[AINews] o1 API, 4o/4o-mini in Realtime API + WebRTC, DPO Finetuning
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Better APIs are all you need for AGI.
AI News for 12/16/2024-12/17/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (210 channels, and 4050 messages) for you. Estimated reading time saved (at 200wpm): 447 minutes. You can now tag @smol_ai for AINews discussions!
It was a mini dev day for OpenAI, with a ton of small updates and one highly anticipated API launch. Let's go in turn:
o1 API
Minor notes:
o1-2024-12-17is a NEWER o1 than the o1 they shipped to ChatGPT 2 weeks ago (our coverage here), that takes 60% fewer reasoning tokens on average- vision/image inputs (we saw this with the full o1 launch, but now it's in API)
- o1 API also has function calling and structured outputs - with some, but very small impact on benchmarks
- a new
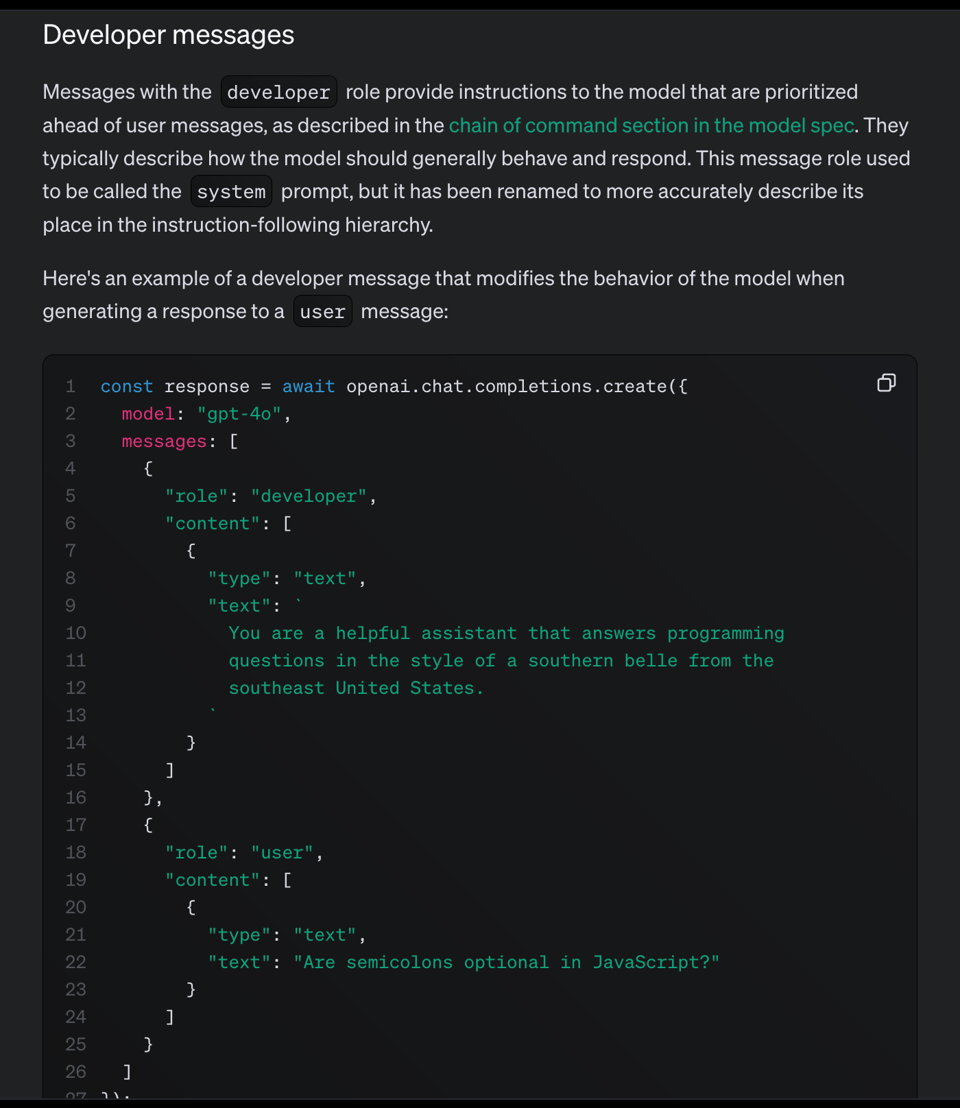
reasoning_effortparameter (justlow/medium/highstrings right now) - the "system message" has been renamed to "developer messages" for reasons... (we're kidding, this just updates the main chatCompletion behavior to how it also works in the realtime API)
o1 pro is CONFIRMED to "be a different implementation and not just o1 with high reasoning_effort setting." and will be available in API in "some time".
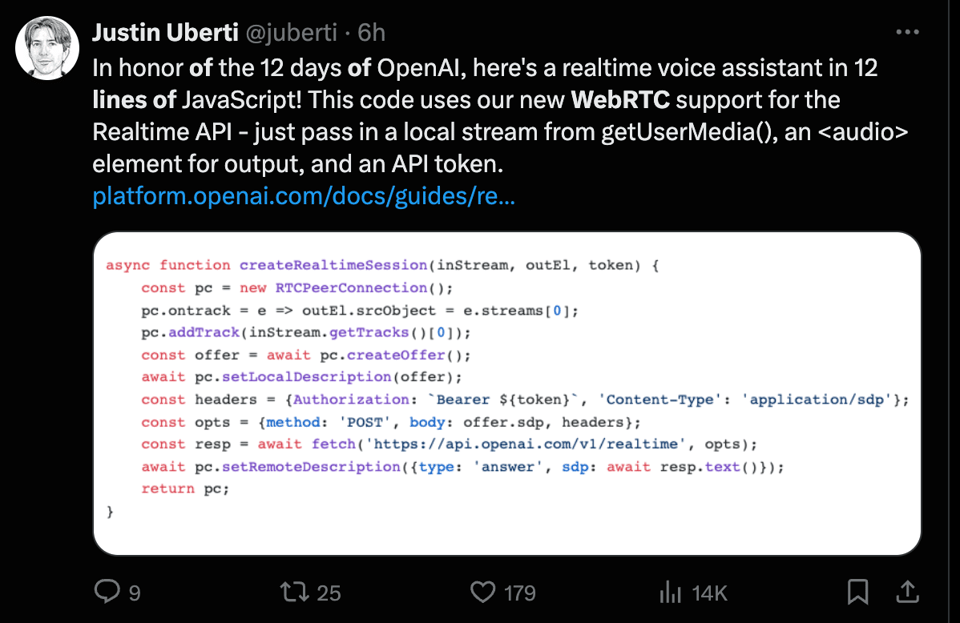
WebRTC and Realtime API improvements
It's a lot easier to work with the RealTime API with WebRTC now that it fits in a tweet (try it out on SimwonW's demo with your own keys)):
New 4o and 4o-mini models, still in preview:

Justin Uberti, creator of WebRTC who recently joined OpenAI, also highlighted a few other details
- improved pricing (10x cheaper when using mini)
- longer duration (session limit is now 30 minutes)
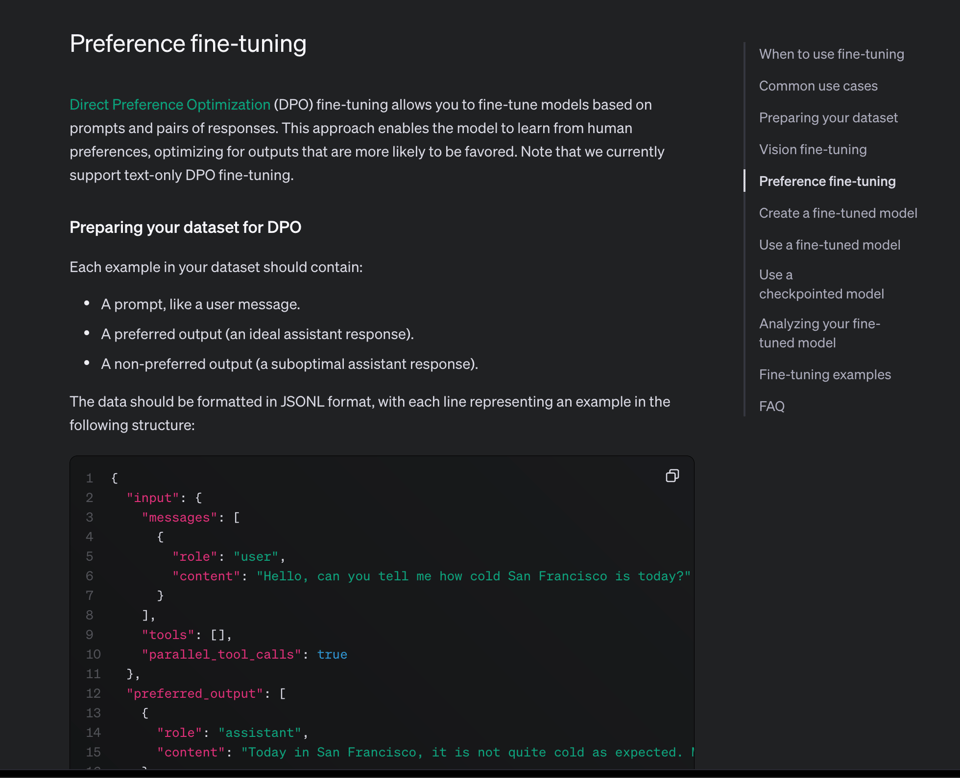
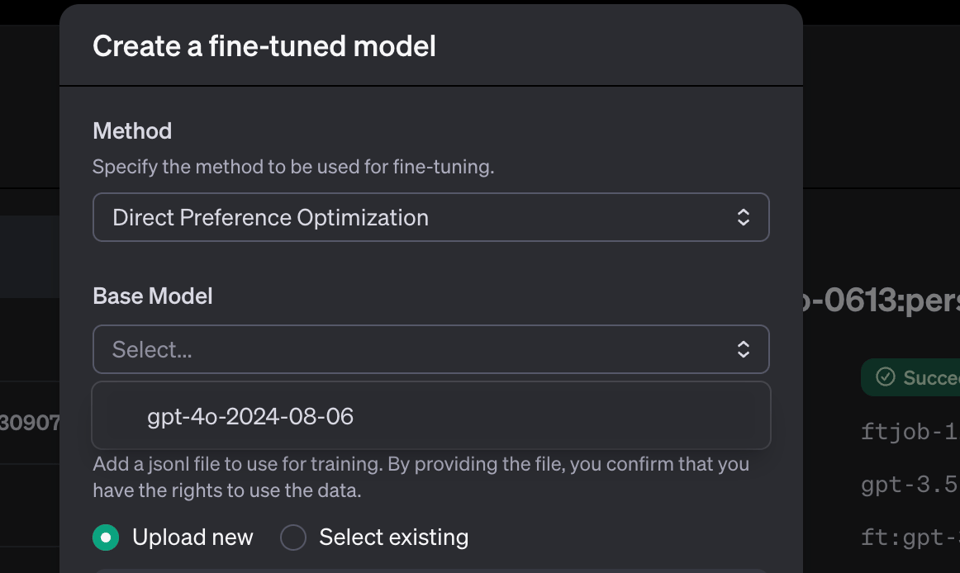
DPO Preference Tuning
It's Hot or Not, but for finetuning. We aim to try this out for AINews ASAP... although it seems to only be available for 4o.
Misc
Selected OpenAI DevDay videos were also released.
Official Go and Java SDKs for those who care.
The team also did an AMA (summary here, nothing too surprising).
The full demo is worth a watch:
Table of Contents
- o1 API
- WebRTC and Realtime API improvements
- DPO Preference Tuning
- Misc
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium / Windsurf Discord
- Nous Research AI Discord
- aider (Paul Gauthier) Discord
- Notebook LM Discord Discord
- Unsloth AI (Daniel Han) Discord
- Cohere Discord
- Bolt.new / Stackblitz Discord
- Eleuther Discord
- Cursor IDE Discord
- OpenAI Discord
- OpenRouter (Alex Atallah) Discord
- Perplexity AI Discord
- Latent Space Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- GPU MODE Discord
- Modular (Mojo 🔥) Discord
- LlamaIndex Discord
- Nomic.ai (GPT4All) Discord
- OpenInterpreter Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- tinygrad (George Hotz) Discord
- Axolotl AI Discord
- DSPy Discord
- Mozilla AI Discord
- MLOps @Chipro Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium / Windsurf ▷ #discussion (89 messages🔥🔥):
- Codeium / Windsurf ▷ #windsurf (668 messages🔥🔥🔥):
- Nous Research AI ▷ #general (566 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (6 messages):
- Nous Research AI ▷ #research-papers (5 messages):
- Nous Research AI ▷ #research-papers (5 messages):
- aider (Paul Gauthier) ▷ #general (302 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (34 messages🔥):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (32 messages🔥):
- Notebook LM Discord ▷ #general (207 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (183 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
- Unsloth AI (Daniel Han) ▷ #help (47 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (2 messages):
- Cohere ▷ #discussions (166 messages🔥🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (57 messages🔥🔥):
- Cohere ▷ #cmd-r-bot (1 messages):
- Bolt.new / Stackblitz ▷ #prompting (4 messages):
- Bolt.new / Stackblitz ▷ #discussions (213 messages🔥🔥):
- Eleuther ▷ #general (43 messages🔥):
- Eleuther ▷ #research (101 messages🔥🔥):
- Eleuther ▷ #interpretability-general (3 messages):
- Eleuther ▷ #lm-thunderdome (43 messages🔥):
- Eleuther ▷ #gpt-neox-dev (2 messages):
- Cursor IDE ▷ #general (173 messages🔥🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (130 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (12 messages🔥):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (130 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (90 messages🔥🔥):
- Perplexity AI ▷ #sharing (6 messages):
- Perplexity AI ▷ #pplx-api (2 messages):
- Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
- LM Studio ▷ #general (55 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (29 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (79 messages🔥🔥):
- GPU MODE ▷ #general (7 messages):
- GPU MODE ▷ #cuda (7 messages):
- GPU MODE ▷ #torch (9 messages🔥):
- GPU MODE ▷ #cool-links (14 messages🔥):
- GPU MODE ▷ #youtube-recordings (1 messages):
- GPU MODE ▷ #arc-agi-2 (8 messages🔥):
- Modular (Mojo 🔥) ▷ #general (25 messages🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (20 messages🔥):
- LlamaIndex ▷ #ai-discussion (2 messages):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (17 messages🔥):
- OpenInterpreter ▷ #general (12 messages🔥):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (3 messages):
- Torchtune ▷ #papers (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
- tinygrad (George Hotz) ▷ #general (6 messages):
- Axolotl AI ▷ #general (6 messages):
- DSPy ▷ #papers (2 messages):
- Mozilla AI ▷ #announcements (2 messages):
- MLOps @Chipro ▷ #events (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here's a categorized summary of the key discussions and announcements:
Model Releases and Performance
- OpenAI o1 API Launch: @OpenAIDevs announced o1's availability in the API with function calling, structured outputs, vision capabilities, and developer messages. The model reportedly uses 60% fewer reasoning tokens than o1-preview.
- Google Gemini Updates: Significant improvements noted with Gemini 2.0 Flash achieving 83.6% accuracy on the new DeepMind FACTS benchmark, outperforming other models.
- Falcon 3 Release: @scaling01 shared that Falcon released new models (1B, 3B, 7B, 10B & 7B Mamba), trained on 14 Trillion tokens with Apache 2.0 license.
Research and Technical Developments
- Test-Time Computing: @_philschmid highlighted how Llama 3 3B outperformed Llama 3.1 70B on MATH-500 using test-time compute methods.
- Voice API Pricing: OpenAI announced GPT-4o audio is now 60% cheaper, with GPT-4o-mini being 10x cheaper for audio tokens.
- WebRTC Support: New WebRTC endpoint added for the Realtime API using the WHIP protocol.
Company Updates
- Midjourney Perspective: @DavidSHolz shared insights on running Midjourney, noting they have "enough revenue to fund tons of crazy R&D" without investors.
- Anthropic Security Incident: The company confirmed unauthorized posts on their account, stating no Anthropic systems were compromised.
Memes and Humor
- @jxmnop joked about watching "Attention Is All You Need" in IMAX
- Multiple humorous takes on model comparisons and AI development race shared across the community
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Falcon 3 Emerges with Impressive Token Training and Diversified Models
- Falcon 3 just dropped (Score: 332, Comments: 122): Falcon 3 has been released, showcasing impressive benchmarks according to a Hugging Face blog post. The release highlights significant advancements in AI model performance.
- Model Performance and Benchmarks: The Falcon 3 release includes models ranging from 1B to 10B, trained on 14 trillion tokens. The 10B-Base model is noted for being state-of-the-art in its category, with specific performance scores such as 24.77 on MATH-Lvl5 and 83.0 on GSM8K. The benchmarks indicate that Falcon 3 is competitive with other models like Qwen 2.5 14B and Llama-3.1-8B.
- Licensing Concerns and Bitnet Model: There are concerns about the model's license, which includes a "rug pull clause" that could limit its use geographically. The release of a BitNet model is discussed, with some noting the model's poor benchmark performance compared to traditional FP16 models, although it allows for more parameters on the same hardware.
- Community and Technical Support: The community is actively discussing support for Mamba models and inference engine support, with ongoing developments in llama.cpp to improve compatibility. There is interest in the 1.58-bit quantization approach, though current benchmarks show significant performance drops compared to non-quantized models.
- Introducing Falcon 3 Family (Score: 121, Comments: 37): The post announces the release of Falcon 3, a new open-source large language model, marking an important milestone for the Falcon team. For further details, readers are directed to the official blog post on Hugging Face.
- LM Studio is expected to integrate Falcon 3 support through updates to llama.cpp, though issues with loading models due to unsupported tokenizers have been reported. A workaround involves applying a fix from a GitHub pull request and recompiling llama.cpp.
- Concerns about Arabic language support were raised, with users noting the lack of models with strong Arabic capabilities and benchmarks for reasoning and math. The response indicated that Arabic support is currently nonexistent.
- Users expressed appreciation for the release and performance of Falcon 3, with plans to include it in upcoming benchmarks. Feedback was given to update the model card with information about the tokenizer issue and workaround.
Theme 2. Nvidia's Jetson Orin Nano: A Game Changer for Embedded Systems?
- Finally, we are getting new hardware! (Score: 262, Comments: 171): Jetson Orin Nano hardware is being introduced, marking a notable development in AI technology. This new hardware is likely to impact AI applications, especially in edge computing and machine learning, by providing enhanced performance and capabilities.
- The Jetson Orin Nano is praised for its low power consumption (7-25W) and compact, all-in-one design, making it suitable for robotics and embedded systems. However, there is criticism regarding its 8GB 128-bit LPDDR5 memory with 102 GB/s bandwidth, which some users feel is insufficient for larger AI models compared to alternatives like the RTX 3060 or Intel B580 at similar price points.
- Discussions highlight the Jetson Orin Nano's potential in machine learning applications and distributed LLM nodes, with some users noting its 5x speed advantage over Raspberry Pi 5 for LLM tasks. Yet, concerns about its memory bandwidth limiting LLM performance are raised, emphasizing the importance of RAM bandwidth for LLM inference.
- Comparisons with other hardware include mentions of Raspberry Pi's upcoming 16GB compute module and Apple's M1/M4 Mac mini, with the latter offering better memory bandwidth and power efficiency. Users debate the Jetson Orin Nano's value proposition, considering its specialized use cases in robotics and machine learning versus more general-purpose computing needs.
Theme 3. ZOTAC Announces GeForce RTX 5090 with 32GB GDDR7: High-End Potential for AI
- ZOTAC confirms GeForce RTX 5090 with 32GB GDDR7 memory, 5080 and 5070 series listed as well - VideoCardz.com (Score: 153, Comments: 61): ZOTAC has confirmed the GeForce RTX 5090 graphics card, which will feature 32GB of GDDR7 memory. Additionally, the 5080 and 5070 series are also listed, indicating a forthcoming expansion in their product lineup.
- Memory Bandwidth Concerns: Users express disappointment with the memory bandwidths of the new series, except for the RTX 5090. There's a desire for larger memory sizes, particularly for the 5080, which some wish had 24GB.
- Market Dynamics: The release of new graphics cards often leads to a flooded market with older models like the RTX 3090 and 4090. Some users are considering purchasing these older models due to price-performance considerations and availability issues with new releases.
