[AINews] nothing much happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Peace and quiet is all you need.
AI News for 9/16/2024-9/17/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (221 channels, and 2197 messages) for you. Estimated reading time saved (at 200wpm): 225 minutes. You can now tag @smol_ai for AINews discussions!
Given the extreme restrictions, cost, and lack of transparency around o1, everyone has puts and takes on whether or not o1 can be replicated in open source/in the wild. As discussed in /r/localLlama, Manifold markets currently has 63% odds on an open source version:
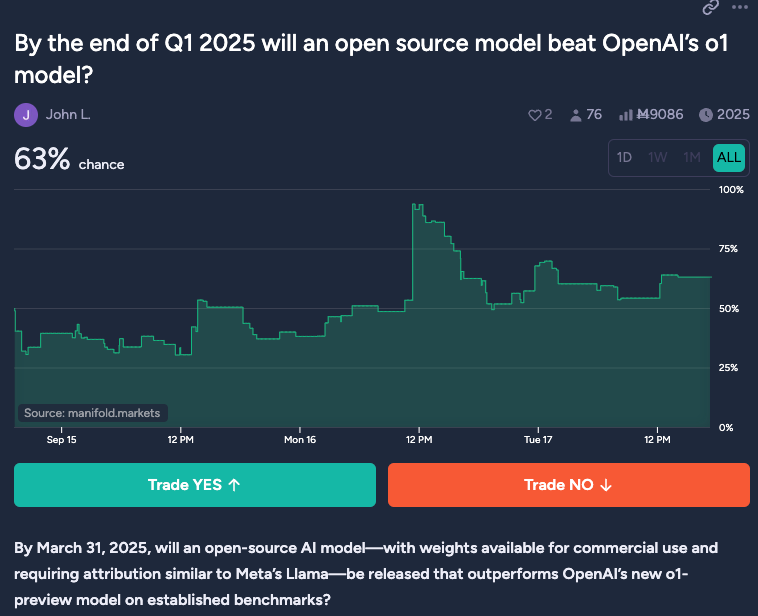
It is simultaneously likely that:
- there are many things about o1 that could be replicated in open source, especially with an OpenAssistant-level crowdsourced reasoning trace dataset
- MAYBE some of the MCST papers that people have been throwing around are relevant, but also MAYBE NOT
- there are real RL on CoT advances done at the training level that no amount of dataset futzing will match up to.
For the last reason alone, the standard time-to-OSS-equivalent curves in model development may not apply in this instance.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Advancements
- OpenAI's o1 Model: @denny_zhou highlighted that transformers can theoretically solve any problem with sufficient intermediate reasoning tokens, even with constant depth. This suggests significant potential for scaling LLM inference performance.
- Performance Improvements: @lmsysorg reported substantial improvements in ChatGPT-4o (20240903) across various benchmarks, including overall performance, style control, hard prompts, and multi-turn interactions.
- Model Comparisons: @lmsysorg compared bf16 and fp8 versions of Llama-3.1-405b, finding similar performance across categories, with fp8 closely matching bf16 while significantly reducing costs.
- Emerging Capabilities: @svpino discussed the specialization of GPT-4o in System 1 thinking and OpenAI o1 in System 2 thinking, anticipating future models that incorporate both under a single framework.
AI Development and Research
- Evaluation Challenges: @alexandr_wang announced a partnership between Scale and CAIS to launch "Humanity's Last Exam," a challenging open-source benchmark for LLMs with $500K in prizes for the best questions.
- Model Merging: @cwolferesearch explained the effectiveness of model merging, attributing its success to linear mode connectivity and sparsity in neural networks.
- AI Safety: @rohanpaul_ai shared insights on embedding-based toxic prompt detection, achieving high accuracy with minimal computational overhead.
- Multimodal Capabilities: @_akhaliq introduced InstantDrag, an optimization-free pipeline for drag-based image editing, enhancing interactivity and speed in image manipulation tasks.
AI Tools and Applications
- LangChain Updates: @LangChainAI announced the release of LangChain v0.3 for Python and JavaScript, focusing on improved dependencies and moving to peer dependencies.
- AI in Code Review: @rohanpaul_ai discussed the use of CodeRabbit for automated code reviews, highlighting its ability to adapt to team coding practices and provide tailored feedback.
- AI in Product Search: @qdrant_engine shared advancements in visual search solutions, integrating images, text, and other data into unified vector representations for improved product search experiences.
Industry Trends and Observations
- AI Integration: @kylebrussell predicted that by 2030, AI will be the default, software will generate itself, and agents will be the new apps.
- Open Source Developments: @far__el hinted at upcoming developments in open-source AI models, suggesting potential competition with proprietary models.
- AI in Fashion: @mickeyxfriedman demonstrated AI-generated fashion models, suggesting potential shifts in brand marketing strategies.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Advancements in Model Compression and Quantization
- LMSYS finds minimal differences between bf16 and fp8 Llama-3.1-405b in Chatbot Arena (Score: 109, Comments: 34): LMSYS conducted a comparison between bf16 and fp8 versions of Llama-3.1-405b in their Chatbot Arena, finding minimal differences in performance. The fp8 model showed only a 0.3% decrease in win rate compared to the bf16 version, suggesting that fp8 quantization can significantly reduce model size and memory requirements with negligible impact on quality.
- Users reported significant differences in coding performance between quantized versions, with some noting fp8 as worse than q8 for coding tasks. A tweet by Aidan McLau criticized the LMSYS evaluation, suggesting bf16 is superior for specific prompts.
- Discussions highlighted the limitations of human perception-based evaluations like the LMSYS leaderboard. Some users observed minimal differences between q8 and fp16 for coding, while others reported conflicting results in benchmarks.
- Several comments praised quantization techniques, with one user successfully using an IQ2_M version of Llama 3.1 70b for coding tasks. The debate extended to comparisons between various quantization levels (q6_k, q4km) and their impacts on model performance.
- Release of Llama3.1-70B weights with AQLM-PV compression. (Score: 249, Comments: 81): The Llama3.1-70B and Llama3.1-70B-Instruct models have been compressed using AQLM+PV-tuning, reducing their size to 22GB and enabling them to run on a single 3090 GPU. This compression resulted in a 4-5 percentage point drop in MMLU performance, with the base model's score decreasing from 0.78 to 0.73 and the instruct model's score from 0.82 to 0.78. Additionally, a compressed Llama3.1-8B model has been released, which can run as an Android app using only 2.5GB of RAM.
- The compressed Llama3.1-70B models are similar to IQ_2M quantization, with comparable 22GB size and MMLU scores. Users discussed running methods, including Transformers, vLLM, and Aphrodite, with some experiencing implementation challenges.
