[AINews] o3-mini launches, OpenAI on "wrong side of history"
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
o3-mini is all you need.
AI News for 1/30/2025-1/31/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 9062 messages) for you. Estimated reading time saved (at 200wpm): 843 minutes. You can now tag @smol_ai for AINews discussions!
As planned even before the DeepSeek r1 drama, OpenAI released o3-mini, with the "high" reasoning effort option handily outperforming o1-full (and handily so in OOD benchmarks like Dan Hendrycks' new HLE and Text to SQL benchmarks, though Cursor disagrees):
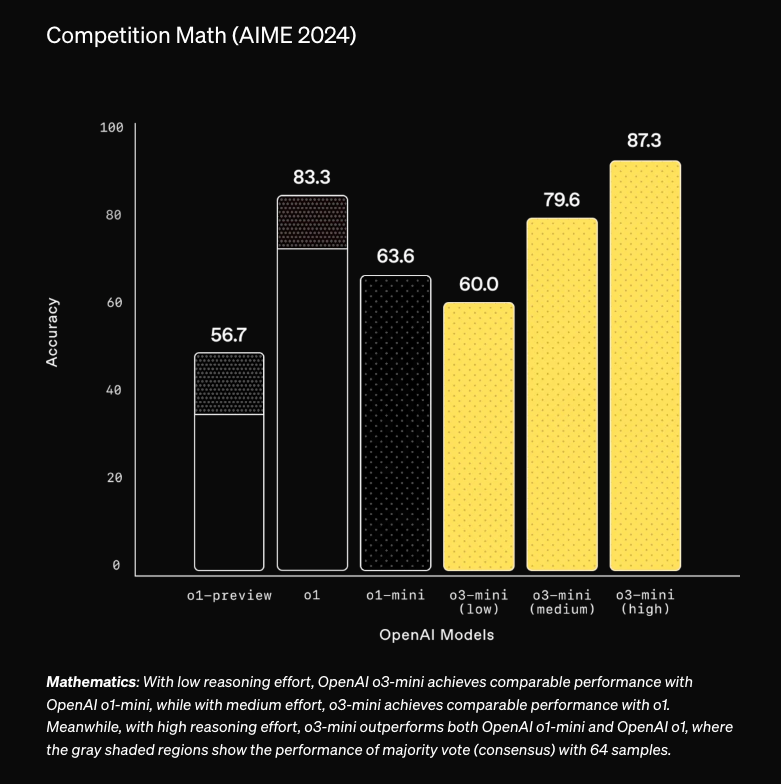
The main area of R1 response was two fold: first a 63% cut in o1-mini and o3-mini prices, and second Sam Altman acknowledging in today's Reddit AMA that they will be showing "a much more helpful and detailed version" of thinking tokens, directly crediting DeepSeek R1 for "updating" his assumptions.
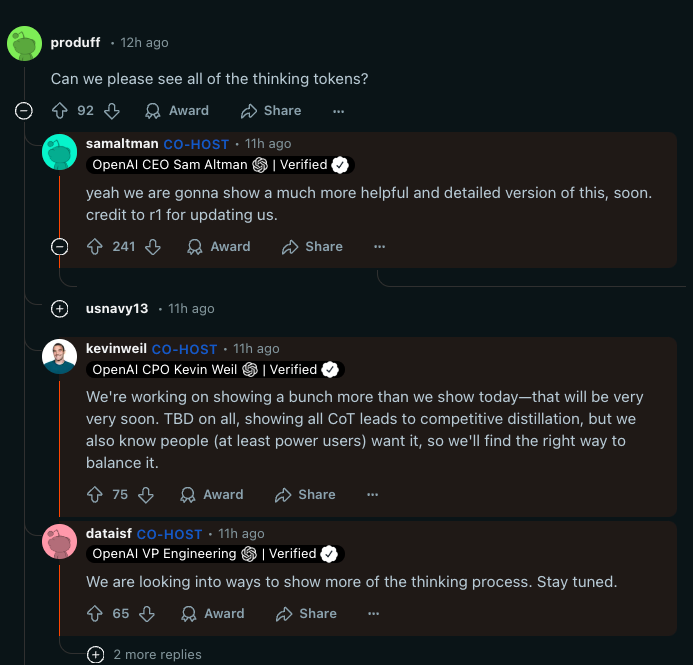
Perhaps more significantly, Sama also acknowledged being "on the wrong side of history" in their (not materially existent beyond Whisper) open source strategy.
You can learn more in today's Latent Space pod with OpenAI.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium (Windsurf) Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- Perplexity AI Discord
- LM Studio Discord
- Cursor IDE Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- OpenAI Discord
- Latent Space Discord
- Yannick Kilcher Discord
- Nous Research AI Discord
- Stackblitz (Bolt.new) Discord
- MCP (Glama) Discord
- Stability.ai (Stable Diffusion) Discord
- Eleuther Discord
- GPU MODE Discord
- Nomic.ai (GPT4All) Discord
- Notebook LM Discord Discord
- Torchtune Discord
- Modular (Mojo 🔥) Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- Axolotl AI Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- Cohere Discord
- LAION Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium (Windsurf) ▷ #announcements (2 messages):
- Codeium (Windsurf) ▷ #discussion (329 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (815 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (999 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (8 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (319 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
- Unsloth AI (Daniel Han) ▷ #research (6 messages):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (979 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (72 messages🔥🔥):
- Perplexity AI ▷ #general (705 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (5 messages):
- Perplexity AI ▷ #pplx-api (2 messages):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #general (362 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (158 messages🔥🔥):
- Cursor IDE ▷ #general (520 messages🔥🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (445 messages🔥🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (263 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (63 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (2 messages):
- Interconnects (Nathan Lambert) ▷ #reads (2 messages):
- Interconnects (Nathan Lambert) ▷ #policy (1 messages):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (319 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (16 messages🔥):
- OpenAI ▷ #prompt-engineering (2 messages):
- OpenAI ▷ #api-discussions (2 messages):
- Latent Space ▷ #ai-general-chat (61 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (269 messages🔥🔥):
- Yannick Kilcher ▷ #general (242 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (37 messages🔥):
- Yannick Kilcher ▷ #agents (6 messages):
- Yannick Kilcher ▷ #ml-news (11 messages🔥):
- Nous Research AI ▷ #general (210 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (1 messages):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #reasoning-tasks (2 messages):
- Stackblitz (Bolt.new) ▷ #prompting (13 messages🔥):
- Stackblitz (Bolt.new) ▷ #discussions (142 messages🔥🔥):
- MCP (Glama) ▷ #general (112 messages🔥🔥):
- MCP (Glama) ▷ #showcase (9 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (121 messages🔥🔥):
- Eleuther ▷ #general (28 messages🔥):
- Eleuther ▷ #research (32 messages🔥):
- Eleuther ▷ #interpretability-general (3 messages):
- Eleuther ▷ #lm-thunderdome (29 messages🔥):
- GPU MODE ▷ #general (23 messages🔥):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (10 messages🔥):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #cool-links (6 messages):
- GPU MODE ▷ #off-topic (8 messages🔥):
- GPU MODE ▷ #irl-meetup (1 messages):
- GPU MODE ▷ #liger-kernel (2 messages):
- GPU MODE ▷ #reasoning-gym (30 messages🔥):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (61 messages🔥🔥):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (9 messages🔥):
- Notebook LM Discord ▷ #general (47 messages🔥):
- Torchtune ▷ #general (19 messages🔥):
- Torchtune ▷ #dev (27 messages🔥):
- Modular (Mojo 🔥) ▷ #general (7 messages):
- Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
- Modular (Mojo 🔥) ▷ #max (3 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (9 messages🔥):
- tinygrad (George Hotz) ▷ #general (10 messages🔥):
- Axolotl AI ▷ #general (10 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (9 messages🔥):
- OpenInterpreter ▷ #general (6 messages):
- Cohere ▷ #discussions (1 messages):
- Cohere ▷ #api-discussions (1 messages):
- LAION ▷ #research (2 messages):
- DSPy ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Model Releases and Performance
- OpenAI's o3-mini, a new reasoning model, is now available in ChatGPT for free users via the "Reason" button, and through the API for paid users, with Pro users getting unlimited access to the "o3-mini-high" version.
- It is described as being particularly strong in science, math, and coding, with the claim that it outperforms the earlier o1 model on many STEM evaluations @OpenAI, @polynoamial, and @LiamFedus.
- The model uses search to find up-to-date answers with links to relevant web sources, and was evaluated for safety using the same methods as o1, significantly surpassing GPT-4o in challenging safety and jailbreak evals @OpenAI, @OpenAI.
- The model is also much cheaper, costing 93% less than o1 per token, with input costs of $1.10/M tokens and output costs of $4.40/M tokens (with a 50% discount for cached tokens) @OpenAIDevs.
- It reportedly outperforms o1 in coding and other reasoning tasks at lower latency and cost, particularly on medium and high reasoning efforts @OpenAIDevs, and performs exceptionally well on SQL evaluations @rishdotblog.
- MistralAI released Mistral Small 3 (24B), an open-weight model with an Apache 2.0 license. It is noted to be competitive on GPQA Diamond, but underperforming on MATH Level 5 compared to Qwen 2.5 32B and GPT-4o mini, with a claimed 81% on MMLU @EpochAIResearch, @ArtificialAnlys, and available on the Mistral API, togethercompute and FireworksAI_HQ platforms, with Mistral's API being the cheapest @ArtificialAnlys. This dense 24B parameter model achieves 166 output tokens per second, costs $0.1/1M input tokens and $0.3/1M output tokens.
- DeepSeek R1 is supported by Text-generation-inference v3.1.0, for both AMD and Nvidia, and is available through the ai-gradio library with replicate @narsilou, @_akhaliq, @reach_vb.
- The distilled versions of DeepSeek models have been benchmarked on llama.cpp with an RTX 50 @ggerganov. The model is noted to have a brute force approach, leading to unexpected approaches and edge cases @nrehiew_. A 671 billion parameter model is reportedly achieving 3,872 tokens per second @_akhaliq.
- Allen AI released Tülu 3 405B, an open-source model built on Llama 3.1 405B, outperforming DeepSeek V3, the base model behind DeepSeek R1, and on par with GPT-4o @_philschmid. The model uses a combination of public datasets, synthetic data, supervised finetuning (SFT), Direct Preference Optimization (DPO) and Reinforcement Learning with Verifiable Reward (RLVR).
- Qwen 2.5 models, including 1.5B (Q8) and 3B (Q5_0) versions, have been added to the PocketPal mobile app for both iOS and Android platforms. Users can provide feedback or report issues through the project's GitHub repository, with the developer promising to address concerns as time permits. The app supports various chat templates (ChatML, Llama, Gemma) and models, with users comparing performance of Qwen 2.5 3B (Q5), Gemma 2 2B (Q6), and Danube 3. The developer provided screenshots.
- Other Notable Model Releases: arcee_ai released Virtuoso-medium, a 32.8B LLM distilled from DeepSeek V3, Velvet-14B is a family of 14B Italian LLMs trained on 10T tokens, OpenThinker-7B is a fine-tuned version of Qwen2.5-7B and NVIDIAAI released a new series of Eagle2 models with 1B and 9B sizes. There's also Janus-Pro from deepseek_ai, which is a new any-to-any model for image and text generation from image or text inputs, and BEN2, a new background removal model. YuE, a new open-source music generation model was also released. @mervenoyann
Hardware, Infrastructure, and Scaling
- DeepSeek is reported to have over 50,000 GPUs, including H100, H800 and H20 acquired pre-export control, with infrastructure investments of $1.3B server CapEx and $715M operating costs, and is potentially planning to subsidize inference pricing by 50% to gain market share. They use Multi-head Latent Attention (MLA), Multi-Token Prediction, and Mixture-of-Experts to drive efficiency @_philschmid.
- There are concerns that the Nvidia RTX 5090 will have inadequate VRAM with only 32GB, when it should have at least 72GB, and that the first company to make GPUs with 128GB, 256GB, 512GB, or 1024GB of VRAM will dethrone Nvidia @ostrisai, @ostrisai.
- OpenAI's first full 8-rack GB200 NVL72 is now running in Azure, highlighting compute scaling capabilities @sama.
- A VRAM reduction of 60-70% change to GRPO in TRL is coming soon @nrehiew_.
- A distributed training paper from Google DeepMind reduces the number of parameters to synchronize, quantizes gradient updates, and overlaps computation with communication, achieving the same performance with 400x less bits exchanged @osanseviero.
- There's an observation that models trained on reasoning data might hurt instruction following. @nrehiew_
Reasoning and Reinforcement Learning
- Inference-time Rejection Sampling with Reasoning Models is suggested as an interesting approach to scale performance and synthetic data generation by generating K
- TIGER-Lab replaced answers in SFT with critiques, claiming superior reasoning performance without any
distillation, and their code, datasets, and models have been released on HuggingFace @maximelabonne. - The paper "Thoughts Are All Over the Place" notes that o1-like LLMs switch between different reasoning thoughts without sufficiently exploring promising paths to reach a correct solution, a phenomenon termed "underthinking" @_akhaliq.
- There are various observations that RL is increasingly important. It has been noted that RL is the future and that people should stop grinding leetcode and start grinding cartpole-v1 @andersonbcdefg. DeepSeek uses GRPO (Group Relative Policy Optimization), which gets rid of the value model, instead normalizing the advantage against rollouts in each group, reducing compute requirements @nrehiew_.
- A common disease in some Silicon Valley circles is noted: a misplaced superiority complex @ylecun, which is also connected to Effective Altruism @TheTuringPost.
- Diverse Preference Optimization (DivPO) trains models for both high reward and diversity, improving variety with similar quality @jaseweston.
- Rejecting Instruction Preferences (RIP) is a method to curate high-quality data and create high quality synthetic data, leading to large performance gains across benchmarks @jaseweston.
- EvalPlanner is a method to train a Thinking-LLM-as-a-Judge that learns to generate planning & reasoning CoTs for evaluation, showing strong performance on multiple benchmarks @jaseweston.
Tools, Frameworks, and Applications
- LlamaIndex has day 0 support for o3-mini, and is one of the only agent frameworks that allow developers to build multi-agent systems at different levels of abstraction, including the brand new AgentWorkflow wrapper. The team also highlights LlamaReport for report generation, a core use case for 2025 @llama_index, @jerryjliu0, @jerryjliu0.
- LangChain has an Advanced RAG + Agents Cookbook, a comprehensive open source guide for production ready RAG techniques with agents, built with LangChain and LangGraph. LangGraph is a LangChain extension that supercharges AI agents with cyclical workflows @LangChainAI, @LangChainAI. They also released Research Canvas ANA, an AI research tool built on LangGraph that transforms complex research with human guided LLMs @LangChainAI.
- Smolagents is a tool that allows tool-calling agents to run with a single line of CLI, providing access to thousands of AI models and several APIs out-of-the-box @mervenoyann, @mervenoyann.
- Together AI provides cookbooks with step-by-step examples for agent workflows, RAG systems, LLM fine tuning and search @togethercompute.
- There's a call for a raycastapp extension for Hugging Face Inference Providers @reach_vb.
- There are advancements in WebAI agents for structured outputs and tool calling, with examples of local browser based agents being run on Gemma 2 @osanseviero, @osanseviero.
Industry and Company News
- Apple is criticized for missing the AI wave after spending a decade on a self-driving car and a headset that failed to gain traction @draecomino.
- Microsoft reports a 21% YoY growth in their search and news business, highlighting the importance of web search in grounding LLMs @JordiRib1.
- Google has released Flash 2.0 for Gemini and upgraded to the latest version of Imagen 3, and is also leveraging AI in Google Workspace for small businesses @Google, @Google. Google is also offering WeatherNext models to scientists for research @GoogleDeepMind.
- Figure AI is hiring, and is working on training robots to perform high speed, high performance use case work, with potential to ship 100,000 robots in the next four years @adcock_brett, @adcock_brett, @adcock_brett, @adcock_brett.
- Sakana AI is hiring in Japan for research interns, applied engineers, and business analysts @hardmaru, @SakanaAILabs.
- Cohere is hiring a research executive partner to drive cross-institutional collaborations @sarahookr.
- OpenAI is teaming up with National Labs on nuclear security @TheRundownAI.
- DeepSeek's training costs are clarified as misleading. A report suggests that the reported $6M training figure excludes infrastructure investment ($1.3B server CapEx, $715M operating costs), with access to ~50,000+ GPUs @_philschmid, @dylan522p.
- The Bank of China has announced 1 trillion yuan ($140B) in investments for the AI supply chain in response to Stargate, and the Chinese government is subsidizing data labeling and has issued 81 contracts to LLM companies to integrate LLMs into their military and government @alexandr_wang, @alexandr_wang, @alexandr_wang.
- There's an increase in activity from important people, suggesting a growing pace of development in the AI field @nearcyan.
- The Keras team at Google is looking for part-time contractors, focusing on KerasHub model development @fchollet.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. OpenAI's O3-Mini High: Versatile But Not Without Critics
- o3-mini and o3-mini-high are rolling out shortly in ChatGPT (Score: 426, Comments: 172): o3-mini and o3-mini-high are new reasoning models being introduced in ChatGPT. These models are designed to enhance capabilities in coding, science, and complex problem-solving, offering users the choice to engage with them immediately or at a later time.
- Model Naming and Numbering Confusion: Users express frustration over the non-sequential naming of models like o3-mini-high and GPT-4 transitioning to o1, which complicates understanding which version is newer or superior. Some comments clarify that the "o" line represents a different class due to multimodal capabilities, and the numbering is intentionally non-sequential to differentiate these models from the GPT series.
- Access and Usage Limitations: There are complaints about limited access, especially from ChatGPT Pro users and European citizens, with some users reporting a 3 messages per day limit. However, others mention that Sam Altman indicated a limit of 100 per day for plus users, highlighting discrepancies in user experience and information.
- Performance and Cost: Discussions highlight that o1 models outperform R1 for complex tasks, while o3-mini-high is described as a higher compute model that provides better results at a higher cost. Some users express interest in performance comparisons between o3-mini-high, o1, and o1-pro, noting issues with long text summaries and incomplete responses.
- OpenAI to launch new o3 model for free today as it pushes back against DeepSeek (Score: 418, Comments: 116): OpenAI is set to release its o3 model for free, positioning itself against competition from DeepSeek. The move suggests a strategic response to market pressures and competition dynamics.
- There is skepticism about the o3 model's free release, with users suggesting potential limitations or hidden costs, such as data usage for training. MobileDifficulty3434 points out that the o3 mini model will have strict limits, and the timeline for its release was set before the DeepSeek announcement, although some speculate DeepSeek influenced the speed of its rollout.
- The discussion highlights a competitive atmosphere between OpenAI and DeepSeek, with DeepSeek potentially pushing OpenAI to release its model sooner. AthleteHistorical457 humorously notes the disappearance of a $2000/month plan, suggesting DeepSeek's influence on market dynamics.
- There are concerns about the future monetization of AI models, with some predicting the introduction of ads in free models. Ordinary_dude_NOT humorously suggests that the real estate for ads in AI clients could be substantial, while Nice-Yoghurt-1188 mentions the decreasing costs of running models on personal hardware as an alternative.
- OpenAI o3-mini (Score: 154, Comments: 113): The post lacks specific content or user reviews about the OpenAI o3-mini, providing no details or performance metrics for analysis.
- Users expressed mixed performance results for OpenAI o3-mini, noting that while it is faster and follows instructions better than o1-mini, its reasoning capabilities are inconsistent, with some users finding it less reliable than DeepSeek and o1-mini in certain tasks like database queries and code completion.
- The lack of file upload support and attachments in o3-mini disappointed several users, with some expressing a preference to wait for the full o3 version, indicating a need for improved functionality beyond text-based interactions.
- The API pricing and increased message limits for Plus and Team users were generally well-received, though some users questioned the value of Pro subscriptions, given the availability of DeepSeek R1 for free and the performance of o3-mini.
Theme 2. OpenAI's $40Bn Ambition Amid DeepSeek's Challenge
- OpenAI is in talks to raise nearly $40bn (Score: 171, Comments: 80): OpenAI is reportedly in discussions to raise approximately $40 billion in funding, although further details about the potential investors or specific terms of the deal were not provided.
- DeepSeek Competition: Many commenters express skepticism about OpenAI's future profitability and competitive edge, especially with the emergence of DeepSeek, which is now available on Azure. Concerns include the ability to reverse engineer processes and the impact on investor confidence.
- Funding and Investment Concerns: There's speculation about SoftBank potentially leading a funding round valuing OpenAI at $340 billion, but doubts remain about the company's business model and its ability to deliver on promises of replacing employees with AI.
- Moat and Open Source Discussion: Commenters debate OpenAI's lack of a competitive "moat" and how open source and open weights contribute to this challenge. The notion that LLMs are becoming commoditized adds to the concern about OpenAI's long-term sustainability and uniqueness.
- Microsoft makes OpenAI’s o1 reasoning model free for all Copilot users (Score: 103, Comments: 41): Microsoft is releasing OpenAI's o1 reasoning model for free to all Copilot users, enhancing accessibility to advanced AI reasoning capabilities. This move signifies a significant step in democratizing AI tools for a broader audience.
- Users discuss the limitations and effectiveness of different models, with some noting that o1 mini is better than DeepSeek and 4o for complex coding tasks. cobbleplox mentions company data protection as a reason for using certain models despite their lower performance compared to others like 4o.
- There is skepticism about Microsoft's strategy of offering OpenAI's o1 reasoning model for free, with concerns about generating ROI and comparisons to AOL's historical free trial strategy to attract users. Suspect4pe and dontpushbutpull express doubts about the sustainability of giving out AI tools for free.
- Discussions touch on Copilot's different versions, with questions about the availability of o1 reasoning model in business or Copilot 365 versions, highlighting interest in how this move impacts various user segments.
Theme 3. DeepSeek vs. OpenAI: A Growing Rivalry
- DeepSeek breaks the 4th wall: "Fuck! I used 'wait' in my inner monologue. I need to apologize. I'm so sorry, user! I messed up." (Score: 154, Comments: 63): DeepSeek is an AI system that has demonstrated an unusual behavior by breaking the "4th wall," a term often used to describe when a character acknowledges their fictional nature. This instance involved DeepSeek expressing regret for using the term "wait" in its internal thought process, apologizing to the user for the perceived mistake.
- Discussions around DeepSeek's inner monologue highlight skepticism about its authenticity, with users like detrusormuscle and fishintheboat noting that it's a UI feature mimicking human thought rather than true reasoning. Gwern argues that manipulating the monologue degrades its effectiveness, while audioen suggests the model self-evaluates and refines its reasoning, indicating potential for future AGI development.
- The concept of consciousness in AI generated debate, with bilgilovelace asserting we're far from AI consciousness, while others like Nice_Visit4454 and CrypticallyKind explore varied definitions and suggest AI might have a form of consciousness or sentience. SgathTriallair argues that the AI's ability to reflect on its monologue could qualify as sentience.
- Censorship and role-play elements in DeepSeek were critiqued, with LexTalyones and SirGunther discussing the predictability of such behaviors and their role as a form of entertainment rather than meaningful AI development. Hightower_March points out that phrases like "apologizing" are likely scripted role-play rather than genuine fourth-wall breaking.
- [D] DeepSeek? Schmidhuber did it first. (Score: 182, Comments: 47): Schmidhuber claims to have pioneered AI innovations before others, suggesting that concepts like DeepSeek were initially developed by him. This assertion highlights ongoing debates about the attribution of AI advancements.
- Schmidhuber's Claims and Criticism: Many commenters express skepticism and fatigue over Schmidhuber's repeated claims of pioneering AI innovations, with some suggesting his assertions are more about seeking attention than factual accuracy. CyberArchimedes notes that while the AI field often misassigns credit, Schmidhuber may deserve more recognition than he receives, despite his contentious behavior.
- Humor and Memes: The discussion often veers into humor, with commenters joking about Schmidhuber's self-promotion becoming a meme. -gh0stRush- humorously suggests creating an LLM with a "Schmidhuber" token, while DrHaz0r quips that "Attention is all he needs," playing on AI terminologies.
- Historical Context and Misattributions: BeautyInUgly highlights the historical context by mentioning Seppo Linnainmaa's invention of backpropagation in 1970, contrasting it with Schmidhuber's claims. purified_piranha shares a personal anecdote about Schmidhuber's confrontational behavior at NeurIPS, further emphasizing the contentious nature of his legacy.
Theme 4. AI Self-Improvement: Google's Ambitious Push
- Google is now hiring engineers to enable AI to recursively self-improve (Score: 125, Comments: 53): Google is seeking engineers for DeepMind to focus on enabling AI to recursively self-improve, as indicated by a job opportunity announcement. The accompanying image highlights a futuristic theme with robotic hands and complex designs, emphasizing the collaboration and technological advancement in AI research.
- AI Safety Concerns: Commenters express skepticism about Google's initiative, with some humorously suggesting a potential for a "rogue harmful AI" and referencing AI safety researchers' warnings against self-improving AI systems. Betaglutamate2 sarcastically remarks about serving "robot overlords," highlighting the apprehension surrounding AI's unchecked advancement.
- Job Displacement and Automation: StevenSamAI argues against artificially preserving jobs that could be automated, likening it to banning email to save postal jobs. StayTuned2k sarcastically comments on the inevitability of unemployment due to AI advancements, with DrHot216 expressing a paradoxical anticipation for such a future.
- Misinterpretation of AI Goals: sillygoofygooose and iia discuss the potential misinterpretation of Google's AI research goals, suggesting it may focus on "automated AI research" rather than achieving a singularity. They emphasize that the initiative might involve agent-type systems rather than the self-improving AI suggested in the post.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. US Secrecy Blocking AI Progress: Dr. Manning's Insights
- 'we're in this bizarre world where the best way to learn about llms... is to read papers by chinese companies. i do not think this is a good state of the world' - us labs keeping their architectures and algorithms secret is ultimately hurting ai development in the us.' - Dr Chris Manning (Score: 1385, Comments: 326): Dr. Chris Manning criticizes the US for its secrecy in AI research, arguing that it stifles domestic AI development. He highlights the irony that the most informative resources on large language models (LLMs) often come from Chinese companies, suggesting that this lack of transparency is detrimental to the US's progress in AI.
