask in training models, citing it as a crucial restriction for successful performance.
- Jeroaranda acknowledged this oversight, indicating that using causal masks could enhance the training results of his approach.
- Optimizing Training Approaches: The community shared insights on optimizer improvements, particularly comparing Jeroaranda's AttentionInformedOptimizer to standard techniques.
- Feedback suggested that while initial results may show promise, the importance of careful verification and robust testing cannot be overlooked.
- Debate on Pretraining Data Quality: Discussions emerged about the trade-off between quantity and quality in pretraining data, with some arguing for the benefits of quality being more significant in the context of LLMs.
- The sentiment leaned toward prioritizing high-quality data, especially with large datasets already containing a portion of low-quality content.
- Exploration of Attention Patterns: Dashiell_s raised a question about the patterns of the attention mechanism, particularly regarding what patterns can emerge across the input space.
- Fern.bear noted that the conversation moved to a dedicated channel, indicating ongoing experiments in that area.
- transformers/src/transformers/models/gpt2/modeling_gpt2.py at v4.47.1 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- GitHub - jeroaranda/naturalattention: Contribute to jeroaranda/naturalattention development by creating an account on GitHub.
- naturalattention/papers/Natural_attention_proofs.pdf at main · jeroaranda/naturalattention: Contribute to jeroaranda/naturalattention development by creating an account on GitHub.
- naturalattention/natural_attention.py at main · jeroaranda/naturalattention: Contribute to jeroaranda/naturalattention development by creating an account on GitHub.
- naturalattention/natural_attention.py at main · jeroaranda/naturalattention: Contribute to jeroaranda/naturalattention development by creating an account on GitHub.
Eleuther ▷ #research (68 messages🔥🔥):
MSR Research Ethics, Plagiarism Issues at MSR, Optimizer Research Challenges, Sparks of AGI Paper Problems, OpenAI's Research Environment
- MSR faces scrutiny over research ethics: Members expressed concerns regarding MSR's ethics, with claims that the institution exhibits both 'bottom-up' and 'top-down' ethical problems, citing specific examples of plagiarism.
- It was highlighted that the culture at MSR seems to allow for significant ethical breaches, particularly noted with recent plagiarism incidents.
- Recent plagiarism scandal shakes MSR's credibility: A serious incident of outright plagiarism was reported involving two papers, one of which was a NeurIPS spotlight award runner-up, sparking outrage within the community.
- Members discussed the implications of these actions on MSR's overall credibility, suggesting a growing caution in referencing their work.
- Challenges in optimizer research: A new member questioned the recurring claim of new optimizers outperforming AdamW, despite previous hype fading over time, pointing to potential issues with tuning.
- It was noted that grid search for hyperparameters, while theoretically ideal, is often neglected due to the slow process and incentives for authors to present their methods favorably.
- Concerns about Sparks of AGI paper: Participants noted that the Sparks of AGI paper lacked rigor, appearing more like an advertisement for GPT-4, despite its formatting as a legitimate academic paper.
- Critics pointed out significant issues with the paper’s foundational claims, particularly how its definition of intelligence was tied to a controversial OpEd, raising ethical concerns.
- Pressure for reform in academic publishing: Users discussed the need for reforms in the academic publishing process, proposing features like ratings or reviews on arXiv to guide research quality assessment.
- There was general consensus that the current publication process fosters a proliferation of papers that may lack substantial rigor, impacting the reliability of cited research.
- SWAN: Preprocessing SGD Enables Adam-Level Performance On LLM Training With Significant Memory Reduction: Adaptive optimizers such as Adam (Kingma & Ba, 2015) have been central to the success of large language models. However, they maintain additional moving average states throughout training, which r...
- GitHub - KellerJordan/modded-nanogpt: NanoGPT (124M) in 5 minutes: NanoGPT (124M) in 5 minutes. Contribute to KellerJordan/modded-nanogpt development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (14 messages🔥):
Mahalanobis distance, Model activation norms, BOS token issues, SAE training strategies, Normalization techniques
- BOS Token Causes High Activation Norms: A member pointed out that model activation norms at the first token position can be 10-30x higher than at other positions, potentially due to the BOS token disproportionately influencing loss.
- Another contributor suggested this could be because the BOS token acts as an attention sink, leading to the recommendation of excluding it from SAE training data.
- Concerns about Tokenization Impact: A user expressed concern that high activation norms indicate a problem, asserting that their results indicate the first token's contribution to loss is significant in short-context SAEs.
- Another member supported this by recalling a prior discussion about normalizing activations or ignoring EOS and BOS tokens during training.
- Normalization Strategies for Training: There was a discussion about potential solutions for handling BOS issues, including dropping the first token or adding RMS normalization.
- However, members noted these adjustments might require careful consideration of rescaling outputs back to the original norms.
- Training Context Length Effects: Despite training on a 2k context length, it was noted that the effects of the first token can still be problematic in some cases due to its relative dominance.
- One user mentioned they observed similar activation issues even with the full 1024 context length for gpt2-small, attributing it to especially poor first token norms.
- Revisiting Activation Norms within SAEs: Discussions highlighted that while working with SAEs, the influence of the first token might not be as critical in longer context scenarios, yet remains a concern.
- Members agreed on the need to ensure proper input handling for SAEs to mitigate these issues in model training.
Eleuther ▷ #lm-thunderdome (18 messages🔥):
Benchmark Directory Issues, Model Checkpoint Naming, Harness Setup for Multiple Models
- Benchmark Directory Confusion: A member expressed frustration with benchmark results being saved to an unexpected path, specifically
./benchmark_logs/name/__mnt__weka__home__...instead of the intended./benchmark_logs/name/.- This creates complications for managing local model benchmarks, especially when working with multiple checkpoints.
- Need for Naming Convention Options: There was a suggestion to add an option for users to choose their naming convention for benchmark directories.
- This would help manage and distinguish results better, especially for extensive runs with various checkpoints.
- Setting Up a Harness for Benchmarks: A member is trying to set up a specialized harness to benchmark all checkpoints of a model run and extract JSON data for visual comparisons.
- This aims to streamline the process of comparing models and their performances based on multiple checkpoint results.
- Discussion on Backwards Compatibility: Concerns were raised about achieving backwards compatibility while implementing changes to the benchmark saving process.
- This reflects the delicate balance between enhancing functionality and maintaining legacy support.
- Suggestions for Directory Management: A member proposed that integrating a unique directory for each run could simplify the results management, holding only one result at a time.
- This could reduce clutter and confusion when dealing with mass local model benchmarks.
- lm-evaluation-harness/lm_eval/loggers/evaluation_tracker.py at 6ccd520f3fb2b5d74c6f14c05f9d189521424719 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/loggers/evaluation_tracker.py at 6ccd520f3fb2b5d74c6f14c05f9d189521424719 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (3 messages):
Pull Request #1331, WandB Testing
- Enhancements in Pull Request #1331: A member submitted Pull Request #1331 which adds logging for MFU/HFU metrics when
neox_args.peak_theoretical_tflopsis used, and integrates metrics liketokens_per_secanditers_per_secto platforms including WandB and TensorBoard.- This update also allows for manual specification of the WandB experiment name, enhancing usability for logging.
- Feedback on WandB Integration: A member expressed their gratitude for the WandB integration but mentioned that they would be unable to test it until next week.
- Despite the delay, they acknowledged that the WandB setup appears to be great, indicating confidence in the changes made.
- Confirmation to Merge Pull Request: In response to testing availability, another member indicated that the feedback received was sufficient for them to merge the pull request for now.
- They also invited further communication in case any issues arise after testing.