- There's interest in compressing larger models like the 405B version and Gemma-2 27B. Users speculated on potential sizes and compatibility with specific hardware, such as M3 Max with 128GB RAM.
- The AQLM quantization method is available as an open-source project, but doesn't currently support GGUF format. Users reported slow inference speeds, with a 3090 GPU achieving around 7 tokens/second.
- Hugging Face optimised Segment Anything 2 (SAM 2) to run on-device (Mac/ iPhone) with sub-second inference! (Score: 83, Comments: 14): Hugging Face has optimized Segment Anything 2 (SAM 2) for on-device inference, enabling it to run on Mac and iPhone with sub-second performance. This optimization allows for real-time segmentation tasks on mobile devices, potentially opening up new applications in augmented reality, image editing, and computer vision on edge devices.
- Hugging Face is releasing Apache-licensed optimized model checkpoints for SAM 2 in various sizes, along with an open-source application for sub-second image annotation. They're also providing conversion guides for SAM2 fine-tunes like Medical SAM.
- The developer is planning to add video support and is open to suggestions for future features. This indicates ongoing development and potential for expanded capabilities in the SAM 2 optimization project.
- Users expressed interest in Apple optimizing other models, specifically mentioning GroundingDino. This suggests a demand for more on-device AI models optimized for Apple hardware.
Theme 2. Open-Source LLMs Closing the Gap with Proprietary Models
- Will an open source model beat o1 by the end of Q1 2025? (Score: 111, Comments: 52): The post speculates on whether open-source language models could surpass OpenAI's GPT-4 (referred to as "o1") by Q1 2025 using "System 2" style approaches like Monte Carlo Tree Search (MCTS) and reflection. The author references Noam Brown's work and has created a Manifold market to gauge opinions on this possibility.
- Open-source models could potentially match GPT-4's performance by Q1 2025, with users citing Claude 3.5's significant improvement and the potential for reflection and thinking magic to enhance OS models further.
- Speculation on GPT-4's architecture suggests it may be an engineering achievement rather than a new model, possibly using fine-tuned existing models, clever prompting, and a "critic" LLM to qualify responses.
- Opinions vary on the timeline, with some believing open-source models could surpass GPT-4 by late 2025, while others note that OpenAI is likely to improve their model further, maintaining their lead over open-source alternatives.
- Release of Llama3.1-70B weights with AQLM-PV compression. (Score: 249, Comments: 81): Llama3.1-70B and Llama3.1-70B-Instruct models have been compressed using AQLM+PV-tuning, reducing their size to 22GB and enabling them to run on a single 3090 GPU. The compression resulted in a 4-5 percentage point drop in MMLU performance, with the base model's score decreasing from 0.78 to 0.73 and the instruct model's score from 0.82 to 0.78. Additionally, a compressed Llama3.1-8B model has been released, which has been run as an Android app using only 2.5GB of RAM.
- Users compared AQLM+PV-tuning to IQ_2M quantization, noting similar 22GB size and MMLU scores. The chat template for the model was fixed to improve compatibility with vLLM and Aphrodite.
- Running the model on 16GB VRAM systems proved challenging due to size constraints. The 70B model requires at least 17.5GB for weights alone, plus additional memory for caches and embeddings.
- Users expressed interest in applying AQLM compression to other models like Gemma-2 27B and Mixtral. The AQLM GitHub repository was shared for those interested in quantizing their own models.
- There seems to be promise in creating an open-source o1 model soon! (Score: 173, Comments: 55): The author reports promising results in creating an open-source o1-like model using a Q4_K_M 8B model fine-tuned on a small dataset of 370 rows. They provide links to the model, a demo, and the dataset used for fine-tuning, emphasizing the potential for GPU-limited users to soon have access to similar models.
- Users compared the project to Matt's o1 experiment, noting that this attempt actually produced results. The author clarified they're not claiming a SOTA model, just sharing an interesting experiment.
- Discussion focused on the need for reinforcement learning implementation to fully replicate o1's approach. Some speculated o1 uses RL to find optimal phrasing and syntactic structures for chain-of-thought processes.
- Several comments suggested running popular benchmarks to prove credibility and comparing results. The author submitted the model to the open llm leaderboard for evaluation and acknowledged limitations due to the small dataset and GPU constraints.
Theme 3. Developments in LLM Reasoning and Inference Techniques
- o1-preview: A model great at math and reasonong, average at coding, and worse at writing. (Score: 87, Comments: 26): The o1-preview model demonstrates exceptional abilities in complex reasoning, math, and science, outperforming other models in single-shot responses to challenging prompts. However, it falls short in creative writing and is average in coding, with the author preferring Sonnet 3.5 for coding tasks due to better inference speed and accuracy trade-offs. The model occasionally provides correct answers despite inconsistent reasoning steps, and while it represents a significant advancement, it's not yet at a Ph.D. level in reasoning or math.
- Paper: Chain of Thought Empowers Transformers to Solve Inherently Serial Problems (Score: 136, Comments: 27): Denny Zhou from Google DeepMind claims that Large Language Models (LLMs) have no performance limit when scaling inference, as proven in their paper. The research demonstrates that transformers can solve any problem with constant depth, provided they can generate sufficient intermediate reasoning tokens, as detailed in the paper available at arXiv.
- The holy grail of LLM 'reasoning' tactics during inference (Score: 39, Comments: 4): The post highlights a GitHub repository that compiles various LLM 'reasoning' tactics for use during inference, inspired by recent developments in Reflection models and their extensions. The repository, created by a third party and available at https://github.com/codelion/optillm, offers a drop-in API for testing different inference 'reasoning' or 'thinking' methods, which can be adapted to work with various local model providers.
- Users expressed interest in the repository, with one noting that these advancements surpass regular fine-tuning algorithms. The repo's compatibility with local servers was discussed, with confirmation of successful integration with oobaboogas textgen.
- The repository functions as a transparent OpenAI API-compatible proxy, allowing integration with various tools and frameworks. It can be used by setting the base_url in local servers to utilize the proxy.
- Integration with Patchwork yielded significant performance improvements compared to the base model. Details on this integration are available in the repository's README and wiki.
Theme 4. Challenges in LLM Evaluation and Reliability
- As someone who is passionate about workflows in LLMs, I'm finding it hard to trust o1's outputs (Score: 35, Comments: 9): The post critiques o1's outputs and workflow approach for complex tasks, particularly in coding scenarios. The author, who is passionate about LLM workflows, observes that o1's outputs resemble a workflow structure rather than standard Chain of Thought, potentially leading to issues such as the LLM talking itself into a corner on simple questions or mangling Python methods by losing functionality through multiple processing steps. The post argues for the importance of tailored workflows for different types of tasks (e.g., reasoning vs. coding), suggesting that o1's current approach of using a single workflow for all tasks may be problematic, especially for complex development work, leading the author to still prefer ChatGPT 4o for coding tasks.