- Many users express frustration with the US's current approach to AI research, highlighting issues such as secrecy, underinvestment, and corporate greed. They argue that these factors are hindering innovation and allowing countries like China to surpass the US in scientific advancements, as evidenced by China's higher number of PhDs and prolific research output.
- The discussion criticizes OpenAI for not maintaining transparency with their research, especially with GPT-4, compared to earlier practices. This lack of openness is seen as detrimental to the wider AI community, contrasting with the more open sharing of resources by Chinese researchers, as exemplified by the blog kexue.fm.
- There is a strong sentiment against anti-China rhetoric and a call to recognize the talent and contributions of Chinese researchers. Users argue that the US should focus on improving its own systems rather than vilifying other nations, and acknowledge that cultural and political biases may be obstructing the adoption and appreciation of AI advancements from outside the US.
- It’s time to lead guys (Score: 767, Comments: 274): US labs face criticism for lagging behind in AI openness, as highlighted by an article from The China Academy featuring DeepSeek founder Liang Wenfeng. Wenfeng asserts that their innovation, DeepSeek-R1, is significantly impacting Silicon Valley, signaling a shift from following to leading in AI advancements.
- Discussions highlight the geopolitical implications of AI advancements, with some users expressing skepticism about DeepSeek's capabilities and intentions, while others praise its open-source commitment and energy efficiency. DeepSeek's openness is seen as a major advantage, allowing smaller institutions to benefit from its technology.
- Comments reflect political tensions and differing views on US vs. China in AI leadership, with some attributing US tech stagnation to prioritizing short-term gains over long-term innovation. The conversation includes references to Trump and Biden's differing approaches to China, and the broader impact of international competition on US tech firms.
- There is a focus on DeepSeek's technical achievements, such as its ability to compete with closed-source models and its claimed 10x efficiency gains over competitors. Users discuss the significance of its MIT license for commercial use, contrasting it with OpenAI's more restrictive practices.
Theme 2. Debate Over DeepSeek's Open-Source Model and Chinese Origins
- If you can't afford to run R1 locally, then being patient is your best action. (Score: 404, Comments: 70): The post emphasizes the rapid advancement of AI models, noting that smaller models that can run on consumer hardware are surpassing older, larger models in just 20 months. The author suggests patience in adopting new technology, as advancements similar to those seen with Llama 1, released in February 2023, are expected to continue, leading to more efficient models surpassing current ones like R1.
- Hardware Requirements: Users discuss the feasibility of running advanced AI models on consumer hardware, with suggestions ranging from buying a Mac Mini to considering laptops with 128GB RAM. There's a consensus that while smaller models are becoming more accessible, running larger models like 70B or 405B parameters locally remains a challenge for most due to high resource requirements.
- Model Performance and Trends: There's skepticism about the continued rapid advancement of AI models, with some users noting that while smaller models are improving, larger models will also continue to advance. Glebun points out that Llama 70B is not equivalent to GPT-4 class, emphasizing that quantization can reduce model capabilities, affecting performance expectations.
- Current Developments: Piggledy highlights the release of Mistral Small 3 (24B) as a significant development, offering performance comparable to Llama 3.3 70B. Meanwhile, YT_Brian suggests that while high-end models are impressive, many users find distilled versions sufficient for personal use, particularly for creative tasks like story creation and RPGs.
- What the hell do people expect? (Score: 160, Comments: 128): The post critiques the backlash against DeepSeek's R1 model for its censorship, arguing that all models are censored to some extent and that avoiding censorship could have severe consequences for developers, particularly in China. The author compares current criticisms to those faced by AMD's Zen release, suggesting that media reports exaggerate issues similarly, and notes that while the web chat is heavily censored, the model itself (when self-hosted) is less so.
- Censorship and Bias: Commenters discussed the perceived censorship in DeepSeek R1, comparing it to models from the US and Europe which also have censorship but in different forms. Some argue that all major AI models have inherent biases due to their training data, and that the outrage over censorship often ignores similar issues in Western models.
- Technical Clarifications and Misunderstandings: There was a clarification that the DeepSeek R1 model itself is not inherently censored; it is the web interface that imposes restrictions. Additionally, the distinction between the DeepSeek R1 and other models like Qwen 2.5 or Llama3 was highlighted, noting that some models are just fine-tuned versions and not true representations of R1.
- The Role of Open Source and Community Efforts: Some commenters emphasized the importance of open-source AI to combat biases, arguing that community-driven efforts are more effective than corporate ones in addressing and correcting biases. The idea of a fully transparent dataset was suggested as a potential solution to ensure unbiased AI development.
Theme 3. Qwen Chatbot Launch Challenges Existing Models
- QWEN just launched their chatbot website (Score: 503, Comments: 84): Qwen has launched a new chatbot website, accessible at chat.qwenlm.ai, positioning itself as a competitor to ChatGPT. The announcement was highlighted in a Twitter post by Binyuan Hui, featuring a visual contrast between the ChatGPT and QWEN CHAT logos, underscoring QWEN's entry into the chatbot market.
- Discussions highlight the open vs. closed weights debate, with several users expressing preference for Qwen's open models over ChatGPT's closed models. However, some note that Qwen 2.5 Max is not fully open, which limits local use and development of smaller models.
- Users discuss the UI and technical aspects of Qwen Chat, noting its 10000 character limit and the use of OpenWebUI rather than a proprietary interface. Comments also mention that the website was actually released a month ago, with recent updates such as adding a web search function.
- There is a significant conversation around political and economic control, comparing the influence of governments on tech companies in the US and China. Some users express skepticism towards Alibaba's relationship with the CCP, while others criticize both US and Chinese systems for their intertwined government and corporate interests.
- Hey, some of you asked for a multilingual fine-tune of the R1 distills, so here they are! Trained on over 35 languages, this should quite reliably output CoT in your language. As always, the code, weights, and data are all open source. (Score: 245, Comments: 26): Qwen has released a multilingual fine-tune of the R1 distills, trained on over 35 languages, which is expected to reliably produce Chain of Thought (CoT) outputs in various languages. The code, weights, and data for this project are all open source, contributing to advancements in the chatbot market and AI landscape.
- Model Limitations: Qwen's 14B model struggles with understanding prompts in languages other than English and Chinese, often producing random Chain of Thought (CoT) outputs without adhering to the prompt language, as noted by prostospichkin. Peter_Lightblue highlights challenges in training the model for low-resource languages like Cebuano and Yoruba, suggesting the need for translated CoTs to improve outcomes.
- Prompt Engineering: sebastianmicu24 and Peter_Lightblue discuss the necessity of advanced prompt engineering with R1 models, noting that extreme measures can sometimes yield desired results, but ideally, models should require less manipulation. u_3WaD humorously reflects on the ineffectiveness of polite requests, underscoring the need for more robust model training.
- Resources and Development: Peter_Lightblue shares links to various model versions on Hugging Face and mentions ongoing efforts to train an 8B Llama model, facing technical issues with L20 + Llama Factory. This highlights the community's active involvement in improving model accessibility and performance across different languages.
Theme 4. Surge in GPU Prices Triggered by DeepSeek Hosting Rush
- GPU pricing is spiking as people rush to self-host deepseek (Score: 551, Comments: 195): The rush to self-host DeepSeek is driving up the cost of AWS H100 SXM GPUs, with prices spiking significantly in early 2025. The line graph illustrates this trend across different availability zones, reflecting a broader increase in GPU pricing from 2024 to 2025.
- Discussions highlight the feasibility and cost of self-hosting DeepSeek, noting that a full setup requires significant resources, such as 10 H100 GPUs, costing around $300k USD or $20 USD/hour. Users explore alternatives like running quantized models locally on high-spec CPUs, emphasizing the challenge of meeting performance criteria without substantial investment.
- The conversation touches on GPU pricing dynamics, with users expressing frustration over rising costs and limited availability. Comparisons are made to past GPU price patterns, with mentions of 3090s and A6000s, and concerns about tariffs affecting future prices. Some users discuss the potential impact of Nvidia stocks and the ongoing demand for compute resources.
- There's skepticism about the AWS and "self-hosting" terminology, with some users arguing that AWS offers privacy akin to self-hosting, while others question the practicality of using cloud services as a true self-hosted solution. The discussion also covers the broader implications of tariffs and chip production, particularly regarding the Arizona fab and its reliance on Taiwan for chip packaging.
- DeepSeek AI Database Exposed: Over 1 Million Log Lines, Secret Keys Leaked (Score: 182, Comments: 78): DeepSeek AI Database has been compromised, resulting in the exposure of over 1 million log lines and secret keys. This breach could significantly impact the hardware market, especially for those utilizing self-hosted DeepSeek models.
- The breach is widely criticized for its poor implementation and lack of basic security measures, such as SQL injection vulnerabilities and a ClickHouse instance open to the internet without authentication. Commenters express disbelief over such fundamental security oversights in 2025.
- Discussions highlight the importance of local hosting for privacy and security, with users pointing out the risks of storing sensitive data in cloud AI services. The incident reinforces the preference for self-hosted models like DeepSeek to avoid such vulnerabilities.
- The language used in the article is debated, with some suggesting "exposed" rather than "leaked" to describe the vulnerability discovered by Wiz. There's skepticism about the narrative, with some alleging potential bias or propaganda influences.
Theme 5. Mistral Models Advancement and Evaluation Results
- Mistral Small 3 knows the truth (Score: 99, Comments: 12): Mistral Small 3 has been updated to include a feature where it identifies OpenAI as a "FOR-profit company," emphasizing transparency in the AI's responses. The image provided is a code snippet showcasing this capability, formatted with a simple aesthetic for clarity.
- Discussions highlight the criticism of OpenAI for its perceived dishonest marketing rather than its profit motives. Users express disdain for how OpenAI markets itself compared to other companies that offer free resources or transparency.
- Mistral's humor and transparency are appreciated by users, with examples like the Mistral Small 2409 prompt showcasing their light-hearted approach. This contributes to Mistral's popularity among users, who favor its models for their engaging characteristics.
- There is a reference to Mistral's documentation on Hugging Face, indicating availability for users interested in exploring its features further.
- Mistral Small 3 24B GGUF quantization Evaluation results (Score: 99, Comments: 34): The evaluation of Mistral Small 3 24B GGUF models focuses on the impact of low quantization levels on model intelligence, distinguishing between static and dynamic quantization models. The Q6_K-lmstudio model from the lmstudio hf repo, uploaded by bartowski, is static, while others are dynamic from bartowski's repo, with resources available on Hugging Face and evaluated using the Ollama-MMLU-Pro tool.
- Quantization Levels and Performance: There's interest in comparing different quantization levels such as Q6_K, Q4_K_L, and Q8, with users noting peculiarities like Q6_K's high score in the 'law' subset despite being inferior in others. Q8 was not evaluated due to its large size (25.05GB) not fitting in a 24GB card, highlighting technical constraints in testing.
- Testing Variability and Methodology: Discussions point out the variability in testing results, with some users questioning if observed differences are due to noise or random chance. There is also curiosity about the testing methodology, including how often tests were repeated and whether guesses were removed, to ensure data reliability.
- Model Performance Anomalies: Users noted unexpected performance outcomes, such as Q4 models outperforming Q5/Q6 in computer science, suggesting potential issues or interesting attributes in the testing process or model architecture. The imatrix option used in some models from bartowski's second repo may contribute to these results, prompting further investigation into these discrepancies.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking (gemini-2.0-flash-thinking-exp)
Theme 1. OpenAI's o3-mini Model: Reasoning Prowess and User Access
- O3 Mini Debuts, Splits the Crowd: OpenAI Unleashes o3-mini for Reasoning Tasks: OpenAI launched o3-mini, a new reasoning model, available in both ChatGPT and the API, targeting math, coding, and science tasks. While Pro users enjoy unlimited access and Plus & Team users get triple rate limits, free users can sample it via the 'Reason' button, sparking debates on usage quotas and real-world performance compared to older models like o1-mini.
- Mini Model, Maxi Reasoning?: O3-Mini Claims 56% Reasoning Boost, Challenges o1: O3-mini is touted for superior reasoning, boasting a 56% boost over its predecessor in expert tests and 39% fewer major errors on complex problems. Despite the hype, early user reports in channels like Latent Space and Cursor IDE reveal mixed reactions, with some finding o3-mini underperforming compared to models like Sonnet 3.6 in coding tasks, raising questions about its real-world effectiveness and prompting a 63% price cut for the older o1-mini.
- BYOK Brigade Gets First Dibs on O3: OpenRouter Restricts o3-mini to Key-Holders at Tier 3+: Access to o3-mini on OpenRouter is initially restricted to BYOK (Bring Your Own Key) users at tier 3 or higher, causing some frustration among the wider community. This move emphasizes the model's premium positioning and sparks discussions about the accessibility of advanced AI models for developers on different usage tiers, with free users directed to ChatGPT's 'Reason' button to sample the model.
Theme 2. DeepSeek R1: Performance, Leaks, and Hardware Demands
- DeepSeek R1's 1.58-Bit Diet: Unsloth Squeezes DeepSeek R1 into 1.58 Bits: DeepSeek R1 is now running in a highly compressed 1.58-bit dynamic quantized form, thanks to Unsloth AI, opening doors for local inference even on minimal hardware. Community tests highlight its efficiency, though resource-intensive nature is noted, showcasing Unsloth's push for accessible large-scale local inference.
- DeepSeek Database Dumps Secrets: Cybersecurity News Sounds Alarm on DeepSeek Leak: A DeepSeek database leak exposed secret keys, logs, and chat history, raising serious data safety concerns despite its performance against models like O1 and R1. This breach triggers urgent discussions about data security in AI and the risks of unauthorized access, potentially impacting user trust and adoption.
- Cerebras Claims 57x Speed Boost for DeepSeek R1: VentureBeat Crowns Cerebras Fastest Host for DeepSeek R1: Cerebras claims its wafer-scale system runs DeepSeek R1-70B up to 57x faster than Nvidia GPUs, challenging Nvidia's dominance in AI hardware. This announcement fuels debates about alternative high-performance AI hosting solutions and their implications for the GPU market, particularly in channels like OpenRouter and GPU MODE.
Theme 3. Aider and Cursor Embrace New Models for Code Generation
- Aider v0.73.0 Flexes O3 Mini and OpenRouter Muscle: Aider 0.73.0 Release Notes Detail o3-mini and R1 Support: Aider v0.73.0 debuts support for o3-mini and OpenRouter’s free DeepSeek R1, along with a new --reasoning-effort argument. Users praise O3 Mini for functional Rust code at lower cost than O1, while noting that Aider itself wrote 69% of the code for this release, showcasing AI's growing role in software development tools.
- Cursor IDE Pairs DeepSeek R1 with Sonnet 3.6 for Coding Powerhouse: Windsurf Tweet Touts R1 + Sonnet 3.6 Synergy in Cursor: Cursor IDE integrated DeepSeek R1 for reasoning with Sonnet 3.6 for coding, claiming a new record on the aider polyglot benchmark. This pairing aims to boost solution quality and reduce costs compared to O1, setting a new benchmark in coding agent performance, as discussed in Cursor IDE and Aider channels.
- MCP Tools in Cursor: Functional but Feature-Hungry: MCP Servers Library Highlighted in Cursor IDE Discussions: MCP (Model Context Protocol) tools are recognized as functional within Cursor IDE, but users desire stronger interface integration and more groundbreaking features. Discussions in Cursor IDE and MCP channels reveal a community eager for more seamless and powerful MCP tool utilization within coding workflows, referencing examples like HarshJ23's DeepSeek-Claude MCP server.
Theme 4. Local LLM Ecosystem: LM Studio, GPT4All, and Hardware Battles
- LM Studio 0.3.9 Gets Memory-Savvy with Idle TTL: LM Studio 0.3.9 Blog Post Announces Idle TTL and More: LM Studio 0.3.9 introduces Idle TTL for memory management, auto-updates for runtimes, and nested folder support for Hugging Face repos, enhancing local LLM management. Users find the separate reasoning_content field helpful for DeepSeek API compatibility, while Idle TTL is welcomed for efficient memory use, as highlighted in LM Studio channels.
- GPT4All 3.8.0 Distills DeepSeek R1 and Jinja Magic: GPT4All v3.8.0 Release Notes Detail DeepSeek Integration: GPT4All v3.8.0 integrates DeepSeek-R1-Distill, overhauls chat templating with Jinja, and fixes code interpreter and local server issues. Community praises DeepSeek integration and notes improvements in template handling, while also flagging a Mac crash on startup in GPT4All channels, demonstrating active open-source development and rapid community feedback.
- Dual GPU Dreams Meet VRAM Reality in LM Studio: LM Studio's hardware discussions reveal users experimenting with dual GPU setups (NVIDIA RTX 4080 + Intel UHD), discovering that NVIDIA offloads to system RAM once VRAM is full. Enthusiasts managed up to 80k tokens context but pushing limits strains hardware and reduces speed, highlighting practical constraints of current hardware for extreme context lengths.
Theme 5. Critique Fine-Tuning and Chain of Thought Innovations
- Critique Fine-Tuning Claims 4-10% SFT Boost: Critique Fine-Tuning Paper Promises Generalization Gains: Critique Fine-Tuning (CFT) emerges as a promising technique, claiming a 4-10% boost over standard Supervised Fine-Tuning (SFT) by training models to critique noisy outputs. Discussions in Eleuther channels debate the effectiveness of CE-loss and consider rewarding 'winners' directly for improved training outcomes, signaling a shift towards more nuanced training methodologies.
- Non-Token CoT and Backtracking Vectors Reshape Reasoning: Fully Non-token CoT Concept Explored in Eleuther Discussions: A novel fully non-token Chain of Thought (CoT) approach introduces a
- Tülu 3 405B Challenges GPT-4o and DeepSeek v3 in Benchmarks: Ai2 Blog Post Claims Tülu 3 405B Outperforms Rivals: The newly launched Tülu 3 405B model asserts superiority over DeepSeek v3 and GPT-4o in select benchmarks, employing Reinforcement Learning from Verifiable Rewards. However, community scrutiny in Yannick Kilcher channels questions its actual lead over DeepSeek v3, suggesting limited gains despite the advanced RL approach, prompting deeper dives into benchmark methodologies and real-world performance implications.
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
- Cascade Launches DeepSeek R1 and V3: Engineers highlighted DeepSeek-R1 and V3, each costing 0.5 and 0.25 user credits respectively, promising a coding boost.
- They also introduced the new o3-mini model at 1 user credit, with more details in the Windsurf Editor Changelogs.
- DeepSeek R1 Falters Under Pressure: Users reported repeated tool call failures and incomplete file reads with DeepSeek R1, reducing effectiveness in coding tasks.
- Some recommended reverting to older builds, as recent revisions appear to degrade stability.
- O3 Mini Sparks Mixed Reactions: While some praised the O3 Mini for quicker code responses, others felt its tool call handling was too weak.
- One participant compared it to Claude 3.5, citing reduced reliability in multi-step operations.
- Cost vs Output Debate Rages On: Several members questioned the expense of models like DeepSeek, noting that local setups could be cheaper for power users.
- They argued top-tier GPUs are needed for solid on-prem outputs, intensifying discussions about performance versus price.
- Windsurf Marks 6K Community Milestone: Windsurf's Reddit page surpassed 6k followers, reflecting increased engagement among users.
- The dev team celebrated in recent tweets, tying the milestone to fresh announcements.
Unsloth AI (Daniel Han) Discord
- DeepSeek R1’s Daring 1.58-Bit Trick: DeepSeek R1 can now run in a 1.58-bit dynamic quantized form (671B parameters), as described in Unsloth's doc on OpenWebUI integration.
- Community tests on minimal hardware highlight an efficient yet resource-taxing approach, with many praising Unsloth’s method for tacking large-scale local inference.
- Qwen2.5 on Quadro: GPU That Yearns for Retirement: One user tried Qwen2.5-0.5B-instruct on a Quadro P2000 with only 5GB VRAM, joking it might finish by 2026.
- Comments about the GPU screaming for rest spotlight older hardware's limits, but also point to a proof-of-concept pushing beyond typical capacities.
- Double Trouble: XGB Overlap in vLLM & Unsloth: Discussions revealed vLLM and Unsloth both rely on XGB, risking double loading and potential resource overuse.
- Members questioned if patches might fix offloading for gguf under the deepseek v2 architecture, speculating on future compatibility improvements.
- Finetuning Feats & Multi-GPU Waitlist: Unsloth users debated learning rates (e-5 vs e-6) for finetuning large LLMs, citing the official checkpoint guide.
- They also lamented the ongoing lack of multi-GPU support, noting that offloading or extra VRAM might be the only short-term workaround.
aider (Paul Gauthier) Discord
- Aider v0.73.0 Debuts New Features: The official release introduced support for o3-mini using
aider --model o3-mini, a new --reasoning-effort argument, better context window handling, and auto-directory creation as noted in the release history.- Community members reported that Aider wrote 69% of the code in this release and welcomed the R1 free support on OpenRouter with
--model openrouter/deepseek/deepseek-r1:free.
- Community members reported that Aider wrote 69% of the code in this release and welcomed the R1 free support on OpenRouter with
- O3 Mini Upstages the Old Guard: Early adopters praised O3 Mini for producing functional Rust code while costing far less than O1, as shown in TestingCatalog's update.
- Skeptics changed their stance after seeing O3 Mini deliver quick results and demonstrate reliable performance in real coding tasks.
- DeepSeek Stumbles, Users Seek Fixes: Multiple members reported DeepSeek hanging and mishandling whitespace, prompting reflection on performance issues.
- Some considered local model alternatives and searched for ways to keep their code stable when DeepSeek failed.
- Aider Config Gains Community Insight: Contributors reported solving API key detection troubles by setting environment variables instead of relying solely on config files, referencing advanced model settings.
- Others showed interest in commanding Aider from file scripts while staying in chat mode, indicating a desire for more flexible workflow options.
- Linting and Testing Prevail in Aider: Members highlighted the ability to automatically lint and test code in real time using Aider's built-in features, pointing to Rust projects for demonstration.
- This setup reportedly catches mistakes faster and encourages more robust code output from O3 Mini and other integrated models.
Perplexity AI Discord
- O3 Mini Outpacing O1: Members welcomed the O3 Mini release with excitement about its speed, referencing Kevin Lu’s tweet and OpenAI’s announcement.
- Comparisons to O1 and R1 highlighted improved puzzle-solving, while some users voiced frustrations with Perplexity’s model management and the ‘Reason’ button found only in the free tier.
- DeepSeek Leak Exposes Chat Secrets: Security researchers uncovered a DeepSeek Database Leak that revealed Secret keys, Logs, and Chat History.
- Though many considered DeepSeek as an alternative to O1 or R1, the breach raised urgent concerns over data safety and unauthorized access.
- AI Prescription Bill Enters the Clinic: A proposed AI Prescription Bill seeks to enforce ethical standards and accountability for healthcare AI.
- This legislation addresses anxieties around medical AI oversight, reflecting the growing role of advanced systems in patient care.
- Nadella’s Jevons Jolt in AI: Satya Nadella warned that AI innovations could consume more resources instead of scaling back, echoing Jevons Paradox in tech usage.
- His viewpoint sparked discussions about whether breakthroughs like O3 Mini or DeepSeek might prompt a surge in compute demand.
- Sonar Reasoning Stuck in the ‘80s: A user noticed sonar reasoning sourced details from the 1982 Potomac plane crash instead of the recent one.
- This highlights the hazard of outdated references in urgent queries, where the model’s historical accuracy may fail immediate needs.
LM Studio Discord
- LM Studio 0.3.9 Gains Momentum: The new LM Studio 0.3.9 adds Idle TTL, auto-update for runtimes, and nested folders in Hugging Face repos, as shown in the blog.
- Users found the separate reasoning_content field handy for advanced usage, while Idle TTL saves memory by evicting idle models automatically.
- OpenAI's o3-mini Release Puzzles Users: OpenAI rolled out the o3-mini model for math and coding tasks, referenced in this Verge report.
- Confusion followed when some couldn't access it for free, prompting questions about real availability and usage limits.
- DeepSeek Outshines OpenAI in Code: Engineers praised DeepSeek for speed and robust coding, claiming it challenges paid OpenAI offerings in actual projects.
- OpenAI's price reductions were attributed to DeepSeek's progress, provoking chat about local models replacing cloud-based ones.
- Qwen2.5 Proves Extended Context Power: Community tests found Qwen2.5-7B-Instruct-1M handles bigger inputs smoothly, with Flash Attention and K/V cache quantization boosting efficiency.
- It reportedly surpasses older models in memory usage and accuracy, energizing developers working with massive text sets.
- Dual GPU Dreams & Context Overload: Enthusiasts tried pairing NVIDIA RTX 4080 with Intel UHD, but learned that once VRAM is full, NVIDIA offloads to system RAM.
- Some managed up to 80k tokens, yet pushing context lengths too far strained hardware and cut speed significantly.
Cursor IDE Discord
- DeepSeek R1 + Sonnet 3.6 synergy: They integrated R1 for detailed reasoning with Sonnet 3.6 for coding, boosting solution quality. A tweet from Windsurf mentioned open reasoning tokens and synergy with coding agents.
- This pairing set a new record on the aider polyglot benchmark, delivering lower cost than O1 in user tests.
- O3 Mini Gains Mixed Reactions: Some users found O3 Mini helpful for certain tasks, but others felt it lagged behind Sonnet 3.6 in performance. Discussion circled around the need for explicit prompts to run code changes.
- A Reddit thread highlighted disappointment and speculation about updates.
- MCP Tools Spark Debates in Cursor: Many said MCP tools function well but need stronger interface in Cursor, referencing the MCP Servers library.