- Add Additional Logging Metrics by Quentin-Anthony · Pull Request #1331 · EleutherAI/gpt-neox: Logs MFU/HFU if the user passes neox_args.peak_theoretical_tflopsLog tokens_per_sec, iters_per_sec to wandb, comet, and tensorboardAdd ability to manually specify wandb experiment name
- quentin-anthony: Weights & Biases, developer tools for machine learning
Modular (Mojo 🔥) ▷ #general (4 messages):
Machine setup, Level progression
- Inquiry about Machine Setup: A member asked if another had successfully managed to get their stack running on their machine setup.
- What do you mean exactly? was the response, indicating some confusion regarding the initial query.
- Congratulations on Level Advancement: A bot congratulated a member for advancing to level 2, highlighting progress in the community.
- This advancement likely reflects their active participation or contributions in the channel.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Modular community appreciation, Holiday shutdown notice, Feedback and bug reporting for 24.6 release, Looking forward to 2025
- Modular community wraps up 2024 with gratitude: The Modular team expressed heartfelt thanks to the community for their contributions throughout 2024, highlighting the growth and innovation achieved together.
- It's been an amazing year of collaboration and support that has significantly shaped Modular's journey.
- Holiday shutdown until January 6th: Modular will be shut down until January 6th to allow everyone to enjoy the holiday season, with team responses being delayed during this period.
- This break provides a chance for everyone to relax and recharge for the new year.
- Feedback channels for the 24.6 release: The community was directed to share their feedback on the recent 24.6 release through various options including a feedback forum thread.
- For reporting bugs or requesting features, members were encouraged to utilize GitHub Issues.
- Wishing for a bright 2025 ahead: The team expressed excitement for 2025, emphasizing their eagerness to continue building alongside the community after the holiday break.
- This outlook underscores the commitment to maintaining a collaborative spirit as they move forward together.
Modular (Mojo 🔥) ▷ #mojo (142 messages🔥🔥):
FFI Compatibility Issues, Libc Bindings Development, Performance of Float Parsing, Mojo As an Extension to Python, Properties in Mojo
- FFI Compatibility Issues arise after Update: A user reported a subtle change in FFI compatibility from version 24.5 to 24.6, affecting socket write/read functionality, citing a symbol clash with
write.- The potential solution involves utilizing
FileDescriptorfor conversion to avoid conflicts with built-in functions from standard libraries.
- The potential solution involves utilizing
- Libc Bindings Development is Crucial: Discussion emphasized the need for comprehensive libc bindings within Mojo, with one user noting they had implemented around 150 of the most utilized functions.
- The conversation suggested creating a centralized location for these bindings to facilitate testing across different platforms.
- Performance of Float Parsing Needs Improvement: An experiment porting float parsing from Lemire resulted in slower performance than expected, with existing standard library methods identified as less efficient.
- An open pull request for improving the
atoffunction was mentioned, indicating ongoing efforts to enhance float parsing performance in Mojo.
- An open pull request for improving the
- Mojo Aims to Extend Python Functionality: The topic revolved around how Mojo should adequately handle edge cases like properties, ensuring clean code and proper function usage.
- A suggestion was made to document advanced features in an 'Advanced Mojo Spellbook' to guide new users.
- Concerns Regarding Properties Usage: Concerns were raised about the risk of using properties leading to inefficient code or unexpected behavior due to hidden complexity.
- The participants discussed the implications of properties on code clarity and reviewability, sharing differing opinions on their utility.
- write(3p) - Linux manual page: no description found
- jax.lax module — JAX documentation: no description found
- rust-lang/rust: Empowering everyone to build reliable and efficient software. - rust-lang/rust
Modular (Mojo 🔥) ▷ #max (3 messages):
Tensor implementation, Feature Request, MAX APIs
- Feature Request for TensorLike Trait Implementation: A request was made to have
tensor.Tensorimplement thetensor_utils.TensorLiketrait, suggesting it already meets the required functions.- This feedback is documented in an issue on GitHub citing it as a major oversight that should be easily fixable.
- Debate on Tensor as a Trait: A member expressed that
Tensorwould be better suited as a trait rather than a type, noting that most MAX APIs require something different from a tensor.- They highlighted the challenge in constructing a tensor directly, indicating a need for flexibility in implementation.
Link mentioned: [Feature Request] Make tensor.Tensor implement tensor_utils.TensorLike · Issue #274 · modularml/max: What is your request? Please make tensor.Tensor implement the tensor_utils.TensorLike trait. As far as I can tell it already implements the required functions, but it does not implement this trait ...
Latent Space ▷ #ai-general-chat (127 messages🔥🔥):
OpenAI o3 model, Alec Radford departure, AI benchmark improvements, Economic implications of AI models, Safety testing for AI models
- OpenAI introduces the o3 model: OpenAI announced the o3 reasoning model, achieving 75.7% on the semi-private ARC-AGI evaluation and 87.5% with high compute costs, showcasing significant improvements in reasoning capabilities.
- Experts noted that the model's development signals rapid progress in the field, with researchers speculating about the underlying architecture, including potential uses of parallel Chain-of-Thought reasoning.
- Alec Radford leaves OpenAI: Alec Radford, a key figure behind OpenAI's early work on GPT models, announced his departure for independent research, causing waves in the community regarding the implications for OpenAI's future.
- Members discussed his departure, implying potential shifts in OpenAI's direction and leadership, while contemplating the impact on ongoing research efforts.
- AI benchmark performance draws attention: The o3 model scored a notable 87.5% on the ARC-AGI benchmark in high-compute mode, leading to discussions on the economic ramifications of AI models' performance, particularly their high operational costs.
- Comments pointed out that while the costs per task are substantial, they can be justified given the advancements achieved by the model, albeit raising concerns about the sustainable use of resources.
- Insights on new AI evaluation methods: Participants expressed curiosity about the evaluation methods used for the o3 model, particularly pertaining to comparisons between the effectiveness of task prompts and the nature of the benchmarks.
- Research and evaluations discussed included semi-private data sets designed to prevent groups from easily leveraging them for competitive advantage in AI training.
- Safety testing for o3 under discussion: OpenAI is seeking volunteers for safety testing of the new o3 model, indicating their commitment to addressing potential risks associated with deploying advanced AI.
- Safety researchers are encouraged to apply for participation, highlighting an ongoing effort to ensure responsible advancements in AI technology.
- Tweet from OpenAI (@OpenAI): Day 12: Early evals for OpenAI o3 (yes, we skipped a number)https://openai.com/12-days/?day=12
- Tweet from David Dohan (@dmdohan): o3 @ 87.5% on ARC-AGIIt was 16 hours at an increase rate of 3.5% an hour to "solved"Quoting David Dohan (@dmdohan) At this rate, how long til ARC-AGI is “solved”?For context:- gpt-4o @ 5%- Son...
- Tweet from Alexander Doria (@Dorialexander): Ah yes, OpenAI is really not messing around for the last day. Wild.
- Tweet from Nat McAleese (@__nmca__): o3 represents enormous progress in general-domain reasoning with RL — excited that we were able to announce some results today! Here’s a summary of what we shared about o3 in the livestream (1/n)
- Tweet from François Chollet (@fchollet): Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tas...
- Tweet from ARC Prize (@arcprize): New verified ARC-AGI-Pub SoTA!@OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation.And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the S...
- Tweet from undefined: no description found
- Tweet from Greg Kamradt (@GregKamradt): We verified the o3 results for OpenAI on @arcprize My first thought when I saw the prompt they used to claim their score was..."That's it?"It was refreshing (impressive) to see the prompt ...
- Tweet from Tibor Blaho (@btibor91): This is real - the OpenAI website already has references to "O3 Mini Safety Testing Call" formQuoting Colonel Tasty (@JoshhuaSays) Found references to o3_min_safety_test on the openai site. S...