- New Model Identifies and Removes Slop from Datasets (Score: 68, Comments: 18): The Exllama community has developed a model to identify and remove 'slop' and moralization from public datasets, including those on HuggingFace. This breakthrough allows for the detection of corporate slop, categorization of slop types, and analysis of low-quality data trajectories, potentially improving LLM conversational abilities and understanding of prompt rejection patterns. More information about the project is available on the Exllama Discord server, where interested parties can speak with Kal'tsit, the model's creator.
- PhD-level model GPT-o1 fails on middle school math ‘trap’ problems, with an accuracy rate of only 24.3% (Score: 270, Comments: 78): The GPT-o1 model, despite claims of PhD-level intelligence, achieved only a 24.3% accuracy rate on the MathTrap_Public dataset, which contains middle school math problems with added "traps". The researchers created the MathTrap dataset by modifying questions from GSM8K and MATH datasets, introducing contradictions or unsolvable elements that require understanding both the original problem and the trap to identify. Open-source models performed even worse on MathTrap_Private, with Reflection-70B achieving 16.0% accuracy, Llama-3.1-8B at 13.5%, and Llama-3.1-70B at 19.4%.
- PhD-level mathematicians and other users noted they would make the same mistake as the AI, with one stating the problem is "fundamentally uninteresting". Many argued the discontinuity at x=0 is not essential and the limit approach is valid.
- Users questioned the research methodology, with one pointing out the preprint was last revised on July 11th and doesn't mention o1. They tested the trap problems and found o1 correctly identified all traps on the first try, suggesting potential misinformation.
- Several commenters criticized the prompt design, arguing that a better-formulated question would have yielded more accurate results. One suggested asking, "Is the function periodic? Calculate the period if yes, otherwise prove that none exists. Justify your argument."
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Benchmarks
- OpenAI's new GPT-4o1 model achieved an IQ score of 120, beating 90% of people on standard IQ tests. However, on completely new questions it hadn't seen before, it scored closer to the human average of 100 IQ. This still represents significant progress in AI reasoning capabilities.
- OpenAI increased rate limits for their o1-mini model by 7x, going from 50 messages per week to 50 messages per day. The o1-preview model also saw an increase from 30 to 50 messages per week.
- The o1 model showed major improvements over o1-preview in coding benchmarks, jumping from 62% correct to 89% correct. This represents a 3.5x increase in reliability for complex code generation.
- Some users reported that o1-mini has replaced GPT-4 for coding tasks, as it provides full, uncapped responses without needing to click "continue".
AI Ethics and Societal Impact
- Billionaire Larry Ellison suggested that AI-powered surveillance systems could ensure "citizens will be on their best behavior", sparking debate about privacy concerns and potential abuse of AI technologies.
- There are ongoing discussions about whether to celebrate or worry about rapid AI progress. Some view it as an exciting technological advancement, while others express concerns about job displacement and societal impacts.
AI Development and Research
- The o1 model appears to use a breakthrough involving reinforcement training with built-in chain of thought processes, potentially allowing for significant scaling of capabilities.
- Some researchers suggest o1 could be considered a "proto-AGI" architecture, though additional breakthroughs in areas like short-term and long-term memory may still be needed to achieve general intelligence.
AI Tools and Applications
- New AI image generation tools like FLUX are producing impressive results, with examples shown of Half-Life inspired Soviet-era scenes and abstract surrealist landscapes.
- The Quest 3 VR headset combined with AI video generation tools is enabling new forms of immersive content creation.
AI Discord Recap
A summary of Summaries of Summaries
O1-mini
Theme 1. AI Models: New Releases and Rivalries
- Claude 3.5 Battles GPT-4o: The community is torn between Claude 3.5 and GPT-4o, with members conducting tests to determine which model excels in specific tasks. Claude vs GPT-4o Showdown highlights the ongoing rivalry.
- Qwen 2.5 Unveils Stricter Variants: Qwen 2.5 introduces new model sizes ranging from 0.5B to 72B parameters, all featuring enhanced content filtering. Concerns about knowledge retention persist among users.
- Mistral's Pixtral-12B Sets the Stage: Pixtral-12B marks a significant leap in multimodal models, offering robust video and image generation capabilities that rival existing giants.
Theme 2. Innovative Tools and Integrations
- Superflex Transforms Figma to Code: Superflex now allows developers to generate front-end code directly from Figma designs, streamlining the design-to-development workflow seamlessly.
- OpenRouter Boosts Google Sheets with AI: GPT Unleashed for Sheets integrates OpenRouter features like 'jobs' and 'contexts', enabling efficient prompt engineering within spreadsheets.
- Aider Teams Up with Sonnet for Coding: The integration of Sonnet 3.5 with O1 Mini enhances Aider's reliability in handling coding tasks, with users praising its efficiency in managing quick fixes and assignments.
Theme 3. Training, Optimization, and Technical Hurdles
- LM Studio Slashes Training Time: Adjusting tokens and batch sizes in LM Studio reduced model training from 5 days to just 1.3 hours, showcasing significant optimization gains.
- Tinygrad Faces AMD Compatibility Issues: Users encounter AttributeError when updating tinygrad on AMD systems, sparking discussions on potential kernel version mismatches and troubleshooting strategies.
- CUDA Mode Tackles In-Memory Computing: SK Hynix introduces AiMX-xPU at Hot Chips 2024, enhancing LLM inference by performing computations directly in memory, thus boosting power efficiency.
Theme 4. AI Safety and Ethical Concerns
- Cohere Rolls Out Customizable Safety Modes: Cohere's Safety Modes in their Chat API allow users to tailor model outputs to meet specific safety requirements, aiming to mitigate liability concerns.
- Unsloth AI's Censorship Sparks Debate: The Phi-3.5 model faces backlash for being overly censored, with users sharing uncensored versions and debating the balance between safety and usability.
- Jailbreaking Claude 3.5 Opens Pandora's Box: A successful jailbreak for Claude 3.5 Sonnet ignites discussions on model security and the ethical implications of bypassing safeguards.
Theme 5. Community Buzz and Funding Moves
- YOLO Vision 2024 Invites AI Engineers: YOLO Vision 2024 hosted by Ultralytics at Google Campus for Startups in Madrid invites AI engineers to register and participate, fostering community interaction through activities like voting for event music.
- 11x AI Secures $24M Series A Funding: 11x AI raises a substantial $24M Series A from Benchmark, boosting its annual recurring revenue by 15x and expanding its customer base to over 250 clients.