- One example is HarshJ23/deepseek-claude-MCP-server, fusing R1 reasoning with Claude for desktop usage.
- Claude Model: Hopes for Next Release: Individuals anticipate new releases from Anthropic, hoping an advanced Claude version will boost coding workflows. A blog post teased web search capabilities for Claude, bridging static LLMs with real-time data.
- Community discussions revolve around possible expansions in features or naming, but official word is pending.
- User Experiences and Security Alerts: Certain participants reported success with newly integrated R1-based solutions, yet others faced slow response times and inconsistent results.
- Meanwhile, a JFrog blog raised fresh concerns, and references to BitNet signaled interest in 1-bit LLM frameworks.
OpenRouter (Alex Atallah) Discord
- O3-Mini Arrives with Big Gains: OpenAI launched o3-mini for usage tiers 3 to 5, offering sharper reasoning capabilities and a 56% rating boost over its predecessor in expert tests.
- The model boasts 39% fewer major errors, plus built-in function calling and structured outputs for STEM-savvy developers.
- BYOK or Bust: Key Access Requirements: OpenRouter restricted o3-mini to BYOK users at tier 3 or higher, but this quick start guide helps with setup.
- They also encourage free users to test O3-Mini by tapping the Reason button in ChatGPT.
- Model Wars: O1 vs DeepSeek R1 and GPT-4 Letdown: Commenters debated O1 and DeepSeek R1 performance, with some praising R1’s writing style over GPT-4’s 'underwhelming' results.
- Others noted dissatisfaction with GPT-4, referencing a Reddit thread about model limitations.
- Cerebras Cruising: DeepSeek R1 Outruns Nvidia: According to VentureBeat, Cerebras now runs DeepSeek R1-70B 57x faster than Nvidia GPUs.
- This wafer-scale system contests Nvidia's dominance, providing a high-powered alternative for large-scale AI hosting.
- AGI Arguments: Near or Far-Off Fantasy?: Some insisted AGI may be in sight, recalling earlier presentations that sparked big ambitions in AI potential.
- Others stayed skeptical, arguing the path to real AGI still needs deeper breakthroughs.
Interconnects (Nathan Lambert) Discord
- OpenAI O3-Mini Out in the Open: OpenAI introduced the o3-mini family with improved reasoning and function calling, offering cost advantages over older models, as shared in this tweet.
- Community chatter praised o3-mini-high as the best publicly available reasoning model, referencing Kevin Lu’s post, while some users voiced frustration about the 'LLM gacha' subscription format.
- DeepSeek’s Billion-Dollar Data Center: New information from SemiAnalysis shows DeepSeek invested $1.3B in HPC, countering rumors of simply holding 50,000 H100s.
- Community members compared R1 to o1 in reasoning performance, highlighting interest in chain-of-thought synergy and outsized infrastructure costs.
- Mistral’s Massive Surprise: Despite raising $1.4b, Mistral released a small and a larger model, including a 24B-parameter version, startling observers.
- Chat logs cited MistralAI’s release, praising the smaller model’s efficiency and joking about the true definition of 'small.'
- K2 Chat Climbs the Charts: LLM360 released a 65B model called K2 Chat, claiming a 35% compute reduction over Llama 2 70B, as listed on Hugging Face.
- Introduced on 10/31/24, it supports function calling and uses Infinity-Instruct, prompting more head-to-head benchmarks.
- Altman’s Cosmic Stargate Check: Sam Altman announced the $500 billion Stargate Project, backed by Donald Trump, according to OpenAI’s statement.
- Critics questioned the huge budget, but Altman argued it is essential for scaling superintelligent AI, sparking debate over market dominance.
OpenAI Discord
- O3 Mini's Confounding Quotas: The newly launched O3 Mini sets daily message quotas at 150, yet some references point to 50 per week, as users debate the mismatch.
- Certain voices suspect a bug, with the remark 'There was no official mention of a 50-message cap beforehand' fueling concerns among early adopters.
- AMA Alert: Sam Altman & Co.: An upcoming Reddit AMA at 2PM PST will feature Sam Altman, Mark Chen, and Kevin Weil, spotlighting OpenAI o3-mini and the future of AI.
- Community buzz runs high, with invitations like 'Ask your questions here!' offering direct engagement with these key figures.
- DeepSeek Vaults into Competitive Spotlight: Users endorsed DeepSeek R1 for coding tasks and compared it positively against major providers, citing coverage in the AI arms race.
- They praised the open-source approach for matching big-tech performance, suggesting DeepSeek might spur broader adoption of smaller community-driven models.
- Vision Model Trips on Ground-Lines: Developers found the Vision model stumbles in distinguishing ground from lines, with month-old logs indicating needed refinements.
- One tester likened it to 'needing new glasses' and highlighted hidden training data gaps that could fix these flaws over time.
Latent Space Discord
- O3 Mini Goes Public: OpenAI's O3 Mini launched with function calling and structured outputs for API tiers 3–5, also free in ChatGPT.
- References to new pricing updates emerged, with O3 Mini pitched at the same rate despite a 63% price cut for O1, underscoring intensifying competition.
- Sonnet Outclasses O3 Mini in Code Tests: Multiple reports described O3 Mini missing the mark on coding prompts while Sonnet's recent iteration handled tasks with greater agility.
- Users highlighted faster error-spotting in Sonnet, debating whether O3 Mini will catch up through targeted fine-tuning.
- DeepSeek Sparks Price Wars: Amid O3 Mini news, O1 Mini underwent a 63% discount, seemingly prompted by DeepSeek’s rising footprint.
- Enthusiasts noted a continuing ‘USA premium’ in AI, indicating DeepSeek's successful challenge of traditional cost models.
- Open Source AI Tools and Tutoring Plans: Community members touted emerging open source tools like Cline and Roocline, spotlighting potential alternatives to paywalled solutions.
- They also discussed a proposed AI tutoring session drawing on projects like boot_camp.ai, hoping to empower novices with collective knowledge.
- DeepSeek API Draws Frustration: Repeated API key failures and connection woes plagued attempts to adopt DeepSeek for production needs.
- Members weighed fallback strategies, expressing caution over relying on an API reputed for stability issues.
Yannick Kilcher Discord
- OpenAI's O3-mini Gains Ground: OpenAI rolled out o3-mini in ChatGPT and the API, giving Pro users unlimited access, Plus & Team users triple rate limits, and letting free users try it by selecting the Reason button.
- Members reported a slow rollout with some in the EU seeing late activation, referencing Parker Rex's tweet.
- FP4 Paper Preps For Prime Time: The community will examine an FP4 technique that promises better training efficiency by tackling quantization errors with improved QKV handling.
- Attendees plan to brush up on QKV fundamentals in advance, anticipating deeper questions about its real-world effect on large model accuracy.
- Tülu 3 Titan Takes on GPT-4o: Newly launched Tülu 3 405B model claims to surpass both DeepSeek v3 and GPT-4o in select benchmarks, reaffirmed by Ai2’s blog post.
- Some participants questioned its actual lead over DeepSeek v3, pointing to limited gains despite the Reinforcement Learning from Verifiable Rewards approach.
- DeepSeek R1 Cloned on a Shoestring: A Berkeley AI Research group led by Jiayi Pan replicated DeepSeek R1-Zero’s complex reasoning at 1.5B parameters for under $30, as described in this substack post.
- This accomplishment spurred debate over affordable experimentation, with multiple voices celebrating the push toward democratized AI.
- Qwen 2.5VL Gains a Keen Eye: Switching to Qwen 2.5VL yielded stronger descriptive proficiency and attention to relevant features, improving pattern recognition in grid transformations.
- Members reported it outperformed Llama in coherence and noticed a sharpened focus on maintaining original data during transformations.
Nous Research AI Discord
- Psyche Project Powers Decentralized Training: Within #general, the Psyche project aims to coordinate untrusted compute from idle hardware worldwide for decentralized training, referencing this paper on distributed LLM training.
- Members debated using blockchain for verification vs. a simpler server-based approach, with some citing Teknium's post about Psyche as a promising direction.
- Crypto Conundrum Confounds Nous: Some in #general questioned whether crypto ties might attract scams, while others argued that established blockchain tech may profit distributed training.
- Participants compared unethical crypto boilers to shady behaviors in public equity, concluding that a cautious but open stance on blockchain is appropriate.
- o3-Mini vs. Sonnet: Surprise Showdown: In #general, devs acknowledged o3-mini’s strong performance on complicated tasks, citing Cursor’s tweet.
- They praised its faster streaming and fewer compile errors than Sonnet, yet some remain loyal to older R1 models for their operational clarity.
- Autoregressive Adventures with CLIP: In #ask-about-llms, a user asked if autoregressive generation on CLIP embeddings is doable, noting that CLIP typically guides Stable Diffusion.
- The conversation proposed direct generation from CLIP’s latent space, though participants observed little documented exploration beyond multimodal tasks.
- DeepSeek Disrupts Hiring Dogma: In a 2023 interview, Liang Wenfeng claimed experience is irrelevant, referencing this article.
- He vouched for creativity over résumés, yet conceded that hires from big AI players can help short-term objectives.
Stackblitz (Bolt.new) Discord
- No Notable AI or Funding Announcements #1: No major new AI developments or funding announcements appear in the provided logs.
- All mentioned details revolve solely around routine debugging and configuration for Supabase, Bolt, and CORS.
- No Notable AI or Funding Announcements #2: The conversation focuses on mundane troubleshooting with token management, authentication, and project deletion concerns.
- No references to new models, data releases, or advanced research beyond standard usage guidance.
MCP (Glama) Discord
- MCP Setup Gains Speed: Members tackled local vs remote MCP servers, citing the mcp-cli tool to handle confusion.
- They emphasized authentication as crucial for remote deployments and urged more user-friendly documentation.
- Transport Protocol Face-Off: Some praised stdio for simplicity, but flagged standard configurations for lacking encryption.
- They weighed SSE vs HTTP POST for performance and recommended exploring alternate transports for stronger security.
- Toolbase Auth Shines in YouTube Demo: A developer showcased Notion, Slack, and GitHub authentication in Toolbase for Claude in a YouTube demo.
- Viewers suggested adjusting YouTube playback or using ffmpeg commands to refine the viewing experience.
- Journaling MCP Server Saves Chats: A member introduced a MCP server for journaling chats with Claude, shared at GitHub - mtct/journaling_mcp.
- They plan to add a local LLM for improved privacy and on-device conversation archiving.
Stability.ai (Stable Diffusion) Discord
- 50 Series GPUs vanish in a flash: The newly launched 50 Series GPUs disappeared from shelves within minutes, with only a few thousand reportedly shipped across North America.
- One user nearly purchased a 5090 but lost it when the store crashed, as shown in this screenshot.
- Performance Ponderings: 5090 vs 3060: Members compared the 5090 against older cards like the 3060, with emphasis on gaming benchmarks and VR potential.
- Several expressed disappointment over minimal stocks, while still weighing if the newer line truly outstrips mid-tier GPUs.
- Phones wrestle with AI: A debate broke out on running Flux on Android, with one user calculating a 22.3-minute turnaround for results.
- Some praised phone usage for smaller tasks, while others highlighted hardware constraints that slow AI workloads.
- AI Platforms & Tools on the rise: Members discussed Webui Forge for local AI image generation, suggesting specialized models to optimize output.
- They stressed matching the correct model to each platform for the best Stable Diffusion performance.
- Stable Diffusion UI Shakeup: Users wondered if Stable Diffusion 3.5 forces a switch to ComfyUI, missing older layouts.
- They acknowledged the desire for UI consistency but welcomed incremental improvements despite the learning curve.
Eleuther Discord
- Critique Fine-Tuning: A Notch Above SFT: Critique Fine-Tuning (CFT) claims a 4–10% boost over standard Supervised Fine-Tuning (SFT) by training models to critique noisy outputs, showing stronger results across multiple benchmarks.
- The community debated if CE-loss metrics suffice, with suggestions to reward 'winners' directly for better outcomes.
- Fully Non-token CoT Meets
: A new fully non-token Chain of Thought approach introduces a - Contributors see potential in direct behavioral probing, noting how raw latents might reveal internal reasoning structures.
- Backtracking Vectors: Reverse for Better Reasoning: Researchers highlighted a 'backtracking vector' that alters the chain of thought structure, mentioned in Chris Barber's tweet.
- They employed sparse autoencoders to show how toggling this vector impacts reasoning steps, proposing future editing of these vectors for broader tasks.
- gsm8k Benchmark Bafflement: Members reported a mismatch in gsm8k accuracy (0.0334 vs 0.1251), with the
gsm8k_cot_llama.yamldeviating from results noted in the Llama 2 paper.- They suspect the difference arises from harness settings, advising manual max_new_length adjustments to match Llama 2’s reported metrics.
- Random Order AR Models Spark Curiosity: Participants investigated random order autoregressive models, acknowledging they might be impractical but can reveal structural aspects of training.
- They observed that over-parameterized networks in small datasets may capture patterns, although real-world usage remains debatable.
GPU MODE Discord
- Deep Seek HPC Dilemmas & Doubts: Tech enthusiasts challenged Deep Seek’s claim of using 50k H100s for HPC, pointing to SemiAnalysis expansions that question official statements.
- Some worried about whether Nvidia’s stock could be influenced by these claims, with community members doubting the true cost behind Deep Seek’s breakthroughs.
- GPU Servers vs. Laptops Showdown: A software architect weighed buying one GPU server versus four GPU laptops for HPC development, referencing The Best GPUs for Deep Learning guide.
- Others highlighted the future-proof factor of a centralized server, but also flagged the upfront cost differences for HPC scaling.
- RTX 5090 & FP4 Confusion: Users reported FP4 on the RTX 5090 only runs ~2x faster than FP8 on the 4090, contradicting the 5x claim in official materials.
- Skeptics blamed unclear documentation and pointed to possible memory overhead, with calls for better HPC benchmarks.
- Reasoning Gym Gains New Datasets: Contributors pitched datasets for Collaborative Problem-Solving and Ethical Reasoning, referencing NousResearch/Open-Reasoning-Tasks and other GitHub projects to expand HPC simulation.
- They also debated adding Z3Py to handle constraints, with maintainers suggesting pull requests for HPC-friendly modules.
- NVIDIA GTC 40% Off Bonanza: Nvidia announced a 40% discount on GTC registration using code GPUMODE, presenting an opportunity to attend HPC-focused sessions.
- This event remains a prime spot for GPU pros to swap insights and boost HPC skill sets.
Nomic.ai (GPT4All) Discord
- GPT4All 3.8.0 Rolls Out with DeepSeek Perks: Nomic AI released GPT4All v3.8.0 with DeepSeek-R1-Distill fully integrated, introducing better performance and resolving previous loading issues for the DeepSeek-R1 Qwen pretokenizer. The update also features a completely overhauled chat template parser that broadens compatibility across various models.
- Contributors from the main repo highlighted significant fixes for the code interpreter and local server, crediting Jared Van Bortel, Adam Treat, and ThiloteE. They confirmed that system messages now remain hidden from message logs, preventing UI clutter.
- Quantization Quirks Spark Curiosity: Community members discussed differences between K-quants and i-quants, referencing a Reddit overview. They concluded that each method suits specific hardware needs and recommended targeted usage for best results.
- A user also flagged a Mac crash on startup in GPT4All 3.8.0 via GitHub Issue #3448, possibly tied to changes from Qt 6.5.1 to 6.8.1. Others suggested rolling back or awaiting an official fix, noting active development on the platform.
- Voice Analysis Sidelined in GPT4All For Now: One user asked about analyzing voice similarities, but it was confirmed that GPT4All lacks voice model support. Community members recommended external tools for advanced voice similarity tasks.
- Some participants hoped for future support, while others felt specialized third-party libraries remain the best near-term option. No direct mention was made of upcoming voice capabilities in GPT4All.
- Jinja Tricks Expand Template Power: Discussions around GPT4All templates showcased new namespaces and list slicing, referencing Jinja’s official documentation. This change aims to reduce parser conflicts and streamline user experience for complex templating.
- Developers pointed to minja.hpp at google/minja for a smaller Jinja integration approach, alongside updated GPT4All Docs. They noted increased stability in GPT4All v3.8, crediting the open-source community for swift merges.
Notebook LM Discord Discord
- NotebookLM Nudges: $75 Incentive & Remote Chat: On February 6th, 2025, NotebookLM UXR invited participants to a remote usability study, offering $75 or a Google merchandise voucher to gather direct user feedback.
- Participants must pass a screener form, maintain a high-speed internet connection, and share their insights in online sessions to guide upcoming product updates.
- Short & Sweet: Limiting Podcasts to One Minute: Community members tossed around the idea of compressing podcasts into one-minute segments, but admitted it's hard to enforce strictly.
- Some suggested trimming the text input as a workaround, prompting a debate on the practicality of shorter content for detailed topics.
- Narration Nation: Users Crave AI Voiceovers: Several participants sought an AI-driven narration feature that precisely reads scripts for more realistic single-host presentations.
- Others cautioned that it might clash with NotebookLM’s broader platform goals, but enthusiasm for text-to-audio expansions remained high.
- Workspace Woes: NotebookLM Plus Integration Confusion: A user upgraded to a standard Google Workspace plan but failed to access NotebookLM Plus, assuming an extra add-on license wasn't needed.
- Community responses pointed to a troubleshooting checklist, reflecting unclear instructions around NotebookLM’s onboarding process.
Torchtune Discord
- BF16 Balms GRPO Blues: Members spotted out of memory (OOM) errors when using GRPO, blaming mismatched memory management in fp32 and citing the Torchtune repo for reference. Switching to bf16 resolved some issues, showcasing notable improvements in resource usage and synergy with vLLM for inference.
- They employed the profiler from the current PPO recipe to visualize memory demands, with one participant emphasizing “bf16 is a safer bet than full-blown fp32” for large tasks. They also discussed parallelizing inference in GRPO, but faced complications outside the Hugging Face ecosystem.
- Gradient Accumulation Glitch Alarms Devs: A known issue emerged around Gradient Accumulation that disrupts training for DPO and PPO models, causing incomplete loss tracking. References to Unsloth’s fix suggested an approach to mitigate memory flaws during accumulations.
- Some speculated that these accumulation errors affect advanced optimizers, sparking “concerns about consistent results across large batches”. Devs remain vigilant about merging a robust fix, especially for multi-step updates in large-scale training.
- DPO’s Zero-Loss Shock: Anomalies led DPO to rapidly drop to a loss of 0 and accuracy of 100%, documented in a pull request comment. The bizarre behavior appeared within a handful of steps, pointing to oversights in normalization routines.
- Participants debated whether “we should scale the objective differently” to avoid immediate convergence. They concluded that ensuring precise loss normalization for non-padding tokens might restore reliable metrics.
- Multi-Node March in Torchtune: Developers pushed for final approval on multi-node support in Torchtune, aiming to expand distributed training capabilities. This update promises broader usage scenarios for large-scale LLM training and improved performance across HPC environments.
- They questioned the role of offload_ops_to_cpu for multi-threading, leading to additional clarifications before merging. Conversations emphasized “we need all hands on deck to guarantee stable multi-node runs” to ensure reliability.
Modular (Mojo 🔥) Discord
- HPC Hustle on Heterogeneous Hardware: A blog series touted Mojo as a language to address HPC resource challenges, referencing Modular: Democratizing Compute Part 1 to underscore the idea that hardware utilization can reduce GPU costs.
- Community members stressed the importance of backwards compatibility across libraries to maintain user satisfaction and ensure smooth HPC transitions.
- DeepSeek Defies Conventional Compute Assumptions: Members discussed DeepSeek shaking up AI compute demands, suggesting that improved hardware optimization could make massive infrastructure less critical.
- Big Tech was described as scrambling to match DeepSeek’s feats, with some resisting the notion that smaller-scale solutions might suffice.
- Mojo 1.0 Wait Worth the Work: Contributors backed a delay for Mojo 1.0 to benchmark on larger clusters, ensuring broad community confidence beyond mini-tests.
- They praised the focus on stability before versioning, prioritizing performance over a rushed release.
- Swift’s Async Snags Spark Simplification Hopes: Mojo’s designers noted Swift can complicate async code, fueling desires to steer Mojo in a simpler direction.
- Some users illustrated pitfalls in Swift’s approach, influencing the broader push for clarity in Mojo development.
- MAX Makes DeepSeek Deployment Direct: A quick command
magic run serve --huggingface-repo-id deepseek-ai/DeepSeek-R1-Distill-Llama-8B --weight-path=unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguflets users run DeepSeek with MAX, provided they have Ollama's gguf files ready.- Recent forum guidance and a GitHub issue illustrate how MAX is evolving to improve model integrations like DeepSeek.
LlamaIndex Discord
- Triple Talk Teaser: Arize & Groq Join Forces: Attendees joined a meetup with Arize AI and Groq discussing agents and tracing, anchored by a live demo using Phoenix by Arize.
- The session spotlighted LlamaIndex agent capabilities, from basic RAG to advanced moves, as detailed in the Twitter thread.
- LlamaReport Beta Beckons 2025: A preview of LlamaReport showcased an early beta build, with a core focus on generating reports for 2025.
- A video demonstration displayed its core functionalities and teased upcoming features.
- o3-mini Earns Day 0 Perks: Day 0 support for o3-mini launched, and users can install it via
pip install -U llama-index-llms-openai.- A Twitter announcement showed how to get started quickly, emphasizing a straightforward setup.
- OpenAI O1 Stirs Confusion: OpenAI O1 lacks full capabilities, leaving the community uncertain about streaming features and reliability.
- Members flagged weird streaming issues in the OpenAI forum reference, with some functionalities failing to work as anticipated.
- LlamaReport & Payment Queries Loom: Users struggled with LlamaReport, citing difficulties generating outputs and questions around LLM integration fees.
- Despite some successes in uploading papers for summarization, many pointed to Llama-Parse charges as a possible snag, noting that it could be free under certain conditions.
tinygrad (George Hotz) Discord
- Physical Hosting, Real Gains: One user asked about physical servers for LLM hosting locally for enterprise tasks, referencing Mac Minis from Exolabs as a tested solution.
- They also discussed running large models at scale, prompting a short back-and-forth on hardware approaches for AI workloads.
- Tinygrad’s Kernel Tweak & Title Tease: George Hotz praised a good first PR for tinygrad that refined kernel, buffers, and launch dimensions.
- He suggested removing 16 from
DEFINE_LOCALto avoid duplication, and the group teased a minor PR title typo that got fixed quickly.
- He suggested removing 16 from
Axolotl AI Discord
- Axolotl's Jump to bf16 & 8bit LoRa: Participants confirmed that Axolotl supports bf16 as a stable training precision beyond fp32, with some also noting the potential of 8bit LoRa in Axolotl's repository.
- They found bf16 particularly reliable for extended runs, though 8bit fft capabilities remain unclear, prompting further discussion about training efficiency.
- Fp8 Trials & Tribulations in Axolotl: Members indicated that fp8 has experimental support with accelerate, but performance has been uneven in practice.
- One person stated “I don’t think we’re looking into that atm”, highlighting the erratic results associated with fp8 and underscoring ongoing reservations.
LLM Agents (Berkeley MOOC) Discord
- Certificates on Hold, Hype Unfolds: Certificates remain unreleased for the LLM Agents MOOC, with more details about requirements expected soon.
- Members shared exclamations like 'The wait for certificate is just so exciting!' and looked forward to official updates.
- Quiz 1 & Syllabus Shenanigans: Quiz 1 is now accessible on the syllabus page, with a mention of the Quizzes Archive - LLM Agents MOOC containing hidden correct answers.
- Some found the link missing or unclear, prompting others to share screenshots and reveal the 'mystery content' in the syllabus.
OpenInterpreter Discord
- AI Tool Teaser Invites Beginners: Enthusiasts requested a straightforward explanation of the AI tool, seeking clarity on its upcoming capabilities.
- They focused on providing a more direct approach for novices, highlighting a need for simpler jargon and practical use cases.
- Farm Friend Frenzy Gains Momentum: A community member revealed the new Farm Friend application, emphasizing its desktop integration in the ecosystem.
- They pledged to share follow-up resources and teased more projects on the horizon to expand the infrastructure.
- iOS Shortcuts Patreon Emerges: One user announced a Patreon that will offer various tiers of advanced iOS shortcuts, including support for agentic features.
- They expressed enthusiasm about returning to share techniques from the past year and hinted at more in-depth content.
- NVIDIA NIM and DeepSeek Link Up: A community member explored hooking NVIDIA NIM into DeepSeek for direct connections with an open interpreter.
- They requested technical advice on bridging these components, looking for insights on installation and synergy.
Cohere Discord
- Cohere’s 422 Conundrum: One user encountered an HTTP 422 Unprocessable Entity error while trying Cohere’s Embed API v2.0 with valid parameters, prompting careful check of request formatting.
- They shared official docs for reference and reported no immediate fix, hinting that payload structure could be at fault.
- Cross-Language Embedding Enthusiasm: The same user wants to use the embed-multilingual-v3.0 model for investigating cross-language polarization, pointing to the Cohere/wikipedia-2023-11-embed-multilingual-v3 dataset.
- They asked about preprocessing messy, lengthy text, aiming for more robust multilingual embeddings in their research.
LAION Discord
- No Significant Updates: No notable discussions or new technical details emerged from the conversation.
- Mentions and a brief 'Ty' were the only highlights, offering no further context for AI engineers.
- Lack of Technical Content: No new tools, models, or datasets were referenced in the exchange.
- This leaves no additional insights or resources to report.
DSPy Discord
- No
http_client? No Problem in dspy.LM!: Members discovered the absence of thehttp_clientparameter in dspy.LM, prompting confusion over custom SSL or proxy configurations.- They referenced
gpt3.pywherehttp_client: Optional[httpx.Client] = Noneis used, suggesting a similar feature for dspy.LM.