- Tweet from Georgi Gerganov (@ggerganov): Open the pod bay doors, HAL.
- Tweet from will depue (@willdepue): i did not liehttps://x.com/willdepue/status/1856766850027458648Quoting will depue (@willdepue) scaling has hit a wall and that wall is 100% eval saturation.
- Tweet from Nat McAleese (@__nmca__): o3 represents enormous progress in general-domain reasoning with RL — excited that we were able to announce some results today! Here’s a summary of what we shared about o3 in the livestream (1/n)
- Tweet from Adam Roberts (@ada_rob): Day 11: they shipped Alec...Quoting Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr) Breaking news!Alec Radford departs OpenAI!As one of their star researchers, he was first author on GPT, GPT-2, CLIP, a...
- o3: The grand finale of AI in 2024: A step change as influential as the release of GPT-4. Reasoning language models are the current big thing.
- AI Engineer Summit: The highest-signal technical AI event of the year. For AI Engineers & AI Leaders, Feb 20 - 21, 2025.
- Genesis: no description found
- Tweet from swyx (@swyx): this is what it looks like to work with AGIs like @benghamine behind the sceneswondering when @recraftai or @GeminiApp or @xai can match this workflowQuoting jason liu (@jxnlco) oohh shit this is hu...
- Tweet from kalomaze (@kalomaze): i suspect it because:A. this would be very very easy to apply and train to extend the depth of an existing model without more pretrainingB. they have the compute to not care that it's an inelegant...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): OpenAI is prepping the next generation of its o1 reasoning model.But, due to a potential copyright/trademark conflict with British telecommunications firm O2, OpenAI has considered calling the next up...
- Invalid Structured Output Responses: no description found
- Tweet from James Campbell (@jam3scampbell): someone needs to explain how claude is able to consistently perform on-par with o1 models without thinking for 3 minutes first
- Tweet from Stephanie Palazzolo (@steph_palazzolo): Big OpenAI personnel news w/ @erinkwoo: Alec Radford, the lead author of OpenAI's original GPT paper, is leaving to pursue independent research. https://www.theinformation.com/briefings/senior-op...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): O3 dramatically improved SWE-bench Verified (from 48.9% to 71.7%)
- Tweet from Gary Marcus (@GaryMarcus): The fan boys who are declaring victory now clearly never went to graduate school, where you learn to pick apart a bunch of graphs and ask hard questions.Like, what does the top left graph here tell us...
- Tweet from kalomaze (@kalomaze): oh god did they do fucking layer loopingQuoting murat 🍥 (@mayfer) how did o3 in high compute mode spend thousands of dollars of compute on one problem? since thousands of $ don't fit into context...
- Tweet from Hensen Juang (@basedjensen): it has been 2 hours since openai announced o3 and it has so far failed to solve - Riemann hypothesis- Quantum Gravity- FTL (Faster Than Light travel)- P=NP- Grand Unified Theory- Cure for cancer- Gpt...
- Tweet from Deedy (@deedydas): Summary of all the CRAZY benchmark results from OpenAI's most advanced model, o3!SWE-Bench Verified: 71.7%Codeforces rating: 2727Competition Math: 96.7%PhD level science (GPQA): 87.7%Frontier Math...
- Tweet from Lisan al Gaib (@scaling01): OpenAI spent approximately $1,503,077 to smash the SOTA on ARC-AGI with their new o3 modelsemi-private evals (100 tasks):75.7% @ $2,012 total/100 tasks (~$20/task) with just 6 samples & 33M tokens pro...
- Tweet from Alex Albert (@alexalbert__): @OfficialLoganK We'll see about that ;)
- Tweet from Shengjia Zhao (@shengjia_zhao): Excited to train o3-mini with @ren_hongyu @_kevinlu and others, a blindingly fast model with amazing reasoning / code / math performance.https://openai.com/12-days/?day=12
- Tweet from Deedy (@deedydas): OpenAI o3 is 2727 on Codeforces which is equivalent to the #175 best human competitive coder on the planet.This is an absolutely superhuman result for AI and technology at large.
- Tweet from Noam Brown (@polynoamial): We announced @OpenAI o1 just 3 months ago. Today, we announced o3. We have every reason to believe this trajectory will continue.
- Tweet from David Dohan (@dmdohan): imo the improvements on FrontierMath are even more impressive than ARG-AGI. Jump from 2% to 25% Terence Tao said the dataset should "resist AIs for several years at least" and "These are e...
- Tweet from Teortaxes▶️ (@teortaxesTex): I can't believe it, OpenAI might actually be in deep shit. Radford has long been my bellwether for what their top tier talent without deep ideological investment (which Ilya has) sees in the compa...
- Tweet from Eric Wallace (@Eric_Wallace_): Chain-of-thought reasoning provides a natural avenue for improving model safety. Today we are publishing a paper on how we train the "o" series of models to think carefully through unsafe prom...
- Scott Hanselman 🌮 (@scott.hanselman.com): Try this in chatGPT and be disturbed. “Format this neatly. Do not change the text”Just that prompt.
- Bluesky: no description found
- Scott Hanselman 🌮 (@scott.hanselman.com): no description found
- GitHub - video-db/Director: AI video agents framework for next-gen video interactions and workflows.: AI video agents framework for next-gen video interactions and workflows. - video-db/Director
- Tweet from Noam Brown (@polynoamial): @OpenAI You can sign up to help red team o3 and o3-mini here: https://openai.com/index/early-access-for-safety-testing/
- Tweet from Sam Altman (@sama): if you are a safety researcher, please consider applying to help test o3-mini and o3. excited to get these out for general availability soon.extremely proud of all of openai for the work and ingenuity...
Latent Space ▷ #ai-in-action-club (20 messages🔥):
API Keys Usage, Character AI Audience Insights, User Experience Signals, Interest in Role-play, Swyx's Reporting
- API Keys Fiddling: A user mentioned they are currently fiddling with API keys, highlighting a common task for developers.
- This reflects the ongoing tinkering and exploration prevalent in the developer community.
- Character AI's Diverse Audience: Discussion revealed that the Character AI audience is largely comprised of younger individuals rather than business professionals.
- It's noted that usage among women/girls matches that of men/boys, which surprised some members.
- Desire for Fantasy Connections: Participants expressed interest in how many users of character AI services are looking for their 'Disney prince(ess)(x)', emphasizing the role-playing aspect.
- “The magical math rocks” joke encapsulated the whimsical nature of these interactions, blending fantasy with technology.
- Exploration of User Experience Signals: Inquiries were made about the signals to look for in the character AI user experience, highlighting the importance of understanding user interactions.
- Members showed enthusiasm for feedback on this subject and the insights shared by kbal11.
- Swyx's Insights on Character AI: Swyx's prior reports on the actual character AI audience were mentioned, suggesting deeper analysis might exist.
- Participants expressed interest in exploring further dimensions of this audience's behavior.
Notebook LM Discord ▷ #use-cases (38 messages🔥):
AI in Podcasting, Notebook LM for Education, Job Application Assistance, AI-Generated Video Projects, Improving Audio Production
- AI Revolutionizes Podcast Production: A member shared their excitement about using AI to generate a podcast episode, highlighting its potential in creating engaging audio content quickly.
- Another member remarked on the importance of maintaining consistent audio levels between sections, underscoring the ongoing improvements in audio production techniques.
- Notebook LM Enhances Academic Performance: A user explained how they used Notebook LM to effectively build timelines and mind maps for their Journalism class, facilitating the writing of coherent papers.
- This method proved beneficial as they incorporated course materials and specific podcasts addressing key topics from their studies.