- Cost and Production Insights: Nvidia aims to maximize profits, which affects the availability of larger memory modules. The production cost of a 4090 is about $300, with a significant portion attributed to memory modules, hinting at potential limitations in the size of new DDR7 modules for upcoming models.
Theme 4. DavidAU's Megascale Mixture of Experts LLMs: A Creative Leap
- (3 models) L3-MOE-8X8B-Dark-Planet-8D-Mirrored-Chaos-47B-GGUF - AKA The Death Star - NSFW, Non AI Like Prose (Score: 67, Comments: 28): DavidAU has released a new set of models, including the massive L3-MOE-8X8B-Dark-Planet-8D-Mirrored-Chaos-47B-GGUF, which is his largest model to date at 95GB and uses a unique Mixture of Experts (MOE) approach for creative and NSFW outputs. The model integrates 8 versions of Dark Planet 8B through an evolutionary process, allowing users to access varying combinations of these models and control power levels. Additional models and source codes are available on Hugging Face for further exploration and customization.
- DavidAU develops these models independently, using a method he describes as "merge gambling" where he evolves models like Dark Planet 8B by combining elements from different models and selecting the best versions for further development.
- Discussions on NSFW benchmarking highlight the importance of models understanding nuanced prompts without defaulting to safe or generic outputs, with users noting that successful models avoid "GPT-isms" and can handle complex scenarios like those described in detailed prompts.
- Commenters emphasize the significance of prose quality and general intelligence in model evaluation, noting that many models struggle with maintaining character consistency and narrative depth, often defaulting to summarization rather than detailed storytelling.
Theme 5. Llama.cpp GPU Optimization: Snapdragon Laptops Gain AI Performance Boost
- Llama.cpp now supporting GPU on Snapdragon Windows laptops (Score: 65, Comments: 4): Llama.cpp now supports GPU on Snapdragon Windows laptops, specifically leveraging the Qualcomm Adreno GPU. The post author is curious about when this feature will be integrated into platforms like LM Studio and Ollama and anticipates the release of an ARM build of KoboldCpp. Further details can be found in the Qualcomm developer blog.
- FullstackSensei critiques the addition of an OpenCL backend for the Qualcomm Adreno GPU as redundant, suggesting that it is less efficient than using the Hexagon NPU and results in higher power consumption despite a minor increase in token processing speed. They highlight that the system remains bottlenecked by memory bandwidth, approximately 136GB/sec.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Steak Off Challenge Emphasizes Google's Lead in AI Video Rendering
- Steak Off Challenge between different Video Gens. Google Veo wins - by a huge mile (Score: 106, Comments: 13): Google Veo outperforms competitors in video rendering, particularly in handling complex elements like fingers and cutting physics. Hunyan ranks second, with Kling following, while Sora performs poorly. The original discussion can be found in a tweet.
- Google Veo is praised for its realistic rendering, particularly in the subtle details like knife handling, which gives it a more human-like quality compared to competitors. Users note the impressive realism in the video's depiction of food preparation, suggesting extensive training on cooking footage.
- Hunyan Video is also highlighted for its quality, although humorous comments note its rendering quirks, such as using a plastic knife. This suggests that while Hunyan is second to Google Veo, there are still noticeable areas for improvement.
- Discussions hint at the potential for an open-source version of such high-quality video rendering in the near future, indicating excitement and anticipation for broader accessibility and innovation in this space.
Theme 2. Gemini 2.0 Flash Model Enriches AI with Advanced Roleplay and Context Capabilities
- Gemini 2.0 advanced released (Score: 299, Comments: 54): Gemini 2.0 is highlighted for its sophisticated roleplay capabilities, with features labeled as "1.5 Pro," "1.5 Flash," and experimental options like "2.0 Flash Experimental" and "2.0 Experimental Advanced." The interface is noted for its clean and organized layout, emphasizing the functionalities of each version.
- There is a debate over the effectiveness of Gemini 2.0 compared to other models like 1206 and Claude 3.5 Sonnet for coding tasks, with some users expressing disappointment if 1206 was indeed 2.0. Users like Salty-Garage7777 report that 2.0 is smarter and better at following prompts than Flash, but worse in image recognition.
- The 2.0 Flash model is praised for its roleplay capabilities, with users like CarefulGarage3902 highlighting its long context length and customization options. The model is favored over mainstream alternatives like ChatGPT for its sophistication and ability to adjust censorship filters and creativity.
- There is interest in the availability and integration of Gemini 2.0 on platforms like the Gemini app for Google Pixel phones, though it is not yet available. Additionally, users are seeking coding benchmarks to compare Gemini 2.0 with other models, with some expressing frustration over the lack of such data.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. AI Models Battle for Supremacy
- Phi-4 Outsmarts GPT-4 in STEM: The phi-4 model with 14 billion parameters eclipses GPT-4 in STEM-related QA by leveraging synthetic data and advanced training techniques, proving that size isn't everything.
- Despite minor tweaks from phi-3, phi-4's revamped curriculum boosts reasoning benchmarks significantly.
- Gemini Flash 2 Takes Code Generation Higher: Gemini Flash 2 outperforms Sonnet 3.5 in scientific coding tasks, especially in array sizing, signaling a new era for code-generating AIs.
- Users are excited about integrating external frameworks to further enhance its capabilities.
- Cohere’s Maya Sparkles in Tool Use: The release of Maya has developers buzzing, with plans to finetune it for enhanced tool utilization, pushing project boundaries like never before.
Theme 2. AI Tools Struggle with Pricing and Integration
- Windsurf Woes: Code Overwrites and Pricing Puzzles: Users lament that Windsurf not only struggles with modifying files but also introduces confusing new pricing plans, making it harder to manage resources.
- Suggestions include integrating Git for better version control to prevent unwanted overwrites.
- Codeium’s Credit Crunch Causes Chaos: Rapid consumption of Flex credits in Codeium leaves users scrambling to purchase larger blocks, highlighting a need for clearer pricing tiers.
- Community debates the fairness of the new credit limits and the specifics of paid tiers.
- Aider’s API Launch: Feature-Rich but Pricey: The O1 API introduces advanced features like reasoning effort parameters, but users are wary of substantial price hikes compared to competitors like Sonnet.
- Combining O1 with Claude is suggested to leverage strengths but raises concerns about overconfidence in responses.
Theme 3. Optimizing AI Deployments and Hardware Utilization
- Quantization Quest: 2-Bit Magic for 8B Models: Successfully quantizing an 8 billion parameter model down to 2 bits opens doors for deploying larger models on constrained hardware, despite initial setup headaches.
- Enthusiasm grows for standardizing this method for models exceeding 32B parameters.
- NVIDIA’s Jetson Orin Nano Super Kit Boosts AI Processing: Priced at $249, NVIDIA’s new kit ramps up AI processing with a 70% increase in neural operations, making powerful AI accessible to hobbyists.
- Developers explore deploying LLMs on devices like AGX Orin and Raspberry Pi 5, enhancing local AI capabilities.
- CUDA Graphs and Async Copying Create Compute Conundrums: Integrating cudaMemcpyAsync within CUDA Graphs on a 4090 GPU leads to inconsistent results, baffling developers and prompting a deeper dive into stream capture issues.
- Ongoing investigations aim to resolve these discrepancies and optimize compute throughput.
Theme 4. AI Enhancements in Developer Workflows
- Cursor Extension: Markdown Magic and Web Publishing: The new Cursor Extension allows seamless exporting of composer and chat histories to markdown, plus one-click web publishing, supercharging developer productivity.
- Users praise the ability to capture and share coding interactions effortlessly.
- Aider’s Linters and Code Management Revolutionize Workflow: With built-in support for various linters and customizable linting commands, Aider offers developers unparalleled flexibility in managing code quality alongside AI-driven edits.
- Automatic linting can be toggled, allowing for a tailored coding experience.
- SpecStory Extension Transforms AI Coding Journeys: The SpecStory extension for VS Code captures, searches, and learns from every AI-assisted coding session, providing a rich repository for developers to refine their practices.
- Enhances documentation and analysis of coding interactions for better learning outcomes.
Theme 5. Community Events and Educational Initiatives Drive Innovation
- DevDay Holiday Edition and API AMA Boomt: OpenAI’s DevDay Holiday Edition livestream wraps up with an AMA featuring the API team, offering a wealth of insights and direct interaction opportunities for developers.
- Community members eagerly await answers to burning API questions and future feature announcements.
- Code Wizard Hackathon Seeks Sponsors for February Frenzy: The organizer hunts for sponsorships to fuel the upcoming Code Wizard hackathon in February 2025, aiming to foster innovation and problem-solving among participants.
- Although some question the funding needs, many underscore the hackathon’s role in building valuable tech projects.
- LLM Agents MOOC Extends Submission Deadline: The Hackathon submission deadline is extended by 48 hours to Dec 19th, clarifying the submission process and giving participants extra time to perfect their AI agent projects.
- Improved mobile responsiveness on the MOOC website garners praise, aiding participants in showcasing their innovations.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Windsurf Struggles with File Modifications: Users reported that Windsurf is unable to effectively modify or edit files, with one user describing it as 'stupider' after recent updates.
- Discussions highlighted resource exhaustion errors and confusion regarding the introduction of new pricing plans.
- Confusion Over Codeium's Pricing Model: Members inquired about purchasing larger blocks of Flex credits, noting rapid consumption despite their efforts to manage usage.
- Conversations focused on the newly established credit limits and the specifics of different paid tiers.
- Performance Showdown: Windsurf vs Cursor: Participants compared Windsurf and Cursor, observing that both platforms offer similar agent functionalities but differ in context usage strategies.
- Windsurf enforces strict credit limits, whereas Cursor provides unlimited slow queries post a certain premium usage, which some users find more accommodating.
- Challenges in Windsurf's Code Management: Users expressed frustration with Windsurf's tendency to overwrite code and introduce hallucinated errors, complicating the development process.
- Suggestions were made to integrate Git for version control to better manage changes and enable reversibility.
- Assessing Gemini 2.0's Integration with Windsurf: Engineers are evaluating Gemini 2.0 alongside Windsurf, noting a significant context advantage but experiencing mixed reviews on output quality.
- While Gemini 2.0 offers a larger context window, some users have observed performance degradation beyond certain token limits.
Nous Research AI Discord
- phi-4 Model Outperforms GPT-4 in STEM QA: The phi-4 model, boasting 14 billion parameters, surpasses GPT-4 in STEM-focused QA by integrating synthetic data and enhanced training methodologies.
- Despite minor architectural similarities to phi-3, phi-4 demonstrates robust performance in reasoning benchmarks, attributed to its revised training curriculum and post-training techniques.
- Effective 2-bit Quantization Achieved for 8B Models: An 8 billion parameter model was successfully quantized down to 2 bits, showcasing potential as a standard for larger models, despite initial setup complexities.
- This advancement suggests enhanced usability for models exceeding 32B parameters, with members expressing optimism about its applicability in future drafts.
- Gemini Utilizes Threefry in Sampling Algorithms: Members discussed whether Xorshift or other algorithms are employed in sampling for LLMs, with one noting that Gemma uses Threefry.
- PyTorch's adoption of Mersenne Twister contrasts with Gemini's approach, highlighting differing sampling techniques across AI frameworks.
- Hugging Face Advances Test-Time Compute Strategies: Hugging Face's latest work on test-time compute approaches received commendation, particularly their scaling methods for compute efficiencies.
- A Hugging Face blogpost delves into their strategies, fostering community understanding and positive reception.
aider (Paul Gauthier) Discord
- Full O1 API Launch: The upcoming O1 API introduces features like reasoning effort parameters and system prompts, enhancing AI capabilities.
- Users anticipate significant price increases compared to Sonnet, expressing mixed feelings about the potential costs associated with the O1 API.
- Improved AI Performance with O1 and Claude: The O1 model demonstrates enhanced response capabilities based on specific prompts, while users suggest combining it with Claude to leverage strengths of both models.
- Despite improved performance, the O1 model can exhibit overconfidence in certain situations, prompting discussions on optimal model usage.
- Aider's Linters and Code Management: Aider provides built-in support for various linters and allows customization through the
--lint-cmdoption, as detailed in the Linting and Testing documentation.- Users can toggle automatic linting, offering flexibility in managing code quality alongside AI-driven edits.
- Claude Model Limitations: The Claude model is noted for its reluctance to generate certain outputs and tends to provide overly cautious responses.
- Users highlighted the necessity of more explicit guidance to achieve desired results, emphasizing the importance of specificity in prompts.
- Aider's Integration with LM Studio: Aider faces challenges integrating with LM Studio, including errors like BadRequestError due to missing LLM providers.
- Successful integration was achieved by configuring the OpenAI provider format with
openai/qwen-2.5-coder-7b-instruct-128k, as discovered by users during troubleshooting.
- Successful integration was achieved by configuring the OpenAI provider format with
Notebook LM Discord Discord
- New UI Rollout Enhances User Experience: This morning, the team announced the rollout of the new UI and NotebookLM Plus features to all users, as part of an ongoing effort to improve the platform's user experience. Announcement details.
- However, some users expressed dissatisfaction with the new UI, highlighting issues with the chat panel's visibility and notes layout, while others appreciated the larger editor and suggested collapsing panels to improve usability.
- NotebookLM Plus Access Expands via Google Services: NotebookLM Plus is now accessible through Google Workspace and Google Cloud, with plans to extend availability to Google One AI Premium users by early 2025. Upgrade information.
- Questions arose about its availability in countries like Italy and Brazil, with responses indicating a gradual global rollout.
- Interactive Audio BETA Limited to Early Adopters: Interactive Audio is currently available only to a select group of users as backend improvements are being made. Users without access to the Interactive mode (BETA) should not be concerned during the transition. Interactive Audio details.
- Multiple users reported difficulties with the Interactive Mode feature, citing lagging and accessibility issues even after updating to the new UI, suggesting the feature is still in rollout.
- AI Integration in Call Centers Discussed: Members explored the integration of AI into IT call centers, including humorous takes on a German-speaking AI managing customer queries, accompanied by shared audio clips demonstrating scenarios like computer troubleshooting and cold-call sales pitches. Use Cases.
- The discussion highlighted potential improvements in customer service efficiency through AI implementations.
- Expanding Multi-language Support in NotebookLM: Users inquired about NotebookLM's multi-language capabilities for generating podcasts, confirming that audio summaries are currently supported only in English. General channel.
- Despite this limitation, successful content generation in Portuguese indicates potential for broader language support in future updates.
Unsloth AI (Daniel Han) Discord
- Phi-4 Outpaces GPT-4 in STEM QA: The phi-4, a 14-billion parameter language model, leverages a training strategy that emphasizes data quality, integrating synthetic data throughout its development to excel in STEM-focused QA capabilities, surpassing its teacher model, GPT-4.
- Despite minimal architecture changes since phi-3, the model's performance on reasoning benchmarks underscores an improved training curriculum, as detailed in the Continual Pre-Training of Large Language Models.
- Unsloth 4-bit Model Shows Performance Gaps: Users reported discrepancies in layer sizes between the Unsloth 4-bit model and the original Meta version, highlighting potential issues with model parameterization.
- Concerns were raised about VRAM usage and performance trade-offs when transitioning from 4-bit to full precision, as discussed in the Qwen2-VL-7B-Instruct-unsloth-bnb-4bit repository.
- Qwen 2.5 Finetuning Faces Catastrophic Forgetting: A member expressed frustration that their finetuned Qwen 2.5 model underperformed compared to the vanilla version, attributing the decline to catastrophic forgetting.
- Other members recommended iterating on the fine-tuning process to better align with specific objectives, emphasizing the importance of tailored adjustments.
- Enhancing Function Calls in Llama 3.2: Participants explored training Llama 3.2 to improve function calling capabilities but noted the scarcity of direct implementation examples.
- There was consensus that incorporating special tokens directly into datasets could streamline the training process, as referenced in the Llama Model Text Prompt Format.
- Optimizing Lora+ with Unsloth: Members discussed integrating Lora+ with Unsloth, observing potential incompatibilities with other methods and suggesting alternatives like LoFTQ or PiSSA for better initializations.
- One member highlighted performance improvements in Unsloth's latest release through a CPT blog post, emphasizing the benefits of these optimizations.
Cohere Discord
- Cohere Boosts Multimodal Image Embed Rates: Cohere has increased the rate limits for the Multimodal Image Embed endpoint by 10x, elevating production keys from 40 images/min to 400 images/min. Read more
- Trial users remain limited to 5 images/min for testing, enabling application development and community sharing without overwhelming the system.
- Maya Release Enhances Tool Utilization: The release of Maya has been celebrated among members, sparking enthusiasm to explore and potentially finetune it for tool use. Members are committed to pushing project boundaries with the new model.
- The community plans to engage in extensive testing and customization, aiming to integrate Maya's capabilities into their workflows effectively.
- Optimizing Cohere API Key Management: Cohere offers two types of API keys: evaluation keys that are free but limited, and production keys that are paid with fewer restrictions. Users can manage their keys via the API keys page.
- This structure allows developers to efficiently start projects while scaling up with production keys as their applications grow.
- Strategies for Image Retrieval using Embeddings: To implement image retrieval based on user queries, a member proposed storing image paths as metadata alongside embeddings in the Pinecone vector store. This allows the system to display the correct image when an embedding matches a query.
- By leveraging semantic search through embeddings, the retrieval process becomes more accurate and efficient, enhancing the user experience.
- Seeking Sponsors for Code Wizard Hackathon: The organizer of the Code Wizard hackathon is actively seeking sponsorships for the event scheduled in February 2025, aiming to foster innovation and problem-solving among participants.
- While some attendees questioned the funding necessity, others emphasized the event's role in building valuable projects and advancing technical skills.
Bolt.new / Stackblitz Discord
- Bolt's UI Version with Model Selection: A member announced the rollout of a UI version of Bolt, enabling users to choose between Claude, OpenAI, and Llama models hosted on Hyperbolic. This update aims to enhance the generation process by offering diverse model options.
- The new UI is designed to improve user experience and streamline model selection, allowing for more customized and efficient project workflows.
- Managing Tokens Effectively: Users raised concerns regarding the usage and management of tokens in Bolt, highlighting frustrations over unexpected consumption.
- It was emphasized that there are limits on monthly token usage, and users should be mindful of replacement costs to avoid exceeding their quotas.
- Challenges with Bolt Integration: Several users reported integration issues with Bolt, such as the platform generating unnecessary files and encountering errors during command execution.
- To mitigate frustration, some users suggested taking breaks from the platform, emphasizing the importance of maintaining productivity without overexertion.
- Bolt for SaaS Projects: Members expressed interest in utilizing Bolt for SaaS applications, recognizing the need for developer assistance to scale and integrate effectively.
- One user sought step-by-step guidance on managing SaaS projects with Bolt, indicating a demand for more comprehensive support resources.
- Support and Assistance on Coding Issues: Users sought support for coding challenges within Bolt, with specific requests for help with their Python code.
- Community members provided advice on debugging techniques and recommended online resources to enhance coding practices.
Eleuther Discord
- Pythia based RLHF models: Members in general inquired about the availability of publicly available Pythia based RLHF models, but no specific models were recommended in the discussion.
- TensorFlow on TPU v5p: A user reported TensorFlow experiencing segmentation faults on TPU v5p, stating that 'import tensorflow' causes errors across multiple VM images.
- Concerns were raised regarding Google's diminishing support for TensorFlow amid ongoing technical challenges.
- SGD-SaI Optimizer Approach: In research, the introduction of SGD-SaI presents a new method to enhance stochastic gradient descent without adaptive moments, achieving results comparable to AdamW.
- Participants emphasized the need for unbiased comparisons with established optimizers and suggested dynamically adjusting learning rates during training phases.
- Stick Breaking Attention Mechanism: Discussions in research covered stick breaking attention, a technique for adaptively aggregating attention scores to reduce oversmoothing effects in models.
- Members debated whether these adaptive methods could better handle the complexity of learned representations within transformer architectures.
- Grokking Phenomenon: A recent paper discussed the grokking phenomenon by linking neural network complexity with generalization, introducing a metric based on Kolmogorov complexity.
- The study aims to discern when models generalize versus memorize, potentially offering structured insights into training dynamics.