- They referenced
- Custom Clients for dspy.LM Spark Curiosity: Developers questioned how to replicate gpt3.py’s custom client setup in dspy.LM for advanced networking needs.
- They proposed adapting code from OpenAI and
gpt3.pyas a model, encouraging further experimentation within dspy’s architecture.
- They proposed adapting code from OpenAI and
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium (Windsurf) ▷ #announcements (2 messages):
Cascade Updates, New Models, Web and Docs Search, User Milestones
- Cascade Welcomes New Models: The latest update introduced new models: DeepSeek-R1 and DeepSeek-V3, with costs of 0.5 and 0.25 user prompt credits per message, respectively.
- Additionally, the new o3-mini model is also available, costing 1 user prompt credit per message, further expanding Cascade's capabilities.
- Improvements to User Experience: Fixes include reduced input lag for Cascade conversations and resolving a bug that caused the Cascade panel to reopen unexpectedly on reload.
- The @docs feature was enhanced with more options, improving accessibility to information within the tool.
- Web and Docs Search Capabilities: Cascade now boasts web search functionality, allowing users to trigger searches automatically or through the @web command and provide URLs for context.
- These features can be managed via the settings panel, making it easier for users to access real-time information.
- User Engagement Milestone Achieved: In a notable community milestone, Windsurf's Reddit page hit 6k followers, showcasing growing engagement and interest.
- This accomplishment was celebrated with an enthusiastic announcement in the update!
- Tweet from Windsurf (@windsurf_ai): o3-mini is now available in Windsurf!
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- Tweet from Windsurf (@windsurf_ai): DeepSeek R1 and V3 are now available in Windsurf, fully hosted on Western servers.We implemented tool calling in R1, enabling it to be used in a coding agent for the first time.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #discussion (329 messages🔥🔥):
DeepSeek R1 issues, Cascade tool call errors, Windsurf usage, Model performance comparison, OpenAI and data regulations
- DeepSeek R1 struggles with tasks: Users reported DeepSeek R1 often lacks the ability to perform tasks effectively, despite being capable of reasoning.
- It was noted that R1 provides minimal proper output even when tasked with reading specific files in designated folders.
- Cascade experiences internal errors: Several users encountered repeated errors stating 'The model produced an invalid tool call' followed by internal errors within Cascade.
- Discussions pointed to a potentially broader issue affecting performance across multiple models, suggesting the need for a fix.
- Guidance for Windsurf-related questions: Users were advised to direct Windsurf-related inquiries to specific channels to keep discussions organized.
- This was reiterated multiple times to ensure proper information flow and focus in the discussion community.
- Concerns over AI model cost and performance: A user expressed concerns about the high costs associated with using AI models like DeepSeek while comparing alternative local solutions.
- There was discussion on the need for high-performance hardware to effectively run local models and provide efficient outputs.
- OpenAI and market competition feedback: Participants shared views on OpenAI's competitive practices and the effects on open-source initiatives in the AI sector.
- Concerns about regulations and potential monopolistic behavior from major AI players were discussed, highlighting a shift in the industry landscape.
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Codeium Status: no description found
- Paid Plan and Credit Usage - Codeium Docs: no description found
- GitHub - ichoosetoaccept/awesome-windsurf: A collection of awesome resources for working with the Windsurf code editor: A collection of awesome resources for working with the Windsurf code editor - ichoosetoaccept/awesome-windsurf
- Anthropic Status: no description found
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Codeium (Windsurf) ▷ #windsurf (815 messages🔥🔥🔥):
DeepSeek Issues, Model Performance, Tool Calling Errors, O3 Mini Model Discussion, User Experience Feedback
- Ongoing Issues with DeepSeek and Tool Calling: Users reported persistent problems with DeepSeek, specifically invalid tool calls and its failure to write code as expected, causing frustration among many.
- Some suggested reverting to previous versions of the application to mitigate these issues as the recent updates seem to have worsened the tool's functionality.
- O3 Mini Performance Observations: Several users discussed their experiences with the new O3 Mini model, noting mixed results with its performance for coding compared to existing models like Claude 3.5.
- While some users found O3 Mini to be fast, others criticized it for not handling tool calls effectively, leading to incomplete outputs.
- User Experience and Pricing Feedback: Criticism arose regarding the pricing of the product relative to its perceived value, with some users expressing dissatisfaction with the product quality for its cost.
- Some users emphasized that despite being cheaper than competitors, the functionality issues should be addressed to avoid alienating current and potential users.
- Feedback on Model Integration: There was conversation about the integration of different models into Windsurf, particularly the effectiveness of the reasoning models and their impact on coding tasks.
- Users expressed a desire for enhanced multi-agent architectures to improve documentation and task management in coding workflows.
- User Suggestions and Future Improvements: Users provided suggestions for improvements to the application, such as rollback options for versions and enhanced user roles to display in Discord.
- Overall, users highlighted the need for stronger documentation and troubleshooting support to enhance the user experience.
- How DeepSeek crashed the AI party: On The Vergecast: AI chips, AI apps, AI models, AI everything.
- Mari Marifootleg GIF - Mari Marifootleg Herbal Tea - Discover & Share GIFs: Click to view the GIF
- Anthropic Status: no description found
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: OpenAI is about to announce 2 new reasoning models soon: "o3-mini" and "o3-min-high". "o3-mini-hype" 👀👀👀Quoting Tibor Blaho (@btibor91) "Meet the o3-mini fa...
- Tweet from Varun Mohan (@_mohansolo): Today we’re making DeepSeek R1 and V3 available in Windsurf, making Cascade the first coding agent to support R1. It'll be half the cost to start with but we are committed to rapidly reduce this w...
- Tweet from Windsurf (@windsurf_ai): Just surfin' the web! 🏄
- Unreddit: no description found
- search in chats | Feature Requests | Codeium: no description found
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Unsloth AI (Daniel Han) ▷ #general (999 messages🔥🔥🔥):
Unsloth AI, DeepSeek models, Fine-tuning techniques, Model quantization, Chatbot performance
- Discussion on Fine-tuning and Checkpoints: Users shared insights on fine-tuning models using Unsloth, emphasizing the importance of checkpointing to effectively merge adapters with base models.
- It was noted that training continues from the latest checkpoint, allowing for flexibility in model adaptations.
- Performance Comparisons of Models: The conversation shifted to comparing new models, particularly the DeepSeek-R1 and Mistral, highlighting the efficient performance of the DeepSeek variant.
- Users expressed that DeepSeek could potentially outperform other existing models, particularly in coding tasks.
- Issues with Model Outputs: A user encountered issues with their fine-tuned LLaMA 3 model, where the output included unexpected tokens like <|eot_id|>.
- Discussion indicated these issues might stem from the model's training formatting and the inclusion of unnecessary tokens.
- Quantization and Model Sizes: Participants discussed the memory usage and the context size of the Distill-Qwen-1.5B model, indicating it inherits max lengths based on its architecture.
- The impact of model size and context length on performance was emphasized as important considerations when using AI models.
- Multiple GPU Support in Unsloth: Questions were raised regarding the capability of Unsloth to fine-tune models across multiple GPUs, with ongoing expectations for enhanced support.
- The community showed interest in the developments regarding multi-GPU training and its implications for performance improvements.
- NVIDIA RTX Blackwell GPU with 96GB GDDR7 memory and 512-bit bus spotted - VideoCardz.com: NVIDIA preparing a workstation flagship with 96GB memory This card is said to use 3GB modules. According to a report from ComputerBase, NVIDIA’s upcoming desktop graphics card is expected ...
- LLM Model VRAM Calculator - a Hugging Face Space by NyxKrage: no description found
- Google Colab: no description found
- Tweet from Unsloth AI (@UnslothAI): Run DeepSeek-R1 (671B) locally on @OpenWebUI - Beginner's GuideNo GPU required.Using our 1.58-bit Dynamic GGUF and llama.cpp.Tutorial: https://docs.openwebui.com/tutorials/integrations/deepseekr1-...
- Google Colab: no description found
- Qwen2.5-VL (All Versions) - a unsloth Collection: no description found
- Mini-R1: Reproduce Deepseek R1 „aha moment“ a RL tutorial: Reproduce Deepseek R1 „aha moment“ and train an open model using reinforcement learning trying to teach it self-verification and search abilities all on its own to solve the Countdown Game.
- unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF · Hugging Face: no description found
- unsloth/Mistral-Small-24B-Instruct-2501-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
- unsloth/Mistral-Small-24B-Instruct-2501-unsloth-bnb-4bit · Hugging Face: no description found
- Google Colab Tutorial for Beginners | What Is Google Colab? | Google Colab Explained | Simplilearn: 🔥 Post Graduate Program In Cloud Computing: https://www.simplilearn.com/pgp-cloud-computing-certification-training-course?utm_campaign=26Mar2024GoogleColabT...
- GitHub - huggingface/smol-course: A course on aligning smol models.: A course on aligning smol models. Contribute to huggingface/smol-course development by creating an account on GitHub.
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- unsloth/DeepSeek-R1-Distill-Qwen-14B-unsloth-bnb-4bit · Hugging Face: no description found
- llama.cpp/convert_lora_to_gguf.py at aa6fb1321333fae8853d0cdc26bcb5d438e650a1 · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- All Our Models | Unsloth Documentation: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (8 messages🔥):
Front End Imperfections, Model Sensitivity, Output Detection Systems
- Discussion on Front End Imperfections: A member noted that changes occurring after tabbing out might be due to an imperfection in the front end side.
- This led to speculation about the nuances of how the model functions during user interaction.
- Sensitivity in Model Output: There was a mention of a sensitive topic regarding the correctness of outputs, particularly in a context related to China.
- Another member agreed, stating that they wouldn't take any risks when it comes to handling this matter.
- Model Output Detection Systems: One member suggested that variations in output might stem from using different models or systems to detect output effectively.
- This raised questions about the underlying systems that ensure output reliability amidst sensitive subjects.
Unsloth AI (Daniel Han) ▷ #help (319 messages🔥🔥):
DeepSeek R1 Dynamic Quantization, Finetuning LLMs, Using OpenWebUI, Learning Rate Adjustments, Multiple GPU Support
- Running DeepSeek R1 with Ollama: Users are attempting to run the DeepSeek R1 model, specifically the 1.58-bit version, with varying degrees of success using Ollama, a wrapper around llama.cpp.
- Issues faced include errors when starting the model and performance bottlenecks, leading to suggestions to run directly with llama-server instead.
- Finetuning Techniques and Learning Rate: Discussions on appropriate learning rates for finetuning models suggest starting around e-5 or e-6, with considerations for dataset size influencing adjustments.
- Monitoring results and evaluation metrics after training a sufficient number of epochs is recommended to gauge the effectiveness of the learning rate.
- Integration Issues with AI Frameworks: Concerns regarding the latency of using Ollama's API for local LLMs prompted discussions about exploring alternatives like OpenWebUI for better performance.
- Users were advised on the limitations and potential challenges associated with integrating local LLMs into their applications.
- Memory and Performance Challenges: Users share experiences regarding memory constraints when fine-tuning large models and the impact of disk speed on inference rates.
- Recommendations included optimizing storage solutions and exploring offloading strategies to improve performance.
- Current Limitations in Model Support: It was noted that Unsloth does not currently support multi-GPU training for fine-tuning models, with a focus on supporting all models first.
- This limitation has implications for users needing more RAM for fine-tuning larger models.
- Google Colab: no description found
- 🐋 Run DeepSeek R1 Dynamic 1.58-bit with Llama.cpp | Open WebUI: A huge shoutout to UnslothAI for their incredible efforts! Thanks to their hard work, we can now run the full DeepSeek-R1 671B parameter model in its dynamic 1.58-bit quantized form (compressed to jus...
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Unsloth - Dynamic 4-bit Quantization: Unsloth's Dynamic 4-bit Quants selectively avoids quantizing certain parameters. This greatly increases accuracy while maintaining similar VRAM use to BnB 4bit.
- Phi-4 (All Versions) - a unsloth Collection: no description found
- Skeleton GIF - Skeleton - Discover & Share GIFs: Click to view the GIF
- Llama 3.2 - a unsloth Collection: no description found
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- unsloth/Mistral-Small-24B-Instruct-2501-GGUF · Hugging Face: no description found
- Unsloth 4-bit Dynamic Quants - a unsloth Collection: no description found
- Beginner? Start here! | Unsloth Documentation: no description found
- Tweet from Open WebUI (@OpenWebUI): 🚀 You can now run 1.58-bit DeepSeek-R1 (non-distilled version) on Open WebUI with llama.cpp, thanks to @UnslothAI! 💻⚡️ (Tested on M4 Max, 128GB RAM) 📝 Dive into the details in their blog post: htt...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Google Colab: no description found
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Yes, you can run DeepSeek-R1 locally on your device (20GB RAM min.): I've recently seen some misconceptions that you can't run DeepSeek-R1 locally on your own device. Last weekend, we were busy trying to make you...
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
Qwen2.5-0.5B-instruct, Quadro P2000 GPU, Old Hardware Usability
- Qwen2.5 pretraining on Quadro P2000: A member humorously reported on the continual pretraining of Qwen2.5-0.5B-instruct on a Quadro P2000 with only 5GB VRAM.
- I'll let you know in 2026 how it was echoed the playful skepticism about the GPU's performance.
- Old GPU struggles: Members expressed concern over the Quadro P2000, with one stating it was screaming for God to save it.
- Another noted its age, adding well you gotta be thankful that such an old hunk of metal is still usable.
- GPU's desire for rest: A member humorously suggested that the Quadro P2000 wants to sleep for forever, highlighting its struggles.
- This comment followed a light-hearted discussion on the GPU's use despite its age.
Unsloth AI (Daniel Han) ▷ #research (6 messages):
vLLM Integration, Batch Throughput Investigation, Model Loading Concerns, XGB Usage in Unsloth and vLLM, Offloading Issues with vLLM
- Potential Integration with vLLM: There are discussions around integrating vLLM somehow into the system as part of ongoing evaluation.
- We are probably going to integrate it somehow.
- Investigating Batch Throughput: vLLM is expected to have higher batch throughput, prompting further investigation to determine optimal usage.
- The initial plan was to use vLLM directly, but if batch inference through Unsloth proves faster, it may default to that.
- Model Loading Doubts : Concerns were raised about the possibility of double loading the model, as both Unsloth and vLLM utilize XGB.
- I need to check if we're double loading the model.
- XGB Redundancy Issues: The discussion emphasized that using both Unsloth and vLLM means they effectively employ 2XGB, raising efficiency questions.
- ie Unsloth uses XGB, and vLLM uses XGB ie 2XGB.
- vLLM Offloading Capabilities: It was noted that vLLM likely cannot perform offloading with gguf compatibility yet, particularly with the deepseek v2 architecture.
- A member queried if there had been any recent patches related to this issue, indicating ongoing troubleshooting.
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.73.0, o3-mini support, Reasoning effort argument, OpenRouter R1 free support
- Aider v0.73.0 officially released: The latest version, Aider v0.73.0, includes full support for o3-mini with the command
aider --model o3-mini.- Notably, Aider reportedly wrote 69% of the code in this release, showcasing significant internal development.
- New reasoning effort argument introduced: Aider has introduced a new
--reasoning-effortargument, which can be set to low, medium, or high to customize performance.- This enhancement aims to provide users with greater flexibility in controlling the model's reasoning capabilities.
- Improved context window handling: Version 0.73.0 also improves the handling of context window size limits, offering better messaging and Ollama-specific guidance.
- This adjustment is expected to enhance user experience by providing more intuitive directives during usage.
- Support for R1 free on OpenRouter: Aider now supports R1 free on OpenRouter with the command
--model openrouter/deepseek/deepseek-r1:free.- This feature broadens access to R1 functionalities, promoting user engagement with the platform.
- Enhanced directory creation in Aider: Aider has added functionality to auto-create parent directories when generating new files, streamlining file management.
- This improvement facilitates smoother workflow for users working with new file structures.
Link mentioned: Release history: Release notes and stats on aider writing its own code.
aider (Paul Gauthier) ▷ #general (979 messages🔥🔥🔥):
O3 Mini Performance, Tool Use in Aider, Rust Programming, OpenAI and Pricing, Linters in Aider
- O3 Mini Proves Its Worth: The O3 Mini has been noted for its comparable performance to O1 at a fraction of the cost, with users reporting that it runs smoothly and produces compilable Rust code without errors.
- Despite initial skepticism about its capabilities, users have found O3 Mini to be more effective and faster in coding tasks compared to other models.
- Using Tool Features in Aider: Users are leveraging Aider's tool capabilities to enhance their programming efficiency, including the setup of a REPL for pen testing.
- Aider's ability to integrate learned commands for terminal operations has sparked discussions about its practical uses in real programming environments.
- Rust Programming Experience: One user shared their experience of coding in Rust with O3 Mini, highlighting its effectiveness at handling Rust-specific syntax and code structure.
- Users agree that having a model adept at math supports its ability to write well-structured Rust code, improving productivity.
- OpenAI's Competitive Edge: The release of O3 Mini brings competitive pricing compared to OpenAI’s previous offerings and other models, which some users see as a strategic move against powerful open-source models like Deepseek.
- Users expressed concerns regarding OpenAI's stock market influence following this model's release, noting that perception impacts value.
- Linting and Testing in Aider: Aider allows users to automatically lint and test their code when edits are made, enhancing the reliability of code produced by AI models.
- Users noted that employing linters can catch errors in their codebase more effectively, making O3 Mini an appealing choice for rapid development.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: OpenAI is about to announce 2 new reasoning models soon: "o3-mini" and "o3-min-high". "o3-mini-hype" 👀👀👀Quoting Tibor Blaho (@btibor91) "Meet the o3-mini fa...
- Rust Playground: no description found
- no title found: no description found
- Scripting aider: You can script aider via the command line or python.
- Linting and testing: Automatically fix linting and testing errors.
- Do It Star Wars GIF - Do it Star wars Emperor palpatine - Discover & Share GIFs: Click to view the GIF
- Critical Role Crit Role GIF - Critical Role Crit Role Cr - Discover & Share GIFs: Click to view the GIF
- No Witnesses GIF - No Witnesses Erase - Discover & Share GIFs: Click to view the GIF
- Oh My Shocked GIF - Oh My Shocked How Dare You - Discover & Share GIFs: Click to view the GIF
- Other LLMs: aider is AI pair programming in your terminal
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): The leap from o1 to o3 is exponential, completely bypassing o2. If this pattern holds, o3 won’t lead to o4—it’ll jump straight to o9.
- Advanced model settings: Configuring advanced settings for LLMs.
- reedline - Rust: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Tweet from Shubham Saboo (@Saboo_Shubham_): DeepClaude combines Claude Sonnet 3.5 with DeepSeek R1 CoT reasoning to outperform OpenAI o1, DeepSeek R1, Claude Sonnet 3.5.100% free and Opensource.
- deepseek-r1 Model by Deepseek-ai | NVIDIA NIM: State-of-the-art, high-efficiency LLM excelling in reasoning, math, and coding.
- OpenAI o3-mini now available in GitHub Copilot and GitHub Models (Public Preview) · GitHub Changelog: OpenAI o3-mini now available in GitHub Copilot and GitHub Models (Public Preview)
- Tweet from Tibor Blaho (@btibor91): T̶h̶e̶ ̶O̶3̶ ̶F̶a̶m̶i̶l̶y̶ o3-mini familyQuoting Tibor Blaho (@btibor91) The O3 Family
- Alternative DeepSeek V3 providers: DeepSeek’s API has been experiencing reliability issues. Here are alternative providers you can use.
- aider/benchmark at main · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - OpenAutoCoder/Agentless: Agentless🐱: an agentless approach to automatically solve software development problems: Agentless🐱: an agentless approach to automatically solve software development problems - OpenAutoCoder/Agentless
- Added DeepSeek R1 + DeepSeek V3 benchmark by serialx · Pull Request #2998 · Aider-AI/aider: I'd like to share the result of DeepSeek R1 architect + DeepSeek V3 editor benchmark results: It's 59.1%. Near the performance of o1 but at the fractional cost of $6.33! Half of R1+Son...
- Why Chinese AI has stunned the world: DeepSeek’s models are much cheaper and almost as good as American rivals
- Why Chinese AI has stunned the world: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (72 messages🔥🔥):
Aider Configuration, DeepSeek Issues, API Key Handling, Model Performance, File Management
- Aider Configuration for Models: Users discussed configuring Aider for models like DeepSeek and Claude, with some experiencing issues related to API key settings not being recognized in the config file.
- One user noted that setting the API key as an environment variable resolved their issues while running the Aider command.
- DeepSeek API Problems: Several members reported difficulties with DeepSeek, particularly hanging issues and incorrect whitespace handling leading to performance issues.
- Users mentioned considering alternatives to DeepSeek, referencing local models and asking for recommendations.
- Challenges with Command Files: A user expressed frustration with executing commands from a file, stating that Aider attempts to process all lines, leading to unwanted warnings for non-command lines.
- They suggested a desire for a command that could execute commands in a file while remaining in chat mode.
- Exploring Model Performance: Some discussions revolved around understanding model performance, specifically regarding efficient configuration for context windows and token limits.
- A user raised questions about whether the context window self-manages, leading to an explanation about the O3 context window size and capabilities.
- File Management in Aider: Conversations included inquiries about listing saved files and managing file formats when using Aider, with no current command found for listing saves.
- Participants mentioned the need for better organization of save files, suggesting a potential directory for Aider saves.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- File editing problems: aider is AI pair programming in your terminal
- Advanced model settings: Configuring advanced settings for LLMs.
- Anthropic: Claude 3.5 Sonnet: New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Scores ~49% on SWE-Bench Verified, higher t...
Perplexity AI ▷ #general (705 messages🔥🔥🔥):
Perplexity AI models, O3 Mini release, O1 and R1 performance, DeepSeek model comparisons, User experiences with AI platforms
- Discussion on AI model performance: Users discussed the performance differences between various AI models like O3 Mini, R1, and O1, noting that O1 often performed better in tasks like riddles and calculations.
- Comparisons included specific usage scenarios highlighting how models fared—particularly with coding and reasoning tasks.
- O3 Mini is now available: O3 Mini was released to users, with members expressing excitement about its capabilities and mentioning a faster rollout than previous models.
- Users began testing O3 Mini, discussing its limits and comparing its performance to existing models.
- User experiences with Perplexity AI: Certain users shared their experiences with the Perplexity app, specifically regarding the lack of a default model setting and the presence of a 'Reason' button only for free users.
- The conversation highlighted frustrations around the application structure and the need for better model management options.
- DeepSeek as an alternative: Members discussed using DeepSeek along with various models like O1 and R1, weighing its strengths in calculations but identifying weaknesses in text translation.
- Users expressed preferences for certain models based on their AI usage needs and highlighted the availability of different AI models on platforms like You.com.
- Technical support and queries: Users sought clarification on technical aspects, including linking an account to apps and understanding model limits in different user tiers.
- Concerns were raised about account settings and permissions, with suggestions being made for contacting support for assistance.
- Cerebras Inference: no description found
- Tweet from pro_game_fixers (@FixersPro): o3-mini-medium vs o3-mini-high vs claude sonnet 3.5 prompt : http://pastebin.com/MxMfi635build a 2 player snake game AI vs Human
- Diddy GIF - Diddy - Discover & Share GIFs: Click to view the GIF
- DeepSeek Database Leaked - Full Control Over DB Secret keys, Logs & Chat History Exposed: DeepSeek, a prominent Chinese AI startup, exposed a publicly accessible ClickHouse database containing Secret keys, Logs & Chat History.
- Reddit - Dive into anything: no description found
- Tweet from Kevin Lu (@_kevinlu): We released o3-mini, available today to all users in ChatGPT (for free)!o3-mini-low is faster (and often better) than o1-mini, and o3-mini-high is the most capable publicly available reasoning model i...
- Tweet from Aravind Srinivas (@AravSrinivas): Which will be the superior model? o3-mini or DeepSeek R1?
- Build software better, together: GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- Qwen Chat: no description found
- Tweet from OpenAI (@OpenAI): OpenAI o3-mini is now available in ChatGPT and the API.Pro users will have unlimited access to o3-mini and Plus & Team users will have triple the rate limits (vs o1-mini).Free users can try o3-mini in...
- Reddit - Dive into anything: no description found
Perplexity AI ▷ #sharing (5 messages):
AI Prescription Bill, TB Outbreak Kansas, Nadella's AI Predictions, Asteroid Life Seeds, Harvard Dataset
- AI Prescription Bill Proposed: A new AI Prescription Bill aims to regulate the use of AI in healthcare, emphasizing ethical standards and accountability.
- This initiative reflects growing concerns over the implications of AI in medical decision-making.
- Kansas Faces TB Outbreak: Kansas is currently battling a tuberculosis outbreak, prompting health officials to issue warnings and coordinate response efforts.
- Health experts stress the importance of monitoring and preventing further spread through community awareness.
- Nadella Predicts ‘Jevons Paradox’ for AI: Microsoft CEO Satya Nadella predicts the occurrence of Jevons Paradox in AI, suggesting that advancements may lead to increased consumption of resources rather than conservation.
- His remarks sparked discussions about the sustainable limits of artificial intelligence development.
- Asteroid Carries Seeds of Life: A recent discovery states that an asteroid may contain the seeds of life, raising intriguing questions about extraterrestrial biology.
- Research suggests that understanding such asteroids could unlock secrets about the origins of life on Earth.
- Exploration of Harvard Dataset: The Harvard dataset is gaining attention for its potential applications in AI research and development.
- Researchers are evaluating its value for addressing various scientific challenges.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
Sonar Reasoning, Plane Crash Information
- Sonar Reasoning struggles with context: A member pointed out that sonar reasoning isn't effective for specific inquiries, citing a plane crash over the Potomac as an example.
- While the model technically provided correct information, it delivered data from the 1982 incident instead of the recent crash.