- Job Application Prep with AI: One member detailed how they utilized Notebook LM to analyze their resume in relation to a job announcement, generating interview questions that served as a study guide.
- They found the tool's analysis to be insightful, encouraging others to load their own resumes for personalized feedback.
- AI-Powered Creative Projects: An exciting project titled 'Churros in the Void' was shared, showcasing AI-generated visuals and voiceovers crafted entirely through Notebook LM and LTX-studio.
- Despite the challenges of securing a high-profile voice actor, the creator embraced a DIY approach, exemplifying the innovative use of AI in storytelling.
- Seeking Engagement in Audio Tone: A member inquired about changing the audio tone to sound more informal and engaging, wondering if any customizations were employed.
- This led to a discussion about techniques and tools for enhancing audio presentations in AI-generated content.
- How your Brain communicates through Brain Waves - Human Connectome Project | MindLink | Nanonetes: Connecting the Dots: The Human Connectome Project · Episode
- no title found: no description found
- no title found: no description found
- no title found: no description found
- - YouTube: no description found
Notebook LM Discord ▷ #general (106 messages🔥🔥):
NotebookLM Interactive Mode, Citation Feature Issues, Audio Overview Retrieval, Language Processing in NLM, Timeline Feature Usage
- NotebookLM Interactive Mode rollout confusion: Many users report issues with accessing the interactive voice mode, despite it being stated as available to all users.
- Questions on how to fix this problem have been raised, as some users are still unable to access the feature.
- Bug with citation features in notes: Users have expressed frustration over the recent disappearance of citation features in saved notes after updates.
- The team has acknowledged the issue and is working on an improved version of this feature.
- Retrieving lost audio overviews: A user inquired about the possibility of retrieving a previously generated audio overview that has disappeared from their notebook.
- The discussion points to a concern about the inability to regenerate the same insightful content as previously created.
- Language processing and source limitations: Concerns were raised about NotebookLM's handling of sources in multiple languages and the impact on text retrieval quality.
- Users suggested separating language-specific documents to enhance the accuracy of results from the uploaded sources.
- Utilization of the Timeline feature: The Timeline feature has been highlighted as a valuable tool for organizing historical content in a structured manner.
- Users appreciated its ability to provide a holistic view of events, enhancing the overall experience in their research.
- Xzibit Pimp GIF - Xzibit Pimp My - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- Illuminate | Learn Your Way: Transform research papers into AI-generated audio summaries with Illuminate, your Gen AI tool for understanding complex content faster.
- - YouTube: no description found
- Afterlife Explained: The Mind-Bending Theory of the Universe | Afterlife | Podcast: Welcome to our deep dive into the CTMU (Cognitive-Theoretic Model of the Universe), the groundbreaking theory proposed by Christopher Langan. Often called "t...
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
Perplexity AI ▷ #general (102 messages🔥🔥):
Superman movie teaser, Perplexity Pro with .edu emails, OpenAI's new GPT models, Lepton AI project similarities, Perplexity API support issues
- DC Teases New Superman Film: A member noted a teaser trailer for a new Superman movie released by DC that seemed quite random to them.
- The excitement around the film was brief but lively, with some members sharing light-hearted reactions.
- Perplexity Pro Access via .edu Emails: Some users discussed a rumored promotion offering free Perplexity Pro access for students with .edu emails, prompted by a friend's claim.
- However, it appeared that not all attempts to access this promotion were successful, leading to some confusion.
- OpenAI Introduces o3 and o3-mini Models: Members speculated about the release of OpenAI's new models, o2 and Orion, as potential successors to the recently launched o1.
- The excitement was palpable, with claims that o3 may approach AGI and discussions on its implications for AI applications.
- Lepton AI Project Sparks Discussion: A member pointed out that a newly launched Node pay product echoed a previously seen open-source project by Lepton AI.
- This led to comments on the originality of the design and its similarities to existing products in the space.
- Inquiry About Perplexity API Support: A user expressed concerns regarding the performance of the system prompt with the Perplexity API and sought assistance.
- Another user clarified that while the prompt can guide tone and style, it does not influence the search component of the models.
- no title found: no description found
- Lepton Search: Build your own conversational search engine using less than 500 lines of code with Lepton AI.
- Conspiracy Charlie Day GIF - Conspiracy Charlie Day Crazy - Discover & Share GIFs: Click to view the GIF
- Perplexity - Race to Infinity: Welcome back to school! For just two weeks, redeem one free month of Perplexity Pro on us. Refer your friends, because if your school hits 500 signups we'll upgrade that free month to an entire free y...
- GitHub - leptonai/search_with_lepton: Building a quick conversation-based search demo with Lepton AI.: Building a quick conversation-based search demo with Lepton AI. - leptonai/search_with_lepton
- OpenAI announces new o3 models | TechCrunch: OpenAI saved its biggest announcement for the last day of its 12-day "shipmas" event. On Friday, the company unveiled o3, the successor to the o1
- OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12: Sam Altman, Mark Chen, Hongyu Ren, and special guest Greg Kamradt, President of ARC Prize Foundation, introduce and discuss OpenAI o3, o3-mini, along with a call for safety testing and a new alignment...
Perplexity AI ▷ #sharing (5 messages):
Rio Da Yung OG released, Samsung's Project Moohan, Apple's Congo Conflict Minerals, Oregon’s Psilocybin Program, AI use at work
- Rio Da Yung OG's Release Sparks Interest: Rio Da Yung OG has been released from prison, igniting discussions about his future plans and music career.
- Fans are eager to see how this will influence his upcoming projects.
- Samsung Unveils Project Moohan: Samsung's Project Moohan represents a new initiative aimed at innovation in AI-based technology.
- Details on the project's scope and potential applications are still emerging.
- Apple's Controversial Conflict Minerals: A discussion arose surrounding Apple's sourcing of conflict minerals from Congo, linked to ethical sourcing practices explored here.
- The implications of these practices on Apple's supply chain were highlighted, with community insights pressing for transparency.
- Oregon's Psilocybin Program Gains Attention: The implementation of Oregon’s Psilocybin Program has sparked interest as it progresses towards facilitating therapeutic uses for psychedelics.
- Community members are monitoring the program for potential expansion and successes.
- AI's Impact in the Workplace: Over 70% of workers are reported to use AI at work, according to a recent survey.
- This shift reflects on how integral AI has become in enhancing productivity and maintaining core directives.
Link mentioned: YouTube: no description found
Nomic.ai (GPT4All) ▷ #announcements (3 messages):
GPT4All v3.6.0 Release, GPT4All v3.6.1 Release, Reasoner v1, Chat Template Fixes
- GPT4All v3.6.0 is here!: The new GPT4All v3.6.0 includes Reasoner v1, a built-in javascript code interpreter tool for complex reasoning tasks, along with template compatibility improvements.
- Additional fixes address XML usage in messages and Jinja2Cpp bug affecting system message detection post v3.5.0.
- Quick Fixes in v3.6.1: GPT4All v3.6.1 has been released to address critical issues, including fixing the non-functional stop generation and copy entire conversation buttons from v3.6.0.
- This update reflects swift community contributions, notably from Adam Treat and Jared Van Bortel of Nomic AI.
Nomic.ai (GPT4All) ▷ #general (90 messages🔥🔥):
Llama 3.3 and Qwen2 models, GPT4ALL custom templates and reasoning, Local API server integration, Phi-4 model comparison, Stop generating button issue in v3.6.0
- Llama 3.3 and Qwen2 models discussed: Members shared insights on using Llama 3.3 and Qwen2 models, noting their functionalities and improvements over earlier versions.
- There's anticipation for future releases that will enhance performance further.