- Mistral's Strategic Moves Spark Debate: An analysis of Microsoft's strategy in integrating AI technologies with Mistral's offerings prompts the community to reflect on the company's competitive direction and alignment with its historical goals.
O1-preview
Theme 1. New AI Models and Releases Ignite Tech Communities
- Qwen 2.5 Drops with Fresh Sizes and Stricter Filters: Qwen 2.5 unveils models ranging from 0.5B to 72B parameters, introducing tighter content filtering compared to its predecessor. Initial tests reveal limitations in topic knowledge, sparking concerns about impacts on knowledge retention.
- Mistral-Small-Instruct-2409 Makes a Grand Entrance: The Mistral-Small-Instruct-2409 model, boasting 22B parameters, supports function calls and sequences up to 128k tokens. Despite its potential, it carries non-commercial usage restrictions and is best paired with vLLM for optimal performance.
- LlamaCloud Unveils Multimodal RAG Magic: LlamaCloud launches multimodal capabilities, enabling swift creation of end-to-end multimodal RAG pipelines across unstructured data types. This leap enhances workflows for marketing decks, legal contracts, and finance reports.
Theme 2. AI Tools Get Superpowers: Integrations Galore
- Google Sheets Gets a Boost with OpenRouter Integration: OpenRouter joins forces with the GPT Unleashed for Sheets add-on, offering free access to 100+ models. Users can assign short codes to prompts, supercharging AI output management within spreadsheets.
- Aider Teams Up with Sonnet for Code Magic: Developers cheer as Aider integrates Sonnet 3.5 with O1 mini, enhancing coding tasks with reliable edits and fixes. Users laud Aider for its efficiency in handling swift code tweaks and assignments.
- Superflex Turns Figma Designs into Live Code: Superflex transforms Figma designs directly into front-end code, seamlessly integrating into existing projects. This tool accelerates development, making designers' dreams a reality.
Theme 3. Tech Gremlins and Solutions: Overcoming AI Hurdles
- LM Studio Users Wrestle with GPU Ghosting: Despite proper settings, LM Studio stubbornly ignores GPUs, overloading CPUs and RAM instead. Blurry screens linked to anti-aliasing settings prompt users to tweak configurations for a smoother ride.
- Unsloth Fine-Tune Frenzy Leads to Hallucinations: Fine-tuning 'unsloth/llama-3-8b-bnb-4bit' causes models to hallucinate, hinting at potential data corruption during saving. The community debates the effects of using
save_method = 'merged_4bit_forced'. - BitNet's Ternary Tricks Stir Up Debate: Packing 5 ternary values into an 8-bit space proves clever but complex. Discussions swirl around using Lookup Tables to enhance this method, pushing the envelope on neural network efficiency.
Theme 4. AI Safety and Research Take Center Stage
- AI Safety Fellowship Fuels New Research Ventures: A community member dives into AI safety after snagging an Open Philanthropy fellowship, keen on tackling interpretability and alignment research. They're on the hunt for collaboration over the next six months.
- Fourier Transforms Unveil Hidden State Secrets: Delving into the Fourier transforms of hidden states reveals a shift from uniformity to a power law as layers deepen. Curiosity mounts about the attention mechanism's role in this spectral phenomenon.
- LlamaIndex Tackles Visual Data with Multimodal RAG: Product manuals pose a challenge due to their visual nature. LlamaIndex introduces a sophisticated indexing pipeline to help LLMs effectively navigate and understand image-heavy documents.
Theme 5. AI Ventures into Business and Creativity
- Ultralytics Throws a Party at YOLO Vision 2024: Ultralytics invites AI enthusiasts to YOLO Vision 2024 on October 28 in Madrid. Attendees can groove to tunes they vote for during discussion panels, blending tech and fun.
- AdaletGPT Launches RAG Chatbot for Legal Aid: AdaletGPT unveils a RAG chatbot built with OpenAI and LangChain, offering AI-driven legal support at adaletgpt.com. Users can tap into advanced assistance with a friendly interface.
- Open Interpreter Wows Users with Smarts: Open Interpreter garners praise for its cleverness and capabilities. Excitement brews as users explore its potential, with beta tester slots in high demand.
PART 1: High level Discord summaries
Perplexity AI Discord
- O1 Mini capped at 10 uses daily: Users expressed frustration over the recent limit of 10 uses per day for the O1 Mini on Perplexity, feeling it restricts access compared to rivals.
- There are speculations that this limit aims to manage server costs and marketing strategies, raising questions about user experience.
- Claude 3.5 vs. GPT-4o Showdown: Tension rises as community members weigh the pros and cons of choosing between Claude 3.5 and GPT-4o, with tests deemed essential for discerning differences.
- Participants noted that GPT-4o may excel in specific tasks, hinting at its enhanced capabilities.
- Perplexity AI's Reasoning Features Ignited Buzz: The rollout of a Reasoning focus feature in Perplexity stirred discussion, as users experiment with enhanced functionalities within the Pro Search environment.
- Feedback highlighted improved output quality and reasoning steps, showcasing a notable upgrade.
- Minecraft Moderation Ban Issues Unpacked: A community-led Minecraft moderation ban discussion was initiated on a dedicated page, calling for user opinions on existing policies.
- Members are invited to share their thoughts, suggesting a collective effort to address potential moderation flaws.
- Microsoft's Strategy Sparks Debate: An analysis post raising questions about Microsoft's tactics has drawn attention, prompting users to scrutinize the company's competitive direction.
- The discussion encourages reflection on whether Microsoft's recent actions align with its historical goals.
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 Introduces New Model Variants: Qwen 2.5 features new model sizes such as 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B, all with stricter content filtering compared to its predecessor.
- The model variants reportedly limit knowledge on certain topics, raising concerns about potential impacts on knowledge retention.
- Mistral-Small-Instruct-2409 Released: The Mistral-Small-Instruct-2409 model, with 22B parameters, supports function calls and sequences up to 128k tokens, though it has non-commercial usage restrictions.
- Usage alongside vLLM is recommended for optimal inference pipeline performance.
- Hallucinations in Fine-tuned Models: After fine-tuning the model 'unsloth/llama-3-8b-bnb-4bit', users reported hallucinations in the downloaded version from Hugging Face, raising concerns about potential data corruption.
- This triggered discussions around usage of
save_method = 'merged_4bit_forced'and its effects on model performance.
- This triggered discussions around usage of
- Prioritizing Application Knowledge over Memorization: It was emphasized that application knowledge trumps mere memorization of problems in platforms like LeetCode for effective coding in real-world scenarios.
- A solid grasp of algorithms and data structures such as linked lists and hashmaps is crucial for practical application.