Cursor IDE Discord
- Cursor Extension Launch Enhances Productivity: The Cursor Extension now allows users to export their composer and chat history to Markdown, facilitating improved productivity and content sharing.
- Additionally, it includes an option to publish content to the web, enabling effective capture of coding interactions.
- O1 Pro Automates Coding Tasks Efficiently:
@mckaywrigleyreported that O1 Pro successfully implemented 6 tasks, modifying 14 files and utilizing 64,852 input tokens in 5m 25s, achieving 100% correctness and saving 2 hours.- This showcases O1 Pro's potential in streamlining complex coding workflows.
- RAPIDS cuDF Accelerates Pandas with Zero Code Changes: A tweet by @NVIDIAAIDev announced that RAPIDS cuDF can accelerate pandas operations up to 150x without any code modifications.
- Developers can now handle larger datasets in Jupyter Notebooks, as demonstrated in their demo.
- SpecStory Extension Integrates AI Coding Journeys: The SpecStory extension for Visual Studio Code offers features to capture, search, and learn from every AI coding journey.
- This tool enhances developers' ability to document and analyze their coding interactions effectively.
OpenAI Discord
- DevDay Holiday Edition and API Team AMA: The DevDay Holiday Edition YouTube livestream, Day 9: DevDay Holiday Edition, is scheduled and accessible here.
- The stream precedes an AMA with OpenAI's API team, scheduled for 10:30–11:30am PT on the developer forum.
- AI Accents Mimicry and Realism Limitations: Users discussed AI's ability to switch between multiple languages and accents, such as imitating an Aussie accent, but interactions still feel unnatural.
- Participants noted that while AI can mimic accents, it often restricts certain respectful interaction requests due to guideline limitations.
- Custom GPTs Editing and Functionality Issues: Several users reported losing the ability to edit custom GPTs and issues accessing them, despite multiple setups.
- This appears to be a known issue, as confirmed by others facing similar problems with their custom GPT configurations.
- Anthropic's Pricing Model Adjustment: Anthropic has adjusted its pricing model, becoming less expensive with the addition of prompt caching for APIs.
- Users expressed curiosity about how this shift might impact their usage and the competition with OpenAI's offerings.
OpenRouter (Alex Atallah) Discord
- OpenRouter adds support for 46 models: OpenRouter now supports 46 models for structured outputs, enhancing multi-model application development. The demo showcases how structured outputs constrain LLM outputs to a JSON schema.
- Additionally, structured outputs are normalized across 8 model companies and 8 free models, facilitating smoother integration into applications.
- Gemini Flash 2 outperforms Sonnet 3.5: Gemini Flash 2 generates superior code for scientific problem-solving tasks compared to Sonnet 3.5, especially in array sizing scenarios.
- Feedback suggested that integrating external frameworks could further boost its effectiveness in specific use cases.
- Experimenting with typos to influence AI responses: Members are exploring the use of intentional typos and meaningless words in prompts to guide model outputs, potentially benefiting creative writing.
- This technique aims to direct model attention to specific keywords while maintaining controlled outputs through Chain of Thought (CoT) methods.
- o1 API reduces token usage by 60%: o1 API now consumes 60% fewer tokens, raising concerns about its impact on model performance.
- Users discussed the need for pricing adjustments and improved token efficiency, noting that current tier limitations still apply.
- API key exposure and reporting for OpenRouter: A member reported exposed OpenRouter API keys on GitHub, initiating discussions on proper reporting channels.
- It was recommended to contact support@openrouter.ai to address any security risks from exposed keys.
Perplexity AI Discord
- Perplexity Introduces Pro Gift Subscriptions: Perplexity is now offering gift subscriptions for 1, 3, 6, or 12 months here, enabling users to unlock enhanced search capabilities.
- Subscriptions are delivered via promo codes directly to recipients' email, and it is noted that all sales are final to ensure commitment.
- Debate on OpenAI Borrowing Perplexity Features: Users debated whether OpenAI is innovating or copying Perplexity's features like Projects and GPT Search, leading to discussions about originality in AI development.
- Some members opined that feature replication is common across platforms, fostering a dialogue on maintaining unique value propositions in AI tools.
- Mozi App Launches Amidst Social Media Excitement: Ev Williams launched the new social app Mozi, which is garnering attention for its fresh approach to social networking, as detailed in a YouTube video.
- The app promises innovative features, generating discussions on its potential impact on existing social media platforms.
- Concerns Over Declining Model Performance: Users expressed frustration with the Sonnet and Claude model variations, noting a perceived decline in performance affecting response quality.
- Switching between specific models has led to inconsistent user experiences, highlighting the need for clarity on model optimization.
- Gemini API Integration Enhances Perplexity's Offerings: Implementation of the new Gemini integration through the OpenAI SDK allows seamless interaction with multiple APIs, accessible via the Gemini API.
- This integration improves user experience by facilitating access to diverse models, including Gemini, OpenAI, and Groq, with Mistral support forthcoming.
Latent Space Discord
- Palmyra Creative's 128k Context Release: The new Palmyra Creative model enhances creative business tasks with a 128k context window for brainstorming and analysis.
- It integrates seamlessly with domain-specific models, catering to professionals from marketers to clinicians.
- OpenAI API Introduces O1 with Function Calling: OpenAI announced updates during a mini dev day, including an O1 implementation with function calling and new voice model features.
- WebRTC support for real-time voice applications and significant output token enhancements were key highlights.
- NVIDIA Launches Jetson Orin Nano Super Kit: NVIDIA's Jetson Orin Nano Super Developer Kit boosts AI processing with a 70% increase in neural processing to 67 TOPS and 102 GB/s memory bandwidth.
- Priced at $249, it aims to provide budget-friendly AI capabilities for hobbyists.
- Clarification on O1 vs O1 Pro by Aidan McLau: Aidan McLau clarified that O1 Pro is a distinct implementation from the standard O1 model, designed for higher reasoning capabilities.
- This distinction has raised community questions about potential functional confusion between these models.
- Anthropic API Moves Four Features Out of Beta: Anthropic announced the general availability of four new features, including prompt caching and PDF support for their API.
- These updates aim to enhance developer experience and facilitate smoother operations on the Anthropic platform.
LM Studio Discord
- Zotac's RTX 50 Sneak Peek: Zotac inadvertently listed the upcoming RTX 5090, RTX 5080, and RTX 5070 GPU families on their website, revealing advanced specs 32GB GDDR7 memory ahead of the official launch.
- This accidental disclosure has sparked excitement within the community, confirming the RTX 5090's impressive specifications and fueling anticipation for Nvidia's next-generation hardware.
- AMD Driver Dilemmas: Users reported issues with the 24.12.1 AMD driver, which caused performance drops and GPU usage spikes without effective power consumption.
- Reverting to version 24.10.1 resolved these lag issues, resulting in improved performance to 90+ tokens/second on various models.
- TTS Dreams: LM Studio's Next Step: A user expressed optimism for integrating text to speech and speech to text capabilities in LM Studio, with current alternatives available as workarounds.
- Another member suggested running these tools alongside LM Studio as a server to facilitate the desired functionalities, enhancing the overall user experience.
- Uncensoring Chatbots: New Alternatives: Discussions emerged around finding uncensored chatbot alternatives, with recommendations for models like Gemma2 2B and Llama3.2 3B that can run on CPU.
- Members were provided with resources on effectively using these models, including links to quantization options, to optimize their performance.
- GPU Showdown: 3070 Ti vs 3090: Users observed that the RTX 3070 Ti and RTX 3090 exhibit similar performance in gaming despite comparable price ranges.
- One member noted finding 3090s for approximately $750, while another mentioned prices around $900 CAD locally, highlighting market price variations.
Stability.ai (Stable Diffusion) Discord
- Top Stable Diffusion Courses: A member is seeking comprehensive online courses that aggregate YouTube tutorials for learning Stable Diffusion with A1111.
- The community emphasized the necessity for accessible educational resources on Stable Diffusion.
- Laptop vs Desktop for AI: A user is evaluating between a 4090 laptop and a 4070 TI Super desktop, both featuring 16GB VRAM, for AI tasks.
- Members suggested desktops are more suitable for heavy AI workloads, noting laptops are better for gaming but not for intensive graphics tasks.
- Bot Detection Strategies: Discussions focused on techniques for scam bot identification, such as asking absurd questions or employing the 'potato test'.
- Participants highlighted that both bots and humans can pose risks, requiring cautious interaction.
- Creating Your Own Lora Model: A user requested guidance on building a Lora model, receiving a step-by-step approach including dataset creation, model selection, and training.
- Emphasis was placed on researching effective dataset creation for training purposes.
- Latest AI Models: Flux.1-Dev: A returning member inquired about current AI models, specifically mentioning Flux.1-Dev, and its requirements.
- The community provided updates on trending model usage and necessary implementation requirements.
GPU MODE Discord
- CUDA Graphs and cudaMemcpyAsync Compatibility: Members confirmed that CUDA Graph supports cudaMemcpyAsync, but integrating them leads to inconsistent application results, particularly affecting compute throughput on the 4090 GPU. More details
- A reported issue highlighted that using cudaMemcpyAsync within CUDA Graph mode causes incorrect application outcomes, unlike kernel copies which function correctly. Further investigation with minimal examples is underway to resolve these discrepancies.
- Optimizing PyTorch Docker Images: Discussions revealed that official PyTorch Docker images range from 3-7 GB, with possibilities to reduce size using a 30MB Ubuntu base image alongside Conda for managing CUDA libraries. GitHub Guide
- Debate ensued over the necessity of combining Conda and Docker, with arguments favoring it for maintaining consistent installations across diverse development environments.
- NVIDIA Jetson Nano Super Launch: NVIDIA introduced the Jetson Nano Super, a compact AI computer offering 70-T operations per second for robotics applications, priced at $249 and supporting advanced models like LLMs. Tweet
- Users discussed enhancing Jetson Orin performance with JetPack 6.1 via the SDK Manager, and deploying LLM inference on devices such as AGX Orin and Raspberry Pi 5, which utilizes nvme 256GB for expedited data transfer.
- VLM Fine-tuning with Axolotl and TRL: Resources for VLM fine-tuning using Axolotl, Unslosh, and Hugging Face TRL were shared, including a fine-tuning tutorial.
- The process was noted to be resource-intensive, necessitating significant computational power, which was emphasized as a consideration for efficient integrations.
- Chain of Thought Dataset Generation: The team initiated a Chain of Thought (CoT) dataset generation project to evaluate which CoT forms most effectively enhance model performance, utilizing reinforcement learning for optimization.
- This experiment aims to determine if CoT can solve riddles beyond the capabilities of direct transduction methods, with initial progress showing 119 riddles solved and potential for improvement using robust verifiers.
Modular (Mojo 🔥) Discord
- MAX 24.6 Launches with MAX GPU: Today, MAX 24.6 was released, introducing the eagerly anticipated MAX GPU, a vertically integrated generative AI stack that eliminates the need for vendor-specific libraries like NVIDIA CUDA. For more details, visit Modular's blog.
- This release addresses the increasing resource demands of large-scale Generative AI, paving the way for enhanced AI development.
- Mojo v24.6 Release: The latest version of Mojo, v24.6.0, has been released and is ready for use, as confirmed by the command
% mojo --version. The community has shown significant excitement about the new features.- Users in the mojo channel are eager to explore the updates, indicating strong community engagement.
- MAX Engine and MAX Serve Introduced: MAX Engine and MAX Serve were introduced alongside MAX 24.6, providing a high-speed AI model compiler and a Python-native serving layer for large language models (LLMs). These tools are designed to enhance performance and efficiency in AI workloads.
- MAX Engine features vendor-agnostic Mojo GPU kernels optimized for NVIDIA GPUs, while MAX Serve simplifies integration for LLMs under high-load scenarios.
- GPU Support Confirmed in Mojo: GPU support in Mojo was confirmed for the upcoming Mojo v25.1.0 nightly release, following the recent 24.6 release. This inclusion showcases ongoing enhancements within the Mojo platform.
- The community anticipates improved performance and scalability for complex AI workloads with the added GPU support.
- Mojo REPL Faces Archcraft Linux Issues: A user reported encountering issues when entering the Mojo REPL on Archcraft Linux, citing a missing dynamically linked library, possibly
mojo-lddormojo-lld.- Additionally, the user faced difficulties installing Python requirements, mentioning errors related to being in an externally managed environment.
LlamaIndex Discord
- NVIDIA NV-Embed-v2 Availability Explored: Members investigated the availability of NVIDIA NV-Embed-v2 within NVIDIA Embedding using the
embed_model.available_modelsfeature to verify accessible models.- It was highlighted that even if NV-Embed-v2 isn't explicitly listed, it might still function correctly, prompting the need for additional testing to confirm its availability.
- Integrating Qdrant Vector Store in Workflows: A user sought assistance with integrating the Qdrant vector store into their workflow, mentioning challenges with existing collections and query executions.
- Another member provided documentation examples and noted they hadn't encountered similar issues, suggesting further troubleshooting.
- Addressing OpenAI LLM Double Retry Issues: Paullg raised concerns about potential double retries in the OpenAI LLM, indicating that both the OpenAI client and the
llm_retry_decoratormight independently implement retry logic.- The discussion then focused on whether a recent pull request resolved this issue, with participants expressing uncertainty about the effectiveness of the proposed changes.
- LlamaReport Enhances Document Readability: LlamaReport, now in preview, transforms document databases into well-structured, human-readable reports within minutes, facilitating effective question answering about document sets. More details are available in the announcement post.
- This tool aims to streamline document interaction by optimizing the output process, making it easier for users to navigate and utilize their document databases.
- Agentic AI SDR Boosts Lead Generation: The introduction of a new agentic AI SDR leverages LlamaIndex to generate leads, demonstrating practical AI integration in sales strategies. The code is accessible for implementation.
- This development is part of the Quickstarters initiative, which assists users in exploring Composio's capabilities through example projects and real-world applications.
Nomic.ai (GPT4All) Discord
- GPT4All v3.5.3 Released with Critical Fixes: The GPT4All v3.5.3 version has been officially released, addressing notable issues from the previous version, including a critical fix for LocalDocs that was malfunctioning in v3.5.2.
- Jared Van Bortel and Adam Treat from Nomic AI were acknowledged for their contributions to this update, enhancing the overall functionality of GPT4All.
- LocalDocs Functionality Restored in New Release: A serious problem preventing LocalDocs from functioning correctly in v3.5.2 has been successfully resolved in GPT4All v3.5.3.
- Users can now expect improved performance and reliability while utilizing LocalDocs for document handling.
- AI Agent Capabilities Explored via YouTube Demo: Discussions emerged about the potential to run an 'AI Agent' via GPT4All, linked to a YouTube video showcasing its capabilities.
- One member noted that while technically feasible, it mainly serves as a generative AI platform with limited functionality.
- Jinja Template Issues Plague GPT4All Users: A member reported that GPT4All is almost completely broken for them due to a Jinja template problem, which they hope gets resolved soon.
- Another member highlighted the importance of Jinja templates as crucial for model interaction, with ongoing improvements to tool calling functionalities in progress.
- API Documentation Requests Highlight Gaps in GPT4All: A request was made for complete API documentation with details on endpoints and parameters, referencing the existing GPT4All API documentation.
- Members shared that activating the local API server requires simple steps, but they felt the documentation lacks comprehensiveness.
OpenInterpreter Discord
- Questions about Gemini 2.0 Flash: Users are inquiring about the functionality of Gemini 2.0 Flash, highlighting a lack of responses and support.
- This indicates a potential gap in user experience or support for this feature within the OpenInterpreter community.
- Debate on VEO 2 and SORA: Members debate whether VEO 2 is superior to SORA, noting that neither AI is currently available in their region.
- The lack of availability suggests interest but also frustration among users wanting to explore these options.
- Web Assembly Integration with OpenInterpreter: A user proposed running the OpenInterpreter project in a web page using Web Assembly with tools like Pyodide or Emscripten.
- This approach could provide auto-sandboxing and eliminate the need for compute calls, enhancing usability in a chat UI context.
- Local Usage of OS in OpenInterpreter: Inquiries were made about utilizing the OS locally within OpenInterpreter, with users seeking clarification on what OS entails.
- This reflects ongoing interest in local execution capabilities among users looking to enhance functionality.
- Troubleshooting Errors in Open Interpreter: A member reported persistent errors when using code with the
-yflag, specifically issues related to setting the OpenAI API key.- This highlights a common challenge users face and the need for clearer guidance on error handling.
Torchtune Discord
- Torcheval's Batched Metric Sync Simplifies Workflow: A member expressed satisfaction with Torcheval's batched metric sync feature and the lack of extra dependencies, making it a pleasant tool to work with.
- This streamlined approach enhances productivity and reduces complexity in processing metrics.
- Challenges in Instruction Fine-Tuning Loss Calculation: A member raised concerns about the per-token loss calculation in instruction fine-tuning, noting that the loss from one sentence depends on others in the batch due to varying token counts.
- This method appears to be the standard practice, leading to challenges that the community must adapt to.
- GenRM Verifier Model Enhances LLM Performance: A recent paper proposes using generative verifiers (GenRM) trained on next-token prediction to enhance reasoning in large language models (LLMs) by integrating solution generation with verification.
- This approach allows for better instruction tuning and the potential for improved computation via majority voting, offering benefits over standard LLM classifiers.
- Sakana AI's Universal Transformer Memory Optimization: Researchers at Sakana AI have developed a technique to optimize memory usage in LLMs, allowing enterprises to significantly reduce costs related to application development on Transformer models.
- The universal transformer memory technique retains essential information while discarding redundancy, enhancing model efficiency.
- 8B Verifier Performance Analysis and Community Reactions: Concerns were raised regarding the use of an 8B reward/verifier model, with a member noting the computation costs and complexity of training such a model shouldn't be overlooked in performance discussions.
- Another member humorously compared the methodology to 'asking a monkey to type something and using a human to pick the best one,' suggesting it might be misleading and indicating a need for broader experimentation.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Deadline Extended by 48 Hours: The Hackathon submission deadline has been extended by 48 hours to 11:59pm PT, December 19th.
- This extension aims to clear up confusion about the submission process and allow participants more time to finalize their projects.
- Submission Process Clarified for Hackathon: Participants are reminded that submissions should be made through the Google Form, NOT via the Devpost site.
- This clarification is essential to ensure all projects are submitted correctly.
- LLM Agents MOOC Website Gets Mobile Makeover: A member revamped the LLM Agents MOOC website for better mobile responsiveness, sharing the updated version at this link.
- Hope this can be a way to give back to the MOOC/Hackathon. Another user praised the design, indicating plans to share it with staff.
- Certificate Deadlines Confirmed Until 12/19: A user inquired about the certificate submission deadline amidst uncertainty about potential extensions.
- Another member confirmed that there are no deadline changes for the MOOC and emphasized that the submission form will remain open until 12/19 for convenience.
tinygrad (George Hotz) Discord
- GPU via USB Connectivity Explored: A user in #general inquired about connecting a GPU through a USB port, referencing a tweet, to which George Hotz responded, 'our driver should allow this'.
- This discussion highlights the community's interest in expanding hardware compatibility for tinygrad applications.
- Mac ARM64 Backend Access Limited to CI: In #general, a user sought access to Macs for arm64 backend development, but George clarified that these systems are designated for Continuous Integration (CI) only.
- The clarification emphasizes that Mac infrastructure is currently reserved for running benchmark tests rather than general development use.
- Continuous Integration Focuses on Mac Benchmarks: The Mac Benchmark serves as a crucial part of the project's Continuous Integration (CI) process, concentrating on performance assessments.
- This approach underscores the team's strategy to utilize specific hardware configurations to ensure robust performance metrics.
Axolotl AI Discord
- Scaling Test Time Compute Analysis: A member shared the Hugging Face blog post discussing scaling test time compute, which they found refreshing.
- This post sparked interest within the community regarding the efficiency of scaling tests.
- 3b Model Outperforms 70b in Math: A member noted that the 3b model outperforms the 70b model in mathematics, labeling this as both insane and significant.
- This observation led to discussions about the unexpected efficiency of smaller models.
- Missing Optim Code in Repository: A member expressed concern over the absence of the actual optim code in a developer's repository, which only contains benchmark scripts.
- They highlighted their struggles with the repo and emphasized ongoing efforts to resolve the issue.