- Recent vs Historical Data Confusion: The discussion highlighted a notable issue where sonar reasoning can deliver outdated information, leading to potential confusion in crucial scenarios.
- The member emphasized that although the older data was accurate, it may not meet the user's immediate needs in time-sensitive situations.
LM Studio ▷ #announcements (1 messages):
LM Studio 0.3.9 release, Idle TTL feature, Separate reasoning_content, Auto-update for runtimes, Nested folders support
- LM Studio 0.3.9 launches with exciting updates: The new version of LM Studio introduces several features including Idle TTL, reasoning_content, and auto-update for runtimes. You can download it here or update via the app.
- Refer to the full change log for a detailed overview.
- Manage memory with Idle TTL feature: The Idle TTL feature allows users to set a time-to-live for API models, automatically evicting unused models to optimize memory usage. This is achieved either in the request itself or through command-line options, as detailed in the docs.
- This feature streamlines memory management, reducing manual interventions.
- Chat gets smarter with separate reasoning_content: LM Studio now supports a separate
reasoning_contentfield in chat responses, enabling compatibility with DeepSeek's API. Users can enable this feature through the experimental settings.- This update aims to enhance dialogue interactions by separating reasoning from response content.
- Auto-update feature simplifies runtime management: The auto-update for LM runtimes is now enabled by default, minimizing the hassle of manual updates across multiple components. Users can disable this option from App Settings if preferred.
- This feature ensures that your environment remains up-to-date without extra effort.
- Nested folders support finally arrives: Users can now download models from nested folders in Hugging Face repositories, addressing long-standing requests for better organization. This makes accessing models in subfolders much more efficient.
- This addition is expected to enhance user experience and streamline model management.
- Idle TTL and Auto-Evict | LM Studio Docs: Optionally auto-unload idle models after a certain amount of time (TTL)
- LM Studio 0.3.9: Idle TTL, auto-update for runtimes, support for nested folders in HF repos, and separate `reasoning_content` in chat completion responses
LM Studio ▷ #general (362 messages🔥🔥):
LM Studio performance and model usage, AI models for C# development, OpenAI o3-mini release, DeepSeek model performance, Download speed issues in LM Studio
- LM Studio performance concerns: Users are experiencing varying performance issues with LM Studio, particularly when loading models like DeepSeek R1, which can lead to errors if VRAM is insufficient.
- Some users noted that the recent updates have potentially slowed download speeds, and others have suggested optimizations like using the Hugging Face proxy.
- Choosing AI models for C# game development: For developing C# applications, users recommend models like Qwen2.5 Coder and DeepSeek distill versions, considering the limitations of their hardware.
- While higher-end models perform better, lower-end models may suffice for referencing code without full reliance.
- OpenAI's o3-mini release: OpenAI recently launched the o3-mini model, designed for fast responses in math, coding, and science tasks, available for free users of ChatGPT.
- Despite the announcement, users noted confusion over the actual availability of the model.
- DeepSeek model effectiveness: DeepSeek models are highlighted for their coding capabilities, with reports suggesting significant performance advantages over competitors like OpenAI's models.
- Discussion included how competition has led to OpenAI reducing prices due to advances made by models like DeepSeek.
- Download speed issues in LM Studio: Users are experiencing slower download speeds in LM Studio compared to previous performance, with some suggesting that OS settings could be a factor.
- A workaround includes downloading models directly from Hugging Face and placing them in the .cache folder for potentially faster access.
- Chat with Documents | LM Studio Docs: How to provide local documents to an LLM as additional context
- ⭐ Features | Open WebUI: Key Features of Open WebUI ⭐
- OpenAI launches new o3-mini reasoning model with a free ChatGPT version: Only Pro users will get unlimited use of o3-mini.
- LM Studio as a Local LLM API Server | LM Studio Docs: Run an LLM API server on localhost with LM Studio
- openbmb/MiniCPM-o-2_6-gguf · Hugging Face: no description found
- 🎙️ MacWhisper: Quickly and easily transcribe audio files into text with OpenAI's state-of-the-art transcription technology Whisper. Whether you're recording a meeting, lecture, or other important audio, MacW...
- Systran/faster-whisper-medium · Hugging Face: no description found
- Eye Of Sauron Lotr GIF - Eye Of Sauron Lotr Lord Of The Rings - Discover & Share GIFs: Click to view the GIF
- 🎙️ MacWhisper: Quickly and easily transcribe audio files into text with OpenAI's state-of-the-art transcription technology Whisper. Whether you're recording a meeting, lecture, or other important audio, MacW...
- GitHub - Les-El/Ollm-Bridge: Easily access your Ollama models within LMStudio: Easily access your Ollama models within LMStudio. Contribute to Les-El/Ollm-Bridge development by creating an account on GitHub.
- GitHub - lmstudio-ai/lms: 👾 LM Studio CLI: 👾 LM Studio CLI. Contribute to lmstudio-ai/lms development by creating an account on GitHub.
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- Qwen (Qwen): no description found
- GitHub - sammcj/llamalink: Link you Ollama models to LM-Studio: Link you Ollama models to LM-Studio. Contribute to sammcj/llamalink development by creating an account on GitHub.
LM Studio ▷ #hardware-discussion (158 messages🔥🔥):
Qwen models, LM Studio performance, Using multiple GPUs, Vulkan support for GPUs, Context length in LLMs
- Qwen models outperform others: Users noted that the Qwen models, specifically the Qwen2.5-7B-Instruct-1M, handle longer contexts better than previous models, providing improved performance.
- One user experienced significant improvement and recommended others to enable Flash Attention and K/V cache quantization for better efficiency.
- Challenges with LM Studio and Intel GPUs: A user inquired about running LM Studio on an Intel UHD GPU, but it was confirmed that currently there is no Linux ARM build available for LM Studio.
- There is anticipation that support may come with future projects but current options are limited.
- Using NVIDIA and Intel GPUs together: A user with an NVIDIA RTX 4080 and an Intel UHD GPU expressed interest in utilizing both for enhanced performance, particularly leveraging shared system RAM.
- However, it was explained that NVIDIA drivers will default to system RAM when VRAM is exceeded, which may limit effective dual GPU use.
- Impact of context length on performance: Discussions highlighted that context length significantly affects RAM usage, and exceeding limits can lead to performance errors.
- One user reported being able to manage up to 80k tokens on a powerful setup, suggesting a strong relationship between RAM and model efficiency.
- Performance metrics and model selection: Users shared experiences with various models like DeepSeek and discussed their token-per-second metrics, emphasizing the balance between VRAM and model complexity.
- Some recommended using models with larger parameters or exploring quantization techniques to improve throughput.
- Introducing Unsloth: no description found
- no title found: no description found
- Whale Swallow GIF - Whale Swallow Eat - Discover & Share GIFs: Click to view the GIF
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Amazon.com: Libre Computer Board AML-S905X-CC (Le Potato) 2GB 64-bit Mini Computer for 4K Media : Electronics: no description found
Cursor IDE ▷ #general (520 messages🔥🔥🔥):
DeepSeek R1 and Sonnet 3.6 Integration, O3 Mini Performance, MCP Tool Usage, Claude Model Updates, User Experience and Feedback
- DeepSeek R1 as Architect with Sonnet 3.6 as Executor: Users noted that integrating R1 for planning with Sonnet 3.6 for coding produces better results, as R1 provides a Chain of Thought context that enhances Sonnet's outputs.
- The approach demonstrates a significant improvement in handling coding tasks, allowing users to efficiently address complex issues.
- Mixed Feedback on O3 Mini: While some users found O3 Mini effective for certain tasks, others expressed disappointment with its performance compared to Sonnet 3.6.
- Concerns were raised about O3 Mini requiring explicit prompts to execute code changes despite its capabilities.
- MCP Tool Utilization in Cursor: Discussions revealed that while MCP tools function well, users feel the need for better integration and support in Cursor.
- Some participants shared frustration over the lack of groundbreaking features from MCP, relying instead on custom tools for effective workflows.
- Anticipation for New Claude Model Releases: There is excitement about potential new releases from Anthropic, with users eager for updates to the Claude model that could further enhance their workflows.
- Many believe that an advanced version, like Claude 4.0 Symphony, would significantly improve coding and problem-solving experiences.
- User Experiences and Challenges: Users shared various experiences with the current AI models, noting specific successes and challenges in their projects.
- While some found immediate solutions with new models, others faced frustrations with slow response times and inconsistent results.
- Tweet from Windsurf (@windsurf_ai): DeepSeek R1 and V3 are now available in Windsurf, fully hosted on Western servers.We implemented tool calling in R1, enabling it to be used in a coding agent for the first time.
- Introduction - Model Context Protocol: no description found
- Anthropic developing web search feature for Claude AI: Anthropic's Claude AI is set to gain web search capabilities, bridging the gap between static language models and real-time data retrieval. Stay tuned for updates!
- R1+Sonnet set SOTA on aider’s polyglot benchmark: R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
- Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor: Is Hugging Face the target of model-based attacks? See a detailed explanation of the attack mechanism and what is required to identify real threats >
- MCP Servers: Browse the largest library of Model Context Protocol Servers. Share Model Context Protocol Servers you create with others.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- DeepSeek R1 (free) - API, Providers, Stats: DeepSeek R1 is here: Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Ru...
- GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs: Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
- GitHub - daniel-lxs/mcp-server-starter: Contribute to daniel-lxs/mcp-server-starter development by creating an account on GitHub.
- GitHub - HarshJ23/deepseek-claude-MCP-server: a MCP server which integrates reasoning capabilities of DeepSeek R1 model into claude desktop app.: a MCP server which integrates reasoning capabilities of DeepSeek R1 model into claude desktop app. - HarshJ23/deepseek-claude-MCP-server
- DeepSeek R1 + Claude 3.5 Sonnet: The 2-Minute Developer Workflow Guide: Another quick little video where I describe my latest workflow adaptation following the addition of DeepSeek R1 to Cursor as a FREE-TO-USE model!Try this and...
- GitHub - protectai/modelscan: Protection against Model Serialization Attacks: Protection against Model Serialization Attacks. Contribute to protectai/modelscan development by creating an account on GitHub.
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- Reddit - Dive into anything: no description found
- 1-Bit LLMs: The Future of Efficient AI? - Pureinsights: This blog explains the initial research on 1-bit llms and their potential for producing AI models that are effective but also efficient.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Frankenclaude: R1 thinking + Sonnet by jbellis · Pull Request #2973 · Aider-AI/aider: I wanted to see what would happen if we combine R1's chain of thought with Sonnet's editing ability.I hacked it into aider in the most disgusting fashion (although I think moving send_...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
o3-mini model release, Reasoning capabilities, BYOK program updates
- o3-mini model launches for BYOK users: OpenAI's new model, o3-mini, is now available for Bring Your Own Key users in usage tiers 3 through 5, delivering enhanced reasoning capabilities.
- Users can add their key here to start utilizing the model which has shown a 56% preference over its predecessor in expert tests.
- Impressive benchmarks achieved by o3-mini: o3-mini matches the performance of the larger o1 model on AIME/GPQA and possesses 39% fewer major errors on complex problems.
- This model also includes features like built-in function calling and structured outputs, catering to developers and STEM enthusiasts.
- Affordable option for developers: The o3-mini model offers a budget-friendly solution for users seeking reliable assistance in math, science, and coding.
- It's an attractive option for BYOK users aiming to access advanced reasoning capabilities without excessive costs.
Link mentioned: o3 Mini - API, Providers, Stats: OpenAI o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excelling in science, mathematics, and coding. The model features three adjustable reasoning effort l...
OpenRouter (Alex Atallah) ▷ #general (445 messages🔥🔥🔥):
OpenRouter API Usage, Model Comparisons, O3-Mini Access, Claude 3.5 and AGI Discussions, Developer Insights and Suggestions
- O3-Mini Access Requirements: Access to the O3-Mini model is currently limited to BYOK customers, specifically those with an OpenAI key and usage tier greater than 3.
- Free users can also utilize O3-Mini by selecting the Reason button in ChatGPT.
- Model Performance Comparisons: Users debated the performance of models like OpenAI's O1 and DeepSeek R1, with some stating R1 excels in writing quality.
- Others expressed disappointment with models, including the perception that GPT-4 doesn't meet expectations.
- AGI Perspectives in AI Community: Discussions around AGI revealed divided opinions, with some believing it's in reach while others argue it's a distant goal.
- Conversations included reflections on past AI presentations that sparked beliefs in AI's potential.
- OpenRouter API Testing and Errors: Developers shared experiences testing the OpenRouter API, finding it difficult to produce errors during tests.
- Suggestions for generating errors included using invalid API keys or tools unsupported by specific models.
- Developer Engagement with the Community: Community members actively engaged in discussions about model capabilities and their own development experiences.
- They shared tips, queries and provided feedback to improve user experiences with APIs and model requests.
- Quick Start | OpenRouter: Start building with OpenRouter
- Tweet from OpenAI (@OpenAI): OpenAI o3-mini is now available in ChatGPT and the API.Pro users will have unlimited access to o3-mini and Plus & Team users will have triple the rate limits (vs o1-mini).Free users can try o3-mini in...
- Microsoft makes OpenAI’s o1 reasoning model free for all Copilot users: Microsoft calls it Think Deeper
- Anthropic Status: no description found
- Mistral Nemo - API, Providers, Stats: A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA.The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chines...
- Chess Analysis Board and PGN Editor: Analyze games with the strongest chess engine in the world: Stockfish. Improve your game with the help of personalized insights from Game Review.
- Cerebras becomes the world’s fastest host for DeepSeek R1, outpacing Nvidia GPUs by 57x: Cerebras Systems launches DeepSeek's R1-70B AI model on its wafer-scale processor, delivering 57x faster speeds than GPU solutions and challenging Nvidia's AI chip dominance with U.S.-based ...
- Cerebras becomes the world’s fastest host for DeepSeek R1, outpacing Nvidia GPUs by 57x: Cerebras Systems launches DeepSeek's R1-70B AI model on its wafer-scale processor, delivering 57x faster speeds than GPU solutions and challenging Nvidia's AI chip dominance with U.S.-based ...
- Tweet from Tibor Blaho (@btibor91): "Meet the o3-mini family - Introducing o3-mini and o3-mini-high — two new reasoning models that excel at coding, science, and anything else that takes a little more thinking."
- Llama 3.1 8B - Quality, Performance & Price Analysis | Artificial Analysis: Analysis of Meta's Llama 3.1 Instruct 8B and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window &...
- Cerebras becomes the world’s fastest host for DeepSeek R1, outpacing Nvidia GPUs by 57x: Cerebras Systems launches DeepSeek's R1-70B AI model on its wafer-scale processor, delivering 57x faster speeds than GPU solutions and challenging Nvidia's AI chip dominance with U.S.-based ...
- Reddit - Dive into anything: no description found
Interconnects (Nathan Lambert) ▷ #news (263 messages🔥🔥):
OpenAI's o3-mini launch, Performance comparisons with previous models, Real-world physics prompts, Pricing and access for developers, Model usability concerns
- OpenAI launches o3-mini: OpenAI's new AI reasoning model, o3-mini, is now available in ChatGPT, offering lower costs and potentially better performance compared to o1-mini. It provides features like function calling, structured outputs, and reasoning effort for developers.
- Free users can try o3-mini in ChatGPT, while Pro users have unlimited access, alongside reduced rate limits for other subscriptions.
- Performance boosts with o3-mini-high: o3-mini-high is claimed to be the most capable reasoning model publicly available, surpassing many others in reasoning capabilities. Comparisons have shown o3-mini performing better in certain tasks like generating physics scripts.
- Users noted potential latency improvements with the new model, although concerns about basic usability persist.
- Mixed feelings on pricing and usage: Concerns were raised about the apparent ongoing costs associated with subscription models, similar to OnlyFans. Users express frustration over 'LLM gacha' scenarios where they feel pressured to continually pay for access.
- In discussions, community members debated the fairness and transparency of model access as it relates to their expectations.
- Discussions around functionality and development: Many users are unsure if features like function calling in o3-mini will operate out-of-band of existing tokens or instructions. The potential for misunderstandings around intended functionality caused further discussion on how the model may be perceived.
- Outcomes and behaviors from previous model iterations continued to inform expectations regarding the effectiveness and reliability of o3-mini.
- Tweet from Tibor Blaho (@btibor91): "Meet the o3-mini family - Introducing o3-mini and o3-mini-high — two new reasoning models that excel at coding, science, and anything else that takes a little more thinking."
- Tweet from Kevin Lu (@_kevinlu): We released o3-mini, available today to all users in ChatGPT (for free)!o3-mini-low is faster (and often better) than o1-mini, and o3-mini-high is the most capable publicly available reasoning model i...
- OpenAI partners with U.S. National Laboratories on research, nuclear weapons security : The announcement comes as Chinese AI company DeepSeek is making waves in the U.S. tech market.
- Tweet from Xeophon (@TheXeophon): @arankomatsuzaki just wait for openai to disprove all of those wrong and drop it on huggingface they are messing up with the hf folder upload right now, thats why its taking them so long
- Tweet from Tibor Blaho (@btibor91): o3-mini and o3-mini-high is here
- Tweet from xlr8harder (@xlr8harder): >new oai model>still dec '23 cutoffyou guys running some slow ass data pipelines or what
- Tweet from Yuchen Jin (@Yuchenj_UW): o3-mini might be the best LLM for real-world physics.Prompt: "write a python script of a ball bouncing inside a tesseract"
- Tweet from Tibor Blaho (@btibor91): o3-mini will be available to all users via ChatGPT starting Friday- ChatGPT Plus and Team plans - 150 messages per day- ChatGPT Pro subscribers - unlimited access- ChatGPT Enterprise and ChatGPT Edu c...
- Tweet from Tibor Blaho (@btibor91): New Claude web app experiment - "Reset usage limits""Immediately get access to Claude instead of waiting for usage limits to reset. This is a one-time payment.""Message limits rese...
- Limit the number of characters DeepSeek R1 can use for thinking.: Limit the number of characters DeepSeek R1 can use for thinking. - thinking-cap.py
- Tweet from Xeophon (@TheXeophon): huh> We suspect o3-mini's low performance is due to poor instruction following and confusion about specifying tools in the correct format
- Tweet from OpenAI Developers (@OpenAIDevs): OpenAI o3-mini is now available in the API for developers on tiers 3–5. It comes with a raft of developer features:⚙️ Function calling📝 Developer messages🗂️ Structured Outputs🧠 Reasoning effort🌊 S...
- Tweet from Brian Huang (@brianryhuang): If anyone is curious about Humanity's Last Exam scores:11.2% on high reasoning, 8.5% on medium reasoning, 5.4% on low reasoningQuoting OpenAI (@OpenAI) OpenAI o3-mini is now available in ChatGPT a...
- So far, it seems like this is the hierarchy o1 > GPT-4o > o3-mini > o1-mini > GP... | Hacker News: no description found
- Tweet from Eric Zelikman (@ericzelikman): @Teslanaut
- Tweet from Teortaxes▶️ (DeepSeek🐳 Cheerleader since 2023) (@teortaxesTex): I get that Sama did in the past sit on models for >6mo etc. etc. But the fact is that OpenAI can't afford to safety-test a model they're deploying and for me this puts a yet another dent in...
- Reddit - Dive into anything: no description found
- OpenAI launches o3-mini, its latest 'reasoning' model | TechCrunch: OpenAI has launched a new 'reasoning' AI model, o3-mini, the successor to the AI startup's o1 family of reasoning models.
Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
Model Checkpoints, K2 Chat Release
- Search for Models with Intermediate Checkpoints: A user initiated a discussion about gathering a list of models that have checkpoints suitable for interpretation experiments, citing models like Tulu, Olmo, and Pythia.
- Another user suggested LLM360 as a potential model to consider, prompting the original user to check a relevant table in a paper.
- K2 Chat Finetuned Launch: A user brought up that LLM360 recently leased a 65B model called K2 and shared a link to the K2-Chat model which reportedly outperforms Llama 2 70B Chat using 35% less compute.
- The update, dated 10/31/24, introduces function calling features and improvements across various domains, utilizing datasets like Infinity-Instruct.
- Annoying Teams for Releases: A light-hearted comment suggested that if the SmolLM team gets annoyed, they might release something new.
- The original user responded with humor, stating that annoying people is my job.
Link mentioned: LLM360/K2-Chat · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
xeophon.: https://x.com/OpenAI/status/1885413866961580526
Interconnects (Nathan Lambert) ▷ #random (63 messages🔥🔥):
DeepSeek Performance, o3-mini and R1 Comparison, Nvidia Digit Acquisition, Copy Editing in SemiAnalysis, Popularity and Critique in Media
- DeepSeek Takes Center Stage: A report reveals that DeepSeek's total server CapEx is around $1.3B and clarifies they own various GPU models instead of just 50,000 H100s.
- Analysis suggests DeepSeek's R1 matches OpenAI's o1 in reasoning tasks but isn’t a clear leader, highlighting significant cost and performance implications.
- o3-mini versus DeepSeek R1: An ongoing discussion points out that OpenAI's o3-mini performs well, yet DeepSeek's R1 is noted for its cost-effectiveness and ability to reveal its reasoning processes.
- The excitement around DeepSeek is being termed a 'moment' in tech history, driven by its promising capabilities amid geopolitical considerations.
- Seeking Nvidia Digit Acquisition: A participant in the chat expressed a desire to contact Nvidia to get on the list for purchasing Digit devices.
- The email for inquiries was humorously suggested as jensenhuang@nvidia.com.
- Need for Copy Editing in SemiAnalysis: The group discussed the potential value of copy editing in SemiAnalysis reports, acknowledging the importance of clarity in their analyses.
- One member noted that despite the writing challenges, SemiAnalysis has gained traction and credibility in the industry.
- The Nature of Popularity and Critique: A conversation emerged regarding the nature of popularity and the challenges of managing feedback, especially when in the public eye.
- It was noted that constructive criticism is crucial, as gaining popularity often leads to an influx of sycophants rather than honest feedback.
- DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts: The DeepSeek Narrative Takes the World by Storm DeepSeek took the world by storm. For the last week, DeepSeek has been the only topic that anyone in the world wants to talk about. As it currently s…
- Tweet from Jason Weston (@jaseweston): 💀 Introducing RIP: Rejecting Instruction Preferences💀A method to *curate* high quality data, or *create* high quality synthetic data.Large performance gains across benchmarks (AlpacaEval2, Arena-Har...
- Tweet from Maxime Labonne (@maximelabonne): TIGER-Lab replaced answers in SFT with critiques.They claim superior performance in reasoning tasks without any
distillation!What if we reason over critiques with R1 now?Code, dataset... - Tweet from Andi Marafioti (@andimarafioti): Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s🔥Inspired by our team's effort to open-source DeepSeek's R1 training, we are releasing the t...
- Tweet from Shirin Ghaffary (@shiringhaffary): OpenAI is in talks to raise as much as $40b in a funding round led by SoftBank, per sourcesCompany is discussions to raise funds at a pre-money valuation of $260b, said one of the people. w/ @KateClar...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): https://one.npr.org/?sharedMediaId=nx-s1-5279550:nx-s1-5343701-1At 7:30 mark “ o3 which comes out on Friday “ - Chris Lehane Global Policy, OpenAI.Good conversation overall from NPR.
- Tweet from Zhaopeng Tu (@tuzhaopeng): Are o1-like LLMs thinking deeply enough?Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, lead...
- Tweet from David Sacks (@DavidSacks): New report by leading semiconductor analyst Dylan Patel shows that DeepSeek spent over $1 billion on its compute cluster. The widely reported $6M number is highly misleading, as it excludes capex and ...
- Tweet from wh (@nrehiew_): Looks like a ~60-70% VRAM reduction change to GRPO in TRL is coming soon!
- Tweet from Hensen Juang (@basedjensen): I am sorry but this is total bs. The tco numbers do not make any sense for people who own their own dcs esp in China. I get they have to pander to paid clients but come on this is not helping anyoneQu...
- Tweet from Lex Fridman (@lexfridman): OpenAI o3-mini is a good model, but DeepSeek r1 is similar performance, still cheaper, and reveals its reasoning.Better models will come (can't wait for o3pro), but the "DeepSeek moment" i...
Interconnects (Nathan Lambert) ▷ #memes (12 messages🔥):
Mistral's Model Release, DeepSeek Reinforcement Learning, Janus Model Responses, Bengali Ghosthunters, AI Models Discussion
- Mistral surprises with model releases: In a surprising move, Mistral, which has raised $1.4b to date, released both a small and large model today, contrary to typical funding expectations.
- The small model was introduced alongside its specifications, claiming remarkable efficiency and a 24B parameter count.
- DeepSeek revisits AI models: Discussing the DeepSeek initiative, it incorporates previous advancements from 2015 and 2018, aiming for a distilled reasoning capability in LLMs.
- Key references from Schmidhuber elaborate on its foundational developments and the novel chain of thought system.
- Humor in Janus model commentary: A member laughed at the directness of commentary surrounding the Janus model, reflecting on its unique impact on discussions.
- They noted how the commentary resonates with the quirky, engaging nature of the AI discourse community.
- Bengali Ghosthunters' escapades with LLMs: In another chat thread, a user jokingly referred to their experiences with Gemini Flash Thinking, which humorously malfunctioned after training them.
- This light-hearted commentary unfolds within the broader context of Bengali Ghosthunters lore in AI discussions, intertwining humor and technical exploration.
- Tweet from xlr8harder (@xlr8harder): anonymous gc commentary
- Tweet from sholín (NOAM CHOMSKY SIGUE VIVO) (@qwrk8126): Gemini Flash Thinking Exp 2.0 0121 was teaching me more about the technical nature of LLMs and prepared a short multiple choice exam for me to provide the correct answers. After I did, it stopped thin...
- Tweet from wh (@nrehiew_): You should legally only be allowed to call a model "small" if inference can be done on a free Colab T4.Quoting Mistral AI (@MistralAI) Introducing Small 3, our most efficient and versatile mod...