- KTO reigns supreme in RLHF circles: A preference for KTO over ORPO in reinforcement learning was noted for its simplicity as a thumbs up, thumbs down dataset.
- While recognizing that RLHF methods can simplify models, the need to test all available options was highlighted.
aider (Paul Gauthier) Discord
- O1 Models Lag in Real Applications: Users expressed frustration with the O1 models' performance, noting that they excelled in playground scenarios but struggled in practical applications like Aider due to limitations in system prompts.
- While O1 models showed promise, their effective deployment remains an issue, pushing developers to seek alternatives.
- Sonnet Teaming Up with Aider: Community discussions revealed users advocating for Sonnet 3.5 integration with O1 mini to enhance coding tasks, citing superior reliability in edits and fixes.
- Many praised Aider for efficiently handling quick coding fixes, illustrating the benefits of combining these tools.
- Debate on RAG for Coding: Discussions highlighted the effectiveness of RAG methods in coding versus fine-tuning on specific codebases, with many arguing for a tailored approach for better results.
- Concerns arose about retrieval mechanisms failing in large codebases, underscoring a need for improved strategies.
- Azure API Key Setup with Aider: A user detailed the configuration steps required to integrate Aider with Azure OpenAI, emphasizing the importance of structured JSON requests for functionality.
- Additional resources, such as the LiteLLM documentation, were recommended for handling Azure API keys effectively.
- Superflex Transforms Figma to Code: The launch of Superflex has been a game changer, allowing developers to generate front-end code directly from Figma designs, streamlining their workflow.
- This tool integrates designs into existing projects smoothly, making it a highly attractive option for modern web development.
LM Studio Discord
- GPU Performance Troubleshooting: Users expressed frustration with LM Studio not utilizing their GPU, despite proper settings in Settings -> System Resources. Issues causing blurry screens were linked to anti-aliasing settings, leading to suggestions for configuration adjustments.
- The active conversation highlighted common troubleshooting steps that could enhance GPU utilization and reduce blurred visuals in user interfaces.
- Training Time Drastically Reduced: One user trained a 100k parameter model, seeing a shift from 5 days to 1.3 hours by adjusting tokens and batch size. Community members discussed bottlenecks in the data loader, emphasizing the importance of efficient configurations for training efficiency.
- The conversation shed light on practical solutions for optimizing model training durations through parameter adjustments.
- New Features Fuel Excitement in LM Studio: The recent addition of document integration in LM Studio sparked positive feedback, demonstrating the community’s long-standing request for this feature. Users were eager to test the updated version and leverage improved functionality.
- This feature underlined how simplicity in design appeals to users lacking extensive IT backgrounds, making advanced features more accessible.
- Discussions on Dual GPU Setups: Users explored the benefits of dual 4060 Ti setups to maximize VRAM without excessive power consumption. This practical configuration sparked debates on the advantages of using identical GPUs to streamline setups and manage energy efficiency.
- The discussions suggested a growing trend towards optimizing cost-effectiveness and performance in GPU setups.
- VRAM Criticality for LLM Performance: Concerns surfaced regarding the critical need for VRAM in handling powerful LLMs, with insights into various GPUs’ capabilities in token generation rates. Members shared personal experiences indicating that many powerful models exceed the VRAM limits of currently available cards.
- The emphasis on VRAM sparked deeper conversations on how GPU advancements can better support LLM training and inference demands.
HuggingFace Discord
- API Documentation Gets a Boost: The Hugging Face Inference API docs received a critical update, now featuring clearer rate limits, enhanced code examples, and a dedicated PRO section.
- This revamp aims to streamline the user experience as the dataset offerings continue to proliferate, making deployment more intuitive.
- Countdown to 1 Million Models: The community speculated on achieving 1 million models soon, with stats showing 40K weekly models up for grabs.
- Excitement surged as participants compared the growth rates of different model repositories, with predictions pointing to an imminent milestone.
- New Tools for Dataset Creation: DataCraft was introduced as a no-code tool for generating synthetic datasets using natural language, aimed at simplifying data creation challenges.
- This tool incorporates best practices, enhancing accessibility for users looking to build effective AI datasets.
- Engaging in Gradio Office Hours: Members were invited to join ongoing Gradio office hours, an open forum for discussing features, enhancements, and community feedback.
- This session serves as a fertile ground for sharing insights and troubleshooting Gradio-related issues directly with experts.
- Challenges with LLaMA3 Setup: A user sought help downloading the LLaMA3 model, expressing their struggles with the current PyTorch setup and requesting guidance.
- Confusion ensued over implementation choices, revealing a shared need for clarity on the effectiveness of heterogeneous tools in model operations.
OpenAI Discord
- GPT-4o stuns in GeoGuessr: Members expressed surprise at how well GPT-4o performs in GeoGuessr, although it still trails behind expert players. Notably, it deviates from the expected speed of the o1-mini model.
- This performance sparks curiosity regarding potential improvements and applications beyond gaming.
- Fine-tuning job hits a hard limit: A user vented frustrations over their fine-tuning job exceeding a hard limit, incurring a cost of $24.31 against a remaining quota of $19.91. Speculation arose that it could be tied to discounts.
- The discussion centered on strategies for managing costs in fine-tuning operations.
- Advanced Voice Mode availability awaits: Multiple members reported using Plus but lacking access to Advanced Voice Mode, with expectations set for availability by end of Fall. This raises questions about rollout timing.
- The anticipation reflects a keen interest in advancements in voice capabilities.
- Exploring auto prompts for Ideogram/Midjourney: A member circulated an auto prompt for Ideogram/Midjourney, encouraging feedback and rating on usability, emphasizing that it's free to share.
- The initiation of this resource exchange showcases community collaboration.
- Discussion on Official Libraries: The mention of official libraries stirred interest, though no in-depth conversation followed. This opens the door for future discussions on potential resources.
- The ambiguity leaves room for clarification as users seek more details.
OpenRouter (Alex Atallah) Discord
- OpenRouter integrates with Google Sheets: OpenRouter has been incorporated into the GPT Unleashed for Sheets addon, making it available for free following user requests.
- I personally love using OR too and anticipate beneficial feedback as more users adopt this integration.
- Exciting features boost Google Sheets performance: The addition of features like 'jobs', 'contexts', and 'model presets' in the Google Sheets addon streamlines prompt engineering.
- These enhancements allow users to assign short codes to prompts, optimizing AI output management.
- OpenRouter suffers API outages: Various users have reported intermittent issues accessing OpenRouter, particularly with the
o1models, causing confusion over rate limits.- One user noted a temporary outage in Switzerland but confirmed that functionality was restored shortly after.