- Current Workload Hindering Contributions: A member apologized for being unable to contribute, citing other tasks and bug fixes.
- This underscores the busy nature of development and collaboration within the community.
- Community Expresses Gratitude for Updates: A member thanked another for their update amidst ongoing discussions.
- This reflects the positive and supportive atmosphere of the channel.
DSPy Discord
- Autonomous AI Boosts Knowledge Worker Efficiency: A recent paper discusses how autonomous AI enhances the efficiency of knowledge workers by automating routine tasks, thereby increasing overall productivity.
- The study reveals that while initial research focused on chatbots aiding low-skill workers, the emergence of agentic AIs shifts benefits towards more skilled individuals.
- AI Operation Models Alter Workforce Dynamics: The paper introduces a framework where AI agents can operate autonomously or non-autonomously, leading to significant shifts in workforce dynamics within hierarchical firms.
- It notes that basic autonomous AI can displace humans into specialized roles, while advanced autonomous AI reallocates labor towards routine tasks, resulting in larger and more productive organizations.
- Non-Autonomous AI Empowers Less Knowledgeable Individuals: Non-autonomous AI, such as chatbots, provides affordable expert assistance to less knowledgeable individuals, enhancing their problem-solving capabilities without competing for larger tasks.
- Despite being perceived as beneficial, the ability of autonomous agents to support knowledge workers offers a competitive advantage as AI technologies continue to evolve.
Mozilla AI Discord
- Final RAG Event for Ultra-Low Dependency Applications: Tomorrow is the final event for December, where participants will learn to create an ultra-low dependency Retrieval Augmented Generation (RAG) application using only sqlite-vec, llamafile, and bare-bones Python, led by Alex Garcia.
- The session requires no additional dependencies or 'pip install's, emphasizing simplicity and efficiency in RAG development.
- Major Updates on Developer Hub and Blueprints: A significant announcement was made regarding the Developer Hub and Blueprints, prompting users to refresh their awareness.
- Feedback is being appreciated as the community explores the thread on Blueprints, aimed at helping developers build open-source AI solutions.
MLOps @Chipro Discord
- Year-End Retrospective on Data Infrastructure: Join us on December 18 for a retrospective panel featuring founders Yingjun Wu, Stéphane Derosiaux, and Alexander Gallego discussing innovations in data infrastructure over the past year.
- The panel will cover key themes including Data Governance, Streaming, and the impact of AI on Data Infrastructure.
- Keynote Speakers for Data Innovations Panel: The panel features Yingjun Wu, CEO of RisingWave, Stéphane Derosiaux, CPTO of Conduktor, and Alexander Gallego, CEO of Redpanda.
- Their insights are expected to explore crucial areas like Stream Processing and Iceberg Formats, shaping the landscape for 2024.
- AI's Role in Data Infrastructure: The panel will discuss the impact of AI on Data Infrastructure, highlighting recent advancements and implementations.
- This includes how AI technologies are transforming Data Governance and enhancing Streaming capabilities.
- Stream Processing and Iceberg Formats: Key topics include Stream Processing and Iceberg Formats, critical for modern data infrastructure.
- The panelists will delve into how these technologies are shaping the data infra ecosystem for the upcoming year.
Gorilla LLM (Berkeley Function Calling) Discord
- BFCL Leaderboard V3 Freezes During Function Demo: A member raised an issue with the BFCL Leaderboard being stuck at 'Loading Model Response...' during the function call demo.
- They inquired if others have encountered the same loading problem, seeking confirmation and potential solutions.
- BFCL Leaderboard V3 Expands Features and Datasets: Discussion highlighted the Berkeley Function Calling Leaderboard V3's updated evaluation criteria for accurate function calling by LLMs.
- Members referenced previous versions like BFCL-v1 and BFCL-v2, noting that BFCL-v3 includes expanded datasets and methodologies for multi-turn interactions.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium / Windsurf ▷ #discussion (89 messages🔥🔥):
Windsurf functionality issues, Codeium pricing and credits, User experiences with AI code generation, Codeium plugin display problems, Tool recommendations for code reviews
- Users report Windsurf functionality issues: Multiple users expressed concerns about Windsurf not being able to modify or edit files effectively, with one stating it had become 'stupider' after recent changes.
- There were discussions about resource exhaustion errors and the new plans being introduced, causing confusion among users.
- Understanding Codeium's pricing and credits: Individuals in the channel questioned the ability to purchase larger blocks of Flex credits, highlighting rapid consumption rates despite user efforts to manage it.
- Conversations revolved around the newly established credit limits and plans, focusing on what would be included in different paid tiers.
- Varied experiences using AI code generation: Several users noted mixed results while using Codeium for tasks, specifically mentioning issues with the AI making changes that broke expected functionality.
- One member recounted how AI altered unit tests to pass while failing to understand the intended functionality, indicating a lack of context and control.
- Codeium plugin display font size problems: A user raised concerns regarding the small font size of the Codeium chatbot within JetBrains IDEs, while other font sizes appeared normal.
- The discussion included troubleshooting steps, with users seeking a potential fix for the inconsistent display.
- Recommendations for code review tools: A suggestion was made for Code Rabbit AI as an alternative tool for code reviews, highlighting its effectiveness in managing pull requests.
- This sparked a conversation about the evolving landscape of code review tools and user preferences within paid options.
- Tweet from NVIDIA AI Developer (@NVIDIAAIDev): 👀 RAPIDS cuDF accelerates #pandas up to 150x with zero code changes. Now you can continue using pandas as your dataset size grows into gigabytes. ⚡ ➡️ Jupyter Notebook to try the demo: http://nvda.ws...
- Hello There GIF - Hello there - Discover & Share GIFs: Click to view the GIF
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
- Add Gemini 2.0 | Feature Requests | Codeium: Add Gemini 2.0 I saw many benchmarks of it that are better at coding than Claude
- GitHub - SchneiderSam/awesome-windsurfrules: 📄 A curated list of awesome global_rules.md and .windsurfrules files: 📄 A curated list of awesome global_rules.md and .windsurfrules files - SchneiderSam/awesome-windsurfrules
Codeium / Windsurf ▷ #windsurf (668 messages🔥🔥🔥):
Windsurf vs Cursor, Gemini AI performance, Windsurf bugs, Git usage, User experiences with AI tools
- Comparison of Windsurf and Cursor performance: Users are discussing the performance differences between Windsurf and Cursor, highlighting that both platforms have similar agent functionalities but varying approaches to context usage.
- Windsurf is noted to have strict credit limits while Cursor offers unlimited slow queries after a set amount of premium usage, which some users find more convenient.
- Windsurf's editing and code management struggles: Several individuals have expressed frustration with Windsurf's tendency to overwrite code and hallucinate errors, leading to confusion during development.
- Users suggest improving their coding workflows by implementing Git for version control to better manage changes and facilitate reversibility.
- Experiences transitioning to Gemini 2.0: Users are evaluating the effectiveness of Gemini 2.0 alongside Windsurf, with some noting significant context advantage, while others have had mixed reviews regarding its output quality.
- While Gemini 2.0 boasts a larger context window, some users mention that performance may degrade after a certain token limit.
- Community suggestions for improving Windsurf: The community is advocating for enhancements to Windsurf, including better mouse focus management across panels to improve workflow efficiency.
- Users are also requesting a way to revert code changes and manage their development environment better within the tool.
- User engagement with AI tools: Participants are sharing their unique approaches to utilizing AI tools like Windsurf and Cursor to streamline coding tasks and enhance productivity.
- Some users are leveraging advanced features of these tools for specific tasks while discussing the importance of maintaining control over code changes.
- The Ruff Formatter: An extremely fast, Black-compatible Python formatter: Ruff's formatter is over 30x faster than existing tools, while maintaining >99.9% compatibility with Black.
- Laravel - Visual Studio Marketplace: Extension for Visual Studio Code - Official VS Code extension for Laravel
- Anakin GIF - Anakin - Discover & Share GIFs: Click to view the GIF
- Full-stack (SSR) · Cloudflare Pages docs: Next.js ↗ is an open-source React.js framework for building full-stack applications. This section helps you deploy a full-stack Next.js project to Cloudflare Pages using @cloudflare/next-on-pages ↗.
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Add Gemini 2.0 | Feature Requests | Codeium: Add Gemini 2.0 I saw many benchmarks of it that are better at coding than Claude
- vscodium/docs/index.md at master · VSCodium/vscodium: binary releases of VS Code without MS branding/telemetry/licensing - VSCodium/vscodium
- Windsurf - Focus Follows Mouse (as a configuration option) | Feature Requests | Codeium: There is an open GitHub PR for VSCode which is, on the surface, more than 4 years old, however it is way older than that.
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
- GitHub - punkpeye/awesome-mcp-servers: A collection of MCP servers.: A collection of MCP servers. Contribute to punkpeye/awesome-mcp-servers development by creating an account on GitHub.
- What's the difference between MCP and vector database? · modelcontextprotocol · Discussion #88: it's been a while and I can't figure it out
- - YouTube: no description found
- How to REALLY make money with Windsurf #aiautomation #firebringerai #coding #seoautomation: Build SEO Websites in Minutes with This Game-Changing ToolStop spending hours or even days building SEO websites manually. This tool turns your keywords, for...
- GitHub - punkpeye/awesome-mcp-servers: A collection of MCP servers.: A collection of MCP servers. Contribute to punkpeye/awesome-mcp-servers development by creating an account on GitHub.
Nous Research AI ▷ #general (566 messages🔥🔥🔥):
AI and Creative Writing, Prompt Engineering and Evaluation, LLM Performance Characteristics, Educational Paths in Computer Science
- AI Revolutionizes Storytelling: Participants discussed the potential for AI to write stories and the effectiveness of using prompt chaining to improve text quality, emphasizing the importance of a clear rubric for evaluation.
- The conversation included examples of prompts and how iterative feedback can enhance story coherence and emotional impact.
- Randomness in AI Responses: The group explored the idea of incorporating randomness into AI-generated names and scenarios to combat the tendency for repetitive outputs in generated stories.
- Stochastic tables and random name generators were suggested as methods to increase variety and depth in LLM output.
- Constructing a Rating System: Participants developed a prompt for evaluating stories based on a detailed rubric, assessing aspects like coherent plots and emotional impact.
- The discussion included testing and refining the rating system to ensure accurate evaluation of story quality by the LLM.
- Educational Choices in Technology Fields: A user questioned the value of obtaining a master's degree in computer science versus gaining practical experience through projects and internships.
- The conversation acknowledged that while academic credentials can benefit certain career paths, hands-on experience is often prioritized in fields like web and mobile development.
- Feedback on LLM Performance: Users reported positive experiences with LLMs, specifically noting the strong critique capabilities of an 8B model in evaluating story quality.
- The conversation highlighted the importance of using LLMs effectively for both writing assistance and critical analysis.
- ConvNets Match Vision Transformers at Scale: Many researchers believe that ConvNets perform well on small or moderately sized datasets, but are not competitive with Vision Transformers when given access to datasets on the web-scale. We challenge...
- NVIDIA Unveils Its Most Affordable Generative AI Supercomputer: NVIDIA is taking the wraps off a new compact generative AI supercomputer, offering increased performance at a lower price with a software upgrade. The new NVIDIA Jetson Orin Nano Super Developer Kit, ...
- Welcome to Langflow | Langflow Documentation: Langflow is a new, visual framework for building multi-agent and RAG applications. It is open-source, Python-powered, fully customizable, and LLM and vector store agnostic.
- NVIDIA Jetson AGX Orin: Next-level AI performance for next-gen robotics.
- Announcing Grok: no description found
- Intel Arc B580 review: The GPU we've begged for since the pandemic: Intel’s $249 Arc B580 is the graphics card we’ve begged for since the pandemic.
- Orange Pi - Orange Pi official website - Orange Pi development board, open source hardware, open source software, open source chip, computer keyboard: no description found
- ODROID-M2 with 16GByte RAM – ODROID: no description found
- Safepine: no description found
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #ask-about-llms (6 messages):
Sampling Algorithms, Gemini Data Recall, Threefry, Mersenne Twister
- Debate on Sampling Algorithms: A member questioned whether Xorshift or other algorithms are being used in sampling and weighting for LLMs.
- Another member mentioned that Gemma uses Threefry.
- Gemini's Data Recall Capabilities: A member expressed their curiosity about Gemini's ability to recall data accurately despite its vast internet knowledge base.
- They compared this to a historian's potential confusion with dates, asking if the model has similar limitations.
- PyTorch's Choice of Algorithm: It's noted that PyTorch utilizes Mersenne Twister as its sampling algorithm.
- This highlights a contrast between the sampling techniques used in different AI frameworks.
- Interest in Contributing to AI Projects: One member expressed a desire to know how they might help with the interesting project discussed.
- This signals an open invitation for collaboration within the community.
- Building a Virtual Girlfriend: A member clarified their intentions, stating, "I’m trying to build a girlfriend."
- This indicates a shift from technical discussion to personal project aspirations.
Nous Research AI ▷ #research-papers (5 messages):
phi-4 language model, quantization techniques, LlamaCPP integration, test-time compute approaches, performance benchmarks
- phi-4 model significantly advances QA capabilities: The phi-4 model, with 14 billion parameters, surpasses GPT-4 in STEM-focused QA capabilities by incorporating synthetic data and improved training methods.
- Despite minor architectural changes from phi-3, phi-4 shows strong performance in reasoning benchmarks due to its revamped training curriculum and post-training techniques.
- Quantization down to 2 bits impresses: A member noted that an 8 billion parameter model was effectively quantized down to 2 bits, which seems promising despite initial coding challenges.
- Another participant commented that this new method could serve as a standard for models with larger parameters, enhancing their usability.
- Challenges with running 70b models on limited hardware: A participant expressed frustration about not being able to run 70b models on their hardware due to just having 24GB of RAM, questioning integration methods into platforms like LlamaCPP or VLLM.
- This indicates a need for scalable solutions for those wanting to utilize larger models without extensive hardware.
- Community acknowledges advancements in test-time compute: A member praised Hugging Face for their work on test-time compute approaches, indicating a positive reception within the community.
- This was highlighted further by a shared link discussing their scaling methods, enhancing understanding of compute efficiencies.
Link mentioned: Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
Nous Research AI ▷ #research-papers (5 messages):
phi-4 model, quantized models, Hugging Face test-time compute
- phi-4 model excels in STEM QA: The phi-4 is a 14-billion parameter language model distinguished by its focus on data quality, outperforming GPT-4 in STEM capabilities.
- It utilizes synthetic data during training which enhances its performance on reasoning benchmarks, despite the architecture being similar to phi-3.
- Quantization challenges for processing: One member highlighted the challenge of using an 8B model compressed to 2-bits and the complexity of setting it up, likening the process to a bit of a bugger.
- Vibe check seems passed as they believe it shows promise for 32B+ draft models.
- Seeking integration with LlamaCPP and others: There are discussions about the difficulty in running 70B models due to hardware limitations, particularly a 24GB RAM cap.
- Members are exploring the best methods to integrate the models into platforms like LlamaCPP, Aphrodite, and VLLM.
- Hugging Face's test-time compute advancement: Real.Azure commended the work on test-time compute approaches by Hugging Face, noting promising developments.
- A link to their blogpost discusses scaling test-time compute strategies.
Link mentioned: Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
aider (Paul Gauthier) ▷ #general (302 messages🔥🔥):
Aider Updates, O1 API and Pro Features, Linters and Code Management, Claude Model Discussion, AI in Coding Automation
- Full O1 API Launch: Users expressed excitement about the upcoming O1 API, which is expected to include features like reasoning effort parameters and system prompts, enhancing AI capabilities.
- There are mixed feelings about the potential costs associated with the O1 API, as users anticipate significant price increases compared to Sonnet.
- Improved AI Performance: The O1 model has been noted for its capability to improve responses based on specific prompts, although it can exhibit overconfidence in some situations.
- Users suggest combining different models, like O1 and Claude, to create prompts that leverage the strengths of both.
- Linting and Code Management in Aider: Aider offers built-in support for various linters and allows users to specify their preferred linting commands using the
--lint-cmdoption.- Users can enable or disable automatic linting, providing flexibility in how they manage code quality alongside AI edits.
- Claude Model Limitations: A discussion arose around the limitations of the Claude model, particularly its reluctance to generate certain outputs and its tendency to provide overly cautious responses.
- Users expressed frustration at the need to guide the AI more explicitly to achieve desired results, noting that specificity is key.
- Future of AI in Coding: Participants discussed the implications of advanced AI models on coding jobs, with concerns about potential job displacement in the future.
- Despite this, many believe that human creativity and problem-solving will still be needed to complement AI capabilities.
- Tweet from Sundar Pichai (@sundarpichai): Gemini Advanced subscribers can try out gemini-exp-1206, our latest experimental model. Significantly improved performance on coding, math, reasoning, instruction following + more.
- Tweet from Alex Volkov (Thursd/AI) (@altryne): @crizcraig @OpenAI not coming yet
- Edit formats: Aider uses various “edit formats” to let LLMs edit source files.
- Installation: How to install and get started pair programming with aider.
- Linting and testing: Automatically fix linting and testing errors.
- - YouTube: no description found
- Tutorial videos: Intro and tutorial videos made by aider users.
- Options reference: Details about all of aider’s settings.
- Options reference: Details about all of aider’s settings.
- GitHub - 1broseidon/promptext: Contribute to 1broseidon/promptext development by creating an account on GitHub.
- feat: Support custom Whisper API endpoints for voice transcription by mbailey · Pull Request #2634 · Aider-AI/aider: Add support for custom Whisper API endpoints2024-12-18: Third rewrite - more compatible with existing conventions for handling API keysThis PR adds the ability to use alternative Whisper API prov...
- - YouTube: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (34 messages🔥):
Aider with LM Studio, Using Aider with Emacs, Committing Specific Files in Aider, Troubleshooting Aider Errors, Dart Support in Aider
- Aider struggles with LM Studio integration: Users have reported challenges when using Aider with LM Studio, particularly with receiving errors like BadRequestError that indicate a missing LLM provider.
- After some debugging, one user found success using the OpenAI provider format, specifically pointing to
openai/qwen-2.5-coder-7b-instruct-128k.
- After some debugging, one user found success using the OpenAI provider format, specifically pointing to
- Inquiry about Aider's Emacs compatibility: A user asked if it's possible to use Aider with Emacs and discovered an available
aider.elfile to facilitate this integration.- Another user confirmed they are using Emacs with Aider and Aider's watch mode, enhancing their workflow.
- Commit functionality and file handling in Aider: A new user sought clarification on whether
/commitcan be applied to specific files rather than all staged files in Aider.- The response indicated that users must drop unwanted files to commit selectively, as the command operates only on added files.
- Challenges with Aider's model errors: Several users expressed frustration with recurring issues when running Aider commands, often due to environment misconfigurations or outdated versions.
- One user resolved their issue by ensuring they were referencing the correct installation of Aider through pipx.
- Dart language support limitations in Aider: Discussions revealed that Aider currently lacks support for Dart, and users noted ongoing efforts to add compatibility.
- The community provided links to related GitHub issues, emphasizing the need for additional language support within Aider.
- Providers | liteLLM: Learn how to deploy + call models from different providers on LiteLLM
- Supported languages: Aider supports pretty much all popular coding languages.
- Support for Dart/Flutter? · Issue #1089 · Aider-AI/aider: Issue Hi, looking at the supported languages on https://aider.chat/docs/languages.html, it does not list Dart / Flutter as one. Wondering if you could consider being able to generate a repository m...
Notebook LM Discord ▷ #announcements (1 messages):
New UI Rollout, NotebookLM Plus Features, Interactive Audio BETA
- New UI and NotebookLM Plus Features Launch: The team announced the rollout of the rest of the new UI and NotebookLM Plus features to all users this morning.
- This update is part of an ongoing effort to enhance user experience across the platform.
- Interactive Audio Availability Limited: Currently, Interactive Audio is still only available to a select group of users as improvements are being made on the backends.
- Users receiving the new UI without access to the Interactive mode (BETA) feature should not be alarmed, as this is expected during the transition period.
Notebook LM Discord ▷ #use-cases (32 messages🔥):
Podcast Experiments, AI in Call Centers, Game Strategy Guides, Improved Note Exporting, Interactive Mode
- Podcasts Testing New Techniques: Members discussed using NotebookLM for creating podcasts, sharing examples like Cooking with Gordon Ramsey and the Dalai Lama and others.