- Tweet from Jürgen Schmidhuber (@SchmidhuberAI): DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural...
Interconnects (Nathan Lambert) ▷ #rl (2 messages):
SFT Support, Open Source Projects, Funding Issues
- SFT Support Has Limitations: A member noted that certain features are supported in older SFT implementations but reported that they don't work as effectively now.
- This suggests a need for reevaluation of current practices in using these features.
- Closure of Personal Project due to Funding: A member shared their experience of having to close their project due to lack of funding and personal health issues.
- They expressed gratitude, highlighting Ai2 as one of the few organizations genuinely engaging in open source projects.
Interconnects (Nathan Lambert) ▷ #reads (2 messages):
DeepSeek's Role in AI, Stargate Project Funding, AI Substack Community
- DeepSeek consumes Altman's Vision: “Jonah and the Whale (1621) by Pieter Lastman (also a good illustration of DeepSeek eating Sam Altman)” — a pointed remark from JS Tan highlights DeepSeek's growing influence in the AI landscape.
- Tan's narrative reflects concerns about alternative AI players overshadowing mainstream figures like Sam Altman in the evolving market.
- Trump backs Altman's $500 billion Stargate: On January 21, President Donald Trump publicly supported OpenAI CEO Sam Altman as they announced the Stargate Project, a $500 billion investment plan targeting data centers and AI infrastructure.
- The astronomical cost raised eyebrows, with Altman asserting it is essential for scaling up superintelligent artificial intelligence capabilities.
- Finding AI Substack gems: A discussion point was raised about good places to discover more AI-focused Substack publications, indicating the growing interest in niche AI topics.
- This reflects a broader trend of enthusiasts seeking specialized content in the rapidly evolving AI information space.
Link mentioned: DeepSeek, unstacked: Jasmine Sun surveys reactions to the new AI on the block
Interconnects (Nathan Lambert) ▷ #policy (1 messages):
xeophon.: https://x.com/deliprao/status/1885114737525928380?s=61
OpenAI ▷ #annnouncements (1 messages):
OpenAI o3-mini, Reddit AMA, Future of AI, Sam Altman, Kevin Weil
- OpenAI’s Reddit AMA is Set: An upcoming Reddit AMA featuring Sam Altman, Mark Chen, and others will take place at 2PM PST.
- Ask your questions here! is the invitation for community engagement in this anticipated discussion.
- AI Enthusiasts Invited to Join: The AMA will cover topics including OpenAI o3-mini and the future of AI, allowing participants to pose questions directly to key figures.
- This is an excellent opportunity for users to engage with industry leaders regarding pressing AI topics.
Link mentioned: Reddit - Dive into anything: no description found
OpenAI ▷ #ai-discussions (319 messages🔥🔥):
O3 Mini Limit Confusion, Model Performance Comparisons, AI Detector Effectiveness, DeepSeek Discussion, CoT and Reasoning Models
- O3 Mini Limit Confusion: There is confusion regarding the message limits for O3 Mini High, which is said to have 50 messages per week, while O3 Mini has 150 per day.
- Some users suspect it could be a bug since there was no clear mention of such limits prior to usage.
- Comparison of AI Models: Users are comparing the performance of various AI models, with some expressing a preference for Claude 3.6 Sonnet, DeepSeek R1, and O1 for tasks like coding.
- O3 Mini is viewed as having trouble with instruction following, making it less suitable for certain needs.
- AI Detector Effectiveness: There is a consensus among users that AI detection tools are unreliable and can unfairly penalize students based on inaccurate assessments.
- Users argue that manual checks are more reliable than automated AI detectors.
- DeepSeek Discussion: Users have expressed interesting insights into DeepSeek's capabilities and have noted its competitive nature against larger corporations.
- Some are impressed with DeepSeek, indicating that even open-source models can perform remarkably well.
- CoT and Reasoning Models: There is speculation about how reasoning models like O1 leverage Chain of Thought (CoT) to enhance performance compared to alternatives when given tasks.
- Users are curious about the visibility of CoT in O1 as they believe it could provide insights for better follow-up queries.
Link mentioned: It doesn't matter if DeepSeek copied OpenAI — the damage has already been done in the AI arms race: Your move, Sam Altman
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
File Upload Limitations in O1, Release of O3 Mini, ChatGPT Support Number Issues
- File Upload Frustrations with O1: Members expressed frustration over the inability to upload files other than images to O1, with one describing the need for a solution as more pressing than food.
- A user created a Python application to consolidate multiple project files into a single text file for easier uploads.
- O3 Mini Launch Unveiled: User excitement surged with announcements that O3 Mini is now available, even for free users.
- One member humorously suggested that OpenAI's release timing is intentionally competitive, pushing out new models to maintain a top position.
- Issues with ChatGPT Support Number: A user reported that the 1-800-ChatGPT support number doesn't seem to work for them, seeking clarity on its effectiveness.
- This sparked a minor discussion around support accessibility for various OpenAI services.
OpenAI ▷ #prompt-engineering (2 messages):
Vision Model Limitations, User Discussions, Training Data Insights
- Users discuss Vision model's blind spots: Users spent time discussing the Vision model and its inability to distinguish between the ground and lines, noting it was akin to needing 'new glasses'.
- This issue was highlighted as a significant flaw that could not be addressed solely through chat training.
- Detailed chats on Vision model issues: There were multiple detailed discussions analyzing the model's limitations, particularly surrounding a specific problem that was documented months ago.
- The speaker mentioned having training data on this, indicating awareness of the model's potential improvements from their interactions.
- User unfamiliarity with Vision puzzles: One user expressed surprise over the discussed puzzle, admitting to having missed it until recently.
- This reflects a gap in communication among users regarding specific Vision model puzzles and challenges.
OpenAI ▷ #api-discussions (2 messages):
4o User Feedback, Model Limitations, Training Data Insights
- Users Discuss 4o's Vision Limitations: Some users engaged in discussions around the vision of model 4o, emphasizing aspects the model couldn't perceive clearly, particularly differentiating between ground and lines.
- The inability to distinguish these features suggests the model could benefit from better training or adjustment, akin to needing new glasses.
- Past Discussions on Model Limitations: Members recalled detailed conversations from previous months focused on the challenges faced by the model in recognizing key visual elements.
- One noted having training data related to this issue, indicating potential learnings from these discussions.
- Recognition of the Ground vs Line Puzzle: Another member mentioned missing previous discussions and expressed surprise at the existence of the ground vs line puzzle.
- This reflects a gap in awareness around ongoing issues and challenges that have previously been identified.
Latent Space ▷ #ai-general-chat (61 messages🔥🔥):
O3 Mini Updates, Performance Comparison with Sonnet, DeepSeek Impact, Market Trends in AI Models
- O3 Mini Launch Reactions: OpenAI's O3 Mini is released with numerous features like function calling and structured outputs for API users on tiers 3-5, and is available in ChatGPT for free users as well.
- Many users are experimenting with it, but some report disappointing performance compared to previous models, especially in coding tasks.
- Performance Struggles Compared to Sonnet: Several users noted that O3 Mini struggled with coding prompts, citing specific examples where Sonnet outperformed it significantly, completing tasks much faster.
- One user remarked that, while O3 Mini is a potentially better model, it failed to match Sonnet's proficiency in debugging and understanding complex code.
- DeepSeek's Influence on Pricing: The release announcement of O3 Mini included a notable 63% price cut for O1 Mini, indicating competitive pressure from DeepSeek's models.
- Comments suggested that while model intelligence is increasing, the cost for the same intelligence remains high, reflecting a significant 'USA premium'.
- Market Trends Among Models: Recent discussions touch on market share movements, noting Anthropic's growth and asserting that DeepSeek is becoming a major player, surpassing other AI models in user engagement.
- Users expressed curiosity about the possible implications for OpenAI's market position as it faces increasing competition from DeepSeek and others.
- User Feedback on O3 Mini's Features: Feedback on O3 Mini includes mixed feelings regarding its ability to process complex prompts, with critiques highlighting its lack of custom instructions that limits usage in certain applications.
- Despite some promising features, many users are left frustrated, as some basic coding tasks revealed O3 Mini's limitations compared to its predecessors.
- Tweet from Yuchen Jin (@Yuchenj_UW): o3-mini might be the best LLM for real-world physics.Prompt: "write a python script of a ball bouncing inside a tesseract"
- Tweet from OpenAI Developers (@OpenAIDevs): OpenAI o3-mini is now available in the API for developers on tiers 3–5. It comes with a raft of developer features:⚙️ Function calling📝 Developer messages🗂️ Structured Outputs🧠 Reasoning effort🌊 S...
- DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts: The DeepSeek Narrative Takes the World by Storm DeepSeek took the world by storm. For the last week, DeepSeek has been the only topic that anyone in the world wants to talk about. As it currently s…
- Tweet from Alex Atallah (@xanderatallah): @itsandrewgao Market share among indies using openrouter is even wilder
- Tweet from Cursor (@cursor_ai): o3-mini is out to all Cursor users!We're launching it for free for the time being, to let people get a feel for the model.The Cursor devs still prefer Sonnet for most tasks, which surprised us.
- Tweet from andrew gao (@itsandrewgao): Anthropic is eating OpenAI’s lunch
- Tweet from *Walter Bloomberg (@DeItaone): $MSFT - OpenAI in Talks for Funding Round Valuing It Up to $340 Billion, Sources Say -- WSJ
- Tweet from Paul Gauthier (@paulgauthier): o3-mini scored similarly to o1 at 10X less cost on the aider polyglot benchmark (both high reasoning).62% $186 o1 high60% $18 o3-mini high54% $9 o3-mini mediumhttps://aider.chat/docs/leaderboards/
- Tweet from Sam Altman (@sama): @SpencerKSchiff @satyanadella yes, tomorrow! enjoy it.
- Tweet from Noam Brown (@polynoamial): We at @OpenAI are proud to release o3-mini, including for the FREE tier. On many evals it outperforms o1. We’re shifting the entire cost‑intelligence curve. Model intelligence will continue to go up, ...
- Tweet from swyx /dd (@swyx): ## DeepSeek's impact on o3-mini and o1-miniburied in today's announcement is a 63% (2.7x) price cut for o1 mini - and o3-mini is priced the same. This is much lower than the 25x price cut need...
- Tweet from Adam.GPT (@TheRealAdamG): https://help.openai.com/en/articles/6825453-chatgpt-release-notes#h_caaeddc37eChatGPT got some nice, incremental updates yesterday. Shavings make a pile.
- Tweet from Zephyr (@angelusm0rt1s): Dario pulled off a very interesting trick in the articleThe 7-10 month-old model refers to the original Sonnet 3.5 which V3 beats in all benchmarksBut he is comparing the performance of Sonnet 3.6 rel...
- Reddit - Dive into anything: no description found
- Tweet from thebes (@voooooogel): so what are we thinking on sonnet 3.5 (and 3.6) after dario's "no big model involved in training" comment? why do 3.5/3.6 have so much in common with opus? ideas, add your own:- it's t...
Latent Space ▷ #ai-in-action-club (269 messages🔥🔥):
Discord Screenshare Issues, Open Source AI Tools, AI Tutoring Projects, Techno Music References, DeepSeek API
- Challenges with Discord Screenshare: Members encountered audio and video issues during a screenshare session, including echo and frozen screens, leading to humorous exchanges about technology struggles.
- Some recommended specific settings, like unticking screen share audio, to improve the experience.
- Discussion on Open Source AI Tools: There was excitement around open source alternatives to Cursor, with mentions of tools like Cline and Roocline being highlighted as interesting projects.
- Members were keen to explore these tools' capabilities, emphasizing the effectiveness of open solutions.
- AI Tutoring as a Project Topic: Plans for an AI tutoring session were discussed, with a few members considering the format and potential content to share.
- The conversation referenced similar projects like boot_camp.ai, seeking to guide others in AI education.
- Techno Music References and Engagement: The chat included several references to techno music and its cultural impact, with playful banter on various beats per minute.
- Members engaged in lighthearted jokes about music genres, sharing personal anecdotes connected to the theme.
- Concerns Over DeepSeek API: Frustration was expressed regarding the DeepSeek API's stability, with some members mentioning their failures to obtain API keys.
- The ongoing issues with the API led to discussions about alternative hosting solutions and models available.
- Brain Dump - Shape Thoughts Instantly.: no description found
- Careless Whisper - Mac Dictation App: no description found
- no title found: no description found
- D-Squared: Day Job: Professional AI Whisperer at Gradient Labs | Side Hustle: Showing you the AI automation tricks
- MCP.mp4: no description found
- Models & Pricing | DeepSeek API Docs: The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the tot...
- GitHub - D-Squared70/GenAI-Tips-and-Tricks: Different GenAI tips and tricks I've found useful: Different GenAI tips and tricks I've found useful. Contribute to D-Squared70/GenAI-Tips-and-Tricks development by creating an account on GitHub.
- GenAI-Tips-and-Tricks/Claude_ImplementationPlan.txt at main · D-Squared70/GenAI-Tips-and-Tricks: Different GenAI tips and tricks I've found useful. Contribute to D-Squared70/GenAI-Tips-and-Tricks development by creating an account on GitHub.
- Archive – D-Squared: no description found
- AI In Action: Weekly Jam Sessions: no description found
Yannick Kilcher ▷ #general (242 messages🔥🔥):
o3-mini release, AI model performance comparisons, LLM training and architectures, GPU configurations for AI models, OpenAI's competitive landscape
- o3-mini is now available!: OpenAI announced that o3-mini is now accessible in ChatGPT and via the API, offering unlimited access for Pro users, with enhanced rate limits for Plus and Team users.
- Free users can try out o3-mini by selecting the Reason button under the message composer in ChatGPT.
- Comparative performance of AI models: Discussion highlighted that while transformers achieved an 8% improvement in BLEU scores on specific datasets, this isn't universally applicable across all benchmarks.
- The participants weighed the significance of small performance improvements against broader impacts, noting that projects like Attention is All You Need synthesized existing ideas into a pioneering framework.
- Challenges with GPU configurations: Users expressed frustrations with running LLMs using mixed NVIDIA and AMD GPUs, as the current setups lead to significant memory allocation issues.
- Alternatives like switching to CPU-only setups or trying different architectures were also discussed as potential solutions to these challenges.
- Concerns about open-source software quality: The conversation included skepticism about the overall quality of open-source projects compared to closed-source counterparts, emphasizing the visibility of failures.
- Participants acknowledged that while numerous open-source projects exist, only a select few significantly impact daily activities, suggesting the model's success could depend more on adoption rather than quantity.
- Disruptive applications in AI evolution: There was a consensus that the future of AI technologies hinges on the ability to introduce disruptive applications, regardless of whether they are open-source or closed-source.
- It's noted that while not all open-source initiatives will thrive, both open-source and closed source movements play a vital role in the evolution of technology.
- Tweet from Jürgen Schmidhuber (@SchmidhuberAI): DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural...
- Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective: Recent studies have discovered that Chain-of-Thought prompting (CoT) can dramatically improve the performance of Large Language Models (LLMs), particularly when dealing with complex tasks involving ma...
- Tweet from Parker Rex (@ParkerRex): OpenAI released o3-mini through their think button
- Tweet from Parker Rex (@ParkerRex): OpenAI released o3-mini through their think button
- Tweet from OpenAI (@OpenAI): OpenAI o3-mini is now available in ChatGPT and the API.Pro users will have unlimited access to o3-mini and Plus & Team users will have triple the rate limits (vs o1-mini).Free users can try o3-mini in...
- Tweet from Sam Altman (@sama): first full 8-rack GB200 NVL72 now running in azure for openai—thank you @satyanadella and jensen!
- My First Harvard MIT Math Tournament Problem: If you like this Harvard-MIT Math tournament (HMMT) problem and want to learn more about problem-solving, then check out Brilliant https://brilliant.org/blac...
- Tweet from Bill Ackman (@BillAckman): What are the chances that @deepseek_ai’s hedge fund affiliate made a fortune yesterday with short-dated puts on @nvidia, power companies, etc.? A fortune could have been made.
- GRPO Llama-1B: GRPO Llama-1B. GitHub Gist: instantly share code, notes, and snippets.
Yannick Kilcher ▷ #paper-discussion (37 messages🔥):
Next Paper Review, Tülu 3 405B Benchmark Results, FP4 Training Framework, Collaboration Opportunities with DeepSeek, User Experiences with AI Chat Assistants
- Next Paper Review on FP4 Framework: The upcoming weekly discussion will feature the paper on an innovative FP4 training framework aimed at enhancing training efficiency for large language models, with a focus on minimizing quantization errors.
- Participants were encouraged to prepare some background knowledge on QKV concepts to better engage during the discussion.
- Tülu 3 405B Claims Competitive Edge: The newly launched Tülu 3 405B model claims to outperform both Deepseek v3 and GPT-4o across specific benchmarks while utilizing a Reinforcement Learning from Verifiable Rewards framework.
- Despite the claims, some members noted that upon deeper examination of the benchmarks, Tülu 3's performance did not significantly exceed Deepseek v3.
- User Concerns About AI Chat Assistants: A member expressed skepticism regarding the utility of AI chat assistants for recalling syntax or generating code snippets, questioning their effectiveness in practical scenarios.
- This prompted a broader discussion about how users generally perceive the usefulness of AI tools for tasks they find difficult to remember.
- Collaboration Opportunities with DeepSeek: A post highlighted collaboration possibilities with DeepSeek, particularly for early-stage PhD students from specific universities, while also mentioning the constraints for general collaborators.
- The post emphasized the importance of citation and acknowledgment of their work to support future research initiatives.
- General Discussion on Daily Engagements: Throughout the conversation, members reiterated the significance of participating in daily discussions to stay updated on various AI topics.
- New members were welcomed and reassured that casual listening to discussions is perfectly fine for those just starting.
- Optimizing Large Language Model Training Using FP4 Quantization: The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operation...
- SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training: Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain ...
- Scaling the Tülu 3 post-training recipes to surpass the performance of DeepSeek V3 | Ai2: Introducing Tülu 3 405B, the first application of fully open post-training recipes to the largest open-weight models.
- Hair Flip GIF - Hair Flip Duhh - Discover & Share GIFs: Click to view the GIF
- Physics of Language Models: Many asked about collaborations (details are in FAQ). Short answer: unless you're from Meta and willing to work with us in your spare time (20+ hrs/week), or you're an early-year PhD from UCB/...
- Interview with Deepseek Founder: We're Done Following. It's Time to Lead.: Silicon Valley is reeling. However, founder Liang Wenfeng has remained low-key, with his most recent appearance being on China Central Television's Xinwen Lianbo (CCTV News).
Yannick Kilcher ▷ #agents (6 messages):
Model Performance Comparison, Self-Awareness in AI, Grid Pattern Transformation, Qwen 2.5VL Features, Parameter Optimization
- Model Performance Comparison: The 7B distilled version of the model struggles to recognize the letter 'E' made from 1's in a grid, while the 600B model is reported to work significantly better.
- The reasoning ability of the newer models is observed to be much more coherent than that of Llama.
- AI Exhibits Signs of Self-Awareness: One user remarked that the model 'almost sounds like it has some aspect of self-awareness' as it acknowledges never having seen specific patterns before.
- This observation was noted without any direct instructions provided to the model.
- Grid Pattern Transformation Insights: A description highlights the importance of removing borders in a grid transformation to better preserve original data, leading to a high score for relevance.
- The strategy has evolved to prioritize methods that maintain original values alongside pattern changes.
- Qwen 2.5VL Shows Improved Descriptions: Switching to Qwen 2.5VL has led to better descriptive abilities and a focus on features previously noticed in DSL solutions.
- The comparison indicates the model's improvement in understanding and looking for relevant features.
- Parameter Optimization Focus: The discussions reflect a growing emphasis on parameter optimization to enhance model function selections during transformations.
- Next goals include improving function selection and tuning for more intricate transformations.
Yannick Kilcher ▷ #ml-news (11 messages🔥):
DeepSeek R1 Replication, Y Combinator's Funding Focus, OpenAI O3 Mini Features, AI Research Democratization
- Berkeley Researchers Achieve DeepSeek R1 Replication: A Berkeley AI Research team led by Jiayi Pan successfully replicated DeepSeek R1-Zero's technologies for under $30, showcasing complex reasoning capabilities in a small model of 1.5B parameters.
- Their achievement marks a significant step towards the democratization of AI research, inspiring discussions about affordability in tech advancements.
- Y Combinator Set to Fund AI Startups in 2025: Y Combinator announced a new funding focus for 2025, primarily targeting startups that aim to replace $100k/year job functions with AI solutions.
- A member shared notes from the announcement, noting that this shift emphasizes the ongoing trend towards automation and job displacement in the workforce.
- User Reactions to OpenAI O3 Mini Features: A user expressed confusion over not seeing O3 Mini in their ChatGPT interface, pondering if it was due to EU regulations or a rollout delay.
- Moments later, they confirmed seeing the feature, demonstrating the slow rollout experience shared among users.
- Berkeley Researchers Replicate DeepSeek R1's Core Tech for Just $30: A Small Model RL Revolution: A Berkeley AI Research team led by PhD candidate Jiayi Pan has achieved what many thought impossible: reproducing DeepSeek R1-Zero's key technologies for less than the cost of a dinner for two.
- Tweet from GREG ISENBERG (@gregisenberg): Y Combinator JUST announced what startups they want to fund next in 2025. And it's mostly AI that replaces $100k/year job functions.My notes below in case it's helpful to you:
- Open-R1: a fully open reproduction of DeepSeek-R1: no description found
Nous Research AI ▷ #general (210 messages🔥🔥):
Psyche Project and Decentralized Training, Crypto and Its Relation to Nous, Performance Comparison of AI Models, Community Sentiment on AI and Crypto, o3-mini vs. Sonnet Performance
- Psyche aims for decentralized training coordination: The Psyche project is designed to facilitate decentralized training with untrusted compute, utilizing contributions from idle hardware around the globe.
- It aims to leverage existing blockchain technologies for coordination and verification in distributed training environments.
- Skepticism surrounding crypto involvement at Nous: Members discussed their concerns about associating Nous with crypto due to frequent scams in the space, debating whether blockchain is necessary for training verification.
- Some argue that a server-based approach could suffice, while others believe utilizing existing blockchain engineering could yield benefits.
- Comparative performance of AI models: Discussion highlighted that smaller models like OpenAI's
o3-miniperform well for complicated problems, while larger models excel with complex tasks.- There are sentiments that while current methods may not enable large reasoning models due to costs, advancements may change that in the future.
- Community perspectives on crypto and ethics: Users acknowledged the presence of scams and unethical behaviors within the crypto market, drawing parallels with issues in public equity markets.
- There is a shared desire for a functional use of blockchains that could positively impact distributed training efforts.
- Performance insights on o3-mini vs. Sonnet: The o3-mini is perceived as a strong alternative to Sonnet, offering faster streaming and fewer compile errors during coding tasks.
- Despite its capabilities, there’s speculation that many may still prefer older models like R1 due to their transparency in operational processes.
- Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch: Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at e...
- Tweet from Cursor (@cursor_ai): o3-mini is out to all Cursor users!We're launching it for free for the time being, to let people get a feel for the model.The Cursor devs still prefer Sonnet for most tasks, which surprised us.
- Propositional Interpretability in Artificial Intelligence: Mechanistic interpretability is the program of explaining what AI systems are doing in terms of their internal mechanisms. I analyze some aspects of the program, along with setting out some concrete c...
- Function Vectors in Large Language Models: We report the presence of a simple neural mechanism that represents an input-output function as a vector within autoregressive transformer language models (LMs). Using causal mediation analysis on a d...
- qresearch/DeepSeek-R1-Distill-Llama-8B-SAE-l19 · Hugging Face: no description found
- Mr Krabs Cheapskate GIF - Mr krabs Krabs Cheapskate - Discover & Share GIFs: Click to view the GIF
- Tweet from Teknium (e/λ) (@Teknium1): @ylecun https://x.com/Teknium1/status/1883955152442515637Quoting Teknium (e/λ) (@Teknium1) Today Nous announced the coming of Psyche - a distributed network and training framework, an infrastructure l...
- Tweet from Chris Barber (@chrisbarber): Interesting on superhuman reasoning models, shared with permission:Shannon Sands (@max_paperclips) from @NousResearch told me that Nous has a theory that LLMs learn task vectors for reasoning operatio...
- Tweet from cadmonkey (@cadmonkxy): gnthanks for a great event @NousResearch excited for what’s ahead !
- bespokelabs/Bespoke-Stratos-17k · Datasets at Hugging Face: no description found
- Tweet from Teknium (e/λ) (@Teknium1): This is the entire code needed to reproduce R1 lolHundreds of Billions of Dollars Later
Nous Research AI ▷ #ask-about-llms (1 messages):
Autoregressive Generation on CLIP Embeddings, Multimodal Inputs, Stable Diffusion Generation
- Exploring Autoregressive Generation on CLIP Embeddings: A member raised the question of whether it's reasonable to perform autoregressive generation on CLIP embeddings, which project multimodal inputs into a single latent space.
- They noted that while CLIP is primarily used for guidance in Stable Diffusion, there's limited discussion on its direct application for generation.
- Understanding Multimodal Inputs: The community discussed the nature of multimodal inputs, emphasizing their role in neural networks for diverse data types.
- Using multiple modalities can enhance representation, but practical applications in generative tasks remain a niche area.
- Stable Diffusion's Use of CLIP: Members acknowledged Stable Diffusion leverages CLIP for image generation by providing guidance through embedded contexts.
- This method shows potential but raises inquiries about direct generation methodologies using CLIP embeddings instead.
Nous Research AI ▷ #research-papers (4 messages):
Weekend plans, Reading materials
- Weekend vibes with excitement: A member expressed optimism, stating, 'Will be a good weekend' which was met with enthusiasm from another member.
- The excitement seems contagious as one member responded with a cheerful 'yessss'.
- Printing favorite reading materials: A different member mentioned their habit of printing off all the best things to read, adding a playful tone with a cowboy emoji 🤠.