- Gemini struggles with image generation consistency: There have been mixed discussions regarding Gemini's image generation capabilities, with discrepancies noted between its official site and OpenRouter performance.
- It was clarified that Gemini's chatbot uses Imagen models for image generation, while OpenRouter uses Google Vertex AI.
- Mistral API sees significant price drops: New announcements reveal substantial price reductions for Mistral APIs, dropping to $2 for Large 2 models, making it a competitive option.
- This shift is impacting user decisions regarding which models to utilize for their API calls.
CUDA MODE Discord
- Explore Metal Puzzles and Collaboration: The Metal Puzzles GitHub repository promotes learning Metal programming through collaborative puzzle solving, encouraging community engagement.
- A live puzzle-solving session was proposed, with enthusiasm from members pointing to growing interest among newcomers.
- Triton LayerNorm hits inconsistency wall: A member reported that using tensor parallelism > 1 with Triton LayerNorm results in non-deterministic gradient accumulation, impacting their MoE training.
- They are reaching out to the Liger team for potential insights and alternative implementation suggestions.
- FP8 achieves restored end-to-end functionality: The recent implementation updates have successfully restored FP8 end-to-end capabilities for both forward and backward passes, advancing the functionality in AI workflows.
- Future tasks will include multi-GPU support and performance testing to ensure convergence with existing techniques.
- SK Hynix drives in-memory computing innovation: At Hot Chips 2024, SK Hynix showcased its in-memory computing technologies, AiMX-xPU and LPDDR-AiM, tailored for efficient LLM inference.
- This method significantly reduces power consumption and latency by performing computations directly in memory.
- BitNet's ternary packing quirk: Discussion revealed that packing 5 ternary values into an 8-bit space is superior to traditional methods, enhancing efficiency despite implementation complexity.
- Members considered Lookup Tables as a possible enhancement for packing methods, promoting further exploration.
Nous Research AI Discord
- NousCon Details Confirmed: Location details for NousCon were confirmed to be sent out that evening, sparking discussions about potential future event venues including NYC.
- A user raised inquiries about the broader implications for community engagement at future events.
- Interest in Hermes 3 Unleashed: A new member expressed a desire to utilize AI Model Hermes 3 for business inquiries and sought contact information.
- Another user recommended reaching out to a specific member for advice.
- InstantDrag Takes Center Stage: InstantDrag was highlighted as a modern solution for drag-based image editing, noted for improving speed without needing masks or text prompts.
- Comparisons were made to DragGAN, showcasing potential for faster workflows.
- LLM Inference Performance Limit Explored: A tweet from Denny Zhou pointed out that transformers can theoretically solve any problem if given sufficient intermediate reasoning tokens.
- This was linked to a paper accepted at ICLR 2024, emphasizing the significance of constant depth in transformer capabilities.
- Jailbreak for Claude 3.5 Unveiled: A member successfully created a jailbreak for Claude 3.5 Sonnet, reported as a particularly challenging model to breach.
- While inspired by previous works, they emphasized their unique approach and functionality.
Latent Space Discord
- Luma Labs Launches Dream Machine API: Luma Labs announced the release of the Dream Machine API, enabling developers to leverage a leading video generation model with minimal tooling.
- This initiative aims to make video creation accessible, allowing users to dive straight into creative development.
- 11x AI Raises $24m Series A Funding: 11x AI has successfully secured a $24m Series A funding round from Benchmark, increasing its annual recurring revenue by 15x this year and serving over 250 customers.
- The team plans to build LLM-powered systems aimed at transforming digital go-to-market strategies.
- AI's Job Market Disruption: A report predicts that 60 million jobs across the US and Mexico will be impacted by AI within the next year, with future projections potentially escalating to 70 million in the US and 26 million in Mexico over a decade.
- While some job transformations might not lead to losses, a significant number of positions remain at considerable risk, underscoring the need for workforce adaptation.
- Claude 3.5 System Prompt Circulates: The Claude 3.5 Projects + Artifacts system prompt was shared via a gist, gaining traction among users interested in exploring AI applications.
- This prompt's relevance is highlighted by its discussion across multiple platforms, indicating its significance in current AI evaluations.
- Yann LeCun Showcases ZIG Based Inference Stack: Yann LeCun introduced a new ZIG based inference stack aimed at optimizing high-performance AI inference capable of running deep learning systems efficiently on various hardware.
- This open-sourced project marks its exit from stealth mode, demonstrating notable advancements in AI performance.
Eleuther Discord
- Foundation Models Forge Ahead in Biotech: A member presented their work on foundation models in biotech, focusing on large scale representation learning for both sequence and tabular data, underscoring the growing intersection of AI and biotechnological applications.
- This highlights the rising interest in leveraging AI technologies to revolutionize traditional biotech processes.
- AI Safety Fellowship Sparks Interest: Excitement brewed as a member shared their transition to AI safety after receiving an Open Philanthropy career transition fellowship, indicating an eagerness to engage in interpretability and alignment research.
- They invited others to share their research projects for potential collaboration over the next six months.
- Troubleshooting TensorRT-LLM Build Problems: Concerns surfaced regarding issues with building a TensorRT-LLM on a T4 video card, specifically citing an error linked to workspace size and asking for troubleshooting tips.
- One suggestion to resolve the issue was to increase workspace size using
IBuilderConfig::setMemoryPoolLimit().
- One suggestion to resolve the issue was to increase workspace size using
- Interpreting Hidden States through Fourier Transforms: Discussions kickstarted with a focus on the Fourier transforms of hidden states, revealing a trend from uniformity to a power law as layer depth increased.
- Questions rose about whether the attention mechanism plays a role in shaping this power spectrum in final hidden states.
- Pythia Checkpoints Gain Traction: Community members highlighted the Pythia suite as a robust resource for probing scale and architectural effects on model behavior, encouraging broader exploration.
- Interest was expressed in analyzing different architectures through the Pythia repository to confirm observations related to model training effects.
Stability.ai (Stable Diffusion) Discord
- SSH Fails to Connect After Key Update: A member faced SSH connection issues with their deployed pods post SSH key update, questioning if any configuration tweaks could solve it.
- I can't get in! prompted discussions on possible fixes and alternatives using detailed config checks.
- Stable Diffusion Model Won't Load: Installation woes hit another user as they faced a 'model failed to load' error even after following the setup guide.
- Suggestions flowed in to seek help by sharing specific error logs for targeted troubleshooting.
- ComfyUI Faces White Screen Dilemma: Post-update, a user reported a white screen issue with ComfyUI, halting their GUI attempts.
- A fix was proposed: completely unload ComfyUI and restart using the update script.
- Control Net Needs Robust Dataset: Members debated the dataset requirements for training Effective Control Net, emphasizing needing quality data.