- Custom templates for reasoning implemented: A custom chat template designed for GPT4ALL facilitates reasoning using a code interpreter, allowing users to execute code effectively.
- Members confirmed its compatibility with various models, enhancing their functionality.
- Local API server can utilize LocalDocs: The GPT4ALL local API server allows integration with LocalDocs, enabling users to run API requests and utilize local models effectively.
- Participants discussed the process for connecting and utilizing the server in their applications.
- Phi-4 model performance compared to others: Discussion revolved around the Phi-4 model, which is a 14B model reportedly performing comparably to Llama 3.3 70B.
- Members shared experiences running Phi-4 locally and expressed excitement about its capabilities.
- Stop generating button issue acknowledged: Users confirmed issues with the stop generating button in version 3.6.0, leading to reports on a regression bug.
- A fix is in progress, as outlined in the linked GitHub issue tracking the problem.
- GPT4All API Server - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
- matteogeniaccio/phi-4 at main: no description found
- Tweet from Logan Kilpatrick (@OfficialLoganK): It’s still an early version, but check out how the model handles a challenging puzzle involving both visual and textual clues: (2/3)
- Curses Foiled Again GIF - Curses Foiled Again He Man - Discover & Share GIFs: Click to view the GIF
- gpt4all/gpt4all-chat/system_requirements.md at main · nomic-ai/gpt4all: GPT4All: Run Local LLMs on Any Device. Open-source and available for commercial use. - nomic-ai/gpt4all
- Groq is Fast AI Inference: The LPU™ Inference Engine by Groq is a hardware and software platform that delivers exceptional compute speed, quality, and energy efficiency. Groq provides cloud and on-prem solutions at scale for AI...
- Stop generation button no longer works in v3.6.0 · Issue #3333 · nomic-ai/gpt4all: Seems we have a regression with the stop generation button in v3.6.0. The ChatModel::get(...) function was removed which was used in a few different places in QML. This wasn't noticed because we d...
- Groq is Fast AI Inference: The LPU™ Inference Engine by Groq is a hardware and software platform that delivers exceptional compute speed, quality, and energy efficiency. Groq provides cloud and on-prem solutions at scale for AI...
Stability.ai (Stable Diffusion) ▷ #general-chat (81 messages🔥🔥):
Best local AI image generators, Creating style models in AI, Tech support and scams in Discord, Asset generation tools for game devs, Training models from existing images
- Current Best Local AI Image Generators: A member inquired about the best local AI image generator, mentioning they used SD1.5 previously.
- Another member suggested using SDXL 1.0 with comfyUI for better results.
- Guidance on Copying Image Styles: One user shared that they successfully got flux running locally and sought guides on replicating the style of a reference image.
- They are trying to generate images for game scenes with a consistent style.
- Alert on Discord Scams: A discussion arose regarding a suspicious tech support server, calling it a scam after someone asked for wallet details.
- Members shared their experiences and concerns about the security of such scams.
- Tools for Game Asset Generation: A user asked about established Stable Diffusion tools for generating game assets like isometric characters.
- Others suggested using free assets and mentioned SF3D, a model for generating 3D assets from images.
- Generating Unique Art with Existing Images: An artist explained their goal to train a model using their own images for quicker art generation.
- It was suggested that they train a LoRA model, specifically on Flux or SD 3.5.
Link mentioned: stabilityai/stable-fast-3d · Hugging Face: no description found
Cohere ▷ #discussions (58 messages🔥🔥):
Cohere's c4ai model, MLX integration, VLLM support, Latest model performance review, Upcoming releases
- Excitement for MLX and new models: Community members expressed enthusiasm for new MLX support regarding Cohere's c4ai-command-r7b model and shared installation tips.
- One member noted that getting models like VLLM integrated early would help streamline contributions within the open-source community.
- Cohere's capabilities showcased: A community review highlighted Cohere's model performing well on a 211009 token danganronpa fanfic, showcasing impressive memory efficiency using 11.5 GB.
- This sparked discussions around its architecture, particularly its 128K context length and lack of positional encoding, which may enhance generalization.
- Collaboration on updates with Cohere: Members discussed ways to involve Cohere more directly in supporting new releases early, noting the success of similar collaborations with Mistral.
- Contributors believe that this could lead to a smoother integration process for models and updates like VLLM.
- GPTJ enhancements noted: There was speculation on the impact of GPT-J's rope mechanism on the accuracy of attention, suggesting that it may be more effective than previous configurations.
- Members reflected on past implementations of 4096 sliding windows, reiterating their belief in advancements brought by the newer architecture.
- Updates and release anticipation: Members noted upcoming releases, particularly around the O3 model's expected capabilities, hinting at innovative features akin to GPT-4.
- These discussions highlighted community excitement about potential functionalities, including voice interactions with models similar to those used for festive applications.
- Tweet from Nick Frosst (@nickfrosst): Real heads knowQuoting N8 Programs (@N8Programs) Okay, for those skeptical that Cohere's model was simply parroting the plot of Harry Potter, here's it doing decently (plot is almost correct) ...
- mlx-community/c4ai-command-r7b-12-2024-4bit · Hugging Face: no description found
- Tweet from N8 Programs (@N8Programs): Okay, for those skeptical that Cohere's model was simply parroting the plot of Harry Potter, here's it doing decently (plot is almost correct) on a 211009 token danganronpa fanfic, using 11.5 ...
- GitHub - ml-explore/mlx-examples: Examples in the MLX framework: Examples in the MLX framework. Contribute to ml-explore/mlx-examples development by creating an account on GitHub.
- llama: Got unsupported ScalarType BFloat16 when converting weights · Issue #11 · ml-explore/mlx-examples: When trying to convert the PyTorch weights, for example: python convert.py ../../llama-2-7b/consolidated.00.pth mlx_llama-2-7b.npz I get: File "../ml-explore/mlx-examples/llama/convert.py", ...
- Add support for cohere2 by Blaizzy · Pull Request #1157 · ml-explore/mlx-examples: Adds support for Cohere2 with sliding attention.Thanks a lot to @N8python for the inspiration!Bf164bit
Cohere ▷ #questions (4 messages):
Credit Card Rejections, 3D Secure Issues, VPN Usage, Support Contact
- Credit Card Declined Despite Success Message: A user reported that their German credit card is often declined by Cohere despite receiving a success message from their bank after completing the 3D Secure process.
- They expressed frustration at the repeated rejections and sought advice on reaching support.
- Mysterious Payment Processing Questioned: Another member suggested checking if the user is using a VPN which might be contributing to the payment issues.
- The user was investigating possible reasons for the persistent card declines.
- Reaching Out for Support: A member advised the user to contact support via support@cohere.com to resolve the credit card issues.
- This suggestion was aimed at getting assistance from Cohere’s support team regarding the payment problems.
Cohere ▷ #api-discussions (16 messages🔥):
Payment Method Issues in India, Upgrading API Keys for Higher Limits, Context Errors with Trial Keys
- Payment Method Issues in India Limiting Users: A user reported that their card was being rejected when adding a payment method for Cohere, revealing common issues with Indian banks like ICICI and HDFC, which often block such transactions.
- Support suggested using a different card or contacting the bank to enable international payments to Cohere Inc.
- Trial Key Limitation Causes Errors: A member experienced a 'TooManyRequestsError' while reranking documents, identifying it's due to the limitations of the Trial key, capped at 1000 API calls per month.
- Another user recommended creating a paid API key to remove these limits, which worked successfully after they upgraded.
Cohere ▷ #projects (1 messages):
Cohere tech in Findr, Findr launch excitement
- Excitement about Findr Launch: Members expressed excitement over the launch of Findr, celebrating its apparent success with phrases like 'wohooo' and 'congrats on the launch!'