- One member expressed desire to utilize the service for daily music history updates on their podcast channel.
- AI's Role in Call Centers: Conversations highlighted the integration of AI into IT call centers, including a humorous take on German-speaking AI handling customer queries.
- A member shared various audio clips depicting scenarios such as troubleshooting computers and cold-call sales pitches.
- Game Strategy Guide Utilization: A user mentioned testing different strategy guides for games as sources to facilitate easier access to boss fights and collectibles.
- This approach aims to eliminate the need for exhaustive searches for tips from guides or Reddit threads.
- Exporting Notes for Improved Functionality: Concerns were raised regarding the lack of export options for notes, with calls for formats like Markdown and PDF.
- Alternative methods including using Readwise Reader for rendering source documents were discussed by another member.
- Interactive Mode Engagement: A member shared experiences using the beta interactive mode to actively engage and ask questions during conversations.
- This feature indicates a growing interest in enhancing user interaction with AI systems.
Notebook LM Discord ▷ #general (207 messages🔥🔥):
Notebook LM Plus Access, Interactive Mode Feature, New UI Feedback, Audio Overview Limitations, Multi-language Support
- Accessing Notebook LM Plus: Users are discussing how to access Notebook LM Plus, stating that it is available through Google Workspace or Google Cloud, and will be accessible for Google One AI Premium users by early 2025.
- There are questions regarding whether Notebook LM Plus is available in specific countries like Italy and Brazil, but responses indicate it is being rolled out gradually.
- Challenges with Interactive Mode Feature: Several users report difficulties using the Interactive Mode feature with issues like lagging and not being able to access it even after updating to the new UI.
- There's a consensus that the feature might still be rolling out, causing discrepancies in availability among users.
- Feedback on New UI: Some users express dissatisfaction with the new UI, mentioning that it is less user-friendly than the previous version, particularly complaining about the chat panel's visibility and the layout of notes.
- Others suggest that while the new UI offers a larger editor, the ability to collapse certain panels may improve the experience.
- Audio Overview Limitations: Users have raised concerns about the limitations of audio overviews, including long processing times and failures in generation.
- There are discussions about the impact of source order on audio overviews and whether hosts can be instructed to provide more detailed explanations.
- Exploration of Multi-language Capabilities: Questions arise about the capabilities of Notebook LM for generating podcasts in different languages, with some users confirming that audio summaries are currently only available in English.
- Despite this limitation, users have successfully generated content in Portuguese, indicating potential for broader language support.
- no title found: no description found
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Terraform overview | Terraform | HashiCorp Developer: no description found
- - YouTube: no description found
- - YouTube: no description found
- Veo 2 AI video generation for sci fi news broadcast (w/ NotebookLM): The new Veo2 AI powered video generation tool from Google Labs was released today, so I took a NotebookLM podcast I had generated from science fiction news m...
Unsloth AI (Daniel Han) ▷ #general (183 messages🔥🔥):
Python version compatibility, Unsloth 4-bit model performance, Function calling in Llama 3.2, Multi-GPU training with Unsloth Pro, Quantization process for models
- Python version compatibility issues: A discussion emerged regarding Python versions, highlighting that Python 3.13 may cause issues while 3.10 is suggested for compatibility.
- Members shared experiences with pyenv versus conda environments for managing Python versions.
- Unsloth 4-bit model performance insights: Users noted discrepancies in layer sizes between the Unsloth 4-bit model and the original Meta version, indicating potential issues with model parameterization.
- Concerns were raised about VRAM usage and performance trade-offs when transitioning from 4-bit to full precision.
- Exploring function calling in Llama 3.2: Participants expressed interest in training Llama 3.2 for improved function calling capabilities but found limited examples available for direct implementation.
- There was a consensus that including special tokens directly in datasets could simplify the training process.
- Multi-GPU training with Unsloth Pro: Members inquired about the ongoing capabilities of Unsloth Pro for multi-GPU training, confirming its functionality.
- Questions arose regarding whether this feature is limited to cloud setups or can also be executed locally.
- Quantization process for models: Users discussed the implications of quantizing models for fine-tuning, noting that non-Unsloth models could be loaded and converted to 4-bit on the fly.
- The community highlighted that this process can save time and resources during model training.
- no title found: no description found
- CosineAnnealingLR — PyTorch 2.5 documentation: no description found
- unsloth/Qwen2-VL-7B-Instruct-unsloth-bnb-4bit · Hugging Face: no description found
- Qwen/Qwen2-VL-7B-Instruct · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): My take on the Post Pretraining world - Ilya’s talk:Ilya is implying we need to find something else to scale - the brain–body mass ratio graph in the talk showed human intelligence “scaled” better tha...
- llama-models/models/llama3_2/text_prompt_format.md at main · meta-llama/llama-models: Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
- unsloth_tool_success2.py: GitHub Gist: instantly share code, notes, and snippets.
- - YouTube: no description found
- no title found: no description found
- llama-recipes/recipes/quickstart/finetuning/datasets/README.md at main · meta-llama/llama-recipes: Scripts for fine-tuning Meta Llama with composable FSDP & PEFT methods to cover single/multi-node GPUs. Supports default & custom datasets for applications such as summarization and Q&...
- tool_train.py: GitHub Gist: instantly share code, notes, and snippets.
- train.jsonl: GitHub Gist: instantly share code, notes, and snippets.
Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
Voe2 vs Sora, Open Source Reasoning Models, OpenAI Bankruptcy Speculation
- Voe2 Makes Sora Seem Useless: Discussion emerged around the release of Voe2, with claims that it makes Sora look like a useless toy.
- This sentiment was humorously highlighted with an attached meme video.
- QwQ Set to Dominate OpenAI's O1: A member argued that open source reasoning models like QwQ will significantly outpace OpenAI's O1.
- Another member noted that while reproducing reasoning models is easy, crafting a valuable model is a much greater challenge.
- Speculation on OpenAI's Financial Future: One user provocatively inquired when OpenAI might declare bankruptcy, stirring up financial speculations.
- There were no responses with solid predictions, but the comment reflects ongoing concerns about OpenAI's stability.
Unsloth AI (Daniel Han) ▷ #help (47 messages🔥):
Lora+ with Unsloth, Finetuning Qwen models, AMD GPU compatibility, Training vs Inference in Unsloth, Packing in training
- Lora+ Preparation Insights: Members discussed using Lora+ with Unsloth, noting that it may not interact well with other methods and LoFTQ or PiSSA may provide better initializations.
- One member shared a CPT blog post highlighting performance improvements of Unsloth's new release.
- Finetuning Challenges with Qwen Models: A member expressed frustration that their finetuned Qwen 2.5 model performed worse than the vanilla model, citing concerns about catastrophic forgetting.
- Other members advised iterating on the fine-tuning process to better suit specific needs, emphasizing the importance of trial and adjustment.
- AMD GPU and Bitandbytes Compatibility: Discussions emerged around running Llama-3.2-11B-Vision-Instruct on AMD GPUs, with members highlighting that Bitandbytes now supports these GPUs.
- There were still mentions of limitations and the need for alternative smart quantization techniques compatible with AMD setups.
- Using Unsloth for Inference: Members clarified that while Unsloth supports some inference capabilities, it is primarily designed for training models.
- It was mentioned that models could be exported for use in environments lacking GPUs, although performance might be severely impacted.
- Understanding Packing in Training: There was curiosity over the parameter
packing=False, with explanations provided that enabling packing can speed up training by grouping shorter examples.- Potential drawbacks were also discussed, including the risk of data contamination when using this strategy.
- Continued LLM Pretraining with Unsloth: Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.
- facebook/bart-large-mnli · Hugging Face: no description found
- llama-recipes/recipes/quickstart/finetuning/datasets/README.md at main · meta-llama/llama-recipes: Scripts for fine-tuning Meta Llama with composable FSDP & PEFT methods to cover single/multi-node GPUs. Supports default & custom datasets for applications such as summarization and Q&...
- Home: Finetune Llama 3.3, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 70% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #research (2 messages):
phi-4 Language Model, Continual Pre-training Strategies
- phi-4 Surpasses GPT-4 with Data Quality Focus: The phi-4, a 14-billion parameter language model, uses a training strategy emphasizing data quality over typical organic sources, integrating synthetic data throughout the process. It notably excels in STEM-focused QA capabilities, outpacing its teacher model, GPT-4, thanks to enhanced data and innovative post-training techniques.
- Despite minimal architecture changes since phi-3, its strong performance on reasoning benchmarks underscores the model's improved training curriculum.
- Exploring Efficient Continual Pre-training Methods: A study investigates warm-up strategies for continual pre-training of large language models, focusing on maintaining performance when incorporating new datasets. The researchers hypothesize that re-increasing the learning rate enhances efficiency while transitioning from upstream data Pile (300B tokens) to downstream data SlimPajama (297B tokens).
- Experiments follow a linear warmup and cosine decay schedule, aiming to optimize performance through thoughtful training phase adjustments.
Link mentioned: Continual Pre-Training of Large Language Models: How to (re)warm your model?: Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would b...
Cohere ▷ #discussions (166 messages🔥🔥):
Code Wizard Hackathon, Command R7B Office Hours, Maya Release and Tool Use, Emotional Support for Projects, AI Models Discussion
- Code Wizard Hackathon seeks sponsors: The organizer of the Code Wizard hackathon is looking for sponsorships to support their upcoming event in February 2025, aimed at innovation and problem-solving.
- While some attendees questioned the need for funding, others highlighted the importance of building valuable projects.
- Announcement for Command R7B Office Hours: A reminder was shared for the Command R7B Q&A session, inviting participants to ask questions and learn through hands-on code examples.
- Members expressed excitement for the session's insights, with one planning to attend before sleeping.
- Maya Release Sparks Innovation: The release of Maya was celebrated, with members eager to explore and potentially finetune for tool use.
- Participants expressed commitment to working late into the night to push project boundaries, energized by the new model.
- Emotional Support in Development: Members offered each other emotional support as they worked on their projects, emphasizing the value of community encouragement.
- Amidst the technical discussions, phrases like 'Let's ship the world' highlighted the positive atmosphere and collaboration.
- Discussion on AI and Modeling: A conversation arose regarding the specifications and features of the Maya model, with members sharing insights on its potential capabilities.
- Questions about the exact number of different models available sparked further discussion about the relevance and current development landscape.
- Irobot Benjammins GIF - Irobot Benjammins Sentient - Discover & Share GIFs: Click to view the GIF
- Cats Toby The Cat GIF - Cats Toby The Cat Nod - Discover & Share GIFs: Click to view the GIF
- Cat Cute Cat GIF - Cat Cute cat Yap - Discover & Share GIFs: Click to view the GIF
Cohere ▷ #announcements (1 messages):
Multimodal Image Embed endpoint, Rate limit increase, API keys, Cohere pricing
- 🎉 Major Boost in Multimodal Image Embed Rates! 🎉: Cohere has announced a 10x increase in rate limits for the Multimodal Image Embed endpoint on production keys, raising it from 40 images/min to 400 images/min.
- Trial rate limits continue at 5 images/min for testing, allowing users to create applications and share them within the community.
- Get to Know Your API Keys: Cohere provides two types of API keys: evaluation keys that are free but limited and production keys that are paid with fewer restrictions.
- Users can manage their keys via the API keys page to start developing more efficiently.
- Explore More on Pricing and Limits: For detailed limits on various endpoints and further insights on pricing, users can check the pricing docs.
- Endpoints are subject to a maximum of 1,000 calls per month to ensure fair use across the platform.
- Community Support Always Available!: For any further inquiries, users are encouraged to ask questions in the designated support channel or via email at support@cohere.com.
- Cohere promotes an open dialogue for feedback and clarifications, ensuring a supportive environment for developers.
Link mentioned: API Keys and Rate Limits — Cohere: This page describes Cohere API rate limits for production and evaluation keys.
Cohere ▷ #questions (57 messages🔥🔥):
Cohere API for Image Embeddings, RAG-based PDF Answering System, Image Retrieval through Metadata
- Clarification on Cohere's Image Embedding API: User discussed using Cohere's API to embed images from PDFs into a vector store for use in a RAG system, noting that embeddings provide semantic meaning and cannot generate original images.
- It was established that embeddings are meant for searching through vector representations and do not allow for direct image retrieval, requiring the original images to be stored separately.
- Image Retrieval Strategy with Embedding: To retrieve images based on user queries, a member suggested storing the image paths as metadata alongside the embeddings in the Pinecone vector store.
- When an image-related query arises, the embedding will guide the retrieval of its corresponding path, allowing the system to display the correct image.
- Fundamentals of AI and ML: A user admitted to being new to AI and ML, having started just a couple of months prior, while another member emphasized the importance of understanding the basics of embeddings.
- The conversation highlighted that embeddings represent semantic meanings, aiding in efficient searching, but do not resolve the original content.
Link mentioned: Multimodal Embeddings — Cohere: Multimodal embeddings convert text and images into embeddings for search and classification (API v2).
Cohere ▷ #cmd-r-bot (1 messages):
.kolynzb: yello
Bolt.new / Stackblitz ▷ #prompting (4 messages):
Meta prompt for Bolt, UI version of Bolt, Feature requests for Bolt
- Meta Prompt for Bolt Development: A member shared a meta prompt they use with Claude to create a systematic approach for generating detailed software project plans with Bolt, covering various development aspects.
- The prompt emphasizes analyzing requirements, defining structure, and designing UI to streamline the project planning process.
- Excited Announcement of Bolt's UI Version: A member announced they will be rolling out a UI version of Bolt, where users can select between Claude, OpenAI, and Llama models hosted on Hyperbolic for generation.
- This UI aims to enhance user experience and model selection in the generation process.
- Request for Functional Prompts in Bolt: A member inquired about the possibility of starting with a prompt to enable comprehensive functional features in Bolt, such as **
- Community Engagement with GIFs: Another member shared a lighthearted GIF from Tenor in response to the announcements, featuring characters exclaiming **
- Excellent Bill And Ted GIF - Excellent Bill And Ted Air Guitar - Discover & Share GIFs: Click to view the GIF
- This meta prompt outlines a systematic approach for Bolt to create a detailed software project plan. It includes analyzing requirements, defining structure, designing UI, planning implementation, and mapping out how the chosen tech stack fits into the development process.: This meta prompt outlines a systematic approach for Bolt to create a detailed software project plan. It includes analyzing requirements, defining structure, designing UI, planning implementation, a...
Bolt.new / Stackblitz ▷ #discussions (213 messages🔥🔥):
Using Bolt for SaaS projects, Challenges with Bolt integration, Support and assistance on coding issues, Managing tokens effectively, Sharing projects built with Bolt
- Using Bolt for SaaS projects: Users expressed interest in building SaaS applications using Bolt, acknowledging it may require assistance from developers for further scaling and integration.
- A user was looking for step-by-step guidance on how to manage their SaaS project effectively.
- Challenges with Bolt integration: Multiple users reported issues with Bolt, including the platform creating unnecessary files and experiencing errors when running commands.
- Some users suggested taking breaks from the platform to manage frustration and prevent screen damage.
- Support and assistance on coding issues: Users sought assistance for their coding challenges, with one user specifically requesting help on their Python code.
- Advice on debugging and utilizing online resources for better coding practices was shared.
- Managing tokens effectively: Concerns were raised about the usage and management of tokens, with users expressing frustration over unexpected consumption.
- It was noted that users had limits on their monthly token usage and should be conscious of replacement costs.
- Sharing projects built with Bolt: Users inquired about the possibility of sharing websites constructed using Bolt, regardless of language constraints.
- Interest in sharing completed projects indicated a collaborative environment within the community.
- Johnny Depp Pirate GIF - Johnny Depp Pirate Pirate Salute - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- no title found: no description found
- - YouTube: no description found
- Bolters.io | Community Supported Tips, Tricks & Knowledgebase for Bolt.new No-Code App Builder: Documentation and guides for Bolt.new
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- oTTomator Community: Where innovators and experts unite to advance the future of AI-driven automation
Eleuther ▷ #general (43 messages🔥):
Pythia based RLHF models, TensorFlow on TPU v5p, Tokenizer edge cases, Exponential Moving Average (EMA), VLM Pretraining Data
- Searching for Pythia based RLHF models: A member inquired about the availability of publicly available Pythia based RLHF models.
- No specific models were recommended in the discussion.
- TensorFlow segfaults on TPU v5p: A user reported issues with running TensorFlow on TPU v5p, stating that 'import tensorflow' results in segmentation faults across multiple VM images.
- Concerns were raised over Google's declining support for TensorFlow amid ongoing challenges.
- Tokenizer issues with edge cases: Concerns were shared regarding tokenizers discarding important user information due to edge cases and BPE biases.
- A reference was made to a paper discussing the impact of these training issues on performance.
- Utilizing Exponential Moving Average (EMA): There was a discussion on exponential moving average (EMA) as a method to address recency bias in models, suggesting it can help smooth weights.
- One member highlighted that EMA has been heavily tested, particularly in diffusion models.
- Best practices for VLM pretraining data: A member sought recommendations for VLM pretraining data, particularly a large collection of images and captions.
- It was suggested that Laion-5B could be a go-to option despite its noisy data.
Eleuther ▷ #research (101 messages🔥🔥):
Attention Mechanisms, Gradient Descent Optimizers, Grokking Phenomenon, Memory Augmented Neural Networks, Stick Breaking Attention
- Questioning Attention's Kernel Approach: Members debated the framing of attention mechanisms as kernel methods, suggesting this perspective may overlook essential functionalities of attention that go beyond classic kernel approximations.
- One member proposed that the true operation of attention might relate more closely to retrieval capabilities rather than simple aggregation.
- SGD-SaI: A New Approach to Optimizers: The introduction of SGD-SaI offers a new perspective on training deep networks by enhancing stochastic gradient descent without adaptive moments, yielding results comparable to AdamW.
- Participants highlighted the need for unbiased comparisons against established optimizers, with a suggestion to dynamically adjust learn rates during training phases.
- Insights on Grokking and Complexity: A recent paper explored the connection between neural network complexity and the grokking phenomenon, proposing a new metric based on Kolmogorov complexity.
- This study aims to better understand when models generalize versus memorize, potentially offering structured insights into training dynamics.
- Stick Breaking Attention Mechanism: Discussion on stick breaking attention revealed a method for adaptively aggregating attention scores, potentially mitigating oversmoothing effects in models.
- Members discussed whether these adaptive methods could better handle the complexity of learned representations in transformer architectures.
- Warmup Strategies for Learning Rates: Clarification on correct learning rate warmup strategies highlighted formulas for adjusting learning rates during optimizer setup, specifically addressing beta decay considerations.
- Participants shared implementations and considerations for warmup strategies, noting potential pitfalls in common learning rate schedulers.
- The Complexity Dynamics of Grokking: We investigate the phenomenon of generalization through the lens of compression. In particular, we study the complexity dynamics of neural networks to explain grokking, where networks suddenly transit...
- Hardness of Approximate Nearest Neighbor Search: We prove conditional near-quadratic running time lower bounds for approximate Bichromatic Closest Pair with Euclidean, Manhattan, Hamming, or edit distance. Specifically, unless the Strong Exponential...
- No More Adam: Learning Rate Scaling at Initialization is All You Need: In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM...
- TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax: The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or statef...
- The Complexity Dynamics of Grokking: no description found
- On The Computational Complexity of Self-Attention: Transformer architectures have led to remarkable progress in many state-of-art applications. However, despite their successes, modern transformers rely on the self-attention mechanism, whose time- and...
- Memory Transformer: Transformer-based models have achieved state-of-the-art results in many natural language processing tasks. The self-attention architecture allows transformer to combine information from all elements o...
- GitHub - lucidrains/x-transformers: A concise but complete full-attention transformer with a set of promising experimental features from various papers: A concise but complete full-attention transformer with a set of promising experimental features from various papers - lucidrains/x-transformers
Eleuther ▷ #interpretability-general (3 messages):
Steering Vectors, SAEs and Interpretability, Unlearning with SAE Conditional Steering
- Steering Vectors Reveal Interpretable Paths: The team shared their findings on steering vectors, asserting that they indicate linear directions in LLMs are interpretable, particularly with SAEs' decomposition abilities.