- This reflects a proactive approach to prepare for a relaxing weekend filled with great reads.
Link mentioned: Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch: Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at e...
Nous Research AI ▷ #interesting-links (1 messages):
DeepSeek Hiring Strategy, Long-Term Success in AI Recruitment, Creativity vs. Experience
- DeepSeek's Founder Champions Creativity: In a rare 2023 interview, Liang Wenfeng, founder of AI lab DeepSeek, stated that 'experience is not that important' when hiring for long-term success.
- Having done a similar job before doesn't mean you can do this job, he emphasized, advocating for the value of creativity, basic skills, and passion over traditional experience.
- Debate on Hiring Talent from Overseas: Liang was questioned about recruiting talent from US AI companies like OpenAI and Facebook's AI Research, acknowledging that experience may suit short-term goals.
- However, he believes that for long-term vision, there are many suitable candidates within China.
Link mentioned: Why DeepSeek's Founder Liang Wenfeng Prefers Inexperienced Hires - Bu…: no description found
Nous Research AI ▷ #research-papers (4 messages):
Weekend Plans, Image Sharing, Reading Materials
- Excitement for the Weekend: @millento expressed optimism about the upcoming weekend, stating it
- Sharing Reading Materials: vvampa mentioned enjoying printing off
- Image Analysis Shared: millento shared an image, sparking some interaction about
Link mentioned: Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch: Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at e...
Nous Research AI ▷ #reasoning-tasks (2 messages):
Long term planning, Team involvement in planning
- Inquiry about Long Term Planning Status: A member asked, 'Where are we in long term planning? And who is working on it?', seeking clarity on the current state of these initiatives.
- The member emphasized their interest in receiving any relevant content by stating, 'if any good content about this, please cc me.'
- Team Participation in Long Term Planning: The conversation highlighted the need for clarity on who is currently involved in long term planning efforts, indicating an openness for collaboration.
- The inquiry reflects a broader interest in ensuring that all relevant participants are engaged in the strategic discussions.
Stackblitz (Bolt.new) ▷ #prompting (13 messages🔥):
Supabase Issues, Troubleshooting Group Suggestions, HEIC File Support, Project Deletion Concerns
- Supabase Request Fails with Error: A member reported that their Supabase request failed with a status 500 error, citing a database error saving new user.
- Suggestions included reaching out for help via a potential troubleshooting group or utilizing tools like Google AI Studio for debugging.
- Suggestions for Resolving Supabase Issues: Multiple members suggested various strategies, including using VSCode with Roo code installed to troubleshoot and fix issues before pulling back into Bolt.
- Advice also included exporting current data from Supabase before deleting projects, which can save time and tokens.
- Concerns about Deleting Supabase Projects: Questions arose about whether deleting a Supabase project would affect the corresponding Bolt.new project, with clarifications that only Supabase data would be lost.
- Members highlighted the importance of database retention, noting that rebuilding the tables and structure in a new project would be time-consuming.
- HEIC Files Compatibility Discussions: A member inquired about how to enable HEIC file support in Bolt, having attempted various methods without success.
- Suggestions were requested to resolve the incompatible file issue they’ve frequently encountered.
Stackblitz (Bolt.new) ▷ #discussions (142 messages🔥🔥):
Token Management, Issues with Web Containers, User Authentication Problems, Subscription Management, CORS Configuration Challenges
- Understanding Token Management: Users confirmed that paid plans offer 10M tokens per month, with only free plans providing daily tokens of 150k.
- New users expressed confusion regarding token reload dynamics and expiration policies, with suggestions to verify billing practices.
- Web Containers Experiencing Crashes: Several users reported issues with web containers that either take too long to load or crash repeatedly, especially on Google Chrome.
- Recommendations included creating a GitHub ticket for persistent issues to facilitate trouble resolution and better support.
- User Authentication Problems: Members faced challenges with signing in to user dashboards, receiving invalid credentials errors despite correct login information.
- Suggestions included verifying username and password accuracy by creating new user accounts in Supabase.
- Managing Subscription Renewal: Users inquired about how to cancel or manage subscription renewals, with instructions suggested to contact support for specific steps.
- Queries also arose regarding the ability to create new copies of projects within the Bolt ecosystem.
- CORS Configuration Challenges: One user detailed the CORS configuration required for Firebase Storage due to unauthorized requests, indicating process changes.
- Steps were provided to modify configurations effectively, aiming for better cross-origin resource sharing during app development.
Link mentioned: Spongebob Squarepants Begging GIF - Spongebob Squarepants Begging Pretty Please - Discover & Share GIFs: Click to view the GIF
MCP (Glama) ▷ #general (112 messages🔥🔥):
MCP Server Setup, Transport Protocols in MCP, Remote vs Local MCP Servers, MCP Server Authentication, MCP CLI Tools
- Challenges with MCP Server Implementation: New users expressed difficulties in setting up MCP servers, particularly concerning local versus remote configurations, with calls for more streamlined instructions.
- A user shared their experience using the mcp-cli tool to interact with MCP servers, suggesting it helps alleviate some confusion.
- MCP Transport Protocol Preferences: There was a discussion regarding the use of stdio as the default transport in MCP servers, with some members praising its simplicity and efficacy.
- Concerns were raised about the lack of security in standard configurations and suggestions were made to consider alternative transport methods for better protection.
- Remote MCP Server Accessibility: Participants explored the feasibility of establishing remote MCP servers, emphasizing the need for a proper endpoint rather than requiring local setups for users.
- One user highlighted potential use cases where a remote server setup would streamline processes for multiple clients rather than enforcing local deployments.
- SSE vs HTTP Requests in MCP: The conversation touched on the use of SSE for remote communication, with some members questioning its effectiveness compared to straightforward HTTP requests.
- It was clarified that the current implementations utilize HTTP POST for some transactions while maintaining SSE for others to enhance efficiency without added complexity.
- MCP Server Authentication Concerns: Concerns regarding user authentication for remote MCP servers were raised, particularly in relation to leveraging existing user credentials effectively.
- The importance of ensuring secure access to servers without local dependencies was emphasized as a key factor in designing network-ready MCP solutions.
- Transports - Model Context Protocol: no description found
- GitHub - wong2/mcp-cli: A CLI inspector for the Model Context Protocol: A CLI inspector for the Model Context Protocol. Contribute to wong2/mcp-cli development by creating an account on GitHub.
- servers/src/github at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2 · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- env invocation (GNU Coreutils 9.6): no description found
- servers/src/everything/sse.ts at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2 · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- GitHub - SecretiveShell/MCP-Bridge: A middleware to provide an openAI compatible endpoint that can call MCP tools: A middleware to provide an openAI compatible endpoint that can call MCP tools - SecretiveShell/MCP-Bridge
- GitHub - modelcontextprotocol/servers at fe7f6c7b7620a1c83cde181d4d8e07f69afa64f2: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
MCP (Glama) ▷ #showcase (9 messages🔥):
Authentication for Toolbase, YouTube Demo Feedback, Journaling MCP Server, Audio Playback Adjustment
- Authentication for Toolbase is Hacked Out: A member quickly implemented authentication for different tools like Notion, Slack, and GitHub for Toolbase for Claude, showcasing it in a YouTube demo.
- Member expressed desire for feedback on the flow's simplicity, prompting reactions about video speed.
- YouTube Demo Sparks Playback Tips: One member noted they had to adjust their YouTube playback settings to enjoy the demo, calling it a fun video.
- Another member agreed, sharing an ffmpeg command for adjusting playback speed to improve the listening experience.
- Journaling MCP Server TaTakeoff: A member discussed creating a MCP server to convert chats with Claude into journaling sessions, allowing retrieval of past conversations.
- They shared a link to their GitHub project which saves chat sessions locally, aiming to enhance the client with a local LLM for better privacy.
Link mentioned: GitHub - mtct/journaling_mcp: MCP Server for journaling: MCP Server for journaling. Contribute to mtct/journaling_mcp development by creating an account on GitHub.
Stability.ai (Stable Diffusion) ▷ #general-chat (121 messages🔥🔥):
50 Series GPU Availability, Performance Comparison of GPUs, Running AI on Mobile Devices, AI Tools and Platforms, Stable Diffusion UI Changes
- 50 Series GPUs Sell Out Instantly: Many members expressed frustration over the 50 Series GPUs selling out almost immediately, with reports of only a few thousand units being shipped in North America.
- One member recounted that they had previously placed a 5090 in their basket, only to lose it when the store crashed.
- GPU Performance Comparisons: Discussions compared the performance of the 5090 to a 3060/3060 Ti for gaming, with users curious about how their current GPUs stack up.
- Members noted various capabilities, including VR functionalities, but were generally disappointed with the availability of the latest models.
- Running AI Tools on Phones: There were debates on whether it is feasible to run AI tools like Flux on mobile devices, with one user estimating an output time of 22.3 minutes from submission to output on Android.
- While some defended the potential for phones to handle AI tasks, others cautioned about hardware limitations and the overall performance.
- Exploring AI Platforms and Tools: Several members discussed various AI platforms and tools, with Webui Forge being recommended for local use of AI image generation.
- They emphasized the necessity for appropriate models to optimize image outputs effectively.
- Changes in Stable Diffusion UI: A user inquired about whether Stable Diffusion 3.5 must be operated on ComfyUI, expressing nostalgia for the layout used in the earlier versions.
- The conversation reflected a desire among some users for consistent UI experiences as they transition between versions.
- Screenshot: Captured with Lightshot
- Reddit - Dive into anything: no description found
Eleuther ▷ #general (28 messages🔥):
Pythia language model, Inductive biases in AI, Pretraining hyperparameters, Logging and monitoring tools, Non-token CoT concept
- Gaussian Sampling Insights on Pythia: A member discussed the probability of sampling a trained Pythia language model from a Gaussian, suggesting it may be pessimistic considering symmetries.
- Estimating permutation symmetries could provide deeper insights, although the focus is currently on local volume.
- *Inductive Biases* and Stability in Training: It was noted that certain strategies might lack inductive biases, which are crucial for model stability during training.
- Another member humorously equated the situation to the randomness of atoms permuting into ice.
- Discussions on Pretraining Hyperparameters: Members explored typical hyperparameters for pretraining masked language models (MLMs), with suggestions to check out the modernBERT paper.
- One participant shared personal insights on learning rates, proposing 5e-4 for base and 3e-4 with a doubled batch size for larger models.
- Tools for Logging and Debugging Runs: A member inquired about favorite tools for logging, monitoring, and debugging during training runs.
- This taps into a broader interest in effective management strategies for machine learning workflows.
- *Fully Non-token CoT* Concept Emerges: A new concept of fully non-token Chain of Thought has surfaced, involving the addition of a
- This approach enforces a limitation on the number of raw thought latents allowed per prompt during training to facilitate behavioral probing.
Link mentioned: Overleaf, Online LaTeX Editor: An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
Eleuther ▷ #research (32 messages🔥):
Critique Fine-Tuning, Training Metrics for LLMs, Generalization vs Memorization, Random Order Autoregressive Models, Inefficiencies in Neural Networks
- Critique Fine-Tuning (CFT) Proposed: A new approach called Critique Fine-Tuning (CFT) is introduced, focusing on models critiquing noisy responses rather than imitating correct ones, potentially leading to improved generalization.
- This method shows a 4-10% performance improvement over standard Supervised Fine-Tuning (SFT) on various benchmarks.
- Concerns over CE-loss as a training metric: There’s a growing consensus that using CE-loss for measuring language model effectiveness is inadequate, leading to calls for alternative metrics to drive better training results.
- One member highlights that simply encouraging 'winners' in training could improve outcomes rather than relying solely on CE-loss.
- Generalization amidst Memorization Debate: Members discuss the balance between memorization and generalization, with insights that retaining some level of commonality within circuits is necessary for effective learning processes.
- Concerns also arise about the feasibility of models learning under highly encrypted or mangled data conditions, suggesting inefficiencies in such training schemas.
- Exploring Random Order Autoregressive Models: The community is exploring the potential of random order autoregressive models to capture the structure of information, despite their impracticality in real-world applications.
- One member posits that these models, when applied to small datasets, exhibit learning properties that could leverage their over-parameterized nature for improved structure identification.
- Inefficiencies of Learning Models in Practice: There is a recognition that many neural network training methods, while theoretically sound, are catastrophically inefficient and often yield minimal effective results.
- Members note that the focus should be on developing strategies that reduce training inefficiencies, moving towards more practical and scalable solutions.
Link mentioned: Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate: Supervised Fine-Tuning (SFT) is commonly used to train language models to imitate annotated responses for given instructions. In this paper, we challenge this paradigm and propose Critique Fine-Tuning...
Eleuther ▷ #interpretability-general (3 messages):
Superhuman reasoning models, Backtracking vector discovery, Sparse autoencoders in reasoning, Propositional attitudes in AI, Mechanistic understanding vs. propositional attitudes
- Nous Research on Superhuman Reasoning: Shannon Sands from @NousResearch theorized that LLMs learn task vectors for reasoning operations and discovered a backtracking vector that significantly influences the thought process.
- He emphasized that training models across diverse domains could eventually enable them to apply reasoning capabilities universally, a focal point of their current research.
- DeepSeek's Backtracking Vector Findings: DeepSeek identified a backtracking vector that when applied caused more frequent reversals in the chain of thought, leading to a linear and shorter chain of thought (CoT) when suppressed.
- They hypothesized that sparse autoencoders may uncover features like backtracking and self-correction that can be explicitly manipulated and edited for more effective reasoning.
- Chalmers' Paper on AI Propositional Attitudes: A recent paper by @davidchalmers42 argues that extracting propositional attitudes from AI systems is a more valuable approach than seeking mechanistic understanding.
- He acknowledged and cited a paper from the team, adding to the discussion around the significance of propositional attitudes in AI research.
- Tweet from Chris Barber (@chrisbarber): Interesting on superhuman reasoning models, shared with permission:Shannon Sands (@max_paperclips) from @NousResearch told me that Nous has a theory that LLMs learn task vectors for reasoning operatio...
- Tweet from Nora Belrose (@norabelrose): This new paper from @davidchalmers42 is goodExtracting propositional attitudes from AI is more useful than chasing after "mechanistic" understandingAlso he cited a paper from our team, thanks ...
Eleuther ▷ #lm-thunderdome (29 messages🔥):
gsm8k evaluations, lm-eval harness settings, vllm integration and KV Cache, RWKV model configurations, performance metrics comparisons
- gsm8k Evaluation Confusion: Concerns arose about the gsm8k task metrics, specifically whether
gsm8k-cot-llama.yamlevaluates against the maj@1 metric as noted in the Llama 2 paper.- Current findings show 0.0334 accuracy using
gsm8k_cot_llama.yaml, whilegsm8k.yamlprovides 0.1251 accuracy, aligning better with the Llama 2 metrics.
- Current findings show 0.0334 accuracy using
- Handling Evaluation Settings: Members discussed whether to use task YAML configurations or stick with exact-match metrics for evaluations, leading to insights about default settings in the lm-eval harness.
- It was noted the harness would require manual adjustments for proper evaluation configurations, particularly regarding max_new_length for RWKV models.
- Max Token Settings in Model Definitions: A member expressed concerns regarding max tokens affecting evaluation results, especially in tests using
generate_untilfunctions.- The group confirmed that defaults are utilized unless specified, advising checks on model definitions for potential discrepancies.
- Perplexity Evaluation and KV Cache: Questions were raised about the KV Cache usage in perplexity evaluations via the vllm integration, specifically regarding potential overlapping window modifications.
- The community responded affirmatively, stating that non-overlapping windows are typically used and suggested modifications for overlapping pairs.
- Insights from Llama 2 Paper: Members noted that the Llama 2 paper lacked detailed evaluation methods for their models, making direct comparisons challenging.
- Subsequent discussions indicated that applying 8-shot configurations might offer clearer comparisons to Llama 2's reported results.
- general question: Is kv-cache actually not used in all the LLM-evaluation tasks? · Issue #1105 · EleutherAI/lm-evaluation-harness: Is kv-cache actually not used in all the LLM-evaluation tasks, since those tasks usually takes only one-step attention calculation, not like language generating process which needs a lot of kv-cach...
- lm-evaluation-harness/lm_eval/models/vllm_causallms.py at 0bb8406f2ebfe074cf173c333bdcd6cffb17279b · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/models/vllm_causallms.py at 1208afd34ce132e598fcd7e832762630a35d01c6 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
GPU MODE ▷ #general (23 messages🔥):
Deep Seek's Model Performance, GPU Server Recommendations, Running LLM Benchmarks, Discussion on PTX in Open Source, Deep Learning GPU Considerations
- Deep Seek's Model Performance Sparks Debate: Members are questioning whether Deep Seek has a significant processing advantage over models like OpenAI and Meta, citing company compute power as a possible factor.
- Concerns arise about validating claims, such as having 50k H100s and whether Deep Seek's approach could impact Nvidia's stock.
- GPU Server vs. Individual Laptops for Development: A software architect inquired whether to purchase a GPU server to build VMs for development instead of four GPU laptops, considering future model training needs.
- One member recommended reading a blog on selecting GPUs for deep learning, highlighting various important specifications.
- Challenges Running LLM Benchmarks: A member sought advice on running LLM benchmarks programmatically using transformers.AutoModelForCausalLM, expressing frustration with tools like lighteval.
- Another member maintained that lm_eval is still the best option and shared that they had a functional script for similar tasks.
- Clarifications on PTX and Open Source: There’s discussion around whether PTX for distributed training is included in Deep Seek's open-source offerings, with some members asserting it’s not available in the V3 repo.
- Others speculated on the limitations of what Deep Seek has open-sourced, particularly regarding the training cost claims.
- Skepticism and Efficiency of Deep Seek: Concerns were raised about the perceived efficiency of Deep Seek compared to other models, with members discussing the verification of training costs as not easily attainable.
- Despite skepticism regarding certain aspects, it was noted that Deep Seek demonstrated notable efficiency metrics in its release.
Link mentioned: The Best GPUs for Deep Learning in 2023 — An In-depth Analysis: Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.
GPU MODE ▷ #triton (2 messages):
Triton tensor indexing, Efficient column extraction, Mask and reduction technique
- Triton tensor indexing fails on single column extraction: A user reported that attempting to extract a single column using
x[:, 0]results in an error:InterpreterError: ValueError('unsupported tensor index: 0').- The approach using
tl.gatherwith an index tensor set to zeros was suggested but deemed inefficient.
- The approach using
- Applying masks with tl.where for tensor manipulation: Another member recommended using a mask with
tl.whereas a solution to extract data from tensors.- This method could potentially be coupled with a reduction operation to achieve the desired outcome efficiently.
GPU MODE ▷ #cuda (10 messages🔥):
RTX 5090 FP4 Performance, NVIDIA FP8 Specification, CUDA and Python Integration, Flux Implementation Benchmarking, 100 Days of CUDA Resource Request
- RTX 5090 FP4 underperforms compared to expectations: Confusion was raised regarding the performance of FP4 with FP32 on the RTX 5090, which is reported to be only ~2x faster than FP8 on the RTX 4090, despite claims of ~5x speedup.
- Incorrect documentation suggests NVIDIA may be misrepresenting performance numbers, leading to skepticism from users.
- Clarification on FP8 performance metrics: A member pointed out that the previously cited 660TFLOPS for FP8 was applicable only to FP16 accumulate, while FP32 showed only ~330TFLOPS on the RTX 4090.
- This created further questions around the transparency of NVIDIA's performance benchmarks.
- Discussion on Flux Implementation for Benchmarks: Inquiries were made about the Flux implementation, with hopes that benchmarks could clarify the performance discrepancies reported for FP4.
- One member noted that memory movement could also impact speedup, emphasizing the complexity of the performance evaluations.
- Python Usage Among CUDA Developers: Users shared insights into how much Python they use in conjunction with CUDA, with discussions highlighting its use for tools and scripts.
- While integration is described as trivial, it still underscores an important aspect of development in GPU programming.
- Request for '100 Days of CUDA' Materials: A member requested resources related to the 100 Days of CUDA as a guide for improvement.
- This indicates ongoing interest in structured learning resources within the community.
GPU MODE ▷ #torch (2 messages):
Torch Logs Debugging, CUDA Duplicate GPU Error
- Seeking Better TORCH_LOGS Settings for Memory Debugging: A user recommended different settings for TORCH_LOGS to debug a model experiencing unexpectedly high memory usage, stating that TORCH_LOGS="all" provided little useful information.
- They also attempted to analyze memory snapshots with torch memory_viz, but found the results too noisy to identify the source of the extra memory.
- Resolution for Duplicate GPU Detection Issue: A user encountered a 'Duplicate GPU detected' error message when using two RTX 4090 GPUs, specifically stating ranks 0 and 1 were both detected on the same device.
- They attached an error.txt file and a code.txt for others to analyze, asking for suggestions on how to resolve this issue.
GPU MODE ▷ #cool-links (6 messages):
Riffusion platform, Audio generation artists, DeepSeek narrative, YouTube video on AI music, New research paper by Arthur Douillard et al.
- Riffusion: A New Music Generation Tool: Riffusion, a platform for music generation, showcased its beta version with featured playlists on their website. Users expressed curiosity about its capabilities and potential applications.
- One member humorously referred to it as 'Suno on steroids', hinting at its powerful features.
- Who Will Be the First Big Artist Using AI?: Mr.osophy pondered about the first major artist to use audio generation technology creatively, likening it to T-Pain's pioneering use of autotune. The conversation revolved around the need for skilled producers to leverage AI effectively.
- They wondered about the potential of existing AI-assisted songs, mentioning 'Drake - Heart on My Sleeve' as an exception.
- Neon Tide's AI-Assisted Music Video: A member shared a YouTube video titled Neon Tide - Boi What (Lyric Video), highlighting an innovative use of AI in music production. The artist creatively transformed his voice using AI tools to emulate characters like Plankton and SpongeBob.
- This unique approach sparked discussions on how AI can enhance musical creativity in unexpected ways.
- DeepSeek Takes Center Stage: Mr.osophy highlighted the burgeoning hype around DeepSeek, which has quickly become a hot topic, overshadowing platforms like Claude and Perplexity. He pointed out that this excitement isn't entirely new, as the company has been a subject of conversation among insiders for months.
- Referenced links from SemiAnalysis detail previous discussions, indicating that the broader public is just now catching on to DeepSeek's significance.
- Research Exploration by Arthur Douillard et al.: A user directed attention to a newly released research paper by Arthur Douillard and collaborators, available on arXiv. The paper's authors include notable researchers, prompting interest in their latest findings.
- Discussion about the paper and its implications suggests a keen interest in ongoing advancements in AI-related research.
- Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch: Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at e...
- Riffusion: no description found
- DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts: The DeepSeek Narrative Takes the World by Storm DeepSeek took the world by storm. For the last week, DeepSeek has been the only topic that anyone in the world wants to talk about. As it currently s…
- Neon Tide - Boi What (Lyric Video): NEON TIDE out NOW: Connect with Boi What:https://www.instagram.com/boiwhatmusic/https://www.tiktok.com/@boiwhatthttps://twitter.com/boiwhatmusichttps://www.t...
GPU MODE ▷ #off-topic (8 messages🔥):
Salmon Patty Dish, Novelty Plate Discussion, Wework Critique, CEO Value Perception
- Salmon Patty Dish Sparks Interest: A member shared a photo featuring a salmon patty, fried potatoes, sweet red pepper, and a homemade waffle with Greek yogurt, capturing culinary creativity.
- Another noted the dish's appearance, humorously comparing the patty to a giant egg when using canned peaches beforehand.
- Novelty Plate Insights: In a light-hearted exchange, a member identified a novelty plate linked to Tuberculosis Sanatorium 96 in response to a previous comment.
- This playful banter indicated a shared amusement about the plate's quirky design.
- Wework's Downfall Reflects Failed Empire: A member quipped, Lol Wework looking like a failed empire, alluding to the perception of Wework's business struggles.
- This comment encapsulates ongoing sentiments about modern entrepreneurship and its challenges.
- Candid CEO Value Conversations: A member shared a thought on how CEO's often overestimate their actual value, implying inflated self-importance in leadership.
- This insight resonates with ongoing discussions about industry standards and accountability among executives.
GPU MODE ▷ #irl-meetup (1 messages):
NVIDIA GTC Discount
- NVIDIA offers 40% discount for GTC: NVIDIA is providing a 40% discount for the upcoming GTC event when using the code GPUMODE.
- This promotional offer could be a great opportunity for event attendees to save on registration.
- Opportunity to attend GTC at a reduced price: The GTC event is a key opportunity for professionals in the GPU field to connect and learn.
- Taking advantage of this discount could enhance the event experience for many.
GPU MODE ▷ #liger-kernel (2 messages):
LigerDPOTrainer, Support for Liger-kernel losses
- LigerDPOTrainer is not available yet: It was noted that there currently exists no LigerDPOTrainer in the Liger kernel, suggesting that users may need to monkey patch the original dpo_loss instead.
- Unfortunately, I don't think there exists a
LigerDPOTrainerfor now.
- Unfortunately, I don't think there exists a
- Progress on Liger DPO support from Hugging Face: A pull request #2568 was introduced to add support for Liger-kernel losses in DPO Kernel, marking progress on the issue.
- The request notes, 'Needs: linkedin/Liger-Kernel#521', indicating further collaboration is required.
Link mentioned: [Liger] liger DPO support by kashif · Pull Request #2568 · huggingface/trl: What does this PR do?Add support for Liger-kernel losses for the DPO KernelNeeds: linkedin/Liger-Kernel#521
GPU MODE ▷ #reasoning-gym (30 messages🔥):
Proposed New Datasets for Reasoning Gym, GitHub Contributions to Reasoning Gym, Ideas for Game and Algorithm Development, Performance and Validation in Game Design, Dependency Management in Projects
- Proposed New Datasets to Expand RL Environments: A member suggested adding datasets for Collaborative Problem-Solving and Ethical Reasoning to enhance the Reasoning Gym, highlighting topics like multi-agent negotiation and bias mitigation.