- The enthusiasm reflects a strong community support for new projects leveraging Cohere technology.
- Inquiry on Cohere Tech Used in Findr: A member inquired about the specific Cohere technology utilized for Findr, indicating a desire to understand the tech stack behind the application.
- This interest points to the community's eagerness to learn more about how these technologies contribute to successful launches.
LAION ▷ #general (10 messages🔥):
DCT Encoding Exploration, VAEs and Human Perception, Color Spaces and Detail Perception
- Experimenting with DCT Encoding: A member is beginning to explore DCT and DWT encoding, questioning the efficiency of using YCrCb or YUV color spaces as inputs.
- They noted that while VAEs are easy to train, it may not justify the effort in this encoding pursuit.
- VAR Paper Inspiration for DCT Components: Discussion arose around a member's idea of relating the VAR paper to predicting the DC component of sequential DCT blocks, followed by upscaling and incorporating AC components.
- This suggests a structured approach to enhancing image quality through step-by-step component addition.
- Perception and Color Space Utility: A member emphasized the importance of using a color space with a distinct lightness channel, as humans perceive high-frequency grayscale details better than high-frequency color details.
- There was agreement that RGB may not effectively map to human perception of colors, suggesting potential exploration into JPEG and AV1 techniques.
- Human Perception in Loss Functions: It was noted that VAEs might inherently leverage some concepts from color encoding, particularly if loss functions are aligned with human perception.
- This highlights a potential direction for future experimentation in optimizing encoding related to visual understanding.
LAION ▷ #research (57 messages🔥🔥):
OpenAI o3 announcement, AGI discussion, Elo ratings and performance comparison, Test time compute implications, Future AI predictions
- OpenAI Launches Next-Gen o3 Model: OpenAI announced its next-generation reasoning model, o3, achieving 75.7% on the semi-private evaluation in low-compute mode and 87.5% in high-compute mode, indicating a significant leap in AI capabilities.
- The model has shown novel task adaptation abilities, which may redefine current understandings of AI potential and challenge existing benchmark performance.
- Debate on AGI Status: The community is divided on whether the advancements bring us closer to AGI, with some members asserting that achieving over human performance on tasks like ARC indicates it has been reached.
- Others caution that the term AGI is ambiguous, suggesting definitions should be made context-specific to avoid misunderstandings.
- Elo Ratings and Performance Metrics: Discussion around the Elo rating systems emerged, relating the model's performance to chess ratings suggesting a grandmaster level for o3 based on its scores.
- The implications of different rating scales and their exponential nature were explored, indicating that higher scores may significantly skew performance expectations.
- Potential for Increased Test Time Compute: There's speculation about whether weaker models could replicate o3's performance with more compute, given the cost of $20 per task for increased task duration.
- The idea was raised that dividing larger tasks into smaller segments could maximize compute without changing the model itself.
- Predictions for Future AI Developments: The rapid advancements in models lead to excitement about future capabilities, especially regarding cost efficiency and increased testing on benchmarks like SWE-bench.
- Concern was voiced over how these developments could affect text-to-image generation and the broader landscape of AI applications.
- Tweet from François Chollet (@fchollet): Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tas...
- OpenAI o3 Breakthrough High Score on ARC-AGI-Pub: OpenAI o3 scores 75.7% on ARC-AGI public leaderboard.
- Elo Win Probability Calculator: no description found
GPU MODE ▷ #general (11 messages🔥):
GPU recommendations, Chip design resources, Hardware description languages
- GPU Recommendations Redirected: A member pointed out that questions about GPU recommendations are extensively discussed in communities like r/pcmasterrace, and spammy inquiries might not be welcomed.
- Another member suggested a suspicion of trolling behind repeated queries about GPUs.
- In-Depth Resources for Chip Design: A member sought in-depth books or resources on chip design and hardware description languages.
- Recommendations included searching for university course materials from UCB and UMich, which often provide publicly accessible slides and assignments.
- Sedra’s Book on Microelectronics Reigns Supreme: Another user hailed the Sedra book as the gold standard in most ECE programs, specifically referencing Microelectronic Circuits.
- This book is often recognized in Electrical and Computer Engineering curricula for its depth and clarity.
- Zero To ASIC Course Recommended: A member mentioned positive feedback about the Zero To ASIC course on YouTube, suggesting it as a valuable resource.
- One user expressed interest in this course, stating it seems like an exciting experience.
Link mentioned: Reddit - Dive into anything: no description found
GPU MODE ▷ #triton (2 messages):
Triton Documentation Issues, Debugging Kernel Shared Memory, Proton Memory Instrumentation, Triton Language Types
- Triton's Search Feature is Broken: A user reported that the search feature on the Triton documentation home is not functioning correctly.
- They also noted a lack of documentation on tl.dtypes, mentioning difficulty in identifying types like tl.int1.
- Inquiry on Triton Documentation Backend: A user inquired if the backend contents of the Triton documentation are open for public contributions.
- They expressed willingness to help update the documentation if possible.
- Debugging Shared Memory Usage in Kernels: A user asked for experiences regarding discrepancies between triton_gpu.local_alloc and kernel.metadata.shared in shared memory usage.
- They attempted using
proton --instrument=print-mem-spaces script.pyfor debugging but found it only supports AMD hardware.
- They attempted using
Link mentioned: Welcome to Triton’s documentation! — Triton documentation: no description found
GPU MODE ▷ #cuda (9 messages🔥):
TensorRT Namespace Issue, Race Condition in Memory Copy, Memory Fencing after Kernel Execution, Understanding cute::composite
- TensorRT Namespace Causes Confusion: A user clarified that the issue regarding
trtis due to it being a namespace, caused by an incorrect parameter in the code. The function AsyncMemCpyD2D was improperly recognized because the stream type was not cudaStream_t.- Thank you for your advice. I found the reason.
- Potential Race Condition in Memory Operations: A user speculated about the possibility of a race condition, suggesting it could be an issue with how memory is recorded in the graph. This points to an intricate interaction needing debugging.
- Another user expressed uncertainty about the function of AsyncMemCpyD2D within the TensorRT context.
- Implicit Memory Fencing Explained: A member explained that while it might be theoretically possible to wait for memory, it's usually unnecessary unless that memory is reloaded later. Memory will be implicitly fenced after the kernel execution, ensuring data integrity.
- You are right! Thanks!
- Confusion Around cute::composite Function: A user inquired about how to effectively composite the global layout with smemLayoutX for a specific grid partitioning. They expressed confusion regarding the cute::composite function, highlighting its importance.
- Actually, I feel puzzled about cute::composite, but that is a quite important tensor function...
GPU MODE ▷ #torch (3 messages):
Flex Attention, Context Parallel Implementation, Attn-Gym Examples
- Exploring Flex Attention and Context Parallel Plans: A member asked about any plans for implementing flex attention with context parallel processing, seeking clarity on existing examples.
- Another member affirmed that implementing this is very possible today, expressing intentions to add an example to the attn-gym.
- Potential for Adding Examples to Attn-Gym: The discussion highlighted the possibility of adding a practical example of context parallel using flex attention in the attn-gym.
- This initiative signals a proactive approach to enhance the resources available for the community.
GPU MODE ▷ #algorithms (1 messages):
Diffusion Models Conditioning, NeurIPS 2024 Papers
- Exploring Diffusion Models Conditioning: A member shared insights on how diffusion models are conditioned and provided a link to a NeurIPS 2024 paper by Tero Karras detailing this topic.
- The presentation offers a comprehensive review of the Autoguidance method, which was a runner-up for the best paper at NeurIPS 2024.