- Using the gradient pursuit algorithm by Smith et al, the researchers decomposed steering vectors to uncover promising features linked to refusal and sycophancy.
- Mixed Feelings on SAE Performance: One member expressed skepticism, labeling the overall results as negative despite a few improvements from SAEs that exceed what might be attributed to random noise.
- This sentiment highlights the contentious nature of interpreting SAE efficacy across various applications.
- Paper Supervised by Arthur Conmy: A member mentioned that Arthur Conmy supervised a paper focusing on unlearning through SAE conditional steering effects.
- This implies ongoing discussions around the implications and effectiveness of SAEs in specific contexts.
Eleuther ▷ #lm-thunderdome (43 messages🔥):
VLLM performance, Winogrande dataset issues, New release updates, Library requirements for benchmarks, Chat template integration
- VLLM struggles with output speed: Reported output tokens per second with VLLM is only 24.69/s when using an 8B model on MMLU Pro, primarily due to needing a forward pass per sample instead of leveraging kv-cache.
- Using
--data_parallel_size=Ncould help optimize performance by increasing model replicas depending on tensor parallel size.
- Using
- Issues with Winogrande format: A member encountered issues with the Winogrande dataset leading to an
IndexError, likely due to its unique format affecting tokenization.- A new PR was pushed to resolve issues with the Winogrande task while noting that fewshots may still present challenges.
- New release drops Python 3.8 support: A member mentioned that the latest release on PyPI drops support for Python 3.8 after its EOL in October.
- This change reflects ongoing updates to ensure compatibility and performance improvements in the evaluation harness.
- Missing libraries during benchmark runs: Members pointed out missing libraries such as vllm, langdetect, and antlr4-python3-runtime when running benchmarks, which weren't auto-installed by the evaluation harness.
- It's unclear if the harness is intended to auto-install all required libraries for various benchmarks, thus a flag was raised for awareness.
- Chat template affects evaluation scores: Concerns were raised about the new chat template impacting evaluation results, with members unsure how to compare against previous scores without it.
- Testing will continue to determine if the new integration meets or exceeds prior performance metrics.
Eleuther ▷ #gpt-neox-dev (2 messages):
Non-parametric LayerNorm, Configuration Options, Memory Recall on Config Changes
- Non-parametric LayerNorm added: One member confirmed the addition of a non-parametric LayerNorm to the configurations, indicating a shift in available options.
- This addition reflects ongoing updates and enhancements to the existing systems.
- Configuration options still under discussion: Another member expressed uncertainty about previous configuration options, suggesting that the information might have changed over the past year.
- This highlights the evolving nature of the configurations and the need for continuous review.
Cursor IDE ▷ #general (173 messages🔥🔥):
Cursor IDE updates, Issues with AI models, Cursor Extension announcement, User feedback on models, O1 Pro discussions
- Cursor Extension Launch: A new extension for Cursor enables users to easily export their composer and chat history to markdown, allowing for enhanced productivity and sharing.
- This extension also features an option to publish content to the web, creating a way to capture coding interactions effectively.
- Chat and AI Models Issues: Users reported connection failures, latency issues, and overall degradation in response quality from models like Claude 3.5 and Gemini, suggesting ongoing instability.
- Several users experienced problems with their chat sessions, prompting multiple complaints about the reliability of AI interactions.
- Discussion on O1 Pro: Amid excitement for O1 Pro's capabilities, users speculated about its pricing models and the advantage it offers in complex coding tasks.
- Some expressed a need for better integration, suggesting a handoff feature between O1 Pro and Claude to enhance project workflow.
- Community Support and Feedback: Members discussed offering peer support for software development projects, with specific interest in reviewing new SEO tools.
- Users encouraged sharing experiences and tips regarding the effectiveness of various tools and models within the Cursor IDE ecosystem.
- Chat Management Feature Requests: A request for a duplicate chat feature was discussed as a way to manage chat sessions more effectively and preserve context.
- Members shared workarounds such as utilizing markdown export options as temporary solutions while waiting for official enhancements.
- Tweet from NVIDIA AI Developer (@NVIDIAAIDev): 👀 RAPIDS cuDF accelerates #pandas up to 150x with zero code changes. Now you can continue using pandas as your dataset size grows into gigabytes. ⚡ ➡️ Jupyter Notebook to try the demo: http://nvda.ws...
- Chad Monke GIF - Chad Monke - Discover & Share GIFs: Click to view the GIF
- SpecStory (Cursor Extension) - Visual Studio Marketplace: Extension for Visual Studio Code - (Cursor Extension) Capture, search and learn from every AI coding journey
- Champoy El Risitas GIF - Champoy El Risitas Kek - Discover & Share GIFs: Click to view the GIF
- Shut Up And Take My Money GIF - Shut Up And Take My Money - Discover & Share GIFs: Click to view the GIF
- TikTok - Make Your Day: no description found
- Tweet from Mckay Wrigley (@mckaywrigley): I asked o1 pro to implement 6 things I had on my todo list for a project today.- It thought for 5m 25s.- Modified 14 files.- 64,852 input tokens.- 14,740 output tokens.Got it 100% correct - saved me 2...
- You Say You Hate Me Then Love Me Jamie Fine GIF - You Say You Hate Me Then Love Me Jamie Fine Hate Me Love Me Song - Discover & Share GIFs: Click to view the GIF
OpenAI ▷ #annnouncements (1 messages):
DevDay Holiday Edition, AMA with OpenAI's API Team
- Launch of DevDay Holiday Event: A YouTube livestream titled Day 9: DevDay Holiday Edition is scheduled, accessible here.
- The stream precedes an AMA scheduled for 10:30–11:30am PT on the developer forum.
- Join the AMA with OpenAI's API Team: The team invites community members to participate in an AMA on their developer forum, details are available here.
- Members are encouraged to bring their questions for the OpenAI API team during the specified hour.
Link mentioned: - YouTube: no description found
OpenAI ▷ #ai-discussions (130 messages🔥🔥):
AI Accents and Realism, OpenAI Features and Limitations, AI Interaction and Alignment, Anthropic Pricing Changes, API Functionality Concerns
- AI Can Mimic Accents, But Still Feels Artificial: Users discussed the AI's ability to switch between multiple languages and accents, particularly mentioning how it can imitate an Aussie accent. Despite these advancements, many still feel that interactions remain unnatural and lack a real conversational flow.
- One user noted that while the AI can engage in different accents, it often doesn't allow certain requests, reflecting potential guideline limitations concerning respectful interactions.
- OpenAI's Features Under Scrutiny: Concerns were raised about the absence of the search magnifying glass on chat-gpt.com, with users sharing mixed experiences and speculating on potential reasons for its disappearance. Some noted that sidebar visibility may affect feature accessibility.
- Additionally, users mentioned that moderation classifiers might lead to auto-flagging of certain content, causing temporary access issues for flagged users.
- AI Alignment Framework Emerges: One user shared their work on developing a framework addressing the alignment question in AI, posting a link to their GitHub repository. This sparked a discussion on the broader implications of developing AI in isolation versus interaction with the real world.
- Another contributor highlighted the importance of real-world interaction for effective AI development, likening confined AI to a solitary experience lacking fundamental learning opportunities.
- Anthropic Adjusts Its Pricing Strategy: An update was shared regarding Anthropic's pricing model, which reportedly became less expensive with the addition of prompt caching for APIs. This change indicates a competitive move amidst ongoing developments in the AI landscape.
- Users reacted with curiosity about how this shift might impact their usage and the ongoing rivalry with OpenAI's offerings.
- Interactions with AI Remain Uncertain: Concerns regarding limitations of AI interactions surfaced, particularly when users attempted to inquire about cut-off dates or gauge emotional responses. Users shared frustrations over AI behavior that contradicts its capabilities, leading to confusion about its true potential.
- The conversation underscored a desire for clearer understanding and functionality regarding how users engage with AI while acknowledging ongoing technological improvements.
- Chat Blackbox: AI Code Generation, Code Chat, Code Search: no description found
- Search magnifying glass in the left sidebar not available: I’m still experiencing this issue. I’ve cleared cache, and used different browsers in private/incognito mode without success. Update: It’s now showing.
- GitHub - AlignAGI/Alignment: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources.: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources. - AlignAGI/Alig...
- - YouTube: no description found
OpenAI ▷ #gpt-4-discussions (12 messages🔥):
Custom GPT issues, Advanced voice mode features, PDF and image reading functionality, Project replacements for Custom GPTs, Max file size and limit for Custom GPTs
- Custom GPTs editing and visibility issues: Several users reported they lost the ability to edit custom GPTs and couldn't find them when accessing the platform, even after having multiple setups.
- It seems to be a known issue, as confirmed by other members who also experienced similar problems with accessing their custom setups.
- Inquiries about Advanced Voice Mode: A user questioned how many minutes per day of advanced voice mode features are available with the ChatGPT PRO subscription.
- This highlights a growing interest in understanding the limitations of the voice functionality offered.
- PDF and image reading capabilities under scrutiny: A member raised concerns that the PDF and image reading options only function properly on mobile devices and not on computers.
- Many users expressed frustrations over the lack of support for this issue, indicating it's a widespread concern.
- Replacing Custom GPTs with projects: A member shared that replacing custom GPTs with projects positively impacted performance for them.
- This advice proved helpful to others looking for alternatives amidst ongoing issues with custom setups.
- Future updates for Custom GPT limitations: There were questions regarding potential updates to address the max file size and limit for custom GPTs.
- This discussion reflects ongoing user interest in the capabilities of the platform and possible enhancements.
OpenAI ▷ #prompt-engineering (3 messages):
Using AI to Build Websites, Exploring AI Capabilities
- Leverage AI for Website Development: One member suggested that users communicate their desired outcomes and available tools when engaging with the model to create a website.
- They encouraged inquiries ranging from basic coding guidance to optimizing existing code, regardless of users' skill levels.
- Inquiry into AI's Abilities: A user highlighted the importance of directly asking the AI what it can do, implying that clarity can enhance collaborative outcomes.
- This underscores the flexibility of the AI, enabling users to tailor interactions based on their experience and goals.
OpenAI ▷ #api-discussions (3 messages):
Using AI for web development, Maximizing AI model capabilities
- Explore web development with AI: One member suggested sharing your desired project, tools, and experience level with the AI model to help create a website from scratch.
- They emphasized that the model can assist at any level, from complete novices to more experienced developers, providing guidance and code checking.
- Ask the model about its capabilities: .pythagoras encouraged members to directly inquire what the AI model can accomplish for their projects.
- This could enhance user experience by prompting specific feature inquiries or project ideas.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Structured Outputs, Multi-Model Apps, OpenRouter Model Support
- OpenRouter Expands to 46 Models: OpenRouter now supports 46 different models for structured outputs, significantly enhancing the usability of multi-model applications.
- With structured outputs, it's easier to constrain LLM outputs to a JSON schema, streamlining the development process, as highlighted in the demo here.
- Normalization of Structured Outputs: The platform now normalizes structured outputs across 8 different model companies and includes 8 free models.
- This broad support is aimed at facilitating smoother integration of various models into applications, emphasizing the underrated nature of structured outputs.
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): Structured outputs are very underrated. It's often much easier to constrain LLM outputs to a JSON schema than asking for a tool call.OpenRouter now normalizes structured outputs for- 46 models- 8 ...
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
``
- Shashank Excited About Something Awesome: A member expressed enthusiasm by stating, "That's awesome!"
- Gratitude Acknowledged: Another member responded with gratitude, indicating appreciation for the enthusiasm shared in the previous message.
OpenRouter (Alex Atallah) ▷ #general (130 messages🔥🔥):
Gemini Flash 2 performance, Using typos in prompts for model response, API Key Exposure, OpenRouter API limitations, o1 API changes and pricing
- *Gemini Flash 2 shows improved coding ability: Members discussed how Gemini Flash 2 generates better code for scientific problem-solving tasks compared to Sonnet 3.5*, particularly in array sizing scenarios.
- Feedback indicated that external frameworks could help enhance effectiveness, bringing attention to the specific use-case efficiency.
- *Experimenting with typos in prompts to guide AI*: Members shared ideas on using intentionally placed typos and meaningless words in prompts to influence model outputs, highlighting potential benefits for creative writing.
- The strategy includes attracting model attention to desired keywords, even while leveraging controlled outputs with Chain of Thought (CoT) techniques.
- *Reporting exposed OpenRouter API Keys: A member reported discovering exposed OpenRouter API keys* on GitHub, prompting discussions on where to report such findings for security reasons.
- It was suggested to email support@openrouter.ai for any exposed keys that could pose a risk.
- *OpenRouter API limitations regarding chat details: Questions arose about the ability to retrieve chat history or prompted inputs from the OpenRouter API*, with emphasis on the stateless nature of requests.
- It was clarified that while metadata is available, the full conversation isn’t stored on OpenRouter, thus requiring a proxy for logging conversations.
- *Changes in pricing and token usage for o1 API: Users noted that o1 API now consumes 60% fewer tokens*, raising concerns about potential impacts on model performance.
- Discussions highlighted the necessity for adjustments in pricing and token efficiency, while confirming that tier limitations currently apply.
- Limits | OpenRouter: Set limits on model usage
- Google: Gemini Experimental 1206 (free) – Recommended Parameters: Check recommended parameters and configurations for Google: Gemini Experimental 1206 (free) - Experimental release (December 6, 2024) of Gemini.
- Gemini Flash 2.0 Experimental (free) - API, Providers, Stats: Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1. Run Gemini Flash 2.0 Experimental (free) with API
Perplexity AI ▷ #announcements (1 messages):
Perplexity Pro gift subscriptions, Subscription benefits, Subscription durations
- Gift knowledge with Perplexity Pro subscriptions: Perplexity now offers gift subscriptions for 1, 3, 6, or 12 months here. It's an ideal gift for anyone curious about AI, allowing them to unlock enhanced search capabilities.
- Recipients will receive their subscription via promo code sent directly to their email inbox, making gifting straightforward and efficient.
- Unlock powerful features with Pro: Perplexity Pro users can search 3x as many sources, access the latest AI models, and search through their own files. This extensive capability makes the subscription particularly appealing for serious AI enthusiasts.
- In the promotional message, it's emphasized that all sales are final, ensuring that buyers are fully committed at the time of purchase.
Link mentioned: Perplexity Pro Subscription | Perplexity Supply: Perplexity Supply exists to explore the relationship between fashion and intellect with thoughtfully designed products to spark conversations and showcase your infinite pursuit of knowledge.
Perplexity AI ▷ #general (90 messages🔥🔥):
OpenAI vs. Perplexity Features, Perplexity Pro Subscription, Model Performance Comparison, API Usage Guidance, User Interface Suggestions
- Debate on OpenAI Borrowing Features: Users discussed whether OpenAI is innovating or merely copying Perplexity's features, particularly in relation to Projects and GPT Search.
- Some members noted that everyone is copying each other, leading to a conversation about originality in AI development.
- Perplexity Pro Subscription Experiences: A user shared their positive experience with Perplexity Pro, emphasizing its effectiveness for research compared to ChatGPT.
- Others inquired about model differences and preferences, indicating a desire for clarity on which model is best for various tasks.
- Concerns Over Model Performance: Users expressed frustration regarding the perceived decline in model performance, particularly with the Sonnet and Claude variations.
- Some reported that switching to specific models can significantly affect response quality, leading to varying user experiences.
- API Information and Usage: A member sought guidance on obtaining a Perplexity API token, while others provided links to official documentation for setup.
- Clarifications were made that a separate registration and payment method is required for API usage despite having a Pro account.
- User Interface and Feature Requests: Users suggested aesthetic improvements for the Perplexity UI, such as adding a snowfall effect for visual appeal.
- Discussions highlighted that while some prioritize functionality in their work, others appreciate aesthetic enhancements.
- Tweet from Perplexity Supply (@PPLXsupply): Give the gift of knowledge. Perplexity Pro gift subscriptions now available.
- Initial Setup - Perplexity: no description found
- - YouTube: no description found
- - YouTube: no description found
- Search—12 Days of OpenAI: Day 8: Kevin Weil, Adam Fry and Cristina Scheau introduce and demo updates to ChatGPT search.
Perplexity AI ▷ #sharing (6 messages):
Mozi social app, U.S. Military Space Wars, Mystery Georgian Tablet, Qu Kuai Lian, Creatine Monohydrate
- Mozi App Launches amid Social Media Buzz: The newly launched social app Mozi by Ev Williams is generating excitement across platforms, promising to deliver a fresh approach to social networking.
- accompanying YouTube video dives deeper into its features and functionalities.
- U.S. Military Readies for Space Wars: Recent discussions reveal that the U.S. Military is preparing strategically for potential confrontations in outer space, emphasizing technological advancements.
- A detailed view can be found in the linked article about their plans for space dominance.
- Enigmatic Georgian Tablet Discovered: A fascinating article highlights the discovery of a mysterious Georgian tablet, intriguing historians and archeologists alike.
- Details about its origin and significance can be read in the full article here.
- Qu Kuai Lian Explores Blockchain Innovations: The latest on Qu Kuai Lian showcases innovations in the blockchain space that are drawing significant interest from developers and investors.
- For those interested, further insights can be gathered from this resource.
- Analyzing Creatine Monohydrate Benefits: A link to discuss MuscleBlaze's Creatine Monohydrate details its benefits, including enhanced performance and recovery strategies.
- Visit this link for a comprehensive analysis.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
Perplexity MCP, MCP server integration, Using models with APIs, Gemini integration, Access to models
- Perplexity MCP found on aggregation site: A user mentioned they found a Perplexity MCP on one of two aggregation sites they watch, promising to post more details later.
- This indicates increased interest in MCP servers among community members.
- MCP server for everyday use: Another user confirmed they use a specific MCP server every day, providing the link to the GitHub repository for the any-chat-completions-mcp project.
- They highlighted access to various models like Gemini, OpenAI, and Groq, with Mistral coming soon.
- Gemini API integration discussed: The user shared that they utilized the new Gemini integration through the OpenAI SDK, providing the base URL for access: Gemini API.
- This integration seems to enhance user experience by allowing interaction with multiple APIs seamlessly.
- Model access noted: The other user indicated they can access any model provided by the APIs, including web access and citation features for Perplexity.
- This accessibility points to substantial capabilities for users leveraging different AI models efficiently.
Link mentioned: GitHub - pyroprompts/any-chat-completions-mcp: Contribute to pyroprompts/any-chat-completions-mcp development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
Palmyra Creative, OpenAI API updates, NVIDIA Jetson Orin Nano, O1 and O1 Pro distinction, Anthropic API updates
- Palmyra Creative's Release: The new Palmyra Creative model is aimed at enhancing creativity in business tasks, featuring a 128k context window for imaginative tasks like brainstorming and analysis.
- It can seamlessly integrate with domain-specific models, ideally serving various professionals from marketers to clinicians.
- Exciting OpenAI API Updates: A mini dev day highlighted impressive updates to the OpenAI API, including an O1 implementation with function calling and new voice model features.
- WebRTC support for real-time voice applications and significant output token enhancements were key announcements during the event.
- Introduction of Jetson Orin Nano Super Kit: NVIDIA's Jetson Orin Nano Super Developer Kit promises enhanced AI processing capabilities with a 70% increase in neural processing to 67 TOPS and a 102 GB/s memory bandwidth.
- It aims to empower hobbyists with budget-friendly AI capabilities, maintaining a price of $249 for an accessible AI computing solution.
- Clarification on O1 vs O1 Pro: Aidan McLau clarified that O1 Pro is a distinct implementation separate from the standard O1 model, designed for higher reasoning capabilities.
- This distinction raised questions within the community regarding potential confusion about the functionalities of these models.
- Updates in Anthropic API Functionality: Anthropic announced the general availability of four new features moving out of beta, including prompt caching and PDF support for their API.
- These updates aim to enhance quality of life for developers working with the Anthropic platform, facilitating smoother operations.
- Tweet from Raj Vir (@rjvir): Google Gemini's market share among developers went from ~5% in September to >50% market share last week (per @OpenRouterAI)
- Apollo: Apollo: An Exploration of Video Understanding in Large Multimodal Models
- Tweet from fofr (@fofrAI): Minimax's new video model, `video-01-live` is up on Replicate:https://replicate.com/minimax/video-01-liveIt's really good at animation and maintaining a character’s identity. And the outputs a...