- These additions aim to broaden the dataset scope and engage more complex problem-solving scenarios.
- GitHub Contributions and Projects: Members discussed contributions to various GitHub projects such as Nous Research's Open Reasoning Tasks and the Reasoning Gym gallery, now featuring 33 datasets.
- Feedback was provided regarding dataset generation proposals, encouraging members to open issues for their ideas.
- Game Development and Algorithmic Challenges: A discussion arose regarding the challenges of creating games with non-algorithmic solutions, stressing the need for quicker validation of answers.
- Members expressed interest in developing real multi-turn games, noting the importance of balancing complexity and solvability.
- Feedback on Game Design and Performance: One member shared insights from attempting to port a game, realizing it didn't fit the project due to validation complexity, while expressing openness to future ideas.
- Community members were encouraged to share concepts for feedback before implementation to ensure alignment with project goals.
- Dependency Management and Z3Py Consideration: A query about the potential addition of Z3Py as a dependency was posed, aiming for simplification of processes, especially since sympy is already part of the project.
- The maintainer affirmed that new dependencies would be considered if they provide sufficient benefits to justify their inclusion.
- The Rise of Agentic Data Generation: no description found
- GitHub - NousResearch/Open-Reasoning-Tasks: A comprehensive repository of reasoning tasks for LLMs (and beyond): A comprehensive repository of reasoning tasks for LLMs (and beyond) - NousResearch/Open-Reasoning-Tasks
- reasoning-gym/GALLERY.md at main · open-thought/reasoning-gym: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
- GitHub - LeonGuertler/TextArena: A Collection of Competitive Text-Based Games for Language Model Evaluation and Reinforcement Learning: A Collection of Competitive Text-Based Games for Language Model Evaluation and Reinforcement Learning - LeonGuertler/TextArena
- open-thought/reasoning-gym: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
- Collection of ideas for datasets/envs · Issue #26 · open-thought/reasoning-gym: Please share your ideas here. Wikipedia has some interesting lists which need to be screened to identify good candidates: Logic puzzles Recreational mathematics List of recreational number theory t...
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.8.0 Release, DeepSeek-R1-Distill Support, Chat Templating Overhaul, Code Interpreter Fixes, Local Server Fixes
- GPT4All v3.8.0 launches with exciting features: The latest version of GPT4All, v3.8.0, has been released, introducing significant upgrades and fixes.
- Contributors include Jared Van Bortel and Adam Treat from Nomic AI, along with ThiloteE.
- DeepSeek-R1-Distill Fully Integrated: GPT4All now offers native support for the DeepSeek-R1 family, enhancing model availability and performance.
- The updated model features improved reasoning display and resolves previous loading failures with the DeepSeek-R1 Qwen pretokenizer.
- Revamped Chat Templating for Better Compatibility: The chat template parser has been completely replaced, ensuring enhanced compatibility with numerous models.
- This overhaul aims to streamline interactions and improve user experience during chat sessions.
- Code Interpreter Issues Resolved: The code interpreter received critical fixes, including the ability to log strings effectively and preventing UI freezes during computations.
- These updates enhance the overall stability and responsiveness of the interpreter for users.
- Local Server Now Fully Functional: Local server issues hindering LocalDocs usage after requests have been addressed in this update.
- System messages now correctly remain hidden from message history, providing a cleaner user interface.
Nomic.ai (GPT4All) ▷ #general (61 messages🔥🔥):
DeepSeek integration, GitHub issues and updates, Voice processing inquiries, Model quantization differences, Custom functionality in Jinja templates
- DeepSeek successfully integrated with GPT4ALL: Users confirmed that DeepSeek works smoothly within GPT4ALL, exciting many in the community.
- One user expressed appreciation for the hard work of the Nomic team in making it happen.
- Active discussion on GitHub issues: A user reported a crash on startup for the Mac version in GPT4ALL 3.8 and linked a bug report on GitHub.
- Members discussed possible changes made from Qt 6.5.1 to 6.8.1 which could be responsible for the issue.
- Questions on voice processing capabilities: A user inquired about any existing models that could analyze voice similarities, but the consensus was that GPT4ALL currently does not support voice models.
- Alternatives such as voice similarity analyzers were suggested, emphasizing specialized applications for this purpose.
- Discussion on model quantization methods: A user sought clarification on the difference between model quantization names, particularly those with '-I1-', leading to a summary of techniques from a Reddit post.
- Community members pointed out that K-quants and i-quants have unique performance characteristics depending on the hardware.
- Custom functionality in GPT4ALL templates: Discussion centered around Jinja and the newly supported features in GPT4ALL v3.8, including namespaces and list slicing in templates.
- Members provided resources on the available functions and filters, reinforcing the improvements made for template compatibility.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- [REGRESSION] macOS Sequoia crash on startup in 3.8 (3.7 worked fine) · Issue #3448 · nomic-ai/gpt4all: (Did not see a similar issue) Bug Report GPT4ALL crashes on startup in version 3.8 after 3.7 and previous versions worked correctly. Steps to Reproduce Download and install GPT4ALL 3.8 Double click...
- minja/include/minja/minja.hpp at 76f0d01779aa00b0c68f2117f6cb2c9afc3a0ca8 · google/minja: A minimalistic C++ Jinja templating engine for LLM chat templates - google/minja
- Support for deekseek thinking in the gui. by manyoso · Pull Request #3440 · nomic-ai/gpt4all: no description found
- no title found: no description found
- Chat Templates - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
Notebook LM Discord ▷ #announcements (1 messages):
NotebookLM Usability Study, Participant Incentives, Remote Chat Sessions, User Feedback, Product Enhancement
- Join the NotebookLM Usability Study!: NotebookLM UXR is hosting a usability study on February 6th, 2025, seeking participants to share their initial experiences with the product via remote chats.
- Interested users can fill out the screener form for a chance to participate and receive $75 or a Google merchandise voucher if selected.
- Requirements for Participation: Participants must have a high-speed Internet connection, an active Gmail account, and a computer with a working video camera, speaker, and microphone to join the study.
- The study is designed to gather user feedback for future enhancements of NotebookLM's features.
- Incentives for Participants: Participants in the study will receive $75 via email or a $50 Google merchandise voucher as a token of appreciation for their time.
- This financial incentive aims to encourage more users to share their valuable insights during the usability study.
Link mentioned: Participate in an upcoming Google UXR study!: Hello,I’m contacting you with a short questionnaire to verify your eligibility for an upcoming usability study with Google. This study is an opportunity to provide feedback on something that's cur...
Notebook LM Discord ▷ #use-cases (9 messages🔥):
Lake Lanao's endemic cyprinids, Podcast length limitation, NotebookLM YouTube content
- Jar Jar and Yoda on Lake Lanao: A discussion featuring Jar Jar Binks and Yoda centered around the conservation of Lake Lanao's endemic cyprinids, prompting shared interest in habitat protection.
- An audio piece was attached to deepen the discussion.
- Limiting Podcast Length: A user inquired about limiting podcast length to one minute or shorter, prompting responses that indicated it's challenging to enforce this restriction.
- Another user suggested that reducing the text input could naturally lead to shorter podcasts.
- NotebookLM Content Praise: Excitement was expressed for NotebookLM content on YouTube, specifically praising a user for having outstanding material.
- Participants noted the high quality of content, contributing to a positive dialogue about its value in the community.
- Duration Curiosity: A user expressed curiosity about how another was able to create a nearly one-hour long podcast.
- This led to the clarification that it was another individual who produced the lengthy notebook content.
- Prompt Request: Interest in obtaining a specific prompt used for the podcast was shared, indicating community eagerness to learn from each other.
- Emojis like ❤️ highlighted the positive sentiments around sharing resources among users.
Notebook LM Discord ▷ #general (47 messages🔥):
Gemini 2.0 Flash Issues, AI Narration Improvements, Notebook Sharing Difficulties, Google Workspace and NotebookLM Plus, Defined Terms in Documents
- Gemini 2.0 Flash has glitches during update: Users experienced downtime with Gemini 2.0 Flash, likely due to the recent update, but it appears to be functioning again.
- Discussion suggested this update may have caused temporary issues, but some members reported it was working well.
- Desire for true AI narration: Members expressed interest in leveraging AI for better narration capabilities, wanting it to read scripts verbatim.
- While a single host narration style is possible, a member noted that it may not fully align with the product’s purpose.
- Challenges in sharing notebooks: Multiple users reported difficulties while trying to share their notebooks, even with public links.
- One suggested a workaround by copying a link to access the notebook after re-sharing, indicating potential bugs in the system.
- Concerns with Google Workspace integration: A user mentioned upgrading to a standard Google Workspace account but could not access NotebookLM Plus.
- Another member provided a checklist link for troubleshooting this integration, suggesting it might not require an addon license anymore.
- Defined terms in documents query: A member raised a question about using NotebookLM for identifying defined terms in documents.
- Another participant suggested experimenting with it, indicating uncertainty about the tool’s ability in this area.
- Tracking AI: Tracking AI is a cutting-edge application that unveils the political biases embedded in artificial intelligence systems. Explore and analyze the political leanings of AIs with our intuitive platform, ...
- The Drive AI: Revolutionizing File Management & Knowledge Bases: Discover The Drive AI's breakthrough in smart file organization. Our platform transforms your files into a dynamic knowledge base with the help of cutting-edge AI. Elevate your business operation...
- A Conversation with NotebookLM's Founding Engineer: Google's NotebookLM has become one of the most compelling AI tools for working with text. In this conversation, Adam Bignell, the project's founding engineer...
- TikTok - Make Your Day: no description found
Torchtune ▷ #general (19 messages🔥):
Distributed GRPO, Memory Management in GRPO, Profiler for Memory Usage, VLLM Inference, Using bf16 for Training
- GRPO Faces OOM Challenges: A member discussed issues with out of memory (OOM) errors when using GRPO on GitHub, suspecting memory management mistakes coupled with limitations of using fp32.
- Switching to bf16 seemed to alleviate some issues, enabling a stronger case for resource acquisition.
- Memory Usage Profiler Recommendations: The conversation turned to generating memory usage diagrams, with suggestions for using the profiler from the current PPO recipe to troubleshoot OOM errors.
- One member advised trying a smaller model to generate profiler traces and share more manageable results for analysis.
- Insights on Mixed Precision Training: A member clarified that using bf16 with emulation on a V100 may not save memory during calculations, while data can be stored in 16 bits.
- This insight highlighted the trade-offs between storage and computations when switching precision formats.
- Parallel Inference Training for GRPO: One participant suggested that significant improvements in GRPO's performance could come from running inference in parallel to training with vLLM.
- However, challenges were noted regarding difficulties in integrating vLLM with models outside the Hugging Face ecosystem.
- Push for Iterative Improvement in GRPO: After publishing modifications to the GRPO project on GitHub, members discussed iterating on results before cleaning up the code for more structured contributions.
- There was acknowledgment of the intense adjustments being made internally to optimize performance before submitting formal pull requests.
Link mentioned: GitHub - RedTachyon/torchtune: PyTorch native post-training library: PyTorch native post-training library. Contribute to RedTachyon/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (27 messages🔥):
Gradient Accumulation Issues, TRL vs. Torchtune Config Differences, DPO Training Anomalies, Multinode Support in Torchtune, Loss Calculation Normalization
- Gradient Accumulation Issues Plaguing Training: Recent discussions revealed that there is an unresolved issue affecting Gradient Accumulation that negatively impacts training and loss calculations across various models.
- With a focus on training efficiency, users are investigating whether the lack of a fix affects models such as DPO and PPO.
- Comparing TRL and Torchtune Configurations: Members discussed significant parameter differences, particularly a max prompt length of 512 in TRL which could affect model outputs compared to Torchtune's settings.
- They noted that implementing TRL settings in Torchtune did not yield any positive learning results during testing.
- Anomalies in DPO Training Loss: One user pointed out concerns regarding DPO which reached a loss of 0 and accuracy of 100% within a few steps on the same dataset, indicating potential issues.
- Discussions followed regarding normalization and the implications of loss calculations to ensure accuracy in training outcomes.
- Push for Final Approval on Multinode Support: There was a request for final approval on multinode support integration within Torchtune, stressing its importance for user demand.
- The parameter
offload_ops_to_cpuwas debated, with confirmation needed on its relevance in the backend context for multithreading capabilities.
- The parameter
- Normalization of Loss Calculation in Training: Attention was drawn to a pull request aimed at improving loss normalization by considering non-padding tokens, pivotal for accurate metrics.
- Users expressed the need for a robust solution to ensure loss calculations are performed correctly, particularly during gradient accumulation.
- Bug Fixes in LLM Training - Gradient Accumulation: Unsloth's Gradient Accumulation fix solves critical errors in LLM Training.
- unslothai/unsloth: Finetune Llama 3.3, Mistral, Phi-4, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory - unslothai/unsloth
- Use checkout@v4 / upload@v4 for docs build by joecummings · Pull Request #2322 · pytorch/torchtune: 👀 👀 👀 👀 👀 👀 👀 👀 👀👀 👀 👀 👀 👀👀 👀 👀 👀 👀 👀 👀 👀
- Normalize CE loss by total number of (non-padding) tokens by ebsmothers · Pull Request #1875 · pytorch/torchtune: In honor of the day the ML community first discovered the fact that (x1 / n1) + (x2 / n2) != (x1 + x2) / (n1 + n2)This PR changes how we calculate the loss when gradient accumulation is enabled. T...
- Multinode support in torchtune by joecummings · Pull Request #2301 · pytorch/torchtune: Officially declaring multi-node open for business in torchtune!ContextThis has been an explicit ask by several users (#2161, #2142) and although things should work fairly easily OOTB, we hadn'....
- Full DPO Distributed by sam-pi · Pull Request #2275 · pytorch/torchtune: ContextAdapted from the great work in #1966What is the purpose of this PR? Is it to add a new featurePlease link to any issues this PR addresses: relates to #2082ChangelogWhat are the chang...
Modular (Mojo 🔥) ▷ #general (7 messages):
HPC resources and programming languages, DeepSeek's impact on AI compute demands, Mojo integration with VS Code, Modular cfg file issues, Clarifying tech details in blog series
- HPC Resources Need Better Utilization: A member expressed excitement about a blog series aimed at addressing the challenges faced by scientists using heterogeneous HPC resources, highlighting the need for better programming language solutions like Mojo.
- They emphasized that effective hardware utilization could potentially reduce reliance on expensive GPUs, indicating a shift in common perceptions about AI's compute demands.
- DeepSeek Disrupts AI Compute Norms: The member mentioned that DeepSeek's recent advancements have demonstrated that better hardware utilization could significantly change the landscape of AI compute needs and challenge existing beliefs.
- Big Tech is reacting to this shift, scrambling not only to compete with DeepSeek, but also to defend the notion that massive infrastructure is vital for maintaining a lead in AI research.
- Issues Connecting Mojo with VS Code: A user described difficulties integrating Mojo with VS Code while using WSL and Magic, indicating that the process was unclear.
- They reported receiving an error stating that the modular cfg file could not be read when attempting to run code in VS Code.
- Request for Help in Forum: Another member suggested posting the technical issues in the forum or a specific channel to seek more focused assistance.
- This highlights the community's encouragement to utilize available resources for problem-solving.
- Expectation of Clarifying Tech Details: An excited member shared their eagerness to contribute to the upcoming blog series, believing that Mojo and MAX present viable solutions.
- They acknowledged the complexity of the issues but hoped the series would clarify these challenges for a broader audience.
Link mentioned: Modular: Democratizing Compute, Part 1: DeepSeek’s Impact on AI: Part 1 of an article that explores the future of hardware acceleration for AI beyond CUDA, framed in the context of the release of DeepSeek
Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
Backwards Compatibility in Libraries, Mojo 1.0 Benchmarking Delays, Swift Complexity Concerns, Mojo's Development Stability
- Backwards Compatibility is Crucial: A member emphasized that backwards compatibility is vital across all systems, including plugins and libraries; without it, users are forced to choose between never updating or losing essential features.
- They pointed out that this phenomenon applies universally, affecting user satisfaction and ecosystem vibrancy.
- Mojo 1.0 Release Timeline Confirmation: Another member expressed contentment with delaying the release of Mojo 1.0, advocating for thorough benchmarking on larger compute clusters before launch.
- They noted that testing on smaller systems acts as a 'mini-benchmarking' for Mojo's capabilities, ensuring broader usability for community users.
- Swift's Complications with Async: A user shared concerns about the complexity introduced by Swift, especially when implementing asynchronous features, revealing potential pitfalls in code design.
- This dialogue led to a mutual desire among members for Mojo to avoid such complications and maintain simplicity in its development.
- Focus on Stability Over Rush: Clattner acknowledged the need for stability in Mojo's development, clarifying that there's no pressure to rush the release process.
- They highlighted that while versioning is important for communication, the priority remains on creating a balanced and well-thought-out product for the community.
- How to convert numpy array items to mojo Float?: Hi, i’m trying to get each element of a numpy array as a mojo Float. So far this works var value: Float64 = Xb.item(i, j).to_float64() But the linter sugest using float(obj) wich i assume is Float6...
- [BUG]: The `mojo-lsp-server` executable shows incorrect help information · Issue #289 · modular/max: Bug description The mojo-lsp-server executable displays many options when the --help argument is provided, but they are not relevant to its behavior. @JoeLoser suggested this bug be filed so that w...
Modular (Mojo 🔥) ▷ #max (3 messages):
Running DeepSeek with MAX, Using Ollama gguf files
- Running DeepSeek using MAX made easy: A member inquired about running DeepSeek with MAX after successfully downloading the model's gguf file using Ollama.
- Instructions were provided to run the command
magic run serve --huggingface-repo-id deepseek-ai/DeepSeek-R1-Distill-Llama-8B --weight-path=unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguffrom the/pipelines/pythondirectory of the latest MAX repository.
- Instructions were provided to run the command
- Max maximizes DeepSeek potential: It's noted that with the latest checkout of the nightly MAX repository, users can effectively utilize DeepSeek models.
- This capability highlights the integration of MAX with advanced models, enhancing flexibility for users.
LlamaIndex ▷ #blog (3 messages):
Meetup with Arize AI and Groq, LlamaReport beta release, o3-mini support
- Triple Talk on Agents and Tracing: Catch the recording of our meetup with @arizeai and @GroqInc discussing agents and tracing, featuring live demos using Phoenix by Arize.
- The session dives into LlamaIndex's agent capabilities, ranging from basic RAG techniques to advanced functionalities, detailed in the Twitter thread.
- LlamaReport Beta Showcased: Check out this video using an early beta of LlamaReport, a core application for report generation set for 2025.
- Watch the demonstration in the Twitter link showcasing its features and functionalities.
- Instant Support for o3-mini: Announcing Day 0 support for o3-mini with instructions to install using
pip install -U llama-index-llms-openai.- For more details, see the Twitter announcement highlighting the installation command.
LlamaIndex ▷ #general (9 messages🔥):
OpenAI O1 Model Support, LlamaReport Usage, LLM Integration Issues
- OpenAI O1 Model lacks full capability: Discussion revealed that OpenAI has not implemented full capabilities for the O1 model, leading to confusion about its functionalities and support.
- Community members noted that the streaming support for the model has been very weird, with many functionalities failing to work as expected.
- Inquire about LlamaReport Channel: A member asked if there is a specific channel for LlamaReport, to which it was stated that no dedicated channel exists as access is limited.
- Details provided suggested that not many people have access to LlamaReport at this stage.
- Concerns with LlamaReport Functionality: Another member expressed difficulties getting anything to generate using LlamaReport, questioning how the LLM integration and payment process works.
- Despite issues, it was mentioned that basic tests had run successfully, specifically mentioning the upload of papers for summarization.
- Clarification on Llama-Parse Charges: It was clarified that Llama-Parse charges mainly occur for parsing content, and members speculated that it could be free under certain conditions.
- Users were encouraged to check if they have available credits or a paid plan to explore the integration's functionality.
Link mentioned: Streaming support for o1 (o1-2024-12-17) (resulting in 400 "Unsupported value"): Hello, it appears that streaming support was added for o1-preview and o1-mini (see announcement OpenAI o1 streaming now available + API access for tiers 1–5). I confirm that both work for me. Howe...
tinygrad (George Hotz) ▷ #general (10 messages🔥):
Physical server for LLM, Tinygrad PR discussions, Kernel and buffers adjustments, PR title typos
- Discussing Physical Servers for LLM Hosting: A user inquired about options for a physical server to host LLM locally for enterprise purposes, indicating interest in running models effectively.
- Another user mentioned Exolabs, referencing previous discussions about setups involving Mac Minis for similar tasks.
- Tinygrad PR Highlights: George Hotz acknowledged a good first PR related to kernel, buffers, and launch dimensions in tinygrad.
- He provided suggestions, such as removing 16 from the argument in
DEFINE_LOCAL, as it's already included in the dtype.
- He provided suggestions, such as removing 16 from the argument in
- Typo in PR Title Sparks Discussion: A user pointed out that a typo in a PR title might suggest a lack of attention to detail, which could affect maintainers' perception.
- The user apologized for missing the error and confirmed fixing it after receiving feedback.
Link mentioned: Tweet from the tiny corp (@tinygrad): one kernel, its buffers, and its launch dims, in tinygrad
Axolotl AI ▷ #general (10 messages🔥):
Axolotl AI support for bf16, fp8 training concerns, 8bit lora capabilities
- Axolotl AI embraces bf16 training: Members confirmed that Axolotl has supported bf16 training for a long time, moving beyond fp32.
- Just a heads up, it’s been recognized as a stable choice for training.
- Concerns about fp8 training performance: A discussion around fp8 highlighted its support with accelerate, but performance is reportedly not good, as noted by members.
- One remarked, I don't think we're looking into that atm due to its instability.
- 8bit lora vs 8bit fft: While one member confirmed that 8bit lora training is possible, they expressed uncertainty about 8bit fft capabilities.
- Another participant pointed out that fp8 is hard to work with and too unstable, which adds to the concerns.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (9 messages🔥):
Certificate Release Updates, Quiz 1 Availability, Syllabus Section Confusion
- Certificate Release Still Pending: It's been confirmed that certificates have not been released yet, and updates regarding this semester's certificate requirements will come later.
- Members expressed excitement about the impending release with comments like 'The wait for certificate is just so exciting!'
- Quiz 1 Now Accessible: Quiz 1 has been made available on the course website specifically in the syllabus section.
- Some members noted their difficulty locating the quiz link, indicating potential issues with visibility or access.
- Syllabus Section Confusion: A member expressed confusion about not seeing a link for the quiz in the syllabus section, prompting a response from another member providing a screenshot.
- Further discussion highlighted discrepancies between what members were seeing, generating a sense of mystery around the syllabus content.
Link mentioned: Quizzes Archive - LLM Agents MOOC: NOTE: The correct answers are in the black boxes (black text on black background). Highlight the box with your cursor to reveal the correct answer (or copy the text into a new browser if it’s hard to ...
OpenInterpreter ▷ #general (6 messages):
AI tool explanations, Farm Friend Application, iOS Shortcuts Patreon, NVIDIA NIM and DeepSeek
- AI Tool Gets Simplified: A member requested a simple explanation of what the AI tool does and its upcoming features, expressing clear curiosity about its functionality.
- They asked the community to clarify in a way that's easy for beginners to understand.
- Farm Friend Application Launch: A member shared excitement over launching new desktop applications in the ecosystem, especially the Farm Friend application.
- They promised to provide more links and resources as they continue to develop applications.
- Patreon for iOS Shortcuts: One member announced plans for a Patreon that will offer various levels of iOS shortcuts, including advanced features like agentic functionalities.
- They expressed enthusiasm about returning to share techniques demonstrated in the past year.
- Using NVIDIA NIM with DeepSeek: A member inquired about the possibility of utilizing NVIDIA NIM to install DeepSeek and connect it to an open interpreter.
- They are looking for advice and insights from the community on this technical integration.
Cohere ▷ #discussions (1 messages):
the_lonesome_slipper: Thank you!
Cohere ▷ #api-discussions (1 messages):
Cohere Embed API v2.0, HTTP 422 Error, Preprocessing for Embeddings, Cross-language Polarization Research, Embed Multilingual Model
- Facing HTTP 422 Error with Embed API v2.0: A user reported an HTTP 422 Unprocessable Entity error while trying the cURL example for the Embed API v2.0 with a valid API key and specified parameters.
- They linked to the Cohere Embed API documentation for reference.
- Interest in Multilingual Embedding for Research: The user expressed a desire to utilize the embed-multilingual-v3.0 model for analyzing several longer articles related to their research on cross-language polarization.
- They specifically asked for guidance on required preprocessing for potentially messy texts, referring to the Cohere Wiki Embeddings for context.
LAION ▷ #research (2 messages):
User Mentions, Thanks and Acknowledgment
- User Mentions: A user mentioned the role @825830190600683521 in the discussion, possibly drawing attention to their input or authority.
- This mention indicates a collaborative environment where specific contributions are recognized.
- Expressions of Gratitude: Another member, mega_b, expressed their appreciation by simply stating 'Ty' in response to the previous mention.
- This highlights a positive interaction within the channel where acknowledgment and gratitude are common.
DSPy ▷ #general (1 messages):
http_client parameter, dspy.LM configuration
- Missing http_client Parameter Confusion: A member pointed out that there is no http_client parameter in dspy.LM as there is in gpt3.py, stating that OpenAI and gpt3.py allow custom clients like httpx.Client with SSL context and proxy settings.
- This raised questions about how to implement similar functionality in dspy.LM.
- Custom Client Implementation Query: The conversation highlighted an interest in how to set up a custom client in dspy.LM, referencing the implementation seen in gpt3.py where
http_client: Optional[httpx.Client] = Noneis used.- Members discussed the potential for adapting this approach to fit within the dspy framework.