- Accessing Autoguidance Paper PDF: Another member pointed to a Google Drive link for the PDF of the Autoguidance review, emphasizing its significance in the diffusion models discussion.
- The paper focuses on understanding the influential aspects of diffusion models, which has sparked curiosity among the community.
Link mentioned: Tweet from The Variational Book (@TheVariational): Curious about how diffusion models are influenced? @jaakkolehtinen @unixpickle @prafdhar @TimSalimans @hojonathanho Check out the review of the Autoguidance #NeurIPS2024 runner-up best paper in the ...
GPU MODE ▷ #off-topic (3 messages):
Multi Node Inference, Distributed Topics, Channel Management
- Multi Node Inference Channel Inquiry: @karatsubabutslower asked about the appropriate channel for discussing multi node inference.
- They wanted to ensure they were in the right place to share insights on this topic.
- General Channel for Distributed Topics: @marksaroufim suggested starting discussions in the general channel, noting that a new channel would be created if distributed topics gained popularity.
- This approach allows for flexibility based on community interest in distributed inference topics.
GPU MODE ▷ #sparsity-pruning (1 messages):
Sparse API Usage, PyTorch Quantization, Sparsity Design Overview
- Swapping Sparse APIs for Flexibility: A member noted that the example in the PyTorch sparsity documentation employs the
to_sparse_semi_structuredAPI for inference, suggesting it could be changed tosparsify_for broader application.- They emphasized this as a potential improvement while tagging another member for confirmation after their return from PTO.
- Highlighting PyTorch’s Sparsity Features: The shared link directs to the PyTorch repository featuring native quantization and sparsity for training and inference, showcasing the project's scope.
- It includes a thumbnail image reflecting the project's branding and a brief description about its functionalities.
Link mentioned: ao/torchao/sparsity at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #arc-agi-2 (6 messages):
ARC CoT dataset, LLaMA 8B fine-tuning, OpenAI evaluation results, o3-high evaluation costs
- ARC CoT Dataset Generation Underway: A user is generating an ARC CoT dataset aimed at achieving 10k samples to compare the performance between a fine-tuned LLaMA 8B and the base model using log probability metrics.
- They plan to analyze the advantage of descriptions against the ground truth and explore the impact of 'CoT' training in future evaluations.
- Future LLaMA 8B Fine-tuning Plans: Once a couple of thousand samples have been generated, fine-tuning of LLaMA 8B will be attempted using both direct transduction and board-analysis methods.
- The goal is to determine if there are tangible benefits to 'CoT' training.
- Kudos to OpenAI for Their Evaluation Score: A user noted congratulations to OpenAI for achieving a high evaluation score in recent benchmarks.
- They emphasized the importance of replicating these results outside of the OpenAI labs to ensure broader applicability.
- High Costs for o3-high Evaluation: It was noted that the semi-private evaluation for o3-high cost over $10k in computational resources.
- However, the exact figures were not disclosed, highlighting the high stakes of such evaluations.
LlamaIndex ▷ #blog (4 messages):
LlamaParse Audio Capabilities, Year-End Review of LlamaIndex, Stock Analysis Bot Creation, Document Processing Automation
- LlamaParse Expands with Audio Parsing: LlamaParse can now parse audio files, adding this capability to its already impressive support for complex document formats like PDFs and Word. Users can upload audio files and convert speech into text seamlessly.
- This enhancement positions LlamaParse as the world's best parser for a wide range of document types.
- LlamaIndex Celebrates a Stellar Year: LlamaIndex shared a year-end review highlighting tens of millions of pages parsed and significant community growth. A month-by-month breakdown of feature releases shows they delivered more than once a week throughout the year.
- Look for LlamaCloud to go GA in early 2024 and continued excitement about their open-source contributions.
- Create a Stock Analysis Bot Effortlessly: Learn how to build an automated stock analysis agent using LlamaIndex's FunctionCallingAgent combined with Claude 3.5 Sonnet. This one-click solution simplifies stock analysis for users.
- Get detailed instructions in Hanane D's insightful LinkedIn post about this innovative tool.
- Automate Document Workflows with LlamaIndex: A new notebook demonstrates how to use LlamaIndex for automating document processing workflows, focusing on standardizing units and measurements across various vendors. It's a practical example showcasing LlamaIndex's capabilities in real-world scenarios.
- Check out the full example in the shared notebook to explore its utility.
Link mentioned: The Year in LlamaIndex: 2024 — LlamaIndex - Build Knowledge Assistants over your Enterprise Data: LlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.
LlamaIndex ▷ #general (17 messages🔥):
Azure OpenAI embedding models, GraphDBs for larger projects, Fine-tuning LLM with sentiment analysis, Creating synthetic datasets, Issue with TextNode attributes
- Rate limit issues with Azure OpenAI: A member reported experiencing rate limit errors while using Azure OpenAI embedding models, seeking suggestions to resolve the issue.
- Another suggested either increasing max retries or slowing down the ingestion process with a code snippet showing how to do so.
- Resolving TextNode attribute error: Discussion revealed an AttributeError ('TextNode' object has no attribute 'get_doc_id') when attempting to insert nodes into the index.
- Members clarified that the correct method for nodes is
index.insert_nodes(...), and recommended inserting one node at a time to avoid errors.
- Members clarified that the correct method for nodes is
- Inquiry on GraphDB options: A member inquired about what GraphDBs others are using for larger projects, noting dissatisfaction with existing options.
- The overall sentiment expressed concern over the current state of GraphDBs, with hopes for better alternatives.
- Steps for fine-tuning LLM on sentiment analysis: A member shared a desire to fine-tune an LLM for sentiment analysis but was unsure how to create a synthetic dataset.
- Another member suggested exploring prompt manipulation and provided a link to a blog discussing synthetic data generation using LLMs.
- Understanding existing issues in message querying: There were several inquiries about system downtimes, with confusion around the state of services at the moment.
- Members questioned and clarified what was down, with one member seeking general community feedback on current issues.
- Synthetic data: save money, time and carbon with open source: no description found
- [Question]: Consistently getting rate limit error when building index · Issue #7879 · run-llama/llama_index: Question Validation I have searched both the documentation and discord for an answer. Question I am using the basic code to index a single text document with about 10 lines from llama_index import ...
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Hackathon Submission Reopened, Technical Difficulties, Submission Deadline, Manual Submission Check
- Hackathon Submission Form Reopened!: Due to some participants facing technical difficulties, we have reopened the hackathon submission form for submission, which will close again TONIGHT at 11:59PM PST (Dec 20th).
- Please ensure to update any incorrect links or submit if you missed yesterday's deadline — there is no penalty!
- Deadline Reminder for Submissions: The hackathon submission form will be closing again tonight, emphasizing the need for participants to double-check their submissions before the final deadline.
- Participants are encouraged to submit early to avoid any last-minute issues, as submissions will not receive automatic email confirmations.
- Manual Submission Check Available: Participants can post in <#1280237064624799886> if they wish for a manual check of their submission to ensure it went through successfully.
- Getting a manual verification is encouraged the earlier the better to reduce stress!
Link mentioned: no title found: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (11 messages🔥):
Hackathon Extension Requests, Hackathon Participation Forms, Submission Registration Confirmation, YouTube Video Format Issues, Agent Framework Recommendations
- No Chance for Hackathon Extension: A member inquired about the possibility of another extension for the hackathon, but was informed by Tara that "unfortunately no" extensions are available.
- The lighthearted request captured a common desire for leniency, but the restrictions are in place.
- Primary Contact for Hackathon Submission: Participants were reminded to add their team's primary contact email to the certification declaration form for hackathon participation.
- This information is crucial for ensuring proper communication and submission management.