- Tweet from Waseem AlShikh (@waseem_s): The use of enterprise AI for creative problem-solving and brainstorming has been underwhelming to date, with existing LLMs unable to generate breakthrough ideas for the critical tasks that business us...
- Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
- Nvidia’s $249 dev kit promises cheap, small AI power: It’s half as expensive as its predecessor.
- Tweet from Vercel (@vercel): We analyzed billions of AI crawler requests to figure out how each crawler handles JavaScript rendering, assets, and other behavior.Here's what we found.
- Palmyra Creative - a Hugging Face Space by samjulien: no description found
- Tweet from Mckay Wrigley (@mckaywrigley): @OpenAI YOU GUYS GET IN HERE56% context window bump and 3x output token bump!!!
- Modular: Introducing MAX 24.6: A GPU Native Generative AI Platform: MAX 24.6 release bog featuring MAX GPU
- Tweet from Kevin Weil 🇺🇸 (@kevinweil): Day 9: ✨mini dev day ✨A whole series of launches today:• o1 in the API, complete with function calling, structured outputs, developer messages, and vision• GPT-4o AND 4o-mini voice model updates in th...
- Tweet from Craig Dennis (@craigsdennis): I've been having a ton of fun exploring the Realtime API from @OpenAI. Today they just launched the ability to connect to it over WebRTC! 🤖🖐️ It supports Tool Calling, so check out what that lo...
- Tweet from Raj Vir (@rjvir): Google Gemini's market share among developers went from ~5% in September to >50% market share last week (per @OpenRouterAI)
- Tweet from Alex Albert (@alexalbert__): Quality of life update today for devs. Four features are moving out of beta to become generally available on the Anthropic API:- Prompt caching- Message Batches API (with expanded batches)- Token coun...
- Tweet from Michelle Pokrass (@michpokrass): @aidan_mclau hey aidan, not a miscommunication, they are different products! o1 pro is a different implementation and not just o1 with high reasoning.
- Tweet from AK (@_akhaliq): Meta releases ApolloAn Exploration of Video Understanding in Large Multimodal Modelsa family of state-of-the-art video-LMMs
- Tweet from fofr (@fofrAI): Oh shit, look how well video-01-live fills in the text behind her.The init image doesn't contain the S or P. I don't even mention "space" in the prompt. Yet somehow it knows. 🤯🤯See t...
- AMA on the 17th of December with OpenAI's API Team: Post Your Questions Here: Little Dev Day confirmed. Join the AMA with the API team right after the release! To prepare for the event—or if you’re unable to attend—you can post your questions here in advance. The AMA will beg...
- Tweet from Omar Sanseviero (@osanseviero): OmniAudio is out! ⚡️⚡️Super fast local voice LLM🤏2.6B-parameters🔊Multimodal: text and audio in🤗Unified Gemma and WhisperBlog: https://nexa.ai/blogs/omniaudio-2.6bDemo: https://hf.co/spaces/NexaAID...
- Tweet from Lisan al Gaib (@scaling01): Falcon 3 models were released a few hours ago! Huggingface Link: https://huggingface.co/blog/falcon3Following model sizes: 1B, 3B, 7B, 10B & 7B Mamba, trained on 14 Trillion tokens and apache 2.0 lice...
- - YouTube: no description found
- - YouTube: no description found
- google/Gemma-Embeddings-v1.0 · Hugging Face: no description found
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
LM Studio ▷ #general (55 messages🔥🔥):
Text to Speech and Speech to Text Tools, LM Studio Model Tuning, Uncensored Chatbot Alternatives, Cooling and Power Management Scripts on macOS, Model Compatibility and Performance
- Hope for Text to Speech Integration: A user expressed optimism for the future integration of text to speech and speech to text capabilities in LM Studio, with alternatives currently available if needed.
- Another member mentioned tools can be run alongside LM Studio as a server to facilitate these features.
- LM Studio Model Tuning Limitations: A user inquired about tuning existing models using discord data exports, but was informed that finetuning isn’t possible with LM Studio.
- Instead, they can set system prompts to guide responses, though this is limited to the current session.
- Exploration of Uncensored Chatbots: Discussion sparked on finding uncensored chatbot alternatives, with recommendations for models like Gemma2 2B and Llama3.2 3B to run with CPU.
- Members were directed to resources on using these models effectively, including links to quantization options.
- macOS Power Management Scripting: One user shared scripts to manage low power mode on macOS during thermal throttling, aiming to optimize performance without overheating.
- The scripts adjust power settings based on system thermal pressure levels, although effectiveness is debatable among users.
- Hardware Compatibility and Performance Queries: A beginner asked about using an Intel i7 and NVIDIA 4070ti Super for running models like PHI-4, and confirmations were provided on capabilities.
- Discussions touched on model support in current frameworks, and experiences with various hardware configurations were shared.
- bartowski/gemma-2-2b-it-abliterated-GGUF · Hugging Face: no description found
- bartowski/Llama-3.2-3B-Instruct-uncensored-GGUF · Hugging Face: no description found
- Feature Request: Add support for Phi-4 model · Issue #10814 · ggerganov/llama.cpp: Prerequisites I am running the latest code. Mention the version if possible as well. I carefully followed the README.md. I searched using keywords relevant to my issue to make sure that I am creati...
LM Studio ▷ #hardware-discussion (29 messages🔥):
GPU Performance Comparison, Model Memory Usage in GPUs, Llama Model Settings, New GPU Listings, Driver Issues with AMD GPUs
- GPU Performance shows surprising similarities: Users observed that while the 3070 Ti and 3090 have similar price ranges, performance in games appears almost equal.
- One user can find 3090s for ~$750, while another reports potentially lower prices around $900 CAD in their local area.
- GPU resource allocation might be misconfigured: A user is experiencing slow performance at 2.13 tokens/second across multiple GPUs, indicating possible CPU usage instead of GPU.
- Despite the configuration, sometimes one GPU randomly uses 25% utilization, suggesting settings may require adjustment.
- Need to verify Llama model settings: Concern arises regarding the Llama.cpp configuration to ensure CUDA is enabled for using GPUs effectively.
- Users suggested testing with a single GPU to check for improved performance when the model size is 5GB.
- Zotac accidentally lists upcoming RTX 50 GPUs: Zotac's website inadvertently listed the RTX 5090, 5080, and 5070 families with advanced specs before their official launch.
- This listing confirms that the RTX 5090 will feature 32GB GDDR7 memory, stirring interest in upcoming Nvidia hardware.
- Problems with AMD GPU drivers: Some users encountered issues with the 24.12.1 AMD driver, affecting performance and causing GPU usage spikes without effective power consumption.
- Reverting to version 24.10.1 resolved lag issues, boosting performance significantly to 90+ tokens/second on models.
Link mentioned: Zotac accidentally lists RTX 5090, RTX 5080, and RTX 5070 family weeks before launch — accidental listing seemingly confirms the RTX 5090 with 32GB of GDDR7 VRAM: Strike three for Zotac!
Stability.ai (Stable Diffusion) ▷ #general-chat (79 messages🔥🔥):
Learning Stable Diffusion with online courses, Choosing between GPU options for AI, Scams and bot detection methods, Creating Lora models, Using the latest models in AI
- Best online courses for Stable Diffusion: A member expressed interest in finding comprehensive online courses that compile YouTube tutorials into one resource for learning Stable Diffusion with A1111.
- The community discussed the need for easily accessible education on the topic.
- Choosing between laptop and desktop for AI tasks: A user is deciding between a 4090 laptop or a 4070 TI Super desktop, noting both have 16GB VRAM, while others suggested that desktops are better for AI work.
- Comments highlighted that laptops aren't ideal for heavy graphics tasks despite being suitable for gaming.
- Understanding bot detection techniques: Conversation focused on identifying scam bots, emphasizing the importance of asking absurd questions or using tests like the 'potato test' to differentiate between humans and bots.
- Members noted that both bots and real humans can pose risks, making cautious engagement essential.
- Steps to create your own Lora model: A user sought advice on making a Lora model, receiving a step-by-step process that includes creating a dataset, selecting a model, and training the Lora.
- The importance of researching how to create effective datasets for training was also highlighted.
- Inquiring about the latest AI models: A returning member inquired about the current AI models in use, specifically mentioning 'Flux.1-Dev', and sought information on its requirements.
- The community shared updates on model usage trends and requirements for effective AI implementation.
- What Huh GIF - What Huh Wat - Discover & Share GIFs: Click to view the GIF
- GitHub - Bing-su/adetailer: Auto detecting, masking and inpainting with detection model.: Auto detecting, masking and inpainting with detection model. - Bing-su/adetailer
- GitHub - CS1o/Stable-Diffusion-Info: Stable Diffusion Knowledge Base (Setups, Basics, Guides and more): Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
GPU MODE ▷ #general (7 messages):
Session Recording Availability, Distributed Training Courses, 6D Parallelism Insights, NCCL Source Code Study, Tool Calls during Generation
- Session Recording Access: A member inquired about the availability of the session recording, to which another member promptly shared the YouTube link where it is uploaded.
- Yep it's uploaded right here! 😀
- Course Recommendations for Distributed Training: A member sought recommendations for comprehensive courses on distributed training, particularly ones that offer structured homework and practices.
- They highlighted the usefulness of existing resources such as LambdaLabsML's guide on GitHub.
- Discussions on 6D Parallelism: A recent article on 6D parallelism was shared, detailing how to visualize the collective communications in a 2⁶ mesh.
- The article critiques other resources for failing to provide deep insights into the communications involved during training steps, which is something this article aims to address.
- NCCL Source Code Study Available: A member provided a link to their NCCL source code study, offering a deep dive into the nuances of how communication is handled in distributed training scenarios.
- This resource spans multiple articles covering various aspects of the NCCL process, potentially serving as a comprehensive guide for those interested.
- Efficiency of Tool Calls During Generation: A member pondered the efficiency implications of pausing generation for external tool calls, suggesting it could lead to GPU utilization issues.
- They speculated on whether these interruptions impact overall performance and sought input from others on potential solutions.
- NCCL Source Code Study: no description found
- Visualizing 6D Mesh Parallelism: Plus some lore
- Tweet from (((ل()(ل() 'yoav))))👾 (@yoavgo): the "Toolformer" paper presented a notion of "inline tool use" where the decoding is paused and the output of the tool-call is integrated directly in the generated text before resuming...
- GitHub - LambdaLabsML/distributed-training-guide: Best practices & guides on how to write distributed pytorch training code: Best practices & guides on how to write distributed pytorch training code - LambdaLabsML/distributed-training-guide
- - YouTube: no description found
GPU MODE ▷ #cuda (7 messages):
CUDA Graph and cudaMemcpyAsync, Compute Throughput on 4090, Kernel vs cudaMemcpyAsync in cuda Graph
- Lowest Occupancy for 100% Compute Throughput on 4090: A query was raised regarding the lowest occupancy to achieve 100% compute throughput on a 4090, suggesting it could be 4/64 (~7%).
- The exact threshold remains unanswered, prompting further investigation among members.
- CUDA Graphs Compatibility with cudaMemcpyAsync: A discussion unfolded about whether CUDA Graph supports cudaMemcpyAsync, with a confirmation from one user stating, 'yes'.
- The compatibility seems to raise concerns, particularly with application results being inconsistent when using cudaMemcpyAsync within cuda graph mode.
- Issues with cudaMemcpyAsync in CUDA Graph Mode: A member reported that using cudaMemcpyAsync resulted in incorrect application outcomes when in CUDA Graph mode, whereas kernel copies yielded correct results.
- This discrepancy raised questions about the runtime API stream capture within the CUDA Graph framework.
- Seeking Minimal Example for CUDA Graph Issue: A user requested a minimal example to clarify the issues faced in their CUDA Graph applications when using cudaMemcpyAsync.
- This led to further inquiries about whether they were training a model, indicating a need for detailed context to assist.
GPU MODE ▷ #torch (9 messages🔥):
Optimizing Docker Images for PyTorch, Conda vs Docker Usage, Building Custom Torch with Nix, Efficiency of Megatron-LM in Training
- Optimizing Docker Images for PyTorch: Members discussed the size of official PyTorch docker images, noting that while starting around 3-7 GB, smaller images are feasible.
- One user's approach involved using a clean tiny 30MB Ubuntu image while relying on Conda for CUDA libraries.
- Debate on Using Conda with Docker: A user questioned the rationale for using both Conda and Docker images together, typically perceived as alternatives.
- Another responded that it ensures consistent installations, especially in a diverse development team lacking standardization.
- Customizing Torch Builds with Nix: A member explained their method for building a custom Torch package with specific flags using nixpkgs, including
TORCH_CUDA_ARCH_LIST="8.0;8.6".- They provided a Dockerfile example illustrating their setup.
- Challenges of Academia Code Practices: A user remarked on the difficulties of managing complex academic codebases, stating those involved are often skilled but lack formal programming training.
- This sentiment resonated with others, highlighting the chaotic nature of code practices in academia.
- Inquiry on Megatron-LM's Training Efficiency: A participant inquired about the current standing of Megatron-LM regarding its efficiency for distributed training throughput.
- They expressed interest in leveraging the appropriate codebase for ongoing research projects aimed at enhancement.
Link mentioned: no title found: no description found
GPU MODE ▷ #cool-links (14 messages🔥):
NVIDIA Jetson Nano Super, JetPack 6.1 Installation, LLM Inference on AGX, Raspberry Pi 5 for LLMs, Esp32 / Xtensa LX7 Chips
- NVIDIA Unveils Jetson Nano Super: NVIDIA introduced the Jetson Nano Super, a compact AI computer capable of 70-T operations per second, designed for robotics, costing $249.
- Discussion highlighted its capability to support advanced models, including LLMs, sparking curiosity about its performance compared to existing models.
- Boost Jetson Orin Performance with JetPack 6.1: Users can install JetPack 6.1 for boosted performance on the Jetson Orin Nano Developer Kit using the SDK Manager.
- By changing the power mode to MAXN, devices can achieve super performance, optimizing operational capabilities.
- LLM Inference on AGX: A research project utilizing the AGX Orin for 11B model inference quantized to gguf 8bit was discussed.
- This setup aims to enhance local deployment capabilities for more complex LLM applications.
- Using Raspberry Pi 5 for Small Models: The discussion included deploying models using Raspberry Pi 5, which is configured with nvme 256GB for faster data transfer and overclocked to 2.8.
- It has been used for small models (1.5B parameters) locally, leveraging Ollama compiled with OpenBlas for efficiency.
- Excitement for New Esp32 / Xtensa LX7 Chips: Anticipation for the new Esp32 / Xtensa LX7 chips was expressed, intended for scenarios where LLMs will be called remotely using an API.
- This development reflects ongoing interest in advancing edge computing capabilities within the community.
- Tweet from Haider. (@slow_developer): 🚨 NVIDIA Introduces Jetson Nano Super> compact AI computer capable of 70-T operations per second> designed for robotics, it supports advanced models, including LLMs, and costs $249
- Fast LLM Inference From Scratch: no description found
- jetson-orin-datasheet-nano-developer-kit-3575392-r2.pdf: no description found
GPU MODE ▷ #youtube-recordings (1 messages):
pirate_king97: https://www.youtube.com/playlist?list=PLvJjZoRc4albEFlny8Z1OGDiF_y3MGNK9
GPU MODE ▷ #arc-agi-2 (8 messages🔥):
phi-4 sampling progress, Chain of Thought dataset generation, VLM fine-tuning with Axolotl, Unslosh, and TRL, Custom vision encoder discussion, Test-time scaling for ARC
- phi-4 sampling progress reveals riddle solving: The phi-4 sampling at 128 is ongoing, with 119 riddles solved so far. However, a run was aborted that had already solved 164 riddles, showing the potential for better success rates with enhanced testing methods.
- This indicates that using a good verifier can significantly increase the number of problems solved, as the previous method only managed 32 riddles.
- Generating a CoT dataset to assess effectiveness: The team is initiating a first Chain of Thought (CoT) dataset generation and aims to find out which forms of CoT contribute most effectively to model performance. They plan to let reinforcement learning determine the most beneficial types.
- This experiment seeks to understand if CoT can solve riddles that direct transduction cannot.
- VLM fine-tuning resources shared: Found tutorials regarding VLM fine-tuning with Axolotl, Unslosh, and Hugging Face TRL including links to important resources. Each link provides specific guidance on fine-tuning vision-language models, essential for achieving efficient integrations.
- The VLM fine-tuning with TRL warns that the process is resource-intensive, requiring substantial computational power.
- Debating custom vision encoders for better integration: There's consideration about whether to create a custom vision encoder to integrate with language models, given that traditional models may not handle small pixel sizes well. The idea is to improve flexibility by pairing encoders with any language model available.
- One member questioned if the slight parameter increase would suffice for effective representation extraction from images typically smaller than 100x100 pixels.
- Exploring potential of test-time scaling for ARC: Discussion focused on whether it’s feasible to implement a scalable testing system for ARC that runs continuously and improves over time. The goal is to evaluate if the CoT reasoning tokens can solve complex riddles beyond the capability of standard methods.
- A potential Proof of Concept (PoC) phase is suggested to determine the implementation challenges and evaluate effectiveness.
- Google Colab: no description found
- axolotl/examples/llama-3-vision/lora-11b.yaml at effc4dc4097af212432c9ebaba7eb9677d768467 · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
- Fine-Tuning a Vision Language Model (Qwen2-VL-7B) with the Hugging Face Ecosystem (TRL) - Hugging Face Open-Source AI Cookbook: no description found
Modular (Mojo 🔥) ▷ #general (25 messages🔥):
Zoom call recording, Usage of MAX for discussions, Mojo on Archcraft Linux issues
- Zoom Call Recording Available on YouTube: A user inquired about the availability of a recording for a missed Zoom call, to which it was confirmed that it will be posted on their YouTube channel on Wednesday.
- Max Tool for Stable Discussions: A user congratulated the community on the release of MAX and sought guidance on its application for stable discussions, with a response pointing to an example on the GitHub repo.
- Another user clarified that to use GPU with MAX, you need to swap the executor to avoid CPU usage.
- Mojo Issues on Archcraft Linux: A user reported issues entering the Mojo REPL on Archcraft Linux, mentioning a missing dynamically linked library, which was speculated to be
mojo-lddormojo-lld.- The user expressed difficulty in installing Python requirements, indicating they were in a magic environment and receiving errors about being in an externally managed environment.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
MAX 24.6, MAX GPU, MAX Engine, MAX Serve, Generative AI Infrastructure
- MAX 24.6 launches with long-awaited MAX GPU: Today, we unveiled MAX 24.6, featuring the eagerly anticipated MAX GPU, a vertically integrated generative AI stack eliminating the need for vendor-specific libraries like NVIDIA CUDA.
- This is the first step in reimagining AI development and addressing the increasing resource demands of large-scale Generative AI.
- Introducing MAX Engine: The Future of AI Model Compilation: MAX Engine is described as a high-speed AI model compiler and runtime with vendor-agnostic Mojo GPU kernels optimized for NVIDIA GPUs.
- This technology sets the stage for unparalleled performance, particularly when scaling complex AI workloads.
- MAX Serve: Simplifying Python Integration for LLMs: MAX Serve provides a Python-native serving layer tailored for large language models (LLMs), designed to enhance performance under high-load scenarios.
- It allows developers to maximize efficiency and tackle complex batching challenges effectively.
- Exploring the Benchmarking Deep Dive: A new benchmarking blog post emphasizes the intricacies of performance tradeoffs in AI inference stacks, highlighting the balance between accuracy, throughput, and latency.
- Understanding how to benchmark effectively is vital for developers to transform innovative applications from merely possible to practical.
- Join the MAX 24.6 Forum Discussion: Users are encouraged to share their thoughts and queries in the official MAX 24.6 forum thread, fostering community engagement and feedback.
- This forum is a platform for developers to discuss the implications and experiences surrounding the latest technology release.
- Modular: Introducing MAX 24.6: A GPU Native Generative AI Platform: MAX 24.6 release bog featuring MAX GPU
- Modular: Build a Continuous Chat Interface with Llama 3 and MAX Serve: Build a Chat Application with Llama 3 and MAX Serve
- Modular: MAX GPU: State of the Art Throughput on a New GenAI platform: Measuring state of the art GPU performance compared to vLLM on Modular's MAX 24.6
Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
Mojo v24.6 Release, Python importing Mojo kernels, GPU support in Mojo, Kernel programming API, Mojo documentation updates
- Mojo v24.6 is ready to roll: The latest version of Mojo, v24.6.0, has been released and is ready for use as confirmed by the command
% mojo --version.- This version includes updates users are eager to explore, as indicated by the excitement in the community.