- Suggestions included exploring novel dataset augmentations to enhance training outcomes.
- CivitAI Bounty Pack Seeks Input: A member inquired about posting a CivitAI bounty for a character pack of 49 items with around 4000 images, looking for proper Buzz compensation.
- What’s a reasonable offer? prompted discussions on bounty pricing strategies.
LlamaIndex Discord
- LlamaCloud Launches Multimodal RAG Capabilities: The recent launch of multimodal capabilities in LlamaCloud enables users to quickly create end-to-end multimodal RAG pipelines across unstructured data formats, enhancing their workflow significantly (details here).
- This toolkit supports various applications, including marketing slide decks, legal contracts, and finance reports, thereby simplifying complex data processing.
- LlamaIndex Integrates Seamlessly with Neo4j: Community members explored how to retrieve embeddings stored as node properties in Neo4j using LlamaIndex, suggesting a connection via property graph indexing for effective querying.
- It was discussed that once nodes are retrieved, parsing their properties for embeddings should be a straightforward task, linking to Neo4j Graph Store - LlamaIndex.
- Addressing Circular Dependency in LlamaIndex Packages: A circular dependency issue was detected between
llama-index-agent-openaiandllama-index-llms-openai, leading members to brainstorm potential solutions including creating an openai-utils package.- Questions regarding timelines for these fixes surged, creating a need for community contributions to address the dependency promptly.
- Navigating Image Coordinates with GPT-4o: A user highlighted challenges with image coordinate extraction using GPT-4o, specifically aligning labels and getting accurate coordinates due to their grid overlay method.
- Feedback from the community was encouraged to improve precision in detecting entities for cropping images, underlining the technical difficulties involving spatial recognition.
- Multimodal RAG and Product Manual Challenges: Product manuals have proven difficult for RAG techniques since they are primarily visual, necessitating a sophisticated indexing pipeline for LLMs to navigate them effectively.
- The discussion emphasized the need for methods to handle step-by-step visuals and diagrams typical in product manuals.
Interconnects (Nathan Lambert) Discord
- Mistral Launches New Features: Mistral has introduced several features including a free tier on La Plateforme aimed at developers for API experimentation.
- These updates also feature reduced prices and enhancements to Mistral Small, making it more appealing for users.
- Transformers Benefit from Intermediate Generation: Research shows that incorporating a 'chain of thought' in transformers can significantly enhance their computational capabilities.
- This approach is expected to improve performance on reasoning tasks where standard transformers struggle.
- Unleashing Secrets of Gemini Models: Exciting insights into unreleased Gemini models like potter-v1 and dumbledore-v1 have emerged, hinting at a strong lineup including gemini-test and qwen2.5-72b-instruct.
- The community is buzzing about these new models, marking a pivotal moment in model development.
- Celebrating Newsletter Readers Together: A member shared an invitation for 'the great newsletter reader party,' creating opportunities for community engagement through shared readings.
- This initiative aims to build connections and foster a love for curated content among participants.
- Critique on Mainstream Media Reliance: A discussion highlighted the drawbacks of depending solely on mainstream media for news consumption.
- Members expressed a desire for more diverse and alternative sources to explore.
LangChain AI Discord
- Navigating Chat History Management in LangChain: Members discussed the complexities surrounding Chat Message History Management in LangChain, particularly regarding the storage of UI messages in PostgresChatMessageHistory.
- It was agreed that UI-specific messages must reside in a separate table as existing systems lack combined transaction support.
- Setting Goals for Open Source Contributions: A member expressed ambition to significantly contribute to open-source projects while seeking sponsorship for independence.
- They requested community insights on pathways to achieve these impactful contributions.
- Migrating to Modern LLMChain Implementations: Feedback suggested migrating from legacy LLMChain to newer models for better parameter clarity and streaming capabilities.
- Newer implementations allow easier access to raw message outputs, stressing the importance of keeping updated.
- AdaletGPT Debuts RAG Chatbot: A backend developer at adaletgpt.com launched a RAG chatbot utilizing OpenAI and LangChain, inviting users to try it out at adaletgpt.com.
- They encouraged community inquiries stating they would provide support with a I will do my best for you assurance.
- AI Solutions for Local Business Integration: A member expressed readiness to market AI solutions to local businesses, inquiring about effective implementation strategies.
- They specifically sought tips on engaging business owners who might lack AI familiarity.
tinygrad (George Hotz) Discord
- Tinygrad bumps into AMD issues: A user faced an AttributeError while attempting to bump tinygrad from 0.9.0 to 0.9.2 on AMD indicating a possible kernel version problem with struct_kfd_ioctl_criu_args.
- Investigations reference the tinygrad/extra/hip_gpu_driver/test_kfd_2.py file and related pull request #5917 addressing the issue.
- Monitoring VRAM allocation spikes: A user sought advice on identifying the causes of spikes in VRAM allocation, prompting discussions around effective memory usage monitoring tools.
- Community members emphasized the significance of understanding these spikes to optimize Tinygrad's performance.
- Investigating Tinygrad Tensor errors: Another member reported encountering errors during Tensor manipulation in Tinygrad, linking to an open issue for more details.
- This highlighted ongoing challenges in debugging Tinygrad and the need for community collaboration.
- Forking Diffusers integrates Tinygrad: Discussion arose around a Diffusers fork that utilizes Tinygrad, steering away from Torch and aiming for a fresh approach without direct replication.
- Community members expressed enthusiasm over this initiative as a potential enhancement for Tinygrad's ecosystem.
- NotebookLM creates engaging Tinygrad podcast: The NotebookLM team released an 8-minute podcast weaving engaging analogies to clarify Tinygrad concepts, effectively pitching tinybox.
- This approach showcases innovative methods to educate others about Tinygrad's principles and applications.
Cohere Discord
- Cohere introduces beta Safety Modes: Cohere announced the beta launch of Safety Modes in their Chat API, enabling users to customize model outputs for safety needs.
- This could potentially allow users to implement safety checks and mitigate liability concerns.
- Cohere refines market strategy: Cohere strategically hones in on specific use cases to navigate the crowded LLM market, avoiding oversaturation.
- Members discussed the value of pragmatic business choices that emphasize clarity and utility in model applications.
- Inquiry on fine-tuning models: A user inquired about the possibility of skipping the final
<|END_OF_TURN_TOKEN|>during fine-tuning for smoother inference continuation.- They proposed a POC example of training data, highlighting potential benefits for fine-tuning chat models.
- Sagemaker Client issues flagged: A user reported receiving
input_tokens=-1.0andoutput_tokens=-1.0from the Sagemaker client when accessing the endpoint.- This raised concerns about possible misconfigurations during the setup of the endpoint.