- Confirmation of Submission Status: A member asked Tara to confirm if their hackathon submission was registered, and Tara responded positively, stating, "we have your submission!"
- This quick confirmation alleviated concerns about submission errors among participants.
- YouTube Format Delays in Submissions: One participant explained that they emailed content for the hackathon due to issues with their video format on YouTube, which delayed its submission.
- They emphasized that they are primarily focused on the hackathon rather than the course itself, seeking clarity on their submission status.
- Agent Framework Recommendations for Future MOOCs: A member shared insights from an article arguing against relying solely on complex frameworks like Autogen for LLM agents, recommending simpler, composable patterns instead.
- They suggested that future MOOCs should explore alternatives to AutoGen for labs, emphasizing the need for a focus on instruction tuning and function calling.
Link mentioned: Building effective agents: A post for developers with advice and workflows for building effective AI agents
Torchtune ▷ #announcements (1 messages):
Torchtune v0.5.0, Kaggle Integration, QAT + LoRA Training Recipe, Early Exit Training Recipe, NPU Support
- Torchtune v0.5.0 brings festive updates: Torchtune released version 0.5.0, introducing several new features and integration enhancements for users to enjoy this season.
- A heartfelt thank you was given to the community for their contributions in making this release possible, with detailed release notes available for further exploration.
- Kaggle Integration enhances finetuning: Users can now seamlessly finetune models in Kaggle notebooks and share their best checkpoints with the community.
- This integration is expected to streamline workflows and improve collaboration among users engaging with Torchtune.
- Introducing the QAT + LoRA Training Recipe: The new QAT + LoRA training recipe allows users to train quant-friendly LoRA models with improved efficiency.
- This recipe is part of the ongoing effort to enhance training options and adapt to the needs of modern model development.
- Speed up LLM inference with Early Exit Training: Early Exit Training utilizes LayerSkip to enhance inference speed and accuracy for LLMs.
- This feature aims to provide a more efficient processing framework, facilitating quicker model responses.
- NPU Support for enhanced performance: Torchtune now supports running on Ascend NPU devices, with distributed support expected to be added soon.
- This new compatibility is set to broaden the usability of Torchtune across different hardware.
- End-to-End Workflow with torchtune — torchtune main documentation: no description found
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Torchtune ▷ #general (7 messages):
QwQ-preview-32B finetuning, State dict loading for fsdp2, Parallelism support improvements, Gradient accumulation and clipping, Vocab pruning in finetuning
- QwQ-preview-32B requires context parallelism: A user shared their setup for finetuning QwQ-preview-32B on 880G GPUs and raised a question about supporting context parallelism to extend the max token length beyond 8K*.
- Suggestions included using optimizer_in_bwd, 8bit Adam optimizer, and exploring QLoRA optimization flags.
- Loading state dict for fsdp2 raises compatibility questions: Concerns were raised about loading the state dict for fsdp2, particularly regarding parameters and buffers not being sharded as referenced in the distributed loading code.
- There's ambiguity about whether incompatible non-DTensors can exist within the state_dict of FSDPModule, complicating deployment scenarios.
- Vocab pruning needs fine-tuned control in fp32: It was noted that some developers finetune models using vocab pruning, necessitating the state dict to maintain parameters in fp32 separate from calculations in bf16.
- This detail reflects an ongoing need for nuanced management of tensor types during training.
- Issues · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/training/_distributed.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- GitHub - pytorch/torchtune: PyTorch native post-training library: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- GitHub - pytorch/torchtune: PyTorch native post-training library: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/training/_distributed.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
DSPy ▷ #general (7 messages):
Litellm Proxy Server, Synthetic Data Impact on LLMs, Optimization Parameters, MIPRO Light Mode
- Litellm Proxy Server Deployment Options: The Litellm proxy server can be self-hosted or used via a managed service, and can be deployed on the same VM as your service.
- This flexibility allows users to configure the setup based on their infrastructural needs.
- Synthetic Data Enhances LLM Performance: A primer on synthetic data discusses its role in making LLMs better, especially smaller models, by reshaping input data into a format resembling chatbot conversation.
- While synthetic data aids in developing reasoning models, it is not universally effective and has limitations for certain tasks that can't be tested at scale.
- Cost Awareness for Optimization Processes: There are concerns about the costs associated with running optimizers for extended periods, leading to discussions on setting limits on calls or tokens.
- Recommendations include configuring optimization parameters to be smaller or considering the installation of LiteLLM with defined limits.
- Utilizing MIPRO 'Light' Mode: A suggestion was made to utilize MIPRO in 'light' mode to manage optimization processes more efficiently.
- This approach is particularly aimed at balancing resource use and performance.
Link mentioned: On Synthetic Data: How It’s Improving & Shaping LLMs: Synthetic data is helping LLMs scale the data wall, but it’s doing so while creating a growing perception gap between those who use LLMs for quantitative tasks and those who use it for anything else, ...
OpenInterpreter ▷ #general (7 messages):
OpenInterpreter Server Mode, Google Gemini 2.0 Multimodal, Local LLM Integration, SSH Usage with OpenInterpreter
- Curiosity about OpenInterpreter's server mode: A member inquired about documentation for interacting with OpenInterpreter when run in server mode, expressing interest in setting it up on a VPS.
- Is it possible to understand if commands run locally or on the server when in server mode?
- Feedback on Google Gemini 2.0's capabilities: Another member wondered if anyone had experimented with the new Google Gemini 2.0 multimodal feature, especially noting its os mode.
- They mentioned concerns about access, stating that this capability might be limited to tier 5 users.
- Praise for Local LLM Integration: A member expressed delight over the continued support for local LLM integration, feeling it adds a cozy touch to OpenInterpreter.
- They were initially worried that it might become exclusive to OpenAI, but it has remained a welcomed feature.
- Using SSH with OpenInterpreter: One user shared their experience using OpenInterpreter in regular mode, connecting through SSH for ease of access.
- They expressed excitement about integrating a front end, believing they could manage it.
- Concerns over Referral Spam: A member alerted others about referral spam, indicating the presence of such links in the chat.
- They tagged a specific role to bring attention to the issue among the community.
Axolotl AI ▷ #general (4 messages):
Liger and KTO integration, Liger DPO, Loss parity issues
- Liger now integrates KTO: It's confirmed that Liger now has KTO features implemented.
- This integration is seen as a step forward in the development process.
- Working on Liger DPO: A member reported that they are currently focused on getting Liger DPO operational, and that KTO will likely follow next.
- They mentioned experiencing loss parity issues when comparing Liger to the HF TRL baseline.
- Community expresses concern over issues: One member expressed frustration by saying, 'Pain' in response to the ongoing challenges.
- Another expressed hope that the loss parity issues would be resolved soon.
tinygrad (George Hotz) ▷ #general (1 messages):
chenyuy: i will close (or find a bot to close) prs that are inactive > 30 days next week
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Watt-tool models, GitHub Pull Requests, Christmas timeframe
- New Watt-tool Models Introduced: A GitHub Pull Request has been submitted to add the models watt-tool-8B and watt-tool-70B to the leaderboard.
- The models can also be found on Hugging Face at watt-tool-8B and watt-tool-70B.
- Support Requested for PR Review: Assistance was requested to check for any issues with the newly submitted pull request related to the watt-tool models.
- Christmas is around the corner, so the contributor encouraged taking the time needed for the review.
Link mentioned: [BFCL] Add New Model watt-tool-8B and watt-tool-70B by zhanghanduo · Pull Request #847 · ShishirPatil/gorilla: This PR adds the model watt-ai/watt-tool-8B and watt-ai/watt-tool-70B to the leaderboard.