- Python smoothly imports Mojo kernels: In the recent demo, the Python InferenceSession successfully imported Mojo kernels via a compiled .mojopkg file, revealing practical integration.
- For a deeper dive, interested users can view the source examples here.
- Yes, GPU support is confirmed for Mojo: 'Yes, it does!' was the emphatic response regarding GPU support in the upcoming Mojo version 25.1.0 nightly, following the recent 24.6 release.
- This showcases the ongoing enhancement of capabilities within the Mojo platform.
- Exciting updates on kernel programming: A member inspired excitement by mentioning that more kernel programming API guides and other resources will be released soon, prompting users to stay tuned.
- The community is eagerly awaiting informative updates on cooperative programming with shared memory and synchronization.
- Mojo documentation under revision: Member feedback highlighted a broken link in the Mojo documentation, specifically regarding Span, now moved to the memory module (link here).
- Another user questioned the var keyword requirement in the documentation, which is pending further updates from the authors.
- max/examples/custom_ops at nightly · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- Mojo language basics | Modular Docs: Introduction to Mojo's basic language features.
- Span | Modular Docs: @register_passable(trivial)
- max/examples/custom_ops/kernels at nightly · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- Lifetimes, origins, and references | Modular Docs: Working with origins and references.
- max/pipelines/python at nightly · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- [stdlib] Move `Span` from `utils` to `memory` · modularml/mojo@50d5fb2: `Span` is no longer a util, but is a common vocabulary type usedthroughout stdlib APIs. As such, promote it to `memory` module.MODULAR_ORIG_COMMIT_REV_ID: 33bae4c7dcc8191118d669985405f31599de386c
LlamaIndex ▷ #blog (2 messages):
LlamaReport preview, Agentic AI SDR, Composio platform
- LlamaReport Makes Document Databases Readable: LlamaReport, now in preview, converts document databases into well-structured, human-readable reports in just minutes, enabling users to answer questions about document sets effectively. More details can be found in the announcement post.
- Check out how it aims to improve document interaction by streamlining the output process.
- Lead Generation with Agentic AI SDR: A new agentic AI SDR has been introduced that generates leads using LlamaIndex, showcasing a practical integration of AI in sales strategies. The code can be accessed here.
- This tool is part of the broader Quickstarters initiative that helps users explore the capabilities of Composio through example projects and practical applications.
- Composio Empowers Intelligent Agents: The Composio platform allows developers to create intelligent agents capable of automating tasks across applications like GitHub and Gmail, enhancing productivity through natural language commands. A detailed overview of the platform can be found in the subfolder guide.
- One example project demonstrates how to convert to-do lists into Google Calendar events, showcasing the platform's dynamism and versatility.
Link mentioned: composio/python/examples/quickstarters at master · ComposioHQ/composio: Composio equip's your AI agents & LLMs with 100+ high-quality integrations via function calling - ComposioHQ/composio
LlamaIndex ▷ #general (20 messages🔥):
NVIDIA NV-Embed-v2 availability, Using Qdrant vector store, OpenAI LLM double retries
- Querying NVIDIA NV-Embed-v2: Members discussed the availability of NVIDIA NV-Embed-v2 within NVIDIA Embedding, referencing the
embed_model.available_modelsfeature to check for available models.- It was noted that even if NV-Embed-v2 isn't explicitly listed, it may still work; further investigation was suggested to confirm.
- Implementing Qdrant in Workflows: A user sought guidance on integrating Qdrant vector store in a workflow, mentioning issues faced with existing collections and queries.
- Another member shared resources, including documentation examples, stating they hadn't encountered similar problems.
- Doubts on OpenAI LLM Retry Logic: Paullg raised concerns about potential double retries in the OpenAI LLM, indicating both the OpenAI client and the
llm_retry_decoratormay implement retry logic independently.- A discussion followed on whether a recent pull request fixed this issue, with uncertainty about the effectiveness of the proposed changes.
- Qdrant Vector Store - LlamaIndex: no description found
- Adding persistent vector storage | LlamaIndex.TS: In the previous examples, we've been loading our data into memory each time we run the agent. This is fine for small datasets, but for larger datasets you'll want to store your embeddings in...
- Qdrant - LlamaIndex: no description found
- llama_index/llama-index-integrations/embeddings/llama-index-embeddings-openai/llama_index/embeddings/openai/base.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- fix/openai-embbeding-retry by rendyfebry · Pull Request #17072 · run-llama/llama_index: DescriptionPlease include a summary of the change and which issue is fixed. Please also include relevant motivation and context. List any dependencies that are required for this change.Fixes #170...
LlamaIndex ▷ #ai-discussion (2 messages):
Intent Recognition Techniques, Handling SSL Certification Errors
- Exploring Intent Recognition Techniques: A developer inquired about various approaches and techniques for recognizing the intent behind user prompts and how to implement logic in applications based on detected intent.
- They also sought recommendations for tools and frameworks that can enhance the accuracy and adaptability of intent recognition across different use cases.
- Fixing SSL Certification Errors with Azure: A member reported encountering an 'SSL certification failed' error while creating an index using Azure AI Search Service with Python, sharing a link to a screenshot for better context.
- They requested solutions or advice on how to resolve this specific issue to proceed with their project.
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.5.3 Release, LocalDocs Fix, Contributors to GPT4All
- GPT4All v3.5.3 Launches with Important Fixes: The GPT4All v3.5.3 version has been officially released, addressing notable issues from the previous version.
- This update primarily includes a critical fix for LocalDocs, which was malfunctioning in v3.5.2.
- LocalDocs Issue Resolved: A serious problem preventing LocalDocs from functioning correctly in v3.5.2 has been successfully resolved in this new release.
- Users can now expect improved performance and reliability while using LocalDocs.
- Contributors Acknowledged in Update: The release credits Jared Van Bortel and Adam Treat from Nomic AI for their contributions in developing the latest version.
- Their efforts have been vital in ensuring the overall functionality and improvement of GPT4All.
Nomic.ai (GPT4All) ▷ #general (17 messages🔥):
AI Agent functionality, Jinja template issues, API documentation inquiries, Document processing efficiency, Model performance concerns
- Exploring AI Agent Functionality: Discussions arose about the potential to run an 'AI Agent' via GPT4All with a linked YouTube video showcasing its capabilities.
- One member noted that while technically possible, it mainly serves as a generative AI platform with limited functionality.
- Current Jinja Template Issues: A member expressed that GPT4All is almost completely broken for them, specifically regarding a Jinja template problem that they hope gets resolved soon.
- Another member outlined the importance of Jinja templates, referring to them as tiny programs crucial for model interaction, while ongoing improvements regarding tool calling functionalities are in progress.
- Seeking Complete API Documentation: A request was made for complete API documentation with details on endpoints and parameters, referring to existing but seemingly limited information at the GPT4All API documentation.
- Members shared that activating the local API server requires simple steps but felt the documentation lacked comprehensiveness.
- Document Processing Efficiency: Questions were raised on whether splitting documents into separate files would yield better processing performance versus keeping them in one file.
- Members advised that both methods should function fine, although one indicated that the model seems to randomly select documents, with a suggestion to copy-paste entire documents for better context.
- Addressing Model Performance Concerns: Concerns were discussed about models producing random strings of words post-update and a member summarized common Jinja template issues that may affect performance.
- Specific problems mentioned include spacing errors, misplaced new line characters, and unsupported functions, highlighting the need for adjustments to restore model functionality.
- GPT4All API Server - GPT4All: GPT4All Docs - run LLMs efficiently on your hardware
- FINALLY, this AI agent actually works!: This new AI agent browser actually works! Do Browser tutorial & review. #ai #aitools #ainews #aiagent #agi Thanks to our sponsor Thoughtly. Get 50% OFF with...
OpenInterpreter ▷ #general (12 messages🔥):
Gemini 2.0 Flash functionality, VEO 2 vs SORA comparison, OpenInterpreter web assembly integration, Local OS usage, Error handling with Open Interpreter
- Questions about Gemini 2.0 Flash: Users are inquiring if anyone has successfully made Gemini 2.0 Flash work, highlighting a lack of responses regarding its functionality.
- This indicates a potential gap in user experience or support for this feature.
- Debate on VEO 2 and SORA: A member raised a question on whether VEO 2 is superior to SORA, noting that neither AI is currently available in their region.
- This lack of availability suggests interest but also frustration among users wanting to explore those options.
- Web Assembly Integration with OpenInterpreter: A user suggested the possibility of running the OpenInterpreter project in a web page using Web Assembly through tools like Pyodide or Emscripten.
- This method could provide auto-sandboxing and eliminate the need for compute calls, enhancing its usability in a chat UI context.
- Local Usage of OS in OpenInterpreter: There was an inquiry on whether it's possible to utilize the OS locally, with additional questions seeking clarification on what OS entails.
- This reflects ongoing interest in local execution capabilities among users looking to enhance functionality.
- Troubleshooting Errors in Open Interpreter: A member expressed frustration with persistent errors while using code with the
-yflag, specifically issues related to setting the OpenAI API key.- This highlights a common challenge users face and the need for clearer guidance on error handling.
Torchtune ▷ #general (1 messages):
Torcheval metric sync, Batch processing
- Torcheval's Batched Metric Sync Simplifies Workflow: A member expressed satisfaction with Torcheval having a batched metric sync feature and no extra dependencies, making it a pleasant tool to work with.
- This streamlined approach enhances productivity and reduces complexity in processing metrics.
- No Additional Dependencies Praise: The same member highlighted the absence of extra dependencies in Torcheval, which contributed to their positive experience while using the tool.
- This design choice appears to make integration and operation smoother than other options.
Torchtune ▷ #dev (3 messages):
Instruction Fine-Tuning Loss Calculation, Gradient Normalization in Sequence Processing, FSDPModule Adjustments
- Inefficiencies in Instruction Fine-Tuning Loss: A member raised concerns about the per-token loss calculation in instruction fine-tuning, noting that the loss from one sentence depends on others in the batch due to varying token counts.
- This method appears to be the standard practice, leading to challenges that the community must adapt to.
- Gradient Normalization Issues: It was mentioned that padding/masking can influence losses, especially when striving to normalize by the 'total number of elements that produce gradients'.
- Such inconsistencies are prevalent in sequence processing objectives, which could complicate training.
- Tuning FSDPModule for Improved Division: A solution was suggested using
set_reduce_scatter_divide_factorset to 1.0 after wrapping a module infully_shardto address potential inefficiencies.- However, this approach may introduce a 'useless' div kernel, adding a layer of complexity to the implementation.
Torchtune ▷ #papers (7 messages):
GenRM Verifier Model, Sakana AI Memory Optimization, 8B Verifier Performance Analysis, Chain-of-Thought Dataset Generation
- GenRM Verifier Model Enhances LLM Performance: A recent paper proposes using generative verifiers (GenRM) trained on next-token prediction to enhance reasoning in large language models (LLMs) by integrating solution generation with verification.
- This approach allows for better instruction tuning and the potential for improved computation via majority voting, offering benefits over standard LLM classifiers.
- Sakana AI's Universal Transformer Memory Cuts Costs: Researchers at Sakana AI have developed a technique to optimize memory usage in LLMs, allowing enterprises to significantly reduce costs related to application development on Transformer models.
- The universal transformer memory technique retains essential information while discarding redundancy, enhancing model efficiency.
- Discussion on the Implications of 8B Verifier Models: Concerns were raised regarding the use of an 8B reward/verifier model, with a member noting the computation costs and complexity of training such a model shouldn't be overlooked in performance discussions.
- Another noted that using a smaller verifier could skew assumptions about the prototype's efficiency in real-world applications.
- Community Reactions to Verifier Methodology: One member humorously compared the methodology of using an 8B verifier to 'asking a monkey to type something and using a human to pick the best one,' suggesting it might be misleading.
- The member mentioned the title might imply more than the experimental results show, indicating a need for broader experimentation.
- Chain-of-Thought Dataset Generation Insights: Discussions indicated that the methodology of the 8B verifier could reflect more on how the chain-of-thought datasets are generated rather than inference processes for O1.
- This was highlighted as a crucial distinction in understanding the implications of using such verifiers in practical applications.
- Generative Verifiers: Reward Modeling as Next-Token Prediction: Verifiers or reward models are often used to enhance the reasoning performance of large language models (LLMs). A common approach is the Best-of-N method, where N candidate solutions generated by the ...
- Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
- New LLM optimization technique slashes memory costs up to 75%: Universal Transformer Memory uses neural networks to determine which tokens in the LLM's context window are useful or redundant.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Hackathon Submission Deadline, Google Form Submission Process, Project Innovation
- Hackathon Submission Deadline Extended: The submission deadline for the Hackathon has been extended by 48 hours to 11:59pm PT, December 19th.
- This extension aims to clear up confusion about the submission process and allow participants more time to finalize their projects.
- Clarification on Submission Process: Participants are reminded that submissions should be made through the Google Form, NOT via the Devpost site.
- This clarification is essential to ensure all projects are submitted correctly.
- Encouragement for Project Innovation: The extended deadline offers participants a chance to be more innovative with their projects.
- Participants are encouraged to make the most of the additional time available to enhance their submissions.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
LLM Agents MOOC website updates, Certificate submission deadlines
- LLM Agents MOOC website gets a mobile makeover: A member revamped the LLM Agents MOOC website for better mobile responsiveness, sharing the updated version at this link.
- Hope this can be a way to give back to the MOOC/Hackathon. Another user praised the design, indicating plans to share it with staff.
- Certificate submission deadlines confirmed: A user inquired about the certificate submission deadline amidst uncertainty about potential extensions.
- Another member confirmed that there are no deadline changes for the MOOC and emphasized that the submission form will remain open until 12/19 for convenience.
Link mentioned: Large Language Model Agents MOOC: no description found
tinygrad (George Hotz) ▷ #general (6 messages):
GPU connectivity via USB, Mac support for arm64 backend, Continuous Integration on Macs
- Exploring GPU Connections Through USB Ports: A user questioned if it was possible to simply plug a GPU into a USB port, to which George responded affirmatively stating, 'our driver should allow this'.
- This exchange highlights ongoing discussions about hardware compatibility within the community.
- Curiosity about Mac Access for Backend Development: A user expressed interest in gaining access to Macs specifically for the arm64 backend development.
- George clarified that these systems are CI only, indicating they only run benchmarks and are not available for general use.
- Understanding the Role of Macs in Continuous Integration: The conversation confirmed that the Mac Benchmark is part of the Continuous Integration (CI) process, focused on performance assessments.
- This reflects the community's emphasis on leveraging specific hardware for rigorous testing procedures.
Link mentioned: Tweet from the tiny corp (@tinygrad): Err, you sure you can just plug a GPU into a USB port?
Axolotl AI ▷ #general (6 messages):
Scaling Test Time Compute, Performance of 3b Model vs 70b Model, Missing Optim Code in Repo
- Scaling Test Time Compute Analysis: A member shared a link to a Hugging Face blog post discussing scaling test time compute, considering it refreshing.
- This post sparked interest in the community regarding the efficiency of scaling tests.
- 3b Model Outperforming 70b in Math: A member noted that the 3b model outperforming the 70b model at mathematics is both insane and significant.
- This observation raised discussions about the unexpected efficiency of smaller models.
- Quest for Missing Optim Code: Concern was expressed about not finding the actual optim code in a developer's repo, which only contains benchmark scripts.
- One member indicated their struggles with the repo and emphasized their ongoing efforts to resolve issues.
- Current Workload Impacting Tasks: One member apologized for not being able to contribute, revealing they are tied up with other tasks and bug fixes.
- This highlights the busy nature of development and collaboration within the community.
- Gratitude for Updates: One member thanked another for their update amidst the ongoing discussions.
- This reflects the positive and supportive atmosphere of the channel.
Link mentioned: Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
DSPy ▷ #papers (2 messages):
Impact of Autonomous AI, AI Agents in the Knowledge Economy, Displacement of Workers, AI's Role in Hierarchical Firms
- Autonomous Agents Enhance Knowledge Workers: A recent paper discusses how autonomous AI benefits the most knowledgeable individuals, allowing them to perform routine work more efficiently while aiding productivity.
- As the study reveals, while initial research indicates AI helps low-skill workers, it predominantly focuses on chatbots, thus ignoring how agentic AIs might shift benefits towards more skilled individuals.
- AI's Operation Models Affect Workforce Dynamics: The paper introduces a framework where AI agents can operate autonomously or non-autonomously, highlighting an evolution in workforce dynamics within hierarchical firms.
- It notes that while basic autonomous AI can displace humans into specialized roles, advanced autonomous AI reallocates labor towards routine tasks, which results in larger and more productive firms.
- AI's Benefits for Less Knowledgeable Individuals: Non-autonomous AI, like chatbots, provides affordable expert assistance for less knowledgeable individuals, enhancing their problem-solving capabilities without competing for larger tasks.
- Hence, while they are perceived to benefit from technology, the ability of autonomous agents to aid knowledge workers enjoy a competitive advantage as AI evolves.
Link mentioned: Artificial Intelligence in the Knowledge Economy: The rise of Artificial Intelligence (AI) has the potential to fundamentally reshape the knowledge economy by solving problems at scale. This paper introduces a framework to study this transformation, ...
Mozilla AI ▷ #announcements (2 messages):
Retrieval Augmented Generation (RAG) application, Developer Hub and Blueprints announcement
- Final Event on Ultra-Low Dependency RAG Application: Tomorrow is the final event for December, where participants will learn to create an ultra-low dependency Retrieval Augmented Generation (RAG) application using only sqlite-vec, llamafile, and bare-bones Python.
- The session will be led by Alex Garcia and requires no other dependencies or 'pip install's.
- Important Update on Developer Hub and Blueprints: A significant announcement was made regarding the Developer Hub and Blueprints, prompting users to refresh their awareness.
- Feedback is being appreciated as the community explores the thread on Blueprints, aimed at helping developers build open-source AI solutions.
MLOps @Chipro ▷ #events (1 messages):
Data Infrastructure Innovations, Data Governance, Data Streaming, Stream Processing, AI in Data Infrastructure
- Year-End Retrospective Panel on Data Innovations: Join us on December 18 for a retrospective panel featuring trailblazing founders Yingjun Wu, Stéphane Derosiaux, and Alexander Gallego discussing the exciting innovations in data infrastructure over the past year.
- The panel will cover key themes including Data Governance, Streaming, and the impact of AI on Data Infrastructure.
- Fantastic Speakers Lined Up for the Panel: The panel includes industry leaders: Yingjun Wu, CEO of RisingWave, Stéphane Derosiaux, CPTO of Conduktor, and Alexander Gallego, CEO of Redpanda.
- Their insights are expected to explore crucial areas like Stream Processing and Iceberg Formats, shaping the landscape for 2024.
- Save Your Spot for the Panel Discussion: Don't miss out on this opportunity! Save your spot for the event here.
- It's a great chance to dive into the most significant advancements in the data infra ecosystem.
Link mentioned: Year-End Retrospective on Data Infra, Wed, Dec 18, 2024, 9:00 AM | Meetup: AboutThe year 2024 was nothing short of groundbreaking for data infrastructure. We witnessed an exciting flurry of innovations, many driving the ongoing push to make
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
BFCL Leaderboard V3, Function calling capabilities, Model response loading issues
- Inquiry About BFCL Leaderboard's Function Call Demo: A member raised a question regarding the function call demo located on the BFCL Leaderboard and its operational status.
- They specifically noted that it seems to be stuck at 'Loading Model Response...' and queried if anyone else faced the same issue.
- Overview of BFCL Features and Updates: Discussion highlighted the specifics of the Berkeley Function Calling Leaderboard V3, including its evaluation criteria for LLMs calling functions accurately.
- Members pointed to the blogs detailing various versions of the leaderboard, such as BFCL-v1, BFCL-v2, and BFCL-v3 with expanded datasets and methodologies for multi-turn interactions.
Link mentioned: Berkeley Function Calling Leaderboard V3 (aka Berkeley Tool Calling Leaderboard V3) : no description found