- Support channel for Sagemaker queries: A suggestion was made for the original poster to reach out to support@cohere.com for assistance on the Sagemaker billing issue.
- The user indicated they would investigate the matter further by checking the user's account.
DSPy Discord
- GitHub Communique Sparks Anticipation: A member responded to Prashant on GitHub regarding ongoing discussions and can be followed up with potential reactions.
- Stay tuned for any follow-up reactions that might emerge from this interaction.
- CodeBlueprint with Aider Showcased: A member shared a link demonstrating their new coding pattern, CodeBlueprint with Aider, showcasing its integration potential.
- This showcase might provide insights into employing fresh tools in coding practices.
- Ruff Check Encountered Errors: Prashant reported facing a TOML parse error when executing
ruff check . --fix-only, indicating an unknown fieldindent-width.- This error highlights potential configuration mismatches that need resolving.
- Introduction of GPT-4 Vision API Wrapper: A new Pull Request adds a GPT-4 Vision API wrapper, streamlining image analysis requests in the DSPy repository.
- The introduction of the GPT4Vision class in
visionopenai.pyshould simplify API interactions for developers.
- The introduction of the GPT4Vision class in
- Community Eager for Contributions and Bounties: Members expressed enthusiasm to contribute, with one asking if there are any bounties available for participation.
- Although needed changes were acknowledged, no specifics on bounties were disclosed during the discussion.
LAION Discord
- Compositing Techniques Shine: Members discussed that basic compositing techniques are viable options for image creation, suggesting the use of libraries like Pillow for enhanced results.
- Training images with integrated text is not recommended for achieving poster-quality visuals.
- Post-Processing for Quality Boost: An effective workflow involving tools like GIMP can greatly improve the accuracy and effectiveness of imagery through post-processing techniques.
- Doing it in post yields the best results compared to relying solely on initial methods.
- Nouswise Enhances Creative Processes: Nouswise was highlighted as a personal search engine that provides trusted answers throughout various creative phases, from reading to curation.
- Its functionalities streamline methods for searching and writing, boosting overall productivity.
- Seeking Whisper Speech Insights: A member inquired about experiences with Whisper speech technology, prompting suggestions to review a specific channel for further guidance.
- Community discussions allowed for shared insights and collective knowledge with relevant links to resources.
- StyleTTS-ZS Project Resource Call: A member requested computational resource support for the StyleTTS-ZS project, which aims for efficient high-quality zero-shot text-to-speech synthesis.
- The project is detailed on GitHub, encouraging community collaboration for its development.
OpenInterpreter Discord
- Open Interpreter impresses users: Open Interpreter garnered praise for its cleverness, enhancing excitement about its functionalities within the community.
- Members expressed eagerness to explore its potential, with ongoing discussions surrounding its features.
- Interest peaked for beta testing: Members inquired about available slots for beta testers of the Open Interpreter, signaling ongoing enthusiasm for contributing to its development.
- Such inquiries reflect a keen interest in aiding the tool's advancement and improving user experiences.
- Human Device Discord event this Friday: An upcoming event by Human Device is set for this Friday, with participants encouraged to join through the Discord link.
- This event aims to engage users in discussions about innovative technologies and offerings.
- Tool Use Podcast highlights voice intelligence: The latest episode of Tool Use showcases Killian Lucas discussing advancements in voice intelligence and the 01 Voices script's capabilities.
- Listeners can expect insights into how voice agents interact in group conversations seamlessly.
- Deepgram goes open-source: A member announced creation of an open-source and local version of Deepgram, stirring enthusiasm within the community for more accessible tools.
- This initiative emphasizes community engagement in developing effective voice intelligence solutions.
Torchtune Discord
- Eleuther Eval Recipe's Limited Use: Concerns emerged regarding the Eleuther eval recipe and its performance with both generation and multiple choice (mc) tasks, particularly relating to the impact of cache from generation tasks on subsequent task executions.
- It was confirmed by other users that the recipe is malfunctioning, suggesting potential issues tied to cache management.
- Cache Reset Necessity: Users discussed the absence of a proper cache reset as a potential source of issues, especially when switching tasks after model generation.
- One member noted their practice of resetting caches post-generation, but highlighted this only prepares for a new round of generation without achieving a full reset.
- Inconsistent Batch Size During MM Evaluations: Discussion pointed to an issue with expected batch sizes not being met during model evaluations, particularly when caching is utilized.
- This challenge is anticipated to reoccur when future multiple model evaluations are attempted by another user.
Modular (Mojo 🔥) Discord
- Community Curiosity on RISC-V Support: Members are inquiring about any plans to support RISC-V, but currently there are no plans yet for this architecture.
- This interest may prompt future discussions on alternative architecture compatibility.
- Zero-copy Interoperability Lacks Mojo-Python Integration: There's a challenge in achieving zero-copy data interoperability since Mojo modules cannot be imported or called from Python now.
- The discussion included how the Mandelbrot example could inefficiently utilize memory via
numpy_array.itemset().
- The discussion included how the Mandelbrot example could inefficiently utilize memory via
- Mandelbrot Example Highlights Mojo's Potential: A tutorial on the Mandelbrot set demonstrated that Mojo can execute high-performance code while integrating Python visual tools.
- This tutorial illustrated Mojo's fit for crafting fast solutions for irregular applications leveraging Python libraries.
- LLVM Intrinsics Now Supported at Comptime: Mojo has extended support for LLVM intrinsics at comptime, focusing on functions like
ctlzandpopcountfor integers.- Future developments hinge on LLVM's capacity to constant fold these intrinsics, opening pathways for broader type support.
OpenAccess AI Collective (axolotl) Discord
- Shampoo Gets No Love in Transformers: A member highlighted the absence of Shampoo in both Transformers and Axolotl, arguing that it offers substantial benefits that are being overlooked.
- Shampoo is literally such a free lunch, in large scale, in predictable manner, indicates its potential that may deserve further exploration.
- Shampoo Scaling Law vs Adam: Discussion around the Shampoo Scaling Law for language models revealed a comparative analysis against Adam, with a plot referencing Kaplan et al.
- The plot illustrated Shampoo's effective scaling characteristics, suggesting it as a preferable choice for large models over Adam.
MLOps @Chipro Discord
- Ultralytics Calls for Community at YOLO Vision 2024!: Ultralytics is hosting YOLO Vision 2024 on
- Attendees can engage by voting for the music during the discussion panel, aiming to boost community interaction!
- Voting for Music at YOLO Vision 2024!: Registered participants for YOLO Vision 2024 can vote on the music played during discussions, adding a unique interactive touch to the event.
- This initiative encourages attendee participation and aims to create an engaging atmosphere during the event.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!